Reading Time: 7 minutes
Долгая дорога начинается с первых шагов, а первый шаг в дополненную реальность и сложные алгоритмы компьютерного зрения это умение загрузить изображение, изменить его размер, цвет и просто вырезать интересный нам фрагмент. Вы удивитесь, как много можно всего достичь, используя самые простые средства.
Весь код, представленный в статье, написан на последней версии Python 3.6 и версии OpenCV 3.3.0. Инструкции по установке OpenCV 3.3.0 вы можете найти у меня на сайте: установка OpenCV 3 на Raspberry Pi 3 Jessie. Весь представленный код может быть запущен как на системах Windows, так и на OSX, и Unix, таких как Raspberry Pi, Banana Pi.
Если вы устанавливали OpenCV 3 в виртуальное окружение, не забудьте перед началом работы войти в него следующими командами:
source ~/.profile workon cv_python3
Открываем локальный файл в OpenCV 3 Python
Начнем мы с главного – открытия файла. Для примера я использовал кадр из замечательного фильма “Matrix”, или “Матрица”.

Оригинальный кадр из фильма “Матрица”
Скачивайте его на свой компьютер, он понадобиться для дальнейших шагов по изучению OpenCV и Python. Готовы? Поехали дальше!
Загрузим кадр в программу и отобразим его встроенными средствами OpenCV 3 командами:
# добавим необходимый пакет с opencv
import cv2
# загружаем изображение и отображаем его
image = cv2.imread("matrix-sunglasses-768x320.jpg")
cv2.imshow("Original image", image)
cv2.waitKey(0)
Выполнение данного кода в Python 3.6 на моем компьютере выводит следующее окно:
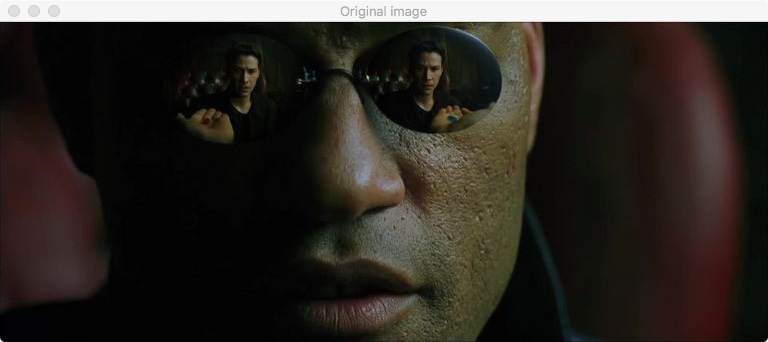
Вывод оригинального изображения
Разберем подробно приведенный код:
- Строка 2: В первой значимой строке мы говорим интерпретатору Python загрузить библиотеку OpenCV
- Строка 5: Тут мы открываем и читаем файл с жесткого диска. Команда cv2.imread возвращает NumPy массив, который содержит представление данных из изображения.
- Строки 6-7: Отображение файла встроенными средствами OpenCV. Тут стоит остановиться подробнее: метод для отображения cv2.imshow() принимает в себя два аргумента, первый это название окна, в котором будет отрисовано изображение, второй – имя переменной, которая хранит данное изображение. Однако выполнение только данной команды отрисует изображение и сразу же закроет программу. Для того, чтобы мы смогли увидеть и работать с изображением, добавим команду cv2.waitKey(0). Данная команда останавливает выполнение скрипта до нажатия клавиши на клавиатуре. Параметр 0 означает что нажатие любой клавиши будет засчитано.
Изменяем размер изображения
Мы загрузили изображение как есть – хорошее начало, но хочется что то сделать с изображением. Сделаем его меньше, чтобы мы могли его использовать как иконку. Мы можем увидеть разрешение оригинального изображения через атрибут изображения shape, который покажет размерность NumPy массива и, таким образом, разрешение снимка:
print(image.shape)
Когда вы выполним код, мы можем увидеть что на терминал выведется (320, 768, 3). Это означает изображение содержит 320 строк, 768 столбцов и 3 канала цвета. Данный формат может показаться знакомым, если вы имели дело в школе или институте с матрицами – там так же сначала писалось количество строк, потом количество столбцов, далее количество матриц.
Но когда мы работаем с изображениями, мы пишем их размеры в нотации – ширина x высоту. Первоначально такой разный подход будет приводить к ошибкам, я сам много раз замечал, что по привычке пишу ширину изображения первой когда обращаюсь к массиву NumPy. Однако вам стоит попрактиковаться, попробовать различные методы, и вы потом сможете с легкостью понимать где ширина а где количество строк.
Изображение у шириной целых 768 пикселей, давайте сожмем его до ширины в 200 пикселей:
# Нам надо сохранить соотношение сторон
# чтобы изображение не исказилось при уменьшении
# для этого считаем коэф. уменьшения стороны
final_wide = 200
r = float(final_wide) / image.shape[1]
dim = (final_wide, int(image.shape[0] * r))
# уменьшаем изображение до подготовленных размеров
resized = cv2.resize(image, dim, interpolation = cv2.INTER_AREA)
cv2.imshow("Resize image", resized)
cv2.waitKey(0)
Выполнение кода выведет следующее изображение:
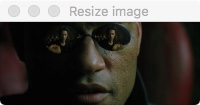
Уменьшенное изображение с шириной 200px
Разберем код:
- Строки 4-6: Мы задаем итоговую ширину изображения, равную 200px. Далее мы хотим сохранить исходные пропорции изображения, чтобы уменьшить его не искажая. Для этого есть два пути: через коэффициент уменьшения и через коэффициент отношения сторон. В данном случае мы используем отношение новой ширины 200px и исходной 768px = r. Умножение данного числа на исходную высоту даст нам новую высоту изображения. Что мы и используем для создания кортежа с новым разрешением.
- Строки 9-11: Уменьшаем изображение методом cv2.resize. Данный метод принимает три параметра и возвращает новое изображение. Первый параметр – исходное изображение, второй – кортеж с требуемым разрешением для нового изображения, третий – алгоритм, который будет использоваться для масштабирования.
Вырезаем нужный фрагмент изображения
Мы открыли изображение, уменьшили, мы уже можем многое ? Для практического применения почти всегда нам не требуется целиком все изображение, нужен только интересующий нас участок. Для получения такого участка воспользуемся методом по получению кропа изображения:
# вырежем участок изображения используя срезы
# мы же используем NumPy
cropped = image[30:130, 150:300]
cv2.imshow("Cropped image", cropped)
cv2.waitKey(0)
Что же мы получили? Ответ:

