In this post, you can find several solutions for:
SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated UXXXXXXXX escape
While this error can appear in different situations the reason for the error is one and the same:
- there are special characters( escape sequence — characters starting with backslash — » ).
- From the error above you can recognize that the culprit is ‘U’ — which is considered as unicode character.
- another possible errors for SyntaxError: (unicode error) ‘unicodeescape’ will be raised for ‘x’, ‘u’
- codec can’t decode bytes in position 2-3: truncated xXX escape
- codec can’t decode bytes in position 2-3: truncated uXXXX escape
- another possible errors for SyntaxError: (unicode error) ‘unicodeescape’ will be raised for ‘x’, ‘u’
Step #1: How to solve SyntaxError: (unicode error) ‘unicodeescape’ — Double slashes for escape characters
Let’s start with one of the most frequent examples — windows paths. In this case there is a bad character sequence in the string:
import json
json_data=open("C:Userstest.txt").read()
json_obj = json.loads(json_data)
The problem is that U is considered as a special escape sequence for Python string. In order to resolved you need to add second escape character like:
import json
json_data=open("C:\Users\test.txt").read()
json_obj = json.loads(json_data)
Step #2: Use raw strings to prevent SyntaxError: (unicode error) ‘unicodeescape’
If the first option is not good enough or working then raw strings are the next option. Simply by adding r (for raw string literals) to resolve the error. This is an example of raw strings:
import json
json_data=open(r"C:Userstest.txt").read()
json_obj = json.loads(json_data)
If you like to find more information about Python strings, literals
2.4.1 String literals
In the same link we can find:
When an r' or R’ prefix is present, backslashes are still used to quote the following character, but all backslashes are left in the string. For example, the string literal r»n» consists of two characters: a backslash and a lowercase `n’.
Step #3: Slashes for file paths -SyntaxError: (unicode error) ‘unicodeescape’
Another possible solution is to replace the backslash with slash for paths of files and folders. For example:
«C:Userstest.txt»
will be changed to:
«C:/Users/test.txt»
Since python can recognize both I prefer to use only the second way in order to avoid such nasty traps. Another reason for using slashes is your code to be uniform and homogeneous.
The picture below demonstrates how the error will look like in PyCharm. In order to understand what happens you will need to investigate the error log.
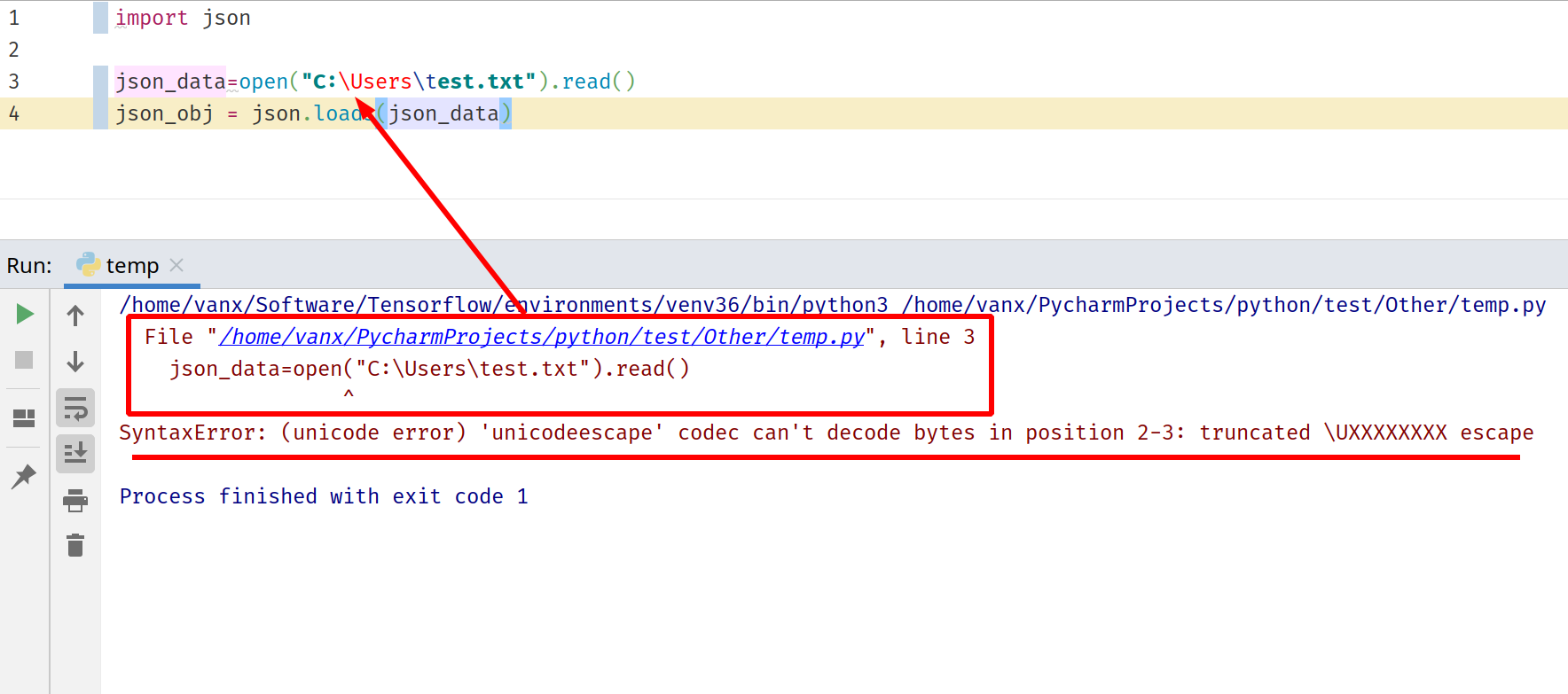
The error log will have information for the program flow as:
/home/vanx/Software/Tensorflow/environments/venv36/bin/python3 /home/vanx/PycharmProjects/python/test/Other/temp.py
File "/home/vanx/PycharmProjects/python/test/Other/temp.py", line 3
json_data=open("C:Userstest.txt").read()
^
SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 2-3: truncated UXXXXXXXX escape
You can see the latest call which produces the error and click on it. Once the reason is identified then you can test what could solve the problem.
