Впервые я столкнулся с Memory Error, когда работал с огромным массивом ключевых слов. Там было около 40 млн. строк, воодушевленный своим гениальным скриптом я нажал Shift + F10 и спустя 20 секунд получил Memory Error.
Memory Error — исключение вызываемое в случае переполнения выделенной ОС памяти, при условии, что ситуация может быть исправлена путем удаления объектов. Оставим ссылку на доку, кому интересно подробнее разобраться с этим исключением и с формулировкой. Ссылка на документацию по Memory Error.
Если вам интересно как вызывать это исключение, то попробуйте исполнить приведенный ниже код.
print('a' * 1000000000000)
Почему возникает MemoryError?
В целом существует всего лишь несколько основных причин, среди которых:
- 32-битная версия Python, так как для 32-битных приложений Windows выделяет лишь 4 гб, то серьезные операции приводят к MemoryError
- Неоптимизированный код
- Чрезмерно большие датасеты и иные инпут файлы
- Ошибки в установке пакетов
Как исправить MemoryError?
Ошибка связана с 32-битной версией
Тут все просто, следуйте данному гайдлайну и уже через 10 минут вы запустите свой код.
Как посмотреть версию Python?
Идем в cmd (Кнопка Windows + R -> cmd) и пишем python. В итоге получим что-то похожее на
Python 3.8.8 (tags/v3.8.8:024d805, Feb 19 2021, 13:18:16) [MSC v.1928 64 bit (AMD64)]
Нас интересует эта часть [MSC v.1928 64 bit (AMD64)], так как вы ловите MemoryError, то скорее всего у вас будет 32 bit.
Как установить 64-битную версию Python?
Идем на официальный сайт Python и качаем установщик 64-битной версии. Ссылка на сайт с официальными релизами. В скобках нужной нам версии видим 64-bit. Удалять или не удалять 32-битную версию — это ваш выбор, я обычно удаляю, чтобы не путаться в IDE. Все что останется сделать, просто поменять интерпретатор.
Идем в PyCharm в File -> Settings -> Project -> Python Interpreter -> Шестеренка -> Add -> New environment -> Base Interpreter и выбираем python.exe из только что установленной директории. У меня это
C:/Users/Core/AppData/LocalPrograms/Python/Python38
Все, запускаем скрипт и видим, что все выполняется как следует.
Оптимизация кода
Пару раз я встречался с ситуацией когда мои костыли приводили к MemoryError. К этому приводили избыточные условия, циклы и буферные переменные, которые не удаляются после потери необходимости в них. Если вы понимаете, что проблема может быть в этом, вероятно стоит закостылить пару del, мануально удаляя ссылки на объекты. Но помните о том, что проблема в архитектуре вашего проекта, и по настоящему решить эту проблему можно лишь правильно проработав структуру проекта.
Явно освобождаем память с помощью сборщика мусора
В целом в 90% случаев проблема решается переустановкой питона, однако, я просто обязан рассказать вам про библиотеку gc. В целом почитать про Garbage Collector стоит отдельно на авторитетных ресурсах в статьях профессиональных программистов. Вы просто обязаны знать, что происходит под капотом управления памятью. GC — это не только про Python, управление памятью в Java и других языках базируется на технологии сборки мусора. Ну а вот так мы можем мануально освободить память в Python:

Introduction to Python Memory Error
Memory Error is a kind of error in python that occurs when where the memory of the RAM we are using could not support the execution of our code since the memory of the RAM is smaller and the code we are executing requires more than the memory of our existing RAM, this often occurs when a large volume of data is fed to the memory and when the program has run out of memory in processing the data.
Syntax of Python Memory Error
When performing an operation that generates or using a big volume of data, it will lead to a Memory Error.
Code:
## Numpy operation which return random unique values
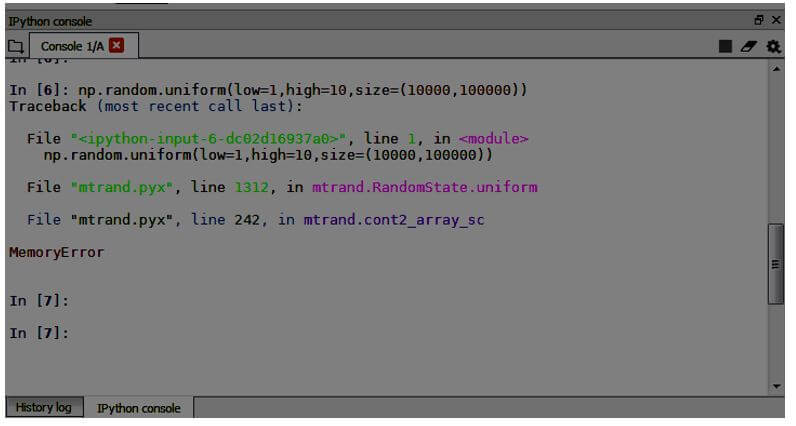
import numpy as np
np.random.uniform(low=1,high=10,size=(10000,100000))Output:
For the same function, let us see the Name Error.
Code:
## Functions which return values
def calc_sum(x,y):
op = x + y
return(op)The numpy operation of generating random numbers with a range from a low value of 1 and highest of 10 and a size of 10000 to 100000 will throw us a Memory Error since the RAM could not support the generation of that large volume of data.
How does Memory Error Works?
Most often, Memory Error occurs when the program creates any number of objects, and the memory of the RAM runs out. When working on Machine Learning algorithms most of the large datasets seems to create Memory Error. Different types of Memory Error occur during python programming. Sometimes even if your RAM size is large enough to handle the datasets, you will get a Memory Error. This is due to the Python version you might be using some times; 32-bit will not work if your system is adopted to a 64-bit version. In such cases, you can go uninstall 32-bit python from your system and install the 64-bit from the Anaconda website. When you are installing different python packages using the pip command or other commands may lead to improper installation and throws a Memory Error.
