-
#1
I had to replace mainboard+cpu (because of unexpected server reboots) and now this errors shows up and pvestatd does not work:
Code:
Oct 2 17:28:49 node-pve1 pmxcfs[2262]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-node/node-pve1: -1 Oct 2 17:28:49 node-pve1 pmxcfs[2262]: [status] notice: RRD update error /var/lib/rrdcached/db/pve2-node/node-pve1: /var/lib/rrdcached/db/pve2-node/node-pve1: illegal attempt to update using time 1380727729 when last update time is 1380730627 (minimum one second step) Oct 2 17:28:49 node-pve1 pvestatd[21060]: WARNING: file '/etc/pve/nodes/node-pve1/qemu-server/101.conf' modified in future Oct 2 17:28:49 node-pve1 pvestatd[21060]: WARNING: file '/etc/pve/nodes/node-pve1/qemu-server/103.conf' modified in future Oct 2 17:28:49 node-pve1 pmxcfs[2262]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-vm/104: -1 Oct 2 17:28:49 node-pve1 pmxcfs[2262]: [status] notice: RRD update error /var/lib/rrdcached/db/pve2-vm/104: /var/lib/rrdcached/db/pve2-vm/104: illegal attempt to update using time 1380727729 when last update time is 1380730388 (minimum one second step) Oct 2 17:28:49 node-pve1 pmxcfs[2262]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-vm/103: -1 Oct 2 17:28:49 node-pve1 pmxcfs[2262]: [status] notice: RRD update error /var/lib/rrdcached/db/pve2-vm/103: /var/lib/rrdcached/db/pve2-vm/103: illegal attempt to update using time 1380727729 when last update time is 1380730388 (minimum one second step) Oct 2 17:28:49 node-pve1 pmxcfs[2262]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-vm/106: -1 Oct 2 17:28:49 node-pve1 pmxcfs[2262]: [status] notice: RRD update error /var/lib/rrdcached/db/pve2-vm/106: /var/lib/rrdcached/db/pve2-vm/106: illegal attempt to update using time 1380727729 when last update time is 1380730388 (minimum one second step) Oct 2 17:28:49 node-pve1 pmxcfs[2262]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-vm/102: -1 Oct 2 17:28:49 node-pve1 pmxcfs[2262]: [status] notice: RRD update error /var/lib/rrdcached/db/pve2-vm/102: /var/lib/rrdcached/db/pve2-vm/102: illegal attempt to update using time 1380727729 when last update time is 1380730627 (minimum one second step) Oct 2 17:28:49 node-pve1 pmxcfs[2262]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-vm/101: -1 Oct 2 17:28:49 node-pve1 pmxcfs[2262]: [status] notice: RRD update error /var/lib/rrdcached/db/pve2-vm/101: /var/lib/rrdcached/db/pve2-vm/101: illegal attempt to update using time 1380727729 when last update time is 1380730388 (minimum one second step) Oct 2 17:28:49 node-pve1 pmxcfs[2262]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-vm/105: -1 Oct 2 17:28:49 node-pve1 pmxcfs[2262]: [status] notice: RRD update error /var/lib/rrdcached/db/pve2-vm/105: /var/lib/rrdcached/db/pve2-vm/105: illegal attempt to update using time 1380727729 when last update time is 1380730388 (minimum one second step) Oct 2 17:28:49 node-pve1 pmxcfs[2262]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-vm/100: -1 Oct 2 17:28:49 node-pve1 pmxcfs[2262]: [status] notice: RRD update error /var/lib/rrdcached/db/pve2-vm/100: /var/lib/rrdcached/db/pve2-vm/100: illegal attempt to update using time 1380727729 when last update time is 1380730627 (minimum one second step)pve version:
Code:
proxmox-ve-2.6.32: 3.1-111 (running kernel: 2.6.32-24-pve)pve-manager: 3.1-14 (running version: 3.1-14/d914b943)pve-kernel-2.6.32-20-pve: 2.6.32-100pve-kernel-2.6.32-24-pve: 2.6.32-111pve-kernel-2.6.32-22-pve: 2.6.32-107pve-kernel-2.6.32-23-pve: 2.6.32-109lvm2: 2.02.98-pve4clvm: 2.02.98-pve4corosync-pve: 1.4.5-1openais-pve: 1.1.4-3libqb0: 0.11.1-2redhat-cluster-pve: 3.2.0-2resource-agents-pve: 3.9.2-4fence-agents-pve: 4.0.0-2pve-cluster: 3.0-7qemu-server: 3.1-4pve-firmware: 1.0-23libpve-common-perl: 3.0-6libpve-access-control: 3.0-6libpve-storage-perl: 3.0-13pve-libspice-server1: 0.12.4-2vncterm: 1.1-4vzctl: 4.0-1pve3vzprocps: 2.0.11-2vzquota: 3.1-2pve-qemu-kvm: 1.4-17ksm-control-daemon: 1.1-1glusterfs-client: 3.4.0-2any idea?
Last edited: Oct 3, 2013
![]()
-
#2
Re: RRDC update error
Your system time is wrong?
-
#3
Re: RRDC update error
seems that running service rrdcached restart helps but some errors still exists:
Code:
Oct 2 18:00:36 node-pve1 pvestatd[23151]: WARNING: file '/etc/pve/nodes/node-pve1/qemu-server/101.conf' modified in future
Oct 2 18:00:36 node-pve1 pvestatd[23151]: WARNING: file '/etc/pve/nodes/node-pve1/qemu-server/103.conf' modified in future
Oct 2 18:00:46 node-pve1 pvestatd[23151]: WARNING: file '/etc/pve/nodes/node-pve1/qemu-server/101.conf' modified in future
Oct 2 18:00:46 node-pve1 pvestatd[23151]: WARNING: file '/etc/pve/nodes/node-pve1/qemu-server/103.conf' modified in future
Oct 2 18:00:56 node-pve1 pvestatd[23151]: WARNING: file '/etc/pve/nodes/node-pve1/qemu-server/101.conf' modified in future
Oct 2 18:00:56 node-pve1 pvestatd[23151]: WARNING: file '/etc/pve/nodes/node-pve1/qemu-server/103.conf' modified in future
Oct 2 18:01:06 node-pve1 pvestatd[23151]: WARNING: file '/etc/pve/nodes/node-pve1/qemu-server/101.conf' modified in future
Oct 2 18:01:06 node-pve1 pvestatd[23151]: WARNING: file '/etc/pve/nodes/node-pve1/qemu-server/103.conf' modified in future
Oct 2 18:01:16 node-pve1 pvestatd[23151]: WARNING: file '/etc/pve/nodes/node-pve1/qemu-server/101.conf' modified in future
Oct 2 18:01:16 node-pve1 pvestatd[23151]: WARNING: file '/etc/pve/nodes/node-pve1/qemu-server/103.conf' modified in future
Oct 2 18:01:26 node-pve1 pvestatd[23151]: WARNING: file '/etc/pve/nodes/node-pve1/qemu-server/101.conf' modified in future
Oct 2 18:01:26 node-pve1 pvestatd[23151]: WARNING: file '/etc/pve/nodes/node-pve1/qemu-server/103.conf' modified in future
Oct 2 18:01:36 node-pve1 pvestatd[23151]: WARNING: file '/etc/pve/nodes/node-pve1/qemu-server/101.conf' modified in future
Oct 2 18:01:36 node-pve1 pvestatd[23151]: WARNING: file '/etc/pve/nodes/node-pve1/qemu-server/103.conf' modified in future
Oct 2 18:01:36 node-pve1 rrdcached[22803]: queue_thread_main: rrd_update_r (/var/lib/rrdcached/db/pve2-storage/node-pve1/backupNAS) failed with status -1. (/var/lib/rrdcached/db/pve2-storage/node-pve1/backupNAS: illegal attempt to update using time 1380729396 when last update time is 1380730627 (minimum one second step))
Oct 2 18:01:36 node-pve1 rrdcached[22803]: queue_thread_main: rrd_update_r (/var/lib/rrdcached/db/pve2-storage/node-pve1/local) failed with status -1. (/var/lib/rrdcached/db/pve2-storage/node-pve1/local: illegal attempt to update using time 1380729396 when last update time is 1380730627 (minimum one second step))
Oct 2 18:01:39 node-pve1 pveproxy[2533]: worker 20535 finished
-
#4
Re: RRDC update error
System time is ok.
