The Rust RFC Book
- Feature Name: compile_error_macro
- Start Date: 2016-08-01
- RFC PR: rust-lang/rfcs#1695
- Rust Issue: rust-lang/rust#40872
Summary
This RFC proposes adding a new macro to libcore, compile_error! which will
unconditionally cause compilation to fail with the given error message when
encountered.
Motivation
Crates which work with macros or annotations such as cfg have no tools to
communicate error cases in a meaningful way on stable. For example, given the
following macro:
macro_rules! give_me_foo_or_bar {
(foo) => {};
(bar) => {};
}
when invoked with baz, the error message will be error: no rules expected the token baz. In a real world scenario, this error may actually occur deep in a
stack of macro calls, with an even more confusing error message. With this RFC,
the macro author could provide the following:
macro_rules! give_me_foo_or_bar {
(foo) => {};
(bar) => {};
($x:ident) => {
compile_error!("This macro only accepts `foo` or `bar`");
}
}
When combined with attributes, this also provides a way for authors to validate
combinations of features.
#[cfg(not(any(feature = "postgresql", feature = "sqlite")))]
compile_error!("At least one backend must be used with this crate.
Please specify `features = ["postgresql"]` or `features = ["sqlite"]`")
Detailed design
The span given for the failure should be the invocation of the compile_error!
macro. The macro must take exactly one argument, which is a string literal. The
macro will then call span_err with the provided message on the expansion
context, and will not expand to any further code.
Drawbacks
None
Alternatives
Wait for the stabilization of procedural macros, at which point a crate could
provide this functionality.
Unresolved questions
None
Published
2021-05-11
on
blog.turbo.fish
This is the third article in my series about procedural macros. The examples
here are based on the Getters derive macro from the previous article.
As the title says, this time I’ll explain error handling, specifically how to
use syn::Error to produce errors that will be shown by the compiler as
originating somewhere in the macro input, rather than pointing at the macro
invocation.
A use case
Before we can start adding meaningful spans to parts of the macro input, there
has to be the possibility for errors other than those already caught by the
Rust compiler itself. Luckily, there is a common way in which the input of a
derive macro can be wrong in a way specific to that macro, so I can continue on
with the previous Getters example rather than coming up with, and explaining,
a new function-like or attribute proc-macro.
That common possibility for errors is attributes: Many derive macros come with
their own attribute(s), and generally they emit an error when one such attribute
is used incorrectly. For the Getters macro there is one obvious (to me)
customization possibility that an attribute would enable: Renaming. As such, we
will add a getter field attribute that is used as #[getter(name = "foo")].
Registering the attribute
The first thing that has to be done before starting to look for attributes in
the DeriveInput is registering the attribute. By default if rustc encounters
an unknown attribute, that is an error:
error: cannot find attribute `getter` in this scope
--> src/ratchet/keys.rs:15:7
|
15 | #[getter(name = "init_vec")]
| ^^^^^^
Making that error disappear is as simple as updating the #[proc_macro_derive]
attribute on our proc-macro entry point:
#[proc_macro_derive(Getters, attributes(getter))]
// ^^^^^^^^^^^^^^^^^^ this is new
pub fn getters(input: TokenStream) -> TokenStream {
let input = parse_macro_input!(input as DeriveInput);
expand_getters(input).into()
}
Parsing the attribute
Since custom parsing is complex enough to deserve its own article, I’m going to
use syn::Attribute::parse_meta here, which is sufficient for the syntax shown
above.
// Note: syn::Ident is a re-export of proc_macro2::Ident
use syn::{Attribute, Ident};
fn get_name_attr(attr: &Attribute) -> syn::Result<Option<Ident>> {
let meta = attr.parse_meta()?;
todo!()
}
The syn::Result<T> type above is simply a type alias for
Result<T, syn::Error>. Since syns Meta type can only represent a limited
subset of the arbitrary token trees allowed within attributes, parsing it is
fallible, and returns syn::Result<syn::Meta>.
Luckily detecting whether an attribute is possible without calling any of
Attributes parse_ methods, so we can detect whether the attribute is for us
before executing this fallible operation.
But I’m getting ahead of myself… First, let’s add more to our new function.
Here is what the most common way of constructing a syn::Error looks like (for
me at least):
use syn::Meta;
let meta_list = match meta {
Meta::List(list) => list,
// *Almost* equivalent (see syn documentation) to:
// use syn::spanned::Spanned;
// return Err(syn::Error::new(meta.span(), "expected a list-style attribute"))
_ => return Err(syn::Error::new_spanned(meta, "expected a list-style attribute")),
};
As you can see, creating a syn::Error is nothing special.
The rest of get_name_attr works in much the same way:
use syn::{Lit, NestedMeta};
let nested = match meta_list.nested.len() {
// `#[getter()]` without any arguments is a no-op
0 => return Ok(None),
1 => &meta_list.nested[0],
_ => {
return Err(syn::Error::new_spanned(
meta_list.nested,
"currently only a single getter attribute is supported",
));
}
};
let name_value = match nested {
NestedMeta::Meta(Meta::NameValue(nv)) => nv,
_ => return Err(syn::Error::new_spanned(nested, "expected `name = "<value>"`")),
};
if !name_value.path.is_ident("name") {
// Could also silently ignore the unexpected attribute by returning `Ok(None)`
return Err(syn::Error::new_spanned(
&name_value.path,
"unsupported getter attribute, expected `name`",
));
}
match &name_value.lit {
Lit::Str(s) => {
// Parse string contents to `Ident`, reporting an error on the string
// literal's span if parsing fails
syn::parse_str(&s.value()).map_err(|e| syn::Error::new_spanned(s, e))
}
lit => Err(syn::Error::new_spanned(lit, "expected string literal")),
}
Adjusting the existing codegen
Now we have a new method to parse #[getter] attributes, but we aren’t using it
yet. We need to update the existing code generation logic to take these
attributes into account, and the first step towards that is making the
expand_getters function fallible as well.
