Если после внесения начальных остатков вы обнаружили ошибки — исправьте их, чтобы не было ошибок в учете. Например, вы продолжали работать в старой учетной системе уже после того, как перенесли остатки в СБИС.
Чтобы исправить остатки после того как вы их зафиксировали, отмените фиксацию. Для этого в разделе «Бухгалтерия» на вкладке «Остатки» или в разделе «Бизнес/Склад» на вкладке «Склады» нажмите «Отменить фиксацию».
Для исправления ошибок вручную, выберите в списке номенклатуру и скорректируйте данные.
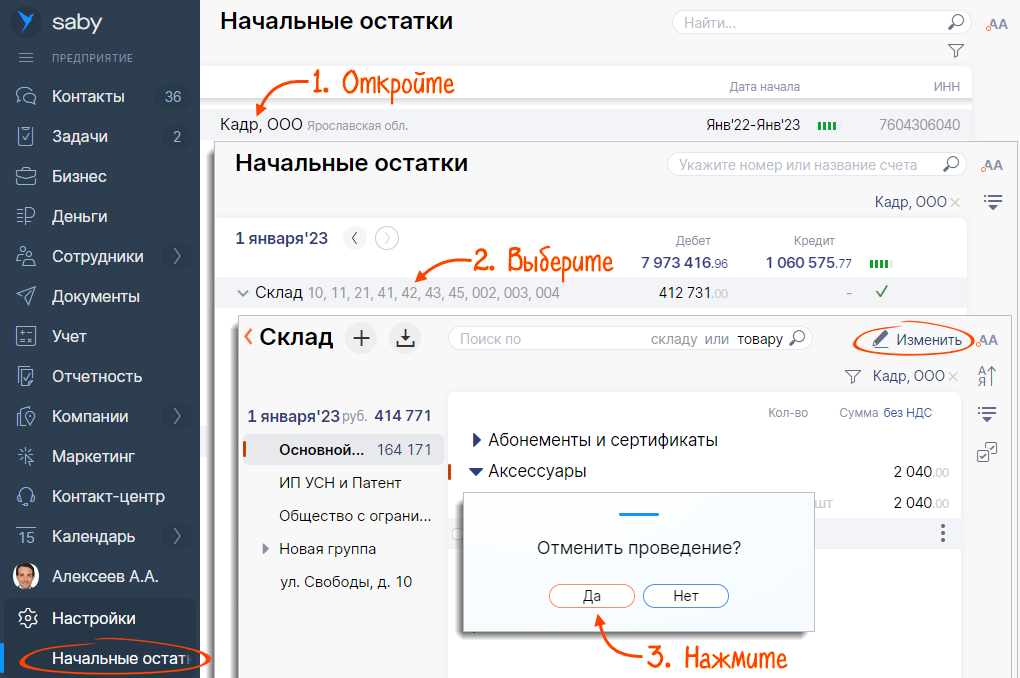
Также вы можете обновить сведения с помощью excel-файла.
Заполните и загрузите файл
Перед началом работы выгрузите остатки из старой учетной системы и отредактируйте файл по шаблону.
![]() Шаблон для загрузки начальных остатков (XLSX, 29 КБ)
Шаблон для загрузки начальных остатков (XLSX, 29 КБ)
Убедитесь, что в нем нет дублей, отрицательных остатков, номенклатуры с видом «Без учета», а количество записей не более 10 000.
- Как загрузить остатки на несколько складов?
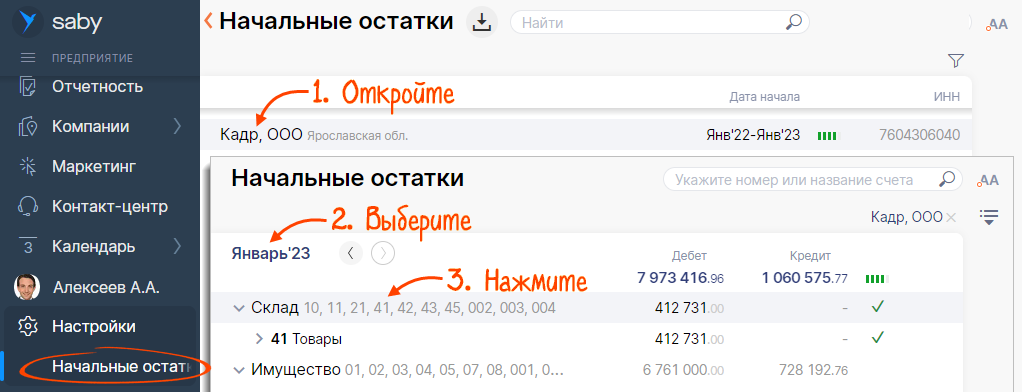
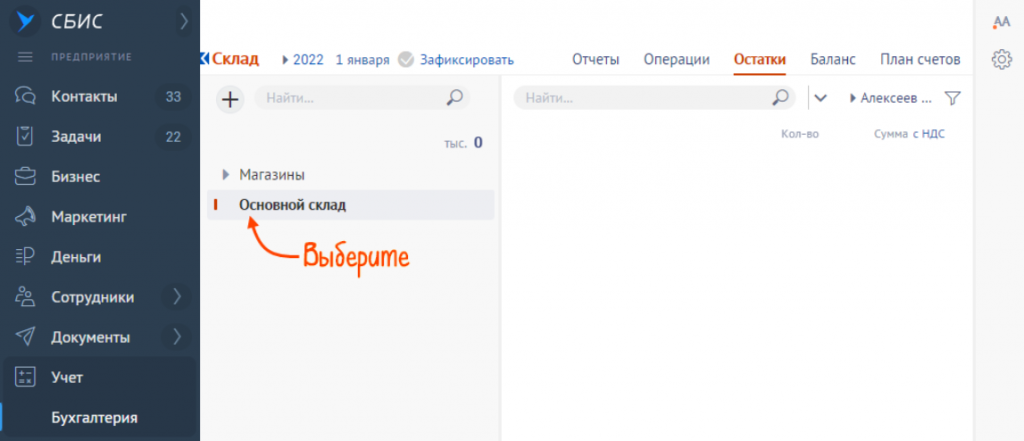
- В разделе «Учет/Бухгалтерия» перейдите на вкладку «Остатки» или в разделе «Бизнес/Склад» переключитесь в режим «Начальный остаток».
- Выберите год, когда вводили остатки и вашу организацию.
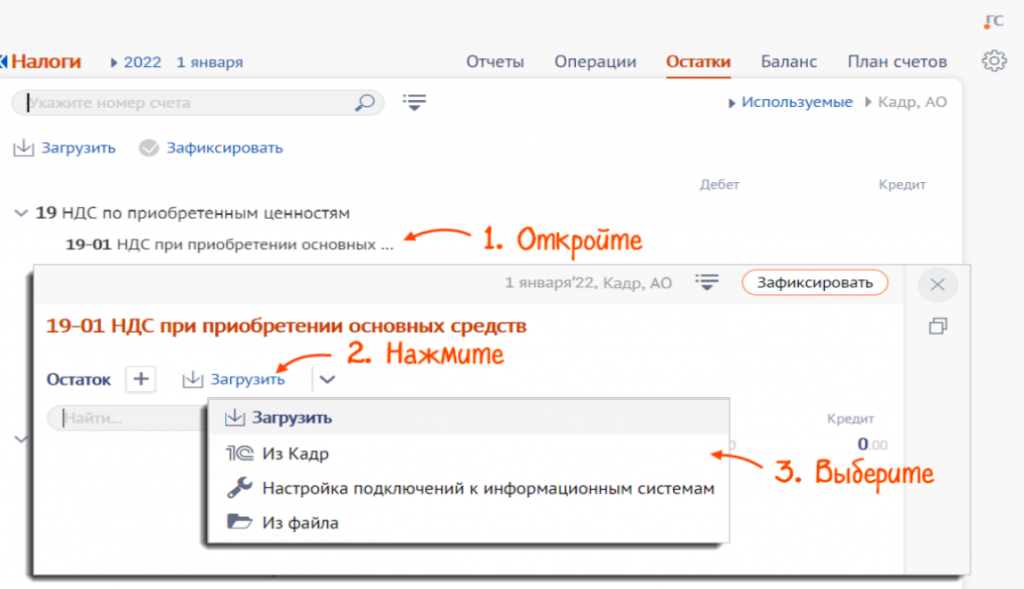
- Наведите курсор на
 и во всплывающем окне перейдите по ссылке «подробнее».
и во всплывающем окне перейдите по ссылке «подробнее».
- В строке «Склад» наведите курсор на и во всплывающем окне нажмите «подробнее».
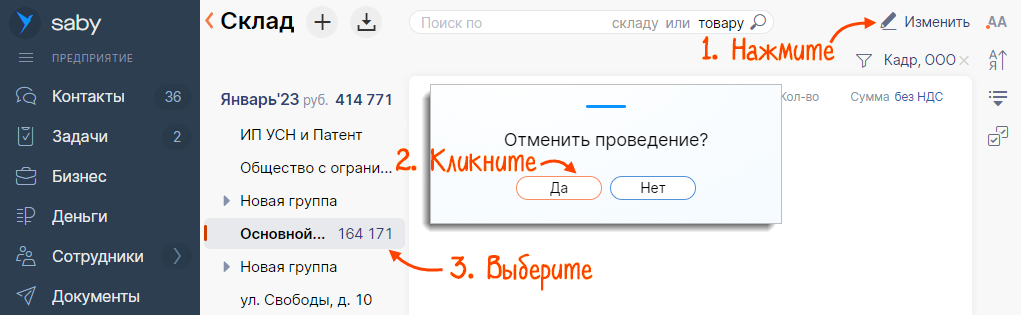
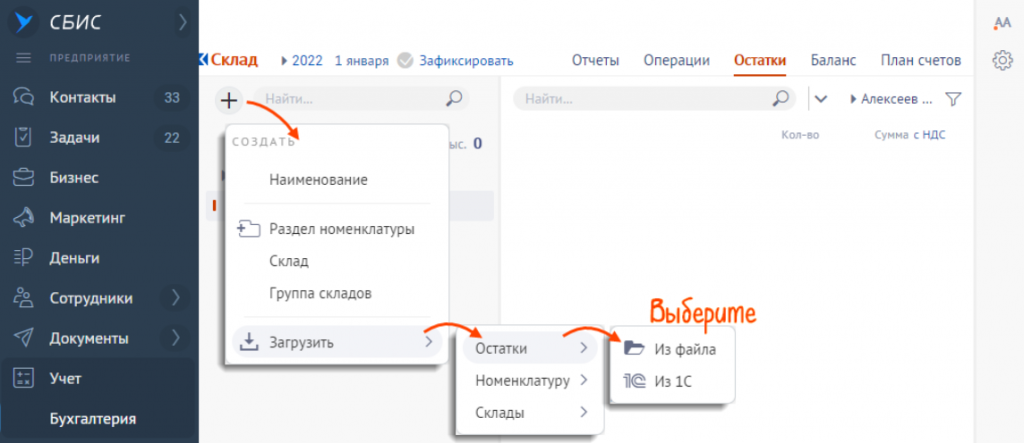
- Выберите склад, нажмите , а затем «Загрузить/Остатки/Из файла» и выберите файл на компьютере.
Настроить параметры загрузки
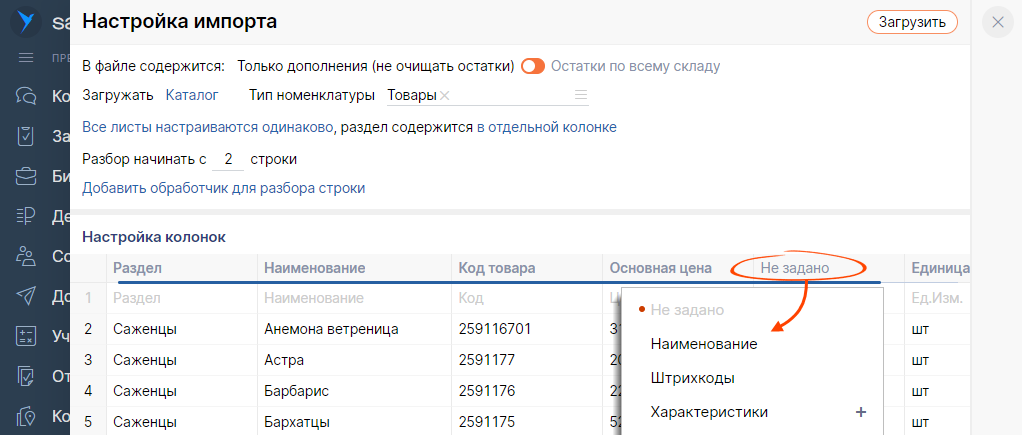
- В блоке «В файле содержится» установите переключатель в положение «Только дополнения (не очищать остатки)». СБИС добавит данные о новых позициях и скорректирует остатки.
Если вы загружаете файл, чтобы удалить предыдущие остатки или загрузить новые, установите «Остатки по всему складу».
- В поле «Тип номенклатуры» выберите тип из справочника, например «Товары» или «Материалы». Это нужно для того, чтобы после загрузки сумма остатков распределилась по счетам учета.
- Как изменить тип номенклатуры в карточках?
- Как задать разные настройки для листов файла?
-
Настройте обязательные колонки и строки:
- «Код» и/или «Наименование»;
- «Остатки/Количество»;
- «Остатки/Сумма» — чтобы правильно рассчитать себестоимость.
Для загрузки остатков по партиям дополнительно настройте:
- «Остатки/Количество» и «Остатки/Сумма» — укажите значения для каждой партии в отдельной строке;
- «Документ партии» — ИНН поставщика, дата накладной, номер накладной.
- «Атрибуты партии» — код партии, ГТД, РНПТ и другое.
- Укажите, какие еще данные нужно импортировать. Для этого в заголовках столбцов вместо «Не используется» выберите название, например «Наименование», «Единица измерения», «Упаковка» и другие.
Чтобы при загрузке наименования распределились по разделам каталога, настройте колонку «Раздел». Если этого не сделать, номенклатура импортируется единым списком в корень каталога и вам потребуется вручную создавать разделы и распределять по ним позиции.
- Нажмите «Загрузить».