-
#5
Re: RRDC update error
After stop/start VM 101 & VM 103 errors went away or it was just a luck — not sure.
Code:
Oct 2 18:25:10 node-pve1 kernel: device tap103i0 entered promiscuous mode
Oct 2 18:25:10 node-pve1 kernel: vmbr0: port 3(tap103i0) entering forwarding state
Oct 2 18:25:11 node-pve1 pvedaemon[23844]: <root@pam> end task UPID:node-pve1:0000629B:0....8E6:qmstart:103:root@pam: OK
Oct 2 18:25:13 node-pve1 ntpd[22582]: Listen normally on 13 tap103i0 fe80::3ce1:c9ff:fe9b:bafd UDP 123
Oct 2 18:25:13 node-pve1 ntpd[22582]: peers refreshedWhat is the meaning of the last two lines?
![]()
-
#6
Re: RRDC update error
After stop/start VM 101 & VM 103 errors went away or it was just a luck — not sure.
The time difference (1380730388 — 1380727729 => 2659) is less than one hour, so I guess the error simply vanished after that time. I assume the system time on the old node was wrong (in future).
-
#7
Hi,
just have the same issue here (after a mainboard replacement).
Managed the RRD problem with a rrdcached restart.
But the logs like this are still flooding syslog:
Code:
Aug 29 19:22:51 hv-co-01-pareq6 pvestatd[6231]: file '/etc/pve/nodes/hv-co-01-pareq6/qemu-server/100.conf' modified in future
Aug 29 19:23:01 hv-co-01-pareq6 pvestatd[6231]: file '/etc/pve/nodes/hv-co-01-pareq6/qemu-server/100.conf' modified in future
Aug 29 19:23:11 hv-co-01-pareq6 pvestatd[6231]: file '/etc/pve/nodes/hv-co-01-pareq6/qemu-server/100.conf' modified in future
Aug 29 19:23:21 hv-co-01-pareq6 pvestatd[6231]: file '/etc/pve/nodes/hv-co-01-pareq6/qemu-server/100.conf' modified in future
Aug 29 19:23:31 hv-co-01-pareq6 pvestatd[6231]: file '/etc/pve/nodes/hv-co-01-pareq6/qemu-server/100.conf' modified in future
Aug 29 19:23:41 hv-co-01-pareq6 pvestatd[6231]: file '/etc/pve/nodes/hv-co-01-pareq6/qemu-server/100.conf' modified in future
Aug 29 19:23:51 hv-co-01-pareq6 pvestatd[6231]: file '/etc/pve/nodes/hv-co-01-pareq6/qemu-server/100.conf' modified in futureThe fun trick is that:
Code:
root@hv-co-01-pareq6:~# tail -n1 /var/log/syslog ; echo ; date ; echo ; stat /etc/pve/nodes/hv-co-01-pareq6/qemu-server/100.conf
Aug 29 19:28:21 hv-co-01-pareq6 pvestatd[6231]: file '/etc/pve/nodes/hv-co-01-pareq6/qemu-server/100.conf' modified in future
Tue Aug 29 19:28:26 CEST 2017
File: /etc/pve/nodes/hv-co-01-pareq6/qemu-server/100.conf
Size: 360 Blocks: 1 IO Block: 4096 regular file
Device: 2dh/45d Inode: 24 Links: 1
Access: (0640/-rw-r-----) Uid: ( 0/ root) Gid: ( 33/www-data)
Access: 2017-08-29 19:04:50.000000000 +0200
Modify: 2017-08-29 19:04:50.000000000 +0200
Change: 2017-08-29 19:04:50.000000000 +0200
Birth: -
So, no, it’s not «modified in future».
About the time, the server is NTP synced ; it’s possible that it was not synced when it booted (systemd’s timedatectl mysteries) since the mainboard has just been replaced, but it is now.
How to get rid of that ? (restarting pvestatd doesn’t do anything).
-
#8
About the time, the server is NTP synced ; it’s possible that it was not synced when it booted (systemd’s timedatectl mysteries) since the mainboard has just been replaced, but it is now.
OK, it’s because of that: pve daemons were started in «Aug 30», and only after systemd decided to properly set the date:
Code:
Aug 30 16:20:08 hv-co-01-pareq6 systemd[1]: Started PVE VM Manager.
[...]
Aug 30 16:20:17 hv-co-01-pareq6 systemd[1]: Started User Manager for UID 0.
Aug 29 16:18:48 hv-co-01-pareq6 systemd[1]: Time has been changed
Aug 29 16:18:48 hv-co-01-pareq6 systemd-timesyncd[1036]: Synchronized to time serverI understand that it will spontaneously fix by itself tomorrow.
However, what to do in the meanwhile, and isn’t there something weird here, since the file as shown by ls isn’t «in the future» ?
For a server, systemd stuff clearly lacks an ntpdate at bootime.
-
#9
I found similar problem with rrd updates.
I inspect /var/lib/rrdcached/ for long-time not-modified files and delete this:
find /var/lib/rrdcached/ -type f -mtime +5 -delete;
After this new files was created automatically, and logs stay clear; no any restarts need;
With last update to pve 5.4-14 this problem also affect one container with UT99 game server:
https://aminux.wordpress.com/2020/05/09/proxmox-rrdcache-issue/
game clients suspended and stuck while this rrd-update logs appear;
fix this issue also solve starnge problem with game server;
-
#10
I found similar problem with rrd updates.
I inspect /var/lib/rrdcached/ for long-time not-modified files and delete this:find /var/lib/rrdcached/ -type f -mtime +5 -delete;
After this new files was created automatically, and logs stay clear; no any restarts need;
With last update to pve 5.4-14 this problem also affect one container with UT99 game server:
https://aminux.wordpress.com/2020/05/09/proxmox-rrdcache-issue/game clients suspended and stuck while this rrd-update logs appear;
fix this issue also solve starnge problem with game server;
Thanks, that helped. Somewhat.
The issue keeps on resurfacing for cpu and cgroups.
-
#11
Hello there
I ll add to your issues mine too which happened today after changing ram dimms. I also set the bios the time correctly (probably needs battery replacement)
My logs are as follows
Code:
Nov 23 11:15:00 pve1 systemd[1]: Starting Proxmox VE replication runner...
Nov 23 11:15:01 pve1 systemd[1]: pvesr.service: Succeeded.