In such cases, we can use the conda install command in python prompt and install those packages to fix the Memory Error.
Example:
Another type of Memory Error occurs when the memory manager has used the Hard disk space of our system to store the data that exceeds the RAM capacity. Upon working, the computer stores all the data and uses up the memory throws a Memory Error.
Avoiding Memory Errors in Python
The most important case for Memory Error in python is one that occurs during the use of large datasets. Upon working on Machine Learning problems, we often come across large datasets which, upon executing an ML algorithm for classification or clustering, the computer memory will instantly run out of memory. We can overcome such problems by executing Generator functions. It can be used as a user-defined function that can be used when working with big datasets.
Generators allow us to efficiently use the large datasets into many segments without loading the complete dataset. Generators are very useful in working on big projects where we have to work with a large volume of data. Generators are functions that are used to return an iterator. Iterators can be used to loop the data over. Writing a normal iterator function in python loops the entire dataset and iters over it. This is where the generator comes in handy it does not allow the complete dataset to loop over since it causes a Memory Error and terminates the program.
The generator function has a special characteristic from other functions where a statement called yield is used in place of the traditional return statement that returns the output of the function.
A sample Generator function is given as an example:
Code:
def sample_generator():
for i in range(10000000):
yield i
gen_integ= sample_generator()
for i in gen_integ:
print(i)Output:
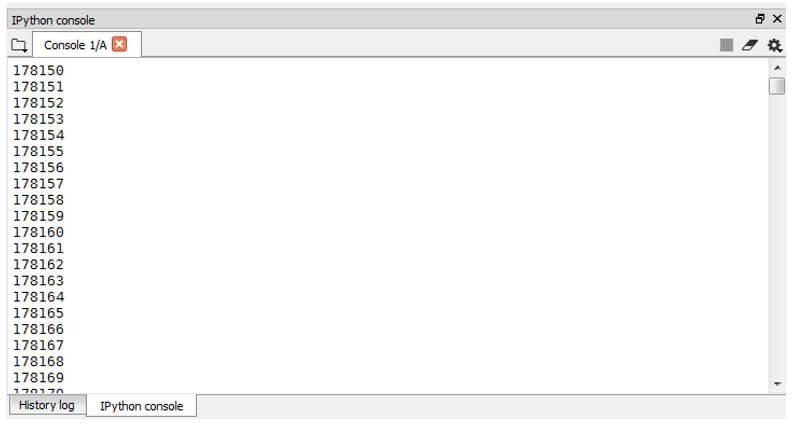
In this sample generator function, we have generated integers using the function sample generator, which is assigned to the variable gen_integ, and then the variable is iterated. This allows us to iter over one single value at a time instead of passing the entire set of integers.
In the sample code given below, we have tried to read a large dataset into small bits using the generator function. This kind of reading would allow us to process large data in a limited size without using up the system memory completely.
Code:
def readbits(filename, mode="r", chunk_size=20):
with open(filename, mode) as f:
while True:
data = f.read(chunk_size)
if not data:
break
yield data
def main():
filename = "C://Users//Balaji//Desktop//Test"
for bits in readbits(filename):
print(bits) Output:
There is another useful technique that can be used to free memory while we are working on a large number of objects. A simple way to erase the objects that are not referenced is by using a garbage collector or gc statement.
Code:
import gc
gc.collect()The import garbage collector and gc.collect() statement allows us to free the memory by removing the objects which the user does not reference.
There are additional ways in which we can manage the memory of our system CPU where we can write code to limit the CPU usage of memory.
Code:
import resource
def limit_memory(Datasize):
min_, max_ = resource.getrlimit(resource.RLIMIT_AS)
resource.setrlimit(resource.RLIMIT_AS, (Datasize, max_)) This allows us to manage CPU usage to prevent Memory Error.
Some of the other techniques that can be used to overcome the Memory Error are to limit our sample size of we are working on, especially while performing complex machine learning algorithms. Or we could update our system with more memory, or we can use the cloud services like Azure, AWS, etc. that provides the user with strong computing capabilities.
Another way is to use the Relational Database Management technique where open-source databases like MySQL are available free of cost. It can be used to store large volumes of data; also, we can adapt to big data storage services to effectively work with large volumes.
Conclusion
In detail, we have seen the Memory Error that occurs in the Python programming language and the techniques to overcome the Name Error. The main take away to remember in python Memory Error is the memory usage of our RAM where the operations are taking place, and efficiently using the above-mentioned techniques will allow us to overcome the Memory Error.
Recommended Articles
This is a guide to Python Memory Error. Here we discuss the introduction, working and avoiding memory errors in python, respectively. You may also have a look at the following articles to learn more –
- Python IOError
- Custom Exception in Python
- Python AssertionError
- Python Object to String
What is Memory Error?
Python Memory Error or in layman language is exactly what it means, you have run out of memory in your RAM for your code to execute.
When this error occurs it is likely because you have loaded the entire data into memory. For large datasets, you will want to use batch processing. Instead of loading your entire dataset into memory you should keep your data in your hard drive and access it in batches.
A memory error means that your program has run out of memory. This means that your program somehow creates too many objects. In your example, you have to look for parts of your algorithm that could be consuming a lot of memory.
If an operation runs out of memory it is known as memory error.
Types of Python Memory Error
Unexpected Memory Error in Python
If you get an unexpected Python Memory Error and you think you should have plenty of rams available, it might be because you are using a 32-bit python installation.
The easy solution for Unexpected Python Memory Error
Your program is running out of virtual address space. Most probably because you’re using a 32-bit version of Python. As Windows (and most other OSes as well) limits 32-bit applications to 2 GB of user-mode address space.
We Python Pooler’s recommend you to install a 64-bit version of Python (if you can, I’d recommend upgrading to Python 3 for other reasons); it will use more memory, but then, it will have access to a lot more memory space (and more physical RAM as well).
