I refer to the following two articles:
https://github.com/coreos/etcd/blob/master/Documentation/op-guide/security.md
https://github.com/coreos/docs/blob/master/os/generate-self-signed-certificates.md
Initialize a certificate authority
$ cat ca-config.json
{
"signing": {
"default": {
"expiry": "8760h"
},
"profiles": {
"server": {
"expiry": "8760h",
"usages": [
"signing",
"key encipherment",
"server auth"
]
},
"client": {
"expiry": "8760h",
"usages": [
"signing",
"key encipherment",
"client auth"
]
},
"peer": {
"expiry": "8760h",
"usages": [
"signing",
"key encipherment",
"server auth",
"client auth"
]
}
}
}
}
$ cat ca-csr.json
{
"CN": "My own CA",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "US",
"L": "CA",
"O": "My Company Name",
"ST": "San Francisco",
"OU": "Org Unit 1",
"OU": "Org Unit 2"
}
]
}
$ cfssl gencert -initca ca-csr.json | cfssljson -bare ca -
Generate server certificate
# cfssl print-defaults csr > server.json $ cat server.json { "CN": "etcd1", "hosts": [ "192.168.1.221" ], "key": { "algo": "ecdsa", "size": 256 }, "names": [ { "C": "US", "L": "CA", "ST": "San Francisco" } ] } $ cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=server server.json | cfssljson -bare server
Etcd Server
etcd --name infra0 --data-dir infra0 --client-cert-auth --trusted-ca-file=ca.pem --cert-file=server.pem --key-file=server-key.pem --advertise-client-urls https://127.0.0.1:2379 --listen-client-urls https://127.0.0.1:2379 2018-05-29 11:17:10.374455 I | etcdmain: etcd Version: 3.3.5 2018-05-29 11:17:10.374527 I | etcdmain: Git SHA: 70c872620 2018-05-29 11:17:10.374534 I | etcdmain: Go Version: go1.9.6 2018-05-29 11:17:10.374540 I | etcdmain: Go OS/Arch: linux/amd64 2018-05-29 11:17:10.374546 I | etcdmain: setting maximum number of CPUs to 4, total number of available CPUs is 4 2018-05-29 11:17:10.374859 I | embed: listening for peers on http://localhost:2380 2018-05-29 11:17:10.374899 I | embed: listening for client requests on 127.0.0.1:2379 2018-05-29 11:17:10.377043 I | etcdserver: name = infra0 2018-05-29 11:17:10.377067 I | etcdserver: data dir = infra0 2018-05-29 11:17:10.377074 I | etcdserver: member dir = infra0/member 2018-05-29 11:17:10.377079 I | etcdserver: heartbeat = 100ms 2018-05-29 11:17:10.377087 I | etcdserver: election = 1000ms 2018-05-29 11:17:10.377092 I | etcdserver: snapshot count = 100000 2018-05-29 11:17:10.377125 I | etcdserver: advertise client URLs = https://127.0.0.1:2379 2018-05-29 11:17:10.377133 I | etcdserver: initial advertise peer URLs = http://localhost:2380 2018-05-29 11:17:10.377143 I | etcdserver: initial cluster = infra0=http://localhost:2380 2018-05-29 11:17:10.379279 I | etcdserver: starting member 8e9e05c52164694d in cluster cdf818194e3a8c32 2018-05-29 11:17:10.379320 I | raft: 8e9e05c52164694d became follower at term 0 2018-05-29 11:17:10.379337 I | raft: newRaft 8e9e05c52164694d [peers: [], term: 0, commit: 0, applied: 0, lastindex: 0, lastterm: 0] 2018-05-29 11:17:10.379344 I | raft: 8e9e05c52164694d became follower at term 1 2018-05-29 11:17:10.385248 W | auth: simple token is not cryptographically signed 2018-05-29 11:17:10.388175 I | etcdserver: starting server... [version: 3.3.5, cluster version: to_be_decided] 2018-05-29 11:17:10.388842 I | etcdserver: 8e9e05c52164694d as single-node; fast-forwarding 9 ticks (election ticks 10) 2018-05-29 11:17:10.389395 I | etcdserver/membership: added member 8e9e05c52164694d [http://localhost:2380] to cluster cdf818194e3a8c32 2018-05-29 11:17:10.392890 I | embed: ClientTLS: cert = server.pem, key = server-key.pem, ca = , trusted-ca = ca.pem, client-cert-auth = true, crl-file = 2018-05-29 11:17:10.479773 I | raft: 8e9e05c52164694d is starting a new election at term 1 2018-05-29 11:17:10.479819 I | raft: 8e9e05c52164694d became candidate at term 2 2018-05-29 11:17:10.479887 I | raft: 8e9e05c52164694d