i
Уведомление:
Общие вопросы по жестким дискам обсуждаются в этой теме.
Там же вы можете найти ряд программ для работы с жесткими дисками.
Что такое S.M.A.R.T.?
— Self-Monitoring, Analysis and Reporting Technology — технология оценки состояния жёсткого диска системой интегрированной аппаратной самодиагностики/самонаблюдения. Основная задача — определить вероятность выхода устройства из строя, предотвратив потерю данных.
Почему показания S.M.A.R.T. жестких дисков различных вендоров (производителей) отличаются?
— Потому что технология развивалась поэтапно, и внедрялась отдельно каждым производителем по-своему: сначала IBM с технологией PFA (Predictive Failure Analysis), потом Compaq с IntelliSafe, затем по инициативе Compaq, компаниями IBM, Seagate, Quantum, Conner и Western Digital было создано стандартизованное подобие нынешнего S.M.A.R.T. симбиозом IntelliSafe и PFA.
— Стандарт SMART I предполагал мониторинг основных параметров и запускался только после команды по интерфейсу.
— Созданию стандарта SMART II способствовали инновации компании Hitachi: методика полной самодиагностики накопителя (Extended Self-Test) и журналирование ошибок.
— Стандарт SMART III обеспечил прозрачное наблюдение за состоянием диска с функцией обнаружения дефектов поверхности и возможностью их восстановления.
— Современные атрибуты S.M.A.R.T. могут различаться для каждого отдельно взятого диска.
Каким образом можно получить показания S.M.A.R.T.?
— С помощью специализированного софта:
— HDTune (вкладка Health/Здоровье)
— Victoria (Документация)
— CrystalDiskInfo
— Advanced SmartCheck
— Hard Disk Sentinel
— Фирменные утилиты SeaGate
— Фирменные утилиты Samsung
— Фирменные утилиты Hitachi
— Фирменные утилиты WD
—- Caviar Green/GP
—- Caviar Blue/SE/SE16 (SATA II)
—- Caviar Black
—- RE3
—- RE4
Что такое система само-тестирования (само-диагностики) диска?
— Иногда диск производит самопроверку, поэтому не пугайтесь, если заметите, что в тот момент, когда никаких интенсивных операций в системе не проходит, а диск на некоторое время начинает интенсивно трещать. Такие операции часто запускаются в том случае, если у вас имеются «pending сектора». Диск сам начнет (в момент минимальной нагрузки) перепроверять «кандидата», для того, чтобы исключить его из списка подозрения, либо наоборот исключить из относительной индексации.
— Документировано существует три типа тестов само-диагностики:
— Фоновый сбор данных (Off-line collection);
— Сокращенный тест (Short Self-test);
— Расширенный тест (Extended Self-test).
— Два последних способны выполняться как в автономном (off-line), так и в монопольном (on-line) режимах. Продолжительность их выполнения может длиться от нескольких секунд до минут и даже часов.
— Во время автономного тестирования возможно выполнение других команд, так как тестирование происходит в фоновом режиме. Во время монопольного режима тестирования выполнение других команд невозможно. Попытка исполнить другую команду приведет к прерыванию теста.
— Типичная задача само-тестирования — избавиться от «бэдов». Нужно заметить, что «релоки» могут быть (почти гарантированно) на диске сразу после его покупки «с нуля». Они будут находится в заводской резервной зоне (Primary list). Уже при непосредственной эксплуатации будет формироваться вторичный резерв (Growth list).
— Заметьте, «ремап» не может происходить до бесконечности, потому как объем пользовательской резервной зоны ограничен. Поэтому не удивляйтесь, если вдруг ваш «умирающий» диск (если вы по показаниям смарта заранее это определили) вдруг резко перестанет работать, хотя до этого вроде как худо-бедно трудился — он сам до отказа заполнит резерв «релоками», после чего уже не будет производить «ремап», и вы начнете терять данные. В том случае, если на «бэд-сектор» системного диска попадет системный файл, вы рискуете полюбоваться «синькой» (Blue Screen Of Death), с последующей невозможностью загрузки системы.
Атрибуты S.M.A.R.T.
— Это характеристики, использующиеся при анализе состояния надежности накопителя.
Значения атрибутов S.M.A.R.T.
— Столбцы:
— Value/Current — текущее значение (в диапазоне от 0/1 до 100/200/255) — надежность конкретного атрибута относительно его эталонного значения, которое определяется производителем.
—Максимальное значение атрибута означает максимальную стабильность. Чем значение ниже, тем быстрее текущий параметр деградирует.
— Worst — означает наихудшее из всех когда-либо запротоколированных значений, т.е. наихудшее (бывшее) состояние атрибута.
— Threshold — пороговое значение для каждого отдельно взятого атрибута.
—Если текущее значение атрибута ниже, чем пороговое, значит вероятность отказа (если этот параметр критичен) велика.
— Raw — значение атрибута во внутреннем формате. Иногда значения могут нести бесполезную нагрузку, гораздо важнее, что из них вычисляется преобразованное значение.
— Data — преобразованное значение атрибута, в большинстве случаев говорящее о состоянии параметра в доступной для восприятия форме.
— Строки:
Основные критические (непосредственно влияющие на надежность работы диска) атрибуты:
— Raw Read Error Rate — частота ошибок при чтении данных с поверхности диска. Возникает в случае, когда при единовременном проходе, головке не удается произвести чтение ячейки. Увеличение параметра вызвано обычно аппаратными неполадками.
— Soft Read Error Rate — частота появления «программных» ошибок при чтении данных с диска. В данном случае виновата не аппаратная часть, а логическая (ошибка микропрограммы диска).
— Write Error Rate — частота появления ошибок записи. Вызвана в большинстве своем неполадками механики.
— Seek Error Rate — ошибки позиционирования головки. Вызваны неполадками движущей механики, либо повреждением «сервометок» (servo)из-за сильного термического расширения дисков или «промахом» самой головки.
— Магнитная головка знает в какое положение относительно дорожки диска ей необходимо закрепиться (сверяя свое положение по сервометкам) для того, чтобы попасть туда, куда нужно и считать запрашиваемую информацию с определенного адреса, и если ее местоположение не совпадает с реальной позицией над запрашиваемой дорожкой, то возникает ошибка позиционирования.
— End-to-End error — ошибка четности при передаче данных между кэшем и хостом.
— Reported Uncorrectable Errors — ошибки, которые не удается исправить методами аппаратной коррекции.
— Current Pending Sector Count — при единовременном проходе у головки может не получиться считать данные с ячейки, в таком случае эта ячейка будет помечена «кандидатом на замену». Параметр этот может меняться, потому как неудача иногда возникает по вине самой головки (когда она виновата в том, что «промахнулась») хотя ячейка при этом исправна. При повторном проходе статус может быть снят, в том случае, если чтение удалось осуществить успешно. Если этот параметр всегда нулевой, это может говорить о том, что качество само-тестирования на низком уровне.
— Reallocated Sectors Count — количество «переназначенных секторов» (remap). Если магнитной головке жесткого диска не удается при нескольких проходах произвести чтение/запись/верификацию ячейки, микропрограмма попытается переместить данные в резервную область диска (spare area — она не входит в область основной разметки) и, в случае успеха, помечает сектор как «переназначенный», т.е. при каждом запросе на чтение данных из этой ячейки, будет происходить «перенаправление» (redirect) на ее резерв, следовательно физически этот переназначенный сектор больше не будет использоваться.
— Благодаря «ремапу», на современных жестких дисках очень редко видны (при тестировании поверхности) «битые сектора» (bad block). Если на графике чтения с поверхности будут заметны «провалы» — резкое падение скорости чтения (до 10% и более), значит вероятны 2 варианта:
—- В этот момент к диску поступило обращение сторонней команды (например, системы);
—- На нем слишком много «ремапов», и головке приходится скакать туда-сюда по поверхности диска из основной разметки в резервную.
— Reallocation Event Count — количество попыток «ремапа». В поле атрибута (raw value) хранится общее число попыток (как успешные, так и безуспешные) переноса информации с переназначенных секторов в резервную область.
— Spin Up Retry Count — число повторных попыток раскрутки шпинделя до рабочей скорости. Возрастание значения говорит о том, что диски по той или иной причине не получилось вывести на расчетную скорость вращения с первой попытки. Ошибки обычно вызваны аппаратными проблемами.
— Recalibration Retries — количество повторов попыток рекалибровки. Неполадки механики иногда приводят к тому, что диску приходится сбросить состояние позиционирования головки в нулевую дорожку. Значения этого атрибута засчитывается в том случае, если рекалибровка происходила большее количество раз, чем положено.
— Read Error Retry Rate — количество повторных операций чтения ячейки. Возрастание параметра атрибута может говорить как о проблемах поверхности диска, так и некорректном функцмонировании считывающей головки.
— Soft ECC correction — количество ошибок ECC (Error-Correcting Code — код коррекции ошибок), удачно скорректированных программным способом.
— Power-off Retract Count — количество операций вывода блока магнитных головок из рабочей зоны в парковочную, результатом которых послужил перебой питания диска.
— Run Out Cancel — количество операций коррекции данных из-за неправильной хэш-суммы.
— Hardware ECC Recovered — число коррекции ошибок аппаратной частью диска (ошибок чтения, ошибок позиционирования, ошибок передачи по интерфейсу).
— Uncorrectable Sector Count — если обычно после ошибки чтения микропрограмма пытается исправить положение дел, то этот параметр показывает те случаи, когда коррекцию произвести не удалось. Чаще всего причина кроется в критической неисправности механики/аппаратной части, либо при наличии софт-бэда.
— UltraDMA CRC Error Count — количество ошибок CRC (контроль целостности передачи данных) при обмене данными между диском и контроллером в режиме UltraDMA по контрольной сумме.
— Ошибка может возникать в нескольких случаях:
—- При сильном завышении частоты PCI (больше номинальных 33.3 MHz);
—- При надломленном или сильно закрученном кабеле;
—- При ошибке драйверов ОС (при чем не только драйверов жесткого диска);
—- При сбое в работе (например, при внезапном скачке напряжения или отключения питания компьютера), когда посланные диском пакеты не доходят до контроллера.
— Command Timeout — количество операций, отмененных по превышении предела ожидания. Возникают такие ошибки обычно при неисправном кабеле или сбоях в подаче питания.
— High Fly Writes — количество операций записи произведенных при положении магнитной головки выше номинального значения (head flying range).
— Disk Shift — дистанция смещения блока дисков относительно шпинделя. В основном возникает из-за удара или падения.
— G-Sense Error Rate — атрибут хранит показания ударо-чувствительного сенсора — общее количество ошибок, возникших в результате полученных накопителем внешних ударных нагрузок (при падении, толчке, излишней вибрации, неправильной установке, и т.п.).
Некритические атрибуты, сообщающие служебную информацию, не оказывающую прямого влияния на надежность диска.
— Throughput Performance — средняя производительность диска по оценки программы само-диагностики. Регламентируется производителем.