Участок с красной таблеткой из “Матрицы”
Данный код показывает преимущества работы с изображениями в стиле NumPy: мы просто используем срезы. В такой нотации мы вырезаем изображение с 30 по 130 пиксель по высоте и со 150 по 300 пиксель по ширине. Заметьте что высота идет первая – как мы говорили выше, первой идет строки, вторыми идут столбцы.
Поворот изображения на OpenCV 3 Python
Теперь перейдем к сложным вещам – афинным преобразованиям. Начнем с простого поворота на 180 градусов, без смещения. Следующий код поставит Нео с ног на голову:
# получим размеры изображения для поворота
# и вычислим центр изображения
(h, w) = image.shape[:2]
center = (w / 2, h / 2)
# повернем изображение на 180 градусов
M = cv2.getRotationMatrix2D(center, 180, 1.0)
rotated = cv2.warpAffine(image, M, (w, h))
cv2.imshow("Rotated image", rotated)
cv2.waitKey(0)
Выполнив код мы получим Нео и Морфеуса вниз ногами – что мы и хотели:
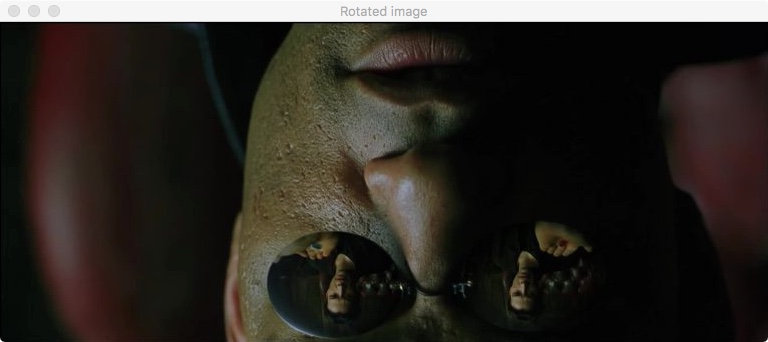
Повернутое изображение из “Матрицы” на OpenCV
Разберем код подробнее:
- Строки 3-4: Мы получаем размеры изображения через атрибут shape и среза по первым двум показателям – высоте и ширине. Далее мы вычисляем середину картинки для передачи ее в матрицу вращения, мы же хотим чтобы изображение осталось в центре. Для этого просто делим числа на 2.
- Строка 7: Считаем матрицу для преобразования. В данном случае мы воспользовались методом cv2.getRotationMatrix2D, который может использоваться как для поворота изображения, так и для изменения его размеров. Данный метод принимает три аргумента – первый это кортеж с точкой, относительно которой будет осуществлен поворот изображения и изменение размера. Второй аргумент – угол поворота, в градусах. И третий аргумент – коэффициент увеличения, который может быть и меньше 1. Метод возвращает матрицу поворота, которая может использоваться в необходимых случаях.
- Строка 8: Поворачиваем изображение. Используем метод cv2.warpAffine, который принимает три параметра – исходное изображения, матрицу преобразования, в данном случае матрицу поворота, и кортеж с размерами выходного изображения. Данный метод возвращает преобразованную картинку.
- Строки 9-10: Показываем полученное изображение.
Отражаем изображение по осям
Рассмотрим такую частую операцию как отражение изображения. Для некоторых вычислений вам потребуется иметь не исходную картинку, а ее зеркальную копию, чего вы не сможете получить операцией поворота или срезом массива. В таком случае мы воспользуемся следующим кодом:
#отразим изображение по горизонтали
flip_image = cv2.flip(image,1)
cv2.imshow("Flip image", flip_image)
cv2.waitKey(0)
Выполнив данный код мы получим Морфеуса в зеркале:
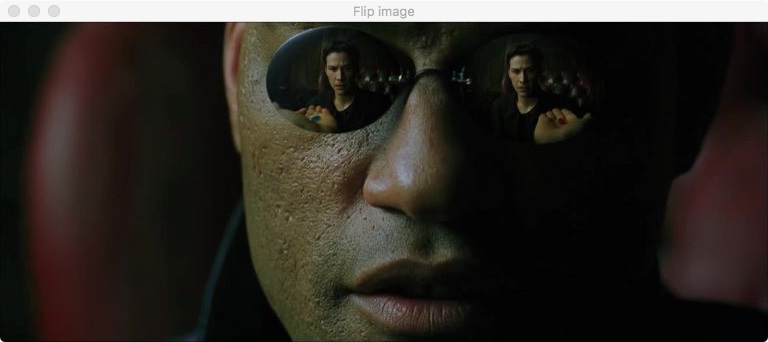
Отражение кадра OpenCV
В данном коде мы воспользовались методом cv2.flip, данный метод принимает два параметра – исходное изображение и ось для отражения. В качестве осей может быть следующие числа: 0 – по вертикали, 1 – по горизонтали, (-1) – по вертикали и по горизонтали.
Сохраняем изображение на локальный диск с OpenCV и Python
После всего что мы сделали с исходным изображением, мы захотим сохранить полученные результаты. Для этого мы воспользуемся командой:
# запишем изображение на диск в формате png
cv2.imwrite("flip.png", flip_image)
Как мы видим, исполнение этого кода создает файл:
Сохраняем файл OpenCV
Как мы можем видеть, мы сохранили файл в формат PNG, при том что исходный файл был в формате JPG. Мы сделали это командой cv2.imwrite, которая принимает два аргумента, первый – путь файла, который будет создан, второй – изображение. Все операции по преобразованию формата OpenCV заботливо взял на себя.
Итог
В данной статье вы научились самым основным и нужным вещам, таким как загрузка и простые операции с изображениями. Весь приведенный код вы можете найти на GitHub. Если вы будете дальше изучать компьютерное зрение, вы очень много раз будете использовать эти приемы. Для закрепления материала выберите интересное вам изображение и разбейте его на интересные участки с сохранением всех фрагментов на диск.
В следующем уроке я расскажу, как иметь дело с видео, и дальше мы начнем веселый урок по созданию приложения для рисования. Мы даже распишемся на полученном проекте с помощью технологий компьютерного зрения ?
Библиотека компьютерного зрения и машинного обучения с открытым исходным кодом. В неё входят более 2500 алгоритмов, в которых есть как классические, так и современные алгоритмы для компьютерного зрения и машинного обучения. Эта библиотека имеет интерфейсы на различных языках, среди которых есть Python (в этой статье используем его), Java, C++ и Matlab.
Содержание
- Установка.
- Импорт и просмотр изображения.
- Обрезка.
- Изменение размера.
- Поворот.
- Градация серого и порог.
- Размытие/сглаживание.
- Рисование прямоугольников.
- Рисование линий.
- Текст на изображении.
- Распознавание лиц.
- Contours — распознавание объектов.
- Сохранение изображения.
Импорт и просмотр изображения
import cv2
image = cv2.imread("./путь/к/изображению.расширение")
cv2.imshow("Image", image)
cv2.waitKey(0)
cv2.destroyAllWindows()Примечание При чтении способом выше изображение находится в цветовом пространстве не RGB (как все привыкли), а BGR. Возможно, в начале это не так важно, но как только вы начнёте работать с цветом — стоит знать об этой особенности. Есть 2 пути решения:
- Поменять местами 1-й канал (R — красный) с 3-м каналом (B — синий), и тогда красный цвет будет
(0,0,255), а не(255,0,0). - Поменять цветовое пространство на RGB:
rgb_image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)И тогда в коде работать уже не с
image, а сrgb_image.
Примечание Чтобы закрыть окно, в котором отображается изображение, нажмите любую клавишу. Если использовать кнопку закрытия окна, можно наткнуться на подвисания.
На протяжении статьи для вывода изображений будет использоваться следующий код:
import cv2
def viewImage(image, name_of_window):
cv2.namedWindow(name_of_window, cv2.WINDOW_NORMAL)
cv2.imshow(name_of_window, image)
cv2.waitKey(0)
cv2.destroyAllWindows()Кадрирование


