Содержание
- Memory Error in Pandas
- What is the Memory Error in Pandas
- How to Avoid the Memory Error in Pandas
- How to avoid Memory errors with Pandas
- Some strategies to scale pandas while working with medium and large datasets
- Context: Exploring unknown datasets
- Strategy 1: Load less data (sub-sampling)
- Strategy 2: Scaling Vertically
- Strategy 4: Horizontal scaling with Terality
- Conclusion
- Python Memory Error | How to Solve Memory Error in Python
- What is Memory Error?
- Types of Python Memory Error
- Unexpected Memory Error in Python
- The easy solution for Unexpected Python Memory Error
- Python Memory Error Due to Dataset
- Python Memory Error Due to Improper Installation of Python
- Out of Memory Error in Python
- How can I explicitly free memory in Python?
- Memory error in Python when 50+GB is free and using 64bit python?
- How do you set the memory usage for python programs?
- How to put limits on Memory and CPU Usage
- Ways to Handle Python Memory Error and Large Data Files
- 1. Allocate More Memory
- 2. Work with a Smaller Sample
- 3. Use a Computer with More Memory
- 4. Use a Relational Database
- 5. Use a Big Data Platform
- Summary
Memory Error in Pandas
This tutorial explores the concept of memory error in Pandas.
What is the Memory Error in Pandas
While working with Pandas, an analyst might encounter multiple errors that the code interpreter throws. These errors are widely ranged and would help us better investigate the issue.
In this tutorial, we aim to better understand the memory error thrown by Pandas, the reason behind it throwing that error and the potential ways by which this error can be resolved.
Firstly, let us understand what this error means. A memory error means that there is not enough memory on the server or the database you’re trying to access to complete the operation or task you wish to perform.
This error is generally associated with files and CSV data that have the order of hundreds of gigabytes. It is important to understand what causes this error and avoid such an error to have more data storage.
Solving this error can also help develop an efficient and thorough database with proper rule management.
Assuming we’re trying to fetch data from a CSV file with more than 1000 gigabytes of data, we will naturally face the memory error discussed above. This error can be illustrated below.
There is a method by which we can avoid this memory error potentially. However, before we do that, let us create a dummy data frame to work with.
We will call this data frame dat1 . Let us create this data frame using the following code.
The query creates 10 columns indexed from 0 to 9 and 100000 values. To view the entries in the data, we use the following code.
The above code gives the following output.
How to Avoid the Memory Error in Pandas
Now let us see the total space that this data frame occupies using the following code.
The code gives the following output.
To avoid spending so much space on just a single data frame, let us do this by specifying exactly the data type we’re dealing with.
This helps us reduce the total memory required as lesser space is required to understand the type of data, and more space can be allotted to the actual data under consideration.
We can do this using the following query.
The output of the code is below.
Since we have specified the data type as int here by not assigning strings, we have successfully reduced the memory space required for our data.
Thus, we have learned the meaning, cause, and potential solution with this tutorial regarding the memory error thrown in Pandas.
Preet writes his thoughts about programming in a simplified manner to help others learn better. With thorough research, his articles offer descriptive and easy to understand solutions.
Источник
How to avoid Memory errors with Pandas
Some strategies to scale pandas while working with medium and large datasets
TL;DR If you often run out of memory with Pandas or have slow-code execution problems, you could amuse yourself by testing manual approaches, or you can solve it in less than 5 minutes using Terality. I had to discover this the hard way.
Context: Exploring unknown datasets
Recently, I had the intention to explore a dataset that contains 720,000 rows and 72 columns from a popular video game: the idea was to discover if there were any consistent patterns in the players’ strategies. But I spent more time trying to load the data — due to memory errors — than actually exploring the data. I’m well aware of the 80/20 rule of data analysis, where most of your time is spent exploring the data — and I am OK with that. I have always thought that a new dataset is like exploring a new country, with its own context and customs that you must decipher in order to explain or discover some pattern; but in this case, I wasn’t able to even start working.
As soon as my data was ready to be processed, I started to experience some issues because some Pandas functions needed way more memory to run than my machine had available. For example, I ran out of memory when I wanted to sort one column. Given that this was not the first time that this has happened to me, I applied the usual techniques to solve this problem. First, I will explain what I tried to do to solve this problem before I discovered Terality.
Strategy 1: Load less data (sub-sampling)
One strategy for solving this kind of problem is to decrease the amount of data by either reducing the number of rows or columns in the dataset. In my case, however, I was only loading 20% of the available data, so this wasn’t an option as I would exclude too many important elements in my dataset.
Strategy 2: Scaling Vertically
If you can’t or shouldn’t use less data, and you have a lack of resources problem, you have two options: scaling vertically, which means adding more physical resources (in this case more RAM) to your environment (i.e. working on a single-bigger computer), or scaling horizontally, which means distributing the problem into several smaller, coordinated instances. Vertical scaling is easier as you only have to plug in the new hardware and play in the same way as before, just faster and better.
