I have:
- one mesos-master in which I configured a consul server;
- one mesos-slave in which I configure consul client, and;
- one bootstrap server for consul.
When I hit start I am seeing the following error:
2016/04/21 19:31:31 [ERR] agent: failed to sync remote state: rpc error: No cluster leader
2016/04/21 19:31:44 [ERR] agent: coordinate update error: rpc error: No cluster leader
How do I recover from this state?
![]()
asked Apr 21, 2016 at 14:05
![]()
Did you look at the Consul docs ?
It looks like you have performed a ungraceful stop and now need to clean your raft/peers.json file by removing all entries there to perform an outage recovery. See the above link for more details.
![]()
prado
1292 silver badges11 bronze badges
answered Apr 28, 2016 at 21:11
![]()
Keyan PKeyan P
89011 silver badges20 bronze badges
1
As of Consul 0.7 things work differently from Keyan P’s answer. raft/peers.json (in the Consul data dir) has become a manual recovery mechanism. It doesn’t exist unless you create it, and then when Consul starts it loads the file and deletes it from the filesystem so it won’t be read on future starts. There are instructions in raft/peers.info. Note that if you delete raft/peers.info it won’t read raft/peers.json but it will delete it anyway, and it will recreate raft/peers.info. The log will indicate when it’s reading and deleting the file separately.
Assuming you’ve already tried the bootstrap or bootstrap_expect settings, that file might help. The Outage Recovery guide in Keyan P’s answer is a helpful link. You create raft/peers.json in the data dir and start Consul, and the log should indicate that it’s reading/deleting the file and then it should say something like «cluster leadership acquired». The file contents are:
[ { "id": "<node-id>", "address": "<node-ip>:8300", "non_voter": false } ]
where <node-id> can be found in the node-id file in the data dir.
![]()
rboarman
8,1308 gold badges56 silver badges87 bronze badges
answered Mar 14, 2019 at 9:30
![]()
Mike PlacentraMike Placentra
8031 gold badge14 silver badges25 bronze badges
If u got raft version more than 2:
[
{
"id": "e3a30829-9849-bad7-32bc-11be85a49200",
"address": "10.88.0.59:8300",
"non_voter": false
},
{
"id": "326d7d5c-1c78-7d38-a306-e65988d5e9a3",
"address": "10.88.0.45:8300",
"non_voter": false
},
{
"id": "a8d60750-4b33-99d7-1185-b3c6d7458d4f",
"address": "10.233.103.119",
"non_voter": false
}
]
answered Dec 12, 2019 at 6:26
![]()
cryptopartycryptoparty
3451 gold badge5 silver badges19 bronze badges
In my case I had 2 worker nodes in the k8s cluster, after adding another node the consul servers could elect a master and everything is up and running.
answered Jan 3, 2021 at 21:39
![]()
MawardyMawardy
3,3902 gold badges33 silver badges36 bronze badges
I will update what I did:
Little Background: We scaled down the AWS Autoscaling so lost the leader. But we had one server still running but without any leader.
What I did was:
- I scaled up to 3 servers(don’t make 2-4)
- stopped consul in all 3 servers.
sudo service consul stop(you can do status/stop/start) - created peers.json file and put it in old server(/opt/consul/data/raft)
- start the 3 servers (peers.json should be placed on 1 server only)
- For other 2 servers join it to leader using
consul join 10.201.8.XXX - check peers are connected to leader using
consul operator raft list-peers
Sample peers.json file
[
{
"id": "306efa34-1c9c-acff-1226-538vvvvvv",
"address": "10.201.n.vvv:8300",
"non_voter": false
},
{
"id": "dbeeffce-c93e-8678-de97-b7",
"address": "10.201.X.XXX:8300",
"non_voter": false
},
{
"id": "62d77513-e016-946b-e9bf-0149",
"address": "10.201.X.XXX:8300",
"non_voter": false
}
]
These id you can get from each server in /opt/consul/data/
[root@ip-10-20 data]# ls
checkpoint-signature node-id raft serf
[root@ip-10-1 data]# cat node-id
Some useful commands:
consul members
curl http://ip:8500/v1/status/peers
curl http://ip:8500/v1/status/leader
consul operator raft list-peers
cd opt/consul/data/raft/
consul info
sudo service consul status
consul catalog services
answered Sep 14, 2021 at 20:18
![]()
ChinmoyChinmoy
1,30612 silver badges14 bronze badges
You may also ensure that bootstrap parameter is set in your Consul configuration file config.json on the first node:
# /etc/consul/config.json
{
"bootstrap": true,
...
