Время прочтения
9 мин
Просмотры 48K
Зачем эта статья?
Об обработке текстов на естественном языке сейчас знают все. Все хоть раз пробовали задавать вопрос Сири или Алисе, пользовались Grammarly (это не реклама), пробовали генераторы стихов, текстов… или просто вводили запрос в Google. Да, вот так просто. На самом деле Google понимает, что вы от него хотите, благодаря штукам, которые умеют обрабатывать и анализировать естественную речь в вашем запросе.
При анализе текста мы можем столкнуться с ситуациями, когда текст содержит специфические символы, которые необходимо проанализировать наравне с «простым текстом» (взять даже наши горячо любимые вставки на французском из «Война и мир») или формулы, например. В таком случае обработка текста может усложниться.
Вы можете заметить, что если ввести в поисковую строку запрос с символами с ударением (так называемый модифицирующий акут), к примеру «ó», поисковая система может показать результаты, содержащие слова из вашего запроса, символы с ударением уже выглядят как обычные символы.
Обратите внимание на следующий запрос:

Запрос содержит символ с модифицирующим акутом, однако во втором результате мы можем заметить, что выделено найденное слово из запроса, только вот оно не содержит вышеупомянутый символ, просто букву «о».
Конечно, уже есть много готовых инструментов, которые довольно неплохо справляются с обработкой текстов и могут делать разные крутые вещи, но я не об этом хочу вам поведать. Я не буду рассказывать про nltk, стемминг, лемматизацию и т.п. Я хочу опуститься на несколько ступенек ниже и обсудить некоторые тонкости кодировок, байтов, их обработки.
Откуда взялась статья?
Одним из важных составляющих в области ИИ является обработка текстов на естественном языке. В процессе изучения данной тематики я начал задавать себе вопросы, которые в конечном итоге привели меня к изучению кодировок, представлению текстов в памяти, как они преобразуются, приводятся к нормальной форме. Я плохо понимал эту тему в начале, потребовалось немало времени и мозгового ресурса, чтобы понять, принять и запомнить некоторые вещи. Написанием данной статьи я хочу облегчить жизнь людям, которые столкнутся с необходимостью чтения и обработки текстов на Python и самому закрепить изученное. А некоторыми полезными поинтами своего изучения я постараюсь поделиться в данной статье.
Важная ремарка: я не являюсь специалистом в области обработки текстов. Изложенный материал является результатом исключительно любительского изучения.
Проблема чтения файлов
Допустим, у нас есть файл с текстом. Нам нужно этот текст прочитать. Казалось бы, пиши себе такой вот скрипт для чтения из файла да и радуйся:
with open("some_text.txt", "r") as file:
content = file.read()
print(content)В файле содержится вот такое вот изречение:
pitónчто переводится с испанского как питон. Однако консоль OC Windows 10 покажет нам немного другой результат:
C:myhabrTextsInPython> python .script1.py
pitónСейчас мы разберёмся, что именно пошло не так и по какой причине.
Кодировка
Думаю, это не будет сюрпризом, если я скажу, что любой символ, который заносится в память компьютера, хранится в виде числа, а не в виде литерала. Это число определяется как идентификатор или кодовая позиция символа. Кодировка определяет, какое именно число будет ассоциировано с символом.
Предположим, у нас есть некоторый файл с неизвестным содержимым, и нам нужно его прочитать, однако мы не знаем, какая у файла кодировка. Попробуем декодировать содержимое файла.
with open("simple_text.txt", "r") as file:
text = file.read()
print(text)Посмотрим на результат:
C:myhabrTextsInPython> python .script2.py
ÿþ<♦8♦@♦Очень интересно, ничего непонятно. По умолчанию Python использует кодировку utf-8, но видимо запись в файл происходила не с её помощью. Здесь нам придёт на помощь дополнительный параметр функции open — параметр encoding, который позволяет указать конкретную кодировку, в которой следует прочитать файл (или записывать в него). Попробуем перебрать несколько кодировок и найти подходящую.
codecs = ["cp1252", "cp437", "utf-16be", "utf-16"]
for codec in codecs:
with open("simple_text.txt", "r", encoding=codec) as file:
text = file.read()
print(codec.rjust(12), "|", text)Результат:
C:myhabrTextsInPython> python .script3.py
cp1252 | ÿþ<8@
cp437 | ■<8@
utf-16be | 㰄㠄䀄
utf-16 | мирРазные кодировки расшифровывают байты из файла по-разному, то есть разным кодовым позициям могут соотвествовать разные символы. Пример примитивный, несложно догадаться, что истинная кодировка файла — это utf-16.
Важный поинт: при записи и чтении из файлов следует указывать конкретную кодировку, это позволит избежать путаницы в дальнейшем.
Ошибки, связанные с кодировками
При возникновении ошибки, связанной с кодировками, интерпретатор выдаст одно из следующих исключений:
-
UnicodeError. Это общее исключение для ошибок кодировки. -
UnicodeDecodeError. Данное исключение возбуждается, если встречается кодовая позиция, которая отсутствует в кодировке. -
UnicodeEncodeError. А это исключение возбуждается, когда символ, который необходимо закодировать, незнаком для кодировки.
Попытка выполнения вот такого кода (в файле всё ещё содержится испанский питон):
with open("some_text.txt", "r", encoding="ascii") as file:
file.read()даст нам следующий результат:
UnicodeDecodeError: 'ascii' codec can't decode byte 0xc3 in position 3: ordinal not in range(128)Кодировка ASCII не поддерживает никакой алфавит, кроме английского. Поэтому декодирование символа «ó» вызывает у ASCII сложности. Однако Python всемогущ и есть механизм, который позволяет обработать ошибки кодировок. Это дополнительный параметр методов encode и decode — параметр errors. Он может принимать следующие значения:
Для обеих функций:
|
Обозначение |
Суть |
|
|
Значение по умолчанию. Несоотвествующие кодировке символы возбуждают исключения |
|
|
Несоответсвующие символы пропускаются без возбуждения исключений. |
Только для метода encode:
|
Обозначение |
Суть |
|---|---|
|
|
Несоотвествующие символы заменяются на символ |
|
|
Несоответствующие символы заменяются на соответсвующие значения XML. |
|
|
Несоответствующие символы заменяются на определённые последовательности с обратным слэшем. |
|
|
Несоответствующие символы заменяются на имена этих символов, которые берутся из базы данных Unicode. |
Также отдельно выделены значения surrogatepass и surrogateescape.
Приведём пример использования таких обработчиков:
>>> text = "pitón"
>>> text.encode("ascii", errors="ignore")
b'pitn'
>>> text.encode("ascii", errors="replace")
b'pit?n'
>>> text.encode("ascii", errors="xmlcharrefreplace")
b'pitón'
>>> text.encode("ascii", errors="backslashreplace")
b'pit\xf3n'
>>> text.encode("ascii", errors="namereplace")
b'pit\N{LATIN SMALL LETTER O WITH ACUTE}n'Важный поинт: если в текстах могут встретиться неожиданные для кодировки символы, во избежание возбуждения исключений можно использовать обработчики.
Cворачивание регистра
Сворачивание регистра — это попытка унифицировать текст любого представления к канонической форме. Например, приведение всего текста в нижний регистр. Также над текстом производятся некоторые преобразования (например, немецкая «эсцет» — «ß» — преобразуется в «ss»). В Python 3.3 появился метод str.casefold(), который как раз выполняет сворачивание регистра. Если текст содержит только символы кодировки latin1, результат применения этого метода будет аналогичен методу str.lower().
И по классике приведём пример:
>>> text = "Die größte Stadt der Welt liegt in China"
>>> text.casefold()
'die grösste stadt der welt liegt in china'В результате применённый метод не только привёл весь текст к нижнему регистру, но и преобразовал специфический немецкий символ.
Важный поинт: привести текст можно не только методом str.lower(), но и методом str.casefold(), который может выполнить дополнительные преобразования текста.
Нормализация
Нормализация — это полноценное приведение текста к единому представлению.
Чтобы обозначить важность нормализации, приведём простой пример:
letter1 = "µ"
letter2 = "μ"Внешне два этих символа выглядят абсолютно одинаково. Однако если мы попытаемся вывести имена этих символов, как их видит интерпретатор Python’a, результат нас порядком удивит.
В Python есть отличный встроенный модуль, который содержит данные о символах Unicode, их имена, являются ли они цифрамии и т.п. (методы по типу str.isdigit() берут информацию из этих данных). Воспользуемся данным модулем, чтобы вывести имена символов, исходя из информации, которая содержится в базе данных Unicode.
import unicodedata
letter1 = "µ"
letter2 = "μ"
print(unicodedata.name(letter1))
print(unicodedata.name(letter2))Результат выполнения данного кода:
C:myhabrTextsInPython> python .script7.py
MICRO SIGN
GREEK SMALL LETTER MUИтак, интерпретатор Python’a видит эти символы как два разных, но в стандарте Unicode они имеют одинаковое отображение.Такие символы называют каноническими эквивалентами. Приложения будут считать два этих символа одинаковыми, но не интерпретатор.
