Содержание
- Radio failed to acknowledge error context 24 status c0000386
- Re: XTS5000 Programming Errors «. c0000368»
- Re: XTS5000 Programming Errors «. c0000368»
- Re: XTS5000 Programming Errors «. c0000368»
- Radio failed to acknowledge error context 24 status c0000386
- RS232 Prgm cable for XTS1500/2500/5000
- Re: RS232 Prgm cable for XTS1500/2500/5000
- Re: RS232 Prgm cable for XTS1500/2500/5000
- Re: RS232 Prgm cable for XTS1500/2500/5000
- Re: RS232 Prgm cable for XTS1500/2500/5000
- Re: RS232 Prgm cable for XTS1500/2500/5000
- Re: RS232 Prgm cable for XTS1500/2500/5000
- Re: RS232 Prgm cable for XTS1500/2500/5000
- Re: RS232 Prgm cable for XTS1500/2500/5000
- Re: RS232 Prgm cable for XTS1500/2500/5000
- Re: RS232 Prgm cable for XTS1500/2500/5000
- Re: RS232 Prgm cable for XTS1500/2500/5000
- Re: RS232 Prgm cable for XTS1500/2500/5000
- Radio failed to acknowledge error context 24 status c0000386
- Re: ASTRO XTL5000 Consolette
- Re: ASTRO XTL5000 Consolette
- Re: ASTRO XTL5000 Consolette
- Re: ASTRO XTL5000 Consolette
- Re: ASTRO XTL5000 Consolette
- Re: ASTRO XTL5000 Consolette
- Re: ASTRO XTL5000 Consolette
- Arch Linux
- #1 2015-05-16 13:44:24
- [SOLVED] Bluetooth won’t pair. bluez5 with current kernel 4.0.x
- #2 2015-05-16 18:11:28
- Re: [SOLVED] Bluetooth won’t pair. bluez5 with current kernel 4.0.x
- #3 2015-05-17 11:34:31
- Re: [SOLVED] Bluetooth won’t pair. bluez5 with current kernel 4.0.x
- #4 2015-05-18 05:32:48
- Re: [SOLVED] Bluetooth won’t pair. bluez5 with current kernel 4.0.x
Radio failed to acknowledge error context 24 status c0000386
Post by SnoForum173 » Thu Apr 03, 2008 12:02 pm
I have an XTS5000 (H18SDF9PW6AN) and I just intsalled Astro25 CPS 10.01.00 on my PC today. I attemped to read the radio using a Kawa aftermarket serial ribless programming cable got off of Ebay and I am recieving a NetGen10 error «Radio Failed to Acknowledge Error Context: 24, Status: c0000386». The radio is on, however the battery is not super fresh. It’s not beeping or anything but it’s just not fresh off the charger. Could this be causing the error?
I also installed the software onto another PC, however both are Windows XP Pro, and I get the same error.
If I unhook the cable from the radio and click the read device button it shows error «. c000039e». So, I came to the conclusion that since the error codes are different, I’m assuming that the cable is making a connection but obvoiusly there must be another issue causing the ‘368’ error? I know you guys are the experts. would you agree with that assumption? What else could it be?
Also, are USB programming cables much better than serial? Is there less of a change of bricking the radio using aftermarket USB over serial? Are there any aftermarket USB cables out there becuase I couldn’t find any on Ebay.
Re: XTS5000 Programming Errors «. c0000368»
Post by Hightower » Thu Apr 03, 2008 12:28 pm
Those Kawa programming cables are junk. From the ones I’ve seen, you have to have a full charged battery if there is any hope of reading the radio with these Kawa cables.
Why use a $20 cable on a $2000 radio — that just don’t make sense.

Re: XTS5000 Programming Errors «. c0000368»
Post by HLA » Thu Apr 03, 2008 1:09 pm

Re: XTS5000 Programming Errors «. c0000368»
Post by Farewell » Thu Apr 03, 2008 11:34 pm
Источник
Radio failed to acknowledge error context 24 status c0000386

RS232 Prgm cable for XTS1500/2500/5000
Post by fineshot1 » Thu Dec 18, 2008 7:54 am
Anyone have any experience with the RS232 ribless programing cables (from greedbay) for the XTS series.
I have one that I purchased from another user on another website(not here or greedbay but for him it was a greedbay purchase)
and I can not seem to get it working at all. He states it worked for him & have no reason to doubt his word. I take it I must
have something set wrong but just seem to be at a loss as to what. All my PC’s run Win XP Pro and have only one RS232 com
port. One is a IBM ThinkCentre desktop and the other is a Panasonic CF-73 laptop.
Any insight to this would be appreciated — TIA.
Re: RS232 Prgm cable for XTS1500/2500/5000
Post by Einstein » Thu Dec 18, 2008 9:13 am
Re: RS232 Prgm cable for XTS1500/2500/5000
Post by fineshot1 » Thu Dec 18, 2008 11:44 am
Duh — should have mentioned that.
No communications to the radio.
Re: RS232 Prgm cable for XTS1500/2500/5000
Post by Einstein » Thu Dec 18, 2008 12:01 pm
When you have the software running, with the cable connected to the radio and computer, and try to read the radio, any error codes? Are you stating that nothing happens at all? The software should state something. Any error codes on the radio screen, assuming its a model II or III
Duh — should have mentioned that.
No communications to the radio.
Re: RS232 Prgm cable for XTS1500/2500/5000
Post by fineshot1 » Thu Dec 18, 2008 12:50 pm
See error below
Radio Failed to Acknowledge.
Error Context: 24, Status: c0000386
The same error happens even if I have nothing plugged into the com port — hence «No communication to radio».
Re: RS232 Prgm cable for XTS1500/2500/5000
Post by Einstein » Thu Dec 18, 2008 1:05 pm
fineshot1 wrote: See error below
Radio Failed to Acknowledge.
Error Context: 24, Status: c0000386
The same error happens even if I have nothing plugged into the com port — hence «No communication to radio».
Re: RS232 Prgm cable for XTS1500/2500/5000
Post by fineshot1 » Thu Dec 18, 2008 1:18 pm
fineshot1 wrote: See error below
Radio Failed to Acknowledge.
Error Context: 24, Status: c0000386
The same error happens even if I have nothing plugged into the com port — hence «No communication to radio».
I know the com ports on each pc work due to using them to program MTS2000’s and other radios that require the RIB.
Not much chance of me getting another cable to test with unless I make a greedbay purchase from the original seller.
Thats why I asked if anyone had experience with these types of cables cause I suspect I may have something setup
wrong on my end — but I steered the XTS5000 CPS 12 to the Com 1 port and no joy so I was wondering if there was
anything else I may have over looked. I am trying to go from using a USB to an RS232 cable so thought I may have
missed something.
Re: RS232 Prgm cable for XTS1500/2500/5000
Post by Einstein » Thu Dec 18, 2008 1:31 pm
Com ports ok. If you have another XTS radio to try, try that. Changing from USB to Serial port connection is straight forward in the software. Probably the cable. I have had one OEM cable that had a bad ground connection in it and was locking up all my XTS 5000’s. Sometimes it would work other times would not.
fineshot1 wrote: See error below
Radio Failed to Acknowledge.
Error Context: 24, Status: c0000386
The same error happens even if I have nothing plugged into the com port — hence «No communication to radio».
I know the com ports on each pc work due to using them to program MTS2000’s and other radios that require the RIB.
Not much chance of me getting another cable to test with unless I make a greedbay purchase from the original seller.
Thats why I asked if anyone had experience with these types of cables cause I suspect I may have something setup
wrong on my end — but I steered the XTS5000 CPS 12 to the Com 1 port and no joy so I was wondering if there was
anything else I may have over looked. I am trying to go from using a USB to an RS232 cable so thought I may have
missed something.
Re: RS232 Prgm cable for XTS1500/2500/5000
Post by cbus » Fri Dec 19, 2008 4:31 am
Re: RS232 Prgm cable for XTS1500/2500/5000
Post by Jim202 » Fri Dec 19, 2008 5:02 am
I have 2 comments.
1. Make sure the software is set to the com port your trying to use. This has to be made
in order for the software to know which port to talk to the radio with.
2. Not all USB ports on all computers will work on the Motorola software. I have a fairly
new HP laptop and it has 4 USB ports, 2 on each side. Only one of the ports on each
side will support the USP programming cable.
3. I have occasionally got the computer out of sync with how I am connecting the
programming cable to the radio. The simple solution is to disconnect the cable from the
radio and waiting about 15 seconds. Then re-connect the programming cable back
to the radio. This lets windows get back into the swing of things and allow the Motorola
software to communicate with the radio.
By the way, for those looking for the Motorola programming cable part numbers,
try going into the CD and going to the help section. Think that was where I
found the list of about 5 or 6 cables listed with the needed part numbers.
Re: RS232 Prgm cable for XTS1500/2500/5000
Post by fineshot1 » Fri Dec 19, 2008 6:39 am

Re: RS232 Prgm cable for XTS1500/2500/5000
Post by escomm » Fri Dec 19, 2008 10:52 am
Is the cable OEM?
What are the speed settings for the com port?
Re: RS232 Prgm cable for XTS1500/2500/5000
Post by fineshot1 » Fri Dec 19, 2008 11:46 am
escomm wrote: 2 questions:
Is the cable OEM?
What are the speed settings for the com port?
This Ribless RS232 is not OEM. There are no markings on it what so ever.
Com 1 is setup for 9600 baud in the XP system device manager.
Источник
Radio failed to acknowledge error context 24 status c0000386
Post by pluto1914 » Tue Sep 23, 2008 10:56 am
I am trying to program an ASTRO XTL5000 Consolette with the front accessory port. I changed the CPS option to the com port. I get an error message that says «Radio Failed to Acknowledge Error Context: 24 Status: c0000386». Do I need to do something special for the consolette?

Re: ASTRO XTL5000 Consolette
Post by Mfire39 » Tue Sep 23, 2008 12:00 pm
Are you using the correct programming cable?
Stupidity creates job security!
If your radio has old firmware, programming it with the latest CPS will not add any new features unless you have the latest firmware to match..
CPS = C ustomer P rogramming S oftware, Not CPS Software.
Re: ASTRO XTL5000 Consolette
Post by pluto1914 » Tue Sep 23, 2008 12:12 pm
I am using a HKN6155A.
Re: ASTRO XTL5000 Consolette
Post by Firebuff66 » Tue Sep 23, 2008 3:18 pm
Re: ASTRO XTL5000 Consolette
Post by RKG » Tue Sep 23, 2008 5:46 pm
The XTL5000 Consolette can be programmed via the data connector on the rear of the radio, using the «data cable.»
We have a bunch of these that are more or less permanently mounted in a console stack. Removing the consolette in order to open the case in order to get access to the rear of the radio deck is, at best, frustrating, so what we did was to mill a small slot on the back of the plastic consolette case and permanently install a «data» cable on each radio. These drape down far enough to be accessible via the cabinet door under the writing surface.
So far as I am aware, no XTL Consolette can be programmed via the control head mike connector.
Re: ASTRO XTL5000 Consolette
Post by AEC » Mon Oct 06, 2008 12:06 am
Firebuff66 is correct, you can’t program the XTL5K from the front, it can only be done from the back of the radio.
Especially if the consolette also has the TRC board installed for two/four wire remote operation, then the control head cabling routes to the TRC and the radio and head on the front panel of the station.
I take it your setup also has the clock and the bar VU meter on the front.
As a side note, watch the stress placed on the adaptor cable as it breaks off at the rear panel easily.
Good cable and ‘N’ connector, just crappy plastic retaining it..WTF?
Assembled by Apple. all plastic, all the time, and NO shielding either!

Re: ASTRO XTL5000 Consolette
Post by MotoFAN » Tue Oct 28, 2008 3:37 pm
Re: ASTRO XTL5000 Consolette
Post by MotoFAN » Tue Oct 28, 2008 11:58 pm
Источник
Arch Linux
You are not logged in.
#1 2015-05-16 13:44:24
[SOLVED] Bluetooth won’t pair. bluez5 with current kernel 4.0.x
I’m trying to pair a Bluetooth mouse. It’s a miniPCIe combo card, Broadcom BCM94352, aka BCM4352, aka AzureWare2123. I’ve searched and searched. It seems I either haven’t found the right thread, or my issue is different than others. I have no problem with bluetoothctl turning on Bluetooth and scanning. It sees all devices as it should. However, when I go to pair with a device, it returns:
I get the same results with using the ‘connect’ command.
I tried checking any status or logs based on what others have experienced. Here is systemctl bluetooth status:
I don’t know where to go from here.
Possibly helpful stuff:
Last edited by FNtastic (2015-05-24 15:17:39)
#2 2015-05-16 18:11:28
Re: [SOLVED] Bluetooth won’t pair. bluez5 with current kernel 4.0.x
It happened to me few times.
Try registering agent first, as in here https://wiki.archlinux.org/index.php/Bl … uetoothctl .
#3 2015-05-17 11:34:31
Re: [SOLVED] Bluetooth won’t pair. bluez5 with current kernel 4.0.x
It happened to me few times.
Try registering agent first, as in here https://wiki.archlinux.org/index.php/Bl … uetoothctl .
Thanks for the suggestion. Here’s what happens when I do that:
I just deleted the original MAC address and tried to scan again. Now a scan returns nothing.
Going to try a restart and see if it helps.
EDIT: This is what I’m seeing after a reboot:
And, I’m unable to connect or pair. I would appear to search, but never found any devices. I confirmed the devices are discoverable, etc. Searched and found them with other devices, etc. For some reason, this doesn’t want to work for me.
Is there a GUI method to accomplishing this, or am I going to be stuck in CLI for this one? I tried using NetworkManager for WiFi and it worked great. I couldn’t find a solution for bluez5 management in cinnamon.
Last edited by FNtastic (2015-05-17 12:56:04)
#4 2015-05-18 05:32:48
Re: [SOLVED] Bluetooth won’t pair. bluez5 with current kernel 4.0.x
I was just messing around with bluetooth last night so I’m feeling your pain. I got some stuff working, but I’m surprised by how primitive this support seems. If you’re using Cinnamon, you’re probably stuck with the CLI for now.
I had an experience removing/deleting the MAC of a bluetooth device yesterday and that was not a good thing because, like you, I couldn’t find it again. I was trying to pair my Galaxy S5 and, after getting it paired, I wanted to go through the process one more time to practice. I removed the device without understanding what that command did. Similar to what you’re seeing, that made it so that the S5 wouldn’t show up no matter what I did. I was eventually able to get it back (and I will never remove it again, LOL). I had to make my computer discoverable and the device discoverable and then I was only able to get the MAC address to show up again on my computer by initiating the connection from my S5. It was a pain in the butt, but I finally got it back. I know you’re pairing a mouse, but maybe it might help to make your mouse and your computer discoverable and try the process again to see if that will get the MAC address back in the list. If worse comes to worst, maybe you might be able to enter the MAC address manually?
I saw something in one of the outputs that you posted that reminded me of something that I read yesterday. Here are the lines from your output that caught my attention:
The part where the pair failed because the authentication was canceled is something that I saw when I didn’t answer yes quickly enough to the pair requests on my computer and my S5. I’m wondering if your mouse has a security code/pin that you need to enter or accept. If not, I remembered reading in the wiki that sometimes mice (or other devices) don’t have a security code/pin and, in those cases, you need to manually trust the device by using the command «trust». It would look something like this (I’m just typing this from memory):
Anyway, hope some of that helps you. Let us know how it goes.
Источник
Moderator: Queue Moderator
-
pluto1914
- Batboard $upporter
- Posts: 218
- Joined: Thu Feb 17, 2005 8:23 pm
- What radios do you own?: A few APXs
ASTRO XTL5000 Consolette
I am trying to program an ASTRO XTL5000 Consolette with the front accessory port. I changed the CPS option to the com port. I get an error message that says «Radio Failed to Acknowledge Error Context: 24 Status: c0000386». Do I need to do something special for the consolette?
Thanks,
David
-

Mfire39
- Moderator
- Posts: 1331
- Joined: Sat Jan 17, 2004 8:53 am
- What radios do you own?: APX

Re: ASTRO XTL5000 Consolette
Post
by Mfire39 » Tue Sep 23, 2008 12:00 pm
Are you using the correct programming cable?
-Marc
Stupidity creates job security!
If your radio has old firmware, programming it with the latest CPS will not add any new features unless you have the latest firmware to match..
CPS = Customer Programming Software, Not CPS Software.
-
Firebuff66
- NOT ALLOWED TO BUY/SELL/TRADE
- Posts: 162
- Joined: Thu Feb 28, 2002 4:00 pm
Re: ASTRO XTL5000 Consolette
Post
by Firebuff66 » Tue Sep 23, 2008 3:18 pm
XTL5000 Consolettes program with the port on the radio not the head.
You have to open the console and its on the front of the radio above the 25 pin conections
-
RKG
- Posts: 2629
- Joined: Mon Dec 10, 2001 4:00 pm
Re: ASTRO XTL5000 Consolette
Post
by RKG » Tue Sep 23, 2008 5:46 pm
The XTL5000 Consolette can be programmed via the data connector on the rear of the radio, using the «data cable.»
We have a bunch of these that are more or less permanently mounted in a console stack. Removing the consolette in order to open the case in order to get access to the rear of the radio deck is, at best, frustrating, so what we did was to mill a small slot on the back of the plastic consolette case and permanently install a «data» cable on each radio. These drape down far enough to be accessible via the cabinet door under the writing surface.
So far as I am aware, no XTL Consolette can be programmed via the control head mike connector.
-
AEC
- No Longer Registered
- Posts: 1889
- Joined: Wed Dec 22, 2004 7:56 pm
Re: ASTRO XTL5000 Consolette
Post
by AEC » Mon Oct 06, 2008 12:06 am
Firebuff66 is correct, you can’t program the XTL5K from the front, it can only be done from the back of the radio.
Especially if the consolette also has the TRC board installed for two/four wire remote operation, then the control head cabling routes to the TRC and the radio and head on the front panel of the station.
I take it your setup also has the clock and the bar VU meter on the front.
As a side note, watch the stress placed on the adaptor cable as it breaks off at the rear panel easily.
Good cable and ‘N’ connector, just crappy plastic retaining it..WTF?
Assembled by Apple…all plastic, all the time, and NO shielding either!
-

MotoFAN
- Posts: 1054
- Joined: Thu Jun 28, 2007 6:46 am
- What radios do you own?: Approx. 50: Moto & Kenwood
Re: ASTRO XTL5000 Consolette
Post
by MotoFAN » Tue Oct 28, 2008 3:37 pm
RKG wrote:The XTL5000 Consolette can be programmed via the data connector on the rear of the radio, using the «data cable.»
What is the P/N on this cable (I mean rear connector programming)?
I am biggest fan of XTS2500 and ASTRO Digital Saber.
Return to “Radio Programming”
Jump to
- Administrative
- ↳ Announcements and Forum News
- ↳ Forum Rules
- General
- ↳ General Motorola Solutions & Legacy Radio Discussion
- ↳ Radio Programming
- ↳ Software & Firmware Releases & Issues
- ↳ Codeplug Information
- ↳ NFPA 1802 Discussion
- Current Motorola Solutions Public Safety / Astro Product Line
- ↳ APX NEXT
- ↳ APX Series Subscribers
- ↳ ASTRO Series (Astro Saber, Spectra, XTS3000/3500) Subscribers
- ↳ ASTRO25 Series (XTS/XTL 1500/2500/5000) Subscribers
- ↳ ASTRO Experimental — How to do things a little out of the box
- ↳ ASTRO Products Feature Requests & Future Speculation
- ↳ Legacy Batboard Motorola ASTRO (VSELP/IMBE/AMBE) Equipment Forum
- Current Motorola Solutions Professional / Business Product Lines
- ↳ MotoTRBO ION Devices
- ↳ Motorola CP/CM Series Subscribers
- ↳ MotoTRBO Portables and Mobiles (4xxx/6xxx) 1.0 Series Subscribers
- ↳ MotoTRBO Portables and Mobiles (3xxx/5xxx/7xxx/SL) 2.0 Series Subscribers
- ↳ MotoTRBO Repeaters, Trunking, and Site Infrastructure
- ↳ MotoTRBO 3rd Party Application Discussion & Support
- ↳ MotoTRBO/Business Products Feature Requests & Future Speculation
- ↳ Experimental — How to do things a little out of the box
- Motorola System Infrastructure (Consoles, Base Stations, Repeaters, Trunking, etc.)
- ↳ Smartnet/Smartzone/Project 25 (Phase I/II) Systems
- ↳ Base Stations, Repeaters, General Infrastructure
- ↳ Consoles
- ↳ Experimental — Mods, and how to do things a little out of the box
- ↳ Infrastructure Product Feature Requests & Future Speculation
- Focused Discussion
- ↳ Motorola Digital and Voice Paging
- ↳ Converting Motorola Equipment to 900MHz Amateur
- ↳ Test Equipment & RF Equipment Alignment
- ↳ Vehicle Radio Installs
- ↳ Experimental and Next Generation LMR
- ↳ Motorola Digital Radio Compatability
- Off-Topic Discussion
- ↳ Vehicle Warning Equipment Discussion
- ↳ Computer/Technical Assistance
- ↳ Knowledge Base
-
To anyone looking to acquire commercial radio programming software:
Please do not make requests for copies of radio programming software which is sold (or was sold) by the manufacturer for any monetary value. All requests will be deleted and a forum infraction issued. Making a request such as this is attempting to engage in software piracy and this forum cannot be involved or associated with this activity. The same goes for any private transaction via Private Message. Even if you attempt to engage in this activity in PM’s we will still enforce the forum rules. Your PM’s are not private and the administration has the right to read them if there’s a hint to criminal activity.
If you are having trouble legally obtaining software please state so. We do not want any hurt feelings when your vague post is mistaken for a free request. It is YOUR responsibility to properly word your request.
To obtain Motorola software see the Sticky in the Motorola forum.
The various other vendors often permit their dealers to sell the software online (i.e., Kenwood). Please use Google or some other search engine to find a dealer that sells the software. Typically each series or individual radio requires its own software package. Often the Kenwood software is less than $100 so don’t be a cheapskate; just purchase it.
For M/A Com/Harris/GE, etc: there are two software packages that program all current and past radios. One package is for conventional programming and the other for trunked programming. The trunked package is in upwards of $2,500. The conventional package is more reasonable though is still several hundred dollars. The benefit is you do not need multiple versions for each radio (unlike Motorola).
This is a large and very visible forum. We cannot jeopardize the ability to provide the RadioReference services by allowing this activity to occur. Please respect this.
-
Thread starter
Aux9011
-
Start date
May 3, 2010
- Status
- Not open for further replies.
-
#1
Is there a certain button sequence that must be held in order to get the radio into programming. I recently acquired an XTs 3000R with a ribless cable and i can not get the radio to read. Any help is appreciated.
Thank you

-
#2
You don’t need to do anything like that. Just attach the cable and it should read. What isn’t working? Are you seeing an error message ?
-
#3
error message
reads «radio failed to acknowledge, error context 24, status c0000386» in astro 25 s/w and error in xts 3000 s/w reads «communication with radio failed»
-
#4
Astro25 software will not work with the XTS3000. You will need XTS3000/Astro Saber software. Make sure that the correct com port is selected, the radio is ON, and that no other program is using the COM port.
-
#5
I have
the Saber/Xts 3000 s/w and have attempted several trys with the com 1 port and its settings. No luck. Im starting to wonder if its a bad cable. Thanks for your time and assistance.

