I get an error message when I use this expression:
re.sub(r"([^sw])(s*1)+","\1","...")
I checked the regex at RegExr and it returns . as expected. But when I try it in Python I get this error message:
raise error, v # invalid expression
sre_constants.error: nothing to repeat
Can someone please explain?
![]()
Alan Moore
73k12 gold badges98 silver badges155 bronze badges
asked Sep 9, 2010 at 9:00
![]()
5
It seems to be a python bug (that works perfectly in vim).
The source of the problem is the (s*…)+ bit. Basically , you can’t do (s*)+ which make sense , because you are trying to repeat something which can be null.
>>> re.compile(r"(s*)+")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/System/Library/Frameworks/Python.framework/Versions/2.5/lib/python2.5/re.py", line 180, in compile
return _compile(pattern, flags)
File "/System/Library/Frameworks/Python.framework/Versions/2.5/lib/python2.5/re.py", line 233, in _compile
raise error, v # invalid expression
sre_constants.error: nothing to repeat
However (s*1) should not be null, but we know it only because we know what’s in 1. Apparently python doesn’t … that’s weird.
answered Sep 9, 2010 at 9:42
![]()
mb14mb14
22k6 gold badges59 silver badges102 bronze badges
3
That is a Python bug between «*» and special characters.
Instead of
re.compile(r"w*")
Try:
re.compile(r"[a-zA-Z0-9]*")
It works, however does not make the same regular expression.
This bug seems to have been fixed between 2.7.5 and 2.7.6.
![]()
Charlie
8,3612 gold badges53 silver badges52 bronze badges
answered Oct 24, 2011 at 8:24
![]()
FranklynFranklyn
2312 silver badges2 bronze badges
It’s not only a Python bug with * actually, it can also happen when you pass a string as a part of your regular expression to be compiled, like ;
import re
input_line = "string from any input source"
processed_line= "text to be edited with {}".format(input_line)
target = "text to be searched"
re.search(processed_line, target)
this will cause an error if processed line contained some «(+)» for example, like you can find in chemical formulae, or such chains of characters.
the solution is to escape but when you do it on the fly, it can happen that you fail to do it properly…
answered Jun 20, 2017 at 15:52
![]()
Ando JuraiAndo Jurai
9792 gold badges12 silver badges29 bronze badges
1
regular expression normally uses * and + in theory of language.
I encounter the same bug while executing the line code
re.split("*",text)
to solve it, it needs to include before * and +
re.split("*",text)
answered Dec 22, 2019 at 0:47
![]()
0
Beyond the bug that was discovered and fixed, I’ll just note that the error message sre_constants.error: nothing to repeat is a bit confusing. I was trying to use r'?.*' as a pattern, and thought it was complaining for some strange reason about the *, but the problem is actually that ? is a way of saying «repeat zero or one times». So I needed to say r'?.*'to match a literal ?
answered Oct 5, 2017 at 19:22
![]()
nealmcbnealmcb
12k7 gold badges64 silver badges89 bronze badges
I had this problem when using the regex b?. Using s? fixed the issue (although it’s not the same thing)
answered Dec 21, 2021 at 23:21
![]()
robertspierrerobertspierre
2,7022 gold badges28 silver badges38 bronze badges
Source code: Lib/re.py
This module provides regular expression matching operations similar to
those found in Perl.
Both patterns and strings to be searched can be Unicode strings (str)
as well as 8-bit strings (bytes).
However, Unicode strings and 8-bit strings cannot be mixed:
that is, you cannot match a Unicode string with a byte pattern or
vice-versa; similarly, when asking for a substitution, the replacement
string must be of the same type as both the pattern and the search string.
Regular expressions use the backslash character ('') to indicate
special forms or to allow special characters to be used without invoking
their special meaning. This collides with Python’s usage of the same
character for the same purpose in string literals; for example, to match
a literal backslash, one might have to write '\\' as the pattern
string, because the regular expression must be \, and each
backslash must be expressed as \ inside a regular Python string
literal.
The solution is to use Python’s raw string notation for regular expression
patterns; backslashes are not handled in any special way in a string literal
prefixed with 'r'. So r"n" is a two-character string containing
'' and 'n', while "n" is a one-character string containing a
newline. Usually patterns will be expressed in Python code using this raw
string notation.
It is important to note that most regular expression operations are available as
module-level functions and methods on
compiled regular expressions. The functions are shortcuts
that don’t require you to compile a regex object first, but miss some
fine-tuning parameters.
See also
The third-party regex module,
which has an API compatible with the standard library re module,
but offers additional functionality and a more thorough Unicode support.
6.2.1. Regular Expression Syntax¶
A regular expression (or RE) specifies a set of strings that matches it; the
functions in this module let you check if a particular string matches a given
regular expression (or if a given regular expression matches a particular
string, which comes down to the same thing).
Regular expressions can be concatenated to form new regular expressions; if A
and B are both regular expressions, then AB is also a regular expression.
In general, if a string p matches A and another string q matches B, the
string pq will match AB. This holds unless A or B contain low precedence
operations; boundary conditions between A and B; or have numbered group
references. Thus, complex expressions can easily be constructed from simpler
primitive expressions like the ones described here. For details of the theory
and implementation of regular expressions, consult the Friedl book referenced
above, or almost any textbook about compiler construction.
A brief explanation of the format of regular expressions follows. For further
information and a gentler presentation, consult the Regular Expression HOWTO.
Regular expressions can contain both special and ordinary characters. Most
ordinary characters, like 'A', 'a', or '0', are the simplest regular
expressions; they simply match themselves. You can concatenate ordinary
characters, so last matches the string 'last'. (In the rest of this
section, we’ll write RE’s in this special style, usually without quotes, and
strings to be matched 'in single quotes'.)
Some characters, like '|' or '(', are special. Special
characters either stand for classes of ordinary characters, or affect
how the regular expressions around them are interpreted.
Repetition qualifiers (*, +, ?, {m,n}, etc) cannot be
directly nested. This avoids ambiguity with the non-greedy modifier suffix
?, and with other modifiers in other implementations. To apply a second
repetition to an inner repetition, parentheses may be used. For example,
the expression (?:a{6})* matches any multiple of six 'a' characters.
The special characters are:
.- (Dot.) In the default mode, this matches any character except a newline. If
theDOTALLflag has been specified, this matches any character
including a newline. ^- (Caret.) Matches the start of the string, and in
MULTILINEmode also
matches immediately after each newline. $- Matches the end of the string or just before the newline at the end of the
string, and inMULTILINEmode also matches before a newline.foo
matches both ‘foo’ and ‘foobar’, while the regular expressionfoo$matches
only ‘foo’. More interestingly, searching forfoo.$in'foo1nfoo2n'
matches ‘foo2’ normally, but ‘foo1’ inMULTILINEmode; searching for
a single$in'foon'will find two (empty) matches: one just before
the newline, and one at the end of the string. *- Causes the resulting RE to match 0 or more repetitions of the preceding RE, as
many repetitions as are possible.ab*will match ‘a’, ‘ab’, or ‘a’ followed
by any number of ‘b’s. +- Causes the resulting RE to match 1 or more repetitions of the preceding RE.
ab+will match ‘a’ followed by any non-zero number of ‘b’s; it will not
match just ‘a’. ?- Causes the resulting RE to match 0 or 1 repetitions of the preceding RE.
ab?will match either ‘a’ or ‘ab’. *?,+?,??- The
'*','+', and'?'qualifiers are all greedy; they match
as much text as possible. Sometimes this behaviour isn’t desired; if the RE
<.*>is matched against'<a> b <c>', it will match the entire
string, and not just'<a>'. Adding?after the qualifier makes it
perform the match in non-greedy or minimal fashion; as few
characters as possible will be matched. Using the RE<.*?>will match
only'<a>'. {m}- Specifies that exactly m copies of the previous RE should be matched; fewer
matches cause the entire RE not to match. For example,a{6}will match
exactly six'a'characters, but not five. {m,n}- Causes the resulting RE to match from m to n repetitions of the preceding
RE, attempting to match as many repetitions as possible. For example,
a{3,5}will match from 3 to 5'a'characters. Omitting m specifies a
lower bound of zero, and omitting n specifies an infinite upper bound. As an
example,a{4,}bwill match'aaaab'or a thousand'a'characters
followed by a'b', but not'aaab'. The comma may not be omitted or the
modifier would be confused with the previously described form. {m,n}?- Causes the resulting RE to match from m to n repetitions of the preceding
RE, attempting to match as few repetitions as possible. This is the
non-greedy version of the previous qualifier. For example, on the
6-character string'aaaaaa',a{3,5}will match 5'a'characters,
whilea{3,5}?will only match 3 characters. -
Either escapes special characters (permitting you to match characters like
'*','?', and so forth), or signals a special sequence; special
sequences are discussed below.If you’re not using a raw string to express the pattern, remember that Python
also uses the backslash as an escape sequence in string literals; if the escape
sequence isn’t recognized by Python’s parser, the backslash and subsequent
character are included in the resulting string. However, if Python would
recognize the resulting sequence, the backslash should be repeated twice. This
is complicated and hard to understand, so it’s highly recommended that you use
raw strings for all but the simplest expressions. []-
Used to indicate a set of characters. In a set:
- Characters can be listed individually, e.g.
[amk]will match'a',
'm', or'k'. - Ranges of characters can be indicated by giving two characters and separating
them by a'-', for example[a-z]will match any lowercase ASCII letter,
[0-5][0-9]will match all the two-digits numbers from00to59, and
[0-9A-Fa-f]will match any hexadecimal digit. If-is escaped (e.g.
[a-z]) or if it’s placed as the first or last character
(e.g.[-a]or[a-]), it will match a literal'-'. - Special characters lose their special meaning inside sets. For example,
[(+*)]will match any of the literal characters'(','+',
'*', or')'. - Character classes such as
worS(defined below) are also accepted
inside a set, although the characters they match depends on whether
ASCIIorLOCALEmode is in force. - Characters that are not within a range can be matched by complementing
the set. If the first character of the set is'^', all the characters
that are not in the set will be matched. For example,[^5]will match
any character except'5', and[^^]will match any character except
'^'.^has no special meaning if it’s not the first character in
the set. - To match a literal
']'inside a set, precede it with a backslash, or
place it at the beginning of the set. For example, both[()[]{}]and
[]()[{}]will both match a parenthesis.
- Characters can be listed individually, e.g.
|A|B, where A and B can be arbitrary REs, creates a regular expression that
will match either A or B. An arbitrary number of REs can be separated by the
'|'in this way. This can be used inside groups (see below) as well. As
the target string is scanned, REs separated by'|'are tried from left to
right. When one pattern completely matches, that branch is accepted. This means
that once A matches, B will not be tested further, even if it would
produce a longer overall match. In other words, the'|'operator is never
greedy. To match a literal'|', use|, or enclose it inside a
character class, as in[|].(...)- Matches whatever regular expression is inside the parentheses, and indicates the
start and end of a group; the contents of a group can be retrieved after a match
has been performed, and can be matched later in the string with thenumber
special sequence, described below. To match the literals'('or')',
use(or), or enclose them inside a character class:[(],[)]. (?...)- This is an extension notation (a
'?'following a'('is not meaningful
otherwise). The first character after the'?'determines what the meaning
and further syntax of the construct is. Extensions usually do not create a new
group;(?P<name>...)is the only exception to this rule. Following are the
currently supported extensions. (?aiLmsux)- (One or more letters from the set
'a','i','L','m',
's','u','x'.) The group matches the empty string; the
letters set the corresponding flags:re.A(ASCII-only matching),
re.I(ignore case),re.L(locale dependent),
re.M(multi-line),re.S(dot matches all),
re.U(Unicode matching), andre.X(verbose),
for the entire regular expression.
(The flags are described in Module Contents.)
This is useful if you wish to include the flags as part of the
regular expression, instead of passing a flag argument to the
re.compile()function. Flags should be used first in the
expression string. (?:...)- A non-capturing version of regular parentheses. Matches whatever regular
expression is inside the parentheses, but the substring matched by the group
cannot be retrieved after performing a match or referenced later in the
pattern. (?aiLmsux-imsx:...)-
(Zero or more letters from the set
'a','i','L','m',
's','u','x', optionally followed by'-'followed by
one or more letters from the'i','m','s','x'.)
The letters set or remove the corresponding flags:
re.A(ASCII-only matching),re.I(ignore case),
re.L(locale dependent),re.M(multi-line),
re.S(dot matches all),re.U(Unicode matching),
andre.X(verbose), for the part of the expression.
(The flags are described in Module Contents.)The letters
'a','L'and'u'are mutually exclusive when used
as inline flags, so they can’t be combined or follow'-'. Instead,
when one of them appears in an inline group, it overrides the matching mode
in the enclosing group. In Unicode patterns(?a:...)switches to
ASCII-only matching, and(?u:...)switches to Unicode matching
(default). In byte pattern(?L:...)switches to locale depending
matching, and(?a:...)switches to ASCII-only matching (default).
This override is only in effect for the narrow inline group, and the
original matching mode is restored outside of the group.New in version 3.6.
Changed in version 3.7: The letters
'a','L'and'u'also can be used in a group. (?P<name>...)-
Similar to regular parentheses, but the substring matched by the group is
accessible via the symbolic group name name. Group names must be valid
Python identifiers, and each group name must be defined only once within a
regular expression. A symbolic group is also a numbered group, just as if
the group were not named.Named groups can be referenced in three contexts. If the pattern is
(?P<quote>['"]).*?(?P=quote)(i.e. matching a string quoted with either
single or double quotes):Context of reference to group “quote” Ways to reference it in the same pattern itself (?P=quote)(as shown)1
when processing match object m m.group('quote')m.end('quote')(etc.)
in a string passed to the repl
argument ofre.sub()g<quote>g<1>1
(?P=name)- A backreference to a named group; it matches whatever text was matched by the
earlier group named name. (?#...)- A comment; the contents of the parentheses are simply ignored.
(?=...)- Matches if
...matches next, but doesn’t consume any of the string. This is
called a lookahead assertion. For example,Isaac (?=Asimov)will match
'Isaac 'only if it’s followed by'Asimov'. (?!...)- Matches if
...doesn’t match next. This is a negative lookahead assertion.
For example,Isaac (?!Asimov)will match'Isaac 'only if it’s not
followed by'Asimov'. (?<=...)-
Matches if the current position in the string is preceded by a match for
...
that ends at the current position. This is called a positive lookbehind
assertion.(?<=abc)defwill find a match in'abcdef', since the
lookbehind will back up 3 characters and check if the contained pattern matches.
The contained pattern must only match strings of some fixed length, meaning that
abcora|bare allowed, buta*anda{3,4}are not. Note that
patterns which start with positive lookbehind assertions will not match at the
beginning of the string being searched; you will most likely want to use the
search()function rather than thematch()function:>>> import re >>> m = re.search('(?<=abc)def', 'abcdef') >>> m.group(0) 'def'
This example looks for a word following a hyphen:
>>> m = re.search('(?<=-)w+', 'spam-egg') >>> m.group(0) 'egg'
Changed in version 3.5: Added support for group references of fixed length.
(?<!...)- Matches if the current position in the string is not preceded by a match for
.... This is called a negative lookbehind assertion. Similar to
positive lookbehind assertions, the contained pattern must only match strings of
some fixed length. Patterns which start with negative lookbehind assertions may
match at the beginning of the string being searched. (?(id/name)yes-pattern|no-pattern)- Will try to match with
yes-patternif the group with given id or
name exists, and withno-patternif it doesn’t.no-patternis
optional and can be omitted. For example,
(<)?(w+@w+(?:.w+)+)(?(1)>|$)is a poor email matching pattern, which
will match with'<user@host.com>'as well as'user@host.com', but
not with'<user@host.com'nor'user@host.com>'.
The special sequences consist of '' and a character from the list below.
If the ordinary character is not an ASCII digit or an ASCII letter, then the
resulting RE will match the second character. For example, $ matches the
character '$'.
number- Matches the contents of the group of the same number. Groups are numbered
starting from 1. For example,(.+) 1matches'the the'or'55 55',
but not'thethe'(note the space after the group). This special sequence
can only be used to match one of the first 99 groups. If the first digit of
number is 0, or number is 3 octal digits long, it will not be interpreted as
a group match, but as the character with octal value number. Inside the
'['and']'of a character class, all numeric escapes are treated as
characters. A- Matches only at the start of the string.
b-
Matches the empty string, but only at the beginning or end of a word.
A word is defined as a sequence of word characters. Note that formally,
bis defined as the boundary between awand aWcharacter
(or vice versa), or betweenwand the beginning/end of the string.
This means thatr'bfoob'matches'foo','foo.','(foo)',
'bar foo baz'but not'foobar'or'foo3'.By default Unicode alphanumerics are the ones used in Unicode patterns, but
this can be changed by using theASCIIflag. Word boundaries are
determined by the current locale if theLOCALEflag is used.
Inside a character range,brepresents the backspace character, for
compatibility with Python’s string literals. B- Matches the empty string, but only when it is not at the beginning or end
of a word. This means thatr'pyB'matches'python','py3',
'py2', but not'py','py.', or'py!'.
Bis just the opposite ofb, so word characters in Unicode
patterns are Unicode alphanumerics or the underscore, although this can
be changed by using theASCIIflag. Word boundaries are
determined by the current locale if theLOCALEflag is used. d-
- For Unicode (str) patterns:
- Matches any Unicode decimal digit (that is, any character in
Unicode character category [Nd]). This includes[0-9], and
also many other digit characters. If theASCIIflag is
used only[0-9]is matched. - For 8-bit (bytes) patterns:
- Matches any decimal digit; this is equivalent to
[0-9].
D- Matches any character which is not a decimal digit. This is
the opposite ofd. If theASCIIflag is used this
becomes the equivalent of[^0-9]. s-
- For Unicode (str) patterns:
- Matches Unicode whitespace characters (which includes
[ tnrfv], and also many other characters, for example the
non-breaking spaces mandated by typography rules in many
languages). If theASCIIflag is used, only
[ tnrfv]is matched. - For 8-bit (bytes) patterns:
- Matches characters considered whitespace in the ASCII character set;
this is equivalent to[ tnrfv].
S- Matches any character which is not a whitespace character. This is
the opposite ofs. If theASCIIflag is used this
becomes the equivalent of[^ tnrfv]. w-
- For Unicode (str) patterns:
- Matches Unicode word characters; this includes most characters
that can be part of a word in any language, as well as numbers and
the underscore. If theASCIIflag is used, only
[a-zA-Z0-9_]is matched. - For 8-bit (bytes) patterns:
- Matches characters considered alphanumeric in the ASCII character set;
this is equivalent to[a-zA-Z0-9_]. If theLOCALEflag is
used, matches characters considered alphanumeric in the current locale
and the underscore.
W- Matches any character which is not a word character. This is
the opposite ofw. If theASCIIflag is used this
becomes the equivalent of[^a-zA-Z0-9_]. If theLOCALEflag is
used, matches characters considered alphanumeric in the current locale
and the underscore. Z- Matches only at the end of the string.
Most of the standard escapes supported by Python string literals are also
accepted by the regular expression parser:
a b f n r t u U v x \
(Note that b is used to represent word boundaries, and means “backspace”
only inside character classes.)
'u' and 'U' escape sequences are only recognized in Unicode
patterns. In bytes patterns they are errors.
Octal escapes are included in a limited form. If the first digit is a 0, or if
there are three octal digits, it is considered an octal escape. Otherwise, it is
a group reference. As for string literals, octal escapes are always at most
three digits in length.
Changed in version 3.3: The 'u' and 'U' escape sequences have been added.
Changed in version 3.6: Unknown escapes consisting of '' and an ASCII letter now are errors.
See also
- Mastering Regular Expressions
- Book on regular expressions by Jeffrey Friedl, published by O’Reilly. The
second edition of the book no longer covers Python at all, but the first
edition covered writing good regular expression patterns in great detail.
6.2.2. Module Contents¶
The module defines several functions, constants, and an exception. Some of the
functions are simplified versions of the full featured methods for compiled
regular expressions. Most non-trivial applications always use the compiled
form.
Changed in version 3.6: Flag constants are now instances of RegexFlag, which is a subclass of
enum.IntFlag.
-
re.compile(pattern, flags=0)¶ -
Compile a regular expression pattern into a regular expression object, which can be used for matching using its
match(),search()and other methods, described
below.The expression’s behaviour can be modified by specifying a flags value.
Values can be any of the following variables, combined using bitwise OR (the
|operator).The sequence
prog = re.compile(pattern) result = prog.match(string)
is equivalent to
result = re.match(pattern, string)
but using
re.compile()and saving the resulting regular expression
object for reuse is more efficient when the expression will be used several
times in a single program.Note
The compiled versions of the most recent patterns passed to
re.compile()and the module-level matching functions are cached, so
programs that use only a few regular expressions at a time needn’t worry
about compiling regular expressions.
-
re.A¶ -
re.ASCII¶ -
Make
w,W,b,B,d,D,sandS
perform ASCII-only matching instead of full Unicode matching. This is only
meaningful for Unicode patterns, and is ignored for byte patterns.
Corresponds to the inline flag(?a).Note that for backward compatibility, the
re.Uflag still
exists (as well as its synonymre.UNICODEand its embedded
counterpart(?u)), but these are redundant in Python 3 since
matches are Unicode by default for strings (and Unicode matching
isn’t allowed for bytes).
-
re.DEBUG¶ -
Display debug information about compiled expression.
No corresponding inline flag.
