Are you experiencing device slowness or freezing, a longer computer startup time, or difficulty updating to the latest version of Windows 10? Here’s what to do when you see the following notifcation:
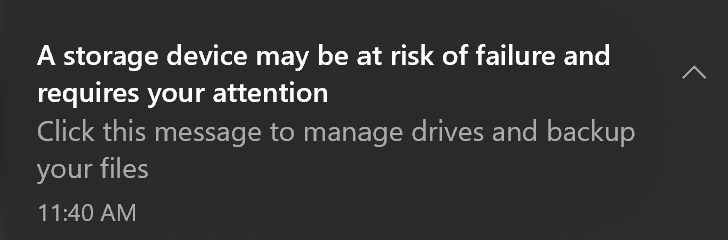
We strongly recommend you pay attention to this message. Back up your data and contact Microsoft support to resolve any additional concerns or issues.
What does this message mean?
When Windows sends this notification, select the message or go to Start > Settings > System > Storage > Manage disks and volumes, then select Properties for the problematic disk to see additional details. For example:
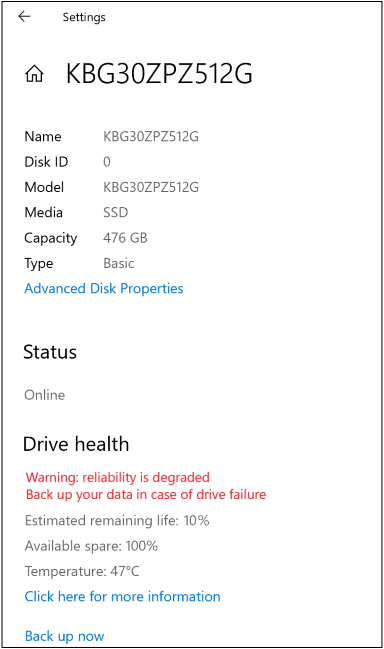
Note: The Manage disks and volumes feature is currenlty available only for Windows Insiders.
There are three types of critical warnings:
|
Warning |
Description |
|
Spare capacity is low |
Spare storage capacity is below the manufacturer’s safety threshold. |
|
Reliability is degraded |
Reliability is degraded because of significant media-related errors or an internal error to the NVM subsystem. |
|
Drive is set to read-only |
Data stored on the device can still be accessed but you can’t write to it. |
There are also three disk health attributes you can watch that affect disk performance:
|
Attribute |
Description |
|
Estimated remaining life |
The approximate percentage used, which is based on the manufacturer’s prediction of drive life. Note that although the value is capped at 0%, a value below that is possible as consumption does not automatically mean device failure. |
|
Available spare |
A normalized percentage (0% to 100%) of the remaining spare capacity available. |
|
Temperature |
Temperature of the overall device in degrees Celsius. |
More about SSD storage devices
SSD storage devices are built-in or external devices based on integrated circuit assemblies and flash memory. SSD is an abbreviation for solid-state drive or solid-state device.
These devices have two main bus interfaces:
-
Traditional: Serial AT Attachment (SATA)
-
High speed: Non-Volatile Memory (NVMe), which is is an associated communications standard.
Note: Windows only monitors NVM SSD and not SATA SSD or hard disk drives (HDD).
Need more help?
Содержание
- What to do about a critical warning for a storage device
- What does this message mean?
- More about SSD storage devices
- Oracle ® Flash Accelerator F320 PCIe Card and Oracle 3.2 TB NVMe SSD Product Notes Release 1.3
- Verify Oracle Oracle Flash Accelerator F320 PCIe Card Operation
- Drive Internal Faults or Other Faults
- Use Instance
- Fault Diagnosis Instance
- New Windows 10 feature alerts users if their SSD is about to fail
- Storage health monitoring only works with NVMe SSDs right now
- Drive Internal Faults or Other Faults
- Use Instance
- Fault Diagnosis Instance
What to do about a critical warning for a storage device
Are you experiencing device slowness or freezing, a longer computer startup time, or difficulty updating to the latest version of Windows 10? Here’s what to do when you see the following notifcation:
We strongly recommend you pay attention to this message. Back up your data and contact Microsoft support to resolve any additional concerns or issues.
What does this message mean?
When Windows sends this notification, select the message or go to Start > Settings > System > Storage > Manage disks and volumes, then select Properties for the problematic disk to see additional details. For example:
Note: The Manage disks and volumes feature is currenlty available only for Windows Insiders.
There are three types of critical warnings:
Spare capacity is low
Spare storage capacity is below the manufacturer’s safety threshold.
Reliability is degraded
Reliability is degraded because of significant media-related errors or an internal error to the NVM subsystem.
Drive is set to read-only
Data stored on the device can still be accessed but you can’t write to it.
There are also three disk health attributes you can watch that affect disk performance:
Estimated remaining life
The approximate percentage used, which is based on the manufacturer’s prediction of drive life. Note that although the value is capped at 0%, a value below that is possible as consumption does not automatically mean device failure.
A normalized percentage (0% to 100%) of the remaining spare capacity available.
Temperature of the overall device in degrees Celsius.
More about SSD storage devices
SSD storage devices are built-in or external devices based on integrated circuit assemblies and flash memory. SSD is an abbreviation for solid-state drive or solid-state device.
These devices have two main bus interfaces:
Traditional: Serial AT Attachment (SATA)
High speed: Non-Volatile Memory (NVMe), which is is an associated communications standard.
Note: Windows only monitors NVM SSD and not SATA SSD or hard disk drives (HDD).
Источник
Oracle ® Flash Accelerator F320 PCIe Card and Oracle 3.2 TB NVMe SSD Product Notes Release 1.3
Verify Oracle Oracle Flash Accelerator F320 PCIe Card Operation
This topic provides instructions to verify Oracle Flash Accelerator F320 PCIe Card operation for the host for supported Oracle Solaris and Linux operating systems. Verify Oracle Flash Accelerator F320 PCIe Card and 3.2 TB NVMe SSD operation using Oracle Hardware Management Pack utility CLI tools.
Before You Begin
Verify that Oracle Hardware Management Pack is installed on the host.
Refer to the Oracle Hardware Management Pack documentation for instructions at http://www.oracle.com/goto/ohmp/docs.
Ensure that you have access to the server (either directly or over the network).
- Observe the Oracle Flash Accelerator F320 PCIe Card status indicators (LEDs).