I have used Google Colab before as my default option to scale my resources vertically. It offers a Jupyter-like environment with 12GB of RAM for free with some limits on time and GPU usage. Since I didn’t need to perform any modeling tasks yet, just a simple Pandas exploration and a couple of transformations, it looked like the perfect solution. But no, again Pandas ran out of memory at the very first operation.
Strategy 3: Modify the Data Types
Given that vertical scaling wasn’t enough, I decided to use some collateral techniques. The first one was to reduce the size of the dataset by modifying the data types used to map some columns. Given a certain data type, for example, int64, python allocates enough memory space to store an integer in the range from -9223372036854775808 to 9223372036854775807. After reading the description of the data I changed the data types to the minimum, thereby reducing the size of the dataset by more than 35%:
Be careful with your choices when applying this technique: some data types will not improve the size in memory, in fact, it can even make it worse. A common suggestion is to change object types to categorical, however, in my case it canceled out my previous gains:
Strategy 4: Horizontal scaling with Terality
Scaling horizontally, which basically means adding more machines, would require that I distribute my code to multiple servers. That’s a tough problem, typically solved by map-reduce or Spark, for instance; but I didn’t know of any solution that could easily do that for Pandas’ code. Some open source solutions could help, but they don’t have some Pandas’ methods, don’t provide the same syntax, and are limited in their scope.
While I was googling for new tricks to apply I discovered Terality. It looks like they are the new kid on the block offering an interesting alternative for this kind of problem: Managed Horizontal Scaling of Pandas. In other words, it seems that Terality spawns a cluster of machines behind the scenes, connects that cluster with the environment, and runs the code in the new cluster. This is perfect because it is hidden from the analyst’s point of view and doesn’t require upgrading the local environment with new hardware to either modify the data or the code. Probably you can get a better description of their offer on this medium article.
After a simple onboarding process, I was ready to test this approach. It really surprised me that the load and merge operations that previously failed in my local and Google Colab environments ran faster and without any issues with Terality. Also, given that they are currently at a private Beta stage, I didn’t have to pay anything. Some other bold claims of the Terality team about their product include:
- Execution of Pandas code 100x faster, even on big datasets
- Full support of the Pandas API (Methods, integrations, errors, etc.)
- Savings on infrastructure costs
My use case wasn’t big enough to test all this functionality, neither was it my intention to build a benchmark with other tools in the same space. But, using the private Beta account, I worked flawlessly with the dataset through Terality. You can check the times recorded for loading and merging in the following screenshot:
The only difference, besides the awesome speed (1 minute 22 seconds for a merge output over 100GB), is that the dataframe is a terality.DataFrame. The integration and setup took less than five (5) minutes, I only needed to Pip install their client Library from PyPy, then replace the import pandas as pd with import terality as pd, and the rest of the code didn’t need any change at all. In the end, using Terality gave me several advantages:
- Super easy setup
- No learning curve — no need to change any code
- Instant and unlimited scalability
- No infrastructure to manage
- Faster pandas execution (However, I need to benchmark this)
I’m tempted to test the limits of this tool by working with datasets larger than a few GB, such as a large, public dataset like COVID-19 Open Research Dataset. My next step would be to test if the 100x improvement over pandas code execution is a legitimate claim. Finally, the idea of running Pandas in a Horizontal Cluster without the setup and administration burden is appealing not only for independent data scientists but also for more sophisticated or enterprise use cases.
Conclusion
There are many use cases with enough data to be processed that can break local or cloud environments with Pandas. Like many other data scientists, I tried several coding techniques and tools before looking out of the box and experimenting with an external solution that gave me better results. You should try Terality now to measure if it is the proper tool to solve your Pandas memory errors too. You just need to contact their team on their website, and they’ll guide you through the process.
Источник
Python Memory Error | How to Solve Memory Error in Python

What is Memory Error?
Python Memory Error or in layman language is exactly what it means, you have run out of memory in your RAM for your code to execute.
When this error occurs it is likely because you have loaded the entire data into memory. For large datasets, you will want to use batch processing. Instead of loading your entire dataset into memory you should keep your data in your hard drive and access it in batches.
A memory error means that your program has run out of memory. This means that your program somehow creates too many objects. In your example, you have to look for parts of your algorithm that could be consuming a lot of memory.
If an operation runs out of memory it is known as memory error.
Types of Python Memory Error
Unexpected Memory Error in Python
If you get an unexpected Python Memory Error and you think you should have plenty of rams available, it might be because you are using a 32-bit python installation.
The easy solution for Unexpected Python Memory Error
Your program is running out of virtual address space. Most probably because you’re using a 32-bit version of Python. As Windows (and most other OSes as well) limits 32-bit applications to 2 GB of user-mode address space.
We Python Pooler’s recommend you to install a 64-bit version of Python (if you can, I’d recommend upgrading to Python 3 for other reasons); it will use more memory, but then, it will have access to a lot more memory space (and more physical RAM as well).