Table of Contents
Hide
- What is SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated UXXXXXXXX escape?
- How to fix SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated UXXXXXXXX escape?
- Solution 1 – Using Double backslash (\)
- Solution 2 – Using raw string by prefixing ‘r’
- Solution 3 – Using forward slash
- Conclusion
The SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated UXXXXXXXX escape occurs if you are trying to access a file path with a regular string.
In this tutorial, we will take a look at what exactly (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated UXXXXXXXX escape means and how to fix it with examples.
The Python String literals can be enclosed in matching single quotes (‘) or double quotes (“).
String literals can also be prefixed with a letter ‘r‘ or ‘R‘; such strings are called raw strings and use different rules for backslash escape sequences.
They can also be enclosed in matching groups of three single or double quotes (these are generally referred to as triple-quoted strings).
The backslash () character is used to escape characters that otherwise have a special meaning, such as newline, backslash itself, or the quote character.
Now that we have understood the string literals. Let us take an example to demonstrate the issue.
import pandas
# read the file
pandas.read_csv("C:UsersitsmycodeDesktoptest.csv")
Output
File "c:PersonalIJSCodeprogram.py", line 4
pandas.read_csv("C:UsersitsmycodeDesktoptest.csv") ^
SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 2-3: truncated UXXXXXXXX escapeWe are using the single backslash in the above code while providing the file path. Since the backslash is present in the file path, it is interpreted as a special character or escape character (any sequence starting with ‘’). In particular, “U” introduces a 32-bit Unicode character.
How to fix SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated UXXXXXXXX escape?
Solution 1 – Using Double backslash (\)
In Python, the single backslash in the string is interpreted as a special character, and the character U(in users) will be treated as the Unicode code point.
We can fix the issue by escaping the backslash, and we can do that by adding an additional backslash, as shown below.
import pandas
# read the file
pandas.read_csv("C:\Users\itsmycode\Desktop\test.csv")Solution 2 – Using raw string by prefixing ‘r’
We can also escape the Unicode by prefixing r in front of the string. The r stands for “raw” and indicates that backslashes need to be escaped, and they should be treated as a regular backslash.
import pandas
# read the file
pandas.read_csv("C:\Users\itsmycode\Desktop\test.csv")Solution 3 – Using forward slash
Another easier way is to avoid the backslash and instead replace it with the forward-slash character(/), as shown below.
import pandas
# read the file
pandas.read_csv("C:/Users/itsmycode/Desktop/test.csv")
Conclusion
The SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated UXXXXXXXX escape occurs if you are trying to access a file path and provide the path as a regular string.