Nov 23 11:15:01 pve1 systemd[1]: Started Proxmox VE replication runner.
Nov 23 11:15:05 pve1 pmxcfs[1463]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-node/pve1: -1
Nov 23 11:15:05 pve1 pmxcfs[1463]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-vm/100: -1
Nov 23 11:15:05 pve1 pmxcfs[1463]: [status] notice: RRD update error /var/lib/rrdcached/db/pve2-vm/100: /var/lib/rrdcached/db/pve2-vm/100: illegal attempt to update using time 1606122905 when last update time is 1606128399 (minimum one second step)
Nov 23 11:15:05 pve1 pmxcfs[1463]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-vm/200: -1
Nov 23 11:15:05 pve1 pmxcfs[1463]: [status] notice: RRD update error /var/lib/rrdcached/db/pve2-vm/200: /var/lib/rrdcached/db/pve2-vm/200: illegal attempt to update using time 1606122905 when last update time is 1606128399 (minimum one second step)
Nov 23 11:15:05 pve1 pmxcfs[1463]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-vm/101: -1
Nov 23 11:15:05 pve1 pmxcfs[1463]: [status] notice: RRD update error /var/lib/rrdcached/db/pve2-vm/101: /var/lib/rrdcached/db/pve2-vm/101: illegal attempt to update using time 1606122905 when last update time is 1606128399 (minimum one second step)
Nov 23 11:15:05 pve1 pmxcfs[1463]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-storage/pve1/local-zfs: -1
Nov 23 11:15:05 pve1 pmxcfs[1463]: [status] notice: RRD update error /var/lib/rrdcached/db/pve2-storage/pve1/local-zfs: /var/lib/rrdcached/db/pve2-storage/pve1/local-zfs: illegal attempt to update using time 1606122905 when last update time is 1606128399 (minimum one second step)
Nov 23 11:15:05 pve1 pmxcfs[1463]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-storage/pve1/local: -1
Nov 23 11:15:05 pve1 pmxcfs[1463]: [status] notice: RRD update error /var/lib/rrdcached/db/pve2-storage/pve1/local: /var/lib/rrdcached/db/pve2-storage/pve1/local: illegal attempt to update using time 1606122905 when last update time is 1606128399 (minimum one second step)
Nov 23 11:15:15 pve1 pmxcfs[1463]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-node/pve1: -1
Nov 23 11:15:15 pve1 pmxcfs[1463]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-vm/100: -1
Nov 23 11:15:15 pve1 pmxcfs[1463]: [status] notice: RRD update error /var/lib/rrdcached/db/pve2-vm/100: /var/lib/rrdcached/db/pve2-vm/100: illegal attempt to update using time 1606122915 when last update time is 1606128399 (minimum one second step)
Nov 23 11:15:15 pve1 pmxcfs[1463]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-vm/200: -1
Nov 23 11:15:15 pve1 pmxcfs[1463]: [status] notice: RRD update error /var/lib/rrdcached/db/pve2-vm/200: /var/lib/rrdcached/db/pve2-vm/200: illegal attempt to update using time 1606122915 when last update time is 1606128399 (minimum one second step)
Nov 23 11:15:15 pve1 pmxcfs[1463]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-vm/101: -1
Nov 23 11:15:15 pve1 pmxcfs[1463]: [status] notice: RRD update error /var/lib/rrdcached/db/pve2-vm/101: /var/lib/rrdcached/db/pve2-vm/101: illegal attempt to update using time 1606122915 when last update time is 1606128399 (minimum one second step)
Nov 23 11:15:15 pve1 pmxcfs[1463]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-storage/pve1/local-zfs: -1
Nov 23 11:15:15 pve1 pmxcfs[1463]: [status] notice: RRD update error /var/lib/rrdcached/db/pve2-storage/pve1/local-zfs: /var/lib/rrdcached/db/pve2-storage/pve1/local-zfs: illegal attempt to update using time 1606122915 when last update time is 1606128399 (minimum one second step)
Nov 23 11:15:15 pve1 pmxcfs[1463]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-storage/pve1/local: -1
Nov 23 11:15:15 pve1 pmxcfs[1463]: [status] notice: RRD update error /var/lib/rrdcached/db/pve2-storage/pve1/local: /var/lib/rrdcached/db/pve2-storage/pve1/local: illegal attempt to update using time 1606122915 when last update time is 1606128399 (minimum one second step)I already tried starting and shutting down my one Vm and 2 lxcs and running service rrdcached restart. Also find /var/lib/rrdcached/ -type f -mtime +5 -delete;
As for time/ntp under pve1 time option the only thing you can set is Europe/your_country nothing else
Nothing seems to help to stop that flooding sys log. Also after a while it logs me out with the << connection error 401 permission denied — invalid pve ticket>>
Also I can t find out why it mentions pve2-vm/200: -1 / pve2-storage/pve1/local: Where did it find pve2 in a one node only system
Last edited: Nov 23, 2020
-
#12
Hello there
I ll add to your issues mine too which happened today after changing ram dimms. I also set the bios the time correctly (probably needs battery replacement)My logs are as follows
Code:
Nov 23 11:15:00 pve1 systemd[1]: Starting Proxmox VE replication runner... Nov 23 11:15:01 pve1 systemd[1]: pvesr.service: Succeeded. Nov 23 11:15:01 pve1 systemd[1]: Started Proxmox VE replication runner. Nov 23 11:15:05 pve1 pmxcfs[1463]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-node/pve1: -1 Nov 23 11:15:05 pve1 pmxcfs[1463]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-vm/100: -1 Nov 23 11:15:05 pve1 pmxcfs[1463]: [status] notice: RRD update error /var/lib/rrdcached/db/pve2-vm/100: /var/lib/rrdcached/db/pve2-vm/100: illegal attempt to update using time 1606122905 when last update time is 1606128399 (minimum one second step) Nov 23 11:15:05 pve1 pmxcfs[1463]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-vm/200: -1 Nov 23 11:15:05 pve1 pmxcfs[1463]: [status] notice: RRD update error /var/lib/rrdcached/db/pve2-vm/200: /var/lib/rrdcached/db/pve2-vm/200: illegal attempt to update using time 1606122905 when last update time is 1606128399 (minimum one second step) Nov 23 11:15:05 pve1 pmxcfs[1463]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-vm/101: -1 Nov 23 11:15:05 pve1 pmxcfs[1463]: [status] notice: RRD update error /var/lib/rrdcached/db/pve2-vm/101: /var/lib/rrdcached/db/pve2-vm/101: illegal attempt to update using time 1606122905 when last update time is 1606128399 (minimum one second step) Nov 23 11:15:05 pve1 pmxcfs[1463]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-storage/pve1/local-zfs: -1 Nov 23 11:15:05 pve1 pmxcfs[1463]: [status] notice: RRD update error /var/lib/rrdcached/db/pve2-storage/pve1/local-zfs: /var/lib/rrdcached/db/pve2-storage/pve1/local-zfs: illegal attempt to update using time 