If it’s been some time since you read the last article, here is its signature
again (you can also review the entire definition here):
pub fn expand_getters(input: DeriveInput) -> TokenStream {
Which now becomes
pub fn expand_getters(input: DeriveInput) -> syn::Result<TokenStream> {
The new expand_getters implementation is a bit longer, but still manageable:
// Same as before
let fields = match input.data {
Data::Struct(DataStruct { fields: Fields::Named(fields), .. }) => fields.named,
_ => panic!("this derive macro only works on structs with named fields"),
};
// All the new logic comes in here
let getters = fields
.into_iter()
.map(|f| {
// Collect getter attributes
let attrs: Vec<_> =
// This `.filter` is how we make sure to ignore builtin attributes, or
// ones meant for consumption by different proc-macros.
f.attrs.iter().filter(|attr| attr.path.is_ident("getter")).collect();
let name_from_attr = match attrs.len() {
0 => None,
1 => get_name_attr(attrs[0])?,
// Since `#[getter(name = ...)]` is the only available `getter` attribute,
// we can just assume any attribute with `path.is_ident("getter")` is a
// `getter(name)` attribute.
//
// Thus, if there is two `getter` attributes, there is a redundancy
// which we should report as an error.
//
// On nightly, you could also choose to report a warning and just use one
// of the attributes, but emitting a warning from a proc-macro is not
// stable at the time of writing.
_ => {
let mut error = syn::Error::new_spanned(
attrs[1],
"redundant `getter(name)` attribute",
);
// `syn::Error::combine` can be used to create an error that spans
// multiple independent parts of the macro input.
error.combine(
syn::Error::new_spanned(attrs[0], "note: first one here"),
);
return Err(error);
}
};
// If there is no `getter(name)` attribute, use the field name like before
let method_name =
name_from_attr.unwrap_or_else(|| f.ident.clone().expect("a named field"));
let field_name = f.ident;
let field_ty = f.ty;
Ok(quote! {
pub fn #method_name(&self) -> &#field_ty {
&self.#field_name
}
})
})
// Since `TokenStream` implements `FromIterator<TokenStream>`, concatenating an
// iterator of token streams without a separator can be using `.collect()` in
// addition to `quote! { #(#iter)* }`. Through std's `FromIterator` impl for
// `Result`, we get short-circuiting on errors on top.
.collect::<syn::Result<TokenStream>>()?;
// Like before
let st_name = input.ident;
let (impl_generics, ty_generics, where_clause) = input.generics.split_for_impl();
// Resulting TokenStream wrapped in Ok
Ok(quote! {
#[automatically_derived]
impl #impl_generics #st_name #ty_generics #where_clause {
// Previously: #(#getters)*
//
// Now we don't need that anymore since we already
// collected the getters into a TokenStream above
#getters
}
})
If this is the first time you have seen .collect::<Result<_, _>>, you can find the documentation
for the trait implementation that makes it possible here.
Passing a syn::Error to the compiler
One final piece of the puzzle is missing: How does syn::Error become a
compiler error? We can’t update our proc-macro entry point to return
syn::Result, that would result in an error because proc-macro entry points are
required to return just a TokenStream.
However, the solution is almost as easy and you might already have seen it if
you had a look at syn::Errors documentation:
// Previously, with expand_getters returning proc_macro2::TokenStream
expand_getters(input).into()
// Now, returning syn::Result<proc_macro2::TokenStream>
expand_getters(input).unwrap_or_else(syn::Error::into_compile_error).into()
What this does under the hood is actually kind of weird: It produces a
TokenStream like
quote! { compile_error!("[user-provided error message]"); }
but with the span being the one given when constructing the syn::Error. As
weird as it is, that’s simply the only way to raise a custom compiler error on
stable (as of the time of writing).
If you haven’t seen compile_error! before, it’s a builtin macro.
And that’s it!
That’s all there really is when it comes to proc-macro specific error handling
knowledge. Like last time, you can review the changes from this blog post in the
accompanying repo:
- Complete code
- Individual commits
If you want to practice your proc-macro skills but haven’t come up with anything
to create or contribute to at this point, I recommend having a look at David
Tolnay’s proc-macro-workshop.
Next time, I will explain how to parse custom syntax, which can be useful for
derive macros when you want to go beyond what syn::Meta allows, and is crucial
for many attribute macros as well as the majority of function-like proc-macros.
Stay tuned!
Rust procedural macros are one of the most exciting feature of the language. They enable you to inject code at compile time, but differently from the method used for generics by monomorphization. Using very specific crates, you can build new code totally from scratch.
I decided to write this article to share my experience, because event though the different resources are more and more widespread, it’s not really straightforward at first sight.
Let’s see how it works.
Building a procedural derive macro
The operating principle of the procedural macros is quite simple: take a piece of code, called an input TokenStream, convert it to an abstract syntax tree (ast) which represents the internal structure of that piece for the compiler, build a new TokenStream from what you’ve got at input (using the syn::parse() method), and inject it in the compiler as an output piece of code.
Using a procedural derive macro
A derive macro is used by declaring the
#[derive()]
Enter fullscreen mode
Exit fullscreen mode
attribute, like for example the well-known:
#[derive(Debug)]
Enter fullscreen mode
Exit fullscreen mode
Building a procedural derive macro
Suppose you want to create a WhoAmI derive macro, to just print out the name of the structure under the derive statement:
#[derive(WhoAmI)]
struct Point {
x: f64,
y: f64
}
Enter fullscreen mode
Exit fullscreen mode
What you need to do:
- create a brand new lib crate (procedural macros must be defined in their own crate, otherwise if you try to use
the macro in the same one, you face the following error: can’t use a procedural macro from the same crate that defines it)
$ cargo new --lib whoami
Enter fullscreen mode
Exit fullscreen mode
- add the required dependencies to Cargo.toml and flags:
[lib]
proc-macro = true
[dependencies]
syn = { version = "1.0.82", features = ["full", "extra-traits"] }
quote = "1.0.10"
Enter fullscreen mode
Exit fullscreen mode
- define a new regular fn Rust fonction like this one in lib.rs:
use proc_macro::TokenStream; // no need to import a specific crate for TokenStream
use syn::parse;
// Generate a compile error to output struct name
#[proc_macro_derive(WhoAmI)]
pub fn whatever_you_want(tokens: TokenStream) -> TokenStream {
// convert the input tokens into an ast, specially from a derive
let ast: syn::DeriveInput = syn::parse(tokens).unwrap();
panic!("My struct name is: <{}>", ast.ident.to_string());
TokenStream::new()
}
Enter fullscreen mode
Exit fullscreen mode
As you can’t use the regular Rust macros to print out some information on stdout (like println!()), the only way is to panic with an output message, to stop the compiler and tell that guy to output the message for you. Not really convenient to debug, nor easy to fully understand the nuts and bolts of a procedural macro !