The issue is that 32-bit python only has access to ~4GB of RAM. This can shrink even further if your operating system is 32-bit, because of the operating system overhead.
For example, in Python 2 zip function takes in multiple iterables and returns a single iterator of tuples. Anyhow, we need each item from the iterator once for looping. So we don’t need to store all items in memory throughout looping. So it’d be better to use izip which retrieves each item only on next iterations. Python 3’s zip functions as izip by default.
Must Read: Python Print Without Newline
Python Memory Error Due to Dataset
Like the point, about 32 bit and 64-bit versions have already been covered, another possibility could be dataset size, if you’re working with a large dataset. Loading a large dataset directly into memory and performing computations on it and saving intermediate results of those computations can quickly fill up your memory. Generator functions come in very handy if this is your problem. Many popular python libraries like Keras and TensorFlow have specific functions and classes for generators.
Python Memory Error Due to Improper Installation of Python
Improper installation of Python packages may also lead to Memory Error. As a matter of fact, before solving the problem, We had installed on windows manually python 2.7 and the packages that I needed, after messing almost two days trying to figure out what was the problem, We reinstalled everything with Conda and the problem was solved.
We guess Conda is installing better memory management packages and that was the main reason. So you can try installing Python Packages using Conda, it may solve the Memory Error issue.
Most platforms return an “Out of Memory error” if an attempt to allocate a block of memory fails, but the root cause of that problem very rarely has anything to do with truly being “out of memory.” That’s because, on almost every modern operating system, the memory manager will happily use your available hard disk space as place to store pages of memory that don’t fit in RAM; your computer can usually allocate memory until the disk fills up and it may lead to Python Out of Memory Error(or a swap limit is hit; in Windows, see System Properties > Performance Options > Advanced > Virtual memory).
Making matters much worse, every active allocation in the program’s address space can cause “fragmentation” that can prevent future allocations by splitting available memory into chunks that are individually too small to satisfy a new allocation with one contiguous block.
1 If a 32bit application has the LARGEADDRESSAWARE flag set, it has access to s full 4gb of address space when running on a 64bit version of Windows.
2 So far, four readers have written to explain that the gcAllowVeryLargeObjects flag removes this .NET limitation. It does not. This flag allows objects which occupy more than 2gb of memory, but it does not permit a single-dimensional array to contain more than 2^31 entries.
How can I explicitly free memory in Python?
If you wrote a Python program that acts on a large input file to create a few million objects representing and it’s taking tons of memory and you need the best way to tell Python that you no longer need some of the data, and it can be freed?
The Simple answer to this problem is:
Force the garbage collector for releasing an unreferenced memory with gc.collect().
Like shown below:
import gc
gc.collect()

Memory error in Python when 50+GB is free and using 64bit python?
On some operating systems, there are limits to how much RAM a single CPU can handle. So even if there is enough RAM free, your single thread (=running on one core) cannot take more. But I don’t know if this is valid for your Windows version, though.
How do you set the memory usage for python programs?
Python uses garbage collection and built-in memory management to ensure the program only uses as much RAM as required. So unless you expressly write your program in such a way to bloat the memory usage, e.g. making a database in RAM, Python only uses what it needs.
Which begs the question, why would you want to use more RAM? The idea for most programmers is to minimize resource usage.
if you wanna limit the python vm memory usage, you can try this:
1、Linux, ulimit command to limit the memory usage on python
2、you can use resource module to limit the program memory usage;
if u wanna speed up ur program though giving more memory to ur application, you could try this:
1threading, multiprocessing
2pypy
3pysco on only python 2.5
How to put limits on Memory and CPU Usage
To put limits on the memory or CPU use of a program running. So that we will not face any memory error. Well to do so, Resource module can be used and thus both the task can be performed very well as shown in the code given below:
Code #1: Restrict CPU time
# importing libraries
import signal
import resource
import os
# checking time limit exceed
def time_exceeded(signo, frame):
print("Time's up !")
raise SystemExit(1)
def set_max_runtime(seconds):
# setting up the resource limit
soft, hard = resource.getrlimit(resource.RLIMIT_CPU)
resource.setrlimit(resource.RLIMIT_CPU, (seconds, hard))
signal.signal(signal.SIGXCPU, time_exceeded)
# max run time of 15 millisecond
if __name__ == '__main__':
set_max_runtime(15)
while True:
pass
Code #2: In order to restrict memory use, the code puts a limit on the total address space
# using resource import resource def limit_memory(maxsize): soft, hard = resource.getrlimit(resource.RLIMIT_AS) resource.setrlimit(resource.RLIMIT_AS, (maxsize, hard))
Ways to Handle Python Memory Error and Large Data Files
1. Allocate More Memory
Some Python tools or libraries may be limited by a default memory configuration.
Check if you can re-configure your tool or library to allocate more memory.
That is, a platform designed for handling very large datasets, that allows you to use data transforms and machine learning algorithms on top of it.
A good example is Weka, where you can increase the memory as a parameter when starting the application.
2. Work with a Smaller Sample
Are you sure you need to work with all of the data?
Take a random sample of your data, such as the first 1,000 or 100,000 rows. Use this smaller sample to work through your problem before fitting a final model on all of your data (using progressive data loading techniques).
I think this is a good practice in general for machine learning to give you quick spot-checks of algorithms and turnaround of results.
You may also consider performing a sensitivity analysis of the amount of data used to fit one algorithm compared to the model skill. Perhaps there is a natural point of diminishing returns that you can use as a heuristic size of your smaller sample.
3. Use a Computer with More Memory
Do you have to work on your computer?
Perhaps you can get access to a much larger computer with an order of magnitude more memory.
For example, a good option is to rent compute time on a cloud service like Amazon Web Services that offers machines with tens of gigabytes of RAM for less than a US dollar per hour.
