Здравствуйте.Я начал программировать на python и встретился с проблемой:при попытке скомпелировать код выдает ошибку:SyntaxError: Non-UTF-8 code starting with ‘xc2’ in file C:pystr_format.py on line 3, but no encoding declared; see python.org/dev/peps/pep-0263 for details.Что это значит и как с этим бороться?Я понял что дело в кодировке но как сделать так,чтобы работало не знаю,помогите,кто знает!!!
-
Вопрос заданболее трёх лет назад
-
52881 просмотр
преобразуйте файл в кодировку UTF-8(например с помощью notepad++), удалите всё лишнее после этого что появится в файле и компильте
Пригласить эксперта
Вы же привели ссылку на решение. Если вам лень читать, то вот концентрат:
в начало файла добавить строку
# -*- coding: utf8 -*-
Насколько я помню, во втором питоне такие строки нужно писать с принудительной кодировкой, в виде u»строка кириллицей»
Не работает: Non-UTF-8 code starting with ‘xf1’ in file C:UsersСашокAppDataLocalProgramsPythonPython39Scriptspyinstaller-script.py on line 1, but no encoding declared; see python.org/dev/peps/pep-0263 for details
PS C:UsersСашок>
-
Показать ещё
Загружается…
10 февр. 2023, в 02:20
3000 руб./за проект
10 февр. 2023, в 01:33
1500 руб./за проект
10 февр. 2023, в 00:54
2000 руб./в час
Минуточку внимания
New issue
Have a question about this project? Sign up for a free GitHub account to open an issue and contact its maintainers and the community.
By clicking “Sign up for GitHub”, you agree to our terms of service and
privacy statement. We’ll occasionally send you account related emails.
Already on GitHub?
Sign in
to your account
Closed
dessant opened this issue
Jan 26, 2016
· 5 comments
Comments
![]()
After packaging the example from #1780 (comment) with the develop branch, i get this error while running the executable:
$ python ./dist/a/a.exe File "./dist/a/a.exe", line 1 SyntaxError: Non-UTF-8 code starting with 'x90' in file ./dist/a/a.exe on line 1, but no encoding declared; see http://python.org/dev/peps/pep-0263/ for details
The error is not present with 3.0 or 3.1, and encoding headers should not be needed for python 3 anyway, because utf-8 is the default.
![]()
a.exe is a Windows executable, not a Python script. Instead of passing it to Python, just run it as is:
./dist/a/a.exe
![]()
Copy link
Contributor
Author
![]()
![]()
Hello,
I have the same issue at the moment. I of course executed the .exe by simply typing in app.exe but it is not working at all for me.
Double clicking on the app to open does not show anything.
Are there modifications to the app.spec file that needs to be appended?
Thanks for any possible inputs!
![]()
Whatever your issue is, it won’t be this. Create a new issue.
![]()
pyinstaller
locked as resolved and limited conversation to collaborators
Feb 21, 2022
|
Ципихович Эндрю 1485 / 459 / 52 Регистрация: 10.04.2009 Сообщений: 7,892 |
||||
|
1 |
||||
|
09.02.2021, 20:21. Показов 24781. Ответов 12 Метки нет (Все метки)
здравствуйте сия ошибка отмечается на строку
что в ней не так, как это лечится? спс
0 |

|
814 / 526 / 214 Регистрация: 22.12.2017 Сообщений: 1,495 |
|
|
09.02.2021, 20:35 |
2 |
|
0 |
|
5403 / 3827 / 1214 Регистрация: 28.10.2013 Сообщений: 9,554 Записей в блоге: 1 |
|
|
09.02.2021, 20:41 |
3 |
|
Код не-UTF-8 Просто перекодируй файл в UTF-8. Это кодировка скриптов принятая в Python по умолчанию и поэтому ее не нужно указывать как раньше в первой строке кода.
0 |

|
1485 / 459 / 52 Регистрация: 10.04.2009 Сообщений: 7,892 |
|
|
10.02.2021, 08:26 [ТС] |
4 |
|
Просто перекодируй файл в UTF-8 какой файл? при чём он?, я привёл строку из кода Питона Добавлено через 4 минуты
я так понял там тоже упор на перекодировку файла?
0 |
|
Нарушитель
14042 / 8230 / 2485 Регистрация: 21.10.2017 Сообщений: 19,708 |
|
|
10.02.2021, 08:43 |
5 |
|
не ясно что делать
Просто перекодируй файл в UTF-8
0 |

|
Ципихович Эндрю 1485 / 459 / 52 Регистрация: 10.04.2009 Сообщений: 7,892 |
||||||||
|
10.02.2021, 10:05 [ТС] |
6 |
|||||||
|
Просто перекодируй файл в UTF-8 тупо открываю файл Notepad ++ вкладка Кодировки уже стоит UTF-8 и?? Добавлено через 27 минут
тупо открываю файл Notepad ++ вкладка Кодировки уже стоит UTF-8 и?? или как-то по другому надо? Добавлено через 6 минут
между ними добавил
а мало-ли…. не помогло, ступор
0 |
|
Ципихович Эндрю 1485 / 459 / 52 Регистрация: 10.04.2009 Сообщений: 7,892 |
||||
|
02.03.2021, 07:12 [ТС] |
7 |
|||
|
тогда проблема рассосалась — так как не стал юзать этот текст в примере, а он был в цикле и прекрасно отрабатывался, пришлось вернуться к этому примеру — и опять ошибка, лечение, две первые строки файла
0 |
|
5403 / 3827 / 1214 Регистрация: 28.10.2013 Сообщений: 9,554 Записей в блоге: 1 |
|
|
02.03.2021, 17:46 |
8 |
|
лечение, две первые строки файл Так давно уже никто не лечит, поскольку эти строчки стали лишними в новых версиях Python, согласно PEP 3120 от 2007 года. НО если у тебя древний Python, об этом нужно было сообщать.
0 |
|
1485 / 459 / 52 Регистрация: 10.04.2009 Сообщений: 7,892 |
|
|
03.03.2021, 11:58 [ТС] |
9 |
|
Так давно уже никто не лечит, поскольку эти строчки стали лишними в новых версиях Python у меня Питон 3.9, 64 бита, и это происходит, у Вас видимо 4.5?
0 |
|
5403 / 3827 / 1214 Регистрация: 28.10.2013 Сообщений: 9,554 Записей в блоге: 1 |
|
|
03.03.2021, 13:21 |
10 |
|
у меня Питон 3.9, 64 бита, и это происходит, Этого уже давно ни у кого не происходит. Потому что все создают свои скрипты в кодировке UTF-8, не имеют никаких проблем и никогда не пишут объявление кодировки в начале файла.
0 |
|
1485 / 459 / 52 Регистрация: 10.04.2009 Сообщений: 7,892 |
|
|
03.03.2021, 13:30 [ТС] |
11 |
|
у меня это происходит, я написал свой способ лечения-кто хочет пусть пробует, если ему поможет лечение-гут
0 |
|
5403 / 3827 / 1214 Регистрация: 28.10.2013 Сообщений: 9,554 Записей в блоге: 1 |
|
|
03.03.2021, 15:02 |
12 |
|
у меня это происходит, Дай мне свой файл и я скажу в чем у тебя проблема.
0 |
|
1485 / 459 / 52 Регистрация: 10.04.2009 Сообщений: 7,892 |
|
|
04.03.2021, 06:59 [ТС] |
13 |
|
пока смысла нет-не проявляется такое и с строкой-лечением № 2 и без неё
0 |
|
IT_Exp Эксперт 87844 / 49110 / 22898 Регистрация: 17.06.2006 Сообщений: 92,604 |
04.03.2021, 06:59 |
|
13 |
-
#1
Я буквально только что решил попробовать освоить Python 3.9, ос вин10. Написал простейший калькулятор и захотел его скомпилировать. При попытках компиляции по разным гайдам получаю одну и ту же ошибку указанную в заголовке, те решения что я нашел воздействия не возымели. Буду очень признателен если подробно и доступно объясните в чем суть проблемы и как ее решить
>pip list
Package Version
————————- ——— altgraph 0.17 colorama 0.4.4
future 0.18.2
pefile 2019.4.18
pip 20.2.4
pyinstaller 4.0
pyinstaller-hooks-contrib 2020.9
pywin32-ctypes 0.2.0 setuptools 47.1.0
Python:
print('number a')
a = float(input())
print('number b')
b = float(input())
print('chose the operation, (+, -, *, /)')
c = (input())
if c == "+":
x = a + b
elif c == "-":
x = a - b
elif c == "*":
x = a * b
elif c == "/":
x = a / b
print(x)
-
#2
ваш код работает, как вы получаете ошибку? как вы запускаете? какую иде используете? вам нужно преобразовать файл в котором пишите в кодировку UTF-8 скорей всего
-
#3
ваш код работает, как вы получаете ошибку? как вы запускаете? какую иде используете?
код работает нормально, но я захотел его скомпилировать через cmd как в одном из гайдов. В том гайде все получилось с первой попытки и поэтому без пояснений, однако когда я повторяю все те же действия(указать директорию файла, pyinstaller -F calculator.py, enter) выдает указанную ошибку. На одном из форумов написали что в начале кода нужен данный комментарий # -*- coding: utf8 -*- и все заработает. К сожалению даже с данным комментарием так и не получилось
-
#4
код работает нормально, но я захотел его скомпилировать через cmd как в одном из гайдов. В том гайде все получилось с первой попытки и поэтому без пояснений, однако когда я повторяю все те же действия(указать директорию файла, pyinstaller -F calculator.py, enter) выдает указанную ошибку
нужно чтобы у файла была кодировка UTF-8
-
#5
нужно чтобы у файла была кодировка UTF-8
а как сделать чтобы файл был с данной кодировкой?
-
#6
а как сделать чтобы файл был с данной кодировкой?
