-
#1
When viewing the content on our ceph rbd within the Proxmox GUI, it displays this error message. No errors for running VMs on the ceph cluster or moving disks or anything.
It’s more annoying than anything but how can I resolve this issue without having to create a new pool and transfer data from the existing one over since that’s not really a fix?
Thanks!
![]()
Alwin
Proxmox Retired Staff
-
#3
I just removed the pool and rebuilt it and the issue was resolved.
Thank you though!
-
#4
I see the same error in the GUI after a fresh 3 node cluster install of 6.0.5.
Everything seems to run fine, but the above error is shown at GUI>node>cephpool>content.
/etc/pve/priv/ceph.client.admin.keyring is identical on all nodes.
What can be done instead of recreating?
Thanks.
![]()
Alwin
Proxmox Retired Staff
-
#6
Unfortunately I’m not sure what you would like to point out.
There’s no external cluster — just the 3 nodes with onboard SSD used to create the ceph cluster with a single pool called «cephpool».
/etc/pve/storage.cfg shows:
rbd: cephpool
content rootdir,images
krbd 0
pool cephpool
And cat /etc/pve/priv/ceph/cephpool.keyring
[client.admin]
key = same-on-all-3-nodes==
caps mds = «allow *»
caps mgr = «allow *»
caps mon = «allow *»
caps osd = «allow *»
The file /etc/ceph/ceph.client.admin.keyring only exists on one node (the first created) though.
/etc/pve/priv/ceph/cephfs.secret contains the same key, so that seems ok.
Any other idea?
-
#7
Ok, solved…
rbd ls -l cephpool
showed a few correct images but also:
rbd: error opening vm-124-disk-1: (2) No such file or directory
NAME SIZE PARENT FMT PROT LOCK
vm-100-disk-0 80 GiB 2
vm-101-disk-0 80 GiB 2
vm-102-disk-0 80 GiB 2
vm-124-disk-2 550 GiB 2
vm-124-disk-1 was created via «GUI>Create CT» for an unprivileged container.
I then made the mistake to try to restore a privileged containers backup — which obviously failed.
Not sure, but I think the container disappeared when the restore failed or maybe I did delete it.
I then recreated the container with ID124 which resulted in the image vm-124-disk-2 to be created.
But obviously vm-124-disk-1 did not correctly deleted and resulted in this problem.
I simply deleted the image manually:
rbd rm vm-124-disk-1 -p cephpool
So there could be a problem after a failed restore…
-
#8
Ok, solved…
rbd ls -l cephpool
showed a few correct images but also:
rbd: error opening vm-124-disk-1: (2) No such file or directory
NAME SIZE PARENT FMT PROT LOCK
vm-100-disk-0 80 GiB 2
vm-101-disk-0 80 GiB 2
vm-102-disk-0 80 GiB 2
vm-124-disk-2 550 GiB 2vm-124-disk-1 was created via «GUI>Create CT» for an unprivileged container.
I then made the mistake to try to restore a privileged containers backup — which obviously failed.
Not sure, but I think the container disappeared when the restore failed or maybe I did delete it.
I then recreated the container with ID124 which resulted in the image vm-124-disk-2 to be created.
But obviously vm-124-disk-1 did not correctly deleted and resulted in this problem.I simply deleted the image manually:
rbd rm vm-124-disk-1 -p cephpoolSo there could be a problem after a failed restore…
Yeah if I cancel a disk move to a ceph pool, it does say `Removing image: 1% complete…` but then is canceled at 2% so it seems that cancelling a disk move cancels the disk from being removed on the ceph pool. @Alwin
![]()
Alwin
Proxmox Retired Staff
-
#9
This is an old thread, please open up a new one. Also if not done so already, upgrade to the latest packages.
-
#10
I have encountered same kind of problem (proxmox v6) with ceph rbd. I problem came from a VM image on the rbd that wasn’t destroyed during the destruction of the VM.
I have found the problem switching from «rbd -p my-pool list» to «rbd -p my-pool list —long«. I had i line more in the short version. It was the faulty image to remove by «rbd -p my-pool rm my-faulty-file«.
-
#11
Hi, helped me out with this error, searching for a loose VM disk and finally destroying it.
-
#12
just a quick follow up, i’ve encountered this error when I move a disk from local storage to ceph storage. All tasks finished without errors but somehow if you already have a disk with the same name on the pool, proxmox will rename your new image and update the VM config.
This happens when you cancel migration jobs — pve does not clean up after a cancelled job.
Just list the pool with —long and without then compare the results in a excel file or diff.
-
#13
Unfortunately I ran into this problem (again).
The last time the info given by wiguyot helped (removing a failed image). But not this time.
I can add an external newly created ceph-pool via gui (or command line)
As long as the pool is empty I can do a list command on one of the proxmox-servers («rbd ls -p rbd» or «rbd ls -p rbd —long»)
But as soon as I copy something over to the new pool on one of the ceph-servers (i.e. «rbd deep cp BackupPool/vm-107-disk-0 rbd/vm-107-disk-0»)
«rbd ls -p rbd» works (and shows the vm-107-disk-0) but «rbd ls -p rbd —long» no longer does (on proxmox). No Output.
And the Webinterface shows no images as well and gives a connection error. («Connection timed out (596)»)
(on the ceph-cluster «rbd ls -p rbd —long» always shows the expected files)
I am stuck here for some days now. Could somebody maybe point me in the right direction or give a hint where to debug more?