Посмотрим на ещё один пример:
>>> s1 = 'café'
>>> s2 = 'cafeu0301'
>>> s1, s2
('café', 'café')
>>> s1 == s2
False
>>> len(s1), len(s2)
(4, 5)
Данные символы также будут являться каноническими эквивалентами. Из примера мы видим, что символ «é» в стандарте Unicodeможет быть представлен двумя способами, которые к тому же имеют разную длину. Символ «é» может быть представлен одним или двумя байтами.
Решением таких конфликтов занимается нормализация. Она реализована в Python в функции unicodedata.normalize.Первым аргумент является так называемая форма нормализации — нормализации строк Unicode, которые позволяют определить, эквивалентны ли какие-либо две строки Unicode друг другу. Всего предлагается четыре формы:
|
Форма |
Описание |
|---|---|
|
Normalization Form D (NFD) |
Canonical Decomposition |
|
Normalization Form C (NFC) |
Canonical Decomposition, следующая за Canonical Composition |
|
Normalization Form KD (NFKD) |
Compatibility Decomposition |
|
Normalization Form KC (NFKC) |
Compatibility Decomposition, следующая за Canonical Composition |
Разберём каждую форму немного подробнее.
-
NFC
При указании данной формы нормализации происходит каноническая композиция (как, собственно, и гласит название) кодовых позиций с целью получения самой короткой эквивалентной строки.
>>> unicodedata.normalize("NFC", s1), unicodedata.normalize("NFC", s2)
('café', 'café')
>>> len(unicodedata.normalize("NFC", s1)), len(unicodedata.normalize("NFC", s2))
(4, 4)
>>> unicodedata.normalize("NFC", s1) == unicodedata.normalize("NFC", s2)
True
>>> len(unicodedata.normalize("NFC", s1)) == len(unicodedata.normalize("NFC", s2))
TrueИтак, нормализация обеих строк внешне их не изменила, однако длина строки s2 стала равной 4 (т.е. на один байт меньше). Была произведена композиция байтов eu0301, которые являлись отображением «é». Данная последовательность была заменена на минимальное представление символа, т.е. теперь представление этого символа для интерпретатора выглядит как в строке s1. Как результат, мы видим, что длина нормализованных строк стала равной, и сами строки также стали равны.
-
NFD
С этой формой ситуация аналогичная, только происходит декомпозиция байтов, т.е. разложение символа на несколько байт.
>>> unicodedata.normalize("NFD", s1), unicodedata.normalize("NFD", s2)
('café', 'café')
>>> len(unicodedata.normalize("NFD", s1)), len(unicodedata.normalize("NFD", s2))
(5, 5)
>>> unicodedata.normalize("NFD", s1) == unicodedata.normalize("NFD", s2)
True
>>> len(unicodedata.normalize("NFD", s1)) == len(unicodedata.normalize("NFD", s2))
TrueЗдесь мы видим, что длина строки s1 увеличилась на один байт. Думаю, уже несложно догадаться, почему.
На данном этапе настал момент ввести понятие символа совместимости. Символы совместимости (compatibility characters) были введены в Unicode ради совместимости с другими стандартами, в частности, стандарты, которые предшествовали Unicode. Это означает, что некоторые символы могут встречаться в стандарте несколько раз. Мы уже могли наблюдать это явление в начале этого раздела на примере с символом «мю». Он считается символом совместимости.
-
NFKC и NFKD
При данных формах нормализации символы совместимости заменяются на его более предпочтительное представление, что также называется совместимой декомпозицией. Однако при данных формах нормализации может быть потеряно форматирование.
Немного модифицируем наш пример из начала раздела. Выведем кодовые позиции символов до и после нормализации:
import unicodedata
letter1 = "µ"
letter2 = "μ"
print("Before normalizing:", ord(letter1), ord(letter2))
letter1 = unicodedata.normalize("NFKC", letter1)
letter2 = unicodedata.normalize("NFKC", letter2)
print("After normalizing:", ord(letter1), ord(letter2))И результат выполнения кода:
Before normalizing: 181 956
After normalizing: 956 956Итак, мы видим, что первый символ (который являлся знаком «микро») был заменён на греческую «мю», т.е. более предпочтительное представление символа. Таким образом, если необходимо, например, провести частотный анализ текста, формы нормализации, которые затрагивают символы совместимости, могут помочь с этим, приводя символы совместимости к единому представлению.
Важный поинт: нормализация может очень помочь для поиска валидных документов или индексирования текста. Если вы занимаетесь разработкой таких систем, не стоит сбрасывать алгоритмы нормализации со счетов.
Дополнительные материалы: что использовалось в статье и что почитать по теме
«Fluent Python», Лучано Ромальо
В этой книге целая глава посвящена изучению строк, байтов и Unicode (Глава 4. Тексты и байты). Она есть на русском и английском языках, но в русском переводе допущено немало ошибок, так что открывайте русский вариант на свой страх и риск. Материал статьи в большей степени опирается на данную книгу. Некоторые примеры также взяты оттуда.
Документация для Unicode на официальном сайте Python
Куда ж без неё, родимой. Там тоже можно найти немало полезной информации, если вам понадобится работать с текстами и делать больше, чем просто считывание из файла. Хотя в некоторых случаях и на этом можно споткнуться.
Unicode® Standard Annex
Это части стандарта Unicode, которые выложены в открытый доступ в виде отдельных статей. Почитать их можно вот здесь.
Работа с кодировкой символов на Python, да и на любом другом языке, временами выглядит довольно сложной. На Stack Overflow можно найти тысячи вопросов, посвящённых таким исключениям, как UnicodeDecodeError и UnicodeEncodeError. Данное руководство призвано прояснить сложные аспекты работы с этими исключениями и продемонстрировать, что работа с текстовыми и двоичными данными на Python 3 может быть приятной. В Python хорошо реализована поддержка Юникода, однако для работы с кодировкой всё же потребуется приложить усилия.
Вводная часть статьи даст общее понимание работы с Юникодом, не привязанное к какому-то определённому языку, однако практические примеры будут приведены именно на Python, а их описание будет довольно лаконичным.
Изучив эту статью, вы:
- Освоите концепции кодировки символов и системы нумерации;
- Поймёте, как кодировка работает с объектами
strиbytes; - Узнаете, как в Python поддерживается система нумерации посредством различных форм литералов
int; - Познакомитесь со встроенными функциями языка, относящимися к кодировке и системе нумерации.
Система нумерации и кодировка символов настолько тесно связаны, что их придётся раскрыть в одном руководстве, в противном случае материал будет неполным.
Прим. Статья ориентирована на Python 3, а все примеры кода созданы с помощью оболочки CPython 3.7.2. Большая часть более ранних версий Python 3 также будут корректно обрабатывать код. Если вы всё ещё используете Python 2 и различия в обработке текста и бинарных данных между 2 и 3 версиями языка вас отпугивают, это руководство может помочь вам преодолеть барьер.
Что такое кодировка символов?
Существуют десятки, если не сотни, кодировок символов. Понять эту концепцию легче всего, разобрав одну из самых простых, ASCII.
Независимо от того, занимаетесь вы самообразованием или получили более формальное образование в сфере IT , наверняка пару раз вы уже видели таблицу ASCII. Эта таблица — хорошее начало для изучения принципов кодировки, так как она простая и маленькая (как вы увидите дальше, даже слишком маленькая).
Она охватывает следующее:
- Символы английского алфавита в нижнем регистре: от a до z;
- Символы английского алфавита в верхнем регистре: от A до Z;
- Некоторые знаки препинания и символы: например «$» или «!»;
- Символы, отображаемые как пустое место: пробел (« »), символ новой строки, возврата каретки, горизонтальной и вертикальной табуляции и несколько других;
- Некоторые непечатаемые символы: такие как бекспейс, «b», которые просто невозможно отобразить, так, как к примеру, букву А.
Приведём формальное определение кодировки символов.
На самом высоком уровне — это способ перевода символов (таких как буквы, знаки пунктуации, служебные знаки, пробелы и контрольные символы) в целые числа и затем непосредственно в биты. Каждый символ может быть закодирован уникальным двоичным кодом. Если вы плохо знакомы с концепцией битов, не волнуйтесь, мы вскоре о ней поговорим.