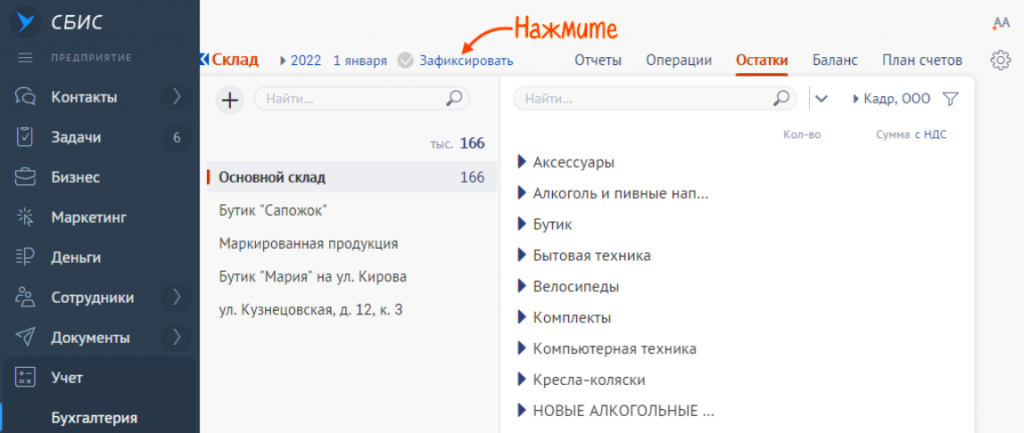
Зафиксировать остатки
Данные об остатках отобразятся в разделе «Учет/Бухгалтерия» на вкладке «Остатки». Убедитесь, что все верно, и нажмите «Зафиксировать».