-
#6
Is your battery good? It sounds dumb but the Chinese ebay ribless cables seem to have an issue with low voltage. They contain surface mount 7805 5v voltage regulators but when measured they are often putting out closer to 4v for whatever reason. I found this to be problem with both of my Astro25 cables. Jumpered it with a 5.1v zener and it worked. It seems the MAX232 chip isn’t getting quite enough voltage to operate properly. If you start out with a good hot battery it might help.
Or, it could just be broken.
-
#7
Is your ribless cable serial port? and are you using a usb to serial port converter?
This can cause many issues as well.
-
#8
The Cable
is ribless serial connected right to the port.
-
#9
Sounds like another case of non-OEM RIB-less cable garbage not working right… unless you’re using some sort of USB to serial converter instead of a serial port right on the computer itself. Is that the case?
It may be a low charged battery, but if you really want to save yourself the headache of having a bricked radio at some point, save yourself headaches and purchase an eBay RIB and proper 25 pin radio cable and work from there. I bought a cheapie kawa mall RIB a few years ago as a cheap fix for my regular Moto RIB which was broken and really haven’t looked back, it works perfectly.
-
#10
I find if you go in to the hardware manager in windows and delete your com port, reboot you computer and your com will auto install.. this is a good way to test if your com port is the problem. If it re-installs and you still have the problem then you know its the cable..if it re-installs and works you know something else was grabbing the port.
-
#11
3000 cable
I literally just sent payment to Kawa for another cable. I will check back in a few days with hopefully better news..
Thanks again everyone
Nick

-
#12
I have to ask since you were trying to use Astro25 software..
You are trying to use a Jedi/XTS3000 cable, right? Not an XTS2500/XTS5000 cable…
-
#13
I have a xts2500 and had problems with the cheep cable. I also got the same error message.
I order a new 30 dollar cable from ebay and works fine again.
good luck. I think I messed the cable up trying to read a radio with low batttery also. so A lesson learned.
-
#14
Thanks Everyone
I recieved my new cable today and works just fine. Thanks for all your efforts
-
#15
Programming XTS3000R
I have a XTS3000R and I dont know how to program it. The software will not run and I dont know if it need to be in DOS or what but im lost can someone please help.
-
#16
Sounds like you need to contact Motorola about the software. What are you using to program the radio? DOS RSS, Windows CPS? What kind of cable?
The XTS3000 needs a serial cable and a Radio interface box to be programmed properly. Anything less is risky.
But in reality, if you have no clue about what you are doing, you probably shouldn’t be doing it. Check out batlabs.com, check out repeater-builder.com as well, there is a wealth of information at both of those sites that will help you out in getting the proper setup.
This is pretty much the best help you are going to get with the vagueness of your post.
-
#17
XTS5000 RIB less
So I am playing with my radio understand the soft ware I think at least, just curious why has someone not came up with a 15 pin Vga male programming cable yet?? Or have they and I just don’t know about it.. What a pain finding a 15 pin Vga to 9 pin, I am thinking about going RIB less any thoughts my Xts is already I am researching for my department who of course will purchase the program(s) legally just wondering .. Thank you and look forward to learning from the group

-
#18
XTL Series "error context 24, status c0000386"
reads «radio failed to acknowledge, error context 24, status c0000386» in astro 25 s/w and error in xts 3000 s/w reads «communication with radio failed»
I also ran into this problem, while programming an XTL2500. I was using a USB to RS232 converter ( Looks like an adapter no cable between USB and RS232) and would get «radio failed to acknowledge, error context 24, status c0000386.» I tried a different USB to RS232 converter, Model HL-340 (converter is blue with 3’silver cable between USB and RS232) and I was able to read the radio. Not all USB to RS232 converters are created equal. Both converters were purchased on ebay for less than 5 bucks.
I have also run into this problem when programming Motorola DTR series radios.
-
#19
So I am playing with my radio understand the soft ware I think at least, just curious why has someone not came up with a 15 pin Vga male programming cable yet??
Wait what?
Where does a 15 pin VGA cable come into play with respect to programming?
All programming with a Motorola RIB is done via the RS232 serial port which is 9 pins (or in some cases, 25 pins with older machines). A VGA port is only for video to connect to your monitor, it has nothing to do with programming what so ever — such an adaptor would do you no good.
There IS a 15 pin connector on the RIB that is used to connect to the computer, however it isn’t a VGA type connector. It is used to connect to either the 9 or 25 pin serial port. If you look, a VGA connector is a 15 pin three row connector that is the same physical size as the 9 pin serial connector. The Motorola RIB needs a 15 pin two row connector that is the same height as the 9 pin serial connector, however wider.
For proper nomenclature, a VGA connector is called a DE15 where as the RIB connector is a DA15. The serial port is a DE9. The «D» is reference to the series whereas the second letter refers to the size (A through E). The numbers refer to how many pins are present.

-
#20
Sometimes they refer to them as a low density DB15 and a high density DB15.
- Status
- Not open for further replies.
Модераторы: GRooVE, alexco
Правила форума
Убедительная просьба юзать теги [code] при оформлении листингов.
Сообщения не оформленные должным образом имеют все шансы быть незамеченными.
-
Гость
- проходил мимо
OpenVPN не заводиться 

Доброго времени суток ВСЕМ
Можете мне подсказать что не так ?
У клиента в логах openvpn.log ругань:
Код: Выделить всё
##########################################################
event_wait : Interrupted system call (code=4)
TCP/UDP: Closing socket
SIGTERM[hard,] received, process exiting
OpenVPN 2.0.6 i386-portbld-freebsd4.8 [SSL] [LZO] built on Sep 17 2008
Control Channel Authentication: using '/usr/local/etc/openvpn/keys/ta.key' as a OpenVPN static key file
Outgoing Control Channel Authentication: Using 128 bit message hash 'MD5' for HMAC authentication
Incoming Control Channel Authentication: Using 128 bit message hash 'MD5' for HMAC authentication
LZO compression initialized
Control Channel MTU parms [ L:1538 D:162 EF:62 EB:0 ET:0 EL:0 ]
Data Channel MTU parms [ L:1538 D:1450 EF:38 EB:135 ET:0 EL:0 AF:3/1 ]
Local Options hash (VER=V4): '03fa487d'
Expected Remote Options hash (VER=V4): '1056bce3'
UDPv4 link local (bound): [undef]:2000
UDPv4 link remote: xxx.xxx.xxx.xxx:2000
[b]TLS Error: TLS key negotiation failed to occur within 60 seconds (check your network connectivity)
TLS Error: TLS handshake failed[/b]
TCP/UDP: Closing socket
SIGUSR1[soft,tls-error] received, process restarting
Restart pause, 2 second(s)
Re-using SSL/TLS context
LZO compression initialized
Control Channel MTU parms [ L:1538 D:162 EF:62 EB:0 ET:0 EL:0 ]
Data Channel MTU parms [ L:1538 D:1450 EF:38 EB:135 ET:0 EL:0 AF:3/1 ]
Local Options hash (VER=V4): '03fa487d'
Expected Remote Options hash (VER=V4): '1056bce3'
UDPv4 link local (bound): [undef]:2000
UDPv4 link remote: xxx.xxx.xxx.xxx:2000А в логах сервера вот такая ругань:
##########################################################
Код: Выделить всё
[b]xx.xx.xx.xx:2000 TLS Error: TLS key negotiation failed to occur within 60 seconds (check your network connectivity)
TLS Error: TLS handshake failed
xx.xx.xx.xx:2000 SIGUSR1[soft,tls-error] received, client-instance restarting
MULTI: multi_create_instance called[/b]
Re-using SSL/TLS context
LZO compression initialized
Control Channel MTU parms [ L:1538 D:162 EF:62 EB:0 ET:0 EL:0 ]
xx.xx.xx.xx:2000 Data Channel MTU parms [ L:1538 D:1450 EF:38 EB:135 ET:0 EL:0 AF:3/1 ]
xx.xx.xx.xx:2000 Local Options hash (VER=V4): '1056bce3'
xx.xx.xx.xx:2000 Expected Remote Options hash (VER=V4): '03fa487d'
xx.xx.xx.xx:2000 TLS: Initial packet from 62.80.178.22:2000, sid=ede7e96a 84c81a85
xx.xx.xx.xx:2000 write UDPv4: Permission denied (code=13)
xx.xx.xx.xx:2000 write UDPv4: Permission denied (code=13)ifconfig сервера:
Код: Выделить всё
##########################################################
tun1: flags=8051<UP,POINTOPOINT,RUNNING,MULTICAST> mtu 1500
inet 10.10.200.1 --> 10.10.200.2 netmask 0xffffffff
Opened by PID 19690
##########################################################Сертификаты готовились на сервере, ось FreeBSD6.2 и OpenVPN 2.0.6
Клиент живет на FreeBSD4.8 и OpenVPN 2.0.6
Подскажите что не так.
Спасибо!
Последний раз редактировалось zingel 2008-09-19 12:45:26, всего редактировалось 1 раз.
Причина: юзай [code][/code]
-

Хостинг HostFood.ru

Услуги хостинговой компании Host-Food.ru
Хостинг HostFood.ru
Тарифы на хостинг в России, от 12 рублей: https://www.host-food.ru/tariffs/hosting/
Тарифы на виртуальные сервера (VPS/VDS/KVM) в РФ, от 189 руб.: https://www.host-food.ru/tariffs/virtualny-server-vps/
Выделенные сервера, Россия, Москва, от 2000 рублей (HP Proliant G5, Intel Xeon E5430 (2.66GHz, Quad-Core, 12Mb), 8Gb RAM, 2x300Gb SAS HDD, P400i, 512Mb, BBU):
https://www.host-food.ru/tariffs/vydelennyi-server-ds/
Недорогие домены в популярных зонах: https://www.host-food.ru/domains/
-

hizel
- дядя поня
- Сообщения: 9032
- Зарегистрирован: 2007-06-29 10:05:02
- Откуда: Выборг

Re: OpenVPN не заводиться
Непрочитанное сообщение
hizel » 2008-09-19 12:41:22
Код: Выделить всё
xx.xx.xx.xx:2000 write UDPv4: Permission denied (code=13)
xx.xx.xx.xx:2000 write UDPv4: Permission denied (code=13)
эти строчки мне не нравятся
фаервол?
В дурацкие игры он не играет. Он просто жуткий, чу-чу, паровозик, и зовут его Блейн. Блейн — это Боль.
-
BI_J
- сержант
- Сообщения: 154
- Зарегистрирован: 2008-09-19 12:21:10
Re: OpenVPN не заводиться
Непрочитанное сообщение
BI_J » 2008-09-19 12:52:58
Все делалось по статье уважаемого mak_v_.
http://www.lissyara.su/?id=1685&comment … mment_4718
После совета проверить firewal, в логах клиента ситуация немного изменилась:
У клиента в логах openvpn.log ругань:
##########################################################
OpenVPN 2.0.6 i386-portbld-freebsd4.8 [SSL] [LZO] built on Sep 17 2008
Control Channel Authentication: using ‘/usr/local/etc/openvpn/keys/ta.key’ as a OpenVPN static key file
Outgoing Control Channel Authentication: Using 128 bit message hash ‘MD5’ for HMAC authentication
Incoming Control Channel Authentication: Using 128 bit message hash ‘MD5’ for HMAC authentication
LZO compression initialized
Control Channel MTU parms [ L:1538 D:162 EF:62 EB:0 ET:0 EL:0 ]
Data Channel MTU parms [ L:1538 D:1450 EF:38 EB:135 ET:0 EL:0 AF:3/1 ]
Local Options hash (VER=V4): ’03fa487d’
Expected Remote Options hash (VER=V4): ‘1056bce3’
UDPv4 link local (bound): [undef]:2000
UDPv4 link remote: ip.ser.ve.ra:2000
TLS Error: Unroutable control packet received from ip.ser.ve.ra:2000 (si=3 op=P_ACK_V1)
TLS Error: Unroutable control packet received from ip.ser.ve.ra:2000 (si=3 op=P_ACK_V1)
.
.
.
VERIFY nsCertType ERROR: /C=UA/ST=Kiev/L=Kiev/O=server/OU=server/CN=server/emailAddress=admin@domen.com.ua, require nsCertType=SERVER
TLS_ERROR: BIO read tls_read_plaintext error: error:14090086:SSL routines:SSL3_GET_SERVER_CERTIFICATE:certificate verify failed
TLS Error: TLS object -> incoming plaintext read error
TLS Error: TLS handshake failed
TCP/UDP: Closing socket
SIGUSR1[soft,tls-error] received, process restarting
Restart pause, 2 second(s)
У сервера ругань почти не изменилась:
##########################################################
ip.cli.en.ta:2000 TLS: new session incoming connection from 62.80.178.22:2000
ip.cli.en.ta:2000 TLS Error: TLS key negotiation failed to occur within 60 seconds (check your network connectivity)
ip.cli.en.ta:2000 TLS Error: TLS handshake failed
ip.cli.en.ta:2000 SIGUSR1[soft,tls-error] received, client-instance restarting
MULTI: multi_create_instance called
как я понимаю что то с сертификатами. Генерил как написано ![]()
-

serge
- майор
- Сообщения: 2133
- Зарегистрирован: 2006-07-30 15:34:14
- Откуда: Саратов
- Контактная информация:

Re: OpenVPN не заводиться
Непрочитанное сообщение
serge » 2008-09-19 14:52:30
Случаем не в клетке OpenVPN сидит?
Вот это смущает…
Unroutable control packet received from ip.ser.ve.ra:2000
-
hizel
- дядя поня
- Сообщения: 9032
- Зарегистрирован: 2007-06-29 10:05:02
- Откуда: Выборг
Re: OpenVPN не заводиться
Непрочитанное сообщение
hizel » 2008-09-19 14:57:22
и всетаки попробуйте ище раз пегенерировать сертификаты
у вас тип сертификата не совпадает ![]()
В дурацкие игры он не играет. Он просто жуткий, чу-чу, паровозик, и зовут его Блейн. Блейн — это Боль.
-
serge
- майор
- Сообщения: 2133
- Зарегистрирован: 2006-07-30 15:34:14
- Откуда: Саратов
- Контактная информация:
Re: OpenVPN не заводиться
Непрочитанное сообщение
serge » 2008-09-19 15:08:49
TLS key negotiation failed to occur within 60 seconds (check your network connectivity)
дословно гуглом
TLS ключевые переговоры «не произойдет в течение 60 секунд (проверьте ваши сетевые подключения)
имхо, главная часть
проверьте ваши сетевые подключения
-
BI_J
- сержант
- Сообщения: 154
- Зарегистрирован: 2008-09-19 12:21:10
Re: OpenVPN не заводиться
Непрочитанное сообщение
BI_J » 2008-09-19 15:14:23
Спасибо за подсказки.
После очередной перегенирации сертификатов ситуация резко улучшилась ![]()
Но VPN так и не поднялся.
Теперь проблема кажеться в маршрутах со стороны клиента.
У клиента в логах openvpn.log
##########################################################
Код: Выделить всё
[server] Peer Connection Initiated with ip.ser.ve.ra:2000
SENT CONTROL [server]: 'PUSH_REQUEST' (status=1)
PUSH: Received control message: 'PUSH_REPLY,route 192.168.0.0 255.255.255.0,route 10.10.200.1,ping 10,ping-
restart 120,ifconfig 10.10.200.2 10.10.200.1'
OPTIONS IMPORT: timers and/or timeouts modified
OPTIONS IMPORT: --ifconfig/up options modified
OPTIONS IMPORT: route options modified
gw ip.pro.vay.da
TUN/TAP device /dev/tun1 opened
/sbin/ifconfig tun1 10.10.200.2 10.10.200.1 mtu 1500 netmask 255.255.255.255 up
/usr/local/etc/openvpn/openvpn_up.sh tun1 1500 1538 10.10.200.2 10.10.200.1 init
/usr/local/etc/openvpn/openvpn_up.sh: permission denied
script failed: shell command exited with error status: 126
Fri Sep 19 14:02:08 2008 Exiting##########################################################
Интернет удаленный клиент получает через модем провайдера через вот такое соединение:
ifconfig:
Код: Выделить всё
tun0: flags=8051<UP,POINTOPOINT,RUNNING,MULTICAST> mtu 1492
inet ip.cli.en.ta --> ip.pro.vay.da netmask 0xffffffff
Opened by PID 88нужно как то рулить это дело
-

zingel
- beastie
- Сообщения: 6204
- Зарегистрирован: 2007-10-30 3:56:49
- Откуда: Moscow
- Контактная информация:

