Сталкивались ли вы с трудностями при отладке Python-кода? Если это так — то изучение того, как наладить логирование (журналирование, logging) в Python, способно помочь вам упростить задачи, решаемые при отладке.

Если вы — новичок, то вы, наверняка, привыкли пользоваться командой print(), выводя с её помощью определённые значения в ходе работы программы, проверяя, работает ли код так, как от него ожидается. Использование print() вполне может оправдать себя при отладке маленьких Python-программ. Но, когда вы перейдёте к более крупным и сложным проектам, вам понадобится постоянный журнал, содержащий больше информации о поведении вашего кода, помогающий вам планомерно отлаживать и отслеживать ошибки.
Из этого учебного руководства вы узнаете о том, как настроить логирование в Python, используя встроенный модуль logging. Вы изучите основы логирования, особенности вывода в журналы значений переменных и исключений, разберётесь с настройкой собственных логгеров, с форматировщиками вывода и со многим другим.
Вы, кроме того, узнаете о том, как Sentry Python SDK способен помочь вам в мониторинге приложений и в упрощении рабочих процессов, связанных с отладкой кода. Платформа Sentry обладает нативной интеграцией со встроенным Python-модулем logging, и, кроме того, предоставляет подробную информацию об ошибках приложения и о проблемах с производительностью, которые в нём возникают.
Начало работы с Python-модулем logging
В Python имеется встроенный модуль logging, применяемый для решения задач логирования. Им мы будем пользоваться в этом руководстве. Первый шаг к профессиональному логированию вы можете выполнить прямо сейчас, импортировав этот модуль в своё рабочее окружение.
import loggingВстроенный модуль логирования Python даёт нам простой в использовании функционал и предусматривает пять уровней логирования. Чем выше уровень — тем серьёзнее неприятность, о которой сообщает соответствующая запись. Самый низкий уровень логирования — это debug (10), а самый высокий — это critical (50).
Дадим краткие характеристики уровней логирования:
-
Debug (10): самый низкий уровень логирования, предназначенный для отладочных сообщений, для вывода диагностической информации о приложении. -
Info (20): этот уровень предназначен для вывода данных о фрагментах кода, работающих так, как ожидается. -
Warning (30): этот уровень логирования предусматривает вывод предупреждений, он применяется для записи сведений о событиях, на которые программист обычно обращает внимание. Такие события вполне могут привести к проблемам при работе приложения. Если явно не задать уровень логирования — по умолчанию используется именноwarning. -
Error (40): этот уровень логирования предусматривает вывод сведений об ошибках — о том, что часть приложения работает не так как ожидается, о том, что программа не смогла правильно выполниться. -
Critical (50): этот уровень используется для вывода сведений об очень серьёзных ошибках, наличие которых угрожает нормальному функционированию всего приложения. Если не исправить такую ошибку — это может привести к тому, что приложение прекратит работу.
В следующем фрагменте кода показано использование вышеперечисленных уровней логирования при выводе нескольких сообщений. Здесь используется синтаксическая конструкция logging.<level>(<message>).
logging.debug("A DEBUG Message")
logging.info("An INFO")
logging.warning("A WARNING")
logging.error("An ERROR")
logging.critical("A message of CRITICAL severity")Ниже приведён результат выполнения этого кода. Как видите, сообщения, выведенные с уровнями логирования warning, error и critical, попадают в консоль. А сообщения с уровнями debug и info — не попадают.
WARNING:root:A WARNING
ERROR:root:An ERROR
CRITICAL:root:A message of CRITICAL severityЭто так из-за того, что в консоль выводятся лишь сообщения с уровнями от warning и выше. Но это можно изменить, настроив логгер и указав ему, что в консоль надо выводить сообщения, начиная с некоего, заданного вами, уровня логирования.
Подобный подход к логированию, когда данные выводятся в консоль, не особо лучше использования print(). На практике может понадобиться записывать логируемые сообщения в файл. Этот файл будет хранить данные и после того, как работа программы завершится. Такой файл можно использовать в качестве журнала отладки.
Обратите внимание на то, что в примере, который мы будем тут разбирать, весь код находится в файле main.py. Когда мы производим рефакторинг существующего кода или добавляем новые модули — мы сообщаем о том, в какой файл (имя которого построено по схеме <module-name>.py) попадает новый код. Это поможет вам воспроизвести у себя то, о чём тут идёт речь.
Логирование в файл
Для того чтобы настроить простую систему логирования в файл — можно воспользоваться конструктором basicConfig(). Вот как это выглядит:
logging.basicConfig(level=logging.INFO, filename="py_log.log",filemode="w")
logging.debug("A DEBUG Message")
logging.info("An INFO")
logging.warning("A WARNING")
logging.error("An ERROR")
logging.critical("A message of CRITICAL severity")Поговорим о логгере root, рассмотрим параметры basicConfig():
-
level: это — уровень, на котором нужно начинать логирование. Если он установлен вinfo— это значит, что все сообщения с уровнемdebugигнорируются. -
filename: этот параметр указывает на объект обработчика файла. Тут можно указать имя файла, в который нужно осуществлять логирование. -
filemode: это — необязательный параметр, указывающий режим, в котором предполагается работать с файлом журнала, заданным параметромfilename. Установкаfilemodeв значениеw(write, запись) приводит к тому, что логи перезаписываются при каждом запуске модуля. По умолчанию параметрfilemodeустановлен в значениеa(append, присоединение), то есть — в файл будут попадать записи из всех сеансов работы программы.
После выполнения модуля main можно будет увидеть, что в текущей рабочей директории был создан файл журнала, py_log.log.

Так как мы установили уровень логирования в значение info — в файл попадут записи с уровнем info и с более высокими уровнями.

Записи в лог-файле имеют формат <logging-level>:<name-of-the-logger>:<message>. По умолчанию <name-of-the-logger>, имя логгера, установлено в root, так как мы пока не настраивали пользовательские логгеры.

Помимо базовой информации, выводимой в лог, может понадобится снабдить записи отметками времени, указывающими на момент вывода той или иной записи. Это упрощает анализ логов. Сделать это можно, воспользовавшись параметром конструктора format:
logging.basicConfig(level=logging.INFO, filename="py_log.log",filemode="w",
format="%(asctime)s %(levelname)s %(message)s")
logging.debug("A DEBUG Message")
logging.info("An INFO")
logging.warning("A WARNING")
logging.error("An ERROR")
logging.critical("A message of CRITICAL severity")
Существуют и многие другие атрибуты записи лога, которыми можно воспользоваться для того чтобы настроить внешний вид сообщений в лог-файле. Настраивая поведение логгера root — так, как это показано выше, проследите за тем, чтобы конструктор logging.basicConfig()вызывался бы лишь один раз. Обычно это делается в начале программы, до использования команд логирования. Последующие вызовы конструктора ничего не изменят — если только не установить параметр force в значение True.
Логирование значений переменных и исключений
Модифицируем файл main.py. Скажем — тут будут две переменных — x и y, и нам нужно вычислить значение выражения x/y. Мы знаем о том, что при y=0 мы столкнёмся с ошибкой ZeroDivisionError. Обработать эту ошибку можно в виде исключения с использованием блока try/except.
Далее — нужно залогировать исключение вместе с данными трассировки стека. Чтобы это сделать — можно воспользоваться logging.error(message, exc_info=True). Запустите следующий код и посмотрите на то, как в файл попадают записи с уровнем логирования info, указывающие на то, что код работает так, как ожидается.
x = 3
y = 4
logging.info(f"The values of x and y are {x} and {y}.")
try:
x/y
logging.info(f"x/y successful with result: {x/y}.")
except ZeroDivisionError as err:
logging.error("ZeroDivisionError",exc_info=True)
Теперь установите значение y в 0 и снова запустите модуль.
Исследуя лог-файл py_log.log, вы увидите, что сведения об исключении были записаны в него вместе со стек-трейсом.
x = 4
y = 0
logging.info(f"The values of x and y are {x} and {y}.")
try:
x/y
logging.info(f"x/y successful with result: {x/y}.")
except ZeroDivisionError as err:
logging.error("ZeroDivisionError",exc_info=True)
Теперь модифицируем код так, чтобы в нём имелись бы списки значений x и y, для которых нужно вычислить коэффициенты x/y. Для логирования исключений ещё можно воспользоваться конструкцией logging.exception(<message>).
x_vals = [2,3,6,4,10]
y_vals = [5,7,12,0,1]
for x_val,y_val in zip(x_vals,y_vals):
x,y = x_val,y_val
logging.info(f"The values of x and y are {x} and {y}.")
try:
x/y
logging.info(f"x/y successful with result: {x/y}.")
except ZeroDivisionError as err:
logging.exception("ZeroDivisionError")Сразу после запуска этого кода можно будет увидеть, что в лог-файл попала информация и о событиях успешного вычисления коэффициента, и об ошибке, когда возникло исключение.

Настройка логирования с помощью пользовательских логгеров, обработчиков и форматировщиков
Отрефакторим код, который у нас уже есть. Объявим функцию test_division.
def test_division(x,y):
try:
x/y
logger2.info(f"x/y successful with result: {x/y}.")
except ZeroDivisionError as err:
logger2.exception("ZeroDivisionError")Объявление этой функции находится в модуле test_div. В модуле main будут лишь вызовы функций. Настроим пользовательские логгеры в модулях main и test_div, проиллюстрировав это примерами кода.
