![]()
Copy link
lr91-089
commented
Sep 1, 2019
•
edited by pytorch-probot
bot
lr91-089
commented
Sep 1, 2019
•
edited by pytorch-probot
bot
I have problems running this file on my machine: https://colab.research.google.com/github/Curt-Park/rainbow-is-all-you-need/blob/master/08.rainbow.ipynb
Yesterday everything worked fine, now I am alway getting this CUDA error. Appears also on my other code, which was working fine before.
cuda
Traceback (most recent call last):
File «», line 1, in
runfile(‘D:/Dokumente/TUM/Masterthesis/PythonModel/BestModels/rainbow/08_rainbow.py’, wdir=’D:/Dokumente/TUM/Masterthesis/PythonModel/BestModels/rainbow’)
File «C:Usersun_poAnaconda3envsrainbowPylibsite-packagesspyder_kernelscustomizespydercustomize.py», line 827, in runfile
execfile(filename, namespace)
File «C:Usersun_poAnaconda3envsrainbowPylibsite-packagesspyder_kernelscustomizespydercustomize.py», line 110, in execfile
exec(compile(f.read(), filename, ‘exec’), namespace)
File «D:/Dokumente/TUM/Masterthesis/PythonModel/BestModels/rainbow/08_rainbow.py», line 858, in
agent = DQNAgent(env, memory_size, batch_size, target_update)
File «D:/Dokumente/TUM/Masterthesis/PythonModel/BestModels/rainbow/08_rainbow.py», line 593, in init
).to(self.device)
RuntimeError: CUDA error: device-side assert triggered
Any ideas how to solve it?
cc @peterjc123
![]()
![]()
Thanks @peterjc123
Partly. I did a pytorch and cuda downgrade to conda install pytorch=0.4.1 cuda90 -c pytorch, now it works.
Any idea why the new versions are not working?
Full error message:
cuda
5C:/w/1/s/tmp_conda_3.6_114131/conda/conda-bld/pytorch_1567251986110/work/aten/src/THC/THCTensorIndex.cu:189: block: [25,0,0], thread: [63,0,0] Assertion `dstIndex < dstAddDimSize` failed.
Traceback (most recent call last):
File "rainbow.py", line 763, in <module>
agent.train(epochs)
File "rainbow.py", line 629, in train
loss = self.update_model()
File "rainbow.py", line 578, in update_model
elementwise_loss_n_loss = self._compute_dqn_loss(samples, gamma)
File "rainbow.py", line 710, in _compute_dqn_loss
dist = self.dqn.dist(state)
File "rainbow.py", line 387, in dist
feature = self.feature_layer(x)
File "C:Usersun_poAnaconda3envsrl-envlibsite-packagestorchnnmodulesmodule.py", line 545, in __call__
result = self.forward(*input, **kwargs)
File "C:Usersun_poAnaconda3envsrl-envlibsite-packagestorchnnmodulescontainer.py", line 92, in forward
input = module(input)
File "C:Usersun_poAnaconda3envsrl-envlibsite-packagestorchnnmodulesmodule.py", line 545, in __call__
result = self.forward(*input, **kwargs)
File "C:Usersun_poAnaconda3envsrl-envlibsite-packagestorchnnmoduleslinear.py", line 87, in forward
return F.linear(input, self.weight, self.bias)
File "C:Usersun_poAnaconda3envsrl-envlibsite-packagestorchnnfunctional.py", line 1370, in linear
ret = torch.addmm(bias, input, weight.t())
RuntimeError: CUDA error: device-side assert triggered
Nvidia specs:
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 436.15 Driver Version: 436.15 CUDA Version: 10.1 |
|-------------------------------+----------------------+----------------------+
| GPU Name TCC/WDDM | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GeForce GTX 1060 WDDM | 00000000:01:00.0 Off | N/A |
| N/A 50C P8 6W / N/A | 92MiB / 6144MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
![]()
What about setting the environmental variable CUDA_LAUNCH_BLOCKING=1 and then rerun that example?
![]()
Then I got the error message in my second post.
But downgrading seems to work. I also installed a new nvidia driver today, maybe this is causing the issue? But I also un- and reinstalled the driver.
![]()
Could you please insert some code before this line and print out these values and their shapes?
File "C:Usersun_poAnaconda3envsrl-envlibsite-packagestorchnnfunctional.py", line 1370, in linear ret = torch.addmm(bias, input, weight.t())
![]()
Would the input be the x in this line?
File "rainbow.py", line 387, in dist
feature = self.feature_layer(x)
![]()
Yes, it should be x. But I want to know the other two values bias and weight too.
![]()
X-tensor: tensor([[0.0966, 0.4998, 1.0000, 0.2143, 0.0164],
[0.1607, 0.5231, 1.0000, 0.2857, 0.0219],
[0.2535, 0.4962, 1.0000, 0.3571, 0.0273],
[0.3150, 0.5427, 1.0000, 0.4286, 0.0328],
[0.4314, 0.5616, 1.0000, 0.5000, 0.0383],
[0.5555, 0.5357, 1.0000, 0.5714, 0.0437],
[0.8409, 0.5187, 1.0000, 0.7143, 0.0546],
[0.8409, 0.5187, 1.0000, 0.7143, 0.0546],
[0.9362, 0.4129, 1.0000, 0.7857, 0.0601],
[0.9389, 0.4930, 1.0000, 0.8571, 0.0656],
[0.9287, 0.5291, 1.0000, 0.9286, 0.0710],
[0.9148, 0.5880, 1.0000, 1.0000, 0.0765],
[0.9148, 0.5880, 1.0000, 1.0000, 0.0765],
[0.9148, 0.5880, 1.0000, 1.0000, 0.0765],
[0.1223, 0.4955, 1.0000, 0.2857, 0.0219],
[0.1223, 0.4955, 1.0000, 0.2857, 0.0219],
[0.2180, 0.4886, 1.0000, 0.3571, 0.0273],
[0.3848, 0.4203, 1.0000, 0.5000, 0.0383],
[0.3848, 0.4203, 1.0000, 0.5000, 0.0383],
[0.6486, 0.3935, 1.0000, 0.6429, 0.0492],
[0.8023, 0.4568, 1.0000, 0.7143, 0.0546],
[0.8023, 0.4568, 1.0000, 0.7143, 0.0546],
[0.9055, 0.4803, 1.0000, 0.8571, 0.0656],
[0.8938, 0.5155, 1.0000, 0.9286, 0.0710],
[0.8858, 0.5976, 1.0000, 1.0000, 0.0765],
[0.8858, 0.5976, 1.0000, 1.0000, 0.0765],
[0.8858, 0.5976, 1.0000, 1.0000, 0.0765],
[0.1044, 0.4968, 1.0000, 0.2143, 0.0164],
[0.1651, 0.5090, 1.0000, 0.2857, 0.0219],
[0.2575, 0.4929, 1.0000, 0.3571, 0.0273],
[0.3177, 0.5142, 1.0000, 0.4286, 0.0328],
[0.4365, 0.5715, 1.0000, 0.5000, 0.0383],
[0.5661, 0.5371, 1.0000, 0.5714, 0.0437],
[0.6990, 0.3731, 1.0000, 0.6429, 0.0492],
[0.8536, 0.4542, 1.0000, 0.7143, 0.0546],
[0.9491, 0.5377, 1.0000, 0.7857, 0.0601],
[0.9560, 0.4722, 1.0000, 0.8571, 0.0656],
[0.9471, 0.5078, 1.0000, 0.9286, 0.0710],
[0.9313, 0.5556, 1.0000, 1.0000, 0.0765],
[0.9313, 0.5556, 1.0000, 1.0000, 0.0765],
[0.9313, 0.5556, 1.0000, 1.0000, 0.0765],
[0.0804, 0.5133, 1.0000, 0.2143, 0.0164],
[0.1423, 0.5190, 1.0000, 0.2857, 0.0219],
[0.2394, 0.4825, 1.0000, 0.3571, 0.0273],
[0.4074, 0.5533, 1.0000, 0.5000, 0.0383],
[0.5376, 0.5345, 1.0000, 0.5714, 0.0437],
[0.5376, 0.5345, 1.0000, 0.5714, 0.0437],
[0.6711, 0.4358, 1.0000, 0.6429, 0.0492],
[0.9216, 0.4641, 1.0000, 0.7857, 0.0601],
[0.9216, 0.4641, 1.0000, 0.7857, 0.0601],
[0.9303, 0.4757, 1.0000, 0.8571, 0.0656],
[0.9196, 0.5143, 1.0000, 0.9286, 0.0710],
[0.9075, 0.5852, 1.0000, 1.0000, 0.0765],
[0.9075, 0.5852, 1.0000, 1.0000, 0.0765],
[0.9075, 0.5852, 1.0000, 1.0000, 0.0765],
[0.0825, 0.5112, 1.0000, 0.2143, 0.0164],
[0.1420, 0.5097, 1.0000, 0.2857, 0.0219],
[0.2364, 0.4865, 1.0000, 0.3571, 0.0273],
[0.4102, 0.4430, 1.0000, 0.5000, 0.0383],
[0.5375, 0.6238, 1.0000, 0.5714, 0.0437],
[0.6707, 0.4532, 1.0000, 0.6429, 0.0492],
[0.8255, 0.2652, 1.0000, 0.7143, 0.0546],
[0.9208, 0.4288, 1.0000, 0.7857, 0.0601],
[0.0000, 0.4878, 0.9636, 0.0000, 0.0656]], device='cuda:0') weight-tensor: Parameter containing:
tensor([[-0.3734, 0.3161, 0.0996, 0.2442, -0.1595],
[-0.2662, 0.0612, 0.3732, -0.0944, 0.0957],
[-0.1173, -0.1154, 0.2352, -0.2978, 0.3999],
