Построение кодов обнаружения ошибок (защитных кодов)
В процессе
преобразования информации, представленной
в закодированной форме, часто возникают
ошибки, связанные со сбоями в работе
технических средств преобразования
информации ,а также допущенные людьми
при работе с компьютером и оргтехникой.
Построение кодов
обнаружения ошибок основано на трех
основных принципах:
1) Использование
признаков делимости
2) Запрещение
использования определенной части
кодовых слов.
3) Запрещение
использования определенных символов.
1. Построение кодов обнаружения ошибок с использованием признака делимости числа
Суть
данного способа построения кодов
обнаружения ошибок состоит в следующем:
допустим необходимо построить код
обнаружения ошибок для табельного
номера, состоящего из четырех цифр:
5621 а)
в данном случае выбирается число М,
называемое модулем (желательно простое
целое число) и исходное кодовое число
делится на модуль М. Например, М=9
5621
: 9
54
22
18
41
36
5
и
остаток от деления (в данном случае
равный 5) дописывается справа от исходного
кодового слова. Таким образом, табельный
номер примет вид 56215,
где первые четыре разряда информационные,
а последний контрольный.
б)
контроль по модулю «10». Допустим,
необходимо построить код обнаружения
ошибок для номенклатурного номера
материала 62154. Находим сумму чисел:
6+2+1+5+4=18.
Далее
определяется ближайшее, большее 18, число
кратное 10. Это число 20. Определяется
разность этих чисел 20-18=2. Полученное
значение и является контрольным разрядом.
Таким образом, будет обрабатываться
на всех стадиях число 621542,
содержащее 5 информационных разрядов
и 1 контрольный. В данном случае
присутствует избыточная информация,
введение которой оправдано необходимостью
контроля правильности преобразования
информации. Однако, данный способ не
позволяет обнаружить ошибки, связанные
с перестановкой цифр.
Для
этого существует способ построения
кодов обнаружения ошибок с
учетом весовых коэффициентов.
Суть которого в том, что на каждый разряд
числа «навешивается» весовой коэффициент.
Далее применяется контроль по модулю
«10», только с использованием весовых
коэффициентов числа.
Например, требуется
построить код инвентарного номера
оборудования 190624. Для каждого разряда
числа вводится весовой коэффициент,
причем, чем старше разряд, тем больше
коэффициент. Данное число имеет весовые
коэффициенты:
6
5 4 3 2 1
1
9 0 6 2 4
Находится
сумма цифр числа, умноженных на весовые
коэффициенты: 1*6+9*5+0*4+6*3+2*2+4*1=77.
Находится разность между ближайшим
большим числом, кратным 10, и данным
числом 80-77=3 и эта разность дописывается
к исходному кодовому числу в качестве
контрольного разряда: 1906243.
Построение
защитных кодов для информации,
представленной в двоичном коде
Одним
из основных способов контроля двоичной
информации является контроль «на
ЧЕТ». В
исходном кодовом числе подсчитывается
количество единиц, если оно является
нечетным, в качестве контрольного
разряда к числу приписывается 1,
если четным — 0.
В полученном кодовом слове число единиц
должно быть обязательно четным.
Например: а)
110011 — исходное кодовое слово
1100110
— кодовое слово с контрольным разрядом
б)
11001 — исходное кодовое слово
110011
— кодовое слово с контрольным разрядом
Коды
обнаружения ошибок, построенные по
принципу применения кодовых словарей
Данный способ
построения кодов обнаружения ошибок
заключается в использовании слов,
входящих в специальным образом
составленные кодовые словари. Только
данные слова являются разрешенными,
все остальные запрещенными для
использования. Если кодовое слово,
подлежащее преобразованию, содержится
в кодовом словаре, значит информация
преобразуется без ошибок, если данного
слова в кодовом словаре нет, значит
выдается сообщение об ошибке. Кодовые
словари могут быть построены на 10 и на
100 слов.
Пример построения
кодового словаря на 10 слов:01 12 23 34 45 56 67
78 89 90. Все остальные двузначные слова
являются запрещенными. В данном случае
коэффициент использования информационной
емкости кода равен: 10/99=0,1.
Здесь
10- количество слов в словаре , 99 —
максимально возможное количество цифр
в словаре.
Например, если
получено при передаче информации слово
13, то выдается сообщение об ошибке, т.к.
данное слово в кодовом словаре
отсутствует. В
случае одиночной ошибки она может быть
исправлена: это может быть либо слово
23,либо — 12.
Кодовый словарь
на 100 слов строится следующим образом:
|
Десятки |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
|
0 1 2 3 4 5 6 7 8 9 |
001 012 023 034 045 056 067 078 089 090 |
102 113 124 135 146 157 168 179 180 191 |
203 214 225 236 247 258 269 270 281 292 |
304 315 326 337 348 359 360 371 382 393 |
405 416 427 438 449 450 461 472 483 494 |
506 517 528 539 540 551 562 573 584 595 |
607 618 629 630 641 652 663 674 685 696 |
708 719 720 731 742 753 764 775 786 797 |
809 810 821 832 843 854 865 876 887 898 |
900 912 923 934 945 956 967 978 989 999 |
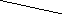 Сотни
СотниПроверка
правильности переданных кодовых слов
выполняется несколькими способами.
Основные способы контроля приведены
ниже:
-
похожие
по написанию цифры кодового слова (3 и
8, 5 и 6, 9 и 0, 6 и 9 и т.д.) ; -
ошибки,
совершенные при вводе с клавиатуры
(рядом расположенные клавиши: с 1 рядом
2 и 4, с 5 – рядом 2, 4 и 6 и т.д.); -
перестановка
цифр числа при вводе с клавиатуры.
Коды
обнаружения ошибок, построенные по
принципу запрещения использования
определенной части символов
Очень часто в
процессе преобразования информации
возникают ошибки, связанные с нечетким
заполнением первичных документов или
с нажатием на устройствах передачи или
подготовки данных ошибочно рядом
расположенной клавиши. При нечетком
заполнении документов бывает сложно
различить похожие по начертанию цифры
4 и 7, 0 и 6, 0 и 9. Для избежания подобного
рода ошибок, а также устранения возможности
ошибок при нажатии рядом расположенных
на клавиатуре клавиш запрещается
использовать для построения кодовых
слов следующие символы: например: 0,6,9.
Все остальные символы являются
разрешенными. В случае, если в процессе
преобразования информации возникает
кодовое слово, содержащее разрешенные
символы, выдается сообщение об ошибке.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Improve Article
Save Article
Improve Article
Save Article
Error Detection Codes :
The binary information is transferred from one location to another location through some communication medium. The external noise can change bits from 1 to 0 or 0 to 1.This changes in values are called errors. For efficient data transfer, there should be an error detection and correction codes. An error detection code is a binary code that detects digital errors during transmission. A famous error detection code is a Parity Bit method.