Verify that the Service Action Required status indicator is not lit and that the green Power status indicator is lit on the Oracle Flash Accelerator F320 PCIe Cards that you updated. Refer to Status Indicators in Oracle Flash Accelerator F320 PCIe Card User Guide.
Log into the target system.
Refer to the server installation guide.
For example, to log into the target system through SSH or through Oracle ILOM Remote System Console, do one of the following:
- If you are using an SSH client connection, perform these steps.
- From a shell command line in a terminal window, establish an SSH connection to the server host.
Type: ssh root@ hostname , where hostname can be the DNS name or the IP address for the server host.
- Access the host console locally or remotely:
To establish a local connection to the host console, perform the following steps:
- Connect a VGA monitor to the VGA port on the server.
- Connect a USB keyboard and mouse to the USB connectors on the server.
- To establish a remote connection to the host console:
Launch an Oracle ILOM Remote System Console Plus session.
For instructions, see Launching Remote KVMS Redirection Sessions in the server administration guide.
You issue Oracle Hardware Management Pack commands from the operating system command-line interface.
Identify all Oracle F320 Flash Cards and verify that the latest firmware packages are installed.
- Type the following command:
# fwupdate list controller
Verify host recognition of all Oracle F320 Flash Cards by checking controller ID enumeration.
In the above example, Oracle F320 Flash Card controllers c1 and c2 are enumerated in the output returned by the above command.
Ensure that all Oracle F320 Flash Card firmware versions are current in the output returned by the above command.
Check NVMe device status (Optional).
- To identify NVMe controllers and current firmware versions type:
Verify host recognition of all Oracle F320 Flash Cards by checking controller ID enumeration.
In the above example, Oracle F320 Flash Card controllers SUNW-NVME-1 and SUNW-NVME-2 are enumerated in the output returned by the above command.
Ensure that all Oracle F320 Flash Card firmware revisions are current in the device output returned by the above command.
To identify NVMe controllers that have updated firmware, view the Firmware Revision: row in the output from the nvmeadm list -v command.
In the above example, controller SUNW-NVME-1 and SUNW-NVME-2 show firmware version KPYABR3Q in the output returned by the above command.
Check health of the Oracle F320 Flash Card.
To check the selected Oracle F320 Flash Card health and SMART information, type:
# nvmeadm getlog -h
Ensure the Oracle F320 Flash Cards have remaining drive life in the output returned by the above command.
The critical warning parameters are described in the following list.
0 — Available spare space has fallen below threshold.
1 — Temperature exceeded critical threshold.
2 — Reliability has degraded due to significant media related errors or any internal error that degrades device reliability.
3 — Media has been placed in read only mode.
4 — Volatile memory backup device has failed.
Источник
Drive Internal Faults or Other Faults
Drive internal faults indicate scenarios where drive internal alarms occur while the OS can properly identify drives. If such faults occur, the drives do not function properly or cannot be used. This section uses an example to describe how to identify such faults.
Use Instance
- Determine the drive health status. For details, see Querying Basic Information About an SSD Device List
# Query the basic information of pd0.
device status in the command output indicates the SSD controller health status.
The value healthy indicates that the device is healthy.
The value warning indicates that an exception occurs on the device. For details, see Step 2.
Determine the SMART status of the drive. For details, see Querying the SMART Information About a Device.
# Query the SMART information of pd0.
Critical Warning: Critical exceptions occur on the device, and emergency handling is required.
Critical warning, such as overtemperature and insufficient redundant space.
- 0: No warning.
- 1: The available spare space has fallen below the threshold.
- 2: The temperature is above an over temperature threshold or below an under temperature threshold.
- 3: The NVM subsystem reliability has been degraded due to significant media related errors or any internal error that degrades NVM subsystem reliability.
- 4: The media has been placed in read only mode.
- 5: The volatile memory backup device has failed.
Typical fault causes are as follows:
- Available spare space below the threshold: Causes include excessive number of damaged blocks.
- Temperature above the overtemperature threshold or below the undertemperature threshold: Causes include drive temperature below 0°C or above 78°C.
- NVM subsystem reliability degraded due to internal errors: Causes include excessive number of failed drive granules or internal subsystem operating exceptions.
- Media placed in read only mode: Causes include capacitor failures.
- Volatile memory backup device failure: Causes include capacitor voltage below 28 V or above 35 V.
Fault Diagnosis Instance
The service life exceeds the threshold.
- Check the value of percentage used in the SMART information, if the value is greater than or equal to 100%, stop using the drive and back up data immediately. Otherwise, go to 2.
- Collect drive log information. For details, see One-Click Log Collection. Contact Huawei technical support.
The temperature exceeds the threshold.
- Check that the server where the drive resides provides proper cooling. If the server reports no temperature alarm and the fan modules are operating properly, go to 2.
- Check that the server where the drive resides provides proper cooling. If the server reports no temperature alarm and the fan modules are operating properly, go to 2.
- Obtain drive logs by following instructions in One-Click Log Collection and contact Huawei technical support.
- The medium is read-only.
- Device backup failed.
- Obtain drive logs by following instructions in One-Click Log Collection and contact Huawei technical support.
Источник
New Windows 10 feature alerts users if their SSD is about to fail
Storage health monitoring only works with NVMe SSDs right now

In brief: Do you worry that your NVMe SSD might suddenly up and die on you? In the latest Insider Preview Build of Windows 10, the OS will alert you of your drive’s health, including its estimated remaining life.
Windows10 Build 20266, which is now available to Windows Insiders in the Dev Channel, introduces storage health monitoring designed to inform users of any abnormalities in their NVMe solid-state drive, giving them time to back up their data before it’s potentially lost forever.
In addition to detecting issues, the feature will show the drive’s estimated remaining life, available space, and its temperature.

Notifications will arrive when spare storage capacity is low, the SSD’s reliability is degraded due to «significant media-related errors or an internal error to the NVM subsystem,» or if the drive is set to read-only.
«It is strongly recommended that users immediately back up their data after receiving a notification,» writes Microsoft.
Users who receive an alert can click on the message or go to Start > Settings > System > Storage > Manage disks and volumes > Properties to get more details about the drive and the detected issues.