We can solve the issue by escaping the single backslash with a double backslash or prefixing the string with ‘r,’ which converts it into a raw string. Alternatively, we can replace the backslash with a forward slash.
Srinivas Ramakrishna is a Solution Architect and has 14+ Years of Experience in the Software Industry. He has published many articles on Medium, Hackernoon, dev.to and solved many problems in StackOverflow. He has core expertise in various technologies such as Microsoft .NET Core, Python, Node.JS, JavaScript, Cloud (Azure), RDBMS (MSSQL), React, Powershell, etc.
Sign Up for Our Newsletters
Subscribe to get notified of the latest articles. We will never spam you. Be a part of our ever-growing community.
By checking this box, you confirm that you have read and are agreeing to our terms of use regarding the storage of the data submitted through this form.
Introduction
The following error message is a common Python error, the «SyntaxError» represents a Python syntax error and the «unicodeescape» means that we made a mistake in using unicode escape character.
SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 0-5: truncated UXXXXXXXX escapeSimply to put, the «SyntaxError» can be occurred accidentally in Python and it is often happens because the (ESCAPE CHARACTER) is misused in a python string, it caused the unicodeescape error.
(Note: «escape character» can convert your other character to be a normal character.)
SyntaxError Example
Let’s look at an example:
print('It's a nice day.')Looks like we want to print «It’s a nice day.«, right? But the program will report an error message.
File "<stdin>", line 1
print('It's a nice day.')
^
SyntaxError: invalid syntaxThe reason is very easy-to-know. In Python, we can use print('xxx') to print out xxx. But in our code, if we had used the ' character, the Python interpreter will misinterpret the range of our characters so it will report an error.
To solve this problem, we need to add an escape character «» to convert our ‘ character to be a normal character, not a superscript of string.
print('It's a nice day.')Output:
It's a nice day.We print it successfully!
So how did the syntax error happen? Let me talk about my example:
One day, I run my program for experiment, I saved some data in a csv file. In order for this file can be viewed on the Windows OS, I add a new code uFFEF in the beginning of file.
This is «BOM» (Byte Order Mark), Explain to the system that the file format is «Big-Ending«.
I got the error message.
SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 0-5: truncated UXXXXXXXX escapeAs mentioned at the beginning of this article, this is an escape character error in Python.
Solutions
There are three solutions you can try:
- Add a «r» character in the right of string
- Change
to be/ - Change
to be\
Solution 1: Add a «r» character in the beginning of string.
title = r'uFFEF'After we adding a r character at right side of python string, it means a complete string not anything else.
Solution 2: Change /.
open("C:UsersClayDesktoptest.txt")Change to:
open("C:/Users/Clay/Desktop/test.txt")This way is avoid to use escape character.
Solution 3: Change \.
open("C:UsersClayDesktoptest.txt")Change the code to:
open("C:\Users\Clay\Desktop\test.txt")It is similar to the solution 2 that it also avoids the use of escape characters.
The above are three common solutions. We can run normally on Windows.
Reference
- https://stackoverflow.com/questions/37400974/unicode-error-unicodeescape-codec-cant-decode-bytes-in-position-2-3-trunca
- https://community.alteryx.com/t5/Alteryx-Designer-Discussions/Error-unicodeescape-codec-can-t-decode-bytes/td-p/427540
Read More
- [Solved][Python] ModuleNotFoundError: No module named ‘cStringIO’
Содержание
- Python SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated UXXXXXXXX escape
- Step #1: How to solve SyntaxError: (unicode error) ‘unicodeescape’ — Double slashes for escape characters
- Step #2: Use raw strings to prevent SyntaxError: (unicode error) ‘unicodeescape’
- Step #3: Slashes for file paths -SyntaxError: (unicode error) ‘unicodeescape’
- Step #4: PyCharm — SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated UXXXXXXXX escape
- Python unicode error unicodeescape codec
- SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated UXXXXXXXX escape #
- SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated UXXXXXXXX escape
- What is SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated UXXXXXXXX escape?