Re: OpenVPN не заводиться
Непрочитанное сообщение
zingel » 2008-09-19 15:14:47
TLS ключевые переговоры «не произойдет в течение 60 секунд (проверьте ваши сетевые подключения)
Это гугловский переводчик такую ересь выдал? Я в шоке…
Z301171463546 — можно пожертвовать мне денег
-
BI_J
- сержант
- Сообщения: 154
- Зарегистрирован: 2008-09-19 12:21:10
Re: OpenVPN не заводиться
Непрочитанное сообщение
BI_J » 2008-09-19 17:03:49
Сижу, смотрю на ошибку и в упор не замечаю грабли (стыдно белое перо ![]() ):
):
Код: Выделить всё
usr/local/etc/openvpn/openvpn_up.sh tun1 1500 1538 10.10.200.2 10.10.200.1 init
/usr/local/etc/openvpn/openvpn_up.sh: permission denied
script failed: shell command exited with error status: 126
после выполнения:
chmod 755 /usr/local/etc/openvpn/openvpn_up.sh
положение улучшилось
пинг пошол между 10.10.200.2 и 10.10.200.1
хух
-
makihtow
- проходил мимо
- Сообщения: 8
- Зарегистрирован: 2009-02-05 14:18:31
OpenVPN не заводиться
Непрочитанное сообщение
makihtow » 2009-02-05 14:23:37
Здрасти ребята. У меня такая вот проблема. Что делать? Подскажите пожалуйста.
Thu Feb 05 13:22:02 2009 Data Channel MTU parms [ L:1538 D:1450 EF:38 EB:135 ET:0 EL:0 AF:3/1 ]
Thu Feb 05 13:22:02 2009 Local Options hash (VER=V4): ’03fa487d’
Thu Feb 05 13:22:02 2009 Expected Remote Options hash (VER=V4): ‘1056bce3’
Thu Feb 05 13:22:02 2009 UDPv4 link local (bound): [undef]:2000
Thu Feb 05 13:22:02 2009 UDPv4 link remote: 22.22.22.22:2000
Thu Feb 05 13:23:01 2009 TLS Error: TLS key negotiation failed to occur within 60 seconds (check your network connectivity)
Thu Feb 05 13:23:01 2009 TLS Error: TLS handshake failed
Thu Feb 05 13:23:01 2009 TCP/UDP: Closing socket
Thu Feb 05 13:23:01 2009 SIGUSR1[soft,tls-error] received, process restarting
Thu Feb 05 13:23:01 2009 Restart pause, 2 second(s)
Thu Feb 05 13:23:03 2009 Re-using SSL/TLS context
Thu Feb 05 13:23:03 2009 LZO compression initialized
Thu Feb 05 13:23:03 2009 Control Channel MTU parms [ L:1538 D:162 EF:62 EB:0 ET:0 EL:0 ]
Thu Feb 05 13:23:03 2009 Data Channel MTU parms [ L:1538 D:1450 EF:38 EB:135 ET:0 EL:0 AF:3/1 ]
Thu Feb 05 13:23:03 2009 Local Options hash (VER=V4): ’03fa487d’
Thu Feb 05 13:23:03 2009 Expected Remote Options hash (VER=V4): ‘1056bce3’
Thu Feb 05 13:23:03 2009 UDPv4 link local (bound): [undef]:2000
Thu Feb 05 13:23:03 2009 UDPv4 link remote: 22.22.22.22:2000
-
hizel
- дядя поня
- Сообщения: 9032
- Зарегистрирован: 2007-06-29 10:05:02
- Откуда: Выборг
Re: OpenVPN не заводиться
Непрочитанное сообщение
hizel » 2009-02-05 14:36:05
check your network connectivity
перевод требуется ? ![]()
В дурацкие игры он не играет. Он просто жуткий, чу-чу, паровозик, и зовут его Блейн. Блейн — это Боль.
-
hizel
- дядя поня
- Сообщения: 9032
- Зарегистрирован: 2007-06-29 10:05:02
- Откуда: Выборг
Re: OpenVPN не заводиться
Непрочитанное сообщение
hizel » 2009-02-05 14:42:50
фаервол прверить
tcpdump-ом посмотреть
В дурацкие игры он не играет. Он просто жуткий, чу-чу, паровозик, и зовут его Блейн. Блейн — это Боль.
-
makihtow
- проходил мимо
- Сообщения: 8
- Зарегистрирован: 2009-02-05 14:18:31
Re: OpenVPN не заводиться
Непрочитанное сообщение
makihtow » 2009-02-05 14:44:35
tcpdump -om
tcpdump version 3.9.4
libpcap version 0.9.4
Usage: tcpdump [-aAdDeflLnNOpqRStuUvxX] [-c count] [ -C file_size ]
[ -E algo:secret ] [ -F file ] [ -i interface ] [ -M secret ]
[ -r file ] [ -s snaplen ] [ -T type ] [ -w file ]
[ -W filecount ] [ -y datalinktype ] [ -Z user ]
[ expression ]
-
hizel
- дядя поня
- Сообщения: 9032
- Зарегистрирован: 2007-06-29 10:05:02
- Откуда: Выборг
Re: OpenVPN не заводиться
Непрочитанное сообщение
hizel » 2009-02-05 14:46:45
где <int> интерфейс через который openvpn ломится в интернет
2000 порт и можно еще приписать
В дурацкие игры он не играет. Он просто жуткий, чу-чу, паровозик, и зовут его Блейн. Блейн — это Боль.
-
makihtow
- проходил мимо
- Сообщения: 8
- Зарегистрирован: 2009-02-05 14:18:31
Re: OpenVPN не заводиться
Непрочитанное сообщение
makihtow » 2009-02-05 15:10:00
#tcpdump -i fxp0 -np port 2000 and udp
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on fxp0, link-type EN10MB (Ethernet), capture size 96 bytes
-
hizel
- дядя поня
- Сообщения: 9032
- Зарегистрирован: 2007-06-29 10:05:02
- Откуда: Выборг
Re: OpenVPN не заводиться
Непрочитанное сообщение
hizel » 2009-02-05 15:11:41
ну и при запущенном tcpdump рестартануть openvpn ![]()
В дурацкие игры он не играет. Он просто жуткий, чу-чу, паровозик, и зовут его Блейн. Блейн — это Боль.
-
makihtow
- проходил мимо
- Сообщения: 8
- Зарегистрирован: 2009-02-05 14:18:31
Re: OpenVPN не заводиться
Непрочитанное сообщение
makihtow » 2009-02-05 15:40:25
Запустил tcpdump и сделал рестарт openvpn. Вот результат.
Код: Выделить всё
#tcpdump -i fxp0 -np port 2000 and udp
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on fxp0, link-type EN10MB (Ethernet), capture size 96 bytes
Код: Выделить всё
38 packets captured
4492 packets received by filter
0 packets dropped by kernel-
hizel
- дядя поня
- Сообщения: 9032
- Зарегистрирован: 2007-06-29 10:05:02
- Откуда: Выборг
Re: OpenVPN не заводиться
Непрочитанное сообщение
hizel » 2009-02-05 15:47:18
у вас openvpn точно работает на 2000 порту udp?
если да то проверяйте фаервол
В дурацкие игры он не играет. Он просто жуткий, чу-чу, паровозик, и зовут его Блейн. Блейн — это Боль.
-
hz
- проходил мимо
- Сообщения: 4
- Зарегистрирован: 2009-03-24 9:59:09
Re: OpenVPN не заводиться
Непрочитанное сообщение
hz » 2009-03-24 10:27:16
День добрый.Помогите советом куда копать.Трабл в следующем:всё поднималось по описанию mac_v (отдельное спасибо).Туннель поднялся.Но проблема в следующем-внутрення сеть «филиала» видит внутреннее пространство за сервером впн.В обратную же сторону,т.е. то что находится внутри «головного офиса» не видит сетку «филиала».Выдаёт на ping ошибку ping: sendto: Invalid argument.Маршуты все прописаны.Руками прописывать пробывал маршрут до подсети «филиала» — ответ маршрут сущ-т.
-
zingel
- beastie
- Сообщения: 6204
- Зарегистрирован: 2007-10-30 3:56:49
- Откуда: Moscow
- Контактная информация:
Re: OpenVPN не заводиться
Непрочитанное сообщение
zingel » 2009-03-24 13:29:05
отдельную тему лучше
Z301171463546 — можно пожертвовать мне денег
-
Sanya0413
- проходил мимо
- Сообщения: 2
- Зарегистрирован: 2010-03-30 15:30:44
Re: OpenVPN не заводиться
Непрочитанное сообщение
Sanya0413 » 2010-03-30 16:31:46
# !/bin/sh
/bin/sh: Event not found.
# /sbin/route add -net 192.168.1.0 10.10.200.1
route: writing to routing socket: Network is unreachable
add net 193.168.1.0: gateway 10.10.200.1: Network is unreachable
при создании файла openvpn_up.sh пишет вот такую ругню.
все создал по статье, sockstat ‘ ом проверил openvpn поднялся на сервере и на клиенте, но пинги не идут((
What to do first ?
Note 80 % of Clusterware startup problems are related to:
- Disk Space Problems
- Network Connectivity Problem with following system Calls are failing
- bind()
-
bind() specifies the address & port on the local side of the connection. Check for local IP changes including changes for Netmask, ...
- connect()
-
connect() specifies the address & port on the remote side of the connection. Check for remote IP changes including changes for Netmask, Firewall issues, ... - gethostbyname()
-
Check your Nameserver connectivity and configuration
- File Protection Problems
This translates to some very important task before starting Clusterware Debugging :
-
- Check your disk space using: # df
- Check whether your are running a firewall: # service iptables status ( <— this command is very important and you should disable iptables asap if enabled )
- Check whether avahi daemon is running : # service avahi-daemon status
- Reboot your system to Cleanup special sockets file in: /var/tmp/.oracle
- Verify Network Connectivity ( ping, nslookup ) and don’t forget to ask your Network Admin for any changes done in last couple of days
- Check your ASM disks with kfed for a a valid ASM diskheader
[grid@ractw21 ~]$ kfed read /dev/sdb1 | egrep 'name|size|type' kfbh.type: 1 ; 0x002: KFBTYP_DISKHEAD kfdhdb.dskname: DATA3 ; 0x028: length=5 kfdhdb.grpname: DATA ; 0x048: length=4 kfdhdb.fgname: DATA3 ; 0x068: length=5 kfdhdb.secsize: 512 ; 0x0b8: 0x0200 kfdhdb.blksize: 4096 ; 0x0ba: 0x1000 kfdhdb.ausize: 4194304 ; 0x0bc: 0x00400000 kfdhdb.dsksize: 5119 ; 0x0c4: 0x000013ff [grid@ractw21 ~]$ kfed read /dev/sdc1 | egrep 'name|size|type' kfbh.type: 1 ; 0x002: KFBTYP_DISKHEAD ...
- If you need to manage multiple RAC clusters follow the Link below and dive into DTRACE more in detail:
- Troubleshooting Clusterware startup problems with DTRACE
Verify your system with cluvfy
1) If possible try to restart your failing node If not - stop and restart at least your CRS stack # crsctl stop crs -f # crsclt start crs 2) If the problem persist collect following data ---> Working node # olsnodes -n -i -s -t # oifcfg getif ---> Failing node # crsctl check crs # crsctl check css # crsctl check evm # crsctl stat res -t -init ---> Run on all nodes and compare the results ( CI device name ,MTU and netmask should be identical ) # ifconfig -a # df # nestat -rn Check that avahi is disabled and no Firewall is configured ( very important !! ) # service iptables status ( Linux specific command ) # service avahi status ( Linux specific command ) # nslookup grac41 ( use any all or your cluster nodes like grac41, grac42, grac43 ) Locate the cluster interconnect and ping the remote nodes # oifcfg getif eth3 192.168.3.0 global cluster_interconnect [root@grac41 Desktop]# ifconfig | egrep 'eth3|192.168.3' eth3 Link encap:Ethernet HWaddr 08:00:27:09:F0:99 inet addr:192.168.3.101 Bcast:192.168.3.255 Mask:255.255.255.0 --> Here we know eth3 is our cluster interconnect device with local address 192.168.3.101 [root@grac41 Desktop]# ping -I 192.168.3.101 192.168.3.102 [root@grac41 Desktop]# ping -I 192.168.3.101 192.168.3.103 Login as Grid-User and check the group permissions (compare results with a working node ) [grid@grac41 ~]$ id 3) Check your voting disks/OCR setup On a working Node: [root@grac41 Desktop]# ocrcheck ... Device/File Name : +OCR Locate the related disks [grid@grac41 ~]$ asmcmd lsdsk -k Total_MB Free_MB OS_MB Name Failgroup Failgroup_Type Library Label UDID Product Redund Path 2047 1695 2047 OCR_0000 OCR_0000 REGULAR System UNKNOWN /dev/asm_ocr_2G_disk1 2047 1697 2047 OCR_0001 OCR_0001 REGULAR System UNKNOWN /dev/asm_ocr_2G_disk2 2047 1697 2047 OCR_0002 OCR_0002 REGULAR System UNKNOWN /dev/asm_ocr_2G_disk3 On the failed node use kfed to read the disk header ( for all disks : asm_ocr_2G_disk1, asm_ocr_2G_disk2, asm_ocr_2G_disk3 ) [grid@grac41 ~]$ kfed read /dev/asm_ocr_2G_disk1 | grep name kfdhdb.dskname: OCR_0000 ; 0x028: length=8 kfdhdb.grpname: OCR ; 0x048: length=3 kfdhdb.fgname: OCR_0000 ; 0x068: length=8 kfdhdb.capname: ; 0x088: length=0 4) Verify your cluster setup by runnig cluvfy Download the 12.1 cluvfy from http://www.oracle.com/technetwork/database/options/clustering/downloads/index.html and run and extract the zip file and run as grid user: Verify CRS installation ( if possible from a working node ) [grid@grac41 cluvf12]$ ./bin/cluvfy stage -post crsinst -n grac41,grac42 -verbose Verify file protections ( run this on all nodes - verifies more than 1100 files ) [grid@grac41 cluvf12]$ ./bin/cluvfy comp software .. 1178 files verified Software check failed
Overview
-
-
- Version tested GRID version 11.2.0.4.2 / OEL 6.5
- Before running any command from this article please backup OLR and OCR and your CW software !
-
It’s your responsibilty to have a valid backup !
Running any CW process as a wrong user can corrupt OLR,OCR and change protection for tracefiles and IPC sockets.
Must Read : Top 5 Grid Infrastructure Startup Issues (Doc ID 1368382.1)
-
-
- Issue #1: CRS-4639: Could not contact Oracle High Availability Services, ohasd.bin not running or ohasd.bin is running but no init.ohasd or other processes
- Issue #2: CRS-4530: Communications failure contacting Cluster Synchronization Services daemon, ocssd.bin is not running
- Issue #3: CRS-4535: Cannot communicate with Cluster Ready Services, crsd.bin is not running
- Issue #4: Agent or mdnsd.bin, gpnpd.bin, gipcd.bin not running
- Issue #5: ASM instance does not start, ora.asm is OFFLINE
-
How can I avoid CW troubleshooting by reading GB of traces – ( step 2 ) ?
Note more than 50 percents of CW startup problems can be avoided be checking the follwing 1. Check Network connectivity with ping, traceroute, nslookup ==> For further details see GENERIC Networking chapter 2. Check CW executable file protections ( compare with a working node ) $ ls -l $ORACLE_HOME/bin/gpnpd* -rwxr-xr-x. 1 grid oinstall 8555 May 20 10:03 /u01/app/11204/grid/bin/gpnpd -rwxr-xr-x. 1 grid oinstall 368780 Mar 19 17:07 /u01/app/11204/grid/bin/gpnpd.bin 3. Check CW log file and pid protections and ( compare with a working node ) $ ls -l ./grac41/gpnpd/grac41.pid -rw-r--r--. 1 grid oinstall 6 May 22 11:46 ./grac41/gpnpd/grac41.pid $ ls -l ./grac41/gpnpd/grac41.pid -rw-r--r--. 1 grid oinstall 6 May 22 11:46 ./grac41/gpnpd/grac41.pid 4. Check IPC sockets protections( /var/tmp/.oracle ) $ ls -l /var/tmp/.oracle/sgrac41DBG_GPNPD srwxrwxrwx. 1 grid oinstall 0 May 22 11:46 /var/tmp/.oracle/sgrac41DBG_GPNPD ==> For further details see GENERIC File Protection chapter
Overview CW startup sequence
In a nutshell, the operating system starts ohasd, ohasd starts agents to start up daemons - Daemons: gipcd, mdnsd, gpnpd, ctssd, ocssd, crsd, evmd asm .. After all local daemons are up crsd start agents that start user resources (database, SCAN, listener etc). Startup sequence (from 11gR2 Clusterware and Grid Home - What You Need to Know (Doc ID 1053147.1) ) Level 1: OHASD Spawns: cssdagent - Agent responsible for spawning CSSD. orarootagent - Agent responsible for managing all root owned ohasd resources. oraagent - Agent responsible for managing all oracle owned ohasd resources. cssdmonitor - Monitors CSSD and node health (along wth the cssdagent). Level 2b: OHASD rootagent spawns: CRSD - Primary daemon responsible for managing cluster resources. ( CTSSD, ACFS , MDNSD, GIPCD, GPNPD, EVMD, ASM resources must be ONLINE ) CTSSD - Cluster Time Synchronization Services Daemon Diskmon - ACFS - ASM Cluster File System Drivers Level 2a: OHASD oraagent spawns: MDNSD - Used for DNS lookup GIPCD - Used for inter-process and inter-node communication GPNPD - Grid Plug & Play Profile Daemon EVMD - Event Monitor Daemon ASM - Resource for monitoring ASM instances Level 3: CRSD spawns: orarootagent - Agent responsible for managing all root owned crsd resources. oraagent - Agent responsible for managing all oracle owned crsd resources. Level 4: CRSD rootagent spawns: Network resource - To monitor the public network SCAN VIP(s) - Single Client Access Name Virtual IPs Node VIPs - One per node ACFS Registery - For mounting ASM Cluster File System GNS VIP (optional) - VIP for GNS Level 4: CRSD oraagent spawns: ASM Resouce - ASM Instance(s) resource Diskgroup - Used for managing/monitoring ASM diskgroups. DB Resource - Used for monitoring and managing the DB and instances SCAN Listener - Listener for single client access name, listening on SCAN VIP Listener - Node listener listening on the Node VIP Services - Used for monitoring and managing services ONS - Oracle Notification Service eONS - Enhanced Oracle Notification Service GSD - For 9i backward compatibility GNS (optional) - Grid Naming Service - Performs name resolution
Stopping CRS after CW startup failures
During testing you may stop CRS very frequently. As the OHASD stack may not fully up you need to run: [root@grac41 gpnp]# crsctl stop crs -f CRS-2791: Starting shutdown of Oracle High Availability Services-managed resources on 'grac41' CRS-2673: Attempting to stop 'ora.crsd' on 'grac41' CRS-4548: Unable to connect to CRSD CRS-5022: Stop of resource "ora.crsd" failed: current state is "INTERMEDIATE" CRS-2675: Stop of 'ora.crsd' on 'grac41' failed CRS-2679: Attempting to clean 'ora.crsd' on 'grac41' CRS-4548: Unable to connect to CRSD CRS-5022: Stop of resource "ora.crsd" failed: current state is "INTERMEDIATE" CRS-2678: 'ora.crsd' on 'grac41' has experienced an unrecoverable failure CRS-0267: Human intervention required to resume its availability. CRS-2799: Failed to shut down resource 'ora.crsd' on 'grac41' CRS-2795: Shutdown of Oracle High Availability Services-managed resources on 'grac41' has failed CRS-4687: Shutdown command has completed with errors. CRS-4000: Command Stop failed, or completed with errors. If this hangs you may need to kill CW processes at OS level [root@grac41 gpnp]# ps -elf | egrep "PID|d.bin|ohas|oraagent|orarootagent|cssdagent|cssdmonitor" | grep -v grep F S UID PID PPID C PRI NI ADDR SZ WCHAN STIME TTY TIME CMD 4 S root 5812 1 0 80 0 - 2847 pipe_w 07:20 ? 00:00:00 /bin/sh /etc/init.d/init.ohasd run 4 S root 19164 5812 24 80 0 - 176663 futex_ 09:52 ? 00:00:04 /u01/app/11204/grid/bin/ohasd.bin restart 4 S root 19204 1 1 80 0 - 171327 futex_ 09:52 ? 00:00:00 /u01/app/11204/grid/bin/orarootagent.bin 4 S root 19207 1 0 -40 - - 159900 futex_ 09:52 ? 00:00:00 /u01/app/11204/grid/bin/cssdagent 4 S root 19209 1 0 -40 - - 160927 futex_ 09:52 ? 00:00:00 /u01/app/11204/grid/bin/cssdmonitor 4 S grid 19283 1 1 80 0 - 167890 futex_ 09:52 ? 00:00:00 /u01/app/11204/grid/bin/oraagent.bin 0 S grid 19308 1 0 80 0 - 74289 poll_s 09:52 ? 00:00:00 /u01/app/11204/grid/bin/mdnsd.bin ==> Kill remaining CW processes [root@grac41 gpnp]# kill -9 19164 19204 19207 19209 19283 19308
Status of a working OHAS stack
-
-
- Note ora.discmon resource become only ONLINE in EXADATA configurations
-
[root@grac41 Desktop]# crsctl check crs CRS-4638: Oracle High Availability Services is online CRS-4537: Cluster Ready Services is online CRS-4529: Cluster Synchronization Services is online CRS-4533: Event Manager is online [root@grac41 Desktop]# crsi NAME TARGET STATE SERVER STATE_DETAILS ------------------------- ---------- ---------- ------------ ------------------ ora.asm ONLINE ONLINE grac41 Started ora.cluster_interconnect.haip ONLINE ONLINE grac41 ora.crf ONLINE ONLINE grac41 ora.crsd ONLINE ONLINE grac41 ora.cssd ONLINE ONLINE grac41 ora.cssdmonitor ONLINE ONLINE grac41 ora.ctssd ONLINE ONLINE grac41 OBSERVER ora.diskmon OFFLINE OFFLINE ora.drivers.acfs ONLINE ONLINE grac41 ora.evmd ONLINE ONLINE grac41 ora.gipcd ONLINE ONLINE grac41 ora.gpnpd ONLINE ONLINE grac41 ora.mdnsd ONLINE ONLINE grac41
Ohasd startup scritps on OEL 6
OHASD Script location [root@grac41 init.d]# find /etc |grep S96 /etc/rc.d/rc5.d/S96ohasd /etc/rc.d/rc3.d/S96ohasd [root@grac41 init.d]# ls -l /etc/rc.d/rc5.d/S96ohasd lrwxrwxrwx. 1 root root 17 May 4 10:57 /etc/rc.d/rc5.d/S96ohasd -> /etc/init.d/ohasd [root@grac41 init.d]# ls -l /etc/rc.d/rc3.d/S96ohasd lrwxrwxrwx. 1 root root 17 May 4 10:57 /etc/rc.d/rc3.d/S96ohasd -> /etc/init.d/ohasd --> Run level 3 and 5 should start ohasd Check status of init.ohasd process [root@grac41 bin]# more /etc/init/oracle-ohasd.conf # Copyright (c) 2001, 2011, Oracle and/or its affiliates. All rights reserved. # # Oracle OHASD startup start on runlevel [35] stop on runlevel [!35] respawn exec /etc/init.d/init.ohasd run >/dev/null 2>&1 </dev/null List current PID [root@grac41 Desktop]# initctl list | grep oracle-ohasd oracle-ohasd start/running, process 27558 Check OS processes [root@grac41 Desktop]# ps -elf | egrep "PID|d.bin|ohas|oraagent|orarootagent|cssdagent|cssdmonitor" | grep -v grep F S UID PID PPID C PRI NI ADDR SZ WCHAN STIME TTY TIME CMD 4 S root 27558 1 0 80 0 - 2878 wait 07:01 ? 00:00:02 /bin/sh /etc/init.d/init.ohasd run
Useful OS and CW commands, GREP commands , OS logfile location and Clusterware logfile location details