СБИС сформирует и проведет документ ««Начальные остатки». Перейдите в раздел «Бизнес/Склад/Инвентаризация», чтобы его посмотреть.
Лицензия, права и роли
Нашли неточность? Выделите текст с ошибкой и нажмите ctrl + enter.
Отправим материал Вам на почту
Ввод первоначальных остатков: как это сделать в СБИС
Предприятия, принявшие решения автоматизировать учет или же меняющие у себя программное обеспечение, должны произвести ввод первоначальных остатков. При переходе на СБИС это можно сделать вручную или через загрузку. Рассказываем, как осуществить этот процесс.
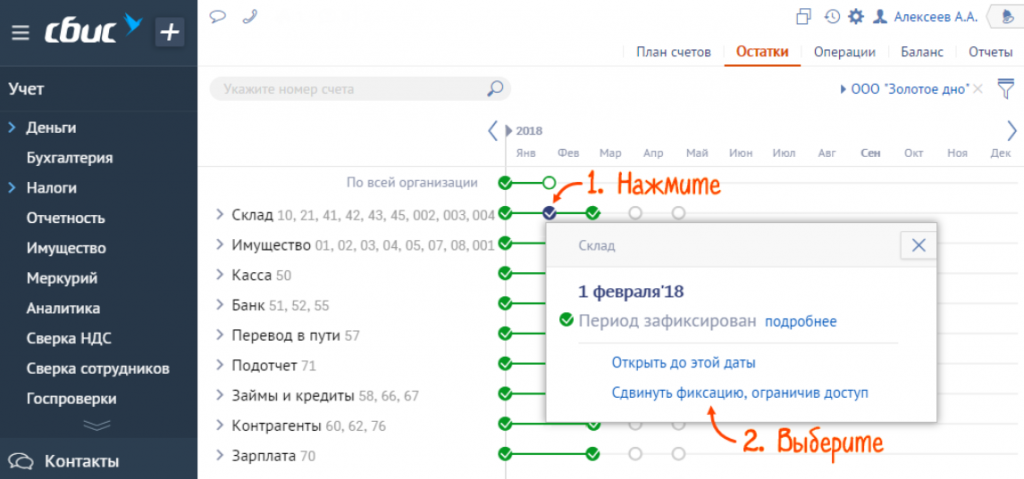
Если ваша организация только начала свою деятельность и еще не успела обзавестись запасами на складе, то вводить начальные остатки в систему учета не требуется. При переходе с сторонней системы учета на СБИС начальные остатки внести будет необходимо. Это нужно для сохранения сальдо по счетам учета. Вносить начальные остатки можно только в открытом периоде. Откройте период, если он уже зафиксирован.
Для корректного формирования отчетности рекомендуется вводить остатки с начала календарного года.
Ввод начальных остатков обеспечивает:
- Фиксирование фактического количества товарно-материальных ценностей на складе
- Корректное движение по счетам учета
- Определение начального сальдо по счетам бухгалтерского учета
До того, как внести остатки, вам потребуется:
- Проверить настройки учетной политики
- Указать данные организации в параметрах склада, на котором будут числиться остатки
- Включить ценообразование по партиям
- Настроить расчет цен
После внесения всех данных по остаткам суммы по дебету и кредиту у вас должны совпадать.
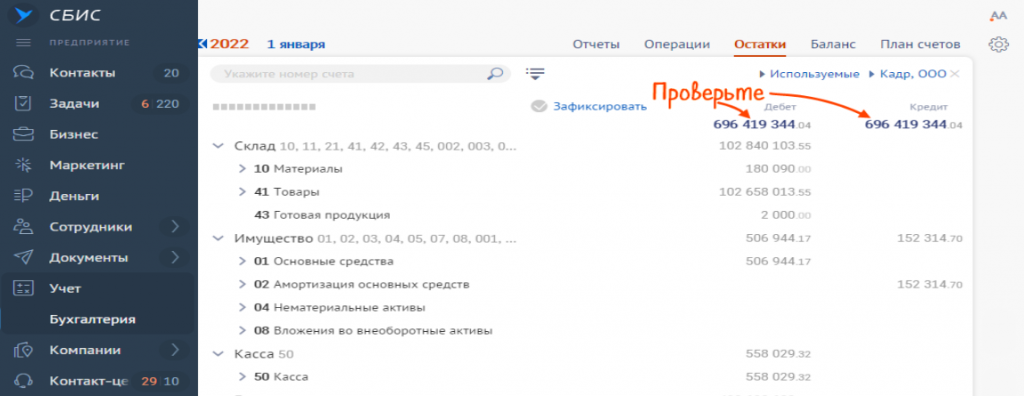
![]()
Если у вас сложности и вам трудно разбираться в деталях или же вы хотите сэкономить свое время, свяжитесь с нашим специалистом, чтобы получить услугу занесения остатков.
Оставить заявку
Ввод начальных остатков
Начните работу с введения сведений о товаре с добавления начальных остатков на участке «Склад». Это можно сделать как вручную, так и при помощи загрузки таблицы в формате excel. При работе с данными прослеживаемых товаров вам нужно указывать коды РНПТ. В случае, если коды РНПТ вы еще не получили, после фиксации остатков вам потребуется оформить «Уведомление об остатках».
К Участку «Склад» относятся счета 10, 21, 41, 42, 43, 45 и забалансовые 002, 003, 004.
Чтобы внести данные в СБИС нужно:
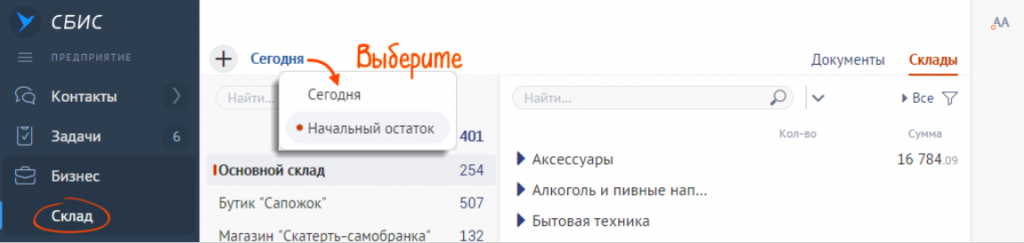
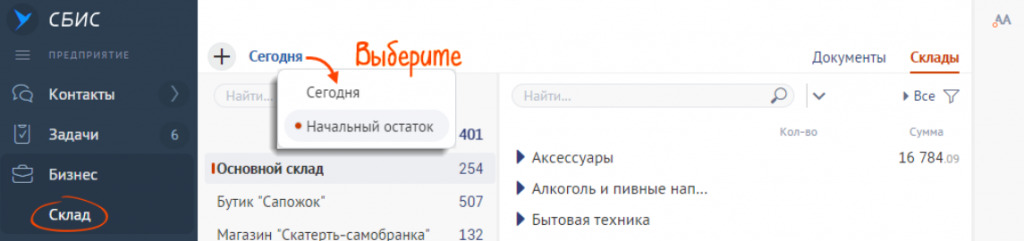
- В разделе «Учет/Бухгалтерия» кликнуть вкладку «Остатки» или в разделе «Бизнес/Склад» выбрать вкладку «Склады». Далее нужно переключиться в режим «Начальный остаток».

