Содержание
- Как исправить Raw Read Error Rate (0x1)?
- Что делать с «0x1 Raw Read Error Rate»?
- Прекратите использование сбойного HDD
- Восстановите удаленные данные диска
- Просканируйте диск на наличие «битых» секторов
- Снизьте температуру диска
- Произведите дефрагментацию жесткого диска
- Ошибка «Raw Read Error Rate» для SSD диска
- Сбросьте ошибку
- Приобретите новый жесткий диск
- Целесообразен ли ремонт HDD?
- Как выбрать новый накопитель?
- Как исправить ошибку S.M.A.R.T. 0x1: Raw Read Error Rate
- Что делать с «0x1 Raw Read Error Rate»?
- Способ 1: Прекратите использование сбойного HDD
- Способ 2: Восстановите удаленные данные диска
- Способ 3: Просканируйте диск на наличие «битых» секторов
- Способ 4: Снизьте температуру диска
- Способ 5: Произведите дефрагментацию жесткого диска
- Способ 6: Ошибка «Raw Read Error Rate» для SSD диска
- Способ 7: Сбросьте ошибку
- Способ 8: Приобретите новый жесткий диск
- Целесообразен ли ремонт HDD?
- Как выбрать новый накопитель?
Как исправить Raw Read Error Rate (0x1)?

Что делать с «0x1 Raw Read Error Rate»?
При загрузке компьютера или ноутбука возникает S.M.A.R.T. ошибка «0x1 Raw Read Error Rate»?
Что означает «0x1»: Raw Read Error Rate? Допустимые значения атрибута «Raw Read Error Rate» отличаются для различных производителей жестких дисков WD (Western Digital), Samsung, Seagate, HGST (Hitachi), Toshiba.
Актуально для ОС: Windows 10, Windows 8.1, Windows Server 2012, Windows 8, Windows Home Server 2011, Windows 7 (Seven), Windows Small Business Server, Windows Server 2008, Windows Home Server, Windows Vista, Windows XP, Windows 2000, Windows NT.
Прекратите использование сбойного HDD
Получение от системы сообщения о диагностике ошибки не означает, что диск уже вышел из строя. Но в случае наличия S.M.A.R.T. ошибки, нужно понимать, что диск уже в процессе выхода из строя. Полный отказ может наступить как в течении нескольких минут, так и через месяц или год. Но в любом случае, это означает, что вы больше не можете доверить свои данные такому диску.
Необходимо побеспокоится о сохранности ваших данных, создать резервную копию или перенести файлы на другой носитель информации. Одновременно с сохранностью ваших данных, необходимо предпринять действия по замене жесткого диска. Жесткий диск, на котором были определены S.M.A.R.T. ошибки нельзя использовать – даже если он полностью не выйдет из строя он может частично повредить ваши данные.
Конечно же, жесткий диск может выйти из строя и без предупреждений S.M.A.R.T. Но данная технология даёт вам преимущество предупреждая о скором выходе диска из строя.
Восстановите удаленные данные диска
В случае возникновения SMART ошибки не всегда требуется восстановление данных с диска. В случае ошибки рекомендуется незамедлительно создать копию важных данных, так как диск может выйти из строя в любой момент. Но бывают ошибки при которых скопировать данные уже не представляется возможным. В таком случае можно использовать программу для восстановления данных жесткого диска — Hetman Partition Recovery.
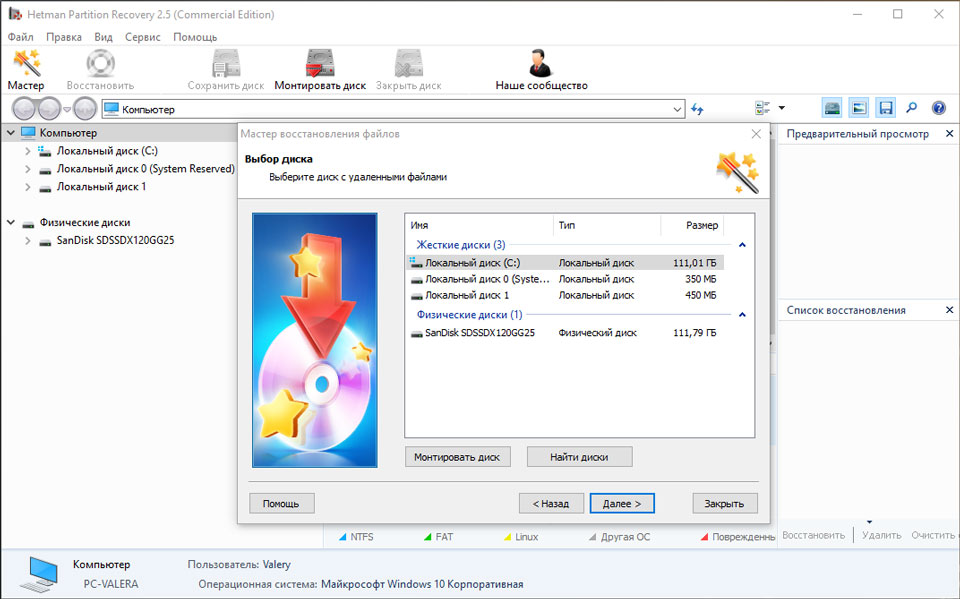
- Загрузите программу, установите и запустите её.
- По умолчанию, пользователю будет предложено воспользоваться Мастером восстановления файлов. Нажав кнопку «Далее», программа предложит выбрать диск, с которого необходимо восстановить файлы.
- Дважды кликните на сбойном диске и выберите необходимый тип анализа. Выбираем «Полный анализ» и ждем завершения процесса сканирования диска.
- После окончания процесса сканирования вам будут предоставлены файлы для восстановления. Выделите нужные файлы и нажмите кнопку «Восстановить».
- Выберите один из предложенных способов сохранения файлов. Не сохраняйте восстановленные файлы на диск с ошибкой «0x1 Raw Read Error Rate».
Просканируйте диск на наличие «битых» секторов

Запустите проверку всех разделов жесткого диска и попробуйте исправить найденные ошибки.
Для этого, откройте папку «Этот компьютер» и кликните правой кнопкой мышки на диске с SMART ошибкой.
Выберите Свойства / Сервис / Проверить в разделе Проверка диска на наличия ошибок. [скриншот]
В результате сканирования обнаруженные на диске ошибки могут быть исправлены.
Снизьте температуру диска

Иногда, причиной возникновения «S M A R T» ошибки может быть превышение максимально допустимой температуры работы диска. Такая ошибка может быть устранена путём улучшения вентиляции компьютера. Во-первых, проверьте оборудован ли ваш компьютер достаточной вентиляцией и все ли вентиляторы исправны.
Если вами обнаружена и устранена проблема с вентиляцией, после чего температура работы диска снизилась до нормального уровня, то SMART ошибка может больше не возникнуть.
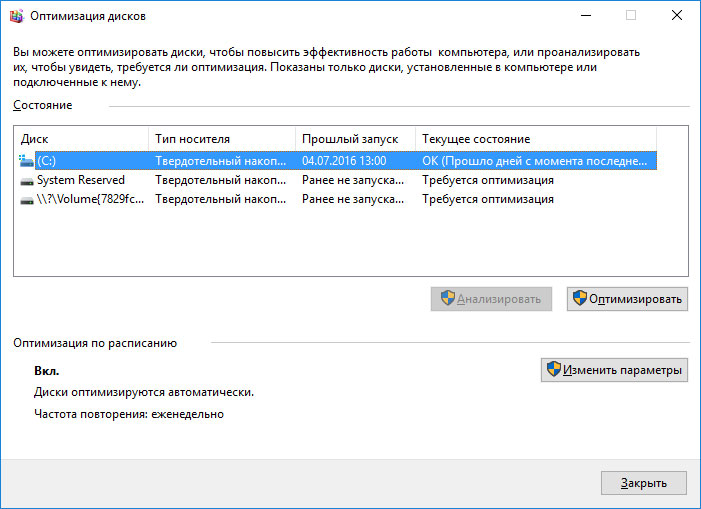
Произведите дефрагментацию жесткого диска
Откройте папку «Этот компьютер» и кликните правой кнопкой мышки на диске с ошибкой « 0x1 Raw Read Error Rate». Выберите Свойства / Сервис / Оптимизировать в разделе Оптимизация и дефрагментация диска. Выберите диск, который необходимо оптимизировать и кликните Оптимизировать.

Примечание. В Windows 10 дефрагментацию и оптимизацию диска можно настроить таким образом, что она будет осуществляться автоматически.
Ошибка «Raw Read Error Rate» для SSD диска

Даже если у вас не претензий к работе SSD диска, его работоспособность постепенно снижается. Причиной этому служит факт того, что ячейки памяти SSD диска имеют ограниченное количество циклов перезаписи. Функция износостойкости минимизирует данный эффект, но не устраняет его полностью.
SSD диски имеют свои специфические SMART атрибуты, которые сигнализируют о состоянии ячеек памяти диска. Например, «209 Remaining Drive Life», «231 SSD life left» и т.д. Данные ошибки могут возникнуть в случае снижения работоспособности ячеек, и это означает, что сохранённая в них информация может быть повреждена или утеряна.
Ячейки SSD диска в случае выхода из строя не восстанавливаются и не могут быть заменены.
Сбросьте ошибку
SMART ошибки можно легко сбросить в BIOS (или UEFI). Но разработчики всех операционных систем категорически не рекомендуют этого делать. Если же для вас не имеют ценности данные на жестком диске, то вывод SMART ошибок можно отключить.
Для этого необходимо сделать следующее:
- Перезагрузите компьютер, и с помощью нажатия указанной на загрузочном экране комбинации клавиш (у разных производителей они разные, обычно «F2» или «Del») перейдите в BIOS (или UEFI).
- Перейдите в: Аdvanced >SMART settings >SMART self test. Установите значение Disabled.
Примечание: место отключения функции указано ориентировочно, так как в зависимости от версии BIOS или UEFI, место расположения такой настройки может незначительно отличаться.
Приобретите новый жесткий диск
Целесообразен ли ремонт HDD?
Важно понимать, что любой из способов устранения SMART ошибки – это самообман. Невозможно полностью устранить причину возникновения ошибки, так как основной причиной её возникновения часто является физический износ механизма жесткого диска.
Для устранения или замены неправильно работающих составляющих жесткого диска, можно обратится в сервисный центр специальной лабораторией для работы с жесткими дисками.
Но стоимость работы в таком случае будет выше стоимости нового устройства. Поэтому, ремонт имеет смысл делать только в случае необходимости восстановления данных с уже неработоспособного диска.
Как выбрать новый накопитель?
Если вы столкнулись со SMART ошибкой жесткого диска то, приобретение нового диска – это только вопрос времени. То, какой жесткий диск нужен вам зависит от вашего стиля работы за компьютером, а также цели с которой его используют.
На что обратить внимание приобретая новый диск:
Источник
Как исправить ошибку S.M.A.R.T. 0x1: Raw Read Error Rate

Что делать с «0x1 Raw Read Error Rate»?
При загрузке компьютера или ноутбука возникает S.M.A.R.T. ошибка «0x1 Raw Read Error Rate» жесткого диска или SSD? После данной ошибки компьютер не работает как прежде, и вы опасаетесь о сохранности ваших данных? Не знаете как исправить «0x1 Raw Read Error Rate»?
Что означает «0x1»: Raw Read Error Rate? Допустимые значения атрибута «Raw Read Error Rate» отличаются для различных производителей жестких дисков WD (Western Digital), Samsung, Seagate, HGST (Hitachi), Toshiba.
Актуально для ОС: Windows 10, Windows 8.1, Windows Server 2012, Windows 8, Windows Home Server 2011, Windows 7 (Seven), Windows Small Business Server, Windows Server 2008, Windows Home Server, Windows Vista, Windows XP, Windows 2000, Windows NT.
Способ 1: Прекратите использование сбойного HDD
Получение от системы сообщения о диагностике ошибки не означает, что диск уже вышел из строя. Но в случае наличия S.M.A.R.T. ошибки, нужно понимать, что диск уже в процессе выхода из строя. Полный отказ может наступить как в течении нескольких минут, так и через месяц или год. Но в любом случае, это означает, что вы больше не можете доверить свои данные такому диску.
Необходимо побеспокоится о сохранности ваших данных, создать резервную копию или перенести файлы на другой носитель информации. Одновременно с сохранностью ваших данных, необходимо предпринять действия по замене жесткого диска. Жесткий диск, на котором были определены S.M.A.R.T. ошибки нельзя использовать – даже если он полностью не выйдет из строя он может частично повредить ваши данные.
Конечно же, жесткий диск может выйти из строя и без предупреждений S.M.A.R.T. Но данная технология даёт вам преимущество предупреждая о скором выходе диска из строя.
Способ 2: Восстановите удаленные данные диска
В случае возникновения SMART ошибки не всегда требуется восстановление данных с диска. В случае ошибки рекомендуется незамедлительно создать копию важных данных, так как диск может выйти из строя в любой момент. Но бывают ошибки при которых скопировать данные уже не представляется возможным. В таком случае можно использовать программу для восстановления данных жесткого диска — Hetman Partition Recovery.

- Загрузите программу, установите и запустите её.
- По умолчанию, пользователю будет предложено воспользоваться Мастером восстановления файлов. Нажав кнопку «Далее», программа предложит выбрать диск, с которого необходимо восстановить файлы.
- Дважды кликните на сбойном диске и выберите необходимый тип анализа. Выбираем «Полный анализ» и ждем завершения процесса сканирования диска.
- После окончания процесса сканирования вам будут предоставлены файлы для восстановления. Выделите нужные файлы и нажмите кнопку «Восстановить».
- Выберите один из предложенных способов сохранения файлов. Не сохраняйте восстановленные файлы на диск с ошибкой «0x1 Raw Read Error Rate».
Способ 3: Просканируйте диск на наличие «битых» секторов
Запустите проверку всех разделов жесткого диска и попробуйте исправить найденные ошибки.
Для этого, откройте папку «Этот компьютер» и кликните правой кнопкой мышки на диске с SMART ошибкой.
Выберите Свойства / Сервис / Проверить в разделе Проверка диска на наличия ошибок. [скриншот]
В результате сканирования обнаруженные на диске ошибки могут быть исправлены.
Способ 4: Снизьте температуру диска
Иногда, причиной возникновения «S M A R T» ошибки может быть превышение максимально допустимой температуры работы диска. Такая ошибка может быть устранена путём улучшения вентиляции компьютера. Во-первых, проверьте оборудован ли ваш компьютер достаточной вентиляцией и все ли вентиляторы исправны.
Если вами обнаружена и устранена проблема с вентиляцией, после чего температура работы диска снизилась до нормального уровня, то SMART ошибка может больше не возникнуть.
Способ 5: Произведите дефрагментацию жесткого диска
Откройте папку «Этот компьютер» и кликните правой кнопкой мышки на диске с ошибкой « 0x1 Raw Read Error Rate». Выберите Свойства / Сервис / Оптимизировать в разделе Оптимизация и дефрагментация диска. Выберите диск, который необходимо оптимизировать и кликните Оптимизировать.
Примечание. В Windows 10 дефрагментацию и оптимизацию диска можно настроить таким образом, что она будет осуществляться автоматически.

