Сталкивались ли вы с трудностями при отладке Python-кода? Если это так — то изучение того, как наладить логирование (журналирование, logging) в Python, способно помочь вам упростить задачи, решаемые при отладке.

Если вы — новичок, то вы, наверняка, привыкли пользоваться командой print(), выводя с её помощью определённые значения в ходе работы программы, проверяя, работает ли код так, как от него ожидается. Использование print() вполне может оправдать себя при отладке маленьких Python-программ. Но, когда вы перейдёте к более крупным и сложным проектам, вам понадобится постоянный журнал, содержащий больше информации о поведении вашего кода, помогающий вам планомерно отлаживать и отслеживать ошибки.
Из этого учебного руководства вы узнаете о том, как настроить логирование в Python, используя встроенный модуль logging. Вы изучите основы логирования, особенности вывода в журналы значений переменных и исключений, разберётесь с настройкой собственных логгеров, с форматировщиками вывода и со многим другим.
Вы, кроме того, узнаете о том, как Sentry Python SDK способен помочь вам в мониторинге приложений и в упрощении рабочих процессов, связанных с отладкой кода. Платформа Sentry обладает нативной интеграцией со встроенным Python-модулем logging, и, кроме того, предоставляет подробную информацию об ошибках приложения и о проблемах с производительностью, которые в нём возникают.
Начало работы с Python-модулем logging
В Python имеется встроенный модуль logging, применяемый для решения задач логирования. Им мы будем пользоваться в этом руководстве. Первый шаг к профессиональному логированию вы можете выполнить прямо сейчас, импортировав этот модуль в своё рабочее окружение.
import loggingВстроенный модуль логирования Python даёт нам простой в использовании функционал и предусматривает пять уровней логирования. Чем выше уровень — тем серьёзнее неприятность, о которой сообщает соответствующая запись. Самый низкий уровень логирования — это debug (10), а самый высокий — это critical (50).
Дадим краткие характеристики уровней логирования:
-
Debug (10): самый низкий уровень логирования, предназначенный для отладочных сообщений, для вывода диагностической информации о приложении. -
Info (20): этот уровень предназначен для вывода данных о фрагментах кода, работающих так, как ожидается. -
Warning (30): этот уровень логирования предусматривает вывод предупреждений, он применяется для записи сведений о событиях, на которые программист обычно обращает внимание. Такие события вполне могут привести к проблемам при работе приложения. Если явно не задать уровень логирования — по умолчанию используется именноwarning. -
Error (40): этот уровень логирования предусматривает вывод сведений об ошибках — о том, что часть приложения работает не так как ожидается, о том, что программа не смогла правильно выполниться. -
Critical (50): этот уровень используется для вывода сведений об очень серьёзных ошибках, наличие которых угрожает нормальному функционированию всего приложения. Если не исправить такую ошибку — это может привести к тому, что приложение прекратит работу.
В следующем фрагменте кода показано использование вышеперечисленных уровней логирования при выводе нескольких сообщений. Здесь используется синтаксическая конструкция logging.<level>(<message>).
logging.debug("A DEBUG Message")
logging.info("An INFO")
logging.warning("A WARNING")
logging.error("An ERROR")
logging.critical("A message of CRITICAL severity")Ниже приведён результат выполнения этого кода. Как видите, сообщения, выведенные с уровнями логирования warning, error и critical, попадают в консоль. А сообщения с уровнями debug и info — не попадают.
WARNING:root:A WARNING
ERROR:root:An ERROR
CRITICAL:root:A message of CRITICAL severityЭто так из-за того, что в консоль выводятся лишь сообщения с уровнями от warning и выше. Но это можно изменить, настроив логгер и указав ему, что в консоль надо выводить сообщения, начиная с некоего, заданного вами, уровня логирования.
Подобный подход к логированию, когда данные выводятся в консоль, не особо лучше использования print(). На практике может понадобиться записывать логируемые сообщения в файл. Этот файл будет хранить данные и после того, как работа программы завершится. Такой файл можно использовать в качестве журнала отладки.
Обратите внимание на то, что в примере, который мы будем тут разбирать, весь код находится в файле main.py. Когда мы производим рефакторинг существующего кода или добавляем новые модули — мы сообщаем о том, в какой файл (имя которого построено по схеме <module-name>.py) попадает новый код. Это поможет вам воспроизвести у себя то, о чём тут идёт речь.
Логирование в файл
Для того чтобы настроить простую систему логирования в файл — можно воспользоваться конструктором basicConfig(). Вот как это выглядит:
logging.basicConfig(level=logging.INFO, filename="py_log.log",filemode="w")
logging.debug("A DEBUG Message")
logging.info("An INFO")
logging.warning("A WARNING")
logging.error("An ERROR")
logging.critical("A message of CRITICAL severity")Поговорим о логгере root, рассмотрим параметры basicConfig():
-
level: это — уровень, на котором нужно начинать логирование. Если он установлен вinfo— это значит, что все сообщения с уровнемdebugигнорируются. -
filename: этот параметр указывает на объект обработчика файла. Тут можно указать имя файла, в который нужно осуществлять логирование. -
filemode: это — необязательный параметр, указывающий режим, в котором предполагается работать с файлом журнала, заданным параметромfilename. Установкаfilemodeв значениеw(write, запись) приводит к тому, что логи перезаписываются при каждом запуске модуля. По умолчанию параметрfilemodeустановлен в значениеa(append, присоединение), то есть — в файл будут попадать записи из всех сеансов работы программы.
После выполнения модуля main можно будет увидеть, что в текущей рабочей директории был создан файл журнала, py_log.log.

Так как мы установили уровень логирования в значение info — в файл попадут записи с уровнем info и с более высокими уровнями.

Записи в лог-файле имеют формат <logging-level>:<name-of-the-logger>:<message>. По умолчанию <name-of-the-logger>, имя логгера, установлено в root, так как мы пока не настраивали пользовательские логгеры.

Помимо базовой информации, выводимой в лог, может понадобится снабдить записи отметками времени, указывающими на момент вывода той или иной записи. Это упрощает анализ логов. Сделать это можно, воспользовавшись параметром конструктора format:
logging.basicConfig(level=logging.INFO, filename="py_log.log",filemode="w",
format="%(asctime)s %(levelname)s %(message)s")
logging.debug("A DEBUG Message")
logging.info("An INFO")
logging.warning("A WARNING")
logging.error("An ERROR")
logging.critical("A message of CRITICAL severity")
Существуют и многие другие атрибуты записи лога, которыми можно воспользоваться для того чтобы настроить внешний вид сообщений в лог-файле. Настраивая поведение логгера root — так, как это показано выше, проследите за тем, чтобы конструктор logging.basicConfig()вызывался бы лишь один раз. Обычно это делается в начале программы, до использования команд логирования. Последующие вызовы конструктора ничего не изменят — если только не установить параметр force в значение True.
Логирование значений переменных и исключений
Модифицируем файл main.py. Скажем — тут будут две переменных — x и y, и нам нужно вычислить значение выражения x/y. Мы знаем о том, что при y=0 мы столкнёмся с ошибкой ZeroDivisionError. Обработать эту ошибку можно в виде исключения с использованием блока try/except.
Далее — нужно залогировать исключение вместе с данными трассировки стека. Чтобы это сделать — можно воспользоваться logging.error(message, exc_info=True). Запустите следующий код и посмотрите на то, как в файл попадают записи с уровнем логирования info, указывающие на то, что код работает так, как ожидается.
x = 3
y = 4
logging.info(f"The values of x and y are {x} and {y}.")
try:
x/y
logging.info(f"x/y successful with result: {x/y}.")
except ZeroDivisionError as err:
logging.error("ZeroDivisionError",exc_info=True)
Теперь установите значение y в 0 и снова запустите модуль.
Исследуя лог-файл py_log.log, вы увидите, что сведения об исключении были записаны в него вместе со стек-трейсом.
x = 4
y = 0
logging.info(f"The values of x and y are {x} and {y}.")
try:
x/y
logging.info(f"x/y successful with result: {x/y}.")
except ZeroDivisionError as err:
logging.error("ZeroDivisionError",exc_info=True)
Теперь модифицируем код так, чтобы в нём имелись бы списки значений x и y, для которых нужно вычислить коэффициенты x/y. Для логирования исключений ещё можно воспользоваться конструкцией logging.exception(<message>).
x_vals = [2,3,6,4,10]
y_vals = [5,7,12,0,1]
for x_val,y_val in zip(x_vals,y_vals):
x,y = x_val,y_val
logging.info(f"The values of x and y are {x} and {y}.")
try:
x/y
logging.info(f"x/y successful with result: {x/y}.")
except ZeroDivisionError as err:
logging.exception("ZeroDivisionError")Сразу после запуска этого кода можно будет увидеть, что в лог-файл попала информация и о событиях успешного вычисления коэффициента, и об ошибке, когда возникло исключение.

Настройка логирования с помощью пользовательских логгеров, обработчиков и форматировщиков
Отрефакторим код, который у нас уже есть. Объявим функцию test_division.
def test_division(x,y):
try:
x/y
logger2.info(f"x/y successful with result: {x/y}.")
except ZeroDivisionError as err:
logger2.exception("ZeroDivisionError")Объявление этой функции находится в модуле test_div. В модуле main будут лишь вызовы функций. Настроим пользовательские логгеры в модулях main и test_div, проиллюстрировав это примерами кода.
Настройка пользовательского логгера для модуля test_div
import logging
logger2 = logging.getLogger(__name__)
logger2.setLevel(logging.INFO)
# настройка обработчика и форматировщика для logger2
handler2 = logging.FileHandler(f"{__name__}.log", mode='w')
formatter2 = logging.Formatter("%(name)s %(asctime)s %(levelname)s %(message)s")
# добавление форматировщика к обработчику
handler2.setFormatter(formatter2)
# добавление обработчика к логгеру
logger2.addHandler(handler2)
logger2.info(f"Testing the custom logger for module {__name__}...")
def test_division(x,y):
try:
x/y
logger2.info(f"x/y successful with result: {x/y}.")
except ZeroDivisionError as err:
logger2.exception("ZeroDivisionError")Настройка пользовательского логгера для модуля main
import logging
from test_div import test_division
# получение пользовательского логгера и установка уровня логирования
py_logger = logging.getLogger(__name__)
py_logger.setLevel(logging.INFO)
# настройка обработчика и форматировщика в соответствии с нашими нуждами
py_handler = logging.FileHandler(f"{__name__}.log", mode='w')
py_formatter = logging.Formatter("%(name)s %(asctime)s %(levelname)s %(message)s")
# добавление форматировщика к обработчику
py_handler.setFormatter(py_formatter)
# добавление обработчика к логгеру
py_logger.addHandler(py_handler)
py_logger.info(f"Testing the custom logger for module {__name__}...")
x_vals = [2,3,6,4,10]
y_vals = [5,7,12,0,1]
for x_val,y_val in zip(x_vals,y_vals):
x,y = x_val, y_val
# вызов test_division
test_division(x,y)
py_logger.info(f"Call test_division with args {x} and {y}")
Разберёмся с тем, что происходит коде, где настраиваются пользовательские логгеры.
Сначала мы получаем логгер и задаём уровень логирования. Команда logging.getLogger(name) возвращает логгер с заданным именем в том случае, если он существует. В противном случае она создаёт логгер с заданным именем. На практике имя логгера устанавливают с использованием специальной переменной name, которая соответствует имени модуля. Мы назначаем объект логгера переменной. Затем мы, используя команду logging.setLevel(level), устанавливаем нужный нам уровень логирования.
Далее мы настраиваем обработчик. Так как мы хотим записывать сведения о событиях в файл, мы пользуемся FileHandler. Конструкция logging.FileHandler(filename) возвращает объект обработчика файла. Помимо имени лог-файла, можно, что необязательно, задать режим работы с этим файлом. В данном примере режим (mode) установлен в значение write. Есть и другие обработчики, например — StreamHandler, HTTPHandler, SMTPHandler.
Затем мы создаём объект форматировщика, используя конструкцию logging.Formatter(format). В этом примере мы помещаем имя логгера (строку) в начале форматной строки, а потом идёт то, чем мы уже пользовались ранее при оформлении сообщений.
Потом мы добавляем форматировщик к обработчику, пользуясь конструкцией вида <handler>.setFormatter(<formatter>). А в итоге добавляем обработчик к объекту логгера, пользуясь конструкцией <logger>.addHandler(<handler>).
Теперь можно запустить модуль main и исследовать сгенерированные лог-файлы.