-
re.I¶ -
re.IGNORECASE¶ -
Perform case-insensitive matching; expressions like
[A-Z]will also
match lowercase letters. Full Unicode matching (such asÜmatching
ü) also works unless there.ASCIIflag is used to disable
non-ASCII matches. The current locale does not change the effect of this
flag unless there.LOCALEflag is also used.
Corresponds to the inline flag(?i).Note that when the Unicode patterns
[a-z]or[A-Z]are used in
combination with theIGNORECASEflag, they will match the 52 ASCII
letters and 4 additional non-ASCII letters: ‘İ’ (U+0130, Latin capital
letter I with dot above), ‘ı’ (U+0131, Latin small letter dotless i),
‘ſ’ (U+017F, Latin small letter long s) and ‘K’ (U+212A, Kelvin sign).
If theASCIIflag is used, only letters ‘a’ to ‘z’
and ‘A’ to ‘Z’ are matched.
-
re.L¶ -
re.LOCALE¶ -
Make
w,W,b,Band case-insensitive matching
dependent on the current locale. This flag can be used only with bytes
patterns. The use of this flag is discouraged as the locale mechanism
is very unreliable, it only handles one “culture” at a time, and it only
works with 8-bit locales. Unicode matching is already enabled by default
in Python 3 for Unicode (str) patterns, and it is able to handle different
locales/languages.
Corresponds to the inline flag(?L).Changed in version 3.6:
re.LOCALEcan be used only with bytes patterns and is
not compatible withre.ASCII.Changed in version 3.7: Compiled regular expression objects with the
re.LOCALEflag no
longer depend on the locale at compile time. Only the locale at
matching time affects the result of matching.
-
re.M¶ -
re.MULTILINE¶ -
When specified, the pattern character
'^'matches at the beginning of the
string and at the beginning of each line (immediately following each newline);
and the pattern character'$'matches at the end of the string and at the
end of each line (immediately preceding each newline). By default,'^'
matches only at the beginning of the string, and'$'only at the end of the
string and immediately before the newline (if any) at the end of the string.
Corresponds to the inline flag(?m).
-
re.S¶ -
re.DOTALL¶ -
Make the
'.'special character match any character at all, including a
newline; without this flag,'.'will match anything except a newline.
Corresponds to the inline flag(?s).
-
re.X¶ -
re.VERBOSE¶ -
This flag allows you to write regular expressions that look nicer and are
more readable by allowing you to visually separate logical sections of the
pattern and add comments. Whitespace within the pattern is ignored, except
when in a character class or when preceded by an unescaped backslash.
When a line contains a#that is not in a character class and is not
preceded by an unescaped backslash, all characters from the leftmost such
#through the end of the line are ignored.This means that the two following regular expression objects that match a
decimal number are functionally equal:a = re.compile(r"""d + # the integral part . # the decimal point d * # some fractional digits""", re.X) b = re.compile(r"d+.d*")
Corresponds to the inline flag
(?x).
-
re.search(pattern, string, flags=0)¶ -
Scan through string looking for the first location where the regular expression
pattern produces a match, and return a corresponding match object. ReturnNoneif no position in the string matches the
pattern; note that this is different from finding a zero-length match at some
point in the string.
-
re.match(pattern, string, flags=0)¶ -
If zero or more characters at the beginning of string match the regular
expression pattern, return a corresponding match object. ReturnNoneif the string does not match the pattern;
note that this is different from a zero-length match.Note that even in
MULTILINEmode,re.match()will only match
at the beginning of the string and not at the beginning of each line.If you want to locate a match anywhere in string, use
search()
instead (see also search() vs. match()).
-
re.fullmatch(pattern, string, flags=0)¶ -
If the whole string matches the regular expression pattern, return a
corresponding match object. ReturnNoneif the
string does not match the pattern; note that this is different from a
zero-length match.New in version 3.4.
-
re.split(pattern, string, maxsplit=0, flags=0)¶ -
Split string by the occurrences of pattern. If capturing parentheses are
used in pattern, then the text of all groups in the pattern are also returned
as part of the resulting list. If maxsplit is nonzero, at most maxsplit
splits occur, and the remainder of the string is returned as the final element
of the list.>>> re.split('W+', 'Words, words, words.') ['Words', 'words', 'words', ''] >>> re.split('(W+)', 'Words, words, words.') ['Words', ', ', 'words', ', ', 'words', '.', ''] >>> re.split('W+', 'Words, words, words.', 1) ['Words', 'words, words.'] >>> re.split('[a-f]+', '0a3B9', flags=re.IGNORECASE) ['0', '3', '9']
If there are capturing groups in the separator and it matches at the start of
the string, the result will start with an empty string. The same holds for
the end of the string:>>> re.split('(W+)', '...words, words...') ['', '...', 'words', ', ', 'words', '...', '']
That way, separator components are always found at the same relative
indices within the result list.Note
split()doesn’t currently split a string on an empty pattern match.
For example:>>> re.split('x*', 'axbc') ['a', 'bc']
Even though
'x*'also matches 0 ‘x’ before ‘a’, between ‘b’ and ‘c’,
and after ‘c’, currently these matches are ignored. The correct behavior
(i.e. splitting on empty matches too and returning['', 'a', 'b', 'c',) will be implemented in future versions of Python, but since this
'']
is a backward incompatible change, aFutureWarningwill be raised
in the meanwhile.Patterns that can only match empty strings currently never split the
string. Since this doesn’t match the expected behavior, a
ValueErrorwill be raised starting from Python 3.5:>>> re.split("^$", "foonnbarn", flags=re.M) Traceback (most recent call last): File "<stdin>", line 1, in <module> ... ValueError: split() requires a non-empty pattern match.
Changed in version 3.1: Added the optional flags argument.
Changed in version 3.5: Splitting on a pattern that could match an empty string now raises
a warning. Patterns that can only match empty strings are now rejected.
-
re.findall(pattern, string, flags=0)¶ -
Return all non-overlapping matches of pattern in string, as a list of
strings. The string is scanned left-to-right, and matches are returned in
the order found. If one or more groups are present in the pattern, return a
list of groups; this will be a list of tuples if the pattern has more than
one group. Empty matches are included in the result unless they touch the
beginning of another match.
-
re.finditer(pattern, string, flags=0)¶ -
Return an iterator yielding match objects over
all non-overlapping matches for the RE pattern in string. The string
is scanned left-to-right, and matches are returned in the order found. Empty
matches are included in the result unless they touch the beginning of another
match.
-
re.sub(pattern, repl, string, count=0, flags=0)¶ -
Return the string obtained by replacing the leftmost non-overlapping occurrences
of pattern in string by the replacement repl. If the pattern isn’t found,
string is returned unchanged. repl can be a string or a function; if it is
a string, any backslash escapes in it are processed. That is,nis
converted to a single newline character,ris converted to a carriage return, and
so forth. Unknown escapes such as&are left alone. Backreferences, such
as6, are replaced with the substring matched by group 6 in the pattern.
For example:>>> re.sub(r'defs+([a-zA-Z_][a-zA-Z_0-9]*)s*(s*):', ... r'static PyObject*npy_1(void)n{', ... 'def myfunc():') 'static PyObject*npy_myfunc(void)n{'
If repl is a function, it is called for every non-overlapping occurrence of
pattern. The function takes a single match object
argument, and returns the replacement string. For example:>>> def dashrepl(matchobj): ... if matchobj.group(0) == '-': return ' ' ... else: return '-' >>> re.sub('-{1,2}', dashrepl, 'pro----gram-files') 'pro--gram files' >>> re.sub(r'sANDs', ' & ', 'Baked Beans And Spam', flags=re.IGNORECASE) 'Baked Beans & Spam'
The pattern may be a string or a pattern object.
The optional argument count is the maximum number of pattern occurrences to be
replaced; count must be a non-negative integer. If omitted or zero, all
occurrences will be replaced. Empty matches for the pattern are replaced only
when not adjacent to a previous match, sosub('x*', '-', 'abc')returns
'-a-b-c-'.In string-type repl arguments, in addition to the character escapes and
backreferences described above,
g<name>will use the substring matched by the group namedname, as
defined by the(?P<name>...)syntax.g<number>uses the corresponding
group number;g<2>is therefore equivalent to2, but isn’t ambiguous
in a replacement such asg<2>0.20would be interpreted as a
reference to group 20, not a reference to group 2 followed by the literal
character'0'. The backreferenceg<0>substitutes in the entire
substring matched by the RE.Changed in version 3.1: Added the optional flags argument.
Changed in version 3.5: Unmatched groups are replaced with an empty string.
Changed in version 3.6: Unknown escapes in pattern consisting of
''and an ASCII letter
now are errors.Changed in version 3.7: Unknown escapes in repl consisting of
''and an ASCII letter
now are errors.
-
re.subn(pattern, repl, string, count=0, flags=0)¶ -
Perform the same operation as
sub(), but return a tuple(new_string,.
number_of_subs_made)Changed in version 3.1: Added the optional flags argument.
Changed in version 3.5: Unmatched groups are replaced with an empty string.
-
re.escape(pattern)¶ -
Escape special characters in pattern.
This is useful if you want to match an arbitrary literal string that may
have regular expression metacharacters in it. For example:>>> print(re.escape('python.exe')) python.exe >>> legal_chars = string.ascii_lowercase + string.digits + "!#$%&'*+-.^_`|~:" >>> print('[%s]+' % re.escape(legal_chars)) [abcdefghijklmnopqrstuvwxyz0123456789!#$%&'*+-.^_`|~:]+ >>> operators = ['+', '-', '*', '/', '**'] >>> print('|'.join(map(re.escape, sorted(operators, reverse=True)))) /|-|+|**|*
This functions must not be used for the replacement string in
sub()
andsubn(), only backslashes should be escaped. For example:>>> digits_re = r'd+' >>> sample = '/usr/sbin/sendmail - 0 errors, 12 warnings' >>> print(re.sub(digits_re, digits_re.replace('\', r'\'), sample)) /usr/sbin/sendmail - d+ errors, d+ warnings
Changed in version 3.3: The
'_'character is no longer escaped.Changed in version 3.7: Only characters that can have special meaning in a regular expression
are escaped.
-
re.purge()¶ -
Clear the regular expression cache.
-
exception
re.error(msg, pattern=None, pos=None)¶ -
Exception raised when a string passed to one of the functions here is not a
valid regular expression (for example, it might contain unmatched parentheses)
or when some other error occurs during compilation or matching. It is never an
error if a string contains no match for a pattern. The error instance has
the following additional attributes:-
msg¶ -
The unformatted error message.
-
pattern¶ -
The regular expression pattern.
-
pos¶ -
The index in pattern where compilation failed (may be
None).
-
lineno¶ -
The line corresponding to pos (may be
None).
-
colno¶ -
The column corresponding to pos (may be
None).
Changed in version 3.5: Added additional attributes.
-
6.2.3. Regular Expression Objects¶
Compiled regular expression objects support the following methods and
attributes:
-
Pattern.search(string[, pos[, endpos]])¶ -
Scan through string looking for the first location where this regular
expression produces a match, and return a corresponding match object. ReturnNoneif no position in the string matches the
pattern; note that this is different from finding a zero-length match at some
point in the string.The optional second parameter pos gives an index in the string where the
search is to start; it defaults to0. This is not completely equivalent to
slicing the string; the'^'pattern character matches at the real beginning
of the string and at positions just after a newline, but not necessarily at the
index where the search is to start.The optional parameter endpos limits how far the string will be searched; it
will be as if the string is endpos characters long, so only the characters
from pos toendpos - 1will be searched for a match. If endpos is less
than pos, no match will be found; otherwise, if rx is a compiled regular
expression object,rx.search(string, 0, 50)is equivalent to
rx.search(string[:50], 0).>>> pattern = re.compile("d") >>> pattern.search("dog") # Match at index 0 <re.Match object; span=(0, 1), match='d'> >>> pattern.search("dog", 1) # No match; search doesn't include the "d"
-
Pattern.match(string[, pos[, endpos]])¶ -
If zero or more characters at the beginning of string match this regular
expression, return a corresponding match object.
ReturnNoneif the string does not match the pattern; note that this is
different from a zero-length match.The optional pos and endpos parameters have the same meaning as for the
search()method.>>> pattern = re.compile("o") >>> pattern.match("dog") # No match as "o" is not at the start of "dog". >>> pattern.match("dog", 1) # Match as "o" is the 2nd character of "dog". <re.Match object; span=(1, 2), match='o'>
If you want to locate a match anywhere in string, use
search()instead (see also search() vs. match()).
-
Pattern.fullmatch(string[, pos[, endpos]])¶ -
If the whole string matches this regular expression, return a corresponding
match object. ReturnNoneif the string does not
match the pattern; note that this is different from a zero-length match.The optional pos and endpos parameters have the same meaning as for the
search()method.>>> pattern = re.compile("o[gh]") >>> pattern.fullmatch("dog") # No match as "o" is not at the start of "dog". >>> pattern.fullmatch("ogre") # No match as not the full string matches. >>> pattern.fullmatch("doggie", 1, 3) # Matches within given limits. <re.Match object; span=(1, 3), match='og'>
New in version 3.4.
-
Pattern.split(string, maxsplit=0)¶ -
Identical to the
split()function, using the compiled pattern.
-
Pattern.findall(string[, pos[, endpos]])¶ -
Similar to the
findall()function, using the compiled pattern, but
also accepts optional pos and endpos parameters that limit the search
region like forsearch().
-
Pattern.finditer(string[, pos[, endpos]])¶ -
Similar to the
finditer()function, using the compiled pattern, but
also accepts optional pos and endpos parameters that limit the search
region like forsearch().
-
Pattern.sub(repl, string, count=0)¶ -
Identical to the
sub()function, using the compiled pattern.
-
Pattern.subn(repl, string, count=0)¶ -
Identical to the
subn()function, using the compiled pattern.
-
Pattern.flags¶ -
The regex matching flags. This is a combination of the flags given to
compile(), any(?...)inline flags in the pattern, and implicit
flags such asUNICODEif the pattern is a Unicode string.
-
Pattern.groups¶ -
The number of capturing groups in the pattern.
-
Pattern.groupindex¶ -
A dictionary mapping any symbolic group names defined by
(?P<id>)to group
numbers. The dictionary is empty if no symbolic groups were used in the
pattern.
-
Pattern.pattern¶ -
The pattern string from which the pattern object was compiled.
Changed in version 3.7: Added support of copy.copy() and copy.deepcopy(). Compiled
regular expression objects are considered atomic.
6.2.4. Match Objects¶
Match objects always have a boolean value of True.
Since match() and search() return None
when there is no match, you can test whether there was a match with a simple
if statement:
match = re.search(pattern, string) if match: process(match)
Match objects support the following methods and attributes:
-
Match.expand(template)¶ -
Return the string obtained by doing backslash substitution on the template
string template, as done by thesub()method.
Escapes such asnare converted to the appropriate characters,
and numeric backreferences (1,2) and named backreferences
(g<1>,g<name>) are replaced by the contents of the
corresponding group.Changed in version 3.5: Unmatched groups are replaced with an empty string.
-
Match.group([group1, …])¶ -
Returns one or more subgroups of the match. If there is a single argument, the
result is a single string; if there are multiple arguments, the result is a
tuple with one item per argument. Without arguments, group1 defaults to zero
(the whole match is returned). If a groupN argument is zero, the corresponding
return value is the entire matching string; if it is in the inclusive range
[1..99], it is the string matching the corresponding parenthesized group. If a
group number is negative or larger than the number of groups defined in the
pattern, anIndexErrorexception is raised. If a group is contained in a
part of the pattern that did not match, the corresponding result isNone.
If a group is contained in a part of the pattern that matched multiple times,
the last match is returned.>>> m = re.match(r"(w+) (w+)", "Isaac Newton, physicist") >>> m.group(0) # The entire match 'Isaac Newton' >>> m.group(1) # The first parenthesized subgroup. 'Isaac' >>> m.group(2) # The second parenthesized subgroup. 'Newton' >>> m.group(1, 2) # Multiple arguments give us a tuple. ('Isaac', 'Newton')
If the regular expression uses the
(?P<name>...)syntax, the groupN
arguments may also be strings identifying groups by their group name. If a
string argument is not used as a group name in the pattern, anIndexError
exception is raised.A moderately complicated example:
>>> m = re.match(r"(?P<first_name>w+) (?P<last_name>w+)", "Malcolm Reynolds") >>> m.group('first_name') 'Malcolm' >>> m.group('last_name') 'Reynolds'
Named groups can also be referred to by their index:
>>> m.group(1) 'Malcolm' >>> m.group(2) 'Reynolds'
If a group matches multiple times, only the last match is accessible:
>>> m = re.match(r"(..)+", "a1b2c3") # Matches 3 times. >>> m.group(1) # Returns only the last match. 'c3'
-
Match.__getitem__(g)¶ -
This is identical to
m.group(g). This allows easier access to
an individual group from a match:>>> m = re.match(r"(w+) (w+)", "Isaac Newton, physicist") >>> m[0] # The entire match 'Isaac Newton' >>> m[1] # The first parenthesized subgroup. 'Isaac' >>> m[2] # The second parenthesized subgroup. 'Newton'
New in version 3.6.
-
Match.groups(default=None)¶ -
Return a tuple containing all the subgroups of the match, from 1 up to however
many groups are in the pattern. The default argument is used for groups that
did not participate in the match; it defaults toNone.For example:
>>> m = re.match(r"(d+).(d+)", "24.1632") >>> m.groups() ('24', '1632')
If we make the decimal place and everything after it optional, not all groups
might participate in the match. These groups will default toNoneunless
the default argument is given:>>> m = re.match(r"(d+).?(d+)?", "24") >>> m.groups() # Second group defaults to None. ('24', None) >>> m.groups('0') # Now, the second group defaults to '0'. ('24', '0')
-
Match.groupdict(default=None)¶ -
Return a dictionary containing all the named subgroups of the match, keyed by
the subgroup name. The default argument is used for groups that did not
participate in the match; it defaults toNone. For example:>>> m = re.match(r"(?P<first_name>w+) (?P<last_name>w+)", "Malcolm Reynolds") >>> m.groupdict() {'first_name': 'Malcolm', 'last_name': 'Reynolds'}
-
Match.start([group])¶ -
Match.end([group])¶ -
Return the indices of the start and end of the substring matched by group;
group defaults to zero (meaning the whole matched substring). Return-1if
group exists but did not contribute to the match. For a match object m, and
a group g that did contribute to the match, the substring matched by group g
(equivalent tom.group(g)) ism.string[m.start(g):m.end(g)]
Note that
m.start(group)will equalm.end(group)if group matched a
null string. For example, afterm = re.search('b(c?)', 'cba'),
m.start(0)is 1,m.end(0)is 2,m.start(1)andm.end(1)are both
2, andm.start(2)raises anIndexErrorexception.An example that will remove remove_this from email addresses:
>>> email = "tony@tiremove_thisger.net" >>> m = re.search("remove_this", email) >>> email[:m.start()] + email[m.end():] 'tony@tiger.net'
-
Match.span([group])¶ -
For a match m, return the 2-tuple
(m.start(group), m.end(group)). Note
that if group did not contribute to the match, this is(-1, -1).
group defaults to zero, the entire match.
-
Match.pos¶ -
The value of pos which was passed to the
search()or
match()method of a regex object. This is
the index into the string at which the RE engine started looking for a match.
-
Match.endpos¶ -
The value of endpos which was passed to the
search()or
match()method of a regex object. This is
the index into the string beyond which the RE engine will not go.
-
Match.lastindex¶ -
The integer index of the last matched capturing group, or
Noneif no group
was matched at all. For example, the expressions(a)b,((a)(b)), and
((ab))will havelastindex == 1if applied to the string'ab', while
the expression(a)(b)will havelastindex == 2, if applied to the same
string.
-
Match.lastgroup¶ -
The name of the last matched capturing group, or
Noneif the group didn’t
have a name, or if no group was matched at all.
-
Match.re¶ -
The regular expression object whose
match()or
search()method produced this match instance.
-
Match.string¶ -
The string passed to
match()orsearch().
Changed in version 3.7: Added support of copy.copy() and copy.deepcopy(). Match objects
are considered atomic.
6.2.5. Regular Expression Examples¶
6.2.5.1. Checking for a Pair¶
In this example, we’ll use the following helper function to display match
objects a little more gracefully:
def displaymatch(match): if match is None: return None return '<Match: %r, groups=%r>' % (match.group(), match.groups())
Suppose you are writing a poker program where a player’s hand is represented as
a 5-character string with each character representing a card, “a” for ace, “k”
for king, “q” for queen, “j” for jack, “t” for 10, and “2” through “9”
representing the card with that value.
To see if a given string is a valid hand, one could do the following:
>>> valid = re.compile(r"^[a2-9tjqk]{5}$") >>> displaymatch(valid.match("akt5q")) # Valid. "<Match: 'akt5q', groups=()>" >>> displaymatch(valid.match("akt5e")) # Invalid. >>> displaymatch(valid.match("akt")) # Invalid. >>> displaymatch(valid.match("727ak")) # Valid. "<Match: '727ak', groups=()>"
That last hand, "727ak", contained a pair, or two of the same valued cards.