4. Use a Relational Database
Relational databases provide a standard way of storing and accessing very large datasets.
Internally, the data is stored on disk can be progressively loaded in batches and can be queried using a standard query language (SQL).
Free open-source database tools like MySQL or Postgres can be used and most (all?) programming languages and many machine learning tools can connect directly to relational databases. You can also use a lightweight approach, such as SQLite.
5. Use a Big Data Platform
In some cases, you may need to resort to a big data platform.
Summary
In this post, you discovered a number of tactics and ways that you can use when dealing with Python Memory Error.
Are there other methods that you know about or have tried?
Share them in the comments below.
Have you tried any of these methods?
Let me know in the comments.
If your problem is still not solved and you need help regarding Python Memory Error. Comment Down below, We will try to solve your issue asap.
A MemoryError means that the interpreter has run out of memory to allocate to your Python program. This may be due to an issue in the setup of the Python environment or it may be a concern with the code itself loading too much data at the same time.
An Example of MemoryError
To have a look at this error in action, let’s start with a particularly greedy piece of code. In the code below, we start with an empty array and use nested arrays to add strings to it. In this case, we use three levels of nested arrays, each with a thousand iterations. This means at the end of the program, the array s has 1,000,000,000 copies of the string «More.«
s = []
for i in range(1000):
for j in range(1000):
for k in range(1000):
s.append("More")Output
As you might expect, these million strings are a bit much for, let’s say, a laptop to handle. The following error is printed out:
C:codePythonMemErrvenv3KScriptspython.exe C:/code/python/MemErr/main.py
Traceback (most recent call last):
File "C:/code/python/MemErr/main.py", line 6, in <module>
s.append("More")
MemoryErrorIn this case, the traceback is relatively simple as there are no libraries involved in this short program. After the traceback showing the exact function call which caused the issue, we see the simple but direct MemoryError.
Two Ways to Handle A MemoryError in Python
Appropriate Python Set-up
This simplest but possibly least intuitive solution to a MemoryError actually has to do with a potential issue with your Python setup. In the event that you have installed the 32-bit version of Python on a 64-bit system, you will have extremely limited access to the system’s memory. This restricted access may cause MemoryErrors on programs that your computer would normally be able to handle.
Attention to Large Nested Loops
If your installation of Python is correct and these issues still persist, it may be time to revisit your code. Unfortunately, there is no cut and dry way to entirely remove this error outside of evaluating and optimizing your code. Like in the example above, pay special attention to any large or nested loops, along with any time you are loading large datasets into your program in one fell swoop.
In these cases, the best practice is often to break the work into batches, allowing the memory to be freed in between calls. As an example, in the code below, we have broken out earlier nested loops into 3 separate loops, each running for 333,333,333 iterations. This program still goes through one million iterations but, as the memory can be cleared through the process using a garbage collection library, it no longer causes a MemoryError.
An Example of Batching Nested Loops
import gc
s = []
t = []
u = []
for i in range(333333333):
s.append("More")
gc.collect()
for j in range(333333333):
t.append("More")
gc.collect()
for k in range(333333334):
u.append("More")
gc.collect()How to Avoid a MemoryError in Python
Python’s garbage collection makes it so that you should never encounter issues in which your RAM is full. As such, MemoryErrors are often indicators of a deeper issue with your code base. If this is happening, it may be an indication that more code optimization or batch processing techniques are required. Thankfully, these steps will often show immediate results and, in addition to avoiding this error, will also vastly shorten the programs’ runtime and resource requirements.
Track, Analyze and Manage Errors With Rollbar
Managing errors and exceptions in your code is challenging. It can make deploying production code an unnerving experience. Being able to track, analyze, and manage errors in real-time can help you proceed with more confidence. Rollbar automates error monitoring and triaging, making fixing Python errors easier than ever. Sign Up Today!

This Python tutorial will assist you in resolving a memory error. We’ll look at all of the possible solutions to memory errors. There are some common issues that arise when memory is depleted.
What is Memory Error?
The python memory error occurs when your python script consumes a large amount of memory that the system does not have.
The python error occurs it is likely because you have loaded the entire data into memory.
The python operation runs out of memory it is known as memory error, due to the python script creates too many objects, or loaded a lot of data into the memory.
You can also checkout other python File tutorials:
- How To Read Write Yaml File in Python3
- Read and Write CSV Data Using Python
- How To Convert Python String To Array
- How to Trim Python string
Unexpected Memory Error Due to 32-bit Python
If you encounter an unexpected Python Memory Error while running a Python script. You may have plenty of memory but still receive a Memory Error. You should check if you are using 32-bit Python libraries, and if so, you should update to 64-bit.
Because 32-bit applications consume more memory than 64-bit applications. Windows allocates 2 GB of user-mode address space to 32-bit applications.
Python Memory Error Due to Dataset
This is yet another possibility for a python memory error to occur when working with a large dataset. Your Python scripts are loading a large dataset into memory and performing operations on it, which can rapidly fill up your memory. You must scan your script and correct any errors in the code, or use third-party Python libraries if they are available.
Python Memory Error Due to inappropriate package
Improper python package installation is also causing memory error, We can use Conda for package installation and management. The Conda is installing better memory management packages. The Conda is an open-source package management system and environment management system that runs on Windows, macOS and Linux. The Conda quickly installs, runs and updates packages and their dependencies.
How To Free memory in Python Using Script
Python uses garbage collection and built-in memory management to ensure the program only uses as much RAM as required.
Force the garbage collector for releasing an unreferenced memory with gc.collect().
Содержание
- Memory error python sklearn
- Что такое MemoryError в Python?
- Почему возникает MemoryError?
- Как исправить MemoryError?
- Ошибка связана с 32-битной версией
- Как посмотреть версию Python?
- Как установить 64-битную версию Python?
