If you’ve spent any time at all using an automatic speech recognition service, you may have seen the phrase “word error rate,” or WER, for short. But even if you’re brand new to transcriptions, WER is the most common metric you’ll see when comparing ASR services. Luckily, you don’t have to be a math whiz to figure it out – you just need to know this formula:
Word Error Rate = (Substitutions + Insertions + Deletions) / Number of Words Spoken
And that’s it! To go a bit more in depth, here’s how to effectively determine each of these factors:
- Substitutions are anytime a word gets replaced (for example, “twinkle” is transcribed as “crinkle”)
- Insertions are anytime a word gets added that wasn’t said (for example, “trailblazers” becomes “tray all blazers”)
- Deletions are anytime a word is omitted from the transcript (for example, “get it done” becomes “get done”)
Word Error Rate in Practice
Let’s take a look at an example audio.
The correct text is below:
We wanted people to know that we’ve got something brand new and essentially this product is, uh, what we call disruptive, changes the way that people interact with technology.
Now, here’s how that sentence was translated using Google’s speech to text API:
We wanted people to know that how to me where i know and essentially this product is what we call scripted changes the way people are rapid technology.
To correctly calculate WER, we take a look at the substitutions, insertions, and deletions between the two.

Add up the substitutions, insertions, and deletions, and you get a total of 11. Divide that by 29 (the total number of words spoken in the original file) to get a word error rate of about 38 percent. In some cases, the entire meaning of the sentence was changed.

Recently, we ran a test. We took 30 popular podcasts of varying topics and number of speakers, and transcribed them with Rev AI, Google, and Speechmatics. The overall WER for each service is below:
- Rev AI: 17.1%
- Google (video model): 18.3%
- Speechmatics: 21.3%
As these results suggest, you’ll get a different word error rate from whichever service you choose. And though WER is an important and standard metric, it’s not the only thing you should focus on.
The Power of Speaker Diarization
Are all of your transcriptions just one person narrating into a recorder? Great! You’ve somehow found the sweet spot of perfect audio.
What’s more likely, however, is that your files contain multiple speakers. Those speakers may sometimes cut each other off or talk over each other. They may even sound fairly similar.
One of the cool features of Rev AI is speaker diarization. This recognizes the different speakers in the room and attributes text to each. Whether it’s two people having an interview or a panel of four speakers, you can see who said what and when they said it. This is particularly useful if you’re planning to quote the speakers later. Imagine attributing a statement to the incorrect person – and even worse, getting the crux of their message wrong because of a high WER rate. You just may have two people upset with you: the actual speaker and the person you incorrectly cited.

Not all ASR services offer diarization, so keep that in mind if you’re often recording multiple people talking at once. You’ll want to be able to quickly discern between them.
Other Factors to Consider
WER can be an incredibly useful tool; however, it’s just one consideration when you’re choosing an ASR service.
A key thing to remember is that your WER will be inaccurate if you don’t normalize things like capitalization, punctuation, or numbers across your transcripts. Rev AI automatically transcribes spoken words into sentences and paragraphs. This is especially important if you are transcribing your audio files to increase accessibility. Transcripts formatted with these features will be significantly easier for your audience to read.
Word error rate can also be influenced by a number of additional factors, such as background noise, speaker volume, and regional dialects. Think about the times you’ve recorded someone or heard an interview during an event. Were you able to find a quiet, secure room away from all the hubbub? Did the speaker have a clear, booming voice? Chances are, there were some extenuating circumstances that didn’t allow for the perfect environment – and that’s just a part of life.
Certain ASR services are unable to distinguish sounds in these situations. Others, like Rev AI, can accurately transcribe the speakers no matter their volume or how far away they are from the recorder. Not everyone is going to have the lung capacity of Mick Jagger, and that’s fine. While we don’t require a minimum volume, other ASR services may. If you tend to interview quieter talkers or are in environments where you can’t make a lot of noise, be mindful of any requirements before making your selection.
Final Thoughts
Now that you’re comfortable calculating word error rate, you can feel more confident in your search for an ASR service. See how the power of a low WER can help your business reach new heights. Try Rev AI for free and get five hours of credit simply for signing up.
Try it free
The Word Error Rate (short: WER) is a way to measure performance of an ASR. It compares a reference to an hypothesis and is defined like this:
$$mathit{WER} = frac{S+D+I}{N}$$
where
- S is the number of substitutions,
- D is the number of deletions,
- I is the number of insertions and
- N is the number of words in the reference
Examples
REF: What a bright day HYP: What a day
In this case, a deletion happened. «Bright» was deleted by the ASR.
REF: What a day HYP: What a bright day
In this case, an insertion happened. «Bright» was inserted by the ASR.
REF: What a bright day HYP: What a light day
In this case, an substitution happened. «Bright» was substituted by «light» by
the ASR.
Range of values
As only addition and division with non-negative
numbers happen, WER cannot get negativ. It is 0 exactly when the hypothesis is
the same as the reference.
WER can get arbitrary large, because the ASR can insert an arbitrary amount of
words.
Interestingly, the WER is just the Levenshtein distance for words.
I’ve understood it after I saw this on the German Wikipedia:
begin{align}
m &= |r|\
n &= |h|\
end{align}
begin{align}
D_{0, 0} &= 0\
D_{i, 0} &= i, 1 leq i leq m\
D_{0, j} &= j, 1 leq j leq n
end{align}
$$
text{For } 1 leq ileq m, 1leq j leq n\
D_{i, j} = min begin{cases}
D_{i — 1, j — 1}&+ 0 {rm if} u_i = v_j\
D_{i — 1, j — 1}&+ 1 {rm(Replacement)} \
D_{i, j — 1}&+ 1 {rm(Insertion)} \
D_{i — 1, j}&+ 1 {rm(Deletion)}
end{cases}
$$
But I have written a piece of pseudocode to make it even easier to code this algorithm:

Python
#!/usr/bin/env python
def wer(r, h):
"""
Calculation of WER with Levenshtein distance.
Works only for iterables up to 254 elements (uint8).
O(nm) time ans space complexity.
Parameters
----------
r : list
h : list
Returns
-------
int
Examples
--------
>>> wer("who is there".split(), "is there".split())
1
>>> wer("who is there".split(), "".split())
3
>>> wer("".split(), "who is there".split())
3
"""
# initialisation
import numpy
d = numpy.zeros((len(r) + 1) * (len(h) + 1), dtype=numpy.uint8)
d = d.reshape((len(r) + 1, len(h) + 1))
for i in range(len(r) + 1):
for j in range(len(h) + 1):
if i == 0:
d[0][j] = j
elif j == 0:
d[i][0] = i
# computation
for i in range(1, len(r) + 1):
for j in range(1, len(h) + 1):
if r[i - 1] == h[j - 1]:
d[i][j] = d[i - 1][j - 1]
else:
substitution = d[i - 1][j - 1] + 1
insertion = d[i][j - 1] + 1
deletion = d[i - 1][j] + 1
d[i][j] = min(substitution, insertion, deletion)
return d[len(r)][len(h)]
if __name__ == "__main__":
import doctest
doctest.testmod()
Explanation
No matter at what stage of the code you are, the following is always true:
- If
r[i]equalsh[j]you don’t have to change anything. The error will be the same as it was forr[:i-1]andh[:j-1] - If its a substitution, you have the same number of errors as you had before when comparing the
r[:i-1]andh[:j-1] - If it was an insertion, then the hypothesis will be longer than the reference. So you can delete one from the hypothesis and compare the rest. As this is the other way around for deletion, you don’t have to worry when you have to delete something.