Настройка пользовательского логгера для модуля test_div
import logging
logger2 = logging.getLogger(__name__)
logger2.setLevel(logging.INFO)
# настройка обработчика и форматировщика для logger2
handler2 = logging.FileHandler(f"{__name__}.log", mode='w')
formatter2 = logging.Formatter("%(name)s %(asctime)s %(levelname)s %(message)s")
# добавление форматировщика к обработчику
handler2.setFormatter(formatter2)
# добавление обработчика к логгеру
logger2.addHandler(handler2)
logger2.info(f"Testing the custom logger for module {__name__}...")
def test_division(x,y):
try:
x/y
logger2.info(f"x/y successful with result: {x/y}.")
except ZeroDivisionError as err:
logger2.exception("ZeroDivisionError")Настройка пользовательского логгера для модуля main
import logging
from test_div import test_division
# получение пользовательского логгера и установка уровня логирования
py_logger = logging.getLogger(__name__)
py_logger.setLevel(logging.INFO)
# настройка обработчика и форматировщика в соответствии с нашими нуждами
py_handler = logging.FileHandler(f"{__name__}.log", mode='w')
py_formatter = logging.Formatter("%(name)s %(asctime)s %(levelname)s %(message)s")
# добавление форматировщика к обработчику
py_handler.setFormatter(py_formatter)
# добавление обработчика к логгеру
py_logger.addHandler(py_handler)
py_logger.info(f"Testing the custom logger for module {__name__}...")
x_vals = [2,3,6,4,10]
y_vals = [5,7,12,0,1]
for x_val,y_val in zip(x_vals,y_vals):
x,y = x_val, y_val
# вызов test_division
test_division(x,y)
py_logger.info(f"Call test_division with args {x} and {y}")
Разберёмся с тем, что происходит коде, где настраиваются пользовательские логгеры.
Сначала мы получаем логгер и задаём уровень логирования. Команда logging.getLogger(name) возвращает логгер с заданным именем в том случае, если он существует. В противном случае она создаёт логгер с заданным именем. На практике имя логгера устанавливают с использованием специальной переменной name, которая соответствует имени модуля. Мы назначаем объект логгера переменной. Затем мы, используя команду logging.setLevel(level), устанавливаем нужный нам уровень логирования.
Далее мы настраиваем обработчик. Так как мы хотим записывать сведения о событиях в файл, мы пользуемся FileHandler. Конструкция logging.FileHandler(filename) возвращает объект обработчика файла. Помимо имени лог-файла, можно, что необязательно, задать режим работы с этим файлом. В данном примере режим (mode) установлен в значение write. Есть и другие обработчики, например — StreamHandler, HTTPHandler, SMTPHandler.
Затем мы создаём объект форматировщика, используя конструкцию logging.Formatter(format). В этом примере мы помещаем имя логгера (строку) в начале форматной строки, а потом идёт то, чем мы уже пользовались ранее при оформлении сообщений.
Потом мы добавляем форматировщик к обработчику, пользуясь конструкцией вида <handler>.setFormatter(<formatter>). А в итоге добавляем обработчик к объекту логгера, пользуясь конструкцией <logger>.addHandler(<handler>).
Теперь можно запустить модуль main и исследовать сгенерированные лог-файлы.


Рекомендации по организации логирования в Python
До сих пор мы говорили о том, как логировать значения переменных и исключения, как настраивать пользовательские логгеры. Теперь же предлагаю вашему вниманию рекомендации по логированию.
-
Устанавливайте оптимальный уровень логирования. Логи полезны лишь тогда, когда их можно использовать для отслеживания важных ошибок, которые нужно исправлять. Подберите такой уровень логирования, который соответствует специфике конкретного приложения. Вывод в лог сообщений о слишком большом количестве событий может быть, с точки зрения отладки, не самой удачной стратегией. Дело в том, что при таком подходе возникнут сложности с фильтрацией логов при поиске ошибок, которым нужно немедленно уделить внимание.
-
Конфигурируйте логгеры на уровне модуля. Когда вы работаете над приложением, состоящим из множества модулей — вам стоит задуматься о том, чтобы настроить свой логгер для каждого модуля. Установка имени логгера в
nameпомогает идентифицировать модуль приложения, в котором имеются проблемы, нуждающиеся в решении. -
Включайте в состав сообщений логов отметку времени и обеспечьте единообразное форматирование сообщений. Всегда включайте в сообщения логов отметки времени, так как они полезны в деле поиска того момента, когда произошла ошибка. Единообразно форматируйте сообщения логов, придерживаясь одного и того же подхода в разных модулях.
-
Применяйте ротацию лог-файлов ради упрощения отладки. При работе над большим приложением, в состав которого входит несколько модулей, вы, вполне вероятно, столкнётесь с тем, что размер ваших лог-файлов окажется очень большим. Очень длинные логи сложно просматривать в поисках ошибок. Поэтому стоит подумать о ротации лог-файлов. Сделать это можно, воспользовавшись обработчиком
RotatingFileHandler, применив конструкцию, которая строится по следующей схеме:logging.handlers.RotatingFileHandler(filename, maxBytes, backupCount). Когда размер текущего лог-файла достигнет размераmaxBytes, следующие записи будут попадать в другие файлы, количество которых зависит от значения параметраbackupCount. Если установить этот параметр в значениеK— у вас будетKфайлов журнала.
Сильные и слабые стороны логирования
Теперь, когда мы разобрались с основами логирования в Python, поговорим о сильных и слабых сторонах этого механизма.
Мы уже видели, как логирование позволяет поддерживать файлы журналов для различных модулей, из которых состоит приложение. Мы, кроме того, можем конфигурировать подсистему логирования и подстраивать её под свои нужды. Но эта система не лишена недостатков. Даже когда уровень логирования устанавливают в значение warning, или в любое значение, которое выше warning, размеры лог-файлов способны быстро увеличиваться. Происходит это в том случае, когда в один и тот же журнал пишут данные, полученные после нескольких сеансов работы с приложением. В результате использование лог-файлов для отладки программ превращается в нетривиальную задачу.
Кроме того, исследование логов ошибок — это сложно, особенно в том случае, если сообщения об ошибках не содержат достаточных сведений о контекстах, в которых происходят ошибки. Когда выполняют команду logging.error(message), не устанавливая при этом exc_info в True, сложно обнаружить и исследовать первопричину ошибки в том случае, если сообщение об ошибке не слишком информативно.
В то время как логирование даёт диагностическую информацию, сообщает о том, что в приложении нужно исправить, инструменты для мониторинга приложений, вроде Sentry, могут предоставить более детальную информацию, которая способна помочь в диагностике приложения и в исправлении проблем с производительностью.
В следующем разделе мы поговорим о том, как интегрировать в Python-проект поддержку Sentry, что позволит упростить процесс отладки кода.
Интеграция Sentry в Python-проект
Установить Sentry Python SDK можно, воспользовавшись менеджером пакетов pip.
pip install sentry-sdkПосле установки SDK для настройки мониторинга приложения нужно воспользоваться таким кодом:
sentry_sdk.init(
dsn="<your-dsn-key-here>",
traces_sample_rate=0.85,
)Как можно видеть — вам, для настройки мониторинга, понадобится ключ dsn. DSN расшифровывается как Data Source Name (имя источника данных). Найти этот ключ можно, перейдя в Your-Project > Settings > Client Keys (DSN).
После того, как вы запустите Python-приложение, вы можете перейти на Sentry.io и открыть панель управления проекта. Там должны быть сведения о залогированных ошибках и о других проблемах приложения. В нашем примере можно видеть сообщение об исключении, соответствующем ошибке ZeroDivisionError.

Изучая подробности об ошибке, вы можете увидеть, что Sentry предоставляет подробную информацию о том, где именно произошла ошибка, а так же — об аргументах x и y, работа с которыми привела к появлению исключения.

Продолжая изучение логов, можно увидеть, помимо записей уровня error, записи уровня info. Налаживая мониторинг приложения с использованием Sentry, нужно учитывать, что эта платформа интегрирована с модулем logging. Вспомните — в нашем экспериментальном проекте уровень логирования был установлен в значение info. В результате Sentry записывает все события, уровень которых соответствует info и более высоким уровням, делая это в стиле «навигационной цепочки», что упрощает отслеживание ошибок.
Sentry позволяет фильтровать записи по уровням логирования, таким, как info и error. Это удобнее, чем просмотр больших лог-файлов в поиске потенциальных ошибок и сопутствующих сведений. Это позволяет назначать решению проблем приоритеты, зависящие от серьёзности этих проблем, и, кроме того, позволяет, используя навигационные цепочки, находить источники неполадок.

В данном примере мы рассматриваем ZeroDivisionError как исключение. В более крупных проектах, даже если мы не реализуем подобный механизм обработки исключений, Sentry автоматически предоставит диагностическую информацию о наличии необработанных исключений. С помощью Sentry, кроме того, можно анализировать проблемы с производительностью кода.

Код, использованный в данном руководстве, можно найти в этом GitHub-репозитории.
Итоги
Освоив это руководство, вы узнали о том, как настраивать логирование с использованием стандартного Python-модуля logging. Вы освоили основы настройки логгера root и пользовательских логгеров, ознакомились с рекомендациями по логированию. Вы, кроме того, узнали о том, как платформа Sentry может помочь вам в деле мониторинга ваших приложений, обеспечивая вас сведениями о проблемах с производительностью и о других ошибках, и используя при этом все возможности модуля logging.
