Синтез речи
Познакомимся, как использовать Python для преобразования текста в речь с использованием кроссплатформенной библиотеки pyttsx3. Этот пакет работает в Windows, Mac и Linux. Он использует родные драйверы речи, когда они доступны, и работает в оффлайн режиме.
Использует разные системы синтеза речи в зависимости от текущей ОС:
- в Windows — SAPI5,
- в Mac OS X — nsss,
- в Linux и на других платформах — eSpeak.
Есть функции, которые здесь не рассматриваются, такие как система событий. Вы можете подключить движок к определенным событиям:
- можно посчитать, сколько слов сказано, и обрезать его,
- можно проверить каждое слово и отрезать его, если есть неуместные слова.
Всегда обращайтесь к официальной документации для получения наиболее точной, полной и актуальной информации https://pyttsx3.readthedocs.io/en/latest/open in new window
Установка пакетов в Windows
Используйте pip для установки пакета. В Windows, вам понадобится дополнительный пакет pypiwin32, который понадобится для доступа к собственному речевому API Windows.
pip install pyttsx3
pip install pypiwin32 # Только для Windows
1
2
Преобразование текста в речь
Для первой программой озвучивания текста используем код:
import pyttsx3
engine = pyttsx3.init() # инициализация движка
# зададим свойства
engine.setProperty('rate', 150) # скорость речи
engine.setProperty('volume', 0.9) # громкость (0-1)
engine.say("I can speak!") # запись фразы в очередь
engine.say("Я могу говорить!") # запись фразы в очередь
# очистка очереди и воспроизведение текста
engine.runAndWait()
# выполнение кода останавливается, пока весь текст не сказан
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
В примере программы даны две фразы на английском и на русском языке. Существует голосовой набор по умолчанию, поэтому вам не нужно выбирать голос. В зависимости от версии windows будет озвучена соответствующая фраза. Например для английской версии windows услышим: «I can speak!»
Доступные синтезаторы по умолчанию
Доступные голоса будут зависеть от версии установленной систем. Вы можете получить список доступных голосов на вашем компьютере. Обратите внимание, что голоса, имеющиеся у вас на компьютере, могут отличаться от чьей-либо машины.
У каждого голоса есть несколько параметров, с которыми можно работать:
- id (идентификатор в операционной системе),
- name (имя),
- languages (поддерживаемые языки),
- gender (пол),
- age (возраст).
У активного движка есть стандартный параметр ‘voices’, где содержится список всех доступных этому движку голосов. Получить список доступных голосов можно так:
import pyttsx3
engine = pyttsx3.init() # Инициализировать голосовой движок.
voices = engine.getProperty('voices')
for voice in voices: # голоса и параметры каждого
print('------')
print(f'Имя: {voice.name}')
print(f'ID: {voice.id}')
print(f'Язык(и): {voice.languages}')
print(f'Пол: {voice.gender}')
print(f'Возраст: {voice.age}')
1
2
3
4
5
6
7
8
9
10
11
12
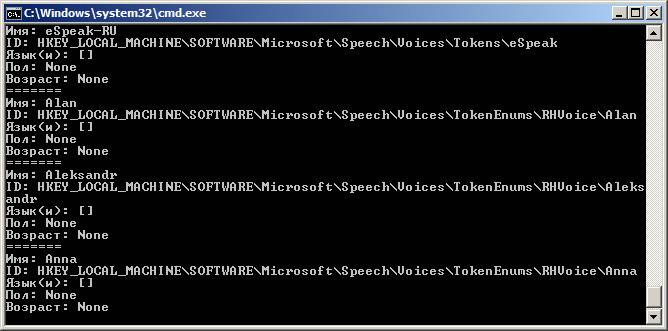
Результат будет примерно таким:
Имя: Microsoft Hazel Desktop - English (Great Britain)
ID: HKEY_LOCAL_MACHINESOFTWAREMicrosoftSpeechVoicesTokensTTS_MS_EN-GB_HAZEL_11.0
Язык(и): []
Пол: None
Возраст: None
------
Имя: Microsoft David Desktop - English (United States)
ID: HKEY_LOCAL_MACHINESOFTWAREMicrosoftSpeechVoicesTokensTTS_MS_EN-US_DAVID_11.0
Язык(и): []
Пол: None
Возраст: None
------
Имя: Microsoft Zira Desktop - English (United States)
ID: HKEY_LOCAL_MACHINESOFTWAREMicrosoftSpeechVoicesTokensTTS_MS_EN-US_ZIRA_11.0
Язык(и): []
Пол: None
Возраст: None
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
Как видите, в Windows для большинства установленных голосов MS SAPI заполнены только «Имя» и ID.
Установка дополнительных голосов в Windows
При желании можно установить дополнительные языковые пакеты согласно инструкции https://support.microsoft.com/en-us/help/14236/language-packs#lptabs=win10open in new window
Для этого выполните указанные ниже действия.