1 : Clusterware logfile structure CW Alert.log alert<hostname>.log ( most important one !! ) OHASD ohsad.log CSSD ocssd.log EVMD evmd.log CRSD crsd.log MDSND mdnsd.log GIPCD gipcd.log GPNPD gpnpd.log Agent directories agent/ohasd agent/ohasd/oraagent_grid agent/ohasd/oracssdagent_root agent/ohasd/oracssdmonitor_root agent/ohasd/orarootagent_root 2 : OS System logs HPUX /var/adm/syslog/syslog.log AIX /bin/errpt–a Linux /var/log/messages Windows Refer .TXT log files under Application/System log using Windows Event Viewer Solaris /var/adm/messages Linux Sample # grep 'May 20' ./grac41/var/log/messages > SYSLOG --> Check SYSLOG for relvant errors An typical CW error could look like: # cat /var/log/messages May 13 13:48:27 grac41 OHASD[22203]: OHASD exiting; Directory /u01/app/11204/grid/log/grac41/ohasd not found 3 : Usefull Commands for a quick check of clusterware status It may be usefull to run all commands below just to get an idea what is working and what is not working 3.1 : OS commands ( assume we have CW startup problems on grac41 ) # ping grac41 # route -n # /bin/netstat -in # /sbin/ifconfig -a # /bin/ping -s <MTU> -c 2 -I source_IP nodename # /bin/traceroute -s source_IP -r -F nodename-priv <MTU-28> # /usr/bin/nslookup grac41 3.2 : Clusterware commands to debug startup problems Check Clusterware status # crsctl check crs # crsctl check css # crsctl check evm # crsctl stat res -t -init If OHASD stack is completly up and running you can check your cluster resources with # crsctl stat res -t 3.3 : Checking OLR to debug startup problems # ocrcheck -local # ocrcheck -local -config 3.4 : Checking OCR/Votedisks to debug startup problems $ crsctl query css votedisk Next 2 commands will only work when startup problems are fixed $ ocrcheck $ ocrcheck -config 3.5 : Checking GPnP to debug startup problems # $GRID_HOME/bin/gpnptool get For futher debugging # $GRID_HOME/bin/gpnptool lfind # $GRID_HOME/bin/gpnptool getpval -asm_spf -p=/u01/app/11204/grid/gpnp/profiles/peer/profile.xml # $GRID_HOME/bin/gpnptool check -p=/u01/app/11204/grid/gpnp/profiles/peer/profile.xml # $GRID_HOME/bin/gpnptool verify -p=/u01/app/11204/grid/gpnp/profiles/peer/profile.xml -w="/u01/app/11204/grid/gpnp/grac41/wallets/peer" -wu=peer 3.6 : Cluvfy commands to debug startup problems Network problems: $ cluvfy comp nodereach -n grac41 -vebose Identify your interfaces used for public and private usage and check related networks $ cluvfy comp nodecon -n grac41,grac42 -i eth1 -verbose ( public Interface ) $ cluvfy comp nodecon -n grac41,grac42 -i eth2 -verbose ( private Interface ) $ cluvfy comp nodecon -n grac41 -verbose Testing multicast communication for multicast group "230.0.1.0" . $ cluvfy stage -post hwos -n grac42 Cluvfy commands to verify ASM DG and Voting disk location Note: Run cluvfy from a working Node ( grac42 ) to get more details [grid@grac42 ~]$ cluvfy comp vdisk -n grac41 ERROR: PRVF-5157 : Could not verify ASM group "OCR" for Voting Disk location "/dev/asmdisk1_udev_sdh1" --> From the error code we know ASM disk group + Voting Disk location $ cluvfy comp olr -verbose $ cluvfy comp software -verbose $ cluvfy comp ocr -n grac42,grac41 $ cluvfy comp sys -n grac41 -p crs -verbose Comp healthcheck is quite helpfull to get an overview but as OHASD is not running most of the errors are related to the CW startup problem. $ cluvfy comp healthcheck -collect cluster -html $ firefox cvucheckreport_523201416347.html 4 : Useful grep Commands GPnP profile is not accessible - gpnpd needs to be fully up to serve profile $ fn_egrep.sh "Cannot get GPnP profile|Error put-profile CALL" TraceFileName: ./grac41/agent/ohasd/orarootagent_root/orarootagent_root.log 2014-05-20 10:26:44.532: [ default][1199552256]Cannot get GPnP profile. Error CLSGPNP_NO_DAEMON (GPNPD daemon is not running). Cannot get GPnP profile 2014-04-21 15:27:06.838: [ GPNP][132114176]clsgpnp_profileCallUrlInt: [at clsgpnp.c:2243] Result: (13) CLSGPNP_NO_DAEMON. Error put-profile CALL to remote "tcp://grac41:56376" disco "mdns:service:gpnp._tcp.local.://grac41:56376/agent=gpnpd,cname=grac4,host=grac41,pid=4548/gpnpd h:grac41 c:grac4" Network socket file doesn't have appropriate ownership or permission # fn_egrep.sh "clsclisten: Permission denied" [ COMMCRS][3534915328]clsclisten: Permission denied for (ADDRESS=(PROTOCOL=ipc)(KEY=grac41DBG_MDNSD)) Problems with Private Interconnect $ fn.sh "2014-06-03" | egrep 'but no network HB|TraceFileName' Search String: no network HB TraceFileName: ./cssd/ocssd.log 2014-06-02 12:51:52.564: [ CSSD][2682775296]clssnmvDHBValidateNcopy: node 3, grac43, has a disk HB, but no network HB , .. or $ fn_egrep.sh "failed to resolve|gipcretFail|gipcretConnectionRefused" | egrep 'TraceFile|2014-05-20 11:0' TraceFileName: ./grac41/crsd/crsd.log and ./grac41/evmd/evmd.log may report 2014-05-20 11:04:02.563: [GIPCXCPT][154781440] gipchaInternalResolve: failed to resolve ret gipcretKeyNotFound (36), host 'grac41', port 'ffac-854b-c525-6f9c', hctx 0x2ed3940 [0000000000000010] { gipchaContext : host 'grac41', name 'd541-9a1e-7807-8f4a', luid 'f733b93a-00000000', numNode 0, numInf 1, usrFlags 0x0, flags 0x5 }, ret gipcretKeyNotFound (36) 2014-05-20 11:04:02.563: [GIPCHGEN][154781440] gipchaResolveF [gipcmodGipcResolve : gipcmodGipc.c : 806]: EXCEPTION[ ret gipcretKeyNotFound (36) ] failed to resolve ctx 0x2ed3940 [0000000000000010] { gipchaContext : host 'grac41', name 'd541-9a1e-7807-8f4a', luid 'f733b93a-00000000', numNode 0, numInf 1, usrFlags 0x0, flags 0x5 }, host 'grac41', port 'ffac-854b-c525-6f9c', flags 0x0 Is there a valid CI network device ? # fn_egrep.sh "NETDATA" | egrep 'TraceFile|2014-06-03' TraceFileName: ./gipcd/gipcd.log 2014-06-03 07:48:45.401: [ CLSINET][3977414400] Returning NETDATA: 1 interfaces <-- ok 2014-06-03 07:52:51.589: [ CLSINET][1140848384] Returning NETDATA: 0 interfaces <-- problems ! Are Voting Disks acessible ? $ fn_egrep.sh "Successful discovery" TraceFileName: ./grac41/cssd/ocssd.log 2014-05-22 13:41:38.776: [ CSSD][1839290112]clssnmvDiskVerify: Successful discovery of 0 disks
Generic trobleshooting hints : How to review CW trace files
1 : Limit trace files size and file count by using TFA command: tfactl diagcollect Note only single node collection is neccessary for CW startup problem - here node grac41 has CW startup problems # tfactl diagcollect -node grac41 -from "May/20/2014 06:00:00" -to "May/20/2014 15:00:00" --> Scanning files from May/20/2014 06:00:00 to May/20/2014 15:00:00 ... Logs are collected to: /u01/app/grid/tfa/repository/collection_Wed_May_21_09_19_10_CEST_2014_node_grac41/grac41.tfa_Wed_May_21_09_19_10_CEST_2014.zip Extract zip file and scan for various Clusterware errors # mkdir /u01/TFA # cd /u01/TFA # unzip /u01/app/grid/tfa/repository/collection_Wed_May_21_09_19_10_CEST_2014_node_grac41/grac41.tfa_Wed_May_21_09_19_10_CEST_2014.zip Locate important files in our unzipped TFA repository # pwd /u01/TFA/ # find . -name "alert*" ./grac41/u01/app/11204/grid/log/grac41/alertgrac41.log ./grac41/asm/+asm/+ASM1/trace/alert_+ASM1.log ./grac41/rdbms/grac4/grac41/trace/alert_grac41.log # find . -name "mess*" ./grac41/var/log/messages ./grac41/var/log/messages-20140504 2 : Review Clusterware alert.log errors # get_ca.sh alertgrac41.log 2014-05-23 -> File searched: alertgrac41.log -> Start search timestamp : 2014-05-23 -> End search timestamp : Begin: CNT 0 - TS -- 2014-05-23 15:29:31.297: [mdnsd(16387)]CRS-5602:mDNS service stopping by request. 2014-05-23 15:29:34.211: [gpnpd(16398)]CRS-2329:GPNPD on node grac41 shutdown. 2014-05-23 15:29:45.785: [ohasd(2736)]CRS-2112:The OLR service started on node grac41. 2014-05-23 15:29:45.845: [ohasd(2736)]CRS-1301:Oracle High Availability Service started on node grac41. 2014-05-23 15:29:45.861: [ohasd(2736)]CRS-8017:location: /etc/oracle/lastgasp has 2 reboot advisory log files, 0 were announced and 0 errors occurred 2014-05-23 15:29:49.999: [/u01/app/11204/grid/bin/orarootagent.bin(2798)]CRS-2302:Cannot get GPnP profile. Error CLSGPNP_NO_DAEMON (GPNPD daemon is not running). 2014-05-23 15:29:55.075: [ohasd(2736)]CRS-2302:Cannot get GPnP profile. Error CLSGPNP_NO_DAEMON (GPNPD daemon is not running). 2014-05-23 15:29:55.081: [gpnpd(2934)]CRS-2328:GPNPD started on node grac41. 2014-05-23 15:29:57.576: [cssd(3040)]CRS-1713:CSSD daemon is started in clustered mode 2014-05-23 15:29:59.331: [ohasd(2736)]CRS-2767:Resource state recovery not attempted for 'ora.diskmon' as its target state is OFFLINE 2014-05-23 15:29:59.331: [ohasd(2736)]CRS-2769:Unable to failover resource 'ora.diskmon'. 2014-05-23 15:30:01.905: [cssd(3040)]CRS-1714:Unable to discover any voting files, retrying discovery in 15 seconds; Details at (:CSSNM00070:) in /u01/app/11204/grid/log/grac41/cssd/ocssd.log 2014-05-23 15:30:16.945: [cssd(3040)]CRS-1714:Unable to discover any voting files, retrying discovery in 15 seconds; Details at (:CSSNM00070:) in /u01/app/11204/grid/log/grac41/cssd/ocssd.log --> Script get_ca.sh adds a timestamp and reduces output and only dumps errors for certain day In the above sample we can easily pin-point the problem to a voting disks issue If you cant find a obvious reason you still need to review your clusterware alert.log 3 : Review Clusterware logfiles for errors and resources failing or not starting up $ fn.sh 2014-05-25 | egrep 'TraceFileName|CRS-|ORA-|TNS-|LFI-|KFNDG-|KFED-|KFOD-|CLSDNSSD-|CLSGN-|CLSMDNS-|CLS.- |NDFN-|EVM-|GIPC-|PRK.-|PRV.-|PRC.-|PRIF-|SCLS-|PROC-|PROCL-|PROT-|PROTL-' TraceFileName: ./crsd/crsd.log 2014-05-25 11:29:04.968: [ CRSPE][1872742144]{1:62631:2} CRS-2672: Attempting to start 'ora.SSD.dg' on 'grac41' 2014-05-25 11:29:04.999: [ CRSPE][1872742144]{1:62631:2} CRS-2672: Attempting to start 'ora.DATA.dg' on 'grac41' 2014-05-25 11:29:05.063: [ CRSPE][1872742144]{1:62631:2} CRS-2672: Attempting to start 'ora.FRA.dg' on 'grac41 .... If a certain resource like ora.net1.network doesn't start - grep for details using resource name [grid@grac42 grac42]$ fn.sh "ora.net1.network" | egrep '2014-05-31 11|TraceFileName' TraceFileName: ./agent/crsd/orarootagent_root/orarootagent_root.log 2014-05-31 11:58:27.899: [ AGFW][1829066496]{2:12808:5} Agent received the message: RESOURCE_START[ora.net1.network grac42 1] ID 4098:403 2014-05-31 11:58:27.899: [ AGFW][1829066496]{2:12808:5} Preparing START command for: ora.net1.network grac42 1 2014-05-31 11:58:27.899: [ AGFW][1829066496]{2:12808:5} ora.net1.network grac42 1 state changed from: OFFLINE to: STARTING 2014-05-31 11:58:27.917: [ AGFW][1826965248]{2:12808:5} Command: start for resource: ora.net1.network grac42 1 completed with status: SUCCESS 2014-05-31 11:58:27.919: [ AGFW][1829066496]{2:12808:5} Agent sending reply for: RESOURCE_START[ora.net1.network grac42 1] ID 4098:403 2014-05-31 11:58:27.969: [ AGFW][1829066496]{2:12808:5} ora.net1.network grac42 1 state changed from: STARTING to: UNKNOWN 4 : Review ASM alert.log 5 : Track generation of new Tints and follow these Tints $ fn.sh 2014-05-25 | egrep 'TraceFileName|Generating new Tint' TraceFileName: ./agent/ohasd/orarootagent_root/orarootagent_root.log 2014-05-25 13:52:07.862: [ AGFW][2550134528]{0:11:3} Generating new Tint for unplanned state change. Original Tint: {0:0:2} 2014-05-25 13:52:36.126: [ AGFW][2550134528]{0:11:6} Generating new Tint for unplanned state change. Original Tint: {0:0:2} [grid@grac41 grac41]$ fn.sh "{0:11:3}" | more Search String: {0:11:3} TraceFileName: ./alertgrac41.log [/u01/app/11204/grid/bin/cssdmonitor(1833)]CRS-5822:Agent '/u01/app/11204/grid/bin/cssdmonitor_root' disconnected from server. Details at (:CRSAGF00117:) {0:11:3} in /u01/app/11204/grid/log/grac41/agent/ohasd/oracssdmonitor_root/oracssdmonitor_root.log. -------------------------------------------------------------------- TraceFileName: ./agent/ohasd/oracssdmonitor_root/oracssdmonitor_root.log 2014-05-19 14:34:03.312: [ AGENT][3481253632]{0:11:3} {0:11:3} Created alert : (:CRSAGF00117:) : Disconnected from server, Agent is shutting down. 2014-05-19 14:34:03.312: [ USRTHRD][3481253632]{0:11:3} clsncssd_exit: CSSD Agent was asked to exit with exit code 2 2014-05-19 14:34:03.312: [ USRTHRD][3481253632]{0:11:3} clsncssd_exit: No connection with CSS, exiting. 6 : Investigate GENERIC File Protection problems for Log File Location, Ownership and Permissions ==> For further details see GENERIC File Protection troubleshooting chapter 7 : Investigate GENERIC Networking problems ==> For further details see GENERIC Networking troubleshooting chapter 8 : Check logs for a certain resource for a certain time ( in this sample ora.gpnpd resource was used) [root@grac41 grac41]# fn.sh "ora.gpnpd" | egrep "TraceFileName|2014-05-22 07" | more TraceFileName: ./agent/ohasd/oraagent_grid/oraagent_grid.log 2014-05-22 07:18:27.281: [ora.gpnpd][3696797440]{0:0:2} [check] clsdmc_respget return: status=0, ecode=0 2014-05-22 07:18:57.291: [ora.gpnpd][3698898688]{0:0:2} [check] clsdmc_respget return: status=0, ecode=0 2014-05-22 07:19:27.290: [ora.gpnpd][3698898688]{0:0:2} [check] clsdmc_respget return: status=0, ecode=0 9 : Check related trace depending on startup dependencies GPndp daemon has the following dependencies: OHASD (root) starts --> OHASD ORAgent (grid) starts --> GPnP (grid) Following tracefile needs to reviewed first for add. info ./grac41/u01/app/11204/grid/log/grac41/gpnpd/gpnpd.log ( see above ) ./grac41/u01/app/11204/grid/log/grac41/ohasd/ohasd.log ./grac41/u01/app/11204/grid/log/grac41/agent/ohasd/oraagent_grid/oraagent_grid.log 10 : Check for tracefiles updated very frequently ( this helps to identify looping processes ) # date ; find . -type f -printf "%CY-%Cm-%Cd %CH:%CM:%CS %h/%fn" | sort -n | tail -5 Thu May 22 07:52:45 CEST 2014 2014-05-22 07:52:12.1781722420 ./grac41/alertgrac41.log 2014-05-22 07:52:44.8401175210 ./grac41/agent/ohasd/oraagent_grid/oraagent_grid.log 2014-05-22 07:52:45.2701299670 ./grac41/client/crsctl_grid.log 2014-05-22 07:52:45.2901305450 ./grac41/ohasd/ohasd.log 2014-05-22 07:52:45.3221314710 ./grac41/client/olsnodes.log # date ; find . -type f -printf "%CY-%Cm-%Cd %CH:%CM:%CS %h/%fn" | sort -n | tail -5 Thu May 22 07:52:48 CEST 2014 2014-05-22 07:52:12.1781722420 ./grac41/alertgrac41.log 2014-05-22 07:52:47.3701907460 ./grac41/client/crsctl_grid.log 2014-05-22 07:52:47.3901913240 ./grac41/ohasd/ohasd.log 2014-05-22 07:52:47.4241923080 ./grac41/client/olsnodes.log 2014-05-22 07:52:48.3812200070 ./grac41/agent/ohasd/oraagent_grid/oraagent_grid.log Check these trace files with tail -f # tail -f ./grac41/agent/ohasd/oraagent_grid/oraagent_grid.log [ clsdmc][1975785216]Fail to connect (ADDRESS=(PROTOCOL=ipc)(KEY=grac41DBG_GPNPD)) with status 9 2014-05-22 07:56:11.198: [ora.gpnpd][1975785216]{0:0:2} [start] Error = error 9 encountered when connecting to GPNPD 2014-05-22 07:56:12.199: [ora.gpnpd][1975785216]{0:0:2} [start] without returnbuf 2014-05-22 07:56:12.382: [ COMMCRS][1966565120]clsc_connect: (0x7fd9500cc070) no listener at (ADDRESS=(PROTOCOL=ipc)(KEY=grac41DBG_GPNPD)) [ clsdmc][1975785216]Fail to connect (ADDRESS=(PROTOCOL=ipc)(KEY=grac41DBG_GPNPD)) with status 9 2014-05-22 07:56:12.382: [ora.gpnpd][1975785216]{0:0:2} [start] Error = error 9 encountered when connecting to GPNPD 2014-05-22 07:56:13.382: [ora.gpnpd][1975785216]{0:0:2} [start] without returnbuf 2014-05-22 07:56:13.553: [ COMMCRS][1966565120]clsc_connect: (0x7fd9500cc070) no listener at (ADDRESS=(PROTOCOL=ipc)(KEY=grac41DBG_GPNPD)) --> Problem is we can't connect to the GPNPD listener # ps -elf | egrep "PID|d.bin|ohas" | grep -v grep F S UID PID PPID C PRI NI ADDR SZ WCHAN STIME TTY TIME CMD 4 S root 1560 1 0 -40 - - 160927 futex_ 07:56 ? 00:00:00 /u01/app/11204/grid/bin/cssdmonitor 4 S root 4494 1 0 80 0 - 2846 pipe_w May21 ? 00:00:00 /bin/sh /etc/init.d/init.ohasd run 4 S root 30441 1 23 80 0 - 176982 futex_ 07:49 ? 00:02:04 /u01/app/11204/grid/bin/ohasd.bin reboot 4 S grid 30612 1 0 80 0 - 167327 futex_ 07:50 ? 00:00:05 /u01/app/11204/grid/bin/oraagent.bin 0 S grid 30623 1 0 80 0 - 74289 poll_s 07:50 ? 00:00:00 /u01/app/11204/grid/bin/mdnsd.bin --> Indeed gpnpd is not running . Investiage this further by debugging CW with strace 11 : If still no root cause was found try to grep all message for that period and review the output carefully # fn.sh "2014-05-20 07:2" | more Search String: 2014-05-20 07:2 ... -------------------------------------------------------------------- TraceFileName: ./grac41/u01/app/11204/grid/log/grac41/agent/ohasd/oraagent_grid/oraagent_grid.l01 2014-05-20 07:23:04.338: [ AGFW][374716160]{0:0:2} Agent received the message: AGENT_HB[Engine] ID 12293:1236 .... -------------------------------------------------------------------- TraceFileName: ./grac41/u01/app/11204/grid/log/grac41/gpnpd/gpnpd.log 2014-05-20 07:23:13.385: [ default][4133218080] 2014-05-20 07:23:13.385: [ default][4133218080]gpnpd START pid=16641 Oracle Grid Plug-and-Play Daemon
GENERIC File Protection problems for Log File Location, Ownership and Permissions
-
-
- Resource reports status STARTING for a long time before failing with CRS errors
- After some time resource becomes OFFLINE
-
Debug startup problems for GPnP daemon Case #1 : Check that GPnP daemon can write to trace file location and new timestamps are written Following directory/files needs to have proper protections : Trace directory : ./log/grac41/gpnpd STDOUT log file : ./log/grac41/gpnpd/gpnpdOUT.log Error log file : ./log/grac41/gpnpd/gpnpd.log If gpnpdOUT.log and gpnpd.log are not updated when starting GPnP daemon you need to review your file protections Sample for GPnP resource: # ls -ld ./grac41/u01/app/11204/grid/log/grac41/gpnpd drwxr-xr-x. 2 root root 4096 May 21 09:52 ./grac41/u01/app/11204/grid/log/grac41/gpnpd # ls -l ./grac41/u01/app/11204/grid/log/grac41/gpnpd -rw-r--r--. 1 root root 420013 May 21 09:35 gpnpd.log -rw-r--r--. 1 root root 26567 May 21 09:31 gpnpdOUT.log ==> Here we can see that trace files are owned by root which is wrong ! After changing directory and tracefils with chown grid:oinstall ... traces where sucessfully written If unsure about protection verify this with a cluster node where CRS is up and running # ls -ld /u01/app/11204/grid/log/grac41/gpnpd drwxr-x---. 2 grid oinstall 4096 May 20 13:53 /u01/app/11204/grid/log/grac41/gpnpd # ls -l /u01/app/11204/grid/log/grac41/gpnpd -rw-r--r--. 1 grid oinstall 122217 May 19 13:35 gpnpd_1.log -rw-r--r--. 1 grid oinstall 1747836 May 20 12:32 gpnpd.log -rw-r--r--. 1 grid oinstall 26567 May 20 12:31 gpnpdOUT.log Case #2 : Check that IPC sockets have proper protection (this info is not available via tfa collector ) ( verify this with a node where CRS is up and running ) # ls -l /var/tmp/.oracle | grep -i gpnp srwxrwxrwx. 1 grid oinstall 0 May 20 12:31 ora_gipc_GPNPD_grac41 -rw-r--r--. 1 grid oinstall 0 May 20 10:11 ora_gipc_GPNPD_grac41_lock srwxrwxrwx. 1 grid oinstall 0 May 20 12:31 sgrac41DBG_GPNPD ==> Again check this against a working cluster node You may consider to compare all IPC socket info available in /var/tmp/.oracle Same sort of debugging can be used for other processes like MDNSD daemon MDNSD process can't listen to IPC socket grac41DBG_MDNSD socket and terminates Grep command: $ fn_egrep.sh "clsclisten: Permission denied" TraceFileName: ./grac41/mdnsd/mdnsd.log 2014-05-19 08:08:53.097: [ COMMCRS][2179102464]clsclisten: Permission denied for (ADDRESS=(PROTOCOL=ipc)(KEY=grac41DBG_MDNSD)) 2014-05-19 08:10:58.177: [ COMMCRS][3534915328]clsclisten: Permission denied for (ADDRESS=(PROTOCOL=ipc)(KEY=grac41DBG_MDNSD)) Trace file extract: ./grac41/mdnsd/mdnsd.log 2014-05-19 08:08:53.087: [ default][2187654912]mdnsd START pid=11855 2014-05-19 08:08:53.097: [ COMMCRS][2179102464]clsclisten: Permission denied for (ADDRESS=(PROTOCOL=ipc)(KEY=grac41DBG_MDNSD)) --> Permissiong problems for MDNSD resource 2014-05-19 08:08:53.097: [ clsdmt][2181203712]Fail to listen to (ADDRESS=(PROTOCOL=ipc)(KEY=grac41DBG_MDNSD)) 2014-05-19 08:08:53.097: [ clsdmt][2181203712]Terminating process 2014-05-19 08:08:53.097: [ MDNS][2181203712] clsdm requested mdnsd exit 2014-05-19 08:08:53.097: [ MDNS][2181203712] mdnsd exit 2014-05-19 08:10:58.168: [ default][3543467776] Case #3 : Check gpnpd.log for sucessful write of the related PID file # egrep "PID for the Process|Creating PID|Writing PID" ./grac41/u01/app/11204/grid/log/grac41/gpnpd/gpnpd.log 2014-05-20 07:23:13.417: [ clsdmt][4121581312]PID for the Process [16641], connkey 10 2014-05-20 07:23:13.417: [ clsdmt][4121581312]Creating PID [16641] file for home /u01/app/11204/grid host grac41 bin gpnp to /u01/app/11204/grid/gpnp/init/ 2014-05-20 07:23:13.417: [ clsdmt][4121581312]Writing PID [16641] to the file [/u01/app/11204/grid/gpnp/init/grac41.pid] Case #4 : Check gpnpd.log file for fatal errors like PROCL-5 PROCL-26 # less ./grac41/u01/app/11204/grid/log/grac41/gpnpd/gpnpd.log 2014-05-20 07:23:14.377: [ GPNP][4133218080]clsgpnpd_openLocalProfile: [at clsgpnpd.c:3477] Got local profile from file cache provider (LCP-FS). 2014-05-20 07:23:14.380: [ GPNP][4133218080]clsgpnpd_openLocalProfile: [at clsgpnpd.c:3532] Got local profile from OLR cache provider (LCP-OLR). 2014-05-20 07:23:14.385: [ GPNP][4133218080]procr_open_key_ext: OLR api procr_open_key_ext failed for key SYSTEM.GPnP.profiles.peer.pending 2014-05-20 07:23:14.386: [ GPNP][4133218080]procr_open_key_ext: OLR current boot level : 7 2014-05-20 07:23:14.386: [ GPNP][4133218080]procr_open_key_ext: OLR error code : 5 2014-05-20 07:23:14.386: [ GPNP][4133218080]procr_open_key_ext: OLR error message : PROCL-5: User does not have permission to perform a local registry operation on this key. Authentication error [User does not have permission to perform this operation] [0] 2014-05-20 07:23:14.386: [ GPNP][4133218080]clsgpnpco_ocr2profile: [at clsgpnpco.c:578] Result: (58) CLSGPNP_OCR_ERR. Failed to open requested OLR Profile. 2014-05-20 07:23:14.386: [ GPNP][4133218080]clsgpnpd_lOpen: [at clsgpnpd.c:1734] Listening on ipc://GPNPD_grac41 2014-05-20 07:23:14.386: [ GPNP][4133218080]clsgpnpd_lOpen: [at clsgpnpd.c:1743] GIPC gipcretFail (1) gipcListen listen failure on 2014-05-20 07:23:14.386: [ default][4133218080]GPNPD failed to start listening for GPnP peers. 2014-05-20 07:23:14.388: [ GPNP][4133218080]clsgpnpd_term: [at clsgpnpd.c:1344] STOP GPnPD terminating. Closing connections... 2014-05-20 07:23:14.400: [ default][4133218080]clsgpnpd_term STOP terminating.
GENERIC Networking troubleshooting chapter
-
-
- Private IP address is not directly used by clusterware
- If changing IP from 192.168.2.102 to 192.168.2.108 CW still comes up as network address 192.168.2.0 does not change
- If changing IP from 192.168.2.102 to 192.168.3.103 CW doesn’t come up as network address changed from 192.168.2.0 to 192.168.3.0 – Network address is used by GPnP profile.xml for private and public network
- Check crfmond/crfmond.trc trace file for private network errors ( usefull for CI errors )
- If you get any GIPC error message always think on a real network problems first
-