Now, in order to use that awesome macro (not really handy because it won’t compile):
- you have to define a new crate:
$ cargo new thisisme
Enter fullscreen mode
Exit fullscreen mode
- add our macro crate as a dependency:
[dependencies]
# provided both crates are on the same directory level, otherwise replace by your crate's path
whoami = { path = "../whoami" }
Enter fullscreen mode
Exit fullscreen mode
- replace main.rs source code with:
// import our crate
use whoami::WhoAmI;
#[derive(WhoAmI)]
struct Point {
x: f64,
y: f64
}
fn main() {
println!("Hello, world!");
}
Enter fullscreen mode
Exit fullscreen mode
- and compile the whole project:
error: proc-macro derive panicked
--> src/main.rs:3:10
|
3 | #[derive(WhoAmI)]
| ^^^^^^
|
= help: message: My struct name is: <Point>
Enter fullscreen mode
Exit fullscreen mode
Your can watch the compiler spitting the error message with defined in the procedural macro.
Using the proc-macro2 crate for debugging and understanding procedural macros
The previous method is unwieldy to say the least, and not meant to make you understand how to really leverage from
procedural macros, because you can’t really debug the macro (although it can change in the future).
That’s why the proc-macro2 exists: you can use its methods, along with its syn::parse2() counterpart, in unit tests or regular binaries. You can then directly output the code generated to stdout or save it into a «*.rs» file to check its content.
Let’s create a procedural macro artefact which auto-magically defines a function which calculates the summation of all fields, for the Point structure.
- create a new binary crate
$ cargo new fields_sum
Enter fullscreen mode
Exit fullscreen mode
- add the dependencies:
syn = { version = "1.0.82", features = ["full", "extra-traits"] }
quote = "1.0.10"
proc-macro2 = "1.0.32"
Enter fullscreen mode
Exit fullscreen mode
Add the following code in the main.rs file:
// necessary for the TokenStream::from_str() implementation
use std::str::FromStr;
use proc_macro2::TokenStream;
use quote::{format_ident, quote};
use syn::ItemStruct;
fn main() {
// struct sample
let s = "struct Point { x : u16 , y : u16 }";
// create a new token stream from our string
let tokens = TokenStream::from_str(s).unwrap();
// build the AST: note the syn::parse2() method rather than the syn::parse() one
// which is meant for "real" procedural macros
let ast: ItemStruct = syn::parse2(tokens).unwrap();
// save our struct type for future use
let struct_type = ast.ident.to_string();
assert_eq!(struct_type, "Point");
// we have 2 fields
assert_eq!(ast.fields.len(), 2);
// syn::Fields is implementing the Iterator trait, so we can iterate through the fields
let mut iter = ast.fields.iter();
// this is x
let x_field = iter.next().unwrap();
assert_eq!(x_field.ident.as_ref().unwrap(), "x");
// this is y
let y_field = iter.next().unwrap();
assert_eq!(y_field.ident.as_ref().unwrap(), "y");
// now the most tricky part: use the quote!() macro to generate code, aka a new
// TokenStream
// first, build our function name: point_summation
let function_name = format_ident!("{}_summation", struct_type.to_lowercase());
// and our argument type. If we don't use the format ident macro, the function prototype
// will be: pub fn point_summation (pt : "Point")
let argument_type = format_ident!("{}", struct_type);
// same for x and y
let x = format_ident!("{}", x_field.ident.as_ref().unwrap());
let y = format_ident!("{}", y_field.ident.as_ref().unwrap());
// the quote!() macro is returning a new TokenStream. This TokenStream is returned to
// the compiler in a "real" procedural macro
let summation_fn = quote! {
pub fn #function_name(pt: &#argument_type) -> u16 {
pt.#x + pt.#y
}
};
// output our function as Rust code
println!("{}", summation_fn);
}
Enter fullscreen mode
Exit fullscreen mode
Now running our crate gives:
pub fn point_summation (pt : & Point) -> u16 { pt . x + pt . y }
Enter fullscreen mode
Exit fullscreen mode
So far, so good.
Combining TokenStreams
The previous example is straightforward because we knew in advance the number of fields in the struct.
What if we don’t know it beforehand ? Well we can use a special construct of quote!() to generate the summation on all fields:
// create the list of tokens
// tokens type is: impl Iterator<Item = TokenStream>
let tokens = fields.iter().map(|i| quote!(pt.#i));
// the trick is made by: 0 #(+ #tokens)*
// which repeats the + sign on all tokens
let summation_fn = quote! {
pub fn #function_name(pt: &#argument_type) -> u16 {
0 #(+ #tokens)*
}
};
Enter fullscreen mode
Exit fullscreen mode
Result is:
pub fn point_summation (pt : & Point) -> u16 { 0 + pt . x + pt . y + pt . z + pt . t }
Enter fullscreen mode
Exit fullscreen mode
Hope this help !
Photo by Stéphane Mingot on Unsplash
Процедурные макросы позволяют создавать расширения синтаксиса как выполнение функции. Процедурные макросы бывают трех видов:
-
Функциональные макросы —
custom!(...) -
Производные макросы —
#[derive(CustomDerive)] -
#[CustomAttribute]атрибутов — # [CustomAttribute]
Процедурные макросы позволяют запускать код во время компиляции,который работает над синтаксисом Rust,как потребляя,так и создавая синтаксис Rust.Вы можете думать о процедурных макросах как о функциях от AST к другому AST.
Процедурные макросы должны быть определены в клети с типом обрешеткой из proc-macro .
Примечание . При использовании Cargo ящики процедурных макросов определяются с помощью ключа
proc-macroв вашем манифесте:[lib] proc-macro = true
В качестве функций они должны либо возвращать синтаксис,панику,либо цикл бесконечно.Возвращаемый синтаксис либо заменяет,либо добавляет синтаксис в зависимости от типа процедурного макроса.Паника перехватывается компилятором и превращается в ошибку компилятора.Бесконечные циклы не перехватываются компилятором,который вешает компилятор.
Процедурные макросы выполняются во время компиляции и поэтому имеют те же ресурсы, что и компилятор. Например, стандартный ввод, ошибка и вывод — те же самые, к которым у компилятора есть доступ. Точно так же и доступ к файлам. Из-за этого процедурные макросы имеют те же проблемы безопасности, что и сценарии сборки Cargo .