-
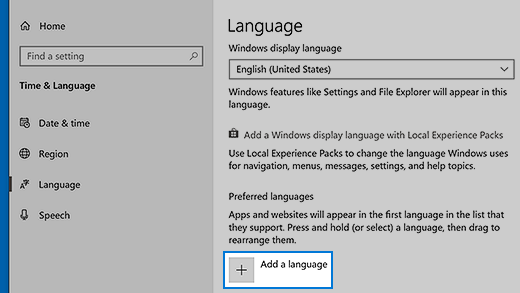
Нажмите кнопку Пуск , затем выберите Параметры > Время и язык > Язык.
-
В разделе Предпочитаемые языки выберите Добавить язык.

-
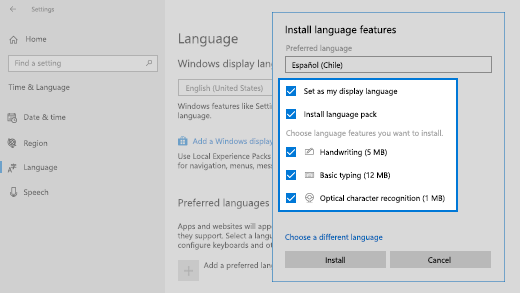
В разделе Выберите язык для установки выберите или введите название языка, который требуется загрузить и установить, а затем нажмите Далее.
-
В разделе Установка языковых компонентов выберите компоненты, которые вы хотите использовать на языке.
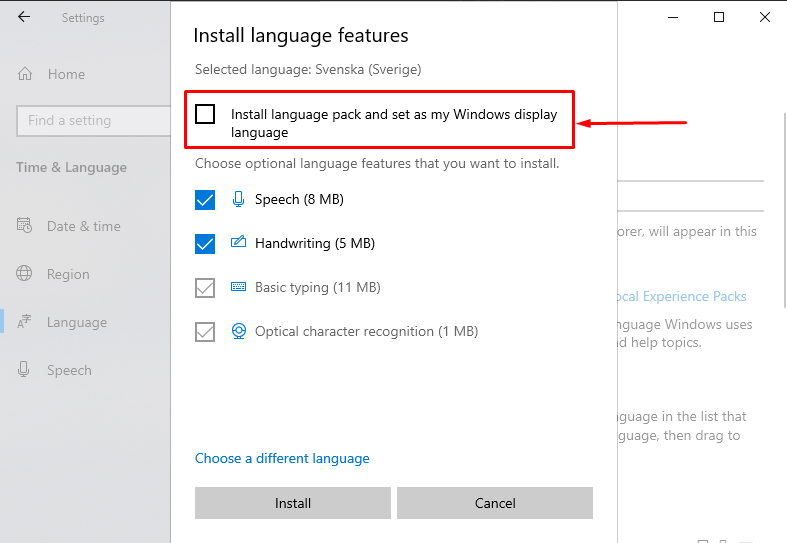
-
ВНИМАНИЕ: отключите первый пакет: «Install language pack and set as my Windows display language» — «Установите языковой пакет и установите мой язык отображения Windows»
Иначе переустановиться язык отображения операционной системы.
-
Нажмите Установить.
После установки нового языкового пакета перезагрузка не требуется. Запустив код проверки установленных языков. Новый язык должен отобразиться в списке.
ПРИМЕЧАНИЕ
Не все языковые пакеты поддерживают синтез речи. Для этого опция Speech должны быть в описании установки.
Выбор голоса
Установить голос можно методом setProperty(). Например, используя голосовые идентификаторы, найденные ранее, вы можете настроить голос. В примере показано, как настроить один голос, чтобы сказать что-то, а затем использовать другой голос из другого языка, чтобы сказать что-то другое.
В Windows идентификатором служит адрес записи в системном реестре:
import pyttsx3
engine = pyttsx3.init()
en_voice_id = "HKEY_LOCAL_MACHINESOFTWAREMicrosoftSpeechVoicesTokensTTS_MS_EN-US_ZIRA_11.0"
ru_voice_id = "HKEY_LOCAL_MACHINESOFTWAREMicrosoftSpeechVoicesTokensTTS_MS_RU-RU_IRINA_11.0"
# Use female English voice
engine.setProperty('voice', en_voice_id)
engine.say('Hello with my new voice.')
# Use female Russian voice
engine.setProperty('voice', ru_voice_id)
engine.say('Привет. Я знаю несколько языков.')
engine.runAndWait()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Как озвучить системное время в Windows
Пример консольного приложения которое будет называть неточное время может быть реализованно следующим кодом:
from datetime import datetime, date, time
import pyttsx3
import time
ru_voice_id = "HKEY_LOCAL_MACHINESOFTWAREMicrosoftSpeechVoicesTokensTTS_MS_RU-RU_IRINA_11.0"
engine = pyttsx3.init()
engine.setProperty('voice', ru_voice_id)
def say_time(msg):
engine.say(msg)
engine.runAndWait()
time_checker = datetime.now()
say_time(f'Не точное Мурманское время: {time_checker.hour} часа {time_checker.minute} плюс минус 7 минут')
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Привер риложения которое каждую минуту проговаривает текущее время по системным часам. Точнее, оно сообщает время при каждой смене минуты. Например, если вы запустите скрипт в 14:59:59, программа заговорит через секунду.