- Оптимизация кода
- Явно освобождаем память с помощью сборщика мусора
- How to avoid memory overloads using SciKit Learn
- A small technique we found while text-mining 40,000 documents
- Why is it taking so much memory?
- How to resolve this memory overload?
- Divide the Document-Term matrix creation process in smaller parts
- Benefits
- Improvements to do
- How to reduce memory used by Random Forest from Scikit-Learn in Python?
- Let’s load packages and the data
- Reduce memory usage of the Scikit-Learn Random Forest
- Extra tip for saving the Scikit-Learn Random Forest in Python
- Join our newsletter
Memory error python sklearn

Впервые я столкнулся с Memory Error, когда работал с огромным массивом ключевых слов. Там было около 40 млн. строк, воодушевленный своим гениальным скриптом я нажал Shift + F10 и спустя 20 секунд получил Memory Error.
Что такое MemoryError в Python?
Memory Error — исключение вызываемое в случае переполнения выделенной ОС памяти, при условии, что ситуация может быть исправлена путем удаления объектов. Оставим ссылку на доку, кому интересно подробнее разобраться с этим исключением и с формулировкой. Ссылка на документацию по Memory Error.
Если вам интересно как вызывать это исключение, то попробуйте исполнить приведенный ниже код.
Почему возникает MemoryError?
В целом существует всего лишь несколько основных причин, среди которых:
- 32-битная версия Python, так как для 32-битных приложений Windows выделяет лишь 4 гб, то серьезные операции приводят к MemoryError
- Неоптимизированный код
- Чрезмерно большие датасеты и иные инпут файлы
- Ошибки в установке пакетов
Как исправить MemoryError?
Ошибка связана с 32-битной версией
Тут все просто, следуйте данному гайдлайну и уже через 10 минут вы запустите свой код.
Как посмотреть версию Python?
Идем в cmd (Кнопка Windows + R -> cmd) и пишем python. В итоге получим что-то похожее на
Нас интересует эта часть [MSC v.1928 64 bit (AMD64)], так как вы ловите MemoryError, то скорее всего у вас будет 32 bit.
Как установить 64-битную версию Python?
Идем на официальный сайт Python и качаем установщик 64-битной версии. Ссылка на сайт с официальными релизами. В скобках нужной нам версии видим 64-bit. Удалять или не удалять 32-битную версию — это ваш выбор, я обычно удаляю, чтобы не путаться в IDE. Все что останется сделать, просто поменять интерпретатор.
Идем в PyCharm в File -> Settings -> Project -> Python Interpreter -> Шестеренка -> Add -> New environment -> Base Interpreter и выбираем python.exe из только что установленной директории. У меня это
Все, запускаем скрипт и видим, что все выполняется как следует.
Оптимизация кода
Пару раз я встречался с ситуацией когда мои костыли приводили к MemoryError. К этому приводили избыточные условия, циклы и буферные переменные, которые не удаляются после потери необходимости в них. Если вы понимаете, что проблема может быть в этом, вероятно стоит закостылить пару del, мануально удаляя ссылки на объекты. Но помните о том, что проблема в архитектуре вашего проекта, и по настоящему решить эту проблему можно лишь правильно проработав структуру проекта.
Явно освобождаем память с помощью сборщика мусора
В целом в 90% случаев проблема решается переустановкой питона, однако, я просто обязан рассказать вам про библиотеку gc. В целом почитать про Garbage Collector стоит отдельно на авторитетных ресурсах в статьях профессиональных программистов. Вы просто обязаны знать, что происходит под капотом управления памятью. GC — это не только про Python, управление памятью в Java и других языках базируется на технологии сборки мусора. Ну а вот так мы можем мануально освободить память в Python:
Источник
How to avoid memory overloads using SciKit Learn
A small technique we found while text-mining 40,000 documents
This article is a part of our making of series on “Islam, media subject”, a study on the perception of Islam by french national daily newspapers. You can see our first published article here and the previous one here.
In “Islam, media subject”, we wanted to quantify how media were treating “Islam”. To do that we used text-mining tools and techniques to analyse the articles published in daily newspapers from France.
One of those techniques was the analysis of (co)occurrences of terms in the articles thanks to Document-Term matrices like bellow. Those matrices hold occurrences of terms (all terms compose the vocabulary) through a set of documents (the corpus). They constitute one of the basic components of many techniques like Topic Modeling, Clustering, study of similarities, etc.
As you can see on this schema, the vocabulary is constituted of part-of-speech tagged words. This is a part of our analysis because we wanted to be able to study what were the terms used in our corpus associated with “Islam”.
But this is not a part of DTM, so you can ignore it for the rest of this article. However if you’re interested in it you can read the first article of this series that details it a bit.
In order to create those kind of matrices, we used a feature took from the Sci-Kit Learn libray (or sklearn, a Python library providing machine learning algorithms and techniques) called CountVectorizer. This feature was exactly what we were looking for because it took in charge the creation of DTM while letting us be able to study more deeply what terms were used in the different parts of our corpus thanks to a vocabulary (as shown above).
Why is it taking so much memory?
This vocabulary is a Python dictionary associating terms to a matrix columns. As we can see in the previous scheme, those terms can be single words or association of words (or n-grams). In our case we used n-grams between 1 and 3 terms and that’s what made this vocabulary get really huge quickly.
In this chart, we can see that the main problem lies in this vocabulary. For instance, when the number of documents in our corpus gets above 14,000 the vocabulary is taking 750MB while the corpus itself (a pandas DataFrame) takes
250MB and the associated DTM is taking only
180MB. This also illustrate the way Python deal with memory allocation for dictionaries (like vocabulary). As we can see, it first allocate an amount of memory, then, when it got filled by new elements, it doubles its space, and so on. That’s why we see a huge gap between 13,000 and 14,000 documents.