From Wikipedia, the free encyclopedia
Word error rate (WER) is a common metric of the performance of a speech recognition or machine translation system.
The general difficulty of measuring performance lies in the fact that the recognized word sequence can have a different length from the reference word sequence (supposedly the correct one). The WER is derived from the Levenshtein distance, working at the word level instead of the phoneme level. The WER is a valuable tool for comparing different systems as well as for evaluating improvements within one system. This kind of measurement, however, provides no details on the nature of translation errors and further work is therefore required to identify the main source(s) of error and to focus any research effort.
This problem is solved by first aligning the recognized word sequence with the reference (spoken) word sequence using dynamic string alignment. Examination of this issue is seen through a theory called the power law that states the correlation between perplexity and word error rate.[1]
Word error rate can then be computed as:

where
- S is the number of substitutions,
- D is the number of deletions,
- I is the number of insertions,
- C is the number of correct words,
- N is the number of words in the reference (N=S+D+C)
The intuition behind ‘deletion’ and ‘insertion’ is how to get from the reference to the hypothesis. So if we have the reference «This is wikipedia» and hypothesis «This _ wikipedia», we call it a deletion.
When reporting the performance of a speech recognition system, sometimes word accuracy (WAcc) is used instead:

Note that since N is the number of words in the reference, the word error rate can be larger than 1.0, and thus, the word accuracy can be smaller than 0.0.
Experiments[edit]
It is commonly believed that a lower word error rate shows superior accuracy in recognition of speech, compared with a higher word error rate. However, at least one study has shown that this may not be true. In a Microsoft Research experiment, it was shown that, if people were trained under «that matches the optimization objective for understanding», (Wang, Acero and Chelba, 2003) they would show a higher accuracy in understanding of language than other people who demonstrated a lower word error rate, showing that true understanding of spoken language relies on more than just high word recognition accuracy.[2]
Other metrics[edit]
One problem with using a generic formula such as the one above, however, is that no account is taken of the effect that different types of error may have on the likelihood of successful outcome, e.g. some errors may be more disruptive than others and some may be corrected more easily than others. These factors are likely to be specific to the syntax being tested. A further problem is that, even with the best alignment, the formula cannot distinguish a substitution error from a combined deletion plus insertion error.
Hunt (1990) has proposed the use of a weighted measure of performance accuracy where errors of substitution are weighted at unity but errors of deletion and insertion are both weighted only at 0.5, thus:

There is some debate, however, as to whether Hunt’s formula may properly be used to assess the performance of a single system, as it was developed as a means of comparing more fairly competing candidate systems. A further complication is added by whether a given syntax allows for error correction and, if it does, how easy that process is for the user. There is thus some merit to the argument that performance metrics should be developed to suit the particular system being measured.
Whichever metric is used, however, one major theoretical problem in assessing the performance of a system is deciding whether a word has been “mis-pronounced,” i.e. does the fault lie with the user or with the recogniser. This may be particularly relevant in a system which is designed to cope with non-native speakers of a given language or with strong regional accents.
The pace at which words should be spoken during the measurement process is also a source of variability between subjects, as is the need for subjects to rest or take a breath. All such factors may need to be controlled in some way.
For text dictation it is generally agreed that performance accuracy at a rate below 95% is not acceptable, but this again may be syntax and/or domain specific, e.g. whether there is time pressure on users to complete the task, whether there are alternative methods of completion, and so on.
The term «Single Word Error Rate» is sometimes referred to as the percentage of incorrect recognitions for each different word in the system vocabulary.
Edit distance[edit]
The word error rate may also be referred to as the length normalized edit distance.[3] The normalized edit distance between X and Y, d( X, Y ) is defined as the minimum of W( P ) / L ( P ), where P is an editing path between X and Y, W ( P ) is the sum of the weights of the elementary edit operations of P, and L(P) is the number of these operations (length of P).[4]
See also[edit]
- BLEU
- F-Measure
- METEOR
- NIST (metric)
- ROUGE (metric)
References[edit]
Notes[edit]
- ^ Klakow, Dietrich; Jochen Peters (September 2002). «Testing the correlation of word error rate and perplexity». Speech Communication. 38 (1–2): 19–28. doi:10.1016/S0167-6393(01)00041-3. ISSN 0167-6393.
- ^ Wang, Y.; Acero, A.; Chelba, C. (2003). Is Word Error Rate a Good Indicator for Spoken Language Understanding Accuracy. IEEE Workshop on Automatic Speech Recognition and Understanding. St. Thomas, US Virgin Islands. CiteSeerX 10.1.1.89.424.
- ^ Nießen et al.(2000)
- ^ Computation of Normalized Edit Distance and Application:AndrCs Marzal and Enrique Vidal
Other sources[edit]
- McCowan et al. 2005: On the Use of Information Retrieval Measures for Speech Recognition Evaluation
- Hunt, M.J., 1990: Figures of Merit for Assessing Connected Word Recognisers (Speech Communication, 9, 1990, pp 239-336)
- Zechner, K., Waibel, A.Minimizing Word Error Rate in Textual Summaries of Spoken Language
Содержание
- Is Word Error Rate Useful?
- What is Word Error Rate?
- How To Calculate Word Error Rate (WER)
- Is Word Error Rate a Good Measure of Speech Recognition Systems?
- Alternatives to Word Error Rate
- Word Error Rate Calculation
- Examples
- Range of values
- Calculation
- Python
- Explanation
- Two minutes NLP — Intro to Word Error Rate (WER) for Speech-to-Text
- Speech Recognition, Levenshtein distance, and BLEU
- What is WER?
- WER, Levenshtein distance, and edit distance
- WER drawbacks
- WER and BLEU
- Как улучшить распознавание русской речи до 3% WER с помощью открытых данных
- Описание данных
- Акустическая модель
- Трансферное обучение
Is Word Error Rate Useful?
What is Word Error Rate? Word Error Rate is a measure of how accurate an Automatic Speech Recognition (ASR) system performs. Quite literally, it calculates how many “errors” are in the transcription text produced by an ASR system, compared to a human transcription.


What is Word Error Rate?
Word Error Rate is a measure of how accurate an Automatic Speech Recognition (ASR) system performs. Quite literally, it calculates how many “errors” are in the transcription text produced by an ASR system, compared to a human transcription.
Broadly speaking, it’s important to measure the accuracy of any machine learning system. Whether it’s a self driving car, NLU system like Amazon Alexa, or an Automatic Speech Recognition system like the ones we develop at AssemblyAI, if you don’t know how accurate your machine learning system is, you’re flying blind!
In the field of Automatic Speech Recognition, the Word Error Rate has become the de facto standard for measuring how accurate a speech recognition model is. A common question we get from customers is “What’s your WER?”. In fact, when our company was accepted into Y Combinator back in 2017, one of the first questions the YC partners asked us was “What’s your WER?”
How To Calculate Word Error Rate (WER)
The actual math behind calculating a Word Error Rate is the following:
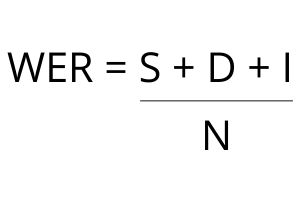 Word Error Rate Algorithm
Word Error Rate Algorithm
What we are doing here is combining the number of Substitutions (S), Deletions (D), and Insertions (N), divided by the Number of Words (N).