Parity Bit Method :
A parity bit is an extra bit included in binary message to make total number of 1’s either odd or even. Parity word denotes number of 1’s in a binary string. There are two parity system-even and odd. In even parity system 1 is appended to binary string it there is an odd number of 1’s in string otherwise 0 is appended to make total even number of 1’s.
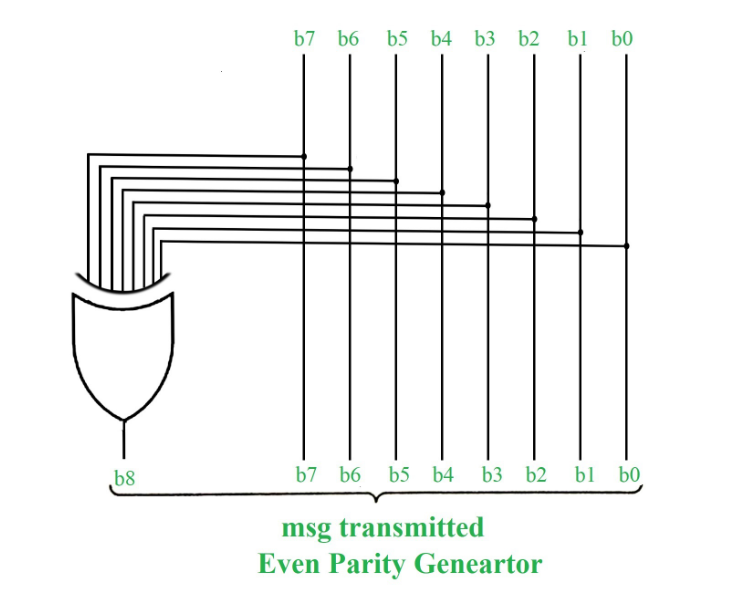
In odd parity system, 1 is appended to binary string if there is even a number of 1’s to make an odd number of 1’s. The receiver knows that whether sender is an odd parity generator or even parity generator. Suppose if sender is an odd parity generator then there must be an odd number of 1’s in received binary string. If an error occurs to a single bit that is either bit is changed to 1 to 0 or O to 1, received binary bit will have an even number of 1’s which will indicate an error.
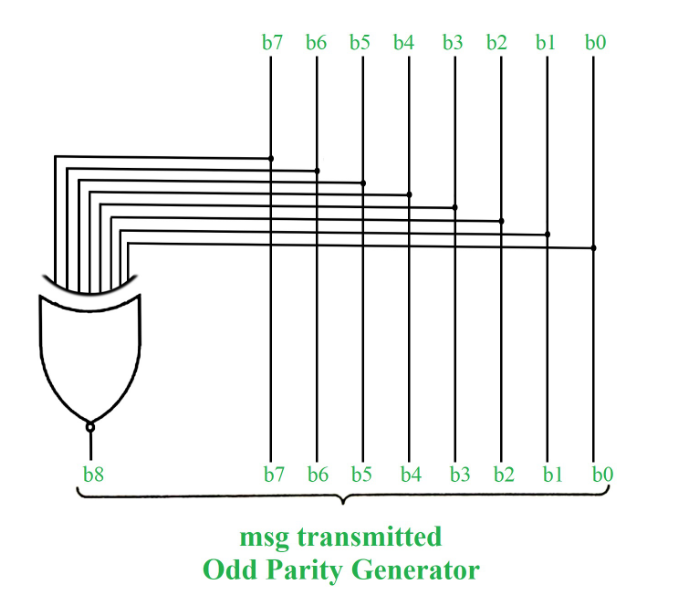
The limitation of this method is that only error in a single bit would be identified.
| Message (XYZ) | P(Odd) | P(Even) |
|---|---|---|
| 000 | 1 | 0 |
| 001 | 0 | 1 |
| 010 | 0 | 1 |
| 011 | 1 | 0 |
| 100 | 0 | 1 |
| 101 | 1 | 0 |
| 110 | 1 | 0 |
| 111 | 0 | 1 |
Figure – Error Detection with Odd Parity Bit
Points to Remember :
- In 1’s complement of signed number +0 and -0 has two different representation.
- The range of signed magnitude representation of an 8-bit number in which 1-bit is used as a signed bit as follows -27 to +27.
- Floating point number is said to be normalized if most significant digit of mantissa is one. For example, 6-bit binary number 001101 is normalized because of two leading 0’s.
- Booth algorithm that uses two n bit numbers for multiplication gives results in 2n bits.
- The booth algorithm uses 2’s complement representation of numbers and work for both positive and negative numbers.
- If k-bits are used to represent exponent then bits number = (2k-1) and range of exponent = – (2k-1 -1) to (2k-1).
Improve Article
Save Article
Improve Article
Save Article
Error Detection Codes :
The binary information is transferred from one location to another location through some communication medium. The external noise can change bits from 1 to 0 or 0 to 1.This changes in values are called errors. For efficient data transfer, there should be an error detection and correction codes. An error detection code is a binary code that detects digital errors during transmission. A famous error detection code is a Parity Bit method.
Parity Bit Method :
A parity bit is an extra bit included in binary message to make total number of 1’s either odd or even. Parity word denotes number of 1’s in a binary string. There are two parity system-even and odd. In even parity system 1 is appended to binary string it there is an odd number of 1’s in string otherwise 0 is appended to make total even number of 1’s.
In odd parity system, 1 is appended to binary string if there is even a number of 1’s to make an odd number of 1’s. The receiver knows that whether sender is an odd parity generator or even parity generator. Suppose if sender is an odd parity generator then there must be an odd number of 1’s in received binary string. If an error occurs to a single bit that is either bit is changed to 1 to 0 or O to 1, received binary bit will have an even number of 1’s which will indicate an error.
The limitation of this method is that only error in a single bit would be identified.
| Message (XYZ) | P(Odd) | P(Even) |
|---|---|---|
| 000 | 1 | 0 |
| 001 | 0 | 1 |
| 010 | 0 | 1 |
| 011 | 1 | 0 |
| 100 | 0 | 1 |
| 101 | 1 | 0 |
| 110 | 1 | 0 |
| 111 | 0 | 1 |
Figure – Error Detection with Odd Parity Bit
Points to Remember :
- In 1’s complement of signed number +0 and -0 has two different representation.
- The range of signed magnitude representation of an 8-bit number in which 1-bit is used as a signed bit as follows -27 to +27.
- Floating point number is said to be normalized if most significant digit of mantissa is one. For example, 6-bit binary number 001101 is normalized because of two leading 0’s.
- Booth algorithm that uses two n bit numbers for multiplication gives results in 2n bits.
- The booth algorithm uses 2’s complement representation of numbers and work for both positive and negative numbers.
- If k-bits are used to represent exponent then bits number = (2k-1) and range of exponent = – (2k-1 -1) to (2k-1).
Кодирование и защита от ошибок
Существует три наиболее распространенных орудия борьбы с ошибками в процессе передачи данных:
- коды обнаружения ошибок;
- коды с коррекцией ошибок, называемые также схемами прямой коррекции ошибок (Forward Error Correction — FEC);
- протоколы с автоматическим запросом повторной передачи (Automatic Repeat Request — ARQ).