- How to fix SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated UXXXXXXXX escape?
- Solution 1 – Using Double backslash ()
- Solution 2 – Using raw string by prefixing ‘r’
- Solution 3 – Using forward slash
- Conclusion
- [Solved] Python SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 0-5: truncated UXXXXXXXX escape
- Introduction
- SyntaxError Example
- Solutions
- Solution 1: Add a «r» character in the beginning of string.
- Solution 2: Change to be / .
- Solution 3: Change to be .
- (unicode error) ‘unicodeescape’ codec can’t decode bytes — string with ‘u’
Python SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated UXXXXXXXX escape

In this post, you can find several solutions for:
SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated UXXXXXXXX escape
While this error can appear in different situations the reason for the error is one and the same:
- there are special characters( escape sequence — characters starting with backslash — » ).
- From the error above you can recognize that the culprit is ‘U’ — which is considered as unicode character.
- another possible errors for SyntaxError: (unicode error) ‘unicodeescape’ will be raised for ‘x’, ‘u’
- codec can’t decode bytes in position 2-3: truncated xXX escape
- codec can’t decode bytes in position 2-3: truncated uXXXX escape
- another possible errors for SyntaxError: (unicode error) ‘unicodeescape’ will be raised for ‘x’, ‘u’
Step #1: How to solve SyntaxError: (unicode error) ‘unicodeescape’ — Double slashes for escape characters
Let’s start with one of the most frequent examples — windows paths. In this case there is a bad character sequence in the string:
The problem is that U is considered as a special escape sequence for Python string. In order to resolved you need to add second escape character like:
Step #2: Use raw strings to prevent SyntaxError: (unicode error) ‘unicodeescape’
If the first option is not good enough or working then raw strings are the next option. Simply by adding r (for raw string literals) to resolve the error. This is an example of raw strings:
If you like to find more information about Python strings, literals
In the same link we can find:
When an r’ or R’ prefix is present, backslashes are still used to quote the following character, but all backslashes are left in the string. For example, the string literal r»n» consists of two characters: a backslash and a lowercase `n’.
Step #3: Slashes for file paths -SyntaxError: (unicode error) ‘unicodeescape’
Another possible solution is to replace the backslash with slash for paths of files and folders. For example:
will be changed to:
Since python can recognize both I prefer to use only the second way in order to avoid such nasty traps. Another reason for using slashes is your code to be uniform and homogeneous.
Step #4: PyCharm — SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated UXXXXXXXX escape
The picture below demonstrates how the error will look like in PyCharm. In order to understand what happens you will need to investigate the error log.
The error log will have information for the program flow as:
You can see the latest call which produces the error and click on it. Once the reason is identified then you can test what could solve the problem.
Источник
Python unicode error unicodeescape codec
Reading time В· 2 min
SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated UXXXXXXXX escape #
The Python «SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position» occurs when we have an unescaped backslash character in a path. To solve the error, prefix the path with r to mark it as a raw string, e.g. r’C:UsersBobDesktopexample.txt’ .
Here is an example of how the error occurs.
The path contains backslash characters which is the cause of the error.
The backslash character has a special meaning in Python — it is used as an escape character (e.g. n or t ).
One way to solve the error is to prefix the string with the letter r to mark it as a raw string.
An alternative way to treat a backslash as a literal character is to escape it with a second backslash \ .
We escaped each backslash character to treat them as literal backslashes.
Here is a string that shows how 2 backslashes only get translated into 1.
Similarly, if you need to have 2 backslashes next to one another, you would have to use 4 backslashes.
An alternative solution to the «unicodeescape codec can’t decode bytes in position» error is to use forward slashes in the path instead of backslashes.
A forward slash can be used in place of a backslash when you need to specify a path.
This solves the error because we no longer have any unescaped backslash characters in the path.
Since backslash characters have a special meaning in Python, we need to treat them as a literal character by:
- prefixing the string with r to mark it as a raw string
- escaping each backslash with a second backslash
- using forward slashes in place of backslashes in the path
Источник
SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated UXXXXXXXX escape
Table of Contents Hide
The SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated UXXXXXXXX escape occurs if you are trying to access a file path with a regular string.
In this tutorial, we will take a look at what exactly (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated UXXXXXXXX escape means and how to fix it with examples.
