[toc]
Introduction
In general, encoding means using a specific code for the letters, symbols, and numbers. Numerous encoding standards that are used for encoding a Unicode character. The most common ones are utf-8, utf-16, ISO-8859-1, latin, etc. For example, the character $ corresponds to U+0024 in utf-8 standard and the same corresponds to U+0024 in UTF-16 encoding standard and might not correspond to any value in some other encoding standard.
Now, when you read the input files in the Pandas library in Python, you may encounter a certain UnicodeDecodeError. This primarily happens when you are reading a file that is encoded in a different standard than the one you are using. Consider the below error as a reference.
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xda in position 6: invalid continuation byte
Here we are specifying the encoding as utf-8. However, the file has a character 0xda, which has no correspondence in utf-8 standard. Hence the error. To fix this error, we should either identify the encoding of the input file and specify that as an encoding parameter or change the encoding of the file.
Encoding and Decoding
The process of converting human-readable data into a specified format for secured data transmission is known as encoding. Decoding is the opposite of encoding which converts the encoded information to normal text (human-readable form).
In Python,
encode()is an inbuilt method used for encoding. In case no encoding is specified,UTF-8is used as default.decode()is an inbuilt method used for decoding.

In this tutorial, let us have a look at the different ways of fixing the UnicodeDecodeError.
#Fix 1: Set an Encoding Parameter
By default, the read_csv() method uses None as the encoding parameter value. If you are aware of the encoding standard of the file, set the encoding parameter accordingly. Note that there can be aliases to the same encoding standard. For example, latin_1 can also be referred to as L1, iso-8859-1, etc. You can find the list of supported Python Encodings and their aliases at this link:
Now, lets us say that your file is encoded in utf-8, then you must set utf-8 as a value to encoding parameter as shown below to avoid the occurence of an error.
import pandas as pd file_data=pd.read_csv(path_to_file, encoding="utf-8")
#Fix 2: Change The Encoding of The File
2.1 Using PyCharm
If you are using the Pycharm IDE then handling the Unicode error becomes a tad simpler. If you have a single input file or a lesser number of input files, you can change the encoding of the files to utf-8 directly within Pycharm. Follow the steps given below to implement encoding to utf-8 in Pycharm:
- Open the input file in PyCharm.
- Right-click and choose Configure Editor Tabs.

3. Select File Encodings.
4. Select a path to your file.
5. Under Project Encoding, choose UTF-8.
6. Save the file.

To become a PyCharm master, check out our full course on the Finxter Computer Science Academy available for free for all Finxter Premium Members:

2.2 Using Notepad++
In case you are using notepad++ for your script, follow the steps given below to enable automatic encoding to utf-8:
- Open the .csv file in Notepad++
- Click on Encoding ➡ Choose required encoding.
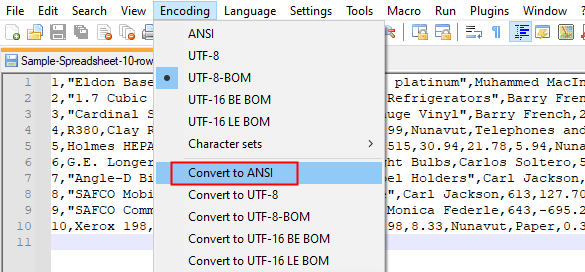
Now, call the read_csv method with encoding=”utf-8” parameter. Refer to the below code snippet for details.
import pandas as pd file_data=pd.read_csv(path_to_file, encoding="utf-8")
#Fix 3: Identify the encoding of the file.
In scenarios where converting the input file is not an option, we can try the following:
3.1 Using Notepad ++
We can identify the encoding of the file and pass the value as an encoding parameter. This is best suited when there is only one or a lesser number of input files.
- Open the .csv file in Notepad++
- Click on Encoding.
- The one with a dot specifies your encoding standard.
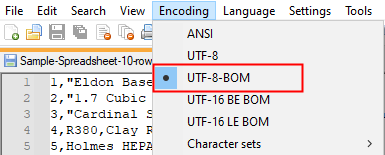
4. In order to know the value that can be assigned to the encoding parameter, refer to Python Encodings
For example, if the Encoding is UTF-16 BE BOM, the read_csv() can be called as shown below. Notice that the value of encoding is utf_16_be.
import pandas as pd file_data=pd.read_csv(path_to_file, encoding="utf_16_be")
3.2 Use The chardet Package
When there are several input files, it becomes difficult to identify the encoding of the single file or to convert all the files. This method comes in handy in such cases.
There is a package in Python that can be used to identify the encoding of a file. Note that it is impossible to detect the exact encoding of a file. However, the best fit can be found.
Firstly, install chardet package using the below command:
pip install chardetRefer to the below code snippet. Here we have used the chardet package to detect the encoding of the file and then passed that value to the encoding parameter in the read_csv() method.
import chardet
import pandas as pd
with open('C:\Users\admin\Desktop\Finxter\Sample-Spreadsheet-10-rows.csv','r') as f:
raw_data= f.read()
result = chardet.detect(raw_data.encode())
charenc = result['encoding']
# set the file-handle to point to the beginning of the file to re-read the file contents.
f.seek(0,0)
data= pd.read_csv(f,delimiter=",", encoding=charenc)
If you do not want to find the encoding of the file, try the below fixes.
#Fix 4: Use engine=’python’
In most cases, the error can be fixed by passing the engine=’python’ argument in the read_csv() as shown below.
import pandas as pd file_data=pd.read_csv(path_to_file, engine="python")
#Fix 5: Use encoding= latin1 or unicode_escape
If you just want to get rid of the error and if having some garbage values in the file does not matter, then you can simply pass encoding=latin1 or encoding=unicode_escape in read_csv()
Example 1: Here, we are passing encoding=latin1
import pandas as pd file_data=pd.read_csv(path_to_file, encoding="latin1")
Example 2: Here, we are passing encoding=unicode_escape
import pandas as pd file_data=pd.read_csv(path_to_file, encoding=”unicode_escape")
Conclusion
In this tutorial, we have covered different ways of finding the encoding of a file and passing that as an argument to the read_csv function to get rid of the UnicodeDecodeError. We hope this has been informative. Please stay tuned and subscribe for more such tips and tricks.
Recommended: Finxter Computer Science Academy
- One of the most sought-after skills on Fiverr and Upwork is web scraping. Make no mistake: extracting data programmatically from websites is a critical life skill in today’s world that’s shaped by the web and remote work.
- So, do you want to master the art of web scraping using Python’s BeautifulSoup?
- If the answer is yes – this course will take you from beginner to expert in Web Scraping.
Programmer Humor
Q: What is the object-oriented way to become wealthy?
💰
A: Inheritance.
I am a professional Python Blogger and Content creator. I have published numerous articles and created courses over a period of time. Presently I am working as a full-time freelancer and I have experience in domains like Python, AWS, DevOps, and Networking.
You can contact me @:
UpWork
LinkedIn
In this short guide, I’ll show you** how to solve the error: UnicodeDecodeError: invalid start byte while reading a CSV with Pandas**:
pandas UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0x97 in position 6785: invalid start byte
The error might have several different reasons:
- different encoding
- bad symbols
- corrupted file
In the next steps you will find information on how to investigate and solve the error.
As always all examples can be found in a handy: Jupyter Notebook
Step 1: UnicodeDecodeError: invalid start byte while reading CSV file
To start, let’s demonstrate the error: UnicodeDecodeError while reading a sample CSV file with Pandas.
The file content is shown below by Linux command cat:
��a,b,c
1,2,3
We can see some strange symbol at the file start: ��
Using method read_csv on the file above will raise error:
df = pd.read_csv('../data/csv/file_utf-16.csv')
raised error:
UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xff in position 0: invalid start byte
Step 2: Solution of UnicodeDecodeError: change read_csv encoding
The first solution which can be applied in order to solve the error UnicodeDecodeError is to change the encoding for method read_csv.
To use different encoding we can use parameter: encoding:
df = pd.read_csv('../data/csv/file_utf-16.csv', encoding='utf-16')
