REST APIs use the Status-Line part of an HTTP response message to inform clients of their request’s overarching result. RFC 2616 defines the Status-Line syntax as shown below:
Status-Line = HTTP-Version SP Status-Code SP Reason-Phrase CRLF
HTTP defines these standard status codes that can be used to convey the results of a client’s request. The status codes are divided into five categories.
- 1xx: Informational – Communicates transfer protocol-level information.
- 2xx: Success – Indicates that the client’s request was accepted successfully.
- 3xx: Redirection – Indicates that the client must take some additional action in order to complete their request.
- 4xx: Client Error – This category of error status codes points the finger at clients.
- 5xx: Server Error – The server takes responsibility for these error status codes.
1xx Status Codes [Informational]
|
Status Code |
Description |
|---|---|
|
100 Continue |
An interim response. Indicates to the client that the initial part of the request has been received and has not yet been rejected by the server. The client SHOULD continue by sending the remainder of the request or, if the request has already been completed, ignore this response. The server MUST send a final response after the request has been completed. |
|
101 Switching Protocol |
Sent in response to an Upgrade request header from the client, and indicates the protocol the server is switching to. |
|
102 Processing (WebDAV) |
Indicates that the server has received and is processing the request, but no response is available yet. |
|
103 Early Hints |
Primarily intended to be used with the |
2xx Status Codes [Success]
|
Status Code |
Description |
|---|---|
|
200 OK |
Indicates that the request has succeeded. |
|
201 Created |
Indicates that the request has succeeded and a new resource has been created as a result. |
|
202 Accepted |
Indicates that the request has been received but not completed yet. It is typically used in log running requests and batch processing. |
|
203 Non-Authoritative Information |
Indicates that the returned metainformation in the entity-header is not the definitive set as available from the origin server, but is gathered from a local or a third-party copy. The set presented MAY be a subset or superset of the original version. |
|
204 No Content |
The server has fulfilled the request but does not need to return a response body. The server may return the updated meta information. |
|
205 Reset Content |
Indicates the client to reset the document which sent this request. |
|
206 Partial Content |
It is used when the |
|
207 Multi-Status (WebDAV) |
An indicator to a client that multiple operations happened, and that the status for each operation can be found in the body of the response. |
|
208 Already Reported (WebDAV) |
Allows a client to tell the server that the same resource (with the same binding) was mentioned earlier. It never appears as a true HTTP response code in the status line, and only appears in bodies. |
|
226 IM Used |
The server has fulfilled a GET request for the resource, and the response is a representation of the result of one or more instance-manipulations applied to the current instance. |
3xx Status Codes [Redirection]
|
Status Code |
Description |
|---|---|
|
300 Multiple Choices |
The request has more than one possible response. The user-agent or user should choose one of them. |
|
301 Moved Permanently |
The URL of the requested resource has been changed permanently. The new URL is given by the |
|
302 Found |
The URL of the requested resource has been changed temporarily. The new URL is given by the |
|
303 See Other |
The response can be found under a different URI and SHOULD be retrieved using a GET method on that resource. |
|
304 Not Modified |
Indicates the client that the response has not been modified, so the client can continue to use the same cached version of the response. |
|
305 Use Proxy (Deprecated) |
Indicates that a requested response must be accessed by a proxy. |
|
306 (Unused) |
It is a reserved status code and is not used anymore. |
|
307 Temporary Redirect |
Indicates the client to get the requested resource at another URI with same method that was used in the prior request. It is similar to |
|
308 Permanent Redirect (experimental) |
Indicates that the resource is now permanently located at another URI, specified by the |
4xx Status Codes (Client Error)
|
Status Code |
Description |
|---|---|
|
400 Bad Request |
The request could not be understood by the server due to incorrect syntax. The client SHOULD NOT repeat the request without modifications. |
|
401 Unauthorized |
Indicates that the request requires user authentication information. The client MAY repeat the request with a suitable Authorization header field |
|
402 Payment Required (Experimental) |
Reserved for future use. It is aimed for using in the digital payment systems. |
|
403 Forbidden |
Unauthorized request. The client does not have access rights to the content. Unlike 401, the client’s identity is known to the server. |
|
404 Not Found |
The server can not find the requested resource. |
|
405 Method Not Allowed |
The request HTTP method is known by the server but has been disabled and cannot be used for that resource. |
|
406 Not Acceptable |
The server doesn’t find any content that conforms to the criteria given by the user agent in the |
|
407 Proxy Authentication Required |
Indicates that the client must first authenticate itself with the proxy. |
|
408 Request Timeout |
Indicates that the server did not receive a complete request from the client within the server’s allotted timeout period. |
|
409 Conflict |
The request could not be completed due to a conflict with the current state of the resource. |
|
410 Gone |
The requested resource is no longer available at the server. |
|
411 Length Required |
The server refuses to accept the request without a defined Content- Length. The client MAY repeat the request if it adds a valid |
|
412 Precondition Failed |
The client has indicated preconditions in its headers which the server does not meet. |
|
413 Request Entity Too Large |
Request entity is larger than limits defined by server. |
|
414 Request-URI Too Long |
The URI requested by the client is longer than the server can interpret. |
|
415 Unsupported Media Type |
The media-type in |
|
416 Requested Range Not Satisfiable |
The range specified by the |
|
417 Expectation Failed |
The expectation indicated by the |
|
418 I’m a teapot (RFC 2324) |
It was defined as April’s lool joke and is not expected to be implemented by actual HTTP servers. (RFC 2324) |
|
420 Enhance Your Calm (Twitter) |
Returned by the Twitter Search and Trends API when the client is being rate limited. |
|
422 Unprocessable Entity (WebDAV) |
The server understands the content type and syntax of the request entity, but still server is unable to process the request for some reason. |
|
423 Locked (WebDAV) |
The resource that is being accessed is locked. |
|
424 Failed Dependency (WebDAV) |
The request failed due to failure of a previous request. |
|
425 Too Early (WebDAV) |
Indicates that the server is unwilling to risk processing a request that might be replayed. |
|
426 Upgrade Required |
The server refuses to perform the request. The server will process the request after the client upgrades to a different protocol. |
|
428 Precondition Required |
The origin server requires the request to be conditional. |
|
429 Too Many Requests |
The user has sent too many requests in a given amount of time (“rate limiting”). |
|
431 Request Header Fields Too Large |
The server is unwilling to process the request because its header fields are too large. |
|
444 No Response (Nginx) |
The Nginx server returns no information to the client and closes the connection. |
|
449 Retry With (Microsoft) |
The request should be retried after performing the appropriate action. |
|
450 Blocked by Windows Parental Controls (Microsoft) |
Windows Parental Controls are turned on and are blocking access to the given webpage. |
|
451 Unavailable For Legal Reasons |
The user-agent requested a resource that cannot legally be provided. |
|
499 Client Closed Request (Nginx) |
The connection is closed by the client while HTTP server is processing its request, making the server unable to send the HTTP header back. |
5xx Status Codes (Server Error)
|
Status Code |
Description |
|---|---|
|
500 Internal Server Error |
The server encountered an unexpected condition that prevented it from fulfilling the request. |
|
501 Not Implemented |
The HTTP method is not supported by the server and cannot be handled. |
|
502 Bad Gateway |
The server got an invalid response while working as a gateway to get the response needed to handle the request. |
|
503 Service Unavailable |
The server is not ready to handle the request. |
|
504 Gateway Timeout |
The server is acting as a gateway and cannot get a response in time for a request. |
|
505 HTTP Version Not Supported (Experimental) |
The HTTP version used in the request is not supported by the server. |
|
506 Variant Also Negotiates (Experimental) |
Indicates that the server has an internal configuration error: the chosen variant resource is configured to engage in transparent content negotiation itself, and is therefore not a proper endpoint in the negotiation process. |
|
507 Insufficient Storage (WebDAV) |
The method could not be performed on the resource because the server is unable to store the representation needed to successfully complete the request. |
|
508 Loop Detected (WebDAV) |
The server detected an infinite loop while processing the request. |
|
510 Not Extended |
Further extensions to the request are required for the server to fulfill it. |
|
511 Network Authentication Required |
Indicates that the client needs to authenticate to gain network access. |
6. REST Specific HTTP Status Codes
200 (OK)
It indicates that the REST API successfully carried out whatever action the client requested and that no more specific code in the 2xx series is appropriate.
Unlike the 204 status code, a 200 response should include a response body. The information returned with the response is dependent on the method used in the request, for example:
- GET an entity corresponding to the requested resource is sent in the response;
- HEAD the entity-header fields corresponding to the requested resource are sent in the response without any message-body;
- POST an entity describing or containing the result of the action;
- TRACE an entity containing the request message as received by the end server.
201 (Created)
A REST API responds with the 201 status code whenever a resource is created inside a collection. There may also be times when a new resource is created as a result of some controller action, in which case 201 would also be an appropriate response.
The newly created resource can be referenced by the URI(s) returned in the entity of the response, with the most specific URI for the resource given by a Location header field.
The origin server MUST create the resource before returning the 201 status code. If the action cannot be carried out immediately, the server SHOULD respond with a 202 (Accepted) response instead.
202 (Accepted)
A 202 response is typically used for actions that take a long while to process. It indicates that the request has been accepted for processing, but the processing has not been completed. The request might or might not be eventually acted upon, or even maybe disallowed when processing occurs.
Its purpose is to allow a server to accept a request for some other process (perhaps a batch-oriented process that is only run once per day) without requiring that the user agent’s connection to the server persist until the process is completed.
The entity returned with this response SHOULD include an indication of the request’s current status and either a pointer to a status monitor (job queue location) or some estimate of when the user can expect the request to be fulfilled.
204 (No Content)
The 204 status code is usually sent out in response to a PUT, POST, or DELETE request when the REST API declines to send back any status message or representation in the response message’s body.
An API may also send 204 in conjunction with a GET request to indicate that the requested resource exists, but has no state representation to include in the body.
If the client is a user agent, it SHOULD NOT change its document view from that which caused the request to be sent. This response is primarily intended to allow input for actions to take place without causing a change to the user agent’s active document view. However, any new or updated metainformation SHOULD be applied to the document currently in the user agent’s dynamic view.
The 204 response MUST NOT include a message-body and thus is always terminated by the first empty line after the header fields.
301 (Moved Permanently)
The 301 status code indicates that the REST API’s resource model has been significantly redesigned, and a new permanent URI has been assigned to the client’s requested resource. The REST API should specify the new URI in the response’s Location header, and all future requests should be directed to the given URI.
You will hardly use this response code in your API as you can always use the API versioning for the new API while retaining the old one.
302 (Found)
The HTTP response status code 302 Found is a common way of performing URL redirection. An HTTP response with this status code will additionally provide a URL in the Location header field. The user agent (e.g., a web browser) is invited by a response with this code to make a second. Otherwise identical, request to the new URL specified in the location field.