Case #1 : Nameserver not running/available Reported error in evmd.log : [ OCRMSG][3360876320]GIPC error [29] msg [gipcretConnectionRefused Reported Clusterware Error in CW alert.log: CRS-5011:Check of resource "+ASM" failed: Testing scenario : Stop nameserver and restart CRS # crsctl start crs CRS-4123: Oracle High Availability Services has been started. Clusterware status [root@grac41 gpnpd]# crsctl check crs CRS-4638: Oracle High Availability Services is online CRS-4535: Cannot communicate with Cluster Ready Services CRS-4529: Cluster Synchronization Services is online CRS-4534: Cannot communicate with Event Manager --> CSS, HAS are ONLINE - EVM and CRS are OFFLINE # ps -elf | egrep "PID|d.bin|ohas|oraagent|orarootagent|cssdagent|cssdmonitor" | grep -v grep F S UID PID PPID C PRI NI ADDR SZ WCHAN STIME TTY TIME CMD 4 S root 5396 1 0 80 0 - 2847 pipe_w 10:52 ? 00:00:00 /bin/sh /etc/init.d/init.ohasd run 4 S root 9526 1 3 80 0 - 178980 futex_ 14:47 ? 00:00:08 /u01/app/11204/grid/bin/ohasd.bin reboot 4 S grid 9705 1 0 80 0 - 174922 futex_ 14:47 ? 00:00:00 /u01/app/11204/grid/bin/oraagent.bin 0 S grid 9716 1 0 80 0 - 74289 poll_s 14:47 ? 00:00:00 /u01/app/11204/grid/bin/mdnsd.bin 0 S grid 9749 1 1 80 0 - 127375 hrtime 14:47 ? 00:00:02 /u01/app/11204/grid/bin/gpnpd.bin 0 S grid 9796 1 1 80 0 - 159711 hrtime 14:47 ? 00:00:04 /u01/app/11204/grid/bin/gipcd.bin 4 S root 9799 1 1 80 0 - 168656 futex_ 14:47 ? 00:00:03 /u01/app/11204/grid/bin/orarootagent.bin 4 S root 9812 1 3 -40 - - 160908 hrtime 14:47 ? 00:00:08 /u01/app/11204/grid/bin/osysmond.bin 4 S root 9823 1 0 -40 - - 162793 futex_ 14:47 ? 00:00:00 /u01/app/11204/grid/bin/cssdmonitor 4 S root 9842 1 0 -40 - - 162920 futex_ 14:47 ? 00:00:00 /u01/app/11204/grid/bin/cssdagent 4 S grid 9855 1 2 -40 - - 166594 futex_ 14:47 ? 00:00:04 /u01/app/11204/grid/bin/ocssd.bin 4 S root 10884 1 1 80 0 - 159388 futex_ 14:48 ? 00:00:02 /u01/app/11204/grid/bin/octssd.bin reboot 0 S grid 10904 1 0 80 0 - 75285 hrtime 14:48 ? 00:00:00 /u01/app/11204/grid/bin/evmd.bin $ crsi NAME TARGET STATE SERVER STATE_DETAILS ------------------------- ---------- ---------- ------------ ------------------ ora.asm ONLINE OFFLINE CLEANING ora.cluster_interconnect.haip ONLINE ONLINE grac41 ora.crf ONLINE ONLINE grac41 ora.crsd ONLINE OFFLINE ora.cssd ONLINE ONLINE grac41 ora.cssdmonitor ONLINE ONLINE grac41 ora.ctssd ONLINE ONLINE grac41 OBSERVER ora.diskmon OFFLINE OFFLINE ora.drivers.acfs ONLINE ONLINE grac41 ora.evmd ONLINE INTERMEDIATE grac41 ora.gipcd ONLINE ONLINE grac41 ora.gpnpd ONLINE ONLINE grac41 ora.mdnsd ONLINE ONLINE grac41 --> Event manager is in INTERMEDIATE state --> need to reivew EVMD logfile first Detailed Tracefile report Grep Syntax: $ fn_egrep.sh "failed to resolve|gipcretFail" | egrep 'TraceFile|2014-05-20 11:0' Failed case: TraceFileName: ./grac41/crsd/crsd.log and ./grac41/evmd/evmd.log may report 2014-05-20 11:04:02.563: [GIPCXCPT][154781440] gipchaInternalResolve: failed to resolve ret gipcretKeyNotFound (36), host 'grac41', port 'ffac-854b-c525-6f9c', hctx 0x2ed3940 [0000000000000010] { gipchaContext : host 'grac41', name 'd541-9a1e-7807-8f4a', luid 'f733b93a-00000000', numNode 0, numInf 1, usrFlags 0x0, flags 0x5 }, ret gipcretKeyNotFound (36) 2014-05-20 11:04:02.563: [GIPCHGEN][154781440] gipchaResolveF [gipcmodGipcResolve : gipcmodGipc.c : 806]: EXCEPTION[ ret gipcretKeyNotFound (36) ] failed to resolve ctx 0x2ed3940 [0000000000000010] { gipchaContext : host 'grac41', name 'd541-9a1e-7807-8f4a', luid 'f733b93a-00000000', numNode 0, numInf 1, usrFlags 0x0, flags 0x5 }, host 'grac41', port 'ffac-854b-c525-6f9c', flags 0x0 --> Both request trying to use a host name. If this isn't resolved we very likely have a Name server problem ! TraceFileName: ./grac41/ohasd/ohasd.log reports 2014-05-20 11:03:21.364: [GIPCXCPT][2905085696]gipchaInternalReadGpnp: No network info configured in GPNP, using defaults, ret gipcretFail (1) TraceFileName: ./evmd/evmd.log 2014-05-13 15:01:00.690: [ OCRMSG][2621794080]prom_waitconnect: CONN NOT ESTABLISHED (0,29,1,2) 2014-05-13 15:01:00.690: [ OCRMSG][2621794080]GIPC error [29] msg [gipcretConnectionRefused] 2014-05-13 15:01:00.690: [ OCRMSG][2621794080]prom_connect: error while waiting for connection complete [24] 2014-05-13 15:01:00.690: [ CRSOCR][2621794080] OCR context init failure. Error: PROC-32: Cluster Ready Services on the local node TraceFileName: ./grac41/gpnpd/gpnpd.log 2014-05-22 11:18:02.209: [ OCRCLI][1738393344]proac_con_init: Local listener using IPC. [(ADDRESS=(PROTOCOL=ipc)(KEY=procr_local_conn_0_PROC))] 2014-05-22 11:18:02.209: [ OCRMSG][1738393344]prom_waitconnect: CONN NOT ESTABLISHED (0,29,1,2) 2014-05-22 11:18:02.209: [ OCRMSG][1738393344]GIPC error [29] msg [gipcretConnectionRefused] 2014-05-22 11:18:02.209: [ OCRMSG][1738393344]prom_connect: error while waiting for connection complete [24] 2014-05-22 11:18:02.209: [ OCRCLI][1738393344]proac_con_init: Failed to connect to server [24] 2014-05-22 11:18:02.209: [ OCRCLI][1738393344]proac_con_init: Post sema. Con count [1] [ OCRCLI][1738393344]ac_init:2: Could not initialize con structures. proac_con_init failed with [32] Debug problem using cluvfy [grid@grac42 ~]$ cluvfy comp nodereach -n grac41 Verifying node reachability Checking node reachability... PRVF-6006 : Unable to reach any of the nodes PRKN-1034 : Failed to retrieve IP address of host "grac41" ==> Confirmation that we have a Name Server problem Verification of node reachability was unsuccessful on all the specified nodes. [grid@grac42 ~]$ cluvfy comp nodecon -n grac41 Verifying node connectivity ERROR: PRVF-6006 : Unable to reach any of the nodes PRKN-1034 : Failed to retrieve IP address of host "grac41" Verification cannot proceed Verification of node connectivity was unsuccessful on all the specified nodes. Debug problem with OS comands like ping and nslookup ==> For futher details see GENERIC Networking troubleshooting chapter Case #2 : Private Interface down or wrong IP address- CSSD not starting Reported Clusterware Error in CW alert.log: [/u01/app/11204/grid/bin/cssdagent(16445)] CRS-5818:Aborted command 'start' for resource 'ora.cssd'. Reported in ocssd.log : [ CSSD][491194112]clssnmvDHBValidateNcopy: node 1, grac41, has a disk HB, but no network HB, Reported in crfmond.log : [ CRFM][4239771392]crfm_connect_to: Wait failed with gipcret: 16 for conaddr tcp://192.168.2.103:61020 Testing scenario : Shutdown private interface [root@grac42 ~]# ifconfig eth2 down [root@grac42 ~]# ifconfig eth2 eth2 Link encap:Ethernet HWaddr 08:00:27:DF:79:B9 BROADCAST MULTICAST MTU:1500 Metric:1 RX packets:754556 errors:0 dropped:0 overruns:0 frame:0 TX packets:631900 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:378302114 (360.7 MiB) TX bytes:221328282 (211.0 MiB) [root@grac42 ~]# crsctl start crs CRS-4123: Oracle High Availability Services has been started. Clusterware status : [root@grac42 grac42]# crsctl check crs CRS-4638: Oracle High Availability Services is online CRS-4535: Cannot communicate with Cluster Ready Services CRS-4530: Communications failure contacting Cluster Synchronization Services daemon CRS-4534: Cannot communicate with Event Manager [grid@grac42 grac42]$ crsi NAME TARGET STATE SERVER STATE_DETAILS ------------------------- ---------- ---------- ------------ ------------------ ora.asm ONLINE OFFLINE grac41 Instance Shutdown ora.cluster_interconnect.haip ONLINE OFFLINE ora.crf ONLINE ONLINE grac42 ora.crsd ONLINE OFFLINE ora.cssd ONLINE OFFLINE STARTING ora.cssdmonitor ONLINE ONLINE grac42 ora.ctssd ONLINE OFFLINE ora.diskmon OFFLINE OFFLINE ora.drivers.acfs ONLINE OFFLINE ora.evmd ONLINE OFFLINE ora.gipcd ONLINE ONLINE grac42 ora.gpnpd ONLINE ONLINE grac42 ora.mdnsd ONLINE ONLINE grac42 --> CSSD in mode STARTING and not progressing over time After some minutes CSSD goes OFFLINE Tracefile Details: alertgrac42.log: [cssd(16469)]CRS-1656:The CSS daemon is terminating due to a fatal error; Details at (:CSSSC00012:) in .../cssd/ocssd.log 2014-05-31 14:15:41.828: [cssd(16469)]CRS-1603:CSSD on node grac42 shutdown by user. 2014-05-31 14:15:41.828: [/u01/app/11204/grid/bin/cssdagent(16445)]CRS-5818:Aborted command 'start' for resource 'ora.cssd'. Details at (:CRSAGF00113:) {0:0:2} in ../agent/ohasd/oracssdagent_root/oracssdagent_root.log. ocssd.log: 2014-05-31 14:23:11.534: [ CSSD][491194112]clssnmvDHBValidateNcopy: node 1, grac41, has a disk HB, but no network HB, DHB has rcfg 296672934, wrtcnt, 25000048, LATS 9730774, lastSeqNo 25000045, uniqueness 1401378465, timestamp 1401538986/54631634 2014-05-31 14:23:11.550: [ CSSD][481683200]clssnmvDHBValidateNcopy: node 1, grac41, has a disk HB, but no network HB, DHB has rcfg 296672934, wrtcnt, 25000050, LATS 9730794, lastSeqNo 25000047, uniqueness 1401378465, timestamp 1401538986/54632024 Using grep to locate errors CRF resource is checking CI every 5s and reports errors: $ fn.sh 2014-06-03 | egrep 'TraceFileName|failed' TraceFileName: ./crfmond/crfmond.log 2014-06-03 08:28:40.859: [ CRFM][4239771392]crfm_connect_to: Wait failed with gipcret: 16 for conaddr tcp://192.168.2.103:61020 2014-06-03 08:28:46.065: [ CRFM][4239771392]crfm_connect_to: Wait failed with gipcret: 16 for conaddr tcp://192.168.2.103:61020 2014-06-03 08:28:51.271: [ CRFM][4239771392]crfm_connect_to: Wait failed with gipcret: 16 for conaddr tcp://192.168.2.103:61020 2014-06-03 08:37:11.264: [ CSSCLNT][4243982080]clsssInitNative: connect to (ADDRESS=(PROTOCOL=ipc)(KEY=OCSSD_LL_grac42_)) failed, rc 13 DHB has rcfg 296672934, wrtcnt, 23890957, LATS 9730794, lastSeqNo 23890939, uniqueness 1401292202, timestamp 1401538981/89600384 Do we have any network problems ? $ fn.sh "2014-06-03" | egrep 'but no network HB|TraceFileName' Search String: no network HB TraceFileName: ./cssd/ocssd.log 2014-06-02 12:51:52.564: [ CSSD][2682775296]clssnmvDHBValidateNcopy: node 3, grac43, has a disk HB, but no network HB, DHB has rcfg 297162159, wrtcnt, 24036295, LATS 167224, lastSeqNo 24036293, uniqueness 1401692525, timestamp 1401706311/13179394 2014-06-02 12:51:53.569: [ CSSD][2682775296]clssnmvDHBValidateNcopy: node 1, grac41, has a disk HB, but no network HB, DHB has rcfg 297162159, wrtcnt, 25145340, LATS 168224, lastSeqNo 25145334, uniqueness 1401692481, timestamp 1401706313/13192074 Is there a valid CI network device ? # fn_egrep.sh "NETDATA" | egrep 'TraceFile|2014-06-03' TraceFileName: ./gipcd/gipcd.log 2014-06-03 07:48:40.372: [ CLSINET][3977414400] Returning NETDATA: 1 interfaces 2014-06-03 07:48:45.401: [ CLSINET][3977414400] Returning NETDATA: 1 interfaces _-> ok 2014-06-03 07:52:51.589: [ CLSINET][1140848384] Returning NETDATA: 0 interfaces --> Problem with CI 2014-06-03 07:52:51.669: [ CLSINET][1492440832] Returning NETDATA: 0 interfaces Debug with cluvfy [grid@grac41 ~]$ cluvfy comp nodecon -n grac41,grac42 -i eth1,eth2 Verifying node connectivity Checking node connectivity... Checking hosts config file... Verification of the hosts config file successful ERROR: PRVG-11049 : Interface "eth2" does not exist on nodes "grac42" Check: Node connectivity for interface "eth1" Node connectivity passed for interface "eth1" TCP connectivity check passed for subnet "192.168.1.0" Check: Node connectivity for interface "eth2" Node connectivity failed for interface "eth2" TCP connectivity check passed for subnet "192.168.2.0" Checking subnet mask consistency... Subnet mask consistency check passed for subnet "10.0.2.0". Subnet mask consistency check passed for subnet "192.168.1.0". Subnet mask consistency check passed for subnet "192.168.2.0". Subnet mask consistency check passed for subnet "169.254.0.0". Subnet mask consistency check passed for subnet "192.168.122.0". Subnet mask consistency check passed. Node connectivity check failed Verification of node connectivity was unsuccessful on all the specified nodes. Debug using OS commands [grid@grac42 NET]$ /bin/ping -s 1500 -c 2 -I 192.168.2.102 192.168.2.101 bind: Cannot assign requested address [grid@grac42 NET]$ /bin/ping -s 1500 -c 2 -I 192.168.2.102 192.168.2.102 bind: Cannot assign requested address Verify GnpP profile and find out CI device [root@grac42 crfmond]# $GRID_HOME/bin/gpnptool get 2>/dev/null | xmllint --format - | egrep 'CSS-Profile|ASM-Profile|Network id' <gpnp:HostNetwork id="gen" HostName="*"> <gpnp:Network id="net1" IP="192.168.1.0" Adapter="eth1" Use="public"/> <gpnp:Network id="net2" IP="192.168.2.0" Adapter="eth2" Use="cluster_interconnect"/> --> eth2 is our cluster interconnect [root@grac42 crfmond]# ifconfig eth2 eth2 Link encap:Ethernet HWaddr 08:00:27:DF:79:B9 inet addr:192.168.3.102 Bcast:192.168.3.255 Mask:255.255.255.0 inet6 addr: fe80::a00:27ff:fedf:79b9/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 -> Here we have a wrong address 192.168.3.102 should be 192.168.2.102 Note CI device should have following flags : UP BROADCAST RUNNING MULTICAST Case #3 : Public Interface down - Public network ora.net1.network not starting Reported in ./agent/crsd/orarootagent_root/orarootagent_root.log 2014-05-31 11:58:27.899: [ AGFW][1829066496]{2:12808:5} Preparing START command for: ora.net1.network grac42 1 2014-05-31 11:58:27.969: [ AGFW][1829066496]{2:12808:5} ora.net1.network grac42 1 state changed from: STARTING to: UNKNOWN 2014-05-31 11:58:27.969: [ AGFW][1829066496]{2:12808:5} ora.net1.network grac42 1 would be continued to monitored! Reported Clusterware Error in CW alert.log: no errors reported Testing scenario : - Shutdown public interface [root@grac42 evmd]# ifconfig eth1 down [root@grac42 evmd]# ifconfig eth1 eth1 Link encap:Ethernet HWaddr 08:00:27:63:08:07 BROADCAST MULTICAST MTU:1500 Metric:1 RX packets:2889 errors:0 dropped:0 overruns:0 frame:0 TX packets:2458 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:484535 (473.1 KiB) TX bytes:316359 (308.9 KiB) [root@grac42 ~]# crsctl start crs CRS-4123: Oracle High Availability Services has been started. Clusterware status : [grid@grac42 grac42]$ crsctl check crs CRS-4638: Oracle High Availability Services is online CRS-4537: Cluster Ready Services is online CRS-4529: Cluster Synchronization Services is online CRS-4533: Event Manager is online --> OHASD stack is ok ! [grid@grac42 grac42]$ crsi NAME TARGET STATE SERVER STATE_DETAILS ------------------------- ---------- ---------- ------------ ------------------ ora.asm ONLINE ONLINE grac42 Started ora.cluster_interconnect.haip ONLINE ONLINE grac42 ora.crf ONLINE ONLINE grac42 ora.crsd ONLINE ONLINE grac42 ora.cssd ONLINE ONLINE grac42 ora.cssdmonitor ONLINE ONLINE grac42 ora.ctssd ONLINE ONLINE grac42 OBSERVER ora.diskmon OFFLINE OFFLINE ora.drivers.acfs ONLINE ONLINE grac42 ora.evmd ONLINE ONLINE grac42 ora.gipcd ONLINE ONLINE grac42 ora.gpnpd ONLINE ONLINE grac42 ora.mdnsd ONLINE ONLINE grac42 --> OAHSD stack is up and running [grid@grac42 grac42]$ crs | grep grac42 NAME TARGET STATE SERVER STATE_DETAILS ------------------------- ---------- ---------- ------------ ------------------ ora.ASMLIB_DG.dg ONLINE ONLINE grac42 ora.DATA.dg ONLINE ONLINE grac42 ora.FRA.dg ONLINE ONLINE grac42 ora.LISTENER.lsnr ONLINE OFFLINE grac42 ora.OCR.dg ONLINE ONLINE grac42 ora.SSD.dg ONLINE ONLINE grac42 ora.asm ONLINE ONLINE grac42 Started ora.gsd OFFLINE OFFLINE grac42 ora.net1.network ONLINE OFFLINE grac42 ora.ons ONLINE OFFLINE grac42 ora.registry.acfs ONLINE ONLINE grac42 ora.grac4.db ONLINE OFFLINE grac42 Instance Shutdown ora.grac4.grac42.svc ONLINE OFFLINE grac42 ora.grac42.vip ONLINE INTERMEDIATE grac43 FAILED OVER --> ora.net1.network OFFLINE ora.grac42.vip n status INTERMEDIATE - FAILED OVER to grac43 Check messages logged for resource ora.net1.network from 2014-05-31 11:00:00 - 2014-05-31 11:59_59 [grid@grac42 grac42]$ fn.sh "ora.net1.network" | egrep '2014-05-31 11|TraceFileName' TraceFileName: ./agent/crsd/orarootagent_root/orarootagent_root.log 2014-05-31 11:58:27.899: [ AGFW][1829066496]{2:12808:5} Agent received the message: RESOURCE_START[ora.net1.network grac42 1] ID 4098:403 2014-05-31 11:58:27.899: [ AGFW][1829066496]{2:12808:5} Preparing START command for: ora.net1.network grac42 1 2014-05-31 11:58:27.899: [ AGFW][1829066496]{2:12808:5} ora.net1.network grac42 1 state changed from: OFFLINE to: STARTING 2014-05-31 11:58:27.917: [ AGFW][1826965248]{2:12808:5} Command: start for resource: ora.net1.network grac42 1 completed with status: SUCCESS 2014-05-31 11:58:27.919: [ AGFW][1829066496]{2:12808:5} Agent sending reply for: RESOURCE_START[ora.net1.network grac42 1] ID 4098:403 2014-05-31 11:58:27.969: [ AGFW][1829066496]{2:12808:5} ora.net1.network grac42 1 state changed from: STARTING to: UNKNOWN 2014-05-31 11:58:27.969: [ AGFW][1829066496]{2:12808:5} ora.net1.network grac42 1 would be continued to monitored! 2014-05-31 11:58:27.969: [ AGFW][1829066496]{2:12808:5} Started implicit monitor for [ora.net1.network grac42 1] interval=1000 delay=1000 2014-05-31 11:58:27.969: [ AGFW][1829066496]{2:12808:5} Agent sending last reply for: RESOURCE_START[ora.net1.network grac42 1] ID 4098:403 2014-05-31 11:58:27.982: [ AGFW][1829066496]{2:12808:5} Agent received the message: RESOURCE_CLEAN[ora.net1.network grac42 1] ID 4100:409 2014-05-31 11:58:27.982: [ AGFW][1829066496]{2:12808:5} Preparing CLEAN command for: ora.net1.network grac42 1 2014-05-31 11:58:27.982: [ AGFW][1829066496]{2:12808:5} ora.net1.network grac42 1 state changed from: UNKNOWN to: CLEANING 2014-05-31 11:58:27.983: [ AGFW][1826965248]{2:12808:5} Command: clean for resource: ora.net1.network grac42 1 completed with status: SUCCESS 2014-05-31 11:58:27.984: [ AGFW][1829066496]{2:12808:5} Agent sending reply for: RESOURCE_CLEAN[ora.net1.network grac42 1] ID 4100:409 2014-05-31 11:58:27.984: [ AGFW][1829066496]{2:12808:5} ora.net1.network grac42 1 state changed from: CLEANING to: OFFLINE Debug with cluvfy Run cluvfy on the failing node [grid@grac42 grac42]$ cluvfy comp nodereach -n grac42 Verifying node reachability Checking node reachability... PRVF-6006 : Unable to reach any of the nodes PRKC-1071 : Nodes "grac42" did not respond to ping in "3" seconds, PRKN-1035 : Host "grac42" is unreachable Verification of node reachability was unsuccessful on all the specified nodes. Debug with OS Commands [grid@grac42 NET]$ /bin/ping -s 1500 -c 2 -I 192.168.1.102 grac42 bind: Cannot assign requested address --> Here we are failing as eht1 is not up and running [grid@grac42 NET]$ /bin/ping -s 1500 -c 2 -I 192.168.1.102 grac41 ping: unknown host grac41 --> Here we are failing due as Nameserver can be reached
Debugging complete CW startup with strace
-
-
- resource STATE remains STARTING for a long time
- resource process gets restarted quickly but could not successful start at all
- Note strace will only help for protection or connection issues.
- If there is a logical corruption you need to review CW log files
-