Группы символов выделяют в отдельные категории. Каждому символу соответствует кодовая точка, которую можно рассматривать просто как целое число. В таблице ASCII символы сегментированы следующим образом:
| Диапазон кодовых точек | Класс |
|---|---|
| от 0 до 31 | Контрольные и неотображаемые символы |
| от 32 до 64 | Знаки пунктуации, символы, числа и пробел |
| от 65 до 90 | Буквы английского алфавита в верхнем регистре |
| от 91 до 96 | Дополнительные графемы, такие как [ и |
| от 97 до 122 | Буквы английского алфавита в нижнем регистре |
| от 123 до 126 | Дополнительные графемы, такие как { и | |
| 127 | Контрольный неотображаемый символ (DEL) |
Всего кодировка ASCII содержит 128 символов. В таблице ниже вы видите исчерпывающий набор знаков, которые позволяет отобразить эта кодировка. Если вы не видите какого-то символа, значит вы просто не сможете его вывести с помощью ASCII.
| Кодовая точка | Символ (имя) | Кодовая точка | Символ (имя) |
|---|---|---|---|
| 0 | NUL (Null) | 64 | @ |
| 1 | SOH (Start of Heading) | 65 | A |
| 2 | STX (Start of Text) | 66 | B |
| 3 | ETX (End of Text) | 67 | C |
| 4 | EOT (End of Transmission) | 68 | D |
| 5 | ENQ (Enquiry) | 69 | E |
| 6 | ACK (Acknowledgment) | 70 | F |
| 7 | BEL (Bell) | 71 | G |
| 8 | BS (Backspace) | 72 | H |
| 9 | HT (Horizontal Tab) | 73 | I |
| 10 | LF (Line Feed) | 74 | J |
| 11 | VT (Vertical Tab) | 75 | K |
| 12 | FF (Form Feed) | 76 | L |
| 13 | CR (Carriage Return) | 77 | M |
| 14 | SO (Shift Out) | 78 | N |
| 15 | SI (Shift In) | 79 | O |
| 16 | DLE (Data Link Escape) | 80 | P |
| 17 | DC1 (Device Control 1) | 81 | Q |
| 18 | DC2 (Device Control 2) | 82 | R |
| 19 | DC3 (Device Control 3) | 83 | S |
| 20 | DC4 (Device Control 4) | 84 | T |
| 21 | NAK (Negative Acknowledgment) | 85 | U |
| 22 | SYN (Synchronous Idle) | 86 | V |
| 23 | ETB (End of Transmission Block) | 87 | W |
| 24 | CAN (Cancel) | 88 | X |
| 25 | EM (End of Medium) | 89 | Y |
| 26 | SUB (Substitute) | 90 | Z |
| 27 | ESC (Escape) | 91 | [ |
| 28 | FS (File Separator) | 92 | |
| 29 | GS (Group Separator) | 93 | ] |
| 30 | RS (Record Separator) | 94 | ^ |
| 31 | US (Unit Separator) | 95 | _ |
| 32 | SP (Space) | 96 | ` |
| 33 | ! |
97 | a |
| 34 | " |
98 | b |
| 35 | # |
99 | c |
| 36 | $ |
100 | d |
| 37 | % |
101 | e |
| 38 | & |
102 | f |
| 39 | ' |
103 | g |
| 40 | ( |
104 | h |
| 41 | ) |
105 | i |
| 42 | * |
106 | j |
| 43 | + |
107 | k |
| 44 | , |
108 | l |
| 45 | - |
109 | m |
| 46 | . |
110 | n |
| 47 | / |
111 | o |
| 48 | 0 |
112 | p |
| 49 | 1 |
113 | q |
| 50 | 2 |
114 | r |
| 51 | 3 |
115 | s |
| 52 | 4 |
116 | t |
| 53 | 5 |
117 | u |
| 54 | 6 |
118 | v |
| 55 | 7 |
119 | w |
| 56 | 8 |
120 | x |
| 57 | 9 |
121 | y |
| 58 | : |
122 | z |
| 59 | ; |
123 | { |
| 60 | < |
124 | | |
| 61 | = |
125 | } |
| 62 | > |
126 | ~ |
| 63 | ? |
127 | DEL (delete) |
Модуль string
Модуль string — простой и удобный инструмент, разграничивающий содержащиеся в ASCII символы по группам, разделяя их в строки-константы. Вот как выглядит основная часть модуля:
# From lib/python3.7/string.py
whitespace = ' tnrvf'
ascii_lowercase = 'abcdefghijklmnopqrstuvwxyz'
ascii_uppercase = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
ascii_letters = ascii_lowercase + ascii_uppercase
digits = '0123456789'
hexdigits = digits + 'abcdef' + 'ABCDEF'
octdigits = '01234567'
punctuation = r"""!"#$%&'()*+,-./:;<=>?@[]^_`{|}~"""
printable = digits + ascii_letters + punctuation + whitespaceБольшинство этих констант исчерпывающе описаны их идентификаторами. Мы вкратце коснёмся констант hexdigits и octdigits.
Мы можем использовать определённые в модуле константы для рутинных операций:
>>> import string
>>> s = "What's wrong with ASCII?!?!?"
>>> s.rstrip(string.punctuation)
'What's wrong with ASCII'Прим. Обратите внимание, string.printable включает string.whitespace. Это несколько не соответствует тому, как печатаемые символы определяет метод str.isprintable(), который не рассматривает ни один из символов {'v', 'n', 'r', 'f', 't'} как печатаемый.
Это различие происходит из определения метода: str.isprintable() рассматривает что-либо печатаемым, если «все символы рассматриваются как печатаемые методом repr().
Что такое биты
Настало время вспомнить, что такое бит, базовая единица информации, которой оперируют вычислительные устройства.
Бит — это сигнал, который имеет два возможных состояния. Есть различные способы символического отображения этих состояний:
- 0 или 1;
- «да» или «нет»;
TrueилиFalse;- «включено» или «выключено».
Таблица ASCII из предыдущего раздела использует то, что обычно назвали бы числами (от 0 до 127), однако для наших целей важно понимать, что это десятичные числа (с основанием 10).
Каждое из этих десятичных чисел можно выразить последовательностью бит (числом с основанием 2). Вот таблица соотношения двоичных и десятичных чисел:
| Десятичное | Двоичное (кратко) | Двоичное (в байте) |
|---|---|---|
| 0 | 0 | 00000000 |
| 1 | 1 | 00000001 |
| 2 | 10 | 00000010 |
| 3 | 11 | 00000011 |
| 4 | 100 | 00000100 |
| 5 | 101 | 00000101 |
| 6 | 110 | 00000110 |
| 7 | 111 | 00000111 |
| 8 | 1000 | 00001000 |
| 9 | 1001 | 00001001 |
| 10 | 1010 | 00001010 |
Обратите внимание, что при увеличении десятичного числа n для его отображения (а следовательно и для отображения символа, относящегося к этому числу) требуется всё больше значимых бит.
Вот удобный метод представить строки ASCII как последовательность бит. Каждый символ из строки ASCII переводится в последовательность из 8 нолей и единиц с пробелами между этими последовательностями:
>>> def make_bitseq(s: str) -> str:
... if not s.isascii():
... raise ValueError("ASCII only allowed")
... return " ".join(f"{ord(i):08b}" for i in s)
>>> make_bitseq("bits")
'01100010 01101001 01110100 01110011'
>>> make_bitseq("CAPS")
'01000011 01000001 01010000 01010011'
>>> make_bitseq("$25.43")
'00100100 00110010 00110101 00101110 00110100 00110011'
>>> make_bitseq("~5")
'01111110 00110101'Прим. Обратите внимание, что метод .isascii() появился в Python 3.7.
Строковой литерал f-string f"{ord(i):08b}" использует мини-язык форматирования Format Specification Mini-Language, а именно его возможность замещения полей при форматировании строк.
- левая часть выражения,
ord(i), представляет объект, значение которого будет отформатировано и отображено при выводе.ord()возвращает кодовую точку одиночного символаstrв десятичном выражении; - Правая сторона выражения определяет форматирование объекта.
08означает ширина 8, заполнение нулями, аbработает как команда вывести число в двоичном (binary) эквиваленте.
На самом деле этот метод можно использовать разве что для развлечения. Он выдаст ошибку для любого символа, не представленного в ASCII-таблице. Позже мы рассмотрим, как эта проблема решается в других кодировках.
Нам нужно больше бит
Исходя из определения бита, можно вывести следующую закономерность: при определённом количестве бит n с их помощью можно выразить 2n разных значений.
def n_possible_values(nbits: int) -> int:
return 2 ** nbitsВот что это означает:
- 1 бит позволяет выразить 21 == 2 возможных значения;
- 8 бит позволяют выразить 28 == 256 возможных значений;
- 64 бита позволяют выразить 264 == 18 446 744 073 709 551 616 возможных значений.
В качестве естественного вывода из приведённой выше формулы мы можем установить следующее: для того, чтобы вычислить количество бит, необходимых для выражения определённого числа разных значений, нам нужно найти n в уравнении 2n=x, где переменная x известна.