The issue is that 32-bit python only has access to
4GB of RAM. This can shrink even further if your operating system is 32-bit, because of the operating system overhead.
For example, in Python 2 zip function takes in multiple iterables and returns a single iterator of tuples. Anyhow, we need each item from the iterator once for looping. So we don’t need to store all items in memory throughout looping. So it’d be better to use izip which retrieves each item only on next iterations. Python 3’s zip functions as izip by default.
Python Memory Error Due to Dataset
Like the point, about 32 bit and 64-bit versions have already been covered, another possibility could be dataset size, if you’re working with a large dataset. Loading a large dataset directly into memory and performing computations on it and saving intermediate results of those computations can quickly fill up your memory. Generator functions come in very handy if this is your problem. Many popular python libraries like Keras and TensorFlow have specific functions and classes for generators.
Python Memory Error Due to Improper Installation of Python
Improper installation of Python packages may also lead to Memory Error. As a matter of fact, before solving the problem, We had installed on windows manually python 2.7 and the packages that I needed, after messing almost two days trying to figure out what was the problem, We reinstalled everything with Conda and the problem was solved.
We guess Conda is installing better memory management packages and that was the main reason. So you can try installing Python Packages using Conda, it may solve the Memory Error issue.
Out of Memory Error in Python
Most platforms return an “Out of Memory error” if an attempt to allocate a block of memory fails, but the root cause of that problem very rarely has anything to do with truly being “out of memory.” That’s because, on almost every modern operating system, the memory manager will happily use your available hard disk space as place to store pages of memory that don’t fit in RAM; your computer can usually allocate memory until the disk fills up and it may lead to Python Out of Memory Error(or a swap limit is hit; in Windows, see System Properties > Performance Options > Advanced > Virtual memory).
Making matters much worse, every active allocation in the program’s address space can cause “fragmentation” that can prevent future allocations by splitting available memory into chunks that are individually too small to satisfy a new allocation with one contiguous block.
1 If a 32bit application has the LARGEADDRESSAWARE flag set, it has access to s full 4gb of address space when running on a 64bit version of Windows.
2 So far, four readers have written to explain that the gcAllowVeryLargeObjects flag removes this .NET limitation. It does not. This flag allows objects which occupy more than 2gb of memory, but it does not permit a single-dimensional array to contain more than 2^31 entries.
How can I explicitly free memory in Python?
If you wrote a Python program that acts on a large input file to create a few million objects representing and it’s taking tons of memory and you need the best way to tell Python that you no longer need some of the data, and it can be freed?
The Simple answer to this problem is:
Force the garbage collector for releasing an unreferenced memory with gc.collect().
Like shown below:

Memory error in Python when 50+GB is free and using 64bit python?
On some operating systems, there are limits to how much RAM a single CPU can handle. So even if there is enough RAM free, your single thread (=running on one core) cannot take more. But I don’t know if this is valid for your Windows version, though.
How do you set the memory usage for python programs?
Python uses garbage collection and built-in memory management to ensure the program only uses as much RAM as required. So unless you expressly write your program in such a way to bloat the memory usage, e.g. making a database in RAM, Python only uses what it needs.
Which begs the question, why would you want to use more RAM? The idea for most programmers is to minimize resource usage.
if you wanna limit the python vm memory usage, you can try this:
1、Linux, ulimit command to limit the memory usage on python
2、you can use resource module to limit the program memory usage;
if u wanna speed up ur program though giving more memory to ur application, you could try this:
1threading, multiprocessing
2pypy
3pysco on only python 2.5
How to put limits on Memory and CPU Usage
To put limits on the memory or CPU use of a program running. So that we will not face any memory error. Well to do so, Resource module can be used and thus both the task can be performed very well as shown in the code given below:
Code #1: Restrict CPU time
Code #2: In order to restrict memory use, the code puts a limit on the total address space
Ways to Handle Python Memory Error and Large Data Files
1. Allocate More Memory
Some Python tools or libraries may be limited by a default memory configuration.
Check if you can re-configure your tool or library to allocate more memory.
That is, a platform designed for handling very large datasets, that allows you to use data transforms and machine learning algorithms on top of it.
A good example is Weka, where you can increase the memory as a parameter when starting the application.
2. Work with a Smaller Sample
Are you sure you need to work with all of the data?
Take a random sample of your data, such as the first 1,000 or 100,000 rows. Use this smaller sample to work through your problem before fitting a final model on all of your data (using progressive data loading techniques).
I think this is a good practice in general for machine learning to give you quick spot-checks of algorithms and turnaround of results.
You may also consider performing a sensitivity analysis of the amount of data used to fit one algorithm compared to the model skill. Perhaps there is a natural point of diminishing returns that you can use as a heuristic size of your smaller sample.
3. Use a Computer with More Memory
Do you have to work on your computer?
Perhaps you can get access to a much larger computer with an order of magnitude more memory.
For example, a good option is to rent compute time on a cloud service like Amazon Web Services that offers machines with tens of gigabytes of RAM for less than a US dollar per hour.