To match this with a regular expression, one could use backreferences as such:
>>> pair = re.compile(r".*(.).*1") >>> displaymatch(pair.match("717ak")) # Pair of 7s. "<Match: '717', groups=('7',)>" >>> displaymatch(pair.match("718ak")) # No pairs. >>> displaymatch(pair.match("354aa")) # Pair of aces. "<Match: '354aa', groups=('a',)>"
To find out what card the pair consists of, one could use the
group() method of the match object in the following manner:
>>> pair.match("717ak").group(1) '7' # Error because re.match() returns None, which doesn't have a group() method: >>> pair.match("718ak").group(1) Traceback (most recent call last): File "<pyshell#23>", line 1, in <module> re.match(r".*(.).*1", "718ak").group(1) AttributeError: 'NoneType' object has no attribute 'group' >>> pair.match("354aa").group(1) 'a'
6.2.5.2. Simulating scanf()¶
Python does not currently have an equivalent to scanf(). Regular
expressions are generally more powerful, though also more verbose, than
scanf() format strings. The table below offers some more-or-less
equivalent mappings between scanf() format tokens and regular
expressions.
scanf() Token |
Regular Expression |
|---|---|
%c |
. |
%5c |
.{5} |
%d |
[-+]?d+ |
%e, %E, %f, %g |
[-+]?(d+(.d*)?|.d+)([eE][-+]?d+)? |
%i |
[-+]?(0[xX][dA-Fa-f]+|0[0-7]*|d+) |
%o |
[-+]?[0-7]+ |
%s |
S+ |
%u |
d+ |
%x, %X |
[-+]?(0[xX])?[dA-Fa-f]+ |
To extract the filename and numbers from a string like
/usr/sbin/sendmail - 0 errors, 4 warnings
you would use a scanf() format like
%s - %d errors, %d warnings
The equivalent regular expression would be
(S+) - (d+) errors, (d+) warnings
6.2.5.3. search() vs. match()¶
Python offers two different primitive operations based on regular expressions:
re.match() checks for a match only at the beginning of the string, while
re.search() checks for a match anywhere in the string (this is what Perl
does by default).
For example:
>>> re.match("c", "abcdef") # No match >>> re.search("c", "abcdef") # Match <re.Match object; span=(2, 3), match='c'>
Regular expressions beginning with '^' can be used with search() to
restrict the match at the beginning of the string:
>>> re.match("c", "abcdef") # No match >>> re.search("^c", "abcdef") # No match >>> re.search("^a", "abcdef") # Match <re.Match object; span=(0, 1), match='a'>
Note however that in MULTILINE mode match() only matches at the
beginning of the string, whereas using search() with a regular expression
beginning with '^' will match at the beginning of each line.
>>> re.match('X', 'AnBnX', re.MULTILINE) # No match >>> re.search('^X', 'AnBnX', re.MULTILINE) # Match <re.Match object; span=(4, 5), match='X'>
6.2.5.4. Making a Phonebook¶
split() splits a string into a list delimited by the passed pattern. The
method is invaluable for converting textual data into data structures that can be
easily read and modified by Python as demonstrated in the following example that
creates a phonebook.
First, here is the input. Normally it may come from a file, here we are using
triple-quoted string syntax:
>>> text = """Ross McFluff: 834.345.1254 155 Elm Street ... ... Ronald Heathmore: 892.345.3428 436 Finley Avenue ... Frank Burger: 925.541.7625 662 South Dogwood Way ... ... ... Heather Albrecht: 548.326.4584 919 Park Place"""
The entries are separated by one or more newlines. Now we convert the string
into a list with each nonempty line having its own entry:
>>> entries = re.split("n+", text) >>> entries ['Ross McFluff: 834.345.1254 155 Elm Street', 'Ronald Heathmore: 892.345.3428 436 Finley Avenue', 'Frank Burger: 925.541.7625 662 South Dogwood Way', 'Heather Albrecht: 548.326.4584 919 Park Place']
Finally, split each entry into a list with first name, last name, telephone
number, and address. We use the maxsplit parameter of split()
because the address has spaces, our splitting pattern, in it:
>>> [re.split(":? ", entry, 3) for entry in entries] [['Ross', 'McFluff', '834.345.1254', '155 Elm Street'], ['Ronald', 'Heathmore', '892.345.3428', '436 Finley Avenue'], ['Frank', 'Burger', '925.541.7625', '662 South Dogwood Way'], ['Heather', 'Albrecht', '548.326.4584', '919 Park Place']]
The :? pattern matches the colon after the last name, so that it does not
occur in the result list. With a maxsplit of 4, we could separate the
house number from the street name:
>>> [re.split(":? ", entry, 4) for entry in entries] [['Ross', 'McFluff', '834.345.1254', '155', 'Elm Street'], ['Ronald', 'Heathmore', '892.345.3428', '436', 'Finley Avenue'], ['Frank', 'Burger', '925.541.7625', '662', 'South Dogwood Way'], ['Heather', 'Albrecht', '548.326.4584', '919', 'Park Place']]
6.2.5.5. Text Munging¶
sub() replaces every occurrence of a pattern with a string or the
result of a function. This example demonstrates using sub() with
a function to “munge” text, or randomize the order of all the characters
in each word of a sentence except for the first and last characters:
>>> def repl(m): ... inner_word = list(m.group(2)) ... random.shuffle(inner_word) ... return m.group(1) + "".join(inner_word) + m.group(3) >>> text = "Professor Abdolmalek, please report your absences promptly." >>> re.sub(r"(w)(w+)(w)", repl, text) 'Poefsrosr Aealmlobdk, pslaee reorpt your abnseces plmrptoy.' >>> re.sub(r"(w)(w+)(w)", repl, text) 'Pofsroser Aodlambelk, plasee reoprt yuor asnebces potlmrpy.'
6.2.5.6. Finding all Adverbs¶
findall() matches all occurrences of a pattern, not just the first
one as search() does. For example, if one was a writer and wanted to
find all of the adverbs in some text, he or she might use findall() in
the following manner:
>>> text = "He was carefully disguised but captured quickly by police." >>> re.findall(r"w+ly", text) ['carefully', 'quickly']
6.2.5.7. Finding all Adverbs and their Positions¶
If one wants more information about all matches of a pattern than the matched
text, finditer() is useful as it provides match objects instead of strings. Continuing with the previous example, if
one was a writer who wanted to find all of the adverbs and their positions in
some text, he or she would use finditer() in the following manner:
>>> text = "He was carefully disguised but captured quickly by police." >>> for m in re.finditer(r"w+ly", text): ... print('%02d-%02d: %s' % (m.start(), m.end(), m.group(0))) 07-16: carefully 40-47: quickly
6.2.5.8. Raw String Notation¶
Raw string notation (r"text") keeps regular expressions sane. Without it,
every backslash ('') in a regular expression would have to be prefixed with
another one to escape it. For example, the two following lines of code are
functionally identical:
>>> re.match(r"W(.)1W", " ff ") <re.Match object; span=(0, 4), match=' ff '> >>> re.match("\W(.)\1\W", " ff ") <re.Match object; span=(0, 4), match=' ff '>
When one wants to match a literal backslash, it must be escaped in the regular
expression. With raw string notation, this means r"\". Without raw string
notation, one must use "\\", making the following lines of code
functionally identical:
>>> re.match(r"\", r"\") <re.Match object; span=(0, 1), match='\'> >>> re.match("\\", r"\") <re.Match object; span=(0, 1), match='\'>
6.2.5.9. Writing a Tokenizer¶
A tokenizer or scanner
analyzes a string to categorize groups of characters. This is a useful first
step in writing a compiler or interpreter.
The text categories are specified with regular expressions. The technique is
to combine those into a single master regular expression and to loop over
successive matches:
import collections import re Token = collections.namedtuple('Token', ['typ', 'value', 'line', 'column']) def tokenize(code): keywords = {'IF', 'THEN', 'ENDIF', 'FOR', 'NEXT', 'GOSUB', 'RETURN'} token_specification = [ ('NUMBER', r'd+(.d*)?'), # Integer or decimal number ('ASSIGN', r':='), # Assignment operator ('END', r';'), # Statement terminator ('ID', r'[A-Za-z]+'), # Identifiers ('OP', r'[+-*/]'), # Arithmetic operators ('NEWLINE', r'n'), # Line endings ('SKIP', r'[ t]+'), # Skip over spaces and tabs ('MISMATCH',r'.'), # Any other character ] tok_regex = '|'.join('(?P<%s>%s)' % pair for pair in token_specification) line_num = 1 line_start = 0 for mo in re.finditer(tok_regex, code): kind = mo.lastgroup value = mo.group(kind) if kind == 'NEWLINE': line_start = mo.end() line_num += 1 elif kind == 'SKIP': pass elif kind == 'MISMATCH': raise RuntimeError(f'{value!r} unexpected on line {line_num}') else: if kind == 'ID' and value in keywords: kind = value column = mo.start() - line_start yield Token(kind, value, line_num, column) statements = ''' IF quantity THEN total := total + price * quantity; tax := price * 0.05; ENDIF; ''' for token in tokenize(statements): print(token)
The tokenizer produces the following output:
Token(typ='IF', value='IF', line=2, column=4) Token(typ='ID', value='quantity', line=2, column=7) Token(typ='THEN', value='THEN', line=2, column=16) Token(typ='ID', value='total', line=3, column=8) Token(typ='ASSIGN', value=':=', line=3, column=14) Token(typ='ID', value='total', line=3, column=17) Token(typ='OP', value='+', line=3, column=23) Token(typ='ID', value='price', line=3, column=25) Token(typ='OP', value='*', line=3, column=31) Token(typ='ID', value='quantity', line=3, column=33) Token(typ='END', value=';', line=3, column=41) Token(typ='ID', value='tax', line=4, column=8) Token(typ='ASSIGN', value=':=', line=4, column=12) Token(typ='ID', value='price', line=4, column=15) Token(typ='OP', value='*', line=4, column=21) Token(typ='NUMBER', value='0.05', line=4, column=23) Token(typ='END', value=';', line=4, column=27) Token(typ='ENDIF', value='ENDIF', line=5, column=4) Token(typ='END', value=';', line=5, column=9)
Регулярные выражения в Python от простого к сложному

Решил я давеча моим школьникам дать задачек на регулярные выражения для изучения. А к задачкам нужна какая-нибудь теория. И стал я искать хорошие тексты на русском. Пяток сносных нашёл, но всё не то. Что-то смято, что-то упущено. У этих текстов был не только фатальный недостаток. Мало картинок, мало примеров. И почти нет разумных задач. Ну неужели поиск IP-адреса — это самая частая задача для регулярных выражений? Вот и я думаю, что нет.
Про разницу (?:…) / (…) фиг найдёшь, а без этого знания в некоторых случаях можно только страдать.
Плюс в питоне есть немало регулярных плюшек. Например, re.split может добавлять тот кусок текста, по которому был разрез, в список частей. А в re.sub можно вместо шаблона для замены передать функцию. Это — реальные вещи, которые прямо очень нужны, но никто про это не пишет.
Так и родился этот достаточно многобуквенный материал с подробностями, тонкостями, картинками и задачами.
Надеюсь, вам удастся из него извлечь что-нибудь новое и полезное, даже если вы уже в ладах с регулярками.
PS. Решения задач школьники сдают в тестирующую систему, поэтому задачи оформлены в несколько формальном виде.
Содержание
Регулярные выражения в Python от простого к сложному;
Содержание;
Примеры регулярных выражений;
Сила и ответственность;
Документация и ссылки;
Основы синтаксиса;
Шаблоны, соответствующие одному символу;
Квантификаторы (указание количества повторений);
Жадность в регулярках и границы найденного шаблона;
Пересечение подстрок;
Эксперименты в песочнице;
Регулярки в питоне;
Пример использования всех основных функций;
Тонкости экранирования в питоне (‘\\\\foo’);
Использование дополнительных флагов в питоне;
Написание и тестирование регулярных выражений;
Задачи — 1;
Скобочные группы (?:…) и перечисления |;
Перечисления (операция «ИЛИ»);
Скобочные группы (группировка плюс квантификаторы);
Скобки плюс перечисления;
Ещё примеры;
Задачи — 2;
Группирующие скобки (…) и match-объекты в питоне;
Match-объекты;
Группирующие скобки (…);
Тонкости со скобками и нумерацией групп.;
Группы и re.findall;
Группы и re.split;
Использование групп при заменах;
Замена с обработкой шаблона функцией в питоне;
Ссылки на группы при поиске;
Задачи — 3;
Шаблоны, соответствующие не конкретному тексту, а позиции;
Простые шаблоны, соответствующие позиции;
Сложные шаблоны, соответствующие позиции (lookaround и Co);
lookaround на примере королей и императоров Франции;
Задачи — 4;
Post scriptum;
Регулярное выражение — это строка, задающая шаблон поиска подстрок в тексте. Одному шаблону может соответствовать много разных строчек. Термин «Регулярные выражения» является переводом английского словосочетания «Regular expressions». Перевод не очень точно отражает смысл, правильнее было бы «шаблонные выражения». Регулярное выражение, или коротко «регулярка», состоит из обычных символов и специальных командных последовательностей. Например, d задаёт любую цифру, а d+ — задает любую последовательность из одной или более цифр. Работа с регулярками реализована во всех современных языках программирования. Однако существует несколько «диалектов», поэтому функционал регулярных выражений может различаться от языка к языку. В некоторых языках программирования регулярками пользоваться очень удобно (например, в питоне), в некоторых — не слишком (например, в C++).
Примеры регулярных выражений

Сила и ответственность
Регулярные выражения, или коротко, регулярки — это очень мощный инструмент. Но использовать их следует с умом и осторожностью, и только там, где они действительно приносят пользу, а не вред. Во-первых, плохо написанные регулярные выражения работают медленно. Во-вторых, их зачастую очень сложно читать, особенно если регулярка написана не лично тобой пять минут назад. В-третьих, очень часто даже небольшое изменение задачи (того, что требуется найти) приводит к значительному изменению выражения. Поэтому про регулярки часто говорят, что это write only code (код, который только пишут с нуля, но не читают и не правят). А также шутят: Некоторые люди, когда сталкиваются с проблемой, думают «Я знаю, я решу её с помощью регулярных выражений.» Теперь у них две проблемы. Вот пример write-only регулярки (для проверки валидности e-mail адреса (не надо так делать!!!)):
(?:[a-z0-9!#$%&'*+/=?^_`{|}~-]+(?:.[a-z0-9!#$%&'*+/=?^_`{|}~-]+)*|"(?:[x01-x08x0bx0cx0e-x1fx21x23-x5bx5d-x7f]|\[x01-x09x0bx0cx0e-x7f])*")@(?:(?:[a-z0-9](?:[a-z0-9-]*[a-z0-9])?.)+[a-z0-9](?:[a-z0-9-]*[a-z0-9])?|[(?:(?:25[0-5]|
2[0-4][0-9]|[01]?[0-9][0-9]?).){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?|[a-z0-9-]*[a-z0-9]:(?:[x01-x08x0bx0cx0e-x1fx21-x5ax53-x7f]|\[x01-x09x0bx0cx0e-x7f])+)])А вот здесь более точная регулярка для проверки корректности email адреса стандарту RFC822. Если вдруг будете проверять email, то не делайте так!Если адрес вводит пользователь, то пусть вводит почти что угодно, лишь бы там была собака. Надёжнее всего отправить туда письмо и убедиться, что пользователь может его получить.
Документация и ссылки
- Оригинальная документация: https://docs.python.org/3/library/re.html;
- Очень подробный и обстоятельный материал: https://www.regular-expressions.info/;
- Разные сложные трюки и тонкости с примерами: http://www.rexegg.com/;
- Он-лайн отладка регулярок https://regex101.com (не забудьте поставить галочку Python в разделе FLAVOR слева);
- Он-лайн визуализация регулярок https://www.debuggex.com/ (не забудьте выбрать Python);
- Могущественный текстовый редактор Sublime text 3, в котором очень удобный поиск по регуляркам;
Основы синтаксиса
Любая строка (в которой нет символов .^$*+?{}[]|()) сама по себе является регулярным выражением. Так, выражению Хаха будет соответствовать строка “Хаха” и только она. Регулярные выражения являются регистрозависимыми, поэтому строка “хаха” (с маленькой буквы) уже не будет соответствовать выражению выше. Подобно строкам в языке Python, регулярные выражения имеют спецсимволы .^$*+?{}[]|(), которые в регулярках являются управляющими конструкциями. Для написания их просто как символов требуется их экранировать, для чего нужно поставить перед ними знак . Так же, как и в питоне, в регулярных выражениях выражение n соответствует концу строки, а t — табуляции.
Шаблоны, соответствующие одному символу
Во всех примерах ниже соответствия регулярному выражению выделяются бирюзовым цветом с подчёркиванием.
Квантификаторы (указание количества повторений)
Жадность в регулярках и границы найденного шаблона
Как указано выше, по умолчанию квантификаторы жадные. Этот подход решает очень важную проблему — проблему границы шаблона. Скажем, шаблон d+ захватывает максимально возможное количество цифр. Поэтому можно быть уверенным, что перед найденным шаблоном идёт не цифра, и после идёт не цифра. Однако если в шаблоне есть не жадные части (например, явный текст), то подстрока может быть найдена неудачно. Например, если мы хотим найти «слова», начинающиеся на СУ, после которой идут цифры, при помощи регулярки СУd*, то мы найдём и неправильные шаблоны:
ПАСУ13 СУ12, ЧТОБЫ СУ6ЕНИЕ УДАЛОСЬ.
В тех случаях, когда это важно, условие на границу шаблона нужно обязательно добавлять в регулярку. О том, как это можно делать, будет дальше.
Пересечение подстрок
В обычной ситуации регулярки позволяют найти только непересекающиеся шаблоны. Вместе с проблемой границы слова это делает их использование в некоторых случаях более сложным. Например, если мы решим искать e-mail адреса при помощи неправильной регулярки w+@w+ (или даже лучше, [w'._+-]+@[w'._+-]+), то в неудачном случае найдём вот что:
foo@boo@goo@moo@roo@zoo
То есть это с одной стороны и не e-mail, а с другой стороны это не все подстроки вида текст-собака-текст, так как boo@goo и moo@roo пропущены.

Эксперименты в песочнице
Если вы впервые сталкиваетесь с регулярными выражениями, то лучше всего сначала попробовать песочницу. Посмотрите, как работают простые шаблоны и квантификаторы. Решите следующие задачи для этого текста (возможно, к части придётся вернуться после следующей теории):
- Найдите все натуральные числа (возможно, окружённые буквами);
- Найдите все «слова», написанные капсом (то есть строго заглавными), возможно внутри настоящих слов (аааБББввв);
- Найдите слова, в которых есть русская буква, а когда-нибудь за ней цифра;
- Найдите все слова, начинающиеся с русской или латинской большой буквы (
b— граница слова); - Найдите слова, которые начинаются на гласную (
b— граница слова);; - Найдите все натуральные числа, не находящиеся внутри или на границе слова;
- Найдите строчки, в которых есть символ
*(.— это точно не конец строки!); - Найдите строчки, в которых есть открывающая и когда-нибудь потом закрывающая скобки;
- Выделите одним махом весь кусок оглавления (в конце примера, вместе с тегами);
- Выделите одним махом только текстовую часть оглавления, без тегов;
- Найдите пустые строчки;
Регулярки в питоне
Функции для работы с регулярками живут в модуле re. Основные функции:
Пример использования всех основных функций
import re
match = re.search(r'ddDdd', r'Телефон 123-12-12')
print(match[0] if match else 'Not found')
# -> 23-12
match = re.search(r'ddDdd', r'Телефон 1231212')
print(match[0] if match else 'Not found')
# -> Not found
match = re.fullmatch(r'ddDdd', r'12-12')
print('YES' if match else 'NO')
# -> YES
match = re.fullmatch(r'ddDdd', r'Т. 12-12')
print('YES' if match else 'NO')
# -> NO
print(re.split(r'W+', 'Где, скажите мне, мои очки??!'))
# -> ['Где', 'скажите', 'мне', 'мои', 'очки', '']
print(re.findall(r'dd.dd.d{4}',
r'Эта строка написана 19.01.2018, а могла бы и 01.09.2017'))
# -> ['19.01.2018', '01.09.2017']
for m in re.finditer(r'dd.dd.d{4}', r'Эта строка написана 19.01.2018, а могла бы и 01.09.2017'):
print('Дата', m[0], 'начинается с позиции', m.start())
# -> Дата 19.01.2018 начинается с позиции 20
# -> Дата 01.09.2017 начинается с позиции 45
print(re.sub(r'dd.dd.d{4}',
r'DD.MM.YYYY',
r'Эта строка написана 19.01.2018, а могла бы и 01.09.2017'))
# -> Эта строка написана DD.MM.YYYY, а могла бы и DD.MM.YYYY
Тонкости экранирования в питоне ('\\\\foo')
Так как символ в питоновских строках также необходимо экранировать, то в результате в шаблонах могут возникать конструкции вида '\\par'. Первый слеш означает, что следующий за ним символ нужно оставить «как есть». Третий также. В результате с точки зрения питона '\\' означает просто два слеша \. Теперь с точки зрения движка регулярных выражений, первый слеш экранирует второй. Тем самым как шаблон для регулярки '\\par' означает просто текст par. Для того, чтобы не было таких нагромождений слешей, перед открывающей кавычкой нужно поставить символ r, что скажет питону «не рассматривай как экранирующий символ (кроме случаев экранирования открывающей кавычки)». Соответственно можно будет писать r'\par'.
Использование дополнительных флагов в питоне
Каждой из функций, перечисленных выше, можно дать дополнительный параметр flags, что несколько изменит режим работы регулярок. В качестве значения нужно передать сумму выбранных констант, вот они:
import re
print(re.findall(r'd+', '12 + ٦٧'))
# -> ['12', '٦٧']
print(re.findall(r'w+', 'Hello, мир!'))