Many web browsers implemented this code in a manner that violated this standard, changing the request type of the new request to GET, regardless of the type employed in the original request (e.g., POST). RFC 1945 and RFC 2068 specify that the client is not allowed to change the method on the redirected request. The status codes 303 and 307 have been added for servers that wish to make unambiguously clear which kind of reaction is expected of the client.
303 (See Other)
A 303 response indicates that a controller resource has finished its work, but instead of sending a potentially unwanted response body, it sends the client the URI of a response resource. The response can be the URI of the temporary status message, or the URI to some already existing, more permanent, resource.
Generally speaking, the 303 status code allows a REST API to send a reference to a resource without forcing the client to download its state. Instead, the client may send a GET request to the value of the Location header.
The 303 response MUST NOT be cached, but the response to the second (redirected) request might be cacheable.
304 (Not Modified)
This status code is similar to 204 (“No Content”) in that the response body must be empty. The critical distinction is that 204 is used when there is nothing to send in the body, whereas 304 is used when the resource has not been modified since the version specified by the request headers If-Modified-Since or If-None-Match.
In such a case, there is no need to retransmit the resource since the client still has a previously-downloaded copy.
Using this saves bandwidth and reprocessing on both the server and client, as only the header data must be sent and received in comparison to the entirety of the page being re-processed by the server, then sent again using more bandwidth of the server and client.
307 (Temporary Redirect)
A 307 response indicates that the REST API is not going to process the client’s request. Instead, the client should resubmit the request to the URI specified by the response message’s Location header. However, future requests should still use the original URI.
A REST API can use this status code to assign a temporary URI to the client’s requested resource. For example, a 307 response can be used to shift a client request over to another host.
The temporary URI SHOULD be given by the Location field in the response. Unless the request method was HEAD, the entity of the response SHOULD contain a short hypertext note with a hyperlink to the new URI(s). If the 307 status code is received in response to a request other than GET or HEAD, the user agent MUST NOT automatically redirect the request unless it can be confirmed by the user, since this might change the conditions under which the request was issued.
400 (Bad Request)
400 is the generic client-side error status, used when no other 4xx error code is appropriate. Errors can be like malformed request syntax, invalid request message parameters, or deceptive request routing etc.
The client SHOULD NOT repeat the request without modifications.
401 (Unauthorized)
A 401 error response indicates that the client tried to operate on a protected resource without providing the proper authorization. It may have provided the wrong credentials or none at all. The response must include a WWW-Authenticate header field containing a challenge applicable to the requested resource.
The client MAY repeat the request with a suitable Authorization header field. If the request already included Authorization credentials, then the 401 response indicates that authorization has been refused for those credentials. If the 401 response contains the same challenge as the prior response, and the user agent has already attempted authentication at least once, then the user SHOULD be presented the entity that was given in the response, since that entity might include relevant diagnostic information.
403 (Forbidden)
A 403 error response indicates that the client’s request is formed correctly, but the REST API refuses to honor it, i.e., the user does not have the necessary permissions for the resource. A 403 response is not a case of insufficient client credentials; that would be 401 (“Unauthorized”).
Authentication will not help, and the request SHOULD NOT be repeated. Unlike a 401 Unauthorized response, authenticating will make no difference.
404 (Not Found)
The 404 error status code indicates that the REST API can’t map the client’s URI to a resource but may be available in the future. Subsequent requests by the client are permissible.
No indication is given of whether the condition is temporary or permanent. The 410 (Gone) status code SHOULD be used if the server knows, through some internally configurable mechanism, that an old resource is permanently unavailable and has no forwarding address. This status code is commonly used when the server does not wish to reveal exactly why the request has been refused, or when no other response is applicable.
405 (Method Not Allowed)
The API responds with a 405 error to indicate that the client tried to use an HTTP method that the resource does not allow. For instance, a read-only resource could support only GET and HEAD, while a controller resource might allow GET and POST, but not PUT or DELETE.
A 405 response must include the Allow header, which lists the HTTP methods that the resource supports. For example:
Allow: GET, POST
406 (Not Acceptable)
The 406 error response indicates that the API is not able to generate any of the client’s preferred media types, as indicated by the Accept request header. For example, a client request for data formatted as application/xml will receive a 406 response if the API is only willing to format data as application/json.
If the response could be unacceptable, a user agent SHOULD temporarily stop receipt of more data and query the user for a decision on further actions.
412 (Precondition Failed)
The 412 error response indicates that the client specified one or more preconditions in its request headers, effectively telling the REST API to carry out its request only if certain conditions were met. A 412 response indicates that those conditions were not met, so instead of carrying out the request, the API sends this status code.
415 (Unsupported Media Type)
The 415 error response indicates that the API is not able to process the client’s supplied media type, as indicated by the Content-Type request header. For example, a client request including data formatted as application/xml will receive a 415 response if the API is only willing to process data formatted as application/json.
For example, the client uploads an image as image/svg+xml, but the server requires that images use a different format.
500 (Internal Server Error)
500 is the generic REST API error response. Most web frameworks automatically respond with this response status code whenever they execute some request handler code that raises an exception.
A 500 error is never the client’s fault, and therefore, it is reasonable for the client to retry the same request that triggered this response and hope to get a different response.
The API response is the generic error message, given when an unexpected condition was encountered and no more specific message is suitable.
501 (Not Implemented)
The server either does not recognize the request method, or it cannot fulfill the request. Usually, this implies future availability (e.g., a new feature of a web-service API).
References :
https://www.iana.org/assignments/http-status-codes/http-status-codes.xhtml
Some Background
REST APIs use the Status-Line part of an HTTP response message to inform clients of their request’s overarching result.
RFC 2616 defines the Status-Line syntax as shown below:
Status-Line = HTTP-Version SP Status-Code SP Reason-Phrase CRLF
A great amount of applications are using Restful APIs that are based on the HTTP protocol for connecting their clients. In all the calls, the server and the endpoint at the client both return a call status to the client which can be in the form of:
- The success of API call.
- Failure of API call.
In both the cases, it is necessary to let the client know so that they can proceed to the next step. In the case of a successful API call they can proceed to the next call or whatever their intent was in the first place but in the case of latter they will be forced to modify their call so that the failed call can be recovered.
RestCase
To enable the best user experience for your customer, it is necessary on the part of the developers to make excellent error messages that can help their client to know what they want to do with the information they get. An excellent error message is precise and lets the user know about the nature of the error so that they can figure their way out of it.
A good error message also allows the developers to get their way out of the failed call.
Next step is to know what error messages to integrate into your framework so that the clients on the end point and the developers at the server are constantly made aware of the situation which they are in. in order to do so, the rule of thumb is to keep the error messages to a minimum and only incorporate those error messages which are helpful.
HTTP defines over 40 standard status codes that can be used to convey the results of a client’s request. The status codes are divided into the five categories presented here:
- 1xx: Informational — Communicates transfer protocol-level information
- 2xx: Success -Indicates that the client’s request was accepted successfully.
- 3xx: Redirection — Indicates that the client must take some additional action in order to complete their request.
- 4xx: Client Error — This category of error status codes points the finger at clients.
- 5xx: Server Error — The server takes responsibility for these error status codes.

If you would ask me 5 years ago about HTTP Status codes I would guess that the talk is about web sites, status 404 meaning that some page was not found and etc. But today when someone asks me about HTTP Status codes, it is 99.9% refers to REST API web services development. I have lots of experience in both areas (Website development, REST API web services development) and it is sometimes hard to come to a conclusion about what and how use the errors in REST APIs.
There are some cases where this status code is always returned, even if there was an error that occurred. Some believe that returning status codes other than 200 is not good as the client did reach your REST API and got response.
Proper use of the status codes will help with your REST API management and REST API workflow management.
If for example the user asked for “account” and that account was not found there are 2 options to use for returning an error to the user:
-
Return 200 OK Status and in the body return a json containing explanation that the account was not found.
-
Return 404 not found status.
The first solution opens up a question whether the user should work a bit harder to parse the json received and to see whether that json contains error or not. -
There is also a third solution: Return 400 Error — Client Error. I will explain a bit later why this is my favorite solution.
It is understandable that for the user it is easier to check the status code of 404 without any parsing work to do.
I my opinion this solution is actually miss-use of the HTTP protocol
We did reach the REST API, we did got response from the REST API, what happens if the users misspells the URL of the REST API – he will get the 404 status but that is returned not by the REST API itself.
I think that these solutions should be interesting to explore and to see the benefits of one versus the other.
There is also one more solution that is basically my favorite – this one is a combination of the first two solutions, he is also gives better Restful API services automatic testing support because only several status codes are returned, I will try to explain about it.
Error handling Overview
Error responses should include a common HTTP status code, message for the developer, message for the end-user (when appropriate), internal error code (corresponding to some specific internally determined ID), links where developers can find more info. For example:
‘{ «status» : 400,
«developerMessage» : «Verbose, plain language description of the problem. Provide developers suggestions about how to solve their problems here»,
«userMessage» : «This is a message that can be passed along to end-users, if needed.»,
«errorCode» : «444444»,
«moreInfo» : «http://www.example.gov/developer/path/to/help/for/444444,
http://tests.org/node/444444»,
}’
How to think about errors in a pragmatic way with REST?
Apigee’s blog post that talks about this issue compares 3 top API providers.

No matter what happens on a Facebook request, you get back the 200 status code — everything is OK. Many error messages also push down into the HTTP response. Here they also throw an #803 error but with no information about what #803 is or how to react to it.
Twilio
Twilio does a great job aligning errors with HTTP status codes. Like Facebook, they provide a more granular error message but with a link that takes you to the documentation. Community commenting and discussion on the documentation helps to build a body of information and adds context for developers experiencing these errors.
SimpleGeo
Provides error codes but with no additional value in the payload.
Error Handling — Best Practises
First of all: Use HTTP status codes! but don’t overuse them.
Use HTTP status codes and try to map them cleanly to relevant standard-based codes.
There are over 70 HTTP status codes. However, most developers don’t have all 70 memorized. So if you choose status codes that are not very common you will force application developers away from building their apps and over to wikipedia to figure out what you’re trying to tell them.
Therefore, most API providers use a small subset.
For example, the Google GData API uses only 10 status codes, Netflix uses 9, and Digg, only 8.

How many status codes should you use for your API?
When you boil it down, there are really only 3 outcomes in the interaction between an app and an API:
- Everything worked
- The application did something wrong
- The API did something wrong
Start by using the following 3 codes. If you need more, add them. But you shouldn’t go beyond 8.
- 200 — OK
- 400 — Bad Request
- 500 — Internal Server Error
Please keep in mind the following rules when using these status codes:
200 (OK) must not be used to communicate errors in the response body
Always make proper use of the HTTP response status codes as specified by the rules in this section. In particular, a REST API must not be compromised in an effort to accommodate less sophisticated HTTP clients.
400 (Bad Request) may be used to indicate nonspecific failure
400 is the generic client-side error status, used when no other 4xx error code is appropriate. For errors in the 4xx category, the response body may contain a document describing the client’s error (unless the request method was HEAD).
500 (Internal Server Error) should be used to indicate API malfunction 500 is the generic REST API error response.
