Содержание
- Что такое ошибка NXDOMAIN и как ее избежать
- Что такое DNS и как работает?
- Что такое ошибка NXDOMAIN
- Возможные причины ошибки NXDOMAIN
- Как исправить ошибку NXDOMAIN
- Изменить DNS
- Избегайте использования VPN
- Проверьте, не мешает ли какой-либо антивирус или брандмауэр
- Обеспечьте бесперебойную работу браузера
- Перезагрузить систему
- DNS lookups fail with ISPs that do NXDOMAIN wildcarding #1901
- Comments
- Solution for Docker issue failed to solve: rpc error: code = unknown desc
- Docker Error Messages
- Problem
- Docker Setup
- Solution
- Conclusion
- Failed create pod sandbox: rpc error: code = Unknown desc #198
- Comments
- Kubernetes ImagePullBackOff: Troubleshooting With Examples
- What Does an ImagePullBackOff Error Mean?
- How Can You Troubleshoot ImagePullBackOff?
- Image Doesn’t Exist, or Name Is Incorrect
- Tag Doesn’t Exist
- Private Image Registry and Wrong Credentials Provided
- Network Issue
- Container Registry Rate Limits
- Monitor ImagePullBackoffs With ContainIQ
- Final Thoughts
Что такое ошибка NXDOMAIN и как ее избежать
При просмотре страниц в Интернете и использовании наших устройств для подключения мы можем столкнуться с проблемами, которые мешают правильной работе подключения. Иногда это может быть аппаратный сбой, а иногда просто плохая конфигурация. Иногда ошибка может быть нашей (сетевая карта, оборудование, маршрутизатор, кабели, система…), но иногда эта ошибка является внешней, от самого оператора Интернета. В этой статье мы поговорим о что за ошибка NXDOMAIN и что делать, если он появится.
Что такое DNS и как работает?
Чтобы понять, что Ошибка NXDOMAIN есть, мы должны сначала вспомнить, что DNS есть и как это работает. Можно сказать, что DNS-серверы действуют как переводчики, позволяя нам просматривать Интернет без запоминания большого количества цифр.
При входе на веб-страницу мы обычно переходим в адресную строку браузера и пишем там имя и адрес. Например, мы пишем redeszone.net. Мы можем это сделать благодаря DNS-серверы которые переводят это сообщение, которое мы пишем, на соответствующий IP-адрес. Таким образом, нам не нужно запоминать, что это за IP-адрес, а просто имя, которое мы пишем.
Таким образом, DNS-серверы действуют как посредники, чтобы иметь возможность отвечать на запросы что мы делаем. Есть много DNS-серверов, которые мы можем использовать. Бывают платные и бесплатные. Некоторые даже могут помочь нам повысить безопасность, поскольку они настроены на фильтрацию возможных вредоносных страниц, а не на отправку содержимого. Иногда смена серверов нашего интернет-оператора может помочь улучшить скорость.
Теперь, иногда в этом типе услуг могут быть проблемы и сбой при поиске в Интернете. Вот тут и возникает ошибка NXDOMAIN, о которой мы и поговорим.
Что такое ошибка NXDOMAIN
Когда мы пытаемся войти на веб-страницу и получаем сообщение об ошибке с указанием NXDOMAIN, это означает, что имя домена не может быть разрешено. Это логически означает, что мы не можем перемещаться по сайту, к которому пытаемся получить доступ.
Отображаемое сообщение может незначительно отличаться. Например, в Google Chrome в браузере появившееся сообщение будет DNS_PROBE_FINISHED_NXDOMAIN . Это означает, что страница, на которую мы пытаемся войти, загружается некорректно.
Возможные причины ошибки NXDOMAIN
Эта ошибка может возникать по разным причинам. Иногда это может быть в наших силах исправить, а в других случаях это зависит от сервера сайта. Посмотрим, что за Основные причины составляют:
- DNS-сервер не работает
- Проблема с DNS-клиентом
- VPN мешает
- Установленные средства безопасности
- Неправильные настройки DNS
- Проблемы с браузером
Как исправить ошибку NXDOMAIN
К счастью, мы можем принять во внимание определенные шаги, чтобы решить Ошибка NXDOMAIN . Это, как мы уже упоминали, может произойти в любом браузере, который мы используем, поэтому совет, который мы собираемся дать, является общим, и мы можем применить его в любом случае.
Некоторые проблемы, вызывающие эту ошибку, мы не сможем решить с нашей стороны, например, когда они присутствуют на стороне сервера.
Изменить DNS
Проблемы такого типа могут быть связаны с ошибками DNS-серверы что мы используем. Мы уже упоминали, что можем использовать много разных, как бесплатных, так и платных.