# -> ['Hello', 'мир']
print(re.findall(r'd+', '12 + ٦٧', flags=re.ASCII))
# -> ['12']
print(re.findall(r'w+', 'Hello, мир!', flags=re.ASCII))
# -> ['Hello']
print(re.findall(r'[уеыаоэяию]+', 'ОООО ааааа ррррр ЫЫЫЫ яяяя'))
# -> ['ааааа', 'яяяя']
print(re.findall(r'[уеыаоэяию]+', 'ОООО ааааа ррррр ЫЫЫЫ яяяя', flags=re.IGNORECASE))
# -> ['ОООО', 'ааааа', 'ЫЫЫЫ', 'яяяя']
text = r"""
Торт
с вишней1
вишней2
"""
print(re.findall(r'Торт.с', text))
# -> []
print(re.findall(r'Торт.с', text, flags=re.DOTALL))
# -> ['Тортnс']
print(re.findall(r'вишw+', text, flags=re.MULTILINE))
# -> ['вишней1', 'вишней2']
print(re.findall(r'^вишw+', text, flags=re.MULTILINE))
# -> ['вишней2']
Написание и тестирование регулярных выражений
Для написания и тестирования регулярных выражений удобно использовать сервис https://regex101.com (не забудьте поставить галочку Python в разделе FLAVOR слева) или текстовый редактор Sublime text 3.
Задачи — 1
Задача 01. Регистрационные знаки транспортных средств
В России применяются регистрационные знаки нескольких видов.
Общего в них то, что они состоят из цифр и букв. Причём используются только 12 букв кириллицы, имеющие графические аналоги в латинском алфавите — А, В, Е, К, М, Н, О, Р, С, Т, У и Х.
У частных легковых автомобилях номера — это буква, три цифры, две буквы, затем две или три цифры с кодом региона. У такси — две буквы, три цифры, затем две или три цифры с кодом региона. Есть также и другие виды, но в этой задаче они не понадобятся.
Вам потребуется определить, является ли последовательность букв корректным номером указанных двух типов, и если является, то каким.
На вход даются строки, которые претендуют на то, чтобы быть номером. Определите тип номера. Буквы в номерах — заглавные русские. Маленькие и английские для простоты можно игнорировать.
Задача 02. Количество слов
Слово — это последовательность из букв (русских или английских), внутри которой могут быть дефисы.
На вход даётся текст, посчитайте, сколько в нём слов.
PS. Задача решается в одну строчку. Никакие хитрые техники, не упомянутые выше, не требуются.
Задача 03. Поиск e-mailов
Допустимый формат e-mail адреса регулируется стандартом RFC 5322.
Если говорить вкратце, то e-mail состоит из одного символа @ (at-символ или собака), текста до собаки (Local-part) и текста после собаки (Domain part). Вообще в адресе может быть всякий беспредел (вкратце можно прочитать о нём в википедии). Довольно странные штуки могут быть валидным адресом, например:
"very.(),:;<>[]".VERY."very@\ "very".unusual"@[IPv6:2001:db8::1]
"()<>[]:,;@\"!#$%&'-/=?^_`{}| ~.a"@(comment)exa-mple
Но большинство почтовых сервисов такой ад и вакханалию не допускают. И мы тоже не будем 
Будем рассматривать только адреса, имя которых состоит из не более, чем 64 латинских букв, цифр и символов '._+-, а домен — из не более, чем 255 латинских букв, цифр и символов .-. Ни Local-part, ни Domain part не может начинаться или заканчиваться на .+-, а ещё в адресе не может быть более одной точки подряд.
Кстати, полезно знать, что часть имени после символа + игнорируется, поэтому можно использовать синонимы своего адреса (например, shаshkоv+spam@179.ru и shаshkоv+vk@179.ru), для того, чтобы упростить себе сортировку почты. (Правда не все сайты позволяют использовать «+», увы)
На вход даётся текст. Необходимо вывести все e-mail адреса, которые в нём встречаются. В общем виде задача достаточно сложная, поэтому у нас будет 3 ограничения:
две точки внутри адреса не встречаются;
две собаки внутри адреса не встречаются;
считаем, что e-mail может быть частью «слова», то есть в boo@ya_ru мы видим адрес boo@ya, а в foo№boo@ya.ru видим boo@ya.ru.
PS. Совсем не обязательно делать все проверки только регулярками. Регулярные выражения — это просто инструмент, который делает часть задач простыми. Не нужно делать их назад сложными
Скобочные группы (?:...) и перечисления |
Перечисления (операция «ИЛИ»)
Чтобы проверить, удовлетворяет ли строка хотя бы одному из шаблонов, можно воспользоваться аналогом оператора or, который записывается с помощью символа |. Так, некоторая строка подходит к регулярному выражению A|B тогда и только тогда, когда она подходит хотя бы к одному из регулярных выражений A или B. Например, отдельные овощи в тексте можно искать при помощи шаблона морковк|св[её]кл|картошк|редиск.
Скобочные группы (группировка плюс квантификаторы)
Зачастую шаблон состоит из нескольких повторяющихся групп. Так, MAC-адрес сетевого устройства обычно записывается как шесть групп из двух шестнадцатиричных цифр, разделённых символами - или :. Например, 01:23:45:67:89:ab. Каждый отдельный символ можно задать как [0-9a-fA-F], и можно весь шаблон записать так:
[0-9a-fA-F]{2}[:-][0-9a-fA-F]{2}[:-][0-9a-fA-F]{2}[:-][0-9a-fA-F]{2}[:-][0-9a-fA-F]{2}[:-][0-9a-fA-F]{2}
Ситуация становится гораздо сложнее, когда количество групп заранее не зафиксировано.
Чтобы разрешить эту проблему в синтаксисе регулярных выражений есть группировка (?:...). Можно писать круглые скобки и без значков ?:, однако от этого у группировки значительно меняется смысл, регулярка начинает работать гораздо медленнее. Об этом будет написано ниже. Итак, если REGEXP — шаблон, то (?:REGEXP) — эквивалентный ему шаблон. Разница только в том, что теперь к (?:REGEXP) можно применять квантификаторы, указывая, сколько именно раз должна повториться группа. Например, шаблон для поиска MAC-адреса, можно записать так:
[0-9a-fA-F]{2}(?:[:-][0-9a-fA-F]{2}){5}
Скобки плюс перечисления
Также скобки (?:...) позволяют локализовать часть шаблона, внутри которого происходит перечисление. Например, шаблон (?:он|тот) (?:шёл|плыл) соответствует каждой из строк «он шёл», «он плыл», «тот шёл», «тот плыл», и является синонимом он шёл|он плыл|тот шёл|тот плыл.
Ещё примеры
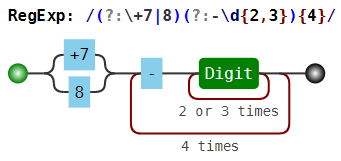
Задачи — 2
Задача 04. Замена времени
Вовочка подготовил одно очень важное письмо, но везде указал неправильное время.
Поэтому нужно заменить все вхождения времени на строку (TBD). Время — это строка вида HH:MM:SS или HH:MM, в которой HH — число от 00 до 23, а MM и SS — число от 00 до 59.
Задача 05. Действительные числа в паскале
Pascal requires that real constants have either a decimal point, or an exponent (starting with the letter e or E, and officially called a scale factor), or both, in addition to the usual collection of decimal digits. If a decimal point is included it must have at least one decimal digit on each side of it. As expected, a sign (+ or -) may precede the entire number, or the exponent, or both. Exponents may not include fractional digits. Blanks may precede or follow the real constant, but they may not be embedded within it. Note that the Pascal syntax rules for real constants make no assumptions about the range of real values, and neither does this problem. Your task in this problem is to identify legal Pascal real constants.
Задача 06. Аббревиатуры
Владимир устроился на работу в одно очень важное место. И в первом же документе он ничего не понял,
там были сплошные ФГУП НИЦ ГИДГЕО, ФГОУ ЧШУ АПК и т.п. Тогда он решил собрать все аббревиатуры, чтобы потом найти их расшифровки на http://sokr.ru/. Помогите ему.
Будем считать аббревиатурой слова только лишь из заглавных букв (как минимум из двух). Если несколько таких слов разделены пробелами, то они
считаются одной аббревиатурой.
Группирующие скобки (...) и match-объекты в питоне
Match-объекты
Если функции re.search, re.fullmatch не находят соответствие шаблону в строке, то они возвращают None, функция re.finditer не выдаёт ничего. Однако если соответствие найдено, то возвращается match-объект. Эта штука содержит в себе кучу полезной информации о соответствии шаблону. Полный набор атрибутов можно посмотреть в документации, а здесь приведём самое полезное.
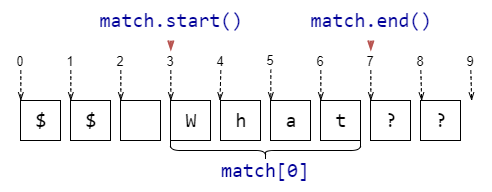
Группирующие скобки (...)
Если в шаблоне регулярного выражения встречаются скобки (...) без ?:, то они становятся группирующими. В match-объекте, который возвращают re.search, re.fullmatch и re.finditer, по каждой такой группе можно получить ту же информацию, что и по всему шаблону. А именно часть подстроки, которая соответствует (...), а также индексы начала и окончания в исходной строке. Достаточно часто это бывает полезно.
import re
pattern = r's*([А-Яа-яЁё]+)(d+)s*'
string = r'--- Опять45 ---'
match = re.search(pattern, string)
print(f'Найдена подстрока >{match[0]}< с позиции {match.start(0)} до {match.end(0)}')
print(f'Группа букв >{match[1]}< с позиции {match.start(1)} до {match.end(1)}')
print(f'Группа цифр >{match[2]}< с позиции {match.start(2)} до {match.end(2)}')
###
# -> Найдена подстрока > Опять45 < с позиции 3 до 16
# -> Группа букв >Опять< с позиции 6 до 11
# -> Группа цифр >45< с позиции 11 до 13
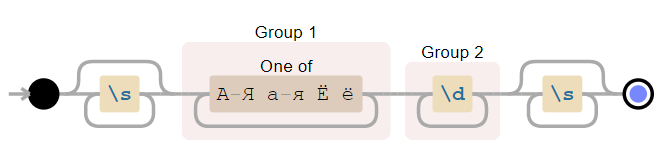
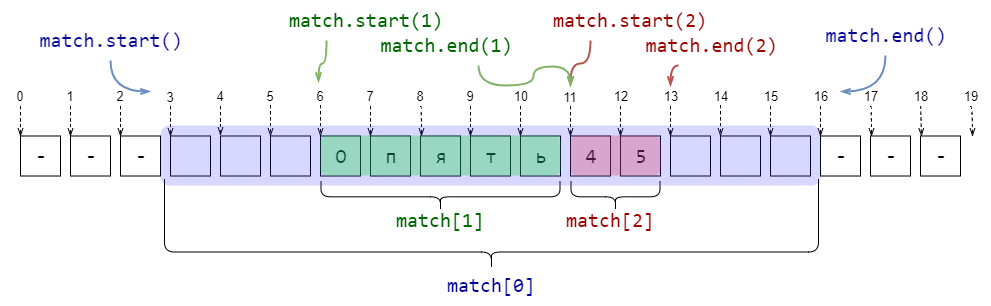
Тонкости со скобками и нумерацией групп.
Если к группирующим скобкам применён квантификатор (то есть указано число повторений), то подгруппа в match-объекте будет создана только для последнего соответствия. Например, если бы в примере выше квантификаторы были снаружи от скобок 's*([А-Яа-яЁё])+(d)+s*', то вывод был бы таким:
# -> Найдена подстрока > Опять45 < с позиции 3 до 16
# -> Группа букв >ь< с позиции 10 до 11
# -> Группа цифр >5< с позиции 12 до 13
Внутри группирующих скобок могут быть и другие группирующие скобки. В этом случае их нумерация производится в соответствии с номером появления открывающей скобки с шаблоне.
import re
pattern = r'((d)(d))((d)(d))'
string = r'123456789'
match = re.search(pattern, string)
print(f'Найдена подстрока >{match[0]}< с позиции {match.start(0)} до {match.end(0)}')
for i in range(1, 7):
print(f'Группа №{i} >{match[i]}< с позиции {match.start(i)} до {match.end(i)}')
###
# -> Найдена подстрока >1234< с позиции 0 до 4
# -> Группа №1 >12< с позиции 0 до 2
# -> Группа №2 >1< с позиции 0 до 1
# -> Группа №3 >2< с позиции 1 до 2
# -> Группа №4 >34< с позиции 2 до 4
# -> Группа №5 >3< с позиции 2 до 3
# -> Группа №6 >4< с позиции 3 до 4
Группы и re.findall
Если в шаблоне есть группирующие скобки, то вместо списка найденных подстрок будет возвращён список кортежей, в каждом из которых только соответствие каждой группе. Это не всегда происходит по плану, поэтому обычно нужно использовать негруппирующие скобки (?:...).
import re
print(re.findall(r'([a-z]+)(d*)', r'foo3, im12, go, 24buz42'))
# -> [('foo', '3'), ('im', '12'), ('go', ''), ('buz', '42')]
Группы и re.split
Если в шаблоне нет группирующих скобок, то re.split работает очень похожим образом на str.split. А вот если группирующие скобки в шаблоне есть, то между каждыми разрезанными строками будут все соответствия каждой из подгрупп.
import re
print(re.split(r'(s*)([+*/-])(s*)', r'12 + 13*15 - 6'))
# -> ['12', ' ', '+', ' ', '13', '', '*', '', '15', ' ', '-', ' ', '6']
В некоторых ситуация эта возможность бывает чрезвычайно удобна! Например, достаточно из предыдущего примера убрать лишние группы, и польза сразу станет очевидна!
import re
print(re.split(r's*([+*/-])s*', r'12 + 13*15 - 6'))
# -> ['12', '+', '13', '*', '15', '-', '6']
Использование групп при заменах
Использование групп добавляет замене (re.sub, работает не только в питоне, а почти везде) очень удобную возможность: в шаблоне для замены можно ссылаться на соответствующую группу при помощи 1, 2, 3, .... Например, если нужно даты из неудобного формата ММ/ДД/ГГГГ перевести в удобный ДД.ММ.ГГГГ, то можно использовать такую регулярку:
import re
text = "We arrive on 03/25/2018. So you are welcome after 04/01/2018."
print(re.sub(r'(dd)/(dd)/(d{4})', r'2.1.3', text))
# -> We arrive on 25.03.2018. So you are welcome after 01.04.2018.
Если групп больше 9, то можно ссылаться на них при помощи конструкции вида g<12>.
Замена с обработкой шаблона функцией в питоне
Ещё одна питоновская фича для регулярных выражений: в функции re.sub вместо текста для замены можно передать функцию, которая будет получать на вход match-объект и должна возвращать строку, на которую и будет произведена замена. Это позволяет не писать ад в шаблоне для замены, а использовать удобную функцию. Например, «зацензурим» все слова, начинающиеся на букву «Х»:
import re
def repl(m):
return '>censored(' + str(len(m[0])) + ')<'
text = "Некоторые хорошие слова подозрительны: хор, хоровод, хороводоводовед."
print(re.sub(r'b[хХxX]w*', repl, text))
# -> Некоторые >censored(7)< слова подозрительны: >censored(3)<, >censored(7)<, >censored(15)<.
Ссылки на группы при поиске
При помощи 1, 2, 3, ... и g<12> можно ссылаться на найденную группу и при поиске. Необходимость в этом встречается довольно редко, но это бывает полезно при обработке простых xml и html.
Только пообещайте, что не будете парсить сложный xml и тем более html при помощи регулярок! Регулярные выражения для этого не подходят. Используйте другие инструменты. Каждый раз, когда неопытный программист парсит html регулярками, в мире умирает котёнок. Если кажется «Да здесь очень простой html, напишу регулярку», то сразу вспоминайте шутку про две проблемы. Не нужно пытаться парсить html регулярками, даже Пётр Митричев не сможет это сделать в общем случае Использование регулярных выражений при парсинге html подобно залатыванию резиновой лодки шилом. Закон Мёрфи для парсинга html и xml при помощи регулярок гласит: парсинг html и xml регулярками иногда работает, но в точности до того момента, когда правильность результата будет очень важна.
Используйте lxml и beautiful soup.
import re
text = "SPAM <foo>Here we can <boo>find</boo> something interesting</foo> SPAM"
print(re.search(r'<(w+?)>.*?</1>', text)[0])
# -> <foo>Here we can <boo>find</boo> something interesting</foo>
text = "SPAM <foo>Here we can <foo>find</foo> OH, NO MATCH HERE!</foo> SPAM"
print(re.search(r'<(w+?)>.*?</1>', text)[0])
# -> <foo>Here we can <foo>find</foo>
Задачи — 3
Задача 07. Шифровка
Владимиру потребовалось срочно запутать финансовую документацию. Но так, чтобы это было обратимо.
Он не придумал ничего лучше, чем заменить каждое целое число (последовательность цифр) на его куб. Помогите ему.
Задача 08. То ли акростих, то ли акроним, то ли апроним
Акростих — осмысленный текст, сложенный из начальных букв каждой строки стихотворения.
Акроним — вид аббревиатуры, образованной начальными звуками (напр. НАТО, вуз, НАСА, ТАСС), которое можно произнести слитно (в отличие от аббревиатуры, которую произносят «по буквам», например: КГБ — «ка-гэ-бэ»).
На вход даётся текст. Выведите слитно первые буквы каждого слова. Буквы необходимо выводить заглавными.
Эту задачу можно решить в одну строчку.
Задача 09. Хайку
Хайку — жанр традиционной японской лирической поэзии века, известный с XIV века.
Оригинальное японское хайку состоит из 17 слогов, составляющих один столбец иероглифов. Особыми разделительными словами — кирэдзи — текст хайку делится на части из 5, 7 и снова 5 слогов. При переводе хайку на западные языки традиционно вместо разделительного слова использую разрыв строки и, таким образом, хайку записываются как трёхстишия.
Перед вами трёхстишия, которые претендуют на то, чтобы быть хайку. В качестве разделителя строк используются символы / . Если разделители делят текст на строки, в которых 5/7/5 слогов, то выведите «Хайку!». Если число строк не равно 3, то выведите строку «Не хайку. Должно быть 3 строки.» Иначе выведите строку вида «Не хайку. В i строке слогов не s, а j.», где строка i — самая ранняя, в которой количество слогов неправильное.
Для простоты будем считать, что слогов ровно столько же, сколько гласных, не задумываясь о тонкостях.
Шаблоны, соответствующие не конкретному тексту, а позиции
Отдельные части регулярного выражения могут соответствовать не части текста, а позиции в этом тексте. То есть такому шаблону соответствует не подстрока, а некоторая позиция в тексте, как бы «между» буквами.
Простые шаблоны, соответствующие позиции
Для определённости строку, в которой мы ищем шаблон будем называть всем текстом.Каждую строчку всего текста (то есть каждый максимальный кусок без символов конца строки) будем называть строчкой текста.
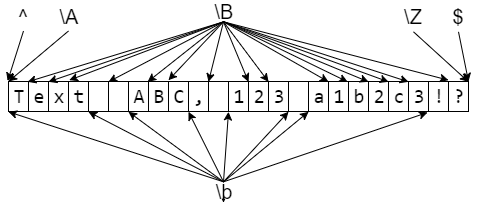
Сложные шаблоны, соответствующие позиции (lookaround и Co)
Следующие шаблоны применяются в основном в тех случаях, когда нужно уточнить, что должно идти непосредственно перед или после шаблона, но при этом
не включать найденное в match-объект.
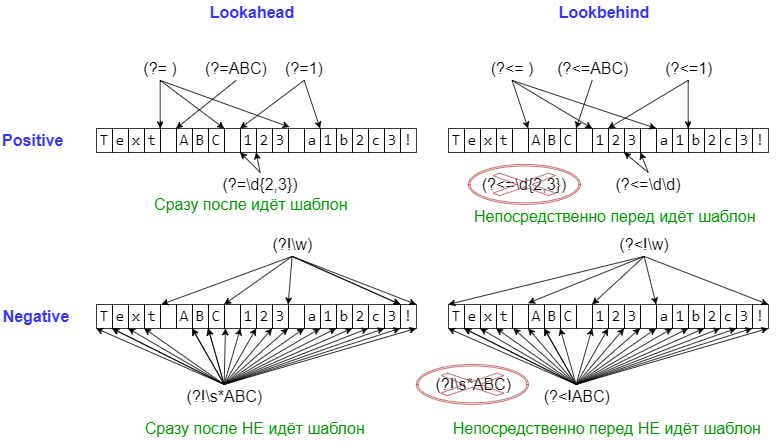
На всякий случай ещё раз. Каждый их этих шаблонов проверяет лишь то, что идёт непосредственно перед позицией или непосредственно после позиции. Если пару таких шаблонов написать рядом, то проверки будут независимы (то есть будут соответствовать AND в каком-то смысле).
lookaround на примере королей и императоров Франции
Людовик(?=VI) — Людовик, за которым идёт VI
КарлIV, КарлIX, КарлV, КарлVI, КарлVII, КарлVIII,
ЛюдовикIX, ЛюдовикVI, ЛюдовикVII, ЛюдовикVIII, ЛюдовикX, …, ЛюдовикXVIII,
ФилиппI, ФилиппII, ФилиппIII, ФилиппIV, ФилиппV, ФилиппVI
Людовик(?!VI) — Людовик, за которым идёт не VI
КарлIV, КарлIX, КарлV, КарлVI, КарлVII, КарлVIII,
ЛюдовикIX, ЛюдовикVI, ЛюдовикVII, ЛюдовикVIII, ЛюдовикX, …, ЛюдовикXVIII,
ФилиппI, ФилиппII, ФилиппIII, ФилиппIV, ФилиппV, ФилиппVI
(?<=Людовик)VI — «шестой», но только если Людовик
КарлIV, КарлIX, КарлV, КарлVI, КарлVII, КарлVIII,
ЛюдовикIX, ЛюдовикVI, ЛюдовикVII, ЛюдовикVIII, ЛюдовикX, …, ЛюдовикXVIII,
ФилиппI, ФилиппII, ФилиппIII, ФилиппIV, ФилиппV, ФилиппVI
(?<!Людовик)VI — «шестой», но только если не Людовик
КарлIV, КарлIX, КарлV, КарлVI, КарлVII, КарлVIII,
ЛюдовикIX, ЛюдовикVI, ЛюдовикVII, ЛюдовикVIII, ЛюдовикX, …, ЛюдовикXVIII,
ФилиппI, ФилиппII, ФилиппIII, ФилиппIV, ФилиппV, ФилиппVI


Прочие фичи
Конечно, здесь описано не всё, что умеют регулярные выражения, и даже не всё, что умеют регулярные выражения в питоне. За дальнейшим можно обращаться к этому разделу. Из полезного за кадром осталась компиляция регулярок для ускорения многократного использования одного шаблона, использование именных групп и разные хитрые трюки.