4. Use a Relational Database
Relational databases provide a standard way of storing and accessing very large datasets.
Internally, the data is stored on disk can be progressively loaded in batches and can be queried using a standard query language (SQL).
Free open-source database tools like MySQL or Postgres can be used and most (all?) programming languages and many machine learning tools can connect directly to relational databases. You can also use a lightweight approach, such as SQLite.
5. Use a Big Data Platform
In some cases, you may need to resort to a big data platform.
Summary
In this post, you discovered a number of tactics and ways that you can use when dealing with Python Memory Error.
Are there other methods that you know about or have tried?
Share them in the comments below.
Have you tried any of these methods?
Let me know in the comments.
If your problem is still not solved and you need help regarding Python Memory Error. Comment Down below, We will try to solve your issue asap.
Источник
- What is the Memory Error in Pandas
- How to Avoid the Memory Error in Pandas

This tutorial explores the concept of memory error in Pandas.
What is the Memory Error in Pandas
While working with Pandas, an analyst might encounter multiple errors that the code interpreter throws. These errors are widely ranged and would help us better investigate the issue.
In this tutorial, we aim to better understand the memory error thrown by Pandas, the reason behind it throwing that error and the potential ways by which this error can be resolved.
Firstly, let us understand what this error means. A memory error means that there is not enough memory on the server or the database you’re trying to access to complete the operation or task you wish to perform.
This error is generally associated with files and CSV data that have the order of hundreds of gigabytes. It is important to understand what causes this error and avoid such an error to have more data storage.
Solving this error can also help develop an efficient and thorough database with proper rule management.
Assuming we’re trying to fetch data from a CSV file with more than 1000 gigabytes of data, we will naturally face the memory error discussed above. This error can be illustrated below.
MemoryError
Press any key to continue . . .
There is a method by which we can avoid this memory error potentially. However, before we do that, let us create a dummy data frame to work with.
We will call this data frame dat1. Let us create this data frame using the following code.
import pandas as pd
dat1 = pd.DataFrame(pd.np.random.choice(['1.0', '0.6666667', '150000.1'],(100000, 10)))
The query creates 10 columns indexed from 0 to 9 and 100000 values. To view the entries in the data, we use the following code.
The above code gives the following output.
0 1 2 ... 7 8 9
0 1.0 1.0 1.0 ... 150000.1 0.6666667 0.6666667
1 0.6666667 0.6666667 1.0 ... 0.6666667 150000.1 0.6666667
2 1.0 1.0 150000.1 ... 150000.1 1.0 150000.1
3 150000.1 0.6666667 0.6666667 ... 1.0 150000.1 1.0
4 150000.1 0.6666667 150000.1 ... 150000.1 0.6666667 0.6666667
... ... ... ... ... ... ... ...
99995 150000.1 150000.1 1.0 ... 150000.1 1.0 0.6666667
99996 1.0 1.0 150000.1 ... 0.6666667 0.6666667 150000.1
99997 150000.1 150000.1 1.0 ... 0.6666667 150000.1 0.6666667
99998 1.0 0.6666667 0.6666667 ... 0.6666667 1.0 150000.1
99999 1.0 0.6666667 150000.1 ... 1.0 150000.1 1.0
[100000 rows x 10 columns]
How to Avoid the Memory Error in Pandas
Now let us see the total space that this data frame occupies using the following code.
resource.getrusage(resource.RUSAGE_SELF).ru_maxrss
The code gives the following output.
To avoid spending so much space on just a single data frame, let us do this by specifying exactly the data type we’re dealing with.
This helps us reduce the total memory required as lesser space is required to understand the type of data, and more space can be allotted to the actual data under consideration.
We can do this using the following query.
df = pd.DataFrame(pd.np.random.choice([1.0, 0.6666667, 150000.1],(100000, 10)))
resource.getrusage(resource.RUSAGE_SELF).ru_maxrss
The output of the code is below.
Since we have specified the data type as int here by not assigning strings, we have successfully reduced the memory space required for our data.
Thus, we have learned the meaning, cause, and potential solution with this tutorial regarding the memory error thrown in Pandas.
Hi,
I am getting an intermittent MemoryError while running code. The same code runs fine on re-installing Anaconda or while re-starting Jupyter Notebook / Sypder Kernel.
The system is 8GB RAM , 64bit OS.
As per the inputs received from Spyder community , this error relates to pandas. Please suggest the resolution steps.
Please note the same error occurs while running pd.read_csv command as well.
Below is the snapshot of the same.