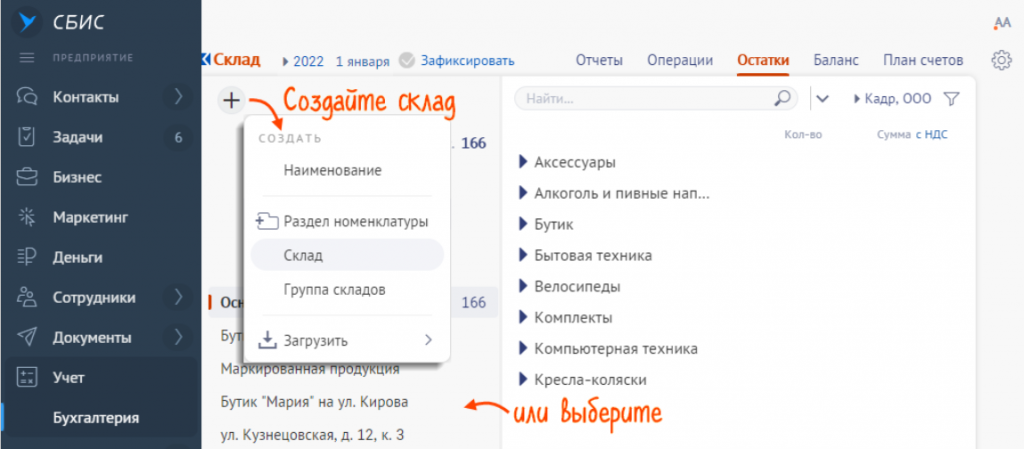
- Выбрать склад из списка или создать новый.
- Нажать «галочки» и выбрать «Рассчитать», а потом подтвердить заполнение по данным учета.
Далее нужно внести данные по остальным товарам.
- После требуется добавить наименования и остатки одним из способов:
- Загрузить через таблицы Excel или 1С
- Создать вручную
- Сформировать автоматически
При использовании схемы налогообложения УСН «Доходы-Расходы» организации вводят остатки по партиям. Это делается для того, чтобы отследить отгрузку и оплату по конкретной партии для правильного принятия сумм в расходы.
- Нажать опцию «Зафиксировать». Наименования без остатка будут обнулены.
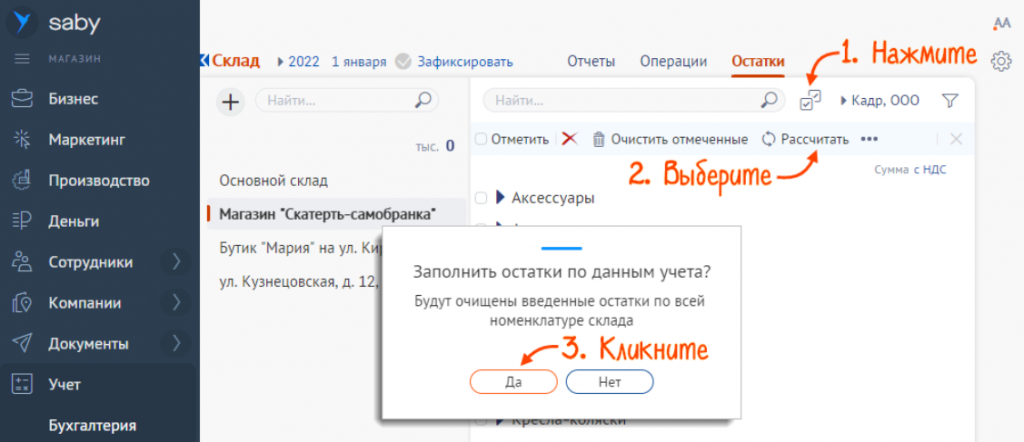
В разделе «Бизнес/Склад/Инвентаризация» СБИС сформирует «Начальные остатки» и примет его к учету. Когда начальные остатки на участке «Склад» фиксированы, проводить или отменять проведение складских документов раньше даты фиксации запрещено. Для корректировки данных вам потребуется открыть период (отменить фиксацию).
Если вы занимаетесь алкогольной продукцией, вам нужно:
- Запросить необработанные ТТН, получить их в СБИС и утвердить накладные.
- Запросить остатки ЕГАИС
- Принять к учету немаркированный товар на регистр «Розница», маркированный – на опт.
- Провести инвентаризацию алкоголя, чтобы зафиксировать остатки на складе.
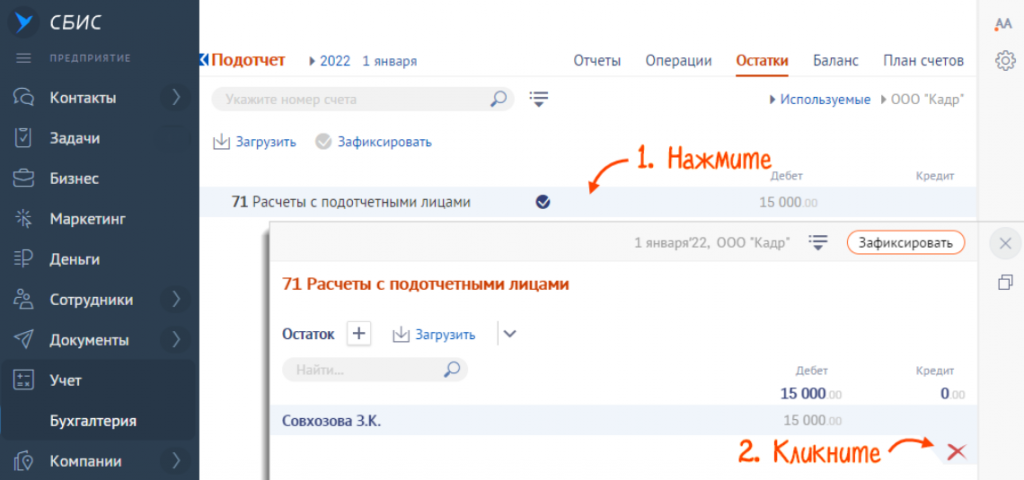
При возникновении ошибок вы можете скорректировать или удалить остатки. Для удаления откройте карточку счета и нажмите на красный крест на записи об остатках.
Для загрузки данных по остаткам из 1С, вам нужно убедиться, что ваша конфигурация относится к следующему списку:
- «1С:Бухгалтерия предприятия» редакции 2.0 с версии 2.0.66.32 и редакции 3.0 с версии 3.0.67.38 — на всех участках бухгалтерского учета;
- «1С:Зарплата и управление персоналом» редакции 2.0 с версии 2.5 и редакции 3.0 с версии 3.1.10.78 (за исключением остатков по вычетам и отпускам) — на участке «Зарплата»;
- «1С:Комплексная автоматизация» редакции 1.0 с версии 1.0 и редакции 2.0 с версии 2.4.7.151 — на всех участках бухгалтерского учета, кроме «Банк» и «Касса»;
- «1С:Управление производственным предприятием» с версии 1.3.92.1 — на участке «Имущество», «Склад»;
- «1С:Камин» с версии 5.0.51.3 — на участке «Зарплата».
Далее вам потребуется загрузить справочники подразделений и сотрудников, а также документы приема, перевода и увольнений. После этого можно будет вносить данные по остаткам. Имейте ввиду, на вкладке «Остатки» все счета объединены в участки с фиксированным набором счетов и субсчетов. Загрузку остатков по всем счетам учета можно производить в любой последовательности.
Загрузку будете осуществлять по шагам:
- Определите дату начала работы
- Загрузите начальные остатки
- Зафиксируйте остатки на участках.
Для загрузки остатков из 1С:
- По участкам. Нажмите стрелку «Загрузить» и выберите базу 1С. При этом объекты 1С автоматически сопоставляются с объектами СБИС. И если какой-то объект на находится, СБИС его создаст.
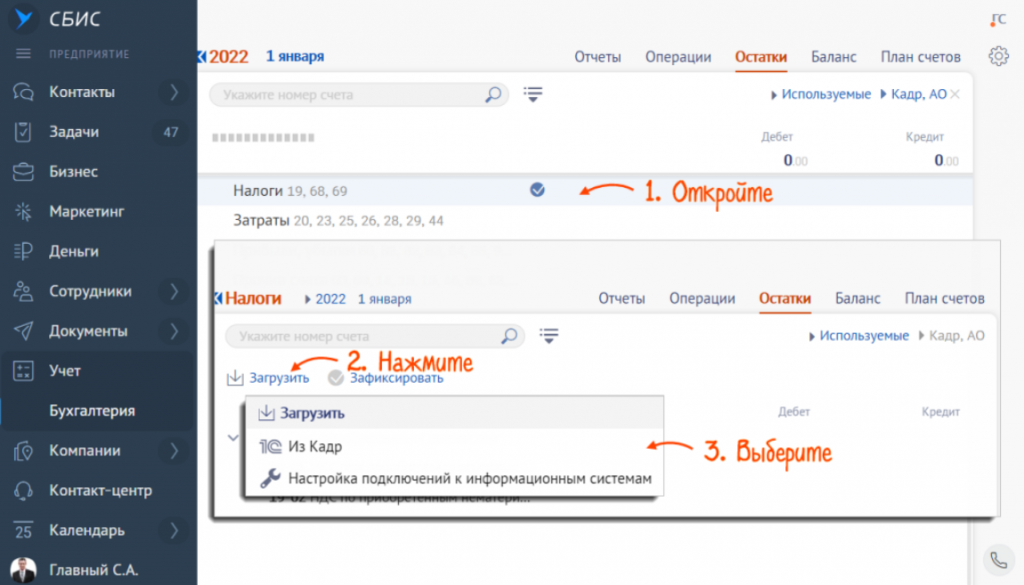
- По субсчету. Откройте субсчет и нажмите стрелку «Загрузить», выберите базу 1С.
![]()
Вам нужна помощь при переходе на СБИС с программ 1С? Наши специалисты окажут услуги загрузки остатков по бухгалтерским счетам на начало ведения учета из 1С.
Оставить заявку
Загрузка начальных остатков на участке «Склад» в СБИС с помощью Excel
Выгрузите все данные из старой учетной системы. Скачайте образец таблицы для загрузки начальных остатков и заполните его. Скачать образец по ссылке.
Перед загрузкой проверьте файл на наличие дублей, отрицательных значений. Обратите внимание, что количество записей не должно быть больше 10 000. Также в файле не должно быть номенклатуры с видом «Без учета».
Если вы работаете на УСН «Доходы-Расходы» или на ОСНО, то вы можете заполнить колонку «Документ партии», чтобы провести загрузку остатков по партиям.
Чтобы загрузить остатки в виде таблицы Excel потребуется:
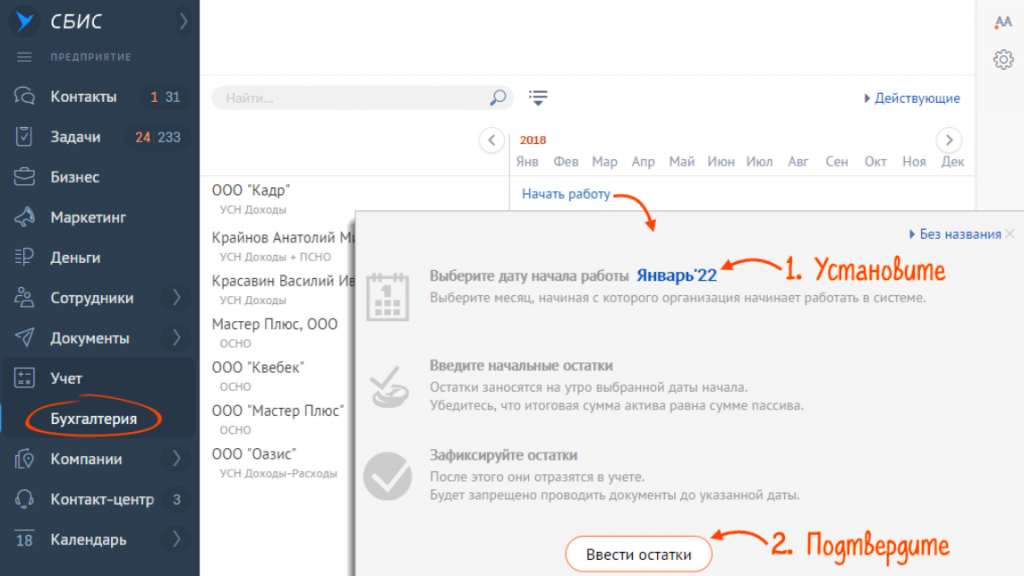
- Перейти в раздел «Учет/Бухгалтерия» на вкладку «Остатки» или в режиме «Начальный остаток» перейти в раздел «Бизнес/Склад».
- Выбрать организацию, затем «Начать работу» и установить дату, на которую будут вводиться остатки.
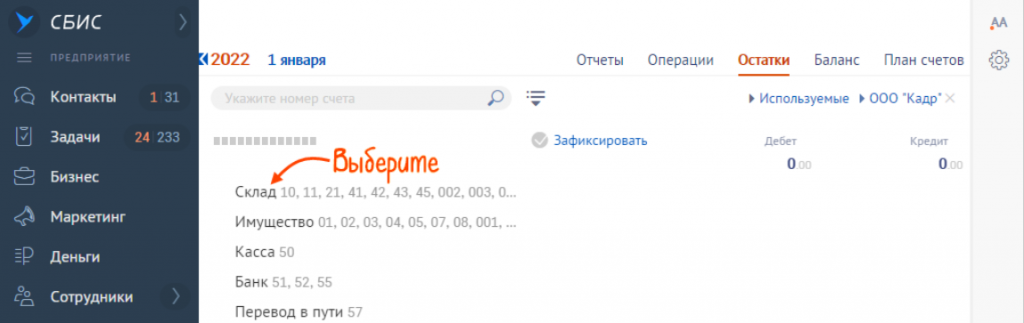
- Перейти во вкладку «Склад».
- Выбрать склад.
- Через опцию «+» перейти «Загрузить/Остатки/Из файла». Выбирайте файл на компьютере и загружайте остатки.
СБИС Бухгалтерия и учет удобна и проста в использовании. В ней уже настроены схемы учета и шаблоны проводок практически на все случаи жизни. Узнайте у наших специалистов, как подключиться к СБИС со скидкой до 50%. Оставьте заявку сейчас, и мы с вами свяжемся.
А если вам требуется техническая поддержка, мы готовы ее оказать круглосуточно. Также наши специалисты помогут вам внести остатки, обучат персонал, подберут выгодные тарифы, проконсультируют по всем сервисам СБИС.
Оставьте заявку и получите бесплатную консультацию уже сегодня!
Видео по теме
150 000
Клиентов на постоянной поддержке
40
Офисов по всей России и продолжаем расширяться
15 лет
Мы успешно работаем в сфере электронных решений
24/7
Всегда на связи с клиентами группа Техподдержки
Благодаря СБИС можно проводить любые операции с электронными документами. Поэтому программа часто используется обычными пользователями и разными организациями для проведения документооборота, контроля и составления отчетов. Главная особенность такого сервера заключается в возможности вносить корректировку. Для этого следует придерживаться общей инструкции. Подробнее о том как сделать корректировку в СБИС тут https://my-sbis.ru/sdelat-korrektirovku/.
Этапы осуществления корректировки в СБИС
Изменение информации в системе необходимо осуществлять в результате скидок, акций, при внесении неправильной информации и прочее. Для корректировки нужно:
- Перейти на официальный сайт https://online.sbis.ru/auth.
- Пройти процедуру авторизации с указанием актуальных логина и пароля.
- На представленной странице оформить процедуру корректировки, используя один из доступных методов.
- Необходимо редактировать только определенный файл, в котором нужно изменить данные.
Важно проверить документ-основание и контрагента. В случае корректировки, причиной которой не является реализация или поступление, стоит связать процедуру с основанием. Другие сведения указываются автоматически.
В получившемся новом списке нужно оставить некоторые позиции, требующие изменений. Остальные позиции можно удалить, используя крестик. Если необходимо, можно добавить список любыми наименованиями.
Последующий этап корректировки в СБИС – указание правильной стоимости товара или услуги, их количество, прочая информация отобразиться сама. По завершению следует нажать на кнопку «Провести». Через некоторое время система обновится и предоставит корректные данные. Подробнее о том как сделать корректировку в СБИС тут https://my-sbis.ru/sdelat-korrektirovku/.
Способы корректировки документов и поданных сведений
Изменение любых сведений в программе можно проводить несколькими способами. Можно выбрать самый удобный:
- Из первоначального документа. В реализации следует нажать «Изменить» и после «Оформить» в нижней части. Затем выбрать строку и внести необходимую корректировку.
- Из нужного раздела. Зайти в категорию «Бизнес/Реализации», выбрать документ. После отметить «Корректировка поступления». Появится документ, где следует сделать корректировку данных.
Последнее изменение: 21.06.2021
Несколько лет назад при переходе от разработки десктоп-приложения с локальной базой у каждого клиента к SaaS-модели с сотнями тысяч клиентов онлайн, нам пришлось сильно пересмотреть некоторые алгоритмы работы с БД при реализации функционала складского учета в СБИС. Этот внутренний доклад посвящен алгоритмическим причинам возникших сложностей и способам их решения.
Очередной семинар про работу с СУБД PostgreSQL. Сегодня расскажу, как суровую прагматику требований бизнеса перенести на разработку высоконагруженных сервисов, как бороться с конкурентным доступом к данным, как это все аккуратно обходить и при этом не «отстрелить себе ногу».
Сегодня мы поговорим про расчет себестоимости в СБИС:
- наша методика расчета
что такое «себестоимость» вообще, зачем она нужна, и как ее считаем именно мы - алгоритмические задачи
концептуальные приемы при построении архитектуры решения «под алгоритм» - технические приемы
зачем и как применять упорядочение операций, делать транзакции короткими и быстрыми, организовать высококонкурентную очередь в БД и другие подходы к оптимизации нагрузки