}
or start the consul agent with the -bootstrap=1 option as described in the official Failure of a single server cluster Consul documentation.
answered Oct 1, 2021 at 18:04
![]()
panticzpanticz
1,96924 silver badges16 bronze badges
I have:
- one mesos-master in which I configured a consul server;
- one mesos-slave in which I configure consul client, and;
- one bootstrap server for consul.
When I hit start I am seeing the following error:
2016/04/21 19:31:31 [ERR] agent: failed to sync remote state: rpc error: No cluster leader
2016/04/21 19:31:44 [ERR] agent: coordinate update error: rpc error: No cluster leader
How do I recover from this state?
![]()
asked Apr 21, 2016 at 14:05
![]()
Did you look at the Consul docs ?
It looks like you have performed a ungraceful stop and now need to clean your raft/peers.json file by removing all entries there to perform an outage recovery. See the above link for more details.
![]()
prado
1292 silver badges11 bronze badges
answered Apr 28, 2016 at 21:11
![]()
Keyan PKeyan P
89011 silver badges20 bronze badges
1
As of Consul 0.7 things work differently from Keyan P’s answer. raft/peers.json (in the Consul data dir) has become a manual recovery mechanism. It doesn’t exist unless you create it, and then when Consul starts it loads the file and deletes it from the filesystem so it won’t be read on future starts. There are instructions in raft/peers.info. Note that if you delete raft/peers.info it won’t read raft/peers.json but it will delete it anyway, and it will recreate raft/peers.info. The log will indicate when it’s reading and deleting the file separately.
Assuming you’ve already tried the bootstrap or bootstrap_expect settings, that file might help. The Outage Recovery guide in Keyan P’s answer is a helpful link. You create raft/peers.json in the data dir and start Consul, and the log should indicate that it’s reading/deleting the file and then it should say something like «cluster leadership acquired». The file contents are:
[ { "id": "<node-id>", "address": "<node-ip>:8300", "non_voter": false } ]
where <node-id> can be found in the node-id file in the data dir.
![]()
rboarman
8,1308 gold badges56 silver badges87 bronze badges
answered Mar 14, 2019 at 9:30
![]()
Mike PlacentraMike Placentra
8031 gold badge14 silver badges25 bronze badges
If u got raft version more than 2:
[
{
"id": "e3a30829-9849-bad7-32bc-11be85a49200",
"address": "10.88.0.59:8300",
"non_voter": false
},
{
"id": "326d7d5c-1c78-7d38-a306-e65988d5e9a3",
"address": "10.88.0.45:8300",
"non_voter": false
},
{
"id": "a8d60750-4b33-99d7-1185-b3c6d7458d4f",
"address": "10.233.103.119",
"non_voter": false
}
]
answered Dec 12, 2019 at 6:26
![]()
cryptopartycryptoparty
3451 gold badge5 silver badges19 bronze badges
In my case I had 2 worker nodes in the k8s cluster, after adding another node the consul servers could elect a master and everything is up and running.
answered Jan 3, 2021 at 21:39
![]()
MawardyMawardy
3,3902 gold badges33 silver badges36 bronze badges
I will update what I did:
Little Background: We scaled down the AWS Autoscaling so lost the leader. But we had one server still running but without any leader.
What I did was:
- I scaled up to 3 servers(don’t make 2-4)
- stopped consul in all 3 servers.
sudo service consul stop(you can do status/stop/start) - created peers.json file and put it in old server(/opt/consul/data/raft)
- start the 3 servers (peers.json should be placed on 1 server only)
- For other 2 servers join it to leader using
consul join 10.201.8.XXX - check peers are connected to leader using
consul operator raft list-peers
Sample peers.json file
[
{
"id": "306efa34-1c9c-acff-1226-538vvvvvv",
"address": "10.201.n.vvv:8300",
"non_voter": false
},
{
"id": "dbeeffce-c93e-8678-de97-b7",
"address": "10.201.X.XXX:8300",
"non_voter": false
},
{
"id": "62d77513-e016-946b-e9bf-0149",
"address": "10.201.X.XXX:8300",
"non_voter": false
}
]
These id you can get from each server in /opt/consul/data/
[root@ip-10-20 data]# ls
checkpoint-signature node-id raft serf
[root@ip-10-1 data]# cat node-id
Some useful commands:
consul members
curl http://ip:8500/v1/status/peers
curl http://ip:8500/v1/status/leader
consul operator raft list-peers
cd opt/consul/data/raft/
consul info
sudo service consul status
consul catalog services
answered Sep 14, 2021 at 20:18
![]()
ChinmoyChinmoy
1,30612 silver badges14 bronze badges
You may also ensure that bootstrap parameter is set in your Consul configuration file config.json on the first node:
# /etc/consul/config.json
{
"bootstrap": true,
...