received MsgVoteResp from 8e9e05c52164694d at term 2 2018-05-29 11:17:10.479906 I | raft: 8e9e05c52164694d became leader at term 2 2018-05-29 11:17:10.479915 I | raft: raft.node: 8e9e05c52164694d elected leader 8e9e05c52164694d at term 2 2018-05-29 11:17:10.480540 I | etcdserver: published {Name:infra0 ClientURLs:[https://127.0.0.1:2379]} to cluster cdf818194e3a8c32 2018-05-29 11:17:10.480670 E | etcdmain: forgot to set Type=notify in systemd service file? 2018-05-29 11:17:10.480694 I | embed: ready to serve client requests 2018-05-29 11:17:10.480718 I | etcdserver: setting up the initial cluster version to 3.3 2018-05-29 11:17:10.481430 N | etcdserver/membership: set the initial cluster version to 3.3 2018-05-29 11:17:10.481638 I | etcdserver/api: enabled capabilities for version 3.3 2018-05-29 11:17:10.532133 I | embed: serving client requests on 127.0.0.1:2379 2018-05-29 11:17:10.539294 I | embed: rejected connection from "127.0.0.1:39794" (error "tls: failed to verify client's certificate: x509: certificate specifies an incompatible key usage", ServerName "") WARNING: 2018/05/29 11:17:10 Failed to dial 127.0.0.1:2379: connection error: desc = "transport: authentication handshake failed: remote error: tls: bad certificate"; please retry.
This is my first attempt at setting up a Kubernetes cluster in my test environment. In preperation, I created 3 instances running Fedora Atomic:
10.11.184.8: master/etcd
10.11.184.5: node01
10.11.184.6: node02
Then using contrib/ansible playbooks for Ansible, I deployed kubernetes to my instances. It completed with «0» failures for each host.
I then connect to my master and begin to check that status of it:
[root@kubemaster ~]# kubectl get cs
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-0 Healthy {"health": "true"}
However, I go to check my nodes and it returns nothing:
[root@kubemaster ~]# kubectl get nodes
No resources found.
I begin to check logs, and I find the below repeating over and over from all three of the IPs listed above:
http: TLS handshake error from 10.11.184.5:32788: remote error: tls: bad certificate
It appears that the ansible playbook did generate some certificates:
[root@kubemaster ~]# ll /etc/kubernetes/certs/
total 40
-r--r-----. 1 kube kube-cert 1220 Aug 15 19:11 ca.crt
-r--r-----. 1 kube kube-cert 4417 Aug 15 19:11 kubecfg.crt
-r--r-----. 1 kube kube-cert 1704 Aug 15 19:11 kubecfg.key
-rw-rw----. 1 root kube-cert 4417 Aug 15 19:11 kubelet.crt
-rw-rw----. 1 root kube-cert 1704 Aug 15 19:11 kubelet.key
-r--r-----. 1 kube kube-cert 4917 Aug 15 19:11 server.crt
-r--r-----. 1 kube kube-cert 1704 Aug 15 19:11 server.key
And the kube-apiserver binary is being passed these as a parameter:
/usr/bin/kube-apiserver --logtostderr=true --v=0 --etcd-servers=http://10.11.184.8:2379 --insecure-bind-address=127.0.0.1 --secure-port=443 --allow-privileged=true --service-cluster-ip-range=10.254.0.0/16 --admission control=NamespaceLifecycle,LimitRanger,ServiceAccount,ResourceQuota --tls-cert-file=/etc/kubernetes/certs/server.crt --tls-private-key-file=/etc/kubernetes/certs/server.key --client-ca-file=/etc/kubernetes/certs/ca.crt --token-auth-file=/etc/kubernetes/tokens/known_tokens.csv --service-account-key-file=/etc/kubernetes/certs/server.crt --bind-address=0.0.0.0 --apiserver-count=1
If I view the logs on one of the nodes, I see a lot of messages like so:
Failed to list *v1.Node: Get https://10.11.184.8:443/api/v1/nodes?fieldSelector=metadata.name%3D10.11.184.8:443/api/v1/nodes?fieldSelector=metadata.name%3D10.11.184.5&resourceVersion=0: x509: certificate is valid for 10.254.0.1, 192.168.0.11, 172.16.63.0, 172.16.63.1, not 10.11.184.8
Is it likely that my certificates were not generated correctly? I am looking at this documentation. Perhaps I should attempt to manually create the certificates using openssl or easyrsa?