Когда вы будете работать над своим следующим Python-проектом — не забудьте реализовать в нём механизмы логирования. И можете испытать бесплатную пробную версию Sentry.
О, а приходите к нам работать? 🤗 💰
Мы в wunderfund.io занимаемся высокочастотной алготорговлей с 2014 года. Высокочастотная торговля — это непрерывное соревнование лучших программистов и математиков всего мира. Присоединившись к нам, вы станете частью этой увлекательной схватки.
Мы предлагаем интересные и сложные задачи по анализу данных и low latency разработке для увлеченных исследователей и программистов. Гибкий график и никакой бюрократии, решения быстро принимаются и воплощаются в жизнь.
Сейчас мы ищем плюсовиков, питонистов, дата-инженеров и мл-рисерчеров.
Присоединяйтесь к нашей команде.
Содержание:развернуть
- Как устроен механизм исключений
- Как обрабатывать исключения в Python (try except)
-
As — сохраняет ошибку в переменную
-
Finally — выполняется всегда
-
Else — выполняется когда исключение не было вызвано
-
Несколько блоков except
-
Несколько типов исключений в одном блоке except
-
Raise — самостоятельный вызов исключений
-
Как пропустить ошибку
- Исключения в lambda функциях
- 20 типов встроенных исключений в Python
- Как создать свой тип Exception
Программа, написанная на языке Python, останавливается сразу как обнаружит ошибку. Ошибки могут быть (как минимум) двух типов:
- Синтаксические ошибки — возникают, когда написанное выражение не соответствует правилам языка (например, написана лишняя скобка);
- Исключения — возникают во время выполнения программы (например, при делении на ноль).
Синтаксические ошибки исправить просто (если вы используете IDE, он их подсветит). А вот с исключениями всё немного сложнее — не всегда при написании программы можно сказать возникнет или нет в данном месте исключение. Чтобы приложение продолжило работу при возникновении проблем, такие ошибки нужно перехватывать и обрабатывать с помощью блока try/except.
Как устроен механизм исключений
В Python есть встроенные исключения, которые появляются после того как приложение находит ошибку. В этом случае текущий процесс временно приостанавливается и передает ошибку на уровень вверх до тех пор, пока она не будет обработано. Если ошибка не будет обработана, программа прекратит свою работу (а в консоли мы увидим Traceback с подробным описанием ошибки).
💁♂️ Пример: напишем скрипт, в котором функция ожидает число, а мы передаём сроку (это вызовет исключение «TypeError»):
def b(value):
print("-> b")
print(value + 1) # ошибка тут
def a(value):
print("-> a")
b(value)
a("10")
> -> a
> -> b
> Traceback (most recent call last):
> File "test.py", line 11, in <module>
> a("10")
> File "test.py", line 8, in a
> b(value)
> File "test.py", line 3, in b
> print(value + 1)
> TypeError: can only concatenate str (not "int") to str
В данном примере мы запускаем файл «test.py» (через консоль). Вызывается функция «a«, внутри которой вызывается функция «b«. Все работает хорошо до сточки print(value + 1). Тут интерпретатор понимает, что нельзя конкатенировать строку с числом, останавливает выполнение программы и вызывает исключение «TypeError».
Далее ошибка передается по цепочке в обратном направлении: «b» → «a» → «test.py«. Так как в данном примере мы не позаботились обработать эту ошибку, вся информация по ошибке отобразится в консоли в виде Traceback.
Traceback (трассировка) — это отчёт, содержащий вызовы функций, выполненные в определенный момент. Трассировка помогает узнать, что пошло не так и в каком месте это произошло.
Traceback лучше читать снизу вверх ↑
В нашем примере Traceback содержится следующую информацию (читаем снизу вверх):
TypeError— тип ошибки (означает, что операция не может быть выполнена с переменной этого типа);can only concatenate str (not "int") to str— подробное описание ошибки (конкатенировать можно только строку со строкой);- Стек вызова функций (1-я линия — место, 2-я линия — код). В нашем примере видно, что в файле «test.py» на 11-й линии был вызов функции «a» со строковым аргументом «10». Далее был вызов функции «b».
print(value + 1)это последнее, что было выполнено — тут и произошла ошибка. most recent call last— означает, что самый последний вызов будет отображаться последним в стеке (в нашем примере последним выполнилсяprint(value + 1)).
В Python ошибку можно перехватить, обработать, и продолжить выполнение программы — для этого используется конструкция try ... except ....
Как обрабатывать исключения в Python (try except)
В Python исключения обрабатываются с помощью блоков try/except. Для этого операция, которая может вызвать исключение, помещается внутрь блока try. А код, который должен быть выполнен при возникновении ошибки, находится внутри except.
Например, вот как можно обработать ошибку деления на ноль:
try:
a = 7 / 0
except:
print('Ошибка! Деление на 0')
Здесь в блоке try находится код a = 7 / 0 — при попытке его выполнить возникнет исключение и выполнится код в блоке except (то есть будет выведено сообщение «Ошибка! Деление на 0»). После этого программа продолжит свое выполнение.
💭 PEP 8 рекомендует, по возможности, указывать конкретный тип исключения после ключевого слова except (чтобы перехватывать и обрабатывать конкретные исключения):
try:
a = 7 / 0
except ZeroDivisionError:
print('Ошибка! Деление на 0')
Однако если вы хотите перехватывать все исключения, которые сигнализируют об ошибках программы, используйте тип исключения Exception:
try:
a = 7 / 0
except Exception:
print('Любая ошибка!')
As — сохраняет ошибку в переменную
Перехваченная ошибка представляет собой объект класса, унаследованного от «BaseException». С помощью ключевого слова as можно записать этот объект в переменную, чтобы обратиться к нему внутри блока except:
try:
file = open('ok123.txt', 'r')
except FileNotFoundError as e:
print(e)
> [Errno 2] No such file or directory: 'ok123.txt'
В примере выше мы обращаемся к объекту класса «FileNotFoundError» (при выводе на экран через print отобразится строка с полным описанием ошибки).
У каждого объекта есть поля, к которым можно обращаться (например если нужно логировать ошибку в собственном формате):
import datetime
now = datetime.datetime.now().strftime("%d-%m-%Y %H:%M:%S")
try:
file = open('ok123.txt', 'r')
except FileNotFoundError as e:
print(f"{now} [FileNotFoundError]: {e.strerror}, filename: {e.filename}")
> 20-11-2021 18:42:01 [FileNotFoundError]: No such file or directory, filename: ok123.txt
Finally — выполняется всегда
При обработке исключений можно после блока try использовать блок finally. Он похож на блок except, но команды, написанные внутри него, выполняются обязательно. Если в блоке try не возникнет исключения, то блок finally выполнится так же, как и при наличии ошибки, и программа возобновит свою работу.
Обычно try/except используется для перехвата исключений и восстановления нормальной работы приложения, а try/finally для того, чтобы гарантировать выполнение определенных действий (например, для закрытия внешних ресурсов, таких как ранее открытые файлы).
В следующем примере откроем файл и обратимся к несуществующей строке:
file = open('ok.txt', 'r')
try:
lines = file.readlines()
print(lines[5])
finally:
file.close()
if file.closed:
print("файл закрыт!")
> файл закрыт!
> Traceback (most recent call last):
> File "test.py", line 5, in <module>
> print(lines[5])
> IndexError: list index out of range
Даже после исключения «IndexError», сработал код в секции finally, который закрыл файл.
p.s. данный пример создан для демонстрации, в реальном проекте для работы с файлами лучше использовать менеджер контекста with.
Также можно использовать одновременно три блока try/except/finally. В этом случае:
- в
try— код, который может вызвать исключения; - в
except— код, который должен выполниться при возникновении исключения; - в
finally— код, который должен выполниться в любом случае.
def sum(a, b):
res = 0
try:
res = a + b
except TypeError:
res = int(a) + int(b)
finally:
print(f"a = {a}, b = {b}, res = {res}")
sum(1, "2")
> a = 1, b = 2, res = 3
Else — выполняется когда исключение не было вызвано
Иногда нужно выполнить определенные действия, когда код внутри блока try не вызвал исключения. Для этого используется блок else.
Допустим нужно вывести результат деления двух чисел и обработать исключения в случае попытки деления на ноль:
b = int(input('b = '))
c = int(input('c = '))
try:
a = b / c
except ZeroDivisionError:
print('Ошибка! Деление на 0')
else:
print(f"a = {a}")
> b = 10
> c = 1
> a = 10.0
В этом случае, если пользователь присвоит переменной «с» ноль, то появится исключение и будет выведено сообщение «‘Ошибка! Деление на 0′», а код внутри блока else выполняться не будет. Если ошибки не будет, то на экране появятся результаты деления.
Несколько блоков except
В программе может возникнуть несколько исключений, например:
- Ошибка преобразования введенных значений к типу
float(«ValueError»); - Деление на ноль («ZeroDivisionError»).
В Python, чтобы по-разному обрабатывать разные типы ошибок, создают несколько блоков except:
try:
b = float(input('b = '))
c = float(input('c = '))
a = b / c
except ZeroDivisionError:
print('Ошибка! Деление на 0')
except ValueError:
print('Число введено неверно')
else:
print(f"a = {a}")
> b = 10
> c = 0
> Ошибка! Деление на 0
> b = 10
> c = питон
> Число введено неверно
Теперь для разных типов ошибок есть свой обработчик.