Программа будет отслеживать и называть время, пока вы не остановите ее сочетанием клавиш Ctrl+C в Windows.
from datetime import datetime, date, time
import pyttsx3
import time
ru_voice_id = "HKEY_LOCAL_MACHINESOFTWAREMicrosoftSpeechVoicesTokensTTS_MS_RU-RU_IRINA_11.0"
engine = pyttsx3.init()
engine.setProperty('voice', ru_voice_id)
def say_time(msg):
engine.say(msg)
engine.runAndWait()
while True:
time_checker = datetime.now()
if time_checker.second == 0:
say_time(f'Мурманское время: {time_checker.hour} часа {time_checker.minute} минут')
time.sleep(55)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
Посмотрите на алгоритм: чтобы уловить смену минуты, следим за значением секунд и ждем, когда оно будет равно нулю. После этого объявляем время и, чтобы поберечь ресурсы производительности, отправляем программу спать на 55 секунд. После этого она снова начнет проверять текущее время и ждать нулевой секунды.
Для дальнейшего изучения библиотеки pyttsx3 вы можете заглянуть в англоязычную документацию, в том числе справку по классу и примеры.
Упражнения tkinter
- Напишите программу часы, которая показывает текущее время и имеет кнорку, при нажатии на которую можно ушлышать текуще время.
- Внесите измеения с программу что бы при произненсении времени программа корректно склоняла слова: «часы» и «минуты».
- Добавьте с помощью радиокнопки выбор языка озвучки часов.
Озвучиваем текст из файла
Не будем довольствоваться текстами в коде программы — пора научиться брать их извне. Тем более, это очень просто. В папке, где хранится только что рассмотренный нами скрипт, создайте файл test.txt с текстом на русском языке и в кодировке UTF-8. Теперь добавьте в конец кода такой блок:
text_file = open("test.txt", "r")
data = text_file.read()
engine.say(data, sync=True)
text_file.close()
1
2
3
4
Открываем файл на чтение, передаем содержимое в переменную data, затем воспроизводим голосом все, что в ней оказалось, и закрываем файл.
Упражнения tkinter
- Напишите программу текстовым полем и кнопкой которая будет озвучивать написанное.
- Добавьте меню выбора голоса с возможностью управлять такими параметрами, как высота голоса, громкость и скорость речи.
Модуль Google TTS — голоса из интернета
Google предлагает онлайн-озвучку текста с записью результата в mp3-файл. Это не для каждой задачи:
- постоянно нужен быстрый интернет;
- нельзя воспроизвести аудио средствами самого gtts;
- скорость обработки текста ниже, чем у офлайн-синтезаторов.
Что касается голосов, английский и французский звучат очень реалистично. Русский голос Гугла — девушка, которая немного картавит и вдобавок произносит «ц» как «ч». По этой причине ей лучше не доверять чтение аудиокниг, имен и топонимов.
Еще один нюанс. Когда будете экспериментировать с кодом, не называйте файл «gtts.py» — он не будет работать! Выберите любое другое имя, например use_gtts.py.
Для работы необходимо установить пакет:
Простейший код, который сохраняет текст на русском в аудиофайл:
from gtts import gTTS
tts = gTTS('И это тоже интересно!', lang='ru')
tts.save('sound_ru.mp3')
tts = gTTS("It's amazing!", lang='en')
tts.save('sound_en.mp3')
1
2
3
4
5
6
После запуска этого кода в директории, где лежит скрипт, появится запись. Для воспроизведения в питоне придется использовать pygame или pyglet.
Упражнения tkinter
- Напишите программу состояющую из текстового поля, кнопки выбора языка, кнопки «получить аудио». Программа должна преобразовывать текст набранный в текстовом поле в аудио файл, который будет сохраняться в папке с программой.
- Добавьте текстовое поле, куда можно ввести имя для получаемого файла. И сохранять полученный файл с заданным иметем. Реализуйте проверку полей и выводом диалогового окна с сообщением о соотвествующей ошибке.
- Добавьте в программу кнопку выбора каталога для сохранения файла.
Improve Article
Save Article
Improve Article
Save Article
There are several APIs available to convert text to speech in python. One such APIs is the Python Text to Speech API commonly known as the pyttsx3 API. pyttsx3 is a very easy to use tool which converts the text entered, into audio.
Installation
To install the pyttsx3 API, open terminal and write
pip install pyttsx3
This library is dependent on win32 for which we may get an error while executing the program. To avoid that simply install pypiwin32 in your environment.
pip install pypiwin32
Some of the important functions available in pyttsx3 are:
- pyttsx3.init([driverName : string, debug : bool]) – Gets a reference to an engine instance that will use the given driver. If the requested driver is already in use by another engine instance, that engine is returned. Otherwise, a new engine is created.
- getProperty(name : string) – Gets the current value of an engine property.
- setProperty(name, value) – Queues a command to set an engine property. The new property value affects all utterances queued after this command.
- say(text : unicode, name : string) – Queues a command to speak an utterance. The speech is output according to the properties set before this command in the queue.