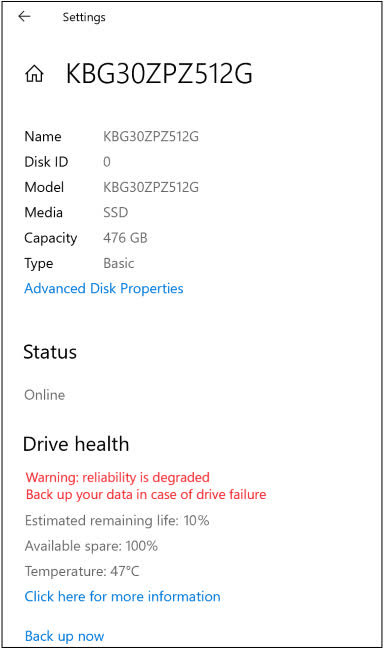
The feature only works with NVMe SSDs right now. Microsoft doesn’t say whether it will eventually cover SATA SSDs or hard disk drives.
Elsewhere in Build 20266, a new settings page has been added to the Your Phone app, allowing users to add, remove, and switch devices easily within the application. There’s also a change that will turn off theme syncing, along with other bug fixes and improvements.
Источник
Drive Internal Faults or Other Faults
Drive internal faults indicate scenarios where drive internal alarms occur while the OS can properly identify drives. If such faults occur, the drives do not function properly or cannot be used. This section uses an example to describe how to identify such faults.
Use Instance
- Determine the drive health status. For details, see Querying Basic Information About an SSD Device List
# Query the basic information of pd0.
device status in the command output indicates the SSD controller health status.
The value healthy indicates that the device is healthy.
The value warning indicates that an exception occurs on the device. For details, see Step 2.
Determine the SMART status of the drive. For details, see Querying the SMART Information About a Device.
# Query the SMART information of pd0.
Critical Warning: Critical exceptions occur on the device, and emergency handling is required.
Critical warning, such as overtemperature and insufficient redundant space.
- 0: No warning.
- 1: The available spare space has fallen below the threshold.
- 2: The temperature is above an over temperature threshold or below an under temperature threshold.
- 3: The NVM subsystem reliability has been degraded due to significant media related errors or any internal error that degrades NVM subsystem reliability.
- 4: The media has been placed in read only mode.
- 5: The volatile memory backup device has failed.
Typical fault causes are as follows:
- Available spare space below the threshold: Causes include excessive number of damaged blocks.
- Temperature above the overtemperature threshold or below the undertemperature threshold: Causes include drive temperature below 0°C or above 78°C.
- NVM subsystem reliability degraded due to internal errors: Causes include excessive number of failed drive granules or internal subsystem operating exceptions.
- Media placed in read only mode: Causes include capacitor failures.
- Volatile memory backup device failure: Causes include capacitor voltage below 28 V or above 35 V.
Fault Diagnosis Instance
The service life exceeds the threshold.
- Check the value of percentage used in the SMART information, if the value is greater than or equal to 100%, stop using the drive and back up data immediately. Otherwise, go to 2.
- Collect drive log information. For details, see One-Click Log Collection. Contact Huawei technical support.
The temperature exceeds the threshold.
- Check that the server where the drive resides provides proper cooling. If the server reports no temperature alarm and the fan modules are operating properly, go to 2.
- Check that the server where the drive resides provides proper cooling. If the server reports no temperature alarm and the fan modules are operating properly, go to 2.
- Obtain drive logs by following instructions in One-Click Log Collection and contact Huawei technical support.
- The medium is read-only.
- Device backup failed.
- Obtain drive logs by following instructions in One-Click Log Collection and contact Huawei technical support.
Источник
Содержание
- Новый SSD (nvme) прибавляет 1 ошибку при каждом запуске компа
- Small Datum
- Saturday, October 21, 2017
- Wearing out an SSD
- [жж] словил сбойные сектора на nvme ssd
- Нужно ли менять SSD NVME Samsung SM951?
- smartctl on nvme, what does the status code mean?
- ehsab
- sretalla
Новый SSD (nvme) прибавляет 1 ошибку при каждом запуске компа
Купил новый SSD, и при каждом ребуте он прибавляет ровно 1 ошибку
Погуглил, нашёл похожие темы, но не нашёл решение. Как исправить, кто знает? Говорят это что-то то ли с прошивкой SSD, то ли с версией kernel, то ли ещё что.


Забей, это реакция ssd на команды, которые к нему не относятся.

У меня в лог RAS тоже такое сыпется, забей, пишут что это не ошибки, а артефакты мониторинга на команды которые к ssd не относятся, либо на те которые эта модель не понимает, например всякие команды по управлению питанием шины.
я так и подумал, просто думал можно что-то где-то прописать чтобы они не прибавлялись)
Вроде пока нигде, я даже толком на обсуждение какое либо сослаться не могу, всюду одно-два упоминания о проблеме и реакция типа «забей», или «я мониторинг дисков в rasdaemon сам при его сборке отломал, чтобы он не мусорил». Разраб rasdaemon говорит что это не его проблемы фильтровать или игнорировать то что по каналам мониторинга ходит, раз там что то лишнее ходит пусть этим ядерные физики займутся. Надо бы как то грамотно дискуссию на эту тему в LKML поднять, лично я не потяну, да и меня не особо припекает.
PS. Извиняюсь за дезу, у меня в NVMe Log ошибок нет, а Disk Errors в ras-mc-ctl это не связанный с твоим баг.

По-моему, такой команды в NVMe нет, поэтому накопитель возвращает ошибку. Возможно, в каком-то софте для мониторинга баг.
Похожий баг точно есть в collectd, но это вряд ли то же самое. Там число ошибок растёт каждые несколько секунд.
Стало интересно разобраться тоже, кто нибудь вообще может сказать, что это за команда такая, 0x100f? Где вообще можно список идентификаторов команд с расшифровкой подсмотреть?
Источник
Small Datum
Saturday, October 21, 2017
Wearing out an SSD
I use Intel NUC servers at home to test open-source databases for performance and efficiency. The servers have an SSD for the database and that is either a Samsung 960 EVO or a Samsung 850 EVO. It is time to replace the 960 EVO after about 5 months of heavy usage. I test MySQL (MyRocks, InnoDB, MyISAM) and MongoDB (MongoRocks, WiredTiger and mmapv1). If I limited myself to MyRocks and MongoRocks then the storage devices would last much longer courtesy of better write efficiency of an LSM versus a B-Tree.