I am start etcd(3.3.13) member using this command:
/usr/local/bin/etcd
--name infra2
--cert-file=/etc/kubernetes/ssl/kubernetes.pem
--key-file=/etc/kubernetes/ssl/kubernetes-key.pem
--peer-cert-file=/etc/kubernetes/ssl/kubernetes.pem
--peer-key-file=/etc/kubernetes/ssl/kubernetes-key.pem
--trusted-ca-file=/etc/kubernetes/ssl/ca.pem
--peer-trusted-ca-file=/etc/kubernetes/ssl/ca.pem
--initial-advertise-peer-urls https://172.19.104.230:2380
--listen-peer-urls https://172.19.104.230:2380
--listen-client-urls http://127.0.0.1:2379
--advertise-client-urls https://172.19.104.230:2379
--initial-cluster-token etcd-cluster
--initial-cluster infra1=https://172.19.104.231:2380,infra2=https://172.19.104.230:2380,infra3=https://172.19.150.82:2380
--initial-cluster-state new
--data-dir=/var/lib/etcd
but the log shows this error:
2019-08-24 13:12:07.981345 I | embed: rejected connection from "172.19.104.231:60474" (error "remote error: tls: bad certificate", ServerName "")
2019-08-24 13:12:08.003918 I | embed: rejected connection from "172.19.104.231:60478" (error "remote error: tls: bad certificate", ServerName "")
2019-08-24 13:12:08.004242 I | embed: rejected connection from "172.19.104.231:60480" (error "remote error: tls: bad certificate", ServerName "")
2019-08-24 13:12:08.045940 E | rafthttp: request cluster ID mismatch (got 52162d7b86a0617a want b125c249de626e35)
2019-08-24 13:12:08.046455 E | rafthttp: request cluster ID mismatch (got 52162d7b86a0617a want b125c249de626e35)
2019-08-24 13:12:08.081290 I | embed: rejected connection from "172.19.104.231:60484" (error "remote error: tls: bad certificate", ServerName "")
2019-08-24 13:12:08.101692 I | embed: rejected connection from "172.19.104.231:60489" (error "remote error: tls: bad certificate", ServerName "")
2019-08-24 13:12:08.102002 I | embed: rejected connection from "172.19.104.231:60488" (error "remote error: tls: bad certificate", ServerName "")
2019-08-24 13:12:08.144928 E | rafthttp: request cluster ID mismatch (got 52162d7b86a0617a want b125c249de626e35)
2019-08-24 13:12:08.145151 E | rafthttp: request cluster ID mismatch (got 52162d7b86a0617a want b125c249de626e35)
2019-08-24 13:12:08.181299 I | embed: rejected connection from "172.19.104.231:60494" (error "remote error: tls: bad certificate", ServerName "")
2019-08-24 13:12:08.201722 I | embed: rejected connection from "172.19.104.231:60500" (error "remote error: tls: bad certificate", ServerName "")
2019-08-24 13:12:08.202096 I | embed: rejected connection from "172.19.104.231:60498" (error "remote error: tls: bad certificate", ServerName "")
I search from internet and find the reason is: should give all etcd node ip in hosts config when generate CA cert,but I config all my etcd node ip in csr.json,this is my csr.json config:
{
"CN": "kubernetes",
"hosts": [
"127.0.0.1",
"172.19.104.230",
"172.19.150.82",
"172.19.104.231"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "BeiJing",
"L": "BeiJing",
"O": "k8s",
"OU": "System"
}
]
}
what should I do to fix the error?