У процедурных макросов есть два способа сообщения об ошибках. Первый — паника. Второй — compile_error вызов макроса compile_error .
proc_macro клеть
Процедурные макро ящики почти всегда будут ссылаться на компилятор при условии proc_macro обрешетки . proc_macro обрешетка обеспечивает типы , необходимые для написания процедурных макросов и средств , чтобы сделать его проще.
Этот ящик в основном содержит тип TokenStream . Процедурные макросы работают с потоками токенов, а не с узлами AST, что с течением времени является гораздо более стабильным интерфейсом как для компилятора, так и для целевых процедурных макросов. Маркер потока примерно эквивалентно Vec<TokenTree> где TokenTree можно грубо думать как лексической маркер. Например , foo является Ident маркер, . — это токен Punct , а 1.2 — токен Literal . Тип TokenStream , в отличие от Vec<TokenTree> , дешево клонировать.
Все токены имеют связанный Span . Span — это непрозрачное значение, которое нельзя изменить, но можно изготовить. Span представляет собой экстент исходного кода в программе и в основном используется для сообщений об ошибках. Хотя вы не можете изменить сам Span , вы всегда можете изменить Span ,связанный с любым токеном, например, путем получения Span из другого токена.
процедурная макрогигиена
Процедурные макросы негигиеничны . Это означает, что они ведут себя так, как если бы поток выходных токенов был просто встроен в код, за которым он находится. Это означает, что на него влияют внешние элементы, а также внешний импорт.
Авторы макросов должны быть осторожны, чтобы их макросы работали в максимально возможном количестве контекстов, учитывая это ограничение. Это часто включает использование абсолютных путей к элементам в библиотеках (например, ::std::option::Option вместо Option ) или обеспечение того, чтобы сгенерированные функции имели имена, которые вряд ли будут конфликтовать с другими функциями (например, __internal_foo вместо foo ) .
Функциональные процедурные макросы
Подобный функциям процедурный макрос — это процедурный макрос, который вызывается с помощью оператора вызова макроса ( ! ).
Эти макросы определяются публичной функцией с атрибутом proc_macro и подписью (TokenStream) -> TokenStream . Входной TokenStream — это то, что находится внутри разделителей вызова макроса, а выходной TokenStream заменяет весь вызов макроса.
Например, следующее определение макроса игнорирует его ввод и выводит answer функции в свою область видимости.
#![crate_type = "proc-macro"] extern crate proc_macro; use proc_macro::TokenStream; #[proc_macro] pub fn make_answer(_item: TokenStream) -> TokenStream { "fn answer() -> u32 { 42 }".parse().unwrap() }
А затем мы используем его в бинарном крейте,чтобы вывести «42» на стандартный вывод.
extern crate proc_macro_examples; use proc_macro_examples::make_answer; make_answer!(); fn main() { println!("{}", answer()); }
Функция типа процедурных макросов может быть использована в любом положении макро вызова, который включает в себя высказывание , выражение , шаблоны , выражение типа , запись позиции, в том числе элементов в extern блоков , врожденной и признак реализации и определение признака .
Derive macros
Макросы derive определяют новые входные данные для атрибута извлечения . Эти макросы могут создавать новые элементы с учетом потока токенов структуры , перечисления или объединения . Они также могут определять вспомогательные атрибуты макроса .
proc_macro_derive настраиваемого вывода определяются публичной функцией с атрибутом proc_macro_derive и подписью (TokenStream) -> TokenStream .
Входной TokenStream — это токен-поток элемента, имеющего атрибут derive . Выходной TokenStream должен быть набором элементов, которые затем добавляются к модулю или блоку , в котором находится элемент из входного TokenStream .
Ниже приведен пример макроса извлечения. Вместо того, чтобы делать что-нибудь полезное со своим вводом, он просто добавляет answer функции .
#![crate_type = "proc-macro"] extern crate proc_macro; use proc_macro::TokenStream; #[proc_macro_derive(AnswerFn)] pub fn derive_answer_fn(_item: TokenStream) -> TokenStream { "fn answer() -> u32 { 42 }".parse().unwrap() }
А затем,используя упомянутый макрос:
extern crate proc_macro_examples; use proc_macro_examples::AnswerFn; #[derive(AnswerFn)] struct Struct; fn main() { assert_eq!(42, answer()); }
Атрибуты макропомощника Derive
Макросы извлечения могут добавлять дополнительные атрибуты в область действия элемента, в котором они находятся. Указанные атрибуты называются вспомогательными атрибутами макроса . Эти атрибуты инертны , и их единственная цель — передать их в макрос производного типа, который их определил. Тем не менее, они видны всем макросам.
Способ определения вспомогательных атрибутов состоит в том, чтобы поместить ключ attributes в макрос proc_macro_derive с разделенным запятыми списком идентификаторов, которые являются именами вспомогательных атрибутов.
Например, следующий макрос Выведите определяет атрибут помощника helper , но в конечном счете , ничего с ним не делать.
#![crate_type="proc-macro"] extern crate proc_macro; use proc_macro::TokenStream; #[proc_macro_derive(HelperAttr, attributes(helper))] pub fn derive_helper_attr(_item: TokenStream) -> TokenStream { TokenStream::new() }
А затем использование на выходе макроса на структуре:
#[derive(HelperAttr)] struct Struct { #[helper] field: () }
Attribute macros
Атрибут макросы определяют новые внешние атрибуты , которые могут быть прикреплены к пунктам , в то числе элементов в extern блоков , врожденной и признак реализации и определение признака .
proc_macro_attribute атрибутов определяются публичной функцией с атрибутом proc_macro_attribute , имеющим подпись (TokenStream, TokenStream) -> TokenStream . Первый TokenStream — это дерево токенов с разделителями, следующее за именем атрибута, не включая внешние разделители. Если атрибут записан как простое имя атрибута, атрибут TokenStream пуст. Второй TokenStream является остальной частью элемента , включая другие атрибуты на изделии . Возвращенный TokenStream заменяет элемент с произвольным числомпредметы .
Например,данный атрибутный макрос берет входной поток и возвращает его как есть,фактически являясь отсутствием атрибутов.