Пёсик после кадрирования
import cv2
cropped = image[10:500, 500:2000]
viewImage(cropped, "Пёсик после кадрирования")Где image[10:500, 500:2000] — это image[y:y + высота, x:x + ширина].
Изменение размера


После изменения размера на 20 %
import cv2
scale_percent = 20 # Процент от изначального размера
width = int(img.shape[1] * scale_percent / 100)
height = int(img.shape[0] * scale_percent / 100)
dim = (width, height)
resized = cv2.resize(img, dim, interpolation = cv2.INTER_AREA)
viewImage(resized, "После изменения размера на 20 %")Эта функция учитывает соотношение сторон оригинального изображения. Другие функции изменения размера изображений можно увидеть здесь.
Поворот


Пёсик после поворота на 180 градусов
import cv2
(h, w, d) = image.shape
center = (w // 2, h // 2)
M = cv2.getRotationMatrix2D(center, 180, 1.0)
rotated = cv2.warpAffine(image, M, (w, h))
viewImage(rotated, "Пёсик после поворота на 180 градусов")image.shape возвращает высоту, ширину и каналы. M — матрица поворота — поворачивает изображение на 180 градусов вокруг центра. -ve — это угол поворота изображения по часовой стрелке, а +ve, соответственно, против часовой.
Перевод в градации серого и в чёрно-белое изображение по порогу