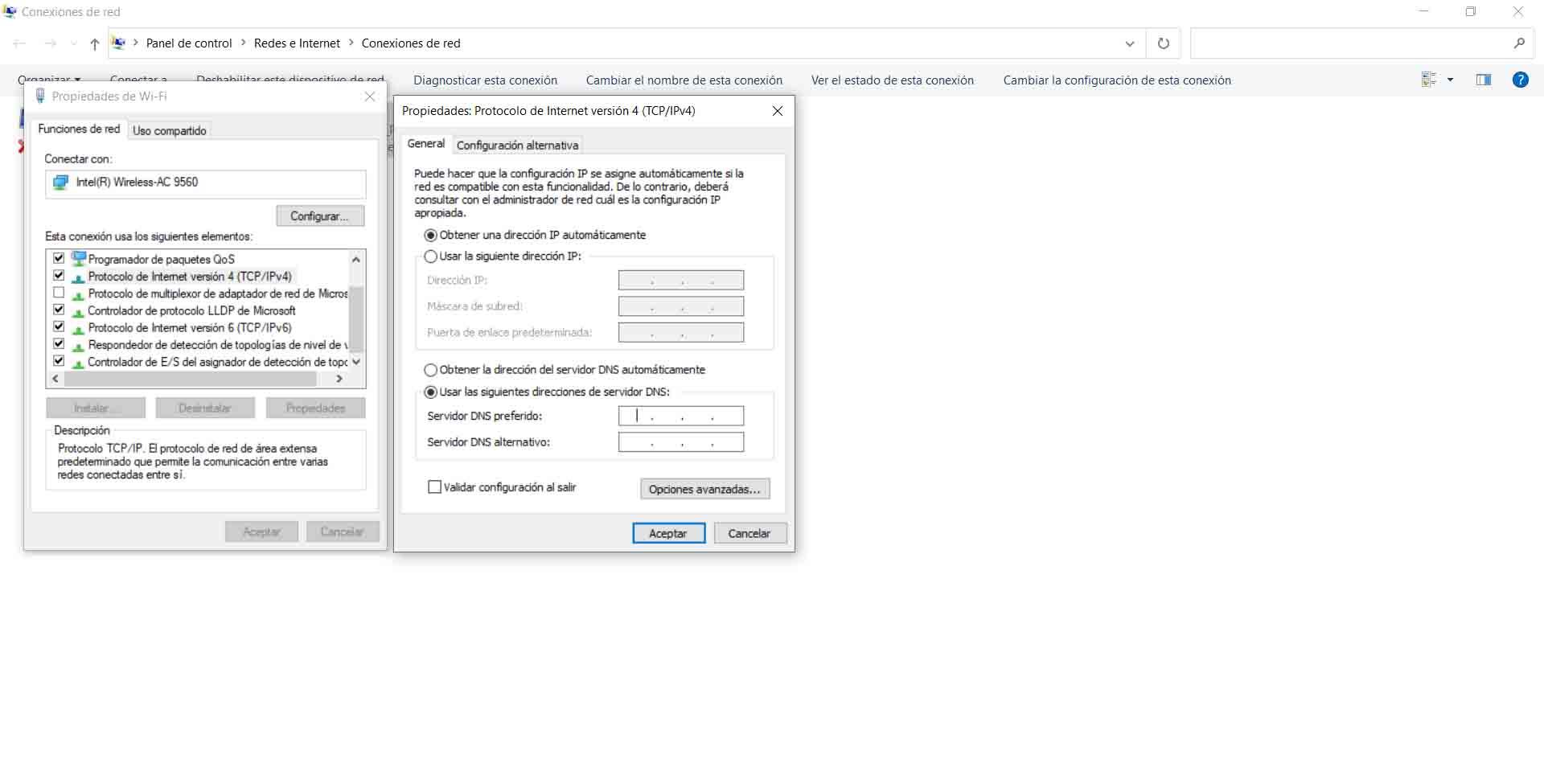
В случае появления такого типа сообщения мы можем попробовать выбрать другой общедоступный DNS, чем те, которые мы используем. Мы можем легко изменить их в Windows, через настройки сети. Для этого заходим в Конфигурацию, Cеть и Интернет, мы вводим Параметры смены адаптера и там выбираем интересующую нас сеть, нажимаем Свойства и откроется окно для изменения IP-адреса и DNS.
Избегайте использования VPN
Мы также видели, что причиной ошибки NXDOMAIN является то, что мы используем VPN и это создает конфликт. Мы можем временно приостановить работу этого инструмента и проверить, действительно ли это связано с этой проблемой.
Если мы обнаружим, что это действительно VPN, мы можем либо не использовать его, либо переключиться на другую службу.
Проверьте, не мешает ли какой-либо антивирус или брандмауэр
Также могло случиться, что антивирус или брандмауэр которые мы используем, создавали проблемы. Мы уже знаем, что инструменты безопасности необходимы для предотвращения сетевых проблем, но они также могут вызвать определенные сбои при неправильной конфигурации.
Обеспечьте бесперебойную работу браузера
Конечно браузер должен работать правильно . Вы должны быть осторожны, например, если используете плохо настроенные расширения. Мы должны убедиться, что все, что окружает браузер, работает правильно, и, таким образом, исправить возможные ошибки, вызывающие эту проблему, чтобы правильно разрешить доменные имена.
Перезагрузить систему
Это базовое решение, но во многих случаях оно может решить проблемы такого типа. Мы должны перезапуск и наш компьютер, и сам роутер. Таким образом, мы можем исправить подобные и подобные ошибки.
В конечном счете, это некоторые варианты, которые мы должны решить, когда появляется ошибка NXDOMAIN.
Источник
DNS lookups fail with ISPs that do NXDOMAIN wildcarding #1901
What happened:
User has an ISP that does «DNS Wildcarding», i.e. responds to domains that would otherwise be NXDOMAIN with webservers that serve ads.
Kind fails to start with these errors, because it got IP addresses for ad servers instead of NXDOMAIN (which I assume would cause it to fall through the correct path to handle whatever nonexistent local domain it’s using for this):
CoreDNS pods reporting failures:
What you expected to happen:
Kind starts and DNS lookups work.
How to reproduce it (as minimally and precisely as possible):
Either have a bad ISP that does this, or point to a DNS server that responds to all queries to nonexistent domains with a webserver ip.