1606122905 when last update time is 1606128399 (minimum one second step) Nov 23 11:15:05 pve1 pmxcfs[1463]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-storage/pve1/local: -1 Nov 23 11:15:05 pve1 pmxcfs[1463]: [status] notice: RRD update error /var/lib/rrdcached/db/pve2-storage/pve1/local: /var/lib/rrdcached/db/pve2-storage/pve1/local: illegal attempt to update using time 1606122905 when last update time is 1606128399 (minimum one second step) Nov 23 11:15:15 pve1 pmxcfs[1463]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-node/pve1: -1 Nov 23 11:15:15 pve1 pmxcfs[1463]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-vm/100: -1 Nov 23 11:15:15 pve1 pmxcfs[1463]: [status] notice: RRD update error /var/lib/rrdcached/db/pve2-vm/100: /var/lib/rrdcached/db/pve2-vm/100: illegal attempt to update using time 1606122915 when last update time is 1606128399 (minimum one second step) Nov 23 11:15:15 pve1 pmxcfs[1463]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-vm/200: -1 Nov 23 11:15:15 pve1 pmxcfs[1463]: [status] notice: RRD update error /var/lib/rrdcached/db/pve2-vm/200: /var/lib/rrdcached/db/pve2-vm/200: illegal attempt to update using time 1606122915 when last update time is 1606128399 (minimum one second step) Nov 23 11:15:15 pve1 pmxcfs[1463]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-vm/101: -1 Nov 23 11:15:15 pve1 pmxcfs[1463]: [status] notice: RRD update error /var/lib/rrdcached/db/pve2-vm/101: /var/lib/rrdcached/db/pve2-vm/101: illegal attempt to update using time 1606122915 when last update time is 1606128399 (minimum one second step) Nov 23 11:15:15 pve1 pmxcfs[1463]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-storage/pve1/local-zfs: -1 Nov 23 11:15:15 pve1 pmxcfs[1463]: [status] notice: RRD update error /var/lib/rrdcached/db/pve2-storage/pve1/local-zfs: /var/lib/rrdcached/db/pve2-storage/pve1/local-zfs: illegal attempt to update using time 1606122915 when last update time is 1606128399 (minimum one second step) Nov 23 11:15:15 pve1 pmxcfs[1463]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-storage/pve1/local: -1 Nov 23 11:15:15 pve1 pmxcfs[1463]: [status] notice: RRD update error /var/lib/rrdcached/db/pve2-storage/pve1/local: /var/lib/rrdcached/db/pve2-storage/pve1/local: illegal attempt to update using time 1606122915 when last update time is 1606128399 (minimum one second step)I already tried starting and shutting down my one Vm and 2 lxcs and running service rrdcached restart. Also find /var/lib/rrdcached/ -type f -mtime +5 -delete;
Nothing seems to help to stop that flooding sys log. Also after a while it logs me out with the << connection error 401 permission denied — invalid pve ticket>>
Also I can t find out why it mentions pve2-vm/200: -1 / pve2-storage/pve1/local: Where did it find pve2 in a one node only system
Maybe this post can help https://forum.proxmox.com/threads/rrdc-and-rrd-update-errors.76219/post-345702
-
#13
Thank you for your quick reply. Well after issuing the commands this is what i get afterwards
Code:
Nov 23 11:59:24 pve1 systemd[1]: Starting LSB: start or stop rrdcached...
Nov 23 11:59:24 pve1 rrdcached[13250]: rrdcached started.
Nov 23 11:59:24 pve1 systemd[1]: Started LSB: start or stop rrdcached.
Nov 23 11:59:39 pve1 systemd[1]: Stopping The Proxmox VE cluster filesystem...
Nov 23 11:59:39 pve1 pmxcfs[1375]: [main] notice: teardown filesystem
Nov 23 11:59:39 pve1 systemd[6633]: etc-pve.mount: Succeeded.
Nov 23 11:59:39 pve1 systemd[1]: etc-pve.mount: Succeeded.
Nov 23 11:59:49 pve1 systemd[1]: pve-cluster.service: State 'stop-sigterm' timed out. Killing.
Nov 23 11:59:49 pve1 systemd[1]: pve-cluster.service: Killing process 1375 (pmxcfs) with signal SIGKILL.
Nov 23 11:59:49 pve1 systemd[1]: pve-cluster.service: Main process exited, code=killed, status=9/KILL
Nov 23 11:59:49 pve1 systemd[1]: pve-cluster.service: Failed with result 'timeout'.
Nov 23 11:59:49 pve1 systemd[1]: Stopped The Proxmox VE cluster filesystem.
Nov 23 11:59:49 pve1 systemd[1]: Starting The Proxmox VE cluster filesystem...
Nov 23 11:59:51 pve1 pve-ha-lrm[1692]: updating service status from manager failed: Connection refused
Nov 23 11:59:51 pve1 pve-firewall[1503]: status update error: Connection refused
Nov 23 11:59:51 pve1 pve-firewall[1503]: firewall update time (10.014 seconds)
Nov 23 11:59:51 pve1 pve-firewall[1503]: status update error: Connection refused
Nov 23 11:59:51 pve1 pvestatd[1506]: ipcc_send_rec[1] failed: Connection refused
Nov 23 11:59:51 pve1 pvestatd[1506]: ipcc_send_rec[2] failed: Connection refused
Nov 23 11:59:51 pve1 pvestatd[1506]: ipcc_send_rec[3] failed: Connection refused
Nov 23 11:59:51 pve1 pvestatd[1506]: ipcc_send_rec[4] failed: Connection refused
Nov 23 11:59:51 pve1 pvestatd[1506]: status update error: Connection refused
Nov 23 11:59:51 pve1 pvestatd[1506]: status update time (10.016 seconds)
Nov 23 11:59:51 pve1 pvestatd[1506]: ipcc_send_rec[1] failed: Connection refused
Nov 23 11:59:51 pve1 pvestatd[1506]: ipcc_send_rec[2] failed: Connection refused
Nov 23 11:59:51 pve1 pvestatd[1506]: ipcc_send_rec[3] failed: Connection refused
Nov 23 11:59:51 pve1 pvestatd[1506]: ipcc_send_rec[4] failed: Connection refused
Nov 23 11:59:51 pve1 pvestatd[1506]: status update error: Connection refused
Nov 23 11:59:51 pve1 systemd[1]: Started The Proxmox VE cluster filesystem.
Nov 23 11:59:51 pve1 systemd[1]: Condition check resulted in Corosync Cluster Engine being skipped.
Nov 23 12:00:00 pve1 systemd[1]: Starting Proxmox VE replication runner...
Nov 23 12:00:01 pve1 systemd[1]: pvesr.service: Succeeded.
Nov 23 12:00:01 pve1 systemd[1]: Started Proxmox VE replication runner.
Nov 23 12:00:50 pve1 pveproxy[1685]: worker exit
Nov 23 12:00:50 pve1 pveproxy[1683]: worker 1685 finished
Nov 23 12:00:50 pve1 pveproxy[1683]: starting 1 worker(s)
Nov 23 12:00:50 pve1 pveproxy[1683]: worker 14618 started
Nov 23 12:01:00 pve1 systemd[1]: Starting Proxmox VE replication runner...
Nov 23 12:01:01 pve1 systemd[1]: pvesr.service: Succeeded.
Nov 23 12:01:01 pve1 systemd[1]: Started Proxmox VE replication runner.
Nov 23 12:02:00 pve1 systemd[1]: Starting Proxmox VE replication runner...
Nov 23 12:02:01 pve1 systemd[1]: pvesr.service: Succeeded.
Nov 23 12:02:01 pve1 systemd[1]: Started Proxmox VE replication runner.
Nov 23 12:03:00 pve1 systemd[1]: Starting Proxmox VE replication runner...
