Здравствуйте.
Ubuntu 16, FastCGI (Nginx + PHP-FPM), PHP 7.2.
Со вчерашнего дня сайт периодически выдает 502 ошибку, в лог пишет:
2018/09/02 08:41:18 [error] 7016#7016: *7584 recv() failed (104: Connection reset by peer) while reading response header from upstream, client: xx.xxx.xxx.xxx, server: site.com, request: "GET /page/url/ HTTP/1.1", upstream: "fastcgi://unix:/run/php/php7.2-fpm.sock:", host: "site.com"Мой конфиг:
user www-data;
worker_processes auto;
worker_rlimit_nofile 65000;
timer_resolution 100ms;
worker_priority -5;
error_log /var/log/nginx/error.log warn;
pid /var/run/nginx.pid;
events {
worker_connections 4096;
multi_accept on;
use epoll;
}
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
keepalive_timeout 65;
reset_timedout_connection on;
include /etc/nginx/conf.d/*.conf;
include /etc/nginx/vhosts/*/*.conf;
client_body_buffer_size 8m;
client_max_body_size 128m;
open_file_cache max=200000 inactive=20s;
open_file_cache_valid 30s;
open_file_cache_min_uses 2;
open_file_cache_errors on;
server {
server_name localhost;
disable_symlinks if_not_owner;
include /etc/nginx/vhosts-includes/*.conf;
location @fallback {
error_log /dev/null crit;
proxy_pass http://127.0.0.1:8080;
proxy_redirect http://127.0.0.1:8080 /;
proxy_set_header Host $host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
access_log off ;
}
listen 80;
listen [::]:80;
}
}И второй конфиг:
server {
server_name site.com www.site.com;
charset UTF-8;
index index.php;
disable_symlinks if_not_owner from=$root_path;
include /etc/nginx/vhosts-includes/*.conf;
include /etc/nginx/vhosts-resources/site.com/*.conf;
error_log /var/www/httpd-logs/site.com.error.log crit;
ssi on;
return 301 https://$host:443$request_uri;
set $root_path /var/www/www-root/data/www/site.com;
root $root_path;
gzip on;
gzip_comp_level 5;
gzip_disable "msie6";
gzip_types text/plain text/css application/json application/x-javascript text/xml application/xml application/xml+rss text/javascript application/javascript;
error_log /var/www/httpd-logs/site.com.error.log notice;
location ~* ^.+.(jpg|jpeg|gif|png|ico|css|js|ico)$ {
expires 7d;
}
location / {
try_files $uri /index.php?do=$uri;
location ~ [^/].ph(pd*|tml)$ {
try_files /does_not_exists @php;
}
}
location @php {
fastcgi_index index.php;
fastcgi_param PHP_ADMIN_VALUE "sendmail_path = /usr/sbin/sendmail -t -i -f znleha@yandex.ru";
fastcgi_pass unix:/run/php/php7.2-fpm.sock;
fastcgi_split_path_info ^((?U).+.ph(?:pd*|tml))(/?.+)$;
try_files $uri =404;
fastcgi_buffers 4 512k;
fastcgi_busy_buffers_size 512k;
fastcgi_temp_file_write_size 512k;
include fastcgi_params;
}
access_log off;
listen 77.222.63.224:80 default_server;
listen [2a02:408:7722:54:77:222:63:224]:80 default_server;
}
server {
server_name site.com www.site.com;
ssl_certificate "/var/www/httpd-cert/www-root/site.com_le1.crtca";
ssl_certificate_key "/var/www/httpd-cert/www-root/site.com_le1.key";
ssl_ciphers EECDH:+AES256:-3DES:RSA+AES:!NULL:!RC4;
ssl_prefer_server_ciphers on;
ssl_protocols TLSv1 TLSv1.1 TLSv1.2;
add_header Strict-Transport-Security "max-age=31536000;";
ssl_dhparam /etc/ssl/certs/dhparam4096.pem;
charset UTF-8;
index index.php;
disable_symlinks if_not_owner from=$root_path;
include /etc/nginx/vhosts-includes/*.conf;
include /etc/nginx/vhosts-resources/site.com/*.conf;
error_log /var/www/httpd-logs/site.com.error.log crit;
ssi on;
set $root_path /var/www/www-root/data/www/site.com;
root $root_path;
gzip on;
gzip_comp_level 5;
gzip_disable "msie6";
gzip_types text/plain text/css application/json application/x-javascript text/xml application/xml application/xml+rss text/javascript application/javascript;
error_log /var/www/httpd-logs/site.com.error.log notice;
listen [2a02:408:7722:54:77:222:63:224]:443 ssl default_server;
listen 77.222.63.224:443 ssl default_server;
location ~* ^.+.(jpg|jpeg|gif|png|ico|css|js|ico)$ {
expires 7d;
}
location / {
try_files $uri /index.php?do=$uri;
location ~ [^/].ph(pd*|tml)$ {
try_files /does_not_exists @php;
}
}
location @php {
fastcgi_index index.php;
fastcgi_param PHP_ADMIN_VALUE "sendmail_path = /usr/sbin/sendmail -t -i -f znleha@yandex.ru";
fastcgi_pass unix:/run/php/php7.2-fpm.sock;
fastcgi_split_path_info ^((?U).+.ph(?:pd*|tml))(/?.+)$;
try_files $uri =404;
fastcgi_buffers 4 512k;
fastcgi_busy_buffers_size 512k;
fastcgi_temp_file_write_size 512k;
include fastcgi_params;
}
access_log off;
}
Ошибка может появиться в любой момент (может и не появиться)… От куда ноги растут, не пойму…
Подскажите, куда копать?