When an (old) Rancher 2 managed Kubernetes cluster needed to be upgraded from Kubernetes 1.14 to 1.15, the upgrade failed. Even when all the steps from the tutorial How to upgrade Kubernetes version in a Rancher 2 managed cluster were followed. What happened?
rke ends with remote error on bad certificate
To enforce another (or newer) Kubernetes version, the original 3-node rke configuration yaml can be adjusted to specify the Kubernetes version to be used:
ck@linux:~/rancher$ cat RANCHER2_STAGE/3-node-rancher-stage.yml
nodes:
— address: 10.10.153.15
user: ansible
role: [controlplane,etcd,worker]
ssh_key_path: ~/.ssh/id_rsa
— address: 10.10.153.16
user: ansible
role: [controlplane,etcd,worker]
ssh_key_path: ~/.ssh/id_rsa
— address: 10.10.153.17
user: ansible
role: [controlplane,etcd,worker]
ssh_key_path: ~/.ssh/id_rsa
kubernetes_version: «v1.15.12-rancher2-2»
services:
etcd:
snapshot: true
creation: 6h
retention: 24h
Note: Please read the special notes on How to upgrade Kubernetes version in a Rancher 2 managed cluster which Kubernetes version to use — it depends on the RKE version.
With this minor change in the yaml config, rke up can be launched against the cluster and the cluster should upgrade the Kubernetes version (all other settings remain in place). In the following output rke 1.1.2 was used against this staging cluster:
ck@linux:~/rancher$ ./rke_linux-amd64-1.1.2 up —config RANCHER2_STAGE/3-node-rancher-stage.yml
INFO[0000] Running RKE version: v1.1.2
INFO[0000] Initiating Kubernetes cluster
INFO[0000] [state] Possible legacy cluster detected, trying to upgrade
INFO[0000] [reconcile] Rebuilding and updating local kube config
[…]
INFO[0056] Pre-pulling kubernetes images
INFO[0056] Pulling image [rancher/hyperkube:v1.15.12-rancher2] on host [10.10.153.15], try #1
INFO[0056] Pulling image [rancher/hyperkube:v1.15.12-rancher2] on host [10.10.153.17], try #1
INFO[0056] Pulling image [rancher/hyperkube:v1.15.12-rancher2] on host [10.10.153.16], try #1
INFO[0079] Image [rancher/hyperkube:v1.15.12-rancher2] exists on host [10.10.153.17]
INFO[0083] Image [rancher/hyperkube:v1.15.12-rancher2] exists on host [10.10.153.16]
INFO[0088] Image [rancher/hyperkube:v1.15.12-rancher2] exists on host [10.10.153.15]
INFO[0088] Kubernetes images pulled successfully
INFO[0088] [etcd] Building up etcd plane..
[…]
INFO[0167] [etcd] Successfully started etcd plane.. Checking etcd cluster health
WARN[0197] [etcd] host [10.10.153.15] failed to check etcd health: failed to get /health for host [10.10.153.15]: Get https://10.10.153.15:2379/health: remote error: tls: bad certificate
WARN[0223] [etcd] host [10.10.153.16] failed to check etcd health: failed to get /health for host [10.10.153.16]: Get https://10.10.153.16:2379/health: remote error: tls: bad certificate
WARN[0240] [etcd] host [10.10.153.17] failed to check etcd health: failed to get /health for host [10.10.153.17]: Get https://10.10.153.17:2379/health: remote error: tls: bad certificate
FATA[0240] [etcd] Failed to bring up Etcd Plane: etcd cluster is unhealthy: hosts [10.10.153.15,10.10.153.16,10.10.153.17] failed to report healthy. Check etcd container logs on each host for more information
The newer Kubernetes 1.15.12 images were successfully pulled. But at the end the Kubernetes upgrade failed due to a bad certificate.