(proxmox is V 7.2.4 and ceph 17.2.0)
Last test for today: When creating a new VM the disk is actually created on the cluster/pool. (as «rbd list —long shows on the ceph-servers) but cannot start and I cannot remove the VM afterwards…)
Update: After rebooting every ceph-node one by one is worked again out of the sudden…. I have no clue what happend.
Last edited: Jun 9, 2022
-
#14
Ok, solved…
rbd ls -l cephpool
showed a few correct images but also:
rbd: error opening vm-124-disk-1: (2) No such file or directory
NAME SIZE PARENT FMT PROT LOCK
vm-100-disk-0 80 GiB 2
vm-101-disk-0 80 GiB 2
vm-102-disk-0 80 GiB 2
vm-124-disk-2 550 GiB 2vm-124-disk-1 was created via «GUI>Create CT» for an unprivileged container.
I then made the mistake to try to restore a privileged containers backup — which obviously failed.
Not sure, but I think the container disappeared when the restore failed or maybe I did delete it.
I then recreated the container with ID124 which resulted in the image vm-124-disk-2 to be created.
But obviously vm-124-disk-1 did not correctly deleted and resulted in this problem.I simply deleted the image manually:
rbd rm vm-124-disk-1 -p cephpoolSo there could be a problem after a failed restore…
Your solution does work for me, GUI can now correctlly show ceph pool and error msg — «rdb error: rdb: listing images failed: (2) No such file or directory (500)» disappeared. THX .).
-
#15
In my case, the error appeared after removing a VM. The output showed that the image was being removed
(«100% complete. Done.») but was followed by this error. The VM was still shown under the respective node. Removing it again did not help. This has happened more than once.
I checked the content of the respective CEPH but the disk image was nowhere to be seen.
I then just deleted the VM’s conf file (in /etc/pve/qemu-server and the VM from the GUI.
-
#16
as I did not the first time of course.
addition: the disk in the virtual machine was eventually removed from the configuration (vm without hdd )
the task was to delete vm-106-disk-1
pay attention to the different types of commands listing the directory of the storage in different ways displayed vm-106-disk-1
================================
Linux pve3 5.15.83-1-pve #1 SMP PVE 5.15.83-1 (2022-12-15T00:00Z) x86_64
The programs included with the Debian GNU/Linux system are free software;
the exact distribution terms for each program are described in the
individual files in /usr/share/doc/*/copyright.
Debian GNU/Linux comes with ABSOLUTELY NO WARRANTY, to the extent
permitted by applicable law.
Last login: Wed Feb 1 16:11:18 MSK 2023 on pts/0
root@pve3:~# rbd -p pool-seph list
vm-100-disk-0
vm-101-disk-0
vm-101-disk-1
vm-102-disk-0
vm-104-disk-0
vm-105-disk-0
vm-107-disk-0
vm-106-disk-1
root@pve3:~# rbd -p pool-seph rm vm-106-disk-1
2023-02-01T16:23:51.715+0300 7f45d2704700 -1 librbd::image::preRemoveRequest: 0x7f45b0068cb0 check_image_watchers: image has watchers - not removing
Removing image: 0% complete...failed.
rbd: error: image still has watchers
This means the image is still open or the client using it crashed. Try again after closing/unmapping it or waiting 30s for the crashed client to timeout.
root@pve3:~# rbd -p pool-seph list
vm-100-disk-0
vm-101-disk-0
vm-101-disk-1
vm-102-disk-0
vm-104-disk-0
vm-105-disk-0
vm-107-disk-0
vm-106-disk-1
root@pve3:~# rbd ls -l pool-seph
rbd: error opening vm-106-disk-1: (2) No such file or directory
NAME SIZE PARENT FMT PROT LOCK
vm-100-disk-0 50 GiB 2 excl
vm-101-disk-0 100 GiB 2 excl
vm-101-disk-1 500 GiB 2 excl
vm-102-disk-0 200 GiB 2 excl
vm-104-disk-0 100 GiB 2 excl
vm-105-disk-0 100 GiB 2 excl
vm-107-disk-0 100 GiB 2 excl
rbd: listing images failed: (2) No such file or directory
root@pve3:~# rbd -p pool-seph list
vm-100-disk-0
vm-101-disk-0
vm-101-disk-1
vm-102-disk-0
vm-104-disk-0
vm-105-disk-0
vm-107-disk-0
vm-106-disk-1
root@pve3:~# rbd -p pool-seph rm vm-106-disk-1
Removing image: 100% complete...done.
root@pve3:~# rbd -p pool-seph list
vm-100-disk-0
vm-101-disk-0
vm-101-disk-1
vm-102-disk-0
vm-104-disk-0
vm-105-disk-0
vm-107-disk-0
root@pve3:~# rbd ls -l pool-seph
NAME SIZE PARENT FMT PROT LOCK
vm-100-disk-0 50 GiB 2 excl
vm-101-disk-0 100 GiB 2 excl
vm-101-disk-1 500 GiB 2 excl
vm-102-disk-0 200 GiB 2 excl
vm-104-disk-0 100 GiB 2 excl
vm-105-disk-0 100 GiB 2 excl
vm-107-disk-0 100 GiB 2 excl
root@pve3:~#
Last edited: Feb 1, 2023
Содержание
- Got messages [rbd error: rbd: listing images failed: (2) No such file or directory (500)] in Cephpool after last upgrade
- rbd error: rbd: listing images failed: (2) No such file or directory (500)
- Kaboom
- Alwin
- Kaboom
- Alwin
- Kaboom
- Alwin
- Kaboom
- Kaboom
- [SOLVED] rbd error: rbd: listing images failed: (2) No such file or directory (500)
- skywavecomm
- Alwin
- skywavecomm
- Ralf Zenklusen
- Alwin
- Ralf Zenklusen
- Ralf Zenklusen
- skywavecomm
- Alwin
- wiguyot
- Urbaman
- brosky
- TASK ERROR: rbd error: rbd: listing images failed
- powersupport
- dcsapak
- powersupport
- dcsapak
- powersupport
- dcsapak
- powersupport
- dcsapak
- powersupport
- dcsapak
- powersupport
- dcsapak
- powersupport
Got messages [rbd error: rbd: listing images failed: (2) No such file or directory (500)] in Cephpool after last upgrade
Active Member
after upgrade all CEPH-Clustermembers to latest 6.1 i got the message
[rbd error: rbd: listing images failed: (2) No such file or directory (500)]
when looking into the cephpool. Subsequently i cannot migrate a VM to another node in the cluster. Not online and also not offline.