File «», line 23, in
df_hist_trans_group = df_hist_trans.groupby (‘card_id’).agg(aggs)
File «C:UsersPrachiAnaconda3libsite-packagespandascoregroupbygroupby.py», line 4656, in aggregate
return super(DataFrameGroupBy, self).aggregate(arg, *args, **kwargs)
File «C:UsersPrachiAnaconda3libsite-packagespandascoregroupbygroupby.py», line 4087, in aggregate
result, how = self._aggregate(arg, _level=_level, *args, **kwargs)
File «C:UsersPrachiAnaconda3libsite-packagespandascorebase.py», line 490, in _aggregate
result = _agg(arg, _agg_1dim)
File «C:UsersPrachiAnaconda3libsite-packagespandascorebase.py», line 441, in _agg
result[fname] = func(fname, agg_how)
File «C:UsersPrachiAnaconda3libsite-packagespandascorebase.py», line 424, in _agg_1dim
return colg.aggregate(how, _level=(_level or 0) + 1)
File «C:UsersPrachiAnaconda3libsite-packagespandascoregroupbygroupby.py», line 3485, in aggregate
(_level or 0) + 1)
File «C:UsersPrachiAnaconda3libsite-packagespandascoregroupbygroupby.py», line 3558, in _aggregate_multiple_funcs
results[name] = obj.aggregate(func)
File «C:UsersPrachiAnaconda3libsite-packagespandascoregroupbygroupby.py», line 3479, in aggregate
return getattr(self, func_or_funcs)(*args, **kwargs)
File «C:UsersPrachiAnaconda3libsite-packagespandascoregroupbygroupby.py», line 3744, in nunique
ids, _, _ = self.grouper.group_info
File «pandas_libsproperties.pyx», line 36, in pandas._libs.properties.CachedProperty.get
File «C:UsersPrachiAnaconda3libsite-packagespandascoregroupbygroupby.py», line 2335, in group_info
comp_ids, obs_group_ids = self._get_compressed_labels()
File «C:UsersPrachiAnaconda3libsite-packagespandascoregroupbygroupby.py», line 2351, in _get_compressed_labels
all_labels = [ping.labels for ping in self.groupings]
File «C:UsersPrachiAnaconda3libsite-packagespandascoregroupbygroupby.py», line 2351, in
all_labels = [ping.labels for ping in self.groupings]
File «C:UsersPrachiAnaconda3libsite-packagespandascoregroupbygroupby.py», line 3070, in labels
self._make_labels()
File «C:UsersPrachiAnaconda3libsite-packagespandascoregroupbygroupby.py», line 3103, in _make_labels
self.grouper, sort=self.sort)
File «C:UsersPrachiAnaconda3libsite-packagespandasutil_decorators.py», line 178, in wrapper
return func(*args, **kwargs)
File «C:UsersPrachiAnaconda3libsite-packagespandascorealgorithms.py», line 630, in factorize
na_value=na_value)
File «C:UsersPrachiAnaconda3libsite-packagespandascorealgorithms.py», line 476, in _factorize_array
na_value=na_value)
File «pandas_libshashtable_class_helper.pxi», line 1420, in pandas._libs.hashtable.StringHashTable.get_labels
MemoryError
Another snapshot while using pd.read_csv in Jupyter Notebook is as below —
MemoryError Traceback (most recent call last)
in
—-> 1 df_hist_trans = pd.read_csv(r’C:UsersPrachiDownloadsallhistorical_transactions.csv’)
~Anaconda3libsite-packagespandasioparsers.py in parser_f(filepath_or_buffer, sep, delimiter, header, names, index_col, usecols, squeeze, prefix, mangle_dupe_cols, dtype, engine, converters, true_values, false_values, skipinitialspace, skiprows, nrows, na_values, keep_default_na, na_filter, verbose, skip_blank_lines, parse_dates, infer_datetime_format, keep_date_col, date_parser, dayfirst, iterator, chunksize, compression, thousands, decimal, lineterminator, quotechar, quoting, escapechar, comment, encoding, dialect, tupleize_cols, error_bad_lines, warn_bad_lines, skipfooter, doublequote, delim_whitespace, low_memory, memory_map, float_precision)
676 skip_blank_lines=skip_blank_lines)
677
—> 678 return _read(filepath_or_buffer, kwds)
679
680 parser_f.name = name
~Anaconda3libsite-packagespandasioparsers.py in _read(filepath_or_buffer, kwds)
444
445 try:
—> 446 data = parser.read(nrows)
447 finally:
448 parser.close()
~Anaconda3libsite-packagespandasioparsers.py in read(self, nrows)
1034 raise ValueError(‘skipfooter not supported for iteration’)
1035
-> 1036 ret = self._engine.read(nrows)
1037
1038 # May alter columns / col_dict
~Anaconda3libsite-packagespandasioparsers.py in read(self, nrows)
1846 def read(self, nrows=None):
1847 try:
-> 1848 data = self._reader.read(nrows)
1849 except StopIteration:
1850 if self._first_chunk:
pandas_libsparsers.pyx in pandas._libs.parsers.TextReader.read()
pandas_libsparsers.pyx in pandas._libs.parsers.TextReader._read_low_memory()
pandas_libsparsers.pyx in pandas._libs.parsers.TextReader._read_rows()
pandas_libsparsers.pyx in pandas._libs.parsers.TextReader._convert_column_data()
pandas_libsparsers.pyx in pandas._libs.parsers.TextReader._convert_tokens()
pandas_libsparsers.pyx in pandas._libs.parsers.TextReader._convert_with_dtype()
pandas_libsparsers.pyx in pandas._libs.parsers._try_int64()
MemoryError:
Впервые я столкнулся с Memory Error, когда работал с огромным массивом ключевых слов. Там было около 40 млн. строк, воодушевленный своим гениальным скриптом я нажал Shift + F10 и спустя 20 секунд получил Memory Error.