What is SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated UXXXXXXXX escape?
The Python String literals can be enclosed in matching single quotes (‘) or double quotes (“).
String literals can also be prefixed with a letter ‘r‘ or ‘R‘; such strings are called raw strings and use different rules for backslash escape sequences.
They can also be enclosed in matching groups of three single or double quotes (these are generally referred to as triple-quoted strings).
The backslash () character is used to escape characters that otherwise have a special meaning, such as newline, backslash itself, or the quote character.
Now that we have understood the string literals. Let us take an example to demonstrate the issue.
Output
We are using the single backslash in the above code while providing the file path. Since the backslash is present in the file path, it is interpreted as a special character or escape character (any sequence starting with ‘’). In particular, “U” introduces a 32-bit Unicode character.
How to fix SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated UXXXXXXXX escape?
Solution 1 – Using Double backslash (\)
In Python, the single backslash in the string is interpreted as a special character, and the character U(in users) will be treated as the Unicode code point.
We can fix the issue by escaping the backslash, and we can do that by adding an additional backslash, as shown below.
Solution 2 – Using raw string by prefixing ‘r’
We can also escape the Unicode by prefixing r in front of the string. The r stands for “raw” and indicates that backslashes need to be escaped, and they should be treated as a regular backslash.
Solution 3 – Using forward slash
Another easier way is to avoid the backslash and instead replace it with the forward-slash character(/), as shown below.
Conclusion
The SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated UXXXXXXXX escape occurs if you are trying to access a file path and provide the path as a regular string.
We can solve the issue by escaping the single backslash with a double backslash or prefixing the string with ‘r,’ which converts it into a raw string. Alternatively, we can replace the backslash with a forward slash.
Источник
[Solved] Python SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 0-5: truncated UXXXXXXXX escape

Introduction
The following error message is a common Python error, the «SyntaxError» represents a Python syntax error and the «unicodeescape» means that we made a mistake in using unicode escape character.
Simply to put, the «SyntaxError» can be occurred accidentally in Python and it is often happens because the (ESCAPE CHARACTER) is misused in a python string, it caused the unicodeescape error.
(Note: «escape character» can convert your other character to be a normal character.)
SyntaxError Example
Let’s look at an example:
Looks like we want to print «It’s a nice day.«, right? But the program will report an error message.
The reason is very easy-to-know. In Python, we can use print(‘xxx’) to print out xxx. But in our code, if we had used the ‘ character, the Python interpreter will misinterpret the range of our characters so it will report an error.
To solve this problem, we need to add an escape character «» to convert our ‘ character to be a normal character, not a superscript of string.
We print it successfully!
So how did the syntax error happen? Let me talk about my example:
One day, I run my program for experiment, I saved some data in a csv file. In order for this file can be viewed on the Windows OS, I add a new code uFFEF in the beginning of file.
This is «BOM» (Byte Order Mark), Explain to the system that the file format is «Big-Ending«.
I got the error message.
As mentioned at the beginning of this article, this is an escape character error in Python.
Solutions
There are three solutions you can try:
- Add a «r» character in the right of string
- Change to be /
- Change to be \
Solution 1: Add a «r» character in the beginning of string.
After we adding a r character at right side of python string, it means a complete string not anything else.
Solution 2: Change to be / .
This way is avoid to use escape character.
Solution 3: Change to be \ .
Change the code to:
It is similar to the solution 2 that it also avoids the use of escape characters.
The above are three common solutions. We can run normally on Windows.
Источник
(unicode error) ‘unicodeescape’ codec can’t decode bytes — string with ‘u’
Writing my code for Python 2.6, but with Python 3 in mind, I thought it was a good idea to put
at the top of some modules. In other words, I am asking for troubles (to avoid them in the future), but I might be missing some important knowledge here. I want to be able to pass a string representing a filepath and instantiate an object as simple as
In Python 2.6, this works just fine, no need to use double backslashes or a raw string, even for a directory starting with ‘u..’ , which is exactly what I want. In the __init__ method I make sure all single occurences are interpreted as ‘ \ ‘, including those before special characters as in a , b , f , n , r , t and v (only x remains a problem). Also decoding the given string into unicode using (local) encoding works as expected.