Спасибо.
Nginx 502 is an uncommon error that causes due to issue with your server Nginx and PHP-FastCGI. If you notice any Nginx 502 error it is better to check the Nginx log.
When you are investigating the Nginx error logs, you can see that the “recv() failed (104: Connection reset by peer) while reading response header from upstream,” error. This also results in a “no live upstreams while connecting to upstream” error. When I’m checking my WordPress site logs I saw that several times appeared that error log. This is an issue with the Nginx and PHP-FPM configurations. Can easily fix it in just a few steps.
There are mainly three different reasons for Nginx Connection reset by peer.
- Nginx and PHP-FPM communication error.
- PHP-FPM is timing out quickly.
- PHP-FPM is not running.
In order to fix 104: Connection reset by peer while reading response header from upstream issue, you should have access to modify the PHP and Nginx configuration files. If you are on shared hosting or a managed hosting package, you can ask your hosting partner to correct that configuration file.
![]()
If you can see continuous connection reset by peer error your visitors may receive “502 Bad Gateway” errors. To correct this Nginx error you must set Nginx keepalive_requests and PHP-FPM pm.max_requests equal value. If these two values are not equal then the Nginx or PHP-FPM end up closing the connection. This is an issue caused by server configuration mismatch, you can fix it by like our Logrotate issue guide.
Change Nginx keepalive_requests.
- Open the nginx.conf configuration file with sudo privileges.
- Change keepalive_requests as per your need. Don’t use too high keepalive_requests, it can cause excessive memory usage.

- Save the configuration file.
Change PHP-FPM www.conf
- Open the www.conf file with sudo privilege.
- In “pm.max_requests” enter the same value you set on “keepalive_requests” in the Nginx conf file.

- Save the configuration file.
- Restart the Nginx and PHP-FPM by running the following command line.
Check PHP permission for session.save_path.
In some situations, your PHP is not able to write the season file. This will generate Nginx 502 connection reset by peer while reading response header from upstream.
There can be several reasons for PHP is not able to write the season file. It can be bad permissions, bad directory ownership, or even bad user/group.
- First check where your PHP session.save_path is. Some situations it is “/var/lib/php/sessions” or “/var/lib/php/session“
- Open your system php.ini file and search for “session.save_path“.
- Then you can see your system PHP session.save_path.
- Run the following command in your SSH terminal to fix the permission issue. In this example my LEMP stack php session.save_path is “/var/lib/php/session“
- Then restart php.
Change FastCGI Timeouts.
Another solution is to change the Nginx Fast-CGI timeouts. Default FastCGI timeout is the 60s. Your application may require higher than the 60s to run, therefore it is better to change the following timeouts to prevent Nginx 502 bad gateway error.
- Open the nginx configuration file. Generally it is “/etc/nginx/nginx.conf“.
- Change add the following timeout values to your nginx.conf.
-
- fastcgi_read_timeout 300;
- fastcgi_send_timeout 300;
- fastcgi_connect_timeout 300;
-
- Save the changes and restart nginx.
Increase opcache memory limit.
If your system PHP uses opcache if the opcache memory gets filled, it will show connection reset by peer while reading response header from upstream. The simple solution is to increase the opcache memory limit.
- Open the php.ini file.
- Search for “opcache.memory_consumption”.
- Change the value to a higher amount like below.
opcache.memory_consumption = 256
- From now, your error should disappear and visitors can access your site without any error.

I have a server which was working ok until 3rd Oct 2013 at 10:50am when it began to intermittently return «502 Bad Gateway» errors to the client.
Approximately 4 out of 5 browser requests succeed but about 1 in 5 fail with a 502.
The nginx error log contains many hundreds of these errors;
2013/10/05 06:28:17 [error] 3111#0: *54528 recv() failed (104: Connection reset by peer) while reading response header from upstream, client: 66.249.66.75, server: www.bec-components.co.uk request: ""GET /?_n=Fridgefreezer/Hotpoint/8591P;_i=x8078 HTTP/1.1", upstream: "fastcgi://127.0.0.1:9000", host: "www.bec-components.co.uk"
However the PHP error log does not contain any matching errors.
Is there a way to get PHP to give me more info about why it is resetting the connection?
This is nginx.conf;
user www-data;
worker_processes 4;
error_log /var/log/nginx/error.log;
pid /var/run/nginx.pid;
events {
worker_connections 1024;
}
http {
include /etc/nginx/mime.types;
access_log /var/log/nginx/access.log;
sendfile on;
keepalive_timeout 30;
tcp_nodelay on;
client_max_body_size 100m;
gzip on;
gzip_types text/plain application/xml text/javascript application/x-javascript text/css;
gzip_disable "MSIE [1-6].(?!.*SV1)";
include /gvol/sites/*/nginx.conf;
}
And this is the .conf for this site;
server {
server_name www.bec-components.co.uk bec3.uk.to bec4.uk.to bec.home;
root /gvol/sites/bec/www/;
index index.php index.html;
location ~ .(js|css|png|jpg|jpeg|gif|ico)$ {
expires 2592000; # 30 days
log_not_found off;
}
## Trigger client to download instead of display '.xml' files.
location ~ .xml$ {
add_header Content-disposition "attachment; filename=$1";
}
location ~ .php$ {
fastcgi_read_timeout 3600;
include /etc/nginx/fastcgi_params;
keepalive_timeout 0;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
fastcgi_pass 127.0.0.1:9000;
fastcgi_index index.php;
}
}
## bec-components.co.uk ##
server {
server_name bec-components.co.uk;
rewrite ^/(.*) http://www.bec-components.co.uk$1 permanent;
}
Connection Reset by peer means the remote side is terminating the session. This error is generated when the OS receives notification of TCP Reset (RST) from the remote peer.