Себестоимость — это оценка затрат нашего бизнеса (себе-стоимость) «в деньгах», необходимая для трех основных вещей:
- знать наценку — то есть прибыль от продажи какого-то конкретного товара
Чисто управленческая метрика, которая позволяет вычислять эффективность работы вложенных средств, их оборачиваемость, прибыльность бизнеса. - рассчитать налоги на прибыль (от той же самой наценки) или на НДС
Это то, что требует от нас как от юрлица налоговая. - подтвердить затраты при расчете того же НДС
Иметь возможность сослаться на первичные документы и сказать: «Да-да, этот товар стоил мне 1000 рублей, потому что я его вот по этой накладной за 1000 рублей купил у Васи»
Из определения следует, что себестоимость — это всего лишь какая-то оценка, а для любой оценки бывает много различных методик. Если посмотреть «Википедию», то там с десяток различных методик описано. Мы для себя выбрали одну и реализовали именно ее, вот что в нее входит:

Мы учитываем только вхождение материалов при расчете себестоимости продукции. То есть все издержки на зарплату, аренду, электричество и прочее — мы не учитываем. В том смысле, что они не участвуют при автоматическом расчете — их можно дораспределить отдельно после калькуляции общих затрат за месяц, например.
Считаем на конец периода: дня, месяца, квартала или года — это настраиваемый пользователем параметр — в зависимости от того, каким методом учета пользуется организация. И, в общем случае, внутри периода можем переставлять движения как угодно.
Расчет ведется в разрезе складов. То есть у нас много-много складов, на каждом из которых себестоимость учитывается независимо.
Например, конкретно у нас как у «Тензора» порядка сотни складов — как минимум, это все «филиальные» склады, на которых хранятся носители для электронных подписей, кассы и прочие товары, которые мы продаем. Склады Presto, которые используют наши столовая и ресторан.
Мы поддерживаем два алгоритма расчета: «по средней» или по партиям с ручным выбором партий или автоматическим подбором по FIFO.
И все это мы считаем с конечной точностью — точностью «одна копейка» для денег и «одна миллионная» для количества. Нам показалось, что такой точности (1 грамм при учете «в тоннах») достаточно для любого товара.

Поскольку в автоматическом режиме мы учитываем только материалы, то нам достаточно уметь обрабатывать всего 4 модели операций:
- расход
Формируется документами реализации, списания и переоценки.
Себестоимость вычисляется от остатка по складской карточке на момент операции. - приход
Формируется документами поступления товара и начальных остатков.
Себестоимость явно указана в документах поставщика — это закупочная цена товара. - зависимые (приход по расходу)
Формируется документами перемещения, пересортицы и выпуска.
Себестоимость прихода в точности равна суммарной себестоимости расхода. - инвентаризация
Фиксирует фактический остаток и формирует отклонения от учетного остатка по моделям прихода и расхода.
Получается, что от алгоритма расчета (по среднему/по партиям) зависят только расходы, все остальные операции из них «выводятся».

Расчет мы делаем на конец периода. То есть мы говорим: «Непонятно, что происходило „внутри“ периода, но „на конец“ состояние вот такое, его и рассчитаем.» И чтобы его рассчитать, вполне возможно, нам придется учитывать операции не в том порядке, в котором они были оформлены.
Типовая бизнес-ситуация — прибежал менеджер на склад: «У меня есть клиент! Вася, вот этот телевизор, хоть ты его еще не заприходовал на склад, отгрузи мне его прямо сейчас, пожалуйста.»
Оформлена отгрузка со склада утром, а приход будет заведен вечером. То есть, формально, какое-то время в течение дня на складе был «минус», поскольку расход оформлен раньше прихода — но все равно все должно по алгоритму рассчитаться. Потому что с бытовой-то точки зрения мы понимаем — вот тут мы отгрузили точно тот телевизор, что был заприходован, и не надо умучивать пользователя переоформлением этих документов!
И для того чтобы наиболее эффективно рассчитать, мы имеем полное право в рамках определенного пользователем периода менять порядок операций так, как нам «удобнее» — то есть чтобы все рассчиталось по максимуму.
На этих двух диаграммках видно, что если мы сначала попробуем взять порядок операций, когда расход раньше прихода, то у нас окажется сразу 2 нерассчитанные операции. Потому что мы ничего не сможем про остаток сказать ни после первого расхода «в минус», ни после прихода. Количественный остаток какой-то будет, а вот про его себестоимость, денежное выражение, сказать уже ничего нельзя.
Но если мы эти операции поменяем местами, то у нас все отлично! Мы четко понимаем, что если у нас приход был по 10р/шт, то и расход будет по столько же.