Рекомендации по организации логирования в Python
До сих пор мы говорили о том, как логировать значения переменных и исключения, как настраивать пользовательские логгеры. Теперь же предлагаю вашему вниманию рекомендации по логированию.
-
Устанавливайте оптимальный уровень логирования. Логи полезны лишь тогда, когда их можно использовать для отслеживания важных ошибок, которые нужно исправлять. Подберите такой уровень логирования, который соответствует специфике конкретного приложения. Вывод в лог сообщений о слишком большом количестве событий может быть, с точки зрения отладки, не самой удачной стратегией. Дело в том, что при таком подходе возникнут сложности с фильтрацией логов при поиске ошибок, которым нужно немедленно уделить внимание.
-
Конфигурируйте логгеры на уровне модуля. Когда вы работаете над приложением, состоящим из множества модулей — вам стоит задуматься о том, чтобы настроить свой логгер для каждого модуля. Установка имени логгера в
nameпомогает идентифицировать модуль приложения, в котором имеются проблемы, нуждающиеся в решении. -
Включайте в состав сообщений логов отметку времени и обеспечьте единообразное форматирование сообщений. Всегда включайте в сообщения логов отметки времени, так как они полезны в деле поиска того момента, когда произошла ошибка. Единообразно форматируйте сообщения логов, придерживаясь одного и того же подхода в разных модулях.
-
Применяйте ротацию лог-файлов ради упрощения отладки. При работе над большим приложением, в состав которого входит несколько модулей, вы, вполне вероятно, столкнётесь с тем, что размер ваших лог-файлов окажется очень большим. Очень длинные логи сложно просматривать в поисках ошибок. Поэтому стоит подумать о ротации лог-файлов. Сделать это можно, воспользовавшись обработчиком
RotatingFileHandler, применив конструкцию, которая строится по следующей схеме:logging.handlers.RotatingFileHandler(filename, maxBytes, backupCount). Когда размер текущего лог-файла достигнет размераmaxBytes, следующие записи будут попадать в другие файлы, количество которых зависит от значения параметраbackupCount. Если установить этот параметр в значениеK— у вас будетKфайлов журнала.
Сильные и слабые стороны логирования
Теперь, когда мы разобрались с основами логирования в Python, поговорим о сильных и слабых сторонах этого механизма.
Мы уже видели, как логирование позволяет поддерживать файлы журналов для различных модулей, из которых состоит приложение. Мы, кроме того, можем конфигурировать подсистему логирования и подстраивать её под свои нужды. Но эта система не лишена недостатков. Даже когда уровень логирования устанавливают в значение warning, или в любое значение, которое выше warning, размеры лог-файлов способны быстро увеличиваться. Происходит это в том случае, когда в один и тот же журнал пишут данные, полученные после нескольких сеансов работы с приложением. В результате использование лог-файлов для отладки программ превращается в нетривиальную задачу.
Кроме того, исследование логов ошибок — это сложно, особенно в том случае, если сообщения об ошибках не содержат достаточных сведений о контекстах, в которых происходят ошибки. Когда выполняют команду logging.error(message), не устанавливая при этом exc_info в True, сложно обнаружить и исследовать первопричину ошибки в том случае, если сообщение об ошибке не слишком информативно.
В то время как логирование даёт диагностическую информацию, сообщает о том, что в приложении нужно исправить, инструменты для мониторинга приложений, вроде Sentry, могут предоставить более детальную информацию, которая способна помочь в диагностике приложения и в исправлении проблем с производительностью.
В следующем разделе мы поговорим о том, как интегрировать в Python-проект поддержку Sentry, что позволит упростить процесс отладки кода.
Интеграция Sentry в Python-проект
Установить Sentry Python SDK можно, воспользовавшись менеджером пакетов pip.
pip install sentry-sdkПосле установки SDK для настройки мониторинга приложения нужно воспользоваться таким кодом:
sentry_sdk.init(
dsn="<your-dsn-key-here>",
traces_sample_rate=0.85,
)Как можно видеть — вам, для настройки мониторинга, понадобится ключ dsn. DSN расшифровывается как Data Source Name (имя источника данных). Найти этот ключ можно, перейдя в Your-Project > Settings > Client Keys (DSN).
После того, как вы запустите Python-приложение, вы можете перейти на Sentry.io и открыть панель управления проекта. Там должны быть сведения о залогированных ошибках и о других проблемах приложения. В нашем примере можно видеть сообщение об исключении, соответствующем ошибке ZeroDivisionError.

Изучая подробности об ошибке, вы можете увидеть, что Sentry предоставляет подробную информацию о том, где именно произошла ошибка, а так же — об аргументах x и y, работа с которыми привела к появлению исключения.

Продолжая изучение логов, можно увидеть, помимо записей уровня error, записи уровня info. Налаживая мониторинг приложения с использованием Sentry, нужно учитывать, что эта платформа интегрирована с модулем logging. Вспомните — в нашем экспериментальном проекте уровень логирования был установлен в значение info. В результате Sentry записывает все события, уровень которых соответствует info и более высоким уровням, делая это в стиле «навигационной цепочки», что упрощает отслеживание ошибок.
Sentry позволяет фильтровать записи по уровням логирования, таким, как info и error. Это удобнее, чем просмотр больших лог-файлов в поиске потенциальных ошибок и сопутствующих сведений. Это позволяет назначать решению проблем приоритеты, зависящие от серьёзности этих проблем, и, кроме того, позволяет, используя навигационные цепочки, находить источники неполадок.

В данном примере мы рассматриваем ZeroDivisionError как исключение. В более крупных проектах, даже если мы не реализуем подобный механизм обработки исключений, Sentry автоматически предоставит диагностическую информацию о наличии необработанных исключений. С помощью Sentry, кроме того, можно анализировать проблемы с производительностью кода.

Код, использованный в данном руководстве, можно найти в этом GitHub-репозитории.
Итоги
Освоив это руководство, вы узнали о том, как настраивать логирование с использованием стандартного Python-модуля logging. Вы освоили основы настройки логгера root и пользовательских логгеров, ознакомились с рекомендациями по логированию. Вы, кроме того, узнали о том, как платформа Sentry может помочь вам в деле мониторинга ваших приложений, обеспечивая вас сведениями о проблемах с производительностью и о других ошибках, и используя при этом все возможности модуля logging.
Когда вы будете работать над своим следующим Python-проектом — не забудьте реализовать в нём механизмы логирования. И можете испытать бесплатную пробную версию Sentry.
О, а приходите к нам работать? 🤗 💰
Мы в wunderfund.io занимаемся высокочастотной алготорговлей с 2014 года. Высокочастотная торговля — это непрерывное соревнование лучших программистов и математиков всего мира. Присоединившись к нам, вы станете частью этой увлекательной схватки.
Мы предлагаем интересные и сложные задачи по анализу данных и low latency разработке для увлеченных исследователей и программистов. Гибкий график и никакой бюрократии, решения быстро принимаются и воплощаются в жизнь.
Сейчас мы ищем плюсовиков, питонистов, дата-инженеров и мл-рисерчеров.
Присоединяйтесь к нашей команде.
Logging is used to track events that happen when an application runs. Logging calls are added to application code to record or log the events and errors that occur during program execution. In Python, the logging module is used to log such events and errors.
An event can be described by a message and can optionally contain data specific to the event. Events also have a level or severity assigned by the developer.
Logging is very useful for debugging and for tracking any required information.
How to Use Logging in Python
The Logging Module
The Python standard library contains a logging module that provides a flexible framework for writing log messages from Python code. This module is widely used and is the starting point for most Python developers to use logging.
The logging module provides ways for applications to configure different log handlers and to route log messages to these handlers. This enables a highly flexible configuration that helps to handle many different use cases.
To write a log message, a caller requests a named logger. This logger can be used to write formatted messages using a log level (DEBUG, INFO, ERROR etc). Here’s an example:
import logging
log = logging.getLogger("mylogger")
log.info("Hello World")Logging Levels
The standard logging levels in Python (in increasing order of severity) and their applicability are:
- DEBUG — Detailed information, typically of interest when diagnosing problems.
- INFO — Confirmation of things working as expected.
- WARNING — Indication of something unexpected or a problem in the near future e.g. ‘disk space low’.
- ERROR — A more serious problem due to which the program was unable to perform a function.
- CRITICAL — A serious error, indicating that the program itself may not be able to continue executing.
The default log level is WARNING, which means that only events of this level and above are logged by default.
Configuring Logging
In general, a configuration consists of adding a Formatter and a Handler to the root logger. The Python logging module provides a number of ways to configure logging:
- Creating loggers, handlers and formatters programmatically that call the configuration methods.
- Creating a logging configuration file and reading it.
- Creating a dictionary of config information and passing it to the
dictConfig()function.
The official Python documentation recommends configuring the error logger via Python dictionary. To do this logging.config.dictConfig needs to be called which accepts the dictionary as an argument. Its schema is:
version— Should be 1 for backwards compatibilitydisable_existing_loggers— Disables the configuration for existing loggers. This isTrueby default.formatters— Formatter settingshandlers— Handler settingsloggers— Logger settings
It is best practice to configure this by creating a new module e.g. settings.py or conf.py. Here’s an example:
import logging.config
MY_LOGGING_CONFIG = {
'version': 1,
'disable_existing_loggers': False,
'formatters': {
'default_formatter': {
'format': '[%(levelname)s:%(asctime)s] %(message)s'
},
},
'handlers': {
'stream_handler': {
'class': 'logging.StreamHandler',
'formatter': 'default_formatter',
},
},
'loggers': {
'mylogger': {
'handlers': ['stream_handler'],
'level': 'INFO',
'propagate': True
}
}
}
logging.config.dictConfig(MY_LOGGING_CONFIG)
logger = logging.getLogger('mylogger')
logger.info('info log')How to Use Logging for Debugging
Besides the logging levels described earlier, exceptions can also be logged with associated traceback information. With logger.exception, traceback information can be included along with the message in case of any errors. This can be highly useful for debugging issues. Here’s an example:
import logging
logger = logging.getLogger(“mylogger”)
logger.setLevel(logging.INFO)
def add(a, b):
try:
result = a + b
except TypeError:
logger.exception("TypeError occurred")
else:
return result
c = add(10, 'Bob')Running the above code produces the following output:
TypeError occurred
Traceback (most recent call last):
File "test.py", line 8, in add
result = a + b
TypeError: unsupported operand type(s) for +: 'int' and 'str'The output includes the message as well as the traceback info, which can be used to debug the issue.
Python Logging Examples
Basic Logging
Here’s a very simple example of logging using the root logger with basic config:
import logging
logging.basicConfig(level=logging.INFO)
logging.info('Hello World')Here, the basic Python error logging configuration was set up using logging.basicConfig(). The log level was set to logging.INFO, which means that messages with a level of INFO and above will be logged. Running the above code produces the following output:
INFO:root:Hello WorldThe message is printed to the console, which is the default output destination. The printed message includes the level and the description of the event provided in the logging call.
Logging to a File
A very common use case is logging events to a file. Here’s an example:
import logging
logging.basicConfig(level=logging.INFO, filename='sample.log', encoding='utf-8')
logging.info('Hello World')Running the above code should create a log file sample.log in the current working directory (if it doesn’t exist already). All subsequent log messages will go straight to this file. The file should contain the following log message after the above code is executed:
INFO:root:Hello WorldLog Message Formatting
The log message format can be specified using the format argument of logging.basicConfig(). Here’s an example:
import logging
logging.basicConfig(level=logging.INFO, format='%(asctime)s:%(levelname)s:%(message)s')
logging.info('Hello World')Running the above code changes the log message format to show the time, level and message and produces the following output:
2021-12-09 16:28:25,008:INFO:Hello WorldPython Error Logging Using Handler and Formatter
Handlers and formatters are used to set up the output location and the message format for loggers. The FileHandler() class can be used to setup the output file for logs:
import logging
logger = logging.getLogger(__name__)
logger.setLevel(logging.INFO)
file_handler = logging.FileHandler('sample.log')
formatter = logging.Formatter('%(asctime)s:%(levelname)s:%(message)s')
file_handler.setFormatter(formatter)
logger.addHandler(file_handler)
logger.info('Hello World')Running the above code will create the log file sample.log if it doesn’t exist already and write the following log message to the file:
2021-12-10 15:49:46,494:INFO:Hello WorldFrequently Asked Questions
What is logging in Python?