- runAndWait() – Blocks while processing all currently queued commands. Invokes callbacks for engine notifications appropriately. Returns when all commands queued before this call are emptied from the queue.
Now we are all set to write a sample program that converts text to speech.
import pyttsx3
converter = pyttsx3.init()
converter.setProperty('rate', 150)
converter.setProperty('volume', 0.7)
converter.say("Hello GeeksforGeeks")
converter.say("I'm also a geek")
converter.runAndWait()
Output:
The output of the above program will be a voice saying, “Hello GeeksforGeeks” and “I’m also a geek”.
Changing Voice
Suppose, you want to change the voice generated from male to female. How do you go about it? Let us see.
As you will notice, when you run the above code to bring about the text to speech conversion, the voice that responds is a male voice. To change the voice you can get the list of available voices by getting voices properties from the engine and you can change the voice according to the voice available in your system.
To get the list of voices, write the following code.
voices = converter.getProperty('voices')
for voice in voices:
print("Voice:")
print("ID: %s" %voice.id)
print("Name: %s" %voice.name)
print("Age: %s" %voice.age)
print("Gender: %s" %voice.gender)
print("Languages Known: %s" %voice.languages)
Output: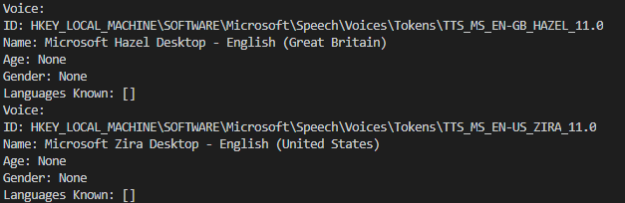
To change the voice, set the voice using setProperty() method. Voice Id found above is used to set the voice.
Below is the implementation of changing voice.
voice_id = "HKEY_LOCAL_MACHINESOFTWAREMicrosoftSpeechVoicesTokensTTS_MS_EN-US_ZIRA_11.0"
converter.setProperty('voice', voice_id)
converter.runAndWait()
Now you’ll be able to switch between voices as and when you want. You can try out running a for loop to assign different statements to different voices. Run the code and enjoy the result.
Озвучиваем системное время и любой текст в Windows и Linux. Используем pytts3, espeak, RHVoice, gTTS, Speech dispatcher.
https://gbcdn.mrgcdn.ru/uploads/post/1991/og_image/84f8204b6001e08386ade835e344324a.png

Синтез речи может пригодиться вам в работе над мобильным помощником, умным домом на Raspberry Pi, искусственным интеллектом, игрой, системой уведомлений и звуковым интерфейсом. Голосовые сообщения донесут информацию до пользователя, которому некогда читать текст. Кроме того, если программа умеет озвучивать свой интерфейс, она доступна незрячим и слабовидящим. Есть системы управления компьютером без опоры на зрение. Одна из самых популярных — NVDA (NonVisual Desktop Access) — написана на Python с добавлением C++.
Давайте посмотрим, как использовать text-to-speech (TTS) в Python и подключать синтезаторы голоса к вашей программе. Эту статью я хотела назвать «Говорящая консоль», потому что мы будем писать консольное приложение для Windows, Linux, а потенциально — и MacOS. Потом решила выбрать более общее название, ведь от наличия GUI суть не меняется. На всякий случай поясню: консоль в данном случае — терминал Linux или знакомая пользователям Windows командная строка.
Цель выберем очень скромную: создадим приложение, которое будет каждую минуту озвучивать текущее системное время.
Готовим поляну
Прежде чем писать и тестировать код, убедимся, что операционная система готова к синтезу речи, в том числе на русском языке.
Чтобы компьютер заговорил, нужны:
- голосовой движок (синтезатор речи) с поддержкой нужных нам языков,
- голоса дикторов для этого движка.
В Windows есть штатный речевой интерфейс Microsoft Speech API (SAPI). Голоса к нему выпускают, помимо Microsoft, сторонние производители: Nuance Communications, Loquendo, Acapela Group, IVONA Software.
Есть и свободные кроссплатформенные голосовые движки:
- RHVoice от Ольги Яковлевой — имеет четыре голоса для русского языка (один мужской и три женских), а также поддерживает татарский, украинский, грузинский, киргизский, эсперанто и английский. Работает в Windows, GNU/Linux и Android.
- eSpeak и его ответвление — eSpeak NG — c поддержкой более 100 языков и диалектов, включая даже латынь. NG означает New Generation — «новое поколение». Эта версия разрабатывается сообществом с тех пор, как автор оригинальной eSpeak перестал выходить на связь. Система озвучит ваш текст в Windows, Android, Linux, Mac, BSD. При этом старый eSpeak стабилен в ОС Windows 7 и XP, а eSpeak NG совместим с Windows 8 и 10.

В статье я ориентируюсь только на перечисленные свободные синтезаторы, чтобы мы могли писать кроссплатформенный код и не были привязаны к проприетарному софту.