Preparing for Python 3.x, simulating my actual problem in an editor (starting with a clean console in Python 2.6), the following happens:
(OK until here: ‘u’ is encoded by the console using the local encoding)
In other words, the (unicode) string is not interpreted as unicode at all, nor does it get decoded automatically with the local encoding. Even so for a raw string:
Also, I would expect isinstance(str(»), unicode) to return True (which it does not), because importing unicode_literals should make all string-types unicode. (edit:) Because in Python 3, all strings are sequences of Unicode characters, I would expect str(»)) to return such a unicode-string, and type(str(»)) to be both , and (because all strings are unicode) but also realise that is not . Confusion all around.
- how can I best pass strings containing ‘ u ‘? (without writing ‘ \u ‘)
- does from __future__ import unicode_literals really implement all Python 3. related unicode changes so that I get a complete Python 3 string environment?
edit: In Python 3, is a Unicode object and simply does not exist. In my case I want to write code for Python 2(.6) that will work in Python 3. But when I import unicode_literals , I cannot check if a string is of because:
- I assume unicode is not part of the namespace
- if unicode is part of the namespace, a literal of is still unicode when it is created in the same module
- type(mystring) will always return for unicode literals in Python 3
My modules use to be encoded in ‘utf-8’ by a # coding: UTF-8 comment at the top, while my locale.getdefaultlocale()[1] returns ‘cp1252’. So if I call MyObject(‘çça’) from my console, it is encoded as ‘cp1252’ in Python 2, and in ‘utf-8’ when calling MyObject(‘çça’) from the module. In Python 3, it will not be encoded, but a unicode literal.
I gave up hope about being allowed to avoid using ‘’ before a u (or x for that matter). Also I understand the limitations of importing unicode_literals . However, the many possible combinations of passing a string from a module to the console and vica versa with each different encoding, and on top of that importing unicode_literals or not and Python 2 vs Python 3, made me want to create an overview by actual testing. Hence the table below. 
In other words, type(str(»)) does not return in Python 3, but , and all of Python 2 problems seem to be avoided.
Источник
In Python, This SyntaxError occurred when you are trying to access a path with normal String. As you know ‘/’ is escape character in Python that’s having different meaning by adding with different characters for example ‘n’ is use for ne line , ‘t’ use for tab.
This error is considered as SyntaxError because unicode forward slash () is not allow in path.
In further section of topic you will learn how to handle this problem in Python while writing path of file to access it.
Example of SyntaxError of Unicode Error
Lets take below example to read CSV file in Windows operating system.
import csv
with open('C:Userssaurabh.guptaDesktopPython Exampleinput.csv','r') as csvfile:
reader=csv.reader(csvfile)
for record in reader:
print(record)
If you notice the above code is having path for windows file system to access input.csv. In windows path mentioned by using forward slash () while in Python programming forward slash() is use for handling unicode characters. That’s why when you execute the above program will throw below exception.
Output
File "C:/Users/saurabh.gupta14/Desktop/Python Example/ReadingCSV.py", line 2
with open('C:Userssaurabh.guptaDesktopPython Exampleinput.csv','r') as csvfile:
Solution
The above error is occurred because of handling forward slash() as normal string. To handle such problem in Python , there are couple of solutions:
1: Just put r in path before your normal string it converts normal string to raw string:
with open(r'C:Userssaurabh.guptaDesktopPython Exampleinput.csv','r')
2: Use back slash (/) instated of forward slash()
with open('C:/Users/saurabh.gupta/Desktop/Python Example/input.csv','r')
3: Use double forward slash (\) instead of forward slash() because in Python the unicode double forward value convert in string as forward slash()’
with open('C:\Users\saurabh.gupta\Desktop\Python Example\input.csv','r')
If this solution help you , Please like and write in comment section or any other way you know to handle this issue write in comment so that help others.
“Learn From Others Experience»
[toc]

Quick Video Walkthrough
(unicode error)’unicodeescape’ codec can’t decode bytes in position 2-3: truncated UXXXXXXXX escape
Have you come across this error – (Unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated UXXXXXXXX escape? It might be really frustrating because the logic might seem to be fone yet you got an error. Don’t worry! I got you covered and we will soon discover the ways to avoid/eliminate this error.
But, first, we must know what Unicode and Unicode escape is and what is a Unicode error.