— Seek Time Performance — средняя производительность операции позиционирования магнитными головками. Аппаратно зависимый параметр.
— Spin Up Time — время, затрачиваемое шпиндлем для того, чтобы выйти на расчетную скорость вращения. Ухудшение значение атрибута указывает на проблемы с приводом или подшипником.
— Start/Stop Count — количество зафиксированных циклов запуска/остановки шпинделя.
— Power-On Time Count — общее количество часов в рабочем состоянии. Значение зависит от отдельно взятого диска/производителя.
— Power On/Off Retract Cycle — количество зафиксированных циклов полного включения/отключения.
— Load/Unload Cycle Count — количество операция вывода блока магнитных головок в или из рабочей зоны.
— Head Flying Hours — общее время, затраченное на позиционирование БМГ.
Пример показаний S.M.A.R.T. исправного диска:
Пример показаний S.M.A.R.T. неисправного диска:
При включении компьютера после POST’а вы увидите предупреждение «S.M.A.R.T. status BAD»:
Что такое «бэды»?
— «Бэды» (bad block) — это ячейки диска, непригодные для хранения информации.
— «Аппаратные бэды» — аппаратно неисправная область поверхности диска, которую никак не исправить кроме извлечения из относительной адресации (remap);
— «Софтовые бэды» («софт-бэд») — ячейки, которые невозможно использовать из-за неисправностей логического характера. «Лечатся» программой «erase»: магнитная головка заполняет область диска нулями, уничтожая таким образом и данные в ячейках, и неисправности.
Изменено 29 октября, 2010 пользователем Cameroon
Эту статью не следует рассматривать как руководство пользователя или документацию для программистов.
Цель проделанной мною работы — попытаться разьяснить в приличной, доступной, а главное — рускоязычной форме, все особенности данной технологии. Естесственно, охватить ПОЛНОСТЬЮ все возможности технологии S.M.A.R.T. просто не возможно по причине ужасающего факта отсутствия какой-либо документации и нежелания подавляющего числа производителей жестких дисков предоставить необходимую информацию или вести какие-либо переговоры.
Текст статьи постоянно обновляется, поэтому на возможные неточности и грамматические ошибки прошу не обращать внимания. Но если Вы заметите явную ошибку или «ужасающую»  неточность — пожалуйста, напишите мне об этом.
неточность — пожалуйста, напишите мне об этом.
Я с удовольствием приму любые комментарии по тексту, а также Ваши пожелания и дополнения.
1.1. Общее описание.
Технология S.M.A.R.T. — Self-Monitoring, Analysis and Reporting Technology (от англ. «Технология Самодиагностики, Анализа и Отчета») — была разработана для повышения надежности и сохранности данных на жестких дисках. В большинстве случаев, SMART-совместимые устройства позволяют предсказать появление наиболее вероятных ошибок и, тем самым, дают пользователю возможность своевременно сделать резервную копию данных и/или полностью заменить накопитель до выхода его из строя.
S.M.A.R.T. представляет собой набор мини-подпрограмм, которые являются частью микрокода накопителя и определяют поддерживаемые диагностические функции. Наиболее распространенные среди них:
- набор атрибутов, отражающих состояние отдельных параметров накопителя (до 30)
- внутренние тесты накопителя (self-test)
- журналы S.M.A.R.T. (ошибок, общего состояния, дефектных секторов и т.п.)
В настоящий момент не существует официальной документации или стандарта на технологию S.M.A.R.T. В связи с этим, производители не публикуют полные характеристики и поддерживаемые функции S.M.A.R.T. в своих накопителях. Обязательный минимум описан в последнем стандарте ATA/ATAPI-6.
1.2. Развитие технологии S.M.A.R.T.
История технологии S.M.A.R.T. не так уж и богата подробностями:
-
SMART I предусматривал мониторинг основных жизненно важных параметров и запускался только после команды по интерфейсу
-
в SMART II появилась возможность фоновой проверки поверхности, которая выполнялась накопителем автоматически во время «холостого хода»; появилась функция журналирования ошибок
-
в SMART III впервые появилась не только функция обнаружения дефектов поверхности, но и возможность их восстановления «прозрачно» для пользователя и многие другие новшества
Известно, что первыми разработали основы и предложили эту технологию совместно Western Digital, Seagate и Quantum. После этого их уже поддержали такие компании как IBM, Maxtor и Samsung. Hitachi приняла участие в развитии технологии S.M.A.R.T. уже на стадии разработки SMART II, первыми предложив методику полной самодиагностики накопителя (extended self-test).
В настоящее время производители жестких дисков готовятся принять к использованию новый вариант технологии S.M.A.R.T. — «1024 S.M.A.R.T.», характерной особенностью которого будет заметно бОльший размер журналов, повсеместное использование мультисекторных журналов, более точные алгоритмы анализа показаний встроенных в накопитель сенсоров (термодатчики, сенсоры ударов, и т.п.) и многое другое. Вот несколько новых функций:
-
введение алгоритма анализа температурного режима накопителя
-
введение ограничения по минимальной и максимальной температуре в рабочем состоянии
-
введение счетчика общего количества записанных секторов на протяжении жизненного цикла накопителя
-
введение счетчика запусков внутренних алгоритмов восстановления (recovery counters)
Главным же плюсом можно считать введение новых атрибутов, которые позволят контролировать состояние и рабочие характеристики по каждой из головок чтения/записи:
-
относительная устойчивость (стабильность «полета») головки
-
исправление ошибок чтения (со «скрытыми» повторными попытками)
-
автоматическое перераспределение дефектных участков поверхности при операциях записи
-
счетчик-накопитель G-List для учета количества принятых ударных нагрузок
-
счетчик-накопитель S-List для учета общего количества «программных» ошибок
Атрибуты.
Атрибуты S.M.A.R.T. — особые характеристики, которые используются при анализе состояния и запаса производительности накопителя. Атрибуты выбираются производителем накопителя, основываясь на способности этих атрибутов предсказывать ухудшение рабочих характеристик накопителя или определить его дефектность. Каждый производитель имеет свой характерный набор атрибутов и может свободно вносить изменения в этот набор в соответствиии со своими собственными требованиями и без уведомления об этом фирм-продавцов и конечных пользователей.
1.3.1. Значения атрибутов.
Значения атрибутов (value) используются для представления относительной надежности отдельного эксплуатационного или эталонного атрибута. Допустимое значение атрибута лежит в диапазоне от 1 до 255. Высокое значение атрибута говорит о том, что результат анализа данной рабочей характеристики указывает на низкую вероятность ее ухудшения или выхода накопителя из строя. Соответственно, низкое значение атрибута говорит о том, что результат анализа данной рабочей характеристики указывает на высокую вероятность ее ухудшения или выхода накопителя из строя.
1.3.2. Пороговые значения атрибутов.
Каждый атрибут имеет собственное пороговое значение (threshold), которое используется для сравнения со значением атрибута (value) и указывает на ухудшение рабочих характеристик или дефектность накопителя. Числовое значение порогового атрибута определяется производителем накопителя через конструкционные особенности накопителя и анализ результатов испытаний на надежность. Пороговое значение каждого атрибута указывает на нижнюю допустимую границу значения атрибута, вплоть до которой сохраняется положительный статус надежности.
Пороговые значения устанавливаются в заводских условиях производителем накопителя и, в большинстве случаев, могут быть изменены только после переключения накопителя в технологический (factory mode). Допустимое пороговое значение атрибута может находится в диапазоне от 1 до 255.
Если значение одного или более атрибутов, имеющих тип pre-failure (в HDD Speed отмечаются символом «*«), меньше или равно соответствующего порогового значения, то это свидетельствует о предстоящем ухудшении рабочих характеристик и/или полном выходе накопителя из строя.
1.3.3. Краткое описание основных атрибутов.
Данный перечень атрибутов является наиболее полным из доступных на сегодняшний момент в Сети или иных источниках. Назначение атрибутов и способ интерпретации их значений выявлены либо опытным путем, либо получены от служб технической поддержки компаний-производителей накопителей.
Ниже приведена сводная таблица всех известных мне атрибутов (55) и краткое описание к большинству (38) из них.
| ID | Название атрибута |
|---|---|
| 0 | = атрибут не используется |
| 1 | Raw Read Error Rate |
| 2 | Throughput Performance |
| 3 | Spin Up Time |
| 4 | Start/Stop Count |
| 5 | Reallocated Sector Count |
| 6 | Read Channel Margin |
| 7 | Seek Error Rate |
| 8 | Seek Time Performance |
| 9 | Power-On Hours Count |
| 10 | Spin Retry Count |
| 11 | Recalibration Retries |
| 12 | Device Power Cycle Count |
| 13 | Soft Read Error Rate |
| ?? | Emergency Re-track (Hitachi) |
| ?? | ECC On-The-Fly Count (Hitachi) |
| 96 | ? (Maxtor) |
| 97 | ? (Maxtor) |
| 98 | ? (Maxtor) |
| 99 | ? (Maxtor) |
| 100 | ? (Maxtor) |
| 101 | ? (Maxtor) |
| 191 | G-Sense Error Rate |
| 192 | Power-Off Retract Cycle |
| 193 | Load/Unload Cycle Count |
| 194 | Temperature |
| 195 | ? (Quantum AS, Seagate, Maxtor) |
| 196 | Reallocation Events Count |
| 197 | Current Pending Sector Count |
| 198 | Uncorrectable Sector Count |
| 199 | UltraDMA CRC Error Rate |
| 200 | Write Error Rate (в WD — MultiZone Error Rate) |
| 201 | TA Counter Detected |
| 202 | TA Counter Increased |
| 203 | ? (Maxtor) |
| 204 | ? (Maxtor) |
| 205 | ? (Maxtor) |
| 206 | ? (Maxtor) |
| 207 | ? (Maxtor) |
| 208 | ? (Maxtor) |
| 209 | ? (Maxtor) |
| 220 | Disk Shift |
| 221 | G-Sense Error Rate (в Hitachi — Shock Sense Error Rate) |
| 222 | Loaded Hours |
| 223 | Load/Unload Retry Count |
| 224 | Load Friction |
| 225 | Load/Unload Cycle Count |
| 226 | Load-in Time |
| 227 | Torque Amplification Count |
| 228 | Power-Off Retract Count |
| 229 | ? (IBM DTTA, thanx to Vladislav Shaklein) |
| 230 | GMR Head Amplitude |
| 231 | Temperature |
| 240 | Head Flying Hours (Hitachi) |
| 250 | Read Error Retry Rate |
Краткое описание известных атрибутов.
-
* (используется в программе HDD Speed)
Данный указатель показывает, что соответствующий атрибут S.M.A.R.T. является критическим для нормального функционирования накопителя. Ухудшение значений таких атрибутов с наибольшей вероятностью приводит к выходу накопителя из строя. В новых материнских платах BIOS имеют встроенную функцию контроля состояния накопителя именно по этим атрибутам. -
Raw Read Error Rate
Частота появления ошибок при чтении данных с диска.