#![crate_type = "proc-macro"] extern crate proc_macro; use proc_macro::TokenStream; #[proc_macro_attribute] pub fn return_as_is(_attr: TokenStream, item: TokenStream) -> TokenStream { item }
В следующем примере показаны TokenStream s, которые видят макросы атрибутов. Вывод будет отображаться в выводе компилятора. Результат показан в комментариях после функции с префиксом «out:».
extern crate proc_macro; use proc_macro::TokenStream; #[proc_macro_attribute] pub fn show_streams(attr: TokenStream, item: TokenStream) -> TokenStream { println!("attr: "{}"", attr.to_string()); println!("item: "{}"", item.to_string()); item }
extern crate my_macro; use my_macro::show_streams; fn invoke1() {} fn invoke2() {} fn invoke3() {} fn invoke4() {}
Декларативные макрокоманды и процедурные макрокоманды
Декларативные макросы macro_rules и процедурные макросы используют похожие, но разные определения для токенов (или, скорее, TokenTree s .)
Деревья токенов в macro_rules (соответствующие сопоставителям tt ) определяются как
- Группы с разделителями (
(...),{...}и т. д.) - Все операторы, поддерживаемые языком, как односимвольные, так и многосимвольные (
+,+=).- Обратите внимание, что этот набор не включает одинарную кавычку
'.
- Обратите внимание, что этот набор не включает одинарную кавычку
- Литералы (
"string",1и т. д.)- Обратите внимание, что отрицание (например,
-1) никогда не является частью таких литеральных токенов, а является отдельным токеном оператора.
- Обратите внимание, что отрицание (например,
- Идентификаторы, включая ключевые слова (
ident,r#ident,fn) - Lifetimes (
'ident) - Подстановки метапеременных в
macro_rules(например$my_exprвmacro_rules! mac { ($my_expr: expr) => { $my_expr } }после расширенияmac, которое будет считаться одним деревом токенов независимо от переданного выражения)
Деревья токенов в процедурных макросах определяются как
- Группы с разделителями (
(...),{...}и т. д.) - Все знаки пунктуации, используемые в операторах, поддерживаемых языком (
+, но не+=), а также символ одинарной кавычки'(обычно используемый во временах жизни, см. ниже поведение разделения и объединения во время жизни) - Литералы (
"string",1и т. д.)- Отрицание (например ,
-1) поддерживается как часть целочисленных литералов и литералов с плавающей запятой.
- Отрицание (например ,
- Идентификаторы, включая ключевые слова (
ident,r#ident,fn)
Несовпадения между этими двумя определениями учитываются при передаче потоков маркеров в процедурные макросы и из них.
Обратите внимание,что приведенные ниже преобразования могут выполняться лениво,поэтому они могут не выполняться,если лексемы не проверяются.
При передаче в макрос proc
- Все многосимвольные операторы разбиваются на односимвольные.
- Время жизни разбито на символ
'и идентификатор. - Все подстановки метапеременных представлены в виде потоков лексем,лежащих в их основе.
- Такие потоки токенов могут быть заключены в группы с разделителями (
Group) с неявными разделителями (Delimiter::None), когда это необходимо для сохранения приоритетов синтаксического анализа. -
ttиidentникогда не включаются в такие группы и всегда представляются как лежащие в их основе деревья токенов.
- Такие потоки токенов могут быть заключены в группы с разделителями (
При испускании из макроса proc
- Знаки препинания вклеиваются в многосимвольные операторы,когда это применимо.
- Одинарные кавычки
'соединенные с идентификаторами, вклеиваются во время жизни. - Отрицательные литералы преобразуются в два токена (
-и литерал), которые могут быть заключены в группу с разделителями (Group) с неявными разделителями (Delimiter::None), когда это необходимо для сохранения приоритетов синтаксического анализа.
Обратите внимание, что ни декларативные, ни процедурные макросы не поддерживают токены комментариев к документам (например , /// Doc ), поэтому они всегда преобразуются в потоки токенов, представляющие их эквивалентные атрибуты #[doc = r"str"] при передаче в макросы.
Rust
1.65
-
Patterns
Синтаксис Шаблон PatternNoTopAlt PatternNoTopAlt PatternWithoutRange RangePattern PatternWithoutRange LiteralPattern IdentifierPattern WildcardPattern RestPattern
-
Range patterns
Синтаксис RangePattern InclusiveRangePattern HalfOpenRangePattern ObsoleteRangePattern InclusiveRangePattern RangePatternBound HalfOpenRangePattern RangePatternBound
-
Ржавчина
В этом разделе описаны функции,определяющие некоторые аспекты выполнения Rust.
-
Специальные типы и черты
Определенные типы и черты,которые существуют в стандартной библиотеке,известны компилятору Rust.
Have you ever seen the Rust compiler give a Python error?
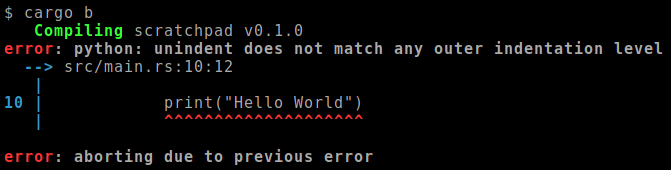
Or better, have you ever seen rust-analyzer
complain about Python syntax?
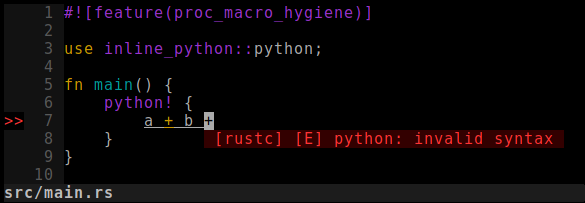
In this post, we’ll extend our python!{} macro to make that happen.
Credit and special thanks:
Everything described in this part was originally implemented for the
inline-python crate
by Maarten de Vries.
Compiling Python code
Before the Python interpreter executes your Python code,
it first compiles it to Python bytecode.
The bytecode for imported modules is usually cached in a directory called __pycache__, as .pyc files,
to save time the when the same code is imported next time.
Since the bytecode will only change when the source is changed,
it’d be interesting to see if we can make python!{} produce the bytecode at compile time,
since the Python code will not change after that anyway.
Then, the resulting program will not have to spend any time compiling the Python code
before it can execute it.
But first, what does “compiling” exactly mean for Python, as an interpreted language?