Способ 6: Ошибка «Raw Read Error Rate» для SSD диска
Даже если у вас не претензий к работе SSD диска, его работоспособность постепенно снижается. Причиной этому служит факт того, что ячейки памяти SSD диска имеют ограниченное количество циклов перезаписи. Функция износостойкости минимизирует данный эффект, но не устраняет его полностью.
SSD диски имеют свои специфические SMART атрибуты, которые сигнализируют о состоянии ячеек памяти диска. Например, «209 Remaining Drive Life», «231 SSD life left» и т.д. Данные ошибки могут возникнуть в случае снижения работоспособности ячеек, и это означает, что сохранённая в них информация может быть повреждена или утеряна.
Ячейки SSD диска в случае выхода из строя не восстанавливаются и не могут быть заменены.
Способ 7: Сбросьте ошибку
SMART ошибки можно легко сбросить в BIOS (или UEFI). Но разработчики всех операционных систем категорически не рекомендуют этого делать. Если же для вас не имеют ценности данные на жестком диске, то вывод SMART ошибок можно отключить.
Для этого необходимо сделать следующее:
- Перезагрузите компьютер, и с помощью нажатия указанной на загрузочном экране комбинации клавиш (у разных производителей они разные, обычно «F2» или «Del») перейдите в BIOS (или UEFI).
- Перейдите в: Аdvanced >SMART settings >SMART self test. Установите значение Disabled.
Примечание: место отключения функции указано ориентировочно, так как в зависимости от версии BIOS или UEFI, место расположения такой настройки может незначительно отличаться.
Способ 8: Приобретите новый жесткий диск
Целесообразен ли ремонт HDD?
Важно понимать, что любой из способов устранения SMART ошибки – это самообман. Невозможно полностью устранить причину возникновения ошибки, так как основной причиной её возникновения часто является физический износ механизма жесткого диска.
Для устранения или замены неправильно работающих составляющих жесткого диска, можно обратится в сервисный центр специальной лабораторией для работы с жесткими дисками.
Но стоимость работы в таком случае будет выше стоимости нового устройства. Поэтому, ремонт имеет смысл делать только в случае необходимости восстановления данных с уже неработоспособного диска.
Как выбрать новый накопитель?
Если вы столкнулись со SMART ошибкой жесткого диска то, приобретение нового диска – это только вопрос времени. То, какой жесткий диск нужен вам зависит от вашего стиля работы за компьютером, а также цели с которой его используют.
На что обратить внимание приобретая новый диск:
Источник
This post mainly illustrates RAW Read Error Rate, including its basic information, possible causes, and prevention tips. More importantly, MiniTool provides you with a solution to recovering lost data due to raw_read_error_rate.
Do you receive the SMART RAW Read Error Rate error? According to user reports, this error occurs frequently. You can see complaints about it while looking through communities and forums related to hard drives.
Here is a true example from the hddguru.com forum. You can take it as your reference.
Hi, I have a 1TB Seagate ST31000528AS and the SMART «RAW Read Error Rate» parameter goes up and down very often, and DiskCheckup reports that it will fail soon. But then, the value changes abruptly and it reports no failures predicted. Can someone please explain how to understand those values and, most importantly, is my disk actually in a predicted failure state? -https://forum.hddguru.com
Here comes the question: what is RAW Read Error Rate. To get the detailed information, move down to the next section.
What Is RAW Read Error Rate
RAW Read Error Rate, a SMART disk error, indicates problems with the disk surface (platter that stores the data), the actuator arm, and the read/write head. The higher RAW Read Error Rate, the higher chances of disk failure.
Hard drives that support the RAW Read Error Rate attribute include Samsung Seagate, IBM (Hitachi), Fujitsu, Maxtor, and Western Digital (WD). Both HDDs and SSDs could be stuck on this error. However, the result is different on two kinds of hard drives.
The SMART RAW Read Error Rate doesn’t affect modern flash storage drives. Though you see a rapid increase in SSD RAW Read Rates with time, the SSD still works properly without performance drops.
In fact, the RAW Read Error Rate on an SSD is an indication that there are some bad connections between disk and the drive controller or the problem is within the SSD. Hence, the SSD may fail after a period of time.
As for HDDs, the RAW Read Error Rate is a sign of drive failure. Besides, it could mean there’s data corruption, mechanical failure, and electrical issues with the drive. What causes the SMART RAW Read Error Rate issue? Find the answers in the section below.
Reasons Behind RAW Read Error Rate
What causes RAW Read Error Rate? Various factors can cause the error. Here, some common causes for it are summarized as follows.
- Aged SSD drive
- Multiple failures in an attempt to read data
- Extensive workload on drive
- Wear-outs because of a large number of erase cycles
- Overall encountered errors
- Other hardware/software conflicts
If the drive is worn out physically, you should replace it with a new one. If you lose data due to this error, recover the data before replacement.
Recover the Lost Data
To recover the lost data because of the RAW Read Error Rate error, you need a data recovery program. As a multifunctional partition manager, MiniTool Partition Wizard comes into hand. Its Data Recovery feature enables you to recover data from the logically damaged, formatted, or RAW partition quickly.
The Partition Recovery feature of MiniTool Partition Wizard helps recover missing partitions due to system update, system corruption, hard drive failure, and other reasons. Compared with Data Recovery, Partition Recovery provides fewer scan options.
The Data Recovery feature allows scanning logical drives (existing partitions, lost partitions, and unallocated space), whole hard disks, and specific locations (Desktop, Recycle Bin, and Select Folder). The Partition Recovery feature offers 3 scanning ranges including full disk, unallocated space, and specified range.
Pick one feature according to your situation to recover the lost data. Here, we show you how to recover lost data via Data Recovery.
Note: Both Data Recovery and Partition Recovery features require MiniTool Partition Wizard Pro Deluxe or higher editions. For the detailed information, please check this edition comparison chart.
Free Download
Step 1: After downloading and installing MiniTool Partition Wizard, double-click on its icon on the desktop to run it.
Step 2: Click Data Recovery on the top bar.
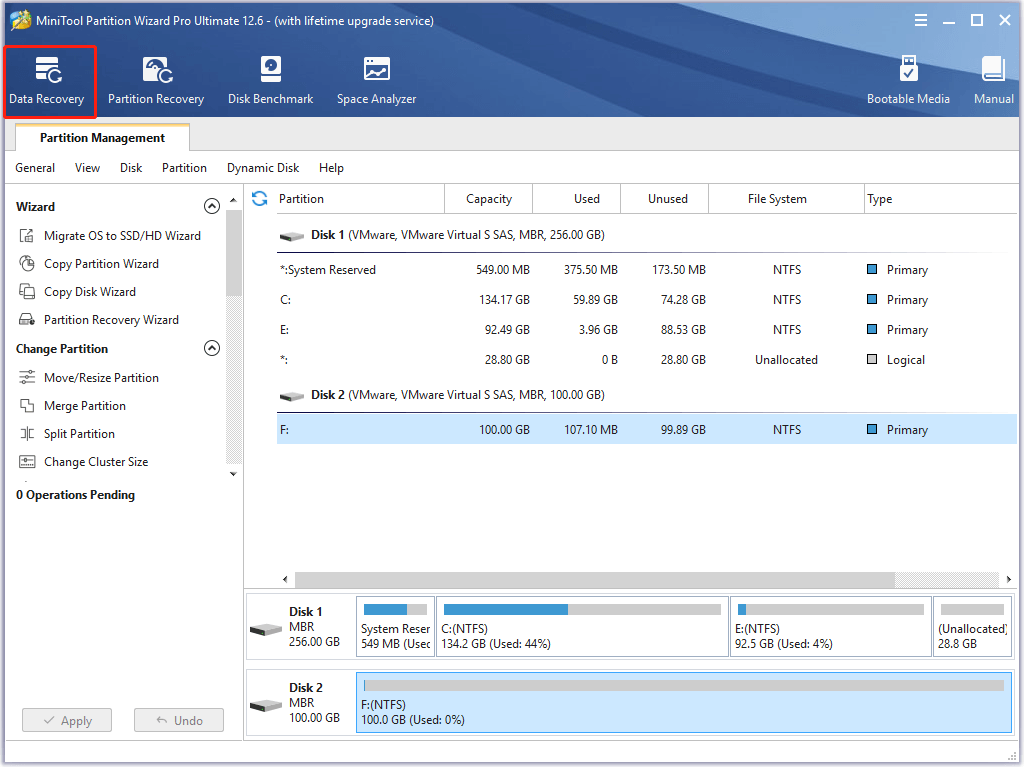
Step 3: In the next window, navigate to the Devices tab. After that, place your cursor at the end of the target disk and click Scan.
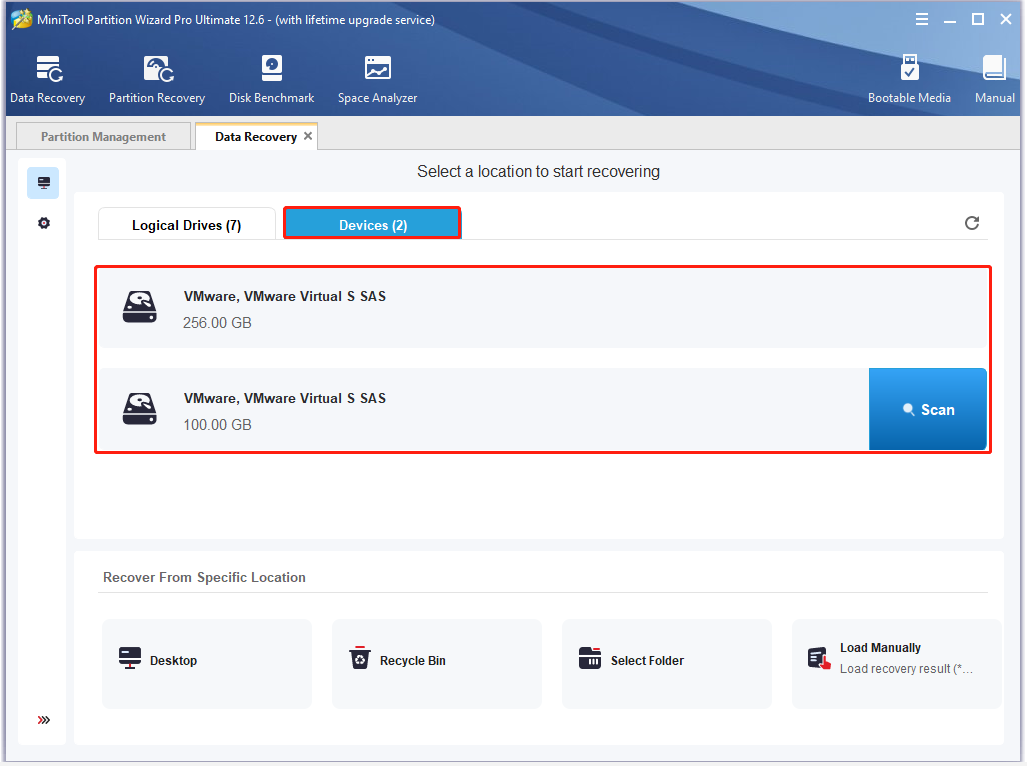
Step 4: Now, the scan process will start automatically. If you want to get the full scan result, wait for the finish of the process.
Note: If the needed data appears while scanning, you are allowed to suspend the process by clicking Pause/Stop icon.
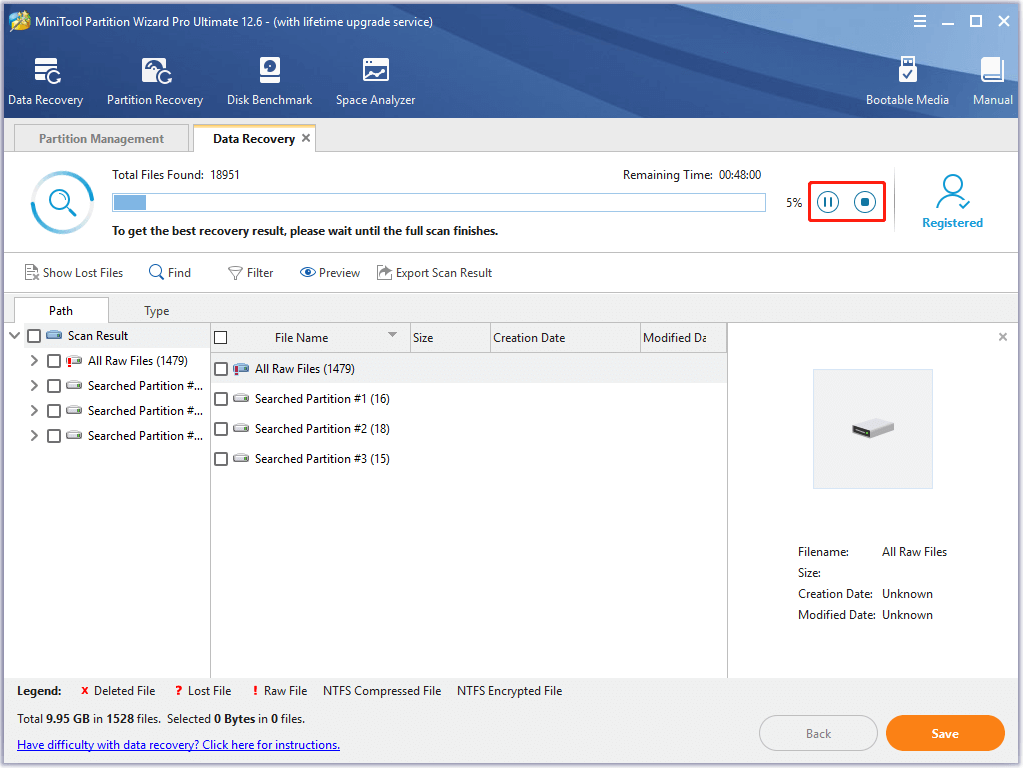
Step 5: Choose the data that you would like to recover from the scanning result and then click Save.
Step 6: In the elevated window, choose a directory for the recovered data and click OK. Then follow the on-screen instructions to finish the operation.
Warning: Don’t save the recovered data on the original drive. Otherwise, the lost/deleted data could be overwritten.
Also read: Undelete Windows 11 Partition with Partition Recovery Software
What is RAW Read Error Rate? What causes it? This post explains them for you. Besides, it tells you how to recover the lost data caused by the error. Click to Tweet
RAW Read Error Rate Prevention Tips
Like other SMART parameters, the Raw Read Error Rate error can’t be solved. Fortunately, you can take some actions to avoid it. Well, here are some tips for you.
#1. Run CHKDSK Scans Regularly
CHKDSK is a built-in utility in Windows that can find and fix issues with your hard drive. By doing so, it optimizes the hard drive performance. It is recommended to run scheduled CHKDSK scans with parameters to prevent the occurrence of the RAW Read Error Rate error.
- Type cmd in the search box, and then right-click on Command Prompt from search results and click Run as administrator.
- Input chkdsk /r /f X in the pop-up window and hit Enter to execute the operation.
Tip: Replace “X” with the actual drive letter.
Also read: Is It Safe to Run CHKDSK on SSD | How to Check SSD Effectively
#2. Check Hard Disk for Errors with MiniTool Partition Wizard
Though CHKDSK works well in most time, it sometimes goes wrong. For instance, you may receive errors like CHKDSK won’t run, CHKDSK deletes data, and so on. Under these circumstances, try using MiniTool Partition Wizard instead.
The Surface Test and Check File System features of MiniTool Partition Wizard can help you check hard drive errors with ease. Additionally, both of the two features are free to use.
Free Download
#3. Defrag the Hard Drive
Disk fragments or file fragments usually are generated while you save files to different parts of the disk instead of the continuous clusters. Free sectors in disks will be spread to discontinuous parts of the disk because of the repeated writing and deleting. Then files can’t be saved to continuous sectors.
The disk defragmentation is the process to arrange the fragments and messy files with the system software or professional disk defragmentation software. This operation can boost the overall performance and the running speed of the PC.
Given that fact, it is advised that you defrag the drive if necessary. For that, follow the steps below.
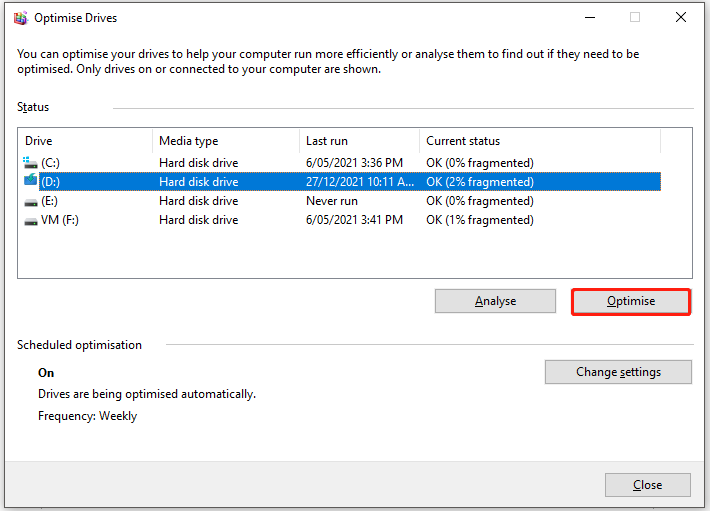
Step 1: Press Windows and S, and then type defragment.
Step 2: Click Defragment and Optimise Drives from listed search results.
Tip: If you are prompted with a confirm window, allow moving forward.
Step 3: In the Optimise Drives window, click on the target drive and click Optimise. Then follow the pop-up instructions to finish the operation.
Alternatively, you can utilize the best defragmentation software to handle disk fragmentation.
#4. Maintain Sufficient Space between the Drive and the Processor
Keeping adequate space between the drive and the processor or exhaust fan within CPU can avoid overheating. If this status lasts for some time, it could damage electrical components, read/write heads, and the magnetic platter, and generate bad sectors. Then it could lead to drive corruption and disk errors.
In addition to that, overheating may cause a computer crash. For more details, please refer to this post: Why Does My Computer Keeps Crashing? Here Are Answers and Fixes
#5. Monitor the Temperature of the Hard Drive
To ensure the hard drive works properly, you should often pay attention to its health condition. Monitoring the temperature of the hard drive is a way for that. Once you find the hard drive is getting hot, you can take some measures to prevent it from overheating.
With disk-monitoring utilities like Drive Monitor or CrystalDiskInfo, you are able to monitor critical hard drive SMART parameters, drive temperature, and performance.
Tip: If you want to know the status of the hard drive, just perform a hard drive check. As for SSDs, you should execute an SSD health check.
#6. Make a Backup
Last but not least, you are recommended to make a regular backup for your hard drive. If you want to obtain higher security, back up the data on multiple storage devices like USB flash drive, external hard drive, etc.
The Copy Disk feature of MiniTool Partition Wizard enables you to clone the data from one drive to another quickly. Alternatively, you can use a piece of professional backup software like MiniTool ShadowMaker to back up data.
Free Download
How to avoid the occurrence of the raw_read_error_rate? Here are 6 bonus tips for you. Try them now! Click to Tweet
Wrap Up
If you want to learn about RAW Read Error Rate, this post is worth reading. It includes the definition, reasons, data recovery solutions, and precaution tips for SMART RAW Read Error Rate. In a word, it is a comprehensive tutorial.
Here comes the end of the post? Is this post helpful for you? Do you have other ideas about Raw Read Error Rate? Well, you can leave your words in the following comment area.
Moreover, if you have any difficulties in using the MiniTool software, don’t hesitate to contact us. Simply send us an email via [email protected]. We will make a reply as soon as possible.
Summary: We will discuss the RAW Read Error Rate in this guide, which is a SMART disk error that indicates problem with the hard disk surface, the actuator arm, and the read/write head. We will also share a few measures to prevent the RAW Read Error Rate along with easy steps to recover the data from hard drives that are facing this error. Before you read further, download free trial of data recovery software which will be required to recover the data.