Вот как можно это рассчитать:
>>> from math import ceil, log
>>> def n_bits_required(nvalues: int) -> int:
... return ceil(log(nvalues) / log(2))
>>> n_bits_required(256)
8Округление вверх в методе n_bits_required() требуется для расчёта значений, которые не являются чистой степенью двойки. К примеру, вам нужно сохранить набор из 110 различных символов. Для этого потребуется log(110) / log(2) == 6.781 бит, но поскольку бит для вычислительной техники является мельчайшей неделимой величиной, для отображения 110 различных значений нам понадобится 7 бит, при этом несколько значений останутся невостребованными.
>>> n_bits_required(110)
7Всё сказанное служит для обоснования одной идеи: ASCII, строго говоря, семибитная кодировка. Эта таблица содержит 128 кодовых точек, и, соответственно, символов, от 0 до 127 включительно. Это требует 7 бит:
>>> n_bits_required(128) # от 0 до 127
7
>>> n_possible_values(7)
128Проблема заключается в том, что современные компьютеры не используют для хранения чего-либо семибитные последовательности. Основной единицей хранения информации современных вычислительных устройств являются восьмибитные последовательности, байты.
Прим. В этой статье под байтом подразумевается группа из 8 бит, как повелось с 60-х годов прошлого века. Если вам не по душе это новомодное название, можете называть их октетами.
То, что ASCII-таблица использует 7 бит из доступных 8, означает, что память вычислительного устройства, занятого строками символов ASCII, наполовину пуста. Для того, чтобы лучше понять, почему это происходит, вернитесь к приведённой выше таблице соответствия двоичных и десятичных чисел. Вы можете выразить числа 0 и 1 с помощью 1 бита, или вы можете использовать 8 бит, чтобы выразить их как 00000000 и 00000001 соответственно.
Прим. перев. Если быть точным, то пустой остаётся только одна восьмая часть памяти. Однако с помощью именно этого незадействованного бита можно было бы создать вдвое больше кодовых точек.
Вы можете выразить числа от 0 до 3 всего двумя битами, от 00 до 11, или использовать 8 бит, чтобы выразить их как 00000000, 00000001, 00000010 и 00000011. Самая большая кодовая точка ASCII, 127, требует только 7 значимых бит.
С учётом этого взгляните, как метод make_bitseq() преобразует строки ASCII в строки, состоящие из байт, где каждый символ требует один байт:
>>> make_bitseq("bits")
'01100010 01101001 01110100 01110011'Неэффективное использование восьмибитной структуры памяти современных вычислительных устройств привело к появлению неструктурированного семейства конфликтующих кодировок, задействующих оставшуюся незанятой половину кодовых точек, доступных в одном байте.
Несмотря на попытку задействовать дополнительный бит, эти конфликтующие кодировки не могли отобразить все возможные символы, используемые человечеством в письменности.
Со временем появилась одна большая схема кодировки, которая объединила их. Однако, прежде чем мы до этого доберёмся, поговорим немного о краеугольных камнях схем кодировки символов — системах счисления.
Изучаем основы: другие системы счисления
В ASCII-таблице, как мы увидели, каждый символ соответствует числу от 0 до 127.
Этот диапазон чисел выражен в десятичной системе счисления. Именно эту систему используют для счёта люди, просто потому что на руках у нас по 10 пальцев.
Однако существуют и другие системы счисления, которые, в частности, широко используются в исходном коде CPython. Следует понимать, что действительное число не изменяется, а системы счисления просто по-разному его выражают.
Вопрос, какое число записано в строке "11" покажется странным, ведь для большинства очевидно, что это одиннадцать.
Однако в строке может быть представлено и другое число, в зависимости от системы счисления. Помимо десятичной, используются такие общепринятые альтернативы:
- Двоичная: с основой 2;
- Восьмеричная: с основой 8;
- Шестнадцатеричная (hex): с основой 16.
Что же мы подразумеваем, говоря что определённая система счисления имеет основу N?
Один из способов объяснения разных систем счисления заключается в том, чтобы представить, что у вас N пальцев.
Если же вам требуется более подробное объяснение систем счисления, обратитесь к книге Чарльза Петцольда «Код». В этой книге детально объясняются основы работы вычислительной техники.
Конструктор int() — один из способов показать, как разные системы счисления преобразуют одну и ту же строку с помощью Python. Если вы передадите str в int(), Python по умолчанию будет считать, что строка содержит число в десятичной системе. Однако вы можете дать другие указания:
>>> int('11')
11
>>> int('11', base=10) # 10 установлено по умолчанию
11
>>> int('11', base=2) # Двоичная
3
>>> int('11', base=8) # Восьмеричная
9
>>> int('11', base=16) # Шестнадцатеричная
17Чаще в Python для обозначения того, что целое число представлено в системе счисления, отличной от десятичной, используют префиксы-литералы. Для каждой из трёх альтернативных систем существует свой литерал.
| Тип литерала | Префикс | Пример |
|---|---|---|
| Нет | Нет | 11 |
| Binary literal | 0b или 0B |
0b11 |
| Octal literal | 0o или 0O |
0o11 |
| Hex literal | 0x или 0X |
0x11 |
Всё это — разновидности целочисленных литералов. Результаты применения префиксов будут такими же, как и в случае использования int() с определением параметра base. Для Python всё это просто целые числа:
>>> 11
11
>>> 0b11 # Двоичный литерал
3
>>> 0o11 # Восьмеричный литерал
9
>>> 0x11 # Шестнадцатеричный литерал
17В таблице ниже отражено, как можно ввести десятичные числа от 0 до 20 в двоичном, восьмеричном и шестнадцатеричном эквиваленте. Любой из этих способов можно использовать как в оболочке интерпретатора Python, так и в исходном коде, и все эти числа будут рассматриваться как относящиеся к типу int.
| Десятичные | Двоичные | Восмеричные | Шестнадцатеричные |
|---|---|---|---|
0 |
0b0 |
0o0 |
0x0 |
1 |
0b1 |
0o1 |
0x1 |
2 |
0b10 |
0o2 |
0x2 |
3 |
0b11 |
0o3 |
0x3 |
4 |
0b100 |
0o4 |
0x4 |
5 |
0b101 |
0o5 |
0x5 |
6 |
0b110 |
0o6 |
0x6 |
7 |
0b111 |
0o7 |
0x7 |
8 |
0b1000 |
0o10 |
0x8 |
9 |
0b1001 |
0o11 |
0x9 |
10 |
0b1010 |
0o12 |
0xa |
11 |
0b1011 |
0o13 |
0xb |
12 |
0b1100 |
0o14 |
0xc |
13 |
0b1101 |
0o15 |
0xd |
14 |
0b1110 |
0o16 |
0xe |
15 |
0b1111 |
0o17 |
0xf |
16 |
0b10000 |
0o20 |
0x10 |
17 |
0b10001 |
0o21 |
0x11 |
18 |
0b10010 |
0o22 |
0x12 |
19 |
0b10011 |
0o23 |
0x13 |
20 |
0b10100 |
0o24 |
0x14 |
Кстати, вы можете сами убедиться, что подобные способы записи чисел очень часто используется в Стандартной Библиотеке Python. Найдите папку lib/python3.7/ в своей системе, перейдите в неё и введите команду:
$ grep -nri --include "*.py" -e "b0x" lib/python3.7Команда сработает в любой Unix-системе с утилитой grep. С её помощью вы найдёте все шестнадцатеричные литералы. Для поиска двоичных используйте b0b, а для восьмеричных — b0o.
Для чего же нужны альтернативные литералы целых чисел? Если коротко, числа 2, 8 и 16, в отличие от 10, являются степенями двойки. Основанные на них системы счисления выражают численные значения способами, более удобными для обработки бинарными вычислительными устройствами. К примеру, 65536, или 216, в шестнадцатеричной системе просто 10000 или, используя литерал, 0x10000.
Введение в Юникод
Как видите, проблема ASCII в том, что этой таблицы недостаточно для отображения знаков, символов и глифов, использующихся во всех языках и диалектах мира. Её недостаточно даже для английского языка.
Юникод служит тем же целям, что и ASCII, но содержит намного больший набор кодовых точек. В период времени между появлением ASCII и принятием Юникода использовалось ещё несколько различных кодировок, но рассматривать их подробно нет смысла, так как Юникод и одна из его схем, UTF-8, в настоящее время стали использоваться практически повсеместно.
Вы можете представить Юникод как расширенную версию ASCII-таблицы — с 1 114 112 возможными кодовыми точками, от 0 до 1 114 111. Это 17*(216) или 0x10ffff в шестнадцатеричном представлении. Фактически, ASCII является частью Юникода, так как первые 128 символов этих кодировок полностью совпадают.
Чтобы соблюсти технические детали, сам по себе Юникод не является кодировкой. Он скорее реализуется в различных кодировках символов, как вы вскоре увидите. По структуре Юникод скорее ассоциативный массив (что-то вроде dict) или база данных, состоящая из таблицы с двумя колонками. В этой таблице разные символы (такие как "a", "¢", или даже "ቈ") соотносятся с различными целыми положительными числами. Кодировка же должна предоставлять несколько больше возможностей.