Несколько типов исключений в одном блоке except
Можно также обрабатывать в одном блоке except сразу несколько исключений. Для этого они записываются в круглых скобках, через запятую сразу после ключевого слова except. Чтобы обработать сообщения «ZeroDivisionError» и «ValueError» в одном блоке записываем их следующим образом:
try:
b = float(input('b = '))
c = float(input('c = '))
a = b / c
except (ZeroDivisionError, ValueError) as er:
print(er)
else:
print('a = ', a)
При этом переменной er присваивается объект того исключения, которое было вызвано. В результате на экран выводятся сведения о конкретной ошибке.
Raise — самостоятельный вызов исключений
Исключения можно генерировать самостоятельно — для этого нужно запустить оператор raise.
min = 100
if min > 10:
raise Exception('min must be less than 10')
> Traceback (most recent call last):
> File "test.py", line 3, in <module>
> raise Exception('min value must be less than 10')
> Exception: min must be less than 10
Перехватываются такие сообщения точно так же, как и остальные:
min = 100
try:
if min > 10:
raise Exception('min must be less than 10')
except Exception:
print('Моя ошибка')
> Моя ошибка
Кроме того, ошибку можно обработать в блоке except и пробросить дальше (вверх по стеку) с помощью raise:
min = 100
try:
if min > 10:
raise Exception('min must be less than 10')
except Exception:
print('Моя ошибка')
raise
> Моя ошибка
> Traceback (most recent call last):
> File "test.py", line 5, in <module>
> raise Exception('min must be less than 10')
> Exception: min must be less than 10
Как пропустить ошибку
Иногда ошибку обрабатывать не нужно. В этом случае ее можно пропустить с помощью pass:
try:
a = 7 / 0
except ZeroDivisionError:
pass
Исключения в lambda функциях
Обрабатывать исключения внутри lambda функций нельзя (так как lambda записывается в виде одного выражения). В этом случае нужно использовать именованную функцию.
20 типов встроенных исключений в Python
Иерархия классов для встроенных исключений в Python выглядит так:
BaseException
SystemExit
KeyboardInterrupt
GeneratorExit
Exception
ArithmeticError
AssertionError
...
...
...
ValueError
Warning
Все исключения в Python наследуются от базового BaseException:
SystemExit— системное исключение, вызываемое функциейsys.exit()во время выхода из приложения;KeyboardInterrupt— возникает при завершении программы пользователем (чаще всего при нажатии клавиш Ctrl+C);GeneratorExit— вызывается методомcloseобъектаgenerator;Exception— исключения, которые можно и нужно обрабатывать (предыдущие были системными и их трогать не рекомендуется).
От Exception наследуются:
1 StopIteration — вызывается функцией next в том случае если в итераторе закончились элементы;
2 ArithmeticError — ошибки, возникающие при вычислении, бывают следующие типы:
FloatingPointError— ошибки при выполнении вычислений с плавающей точкой (встречаются редко);OverflowError— результат вычислений большой для текущего представления (не появляется при операциях с целыми числами, но может появиться в некоторых других случаях);ZeroDivisionError— возникает при попытке деления на ноль.
3 AssertionError — выражение, используемое в функции assert неверно;
4 AttributeError — у объекта отсутствует нужный атрибут;
5 BufferError — операция, для выполнения которой требуется буфер, не выполнена;
6 EOFError — ошибка чтения из файла;
7 ImportError — ошибка импортирования модуля;
8 LookupError — неверный индекс, делится на два типа:
IndexError— индекс выходит за пределы диапазона элементов;KeyError— индекс отсутствует (для словарей, множеств и подобных объектов);
9 MemoryError — память переполнена;
10 NameError — отсутствует переменная с данным именем;
11 OSError — исключения, генерируемые операционной системой:
ChildProcessError— ошибки, связанные с выполнением дочернего процесса;ConnectionError— исключения связанные с подключениями (BrokenPipeError, ConnectionResetError, ConnectionRefusedError, ConnectionAbortedError);FileExistsError— возникает при попытке создания уже существующего файла или директории;FileNotFoundError— генерируется при попытке обращения к несуществующему файлу;InterruptedError— возникает в том случае если системный вызов был прерван внешним сигналом;IsADirectoryError— программа обращается к файлу, а это директория;NotADirectoryError— приложение обращается к директории, а это файл;PermissionError— прав доступа недостаточно для выполнения операции;ProcessLookupError— процесс, к которому обращается приложение не запущен или отсутствует;TimeoutError— время ожидания истекло;
12 ReferenceError — попытка доступа к объекту с помощью слабой ссылки, когда объект не существует;
13 RuntimeError — генерируется в случае, когда исключение не может быть классифицировано или не подпадает под любую другую категорию;
14 NotImplementedError — абстрактные методы класса нуждаются в переопределении;
15 SyntaxError — ошибка синтаксиса;
16 SystemError — сигнализирует о внутренне ошибке;
17 TypeError — операция не может быть выполнена с переменной этого типа;
18 ValueError — возникает когда в функцию передается объект правильного типа, но имеющий некорректное значение;
19 UnicodeError — исключение связанное с кодирование текста в unicode, бывает трех видов:
UnicodeEncodeError— ошибка кодирования;UnicodeDecodeError— ошибка декодирования;UnicodeTranslateError— ошибка переводаunicode.
20 Warning — предупреждение, некритическая ошибка.
💭 Посмотреть всю цепочку наследования конкретного типа исключения можно с помощью модуля inspect:
import inspect
print(inspect.getmro(TimeoutError))
> (<class 'TimeoutError'>, <class 'OSError'>, <class 'Exception'>, <class 'BaseException'>, <class 'object'>)
📄 Подробное описание всех классов встроенных исключений в Python смотрите в официальной документации.
Как создать свой тип Exception
В Python можно создавать свои исключения. При этом есть одно обязательное условие: они должны быть потомками класса Exception:
class MyError(Exception):
def __init__(self, text):
self.txt = text
try:
raise MyError('Моя ошибка')
except MyError as er:
print(er)
> Моя ошибка
С помощью try/except контролируются и обрабатываются ошибки в приложении. Это особенно актуально для критически важных частей программы, где любые «падения» недопустимы (или могут привести к негативным последствиям). Например, если программа работает как «демон», падение приведет к полной остановке её работы. Или, например, при временном сбое соединения с базой данных, программа также прервёт своё выполнение (хотя можно было отловить ошибку и попробовать соединиться в БД заново).
Вместе с try/except можно использовать дополнительные блоки. Если использовать все блоки описанные в статье, то код будет выглядеть так:
try:
# попробуем что-то сделать
except (ZeroDivisionError, ValueError) as e:
# обрабатываем исключения типа ZeroDivisionError или ValueError
except Exception as e:
# исключение не ZeroDivisionError и не ValueError
# поэтому обрабатываем исключение общего типа (унаследованное от Exception)
# сюда не сходят исключения типа GeneratorExit, KeyboardInterrupt, SystemExit
else:
# этот блок выполняется, если нет исключений
# если в этом блоке сделать return, он не будет вызван, пока не выполнился блок finally
finally:
# этот блок выполняется всегда, даже если нет исключений else будет проигнорирован
# если в этом блоке сделать return, то return в блоке
Подробнее о работе с исключениями в Python можно ознакомиться в официальной документации.
При выполнении заданий к главам вы скорее всего нередко сталкивались с возникновением различных ошибок. На этой главе мы изучим подход, который позволяет обрабатывать ошибки после их возникновения.
Напишем программу, которая будет считать обратные значения для целых чисел из заданного диапазона и выводить их в одну строку с разделителем «;». Один из вариантов кода для решения этой задачи выглядит так:
print(";".join(str(1 / x) for x in range(int(input()), int(input()) + 1)))
Программа получилась в одну строчку за счёт использования списочных выражений. Однако при вводе диапазона чисел, включающем в себя 0 (например, от -1 до 1), программа выдаст следующую ошибку:
ZeroDivisionError: division by zero
В программе произошла ошибка «деление на ноль». Такая ошибка, возникающая при выполнении программы и останавливающая её работу, называется исключением.
Попробуем в нашей программе избавиться от возникновения исключения деления на ноль. Пусть при попадании 0 в диапазон чисел, обработка не производится и выводится сообщение «Диапазон чисел содержит 0». Для этого нужно проверить до списочного выражения наличие нуля в диапазоне:
interval = range(int(input()), int(input()) + 1)
if 0 in interval:
print("Диапазон чисел содержит 0.")
else:
print(";".join(str(1 / x) for x in interval))
Теперь для диапазона, включающего в себя 0, например, от -2 до 2, исключения ZeroDivisionError не возникнет. Однако при вводе строки, которую невозможно преобразовать в целое число (например, «a»), будет вызвано другое исключение:
ValueError: invalid literal for int() with base 10: 'a'
Произошло исключение ValueError. Для борьбы с этой ошибкой нам придётся проверить, что строка состоит только из цифр. Сделать это нужно до преобразования в число. Тогда наша программа будет выглядеть так:
start = input()
end = input()
# Метод lstrip("-"), удаляющий символы "-" в начале строки, нужен для учёта
# отрицательных чисел, иначе isdigit() вернёт для них False
if not (start.lstrip("-").isdigit() and end.lstrip("-").isdigit()):
print("Необходимо ввести два числа.")
else:
interval = range(int(start), int(end) + 1)
if 0 in interval:
print("Диапазон чисел содержит 0.")
else:
print(";".join(str(1 / x) for x in interval))
Теперь наша программа работает без ошибок и при вводе строк, которые нельзя преобразовать в целое число.