Nov 23 12:03:01 pve1 systemd[1]: pvesr.service: Succeeded.
Nov 23 12:03:01 pve1 systemd[1]: Started Proxmox VE replication runner.
Nov 23 12:03:19 pve1 systemd[1]: Starting Cleanup of Temporary Directories...
Nov 23 12:03:19 pve1 systemd[1]: systemd-tmpfiles-clean.service: Succeeded.
Nov 23 12:03:19 pve1 systemd[1]: Started Cleanup of Temporary Directories.
Nov 23 12:03:24 pve1 pvedaemon[1531]: <root@pam> successful auth for user 'root@pam'
Nov 23 12:04:00 pve1 systemd[1]: Starting Proxmox VE replication runner...
Nov 23 12:04:01 pve1 systemd[1]: pvesr.service: Succeeded.
Nov 23 12:04:01 pve1 systemd[1]: Started Proxmox VE replication runner.
Nov 23 12:05:00 pve1 systemd[1]: Starting Proxmox VE replication runner...
Nov 23 12:05:01 pve1 systemd[1]: pvesr.service: Succeeded.
Nov 23 12:05:01 pve1 systemd[1]: Started Proxmox VE replication runner.
Nov 23 12:06:00 pve1 systemd[1]: Starting Proxmox VE replication runner...
Nov 23 12:06:01 pve1 systemd[1]: pvesr.service: Succeeded.
Nov 23 12:06:01 pve1 systemd[1]: Started Proxmox VE replication runner.
Nov 23 12:07:00 pve1 systemd[1]: Starting Proxmox VE replication runner...
Nov 23 12:07:01 pve1 systemd[1]: pvesr.service: Succeeded.
Nov 23 12:07:01 pve1 systemd[1]: Started Proxmox VE replication runner.
Nov 23 12:08:00 pve1 systemd[1]: Starting Proxmox VE replication runner...
Nov 23 12:08:01 pve1 systemd[1]: pvesr.service: Succeeded.
Nov 23 12:08:01 pve1 systemd[1]: Started Proxmox VE replication runner.
Nov 23 12:09:00 pve1 systemd[1]: Starting Proxmox VE replication runner...
Nov 23 12:09:01 pve1 systemd[1]: pvesr.service: Succeeded.
Nov 23 12:09:01 pve1 systemd[1]: Started Proxmox VE replication runner.is it normal this loop of replication runner and the message afterwards that the pvesr.service: succeded ??
PS In case of any interest I am using proxmox upon the zfs file system on a raid 1 array
New Update after a restart back to basics
Code:
Nov 23 12:38:00 pve1 systemd[1]: Starting Proxmox VE replication runner...
Nov 23 12:38:01 pve1 systemd[1]: pvesr.service: Succeeded.
Nov 23 12:38:01 pve1 systemd[1]: Started Proxmox VE replication runner.
Nov 23 12:38:06 pve1 pmxcfs[1356]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-node/pve1: -1
Nov 23 12:38:06 pve1 pmxcfs[1356]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-vm/100: -1
Nov 23 12:38:06 pve1 pmxcfs[1356]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-vm/101: -1
Nov 23 12:38:06 pve1 pmxcfs[1356]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-vm/200: -1
Nov 23 12:38:06 pve1 pmxcfs[1356]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-storage/pve1/local-zfs: -1
Nov 23 12:38:06 pve1 pmxcfs[1356]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-storage/pve1/local: -1
Nov 23 12:38:16 pve1 pmxcfs[1356]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-node/pve1: -1
Nov 23 12:38:16 pve1 pmxcfs[1356]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-vm/100: -1
Nov 23 12:38:16 pve1 pmxcfs[1356]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-vm/200: -1
Nov 23 12:38:16 pve1 pmxcfs[1356]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-vm/101: -1
Nov 23 12:38:16 pve1 pmxcfs[1356]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-storage/pve1/local: -1
Nov 23 12:38:16 pve1 pmxcfs[1356]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-storage/pve1/local-zfs: -1
Nov 23 12:38:26 pve1 pmxcfs[1356]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-node/pve1: -1
Nov 23 12:38:26 pve1 pmxcfs[1356]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-vm/100: -1
Nov 23 12:38:26 pve1 pmxcfs[1356]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-vm/101: -1
Nov 23 12:38:26 pve1 pmxcfs[1356]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-vm/200: -1
Nov 23 12:38:26 pve1 pmxcfs[1356]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-storage/pve1/local: -1
Nov 23 12:38:26 pve1 pmxcfs[1356]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-storage/pve1/local-zfs: -1
Nov 23 12:38:36 pve1 pmxcfs[1356]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-node/pve1: -1
Nov 23 12:38:36 pve1 pmxcfs[1356]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-vm/100: -1
Nov 23 12:38:36 pve1 pmxcfs[1356]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-vm/200: -1
Nov 23 12:38:36 pve1 pmxcfs[1356]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-vm/101: -1
Nov 23 12:38:36 pve1 pmxcfs[1356]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-storage/pve1/local-zfs: -1
Nov 23 12:38:36 pve1 pmxcfs[1356]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-storage/pve1/local: -1
Nov 23 12:38:46 pve1 pmxcfs[1356]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-node/pve1: -1
Nov 23 12:38:46 pve1 pmxcfs[1356]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-vm/100: -1
Nov 23 12:38:46 pve1 pmxcfs[1356]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-vm/200: -1
Nov 23 12:38:46 pve1 pmxcfs[1356]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-vm/101: -1
Nov 23 12:38:46 pve1 pmxcfs[1356]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-storage/pve1/local: -1
Nov 23 12:38:46 pve1 pmxcfs[1356]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-storage/pve1/local-zfs: -1
Nov 23 12:38:56 pve1 pmxcfs[1356]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-node/pve1: -1
Nov 23 12:38:56 pve1 pmxcfs[1356]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-vm/100: -1
Nov 23 12:38:56 pve1 pmxcfs[1356]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-vm/101: -1
Nov 23 12:38:56 pve1 pmxcfs[1356]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-vm/200: -1
Nov 23 12:38:56 pve1 pmxcfs[1356]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-storage/pve1/local-zfs: -1
Nov 23 12:38:56 pve1 pmxcfs[1356]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-storage/pve1/local: -1Last edited: Nov 23, 2020
-
#14
Thank you for your quick reply. Well after issuing the commands this is what i get afterwards
Code:
Nov 23 11:59:24 pve1 systemd[1]: Starting LSB: start or stop rrdcached... Nov 23 11:59:24 pve1 rrdcached[13250]: rrdcached started. Nov 23 11:59:24 pve1 systemd[1]: Started LSB: start or stop rrdcached. Nov 23 11:59:39 pve1 systemd[1]: Stopping The Proxmox VE cluster filesystem... Nov 23 11:59:39 pve1 pmxcfs[1375]: [main] notice: teardown filesystem Nov 23 11:59:39 pve1 systemd[6633]: etc-pve.mount: Succeeded. Nov 23 11:59:39 pve1 systemd[1]: etc-pve.mount: Succeeded. Nov 23 11:59:49 pve1 systemd[1]: pve-cluster.service: State 'stop-sigterm' timed out. Killing. Nov 23 11:59:49 pve1 systemd[1]: pve-cluster.service: Killing process 1375 (pmxcfs) with signal SIGKILL. Nov 23 11:59:49 pve1 systemd[1]: pve-cluster.service: Main process exited, code=killed, status=9/KILL Nov 23 11:59:49 pve1 systemd[1]: pve-cluster.service: Failed with result 'timeout'. Nov 23 11:59:49 pve1 systemd[1]: Stopped The Proxmox VE cluster filesystem. Nov 23 11:59:49 pve1 systemd[1]: Starting The Proxmox VE cluster filesystem... Nov 23 11:59:51 pve1 pve-ha-lrm[1692]: updating service status from manager failed: Connection refused Nov 23 11:59:51 pve1 pve-firewall[1503]: status update error: Connection refused Nov 23 11:59:51 pve1 pve-firewall[1503]: firewall update time (10.014 seconds) Nov 23 11:59:51 pve1 pve-firewall[1503]: status update error: Connection refused Nov 23 11:59:51 pve1 pvestatd[1506]: ipcc_send_rec[1] failed: Connection refused Nov 23 11:59:51 pve1 pvestatd[1506]: ipcc_send_rec[2] failed: Connection refused ..... Nov 23 12:08:01 pve1 systemd[1]: pvesr.service: Succeeded. Nov 23 12:08:01 pve1 systemd[1]: Started Proxmox VE replication runner. Nov 23 12:09:00 pve1 systemd[1]: Starting Proxmox VE replication runner... Nov 23 12:09:01 pve1 systemd[1]: pvesr.service: Succeeded. Nov 23 12:09:01 pve1 systemd[1]: Started Proxmox VE replication runner.is it normal this loop of replication runner and the message afterwards that the pvesr.service: succeded ??