and the file will be read correctly.
The weird start of the file was suggesting that probably the encoding is not utf-8.
In order to check what is the correct encoding of the CSV file we can use next Linux command or Jupyter magic:
!file '../data/csv/file_utf-16.csv'
this will give us:
../data/csv/file_utf-16.csv: Little-endian UTF-16 Unicode text
Another popular encodings are:
cp1252iso-8859-1latin1
Python has option to check file encoding but it may be wrong in some cases like:
with open('../data/csv/file_utf-16.csv') as f:
print(f)
result:
<_io.TextIOWrapper name='../data/csv/file_utf-16.csv' mode='r' encoding='UTF-8'>
Step 3: Solution of UnicodeDecodeError: skip encoding errors with encoding_errors=’ignore’
Pandas read_csv has a parameter — encoding_errors='ignore' which defines how encoding errors are treated — to be skipped or raised.
The parameter is described as:
How encoding errors are treated.
Note: Important change in the new versions of Pandas:
Changed in version 1.3.0: encoding_errors is a new argument. encoding has no longer an influence on how encoding errors are handled.
Let’s demonstrate how parameter of read_csv — encoding_errors works:
from pathlib import Path
import pandas as pd
file = Path('../data/csv/file_utf-8.csv')
file.write_bytes(b"xe4nan1") # non utf-8 character
df = pd.read_csv(file, encoding_errors='ignore')
The above will result into:
| a |
|---|
| 1 |
To prevent Pandas read_csv reading incorrect CSV data due to encoding use: encoding_errors='strinct' — which is the default behavior:
df = pd.read_csv(file, encoding_errors='strict')
This will raise an error:
UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xe4 in position 0: invalid continuation byte
Another possible encoding error which can be raised by the same parameter is:
Pandas UnicodeEncodeError: ‘charmap’ codec can’t encode character
Step 4: Solution of UnicodeDecodeError: fix encoding errors with unicode_escape
The final solution to fix encoding errors like:
- UnicodeDecodeError
- UnicodeEncodeError
is by using option unicode_escape. It can be described as:
Encoding suitable as the contents of a Unicode literal in ASCII-encoded Python source code, except that quotes are not escaped. Decode from Latin-1 source code. Beware that Python source code actually uses UTF-8 by default.
Pandas read_csv and encoding can be used 'unicode_escape' as:
df = pd.read_csv(file, encoding='unicode_escape')
to prevent encoding errors.
Resources
- Notebook
- pandas.read_csv
- BUG: read_csv does not raise UnicodeDecodeError on non utf-8 characters
- What’s new in 1.3.0 (July 2, 2021) — encoding_errors
- Text Encodings
Several errors can arise when an attempt to decode a byte string from a certain coding scheme is made. The reason is the inability of some encoding schemes to represent all code points. One of the most common errors during these conversions is UnicodeDecode Error which occurs when decoding a byte string by an incorrect coding scheme. This article will teach you how to resolve a UnicodeDecodeError for a CSV file in Python.
Why does the UnicodeDecodeError error arise?
The error occurs when an attempt to represent code points outside the range of the coding is made. To solve the issue, the byte string should be decoded using the same coding scheme in which it was encoded. i.e., The encoding scheme should be the same when the string is encoded and decoded.
For demonstration, the same error would be reproduced and then fixed. In the below code, firstly the character a (byte string) is decoded using ASCII encoding successfully. Then an attempt to decode the byte string axf1 is made, which led to an error. This is because the ASCII encoding standard only allows representation of the characters within the range 0 to 127. Any attempt to address a character outside this range would lead to the ordinal not-in-range error.
Python3
t = b"a".decode("ascii")
t1 = b"axf1".decode("ascii")
Output:
Traceback (most recent call last):
File "C:/Users/Sauleyayan/PycharmProjects/untitled1/venv/mad philes.py", line 5, in <module>
t1 = b"axf1".decode("ascii")
UnicodeDecodeError: 'ascii' codec can't decode byte 0xf1 in position 1: ordinal not in range(128)
To rectify the error, an encoding scheme would be used that would be sufficient to represent the xf1 code point. In this case, the unicode_escape coding scheme would be used:
Python3
t1 = b"axf1".decode("unicode_escape")
print(t1)
Output:
añ
How to Resolve a UnicodeDecodeError for a CSV file
It is common to encounter the error mentioned above when processing a CSV file. This is because the CSV file may have a different encoding than the one used by the Python program. To fix such an error, the encoding used in the CSV file would be specified while opening the file. If the encoding standard of the CSV file is known, the Python interpreter could be instructed to use a specific encoding standard while that CSV file is being opened. This method is only usable if the encoding of the CSV is known.
To demonstrate the occurrence of the error, the following CSV file will be used:
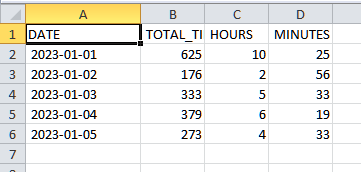
The encoding of the CSV file is UTF-16
Generating UnicodeDecodeError for a CSV file
The following code attempts to open the CSV file for processing. The above code, upon execution, led to the following error:
Python3
import pandas as pd
path = "test.csv"
file = pd.read_csv(path)
print(file.head())
Output:

Understanding the Problem
The error occurred as the read_csv method could not decode the contents of the CSV file by using the default encoding, UTF-8. This is because the encoding of the file is UTF-16. Hence the encoding of the CSV file needs to be mentioned while opening the CSV file to fix the error and allow the processing of the CSV file.
Solution
Firstly, the pandas‘ library is imported, and the path to the CSV file is specified. Then the program calls the read_csv function to read the contents of the CSV file specified by the path and also passes the encoding through which the CSV file must be decoded (UTF-16 in this case). Since the decoding scheme mentioned in the argument is the one with which the CSV file was originally encoded, the file gets decoded successfully.
Python3
import pandas as pd
path = "test.csv"
file = pd.read_csv(path, encoding="utf-16")
print(file.head())
Output:

Alternate Method to Solve UnicodeDecodeError
Another way of resolving the issue is by changing the encoding of the CSV file itself. For that, firstly, open the CSV file as a text file (using notepad or Wordpad):

Now go to file and select Save as:

A prompt would appear, and from there, select the encoding option and change it to UTF-8 (the default for Python and pandas), and select Save.
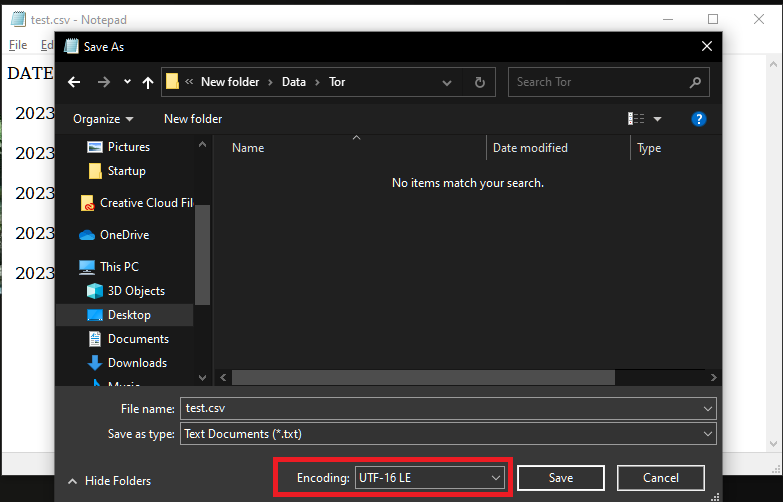