So we can guess that the next allocated memory space, for this dictionary alone, will be around 1.5GB when we will reach a bigger number of documents. So as the number of documents get bigger, you will reach a point where the allocated memory space is so big that CountVectorizer can’t compute the DTM anymore without throwing a Memory Error.
How to resolve this memory overload?
First, if you don’t need to, don’t use CountVectorizer. Sklearn have other less memory-consuming features like HashingVectorizer . However it didn’t allow us to have an in-memory vocabulary (since text got hashed). This made us stick with CountVectorizer in order to be able to query this vocabulary to study terms usage in our corpus.
But if you need to use CountVectorizer, what you can do is to separate this costful operation into several smaller operations and construct the Document-Term matrix with multiple operations, not one. That’s what we’re going to see next.
Divide the Document-Term matrix creation process in smaller parts
This sounds like an easy task to do. It seems you “just” have to separate your documents in small batches (chunks); then you apply CountVectorizer on them to create small DTMs, then combine them to get a big DTM, right? Well, no. If you do that, you will end up with incompatible matrices. Because every chunks’ DTM will have columns corresponding to different vocabulary terms. Indeed, the vocabulary depends on the texts content.
Different set of texts will produce different vocabularies and this is what prevents you to concatenate those matrices; simply because it doesn’t make any sense to concatenate two matrices having columns representing different terms. So, in order to separate this DTM creation in smaller parts, you should instead:
- Create a single vocabulary of the whole corpus,
- separate your corpus in different chunks,
- for each chunk create a corresponding DTM with the vocabulary created earlier (this way you can be sure your matrices will have the same shape),
- and finally concatenate your matrices.
We’ve summed this in the schema bellow. Remember that the Part-of-Speech Tagging process is not mandatory at all, but if you want to use such technique then you should do it with the depicted order. You can also look at a simplified version of what we implemented in this gist.
Benefits
This approach have several benefits. First, if your corpus computation fail (for various reasons) you could take back computation to where it failed (if you took care of saving computed parts during the process). This saves a lot of time and helps to keep a relatively good mental sanity.
Second, this solution could be parallelized/distributed since we have small independent corpus chunks and a single shared vocabulary, it won’t be an issue to process those matrices independently.
And finally, it makes computation of DTM smaller in terms of memory consumption. That’s why it’s less prone to break with a Memory Error.
Improvements to do
We didn’t spend additional time on this issue but we can imagine different improvements or different approaches to improve our solution.
As I’ve said earlier, the biggest problem lies in the memory space took by our vocabulary and our solution don’t reduce this space. And things will get worse when the corpus gets bigger (like in CountVectorizer); to a point where this vocabulary will get too big to do anything on the side. That’s why we should consider different approaches to reduce this space.
- Reduce the size of the vocabulary
You could, for instance, remove terms appearing only once in the whole corpus or terms appearing too many times (like tool words, stop words). However, this approach won’t be enough to reduce its size significantly. - Get the vocabulary out of the RAM, store it in a database
This would be a huge improvement. By storing this vocabulary in a database would save a lot of memory space for other parts of the analysis. We didn’t look for what would be the “perfect” database for this job but if we can manage to have a working solution with PostgreSQL it will be good enough for us. - Use a different data structure
Python dictionaries are taking a lot of memory space. Heading for a similar data structure but with a memory consumption focus could be the solution. The only clue I have right now is to look at Trie (and the marisa-trie implementation).
If you know simpler, more efficient or just different approaches that could tackle this issue, feel free to comment!
Источник
How to reduce memory used by Random Forest from Scikit-Learn in Python?
June 24, 2020 by Piotr PЕ‚oЕ„ski Random forest June 24, 2020 by Piotr PЕ‚oЕ„ski —>
The Random Forest algorithm from scikit-learn package can sometimes consume too much memory:
- max_depth=None ,
- min_samples_split=2 ,
- min_samples_leaf=1 ,
which means that full trees are built. Bulding full trees is by design (see Leo Breiman, Random Forests article from 2001). The Random Forest creates full trees to fit the data well. If there will be one tree in the Random Forest, then the model will overfit the data. However, in the Random Forest there are created set of trees (for example 100 trees). To overcome the overfitting (and increase stability) the bagging and random subspace sampling are used. (Bagging — selecting subset of rows for training, random subspace sampling — selecting subset of columns in each node split search).
In the case of large data sets or complex datasets, the full tree can be really deep and have thousands of nodes. Such single decision tree will use a lot of memory and thus the memory consumption of the Random Forest will grow very fast. In this post I will show how to reduce memory consumption of the Random Forest. In the example I will use Adult Income dataset.
Let’s load packages and the data
The dataset has 32,561 rows and 15 columns (including the target column). We see that data use about 3.8 MB in the memory (similar memory is also needed to store the data on the hard drive disk).
| age | workclass | fnlwgt | education | education-num | marital-status | occupation | relationship | race | sex | capital-gain | capital-loss | hours-per-week | native-country | income | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 39 | State-gov | 77516 | Bachelors | 13 | Never-married | Adm-clerical | Not-in-family | White | Male | 2174 | 40 | United-States | 14 columns will be used as input to the model. The last column income will be the target column. |
Let’s use 25% of the data for testing and the rest for training.
I create the Random Forest Classifier with default parameters. This means that full trees will be built. There will be created 100 trees (the default of n_estimators ).
Let’s train the model:
Check the depth of the first tree in the Random Forest
Let’s check the depth of all the trees in the Forest:
Check the size of single tree in the disk after saving with joblib:
Our dataset size was 3.8 MB so the resulting Random Forest is about 13 times larger than the dataset! The dataset was pretty small, you can easily imagine how the Random Forest size will explode for larger files (the complexity of the dataset matters a lot because it determines the depth of the full tree).
Before changing anything in the Random Forest let’s check its performance.