The Python Standard Library contains a module called dis,
which can show us the Python bytecode for a piece of code in a readable (disassembled) format:
$ python
>>> import dis
>>> dis.dis("abc = xyz + f()")
1 0 LOAD_NAME 0 (xyz)
2 LOAD_NAME 1 (f)
4 CALL_FUNCTION 0
6 BINARY_ADD
8 STORE_NAME 2 (abc)
10 LOAD_CONST 0 (None)
12 RETURN_VALUE
The Python statement abc = xyz + f() results in 7 bytecode instructions.
It loads some things by name (xyz, f, abc),
executes a function call, adds two things, stores a thing, and finally loads None and returns that.
We’ll not go into the details of this bytecode language,
but now we have a slightly clearer idea of what ‘compiling Python’ means.
Unlike many compiled languages, Python doesn’t resolve names during the compilation step.
It didn’t even notice that xyz (or f) is not defined,
but simply generated the instruction to load “whatever is named xyz” at run time.
Because Python is a very dynamic language,
you can’t possibly find out if a name exists without actually running the code.
This means that compiling Python mostly consists of parsing Python,
since there’s not a lot of other things that can be done without executing it.
This is why trying to run a Python file with a syntax error in the last line
will error out before even running the first line.
The entire file gets compiled first, before it gets to executing it:
$ cat > bla.py
print('Hello')
abc() +
$ python bla.py
File "bla.py", line 2
abc() +
^
SyntaxError: invalid syntax
On the other hand, calling a non-existing function will only give an error once that line
is actually executed. It passes through the compilation step just fine:
$ cat > bla.py
print('Hello')
abc()
$ python bla.py
Hello
Traceback (most recent call last):
File "bla.py", line 2, in <module>
abc()
NameError: name 'abc' is not defined
(Note the Hello in the output before the error.)
From Rust
Now how does one go about compiling Python to bytecode from Rust?
So far, we’ve used to PyO3 crate for all our Python needs,
as it provides a nice Rust interface for all we needed.
Unfortunately, it doesn’t have any functionality exposed related to Python bytecode.
However, it does expose the C interface of (C)Python,
through the pyo3::ffi module.
Normally, we wouldn’t use this C interface directly,
but use all of PyO3’s nice wrappers that provide proper types and safety.
But if the functionality we need is not wrapped by PyO3,
we’ll have to call some of the C functions directly.
If we look through that C interface, we see a few functions starting with Py_Compile.
Looks like that’s what we need!
Py_CompileString
takes the source code string, a filename, and some parameter called start.
It returns a Python object representing the compiled code.
The filename makes it seem like it reads from a file, but the documentation tells us otherwise:
The filename specified by
filenameis used to construct the code object and
may appear in tracebacks orSyntaxErrorexception messages.
So we can put whatever we want there, it is only used in messages as if the
source code we provide was originally read from that file.
The start parameter is also not directly obvious:
The start token is given by start; this can be used to constrain the code
which can be compiled and should bePy_eval_input,Py_file_input, or
Py_single_input.
It tells the function what the code should be parsed as: as an argument to
eval(),
as a .py file, or as a line of interactive input.
Py_eval_input only accepts expressions, and Py_single_input only a single statement.
So in our case, Py_file_input is what we want.
Let’s try to use it.
For now, we’ll just modify our existing run_python function to see how it works.
Once we have it working, we’ll try to move this to the procedural macro, to make it happen at compile time.
use pyo3::types::PyDict;
use pyo3::{AsPyRef, ObjectProtocol, PyObject};
use std::ffi::CString;
pub fn run_python(code: &str, _: impl FnOnce(&PyDict)) {
// Lock Python's global interpreter lock.
let gil = pyo3::Python::acquire_gil();
let py = gil.python();
let obj = unsafe {
// Call the Py_CompileString C function directly,
// using 0-terminated C strings.
let ptr = pyo3::ffi::Py_CompileString(
CString::new(code).unwrap().as_ptr(),
CString::new("dummy-file-name").unwrap().as_ptr(),
pyo3::ffi::Py_file_input,
);
// Wrap the raw pointer in PyO3's PyObject,
// or get the error (a PyErr) if it was null.
PyObject::from_owned_ptr_or_err(py, ptr)
};
// Print and panic if there was an error.
let obj = obj.unwrap_or_else(|e| {
e.print(py);
panic!("Error while compiling Python code.");
});
// Just print the result using Python's `str()` for now.
println!("{}", obj.as_ref(py).str().unwrap());
todo!();
}
#![feature(proc_macro_hygiene)]
use inline_python::python;
fn main() {
python! {
print("hi")
}
}
$ cargo r
Compiling inline-python v0.1.0
Compiling example v0.1.0
Finished dev [unoptimized + debuginfo] target(s) in 0.41s
Running `target/debug/example`
<code object <module> at 0x7f04ba0f65b0, file "dummy-file-name", line 6>
thread 'main' panicked (...)
So we got a ‘code object’. Sounds good.
Now, how to execute it?
Digging a bit through the Python C API docs will lead to
PyEval_EvalCode:
PyObject* PyEval_EvalCode(PyObject *co, PyObject *globals, PyObject *locals);
This looks very much like PyO3’s Python::run function that we used earlier,
except it takes the code as a PyObject instead of a string.
use pyo3::types::PyDict;
use pyo3::{AsPyPointer, PyObject};
use std::ffi::CString;
pub fn run_python(code: &str, f: impl FnOnce(&PyDict)) {
// <snip>
// Make the globals dictionary, just like in Part 2.
let globals = PyDict::new(py);
f(globals);
// Execute the code object.
let result = unsafe {
let ptr = pyo3::ffi::PyEval_EvalCode(
obj.as_ptr(),
globals.as_ptr(),
std::ptr::null_mut(),
);
PyObject::from_owned_ptr_or_err(py, ptr)
};
if let Err(e) = result {
e.print(py);
panic!("Error while executing Python code.");
}
}
$ cargo r
Compiling inline-python v0.1.0
Compiling example v0.1.0
Finished dev [unoptimized + debuginfo] target(s) in 0.41s
Running `target/debug/example`
Traceback (most recent call last):
File "dummy-file-name", line 6, in <module>
NameError: name 'print' is not defined
thread 'main' panicked (...)
Uh, what? 'print' is not defined?
It executed the Python code, but somehow Python forgot about its own print() function?
Looks like the builtins aren’t loaded. Is that something PyO3 did for us before?