[ 0.2761, 0.2907, -0.1543, 0.1034, -0.0534],
[-0.2571, -0.2808, -0.0150, 0.3931, -0.3421],
[-0.1852, -0.3157, 0.1033, 0.1615, -0.1933],
[-0.1524, 0.3934, -0.3712, -0.4113, 0.0271],
[ 0.1970, 0.2263, -0.1470, 0.4033, 0.3916],
[ 0.3935, -0.0994, 0.4162, 0.0541, -0.0186],
[-0.2060, 0.4312, -0.3696, 0.2850, 0.2905],
[-0.0022, 0.1726, -0.1714, -0.4120, 0.3267],
[ 0.0416, 0.0353, -0.4196, 0.3645, 0.3494],
[ 0.2480, -0.3457, 0.0450, -0.0888, 0.0921],
[ 0.2898, -0.1654, -0.2198, -0.1305, 0.1143],
[-0.1438, 0.0527, 0.4029, 0.4296, 0.2450],
[ 0.0621, -0.1332, -0.3792, -0.1452, -0.2068],
[ 0.2395, 0.2141, -0.4331, -0.0892, 0.1816],
[-0.1270, 0.1724, -0.2525, 0.4327, -0.3766],
[ 0.3978, 0.3829, 0.3145, 0.0266, 0.3325],
[-0.4396, 0.0928, -0.2067, -0.3383, 0.2727],
[ 0.2536, -0.1647, 0.2435, -0.1929, 0.4073],
[-0.2202, -0.2205, -0.1504, -0.0211, 0.0181],
[-0.3921, 0.0225, 0.0606, 0.2245, -0.4002],
[ 0.2944, 0.1924, 0.1344, -0.0895, 0.3855],
[ 0.1352, -0.2332, 0.1783, -0.2048, 0.2991],
[ 0.3728, -0.0934, 0.3848, 0.2411, -0.3239],
[ 0.1624, 0.3680, -0.0278, -0.4151, 0.1564],
[-0.2820, 0.1316, 0.4393, -0.3855, -0.3037],
[-0.0118, 0.0697, 0.1839, -0.1895, 0.3729],
[ 0.0602, 0.1946, -0.2394, 0.0987, 0.4307],
[ 0.1882, -0.4151, -0.1522, 0.1199, 0.3760],
[-0.2405, 0.4344, 0.2478, 0.2685, 0.0587],
[-0.0706, 0.3291, 0.0259, -0.3197, -0.3109],
[-0.1179, -0.3429, -0.1125, -0.0772, -0.1782],
[ 0.1513, 0.2418, 0.4385, 0.2863, -0.3633],
[ 0.2388, 0.1648, 0.0999, -0.3769, -0.3784],
[-0.2290, 0.0247, -0.3213, 0.1120, 0.3148],
[ 0.0503, 0.1597, -0.4257, -0.4142, 0.0976],
[ 0.3146, 0.3519, 0.4088, -0.2033, -0.3151],
[-0.4109, -0.3416, 0.0643, 0.3063, 0.4181],
[-0.0478, -0.2036, 0.4446, -0.2136, -0.1947],
[ 0.3950, -0.2729, 0.0791, 0.1141, -0.0281],
[ 0.1592, -0.0718, 0.2512, -0.0523, -0.4444],
[ 0.1715, -0.4154, 0.2372, -0.3296, -0.1424],
[-0.0611, 0.4362, -0.3599, 0.1851, 0.3870],
[ 0.1186, 0.2285, -0.0442, -0.0823, 0.4102],
[ 0.2100, -0.1096, 0.0391, -0.3782, 0.0080],
[ 0.4471, 0.3709, 0.2498, 0.1845, -0.3295],
[ 0.1825, 0.3164, -0.1553, -0.0628, 0.2055],
[ 0.2520, -0.0208, 0.0879, 0.3667, -0.0854],
[-0.3825, -0.1077, -0.0011, -0.4290, 0.2207],
[ 0.3010, 0.3401, 0.3079, 0.1596, -0.1537],
[ 0.2391, -0.2995, -0.0890, -0.2818, -0.0710],
[ 0.3503, -0.2023, -0.3616, -0.1167, -0.0967],
[-0.1894, -0.2739, -0.3284, -0.3793, -0.2694],
[-0.1840, 0.0243, 0.2967, -0.0857, -0.4192],
[ 0.2077, 0.0300, 0.0740, 0.1109, -0.3731],
[ 0.3524, -0.3960, -0.2170, -0.4430, 0.3666],
[-0.4469, -0.0623, 0.2683, -0.4264, 0.3847],
[-0.2539, 0.3993, 0.2296, 0.4165, 0.0360],
[ 0.3815, -0.2168, -0.1215, -0.2887, -0.1709],
[ 0.4438, -0.1404, 0.3542, -0.1282, 0.1013],
[-0.1826, 0.2179, -0.2127, -0.0541, -0.3070],
[-0.4167, 0.1256, -0.4459, -0.0291, 0.2769],
[ 0.4117, 0.3886, 0.0033, 0.0336, -0.2435],
[ 0.1371, -0.2124, 0.4413, -0.0811, -0.0205],
[ 0.2711, 0.2374, 0.2743, -0.1104, -0.2828],
[ 0.1762, -0.1136, -0.3584, -0.1727, -0.0672],
[-0.0482, 0.1174, -0.1587, -0.2705, -0.2734],
[-0.2146, -0.3401, -0.3800, -0.3924, -0.4107],
[-0.3063, 0.0101, 0.3600, -0.3988, -0.1448],
[-0.1099, 0.2110, -0.3372, 0.2355, -0.0438],
[-0.1697, 0.4072, 0.3402, -0.2105, 0.2099],
[-0.2003, -0.3394, -0.1139, -0.2225, 0.3828],
[-0.0987, 0.1328, 0.1459, 0.1367, 0.2731],
[ 0.3758, -0.0134, 0.1923, -0.0204, 0.0859],
[ 0.3907, -0.1017, 0.2068, 0.1853, 0.3852],
[ 0.3719, 0.2997, 0.3033, -0.4468, 0.0085],
[ 0.2854, 0.1571, 0.1212, 0.0050, 0.1446],
[-0.3038, -0.1560, -0.0870, 0.2865, -0.3420],
[ 0.3414, -0.1086, 0.0106, -0.3617, -0.2502],
[ 0.4160, -0.1724, 0.3352, -0.4437, 0.3014],
[-0.2102, 0.2256, 0.2382, 0.3484, 0.0767],
[-0.0398, 0.3586, 0.3979, 0.0803, 0.3840],
[-0.0316, 0.2225, -0.1941, 0.1116, -0.0645],
[-0.1004, -0.0962, 0.3964, 0.1549, -0.2622],
[ 0.0411, 0.2712, 0.0116, 0.3561, -0.2491],
[ 0.2155, 0.2110, 0.3669, 0.2620, -0.2209],
[-0.4286, -0.3548, 0.2004, 0.3278, -0.2792],
[ 0.4462, -0.0828, -0.0527, -0.3143, 0.3964],
[-0.1797, 0.2302, -0.2067, 0.4361, 0.2438],
[ 0.3527, -0.1347, 0.3873, 0.2871, -0.2746],
[ 0.1693, 0.3117, -0.2229, -0.3353, 0.3192],
[-0.3096, -0.2497, 0.3368, -0.1047, -0.2475],
[ 0.0510, -0.2777, 0.3701, -0.3160, -0.4467],
[ 0.1633, 0.4311, 0.3066, 0.3084, -0.1997],
[ 0.1077, -0.2649, -0.4200, -0.3931, -0.1456],
[ 0.1439, 0.1507, 0.2141, -0.2448, -0.2178],
[-0.1369, 0.1000, 0.1308, 0.0868, 0.1557],
[-0.0858, -0.1970, -0.1048, 0.0907, 0.1546],
[ 0.3685, 0.3852, 0.2270, 0.3794, -0.2886],
[-0.2368, -0.2260, 0.3286, -0.3553, 0.0514],
[-0.3147, -0.3640, -0.3823, 0.3316, 0.0699],
[ 0.3766, -0.2374, -0.1822, 0.0034, -0.3551],
[ 0.3784, -0.1908, 0.0627, -0.2977, -0.1419],
[-0.2994, -0.0684, 0.3376, -0.0884, -0.1821],
[-0.3722, -0.1578, 0.3703, -0.2728, -0.2601],
[ 0.0885, 0.1443, 0.3801, -0.4137, -0.3413],
[ 0.0131, -0.2688, 0.3376, 0.1889, 0.4302],
[ 0.0183, -0.1062, -0.0910, 0.2889, -0.0376],
[ 0.3484, 0.0247, 0.3001, 0.2557, -0.4226],
[-0.1666, -0.0090, -0.3396, -0.1254, -0.1651],
[-0.1958, -0.0380, -0.3314, 0.2669, 0.4173],
[ 0.0339, 0.4060, 0.3535, 0.1454, -0.2106],
[-0.3047, -0.0237, 0.2301, 0.4397, 0.4357],
[ 0.2233, -0.1683, -0.0899, -0.4248, -0.0035],
[-0.3961, -0.3028, 0.2416, 0.1443, -0.0020],
[ 0.2982, 0.1459, 0.2461, 0.2480, -0.1866],
[ 0.1570, -0.2091, -0.3804, 0.3258, -0.0059],
[-0.0838, -0.3534, 0.3834, -0.4384, -0.2606],
[ 0.4399, 0.3886, 0.3049, -0.0844, -0.3339],
[-0.2412, -0.1984, 0.2985, -0.1648, 0.2834],
[ 0.0840, 0.2567, -0.1519, -0.0342, 0.4089],
[-0.0658, -0.3230, -0.1302, -0.0511, -0.4060],
[ 0.1153, -0.2072, -0.1827, 0.2645, -0.0908],
[-0.1048, 0.1989, 0.1617, 0.2114, 0.0545],
[-0.0856, 0.1638, -0.2672, 0.0729, 0.4414],
[-0.2597, 0.0684, -0.1172, 0.0709, 0.1739]], device='cuda:0',
requires_grad=True) bias-tensor: Parameter containing:
tensor([-0.4121, -0.2680, 0.3437, 0.3309, -0.1466, -0.2350, -0.3797, -0.2821,
-0.1278, 0.3840, -0.2520, -0.0384, 0.3870, -0.2426, 0.3764, 0.3631,
0.0580, -0.0817, 0.2886, -0.4239, -0.1227, 0.1342, -0.2911, 0.2356,
0.1254, 0.3094, 0.3222, 0.3492, -0.0563, 0.0787, 0.0790, 0.0475,
-0.0620, -0.2466, 0.0153, 0.2684, 0.4160, 0.0192, -0.3554, 0.3896,
-0.1807, -0.1653, 0.3222, 0.2462, -0.3811, -0.0232, -0.1342, -0.3190,
-0.0692, -0.1073, 0.1412, 0.2858, 0.4416, 0.3799, -0.0304, 0.0942,
-0.3162, -0.0970, -0.2893, 0.3930, -0.2779, 0.4123, -0.4099, -0.1262,
0.3631, 0.1191, -0.1953, -0.0528, 0.2297, -0.1849, -0.2701, 0.2762,
-0.2263, -0.0765, -0.1990, 0.2963, 0.2974, 0.1819, -0.0951, 0.0901,
-0.1446, -0.2855, -0.1965, 0.0583, -0.3327, -0.1822, -0.0286, -0.0959,
0.2003, -0.1924, 0.3466, -0.0152, -0.3146, -0.2195, -0.2716, 0.4184,
-0.3303, -0.2658, -0.3078, 0.0147, 0.1638, -0.1246, 0.0576, 0.4332,
0.1825, -0.3162, 0.1732, -0.2859, -0.1827, 0.3686, -0.1244, 0.2515,
-0.3614, -0.2369, 0.0778, -0.3364, -0.2306, 0.2620, 0.1740, -0.0486,
-0.2809, 0.0748, 0.0133, -0.1514, -0.0919, -0.4121, 0.0982, -0.4283],
device='cuda:0', requires_grad=True)
C:/w/1/s/tmp_conda_3.6_045031/conda/conda-bld/pytorch_1565412750030/work/aten/src/THC/THCTensorIndex.cu:189: block: [25,0,0], thread: [62,0,0] Assertion `dstIndex < dstAddDimSize` failed.