PS In case of any interest I am using proxmox upon the zfs file system on a raid 1 array
New Update after a restart back to basics
Code:
Nov 23 12:38:00 pve1 systemd[1]: Starting Proxmox VE replication runner... Nov 23 12:38:01 pve1 systemd[1]: pvesr.service: Succeeded. Nov 23 12:38:01 pve1 systemd[1]: Started Proxmox VE replication runner. Nov 23 12:38:06 pve1 pmxcfs[1356]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-node/pve1: -1 Nov 23 12:38:06 pve1 pmxcfs[1356]: [status] notice: RRDC update error /var/lib/rrdcached/db/pve2-vm/100: -1 .... [/QUOTE] [/QUOTE] Yeah, i do remember a lot of noise as well. I think what you are now seeing is exclusively due to filesystem permission issues or non existent file. Try something like: touch /var/lib/rrdcached/db/pve2-vm/100 and see what happens
Yeah, i do remember a lot of noise as well.
I think what you are now seeing is exclusively due to filesystem permission issues or non existent file.
Try something like: touch /var/lib/rrdcached/db/pve2-vm/100
and see what happens[/CODE]
-
#15
Yeah, i do remember a lot of noise as well.
I think what you are now seeing is exclusively due to filesystem permission issues or non existent file.
Try something like: touch /var/lib/rrdcached/db/pve2-vm/100
and see what happens[/CODE]
For several minutes now (by the way i run the touch line for all vm and lxcs) i have the below trilogy all over again. Is it a normal procedure? What the hell is it trying to replicate?
Code:
Nov 23 16:05:01 pve1 systemd[1]: Started Proxmox VE replication runner.
Nov 23 16:06:00 pve1 systemd[1]: Starting Proxmox VE replication runner...
Nov 23 16:06:01 pve1 systemd[1]: pvesr.service: Succeeded.
Nov 23 16:06:01 pve1 systemd[1]: Started Proxmox VE replication runner.
Nov 23 16:07:00 pve1 systemd[1]: Starting Proxmox VE replication runner...
Nov 23 16:07:01 pve1 systemd[1]: pvesr.service: Succeeded.
Nov 23 16:07:01 pve1 systemd[1]: Started Proxmox VE replication runner.
Nov 23 16:08:00 pve1 systemd[1]: Starting Proxmox VE replication runner...
Nov 23 16:08:01 pve1 systemd[1]: pvesr.service: Succeeded.
Nov 23 16:08:01 pve1 systemd[1]: Started Proxmox VE replication runner.
Nov 23 16:09:00 pve1 systemd[1]: Starting Proxmox VE replication runner...
Nov 23 16:09:01 pve1 systemd[1]: pvesr.service: Succeeded.
Nov 23 16:09:01 pve1 systemd[1]: Started Proxmox VE replication runner.By the way the one VM and two lxcs I have are shut down
Last edited: Nov 23, 2020
-
#16
It happened in my server (6.2-4) right now. Today is Dec, 29, and the server was stopped at Dec, 26 at 09:35…
The only solution was a server reboot.
Weird.
-
#17
yeah, it went away and came back again. This truely a mess and left unaddressed. Somehow nobody knows where these messages come from, how to stop them.
-
#18
Had the same errors and just resetting the rrdcached dbs helped if you don´t want to wait 
-
#19
Had the same errors and just resetting the rrdcached dbs helped if you don´t want to wait

How did you do that and is it safe to do?
Posted: 2020-05-09 in IT
Метки:linux
Обнаружил тут на одной из нод кластера проксмокса примерно такую пургу в логах ( journalctl -f ):
node1-proxmox rrdcached[id]: queue_thread_main: rrd_update_r (/var/lib/rrdcached/...) failed with status -1. (/var/lib/rrdcached/...: illegal attempt to update using time 1380729396 when last update time is 1380730627 (minimum one second step))
Гугление привело на сайт проксмокса:
https://forum.proxmox.com/threads/solved-rrdc-update-error.16256/
Однако помимо очевидного момента с необходимостью проверки одинаковости времени и работоспособности NTP, есть ещё одна связанная проблема. Похоже, иногда обновление этих файлов RRD (в них содержится статистика по нагрузке для построения графиков в веб-морде) как-то ломается, и данные перестают обновляться. Один из симптомов этого — при логине на некоторые ноды статистика по загрузке CPU/Mem/Net/IO некоторых контенеров/ВМ в веб-морде будет рисовать пустой график с датами на оси от 1970-01-01.
Для фикса этой беды помогает вот такая команда:
find /var/lib/rrdcached/ -type f -mtime +5 -delete;
Она удалит из кэша RRD-файлы статистики, не обновлявшиеся более 5 дней. Не бойтесь удалить данные существующего объекта — если объект есть, новый файл будет создан заново. Никаких демонов и процессов при этом перезапускать не надо. Выполнить лучше на всех нодах.
Заодно это удалит архив старой статистики от давно удалённых виртуалок и старых точек монтирования.
После этого графики нагрузки снова начали отображаться, а ошибка «… illegal attempt to update using time … minimum one second step …» перестала сыпаться в логи.
Казалось бы, что прям такого плохого может быть в такой малозначительной, на первый взгляд, ошибке, как невозможность обновить статистику, что я решил об этом написать ?
В моём случае на проблемной ноде висел контейнер с игровым сервером UT’99. И в процессе гамания раз в 2-3 минуты клиенты подвисали в воздухе, иногда отображался индикатор потери связи с сервером. При этом в системных логах внутри самого контейнера, в логах гейм-сервера, на сетевых интерфейсах и в *top-ах никакого особого криминала не наблюдалось.
И проявилось это только на последнем апдейте проксмокса из ветки 5.4. Аналогично, это могло подействовать на любые реалтайм-сервисы схожим образом.