I read something about keyring with those incident. But why is this the result off only a carried out upgrade?

Proxmox Retired Staff
Do you already have a Commercial Support Subscription? — If not, Buy now and read the documentation
Active Member
I’m not shure that the failure is really since the last upgrade. I can see the overview of the ceph-pooI, but cannot see the content of it, with the message:
[rbd error: rbd: listing images failed: (2) No such file or directory (500)].
It’s possible that this failure is since a longer time than the last upgrade.
My last upgrade was from 6.0 to 6.1.
Also i’m not shure that it is a mistake to name the hosts in a ceph-cluster with overlapping hostnames. I.e.
virthost-1
virthost-1a
virthost-1b
.
In this scenario i saw the first one in the ceph mon overview twice and on of them as inactive
Is it possible to repair the pool online?
What kind of ongoing information (logs) do you need?
Источник
rbd error: rbd: listing images failed: (2) No such file or directory (500)
Kaboom
Member
I got this error when I want to see Storage ‘ceph_ssd’ (Ceph pool name) on node ‘node002’ (on all nodes).
rbd error: rbd: listing images failed: (2) No such file or directory (500)
When I run rbd ls -l ceph_ssd, I get this at the end:
rbd: listing images failed: (2) No such file or directory
Anyone familiar with this error? Seen some other topics about this, but they all came with a ‘vm disk name’, but not in my situation.

Alwin
Proxmox Retired Staff
Is there some more information in the logs?
Best regards,
Alwin
Do you already have a Commercial Support Subscription? — If not, Buy now and read the documentation
Kaboom
Member
I don’t get any errors about a VM:
. vm-223-disk-0 50 GiB 2 excl vm-246-disk-0 50 GiB 2 excl vm-247-disk-0 50 GiB 2 excl vm-248-disk-0 50 GiB 2 excl rbd: listing images failed: (2) No such file or directory
Alwin
Proxmox Retired Staff
Possibly there is a defekt image in that pool. :/
Do you see any entries in the ceph logs? Somewhere it should say if a object is defekt.
Best regards,
Alwin
Do you already have a Commercial Support Subscription? — If not, Buy now and read the documentation
Kaboom
Member
Alwin
Proxmox Retired Staff
Best regards,
Alwin
Do you already have a Commercial Support Subscription? — If not, Buy now and read the documentation
Kaboom
Member
Kaboom
Member
I also notice just now when I want to migrate a VM to another node I get this error:
task started by HA resource agent
2020-03-25 21:59:43 starting migration of VM 108 to node ‘node004’ (10.0.0.1)
2020-03-25 21:59:43 ERROR: Failed to sync data — rbd error: rbd: listing images failed: (2) No such file or directory
2020-03-25 21:59:43 aborting phase 1 — cleanup resources
2020-03-25 21:59:43 ERROR: migration aborted (duration 00:00:00): Failed to sync data — rbd error: rbd: listing images failed: (2) No such file or directory
TASK ERROR: migration aborted
When I want to migrate a container to another node I have no (!) problems.
Источник
[SOLVED] rbd error: rbd: listing images failed: (2) No such file or directory (500)
skywavecomm
Member
When viewing the content on our ceph rbd within the Proxmox GUI, it displays this error message. No errors for running VMs on the ceph cluster or moving disks or anything.
It’s more annoying than anything but how can I resolve this issue without having to create a new pool and transfer data from the existing one over since that’s not really a fix?
Alwin
Proxmox Retired Staff
Best regards,
Alwin
Do you already have a Commercial Support Subscription? — If not, Buy now and read the documentation
skywavecomm
Member
I just removed the pool and rebuilt it and the issue was resolved.
Thank you though!
Ralf Zenklusen
New Member
I see the same error in the GUI after a fresh 3 node cluster install of 6.0.5.
Everything seems to run fine, but the above error is shown at GUI>node>cephpool>content.
/etc/pve/priv/ceph.client.admin.keyring is identical on all nodes.
What can be done instead of recreating?
Alwin
Proxmox Retired Staff
Best regards,
Alwin
Do you already have a Commercial Support Subscription? — If not, Buy now and read the documentation
Ralf Zenklusen
New Member
Unfortunately I’m not sure what you would like to point out.
There’s no external cluster — just the 3 nodes with onboard SSD used to create the ceph cluster with a single pool called «cephpool».
/etc/pve/storage.cfg shows:
rbd: cephpool
content rootdir,images
krbd 0
pool cephpool
And cat /etc/pve/priv/ceph/cephpool.keyring
[client.admin]
key = same-on-all-3-nodes==
caps mds = «allow *»
caps mgr = «allow *»
caps mon = «allow *»
caps osd = «allow *»
The file /etc/ceph/ceph.client.admin.keyring only exists on one node (the first created) though.