Now the following code would run without errors
The code ran without errors. This is because the default encoding of the CSV file was changed to UTF-8 before opening it with pandas. Since the default encoding used by pandas is UTF-8, the CSV file opened without error.
Python3
import pandas as pd
path = "test.csv"
file = pd.read_csv(path)
print(file.head())
Output:
Reading CSVs is always a little bit living on the edge, especially when multiple regions are involved in producing them. In this blog post, we’re solving UnicodeDecodeError: ‘utf-8’ codec can’t decode byte […] in position […]: invalid continuation byte.
Important, I’m assuming you got the error when you used Pandas’ read_csv() to read a CSV file into memory.
df = pd.read_csv('your_file.csv')
When Pandas reads a CSV, by default it assumes that the encoding is UTF-8. When the following error occurs, the CSV parser encounters a character that it can’t decode.
UnicodeDecodeError: 'utf-8' codec can't decode byte [...] in position [...]: invalid continuation byte.😐 Okay, so how do I solve it?
If you know the encoding of the file, you can simply pass it to the read_csv function, using the encoding parameter. Here’s a list of all the encodings that are accepted in Python.
df = pd.read_csv('your_file.csv', encoding = 'ISO-8859-1')
If you don’t know the encoding, there are multiple things you can do.
Use latin1: In the example below, I use the latin1 encoding. Latin1 is known for interpreting basically every character (but not necessarily as the character you’d expect). Consequently, the chances are that latin1 will be able to read the file without producing errors.
df = pd.read_csv('your_file.csv', encoding = 'latin1')
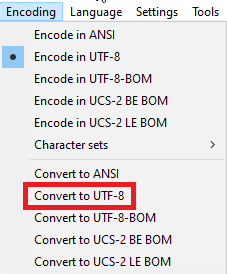
Manual conversion: Your next option would be to manually convert the CSV file to UTF-8. For example, in Notepad++, you can easily do that by selecting Convert to UTF-8 in the Encoding menu.
Automatic detection: However, a much easier solution would be to use Python’s chardet package, aka “The Universal Character Encoding Detector”. In the following code chunk, the encoding of the file is stored in the enc variable, which can be retrieved using enc[‘encoding’].
import chardet
import pandas as pd
with open('your_file.csv', 'rb') as f:
enc = chardet.detect(f.read()) # or readline if the file is large
pd.read_csv('your_file.csv', encoding = enc['encoding'])
Great success!
By the way, I didn’t necessarily come up with this solution myself. Although I’m grateful you’ve visited this blog post, you should know I get a lot from websites like StackOverflow and I have a lot of coding books. This one by Matt Harrison (on Pandas 1.x!) has been updated in 2020 and is an absolute primer on Pandas basics. If you want something broad, ranging from data wrangling to machine learning, try “Mastering Pandas” by Stefanie Molin.
Say thanks, ask questions or give feedback
Technologies get updated, syntax changes and honestly… I make mistakes too. If something is incorrect, incomplete or doesn’t work, let me know in the comments below and help thousands of visitors.
Table of Contents
Hide
- What is UnicodeDecodeError ‘utf8’ codec can’t decode byte?
- Solution for Importing and Reading CSV files using Pandas
- Solution for Loading and Parsing JSON files
- Solution for Loading and Parsing any other file formats
- Solution for decoding the string contents efficiently
The UnicodeDecodeError occurs mainly while importing and reading the CSV or JSON files in your Python code. If the provided file has some special characters, Python will throw an UnicodeDecodeError: ‘utf8’ codec can’t decode byte 0xa5 in position 0: invalid start byte.
The UnicodeDecodeError normally happens when decoding a string from a certain coding. Since codings map only a limited number of str strings to Unicode characters, an illegal sequence of str characters (non-ASCII) will cause the coding-specific decode() to fail.
When importing and reading a CSV file, Python tries to convert a byte-array (bytes which it assumes to be a utf-8-encoded string) to a Unicode string (str). It is a decoding process according to UTF-8 rules. When it tries this, it encounters a byte sequence that is not allowed in utf-8-encoded strings (namely this 0xff at position 0).
Example
import pandas as pd
a = pd.read_csv("filename.csv")Output
Traceback (most recent call last):
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x96 in position 2: invalid start byte
There are multiple solutions to resolve this issue, and it depends on the different use cases. Let’s look at the most common occurrences, and the solution to each of these use cases.
Solution for Importing and Reading CSV files using Pandas
If you are using pandas to import and read the CSV files, then you need to use the proper encoding type or set it to unicode_escape to resolve the UnicodeDecodeError as shown below.
import pandas as pd
data=pd.read_csv("C:\Employess.csv",encoding=''unicode_escape')
print(data.head())Solution for Loading and Parsing JSON files
If you are getting UnicodeDecodeError while reading and parsing JSON file content, it means you are trying to parse the JSON file, which is not in UTF-8 format. Most likely, it might be encoded in ISO-8859-1. Hence try the following encoding while loading the JSON file, which should resolve the issue.
json.loads(unicode(opener.open(...), "ISO-8859-1"))Solution for Loading and Parsing any other file formats
In case of any other file formats such as logs, you could open the file in binary mode and then continue the file read operation. If you just specify only read mode, it opens the file and reads the file content as a string, and it doesn’t decode properly.
You could do the same even for the CSV, log, txt, or excel files also.
with open(path, 'rb') as f:
text = f.read()Alternatively, you can use decode() method on the file content and specify errors=’replace’ to resolve UnicodeDecodeError
with open(path, 'rb') as f:
text = f.read().decode(errors='replace')When you call .decode() an a unicode string, Python 2 tries to be helpful and decides to encode the Unicode string back to bytes (using the default encoding), so that you have something that you can really decode. This implicit encoding step doesn’t use errors='replace', so if there are any characters in the Unicode string that aren’t in the default encoding (probably ASCII) you’ll get a UnicodeEncodeError.
(Python 3 no longer does this as it is terribly confusing.)
Check the type of message and assuming it is indeed Unicode, works back from there to find where it was decoded (possibly implicitly) to replace that with the correct decoding.
Solution for decoding the string contents efficiently
If you encounter UnicodeDecodeError while reading a string variable, then you could simply use the encode method and encode into a utf-8 format which inturns resolve the error.
str.encode('utf-8').strip()
Srinivas Ramakrishna is a Solution Architect and has 14+ Years of Experience in the Software Industry. He has published many articles on Medium, Hackernoon, dev.to and solved many problems in StackOverflow. He has core expertise in various technologies such as Microsoft .NET Core, Python, Node.JS, JavaScript, Cloud (Azure), RDBMS (MSSQL), React, Powershell, etc.
Sign Up for Our Newsletters
Subscribe to get notified of the latest articles. We will never spam you. Be a part of our ever-growing community.
By checking this box, you confirm that you have read and are agreeing to our terms of use regarding the storage of the data submitted through this form.