Logging in Python allows the tracking of events during program execution. Logs are added to application code to indicate the occurrence of certain events. An event is described by a message and optional variable data specific to the event. In Python, the built-in logging module can be used to log events.
Log messages can have 5 levels — DEBUG, INGO, WARNING, ERROR and CRITICAL. They can also include traceback information for exceptions. Logs can be especially useful in case of errors to help identify their cause.
What is logging getLogger Python?
To start logging using the Python logging module, the factory function logging.getLogger(name) is typically executed. The getLogger() function accepts a single argument — the logger’s name. It returns a reference to a logger instance with the specified name if provided, or root if not. Multiple calls to getLogger() with the same name will return a reference to the same logger object.
Any logger name can be provided, but the convention is to use the __name__ variable as the argument, which holds the name of the current module. The names are separated by periods(.) and are hierarchical structures. Loggers further down the list are children of loggers higher up the list. For example, given a logger foo, loggers further down such as foo.bar are descendants of foo.
Track, Analyze and Manage Errors With Rollbar
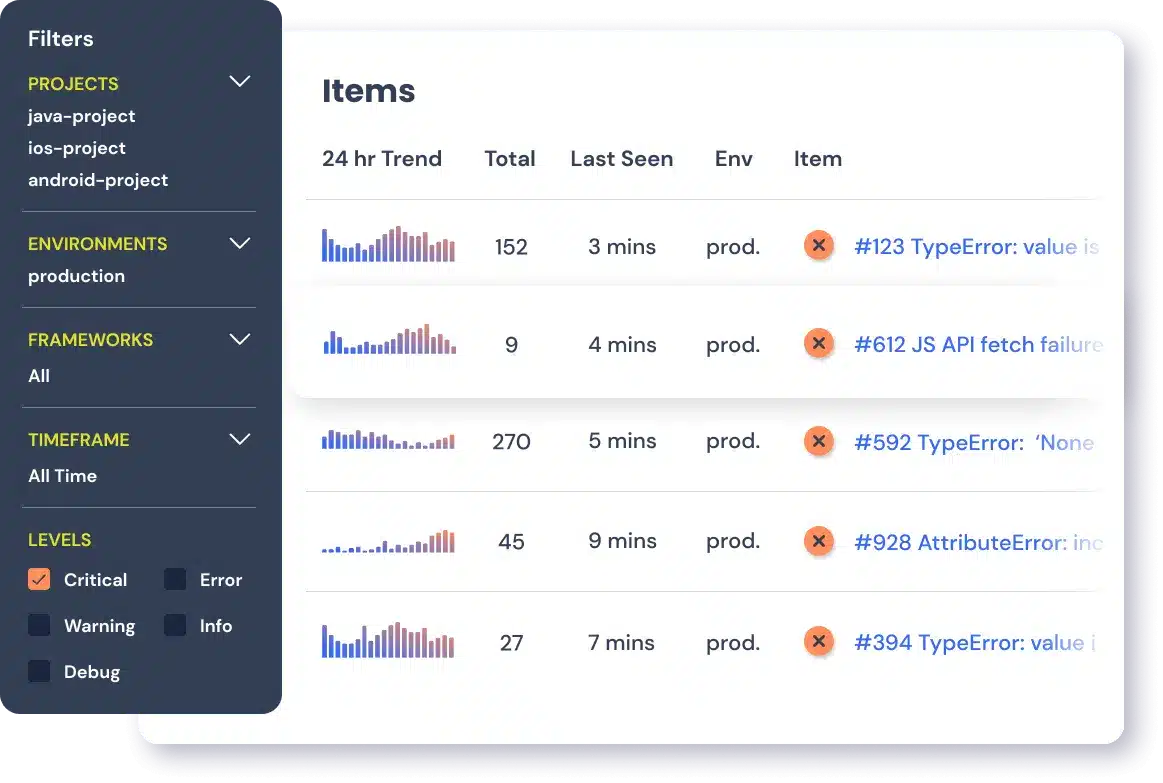 Managing errors and exceptions in your code is challenging. It can make deploying production code an unnerving experience. Being able to track, analyze, and manage errors in real-time can help you to proceed with more confidence. Rollbar automates error monitoring and triaging, making fixing Java errors easier than ever. Sign Up Today!
Managing errors and exceptions in your code is challenging. It can make deploying production code an unnerving experience. Being able to track, analyze, and manage errors in real-time can help you to proceed with more confidence. Rollbar automates error monitoring and triaging, making fixing Java errors easier than ever. Sign Up Today!
Watch Now This tutorial has a related video course created by the Real Python team. Watch it together with the written tutorial to deepen your understanding: Logging in Python
Logging is a very useful tool in a programmer’s toolbox. It can help you develop a better understanding of the flow of a program and discover scenarios that you might not even have thought of while developing.
Logs provide developers with an extra set of eyes that are constantly looking at the flow that an application is going through. They can store information, like which user or IP accessed the application. If an error occurs, then they can provide more insights than a stack trace by telling you what the state of the program was before it arrived at the line of code where the error occurred.
By logging useful data from the right places, you can not only debug errors easily but also use the data to analyze the performance of the application to plan for scaling or look at usage patterns to plan for marketing.
Python provides a logging system as a part of its standard library, so you can quickly add logging to your application. In this article, you will learn why using this module is the best way to add logging to your application as well as how to get started quickly, and you will get an introduction to some of the advanced features available.
The Logging Module
The logging module in Python is a ready-to-use and powerful module that is designed to meet the needs of beginners as well as enterprise teams. It is used by most of the third-party Python libraries, so you can integrate your log messages with the ones from those libraries to produce a homogeneous log for your application.
Adding logging to your Python program is as easy as this:
With the logging module imported, you can use something called a “logger” to log messages that you want to see. By default, there are 5 standard levels indicating the severity of events. Each has a corresponding method that can be used to log events at that level of severity. The defined levels, in order of increasing severity, are the following:
- DEBUG
- INFO
- WARNING
- ERROR
- CRITICAL
The logging module provides you with a default logger that allows you to get started without needing to do much configuration. The corresponding methods for each level can be called as shown in the following example:
import logging
logging.debug('This is a debug message')
logging.info('This is an info message')
logging.warning('This is a warning message')
logging.error('This is an error message')
logging.critical('This is a critical message')
The output of the above program would look like this:
WARNING:root:This is a warning message
ERROR:root:This is an error message
CRITICAL:root:This is a critical message
The output shows the severity level before each message along with root, which is the name the logging module gives to its default logger. (Loggers are discussed in detail in later sections.) This format, which shows the level, name, and message separated by a colon (:), is the default output format that can be configured to include things like timestamp, line number, and other details.
Notice that the debug() and info() messages didn’t get logged. This is because, by default, the logging module logs the messages with a severity level of WARNING or above. You can change that by configuring the logging module to log events of all levels if you want. You can also define your own severity levels by changing configurations, but it is generally not recommended as it can cause confusion with logs of some third-party libraries that you might be using.
Basic Configurations
You can use the basicConfig(**kwargs) method to configure the logging:
“You will notice that the logging module breaks PEP8 styleguide and uses
camelCasenaming conventions. This is because it was adopted from Log4j, a logging utility in Java. It is a known issue in the package but by the time it was decided to add it to the standard library, it had already been adopted by users and changing it to meet PEP8 requirements would cause backwards compatibility issues.” (Source)
Some of the commonly used parameters for basicConfig() are the following:
level: The root logger will be set to the specified severity level.filename: This specifies the file.filemode: Iffilenameis given, the file is opened in this mode. The default isa, which means append.format: This is the format of the log message.
By using the level parameter, you can set what level of log messages you want to record. This can be done by passing one of the constants available in the class, and this would enable all logging calls at or above that level to be logged. Here’s an example:
import logging
logging.basicConfig(level=logging.DEBUG)
logging.debug('This will get logged')
DEBUG:root:This will get logged
All events at or above DEBUG level will now get logged.
Similarly, for logging to a file rather than the console, filename and filemode can be used, and you can decide the format of the message using format. The following example shows the usage of all three:
import logging
logging.basicConfig(filename='app.log', filemode='w', format='%(name)s - %(levelname)s - %(message)s')
logging.warning('This will get logged to a file')
root - ERROR - This will get logged to a file
The message will look like this but will be written to a file named app.log instead of the console. The filemode is set to w, which means the log file is opened in “write mode” each time basicConfig() is called, and each run of the program will rewrite the file. The default configuration for filemode is a, which is append.
You can customize the root logger even further by using more parameters for basicConfig(), which can be found here.
It should be noted that calling basicConfig() to configure the root logger works only if the root logger has not been configured before. Basically, this function can only be called once.
debug(), info(), warning(), error(), and critical() also call basicConfig() without arguments automatically if it has not been called before. This means that after the first time one of the above functions is called, you can no longer configure the root logger because they would have called the basicConfig() function internally.
The default setting in basicConfig() is to set the logger to write to the console in the following format:
ERROR:root:This is an error message
Formatting the Output
While you can pass any variable that can be represented as a string from your program as a message to your logs, there are some basic elements that are already a part of the LogRecord and can be easily added to the output format. If you want to log the process ID along with the level and message, you can do something like this:
import logging
logging.basicConfig(format='%(process)d-%(levelname)s-%(message)s')
logging.warning('This is a Warning')
18472-WARNING-This is a Warning
format can take a string with LogRecord attributes in any arrangement you like. The entire list of available attributes can be found here.
Here’s another example where you can add the date and time info:
import logging
logging.basicConfig(format='%(asctime)s - %(message)s', level=logging.INFO)
logging.info('Admin logged in')
2018-07-11 20:12:06,288 - Admin logged in
%(asctime)s adds the time of creation of the LogRecord. The format can be changed using the datefmt attribute, which uses the same formatting language as the formatting functions in the datetime module, such as time.strftime():
import logging
logging.basicConfig(format='%(asctime)s - %(message)s', datefmt='%d-%b-%y %H:%M:%S')
logging.warning('Admin logged out')
12-Jul-18 20:53:19 - Admin logged out
You can find the guide here.
Logging Variable Data
In most cases, you would want to include dynamic information from your application in the logs. You have seen that the logging methods take a string as an argument, and it might seem natural to format a string with variable data in a separate line and pass it to the log method. But this can actually be done directly by using a format string for the message and appending the variable data as arguments. Here’s an example:
import logging
name = 'John'
logging.error('%s raised an error', name)
ERROR:root:John raised an error
The arguments passed to the method would be included as variable data in the message.
While you can use any formatting style, the f-strings introduced in Python 3.6 are an awesome way to format strings as they can help keep the formatting short and easy to read:
import logging
name = 'John'
logging.error(f'{name} raised an error')
ERROR:root:John raised an error
Capturing Stack Traces
The logging module also allows you to capture the full stack traces in an application. Exception information can be captured if the exc_info parameter is passed as True, and the logging functions are called like this:
import logging
a = 5
b = 0
try:
c = a / b
except Exception as e:
logging.error("Exception occurred", exc_info=True)
ERROR:root:Exception occurred
Traceback (most recent call last):
File "exceptions.py", line 6, in <module>
c = a / b
ZeroDivisionError: division by zero
[Finished in 0.2s]
If exc_info is not set to True, the output of the above program would not tell us anything about the exception, which, in a real-world scenario, might not be as simple as a ZeroDivisionError. Imagine trying to debug an error in a complicated codebase with a log that shows only this:
ERROR:root:Exception occurred
Here’s a quick tip: if you’re logging from an exception handler, use the logging.exception() method, which logs a message with level ERROR and adds exception information to the message. To put it more simply, calling logging.exception() is like calling logging.error(exc_info=True). But since this method always dumps exception information, it should only be called from an exception handler. Take a look at this example:
import logging
a = 5
b = 0
try:
c = a / b
except Exception as e:
logging.exception("Exception occurred")
ERROR:root:Exception occurred
Traceback (most recent call last):
File "exceptions.py", line 6, in <module>
c = a / b
ZeroDivisionError: division by zero
[Finished in 0.2s]
Using logging.exception() would show a log at the level of ERROR. If you don’t want that, you can call any of the other logging methods from debug() to critical() and pass the exc_info parameter as True.
Classes and Functions
So far, we have seen the default logger named root, which is used by the logging module whenever its functions are called directly like this: logging.debug(). You can (and should) define your own logger by creating an object of the Logger class, especially if your application has multiple modules. Let’s have a look at some of the classes and functions in the module.