/etc/pve/priv/ceph/cephfs.secret contains the same key, so that seems ok.
Ralf Zenklusen
New Member
rbd ls -l cephpool
showed a few correct images but also:
rbd: error opening vm-124-disk-1: (2) No such file or directory
NAME SIZE PARENT FMT PROT LOCK
vm-100-disk-0 80 GiB 2
vm-101-disk-0 80 GiB 2
vm-102-disk-0 80 GiB 2
vm-124-disk-2 550 GiB 2
vm-124-disk-1 was created via «GUI>Create CT» for an unprivileged container.
I then made the mistake to try to restore a privileged containers backup — which obviously failed.
Not sure, but I think the container disappeared when the restore failed or maybe I did delete it.
I then recreated the container with ID124 which resulted in the image vm-124-disk-2 to be created.
But obviously vm-124-disk-1 did not correctly deleted and resulted in this problem.
I simply deleted the image manually:
rbd rm vm-124-disk-1 -p cephpool
So there could be a problem after a failed restore.
skywavecomm
Member
rbd ls -l cephpool
showed a few correct images but also:
rbd: error opening vm-124-disk-1: (2) No such file or directory
NAME SIZE PARENT FMT PROT LOCK
vm-100-disk-0 80 GiB 2
vm-101-disk-0 80 GiB 2
vm-102-disk-0 80 GiB 2
vm-124-disk-2 550 GiB 2
vm-124-disk-1 was created via «GUI>Create CT» for an unprivileged container.
I then made the mistake to try to restore a privileged containers backup — which obviously failed.
Not sure, but I think the container disappeared when the restore failed or maybe I did delete it.
I then recreated the container with ID124 which resulted in the image vm-124-disk-2 to be created.
But obviously vm-124-disk-1 did not correctly deleted and resulted in this problem.
I simply deleted the image manually:
rbd rm vm-124-disk-1 -p cephpool
So there could be a problem after a failed restore.
Alwin
Proxmox Retired Staff
Best regards,
Alwin
Do you already have a Commercial Support Subscription? — If not, Buy now and read the documentation
wiguyot
New Member
Urbaman
Member
brosky
Active Member
just a quick follow up, i’ve encountered this error when I move a disk from local storage to ceph storage. All tasks finished without errors but somehow if you already have a disk with the same name on the pool, proxmox will rename your new image and update the VM config.
This happens when you cancel migration jobs — pve does not clean up after a cancelled job.
Just list the pool with —long and without then compare the results in a excel file or diff.
Member
Unfortunately I ran into this problem (again).
The last time the info given by wiguyot helped (removing a failed image). But not this time.
I can add an external newly created ceph-pool via gui (or command line)
As long as the pool is empty I can do a list command on one of the proxmox-servers («rbd ls -p rbd» or «rbd ls -p rbd —long»)
But as soon as I copy something over to the new pool on one of the ceph-servers (i.e. «rbd deep cp BackupPool/vm-107-disk-0 rbd/vm-107-disk-0»)
«rbd ls -p rbd» works (and shows the vm-107-disk-0) but «rbd ls -p rbd —long» no longer does (on proxmox). No Output.
And the Webinterface shows no images as well and gives a connection error. («Connection timed out (596)»)
(on the ceph-cluster «rbd ls -p rbd —long» always shows the expected files)
I am stuck here for some days now. Could somebody maybe point me in the right direction or give a hint where to debug more?
(proxmox is V 7.2.4 and ceph 17.2.0)
Last test for today: When creating a new VM the disk is actually created on the cluster/pool. (as «rbd list —long shows on the ceph-servers) but cannot start and I cannot remove the VM afterwards. )
Update: After rebooting every ceph-node one by one is worked again out of the sudden. I have no clue what happend.
Источник
TASK ERROR: rbd error: rbd: listing images failed

powersupport
Member
We recently faced an issue with the Proxmox when trying to delete the template or VM. please find the attached screenshot.
As per your suggestion in a previous thread, we have created in Proxmox storage a storage named «rbd-vm».But the issue still persists.
TASK ERROR: rbd error: rbd: listing images failed: (2) No such file or directory
Please have a look.

dcsapak
Proxmox Staff Member
there is no screeshot attached..
can you please post the vm config as well as the storage config and the command you try to execute?
Best regards,
Dominik
Do you already have a Commercial Support Subscription? — If not, Buy now and read the documentation
powersupport
Member
Please be informed that we have tried to delete Templates from the frontend not using the commands
Please refer to the files attached.
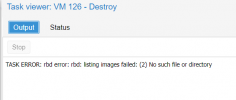
dcsapak
Proxmox Staff Member
Best regards,
Dominik
Do you already have a Commercial Support Subscription? — If not, Buy now and read the documentation
powersupport
Member
HI,
qm config 106 the command showing » Configuration file ‘nodes/pnode-sg1-n1/qemu-server/106.conf’ does not exist»
Showing same for all VMs
Also,
cat /etc/pve/storage.cfg
dir: local
path /var/lib/vz
content iso
shared 0
lvmthin: local-lvm
thinpool data
vgname pve
content rootdir,images
rbd: satapx-storage
content images,rootdir
krbd 0
pool satapx-storage
nfs: NFS-ISO
export /mnt/iso
path /mnt/pve/NFS-ISO
server 103.3.164.251
content vztmpl,iso,backup
prune-backups keep-last=5
nfs: NFS-VM-backup
export /home/nfsproxmox
path /mnt/pve/NFS-VM-backup
server 117.120.4.114
content backup,images,vztmpl,rootdir,iso
prune-backups keep-last=5
dcsapak
Proxmox Staff Member
Best regards,
Dominik
Do you already have a Commercial Support Subscription? — If not, Buy now and read the documentation
powersupport
Member
dcsapak
Proxmox Staff Member
Best regards,
Dominik
Do you already have a Commercial Support Subscription? — If not, Buy now and read the documentation
powersupport
Member
Here is the qm config output.