Но есть одна проблема. Если у нас где-то внутри интервала возникает инвентаризация, то такие операции через нее мы переносить уже не можем.
Потому что в жизни что это бывает за инвентаризация? Кто в «Метро» был, тот видел, может быть, что периодически они закрывают цепочками некоторые стеллажи и начинают там что-то делать. Бегает менеджер со штрих-сканером и «щелкает» товар. Вот он его количественно измеряет, инвентаризирует, получает какое-то число. Так вот это число он получает на определенную точку во времени. Если расход был проведен раньше — он уже учелся в данных этой инвентаризации. А если будет проведен позже, то переставить его мы не имеем права, потому что из-за этого остатки, зафиксированные в инвентаризации как-то начнут «ехать».
Поэтому инвентаризации разбивают интервалы расчета на сегменты.
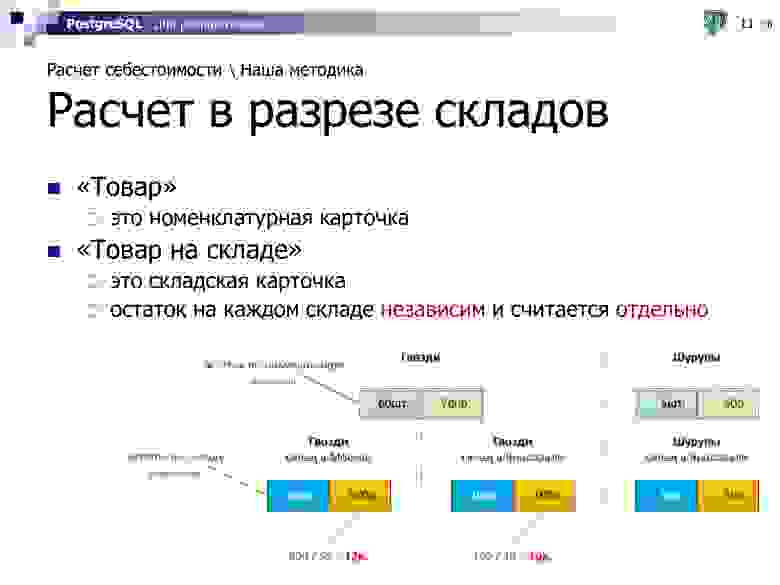
Вполне очевидно, что себестоимость разных товаров — «шурупы» и «гвозди» — можно рассчитывать независимо. Но если при этом у нас есть гвозди на складе в Москве и на складе в Ярославле, то для нас это такие же разные объекты для расчета, и у них может быть абсолютно независимая друг от друга себестоимость.
Например, гвозди на московский склад точно такие же мы купили «задорого» по 12р., а в Ярославле «задешево» по 10р., потому что тут мы закупаем оптом и имеем у местного поставщика лучшие скидки, например.
То есть остаток и себестоимость для каждой складской карточки рассчитываются независимо.
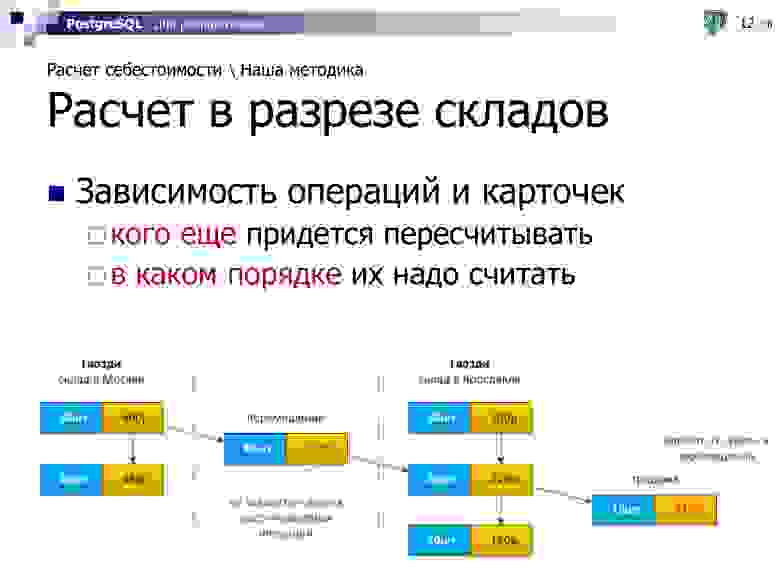
Соответственно, наличие нескольких складов даже по одной номенклатурной карточке приводит нас к ситуации, что иногда возникает зависимость операций и карточек друг от друга.
Например, если мы взяли и сделали перемещение, погрузили 10 коробок гвоздей в Москве и повезли их на склад в Ярославль, то у нас на этом складе себестоимость-то как-то изменится после этой приходной операции. И дальнейшие продажи с него уже будут зависеть от того, какое количество, по какой сумме мы переместили, с какого склада — если из Москвы, то по одной себестоимости, если из Питера — по другой.
У нас возникают «цепочки» операций, определяющих порядок расчета. На этом примере перемещение должно быть рассчитано раньше продажи, иначе мы не сможем ее корректно рассчитать.
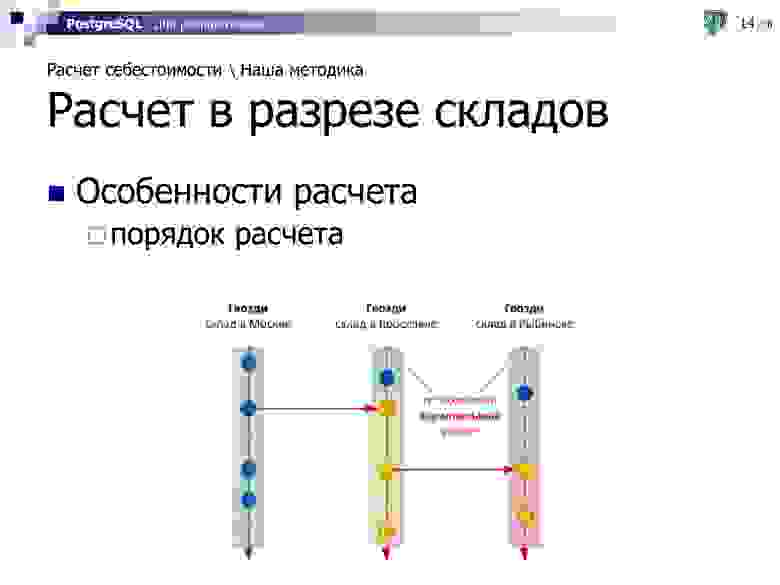
А иногда такие зависимости возникают еще и каскадно — когда мы, например, сначала из Москвы привезли гвозди в Ярославль, а на следующий день часть этих гвоздей отправили в Рыбинск.
Но когда возник такой каскад, мы понимаем, что можем все интервалы операций разбить на некоторые сегменты, которые могут быть рассчитаны параллельно, независимо друг от друга, не конкурируя ни за какой ресурс. То есть сначала все «зеленые» сегменты по трем этим карточкам могут считаться тремя параллельными потоками, потом строго «желтый» сегмент, потом — «красный».

Но есть проблема. В случае, если у нас в рамках одного интервала расчета (например, суток) было перемещение сначала с оптового московского склада на розничный ярославский, а потом назад мы вернули часть продукции, то эти две операции начинают зависеть друг от друга.
И они могут быть рассчитаны только совместно — сразу все операции этих двух складов в рамках одного интервала. То есть мы не можем разорвать расчет этих двух карточек, и на этом интервале должны рассчитать их сразу обе.
Для решения задачи перебора перестановок таких операций реализован отдельный алгоритм. Я про него сегодня рассказывать не буду, поскольку он, скорее, оптимизационно-математический и к работе с базой имеет отношения мало.

Первый алгоритм расчета, который мы реализовали — это «по среднему». Тут все просто — на момент операции берем суммовой и количественный остаток по карточке, делим одно на другое — узнаем себестоимость за единицу. Умножаем ее на количество товара в операции — получаем себестоимость операции.

Второй алгоритм — подбор по партиям.
Партия — это факт отгрузки поставщиком нам определенного наименования. То есть он его отгрузил, во-первых, в определенную дату, во-вторых, по определенной цене, в-третьих, с определенными параметрами. Это особенно важно, когда атрибуты партий критичны — например, срок годности. Понятно, что молоко «позавчерашнее» совсем не то же самое, которое мне отгрузили «сегодня», и его надо как-то друг от друга отделять.
Для этого существует такая штука как партионный учет, он же «учет по партиям». На партии могут быть «завязаны» определенные атрибуты. Соответственно, все операции, которые происходят, учитываются в разрезе партий.
Внезапно, для тех же вводных, что и в предыдущем примере, себестоимость операции оказалась другой, потому что в нее вошло сразу две операции по разной исходной себестоимости. Соответственно, при партионном учете у нас не только операции ведутся в разрезе партий, но и остатки на складских карточках.
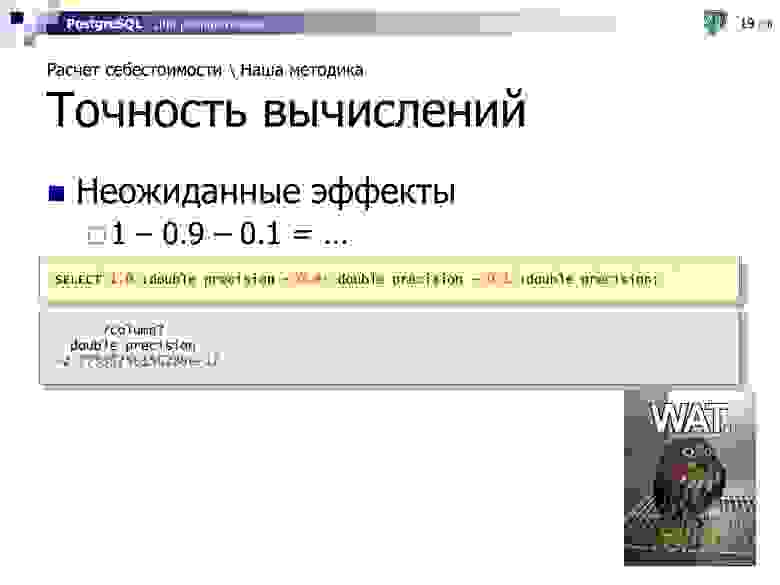
И последний момент, почему при описании нашей методики я в явном виде остановился на точности учета. Потому что при неопределенной точности учета, когда мы не говорим об использовании какой-то фиксированной, у нас возможны весьма неожиданные эффекты.
Кто-то, возможно, уже сталкивался в своей работе, кто-то, может быть еще столкнется, но уже хотя бы будет знать, как такие вещи решаются. Вроде логика подсказывает, что при вычислении такого выражения должен получиться ноль, но… не совсем!
Эта проблема вызвана конечной разрядностью представления числа внутри вычислительного устройства. И чем больше вычислительных операций мы будем проводить (а на предыдущих слайдах видно, что проводить, как минимум, умножение и деление при расчете каждого складского движения), тем сильнее это отклонение «от нуля» будет накапливаться.
И чтобы такого «ноль, но не совсем» не получать, мы должны оперировать с numeric-типами:
SELECT 1.0::numeric - 0.9::numeric - 0.1::numeric;
-- 0.0
Так количество неожиданностей при вычислениях будет гораздо меньше, но не пропадет совсем. Потому что в зависимости от ЯП само округление до точности может происходить не всегда одинаково.
Например, если для SQL мы получаем округление «конечной 5» всегда в большую сторону, то для Python, например, это не так. И чтобы добиться одинакового поведения при вычислениях, необходимо прикладывать дополнительные усилия на каждом из используемых вами языков.