Код обнаружения ошибок позволяет довольно легко установить наличие ошибки. Как правило, подобные коды используются совместно с определенными протоколами канального или транспортного уровней, имеющими схему ARQ. В схеме ARQ приемник попросту отклоняет блок данных, в котором была обнаружена ошибка, после чего передатчик передает этот блок повторно. Коды с прямой коррекцией ошибок позволяют не только обнаружить ошибки, но и исправить их, не прибегая к повторной передаче. Схемы FEC часто используются в беспроводной передаче, где повторная передача крайне неэффективна, а уровень ошибок довольно высок.
1) Методы обнаружения ошибок
Методы обнаружения ошибок основаны на передаче в составе блока данных избыточной служебной информации, по которой можно судить с некоторой степенью вероятности о достоверности принятых данных.
Избыточную служебную информацию принято называть контрольной суммой, или контрольной последовательностью кадра (Frame Check Sequence, FCS). Контрольная сумма вычисляется как функция от основной информации, причем не обязательно путем суммирования. Принимающая сторона повторно вычисляет контрольную сумму кадра по известному алгоритму и в случае ее совпадения с контрольной суммой, вычисленной передающей стороной, делает вывод о том, что данные были переданы через сеть корректно. Рассмотрим несколько распространенных алгоритмов вычисления контрольной суммы, отличающихся вычислительной сложностью и способностью обнаруживать ошибки в данных.
Контроль по паритету представляет собой наиболее простой метод контроля данных. В то же время это наименее мощный алгоритм контроля, так как с его помощью можно обнаружить только одиночные ошибки в проверяемых данных. Метод заключается в суммировании по модулю 2 всех битов контролируемой информации. Нетрудно заметить, что для информации, состоящей из нечетного числа единиц, контрольная сумма всегда равна 1, а при четном числе единиц — 0. Например, для данных 100101011 результатом контрольного суммирования будет значение 1. Результат суммирования также представляет собой один дополнительный бит данных, который пересылается вместе с контролируемой информацией. При искажении в процессе пересылки любого бита исходных данных (или контрольного разряда) результат суммирования будет отличаться от принятого контрольного разряда, что говорит об ошибке.
Однако двойная ошибка, например 110101010, будет неверно принята за корректные данные. Поэтому контроль по паритету применяется к небольшим порциям данных, как правило, к каждому байту, что дает коэффициент избыточности для этого метода 1/8. Метод редко применяется в компьютерных сетях из-за значительной избыточности и невысоких диагностических способностей.
Вертикальный и горизонтальный контроль по паритету представляет собой модификацию описанного выше метода. Его отличие состоит в том, что исходные данные рассматриваются в виде матрицы, строки которой составляют байты данных. Контрольный разряд подсчитывается отдельно для каждой строки и для каждого столбца матрицы. Этот метод обнаруживает значительную часть двойных ошибок, однако обладает еще большей избыточностью. Он сейчас также почти не применяется при передаче информации по сети.
Циклический избыточный контроль (Cyclic Redundancy Check — CRC) является в настоящее время наиболее популярным методом контроля в вычислительных сетях (и не только в сетях; в частности, этот метод широко применяется при записи данных на гибкие и жесткие диски). Метод основан на рассмотрении исходных данных в виде одного многоразрядного двоичного числа. Например, кадр стандарта Ethernet, состоящий из 1024 байт, будет рассматриваться как одно число, состоящее из 8192 бит. Контрольной информацией считается остаток от деления этого числа на известный делитель R. Обычно в качестве делителя выбирается семнадцати- или тридцатитрехразрядное число, чтобы остаток от деления имел длину 16 разрядов (2 байт) или 32 разряда (4 байт). При получении кадра данных снова вычисляется остаток от деления на тот же делитель R, но при этом к данным кадра добавляется и содержащаяся в нем контрольная сумма.
Если остаток от деления на R равен нулю, то делается вывод об отсутствии ошибок в полученном кадре, в противном случае кадр считается искаженным.
Этот метод обладает более высокой вычислительной сложностью, но его диагностические возможности гораздо шире, чем у методов контроля по паритету. Метод CRC обнаруживает все одиночные ошибки, двойные ошибки и ошибки в нечетном числе битов. Метод также обладает невысокой степенью избыточности. Например, для кадра Ethernet размером 1024 байта контрольная информация длиной 4 байта составляет только 0,4 %.
2) Методы коррекции ошибок
Техника кодирования, которая позволяет приемнику не только понять, что присланные данные содержат ошибки, но и исправить их, называется прямой коррекцией ошибок (Forward Error Correction — FEC). Коды, обеспечивающие прямую коррекцию ошибок, требуют введения большей избыточности в передаваемые данные, чем коды, которые только обнаруживают ошибки.
При применении любого избыточного кода не все комбинации кодов являются разрешенными. Например, контроль по паритету делает разрешенными только половину кодов. Если мы контролируем три информационных бита, то разрешенными 4-битными кодами с дополнением до нечетного количества единиц будут:
000 1, 001 0, 010 0, 011 1, 100 0, 101 1, 110 1, 111 0, то есть всего 8 кодов из 16 возможных.
Для того чтобы оценить количество дополнительных битов, необходимых для исправления ошибок, нужно знать так называемое расстояние Хемминга между разрешенными комбинациями кода. Расстоянием Хемминга называется минимальное число битовых разрядов, в которых отличается любая пара разрешенных кодов. Для схем контроля по паритету расстояние Хемминга равно 2.
Можно доказать, что если мы сконструировали избыточный код с расстоянием Хемминга, равным n, такой код будет в состоянии распознавать (n-1) -кратные ошибки и исправлять (n-1)/2 -кратные ошибки. Так как коды с контролем по паритету имеют расстояние Хемминга, равное 2, они могут только обнаруживать однократные ошибки и не могут исправлять ошибки.
Коды Хемминга эффективно обнаруживают и исправляют изолированные ошибки, то есть отдельные искаженные биты, которые разделены большим количеством корректных битов. Однако при появлении длинной последовательности искаженных битов (пульсации ошибок) коды Хемминга не работают.
Наиболее часто в современных системах связи применяется тип кодирования, реализуемый сверхточным кодирующим устройством (Сonvolutional coder), потому что такое кодирование несложно реализовать аппаратно с использованием линий задержки (delay) и сумматоров. В отличие от рассмотренного выше кода, который относится к блочным кодам без памяти, сверточный код относится к кодам с конечной памятью (Finite memory code); это означает, что выходная последовательность кодера является функцией не только текущего входного сигнала, но также нескольких из числа последних предшествующих битов. Длина кодового ограничения (Constraint length of a code) показывает, как много выходных элементов выходит из системы в пересчете на один входной. Коды часто характеризуются их эффективной степенью (или коэффициентом) кодирования (Code rate). Вам может встретиться сверточный код с коэффициентом кодирования 1/2.