Rotate the Kubernetes certificates
Unfortunately the error message does not contain the exact reason, why the Kubernetes certificates would be shown as «bad». But the most plausible reason is that the certificates expired. A similar problem was already discovered once and documented in Rancher 2 Kubernetes certificates expired! How to rotate your expired certificates. rke can be used to rotate and renew the Kubernetes certificates:
ck@linux:~/rancher$ ./rke_linux-amd64-1.1.2 cert rotate —config RANCHER2_STAGE/3-node-rancher-stage.yml
INFO[0000] Running RKE version: v1.1.2
INFO[0000] Initiating Kubernetes cluster
INFO[0000] Rotating Kubernetes cluster certificates
INFO[0000] [certificates] GenerateServingCertificate is disabled, checking if there are unused kubelet certificates
INFO[0000] [certificates] Generating Kubernetes API server certificates
INFO[0000] [certificates] Generating Kube Controller certificates
INFO[0000] [certificates] Generating Kube Scheduler certificates
INFO[0000] [certificates] Generating Kube Proxy certificates
INFO[0001] [certificates] Generating Node certificate
INFO[0001] [certificates] Generating admin certificates and kubeconfig
INFO[0001] [certificates] Generating Kubernetes API server proxy client certificates
INFO[0001] [certificates] Generating kube-etcd-192-168-253-15 certificate and key
INFO[0001] [certificates] Generating kube-etcd-192-168-253-16 certificate and key
INFO[0001] [certificates] Generating kube-etcd-192-168-253-17 certificate and key
INFO[0002] Successfully Deployed state file at [RANCHER2_STAGE/3-node-rancher-stage.rkestate]
INFO[0002] Rebuilding Kubernetes cluster with rotated certificates
INFO[0002] [dialer] Setup tunnel for host [10.10.153.15]
INFO[0002] [dialer] Setup tunnel for host [10.10.153.16]
INFO[0002] [dialer] Setup tunnel for host [10.10.153.17]
INFO[0010] [certificates] Deploying kubernetes certificates to Cluster nodes
[…]
INFO[0058] [controlplane] Successfully restarted Controller Plane..
INFO[0058] [worker] Restarting Worker Plane..
INFO[0058] Restarting container [kubelet] on host [10.10.153.17], try #1
INFO[0058] Restarting container [kubelet] on host [10.10.153.15], try #1
INFO[0058] Restarting container [kubelet] on host [10.10.153.16], try #1
INFO[0060] [restart/kubelet] Successfully restarted container on host [10.10.153.17]
INFO[0060] Restarting container [kube-proxy] on host [10.10.153.17], try #1
INFO[0060] [restart/kubelet] Successfully restarted container on host [10.10.153.16]
INFO[0060] Restarting container [kube-proxy] on host [10.10.153.16], try #1
INFO[0060] [restart/kubelet] Successfully restarted container on host [10.10.153.15]
INFO[0060] Restarting container [kube-proxy] on host [10.10.153.15], try #1
INFO[0066] [restart/kube-proxy] Successfully restarted container on host [10.10.153.17]
INFO[0066] [restart/kube-proxy] Successfully restarted container on host [10.10.153.16]
INFO[0073] [restart/kube-proxy] Successfully restarted container on host [10.10.153.15]
INFO[0073] [worker] Successfully restarted Worker Plane..
The rke cert rotate command ran through successfully and the cluster remained up. After waiting a couple of minutes to make sure all services and pods were correctly restarted on the Kubernetes cluster, the Kubernetes upgrade can launched again.
Run the upgrade again
The big question is of course: Was the certificate rotation enough to fix the problem? Let’s find out:
ck@linux:~/rancher$ ./rke_linux-amd64-1.1.2 up —config RANCHER2_STAGE/3-node-rancher-stage.yml
INFO[0000] Running RKE version: v1.1.2
INFO[0000] Initiating Kubernetes cluster
INFO[0000] [certificates] GenerateServingCertificate is disabled, checking if there are unused kubelet certificates
INFO[0000] [certificates] Generating admin certificates and kubeconfig
INFO[0000] Successfully Deployed state file at [RANCHER2_STAGE/3-node-rancher-stage.rkestate]
INFO[0000] Building Kubernetes cluster
INFO[0000] [dialer] Setup tunnel for host [10.10.153.17]
INFO[0000] [dialer] Setup tunnel for host [10.10.153.15]
INFO[0000] [dialer] Setup tunnel for host [10.10.153.16]
[…]
INFO[0027] Pre-pulling kubernetes images
INFO[0027] Image [rancher/hyperkube:v1.15.12-rancher2] exists on host [10.10.153.16]
INFO[0027] Image [rancher/hyperkube:v1.15.12-rancher2] exists on host [10.10.153.15]
INFO[0027] Image [rancher/hyperkube:v1.15.12-rancher2] exists on host [10.10.153.17]
INFO[0027] Kubernetes images pulled successfully
INFO[0027] [etcd] Building up etcd plane..