So for example, let’s say the following sentence is spoken:
If our Automatic Speech Recognition (ASR) is not very good, and predicts the following transcription:
Then our Word Error Rate (WER) would be 50%! That’s because there was 1 Substitution, “there” was substituted with “bear”. Let’s say our ASR system instead only predicted:
And for some reason didn’t even predict a second word. In this case our Word Error Rate (WER) would also be 50%! That’s because there is a single Deletion — only 1 word was predicted by our ASR system when what was actually spoken was 2 words. The lower the Word Error Rate the better. You can think of word accuracy as 1 minus the Word Error Rate. So if your Word Error Rate is 20%, then your word accuracy, ie how accurate your transcription is, is 80%:
Is Word Error Rate a Good Measure of Speech Recognition Systems?
As with everything, it is not black and white. Overall, Word Error Rate can tell you how “different” the automatic transcription was compared to the human transcription, and generally, this is a reliable metric to determine how “good” an automatic transcription is.
For example, take the following:
As we can see, model 2 has a lower WER of 15%, and is obviously way more accurate to us as humans than the predicted text from model 1. This is why, in general, WER is a good metric for determining the accuracy of an Automatic Speech Recognition system.
However, take the following example:
In the above example, both Model 1 text and Model 2 text have a WER of 20%. But Model 1 clearly results in a more understandable transcription compared to Model 2. That’s because even with the error that Model 1 makes, it still results in a more legible and easy to understand transcription. This is compared to Model 2, which makes a mistake in the transcription that results in the transcription text being illegible (ie, “word soup”).
To further illustrate the downfalls of Word Error Rate, take the following example:
In this example, Model 2 does a much better job producing an understandable transcription, but it has double (!!) the WER compared to Model 1. This difference in WER is especially pronounced in this example because the text contains so few words, but still, this illustrates some “gotchas” to be aware of when reviewing WER.
What these above examples illustrate is that the Word Error Calculation is not “smart”. It is literally just looking at the number of substitutions, deletions, and insertions that appear in the automatic transcription compared to the human transcription. This is why WER in the “real world” can be so problematic.
Take for example the simple mistake of not normalizing the casing in the human transcription and automatic transcription.
In this example, we see that the automatic transcription has a WER of 60% (!!) even though it perfectly transcribed what was spoken. Simply because we were comparing the human transcription with New York capitalized, compared to new york lowercase, the WER algorithm sees these as completely different words!
This is a major “gotcha” we see in the wild, and it’s why we internally always normalize our human transcriptions and automatic transcriptions when computing a WER, through things like:
- Lowercasing all text
- Removing all punctuation
- Changing all numbers to their written form («7» -> «seven»)
- Etc.
Alternatives to Word Error Rate
Unfortunately, Word Error Rate is the best metric we have today to determine the accuracy of an Automatic Speech Recognition system. There have been some alternatives proposed, but none have stuck in the research or commercial communities. A common technique used is to weight Substitutions, Insertions, and Deletions differently. So, for example, adding 0.5 for every Deletion versus 1.0.
However, unless the weights are standardized, it’s not really a “fair” way to compute WER. System 1 could be reporting a much lower WER because it used lower “weights” for Substitutions, for example, compared to System 2.
That’s why, for the time being, Word Error Rate is here to stay, but it’s important to keep the pitfalls we demonstrated in mind when calculating WER yourself!
Источник
Word Error Rate Calculation
The Word Error Rate (short: WER) is a way to measure performance of an ASR . It compares a reference to an hypothesis and is defined like this:
- S is the number of substitutions,
- D is the number of deletions,
- I is the number of insertions and
- N is the number of words in the reference
Examples
In this case, a deletion happened. «Bright» was deleted by the ASR.
In this case, an insertion happened. «Bright» was inserted by the ASR.
In this case, an substitution happened. «Bright» was substituted by «light» by the ASR.
Range of values
As only addition and division with non-negative numbers happen, WER cannot get negativ. It is 0 exactly when the hypothesis is the same as the reference.
WER can get arbitrary large, because the ASR can insert an arbitrary amount of words.
Calculation
Interestingly, the WER is just the Levenshtein distance for words.
I’ve understood it after I saw this on the German Wikipedia:
But I have written a piece of pseudocode to make it even easier to code this algorithm:
WER calculation
Python
Explanation
No matter at what stage of the code you are, the following is always true:
- If r[i] equals h[j] you don’t have to change anything. The error will be the same as it was for r[:i-1] and h[:j-1]
- If its a substitution, you have the same number of errors as you had before when comparing the r[:i-1] and h[:j-1]
- If it was an insertion, then the hypothesis will be longer than the reference. So you can delete one from the hypothesis and compare the rest. As this is the other way around for deletion, you don’t have to worry when you have to delete something.
Источник
Two minutes NLP — Intro to Word Error Rate (WER) for Speech-to-Text
Speech Recognition, Levenshtein distance, and BLEU
Hello fellow NLP enthusiasts! While in the past few weeks I was researching to write articles on the BLEU and ROUGE metrics, I came across WER. Many of the models we use every day are trained and evaluated with metrics like these, so I think it’s very important to know them (even if they may be not the sexiest of the topics) 🤷🏻♂️. I then added WER to my editorial plan of articles to write, and today is the day to talk about it! Enjoy! 😄
What is WER?
Word Error Rate (WER) is a common performance metric mainly used for speech recognition.
When recognizing speech and transcribing it into text, some words may be left out or misinterpreted. WER compares the predicted output and the reference transcript word by word to figure out the number of differences between them.
There are three types of errors considered when computing WER:
- Insertions: when the predicted output contains additional words that are not present in the transcript;
- Deletions: when the predicted output doesn’t contain words that are present in the transcript;
- Substitutions: when the predicted output contains some misinterpreted words that replace words in the transcript;
Let’s make an example. Consider the following reference transcript and predicted output:
- Reference transcript: “ The dog is under the table”.
- Predicted output: “ The dog is the fable”.
In this case, the predicted output has one deletion (the word “ under” disappears) and one substitution (“ table” becomes “ fable”).
So, what is the Word Error Rate of this translation? Basically, WER is the number of errors divided by the number of words in the reference transcript.
WER = (num inserted + num deleted + num substituted) / num words in the reference
Thus, in our example:
Lower WER often indicates that the Automated Speech Recognition (ASR) software is more accurate in recognizing speech. A higher WER, then, often indicates lower ASR accuracy.
WER, Levenshtein distance, and edit distance
The WER calculation is based on the Levenshtein distance, which measures the differences between two words. Informally, the Levenshtein distance between two words is the minimum number of single-character edits (insertions, deletions, or substitutions) required to change one word into the other.
The Word Error Rate may also be referred to as the length normalized edit distance.
WER drawbacks
Although WER is the most widely used metric for Speech Recognition, it has some drawbacks:
- There is no differentiation between the words that are essential to the meaning of the sentence and those that are not as important.
- It doesn’t take into consideration if two words differ just by one character or if they differ completely.
Moreover, WER does not account for the reason why errors may happen, which may affect WER without necessarily reflecting the capabilities of the ASR technology itself. Some examples of these factors are the recording quality, the speaker’s pronunciation, and the presence of unusual names or domain-specific terms.
WER and BLEU
Why is the BLEU score used for machine translation and summarization but not for speech-to-text?