}
or start the consul agent with the -bootstrap=1 option as described in the official Failure of a single server cluster Consul documentation.
answered Oct 1, 2021 at 18:04
![]()
panticzpanticz
1,96924 silver badges16 bronze badges
Я уже описывал это проблему в своей прошлой статье, но тогда я ещё не понимал всей сути. Сейчас я зашёл в своих исследованиях немного дальше и могу предложить лучшее решение.
Так вот. Проблема в том, что после перезапуска minikube консул не может выбрать лидера, а соответственно находится в нерабочем состоянии. В прошлой статье я описывал процесс удаления persistent volumes, что, разумеется, помогает, но не подходит в большинстве реальных ситуаций, так как мы хотим сохранить данные, которые были в Consul.
Правильное решение проблемы описано в официальной документации в статье про Outage Recovery.
Не буду слишком сильно вдаваться в подробности. Расскажу лишь, что на самом деле нужно сделать, чтобы завести Consul после перезапуска.
Для начала нам нужно подготовить файл “peers.json” примерно такого содержания:
|
[ «172.17.0.15:8300», «172.17.0.17:8300», «172.17.0.25:8300» ] |
Это был файл для Raft протокола версии 2, как написано в документации. Мне помог файл именно с таким форматом. Как вы можете видеть, в этом файле описаны адреса нод консула с портами. Если же у вас Raft протокол версии 3 и позже, то формат файла становится таким:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
[ { «id»: «5d86e16f-e232-4cf7-80f2-39ad22629e77», «address»: «172.17.0.15:8300», «non_voter»: false }, { «id»: «f64e19c1-1404-4522-a153-c59caa3e395b», «address»: «172.17.0.17:8300», «non_voter»: false }, { «id»: «ab448371-2ec3-4fc5-a497-77dc580af316», «address»: «172.17.0.25:8300», «non_voter»: false } ] |
Ещё раз повторюсь, что мне помог файл первого формата, к тому же у меня был только одна нода Consulа, так что у меня он выглядел вот так:
Адреса нод Consul-а можно узнать командой:
|
> kubectl describe pod —namespace mynamespace consul-consul-0 | grep -A1 -B1 «IP:» Status: Running IP: 172.17.0.17 Created By: StatefulSet/consul-consul — STATEFULSET_NAME: consul-consul POD_IP: (v1:status.podIP) STATEFULSET_NAMESPACE: mynamespace (v1:metadata.namespace) |
Где вместо consul-consul-0 нужно подставить имя пода с Consul. В нашем случае IP будет 172.17.0.17.
Теперь нам нужно запихнуть этот файл в каталог, указанный в
-data-dir . В моём случае это файл нужно было разместить по адресу “/var/lib/consul/raft/peers.json”. Вы можете проверить правильность пути тем, что в каталоге, куда вы собираетесь поместить “peers.json”, уже должен находиться файл “peers.info”. У меня Consul был развёрнут внутри Kubernetes, поэтому я проверял вот такой командой:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 |
> kubectl exec —namespace mynamespace consul-consul-0 — cat /var/lib/consul/raft/peers.info As of Consul 0.7.0, the peers.json file is only used for recovery after an outage. The format of this file depends on what the server has configured for its Raft protocol version. Please see the agent configuration page at https://www.consul.io/docs/agent/options.html#_raft_protocol for more details about this parameter. For Raft protocol version 2 and earlier, this should be formatted as a JSON array containing the address and port of each Consul server in the cluster, like this: [ «10.1.0.1:8300», «10.1.0.2:8300», «10.1.0.3:8300» ] For Raft protocol version 3 and later, this should be formatted as a JSON array containing the node ID, address:port, and suffrage information of each Consul server in the cluster, like this: [ { «id»: «adf4238a-882b-9ddc-4a9d-5b6758e4159e», «address»: «10.1.0.1:8300», «non_voter»: false }, { «id»: «8b6dda82-3103-11e7-93ae-92361f002671», «address»: «10.1.0.2:8300», «non_voter»: false }, { «id»: «97e17742-3103-11e7-93ae-92361f002671», «address»: «10.1.0.3:8300», «non_voter»: false } ] The «id» field is the node ID of the server. This can be found in the logs when the server starts up, or in the «node-id» file inside the server’s data directory. The «address» field is the address and port of the server. The «non_voter» field controls whether the server is a non-voter, which is used in some advanced Autopilot configurations, please see https://www.consul.io/docs/guides/autopilot.html for more information. If «non_voter» is omitted it will default to false, which is typical for most clusters. Under normal operation, the peers.json file will not be present. When Consul starts for the first time, it will create this peers.info file and delete any existing peers.json file so that recovery doesn’t occur on the first startup. Once this peers.info file is present, any peers.json file will be ingested at startup, and will set the Raft peer configuration manually to recover from an outage. It’s crucial that all servers in the cluster are shut down before creating the peers.json file, and that all servers receive the same configuration. Once the peers.json file is successfully ingested and applied, it will be deleted. Please see https://www.consul.io/docs/guides/outage.html for more information. |
Копируем файл во все поды с Consul-ом по указанному выше пути (в моём случае был только один pod):
|
kubectl cp peers.json mynamespace/consul-consul-0:/var/lib/consul/raft/peers.json |
Перезапускаем поды, для чего удаляем их и ждём, пока replicaset его пересоздаст:
|
kubectl delete pod —namespace mynamespace consul-consul-0 |
Смотрим логи:
|
kubectl logs —namespace mynamespace consul-consul-0 |
В логах обязательно увидим надпись:
|
2017/10/25 06:43:21 [INFO] consul: cluster leadership acquired 2017/10/25 06:43:21 [INFO] consul: New leader elected: consul-consul-0 2017/10/25 06:43:21 [INFO] consul: member ‘consul-consul-0’ joined, marking health alive 2017/10/25 06:43:22 [INFO] agent: Synced service ‘consul’ |
Эта надпись означает, что лидер был успешно выбран. Consul в рабочем состоянии.
Эту процедуру нужно проделывать после каждого перезапуска Consul-а. Видимо, предполагается, что Consul будет рамботать всегда, и остановки будут происходить только во время внезапных отключений электричества. Мне, правда, всё равно не понятно, зачем было делать такую сложную процедуру восстановления. Почему он не может восстановиться сам и выбрать лидера без нашего вмешательства, но это, скорее всего, из-за того, что я чего-нибудь ещё более глобального не понимаю.
For a new project Consul was checked if it could be used as a backend system for data. By quick-reading through the documentation, Consul looks promising, so far. Although the installation was quick and painless, a couple of communication errors occurred due to blocked firewall ports. Unfortunately the logged errors were not really helpful nor did they give a hint what exactly could be the problem. Here’s an overview of the Consul installation, configuration and how to solve communication errors in the Consul cluster.
Setting up Consul
The setup is pretty easy as Consul is just a single binary file. And a config file you create which the binary will read. That’s it. This means that installation is equal to a download, unzip and move:
root@consul01:~# wget https://releases.hashicorp.com/consul/1.5.3/consul_1.5.3_linux_amd64.zip
root@consul01:~# unzip consul_1.5.3_linux_amd64.zip
root@consul01:~# mv consul /usr/local/bin/
Create a dedicated user/group for Consul and create the destination directory for its data:
root@consul01:~# useradd -m -d /home/consul -s /sbin/nologin consul
root@consul01:~# mkdir /var/lib/consul
root@consul01:~# chown -R consul:consul /var/lib/consul
Create the config file. This config file can have any name you want and place it in any directory, as long as the «consul» user is able to read it.