Этот коэффициент указывает, что на каждый входной бит приходится два выходных. При сравнении кодов обращайте внимание на то, что, хотя коды с более высокой эффективной степенью кодирования позволяют передавать данные с более высокой скоростью, они, соответственно, более чувствительны к шуму.
В беспроводных системах с блочными кодами широко используется метод чередования блоков. Преимущество чередования состоит в том, что приемник распределяет пакет ошибок, исказивший некоторую последовательность битов, по большому числу блоков, благодаря чему становится возможным исправление ошибок. Чередование выполняется с помощью чтения и записи данных в различном порядке. Если во время передачи пакет помех воздействует на некоторую последовательность битов, то все эти биты оказываются разнесенными по различным блокам. Следовательно, от любой контрольной последовательности требуется возможность исправить лишь небольшую часть от общего количества инвертированных битов.
3) Методы автоматического запроса повторной передачи
В простейшем случае защита от ошибок заключается только в их обнаружении. Система должна предупредить передатчик об обнаружении ошибки и необходимости повторной передачи. Такие процедуры защиты от ошибок известны как методы автоматического запроса повторной передачи (Automatic Repeat Request — ARQ). В беспроводных локальных сетях применяется процедура «запрос ARQ с остановками» (stop-and-wait ARQ).
В этом случае источник, пославший кадр, ожидает получения подтверждения (Acknowledgement — ACK), или, как еще его называют, квитанции, от приемника и только после этого посылает следующий кадр. Если же подтверждение не приходит в течение тайм-аута, то кадр (или подтверждение) считается утерянным и его передача повторяется. На
рис.
1.13 видно, что в этом случае производительность обмена данными ниже потенциально возможной; хотя передатчик и мог бы послать следующий кадр сразу же после отправки предыдущего, он обязан ждать прихода подтверждения.
Цель функционального тестирования — обнаружение несоответствий между реальным поведением реализованных функций и ожидаемым поведением в соответствии со спецификацией и исходными требованиями. Функциональные тесты должны охватывать все реализованные функции с учетом наиболее вероятных типов ошибок. Тестовые сценарии, объединяющие отдельные тесты, ориентированы на проверку качества решения функциональных задач.
Функциональные тесты создаются по внешним спецификациям функций, проектной информации и по тексту на ЯП, относятся к функциональным его характеристикам и применяются на этапе комплексного тестирования и испытаний для определения полноты реализации функциональных задач и их соответствия исходным требованиям.
В задачи функционального тестирования входят:
· идентификация множества функциональных требований;
· идентификация внешних функций и построение последовательностей функций в соответствии с их использованием в ПС;- идентификация множества входных данных каждой функции и определение областей их изменения;
· построение тестовых наборов и сценариев тестирования функций;
· выявление и представление всех функциональных требований с помощью тестовых наборов и проведение тестирования ошибок в программе и при взаимодействии со средой.
Тесты, создаваемые по проектной информации, связаны со структурами данных, алгоритмами, интерфейсами между отдельными компонентами и применяются для тестирования компонентов и их интерфейсов. Основная цель — обеспечение полноты и согласованности реализованных функций и интерфейсов между ними.
Комбинированный метод «черного ящика» и «прозрачного ящика» основан на разбиении входной области функции на подобласти обнаружения ошибок. Подобласть содержит однородные элементы, которые все обрабатываются корректно либо некорректно. Для тестирования подобласти производится выполнение программы на одном из элементов этой области.
Предпосылки функционального тестирования:
· корректное оформление требований и ограничений к качеству ПО;
· корректное описание модели функционирования ПО в среде эксплуатации у заказчика;
· адекватность модели ПО заданному классу.
Под инфраструктурой процесса тестирования понимается:
· выделение объектов тестирования;
· проведение классификации ошибок для рассматриваемого класса тестируемых программ;
· подготовка тестов, их выполнение и поиск разного рода ошибок и отказов в компонентах и в системе в целом;
· служба проведения и управление процессом тестирования;
· анализ результатов тестирования.
Объекты тестирования — компоненты, группы компонентов, подсистемы и система. Для каждого из них формируется стратегия проведения тестирования. Если объект тестирования относится к «белому ящику» или «черному ящику», состав компонентов которого неизвестный, то тестирование проводится посредством ввода внего входных тестовых данных для получения выходных данных. Стратегическая цель тестирования состоит в том, чтобы убедиться, что каждый рассматриваемый входной набор данных соответствует ожидаемым выходным выходных данным. При таком подходе к тестированию не требуется знания внутренней структуры и логики объекта тестирования.
Проектировщик тестов должен заглянуть внутрь «черного ящика» и исследовать детали процессов обработки данных, вопросы обеспечения защиты и восстановления данных, а также интерфейсы с другими программами и системами. Это способствует подготовке тестовых данных для проведения тестирования.
Для некоторых типов объектов группа тестирования не может сгенерировать представительное множество тестовых наборов, которые демонстрировали бы функциональную правильность работы компоненты при всех возможных наборах тестов.
Поэтому предпочтительным является метод «белого ящика», при котором можно использовать структуру объекта для организации тестирования по различным ветвям. Например, можно выполнить тестовые наборы, которые проходят через все операторы или все контрольные точки компонента для того, чтобы убедиться в правильности их работы.
Международный стандарт ANSI/IEEE-729-83 разделяет все ошибки в разработке программ на следующие типы.
Ошибка (error) — состояние программы, при котором выдаются неправильные результаты, причиной которых являются изъяны (flaw) в операторах программы или в технологическом процессе ее разработки, что приводит к неправильной интерпретации исходной информации, следовательно, и к неверному решению.
Дефект (fault) в программе — следствие ошибок разработчика на любом из этапов разработки, которая может содержаться в исходных или проектных спецификациях, текстах кодов программ, эксплуатационной документация и т.п. В процессе выполнения программы может быть обнаружен дефект или сбой.
Отказ (failure) — это отклонение программы от функционирования или невозможность программы выполнять функции, определенные требованиями и ограничениями, что рассматривается как событие, способствующее переходу программы в неработоспособное состояние из-за ошибок, скрытых в ней дефектов или сбоев в среде функционирования. Отказ может быть результатом следующих причин:
· ошибочная спецификация или пропущенное требование, означающее, что спецификация точно не отражает того, что предполагал пользователь;
· спецификация может содержать требование, которое невозможно выполнить на данной аппаратуре и программном обеспечении;
· проект программы может содержать ошибки (например, база данных спроектирована без средств защиты от несанкционированного доступа пользователя, а требуется защита);
· программа может быть неправильной, т.е. она выполняет несвойственный алгоритм или он реализован не полностью.
Таким образом, отказы, как правило, являются результатами одной или более ошибок в программе, а также наличия разного рода дефектов.
Ошибки на этапах процесса тестирования. Приведенные типы ошибок распределяются по этапам ЖЦ и им соответствуют такие источники их возникновения:
· непреднамеренное отклонение разработчиков от рабочих стандартов или планов реализации;
· спецификации функциональных и интерфейсных требований выполнены без соблюдения стандартов разработки, что приводит к нарушению функционирования программ;
· организации процесса разработки — несовершенная или недостаточное управление руководителем проекта ресурсами (человеческими, техническими, программными и т.д.) и вопросами тестирования и интеграции элементов проекта.