Пёсик в градациях серого

Чёрно-белый пёсик
import cv2
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
ret, threshold_image = cv2.threshold(im, 127, 255, 0)
viewImage(gray_image, "Пёсик в градациях серого")
viewImage(threshold_image, "Чёрно-белый пёсик")gray_image — это одноканальная версия изображения.
Функция threshold возвращает изображение, в котором все пиксели, которые темнее (меньше) 127 заменены на 0, а все, которые ярче (больше) 127, — на 255.
Для ясности другой пример:
ret, threshold = cv2.threshold(im, 150, 200, 10)Здесь всё, что темнее, чем 150, заменяется на 10, а всё, что ярче, — на 200.
Остальные threshold-функции описаны здесь.
Размытие/сглаживание


Размытый пёсик
import cv2
blurred = cv2.GaussianBlur(image, (51, 51), 0)
viewImage(blurred, "Размытый пёсик")Функция GaussianBlur (размытие по Гауссу) принимает 3 параметра:
- Исходное изображение.
- Кортеж из 2 положительных нечётных чисел. Чем больше числа, тем больше сила сглаживания.
- sigmaX и sigmaY. Если эти параметры оставить равными 0, то их значение будет рассчитано автоматически.
Больше про размытие здесь.
Рисование прямоугольников


Обводим прямоугольником мордочку пёсика
import cv2
output = image.copy()
cv2.rectangle(output, (2600, 800), (4100, 2400), (0, 255, 255), 10)
viewImage(output, "Обводим прямоугольником лицо пёсика")Эта функция принимает 5 параметров:
- Само изображение.
- Координата верхнего левого угла
(x1, y1). - Координата нижнего правого угла
(x2, y2). - Цвет прямоугольника (GBR/RGB в зависимости от выбранной цветовой модели).
- Толщина линии прямоугольника.
Рисование линий


2 пёсика, разделённые линией
import cv2
output = image.copy()
cv2.line(output, (60, 20), (400, 200), (0, 0, 255), 5)
viewImage(output, "2 пёсика, разделённые линией")Функция line принимает 5 параметров:
- Само изображение, на котором рисуется линия.
- Координата первой точки
(x1, y1). - Координата второй точки
(x2, y2). - Цвет линии (GBR/RGB в зависимости от выбранной цветовой модели).
- Толщина линии.
Текст на изображении


Изображение с текстом
import cv2
output = image.copy()
cv2.putText(output, "We <3 Dogs", (1500, 3600),cv2.FONT_HERSHEY_SIMPLEX, 15, (30, 105, 210), 40)
viewImage(output, "Изображение с текстом")Функция putText принимает 7 параметров:
- Непосредственно изображение.
- Текст для изображения.
- Координата нижнего левого угла начала текста
(x, y). - Используемый шрифт.
- Размер шрифта.
- Цвет текста (GBR/RGB в зависимости от выбранной цветовой модели).
- Толщина линий букв.
Распознавание лиц
На этот раз без пёсиков.


Лиц обнаружено: 2
import cv2
image_path = "./путь/к/фото.расширение"
face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
image = cv2.imread(image_path)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(
gray,
scaleFactor= 1.1,
minNeighbors= 5,
minSize=(10, 10)
)
faces_detected = "Лиц обнаружено: " + format(len(faces))
print(faces_detected)
# Рисуем квадраты вокруг лиц
for (x, y, w, h) in faces:
cv2.rectangle(image, (x, y), (x+w, y+h), (255, 255, 0), 2)
viewImage(image,faces_detected)detectMultiScale — общая функция для распознавания как лиц, так и объектов. Чтобы функция искала именно лица, мы передаём ей соответствующий каскад.
Функция detectMultiScale принимает 4 параметра:
- Обрабатываемое изображение в градации серого.
- Параметр
scaleFactor. Некоторые лица могут быть больше других, поскольку находятся ближе, чем остальные. Этот параметр компенсирует перспективу. - Алгоритм распознавания использует скользящее окно во время распознавания объектов. Параметр
minNeighborsопределяет количество объектов вокруг лица. То есть чем больше значение этого параметра, тем больше аналогичных объектов необходимо алгоритму, чтобы он определил текущий объект, как лицо. Слишком маленькое значение увеличит количество ложных срабатываний, а слишком большое сделает алгоритм более требовательным. minSize— непосредственно размер этих областей.
Contours — распознавание объектов
Распознавание объектов производится с помощью цветовой сегментации изображения. Для этого есть две функции: cv2.findContours и cv2.drawContours.
В этой статье детально описано обнаружение объектов с помощью цветовой сегментации. Всё, что вам нужно для неё, находится там.
Сохранение изображения
import cv2
image = cv2.imread("./импорт/путь.расширение")
cv2.imwrite("./экспорт/путь.расширение", image)Заключение
OpenCV — отличная библиотека с лёгкими алгоритмами, которые могут использоваться в 3D-рендере, продвинутом редактировании изображений и видео, отслеживании и идентификации объектов и людей на видео, поиске идентичных изображений из набора и для много-много чего ещё.
Эта библиотека очень важна для тех, кто разрабатывает проекты, связанные с машинным обучением в области изображений.
Перевод статьи «OpenCV-Python Cheat Sheet: From Importing Images to Face Detection»