C:/w/1/s/tmp_conda_3.6_045031/conda/conda-bld/pytorch_1565412750030/work/aten/src/THC/THCTensorIndex.cu:189: block: [25,0,0], thread: [63,0,0] Assertion `dstIndex < dstAddDimSize` failed.
Traceback (most recent call last):
File "rainbow.py", line 773, in <module>
agent.train(epochs)
File "rainbow.py", line 645, in train
loss = self.update_model()
File "rainbow.py", line 579, in update_model
elementwise_loss_n_loss = self._compute_dqn_loss(samples, gamma)
File "rainbow.py", line 720, in _compute_dqn_loss
dist = self.dqn.dist(state)
File "rainbow.py", line 388, in dist
feature = self.feature_layer(x)
File "C:Usersun_poAnaconda3envsrainbowPylibsite-packagestorchnnmodulesmodule.py", line 547, in __call__
result = self.forward(*input, **kwargs)
File "C:Usersun_poAnaconda3envsrainbowPylibsite-packagestorchnnmodulescontainer.py", line 92, in forward
input = module(input)
File "C:Usersun_poAnaconda3envsrainbowPylibsite-packagestorchnnmodulesmodule.py", line 547, in __call__
result = self.forward(*input, **kwargs)
File "C:Usersun_poAnaconda3envsrainbowPylibsite-packagestorchnnmoduleslinear.py", line 87, in forward
return F.linear(input, self.weight, self.bias)
File "C:Usersun_poAnaconda3envsrainbowPylibsite-packagestorchnnfunctional.py", line 1369, in linear
ret = torch.addmm(bias, input, weight.t())
RuntimeError: CUDA error: device-side assert triggered
Mhm… is this a batch-size — layer missmatch? I am quite new in this tensor and neural network operations, so I don’t really understand this so good…
I did print the bias and weight from layer[0]. Should I use a different layer?
![]()
No, the inputs are correct. I checked the result locally, but could not reproduce that.
@soumith @ezyang Any ideas?
![]()
@lr91-089 Does it error out if you call this line directly?
torch.addmm(bias, input, weight.t())
![]()
Works with CPU.
>>> torch.addmm(bias, input, weight.t())
tensor([[-0.1409, 0.0914, 0.4526, ..., -0.1149, -0.0725, -0.5184],
[-0.1409, 0.0696, 0.4234, ..., -0.1016, -0.0666, -0.5274],
[-0.1675, 0.0370, 0.3965, ..., -0.1013, -0.0713, -0.5473],
...,
[-0.3712, -0.1605, 0.2606, ..., -0.1302, -0.1201, -0.6816],
[-0.3385, -0.1821, 0.2115, ..., -0.0922, -0.0938, -0.6891],
[-0.1724, 0.1277, 0.5403, ..., -0.1557, -0.0504, -0.4965]])
This old build is working on another conda environment through: conda install pytorch=0.4.1 cuda90 -c pytorch
Sorry. I made a mistake again. The above example works on cuda and cpu. Had a typo.
test script:
import torch
device = torch.device(
"cuda" if torch.cuda.is_available() else "cpu"
)
inputx = torch.tensor([[0.0966, 0.4998, 1.0000, 0.2143, 0.0164],
[0.1607, 0.5231, 1.0000, 0.2857, 0.0219],
[0.2535, 0.4962, 1.0000, 0.3571, 0.0273],
[0.3150, 0.5427, 1.0000, 0.4286, 0.0328],
[0.4314, 0.5616, 1.0000, 0.5000, 0.0383],
[0.5555, 0.5357, 1.0000, 0.5714, 0.0437],
[0.8409, 0.5187, 1.0000, 0.7143, 0.0546],
[0.8409, 0.5187, 1.0000, 0.7143, 0.0546],
[0.9362, 0.4129, 1.0000, 0.7857, 0.0601],
[0.9389, 0.4930, 1.0000, 0.8571, 0.0656],
[0.9287, 0.5291, 1.0000, 0.9286, 0.0710],
[0.9148, 0.5880, 1.0000, 1.0000, 0.0765],
[0.9148, 0.5880, 1.0000, 1.0000, 0.0765],
[0.9148, 0.5880, 1.0000, 1.0000, 0.0765],
[0.1223, 0.4955, 1.0000, 0.2857, 0.0219],
[0.1223, 0.4955, 1.0000, 0.2857, 0.0219],
[0.2180, 0.4886, 1.0000, 0.3571, 0.0273],
[0.3848, 0.4203, 1.0000, 0.5000, 0.0383],
[0.3848, 0.4203, 1.0000, 0.5000, 0.0383],
[0.6486, 0.3935, 1.0000, 0.6429, 0.0492],
[0.8023, 0.4568, 1.0000, 0.7143, 0.0546],
[0.8023, 0.4568, 1.0000, 0.7143, 0.0546],
[0.9055, 0.4803, 1.0000, 0.8571, 0.0656],
[0.8938, 0.5155, 1.0000, 0.9286, 0.0710],
[0.8858, 0.5976, 1.0000, 1.0000, 0.0765],
[0.8858, 0.5976, 1.0000, 1.0000, 0.0765],
[0.8858, 0.5976, 1.0000, 1.0000, 0.0765],
[0.1044, 0.4968, 1.0000, 0.2143, 0.0164],
[0.1651, 0.5090, 1.0000, 0.2857, 0.0219],
[0.2575, 0.4929, 1.0000, 0.3571, 0.0273],
[0.3177, 0.5142, 1.0000, 0.4286, 0.0328],
[0.4365, 0.5715, 1.0000, 0.5000, 0.0383],
[0.5661, 0.5371, 1.0000, 0.5714, 0.0437],
[0.6990, 0.3731, 1.0000, 0.6429, 0.0492],
[0.8536, 0.4542, 1.0000, 0.7143, 0.0546],
[0.9491, 0.5377, 1.0000, 0.7857, 0.0601],
[0.9560, 0.4722, 1.0000, 0.8571, 0.0656],
[0.9471, 0.5078, 1.0000, 0.9286, 0.0710],
[0.9313, 0.5556, 1.0000, 1.0000, 0.0765],
[0.9313, 0.5556, 1.0000, 1.0000, 0.0765],
[0.9313, 0.5556, 1.0000, 1.0000, 0.0765],
[0.0804, 0.5133, 1.0000, 0.2143, 0.0164],
[0.1423, 0.5190, 1.0000, 0.2857, 0.0219],
[0.2394, 0.4825, 1.0000, 0.3571, 0.0273],
[0.4074, 0.5533, 1.0000, 0.5000, 0.0383],
[0.5376, 0.5345, 1.0000, 0.5714, 0.0437],
[0.5376, 0.5345, 1.0000, 0.5714, 0.0437],
[0.6711, 0.4358, 1.0000, 0.6429, 0.0492],
[0.9216, 0.4641, 1.0000, 0.7857, 0.0601],
[0.9216, 0.4641, 1.0000, 0.7857, 0.0601],
[0.9303, 0.4757, 1.0000, 0.8571, 0.0656],
[0.9196, 0.5143, 1.0000, 0.9286, 0.0710],
[0.9075, 0.5852, 1.0000, 1.0000, 0.0765],
[0.9075, 0.5852, 1.0000, 1.0000, 0.0765],
[0.9075, 0.5852, 1.0000, 1.0000, 0.0765],
[0.0825, 0.5112, 1.0000, 0.2143, 0.0164],
[0.1420, 0.5097, 1.0000, 0.2857, 0.0219],
[0.2364, 0.4865, 1.0000, 0.3571, 0.0273],
[0.4102, 0.4430, 1.0000, 0.5000, 0.0383],
[0.5375, 0.6238, 1.0000, 0.5714, 0.0437],
[0.6707, 0.4532, 1.0000, 0.6429, 0.0492],
[0.8255, 0.2652, 1.0000, 0.7143, 0.0546],
[0.9208, 0.4288, 1.0000, 0.7857, 0.0601],
[0.0000, 0.4878, 0.9636, 0.0000, 0.0656]]).to(device)
weight = torch.tensor([[-0.3734, 0.3161, 0.0996, 0.2442, -0.1595],
[-0.2662, 0.0612, 0.3732, -0.0944, 0.0957],
[-0.1173, -0.1154, 0.2352, -0.2978, 0.3999],
[ 0.2761, 0.2907, -0.1543, 0.1034, -0.0534],
[-0.2571, -0.2808, -0.0150, 0.3931, -0.3421],
[-0.1852, -0.3157, 0.1033, 0.1615, -0.1933],
[-0.1524, 0.3934, -0.3712, -0.4113, 0.0271],
[ 0.1970, 0.2263, -0.1470, 0.4033, 0.3916],
[ 0.3935, -0.0994, 0.4162, 0.0541, -0.0186],
[-0.2060, 0.4312, -0.3696, 0.2850, 0.2905],
[-0.0022, 0.1726, -0.1714, -0.4120, 0.3267],
[ 0.0416, 0.0353, -0.4196, 0.3645, 0.3494],
[ 0.2480, -0.3457, 0.0450, -0.0888, 0.0921],
[ 0.2898, -0.1654, -0.2198, -0.1305, 0.1143],
[-0.1438, 0.0527, 0.4029, 0.4296, 0.2450],
[ 0.0621, -0.1332, -0.3792, -0.1452, -0.2068],
[ 0.2395, 0.2141, -0.4331, -0.0892, 0.1816],
[-0.1270, 0.1724, -0.2525, 0.4327, -0.3766],
[ 0.3978, 0.3829, 0.3145, 0.0266, 0.3325],
[-0.4396, 0.0928, -0.2067, -0.3383, 0.2727],
[ 0.2536, -0.1647, 0.2435, -0.1929, 0.4073],