А уж какие извращения можно делать с регулярными выражениями в языке Perl — поручик Ржевский просто отдыхает
Задачи — 4
Задача 10. CamelCase -> under_score
Владимир написал свой открытый проект, именуя переменные в стиле «ВерблюжийРегистр».
И только после того, как написал о нём статью, он узнал, что в питоне для имён переменных принято использовать подчёркивания для разделения слов (under_score). Нужно срочно всё исправить, пока его не «закидали тапками».
Задача могла бы оказаться достаточно сложной, но, к счастью, Владимир совсем не использовал строковых констант и классов.
Поэтому любая последовательность букв и цифр, внутри которой есть заглавные, — это имя переменной, которое нужно поправить.
Задача 11. Удаление повторов
Довольно распространённая ошибка ошибка — это повтор слова.
Вот в предыдущем предложении такая допущена. Необходимо исправить каждый такой повтор (слово, один или несколько пробельных символов, и снова то же слово).
Задача 12. Близкие слова
Для простоты будем считать словом любую последовательность букв, цифр и знаков _ (то есть символов w).
Дан текст. Необходимо найти в нём любой фрагмент, где сначала идёт слово «олень», затем не более 5 слов, и после этого идёт слово «заяц».
Задача 13. Форматирование больших чисел
Большие целые числа удобно читать, когда цифры в них разделены на тройки запятыми.
Переформатируйте целые числа в тексте.
Задача 14. Разделить текст на предложения
Для простоты будем считать, что:
- каждое предложение начинается с заглавной русской или латинской буквы;
- каждое предложение заканчивается одним из знаков препинания
.;!?; - между предложениями может быть любой непустой набор пробельных символов;
- внутри предложений нет заглавных и точек (нет пакостей в духе «Мы любим творчество А. С. Пушкина)».
Разделите текст на предложения так, чтобы каждое предложение занимало одну строку.
Пустых строк в выводе быть не должно. Любые наборы из полее одного пробельного символа замените на один пробел.
Задача 15. Форматирование номера телефона
Если вы когда-нибудь пытались собирать номера мобильных телефонов, то наверняка знаете, что почти любые 10 человек используют как минимум пяток различных способов записать номер телефона. Кто-то начинает с +7, кто-то просто с 7 или 8, а некоторые вообще не пишут префикс. Трёхзначный код кто-то отделяет пробелами, кто-то при помощи дефиса, кто-то скобками (и после скобки ещё пробел некоторые добавляют). После следующих трёх цифр кто-то ставит пробел, кто-то дефис, кто-то ничего не ставит. И после следующих двух цифр — тоже. А некоторые начинают за здравие, а заканчивают… В общем очень неудобно!
На вход даётся номер телефона, как его мог бы ввести человек. Необходимо его переформатировать в формат +7 123 456-78-90. Если с номером что-то не так, то нужно вывести строчку Fail!.
Задача 16. Поиск e-mail’ов — 2
В предыдущей задаче мы немного схалтурили.
Однако к этому моменту задача должна стать посильной!
На вход даётся текст. Необходимо вывести все e-mail адреса, которые в нём встречаются. При этом e-mail не может быть частью слова, то есть слева и справа от e-mail’а должен быть либо конец строки, либо не-буква и при этом не один из символов '._+-, допустимых в адресе.
Post scriptum
PS. Текст длинный, в нём наверняка есть опечатки и ошибки. Пишите о них скорее в личку, я тут же исправлю.
PSS. Ух и намаялся я нормальный html в хабра-html перегонять. Кажется, парсер хабра писан на регулярках, иначе как объяснить все те странности, которые приходилось вылавливать бинпоиском?
In the previous tutorial in this series, you covered a lot of ground. You saw how to use re.search() to perform pattern matching with regexes in Python and learned about the many regex metacharacters and parsing flags that you can use to fine-tune your pattern-matching capabilities.
But as great as all that is, the re module has much more to offer.
In this tutorial, you’ll:
- Explore more functions, beyond
re.search(), that theremodule provides - Learn when and how to precompile a regex in Python into a regular expression object
- Discover useful things that you can do with the match object returned by the functions in the
remodule
Ready? Let’s dig in!
re Module Functions
In addition to re.search(), the re module contains several other functions to help you perform regex-related tasks.
The available regex functions in the Python re module fall into the following three categories:
- Searching functions
- Substitution functions
- Utility functions
The following sections explain these functions in more detail.
Searching Functions
Searching functions scan a search string for one or more matches of the specified regex:
| Function | Description |
|---|---|
re.search() |
Scans a string for a regex match |
re.match() |
Looks for a regex match at the beginning of a string |
re.fullmatch() |
Looks for a regex match on an entire string |
re.findall() |
Returns a list of all regex matches in a string |
re.finditer() |
Returns an iterator that yields regex matches from a string |
As you can see from the table, these functions are similar to one another. But each one tweaks the searching functionality in its own way.
re.search(<regex>, <string>, flags=0)
Scans a string for a regex match.
If you worked through the previous tutorial in this series, then you should be well familiar with this function by now. re.search(<regex>, <string>) looks for any location in <string> where <regex> matches:
>>>
>>> re.search(r'(d+)', 'foo123bar')
<_sre.SRE_Match object; span=(3, 6), match='123'>
>>> re.search(r'[a-z]+', '123FOO456', flags=re.IGNORECASE)
<_sre.SRE_Match object; span=(3, 6), match='FOO'>
>>> print(re.search(r'd+', 'foo.bar'))
None
The function returns a match object if it finds a match and None otherwise.
re.match(<regex>, <string>, flags=0)
Looks for a regex match at the beginning of a string.
This is identical to re.search(), except that re.search() returns a match if <regex> matches anywhere in <string>, whereas re.match() returns a match only if <regex> matches at the beginning of <string>:
>>>
>>> re.search(r'd+', '123foobar')
<_sre.SRE_Match object; span=(0, 3), match='123'>
>>> re.search(r'd+', 'foo123bar')
<_sre.SRE_Match object; span=(3, 6), match='123'>
>>> re.match(r'd+', '123foobar')
<_sre.SRE_Match object; span=(0, 3), match='123'>
>>> print(re.match(r'd+', 'foo123bar'))
None
In the above example, re.search() matches when the digits are both at the beginning of the string and in the middle, but re.match() matches only when the digits are at the beginning.
Remember from the previous tutorial in this series that if <string> contains embedded newlines, then the MULTILINE flag causes re.search() to match the caret (^) anchor metacharacter either at the beginning of <string> or at the beginning of any line contained within <string>:
>>>
1>>> s = 'foonbarnbaz'
2
3>>> re.search('^foo', s)
4<_sre.SRE_Match object; span=(0, 3), match='foo'>
5>>> re.search('^bar', s, re.MULTILINE)
6<_sre.SRE_Match object; span=(4, 7), match='bar'>
The MULTILINE flag does not affect re.match() in this way:
>>>
1>>> s = 'foonbarnbaz'
2
3>>> re.match('^foo', s)
4<_sre.SRE_Match object; span=(0, 3), match='foo'>
5>>> print(re.match('^bar', s, re.MULTILINE))
6None
Even with the MULTILINE flag set, re.match() will match the caret (^) anchor only at the beginning of <string>, not at the beginning of lines contained within <string>.
Note that, although it illustrates the point, the caret (^) anchor on line 3 in the above example is redundant. With re.match(), matches are essentially always anchored at the beginning of the string.
re.fullmatch(<regex>, <string>, flags=0)
Looks for a regex match on an entire string.
This is similar to re.search() and re.match(), but re.fullmatch() returns a match only if <regex> matches <string> in its entirety:
>>>
1>>> print(re.fullmatch(r'd+', '123foo'))
2None
3>>> print(re.fullmatch(r'd+', 'foo123'))
4None
5>>> print(re.fullmatch(r'd+', 'foo123bar'))
6None
7>>> re.fullmatch(r'd+', '123')
8<_sre.SRE_Match object; span=(0, 3), match='123'>
9
10>>> re.search(r'^d+$', '123')
11<_sre.SRE_Match object; span=(0, 3), match='123'>
In the call on line 7, the search string '123' consists entirely of digits from beginning to end. So that is the only case in which re.fullmatch() returns a match.
The re.search() call on line 10, in which the d+ regex is explicitly anchored at the start and end of the search string, is functionally equivalent.
re.findall(<regex>, <string>, flags=0)
Returns a list of all matches of a regex in a string.
re.findall(<regex>, <string>) returns a list of all non-overlapping matches of <regex> in <string>. It scans the search string from left to right and returns all matches in the order found:
>>>
>>> re.findall(r'w+', '...foo,,,,bar:%$baz//|')
['foo', 'bar', 'baz']
If <regex> contains a capturing group, then the return list contains only contents of the group, not the entire match:
>>>
>>> re.findall(r'#(w+)#', '#foo#.#bar#.#baz#')
['foo', 'bar', 'baz']
In this case, the specified regex is #(w+)#. The matching strings are '#foo#', '#bar#', and '#baz#'. But the hash (#) characters don’t appear in the return list because they’re outside the grouping parentheses.
If <regex> contains more than one capturing group, then re.findall() returns a list of tuples containing the captured groups. The length of each tuple is equal to the number of groups specified:
>>>
1>>> re.findall(r'(w+),(w+)', 'foo,bar,baz,qux,quux,corge')
2[('foo', 'bar'), ('baz', 'qux'), ('quux', 'corge')]
3
4>>> re.findall(r'(w+),(w+),(w+)', 'foo,bar,baz,qux,quux,corge')
5[('foo', 'bar', 'baz'), ('qux', 'quux', 'corge')]
In the above example, the regex on line 1 contains two capturing groups, so re.findall() returns a list of three two-tuples, each containing two captured matches. Line 4 contains three groups, so the return value is a list of two three-tuples.
re.finditer(<regex>, <string>, flags=0)
Returns an iterator that yields regex matches.
re.finditer(<regex>, <string>) scans <string> for non-overlapping matches of <regex> and returns an iterator that yields the match objects from any it finds. It scans the search string from left to right and returns matches in the order it finds them:
>>>
>>> it = re.finditer(r'w+', '...foo,,,,bar:%$baz//|')
>>> next(it)
<_sre.SRE_Match object; span=(3, 6), match='foo'>
>>> next(it)
<_sre.SRE_Match object; span=(10, 13), match='bar'>
>>> next(it)
<_sre.SRE_Match object; span=(16, 19), match='baz'>
>>> next(it)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration
>>> for i in re.finditer(r'w+', '...foo,,,,bar:%$baz//|'):
... print(i)
...
<_sre.SRE_Match object; span=(3, 6), match='foo'>
<_sre.SRE_Match object; span=(10, 13), match='bar'>
<_sre.SRE_Match object; span=(16, 19), match='baz'>
re.findall() and re.finditer() are very similar, but they differ in two respects:
-
re.findall()returns a list, whereasre.finditer()returns an iterator. -
The items in the list that
re.findall()returns are the actual matching strings, whereas the items yielded by the iterator thatre.finditer()returns are match objects.
Any task that you could accomplish with one, you could probably also manage with the other. Which one you choose will depend on the circumstances. As you’ll see later in this tutorial, a lot of useful information can be obtained from a match object. If you need that information, then re.finditer() will probably be the better choice.
Substitution Functions
Substitution functions replace portions of a search string that match a specified regex:
| Function | Description |
|---|---|
re.sub() |
Scans a string for regex matches, replaces the matching portions of the string with the specified replacement string, and returns the result |
re.subn() |
Behaves just like re.sub() but also returns information regarding the number of substitutions made |
Both re.sub() and re.subn() create a new string with the specified substitutions and return it. The original string remains unchanged. (Remember that strings are immutable in Python, so it wouldn’t be possible for these functions to modify the original string.)
re.sub(<regex>, <repl>, <string>, count=0, flags=0)
Returns a new string that results from performing replacements on a search string.
re.sub(<regex>, <repl>, <string>) finds the leftmost non-overlapping occurrences of <regex> in <string>, replaces each match as indicated by <repl>, and returns the result. <string> remains unchanged.
<repl> can be either a string or a function, as explained below.
Substitution by String
If <repl> is a string, then re.sub() inserts it into <string> in place of any sequences that match <regex>:
>>>
1>>> s = 'foo.123.bar.789.baz'
2
3>>> re.sub(r'd+', '#', s)
4'foo.#.bar.#.baz'
5>>> re.sub('[a-z]+', '(*)', s)
6'(*).123.(*).789.(*)'
On line 3, the string '#' replaces sequences of digits in s. On line 5, the string '(*)' replaces sequences of lowercase letters. In both cases, re.sub() returns the modified string as it always does.
re.sub() replaces numbered backreferences (<n>) in <repl> with the text of the corresponding captured group:
>>>
>>> re.sub(r'(w+),bar,baz,(w+)',
... r'2,bar,baz,1',
... 'foo,bar,baz,qux')
'qux,bar,baz,foo'
Here, captured groups 1 and 2 contain 'foo' and 'qux'. In the replacement string '2,bar,baz,1', 'foo' replaces 1 and 'qux' replaces 2.
You can also refer to named backreferences created with (?P<name><regex>) in the replacement string using the metacharacter sequence g<name>:
>>>
>>> re.sub(r'foo,(?P<w1>w+),(?P<w2>w+),qux',
... r'foo,g<w2>,g<w1>,qux',
... 'foo,bar,baz,qux')
'foo,baz,bar,qux'
In fact, you can also refer to numbered backreferences this way by specifying the group number inside the angled brackets:
>>>
>>> re.sub(r'foo,(w+),(w+),qux',
... r'foo,g<2>,g<1>,qux',
... 'foo,bar,baz,qux')
'foo,baz,bar,qux'
You may need to use this technique to avoid ambiguity in cases where a numbered backreference is immediately followed by a literal digit character. For example, suppose you have a string like 'foo 123 bar' and want to add a '0' at the end of the digit sequence. You might try this:
>>>
>>> re.sub(r'(d+)', r'10', 'foo 123 bar')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/lib/python3.6/re.py", line 191, in sub
return _compile(pattern, flags).sub(repl, string, count)
File "/usr/lib/python3.6/re.py", line 326, in _subx
template = _compile_repl(template, pattern)
File "/usr/lib/python3.6/re.py", line 317, in _compile_repl
return sre_parse.parse_template(repl, pattern)
File "/usr/lib/python3.6/sre_parse.py", line 943, in parse_template
addgroup(int(this[1:]), len(this) - 1)
File "/usr/lib/python3.6/sre_parse.py", line 887, in addgroup
raise s.error("invalid group reference %d" % index, pos)
sre_constants.error: invalid group reference 10 at position 1
Alas, the regex parser in Python interprets 10 as a backreference to the tenth captured group, which doesn’t exist in this case. Instead, you can use g<1> to refer to the group:
>>>
>>> re.sub(r'(d+)', r'g<1>0', 'foo 123 bar')
'foo 1230 bar'
The backreference g<0> refers to the text of the entire match. This is valid even when there are no grouping parentheses in <regex>:
>>>
>>> re.sub(r'd+', '/g<0>/', 'foo 123 bar')
'foo /123/ bar'
If <regex> specifies a zero-length match, then re.sub() will substitute <repl> into every character position in the string:
>>>
>>> re.sub('x*', '-', 'foo')
'-f-o-o-'
In the example above, the regex x* matches any zero-length sequence, so re.sub() inserts the replacement string at every character position in the string—before the first character, between each pair of characters, and after the last character.
If re.sub() doesn’t find any matches, then it always returns <string> unchanged.
Substitution by Function
If you specify <repl> as a function, then re.sub() calls that function for each match found. It passes each corresponding match object as an argument to the function to provide information about the match. The function return value then becomes the replacement string:
>>>
>>> def f(match_obj):
... s = match_obj.group(0) # The matching string
...
... # s.isdigit() returns True if all characters in s are digits
... if s.isdigit():
... return str(int(s) * 10)
... else:
... return s.upper()
...
>>> re.sub(r'w+', f, 'foo.10.bar.20.baz.30')
'FOO.100.BAR.200.BAZ.300'
In this example, f() gets called for each match. As a result, re.sub() converts each alphanumeric portion of <string> to all uppercase and multiplies each numeric portion by 10.
Limiting the Number of Replacements
If you specify a positive integer for the optional count parameter, then re.sub() performs at most that many replacements:
>>>
>>> re.sub(r'w+', 'xxx', 'foo.bar.baz.qux')
'xxx.xxx.xxx.xxx'
>>> re.sub(r'w+', 'xxx', 'foo.bar.baz.qux', count=2)
'xxx.xxx.baz.qux'
As with most re module functions, re.sub() accepts an optional <flags> argument as well.
re.subn(<regex>, <repl>, <string>, count=0, flags=0)
Returns a new string that results from performing replacements on a search string and also returns the number of substitutions made.
re.subn() is identical to re.sub(), except that re.subn() returns a two-tuple consisting of the modified string and the number of substitutions made:
>>>
>>> re.subn(r'w+', 'xxx', 'foo.bar.baz.qux')
('xxx.xxx.xxx.xxx', 4)
>>> re.subn(r'w+', 'xxx', 'foo.bar.baz.qux', count=2)
('xxx.xxx.baz.qux', 2)
>>> def f(match_obj):
... m = match_obj.group(0)
... if m.isdigit():
... return str(int(m) * 10)
... else:
... return m.upper()
...
>>> re.subn(r'w+', f, 'foo.10.bar.20.baz.30')
('FOO.100.BAR.200.BAZ.300', 6)
In all other respects, re.subn() behaves just like re.sub().
Utility Functions
There are two remaining regex functions in the Python re module that you’ve yet to cover:
| Function | Description |
|---|---|
re.split() |
Splits a string into substrings using a regex as a delimiter |
re.escape() |
Escapes characters in a regex |
These are functions that involve regex matching but don’t clearly fall into either of the categories described above.
re.split(<regex>, <string>, maxsplit=0, flags=0)
Splits a string into substrings.
re.split(<regex>, <string>) splits <string> into substrings using <regex> as the delimiter and returns the substrings as a list.
The following example splits the specified string into substrings delimited by a comma (,), semicolon (;), or slash (/) character, surrounded by any amount of whitespace:
>>>
>>> re.split('s*[,;/]s*', 'foo,bar ; baz / qux')
['foo', 'bar', 'baz', 'qux']
If <regex> contains capturing groups, then the return list includes the matching delimiter strings as well:
>>>
>>> re.split('(s*[,;/]s*)', 'foo,bar ; baz / qux')
['foo', ',', 'bar', ' ; ', 'baz', ' / ', 'qux']
This time, the return list contains not only the substrings 'foo', 'bar', 'baz', and 'qux' but also several delimiter strings:
','' ; '' / '
This can be useful if you want to split <string> apart into delimited tokens, process the tokens in some way, then piece the string back together using the same delimiters that originally separated them:
>>>
>>> string = 'foo,bar ; baz / qux'
>>> regex = r'(s*[,;/]s*)'
>>> a = re.split(regex, string)
>>> # List of tokens and delimiters
>>> a
['foo', ',', 'bar', ' ; ', 'baz', ' / ', 'qux']
>>> # Enclose each token in <>'s
>>> for i, s in enumerate(a):
...
... # This will be True for the tokens but not the delimiters
... if not re.fullmatch(regex, s):
... a[i] = f'<{s}>'
...