Подход, который был нами применён для предотвращения ошибок, называется «Look Before You Leap» (LBYL), или «посмотри перед прыжком». В программе, реализующей такой подход, проверяются возможные условия возникновения ошибок до исполнения основного кода.
Подход LBYL имеет недостатки. Программу из примера стало сложнее читать из-за вложенного условного оператора. Проверка условия, что строка может быть преобразована в число, выглядит даже сложнее, чем списочное выражение. Вложенный условный оператор не решает поставленную задачу, а только лишь проверяет входные данные на корректность. Легко заметить, что решение основной задачи заняло меньше времени, чем составление условий проверки корректности входных данных.
Существует другой подход для работы с ошибками: «Easier to Ask Forgiveness than Permission» (EAFP) или «проще извиниться, чем спрашивать разрешение». В этом подходе сначала исполняется код, а в случае возникновения ошибок происходит их обработка. Подход EAFP реализован в Python в виде обработки исключений.
Исключения в Python являются классами ошибок. В Python есть много стандартных исключений. Они имеют определённую иерархию за счёт механизма наследования классов. В документации Python версии 3.10.8 приводится следующее дерево иерархии стандартных исключений:
BaseException
+-- SystemExit
+-- KeyboardInterrupt
+-- GeneratorExit
+-- Exception
+-- StopIteration
+-- StopAsyncIteration
+-- ArithmeticError
| +-- FloatingPointError
| +-- OverflowError
| +-- ZeroDivisionError
+-- AssertionError
+-- AttributeError
+-- BufferError
+-- EOFError
+-- ImportError
| +-- ModuleNotFoundError
+-- LookupError
| +-- IndexError
| +-- KeyError
+-- MemoryError
+-- NameError
| +-- UnboundLocalError
+-- OSError
| +-- BlockingIOError
| +-- ChildProcessError
| +-- ConnectionError
| | +-- BrokenPipeError
| | +-- ConnectionAbortedError
| | +-- ConnectionRefusedError
| | +-- ConnectionResetError
| +-- FileExistsError
| +-- FileNotFoundError
| +-- InterruptedError
| +-- IsADirectoryError
| +-- NotADirectoryError
| +-- PermissionError
| +-- ProcessLookupError
| +-- TimeoutError
+-- ReferenceError
+-- RuntimeError
| +-- NotImplementedError
| +-- RecursionError
+-- SyntaxError
| +-- IndentationError
| +-- TabError
+-- SystemError
+-- TypeError
+-- ValueError
| +-- UnicodeError
| +-- UnicodeDecodeError
| +-- UnicodeEncodeError
| +-- UnicodeTranslateError
+-- Warning
+-- DeprecationWarning
+-- PendingDeprecationWarning
+-- RuntimeWarning
+-- SyntaxWarning
+-- UserWarning
+-- FutureWarning
+-- ImportWarning
+-- UnicodeWarning
+-- BytesWarning
+-- EncodingWarning
+-- ResourceWarning
Для обработки исключения в Python используется следующий синтаксис:
try:
<код , который может вызвать исключения при выполнении>
except <классисключения_1>:
<код обработки исключения>
except <классисключения_2>:
<код обработки исключения>
...
else:
<код выполняется, если не вызвано исключение в блоке try>
finally:
<код , который выполняется всегда>
Блок try содержит код, в котором нужно обработать исключения, если они возникнут. При возникновении исключения интерпретатор последовательно проверяет в каком из блоков except обрабатывается это исключение. Исключение обрабатывается в первом блоке except, обрабатывающем класс этого исключения или базовый класс возникшего исключения. Необходимо учитывать иерархию исключений для определения порядка их обработки в блоках except. Начинать обработку исключений следует с более узких классов исключений. Если начать с более широкого класса исключения, например, Exception, то всегда при возникновении исключения будет срабатывать первый блок except. Сравните два следующих примера. В первом порядок обработки исключений указан от производных классов к базовым, а во втором – наоборот.
try:
print(1 / int(input()))
except ZeroDivisionError:
print("Ошибка деления на ноль.")
except ValueError:
print("Невозможно преобразовать строку в число.")
except Exception:
print("Неизвестная ошибка.")
При вводе значений «0» и «a» получим ожидаемый соответствующий возникающим исключениям вывод:
Невозможно преобразовать строку в число.
и
Ошибка деления на ноль.
Второй пример:
try:
print(1 / int(input()))
except Exception:
print("Неизвестная ошибка.")
except ZeroDivisionError:
print("Ошибка деления на ноль.")
except ValueError:
print("Невозможно преобразовать строку в число.")
При вводе значений «0» и «a» получим в обоих случаях неинформативный вывод:
Неизвестная ошибка.
Необязательный блок else выполняет код в случае, если в блоке try не вызвано исключение. Добавим блок else в пример для вывода сообщения об успешном выполнении операции:
try:
print(1 / int(input()))
except ZeroDivisionError:
print("Ошибка деления на ноль.")
except ValueError:
print("Невозможно преобразовать строку в число.")
except Exception:
print("Неизвестная ошибка.")
else:
print("Операция выполнена успешно.")
Теперь при вводе корректного значения, например, «5», вывод программы будет следующим:
2.0 Операция выполнена успешно.
Блок finally выполняется всегда, даже если возникло какое-то исключение, не учтённое в блоках except или код в этих блоках сам вызвал какое-либо исключение. Добавим в нашу программу вывод строки «Программа завершена» в конце программы даже при возникновении исключений:
try:
print(1 / int(input()))
except ZeroDivisionError:
print("Ошибка деления на ноль.")
except ValueError:
print("Невозможно преобразовать строку в число.")
except Exception:
print("Неизвестная ошибка.")
else:
print("Операция выполнена успешно.")
finally:
print("Программа завершена.")
Перепишем код, созданный с применением подхода LBYL, для первого примера из этой главы с использованием обработки исключений:
try:
print(";".join(str(1 / x) for x in range(int(input()), int(input()) + 1)))
except ZeroDivisionError:
print("Диапазон чисел содержит 0.")
except ValueError:
print("Необходимо ввести два числа.")
Теперь наша программа читается намного легче. При этом создание кода для обработки исключений не заняло много времени и не потребовало проверки сложных условий.
Исключения можно принудительно вызывать с помощью оператора raise. Этот оператор имеет следующий синтаксис:
raise <класс исключения>(параметры)
В качестве параметра можно, например, передать строку с сообщением об ошибке.
В Python можно создавать свои собственные исключения. Синтаксис создания исключения такой же, как и у создания класса. При создании исключения его необходимо наследовать от какого-либо стандартного класса-исключения.
Напишем программу, которая выводит сумму списка целых чисел, и вызывает исключение, если в списке чисел есть хотя бы одно чётное или отрицательное число. Создадим свои классы исключений:
- NumbersError – базовый класс исключения;
- EvenError – исключение, которое вызывается при наличии хотя бы одного чётного числа;
- NegativeError – исключение, которое вызывается при наличии хотя бы одного отрицательного числа.
class NumbersError(Exception):
pass
class EvenError(NumbersError):
pass
class NegativeError(NumbersError):
pass
def no_even(numbers):
if all(x % 2 != 0 for x in numbers):
return True
raise EvenError("В списке не должно быть чётных чисел")
def no_negative(numbers):
if all(x >= 0 for x in numbers):
return True
raise NegativeError("В списке не должно быть отрицательных чисел")
def main():
print("Введите числа в одну строку через пробел:")
try:
numbers = [int(x) for x in input().split()]
if no_negative(numbers) and no_even(numbers):
print(f"Сумма чисел равна: {sum(numbers)}.")
except NumbersError as e: # обращение к исключению как к объекту
print(f"Произошла ошибка: {e}.")
except Exception as e:
print(f"Произошла непредвиденная ошибка: {e}.")
if __name__ == "__main__":
main()
Обратите внимание: в программе основной код выделен в функцию main. А код вне функций содержит только условный оператор и вызов функции main при выполнении условия __name__ == "__main__". Это условие проверяет, запущен ли файл как самостоятельная программа или импортирован как модуль.
Любая программа, написанная на языке программирования Python может быть импортирована как модуль в другую программу. В идеологии Python импортировать модуль – значит полностью его выполнить. Если основной код модуля содержит вызовы функций, ввод или вывод данных без использования указанного условия __name__ == "__main__", то произойдёт полноценный запуск программы. А это не всегда удобно, если из модуля нужна только отдельная функция или какой-либо класс.
При изучении модуля itertools, мы говорили о том, как импортировать модуль в программу. Покажем ещё раз два способа импорта на примере собственного модуля.
Для импорта модуля из файла, например example_module.py, нужно указать его имя, если он находится в той же папке, что и импортирующая его программа:
import example_module
Если требуется отдельный компонент модуля, например функция или класс, то импорт можно осуществить так:
from example_module import some_function, ExampleClass
Обратите внимание: при втором способе импортированные объекты попадают в пространство имён новой программы. Это означает, что они будут объектами новой программы, и в программе не должно быть других объектов с такими же именами.