Данный параметр показывает частоту появления ошибок при операциях чтения с поверхности диска по вине аппаратной части накопителя. -
Throughput Performance
Средняя производительность (пропускная способность) диска.Уменьшение значения value этого атрибута с большой вероятностью указывает на проблемы в накопителе.
-
Spin Up Time
Время раскрутки шпинделя.
Среднее время раскрутки шпинделя диска от 0 RPM до рабочей скорости. Предположительно, в поле raw value содержится время в миллисекундах/секундах. -
Start/Stop Count
Количество циклов запуск/останов шпинделя.
Поле raw value хранит общее количество включений/выключений диска. -
Reallocated Sectors Count
Количество переназначенных секторов.
Когда жесткий диск встречает ошибку чтения/записи/верификации он пытается переместить данные из него в специальную резервную область (spare area) и, в случае успеха, помечает сектор как «переназначенный». Также, этот процесс называют remapping, а переназначенный сектор — remap. Благодаря этой возможности, на современных жестких дисках очень редко видны [при тестировании поверхности] так называемые bad block. Однако, при большом количестве ремапов, на графике чтения с поверхности будут заметны «провалы» — резкое падение скорости чтения (до 10% и более).
Поле raw value содержит общее количество переназначенных секторов. -
Read Channel Margin
Запас канала чтения.
Назначение этого атрибута не документировано и в современных накопителях он не используется. -
Seek Error Rate
Частота появления ошибок позиционирования БМГ.
В случае сбоя в механической системе позиционирования, повреждения сервометок (servo), сильного термического расширения дисков и т.п. возникают ошибки позиционирования. Чем их больше, тем хуже состояние механики и/или поверхности жесткого диска. -
Seek Time Performance
Средняя производительность операций позиционирования БМГ.
Данный параметр показывает среднюю скорость позиционирования привода БМГ на указанный сектор. Снижение значения этого атрибута говорит о неполадках в механике привода. -
Power-On Hours
Количество отработанных часов во включенном состоянии.
Поле raw value этого атрибута показывает количество часов (минут, секунд — в зависимости от производителя), отработанных жестким диском. Снижение значения (value) атрибута до критического уровня (threshold) указывает на выработку диском ресурса (MTBF — Mean Time Between Failures). На практике, даже падение этого атрибута до нулевого значения не всегда указывает на реальное исчерпывание ресурса и накопитель может продолжать нормально функционировать. -
Spin Retry Count
Количество повторов попыток старта шпинделя диска.
Данный атрибут фиксирует общее количество попыток раскрутки шпинделя и его выхода на рабочую скорость, при условии, что первая попытка была неудачной. Снижение значения этого атрибута говорит о неполадках в механике привода. -
Recalibration Retries
Количество повторов попыток рекалибровки накопителя.
Данный атрибут фиксирует общее количество попыток сброса состояния накопителя и установки головок на нулевую дорожку, при условии, что первая попытка была неудачной. Снижение значения этого атрибута говорит о неполадках в механике привода. -
Device Power Cycle Count
Количество полных циклов запуска/останова жесткого диска. -
Soft Read Error Rate
Частота появления «программных» ошибок при чтении данных с диска.
Данный параметр показывает частоту появления ошибок при операциях чтения с поверхности диска по вине программного обеспечения, а не аппаратной части накопителя. -
Emergency Re-track
-
ECC On-The-Fly Count
-
Load/Unload Cycle Count
Количество циклов вывода БМГ в специальную парковочную зону/в рабочее положение.
Подробнее — см. описание технологии Head Load/Unload Technology. -
Temperature
Температура.
Данный параметр отражает в поле raw value показание встроенного температурного сенсора в градусах Цельсия. -
Reallocation Event Count
Количество операций переназначения (ремаппинга).
Поле raw value этого атрибута показывает общее количество попыток переназначения сбойных секторов в резервную область, предпринятых накопителем. При этом, учитываются как успешные, так и неудачные операции. -
Current Pending Sector Count
Текущее количество нестабильных секторов.
Поле raw value этого атрибута показывает общее количество секторов, которые накопитель в данный момент считает претендентами на переназначение в резервную область (remap). Если в дальнейшем какой-то из этих секторов будет прочитан успешно, то он исключается из списка претендентов. Если же чтение сектора будет сопровождаться ошибками, то накопитель попытается восстановить данные и перенести их в резервную область, а сам сектор пометить как переназначенный (remapped). Постоянно ненулевое значение raw value этого атрибута говорит о низком качестве (отдельной зоны) поверхности диска. -
Uncorrectable Sector Count
Количество нескорректированных ошибок.
Атрибут показывает общее количество ошибок, возникших при чтении/записи сектора и которые не удалось скорректировать. Рост значения в поле raw value этого атрибута указывает на явные дефекты поверхности и/или проблемы в работе механики накопителя. -
UltraDMA CRC Error Count
Общее количество ошибок CRC в режиме UltraDMA.
Поле raw value содержит количество ошибок, возникших в режиме передачи данных UltraDMA в контрольной сумме (ICRC — Interface CRC).Примечание автора
. Практика, собранная статистика и изучение журналов ошибок SMART показывают: в большинстве случаев ошибки CRC возникают при сильном завышении частоты PCI (больше номинальных 33.6 MHz), сильно перекрученом кабеле, а также — по вине драйверов ОС, которые не соблюдают требований к передачи/приему данных в режимах UltraDMA.
-
Write Error Rate (Multi Zone Error Rate)
Частота появления ошибок при записи данных.
Показывает общее количество ошибок, обнаруженных во время записи сектора. Чем больше значение в поле raw value (и ниже значение value), тем хуже состояние поверхности диска и/или механики привода. -
Disk Shift
Сдвиг пакета дисков относительно оси шпинделя.
Актуальное значение атрибута содержится в поле raw value. Единицы измерения — не известны.
Подробности — см. в описании технологии G-Force Protection.Примечание
. Сдвиг пакета дисков возможен в результате сильной ударной нагрузки на накопитель в результате его падения или по иным причинам.
-
G-Sense Error Rate
Частота появления ошибок в результате ударных нагрузок.
Данный атрибут хранит показания ударочувствительного сенсора — общее количество ошибок, возникших в результате полученных накопителем внешних ударных нагрузок (при падении, неправильной установке, и т.п.).
Подробнее — см. описание технологии G-Force Protection. -
Loaded Hours
Нагрузка на привод БМГ, вызванная общей наработкой часов накопителем.
Учитывается только период, в течении которого головки находились в рабочем положении. -
Load/Unload Retry Count
Нагрузка на привод БМГ, вызванная многочисленными повторениями операций чтения, записи, позиционирования головок и т.п. Учитывается только период, в течении которого головки находились в рабочем положении. -
Load Friction
Нагрузка на привод БМГ, вызванная трением в механических частях накопителя.
Учитывается только период, в течении которого головки находились в рабочем положении. -
Load/Unload Cycle Count
Общее количество циклов нагрузки на привод БМГ.
Учитывается только период, в течении которого головки находились в рабочем положении. -
Load-in Time
Общее время нагрузки на привод БМГ.
Предположительно, данный атрибут показывает общее время работы накопителя под нагрузкой, при условии, что головки находятся в рабочем состоянии (вне парковочной зоны). -
Torque Amplification Count
Количество усилий вращающего момента привода. -
Power-Off Retract Count
Количество зафиксированных повторов в(ы)ключения питания накопителя. -
GMR Head Amplitude
Амплитуда дрожания головок (GMR-head) в рабочем состоянии. -
Head Flying Hours
-
Read Error Retry Rate
1.3.4. Типы атрибутов.
Каждый атрибут может иметь некоторый набор флагов, определяющих его функциональные особенности. Ниже приводятся все шесть основных типов и их краткие описания.
-
Pre-failure (PF). Если атрибут имеет этот тип, то поле threshold атрибута содержит минимально допустимое значение атрибута, ниже которого не гарантируется работоспособность накопителя и резко увеличивается вероятность его выхода из строя.
-
On-line collection (OC). Указывает, что значение данного атрибута обновляется (вычисляется) во время выполнения on-line тестов S.M.A.R.T. или же во время обоих видов тестов (on-line/off-line). В противном случае, значение атрибута обновляется только при выполнении off-line тестов.
-
Performance related (PR). Указывает на то, что значение этого атрибута напрямую зависит от производительности накопителя по отдельным показателям (seek/throughput/etc. performance). Обычно обновляется после выполнения self-test`ов SMART.
-
Error rate (ER). Указывает на то, что значение атрибута отражает относительную частоту ошибок по данному параметру (raw read/write, seek, etc.).
-
Events count (EC). Указывает на то, что атрибут является счетчиком событий.
-
Self-preserve (SP). Указывает на то, что значение атрибута обновляется и сохраняется автоматически (обычно при каждом старте накопителя и при выполнении тестов SMART).
Автономное сканирование поверхности
(off-line read scanning)
Большинство накопителей обеспечивают поддержку автономного сканирования поверхности, которое является одной из функций подпрограммы автономного сбора данных о состоянии накопителя (off-line data collection). При выполнении этой функции, накопитель выполняет полное сканирование поверхности путем чтения каждого сектора и замещением ненадежных секторов на запасные сектора из резервной области (spare area) для предотвращения потери пользовательских данных.
Примечание. Если во время выполнения сканирования накопитель получает команду по интерфейсу, то процесс сканирования прерывается и накопитель приступает к обработке поступившей команды. При этом гарантируется максимальное время реагирования на поступившую команду — до 2 секунд.
Журналы ошибок
(SMART error log)
В большинстве современных накопителей реализованна функция журналирования появляющихся в течении работы накопителя ошибок или иных событий. В основном, накопители предоставляют информацию о пяти последних ошибках. При этом сохраняются последние 5 поступивших в накопитель команд, предшествующих возникновению этой ошибки, и другая необходимая информация.Накопитель может также поддерживать дополнительные журналы. Их структура, размер и назначение устанавливаются фирмой-производителем. При обновлении микропрограммы накопителя, все журналы накопителя очищаются, а общее количество ошибок устанавливается в значение 0.
Примечание: в журналах сохраняется время по внутренним часам накопителя, т.е. либо общее отработанное время на данный момент, либо время от момента последнего включения накопителя.
1.5.1. Log Directory
Тип: Каталог журналов S.M.A.R.T.
Вид доступа: только чтение (RO)
Размер: 1 сектор (512 байт)
Примечание: поддержка мультисекторных журналов
Данный журнал представляет собой своего рода каталог, в котором указаны адреса всех поддерживаемых журналов S.M.A.R.T. и их размер в секторах. Максимальное количество журналов — 255.