When we take a look at the source code of PyO3,
we see that it loads the __main__ module.
But if we take a closer look, we see the import is completely ignored in case we provide our own globals dictionary, like we did.
All that’s left is a call to PyRun_StringFlags.
Into CPython’s source code we go.
There
we see PyRun_StringFlags calls an internal function called run_mod.
Going deeper,
run_mod calls run_eval_code_obj, and … gotcha!
/* Set globals['__builtins__'] if it doesn't exist */
if (globals != NULL && PyDict_GetItemString(globals, "__builtins__") == NULL) {
if (PyDict_SetItemString(globals, "__builtins__",
tstate->interp->builtins) < 0) {
return NULL;
}
}
v = PyEval_EvalCode((PyObject*)co, globals, locals);
It sneakily adds __builtins__ to the globals dictionary, before calling PyEval_EvalCode.
This wasn’t documented in the API reference, but at least the project is open source so we could find out ourselves.
Going back a bit, what was up with that __main__ module that PyO3 uses as a fallback?
What does it even contain?
$ python
>>> import __main__
>>> dir(__main__)
['__annotations__', '__builtins__', '__doc__', '__loader__', '__main__', '__name__', '__package__', '__spec__']
Oh! __builtins__! And some other things that look like they should be there by default as well.
Maybe we should just import __main__:
// <snip>
// Use (a copy of) __main__'s dict to start with, instead of an empty dict.
let globals = py.import("__main__").unwrap().dict().copy().unwrap();
f(globals);
// <snip>
$ cargo r
Compiling inline-python v0.1.0 (/home/mara/blog/scratchpad/inline-python)
Compiling example v0.1.0 (/home/mara/blog/scratchpad)
Finished dev [unoptimized + debuginfo] target(s) in 0.44s
Running `target/debug/example`
hi
Yes!
At compile time
Okay, now that compiling and running as separate steps works,
the next challenge is to try to move the first step to the procedural macro,
so it happens at compile time.
First of all, this means we’ll be using Python in our proc-macro crate.
So we add PyO3 to its dependencies:
[dependencies]
# <snip>
pyo3 = "0.9.2"
We then split our run_python function into two parts.
The first part, that compiles the code, goes into our proc-macro crate:
fn compile_python(code: &str, filename: &str) -> PyObject {
let gil = pyo3::Python::acquire_gil();
let py = gil.python();
let obj = unsafe {
let ptr = pyo3::ffi::Py_CompileString(
CString::new(code).unwrap().as_ptr(),
CString::new(filename).unwrap().as_ptr(),
pyo3::ffi::Py_file_input,
);
PyObject::from_owned_ptr_or_err(py, ptr)
};
obj.unwrap_or_else(|e| {
e.print(py);
panic!("Error while compiling Python code.");
})
}
And the second half stays where it is:
pub fn run_python(code: PyObject, f: impl FnOnce(&PyDict)) {
let gil = pyo3::Python::acquire_gil();
let py = gil.python();
let globals = py.import("__main__").unwrap().dict().copy().unwrap();
f(globals);
let result = unsafe {
let ptr = pyo3::ffi::PyEval_EvalCode(
code.as_ptr(),
globals.as_ptr(),
std::ptr::null_mut()
);
PyObject::from_owned_ptr_or_err(py, ptr)
};
if let Err(e) = result {
e.print(py);
panic!("Error while executing Python code.");
}
}
All that’s left, is passing the PyObject from the first function into the second one.
But, uh, wait. They run in different processes.
The first function runs as part of rustc while buiding the program, and the second runs much later, while executing it.
The PyObject from compile_python is simply a pointer, pointing to somewhere in the memory of the first process,
which is long gone by the time we need it.
Before, we only had a string to pass on. So then we just used quote!() to
turn that string into a string literal token (e.g. "blabla")
which ended up verbatim in the generated code.
But now, we have an object that represents compiled Python code, presumably containing Python bytecode, as we’ve seen above.
If we can actually extract the bytecode, we can put that in the generated code as a byte-string (b"x01x02x03") or array ([1,2,3]),
so it can be properly embedded into the resulting executable.
Browsing a bit more through Python C API,
the ‘data marshalling’ module looks interesting.
According to Wikipedia:
In computer science, marshalling or marshaling is the process of transforming
the memory representation of an object to a data format suitable for storage
or transmission
Sounds good!
PyMarshal_WriteObjectToString and
PyMarshal_ReadObjectFromString
are exactly what we need.
Let’s start with the proc-macro side.
PyObject* PyMarshal_WriteObjectToString(PyObject *value, int version);
It wants a PyObject to turn into bytes, the encoding format version, and returns a bytes object.
As for the version number, the documentation tells us: ‘Py_MARSHAL_VERSION indicates the current file format (currently 2).’
$ rg Py_MARSHAL_VERSION cpython/
cpython/Include/marshal.h
10:#define Py_MARSHAL_VERSION 4
...
Uh. Okay. Well, let’s just use that one. PyO3 wrapped it as pyo3::marshal::VERSION.
fn compile_python(code: &str, filename: &str) -> Literal {
let gil = pyo3::Python::acquire_gil();
let py = gil.python();
let obj = /* snip */;
let bytes = unsafe {
let ptr = pyo3::ffi::PyMarshal_WriteObjectToString(obj.as_ptr(), pyo3::marshal::VERSION);
PyBytes::from_owned_ptr_or_panic(py, ptr)
};
Literal::byte_string(bytes.as_bytes())
}
And in the proc_macro function itself:
// <snip>
// We take the file name from the 'call site span',
// which is the place where python!{} was invoked.
let filename = proc_macro::Span::call_site().source_file().path().display().to_string();
let bytecode = compile_python(&source, &filename);
quote!(
inline_python::run_python(
// Instead of #source, a string literal ("...") containing the raw source,
// we now provide a byte string literal (b"...") containing the bytecode.
#bytecode,
// <snip>
);
).into()
$ cargo b
Compiling inline-python-macros v0.1.0
Compiling inline-python v0.1.0
Compiling example v0.1.0
error[E0308]: mismatched types
--> src/main.rs:7:5
|
7 | / python! {
8 | | c = 100
9 | | print('a + 'b + c)
10 | | }
| |_____^ expected struct `pyo3::object::PyObject`, found `&[u8; 102]`
|
Perfect!
The code was compiled into a byte array (of 102 bytes, apparently)
and inserted into the generated code,
which then fails to compile because we still have to convert the bytes back into a PyObject.