>>> # Put the tokens back together using the same delimiters
>>> ''.join(a)
'<foo>,<bar> ; <baz> / <qux>'
If you need to use groups but don’t want the delimiters included in the return list, then you can use noncapturing groups:
>>>
>>> string = 'foo,bar ; baz / qux'
>>> regex = r'(?:s*[,;/]s*)'
>>> re.split(regex, string)
['foo', 'bar', 'baz', 'qux']
If the optional maxsplit argument is present and greater than zero, then re.split() performs at most that many splits. The final element in the return list is the remainder of <string> after all the splits have occurred:
>>>
>>> s = 'foo, bar, baz, qux, quux, corge'
>>> re.split(r',s*', s)
['foo', 'bar', 'baz', 'qux', 'quux', 'corge']
>>> re.split(r',s*', s, maxsplit=3)
['foo', 'bar', 'baz', 'qux, quux, corge']
Explicitly specifying maxsplit=0 is equivalent to omitting it entirely. If maxsplit is negative, then re.split() returns <string> unchanged (in case you were looking for a rather elaborate way of doing nothing at all).
If <regex> contains capturing groups so that the return list includes delimiters, and <regex> matches the start of <string>, then re.split() places an empty string as the first element in the return list. Similarly, the last item in the return list is an empty string if <regex> matches the end of <string>:
>>>
>>> re.split('(/)', '/foo/bar/baz/')
['', '/', 'foo', '/', 'bar', '/', 'baz', '/', '']
In this case, the <regex> delimiter is a single slash (/) character. In a sense, then, there’s an empty string to the left of the first delimiter and to the right of the last one. So it makes sense that re.split() places empty strings as the first and last elements of the return list.
re.escape(<regex>)
Escapes characters in a regex.
re.escape(<regex>) returns a copy of <regex> with each nonword character (anything other than a letter, digit, or underscore) preceded by a backslash.
This is useful if you’re calling one of the re module functions, and the <regex> you’re passing in has a lot of special characters that you want the parser to take literally instead of as metacharacters. It saves you the trouble of putting in all the backslash characters manually:
>>>
1>>> print(re.match('foo^bar(baz)|qux', 'foo^bar(baz)|qux'))
2None
3>>> re.match('foo^bar(baz)|qux', 'foo^bar(baz)|qux')
4<_sre.SRE_Match object; span=(0, 16), match='foo^bar(baz)|qux'>
5
6>>> re.escape('foo^bar(baz)|qux') == 'foo^bar(baz)|qux'
7True
8>>> re.match(re.escape('foo^bar(baz)|qux'), 'foo^bar(baz)|qux')
9<_sre.SRE_Match object; span=(0, 16), match='foo^bar(baz)|qux'>
In this example, there isn’t a match on line 1 because the regex 'foo^bar(baz)|qux' contains special characters that behave as metacharacters. On line 3, they’re explicitly escaped with backslashes, so a match occurs. Lines 6 and 8 demonstrate that you can achieve the same effect using re.escape().
Compiled Regex Objects in Python
The re module supports the capability to precompile a regex in Python into a regular expression object that can be repeatedly used later.
re.compile(<regex>, flags=0)
Compiles a regex into a regular expression object.
re.compile(<regex>) compiles <regex> and returns the corresponding regular expression object. If you include a <flags> value, then the corresponding flags apply to any searches performed with the object.
There are two ways to use a compiled regular expression object. You can specify it as the first argument to the re module functions in place of <regex>:
re_obj = re.compile(<regex>, <flags>)
result = re.search(re_obj, <string>)
You can also invoke a method directly from a regular expression object:
re_obj = re.compile(<regex>, <flags>)
result = re_obj.search(<string>)
Both of the examples above are equivalent to this:
result = re.search(<regex>, <string>, <flags>)
Here’s one of the examples you saw previously, recast using a compiled regular expression object:
>>>
>>> re.search(r'(d+)', 'foo123bar')
<_sre.SRE_Match object; span=(3, 6), match='123'>
>>> re_obj = re.compile(r'(d+)')
>>> re.search(re_obj, 'foo123bar')
<_sre.SRE_Match object; span=(3, 6), match='123'>
>>> re_obj.search('foo123bar')
<_sre.SRE_Match object; span=(3, 6), match='123'>
Here’s another, which also uses the IGNORECASE flag:
>>>
1>>> r1 = re.search('ba[rz]', 'FOOBARBAZ', flags=re.I)
2
3>>> re_obj = re.compile('ba[rz]', flags=re.I)
4>>> r2 = re.search(re_obj, 'FOOBARBAZ')
5>>> r3 = re_obj.search('FOOBARBAZ')
6
7>>> r1
8<_sre.SRE_Match object; span=(3, 6), match='BAR'>
9>>> r2
10<_sre.SRE_Match object; span=(3, 6), match='BAR'>
11>>> r3
12<_sre.SRE_Match object; span=(3, 6), match='BAR'>
In this example, the statement on line 1 specifies regex ba[rz] directly to re.search() as the first argument. On line 4, the first argument to re.search() is the compiled regular expression object re_obj. On line 5, search() is invoked directly on re_obj. All three cases produce the same match.
Why Bother Compiling a Regex?
What good is precompiling? There are a couple of possible advantages.
If you use a particular regex in your Python code frequently, then precompiling allows you to separate out the regex definition from its uses. This enhances modularity. Consider this example:
>>>
>>> s1, s2, s3, s4 = 'foo.bar', 'foo123bar', 'baz99', 'qux & grault'
>>> import re
>>> re.search('d+', s1)
>>> re.search('d+', s2)
<_sre.SRE_Match object; span=(3, 6), match='123'>
>>> re.search('d+', s3)
<_sre.SRE_Match object; span=(3, 5), match='99'>
>>> re.search('d+', s4)
Here, the regex d+ appears several times. If, in the course of maintaining this code, you decide you need a different regex, then you’ll need to change it in each location. That’s not so bad in this small example because the uses are close to one another. But in a larger application, they might be widely scattered and difficult to track down.
The following is more modular and more maintainable:
>>>
>>> s1, s2, s3, s4 = 'foo.bar', 'foo123bar', 'baz99', 'qux & grault'
>>> re_obj = re.compile('d+')
>>> re_obj.search(s1)
>>> re_obj.search(s2)
<_sre.SRE_Match object; span=(3, 6), match='123'>
>>> re_obj.search(s3)
<_sre.SRE_Match object; span=(3, 5), match='99'>
>>> re_obj.search(s4)
Then again, you can achieve similar modularity without precompiling by using variable assignment:
>>>
>>> s1, s2, s3, s4 = 'foo.bar', 'foo123bar', 'baz99', 'qux & grault'
>>> regex = 'd+'
>>> re.search(regex, s1)
>>> re.search(regex, s2)
<_sre.SRE_Match object; span=(3, 6), match='123'>
>>> re.search(regex, s3)
<_sre.SRE_Match object; span=(3, 5), match='99'>
>>> re.search(regex, s4)
In theory, you might expect precompilation to result in faster execution time as well. Suppose you call re.search() many thousands of times on the same regex. It might seem like compiling the regex once ahead of time would be more efficient than recompiling it each of the thousands of times it’s used.
In practice, though, that isn’t the case. The truth is that the re module compiles and caches a regex when it’s used in a function call. If the same regex is used subsequently in the same Python code, then it isn’t recompiled. The compiled value is fetched from cache instead. So the performance advantage is minimal.
All in all, there isn’t any immensely compelling reason to compile a regex in Python. Like much of Python, it’s just one more tool in your toolkit that you can use if you feel it will improve the readability or structure of your code.
Regular Expression Object Methods
A compiled regular expression object re_obj supports the following methods:
re_obj.search(<string>[, <pos>[, <endpos>]])re_obj.match(<string>[, <pos>[, <endpos>]])re_obj.fullmatch(<string>[, <pos>[, <endpos>]])re_obj.findall(<string>[, <pos>[, <endpos>]])re_obj.finditer(<string>[, <pos>[, <endpos>]])
These all behave the same way as the corresponding re functions that you’ve already encountered, with the exception that they also support the optional <pos> and <endpos> parameters. If these are present, then the search only applies to the portion of <string> indicated by <pos> and <endpos>, which act the same way as indices in slice notation:
>>>
1>>> re_obj = re.compile(r'd+')
2>>> s = 'foo123barbaz'
3
4>>> re_obj.search(s)
5<_sre.SRE_Match object; span=(3, 6), match='123'>
6
7>>> s[6:9]
8'bar'
9>>> print(re_obj.search(s, 6, 9))
10None
In the above example, the regex is d+, a sequence of digit characters. The .search() call on line 4 searches all of s, so there’s a match. On line 9, the <pos> and <endpos> parameters effectively restrict the search to the substring starting with character 6 and going up to but not including character 9 (the substring 'bar'), which doesn’t contain any digits.
If you specify <pos> but omit <endpos>, then the search applies to the substring from <pos> to the end of the string.
Note that anchors such as caret (^) and dollar sign ($) still refer to the start and end of the entire string, not the substring determined by <pos> and <endpos>:
>>>
>>> re_obj = re.compile('^bar')
>>> s = 'foobarbaz'
>>> s[3:]
'barbaz'
>>> print(re_obj.search(s, 3))
None
Here, even though 'bar' does occur at the start of the substring beginning at character 3, it isn’t at the start of the entire string, so the caret (^) anchor fails to match.
The following methods are available for a compiled regular expression object re_obj as well:
re_obj.split(<string>, maxsplit=0)re_obj.sub(<repl>, <string>, count=0)re_obj.subn(<repl>, <string>, count=0)
These also behave analogously to the corresponding re functions, but they don’t support the <pos> and <endpos> parameters.
Regular Expression Object Attributes
The re module defines several useful attributes for a compiled regular expression object:
| Attribute | Meaning |
|---|---|
re_obj.flags |
Any <flags> that are in effect for the regex |
re_obj.groups |
The number of capturing groups in the regex |
re_obj.groupindex |
A dictionary mapping each symbolic group name defined by the (?P<name>) construct (if any) to the corresponding group number |
re_obj.pattern |
The <regex> pattern that produced this object |
The code below demonstrates some uses of these attributes:
>>>
1>>> re_obj = re.compile(r'(?m)(w+),(w+)', re.I)
2>>> re_obj.flags
342
4>>> re.I|re.M|re.UNICODE
5<RegexFlag.UNICODE|MULTILINE|IGNORECASE: 42>
6>>> re_obj.groups
72
8>>> re_obj.pattern
9'(?m)(\w+),(\w+)'
10
11>>> re_obj = re.compile(r'(?P<w1>),(?P<w2>)')
12>>> re_obj.groupindex
13mappingproxy({'w1': 1, 'w2': 2})
14>>> re_obj.groupindex['w1']
151
16>>> re_obj.groupindex['w2']
172
Note that .flags includes any flags specified as arguments to re.compile(), any specified within the regex with the (?flags) metacharacter sequence, and any that are in effect by default. In the regular expression object defined on line 1, there are three flags defined:
re.I: Specified as a<flags>value in there.compile()callre.M: Specified as(?m)within the regexre.UNICODE: Enabled by default
You can see on line 4 that the value of re_obj.flags is the logical OR of these three values, which equals 42.
The value of the .groupindex attribute for the regular expression object defined on line 11 is technically an object of type mappingproxy. For practical purposes, it functions like a dictionary.
Match Object Methods and Attributes
As you’ve seen, most functions and methods in the re module return a match object when there’s a successful match. Because a match object is truthy, you can use it in a conditional:
>>>
>>> m = re.search('bar', 'foo.bar.baz')
>>> m
<_sre.SRE_Match object; span=(4, 7), match='bar'>
>>> bool(m)
True
>>> if re.search('bar', 'foo.bar.baz'):
... print('Found a match')
...
Found a match
But match objects also contain quite a bit of handy information about the match. You’ve already seen some of it—the span= and match= data that the interpreter shows when it displays a match object. You can obtain much more from a match object using its methods and attributes.
Match Object Methods
The table below summarizes the methods that are available for a match object match:
| Method | Returns |
|---|---|
match.group() |
The specified captured group or groups from match |
match.__getitem__() |
A captured group from match |
match.groups() |
All the captured groups from match |
match.groupdict() |
A dictionary of named captured groups from match |
match.expand() |
The result of performing backreference substitutions from match |
match.start() |
The starting index of match |
match.end() |
The ending index of match |
match.span() |
Both the starting and ending indices of match as a tuple |
The following sections describe these methods in more detail.
match.group([<group1>, ...])
Returns the specified captured group(s) from a match.
For numbered groups, match.group(n) returns the nth group:
>>>
>>> m = re.search(r'(w+),(w+),(w+)', 'foo,bar,baz')
>>> m.group(1)
'foo'
>>> m.group(3)
'baz'
If you capture groups using (?P<name><regex>), then match.group(<name>) returns the corresponding named group:
>>>
>>> m = re.match(r'(?P<w1>w+),(?P<w2>w+),(?P<w3>w+)', 'quux,corge,grault')
>>> m.group('w1')
'quux'
>>> m.group('w3')
'grault'
With more than one argument, .group() returns a tuple of all the groups specified. A given group can appear multiple times, and you can specify any captured groups in any order:
>>>
>>> m = re.search(r'(w+),(w+),(w+)', 'foo,bar,baz')
>>> m.group(1, 3)
('foo', 'baz')
>>> m.group(3, 3, 1, 1, 2, 2)
('baz', 'baz', 'foo', 'foo', 'bar', 'bar')
>>> m = re.match(r'(?P<w1>w+),(?P<w2>w+),(?P<w3>w+)', 'quux,corge,grault')
>>> m.group('w3', 'w1', 'w1', 'w2')
('grault', 'quux', 'quux', 'corge')
If you specify a group that’s out of range or nonexistent, then .group() raises an IndexError exception:
>>>
>>> m = re.search(r'(w+),(w+),(w+)', 'foo,bar,baz')
>>> m.group(4)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: no such group
>>> m = re.match(r'(?P<w1>w+),(?P<w2>w+),(?P<w3>w+)', 'quux,corge,grault')
>>> m.group('foo')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: no such group
It’s possible for a regex in Python to match as a whole but to contain a group that doesn’t participate in the match. In that case, .group() returns None for the nonparticipating group. Consider this example:
>>>
>>> m = re.search(r'(w+),(w+),(w+)?', 'foo,bar,')
>>> m
<_sre.SRE_Match object; span=(0, 8), match='foo,bar,'>
>>> m.group(1, 2)
('foo', 'bar')
This regex matches, as you can see from the match object. The first two captured groups contain 'foo' and 'bar', respectively.
A question mark (?) quantifier metacharacter follows the third group, though, so that group is optional. A match will occur if there’s a third sequence of word characters following the second comma (,) but also if there isn’t.
In this case, there isn’t. So there is match overall, but the third group doesn’t participate in it. As a result, m.group(3) is still defined and is a valid reference, but it returns None:
>>>
>>> print(m.group(3))
None
It can also happen that a group participates in the overall match multiple times. If you call .group() for that group number, then it returns only the part of the search string that matched the last time. The earlier matches aren’t accessible:
>>>
>>> m = re.match(r'(w{3},)+', 'foo,bar,baz,qux')
>>> m
<_sre.SRE_Match object; span=(0, 12), match='foo,bar,baz,'>
>>> m.group(1)
'baz,'
In this example, the full match is 'foo,bar,baz,', as shown by the displayed match object. Each of 'foo,', 'bar,', and 'baz,' matches what’s inside the group, but m.group(1) returns only the last match, 'baz,'.
If you call .group() with an argument of 0 or no argument at all, then it returns the entire match:
>>>
1>>> m = re.search(r'(w+),(w+),(w+)', 'foo,bar,baz')
2>>> m
3<_sre.SRE_Match object; span=(0, 11), match='foo,bar,baz'>
4
5>>> m.group(0)
6'foo,bar,baz'
7>>> m.group()
8'foo,bar,baz'
This is the same data the interpreter shows following match= when it displays the match object, as you can see on line 3 above.
match.__getitem__(<grp>)
Returns a captured group from a match.
match.__getitem__(<grp>) is identical to match.group(<grp>) and returns the single group specified by <grp>:
>>>
>>> m = re.search(r'(w+),(w+),(w+)', 'foo,bar,baz')
>>> m.group(2)
'bar'
>>> m.__getitem__(2)
'bar'
If .__getitem__() simply replicates the functionality of .group(), then why would you use it? You probably wouldn’t directly, but you might indirectly. Read on to see why.
A Brief Introduction to Magic Methods
.__getitem__() is one of a collection of methods in Python called magic methods. These are special methods that the interpreter calls when a Python statement contains specific corresponding syntactical elements.
The particular syntax that .__getitem__() corresponds to is indexing with square brackets. For any object obj, whenever you use the expression obj[n], behind the scenes Python quietly translates it to a call to .__getitem__(). The following expressions are effectively equivalent:
obj[n]
obj.__getitem__(n)
The syntax obj[n] is only meaningful if a .__getitem()__ method exists for the class or type to which obj belongs. Exactly how Python interprets obj[n] will then depend on the implementation of .__getitem__() for that class.
Back to Match Objects
As of Python version 3.6, the re module does implement .__getitem__() for match objects. The implementation is such that match.__getitem__(n) is the same as match.group(n).
The result of all this is that, instead of calling .group() directly, you can access captured groups from a match object using square-bracket indexing syntax instead:
>>>
>>> m = re.search(r'(w+),(w+),(w+)', 'foo,bar,baz')
>>> m.group(2)
'bar'
>>> m.__getitem__(2)
'bar'
>>> m[2]
'bar'
This works with named captured groups as well:
>>>
>>> m = re.match(
... r'foo,(?P<w1>w+),(?P<w2>w+),qux',
... 'foo,bar,baz,qux')
>>> m.group('w2')
'baz'
>>> m['w2']
'baz'
This is something you could achieve by just calling .group() explicitly, but it’s a pretty shortcut notation nonetheless.
When a programming language provides alternate syntax that isn’t strictly necessary but allows for the expression of something in a cleaner, easier-to-read way, it’s called syntactic sugar. For a match object, match[n] is syntactic sugar for match.group(n).
match.groups(default=None)
Returns all captured groups from a match.
match.groups() returns a tuple of all captured groups:
>>>
>>> m = re.search(r'(w+),(w+),(w+)', 'foo,bar,baz')
>>> m.groups()
('foo', 'bar', 'baz')
As you saw previously, when a group in a regex in Python doesn’t participate in the overall match, .group() returns None for that group. By default, .groups() does likewise.
If you want .groups() to return something else in this situation, then you can use the default keyword argument:
>>>
1>>> m = re.search(r'(w+),(w+),(w+)?', 'foo,bar,')
2>>> m
3<_sre.SRE_Match object; span=(0, 8), match='foo,bar,'>
4>>> print(m.group(3))
5None
6
7>>> m.groups()
8('foo', 'bar', None)
9>>> m.groups(default='---')
10('foo', 'bar', '---')
Here, the third (w+) group doesn’t participate in the match because the question mark (?) metacharacter makes it optional, and the string 'foo,bar,' doesn’t contain a third sequence of word characters. By default, m.groups() returns None for the third group, as shown on line 8. On line 10, you can see that specifying default='---' causes it to return the string '---' instead.
There isn’t any corresponding default keyword for .group(). It always returns None for nonparticipating groups.
match.groupdict(default=None)
Returns a dictionary of named captured groups.
match.groupdict() returns a dictionary of all named groups captured with the (?P<name><regex>) metacharacter sequence. The dictionary keys are the group names and the dictionary values are the corresponding group values:
>>>
>>> m = re.match(
... r'foo,(?P<w1>w+),(?P<w2>w+),qux',
... 'foo,bar,baz,qux')
>>> m.groupdict()
{'w1': 'bar', 'w2': 'baz'}
>>> m.groupdict()['w2']
'baz'
As with .groups(), for .groupdict() the default argument determines the return value for nonparticipating groups:
>>>
>>> m = re.match(
... r'foo,(?P<w1>w+),(?P<w2>w+)?,qux',
... 'foo,bar,,qux')
>>> m.groupdict()
{'w1': 'bar', 'w2': None}
>>> m.groupdict(default='---')
{'w1': 'bar', 'w2': '---'}
Again, the final group (?P<w2>w+) doesn’t participate in the overall match because of the question mark (?) metacharacter. By default, m.groupdict() returns None for this group, but you can change it with the default argument.
match.expand(<template>)
Performs backreference substitutions from a match.
match.expand(<template>) returns the string that results from performing backreference substitution on <template> exactly as re.sub() would do:
>>>
1>>> m = re.search(r'(w+),(w+),(w+)', 'foo,bar,baz')
2>>> m
3<_sre.SRE_Match object; span=(0, 11), match='foo,bar,baz'>
4>>> m.groups()
5('foo', 'bar', 'baz')
6
7>>> m.expand(r'2')
8'bar'
9>>> m.expand(r'[3] -> [1]')
10'[baz] -> [foo]'
11
12>>> m = re.search(r'(?P<num>d+)', 'foo123qux')
13>>> m
14<_sre.SRE_Match object; span=(3, 6), match='123'>
15>>> m.group(1)
16'123'
17
18>>> m.expand(r'--- g<num> ---')
19'--- 123 ---'
This works for numeric backreferences, as on lines 7 and 9 above, and also for named backreferences, as on line 18.
match.start([<grp>])
match.end([<grp>])
Return the starting and ending indices of the match.
match.start() returns the index in the search string where the match begins, and match.end() returns the index immediately after where the match ends:
>>>
1>>> s = 'foo123bar456baz'
2>>> m = re.search('d+', s)
3>>> m
4<_sre.SRE_Match object; span=(3, 6), match='123'>
5>>> m.start()
63
7>>> m.end()
86
When Python displays a match object, these are the values listed with the span= keyword, as shown on line 4 above. They behave like string-slicing values, so if you use them to slice the original search string, then you should get the matching substring:
>>>
>>> m
<_sre.SRE_Match object; span=(3, 6), match='123'>
>>> s[m.start():m.end()]
'123'
match.start(<grp>) and match.end(<grp>) return the starting and ending indices of the substring matched by <grp>, which may be a numbered or named group:
>>>
>>> s = 'foo123bar456baz'
>>> m = re.search(r'(d+)D*(?P<num>d+)', s)
>>> m.group(1)
'123'
>>> m.start(1), m.end(1)
(3, 6)
>>> s[m.start(1):m.end(1)]
'123'
>>> m.group('num')
'456'
>>> m.start('num'), m.end('num')
(9, 12)
>>> s[m.start('num'):m.end('num')]
'456'
If the specified group matches a null string, then .start() and .end() are equal:
>>>
>>> m = re.search('foo(d*)bar', 'foobar')
>>> m[1]
''
>>> m.start(1), m.end(1)
(3, 3)
This makes sense if you remember that .start() and .end() act like slicing indices. Any string slice where the beginning and ending indices are equal will always be an empty string.