1.5.2. Summary Error Log
Тип: Суммарный журнал ошибок
Вид доступа: только чтение (RO)
Размер: 1 сектор (512 байт)
Примечание: поддерживается только 28-битная адресация секторов (28-bit LBA)
Данный журнал содержит информацию об общем количестве ошибок, зафиксированных накопителем с момента первого включения (или обновления микропрограммы) и подробные записи о последних 5 ошибках. Для каждой из 5 зафиксированных ошибок сохраняются последние 5 поступивших в накопитель команд. В этом журнале сохраняются все ошибки UNC, IDNF, ошибки сервосистемы, записи/чтения и т.д. При этом, для каждой команды сохраняется значения всех регистров, время и текущее состояние накопителя на момент подачи самой команды. Ошибки, вызванные подачей неподдерживаемых команд или командами с ошибочными параментами не фиксируются в журнале. Если накопитель поддерживает Comprehensive Error Log, то журнал Summary Error Log дублирует последние пять записей из журнала Comprehensive Error Log.
1.5.3. Comprehensive Error Log
Тип: Комплексный журнал ошибок [SMART Error Logging]
Вид доступа: только чтение (RO)
Размер: 1..51 сектор (максимум 26,112 байт)
Примечание: поддерживается только 28-битная адресация секторов (28-bit LBA)
Данный журнал содержит подробную информацию о общем количестве ошибок, зафиксированных накопителем с момента первого включения (или обновления микропрограммы) и подробные записи о последних ошибках. Максимальное количество сохраняемых ошибок — 255. Для каждой зафиксированной ошибки сохраняются последние 5 поступивших в накопитель команд. В этом журнале сохраняются все ошибки UNC, IDNF, ошибки сервосистемы, записи/чтения и т.д. При этом, для каждой команды сохраняется значения всех регистров, время и текущее состояние накопителя на момент подачи самой команды. Ошибки, вызванные подачей неподдерживаемых команд или командами с ошибочными параментами не фиксируются в журнале.
1.5.4. Extended Comprehensive Error Log
Тип: Расширенный комплексный журнал ошибок [SMART Error Logging]
Вид доступа: только чтение (RO)
Размер: 1..65,536 секторов (максимум 32 Мбайт)
Примечание: поддерживается 28/48-битная адресация секторов
Назначение данного журнала аналогично журналу Comprehensive Error Log и содержит в себе копию его записей, однако этот журнал имеет иную структуру, которая позволяет реализовать поддержку как 28-битной, так и 48-битной адресации секторов. Максимальное количество сохраняемых ошибок — 327,680.
1.5.5. Self-test Log
Тип: Журнал результатов самоконтроля [SMART self-test]
Вид доступа: только чтение (RO)
Размер: 1 сектор (512 байт)
Примечание: поддерживается только 28-битная адресация секторов (28-bit LBA)
Данный журнал содержит информацию о результатах выполнения команд внутренней самодиагностики накопителя. Журнал может хранить до 21 записи. При превышении этого количества, журнал начинает заполняться заново, перезаписывая 1-ю запись 22-й, 2-ю — 23-ей и так далее. В каждой записи журнала сохраняется регистр с номером теста, код статуса выполнения теста, время на момент запуска/прерывания теста, номер текущей контрольной точки (или точки останова) теста, а также LBA-адрес сектора, на котором произошло прерывание/отмена теста.
1.5.6. Extended Self-test Log
Тип: Расширенный журнал результатов самоконтроля [SMART self-test]
Вид доступа: только чтение (RO)
Размер: 1..65,536 секторов (максимум 32 Мбайт)
Примечание: поддерживается 28/48-битная адресация секторов
Назначение данного журнала аналогично журналу Self-test Log и содержит в себе копию его записей, однако этот журнал имеет иную структуру, которая позволяет реализовать поддержку как 28-битной, так и 48-битной адресации секторов. Максимальное количество записей — 1,179,648.
1.5.7. Streaming Performance Log
Тип: Журнал параметров производительности потоков [Streaming]
Вид доступа: только чтение (RO)
Размер: 1..65,536 секторов (максимум 32 Мбайт)
Данный журнал содержит информацию о переданных накопителю параметров командами управления режимом Automatic Acoustic Management и Typical Host Interface Sector Time (подробнее — см. ATA/ATAPI-6 rev 1e). В журнале сохраняется набор параметров, по которым производится настройка накопителя и перевод в его в режим, когда все операции чтения/записи возможны только специальными командами и передача данных происходит в виде непрерывного потока, для которого гарантированны и учитываются все временные интервалы (на обработку команды, чтение и передачу данных; минимальные/максимальные задержки, время доступа, позиционирования и т.п.). Подробнее о назначении данного вида журналов можно узнать из описания технологии Audio/Video (AV) Streaming Feature.
1.5.8. Write Stream Error Log
Тип: Журнал ошибок потоковой записи [Streaming]
Вид доступа: только чтение (RO)
Размер: 1 сектор (512 байт)
Примечание: поддерживается 48-битная адресация секторов
Данный журнал содержит информацию о возникших ошибках записи в период работы накопителя в потоковом режиме (streaming mode). В этом журнале сохраняется общее количество подобных ошибок, номер последней ошибки, предыдущее и текущее значения регистров состояния и ошибки, количество и LBA-номер сектора, на котором данная ошибка была зафиксирована. После чтения данного журнала, накопитель сбрасывает счетчик общего количества ошибок и очищает журнал. Содержимое журнала сохраняется только во время работы и очищается в момент следующего включения/выключения накопителя или при поступлении сигнала аппаратного сброса (hardware reset). Максимальное количество сохраняемых ошибок — 31.
1.5.9. Read Stream Error Log
Тип: Журнал ошибок потокового чтения [Streaming]
Вид доступа: только чтение (RO)
Размер: 1 сектор (512 байт)
Примечание: поддерживается 48-битная адресация секторов
Данный журнал содержит информацию о возникших ошибках чтения в период работы накопителя в потоковом режиме (streaming mode). В этом журнале сохраняется общее количество подобных ошибок, номер последней ошибки, предыдущее и текущее значения регистров состояния и ошибки; количество и LBA-номер сектора, на котором данная ошибка была зафиксирована. После чтения данного журнала, накопитель сбрасывает счетчик общего количества ошибок и очищает журнал. Содержимое журнала сохраняется только во время работы и очищается в момент следующего включения/выключения накопителя или при поступлении сигнала аппаратного сброса (hardware reset). Максимальное количество сохраняемых ошибок — 31.
1.5.10. Delayed LBA Sector Log
Тип: Vendor Specified [General Purpose Logging]
Вид доступа: только чтение (RO)
Размер: устанавливается производителем (VS)
Примечание: поддерживается 48-битная адресация секторов
Данный журнал содержит LBA-адреса всех секторов, которые были перемещены со своего нормального физического расположения, а также адреса границ недоступной последовательности секторов. Таким образом ведется журнал всех дефектных или нестабильных секторов. Максимальный размер журнала устанавливается производителем. Новое физическое расположение, метод и время доступа к замещенным секторам также устанавливается производителем и не документируется. Запись в данный журнал может быть добавлена в любой момент времени, при условии активности (питания) самого накопителя. Для процесса обновления журнала устанавливается наивысший приоритет и выполнение всех других команд приостанавливается. При этом удалить существующую запись из журнала не возможно. Содержимое журнала сохраняется при циклах включения/выключения накопителя и при поступлении сигнала аппаратного сброса (hardware reset).
1.5.11. ECC Uncorrectable Sector Log
Тип: Журнал неисправимых ошибок ECC [SMART Recovering]
Вид доступа: только чтение (RO)
Размер: 1 сектор (512 байт)
Примечание: поддерживается только 28-битная адресация секторов (28-bit LBA)
Данный журнал содержит список LBA-адресов секторов, на которых была зафиксирована и проигнорирована некорректируемая ошибка ECC при выполнении операции READ CONTINUOUS (см. AV feature). При этом, выполнение процедуры автоматического переназначения сбойного сектора (ADR — Automatic Defects Reassigment) накопителем заблокировано. Журнал может содержать до 126 записей.
Примечание. Данный журнал доступен для чтения только при разрешенной операции READ CONTINUOUS. В противном случае накопитель возвратит код ошибки ERR->ABRT, прервет выполнение команды или возвратит пустой журнал. После успешного чтения журнала, в самом накопителе он будет очищен.
1.5.12. Reassigned Sector Log
[under construction]
1.5.13. Drive Activity Log
[under construction]
1.5.14. Drive Time Buffer Log
[under construction]
1.5.15. Host Vendor Specific Log
Тип: Пользовательские журналы
Вид доступа: чтение/запись (R/W)
Размер: максимум 31 журнал по 16 секторов (253,952 байт)
Примечание: содержание и формат журнала — любое, на усмотрение пользователя
Этот вид журнала может быть использован для хранения произвольных пользовательских данных. Для записи этого журнала используется команда WRITE SMART LOG. Если данный журнал ни разу не был записан, то при чтении накопитель возвратит пустой журнал, заполненный нулями.
1.5.16. Device Vendor Specific Log
Тип: Технические журналы изготовителя
Вид доступа: не определен, на усмотрение производителя (VS)
Размер: максимум 31 журнал по 16 секторов (253,952 байт)
Примечание: содержание, формат и размеры журнала — на усмотрение производителя
Этот вид журнала предназначен для внутреннего использования фирменными утилитами производителя, для хранения результатов работы встроенных подпрограмм анализа и диагностики состояния накопителя и т.п. Возможность чтения/записи этого вида журнала устанавливается производителем и не не документируется.
Примечание. Новые накопители Seagate (модели Ux и Barracuda ATA) поддерживают и даже реально используют еще три вида журналов SMART, однако их назначение и описание пока не известны.
Встроенные функции самоконтроля
(self-test)
Практически с момента появления стандарта S.M.A.R.T. II, в большинстве накопителей появилась новая функция — внутренняя диагностика и самоконтроль, для углубленного контроля состояния механики накопителя, поверхности дисков и т.п. Для запуска этой функции, в набор команд S.M.A.R.T. была введена новая команда — SMART EXECUTE OFF-LINE IMMEDIATE. Результат работы сохраняется либо в специализированных атрибутах, либо отдельным параметром среди других данных в атрибутах. Если накопитель поддерживает журналы S.M.A.R.T., то результат выполнения тестов сохраняется также в журнале Self-test Log. После выполнения теста, накопитель в обязательном порядке обновляет показания во всех атрибутах и других параметрах. Если во время выполнения внутреннего теста накопитель получит по интерфейсу новую команду, то выполнение теста прерывается и накопитель приступает к обработке поступившей команды.
1.6.1. Методы тестирования
Существует два способа запуска тестов S.M.A.R.T.: автономный (off-line) или монопольный (captive). Результат теста всегда сохраняется накопителем в данных S.M.A.R.T. При автономном запуске накопитель сообщает о успешном завершении команды ДО ее ФАКТИЧЕСКОГО исполнения и только после этого выполняет тест. При этом, по интерфейсу флаг ЗАНЯТО (BSY) не выставляется и накопитель в любой момент готов приступить к выполнению очередной интерфейсной команды, приостанавливая работу теста. Фактически, тест выполняется в фоновом режиме. При запуске теста в монопольном режиме, по интерфейсу выставляется флаг ЗАНЯТО (BSY) и накопитель начинает непосредственное выполнение теста в режиме реального времени. Любая интерфейсная команда во время выполнения этого теста приведет к его прерыванию и остановке, после чего накопитель приступит к обработке поступившей команды.