Contents
- What is RAW Read Error Rate?
- How critical is the RAW Read Error Rate?
- How to Safely Resolve RAW Read Error Rate – Without Data Loss
- How Does Stellar Data Recovery Premium Help?
- How to Detect RAW Read Error Rate
- How to Prevent Raw Read Error Rate
- Conclusion

Modern hard drives are equipped with Self-Monitoring and Analysis Reporting Technology (S.M.A.R.T.) that intelligently records the vital disk info and parameters such as Reallocated Sector Count, Seek Error Rate, Raw Read Error Rate, and several more. SMART is an error detection utility that displays those early signs of disk failure to help avoid data loss situations.
What is RAW Read Error Rate?
RAW Read Error Rate is a SMART disk error that appears only in the traditional hard drives. It doesn’t affect the modern flash storage drives.
It’s a critical SMART parameter that indicates problem with the disk surface (platter that stores the data), the actuator arm, and the read/write head. A higher RAW Read Error Rate indicates higher chances of disk failure.
How critical is the RAW Read Error Rate?
Quite critical! It can lead to permanent data loss, if not resolved timely. Here’s what RAW Read Error Rate means for a hard drive:
- Early indicator of drive failure.
- Data Corruption
- Mechanical failure
- Electrical issues – leads to data loss.
In a nutshell, the drive is physically worn out, and it’s time to replace it. Use a disk cloning utility to create a ‘healthy’ clone, and if needed, run a data recovery software on this clone to restore any lost data.
How to Safely Resolve RAW Read Error Rate – Without Data Loss
Like other SMART parameters, Raw Read Error Rate can’t be fixed. Though, it can be prevented with measures discussed at the end of this post.
However, the data lost as a result of Raw Read Error Rate SMART error can be recovered with the help of Stellar Data Recovery Premium software.
How Does Stellar Data Recovery Premium Help?
It helps is the following ways:
- Repairs corrupt photos and video files.
- Checks and monitors the SMART parameters and vital disk health stats.
- Clones the hard drive to allow secure data recovery in case you’d lost data due to RAW Read Error Rate.
Steps to Recover Data from Drive with RAW Read Error Rate
Step 1: Remove the Hard Drive with RAW Read Rate Error and connect it to a working Windows PC via SATA to USB converter cable or drive enclosure.
Step 2: Download, install and run Stellar Data Recovery Premium software.
Step 3: Choose ‘All Data’ you wish to recover and click ‘Next’.

Step 4: Select the connected hard drive volume from the ‘Connected Drives’ list.

Step 5: Turn on ‘Deep Scan’ toggle switch at bottom left and click ‘Scan.’
Step 6: After the scan, the recovered files are listed in the left Tree View pane. Expand the tree to see files.

Step 7: You may click on File Type to sort the files according to their file format and click on a file to see its preview before recovery.

Step 8: Once satisfied with the preview, select the files and click ‘Recover.’

Step 9: Click ‘Browse’ and choose a location to save recovered data on the PC.
CAUTION: Do not select the connected hard drive volumes.

Step 10: Click ‘Start Saving’ and that’s it.
How to Detect RAW Read Error Rate
The OS reads the file system – i.e. NTFS, FAT (FAT16/32), or exFAT, etc. to read/write/update/delete data on a storage media. However, there is no way to access the disk SMART-info without a third party tool. Thus, to read the SMART parameters such as Raw Read Error Rate on the disk, you need a specialized tool such as Drive Monitor which comes built-in with Stellar Data Recovery Premium software.
The Drive Monitor tool monitors the system hard drive and detects SMART errors such as RAW Read Error Rate in real-time. This helps prevent data loss situation.
How to Prevent Raw Read Error Rate
Storage media optimization helps prevent most of the drive errors. Use free tools such as disk defragmenter and CHKDSK available in Windows to optimize your hard drive performance.
You may also use a third-party tool such as the Drive Monitor or CrystalDiskInfo to track vital SMART parameters. These utilities also warn you of critical SMART parameters in real-time.
Follow these tips to prevent Raw Read Error Rate on a mechanical hard drive:

1. Run Scheduled CHKDSK scan with parameters
Open the command prompt window in admin mode and type chkdsk /r /f X: followed by an ‘Enter’ keypress.
2. Defragment Drive for better performance and longer life
- Press Windows+S and type Defragment. Click ‘Defragment and Optimize Drives’ option.
- Select the Drive Volumes and click ‘Optimize.’
- You may have to grant admin permission.
- This can take a while depending on the drive size, file size and read/write speeds of the drive.
Defragment the drive once in a month with medium to low data transfer tasks. Perform weekly if data transfer is more frequent.
3. Keep adequate spacing between the drive and the processor or exhaust fan within CPU
This will avoid drive overheating which can damage electrical components, read/write heads, and the magnetic platter, and create bad sectors – leading to drive corruption and disk errors.
4. Monitor Drive Temperature
Use disk-monitoring utilities such as Drive Monitor or CrystalDiskInfo to monitor critical hard drive SMART parameters, drive temperature, and performance.
Conclusion
Monitoring SMART parameters – especially critical parameters such as Reallocated Sector Count, Seek Error Rate, RAW Read Error Rate, etc.—is critically important for the data stored on the hard drive. These SMART parameters indicate early signs of drive failure and data loss. If you actively monitor these parameters, you can detect these signs early on and respond before the drive fails.
SMART disk monitoring tools such as Drive Monitor help you actively monitor the SMART parameters, thereby preventing data loss. The Drive Monitor utility comes equipped with Stellar Data Recovery Premium, a software that can also fix photo and video file corruption due to SMART errors such as RAW Read Error Rate.
About The Author
Satyeshu Kumar
Satyeshu is a Windows blogger and data recovery expert. He is having good technical knowledge and experience in Windows data recovery. He writes about latest technical tips, Windows issues and tutorials.
Best Selling Products

Stellar Data Recovery Premium
Stellar Data Recovery Premium for Window
Read More

Stellar Data Recovery Technician
Stellar Data Recovery Technician intelli
Read More