agent: 1
boot: order=scsi0;ide2;net0
cores: 6
ide2: NFS-ISO:iso/CentOS-7-x86_64-Minimal-1810__2_.iso,media=cdrom
memory: 63488
name: test-bu-server
net0: virtio=12:04:6C:EA:9F:47,bridge=vmbr0,firewall=1
numa: 0
ostype: l26
scsi0: satapx-storage:vm-127-disk-0,size=500G
scsihw: virtio-scsi-pci
smbios1: uuid=8f4cd2d6-212a-4165-a244-66b473d23bdc
sockets: 2
vmgenid: b430c56b-bda8-4bda-8af5-a5a01b4abc46
dcsapak
Proxmox Staff Member
Best regards,
Dominik
Do you already have a Commercial Support Subscription? — If not, Buy now and read the documentation
powersupport
Member
Please find the outputs of ‘pvesm status’ and ‘pvesm list satapx-storage’.
# pvesm status
Name Type Status Total Used Available %
NFS-ISO nfs active 524276736 232446208 291830528 44.34%
local dir active 98559220 9820244 83689428 9.96%
local-lvm lvmthin active 335646720 0 335646720 0.00%
satapx-storage rbd active 47677968555 15707891883 31970076672 32.95%
# pvesm list satapx-storage
rbd error: rbd: listing images failed: (2) No such file or directory
dcsapak
Proxmox Staff Member
ok it seems the rbd command fails for some reason.
can youpost the ouput of the following two commands?
Best regards,
Dominik
Do you already have a Commercial Support Subscription? — If not, Buy now and read the documentation
powersupport
Member
Please find the below results.
# rbd -p satapx-storage list
base-106-disk-0
base-107-disk-0
base-110-disk-0
base-111-disk-0
base-112-disk-0
base-113-disk-0
base-114-disk-0
base-115-disk-0
base-120-disk-0
base-125-disk-0
base-126-disk-0
base-134-disk-0
base-135-disk-0
base-136-disk-0
base-137-disk-0
base-139-disk-0
base-144-disk-0
base-147-disk-0
vm-100-cloudinit
vm-100-disk-0
vm-1004-cloudinit
vm-1004-disk-0
vm-101-cloudinit
vm-101-disk-0
vm-101-disk-1
vm-101-disk-2
vm-102-cloudinit
vm-102-disk-0
vm-103-cloudinit
vm-103-disk-0
vm-104-cloudinit
vm-104-disk-0
vm-104-disk-1
vm-105-cloudinit
vm-105-disk-0
vm-106-cloudinit
vm-107-cloudinit
vm-108-cloudinit
vm-108-disk-0
vm-109-cloudinit
vm-109-disk-0
vm-110-cloudinit
vm-111-cloudinit
vm-112-cloudinit
vm-113-cloudinit
vm-114-cloudinit
vm-115-cloudinit
vm-116-cloudinit
vm-116-disk-0
vm-117-cloudinit
vm-117-disk-0
vm-118-cloudinit
vm-118-disk-0
vm-119-cloudinit
vm-120-cloudinit
vm-121-cloudinit
vm-121-disk-0
vm-123-cloudinit
vm-123-disk-0
vm-124-cloudinit
vm-124-disk-0
vm-125-cloudinit
vm-126-cloudinit
vm-128-cloudinit
vm-128-disk-0
vm-134-cloudinit
vm-135-cloudinit
vm-136-cloudinit
vm-137-cloudinit
vm-139-cloudinit
vm-144-cloudinit
vm-121-cloudinit
root@pxvm:
# rbd -p satapx-storage list —long
rbd: error opening vm-121-cloudinit: (2) No such file or directory
rbd: error opening vm-121-cloudinit: (2) No such file or directory
NAME SIZE PARENT FMT PROT LOCK
base-106-disk-0 30 GiB 2
base-106-disk-0@__base__ 30 GiB 2 yes
base-107-disk-0 20 GiB 2
base-107-disk-0@__base__ 20 GiB 2 yes
base-110-disk-0 50 GiB 2
base-110-disk-0@__base__ 50 GiB 2 yes
base-111-disk-0 50 GiB 2
base-111-disk-0@__base__ 50 GiB 2 yes
base-112-disk-0 30 GiB 2
base-112-disk-0@__base__ 30 GiB 2 yes
base-113-disk-0 10 GiB 2
base-113-disk-0@__base__ 10 GiB 2 yes
base-114-disk-0 50 GiB 2
base-114-disk-0@__base__ 50 GiB 2 yes
base-115-disk-0 30 GiB 2
base-115-disk-0@__base__ 30 GiB 2 yes
base-120-disk-0 50 GiB 2
base-120-disk-0@__base__ 50 GiB 2 yes
base-125-disk-0 20 GiB 2
base-125-disk-0@__base__ 20 GiB 2 yes
base-126-disk-0 80 GiB 2
base-126-disk-0@__base__ 80 GiB 2 yes
base-134-disk-0 50 GiB 2
base-134-disk-0@__base__ 50 GiB 2 yes
base-135-disk-0 30 GiB 2
base-135-disk-0@__base__ 30 GiB 2 yes
base-136-disk-0 30 GiB 2
base-136-disk-0@__base__ 30 GiB 2 yes
base-137-disk-0 20 GiB 2
base-137-disk-0@__base__ 20 GiB 2 yes