Understanding Connection Reset by peer
Connection reset by peer means the TCP stream was abnormally closed from the other end. A TCP RST was received and the connection is now closed. This occurs when a packet is sent from our end of the connection but the other end does not recognize the connection; it will send back a packet with the RST bit set in order to forcibly close the connection.
“Connection reset by peer” is the TCP/IP equivalent of slamming the phone back on the hook. It’s more polite than merely not replying, leaving one hanging. But it’s not the FIN-ACK expected of the truly polite TCP/IP.
Understanding RST TCP Flag
RST is used to abort connections. It is very useful to troubleshoot a network connection problem.
RST (Reset the connection). Indicates that the connection is being aborted. For active connections, a node sends a TCP segment with the RST flag in response to a TCP segment received on the connection that is incorrect, causing the connection to fail.
The sending of an RST segment for an active connection forcibly terminates the connection, causing data stored in send and receive buffers or in transit to be lost. For TCP connections being established, a node sends an RST segment in response to a connection establishment request to deny the connection attempt. The sender will get Connection Reset by peer error.
Understanding TCP Flags SYN ACK RST FIN URG PSH
Check network connectivity
The “ping” command is a tool used to test the availability of a network resource. The “ping” command sends a series of packets to a network resource and then measures the amount of time it takes for the packets to return.
If you want to ping a remote server, you can use the following command: ping <remote server>
In this example, “<remote server>” is the IP address or hostname of the remote server that you want to ping.
Ping the remote host we were connected to. If it doesn’t respond, it might be offline or there might be a network problem along the way. If it does respond, this problem might have been a transient one (so we can reconnect now)
If you are experiencing packet loss when pinging a remote server, there are a few things that you can do to troubleshoot the issue.
The first thing that you can do is check the network interface on the remote server. To do this, use the “ifconfig” command. The output of the “ifconfig” command will show you the status of all network interfaces on the system. If there is a problem with one of the interfaces, it will be shown in the output.
You can also use the “ip route” command to check routing information. The output of the “ip route” command will show you a list of all routes on the system. If there is a problem with one of the routes, it will be shown in the output.
If you are still experiencing packet loss, you can try to use a different network interface. To do this, use the “ping” command with the “-i” option. For example, the following command will use the eth0 interface:
ping -i eth0 google.com
Check remote service port is open
A port is a logical entity which acts as a endpoint of communication associated with an application or process on an Linux operating system. We can use some Linux commands to check remote port status.
Commands like nc, curl can be used to check if remote ports are open or not. For example, the following command will check if port 80 is open on google.com:
nc -zv google.com 80
The output of the above command should look something like this: Connection to google.com port 80 [tcp/80] succeeded!
This means that the port is open and we can establish a connection to it.
6 ways to Check a remote port is open in Linux
Check application log on remote server
For example, if the error is related with SSH. we can debug this on the remote server from sshd logs. The log entries will be in one of the files in the /var/log directory. SSHD will be logging something every time it drops our session.
Oct 22 12:09:10 server internal-sftp[4929]: session closed for local user fred from [192.0.2.33]
Check related Linux kernel parameters
Kernel parameter is also related to Connection Reset by peer error. The keepalive concept is very simple: when we set up a TCP connection, we associate a set of timers. Some of these timers deal with the keepalive procedure. When the keepalive timer reaches zero, we send our peer a keepalive probe packet with no data in it and the ACK flag turned on.
we can do this because of the TCP/IP specifications, as a sort of duplicate ACK, and the remote endpoint will have no arguments, as TCP is a stream-oriented protocol. On the other hand, we will receive a reply from the remote host (which doesn’t need to support keepalive at all, just TCP/IP), with no data and the ACK set.
If we receive a reply to we keepalive probe, we can assert that the connection is still up and running without worrying about the user-level implementation. In fact, TCP permits us to handle a stream, not packets, and so a zero-length data packet is not dangerous for the user program.
we usually use tcp keepalive for two tasks:
- Checking for dead peers
- Preventing disconnection due to network inactivity
Check Application heartbeat configuration
Connection Reset by peer error is also related to the application. Certain networking tools (HAproxy, AWS ELB) and equipment (hardware load balancers) may terminate “idle” TCP connections when there is no activity on them for a certain period of time. Most of the time it is not desirable.
We will use rabbitmq as an example. When heartbeats are enabled on a connection, it results in periodic light network traffic. Therefore heartbeats have a side effect of guarding client connections that can go idle for periods of time against premature closure by proxies and load balancers.
With a heartbeat timeout of 30 seconds the connection will produce periodic network traffic roughly every 15 seconds. Activity in the 5 to 15 second range is enough to satisfy the defaults of most popular proxies and load balancers. Also see the section on low timeouts and false positives above.
Check OS metric on peer side
Connection Reset by peer can be triggered by a busy system. we can setup a monitoring for our Linux system to the metrics like CPU, memory, network etc. If the system is too busy, the network will be impacted by this.