Reduce memory usage of the Scikit-Learn Random Forest
The memory usage of the Random Forest depends on the size of a single tree and number of trees. The most straight forward way to reduce memory consumption will be to reduce the number of trees. For example 10 trees will use 10 times less memory than 100 trees. However, the more trees in the Random Forest the better for performance and I will search for other hyper-parameters to control the Random Forest size.
The simplest way to reduce the memory consumption is to limit the depth of the tree. Shallow trees will use less memory. Let’s train shallow Random Forest with max_depth=6 (keep number of trees as default 100 ):
Let’s save the shallow Decision Tree to the disk:
You see, the full single tree size was: 0.52 MB while the shallow tree size is 0.01 MB. Let’s save the whole forest:
The Random Forest with full trees has size 49.67 MB and the shallow Random Forest size is 0.75 MB so 66 times less!
Let’s check the performance of such shallow tree:
The perfomance is better! The shallow Random Forest has about 4% better logloss (the lower value the better). So we reduced the size of Random Forest by 66 times and increase the perfomance! 🙂
The shallow trees can be also obtained by tuning min_samples_split or min_samples_leaf (or even other hyper-parameters, like: min_weight_fraction_leaf , max_features , max_leaf_nodes ). However, I prefer to tune max_depth because it is more intuitive.
Extra tip for saving the Scikit-Learn Random Forest in Python
While saving the scikit-learn Random Forest with joblib you can use compress parameter to save the disk space. In the joblib docs there is information that compress=3 is a good compromise between size and speed. Example below:
Compressed Random Forest is 6 times smaller!
The same obervation about memory consumption should be valid for Extra Trees Classifier and Extra Trees Regressor .

Join our newsletter
Subscribe to our newsletter to receive product updates
Источник
What exactly is a Memory Error?
Python Memory Error or, in layman’s terms, you’ve run out of Random access memory (RAM) to sustain the running of your code. This error indicates that you have loaded all of the data into memory. For large datasets, batch processing is advised. Instead of packing your complete dataset into memory, please save it to your hard disk and access it in batches.
Your software has run out of memory, resulting in a memory error. It indicates that your program generates an excessive number of items. You’ll need to check for parts of your algorithm that consume a lot of memory in your case.
A memory error occurs when an operation runs out of memory.
Python has a fallback exception, as do all programming languages, for when the interpreter runs out of memory and must abandon the current execution. Python issues a MemoryError in these (hopefully infrequent) cases, giving the script a chance to catch up and break free from the present memory dearth. However, because Python’s memory management architecture is based on the C language’s malloc() function, It is unlikely that all processes will recover – in some situations, a MemoryError will result in an unrecoverable crash.
A MemoryError usually signals a severe fault in the present application. A program that takes files or user data input, for example, may encounter MemoryErrors if it lacks proper sanity checks. Memory restrictions might cause problems in various situations, but we’ll stick with a simple allocation in local memory utilizing strings and arrays for our code example.
The computer architecture on which the executing system runs is the most crucial element in whether your applications are likely to incur MemoryErrors. Or, to be more particular, the architecture of the Python version you’re using. The maximum memory allocation granted to the Python process is meager if you’re running a 32-bit Python. The maximum memory allocation limit fluctuates and is dependent on your system. However, it is generally around 2 GB and never exceeds 4 GB.
64-bit Python versions, on the other hand, are essentially restricted only by the amount of memory available on your system. Thus, in practice, a 64-bit Python interpreter is unlikely to have memory problems, and if it does, the pain is much more severe because it would most likely affect the rest of the system.
To verify this, we’ll use psutil to get information about the running process, specifically the psutil.virtual memory() method, which returns current memory consumption statistics when called. The print() memory usage method prints the latter information:
Python Memory Errors There are Several Types of Python Memory Errors
In Python, an unexpected memory error occurs
Even if you have enough RAM, you could get an unexpected Python Memory Error, and you may be using a 32-bit Python installation.
Unexpected Python Memory Error: A Simple Solution
Your software has used up all of the virtual address space available to it. It’s most likely because you’re using a 32-bit Python version. Because 32-bit applications are limited to 2 GB of user-mode address space in Windows (and most other operating systems),
We Python Poolers recommend installing a 64-bit version of Python (if possible, update to Python 3 for various reasons); it will use more memory, but it will also have much more memory space available (and more physical RAM as well).
The problem is Python 32-bit only has 4GB of RAM. So it can be reduced due to operating system overhead even more if your operating system is 32-bit.
For example, the zip function in Python 2 accepts many iterables and produces a single tuple iterator. In any case, for looping, we only require each item from the iterator once. As a result, we don’t need to keep all of the things in memory while looping. As a result, it’s preferable to utilize izip, which retrieves each item only on subsequent cycles. Thus, by default, Python 3’s zip routines are called izip.
Memory Error in Python Because of the Dataset
Another choice, if you’re working with a huge dataset, is dataset size. The latter has already been mentioned concerning 32-bit and 64-bit versions. Loading a vast dataset into memory and running computations on it, and preserving intermediate results of such calculations can quickly consume memory. If this is the case, generator functions can be pretty helpful. Many major Python libraries, such as Keras and TensorFlow, include dedicated generator methods and classes.
Memory Error in Python Python was installed incorrectly
Improper Python package installation can also result in a Memory Error. In fact, before resolving the issue, we had manually installed python 2.7 and the programs that I need on Windows. We replaced everything using Conda after spending nearly two days attempting to figure out what was wrong, and the issue was resolved.
Conda is probably installing improved memory management packages, which is the main reason. So you might try installing Python Packages with Conda to see if that fixes the Memory Error.
Conda is a free and open-source package management and environment management system for Windows, Mac OS X, and Linux. Conda is a package manager that installs, runs, and updates packages and their dependencies in a matter of seconds.