Любой текстовый редактор это умеет погуглите быстро найдете ответ
-
#7
Любой текстовый редактор это умеет погуглите быстро найдете ответ
я сохранил его через текстовый редактор с кодировкой utf-8, но проблема не исчезла
-
#8
При попытках компиляции по разным гайдам получаю одну и ту же ошибку указанную в заголовке
Возможно путь к файлу содержит кириллицу (русские буквы) и из-за этого pyinstaller выдает такую ошибку.
Chapter 4. Text versus Bytes
Humans use text. Computers speak bytes.1
Esther Nam and Travis Fischer, Character Encoding and Unicode in Python
Python 3 introduced a sharp distinction between strings of human text and sequences of raw bytes. Implicit conversion of byte sequences to Unicode text is a thing of the past. This chapter deals with Unicode strings, binary sequences, and the encodings used to convert between them.
Depending on your Python programming context, a deeper understanding of Unicode may or may not be of vital importance to you. In the end, most of the issues covered in this chapter do not affect programmers who deal only with ASCII text. But even if that is your case, there is no escaping the str versus byte divide. As a bonus, you’ll find that the specialized binary sequence types provide features that the “all-purpose” Python 2 str type does not have.
In this chapter, we will visit the following topics:
-
Characters, code points, and byte representations
-
Unique features of binary sequences:
bytes,bytearray, andmemoryview -
Codecs for full Unicode and legacy character sets
-
Avoiding and dealing with encoding errors
-
Best practices when handling text files
-
The default encoding trap and standard I/O issues
-
Safe Unicode text comparisons with normalization
-
Utility functions for normalization, case folding, and brute-force diacritic removal
-
Proper sorting of Unicode text with
localeand the PyUCA library -
Character metadata in the Unicode database
-
Dual-mode APIs that handle
strandbytes
Let’s start with the characters, code points, and bytes.
Character Issues
The concept of “string” is simple enough: a string is a sequence of characters. The problem lies in the definition of “character.”
In 2015, the best definition of “character” we have is a Unicode character. Accordingly, the items you get out of a Python 3 str are Unicode characters, just like the items of a unicode object in Python 2—and not the raw bytes you get from a Python 2 str.
The Unicode standard explicitly separates the identity of characters from specific byte representations:
-
The identity of a character—its code point—is a number from 0 to 1,114,111 (base 10), shown in the Unicode standard as 4 to 6 hexadecimal digits with a “U+” prefix. For example, the code point for the letter A is U+0041, the Euro sign is U+20AC, and the musical symbol G clef is assigned to code point U+1D11E. About 10% of the valid code points have characters assigned to them in Unicode 6.3, the standard used in Python 3.4.
-
The actual bytes that represent a character depend on the encoding in use. An encoding is an algorithm that converts code points to byte sequences and vice versa. The code point for A (U+0041) is encoded as the single byte
x41in the UTF-8 encoding, or as the bytesx41x00in UTF-16LE encoding. As another example, the Euro sign (U+20AC) becomes three bytes in UTF-8—xe2x82xac—but in UTF-16LE it is encoded as two bytes:xacx20.
Converting from code points to bytes is encoding; converting from bytes to code points is decoding. See Example 4-1.

-
The
str'café'has four Unicode characters. -
Encode
strtobytesusing UTF-8 encoding. -
bytesliterals start with abprefix. -
bytesbhas five bytes (the code point for “é” is encoded as two bytes in UTF-8). -
Decode
bytestostrusing UTF-8 encoding.
Tip
If you need a memory aid to help distinguish .decode() from .encode(), convince yourself that byte sequences can be cryptic machine core dumps while Unicode str objects are “human” text. Therefore, it makes sense that we decode bytes to str to get human-readable text, and we encode str to bytes for storage or transmission.
Although the Python 3 str is pretty much the Python 2 unicode type with a new name, the Python 3 bytes is not simply the old str renamed, and there is also the closely related bytearray type. So it is worthwhile to take a look at the binary sequence types before advancing to encoding/decoding issues.
Byte Essentials
The new binary sequence types are unlike the Python 2 str in many regards. The first thing to know is that there are two basic built-in types for binary sequences: the immutable bytes type introduced in Python 3 and the mutable bytearray, added in Python 2.6. (Python 2.6 also introduced bytes, but it’s just an alias to the str type, and does not behave like the Python 3 bytes type.)
Each item in bytes or bytearray is an integer from 0 to 255, and not a one-character string like in the Python 2 str. However, a slice of a binary sequence always produces a binary sequence of the same type—including slices of length 1. See Example 4-2.
-
bytescan be built from astr, given an encoding. -
Each item is an integer in
range(256). -
Slices of
bytesare alsobytes—even slices of a single byte. -
There is no literal syntax for
bytearray: they are shown asbytearray()with abytesliteral as argument. -
A slice of
bytearrayis also abytearray.
Note
The fact that my_bytes[0] retrieves an int but my_bytes[:1] returns a bytes object of length 1 should not be surprising. The only sequence type where s[0] == s[:1] is the str type. Although practical, this behavior of str is exceptional. For every other sequence, s[i] returns one item, and s[i:i+1] returns a sequence of the same type with the s[i] item inside it.
Although binary sequences are really sequences of integers, their literal notation reflects the fact that ASCII text is often embedded in them. Therefore, three different displays are used, depending on each byte value:
-
For bytes in the printable ASCII range—from space to
~—the ASCII character itself is used. -
For bytes corresponding to tab, newline, carriage return, and
, the escape sequencest,n,r, and\are used. -
For every other byte value, a hexadecimal escape sequence is used (e.g.,
x00is the null byte).
That is why in Example 4-2 you see b'cafxc3xa9': the first three bytes b'caf' are in the printable ASCII range, the last two are not.
Both bytes and bytearray support every str method except those that do formatting (format, format_map) and a few others that depend on Unicode data, including casefold, isdecimal, isidentifier, isnumeric, isprintable, and encode. This means that you can use familiar string methods like endswith, replace, strip, translate, upper, and dozens of others with binary sequences—only using bytes and not str arguments. In addition, the regular expression functions in the re module also work on binary sequences, if the regex is compiled from a binary sequence instead of a str. The % operator does not work with binary sequences in Python 3.0 to 3.4, but should be supported in version 3.5 according to PEP 461 — Adding % formatting to bytes and bytearray.
Binary sequences have a class method that str doesn’t have, called fromhex, which builds a binary sequence by parsing pairs of hex digits optionally separated by spaces:
>>>bytes.fromhex('31 4B CE A9')b'1Kxcexa9'
The other ways of building bytes or bytearray instances are calling their constructors with:
-
A
strand anencodingkeyword argument. -
An iterable providing items with values from 0 to 255.
-
A single integer, to create a binary sequence of that size initialized with null bytes. (This signature will be deprecated in Python 3.5 and removed in Python 3.6. See PEP 467 — Minor API improvements for binary sequences.)
-
An object that implements the buffer protocol (e.g.,
bytes,bytearray,memoryview,array.array); this copies the bytes from the source object to the newly created binary sequence.
Building a binary sequence from a buffer-like object is a low-level operation that may involve type casting. See a demonstration in Example 4-3.
-
Typecode
'h'creates anarrayof short integers (16 bits). -
octetsholds a copy of the bytes that make upnumbers. -
These are the 10 bytes that represent the five short integers.
Creating a bytes or bytearray object from any buffer-like source will always copy the bytes. In contrast, memoryview objects let you share memory between binary data structures. To extract structured information from binary sequences, the struct module is invaluable. We’ll see it working along with bytes and memoryview in the next section.
Structs and Memory Views
The struct module provides functions to parse packed bytes into a tuple of fields of different types and to perform the opposite conversion, from a tuple into packed bytes. struct is used with bytes, bytearray, and memoryview objects.
As we’ve seen in “Memory Views”, the memoryview class does not let you create or store byte sequences, but provides shared memory access to slices of data from other binary sequences, packed arrays, and buffers such as Python Imaging Library (PIL) images,2 without copying the bytes.
Example 4-4 shows the use of memoryview and struct together to extract the width and height of a GIF image.
-
structformat:<little-endian;3s3stwo sequences of 3 bytes;HHtwo 16-bit integers. -
Create
memoryviewfrom file contents in memory… -
…then another
memoryviewby slicing the first one; no bytes are copied here. -
Convert to
bytesfor display only; 10 bytes are copied here. -
Unpack
memoryviewinto tuple of: type, version, width, and height. -
Delete references to release the memory associated with the
memoryviewinstances.
Note that slicing a memoryview returns a new memoryview, without copying bytes (Leonardo Rochael—one of the technical reviewers—pointed out that even less byte copying would happen if I used the mmap module to open the image as a memory-mapped file. I will not cover mmap in this book, but if you read and change binary files frequently, learning more about mmap — Memory-mapped file support will be very fruitful).
We will not go deeper into memoryview or the struct module in this book, but if you work with binary data, you’ll find it worthwhile to study their docs: Built-in Types » Memory Views and struct — Interpret bytes as packed binary data.
After this brief exploration of binary sequence types in Python, let’s see how they are converted to/from strings.
Basic Encoders/Decoders
The Python distribution bundles more than 100 codecs (encoder/decoder) for text to byte conversion and vice versa. Each codec has a name, like 'utf_8', and often aliases, such as 'utf8', 'utf-8', and 'U8', which you can use as the encoding argument in functions like open(), str.encode(), bytes.decode(), and so on. Example 4-5 shows the same text encoded as three different byte sequences.
Example 4-5. The string “El Niño” encoded with three codecs producing very different byte sequences
>>>forcodecin['latin_1','utf_8','utf_16']:...(codec,'El Niño'.encode(codec),sep='t')...latin_1 b'El Nixf1o'utf_8 b'El Nixc3xb1o'utf_16 b'xffxfeEx00lx00 x00Nx00ix00xf1x00ox00'
Figure 4-1 demonstrates a variety of codecs generating bytes from characters like the letter “A” through the G-clef musical symbol. Note that the last three encodings are variable-length, multibyte encodings.