I have 3 servers with the 960 EVO and I will replace the SSD in all of them at the same time. I assume that device performance changes as it ages, but I have never tried to quantify that. For the 850 EVO I will buy extra spares and will upgrade from the 120gb device to a 250gb device because they cost the same and the 120gb device is hard to find. I just hope the devices I use right now will last long enough to finish my current round of testing. One day I will switch to EC2 and GCE and wear out their devices, but I like the predictability I get from my home servers.
I use Ubuntu 16.04 and its version of smartctl doesn’t yet support NVMe devices so I used the nvme utility. Percona has a useful blog post on this. The percentage_used value is 250% which means the estimated device endurance has been greatly exceeded. The value of critical_warning is 0x4 which means NVM subsystem reliability has been degraded due to significant media related errors or any internal error that degrades NVM subsystem reliability per the NVMe spec. The data_units_written value is the number of 512 bytes units written and is reported in thousands. The value 1,400,550,163 means that 652TB has been written to the device. The device is 250GB which is about 2700 full device writes. If I wave my hands and expect 2000 full device writes from 3D NAND and ignore overprovisioning (OP) then it seems reasonable that the device is done. I assume that OP is 10% based on available_spare_threshold. The warranty on the 250gb 960 EVO is 3 years or 100 TBW and I wrote 652TB so I am happy about that. My previous post on this is here.
This is from the 960 EVO.
$ sudo nvme smart-log /dev/nvme0
Smart Log for NVME device:nvme0 namespace-id:ffffffff
critical_warning : 0x4
temperature : 32 C
available_spare : 100%
available_spare_threshold : 10%
percentage_used : 250%
data_units_read : 159,094,604
data_units_written : 1,400,550,163
host_read_commands : 4,698,541,096
host_write_commands : 19,986,018,997
controller_busy_time : 32,775
power_cycles : 30
power_on_hours : 3,039
unsafe_shutdowns : 7
media_errors : 0
num_err_log_entries : 0
Warning Temperature Time : 0
Critical Composite Temperature Time : 0
Temperature Sensor 1 : 32 C
Temperature Sensor 2 : 45 C
Temperature Sensor 3 : 0 C
Temperature Sensor 4 : 0 C
Temperature Sensor 5 : 0 C
Temperature Sensor 6 : 0 C
Temperature Sensor 7 : 0 C
Temperature Sensor 8 : 0 C
This is from the 850 EVO and the server with the largest value for Total_LBAs_Written. The device has a 512 byte sector and with Total_LBAs_Written at 739353756925 then 344TB has been written to the 120gb device. That is about 2900 full device writes assuming no OP. Once again, I should be happy that the device lasted this long. The warranty on the 120gb 850 EVO is 5 years or 75TBW. I wrote a lot more than 75TB. The Wear_Leveling_Count value is 3335 and that is the average number of P/E cycles. That value is similar to my estimate of 2900 full device writes. I assume that I will get about 2000 from 3D NAND and I exceeded that.
$ sudo smartctl —all /dev/sdb
.
SMART Attributes Data Structure revision number: 1
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
5 Reallocated_Sector_Ct 0x0033 100 100 010 Pre-fail Always — 0
9 Power_On_Hours 0x0032 099 099 000 Old_age Always — 4430
12 Power_Cycle_Count 0x0032 099 099 000 Old_age Always — 11
177 Wear_Leveling_Count 0x0013 001 001 000 Pre-fail Always — 3335
179 Used_Rsvd_Blk_Cnt_Tot 0x0013 100 100 010 Pre-fail Always — 0
181 Program_Fail_Cnt_Total 0x0032 100 100 010 Old_age Always — 0
182 Erase_Fail_Count_Total 0x0032 100 100 010 Old_age Always — 0
183 Runtime_Bad_Block 0x0013 100 100 010 Pre-fail Always — 0
187 Reported_Uncorrect 0x0032 100 100 000 Old_age Always — 0
190 Airflow_Temperature_Cel 0x0032 047 038 000 Old_age Always — 53
195 Hardware_ECC_Recovered 0x001a 200 200 000 Old_age Always — 0
199 UDMA_CRC_Error_Count 0x003e 100 100 000 Old_age Always — 0
235 Unknown_Attribute 0x0012 099 099 000 Old_age Always — 2
241 Total_LBAs_Written 0x0032 099 099 000 Old_age Always — 739353756925
SMART Error Log Version: 1
No Errors Logged
Источник
[жж] словил сбойные сектора на nvme ssd
Дорогой Уважаемый ЛОР,
Я словил первое в своей жизни проявление сбойных секторов на SSD. Пациент — Samsung SSD 970 EVO 2TB с прошивкой 2B2QEXE7, в эксплуатации примерно год. Пару-тройку дней назад мне почему-то захотелось сделать копию вообще всех данных из домашней директории, включая файлы, которые легко скачать из сети при надобности. Некоторые из этих файлов лежали там с момента миграции на накопитель, без обращений. И при копировании одного из таких файлов программа сказала: «А я, кажись, чот не могу». После того, как потихоньку пришло осознание произошедшего, я глянул в лог и увидел там:
Что интересно, во второй раз файл успешно скопировался. Не знаю, прочитались там настоящие данные или мусор. К сожалению, вот этот конкретный файл повторно скачать оказалось неоткуда. Чтение данных с nvme0n1 по тому адресу выдало какие-то данные, не нули. Тут я решил, что SSD умный, что он понял, что страница не читается стабильно, и увёл её в чулан, на её место подставил новую, а данные всё-таки скопировал. Но на всякий случай решил запустить холостое чтение с блочного устройства. Сбойных блоков оказалось больше. Пробовал читать конкретные места. Зачастую чтение было успешным, но через много чтений всё же происходили ошибки. Попробовал перезаписать место с ошибками чтения теми же данными. Ошибки там прекратились.
В итоге сделал дамп через ddrescue, а потом записал этот дамп обратно. Последующие попытки прочитать накопитель целиком уже никаких ошибок не давали. Сижу вот теперь как на пороховой бочке. Пользоваться дальше немного боязно, но и выбрасывать накопитель, который вроде работает, как-то жалко.
За время тестов в логи свалилось 546 строк с «blk_update_request: critical medium error», но ошибки иногда сыпались так часто, что в сумме набралось 888 «callbacks suppressed». В статусе накопителя написано, что ошибок доступа к носителю было 1484. Так как в логи основной системы не попало происходившее на LiveUSB, можно считать, что числа сходятся. К сожалению, не помню, были ли там ошибки до недавних событий. Всего различных сбойных секторов было 167 штук.