Although Automatic Speech Recognition models output text similarly to machine translation systems, the target sentence is unambiguous and usually not subject to interpretation. In this case, the BLEU score is not the ideal metric.
Thank you for reading! If you are interested in learning more about NLP, remember to follow NLPlanet on Medium, LinkedIn, and Twitter!
Источник
Как улучшить распознавание русской речи до 3% WER с помощью открытых данных
Меня зовут Николай. Когда в 2009 году я защищал диссертацию по распознаванию речи, скептики мне говорили, что слишком поздно, так как Microsoft и Google уже “всё сделали”. Сейчас в SberDevices я обучаю модели распознавания речи, которые используются в семействе виртуальных ассистентов Салют и других банковских сервисах. Я расскажу, как обучил модель распознавания речи, используя Common Voice и недавно открытый датасет Golos. Ошибка распознавания составила от 3 до 11 % в зависимости от типа тестовой выборки, что очень неплохо для открытой модели.
Не так давно наша команда подготовила и опубликовала общедоступный датасет Golos. Почему встал вопрос об обучении и публикации акустической модели QuartzNet? Во-первых, для того, чтобы узнать, какую точность достигает система распознавания речи при обучении на новом датасете. Во-вторых, обучение само по себе ресурсоёмкое, поэтому сообществу полезно иметь в открытом доступе предобученную модель на русском языке. Полная версия статьи опубликована на сайте arxiv.org и будет представлена на конференции INTERSPEECH2021.
Описание данных
На момент скачивания данных из Common Voice (CV) проверенная часть датасета, которая не относится к Test- и Dev-частям, составляла 100.48 часа. Эта часть использовалась в составе тренировочной выборки. Выборки Test и Dev длительностью по 13.33 и 12.44 часов соответственно использовались только для оценки качества в процессе обучения.
Датасет Golos состоит из двух доменов – Crowd и Farfield. Тренировочная часть составляет 1227.4 часов, тестовая – 12.6 часов. Основной плюс его в том, что разметка данных в нём трижды проверенная очень качественная. Подробнее о структуре и способе формирования можно почитать в статье: “Golos — самый большой русскоязычный речевой датасет, размеченный вручную, теперь в открытом доступе”.
Акустическая модель
Задача акустической модели – получать на вход аудиозапись и выдавать логарифм вероятностей символов для каждого временного фрейма записи. Пример такого выходного массива приведён на цветовой диаграмме, обычно его называют “логитами”.

На цветовой диаграмме по оси Х – номер фрейма, каждый длинной 20 миллисекунд. По оси Y – 34 символа из алфавита, включая пробел и бланк (|). По оси Z – величина логарифма вероятности, отображённая цветовой шкалой. Красным цветом обозначены максимальные значения. По ним можно прочитать распознанное слово «привет». Здесь используется простой алгоритм декодирования логитов, основанный на функции argmax, обычно называемый “жадным” (greedy).
В качестве акустической модели мы выбрали нейронную сеть с архитектурой QuartzNet15x5, так как в тот момент она была SOTA (State Of The Art) по скорости и качеству. Её архитектура состоит из последовательных свёрточных слоёв, как показано в таблице:
В начале идёт блок С1, за которым следует группа из пяти блоков B2 — B5. Блоки в группе идентичны, каждый Bk состоит из повторяющихся R-раз свёрток размером K и числом каналов на выходе C. Каждый блок повторяется S раз. Далее идут три слоя (C2, C3, C4). Размерность на выходе сети равна количеству символов алфавита – 34. Полный конфиг доступен в открытой библиотеке NeMo, которую мы использовали для обучения: https://github.com/NVIDIA/NeMo. Стоит сказать, что кроме QuartzNet там много других интересных моделей, которые интересно попробовать, например, для синтеза речи, распознавания диктора и т.д.
Акустическую модель мы обучали, перемешивая случайным образом объединённый тренировочный набор Golos + Common Voice. В процессе обучения его оценка проводилась на четырёх тестовых наборах: Golos Crowd и Farfield, Common Voice Dev и Test. Аугментация данных производилась при помощи маскирования частотных и временных полос, аналогично со SpecAugment, Dropout между слоями не применялся. Для экономии объёма памяти и времени мы обучали модель в режиме mixed-precision. Использовались 16 видеокарт Nvidia Tesla v100 с размером батча 88 на одну видеокарту и аккумуляцией градиента по 10 батчам. Таким образом эффективный размер батча составил 16x88x10 = 14080. Ошибки распознавания WER (Word Error Rate) в ходе трёх экспериментов с разным числом шагов (10000, 20000, 50000) и применением трансферного обучения представлены на графиках:
 а) WER на выборке Golos Сrowd Test б) WER на выборке Golos Farfield Test
а) WER на выборке Golos Сrowd Test б) WER на выборке Golos Farfield Test  в) WER на выборке Common Voice Dev г) WER на выборке Common Voice Test
в) WER на выборке Common Voice Dev г) WER на выборке Common Voice Test
Ожидаемо, что чем больше количество шагов в эксперименте, тем лучше обучилась модель и тем меньше ошибок распознавания.
Трансферное обучение
Вообще, трансферное обучение или Transfer Learning – очень популярная техника в глубоком обучении, например обработке изображений. В нашем случае в каталоге NGC доступна акустическая модель QuartzNet15x5, обученная на английском. В английском алфавите меньше символов, поэтому для переноса требуется заменить последний слой (голову). При этом можно не выбрасывать созвучные буквы, а переиспользовать их, сгенерировав веса только для новых букв. Подробно о том, как это можно делать, я рассказывал на конференции GTC21: https://youtu.be/Tavu52IrTFM.
Сравним два эксперимента: обучение модели, начиная со случайных и с предобученных весов на английском языке. Для верности проведём их дважды, с разным числом шагов. Получается четыре эксперимента, которые соответствуют кривым четырёх цветов на рисунке:
 а) WER на выборке Golos Сrowd Test б) WER на выборке Golos Farfield Test
а) WER на выборке Golos Сrowd Test б) WER на выборке Golos Farfield Test
· Красный – старт с английских весов и 10000 шагов обучения.
· Фиолетовый – старт с английских весов и 20000 шагов обучения.
· Зелёный – старт со случайных весов и 10000 шагов обучения.
· Синий – старт со случайных весов и 20000 шагов обучения.
В процессе обучения анализировалась величина WER на двух тестовых датасетах Golos: Сrowd и Farfield. В таблице ниже приведены значения итоговой величины WER:
Источник
The transcription industry has evolved a lot over the past 10 years. Academic and Healthcare firms remain the largest transcription customers. However, other industries such as financial, legal, manufacturing, and education also make up a significant percentage of the customer base.
Automatic Speech Recognition (ASR) software have made our daily routines more convenient. For instance, Alexa can now tell you how the weather will look like today.
Perhaps like most industries, transcription industry has been affected by ASR. This software are increasingly being used by various players that require transcripts. ASR is a cheap transcription solution. However, there is a big problem with the accuracy of ASR transcripts.
According to research comparing the accuracy rates of human transcriptionists and ASR software, human transcriptionists had an error rate of about 4% while commercially available ASR transcription software’s error rate was found to be 12%.
In a nutshell, the error rate of ASR is three times as bad as that of humans.
In 2017, Google announced that its voice recognition software had attained a Word Error Rate (WER) of about 4.7%. Is it really possible?