Рассмотрим процесс тестирования, исходя из рекомендаций стандарта ISO/IEC 12207, и приведем типы ошибок, которые обнаруживаются на каждом процессе ЖЦ.
Процесс разработки требований. При определении исходной концепции системы и исходных требований к системе возникают ошибки аналитиков при спецификации верхнего уровня системы и построении концептуальной модели предметной области.
Характерными ошибками этого процесса являются:
· неадекватность спецификации требований конечным пользователям;- некорректность спецификации взаимодействия ПО со средой функционирования или с пользователями;
· несоответствие требований заказчика к отдельным и общим свойствам ПО;
· некорректность описания функциональных характеристик;
· необеспеченность инструментальными средствами всех аспектов реализации требований заказчика и др.
Процесс проектирования. Ошибки при проектировании компонентов могут возникать при описании алгоритмов, логики управления, структур данных, интерфейсов, логики моделирования потоков данных, форматов ввода-вывода и др. В основе этих ошибок лежат дефекты спецификаций аналитиков и недоработки проектировщиков. К ним относятся ошибки, связанные:
· с определением интерфейса пользователя со средой;
· с описанием функций (неадекватность целей и задач компонентов, которые обнаруживаются при проверке комплекса компонентов);
· с определением процесса обработки информации и взаимодействия между процессами (результат некорректного определения взаимосвязей компонентов и процессов);
· с некорректным заданием данных и их структур при описании отдельных компонентов и ПС в целом;
· с некорректным описанием алгоритмов модулей;
· с определением условий возникновения возможных ошибок в программе;
· с нарушением принятых для проекта стандартов и технологий.
Этап кодирования. На данном этапе возникают ошибки, которые являются результатом дефектов проектирования, ошибок программистов и менеджеров в процессе разработки и отладки системы. Причиной ошибок являются:
· бесконтрольность значений входных параметров, индексов массивов, параметров циклов, выходных результатов, деления на 0 и др.;
· неправильная обработка нерегулярных ситуаций при анализе кодов возврата от вызываемых подпрограмм, функций и др.;
· нарушение стандартов кодирования (плохие комментарии, нерациональное выделение модулей и компонент и др.);
· использование одного имени для обозначения разных объектов или разных имен одного объекта, плохая мнемоника имен;- несогласованное внесение изменений в программу разными разработчиками и др.
Процесс тестирования. На этом процессе ошибки допускаются программистами и тестировщиками при выполнении технологии сборки и тестирования, выбора тестовых наборов и сценариев тестирования и др. Отказы в программном обеспечении, вызванные такого рода ошибками, должны выявляться, устраняться и не отражаться на статистике ошибок компонент и программного обеспечения в целом.
Процесс сопровождения. На процессе сопровождения обнаруживаются ошибки, причиной которых являются недоработки и дефекты эксплуатационной документации, недостаточные показатели модифицируемости и удобочитаемости, а также некомпетентность лиц, ответственных за сопровождение и/или усовершенствование ПО. В зависимости от сущности вносимых изменений на этом этапе могут возникать практически любые ошибки, аналогичные ранее перечисленным ошибкам на предыдущих этапах.
Все ошибки, которые возникают в программах, принято подразделять на следующие классы:
· логические и функциональные ошибки;
· ошибки вычислений и времени выполнения;
· ошибки ввода-вывода и манипулирования данными;
· ошибки интерфейсов;
· ошибки объема данных и др.
Логические ошибки являются причиной нарушения логики алгоритма, внутренней несогласованности переменных и операторов, а также правил программирования. Функциональные ошибки — следствие неправильно определенных функций, нарушения порядка их применения или отсутствия полноты их реализации и т.д.
Ошибки вычислений возникают по причине неточности исходных данных и реализованных формул, погрешностей методов, неправильного применения операций вычислений или операндов. Ошибки времени выполнения связаны с не обеспечением требуемой скорости обработки запросов или времени восстановления программы.
Ошибки ввода-вывода и манипулирования данными являются следствием некачественной подготовки данных для выполнения программы, сбоев при занесении их в базы данных или при выборке из нее.
Ошибки интерфейса относятся к ошибкам взаимосвязи отдельных элементов друг с другом, что проявляется при передаче данных между ними, а также при взаимодействии со средой функционирования.
Ошибки объема относятся к данным и являются следствием того, что реализованные методы доступа и размеры баз данных не удовлетворяют реальным объемам информации системы или интенсивности их обработки.
Приведенные основные классы ошибок свойственны разным типам компонентов ПО и проявляются они в программах по разному. Так, при работе с БД возникают ошибки представления и манипулирования данными, логические ошибки в задании прикладных процедур обработки данных и др. В программах вычислительного характера преобладают ошибки вычислений, а в программах управления и обработки — логические и функциональные ошибки. В ПО, которое состоит из множества разноплановых программ, реализующих разные функции, могут содержаться ошибки разных типов. Ошибки интерфейсов и нарушение объема характерны для любого типа систем.
Анализ типов ошибок в программах является необходимым условием создания планов тестирования и методов тестирования для обеспечения правильности ПО.
На современном этапе развития средств поддержки разработки ПО (CASE-технологии, объектно-ориентированные методы и средства проектирования моделей и программ) проводится такое проектирование, при котором ПО защищается от наиболее типичных ошибок и тем самым предотвращается появление программных дефектов.
Связь ошибки с отказом. Наличие ошибки в программе, как правило, приводит к отказу ПО при его функционировании. Для анализа причинно-следственных связей «ошибка отказ» выполняются следующие действия:
· идентификация изъянов в технологиях проектирования и программирования;
· взаимосвязь изъянов процесса проектирования и допускаемых человеком ошибок;
· классификация отказов, изъянов и возможных ошибок, а также дефектов на каждом этапе разработки;- сопоставление ошибок человека, допускаемых на определенном процессе разработки, и дефектов в объекте, как следствий ошибок спецификации проекта, моделей программ;
· проверка и защита от ошибок на всех этапах ЖЦ, а также обнаружение дефектов на каждом этапе разработки;
· сопоставление дефектов и отказов в ПО для разработки системы взаимосвязей и методики локализации, сбора и анализа информации об отказах и дефектах;
· разработка подходов к процессам документирования и испытания ПО.
Конечная цель причинно-следственных связей «ошибка отказ» заключается в определении методов и средств тестирования и обнаружения ошибок определенных классов, а также критериев завершения тестирования на множестве наборов данных; в определении путей совершенствования организации процесса разработки, тестирования и сопровождения ПО.
Приведем следующую классификацию типов отказов:
· аппаратный, при котором общесистемное ПО не работоспособно;
· информационный, вызванный ошибками во входных данных и передаче данных по каналам связи, а также при сбое устройств ввода (следствие аппаратных отказов);
· эргономический, вызванный ошибками оператора при его взаимодействии с машиной (этот отказ — вторичный отказ, может привести к информационному или функциональному отказам);
· программный, при наличии ошибок в компонентах и др.