Most web frameworks automatically respond with this response status code whenever they execute some request handler code that raises an exception. A 500 error is never the client’s fault and therefore it is reasonable for the client to retry the exact same request that triggered this response, and hope to get a different response.
If you’re not comfortable reducing all your error conditions to these 3, try adding some more but do not go beyond 8:
- 401 — Unauthorized
- 403 — Forbidden
- 404 — Not Found
Please keep in mind the following rules when using these status codes:
A 401 error response indicates that the client tried to operate on a protected resource without providing the proper authorization. It may have provided the wrong credentials or none at all.
403 (Forbidden) should be used to forbid access regardless of authorization state
A 403 error response indicates that the client’s request is formed correctly, but the REST API refuses to honor it. A 403 response is not a case of insufficient client credentials; that would be 401 (“Unauthorized”). REST APIs use 403 to enforce application-level permissions. For example, a client may be authorized to interact with some, but not all of a REST API’s resources. If the client attempts a resource interaction that is outside of its permitted scope, the REST API should respond with 403.
404 (Not Found) must be used when a client’s URI cannot be mapped to a resource
The 404 error status code indicates that the REST API can’t map the client’s URI to a resource.
RestCase
Conclusion
I believe that the best solution to handle errors in a REST API web services is the third option, in short:
Use three simple, common response codes indicating (1) success, (2) failure due to client-side problem, (3) failure due to server-side problem:
- 200 — OK
- 400 — Bad Request (Client Error) — A json with error more details should return to the client.
- 401 — Unauthorized
- 500 — Internal Server Error — A json with an error should return to the client only when there is no security risk by doing that.
I think that this solution can also ease the client to handle only these 4 status codes and when getting either 400 or 500 code he should take the response message and parse it in order to see what is the problem exactly and on the other hand the REST API service is simple enough.
The decision of choosing which error messages to incorporate and which to leave is based on sheer insight and intuition. For example: if an app and API only has three outcomes which are; everything worked, the application did not work properly and API did not respond properly then you are only concerned with three error codes. By putting in unnecessary codes, you will only distract the users and force them to consult Google, Wikipedia and other websites.
Most important thing in the case of an error code is that it should be descriptive and it should offer two outputs:
- A plain descriptive sentence explaining the situation in the most precise manner.
- An ‘if-then’ situation where the user knows what to do with the error message once it is returned in an API call.
The error message returned in the result of the API call should be very descriptive and verbal. A code is preferred by the client who is well versed in the programming and web language but in the case of most clients they find it hard to get the code.
As I stated before, 404 is a bit problematic status when talking about Restful APIs. Does this status means that the resource was not found? or that there is not mapping to the requested resource? Everyone can decide what to use and where 
REST API использует строку состояния в HTTP ответе (статус ответа), чтобы информировать Клиентов о результате запроса.
Вообще HTTP определяет 40 стандартных кодов состояния (статусов ответа), которые делятся на пять категорий. Ниже выделены только те коды состояния, которые часто используются в REST API.
| Категория | Описание |
|---|---|
| 1xx: Информация | В этот класс содержит заголовки информирующие о процессе передачи. Это обычно предварительный ответ, состоящий только из Status-Line и опциональных заголовков, и завершается пустой строкой. Нет обязательных заголовков. Серверы НЕ ДОЛЖНЫ посылать 1xx ответы HTTP/1.0 клиентам. |
| 2xx: Успех | Этот класс кодов состояния указывает, что запрос клиента был успешно получен, понят, и принят. |
| 3xx: Перенаправление | Коды этого класса сообщают клиенту, что для успешного выполнения операции необходимо сделать другой запрос, как правило, по другому URI. Из данного класса пять кодов 301, 302, 303, 305 и 307 относятся непосредственно к перенаправлениям. |
| 4xx: Ошибка клиента | Класс кодов 4xx предназначен для указания ошибок со стороны клиента. |
| 5xx: Ошибка сервера | Коды ответов, начинающиеся с «5» указывают на случаи, когда сервер знает, что произошла ошибка или он не может обработать запрос. |
Коды состояний в REST
Звездочкой * помечены популярные (часто используемые) коды ответов.
200 * (OK)
Запрос выполнен успешно. Информация, возвращаемая с ответом зависит от метода, используемого в запросе, например при:
- GET Получен объект, соответствующий запрошенному ресурсу.
- HEAD Получены поля заголовков, соответствующие запрошенному ресурсу, тело ответа пустое.
- POST Запрошенное действие выполнено.
201 * (Created — Создано)
REST API отвечает кодом состояния 201 при каждом создании ресурса в коллекции. Также могут быть случаи, когда новый ресурс создается в результате какого-либо действия контроллера, и в этом случае 201 также будет подходящем ответом.
Ссылка (URL) на новый ресурс может быть в теле ответа или в поле заголовка ответа Location.
Сервер должен создать ресурс перед тем как вернуть 201 статус. Если это невозможно сделать сразу, тогда сервер должен ответить кодом 202 (Accepted).
202 (Accepted — Принято)
Ответ 202 обычно используется для действий, которые занимают много времени для обработки и не могут быть выполнены сразу. Это означает, что запрос принят к обработке, но обработка не завершена.
Его цель состоит в том, чтобы позволить серверу принять запрос на какой-либо другой процесс (возможно, пакетный процесс, который выполняется только один раз в день), не требуя, чтобы соединение агента пользователя с сервером сохранялось до тех пор, пока процесс не будет завершен.
Сущность, возвращаемая с этим ответом, должна содержать указание на текущее состояние запроса и указатель на монитор состояния (расположение очереди заданий) или некоторую оценку того, когда пользователь может ожидать выполнения запроса.
203 (Non-Authoritative Information — Неавторитетная информация)
Предоставленная информация взята не из оригинального источника (а, например, из кэша, который мог устареть, или из резервной копии, которая могла потерять актуальность). Этот факт отражен в заголовке ответа и подтверждается этим кодом. Предоставленная информация может совпадать, а может и не совпадать с оригинальными данными.
204 * (No Content — Нет контента)
Код состояния 204 обычно отправляется в ответ на запрос PUT, POST или DELETE, когда REST API отказывается отправлять обратно любое сообщение о состоянии проделанной работы.
API может также отправить 204 статус в ответ на GET запрос, чтобы указать, что запрошенный ресурс существует, но не имеет данных для добавления их в тело ответа.
Ответ 204 не должен содержать тело сообщения и, таким образом, всегда завершается первой пустой строкой после полей заголовка.
205 — (Reset Content — Сброшенное содержимое)
Сервер успешно обработал запрос и обязывает клиента сбросить введенные пользователем данные. В ответе не должно передаваться никаких данных (в теле ответа). Обычно применяется для возврата в начальное состояние формы ввода данных на клиенте.
206 — (Partial Content — Частичное содержимое)
Сервер выполнил часть GET запроса ресурса. Запрос ДОЛЖЕН был содержать поле заголовка Range (секция 14.35), который указывает на желаемый диапазон и МОГ содержать поле заголовка If-Range (секция 14.27), который делает запрос условным.
Запрос ДОЛЖЕН содержать следующие поля заголовка:
- Либо поле Content-Range (секция 14.16), который показывает диапазон, включённый в этот запрос, либо Content-Type со значением multipart/byteranges, включающими в себя поля Content-Range для каждой части. Если в заголовке запроса есть поле Content-Length, его значение ДОЛЖНО совпадать с фактическим количеством октетов, переданных в теле сообщения.
- Date
- ETag и/или Content-Location, если ранее был получен ответ 200 на такой же запрос.
- Expires, Cache-Control, и/или Vary, если значение поля изменилось с момента отправления последнего такого же запроса
Если ответ 206 — это результат выполнения условного запроса, который использовал строгий кэш-валидатор (подробнее в секции 13.3.3), в ответ НЕ СЛЕДУЕТ включать какие-либо другие заголовки сущности. Если такой ответ — результат выполнения запроса If-Range, который использовал «слабый» валидатор, то ответ НЕ ДОЛЖЕН содержать другие заголовки сущности; это предотвращает несоответствие между закэшированными телами сущностей и обновлёнными заголовками. В противном случае ответ ДОЛЖЕН содержать все заголовки сущностей, которые вернули статус 200 (OK) на тот же запрос.
Кэш НЕ ДОЛЖЕН объединять ответ 206 с другими ранее закэшированными данными, если поле ETag или Last-Modified в точности не совпадают (подробнее в секции 16.5.4)
Кэш, который не поддерживает заголовки Range и Content-Range НЕ ДОЛЖЕН кэшировать ответы 206 (Partial).
300 — (Multiple Choices — Несколько вариантов)
По указанному URI существует несколько вариантов предоставления ресурса по типу MIME, по языку или по другим характеристикам. Сервер передаёт с сообщением список альтернатив, давая возможность сделать выбор клиенту автоматически или пользователю.
Если это не запрос HEAD, ответ ДОЛЖЕН включать объект, содержащий список характеристик и адресов, из которого пользователь или агент пользователя может выбрать один наиболее подходящий. Формат объекта определяется по типу данных приведённых в Content-Type поля заголовка. В зависимости от формата и возможностей агента пользователя, выбор наиболее подходящего варианта может выполняться автоматически. Однако эта спецификация не определяет никакого стандарта для автоматического выбора.
Если у сервера есть предпочтительный выбор представления, он ДОЛЖЕН включить конкретный URI для этого представления в поле Location; агент пользователя МОЖЕТ использовать заголовок Location для автоматического перенаправления к предложенному ресурсу. Этот запрос может быть закэширован, если явно не было указано иного.
301 (Moved Permanently — Перемещено навсегда)
Код перенаправления. Указывает, что модель ресурсов REST API была сильно изменена и теперь имеет новый URL. Rest API должен указать новый URI в заголовке ответа Location, и все будущие запросы должны быть направлены на указанный URI.
Вы вряд ли будете использовать этот код ответа в своем API, так как вы всегда можете использовать версию API для нового API, сохраняя при этом старый.
302 (Found — Найдено)
Является распространенным способом выполнить перенаправление на другой URL. HTTP-ответ с этим кодом должен дополнительно предоставит URL-адрес куда перенаправлять в поле заголовка Location. Агенту пользователя (например, браузеру) предлагается в ответе с этим кодом сделать второй запрос на новый URL.
Многие браузеры реализовали этот код таким образом, что нарушили стандарт. Они начали изменять Тип исходного запроса, например с POST на GET. Коды состояния 303 и 307 были добавлены для серверов, которые хотят однозначно определить, какая реакция ожидается от клиента.
303 (See Other — Смотрите другое)
Ответ 303 указывает, что ресурс контроллера завершил свою работу, но вместо отправки нежелательного тела ответа он отправляет клиенту URI ресурса. Это может быть URI временного сообщения о состоянии ресурса или URI для уже существующего постоянного ресурса.
Код состояния 303 позволяет REST API указать ссылку на ресурс, не заставляя клиента загружать ответ. Вместо этого клиент может отправить GET запрос на URL указанный в заголовке Location.