Anything else we need to know?:
I don’t know if this is the right place for this issue, but I was thinking that kind could check for this case (may be an easy check, look up a domain that shouldn’t exist and see what comes back).
Environment:
(this wasn’t on my machine, but I’ll get this information. We should all be on v0.9.0 of kind)
- kind version: (use kind version ):
- Kubernetes version: (use kubectl version ):
- Docker version: (use docker info ):
- OS (e.g. from /etc/os-release ):
The text was updated successfully, but these errors were encountered:
Источник
Solution for Docker issue failed to solve: rpc error: code = unknown desc
This post presents a solution to an error I encountered recently with Docker when trying to bring up a docker container using docker-compose.
The solution in the post helped me fix the Docker issue failed to solve: rpc error: code = unknown desc = failed to solve with frontend dockerfile v0
Docker Error Messages
If you have been having the same problem as me, you might get one of the following error messages from Docker:
docker failed to solve rpc error code = unknown desc
docker failed to solve with frontend dockerfile.v0
failed to solve: rpc error: code = unknown desc = failed to solve with frontend dockerfile v0
Docker build error: failed to solve with the frontend dockerfile
Problem
The problem with Docker was happening when I was trying to bring up docker using a docker-compose file. I was using a command similar to this one:
> sudo -E docker-compose -f docker-compose.yml -f docker-compose.local.yml up —build
The error message I got was as follows:
I tried a few variations to bring up the docker containers
> sudo docker-compose -f docker-compose.local.yml up -d
I got similar error messages from docker:
I also tried to clear out existing docker containers and images from the cache. > sudo docker system prune -a -f This did not work when I tried to rebuild docker containers as above.
The consistent error from each of the commands I tried that failed seemed to be not finding a docker file.
Docker Setup
You can skip to the solution here, as this section helps check if docker is correctly installed.
The first step you can try is to make sure you can actually run a вЂhello world’ docker image successfully. You can do this by executing the following command:
> docker run hello-world
The output of this command should be as follows:
As suggested in the output of the docker hello world example, you can try a more advanced docker test, which would be to run the latest ubuntu image and execute command via the bash terminal in ubuntu.
> docker run -it ubuntu bash
The output should be as follow, and should give you terminal access as the root user.
Solution
The solution is to explicitly give the name of the docker file in the docker-compose.yml. Change how you specify the location of your dockerfile from dockerfile: . to dockerfile: Dockerfile
This is an sample of the docker-compose file which did not work on Ubuntu 20.04 or Windows10, it only seems to work on MacOS only. As you can see, the dockerfile location is specified as a вЂ.’
The sample docker-compose file shown below is a working cross platform file, which works on MacOS, Ubuntu, Windows10.
As you can see, the line specifying the dockerfile has been changed from a dot вЂ.’ to the explicit file name, in my case, it was вЂDockerfile’.
This also works with lower and uppercase docker files as dockerfile: Dockerfile or dockerfile: dockerfile
Conclusion
The problem seemed to originate from the cross platform development and testing of the docker-compose script, between MacOS and Ubuntu / Window10 using version 3 of docker-compose. In the scenario of specifying the location of the dockerfile.
The original docker-compose file was built on MacOS, I was trying to use the same file but on Ubuntu 20.04. I believe this same problem can also occur if also trying to use docker-compose developed using MacOS on Windows10.
If you are using MacOS, then this docker-compose file will most likely run without any problems (if you do not have any other unrelated problems).
You can read more about how I have used docker in my other projects.
What can you do to improve your life as a programmer?
my article provides some ideas!
If this article helped you out, consider buying me a beer coffee?
Creating your first programming language is easier than you think,
. also looks great on your resume/cv.
Any comments? Send me a message on twitter @AyeshAlshukri or on Reddit /user/AyeshAlshukri/
Источник
Failed create pod sandbox: rpc error: code = Unknown desc #198
coredns pod doenst start
Failed create pod sandbox: rpc error: code = Unknown desc = failed to start sandbox container for pod «coredns-74c9d4d795-xpbsd»: Error response from daemon: OCI runtime create failed: container_linux.go:345: starting container process caused «process_linux.go:303: getting the final child’s pid from pipe caused »read init-p: connection reset by peer»»: unknown 
The text was updated successfully, but these errors were encountered:
looks like a docker problem
can you sudo docker run —rm -it hello-world on the same node that the coredns pod cannot start?
So that node cannot reach the outside world?
Hmm , I can ping google:
It seems that at least docker cannot reach the docker registry. Maybe thats blocked on your network. Does . docker run —rm -it k8s.gcr.io/coredns:1.6.2 work?
Then restart Docker:
Is it normal that the coredns works on the master node and on worker1, although there are three workers, should it not only be on the master as a service service? 
Is it normal that the coredns works on the master node and on worker1, although there are three workers
Yes. This can happen if your master doesn’t have the no-schedule taint so it accepts scheduled pods. It also will happen if your coredns Deployment is configured to tolerate (ignore) the no-schedule taint.
docker: Error response from daemon
Looks like docker is broken on worker1.
Try testing docker connectivity from other nodes to see if they suffer the same issue. You may want to make sure you dont have a firewall somewhere blocking https.
I’m not adept at diagnosing and resolving docker issues. But I would try rebooting the affected node to see if that helps. If that doesn’t help maybe try uninstalling/re-installing docker server and client, or rebuilding the node.
thx for feedback.
the same erorror on others nodes.
But I do not want to risk and update the kernel
but it does not work’s , if even I stop firewalld.