[-0.2202, -0.2205, -0.1504, -0.0211, 0.0181],
[-0.3921, 0.0225, 0.0606, 0.2245, -0.4002],
[ 0.2944, 0.1924, 0.1344, -0.0895, 0.3855],
[ 0.1352, -0.2332, 0.1783, -0.2048, 0.2991],
[ 0.3728, -0.0934, 0.3848, 0.2411, -0.3239],
[ 0.1624, 0.3680, -0.0278, -0.4151, 0.1564],
[-0.2820, 0.1316, 0.4393, -0.3855, -0.3037],
[-0.0118, 0.0697, 0.1839, -0.1895, 0.3729],
[ 0.0602, 0.1946, -0.2394, 0.0987, 0.4307],
[ 0.1882, -0.4151, -0.1522, 0.1199, 0.3760],
[-0.2405, 0.4344, 0.2478, 0.2685, 0.0587],
[-0.0706, 0.3291, 0.0259, -0.3197, -0.3109],
[-0.1179, -0.3429, -0.1125, -0.0772, -0.1782],
[ 0.1513, 0.2418, 0.4385, 0.2863, -0.3633],
[ 0.2388, 0.1648, 0.0999, -0.3769, -0.3784],
[-0.2290, 0.0247, -0.3213, 0.1120, 0.3148],
[ 0.0503, 0.1597, -0.4257, -0.4142, 0.0976],
[ 0.3146, 0.3519, 0.4088, -0.2033, -0.3151],
[-0.4109, -0.3416, 0.0643, 0.3063, 0.4181],
[-0.0478, -0.2036, 0.4446, -0.2136, -0.1947],
[ 0.3950, -0.2729, 0.0791, 0.1141, -0.0281],
[ 0.1592, -0.0718, 0.2512, -0.0523, -0.4444],
[ 0.1715, -0.4154, 0.2372, -0.3296, -0.1424],
[-0.0611, 0.4362, -0.3599, 0.1851, 0.3870],
[ 0.1186, 0.2285, -0.0442, -0.0823, 0.4102],
[ 0.2100, -0.1096, 0.0391, -0.3782, 0.0080],
[ 0.4471, 0.3709, 0.2498, 0.1845, -0.3295],
[ 0.1825, 0.3164, -0.1553, -0.0628, 0.2055],
[ 0.2520, -0.0208, 0.0879, 0.3667, -0.0854],
[-0.3825, -0.1077, -0.0011, -0.4290, 0.2207],
[ 0.3010, 0.3401, 0.3079, 0.1596, -0.1537],
[ 0.2391, -0.2995, -0.0890, -0.2818, -0.0710],
[ 0.3503, -0.2023, -0.3616, -0.1167, -0.0967],
[-0.1894, -0.2739, -0.3284, -0.3793, -0.2694],
[-0.1840, 0.0243, 0.2967, -0.0857, -0.4192],
[ 0.2077, 0.0300, 0.0740, 0.1109, -0.3731],
[ 0.3524, -0.3960, -0.2170, -0.4430, 0.3666],
[-0.4469, -0.0623, 0.2683, -0.4264, 0.3847],
[-0.2539, 0.3993, 0.2296, 0.4165, 0.0360],
[ 0.3815, -0.2168, -0.1215, -0.2887, -0.1709],
[ 0.4438, -0.1404, 0.3542, -0.1282, 0.1013],
[-0.1826, 0.2179, -0.2127, -0.0541, -0.3070],
[-0.4167, 0.1256, -0.4459, -0.0291, 0.2769],
[ 0.4117, 0.3886, 0.0033, 0.0336, -0.2435],
[ 0.1371, -0.2124, 0.4413, -0.0811, -0.0205],
[ 0.2711, 0.2374, 0.2743, -0.1104, -0.2828],
[ 0.1762, -0.1136, -0.3584, -0.1727, -0.0672],
[-0.0482, 0.1174, -0.1587, -0.2705, -0.2734],
[-0.2146, -0.3401, -0.3800, -0.3924, -0.4107],
[-0.3063, 0.0101, 0.3600, -0.3988, -0.1448],
[-0.1099, 0.2110, -0.3372, 0.2355, -0.0438],
[-0.1697, 0.4072, 0.3402, -0.2105, 0.2099],
[-0.2003, -0.3394, -0.1139, -0.2225, 0.3828],
[-0.0987, 0.1328, 0.1459, 0.1367, 0.2731],
[ 0.3758, -0.0134, 0.1923, -0.0204, 0.0859],
[ 0.3907, -0.1017, 0.2068, 0.1853, 0.3852],
[ 0.3719, 0.2997, 0.3033, -0.4468, 0.0085],
[ 0.2854, 0.1571, 0.1212, 0.0050, 0.1446],
[-0.3038, -0.1560, -0.0870, 0.2865, -0.3420],
[ 0.3414, -0.1086, 0.0106, -0.3617, -0.2502],
[ 0.4160, -0.1724, 0.3352, -0.4437, 0.3014],
[-0.2102, 0.2256, 0.2382, 0.3484, 0.0767],
[-0.0398, 0.3586, 0.3979, 0.0803, 0.3840],
[-0.0316, 0.2225, -0.1941, 0.1116, -0.0645],
[-0.1004, -0.0962, 0.3964, 0.1549, -0.2622],
[ 0.0411, 0.2712, 0.0116, 0.3561, -0.2491],
[ 0.2155, 0.2110, 0.3669, 0.2620, -0.2209],
[-0.4286, -0.3548, 0.2004, 0.3278, -0.2792],
[ 0.4462, -0.0828, -0.0527, -0.3143, 0.3964],
[-0.1797, 0.2302, -0.2067, 0.4361, 0.2438],
[ 0.3527, -0.1347, 0.3873, 0.2871, -0.2746],
[ 0.1693, 0.3117, -0.2229, -0.3353, 0.3192],
[-0.3096, -0.2497, 0.3368, -0.1047, -0.2475],
[ 0.0510, -0.2777, 0.3701, -0.3160, -0.4467],
[ 0.1633, 0.4311, 0.3066, 0.3084, -0.1997],
[ 0.1077, -0.2649, -0.4200, -0.3931, -0.1456],
[ 0.1439, 0.1507, 0.2141, -0.2448, -0.2178],
[-0.1369, 0.1000, 0.1308, 0.0868, 0.1557],
[-0.0858, -0.1970, -0.1048, 0.0907, 0.1546],
[ 0.3685, 0.3852, 0.2270, 0.3794, -0.2886],
[-0.2368, -0.2260, 0.3286, -0.3553, 0.0514],
[-0.3147, -0.3640, -0.3823, 0.3316, 0.0699],
[ 0.3766, -0.2374, -0.1822, 0.0034, -0.3551],
[ 0.3784, -0.1908, 0.0627, -0.2977, -0.1419],
[-0.2994, -0.0684, 0.3376, -0.0884, -0.1821],
[-0.3722, -0.1578, 0.3703, -0.2728, -0.2601],
[ 0.0885, 0.1443, 0.3801, -0.4137, -0.3413],
[ 0.0131, -0.2688, 0.3376, 0.1889, 0.4302],
[ 0.0183, -0.1062, -0.0910, 0.2889, -0.0376],
[ 0.3484, 0.0247, 0.3001, 0.2557, -0.4226],
[-0.1666, -0.0090, -0.3396, -0.1254, -0.1651],
[-0.1958, -0.0380, -0.3314, 0.2669, 0.4173],
[ 0.0339, 0.4060, 0.3535, 0.1454, -0.2106],
[-0.3047, -0.0237, 0.2301, 0.4397, 0.4357],
[ 0.2233, -0.1683, -0.0899, -0.4248, -0.0035],
[-0.3961, -0.3028, 0.2416, 0.1443, -0.0020],
[ 0.2982, 0.1459, 0.2461, 0.2480, -0.1866],
[ 0.1570, -0.2091, -0.3804, 0.3258, -0.0059],
[-0.0838, -0.3534, 0.3834, -0.4384, -0.2606],
[ 0.4399, 0.3886, 0.3049, -0.0844, -0.3339],
[-0.2412, -0.1984, 0.2985, -0.1648, 0.2834],
[ 0.0840, 0.2567, -0.1519, -0.0342, 0.4089],
[-0.0658, -0.3230, -0.1302, -0.0511, -0.4060],
[ 0.1153, -0.2072, -0.1827, 0.2645, -0.0908],
[-0.1048, 0.1989, 0.1617, 0.2114, 0.0545],
[-0.0856, 0.1638, -0.2672, 0.0729, 0.4414],
[-0.2597, 0.0684, -0.1172, 0.0709, 0.1739]]).to(device)
bias = torch.tensor([-0.4121, -0.2680, 0.3437, 0.3309, -0.1466, -0.2350, -0.3797, -0.2821,
-0.1278, 0.3840, -0.2520, -0.0384, 0.3870, -0.2426, 0.3764, 0.3631,
0.0580, -0.0817, 0.2886, -0.4239, -0.1227, 0.1342, -0.2911, 0.2356,
0.1254, 0.3094, 0.3222, 0.3492, -0.0563, 0.0787, 0.0790, 0.0475,
-0.0620, -0.2466, 0.0153, 0.2684, 0.4160, 0.0192, -0.3554, 0.3896,
-0.1807, -0.1653, 0.3222, 0.2462, -0.3811, -0.0232, -0.1342, -0.3190,
-0.0692, -0.1073, 0.1412, 0.2858, 0.4416, 0.3799, -0.0304, 0.0942,
-0.3162, -0.0970, -0.2893, 0.3930, -0.2779, 0.4123, -0.4099, -0.1262,
0.3631, 0.1191, -0.1953, -0.0528, 0.2297, -0.1849, -0.2701, 0.2762,
-0.2263, -0.0765, -0.1990, 0.2963, 0.2974, 0.1819, -0.0951, 0.0901,
-0.1446, -0.2855, -0.1965, 0.0583, -0.3327, -0.1822, -0.0286, -0.0959,
0.2003, -0.1924, 0.3466, -0.0152, -0.3146, -0.2195, -0.2716, 0.4184,
-0.3303, -0.2658, -0.3078, 0.0147, 0.1638, -0.1246, 0.0576, 0.4332,
0.1825, -0.3162, 0.1732, -0.2859, -0.1827, 0.3686, -0.1244, 0.2515,
-0.3614, -0.2369, 0.0778, -0.3364, -0.2306, 0.2620, 0.1740, -0.0486,
-0.2809, 0.0748, 0.0133, -0.1514, -0.0919, -0.4121, 0.0982, -0.4283]).to(device)
print(device)
print(inputx,weight,bias)
print(torch.addmm(bias, inputx, weight.t()))
![]()
I ran your script on PyTorch 1.2.0 on Linux with Tesla M40 Driver Version: 396.69 and was not able to repro. In your original test were you running 1.2.0 on CUDA 10? Can you try running it with 1.2.0 with CUDA 9.2?