По качеству голоса RHVoice неплох и к нему быстро привыкаешь, а вот eSpeak очень специфичен и с акцентом. Зато eSpeak запускается на любом утюге и подходит как вариант на крайний случай, когда ничто другое не работает или не установлено у пользователя.
Установка речевых движков, голосов и модулей в Windows
С установкой синтезаторов в Windows проблем возникнуть не должно. Единственный нюанс — для русского голоса eSpeak и eSpeak NG нужно скачать расширенный словарь произношения. Распакуйте архив в подкаталог espeak-data или espeak-ng-data в директории программы. Теперь замените старый словарь новым: переименуйте ru_dict-48 в ru_dict, предварительно удалив имеющийся файл с тем же именем (ru_dict).
Теперь установите модули pywin32, python-espeak и py-espeak-ng, которые потребуются нам для доступа к возможностям TTS:
pip install pywin32 python-espeak pyttsx3 py-espeak-ng
Если у вас на компьютере соседствуют Python 2 и 3, здесь и далее пишите «pip3», а при запуске скриптов — «python3».
Установка eSpeak(NG) в Linux
Подружить «пингвина» с eSpeak, в том числе NG, можно за минуту:
sudo apt-get install espeak-ng python-espeak
pip3 install py-espeak-ng pyttsx3
Дальше загружаем и распаковываем словарь ru_dict с официального сайта:
wget http://espeak.sourceforge.net/data/ru_dict-48.zip
unzip ru_dict-48.zip
Теперь ищем адрес каталога espeak-data (или espeak-ng-data) где-то в /usr/lib/ и перемещаем словарь туда. В моем случае команда на перемещение выглядела так:
sudo mv ru_dict-48 /usr/lib/i386-linux-gnu/espeak-data/ru_dict
Обратите внимание: вместо «i386» у вас в системе может быть «x86_64…» или еще что-то. Если не уверены, воспользуйтесь поиском:
find /usr/lib/ -name «espeak-data»
Готово!
RHVoice в Linux
Инструкцию по установке RHVoice в Linux вы найдете, например, в начале этой статьи. Ничего сложного, но времени занимает больше, потому что придется загрузить несколько сотен мегабайт.
Смысл в том, что мы клонируем git-репозиторий и собираем необходимые компоненты через scons.
Для экспериментов в Windows и Linux я использую одни и те же русские голоса: стандартный ‘ru’ в eSpeak и Aleksandr в RHVoice.

Как проверить работоспособность синтезатора
Прежде чем обращаться к движку, убедитесь, что он установлен и работает правильно.
Проверить работу eSpeak в Windows проще всего через GUI — достаточно запустить TTSApp.exe в папке с программой. Дальше открываем список голосов, выбираем eSpeak-RU, вводим текст в поле редактирования и жмем на кнопку Speak.
Обратиться к espeak можно и из терминала. Базовые консольные команды для eSpeak и NG совпадают — надо только добавлять или убирать «-ng» после «espeak»:
espeak -v ru -f D:my.txt
espeak-ng -v en «The Cranes are Flying»
echo «Да, это от души. Замечательно. Достойно восхищения» |RHVoice-test -p Aleksandr
Как нетрудно догадаться, первая команда с ключом -f читает русский текст из файла. Чтобы в Windows команда espeak подхватывалась вне зависимости от того, в какой вы директории, добавьте путь к консольной версии eSpeak (по умолчанию — C:Program FileseSpeakcommand_line) в переменную окружения Path. Вот как это сделать.
Библиотека pyttsx3
PyTTSx3 — удобная кроссплатформенная библиотека для реализации TTS в приложениях на Python 3. Использует разные системы синтеза речи в зависимости от текущей ОС:
- в Windows — SAPI5,
- в Mac OS X — nsss,
- в Linux и на других платформах — eSpeak.
Это очень удобно: пишете код один раз и он работает везде. Кстати, eSpeak NG поддерживается наравне с исходной версией.
А теперь примеры!
Просмотр голосов
У каждого голоса есть несколько параметров, с которыми можно работать:
- id (идентификатор в операционной системе),
- name (имя),
- languages (поддерживаемые языки),
- gender (пол),
- age (возраст).
Первый вопрос всегда в том, какие голоса установлены на стороне пользователя. Поэтому создадим скрипт, который покажет все доступные голоса, их имена и ID. Назовем файл, например, list_voices.py:
import pyttsx3
tts = pyttsx3.init() # Инициализировать голосовой движок.
У активного движка есть стандартный параметр ‘voices’, где содержится список всех доступных этому движку голосов. Это нам и нужно:
voices = tts.getProperty(‘voices’)
# Перебрать голоса и вывести параметры каждого
for voice in voices:
print(‘=======’)
print(‘Имя: %s’ % voice.name)
print(‘ID: %s’ % voice.id)
print(‘Язык(и): %s’ % voice.languages)
print(‘Пол: %s’ % voice.gender)
print(‘Возраст: %s’ % voice.age)
Теперь открываем терминал или командную строку, переходим в директорию, куда сохранили скрипт, и запускаем list_voices.py.
Результат будет примерно таким:
В Linux картина будет похожей, но с другими идентификаторами.