Here’s an example config file with placeholders:
root@consul01:~# cat /etc/consul.json
{
«server»: true,
«node_name»: «$NODE_NAME»,
«datacenter»: «dc1»,
«data_dir»: «$CONSUL_DATA_PATH»,
«bind_addr»: «0.0.0.0»,
«client_addr»: «0.0.0.0»,
«advertise_addr»: «$ADVERTISE_ADDR»,
«bootstrap_expect»: 3,
«retry_join»: [«$JOIN1», «$JOIN2», «$JOIN3»],
«ui»: true,
«log_level»: «DEBUG»,
«enable_syslog»: true,
«acl_enforce_version_8»: false
}
In order to launch Consul as a service, a Systemd unit file should be created:
root@consul01:~# cat /etc/systemd/system/consul.service
### BEGIN INIT INFO
# Provides: consul
# Required-Start: $local_fs $remote_fs
# Required-Stop: $local_fs $remote_fs
# Default-Start: 2 3 4 5
# Default-Stop: 0 1 6
# Short-Description: Consul agent
# Description: Consul service discovery framework
### END INIT INFO
[Unit]
Description=Consul server agent
Requires=network-online.target
After=network-online.target
[Service]
User=consul
Group=consul
PIDFile=/var/run/consul/consul.pid
PermissionsStartOnly=true
ExecStartPre=-/bin/mkdir -p /var/run/consul
ExecStartPre=/bin/chown -R consul:consul /var/run/consul
ExecStart=/usr/local/bin/consul agent
-config-file=/etc/consul.json
-pid-file=/var/run/consul/consul.pid
ExecReload=/bin/kill -HUP $MAINPID
KillMode=process
KillSignal=SIGTERM
Restart=on-failure
RestartSec=42s
[Install]
WantedBy=multi-user.target
Make sure, the paths are correct!
Now enable the service:
root@consul01:~# systemctl daemon-reload
root@consul01:~# systemctl enable consul.service
Configure Consul Cluster
A Consul cluster should have a minimum of three cluster nodes. In this example I created three nodes:
- consul01: 192.168.253.8
- consul02: 192.168.253.9
- consul03: 10.10.1.45
Note: Although the third note runs in a different range, it’s still part of the same LAN.
Once Consul is set up and prepared on all three nodes, the config files must be adjusted on each node. To do this quickly (and automated if you like):
# sed -i «s/$NODE_NAME/$(hostname)/» /etc/consul.json
# sed -i «s/$CONSUL_DATA_PATH//var/lib/consul/» /etc/consul.json
# sed -i «s/$ADVERTISE_ADDR/$(ip addr show dev eth0 | awk ‘/inet.*eth0/ {print $2}’ | cut -d «/» -f1)/» /etc/consul.json
# sed -i «s/$JOIN1/192.168.253.8/» /etc/consul.json
# sed -i «s/$JOIN2/192.168.253.9/» /etc/consul.json
# sed -i «s/$JOIN3/10.10.1.45/» /etc/consul.json
This will place the local values into the variables NODE_NAME, CONSUL_DATA_PATH and ADVERTISE_ADDRESS. The JOINn variables are used to define the cluster nodes (see above).
Once this is completed, the cluster is ready and Consul can be started on each node.
# systemctl start consul
Cluster and data communication
Before going into the communication errors, the needed ports should be explained. These need to be opened between all the nodes, in any direction. The following network architecture (from the official documentation) graph helps understanding how the nodes communicate between each other:
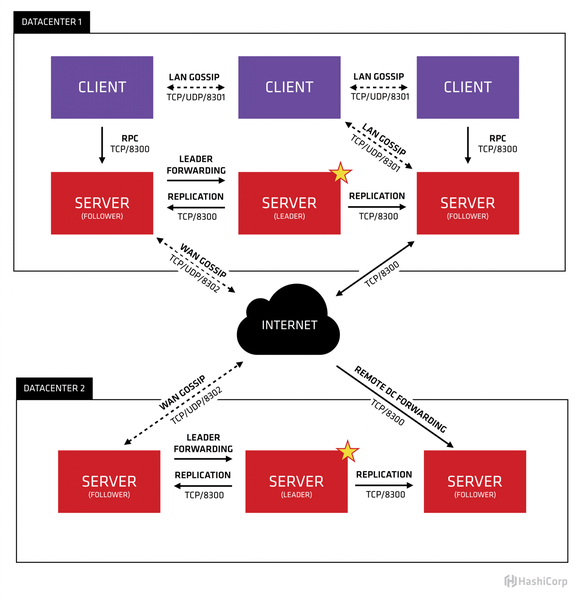
- tcp/8300: Used for data replication
- tcp,udp/8301: Used for «LAN Gossip», meaning cluster communication between nodes in the same LAN (e.g. DC1)
- tcp,udp/8302: Used for «WAN Gossip», meaning cluster communication between nodes in separate data centers (e.g. DC2)
Something the documentation isn’t telling: tcp,udp/8302 need to be opened between LAN nodes, too — even though it is marked as «WAN Gossip».
Handling communication errors
Fortunately the setup, configuration and cluster architecture of Consul is not complex at all. But understanding the logged errors, interpreting them to find the exact problem, can be a challenge.