![]()
Mhm after downgrading some scripts are working again, but the main file not. Is it maybe an error because of the input of my tensors? But it is basically a 5 d numpy array with each input values ranging from 0-1.
C:/w/1/s/tmp_conda_3.6_155139/conda/conda-bld/pytorch_1565366019852/work/aten/src/THC/THCTensorIndex.cu:189: block: [50,0,0], thread: [127,0,0] Assertion `dstIndex < dstAddDimSize` failed.
steps: 125 episodes: 8 running reward: -0.4091374322Traceback (most recent call last):
File "rainbow.py", line 773, in <module>
agent.train(epochs)
File "rainbow.py", line 645, in train
loss = self.update_model()
File "rainbow.py", line 568, in update_model
elementwise_loss = self._compute_dqn_loss(samples, self.gamma)
File "rainbow.py", line 720, in _compute_dqn_loss
dist = self.dqn.dist(state)
File "rainbow.py", line 396, in dist
q_atoms = value + advantage - advantage.mean(dim=1, keepdim=True)
RuntimeError: CUDA error: device-side assert triggered
(rainbowPy) D:DokumenteTUMMasterthesisPythonModelBestModelsrainbow>python rainbow.py
cuda
C:/w/1/s/tmp_conda_3.6_155139/conda/conda-bld/pytorch_1565366019852/work/aten/src/THC/THCTensorIndex.cu:189: block: [50,0,0], thread: [127,0,0] Assertion `dstIndex < dstAddDimSize` failed.
steps: 125 episodes: 8 running reward: -0.4091374322Traceback (most recent call last):
File "rainbow.py", line 773, in <module>
agent.train(epochs)
File "rainbow.py", line 645, in train
loss = self.update_model()
File "rainbow.py", line 568, in update_model
elementwise_loss = self._compute_dqn_loss(samples, self.gamma)
File "rainbow.py", line 720, in _compute_dqn_loss
dist = self.dqn.dist(state)
File "rainbow.py", line 388, in dist
feature = self.feature_layer(x)
File "C:Usersun_poAnaconda3envsrainbowPylibsite-packagestorchnnmodulesmodule.py", line 547, in __call__
result = self.forward(*input, **kwargs)
File "C:Usersun_poAnaconda3envsrainbowPylibsite-packagestorchnnmodulescontainer.py", line 92, in forward
input = module(input)
File "C:Usersun_poAnaconda3envsrainbowPylibsite-packagestorchnnmodulesmodule.py", line 547, in __call__
result = self.forward(*input, **kwargs)
File "C:Usersun_poAnaconda3envsrainbowPylibsite-packagestorchnnmoduleslinear.py", line 87, in forward
return F.linear(input, self.weight, self.bias)
File "C:Usersun_poAnaconda3envsrainbowPylibsite-packagestorchnnfunctional.py", line 1369, in linear
ret = torch.addmm(bias, input, weight.t())
RuntimeError: CUDA error: device-side assert triggered
![]()
THCTensorIndex.cu:189: block: [50,0,0], thread: [127,0,0] Assertion dstIndex < dstAddDimSize failed. looks relevant.
Are you doing an indexing operation somewhere in your program? (You didn’t run this example with CUDA_LAUNCH_BLOCKING=1 so the backtraces are too late—if you rerun with this envvar you’ll get better back traces). If so, can you check that your indices are all in bounds?
![]()
Yeah, I also came across this error yesterday and it turned out to be «index out of range» error. Maybe you should check your index via pdb and make sure they’re not out of range. Hope it will help you!
![]()
pbelevich
added
module: nn
Related to torch.nn
triaged
This issue has been looked at a team member, and triaged and prioritized into an appropriate module
labels
Sep 3, 2019
![]()
@ezyang I did run this example with CUDA_LAUNCH_BLOCKING=1. Its the second output above. I have put os.environ[‘CUDA_LAUNCH_BLOCKING’] = «1» in the code, that is correct right?
@Wuziyi616 could you please provide me more information about pdb debugging?
I basically pass values to the network, I want to investigate, right? And could you give me more information about what kind of index error? Maybe in the batch?
![]()
@lr91-089 I actually think this does not actually work. Can you set the environment variable outside of the script?
![]()
Any ways to set it up in anaconda on windwos?
CUDA_LAUNCH_BLOCKING=1 python myscript.py does not work and did not find any other method than the os method.
I did the follwing:
(rainbowPy) D:DokumenteTUMMasterthesisPythonModelBestModelsrainbow>set CUDA_LAUNCH_BLOCKING=1
(rainbowPy) D:DokumenteTUMMasterthesisPythonModelBestModelsrainbow>python rainbow_256.py
cuda
C:/w/1/s/tmp_conda_3.6_155139/conda/conda-bld/pytorch_1565366019852/work/aten/src/THC/THCTensorIndex.cu:189: block: [50,0,0], thread: [127,0,0] Assertion `dstIndex < dstAddDimSize` failed.
steps: 125 episodes: 8 running reward: -0.4091374322Traceback (most recent call last):
File "rainbow_256.py", line 778, in <module>
agent.train(epochs)
File "rainbow_256.py", line 649, in train
loss = self.update_model()
File "rainbow_256.py", line 572, in update_model
elementwise_loss = self._compute_dqn_loss(samples, self.gamma)
File "rainbow_256.py", line 725, in _compute_dqn_loss
dist = self.dqn.dist(state)
File "rainbow_256.py", line 389, in dist
feature = self.feature_layer(x)
File "C:Usersun_poAnaconda3envsrainbowPylibsite-packagestorchnnmodulesmodule.py", line 547, in __call__
result = self.forward(*input, **kwargs)
File "C:Usersun_poAnaconda3envsrainbowPylibsite-packagestorchnnmodulescontainer.py", line 92, in forward
input = module(input)
File "C:Usersun_poAnaconda3envsrainbowPylibsite-packagestorchnnmodulesmodule.py", line 547, in __call__
result = self.forward(*input, **kwargs)
File "C:Usersun_poAnaconda3envsrainbowPylibsite-packagestorchnnmoduleslinear.py", line 87, in forward
return F.linear(input, self.weight, self.bias)
File "C:Usersun_poAnaconda3envsrainbowPylibsite-packagestorchnnfunctional.py", line 1369, in linear
ret = torch.addmm(bias, input, weight.t())
RuntimeError: CUDA error: device-side assert triggered
Also tried, but same:
(rainbowPy) D:DokumenteTUMMasterthesisPythonModelBestModelsrainbow>setx CUDA_LAUNCH_BLOCKING 1
ERFOLGREICH: Angegebener Wert wurde gespeichert.