The most commonly used classes defined in the logging module are the following:
-
Logger: This is the class whose objects will be used in the application code directly to call the functions. -
LogRecord: Loggers automatically createLogRecordobjects that have all the information related to the event being logged, like the name of the logger, the function, the line number, the message, and more. -
Handler: Handlers send theLogRecordto the required output destination, like the console or a file.Handleris a base for subclasses likeStreamHandler,FileHandler,SMTPHandler,HTTPHandler, and more. These subclasses send the logging outputs to corresponding destinations, likesys.stdoutor a disk file. -
Formatter: This is where you specify the format of the output by specifying a string format that lists out the attributes that the output should contain.
Out of these, we mostly deal with the objects of the Logger class, which are instantiated using the module-level function logging.getLogger(name). Multiple calls to getLogger() with the same name will return a reference to the same Logger object, which saves us from passing the logger objects to every part where it’s needed. Here’s an example:
import logging
logger = logging.getLogger('example_logger')
logger.warning('This is a warning')
This creates a custom logger named example_logger, but unlike the root logger, the name of a custom logger is not part of the default output format and has to be added to the configuration. Configuring it to a format to show the name of the logger would give an output like this:
WARNING:example_logger:This is a warning
Again, unlike the root logger, a custom logger can’t be configured using basicConfig(). You have to configure it using Handlers and Formatters:
“It is recommended that we use module-level loggers by passing
__name__as the name parameter togetLogger()to create a logger object as the name of the logger itself would tell us from where the events are being logged.__name__is a special built-in variable in Python which evaluates to the name of the current module.” (Source)
Using Handlers
Handlers come into the picture when you want to configure your own loggers and send the logs to multiple places when they are generated. Handlers send the log messages to configured destinations like the standard output stream or a file or over HTTP or to your email via SMTP.
A logger that you create can have more than one handler, which means you can set it up to be saved to a log file and also send it over email.
Like loggers, you can also set the severity level in handlers. This is useful if you want to set multiple handlers for the same logger but want different severity levels for each of them. For example, you may want logs with level WARNING and above to be logged to the console, but everything with level ERROR and above should also be saved to a file. Here’s a program that does that:
# logging_example.py
import logging
# Create a custom logger
logger = logging.getLogger(__name__)
# Create handlers
c_handler = logging.StreamHandler()
f_handler = logging.FileHandler('file.log')
c_handler.setLevel(logging.WARNING)
f_handler.setLevel(logging.ERROR)
# Create formatters and add it to handlers
c_format = logging.Formatter('%(name)s - %(levelname)s - %(message)s')
f_format = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
c_handler.setFormatter(c_format)
f_handler.setFormatter(f_format)
# Add handlers to the logger
logger.addHandler(c_handler)
logger.addHandler(f_handler)
logger.warning('This is a warning')
logger.error('This is an error')
__main__ - WARNING - This is a warning
__main__ - ERROR - This is an error
Here, logger.warning() is creating a LogRecord that holds all the information of the event and passing it to all the Handlers that it has: c_handler and f_handler.
c_handler is a StreamHandler with level WARNING and takes the info from the LogRecord to generate an output in the format specified and prints it to the console. f_handler is a FileHandler with level ERROR, and it ignores this LogRecord as its level is WARNING.
When logger.error() is called, c_handler behaves exactly as before, and f_handler gets a LogRecord at the level of ERROR, so it proceeds to generate an output just like c_handler, but instead of printing it to console, it writes it to the specified file in this format:
2018-08-03 16:12:21,723 - __main__ - ERROR - This is an error
The name of the logger corresponding to the __name__ variable is logged as __main__, which is the name Python assigns to the module where execution starts. If this file is imported by some other module, then the __name__ variable would correspond to its name logging_example. Here’s how it would look:
# run.py
import logging_example
logging_example - WARNING - This is a warning
logging_example - ERROR - This is an error
Other Configuration Methods
You can configure logging as shown above using the module and class functions or by creating a config file or a dictionary and loading it using fileConfig() or dictConfig() respectively. These are useful in case you want to change your logging configuration in a running application.
Here’s an example file configuration:
[loggers]
keys=root,sampleLogger
[handlers]
keys=consoleHandler
[formatters]
keys=sampleFormatter
[logger_root]
level=DEBUG
handlers=consoleHandler
[logger_sampleLogger]
level=DEBUG
handlers=consoleHandler
qualname=sampleLogger
propagate=0
[handler_consoleHandler]
class=StreamHandler
level=DEBUG
formatter=sampleFormatter
args=(sys.stdout,)
[formatter_sampleFormatter]
format=%(asctime)s - %(name)s - %(levelname)s - %(message)s
In the above file, there are two loggers, one handler, and one formatter. After their names are defined, they are configured by adding the words logger, handler, and formatter before their names separated by an underscore.
To load this config file, you have to use fileConfig():
import logging
import logging.config
logging.config.fileConfig(fname='file.conf', disable_existing_loggers=False)
# Get the logger specified in the file
logger = logging.getLogger(__name__)
logger.debug('This is a debug message')
2018-07-13 13:57:45,467 - __main__ - DEBUG - This is a debug message
The path of the config file is passed as a parameter to the fileConfig() method, and the disable_existing_loggers parameter is used to keep or disable the loggers that are present when the function is called. It defaults to True if not mentioned.
Here’s the same configuration in a YAML format for the dictionary approach:
version: 1
formatters:
simple:
format: '%(asctime)s - %(name)s - %(levelname)s - %(message)s'
handlers:
console:
class: logging.StreamHandler
level: DEBUG
formatter: simple
stream: ext://sys.stdout
loggers:
sampleLogger:
level: DEBUG
handlers: [console]
propagate: no
root:
level: DEBUG
handlers: [console]
Here’s an example that shows how to load config from a yaml file:
import logging
import logging.config
import yaml
with open('config.yaml', 'r') as f:
config = yaml.safe_load(f.read())
logging.config.dictConfig(config)
logger = logging.getLogger(__name__)
logger.debug('This is a debug message')
2018-07-13 14:05:03,766 - __main__ - DEBUG - This is a debug message
Keep Calm and Read the Logs
The logging module is considered to be very flexible. Its design is very practical and should fit your use case out of the box. You can add basic logging to a small project, or you can go as far as creating your own custom log levels, handler classes, and more if you are working on a big project.
If you haven’t been using logging in your applications, now is a good time to start. When done right, logging will surely remove a lot of friction from your development process and help you find opportunities to take your application to the next level.
Watch Now This tutorial has a related video course created by the Real Python team. Watch it together with the written tutorial to deepen your understanding: Logging in Python
In the vast computing world, there are different programming languages that include facilities for logging. From our previous posts, you can learn best practices about Node logging, Java logging, and Ruby logging. As part of the ongoing logging series, this post describes what you need to discover about Python logging best practices.
Considering that “log” has the double meaning of a (single) log-record and a log-file, this post assumes that “log” refers to a log-file.
Advantages of Python logging
So, why learn about logging in Python? One of Python’s striking features is its capacity to handle high traffic sites, with an emphasis on code readability. Other advantages of logging in Python is its own dedicated library for this purpose, the various outputs where the log records can be directed, such as console, file, rotating file, Syslog, remote server, email, etc., and the large number of extensions and plugins it supports. In this post, you’ll find out examples of different outputs.
Python logging description
The Python standard library provides a logging module as a solution to log events from applications and libraries. Once the Python JSON logger is configured, it becomes part of the Python interpreter process that is running the code. In other words, it is global. You can also configure Python logging subsystem using an external configuration file. The specifications for the logging configuration format are found in the Python standard library.
The logging library is based on a modular approach and includes categories of components: loggers, handlers, filters, and formatters. Basically:
- Loggers expose the interface that application code directly uses.
- Handlers send the log records (created by loggers) to the appropriate destination.
- Filters provide a finer grained facility for determining which log records to output.
- Formatters specify the layout of log records in the final output.
These multiple logger objects are organized into a tree that represents various parts of your system and different third-party libraries that you have installed. When you send a message into one of the loggers, the message gets output on all of that logger’s handlers, using a formatter that’s attached to each handler. The message then propagates up the logger tree until it hits the root logger, or a logger up in the tree that is configured with propagate=False.
Python logging platforms
This is an example of a basic logger in Python:
import logging logging.basicConfig(level=logging.DEBUG, format='%(asctime)s %(levelname)s %(message)s', filename='/tmp/myapp.log', filemode='w') logging.debug("Debug message") logging.info("Informative message") logging.error("Error message")
Line 1: import the logging module.
Line 2: create a basicConf function and pass some arguments to create the log file. In this case, we indicate the severity level, date format, filename and file mode to have the function overwrite the log file.
Line 3 to 5: messages for each logging level.
The default format for log records is SEVERITY: LOGGER: MESSAGE. Hence, if you run the code above as is, you’ll get this output:
2021-07-02 13:00:08,743 DEBUG Debug message 2021-07-02 13:00:08,743 INFO Informative message 2021-07-02 13:00:08,743 ERROR Error message
Regarding the output, you can set the destination of the log messages. As a first step, you can print messages to the screen using this sample code:
import logging logging.basicConfig(level=logging.DEBUG, format='%(asctime)s - %(levelname)s - %(message)s') logging.debug('This is a log message.')
If your goals are aimed at the Cloud, you can take advantage of Python’s set of logging handlers to redirect content. Currently in beta release, you can write logs to Stackdriver Logging from Python applications by using Google’s Python logging handler included with the Stackdriver Logging client library, or by using the client library to access the API directly. When developing your logger, take into account that the root logger doesn’t use your log handler. Since the Python Client for Stackdriver Logging library also does logging, you may get a recursive loop if the root logger uses your Python log handler.
Python logging best practices
The possibilities with Python logging are endless and you can customize them to your needs. The following are some tips for web application logging best practices, so you can take the most from Python logging:
Setting level names: This supports you in maintaining your own dictionary of log messages and reduces the possibility of typo errors.
LogWithLevelName = logging.getLogger('myLoggerSample') level = logging.getLevelName('INFO') LogWithLevelName.setLevel(level)
logging.getLevelName(logging_level) returns the textual representation of the severity called logging_level. The predefined values include, from highest to lowest severity:
- CRITICAL
- ERROR
- WARNING
- INFO
- DEBUG
Logging from multiple modules: if you have various modules, and you have to perform the initialization in every module before logging messages, you can use cascaded logger naming:
logging.getLogger(“coralogix”) logging.getLogger(“coralogix.database”) logging.getLogger(“coralogix.client”)
Making coralogix.client and coralogix.database descendants of the logger coralogix, and propagating their messages to it, it thereby enables easy multi-module logging. This is one of the positive side-effects of name in case the library structure of the modules reflects the software architecture.
Logging with Django and uWSGI: To deploy web applications you can use StreamHandler as logger which sends all logs to For Django you have:
'handlers': { 'stderr': { 'level': 'INFO', 'class': 'logging.StreamHandler', 'formatter': 'your_formatter', }, },
Next, uWSGI forwards all of the app output, including prints and possible tracebacks, to syslog with the app name attached:
$ uwsgi --log-syslog=yourapp …
Logging with Nginx: In case you need having additional features not supported by uWSGI — for example, improved handling of static resources (via any combination of Expires or E-Tag headers, gzip compression, pre-compressed gzip, etc.), access logs and their format can be customized in conf. You can use the combined format, such the example for a Linux system:
access_log /var/log/nginx/access.log;
This line is similar to explicitly specifying the combined format as this:
# note that the log_format directly below is a single line log_format mycombined '$remote_addr - $remote_user [$time_local] "$request" $status $body_bytes_sent "$http_referer" "$http_user_agent"'server_port'; access_log /var/log/nginx/access.log mycombinedplus;
Log analysis and filtering: after writing proper logs, you might want to analyze them and obtain useful insights. First, open files using blocks, so you won’t have to worry about closing them. Moreover, avoid reading everything into memory at once. Instead, read a line at a time and use it to update the cumulative statistics. The use of the combined log format can be practical if you are thinking on using log analysis tools because they have pre-built filters for consuming these logs.
If you need to parse your log output for analysis you might want to use the code below:
with open(logfile, "rb") as f: for line in csv.reader(f, delimiter=' '): self._update(**self._parse(line))
Python’s CSV module contains code the read CSV files and other files with a similar format. In this way, you can combine Python’s logging library to register the logs and the CSV library to parse them.
And of course, the Coralogix way for python logging, using the Coralogix Python appender allows sending all Python written logs directly to Coralogix for search, live tail, alerting, and of course, machine learning powered insights such as new error detection and flow anomaly detection.