В этом руководстве мы расскажем, как обрабатывать исключения в Python с помощью try и except. Рассмотрим общий синтаксис и простые примеры, обсудим, что может пойти не так, и предложим меры по исправлению положения.
Зачастую разработчик может предугадать возникновение ошибок при работе даже синтаксически и логически правильной программы. Эти ошибки могут быть вызваны неверными входными данными или некоторыми предсказуемыми несоответствиями.
Для обработки большей части этих ошибок как исключений в Python есть блоки try и except.
Для начала разберем синтаксис операторов try и except в Python. Общий шаблон представлен ниже:
try:
# В этом блоке могут быть ошибки
except <error type>:
# Сделай это для обработки исключения;
# выполняется, если блок try выбрасывает ошибку
else:
# Сделай это, если блок try выполняется успешно, без ошибок
finally:
# Этот блок выполняется всегда
Давайте посмотрим, для чего используются разные блоки.
Блок try
Блок try — это блок кода, который вы хотите попробовать выполнить. Однако во время выполнения из-за какого-нибудь исключения могут возникнуть ошибки. Поэтому этот блок может не работать должным образом.
Блок except
Блок except запускается, когда блок try не срабатывает из-за исключения. Инструкции в этом блоке часто дают некоторый контекст того, что пошло не так внутри блока try.
Если собираетесь перехватить ошибку как исключение, в блоке except нужно обязательно указать тип этой ошибки. В приведенном выше сниппете место для указания типа ошибки обозначено плейсхолдером <error type> .
except можно использовать и без указания типа ошибки. Но лучше так не делать. При таком подходе не учитывается, что возникающие ошибки могут быть разных типов. То есть вы будете знать, что что-то пошло не так, но что именно произошло, какая была ошибка — вам будет не известно.
При попытке выполнить код внутри блока try также существует вероятность возникновения нескольких ошибок.
Например, вы можете попытаться обратиться к элементу списка по индексу, выходящему за пределы допустимого диапазона, использовать неправильный ключ словаря и попробовать открыть несуществующий файл – и все это внутри одного блока try.
В результате вы можете столкнуться с IndexError, KeyError и FileNotFoundError. В таком случае нужно добавить столько блоков except, сколько ошибок ожидается – по одному для каждого типа ошибки.
Блок else
Блок else запускается только в том случае, если блок try выполняется без ошибок. Это может быть полезно, когда нужно выполнить ещё какие-то действия после успешного выполнения блока try. Например, после успешного открытия файла вы можете прочитать его содержимое.
Блок finally
Блок finally выполняется всегда, независимо от того, что происходит в других блоках. Это полезно, когда вы хотите освободить ресурсы после выполнения определенного блока кода.
Примечание: блоки else и finally не являются обязательными. В большинстве случаев вы можете использовать только блок try, чтобы что-то сделать, и перехватывать ошибки как исключения внутри блока except.
[python_ad_block]
Итак, теперь давайте используем полученные знания для обработки исключений в Python. Приступим!
Обработка ZeroDivisionError
Рассмотрим функцию divide(), показанную ниже. Она принимает два аргумента – num и div – и возвращает частное от операции деления num/div.
def divide(num,div):
return num/div
Вызов функции с разными аргументами возвращает ожидаемый результат:
res = divide(100,8) print(res) # Output # 12.5 res = divide(568,64) print(res) # Output # 8.875
Этот код работает нормально, пока вы не попробуете разделить число на ноль:
divide(27,0)
Вы видите, что программа выдает ошибку ZeroDivisionError:
# Output
---------------------------------------------------------------------------
ZeroDivisionError Traceback (most recent call last)
<ipython-input-19-932ea024ce43> in <module>()
----> 1 divide(27,0)
<ipython-input-1-c98670fd7a12> in divide(num, div)
1 def divide(num,div):
----> 2 return num/div
ZeroDivisionError: division by zero
Можно обработать деление на ноль как исключение, выполнив следующие действия:
- В блоке
tryпоместите вызов функцииdivide(). По сути, вы пытаетесь разделитьnumнаdiv(try в переводе с английского — «пытаться», — прим. перев.). - В блоке
exceptобработайте случай, когдаdivравен 0, как исключение. - В результате этих действий при делении на ноль больше не будет выбрасываться ZeroDivisionError. Вместо этого будет выводиться сообщение, информирующее пользователя, что он попытался делить на ноль.
Вот как все это выглядит в коде:
try:
res = divide(num,div)
print(res)
except ZeroDivisionError:
print("You tried to divide by zero :( ")
При корректных входных данных наш код по-прежнему работает великолепно:
divide(10,2) # Output # 5.0
Когда же пользователь попытается разделить на ноль, он получит уведомление о возникшем исключении. Таким образом, программа завершается корректно и без ошибок.
divide(10,0) # Output # You tried to divide by zero :(
Обработка TypeError
В этом разделе мы разберем, как использовать try и except для обработки TypeError в Python.
Рассмотрим функцию add_10(). Она принимает число в качестве аргумента, прибавляет к нему 10 и возвращает результат этого сложения.
def add_10(num):
return num + 10
Вы можете вызвать функцию add_10() с любым числом, и она будет работать нормально, как показано ниже:
result = add_10(89) print(result) # Output # 99
Теперь попробуйте вызвать функцию add_10(), передав ей в качестве аргумента не число, а строку.
add_10 ("five")
Ваша программа вылетит со следующим сообщением об ошибке:
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-15-9844e949c84e> in <module>()
----> 1 add_10("five")
<ipython-input-13-2e506d74d919> in add_10(num)
1 def add_10(num):
----> 2 return num + 10
TypeError: can only concatenate str (not "int") to str
Сообщение об ошибке TypeError: can only concatenate str (not "int") to str говорит о том, что можно сложить только две строки, а не добавить целое число к строке.
Обработаем TypeError:
- В блок try мы помещаем вызов функции
add_10()с my_num в качестве аргумента. Если аргумент допустимого типа, исключений не возникнет. - В противном случае срабатывает блок
except, в который мы помещаем вывод уведомления для пользователя о том, что аргумент имеет недопустимый тип.
Это показано ниже:
my_num = "five"
try:
result = add_10(my_num)
print(result)
except TypeError:
print("The argument `num` should be a number")
Поскольку теперь вы обработали TypeError как исключение, при передаче невалидного аргумента ошибка не возникает. Вместо нее выводится сообщение, что аргумент имеет недопустимый тип.
The argument `num` should be a number
Обработка IndexError
Если вам приходилось работать со списками или любыми другими итерируемыми объектами, вы, вероятно, сталкивались с IndexError.
Это связано с тем, что часто бывает сложно отслеживать все изменения в итерациях. И вы можете попытаться получить доступ к элементу по невалидному индексу.
В этом примере список my_list состоит из 4 элементов. Допустимые индексы — 0, 1, 2 и 3 и -1, -2, -3, -4, если вы используете отрицательную индексацию.
Поскольку 2 является допустимым индексом, вы видите, что элемент с этим индексом (C++) распечатывается:
my_list = ["Python","C","C++","JavaScript"] print(my_list[2]) # Output # C++
Но если вы попытаетесь получить доступ к элементу по индексу, выходящему за пределы допустимого диапазона, вы столкнетесь с IndexError:
print(my_list[4])
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
<ipython-input-7-437bc6501dea> in <module>()
1 my_list = ["Python","C","C++","JavaScript"]
----> 2 print(my_list[4])
IndexError: list index out of range
Теперь вы уже знакомы с шаблоном, и вам не составит труда использовать try и except для обработки данной ошибки.
В приведенном ниже фрагменте кода мы пытаемся получить доступ к элементу по индексу search_idx.
search_idx = 3
try:
print(my_list[search_idx])
except IndexError:
print("Sorry, the list index is out of range")
Здесь search_idx = 3 является допустимым индексом, поэтому в результате выводится соответствующий элемент — JavaScript.
Если search_idx находится за пределами допустимого диапазона индексов, блок except перехватывает IndexError как исключение, и больше нет длинных сообщений об ошибках.
search_idx = 4
try:
print(my_list[search_idx])
except IndexError:
print("Sorry, the list index is out of range")
Вместо этого отображается сообщение о том, что search_idx находится вне допустимого диапазона индексов:
Sorry, the list index is out of range
Обработка KeyError
Вероятно, вы уже сталкивались с KeyError при работе со словарями в Python.
Рассмотрим следующий пример, где у нас есть словарь my_dict.
my_dict ={"key1":"value1","key2":"value2","key3":"value3"}
search_key = "non-existent key"
print(my_dict[search_key])
В словаре my_dict есть 3 пары «ключ-значение»: key1:value1, key2:value2 и key3:value3.
Теперь попытаемся получить доступ к значению, соответствующему несуществующему ключу non-existent key.
Как и ожидалось, мы получим KeyError:
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
<ipython-input-2-2a61d404be04> in <module>()
1 my_dict ={"key1":"value1","key2":"value2","key3":"value3"}
2 search_key = "non-existent key"
----> 3 my_dict[search_key]
KeyError: 'non-existent key'
Вы можете обработать KeyError почти так же, как и IndexError.
- Пробуем получить доступ к значению, которое соответствует ключу, определенному
search_key. - Если
search_key— валидный ключ, мы распечатываем соответствующее значение. - Если ключ невалиден и возникает исключение — задействуется блок except, чтобы сообщить об этом пользователю.