OpenCV — известная библиотека машинного обучения и компьютерного зрения, имеющая открытый исходный код. Она включает в себя более 2500 алгоритмов, среди которых есть и классические, и современные. В принципе, OpenCV имеет интерфейсы на разных языках программирования (Java, C++ и Matlab), но сегодня мы поработаем с Python.
На установке долго останавливаться не будем, т. к. подробные инструкции есть здесь (для Windows) и здесь (для Linux).
Импорт и просмотр изображений
Импорт и просмотр изображений осуществляется следующим образом:
import cv2 image = cv2.imread("./путь/к/изображению.расширение") cv2.imshow("Image", image) cv2.waitKey(0) cv2.destroyAllWindows()Замечание 1: во время чтения способом, который представлен выше, изображение находится не в RGB, а в BGR. Поначалу это, может, и неважно, но знать стоит. Тут есть несколько путей решения вопроса:
1. Поменяйте местами первый канал (R — красный) с третьим каналом (B — синий). В результате красный цвет будет не (255,0,0), а (0,0,255).
2. Поменяйте непосредственно цветовое пространство на RGB с помощью следующего кода:rgb_image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)Замечание 2: если вы захотите закрыть окно, в котором изображение отображается, нажмите любую клавишу. Дело в том, что используя кнопку закрытия окна, можно столкнуться с подвисанием.
Идём дальше. На протяжении этой статьи мы будем применять для вывода изображений следующий код:
import cv2 def viewImage(image, name_of_window): cv2.namedWindow(name_of_window, cv2.WINDOW_NORMAL) cv2.imshow(name_of_window, image) cv2.waitKey(0) cv2.destroyAllWindows()Кадрирование
Посмотрите на эту картинку:
А теперь на то, как она будет выглядеть после кадрирования:
Для кадрирования:
import cv2 cropped = image[10:500, 500:2000] viewImage(cropped, "Пёсик после кадрирования")Здесь image[10:500, 500:2000] — это image[y:y + высота, x:x + ширина].
Меняем размер
Вот эта фотография довольно большая:
Давайте уменьшим её размер на 20 %:
 import cv2 scale_percent = 20 # Это % от изначального размера width = int(img.shape[1] * scale_percent / 100) height = int(img.shape[0] * scale_percent / 100) dim = (width, height) resized = cv2.resize(img, dim, interpolation = cv2.INTER_AREA) viewImage(resized, "После изменения размера изображения на 20 %")
import cv2 scale_percent = 20 # Это % от изначального размера width = int(img.shape[1] * scale_percent / 100) height = int(img.shape[0] * scale_percent / 100) dim = (width, height) resized = cv2.resize(img, dim, interpolation = cv2.INTER_AREA) viewImage(resized, "После изменения размера изображения на 20 %")Обратите внимание, что данная функция учитывает соотношение сторон оригинального фото.
Поворот
Допустим, нам не нравится такой ракурс:
Давайте его перевернём на 180°:
import cv2 (h, w, d) = image.shape center = (w // 2, h // 2) M = cv2.getRotationMatrix2D(center, 180, 1.0) rotated = cv2.warpAffine(image, M, (w, h)) viewImage(rotated, "Фото после поворота на 180°")Что тут что:
— image.shape возвратит высоту, ширину и каналы;
— М — матрица поворота, поворачивающая фото на 180° относительно центра;
— -ve — угол поворота по часовой стрелке;
— +ve — угол поворота против часовой.Переводим изображение в градации серого и в чёрно-белое отображение по порогу
Вот исходное фото:
Вот градации серого:
А вот чёрно-белый вариант:
«`python
import cv2
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
ret, threshold_image = cv2.threshold(im, 127, 255, 0)
viewImage(gray_image, «Градации серого»)
viewImage(threshold_image, «Чёрно-белый вариант»)В нашем случае gray_image является одноканальной версией изображения. Что касается функции threshold, то она возвращает изображение, где все пиксели, которые темнее (менее) 127 заменяются на 0, а все, которые больше (ярче) 127, заменяются на 255. Ещё примерчик для ясности: ```python ret, threshold = cv2.threshold(im, 150, 200, 10)Тут всё, что темнее 150, меняется на 10, а всё, что ярче, меняется на 200.
Размытие/сглаживание
Вот отчётливое фото:
А вот оно же после размытия:
import cv2 blurred = cv2.GaussianBlur(image, (51, 51), 0) viewImage(blurred, "Размытое изображение")Здесь функция GaussianBlur осуществляет размытие по Гауссу, принимая три параметра:
1. Исходное фото.
2. Кортеж из двух нечётных положительных чисел (чем числа больше, тем, соответственно, больше сила сглаживания).
3. Параметры sigmaX и sigmaY. Если их оставить равными 0, значение параметров рассчитается автоматически.Рисуем прямоугольники
Поместим лицо пёсика в прямоугольник:
import cv2 output = image.copy() cv2.rectangle(output, (2600, 800), (4100, 2400), (0, 255, 255), 10) viewImage(output, "Обводим прямоугольником")Данная функция принимает пять параметров:
1. Непосредственно, изображение.
2. Координату левого верхнего угла (x1, y1).
3. Координату правого нижнего угла (x2, y2).
4. Цвет прямоугольника (GBR/RGB с учётом выбранной цветовой модели).
5. Толщину линии прямоугольника.Рисуем линии
Вот два четвероногих друга:
Давайте разделим их прямой линией:
import cv2 output = image.copy() cv2.line(output, (60, 20), (400, 200), (0, 0, 255), 5) viewImage(output, "Два пса, разделённые линией")Тут функция line тоже принимает пять параметров:
1. Непосредственно, само изображение, где линия рисуется.
2. Координату 1-й точки (x1, y1).
3. Координату 2-й точки (x2, y2).
4. Цвет линии (GBR/RGB с учётом выбранной цветовой модели).
5. Толщину линии.Текст на изображении
Допустим, на изображение нужно нанести текст:
Сделаем это:
import cv2 output = image.copy() cv2.putText(output, "We <3 Dogs", (1500, 3600),cv2.FONT_HERSHEY_SIMPLEX, 15, (30, 105, 210), 40) viewImage(output, "Изображение с текстом")Здесь главную роль играет функция putText, принимающая аж семь параметров:
1. Изображение.
2. Текст для фото.
3. Координату левого нижнего угла начала текста (x, y).
4. Шрифт.
5. Размер шрифта.
6. Цвет текста (GBR/RGB с учётом выбранной цветовой модели).
7. Толщину линий букв.Распознаём лица
Теперь обойдёмся без собак:
Итого: обнаружено 2 лица:
import cv2 image_path = "./путь/к/фото.расширение" face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml') image = cv2.imread(image_path) gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) faces = face_cascade.detectMultiScale( gray, scaleFactor= 1.1, minNeighbors= 5, minSize=(10, 10) ) faces_detected = "Лиц обнаружено: " + format(len(faces)) print(faces_detected) # Рисуем квадраты вокруг лиц for (x, y, w, h) in faces: cv2.rectangle(image, (x, y), (x+w, y+h), (255, 255, 0), 2) viewImage(image,faces_detected)Тут используется общая функция распознавания лиц и объектов detectMultiScale. Чтобы она искала именно лица, передаём ей соответствующий каскад.
Функция принимает четыре параметра:
1. Обрабатываемое фото в градации серого.
2. Параметр scaleFactor. Параметр компенсирует перспективу, ведь одни лица бывают больше, т. к. находятся ближе.
3. Параметр minNeighbors, определяющий число объектов вокруг лица. Вообще, во время распознавания объектов соответствующий алгоритм использует скользящее окно. И чем больше значение вышеназванного параметра, тем больше аналогичных объектов нужно алгоритму, чтобы он определил, что текущий объект — это лицо. Если значение будет слишком маленьким, повысится число ложных срабатываний, если слишком большим, алгоритм станет более требовательным.
4. Последний параметр — minSize отвечает за размер этих областей.Сохранение изображения
Когда нужные манипуляции произведены, можем сохранить изображение:
import cv2 image = cv2.imread("./импорт/путь.расширение") cv2.imwrite("./экспорт/путь.расширение", image)Вывод
OpenCV — прекрасная библиотека с простыми алгоритмами. Она пригодится вам при продвинутом редактировании изображений, 3D-рендере, идентификации и отслеживании людей и объектов на видео, поиске идентичных фото из определённого набора и т. д. Пожалуй, правы те, кто говорит, что нельзя переоценить важность OpenCV для людей, разрабатывающих ML-проекты в области изображений и не только.
Источник



