Stellar Data Recovery Toolkit
Stellar Data Recovery Toolkit is an adva
Read More

BitRaser File Eraser
BitRaser File Eraser is a 100% secure so
Read More
Современный жёсткий диск — уникальный компонент компьютера. Он уникален тем, что хранит в себе служебную информацию, изучая которую, можно оценить «здоровье» диска. Эта информация содержит в себе историю изменения множества параметров, отслеживаемых винчестером в процессе функционирования. Больше ни один компонент системного блока не предоставляет владельцу статистику своей работы! Вкупе с тем, что HDD является одним из самых ненадёжных компонентов компьютера, такая статистика может быть весьма полезной и помочь его владельцу избежать нервотрёпки и потери денег и времени.
Информация о состоянии диска доступна благодаря комплексу технологий, называемых общим именем S.M.A.R.T. (Self-Monitoring, Analisys and Reporting Technology, т. е. технология самомониторинга, анализа и отчёта). Этот комплекс довольно обширен, но мы поговорим о тех его аспектах, которые позволяют посмотреть на атрибуты S.M.A.R.T., отображаемые в какой-либо программе по тестированию винчестера, и понять, что творится с диском.
Отмечу, что нижесказанное относится к дискам с интерфейсами SATA и РАТА. У дисков SAS, SCSI и других серверных дисков тоже есть S.M.A.R.T., но его представление сильно отличается от SATA/PATA. Да и мониторит серверные диски обычно не человек, а RAID-контроллер, потому про них мы говорить не будем.
Итак, если мы откроем S.M.A.R.T. в какой-либо из многочисленных программ, то увидим приблизительно следующую картину (на скриншоте приведён S.M.A.R.T. диска Hitachi Deskstar 7К1000.С HDS721010CLA332 в HDDScan 3.3):
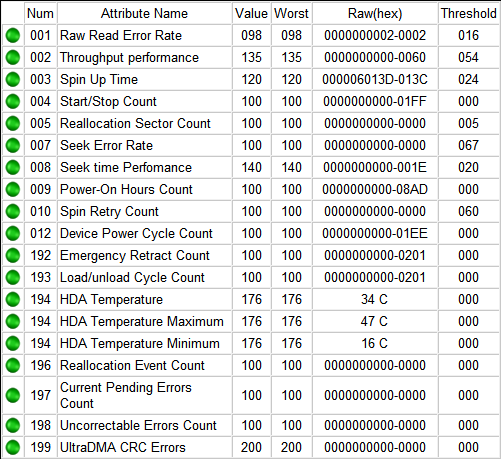
S.M.A.R.T. в HDDScan 3.3
В каждой строке отображается отдельный атрибут S.M.A.R.T. Атрибуты имеют более-менее стандартизованные названия и определённый номер, которые не зависят от модели и производителя диска.
Каждый атрибут S.M.A.R.T. имеет несколько полей. Каждое поле относится к определённому классу из следующих: ID, Value, Worst, Threshold и RAW. Рассмотрим каждый из классов.
- ID (может также именоваться Number) — идентификатор, номер атрибута в технологии S.M.A.R.T. Название одного и того же атрибута программами может выдаваться по-разному, а вот идентификатор всегда однозначно определяет атрибут. Особенно это полезно в случае программ, которые переводят общепринятое название атрибута с английского языка на русский. Иногда получается такая белиберда, что понять, что же это за параметр, можно только по его идентификатору.
- Value (Current) — текущее значение атрибута в попугаях (т. е. в величинах неизвестной размерности). В процессе работы винчестера оно может уменьшаться, увеличиваться и оставаться неизменным. По показателю Value нельзя судить о «здоровье» атрибута, не сравнивая его со значением Threshold этого же атрибута. Как правило, чем меньше Value, тем хуже состояние атрибута (изначально все классы значений, кроме RAW, на новом диске имеют максимальное из возможных значение, например 100).
- Worst — наихудшее значение, которого достигало значение Value за всю жизнь винчестера. Измеряется тоже в «попугаях». В процессе работы оно может уменьшаться либо оставаться неизменным. По нему тоже нельзя однозначно судить о здоровье атрибута, нужно сравнивать его с Threshold.
- Threshold — значение в «попугаях», которого должен достигнуть Value этого же атрибута, чтобы состояние атрибута было признано критическим. Проще говоря, Threshold — это порог: если Value больше Threshold — атрибут в порядке; если меньше либо равен — с атрибутом проблемы. Именно по такому критерию утилиты, читающие S.M.A.R.T., выдают отчёт о состоянии диска либо отдельного атрибута вроде «Good» или «Bad». При этом они не учитывают, что даже при Value, большем Threshold, диск на самом деле уже может быть умирающим с точки зрения пользователя, а то и вовсе ходячим мертвецом, поэтому при оценке здоровья диска смотреть стоит всё-таки на другой класс атрибута, а именно — RAW. Однако именно значение Value, опустившееся ниже Threshold, может стать легитимным поводом для замены диска по гарантии (для самих гарантийщиков, конечно же) — кто же яснее скажет о здоровье диска, как не он сам, демонстрируя текущее значение атрибута хуже критического порога? Т. е. при значении Value, большем Threshold, сам диск считает, что атрибут здоров, а при меньшем либо равном — что болен. Очевидно, что при Threshold=0 состояние атрибута не будет признано критическим никогда. Threshold — постоянный параметр, зашитый производителем в диске.
- RAW (Data) — самый интересный, важный и нужный для оценки показатель. В большинстве случаев он содержит в себе не «попугаи», а реальные значения, выражаемые в различных единицах измерения, напрямую говорящие о текущем состоянии диска. Основываясь именно на этом показателе, формируется значение Value (а вот по какому алгоритму оно формируется — это уже тайна производителя, покрытая мраком). Именно умение читать и анализировать поле RAW даёт возможность объективно оценить состояние винчестера.
Этим мы сейчас и займёмся — разберём все наиболее используемые атрибуты S.M.A.R.T., посмотрим, о чём они говорят и что нужно делать, если они не в порядке.
| Аттрибуты S.M.A.R.T. | |||||||||||||||||
| 01 | 02 | 03 | 04 | 05 | 07 | 08 | 09 | 10 | 11 | 12 | 183 | 184 | 187 | 188 | 189 | 190 | |
| 0x | 01 | 02 | 03 | 04 | 05 | 07 | 08 | 09 | 0A | 0B | 0C | B7 | B8 | BB | BC | BD | BE |
| 191 | 192 | 193 | 194 | 195 | 196 | 197 | 198 | 199 | 200 | 201 | 202 | 203 | 220 | 240 | 254 | ||
| 0x | BF | С0 | С1 | С2 | С3 | С4 | С5 | С6 | С7 | С8 | С9 | СА | CB | DC | F0 | FE |
Перед тем как описывать атрибуты и допустимые значения их поля RAW, уточню, что атрибуты могут иметь поле RAW разного типа: текущее и накапливающее. Текущее поле содержит значение атрибута в настоящий момент, для него свойственно периодическое изменение (для одних атрибутов — изредка, для других — много раз за секунду; другое дело, что в программах чтения S.M.A.R.T. такое быстрое изменение не отображается). Накапливающее поле — содержит статистику, обычно в нём содержится количество возникновений конкретного события со времени первого запуска диска.
Текущий тип характерен для атрибутов, для которых нет смысла суммировать их предыдущие показания. Например, показатель температуры диска является текущим: его цель — в демонстрации температуры в настоящий момент, а не суммы всех предыдущих температур. Накапливающий тип свойственен атрибутам, для которых весь их смысл заключается в предоставлении информации за весь период «жизни» винчестера. Например, атрибут, характеризующий время работы диска, является накапливающим, т. е. содержит количество единиц времени, отработанных накопителем за всю его историю.
Приступим к рассмотрению атрибутов и их RAW-полей.
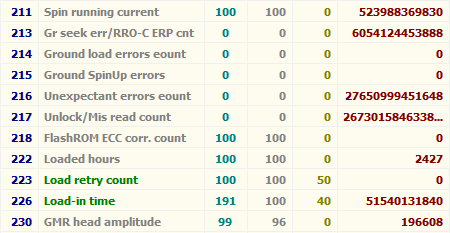
Атрибут: 01 Raw Read Error Rate
| Тип | текущий, может быть накапливающим для WD и старых Hitachi |
| Описание | содержит частоту возникновения ошибок при чтении с пластин |
Для всех дисков Seagate, Samsung (начиная с семейства SpinPoint F1 (включительно)) и Fujitsu 2,5″ характерны огромные числа в этих полях.
Для остальных дисков Samsung и всех дисков WD в этом поле характерен 0.
Для дисков Hitachi в этом поле характерен 0 либо периодическое изменение поля в пределах от 0 до нескольких единиц.
Такие отличия обусловлены тем, что все жёсткие диски Seagate, некоторые Samsung и Fujitsu считают значения этих параметров не так, как WD, Hitachi и другие Samsung. При работе любого винчестера всегда возникают ошибки такого рода, и он преодолевает их самостоятельно, это нормально, просто на дисках, которые в этом поле содержат 0 или небольшое число, производитель не счёл нужным указывать истинное количество этих ошибок.
Таким образом, ненулевой параметр на дисках WD и Samsung до SpinPoint F1 (не включительно) и большое значение параметра на дисках Hitachi могут указывать на аппаратные проблемы с диском. Необходимо учитывать, что утилиты могут отображать несколько значений, содержащихся в поле RAW этого атрибута, как одно, и оно будет выглядеть весьма большим, хоть это и будет неверно (подробности см. ниже).
На дисках Seagate, Samsung (SpinPoint F1 и новее) и Fujitsu на этот атрибут можно не обращать внимания.
Атрибут: 02 Throughput Performance
| Тип | текущий |
| Описание | содержит значение средней производительности диска и измеряется в каких-то «попугаях». Обычно его ненулевое значение отмечается на винчестерах Hitachi. На них он может изменяться после изменения параметров ААМ, а может и сам по себе по неизвестному алгоритму |
Параметр не даёт никакой информации пользователю и не говорит ни о какой опасности при любом своём значении.
Атрибут: 03 Spin-Up Time
| Тип | текущий |
| Описание | содержит время, за которое шпиндель диска в последний раз разогнался из состояния покоя до номинальной скорости. Может содержать два значения — последнее и, например, минимальное время раскрутки. Может измеряться в миллисекундах, десятках миллисекунд и т. п. — это зависит от производителя и модели диска |
Время разгона может различаться у разных дисков (причём у дисков одного производителя тоже) в зависимости от тока раскрутки, массы блинов, номинальной скорости шпинделя и т. п.
Кстати, винчестеры Fujitsu всегда имеют единицу в этом поле в случае отсутствия проблем с раскруткой шпинделя.
Практически ничего не говорит о здоровье диска, поэтому при оценке состояния винчестера на параметр можно не обращать внимания.
Атрибут: 04 Number of Spin-Up Times (Start/Stop Count)
| Тип | накапливающий |
| Описание | содержит количество раз включения диска. Бывает ненулевым на только что купленном диске, находившемся в запаянной упаковке, что может говорить о тестировании диска на заводе. Или ещё о чём-то, мне не известном  |
При оценке здоровья не обращайте на атрибут внимания.
Атрибут: 05 Reallocated Sector Count
| Тип | накапливающий |
| Описание | содержит количество секторов, переназначенных винчестером в резервную область. Практически ключевой параметр в оценке состояния |
Поясним, что вообще такое «переназначенный сектор». Когда диск в процессе работы натыкается на нечитаемый/плохо читаемый/незаписываемый/плохо записываемый сектор, он может посчитать его невосполнимо повреждённым. Специально для таких случаев производитель предусматривает на каждом диске (на каких-то моделях — в центре (логическом конце) диска, на каких-то — в конце каждого трека и т. д.) резервную область. При наличии повреждённого сектора диск помечает его как нечитаемый и использует вместо него сектор в резервной области, сделав соответствующие пометки в специальном списке дефектов поверхности — G-list. Такая операция по назначению нового сектора на роль старого называется remap (ремап) либо переназначение, а используемый вместо повреждённого сектор — переназначенным. Новый сектор получает логический номер LBA старого, и теперь при обращении ПО к сектору с этим номером (программы же не знают ни о каких переназначениях!) запрос будет перенаправляться в резервную область.
Таким образом, хоть сектор и вышел из строя, объём диска не изменяется. Понятно, что не изменяется он до поры до времени, т. к. объём резервной области не бесконечен. Однако резервная область вполне может содержать несколько тысяч секторов, и допустить, чтобы она закончилась, будет весьма безответственно — диск нужно будет заменить задолго до этого.
Кстати, ремонтники говорят, что диски Samsung очень часто ни в какую не хотят выполнять переназначение секторов.
На счёт этого атрибута мнения разнятся. Лично я считаю, что если он достиг 10, диск нужно обязательно менять — ведь это означает прогрессирующий процесс деградации состояния поверхности либо блинов, либо головок, либо чего-то ещё аппаратного, и остановить этот процесс возможности уже нет. Кстати, по сведениям лиц, приближенных к Hitachi, сама Hitachi считает диск подлежащим замене, когда на нём находится уже 5 переназначенных секторов. Другой вопрос, официальная ли эта информация, и следуют ли этому мнению сервис-центры. Что-то мне подсказывает, что нет
Другое дело, что сотрудники сервис-центров могут отказываться признавать диск неисправным, если фирменная утилита производителя диска пишет что-то вроде «S.M.A.R.T. Status: Good» или значения Value либо Worst атрибута будут больше Threshold (собственно, по такому критерию может оценивать и сама утилита производителя). И формально они будут правы. Но кому нужен диск с постоянным ухудшением его аппаратных компонентов, даже если такое ухудшение соответствует природе винчестера, а технология производства жёстких дисков старается минимизировать его последствия, выделяя, например, резервную область?
Атрибут: 07 Seek Error Rate
| Тип | текущий |
| Описание | содержит частоту возникновения ошибок при позиционировании блока магнитных головок (БМГ) |
Описание формирования этого атрибута почти полностью совпадает с описанием для атрибута 01 Raw Read Error Rate, за исключением того, что для винчестеров Hitachi нормальным значением поля RAW является только 0.
Таким образом, на атрибут на дисках Seagate, Samsung SpinPoint F1 и новее и Fujitsu 2,5″ не обращайте внимания, на остальных моделях Samsung, а также на всех WD и Hitachi ненулевое значение свидетельствует о проблемах, например, с подшипником и т. п.
Атрибут: 08 Seek Time Performance
| Тип | текущий |
| Описание | содержит среднюю производительность операций позиционирования головок, измеряется в «попугаях». Как и параметр 02 Throughput Performance, ненулевое значение обычно отмечается на дисках Hitachi и может изменяться после изменения параметров ААМ, а может и само по себе по неизвестному алгоритму |
Не даёт никакой информации пользователю и не говорит ни о какой опасности при любом своём значении.
Атрибут: 09 Power On Hours Count (Power-on Time)
| Тип | накапливающий |
| Описание | содержит количество часов, в течение которых винчестер был включён |
Ничего не говорит о здоровье диска.
Атрибут: 10 (0А — в шестнадцатеричной системе счисления) Spin Retry Count
| Тип | накапливающий |
| Описание | содержит количество повторов запуска шпинделя, если первая попытка оказалась неудачной |
О здоровье диска чаще всего не говорит.
Основные причины увеличения параметра — плохой контакт диска с БП или невозможность БП выдать нужный ток в линию питания диска.
В идеале должен быть равен 0. При значении атрибута, равном 1-2, внимания можно не обращать. Если значение больше, в первую очередь следует обратить пристальное внимание на состояние блока питания, его качество, нагрузку на него, проверить контакт винчестера с кабелем питания, проверить сам кабель питания.
Наверняка диск может стартовать не сразу из-за проблем с ним самим, но такое бывает очень редко, и такую возможность нужно рассматривать в последнюю очередь.
Атрибут: 11 (0B) Calibration Retry Count (Recalibration Retries)
| Тип | накапливающий |
| Описание | содержит количество повторных попыток сброса накопителя (установки БМГ на нулевую дорожку) при неудачной первой попытке |
Ненулевое, а особенно растущее значение параметра может означать проблемы с диском.
Атрибут: 12 (0C) Power Cycle Count
| Тип | накапливающий |
| Описание | содержит количество полных циклов «включение-отключение» диска |
Не связан с состоянием диска.
Атрибут: 183 (B7) SATA Downshift Error Count
| Тип | накапливающий |
| Описание | содержит количество неудачных попыток понижения режима SATA. Суть в том, что винчестер, работающий в режимах SATA 3 Гбит/с или 6 Гбит/с (и что там дальше будет в будущем), по какой-то причине (например, из-за ошибок) может попытаться «договориться» с дисковым контроллером о менее скоростном режиме (например, SATA 1,5 Гбит/с или 3 Гбит/с соответственно). В случае «отказа» контроллера изменять режим диск увеличивает значение атрибута |
Не говорит о здоровье накопителя.
Атрибут: 184 (B8) End-to-End Error
| Тип | накапливающий |
| Описание | содержит количество ошибок, возникших при передаче данных через кэш винчестера |
Ненулевое значение указывает на проблемы с диском.
Атрибут: 187 (BB) Reported Uncorrected Sector Count (UNC Error)
| Тип | накапливающий |
| Описание | содержит количество секторов, которые были признаны кандидатами на переназначение (см. атрибут 197) за всю историю жизни диска. Причём если сектор становится кандидатом повторно, значение атрибута тоже увеличивается |
Ненулевое значение атрибута явно указывает на ненормальное состояние диска (в сочетании с ненулевым значением атрибута 197) или на то, что оно было таковым ранее (в сочетании с нулевым значением 197).
Атрибут: 188 (BC) Command Timeout
| Тип | накапливающий |
| Описание | содержит количество операций, выполнение которых было отменено из-за превышения максимально допустимого времени ожидания отклика |
Такие ошибки могут возникать из-за плохого качества кабелей, контактов, используемых переходников, удлинителей и т. д., а также из-за несовместимости диска с конкретным контроллером SATA/РАТА на материнской плате (либо дискретным). Из-за ошибок такого рода возможны BSOD в Windows.
Ненулевое значение атрибута говорит о потенциальной «болезни» диска.
Атрибут: 189 (BD) High Fly Writes
| Тип | накапливающий |
| Описание | содержит количество зафиксированных случаев записи при высоте полета головки выше рассчитанной — скорее всего, из-за внешних воздействий, например вибрации |
Для того чтобы сказать, почему происходят такие случаи, нужно уметь анализировать логи S.M.A.R.T., которые содержат специфичную для каждого производителя информацию, что на сегодняшний день не реализовано в общедоступном ПО — следовательно, на атрибут можно не обращать внимания.
Атрибут: 190 (BE) Airflow Temperature
| Тип | текущий |
| Описание | содержит температуру винчестера для дисков Hitachi, Samsung, WD и значение «100 − [RAW-значение атрибута 194]» для Seagate |
Не говорит о состоянии диска.
Атрибут: 191 (BF) G-Sensor Shock Count (Mechanical Shock)
| Тип | накапливающий |
| Описание | содержит количество критических ускорений, зафиксированных электроникой диска, которым подвергался накопитель и которые превышали допустимые. Обычно это происходит при ударах, падениях и т. п. |
Актуален для мобильных винчестеров. На дисках Samsung на него часто можно не обращать внимания, т. к. они могут иметь очень чувствительный датчик, который, образно говоря, реагирует чуть ли не на движение воздуха от крыльев пролетающей в одном помещении с диском мухи.
Вообще срабатывание датчика не является признаком удара. Может расти даже от позиционирования БМГ самим диском, особенно если его не закрепить. Основное назначение датчика — прекратить операцию записи при вибрациях, чтобы избежать ошибок.
Не говорит о здоровье диска.
Атрибут: 192 (С0) Power Off Retract Count (Emergency Retry Count)
| Тип | накапливающий |
| Описание | для разных винчестеров может содержать одну из следующих двух характеристик: либо суммарное количество парковок БМГ диска в аварийных ситуациях (по сигналу от вибродатчика, обрыву/понижению питания и т. п.), либо суммарное количество циклов включения/выключения питания диска (характерно для современных WD и Hitachi) |
Не позволяет судить о состоянии диска.
Атрибут: 193 (С1) Load/Unload Cycle Count
| Тип | накапливающий |