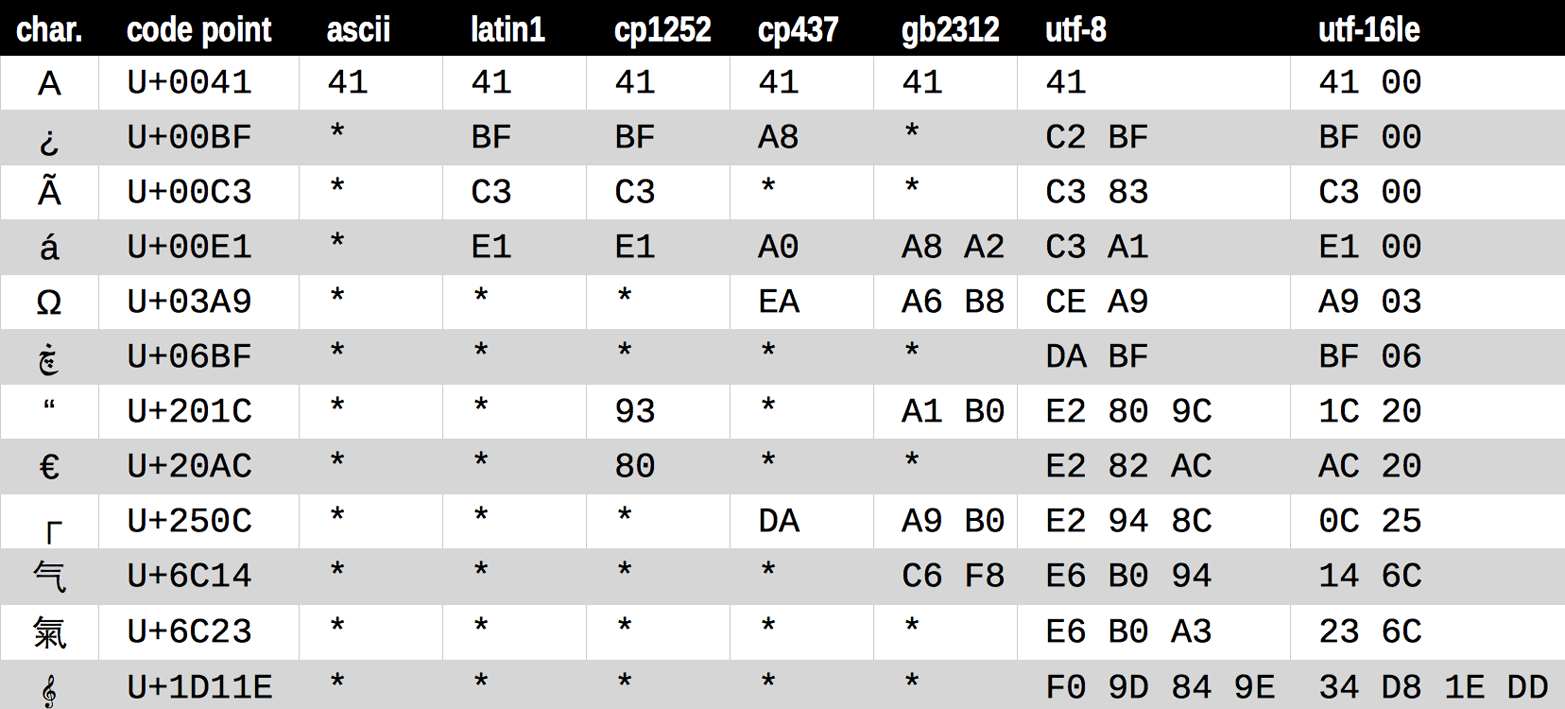
Figure 4-1. Twelve characters, their code points, and their byte representation (in hex) in seven different encodings (asterisks indicate that the character cannot be represented in that encoding)
All those asterisks in Figure 4-1 make clear that some encodings, like ASCII and even the multibyte GB2312, cannot represent every Unicode character. The UTF encodings, however, are designed to handle every Unicode code point.
The encodings shown in Figure 4-1 were chosen as a representative sample:
latin1a.k.a.iso8859_1-
Important because it is the basis for other encodings, such as
cp1252and Unicode itself (note how thelatin1byte values appear in thecp1252bytes and even in the code points). cp1252-
A
latin1superset by Microsoft, adding useful symbols like curly quotes and the € (euro); some Windows apps call it “ANSI,” but it was never a real ANSI standard. cp437-
The original character set of the IBM PC, with box drawing characters. Incompatible with
latin1, which appeared later. gb2312-
Legacy standard to encode the simplified Chinese ideographs used in mainland China; one of several widely deployed multibyte encodings for Asian languages.
utf-8-
The most common 8-bit encoding on the Web, by far;3 backward-compatible with ASCII (pure ASCII text is valid UTF-8).
utf-16le-
One form of the UTF-16 16-bit encoding scheme; all UTF-16 encodings support code points beyond U+FFFF through escape sequences called “surrogate pairs.”
Warning
UTF-16 superseded the original 16-bit Unicode 1.0 encoding—UCS-2—way back in 1996. UCS-2 is still deployed in many systems, but it only supports code points up to U+FFFF. As of Unicode 6.3, more than 50% of the allocated code points are above U+10000, including the increasingly popular emoji pictographs.
With this overview of common encodings now complete, we move to handling issues in encoding and decoding operations.
Understanding Encode/Decode Problems
Although there is a generic UnicodeError exception, the error reported is almost always more specific: either a UnicodeEncodeError (when converting str to binary sequences) or a UnicodeDecodeError (when reading binary sequences into str). Loading Python modules may also generate a SyntaxError when the source encoding is unexpected. We’ll show how to handle all of these errors in the next sections.
Tip
The first thing to note when you get a Unicode error is the exact type of the exception. Is it a UnicodeEncodeError, a UnicodeDecodeError, or some other error (e.g., SyntaxError) that mentions an encoding problem? To solve the problem, you have to understand it first.
Coping with UnicodeEncodeError
Most non-UTF codecs handle only a small subset of the Unicode characters. When converting text to bytes, if a character is not defined in the target encoding, UnicodeEncodeError will be raised, unless special handling is provided by passing an errors argument to the encoding method or function. The behavior of the error handlers is shown in Example 4-6.
-
The
'utf_?'encodings handle anystr. -
'iso8859_1'also works for the'São Paulo'str. -
'cp437'can’t encode the'ã'(“a” with tilde). The default error handler—'strict'—raisesUnicodeEncodeError. -
The
error='ignore'handler silently skips characters that cannot be encoded; this is usually a very bad idea. -
When encoding,
error='replace'substitutes unencodable characters with'?'; data is lost, but users will know something is amiss. -
'xmlcharrefreplace'replaces unencodable characters with an XML entity.
Note
The codecs error handling is extensible. You may register extra strings for the errors argument by passing a name and an error handling function to the codecs.register_error function. See the codecs.register_error documentation.
Coping with UnicodeDecodeError
Not every byte holds a valid ASCII character, and not every byte sequence is valid UTF-8 or UTF-16; therefore, when you assume one of these encodings while converting a binary sequence to text, you will get a UnicodeDecodeError if unexpected bytes are found.
On the other hand, many legacy 8-bit encodings like 'cp1252', 'iso8859_1', and 'koi8_r' are able to decode any stream of bytes, including random noise, without generating errors. Therefore, if your program assumes the wrong 8-bit encoding, it will silently decode garbage.
Tip
Garbled characters are known as gremlins or mojibake (文字化け—Japanese for “transformed text”).
Example 4-7 illustrates how using the wrong codec may produce gremlins or a UnicodeDecodeError.
-
These bytes are the characters for “Montréal” encoded as
latin1;'xe9'is the byte for “é”. -
Decoding with
'cp1252'(Windows 1252) works because it is a proper superset oflatin1. -
ISO-8859-7 is intended for Greek, so the
'xe9'byte is misinterpreted, and no error is issued. -
KOI8-R is for Russian. Now
'xe9'stands for the Cyrillic letter “И”. -
The
'utf_8'codec detects thatoctetsis not valid UTF-8, and raisesUnicodeDecodeError. -
Using
'replace'error handling, thexe9is replaced by “�” (code point U+FFFD), the official UnicodeREPLACEMENT CHARACTERintended to represent unknown characters.
SyntaxError When Loading Modules with Unexpected Encoding
UTF-8 is the default source encoding for Python 3, just as ASCII was the default for Python 2 (starting with 2.5). If you load a .py module containing non-UTF-8 data and no encoding declaration, you get a message like this:
SyntaxError: Non-UTF-8 code starting with 'xe1' in file ola.py on line 1, but no encoding declared; see http://python.org/dev/peps/pep-0263/ for details
Because UTF-8 is widely deployed in GNU/Linux and OSX systems, a likely scenario is opening a .py file created on Windows with cp1252. Note that this error happens even in Python for Windows, because the default encoding for Python 3 is UTF-8 across all platforms.
To fix this problem, add a magic coding comment at the top of the file, as shown in Example 4-8.
Example 4-8. ola.py: “Hello, World!” in Portuguese
# coding: cp1252('Olá, Mundo!')
Tip
Now that Python 3 source code is no longer limited to ASCII and defaults to the excellent UTF-8 encoding, the best “fix” for source code in legacy encodings like 'cp1252' is to convert them to UTF-8 already, and not bother with the coding comments. If your editor does not support UTF-8, it’s time to switch.
Suppose you have a text file, be it source code or poetry, but you don’t know its encoding. How do you detect the actual encoding? The next section answers that with a library recommendation.
How to Discover the Encoding of a Byte Sequence
How do you find the encoding of a byte sequence? Short answer: you can’t. You must be told.