P.S. Вариант не ставить секурити-апдейты даже не рассматривается =)
 Время от времени в повседневной практике встречается следующий тип неисправностей — мелкие, но неприятные. Решаются они, как правило, походя, но именно поэтому решение редко запоминается и столкнувшись с такой неисправностью в следующий раз приходится искать способ ее устранения заново. Данная заметка как раз про такой случай. В очередной раз столкнувшись с тем, что Proxmox перестал показывать графики статистики в веб-интерфейсе нам пришлось снова искать решение, хотя мы помнили, что там все очень просто…
Время от времени в повседневной практике встречается следующий тип неисправностей — мелкие, но неприятные. Решаются они, как правило, походя, но именно поэтому решение редко запоминается и столкнувшись с такой неисправностью в следующий раз приходится искать способ ее устранения заново. Данная заметка как раз про такой случай. В очередной раз столкнувшись с тем, что Proxmox перестал показывать графики статистики в веб-интерфейсе нам пришлось снова искать решение, хотя мы помнили, что там все очень просто…
Научиться настраивать MikroTik с нуля или систематизировать уже имеющиеся знания можно на углубленном курсе по администрированию MikroTik. Автор курса, сертифицированный тренер MikroTik Дмитрий Скоромнов, лично проверяет лабораторные работы и контролирует прогресс каждого своего студента. В три раза больше информации, чем в вендорской программе MTCNA, более 20 часов практики и доступ навсегда.
В один из длинных зимних вечеров мы обратили внимание, что на одном из свежеустановленных серверов Proxmox не показывается статистика. Еще одной характерной деталью является указанное на графиках время — 1 января 1970 года.
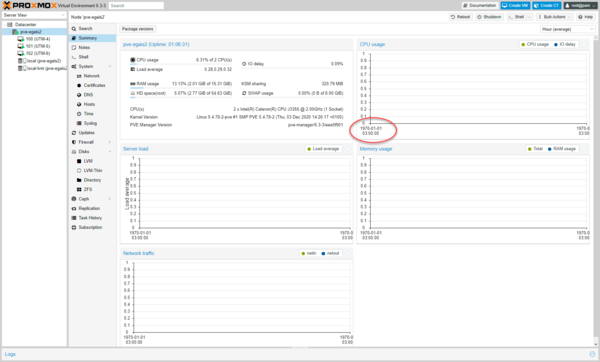 За отображение графиков статистики в Proxmox отвечают данные RRD (round-robin database), которые хранятся на основе циклического буфера, что обеспечивает постоянный размер базы данных. Указанная дата тоже не случайна, именно с 1 января 1970 года начинается отсчет времени UNIX и текущее время в Linux системах представляет количество секунд, прошедших с этой даты.
За отображение графиков статистики в Proxmox отвечают данные RRD (round-robin database), которые хранятся на основе циклического буфера, что обеспечивает постоянный размер базы данных. Указанная дата тоже не случайна, именно с 1 января 1970 года начинается отсчет времени UNIX и текущее время в Linux системах представляет количество секунд, прошедших с этой даты.
Зная это становится проще понять причину неисправности — при формировании файла базы данных RRD была неверно определена системная дата и он оказался сформирован с нулевой отметкой времени. Что делать в таком случае? Просто удалить неисправный файл, для этого перейдите в директорию
/var/lib/rrdcached/db/pve2-nodeи очистите ее содержимое. Перезапускать какие-либо службы при этом не нужно, новая база данных RRD будет создана автоматически, после чего графики статистики начнут отображаться.
 Как видим, неисправность действительно мелкая — на работоспособность гипервизора она не влияет — но достаточно неприятная. И способ решения у нее весьма прост. Но поиск решения иногда способен занять определенное время. Поэтому мы и решили создать эту заметку, чтобы было где посмотреть в следующий раз. Надеемся, что для вас она тоже окажется полезной.
Как видим, неисправность действительно мелкая — на работоспособность гипервизора она не влияет — но достаточно неприятная. И способ решения у нее весьма прост. Но поиск решения иногда способен занять определенное время. Поэтому мы и решили создать эту заметку, чтобы было где посмотреть в следующий раз. Надеемся, что для вас она тоже окажется полезной.
Научиться настраивать MikroTik с нуля или систематизировать уже имеющиеся знания можно на углубленном курсе по администрированию MikroTik. Автор курса, сертифицированный тренер MikroTik Дмитрий Скоромнов, лично проверяет лабораторные работы и контролирует прогресс каждого своего студента. В три раза больше информации, чем в вендорской программе MTCNA, более 20 часов практики и доступ навсегда.
![]()

-
- #1
Seeing same errors as in http://phpbb.openmediavault.or…1ea5de8395633b041daeb7a06
OMV/Debian on /, RAID1 built on btrfs (custom made, not through OMV interface)
Any solution?
Thanks in advance.
Jun 29 08:01:53 homeserver rsyslogd: [origin software="rsyslogd" swVersion="5.8.11" x-pid="2545" x-info="http://www.rsyslog.com"] rsyslogd was HUPed Jun 29 08:01:53 homeserver postfix/postsuper[19827]: fatal: scan_dir_push: open directory hold: No such file or directory Jun 29 08:01:54 homeserver anacron[19191]: Job `cron.daily' terminated (exit status: 1) (mailing output) Jun 29 08:01:54 homeserver postfix/postdrop[19836]: warning: unable to look up public/pickup: No such file or directory Jun 29 08:01:54 homeserver anacron[19191]: Normal exit (1 job run) Jun 29 08:01:57 homeserver collectd[9066]: rrdcached plugin: rrdc_update (/var/lib/rrdcached/db/localhost/df-root/df_complex-free.rrd, [1404025317:177968939008.000000], 1) failed with status -1. Jun 29 08:01:57 homeserver collectd[9066]: Filter subsystem: Built-in target `write': Dispatching value to all write plugins failed with status -1. Jun 29 08:01:57 homeserver collectd[9066]: rrdcached plugin: rrdc_update (/var/lib/rrdcached/db/localhost/df-root/df_complex-reserved.rrd, [1404025317:9595465728.000000], 1) failed with status -1. Jun 29 08:01:57 homeserver collectd[9066]: Filter subsystem: Built-in target `write': Dispatching value to all write plugins failed with status -1. Jun 29 08:01:57 homeserver collectd[9066]: rrdcached plugin: rrdc_update (/var/lib/rrdcached/db/localhost/df-root/df_complex-used.rrd, [1404025317:1333485568.000000], 1) failed with status -1. Jun 29 08:01:57 homeserver collectd[9066]: Filter subsystem: Built-in target `write': Dispatching value to all write plugins failed with status -1. Jun 29 08:02:07 homeserver collectd[9066]: rrdcached plugin: rrdc_update (/var/lib/rrdcached/db/localhost/df-root/df_complex-free.rrd, [1404025327:177968914432.000000], 1) failed with status -1. Jun 29 08:02:07 homeserver collectd[9066]: Filter subsystem: Built-in target `write': Dispatching value to all write plugins failed with status -1. Jun 29 08:02:07 homeserver collectd[9066]: rrdcached plugin: rrdc_update (/var/lib/rrdcached/db/localhost/df-root/df_complex-reserved.rrd, [1404025327:9595465728.000000], 1) failed with status -1. Jun 29 08:02:07 homeserver collectd[9066]: Filter subsystem: Built-in target `write': Dispatching value to all write plugins failed with status -1. Jun 29 08:02:07 homeserver collectd[9066]: rrdcached plugin: rrdc_update (/var/lib/rrdcached/db/localhost/df-root/df_complex-used.rrd, [1404025327:1333510144.000000], 1) failed with status -1. Jun 29 08:02:07 homeserver collectd[9066]: Filter subsystem: Built-in target `write': Dispatching value to all write plugins failed with status -1. Jun 29 08:02:17 homeserver collectd[9066]: rrdcached plugin: rrdc_update (/var/lib/rrdcached/db/localhost/df-root/df_complex-free.rrd, [1404025337:177968898048.000000], 1) failed with status -1. Jun 29 08:02:17 homeserver collectd[9066]: Filter subsystem: Built-in target `write': Dispatching value to all write plugins failed with status -1. Jun 29 08:02:17 homeserver collectd[9066]: rrdcached plugin: rrdc_update (/var/lib/rrdcached/db/localhost/df-root/df_complex-reserved.rrd, [1404025337:9595465728.000000], 1) failed with status -1. Jun 29 08:02:17 homeserver collectd[9066]: Filter subsystem: Built-in target `write': Dispatching value to all write plugins failed with status -1. Jun 29 08:02:17 homeserver collectd[9066]: rrdcached plugin: rrdc_update (/var/lib/rrdcached/db/localhost/df-root/df_complex-used.rrd, [1404025337:1333526528.000000], 1) failed with status -1. Dispatching value to all write plugins failed with status -1.Alles anzeigen
-
- #2
I had the same errors on my system. I have two different Raids (Raid1 for system, Raid5 for data).