What is Unicode and Encoding with utf-8?
Unicode is a standard that encourages character encoding utilizing variable piece encoding. There’s a high chance that you have heard about ASCII if you are into computer programming. ASCII addresses 128 characters while Unicode characterizes 221 characters. Along these lines, Unicode can be viewed as a superset of ASCII.
The way of converting over comprehensible data (easily read by humans) into a specified format, for the secure transmission of the data, is known as encoding. In Python, encode() is an inbuilt function utilized for encoding. If no encoding is indicated, then UTF-8 is utilized as default.
Example 1: Let’s consider that you are trying to open a file through the codecs module with utf-8.
import codecs
f = codecs.open('C:UsersSHUBHAM SAYONPycharmProjectsFinxterGeneraldata.txt', "w", encoding = "utf-8")
f.write('να έχεις μια όμορφη μέρα')
f.close()
Output:
File "C:UsersSHUBHAM SAYONPycharmProjectsFinxterErrorsUnicode Escape Error.py", line 2
f = codecs.open('C:UsersSHUBHAM SAYONPycharmProjectsFinxterGeneraldata.txt', "w", encoding = "utf-8")
^
SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 2-3: truncated UXXXXXXXX escape
Example 2:
import csv
d = open("C:UsersSHUBHAM SAYONPycharmProjectsFinxterGeneraldata.csv")
d = csv.reader(d)
print(d)
Output:
File "C:UsersSHUBHAM SAYONPycharmProjectsFinxterErrorsUnicode Escape Error.py", line 2
d = open("C:UsersSHUBHAM SAYONPycharmProjectsFinxterGeneraldata.csv")
^
SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 2-3: truncated UXXXXXXXX escape
How frustrating! But do you know that a slight change in a single line will solve your problem. So, without further ado, let’s dive into the fixes.
Fix: Prefix the Path String with “r” or Use Double Backslashes “//” or Use Single Forwardslash “”
The Unicode error-unicodeescape usually occurs because the problem lies in the string that denotes your file Path. We can solve this error either by either duplicating the backslashes or producing a raw string. To produce the raw string, we need to prefix the string with r.
FIX 1- Duplicating the backlashes
In Python, the first backslash in the string gets interpreted as a special character, and the fact that it is followed by a U (U in Users) gets interpreted as the beginning of a Unicode code point. To fix this you need to duplicate the backslashes (by doubling the backslashes) in the string
# Example 1
import codecs
f = codecs.open('C:\Users\SHUBHAM SAYON\PycharmProjects\Finxter\General\data.txt', "w", encoding = "utf-8")
f.write('να έχεις μια όμορφη μέρα')
f.close()
# Example 2
import csv
d = open("C:\Users\SHUBHAM SAYON\PycharmProjects\Finxter\General\data.csv")
d = csv.reader(d)
print(d)
FIX 2- Using Forwardslash
Another way to deal with it is to use the forwardslash character (/) to fix the error as follows:
# Example 1
import codecs
f = codecs.open('C:/Users/SHUBHAM SAYON/PycharmProjects/Finxter/General/data.txt', "w", encoding = "utf-8")
f.write('να έχεις μια όμορφη μέρα')
f.close()
#Example 2
import csv
d = open("C:/Users/SHUBHAM SAYON/PycharmProjects/Finxter/General/data.csv")
d = csv.reader(d)
print(d)
FIX 3- Prefix the String with “r”
You just need to add an “r” before the path link to solve the Unicode escape error as follows:
# Example 1
import codecs
f = codecs.open(r'C:UsersSHUBHAM SAYONPycharmProjectsFinxterGeneraldata.txt', "w", encoding = "utf-8")
f.write('να έχεις μια όμορφη μέρα')
f.close()
#Example 2
import csv
d = open(r"C:UsersSHUBHAM SAYONPycharmProjectsFinxterGeneraldata.csv")
d = csv.reader(d)
print(d)
When we add ‘r’ before the file path, the Python interpreter gets instructed to instead treat the string as a raw literal.
How to know if a string is valid utf-8 or ASCII?
In Python 3, str(string) is a sequence of bytes. It does not know what its encoding is. Hence, the Unicode type is the better way to store a text.
In Python versions less than 3, to check whether it’s an utf-8 or ASCII, we can call the decode method. If the decode method raises a UnicodeDecodeError exception, it is not valid.