| Описание | содержит количество полных циклов парковки/распарковки БМГ. Анализ этого атрибута — один из способов определить, включена ли на диске функция автоматической парковки (столь любимая, например, компанией Western Digital): если его содержимое превосходит (обычно — многократно) содержимое атрибута 09 — счётчик отработанных часов, — то парковка включена |
Не говорит о здоровье диска.
Атрибут: 194 (С2) Temperature (HDA Temperature, HDD Temperature)
| Тип | текущий/накапливающий |
| Описание | содержит текущую температуру диска. Температура считывается с датчика, который на разных моделях может располагаться в разных местах. Поле вместе с текущей также может содержать максимальную и минимальную температуры, зафиксированные за всё время эксплуатации винчестера |
О состоянии диска атрибут не говорит, но позволяет контролировать один из важнейших параметров. Моё мнение: при работе старайтесь не допускать повышения температуры винчестера выше 50 градусов, хоть производителем обычно и декларируется максимальный предел температуры в 55-60 градусов.
Атрибут: 195 (С3) Hardware ECC Recovered
| Тип | накапливающий |
| Описание | содержит количество ошибок, которые были скорректированы аппаратными средствами ECC диска |
Особенности, присущие этому атрибуту на разных дисках, полностью соответствуют таковым атрибутов 01 и 07.
Атрибут: 196 (С4) Reallocated Event Count
| Тип | накапливающий |
| Описание | содержит количество операций переназначения секторов |
Косвенно говорит о здоровье диска. Чем больше значение — тем хуже. Однако нельзя однозначно судить о здоровье диска по этому параметру, не рассматривая другие атрибуты.
Этот атрибут непосредственно связан с атрибутом 05. При росте 196 чаще всего растёт и 05. Если при росте атрибута 196 атрибут 05 не растёт, значит, при попытке ремапа кандидат в бэд-блоки оказался софт-бэдом (подробности см. ниже), и диск исправил его, так что сектор был признан здоровым, и в переназначении не было необходимости.
Если атрибут 196 меньше атрибута 05, значит, во время некоторых операций переназначения выполнялся перенос нескольких повреждённых секторов за один приём.
Если атрибут 196 больше атрибута 05, значит, при некоторых операциях переназначения были обнаружены исправленные впоследствии софт-бэды.
Атрибут: 197 (С5) Current Pending Sector Count
| Тип | текущий |
| Описание | содержит количество секторов-кандидатов на переназначение в резервную область |
Натыкаясь в процессе работы на «нехороший» сектор (например, контрольная сумма сектора не соответствует данным в нём), диск помечает его как кандидат на переназначение, заносит его в специальный внутренний список и увеличивает параметр 197. Из этого следует, что на диске могут быть повреждённые секторы, о которых он ещё не знает — ведь на пластинах вполне могут быть области, которые винчестер какое-то время не использует.
При попытке записи в сектор диск сначала проверяет, не находится ли этот сектор в списке кандидатов. Если сектор там не найден, запись проходит обычным порядком. Если же найден, проводится тестирование этого сектора записью-чтением. Если все тестовые операции проходят нормально, то диск считает, что сектор исправен. (Т. е. был т. н. «софт-бэд» — ошибочный сектор возник не по вине диска, а по иным причинам: например, в момент записи информации отключилось электричество, и диск прервал запись, запарковав БМГ. В итоге данные в секторе окажутся недописанными, а контрольная сумма сектора, зависящая от данных в нём, вообще останется старой. Налицо будет расхождение между нею и данными в секторе.) В таком случае диск проводит изначально запрошенную запись и удаляет сектор из списка кандидатов. При этом атрибут 197 уменьшается, также возможно увеличение атрибута 196.
Если же тестирование заканчивается неудачей, диск выполняет операцию переназначения, уменьшая атрибут 197, увеличивая 196 и 05, а также делает пометки в G-list.
Итак, ненулевое значение параметра говорит о неполадках (правда, не может сказать о том, в само́м ли диске проблема).
При ненулевом значении нужно обязательно запустить в программах Victoria или MHDD последовательное чтение всей поверхности с опцией remap. Тогда при сканировании диск обязательно наткнётся на плохой сектор и попытается произвести запись в него (в случае Victoria 3.5 и опции Advanced remap — диск будет пытаться записать сектор до 10 раз). Таким образом программа спровоцирует «лечение» сектора, и в итоге сектор будет либо исправлен, либо переназначен.
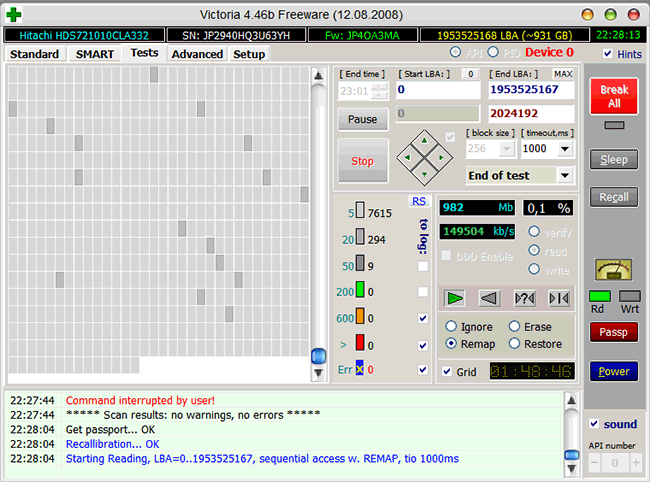
Идёт последовательное чтение с ремапом в Victoria 4.46b
В случае неудачи чтения как с remap, так и с Advanced remap, стоит попробовать запустить последовательную запись в тех же Victoria или MHDD. Учитывайте, что операция записи стирает данные, поэтому перед её применением обязательно делайте бэкап!
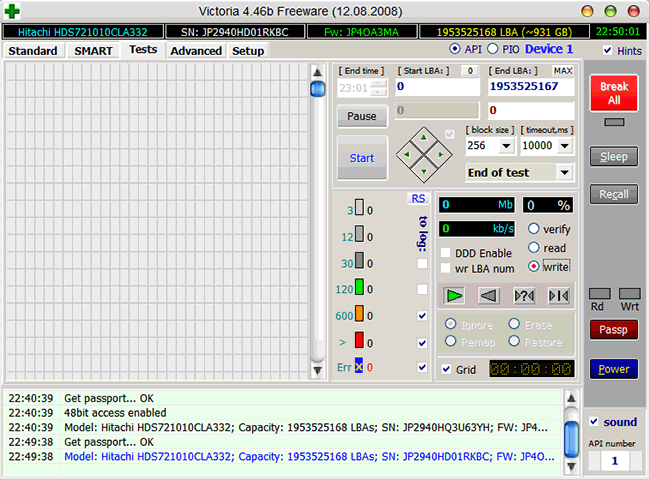
Запуск последовательной записи в Victoria 4.46b
Иногда от невыполнения ремапа могут помочь следующие манипуляции: снимите плату электроники диска и почистите контакты гермоблока винчестера, соединяющие его с платой — они могут быть окислены. Будь аккуратны при выполнении этой процедуры — из-за неё можно лишиться гарантии!
Невозможность ремапа может быть обусловлена ещё одной причиной — диск исчерпал резервную область, и ему просто некуда переназначать секторы.
Если же значение атрибута 197 никакими манипуляциями не снижается до 0, следует думать о замене диска.
Атрибут: 198 (С6) Offline Uncorrectable Sector Count (Uncorrectable Sector Count)
| Тип | текущий |
| Описание | означает то же самое, что и атрибут 197, но отличие в том, что данный атрибут содержит количество секторов-кандидатов, обнаруженных при одном из видов самотестирования диска — оффлайн-тестировании, которое диск запускает в простое в соответствии с параметрами, заданными прошивкой |
Параметр этот изменяется только под воздействием оффлайн-тестирования, никакие сканирования программами на него не влияют. При операциях во время самотестирования поведение атрибута такое же, как и атрибута 197.
Ненулевое значение говорит о неполадках на диске (точно так же, как и 197, не конкретизируя, кто виноват).
Атрибут: 199 (С7) UltraDMA CRC Error Count
| Тип | накапливающий |
| Описание | содержит количество ошибок, возникших при передаче по интерфейсному кабелю в режиме UltraDMA (или его эмуляции винчестерами SATA) от материнской платы или дискретного контроллера контроллеру диска |
В подавляющем большинстве случаев причинами ошибок становятся некачественный шлейф передачи данных, разгон шин PCI/PCI-E компьютера либо плохой контакт в SATA-разъёме на диске или на материнской плате/контроллере.
Ошибки при передаче по интерфейсу и, как следствие, растущее значение атрибута могут приводить к переключению операционной системой режима работы канала, на котором находится накопитель, в режим PIO, что влечёт резкое падение скорости чтения/записи при работе с ним и загрузку процессора до 100% (видно в Диспетчере задач Windows).
В случае винчестеров Hitachi серий Deskstar 7К3000 и 5К3000 растущий атрибут может говорить о несовместимости диска и SATA-контроллера. Чтобы исправить ситуацию, нужно принудительно переключить такой диск в режим SATA 3 Гбит/с.
Моё мнение: при наличии ошибок — переподключите кабель с обоих концов; если их количество растёт и оно больше 10 — выбрасывайте шлейф и ставьте вместо него новый или снимайте разгон.
Можно считать, что о здоровье диска атрибут не говорит.
Атрибут: 200 (С8) Write Error Rate (MultiZone Error Rate)
| Тип | текущий |
| Описание | содержит частоту возникновения ошибок при записи |
Ненулевое значение говорит о проблемах с диском — в частности, у дисков WD большие цифры могут означать «умирающие» головки.
Атрибут: 201 (С9) Soft Read Error Rate
| Тип | текущий |
| Описание | содержит частоту возникновения ошибок чтения, произошедших по вине программного обеспечения |
Влияние на здоровье неизвестно.
Атрибут: 202 (СА) Data Address Mark Error
| Тип | неизвестно |
| Описание | содержание атрибута — загадка, но проанализировав различные диски, могу констатировать, что ненулевое значение — это плохо |
Атрибут: 203 (CB) Run Out Cancel
| Тип | текущий |
| Описание | содержит количество ошибок ECC |
Влияние на здоровье неизвестно.
Атрибут: 220 (DC) Disk Shift
| Тип | текущий |
| Описание | содержит измеренный в неизвестных единицах сдвиг пластин диска относительно оси шпинделя |
Влияние на здоровье неизвестно.
Атрибут: 240 (F0) Head Flying Hours
| Тип | накапливающий |
| Описание | содержит время, затраченное на позиционирование БМГ. Счётчик может содержать несколько значений в одном поле |
Влияние на здоровье неизвестно.
Атрибут: 254 (FE) Free Fall Event Count
| Тип | накапливающий |
| Описание | содержит зафиксированное электроникой количество ускорений свободного падения диска, которым он подвергался, т. е., проще говоря, показывает, сколько раз диск падал |
Влияние на здоровье неизвестно.
Подытожим описание атрибутов. Ненулевые значения:
- атрибутов 01, 07, 195 — вызывают подозрения в «болезни» у некоторых моделей дисков;
- атрибутов 10, 11, 188, 196, 199, 202 — вызывают подозрения у всех дисков;
- и, наконец, атрибутов 05, 184, 187, 197, 198, 200 — прямо говорят о неполадках.
При анализе атрибутов учитывайте, что в некоторых параметрах S.M.A.R.T. могут храниться несколько значений этого параметра: например, для предпоследнего запуска диска и для последнего. Такие параметры длиной в несколько байт логически состоят из нескольких значений длиной в меньшее количество байт — например, параметр, хранящий два значения для двух последних запусков, под каждый из которых отводится 2 байта, будет иметь длину 4 байта. Программы, интерпретирующие S.M.A.R.T., часто не знают об этом, и показывают этот параметр как одно число, а не два, что иногда приводит к путанице и волнению владельца диска. Например, «Raw Read Error Rate», хранящий предпоследнее значение «1» и последнее значение «0», будет выглядеть как 65536.
Надо отметить, что не все программы умеют правильно отображать такие атрибуты. Многие как раз и переводят атрибут с несколькими значениями в десятичную систему счисления как одно огромное число. Правильно же отображать такое содержимое — либо с разбиением по значениям (тогда атрибут будет состоять из нескольких отдельных чисел), либо в шестнадцатеричной системе счисления (тогда атрибут будет выглядеть как одно число, но его составляющие будут легко различимы с первого взгляда), либо и то, и другое одновременно. Примерами правильных программ служат HDDScan, CrystalDiskInfo, Hard Disk Sentinel.
Продемонстрируем отличия на практике. Вот так выглядит мгновенное значение атрибута 01 на одном из моих Hitachi HDS721010CLA332 в неучитывающей особенности этого атрибута Victoria 4.46b:
![]()
Атрибут 01 в Victoria 4.46b
А так выглядит он же в «правильной» HDDScan 3.3:
![]()
Атрибут 01 в HDDScan 3.3
Плюсы HDDScan в данном контексте очевидны, не правда ли?
Если анализировать S.M.A.R.T. на разных дисках, то можно заметить, что одни и те же атрибуты могут вести себя по-разному. Например, некоторые параметры S.M.A.R.T. винчестеров Hitachi после определённого периода неактивности диска обнуляются; параметр 01 имеет особенности на дисках Hitachi, Seagate, Samsung и Fujitsu, 03 — на Fujitsu. Также известно, что после перепрошивки диска некоторые параметры могут установиться в 0 (например, 199). Однако подобное принудительное обнуление атрибута ни в коем случае не будет говорить о том, что проблемы с диском решены (если таковые были). Ведь растущий критичный атрибут — это следствие неполадок, а не причина.
При анализе множества массивов данных S.M.A.R.T. становится очевидным, что набор атрибутов у дисков разных производителей и даже у разных моделей одного производителя может отличаться. Связано это с так называемыми специфичными для конкретного вендора (vendor specific) атрибутами (т. е. атрибутами, используемыми для мониторинга своих дисков определённым производителем) и не должно являться поводом для волнения. Если ПО мониторинга умеет читать такие атрибуты (например, Victoria 4.46b), то на дисках, для которых они не предназначены, они могут иметь «страшные» (огромные) значения, и на них просто не нужно обращать внимания. Вот так, например, Victoria 4.46b отображает RAW-значения атрибутов, не предназначенных для мониторинга у Hitachi HDS721010CLA332:
«Страшные» значения в Victoria 4.46b
Нередко встречается проблема, когда программы не могут считать S.M.A.R.T. диска. В случае исправного винчестера это может быть вызвано несколькими факторами. Например, очень часто не отображается S.M.A.R.T. при подключении диска в режиме AHCI. В таких случаях стоит попробовать разные программы, в частности HDD Scan, которая обладает умением работать в таком режиме, хоть у неё и не всегда это получается, либо же стоит временно переключить диск в режим совместимости с IDE, если есть такая возможность. Далее, на многих материнских платах контроллеры, к которым подключаются винчестеры, бывают не встроенными в чипсет или южный мост, а реализованы отдельными микросхемами. В таком случае DOS-версия Victoria, например, не увидит подключённый к контроллеру жёсткий диск, и ей нужно будет принудительно указывать его, нажав клавишу [Р] и введя номер канала с диском. Часто не читаются S.M.A.R.T. у USB-дисков, что объясняется тем, что USB-контроллер просто не пропускает команды для чтения S.M.A.R.T. Практически никогда не читается S.M.A.R.T. у дисков, функционирующих в составе RAID-массива. Здесь тоже есть смысл попробовать разные программы, но в случае аппаратных RAID-контроллеров это бесполезно.
Если после покупки и установки нового винчестера какие-либо программы (HDD Life, Hard Drive Inspector и иже с ними) показывают, что: диску осталось жить 2 часа; его производительность — 27%; здоровье — 19,155% (выберите по вкусу) — то паниковать не стоит. Поймите следующее. Во-первых, нужно смотреть на показатели S.M.A.R.T., а не на непонятно откуда взявшиеся числа здоровья и производительности (впрочем, принцип их подсчёта понятен: берётся наихудший показатель). Во-вторых, любая программа при оценке параметров S.M.A.R.T. смотрит на отклонение значений разных атрибутов от предыдущих показаний. При первых запусках нового диска параметры непостоянны, необходимо некоторое время на их стабилизацию. Программа, оценивающая S.M.A.R.T., видит, что атрибуты изменяются, производит расчёты, у неё получается, что при их изменении такими темпами накопитель скоро выйдет из строя, и она начинает сигнализировать: «Спасайте данные!» Пройдёт некоторое время (до пары месяцев), атрибуты стабилизируются (если с диском действительно всё в порядке), утилита наберёт данных для статистики, и сроки кончины диска по мере стабилизации S.M.A.R.T. будут переноситься всё дальше и дальше в будущее. Оценка программами дисков Seagate и Samsung — вообще отдельный разговор. Из-за особенностей атрибутов 1, 7, 195 программы даже для абсолютно здорового диска обычно выдают заключение, что он завернулся в простыню и ползёт на кладбище.
Обратите внимание, что возможна следующая ситуация: все атрибуты S.M.A.R.T. — в норме, однако на самом деле диск — с проблемами, хоть этого пока ни по чему не заметно. Объясняется это тем, что технология S.M.A.R.T. работает только «по факту», т. е. атрибуты меняются только тогда, когда диск в процессе работы встречает проблемные места. А пока он на них не наткнулся, то и не знает о них и, следовательно, в S.M.A.R.T. ему фиксировать нечего.
Таким образом, S.M.A.R.T. — это полезная технология, но пользоваться ею нужно с умом. Кроме того, даже если S.M.A.R.T. вашего диска идеален, и вы постоянно устраиваете диску проверки — не полагайтесь на то, что ваш диск будет «жить» ещё долгие годы. Винчестерам свойственно ломаться так быстро, что S.M.A.R.T. просто не успевает отобразить его изменившееся состояние, а бывает и так, что с диском — явные нелады, но в S.M.A.R.T. — всё в порядке. Можно сказать, что хороший S.M.A.R.T. не гарантирует, что с накопителем всё хорошо, но плохой S.M.A.R.T. гарантированно свидетельствует о проблемах. При этом даже с плохим S.M.A.R.T. утилиты могут показывать, что состояние диска — «здоров», из-за того, что критичными атрибутами не достигнуты пороговые значения. Поэтому очень важно анализировать S.M.A.R.T. самому, не полагаясь на «словесную» оценку программ.
Хоть технология S.M.A.R.T. и работает, винчестеры и понятие «надёжность» настолько несовместимы, что принято считать их просто расходным материалом. Ну, как картриджи в принтере. Поэтому во избежание потери ценных данных делайте их периодическое резервное копирование на другой носитель (например, другой винчестер). Оптимально делать две резервные копии на двух разных носителях, не считая винчестера с оригинальными данными. Да, это ведёт к дополнительным затратам, но поверьте: затраты на восстановление информации со сломавшегося HDD обойдутся вам в разы — если не на порядок-другой — дороже. А ведь данные далеко не всегда могут восстановить даже профессионалы. Т. е. единственная возможность обеспечить надёжное хранение ваших данных — это делать их бэкап.
Напоследок упомяну некоторые программы, которые хорошо подходят для анализа S.M.A.R.T. и тестирования винчестеров: HDDScan (работает в Windows, бесплатная), CrystalDiskInfo (Windows, бесплатная), Hard Disk Sentinel (платная для Windows, бесплатная для DOS), HD Tune (Windows, платная, есть бесплатная старая версия).
И наконец, мощнейшие программы для тестирования: Victoria (Windows, DOS, бесплатная), MHDD (DOS, бесплатная).
Contents
- Stop Using The Faulty HDD
- Restore The Deleted Data From The Disk
- Scan The Disk For Bad Sectors
- Reduce The Disk Temperature
- Run Hard Disk Defragmentation
- «0x1» In an SSD
- How Can You Reset «0x1 Raw Read Error Rate»?
-
Buy a New Hard Disk
- Is It Worth Repairing an HDD?
- How to choose a new HDD?
- Article Suitable for:
Read more how to fix «0x1 Raw Read Error Rate» in Windows 11, Windows 10, Windows 8.1, Windows Server 2012, Windows 8, Windows Home Server 2011, Windows 7 (Seven), Windows Small Business Server, Windows Server 2008, Windows Home Server, Windows Vista, Windows XP, Windows 2000, Windows NT.
Stop Using The Faulty HDD
If you receive a system message about an error diagnosed, it doesn’t mean the disk is out of order already. However, in case of a S.M.A.R.T. error, you should realize the disk is on the way to its breakdown. It can fail completely anytime – both within several minutes or in a month or even in a year. Anyway, it does mean you cannot trust to keep your data there.
You should take some care about the safety of your data, make a backup copy or transfer files to another media. Along with these actions meant to save your data, you should also replace your hard disk. The disk where S.M.A.R.T. errors were found cannot be used – even if it doesn’t break down completely, it can still damage your data partially.
Of course, a hard disk can fail even without showing any S.M.A.R.T. messages, but this technology gives you a certain advantage of warning you about the coming breakdown problem.
Restore The Deleted Data From The Disk
If there is a SMART error, restoring data from the disk is not always necessary. In case of an error, it is recommended to create a backup copy of important information immediately, because now the disk can fail completely at any time. However, there are errors that make data copying impossible. In this case, you can use special hard disk data recovery software — Hetman Partition Recovery.
The tool recovers data from any devices, regardless of the cause of data loss.