В данных из плохих секторов нашлись обрывки Packages из Debian. Судя по версиям пакетов, эти куски из очень старых Packages, возможно ещё из 2016. Если это так, они приехали во время миграции на накопитель, и с тех пор не перезаписывались и не читались. Один кусок оказался очень похож на файл переводов и нашёлся в /usr/share/locale/gl/LC_MESSAGES/coreutils.mo , который конечно же ни разу не читался с момента последней переустановки пакета coreutils в начале августа 2019.
Терабайт тридцать-сорок я добавил чтением накопителя во время тестов.
Думаю, из произошедшего можно сделать, как минимум, следующие выводы:
- полгода без чтения страницы на SSD достаточно для последующих ошибок чтения;
- чтение такой страницы не заставляет SSD подменять страницу на новую, он с радостью выдаёт ошибку чтения на одном и том же месте много раз подряд;
- trim не означает очистку всех неиспользуемых блоков ФС, они же меньше страницы. Некоторые данные могут жить в закоулках годами;
- SSD желательно периодически прочёсывать чтением, чтобы словить сюрпризы пораньше;
- если такое происходит на TLC 3D V-NAND, страшно подумать, что будет на QLC.
Upd.
Узнал, что в NVMe есть фича 0x10, которая управляет температурами, при которых SSD должен начать тормозить для снижения нагрева. Правда для 970 EVO эти температуры дожны быть в диапазоне 80–82 °C, а попытка установить любые значения кроме 0 для фичи 0x10 завершаются неудачай.
Upd. 11 мая 2021, то есть примерно через год и два месяца после первого раза, появились новые ошибки чтения. При повторном чтении тех же мест ошибки повторялись, но через некоторое время пропали.
Upd. 5 июня 2021. Аккумулятор оказался вздут в той секции, что прилегает к SSD. Видимо, предупреждение о температурном лимите в 65°C на аккумуляторе написано не просто так.
Upd. 20 февраля 2022. Накопитель отправился на пенсию.
Источник
Нужно ли менять SSD NVME Samsung SM951?
В логах messages наали появляться сообщения на диске Mysql, где-то 5 лет работал.
smartd[1206]: Device: /dev/nvme0, Critical Warning (0x04): Reliability
Команда
smartctl -a /dev/nvme0
smartctl 7.0 2018-12-30 r4883 [x86_64-linux-5.6.14-1.el7.elrepo.x86_64] (local build)
Copyright (C) 2002-18, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Number: SAMSUNG MZVPV256HDGL-00000
Serial Number: S1XWNY0HA01300
Firmware Version: BXW7300Q
PCI Vendor/Subsystem ID: 0x144d
IEEE OUI Identifier: 0x002538
Controller ID: 1
Number of Namespaces: 1
Namespace 1 Size/Capacity: 256 060 514 304 [256 GB]
Namespace 1 Utilization: 45 267 107 840 [45,2 GB]
Namespace 1 Formatted LBA Size: 512
Local Time is: Tue Oct 13 07:14:21 2020 MSK
Firmware Updates (0x06): 3 Slots
Optional Admin Commands (0x0007): Security Format Frmw_DL
Optional NVM Commands (0x001f): Comp Wr_Unc DS_Mngmt Wr_Zero Sav/Sel_Feat
Maximum Data Transfer Size: 32 Pages
Supported Power States
St Op Max Active Idle RL RT WL WT Ent_Lat Ex_Lat
0 + 9.00W — — 0 0 0 0 5 5
1 + 4.60W — — 1 1 1 1 30 30
2 + 3.80W — — 2 2 2 2 100 100
3 — 0.0700W — — 3 3 3 3 500 5000
4 — 0.0050W — — 4 4 4 4 2000 22000
Supported LBA Sizes (NSID 0x1)
Id Fmt Data Metadt Rel_Perf
0 + 512 0 0
=== START OF SMART DATA SECTION ===
SMART overall-health self-assessment test result: FAILED!
— NVM subsystem reliability has been degraded
SMART/Health Information (NVMe Log 0x02)
Critical Warning: 0x04
Temperature: 44 Celsius
Available Spare: 96%
Available Spare Threshold: 10%
Percentage Used: 123%
Data Units Read: 7 344 994 [3,76 TB]
Data Units Written: 308 698 968 [158 TB]
Host Read Commands: 231 630 418
Host Write Commands: 8 135 588 810
Controller Busy Time: 106 978
Power Cycles: 145
Power On Hours: 33 898
Unsafe Shutdowns: 79
Media and Data Integrity Errors: 0
Error Information Log Entries: 20
Error Information (NVMe Log 0x01, max 64 entries)
Num ErrCount SQId CmdId Status PELoc LBA NSID VS
0 20 0 0x000a 0x4016 0x000 0 1 —
1 19 0 0x000a 0x4016 0x000 0 1 —
2 18 0 0x000a 0x4016 0x000 0 1 —
3 17 0 0x000a 0x4016 0x000 0 1 —
4 16 0 0x000a 0x4016 0x000 0 1 —
5 15 0 0x000a 0x4016 0x000 0 1 —
6 14 0 0x001c 0x4004 0x000 0 0 —
7 13 0 0x001b 0x4004 0x000 0 0 —
8 12 0 0x001a 0x4004 0x000 0 0 —
9 11 0 0x001c 0x4004 0x000 0 0 —
10 10 0 0x001b 0x4004 0x000 0 0 —
11 9 0 0x000a 0x4016 0x000 0 1 —
12 8 0 0x000a 0x4016 0x000 0 1 —
13 7 0 0x000a 0x4016 0x000 0 1 —
14 6 0 0x000a 0x4016 0x000 0 1 —
15 5 0 0x000a 0x4016 0x000 0 1 —
. (4 entries not shown)
Источник
smartctl on nvme, what does the status code mean?

ehsab
Dabbler
Hi,
I installed a PCIe NVMe disk the other day and Truenas 12 BETA2 reports a critical issue with it.
When i run smartctl -x /dev/nvme0 i get this:
I can’t find what 0x400c stands for when i google and searches (in this community) gives me nothing either.