Ответ 303 не должен кэшироваться, но ответ на второй (перенаправленный) запрос может быть кэшируемым.
304 * (Not Modified — Не изменен)
Этот код состояния похож на 204 (Нет контента), так как тело ответа должно быть пустым. Ключевое различие состоит в том, что 204 используется, когда нет ничего для отправки в теле, тогда как 304 используется, когда ресурс не был изменен с версии, указанной заголовками запроса If-Modified-Since или If-None-Match.
В таком случае нет необходимости повторно передавать ресурс, так как у клиента все еще есть ранее загруженная копия.
Все это экономит ресурсы клиента и сервера, так как только заголовки должны быть отправлены и приняты, и серверу нет необходимости генерировать контент снова, а клиенту его получать.
305 — (Use Proxy — Используйте прокси)
Доступ к запрошенному ресурсу ДОЛЖЕН быть осуществлен через прокси-сервер, указанный в поле Location. Поле Location предоставляет URI прокси. Ожидается, что получатель повторит этот запрос с помощью прокси. Ответ 305 может генерироваться ТОЛЬКО серверами-источниками.
Заметьте: в спецификации RFC 2068 однозначно не сказано, что ответ 305 предназначен для перенаправления единственного запроса, и что он должен генерироваться только сервером-источником. Упущение этих ограничений вызвало ряд значительных последствий для безопасности.
Многие HTTP клиенты (такие, как Mozilla и Internet Explorer) обрабатывают этот статус некорректно прежде всего из соображений безопасности.
307 (Temporary Redirect — Временный редирект)
Ответ 307 указывает, что rest API не будет обрабатывать запрос клиента. Вместо этого клиент должен повторно отправить запрос на URL, указанный в заголовке Location. Однако в будущих запросах клиент по-прежнему должен использоваться исходный URL.
Rest API может использовать этот код состояния для назначения временного URL запрашиваемому ресурсу.
Если метод запроса не HEAD, тело ответа должно содержать короткую заметку с гиперссылкой на новый URL. Если код 307 был получен в ответ на запрос, отличный от GET или HEAD, Клиент не должен автоматически перенаправлять запрос, если он не может быть подтвержден Клиентом, так как это может изменить условия, при которых был создан запрос.
308 — (Permanent Redirect — Постоянное перенаправление) (experimental)
Нужно повторить запрос на другой адрес без изменения применяемого метода.
Этот и все последующие запросы нужно повторить на другой URI. 307 и 308 (как предложено) Схож в поведении с 302 и 301, но не требуют замены HTTP метода. Таким образом, например, отправку формы на «постоянно перенаправленный» ресурс можно продолжать без проблем.
400 * (Bad Request — Плохой запрос)
Это общий статус ошибки на стороне Клиента. Используется, когда никакой другой код ошибки 4xx не уместен. Ошибки могут быть как неправильный синтаксис запроса, неверные параметры запроса, запросы вводящие в заблуждение или маршрутизатор и т.д.
Клиент не должен повторять точно такой же запрос.
401 * (Unauthorized — Неавторизован)
401 сообщение об ошибке указывает, что клиент пытается работать с закрытым ресурсом без предоставления данных авторизации. Возможно, он предоставил неправильные учетные данные или вообще ничего. Ответ должен включать поле заголовка WWW-Authenticate, содержащего описание проблемы.
Клиент может повторить запрос указав в заголовке подходящее поле авторизации. Если это уже было сделано, то в ответе 401 будет указано, что авторизация для указанных учетных данных не работает. Если в ответе 401 содержится та же проблема, что и в предыдущем ответе, и Клиент уже предпринял хотя бы одну попытку проверки подлинности, то пользователю Клиента следует представить данные полученные в ответе, владельцу сайта, так как они могут помочь в диагностике проблемы.
402 — (Payment Required — Требуется оплата)
Этот код зарезервирован для использования в будущем.
Предполагается использовать в будущем. В настоящий момент не используется. Этот код предусмотрен для платных пользовательских сервисов, а не для хостинговых компаний. Имеется в виду, что эта ошибка не будет выдана хостинговым провайдером в случае просроченной оплаты его услуг. Зарезервирован, начиная с HTTP/1.1.
403 * (Forbidden — Запрещено)
Ошибка 403 указывает, что rest API отказывается выполнять запрос клиента, т.е. Клиент не имеет необходимых разрешений для доступа. Ответ 403 не является случаем, когда нужна авторизация (для ошибки авторизации используется код 401).
Попытка аутентификация не поможет, и повторные запросы не имеют смысла.
404 * (Not Found — Не найдено)
Указывает, что rest API не может сопоставить URL клиента с ресурсом, но этот URL может быть доступен в будущем. Последующие запросы клиента допустимы.
404 не указывает, является ли состояние временным или постоянным. Для указания постоянного состояния используется код 410 (Gone — Пропал). 410 использоваться, если сервер знает, что старый ресурс постоянно недоступен и более не имеет адреса.
405 (Method Not Allowed — Метод не разрешен)
API выдает ошибку 405, когда клиент пытался использовать HTTP метод, который недопустим для ресурса. Например, указан метод PUT, но такого метода у ресурса нет.
Ответ 405 должен включать Заголовок Allow, в котором перечислены поддерживаемые HTTP методы, например, Allow: GET, POST.
406 (Not Acceptable — Неприемлемый)
API не может генерировать предпочитаемые клиентом типы данных, которые указаны в заголовке запроса Accept. Например, запрос клиента на данные в формате application/xml получит ответ 406, если API умеет отдавать данные только в формате application/json.
В таких случаях Клиент должен решить проблему данных у себя и только потом отправлять запросы повторно.
407 — (Proxy Authentication Required — Требуется прокси-аутентификация)
Ответ аналогичен коду 401, за исключением того, что аутентификация производится для прокси-сервера. Механизм аналогичен идентификации на исходном сервере.
Пользователь должен сначала авторизоваться через прокси. Прокси-сервер должен вернуть Proxy-Authenticate заголовок, содержащий запрос ресурса. Клиент может повторить запрос вместе с Proxy-Authenticate заголовком. Появился в HTTP/1.1.
408 — (Request Timeout — Таймаут запроса)
Время ожидания сервером передачи от клиента истекло. Клиент не предоставил запрос за то время, пока сервер был готов его принят. Клиент МОЖЕТ повторить запрос без изменений в любое время.
Например, такая ситуация может возникнуть при загрузке на сервер объёмного файла методом POST или PUT. В какой-то момент передачи источник данных перестал отвечать, например, из-за повреждения компакт-диска или потери связи с другим компьютером в локальной сети. Пока клиент ничего не передаёт, ожидая от него ответа, соединение с сервером держится. Через некоторое время сервер может закрыть соединение со своей стороны, чтобы дать возможность другим клиентам сделать запрос.
409 * (Conflict — Конфликт)
Запрос нельзя обработать из-за конфликта в текущем состоянии ресурса. Этот код разрешается использовать только в тех случаях, когда ожидается, что пользователь может самостоятельно разрешить этот конфликт и повторить запрос. В тело ответа СЛЕДУЕТ включить достаточное количество информации для того, чтобы пользователь смог понять причину конфликта. В идеале ответ должен содержать такую информацию, которая поможет пользователю или его агенту исправить проблему. Однако это не всегда возможно и это не обязательно.
Как правило, конфликты происходят во время PUT-запроса. Например, во время использования версионирования, если сущность, к которой обращаются методом PUT, содержит изменения, конфликтующие с теми, что были сделаны ранее третьей стороной, серверу следует использовать ответ 409, чтобы дать понять пользователю, что этот запрос нельзя завершить. В этом случае в ответной сущности должен содержаться список изменений между двумя версиями в формате, который указан в поле заголовка Content-Type.
410 — (Gone — Исчез)
Такой ответ сервер посылает, если ресурс раньше был по указанному URL, но был удалён и теперь недоступен. Серверу в этом случае неизвестно и местоположение альтернативного документа, например, копии. Если у сервера есть подозрение, что документ в ближайшее время может быть восстановлен, то лучше клиенту передать код 404. Появился в HTTP/1.1.
411 — (Length Required — Требуется длина)
Для указанного ресурса клиент должен указать Content-Length в заголовке запроса. Без указания этого поля не стоит делать повторную попытку запроса к серверу по данному URI. Такой ответ естественен для запросов типа POST и PUT. Например, если по указанному URI производится загрузка файлов, а на сервере стоит ограничение на их объём. Тогда разумней будет проверить в самом начале заголовок Content-Length и сразу отказать в загрузке, чем провоцировать бессмысленную нагрузку, разрывая соединение, когда клиент действительно пришлёт слишком объёмное сообщение.
412 — (Precondition Failed — Предварительное условие не выполнено)
Возвращается, если ни одно из условных полей заголовка запроса не было выполнено.
Когда клиент указывает rest API выполнять запрос только при выполнении определенных условий, а API не может выполнить запрос при таких условиях, то возвращается ответ 412.
Этот код ответа позволяет клиенту записывать предварительные условия в метаинформации текущего ресурса, таким образом, предотвращая применение запрошенного метода к ресурсу, кроме того, что ожидается.
413 — (Request Entity Too Large — Сущность запроса слишком большая)
Возвращается в случае, если сервер отказывается обработать запрос по причине слишком большого размера тела запроса. Сервер может закрыть соединение, чтобы прекратить дальнейшую передачу запроса.
Если проблема временная, то рекомендуется в ответ сервера включить заголовок Retry-After с указанием времени, по истечении которого можно повторить аналогичный запрос.
414 — (Request-URI Too Long — Запрос-URI Слишком длинный)
Сервер не может обработать запрос из-за слишком длинного указанного URL. Эту редкую ошибку можно спровоцировать, например, когда клиент пытается передать длинные параметры через метод GET, а не POST, когда клиент попадает в «чёрную дыру» перенаправлений (например, когда префикс URI указывает на своё же окончание), или когда сервер подвергается атаке со стороны клиента, который пытается использовать дыры в безопасности, которые встречаются на серверах с фиксированной длиной буфера для чтения или обработки Request-URI.
415 (Unsupported Media Type — Неподдерживаемый медиа тип)
Сообщение об ошибке 415 указывает, что API не может обработать предоставленный клиентом Тип медиа, как указано в заголовке запроса Content-Type.
Например, запрос клиента содержит данные в формате application/xml, а API готов обработать только application/json. В этом случае клиент получит ответ 415.
Например, клиент загружает изображение как image/svg+xml, но сервер требует, чтобы изображения использовали другой формат.
428 — (Precondition Required — Требуется предварительное условие)
Код состояния 428 указывает, что исходный сервер требует, чтобы запрос был условным.
Его типичное использование — избежать проблемы «потерянного обновления», когда клиент ПОЛУЧАЕТ состояние ресурса, изменяет его и ОТПРАВЛЯЕТ обратно на сервер, когда тем временем третья сторона изменила состояние на сервере, что привело к конфликту. Требуя, чтобы запросы были условными, сервер может гарантировать, что клиенты работают с правильными копиями.
Ответы с этим кодом состояния ДОЛЖНЫ объяснять, как повторно отправить запрос.