Источник
Kubernetes ImagePullBackOff: Troubleshooting With Examples
If you’ve worked with Kubernetes for a while, chances are good that you have experienced the ImagePullBackOff status. This issue can be frustrating if you are unfamiliar with it, so in this guide, you will walk the reader through how to troubleshoot this issue, what some common causes are, and where to start if they encounter this problem.


Troubleshooting an issue on a distributed system like Kubernetes can be challenging at times. There are just so many things that can go wrong with a distributed system. It can be even more challenging when a particular error has multiple reasons for occurring.
One such error is ImagePullBackOff . It typically shows up when the kubelet agent instructs the container runtime and can’t pull the image from the container registry for various reasons.
This article will provide an in-depth overview of possible causes for your pod entering into ImagePullBackOff state while starting your container. More importantly, you’ll learn how to troubleshoot and solve this notorious error.
What Does an ImagePullBackOff Error Mean?
The ImagePull part of the ImagePullBackOff error primarily relates to your Kubernetes container runtime being unable to pull the image from a private or public container registry. The Backoff part indicates that Kubernetes will continuously pull the image with an increasing backoff delay. Kubernetes will keep on increasing the delay with each attempt until it reaches the limit of five minutes.
It seems like a generalized statement to say that container runtime (be it Docker, containerd, etc.) fails to pull the image from the registry, but let’s try to understand the possible causes for this issue.
Here are some of the possible causes behind your pod getting stuck in the ImagePullBackOff state:
- Image doesn’t exist.
- Image tag or name is incorrect.
- Image is private, and there is an authentication failure.
- Network issue.
- Registry name is incorrect.
- Container registry rate limits.
How Can You Troubleshoot ImagePullBackOff?
Let’s try to troubleshoot each of the possible causes in that bulleted list.
Image Doesn’t Exist, or Name Is Incorrect
In most cases, the error could be either from a typo or the image was not pushed to the container registry, and you’re referring to an image that doesn’t exist. Let’s try to replicate this by creating a pod with a fake image name.
As you can see, the pod is stuck in an ImagePullBackOff because the image doesn’t exist and we cannot pull the image.
$ kubectl get pod
| NAME | READY | STATUS | RESTARTS | AGE |
|---|---|---|---|---|
| myapp | 0/1 | ImagePullBackOff | 4m59s |
To understand the root cause and find more details about this error, use the kubectl describe command. The command itself gives a verbose output, so we’ll just show the parts of output that are relevant to our discussion.
In the following output under Events in the Message column, you can see the actual error message:
Which confirms that the image doesn’t exist.
$ kubectl describe pod myapp
| Type | Reason | Age | From | Message |
|---|---|---|---|---|
| —- | —— | —- | —- | ——- |
| Normal | Scheduled | 2m54s | default-scheduler | Successfully assigned default/myapp to minikube |
| Normal | Pulling | 71s (x4 over 2m53s) | kubelet | Pulling image «myimage/myimage:latest» |
| Warning | Failed | 67s (x4 over 2m49s) | kubelet | Failed to pull image «myimage/myimage:latest»: rpc error: code = Unknown desc = Error response from daemon: pull access denied for myimage/myimage, repository does not exist or may require ‘docker login’: denied: requested access to the resource is denied |
| Warning | Failed | 67s (x4 over 2m49s) | kubelet | Error: ErrImagePull |
| Warning | Failed | 54s (x6 over 2m48s) | kubelet | Error: ImagePullBackOff |
| Normal | Backoff | 41s (x7 over 2m48s) | kubelet | Back-off pulling image «myimage/myimage:latest» |





Tag Doesn’t Exist
There could be cases where the image tag you’re trying to pull is retired, or you entered the wrong tag name. In those cases, your pod will again get stuck in the ImagePullBackOff state, as seen in the following code snippet.
We have deliberately entered the wrong tag name, lates instead of latest , to replicate this issue.
kubectl get pod
| NAME | READY | STATUS | RESTARTS | AGE |
|---|---|---|---|---|
| nginx | 0/1 | ImagePullBackOff | 3m3s |
In the following output, the message indicates that tag lates doesn’t exist for image nginx .
Hence the image pull is unsuccessful.
$ kubectl describe pod nginx
| Type | Reason | Age | From | Message |
|---|---|---|---|---|
| —- | —— | —- | —- | ——- |
| Normal | Scheduled | 26s | default-scheduler | Successfully assigned default/nginx to minikube |
| Normal | Backoff | 20s | kubelet | Back-off pulling image «nginx:lates» |
| Warning | Failed | 20s | kubelet | Error: ImagePullBackOff |
| Normal | Pulling | 6s (x2 over 25s) | kubelet | Pulling image «nginx:lates» |
| Warning | Failed | 2s (x2 over 20s) | kubelet | Failed to pull image «nginx:lates»: rpc error: code = Unknown desc = Error response from daemon: manifest for nginx:lates not found: manifest unknown: manifest unknown |
| Warning | Failed | 2s (x2 over 20s) | kubelet | Error: ErrImagePull |
Private Image Registry and Wrong Credentials Provided
Most enterprises typically use an internal private container registry instead of DockerHub because they don’t want to push their internal applications to someone outside their organization. Even with DockerHub or any other publicly accessible password-protected registry, you must provide proper credentials to Kubernetes using the secret to pull the image from the registry.
In the following example, we’re trying to replicate this issue by spinning up a pod that uses an image from a private registry.