[…]
INFO[0126] Checking if container [kubelet] is running on host [10.10.153.15], try #1
INFO[0126] Image [rancher/hyperkube:v1.15.12-rancher2] exists on host [10.10.153.15]
INFO[0126] Checking if container [old-kubelet] is running on host [10.10.153.15], try #1
INFO[0126] Stopping container [kubelet] on host [10.10.153.15] with stopTimeoutDuration [5s], try #1
INFO[0127] Waiting for [kubelet] container to exit on host [10.10.153.15]
INFO[0127] Renaming container [kubelet] to [old-kubelet] on host [10.10.153.15], try #1
INFO[0127] Starting container [kubelet] on host [10.10.153.15], try #1
INFO[0127] [worker] Successfully updated [kubelet] container on host [10.10.153.15]
INFO[0127] Removing container [old-kubelet] on host [10.10.153.15], try #1
INFO[0128] [healthcheck] Start Healthcheck on service [kubelet] on host [10.10.153.15]
INFO[0155] [healthcheck] service [kubelet] on host [10.10.153.15] is healthy
[…]
INFO[0387] [sync] Syncing nodes Labels and Taints
INFO[0387] [sync] Successfully synced nodes Labels and Taints
INFO[0387] [network] Setting up network plugin: canal
INFO[0387] [addons] Saving ConfigMap for addon rke-network-plugin to Kubernetes
INFO[0387] [addons] Successfully saved ConfigMap for addon rke-network-plugin to Kubernetes
INFO[0387] [addons] Executing deploy job rke-network-plugin
INFO[0402] [addons] Setting up coredns
INFO[0402] [addons] Saving ConfigMap for addon rke-coredns-addon to Kubernetes
INFO[0402] [addons] Successfully saved ConfigMap for addon rke-coredns-addon to Kubernetes
INFO[0402] [addons] Executing deploy job rke-coredns-addon
INFO[0418] [addons] CoreDNS deployed successfully
INFO[0418] [dns] DNS provider coredns deployed successfully
INFO[0418] [addons] Setting up Metrics Server
INFO[0418] [addons] Saving ConfigMap for addon rke-metrics-addon to Kubernetes
INFO[0418] [addons] Successfully saved ConfigMap for addon rke-metrics-addon to Kubernetes
INFO[0418] [addons] Executing deploy job rke-metrics-addon
INFO[0438] [addons] Metrics Server deployed successfully
INFO[0438] [ingress] Setting up nginx ingress controller
INFO[0438] [addons] Saving ConfigMap for addon rke-ingress-controller to Kubernetes
INFO[0438] [addons] Successfully saved ConfigMap for addon rke-ingress-controller to Kubernetes
INFO[0438] [addons] Executing deploy job rke-ingress-controller
INFO[0448] [ingress] ingress controller nginx deployed successfully
INFO[0448] [addons] Setting up user addons
INFO[0448] [addons] no user addons defined
INFO[0448] Finished building Kubernetes cluster successfully
This time, rke continued its job to upgrade the Kubernetes cluster. Instead of a certificate error showing up, rke deployed the new Kubernetes version and renamed the previous K8s related containers (e.g. old-kubelet). While the upgrade was running, the current status could also be seen in the user interface where the current active node is seen as cordoned.