Все это можно видеть в следующем коде:
try:
print(my_dict[search_key])
except KeyError:
print("Sorry, that's not a valid key!")
# Output:
# Sorry, that's not a valid key!
Если вы хотите предоставить дополнительный контекст, например имя невалидного ключа, это тоже можно сделать. Возможно, ключ оказался невалидным из-за ошибки в написании. Если вы укажете этот ключ в сообщении, это поможет пользователю исправить опечатку.
Вы можете сделать это, перехватив невалидный ключ как <error_msg> и используя его в сообщении, которое печатается при возникновении исключения:
try:
print(my_dict[search_key])
except KeyError as error_msg:
print(f"Sorry,{error_msg} is not a valid key!")
Обратите внимание, что теперь в сообщении об ошибки указано также и имя несуществующего ключа:
Sorry, 'non-existent key' is not a valid key!
Обработка FileNotFoundError
При работе с файлами в Python часто возникает ошибка FileNotFoundError.
В следующем примере мы попытаемся открыть файл my_file.txt, указав его путь в функции open(). Мы хотим прочитать файл и вывести его содержимое.
Однако мы еще не создали этот файл в указанном месте.
my_file = open("/content/sample_data/my_file.txt")
contents = my_file.read()
print(contents)
Поэтому, попытавшись запустить приведенный выше фрагмент кода, мы получим FileNotFoundError:
---------------------------------------------------------------------------
FileNotFoundError Traceback (most recent call last)
<ipython-input-4-4873cac1b11a> in <module>()
----> 1 my_file = open("my_file.txt")
FileNotFoundError: [Errno 2] No such file or directory: 'my_file.txt'
А с помощью try и except мы можем сделать следующее:
- Попробуем открыть файл в блоке
try. - Обработаем
FileNotFoundErrorв блокеexcept, сообщив пользователю, что он попытался открыть несуществующий файл. - Если блок
tryзавершается успешно и файл действительно существует, прочтем и распечатаем содержимое. - В блоке
finallyзакроем файл, чтобы не терять ресурсы. Файл будет закрыт независимо от того, что происходило на этапах открытия и чтения.
try:
my_file = open("/content/sample_data/my_file.txt")
except FileNotFoundError:
print(f"Sorry, the file does not exist")
else:
contents = my_file.read()
print(contents)
finally:
my_file.close()
Обратите внимание: мы обработали ошибку как исключение, и программа завершает работу, отображая следующее сообщение:
Sorry, the file does not exist
Теперь рассмотрим случай, когда срабатывает блок else. Файл my_file.txt теперь присутствует по указанному ранее пути.
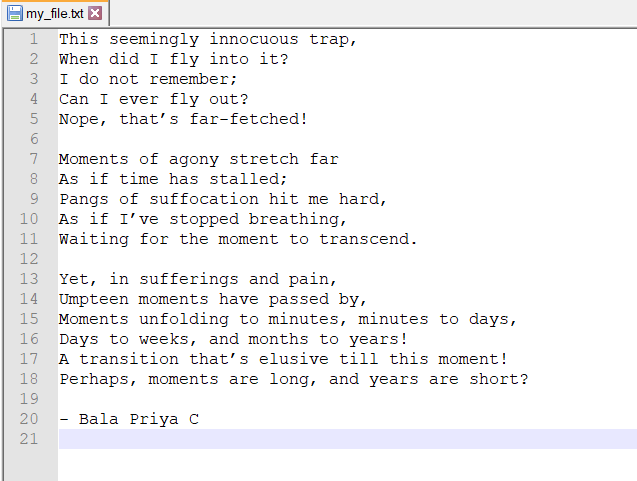
Вот содержимое этого файла:
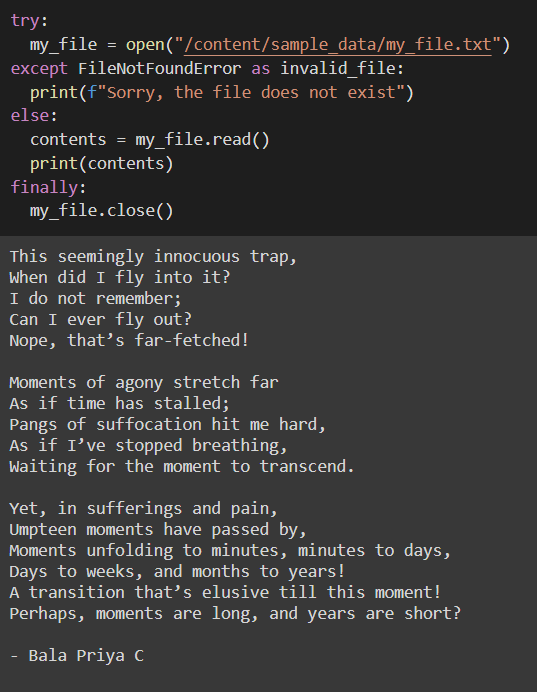
Теперь повторный запуск нашего кода работает должным образом.
На этот раз файл my_file.txt присутствует, поэтому запускается блок else и содержимое распечатывается, как показано ниже:
Надеемся, теперь вы поняли, как обрабатывать исключения при работе с файлами.
Заключение
В этом руководстве мы рассмотрели, как обрабатывать исключения в Python с помощью try и except.
Также мы разобрали на примерах, какие типы исключений могут возникать и как при помощи except ловить наиболее распространенные ошибки.
Надеемся, вам понравился этот урок. Успехов в написании кода!
Перевод статьи «Python Try and Except Statements – How to Handle Exceptions in Python».
Исключения (exceptions) — ещё один тип данных в python. Исключения необходимы для того, чтобы сообщать программисту об ошибках.
Самый простейший пример исключения — деление на ноль:
>>> 100 / 0 Traceback (most recent call last): File "", line 1, in 100 / 0 ZeroDivisionError: division by zero
Разберём это сообщение подробнее: интерпретатор нам сообщает о том, что он поймал исключение и напечатал информацию (Traceback (most recent call last)).
Далее имя файла (File «»). Имя пустое, потому что мы находимся в интерактивном режиме, строка в файле (line 1);
Выражение, в котором произошла ошибка (100 / 0).
Название исключения (ZeroDivisionError) и краткое описание исключения (division by zero).
Разумеется, возможны и другие исключения:
>>> 2 + '1' Traceback (most recent call last): File "", line 1, in 2 + '1' TypeError: unsupported operand type(s) for +: 'int' and 'str' >>> int('qwerty') Traceback (most recent call last): File "", line 1, in int('qwerty') ValueError: invalid literal for int() with base 10: 'qwerty'
В этих двух примерах генерируются исключения TypeError и ValueError соответственно. Подсказки дают нам полную информацию о том, где порождено исключение, и с чем оно связано.
Рассмотрим иерархию встроенных в python исключений, хотя иногда вам могут встретиться и другие, так как программисты могут создавать собственные исключения. Данный список актуален для python 3.3, в более ранних версиях есть незначительные изменения.
- BaseException — базовое исключение, от которого берут начало все остальные.
- SystemExit — исключение, порождаемое функцией sys.exit при выходе из программы.
- KeyboardInterrupt — порождается при прерывании программы пользователем (обычно сочетанием клавиш Ctrl+C).
- GeneratorExit — порождается при вызове метода close объекта generator.
- Exception — а вот тут уже заканчиваются полностью системные исключения (которые лучше не трогать) и начинаются обыкновенные, с которыми можно работать.
- StopIteration — порождается встроенной функцией next, если в итераторе больше нет элементов.
- ArithmeticError — арифметическая ошибка.
- FloatingPointError — порождается при неудачном выполнении операции с плавающей запятой. На практике встречается нечасто.
- OverflowError — возникает, когда результат арифметической операции слишком велик для представления. Не появляется при обычной работе с целыми числами (так как python поддерживает длинные числа), но может возникать в некоторых других случаях.
- ZeroDivisionError — деление на ноль.
- AssertionError — выражение в функции assert ложно.
- AttributeError — объект не имеет данного атрибута (значения или метода).
- BufferError — операция, связанная с буфером, не может быть выполнена.
- EOFError — функция наткнулась на конец файла и не смогла прочитать то, что хотела.
- ImportError — не удалось импортирование модуля или его атрибута.
- LookupError — некорректный индекс или ключ.
- IndexError — индекс не входит в диапазон элементов.
- KeyError — несуществующий ключ (в словаре, множестве или другом объекте).
- MemoryError — недостаточно памяти.
- NameError — не найдено переменной с таким именем.
- UnboundLocalError — сделана ссылка на локальную переменную в функции, но переменная не определена ранее.
- OSError — ошибка, связанная с системой.
- BlockingIOError
- ChildProcessError — неудача при операции с дочерним процессом.
- ConnectionError — базовый класс для исключений, связанных с подключениями.
- BrokenPipeError
- ConnectionAbortedError
- ConnectionRefusedError
- ConnectionResetError
- FileExistsError — попытка создания файла или директории, которая уже существует.
- FileNotFoundError — файл или директория не существует.
- InterruptedError — системный вызов прерван входящим сигналом.
- IsADirectoryError — ожидался файл, но это директория.
- NotADirectoryError — ожидалась директория, но это файл.
- PermissionError — не хватает прав доступа.
- ProcessLookupError — указанного процесса не существует.
- TimeoutError — закончилось время ожидания.