If the devices on the raid 5 (2 LVM Volumes) were unmounted (but formatted) the errors would come every minute, after mounting the drives the errors did go away.So if you have unmounted drives or volumes try to mount them.
-
- #3
All drives are mounted already, the problem seems to be that I’m using btrfs which is not yet supported by OMV.
Edit: Is there no way to temporarily disable this alert??? Thx.
-
-
- #5
Did you create filesystem and mount a drive yet??? It is trying to cache info but maybe no data drive is available yet.
-
- #6
I use btrfs so the filesystem is manually mounted, not via omv. Any possible solution…?
An ugly hack will do, the logs files ballooned into several GBs taking down the server.
Thx in advance.
-
-
- Offizieller Beitrag
- #8
Comment out the «LoadPlugin df» section in /etc/collectd/collectd.conf. Then monit restart collectd. This change will be overwritten with certain changes in the web interface or possibly an omv update.
-
- #9
ok. so not a good solution.
but here is what I did:
what is the downside of this? besides not getting constant information I actually do not need. I mean if I need to monitor I can probably also do it with some other CLI tools.
Would this be a good work arround until a fix is found or at least until Jessie is out? Or will it break some other thing?
I tried it only in virtualbox and it seemed to stop the logs and I ahvent’ noticed any side effects, but I did this just before going to work so I only had a min or two to do the checks.
-
- #10
maybe btrfs is not supported by collectd
Do, what Aaron says -
- #11
no it’s a df debian bug (explained in another thread).: mass errors in syslog (clean install upgraded to .6)
solution provided by chrunchbang (http://crunchbang.org/forums/viewtopic.php?id=25901) doesn’t solve the collectd issue though it does make the logs look slightly nicer.What Aaron suggest works but as he noted
Zitat
This change will be overwritten with certain changes in the web interface or possibly an omv update.
for update it would be an easy fix (e.g. with a script) but changes to web interface….
So again my question is — is stopping collectd a good workaround? or do I break anything else with that? I use ext4 and as I understand here the collectd is only collecting system data for display.
another option would be to make that file read only after that change, however again I am not sure what that would mean when
Zitat
certain changes in the web interface or possibly an omv update
appear.
-
- Offizieller Beitrag
- #12
You are fine to stop collectd but upgrades or even a reboot (if you just use monit stop) will start it again.
-
- #13
excellent! I’ve been checking collectd pages. I am not familiar with code or git… but is this some kind of fix?:
https://github.com/svn2github/…272c85afc46e6724f5ca4cfd0or is this just a proposal for a solution from Openmediavault?
I will either try to implement your fix in some way (read only config or maybe to get notified if file changes) or maybe just turn it off completely until it gets fixed. The logs stay more or less quiet after this is turned off. I am off to find other tools for monitoring I could use.
Never expected such issues from Debian stable and it’s official packages…
-
- Offizieller Beitrag
- #14
That fix is very old (omv 0.6) and was an attempt to fix the problem.
While it is a bug, it really doesn’t hurt much other than logging too much. It is a big deal for a RPi but not really any other system.
-
- #15
Hi,
I have a lot of message in log (clean last omv from scratch)Oct 25 22:52:31 omv collectd[2191]: rrdcached plugin: rrdc_update (/var/lib/rrdcached/db/localhost/df-root/df_complex-free.rrd, [1414270351:55327059968.000000], 1) failed with status -1. Oct 25 22:52:31 omv collectd[2191]: Filter subsystem: Built-in target `write': Dispatching value to all write plugins failed with status -1. Oct 25 22:52:31 omv collectd[2191]: rrdcached plugin: rrdc_update (/var/lib/rrdcached/db/localhost/df-root/df_complex-reserved.rrd, [1414270351:3020947456.000000], 1) failed with status -1. Oct 25 22:52:31 omv collectd[2191]: Filter subsystem: Built-in target `write': Dispatching value to all write plugins failed with status -1. Oct 25 22:52:31 omv collectd[2191]: rrdcached plugin: rrdc_update (/var/lib/rrdcached/db/localhost/df-root/df_complex-used.rrd, [1414270351:1121165312.000000], 1) failed with status -1.Is there any way stop this ?
Thanks -
- Offizieller Beitrag
- #16
-
- #17
I had already put 4 data drive in Raid5. Anyway, I add a usb key and it solves my issue
Thanks ! -
- #18
Hi!
I have exactly the same problem:
Nov 6 18:45:23 NAS collectd[2301]: rrdcached plugin: rrdc_update (/var/lib/rrdcached/db/localhost/df-root/df_complex-free.rrd, [1415295923:6860156928.000000], 1) failed with status -1.
Nov 6 18:45:23 NAS collectd[2301]: Filter subsystem: Built-in target `write’: Dispatching value to all write plugins failed with status -1.
Nov 6 18:45:23 NAS collectd[2301]: rrdcached plugin: rrdc_update (/var/lib/rrdcached/db/localhost/df-root/df_complex-reserved.rrd, [1415295923:446271488.000000], 1) failed with status -1.
Nov 6 18:45:23 NAS collectd[2301]: Filter subsystem: Built-in target `write’: Dispatching value to all write plugins failed with status -1.and yes, I have a data drive…how can this be stopped? Its logging like 40 lines per minute….(and I have an ARM device)
I also read mass errors in syslog (clean install upgraded to .6) but it seems this issue is still open.
pls note that I have mounted by EXT4 without ACL, QUOTA (OMV 1.0.29 Partition mount problem) in case its related
and for the graphs, the only one that doesn’t get done is the «disk usage»
-
- #19
got it !!

in /etc/collectd/collectd.conf
the DF section was:
LoadPlugin df <Plugin df> # MountPoint "/" IgnoreSelected false </Plugin>so I uncommented MountPoint and manually pointed to the correct mount in /media…for the data drive that appears in the tab of «system information», «state», «disk usage»