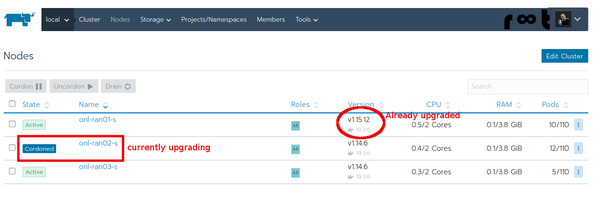
Oh no, I can’t access the user interface anymore!
Depending on the load balancing or reverse proxy setup, after this Kubernetes version upgrade a redirect problem might happen when trying to access the Rancher 2 user interface:
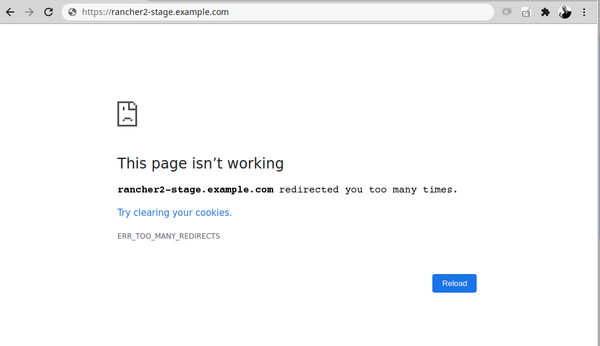
With this Kubernetes upgrade also came a newer Nginx ingress version, which stopped listening on http and switched to https. If the reverse proxy was previously using plain http to the Rancher 2 node, it should now be replaced with using https. Here the snippet for HAProxy:
#####################
# Rancher
#####################
backend rancher-out
balance hdr(X-Forwarded-For)
timeout server 1h
option httpchk GET /healthz HTTP/1.1rnHost: rancher2-stage.example.comrnConnection: close
server onl-ran01-s 10.10.153.15:443 check ssl verify none inter 1000 fall 1 rise 2
server onl-ran02-s 10.10.153.16:443 check ssl verify none inter 1000 fall 1 rise 2
server onl-ran03-s 10.10.153.17:443 check ssl verify none inter 1000 fall 1 rise 2
Because the Rancher 2 generated Kubernetes certificates (which is the default setting in rke) are self-signed, the option «ssl verify none» should be added in HAProxy’s backend server configuration.
Looking for a managed dedicated Kubernetes environment?
If you are looking for a managed and dedicated Kubernetes environment, managed by Rancher 2, with server location Switzerland, check out our Private Kubernetes Container Cloud Infrastructure service at Infiniroot.
Add a comment
Show form to leave a comment
Comments (newest first)
No comments yet.
When installing and running Consul, there are some common messages you might see. Usually they indicate an issue in your network or in your server’s configuration. Some of the more common errors and their solutions are listed below.
If you are getting an error message you don’t see listed on this page, please consider following our general Troubleshooting Guide.
For common errors messages related to Kubernetes, please go to Common errors on Kubernetes.
Multiple network interfaces
Multiple private IPv4 addresses found. Please configure one with 'bind' and/or 'advertise'.
Your server has multiple active network interfaces. Consul needs to know which interface to use for local LAN communications. Add the bind option to your configuration.
Tip: If your server does not have a static IP address, you can use a go-sockaddr template as the argument to the bind option, e.g. "bind_addr": "{{GetInterfaceIP "eth0"}}".
Configuration syntax errors
Error parsing config.hcl: At 1:12: illegal char
Error parsing config.hcl: At 1:32: key 'foo' expected start of object ('{') or assignment ('=')
Error parsing server.json: invalid character '`' looking for beginning of value
There is a syntax error in your configuration file. If the error message doesn’t identify the exact location in the file where the problem is, try using jq to find it, for example:
$ consul agent -server -config-file server.json
==> Error parsing server.json: invalid character '`' looking for beginning of value
$ cat server.json | jq .
parse error: Invalid numeric literal at line 3, column 29
Node name "consul_client.internal" will not be discoverable via DNS due to invalid characters.
Add the node name option to your agent configuration and provide a valid DNS name.
Failed to join 10.0.0.99: dial tcp 10.0.0.99:8301: i/o timeout
Failed to sync remote state: No cluster leader
If the Consul client and server are on the same LAN, then most likely, a firewall is blocking connections to the Consul server.
If they are not on the same LAN, check the retry_join settings in the Consul client configuration. The client should be configured to join a cluster inside its local network.