Python Logging Deep Dive
The rest of this guide is focused on how to log in Python using the built-in support for logging. It introduces various concepts that are relevant to understanding Python logging, discusses the corresponding logging APIs in Python and how to use them, and presents best practices and performance considerations for using these APIs.
We will introduce various concepts relevant to understanding logging in Python, discuss the corresponding logging APIs in Python and how to use them, and present best practices and performance considerations for using these APIs.
This Python tutorial assumes the reader has a good grasp of programming in Python; specifically, concepts and constructs pertaining to general programming and object-oriented programming. The information and Python logging examples in this article are based on Python version 3.8.
Python has offered built-in support for logging since version 2.3. This support includes library APIs for common concepts and tasks that are specific to logging and language-agnostic. This article introduces these concepts and tasks as realized and supported in Python’s logging library.
Basic Python Logging Concepts
When we use a logging library, we perform/trigger the following common tasks while using the associated concepts (highlighted in bold).
- A client issues a log request by executing a logging statement. Often, such logging statements invoke a function/method in the logging (library) API by providing the log data and the logging level as arguments. The logging level specifies the importance of the log request. Log data is often a log message, which is a string, along with some extra data to be logged. Often, the logging API is exposed via logger objects.
- To enable the processing of a request as it threads through the logging library, the logging library creates a log record that represents the log request and captures the corresponding log data.
- Based on how the logging library is configured (via a logging configuration), the logging library filters the log requests/records. This filtering involves comparing the requested logging level to the threshold logging level and passing the log records through user-provided filters.
- Handlers process the filtered log records to either store the log data (e.g., write the log data into a file) or perform other actions involving the log data (e.g., send an email with the log data). In some logging libraries, before processing log records, a handler may again filter the log records based on the handler’s logging level and user-provided handler-specific filters. Also, when needed, handlers often rely on user-provided formatters to format log records into strings, i.e., log entries.
Independent of the logging library, the above tasks are performed in an order similar to that shown in Figure 1.
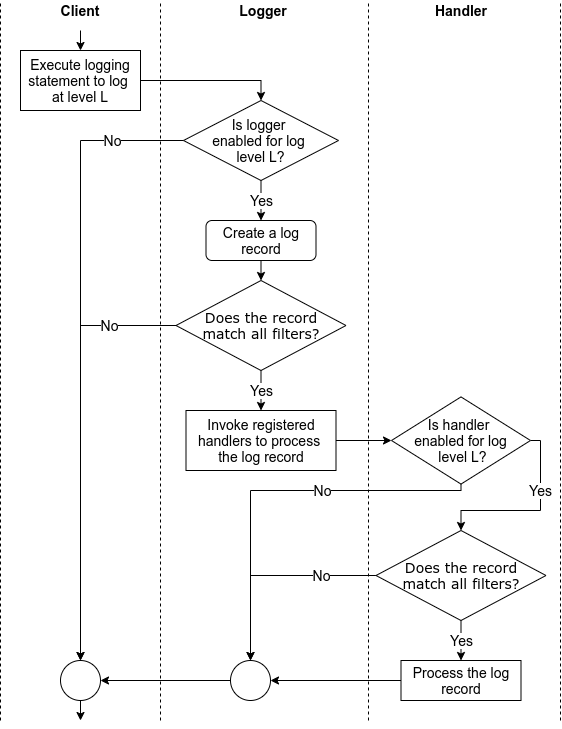
Figure 1: The flow of tasks when logging via a logging library
Python Logging Module
Python’s standard library offers support for logging via logging, logging.config, and logging.handlers modules.
loggingmodule provides the primary client-facing API.logging.configmodule provides the API to configure logging in a client.logging.handlersmodule provides different handlers that cover common ways of processing and storing log records.
We collectively refer to these modules as Python’s logging library.
These Python log modules realize the concepts introduced in the previous section as classes, a set of module-level functions, or a set of constants. Figure 2 shows these classes and the associations between them.
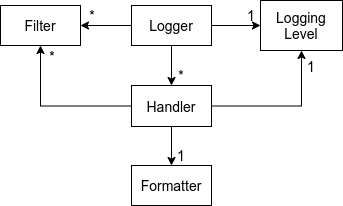
Figure 2: Python classes and constants representing various logging concepts
Python Logging Levels
Out of the box, the Python logging library supports five logging levels: critical, error, warning, info, and debug. These levels are denoted by constants with the same name in the logging module, i.e., logging.CRITICAL, logging.ERROR, logging.WARNING, logging.INFO, and logging.DEBUG. The values of these constants are 50, 40, 30, 20, and 10, respectively.
At runtime, the numeric value of a logging level determines the meaning of a logging level. Consequently, clients can introduce new logging levels by using numeric values that are greater than 0 and not equal to pre-defined logging levels as logging levels.
Logging levels can have names. When names are available, logging levels appear by their names in log entries. Every pre-defined logging level has the same name as the name of the corresponding constant; hence, they appear by their names in log entries, e.g., logging.WARNING and 30 levels appear as ‘WARNING’. In contrast, custom logging levels are unnamed by default. So, an unnamed custom logging level with numeric value n appears as ‘Level n’ in log entries, and this results in inconsistent and human-unfriendly log entries. To address this, clients can name a custom logging level using the module-level function logging.addLevelName(level, levelName). For example, by using logging.addLevelName(33, 'CUSTOM1'), level 33 will be recorded as ‘CUSTOM1’.
The Python logging library adopts the community-wide applicability rules for logging levels, i.e., when should logging level X be used?
- Debug: Use
logging.DEBUGto log detailed information, typically of interest only when diagnosing problems, e.g., when the app starts. - Info: Use
logging.INFOto confirm the software is working as expected, e.g., when the app initializes successfully. - Warning: Use
logging.WARNINGto report behaviors that are unexpected or are indicative of future problems but do not affect the current functioning of the software, e.g., when the app detects low memory, and this could affect the future performance of the app. - Error: Use
logging.ERRORto report the software has failed to perform some function, e.g., when the app fails to save the data due to insufficient permission. - Critical: Use
logging.CRITICALto report serious errors that may prevent the continued execution of the software, e.g., when the app fails to allocate memory.
Python Loggers
The logging.Logger objects offer the primary interface to the logging library. These objects provide the logging methods to issue log requests along with the methods to query and modify their state. From here on out, we will refer to Logger objects as loggers.
Creation
The factory function logging.getLogger(name) is typically used to create loggers. By using the factory function, clients can rely on the library to manage loggers and to access loggers via their names instead of storing and passing references to loggers.
The name argument in the factory function is typically a dot-separated hierarchical name, e.g., a.b.c. This naming convention enables the library to maintain a hierarchy of loggers. Specifically, when the factory function creates a logger, the library ensures a logger exists for each level of the hierarchy specified by the name, and every logger in the hierarchy is linked to its parent and child loggers.
Threshold Logging Level
Each logger has a threshold logging level that determines if a log request should be processed. A logger processes a log request if the numeric value of the requested logging level is greater than or equal to the numeric value of the logger’s threshold logging level. Clients can retrieve and change the threshold logging level of a logger via Logger.getEffectiveLevel() and Logger.setLevel(level) methods, respectively.
When the factory function is used to create a logger, the function sets a logger’s threshold logging level to the threshold logging level of its parent logger as determined by its name.
Python Logging Methods
Every logger offers the following logging methods to issue log requests.
Logger.critical(msg, *args, **kwargs)Logger.error(msg, *args, **kwargs)Logger.debug(msg, *args, **kwargs)Logger.info(msg, *args, **kwargs)Logger.warn(msg, *args, **kwargs)
Each of these methods is a shorthand to issue log requests with corresponding pre-defined logging levels as the requested logging level.
In addition to the above methods, loggers also offer the following two methods:
Logger.log(level, msg, *args, **kwargs)issues log requests with explicitly specified logging levels. This method is useful when using custom logging levels.Logger.exception(msg, *args, **kwargs)issues log requests with the logging levelERRORand that capture the current exception as part of the log entries. Consequently, clients should invoke this method only from an exception handler.
msg and args arguments in the above methods are combined to create log messages captured by log entries. All of the above methods support the keyword argument exc_info to add exception information to log entries and stack_info and stacklevel to add call stack information to log entries. Also, they support the keyword argument extra, which is a dictionary, to pass values relevant to filters, handlers, and formatters.
When executed, the above methods perform/trigger all of the tasks shown in Figure 1 and the following two tasks:
- After deciding to process a log request based on its logging level and the threshold logging level, the logger creates a
LogRecordobject to represent the log request in the downstream processing of the request.LogRecordobjects capture themsgandargsarguments of logging methods and the exception and call stack information along with source code information. They also capture the keys and values in the extra argument of the logging method as fields. - After every handler of a logger has processed a log request, the handlers of its ancestor loggers process the request (in the order they are encountered walking up the logger hierarchy). The
Logger.propagatefield controls this aspect, which isTrueby default.
Beyond logging levels, filters provide a finer means to filter log requests based on the information in a log record, e.g., ignore log requests issued in a specific class. Clients can add and remove filters to/from loggers using Logger.addFilter(filter) and Logger.removeFilter(filter) methods, respectively.
Python Logging Filters
Any function or callable that accepts a log record argument and returns zero to reject the record and a non-zero value to admit the record can serve as a filter. Any object that offers a method with the signature filter(record: LogRecord) -> int can also serve as a filter.
A subclass of logging.Filter(name: str) that optionally overrides the logging.Filter.filter(record) method can also serve as a filter. Without overriding the filter method, such a filter will admit records emitted by loggers that have the same name as the filter and are children of the filter (based on the name of the loggers and the filter). If the name of the filter is empty, then the filter admits all records. If the method is overridden, then it should return zero value to reject the record and a non-zero value to admit the record.
Python Logging Handler
The logging.Handler objects perform the final processing of log records, i.e., logging log requests. This final processing often translates into storing the log record, e.g., writing it into system logs or files. It can also translate it to communicate the log record data to specific entities (e.g., send an email) or passing the log record to other entities for further processing (e.g., provide the log record to a log collection process or a log collection service).
Like loggers, handlers have a threshold logging level, which can be set via theHandler.setLevel(level) method. They also support filters via Handler.addFilter(filter) and Handler.removeFilter(filter) methods.
The handlers use their threshold logging level and filters to filter log records for processing. This additional filtering allows context-specific control over logging, e.g., a notifying handler should only process log requests that are critical or from a flaky module.
While processing the log records, handlers format log records into log entries using their formatters. Clients can set the formatter for a handler via Handler.setFormatter(formatter) method. If a handler does not have a formatter, then it uses the default formatter provided by the library.
The logging.handler module provides a rich collection of 15 useful handlers that cover many common use cases (including the ones mentioned above). So, instantiating and configuring these handlers suffices in many situations.
In situations that warrant custom handlers, developers can extend the Handler class or one of the pre-defined Handler classes by implementing the Handler.emit(record) method to log the provided log record.
Python Logging Formatter
The handlers use logging.Formatter objects to format a log record into a string-based log entry.
Note: Formatters do not control the creation of log messages.
A formatter works by combining the fields/data in a log record with the user-specified format string.
Unlike handlers, the logging library only provides a basic formatter that logs the requested logging level, the logger’s name, and the log message. So, beyond simple use cases, clients need to create new formatters by creating logging.Formatter objects with the necessary format strings.
Formatters support three styles of format strings:
printf, e.g., ‘%(levelname)s:%(name)s:%(message)s’
str.format(), e.g., ‘{levelname}:{name}:{message}’
str.template, e.g., ‘$levelname:$name:$message’
The format string of a formatter can refer to any field of LogRecord objects, including the fields based on the keys of the extra argument of the logging method.
Before formatting a log record, the formatter uses the LogRecord.getMessage() method to construct the log message by combining the msg and args arguments of the logging method (stored in the log record) using the string formatting operator (%). The formatter then combines the resulting log message with the data in the log record using the specified format string to create the log entry.
Python Logging Module
To maintain a hierarchy of loggers, when a client uses the logging library, the library creates a root logger that serves as the root of the hierarchy of loggers. The default threshold logging level of the root logger is logging.WARNING.
The module offers all of the logging methods offered by the Logger class as module-level functions with identical names and signature, e.g., logging.debug(msg, *args, **kwargs). Clients can use these functions to issue log requests without creating loggers, and the root logger services these requests. If the root logger has no handlers when servicing log requests issued via these methods, then the logging library adds a logging.StreamHandler instance based on the sys.stderr stream as a handler to the root logger.