Некоторые ошибки могут быть следствием недоработок при определении требований, проекта, генерации выходного кода или документации. С другой стороны, они порождаются в процессе разработки программы или при разработке интерфейсов отдельных элементов программы (нарушение порядка параметров, меньше или больше параметров и т.п.).
Источники ошибок. Ошибки могут быть порождены в процессе разработки проекта, компонентов, кода и документации. Как правило, они обнаруживаются при выполнении или сопровождении программного обеспечения в самых неожиданных и разных ее точках.
Некоторые ошибки в программе могут быть следствием недоработок при определении требований, проекта, генерации кода или документации. С другой стороны, ошибки порождаются в процессе разработки программы или интерфейсов ее элементов (например, при нарушении порядка задания параметров связи — меньше или больше, чем требуется и т.п.).
Причиной появления ошибок — непонимание требований заказчика; неточная спецификация требований в документах проекта и др. Это приводит к тому, что реализуются некоторые функции системы, которые будут работать не так, как предлагает
заказчик. В связи с этим проводится совместное обсуждение заказчиком и разработчиком некоторых деталей требований для их уточнения.
Команда разработчиков системы может также изменить синтаксис и семантику описания системы. Однако некоторые ошибки могут быть не обнаружены (например, неправильно заданы индексы или значения переменных этих операторов).
Канальный уровень должен обнаруживать ошибки передачи данных, связанные с
искажением бит в принятом кадре данных или с потерей кадра, и по возможности их
корректировать.
Большая часть протоколов канального уровня выполняет только первую задачу —
обнаружение ошибок, считая, что корректировать ошибки, то есть повторно
передавать данные, содержавшие искаженную информацию, должны протоколы верхних
уровней. Так работают такие популярные протоколы локальных сетей, как Ethernet,
Token Ring, FDDI и другие. Однако существуют протоколы канального уровня, например
LLC2 или LAP-B, которые самостоятельно решают задачу восстановления искаженных
или потерянных кадров.
Очевидно, что протоколы должны работать наиболее эффективно в типичных
условиях работы сети. Поэтому для сетей, в которых искажения и потери кадров являются
очень редкими событиями, разрабатываются протоколы типа Ethernet, в которых не
предусматриваются процедуры устранения ошибок. Действительно, наличие процедур
восстановления данных потребовало бы от конечных узлов дополнительных
вычислительных затрат, которые в условиях надежной работы сети являлись бы
избыточными.
Напротив, если в сети искажения и потери случаются часто, то желательно уже
на канальном уровне использовать протокол с коррекцией ошибок, а не оставлять
эту работу протоколам верхних уровней. Протоколы верхних уровней, например
транспортного или прикладного, работая с большими тайм-аутами, восстановят
потерянные данные с большой задержкой. В глобальных сетях первых поколений,
например сетях Х.25, которые работали через ненадежные каналы связи, протоколы
канального уровня всегда выполняли процедуры восстановления потерянных и
искаженных кадров.
Поэтому нельзя считать, что один протокол лучше другого потому, что он
восстанавливает ошибочные кадры, а другой протокол — нет. Каждый протокол должен
работать в тех условиях, для которых он разработан.
Методы обнаружения ошибок
Все методы обнаружения ошибок основаны на передаче в составе кадра данных
служебной избыточной информации, по которой можно судить с некоторой степенью
вероятности о достоверности принятых данных. Эту служебную информацию принято
называть контрольной суммой или (последовательностью
контроля кадра — Frame Check Sequence, FCS). Контрольная сумма вычисляется
как функция от основной информации, причем необязательно только путем суммирования.
Принимающая сторона повторно вычисляет контрольную сумму кадра по известному
алгоритму и в случае ее совпадения с контрольной суммой, вычисленной передающей
стороной, делает вывод о том, что данные были переданы через сеть корректно.
Существует несколько распространенных алгоритмов вычисления контрольной
суммы, отличающихся вычислительной сложностью и способностью обнаруживать
ошибки в данных.
Контроль по паритету представляет собой наиболее простой метод контроля данных. В то же
время это наименее мощный алгоритм контроля, так как с его помощью можно
обнаружить только одиночные ошибки в проверяемых данных. Метод заключается в
суммировании по модулю 2 всех бит контролируемой информации. Например, для
данных 100101011 результатом контрольного суммирования будет значение 1.
Результат суммирования также представляет собой один бит данных, который
пересылается вместе с контролируемой информацией. При искажении при пересылке
любого одного бита исходных данных (или контрольного разряда) результат суммирования
будет отличаться от принятого контрольного разряда, что говорит об ошибке.
Однако двойная ошибка, например 110101010, будет неверно принята за корректные
данные. Поэтому контроль по паритету применяется к небольшим порциям данных,
как правило, к каждому байту, что дает коэффициент избыточности для этого
метода 1/8. Метод редко применяется в вычислительных сетях из-за его большой
избыточности и невысоких диагностических способностей.
Вертикальный и горизонтальный контроль по паритету представляет собой модификацию
описанного выше метода. Его отличие состоит в том, что исходные данные
рассматриваются в виде матрицы, строки которой составляют байты данных.
Контрольный разряд подсчитывается отдельно для каждой строки и для каждого
столбца матрицы. Этот метод обнаруживает большую часть двойных ошибок, однако
обладает еще большей избыточностью. На практике сейчас также почти не
применяется.
Циклический избыточный контроль (Cyclic Redundancy Check, CRC) является в настоящее время наиболее
популярным методом контроля в вычислительных сетях (и не только в сетях,
например, этот метод широко применяется при записи данных на диски и дискеты).
Метод основан на рассмотрении исходных данных в виде одного многоразрядного
двоичного числа. Например, кадр стандарта Ethernet, состоящий из 1024 байт,
будет рассматриваться как одно число, состоящее из 8192 бит. В качестве
контрольной информации рассматривается остаток от деления этого числа на
известный делитель R. Обычно в качестве делителя выбирается семнадцати- или тридцати
трехразрядное число, чтобы остаток от деления имел длину 16 разрядов (2 байт)
или 32 разряда (4 байт). При получении кадра данных снова вычисляется остаток
от деления на тот же делитель R, но при этом к данным кадра добавляется и
содержащаяся в нем контрольная сумма. Если остаток от деления на R равен нулю1 (1 Существуетнесколько
модифицированная процедура вычисления остатка, приводящая к получению в случае
отсутствия ошибок известного ненулевого остатка, что является более надежным
показателем корректности.), то делается вывод об отсутствии ошибок в полученном
кадре, в противном случае кадр считается искаженным.
Этот метод обладает более высокой вычислительной сложностью, но его
диагностические возможности гораздо выше, чем у методов контроля по паритету.