Goals¶
- Learn to apply different geometric transformation to images like translation, rotation, affine transformation etc.
- You will see these functions: cv2.getPerspectiveTransform
Transformations¶
OpenCV provides two transformation functions, cv2.warpAffine and cv2.warpPerspective, with which you can have all kinds of transformations. cv2.warpAffine takes a 2×3 transformation matrix while cv2.warpPerspective takes a 3×3 transformation matrix as input.
Scaling¶
Scaling is just resizing of the image. OpenCV comes with a function cv2.resize() for this purpose. The size of the image can be specified manually, or you can specify the scaling factor. Different interpolation methods are used. Preferable interpolation methods are cv2.INTER_AREA for shrinking and cv2.INTER_CUBIC (slow) & cv2.INTER_LINEAR for zooming. By default, interpolation method used is cv2.INTER_LINEAR for all resizing purposes. You can resize an input image either of following methods:
import cv2 import numpy as np img = cv2.imread('messi5.jpg') res = cv2.resize(img,None,fx=2, fy=2, interpolation = cv2.INTER_CUBIC) #OR height, width = img.shape[:2] res = cv2.resize(img,(2*width, 2*height), interpolation = cv2.INTER_CUBIC)
Translation¶
Translation is the shifting of object’s location. If you know the shift in (x,y) direction, let it be 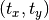 , you can create the transformation matrix
, you can create the transformation matrix 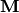 as follows:
as follows:
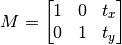
You can take make it into a Numpy array of type np.float32 and pass it into cv2.warpAffine() function. See below example for a shift of (100,50):
import cv2 import numpy as np img = cv2.imread('messi5.jpg',0) rows,cols = img.shape M = np.float32([[1,0,100],[0,1,50]]) dst = cv2.warpAffine(img,M,(cols,rows)) cv2.imshow('img',dst) cv2.waitKey(0) cv2.destroyAllWindows()
Warning
Third argument of the cv2.warpAffine() function is the size of the output image, which should be in the form of (width, height). Remember width = number of columns, and height = number of rows.
See the result below:

Rotation¶
Rotation of an image for an angle 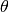 is achieved by the transformation matrix of the form
is achieved by the transformation matrix of the form
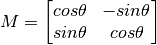
But OpenCV provides scaled rotation with adjustable center of rotation so that you can rotate at any location you prefer. Modified transformation matrix is given by
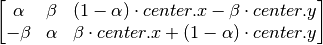
where:
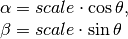
To find this transformation matrix, OpenCV provides a function, cv2.getRotationMatrix2D. Check below example which rotates the image by 90 degree with respect to center without any scaling.
img = cv2.imread('messi5.jpg',0) rows,cols = img.shape M = cv2.getRotationMatrix2D((cols/2,rows/2),90,1) dst = cv2.warpAffine(img,M,(cols,rows))
See the result:

Affine Transformation¶
In affine transformation, all parallel lines in the original image will still be parallel in the output image. To find the transformation matrix, we need three points from input image and their corresponding locations in output image. Then cv2.getAffineTransform will create a 2×3 matrix which is to be passed to cv2.warpAffine.
Check below example, and also look at the points I selected (which are marked in Green color):
img = cv2.imread('drawing.png') rows,cols,ch = img.shape pts1 = np.float32([[50,50],[200,50],[50,200]]) pts2 = np.float32([[10,100],[200,50],[100,250]]) M = cv2.getAffineTransform(pts1,pts2) dst = cv2.warpAffine(img,M,(cols,rows)) plt.subplot(121),plt.imshow(img),plt.title('Input') plt.subplot(122),plt.imshow(dst),plt.title('Output') plt.show()
See the result:
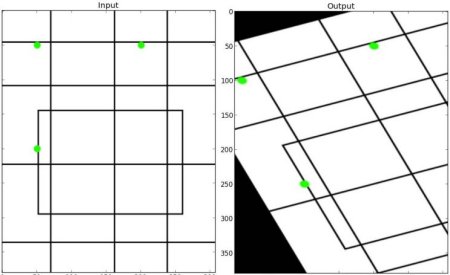
Perspective Transformation¶
For perspective transformation, you need a 3×3 transformation matrix. Straight lines will remain straight even after the transformation. To find this transformation matrix, you need 4 points on the input image and corresponding points on the output image. Among these 4 points, 3 of them should not be collinear. Then transformation matrix can be found by the function cv2.getPerspectiveTransform. Then apply cv2.warpPerspective with this 3×3 transformation matrix.
See the code below:
img = cv2.imread('sudokusmall.png') rows,cols,ch = img.shape pts1 = np.float32([[56,65],[368,52],[28,387],[389,390]]) pts2 = np.float32([[0,0],[300,0],[0,300],[300,300]]) M = cv2.getPerspectiveTransform(pts1,pts2) dst = cv2.warpPerspective(img,M,(300,300)) plt.subplot(121),plt.imshow(img),plt.title('Input') plt.subplot(122),plt.imshow(dst),plt.title('Output') plt.show()
Result:
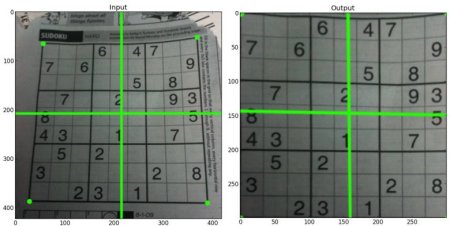
Additional Resources¶
- “Computer Vision: Algorithms and Applications”, Richard Szeliski
Exercises¶
Сегодня мы продолжим изучать библиотеку OpenCV. А точнее познакомимся с базовыми возможностями по работе с изображением. Что такое OpenCV как установить и т.д читаем тут.
Первым делом мы выведем картинку на экран :
import cv2
#Загружаем изображение
image = cv2.imread("fice_11.jpg")
#Отображение файла встроенными средствами OpenCV.
cv2.imshow("Original image", image) #
cv2.waitKey(0) # Ждем нажатия любой клавиши