Command used as user root : # strace -t -f -o /tmp/ohasd.trc crsctl start crs CW status : GPNP daemon doesn't come up Verify OHASD stack NAME TARGET STATE SERVER STATE_DETAILS ------------------------- ---------- ---------- ------------ ------------------ ora.asm ONLINE OFFLINE Instance Shutdown ora.cluster_interconnect.haip ONLINE OFFLINE ora.crf ONLINE OFFLINE ora.crsd ONLINE OFFLINE ora.cssd ONLINE OFFLINE ora.cssdmonitor ONLINE OFFLINE ora.ctssd ONLINE OFFLINE ora.diskmon ONLINE OFFLINE ora.drivers.acfs ONLINE ONLINE grac41 ora.evmd ONLINE OFFLINE ora.gipcd ONLINE OFFLINE ora.gpnpd ONLINE OFFLINE STARTING ora.mdnsd ONLINE ONLINE grac41 --> gpnpd daemon does not progress over time : STATE shows STARTING Now stop CW and restart CW startup with strace -t -f [root@grac41 gpnpd]# strace -t -f -o /tmp/ohasd.trc crsctl start crs [root@grac41 gpnpd]# grep -i gpnpd /tmp/ohasd.trc | more Check whether gpnpd shell and gpnpd.bin were scheduled for running : root@grac41 log]# grep -i execve /tmp/ohasd.trc | grep gpnp 9866 08:13:56 execve("/u01/app/11204/grid/bin/gpnpd", ["/u01/app/11204/grid/bin/gpnpd"], [/* 72 vars */] <unfinished ...> 9866 08:13:56 execve("/u01/app/11204/grid/bin/gpnpd.bin", ["/u01/app/11204/grid/bin/gpnpd.bi"...], [/* 72 vars */] <unfinished ...> 11017 08:16:01 execve("/u01/app/11204/grid/bin/gpnpd", ["/u01/app/11204/grid/bin/gpnpd"], [/* 72 vars */] <unfinished ...> 11017 08:16:01 execve("/u01/app/11204/grid/bin/gpnpd.bin", ["/u01/app/11204/grid/bin/gpnpd.bi"...], [/* 72 vars */] <unfinished ...> --> gpnpd.bin was scheduled 2x in 5 seconeds - seems we have problem here check return codes Check ohasd.trc for errors like: $ egrep 'EACCES|ENOENT|EADDRINUSE|ECONNREFUSED|EPERM' /tmp/ohasd.trc Check ohasd.trc for certain return codes # grep EACCES /tmp/ohasd.trc # grep ENOENT ohasd.trc # returns a lot of info Linux error codes leading to a failed CW startup EACCES : open("/u01/app/11204/grid/log/grac41/gpnpd/gpnpdOUT.log", O_RDWR|O_CREAT|O_APPEND, 0644) = -1 EACCES (Permission denied) ENOENT : stat("/u01/app/11204/grid/log/grac41/ohasd", 0x7fff17d68f40) = -1 ENOENT (No such file or directory) EADDRINUSE : [pid 7391] bind(6, {sa_family=AF_FILE, path="/var/tmp/.oracle/sgrac41DBG_MDNSD"}, 110) = -1 EADDRINUSE (Address already in use) ECONNREFUSED : [pid 7391] connect(6, {sa_family=AF_FILE, path="/var/tmp/.oracle/sgrac41DBG_MDNSD"}, 110) = -1 ECONNREFUSED (Connection refused) EPERM : [pid 7391] unlink("/var/tmp/.oracle/sgrac41DBG_MDNSD") = -1 EPERM (Operation not permitted) Check for LOGfile and PID file usage PID file usage : # grep ".pid" ohasd.trc Sucessful open of mdns/init/grac41.pid through MDSND 9848 08:13:55 stat("/u01/app/11204/grid/mdns/init/grac41.pid", <unfinished ...> 9848 08:13:55 stat("/u01/app/11204/grid/mdns/init/grac41.pid", <unfinished ...> 9848 08:13:55 access("/u01/app/11204/grid/mdns/init/grac41.pid", F_OK <unfinished ...> 9848 08:13:55 statfs("/u01/app/11204/grid/mdns/init/grac41.pid", <unfinished ...> 9848 08:13:55 open("/u01/app/11204/grid/mdns/init/grac41.pid", O_WRONLY|O_CREAT|O_TRUNC, 0666) = 7 9841 08:13:56 stat("/u01/app/11204/grid/mdns/init/grac41.pid", {st_mode=S_IFREG|0644, st_size=5, ...}) = 0 9841 08:13:56 stat("/u01/app/11204/grid/mdns/init/grac41.pid", {st_mode=S_IFREG|0644, st_size=5, ...}) = 0 9841 08:13:56 access("/u01/app/11204/grid/mdns/init/grac41.pid", F_OK) = 0 9841 08:13:56 statfs("/u01/app/11204/grid/mdns/init/grac41.pid", {f_type="EXT2_SUPER_MAGIC", f_bsize=4096, f_blocks=9900906, f_bfree=2564283, f_bavail=2061346, f_files=2514944, f_ffree=2079685, f_fsid={1657171729, 223082106}, f_namelen=255, f_frsize=4096}) = 0 9841 08:13:56 open("/u01/app/11204/grid/mdns/init/grac41.pid", O_RDONLY) = 27 9845 08:13:56 open("/var/tmp/.oracle/mdnsd.pid", O_WRONLY|O_CREAT|O_TRUNC, 0666 <unfinished ...> Failed open of gpnp/init/grac41.pid through GPNPD 9842 08:16:00 stat("/u01/app/11204/grid/gpnp/init/grac41.pid", <unfinished ...> 9842 08:16:00 stat("/u01/app/11204/grid/gpnp/init/grac41.pid", <unfinished ...> 9842 08:16:00 access("/u01/app/11204/grid/gpnp/init/grac41.pid", F_OK <unfinished ...> 9842 08:16:00 statfs("/u01/app/11204/grid/gpnp/init/grac41.pid", <unfinished ...> 9842 08:16:00 open("/u01/app/11204/grid/gpnp/init/grac41.pid", O_RDONLY <unfinished ...> 9860 08:16:01 stat("/u01/app/11204/grid/gpnp/init/grac41.pid", <unfinished ...> 9860 08:16:01 stat("/u01/app/11204/grid/gpnp/init/grac41.pid", <unfinished ...> 9860 08:16:01 access("/u01/app/11204/grid/gpnp/init/grac41.pid", F_OK <unfinished ...> 9860 08:16:01 statfs("/u01/app/11204/grid/gpnp/init/grac41.pid", <unfinished ...> 9860 08:16:01 open("/u01/app/11204/grid/gpnp/init/grac41.pid", O_RDONLY <unfinished ...> Sucessful open of Logfile log/grac41/mdnsd/mdnsd.log through MDSND # grep ".log" /tmp/ohasd.trc # this on is very helplful 9845 08:13:55 open("/u01/app/11204/grid/log/grac41/mdnsd/mdnsd.log", O_WRONLY|O_APPEND) = 4 9845 08:13:55 stat("/u01/app/11204/grid/log/grac41/mdnsd/mdnsd.log", {st_mode=S_IFREG|0644, st_size=509983, ...}) = 0 9845 08:13:55 chmod("/u01/app/11204/grid/log/grac41/mdnsd/mdnsd.log", 0644) = 0 9845 08:13:55 stat("/u01/app/11204/grid/log/grac41/mdnsd/mdnsd.log", {st_mode=S_IFREG|0644, st_size=509983, ...}) = 0 9845 08:13:55 chmod("/u01/app/11204/grid/log/grac41/mdnsd/mdnsd.log", 0644) = 0 9845 08:13:55 stat("/u01/app/11204/grid/log/grac41/mdnsd/mdnsd.log", {st_mode=S_IFREG|0644, st_size=509983, ...}) = 0 9845 08:13:55 stat("/u01/app/11204/grid/log/grac41/mdnsd/mdnsd.log", {st_mode=S_IFREG|0644, st_size=509983, ...}) = 0 9845 08:13:55 access("/u01/app/11204/grid/log/grac41/mdnsd/mdnsd.log", F_OK) = 0 9845 08:13:55 statfs("/u01/app/11204/grid/log/grac41/mdnsd/mdnsd.log", {f_type="EXT2_SUPER_MAGIC", f_bsize=4096, f_blocks=9900906, f_bfree=2564312, f_bavail=2061375, f_files=2514944, f_ffree=2079685, f_fsid={1657171729, 223082106}, f_namelen=255, f_frsize=4096}) = 0 9845 08:13:55 open("/u01/app/11204/grid/log/grac41/mdnsd/mdnsd.log", O_WRONLY|O_APPEND) = 4 9845 08:13:55 stat("/u01/app/11204/grid/log/grac41/mdnsd/mdnsd.log", {st_mode=S_IFREG|0644, st_size=509983, ...}) = 0 9845 08:13:55 stat("/u01/app/11204/grid/log/grac41/mdnsd/mdnsd.log", <unfinished ...> Failed open of Logfile log/grac41/gpnpd/gpnpdOUT.log and through GPNPD 9866 08:13:56 open("/u01/app/11204/grid/log/grac41/gpnpd/gpnpdOUT.log", O_RDWR|O_CREAT|O_APPEND, 0644 <unfinished ...> --> We need to get a file descriptor back from open call 9842 08:15:56 stat("/u01/app/11204/grid/log/grac41/alertgrac41.log", {st_mode=S_IFREG|0664, st_size=1877580, ...}) = 0 9842 08:15:56 stat("/u01/app/11204/grid/log/grac41/alertgrac41.log", {st_mode=S_IFREG|0664, st_size=1877580, ...}) = 0 Checking IPC sockets usage Succesfull opening of IPC sockets throuph of MSDMD process # grep MDNSD /tmp/ohasd.trc 9849 08:13:56 chmod("/var/tmp/.oracle/sgrac41DBG_MDNSD", 0777) = 0 9862 08:13:56 access("/var/tmp/.oracle/sgrac41DBG_MDNSD", F_OK <unfinished ...> 9862 08:13:56 connect(28, {sa_family=AF_FILE, path="/var/tmp/.oracle/sgrac41DBG_MDNSD"}, 110 <unfinished ...> 9849 08:13:56 <... getsockname resumed> {sa_family=AF_FILE, path="/var/tmp/.oracle/sgrac41DBG_MDNSD"}, [36]) = 0 9849 08:13:56 chmod("/var/tmp/.oracle/sgrac41DBG_MDNSD", 0777 <unfinished ...> --> connect was successfull at 13:56 - further processing with system calls like bind() will be seend in trace No furhter connect requests are happing for /var/tmp/.oracle/sgrac41DBG_MDNSD Complete log including a successful connect 9862 08:13:56 connect(28, {sa_family=AF_FILE, path="/var/tmp/.oracle/sgrac41DBG_MDNSD"}, 110 <unfinished ...> 9834 08:13:56 <... times resumed> {tms_utime=3, tms_stime=4, tms_cutime=0, tms_cstime=0}) = 435715860 9862 08:13:56 <... connect resumed> ) = 0 9862 08:13:56 connect(28, {sa_family=AF_FILE, path="/var/tmp/.oracle/sgrac41DBG_MDNSD"}, 110 <unfinished ...> 9834 08:13:56 <... times resumed> {tms_utime=3, tms_stime=4, tms_cutime=0, tms_cstime=0}) = 435715860 9862 08:13:56 <... connect resumed> ) = 0 .. 9849 08:13:55 bind(6, {sa_family=AF_FILE, path="/var/tmp/.oracle/sgrac41DBG_MDNSD"}, 110) = 0 .. 9849 08:13:55 listen(6, 500 <unfinished ...> 9731 08:13:55 nanosleep({0, 1000000}, <unfinished ...> 9849 08:13:55 <... listen resumed> ) = 0 --> After a successfull listen system call clients can connect To allow clients to connect we need as succesful connect(), bind() and listen() system call ! Failed opening of IPC sockets throuph of GPNPD process # grep MDNSD /tmp/ohasd.trc 9924 08:14:37 access("/var/tmp/.oracle/sgrac41DBG_GPNPD", F_OK) = 0 9924 08:14:37 connect(30, {sa_family=AF_FILE, path="/var/tmp/.oracle/sgrac41DBG_GPNPD"}, 110) = -1 ECONNREFUSED (Connection refused) 9924 08:14:37 access("/var/tmp/.oracle/sgrac41DBG_GPNPD", F_OK) = 0 9924 08:14:37 connect(30, {sa_family=AF_FILE, path="/var/tmp/.oracle/sgrac41DBG_GPNPD"}, 110) = = -1 ECONNREFUSED (Connection refused) --> The connect request was unsucssful and was repeated again and again.
Debugging a single CW process with strace
-
-
- resource STATE remains STARTING for a long time
- resource process gets restarted quickly but could not succesfully start at all
- Note strace will only help for protection or connection issues.
- If there is a logical corruption you need to review CW log files
-
[root@grac41 .oracle]# crsi NAME TARGET STATE SERVER STATE_DETAILS ------------------------- ---------- ---------- ------------ ------------------ ora.asm ONLINE OFFLINE Instance Shutdown ora.cluster_interconnect.haip ONLINE OFFLINE ora.crf ONLINE OFFLINE ora.crsd ONLINE OFFLINE ora.cssd ONLINE OFFLINE ora.cssdmonitor ONLINE OFFLINE ora.ctssd ONLINE OFFLINE ora.diskmon ONLINE OFFLINE ora.drivers.acfs ONLINE OFFLINE ora.evmd ONLINE OFFLINE ora.gipcd ONLINE OFFLINE ora.gpnpd ONLINE OFFLINE STARTING ora.mdnsd ONLINE ONLINE grac41 Check whether the related process is running ? [root@grac41 .oracle]# ps -elf | egrep "PID|d.bin|ohas|oraagent|orarootagent|cssdagent|cssdmonitor" | grep -v grep F S UID PID PPID C PRI NI ADDR SZ WCHAN STIME TTY TIME CMD 4 S root 7023 1 0 80 0 - 2846 pipe_w 06:01 ? 00:00:00 /bin/sh /etc/init.d/init.ohasd run 0 S grid 17764 10515 0 80 0 - 1113 wait 12:11 pts/8 00:00:00 strace -t -f -o /tmp/mdnsd.trc /u01/app/11204/grid/bin/mdnsd 0 S grid 17767 17764 0 80 0 - 78862 poll_s 12:11 ? 00:00:00 /u01/app/11204/grid/bin/mdnsd.bin 4 S root 18501 1 23 80 0 - 176836 futex_ 12:13 ? 00:05:07 /u01/app/11204/grid/bin/ohasd.bin reboot 4 S grid 18567 1 1 80 0 - 170697 futex_ 12:13 ? 00:00:14 /u01/app/11204/grid/bin/oraagent.bin 4 S root 20306 1 0 -40 - - 160927 futex_ 12:19 ? 00:00:03 /u01/app/11204/grid/bin/cssdmonitor 4 S root 21396 1 0 80 0 - 163115 futex_ 12:23 ? 00:00:00 /u01/app/11204/grid/bin/orarootagent.bin --> gpnpd.bin is not running - but was restarted very often Starting gpnpd.bin process with strace : $ strace -t -f -o /tmp/gpnpd.trc /u01/app/11204/grid/bin/gpnpd Note this is very very dangerous as you need to know which user start this process IF you run this procless as the wrong user OLR,OCR, IPC sockest privs and log file location can we corrupted ! Before tracing a single process you may run strace -t -f -o ohasd.trc crsctl start crs ( see the above chapater ) as this command alwas starts the process as correct user, in correct order and pull up needed resources Run the following commands only our your test system as a last ressort. Manually start gpnpd as user grid with strace attached! [grid@grac41 grac41]$ strace -t -f -o /tmp/gpnpd.trc /u01/app/11204/grid/bin/gpnpd Unable to open file /u01/app/11204/grid/log/grac41/gpnpd/gpnpdOUT.log: % [grid@grac41 grac41]$ egrep 'EACCES|ENOENT|EADDRINUSE|ECONNREFUSED|EPERM' /tmp/gpnpd.trc 25251 12:37:39 open("/u01/app/11204/grid/log/grac41/gpnpd/gpnpdOUT.log", O_RDWR|O_CREAT|O_APPEND, 0644) = -1 EACCES (Permission denied) -==> Fix: # chown grid:oinstall /u01/app/11204/grid/log/grac41/gpnpd/gpnpdOUT.log Repeat the above command as long we errors [grid@grac41 grac41]$ strace -t -f -o /tmp/gpnpd.trc /u01/app/11204/grid/bin/gpnpd [grid@grac41 grac41]$ egrep 'EACCES|ENOENT|EADDRINUSE|ECONNREFUSED|EPERM' /tmp/gpnpd.trc 27089 12:44:35 connect(45, {sa_family=AF_FILE, path="/var/tmp/.oracle/sprocr_local_conn_0_PROC"}, 110) = = -1 ENOENT (No such file or directory) 27089 12:44:58 connect(45, {sa_family=AF_FILE, path="/var/tmp/.oracle/sprocr_local_conn_0_PROC"}, 110) = -1 ENOENT (No such file or directory) .. 32486 13:03:52 connect(45, {sa_family=AF_FILE, path="/var/tmp/.oracle/sprocr_local_conn_0_PROC"}, 110) = -1 ENOENT (No such file or directory) --> Connect was unsuccesfull - check IPC socket protections ! Note strace will only help for protection or connection issues. If there is a logical corruption you need to review CW log files Details of a logical OCR corruption with PROCL-5 error : ./gpnpd/gpnpd.log .. [ CLWAL][3606726432]clsw_Initialize: OLR initlevel [70000] [ OCRAPI][3606726432]a_init:10: AUTH LOC [/u01/app/11204/grid/srvm/auth] [ OCRMSG][3606726432]prom_init: Successfully registered comp [OCRMSG] in clsd. 2014-05-20 07:57:51.118: [ OCRAPI][3606726432]a_init:11: Messaging init successful. [ OCRCLI][3606726432]oac_init: Successfully registered comp [OCRCLI] in clsd. 2014-05-20 07:57:51.118: [ OCRCLI][3606726432]proac_con_init: Local listener using IPC. [(ADDRESS=(PROTOCOL=ipc)(KEY=procr_local_conn_0_PROL))] 2014-05-20 07:57:51.119: [ OCRCLI][3606726432]proac_con_init: Successfully connected to the server 2014-05-20 07:57:51.119: [ OCRCLI][3606726432]proac_con_init: Post sema. Con count [1] 2014-05-20 07:57:51.120: [ OCRAPI][3606726432]a_init:12: Client init successful. 2014-05-20 07:57:51.120: [ OCRAPI][3606726432]a_init:21: OCR init successful. Init Level [7] 2014-05-20 07:57:51.120: [ OCRAPI][3606726432]a_init:2: Init Level [7] 2014-05-20 07:57:51.132: [ OCRCLI][3606726432]proac_con_init: Post sema. Con count [2] [ clsdmt][3595089664]Listening to (ADDRESS=(PROTOCOL=ipc)(KEY=grac41DBG_GPNPD)) 2014-05-20 07:57:51.133: [ clsdmt][3595089664]PID for the Process [31034], connkey 10 2014-05-20 07:57:51.133: [ clsdmt][3595089664]Creating PID [31034] file for home /u01/app/11204/grid host grac41 bin gpnp to /u01/app/11204/grid/gpnp/init/ 2014-05-20 07:57:51.133: [ clsdmt][3595089664]Writing PID [31034] to the file [/u01/app/11204/grid/gpnp/init/grac41.pid] 2014-05-20 07:57:52.108: [ GPNP][3606726432]clsgpnpd_validateProfile: [at clsgpnpd.c:2919] GPnPD taken cluster name 'grac4' 2014-05-20 07:57:52.108: [ GPNP][3606726432]clsgpnpd_openLocalProfile: [at clsgpnpd.c:3477] Got local profile from file cache provider (LCP-FS). 2014-05-20 07:57:52.111: [ GPNP][3606726432]clsgpnpd_openLocalProfile: [at clsgpnpd.c:3532] Got local profile from OLR cache provider (LCP-OLR). 2014-05-20 07:57:52.113: [ GPNP][3606726432]procr_open_key_ext: OLR api procr_open_key_ext failed for key SYSTEM.GPnP.profiles.peer.pending 2014-05-20 07:57:52.113: [ GPNP][3606726432]procr_open_key_ext: OLR current boot level : 7 2014-05-20 07:57:52.113: [ GPNP][3606726432]procr_open_key_ext: OLR error code : 5 2014-05-20 07:57:52.126: [ GPNP][3606726432]procr_open_key_ext: OLR error message : PROCL-5: User does not have permission to perform a local registry operation on this key. Authentication error [User does not have permission to perform this operation] [0] 2014-05-20 07:57:52.126: [ GPNP][3606726432]clsgpnpco_ocr2profile: [at clsgpnpco.c:578] Result: (58) CLSGPNP_OCR_ERR. Failed to open requested OLR Profile. 2014-05-20 07:57:52.127: [ GPNP][3606726432]clsgpnpd_lOpen: [at clsgpnpd.c:1734] Listening on ipc://GPNPD_grac41 2014-05-20 07:57:52.127: [ GPNP][3606726432]clsgpnpd_lOpen: [at clsgpnpd.c:1743] GIPC gipcretFail (1) gipcListen listen failure on 2014-05-20 07:57:52.127: [ default][3606726432]GPNPD failed to start listening for GPnP peers. 2014-05-20 07:57:52.135: [ GPNP][3606726432]clsgpnpd_term: [at clsgpnpd.c:1344] STOP GPnPD terminating. Closing connections... 2014-05-20 07:57:52.137: [ default][3606726432]clsgpnpd_term STOP terminating. 2014-05-20 07:57:53.136: [ OCRAPI][3606726432]a_terminate:1:current ref count = 1 2014-05-20 07:57:53.136: [ OCRAPI][3606726432]a_terminate:1:current ref count = 0 --> Fatal OLR error ==> OLR is corrupted ==> GPnPD terminating . For details how to fix PROCL-5 error please read following link.
OHASD does not start
Understanding CW startup configuration in OEL 6 OHASD Script location [root@grac41 init.d]# find /etc |grep S96 /etc/rc.d/rc5.d/S96ohasd /etc/rc.d/rc3.d/S96ohasd [root@grac41 init.d]# ls -l /etc/rc.d/rc5.d/S96ohasd lrwxrwxrwx. 1 root root 17 May 4 10:57 /etc/rc.d/rc5.d/S96ohasd -> /etc/init.d/ohasd [root@grac41 init.d]# ls -l /etc/rc.d/rc3.d/S96ohasd lrwxrwxrwx. 1 root root 17 May 4 10:57 /etc/rc.d/rc3.d/S96ohasd -> /etc/init.d/ohasd --> Run level 3 and 5 should start ohasd daemon Check status of init.ohasd process [root@grac41 bin]# more /etc/init/oracle-ohasd.conf # Copyright (c) 2001, 2011, Oracle and/or its affiliates. All rights reserved. # # Oracle OHASD startup start on runlevel [35] stop on runlevel [!35] respawn exec /etc/init.d/init.ohasd run >/dev/null 2>&1 </dev/null List current PID [root@grac41 Desktop]# initctl list | grep oracle-ohasd oracle-ohasd start/running, process 27558 [root@grac41 Desktop]# ps -elf | egrep "PID|d.bin|ohas|oraagent|orarootagent|cssdagent|cssdmonitor" | grep -v grep F S UID PID PPID C PRI NI ADDR SZ WCHAN STIME TTY TIME CMD 4 S root 27558 1 0 80 0 - 2878 wait 07:01 ? 00:00:02 /bin/sh /etc/init.d/init.ohasd run Case #1 : OHASD does not start Check your runlevel, running init.ohasd process and clusterware configuration # who -r run-level 5 2014-05-19 14:48 # ps -elf | egrep "PID|d.bin|ohas" | grep -v grep F S UID PID PPID C PRI NI ADDR SZ WCHAN STIME TTY TIME CMD 4 S root 6098 1 0 80 0 - 2846 wait 04:44 ? 00:00:00 /bin/sh /etc/init.d/init.ohasd run # crsctl config crs CRS-4622: Oracle High Availability Services autostart is enabled. Case #2 : OLR not accessilbe - CW doesn't start - Error CRS-4124 Reported error in ocssd.log : Reported Clusterware Error in CW alert.log: CRS-0704:Oracle High Availability Service aborted due to Oracle Local Registry error [PROCL-33: Oracle Local Registry is not configured Storage layer error [Error opening olr.loc file. No such file or directory] [2]]. Details at (:OHAS00106:) in /u01/app/11204/grid/log/grac41/ohasd/ohasd.log. Testing scenario : # mv /etc/oracle/olr.loc /etc/oracle/olr.loc_bck # crsctl start crs CRS-4124: Oracle High Availability Services startup failed. CRS-4000: Command Start failed, or completed with errors. Clusterware status : # crsi NAME TARGET STATE SERVER STATE_DETAILS ------------------------- ---------- ---------- ------------ ------------------ CRS-4639: Could not contact Oracle CRS-4000: Command Status failed, or [root@grac41 Desktop]# ps -elf | egrep "PID|d.bin|ohas" | grep -v grep F S UID PID PPID C PRI NI ADDR SZ WCHAN STIME TTY TIME CMD 4 S root 6098 1 0 80 0 - 2846 wait 04:44 ? 00:00:00 /bin/sh /etc/init.d/init.ohasd run --> OHASD.bin does not start Tracefile Details: ./grac41/alertgrac41.log [ohasd(20436)]CRS-0704:Oracle High Availability Service aborted due to Oracle Local Registry error [PROCL-33: Oracle Local Registry is not configured Storage layer error [Error opening olr.loc file. No such file or directory] [2]]. Details at (:OHAS00106:) in /u01/app/11204/grid/log/grac41/ohasd/ohasd.log. ./grac41/ohasd/ohasd.log 2014-05-11 11:45:42.892: [ CRSOCR][149608224] OCR context init failure. Error: PROCL-33: Oracle Local Registry is not configured Storage layer error [Error opening olr.loc file. No such file or directory] [2] 2014-05-11 11:45:42.893: [ default][149608224] Created alert : (:OHAS00106:) : OLR initialization failed, error: PROCL-33: Oracle Local Registry is not configured Storage layer error [Error opening olr.loc file. No such file or directory] [2] 2014-05-11 11:45:42.893: [ default][149608224][PANIC] OHASD exiting; Could not init OLR 2014-05-11 11:45:42.893: [ default][149608224] Done. OS log : /var/log/messages May 24 09:21:53 grac41 clsecho: /etc/init.d/init.ohasd: Ohasd restarts 11 times in 2 seconds. May 24 09:21:53 grac41 clsecho: /etc/init.d/init.ohasd: Ohasd restarts too rapidly. Stop auto-restarting. Debugging steps Verify your local Cluster repository # ocrcheck -local -config PROTL-604: Failed to retrieve the configured location of the local registry Error opening olr.loc file. No such file or directory # ocrcheck -local PROTL-601: Failed to initialize ocrcheck PROCL-33: Oracle Local Registry is not configured Storage layer error [Error opening olr.loc file. No such file or directory] [2] # ls -l /etc/oracle/olr.loc ls: cannot access /etc/oracle/olr.loc: No such file or directory Note a working OLR should look like: # more /etc/oracle/olr.loc olrconfig_loc=/u01/app/11204/grid/cdata/grac41.olr crs_home=/u01/app/11204/grid # ls -l /u01/app/11204/grid/cdata/grac41.olr -rw-------. 1 root oinstall 272756736 May 24 09:15 /u01/app/11204/grid/cdata/grac41.olr Verify your OLR configuration with cluvfy [grid@grac41 ~]$ cluvfy comp olr -verbose ERROR: Oracle Grid Infrastructure not configured. You cannot run '/u01/app/11204/grid/bin/cluvfy' without the Oracle Grid Infrastructure. Strace the command to get more details: [grid@grac41 crsd]$ strace -t -f -o clu.trc cluvfy comp olr -verbose clu.trc reports : 29993 09:32:19 open("/etc/oracle/olr.loc", O_RDONLY) = -1 ENOENT (No such file or directory)
OHASD Agents do not start
-
-
- OHASD.BIN will spawn four agents/monitors to start resource:
- oraagent: responsible for ora.asm, ora.evmd, ora.gipcd, ora.gpnpd, ora.mdnsd etc
- orarootagent: responsible for ora.crsd, ora.ctssd, ora.diskmon, ora.drivers.acfs etc
- cssdagent / cssdmonitor: responsible for ora.cssd(for ocssd.bin) and ora.cssdmonitor(for cssdmonitor itself)
-
If ohasd.bin can not start any of above agents properly, clusterware will not come to healthy state. Potential Problems 1. Common causes of agent failure are that the log file or log directory for the agents don't have proper ownership or permission. 2. If agent binary (oraagent.bin or orarootagent.bin etc) is corrupted, agent will not start resulting in related resources not coming up: Debugging CRS startup if trace file location is not accessible Action - Change trace directory [grid@grac41 log]$ mv $GRID_HOME/log/grac41 $GRID_HOME/log/grac41_nw [grid@grac41 log]$ crsctl start crs CRS-4124: Oracle High Availability Services startup failed. CRS-4000: Command Start failed, or completed with errors. Process Status and CRS status [root@grac41 .oracle]# ps -elf | egrep "PID|d.bin|ohas|oraagent|orarootagent|cssdagent|cssdmonitor" | grep -v grep F S UID PID PPID C PRI NI ADDR SZ WCHAN STIME TTY TIME CMD 4 S root 5396 1 0 80 0 - 2847 pipe_w 10:52 ? 00:00:00 /bin/sh /etc/init.d/init.ohasd run 4 S root 26705 25370 1 80 0 - 47207 hrtime 14:05 pts/7 00:00:00 /u01/app/11204/grid/bin/crsctl.bin start crs [root@grac41 .oracle]# crsctl check crs CRS-4639: Could not contact Oracle High Availability Services OS Tracefile: /var/log/messages May 13 13:48:27 grac41 root: exec /u01/app/11204/grid/perl/bin/perl -I/u01/app/11204/grid/perl/lib /u01/app/11204/grid/bin/crswrapexece.pl /u01/app/11204/grid/crs/install/s_crsconfig_grac41_env.txt /u01/app/11204/grid/bin/ohasd.bin "reboot" May 13 13:48:27 grac41 OHASD[22203]: OHASD exiting; Directory /u01/app/11204/grid/log/grac41/ohasd not found Debugging steps [root@grac41 gpnpd]# strace -f -o ohas.trc crsctl start crs CRS-4124: Oracle High Availability Services startup failed. CRS-4000: Command Start failed, or completed with errors. [root@grac41 gpnpd]# grep ohasd ohas.trc ... 22203 execve("/u01/app/11204/grid/bin/ohasd.bin", ["/u01/app/11204/grid/bin/ohasd.bi"..., "reboot"], [/* 60 vars */]) = 0 22203 stat("/u01/app/11204/grid/log/grac41/ohasd", 0x7fff17d68f40) = -1 ENOENT (No such file or directory) ==> Directory /u01/app/11204/grid/log/grac41/ohasd was missing or has wrong protection Using clufy comp olr [grid@grac41 ~]$ cluvfy comp olr Verifying OLR integrity Checking OLR integrity... Checking OLR config file... ERROR: 2014-05-17 18:26:41.576: CLSD: A file system error occurred while attempting to create default permissions for file "/u01/app/11204/grid/log/grac41/alertgrac41.log" during alert open processing for process "client". Additional diagnostics: LFI-00133: Trying to create file /u01/app/11204/grid/log/grac41/alertgrac41.log that already exists. LFI-01517: open() failed(OSD return value = 13). 2014-05-17 18:26:41.585: CLSD: An error was encountered while attempting to open alert log "/u01/app/11204/grid/log/grac41/alertgrac41.log". Additional diagnostics: (:CLSD00155:) 2014-05-17 18:26:41.585: OLR config file check successful Checking OLR file attributes... ERROR: PRVF-4187 : OLR file check failed on the following nodes: grac41 grac41:PRVF-4127 : Unable to obtain OLR location /u01/app/11204/grid/bin/ocrcheck -config -local <CV_CMD>/u01/app/11204/grid/bin/ocrcheck -config -local </CV_CMD><CV_VAL>2014-05-17 18:26:45.202: CLSD: A file system error occurred while attempting to create default permissions for file "/u01/app/11204/grid/log/grac41/alertgrac41.log" during alert open processing for process "client". Additional diagnostics: LFI-00133: Trying to create file /u01/app/11204/grid/log/grac41/alertgrac41.log that already exists. LFI-01517: open() failed(OSD return value = 13). 2014-05-17 18:26:45.202: CLSD: An error was encountered while attempting to open alert log "/u01/app/11204/grid/log/grac41/alertgrac41.log". Additional diagnostics: (:CLSD00155:) 2014-05-17 18:26:45.202: CLSD: Alert logging terminated for process client. File name: "/u01/app/11204/grid/log/grac41/alertgrac41.log" 2014-05-17 18:26:45.202: CLSD: A file system error occurred while attempting to create default permissions for file "/u01/app/11204/grid/log/grac41/client/ocrcheck_7617.log" during log open processing for process "client". Additional diagnostics: LFI-00133: Trying to create file /u01/app/11204/grid/log/grac41/client/ocrcheck_7617.log that already exists. LFI-01517: open() failed(OSD return value = 13). 2014-05-17 18:26:45.202: CLSD: An error was encounteredcluvfy comp gpnp while attempting to open log file "/u01/app/11204/grid/log/grac41/client/ocrcheck_7617.log". Additional diagnostics: (:CLSD00153:) 2014-05-17 18:26:45.202: CLSD: Logging terminated for process client. File name: "/u01/app/11204/grid/log/grac41/client/ocrcheck_7617.log" Oracle Local Registry configuration is : Device/File Name : /u01/app/11204/grid/cdata/grac41.olr </CV_VAL><CV_VRES>0</CV_VRES><CV_LOG>Exectask: runexe was successful</CV_LOG><CV_ERES>0</CV_ERES> OLR integrity check failed Verification of OLR integrity was unsuccessful.