Теперь перейдем от «общечеловеческого» описания алгоритма к тому, что конкретно пришлось делать.
Сначала мы подумали — а ведь в десктоп-приложении СБИС 2.x расчет себестоимости уже был реализован, почему бы его не взять готовый и не перенести?
Pro:
- единая транзакция расчета и блокировка всех участвующих карточек
Нет необходимости беспокоиться о том, что кто-то изменил остаток на карточке. - извлекаем все движения периода
Отсутствуют конфликты с конкурентным изменением списка операций. - сквозной порядок всех-всех операций
Все зависимости карточек и конфликты циклических операций разрешались прямо в памяти. Нет необходимости дополнительно хранить списки зависимостей.
Но этот алгоритм разрабатывался под свои условия — когда база у клиента стоит одна, на выделенном сервере, в ней максимум сотни тысяч, но явно не миллионы операций. И бухгалтер может себе позволить при закрытии квартала запустить процесс пересчета всех движений «на всю ночь».
Для онлайн-приложения, где в одной PostgreSQL-базе сосуществуют сотни клиентов, а работа ведется в режиме 24×7, такое уже не подходит.
Contra:
- длинная транзакция
В условиях работы MVCC это создает массу проблем, которые потом приходится героически решать. Например, «по цепочке» нарастающее количество блокировок. - блокировка всех участвующих карточек
В таких условиях кладовщик во Владивостоке не сможет закрыть ни одного складского документа, пока бухгалтер в Москве делает полный расчет за отчетный период. - извлекаем все движения периода
Нет анализа надо ли извлекать и пересчитывать эти движения — избыточная нагрузка на БД/БЛ. Если сказано «посчитать за квартал» — значит, все движения за квартал сразу же извлекаются. - сквозной порядок всех-всех операций
Поскольку все зависимости разрешались прямо в памяти, рекурсивно, то ее требовалось много — доходило до 300-400MB на расчет движений за квартал. - единственный поток расчета
Нет возможности «распараллелить» вычислительную работу, хотя для многоядерных CPU — самое то. - ручной запуск
Поскольку алгоритм получался вычислительно тяжелым и мог создавать проблемы, запускать его в автоматическом режиме было опасно.
Поэтому смасштабировать тот же самый алгоритм на миллион клиентов онлайн не получилось, и пришлось придумывать заново.

Нам необходим некоторый итерационный алгоритм, который пользуется короткими транзакциями, всегда помнит, что мы уже посчитали, и имеет полное право корректно прерываться в любой момент времени — например, для оптимизации нагрузки на элементы серверной инфраструктуры. То есть он должен уметь досчитывать дальше по ранее намеченному маршруту.
Никакой рекурсии, никаких вложенных проверок — чем «тупее и проще», тем эффективнее.
Поскольку у нас web-система, с которой работает сразу множество пользователей даже в рамках одного клиента, мы понимаем, что в процессе нашего расчета запросто может возникнуть ситуация, когда движение-к-расчету может быть конкурентно удалено или создано «вот прямо под ногами» в тот самый момент, когда мы рассчитываем этот интервал. И наша реализация должна от такой ситуации страховать алгоритм.
И раз уже все равно «все переделывать», к задаче стало можно подойти более свободно, и ускорить расчет за счет его реализации в многопоточном режиме и оптимизаций работы с БД — теперь те самые «разноцветные» сегменты мы действительно сможем посчитать параллельно за меньшее время.
И последний немаловажный момент — хотелось сократить время расчета для пользователя «до нуля». То есть пользователь еще только закрывает документ, а у него уже движения рассчитались по всем правилам партионного учета. И чтобы несчастному бухгалтеру больше не надо было в конце отчетного периода запускать расчет на всю ночь.
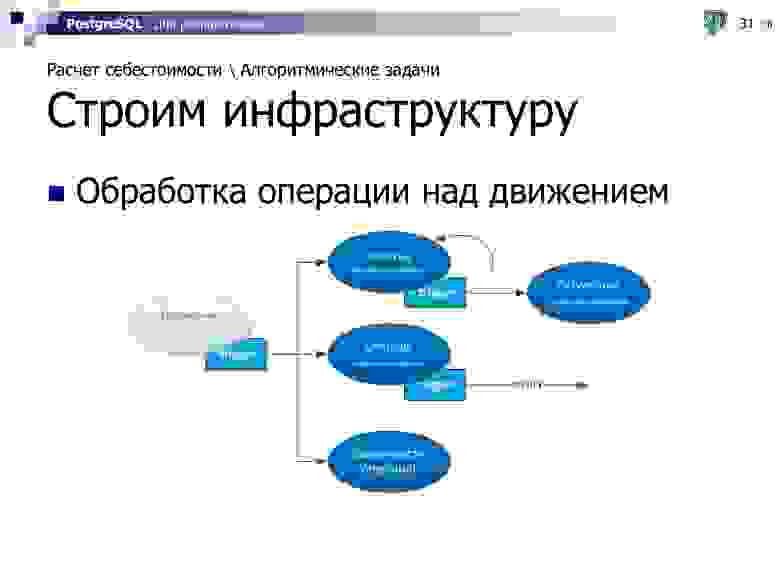
Казалось бы, все хорошо. Наш типовой кейс прост — дождаться сигнала об изменении в данных, быстро все рассчитать и снова ждать. Но так просто взять и сделать — нельзя, будет тормозить, поэтому пришлось построить определенную инфраструктуру, которая завязана на вспомогательные сущности, в дополнение к самим операциям движений.
- На основном сервисе пользователь проводит какие-то операции движений, которые фиксируются в БД.
- Этот сервис «кидает» асинхронное событие в адрес координирующего сервиса расчета себестоимости, который дозирует нагрузку на каждый отдельный экземпляр БД, что вот в этой клиентской схеме есть какая-то работа.
- Сервис инициирует итеративный процесс расчета в контексте конкретного клиента.
Теперь что происходит конкретно в базе:
- Триггер на операциях движений заносит в очередь расчета соответствующие складские карточки с минимальным временем операции по каждой из них и с минимальным же приоритетом.
- Он же формирует запись в таблицу зависимостей, что в такой-то точке во времени, благодаря такой-то операции складская карточка X стала зависеть от карточки Y.
- … на базу асинхронно и многопоточно приходит процесс расчета…
- Извлекаем из очереди первую незаблокированную складскую карточку с максимальным приоритетом.
- Убираем по ней все рассчитанные остатки после соответствующей точки во времени и начинаем считать в отдельной транзакции каждый следующий «квант» (день/месяц/…).
- Если «следующего» нет, то есть больше нет движений по карточке — убираем ее из очереди, мы ее рассчитали до конца.
- Если на «кванте» в соответствии с таблицей зависимостей есть непросчитанные карточки-основания — заносим их в очередь с максимальным приоритетом, а текущий расчет прерываем.
- Если непросчитанных оснований, то…
- вычитываем движения только текущего интервала
- переупорядочиваем для достижения оптимального результата расчета
- заносим результат расчета (дробления по партиям) в отдельную от движений таблицу, где все операции по карточке имеют сквозной порядок в рамках интервала
- заносим в таблицу остатков данные по карточке на конец интервала — количество, сумму, распределение по партиям
- если есть зависимости от нее карточек-следствий на этом «кванте», заносим их в очередь с минимальным приоритетом
То есть для реализации нашего алгоритма потребовалось 4 дополнительные таблицы:
- очередь расчета
которая «растет» в две стороны — как «в плюс», так и «в минус», что определяет приоритет карточки - рассчитанные остатки
на конец каждого интервала по каждой карточке - зависимости
между карточкой-основанием и карточкой-следствием - результаты расчета
дробления по партиям строго в подобранном алгоритмом порядке расчета
Теперь переходим к самому интересному — как же реализовать все, о чем мы говорили выше, и при этом аккуратно обойти все возникающие «грабли».
Решение формировалось еще под версию PostgreSQL 9.1, поэтому тут нет использования позднее появившихся возможностей вроде
SKIP LOCKEDиlock_timeout.

Первое с чем мы сразу встречаемся — это «проведение» записей наименований при «закрытии» складского документа. Самый простой вариант — сделать обычный UPDATE сразу по всем наименованиям. Но если в какой-то момент оказывалось два одновременно обрабатываемых документа с разным порядком одних и тех же складских карточек — deadlock.
Решением стало принудительное упорядочивание записей при обработке. Это может быть как хранимая процедура, так и DO-блок:
FOR id IN (SELECT … ORDER BY Номенклатура, Склад, @НД) LOOP
UPDATE … WHERE @НД = id;
END LOOP;
Причем важно сохранять один и тот же порядок не только в этом месте, но и на всем протяжении работы алгоритма.

Следующий момент, который помог все сделать хорошо — это короткие транзакции.
У нас вообще web-система, поэтому держать длинные транзакции нехорошо в PostgreSQL — это приводит к различным долговременным блокировкам, к дополнительной нагрузке на сервер. Поэтому если есть возможность сделать что-то с помощью маленьких транзакций — лучше так и сделать.
В результате, мы получаем большое количество мелких транзакций, которые как муравьи на сервере суетятся, но друг другу не мешают и сообща делают одну и ту же работу. Чтобы этого добиться, использовали следующие подходы:
- обрабатываем мало данных
но много-много раз - быстро заканчиваем
то есть нормируем время на все собственные «тупняки», чтобы никому не мешать - максимально быстро
используем понимание внутренних механизмов PostgreSQL
В соответствии с приведенным выше алгоритмом самым разумным оказалось сделать транзакцию для расчета ровно одного «кванта» — то есть при базовых настройках это будут движения за один день по одной складской карточке.
Ну и чтобы остатки по карточке, от которых мы «стартуем» при расчете «кванта» не перевычислять каждый раз, мы их просто сохраняем в базе.