Some communication protocols and file formats, like HTTP and XML, contain headers that explicitly tell us how the content is encoded. You can be sure that some byte streams are not ASCII because they contain byte values over 127, and the way UTF-8 and UTF-16 are built also limits the possible byte sequences. But even then, you can never be 100% positive that a binary file is ASCII or UTF-8 just because certain bit patterns are not there.
However, considering that human languages also have their rules and restrictions, once you assume that a stream of bytes is human plain text it may be possible to sniff out its encoding using heuristics and statistics. For example, if b'x00' bytes are common, it is probably a 16- or 32-bit encoding, and not an 8-bit scheme, because null characters in plain text are bugs; when the byte sequence b'x20x00' appears often, it is likely to be the space character (U+0020) in a UTF-16LE encoding, rather than the obscure U+2000 EN QUAD character—whatever that is.
That is how the package Chardet — The Universal Character Encoding Detector works to identify one of 30 supported encodings. Chardet is a Python library that you can use in your programs, but also includes a command-line utility, chardetect. Here is what it reports on the source file for this chapter:
$ chardetect 04-text-byte.asciidoc
04-text-byte.asciidoc: utf-8 with confidence 0.99Although binary sequences of encoded text usually don’t carry explicit hints of their encoding, the UTF formats may prepend a byte order mark to the textual content. That is explained next.
BOM: A Useful Gremlin
In Example 4-5, you may have noticed a couple of extra bytes at the beginning of a UTF-16 encoded sequence. Here they are again:
>>>u16='El Niño'.encode('utf_16')>>>u16b'xffxfeEx00lx00 x00Nx00ix00xf1x00ox00'
The bytes are b'xffxfe'. That is a BOM—byte-order mark—denoting the “little-endian” byte ordering of the Intel CPU where the encoding was performed.
On a little-endian machine, for each code point the least significant byte comes first: the letter 'E', code point U+0045 (decimal 69), is encoded in byte offsets 2 and 3 as 69 and 0:
>>>list(u16)[255, 254, 69, 0, 108, 0, 32, 0, 78, 0, 105, 0, 241, 0, 111, 0]
On a big-endian CPU, the encoding would be reversed; 'E' would be encoded as 0 and 69.
To avoid confusion, the UTF-16 encoding prepends the text to be encoded with the special character ZERO WIDTH NO-BREAK SPACE (U+FEFF), which is invisible. On a little-endian system, that is encoded as b'xffxfe' (decimal 255, 254). Because, by design, there is no U+FFFE character, the byte sequence b'xffxfe' must mean the ZERO WIDTH NO-BREAK SPACE on a little-endian encoding, so the codec knows which byte ordering to use.
There is a variant of UTF-16—UTF-16LE—that is explicitly little-endian, and another one explicitly big-endian, UTF-16BE. If you use them, a BOM is not generated:
>>>u16le='El Niño'.encode('utf_16le')>>>list(u16le)[69, 0, 108, 0, 32, 0, 78, 0, 105, 0, 241, 0, 111, 0]>>>u16be='El Niño'.encode('utf_16be')>>>list(u16be)[0, 69, 0, 108, 0, 32, 0, 78, 0, 105, 0, 241, 0, 111]
If present, the BOM is supposed to be filtered by the UTF-16 codec, so that you only get the actual text contents of the file without the leading ZERO WIDTH NO-BREAK SPACE. The standard says that if a file is UTF-16 and has no BOM, it should be assumed to be UTF-16BE (big-endian). However, the Intel x86 architecture is little-endian, so there is plenty of little-endian UTF-16 with no BOM in the wild.
This whole issue of endianness only affects encodings that use words of more than one byte, like UTF-16 and UTF-32. One big advantage of UTF-8 is that it produces the same byte sequence regardless of machine endianness, so no BOM is needed. Nevertheless, some Windows applications (notably Notepad) add the BOM to UTF-8 files anyway—and Excel depends on the BOM to detect a UTF-8 file, otherwise it assumes the content is encoded with a Windows codepage. The character U+FEFF encoded in UTF-8 is the three-byte sequence b'xefxbbxbf'. So if a file starts with those three bytes, it is likely to be a UTF-8 file with a BOM. However, Python does not automatically assume a file is UTF-8 just because it starts with b'xefxbbxbf'.
We now move on to handling text files in Python 3.
Handling Text Files
The best practice for handling text is the “Unicode sandwich” (Figure 4-2).4 This means that bytes should be decoded to str as early as possible on input (e.g., when opening a file for reading). The “meat” of the sandwich is the business logic of your program, where text handling is done exclusively on str objects. You should never be encoding or decoding in the middle of other processing. On output, the str are encoded to bytes as late as possible. Most web frameworks work like that, and we rarely touch bytes when using them. In Django, for example, your views should output Unicode str; Django itself takes care of encoding the response to bytes, using UTF-8 by default.
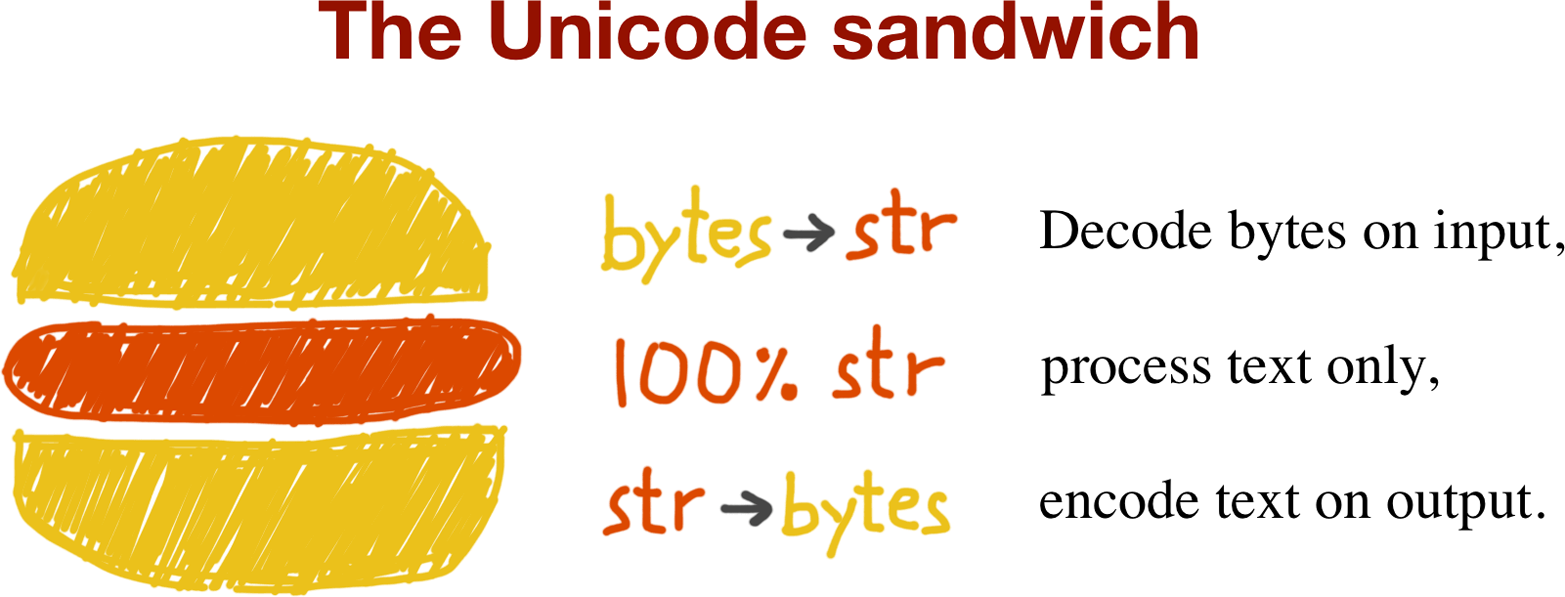
Figure 4-2. Unicode sandwich: current best practice for text processing
Python 3 makes it easier to follow the advice of the Unicode sandwich, because the open built-in does the necessary decoding when reading and encoding when writing files in text mode, so all you get from my_file.read() and pass to my_file.write(text) are str objects.5
Therefore, using text files is simple. But if you rely on default encodings you will get bitten.
Consider the console session in Example 4-9. Can you spot the bug?
Example 4-9. A platform encoding issue (if you try this on your machine, you may or may not see the problem)
>>>open('cafe.txt','w',encoding='utf_8').write('café')4>>>open('cafe.txt').read()'café'
The bug: I specified UTF-8 encoding when writing the file but failed to do so when reading it, so Python assumed the system default encoding—Windows 1252—and the trailing bytes in the file were decoded as characters 'é' instead of 'é'.
I ran Example 4-9 on a Windows 7 machine. The same statements running on recent GNU/Linux or Mac OSX work perfectly well because their default encoding is UTF-8, giving the false impression that everything is fine. If the encoding argument was omitted when opening the file to write, the locale default encoding would be used, and we’d read the file correctly using the same encoding. But then this script would generate files with different byte contents depending on the platform or even depending on locale settings in the same platform, creating compatibility problems.
Tip
Code that has to run on multiple machines or on multiple occasions should never depend on encoding defaults. Always pass an explicit encoding= argument when opening text files, because the default may change from one machine to the next, or from one day to the next.
A curious detail in Example 4-9 is that the write function in the first statement reports that four characters were written, but in the next line five characters are read. Example 4-10 is an extended version of Example 4-9, explaining that and other details.
-
By default,
openoperates in text mode and returns aTextIOWrapperobject. -
The
writemethod on aTextIOWrapperreturns the number of Unicode characters written. -
os.statreports that the file holds 5 bytes; UTF-8 encodes'é'as 2 bytes, 0xc3 and 0xa9. -
Opening a text file with no explicit encoding returns a
TextIOWrapperwith the encoding set to a default from the locale. -
A
TextIOWrapperobject has an encoding attribute that you can inspect:cp1252in this case. -
In the Windows
cp1252encoding, the byte 0xc3 is an “Ô (A with tilde) and 0xa9 is the copyright sign. -
Opening the same file with the correct encoding.