OCSSD.BIN does not start
Case #1 : GPnP profile is not accessible - gpnpd needs to be fully up to serve profile Grep option to search traces : $ fn_egrep.sh "Cannot get GPnP profile|Error put-profile CALL" TraceFileName: ./grac41/agent/ohasd/orarootagent_root/orarootagent_root.log 2014-05-20 10:26:44.532: [ default][1199552256]Cannot get GPnP profile. Error CLSGPNP_NO_DAEMON (GPNPD daemon is not running). Cannot get GPnP profile 2014-04-21 15:27:06.838: [ GPNP][132114176]clsgpnp_profileCallUrlInt: [at clsgpnp.c:2243] Result: (13) CLSGPNP_NO_DAEMON. Error put-profile CALL to remote "tcp://grac41:56376" disco "mdns:service:gpnp._tcp.local.://grac41:56376/agent=gpnpd,cname=grac4,host=grac41, pid=4548/gpnpd h:grac41 c:grac4" The above problem was related to a Name Server problem ==> For further details see GENERIC Networking chapter Case #2 : Voting Disk is not accessible In 11gR2, ocssd.bin discover voting disk with setting from GPnP profile, if not enough voting disks can be identified, ocssd.bin will abort itself. Reported error in ocssd.log : clssnmvDiskVerify: Successful discovery of 0 disks Reported Clusterware Error in CW alert.log: CRS-1714:Unable to discover any voting files, retrying discovery in 15 seconds Testing scenario : [grid@grac41 ~]$ chmod 000 /dev/asmdisk1_udev_sdf1 [grid@grac41 ~]$ chmod 000 /dev/asmdisk1_udev_sdg1 [grid@grac41 ~]$ chmod 000 /dev/asmdisk1_udev_sdh1 [grid@grac41 ~]$ ls -l /dev/asmdisk1_udev_sdf1 /dev/asmdisk1_udev_sdg1 /dev/asmdisk1_udev_sdh1 b---------. 1 grid asmadmin 8, 81 May 14 09:51 /dev/asmdisk1_udev_sdf1 b---------. 1 grid asmadmin 8, 97 May 14 09:51 /dev/asmdisk1_udev_sdg1 b---------. 1 grid asmadmin 8, 113 May 14 09:51 /dev/asmdisk1_udev_sdh1 Clusterware status : NAME TARGET STATE SERVER STATE_DETAILS ------------------------- ---------- ---------- ------------ ------------------ ora.asm ONLINE OFFLINE Instance Shutdown ora.cluster_interconnect.haip ONLINE OFFLINE ora.crf ONLINE ONLINE grac41 ora.crsd ONLINE OFFLINE ora.cssd ONLINE OFFLINE STARTING ora.cssdmonitor ONLINE ONLINE grac41 ora.ctssd ONLINE OFFLINE ora.diskmon OFFLINE OFFLINE ora.drivers.acfs ONLINE OFFLINE ora.evmd ONLINE OFFLINE ora.gipcd ONLINE ONLINE grac41 ora.gpnpd ONLINE ONLINE grac41 ora.mdnsd ONLINE ONLINE grac41 --> cssd is STARTING mode for a long time before switching to OFFLINE # ps -elf | egrep "PID|d.bin|ohas|oraagent|orarootagent|cssdagent|cssdmonitor" | grep -v grep F S UID PID PPID C PRI NI ADDR SZ WCHAN STIME TTY TIME CMD 4 S root 6098 1 0 80 0 - 2846 pipe_w 04:44 ? 00:00:00 /bin/sh /etc/init.d/init.ohasd run 4 R root 31696 1 4 80 0 - 179039 - 07:59 ? 00:00:06 /u01/app/11204/grid/bin/ohasd.bin reboot 4 S grid 31825 1 0 80 0 - 169311 futex_ 07:59 ? 00:00:00 /u01/app/11204/grid/bin/oraagent.bin 0 S grid 31836 1 0 80 0 - 74289 poll_s 07:59 ? 00:00:00 /u01/app/11204/grid/bin/mdnsd.bin 0 S grid 31847 1 0 80 0 - 127382 hrtime 07:59 ? 00:00:00 /u01/app/11204/grid/bin/gpnpd.bin 0 S grid 31859 1 2 80 0 - 159711 hrtime 07:59 ? 00:00:03 /u01/app/11204/grid/bin/gipcd.bin 4 S root 31861 1 0 80 0 - 165832 futex_ 07:59 ? 00:00:00 /u01/app/11204/grid/bin/orarootagent.bin 4 S root 31875 1 5 -40 - - 160907 hrtime 07:59 ? 00:00:08 /u01/app/11204/grid/bin/osysmond.bin 4 S root 31934 1 0 -40 - - 162468 futex_ 07:59 ? 00:00:00 /u01/app/11204/grid/bin/cssdmonitor 4 S root 31953 1 0 -40 - - 161056 futex_ 07:59 ? 00:00:00 /u01/app/11204/grid/bin/cssdagent 4 S grid 31965 1 0 -40 - - 109118 futex_ 07:59 ? 00:00:00 /u01/app/11204/grid/bin/ocssd.bin 4 S root 32201 1 0 -40 - - 161632 poll_s 07:59 ? 00:00:01 /u01/app/11204/grid/bin/ologgerd -M -d /u01/app/11204/grid/crf/db/grac41 Quick Tracefile Review using grep $ fn_egrep.sh "Successful discovery" Working case: TraceFileName: ./grac41/cssd/ocssd.log 2014-05-22 11:46:57.229: [ CSSD][201324288]clssnmvDiskVerify: Successful discovery for disk /dev/asmdisk1_udev_sdg1, UID 88c2a08b-4c8c4f85-bf0109e0-990388e4, Pending CIN 0:1399993206:1, Committed CIN 0:1399993206:1 2014-05-22 11:46:57.230: [ CSSD][201324288]clssnmvDiskVerify: Successful discovery for disk /dev/asmdisk1_udev_sdf1, UID b0e94e5d-83054fe9-bf58b6b9-8bfacd65, Pending CIN 0:1399993206:1, Committed CIN 0:1399993206:1 2014-05-22 11:46:57.230: [ CSSD][201324288]clssnmvDiskVerify: Successful discovery for disk /dev/asmdisk1_udev_sdh1, UID 2121ff6e-acab4f49-bf01195f-a0a3e00b, Pending CIN 0:1399993206:1, Committed CIN 0:1399993206:1 2014-05-22 11:46:57.231: [ CSSD][201324288]clssnmvDiskVerify: Successful discovery of 3 disks Failed case: 2014-05-22 13:41:38.776: [ CSSD][1839290112]clssnmvDiskVerify: Successful discovery of 0 disks 2014-05-22 13:41:53.803: [ CSSD][1839290112]clssnmvDiskVerify: Successful discovery of 0 disks 2014-05-22 13:42:08.851: [ CSSD][1839290112]clssnmvDiskVerify: Successful discovery of 0 disks --> disk redicovery is restarted every 15 seconds in case of errors Tracefile Details: grid@grac41 grac41]$c d $GRID_HOME/log/grac41 ; get_ca.sh alertgrac41.log "2014-05-24" 2014-05-24 07:59:27.167: [cssd(31965)]CRS-1714:Unable to discover any voting files, retrying discovery in 15 seconds; Details at (:CSSNM00070:) in /u01/app/11204/grid/log/grac41/cssd/ocssd.log 2014-05-24 07:59:42.197: [cssd(31965)]CRS-1714:Unable to discover any voting files, retrying discovery in 15 seconds; Details at (:CSSNM00070:) in /u01/app/11204/grid/log/grac41/cssd/ocssd.log grac41/cssd/ocssd.log 2014-05-24 08:10:14.145: [ SKGFD][268433152]Lib :UFS:: closing handle 0x7fa3041525a0 for disk :/dev/asmdisk1_udev_sdb1: 2014-05-24 08:10:14.145: [ SKGFD][268433152]Lib :UFS:: closing handle 0x7fa304153050 for disk :/dev/asmdisk8_ssd3: 2014-05-24 08:10:14.145: [ SKGFD][268433152]Lib :UFS:: closing handle 0x7fa304153c70 for disk :/dev/oracleasm/disks/ASMLIB_DISK1: 2014-05-24 08:10:14.145: [ SKGFD][268433152]Lib :UFS:: closing handle 0x7fa304154ac0 for disk :/dev/oracleasm/disks/ASMLIB_DISK2: 2014-05-24 08:10:14.145: [ SKGFD][268433152]Lib :UFS:: closing handle 0x7fa304155570 for disk :/dev/oracleasm/disks/ASMLIB_DISK3: 2014-05-24 08:10:14.145: [ CSSD][268433152]clssnmvDiskVerify: Successful discovery of 0 disks 2014-05-24 08:10:14.145: [ CSSD][268433152]clssnmvDiskVerify: exit 2014-05-24 08:10:14.145: [ CSSD][268433152]clssnmCompleteInitVFDiscovery: Completing initial voting file discovery 2014-05-24 08:10:14.145: [ CSSD][268433152]clssnmvFindInitialConfigs: No voting files found Debugging steps with cluvfy Note you must run cluvfy from a node which is up and running as we need ASM to retrieve Voting Disk location Here we are ruuning cluvfy from grac42 to test voting disks on grac41 [grid@grac42 ~]$ cluvfy comp vdisk -n grac41 Verifying Voting Disk: Checking Oracle Cluster Voting Disk configuration... ERROR: PRVF-4194 : Asm is not running on any of the nodes. Verification cannot proceed. ERROR: PRVF-5157 : Could not verify ASM group "OCR" for Voting Disk location "/dev/asmdisk1_udev_sdf1" ERROR: PRVF-5157 : Could not verify ASM group "OCR" for Voting Disk location "/dev/asmdisk1_udev_sdg1" ERROR: PRVF-5157 : Could not verify ASM group "OCR" for Voting Disk location "/dev/asmdisk1_udev_sdh1" PRVF-5431 : Oracle Cluster Voting Disk configuration check failed UDev attributes check for Voting Disk locations started... UDev attributes check passed for Voting Disk locations Verification of Voting Disk was unsuccessful on all the specified nodes. Verify disk protections by using kfed and ls [grid@grac41 ~/cluvfy]$ ls -l /dev/asmdisk1_udev_sdf1 /dev/asmdisk1_udev_sdg1 /dev/asmdisk1_udev_sdh1 b---------. 1 grid asmadmin 8, 81 May 14 09:51 /dev/asmdisk1_udev_sdf1 b---------. 1 grid asmadmin 8, 97 May 14 09:51 /dev/asmdisk1_udev_sdg1 b---------. 1 grid asmadmin 8, 113 May 14 09:51 /dev/asmdisk1_udev_sdh1 [grid@grac41 ~/cluvfy]$ kfed read /dev/asmdisk1_udev_sdf1 KFED-00303: unable to open file '/dev/asmdisk1_udev_sdf Case #3 : GENERIC NETWORK problems ==> For futher details see GENERIC Networking chapter
ASM instance does not start / EVMD.BIN in State INTERMEDIATE
Reported error in oraagent_grid.log : CRS-5017: The resource action "ora.asm start" encountered the following error: ORA-12546: TNS:permission denied Reported Clusterware Error in CW alert.log: [/u01/app/11204/grid/bin/oraagent.bin(6784)]CRS-5011:Check of resource "+ASM" failed: [ohasd(6536)]CRS-2807:Resource 'ora.asm' failed to start automatically. Reported Error in ASM alert log : ORA-07274: spdcr: access error, access to oracle denied. Linux-x86_64 Error: 13: Permission denied PSP0 (ospid: 3582): terminating the instance due to error 7274 ... Testing scenario : [grid@grac41 grac41]$ cd $GRID_HOME/bin [grid@grac41 bin]$ chmod 444 oracle [grid@grac41 bin]$ ls -l oracle -r--r--r--. 1 grid oinstall 209950863 May 4 10:26 oracle # crsctl start crs CRS-4123: Oracle High Availability Services has been started. Clusterware status : [grid@grac41 bin]$ crsctl check crs CRS-4638: Oracle High Availability Services is online CRS-4535: Cannot communicate with Cluster Ready Services CRS-4529: Cluster Synchronization Services is online CRS-4534: Cannot communicate with Event Manager [grid@grac41 bin]$ crsi NAME TARGET STATE SERVER STATE_DETAILS ------------------------- ---------- ---------- ------------ ------------------ ora.asm ONLINE OFFLINE ora.cluster_interconnect.haip ONLINE ONLINE grac41 ora.crf ONLINE ONLINE grac41 ora.crsd ONLINE OFFLINE ora.cssd ONLINE ONLINE grac41 ora.cssdmonitor ONLINE ONLINE grac41 ora.ctssd ONLINE ONLINE grac41 OBSERVER ora.diskmon OFFLINE OFFLINE ora.drivers.acfs ONLINE ONLINE grac41 ora.evmd ONLINE INTERMEDIATE grac41 ora.gipcd ONLINE ONLINE grac41 ora.gpnpd ONLINE ONLINE grac41 ora.mdnsd ONLINE ONLINE grac41 [grid@grac41 bin]$ ps -elf | egrep "PID|d.bin|ohas|oraagent|orarootagent|cssdagent|cssdmonitor" | grep -v grep F S UID PID PPID C PRI NI ADDR SZ WCHAN STIME TTY TIME CMD 4 S root 3408 28369 0 80 0 - 30896 poll_s 10:03 pts/3 00:00:00 view ./agent/crsd/oraagent_grid/oraagent_grid.log 4 S root 6098 1 0 80 0 - 2846 pipe_w May24 ? 00:00:01 /bin/sh /etc/init.d/init.ohasd run 4 S root 6536 1 2 80 0 - 179140 futex_ 13:51 ? 00:01:11 /u01/app/11204/grid/bin/ohasd.bin reboot 4 S grid 6784 1 0 80 0 - 173902 futex_ 13:52 ? 00:00:05 /u01/app/11204/grid/bin/oraagent.bin 0 S grid 6795 1 0 80 0 - 74289 poll_s 13:52 ? 00:00:00 /u01/app/11204/grid/bin/mdnsd.bin 0 S grid 6806 1 0 80 0 - 127382 hrtime 13:52 ? 00:00:04 /u01/app/11204/grid/bin/gpnpd.bin 0 S grid 6823 1 1 80 0 - 159711 hrtime 13:52 ? 00:00:39 /u01/app/11204/grid/bin/gipcd.bin 4 S root 6825 1 0 80 0 - 168698 futex_ 13:52 ? 00:00:24 /u01/app/11204/grid/bin/orarootagent.bin 4 S root 6840 1 4 -40 - - 160907 hrtime 13:52 ? 00:02:29 /u01/app/11204/grid/bin/osysmond.bin 4 S root 6851 1 0 -40 - - 162793 futex_ 13:52 ? 00:00:07 /u01/app/11204/grid/bin/cssdmonitor 4 S root 6870 1 0 -40 - - 162920 futex_ 13:52 ? 00:00:07 /u01/app/11204/grid/bin/cssdagent 4 S grid 6881 1 2 -40 - - 166593 futex_ 13:52 ? 00:01:24 /u01/app/11204/grid/bin/ocssd.bin 4 S root 7256 1 6 -40 - - 178527 poll_s 13:52 ? 00:03:28 /u01/app/11204/grid/bin/ologgerd -M -d .. 4 S root 7847 1 0 80 0 - 159388 futex_ 13:52 ? 00:00:29 /u01/app/11204/grid/bin/octssd.bin reboot 0 S grid 7875 1 0 80 0 - 76018 hrtime 13:52 ? 00:00:05 /u01/app/11204/grid/bin/evmd.bin Tracefile Details: CW alert.log [/u01/app/11204/grid/bin/oraagent.bin(6784)]CRS-5011:Check of resource "+ASM" failed: details at "(:CLSN00006:)" in "../agent/ohasd/oraagent_grid/oraagent_grid.log" [/u01/app/11204/grid/bin/oraagent.bin(6784)]CRS-5011:Check of resource "+ASM" failed: details at "(:CLSN00006:)" in "../agent/ohasd/oraagent_grid/oraagent_grid.log" 2014-05-25 13:55:04.626: [ohasd(6536)]CRS-2807:Resource 'ora.asm' failed to start automatically. 2014-05-25 13:55:04.626: [ohasd(6536)]CRS-2807:Resource 'ora.crsd' failed to start automatically. ASM alert log : ./log/diag/asm/+asm/+ASM1/trace/alert_+ASM1.log Sun May 25 13:50:50 2014 Errors in file /u01/app/11204/grid/log/diag/asm/+asm/+ASM1/trace/+ASM1_psp0_3582.trc: ORA-07274: spdcr: access error, access to oracle denied. Linux-x86_64 Error: 13: Permission denied PSP0 (ospid: 3582): terminating the instance due to error 7274 Sun May 25 13:50:50 2014 System state dump requested by (instance=1, osid=3591 (DIAG)), summary=[abnormal instance termination]. System State dumped to trace file /u01/app/11204/grid/log/diag/asm/+asm/+ASM1/trace/+ASM1_diag_3591_20140525135050.trc Dumping diagnostic data in directory=[cdmp_20140525135050], requested by (instance=1, osid=3591 (DIAG)), summary=[abnormal instance termination]. Instance terminated by PSP0, pid = 3582 agent/ohasd/oraagent_grid/oraagent_grid.log 2014-05-25 13:54:54.226: [ AGFW][3273144064]{0:0:2} ora.asm 1 1 state changed from: STARTING to: OFFLINE 2014-05-25 13:54:54.229: [ AGFW][3273144064]{0:0:2} Agent sending last reply for: RESOURCE_START[ora.asm 1 1] ID 4098:624 2014-05-25 13:54:54.239: [ AGFW][3273144064]{0:0:2} Agent received the message: RESOURCE_CLEAN[ora.asm 1 1] ID 4100:644 2014-05-25 13:54:54.239: [ AGFW][3273144064]{0:0:2} Preparing CLEAN command for: ora.asm 1 1 2014-05-25 13:54:54.239: [ AGFW][3273144064]{0:0:2} ora.asm 1 1 state changed from: OFFLINE to: CLEANING Debugging steps : Try to start ASM databbase manually [grid@grac41 grid]$ sqlplus / as sysasm ERROR: ORA-12546: TNS:permission denied Fix: [grid@grac41 grid]$ chmod 6751 $GRID_HOME/bin/oracle [grid@grac41 grid]$ ls -l $GRID_HOME/bin/oracle -rwsr-s--x. 1 grid oinstall 209950863 May 4 10:26 /u01/app/11204/grid/bin/oracle [grid@grac41 grid]$ sqlplus / as sysasm --> works now again EVMD.BIN does not start : State INTERMEDIATE ==> For further details see GENERIC Networking troubleshooting chapter
CRSD.BIN does not start
-
-
- Note: in 11.2 ASM starts before crsd.bin, and brings up the diskgroup automatically if it contains the OCR.
- Typical Problems :
- OCR not acessible
- Networking problems ( includes firewall, Nameserver problems and Network related errors ) ==> For futher details see GENERIC Networking troubleshooting chapter
- Common File Protection problems ( Oracle executable, Log Files, IPC sockets ) ==> For futher details see GENERIC File Protection troubleshooting chapter
-
Case #1: OCR not accessbible - CRS-5019 error Reported error in ocssd.log : [check] DgpAgent::queryDgStatus no data found in v$asm_diskgroup_stat Reported Clusterware Error in CW alert.log: CRS-5019:All OCR locations are on ASM disk groups [OCR3], and none of these disk groups are mounted. Details are at "(:CLSN00100:)" in ".../ohasd/oraagent_grid/oraagent_grid.log". Testing scenario : In file /etc/oracle/ocr.loc Change entry ocrconfig_loc=+OCR to ocrconfig_loc=+OCR3 Clusterware status : # crsctl check crs CRS-4638: Oracle High Availability Services is online CRS-4535: Cannot communicate with Cluster Ready Services CRS-4529: Cluster Synchronization Services is online CRS-4534: Cannot communicate with Event Manager # crsi NAME TARGET STATE SERVER STATE_DETAILS ------------------------- ---------- ---------- ------------ ------------------ ora.asm ONLINE INTERMEDIATE grac41 OCR not started ora.cluster_interconnect.haip ONLINE ONLINE grac41 ora.crf ONLINE ONLINE grac41 ora.crsd ONLINE OFFLINE ora.cssd ONLINE ONLINE grac41 ora.cssdmonitor ONLINE ONLINE grac41 ora.ctssd ONLINE ONLINE grac41 OBSERVER ora.diskmon OFFLINE OFFLINE ora.drivers.acfs ONLINE ONLINE grac41 ora.evmd ONLINE INTERMEDIATE grac41 ora.gipcd ONLINE ONLINE grac41 ora.gpnpd ONLINE ONLINE grac41 ora.mdnsd ONLINE ONLINE grac41 --> Both resoruces ora.evmd and ora.asm reports their state in INTERMEDIATE - CRSD/EVMD doesn't come up # ps -elf | egrep "PID|d.bin|ohas|oraagent|orarootagent|cssdagent|cssdmonitor" | grep -v grep F S UID PID PPID C PRI NI ADDR SZ WCHAN STIME TTY TIME CMD 4 S root 6098 1 0 80 0 - 2846 pipe_w 04:44 ? 00:00:00 /bin/sh /etc/init.d/init.ohasd run 4 S root 10132 1 1 80 0 - 179077 futex_ 10:09 ? 00:00:07 /u01/app/11204/grid/bin/ohasd.bin reboot 4 S grid 10295 1 0 80 0 - 175970 futex_ 10:09 ? 00:00:03 /u01/app/11204/grid/bin/oraagent.bin 0 S grid 10306 1 0 80 0 - 74289 poll_s 10:09 ? 00:00:00 /u01/app/11204/grid/bin/mdnsd.bin 0 S grid 10317 1 0 80 0 - 127382 hrtime 10:09 ? 00:00:01 /u01/app/11204/grid/bin/gpnpd.bin 0 S grid 10328 1 1 80 0 - 159711 hrtime 10:09 ? 00:00:04 /u01/app/11204/grid/bin/gipcd.bin 4 S root 10330 1 1 80 0 - 168735 futex_ 10:09 ? 00:00:04 /u01/app/11204/grid/bin/orarootagent.bin 4 S root 10344 1 6 -40 - - 160907 hrtime 10:09 ? 00:00:25 /u01/app/11204/grid/bin/osysmond.bin 4 S root 10355 1 0 -40 - - 162793 futex_ 10:09 ? 00:00:01 /u01/app/11204/grid/bin/cssdmonitor 4 S root 10374 1 0 -40 - - 162921 futex_ 10:09 ? 00:00:01 /u01/app/11204/grid/bin/cssdagent 4 S grid 10385 1 4 -40 - - 166593 futex_ 10:09 ? 00:00:17 /u01/app/11204/grid/bin/ocssd.bin 4 S root 10733 1 0 -40 - - 127270 poll_s 10:09 ? 00:00:03 /u01/app/11204/grid/bin/ologgerd 4 S root 11286 1 0 80 0 - 159388 futex_ 10:09 ? 00:00:03 /u01/app/11204/grid/bin/octssd.bin reboot 0 S grid 11307 1 0 80 0 - 75351 hrtime 10:09 ? 00:00:00 /u01/app/11204/grid/bin/evmd.bin Tracefile Details : alertgrac41.log: 2014-05-24 10:13:48.085: [/u01/app/11204/grid/bin/oraagent.bin(10295)]CRS-5019:All OCR locations are on ASM disk groups [OCR3], and none of these disk groups are mounted. Details are at "(:CLSN00100:)" in ".../agent/ohasd/oraagent_grid/oraagent_grid.log". 