We have neither added a secret to Kubernetes nor reference of the secret in pod definition. The pod will again get stuck in the ImagePullBackOff status and the message confirms that access is denied to pull an image from the registry:
$ kubectl describe pod mypod
| Type | Reason | Age | From | Message |
|---|---|---|---|---|
| —- | —— | —- | —- | ——- |
| Normal | Scheduled | 39s | default-scheduler | Successfully assigned default/mypod to minikube |
| Normal | Pulling | 20s (x2 over 37s) | kubelet | Pulling image «docker.io/hiyou/image» |
| Warning | Failed | 16s (x2 over 33s) | kubelet | Failed to pull image «docker.io/hiyou/image»: rpc error: code = Unknown desc = Error response from daemon: pull access denied for hiyou/image, repository does not exist or may require ‘docker login’: denied: requested access to the resource is denied |
| Warning | Failed | 16s (x2 over 33s) | kubelet | Error: ErrImagePull |
| Normal | Backoff | 3s (x2 over 32s) | kubelet | Back-off pulling image «docker.io/hiyou/image» |
| Warning | Failed | 3s (x2 over 32s) | kubelet | Error: ImagePullBackOff |
To resolve this error, create a secret using the following kubectl command. The following kubectl command creates a secret for a private Docker registry.
Add your secret to your pod definition, as explained in the following snippet.
Network Issue
There could be a widespread network issue on all the nodes of your Kubernetes cluster, and the container runtime will not be able to pull the image from the container registry. Let’s try to replicate that scenario.
$ kubectl describe pod nginx
| Type | Reason | Age | From | Message |
|---|---|---|---|---|
| —- | —— | —- | —- | ——- |
| Normal | Scheduled | 35s | default-scheduler | Successfully assigned default/mypod to minikube |
| Normal | Pulling | 19s (x2 over 32s) | kubelet | Pulling image «nginx:latest» |
| Warning | Failed | 19s (x2 over 32s) | kubelet | Failed to pull image «nginx:latest»: rpc error: code = Unknown desc = failed to pull and unpack image «docker.io/library/nginx:latest»: failed to resolve reference «docker.io/library/nginx:latest»: failed to do request: Head https://registry-1.docker.io/v2/library/nginx/manifests/latest: dial tcp: lookup registry-1.docker.io on 192.168.64.1:53: server misbehaving |
| Warning | Failed | 19s (x2 over 32s) | kubelet | Error: ErrImagePull |
| Normal | Backoff | 5s (x2 over 32s) | kubelet | Back-off pulling image «nginx:latest» |
| Warning | Failed | 5s (x2 over 32s) | kubelet | Error: ImagePullBackOff |
In the preceding output, the message indicates that there is a network issue.
Container Registry Rate Limits
Most container registries have implemented some rate limits (i.e., number of images you can pull) to protect their infrastructure. For example, with Docker Hub, anonymous and free Docker Hub users can only request 100 and 200 container image pull requests per six hours. If you exceed your maximum download limit, you’ll be blocked, resulting in ImagePullBackOff error.
To resolve this for Docker Hub, you would need to upgrade to a Pro or Team account. Many other popular container image registries like GCR or ECR propose similar limitations.
Monitor ImagePullBackoffs With ContainIQ
Using ContainIQ, you can monitor, track, and alert on`ImagePullBackoff` events.
ContainIQ, a tool for monitoring Kubernetes clusters, allows users to view and graph `ImagePullBackoff` events over time. Users can also track the events leading up to the backoff, like `ErrImagePull`, to get alerted as the image pull fails but before the backoff event fires.
ContainIQ provides tooling to set alerts on `ImagePullBackoff` events by pod and get notified in Slack when they occur.В Users can also use the filtering features to view other related Warning events as they happen or during a specific period of time.
For example, a ContainIQ user could be alerted if a pod’s state becomes `ImagePullBackoff` because the image is private, and there is an authentication failure, or if the registry / tag name is incorrect. On the other hand, users can also view and graph Normal events such as an image pulling successfully. With this information you could see how often certain images are being pulled and which applications are being deployed the most frequently.В
Using the New Monitor button, users can set alerts on `ImagePullBackoff events` for specific pods, or across all pods. Alerts can be toggled on and off with one click from the Monitors tab. A user can also alert on other events like job failures, pod evictions, or health check failures.
You can sign up for ContainIQ here, or book a demo to learn more.
Final Thoughts
In this article, you learned some possible reasons why a pod would get stuck in an ImagePullBackOff state. You checked out some different examples to understand the error better and troubleshoot it with commands like kubectl describe .
If you’re confident there is no typo in the image, registry, or tag name, then kubectl describe will reveal the chain of events that led to the failure. In some cases, you may be able to pull the image using docker pull , but your cluster can’t, then that probably means there’s a network issue.
Источник
What happened:
User has an ISP that does «DNS Wildcarding», i.e. responds to domains that would otherwise be NXDOMAIN with webservers that serve ads.
See Redirecting DNS for Ads and Profit and DNS Wildcarding.