base-139-disk-0 50 GiB 2
base-139-disk-0@__base__ 50 GiB 2 yes
base-144-disk-0 20 GiB 2
base-144-disk-0@__base__ 20 GiB 2 yes
base-147-disk-0 30 GiB 2
base-147-disk-0@__base__ 30 GiB 2 yes
vm-100-cloudinit 4 MiB 2
vm-100-disk-0 20 GiB 2
vm-1004-cloudinit 4 MiB 2
vm-1004-disk-0 10 TiB 2 excl
vm-101-cloudinit 4 MiB 2
vm-101-disk-0 50 GiB 2 excl
vm-101-disk-1 32 GiB 2 excl
vm-101-disk-2 2 TiB 2 excl
vm-102-cloudinit 4 MiB 2
vm-102-disk-0 5 TiB 2 excl
vm-103-cloudinit 4 MiB 2
vm-103-disk-0 10 GiB 2 excl
vm-104-cloudinit 4 MiB 2
vm-104-disk-0 6.3 TiB 2 excl
vm-104-disk-1 1 MiB 2
vm-105-cloudinit 4 MiB 2
vm-105-disk-0 50 GiB 2
vm-106-cloudinit 4 MiB 2
vm-107-cloudinit 4 MiB 2
vm-108-cloudinit 4 MiB 2
vm-108-disk-0 10 GiB 2 excl
vm-109-cloudinit 4 MiB 2
vm-109-disk-0 50 GiB 2
vm-110-cloudinit 4 MiB 2
vm-111-cloudinit 4 MiB 2
vm-112-cloudinit 4 MiB 2
vm-113-cloudinit 4 MiB 2
vm-114-cloudinit 4 MiB 2
vm-115-cloudinit 4 MiB 2
vm-116-cloudinit 4 MiB 2
vm-116-disk-0 50 GiB 2
vm-117-cloudinit 4 MiB 2
vm-117-disk-0 50 GiB 2
vm-118-cloudinit 4 MiB 2
vm-118-disk-0 180 GiB 2
vm-119-cloudinit 4 MiB 2
vm-120-cloudinit 4 MiB 2
vm-121-disk-0 6.3 TiB 2
vm-123-cloudinit 4 MiB 2
vm-123-disk-0 20 GiB 2 excl
vm-124-cloudinit 4 MiB 2
vm-124-disk-0 10 GiB 2 excl
vm-125-cloudinit 4 MiB 2
vm-126-cloudinit 4 MiB 2
vm-128-cloudinit 4 MiB 2
vm-128-disk-0 2 TiB 2 excl
vm-134-cloudinit 4 MiB 2
vm-135-cloudinit 4 MiB 2
vm-136-cloudinit 4 MiB 2
vm-137-cloudinit 4 MiB 2
vm-139-cloudinit 4 MiB 2
vm-144-cloudinit 4 MiB 2
rbd: listing images failed: (2) No such file or directory
root@pxvm:
Источник
rbd: listing images failed: (2) No such file or directory
Description
While looking at the rbd images, I found a lot of errors with «No such file or directory» while running the command: rbd list -h <pool-name>
Some intermediary errors include
2021-04-14T12:12:33.313+0000 7f8e0effd700 -1 librbd::io::AioCompletion: 0x55de121839a0 fail: (2) No such file or directory
rbd: error opening volume-44c2f74c-0c2c-4237-9582-96da9c3cbc64: (2) No such file or directory
Please see attached log file (crash1.log) for more details.
As a side note, we are using Openstack with a ceph storage backend, and noticed that the ceph storage increased over time although this did not reflect the Openstack usage. This was the trigger which lead to this finding on ceph rbd.
Sorry in advance, if I did not create the ticket correctly. It is my first time opening a bug on this project.
crash1.log View
— ceph rbs ls -f
(88.8 KB)
Adrian Dabuleanu, 04/14/2021 12:23 PM
History
#1
Updated by Adrian Dabuleanu almost 2 years ago
Adrian Dabuleanu wrote:
While looking at the rbd images, I found a lot of errors with «No such file or directory» while running the command: rbd list -f <pool-name>
Some intermediary errors include
2021-04-14T12:12:33.313+0000 7f8e0effd700 -1 librbd::io::AioCompletion: 0x55de121839a0 fail: (2) No such file or directory
rbd: error opening volume-44c2f74c-0c2c-4237-9582-96da9c3cbc64: (2) No such file or directoryPlease see attached log file (crash1.log) for more details.
As a side note, we are using Openstack with a ceph storage backend, and noticed that the ceph storage increased over time although this did not reflect the Openstack usage. This was the trigger which lead to this finding on ceph rbd.
Sorry in advance, if I did not create the ticket correctly. It is my first time opening a bug on this project.
Also available in: Atom
PDF
I’m trying to use CEPH to provision PersistenceVolumes in my OpenShift cluster, but get errors from persistentvolume-controller that it can’t read /etc/ceph/ceph.conf and then authentication timeout. Both OpenShift and CEPH are fresh installed.