To do it:
-
Download the program, install and launch it.
-
By default, you will be suggested to use File Recovery Wizard. After clicking Next the program will suggest you to choose a disk to recover files from.
-
Double-click on the faulty disk and choose the type of analysis. Select Full analysis and wait for the scanning process to finish.
-
After the scanning process is over you will be shown files for recovery. Select the necessary files and click Recover.
-
Select one of the suggested ways to save files. Do not save the recovered files to the disk having an error «0x1 Raw Read Error Rate».
Scan The Disk For Bad Sectors
Start scanning all partitions of the disk and try correcting any mistakes that are found.
To do it, open This PC and right-click on the disk with a SMART error.
Select Properties / Tools / Check in the tab Error checking.

Errors found on the disk as a result of scanning can be corrected.
Go to view

How to Check Your Hard Disk for Errors and Fix Them in Windows 10
Reduce The Disk Temperature
Sometimes a SMART error can be caused by exceeding the maximum temperature of the disk. This problem can be eliminated by improving the case ventilation. First of all, make sure that your computer has sufficient ventilation and that all coolers are in proper working order.
If you found and eliminated the ventilation problem, which helped to bring the disk temperature back to normal, this SMART error can never appear again.
Go to view
How to Check the Processor (CPU), Video Card (GPU) or Hard Disk (HDD) Temperature
Run Hard Disk Defragmentation
Open This PC and right-click on the disk having an error «0x1 Raw Read Error Rate». Select Properties / Tools / Optimize in the tab Optimize and defragment drive.
Go to view
How to Defragment Your PC’s Hard Drive on Windows 10