It’s not been used much:

sretalla
Hall of Famer
Aiming to mostly replicate the build from @Stux (with some mods, hopefully around about as good as that link)
- 4 xSamsung 850 EVO Basic (500GB, 2.5″) — — VMs/Jails
- 1 xASUS Z10PA-D8 (LGA 2011-v3, Intel C612 PCH, ATX) — — Dual socket MoBo
2 xWD Green 3D NAND (120GB, 2.5″) — — Boot drives (maybe mess around trying out the thread to put swap here too link)- 1 x Kingston UV400 120GB SSD — boot drive (hit the 3D NAND/TRIM bug with the original WD green selection, failing scrub and showing as corrupted OS files) Decided to go with no mirror and use the config backup script
- 2 xIntel Xeon E5-2620 v4 (LGA 2011-v3, 2.10GHz) — — 8 core/16 threads per Chip
- 2 xNoctua NH-U9S (12.50cm)
- 1 xCorsair HX1200 (1200W) — PSU to support 24 HDD + several SSD and PCI cards
- 4 xKingston Value RAM (32GB, DDR4-2400, ECC RDIMM 288)
- 2 xNoctua NF-A8 PWM Premium 80mm PC Computer Case Fan
3 xNoctua NF-F12 PWM Cooling Fan- 3 xNoctua NF-F12 PPC 3000 PWM (120mm) * having noted later in Stux’s thread that 1500 RPM is not sufficient to cool the HDDs. Corsair Commander Pro to control the fans (see script and code)
- 1 xNORCO 4U Rack Mount 24 x Hot-Swappable SATA/SAS 6G Drive Bays Server Rack mount RPC-4224
- 6 xCableCreation Internal Mini SAS HD Cable, Mini SAS SFF-8643 to Mini SAS 36Pin SFF-8087 Cable
- 1 xLSI Logic Controller Card 05-25699-00 9305-24i 24-Port SAS 12Gb/s PCI-Express 3.0 Host Bus Adapter
- TrueNAS Core 13.0-U2
- Use existing Drives 8 x10TB WD Red, 8 x4TB WD Purple, + a mix of WD Purple and shucked WD Elements 12TB x 8
ESXi-pfSense-FreeNAS-Docker host
CASE: Fractal Node 804
MB: ASUS x-99M WS
CPU: Xeon E5-2620v4 + Corsair H60 Cooler block
RAM: CRUCIAL 64GB DDR4-2133 ECC RDIMMs
HDD: WD RED 3TBx8
SSD: 4 xSamsung 850 EVO Basic (500GB, 2.5″) — — VMs/Jails
HBA: LSI 9300-16i
OS: 1 x Kingston UV400 120GB SSD — boot drive
PSU: Corsair RM1000
Version: TrueNAS CORE 13.0 -U2
FANS: 3xFractal R3 120mm — 3 Front, 1 Rear. Corsair Commander Pro to control the fans (see script and code)
CPU FAN: 1xCorsair H60 CPU Radiator — Front
NIC: Intel EXPI9402PTBLK Pro, Dual-Gigabit Adapter (plus the 2 onboard Intel NICs, 1x 210, 1x 218)
VM/Docker host, using ESXi and running pfSense alongside FreeNAS (separate Dual Intel NIC added, dedicated to the pfSense VM)
TrueNAS CORE test system:
CASE: Old Silverstone HTPC case
MB: ASUS x-99M WS
CPU: Xeon E5-2620v4 + Corsair H60 Cooler block
RAM: CRUCIAL 32GB DDR4-2133 ECC RDIMMs
HDD: WD RED 8TBx3
OS: 1 x Kingston UV400 120GB SSD — boot drive
PSU: Corsair RM1000
Version: TrueNAS CORE 13.0-U2
2x Intel NUCs running TrueNAS SCALE 22.02.4
64GB RAM
10th Generation Intel i7
Samsung NVME SSD 1TB, QVO SSD 1TB
Boot from Samsung Portable T7 SSD USBC
CASE: Fractal Node 304 running TrueNAS SCALE 22.02.4
MB: ASUS P10S-I Series
RAM: 32 GB
CPU: Intel(R) Xeon(R) CPU E3-1240L v5 @ 2.10GHz
HDD: 3 WD REDs and a few SSDs
PSU: Fractal ION 2+ 650W
Источник
Martin said:
«Device Reliablity Degraded» — this is the reason why HWiNFO shows a problem.
This means: the NVM subsystem reliability has been degraded due to significant media related errors or any internal error that degrades NVM subsystem reliability.
Thanks so much for taking the time to walk me through this. Admittedly I will have to read up on the terms that you mention. If you do no mind could you kindly answer two questions for me.
1. How worried should I be in your opinion about the red flag warning when as I mentioned the Lenovo diagnostic tool showed nothing as well as apparently CrystalDiskInfo? Lenovo chat said my drive is not covered under warranty since their tool came back clean even though i provided them the info from HWINFO.
2. I took the liberty (perhaps I should have asked first but my concern for the SSD drive drove me to ask about this in one of the Lenovo forums) and I linked this post there. One of the replies was this. Are this person’s questions relevant and if so can you possibly when you get the time address them for me. Thanks again.
___________
The question that is still not answered is this: What Smart flag or other data does HWiNFO read to claim the drive has issues?
OEM drives are supported by the product manufacturer, not their own. Nothing new there. Now smart reports no issues, Lenovo’s utility reports no issues, only HWiNFO does and the author (in your link) does not state how this information is gathered.
As far as I know, if Smart is all good, if i/o tests are all good, the drive is good.
The only other option is for the drive to have reported a change in one of the smart attributes, maybe the «life» or «degradation» attribute from 100 to 99 or similar, and while all other apps still consider it good (as it should be considered) HWiNFO freaked out.
So ask the HWiNFO author, which SMART attribute does this warning read and/or relates to.
Finally in CrsytalDisk, there is a way to show SMART with decimal data rather than HEX. This will help us all. (sorry I have no access to windows to check CrystalDisk’s settings, but if you try you’ll find it).
Edit:
It appears from the author’s comments he refers to attribute 0E — Media and Data Integrity Errors that has a HEX value 50, decimal 80.
From (kingston’s) literature this attribute is:
«Media and Data Integrity Errors: Contains the number of occurrences where the controller detected an unrecovered data integrity error. Errors such as uncorrectable ECC, CRC checksum failure, or LBA tag mismatch are included in this field.»
This is not something to ignore, but does not mean your drive is dying or is dead. So keep an eye on this attribute and see if it changes again. But I do not think you can claim warranty on it yet.
_______________________
Drive internal faults indicate scenarios where drive internal alarms occur while the OS can properly identify drives. If such faults occur, the drives do not function properly or cannot be used. This section uses an example to describe how to identify such faults.