Memory Error — исключение вызываемое в случае переполнения выделенной ОС памяти, при условии, что ситуация может быть исправлена путем удаления объектов. Оставим ссылку на доку, кому интересно подробнее разобраться с этим исключением и с формулировкой. Ссылка на документацию по Memory Error.
Если вам интересно как вызывать это исключение, то попробуйте исполнить приведенный ниже код.
print('a' * 1000000000000)
Почему возникает MemoryError?
В целом существует всего лишь несколько основных причин, среди которых:
- 32-битная версия Python, так как для 32-битных приложений Windows выделяет лишь 4 гб, то серьезные операции приводят к MemoryError
- Неоптимизированный код
- Чрезмерно большие датасеты и иные инпут файлы
- Ошибки в установке пакетов
Как исправить MemoryError?
Ошибка связана с 32-битной версией
Тут все просто, следуйте данному гайдлайну и уже через 10 минут вы запустите свой код.
Как посмотреть версию Python?
Идем в cmd (Кнопка Windows + R -> cmd) и пишем python. В итоге получим что-то похожее на
Python 3.8.8 (tags/v3.8.8:024d805, Feb 19 2021, 13:18:16) [MSC v.1928 64 bit (AMD64)]
Нас интересует эта часть [MSC v.1928 64 bit (AMD64)], так как вы ловите MemoryError, то скорее всего у вас будет 32 bit.
Как установить 64-битную версию Python?
Идем на официальный сайт Python и качаем установщик 64-битной версии. Ссылка на сайт с официальными релизами. В скобках нужной нам версии видим 64-bit. Удалять или не удалять 32-битную версию — это ваш выбор, я обычно удаляю, чтобы не путаться в IDE. Все что останется сделать, просто поменять интерпретатор.
Идем в PyCharm в File -> Settings -> Project -> Python Interpreter -> Шестеренка -> Add -> New environment -> Base Interpreter и выбираем python.exe из только что установленной директории. У меня это
C:/Users/Core/AppData/LocalPrograms/Python/Python38
Все, запускаем скрипт и видим, что все выполняется как следует.
Оптимизация кода
Пару раз я встречался с ситуацией когда мои костыли приводили к MemoryError. К этому приводили избыточные условия, циклы и буферные переменные, которые не удаляются после потери необходимости в них. Если вы понимаете, что проблема может быть в этом, вероятно стоит закостылить пару del, мануально удаляя ссылки на объекты. Но помните о том, что проблема в архитектуре вашего проекта, и по настоящему решить эту проблему можно лишь правильно проработав структуру проекта.
Явно освобождаем память с помощью сборщика мусора
В целом в 90% случаев проблема решается переустановкой питона, однако, я просто обязан рассказать вам про библиотеку gc. В целом почитать про Garbage Collector стоит отдельно на авторитетных ресурсах в статьях профессиональных программистов. Вы просто обязаны знать, что происходит под капотом управления памятью. GC — это не только про Python, управление памятью в Java и других языках базируется на технологии сборки мусора. Ну а вот так мы можем мануально освободить память в Python:
At Simpl, we use pandas heavily to run a bunch of our machine learning models many of them implemented with scikit-learn. We’ve been growing rapidly and sometime back, one of the models crashed with python’s MemoryError exception. We were pretty sure that the hardware resources are enough to run the task.
What is the MemoryError? It’s an exception thrown by interpreter when not enough memory is available for creation of new python objects or for a running operation.
The catch here is that, it doesn’t necessarily mean “not enough memory available”. It could also mean that, there are some objects that are still not cleaned up by Garbage Cleaner (GC).
To test this, I wrote a very small script:
arr = numpy.random.randn(10000000, 5)
def blast():
for i in range(10000):
x = pandas.DataFrame(arr.copy())
result = x.xs(1000)
blast()
Below is the distribution (Memory usage w.r.t Time) before the program crashed with MemoryError exception.