Kind fails to start with these errors, because it got IP addresses for ad servers instead of NXDOMAIN (which I assume would cause it to fall through the correct path to handle whatever nonexistent local domain it’s using for this):
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 13m default-scheduler Successfully assigned cert-manager/cert-manager-cainjector-7976f978f-qtztr to local1-1-worker3
Warning Failed 13m kubelet, local1-1-worker3 Failed to pull image "quay.io/jetstack/cert-manager-cainjector:v0.14.2": rpc error: code = Unknown desc = failed to pull and unpack image "quay.io/jetstack/cert-manager-cainjector:v0.14.2": failed to resolve reference "quay.io/jetstack/cert-manager-cainjector:v0.14.2": failed to do request: Head https://quay.io/v2/jetstack/cert-manager-cainjector/manifests/v0.14.2: dial tcp: lookup quay.io on 23.217.138.110:53: read udp 172.18.0.5:52546->23.217.138.110:53: i/o timeout
Warning Failed 13m kubelet, local1-1-worker3 Failed to pull image "quay.io/jetstack/cert-manager-cainjector:v0.14.2": rpc error: code = Unknown desc = failed to pull and unpack image "quay.io/jetstack/cert-manager-cainjector:v0.14.2": failed to resolve reference "quay.io/jetstack/cert-manager-cainjector:v0.14.2": failed to do request: Head https://quay.io/v2/jetstack/cert-manager-cainjector/manifests/v0.14.2: dial tcp: lookup quay.io on 23.217.138.110:53: read udp 172.18.0.5:50590->23.217.138.110:53: i/o timeout
Warning Failed 12m kubelet, local1-1-worker3 Failed to pull image "quay.io/jetstack/cert-manager-cainjector:v0.14.2": rpc error: code = Unknown desc = failed to pull and unpack image "quay.io/jetstack/cert-manager-cainjector:v0.14.2": failed to resolve reference "quay.io/jetstack/cert-manager-cainjector:v0.14.2": failed to do request: Head https://quay.io/v2/jetstack/cert-manager-cainjector/manifests/v0.14.2: dial tcp: lookup quay.io on 23.217.138.110:53: read udp 172.18.0.5:42254->23.217.138.110:53: i/o timeout
Normal Pulling 11m (x4 over 13m) kubelet, local1-1-worker3 Pulling image "quay.io/jetstack/cert-manager-cainjector:v0.14.2"
Warning Failed 11m (x4 over 13m) kubelet, local1-1-worker3 Error: ErrImagePull
Warning Failed 11m kubelet, local1-1-worker3 Failed to pull image "quay.io/jetstack/cert-manager-cainjector:v0.14.2": rpc error: code = Unknown desc = failed to pull and unpack image "quay.io/jetstack/cert-manager-cainjector:v0.14.2": failed to resolve reference "quay.io/jetstack/cert-manager-cainjector:v0.14.2": failed to do request: Head https://quay.io/v2/jetstack/cert-manager-cainjector/manifests/v0.14.2: dial tcp: lookup quay.io on 23.217.138.110:53: read udp 172.18.0.5:45379->23.217.138.110:53: i/o timeout
Warning Failed 11m (x6 over 13m) kubelet, local1-1-worker3 Error: ImagePullBackOff
Normal BackOff 3m50s (x38 over 13m) kubelet, local1-1-worker3 Back-off pulling image "quay.io/jetstack/cert-manager-cainjector:v0.14.2"
CoreDNS pods reporting failures:
kubectl logs coredns-5644d7b6d9-d88qh -n kube-system
.:53
2020-09-28T20:21:48.016Z [INFO] plugin/reload: Running configuration MD5 = f64cb9b977c7dfca58c4fab108535a76
2020-09-28T20:21:48.016Z [INFO] CoreDNS-1.6.2
2020-09-28T20:21:48.016Z [INFO] linux/amd64, go1.12.8, 795a3eb
CoreDNS-1.6.2
linux/amd64, go1.12.8, 795a3eb
2020-09-28T20:21:54.022Z [ERROR] plugin/errors: 2 2524305934256981297.6425277095225785637. HINFO: read udp 10.0.0.4:34827->23.202.231.169:53: i/o timeout
2020-09-28T20:21:57.016Z [ERROR] plugin/errors: 2 2524305934256981297.6425277095225785637. HINFO: read udp 10.0.0.4:40448->23.202.231.169:53: i/o timeout
2020-09-28T20:21:58.016Z [ERROR] plugin/errors: 2 2524305934256981297.6425277095225785637. HINFO: read udp 10.0.0.4:47592->23.202.231.169:53: i/o timeout
2020-09-28T20:21:59.017Z [ERROR] plugin/errors: 2 2524305934256981297.6425277095225785637. HINFO: read udp 10.0.0.4:50607->23.202.231.169:53: i/o timeout
2020-09-28T20:22:02.020Z [ERROR] plugin/errors: 2 2524305934256981297.6425277095225785637. HINFO: read udp 10.0.0.4:57676->23.202.231.169:53: i/o timeout
2020-09-28T20:22:05.024Z [ERROR] plugin/errors: 2 2524305934256981297.6425277095225785637. HINFO: read udp 10.0.0.4:43239->23.202.231.169:53: i/o timeout
2020-09-28T20:22:08.025Z [ERROR] plugin/errors: 2 2524305934256981297.6425277095225785637. HINFO: read udp 10.0.0.4:52554->23.202.231.169:53: i/o timeout
2020-09-28T20:22:11.025Z [ERROR] plugin/errors: 2 2524305934256981297.6425277095225785637. HINFO: read udp 10.0.0.4:43889->23.202.231.169:53: i/o timeout
2020-09-28T20:22:14.025Z [ERROR] plugin/errors: 2 2524305934256981297.6425277095225785637. HINFO: read udp 10.0.0.4:57328->23.202.231.169:53: i/o timeout
2020-09-28T20:22:17.026Z [ERROR] plugin/errors: 2 2524305934256981297.6425277095225785637. HINFO: read udp 10.0.0.4:51641->23.202.231.169:53: i/o timeout
What you expected to happen:
Kind starts and DNS lookups work.