Точно так же мы не пытаемся получить расчет карточек-оснований по зависимостям «здесь и сейчас», а выносим в другую транзакцию их с помощью очереди.
И вообще — где можно «разрываем» длинную транзакцию с помощью очереди. Не рассчитано основание? В очередь! Надо будет посчитать потом следствие? В очередь! Вот когда очередь до них дойдет, тогда и будем с ними разбираться, а в текущей транзакции делаем все максимально быстро и поэтому никого не ждем.
Можно «не ждать» с помощью NOWAIT в запросе, но это не очень хорошо, если блокировка чаще всего существует. Так мы будем постоянно вылетать в EXCEPTION и либо получать «мусор» в логе, либо придется писать хранимую процедуру/DO-блок для изоляции такого запроса.
Мы понимаем, что в условиях коротких транзакций, блокировка если и есть, то долго не продлится. Поэтому мы можем воспользоваться установкой ключевого параметра statement_timeout и переопределить его тем значением, которое нас устраивает для «ну столько-то еще можно подождать».
Ну а уж если за таймаут дождаться блокировки не удалось — только тогда и получаем EXCEPTION. А во всех остальных случаях, даже если нам пришлось немного подождать, но мы все-таки дождались результата — то хорошо, и мы продолжаем нормально работать, и никаких ошибок ни у кого не возникает.
Но даже если ошибка возникла, и мы «упали» при слишком длинном ожидании результата запроса — это не трагедия, а вполне нормально. Поскольку транзакции короткие — мы достаточно безболезненно делаем ее ROLLBACK и пытаемся повторить снова и снова, пока она успешно не выполнится. Как правило, хватает единичного повтора.

Чтобы у нас все работало максимально быстро, мы «фиксируем карточку» на соединении с БД. Это означает, что если нам надо просчитать, например, соль на интервале последней недели, а на базе расчетом одновременно занимается несколько потоков (каждый на отдельном соединении с БД, конечно), то всю соль за все дни нам эффективнее обработать в одном потоке.
Несмотря на то, что это будут разные транзакции, лучше это соединение никому конкурирующему не отдавать. Потому что при расчете одной и той же складской карточки нам приходится обращаться к базе практически за одними и теми же данными, одними и теми же сегментами индекса, разве что «чуть-чуть в сторону». А эти данные уже находятся в локальной памяти процесса PG, который обслуживает наше подключение к базе.
Есть небольшая проблема, что если вся ваша инфраструктура настроена на работу через pgbouncer в transaction mode, то так зафиксировать соединение не удастся. Поэтому если возникает задача, когда предполагается высокая нагрузка на базу — лучше иметь отдельный прямой коннект до базы, который от вас никуда не «убегает» и который вам никто не подменяет «втемную».

Следующий момент, который помогает добиться максимальной производительности — минимизация количества данных, которыми клиентский процесс обменивается с базой. Поэтому для хранения промежуточных результатов расчета используем временную таблицу, которая зачищается при завершении транзакции.
Про особенности работы с временными таблицами в PostgreSQL и способами их наиболее эффективного использования уже есть отдельная статья.

И третий аспект «ускорялок» — использование prepared statements. Достаточно простой синтаксис — PREPARE/EXECUTE, но дает устранение достаточно существенных задержек на разбор текста запроса.
Если у нас идут тысячи однотипных и простых запросов, которые повторяются из раза в раз и отличаются только значением параметра, то можно получить ускорение до 4-10мс на каждый запрос, а иногда и вовсе до нуля.
То есть иногда реально доходит до того, что начинаешь замерять производительность, получаешь два таймстампа одинаковых (с точностью до миллисекунд, конечно) — до получения данных и после получения данных, при этом данные-то ты получил.
А раз базе данных не требуется больше каждый раз заниматься разбором текстов наших запросов, то и нагрузка на CPU от обслуживающего наше подключение процесса легко уменьшается в 1.5 раза.

Поскольку расчет у нас ведется многопоточно, то необходима некоторая точка синхронизации этих потоков, чтобы распределять между ними задачи. В нашем случае мы ее реализовали с помощью единой таблицы-очереди заданий, которая хранится непосредственно в базе данных.
С точки зрения обслуживания высококонкурентной очереди заданий есть три ключевых момента:
- распределение обработки
как именно поделить весь фронт работы между worker’ами - защита от конкурента
от удаления или вставки записей сторонними процессами - оптимизация нагрузки
сама координация работы не должна стоить слишком «дорого»
Для распределения работы есть два основных метода:
- push
Из самой очереди последовательно вычитывает данные только выделенный процесс-координатор, и самостоятельно раздает задачи каждому из worker’ов. Это приводит к двум ограничениям:- пропускная способность координатора конечна и не масштабируется, при этом в случае возникновения в нем ошибки встает сразу вся работа
- очередь должна быть строго однонаправленной, чтобы координатору было понятно, в какую сторону дальше читать
- pull
Независимые одинаковые worker’ы «вытаскивают» данные из очереди самостоятельно. При этом очередь может изменяться произвольно — как раз наш вариант!

Вариант конкурентной производительной очереди на PostgreSQL можно реализовать с помощью рекомендательных блокировок (advisory locks) по модели, изначально предложенной DmitryKoterov в одной из своих статей (архив).
Более подробно про рекомендательные блокировки, связанные с ними проблемы и решения можно ознакомиться в статье «Фантастические advisory locks, и где они обитают».
Про способы борьбы с «разбуханием» таблицы-очереди в условиях работы механизма MVCC в окружении длинных транзакций читайте в «DBA: когда пасует VACUUM — чистим таблицу вручную».

С действиями конкурирующих на базе процессов проблемы возникают не только при обслуживании очереди, но и при обработке самих данных.
Например, «дыра» в рассчитанных остатках может возникнуть, если кто-то уже успеет удалить последнюю запись, которая еще существовала на момент начала нашей итерации расчета.
Чтобы защититься от такой ситуации — используем SELECT ... FOR UPDATE. В таком случае уже никакой конкурирующий DELETE не сможет «выдернуть» их у нас из-под ног. Точнее, будет пытаться и повиснет в блокировке — ну и пускай висит, мы его надолго не задержим, зато вся цепочка рассчитанных остатков у нас всегда будет в целостном состоянии.

Но защита помогает не всегда — например, если пользователь параллельно удаляет или добавляет движение в «квант», который мы прямо сейчас считаем. То есть он еще никогда не был рассчитан и не существует той записи остатков, которую можно было бы заблокировать.

Но все-таки существует возможность узнать, что состояние движений «кванта» изменилось. Для этого достаточно ввести версию в запись очереди, которая инкрементится триггером при каждой операции с движениями по карточке.
Вычитываем ее вместе с записью из очереди в начале нашей транзакции, повторно вычитываем в конце — и если они не совпали, уходим на ROLLBACK. Да, мы не сможем понять что именно изменилось и как, но нам это и не нужно — ведь транзакции у нас очень быстрые.
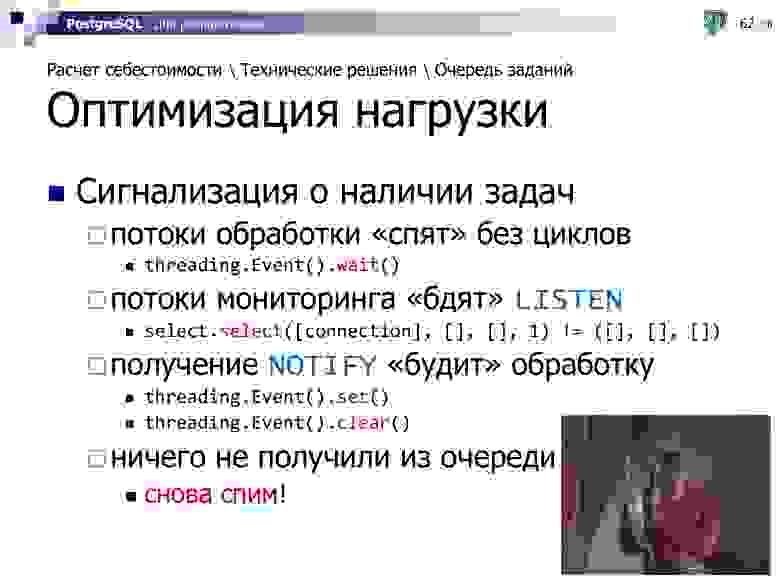
Но чтобы эти предельно быстрые транзакции не «ушатали» все вместе базу, нагрузку надо дозировать. И, как минимум, не работать, пока это никому не нужно.
Мы можем рассчитывать все в несколько потоков, но обычно-то карточка к расчету оказывается всего одна, и заставлять «соседей» итерировать попусту — только базу грузить. Поэтому лучше заставить эти потоки «спать», пока триггер на вставку в очередь не пришлет им NOTIFY, что появилось что-то новое.
Как показывает практика, в большинстве случаев уже первый поток справляется с расчетом настолько быстро, что дополнительные потоки даже не успевают стартовать. Поэтому нагрузка на базу минимальна и исходит только от того потока, которому работа все-таки досталась.

Второй момент, который позволяет оптимизировать нагрузку на базе — это отложенный старт обработки. Идея в том, что даже при поступлении сигнала потоки не должны ломиться все одновременно и создавать «шторм».
При этом, как правило, работа-то достанется только одному из них, потому что обычно ее там нет для полной загрузки. Поэтому мы можем спокойно «докидывать» новые worker’ы с паузой, например, в 10мс, пока работа все еще есть. Если же мы за первые 10мс уже все успели сделать, то дополнительные потоки никак не будут задействованы.
Да, в некоторых крайне редких случаях такой подход может снизить максимальную пропускную способность обработки, зато в большинстве типовых ситуаций он и сэкономит ресурсы, и позволит избежать пиковой нагрузки.
Ну а если вдруг в одном из потоков случилась какая-то ошибка — давайте просто немного подождем. Если причиной стала какая-то блокировка, которая нам помешала, она наверняка успеет «рассосаться» за это время, а потоки-соседи не дадут очереди простаивать, пока мы «отдыхаем».

В итоге, эти подходы помогли снизить суммарную нагрузку на БД/БЛ примерно в 4 раза!
Ну и, в очередной раз, призываю всех — измеряйте все, до чего можете дотянуться:
- пропускную способность вашего решения (op/s)
- длину очереди и количество активных worker’ов
- задержку от поступления записи в очередь до обработки
- фактическую нагрузку, которая создается на «железе»