Юникод содержит практически любой символ, который только можно представить, включая дополнительные непечатаемые. Например, кодовая точка 8207 соответствует отметке RTL, которая используется для смены направления письма. Она полезна в текстах, где абзацы на одном из европейских языков соседствуют с абзацами на арабских языках.
Прим. Кстати, если уж мы хотим быть совсем точны в деталях, то надо отметить ещё один факт. Исторически сложилось, что в Юникоде доступны только 1 111 998 кодовых точек.
Юникод и UTF-8
Довольно скоро стало понятно, что все необходимые символы невозможно вместить в таблицу, используя только один байт. Современные, более ёмкие кодировки требовали использования больших объёмов.
Ранее мы упоминали, что Юникод сам по себе не является кодировкой. И вот почему.
Юникод не содержит указаний по извлечению из текста бит, он работает только с кодовыми точками. В нём нет стандарта конверсии текста в двоичные данные и обратно.
Юникод является абстрактным стандартом кодировки. Для практического его применения чаще всего используют схему UTF-8. Стандарт Юникод (таблица соответствий символов кодовыми точкам) определяет несколько различных кодировок на основе единого набора символов.
Как и менее распространённые UTF-16 и UTF-32, UTF-8 — формат кодировки для отображения символов Юникода в двоичном виде, используя один или несколько байт на один символ. UTF-16 и UTF-32 мы обсудим чуть позже, но пока нам интересен UTF-8 как самый популярный формат.
Сначала требуется разобрать термины «кодирование» и «декодирование».
Кодирование и декодирование в Python 3
Тип данных str в Python 3 рассчитан на представление текста в удобном для чтения формате и может содержать любые символы Юникода.
Тип bytes, напротив, представляет двоичные данные, последовательность байт, без указания на кодировку.
Кодирование и декодирование — это процесс перехода данных из одной формы в другую.
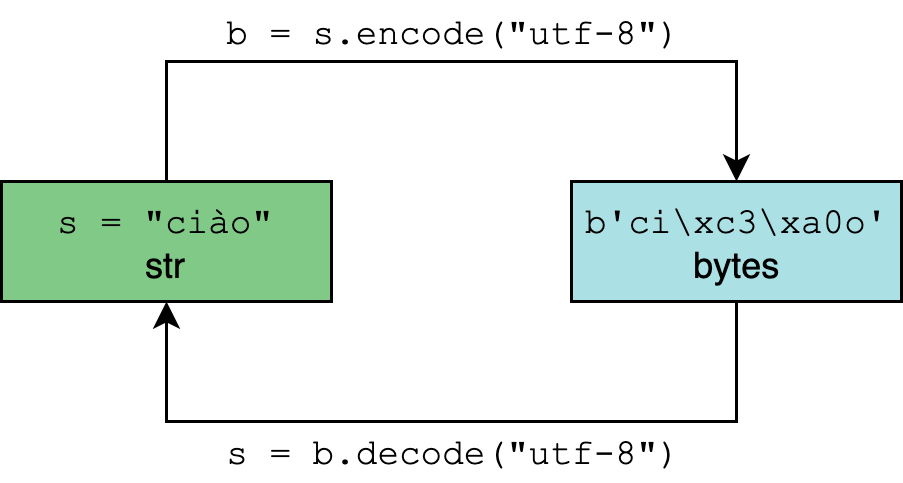
В методах .encode() и .decode() по умолчанию используется параметр "utf-8", однако для большей уверенности этот параметр можно определить самостоятельно:
>>> "résumé".encode("utf-8")
b'rxc3xa9sumxc3xa9'
>>> "El Niño".encode("utf-8")
b'El Nixc3xb1o'
>>> b"rxc3xa9sumxc3xa9".decode("utf-8")
'résumé'
>>> b"El Nixc3xb1o".decode("utf-8")
'El Niño'str.encode() возвращает объект типа bytes. И литералы этого типа объектов (такие как b"rxc3xa9sumxc3xa9"), и его отображение допускают только символы ASCII.
Вот почему при вызове "El Niño".encode("utf-8"), ASCII-совместимое "El" отображается как есть, а n с тильдой экранируется в "xc3xb1". Этой с виду неудобочитаемой последовательностью представлены два байта, 0xc3 и 0xb1 в шестнадцатеричной системе:
>>> " ".join(f"{i:08b}" for i in (0xc3, 0xb1))
'11000011 10110001'Таким образом символ ñ требует два байта для бинарного представления с помощью UTF-8.
Прим. Если вы введёте help(str.encode), скорее всего, увидите параметр по умолчанию encoding='utf-8'. Однако имейте в виду, что настройки Windows для Python 3.6 могут отличаться, поэтому использовать методы кодирования и декодирования без указания необходимой кодировки (например "résumé".encode()) следует с осторожностью.
Python 3: всё на Юникоде
Python 3 полностью реализован на Юникоде, а точнее на UTF-8. Вот что это означает:
- По умолчанию предполагается, что исходный код Python 3 написан с помощью UTF-8. Это значит, что вам не нужно использовать определение
# -*- coding: UTF-8 -*-в начале файлов.pyв этой версии языка. - Все тексты (объекты формата
str) реализованы на Юникоде. Кодированный текст представлен двоичными данными (bytes). Типstrможет содержать любой символ-литерал из Юникода (например"Δv / Δt"), и все они хранятся в Юникоде. - Любой из символов Юникода приемлем в качестве идентификатора. Например, вы можете использовать выражение
résumé = "~/Documents/resume.pdf". - В модуле
reпо умолчанию установлен флагre.UNICODE, а неre.ASCII. Это означает, чтоr"w"соответствует буквам из Юникода, а не просто символам ASCII. - По умолчанию
encodingвstr.encode()вbytes.decode()установлен в UTF-8.
Нужно отметить также нюанс, касающийся встроенного метода open(). Его параметр encoding зависит от платформы и определяется значением locale.getpreferredencoding():
>>> # Mac OS X High Sierra
>>> import locale
>>> locale.getpreferredencoding()
'UTF-8'
>>> # Windows Server 2012; другие сборки Windows могут использовать UTF-16
>>> import locale
>>> locale.getpreferredencoding()
'cp1252'Мы делаем упор на эти моменты, чтобы вы вдруг не подумали, что кодировка UTF-8 является универсальной. Она действительно широко распространена, но вы вполне можете столкнуться и с другими вариантами. Не будет лишним предусмотреть это в коде.
Один байт, два байта, три байта, четыре…
Одна из важнейших особенностей UTF-8 состоит в том, что это кодировка с переменным размером.
Вспомните раздел, посвящённый ASCII. Любой символ в этой таблице требует максимум одного байта пространства. Это можно быстро проверить с помощью следующего генератора:
>>> all(len(chr(i).encode("ascii")) == 1 for i in range(128))
TrueС UTF-8 дела обстоят по-другому. Символы Юникода могут занимать от одного до четырёх байт. Вот пример четырёхбайтного символа:
>>> ibrow = "?"
>>> len(ibrow)
1
>>> ibrow.encode("utf-8")
b'xf0x9fxa4xa8'
>>> len(ibrow.encode("utf-8"))
4
>>> # Вызов list() с объектом типа bytes возвращает
>>> # значение каждого байта
>>> list(b'xf0x9fxa4xa8')
[240, 159, 164, 168]Это небольшая, но важная особенность метода len():
- Размер единичного символа Юникода в объекте
strязыка Python всегда будет равен 1, вне зависимости от количества занимаемых байт. - Длина того же символа в объекте типа
bytesбудет варьироваться от 1 до 4.
Таблица ниже показывает, сколько байт занимают основные типы символов.
| Десятичный диапазон | Шестнадцатеричный диапазон |
Включённые символы | Примеры |
|---|---|---|---|
| от 0 до 127 | от "u0000" до "u007F" |
U.S. ASCII | "A", "n", "7", "&" |
| от 128 до 2047 | от "u0080" до "u07FF" |
Большая часть латинских алфавитов* | "ę", "±", "ƌ", "ñ" |
| от 2048 до 65535 | от "u0800" до "uFFFF" |
Дополнительные части многоязыковых символов (BMP)** | "ത", "ᄇ", "ᮈ", "‰" |
| от 65536 до 1114111 | от "U00010000" до "U0010FFFF" |
Другое*** | "?", "?", "?", "?", |
*Такие как английский, арабский, греческий, ирландский.