Метод CRC обнаруживает все одиночные ошибки, двойные ошибки и ошибки в нечетном
числе бит. Метод обладает также невысокой степенью избыточности. Например, для
кадра Ethernet размером в 1024 байт контрольная информация длиной в 4 байт
составляет только 0,4 %.
Методы восстановления искаженных и потерянных кадров
Методы коррекции ошибок в вычислительных сетях основаны на повторной
передаче кадра данных в том случае, если кадр теряется и не доходит до адресата
или приемник обнаружил в нем искажение информации. Чтобы убедиться в
необходимости повторной передачи данных, отправитель нумерует отправляемые
кадры и для каждого кадра ожидает от приемника так называемой положительной
квитанции — служебного кадра, извещающего о том, что исходный кадр был
получен и данные в нем оказались корректными. Время этого ожидания ограничено —
при отправке каждого кадра передатчик запускает таймер, и, если по его
истечении положительная квитанция на получена, кадр считается утерянным.
Приемник в случае получения кадра с искаженными данными может отправить отрицательную
квитанцию — явное указание на то, что данный кадр нужно передать
повторно.
Существуют два подхода к организации процесса обмена квитанциями: с
простоями и с организацией «окна».
Метод с простоями (Idle Source) требует, чтобы источник, пославший кадр, ожидал получения квитанции
(положительной или отрицательной) от приемника и только после этого посылал
следующий кадр (или повторял искаженный). Если же квитанция не приходит в
течение тайм-аута, то кадр (или квитанция) считается утерянным и его передача
повторяется. На рис. 2.24, а видно, что в этом случае производительность обмена
данными существенно снижается, — хотя передатчик и мог бы послать следующий
кадр сразу же после отправки предыдущего, он обязан ждать прихода квитанции.
Снижение производительности этого метода коррекции особенно заметно на
низкоскоростных каналах связи, то есть в территориальных сетях.

Рис. 2.24. Методы восстановления искаженных и
потерянных кадров
Второй метод называется методом «скользящего окна» (sliding
window). В этом методе для повышения коэффициента использования линии
источнику разрешается передать некоторое количество кадров в непрерывном
режиме, то есть в максимально возможном для источника темпе, без получения на
эти кадры положительных ответных квитанций. (Далее, где это не искажает
существо рассматриваемого вопроса, положительные квитанции для краткости будут
называться просто «квитанциями».) Количество кадров, которые разрешается
передавать таким образом, называется размером окна. Рисунок 2.24, б
иллюстрирует данный метод для окна размером в W кадров.
В начальный момент, когда еще не послано ни одного кадра, окно определяет
диапазон кадров с номерами от 1 до W включительно. Источник начинает передавать
кадры и получать в ответ квитанции. Для простоты предположим, что квитанции
поступают в той же последовательности, что и кадры, которым они соответствуют.
В момент t1 при получении первой квитанции К1 окно сдвигается
на одну позицию, определяя новый диапазон от 2 до (W+1).
Процессы отправки кадров и получения квитанций идут достаточно независимо
друг от друга. Рассмотрим произвольный момент времени tn, когда источник
получил квитанцию на кадр с номером n. Окно сдвинулось вправо и определило
диапазон разрешенных к передаче кадров от (n+1) до (W+n). Все множество кадров,
выходящих из источника, можно разделить на перечисленные ниже группы (рис.
2.24, б).
- Кадры с номерами от 1 доп. уже были отправлены и квитанции на них
получены, то есть они находятся за пределами окна слева. - Кадры, начиная с номера (п+1) и кончая номером
(W+n), находятся в пределах окна и
потому могут быть отправлены не дожидаясь прихода какой-либо квитанции.
Этот диапазон может быть разделен еще на два поддиапазона: - кадры с номерами от (n+1) до
т, которые уже отправлены, но квитанции на них еще не получены; - кадры с номерами от m до
(W+n), которые пока не отправлены, хотя запрета на это нет. - Все кадры с номерами, большими или равными
(W+n+1), находятся за пределами окна
справа и поэтому пока не могут быть отправлены.
Перемещение окна вдоль последовательности номеров кадров показано на рис.
2.24, в. Здесь t0 — исходный момент, t1 и tn —
моменты прихода квитанций на первый и n-й кадр соответственно. Каждый раз,
когда приходит квитанция, окно сдвигается влево, но его размер при этом не
меняется и остается равным W. Заметим, что хотя в данном примере размер окна в
процессе передачи остается постоянным, в реальных протоколах (например, TCP)
можно встретить варианты данного алгоритма с изменяющимся размером окна.
Итак, при отправке кадра с номером n источнику разрешается передать еще W-1
кадров до получения квитанции на кадр n, так что в сеть последним уйдет кадр с
номером (W+n-1). Если же за это время квитанция на кадр n так и не пришла, то
процесс передачи приостанавливается, и по истечении некоторого тайм-аута кадр n
(или квитанция на него) считается утерянным, и он передается снова.
Если же поток квитанций поступает более-менее регулярно, в пределах допуска
в W кадров, то скорость обмена достигает максимально возможной величины для
данного канала и принятого протокола.
Метод скользящего окна более сложен в реализации, чем метод с простоями,
так как передатчик должен хранить в буфере все кадры, на которые пока не
получены положительные квитанции. Кроме того, требуется отслеживать несколько
параметров алгоритма: размер окна W, номер кадра, на который получена
квитанция, номер кадра, который еще можно передать до получения новой
квитанции.
Приемник может не посылать квитанции на каждый принятый корректный кадр.
Если несколько кадров пришли почти одновременно, то приемник может послать
квитанцию только на последний кадр. При этом подразумевается, что все
предыдущие кадры также дошли благополучно.
Некоторые методы используют отрицательные квитанции. Отрицательные
квитанции бывают двух типов — групповые и избирательные. Групповая квитанция
содержит номер кадра, начиная с которого нужно повторить передачу всех кадров,
отправленных передатчиком в сеть. Избирательная отрицательная квитанция требует
повторной передачи только одного кадра.
Метод скользящего окна реализован во многих протоколах: LLC2, LAP-B, X.25,
TCP, Novell NCP Burst Mode.
Метод с простоями является частным случаем метода скользящего окна, когда
размер окна равен единице.
Метод скользящего окна имеет два параметра, которые могут заметно влиять на
эффективность передачи данных между передатчиком и приемником, — размер окна и
величина тайм-аута ожидания квитанции. В надежных сетях, когда кадры искажаются
и теряются редко, для повышения скорости обмена данными размер окна нужно
увеличивать, так как при этом передатчик будет посылать кадры с меньшими
паузами. В ненадежных сетях размер окна следует уменьшать, так как при частых
потерях и искажениях кадров резко возрастает объем вторично передаваемых через
сеть кадров, а значит, пропускная способность сети будет расходоваться во
многом вхолостую — полезная пропускная способность сети будет падать.
Выбор тайм-аута зависит не от надежности сети, а от задержек передачи
кадров сетью.
Во многих реализациях метода скользящего окна величина окна и тайм-аут
выбираются адаптивно, в зависимости от текущего состояния сети.