When loggers without handlers receive log requests, the logging library directs such log requests to the last resort handler, which is a logging.StreamHandler instance based on sys.stderr stream. This handler is accessible via the logging.lastResort attribute.
Python Logging Examples
Here are a few code snippets illustrating how to use the Python logging library.
Snippet 1: Creating a logger with a handler and a formatter
# main.py
import lo
gging, sys
def _init_logger():
logger = logging.getLogger('app') #1
logger.setLevel(logging.INFO) #2
handler = logging.StreamHandler(sys.stderr) #3
handler.setLevel(logging.INFO) #4
formatter = logging.Formatter(
'%(created)f:%(levelname)s:%(name)s:%(module)s:%(message)s') #5
handler.setFormatter(formatter) #6
logger.addHandler(handler) #7
_init_logger()
_logger = logging.getLogger('app')
This snippet does the following.
- Create a logger named ‘app’.
- Set the threshold logging level of the logger to INFO.
- Create a stream-based handler that writes the log entries into the standard error stream.
- Set the threshold logging level of the handler to INFO.
- Create a formatter to capture
- the time of the log request as the number of seconds since epoch,
- the logging level of the request,
- the logger’s name,
- the name of the module issuing the log request, and
- the log message.
- Set the created formatter as the formatter of the handler.
- Add the created handler to this logger.
By changing the handler created in step 3, we can redirect the log entries to different locations or processors.
Snippet 2: Issuing log requests
# main.py
_logger.info('App started in %s', os.getcwd())
This snippet logs informational messages stating the app has started.
When the app is started in the folder /home/kali with the logger created using snippet 1, this snippet will generate the log entry 1586147623.484407:INFO:app:main:App started in /home/kali/ in standard error stream.
Snippet 3: Issuing log requests
# app/io.py
import logging
def _init_logger():
logger = logging.getLogger('app.io')
logger.setLevel(logging.INFO)
_init_logger()
_logger = logging.getLogger('app.io')
def write_data(file_name, data):
try:
# write data
_logger.info('Successfully wrote %d bytes into %s', len(data), file_name)
except FileNotFoundError:
_logger.exception('Failed to write data into %s', file_name)
This snippet logs an informational message every time data is written successfully via write_data. If a write fails, then the snippet logs an error message that includes the stack trace in which the exception occurred.
With the logger created using snippet 1, if the execution of app.write_data('/tmp/tmp_data.txt', image_data) succeeds, then this snippet will generate a log entry similar to 1586149091.005398:INFO:app.io:io:Successfully wrote 134 bytes into /tmp/tmp_data.txt. If the execution of app.write_data('/tmp/tmp_data.txt', image_data) fails, then this snippet will generate the following log entry:
1586149219.893821:ERROR:app:io:Failed to write data into /tmp1/tmp_data.txt
Traceback (most recent call last):
File "/home/kali/program/app/io.py", line 12, in write_data
print(open(file_name), data)
FileNotFoundError: [Errno 2] No such file or directory: '/tmp1/tmp_data.txt'
Instead of using positional arguments in the format string in the logging method, we could achieve the same output by using the arguments via their names as follows:
_logger.info('Successfully wrote %(data_size)s bytes into %(file_name)s',
{'data_size': len(data), 'file_name': file_name})
Snippet 4: Filtering log requests
# main.py
import logging, os, sys
import app.io
def _init_logger():
logger = logging.getLogger('app')
logger.setLevel(logging.INFO)
formatter = logging.Formatter(
'%(created)f:%(levelname)s:%(name)s:%(module)s:%(message)s')
handler = logging.StreamHandler(sys.stderr)
handler.setLevel(logging.INFO)
handler.setFormatter(formatter)
handler.addFilter(lambda record: record.version > 5 or #1
record.levelno >= logging.ERROR) #1
logger.addHandler(handler)
_init_logger()
_logger = logging.LoggerAdapter(logging.getLogger('app'), {'version': 6}) #2
This snippet modifies Snippet 1 as follows.
- Lines marked #1 add a filter to the handler. This filter admits log records only if their logging level is greater than or equal to
logging.ERRORor they are from a component whose version is higher than 4. - Line marked #2 wraps the logger in a
logging.LoggerAdapterobject to inject version information into log records.
The logging.LoggerAdapter class provides a mechanism to inject contextual information into log records. We discuss other mechanisms to inject contextual information in the Good Practices and Gotchas section.
# app/io.py
import logging
def _init_logger():
logger = logging.getLogger('app.io')
logger.setLevel(logging.INFO)
_init_logger()
_logger = logging.LoggerAdapter(logging.getLogger('app.io'), {'version': 3}) # 1
def write_data(file_name, data):
try:
# write data
_logger.info('Successfully wrote %d bytes into %s', len(data),
file_name)
except FileNotFoundError:
_logger.exception('Failed to write data into %s', file_name)
This snippet modifies Snippet 3 by wrapping the logger in a LoggerAdapter object to inject version information.
All of the above changes affect the logging behavior of the app described in Snippet 2 and Snippet 3 as follows.
- The request to log the informational message about the start of the app is processed as the version info supplied by the module satisfies the filter.
- The request to log the informational message about the successful write is ignored as the version info supplied by the module fails to satisfy the filter.
- The request to log the error message about the failure to write data is processed as the logging level of the message satisfies the filter.
What do you suppose would have happened if the filter was added to the logger instead of the handler? See Gotchas for the answer.
Python Logging Configuration
The logging classes introduced in the previous section provide methods to configure their instances and, consequently, customize the use of the logging library. Snippet 1 demonstrates how to use configuration methods. These methods are best used in simple single-file programs.
When involved programs (e.g., apps, libraries) use the logging library, a better option is to externalize the configuration of the logging library. Such externalization allows users to customize certain facets of logging in a program (e.g., specify the location of log files, use custom loggers/handlers/formatters/filters) and, hence, ease the deployment and use of the program. We refer to this approach to configuration as data-based approach.
Configuring the Library
Clients can configure the logging library by invoking logging.config.dictConfig(config: Dict) function. The config argument is a dictionary and the following optional keys can be used to specify a configuration.
filters key maps to a dictionary of strings and dictionaries. The strings serve as filter ids used to refer to filters in the configuration (e.g., adding a filter to a logger) while the mapped dictionaries serve as filter configurations. The string value of the name key in filter configurations is used to construct logging.Filter instances.
"filters": {
"io_filter": {
"name": "app.io"
}
}
This configuration snippet results in the creation of a filter that admits all records created by the logger named ‘app.io’ or its descendants.
formatters key maps to a dictionary of strings and dictionaries. The strings serve as formatter ids used to refer to formatters in the configuration (e.g., adding a formatter to a handler) while the mapped dictionaries serve as formatter configurations. The string values of the datefmt and format keys in formatter configurations are used as the date and log entry formatting strings, respectively, to construct logging.Formatter instances. The boolean value of the (optional) validate key controls the validation of the format strings during the construction of a formatter.
"formatters": {
"simple": {
"format": "%(asctime)s - %(message)s",
"datefmt": "%y%j-%H%M%S"
},
"detailed": {
"format": "%(asctime)s - %(pathname):%(lineno) - %(message)s"
}
}
This configuration snippet results in the creation of two formatters. A simple formatter with the specified log entry and date formatting strings and detailed formatter with specified log entry formatting string and default date formatting string.
handlers key maps to a dictionary of strings and dictionaries. The strings serve as handler ids used to refer to handlers in the configuration (e.g., adding a handler to a logger) while the mapped dictionaries serve as handler configurations. The string value of the class key in a handler configuration names the class to instantiate to construct a handler. The string value of the (optional) level key specifies the logging level of the instantiated handler. The string value of the (optional) formatter key specifies the id of the formatter of the handler. Likewise, the list of values of the (optional) filters key specifies the ids of the filters of the handler. The remaining keys are passed as keyword arguments to the handler’s constructor.
"handlers": {
"stderr": {
"class": "logging.StreamHandler",
"level": "INFO",
"filters": ["io_filter"],
"formatter": "simple",
"stream": "ext://sys.stderr"
},
"alert": {
"class": "logging.handlers.SMTPHandler",
"level": "ERROR",
"formatter": "detailed",
"mailhost": "smtp.skynet.com",
"fromaddr": "[email protected]",
"toaddrs": [ "[email protected]", "[email protected]" ],
"subject": "System Alert"
}
}
This configuration snippet results in the creation of two handlers:
- A
stderrhandler that formats log requests with INFO and higher logging level log via thesimpleformatter and emits the resulting log entry into the standard error stream. Thestreamkey is passed as keyword arguments tologging.StreamHandlerconstructor.
The value of thestreamkey illustrates how to access objects external to the configuration. Theext://prefixed string refers to the object that is accessible when the string without the ext:// prefix (i.e., sys.stderr) is processed via the normal importing mechanism. Refer to Access to external objects for more details. Refer to Access to internal objects for details about a similar mechanism based oncfg://prefix to refer to objects internal to a configuration. - An alert handler that formats ERROR and CRITICAL log requests via the
detailedformatter and emails the resulting log entry to the given email addresses. The keysmailhost,formaddr,toaddrs, and subject are passed as keyword arguments tologging.handlers.SMTPHandler’s constructor.
loggers key maps to a dictionary of strings that serve as logger names and dictionaries that serve as logger configurations. The string value of the (optional) level key specifies the logging level of the logger. The boolean value of the (optional) propagate key specifies the propagation setting of the logger. The list of values of the (optional) filters key specifies the ids of the filters of the logger. Likewise, the list of values of the (optional) handlers key specifies the ids of the handlers of the logger.
"loggers": {
"app": {
"handlers": ["stderr", "alert"],
"level": "WARNING"
},
"app.io": {
"level": "INFO"
}
}
This configuration snippet results in the creation of two loggers. The first logger is named app, its threshold logging level is set to WARNING, and it is configured to forward log requests to stderr and alert handlers. The second logger is named app.io, and its threshold logging level is set to INFO. Since a log request is propagated to the handlers associated with every ascendant logger, every log request with INFO or a higher logging level made via the app.io logger will be propagated to and handled by both stderr and alert handlers.
root key maps to a dictionary of configuration for the root logger. The format of the mapped dictionary is the same as the mapped dictionary for a logger.
incremental key maps to either True or False (default). If True, then only logging levels and propagate options of loggers, handlers, and root loggers are processed, and all other bits of the configuration is ignored. This key is useful to alter existing logging configuration. Refer to Incremental Configuration for more details.
disable_existing_loggers key maps to either True (default) or False. If False, then all existing non-root loggers are disabled as a result of processing this configuration.
Also, the config argument should map the version key to 1.
Here’s the complete configuration composed of the above snippets.
{
"version": 1,
"filters": {
"io_filter": {
"name": "app.io"
}
},
"formatters": {
"simple": {
"format": "%(asctime)s - %(message)s",
"datefmt": "%y%j-%H%M%S"
},
"detailed": {
"format": "%(asctime)s - %(pathname):%(lineno) - %(message)s"
}
},
"handlers": {
"stderr": {
"class": "logging.StreamHandler",
"level": "INFO",
"filters": ["io_filter"],
"formatter": "simple",
"stream": "ext://sys.stderr"
},
"alert": {
"class": "logging.handlers.SMTPHandler",
"level": "ERROR",
"formatter": "detailed",
"mailhost": "smtp.skynet.com",
"fromaddr": "[email protected]",
"toaddrs": [ "[email protected]", "[email protected]" ],
"subject": "System Alert"
}
},
"loggers": {
"app": {
"handlers": ["stderr", "alert"],
"level": "WARNING"
},
"app.io": {
"level": "INFO"
}
}
}
Customizing via Factory Functions
The configuration schema for filters supports a pattern to specify a factory function to create a filter. In this pattern, a filter configuration maps the () key to the fully qualified name of a filter creating factory function along with a set of keys and values to be passed as keyword arguments to the factory function. In addition, attributes and values can be added to custom filters by mapping the . key to a dictionary of attribute names and values.
For example, the below configuration will cause the invocation of app.logging.customFilterFactory(startTime='6PM', endTime='6AM') to create a custom filter and the addition of local attribute with the value True to this filter.
"filters": {
"time_filter": {
"()": "app.logging.create_custom_factory",
"startTime": "6PM",
"endTime": "6PM",
".": {
"local": true
}
}
}
Configuration schemas for formatters, handlers, and loggers also support the above pattern. In the case of handlers/loggers, if this pattern and the class key occur in the configuration dictionary, then this pattern is used to create handlers/loggers. Refer to User-defined Objects for more details.