Let’s understand how ASR works and what are its implications in our transcription and translation industry.
What is Word Error Rate Mechanism (WER): By Definition
Word Error Rate (WER) is a common metric used to compare the accuracy of the transcripts produced by speech recognition APIs.
How to calculate WER (Word Error Rate Mechanism)
Here is a simple formula to understand how Word Error Rate (WER) is calculated:

- S stands for substitutions,
- I stands for insertions,
- D stands for deletions,
- N is the number of words in the reference (that were actually said).
What Affects the Word Error Rate?
For speech recognition APIs like IBM Watson and Google Speech, a 25%-word error rate is about average for regular speech recognition. If the speech data is more technical, more “accented”, more industry-specific, and noisier, it becomes less likely that a general speech recognition API (or humans) will be more accurate.
Technical and Industry-specific Language
Human transcriptionists charge more for technical and industry-specific language, and there’s a reason for it. Reliably recognizing industry terms is complex and does take effort. Due to this, speech recognition systems trained on “average” data are found struggling with more specialized words.
Speaking with Different Accents and Dialects
What is construed as a strong accent in Dublin is normal in New York. Large companies like Google, Nuance and IBM have built speech recognition systems which are very familiar with “General American English” and British English. However, they may not be familiar with the different accents and dialects of English spoken in different cities around the world..
Disruptive Noise
Noisy audio and background noise is unwelcome but is common in many audio files. People rarely make business calls to us from a sound studio, or using VoIP and traditional phone systems compress audio that cut off many frequencies and add noise artifacts.
ASR Transcription Challenges and Word Error Rate Mechanism
Enterprise ASR software is built to understand a given accent and a limited number of words. For example, with some large companies their ASR software can recognize the National Switchboard Corpus, which is a popular database of words used in phone calls conversations that have already been transcribed.
Unfortunately, in the real world, audio files are different. For example, they may feature speakers with different accents or speaking different languages.
Also, most ASR software use WER to measure transcription errors. This measure has its shortfalls, such as:
- WER ignores the importance of words, giving the same score for each error in a document. In the real world, this isn’t accurate as some errors in a transcript matter compared to others.
- WER disregards punctuation and speaker labels.
- The test ignores the uhhs… and the mmhs…, duplicates and false starts that can interfere with the reading of your transcript.
Recent Research Findings on ASR
Researchers from leading companies like Google, Baidu, IBM, and Microsoft have been racing towards achieving the lowest-ever Word Error Rates from their speech recognition engines that has yielded remarkable results.
Gaining momentum from advances in neural networks and massive datasets compiled by them, WERs have improved to the extent of grabbing headlines about matching or even surpassing human efficiency.
Microsoft researchers, in contrast, report that their ASR engine has a WER of 5.1%, while for IBM Watson, it is 5.5%, and Google claims an error rate of just 4.9% (info source).
However, these tests were conducted by using a common set of audio recordings, i.e., a corpus called Switchboard, which consists of a large number of recordings of phone conversations covering a broad array of topics. Switchboard is a reasonable choice, as it has been used in the field for many years and is nearly ubiquitous in the current literature. Also, by testing against the audio corpus (database of speech audio files), researchers are able to make comparisons between themselves and competitors. Google is the lone exception, as it uses its own, internal test corpus (large structured set of texts).
This type of testing leads is limited as the claims of surpassing human transcriptionists are based on a very specific kind of audio. However, audio isn’t perfect or consistent and has many variables, and all of them can have a significant impact on transcription accuracy.
Is ASR Software’s WER Good Enough For Your Industry?
Stats reference:- An article written and shared by Andy Anderegg on Medium
ASR transcription accuracy rates don’t come close to the accuracy of human transcriptionists.
ASR transcription is also affected by cross talk, accents, background noise in the audio, and unknown words. In such instances, the accuracy will be poorer.
If you want to use ASR for transcription, be prepared to deal with:
- Inaccurate Transcripts
Accurate transcription is important, especially in the legal, business, and health industries. For instance, an inaccurate medical transcript can lead to a misdiagnosis and miscommunication.
ASR software produce more transcription errors than human transcriptionists. It is not uncommon to get a completely unintelligible transcript after using ASR. - Minimal Transcription Options
ASR software doesn’t have formatting or transcript options. The result will be transcripts that are not suited to your needs.
On the other hand, human transcriptionists can produce word to word or verbatim transcripts. - Different Speaking Styles
English is widely spoken in many parts of the world. However, there are considerable differences in the pronunciation and meaning of different words. People from different regions have their own way of speaking which is usually influenced by local dialects. Training voice recognition software to understand the various ways that English is spoken has proven to be quite difficult.
Transcription software also struggle when audio files have background noises. While AI has gotten incredibly good at reducing background noises in audio files, it is still far from perfect. If your file has background noises, you shouldn’t expect 100% accurate transcripts from using transcription software. - Ambiguous Vocabularies and Homophones
Transcription software also struggle to understand the context in speech. As a result, they cannot automatically detect missing parts of conversations in files. The inability to comprehend context can also lead to serious translation errors, which can have dire consequences in various industries. When words are spoken with a clear pause after every word, transcription software can easily and accurately transcribe the content. Therefore, the software would be best for dictations that revolve around short sentences.
However, in reality, humans speak in a more complex fashion. For example, some people talk softly while others talk faster when they are anxious. Transcription tools struggle to produce accurate transcripts in such contexts.
The Cost of Ignoring Quality Over Price
If you chose ASR transcription because it’s cheap, you will get low-quality transcripts full of errors. Such a transcript can cost you your business, money and even customers.
Here are two examples of businesses that had to pay dearly for machine-made transcription errors.
In 2006, Alitalia Airlines offered business class flights to its customers at a subsidized price of $39 compared to their usual $3900 price. Unknown to the customers, a copy-paste error had been made and the subsidized price was a mistake. More than 2000 customers had already booked the flight by the time the error was corrected. The customers wouldn’t accept the cancellation of their purchased tickets, and the airline had no choice but to reduce its prices leading to a loss of more than $7.2 million.
Another company, Fidelity Magellan Fund, had to cancel its dividend distribution when a transcription error saw it posting a capital gain of $1.3 billion rather than a loss of a similar amount. The transcription had omitted the negative sign causing the dividend estimate to be higher by $2.6million.
ASR transcription may be cheaper than human transcription. However, its errors can be costly. When you want accurate transcripts, human transcriptions are still the best option.
So, What Should You Do?
What is the way forward? Should you transition to automatic transcription or stay with the reliable manual transcription services provider?
Automatic transcription is fast and will save you time when you are on a deadline. However, in almost all cases, the transcripts will have to be brushed up for accuracy by professional transcriptionists.
Trained human transcriptionists can accurately identify complex terminology, accents, different dialects, and the presence of multiple speakers. The type of project should help you determine what form of transcription is best for you. If you are looking for highly accurate transcripts or work in a specialized industry like legal, academia, or medical, then working with a transcription company specialized in human transcription will be your best option.
Our Promise To You!
Unlike our peers, who have moved towards automated technology to gain a competitive cost advantage and maximize profits at the cost of accuracy, we stand our ground by only employing US-based human transcriptionist to whom we can trust for quality and confidentiality.
Our clients generally belong to different niche like legal, academic, businesses and more where quality matters above all. We have an unwavering commitment to client satisfaction, rather than mere concern for profit.