-
The expected result: the same four Unicode characters for
'café'. -
The
'rb'flag opens a file for reading in binary mode. -
The returned object is a
BufferedReaderand not aTextIOWrapper. -
Reading that returns bytes, as expected.
Tip
Do not open text files in binary mode unless you need to analyze the file contents to determine the encoding—even then, you should be using Chardet instead of reinventing the wheel (see “How to Discover the Encoding of a Byte Sequence”). Ordinary code should only use binary mode to open binary files, like raster images.
The problem in Example 4-10 has to do with relying on a default setting while opening a text file. There are several sources for such defaults, as the next section shows.
Encoding Defaults: A Madhouse
Several settings affect the encoding defaults for I/O in Python. See the default_encodings.py script in Example 4-11.
Example 4-11. Exploring encoding defaults
importsys,localeexpressions="""locale.getpreferredencoding()type(my_file)my_file.encodingsys.stdout.isatty()sys.stdout.encodingsys.stdin.isatty()sys.stdin.encodingsys.stderr.isatty()sys.stderr.encodingsys.getdefaultencoding()sys.getfilesystemencoding()"""my_file=open('dummy','w')forexpressioninexpressions.split():value=eval(expression)(expression.rjust(30),'->',repr(value))
The output of Example 4-11 on GNU/Linux (Ubuntu 14.04) and OSX (Mavericks 10.9) is identical, showing that UTF-8 is used everywhere in these systems:
$python3 default_encodings.py locale.getpreferredencoding()->'UTF-8'type(my_file)-> <class'_io.TextIOWrapper'> my_file.encoding ->'UTF-8'sys.stdout.isatty()-> True sys.stdout.encoding ->'UTF-8'sys.stdin.isatty()-> True sys.stdin.encoding ->'UTF-8'sys.stderr.isatty()-> True sys.stderr.encoding ->'UTF-8'sys.getdefaultencoding()->'utf-8'sys.getfilesystemencoding()->'utf-8'
On Windows, however, the output is Example 4-12.
-
chcpshows the active codepage for the console: 850. -
Running default_encodings.py with output to console.
-
locale.getpreferredencoding()is the most important setting. -
Text files use
locale.getpreferredencoding()by default. -
The output is going to the console, so
sys.stdout.isatty()isTrue. -
Therefore,
sys.stdout.encodingis the same as the console encoding.
If the output is redirected to a file, like this:
Z:>python default_encodings.py > encodings.log
The value of sys.stdout.isatty() becomes False, and sys.stdout.encoding is set by locale.getpreferredencoding(), 'cp1252' in that machine.
Note that there are four different encodings in Example 4-12:
-
If you omit the
encodingargument when opening a file, the default is given bylocale.getpreferredencoding()('cp1252'in Example 4-12). -
The encoding of
sys.stdout/stdin/stderris given by thePYTHONIOENCODINGenvironment variable, if present, otherwise it is either inherited from the console or defined bylocale.getpreferredencoding()if the output/input is redirected to/from a file. -
sys.getdefaultencoding()is used internally by Python to convert binary data to/fromstr; this happens less often in Python 3, but still happens.6 Changing this setting is not supported.7 -
sys.getfilesystemencoding()is used to encode/decode filenames (not file contents). It is used whenopen()gets astrargument for the filename; if the filename is given as abytesargument, it is passed unchanged to the OS API. The Python Unicode HOWTO says: “on Windows, Python uses the namembcsto refer to whatever the currently configured encoding is.” The acronym MBCS stands for Multi Byte Character Set, which for Microsoft are the legacy variable-width encodings likegb2312orShift_JIS, but not UTF-8. (On this topic, a useful answer on StackOverflow is “Difference between MBCS and UTF-8 on Windows”.)
Note
On GNU/Linux and OSX all of these encodings are set to UTF-8 by default, and have been for several years, so I/O handles all Unicode characters. On Windows, not only are different encodings used in the same system, but they are usually codepages like 'cp850' or 'cp1252' that support only ASCII with 127 additional characters that are not the same from one encoding to the other. Therefore, Windows users are far more likely to face encoding errors unless they are extra careful.
To summarize, the most important encoding setting is that returned by locale.getpreferredencoding(): it is the default for opening text files and for sys.stdout/stdin/stderr when they are redirected to files. However, the documentation reads (in part):
locale.getpreferredencoding(do_setlocale=True)Return the encoding used for text data, according to user preferences. User preferences are expressed differently on different systems, and might not be available programmatically on some systems, so this function only returns a guess. […]
Therefore, the best advice about encoding defaults is: do not rely on them.
If you follow the advice of the Unicode sandwich and always are explicit about the encodings in your programs, you will avoid a lot of pain. Unfortunately, Unicode is painful even if you get your bytes correctly converted to str. The next two sections cover subjects that are simple in ASCII-land, but get quite complex on planet Unicode: text normalization (i.e., converting text to a uniform representation for comparisons) and sorting.
Normalizing Unicode for Saner Comparisons
String comparisons are complicated by the fact that Unicode has combining characters: diacritics and other marks that attach to the preceding character, appearing as one when printed.
For example, the word “café” may be composed in two ways, using four or five code points, but the result looks exactly the same:
>>>s1='café'>>>s2='cafeu0301'>>>s1,s2('café', 'café')>>>len(s1),len(s2)(4, 5)>>>s1==s2False
The code point U+0301 is the COMBINING ACUTE ACCENT. Using it after “e” renders “é”. In the Unicode standard, sequences like 'é' and 'eu0301' are called “canonical equivalents,” and applications are supposed to treat them as the same. But Python sees two different sequences of code points, and considers them not equal.
The solution is to use Unicode normalization, provided by the unicodedata.normalize function. The first argument to that function is one of four strings: 'NFC', 'NFD', 'NFKC', and 'NFKD'. Let’s start with the first two.
Normalization Form C (NFC) composes the code points to produce the shortest equivalent string, while NFD decomposes, expanding composed characters into base characters and separate combining characters. Both of these normalizations make comparisons work as expected:
>>>fromunicodedataimportnormalize>>>s1='café'# composed "e" with acute accent>>>s2='cafeu0301'# decomposed "e" and acute accent>>>len(s1),len(s2)(4, 5)>>>len(normalize('NFC',s1)),len(normalize('NFC',s2))(4, 4)>>>len(normalize('NFD',s1)),len(normalize('NFD',s2))(5, 5)>>>normalize('NFC',s1)==normalize('NFC',s2)True>>>normalize('NFD',s1)==normalize('NFD',s2)True
Western keyboards usually generate composed characters, so text typed by users will be in NFC by default. However, to be safe, it may be good to sanitize strings with normalize('NFC', user_text) before saving. NFC is also the normalization form recommended by the W3C in Character Model for the World Wide Web: String Matching and Searching.
Some single characters are normalized by NFC into another single character. The symbol for the ohm (Ω) unit of electrical resistance is normalized to the Greek uppercase omega. They are visually identical, but they compare unequal so it is essential to normalize to avoid surprises:
>>>fromunicodedataimportnormalize,name>>>ohm='u2126'>>>name(ohm)'OHM SIGN'>>>ohm_c=normalize('NFC',ohm)>>>name(ohm_c)'GREEK CAPITAL LETTER OMEGA'>>>ohm==ohm_cFalse>>>normalize('NFC',ohm)==normalize('NFC',ohm_c)True
In the acronyms for the other two normalization forms—NFKC and NFKD—the letter K stands for “compatibility.” These are stronger forms of normalization, affecting the so-called “compatibility characters.” Although one goal of Unicode is to have a single “canonical” code point for each character, some characters appear more than once for compatibility with preexisting standards. For example, the micro sign, 'µ' (U+00B5), was added to Unicode to support round-trip conversion to latin1, even though the same character is part of the Greek alphabet with code point U+03BC (GREEK SMALL LETTER MU). So, the micro sign is considered a “compatibility character.”
In the NFKC and NFKD forms, each compatibility character is replaced by a “compatibility decomposition” of one or more characters that are considered a “preferred” representation, even if there is some formatting loss—ideally, the formatting should be the responsibility of external markup, not part of Unicode. To exemplify, the compatibility decomposition of the one half fraction '½' (U+00BD) is the sequence of three characters '1/2', and the compatibility decomposition of the micro sign 'µ' (U+00B5) is the lowercase mu 'μ' (U+03BC).8
Here is how the NFKC works in practice:
>>>fromunicodedataimportnormalize,name>>>half='½'>>>normalize('NFKC',half)'1⁄2'>>>four_squared='4²'>>>normalize('NFKC',four_squared)'42'>>>micro='µ'>>>micro_kc=normalize('NFKC',micro)>>>micro,micro_kc('µ', 'μ')>>>ord(micro),ord(micro_kc)(181, 956)>>>name(micro),name(micro_kc)('MICRO SIGN', 'GREEK SMALL LETTER MU')
Although '1⁄2' is a reasonable substitute for '½', and the micro sign is really a lowercase Greek mu, converting '4²' to '42' changes the meaning. An application could store '4²' as '4<sup>2</sup>', but the normalize function knows nothing about formatting. Therefore, NFKC or NFKD may lose or distort information, but they can produce convenient intermediate representations for searching and indexing: users may be pleased that a search for '1⁄2 inch' also finds documents containing '½ inch'.
Warning
NFKC and NFKD normalization should be applied with care and only in special cases—e.g., search and indexing—and not for permanent storage, because these transformations cause data loss.
When preparing text for searching or indexing, another operation is useful: case folding, our next subject.
Case Folding
Case folding is essentially converting all text to lowercase, with some additional transformations. It is supported by the str.casefold() method (new in Python 3.3).