**Масса языков и символов, в основном китайский, японский и корейский с разделением по томам (а также ASCII и латиница).
***Дополнительные символы китайского, японского, корейского и вьетнамского, а также другие символы и эмоджи.
Прим. У UTF-8 есть и другие технические особенности. Те, кто работает на Python, редко с ними сталкиваются, поэтому мы не будем раскрывать их в этой статье, но упомянем вкратце, чтобы сохранить полноту картины. Так, UTF-8 использует коды-префиксы, указывающие на количество байт в последовательности. Такой приём позволяет декодеру группировать байты в условиях кодировки с переменным размером. Количество байт в последовательности определяется первым её байтом. Другие технические подробности можно найти на странице Википедии, посвящённой UTF-8 или на официальном сайте.
Особенности UTF-16 и UTF-32
Рассмотрим альтернативные кодировки, UTF-16 и UTF-32. Различие между ними и UTF-8 в основном практическое. Продемонстрируем величину расхождения с помощью перевода туда и обратно:
>>> letters = "αβγδ"
>>> rawdata = letters.encode("utf-8")
>>> rawdata.decode("utf-8")
'αβγδ'
>>> rawdata.decode("utf-16") # ?
'뇎닎돎듎'В данном случае, когда мы кодируем четыре буквы греческого алфавита в двоичные данные с помощью UTF-8, а декодируем обратно в текст с использованием UTF-16, на выходе получается строка с совершенно другими символами (из корейского алфавита).
Так происходит, если для кодирования и декодирования применяют разные кодировки. Два варианта декодирования одного бинарного объекта могут вернуть текст даже на другом языке.
Таблица ниже демонстрирует количество байт, используемых в разных кодировках:
| Кодировка | Байт на символ (включительно) | Варьируемая длина |
|---|---|---|
| UTF-8 | От 1 до 4 | Да |
| UTF-16 | От 2 до 4 | Да |
| UTF-32 | 4 | Нет |
Любопытный аспект семейства UTF: UTF-8 не всегда занимает меньше памяти, чем UTF-16. Хотя с точки зрения математики это выглядит маловероятным, однако это возможно:
>>> text = "記者 鄭啟源 羅智堅"
>>> len(text.encode("utf-8"))
26
>>> len(text.encode("utf-16"))
22Так получается из-за того, что кодовые точки в диапазоне от U+0800 до U+FFFF (от 2048 до 65535 в десятичной системе) в кодировке UTF-8 занимают три байта, а в UTF-16 только два.
Это не означает, что нужно работать с UTF-16, независимо от того, насколько часто вы работаете с символами в этом диапазоне. Один из самых важных поводов придерживаться UTF-8 — в мире кодировок лучше держаться вместе с большинством.
Кроме того, в 2019 году компьютерная память стоит дёшево, и экономия четырёх байт за счёт использования нестандартной кодировки вряд ли стоит усилий.
Прим. перев. Есть и более весомые причины использовать UTF-8. Среди них её обратная совместимость с ASCII, а также то, что это самосинхронизирующаяся кодировка.
Вы освоили самую сложную часть статьи. Теперь посмотрим, как всё изученное реализуется на Python.
В Python есть несколько встроенных функций, каким-либо образом относящихся к системам счисления и кодировке:
ascii()bin()bytes()chr()hex()int()oct()ord()str()
Логически их можно сгруппировать по назначению.
ascii(),bin(),hex()иoct()предназначены для различного представления вводных данных. Все они возвращаютstr. Первая,ascii(), производит представление объекта в ASCII, экранируя не входящие в эту таблицу символы. Оставшиеся три дают соответственно двоичное, шестнадцатеричное и восьмеричное представление целого числа. Все эти функции меняют только представление объекта, не изменяя непосредственно вводные данные.bytes(),str()иint()— конструкторы классов соответствующих типов:bytes,str, иint. Все они предлагают способы подогнать данные под желаемый тип.ord()иchr()выполняют противоположные действия.ord()конвертирует символ в десятичную кодовую точку, аchr()принимает в качестве аргумента целое число, и возвращает символ, кодовой точкой которого это число является.
В таблице ниже эти функции разобраны более подробно:
| Функция | Форма | Тип аргументов | Тип возвращаемых данных | Назначение |
|---|---|---|---|---|
ascii() |
ascii(obj) |
Различный | str |
Представление объекта символами ASCII. Не входящие в таблицу символы экранируются |
bin() |
bin(number) |
number: int |
str |
Бинарное представление целого чиста с префиксом "0b" |
bytes() |
bytes(последовательность_целых_чисел)
|
Различный | bytes |
Приводит аргумент к двоичным данным, типу bytes |
chr() |
chr(i) |
i: int
|
str |
Преобразует кодовую точку (целочисленное значение) в символ Юникода |
hex() |
hex(number) |
number: int |
str |
Шестнадцатеричное представление целого числа с префиксом "0x" |
int() |
int([x])
|
Различный | int |
Приводит аргумент к типу int |
oct() |
oct(number) |
number: int |
str |
Восьмеричное представление целого числа с префиксом "0o" |
ord() |
ord(c) |
c: str
|
int |
Возвращает значение кодовой точки символа Юникода |
str() |
str(object=’‘)
|
Различный | str |
Приводит аргумент к текстовому представлению, типу str |
Дальше можно посмотреть полезные примеры использования этих функций.
ascii():
>>> ascii("abcdefg")
"'abcdefg'"
>>> ascii("jalepeño")
"'jalepe\xf1o'"
>>> ascii((1, 2, 3))
'(1, 2, 3)'
>>> ascii(0xc0ffee) # Шестнадцатеричный литерал (int)
'12648430'bin():
>>> bin(0)
'0b0'
>>> bin(400)
'0b110010000'
>>> bin(0xc0ffee) # Шестнадцатеричный литерал (int)
'0b110000001111111111101110'
>>> [bin(i) for i in [1, 2, 4, 8, 16]] # `int` + обработка списка
['0b1', '0b10', '0b100', '0b1000', '0b10000']bytes():
>>> # Последовательность целых чисел
>>> bytes((104, 101, 108, 108, 111, 32, 119, 111, 114, 108, 100))
b'hello world'
>>> bytes(range(97, 123)) # Последовательность целых чисел
b'abcdefghijklmnopqrstuvwxyz'
>>> bytes("real ?", "utf-8") # Строка + кодировка
b'real xf0x9fx90x8d'
>>> bytes(10)
b'x00x00x00x00x00x00x00x00x00x00'
>>> bytes.fromhex('c0 ff ee')
b'xc0xffxee'
>>> bytes.fromhex("72 65 61 6c 70 79 74 68 6f 6e")
b'realpython'chr():
>>> chr(97)
'a'
>>> chr(7048)
'ᮈ'
>>> chr(1114111)
'U0010ffff'
>>> chr(0x10FFFF) # Шестнадцатеричный литерал (int)
'U0010ffff'
>>> chr(0b01100100) # Двоичный литерал (int)
'd'hex():
>>> hex(100)
'0x64'
>>> [hex(i) for i in [1, 2, 4, 8, 16]]
['0x1', '0x2', '0x4', '0x8', '0x10']
>>> [hex(i) for i in range(16)]
['0x0', '0x1', '0x2', '0x3', '0x4', '0x5', '0x6', '0x7',
'0x8', '0x9', '0xa', '0xb', '0xc', '0xd', '0xe', '0xf']int():
>>> int(11.0)
11
>>> int('11')
11
>>> int('11', base=2)
3
>>> int('11', base=8)
9
>>> int('11', base=16)
17
>>> int(0xc0ffee - 1.0)
12648429
>>> int.from_bytes(b"x0f", "little")
15
>>> int.from_bytes(b'xc0xffxee', "big")
12648430oct():
>>> ord("a")
97
>>> ord("ę")
281
>>> ord("ᮈ")
7048
>>> [ord(i) for i in "hello world"]
[104, 101, 108, 108, 111, 32, 119, 111, 114, 108, 100]str():
>>> str("str of string")
'str of string'
>>> str(5)
'5'
>>> str([1, 2, 3, 4]) # Like [1, 2, 3, 4].__str__(), but use str()
'[1, 2, 3, 4]'
>>> str(b"xc2xbc cup of flour", "utf-8")
'¼ cup of flour'
>>> str(0xc0ffee)
'12648430'Литералы для строк на Python
Вместо использования конструктора str(), объект этого типа чаще вводят напрямую:
>>> meal = "shrimp and grits"Выглядит достаточно просто. Но есть один аспект, о котором нужно помнить. Поскольку Python позволяет использовать все возможности Юникода, можно «напечатать» символы, которых вы никогда не найдёте на клавиатуре. Можно скопировать и вставить их прямо в оболочку интерпретатора:
>>> alphabet = 'αβγδεζηθικλμνξοπρςστυφχψ'
>>> print(alphabet)
αβγδεζηθικλμνξοπρςστυφχψКроме ввода через консоль реальных, неэкранированых символов Юникода, существуют и другие способы ввода текстовых строк.
Самые насыщенные разделы документации Python посвящены лексическому анализу. В частности, раздел о строках и литералах. Возможно, для понимания данного аспекта языка этот раздел придётся неоднократно перечитать.