- ReferenceError — попытка доступа к атрибуту со слабой ссылкой.
- RuntimeError — возникает, когда исключение не попадает ни под одну из других категорий.
- NotImplementedError — возникает, когда абстрактные методы класса требуют переопределения в дочерних классах.
- SyntaxError — синтаксическая ошибка.
- IndentationError — неправильные отступы.
- TabError — смешивание в отступах табуляции и пробелов.
- IndentationError — неправильные отступы.
- SystemError — внутренняя ошибка.
- TypeError — операция применена к объекту несоответствующего типа.
- ValueError — функция получает аргумент правильного типа, но некорректного значения.
- UnicodeError — ошибка, связанная с кодированием / раскодированием unicode в строках.
- UnicodeEncodeError — исключение, связанное с кодированием unicode.
- UnicodeDecodeError — исключение, связанное с декодированием unicode.
- UnicodeTranslateError — исключение, связанное с переводом unicode.
- Warning — предупреждение.
Теперь, зная, когда и при каких обстоятельствах могут возникнуть исключения, мы можем их обрабатывать. Для обработки исключений используется конструкция try — except.
Первый пример применения этой конструкции:
>>> try: ... k = 1 / 0 ... except ZeroDivisionError: ... k = 0 ... >>> print(k) 0
В блоке try мы выполняем инструкцию, которая может породить исключение, а в блоке except мы перехватываем их. При этом перехватываются как само исключение, так и его потомки. Например, перехватывая ArithmeticError, мы также перехватываем FloatingPointError, OverflowError и ZeroDivisionError.
>>> try: ... k = 1 / 0 ... except ArithmeticError: ... k = 0 ... >>> print(k) 0
Также возможна инструкция except без аргументов, которая перехватывает вообще всё (и прерывание с клавиатуры, и системный выход и т. д.). Поэтому в такой форме инструкция except практически не используется, а используется except Exception. Однако чаще всего перехватывают исключения по одному, для упрощения отладки (вдруг вы ещё другую ошибку сделаете, а except её перехватит).
Ещё две инструкции, относящиеся к нашей проблеме, это finally и else. Finally выполняет блок инструкций в любом случае, было ли исключение, или нет (применима, когда нужно непременно что-то сделать, к примеру, закрыть файл). Инструкция else выполняется в том случае, если исключения не было.
>>> f = open('1.txt') >>> ints = [] >>> try: ... for line in f: ... ints.append(int(line)) ... except ValueError: ... print('Это не число. Выходим.') ... except Exception: ... print('Это что ещё такое?') ... else: ... print('Всё хорошо.') ... finally: ... f.close() ... print('Я закрыл файл.') ... # Именно в таком порядке: try, группа except, затем else, и только потом finally. ... Это не число. Выходим. Я закрыл файл.

Error tracking is essential for any application when many people are relying on the app. If your application is not working in production for whatever reason, it can be a nightmare experience for users depending on correct functionality.
There are many exceptions tracking plugins and modules available. Some of them are open source whereas others are paid, like HoneyBadger, NewRelic, ELK, etc.
What about having a custom exception handler that can track errors in different contexts with additional features like:
-
Send emails or notify developers (interested entities).
-
Create or update tickets in Bugzilla or Jira.
-
Push exceptions to the ELK stack or any other system for analytics and store detailed exceptions in DB.
-
While capturing exceptions, provide local and global variables details (failure context).
You may also like: The Top Four Exception Tracking Services
Error Tracker
Error tracker is a python library. It provides all required interfaces and supports all the above features. One interesting thing about this library is that it can mask variables that are sensitive (i.e should not be exposed, like password, credit card number, etc.). It’s well documented at Error Tracker doc and available via PyPI
A typical setup of Error Tracker can be visualized as:
![]()
Error Tracker can be used with any type of Python application. We’ll start with Flask.
Tools we need:
-
Editor any IDE.
-
Python.
-
Pip.
Installation
pip install error-tracker
We’ll use settings file for app configuration you might call it config.py or some other format like YAML etc, we’ll use python file for simplicity.
settings.py
APP_ERROR_SEND_NOTIFICATION = True
APP_ERROR_RECIPIENT_EMAIL = ('dev@example.com',)
APP_ERROR_EMAIL_SENDER="server@example.com"
APP_ERROR_SUBJECT_PREFIX = ""
APP_ERROR_MASK_WITH = "**************"
APP_ERROR_MASKED_KEY_HAS = ("password", "secret")
APP_ERROR_URL_PREFIX = "/dev/error"There’re seven configurations in this file:
APP_ERROR_SEND_NOTIFICATION — This configures whether a notification has to be sent or not. If it’s set, then it will try to send notification using the notification interface.
APP_ERROR_RECIPIENT_EMAIL — This refers to whom the email has to be sent to. It is required to build email content. It can be a list of emails or a single email address.
APP_ERROR_EMAIL_SENDER — Who is sending email to the recipient(s).
APP_ERROR_SUBJECT_PREFIX — Any email subject prefix. By default, it will be [IndexError] [GET] http://127.0.0.1:5000/go.
APP_ERROR_MASK_WITH — What should be used to mask the sensitive information.
APP_ERROR_MASKED_KEY_HAS — What variables should be masked. It can mask all local and global variables. Masking is done based on the variable name. If a data type is a dictionary, or it’s subclass then their keys are examined.
APP_ERROR_URL_PREFIX — All unique exceptions are stored in the database and can be browsed at this endpoint.
Create another python file
For email-sender, we’ll implement NotificationMixin
from flask_mail import Mail, Message
class Notifier(Mail, NotificationMixin):
def notify(self, request, exception,
email_subject=None,
email_body=None,
from_email=None,
recipient_list=None):
message = Message(email_subject, recipient_list, email_body, sender=from_email)
self.send(message)
For issue tracking, we’ll implement TicketingMixin
class Ticketing(TicketingMixin):
def raise_ticket(self, exception, request=None):
# implement this method to communicate with Jira or Bugzilla etc
passLet’s create a Flask app to serve requests. We’ll use SQLite for simplicity.
app = Flask(__name__)
app.config.from_object(settings)
app.config['SQLALCHEMY_DATABASE_URI'] = "sqlite:///tmp.sqlite"
db = SQLAlchemy(app)
The errors can be tracked by creating an instance of AppErrorTracker and initializing this with proper details. This application can store all the exceptions in the database.
app_error = AppErrorTracker(app=app, db=db,
notifier=Notifier(app=app), ticketing=Ticketing())
db.create_all()For error tracking, we are going to use the decorator track_exception provided by AppErrorTracker class. We’ll attach this decorator whenever HTTP 500 occurs.
@app.errorhandler(500)
@app_error.track_exception
def error_500(e):
return render_template('500.html'), 500Now, it’s ready to be used. We can fire some requests and see how it works. For testing, let’s add one endpoint that will throw 500 errors with different types of exceptions.
@app.route('/go')
def die():
import random
password = "test"
foo = {}
foo['password'] = "Oh! My Gosh"
foo['secret'] = "NO ONE KNOWS"
exceptions = [KeyError, ArithmeticError, BaseException, IndentationError, IndexError, MemoryError,
NameError, NotImplementedError, ImportError, FloatingPointError, EOFError,
OSError, AssertionError, AttributeError, GeneratorExit, Exception,
EnvironmentError, ImportError,
NotImplementedError, RuntimeError]
raise random.choice(exceptions)Now, run the app in debug=False mode and browse, as it will fail. Now, go to http://127.0.0.1:5000/dev/error/. This will display the current exceptions in a table like:

Any of the specific exceptions can be browsed by clicking the corresponding link, in the Exception detail section, all frame details that have been captured can be seen.

The complete Flask application can be found at https://github.com/sonus21/error-tracker/tree/master/examples/flask-sample.
Implementation With Django
Using Exception Tracker with Django is also very simple. Install the application using pip install error-tracker. Once we’ve installed it, we need to configure some part of the applications using the settings.py file.
For the Django application, we need to add this app in the INSTALLED_APPS list and add Middleware to catch exceptions. Middleware should be added at the end of the list so that it will be called first whenever an exception occurs.
APP_ERROR_RECIPIENT_EMAIL = ('example@example.com',)
APP_ERROR_SUBJECT_PREFIX = "Server Error"
APP_ERROR_EMAIL_SENDER = 'user@example.com'
INSTALLED_APPS = [
...
'error_tracker.DjangoErrorTracker'
]
MIDDLEWARE = [
...
'error_tracker.django.middleware.ExceptionTrackerMiddleWare'
]Error Tracker provides a few default pages for listing exception, deleting exception, and browsing a specific exception. These endpoints can be plugged in with Django’s other URLs.
from error_tracker.django import urls
urlpatterns = [
...
url("dev/", include(urls)),
]These are all the code changes we need for the Django app. The complete code is available at https://github.com/sonus21/error-tracker/tree/master/examples/DjangoSample.
Conclusion
Apps using Error Tracker can be further customized, like what models to use. Currently, it records only one instance of failure, while all failures can be tracked and dumped to some database. Read more about them at https://error-tracker.readthedocs.io/en/latest/index.html#.
The complete code is available on GitHub.
If you found this post helpful, please share and give a thumbs up.
Further Reading
- Python: How to Create an Exception Logging Decorator.
- Error Handling Strategies.
- Create a Simple API Using Django REST Framework in Python.
Opinions expressed by DZone contributors are their own.