Python Out of Memory Error
When an attempt to allocate a block of memory fails, most systems return an “Out of Memory” error, but the core cause of the problem rarely has anything to do with being “out of memory.” That’s because the memory manager on almost every modern operating system will gladly use your available hard disk space for storing memory pages that don’t fit in RAM. In addition, your computer can usually allocate memory until the disk fills up, which may result in a Python Out of Memory Error (or a swap limit is reached; in Windows, see System Properties > Performance Options > Advanced > Virtual memory).
To make matters worse, every current allocation in the program’s address space can result in “fragmentation,” which prevents further allocations by dividing available memory into chunks that are individually too small to satisfy a new allocation with a single contiguous block.
- When operating on a 64bit version of Windows, a 32bit application with the LARGEADDRESSAWARE flag set has access to the entire 4GB of address space.
- Four readers have contacted in to say that the gcAllowVeryLargeObjects setting removes the.NET restriction. No, it doesn’t. This setting permits objects to take up more than 2GB of memory, limiting the number of elements in a single-dimensional array to 231 entries.
In Python, how do I manually free memory?
If you’ve written a Python program that uses a large input file to generate a few million objects, and it’s eating up a lot of memory, what’s the best approach to tell Python that some of the data is no longer needed and may be freed?
This problem has a simple solution:
You can cause the garbage collector to release an unreferenced memory() by using gc.collect.
As illustrated in the example below:
Do you get a memory error when there are more than 50GB of free space in Python, and you’re using 64-bit Python?
On some operating systems, the amount of RAM that a single CPU can handle is limited. So, even if there is adequate RAM available, your single thread (=one core) will not be able to take it anymore. However, we are not certain that this applies to your Windows version.
How can you make python scripts use less memory?
Python uses garbage collection and built-in memory management to ensure that the application consumes as much memory as needed. So, unless you explicitly construct your program to balloon memory utilization, such as creating a RAM database, Python only utilizes what it requires.
Which begs the question of why you’d want to do it in the first place – consume more RAM in the first place. For most programmers, the goal is to use as few resources as possible.
If you wish to keep Python’s memory use low, virtual machine to a minimum, try this:
- On Linux, use the ulimit command to set a memory limit for Python.
- You can use the resource module to limit how much memory the program uses
Consider the following if you wish to speed up your software by giving it more memory: Multiprocessing, threading.
On only python 2.5, use pysco
How can I set memory and CPU usage limits?
To limit the amount of memory or CPU used by an application while it is running. So that we don’t have any memory problems. To accomplish so, the Resource module can be used, and both tasks can be completed successfully, as demonstrated in the code below:
Code 1: Limit CPU usage
# libraries being imported
import signal
import resource
import os
# confirm_exceed_in_time.py
# confirm if there is an exceed in time limit
def exceeded_time(sig_number, frame):
print("Time is finally up !")
raise SystemExit(1)
def maximum_runtime(count_seconds):
# resource limit setup
if_soft, if_hard = resource.getrlimit(resource.RLIMIT_CPU)
resource.setrlimit(resource.RLIMIT_CPU, (count_seconds, if_hard))
signal.signal(signal.SIGXCPU, exceeded_time)
# set a maximum running time of about 25 millisecond
if __name__ == '__main__':
maximum_runtime(25)
while True:
pass
Code #2: To minimize memory usage, the code restricts the total address space available.
# using resource
import resource
def limit_memory(maxsize):
if_soft, if_hard = resource.getrlimit(resource.RLIMIT_AS)
resource.setrlimit(resource.RLIMIT_AS, (maxsize, if_hard))
How to Deal with Python Memory Errors and Big Data Files
Increase the amount of memory available
A default memory setup may limit some Python tools or modules.
Check to see if your tool or library may be re-configured to allocate more RAM.
That is a platform built to handle massive datasets and allow data transformations. On top of that and machine learning algorithms will be applied.
Weka is a fantastic example of this, as you may increase memory as a parameter when running the app.
Use a Smaller Sample Size
Are you sure you require all of the data?
Take a random sample of your data, such as the first 5,000 or 100,000 rows, before fitting a final model to Use this smaller sample to work through your problem instead of all of your data (using progressive data loading techniques).
It is an excellent practice for machine learning in general, as it allows for quick spot-checks of algorithms and results turnaround.
You may also compare the amount of data utilized to fit one algorithm to the model skill in a sensitivity analysis. Perhaps you can use a natural point of declining returns as a guideline for the size of your smaller sample.
Make use of a computer that has more memory
Is it necessary for you to use your computer? Of course, – it is possible to lay your hand’s on a considerably larger PC with significantly more memory. A good example is renting computing time from a cloud provider like Amazon Web Services, which offers workstations with tens of gigabytes of RAM for less than a dollar per hour.
Make use of a database that is relational
Relational databases are a standard method of storing and retrieving massive datasets.
Internally, data is saved on a disk, loaded in batches, and searched using a standard query language (SQL).
Most (all?) programming languages and many machine learning tools can connect directly to relational databases, as can free open-source database solutions like MySQL or Postgres. You can also use SQLite, which is a lightweight database.
Use a big data platform to your advantage
In some cases, you may need to use a big data platform.
Error Monitoring Software
Airbrake’s powerful error monitoring software delivers real-time error monitoring and automatic exception reporting for all of your development projects. Airbrake’s cutting-edge web dashboard keeps you up to current on your application’s health and error rates at all times. Airbrake effortlessly interacts with all of the most common languages and frameworks, no matter what you’re working on. Furthermore, Airbrake makes it simple to adjust exception parameters while providing you complete control over the active error filter system, ensuring that only the most critical errors are collected.
Check out Airbrake’s error monitoring software for yourself and see why so many of the world’s greatest engineering teams rely on it to transform their exception handling techniques!
Summary
In this article, you learned about various strategies and methods for coping with Python Memory Error.
Would you mind letting us know in the comments section if you have used any of these methods?