How to reproduce it (as minimally and precisely as possible):
Either have a bad ISP that does this, or point to a DNS server that responds to all queries to nonexistent domains with a webserver ip.
Anything else we need to know?:
I don’t know if this is the right place for this issue, but I was thinking that kind could check for this case (may be an easy check, look up a domain that shouldn’t exist and see what comes back).
Environment:
(this wasn’t on my machine, but I’ll get this information. We should all be on v0.9.0 of kind)
- kind version: (use
kind version): - Kubernetes version: (use
kubectl version): - Docker version: (use
docker info): - OS (e.g. from
/etc/os-release):
Содержание
- Что такое DNS и как работает?
- Что такое ошибка NXDOMAIN
- Возможные причины ошибки NXDOMAIN
- Как исправить ошибку NXDOMAIN
- Изменить DNS
- Избегайте использования VPN
- Проверьте, не мешает ли какой-либо антивирус или брандмауэр
- Обеспечьте бесперебойную работу браузера
- Перезагрузить систему
Что такое DNS и как работает?
Чтобы понять, что Ошибка NXDOMAIN есть, мы должны сначала вспомнить, что DNS есть и как это работает. Можно сказать, что DNS-серверы действуют как переводчики, позволяя нам просматривать Интернет без запоминания большого количества цифр.

При входе на веб-страницу мы обычно переходим в адресную строку браузера и пишем там имя и адрес. Например, мы пишем redeszone.net. Мы можем это сделать благодаря DNS-серверы которые переводят это сообщение, которое мы пишем, на соответствующий IP-адрес. Таким образом, нам не нужно запоминать, что это за IP-адрес, а просто имя, которое мы пишем.
Таким образом, DNS-серверы действуют как посредники, чтобы иметь возможность отвечать на запросы что мы делаем. Есть много DNS-серверов, которые мы можем использовать. Бывают платные и бесплатные. Некоторые даже могут помочь нам повысить безопасность, поскольку они настроены на фильтрацию возможных вредоносных страниц, а не на отправку содержимого. Иногда смена серверов нашего интернет-оператора может помочь улучшить скорость.
Теперь, иногда в этом типе услуг могут быть проблемы и сбой при поиске в Интернете. Вот тут и возникает ошибка NXDOMAIN, о которой мы и поговорим.

Когда мы пытаемся войти на веб-страницу и получаем сообщение об ошибке с указанием NXDOMAIN, это означает, что имя домена не может быть разрешено. Это логически означает, что мы не можем перемещаться по сайту, к которому пытаемся получить доступ.
Отображаемое сообщение может незначительно отличаться. Например, в Google Chrome в браузере появившееся сообщение будет DNS_PROBE_FINISHED_NXDOMAIN . Это означает, что страница, на которую мы пытаемся войти, загружается некорректно.
Возможные причины ошибки NXDOMAIN
Эта ошибка может возникать по разным причинам. Иногда это может быть в наших силах исправить, а в других случаях это зависит от сервера сайта. Посмотрим, что за Основные причины составляют:
- DNS-сервер не работает
- Проблема с DNS-клиентом
- VPN мешает
- Установленные средства безопасности
- Неправильные настройки DNS
- Проблемы с браузером
Как исправить ошибку NXDOMAIN
К счастью, мы можем принять во внимание определенные шаги, чтобы решить Ошибка NXDOMAIN . Это, как мы уже упоминали, может произойти в любом браузере, который мы используем, поэтому совет, который мы собираемся дать, является общим, и мы можем применить его в любом случае.
Некоторые проблемы, вызывающие эту ошибку, мы не сможем решить с нашей стороны, например, когда они присутствуют на стороне сервера.
Изменить DNS
Проблемы такого типа могут быть связаны с ошибками DNS-серверы что мы используем. Мы уже упоминали, что можем использовать много разных, как бесплатных, так и платных.
В случае появления такого типа сообщения мы можем попробовать выбрать другой общедоступный DNS, чем те, которые мы используем. Мы можем легко изменить их в Windows, через настройки сети. Для этого заходим в Конфигурацию, Cеть и Интернет, мы вводим Параметры смены адаптера и там выбираем интересующую нас сеть, нажимаем Свойства и откроется окно для изменения IP-адреса и DNS.
Избегайте использования VPN
Мы также видели, что причиной ошибки NXDOMAIN является то, что мы используем VPN и это создает конфликт. Мы можем временно приостановить работу этого инструмента и проверить, действительно ли это связано с этой проблемой.
Если мы обнаружим, что это действительно VPN, мы можем либо не использовать его, либо переключиться на другую службу.
Проверьте, не мешает ли какой-либо антивирус или брандмауэр
Также могло случиться, что антивирус или брандмауэр которые мы используем, создавали проблемы. Мы уже знаем, что инструменты безопасности необходимы для предотвращения сетевых проблем, но они также могут вызвать определенные сбои при неправильной конфигурации.
Обеспечьте бесперебойную работу браузера
Конечно браузер должен работать правильно . Вы должны быть осторожны, например, если используете плохо настроенные расширения. Мы должны убедиться, что все, что окружает браузер, работает правильно, и, таким образом, исправить возможные ошибки, вызывающие эту проблему, чтобы правильно разрешить доменные имена.
Перезагрузить систему
Это базовое решение, но во многих случаях оно может решить проблемы такого типа. Мы должны перезапуск и наш компьютер, и сам роутер. Таким образом, мы можем исправить подобные и подобные ошибки.
В конечном счете, это некоторые варианты, которые мы должны решить, когда появляется ошибка NXDOMAIN.