I’ve tried to manually create and bind RBD image on one of OpenShift nodes and it worked so CEPH Cluster is accessible from the node. Also when I manually create PV and try to bind it to PVC I get «timeout expired waiting for volumes to attach» error even thou I also manually created RBD image.
apiVersion: storage.k8s.io/v1beta1
kind: StorageClass
metadata:
name: dynamic
annotations:
storageclass.kubernetes.io/is-default-class: "true"
provisioner: kubernetes.io/rbd
parameters:
monitors: 172.16.15.7:6789,172.16.15.8:6789
adminId: admin
adminSecretName: ceph-secret
adminSecretNamespace: kube-system
pool: kube
userId: kube
userSecretName: ceph-user-secret
imageFormat: "1"
oc v3.11.0+62803d0-1
kubernetes v1.11.0+d4cacc0
features: Basic-Auth GSSAPI Kerberos SPNEGO
Server https://****:443
openshift v3.11.0+d0a16e1-79
kubernetes v1.11.0+d4cacc0
ceph version 13.2.4 (b10be4d44915a4d78a8e06aa31919e74927b142e) mimic (stable)
<invalid> <invalid> 1 test1.1577e745b7b81491 PersistentVolumeClaim Warning ProvisioningFailed persistentvolume-controller Failed to provisi
on volume with StorageClass "dynamic": failed to create rbd image: exit status 110, command output: 2019-01-08 14:49:43.581088 7fad48773d40 -1 did not load config file, using default s
ettings.
2019-01-08 14:49:43.595698 7fad48773d40 -1 Errors while parsing config file!
2019-01-08 14:49:43.595705 7fad48773d40 -1 parse_file: cannot open /etc/ceph/ceph.conf: (2) No such file or directory
2019-01-08 14:49:43.595706 7fad48773d40 -1 parse_file: cannot open ~/.ceph/ceph.conf: (2) No such file or directory
2019-01-08 14:49:43.595707 7fad48773d40 -1 parse_file: cannot open ceph.conf: (2) No such file or directory
2019-01-08 14:49:43.597857 7fad48773d40 -1 Errors while parsing config file!
2019-01-08 14:49:43.597866 7fad48773d40 -1 parse_file: cannot open /etc/ceph/ceph.conf: (2) No such file or directory
2019-01-08 14:49:43.597867 7fad48773d40 -1 parse_file: cannot open ~/.ceph/ceph.conf: (2) No such file or directory
2019-01-08 14:49:43.597868 7fad48773d40 -1 parse_file: cannot open ceph.conf: (2) No such file or directory
rbd: image format 1 is deprecated
2019-01-08 14:49:43.638763 7fad48773d40 -1 auth: unable to find a keyring on /etc/ceph/ceph.client.admin.keyring,/etc/ceph/ceph.keyring,/etc/ceph/keyring,/etc/ceph/keyring.bin,: (2) No
such file or directory
2019-01-08 14:54:43.639625 7fad48773d40 0 monclient(hunting): authenticate timed out after 300
2019-01-08 14:54:43.639726 7fad48773d40 0 librados: client.admin authentication error (110) Connection timed out
rbd: couldn't connect to the cluster!
[Impact]
* Cinder-volume service gets marked as down when rbd pool contains partially deleted images
[Test Case]
1) Use this bundle (pastebin: http://paste.ubuntu.com/p/XxJPcs7YX9/)
2) Force a volume deletion
root@juju-30736a-1698786-cinder-0:/home/ubuntu# rbd -p cinder-ceph info volume-ad50fecd-bc7e-47a7-81d8-9a48ff996a04
rbd image ‘volume-ad50fecd-bc7e-47a7-81d8-9a48ff996a04’:
size 10240 MB in 2560 objects
order 22 (4096 kB objects)
block_name_prefix: rbd_data.10f96b8b4567
format: 2
features: layering, exclusive-lock, object-map, fast-diff, deep-flatten
flags:
root@juju-30736a-1698786-cinder-0:/home/ubuntu# rados -p cinder-ceph rm rbd_id.volume-ad50fecd-bc7e-47a7-81d8-9a48ff996a04
root@juju-30736a-1698786-cinder-0:/home/ubuntu# rbd -p cinder-ceph info volume-ad50fecd-bc7e-47a7-81d8-9a48ff996a04
rbd: error opening image volume-ad50fecd-bc7e-47a7-81d8-9a48ff996a04: (2) No such file or directory
3) Wait for a few seconds. The following exception gets raised and the cinder-volume
service gets reported as down.
2020-02-10 20:42:47.491 14050 ERROR cinder.volume.drivers.rbd [req-21a9da64-4d10-4c75-b5fd-4bb3328d6057 — — — — -] error opening rbd image volume-ad50fecd-bc7e-47a7-81d8-9a48ff996a04
2020-02-10 20:42:47.491 14050 ERROR cinder.volume.drivers.rbd Traceback (most recent call last):
2020-02-10 20:42:47.491 14050 ERROR cinder.volume.drivers.rbd File «/usr/lib/python2.7/dist-packages/cinder/volume/drivers/rbd.py», line 131, in __init__
2020-02-10 20:42:47.491 14050 ERROR cinder.volume.drivers.rbd read_only=read_only)
2020-02-10 20:42:47.491 14050 ERROR cinder.volume.drivers.rbd File «rbd.pyx», line 1061, in rbd.Image.__init__ (/build/ceph-eXkpH5/ceph-10.2.11/src/build/rbd.c:9939)
2020-02-10 20:42:47.491 14050 ERROR cinder.volume.drivers.rbd ImageNotFound: error opening image volume-ad50fecd-bc7e-47a7-81d8-9a48ff996a04 at snapshot None
2020-02-10 20:42:47.491 14050 ERROR cinder.volume.drivers.rbd
[Regression Potential]
* Minor backport, added a new exception to the try block.