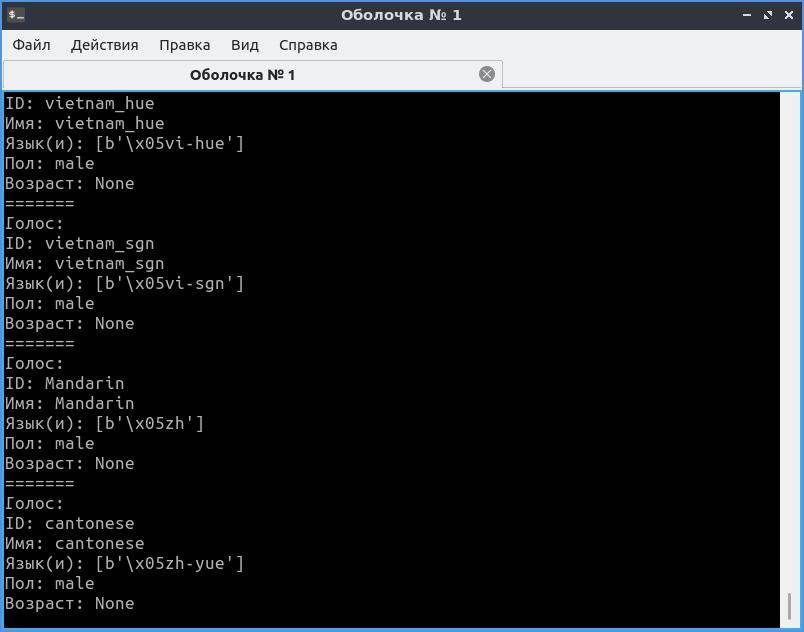
Как видите, в Windows для большинства установленных голосов MS SAPI заполнены только «Имя» и ID. Однако этого хватит, чтобы решить следующую нашу задачу: написать код, который выберет русский голос и что-то им произнесет.
Например, у голоса RHVoice Aleksandr есть преимущество — его имя уникально, потому что записано транслитом и в таком виде не встречается у других известных производителей голосов. Но через pyttsx3 этот голос будет работать только в Windows. Для воспроизведения в Linux ему нужен Speech Dispatcher (подробнее чуть позже), с которым библиотека взаимодействовать не умеет. Как общаться с «диспетчером» еще обсудим, а пока разберемся с доступными голосами.
Как выбрать голос по имени
В Windows голос удобно выбирать как по ID, так и по имени. В Linux проще работать с именем или языком голоса. Создадим новый файл set_voice_and_say.py:
import pyttsx3
tts = pyttsx3.init()
voices = tts.getProperty(‘voices’)
# Задать голос по умолчанию
tts.setProperty(‘voice’, ‘ru’)
# Попробовать установить предпочтительный голос
for voice in voices:
if voice.name == ‘Aleksandr’:
tts.setProperty(‘voice’, voice.id)
tts.say(‘Командный голос вырабатываю, товарищ генерал-полковник!’)
tts.runAndWait()
В Windows вы услышите голос Aleksandr, а в Linux — стандартный русский eSpeak. Если бы мы вовсе не указали голос, после запуска нас ждала бы тишина, так как по умолчанию синтезатор говорит по-английски.
Обратите внимание: tts.say() не выводит реплики мгновенно, а собирает их в очередь, которую затем нужно запустить на воспроизведение командой tts.runAndWait().
Выбор голоса по ID
Часто бывает, что в системе установлены голоса с одинаковыми именами, поэтому надежнее искать необходимый голос по ID.
Заменим часть написанного выше кода:
for voice in voices:
ru = voice.id.find(‘RHVoiceAnna’) # Найти Анну от RHVoice
if ru > -1: # Eсли нашли, выбираем этот голос
tts.setProperty(‘voice’, voice.id)
Теперь в Windows мы точно не перепутаем голоса Anna от Microsoft и RHVoice. Благодаря поиску в подстроке нам даже не пришлось вводить полный ID голоса.
Но когда мы пишем под конкретную машину, для экономии ресурсов можно прописать голос константой. Выше мы запускали скрипт list_voices.py — он показал параметры каждого голоса в ОС. Тогда-то вы и могли обратить внимание, что в Windows идентификатором служит адрес записи в системном реестре:
import pyttsx3
tts = pyttsx3.init()
EN_VOICE_ID = «HKEY_LOCAL_MACHINESOFTWAREMicrosoftSpeechVoicesTokensMS-Anna-1033-20DSK»
RU_VOICE_ID = «HKEY_LOCAL_MACHINESOFTWAREMicrosoftSpeechVoicesTokenEnumsRHVoiceAnna»
# Использовать английский голос
tts.setProperty(‘voice’, EN_VOICE_ID)
tts.say(«Can you hear me say it’s a lovely day?»)
# Теперь — русский
tts.setProperty(‘voice’, RU_VOICE_ID)
tts.say(«А напоследок я скажу»)
tts.runAndWait()
Как озвучить системное время в Windows и Linux

Это крошечное приложение каждую минуту проговаривает текущее время по системным часам. Точнее, оно сообщает время при каждой смене минуты. Например, если вы запустите скрипт в 14:59:59, программа заговорит через секунду.