429 — (Too Many Requests — Слишком много запросов)
Пользователь отправил слишком много запросов за заданный промежуток времени.
Представления ответа ДОЛЖНЫ включать подробности, объясняющие условие, и МОГУТ включать заголовок Retry-After, указывающий, как долго ждать, прежде чем делать новый запрос.
431 — (Request Header Fields Too Large — Слишком большие поля заголовка запроса)
Код состояния 431 указывает на то, что сервер не желает обрабатывать запрос, поскольку его поля заголовка слишком велики. Запрос МОЖЕТ быть отправлен повторно после уменьшения размера полей заголовка запроса.
Его можно использовать как в случае, когда совокупность полей заголовка запроса слишком велика, так и в случае неисправности одного поля заголовка. В последнем случае представление ответа ДОЛЖНО указывать, какое поле заголовка было слишком большим.
444 — (No Response — Нет ответа) (Nginx)
Код ответа Nginx. Сервер не вернул информацию и закрыл соединение. (полезно в качестве сдерживающего фактора для вредоносных программ)
451 — (Unavailable For Legal Reasons — Недоступен по юридическим причинам)
Доступ к ресурсу закрыт по юридическим причинам. Наиболее близким из существующих является код 403 Forbidden (сервер понял запрос, но отказывается его обработать). Однако в случае цензуры, особенно когда это требование к провайдерам заблокировать доступ к сайту, сервер никак не мог понять запроса — он его даже не получил. Совершенно точно подходит другой код: 305 Use Proxy. Однако такое использование этого кода может не понравиться цензорам. Было предложено несколько вариантов для нового кода, включая «112 Emergency. Censorship in action» и «460 Blocked by Repressive Regime»
500 * (Internal Server Error — Внутренняя ошибка сервера)
Общий ответ при ошибке в коде. Универсальное сообщение о внутренней ошибке сервера, когда никакое более определенное сообщение не подходит.
Большинство веб-платформ автоматически отвечают этим кодом состояния, когда при выполнении кода обработчика запроса возникла ошибка.
Ошибка 500 никогда не зависит от клиента, поэтому для клиента разумно повторить точно такой же запрос, и надеяться что в этот раз сервер отработает без ошибок.
501 (Not Implemented — Не реализован)
Серверу либо неизвестен метод запроса, или ему (серверу) не хватает возможностей выполнить запрос. Обычно это подразумевает будущую доступность (например, новая функция API веб-сервиса).
Если же метод серверу известен, но он не применим к данному ресурсу, то нужно вернуть ответ 405.
502 — (Bad Gateway — Плохой шлюз)
Сервер, выступая в роли шлюза или прокси-сервера, получил некорректный ответ от вышестоящего сервера, к которому он обратился. Появился в HTTP/1.0.
503 — (Service Unavailable — Служба недоступна)
Сервер не может обработать запрос из-за временной перегрузки или технических работ. Это временное состояние, из которого сервер выйдет через какое-то время. Если это время известно, то его МОЖНО передать в заголовке Retry-After.
504 — (Gateway Timeout — Таймаут шлюза)
Сервер, в роли шлюза или прокси-сервера, не дождался в рамках установленного таймаута ответа от вышестоящего сервера текущего запроса.
505 — (HTTP Version Not Supported — Версия HTTP не поддерживается)
Сервер не поддерживает или отказывается поддерживать указанную в запросе версию протокола HTTP.
510 — (Not Extended — Не расширен)
В запросе не соблюдена политика доступа к ресурсу. Сервер должен отправить обратно всю информацию, необходимую клиенту для отправки расширенного запроса. Указание того, как расширения информируют клиента, выходит за рамки данной спецификации.
—
Источники и более подробная информация:
- https://restapitutorial.ru/httpstatuscodes.html
- https://www.restapitutorial.com/httpstatuscodes.html
- https://restfulapi.net/http-status-codes/
- https://developer.mozilla.org/en-US/docs/Web/HTTP/Status/428
ReST uses HTTP status codes as operation response codes. HTTP status codes are sufficiently comprehensive for ReST, yet target no specific domain; each service provider must figure out how to map their infrastructure and logical errors into the status code set.
This article focuses on a fairly narrow domain: ReST services within a SOA network. It attempts to present a minimal yet expressive set of error codes that allow collaborators to understand current state of upstream providers and react appropriately.
Goals
Appropriate HTTP status code use provides rich error information that should improve each part of the product life cycle. The following goals are used as a guide to developing an “appropriate” set.
- Minimal: The entire set should be as small as possible: simple to understand, simple to handle in code
- Expressive: Each code should imply a distinct client or support action or significantly clarify the API
- Consistent: Every service should be able to use the same set of codes, with the same meanings so every client developer learns one idiom and applies it to every application
Specific benefits for the product team:
- The client developer has rich API error information
- simplifies fault identification and correction in code development and testing
- eliminates time lost tracking down another developer or log to understand the error
- enables common error handling routines instead of per API/method error handling
- improves productivity, more enjoyable work experience
- The service developer has response code guidance
- same error codes for the same error conditions provided by all developers in all APIs
- acts as a checklist for all errors a developer should look for
- encourages developing common error detection and handling routines
- less lost time researching and explaining errors to client developers and testers
- improves productivity, more enjoyable work experience
- The quality engineering developer has a conformance specification
- can produce and test for all errors in new code, verify compliance
- can create common error handlers instead of discovering and implementing separate error handlers for each API
- improves productivity, more enjoyable work experience
- Support staff has status code definitions
- can more easily/quickly identify specific issue faults and locate root cause
- can monitor for poorly performing APIs using common values instead of researching each API to understand its error meanings
- can create common log monitor dashboards, aggregating many APIs, for evaluating entire system performance
- speeds remediation, reduces work, more enjoyable work experience
References
- Apigee: What about errors
- SOA Bits: Error Handling
- Stormpath: Spring ReST error best practices
- w3.org: RFC 2616 sec 9
- w3.org: RFC 2616 sec 10
- IANA: HTTP Status Codes
- Wikipedia: HTTP Status Codes
- IETF: RFC 6585
- IETF: RFC 5789
HTTP Methods
Many APIs and articles have different opinions about how to use HTTP verbs, so to start, let’s define the verbs and their meanings in this domain.
| Verb | Description |
|---|---|
| GET | Read. Safe (no modifications allowed on GET). Uses a URI path element to select from a resource collection or query parameters to return a list of resources |
| DELETE | Delete. Idempotent. Remove the specified item from the collection so it is not visible in other operations. Frequently, this is a soft delete where the item is marked inactive, but depends on resource implementation. |
| PATCH | Update. Modify subset of fields in a resource. Implies that unspecified fields are not modified. |
| POST | Create. Introduces a new resource into a collection. |
| PUT | Update. Idempotent. Modifies a whole resource, providing a new version of that resource. Implies that unspecified fields are nulls. |
NOTE: The PATCH verb significantly clarifies update operations, especially for Enterprise ReST, and has seen significant early adoption although RFC 5789 still in a “proposed” state. Some older web proxies and containers cannot generate or consume a PATCH method. If you are not subject to this constraint, you should use PATCH because of the clarity it provides: PUT always means resource replacement (e.g. user edits from a browser) and PATCH always means selected field update (services can set selected fields without first fetching the resource, then merging changes).
Using PATCH: If using Java, you will likely have to create your own PATCH annotation (trivial), but this will integrate cleanly with a standard spring+jersey ReST infrastructure — simply annotate your ReST interface method with the new @PATCH.
Response Codes
This list contains all HTTP response codes that should be used in ReST services; an expressive, yet minimal, list arranged in blocks
- 2XX Success
- 4XX Client Errors
- 5XX Service Provider Errors
Note: In Java, use javax.ws.core.Response Status enums when possible for clarity and to avoid magic numbers.
| Code | Enum | Description |
|---|---|---|
| 200 | OK | General success. No entity returned. Applies to: GET, DELETE, PATCH, PUT |
| 201 | CREATED | New resource created. Unique identifier returned. Applies to: POST, PUT |
| 202 | ACCEPTED | Action accepted but not yet enacted. E.g. In asynchronous processing reliable acquisition where a message is validated and placed on a queue for another actor to complete. Applies to: GET, DELETE, PATCH, POST, PUT |
| 400 | BAD_REQUEST | Client supplied request has invalid parameters. This indicates an error in client code or data and should be logged so clients can fix their code. Provide specific details on the parameters that failed validation and why. Applies to: GET, DELETE, PATCH, POST, PUT |
| 401 | UNAUTHORIZED | The request requires authentication and no token was provided, or, the authentication token failed validation. IOW: “Unauthorized” really means “Unauthenticated”; “You need valid credentials for me to respond to this request”. Applies to: GET, DELETE, PATCH, POST, PUT |
| 403 | FORBIDDEN | The authenticated user does not have authorization to submit the request. IOW: “Forbidden” really means Unauthorized “I understood your credentials, but so sorry, you’re not allowed!”. Applies to: GET, DELETE, PATCH, POST, PUT |
| 404 | NOT_FOUND | The resource cannot be found. If the URI contains multiple path variables, the response entity should indicate which item was not found. E.g. /incidents/INC000123/configItems/OI-0001/policies, indicate if the incident or the configItem was not found. Applies to: GET, DELETE, PATCH, POST, PUT |
| 405 | Method not allowed for this resource. E.g. If all resources can be DELETEd but one, return 405 when the client tries to DELETE that restricted resource to clearly indicate the restriction is intentional. Applies to: GET, DELETE, PATCH, POST, PUT |
|
| 409 | CONFLICT | The request could not be completed due to a conflict with the current state of the resource. E.g. Submitting a resource change with a base revision earlier than the current revision; similar to a database dirty write. This implies there is a resource version parameter (e.g. timestamp) and it was out of date. Applies to: PATCH, PUT. |
| 429 | Too many requests. The user has sent too many requests in a given amount of time. Used with rate limiting, expected to be implemented through Layer 7. Applies to: GET, DELETE, PATCH, POST, PUT |
|
| 500 | INTERNAL_SERVER_ERROR | Any local or upstream generated error that the service does not understand. Repeated submission of this request will fail. Requires developer changes to fix the fault or catch the upstream provider error. Return rich error information including stack traces for internal only services to speed remediation, but never to external clients. Applies to: GET, DELETE, PATCH, POST, PUT |
| 501 | Method not implemented. Could use for partial implementations where an implementation is planned but not yet complete. Applies to: GET, DELETE, PATCH, POST, PUT |
|
| 503 | SERVICE_UNAVAILABLE | Any upstream connection refused, timeout, or other service unavailable error. An upstream provider is unable to handle the request due to a temporary overloading or maintenance. Used to distinguish code problems that cannot be retried from connectivity problems which could resolve themselves in a small time frame allowing a retry strategy. Applies to: GET, DELETE, PATCH, POST, PUT |
Implementation Guidelines
200 vs 201: Return 201 on create success
When you create a resource within a collection that has a well known identifier, you use PUT. Consider a provisioning or management API for Windows that wants to record the applications installed on the C drive. One might imagine a URI like
/departments/POR0000022222/servers/SL2LS431785/drives/CThe caller audits the C drive and PUTs the audit results to the above URI. The only way the caller can tell if they created a new resource or modified an existing one is by the response code; otherwise the calls look exactly the same. The RFC created a special code for this case to distinguish between general success and resource creation. If the caller receives a 201, they know that they created a new resource. If they receive a 200, they know they modified an existing one.