1.6.2. Разновидности тестов S.M.A.R.T.
Официально документированы три вида внутренних тестов, однако еще существует набор так называемых «активных» тестов, функциональные особенности которых различны у разных производителей и для широкой публики не документированы.
| № |
Название теста |
off-line | captive |
|---|---|---|---|
| 1 | Off-line collection | + | — |
| 2 | Short Self-test | + | + |
| 3 | Extended Self-test | + | + |
| 4 | Drive Activity test #1..#4 | + | + |
Время тестирования может варьироваться от 1 секунды (Quantum) до 54 минут (Fujitsu MPG3409AT). Поддержка первого теста наиболее вероятна даже в очень старых накопителях 4-5 летней давности.
Второй и третий тесты появились относительно недавно, как дань внедренным сложным технологическим решениям — для полного контроля состояния накопителя пришлось реализовывать более глубокие и точные тесты. Поддержка 4-х «активных» тестов (см. таблицу, п.4) официально не документированна.
Реальный набор выполняемых тестами функций можно рассмотреть на примере тестов, поддерживаемых жесткими дисками Hitachi:
| Функция теста | Short Self test | Extended Self test | Off-line Collection |
|---|---|---|---|
| Raw Read Error Rate Test | YES | YES | YES |
| Write Test | YES | YES | NO |
| Servo Test | YES | YES | NO |
| Partial Read Scanning | YES | NO | NO |
| Full Read Scanning | NO | YES | YES |
Этот перечень тестов не является одинаковым для всех накопителей и приведен лишь в качестве примера.
Версия от 03.09.2001.
25.08.2012, 03:11. Показов 587198. Ответов 2

В первую очередь хочу сказать спасибо Charles Kludge и nonym4uk за помощь в написании этой статьи.
Итак, S.M.A.R.T. (от англ. self-monitoring, analysis and reporting technology — технология самоконтроля, анализа и отчётности) — технология оценки состояния жёсткого диска встроенной аппаратурой самодиагностики, а также механизм предсказания времени выхода его из строя.
Много пользователей знает что такое S.M.A.R.T., немного меньше даже знают как его получить… Но когда встает вопрос проанализировать полученную таблицу, обычно дело стопорится. В этой статье я приведу основные значения и их расшифровку
Для любознательных
SMART производит наблюдение за основными характеристиками накопителя, каждая из которых получает оценку. Характеристики можно разбить на две группы:
параметры, отражающие процесс естественного старения жёсткого диска (число оборотов шпинделя, число премещений головок, количество циклов включения-выключения);
текущие параметры накопителя (высота головок над поверхностью диска, число переназначенных секторов, время поиска дорожки и количество ошибок поиска).
Данные хранятся в шестнадцатеричном виде, называемом «raw value», а потом пересчитываются в «value» — значение, символизирующее надёжность относительно некоторого эталонного значения. Обычно «value» располагается в диапазоне от 0 до 100 (некоторые атрибуты имеют значения от 0 до 200 и от 0 до 253).
Высокая оценка говорит об отсутствии изменений данного параметра или медленном его ухудшении. Низкая говорит о возможном скором сбое.
Значение, меньшее, чем минимальное, при котором производителем гарантируется безотказная работа накопителя, означает выход узла из строя.
Технология SMART позволяет осуществлять:
мониторинг параметров состояния;
сканирование поверхности;
сканирование поверхности с автоматической заменой сомнительных секторов на надёжные.
Следует заметить, что технология SMART позволяет предсказывать выход устройства из строя в результате механических неисправностей, что составляет около 60 % причин, по которым винчестеры выходят из строя.
Предсказать последствия скачка напряжения или повреждения накопителя в результате удара SMART не способна.
Следует отметить, что накопители НЕ МОГУТ сами сообщать о своём состоянии посредством технологии SMART, для этого существуют специальные программы.
Любая программа, показывающая S.M.A.R.T. для каждого атрибута имеет несколько значений, разберемся сначала с ними — ID, Value, Worst, Threshold и RAW. Итак:
ID (Number) — собственно, сам индикатор атрибута. Номера стандартны для значений атрибутов, но например,из-за кривизны перевода один и тот же атрибут может называться по-разному, проще орентироваться по ID, логично?
Value
(Current) — текущее значение атрибута в условных единицах, никому наверное неведомых . В процессе работы винчестера оно может уменьшаться, увеличиваться и оставаться неизменным. По показателю Value нельзя судить о «здоровье» атрибута, не сравнивая его со значением Threshold этого же атрибута. Как правило, чем меньше Value, тем хуже состояние атрибута (изначально все классы значений, кроме RAW, на новом диске имеют максимальное из возможных значение, например 100).
Worst — наихудшее значение, которого достигало значение Value за всю жизнь винчестера. Измеряется тоже в уе. В процессе работы оно может уменьшаться либо оставаться неизменным. По нему тоже нельзя однозначно судить о здоровье атрибута, нужно сравнивать его с Threshold.
Threshold — значение в (сюрприз!!!) уе, которого должен достигнуть Value этого же атрибута, чтобы состояние атрибута было признано критическим. Проще говоря, Threshold — это порог: если Value больше Threshold — атрибут в порядке; если меньше либо равен — с атрибутом проблемы. Именно по такому критерию утилиты, читающие S.M.A.R.T., выдают отчёт о состоянии диска либо отдельного атрибута вроде «Good» или «Bad». При этом они не учитывают, что даже при Value, большем Threshold, диск на самом деле уже может быть умирающим с точки зрения пользователя, а то и вовсе ходячим мертвецом, поэтому при оценке здоровья диска смотреть стоит всё-таки на другой класс атрибута, а именно — RAW. Однако именно значение Value, опустившееся ниже Threshold, может стать легитимным поводом для замены диска по гарантии (для самих гарантийщиков, конечно же) — кто же яснее скажет о здоровье диска, как не он сам, демонстрируя текущее значение атрибута хуже критического порога? Т. е. при значении Value, большем Threshold, сам диск считает, что атрибут здоров, а при меньшем либо равном — что болен. Очевидно, что при Threshold=0 состояние атрибута не будет признано критическим никогда. Threshold — постоянный параметр, зашитый производителем в диске.
RAW (Data) — самый интересный, важный и нужный для оценки показатель. В большинстве случаев он содержит в себе не уе, а реальные значения, выражаемые в различных единицах измерения, напрямую говорящие о текущем состоянии диска. Основываясь именно на этом показателе, формируется значение Value (а вот по какому алгоритму оно формируется — это уже тайна производителя, покрытая мраком). Именно умение читать и анализировать поле RAW даёт возможность объективно оценить состояние винчестера.
Теперь перейдем непосредственно к самим атрибутам.
01 (01) Raw Read Error Rate — Частота ошибок при чтении данных с диска, происхождение которых обусловлено аппаратной частью диска. Для всех дисков Seagate, Samsung (семейства F1 и более новые) и Fujitsu 2,5″ это — число внутренних коррекций данных, проведенных до выдачи в интерфейс, следовательно, на пугающе огромные цифры можно реагировать спокойно.
02 (02) Throughput Performance — Общая производительность диска. Если значение атрибута уменьшается, то велика вероятность, что с диском есть проблемы.
03 (03) Spin-Up Time — Время раскрутки пакета дисков из состояния покоя до рабочей скорости. Растет при износе механики (повышенное трение в подшипнике и т. п.), также может свидетельствовать о некачественном питании (например, просадке напряжения при старте диска).
04 (04) Start/Stop Count — Полное число циклов запуск-остановка шпинделя. У дисков некоторых производителей (например, Seagate) — счётчик включения режима энергосбережения. В поле raw value хранится общее количество запусков/остановок диска.
05 (05) Reallocated Sectors Count — Число операций переназначения секторов. Когда диск обнаруживает ошибку чтения/записи, он помечает сектор «переназначенным» и переносит данные в специально отведённую резервную область. Вот почему на современных жёстких дисках нельзя увидеть bad-блоки — все они спрятаны в переназначенных секторах. Этот процесс называют remapping, а переназначенный сектор — remap. Чем больше значение, тем хуже состояние поверхности дисков. Поле raw value содержит общее количество переназначенных секторов. Рост значения этого атрибута может свидетельствовать об ухудшении состояния поверхности блинов диска.
06 (06) Read Channel Margin — Запас канала чтения. Назначение этого атрибута не документировано. В современных накопителях не используется.
07 (07) Seek Error Rate — Частота ошибок при позиционировании блока магнитных головок. Чем их больше, тем хуже состояние механики и/или поверхности жёсткого диска. Также на значение параметра может повлиять перегрев и внешние вибрации (например, от соседних дисков в корзине).
08 (08) Seek Time Performance — Средняя производительность операции позиционирования магнитными головками. Если значение атрибута уменьшается (замедление позиционирования), то велика вероятность проблем с механической частью привода головок.
09 (09) Power-On Hours (POH) — Число часов (минут, секунд — в зависимости от производителя), проведённых во включенном состоянии. В качестве порогового значения для него выбирается паспортное время наработки на отказ (MTBF — mean time between failure).
10 (0А) Spin-Up Retry Count — Число повторных попыток раскрутки дисков до рабочей скорости в случае, если первая попытка была неудачной. Если значение атрибута увеличивается, то велика вероятность неполадок с механической частью.
11 (0В) Recalibration Retries — Количество повторов запросов рекалибровки в случае, если первая попытка была неудачной. Если значение атрибута увеличивается, то велика вероятность проблем с механической частью.
12 (0С) Device Power Cycle Count — Количество полных циклов включения-выключения диска.
13 (0D) Soft Read Error Rate — Число ошибок при чтении, по вине программного обеспечения, которые не поддались исправлению. Все ошибки имеют
не механическую
природу и указывают лишь на неправильную размётку/взаимодействие с диском программ или операционной системы.
100(64) Erase/Program Cycles (для SSD) Общее количество циклов стирания/программирования для всей флэш-памяти за всё время ее существования. Твердотельный накопитель имеет ограничение на количество записей в него. Точные значения (ресурс) зависят от установленных микросхем флэш-памяти.
В накопителях Kingston — объём стёртого в гигабайтах.
103(67) Translation Table Rebuild (для SSD) Количество событий, когда внутренние таблицы адресов блоков были повреждены и впоследствии восстановлены. Raw-значение этого атрибута указывает фактическое количество событий.
170(AA) Reserved Block Count (для SSD) Состояние пула резервных блоков. Значение атрибута показывает процент оставшегося пула. Иногда raw-значение содержит фактическое количество использованных резервных блоков.
170 атрибут связан с атрибутом 5, числом использованных резервных блоков.
171(AB) Program Fail Count (для SSD) Число попыток, когда запись во флэш-память не удалась. Raw-значение показывает фактическое количество отказов. Процесс записи технически называется «программирование флэш-памяти» — отсюда и название атрибута. Когда флэш-память изношена, она больше не может быть записана и становится доступной только для чтения.