Кроме прочего, там говорится о шести возможных способах ввода одного символа Юникода.
Первый, и самый распространённый метод, как вы уже видели — прямой ввод. Проблема состоит в поиске необходимых сочетаний клавиш. Здесь и могут пригодиться другие способы получения и представления символов. Вот полный список:
| Экранирующая последовательность | Значение | Как отобразить "a" |
|---|---|---|
"ooo" |
Символ с восьмеричным значением ooo |
"141" |
"xhh" |
Символ с шестнадцатеричным значением hh |
"x61" |
"N{name}" |
Символ с именем name в базе данных Юникода |
"N{LATIN SMALL LETTER A}" |
"uxxxx" |
Символ с шестнадцатибитным (двухбайтным) шестнадцатеричным значением xxxx |
"u0061" |
"Uxxxxxxxx" |
Символ с тридцатидвухбитным (четырёхбайтным) шестнадцатеричным значением xxxxxxxx |
"U00000061" |
Это соответствие можно проверить на практике:
>>> (
... "a" ==
... "x61" ==
... "N{LATIN SMALL LETTER A}" ==
... "u0061" ==
... "U00000061"
... )
TrueНужно однако упомянуть и два основных затруднения при использовании этих методов:
- Не каждый способ работает со всеми символами. Шестнадцатеричное представление числа 300 выглядит как
0x012c, а это значение просто не поместится в экранирующий код"xhh", так как в нём допускаются всего две цифры. Самая большая кодовая точка, которую можно втиснуть в этот формат —"xff"("ÿ"). Аналогичо"ooo"можно использовать только до"777"("ǿ"). - Для
xhh,uxxxx, иUxxxxxxxxтребуется вводить ровно столько цифр, сколько указано в примерах. Это может стать неприятным сюрпризом, поскольку обычно основанные на Юникоде таблицы содержат кодовые точки для символов с префиксомU+и варьирующимся количеством шестнадцатеричных символов. В этих таблицах кодовые точки отображают только значимые цифры.
Например, если вы обратитесь к сайту unicode-table.com с целью получить данные готического символа faihu (или fehu), "?", его кодовая точка будет U+10346.
Как же можно разместить его в "uxxxx" или "Uxxxxxxxx"? В "uxxxx" эту кодовую точку вместить невозможно, поскольку она соответствует четырёхбайтному символу. А чтобы представить его в "Uxxxxxxxx", придётся выровнять последовательность с левой стороны:
>>> "U00010346"
'?'Это также значит, что экранирующая последовательность "Uxxxxxxxx" — единственная последовательность, способная вместить любой символ Юникода.
Прим. Вот код небольшой, но удобной функции, переводящей записи типа "U+10346" в приемлемый для Python формат с помощью str.zfill():
>>> def make_uchr(code: str):
... return chr(int(code.lstrip("U+").zfill(8), 16))
>>> make_uchr("U+10346")
'?'
>>> make_uchr("U+0026")
'&'Другие поддерживаемые Python кодировки
Пока что мы рассказали про 4 разные кодировки символов:
- ASCII;
- UTF-8;
- UTF-16;
- UTF-32.
Однако существует большое количество и других вариантов кодировки.
Один из примеров — Latin-1 (другое название ISO-8859-1). Это базовая кодировка для Hypertext Transfer Protocol (HTTP) в спецификации RFC 2616. Для Windows существует собственный вариант Latin-1, который называется cp1252.
Прим. Кодировка ISO-8859-1 всё ещё широко используется. Библиотека requests неукоснительно придерживается спецификации RFC 2616, используя её по умолчанию для содержимого отзывов HTTP/HTTPS. Если в заголовке Content-Type находится слово «text» и не выбрана другая кодировка, requests использует ISO-8859-1.
Полный список допустимых кодировок можно найти в документации модуля codecs, входящего в набор стандартных библиотек Python.
Среди этих кодировок стоит упомянуть ещё одну, зачастую весьма полезную. Это "unicode-escape". Если вы декодировали str и хотите быстро получить представление содержащихся в ней экранированных литералов Юникода, можно определить эту кодировку в .encode:
>>> alef = chr(1575) # Или "u0627"
>>> alef_hamza = chr(1571) # Или "u0623"
>>> alef, alef_hamza
('ا', 'أ')
>>> alef.encode("unicode-escape")
b'\u0627'
>>> alef_hamza.encode("unicode-escape")
b'\u0623'Вы знаете, что говорят насчёт предположений…
Хотя Python по умолчанию предполагает, что файлы и код созданы на основе кодировки UTF-8, вам, как программисту, не следует делать аналогичное предположение относительно сторонних данных.
Когда вы получаете данные в двоичном коде из внешних источников, из файла или по сетевому соединению, стоит проверить, указана ли кодировка. Если нет — вы можете уточнить.
Все операции ввода-вывода осуществляют в байтах, наборе нулей и единиц, пока вы не сообщите системе кодировку для преобразования этих данных в текст.
Приведём пример того, что может пойти не так. Допустим, вы подписаны на API, который передаёт вам рецепт блюда дня. Вы получаете его в формате bytes и раньше всегда без проблем декодировали с использованием .decode("utf-8") . Но именно в этот день часть рецепта выглядела так:
>>> data = b"xbc cup of flour"Похоже, нам потребуется мука, но сколько?
>>> data.decode("utf-8")
Traceback (most recent call last):
File "", line 1, in
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xbc in position 0: invalid start byteА вот и та самая неприятная ошибка UnicodeDecodeError. Подобное вполне может произойти, когда вы делаете предположение об используемой кодировке. Уточняем у разработчика ресурса, предоставляющего API. Выясняется, что полученный вами файл был закодирован с помощью Latin-1:
>>> data.decode("latin-1")
'¼ cup of flour'Именно в этом и крылась проблема. В Latin-1 каждый символ кодируется одним байтом, в вот в UTF-8 символ «¼» требует два байта ("xc2xbc").
Как видите, делать предположения относительно кодировки полученных данных довольно рискованно. Обычно это UTF-8, однако в тех случаях, когда это не так, у вас могут возникнуть проблемы.
Если уж у вас нет другого выхода и кодировку приходится угадывать, обратите внимание на библиотеку chardet. В ней используются разработанные в Mozilla методы, позволяющие сделать обоснованное предположение насчёт кодировки данных. Однако учтите, что такие инструменты должны быть вашим последним средством, не стоит прибегать к ним, если есть возможность решить вопрос другим способом.
Всякая всячина: unicodedata
Нельзя не упомянуть также модуль unicodedata. Он позволяет взаимодействовать с базой данных символов Юникода (Unicode Character Database, UCD).
>>> import unicodedata
>>> unicodedata.name("€")
'EURO SIGN'
>>> unicodedata.lookup("EURO SIGN")
'€'Подводим итоги
Итак, в этой статье вы познакомились со следующими концепциями кодировки символов в Python:
- Фундаментальные принципы кодировки символов и систем счисления;
- Целочисленные, двоичные, восьмеричные, шестнадцатеричные, строковые и байтовые литералы в Python;
- Встроенные функции языка, работающие с кодировкой и системами счисления;
- Особенности обработки текстовых и двоичных данных.
Дополнительные источники
Ещё больше информации можно получить из следующих материалов (на английском языке):
- UTF-8 Everywhere Manifesto.
- Joel Spolsky: Минимальный уровень знаний о Юникоде и наборах символов, требующийся каждому разработчику ПО (Без отговорок!).
- David Zentgraf: Что обязательно должен знать о кодировках и наборах символов каждый программист для работы с текстом.
- Mozilla: Комплексный подход к определению языков и кодировок.
- Wikipedia.
- John Skeet: Юникод и .NET.
- Network Working Group, RFC 3629: UTF-8, формат преобразования ISO 10646.
- Unicode Technical Standard #18: Регулярные выражения Юникода.
В документации языка нашему вопросу посвящены два раздела:
- What’s New in Python 3.0;
- Unicode HOWTO.
Перевод статьи Unicode & Character Encodings in Python: A Painless Guide
Python 2.7. Unicode Errors Simply Explained
I know I’m late with this article for about 5 years or so, but people are still using Python 2.x, so this subject is relevant I think.
Some facts first:
- Unicode is an international encoding standard for use with different languages and scripts
- In python-2.x, there are two types that deal with text.
stris an 8-bit string.unicodeis for strings of unicode code points.
A code point is a number that maps to a particular abstract character. It is written using the notation U+12ca to mean the character with value 0x12ca (4810 decimal)
- Encoding (noun) is a map of Unicode code points to a sequence of bytes. (Synonyms: character encoding, character set, codeset). Popular encodings: UTF-8, ASCII, Latin-1, etc.