A special case occurs when the regex contains a group that doesn’t participate in the match:
>>>
>>> m = re.search(r'(w+),(w+),(w+)?', 'foo,bar,')
>>> print(m.group(3))
None
>>> m.start(3), m.end(3)
(-1, -1)
As you’ve seen previously, in this case the third group doesn’t participate. m.start(3) and m.end(3) aren’t really meaningful here, so they return -1.
match.span([<grp>])
Returns both the starting and ending indices of the match.
match.span() returns both the starting and ending indices of the match as a tuple. If you specified <grp>, then the return tuple applies to the given group:
>>>
>>> s = 'foo123bar456baz'
>>> m = re.search(r'(d+)D*(?P<num>d+)', s)
>>> m
<_sre.SRE_Match object; span=(3, 12), match='123bar456'>
>>> m[0]
'123bar456'
>>> m.span()
(3, 12)
>>> m[1]
'123'
>>> m.span(1)
(3, 6)
>>> m['num']
'456'
>>> m.span('num')
(9, 12)
The following are effectively equivalent:
match.span(<grp>)(match.start(<grp>), match.end(<grp>))
match.span() just provides a convenient way to obtain both match.start() and match.end() in one method call.
Match Object Attributes
Like a compiled regular expression object, a match object also has several useful attributes available:
| Attribute | Meaning |
|---|---|
match.posmatch.endpos |
The effective values of the <pos> and <endpos> arguments for the match |
match.lastindex |
The index of the last captured group |
match.lastgroup |
The name of the last captured group |
match.re |
The compiled regular expression object for the match |
match.string |
The search string for the match |
The following sections provide more detail on these match object attributes.
match.pos
match.endpos
Contain the effective values of
<pos>and<endpos>for the search.
Remember that some methods, when invoked on a compiled regex, accept optional <pos> and <endpos> arguments that limit the search to a portion of the specified search string. These values are accessible from the match object with the .pos and .endpos attributes:
>>>
>>> re_obj = re.compile(r'd+')
>>> m = re_obj.search('foo123bar', 2, 7)
>>> m
<_sre.SRE_Match object; span=(3, 6), match='123'>
>>> m.pos, m.endpos
(2, 7)
If the <pos> and <endpos> arguments aren’t included in the call, either because they were omitted or because the function in question doesn’t accept them, then the .pos and .endpos attributes effectively indicate the start and end of the string:
>>>
1>>> re_obj = re.compile(r'd+')
2>>> m = re_obj.search('foo123bar')
3>>> m
4<_sre.SRE_Match object; span=(3, 6), match='123'>
5>>> m.pos, m.endpos
6(0, 9)
7
8>>> m = re.search(r'd+', 'foo123bar')
9>>> m
10<_sre.SRE_Match object; span=(3, 6), match='123'>
11>>> m.pos, m.endpos
12(0, 9)
The re_obj.search() call above on line 2 could take <pos> and <endpos> arguments, but they aren’t specified. The re.search() call on line 8 can’t take them at all. In either case, m.pos and m.endpos are 0 and 9, the starting and ending indices of the search string 'foo123bar'.
match.lastindex
Contains the index of the last captured group.
match.lastindex is equal to the integer index of the last captured group:
>>>
>>> m = re.search(r'(w+),(w+),(w+)', 'foo,bar,baz')
>>> m.lastindex
3
>>> m[m.lastindex]
'baz'
In cases where the regex contains potentially nonparticipating groups, this allows you to determine how many groups actually participated in the match:
>>>
>>> m = re.search(r'(w+),(w+),(w+)?', 'foo,bar,baz')
>>> m.groups()
('foo', 'bar', 'baz')
>>> m.lastindex, m[m.lastindex]
(3, 'baz')
>>> m = re.search(r'(w+),(w+),(w+)?', 'foo,bar,')
>>> m.groups()
('foo', 'bar', None)
>>> m.lastindex, m[m.lastindex]
(2, 'bar')
In the first example, the third group, which is optional because of the question mark (?) metacharacter, does participate in the match. But in the second example it doesn’t. You can tell because m.lastindex is 3 in the first case and 2 in the second.
There’s a subtle point to be aware of regarding .lastindex. It isn’t always the case that the last group to match is also the last group encountered syntactically. The Python documentation gives this example:
>>>
>>> m = re.match('((a)(b))', 'ab')
>>> m.groups()
('ab', 'a', 'b')
>>> m.lastindex
1
>>> m[m.lastindex]
'ab'
The outermost group is ((a)(b)), which matches 'ab'. This is the first group the parser encounters, so it becomes group 1. But it’s also the last group to match, which is why m.lastindex is 1.
The second and third groups the parser recognizes are (a) and (b). These are groups 2 and 3, but they match before group 1 does.
match.lastgroup
Contains the name of the last captured group.
If the last captured group originates from the (?P<name><regex>) metacharacter sequence, then match.lastgroup returns the name of that group:
>>>
>>> s = 'foo123bar456baz'
>>> m = re.search(r'(?P<n1>d+)D*(?P<n2>d+)', s)
>>> m.lastgroup
'n2'
match.lastgroup returns None if the last captured group isn’t a named group:
>>>
>>> s = 'foo123bar456baz'
>>> m = re.search(r'(d+)D*(d+)', s)
>>> m.groups()
('123', '456')
>>> print(m.lastgroup)
None
>>> m = re.search(r'd+D*d+', s)
>>> m.groups()
()
>>> print(m.lastgroup)
None
As shown above, this can be either because the last captured group isn’t a named group or because there were no captured groups at all.
match.re
Contains the regular expression object for the match.
match.re contains the regular expression object that produced the match. This is the same object you’d get if you passed the regex to re.compile():
>>>
1>>> regex = r'(w+),(w+),(w+)'
2
3>>> m1 = re.search(regex, 'foo,bar,baz')
4>>> m1
5<_sre.SRE_Match object; span=(0, 11), match='foo,bar,baz'>
6>>> m1.re
7re.compile('(\w+),(\w+),(\w+)')
8
9>>> re_obj = re.compile(regex)
10>>> re_obj
11re.compile('(\w+),(\w+),(\w+)')
12>>> re_obj is m1.re
13True
14
15>>> m2 = re_obj.search('qux,quux,corge')
16>>> m2
17<_sre.SRE_Match object; span=(0, 14), match='qux,quux,corge'>
18>>> m2.re
19re.compile('(\w+),(\w+),(\w+)')
20>>> m2.re is re_obj is m1.re
21True
Remember from earlier that the re module caches regular expressions after it compiles them, so they don’t need to be recompiled if used again. For that reason, as the identity comparisons on lines 12 and 20 show, all the various regular expression objects in the above example are the exact same object.
Once you have access to the regular expression object for the match, all of that object’s attributes are available as well:
>>>
>>> m1.re.groups
3
>>> m1.re.pattern
'(\w+),(\w+),(\w+)'
>>> m1.re.pattern == regex
True
>>> m1.re.flags
32
You can also invoke any of the methods defined for a compiled regular expression object on it:
>>>
>>> m = re.search(r'(w+),(w+),(w+)', 'foo,bar,baz')
>>> m.re
re.compile('(\w+),(\w+),(\w+)')
>>> m.re.match('quux,corge,grault')
<_sre.SRE_Match object; span=(0, 17), match='quux,corge,grault'>
Here, .match() is invoked on m.re to perform another search using the same regex but on a different search string.
match.string
Contains the search string for a match.
match.string contains the search string that is the target of the match:
>>>
>>> m = re.search(r'(w+),(w+),(w+)', 'foo,bar,baz')
>>> m.string
'foo,bar,baz'
>>> re_obj = re.compile(r'(w+),(w+),(w+)')
>>> m = re_obj.search('foo,bar,baz')
>>> m.string
'foo,bar,baz'
As you can see from the example, the .string attribute is available when the match object derives from a compiled regular expression object as well.
Conclusion
That concludes your tour of Python’s re module!
This introductory series contains two tutorials on regular expression processing in Python. If you’ve worked through both the previous tutorial and this one, then you should now know how to:
- Make full use of all the functions that the
remodule provides - Precompile a regex in Python
- Extract information from match objects
Regular expressions are extremely versatile and powerful—literally a language in their own right. You’ll find them invaluable in your Python coding.
Next up in this series, you’ll explore how Python avoids conflict between identifiers in different areas of code. As you’ve already seen, each function in Python has its own namespace, distinct from those of other functions. In the next tutorial, you’ll learn how namespaces are implemented in Python and how they define variable scope.
A Regex (Regular Expression) is a sequence of characters used for defining a pattern. This pattern could be used for searching, replacing and other operations. Regex is extensively utilized in applications that require input validation, Password validation, Pattern Recognition, search and replace utilities (found in word processors) etc. This is due to the fact that regex syntax stays the same across different programming languages and implementations. Therefore, one having the grasp of it provides longevity across languages. In this article, we will be creating a program for checking the validity of a regex string.
The method we would be using will require a firm understanding of the try-except construct of python. Therefore, it would be wise if we touch upon that before moving over to the actual code.
Exception handling
Try except block is used to catch and handle exceptions encountered during the execution of a particular block of code (construct exists in other programming languages under the name try-catch). The general syntax of a try-except block is as follows:
try:
# Execute this code
.
.
except [Exception]:
# Execute this code, if an exception arises during the execution of the try block
.
.
In the above syntax, any code found within the try block would be executed. If an exception/error arises during the execution of the try block then (only) the except block is executed. If the try block executes without producing an exception, then the except block won’t be executed. If a bare except clause is used, then it would catch any exception (and certain even System_Exits) encountered during the execution of try block. To prevent such from happening, it is generally a good practice to specify an exception after the except. This ensures that only after encountering that specific exception/error, the except block will execute. This prevents concealment of other errors encountered during the execution of the try block. Also, multiple except clauses can be used within the same try-except block, this enables it to trap a plethora of exceptions, and deal with them specifically. This construct contains other keywords as well such as finally, else etc. which aren’t required in current context. Therefore, only the relevant sections are described.
Code:
In the following code, we would be specifying re.error as the exception in the except clause of the try-except block. This error is encountered when an invalid regex pattern is found, during the compilation of the pattern.
Python3
import re
pattern = r"[.*"
try:
re.compile(pattern)
except re.error:
print("Non valid regex pattern")
exit()
Output
Non valid regex pattern
Explanation:
Firstly we imported the re library, for enabling regex functionality in our code. Then we assigned a string containing the regex pattern to the variable pattern. The pattern provided is invalid as it contains an unclosed character class (in regex square brackets `[ ]`are used for defining a character class). We placed the re.compile() (used to compile regex patterns) function within the try block. This will firstly try to compile the pattern and if any exception occurs during the compilation, it would firstly check whether it is re.error, if it is then only the except block will execute. Otherwise, the exception will be displayed in the traceback, leading to program termination. The except block contains print statements that outputs the user defined message to the stdout and then exits the program (via exit()). Since the pattern provided is invalid (explained earlier) this lead to the except block getting executed.
Note:
The above code only deals with re.error exception. But other exceptions related to regex also exist such as RecursionError, Which needs to be dealt with specifically(by adding a separate except clause for that exception as well or changing the maximum stack depth using sys.setrecursionlimit() as of this case).
Checking whether the input string matches the Regex pattern
In the following example, we will test whether an input string matches a given regex pattern or not. This is assuming the regex pattern is a valid one (could be ensured using the aforementioned example). We would be checking whether the input string is a alphanumeric string (one containing alphabets or digits throughout its length) or not. We would be using the following class for checking the string:
^[A-Za-z0-9]+$
Even though there exists a special sequence in regex (w)for finding alphanumeric characters. But we won’t be using it as it contains the underscore ( _ ) in its character class (A-Za-z0-9_), which isn’t considered as an alphanumeric character under most standards.
Code:
Python3
import re
pat = re.compile(r"[A-Za-z0-9]+")
test = input("Enter the string: ")
if re.fullmatch(pat, test):
print(f"'{test}' is an alphanumeric string!")
else:
print(f"'{test}' is NOT a alphanumeric string!")
Output:
> Enter the string: DeepLearnedSupaSampling01 'DeepLearnedSupaSampling01' is an alphanumeric string!
> Enter the string: afore 89df 'afore 89df' is NOT a alphanumeric string!
Explanation:
Firstly, we compiled the regex pattern using re.compile(). The Regex pattern contains a character set which is used to specify that all alphabets (lowercase and uppercase) and digits (0-9) are to be included in the pattern. Following the class is the plus sign ( + ) which is a repetition qualifier. This allows the resulting Regular Expression search to match 1 or more repetitions of the preceding Regular Expression (for us which is the alphanumeric character set). Then we prompt the user for the input string. After which we passed the input string and compiled regex pattern to re.fullmatch(). This method checks if the whole string matches the regular expression pattern or not. If it does then it returns 1, otherwise a 0. Which we used inside the if-else construct to display the success/failure message accordingly.
Complexity :
Time complexity : O(n), where n is the length of the input string. The function iterates through the input string once to check if it matches the regular expression pattern, and then once more to check if it matches the fullmatch.
Space complexity : O(1), as the function creates a constant number of variables regardless of the input string size.
Регулярные выражения — специальная последовательность символов, которая помогает сопоставлять или находить строки python с использованием специализированного синтаксиса, содержащегося в шаблоне. Регулярные выражения распространены в мире UNIX.
Модуль re предоставляет полную поддержку выражениям, подобным Perl в Python. Модуль re поднимает исключение re.error, если возникает ошибка при компиляции или использовании регулярного выражения.
Давайте рассмотрим две функции, которые будут использоваться для обработки регулярных выражений. Важно так же заметить, что существуют символы, которые меняют свое значение, когда используются в регулярном выражении.Чтобы избежать путаницы при работе с регулярными выражениями, записывайте строку как r'expression'.
Функция match
Эта функция ищет pattern в string и поддерживает настройки с помощью дополнительного flags.
Ниже можно увидеть синтаксис данной функции:
re.match(pattern, string, flags=0)
Описание параметров:
| № | Параметр & Описание |
|---|---|
| 1 | pattern — строка регулярного выражения (r'g.{3}le') |
| 2 | string — строка, в которой мы будем искать соответствие с шаблоном в начале строки ('google') |
| 3 | flags — модификаторы, перечисленными в таблице ниже. Вы можете указать разные флаги с помощью побитового OR |
Функция re.match возвращает объект match при успешном завершении, или None при ошибке. Мы используем функцию group(num) или groups() объекта match для получения результатов поиска.
| № | Метод совпадения объектов и описание |
|---|---|
| 1 | group(num=0) — этот метод возвращает полное совпадение (или совпадение конкретной подгруппы) |
| 2 | groups() — этот метод возвращает все найденные подгруппы в tuple |
Пример функции re.match
import re
title = "Error 404. Page not found"
exemple = re.match( r'(.*). (.*?) .*', title, re.M|re.I)
if exemple:
print("exemple.group() : ", exemple.group())
print("exemple.group(1) : ", exemple.group(1))
print("exemple.group(2) : ", exemple.group(2))
print("exemple.groups():", exemple.groups())
else:
print("Нет совпадений!")
Когда вышеуказанный код выполняется, он производит следующий результат:
exemple.group(): Error 404. Page not found
exemple.group(1): Error 404
exemple.group(2): Page
exemple.groups(): ('Error 404', 'Page')
Функция search
Эта функция выполняет поиск первого вхождения pattern внутри string с дополнительным flags.
Пример синтаксиса для этой функции:
re.search(pattern, string, flags=0)
Описание параметров:
| № | Параметр & Описание |
|---|---|
| 1 | pattern — строка регулярного выражения |
| 2 | string — строка, в которой мы будем искать первое соответствие с шаблоном |
| 3 | flags — модификаторы, перечисленными в таблице ниже. Вы можете указать разные флаги с помощью побитового OR |
Функция re.search возвращает объект match если совпадение найдено, и None, когда нет совпадений. Используйте функцию group(num) или groups() объекта match для получения результата функции.
| № | Способы совпадения объектов и описание |
|---|---|
| 1 | group(num=0) — метод, который возвращает полное совпадение (или же совпадение конкретной подгруппы) |
| 2 | groups() — метод возвращает все сопоставимые подгруппы в tuple |
Пример функции re.search
import re
title = "Error 404. Page not found"
# добавим пробел в начало паттерна
exemple = re.search( r' (.*). (.*?) .*', title, re.M|re.I)
if exemple:
print("exemple.group():", exemple.group())
print("exemple.group(1):", exemple.group(1))
print("exemple.group(2):", exemple.group(2))
print("exemple.groups():", exemple.groups())
else:
print("Нет совпадений!")
Запускаем скрипт и получаем следующий результат:
exemple.group(): 404. Page not found
exemple.group(1): 404
exemple.group(2): Page
exemple.groups(): ('404', 'Page')
Match и Search
Python предлагает две разные примитивные операции, основанные на регулярных выражениях: match выполняет поиск паттерна в начале строки, тогда как search выполняет поиск по всей строке.
Пример разницы re.match и re.search
import re
title = "Error 404. Page not found"
match_exemple = re.match( r'not', title, re.M|re.I)
if match_exemple:
print("match --> match_exemple.group():", match_exemple.group())
else:
print("Нет совпадений!")
search_exemple = re.search( r'not', title, re.M|re.I)
if search_exemple:
print("search --> search_exemple.group():", search_exemple.group())
else:
print("Нет совпадений!")
Когда этот код выполняется, он производит следующий результат:
Нет совпадений!
search --> search_exemple.group(): not
Метод Sub
Одним из наиболее важных методов модуля re, которые используют регулярные выражения, является re.sub.
Пример синтаксиса sub:
re.sub(pattern, repl, string, max=0)
Этот метод заменяет все вхождения pattern в string на repl, если не указано на max. Он возвращает измененную строку.
Пример
import re
born = "05-03-1987 # Дата рождения"
# Удалим комментарий из строки
dob = re.sub(r'#.*$', "", born)
print("Дата рождения:", dob)
# Заменим дефисы на точки
f_dob = re.sub(r'-', ".", born)
print(f_dob)
Запускаем скрипт и получаем вывод:
Дата рождения: 05-03-1987
05.03.1987 # Дата рождения
Модификаторы регулярных выражений: flags
Функции регулярных выражений включают необязательный модификатор для управления изменения условий поиска. Модификаторы задают в необязательном параметре flags. Несколько модификаторов задают с помощью побитового ИЛИ (|), как показано в примерах выше.
| № | Модификатор & Описание |
|---|---|
| 1 | re.I — делает поиск нечувствительным к регистру |
| 2 | re.L — ищет слова в соответствии с текущим языком. Эта интерпретация затрагивает алфавитную группу (w и W), а также поведение границы слова (b и B). |
| 3 | re.M — символ $ выполняет поиск в конце любой строки текста (не только конце текста) и символ ^ выполняет поиск в начале любой строки текста (не только в начале текста). |
| 4 | re.S — изменяет значение точки (.) на совпадение с любым символом, включая новую строку |
| 5 | re.U— интерпретирует буквы в соответствии с набором символов Unicode. Этот флаг влияет на поведение w, W, b, B. В python 3+ этот флаг установлен по умолчанию. |
| 6 | re.X— позволяет многострочный синтаксис регулярного выражения. Он игнорирует пробелы внутри паттерна (за исключением пробелов внутри набора [] или при экранировании обратным слешем) и обрабатывает не экранированный “#” как комментарий. |
Шаблоны регулярных выражений
За исключением символов (+?. * ^ $ () [] {} | ), все остальные соответствуют самим себе. Вы можете избежать экранировать специальный символ с помощью бэкслеша (/).