On we go:
pub fn run_python(bytecode: &[u8], f: impl FnOnce(&PyDict)) {
let gil = pyo3::Python::acquire_gil();
let py = gil.python();
let code = unsafe {
let ptr = pyo3::ffi::PyMarshal_ReadObjectFromString(
bytecode.as_ptr() as *const _,
bytecode.len() as isize
);
PyObject::from_owned_ptr_or_panic(py, ptr)
};
// <snip>
$ cargo r
Compiling inline-python v0.1.0
Compiling example v0.1.0
Finished dev [unoptimized + debuginfo] target(s) in 0.37s
Running `target/debug/example`
hi
🎉
Errors
Now that we’re compiling the Python code during compile time,
syntax errors should show up during cargo build, before even running the code.
Let’s see what that looks like now:
#![feature(proc_macro_hygiene)]
use inline_python::python;
fn main() {
python! {
!@#$
}
}
$ cargo build
Compiling example v0.1.0
File "src/main.rs", line 6
!@#$
^
SyntaxError: invalid syntax
error: proc macro panicked
--> src/main.rs:5:5
|
5 | / python! {
6 | | !@#$
7 | | }
| |_____^
|
= help: message: Error while compiling Python code.
And there you go, the Rust compiler giving a Python error!
It’s a bit of a mess though.
Our macro first lets Python print the error (which contains the correct file name and line number!),
and then panics, causing the Rust compiler to show the panic message as an error about the whole python!{} block.
Ideally, the error would be displayed like any other Rust error.
That way, it’ll be less noisy, and IDEs will hopefully be able to point to the right spot automatically.
Pretty errors
There are several ways to spit out errors from procedural macros.
The first one we’ve already seen: just panic!().
The panic message will show up as the error, and it will point at the entire macro invocation.
The second one is to not panic, but to generate code that will cause a compiler error afterwards.
The compile_error!() macro
will generate an error as soon as the compiler comes across it.
So, by emitting code containing a compile_error!("..."); statement,
a compiler error will be displayed.
But where will that error point at? Normally, when such a statement appears in Rust code,
it’ll point directly at the compile_error!() invocation itself.
But if a macro generates it, it doesn’t appear in the orignal code, so what then?
Well, that’s up to the macro itself. For every token it generates, it can also set its Span,
containing the location information. By lying a bit, we can make the error appear everywhere:
#[proc_macro]
pub fn python(input: proc_macro::TokenStream) -> proc_macro::TokenStream {
// Get the span of the second token.
let second_token_span = TokenStream::from(input).into_iter().nth(1).unwrap().span();
// Generate code that pretends to be located at that span.
quote_spanned!(second_token_span =>
compile_error!("Hello");
).into()
}
python! {
one two three
}
$ cargo build
Compiling inline-python-macros v0.1.0
Compiling inline-python v0.1.0
Compiling example v0.1.0
error: Hello
--> src/main.rs:6:13
|
6 | one two three
| ^^^
The third and last method is more flexible, but (at the time of writing) unstable and gated behind #![feature(proc_macro_diagnostic)].
This feature adds functions like .error(),
.warning(),
and .note() on proc_macro::Span.
These functions return a Diagnostic
which we can .emit(), or first add more notes to:
#[proc_macro]
pub fn python(input: proc_macro::TokenStream) -> proc_macro::TokenStream {
let second_token_span = input.into_iter().nth(1).unwrap().span();
second_token_span.error("Hello").note("World").emit();
quote!().into()
}
Compiling inline-python-macros v0.1.0
Compiling inline-python v0.1.0
Compiling example v0.1.0
error: Hello
--> src/main.rs:6:13
|
6 | one two three
| ^^^
|
= note: World
Since we already use nightly features anyway, let’s just go for this one.
Displaying Python errors
The PyErr that we get from Py_CompileString represents a SyntaxError.
We can extract the SyntaxError object using .to_object(), and then access the properties lineno and msg to get the details:
fn compile_python(code: &str, filename: &str) -> Result<Literal, (usize, String)> {
// <snip>
let obj = obj.map_err(|e| {
let error = e.to_object(py);
let line: usize = error.getattr(py, "lineno").unwrap().extract(py).unwrap();
let msg: String = error.getattr(py, "msg").unwrap().extract(py).unwrap();
(line, msg)
})?;
// <snip>
Ok(...)
}
Then all we need to do, is find the Spans for that line, and emit the Diagnostic:
// <snip>
s.reconstruct_from(input.clone()); // Make a clone, so we keep the original input around.
// <snip>
let bytecode = compile_python(&source, &filename).unwrap_or_else(|(line, msg)| {
input
.into_iter()
.map(|x| x.span().unwrap()) // Get the spans for all the tokens.
.skip_while(|span| span.start().line < line) // Skip to the right line
.take_while(|span| span.start().line == line) // Take all the tokens on this line
.fold(None, |a, b| Some(a.map_or(b, |s: proc_macro::Span| s.join(b).unwrap()))) // Join the Spans into a single one
.unwrap()
.error(format!("python: {}", msg))
.emit();
Literal::byte_string(&[]) // Use an empty array for the bytecode, to allow rustc to continue compiling and find other errors.
});
// <snip>
python! {
print("Hello")
if True:
print("World")
}
$ cargo build
Compiling inline-python-macros v0.1.0
Compiling inline-python v0.1.0
Compiling example v0.1.0
error: python: expected an indented block
--> src/main.rs:8:9
|
8 | print("World")
| ^^^^^^^^^^^^^^
🎉
Success!
Replacing all the remaining .unwrap()s by nice errors is left as an exercise to the reader. 
RLS / rust-analyzer
Now how to make it show up nicely in your IDE, when using a Rust language server like rust-analyzer?
Well.. Turns out that already works!
All you need to do is make sure executing procedural macros is enabled (e.g. "rust-analyzer.procMacro.enable": true),
and poof, magic.
✨
What’s next?
In the next post,
we’ll make it possible to keep the variables of a python!{} block around
after execution to get data back into Rust, or re-use them in another python!{} block:
let c: Context = python! {
abc = 5
};
assert_eq!(c.get::<i32>("abc"), 5);
c.run(python! {
assert abc == 5
});
In order to do so, we’ll extend the macro to
make its behaviour depend on whether it’s used as an argument or not.