At first, always do…
The command consul members gives a quick overview on all cluster members and their current state. This is helpful to find major communication problems. However certain errors might still appear in logs, yet no problems are shown in the output.
root@consul01:~# consul members
Node Address Status Type Build Protocol DC Segment
consul01 192.168.253.8:8301 alive server 1.5.3 2 dc1
consul02 192.168.253.9:8301 alive server 1.5.3 2 dc1
consul03 10.10.1.45:8301 alive server 1.5.3 2 dc1
Coordinate update error: No cluster leader
The first error occurred right after the first cluster start:
Aug 19 13:50:46 consul02 consul[11395]: 2019/08/19 13:50:46 [DEBUG] serf: messageJoinType: consul02
Aug 19 13:50:46 consul02 consul[11395]: serf: messageJoinType: consul02
Aug 19 13:50:46 consul02 consul[11395]: 2019/08/19 13:50:46 [DEBUG] serf: messageJoinType: consul02
Aug 19 13:50:46 consul02 consul[11395]: serf: messageJoinType: consul02
Aug 19 13:50:46 consul02 consul[11395]: 2019/08/19 13:50:46 [DEBUG] serf: messageJoinType: consul02
Aug 19 13:50:46 consul02 consul[11395]: serf: messageJoinType: consul02
Aug 19 13:50:47 consul02 consul[11395]: 2019/08/19 13:50:47 [DEBUG] serf: messageJoinType: consul02
Aug 19 13:50:47 consul02 consul[11395]: serf: messageJoinType: consul02
Aug 19 13:51:01 consul02 consul[11395]: 2019/08/19 13:51:01 [ERR] agent: Coordinate update error: No cluster leader
Aug 19 13:51:01 consul02 consul[11395]: agent: Coordinate update error: No cluster leader
This happened because not all nodes were able to communicate with each other (in any direction) on port 8301. Using telnet, a quick verification can be done on each node:
root@consul01:~# telnet 192.168.253.8 8301
Trying 192.168.253.8…
Connected to 192.168.253.8.
Escape character is ‘^]’.
root@consul02:~# telnet 192.168.253.8 8301
Trying 192.168.253.8…
Connected to 192.168.253.8.
Escape character is ‘^]’.
root@consul03:~# telnet 192.168.253.8 8301
Trying 192.168.253.8…
telnet: Unable to connect to remote host: Connection timed out
It’s pretty obvious: Node consul03 is not able to communicate with the other nodes on port 8301. Remember: consul03 is the one in the different network range.
Was able to connect to X but other probes failed, network may be misconfigured
Although all cluster members are shown as alive in consul members output, a lot of warnings might be logged, indicating failed pings and a misconfigured network:
Aug 26 14:43:40 consul01 consul[15046]: memberlist: Failed ping: consul03.dc1 (timeout reached)
Aug 26 14:43:42 consul01 consul[15046]: 2019/08/26 14:43:42 [WARN] memberlist: Was able to connect to consul03.dc1 but other probes failed, network may be misconfigured
Aug 26 14:43:42 consul01 consul[15046]: memberlist: Was able to connect to consul03.dc1 but other probes failed, network may be misconfigured
Aug 26 14:43:43 consul01 consul[15046]: 2019/08/26 14:43:43 [DEBUG] memberlist: Stream connection from=192.168.253.9:42330
Aug 26 14:43:43 consul01 consul[15046]: memberlist: Stream connection from=192.168.253.9:42330
Aug 26 14:43:45 consul01 consul[15046]: 2019/08/26 14:43:45 [DEBUG] memberlist: Failed ping: consul03.dc1 (timeout reached)
Aug 26 14:43:45 consul01 consul[15046]: memberlist: Failed ping: consul03.dc1 (timeout reached)
Aug 26 14:43:47 consul01 consul[15046]: 2019/08/26 14:43:47 [WARN] memberlist: Was able to connect to consul03.dc1 but other probes failed, network may be misconfigured
Aug 26 14:43:47 consul01 consul[15046]: memberlist: Was able to connect to consul03.dc1 but other probes failed, network may be misconfigured
Aug 26 12:43:39 consul02 consul[20492]: 2019/08/26 14:43:39 [DEBUG] memberlist: Failed ping: consul03.dc1 (timeout reached)
Aug 26 12:43:39 consul02 consul[20492]: memberlist: Failed ping: consul03.dc1 (timeout reached)