Error getting server health from "XXX": context deadline exceeded
These error messages indicate a general performance problem on the Consul server. Make sure you are monitoring Consul telemetry and system metrics according to our monitoring guide. Increase the CPU or memory allocation to the server if needed. Check the performance of the network between Consul nodes.
Error accepting TCP connection: accept tcp [::]:8301: too many open files in system
Get http://localhost:8500/: dial tcp 127.0.0.1:31643: socket: too many open files
On a busy cluster, the operating system may not provide enough file descriptors to the Consul process. You will need to increase the limit for the Consul user, and maybe the system-wide limit as well. A good guide for Linux can be found here.
Or, if you are starting Consul from systemd, you could add LimitNOFILE=65536 to the unit file for Consul. You can see our example unit file here.
Our RPC protocol requires support for a TCP half-close in order to signal the other side that they are done reading the stream, since we don’t know the size in advance. This saves us from having to buffer just to calculate the size.
If a host does not properly implement half-close you may see an error message [ERR] consul: Failed to close snapshot: write tcp <source>-><destination>: write: broken pipe when saving snapshots. This should not affect saving and restoring snapshots.
This has been a known issue in Docker, but may manifest in other environments as well.
RPC error making call: rpc error making call: ACL not found
This indicates that you have ACL enabled in your cluster, but you aren’t passing a valid token. Make sure that when creating your tokens that they have the correct permissions set. In addition, you would want to make sure that an agent token is provided on each call.
Incorrect certificate or certificate name
Remote error: tls: bad certificate
X509: certificate signed by unknown authority
Make sure that your Consul clients and servers are using the correct certificates, and that they’ve been signed by the same CA. The easiest way to do this is to follow our guide.
If you generate your own certificates, make sure the server certificates include the special name server.dc1.consul in the Subject Alternative Name (SAN) field. (If you change the values of datacenter or domain in your configuration, update the SAN accordingly.)
HTTP instead of HTTPS
Error querying agent: malformed HTTP response
Net/http: HTTP/1.x transport connection broken: malformed HTTP response "x15x03x01x00x02x02"
You are attempting to connect to a Consul agent with HTTP on a port that has been configured for HTTPS.
If you are using the Consul CLI, make sure you are specifying «https» in the -http-addr flag or the CONSUL_HTTP_ADDR environment variable.
If you are interacting with the API, change the URI scheme to «https».
License: expiration time: YYYY-MM-DD HH:MM:SS -0500 EST, time left: 29m0s
You have installed an Enterprise version of Consul. If you are an Enterprise customer, provide a license key to Consul before it shuts down. Otherwise, install the open-source Consul binary instead.
Note: Enterprise binaries can be identified on our download site by the +ent suffix.
Unable to connect to the Consul client on the same host
If the pods are unable to connect to a Consul client running on the same host,
first check if the Consul clients are up and running with kubectl get pods.
$ kubectl get pods --selector="component=client"
NAME READY STATUS RESTARTS AGE
consul-kzws6 1/1 Running 0 58s
If you are still unable to connect
and see i/o timeout or connection refused errors when connecting to the Consul client on the Kubernetes worker,
this could be because the CNI (Container Networking Interface)
does not support
the use of hostPort.
Put http://10.0.0.10:8500/v1/catalog/register: dial tcp 10.0.0.10:8500: connect: connection refused
Put http://10.0.0.10:8500/v1/agent/service/register: dial tcp 10.0.0.10:8500: connect: connection refused
Get http://10.0.0.10:8500/v1/status/leader: dial tcp 10.0.0.10:8500: i/o timeout
The IP 10.0.0.10 above refers to the IP of the host where the Consul client pods are running.
To work around this issue,
enable hostNetwork in your Helm values.
Using the host network will enable the pod to use the host’s network namespace without
the need for CNI to support port mappings between containers and the host.
client:
hostNetwork: true
dnsPolicy: ClusterFirstWithHostNet
Note: Using host network has security implications
as doing so gives the Consul client unnecessary access to all network traffic on the host.
We recommend raising an issue with the CNI you’re using to add support for hostPort
and switching back to hostPort eventually.