When you create a resource without a well known identifier, you use POST and the service returns a unique identifier for the new resource.
To ensure 201 means resource created for every verb (PUT, POST), and to adhere to the RFC, return 201 when a resource is created either by PUT or POST.
404: Do not return NOT_FOUND for empty search results
A ReST API is organized as a collection of resources and selectors. The URI is a path through that hierarchy that allows the client to manipulate a specific resource.
/companies/CPY0000011111/departments/POR0000022222/employees/PPL0000033333If the client misspells “companies”, jersey will return 404 for you because it will not know which part of your code to invoke.
Similarly, if you use a URI element (path variable) to locate an item in a collection (look up company CPY0000011111) and that company does not exist, you should return a 404.
In both cases, no operation could be performed, because the resource could not be found.
Although you had to look up the company, this is not a search because, in our domain, all elements of a resource path are assumed to exist. The client should have already verified that the ids are valid.
Use query params to provide a search facility where a resource may not exist
/companies/CPY0000011111/departments/POR0000022222/employees?id=PPL0000033333
/companies/CPY0000011111/departments/POR0000022222/employees?lastName=smithIn a search, if the operation succeeds, a 200 is returned even when no items matching the search criteria in the collection.
The specification is clear that 404 is reserved for identifying an invalid Request-URI (the part of the URL between host[:port] and optional ?).
A 404 is not appropriate above because the requested resource (/companies/CPY0000011111/departments/POR0000022222/employees) exists and was found, and the operation was applied successfully.
405, 501: Clearly identify inappropriate/unimplemented methods
The default spring+jersey on Tomcat implementation returns a NullPointerException with a stack trace when you send an HTTP verb that is not implemented.
Provide an implementation for each of DELETE, GET, PATCH, POST, PUT, returning 405 when the verb is inappropriate and 501 when it will be in a future implementation.
TODO: Provide example of how to configure Spring to do this automatically.
409: Protecting against dirty writes
Scenario: Mohammad gets a customer email change request, opens his browser, pulls up the customer, and suddenly gets the need for some go-juice. Meanwhile, Surya gets a phone number change request from the same customer which she completes immediately. Mohammad comes back and finishes the email change and pushes the submit button. He also just reverted the new phone number to the previous phone number.
If multiple modifications for a single resource can overlap, or if it is essential that this never happen, you should design a versioning system for your resource.
A database example for the scenario above:
- Add a TimeDate column (millis since epoch)
- Add a trigger that updates that column on record change.
- Include the timestamp column in your resource representation as version
- On PUT to a resource, first verify that the resource version matches the database version
- On match fail, return 409
409 CONFLICT indicates to the client that the base version of the resource they submitted has been changed since they fetched it. GUI clients should present the data to the user for edit, other services should request a fresh version of the resource and merge in their changes.
500 vs 503: Separating connectivity from code errors
When 500 (code errors) are clearly separated from 503 (connectivity errors):
- each 500 error can be treated as a work item for a developer
- each 503 can be treated as remediation issue for support
- 503 can be used to selectively implement retry strategies and eliminate commonly dropped service calls eliminating manual cleanup
- 503 can be monitored in the log and when a threshold is exceeded, a trap can be sent to support and cases created/remediated quickly
- 500 and 503 can be charted in splunk, including aggregating multiple services and methods to show spikes in code and connectivity problems
If 500 errors can be treated as developer work items, exceptions from upstream providers should be avoided by validating/conditioning the message or fixing the upstream provider code. If that is impossible, those types of 500 errors should be marked so they can be easily eliminated from the work list.
503: Provide for retry strategies
When a service layer is provided on top of a database, an API method could fail if the service could not get a database connection. This situation could clear up quickly and a subsequent try could succeed. This pattern is seen frequently and not limited to databases.
Inability to connect to an upstream service provider (WS, database, etc) should be identified and returned as a separate status code (503).
Separating connectivity errors from general 500 errors in the initial design allows applying a Layer 7 retry policy in minutes to remediate production capacity and latency problems in the future.
This is a significant boon since these failures must otherwise be cleaned up manually, which can be tedious and time consuming, and diminishes our reputation with our customers.
WARNING: Retry policies must be implemented cautiously. Retry with some strategies and in situations could exacerbate the problem. In cloud scale architectures, circuit breakers are a good defense against excessive retries.
Время прочтения
8 мин
Просмотры 37K

Давно я хотел написать эту статью. Все думал — с какой стороны зайти правильнее? Но, вдруг, недавно, на Хабре появилась подобная статья, которая вызвала бурю в стакане. Больше всего меня удивил тот факт, что статью начали вбивать в минуса, хотя она даже не декларировала что-то, а скорее поднимала вопрос об использовании кодов ответа web-сервера в REST. Дебаты разгорелись жаркие. А апофеозом стало то, что статья ушла в черновики… килобайты комментариев, мнений и т.д. просто исчезли. Многие стали кармо-жертвами, считай, ни за что
В общем, именно судьба той статьи побудила меня написать эту. И я очень надеюсь, что она будет полезна и прояснит многое.
Предупреждаю, все ниже написанное является реальным опытом, а не когнитивной эквилибристикой. И так, погнали.
HTTP
Первым делом нужно очень четко разделить слои. Слой транспорта — http. Ну и собственно REST. Это фундаментально важная вещь в принятии всего и “себя” в нем. Давайте сначала поговорим только о http.
Я использовал термин “слой транспорта”. И я не оговорился. Все дело в том, что сам http реализует функции транспортировки запросов к серверу и контента к клиенту независимо от tcp/ip. Да, он базируется на tcp/ip. И вроде, нужно считать именно его транспортным. Но, нет. И вот почему — сокет-соединения не являются прямыми, т.е. это не соединение клиент-сервер. Как http запрос, так и http ответ могут пройти длинный путь через уйму сервисов. Могут быть агрегированы или напротив декомпозированы. Могут кэшироваться, могут модифицироваться.
Т.е. у http запроса как и http ответа есть свой маршрут. И он не зависит ни от конечного бэка, ни от конечного фронта. Прошу на это обратить особое внимание.
Маршруты http не являются статическими. Они могут быть очень сложными. Например, если в инфраструктуру встроен балансировщик, полученные запросы он может отправить на любую из нод бэка. При этом, сам бэк может реализовывать собственную стратегию работы с запросами. Часть из них пойдет на микросервисы напрямую, часть будет обработана самим web-сервером, часть дополнена и передана кому-то еще, а часть выдана из кэша и т.п. Так работает Интернет. Ничего нового.
И тут важно понять — зачем нам коды ответов? Все дело в том, что вся вышеописанная модель принимает решения на их базе. Т.е. это коды, позволяющие принимать инфраструктурные и транспортные решения в ходе маршрутизации http.
К примеру, если балансировщик встретится с кодом ответа от бэка 503, при передаче запроса, он может принять это за основание считать, что нода временно недоступна. Отмечу, что в ответе с кодом 503 предусмотрен заголовок Retry-After. Получив из заголовка интервал для повторного опроса, балансировщик оставит ноду в покое на указанный срок и будет работать с доступными. Причем, подобные стратегии реализуются “из коробки” web-серверами.
Небольшой офтопик для глубины понимания — а если нода ответила 500? Что должен сделать балансировщик? Переключать на другую? И многие ответят — конечно, все 5xx основание для отключение ноды. И будут неправы. Код 500 это код неожиданной ошибки. Т.е. той, которая может больше никогда и не повториться. И главное, что переключение на другую ноду может ничего и не изменить. Т.е. мы просто отключаем ноды без малейшей пользы.
В случае с 500 нам на помощь приходит статистика. Локальный WEB-сервер ноды, может переводить саму ноду в статус недоступности при большом количестве ответов 500. В этом случае, балансировщик обратившись на эту ноду, получит ответ 503 и не будет ее трогать. Результат тотже, но теперь, такое решение осмысленно и исключает “ложные” срабатывания.
Но и это еще не все. В такой ситуации мониторинг позволит админам подключиться к ситуации для обслуживания ноды. Т.е. мы получаем не просто реализацию высокодоступного сервиса, с балансировками и т.п., но еще и эффективный процесс поддержки.
И все это позволяют делать коды ответа сервера. Любая архитектура WEB-приложения должна начинаться с проектирования транспортного слоя. Надеюсь, сомнений в этом не осталось.
REST
Задам риторический вопрос — что это такое? И что вы ответили себе на него? Не буду давать ссылки на очевидные пруфы, но скорее всего не совсем то, чем он является по сути Это лишь идеология, стиль. Некие соображения на тему — как лучше общаться с бэком. И не просто общаться, а общаться в WEB инфраструктуре. Т.е. на базе http. Со всеми теми “полезными штуками”, о которых я написал выше. Конечные решения по реализации вашего интерфейса остаются всегда за вами.
Вы задумывались почему не придуман отдельный транспорт для REST? Например, для websocket он есть. Да, он тоже начинается с http, но потом, после установки соединения, это вообще отдельная песня. Почему бы не сделать такую же для REST?
Ответ прост — а зачем? Есть прекрасный, уже готовый, выверенный протокол — http. Он хорошо масштабируется. Позволяет реализовывать сложные, высокодоступные сервисы, способные справляться с большой нагрузкой. Все, что нужно — ввести некие концептуальные правила, чтобы разработчики друг друга понимали.
Отсюда следует простой, очевидный вывод — все, что присуще http, присуще и REST. Это неотделимые сущности. Нет отдельного заголовка REST, нет даже намека на то, что REST это REST. Для любого сервера REST запрос ровно такой же, как и любой другой. Т.е. REST это только то, что у нас “в голове”.
Коды ответа http в REST
Давайте поговорим о том, каким же кодом должен отвечать ваш сервер на REST запрос? Лично мне кажется, что из всего выше написанного уже очевиден ответ, что т.к. REST не отличается от любого другого запроса, он должен быть подчинен ровно тем же правилам. Код ответа — неотъемлемая часть REST и он должен быть релевантен сути ответа. Т.е. если не найден объект по запросу, это 404, если клиент обратился с некорректным запросом 400 и т.д. Но, чаще всего, дебаты на сём не заканчиваются. Поэтому, продолжу и я.
Можно ли отвечать на всё кодом 200? А кто вам запретит? Пожалуйста… код 200 такой же код как и другие. Правда, в основе такого подхода лежит очень простой тезис — моя система идеальная, у нее не бывает ошибок. Если вы человек, который может создавать такие системы — этому можно только позавидовать!