For any string s containing only latin1 characters, s.casefold() produces the same result as s.lower(), with only two exceptions—the micro sign 'µ' is changed to the Greek lowercase mu (which looks the same in most fonts) and the German Eszett or “sharp s” (ß) becomes “ss”:
>>>micro='µ'>>>name(micro)'MICRO SIGN'>>>micro_cf=micro.casefold()>>>name(micro_cf)'GREEK SMALL LETTER MU'>>>micro,micro_cf('µ', 'μ')>>>eszett='ß'>>>name(eszett)'LATIN SMALL LETTER SHARP S'>>>eszett_cf=eszett.casefold()>>>eszett,eszett_cf('ß', 'ss')
As of Python 3.4, there are 116 code points for which str.casefold() and str.lower() return different results. That’s 0.11% of a total of 110,122 named characters in Unicode 6.3.
As usual with anything related to Unicode, case folding is a complicated issue with plenty of linguistic special cases, but the Python core team made an effort to provide a solution that hopefully works for most users.
In the next couple of sections, we’ll put our normalization knowledge to use developing utility functions.
Utility Functions for Normalized Text Matching
As we’ve seen, NFC and NFD are safe to use and allow sensible comparisons between Unicode strings. NFC is the best normalized form for most applications. str.casefold() is the way to go for case-insensitive comparisons.
If you work with text in many languages, a pair of functions like nfc_equal and fold_equal in Example 4-13 are useful additions to your toolbox.
Example 4-13. normeq.py: normalized Unicode string comparison
"""Utility functions for normalized Unicode string comparison.Using Normal Form C, case sensitive:>>> s1 = 'café'>>> s2 = 'cafeu0301'>>> s1 == s2False>>> nfc_equal(s1, s2)True>>> nfc_equal('A', 'a')FalseUsing Normal Form C with case folding:>>> s3 = 'Straße'>>> s4 = 'strasse'>>> s3 == s4False>>> nfc_equal(s3, s4)False>>> fold_equal(s3, s4)True>>> fold_equal(s1, s2)True>>> fold_equal('A', 'a')True"""fromunicodedataimportnormalizedefnfc_equal(str1,str2):returnnormalize('NFC',str1)==normalize('NFC',str2)deffold_equal(str1,str2):return(normalize('NFC',str1).casefold()==normalize('NFC',str2).casefold())
Beyond Unicode normalization and case folding—which are both part of the Unicode standard—sometimes it makes sense to apply deeper transformations, like changing 'café' into 'cafe'. We’ll see when and how in the next section.
Extreme “Normalization”: Taking Out Diacritics
The Google Search secret sauce involves many tricks, but one of them apparently is ignoring diacritics (e.g., accents, cedillas, etc.), at least in some contexts. Removing diacritics is not a proper form of normalization because it often changes the meaning of words and may produce false positives when searching. But it helps coping with some facts of life: people sometimes are lazy or ignorant about the correct use of diacritics, and spelling rules change over time, meaning that accents come and go in living languages.
Outside of searching, getting rid of diacritics also makes for more readable URLs, at least in Latin-based languages. Take a look at the URL for the Wikipedia article about the city of São Paulo:
http://en.wikipedia.org/wiki/S%C3%A3o_Paulo
The %C3%A3 part is the URL-escaped, UTF-8 rendering of the single letter “ã” (“a” with tilde). The following is much friendlier, even if it is not the right spelling:
http://en.wikipedia.org/wiki/Sao_Paulo
To remove all diacritics from a str, you can use a function like Example 4-14.
-
Decompose all characters into base characters and combining marks.
-
Filter out all combining marks.
-
Recompose all characters.
Example 4-15 shows a couple of uses of shave_marks.
-
Only the letters “è”, “ç”, and “í” were replaced.
-
Both “έ” and “é” were replaced.
The function shave_marks from Example 4-14 works all right, but maybe it goes too far. Often the reason to remove diacritics is to change Latin text to pure ASCII, but shave_marks also changes non-Latin characters—like Greek letters—which will never become ASCII just by losing their accents. So it makes sense to analyze each base character and to remove attached marks only if the base character is a letter from the Latin alphabet. This is what Example 4-16 does.
-
Decompose all characters into base characters and combining marks.
-
Skip over combining marks when base character is Latin.
-
Otherwise, keep current character.
-
Detect new base character and determine if it’s Latin.
-
Recompose all characters.
An even more radical step would be to replace common symbols in Western texts (e.g., curly quotes, em dashes, bullets, etc.) into ASCII equivalents. This is what the function asciize does in Example 4-17.
Example 4-17. Transform some Western typographical symbols into ASCII (this snippet is also part of sanitize.py from Example 4-14)
single_map=str.maketrans("""‚ƒ„†ˆ‹‘’“”•–—˜›""","""'f"*^<''""---~>""")multi_map=str.maketrans({'€':'<euro>','…':'...','Œ':'OE','™':'(TM)','œ':'oe','‰':'<per mille>','‡':'**',})multi_map.update(single_map)defdewinize(txt):"""Replace Win1252 symbols with ASCII chars or sequences"""returntxt.translate(multi_map)defasciize(txt):no_marks=shave_marks_latin(dewinize(txt))no_marks=no_marks.replace('ß','ss')returnunicodedata.normalize('NFKC',no_marks)
-
Build mapping table for char-to-char replacement.
-
Build mapping table for char-to-string replacement.
-
Merge mapping tables.
-
dewinizedoes not affectASCIIorlatin1text, only the Microsoft additions in tolatin1incp1252. -
Apply
dewinizeand remove diacritical marks. -
Replace the Eszett with “ss” (we are not using case fold here because we want to preserve the case).
-
Apply NFKC normalization to compose characters with their compatibility code points.
Example 4-18 shows asciize in use.
-
dewinizereplaces curly quotes, bullets, and ™ (trademark symbol). -
asciizeappliesdewinize, drops diacritics, and replaces the'ß'.
Warning
Different languages have their own rules for removing diacritics. For example, Germans change the 'ü' into 'ue'. Our asciize function is not as refined, so it may or not be suitable for your language. It works acceptably for Portuguese, though.
To summarize, the functions in sanitize.py go way beyond standard normalization and perform deep surgery on the text, with a good chance of changing its meaning. Only you can decide whether to go so far, knowing the target language, your users, and how the transformed text will be used.
This wraps up our discussion of normalizing Unicode text.
The next Unicode matter to sort out is… sorting.
Sorting Unicode Text
Python sorts sequences of any type by comparing the items in each sequence one by one. For strings, this means comparing the code points. Unfortunately, this produces unacceptable results for anyone who uses non-ASCII characters.
Consider sorting a list of fruits grown in Brazil:
>>>fruits=['caju','atemoia','cajá','açaí','acerola']>>>sorted(fruits)['acerola', 'atemoia', 'açaí', 'caju', 'cajá']
Sorting rules vary for different locales, but in Portuguese and many languages that use the Latin alphabet, accents and cedillas rarely make a difference when sorting.9 So “cajá” is sorted as “caja,” and must come before “caju.”
The sorted fruits list should be:
['açaí','acerola','atemoia','cajá','caju']
The standard way to sort non-ASCII text in Python is to use the locale.strxfrm function which, according to the locale module docs, “transforms a string to one that can be used in locale-aware comparisons.”
To enable locale.strxfrm, you must first set a suitable locale for your application, and pray that the OS supports it. On GNU/Linux (Ubuntu 14.04) with the pt_BR locale, the sequence of commands in Example 4-19 works.
Example 4-19. Using the locale.strxfrm function as sort key
>>>importlocale>>>locale.setlocale(locale.LC_COLLATE,'pt_BR.UTF-8')'pt_BR.UTF-8'>>>fruits=['caju','atemoia','cajá','açaí','acerola']>>>sorted_fruits=sorted(fruits,key=locale.strxfrm)>>>sorted_fruits['açaí', 'acerola', 'atemoia', 'cajá', 'caju']
So you need to call setlocale(LC_COLLATE, «your_locale») before using locale.strxfrm as the key when sorting.
There are a few caveats, though:
-
Because locale settings are global, calling
setlocalein a library is not recommended. Your application or framework should set the locale when the process starts, and should not change it afterwards. -
The locale must be installed on the OS, otherwise
setlocaleraises alocale.Error: unsupported locale settingexception. -
You must know how to spell the locale name. They are pretty much standardized in the Unix derivatives as
'language_code.encoding', but on Windows the syntax is more complicated:Language Name-Language Variant_Region Name.codepage. Note that the Language Name, Language Variant, and Region Name parts can have spaces inside them, but the parts after the first are prefixed with special different characters: a hyphen, an underline character, and a dot. All parts seem to be optional except the language name. For example:English_United States.850means Language Name “English”, region “United States”, and codepage “850”. The language and region names Windows understands are listed in the MSDN article Language Identifier Constants and Strings, while Code Page Identifiers lists the numbers for the last part.10 -
The locale must be correctly implemented by the makers of the OS. I was successful on Ubuntu 14.04, but not on OSX (Mavericks 10.9). On two different Macs, the call
setlocale(LC_COLLATE, 'pt_BR.UTF-8')returns the string'pt_BR.UTF-8'with no complaints. Butsorted(fruits, key=locale.strxfrm)produced the same incorrect result assorted(fruits)did. I also tried thefr_FR,es_ES, andde_DElocales on OSX, butlocale.strxfrmnever did its job.11
So the standard library solution to internationalized sorting works, but seems to be well supported only on GNU/Linux (perhaps also on Windows, if you are an expert). Even then, it depends on locale settings, creating deployment headaches.
Fortunately, there is a simpler solution: the PyUCA library, available on PyPI.
Sorting with the Unicode Collation Algorithm
James Tauber, prolific Django contributor, must have felt the pain and created PyUCA, a pure-Python implementation of the Unicode Collation Algorithm (UCA). Example 4-20 shows how easy it is to use.