В таблицах ниже описаны все символы и комбинации символов для регулярных выражений, которые доступны в Python:
| № | Шаблон & Описание |
|---|---|
| 1 | ^ — соответствует началу строки. |
| 2 | $— соответствует концу строки. |
| 3 | . — соответствует любому символу, кроме новой строки. Использование флага re.M позволяет также соответствовать новой строке. |
| 4 | [4fw] — соответствует любому из символов в скобках. |
| 5 | [^4fw] — соответствует любому символу, кроме тех, что в квадратных скобках. |
| 6 | foo* — соответствует 0 или более вхождений “foo”. |
| 7 | bar+ —- соответствует 1 или более вхождениям “bar”. |
| 8 | foo? —- соответствует 0 или 1 вхождению “foo”. |
| 9 | bar{3} —- соответствует трем подряд вхождениям “bar”. |
| 10 | foo{3,} — соответствует 3 или более вхождениям “foo”. |
| 11 | bar{2,5} —- соответствует от 2 до 5 вхождениям “bar”. |
| 12 | a|b — соответствует либо a, либо b. |
| 13 | (foo) — группирует регулярные выражения. |
| 14 | (?imx) — временно включает параметры i, m или x в регулярное выражение. Если используются круглые скобки — затрагивается только эта область. |
| 15 | (?-imx) — временно отключает опции i, m или x в регулярном выражении. Если используются круглые скобки — затрагивается только эта область. |
| 16 | (?: foo) — Группирует регулярные выражения без сохранения совпадающего текста. |
| 17 | (?imx: re) — Временно включает параметры i, m или x в круглых скобках. |
| 18 | (?-imx: re) — временно отключает опции i, m или x в круглых скобках. |
| 19 | (?#…) — комментарий. |
| 20 | (?= foo) — совпадает со всеми словами после которых » foo». |
| 21 | (?! foo) — совпадает со всеми словами после которых нет » foo». |
| 22 | (?> foo) — совпадает со всеми словами перед которыми » foo». |
| 23 | w — совпадает с буквенным символом. |
| 24 | W — совпадает с не буквенным символом. |
| 25 | s — совпадает с пробельными символами (t, n, r, f и пробелом). |
| 26 | S — все кроме пробельных символов. |
| 27 | d — соответствует цифрам (0-9). |
| 28 | D — все кроме цифры. |
| 29 | A — соответствует началу строки. |
| 30 | Z – соответствует концу строки. Включая перевод на новую строку, если такая есть. |
| 31 | z — соответствует концу строки. |
| 32 | G — соответствует месту, где закончилось последнее соответствие. |
| 33 | b — соответствует границам слов, когда поставлены внешние скобки. |
| 34 | B — все кроме границы слова. |
| 35 | **n,t,r,f ** — соответствует новым строкам, подстрокам. |
| 36 | 1…9 — соответствует подгруппе n-й группы. |
| 37 | 10 — соответсвуйет номеру группы. В противном случае относится к восьмеричному представлению символьного кода. |
Примеры регулярных выражений
Поиск по буквам
python – находит “python”. |
Поиск по наборам символов
| № | Паттерн & Результаты |
|---|---|
| 1 | [Pp]ython соответствует “Python” и “python” |
| 2 | rub[ye] соответствует “ruby” и “rube” |
| 3 | [aeiou] Соответствует любой гласной нижнего регистра английского алфавита ([ауоыиэяюёе] для русского) |
| 4 | [0-9] соответствует любой цифре; так же как и [0123456789] |
| 5 | [a-z] соответствует любой строчной букве ASCII (для кириллицы [а-яё]) |
| 6 | [A-Z] соответствует любой прописной букве ASCII (для кириллицы [А-ЯЁ]) |
| 7 | [a-zA-Z0-9] соответствует всем цифрам и буквам |
| 8 | [^aeiou] соответствует всем символам, кроме строчной гласной |
| 9 | [^0-9] Соответствует всем символам, кроме цифр |
Специальные классы символов
| № | Пример & Описание |
|---|---|
| 1 | . соответствует любому символу, кроме символа новой строки |
| 2 | d соответствует цифрам: [0-9] |
| 3 | D не соответствует цифрам: [^0-9] |
| 4 | s соответствует пробельным символам: [trnf] |
| 5 | S не соответствует пробельным символам: [^ trnf] |
| 6 | w соответствует одному из буквенных символов: [A-Za-z0-9_] |
| 7 | W не соответствует ни одному из буквенных символов: [^A-Za-z0-9_] |
Случаи повторения
| № | Примеры |
|---|---|
| 1 | ruby? совпадает с “rub” и “ruby”: “y” необязателен |
| 2 | ruby* совпадает с “rub” и “rubyyyyy”: “y” необязателен и может повторятся несколько раз |
| 3 | ruby+ совпадает с “ruby”: “y” обязателен |
| 4 | d{3} совпадает с тремя цифрами подряд |
| 5 | d{3,} совпадает с тремя и более цифрами подряд |
| 6 | d{3,5} совпадает с 3,4,5 цифрами подряд |
Жадный поиск
| № | Пример & Описание |
|---|---|
| 1 | <.*> Жадное повторение: соответствует “perl>” |
| 2 | <.*?> Ленивый поиск: соответствует “” в “perl>” |
Группирование со скобками
| № | Пример & Описание |
|---|---|
| 1 | Dd+ Нет группы: + относится только к d |
| 2 | (Dd)+ Группа: + относится к паре Dd |
| 3 | ([Pp]ython(, )?)+ соответствует “Python”, “Python, python, python”. |
Ссылки на группы
| № | Пример & Описание |
|---|---|
| 1 | ([Pp])ython&1ails совпадает с python&pails и Python&Pails |
| 2 | ([’»])[^1]*1 Строка с одним или двумя кавычками. 1 соответствует 1-й группе. 2 соответствует второй группе и т. д. |
Или
| № | Пример & Описание |
|---|---|
| 1 | python|perl соответствует “python” или “perl” |
| 2 | rub(y|le)) соответствует “ruby” или “ruble” |
| 3 | Python(!+|?) после «Python» следует 1 и более “!” или один “?” |
Границы слов и строк
| № | Пример & Описание |
|---|---|
| 1 | ^Python соответствует “Python” в начале текста или новой строки текста. |
| 2 | Python$ соответствует “Python” в конце текста или строки текста. |
| 3 | APython соответствует “Python” в начале текста |
| 4 | PythonZ соответствует “Python” в конце текста |
| 5 | bPythonb соответствует “Python” как отдельному слову |
| 6 | brubB соответствует «rub» в начале слова: «rube» и «ruby». |
| 7 | Python(?=!) соответствует “Python”, если за ним следует восклицательный знак. |
| 8 | Python(?!!) соответствует “Python”, если за ним не следует восклицательный знак |
Специальный синтаксис в группах
| № | Пример & Описание |
|---|---|
| 1 | R(?#comment) соответствует «R». Все, что следует дальше — комментарий |
| 2 | R(?i)uby нечувствительный к регистру при поиске “uby” |
| 3 | R(?i:uby) аналогично указанному выше |
| 4 | rub(?:y le)) группируется только без создания обратной ссылки (1) |
Рассмотрим регулярные выражения в Python, начиная синтаксисом и заканчивая примерами использования.
Примечание Вы читаете улучшенную версию некогда выпущенной нами статьи.
- Основы регулярных выражений
- Регулярные выражения в Python
- Задачи
Основы регулярных выражений
Регулярками называются шаблоны, которые используются для поиска соответствующего фрагмента текста и сопоставления символов.
Грубо говоря, у нас есть input-поле, в которое должен вводиться email-адрес. Но пока мы не зададим проверку валидности введённого email-адреса, в этой строке может оказаться совершенно любой набор символов, а нам это не нужно.
Чтобы выявить ошибку при вводе некорректного адреса электронной почты, можно использовать следующее регулярное выражение:
r'^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+(?:.[a-zA-Z0-9-]+)+$'По сути, наш шаблон — это набор символов, который проверяет строку на соответствие заданному правилу. Давайте разберёмся, как это работает.
Синтаксис RegEx
Синтаксис у регулярок необычный. Символы могут быть как буквами или цифрами, так и метасимволами, которые задают шаблон строки:
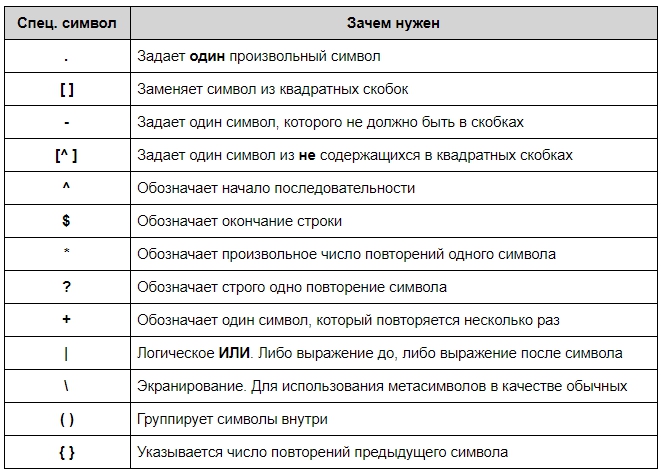
Также есть дополнительные конструкции, которые позволяют сокращать регулярные выражения:
- d — соответствует любой одной цифре и заменяет собой выражение [0-9];
- D — исключает все цифры и заменяет [^0-9];
- w — заменяет любую цифру, букву, а также знак нижнего подчёркивания;
- W — любой символ кроме латиницы, цифр или нижнего подчёркивания;
- s — соответствует любому пробельному символу;
- S — описывает любой непробельный символ.
Для чего используются регулярные выражения
- для определения нужного формата, например телефонного номера или email-адреса;
- для разбивки строк на подстроки;
- для поиска, замены и извлечения символов;
- для быстрого выполнения нетривиальных операций.
Синтаксис таких выражений в основном стандартизирован, так что вам следует понять их лишь раз, чтобы использовать в любом языке программирования.
Примечание Не стоит забывать, что регулярные выражения не всегда оптимальны, и для простых операций часто достаточно встроенных в Python функций.
Хотите узнать больше? Обратите внимание на статью о регулярках для новичков.
В Python для работы с регулярками есть модуль re. Его нужно просто импортировать:
import reА вот наиболее популярные методы, которые предоставляет модуль:
re.match()re.search()re.findall()re.split()re.sub()re.compile()
Рассмотрим каждый из них подробнее.
re.match(pattern, string)
Этот метод ищет по заданному шаблону в начале строки. Например, если мы вызовем метод match() на строке «AV Analytics AV» с шаблоном «AV», то он завершится успешно. Но если мы будем искать «Analytics», то результат будет отрицательный:
import re
result = re.match(r'AV', 'AV Analytics Vidhya AV')
print result
Результат:
<_sre.SRE_Match object at 0x0000000009BE4370>
Искомая подстрока найдена. Чтобы вывести её содержимое, применим метод group() (мы используем «r» перед строкой шаблона, чтобы показать, что это «сырая» строка в Python):
result = re.match(r'AV', 'AV Analytics Vidhya AV')
print result.group(0)
Результат:
AVТеперь попробуем найти «Analytics» в данной строке. Поскольку строка начинается на «AV», метод вернет None:
result = re.match(r'Analytics', 'AV Analytics Vidhya AV')
print result
Результат:
NoneТакже есть методы start() и end() для того, чтобы узнать начальную и конечную позицию найденной строки.
result = re.match(r'AV', 'AV Analytics Vidhya AV')
print result.start()
print result.end()
Результат:
0
2Эти методы иногда очень полезны для работы со строками.
re.search(pattern, string)
Метод похож на match(), но ищет не только в начале строки. В отличие от предыдущего, search() вернёт объект, если мы попытаемся найти «Analytics»:
result = re.search(r'Analytics', 'AV Analytics Vidhya AV')
print result.group(0)
Результат:
AnalyticsМетод search() ищет по всей строке, но возвращает только первое найденное совпадение.
re.findall(pattern, string)
Возвращает список всех найденных совпадений. У метода findall() нет ограничений на поиск в начале или конце строки. Если мы будем искать «AV» в нашей строке, он вернет все вхождения «AV». Для поиска рекомендуется использовать именно findall(), так как он может работать и как re.search(), и как re.match().
result = re.findall(r'AV', 'AV Analytics Vidhya AV')
print result
Результат:
['AV', 'AV']re.split(pattern, string, [maxsplit=0])
Этот метод разделяет строку по заданному шаблону.
result = re.split(r'y', 'Analytics')
print result
Результат:
['Anal', 'tics']В примере мы разделили слово «Analytics» по букве «y». Метод split() принимает также аргумент maxsplit со значением по умолчанию, равным 0. В данном случае он разделит строку столько раз, сколько возможно, но если указать этот аргумент, то разделение будет произведено не более указанного количества раз. Давайте посмотрим на примеры Python RegEx:
result = re.split(r'i', 'Analytics Vidhya')
print result
Результат:
['Analyt', 'cs V', 'dhya'] # все возможные участки.result = re.split(r'i', 'Analytics Vidhya',maxsplit=1)
print result
Результат:
['Analyt', 'cs Vidhya']Мы установили параметр maxsplit равным 1, и в результате строка была разделена на две части вместо трех.
re.sub(pattern, repl, string)
Ищет шаблон в строке и заменяет его на указанную подстроку. Если шаблон не найден, строка остается неизменной.
result = re.sub(r'India', 'the World', 'AV is largest Analytics community of India')
print result
Результат:
'AV is largest Analytics community of the World're.compile(pattern, repl, string)
Мы можем собрать регулярное выражение в отдельный объект, который может быть использован для поиска. Это также избавляет от переписывания одного и того же выражения.
pattern = re.compile('AV')
result = pattern.findall('AV Analytics Vidhya AV')
print result
result2 = pattern.findall('AV is largest analytics community of India')
print result2
Результат:
['AV', 'AV']
['AV']До сих пор мы рассматривали поиск определенной последовательности символов. Но что, если у нас нет определенного шаблона, и нам надо вернуть набор символов из строки, отвечающий определенным правилам? Такая задача часто стоит при извлечении информации из строк. Это можно сделать, написав выражение с использованием специальных символов. Вот наиболее часто используемые из них:
| Оператор | Описание |
|---|---|
| . | Один любой символ, кроме новой строки n. |
| ? | 0 или 1 вхождение шаблона слева |
| + | 1 и более вхождений шаблона слева |
| * | 0 и более вхождений шаблона слева |
| w | Любая цифра или буква (W — все, кроме буквы или цифры) |
| d | Любая цифра [0-9] (D — все, кроме цифры) |
| s | Любой пробельный символ (S — любой непробельный символ) |
| b | Граница слова |
| [..] | Один из символов в скобках ([^..] — любой символ, кроме тех, что в скобках) |
| Экранирование специальных символов (. означает точку или + — знак «плюс») | |
| ^ и $ | Начало и конец строки соответственно |
| {n,m} | От n до m вхождений ({,m} — от 0 до m) |
| a|b | Соответствует a или b |
| () | Группирует выражение и возвращает найденный текст |
| t, n, r | Символ табуляции, новой строки и возврата каретки соответственно |
Больше информации по специальным символам можно найти в документации для регулярных выражений в Python 3.
Перейдём к практическому применению Python регулярных выражений и рассмотрим примеры.
Задачи
Вернуть первое слово из строки
Сначала попробуем вытащить каждый символ (используя .)
result = re.findall(r'.', 'AV is largest Analytics community of India')
print result
Результат:
['A', 'V', ' ', 'i', 's', ' ', 'l', 'a', 'r', 'g', 'e', 's', 't', ' ', 'A', 'n', 'a', 'l', 'y', 't', 'i', 'c', 's', ' ', 'c', 'o', 'm', 'm', 'u', 'n', 'i', 't', 'y', ' ', 'o', 'f', ' ', 'I', 'n', 'd', 'i', 'a']Для того, чтобы в конечный результат не попал пробел, используем вместо . w.
result = re.findall(r'w', 'AV is largest Analytics community of India')
print result
Результат:
['A', 'V', 'i', 's', 'l', 'a', 'r', 'g', 'e', 's', 't', 'A', 'n', 'a', 'l', 'y', 't', 'i', 'c', 's', 'c', 'o', 'm', 'm', 'u', 'n', 'i', 't', 'y', 'o', 'f', 'I', 'n', 'd', 'i', 'a']Теперь попробуем достать каждое слово (используя * или +)
result = re.findall(r'w*', 'AV is largest Analytics community of India')
print result
Результат:
['AV', '', 'is', '', 'largest', '', 'Analytics', '', 'community', '', 'of', '', 'India', '']И снова в результат попали пробелы, так как * означает «ноль или более символов». Для того, чтобы их убрать, используем +:
result = re.findall(r'w+', 'AV is largest Analytics community of India')
print result
Результат:
['AV', 'is', 'largest', 'Analytics', 'community', 'of', 'India']Теперь вытащим первое слово, используя ^:
result = re.findall(r'^w+', 'AV is largest Analytics community of India')
print result
Результат:
['AV']Если мы используем $ вместо ^, то мы получим последнее слово, а не первое:
result = re.findall(r'w+$', 'AV is largest Analytics community of India')
print result
Результат:
[‘India’]Вернуть первые два символа каждого слова
Вариант 1: используя w, вытащить два последовательных символа, кроме пробельных, из каждого слова:
result = re.findall(r'ww', 'AV is largest Analytics community of India')
print result
Результат:
['AV', 'is', 'la', 'rg', 'es', 'An', 'al', 'yt', 'ic', 'co', 'mm', 'un', 'it', 'of', 'In', 'di']Вариант 2: вытащить два последовательных символа, используя символ границы слова (b):
result = re.findall(r'bw.', 'AV is largest Analytics community of India')
print result
Результат:
['AV', 'is', 'la', 'An', 'co', 'of', 'In']Вернуть домены из списка email-адресов
Сначала вернём все символы после «@»:
result = re.findall(r'@w+', 'abc.test@gmail.com, xyz@test.in, test.first@analyticsvidhya.com, first.test@rest.biz')
print result
Результат:
['@gmail', '@test', '@analyticsvidhya', '@rest']Как видим, части «.com», «.in» и т. д. не попали в результат. Изменим наш код:
result = re.findall(r'@w+.w+', 'abc.test@gmail.com, xyz@test.in, test.first@analyticsvidhya.com, first.test@rest.biz')
print result
Результат:
['@gmail.com', '@test.in', '@analyticsvidhya.com', '@rest.biz']Второй вариант — вытащить только домен верхнего уровня, используя группировку — ( ):
result = re.findall(r'@w+.(w+)', 'abc.test@gmail.com, xyz@test.in, test.first@analyticsvidhya.com, first.test@rest.biz')
print result
Результат:
['com', 'in', 'com', 'biz']Извлечь дату из строки
Используем d для извлечения цифр.
result = re.findall(r'd{2}-d{2}-d{4}', 'Amit 34-3456 12-05-2007, XYZ 56-4532 11-11-2011, ABC 67-8945 12-01-2009')
print result
Результат:
['12-05-2007', '11-11-2011', '12-01-2009']Для извлечения только года нам опять помогут скобки:
result = re.findall(r'd{2}-d{2}-(d{4})', 'Amit 34-3456 12-05-2007, XYZ 56-4532 11-11-2011, ABC 67-8945 12-01-2009')
print result
Результат:
['2007', '2011', '2009']Извлечь слова, начинающиеся на гласную
Для начала вернем все слова:
result = re.findall(r'w+', 'AV is largest Analytics community of India')
print result
Результат:
['AV', 'is', 'largest', 'Analytics', 'community', 'of', 'India']А теперь — только те, которые начинаются на определенные буквы (используя []):
result = re.findall(r'[aeiouAEIOU]w+', 'AV is largest Analytics community of India')
print result
Результат:
['AV', 'is', 'argest', 'Analytics', 'ommunity', 'of', 'India']Выше мы видим обрезанные слова «argest» и «ommunity». Для того, чтобы убрать их, используем b для обозначения границы слова:
result = re.findall(r'b[aeiouAEIOU]w+', 'AV is largest Analytics community of India')
print result
Результат:
['AV', 'is', 'Analytics', 'of', 'India']Также мы можем использовать ^ внутри квадратных скобок для инвертирования группы:
result = re.findall(r'b[^aeiouAEIOU]w+', 'AV is largest Analytics community of India')
print result
Результат:
[' is', ' largest', ' Analytics', ' community', ' of', ' India']В результат попали слова, «начинающиеся» с пробела. Уберем их, включив пробел в диапазон в квадратных скобках:
result = re.findall(r'b[^aeiouAEIOU ]w+', 'AV is largest Analytics community of India')
print result
Результат:
['largest', 'community']Проверить формат телефонного номера
Номер должен быть длиной 10 знаков и начинаться с 8 или 9. Есть список телефонных номеров, и нужно проверить их, используя регулярки в Python:
li = ['9999999999', '999999-999', '99999x9999']
for val in li:
if re.match(r'[8-9]{1}[0-9]{9}', val) and len(val) == 10:
print 'yes'
else:
print 'no'
Результат:
yes
no
noРазбить строку по нескольким разделителям
Возможное решение:
line = 'asdf fjdk;afed,fjek,asdf,foo' # String has multiple delimiters (";",","," ").
result = re.split(r'[;,s]', line)
print result
Результат:
['asdf', 'fjdk', 'afed', 'fjek', 'asdf', 'foo']Также мы можем использовать метод re.sub() для замены всех разделителей пробелами:
line = 'asdf fjdk;afed,fjek,asdf,foo'
result = re.sub(r'[;,s]',' ', line)
print result
Результат:
asdf fjdk afed fjek asdf fooИзвлечь информацию из html-файла
Допустим, нужно извлечь информацию из html-файла, заключенную между <td> и </td>, кроме первого столбца с номером. Также будем считать, что html-код содержится в строке.
Пример содержимого html-файла:
1NoahEmma2LiamOlivia3MasonSophia4JacobIsabella5WilliamAva6EthanMia7MichaelEmilyС помощью регулярных выражений в Python это можно решить так (если поместить содержимое файла в переменную test_str):
result = re.findall(r'd([A-Z][A-Za-z]+)([A-Z][A-Za-z]+)', test_str)
print result
Результат:
[('Noah', 'Emma'), ('Liam', 'Olivia'), ('Mason', 'Sophia'), ('Jacob', 'Isabella'), ('William', 'Ava'), ('Ethan', 'Mia'), ('Michael', 'Emily')]Адаптированный перевод «Beginners Tutorial for Regular Expressions in Python»