Создадим новый файл с именем time_tts.py. Всего, что мы разобрали выше, должно хватить, чтобы вы без проблем прочли и поняли следующий код:
# «Говорящие часы» — программа озвучивает системное время
from datetime import datetime, date, time
import pyttsx3, time
tts = pyttsx3.init()
tts.setProperty(‘voice’, ‘ru’) # Наш голос по умолчанию
tts.setProperty(‘rate’, 150) # Скорость в % (может быть > 100)
tts.setProperty(‘volume’, 0.8) # Громкость (значение от 0 до 1)
def set_voice(): # Найти и выбрать нужный голос по имени
voices = tts.getProperty(‘voices’)
for voice in voices:
if voice.name == ‘Aleksandr’:
tts.setProperty(‘voice’, voice.id)
else:
pass
def say_time(msg): # Функция, которая будет называть время в заданном формате
set_voice() # Настроить голос
tts.say(msg)
tts.runAndWait() # Воспроизвести очередь реплик и дождаться окончания речи
while True:
time_checker = datetime.now() # Получаем текущее время с помощью datetime
if time_checker.second == 0:
say_time(‘{h} {m}’.format(h=time_checker.hour, m=time_checker.minute))
time.sleep(55)
else:
pass
Программа будет отслеживать и называть время, пока вы не остановите ее сочетанием клавиш Ctrl+Break или Ctrl+C (в Windows и Linux соответственно).
Посмотрите на алгоритм: чтобы уловить смену минуты, следим за значением секунд и ждем, когда оно будет равно нулю. После этого объявляем время и, чтобы поберечь оперативную память, отправляем программу спать на 55 секунд. После этого она снова начнет проверять текущее время и ждать нулевой секунды.
Для дальнейшего изучения библиотеки pyttsx3 вы можете заглянуть в англоязычную документацию, в том числе справку по классу и примеры. А пока посмотрим на другие инструменты.
Обертка для eSpeak NG
Модуль называется py-espeak-ng. Это альтернатива pyttsx3 для случаев, когда вам нужен или доступен только один синтезатор — eSpeak NG. Не дай бог, конечно. Впрочем, для быстрых экспериментов с голосом очень даже подходит. Принцип использования покажется вам знакомым:
from espeakng import ESpeakNG
engine = ESpeakNG()
engine.speed = 150
engine.say(«I’d like to be under the sea. In an octopus’s garden, in the shade!», sync=True)
engine.speed = 95
engine.pitch = 32
engine.voice = ‘russian’
engine.say(‘А теперь Горбатый!’, sync=True)
Обратите внимание на параметр синхронизации реплик sync=True. Без него синтезатор начнет читать все фразы одновременно — вперемешку. В отличие от pyttsx3, обертка espeakng не использует команду runAndWait(), и пропуск параметра sync сбивает очередь чтения.
Озвучиваем текст из файла
Не будем довольствоваться текстами в коде программы — пора научиться брать их извне. Тем более, это очень просто. В папке, где хранится только что рассмотренный нами скрипт, создайте файл test.txt с текстом на русском языке и в кодировке UTF-8. Теперь добавьте в конец кода такой блок:
text_file = open(«test.txt», «r»)
data = text_file.read()
tts.say(data, sync=True)
text_file.close()
Открываем файл на чтение, передаем содержимое в переменную data, затем воспроизводим голосом все, что в ней оказалось, и закрываем файл.
Управляем речью через Speech Dispatcher в Linux
До сих пор по результатам работы нашего кода в Linux выводился один суровый eSpeak. Пришло время позаботиться о друзьях Tux’а и порадовать их сравнительно реалистичными голосами RHVoice. Для этого нам понадобится Speech Dispatcher — аналог MS SAPI. Он позволяет управлять всеми установленными в системе голосовыми движками и вызывать любой из них по необходимости.
Скорее всего Speech Dispatcher есть у вас в системе по умолчанию. Чтобы обращаться к нему из кода Python, надо установить модуль speechd:
sudo apt install python3-speechd
Пробуем выбрать синтезатор RHVoice с помощью «диспетчера» и прочесть текст:
import speechd
tts_d = speechd.SSIPClient(‘test’)
tts_d.set_output_module(‘rhvoice’)
tts_d.set_language(‘ru’)
tts_d.set_rate(50)
tts_d.set_punctuation(speechd.PunctuationMode.SOME)
tts_d.speak(‘И нежный вкус родимой речи так чисто губы холодит’)
tts_d.close()
Ура! Наконец-то наше Linux-приложение говорит голосом, похожим на человеческий. Обратите внимание на метод .set_output_module() — он позволяет выбрать любой установленный движок, будь то espeak, rhvoice или festival. После этого синтезатор прочтет текст голосом, предписанным для данного движка по умолчанию. Если задан только язык — голосом по умолчанию для данного языка.