Но скорее всего… она не идеальна. И ошибки все же случаются. А бывает, что они случаются по независящим от нас обстоятельствам. И тут типовым решением является создание собственной системы кодирования ошибок. Это плохо? Да, это плохо. Это супер-плохо. Давайте разбираться почему.
И так, принимая код 200 как единственно верный, мы берем на себя обязанности на разработку целого слоя (критического слоя) системы — обработку ошибок. Т.е. труд многих людей по разработке этого слоя отправляется в утиль. И начинается постройка своего “велосипеда”. Но эта мегастройка обречена на провал.
Начнем с кода. Если мы собираемся на все отвечать 200, нам самим придется обрабатывать ошибки. Классическим методом является try конструкции. Каждый сегмент кода мы оборачиваем дополнительным кодом. Обработчиками, которые что-то делают полезное. Например, что-то кладут в лог. Что-то важное. Что позволит локализовать ошибку. А если ошибка возникла не там где ее ожидали? Или если ошибка возникла в обработчике ошибки? Т.е. эта стратегия на уровне кода нерабочая априори. И в конце концов, обрабатывать ваши баги будет интерпретатор или платформа. ОС, наконец. Суть бага в том, что вы его не ждете. Не нужно его прятать, его нужно находить и фиксить. Поэтому, если на какие-то запросы REST ответит ошибкой 500 это нормально. И более того — правильно.
Давайте еще раз вернемся к вопросу — почему это правильно? Потому что:
- Код 500 это инфраструктурный маркер, на основании которого нода на которой возникает проблема может быть отключена;
- Коды 5xx это то, что мониторится и если такой код возникает, любая система мониторинга тут же вас известит об этом. И служба поддержки вовремя сможет подключиться к решению проблемы;
- Вы не пишите дополнительный код. Не тратите на это драгоценное время. Не усложняете архитектуру. Вы не занимаетесь несвойственными вам проблемами — вы пишите прикладной код. То, что от вас хотят. За что платят.
- Трейс который выпадет по ошибке 500 будет куда как полезнее, чем ваши попытки его превзойти.
- Если REST запрос вернет 500 код, фронт уже на моменте обработки ответа будет знать, по какому алгоритму его обрабатывать. Причем, суть дела никак не изменится, вы как ничего толкового не получили и с 200, так и с 500. Но с 500 вы получили профит — осознание того, что это НЕОЖИДАННАЯ ошибка.
- Код 500 придет гарантированно. Независимо от того насколько плохо или хорошо вы написали свой код. Это ваша точка опоры.
Отдельно забью гвоздь во все “тело” кода 200:
7. Даже если вы очень сильно постараетесь избежать иных кодов ответа от сервера кроме как 200 на ваши запросы, вы не сможете это сделать. Вам может ответить на ваш запрос любой сервер посредник, совершенно любым кодом. И вы ДОЛЖНЫ будете такой ответ обработать корректно.
Итого, на логическом уровне борьба за код 200 бессмысленна.
Теперь давайте вернемся к инфраструктурному уровню. Очень часто слышу мнение — код 5xx не прикладного уровня, его нельзя отдавать бэком. Кхм, ну… тут есть противоречие в самом утверждении. Отдавать можно. Но код этот не прикладного уровня. Вот так вернее. Для понимания этого, предлагаю рассмотреть кейс:
Вы реализуете шлюз. У вас несколько ДЦ, на каждом свой канал связи к некоему приватному сервису. Ну, к примеру, к платежке по VPN. И есть канал коммуникации с Интернет. Вы получаете запрос на операцию со шлюзом, но… сервис оказывается недоступен.
И так, что вы должны ответить? Кому? Это проблема именно инфраструктурная и, именно, бэк столкнулся с ней. Конечно, нужно смело отвечать 503. Эти действия приведут к тому, что нода будет отключена балансировщиком на какое-то время. При этом, балансировщик при правильной настройке, не разрывая соединение с клиентом, отправит запрос в другую ноду. И… конечный клиент, с великой долей вероятности получил 200. А не кастомное описание ошибки, которая ему ничем не поможет.
Где и какой код использовать
Вопрос непростой. На него нет однозначного ответа. Для каждой системы проектируется транспортный слой и коды в нем могут быть специфичные.
Есть принятые стандарты. Их можно легко найти и, опять же, не буду очевидные пруфы приводить. Но, приведу неочевидный — developer.mozilla.org/ru/docs/Web/HTTP/Status
Почему его? Все дело в том, что обработчики кода могут вести себя по разному, в зависимости от реализации и контекста “понимания кода”. К примеру, в браузерах есть стратегия кеширования, завязанная на коды ответа. А в некоторых сервисах есть свои, кастомные коды. Например, CloudFlare.
Т.е. принятие решений об использовании кодов, нужно базировать на всех элементах входящих в транспортный слой от вашего кода на бэке до кода на клиенте. Только так можно найти верные ответы. Я даже пытаться тут дать всем универсальную пилюлю не буду.
Корни зла
Уже третий проект, в который я прихожу страдает кодом 200 в REST. Именно страдает. Другого слова нет. Если вы внимательно прочли всё до текущего момента, вы уже понимаете, что как только проект начинает расти, у него появляется потребность в развитии инфраструктуры, в ее устойчивости. Код 200 убивает все эти потуги на корню. И первое, что приходится делать — ломать стереотипы.
Корень зла, мне кажется лежит в том, что код 500, это первое, что web-разработчик встречает в своей профессиональной деятельности. Это, можно сказать, детская травма. И все его старания поначалу сводятся к тому, чтобы получить код 200.
Кстати, по какой-то причине, на этом же этапе развивается устойчивое мнение, что только ответы с кодом 200 могут быть снабжены телом. Конечно, это не так и с любым кодом может “приехать” любой ответ. Код это код. Тело это тело.
Далее, с развитием разработчика, у него возникают потребности в управлении багами собственного приложения. Но…, он не умеет пользоваться логами. Не умеет настраивать web-сервер. Он учится. И рождаются те самые «велики». Потому что, они ему доступны и он может их быстро сделать. Далее, на этот «велик» он монтирует новые колеса, усиливает раму и т.д. И этот велик становится его спутником на достаточно длительный промежуток времени, пока… пока у него не появляются реально сложные, многокомпонентные задачи. И тут, как говорится — вход в супермаркет с «великами» и на роликах запрещен.
P.S.: Автор упомянутой статьи восстановил ее из черновиков — habr.com/ru/post/440382, поэтому можно ознакомиться с ней тоже.
P.P.S.: Я постарался изложить все грани необходимости использования релевантных кодов ответа в REST. Я не буду отвечать на комментарии, прошу понять меня правильно. С большим вниманием буду их читать, но добавить мне нечего. Огромное спасибо за то, что вам хватило терпения прочесть статью!
Reference: RFC 2616 — HTTP Status Code Definitions
- HTTP/1.1 Status Code Definitions
- Additional HTTP Status Codes
General
- 400 BAD REQUEST: The request was invalid or cannot be otherwise served. An accompanying error message will explain further. For security reasons, requests without authentication are considered invalid and will yield this response.
- 401 UNAUTHORIZED: The authentication credentials are missing, or if supplied are not valid or not sufficient to access the resource.
- 403 FORBIDDEN: The request has been refused. See the accompanying message for the specific reason (most likely for exceeding rate limit).
- 404 NOT FOUND: The URI requested is invalid or the resource requested does not exists.
- 406 NOT ACCEPTABLE: The request specified an invalid format.
- 410 GONE: This resource is gone. Used to indicate that an API endpoint has been turned off.
- 429 TOO MANY REQUESTS: Returned when a request cannot be served due to the application’s rate limit having been exhausted for the resource.
- 500 INTERNAL SERVER ERROR: Something is horribly wrong.
- 502 BAD GATEWAY: The service is down or being upgraded. Try again later.
- 503 SERVICE UNAVAILABLE: The service is up, but overloaded with requests. Try again later.
- 504 GATEWAY TIMEOUT: Servers are up, but the request couldn’t be serviced due to some failure within our stack. Try again later.
HTTP GET
- 200 OK: The request was successful and the response body contains the representation requested.
- 302 FOUND: A common redirect response; you can GET the representation at the URI in the Location response header.
- 304 NOT MODIFIED: There is no new data to return.
HTTP POST or PUT
- 201 OK: The request was successful, we updated the resource and the response body contains the representation.
- 202 ACCEPTED: The request has been accepted for further processing, which will be completed sometime later.
HTTP DELETE
- 202 ACCEPTED: The request has been accepted for further processing, which will be completed sometime later.
- 204 OK: The request was successful; the resource was deleted.
- I’d Rather Be Writing
- Learn API Doc
- Conceptual topics in API docs
Last updated: May 10, 2020
Status and error codes refer to a code number in the response header that indicates the general classification of the response — for example, whether the request was successful (200), resulted in a server error (500), had authorization issues (403), and so on. Standard status codes don’t usually need much documentation, but custom status and error codes specific to your API do. Error codes in particular help in troubleshooting bad requests.
- Sample status code in curl header
- Where to list the HTTP response and error codes
- Where to get status and error codes
- How to list status codes
- Status/error codes can assist in troubleshooting
- Example of status and error codes
- Context.io
- Mailchimp
- Flickr
- Activity with status and error codes
Status codes don’t appear in the response body. They appear in the response header, which you might not see by default.
Remember when you submitted the curl call back in Make a curl call? To get the response header, you add --include or -i to the curl request. If you want only the response header returned in the response (and nothing else), capitalize the -I, like this:
curl -I -X GET "https://api.openweathermap.org/data/2.5/weather?zip=95050&appid=APIKEY&units=imperial"
Replace APIKEY with your actual API key.
The response header looks as follows:
HTTP/1.1 200 OK
Server: openresty
Date: Thu, 06 Dec 2018 22:58:41 GMT
Content-Type: application/json; charset=utf-8
Content-Length: 446
Connection: keep-alive
X-Cache-Key: /data/2.5/weather?units=imperial&zip=95050
Access-Control-Allow-Origin: *
Access-Control-Allow-Credentials: true
Access-Control-Allow-Methods: GET, POST
The first line, HTTP/1.1 200 OK, tells us the status of the request (200). Most REST APIs follow a standard protocol for response headers. For example, 200 isn’t just an arbitrary code decided upon by the OpenWeatherMap API developers. 200 is a universally accepted code for a successful HTTP request. (If you change the method, you’ll get back a different status code.)
With a GET request, it’s pretty easy to tell if the request is successful because you get back the expected response. But suppose you’re making a POST, PUT, or DELETE call, where you’re changing data contained in the resource. How do you know if the request was successfully processed and received by the API? HTTP response codes in the header of the response will indicate whether the operation was successful. The HTTP status codes are just abbreviations for longer messages.

All too often, status codes are uninformative, poorly written, and communicate little or no helpful information to the user to overcome the error. Ultimately, status codes should assist users in recovering from errors.
You can see a list of common REST API status codes here and a general list of HTTP status codes here. Although it’s probably good to include a few standard status codes, comprehensively documenting all standard status codes, especially if rarely triggered by your API, is unnecessary.