Configuring using Configparse-Format Files
The logging library also supports loading configuration from a configparser-format file via the <a href="https://docs.python.org/3/library/logging.config.html#logging.config.fileConfig" target="_blank" rel="noopener noreferrer">logging.config.fileConfig() function. Since this is an older API that does not provide all of the functionalities offered by the dictionary-based configuration scheme, the use of the dictConfig() function is recommended; hence, we’re not discussing the fileConfig() function and the configparser file format in this tutorial.
Configuring Over The Wire
While the above APIs can be used to update the logging configuration when the client is running (e.g., web services), programming such update mechanisms from scratch can be cumbersome. The logging.config.listen() function alleviates this issue. This function starts a socket server that accepts new configurations over the wire and loads them via dictConfig() or fileConfig() functions. Refer to logging.config.listen() for more details.
Loading and Storing Configuration
Since the configuration provided to dictConfig() is nothing but a collection of nested dictionaries, a logging configuration can be easily represented in JSON and YAML format. Consequently, programs can use the json module in Python’s standard library or external YAML processing libraries to read and write logging configurations from files.
For example, the following snippet suffices to load the logging configuration stored in JSON format.
import json, logging.config
with open('logging-config.json', 'rt') as f:
config = json.load(f)
logging.config.dictConfig(config)
Limitations
In the supported configuration scheme, we cannot configure filters to filter beyond simple name-based filtering. For example, we cannot create a filter that admits only log requests created between 6 PM and 6 AM. We need to program such filters in Python and add them to loggers and handlers via factory functions or the addFilter() method.
Python Logging Good Practices and Gotchas
In this section, we will list a few good practices and gotchas related to the logging library. This list stems from our experience, and we intend it to complement the extensive information available in the Logging HOWTO and Logging Cookbook sections of Python’s documentation.
Since there are no silver bullets, all good practices and gotchas have exceptions that are almost always contextual. So, before using the following good practices and gotchas, consider their applicability in the context of your application and ascertain whether they are appropriate in your application’s context.
Best Practices
Create Loggers Using getlogger Function
The logging.getLogger() factory function helps the library manage the mapping from logger names to logger instances and maintain a hierarchy of loggers. In turn, this mapping and hierarchy offer the following benefits:
- Clients can use the
factoryfunction to access the same logger in different parts of the program by merely retrieving the logger by its name. - Only a finite number of loggers are created at runtime (under normal circumstances).
- Log requests can be propagated up the logger hierarchy.
- When unspecified, the threshold logging
levelof a logger can be inferred from its ascendants. - The configuration of the logging library can be updated at runtime by merely relying on the logger names.
Use Logging Level Function
Use the logging.<logging level>() function or the Logger.<logging level>() methods to log at pre-defined logging levels
Besides making the code a bit shorter, the use of these functions/methods helps partition the logging statements in a program into two sets:
- Those that issue log requests with pre-defined logging levels
- Those that issue log requests with custom logging levels.
Use Pre-defined Logging Levels
As described in the Logging Level section in the Concepts and API chapter, the pre-defined logging levels offered by the library capture almost all logging scenarios that occur in programs. Further, since most developers are familiar with pre-defined logging levels (as most logging libraries across different programming languages offer very similar levels), the use of pre-defined levels can help lower deployment, configuration, and maintenance burden. So, unless required, use pre-defined logging levels.
Create module-level loggers
While creating loggers, we can create a logger for each class or create a logger for each module. While the first option enables fine-grained configuration, it leads to more loggers in a program, i.e., one per class. In contrast, the second option can help reduce the number of loggers in a program. So, unless such fine-grained configuration is necessary, create module-level loggers.
Name module-level loggers with the name of the corresponding modules.
Since the logger names are string values that are not part of the namespace of a Python program, they will not clash with module names. Hence, use the name of a module as the name of the corresponding module-level logger. With this naming, logger naming piggybacks on the dot notation based module naming and, consequently, simplifies referring to loggers.
Use logging.LoggerAdatper to inject local contextual information
As demonstrated in Snippet 4, we can use logging.LoggerAdapter to inject contextual information into log records. LoggerAdapter can also be used to modify the log message and the log data provided as part of a log request.
Since the logging library does not manage these adapters, they cannot be accessed via common names. For this reason, use them to inject contextual information that is local to a module or a class.
Use filters or logging.setLogRecordFactory() to inject global contextual information
There are two options to seamlessly inject global contextual information (that is common across an app) into log records.
The first option is to use the filter support to modify the log record arguments provided to filters. For example, the following filter injects version information into incoming log records.
def version_injecting_filter(logRecord):
logRecord.version = '3'
return True
There are two downsides to this option. First, if filters depend on the data in log records, then filters that inject data into log records should be executed before filters that use the injected data. Hence, the order of filters added to loggers and handlers becomes crucial. Second, the option “abuses” the support to filter log records to extend log records.
The second option is to initialize the logging library with a log record creating factory function via logging.setLogRecordFactory(). Since the injected contextual information is global, it can be injected into log records when they are created in the factory function and be sure the data will be available to every filter, formatter, logger, and handler in the program.
The downside of this option is that we have to ensure factory functions contributed by different components in a program play nicely with each other. While log record factory functions could be chained, such chaining increases the complexity of programs.
Use the data-based approach to configure the logging library
If your program involves multiple modules and possibly third-party components, then use the data-based approach described in the Configuration chapter to configure the logging library.
Attach common handlers to the loggers higher up the logger hierarchy
If a handler is common to two loggers of which one is the descendant of the other, then attach the handler to the ascendant logger and rely on the logging library to propagate the log requests from the descendant logger to the handlers of the ascendant logger. If the propagate attribute of loggers has not been modified, this pattern helps avoid duplicate messages.
Use logging.disable() function to inhibit the processing of log requests below a certain logging level across all loggers
A logger processes a log request if the logging level of the log request is at least as high as the logger’s effective logging level. A logger’s effective logging level is the higher of two logging levels: the logger’s threshold logging level and the library-wide logging level. We can set the library-wide logging level via the logging.disable(level) function. By default, the library-wide logging level is 0, i.e., log requests of every logging level will be processed.
Using this function, we can throttle the logging output of an app by increasing the logging level across the entire app.
What about caching references to loggers?
Before moving on to gotchas, let’s consider the goodness of the common practice of caching references to loggers and accessing loggers via cached references, e.g., this is how the _logger attribute was used in the previous code snippets.
This coding pattern avoids repeated invocations of the logging.getLogger() function to retrieve the same module-level logger; hence, it helps eliminate redundant retrievals. However, such eliminations can lead to lost log requests if retrievals are not redundant. For example, suppose the logging library configuration in a long-running web service is updated with this disabling_existing_loggers option. Since such an update would disable cached loggers, none of the logging statements that use cached loggers would log any requests. While we can remedy this situation by updating cached references to loggers, a simpler solution would be to use the logging.getLogger() function instead of caching references.
In short, caching references to loggers is not always a good practice. So, consider the context of the program while deciding to cache references to loggers.
Troubleshooting
Filters Fail
When the logging library invokes the filters associated with handlers and loggers, the library assumes the filters will always execute to completion, i.e., not fail on errors. So, there is no error handling logic in the library to deal with failing filters. Consequently, when a filter fails (to execute to completion), the corresponding log request will not be logged.
Ensure filters will execute to completion. More so, when using custom filters and using additional data in filtering.
Formatters Fail
The logging library makes a similar assumption about formatters, i.e., formatters will always execute to completion. Consequently, when a formatter fails to execute to completion, the corresponding log request will not be logged.
Ensure formatters will execute to completion.
Required keys are missing is the extra argument
If the filters/formatters refer to keys of the extra argument provided as part of logging methods, then the filters/formatters can fail when the extra argument does not provide a referred key.
Ensure every key of the extra argument used in a filter or a formatter are available in every triggering logging statement.
Keys in the extra argument clash with required attributes
The logging library adds the keys of the extra argument (to various logging methods) as attributes to log records. However, if asctime and message occur as keys in the extra argument, then the creation of log records will fail, and the corresponding log request will not be logged.
Similar failure occurs if args, exc_info, lineno, msg, name, or pathname occur as keys in the extra argument; these are attributes of the LogRecord class.
Ensure asctime, message, and certain attributes of LogRecord do not appear as keys in the extra argument of logging methods.
Libraries using custom logging levels are combined
When a program and its dependent libraries use the logging library, their logging requirements are combined by the underlying logging library that services these requirements. In this case, if the components of a program use custom logging levels that are mutually inconsistent, then the logging outcome can be unpredictable.
Don’t use custom logging levels, specifically, in libraries.
Filters of ancestor loggers do not fire
By default, log requests are propagated up the logger hierarchy to be processed by the handlers of ancestor loggers. While the filters of the handlers process such log requests, the filters of the corresponding loggers do not process such log requests.
To apply a filter to all log requests submitted to a logger, add the filter to the logger.
Ids of handlers/filters/formatters clash
If multiple handlers share the same handler id in a configuration, then the handler id refers to the handler that is created last when the configuration is processed. The same happens amongst filters and formatters that share ids.
When a client terminates, the logging library will execute the cleanup logic of the handler associated with each handler id. So, if multiple handlers have the same id in a configuration, then the cleanup logic of all but the handler created last will not be executed and, hence, result in resource leaks.
Use unique ids for objects of a kind in a configuration.
Python Logging Performance
While logging statements help capture information at locations in a program, they contribute to the cost of the program in terms of execution time (e.g., logging statements in loops) and storage (e.g., logging lots of data). Although cost-free yet useful logging is impossible, we can reduce the cost of logging by making choices that are informed by performance considerations.
Configuration-Based Considerations
After adding logging statements to a program, we can use the support to configure logging (described earlier) to control the execution of logging statements and the associated execution time. In particular, consider the following configuration capabilities when making decisions about logging-related performance.
- Change logging levels of loggers: This change helps suppress log messages below a certain log level. This helps reduce the execution cost associated with unnecessary creation of log records.
- Change handlers: This change helps replace slower handlers with faster handlers (e.g., during testing, use a transient handler instead of a persistent handler) and even remove context-irrelevant handlers. This reduces the execution cost associated with unnecessary handling of log records.
- Change format: This change helps exclude unnecessary parts of a log record from the log (e.g., exclude IP addresses when executing in a single node setting). This reduces the execution cost associated with unnecessary handling of parts of log records.
The above changes the range over coarser to finer aspects of logging support in Python.
Code-Based Considerations
While the support to configure logging is powerful, it cannot help control the performance impact of implementation choices baked into the source code. Here are a few such logging-related implementation choices and the reasons why you should consider them when making decisions about logging-related performance.
Do not execute inactive logging statements
Upon adding the logging module to Python’s standard library, there were concerns about the execution cost associated with inactive logging statements — logging statements that issue log requests with logging level lower than the threshold logging level of the target logger. For example, how much extra time will a logging statement that invokes logger.debug(...) add to a program’s execution time when the threshold logging level of logger is logging.WARN? This concern led to client-side coding patterns (as shown below) that used the threshold logging level of the target logger to control the execution of the logging statement.
# client code
...
if logger.isEnabledFor(logging.DEBUG):
logger.debug(msg)
...
Today, this concern is not valid because the logging methods in the logging.Logger class perform similar checks and process the log requests only if the checks pass. For example, as shown below, the above check is performed in the logging.Logger.debug method.
# client code
...
logger.debug(msg)
...
# logging library code
class Logger:
...
def debug(self, msg, *args, **kwargs):
if self.isEnabledFor(DEBUG):
self._log(DEBUG, msg, args, **kwargs)
Consequently, inactive logging statements effectively turn into no-op statements and do not contribute to the execution cost of the program.
Even so, one should consider the following two aspects when adding logging statements.
- Each invocation of a logging method incurs a small overhead associated with the invocation of the logging method and the check to determine if the logging request should proceed, e.g., a million invocations of
logger.debug(...)when threshold logging level of logger waslogging.WARNtook half a second on a typical laptop. So, while the cost of an inactive logging statement is trivial, the total execution cost of numerous inactive logging statements can quickly add up to be non-trivial. - While disabling a logging statement inhibits the processing of log requests, it does not inhibit the calculation/creation of arguments to the logging statement. So, if such calculations/creations are expensive, then they can contribute non-trivially to the execution cost of the program even when the corresponding logging statement is inactive.
Do not construct log messages eagerly
Clients can construct log messages in two ways: eagerly and lazily.
- The client constructs the log message and passes it on to the
loggingmethod, e.g.,logger.debug(f'Entering method Foo: {x=}, {y=}').