Select the disk you need to optimize and click Optimize.
Note. In Windows 10 disk defragmentation and optimization can be adjusted to take place automatically.
«Raw Read Error Rate» In an SSD
Even if you have no problems with an SSD performance, its operability is reducing slowly because SSD memory cells have a limited number of overwrite cycles. The wear resistance function minimizes this effect but never takes it away completely.
SSD disks have their specific SMART attributes which send signals about the state of disk memory cells. For example, «209 Remaining Drive Life,» «231 SSD life left» etc. Such errors may occur when memory cell operability is reduced, and it means the information kept there can be damaged or lost.
In case of failure, SSD cells cannot be recovered or replaced.
Go to view
SSD Diagnostics: Programs to Find and Fix SSD Errors
How Can You Reset «0x1 Raw Read Error Rate»?
SMART errors can be easily reset in BIOS (or UEFI) but all OS developers strongly discourage users from this step. Yet if the data on the hard disk is of little importance for you, displaying SMART errors can be disabled.
Here is the procedure to follow:
-
Restart the computer, and use combinations of keys shown on the loading screen (they depend on a specific manufacturer, usually «F2» or «Del») to go to BIOS (or UEFI).
-
Go to Аdvanced > SMART settings > SMART self test. Set the value as Disabled.
Note: The place where you disable the function is given approximately, because its specific location depends on the version of BIOS or UEFI and can differ slightly.
Buy a New Hard Disk
Is It Worth Repairing an HDD?
It is important to realize that any of the ways to eliminate a SMART error is self-deception. It is impossible to completely remove the cause of the error, as it often involves physical wear of the hard disk mechanism.
To replace the hard disk components which operate incorrectly you can go to a service center or a special laboratory dealing with hard disks.
However, the cost of work will be higher than the price of a new device, so it is justified only when you need to restore data from a disk which is no longer operable.
How to choose a new HDD?
If you encounter a hard disk SMART error, then buying a new HDD is only a matter of time. The disk type you need depends on how you work on the computer and the purposes you use your computer for.
Here are some points to consider when buying a new hard disk:
-
Disk type: HDD, SSD или SSHD. Each type has its advantages and disadvantages which may be unimportant for one user and crucial for another. These are read and write speed, capacity and tolerance to multiple overwriting.
-
Size. There are two main form factors for hard disks, 3.5 inch and 2.5 inch. The size of disks is determined in accordance to the slot in a particular computer or laptop.
-
Interface. The main interfaces of hard disks are as follows:
-
SATA;
-
IDE, ATAPI, ATA;
-
SCSI;
-
External Disk (USB, FireWire etc).
-
-
Technical characteristics and performance:
-
Capacity;
-
Read and write speed;
-
Memory cache size;
-
Response time;
-
Fail safety.
-
-
S.M.A.R.T. Availability of this technology in the disk will help determining possible mistakes in its work and prevent loss of data before it is too late.
-
Package. This item can include interface or power cables as well as warranty and service options.
Article Suitable for:
WD HDD
- WD Blue
- WD Green
- WD Black
- WD Red
- WD Purple
- WD Gold
Seagate HDD
- BarraCuda
- FireCuda
- Backup/Expansion
- Enterprise (NAS)
- IronWolf (NAS)
- SkyHawk
Transcend HDD
- 25M (wstrząsoodporny)
- 25H (wstrząsoodporny)
- 25C (proste)
- 25A (wzorzec)
- 35T (pulpitowe)
Hitachi HDD
- Travelstar
- Deskstar (NAS)
- Ultrastar
HP HDD
- MSA SAS
- Server SATA
- Server SAS
- Midline SATA
- Midline SAS
IBM HDD
- V3700
- Near Line
- Express 2.5
- V3700 2.5
- Server
- Near Line 2.5
LaCie HDD
- Porsche/Mobile
- Porsche
- Rugged
- d2
A-Data HDD
- DashDrive
- HV
- Durable)
- HD
Silicon Power HDD
- Armor
- Diamond
- Stream
Toshiba HDD
- MG, DT, MQ
- P, X, L
- N, S, V
- DT, AL
Dell HDD
- SAS
- SCI
- Hot-Plug
Verbatim HDD
- Go (przenośny)
- Save (pulpitowe)
Team Group SSD
- EVO/Lite/GX2 (TLC)
- PD (портативные)
Silicon Power SSD
- Velox/M/Slim
- Ace (3D TLC)
Apacer SSD
- M.2
- ProII
- Portable
- Panther
Crucial SSD
- BX
- MX
GOODRAM SSD
- CL (TLC)
- PX (TLC)
- Iridium (MLC/TLC)
Kingston SSD
- Consumer
- HyperX
- Enterprise
- Builder
WD HDD
- WD Blue
- WD Green
- WD Black
- WD Red
- WD Purple
- WD Gold
Seagate HDD
- BarraCuda
- FireCuda
- Backup/Expansion
- Enterprise (NAS)
- IronWolf (NAS)
- SkyHawk
Transcend HDD
- 25M (ударостойкие)
- 25H (ударостойкие)
- 25C (простые)
- 25A (с узором)
- 35T (настольные)
Hitachi HDD
- Travelstar
- Deskstar (NAS)
- Ultrastar
HP HDD
- MSA SAS
- Server SATA
- Server SAS
- Midline SATA
- Midline SAS
IBM HDD
- V3700
- Near Line
- Express 2.5
- V3700 2.5
- Server
- Near Line 2.5
LaCie HDD
- Porsche/Mobile
- Porsche
- Rugged
- d2
A-Data HDD
- DashDrive
- HV
- Durable)
- HD
Silicon Power HDD
- Armor
- Diamond
- Stream
Toshiba HDD
- MG, DT, MQ
- P, X, L
- N, S, V
- DT, AL
Dell HDD
- SAS
- SCI
- Hot-Plug
Verbatim HDD
- Go (портативные)
- Save (настольные)
Team Group SSD
- EVO/Lite/GX2 (TLC)
- PD (портативные)
Silicon Power SSD
- Velox/M/Slim
- Ace (3D TLC)
Apacer SSD
- M.2
- ProII
- Portable
- Panther
Crucial SSD
- BX
- MX
GOODRAM SSD
- CL (TLC)
- PX (TLC)
- Iridium (MLC/TLC)
Kingston SSD
- Consumer
- HyperX
- Enterprise
- Builder
Patriot SSD
- Flare (MLC)
- Scorch (MLC, M.2)
- Spark (TLC)
- Blast/P (TLC)
- Burst (3D TLC)
- Viper (TLC, M.2)
Samsung SSD
- PRO (3D MLC)
- EVO
- QVO (3D QLC)
- Portable (внешние)
- DCT (серверные)
- PM (серверные)
Seagate SSD
- Nytro
- Maxtor
- FireCuda
- BarraCuda
- Expansion
- IronWolf
A-Data SSD
- Premier (MLC/TLC)
- Ultimate (3D NAND)
- XPG
- SC (внешние)
- SE (внешние)
- Durable
WD SSD
- WD Blue
- WD Green
- WD Black
- WD Red
- WD Purple
- WD Gold
Transcend SSD
- SSDXXX
- PATA
- MTSXXX
- MSAXXX
- ESDXXX
-
#1
Hi!
Short version: Raw_Read_Error_Rate has creeped up to 1 on a new WD Red after running SMART tests and badblocks. RMA the drive?
Long version:
System:
- Supermicro X10SLH-F-O
- Xeon E3-1231 v3
- 4 x 8GB Samsung ECC Memory (from Supermicro’s compatibility list)
- 6 x 4TB Western Digital Reds (WD40EFRX)
- Seasonic 460W Fanless (SS-460FL2 Active PFC F3)
- Antec 300 Illusion
- FreeNAS 9.2.1.7
Built the system, original PSU was DOA, ran memtest for 48 hours, memory checked out. Then ran SMART tests. My testing went something like this:
For each disk:
$ smartctl -t short /dev/adaX
$ smartctl -t conveyance /dev/adaX
$ smartctl -t long /dev/adaX
Then:
$ sysctl kern.geom.debugflags=0x10
And for each disk:
$ badblocks -ws /dev/adaX
$ smartctl -t long /dev/adaX
$ smartctl -A /dev/adaX
First time I did this everything went fine. Disks were staying around 30 deg C, they weren’t agressively spinning down, no errors reported. SMART values all looked sane. (The runtime for the long tests and badblocks seemed to vary between the drives, but I’m guessing this is due to slightly different rotation speeds?)
I rebooted and repeated the SMART and badblocks tests again. Tests passed (again), but I noticed that Raw_Read_Error_Rate is now 1 on one of the disks. This disk is the «oldest» of the bunch: I bought the drives over a period of ~2 months and was playing with FreeNAS before I had all the drives.
Should I be worried? I’m running the long tests again on that drive, and am thinking of running badblocks again. The system has been on for several weeks straight at this point, but besides testing it has been unused (been really busy… :/). Thoughts?
(I tried searching the forums for Raw_Read_Error_Rate but just found a lot of people posting their smartctl output… sorry if this has been asked many times before…)
Code:
# smartctl -A /dev/ada4 smartctl 6.2 2013-07-26 r3841 [FreeBSD 9.2-RELEASE-p10 amd64] (local build) Copyright (C) 2002-13, Bruce Allen, Christian Franke, www.smartmontools.org === START OF READ SMART DATA SECTION === SMART Attributes Data Structure revision number: 16 Vendor Specific SMART Attributes with Thresholds: ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE 1 Raw_Read_Error_Rate 0x002f 200 200 051 Pre-fail Always - 1 3 Spin_Up_Time 0x0027 180 178 021 Pre-fail Always - 7983 4 Start_Stop_Count 0x0032 100 100 000 Old_age Always - 20 5 Reallocated_Sector_Ct 0x0033 200 200 140 Pre-fail Always - 0 7 Seek_Error_Rate 0x002e 200 200 000 Old_age Always - 0 9 Power_On_Hours 0x0032 099 099 000 Old_age Always - 829 10 Spin_Retry_Count 0x0032 100 253 000 Old_age Always - 0 11 Calibration_Retry_Count 0x0032 100 253 000 Old_age Always - 0 12 Power_Cycle_Count 0x0032 100 100 000 Old_age Always - 20 192 Power-Off_Retract_Count 0x0032 200 200 000 Old_age Always - 7 193 Load_Cycle_Count 0x0032 200 200 000 Old_age Always - 25 194 Temperature_Celsius 0x0022 123 119 000 Old_age Always - 29 196 Reallocated_Event_Count 0x0032 200 200 000 Old_age Always - 0 197 Current_Pending_Sector 0x0032 200 200 000 Old_age Always - 0 198 Offline_Uncorrectable 0x0030 100 253 000 Old_age Offline - 0 199 UDMA_CRC_Error_Count 0x0032 200 200 000 Old_age Always - 0 200 Multi_Zone_Error_Rate 0x0008 200 200 000 Old_age Offline - 0
-
#2
There is no problem here. The RAW value of that attribute often isn’t meaningful as a decimal number. What you typically look at are the value, worst, and thresh. When a disk starts to get read errors the value will become lower and you don’t want it to cross the thresh. That’s the value the disk manufacturer has determined is a failed disk. Worst keeps track of the worst the read error rate has ever been since the rate of read errors could go both up and down.
All disks are going to get read errors like that and as long as it’s a low enough amount of them then the disk’s error correction systems keep it working reliably as intended.
-
#3
A value of 1 for raw error rates is cause to be cautious but not cause for concern. The fact that badblocks found no errors and the disk has no bad sectors identified by SMART tells me the disk is fine and your drive may have hit one of those UREs or some kind of temporary situation.
Anyway, I wouldn’t worry about it. I’d use the disk. But I’d definitely be sure to setup a good SMART schedule as well as a good scrub schedule just as a precaution. Of course, you should be setting those up even if the raw error rate was zero.

-
#4
The raw read error rate is not particularly relevant if it’s low.
One of my brand-new WD Reds almost immediately wound up with a Read Error Rate of 2 and a Multi Zone Error Rate of 1.
The latter went back to 0 after a few rounds of badblocks, the former stayed at 2. Badblocks found no errors in 8 passes.
tl;dr — just make sure the drives are monitored (and the pool is scrubbed) so you’re warned if things deteriorated.
-
#5
Raw read error rate would not indicate a URE if it’s the only attribute that’s changing.
Raw read error rate are the raw errors before error correction is applied by the disk firmware. A URE would be an error that was not able to be corrected by the ECC within the disk and would show up in a different SMART attribute as well.
-
#6
Raw read error rate would not indicate a URE if it’s the only attribute that’s changing.
Raw read error rate are the raw errors before error correction is applied by the disk firmware. A URE would be an error that was not able to be corrected by the ECC within the disk and would show up in a different SMART attribute as well.
That’s not true. WD, Seagate and Toshiba have different definitions for what hits the raw read error rate. 
That’s why I said it «may» have been a URE. I can’t remember which is which though. But, you’d be surprised to find that typically one out of every 1000 reads has to be corrected by ECC within the disk. There’s tools that allow you to actually monitor the number of ECC corrections since the disk was powered on, and it can very quickly turn into rather high numbers.
-
#7
Yeah with the shear size and speed of hard drives read errors are happening all the time but most of the time the disk can correct them itself so the OS never needs to know about them.
From what I understand a URE is when the disk can’t fix it by retrying or by ECC and then it’s up to the OS ultimately (ZFS) to deal with the error.
My Seagate drives use the raw read error rate differently. They have a very large number in the raw column which I believe specifies just how many of these «soft» raw read errors are occurring per some timeframe, hence «rate». And the current, worst, and thresh is a score of how low or high the current rate is compared to what the manufacture deems acceptable.
-
#8
Thanks for all the replies! Long test on that drive finished with no errors. Running another round of `badblocks` just to be sure…
Anyway, I wouldn’t worry about it. I’d use the disk. But I’d definitely be sure to setup a good SMART schedule as well as a good scrub schedule just as a precaution. Of course, you should be setting those up even if the raw error rate was zero.
That’s the plan! (Following your recommendations from here.)
From what I understand a URE is when the disk can’t fix it by retrying or by ECC and then it’s up to the OS ultimately (ZFS) to deal with the error.
But that’s the whole point of the `zpool scrub`, right? The scrub checks all the data in the pool, and if it does encounter a URE it can heal itself, correct?
My Seagate drives use the raw read error rate differently. They have a very large number in the raw column which I believe specifies just how many of these «soft» raw read errors are occurring per some timeframe, hence «rate». And the current, worst, and thresh is a score of how low or high the current rate is compared to what the manufacture deems acceptable.
Interesting. I will keep an eye on all the drives over the next few weeks to see if the WD Reds are doing something similar. All the disks have the same VALUE and WORST (200), but only this one disk has a RAW_VALUE of 1.
-
#9
The raw read error rate is not particularly relevant if it’s low.
One of my brand-new WD Reds almost immediately wound up with a Read Error Rate of 2 and a Multi Zone Error Rate of 1.
The latter went back to 0 after a few rounds of badblocks, the former stayed at 2. Badblocks found no errors in 8 passes.tl;dr — just make sure the drives are monitored (and the pool is scrubbed) so you’re warned if things deteriorated.
Eric,
I have the same issue you had, i am rerunning badblocks again hoping it will go back to a lower value. Is this RMA worthy if not?
Code:
=== START OF READ SMART DATA SECTION === SMART Attributes Data Structure revision number: 16 Vendor Specific SMART Attributes with Thresholds: ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE 1 Raw_Read_Error_Rate 0x002f 200 200 051 Pre-fail Always - 6 3 Spin_Up_Time 0x0027 187 182 021 Pre-fail Always - 5616 4 Start_Stop_Count 0x0032 100 100 000 Old_age Always - 11 5 Reallocated_Sector_Ct 0x0033 200 200 140 Pre-fail Always - 0 7 Seek_Error_Rate 0x002e 200 200 000 Old_age Always - 0 9 Power_On_Hours 0x0032 100 100 000 Old_age Always - 86 10 Spin_Retry_Count 0x0032 100 253 000 Old_age Always - 0 11 Calibration_Retry_Count 0x0032 100 253 000 Old_age Always - 0 12 Power_Cycle_Count 0x0032 100 100 000 Old_age Always - 11 192 Power-Off_Retract_Count 0x0032 200 200 000 Old_age Always - 7 193 Load_Cycle_Count 0x0032 200 200 000 Old_age Always - 24 194 Temperature_Celsius 0x0022 122 117 000 Old_age Always - 28 196 Reallocated_Event_Count 0x0032 200 200 000 Old_age Always - 0 197 Current_Pending_Sector 0x0032 200 200 000 Old_age Always - 0 198 Offline_Uncorrectable 0x0030 100 253 000 Old_age Offline - 0 199 UDMA_CRC_Error_Count 0x0032 200 200 000 Old_age Always - 0 200 Multi_Zone_Error_Rate 0x0008 200 200 000 Old_age Offline - 2
-
#10
Unless you can run a short (or long) SMART test and it fail it generally isn’t considered «worthy» for an RMA. That depends on the manufacturer of your disk though, so you’d need to see their RMA requirements.
-
#11
Unless you can run a short (or long) SMART test and it fail it generally isn’t considered «worthy» for an RMA. That depends on the manufacturer of your disk though, so you’d need to see their RMA requirements.
Cyberjock — i followed your steps and did a short test,long test, badblocks random, short test, long test. No errors reported on badblocks and this was only drive w/smart data that looked concerning. It is a WD 3TB Red Drive btw.
-
#12
Your values are a bit higher. I didn’t worry too much about mine, since the error rates are poorly defined and monitoring is in place to warn me if needed.
I’d recommend you stress that drive as much as you can. If it holds up, stop worrying (and optionally start loving the bomb — or in this case, RAIDZ2). If it fails, you can RMA it and the problem is solved.
-
#13
Your values are a bit higher. I didn’t worry too much about mine, since the error rates are poorly defined and monitoring is in place to warn me if needed.
I’d recommend you stress that drive as much as you can. If it holds up, stop worrying (and optionally start loving the bomb — or in this case, RAIDZ2). If it fails, you can RMA it and the problem is solved.
I’m running another round of badblocks testing as we speak, just in case. I’m just so upset i need to wait another few days to get my beast up and running, cant wait
Thanks everyone for advice!
-
#14
For Seagate drives the least significant 32 bits of the Raw_Read_Error_Rate and the Seek_Error_Rate refer to the number of operations, and the most significant 16—to the error count; as such, for Seagate drives, if the raw values in the error rates attributes are below 4294967296 (2^32) then no errors have occurred.
-
#15
For Seagate drives the least significant 32 bits of the Raw_Read_Error_Rate and the Seek_Error_Rate refer to the number of operations, and the most significant 16—to the error count; as such, for Seagate drives, if the raw values in the error rates attributes are below 4294967296 (2^32) then no errors have occurred.
Actually I think that’s for Seagate and Hitachis.
Why exactly is a «Raw Read Error Rate» of 1 considered bad? Isn’t it the lower the read error rate, the better the reads (and the less the errors)?
Your research has found that this Raw Read Error Rate is derived from the «total number of correctable and uncorrectable ECC error events». The number is normalized and treated as a percentage, so the current value represents 1%, i.e. 1% of read operations have had an issue.
Modern NAND chips explicitly mandate ECC capability because occasional bit errors on read can occur during normal operation. The requirement will specify a permissible number of bits that might be in error per NAND page read, and need correction.
In other words a read operation may occasionally incur correctable errors, and therefore this is not an indicator of pending failure.
The occurrence of uncorrectable read errors could be problematic. In theory a sector/page/block that (consistently) generates uncorrectable read errors should be identified by the integrated drive controller, marked as a bad block, and retired from use.
The Raw Read Error Rate is not as significant as the number of uncorrectable read errors (which is now available in the SMART report that you appended).
The number of uncorrectable read errors seems to be indicated in Reported Uncorrectable Errors as 0x1B3 or 435.
Compared to the total read errors of 0x1C9 or 457, that would indicate that there were only 22 (benign) correctable read errors (assuming no wrap-around), but 95% of that total are the concerning uncorrectable read errors.
Does this mean my SSD is about to fail imminently? It has been working fine since I bought my laptop years ago…
If you think that the drive is «working fine», then that could mean that the drive was able to recover from those errors by retrying successfully and/or remapping was successful. (Note that the SMART report indicates that 9 blocks have been retired so far during this drive’s lifetime.)
At the very least you could backup your data from that drive, and regularity monitor the SMART report for changes.
With almost 20,000 hours of use, there’s no way to determine when these errors occurred.
But you could try to generate fresh read errors by scanning the entire drive, either using the SMART long/extended test or using a Linux command such as sudo dd if=/dev/sdX of=/dev/null. The first test is a lot faster but would only increment the SMART statistics, whereas the later test could also abort on a read error and thus provide a LBA of a problem area.
If you do not encounter more read errors, then that could be reassuring.
Note that the SMART report indicates the current value of 98% for Percent Lifetime Used indicates that only 2% of the expected lifetime has been used. The raw value of 2 indicates that neither of the two salient end-of-life indicators (average block wear and available spare blocks) are problematic.
- Status
- Not open for further replies.
-
#1