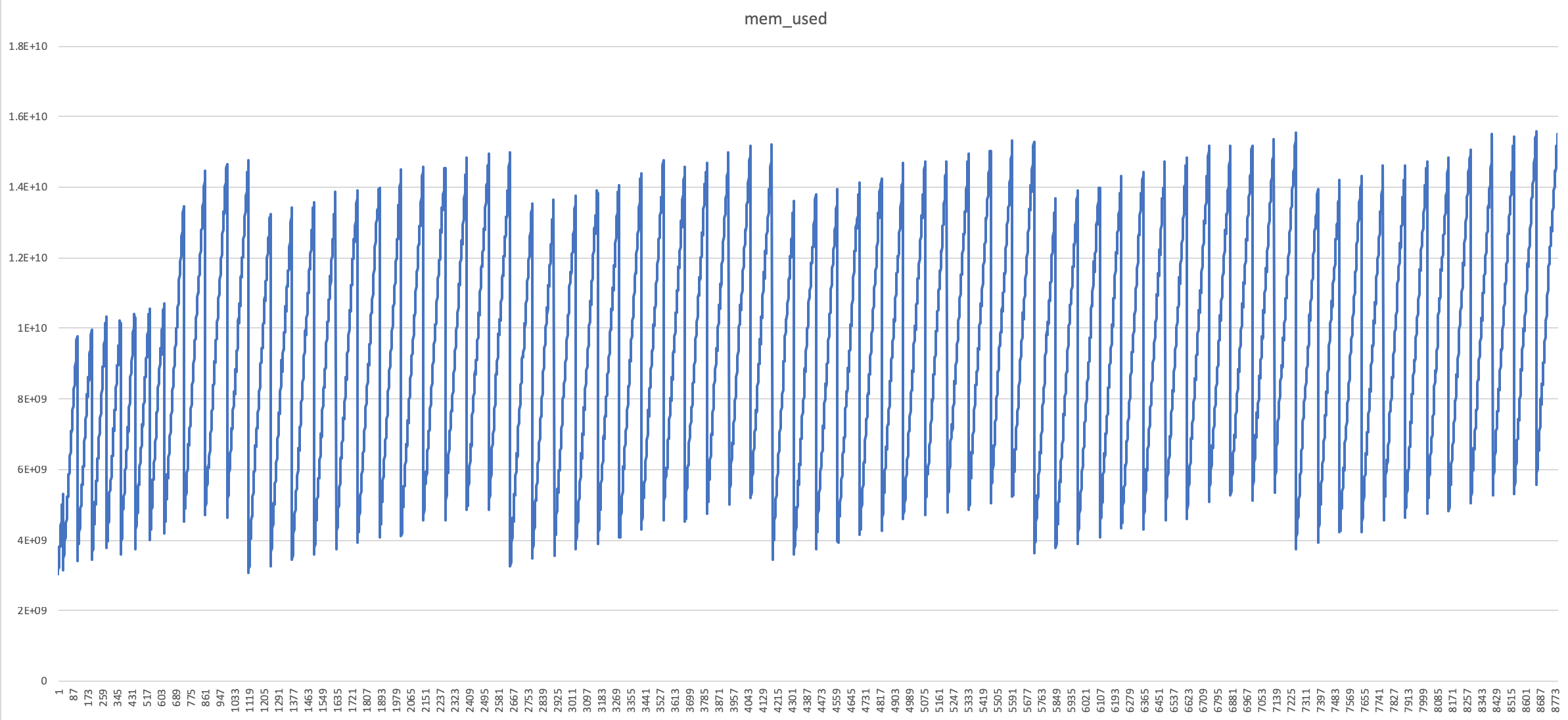
The GC seems to be working fine, but it’s not able to clean up the objects as fast as it’s required in this case.
What’s the issue?
Python’s default implementation is CPython (github) which is implemented in C. The problem was this bug; in the implementation of malloc in glibc (which is GNU’s implementation of C standard library).
Issue Details:
M_MXFAST is the maximum size of a requested block that is served by using optimized memory containers called fastbins. free() is called when a memory cleanup of allocated space is required; which triggers the trimming of fastbins. Apparently, when malloc() is less than M_MXFAST, free() is not trimming fastbins. But, if we manually call malloc_trim(0) at that point, it should free() up those fastbins as well.
Here is a snippet from malloc.c’s free() implementation (alias __libc_free). (link)
p = mem2chunk (mem);
if (chunk_is_mmapped (p)) /* release mmapped memory. */
{
/* See if the dynamic brk/mmap threshold needs adjusting.
Dumped fake mmapped chunks do not affect the threshold. */
if (!mp_.no_dyn_threshold
&& chunksize_nomask (p) > mp_.mmap_threshold
&& chunksize_nomask (p) <= DEFAULT_MMAP_THRESHOLD_MAX
&& !DUMPED_MAIN_ARENA_CHUNK (p))
{
mp_.mmap_threshold = chunksize (p);
mp_.trim_threshold = 2 * mp_.mmap_threshold;
LIBC_PROBE (memory_mallopt_free_dyn_thresholds, 2,
mp_.mmap_threshold, mp_.trim_threshold);
}
munmap_chunk (p);
return;
}
Therefore, we need to trigger malloc_trim(0) from our python code written above; which we can easily do using ctypes module.