For example, we can use the “top” command to check the CPU usage. The output of the “top” command will show us the list of processes sorted by CPU usage. If there is a process which is using a lot of CPU, we can investigate this further to see if it is causing the network issues.
We can also use the “netstat” command to check network statistics. The output of the “netstat” command will show us a list of active network connections. If there are too many connections established, this could be causing the network issues.
We can use these commands to troubleshoot network issues on a Linux system. By using these commands, we can narrow down the root cause of the issue and fix it.
Monitoring Linux System with Telegraf Influxdb Grafana
Troubleshoot Network Slow Problems In Linux
What? Connection reset by peer?
We are running Node.js web services behind AWS Classic Load Balancer. I noticed that many 502 errors after I migrate AWS Classic Load Balancer to Application Load Balancer. In order to understand what happened, I added Nginx in front of the Node.js web server, and then found that there are more than 100 ‘connection reset’ errors everyday in Nginx logs.
Here are some example logs:
2017/11/12 06:11:15 [error] 7#7: *2904 recv() failed (104: Connection reset by peer) while reading response header from upstream, client: 172.18.0.1, server: localhost, request: "GET /_healthcheck HTTP/1.1", upstream: "http://172.18.0.2:8000/_healthcheck", host: "localhost" 2017/11/12 06:11:27 [error] 7#7: *2950 recv() failed (104: Connection reset by peer) while reading response header from upstream, client: 172.18.0.1, server: localhost, request: "GET /_healthcheck HTTP/1.1", upstream: "http://172.18.0.2:8000/_healthcheck", host: "localhost" 2017/11/12 06:11:31 [error] 7#7: *2962 upstream prematurely closed connection while reading response header from upstream, client: 172.18.0.1, server: localhost, request: "GET /_healthcheck HTTP/1.1", upstream: "http://172.18.0.2:8000/_healthcheck", host: "localhost" 2017/11/12 06:11:44 [error] 7#7: *3005 recv() failed (104: Connection reset by peer) while reading response header from upstream, client: 172.18.0.1, server: localhost, request: "GET /_healthcheck HTTP/1.1", upstream: "http://172.18.0.2:8000/_healthcheck", host: "localhost" 2017/11/12 06:11:47 [error] 7#7: *3012 recv() failed (104: Connection reset by peer) while reading response header from upstream, client: 172.18.0.1, server: localhost, request: "GET /_healthcheck HTTP/1.1", upstream: "http://172.18.0.2:8000/_healthcheck", host: "localhost"
Analyzing the errors
The number of errors was increased after I migrate Classic LB to Application LB, and one of the differences between them is Classic LB is using pre-connected connections, and Application LB only using Http/1.1 Keep-Alive feature.
From the documentation of AWS Load Balancer:
Possible causes:
- The load balancer received a TCP RST from the target when attempting to establish a connection.
- The target closed the connection with a TCP RST or a TCP FIN while the load balancer had an outstanding request to the target.
- The target response is malformed or contains HTTP headers that are not valid.
- A new target group was used but no targets have passed an initial health check yet. A target must pass one health check to be considered healthy
Because there’s no any errors on Node.js side, so I’m guessing it was because of the keep-alive behaviour. There’s no upstream keep-alive timeout settings in the current Nginx version (1.13.6), then I tried Tengine – a taobao forked nginx which support upstream keepalive timeout. After running a couple of days, there’s no such errors any more. In order to understand what’s causing the issue, I tried to reproduce it on my local machine.
Capture network packages
In order to send a request at the same time when Node.js closing the connection after keep-alive timeout, I need to keep requesting the url until the issue reproduced. Here’s my settings for the testing environment:
Upstream (Node.js server):
- Set keep-alive timeout to 500 ms
Test client:
- Keep sending requests with an interval
- Interval starts from 500 ms and decrease 1 ms after each request
For the normal requests, upstream send a [FIN, ACK] to nginx after keep-alive timeout (500 ms), and nginx also send a [FIN, ACK] back, then upstream send a [ACK] to close the connection completely.