Where to list the HTTP response and error codes
Most APIs should have a general page listing response and error codes across the entire API. A standalone page listing the status codes (rather than including these status codes with each endpoint) allows you to expand on each code with more detail without crowding the other documentation. It also reduces redundancy and the sense of information overload.
On the other hand, if some endpoints are prone to triggering certain status and error codes more than others, it makes sense to highlight those status and error codes on same API reference pages. One strategy might be to call attention to any particularly relevant status or error codes for a specific endpoint, and then link to the centralized “Response and Status Codes” page for full information.
Where to get status and error codes
Status and error codes may not be readily apparent when you’re documenting your API. You’ll probably need to ask developers for a list of all the status and error codes that are unique to your API. Sometimes developers hard-code these status and error codes directly in the programming code and don’t have easy ways to hand you a comprehensive list (this makes localization problematic as well).
As a result, you may need to experiment a bit to ferret out all the codes. Specifically, you might need to try to break the API to see all the potential error codes. For example, if you exceed the rate limit for a specific call, the API might return a special error or status code. You would especially need to document this custom code. A troubleshooting section in your API might make special use of the error codes.
How to list status codes
You can list your status and error codes in a basic table or definition list, somewhat like this:
| Status code | Meaning |
|---|---|
| 200 | Successful request and response. |
| 400 | Malformed parameters or other bad request. |
Status/error codes can assist in troubleshooting
Status and error codes can be particularly helpful when it comes to troubleshooting. As such, you can think of these error codes as complementary to a section on troubleshooting.
Almost every set of documentation could benefit from a section on troubleshooting. In a troubleshooting topic, you document what happens when users get off the happy path and stumble around in the dark forest. Status codes are like the poorly illuminated trail signs that will help users get back onto the right path.
A section on troubleshooting could list error messages related to the following situations:
- The wrong API keys are used
- Invalid API keys are used
- The parameters don’t fit the data types
- The API throws an exception
- There’s no data for the resource to return
- The rate limits have been exceeded
- The parameters are outside the max and min boundaries of what’s acceptable
- A required parameter is absent from the endpoint
Where possible, document the exact text of the error in the documentation so that it easily surfaces in searches.
Example of status and error codes
The following are some sample status and error code pages in API documentation.
Context.io
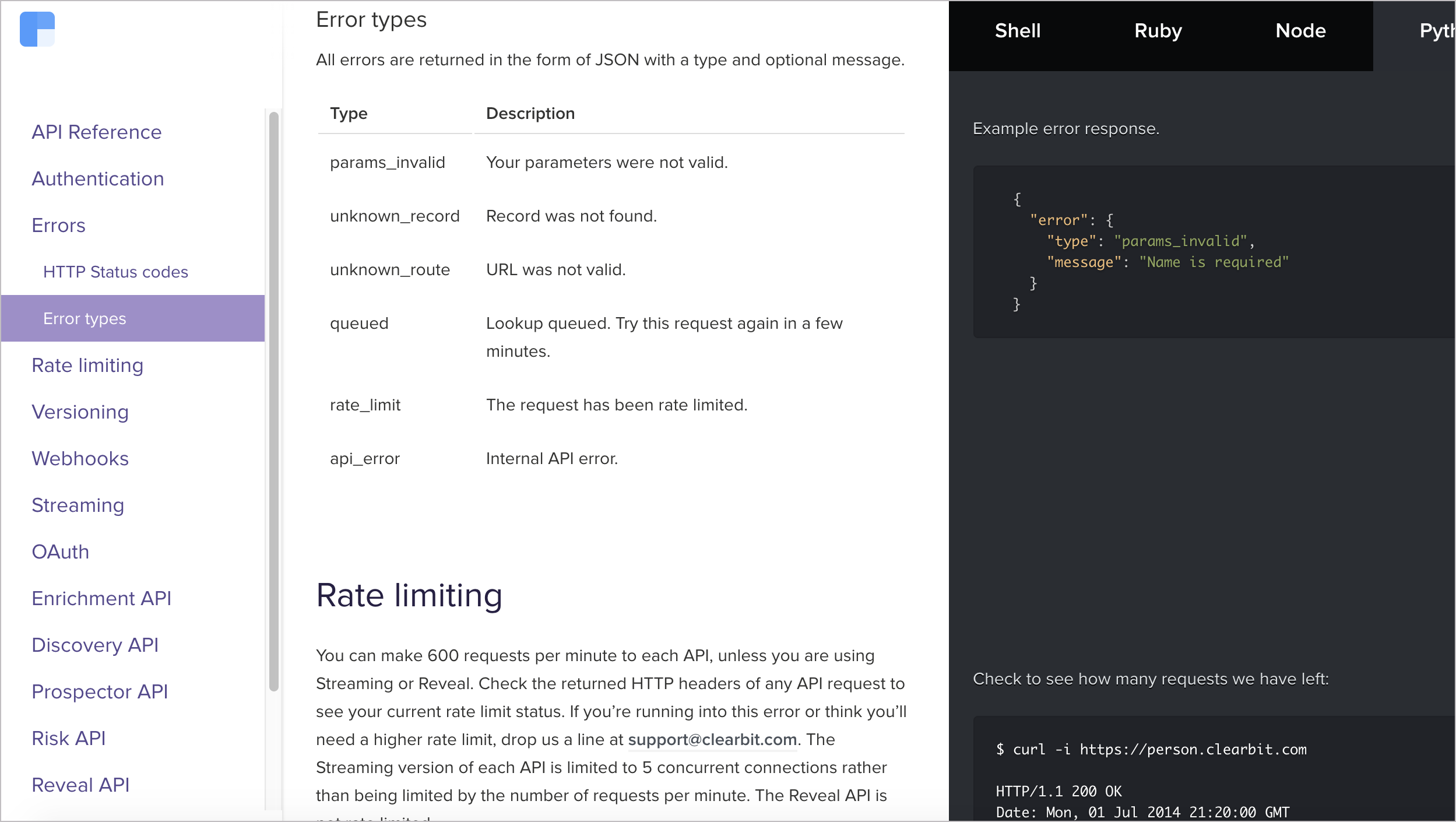
Clearbit not only documents the standard status codes but also describes the unique parameters returned by their API. Most developers will probably be familiar with 200, 400, and 500 codes, so these codes don’t need a lot of explanatory detail. But if your API has unique codes, make sure to describe these adequately.
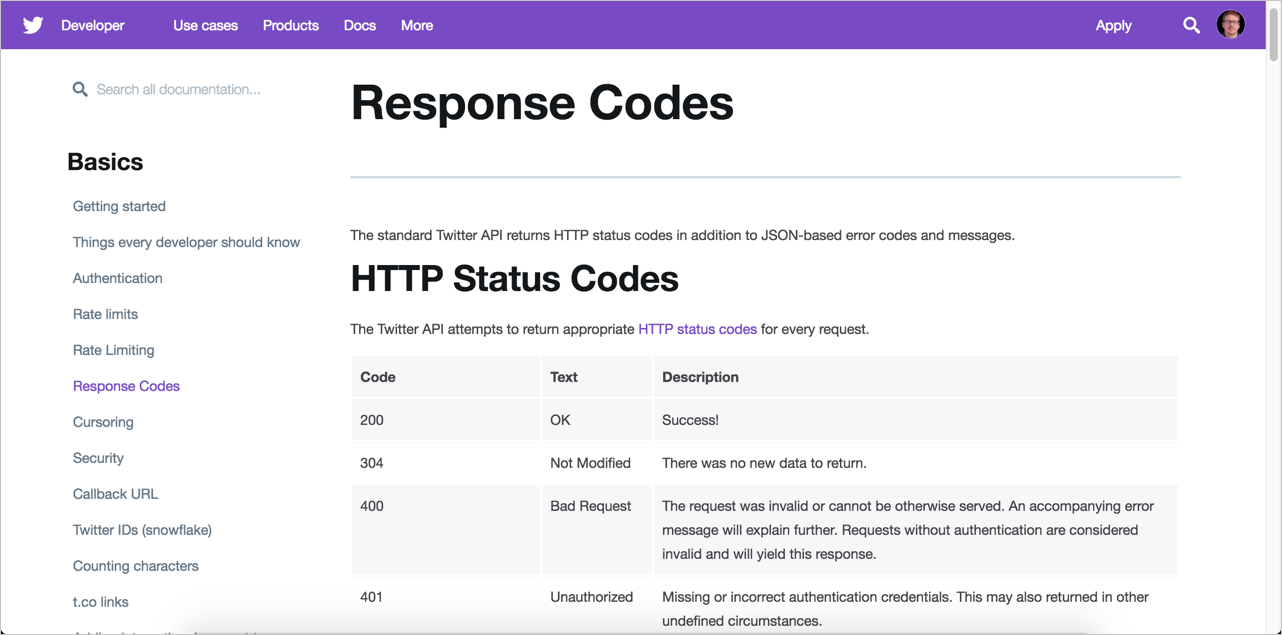
With Twitter’s status code documentation, they not only describe the code and status but also provide helpful troubleshooting information, potentially assisting with error recovery. For example, with the 500 error, the authors don’t just say the status refers to a broken service, they explain, “This is usually a temporary error, for example in a high load situation or if an endpoint is temporarily having issues. Check in the developer forums in case others are having similar issues, or try again later.”
This kind of helpful message is what tech writers should aim for with status codes (at least for those codes that indicate problems).
Mailchimp
Mailchimp provides readable and friendly descriptions of the error message. For example, with the 403 errors, instead of just writing “Forbidden,” Mailchimp explains reasons why you might receive the Forbidden code. With Mailchimp, there are several types of 403 errors. Your request might be forbidden due to a disabled user account or request made to the wrong data center. For the “WrongDataCenter” error, Mailchimp notes that “It’s often associated with misconfigured libraries” and they link to more information on data centers. This is the type of error code documentation that is helpful to users.
Flickr
With Flickr, the Response Codes section is embedded within each API reference topic. As such, the descriptions are short. While embedding the Response Codes in each topic makes the error codes more visible, in some ways it’s less helpful. Because it’s embedded within each API topic, the descriptions about the error codes must be brief, or the content would overwhelm the endpoint request information.
In contrast, a standalone page listing error codes allows you to expand on each code with more detail without crowding out the other documentation. The standalone page also reduces redundancy and the appearance of a heavy amount of information (information which is just repeated).
If some endpoints are prone to triggering certain status and error codes more than others, it makes sense to highlight those status and error codes on their relevant API reference pages. I recommend calling attention to any particularly relevant status or error codes on an endpoint’s page and then linking to the centralized page for full information.
Activity with status and error codes
With the open-source project you identified, identify the status and error code information. Answer the following questions:
- Does the project describe status and error codes?
- Where is the status and error code information located within the context of the documentation? As a standalone topic? Below each endpoint? Somewhere else?
- Does the API have any unique status and error codes?
- Do the error codes help users recover from errors?
- Make a request to one of the endpoints. Then purposefully change a parameter so that it invalidates the call. What status code gets returned in the response? Is this status code documented?
71/162 pages complete. Only 91 more pages to go.