Значение обычно идентично атрибуту 181.
172(AC) Erase Fail Count (для SSD) Количество сбоев операции стирания на флэш-памяти. Raw-значение показывает фактическое количество отказов. Полный цикл записи флэш-памяти состоит из двух этапов. Сначала необходимо удалить память, а затем данные должны быть записаны («запрограммированы») в память. Когда флэш-память изношена, она больше не может быть записана и становится доступной только для чтения.
Идентичен атрибуту 182.
173(AD) Wear Leveller Worst Case Erase Count (для SSD) Максимальное количество операций стирания, выполняемых для одного блока флэш-памяти.
174(AE) Unexpected Power Loss (для SSD) Число неожиданных отключений питания, когда питание было потеряно до получения команды на отключение диска. На жестком диске срок службы при таких отключениях намного меньше, чем при обычном отключении. На SSD существует риск потери внутренней таблицы состояний при неожиданном завершении работы.
175(AF) Program Fail Count (для SSD) Число попыток, когда запись во флэш-память не удалась. Raw-значение показывает фактическое количество отказов. Процесс записи технически называется «программирование флэш-памяти», отсюда и название атрибута. Когда флэш-память изношена, она больше не может быть записана и становится доступной только для чтения.
176(B0) Erase Fail Count (для SSD) Количество сбоев операции стирания на флэш-памяти. Raw-значение показывает фактическое количество отказов. Полный цикл записи флэш-памяти состоит из двух этапов. Сначала необходимо удалить память, а затем данные должны быть записаны («запрограммированы») в память. Когда флэш-память изношена, она больше не может быть записана и становится доступной только для чтения.
177(B1) Wear Leveling Count (для SSD)
Wear Range Delta В зависимости от производителя, максимальное количество операций стирания, выполняемых для одного блока флэш-памяти[источник не указан 269 дней] или разница между максималоьно изношенными (больше всего раз записанными) и минимально изношенными (записанными наименьшее число раз) блоками[4].
178(B2) Used Reserved Block Count (для SSD) Состояние пула резервных блоков. Значение атрибута показывает процент оставшегося пула. Raw-значение этого атрибута иногда содержит фактическое количество использованных резервных блоков.
179(B3) Used Reserved Block Count (для SSD) Состояние пула резервных блоков. Значение атрибута показывает процент оставшегося пула. Raw-значение этого атрибута иногда содержит фактическое количество использованных резервных блоков.
180(B4) Unused Reserved Block Count (для SSD) Состояние пула резервных блоков. Значение атрибута показывает процент оставшегося пула. Raw-значение этого атрибута иногда содержит фактическое количество неиспользованных резервных блоков.
181(B5) Program Fail Count (для SSD) Число попыток, когда запись во флэш-память не удалась. Raw-значение показывает фактическое количество отказов.
182(B6) Erase Fail Count (для SSD) Количество сбоев операции стирания на флэш-памяти. Raw-значение показывает фактическое количество отказов.
183(B7) SATA Downshifts (для SSD) Указывает, как часто требовалось снизить скорость передачи данных SATA (с 6 Гбит/с до 3 или 1,5 Гбит/с или с 3 Гбит/с до 1,5 Гбит/с) для успешной передачи данных. Если значение атрибута уменьшается, попробуйте заменить кабель SATA.
Суть в том, что винчестер, работающий в режимах SATA 3 Гбит/с или 6 Гбит/с (и что там дальше будет в будущем), по какой-то причине (например, из-за ошибок) может попытаться «договориться» с дисковым контроллером о менее скоростном режиме (например, SATA 1.5 Гбит/с или 3 Гбит/с соответственно). В случае «отказа» контроллера изменять режим диск увеличивает значение атрибута (Western Digital und Samsung).
184 (B8) End-to-End error — Назначение зависит от производителя.
У HP (часть технологии HP SMART IV) увеличивается в случае, когда после передачи данных через кэш-память чётность данных между хостом и жёстким диском не совпадает.
У Kinston это количество ошибок чтения из флэш-памяти.
185 (B9) Head Stability Стабильность головок (Western Digital).
187 (BB) Reported UNC Errors — Количество ошибок, которое накопитель сообщил хосту (интерфейсу компьютера) при любых операциях, обычно это ошибки данных на диске, которые не исправлены средствами ECC
188 (BC) Command Timeout — содержит количество операций, выполнение которых было отменено из–за превышения максимально допустимого времени ожидания отклика.Такие ошибки могут возникать из-за плохого качества кабелей, контактов, используемых переходников, удлинителей и т.д., несовместимости диска с конкретным контроллером SATA/РАТА на материнской плате и т.д. Из-за ошибок такого рода возможны BSOD в Windows.
Ненулевое значение атрибута говорит о потенциальной «болезни» диска.
189 (BD) High Fly Writes — содержит количество зафиксированных случаев записи при высоте «полета» головки выше рассчитанной, скорее всего, из-за внешних воздействий, например, вибрации.
Для того, чтобы сказать, почему происходят такие случаи, нужно уметь анализировать логи S.M.A.R.T., которые содержат специфичную для каждого производителя информацию
190 (BE) Airflow Temperature (WDC) — Температура воздуха внутри корпуса жёсткого диска. Для дисков Seagate рассчитывается по формуле (100 — HDA temperature). Для дисков
Western Digital
— (125 — HDA).
191 (BF) G-sense error rate — Количество ошибок, возникающих в результате ударных нагрузок. Атрибут хранит показания встроенного акселерометра, который
фиксирует все удары, толчки, падения и даже неаккуратную установку диска в корпус компьютера.
Актуален для мобильных винчестеров. На дисках Samsung на него часто можно не обращать внимания, т.к. они могут иметь очень чувствительный датчик, который, образно говоря, реагирует чуть ли не на движение воздуха от крыльев пролетающей в одном помещении с диском мухой.
Вообще срабатывание датчика не является признаком удара. Может расти даже от позиционирования БМГ самим диском, особенно, если его не закрепить. Основное назначение датчика – прекратить операцию записи при вибрациях, чтобы избежать ошибок.
75

-
- May 7, 2002
-
- 10,376
-
- 762
-
- 126
-
#1
It seems to be a common problem, if you search via the search engine, but nobody has the answer as to why this happens.
You ask Seagate, and they just say RMA it. 
The drives are still fine, from what I can tell, just that annoying hiccup.
— S.M.A.R.T. —————————————————————
ID Cur Wor Thr Raw Values Attribute Name
07 _79 _60 _30 0000051522B8 Seek Error Rate
and it increases by 5 anytime I refresh it.
I am just curious if anyone that has recently gotten a seagate can check their HD out, and see if it still happens?
CrystalDiskInfo (http://crystalmark.info/softwa…DiskInfo/index-e.html) is pretty nice for windows users to check SMART status.
For what it is worth, I also checked the SMART info in linux, and it mimics the findings of crystaldiskinfo.
-
#2
Long story short is that while the drives may seem fine, and may very well run fine for another year while getting some seek errors, is that the drive is no longer 100%….it is liable to fail at any time.
-
- May 7, 2002
-
- 10,376
-
- 762
-
- 126
-
#3
HDs range from under 1 year to 3 years old. A total of 8 of them.
Something else must be going on…
-
#4
The only way you don’t have any seek error or trajectory error is if you do not have any movement. As long as the final destination is arrived and you have enough time for the final movement to settle, it is ok to move faster and tolerate a larger seek error.
-
- May 7, 2002
-
- 10,376
-
- 762
-
- 126
-
#5
Originally posted by: PandaBear
The «Seek Error» you saw is not a software failure or mechanical failure, but rather the overshot/undershot of the head trajectory in the particular position/time of the actuator movement. You can think of it as I’m suppose to be at track 20000 but I’m actually at 19997, so I need to apply more current to move faster, or vice versa.The only way you don’t have any seek error or trajectory error is if you do not have any movement. As long as the final destination is arrived and you have enough time for the final movement to settle, it is ok to move faster and tolerate a larger seek error.
There is no access to the HDs, except for getting the SMART info, and that is stored on a EEPROM I thought?
Which is why I said it is weird, that the drive isn’t doing and reading / writing, yes, it is spinning, but no access to it besides polling it for the SMART info. And each and everytime it polls the drive, the counter goes up by 5.
-
#6
Having these counters go up is honest and fine. You probably don’t want a drive that hide everything until it suddenly fail, that, IMO, is not honest.
These errors are fine as a huge portion of HD has bad sectors or bits. When I was working for Maxtor we typically see bad sectors in the scale of 400-1000, and that’s the uncorrectable ECC ones, the correctable ECC basically take care of any sectors with less than 40 bits of error. Without ECC every drive will have to scrap 20% of its space easily.
Don’t worry, just keep an eye on the reassigned/reallocated sectors and you’ll be fine.
- Advertising
- Cookies Policies
- Privacy
- Term & Conditions
- About us
-
This site uses cookies to help personalise content, tailor your experience and to keep you logged in if you register.
By continuing to use this site, you are consenting to our use of cookies.
Skip to content
Как исправить Seek Error Rate (0x7)?

Что делать с «0x7 Seek Error Rate»?
При загрузке компьютера или ноутбука возникает S.M.A.R.T. ошибка «0x7 Seek Error Rate»?
Что означает «0x7»: Seek Error Rate? Допустимые значения атрибута «Seek Error Rate» отличаются для различных производителей жестких дисков WD (Western Digital), Samsung, Seagate, HGST (Hitachi), Toshiba.
Актуально для ОС: Windows 10, Windows 8.1, Windows Server 2012, Windows 8, Windows Home Server 2011, Windows 7 (Seven), Windows Small Business Server, Windows Server 2008, Windows Home Server, Windows Vista, Windows XP, Windows 2000, Windows NT.
Программа для восстановления данных
Прекратите использование сбойного HDD
Получение от системы сообщения о диагностике ошибки не означает, что диск уже вышел из строя. Но в случае наличия S.M.A.R.T. ошибки,
нужно понимать, что диск уже в процессе выхода из строя. Полный отказ может наступить как в течении нескольких минут,
так и через месяц или год. Но в любом случае, это означает, что вы больше не можете доверить свои данные такому диску.
Необходимо побеспокоится о сохранности ваших данных, создать резервную копию или перенести файлы на другой носитель информации.
Одновременно с сохранностью ваших данных, необходимо предпринять действия по замене жесткого диска.
Жесткий диск, на котором были определены S.M.A.R.T. ошибки нельзя использовать – даже если он полностью не выйдет из строя он может частично повредить ваши данные.
Конечно же, жесткий диск может выйти из строя и без предупреждений S.M.A.R.T. Но данная технология даёт вам преимущество предупреждая о скором выходе диска из строя.
Восстановите удаленные данные диска
В случае возникновения SMART ошибки не всегда требуется восстановление данных с диска. В случае ошибки рекомендуется незамедлительно
создать копию важных данных, так как диск может выйти из строя в любой момент. Но бывают ошибки при которых скопировать данные уже не представляется возможным.