No. Time Source Destination Protocol Length Info
1 2017-11-12 17:11:04.299146 172.18.0.3 172.18.0.2 TCP 74 48528 → 8000 [SYN] Seq=0 Win=29200 Len=0 MSS=1460 SACK_PERM=1 TSval=32031305 TSecr=0 WS=128
2 2017-11-12 17:11:04.299171 172.18.0.2 172.18.0.3 TCP 74 8000 → 48528 [SYN, ACK] Seq=0 Ack=1 Win=28960 Len=0 MSS=1460 SACK_PERM=1 TSval=32031305 TSecr=32031305 WS=128
3 2017-11-12 17:11:04.299194 172.18.0.3 172.18.0.2 TCP 66 48528 → 8000 [ACK] Seq=1 Ack=1 Win=29312 Len=0 TSval=32031305 TSecr=32031305
4 2017-11-12 17:11:04.299259 172.18.0.3 172.18.0.2 HTTP 241 GET /_healthcheck HTTP/1.1
5 2017-11-12 17:11:04.299267 172.18.0.2 172.18.0.3 TCP 66 8000 → 48528 [ACK] Seq=1 Ack=176 Win=30080 Len=0 TSval=32031305 TSecr=32031305
6 2017-11-12 17:11:04.299809 172.18.0.2 172.18.0.3 HTTP 271 HTTP/1.1 200 OK (text/html)
7 2017-11-12 17:11:04.299852 172.18.0.3 172.18.0.2 TCP 66 48528 → 8000 [ACK] Seq=176 Ack=206 Win=30336 Len=0 TSval=32031305 TSecr=32031305
8 2017-11-12 17:11:04.800805 172.18.0.2 172.18.0.3 TCP 66 8000 → 48528 [FIN, ACK] Seq=206 Ack=176 Win=30080 Len=0 TSval=32031355 TSecr=32031305
9 2017-11-12 17:11:04.801120 172.18.0.3 172.18.0.2 TCP 66 48528 → 8000 [FIN, ACK] Seq=176 Ack=207 Win=30336 Len=0 TSval=32031355 TSecr=32031355
10 2017-11-12 17:11:04.801151 172.18.0.2 172.18.0.3 TCP 66 8000 → 48528 [ACK] Seq=207 Ack=177 Win=30080 Len=0 TSval=32031355 TSecr=32031355
For the failed requests, the upstream closed the connection after keep-alive timeout (500 ms), the client sends a new http request before it receives and processes the [FIN] package. Because of the connection has been closed from upstream’s perspective, so it send a [RST] response for this request. This would happen in following scenarios:
- Upstream hasn’t send the [FIN] package yet (pending to send package at network layer)
- Upstream has sent the [FIN] package, but client hasn’t received it yet
- Client received the [FIN] package, but hasn’t processed it yet
Example of the first scenario, hasn’t send [FIN] yet:
No. Time Source Destination Protocol Length Info
433 2017-11-12 17:11:26.548449 172.18.0.3 172.18.0.2 TCP 74 48702 → 8000 [SYN] Seq=0 Win=29200 Len=0 MSS=1460 SACK_PERM=1 TSval=32033530 TSecr=0 WS=128
434 2017-11-12 17:11:26.548476 172.18.0.2 172.18.0.3 TCP 74 8000 → 48702 [SYN, ACK] Seq=0 Ack=1 Win=28960 Len=0 MSS=1460 SACK_PERM=1 TSval=32033530 TSecr=32033530 WS=128
435 2017-11-12 17:11:26.548502 172.18.0.3 172.18.0.2 TCP 66 48702 → 8000 [ACK] Seq=1 Ack=1 Win=29312 Len=0 TSval=32033530 TSecr=32033530
436 2017-11-12 17:11:26.548609 172.18.0.3 172.18.0.2 HTTP 241 GET /_healthcheck HTTP/1.1
437 2017-11-12 17:11:26.548618 172.18.0.2 172.18.0.3 TCP 66 8000 → 48702 [ACK] Seq=1 Ack=176 Win=30080 Len=0 TSval=32033530 TSecr=32033530
438 2017-11-12 17:11:26.549173 172.18.0.2 172.18.0.3 HTTP 271 HTTP/1.1 200 OK (text/html)
439 2017-11-12 17:11:26.549230 172.18.0.3 172.18.0.2 TCP 66 48702 → 8000 [ACK] Seq=176 Ack=206 Win=30336 Len=0 TSval=32033530 TSecr=32033530
440 2017-11-12 17:11:27.049668 172.18.0.3 172.18.0.2 HTTP 241 GET /_healthcheck HTTP/1.1
441 2017-11-12 17:11:27.050324 172.18.0.2 172.18.0.3 HTTP 271 HTTP/1.1 200 OK (text/html)
442 2017-11-12 17:11:27.050378 172.18.0.3 172.18.0.2 TCP 66 48702 → 8000 [ACK] Seq=351 Ack=411 Win=31360 Len=0 TSval=32033580 TSecr=32033580
443 2017-11-12 17:11:27.551182 172.18.0.3 172.18.0.2 HTTP 241 GET /_healthcheck HTTP/1.1
444 2017-11-12 17:11:27.551294 172.18.0.2 172.18.0.3 TCP 66 8000 → 48702 [RST, ACK] Seq=411 Ack=526 Win=32256 Len=0 TSval=32033630 TSecr=32033630
Example of the second scenario, Sent [FIN] at the same time of receiving a new request:
No. Time Source Destination Protocol Length Info 13 2018-06-15 21:40:00.522110 127.0.0.1 127.0.0.1 TCP 68 50678 > 8000 [SYN] Seq=0 Win=65535 Len=0 MSS=16344 WS=32 TSval=1503957438 TSecr=0 SACK_PERM=1 14 2018-06-15 21:40:00.522210 127.0.0.1 127.0.0.1 TCP 68 8000 > 50678 [SYN, ACK] Seq=0 Ack=1 Win=65535 Len=0 MSS=16344 WS=32 TSval=1503957438 TSecr=1503957438 SACK_PERM=1 15 2018-06-15 21:40:00.522219 127.0.0.1 127.0.0.1 TCP 56 50678 > 8000 [ACK] Seq=1 Ack=1 Win=408288 Len=0 TSval=1503957438 TSecr=1503957438 16 2018-06-15 21:40:00.522228 127.0.0.1 127.0.0.1 TCP 56 [TCP Window Update] 8000 > 50678 [ACK] Seq=1 Ack=1 Win=408288 Len=0 TSval=1503957438 TSecr=1503957438 17 2018-06-15 21:40:00.522315 127.0.0.1 127.0.0.1 HTTP 189 GET / HTTP/1.1 18 2018-06-15 21:40:00.522358 127.0.0.1 127.0.0.1 TCP 56 8000 > 50678 [ACK] Seq=1 Ack=134 Win=408160 Len=0 TSval=1503957438 TSecr=1503957438 19 2018-06-15 21:40:00.522727 127.0.0.1 127.0.0.1 HTTP 261 HTTP/1.1 200 OK (text/html) 20 2018-06-15 21:40:00.522773 127.0.0.1 127.0.0.1 TCP 56 50678 > 8000 [ACK] Seq=134 Ack=206 Win=408064 Len=0 TSval=1503957438 TSecr=1503957438 21 2018-06-15 21:40:01.025685 127.0.0.1 127.0.0.1 HTTP 189 GET / HTTP/1.1 22 2018-06-15 21:40:01.025687 127.0.0.1 127.0.0.1 TCP 56 8000 > 50678 [FIN, ACK] Seq=206 Ack=134 Win=408160 Len=0 TSval=1503957939 TSecr=1503957438 23 2018-06-15 21:40:01.025748 127.0.0.1 127.0.0.1 TCP 44 8000 > 50678 [RST] Seq=206 Win=0 Len=0 24 2018-06-15 21:40:01.025760 127.0.0.1 127.0.0.1 TCP 56 50678 > 8000 [ACK] Seq=267 Ack=207 Win=408064 Len=0 TSval=1503957939 TSecr=1503957939 25 2018-06-15 21:40:01.025769 127.0.0.1 127.0.0.1 TCP 44 8000 > 50678 [RST] Seq=207 Win=0 Len=0
When the client receives the [RST] package, it will log a ‘Connection reset’ error.