(rainbowPy) D:DokumenteTUMMasterthesisPythonModelBestModelsrainbow>python rainbow_256.py
cuda
C:/w/1/s/tmp_conda_3.6_155139/conda/conda-bld/pytorch_1565366019852/work/aten/src/THC/THCTensorIndex.cu:189: block: [50,0,0], thread: [127,0,0] Assertion `dstIndex < dstAddDimSize` failed.
steps: 125 episodes: 8 running reward: -0.4091374322Traceback (most recent call last):
File "rainbow_256.py", line 778, in <module>
agent.train(epochs)
File "rainbow_256.py", line 649, in train
loss = self.update_model()
File "rainbow_256.py", line 572, in update_model
elementwise_loss = self._compute_dqn_loss(samples, self.gamma)
File "rainbow_256.py", line 725, in _compute_dqn_loss
dist = self.dqn.dist(state)
File "rainbow_256.py", line 389, in dist
feature = self.feature_layer(x)
File "C:Usersun_poAnaconda3envsrainbowPylibsite-packagestorchnnmodulesmodule.py", line 547, in __call__
result = self.forward(*input, **kwargs)
File "C:Usersun_poAnaconda3envsrainbowPylibsite-packagestorchnnmodulescontainer.py", line 92, in forward
input = module(input)
File "C:Usersun_poAnaconda3envsrainbowPylibsite-packagestorchnnmodulesmodule.py", line 547, in __call__
result = self.forward(*input, **kwargs)
File "C:Usersun_poAnaconda3envsrainbowPylibsite-packagestorchnnmoduleslinear.py", line 87, in forward
return F.linear(input, self.weight, self.bias)
File "C:Usersun_poAnaconda3envsrainbowPylibsite-packagestorchnnfunctional.py", line 1369, in linear
ret = torch.addmm(bias, input, weight.t())
RuntimeError: CUDA error: device-side assert triggered
I have set up the environment variable in the windows cmd and then launched anaconda:
(rainbowPy) D:DokumenteTUMMasterthesisPythonModelBestModelsrainbow>python rainbow_256.py
cuda
C:/w/1/s/tmp_conda_3.6_155139/conda/conda-bld/pytorch_1565366019852/work/aten/src/THC/THCTensorIndex.cu:189: block: [50,0,0], thread: [127,0,0] Assertion `dstIndex < dstAddDimSize` failed.
steps: 125 episodes: 8 running reward: -0.4091374322Traceback (most recent call last):
File "rainbow_256.py", line 778, in <module>
agent.train(epochs)
File "rainbow_256.py", line 649, in train
loss = self.update_model()
File "rainbow_256.py", line 572, in update_model
elementwise_loss = self._compute_dqn_loss(samples, self.gamma)
File "rainbow_256.py", line 725, in _compute_dqn_loss
dist = self.dqn.dist(state)
File "rainbow_256.py", line 391, in dist
val_hid = F.relu(self.value_hidden_layer(feature))
File "C:Usersun_poAnaconda3envsrainbowPylibsite-packagestorchnnmodulesmodule.py", line 547, in __call__
result = self.forward(*input, **kwargs)
File "rainbow_256.py", line 338, in forward
self.weight_mu + self.weight_sigma * self.weight_epsilon,
RuntimeError: CUDA error: device-side assert triggered
is this somehow more meaningful?
![]()
Yes, the last trace looks better. What’s the full contents of the line at line 338?
![]()
Do you mean the tensors? This is the last output.
"Parameter containing:
tensor([[-0.0849, 0.0285, 0.0204, ..., 0.0880, 0.0489, 0.0734],
[ 0.0088, -0.0316, 0.0773, ..., 0.0854, 0.0805, -0.0868],
[-0.0383, 0.0710, 0.0835, ..., 0.0758, 0.0208, 0.0019],
...,
[-0.0037, -0.0028, -0.0285, ..., 0.0766, 0.0176, -0.0440],
[-0.0077, -0.0180, 0.0842, ..., -0.0302, 0.0204, 0.0343],
[-0.0404, -0.0514, -0.0560, ..., 0.0157, 0.0820, 0.0326]],
device='cuda:0', requires_grad=True)","Parameter containing:
tensor([[0.0442, 0.0442, 0.0442, ..., 0.0442, 0.0442, 0.0442],
[0.0442, 0.0442, 0.0442, ..., 0.0442, 0.0442, 0.0442],
[0.0442, 0.0442, 0.0442, ..., 0.0442, 0.0442, 0.0442],
...,
[0.0442, 0.0442, 0.0442, ..., 0.0442, 0.0442, 0.0442],
[0.0442, 0.0442, 0.0442, ..., 0.0442, 0.0442, 0.0442],
[0.0442, 0.0442, 0.0442, ..., 0.0442, 0.0442, 0.0442]],
device='cuda:0', requires_grad=True)","tensor([[-0.3787, -0.5588, -0.9302, ..., 0.4656, 0.5676, -1.1919],
[-0.4000, -0.5903, -0.9827, ..., 0.4918, 0.5996, -1.2591],
[-0.1744, -0.2574, -0.4285, ..., 0.2145, 0.2615, -0.5491],
...,
[ 0.1534, 0.2263, 0.3768, ..., -0.1886, -0.2299, 0.4828],
[-0.5306, -0.7830, -1.3035, ..., 0.6524, 0.7954, -1.6703],
[ 0.2233, 0.3295, 0.5485, ..., -0.2745, -0.3347, 0.7029]],
device='cuda:0')"
Got a new error message this time:
cuda
C:/w/1/s/tmp_conda_3.6_155139/conda/conda-bld/pytorch_1565366019852/work/aten/src/THC/THCTensorIndex.cu:189: block: [50,0,0], thread: [127,0,0] Assertion `dstIndex < dstAddDimSize` failed.
THCudaCheck FAIL file=..atensrcTHCTHCCachingHostAllocator.cpp line=296 error=59 : device-side assert triggered
steps: 125 episodes: 8 running reward: -0.4091374322Traceback (most recent call last):
File "rainbow_256.py", line 779, in <module>
agent.train(epochs)
File "rainbow_256.py", line 650, in train
loss = self.update_model()
File "rainbow_256.py", line 573, in update_model
elementwise_loss = self._compute_dqn_loss(samples, self.gamma)
File "rainbow_256.py", line 726, in _compute_dqn_loss
dist = self.dqn.dist(state)
File "rainbow_256.py", line 391, in dist
adv_hid = F.relu(self.advantage_hidden_layer(feature))
File "C:Usersun_poAnaconda3envsrainbowPylibsite-packagestorchnnmodulesmodule.py", line 547, in __call__
result = self.forward(*input, **kwargs)
File "rainbow_256.py", line 336, in forward
writecsv((self.weight_mu,self.weight_sigma,self.weight_epsilon),1111),
File "rainbow_256.py", line 45, in writecsv
newFileWriter.writerow(line)
File "C:Usersun_poAnaconda3envsrainbowPylibsite-packagestorchnnparameter.py", line 37, in __repr__
return 'Parameter containing:n' + super(Parameter, self).__repr__()
File "C:Usersun_poAnaconda3envsrainbowPylibsite-packagestorchtensor.py", line 82, in __repr__
return torch._tensor_str._str(self)
File "C:Usersun_poAnaconda3envsrainbowPylibsite-packagestorch_tensor_str.py", line 300, in _str
tensor_str = _tensor_str(self, indent)
File "C:Usersun_poAnaconda3envsrainbowPylibsite-packagestorch_tensor_str.py", line 201, in _tensor_str
formatter = _Formatter(get_summarized_data(self) if summarize else self)
File "C:Usersun_poAnaconda3envsrainbowPylibsite-packagestorch_tensor_str.py", line 234, in get_summarized_data
return torch.stack([get_summarized_data(x) for x in (start + end)])
File "C:Usersun_poAnaconda3envsrainbowPylibsite-packagestorch_tensor_str.py", line 234, in <listcomp>
return torch.stack([get_summarized_data(x) for x in (start + end)])
File "C:Usersun_poAnaconda3envsrainbowPylibsite-packagestorch_tensor_str.py", line 227, in get_summarized_data
return torch.cat((self[:PRINT_OPTS.edgeitems], self[-PRINT_OPTS.edgeitems:]))
RuntimeError: cuda runtime error (59) : device-side assert triggered at ..atensrcTHCTHCCachingHostAllocator.cpp:296
![]()
Sorry, not the tensor, I mean the code.
return torch.cat((self[:PRINT_OPTS.edgeitems], self[-PRINT_OPTS.edgeitems:]))
looks like an indexing operation. Though maybe PRINT_OPTS is just a plain old number?
![]()
Yes sorry, the second or new error message was just because I wrote the tensors to the csv files for tracing the error/result.
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""Forward method implementation.
We don't use separate statements on train / eval mode.
It doesn't show remarkable difference of performance.
"""
return F.linear(
x,
self.weight_mu + self.weight_sigma * self.weight_epsilon,
self.bias_mu + self.bias_sigma * self.bias_epsilon,
)
![]()
Yeah, I don’t know why the trace isn’t showing up. You should manually audit your code looking for indexing operations.
![]()
Thanks a lot for the help. I will try to trace the error in october, when I have more time.
Hopefully I can resolve it then 
![]()
I had this problem and it turns out I had a inf loss in my previous calculation.
In my case I have a mask for loss and I need to do something like 1/mask.mean() to scale loss value, and if mask is all zero, it would trigger this bug.
![]()
Closing as we think it is not a framework problem. If you have more info, please feel free to reopen.
![]()
I had a similar error and for me it was resolved with this link: https://towardsdatascience.com/cuda-error-device-side-assert-triggered-c6ae1c8fa4c3
Traceback (most recent call last):
File "automl-proj/experiments/meta_learning/supervised_experiments_submission.py", line 465, in <module>
main(args)
File "automl-proj/experiments/meta_learning/supervised_experiments_submission.py", line 451, in main
meta_valloader)
File "/home/miranda9/automl-meta-learning/automl-proj/meta_learning/training/supervised_training.py", line 43, in supervised_train
train_acc, acc5, train_loss = train(args, base_model, opt, train_sl_loader)
File "/home/miranda9/automl-meta-learning/automl-proj/meta_learning/training/supervised_training.py", line 114, in train
acc1, acc5 = accuracy(output, target, topk=(1, 5))
File "/home/miranda9/ultimate-utils/ultimate-utils-project/torch_uutils/__init__.py", line 467, in accuracy
correct = pred.eq(target.view(1, -1).expand_as(pred))
RuntimeError: CUDA error: device-side assert triggered
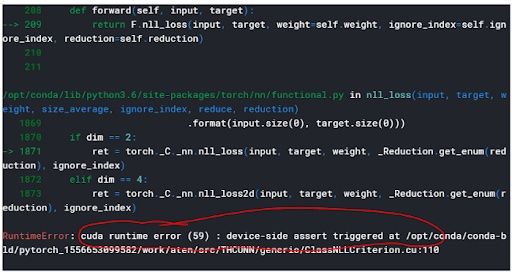
/opt/conda/conda-bld/pytorch_1595629427478/work/aten/src/THCUNN/ClassNLLCriterion.cu:108: cunn_ClassNLLCriterion_updateOutput_kernel: block: [0,0,0], thread: [31,0,0] Assertion `t >= 0 && t < n_classes` failed.