The fixed implementation looks like this:
from ctypes import cdll, CDLL
cdll.LoadLibrary("libc.so.6")
libc = CDLL("libc.so.6")
libc.malloc_trim(0)
arr = numpy.random.randn(10000000, 5)
def blast():
for i in range(10000):
x = pandas.DataFrame(arr.copy())
result = x.xs(1000)
libc.malloc_trim(0)
blast()
In another solution, I tried forcing the GC using python’s gc module; which gave the results similar to above method.
import gc
arr = numpy.random.randn(10000000, 5)
def blast():
for i in range(10000):
x = pandas.DataFrame(arr.copy())
result = x.xs(1000)
gc.collect() # Forced GC
blast()
The distrubution of Memory usage w.r.t Time looked much better now, and there was almost no difference in execution time. (see the “dark blue” line)
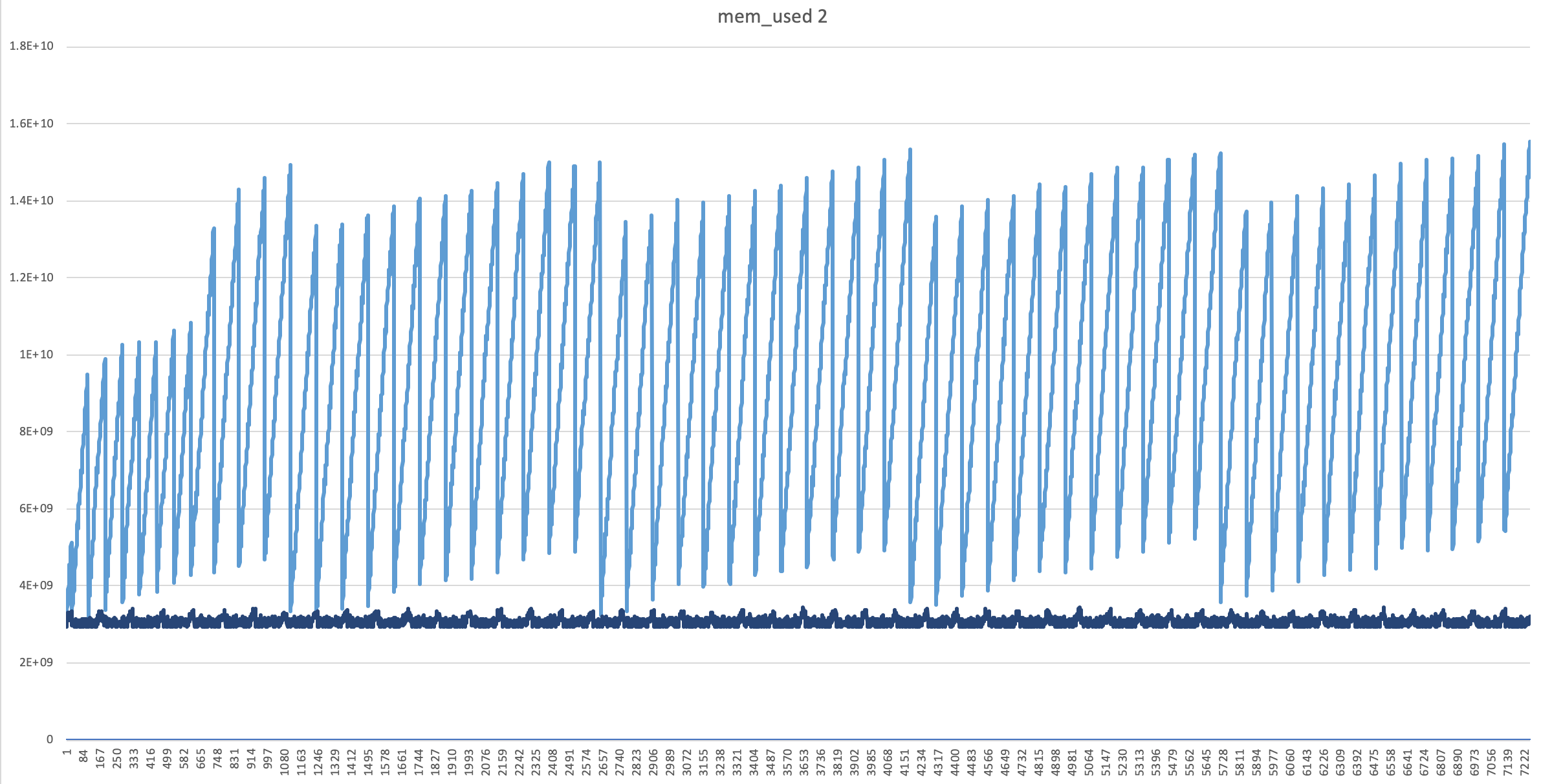
Similar cases, References and other notes:
- Even after doing
low_memory=Falsewhile reading a CSV usingpandas.read_csv, it crashes withMemoryErrorexception, even though the CSV is not bigger than the RAM. - Explanation of malloc(), calloc(), free(), realloc() deserves a separate post altogether. I’ll post that soon.
- Similar reported issues:
— https://github.com/pandas-dev/pandas/issues/2659
— https://github.com/pandas-dev/pandas/issues/21353
Tags:
Python
Pandas