This approach offers formatting flexibility viaf-stringsand theformat()method, but it involves the eager construction of log messages, i.e., before the logging statements are deemed as active. - The client provides a
printf-style message format string (as amsgargument) and the values (as aargsargument) to construct the log message to the logging method, e.g.,logger.debug('Entering method %s: x=%d, y=%f', 'Foo', x, y). After the logging statement is deemed as active, the logger constructs the log message using the string formatting operator%.
This approach relies on an older and quirky string formatting feature of Python but it involves the lazy construction of log messages.
While both approaches result in the same outcome, they exhibit different performance characteristics due to the eagerness and laziness of message construction.
For example, on a typical laptop, a million inactive invocations of logger.debug('Test message {0}'.format(t)) takes 2197ms while a million inactive invocations of logger.debug('Test message %s', t) takes 1111ms when t is a list of four integers. In the case of a million active invocations, the first approach takes 11061ms and the second approach took 10149ms. A savings of 9–50% of the time taken for logging!
So, the second (lazy) approach is more performant than the first (eager) approach in cases of both inactive and active logging statements. Further, the gains would be larger when the message construction is non-trivial, e.g., use of many arguments, conversion of complex arguments to strings.
Do not gather unnecessary under-the-hood information
By default, when a log record is created, the following data is captured in the log record:
- Identifier of the current process
- Identifier and name of the current thread
- Name of the current process in the multiprocessing framework
- Filename, line number, function name, and call stack info of the logging statement
Unless these bits of data are logged, gathering them unnecessarily increases the execution cost. So, if these bits of data will not be logged, then configure the logging framework to not gather them by setting the following flags.
logging.logProcesses = Falselogging.logThreads = Falselogging.logMultiProcessing = Falselogging._srcFile = None
Do not block the main thread of execution
There are situations where we may want to log data in the main thread of execution without spending almost any time logging the data. Such situations are common in web services, e.g., a request processing thread needs to log incoming web requests without significantly increasing its response time. We can tackle these situations by separating concerns across threads: a client/main thread creates a log record while a logging thread logs the record. Since the task of logging is often slower as it involves slower resources (e.g., secondary storage) or other services (e.g., logging services such as Coralogix, pub-sub systems such as Kafka), this separation of concerns helps minimize the effort of logging on the execution time of the main/client thread.
The Python logging library helps handle such situations via the QueueHandler and QueueListener classes as follows.
- A pair of
QueueHandlerandQueueListenerinstances are initialized with a queue. - When the
QueueHandlerinstance receives a log record from the client, it merely places the log request in its queue while executing in the client’s thread. Given the simplicity of the task performed by theQueueHandler, the client thread hardly pauses. - When a log record is available in the
QueueListenerqueue, the listener retrieves the log record and executes the handlers registered with the listener to handle the log record. In terms of execution, the listener and the registered handlers execute in a dedicated thread that is different from the client thread.
Note: While QueueListener comes with a default threading strategy, developers are not required to use this strategy to use QueueHandler. Instead, developers can use alternative threading strategies that meet their needs.
That about wraps it up for this Python logging guide. If you’re looking for a log management solution to centralize your Python logs, check out our easy-to-configure Python integration.
Если Вы хотя бы немного знакомы с программированием и пробовали запускать что-то «в продакшен», то вам наверняка станет больно от такого диалога:
— Вась, у нас там приложение слегло. Посмотри, что случилось?
— Эмм… А как я это сделаю?..
Да, у Василия, судя по всему, не настроено логирование. И это ужасно, хотя бы по нескольким причинам:
- Он никогда не узнает, из-за чего его приложение упало.
- Он не сможет отследить, что привело к ошибке (даже если приложение не упало).
- Он не сможет посмотреть состояние своей системы в момент времени N.
- Он не сможет профилактически поглядывать в логи, чтобы следить за работоспособностью приложения.
- Он не сможет хвастаться своим… (кхе-кхе).
Впрочем, последний пункт, наверно, лишний. Однако, одну вещь мы поняли наверняка:
Логирование — крайне важная штука в программировании.
В языке Python основным инструментом для логирования является библиотека logging. Так давайте вместе с IT Resume рассмотрим её подробней.
Что такое logging?
Модуль logging в Python — это набор функций и классов, которые позволяют регистрировать события, происходящие во время работы кода. Этот модуль входит в стандартную библиотеку, поэтому для его использования достаточно написать лишь одну строку:
import loggingОсновная функция, которая пригодится Вам для работы с этим модулем — basicConfig(). В ней Вы будете указывать все основные настройки (по крайней мере, на базовом уровне).
У функции basicConfig() 3 основных параметра:
level— уровень логирования на Python;filename— место, куда мы направляем логи;format— вид, в котором мы сохраняем результат.
Давайте рассмотрим каждый из параметров более подробно.
Наверно, всем очевидно, что события, которые генерирует наш код кардинально могут отличаться между собой по степени важности. Одно дело отлавливать критические ошибки (FatalError), а другое — информационные сообщения (например, момент логина пользователя на сайте).
Соответственно, чтобы не засорять логи лишней информацией, в basicConfig() Вы можете указать минимальный уровень фиксируемых событий.
По умолчанию фиксируются только предупреждения (WARNINGS) и события с более высоким приоритетом: ошибки (ERRORS) и критические ошибки (CRITICALS).
logging.basicConfig(level=logging.DEBUG)А далее, чтобы записать информационное сообщение (или вывести его в консоль, об этом поговорим чуть позже), достаточно написать такой код:
logging.debug('debug message')
logging.info('info message')
И так далее. Теперь давайте обсудим, куда наши сообщения попадают.
Отображение лога и запись в файл
За место, в которое попадают логи, отвечает параметр filename в basicConfig. По умолчанию все Ваши логи будут улетать в консоль.
Другими словами, если Вы просто выполните такой код:
import logging
logging.error('WOW')То сообщение WOW придёт Вам в консоль. Понятно, что в консоли никому эти сообщения не нужны. Как же тогда направить запись лога в файл? Очень просто:
logging.basicConfig(filename = "mylog.log")Ок, с записью в файл и выбором уровня логирования все более-менее понятно. А как настроить свой шаблон? Разберёмся.
Кстати, мы собрали для Вас сублимированную шпаргалку по логированию на Python в виде карточек. У нас ещё много полезностей, не пожалеете 🙂
Форматирование лога
Итак, последнее, с чем нам нужно разобраться — форматирование лога. Эта опция позволяет Вам дополнять лог полезной информацией — датой, названием файла с ошибкой, номером строки, названием метода и так далее.
Сделать это можно, как все уже догадались, с помощью параметра format.
Например, если внутри basicConfig указать:
format = "%(asctime)s - %(levelname)s - %(funcName)s: %(lineno)d - %(message)s"То вывод ошибки будет выглядеть так:
2019-01-16 10:35:12,468 - ERROR - <module>:1 - Hello, world!Вы можете сами выбирать, какую информацию включить в лог, а какую оставить. По умолчанию формат такой:
<УРОВЕНЬ>: <ИМЯ_ЛОГГЕРА>: <СООБЩЕНИЕ>.
Важно помнить, что все параметры logging.basicConfig должны передаваться до первого вызова функций логирования.
Эпилог
Что же, мы разобрали все основные параметры модуля logging и функции basicConfig, которые позволят Вам настроить базовое логирование в Вашем проекте. Дальше — только практика и набивание шишек 🙂
Вместо заключения просто оставим здесь рабочий кусочек кода, который можно использовать 🙂
import logging
logging.basicConfig(
level=logging.DEBUG,
filename = "mylog.log",
format = "%(asctime)s - %(module)s - %(levelname)s - %(funcName)s: %(lineno)d - %(message)s",
datefmt='%H:%M:%S',
)
logging.info('Hello')Если хотите разобраться с параметрами более подробно, Вам поможет официальная документация (очень неплохая, кстати).
Logging is a means of tracking events that happen when some software runs. Logging is important for software developing, debugging, and running. If you don’t have any logging record and your program crashes, there are very few chances that you detect the cause of the problem. And if you detect the cause, it will consume a lot of time. With logging, you can leave a trail of breadcrumbs so that if something goes wrong, we can determine the cause of the problem.
There are a number of situations like if you are expecting an integer, you have been given a float and you can a cloud API, the service is down for maintenance, and much more. Such problems are out of control and are hard to determine.
Why Printing is not a good option?
Some developers use the concept of printing the statements to validate if the statements are executed correctly or some error has occurred. But printing is not a good idea. It may solve your issues for simple scripts but for complex scripts, the printing approach will fail.
Python has a built-in module logging which allows writing status messages to a file or any other output streams. The file can contain the information on which part of the code is executed and what problems have been arisen.
Levels of Log Message
There are five built-in levels of the log message.
- Debug : These are used to give Detailed information, typically of interest only when diagnosing problems.
- Info : These are used to confirm that things are working as expected
- Warning : These are used an indication that something unexpected happened, or is indicative of some problem in the near future
- Error : This tells that due to a more serious problem, the software has not been able to perform some function
- Critical : This tells serious error, indicating that the program itself may be unable to continue running
If required, developers have the option to create more levels but these are sufficient enough to handle every possible situation. Each built-in level has been assigned its numeric value.

Logging module is packed with several features. It has several constants, classes, and methods. The items with all caps are constant, the capitalize items are classes and the items which start with lowercase letters are methods.
There are several logger objects offered by the module itself.
- Logger.info(msg) : This will log a message with level INFO on this logger.
- Logger.warning(msg) : This will log a message with a level WARNING on this logger.
- Logger.error(msg) : This will log a message with level ERROR on this logger.
- Logger.critical(msg) : This will log a message with level CRITICAL on this logger.
- Logger.log(lvl,msg) : This will Logs a message with integer level lvl on this logger.
- Logger.exception(msg) : This will log a message with level ERROR on this logger.
- Logger.setLevel(lvl) : This function sets the threshold of this logger to lvl. This means that all the messages below this level will be ignored.
- Logger.addFilter(filt) : This adds a specific filter filt into this logger.
- Logger.removeFilter(filt) : This removes a specific filter filt into this logger.
- Logger.filter(record) : This method applies the logger’s filter to the record provided and returns True if the record is to be processed. Else, it will return False.
- Logger.addHandler(hdlr) : This adds a specific handler hdlr to this logger.
- Logger.removeHandler(hdlr) : This removes a specific handler hdlr into this logger.
- Logger.hasHandlers() : This checks if the logger has any handler configured or not.
The Basics
Basics of using the logging module to record the events in a file are very simple.
For that, simply import the module from the library.
- Create and configure the logger. It can have several parameters. But importantly, pass the name of the file in which you want to record the events.
- Here the format of the logger can also be set. By default, the file works in append mode but we can change that to write mode if required.
- Also, the level of the logger can be set which acts as the threshold for tracking based on the numeric values assigned to each level.
There are several attributes which can be passed as parameters. - The list of all those parameters is given in Python Library. The user can choose the required attribute according to the requirement.
After that, create an object and use the various methods as shown in the example.
Python
import logging
logging.basicConfig(filename="newfile.log",
format='%(asctime)s %(message)s',
filemode='w')
logger = logging.getLogger()
logger.setLevel(logging.DEBUG)
logger.debug("Harmless debug Message")
logger.info("Just an information")
logger.warning("Its a Warning")
logger.error("Did you try to divide by zero")
logger.critical("Internet is down")
The above code will generate a file with the provided name and if we open the file, the file contains the following data.
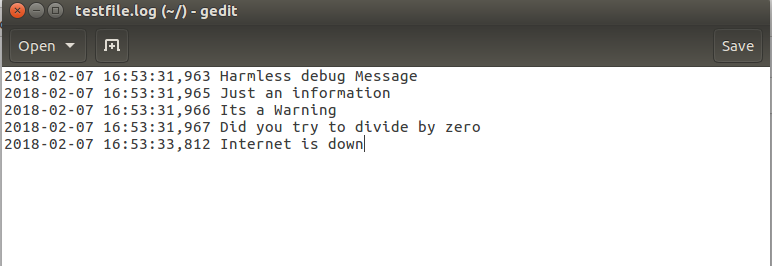
This article is contributed by Rishabh Bansal. If you like GeeksforGeeks and would like to contribute, you can also write an article using write.geeksforgeeks.org or mail your article to review-team@geeksforgeeks.org. See your article appearing on the GeeksforGeeks main page and help other Geeks.
Please write comments if you find anything incorrect, or you want to share more information about the topic discussed above.