0%| | 0/200 [00:01<?, ?it/s]
Traceback (most recent call last):
File "automl-proj/experiments/meta_learning/supervised_experiments_submission.py", line 465, in <module>
main(args)
File "automl-proj/experiments/meta_learning/supervised_experiments_submission.py", line 451, in main
meta_valloader)
File "/home/miranda9/automl-meta-learning/automl-proj/meta_learning/training/supervised_training.py", line 43, in supervised_train
train_acc, acc5, train_loss = train(args, base_model, opt, train_sl_loader)
File "/home/miranda9/automl-meta-learning/automl-proj/meta_learning/training/supervised_training.py", line 114, in train
acc1, acc5 = accuracy(output, target, topk=(1, 5))
File "/home/miranda9/ultimate-utils/ultimate-utils-project/torch_uutils/__init__.py", line 466, in accuracy
_, pred = output.topk(maxk, 1, True, True)
RuntimeError: cuda runtime error (710) : device-side assert triggered at /opt/conda/conda-bld/pytorch_1595629427478/work/aten/src/THC/generic/THCTensorSort.cu:151
does this not solve it for you?
![]()
Great! It works for me!!!
![]()
I met the same error, then I set ‘device = torch.device(«cpu»)’ to run codes on cpu, the error statements were much more clear.
Anyone has a similar error can have a try.
![]()
For me, what caused this particular problem was that my labels were from 1 to k instead of from 0 to k-1,
i.e. set(Y_Train) and set(Y_Test ) gave [1, 2, …, k] instead of [0, 1, …, k-1].
Hope someone finds this helpful
If you happen to run into this error — cuda runtime error (59): device-side assert triggered — you know how frustrating it can be. The most frustrating part for me was the lack of a clear, step-by-step solution to this problem. This could be due to the fact that PyTorch is still relatively new.
I first encountered this problem while working on the Stanford car data set during a hackathon for the Udacity Pytorch Challenge. It took me a while to fix it, and it didn’t help that I was using Kaggle Kernels, which presented its own challenges in regards to GPU.
A CUDA error: device-side assert triggered is an error that’s often caused when you either have inconsistency between the number of labels and output units or you input the loss function incorrectly. To solve it, you need to make sure your output units match the number of classes and that your output layer returns values in the range of the loss function (criterion) that you chose.
What Causes a CUDA Error: Device-Side Assert Triggered?
The following two reasons cause a CUDA error to occur:
- Inconsistency between the number of labels/classes and the number of output units
- The input of the loss function may be incorrect.
Let’s unpack these reasons and their solutions below.
Inconsistency Between the Number of Labels and Output Units
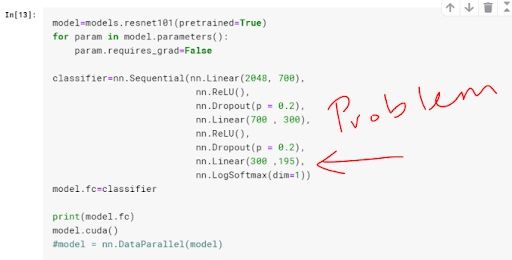
When defining the final fully connected layer of my model, instead of putting 196 — the total number of classes for the Stanford car data set — as the number of output units, I put 195.
The error is usually identified in the line where you do the backpropagation. Your loss function will be comparing the output from your model and the label of that observation in your data set. Just in case you are confused between labels and output, I define them as:
- Label: These are the tags associated with an observation. When working on a classification problem, the label is the class. For example, in the classic dog vs. cat problem, the labels are cat and dog.
- Output: This is the predicted “label” from your model. You give your model a set of features from an observation, and it gives out a prediction called “output” in the PyTorch ecosystem. Think of it as a predicted label.
In my case, some of the labels had a value of 195, which was beyond the range of output for my model in which the greatest possible value was 194 (you start counting from zero). This triggered the error.
More on Machine LearningA Complete Guide to PySpark Data Frames
How Do You Fix This Error?
Make sure the number of output units match the number of your classes. That would involve changing my classifier to be as follows:
classifier = nn.Sequential(nn.Linear(2048, 700),
nn.ReLU(),
nn.Dropout(p = 0.2),
nn.Linear(700 , 300),
nn.ReLU(),
nn.Dropout(p = 0.2),
nn.Linear(300 ,196), #changed this from 195 to 196
nn.LogSoftmax(dim = 1))
model.fc = classifierThis is how you get the number of classes in your data set programmatically:
#.classes returns a list of the classes in your dataset, usually #numbered from 0 to number_of_classes-1
len(dataset.classes)
#Calling len() function on the list will return the number of classes in your datasetReason 2: Wrong Input for the Loss Function
Loss functions have different ranges for the possible inputs that they can accept. If you choose an incompatible activation function for your output layer, it will trigger this error. For example, BCELoss() requires its input to be between zero and one. If the input (output from your model) is beyond the acceptable range for that particular loss function, the error will get triggered.
What Are Activation Loss Functions?
Activation functions are the mathematical equations that determine the output of your neural network. The purpose of the activation function is to introduce non-linearity into the output of a model, thus making a model capable of learning and performing more complex tasks. In turn, they determine how accurate your network will be.
Loss functions are the equations that compute the error that is used to learn via backpropagation.
More on Loss FunctionsThink You Don’t Need Loss Functions in Deep Learning? Think Again.
How to Resolve a CUDA Error: Device-Side Assert Triggered in PyTorch
Make sure your output layer returns values in the range of the loss function (criterion) that you chose. This implies that you’re using the appropriate activation function (sigmoid, softmax, LogSoftmax) in your final output layer.
Example of Problematic Code
model = nn.Linear()
input = torch.randn(128, 2)
output = model(input)
criterion=nn.BCELoss()
torch.empty(128).random_(2)
loss=criterion(output, target)The code above will trigger a CUDA runtime error 59 if you are using a GPU. You can fix it by passing your output through the sigmoid function or using BCEWithLogitsLoss().
Solution 1: Pass the Results Through Sigmoid Function
model = nn.Linear() #The sigmoid funtion can also be applied here as model=nn.Sigmoid(nn.Linear())
input = torch.randn(128, 2)
output = model(input)
criterion=nn.BCELoss()
target=torch.empty(128).random_(2)
loss=criterion(nn.Sigmoid(output), target)Solution 2: Using “BCEWithLogitsLoss()”
model = nn.Linear()
input = torch.randn(128, 2)
output = model(input)
criterion=nn.BCEWithLogitsLoss() #changed fromBCELoss
target = torch.empty(128).random_(2)
loss=criterion(output, target)Fixing CUDA Error: Device-Side Assert Triggered on Kaggle
Once that error is triggered, you cannot continue using your GPU. Even after changing the problematic line and reloading the entire kernel, you will still get the error presented in different forms. The form depends on which line is the first one to attempt to use the GPU. Look at the image below for an idea.
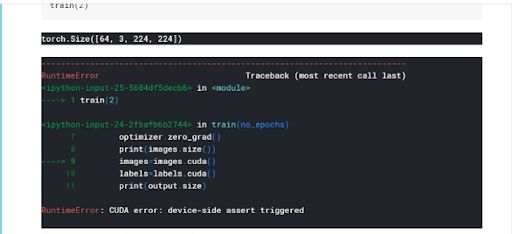
The reason this happens is that even though you may have fixed the bug in your code, once the runtime error 59 is triggered, you are blocked from using the GPU entirely during the same GPU session in which the error was triggered.
The Solution
Stop your current kernel session and start a new one.
To do this, follow the steps below:
- From your kernel, click the ‘K’ on the top left. It automatically takes you to your kernels
- You will see a list of your kernels, which will have have edit option and additional stop for the ones currently running.
- Click “Stop kernel.”
- Restart your kernel session fresh. Every variable should reset, and you should have a brand new GPU session
CUDA Error: Device-Side Assert Triggered Tips
The error messages you get when running into this error may not be very descriptive. To make sure you get a complete and useful stack trace, enter CUDA_LAUNCH_BLOCKING="1" at the very beginning of your code and run it before anything else.
The questions are as follows:
1. The problems are as follows:
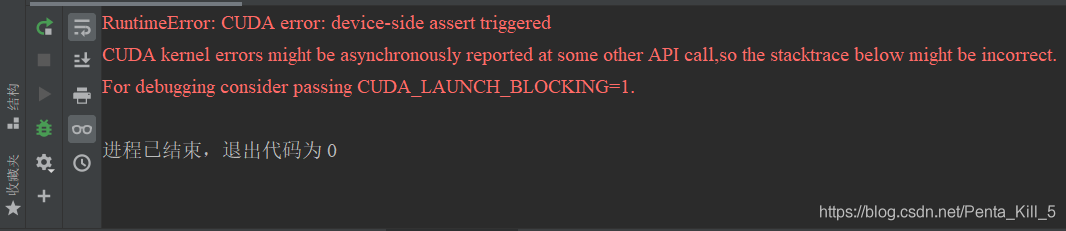
RuntimeError: CUDA error: device-side assert triggered
CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect.
For debugging consider passing CUDA_ LAUNCH_ BLOCKING=1.
2. Solution:
(1) At the beginning, I searched for solutions on the Internet. As a result, most netizens’ solutions are similar to this:
Some people say that the reason for this problem is that there are tags exceeding the number of categories in the training data when doing the classification task. For example: if you set up a total of 8 classes, but there is 9 in the tag in the training data, this error will be reported. So here’s the problem. There’s a trap. If the tag in the training data contains 0, the above error will also be reported. This is very weird. Generally, we start counting from 0, but in Python, the category labels below 0 have to report an error. So if the category label starts from 0, add 1 to all category labels.