Aug 26 12:43:41 consul02 consul[20492]: 2019/08/26 14:43:41 [WARN] memberlist: Was able to connect to consul03.dc1 but other probes failed, network may be misconfigured
Aug 26 12:43:41 consul02 consul[20492]: memberlist: Was able to connect to consul03.dc1 but other probes failed, network may be misconfigured
Aug 26 12:43:47 consul02 consul[20492]: 2019/08/26 14:43:47 [DEBUG] memberlist: Initiating push/pull sync with: 10.10.1.45:8301
Aug 26 12:43:47 consul02 consul[20492]: memberlist: Initiating push/pull sync with: 10.10.1.45:8301
Aug 26 12:43:49 consul02 consul[20492]: 2019/08/26 14:43:49 [DEBUG] memberlist: Initiating push/pull sync with: 192.168.253.8:8302
Aug 26 12:43:49 consul02 consul[20492]: memberlist: Initiating push/pull sync with: 192.168.253.8:8302
Aug 26 12:43:54 consul02 consul[20492]: 2019/08/26 14:43:54 [DEBUG] memberlist: Failed ping: consul03.dc1 (timeout reached)
Aug 26 12:43:54 consul02 consul[20492]: memberlist: Failed ping: consul03.dc1 (timeout reached)
Aug 26 12:43:56 consul02 consul[20492]: 2019/08/26 14:43:56 [WARN] memberlist: Was able to connect to consul03.dc1 but other probes failed, network may be misconfigured
Aug 26 12:43:56 consul02 consul[20492]: memberlist: Was able to connect to consul03.dc1 but other probes failed, network may be misconfigured
A helpful hint to correctly interpret these log entries can be found on issue #3058 in Consul’s GitHub repository. Although all nodes are running as LAN nodes in the cluster, the WAN gossip ports tcp,udp/8302 need to be opened. As soon as this port was opened, these log entries disappeared.
Failed to get conn: dial tcp X: i/o timeout
Aug 26 15:34:50 consul03 consul[13097]: 2019/08/26 15:34:50 [ERR] agent: Coordinate update error: rpc error getting client: failed to get conn: dial tcp ->192.168.253.9:8300: i/o timeout
Aug 26 15:34:50 consul03 consul[13097]: agent: Coordinate update error: rpc error getting client: failed to get conn: dial tcp ->192.168.253.9:8300: i/o timeout
Aug 26 15:34:50 consul03 consul[13097]: 2019/08/26 15:34:50 [WARN] agent: Syncing node info failed. rpc error getting client: failed to get conn: rpc error: lead thread didn’t get connection
Aug 26 15:34:50 consul03 consul[13097]: agent: Syncing node info failed. rpc error getting client: failed to get conn: rpc error: lead thread didn’t get connection
Aug 26 15:34:50 consul03 consul[13097]: 2019/08/26 15:34:50 [ERR] agent: failed to sync remote state: rpc error getting client: failed to get conn: rpc error: lead thread didn’t get connection
Aug 26 15:34:50 consul03 consul[13097]: agent: failed to sync remote state: rpc error getting client: failed to get conn: rpc error: lead thread didn’t get connection
This error turned out to be a misunderstanding when the firewall rules were created. Instead of opening all the ports mentioned above in both directions (bi-directional), the ports were only opened from Range 1 -> Range 2. The other way around (Range 2 -> Range 1) was still blocked by the firewall. Once this was fixed, these errors on consul03 disappeared, too.
Add a comment
Show form to leave a comment
Comments (newest first)
No comments yet.

Whenever you are installing and running Consul from HashiCorp on Oracle Linux you might run into some strange errors. Even though your configuration JSON file passes the configuration validation the log file contains a long repetitive lst of the same error complaining about «failed to sync remote state: No cluster leader» and » coordinate update error: No cluster leader».
Consul is a tool for service discovery and configuration. It provides high level features such as service discovery, health checking and key/value storage. It makes use of a group of strongly consistent servers to manage the datacenter. Consul is developed by HasiCorp and is available from its own website.