В таком случае можно использовать программу для восстановления данных жесткого диска — Hetman Partition Recovery.
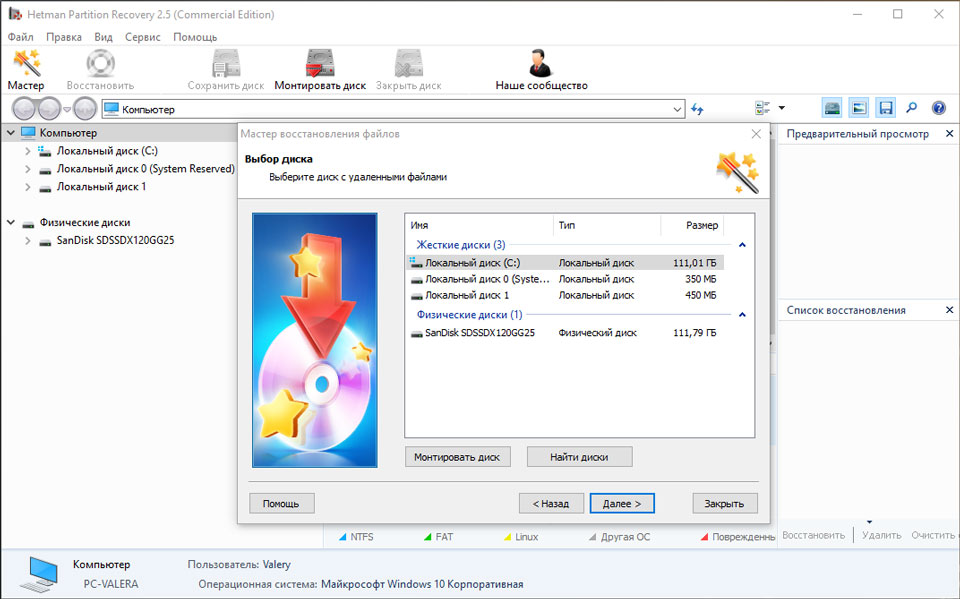
Для этого:
- Загрузите программу, установите и запустите её.
- По умолчанию, пользователю будет предложено воспользоваться Мастером восстановления файлов. Нажав кнопку «Далее», программа предложит выбрать диск, с которого необходимо восстановить файлы.
- Дважды кликните на сбойном диске и выберите необходимый тип анализа. Выбираем «Полный анализ» и ждем завершения процесса сканирования диска.
- После окончания процесса сканирования вам будут предоставлены файлы для восстановления. Выделите нужные файлы и нажмите кнопку «Восстановить».
- Выберите один из предложенных способов сохранения файлов. Не сохраняйте восстановленные файлы на диск с ошибкой «0x7 Seek Error Rate».
Программа для восстановления данных
Просканируйте диск на наличие «битых» секторов

Запустите проверку всех разделов жесткого диска и попробуйте исправить найденные ошибки.
Для этого, откройте папку «Этот компьютер» и кликните правой кнопкой мышки на диске с SMART ошибкой.
Выберите Свойства / Сервис / Проверить в разделе Проверка диска на наличия ошибок.
[скриншот]
В результате сканирования обнаруженные на диске ошибки могут быть исправлены.
Снизьте температуру диска

Иногда, причиной возникновения «S M A R T» ошибки может быть превышение максимально допустимой температуры работы диска.
Такая ошибка может быть устранена путём улучшения вентиляции компьютера.
Во-первых, проверьте оборудован ли ваш компьютер достаточной вентиляцией и все ли вентиляторы исправны.
Если вами обнаружена и устранена проблема с вентиляцией, после чего температура работы диска снизилась
до нормального уровня, то SMART ошибка может больше не возникнуть.
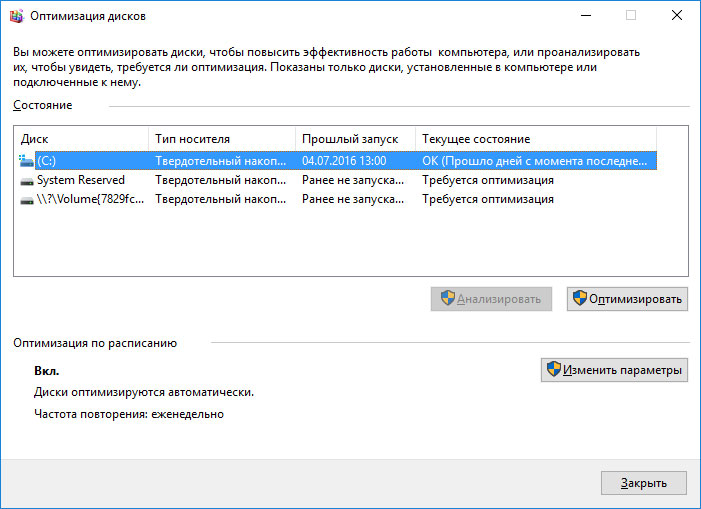
Произведите дефрагментацию жесткого диска
Откройте папку «Этот компьютер» и кликните правой кнопкой мышки на диске с ошибкой «
0x7
Seek Error Rate». Выберите Свойства / Сервис / Оптимизировать в разделе Оптимизация и дефрагментация диска. Выберите диск, который необходимо оптимизировать и кликните Оптимизировать.

Примечание. В Windows 10 дефрагментацию и оптимизацию диска можно настроить таким образом, что она будет осуществляться автоматически.
Ошибка «Seek Error Rate» для SSD диска

Даже если у вас не претензий к работе SSD диска, его работоспособность постепенно снижается. Причиной этому служит факт того,
что ячейки памяти SSD диска имеют ограниченное количество циклов перезаписи. Функция износостойкости минимизирует данный эффект, но не устраняет его полностью.
SSD диски имеют свои специфические SMART атрибуты, которые сигнализируют о состоянии ячеек памяти диска.
Например, «209 Remaining Drive Life», «231 SSD life left» и т.д. Данные ошибки могут возникнуть в случае снижения работоспособности ячеек,
и это означает, что сохранённая в них информация может быть повреждена или утеряна.
Ячейки SSD диска в случае выхода из строя не восстанавливаются и не могут быть заменены.
Сбросьте ошибку
SMART ошибки можно легко сбросить в BIOS (или UEFI). Но разработчики всех операционных систем категорически не рекомендуют этого делать.
Если же для вас не имеют ценности данные на жестком диске, то вывод SMART ошибок можно отключить.
Для этого необходимо сделать следующее:
- Перезагрузите компьютер, и с помощью нажатия указанной на загрузочном экране комбинации клавиш (у разных производителей они разные, обычно «F2» или «Del») перейдите в BIOS (или UEFI).
- Перейдите в: Аdvanced > SMART settings > SMART self test. Установите значение Disabled.
Примечание: место отключения функции указано ориентировочно, так как в зависимости от версии BIOS или UEFI,
место расположения такой настройки может незначительно отличаться.
Приобретите новый жесткий диск
Целесообразен ли ремонт HDD?
Важно понимать, что любой из способов устранения SMART ошибки – это самообман.
Невозможно полностью устранить причину возникновения ошибки, так как основной причиной её возникновения
часто является физический износ механизма жесткого диска.
Для устранения или замены неправильно работающих составляющих жесткого диска,
можно обратится в сервисный центр специальной лабораторией для работы с жесткими дисками.
Но стоимость работы в таком случае будет выше стоимости нового устройства.
Поэтому, ремонт имеет смысл делать только в случае необходимости восстановления данных с уже неработоспособного диска.
Как выбрать новый накопитель?
Если вы столкнулись со SMART ошибкой жесткого диска то, приобретение нового диска – это только вопрос времени.
То, какой жесткий диск нужен вам зависит от вашего стиля работы за компьютером, а также цели с которой его используют.
На что обратить внимание приобретая новый диск:
- Тип диска: HDD, SSD или SSHD. Каждому типу присущи свои плюсы и минусы, которые не имеют решающего значения для одних пользователей и очень важны для других. Основные из них — это скорость чтения и записи информации, объём и устойчивость к многократной перезаписи.
- Размер. Два основных форм-фактора дисков: 3,5 дюймов и 2,5 дюймов. Размер диска определяется в соответствии с установочным местом конкретного компьютера или ноутбука.
- Интерфейс. Основные интерфейсы жестких дисков: SATA, IDE, ATAPI, ATA, SCSI, Внешний диск (USB, FireWire и.т.д.).
-
Технические характеристики и производительность:
- Вместимость;
- Скорость чтения и записи;
- Размер буфера памяти или cache;
- Время отклика;
- Отказоустойчивость.
- S.M.A.R.T. Наличие в диске данной технологи поможет определить возможные ошибки его работы и вовремя предупредить утерю данных.
- Комплектация. К данному пункту можно отнести возможное наличие кабелей интерфейса или питания, а также гарантии и сервиса.
Актуально для:
WD HDD
- WD Blue
- WD Green
- WD Black
- WD Red
- WD Purple
- WD Gold
Seagate HDD
- BarraCuda
- FireCuda
- Backup/Expansion
- Enterprise (NAS)
- IronWolf (NAS)
- SkyHawk
Transcend HDD
- 25M (ударостойкие)
- 25H (ударостойкие)
- 25C (простые)
- 25A (с узором)
- 35T (настольные)
Hitachi HDD
- Travelstar
- Deskstar (NAS)
- Ultrastar
HP HDD
- MSA SAS
- Server SATA
- Server SAS
- Midline SATA
- Midline SAS
IBM HDD
- V3700
- Near Line
- Express 2.5
- V3700 2.5
- Server
- Near Line 2.5
LaCie HDD
- Porsche/Mobile
- Porsche
- Rugged
- d2
A-Data HDD
- DashDrive
- HV
- Durable)
- HD
Silicon Power HDD
- Armor
- Diamond
- Stream
Toshiba HDD
- MG, DT, MQ
- P, X, L
- N, S, V
- DT, AL
Dell HDD
- SAS
- SCI
- Hot-Plug
Verbatim HDD
- Go (портативные)
- Save (настольные)
Team Group SSD
- EVO/Lite/GX2 (TLC)
- PD (портативные)
Silicon Power SSD
- Velox/M/Slim
- Ace (3D TLC)
Apacer SSD
- M.2
- ProII
- Portable
- Panther
GOODRAM SSD
- CL (TLC)
- PX (TLC)
- Iridium (MLC/TLC)
Kingston SSD
- Consumer
- HyperX
- Enterprise
- Builder
Patriot SSD
- Flare (MLC)
- Scorch (MLC, M.2)
- Spark (TLC)
- Blast/P (TLC)
- Burst (3D TLC)
- Viper (TLC, M.2)
Samsung SSD
- PRO (3D MLC)
- EVO
- QVO (3D QLC)
- Portable (внешние)
- DCT (серверные)
- PM (серверные)
Seagate SSD
- Nytro
- Maxtor
- FireCuda
- BarraCuda
- Expansion
- IronWolf
A-Data SSD
- Premier (MLC/TLC)
- Ultimate (3D NAND)
- XPG
- SC (внешние)
- SE (внешние)
- Durable
WD SSD
- WD Blue
- WD Green
- WD Black
- WD Red
- WD Purple
- WD Gold
Transcend SSD
- SSDXXX
- PATA
- MTSXXX
- MSAXXX
- ESDXXX
Сидит программист за компьютером. Звонок в дверь.