Python scans the train itself_ Each folder under path (each type of picture is under its category folder), and map each class to a numerical value. For example, there are four categories, and the category label is [0,1,2,3]. In the second classification, the label is mapped to [0,1], but in the fourth classification, the label is mapped to [1,2,3,4], so an error will be reported.
(2) In fact, it’s useless for me to solve the same problem that I still report an error. Later, I looked up the code carefully and found that it was not the label that didn’t match the category of the classification, but there was a problem with the code of the last layer of the network. If you want to output the categories, you should fill in the categories.
self.outlayer = nn.Linear(256 * 1 * 1, 3) # The final fully connected layer
# Others are 3 categories, while mine is 5 categories, corrected here to solve
self.outlayer = nn.Linear(256 * 1 * 1, 5) # The last fully connected layer(3) It’s actually a small problem, but it’s been working for a long time. Let’s make a record here. The actual situation after the solution:
As easy as modern-day programming has become, there are still several different hoops developers have to jump through to figure out what’s causing bugs in their code, especially if they’re working with bleeding-edge technologies like AI, ML or computer vision.
In this article, we’re looking at the “CUDA error: Device-side assert triggered” when working with Python and PyTorch.
What causes this error?
The error mainly occurs because of the following two reasons.
- The number of labels/classes isn’t matching up to the number of output units.
- The loss function input might be incorrect.
Also read: What is Ring streaming error? 6 Fixes
How to fix this?
You can try out the following fixes.
Match output units with the number of classes
You should first check to see if the number of classes you’ve assigned to your dataset matches the number of output units you have. For example, if your model’s greatest possible output value is 100, any label that produces an output value greater than 100 will trigger this error. This can be resolved by changing the corresponding value in your classifier.
Fix the loss function input
Make sure that your output layer returns values that fall in the range of your selected loss function (also known as a criterion). You will have to use appropriate activation functions (Sigmoid, Softmax or LogSoftmax) in your final output layer.

The quickest way to turn this around is to experiment with all three functions to see which one works best. Sometimes, a function might only work on the CPU but not on GPU or vice-versa, so you’ll have to play around with the code a little bit to figure out the correct answer.
Check the ground label index
Make sure your ground index labels are set accordingly. If your ground truth label starts at 1, you should subtract 1 from every label. This should fix the problem for you.
Keep this in mind as a general rule. As array indexes start from zero, your class index should also start from zero.
Further troubleshooting
If the fixes mentioned above didn’t solve the problem for you, try running your script again, but this time with the CUDA_LAUNCH_BLOCKING=1 flag to get an accurate stack trace. Depending on the error you get, you might want to research further on what went wrong.
Also read: Coursera financial aid: Everything you need to know

Someone who writes/edits/shoots/hosts all things tech and when he’s not, streams himself racing virtual cars.
You can contact him here: [email protected]
Перевод
Ссылка на автора

Если вы случайно столкнулись с этой ошибкой, вы знаете, как это может быть неприятно. Самым разочаровывающим моментом для меня было отсутствие четкого, пошагового решения этой проблемы. Это может быть вызвано тем, что PyTorch все еще относительно нов.
Немного предыстории …
Я работал над Стэнфордский автомобильный набор данных как часть хакатона, рожденного от моего участия в Udacity Pytorch Challenge когда я столкнулся с этой проблемой. Мне потребовалось много времени, чтобы это исправить, и это усугубилось тем фактом, что я использовал ядра Kaggle, которые представляли свои собственные проблемы в отношении GPU.
В чем ошибка?
Эта ошибка возникает из-за следующих двух причин:
- Несоответствие между количеством меток / классов и количеством выходных единиц
- Ввод функции потерь может быть неправильным.
Давайте распакуем эти причины и их решения ниже:
Причина 1: несоответствие между количеством меток и количеством выходных единиц

При определении окончательного полностью связанного слоя моей модели вместо числа 196 (общее количество классов для автомобильного набора данных Стэнфорда) в качестве количества выходных единиц я выбрал 195.
Ошибка обычно указывается в строке, где вы делаете обратное распространение. Ваша функция потери будет сравниватьвыходот вашей модели и томуэтикеткаэтого наблюдения в вашем наборе данных. На всякий случай, если вы путаетесь между метками и выводом, посмотрите, как я их определяю ниже:
этикетка: Это теги, связанные с наблюдением. При работе над проблемой классификации метка является классом. Например, в классической проблеме «собака против кошки» ярлыки обозначают кошка и собака.
Выход: Это предсказанный «ярлык» вашей модели. Вы даете своей модели набор функций из наблюдения, и она выдает прогноз, называемый выходом в экосистеме PyTorch. Думайте об этом как о предсказанном ярлыке.
В моем случае некоторые метки будут иметь значение 195, которое выходит за пределы диапазона выходных данных для моей модели, максимально возможное значение которой составляет 194 (начать отсчет с нуля). Это вызывает ошибку, которая будет вызвана.
Как вы можете это исправить?
Убедитесь, что количество выходных единиц соответствует количеству ваших классов
Это изменило бы мой классификатор следующим образом:
classifier = nn.Sequential(nn.Linear(2048, 700),
nn.ReLU(),
nn.Dropout(p = 0.2),
nn.Linear(700 , 300),
nn.ReLU(),
nn.Dropout(p = 0.2),
nn.Linear(300 ,196), #changed this from 195 to 196
nn.LogSoftmax(dim = 1))
model.fc = classifier
Вот как вы получаете количество классов в вашем наборе данных программным способом:
#.classes returns a list of the classes in your dataset, usually #numbered from 0 to number_of_classes-1len(dataset.classes)#Calling len() function on the list will return the number of classes in your dataset
Причина 2: неверный ввод для функции потерь
Функции потери имеют разные диапазоны для возможных входов, которые они могут принять. Если вы выберете несовместимую функцию активации для выходного слоя, эта ошибка будет вызвана. Например, BCELoss требует, чтобы его входное значение находилось в диапазоне от 0 до 1. Если входное значение (выходное значение вашей модели) выходит за пределы допустимого диапазона для этой конкретной функции потерь, возникает ошибка.
Резюме на функции потери активации
Функции активации — это математические уравнения, которые определяют выход вашей нейронной сети. Целью функции активации являетсяввести нелинейностьв вывод модели, тем самым делая модель способной учиться и выполнять более сложные задачи. Они, в свою очередь, определяют, насколько точной будет ваша сеть.
Функции потерь — это уравнения, которые вычисляют ошибку, используемую для обучения посредствомобратное распространение,
Для подробного объяснения функций потери и как они работают, пожалуйста, проверьте это статья и Pytorch документация, Найти информацию о функция активации здесь,

Как вы можете это исправить?
Убедитесь, что ваш выходной слой возвращает значения в диапазоне выбранной вами функции потерь (критерия). Это подразумевает использование соответствующей функции активации (Sigmoid, Softmax, LogSoftmax) в вашем конечном выходном слое.
Пример проблемного кода
model = nn.Linear()
input = torch.randn(128, 2)
output = model(input)criterion=nn.BCELoss()
torch.empty(128).random_(2)loss=criterion(output, target)
Приведенный выше код вызовет ошибку времени выполнения 59, если мы используем графический процессор. Вы можете исправить это, передав свой вывод через функцию сигмоида или используя BCEWithLogitsLoss ().
Исправление 1: передача результатов через функцию Sigmoid
model = nn.Linear() #The sigmoid funtion can also be applied here as model=nn.Sigmoid(nn.Linear())input = torch.randn(128, 2)
output = model(input)criterion=nn.BCELoss()
target=torch.empty(128).random_(2)loss=criterion(nn.Sigmoid(output), target)
Исправление 2: вместо этого используется BCEWithLogitsLoss ()
model = nn.Linear()
input = torch.randn(128, 2)
output = model(input)criterion=nn.BCEWithLogitsLoss() #changed fromBCELoss
target = torch.empty(128).random_(2)loss=criterion(output, target)
Работаете над Kaggle? Вот почему даже после выполнения вышеуказанных шагов, вы все еще боретесь
Как только эта ошибка вызвана, вы не можете продолжать использовать свой графический процессор. Даже после изменения проблемной строки и перезагрузки всего ядра, вы все равно получите ошибку, представленную в разных формах. Форма зависит от того, какая строка первой попытается использовать графический процессор. Посмотрите на изображение ниже для идеи.

Причина, по которой это происходит, даже несмотря на то, что вы исправили ошибку в своем коде, заключается в том, что, как только ошибка 59 времени выполнения сработает, вы не сможете использовать GPU полностью во время того же сеанса GPU, в котором была вызвана ошибка.
Как вы можете это исправить?
Остановите текущий сеанс ядра и начните новый.
Для этого выполните следующие действия:
- В вашем Ядре нажмите «К» в левом верхнем углу. Это автоматически приведет вас к вашим ядрам
- Вы увидите список ваших ядер с возможностью редактирования и дополнительной остановкой для тех, которые в данный момент работают.
- Нажмите остановить ядро
- Снова откройте ядро, все переменные будут сброшены, и у вас будет новый сеанс GPU
Дополнительный совет
Сообщения об ошибках, которые вы получаете, сталкиваясь с этой ошибкой, могут быть не очень описательными. Чтобы убедиться, что вы получите полный иполезнымтрассировка стека, имейте это в самом начале вашего кода и запустите его прежде всего:
CUDA_LAUNCH_BLOCKING="1"
Ссылки
[1] Автор, GPU уходит после ошибки # 1010 ( 2018), Pytorch Github Выпуски страниц
[2] Лернаппрат, Отладка утверждения на стороне устройства CUDA в PyTorch (2018), https://lernapparat.de/
Я надеюсь, что эта статья помогла вам. Не стесняйтесь оставлять свои комментарии по любому аспекту этого урока в разделе ответов ниже.