- Encoding (verb) is a process of converting
unicodeto bytes ofstr, and decoding is the reverce operation. - Python 2.x uses ASCII as a default encoding. (More about this later)
SyntaxError: Non-ASCII character
When you sees something like this
SyntaxError: Non-ASCII character 'xd0' in file /tmp/p.py on line 2, but no encoding declared; see http://www.python.org/peps/pep-0263.html for details
you just need to define encoding in the first or second line of your file.
All you need is to have string coding=utf8 or coding: utf8 somewhere in your comments.
Python doesn’t care what goes before or after those string, so the following will work fine too:
# -*- encoding: utf-8 -*-
Notice the dash in utf-8. Python has many aliases for UTF-8 encoding, so you should not worry about dashes or case sensitivity.
UnicodeEncodeError Explained
>>> str(u'café') Traceback (most recent call last): File "<input>", line 1, in <module> UnicodeEncodeError: 'ascii' codec can't encode character u'xe9' in position 3: ordinal not in range(128)
str() function encodes a string. We passed a unicode string, and it tried to encode it using a default encoding, which is ASCII. Now the error makes sence because ASCII is 7-bit encoding which doesn’t know how to represent characters outside of range 0..128.
Here we called str() explicitly, but something in your code may call it implicitly and you will also get UnicodeEncodeError.
How to fix: encode unicode string manually using .encode('utf8') before passing to str()
UnicodeDecodeError Explained
>>> utf_string = u'café' >>> byte_string = utf_string.encode('utf8') >>> unicode(byte_string) Traceback (most recent call last): File "<input>", line 1, in <module> UnicodeDecodeError: 'ascii' codec can't decode byte 0xc3 in position 3: ordinal not in range(128)
Let’s say we somehow obtained a byte string byte_string which contains encoded UTF-8 characters. We could get this by simply using a library that returns str type.
Then we passed the string to a function that converts it to unicode. In this example we explicitly call unicode(), but some functions may call it implicitly and you’ll get the same error.
Now again, Python uses ASCII encoding by default, so it tries to convert bytes to a default encoding ASCII. Since there is no ASCII symbol that converts to 0xc3 (195 decimal) it fails with UnicodeDecodeError.
How to fix: decode str manually using .decode('utf8') before passing to your function.
Rule of Thumb
Make sure your code works only with Unicode strings internally, converting to a particular encoding on output, and decoding str on input.
Learn the libraries you are using, and find places where they return str. Decode str before return value is passed further in your code.
I use this helper function in my code:
def force_to_unicode(text): "If text is unicode, it is returned as is. If it's str, convert it to Unicode using UTF-8 encoding" return text if isinstance(text, unicode) else text.decode('utf8')
Source: https://docs.python.org/2/howto/unicode.html
В python есть 2 объекта работающими с текстом: unicode и str, объект unicode хранит символы в формате (кодировке) unicode, объект str является набором байт/символов в которых python хранит остальные кодировки (utf8, cp1251, cp866, koi8-r и др).
Кодировку unicode можно считать рабочей кодировкой питона т.к. она предназначена для её использования в самом скрипте — для разных операций над строками.
Внешняя кодировка (объект str) предназначена для хранения и передачи текстовой информации вне скрипта, например для сохранения в файл или передачи по сети. Поэтому в данной статье я её назвал внешней. Самой используемой кодировкой в мире является utf8 и число приложений переходящих на эту кодировку растет каждый день, таким образом превращаясь в «стандарт».
Эта кодировка хороша тем что для хранения текста она занимает оптимальное кол-во памяти и с помощью её можно закодировать почти все языки мира ( в отличие от cp1251 и подобных однобайтовых кодировок). Поэтому рекомендуется везде использовать utf8, и при написании скриптов.
Использование
Скрипт питона, в самом начале скрипта указываем кодировку файла и сохраняем в ней файл
# coding: utf8
либо
# -*- coding: utf-8 -*-
для того что-бы интерпретатор python понял в какой кодировке файл
Строки в скрипте
Строки в скрипте хранятся байтами, от кавычки до кавычки:
print 'Привет'
= 6 байт при cp1251
= 12 байт при utf8
Если перед строкой добавить символ u, то при запуске скрипта, эта байтовая строка будет декодирована в unicode из кодировки указанной в начале:
# coding:utf8 print u'Привет'
и если кодировка содержимого в файле отличается от указанной, то в строке могут быть «битые символы»
Загрузка и сохранение файла
# coding: utf8
# Загружаем файл с кодировкай utf8
text = open('file.txt','r').read()
# Декодируем из utf8 в unicode - из внешней в рабочую
text = text.decode('utf8')
# Работаем с текстом
text += text
# Кодируем тест из unicode в utf8 - из рабочей во внешнюю
text = text.encode('utf8')
# Сохраняем в файл с кодировкий utf8
open('file.txt','w').write(text)
Текст в скрипте
# coding: utf8
a = 'Текст в utf8'
b = u'Текст в unicode'
# Эквивалентно: b = 'Текст в unicode'.decode('utf8')
# т.к. сам скрипт хранится в utf8
print 'a =',type(a),a
# декодируем из utf-8 в unicode и далее unicode в cp866 (кодировка консоли winXP ru)
print 'a2 =',type(a),a.decode('utf8').encode('cp866')
print 'b =',type(b),b
Процедуре print текст желательно передавать в рабочей кодировке либо кодировать в кодировку ОС.
Результат скрипта при запуске из консоли windows XP:
a = ╨в╨╡╨║╤Б╤В ╨▓ utf8
a2 = Текст в utf8
b = Текст в unicode
В последней строке print преобразовал unicode в cp866 автоматический, см. следующий пункт
Авто-преобразование кодировки
В некоторых случаях для упрощения разработки python делает преобразование кодировки, пример с методом print можно посмотреть в предыдущем пункте.
В примере ниже, python сам переводит utf8 в unicode — приводит к одной кодировке для того что-бы сложить строки.
# coding: utf8
# Устанавливаем стандартную внешнюю кодировку = utf8
import sys
reload(sys)
sys.setdefaultencoding('utf8')
a = 'Текст в utf8'
b = u'Текст в unicode'
c = a + b
print 'a =',type(a),a
print 'b =',type(b),b
print 'c =',type(c),c
Результат
a = Текст в utf8
b = Текст в unicode
c = Текст в utf8Текст в unicode
Как видим результирующая строка «c» в unicode. Если бы кодировки строк совпадали то авто-перекодирования не произошло бы и результирующая строка содержала кодировку слагаемых строк.
Авто-перекодирование обычно срабатывает когда происходит взаимодействие разных кодировок.
Пример авто-преобразования кодировок в сравнении
# coding: utf8
# Устанавливаем стандартную внешнюю кодировку = utf8
import sys
reload(sys)
sys.setdefaultencoding('utf8')
print '1. utf8 and unicode', 'true' if u'Слово'.encode('utf8') == u'Слово' else 'false'
print '2. utf8 and cp1251', 'true' if u'Слово'.encode('utf8') == u'Слово'.encode('cp1251') else 'false'
print '3. cp1251 and unicode', 'true' if u'Слово'.encode('cp1251') == u'Слово' else 'false'
Результат
1. utf8 and unicode true
2. utf8 and cp1251 false
script.py:10: UnicodeWarning: Unicode equal comparison failed to convert both arguments to Unicode — interpreting them as being unequal
print ‘3. cp1251 and unicode’, ‘true’ if u’Слово’.encode(‘cp1251′) == u’Слово’ else ‘false’
3. cp1251 and unicode false
В сравнении 1, кодировка utf8 преобразовалась в unicode и сравнение произошло корректно.
В сравнении 2, сравниваются кодировки одного вида — обе внешние, т.к. кодированы они в разных кодировках условие выдало что они не равны.
В сравнении 3, выпало предупреждение из за того что выполняется сравнение кодировок разного вида — рабочая и внешняя, а авто-декодирование не произошло т.к. стандартная внешняя кодировка = utf8, и декодировать строку в кодировке cp1251 методом utf8 питон не смог.
Вывод списков
# coding: utf8 d = ['Тест','списка'] print '1',d print '2',d.__repr__() print '3',','.join(d)
Результат:
1 [‘xd0xa2xd0xb5xd1x81xd1x82’, ‘xd1x81xd0xbfxd0xb8xd1x81xd0xbaxd0xb0’]
2 [‘xd0xa2xd0xb5xd1x81xd1x82’, ‘xd1x81xd0xbfxd0xb8xd1x81xd0xbaxd0xb0’]
3 Тест,списка
При выводе списка, происходит вызов [{repr}]() который возвращает внутреннее представление этого спиcка — print 1 и 2 являются аналогичными. Для корректного вывода списка, его нужно преобразовать в строку — print 3.
Установка внешней кодировки при запуске
PYTHONIOENCODING=utf8 python 1.py
В обучении ребенка важно правильное толкование окружающего его мира. Существует масса полезных журналов которые начнут экологическое воспитание дошкольников правильным путем. Развивать интерес к окружающему миру очень трудный но интересный процесс, уделите этому особое внимание.