Testing Code
This issue is a generic issue when closing the connection on the server side while HTTP keep-alive enabled, so you can easily reproduce it by clone the example code (Node.js) from https://github.com/weixu365/test-connection-reset
npm install npm start # In a separate terminal npm run client
- Upstream Node.js Web Server
const express = require('express');
const app = express();
app.get('/', (req, res) => res.send('OK'));
const port = process.env.PORT || 8000;
app.listen(port, () => {
console.log(`Listening on http://localhost:${port}`)
})
.keepAliveTimeout = 500;
- Test client in Node.js
const axios = require('axios');
const Bluebird = require('bluebird');
const HttpAgent = require('agentkeepalive');
const keepAliveOption = {
freeSocketKeepAliveTimeout: 30 * 1000, // Should be less than server keep alive timeout
socketActiveTTL: 50 * 1000 // Should be less than dns ttl
};
const httpAgent = new HttpAgent(keepAliveOption);
let host = 'http://localhost:8000';
let path = '/';
const httpClient = axios.create({
baseURL: host,
timeout: 5000,
});
const sendRequest = () =>
httpClient.request({
url: path,
httpAgent,
})
.then(res => {
console.log('Received response', res.status);
})
.catch(e => {
console.error('Error occurred', e.message);
});
let delay=501;
const start = () =>
sendRequest()
.then(() => delay -= 1)
.then(() => delay > 450 ? Bluebird.delay(delay).then(start) : 'Done')
start();
- Capture network packages
tcpdump -i eth0 tcp port 8000 -w /tmp/connection.pcap
- Nginx config (Optional)
upstream nodejs {
least_conn;
server chalice:8000 fail_timeout=1s max_fails=3;
keepalive 16;
}
server_tokens off;
log_format detailed escape=json
'{'
'"timestamp": "$time_iso8601",'
'"remote_addr": "$remote_addr",'
'"upstream_addr": "$upstream_addr",'
'"connection": "$connection",'
'"connection_requests": "$connection_requests",'
'"request_time": "$request_time",'
'"upstream_response_time": "$upstream_response_time",'
'"status": "$status",'
'"upstream_status": "$upstream_status",'
'"body_bytes_sent": "$body_bytes_sent ",'
'"request": "$request",'
'"http_user_agent": "$http_user_agent"'
'}';
access_log /var/log/nginx/access.log detailed;
server {
listen 80;
server_name localhost;
location / {
proxy_http_version 1.1;
proxy_redirect off;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarder-For $proxy_add_x_forwarded_for;
proxy_set_header Host $http_host;
proxy_set_header X-NginX-Proxy true;
proxy_set_header Connection "";
proxy_pass http://nodejs;
}
}
References:
- https://github.com/weixu365/test-connection-reset
The connection reset by peer is a TCP/IP error that occurs when the other end (peer) has unexpectedly closed the connection. It happens when you send a packet from your end, but the other end crashes and forcibly closes the connection with the RST packet instead of the TCP FIN, which is used to close a connection under normal circumstances. In Go, you can detect the connection reset by peer by checking if the error returned by the peer is equal to syscall.ECONNRESET.
Reproduce the connection reset by peer error
We can reproduce the error by creating a server and client that do the following:
- the server reads a single byte and then closes the connection
- the client sends more than one byte
If the server closes the connection with the remaining bytes in the socket’s receive buffer, then an RST packet is sent to the client. When the client tries to read from such a closed connection, it will get the connection reset by peer error.