Example 4-20. Using the pyuca.Collator.sort_key method
>>>importpyuca>>>coll=pyuca.Collator()>>>fruits=['caju','atemoia','cajá','açaí','acerola']>>>sorted_fruits=sorted(fruits,key=coll.sort_key)>>>sorted_fruits['açaí', 'acerola', 'atemoia', 'cajá', 'caju']
This is friendly and just works. I tested it on GNU/Linux, OSX, and Windows. Only Python 3.X is supported at this time.
PyUCA does not take the locale into account. If you need to customize the sorting, you can provide the path to a custom collation table to the Collator() constructor. Out of the box, it uses allkeys.txt, which is bundled with the project. That’s just a copy of the Default Unicode Collation Element Table from Unicode 6.3.0.
By the way, that table is one of the many that comprise the Unicode database, our next subject.
The Unicode Database
The Unicode standard provides an entire database—in the form of numerous structured text files—that includes not only the table mapping code points to character names, but also metadata about the individual characters and how they are related. For example, the Unicode database records whether a character is printable, is a letter, is a decimal digit, or is some other numeric symbol. That’s how the str methods isidentifier, isprintable, isdecimal, and isnumeric work. str.casefold also uses information from a Unicode table.
The unicodedata module has functions that return character metadata; for instance, its official name in the standard, whether it is a combining character (e.g., diacritic like a combining tilde), and the numeric value of the symbol for humans (not its code point). Example 4-21 shows the use of unicodedata.name() and unicodedata.numeric() along with the .isdecimal() and .isnumeric() methods of str.
-
Code point in
U+0000format. -
Character centralized in a
strof length 6. -
Show
re_digif character matches ther'd'regex. -
Show
isdigifchar.isdigit()isTrue. -
Show
isnumifchar.isnumeric()isTrue. -
Numeric value formated with width 5 and 2 decimal places.
-
Unicode character name.
Running Example 4-21 gives you the result in Figure 4-3.
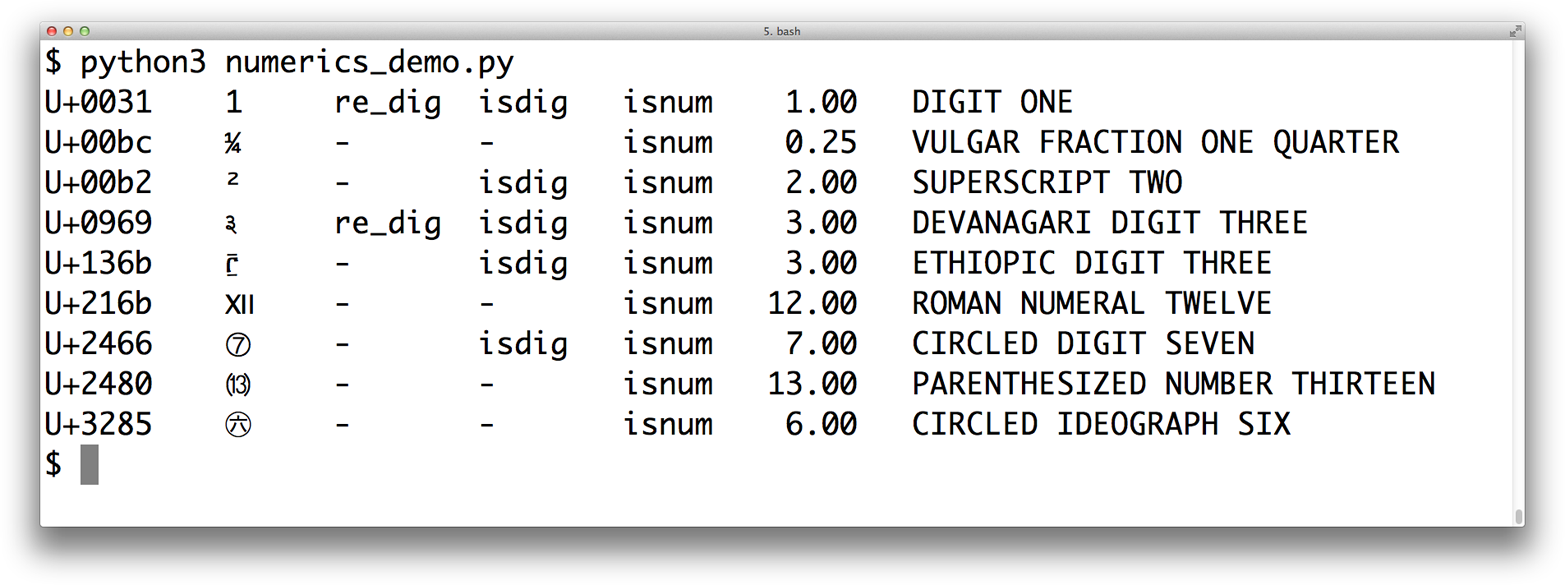
Figure 4-3. Nine numeric characters and metadata about them; re_dig means the character matches the regular expression r’d’
The sixth column of Figure 4-3 is the result of calling unicodedata.numeric(char) on the character. It shows that Unicode knows the numeric value of symbols that represent numbers. So if you want to create a spreadsheet application that supports Tamil digits or Roman numerals, go for it!
Figure 4-3 shows that the regular expression r'd' matches the digit “1” and the Devanagari digit 3, but not some other characters that are considered digits by the isdigit function. The re module is not as savvy about Unicode as it could be. The new regex module available in PyPI was designed to eventually replace re and provides better Unicode support.12 We’ll come back to the re module in the next section.
Throughout this chapter we’ve used several unicodedata functions, but there are many more we did not cover. See the standard library documentation for the unicodedata module.
We will wrap up our tour of str versus bytes with a quick look at a new trend: dual-mode APIs offering functions that accept str or bytes arguments with special handling depending on the type.
Dual-Mode str and bytes APIs
The standard library has functions that accept str or bytes arguments and behave differently depending on the type. Some examples are in the re and os modules.
str Versus bytes in Regular Expressions
If you build a regular expression with bytes, patterns such as d and w only match ASCII characters; in contrast, if these patterns are given as str, they match Unicode digits or letters beyond ASCII. Example 4-22 and Figure 4-4 compare how letters, ASCII digits, superscripts, and Tamil digits are matched by str and bytes patterns.
-
The first two regular expressions are of the
strtype. -
The last two are of the
bytestype. -
Unicode text to search, containing the Tamil digits for 1729 (the logical line continues until the right parenthesis token).
-
This string is joined to the previous one at compile time (see “2.4.2. String literal concatenation” in The Python Language Reference).
-
A
bytesstring is needed to search with thebytesregular expressions. -
The
strpatternr'd+'matches the Tamil and ASCII digits. -
The
bytespatternrb'd+'matches only the ASCII bytes for digits. -
The
strpatternr'w+'matches the letters, superscripts, Tamil, and ASCII digits. -
The
bytespatternrb'w+'matches only the ASCII bytes for letters and digits.
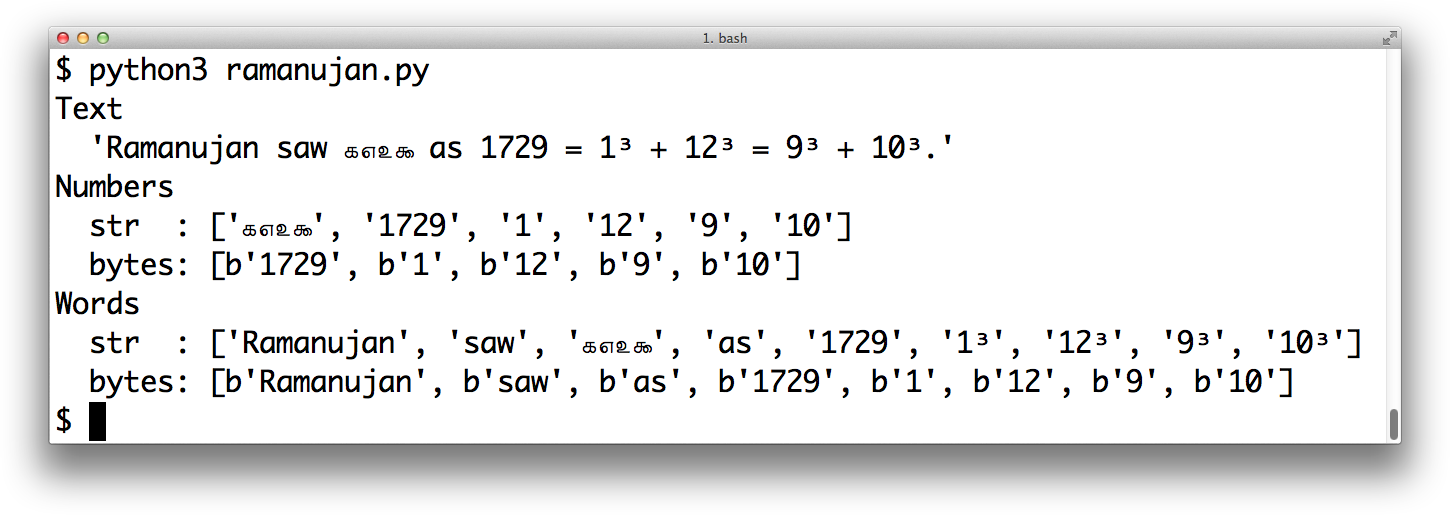
Figure 4-4. Screenshot of running ramanujan.py from Example 4-22
Example 4-22 is a trivial example to make one point: you can use regular expressions on str and bytes, but in the second case bytes outside of the ASCII range are treated as nondigits and nonword characters.
For str regular expressions, there is a re.ASCII flag that makes w, W, b, B, d, D, s, and S perform ASCII-only matching. See the documentation of the re module for full details.
Another important dual-mode module is os.
str Versus bytes on os Functions
The GNU/Linux kernel is not Unicode savvy, so in the real world you may find filenames made of byte sequences that are not valid in any sensible encoding scheme, and cannot be decoded to str. File servers with clients using a variety of OSes are particularly prone to this problem.