[Other Info]
If `rbd_remove` image operation fails by some reason [*] the image being deleted may be left in a state, when its data and part of metadata (rbd_header object) is deleted, but it still has an entry in rbd_directory object. As a result the image is seen in `rbd_list` output but `open` fails.
To calculate rbd pool capacity the cinder-volume scans the pool images using `rbd_list` and then tries to get images size by opening every image. If there is such a partially removed image this causes cinder-volume failure like below:
2017-06-15 17:47:58.045 26352 ERROR cinder.volume.drivers.rbd [req-caa6f7fa-23c2-4972-b48a-264bcec6dbb1 — — — — -] error opening rbd image volume-099313f9-2f6f-4e86-9b46-8da16b138090
2017-06-15 17:47:58.045 26352 ERROR cinder.volume.drivers.rbd Traceback (most recent call last):
2017-06-15 17:47:58.045 26352 ERROR cinder.volume.drivers.rbd File «/usr/lib/python2.7/dist-packages/cinder/volume/drivers/rbd.py», line 119, in __init__
2017-06-15 17:47:58.045 26352 ERROR cinder.volume.drivers.rbd read_only=read_only)
2017-06-15 17:47:58.045 26352 ERROR cinder.volume.drivers.rbd File «rbd.pyx», line 1061, in rbd.Image.__init__ (/build/ceph-25Z60r/ceph-10.2.7/src/build/rbd.c:9939)
2017-06-15 17:47:58.045 26352 ERROR cinder.volume.drivers.rbd ImageNotFound: error opening image volume-099313f9-2f6f-4e86-9b46-8da16b138090 at snapshot None
2017-06-15 17:47:58.045 26352 ERROR cinder.volume.drivers.rbd
2017-06-15 17:47:58.050 26352 ERROR oslo_service.service [req-caa6f7fa-23c2-4972-b48a-264bcec6dbb1 — — — — -] Error starting thread.
2017-06-15 17:47:58.050 26352 ERROR oslo_service.service Traceback (most recent call last):
2017-06-15 17:47:58.050 26352 ERROR oslo_service.service File «/usr/lib/python2.7/dist-packages/oslo_service/service.py», line 722, in run_service
2017-06-15 17:47:58.050 26352 ERROR oslo_service.service service.start()
2017-06-15 17:47:58.050 26352 ERROR oslo_service.service File «/usr/lib/python2.7/dist-packages/cinder/service.py», line 241, in start
2017-06-15 17:47:58.050 26352 ERROR oslo_service.service service_id=Service.service_id)
2017-06-15 17:47:58.050 26352 ERROR oslo_service.service File «/usr/lib/python2.7/dist-packages/cinder/volume/manager.py», line 442, in init_host
2017-06-15 17:47:58.050 26352 ERROR oslo_service.service self.driver.init_capabilities()
2017-06-15 17:47:58.050 26352 ERROR oslo_service.service File «/usr/lib/python2.7/dist-packages/cinder/volume/driver.py», line 719, in init_capabilities
2017-06-15 17:47:58.050 26352 ERROR oslo_service.service stats = self.get_volume_stats(True)
2017-06-15 17:47:58.050 26352 ERROR oslo_service.service File «/usr/lib/python2.7/dist-packages/cinder/volume/drivers/rbd.py», line 432, in get_volume_stats
2017-06-15 17:47:58.050 26352 ERROR oslo_service.service self._update_volume_stats()
2017-06-15 17:47:58.050 26352 ERROR oslo_service.service File «/usr/lib/python2.7/dist-packages/cinder/volume/drivers/rbd.py», line 418, in _update_volume_stats
2017-06-15 17:47:58.050 26352 ERROR oslo_service.service self._get_usage_info()
2017-06-15 17:47:58.050 26352 ERROR oslo_service.service File «/usr/lib/python2.7/dist-packages/cinder/volume/drivers/rbd.py», line 365, in _get_usage_info
2017-06-15 17:47:58.050 26352 ERROR oslo_service.service with RBDVolumeProxy(self, t, read_only=True) as v:
2017-06-15 17:47:58.050 26352 ERROR oslo_service.service File «/usr/lib/python2.7/dist-packages/cinder/volume/drivers/rbd.py», line 119, in __init__
2017-06-15 17:47:58.050 26352 ERROR oslo_service.service read_only=read_only)
2017-06-15 17:47:58.050 26352 ERROR oslo_service.service File «rbd.pyx», line 1061, in rbd.Image.__init__ (/build/ceph-25Z60r/ceph-10.2.7/src/build/rbd.c:9939)
2017-06-15 17:47:58.050 26352 ERROR oslo_service.service ImageNotFound: error opening image volume-099313f9-2f6f-4e86-9b46-8da16b138090 at snapshot None
2017-06-15 17:47:58.050 26352 ERROR oslo_service.service
[*] Situations when `rbd_remove` fails leaving partially removed image linked in rbd_directory is not avoidable in general case. The operation involves scanning and removing many objects and can’t be atomic. It may be interrupted by many different reasons: user intervention, client crash, network or Ceph cluster error. For this reason removal from rbd_directory is done as the last operation so users could still see such images and could complete the removal by rerunning `rbd remove`.
Note, if `rbd_remove` fails for some reason it should return an error, so this can be detected.