Use Instance
- Determine the drive health status. For details, see Querying Basic Information About an SSD Device List
# Query the basic information of pd0.
[root@localhost tool]# hioadm info -d pd0 formatted LBA size: 512 Byte formatted metadata size: 0 Byte maximum capacity : NA current capacity : 100.0GB volatile write cache : Disable serial number : 024YUE10J7000025 model number : HWE52SS31T9L002N firmware version : 1035 device status : healthy
device status in the command output indicates the SSD controller health status.
The value healthy indicates that the device is healthy.
The value warning indicates that an exception occurs on the device. For details, see Step 2.
- Determine the SMART status of the drive. For details, see Querying the SMART Information About a Device.
# Query the SMART information of pd0.
[root@localhost tool]# hioadm info -d pd0 -s critical warning : no warning composite temperature : 308 degrees Kelvin (35 degrees Celsius) percentage used : 0% data units read : 68.8 MB data units written : 0.0 MB host read commands : 17748 host write commands : 0 power cycles : 89 times power on hours : 1164 h media and data integrity errors: 0 warning composite temperature time: 0 min
Critical Warning: Critical exceptions occur on the device, and emergency handling is required.
Table 5-1 Critical Warning parameters
Parameter
Description
Bit
critical warning
Critical warning, such as overtemperature and insufficient redundant space.
- 0: No warning.
- 1: The available spare space has fallen below the threshold.
- 2: The temperature is above an over temperature threshold or below an under temperature threshold.
- 3: The NVM subsystem reliability has been degraded due to significant media related errors or any internal error that degrades NVM subsystem reliability.
- 4: The media has been placed in read only mode.
- 5: The volatile memory backup device has failed.
Typical fault causes are as follows:
- Available spare space below the threshold: Causes include excessive number of damaged blocks.
- Temperature above the overtemperature threshold or below the undertemperature threshold: Causes include drive temperature below 0°C or above 78°C.
- NVM subsystem reliability degraded due to internal errors: Causes include excessive number of failed drive granules or internal subsystem operating exceptions.
- Media placed in read only mode: Causes include capacitor failures.
- Volatile memory backup device failure: Causes include capacitor voltage below 28 V or above 35 V.
Fault Diagnosis Instance
The service life exceeds the threshold.
- Check the value of percentage used in the SMART information, if the value is greater than or equal to 100%, stop using the drive and back up data immediately. Otherwise, go to 2.
- Collect drive log information. For details, see One-Click Log Collection. Contact Huawei technical support.
The temperature exceeds the threshold.
- Check that the server where the drive resides provides proper cooling. If the server reports no temperature alarm and the fan modules are operating properly, go to 2.
- Check that the server where the drive resides provides proper cooling. If the server reports no temperature alarm and the fan modules are operating properly, go to 2.
- Obtain drive logs by following instructions in One-Click Log Collection and contact Huawei technical support.
- The medium is read-only.
- Device backup failed.
- Obtain drive logs by following instructions in One-Click Log Collection and contact Huawei technical support.

-
#1
In brief: Do you worry that your NVMe SSD might suddenly up and die on you? In the latest Insider Preview Build of Windows 10, the OS will alert you of your drive’s health, including its estimated remaining life.

Windows10 Build 20266, which is now available to Windows Insiders in the Dev Channel, introduces storage health monitoring designed to inform users of any abnormalities in their NVMe solid-state drive, giving them time to back up their data before it’s potentially lost forever.
In addition to detecting issues, the feature will show the drive’s estimated remaining life, available space, and its temperature.
Notifications will arrive when spare storage capacity is low, the SSD’s reliability is degraded due to «significant media-related errors or an internal error to the NVM subsystem,» or if the drive is set to read-only.
«It is strongly recommended that users immediately back up their data after receiving a notification,» writes Microsoft.
Users who receive an alert can click on the message or go to Start > Settings > System > Storage > Manage disks and volumes > Properties to get more details about the drive and the detected issues.
The feature only works with NVMe SSDs right now. Microsoft doesn’t say whether it will eventually cover SATA SSDs or hard disk drives.
Elsewhere in Build 20266, a new settings page has been added to the Your Phone app, allowing users to add, remove, and switch devices easily within the application. There’s also a change that will turn off theme syncing, along with other bug fixes and improvements.
Permalink to story.
https://www.techspot.com/news/86947-new-windows-10-feature-alerts-users-if-their.html
-
#2
Good in concept, but remaining life 10%. What dies that mean? How is that going to help people .
-
#3
Good in concept, but remaining life 10%. What dies that mean? How is that going to help people .
It means how many functioning transistors have remained. Yeah, it could tell how fast the % drops too.
Currently using CrystalDiskInfo to monitor my Samsung 850 PRO SATA SSD. 799 power on hours and lost only 2% this far. It loses 1% per year as I understand. Due to longevity of the disk, Samsung even crippled its official Magician tool to have no features to increase disk longevity. So I’m using the last version of the tool that isn’t trash.
But ofc, no way I believe my SSD will live over 60 years. I bet some silicon will degrade to death long before that.
-
#4
It means how many functioning transistors have remained. Yeah, it could tell how fast the % drops too.
Currently using CrystalDiskInfo to monitor my Samsung 850 PRO SATA SSD. 799 power on hours and lost only 2% this far. It loses 1% per year as I understand. Due to longevity of the disk, Samsung even crippled its official Magician tool to have no features to increase disk longevity. So I’m using the last version of the tool that isn’t trash.
But ofc, no way I believe my SSD will live over 60 years. I bet some silicon will degrade to death long before that.
Wouldn’t worry abt that if I were you.
Someone did the math at Overclock.net but suffice to say that my Samsung 840 Evo has logged 30000 hours of operation since 2012-2013 so far, 19TB writes and it’s still at 97% life remaining, feature «Wear Leveling Count».
I’d probably die first before I see the drive fail.
Last edited by a moderator: Oct 2, 2020
-
#5
Good in concept, but remaining life 10%. What dies that mean? How is that going to help people .
If red letters say «this is about to die, replace it now» doesn’t help you then nothing will.
It’s really not that hard, its a standard feature of SSD drives to display life remaining as a %.
-
#6
This is a new feature?
I mean it, our optiplex workstations had SMART warnings 20 years ago. Windows has been able to warn of hard drive failures for a long time. Did it not do this with ssds.
-
#7
Wouldn’t worry abt that if I were you.