Меня зовут Николай. Когда в 2009 году я защищал диссертацию по распознаванию речи, скептики мне говорили, что слишком поздно, так как Microsoft и Google уже “всё сделали”. Сейчас в SberDevices я обучаю модели распознавания речи, которые используются в семействе виртуальных ассистентов Салют и других банковских сервисах. Я расскажу, как обучил модель распознавания речи, используя Common Voice и недавно открытый датасет Golos. Ошибка распознавания составила от 3 до 11 % в зависимости от типа тестовой выборки, что очень неплохо для открытой модели.
Не так давно наша команда подготовила и опубликовала общедоступный датасет Golos. Почему встал вопрос об обучении и публикации акустической модели QuartzNet? Во-первых, для того, чтобы узнать, какую точность достигает система распознавания речи при обучении на новом датасете. Во-вторых, обучение само по себе ресурсоёмкое, поэтому сообществу полезно иметь в открытом доступе предобученную модель на русском языке. Полная версия статьи опубликована на сайте arxiv.org и будет представлена на конференции INTERSPEECH2021.
Описание данных
На момент скачивания данных из Common Voice (CV) проверенная часть датасета, которая не относится к Test- и Dev-частям, составляла 100.48 часа. Эта часть использовалась в составе тренировочной выборки. Выборки Test и Dev длительностью по 13.33 и 12.44 часов соответственно использовались только для оценки качества в процессе обучения.
Датасет Golos состоит из двух доменов – Crowd и Farfield. Тренировочная часть составляет 1227.4 часов, тестовая – 12.6 часов. Основной плюс его в том, что разметка данных в нём трижды проверенная очень качественная. Подробнее о структуре и способе формирования можно почитать в статье: “Golos — самый большой русскоязычный речевой датасет, размеченный вручную, теперь в открытом доступе”.
Акустическая модель
Задача акустической модели – получать на вход аудиозапись и выдавать логарифм вероятностей символов для каждого временного фрейма записи. Пример такого выходного массива приведён на цветовой диаграмме, обычно его называют “логитами”.
На цветовой диаграмме по оси Х – номер фрейма, каждый длинной 20 миллисекунд. По оси Y – 34 символа из алфавита, включая пробел и бланк (|). По оси Z – величина логарифма вероятности, отображённая цветовой шкалой. Красным цветом обозначены максимальные значения. По ним можно прочитать распознанное слово «привет». Здесь используется простой алгоритм декодирования логитов, основанный на функции argmax, обычно называемый “жадным” (greedy).
В качестве акустической модели мы выбрали нейронную сеть с архитектурой QuartzNet15x5, так как в тот момент она была SOTA (State Of The Art) по скорости и качеству. Её архитектура состоит из последовательных свёрточных слоёв, как показано в таблице:
|
Блок |
R |
K |
C |
S |
|
C1 |
1 |
33 |
256 |
1 |
|
B1 |
5 |
33 |
256 |
3 |
|
B2 |
5 |
39 |
512 |
3 |
|
B3 |
5 |
51 |
512 |
3 |
|
B4 |
5 |
63 |
512 |
3 |
|
B5 |
5 |
75 |
512 |
3 |
|
C2 |
1 |
87 |
512 |
1 |
|
C3 |
1 |
1 |
1024 |
1 |
|
C4 |
1 |
1 |
34 |
1 |
В начале идёт блок С1, за которым следует группа из пяти блоков B2 — B5. Блоки в группе идентичны, каждый Bk состоит из повторяющихся R-раз свёрток размером K и числом каналов на выходе C. Каждый блок повторяется S раз. Далее идут три слоя (C2, C3, C4). Размерность на выходе сети равна количеству символов алфавита – 34. Полный конфиг доступен в открытой библиотеке NeMo, которую мы использовали для обучения: https://github.com/NVIDIA/NeMo. Стоит сказать, что кроме QuartzNet там много других интересных моделей, которые интересно попробовать, например, для синтеза речи, распознавания диктора и т.д.
Акустическую модель мы обучали, перемешивая случайным образом объединённый тренировочный набор Golos + Common Voice. В процессе обучения его оценка проводилась на четырёх тестовых наборах: Golos Crowd и Farfield, Common Voice Dev и Test. Аугментация данных производилась при помощи маскирования частотных и временных полос, аналогично со SpecAugment, Dropout между слоями не применялся. Для экономии объёма памяти и времени мы обучали модель в режиме mixed-precision. Использовались 16 видеокарт Nvidia Tesla v100 с размером батча 88 на одну видеокарту и аккумуляцией градиента по 10 батчам. Таким образом эффективный размер батча составил 16x88x10 = 14080. Ошибки распознавания WER (Word Error Rate) в ходе трёх экспериментов с разным числом шагов (10000, 20000, 50000) и применением трансферного обучения представлены на графиках:
Ожидаемо, что чем больше количество шагов в эксперименте, тем лучше обучилась модель и тем меньше ошибок распознавания.
Трансферное обучение
Вообще, трансферное обучение или Transfer Learning – очень популярная техника в глубоком обучении, например обработке изображений. В нашем случае в каталоге NGC доступна акустическая модель QuartzNet15x5, обученная на английском. В английском алфавите меньше символов, поэтому для переноса требуется заменить последний слой (голову). При этом можно не выбрасывать созвучные буквы, а переиспользовать их, сгенерировав веса только для новых букв. Подробно о том, как это можно делать, я рассказывал на конференции GTC21: https://youtu.be/Tavu52IrTFM.
Сравним два эксперимента: обучение модели, начиная со случайных и с предобученных весов на английском языке. Для верности проведём их дважды, с разным числом шагов. Получается четыре эксперимента, которые соответствуют кривым четырёх цветов на рисунке:
· Красный – старт с английских весов и 10000 шагов обучения.
· Фиолетовый – старт с английских весов и 20000 шагов обучения.
· Зелёный – старт со случайных весов и 10000 шагов обучения.
· Синий – старт со случайных весов и 20000 шагов обучения.
В процессе обучения анализировалась величина WER на двух тестовых датасетах Golos: Сrowd и Farfield. В таблице ниже приведены значения итоговой величины WER:
|
Golos Crowd Test WER |
Golos Farfield Test WER |
|
|
Случайный старт, 10000 шагов |
28.84% |
52.82% |
|
«Английский» старт, 10000 шагов |
5.095% |
17.13% |
|
Случайный старт, 20000 шагов |
26.24% |
50.82% |
|
«Английский» старт, 20000 шагов |
4.629% |
15.95% |
Видно, что использование предобученных «английских» весов уменьшает ошибку распознавания русской акустической модели с 26.24% до 4.629% на наборе Crowd и с 50.82% до 15.95% – на наборе Farfield.
Языковая модель
При помощи алгоритма Beam Search вместе с языковой моделью можно ещё немного улучшить качество распознавания речи. Это происходит благодаря добавлению дополнительного знания о структуре языка, которого не хватило в обучающей выборке акустической модели. На вход алгоритма Beam Search поступают логиты, на выходе имеем текст.
Мы сделали языковую модель, используя корпус Common Crawl на русском языке и KenLM Toolkit. Common Crawl – это коллекция текстовых данных, собранных из интернета автоматически, доступная для свободного скачивания. KenLM Toolkit позволяет создавать, обрабатывать и, самое главное, быстро применять N-граммные языковые модели.