Scanning the File Path eliminates the possibility of an error
We can solve the 'unicodeescape' codec that can't decode bytes error by scanning the file path before running it. Mostly the developers know which path they are looking for and hence checking it beforehand helps eliminate the possibility of an error.
How to list the elements from any folder?
Let’s suppose we have to list the elements from any folder. For this purpose, we can use the os module in Python. The os.listdir method from the module helps to list all the strings (In this case, the path filenames.)
Example: Let’s check the general folder and its contents –

import os
pth = r"C:UsersSHUBHAM SAYONPycharmProjectsFinxterGeneral"
files = os.listdir(pth)
for file in files:
print(file)
Output:
check_empty_string.py data.csv data.txt logical and in Python.py remove_multiple_spaces_string.py rough.py user_input_stdin.py
Conclusion
In this article, we learned different ways, i.e., Using backlash and forward slash characters, Using prefix ‘r’ to solve the Error – (Unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated UXXXXXXXX escape. I hope this tutorial helped to answered your queries. Please stay tuned and subscribe for more such articles.
Related Article: Python Unicode Encode Error
Finxter Computer Science Academy
- One of the most sought-after skills on Fiverr and Upwork is web scraping. Make no mistake: extracting data programmatically from websites is a critical life skill in today’s world that’s shaped by the web and remote work.
- So, do you want to master the art of web scraping using Python’s BeautifulSoup?
- If the answer is yes – this course will take you from beginner to expert in Web Scraping.

I am a professional Python Blogger and Content creator. I have published numerous articles and created courses over a period of time. Presently I am working as a full-time freelancer and I have experience in domains like Python, AWS, DevOps, and Networking.
You can contact me @:
UpWork
LinkedIn
Hello Guys, How are you all? Hope You all Are Fine. Today I am just trying to read .csv file But I am facing following error SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated UXXXXXXXX escape in python. So Here I am Explain to you all the possible solutions here.
Without wasting your time, Let’s start This Article to Solve This Error.
Contents
- How SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated UXXXXXXXX escape Error Occurs ?
- How To Solve SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated UXXXXXXXX escape Error ?
- Solution 1: put
rbefore your path string - Solution 2: doubling the backslashes
- Solution 3: Use double quotes and forwardslash character
- Solution 4: Use double quotes and escaping backslash character
- Solution 5: Use raw prefix and single quotes
- Summary
I am just trying to read .csv file But I am facing following error.
SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 2-3: truncated UXXXXXXXX escape
How To Solve SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated UXXXXXXXX escape Error ?
- How To Solve SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated UXXXXXXXX escape Error ?
To Solve SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated UXXXXXXXX escape Error You just need to put
rbefore your path string Just like this pandas.read_csv(r”C:UserssscDesktopaccount_summery.csv”) OR Just Use double quotes and forwardslash character. Third solution is Just Use double quotes and forwardslash character. - SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated UXXXXXXXX escape
To Solve SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated UXXXXXXXX escape Error You just need to put
rbefore your path string Just like this pandas.read_csv(r”C:UserssscDesktopaccount_summery.csv”) OR Just Use double quotes and forwardslash character. Third solution is Just Use double quotes and forwardslash character.
Solution 1: put r before your path string
You just need to put r before your path string Just like this.
pandas.read_csv(r"C:UserssscDesktopaccount_summery.csv")Solution 2: doubling the backslashes
Just doubling the backslashes Just like this.
pandas.read_csv("C:\Users\DeePak\Desktop\myac.csv")Solution 3: Use double quotes and forwardslash character
Just Use double quotes and forwardslash character
data = open("C:/Users/ssc/Desktop/account_summery.csv")
Solution 4: Use double quotes and escaping backslash character
Just Use double quotes and escaping backslash character.
data = open("C:\Users\ssc\Desktop\account_summery.csv")Solution 5: Use raw prefix and single quotes
Just Use raw prefix and single quotes.
data = open(r'C:UserssscDesktopaccount_summery.csv')Summary
It’s all About this issue. Hope all solution helped you a lot. Comment below Your thoughts and your queries. Also, Comment below which solution worked for you?
Also, Read
- ‘pyinstaller’ is not recognized as an internal or external command operable program or batch file