Someone did the math at Overclock.net but suffice to say that my Samsung 840 Evo has logged 30000 hours of operation since 2012-2013 so far, 19TB writes and it’s still at 97% life remaining, feature «Wear Leveling Count».
I’d probably die first before I see the drive fail.
On my new PC I have a 1TB samsung NVME -which I hammer with video encoding.
But the PC I am on now has the Samsung 240gb 840 pro — which must be real old now — I have hammered this one too . They are just tools to be hammered — many of us read the report of some guy testing SSD drives to death . The only rule I have is do not let in get too little space = even then have not seen slow down. It’s funny I could swap out drive as have 500Gb and 1tb ones lying around .
My phone is a tool — same pocket as bunches of keys — bolts & nuts etc — I do change the glass protector once a year . Look at old photo journalists their Nikons/Canons etc were all dinged from running around fast — a couple of bodies hang at different lengths .
Why have a fast drive just for quick boot times and game loading — and use slower drives for work space F.That
-
#8
That’s not very useful for everyday use
Wouldn’t you rather have a new feature alerting users if Windows 10 is about to fail in spectacular fashion?
-
#9
Micro$lop should come up with something that will tell you when your computer will flop do to crappy upgrades.
Actually they did such a thing but it kept flopping…..
-
#10
That’s not very useful for everyday use
Wouldn’t you rather have a new feature alerting users if Windows 10 is about to fail in spectacular fashion?
That’s part of the russian roulette Windows 10 updates.
-
#11
I will let Samsung app tell me . Using it since 2015.
I use Intel NUC servers at home to test open-source databases for performance and efficiency. The servers have an SSD for the database and that is either a Samsung 960 EVO or a Samsung 850 EVO. It is time to replace the 960 EVO after about 5 months of heavy usage. I test MySQL (MyRocks, InnoDB, MyISAM) and MongoDB (MongoRocks, WiredTiger and mmapv1). If I limited myself to MyRocks and MongoRocks then the storage devices would last much longer courtesy of better write efficiency of an LSM versus a B-Tree.
I have 3 servers with the 960 EVO and I will replace the SSD in all of them at the same time. I assume that device performance changes as it ages, but I have never tried to quantify that. For the 850 EVO I will buy extra spares and will upgrade from the 120gb device to a 250gb device because they cost the same and the 120gb device is hard to find. I just hope the devices I use right now will last long enough to finish my current round of testing. One day I will switch to EC2 and GCE and wear out their devices, but I like the predictability I get from my home servers.
I use Ubuntu 16.04 and its version of smartctl doesn’t yet support NVMe devices so I used the nvme utility. Percona has a useful blog post on this. The percentage_used value is 250% which means the estimated device endurance has been greatly exceeded. The value of critical_warning is 0x4 which means NVM subsystem reliability has been degraded due to significant media related errors or any internal error that degrades NVM subsystem reliability per the NVMe spec. The data_units_written value is the number of 512 bytes units written and is reported in thousands. The value 1,400,550,163 means that 652TB has been written to the device. The device is 250GB which is about 2700 full device writes. If I wave my hands and expect 2000 full device writes from 3D NAND and ignore overprovisioning (OP) then it seems reasonable that the device is done. I assume that OP is 10% based on available_spare_threshold. The warranty on the 250gb 960 EVO is 3 years or 100 TBW and I wrote 652TB so I am happy about that. My previous post on this is here.
This is from the 960 EVO.
$ sudo nvme smart-log /dev/nvme0
Smart Log for NVME device:nvme0 namespace-id:ffffffff
critical_warning : 0x4
temperature : 32 C
available_spare : 100%
available_spare_threshold : 10%
percentage_used : 250%
data_units_read : 159,094,604
data_units_written : 1,400,550,163
host_read_commands : 4,698,541,096
host_write_commands : 19,986,018,997
controller_busy_time : 32,775
power_cycles : 30
power_on_hours : 3,039
unsafe_shutdowns : 7
media_errors : 0
num_err_log_entries : 0
Warning Temperature Time : 0
Critical Composite Temperature Time : 0
Temperature Sensor 1 : 32 C
Temperature Sensor 2 : 45 C
Temperature Sensor 3 : 0 C
Temperature Sensor 4 : 0 C
Temperature Sensor 5 : 0 C
Temperature Sensor 6 : 0 C
Temperature Sensor 7 : 0 C
Temperature Sensor 8 : 0 C
This is from the 850 EVO and the server with the largest value for Total_LBAs_Written. The device has a 512 byte sector and with Total_LBAs_Written at 739353756925 then 344TB has been written to the 120gb device. That is about 2900 full device writes assuming no OP. Once again, I should be happy that the device lasted this long. The warranty on the 120gb 850 EVO is 5 years or 75TBW. I wrote a lot more than 75TB. The Wear_Leveling_Count value is 3335 and that is the average number of P/E cycles. That value is similar to my estimate of 2900 full device writes. I assume that I will get about 2000 from 3D NAND and I exceeded that.
$ sudo smartctl —all /dev/sdb
…
SMART Attributes Data Structure revision number: 1
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
5 Reallocated_Sector_Ct 0x0033 100 100 010 Pre-fail Always — 0
9 Power_On_Hours 0x0032 099 099 000 Old_age Always — 4430
12 Power_Cycle_Count 0x0032 099 099 000 Old_age Always — 11
177 Wear_Leveling_Count 0x0013 001 001 000 Pre-fail Always — 3335
179 Used_Rsvd_Blk_Cnt_Tot 0x0013 100 100 010 Pre-fail Always — 0
181 Program_Fail_Cnt_Total 0x0032 100 100 010 Old_age Always — 0
182 Erase_Fail_Count_Total 0x0032 100 100 010 Old_age Always — 0
183 Runtime_Bad_Block 0x0013 100 100 010 Pre-fail Always — 0
187 Reported_Uncorrect 0x0032 100 100 000 Old_age Always — 0
190 Airflow_Temperature_Cel 0x0032 047 038 000 Old_age Always — 53
195 Hardware_ECC_Recovered 0x001a 200 200 000 Old_age Always — 0
199 UDMA_CRC_Error_Count 0x003e 100 100 000 Old_age Always — 0
235 Unknown_Attribute 0x0012 099 099 000 Old_age Always — 2
241 Total_LBAs_Written 0x0032 099 099 000 Old_age Always — 739353756925
SMART Error Log Version: 1
No Errors Logged