Функция imread загружает изображение из указанного файла и возвращает его. Если изображение не может быть прочитано ( из-за отсутствия файла, неправильных разрешений, неподдерживаемого или недопустимого формата), функция возвращает пустую матрицу (Mat::data ==NULL ).
print(image.shape)
Посмотрев размер массива мы можем узнать разрешение картинки, например (1024, 1536, 3). Высота 1024, Ширина 1536, 3 канала цвета.
Давайте изменим размер картинки(resize image) :
# Считаем коэффициент соотношения сторон, что бы сохранить пропорции
final_wide = int(input())
k = float(final_wide) / image.shape[1]
new_size = (final_wide, int(image.shape[0] * k))
# уменьшаем изображение до подготовленных размеров
resized = cv2.resize(image, new_size, interpolation=cv2.INTER_AREA)
cv2.imshow("Resize image", resized)
cv2.waitKey(0)
Первым делом мы почитали новый размер картинки и поместили его в переменную new_size. Далее с помощь метода cv2.resize () изменили размер картинки на новый. interpolation=cv2.INTER_AREA -алгоритм интерполяции :
- cv.INTER_NEAREST интерполяция ближайшего соседа .
- cv.INTER_LINEAR билинейная интерполяция.
- cv.INTER_CUBIC бикубическая интерполяция.
- cv.INTER_AREA пересчет с использованием отношения площадей пикселей. Это может быть предпочтительным методом для децимации изображения, так как он он дает результаты без муара. Но когда изображение масштабируется, это похоже на метод INTER_NEAREST.
- cv.INTER_LANCZOS4 Интерполяция Lanczos по окрестности 8×8 .
Теперь сохраним полученное изображение в новый файл :
# запишем изображение на диск в формате png
cv2.imwrite("resize.png", resized)
Переворот (flip) :
#отразим изображение по горизонтали
flip_image = cv2.flip(resized, 1)
cv2.imshow("Flip image", flip_image)
cv2.waitKey(0)
cv2.flip () Переворачивает 2D массив вокруг вертикальной, горизонтальной или обеих осей.
- 1 — означает переворот вокруг оси y .
- 0 — означает переворот вокруг оси x .
- -1 — означает переворот по обоим осям .

Кадрирование :
Загружаем фото в виде массива Numpy. Поэтому нам ничего не мешает взять любой кусок массива и сохранить в новый файл и т.д. Для этого можно легко воспользоваться срезами:
# вырежем участок изображения используя срезы
cropped = image[0:700, 300:1200]
cv2.imshow("Cropped image", cropped)
cv2.waitKey(0)

Размытие по Гауссу ( Gaussian blur) :
# Размытие по гауссу
gaus = cv2.GaussianBlur(image, (9, 9), 10)
cv2.imshow("Gaussian blur", gaus)
cv2.waitKey(0)

cv2.GaussianBlur() — Первый параметр массив картинки, далее (9, 9) так называемый размер ядра фильтра, чем больше значение тем больше размытие(значения должны быть не четными) . Далее идет стандартное отклонение по оси X .
Наложение текста и графики на картинку :
color_yellow = (0,255,255)
text = cv2.putText(resized, "Yooohhoo!", (100,50), cv2.FONT_HERSHEY_SIMPLEX, 1, color_yellow, 2)
cv2.imshow("Text", text)
cv2.waitKey(0)

Мы наложили текс, а теперь по по порядку. Первый параметр понятен, массив картинки (resized). Второй тоже очевиден, текст («Yooohhoo!»).
Третий (100, 50) кортеж из двух координат нижнего левого угла текста.
Далее идет тип шрифта :
- FONT_HERSHEY_SIMPLEX
- FONT_HERSHEY_PLAIN
- FONT_HERSHEY_DUPLEX
- FONT_HERSHEY_COMPLEX
- FONT_HERSHEY_TRIPLEX
- FONT_HERSHEY_COMPLEX_SMALL
- FONT_HERSHEY_SCRIPT_SIMPLEX
- FONT_HERSHEY_SCRIPT_COMPLEX
Далее идет масштаб шрифта (1) : у шрифта есть некий стандартный размер, который довольно таки большой. Этот параметр позволяет уменьшать или увеличивать шрифт относительно стандартного. Например, для увеличения в два раза — пишем 2, для уменьшения в 2 раза — 0.5.
Далее идет кортеж из трех чисел от 0 до 255 (color_yellow), которые задают цвет в модели RGB. Нужно помнить, что в этом кортеже, цвета идут задом на перед: BGR. Синий цвет — (255,0,0).
Далее идут не обязательны параметры :
- толщина пера (2) — необязательный параметр;
- тип линии — необязательный параметр, одно из трех значений: LINE_8 пунктир мелкий, LINE_4 — пунктир крупный, LINE_AA — сглаженная линия;
- центр координат — необязательный параметр. По-умолчанию координаты текста отсчитываются от верхнего левого угла. Если этот параметр равен True, то будут от нижнего левого угол.
Чертим линии :
line( кадр, координаты начала, координаты конца, цвет [, толщина пера [, тип линии [, сдвиг]]])
Помимо известных уже аргументов есть и один новый:
- сдвиг — необязательный параметр. Отвечает за смещение координат по формуле x = x*2^-сдвиг. Применяется для создания сглаженных линий.
Переходим к прямоугольнику:
rectangle( кадр, координаты 1, координаты 2, цвет [, толщина пера [, тип линии [, сдвиг]]])
Здесь:
- координаты 1 — координаты верхнего левого угла;
- координаты 2 — координаты нижнего правого угла.
color_red = (0, 0, 255)
line = cv2.line(resized, (180, 85), (370, 85), color_red, thickness=2, lineType=8, shift=0)
line = cv2.rectangle(line, (180, 140), (370, 180), color_red, thickness=2, lineType=8, shift=0)
cv2.imshow("Line", line)
cv2.waitKey(0)

Ошибка в тексте? Выделите её и нажмите «Ctrl + Enter»