-
- Sep 22, 2010
-
- 8,597
-
- 545
-
- 36,390
- 986
-
#9
A value of 0x179 corresponds to 377 in decimal, and 0x57 = 87.
Here is an example of a bad drive:
http://malthus.mooo.com/viewtopic.php?t=1024
I would keep an eye on those values.
-
- Sep 22, 2010
-
- 8,597
-
- 545
-
- 36,390
- 986

-
- Jul 30, 2014
-
- 6,758
-
- 3
-
- 45,960
- 3,002
-
#3
I’d suggest to back up all the data from that drive ASAP.
Read Error Rate indicates that there is a problem with the disk heads or maybe a bad connection with to the PSU. I’d suggest to re-seat the cables to the HDD and test it once again. The higher this Read Error Rate parameter is, the more possible HDD failures!
The Write Error Rate parameter indicates the number of errors appearing while you are recording data to the drive. It may be caused by problems with the disk surface or the read/write heads.
I strongly recommend checking your warranty and contacting your HDD manufacturer to RMA your drive.
You should be able to get a replacement product, just make sure you backup the data beforehand.
Hope this helps!
SuperSoph_WD
-
#4
I’d suggest to back up all the data from that drive ASAP.
Read Error Rate indicates that there is a problem with the disk heads or maybe a bad connection with to the PSU. I’d suggest to re-seat the cables to the HDD and test it once again. The higher this Read Error Rate parameter is, the more possible HDD failures!
The Write Error Rate parameter indicates the number of errors appearing while you are recording data to the drive. It may be caused by problems with the disk surface or the read/write heads.
I strongly recommend checking your warranty and contacting your HDD manufacturer to RMA your drive.
You should be able to get a replacement product, just make sure you backup the data beforehand.
Hope this helps!
SuperSoph_WD
Hi!
Thanks for the reply. Is it really that bad?! I tested with HD Tune and Sentinel as well and all say that the HD is healthy.

-
- Aug 24, 2012
-
- 15,250
-
- 1,087
-
- 69,540
- 1,656
-
#5
-
- Jul 30, 2014
-
- 6,758
-
- 3
-
- 45,960
- 3,002
-
#6
Thanks for the reply. Is it really that bad?! I tested with HD Tune and Sentinel as well and all say that the HD is healthy.
Not necessarily. If two out of three utilities say it’s okay, I’d be inclined to believe them (and those specifically are pretty good diagnostics/testing tools). I’d still backup the data regularly, this is the best way to avoid the headaches of data loss. Unfortunately, mechanical drives often fail unexpectedly.
However, I’d recommend keeping an eye on the SMART data every once in awhile though, making sure everything is okay.
You can still post the screenshots of those utilities if you want to. ")
PS: Just saw what @ex_bubblehead mentioned, he is right! Wouldn’t hurt to try with a different SATA cable.
Hope we were helpful!
SuperSoph_WD
-
#7
So, it’s probably the cable and not a physical problem and I shouldn’t worry as long as the number stays the same?!
Not necessarily. If two out of three utilities say it’s okay, I’d be inclined to believe them (and those specifically are pretty good diagnostics/testing tools). I’d still backup the data regularly, this is the best way to avoid the headaches of data loss. Unfortunately, mechanical drives often fail unexpectedly.
However, I’d recommend keeping an eye on the SMART data every once in awhile though, making sure everything is okay.
You can still post the screenshots of those utilities if you want to.
PS: Just saw what @ex_bubblehead mentioned, he is right! Wouldn’t hurt to try with a different SATA cable.
Hope we were helpful!
SuperSoph_WD
Yeah, I tested with CrystalDiskInfo, HD Tune and Sentinel and they all say it’s ok.
Just wondering if those values will be a problem on the near future.
-
- Jul 30, 2014
-
- 6,758
-
- 3
-
- 45,960
- 3,002
-
#8
So, it’s probably the cable and not a physical problem and I shouldn’t worry as long as the number stays the same?!
Yeah, I tested with CrystalDiskInfo, HD Tune and Sentinel and they all say it’s ok.
Just wondering if those values will be a problem on the near future.
Most probably if those were the problem, you’d hear it and feel it in the overall performance of the drive.
Swap the SATA cables and test it again, I think that will get the S.M.A.R.T. values back to normal.
SuperSoph_WD
-
- Sep 22, 2010
-
- 8,597
-
- 545
-
- 36,390
- 986
-
#9
A value of 0x179 corresponds to 377 in decimal, and 0x57 = 87.
Here is an example of a bad drive:
http://malthus.mooo.com/viewtopic.php?t=1024
I would keep an eye on those values.
- Status
- Not open for further replies.
| Thread starter | Similar threads | Forum | Replies | Date |
|---|---|---|---|---|
|
T
|
Question adding a new M.2 SSD to my motherboard causes PC to receive a boot error | Storage | 6 | Feb 1, 2023 |
|
|
[SOLVED] Repairing Disc Errors This May Take Over an Hour to Complete? | Storage | 22 | Jan 31, 2023 |
|
R
|
Question Seagate HDD in intermittent state (can’t initialize) (I/O ERROR) after I cancelled their software’s sanitization progress | Storage | 0 | Jan 26, 2023 |
|
D
|
Question Standard NVM Express Controller error — NVMe drive not detected in BIOS ? | Storage | 2 | Jan 14, 2023 |
|
S
|
[SOLVED] Is there a way to fix HDD CRC error | Storage | 1 | Jan 2, 2023 |
|
J
|
Question Really struggling to clone my hard disk on to SSD with Macrium Reflect , Error 0 and 23 | Storage | 9 | Dec 8, 2022 |
|
I
|
Question Why do we erratically get BSOD 14c error only on multiple HDD/SSD, with M.2 SSD as Boot drive ? | Storage | 5 | Dec 2, 2022 |
|
|
Question HDD i/o error | Storage | 2 | Nov 29, 2022 |
|
T
|
Question Whea uncorrectable error Stop Code Bluescreen | Storage | 3 | Nov 24, 2022 |
|
I
|
[SOLVED] Write Error Rate values ? Data corruption ? | Storage | 12 | Sep 1, 2022 |


- Advertising
- Cookies Policies
- Privacy
- Term & Conditions
- Topics
Skip to content
Что делать с «0x1 Raw Read Error Rate»?
При загрузке компьютера или ноутбука возникает S.M.A.R.T. ошибка «0x1 Raw Read Error Rate» жесткого диска или SSD? После данной ошибки компьютер не работает как прежде, и вы опасаетесь о сохранности ваших данных? Не знаете как исправить «0x1 Raw Read Error Rate»?
Что означает «0x1»: Raw Read Error Rate? Допустимые значения атрибута «Raw Read Error Rate» отличаются для различных производителей жестких дисков WD (Western Digital), Samsung, Seagate, HGST (Hitachi), Toshiba.
Актуально для ОС: Windows 10, Windows 8.1, Windows Server 2012, Windows 8, Windows Home Server 2011, Windows 7 (Seven), Windows Small Business Server, Windows Server 2008, Windows Home Server, Windows Vista, Windows XP, Windows 2000, Windows NT.
Программа для восстановления данных
Способ 2: Восстановите удаленные данные диска
В случае возникновения SMART ошибки не всегда требуется восстановление данных с диска. В случае ошибки рекомендуется незамедлительно
создать копию важных данных, так как диск может выйти из строя в любой момент. Но бывают ошибки при которых скопировать данные уже не представляется возможным.
В таком случае можно использовать программу для восстановления данных жесткого диска — Hetman Partition Recovery.
Для этого:
- Загрузите программу, установите и запустите её.
- По умолчанию, пользователю будет предложено воспользоваться Мастером восстановления файлов. Нажав кнопку «Далее», программа предложит выбрать диск, с которого необходимо восстановить файлы.
- Дважды кликните на сбойном диске и выберите необходимый тип анализа. Выбираем «Полный анализ» и ждем завершения процесса сканирования диска.
- После окончания процесса сканирования вам будут предоставлены файлы для восстановления. Выделите нужные файлы и нажмите кнопку «Восстановить».
- Выберите один из предложенных способов сохранения файлов. Не сохраняйте восстановленные файлы на диск с ошибкой «0x1 Raw Read Error Rate».
Программа для восстановления данных
Способ 4: Снизьте температуру диска
Иногда, причиной возникновения «S M A R T» ошибки может быть превышение максимально допустимой температуры работы диска.
Такая ошибка может быть устранена путём улучшения вентиляции компьютера.
Во-первых, проверьте оборудован ли ваш компьютер достаточной вентиляцией и все ли вентиляторы исправны.
Если вами обнаружена и устранена проблема с вентиляцией, после чего температура работы диска снизилась
до нормального уровня, то SMART ошибка может больше не возникнуть.
Способ 6: Ошибка «Raw Read Error Rate» для SSD диска
Даже если у вас не претензий к работе SSD диска, его работоспособность постепенно снижается. Причиной этому служит факт того,
что ячейки памяти SSD диска имеют ограниченное количество циклов перезаписи. Функция износостойкости минимизирует данный эффект, но не устраняет его полностью.
SSD диски имеют свои специфические SMART атрибуты, которые сигнализируют о состоянии ячеек памяти диска.
Например, «209 Remaining Drive Life», «231 SSD life left» и т.д. Данные ошибки могут возникнуть в случае снижения работоспособности ячеек,
и это означает, что сохранённая в них информация может быть повреждена или утеряна.
Ячейки SSD диска в случае выхода из строя не восстанавливаются и не могут быть заменены.
Способ 8: Приобретите новый жесткий диск
Целесообразен ли ремонт HDD?
Важно понимать, что любой из способов устранения SMART ошибки – это самообман.
Невозможно полностью устранить причину возникновения ошибки, так как основной причиной её возникновения
часто является физический износ механизма жесткого диска.
Для устранения или замены неправильно работающих составляющих жесткого диска,
можно обратится в сервисный центр специальной лабораторией для работы с жесткими дисками.
Но стоимость работы в таком случае будет выше стоимости нового устройства.
Поэтому, ремонт имеет смысл делать только в случае необходимости восстановления данных с уже неработоспособного диска.
Как выбрать новый накопитель?
Если вы столкнулись со SMART ошибкой жесткого диска то, приобретение нового диска – это только вопрос времени.
То, какой жесткий диск нужен вам зависит от вашего стиля работы за компьютером, а также цели с которой его используют.
На что обратить внимание приобретая новый диск:
- Тип диска: HDD, SSD или SSHD. Каждому типу присущи свои плюсы и минусы, которые не имеют решающего значения для одних пользователей и очень важны для других. Основные из них — это скорость чтения и записи информации, объём и устойчивость к многократной перезаписи.
- Размер. Два основных форм-фактора дисков: 3,5 дюймов и 2,5 дюймов. Размер диска определяется в соответствии с установочным местом конкретного компьютера или ноутбука.
- Интерфейс. Основные интерфейсы жестких дисков: SATA, IDE, ATAPI, ATA, SCSI, Внешний диск (USB, FireWire и.т.д.).
- Технические характеристики и производительность:
- Вместимость;
- Скорость чтения и записи;
- Размер буфера памяти или cache;
- Время отклика;
- Отказоустойчивость.
- S.M.A.R.T. Наличие в диске данной технологи поможет определить возможные ошибки его работы и вовремя предупредить утерю данных.
- Комплектация. К данному пункту можно отнести возможное наличие кабелей интерфейса или питания, а также гарантии и сервиса.