Всего мы сделали три разные 3-граммные языковые модели. Первая составлена из очищенных и предобработанных текстов корпуса Common Crawl. Предобработка заключалась в удалении знаков пунктуации и других лишних символов. Вторая модель построена исключительно на основе текстов транскрипций тренировочной части датасета Golos. Третья является комбинацией первых двух языковых моделей с равными весами (50 / 50).
В таблице ниже приведены результаты инференса на тестовых подмножествах после применения языковых моделей алгоритмом Beam Search с параметрами: beam size=16, alpha=2, beta=1.5. Alpha – это вес (важность) N-граммной языковой модели. Beta – это штраф за длинную последовательность слов.
Процент WER (Word Error Rate) для различных тестовых сетов:
|
Decoder Test set |
Crowd Golos Test |
Farfield Golos Test |
Common Voice Dev |
Common Voice Test |
|
Greedy |
4.389 % |
14.949 % |
9.314 % |
11.278 % |
|
Beam Search + Common Crawl LM |
4.709 % |
12.503 % |
6.341 % |
7.976 % |
|
Beam Search + Golos LM |
3.548 % |
12.384 % |
— |
— |
|
Beam Search + Common Crawl, Golos LM |
3.318 % |
11.488 % |
6.4 % |
8.06 % |
Из таблицы видно, как разные языковые модели влияют на ошибку распознавания (WER) на различных тестовых множествах. Самые лучшие результаты для Crowd (3.318 %) и Farfield (11.488 %) достигаются с языковой моделью, построенной на Common Crawl и Golos вместе. Пример скрипта для инференса доступен в репозитории Golos.
Буду рад увидеть использование датасета Golos и предобученных моделей (акустической и языковой) в ваших экспериментах. Больше деталей можно найти в полном тексте статьи.
Word Error Rate is a measure of how accurate an Automatic Speech Recognition (ASR) system performs. Quite literally, it calculates how many “errors” are in the transcription text produced by an ASR system, compared to a human transcription.
Broadly speaking, it’s important to measure the accuracy of any machine learning system. Whether it’s a self driving car, NLU system like Amazon Alexa, or an Automatic Speech Recognition system like the ones we develop at AssemblyAI, if you don’t know how accurate your machine learning system is, you’re flying blind!
In the field of Automatic Speech Recognition, the Word Error Rate has become the de facto standard for measuring how accurate a speech recognition model is. A common question we get from customers is “What’s your WER?”. In fact, when our company was accepted into Y Combinator back in 2017, one of the first questions the YC partners asked us was “What’s your WER?”
How To Calculate Word Error Rate (WER)
The actual math behind calculating a Word Error Rate is the following:
What we are doing here is combining the number of Substitutions (S), Deletions (D), and Insertions (N), divided by the Number of Words (N).
So for example, let’s say the following sentence is spoken:
"Hello there"If our Automatic Speech Recognition (ASR) is not very good, and predicts the following transcription:
"Hello bear"
Then our Word Error Rate (WER) would be 50%! That’s because there was 1 Substitution, “there” was substituted with “bear”. Let’s say our ASR system instead only predicted:
"Hello"And for some reason didn’t even predict a second word. In this case our Word Error Rate (WER) would also be 50%! That’s because there is a single Deletion — only 1 word was predicted by our ASR system when what was actually spoken was 2 words. The lower the Word Error Rate the better. You can think of word accuracy as 1 minus the Word Error Rate. So if your Word Error Rate is 20%, then your word accuracy, ie how accurate your transcription is, is 80%:
Is Word Error Rate a Good Measure of Speech Recognition Systems?
As with everything, it is not black and white. Overall, Word Error Rate can tell you how “different” the automatic transcription was compared to the human transcription, and generally, this is a reliable metric to determine how “good” an automatic transcription is.
For example, take the following:
Spoken text:
“Hi my name is Bob and I like cheese. Cheese is very good.”
Predicted text by model 1:
"Hi my frame is knob and I bike leafs. Cheese is berry wood"
WER: 46%
Predicted text by model 2:
"Hi my name is Bob and I bike cheese. Cheese is good."
WER: 15%As we can see, model 2 has a lower WER of 15%, and is obviously way more accurate to us as humans than the predicted text from model 1. This is why, in general, WER is a good metric for determining the accuracy of an Automatic Speech Recognition system.
However, take the following example:
Spoken:
"I like to bike around"
Model 1 prediction:
"I liked to bike around"
WER: 20%
Model 2 prediction:
"I like to bike pound"
WER: 20%In the above example, both Model 1 text and Model 2 text have a WER of 20%. But Model 1 clearly results in a more understandable transcription compared to Model 2. That’s because even with the error that Model 1 makes, it still results in a more legible and easy to understand transcription. This is compared to Model 2, which makes a mistake in the transcription that results in the transcription text being illegible (ie, “word soup”).
To further illustrate the downfalls of Word Error Rate, take the following example:
Spoken:
"My name is Paul and I am an engineer"
Model 1 prediction:
"My name is ball and I am an engineer"
WER: 11.11%
Model 2 prediction:
"My name is Paul and I'm an engineer"
WER: 22.22%In this example, Model 2 does a much better job producing an understandable transcription, but it has double (!!) the WER compared to Model 1. This difference in WER is especially pronounced in this example because the text contains so few words, but still, this illustrates some “gotchas” to be aware of when reviewing WER.
What these above examples illustrate is that the Word Error Calculation is not “smart”. It is literally just looking at the number of substitutions, deletions, and insertions that appear in the automatic transcription compared to the human transcription. This is why WER in the “real world” can be so problematic.
Take for example the simple mistake of not normalizing the casing in the human transcription and automatic transcription.
Human transcription:
"I live in New York"
Automatic transcription:
"i live in new york"
WER: 60%In this example, we see that the automatic transcription has a WER of 60% (!!) even though it perfectly transcribed what was spoken. Simply because we were comparing the human transcription with New York capitalized, compared to new york lowercase, the WER algorithm sees these as completely different words!
This is a major “gotcha” we see in the wild, and it’s why we internally always normalize our human transcriptions and automatic transcriptions when computing a WER, through things like:
- Lowercasing all text
- Removing all punctuation
- Changing all numbers to their written form («7» -> «seven»)
- Etc.
Alternatives to Word Error Rate
Unfortunately, Word Error Rate is the best metric we have today to determine the accuracy of an Automatic Speech Recognition system. There have been some alternatives proposed, but none have stuck in the research or commercial communities. A common technique used is to weight Substitutions, Insertions, and Deletions differently. So, for example, adding 0.5 for every Deletion versus 1.0.
However, unless the weights are standardized, it’s not really a “fair” way to compute WER. System 1 could be reporting a much lower WER because it used lower “weights” for Substitutions, for example, compared to System 2.
That’s why, for the time being, Word Error Rate is here to stay, but it’s important to keep the pitfalls we demonstrated in mind when calculating WER yourself!
Word Error Rate (WER) is a common metric used to compare the accuracy of the transcripts produced by speech recognition APIs. Speech recognition APIs are used to surface actionable insights from large volumes of audio data in addition to powering robust IVRs and voice-command-enabled devices such as the Amazon Echo. Product developers and data scientists can choose from many speech recognition APIs. How are they to judge which will be a good fit for their application? When evaluating speech recognition APIs, the first metric they’ll consider is likely to be WER. However, a metric has no value unless we understand what it tells us. Let’s break down WER to find out what it means and how useful a metric it is.