In order to work around this issue, all os module functions that accept filenames or pathnames take arguments as str or bytes. If one such function is called with a str argument, the argument will be automatically converted using the codec named by sys.getfilesystemencoding(), and the OS response will be decoded with the same codec. This is almost always what you want, in keeping with the Unicode sandwich best practice.
But if you must deal with (and perhaps fix) filenames that cannot be handled in that way, you can pass bytes arguments to the os functions to get bytes return values. This feature lets you deal with any file or pathname, no matter how many gremlins you may find. See Example 4-23.
-
The second filename is “digits-of-π.txt” (with the Greek letter pi).
-
Given a
byteargument,listdirreturns filenames as bytes:b'xcfx80'is the UTF-8 encoding of the Greek letter pi).
To help with manual handling of str or bytes sequences that are file or pathnames, the os module provides special encoding and decoding functions:
fsencode(filename)-
Encodes
filename(can bestrorbytes) tobytesusing the codec named bysys.getfilesystemencoding()iffilenameis of typestr, otherwise returns thefilenamebytesunchanged. fsdecode(filename)-
Decodes
filename(can bestrorbytes) tostrusing the codec named bysys.getfilesystemencoding()iffilenameis of typebytes, otherwise returns thefilenamestrunchanged.
On Unix-derived platforms, these functions use the surrogateescape error handler (see the sidebar that follows) to avoid choking on unexpected bytes. On Windows, the strict error handler is used.
This ends our exploration of str and bytes. If you are still with me, congratulations!
Chapter Summary
We started the chapter by dismissing the notion that 1 character == 1 byte. As the world adopts Unicode (80% of websites already use UTF-8), we need to keep the concept of text strings separated from the binary sequences that represent them in files, and Python 3 enforces this separation.
After a brief overview of the binary sequence data types—bytes, bytearray, and memoryview—we jumped into encoding and decoding, with a sampling of important codecs, followed by approaches to prevent or deal with the infamous UnicodeEncodeError, UnicodeDecodeError, and the SyntaxError caused by wrong encoding in Python source files.
While on the subject of source code, I presented my position on the debate about non-ASCII identifiers: if the maintainers of the code base want to use a human language that has non-ASCII characters, the identifiers should follow suit—unless the code needs to run on Python 2 as well. But if the project aims to attract an international contributor base, identifiers should be made from English words, and then ASCII suffices.
We then considered the theory and practice of encoding detection in the absence of metadata: in theory, it can’t be done, but in practice the Chardet package pulls it off pretty well for a number of popular encodings. Byte order marks were then presented as the only encoding hint commonly found in UTF-16 and UTF-32 files—sometimes in UTF-8 files as well.
In the next section, we demonstrated opening text files, an easy task except for one pitfall: the encoding= keyword argument is not mandatory when you open a text file, but it should be. If you fail to specify the encoding, you end up with a program that manages to generate “plain text” that is incompatible across platforms, due to conflicting default encodings. We then exposed the different encoding settings that Python uses as defaults and how to detect them: locale.getpreferredencoding(), sys.getfilesystemencoding(), sys.getdefaultencoding(), and the encodings for the standard I/O files (e.g., sys.stdout.encoding). A sad realization for Windows users is that these settings often have distinct values within the same machine, and the values are mutually incompatible; GNU/Linux and OSX users, in contrast, live in a happier place where UTF-8 is the default pretty much everywhere.
Text comparisons are surprisingly complicated because Unicode provides multiple ways of representing some characters, so normalizing is a prerequisite to text matching. In addition to explaining normalization and case folding, we presented some utility functions that you may adapt to your needs, including drastic transformations like removing all accents. We then saw how to sort Unicode text correctly by leveraging the standard locale module—with some caveats—and an alternative that does not depend on tricky locale configurations: the external PyUCA package.
Finally, we glanced at the Unicode database (a source of metadata about every character), and wrapped up with brief discussion of dual-mode APIs (e.g., the re and os modules, where some functions can be called with str or bytes arguments, prompting different yet fitting results).
Further Reading
Ned Batchelder’s 2012 PyCon US talk “Pragmatic Unicode — or — How Do I Stop the Pain?” was outstanding. Ned is so professional that he provides a full transcript of the talk along with the slides and video. Esther Nam and Travis Fischer gave an excellent PyCon 2014 talk “Character encoding and Unicode in Python: How to (╯°□°)╯︵ ┻━┻ with dignity” (slides, video), from which I quoted this chapter’s short and sweet epigraph: “Humans use text. Computers speak bytes.” Lennart Regebro—one of this book’s technical reviewers—presents his “Useful Mental Model of Unicode (UMMU)” in the short post “Unconfusing Unicode: What Is Unicode?”. Unicode is a complex standard, so Lennart’s UMMU is a really useful starting point.
The official Unicode HOWTO in the Python docs approaches the subject from several different angles, from a good historic intro to syntax details, codecs, regular expressions, filenames, and best practices for Unicode-aware I/O (i.e., the Unicode sandwich), with plenty of additional reference links from each section. Chapter 4, “Strings”, of Mark Pilgrim’s awesome book Dive into Python 3 also provides a very good intro to Unicode support in Python 3. In the same book, Chapter 15 describes how the Chardet library was ported from Python 2 to Python 3, a valuable case study given that the switch from the old str to the new bytes is the cause of most migration pains, and that is a central concern in a library designed to detect encodings.
If you know Python 2 but are new to Python 3, Guido van Rossum’s What’s New in Python 3.0 has 15 bullet points that summarize what changed, with lots of links. Guido starts with the blunt statement: “Everything you thought you knew about binary data and Unicode has changed.” Armin Ronacher’s blog post “The Updated Guide to Unicode on Python” is deep and highlights some of the pitfalls of Unicode in Python 3 (Armin is not a big fan of Python 3).
Chapter 2, “Strings and Text,” of the Python Cookbook, Third Edition (O’Reilly), by David Beazley and Brian K. Jones, has several recipes dealing with Unicode normalization, sanitizing text, and performing text-oriented operations on byte sequences. Chapter 5 covers files and I/O, and it includes “Recipe 5.17. Writing Bytes to a Text File,” showing that underlying any text file there is always a binary stream that may be accessed directly when needed. Later in the cookbook, the struct module is put to use in “Recipe 6.11. Reading and Writing Binary Arrays of Structures.”
Nick Coghlan’s Python Notes blog has two posts very relevant to this chapter: “Python 3 and ASCII Compatible Binary Protocols” and “Processing Text Files in Python 3”. Highly recommended.
Binary sequences are about to gain new constructors and methods in Python 3.5, with one of the current constructor signatures being deprecated (see PEP 467 — Minor API improvements for binary sequences). Python 3.5 should also see the implementation of PEP 461 — Adding % formatting to bytes and bytearray.
A list of encodings supported by Python is available at Standard Encodings in the codecs module documentation. If you need to get that list programmatically, see how it’s done in the /Tools/unicode/listcodecs.py script that comes with the CPython source code.
Martijn Faassen’s “Changing the Python Default Encoding Considered Harmful” and Tarek Ziadé’s “sys.setdefaultencoding Is Evil” explain why the default encoding you get from sys.getdefaultencoding() should never be changed, even if you discover how.
The books Unicode Explained by Jukka K. Korpela (O’Reilly) and Unicode Demystified by Richard Gillam (Addison-Wesley) are not Python-specific but were very helpful as I studied Unicode concepts. Programming with Unicode by Victor Stinner is a free, self-published book (Creative Commons BY-SA) covering Unicode in general as well as tools and APIs in the context of the main operating systems and a few programming languages, including Python.
The W3C pages Case Folding: An Introduction and Character Model for the World Wide Web: String Matching and Searching cover normalization concepts, with the former being a gentle introduction and the latter a working draft written in dry standard-speak—the same tone of the Unicode Standard Annex #15 — Unicode Normalization Forms. The Frequently Asked Questions / Normalization from Unicode.org is more readable, as is the NFC FAQ by Mark Davis—author of several Unicode algorithms and president of the Unicode Consortium at the time of this writing.
1 Slide 12 of PyCon 2014 talk “Character Encoding and Unicode in Python” (slides, video).
2 Pillow is PIL’s most active fork.
3 As of September, 2014, W3Techs: Usage of Character Encodings for Websites claims that 81.4% of sites use UTF-8, while Built With: Encoding Usage Statistics estimates 79.4%.
4 I first saw the term “Unicode sandwich” in Ned Batchelder’s excellent “Pragmatic Unicode” talk at US PyCon 2012.
5 Python 2.6 or 2.7 users have to use io.open() to get automatic decoding/encoding when reading/writing.
6 While researching this subject, I did not find a list of situations when Python 3 internally converts bytes to str. Python core developer Antoine Pitrou says on the comp.python.devel list that CPython internal functions that depend on such conversions “don’t get a lot of use in py3k.”
7 The Python 2 sys.setdefaultencoding function was misused and is no longer documented in Python 3. It was intended for use by the core developers when the internal default encoding of Python was still undecided. In the same comp.python.devel thread, Marc-André Lemburg states that the sys.setdefaultencoding must never be called by user code and the only values supported by CPython are 'ascii' in Python 2 and 'utf-8' in Python 3.
8 Curiously, the micro sign is considered a “compatibility character” but the ohm symbol is not. The end result is that NFC doesn’t touch the micro sign but changes the ohm symbol to capital omega, while NFKC and NFKD change both the ohm and the micro into other characters.
9 Diacritics affect sorting only in the rare case when they are the only difference between two words—in that case, the word with a diacritic is sorted after the plain word.
10 Thanks to Leonardo Rochael who went beyond his duties as tech reviewer and researched these Windows details, even though he is a GNU/Linux user himself.
11 Again, I could not find a solution, but did find other people reporting the same problem. Alex Martelli, one of the tech reviewers, had no problem using setlocale and locale.strxfrm on his Mac with OSX 10.9. In summary: your mileage may vary.
12 Although it was not better than re at identifying digits in this particular sample.