It might be that you have the below output when you start consul:
2016/11/25 21:03:50 [INFO] raft: Initial configuration (index=0): []
2016/11/25 21:03:50 [INFO] raft: Node at 127.0.0.1:8300 [Follower] entering Follower state (Leader: "")
2016/11/25 21:03:50 [INFO] serf: EventMemberJoin: consul_1 127.0.0.1
2016/11/25 21:03:50 [INFO] serf: EventMemberJoin: consul_1.private_dc 127.0.0.1
2016/11/25 21:03:50 [INFO] consul: Adding LAN server consul_1 (Addr: tcp/127.0.0.1:8300) (DC: private_dc)
2016/11/25 21:03:50 [INFO] consul: Adding WAN server consul_1.private_dc (Addr: tcp/127.0.0.1:8300) (DC: private_dc)
2016/11/25 21:03:55 [WARN] raft: no known peers, aborting election
2016/11/25 21:03:57 [ERR] agent: failed to sync remote state: No cluster leader
2016/11/25 21:04:14 [ERR] agent: coordinate update error: No cluster leader
2016/11/25 21:04:30 [ERR] agent: failed to sync remote state: No cluster leader
2016/11/25 21:04:50 [ERR] agent: coordinate update error: No cluster leader
2016/11/25 21:05:01 [ERR] agent: failed to sync remote state: No cluster leader
2016/11/25 21:05:26 [ERR] agent: coordinate update error: No cluster leader
2016/11/25 21:05:34 [ERR] agent: failed to sync remote state: No cluster leader
2016/11/25 21:06:02 [ERR] agent: coordinate update error: No cluster leader
2016/11/25 21:06:10 [ERR] agent: failed to sync remote state: No cluster leader
2016/11/25 21:06:35 [ERR] agent: coordinate update error: No cluster leader
The main reason for the above is that you try to start consul in an environment where there is no cluster available, or it is the first node of the cluster. In case you start it as the first node of the cluster or as the only node of the cluster you have to ensure that you include -bootstrap-expect 1 as a command line option when starting (in case you will only have one node).
You can also include «bootstrap_expect»: 1 in the json configuration file if you use a configuration file to start Consul.
As an example, the below start of Consult will prevent the above errors:
consul agent -server -bootstrap-expect 1 -data-dir /tmp/consul
I have tried to follow this guide and while it doesn’t seem to work I also followed an old guide we had created before for an upgrade from 0.5.2 to 0.7.1. The below method is the guide we created before but with updated versions and slight changes to it.
My reason for not following the guide I linked to is that with chef and our script is sees that one or more servers still exist and will not bootstrap the server.
Do this on all nodes first
wget https:
//releases.hashicorp.com/consul/1.3.1/consul_1.3.1_linux_amd64.zip
unzip consul_1.3.1_linux_amd64.zip # rename to consul_1.3.1 when prompt'd
rm consul_1.3.1_linux_amd64.zip
Do this on all nodes
./consul leave
Then rename everything
mv consul consul_0.7.1
mv consul_1.3.1 consul
Finally re-run chef-client which in turn runs a ruby script that checks for existing nodes and if found will create a new regular server and but if no nodes exist it will use the -bootstrap flag to bootstrap the server.
When I do the above steps I can’t seem to check with ./consul monitor -token=<master acl token> so what I have done is copied the commands from the ruby script and manually did them which allowed me to see the output where it says it can’t select a leader. See below log
2018/12/13 14:57:15 [INFO] consul: New leader elected: consul-testing-node-2
2018/12/13 14:57:16 [ERR] agent: Coordinate update error: No cluster leader
2018/12/13 14:57:17 [WARN] raft: Election timeout reached, restarting election
2018/12/13 14:57:17 [INFO] raft: Node at 10.7.1.5:8300 [Candidate] entering Candidate state in term 175
2018/12/13 14:57:17 [WARN] raft: Unable to get address for server id 10.7.1.6:8300, using fallback address 10.7.1.6:8300: Could not find address for server id 10.7.1.6:8300
2018/12/13 14:57:17 [ERR] agent: failed to sync remote state: No cluster leader
Commands used
/work-disk/consul/consul agent -bootstrap -data-dir /work-disk/consul_data -config-file /work-disk/consul/conf.json -bind 10.7.1.5
/work-disk/consul/consul agent -data-dir /work-disk/consul_data -config-file /work-disk/consul/conf.json -bind 10.7.1.5
Conf.json file
{
"client_addr": "0.0.0.0",
"datacenter": "consul-testing",
"acl_datacenter": "consul-testing",
"acl_default_policy":"deny",
"acl_down_policy": "deny",
"acl_master_token": "<master acl token>",
"acl_agent_token": "<agent acl token>",
"data_dir": "/work-disk/consul_data",
"domain": "consul",
"enable_script_checks": true,
"dns_config": {
"enable_truncate": true,
"only_passing": true
},
"enable_syslog": true,
"encrypt": "<enc key>==",
"leave_on_terminate": true,
"log_level": "INFO",
"rejoin_after_leave": true,
"server": true,
"start_join": ["10.7.1.5", "10.7.1.6"]
}