How to Calculate WER
Word error rate is the most common metric used today to evaluate the effectiveness of an automatic speech recognition system (ASR). It is simply calculated as:
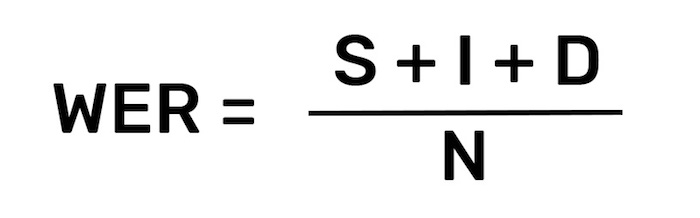
S stands for substitutions (replacing a word). I stands for insertions (inserting a word). D stands for deletions (omitting a word). N is the number of words that were actually said Note: WER will be calculated incorrectly if you forget to normalize capitalization, punctuation, numbers, etc. across all transcripts
Imagine you are using speech recognition to find out why customers are calling. You have thousands of hours of calls, and you want to automatically categorize the calls. On playback, one such call starts as follows:

However, when the machine transcribes this same call, the output may look like this:
![]()
If you compare this transcript with the one above, it’s clear that the machine’s one has problems. Let’s analyze them in terms of our WER formula.
-
In line one, we see that the word «Upsilon», has been interpreted as «up silent». We will say that this represents (1) substitution-a wrong word in place of the correct word-and (1) insertion-adding of a word that was never said.
-
On line two, we have (1) substitution: «brat» instead of «Pratt.»
-
On line three we have (1) substitution: «designed» instead of «declined.»
-
On line four we have (2) substitutions: «cart» instead of «card» and «because» instead of cause. On this line we also have (1) deletion: the word «it» is gone.
The original phone call contained 36 words. With a total of 9 errors, the WER comes out to 25%.
What WER Really Means
How well a speech recognition API can transcribe audio depends on a number of factors, which we will discuss below. Before we do, we must ask ourselves the most important question one can ask when assessing a speech recognition system: «is the transcript usable for my purposes?» Let’s consider our example. This is a good transcription if you are trying to figure whether customers are calling to solve issues with credit cards or debit cards. However, if your goal is to figure why out each person called your call center (to deal with a declined card, lost card, etc.) then this phone call would likely get mis-sorted. This is because the system did not properly transcribe a keyword: «declined.» When a speech recognition API fails to recognize words important to your analysis, it is not good enough-no matter what the WER is. Word error rate, as a metric, does not give us any information about how the errors will affect usability for users. As you can see, you the human can read the flawed transcript and still manage to figure out the problem. The only piece of information you might have trouble reconstructing is the name and location of the gas station. Unfamiliar proper names are troublesome for both humans and machines.
A Low WER can be Deceptive-Depending on the Data
Depending on the data we want to look at, even low word error rate transcripts may prove less useful than expected. For example, notice how on line 4, «’cause» was transcribed as «because» and the object pronoun «it» was omitted. These two errors may not matter, especially if your goal is to find out why customers are calling. If the speech recognition API had not made these errors, we would have a 19.4% WER-almost as good as it gets for general, off-the-shelf speech recognition. But, as you can see, a low(er) error rate does not necessarily translate into a more useful transcript. This is because adverbs like «because» and object pronouns like «it» are not of much interest to us in this case.
«You can have two systems with similar accuracy rates that produce wildly differently transcripts in terms of understandability. You can have two different systems that are similar in terms of accuracy but maybe one handles particular vocabulary that’s germane to your application better than the other. There’s more than just accuracy at the heart of it.»
—Klint Kanopka Stanford Ph.D. Researcher
While WER is a good, first-blush metric for comparing the accuracy of speech recognition APIs, it is by no means the only metric which you should consider. Importantly, you should understand how the speech recognition API will deal with your data. What words will it transcribe with ease? What words will give it trouble? What words matter to you? In our example, the words «declined» and «credit card» are likely the ones we want to get right every time.
What Affects the Word Error Rate?
A 25% word error rate is about average for «off the shelf» speech recognition APIs like Amazon, Google, IBM Watson, and Nuance. The more technical, the more industry-specific, the more «accented» and the more noisy your speech data is, the less likely that a general speech recognition API (or humans) will do as well.
Technical and Industry-specific Language
There’s a reason that human transcriptionists charge more for technical or industry-specific language. It simply takes more time and effort for human brains to reliably recognize niche terms. The language that is normal to call center manager, a lawyer or a business executive is rare elsewhere. As a result, speech recognition systems trained on «average» data also struggle with more specialized words. As you’d guess, the technical language was created for a reason and accordingly, it’s the language that businesses care the most about.
Accented Language
Accent is a highly relative, very human concept. This author has a strong accent in Dublin, but almost none in New York. The speech recognition systems built by large companies such as Google, Nuance and IBM are very familiar with the sort of English one hears on TV: «general American English» and RP (received pronunciation-the form of British English spoken by the Queen, the BBC and Oxford graduates). They are not necessarily familiar with the «real» English spoken in Palo Alto, CA; Athens, Georgia; New Dehli, India or Edinburgh, Scotland. However, companies are interested in the «real» language since a very tiny subset of their employees are TV anchors.

In New Delhi-English is spoken natively and non-natively by a large percentage of the population. Photo Credit: Raghu Nayyar.
Therefore, if your data has a wider variety of accents (it almost certainly does), or is limited to a set of accents not well represented in the data used to create general speech recognition APIs, then you probably need a custom-built model to really get a good look at your data.
Noisy Data
Wouldn’t it be nice if everyone who called us to do business did so from a sound studio? Wouldn’t you love that crisp, bassy, noise-free audio? Better yet, how about they didn’t call us over the phone, since VoIP and traditional phone systems compress audio, cut off many frequencies and add noise artifacts? The real world is full of noise. Phone calls are inherently bad quality, people call while rushing to work, or walking by a seemingly endless line of jackhammers, fire engines and screaming 4-month-olds.

Somehow, human transcribers do okay with such noisy data, and speech recognition APIs, if properly trained, can do okay too. However, as you can imagine, when companies advertise super-low word error rates, these are not the WERs they get when transcribing audio captured at Iron Maiden concerts held in the middle of 16 lane interstate highways.
Choosing an Speech Recognition API
Speech recognition APIs are fantastic tools that allow us to look into vast amounts of audio data in order to learn meaningful things about our customers, our operations and the world in general. WER is one metric that allows us to compare speech recognition APIs. However, as it is the case in any science, there is no one «best» metric.
I like analogies, so here is one: Asking which is the best metric to judge the quality of a bicycle could end in disaster. If your say «weight is the best metric, the lighter the better,» then people like me who use their bikes to carry heavy groceries, 2 months of laundry and the occasional 2×4 would be in trouble. If you said «the number of pannier racks on a bike» is a good metric, then Tour de France cyclists would become a lot more winded, faster. All in all, you need to choose what’s right for you.

This bike is a robust touring bike with pannier racks-great for shopping and 10,000 mile tours, bad for Tour de France. Photo credit: Derek Thomson
When you want to decide which speech recognition API to use, ask yourself:
-
Are there particular audio types that you need the speech recognition API to perform well on (phone call, TV, radio, meetings)?
-
Are there certain words or accents that the speech recognition API should do well on?
-
Can you customize the API to perform better on your data?
For more, check out our step by step guide on how to evaluate an ASR provider or have us evaluate the ASR provider for you.