6.2.1. Связность оконечных устройств
6.2.2. Автоматический запрос повторной передачи
Перед тем как начать обсуждение структурированной избыточности, рассмотрим два основных метода использования избыточности для защиты от ошибок. В первом методе, обнаружение ошибок и повторная передача, для проверки на наличие ошибки используется контрольный бит четности (дополнительный бит, присоединяемый к данным). При этом приемное оконечное устройство не предпринимает попыток исправить ошибку, оно просто посылает передатчику запрос на повторную передачу данных. Следует заметить, что для такого диалога между передатчиком и приемником необходима двухсторонняя связь. Второй метод, прямое исправление ошибок (forward error correction — FEC), требует лишь односторонней линии связи, поскольку в этом случае контрольный бит четности служит как для обнаружения, так и исправления ошибок. Далее мы увидим, что не все комбинации ошибок можно исправить, так что коды коррекции классифицируются в соответствии с их возможностями исправления ошибок.
6.2.1. Связность оконечных устройств
Оконечные устройства систем связи часто классифицируют согласно их связности с другими оконечными устройствами. Возможные типы соединения, показанные на рис. 6.6, называются симплексными (simplex) (не путайте с симплексными, или трансортогональными кодами), полудуплексными (half-duplex) и полнодуплексными (full-duplex). Симплексное соединение на рис. 6.6, а — это односторонняя линия связи.
Передача сигналов производится только от оконечного устройства А к оконечному устройству В. Полудуплексное соединение на рис. 6.6,б это линии связи, посредством которой можно осуществлять передачи сигналов в обоих направлениях, но не одновременно. И наконец, полнодуплексное соединение (рис. 6.6, в) — это двусторонняя связь, где передача сигналов происходит одновременно в обоих направлениях.
Передача только в одном направлении а)
а)
б)
в)
Рис. 6.6. Классификация связности оконечных устройств: а) симплексная; б) полудуплексная; в) полнодуплексная
6.2.2. Автоматический запрос повторной передачи
Если зашита от ошибок заключается только в их обнаружении, система связи должна обеспечить средства предупреждения передатчика об опасности, сообщающие, что была обнаружена ошибка и требуется повторная передача. Подобные процедуры защиты от ошибок известны как методы автоматического запроса повторной передачи (Automatic Repeat Request — ARQ). На рис. 6.7 показаны три наиболее распространенные процедуры ARQ. На каждой схеме ось времени направлена слева направо. Первая процедура ARQ, запрос ARQ с остановками (stop-and-wait ARQ), показана на рис. 6.7, а. Ее реализация требует только полудуплексного соединения, поскольку передатчик перед началом очередной передачи ожидает подтверждения об успешном приеме (acknowledgement — АСК) предыдущей. В примере, приведенном на рисунке, третий блок передаваемых данных принят с ошибкой. Следовательно, приемник передает отрицательное подтверждение приема (negative acknowledgment — NAK); передатчик повторяет передачу третьего блока сообщения и только после этого передает следующий по очередности блок. Вторая процедура ARQ, непрерывный запрос ARQ с возвратом (continuous ARQ with pullback), показана на рис. 6.7,б. Здесь требуется полно-дуплексное соединение. Оба оконечных устройства начинают передачу одновременно: передатчик отправляет информацию, а приемник передает подтверждение о приеме данных. Следует .отметить,„что каждому блоку передаваемых данных присваивается порядковый номер. Кроме того, номера кадров АСК и NAK должны быть согласованы; иначе говоря, задержка распространения сигнала должна быть известна априори, чтобы передатчик знал, к какому блоку сообщения относится данный кадр подтверждения приема. В примере на рис. 6,7,б время подобрано так, что между отправленным блоком сообщений и полученным подтверждением о приеме существует постоянный интервал в четыре блока. Например, после отправки сообщения 8, приводит сигнал NAK, сообщающий об ошибке в блоке 4. При использовании процедуры ARQ передатчик «возвращается» к сообщению с ошибкой и снова передает всю информацию, начиная с поврежденного сообщения. И наконец, третья процедура, именуемая непрерывным запросом ARQ с выборочным повторением (continuous ARQ with selective repeat), показана на рис. 6.7, в. Здесь, как и во второй процедуре, требуется полнодуплексное соединение. Впрочем, в этой процедуре повторно передается только искаженное сообщение; затем передатчик продолжает передачу с того места, где она прервалась, не выполняя повторной передачи правильно принятых сообщений.

а)
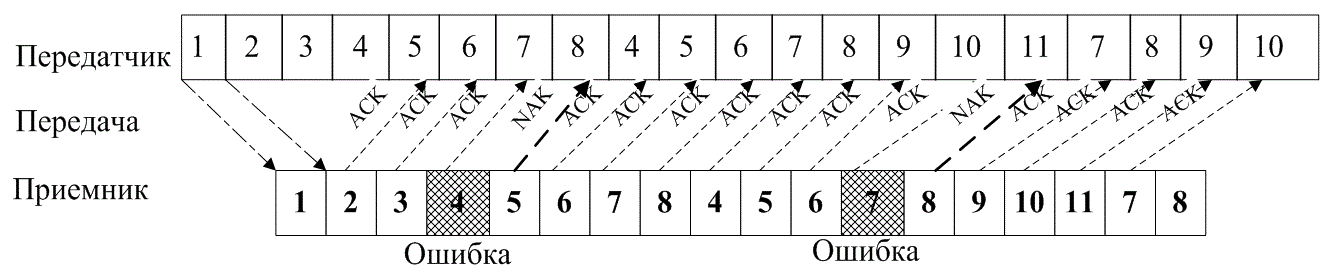
б)

в)
Рис. 6.7. Автоматический запрос повторной передачи (ARQ): а) запрос
ARQ с остановками (полудуплексная связь); б) непрерывный запрос ARQ с возвратом (полнодуплексная связь); в) непрерывный запрос ARQ с выборочным повторением (полнодуплексная связь)
Выбор конкретной процедуры ARQ является компромиссом между требованиями эффективности применения ресурсов связи и необходимостью полнодуплексной связи. Полудуплексная связь (рис. 6.7, а) требует меньших затрат, нежели полнодуплексная; в то же время она менее эффективна, что можно определить по количеству пустых временных интервалов. Более эффективная работа, показанная на рис. 6.7, б, требует более дорогой полнодуплексной связи.
Главное преимущество схем ARQ перед схемами прямого исправления ошибок (forward error correction — FEC) заключается в том, что «обнаружение ошибок требует более простого декодирующего оборудования и меньшей избыточности, чем коррекция ошибок. Кроме того, она гибче; информация передается повторно только при обнаружении ошибки. С другой стороны, метод FEC может оказаться более приемлемым (или дополняющим) по какой-либо из следующих причин.
1. Обратный канал недоступен или задержка при использовании ARQ слишком велика.
2. Алгоритм повторной передачи нельзя реализовать удобным образом.
3. При ожидаемом количестве ошибок потребуется слишком много повторных передач.