-
Главная
Список форумов
Ошибки Open Server
-
Поиск
-
- Текущее время: 10 фев 2023, 04:52
- Часовой пояс: UTC+03:00
Ответить
-
Версия для печати
Расширенный поиск
Первое новое сообщение • 4 сообщения
• Страница 1 из 1
-
Dim233
- Сообщения: 4
- Зарегистрирован: 22 апр 2022, 22:15
Не работает сайт wordpress
-
Цитата
Непрочитанное сообщение
Dim233 » 22 апр 2022, 22:22
Установил OpenServer, при попытке зайти на сайт на WP из меню «Мои проекты» выдаёт следующее:
error resolving «wp:80″»/» («») for «10.238.0.112»: rpc error: code = Unknown desc = NXDOMAIN
C joomla ситуация такая же
Что делать?
Вернуться к началу
-
Dim233
- Сообщения: 4
- Зарегистрирован: 22 апр 2022, 22:15
Re: Не работает сайт wordpress
-
Цитата
Непрочитанное сообщение
Dim233 » 22 апр 2022, 22:44
Вышел и вошёл в Windows и всё заработало!
Вернуться к началу
-
Dim233
- Сообщения: 4
- Зарегистрирован: 22 апр 2022, 22:15
Re: Не работает сайт wordpress
-
Цитата
Непрочитанное сообщение
Dim233 » 27 апр 2022, 22:15
Данная проблема повторяется время от времени, приходится выходить и заходить в виндоус чтоб её решить.
В чем же причина данной проблемы?
Вернуться к началу
-
Dim233
- Сообщения: 4
- Зарегистрирован: 22 апр 2022, 22:15
Re: Не работает сайт wordpress
-
Цитата
Непрочитанное сообщение
Dim233 » 27 апр 2022, 22:23
Нашёл причину, оказалось ошибка выскакивает когда включен VPN в браузере
Вернуться к началу
Ответить
-
Версия для печати
Показать:
Поле сортировки:
Порядок:
4 сообщения
• Страница 1 из 1
Вернуться в «Ошибки Open Server»
The shortest and simplest answer is this:
These ‘errors’ in your syslog are generated as a result of the workaround identified in DVE-2018-0001, indicating that the system is attempting to mitigate further cases of DVE-2018-0001 violations by retrying the same request without EDNS extensions. This does not indicate an error you yourself can fix, nor does it mean there’s anything to fix in this case.
It simply indicates that the systemd-resolved service is attempting to retry the same query to try and prevent further issues of DVE-2018-0001 which can be caused by captive portals not supporting EDNS0 extensions.
There is no further action needed by you in this case, this is more ‘informational’ information provided to the syslog by systemd-resolved.
However… if you want to know a little more about what exactly is going on here, then read on further, I provide a summary of this and some example data to show you exactly what’s going on behind the scenes of these messages.
The Details (if you care to read them):
The error you are seeing is not actually an error message you have to act upon, and the statement of «Server returned error» is misleading. Rather, this is a notice that we’re following a workaround defined in DNS Violation DVE-2018-0001.
This is an example of the log itself from my computer here:
Feb 5 13:29:17 overlord systemd-resolved[857]: Server returned error NXDOMAIN, mitigating potential DNS violation DVE-2018-0001, retrying transaction with reduced feature level UDP.
Per DVE-2018-0001, it was discovered that, in Ubuntu 17.10 and later:
When trying to connect and authorise with the captive portal at securelogin.arubanetworks.com, at some point it fails to resolve correctly and thus users are failing to pass captive portal authorisation and access internet.
Further, this goes on to explain the problem:
Originally this was reports on Ubuntu bug tracker at https://bugs.launchpad.net/ubuntu/+source/systemd/+bug/1727237
This might be a bug in Ubuntu/systemd-resolved and/or securelogin.arubanetworks.com DNS spoofing/captivity and/or both.
From packet capture it appears that DNS query with EDNS0 DO (DNSSEC OK) bit set to zero, is responded to with NXDOMAIN.
Requests without EDNS0, are responded to with the correct portal IP address.
What this means is that there are certain responses going to the captive portals here that do not properly support EDNS0 queries; and that this needs to be adjusted by manufacturers.
The current workaround implemented in systemd-resolved within Ubuntu is what is generating the informational messages you see. This is in conjunction with the proposed workaround in the DVE (bold text emphasis and plain-text formatting for command names and codes/responses are mine):
In
systemd-resolved, when performing lookup of domain names with ‘secure’ in them, and receivingNXDOMAINrepsonse, retry again without EDNS0.
This therefore is what your messages are stating, but with a more broad coverage. Namely, when a DNS request is filed and you get an NXDOMAIN response from the DNS lookup, we want to make sure that we aren’t hitting this EDNS0 problem; therefore, systemd-resolved is attempting the DNS lookup again but without the EDNS0 extensions — we can see this in my Bind9 nameserver which handles all requests on my machine as well with an example (though this is a prime example of a non-domain being queried, and in turn a prime example of how this mitigation can show itself when the ‘mitigation’ is not actually going to solve the headache):
05-Feb-2019 13:29:17.976 queries: info: client @0x7f6cd400aee0 127.0.0.1#41213 (favicon.png): query: favicon.png IN A +E(0) (127.0.2.1)
05-Feb-2019 13:29:17.976 queries: info: client @0x7f6cd400aee0 127.0.0.1#41213 (favicon.png): query: favicon.png IN A + (127.0.2.1)
As you can see, instead of +E(0) the request is retried without that extension; this is the ‘reduced feature level UDP’ request behavior.