2014-05-24 10:14:18.144: [/u01/app/11204/grid/bin/oraagent.bin(10295)]CRS-5019:All OCR locations are on ASM disk groups [OCR3], and none of these disk groups are mounted. Details are at "(:CLSN00100:)" in ".../agent/ohasd/oraagent_grid/oraagent_grid.log". ohasd/oraagent_grid/oraagent_grid.log 2014-05-24 10:10:47.848: [ora.asm][4179105536]{0:0:2} [check] AsmAgent::check ocrCheck 1 m_OcrOnline 0 m_OcrTimer 30 2014-05-24 10:10:47.848: [ora.asm][4179105536]{0:0:2} [check] DgpAgent::initOcrDgpSet { entry 2014-05-24 10:10:47.848: [ora.asm][4179105536]{0:0:2} [check] DgpAgent::initOcrDgpSet procr_get_conf: retval [0] configured [1] local only [0] error buffer [] 2014-05-24 10:10:47.848: [ora.asm][4179105536]{0:0:2} [check] DgpAgent::initOcrDgpSet procr_get_conf: OCR loc [0], Disk Group : [+OCR3] 2014-05-24 10:10:47.848: [ora.asm][4179105536]{0:0:2} [check] DgpAgent::initOcrDgpSet m_ocrDgpSet 02d965f8 dgName OCR3 2014-05-24 10:10:47.848: [ora.asm][4179105536]{0:0:2} [check] DgpAgent::initOcrDgpSet ocrret 0 found 1 2014-05-24 10:10:47.848: [ora.asm][4179105536]{0:0:2} [check] DgpAgent::initOcrDgpSet ocrDgpSet OCR3 2014-05-24 10:10:47.848: [ora.asm][4179105536]{0:0:2} [check] DgpAgent::initOcrDgpSet exit } 2014-05-24 10:10:47.848: [ora.asm][4179105536]{0:0:2} [check] DgpAgent::ocrDgCheck Entry { 2014-05-24 10:10:47.848: [ora.asm][4179105536]{0:0:2} [check] DgpAgent::getConnxn connected 2014-05-24 10:10:47.850: [ora.asm][4179105536]{0:0:2} [check] DgpAgent::queryDgStatus excp no data found 2014-05-24 10:10:47.850: [ora.asm][4179105536]{0:0:2} [check] DgpAgent::queryDgStatus no data found in v$asm_diskgroup_stat 2014-05-24 10:10:47.851: [ora.asm][4179105536]{0:0:2} [check] DgpAgent::queryDgStatus dgName OCR3 ret 1 2014-05-24 10:10:47.851: [ora.asm][4179105536]{0:0:2} [check] (:CLSN00100:)DgpAgent::ocrDgCheck OCR dgName OCR3 state 1 2014-05-24 10:10:47.851: [ora.asm][4179105536]{0:0:2} [check] AsmAgent::check ocrCheck 2 m_OcrOnline 0 m_OcrTimer 31 2014-05-24 10:10:47.851: [ora.asm][4179105536]{0:0:2} [check] CrsCmd::ClscrsCmdData::stat entity 5 statflag 32 useFilter 1 2014-05-24 10:10:48.053: [ COMMCRS][3665618688]clsc_connect: (0x7f77d4101f30) no listener at (ADDRESS=(PROTOCOL=IPC)(KEY=CRSD_UI_SOCKET)) Debugging steps Identify OCR ASM DG on a running instance with asmcmd [grid@grac42 ~]$ asmcmd lsdg State Type Rebal Sector Block AU Total_MB Offline_disks Voting_files Name MOUNTED NORMAL N 512 4096 1048576 3057 0 N ASMLIB_DG/ MOUNTED NORMAL N 512 4096 1048576 30708 0 N DATA/ MOUNTED EXTERN N 512 4096 1048576 40946 0 N FRA/ MOUNTED NORMAL N 512 4096 1048576 6141 0 Y OCR/ MOUNTED NORMAL N 512 4096 1048576 3057 0 N SSD/ --> diskgroup OCR is serving our voting disks ( and not DG +OCR3 ) Check availale disks: [grid@grac42 ~]$ asmcmd lsdsk -k Total_MB Free_MB OS_MB Name Failgroup Failgroup_Type Library Path 10236 2809 10236 DATA_0001 DATA_0001 REGULAR System /dev/asmdisk1_udev_sdc1 10236 2804 10236 DATA_0002 DATA_0002 REGULAR System /dev/asmdisk1_udev_sdd1 10236 2804 10236 DATA_0003 DATA_0003 REGULAR System /dev/asmdisk1_udev_sde1 2047 1696 2047 OCR_0000 OCR_0000 REGULAR System /dev/asmdisk1_udev_sdf1 2047 1696 2047 OCR_0001 OCR_0001 REGULAR System /dev/asmdisk1_udev_sdg1 2047 1697 2047 OCR_0002 OCR_0002 REGULAR System /dev/asmdisk1_udev_sdh1 1019 875 1019 SSD_0000 SSD_0000 REGULAR System /dev/asmdisk8_ssd1 1019 875 1019 SSD_0001 SSD_0001 REGULAR System /dev/asmdisk8_ssd2 1019 875 1019 SSD_0002 SSD_0002 REGULAR System /dev/asmdisk8_ssd3 20473 10467 20473 FRA_0001 FRA_0001 REGULAR System /dev/asmdisk_fra1 20473 10461 20473 FRA_0002 FRA_0002 REGULAR System /dev/asmdisk_fra2 1019 882 1019 ASMLIB_DG_0000 ASMLIB_DG_0000 REGULAR System /dev/oracleasm/disks/ASMLIB_DISK1 1019 882 1019 ASMLIB_DG_0001 ASMLIB_DG_0001 REGULAR System /dev/oracleasm/disks/ASMLIB_DISK2 1019 882 1019 ASMLIB_DG_0002 ASMLIB_DG_0002 REGULAR System /dev/oracleasm/disks/ASMLIB_DISK3 --> /dev/asmdisk1_udev_sdf1, /dev/asmdisk1_udev_sdg1 , /dev/asmdisk1_udev_sdh1 are our disk serving the voting files Verify on a working system the voting disk [grid@grac42 ~]$ kfed read /dev/asmdisk1_udev_sdf1 | egrep 'vf|name' kfdhdb.dskname: OCR_0000 ; 0x028: length=8 kfdhdb.grpname: OCR ; 0x048: length=3 kfdhdb.fgname: OCR_0000 ; 0x068: length=8 kfdhdb.capname: ; 0x088: length=0 kfdhdb.vfstart: 320 ; 0x0ec: 0x00000140 kfdhdb.vfend: 352 ; 0x0f0: 0x00000160 Note: If the markers between vfstart & vfend are not 0 then disk does contain voting disk ! Check OCR with ocrcheck [grid@grac41 ~]$ ocrcheck PROT-602: Failed to retrieve data from the cluster registry PROC-26: Error while accessing the physical storage Tracing ocrcheck [grid@grac41 ~]$ strace -f -o ocrcheck.trc ocrcheck [grid@grac41 ~]$ grep open ocrcheck.trc | grep ocr.loc 17530 open("/etc/oracle/ocr.loc", O_RDONLY) = 6 --> ocrcheck reads /etc/oracle/ocr.loc [grid@grac41 ~]$ cat /etc/oracle/ocr.loc ocrconfig_loc=+OCR3 local_only=false ==> +OCR3 is a wrong entry Verify CW state with cluvfy [grid@grac42 ~]$ cluvfy comp ocr -n grac42,grac41 Verifying OCR integrity Checking OCR integrity... Checking the absence of a non-clustered configuration... All nodes free of non-clustered, local-only configurations ERROR: PRVF-4193 : Asm is not running on the following nodes. Proceeding with the remaining nodes. grac41 Checking OCR config file "/etc/oracle/ocr.loc"... OCR config file "/etc/oracle/ocr.loc" check successful ERROR: PRVF-4195 : Disk group for ocr location "+OCR" not available on the following nodes: grac41 NOTE: This check does not verify the integrity of the OCR contents. Execute 'ocrcheck' as a privileged user to verify the contents of OCR. OCR integrity check failed Verification of OCR integrity was unsuccessful. Checks did not pass for the following node(s): grac41
Some agents of the OHASD stack like mdnsd.bin, gpnpd.bin or gipcd.bin are not starting up
Case 1 : Wrong protection for executable $GRID_HOME/bin/gpnpd.bin ==> For add. details see GENERIC File Protection chapter Reported error in oraagent_grid.log : [ clsdmc][1103787776]Fail to connect (ADDRESS=(PROTOCOL=ipc) (KEY=grac41DBG_GPNPD)) with status 9 [ora.gpnpd][1103787776]{0:0:2} [start] Error = error 9 encountered when connecting to GPNPD Reported Clusterware Error in CW alert.log: [/u01/app/11204/grid/bin/oraagent.bin(20333)] CRS-5818:Aborted command 'start' for resource 'ora.gpnpd'. Details at (:CRSAGF00113:) {0:0:2} in ..... ohasd/oraagent_grid/oraagent_grid.log Testing scenario : [grid@grac41 ~]$ chmod 444 $GRID_HOME/bin/gpnpd.bin [grid@grac41 ~]$ ls -l $GRID_HOME/bin/gpnpd.bin -r--r--r--. 1 grid oinstall 368780 Mar 19 17:07 /u01/app/11204/grid/bin/gpnpd.bin [root@grac41 gpnp]# crsctl start crs CRS-4123: Oracle High Availability Services has been started. Clusterware status : $ crsctl check crs CRS-4638: Oracle High Availability Services is online CRS-4535: Cannot communicate with Cluster Ready Services CRS-4530: Communications failure contacting Cluster Synchronization Services daemon CRS-4534: Cannot communicate with Event Manager $ crsi NAME TARGET STATE SERVER STATE_DETAILS ------------------------- ---------- ---------- ------------ ------------------ ora.asm ONLINE OFFLINE Instance Shutdown ora.cluster_interconnect.haip ONLINE OFFLINE ora.crf ONLINE OFFLINE ora.crsd ONLINE OFFLINE ora.cssd ONLINE OFFLINE ora.cssdmonitor OFFLINE OFFLINE ora.ctssd ONLINE OFFLINE ora.diskmon OFFLINE OFFLINE ora.drivers.acfs ONLINE OFFLINE ora.evmd ONLINE OFFLINE ora.gipcd ONLINE OFFLINE ora.gpnpd ONLINE OFFLINE STARTING ora.mdnsd ONLINE ONLINE grac41 --> GPnP deamon remains ins starting Mode $ ps -elf | egrep "PID|d.bin|ohas" | grep -v grep F S UID PID PPID C PRI NI ADDR SZ WCHAN STIME TTY TIME CMD 4 S root 6098 1 0 80 0 - 2846 pipe_w 04:44 ? 00:00:00 /bin/sh /etc/init.d/init.ohasd run 4 S root 20127 1 23 80 0 - 176890 futex_ 11:52 ? 00:00:51 /u01/app/11204/grid/bin/ohasd.bin reboot 4 S grid 20333 1 0 80 0 - 166464 futex_ 11:52 ? 00:00:02 /u01/app/11204/grid/bin/oraagent.bin 0 S grid 20344 1 0 80 0 - 74289 poll_s 11:52 ? 00:00:00 /u01/app/11204/grid/bin/mdnsd.bin Review Tracefile : alertgrac41.log [/u01/app/11204/grid/bin/oraagent.bin(27632)]CRS-5818:Aborted command 'start' for resource 'ora.gpnpd'. Details at (:CRSAGF00113:) {0:0:2} in ... agent/ohasd/oraagent_grid/oraagent_grid.log. 2014-05-12 10:27:51.747: [ohasd(27477)]CRS-2757:Command 'Start' timed out waiting for response from the resource 'ora.gpnpd'. Details at (:CRSPE00111:) {0:0:2} in /u01/app/11204/grid/log/grac41/ohasd/ohasd.log oraagent_grid.log [ clsdmc][1103787776]Fail to connect (ADDRESS=(PROTOCOL=ipc)(KEY=grac41DBG_GPNPD)) with status 9 2014-05-12 10:27:17.476: [ora.gpnpd][1103787776]{0:0:2} [start] Error = error 9 encountered when connecting to GPNPD 2014-05-12 10:27:18.477: [ora.gpnpd][1103787776]{0:0:2} [start] without returnbuf 2014-05-12 10:27:18.659: [ COMMCRS][1125422848]clsc_connect: (0x7f3b300d92d0) no listener at (ADDRESS=(PROTOCOL=ipc)(KEY=grac41DBG_GPNPD)) ohasd.log 2014-05-12 10:27:51.745: [ AGFW][2693531392]{0:0:2} Received the reply to the message: RESOURCE_START[ora.gpnpd 1 1] ID 4098:362 from the agent /u01/app/11204/grid/bin/oraagent_grid 2014-05-12 10:27:51.745: [ AGFW][2693531392]{0:0:2} Agfw Proxy Server sending the reply to PE for message: RESOURCE_START[ora.gpnpd 1 1] ID 4098:361 2014-05-12 10:27:51.747: [ CRSPE][2212488960]{0:0:2} Received reply to action [Start] message ID: 361 2014-05-12 10:27:51.747: [ INIT][2212488960]{0:0:2} {0:0:2} Created alert : (:CRSPE00111:) : Start action timed out! 2014-05-12 10:27:51.747: [ CRSPE][2212488960]{0:0:2} Start action failed with error code: 3 2014-05-12 10:27:52.123: [ AGFW][2693531392]{0:0:2} Received the reply to the message: RESOURCE_START[ora.gpnpd 1 1] ID 4098:362 from the agent /u01/app/11204/grid/bin/oraagent_grid 2014-05-12 10:27:52.123: [ AGFW][2693531392]{0:0:2} Agfw Proxy Server sending the last reply to PE for message: RESOURCE_START[ora.gpnpd 1 1] ID 4098:361 2014-05-12 10:27:52.123: [ CRSPE][2212488960]{0:0:2} Received reply to action [Start] message ID: 361 2014-05-12 10:27:52.123: [ CRSPE][2212488960]{0:0:2} RI [ora.gpnpd 1 1] new internal state: [STABLE] old value: [STARTING] 2014-05-12 10:27:52.123: [ CRSPE][2212488960]{0:0:2} CRS-2674: Start of 'ora.gpnpd' on 'grac41' failed --> Here we see that are failing to start GPnP resource Debugging steps : Is process gpnpd.bin running ? [root@grac41 ~]# ps -elf | egrep "PID|gpnpd" | grep -v grep F S UID PID PPID C PRI NI ADDR SZ WCHAN STIME TTY TIME CMD --> Missing process gpnpd.bin Restart CRS with strace support # crsctl stop crs -f # strace -t -f -o crs_startup.trc crsctl start crs Check for EACESS erros and check return values of execve() and aceess() sytem calls : [root@grac41 oracle]# grep EACCES crs_startup.trc 28301 12:19:46 access("/u01/app/11204/grid/bin/gpnpd.bin", X_OK) = -1 EACCES (Permission denied) Review crs_startup.trc more in detail 27345 12:15:35 execve("/u01/app/11204/grid/bin/gpnpd.bin", ["/u01/app/11204/grid/bin/gpnpd.bi"...], [/* 73 vars */] <unfinished ...> 27238 12:15:35 <... lseek resumed> ) = 164864 27345 12:15:35 <... execve resumed> ) = -1 EACCES (Permission denied) 27345 12:15:35 access("/u01/app/11204/grid/bin/gpnpd.bin", X_OK <unfinished ...> 27238 12:15:35 <... read resumed> "2523"1233tt"..., 256) = 256 27345 12:15:35 <... access resumed> ) = -1 EACCES (Permission denied) Verify problem with cluvfy [grid@grac41 ~]$ cluvfy comp software -verbose Verifying software Check: Software Component: crs Node Name: grac41 .. Permissions of file "/u01/app/11204/grid/bin/gpnpd.bin" did not match the expected value. [Expected = "0755" ; Found = "0444"] /u01/app/11204/grid/bin/gpnptool.bin..."Permissions" did not match reference ..
References
-
- Troubleshoot Grid Infrastructure Startup Issues (Doc ID 1050908.1)
- Top 5 Grid Infrastructure Startup Issues [ID 1368382.1]
- 11gR2 Clusterware and Grid Home – What You Need to Know (Doc ID 1053147.1)
- How to Validate Network and Name Resolution Setup for the Clusterware and RAC (Doc ID 1054902.1)
- Multicasting Requirement for RAC
- Debugging Network problems in a 3 node cluster
- Using Dtrace – http://localhost/racblog/using-dtrace/
- Troubleshooting Clusterware and Clusterware component error : Address already in use
- Pitfalls changing Public IP address in a RAC cluster env with detailed debugging steps
- Troubleshooting Clusterware startup problems with DTRACE
New issue
Have a question about this project? Sign up for a free GitHub account to open an issue and contact its maintainers and the community.
By clicking “Sign up for GitHub”, you agree to our terms of service and
privacy statement. We’ll occasionally send you account related emails.
Already on GitHub?
Sign in
to your account
Comments
![]()
What is the issue?
When I try to click the button to log in the menu, it does nothing. I tried quitting the tailscaled.exe and reopening it so that I could see the log and this is what happens when I click it.
StartLoginInteractive: url=false
control: client.Login(false, 2)
control: LoginInteractive -> regen=true
control: doLogin(regen=true, hasUrl=false)
Received error: fetch control key: Get «https://controlplane.tailscale.com/key?v=57»: read tcp [::1]:64367->[2a05:d014:386:202:24dd:46aa:f98e:9997]:443: wsarecv: An established connection was aborted by the software in your host machine.
Steps to reproduce
Install Tailscale Client for Windows 1.37.32
Try to Log In
Are there any recent changes that introduced the issue?
No
OS
Windows
OS version
Windows 11 64-Bit
Tailscale version
1.37.32
Other software
Mc Afee Live Safe
Windows Defender Firewall
VirtualBox
VMWare
Bug report
BUG-20f2f893f7695884f50d853637d26067e9c887bd0c972647fb3ea6b637ec180a-20230203161925Z-d7e18cb0e67c3b69
![]()
JerryBerry12
changed the title
Log in button no working
Log in button not working
Feb 3, 2023
![]()
In a command prompt, what does it say when you run:
tailscale debug ts2021
![]()
11:33:21.358731 Fetching keys from https://controlplane.tailscale.com/key?v=57 …
11:33:22.846787 Dial(«tcp», «[2a05:d014:386:201:7200:6340:b22f:7df6]:80») …
11:33:22.848885 Dial(«tcp», «[2a05:d014:386:201:7200:6340:b22f:7df6]:80») = [::1]:49335 / [2a05:d014:386:201:7200:6340:b22f:7df6]:80
11:33:22.867099 Dial(«tcp», «[2a05:d014:386:202:6dd4:fc68:35ae:2b80]:443») …
11:33:22.868100 Dial(«tcp», «[2a05:d014:386:202:6dd4:fc68:35ae:2b80]:443») = [::1]:49337 / [2a05:d014:386:202:6dd4:fc68:35ae:2b80]:443
11:33:22.870290 controlhttp.Dial = 0x0, all connection attempts failed (HTTP: EOF, HTTPS: read tcp [::1]:49337->[2a05:d014:386:202:6dd4:fc68:35ae:2b80]:443: wsarecv: An established connection was aborted by the software in your host machine.)
all connection attempts failed (HTTP: EOF, HTTPS: read tcp [::1]:49337->[2a05:d014:386:202:6dd4:fc68:35ae:2b80]:443: wsarecv: An established connection was aborted by the software in your host machine.)
I have to go but I’ll be back at 3
![]()
Something on your machine is interfering and breaking the connection. Of the software you listed, I’d guess McAfee LiveSafe is the most likely culprit. It might be keeping you too safe. Can you try disabling it?
![]()
OK, I’ll be in front of my computer in like an hour, so I’ll try it out and get back to you. Thanks so much. (you’re right. It might be keeping me to safe…
🤣🤣🤣🤣
On Feb 3, 2023, at 3:02 PM, Brad Fitzpatrick ***@***.***> wrote:
Something on your machine is interfering and breaking the connection. Of the software you listed, I’d guess McAfee LiveSafe is the most likely culprit. It might be keeping you too safe. Can you try disabling it?
—
Reply to this email directly, view it on GitHub<#7172 (comment)>, or unsubscribe<https://github.com/notifications/unsubscribe-auth/AUMMHHIOVAFU5FYV7I7V3G3WVVP5PANCNFSM6AAAAAAUQOEYGI>.
You are receiving this because you authored the thread.Message ID: ***@***.***>
![]()
Keepin’ us in suspense! 😅
![]()
SO SORRY! I ment to reply sooner, but it just slipped off my head. When I tried allowing it to all ports in McAfee (Not just designated ports) Nothing happened. When I turned off firewall completely, it were these two errors. (I think number 2 is old)
1.
control: LoginInteractive -> regen=true
control: doLogin(regen=true, hasUrl=false)
Received error: fetch control key: Get "https://controlplane.tailscale.com/key?v=57": read tcp [::1]:56862->[2a05:d014:386:201:7200:6340:b22f:7df6]:443: wsarecv: An existing connection was forcibly closed by the remote host.
control: LoginInteractive -> regen=true
control: doLogin(regen=true, hasUrl=false)
Received error: fetch control key: Get "https://controlplane.tailscale.com/key?v=57": read tcp [::1]:56856->[2a05:d014:386:201:7200:6340:b22f:7df6]:443: wsarecv: An established connection was aborted by the software in your host machine.
logtail: dial "log.tailscale.io:443" failed: dial tcp 34.229.201.48:443: connectex: The requested address is not valid in its context. (in 35ms), trying bootstrap...
logtail: bootstrap dial succeeded
logtail: upload: log upload of 25714 bytes compressed failed: Post "https://log.tailscale.io/c/tailnode.log.tailscale.io/a072fae0288dc1cc1fc90523eacf40f2a57e7d1bcfd25cd997ad1f5ea93e5863": read tcp [::1]:56860->[2600:1f18:429f:9305:4043:217b:512c:f8d4]:443: wsarecv: An established connection was aborted by the software in your host machine.
logtail: [v1] backoff: 9197 msec
Thanks!
![]()
That basically just says something is blocking it. I don’t know what.
I don’t think we’ll be able to help more without knowing what else is running on your machine.
![]()
I’ve tried opening ports 443 as it says here:
⬇️ ⬇️
logtail: dial "log.tailscale.io:443" failed: dial tcp 34.229.201.48:443: connectex: The requested address is not valid in its context. (in 35ms), trying bootstrap...
But didn’t do anything. I’m gonna try vmware next because I don’t use it, then VirtualBox. Thanks!
![]()
I’m sorry, but nothing seems to be working. I’m gonna try using something else. I may try to use wireguard. I don’t mean to say I don’t like your project, but I don’t think its working for me. Thank you for all your time, and if this ever gets fixed, I’ll come back.
-Jerry
![]()
I even tried disabling all the wireless adapters except for ethernet and Bluetooth, and It still didn’t work
2 participants
![]()
![]()
Время прочтения
3 мин
Просмотры 213K
 Как известно, в операционной системе Windows Vista, 7, 8 и 10 есть своеобразная пасхалка — GodMode (режим Бога). Начиная с версии Vista можно создать папку со специфическим именем, которая перенаправляет на настройки Windows или служебные папки, такие как «Панель управления», «Компьютер», «Принтеры» и проч.
Как известно, в операционной системе Windows Vista, 7, 8 и 10 есть своеобразная пасхалка — GodMode (режим Бога). Начиная с версии Vista можно создать папку со специфическим именем, которая перенаправляет на настройки Windows или служебные папки, такие как «Панель управления», «Компьютер», «Принтеры» и проч.
Например, если создать на рабочем столе папку с названием GodMode.{ED7BA470-8E54-465E-825C-99712043E01C} (вместо GodMode можно указать любые символы), то внутри будут отображаться все настройки, в том числе и те, которые не включены в меню «Панели управления» или «Параметры»: скриншот.
Очень удобная фича для управления настройками в системе и для системного администрирования.
К сожалению, режим Бога используют не только сисадмины, но и авторы вирусов.
Специалисты из антивирусной компании McAfee Labs рассказывают о трояне Dynamer, который использует режим Бога, чтобы скрыться от обнаружения в системе.
Dynamer при установке записывает свои файлы в одну из таких папок внутри %AppData%. В реестре создаётся ключ, который сохраняется после перезагрузки, запуская каждый раз бинарник зловреда.
HKEY_CURRENT_USERSOFTWAREMicrosoftWindowsCurrentVersionRun
lsm = C:UsersadminAppDataRoamingcom4.{241D7C96-F8BF-4F85-B01F-E2B043341A4B}lsm.exeТаким образом, исполняемый файл нормально запускается по команде из реестра, но вручную зайти в эту папку нельзя: как указано в списке выше, папка {241D7C96-F8BF-4F85-B01F-E2B043341A4B} работает как ярлык на настройки «Подключение к компьютерам и программам на рабочем месте» (RemoteApp and Desktop Connections).
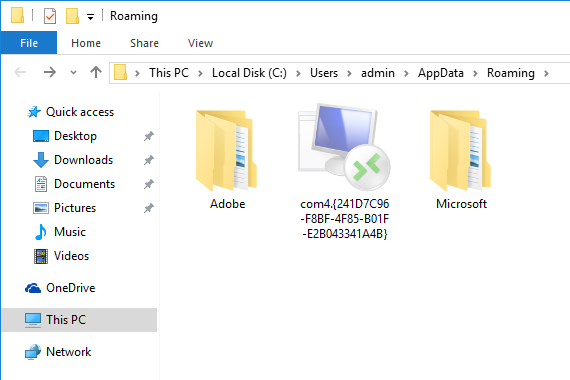
Вот содержимое папки, если открыть её в проводнике.
Более того, авторы трояна добавили к названию папки «com4.», так что Windows считает папку аппаратным устройством. Проводник Windows не может удалить папку с таким названием.
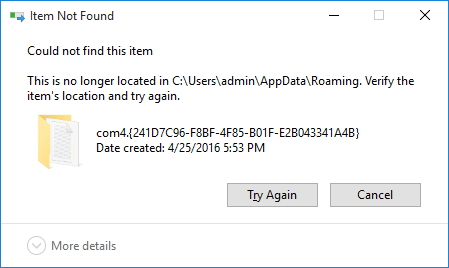
Аналогично, удаление невозможно из консоли.
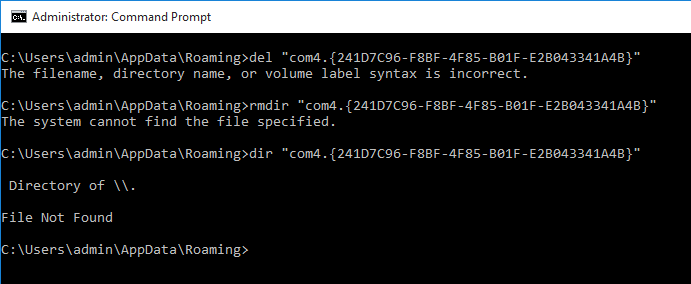
Нормальные антивирусы обходят этот трюк вирусописателей. Чтобы удалить папку вручную, нужно запустить из консоли следующую команду.
rd “\.%appdata%com4.{241D7C96-F8BF-4F85-B01F-E2B043341A4B}” /S /Q
Троян Dynamer впервые обнаружен несколько лет назад, но Microsoft до сих пор считает его «серьёзной угрозой» для пользователей Windows.
В качестве бонуса.
Список имён папок (GUID) в режиме Бога для быстрого доступа к отдельным настройкам Windows
Action Center.{BB64F8A7-BEE7-4E1A-AB8D-7D8273F7FDB6}
Backup and Restore.{B98A2BEA-7D42-4558-8BD1-832F41BAC6FD}
Biometric Devices.{0142e4d0-fb7a-11dc-ba4a-000ffe7ab428}
Credential Manager.{1206F5F1-0569-412C-8FEC-3204630DFB70}
Default Location.{00C6D95F-329C-409a-81D7-C46C66EA7F33}
Devices and Printers.{A8A91A66-3A7D-4424-8D24-04E180695C7A}
Display.{C555438B-3C23-4769-A71F-B6D3D9B6053A}
HomeGroup.{67CA7650-96E6-4FDD-BB43-A8E774F73A57}
Location and Other Sensors.{E9950154-C418-419e-A90A-20C5287AE24B}
Notification Area Icons.{05d7b0f4-2121-4eff-bf6b-ed3f69b894d9}
Recovery.{9FE63AFD-59CF-4419-9775-ABCC3849F861}
RemoteApp and Desktop Connections.{241D7C96-F8BF-4F85-B01F-E2B043341A4B}
Speech Recognition.{58E3C745-D971-4081-9034-86E34B30836A}
Troubleshooting.{C58C4893-3BE0-4B45-ABB5-A63E4B8C8651}
Administrative Tools.{D20EA4E1-3957-11d2-A40B-0C5020524153}
All .NET Frameworks and COM Libraries.{1D2680C9-0E2A-469d-B787-065558BC7D43}
All Tasks (Control Panel).{ED7BA470-8E54-465E-825C-99712043E01C}
AutoPlay.{9C60DE1E-E5FC-40f4-A487-460851A8D915}
BitLocker Drive Encryption.{D9EF8727-CAC2-4e60-809E-86F80A666C91}
Computer Folder.{20D04FE0-3AEA-1069-A2D8-08002B30309D}
Default Programs.{17cd9488-1228-4b2f-88ce-4298e93e0966}
Ease of Access Center.{D555645E-D4F8-4c29-A827-D93C859C4F2A}
Font Settings.{93412589-74D4-4E4E-AD0E-E0CB621440FD}
Get Programs.{15eae92e-f17a-4431-9f28-805e482dafd4}
Manage Wireless Networks.{1FA9085F-25A2-489B-85D4-86326EEDCD87}
Network and Sharing Center.{8E908FC9-BECC-40f6-915B-F4CA0E70D03D}
Network Connections.{7007ACC7-3202-11D1-AAD2-00805FC1270E}
Network Folder.{208D2C60-3AEA-1069-A2D7-08002B30309D}
Parental Controls.{96AE8D84-A250-4520-95A5-A47A7E3C548B}
Performance Information and Tools.{78F3955E-3B90-4184-BD14-5397C15F1EFC}
Personalization.{ED834ED6-4B5A-4bfe-8F11-A626DCB6A921}
Power Options.{025A5937-A6BE-4686-A844-36FE4BEC8B6D}
Programs and Features.{7b81be6a-ce2b-4676-a29e-eb907a5126c5}
Sync Center.{9C73F5E5-7AE7-4E32-A8E8-8D23B85255BF}
System.{BB06C0E4-D293-4f75-8A90-CB05B6477EEE}
User Accounts.{60632754-c523-4b62-b45c-4172da012619}
Windows Firewall.{4026492F-2F69-46B8-B9BF-5654FC07E423}
Windows SideShow.{E95A4861-D57A-4be1-AD0F-35267E261739}
Windows Update.{36eef7db-88ad-4e81-ad49-0e313f0c35f8}
Полный список GUID с указанием поддерживаемых версий Windows см. в документации Microsoft.