Получается, чтобы сделать кроссплатформенное приложение с поддержкой синтезатора RHVoice, нужно совместить pyttsx3 и speechd: проверить, в какой системе работает наш код, и выбрать SAPI или Speech Dispatcher. А в любой непонятной ситуации — откатиться на неказистый, но вездеходный eSpeak.
Однако для этого программа должна знать, где работает. Определить текущую ОС и ее разрядность очень легко! Лично я предпочитаю использовать для этого стандартный модуль platform, который не нужно устанавливать:
import platform
system = platform.system() # Вернет тип системы.
bit = platform.architecture() # Вернет кортеж, где разрядность — нулевой элемент
print(system)
print(bit[0])
Пример результата:
Windows
64bit
Кстати, не обязательно решать все за пользователя. На базе pyttsx3 вы при желании создадите меню выбора голоса с возможностью управлять такими параметрами, как высота голоса, громкость и скорость речи.
Модуль Google TTS — голоса из интернета

Google предлагает онлайн-озвучку текста с записью результата в mp3-файл. Это не для каждой задачи:
- постоянно нужен быстрый интернет;
- нельзя воспроизвести аудио средствами самого gtts;
- скорость обработки текста ниже, чем у офлайн-синтезаторов.
Что касается голосов, английский и французский звучат очень реалистично. Русский голос Гугла — девушка, которая немного картавит и вдобавок произносит «ц» как «ч». По этой причине ей лучше не доверять чтение аудиокниг, имен и топонимов.
Еще один нюанс. Когда будете экспериментировать с кодом, не называйте файл «gtts.py» — он не будет работать! Выберите любое другое имя, например use_gtts.py.
Простейший код, который сохраняет текст на русском в аудиофайл:
from gtts import gTTS
tts = gTTS(‘Иван Федорович Крузенштерн. Человек и пароход!’, lang=’ru’)
tts.save(‘tts_output.mp3’)
После запуска этого кода в директории, где лежит скрипт, появится запись. Чтобы воспроизвести файл «не отходя от кассы», придется использовать еще какой-то модуль или фреймворк. Годится pygame или pyglet.
Вот листинг приложения, которое построчно читает txt-файлы с помощью связки gtts и PyGame. Я заметила, что для нормальной работы этого скрипта текст из text.txt должен быть в кодировке Windows-1251 (ANSI).
Выводим текст через NVDA

Мы научились озвучивать приложение с помощью установленных в системе синтезаторов. Но что если большинству пользователей эта фишка не нужна, и мы хотим добавить речь исключительно как опцию для слабовидящих? В таком случае не обязательно писать код озвучивания: достаточно передать текст интерфейса другому приложению — экранному диктору.
Одна из самых популярных программ экранного доступа в Windows — бесплатная и открытая NVDA. Для связи с ней к нашему приложению нужно привязать библиотеку nvdaControllerClient (есть варианты для 32- и 64-разрядных систем). Узнавать разрядность системы вы уже умеете.
Еще для работы с экранным диктором нам понадобятся модули ctypes и time. Создадим файл nvda.py, где напишем модуль связи с NVDA:
import time, ctypes, platform
# Загружаем библиотеку клиента NVDA
bit = platform.architecture()
if bit[0] == ’32bit’:
clientLib = ctypes.windll.LoadLibrary(‘nvdaControllerClient32.dll’)
elif bit[0] == ’64bit’:
clientLib = ctypes.windll.LoadLibrary(‘nvdaControllerClient64.dll’)
else:
errorMessage=str(ctypes.WinError(res))
ctypes.windll.user32.MessageBoxW(0,u»Ошибка! Не удалось определить разрядность системы!»,0)
# Проверяем, запущен ли NVDA
res = clientLib.nvdaController_testIfRunning()
if res != 0:
errorMessage=str(ctypes.WinError(res))
ctypes.windll.user32.MessageBoxW(0,u»Ошибка: %s»%errorMessage,u»нет доступа к NVDA»,0)
def say(msg):
clientLib.nvdaController_speakText(msg)
time.sleep(1.0)
def close_speech():
clientLib.nvdaController_cancelSpeech()
Теперь эту заготовку можно применить в коде основной программы:
import nvda
nvda.say(‘Начать игру’)
# … другие реплики или сон
nvda.close_speech()
Если NVDA неактивна, после запуска кода мы увидим окошко с сообщением об ошибке, а если работает — услышим от нее заданный текст.
Плюс подхода в том, что незрячий пользователь будет слышать тот голос, который сам выбрал и настроил в NVDA.
Заключение
Ваша программа уже глаголет устами хотя бы одного из установленных синтезаторов? Поздравляю! Как видите, это не слишком сложно и «в выигрыше даже начинающий». Еще больше радуют перспективы использования TTS в ваших проектах. Все, что можно вывести как текст, можно и озвучить.
Представьте утилиту, которая при внезапной проблеме с экраном телефона или монитора сориентирует пользователя по речевым подсказкам, поможет спокойно сохранить данные и штатно завершить работу. Или как насчет прослушивания входящей почты, когда вы не за монитором? Напишите, когда, на ваш взгляд, TTS полезна, а когда только раздражает. Говорящая программа с какими функциями пригодилась бы вам?