See the following example, which simulates this behavior.
package main
import (
"errors"
"log"
"net"
"os"
"syscall"
"time"
)
func server() {
listener, err := net.Listen("tcp", ":8080")
if err != nil {
log.Fatal(err)
}
defer listener.Close()
conn, err := listener.Accept()
if err != nil {
log.Fatal("server", err)
os.Exit(1)
}
data := make([]byte, 1)
if _, err := conn.Read(data); err != nil {
log.Fatal("server", err)
}
conn.Close()
}
func client() {
conn, err := net.Dial("tcp", "localhost:8080")
if err != nil {
log.Fatal("client", err)
}
if _, err := conn.Write([]byte("ab")); err != nil {
log.Printf("client: %v", err)
}
time.Sleep(1 * time.Second) // wait for close on the server side
data := make([]byte, 1)
if _, err := conn.Read(data); err != nil {
log.Printf("client: %v", err)
if errors.Is(err, syscall.ECONNRESET) {
log.Print("This is connection reset by peer error")
}
}
}
func main() {
go server()
time.Sleep(3 * time.Second) // wait for server to run
client()
}
Output:
2021/10/20 19:01:58 client: read tcp [::1]:59897->[::1]:8080: read: connection reset by peer
2021/10/20 19:01:58 This is connection reset by peer error
Handle the connection reset by peer error
Typically, you can see the connection reset by peer error in response to a request being sent from the client to the server. It means that something bad has happened to the server: it has rebooted, the program has crashed, or other problems have occurred that cause the connection to be forcibly closed. Since TCP connections can be broken, there is no need to handle the connection reset by peer in any special way on the client side. You can log the error, ignore it or retry the connection when it occurs. In the example above, we detect the error using the errors.Is() function by checking if the returned error is an instance of syscall.ECONNRESET.
Difference between connection reset by peer and broken pipe
Both connection reset by peer and broken pipe errors occur when a peer (the other end) unexpectedly closes the underlying connection. However, there is a subtle difference between them. Usually, you get the connection reset by peer when you read from the connection after the server sends the RST packet, and when you write to the connection after the RST instead, you get the broken pipe error.
Check how to handle the
broken pipeerror in Go post, where will find another example of generating anRSTpacket and thebroken pipeerror.
Replace the client() function in the example above with the following code to reproduce the broken pipe error.
func client() {
conn, err := net.Dial("tcp", "localhost:8080")
if err != nil {
log.Fatal("client", err)
}
if _, err := conn.Write([]byte("ab")); err != nil {
log.Printf("client: %v", err)
}
time.Sleep(1 * time.Second) // wait for close on the server side
if _, err := conn.Write([]byte("b")); err != nil {
log.Printf("client: %v", err)
}
}
With the new client, you will see the output:
2021/10/20 19:55:40 client: write tcp [::1]:60399->[::1]:8080: write: broken pipe
Note that these simple examples do not cover all cases where connection reset by peer and broken pipe may occur. There are much more situations where you can see these errors, and what error you see in what situation requires a deep understanding of the TCP design.
Introduction
A remote machine has prevented an SSH connection you were attempting to establish or maintain. The “ssh_exchange_identification: read: Connection reset by peer” message is not specific enough to immediately explain what triggered the error.
To be able to resolve the issue successfully, we first need to identify its cause. This article provides an in-depth analysis of the likely causes and provides the most effective solutions.
By reading this tutorial, you will learn how to fix the “ssh_exchange_identification: read: Connection reset by peer” Error.

Prerequisites
- Necessary permissions to access remote server
- A user account with root or sudo privileges
The “ssh_exchange_identification: read: Connection reset by peer” error indicates that the remote machine abruptly closed the Transition Control Protocol (TCP) stream. In most instances, a quick reboot of a remote server might solve a temporary outage or connectivity issue.
Note: Network-based firewalls or load-balancers can sometimes distort IPs or security permissions. This type of problem can be resolved by contacting your service provider.
Learning how to troubleshoot this issue, and determining the underlying cause, helps you prevent future occurrences on your system. The most common causes of the “ssh_exchange_identification: read: Connection reset by peer” error are:
- The connection is being blocked due to the Host-Based Access Control Lists.
- Intrusion prevention software is blocking your IP by updating firewall rules (Fail2ban, DenyHosts, etc.).
- Changes to the SSH daemon configuration file.
Check the hosts.deny and hosts.allow File
The hosts.deny and hosts.allow files are TCP wrappers. As a security feature, these files are used to limit which IP address or hostname can establish a connection to the remote machine.
Note: Inspect the hosts.deny and hosts.allow files on the remote server, not on the local client.
How to Edit hosts.deny File
Access your remote server and open the hosts.deny file using your preferred text editor. If you are using nano on a Debian based system, enter the following command:
sudo nano /etc/hosts.denyEmpty lines and lines starting with the ‘#’ symbol are comments. Check if you can locate your local IP or host-name in the file. If it is present, it should be removed or commented out, or else it prevents you from establishing a remote connection.
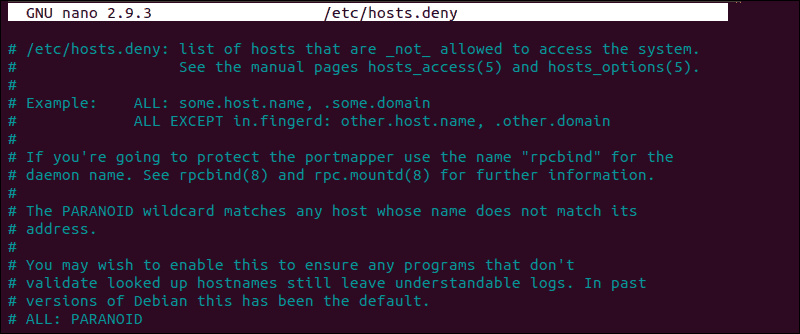
After making the necessary changes, save the file and exit. Attempt to reconnect via SSH.
How to Edit hosts.allow File
As an additional precaution, edit the hosts.allow file. Access rules within the hosts.allow are applied first. They take precedence over rules specified in hosts.deny file. Enter the following command to access the hosts.allow file:
sudo nano /etc/hosts.allowAdding host-names and IPs to the file defines exceptions to the settings in the hosts.deny file.
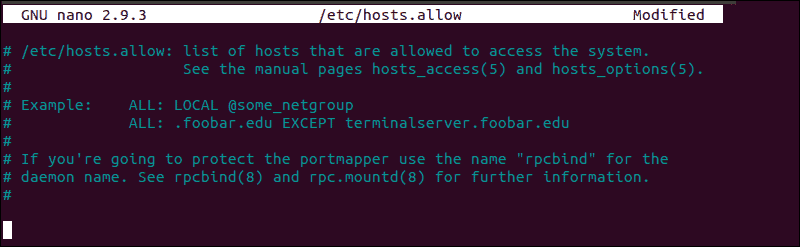
For example, a strict security policy within the etc/hosts.deny file, would deny access to all hosts:
sshd : ALL
ALL : ALLSubsequently, you can add a single IP address, an IP range, or a hostname to the etc/hosts.allow file. By adding the following line, only the following IP would be allowed to establish an SSH connection with your remote server:
sshd : 10.10.0.5, LOCALKeep in mind that such a limiting security setting can affect administering capabilities on your remote servers.
Check if fail2ban Banned Your IP Address
If you’ve tried to connect on multiple occasions, your IP might be blocked by an intrusion prevention software. Fail2ban is a service designed to protect you from brute force attacks, and it can misinterpret your authentication attempts as an attack.
Fail2ban monitors and dynamically alters firewall rules to ban IP addresses that exhibit suspicious behavior. It monitors logs, like the hosts.deny and hosts.allow files we edited previously.
In our example, we used the following command to check if the iptables tool is rejecting your attempted connections:
sudo iptables -L --line-numberThe output in your terminal window is going to list all authentication attempts. If you find that a firewall is indeed preventing your SSH connection, you can white-list your IP with fail2ban. Otherwise, the service is going to block all future attempts continuously. To access the fail2ban configuration file, enter the following command:
sudo nano /etc/fail2ban/jail.confEdit the file by uncommenting the line that contains "ignoreip =" add the IP or IP range you want to white-list.
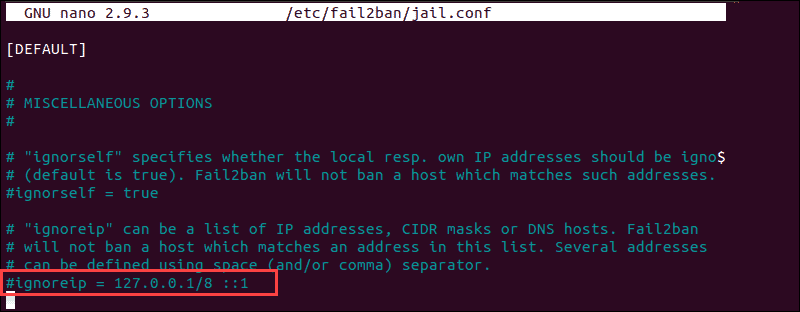
Fail2ban is now going to make an exception and not report suspicious behavior for the IP in question.
Check the sshd_config File
If you are continuing to experience the ‘ssh_exchange_identification: read: Connection reset by peer’ error, examine the authentication log entry. By default, the SSH daemon sends logging information to the system logs. Access the /var/log/auth.log file after your failed attempt to login. To review the latest log entries type:
tail -f /var/log/auth.logThe output presents the results of your authentication attempts, information about your user account, authentication key, or password.
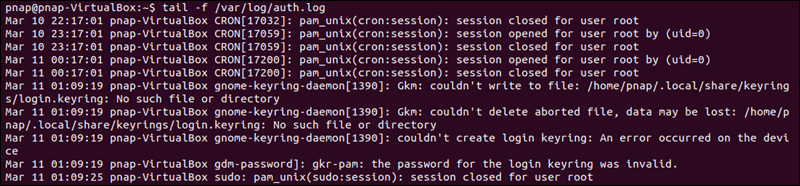
The log provides you with information that can help you find possible issues in the sshd configuration file, sshd_config. Any changes made to the file can affect the terms under which an ssh connection is established and lead the remote server to treat the client as incompatible. To access the sshd_config file type:
sudo nano /etc/ssh/sshd_configThe sshd configuration file enables you to change basic settings, such as the default TCP port or SSH key pairs for authentication, as well as more advanced functions such as port-forwarding.
For example, the MaxStartups variable defines how many connections a system accepts in a predefined period. If you have a system that makes a large number of connections in a short timeframe, it might be necessary to increase the default values for this variable. Otherwise, the remote system might refuse additional attempted ssh connections.

Anytime you edit the sshd_config file, restart the sshd service for the changes to take effect:
service sshd restartOnly edit the variables that you are familiar with. A server can become unreachable as a result of a faulty configuration file.
Conclusion
You have thoroughly checked the most common reasons behind the “ssh_exchange_identification: read: Connection reset by peer” error. By looking at each possibility, in turn, you have successfully solved the issue and now know how to deal with similar problems going forward.
The number of potential causes is vast and difficult to troubleshoot in every respect. Ultimately, if the error persists, it might be necessary to contact your host.