Открывает, а там маленькая Смерть с отверткой.
— Мне рано умирать, я еще молод!
— Не бойся, парень, я за винтом пришла…
Анекдот
Жесткий диск — зверь очень хитрый. Так и норовит куда-то упасть, рассыпать таблицы разделов, забыть пару кластеров, а то и рухнуть всеми 32-мя битами FAT’а на голову несчастному пользователю. В один миг вы можете лишиться всей бесценной, накопленной за долгие годы работы информации. Конечно, можно проклинать судьбу и тщательно затирать свое горе спиртом — но не разумнее ли будет предупредить возможный сбой, нежели надеяться на его величество случай!?
Что такое S.M.A.R.T?
Впервые над этим задумались в 1995 году. Именно тогда инженеры IBM предложили систему предсказания надежности Predictive Failure Analysis. Вся соль технологии состояла в попытке предсказания того самого дня X и времени Ч, когда наш друг-винчестер решит отойти в мир иной. Немногим позже корпорация Compaq в коалиции с Seagate, Quantum и Conner разработали собственную технологию мониторинга состояния жесткого диска. Проект получил название IntelliSafe. Новоиспеченная технология отслеживала ряд критических характеристик диска, сравнивала полученные значения с допустимыми и рапортовала системе в случае опасности.
 |
| — DTemp — грамотно, просто и со вкусом |
Еще некоторое время спустя при участии большинства крупных производителей жестких дисков появилась технология S.M.A.R.T. — Self Monitoring Analysing and Reporting Technology (от англ. «технология самодиагностики, анализа и отчета»), в основе которой лежали наработки как IntelliSafe, так и PFA.
Вкратце, технология работает следующим образом. Устройство — дисковый накопитель, в котором реализованы функции S.M.A.R.T., — ведет статистику своих рабочих параметров (количество наработанных часов, время разгона шпинделя, обнаруженные/исправленные ошибки и т.п.). Показания S.M.A.R.T. накапливаются в служебных зонах или в энергонезависимой памяти носителя. На основе этой информации можно судить о состоянии механики, условиях эксплуатации, а также своевременно заметить предаварийное состояние диска. Между тем, необходимо понимать, что технология S.M.A.R.T. не в силах устранить возникшую проблему. Она лишь способна предупредить о возможном крушении диска и последующей за этим потере информации.
В своем развитии технология S.M.A.R.T. прошла три этапа. В первом поколении было реализовано наблюдение лишь за небольшим количеством параметров диска. Никаких самостоятельных действий со стороны накопителя не предусматривалось. Все функции управления ложились на внешние программные утилиты. Строгих спецификаций, четко описывающих стандарт, не было. Как следствие, каждый производитель самостоятельно решал, какие именно показатели надлежит мониторить в каждой конкретной модели дискового накопителя. Только в следующем воплощении S.M.A.R.T. появилась фоновая проверка поверхности в автоматическом режиме и ведение журналов ошибок. Значительно расширился список контролируемых параметров и появилось нечто вроде спецификации, определяющей, какие из этих параметров являются обязательными и критически важными, а какие можно причислить к вспомогательным и необязательным.
Разумно сделать небольшое лирическое отступление и вкратце поведать о такой неотъемлемой части технологии, как «журнал ошибок диска». По спецификации, винчестер сохраняет историю пяти последних ошибок (это число может варьироваться). Кроме того, запоминаются последние пять команд, за которыми, собственно, и последовала каждая из ошибок. Зачем это надо? Дело в том, что журналы ошибок S.M.A.R.T. помогают в деталях воссоздать картину крушения диска. Другой вопрос — кому это надо. Ясное дело — рядовой пользователь слыхом не слыхивал ни об ATA-командах, ни о кодах и расшифровках сбойных ситуаций. Потому расшифровать журнал могут только высококвалифицированные специалисты, которым по гарантии возвращается диск.
|
Воля случая |
| Как известно, жесткий диск — устройство очень хрупкое. Порой падение винчестера даже с небольшой высоты может вызвать внутренние повреждения или клиническую смерть. Такова жизнь, и никто в этом мире не застрахован от роковой случайности… Самым распространенным последствием удара является «шлепок головок». Он происходит, когда энергия удара направлена вертикально или под некоторым углом к горизонтальной плоскости диска. Проще говоря, подобного эффекта можно добиться, если как следует — резко и энергично — потрясти диск вверх-вниз. При особо сильных пертурбациях происходит отрыв магнитной головки от поверхности накопителя, а затем резкий удар о поверхность магнитного диска. Результаты подобных коллизий довольно плачевны. На месте соприкосновения головки с диском появляются поврежденные сектора, и как следствие — теряется бесценная информация. |
Это могут быть как лаборанты на мощностях вендора/дилера/продавца, так и инженеры с завода самого производителя.
Современный этап развития представлен технологией третьего поколения — S.M.A.R.T III. Конечно, спецификация еще далека от совершенства, однако в сравнении с предыдущими версиями она стала значительным шагом вперед. Наглядный пример тому — неумолимая статистика, которая утверждает, что число правильно и своевременно предсказанных сбоев достигло 80%! Важно отметить, что в третьей модификации S.M.A.R.T. появилась функция обнаружения дефектов поверхностии возможность их последующего «прозрачного» восстановления. Выражаясь простыми словами, жесткий диск неспешно сканирует поверхность и при наличии испорченных секторов замещает их на запасные из резервной области. Причем пользователь даже не заметит каких-либо действий со стороны винчестера. Меньше знаешь — крепче спишь!
Атрибуты «умного» диска
Нам уже известно, что S.M.A.R.T. производит наблюдение за основными характеристиками или, как их еще называют, атрибутами винчестера. Каждый атрибут имеет вполне определенное значение — value, которое характеризует собой степень надежности. Обычно эта величина изменяется в диапазоне от 1 до 100. Реже встречаются значения от 1 до 253. Чем выше значение value, тем лучше. Исправный жесткий диск должен выдавать максимум по всем параметрам, а изменяющиеся во времени или уверенно убывающие значения не сулят ничего хорошего. Это в теории. На практике же нужно учитывать, что спецификация универсальна и адаптирована для огромного спектра дисковых накопителей, имеющих разное механическое устройство и электронику. То есть конкретное устройство вполне может иметь средние показатели надежности по всем атрибутам, работая при этом исправно много лет. Поэтому для каждого атрибута принято выбирать минимальное значение (это делает сам производитель), при котором гарантируется безотказная работа данной конкретной модели жесткого диска. Эта величина именуется пороговым значением — threshold.
В настоящий момент официальная документация и подробные описания технологии S.M.A.R.T. журналистам недоступны. В связи с этим отыскать исчерпывающую информацию по всем параметрам S.M.A.R.T. достаточно трудно. Тем не менее мы собрали и систематизировали те из них, которые тем или иным способом стали известны широкой общественности. Полагаю, начать следует с наиболее важных и повсеместно наблюдаемых атрибутов.
* Raw Read Error Rate — частота ошибок при чтении данных с диска.
Частота ошибок чтения информации с диска, происхождение которых обусловлено аппаратной частью жесткого диска.
* Read Channel Margin — запас канала чтения.
Увы, назначение этого атрибута покрыто завесой тайны.
 |
| — DriveHealth сочетает в себе массу полезных возможностей. Огорчает лишь то, что за полноценное использование программы разработчик требует пеню |
Доподлинно известно лишь одно — он используется в накопителях производства Maxtor.
* Reallocated Sector Count — число переназначенных секторов.
Когда жесткий диск встречает ошибку чтения/записи, он пытается переместить поврежденные данные в специальную резервную область и, в случае успеха, помечает сектор как переназначенный. Благодаря этой возможности современные жесткие диски способны скрывать незначительное число плохих секторов. Однако при большом количестве переназначенных секторов (до 10% от общего количества секторов и более) наблюдается резкое падение скорости чтения.
* Reallocation Event Count — количество операций переназначения сбойных секторов.
Показывает общее число попыток переназначения сбойных секторов в резервную область диска. При этом учитываются как успешные, так и неудачные операции.
* Seek Error Rate — ошибки позиционирования блока головок.
Ошибки позиционирования возникают при повреждении сервометок, перегреве носителя или в случае сбоя механической системы позиционирования. Большое количество ошибок позиционирования свидетельствует о низком качестве поверхности или поврежденной механике головок носителя.
* Spin Up Time — время раскрутки диска из состояния покоя до рабочей скорости.
Среднее время раскрутки шпинделя диска до рабочей скорости. Предположительно, в поле «value» содержится время в миллисекундах/секундах.
* Spin Retry Count — число повторных попыток раскрутки дисков до рабочей скорости.
Данный атрибут характеризует число попыток раскрутки шпинделя до рабочей скорости, при условии что первая попытка была неудачной. Напомним, что атрибут имеет не прямое значение, а отражает лишь некий сборный параметр надежности по отдельно взятой характеристике. Соответственно, большое значение — значит «хорошо», а маленькое говорит о неполадках в механике привода.
Разобравшись с критически важными атрибутами, поговорим об информационных значениях S.M.A.R.T.
* Current Pending Sector Count — текущее число нестабильных секторов.
Здесь хранится число претендентов на переназначение в резервную область диска. Судьба отдельно взятого сектора, попавшего в этот список, решается следующим образом. Если сектор будет считываться успешно, то он исключается из списка. Если же чтение сектора будет сопровождаться ошибками, то накопитель попытается восстановить и перенести информацию в резервную область, а сам сектор пометит как переназначенный. Постоянно ненулевое значение этого атрибута говорит о низком качестве поверхности диска.
* Drive Temperature — температура.
Отображает показания встроенного термодатчика.
|
Анатомия жесткого диска |
| Все знают, что такое винчестер. Однако немногие знают, что у него внутри. Позволю себе приоткрыть завесу тайны. Любой винчестер состоит из гермоблока и платы электроники. В гермоблоке размещена вся механика, то есть сами диски, двигатель и магнитные головки по одной на каждый диск. Между тем, дисков, также называемых «блинами», в устройстве может быть несколько. На один блин вмещается до 80 гигабайт (в последних моделях) информации. К примеру, 120-гигабайтный винчестер может состоять из трех дисков по 40 Гб или двух по 60 Гб. В свою очередь, диски собраны в так называемый дисковый пакет. Оный пакет дисков закрепляется на оси шпинделя, в котором, собственно, и находится движок винчестера. Что касается электронной части винчестера… На самом деле, плата электроники современного жесткого диска — это настоящий микрокомпьютер с собственным процессором, памятью, внешними интерфейсами, устройствами ввода/вывода и прочими неотъемлемыми компонентами. Нетрудно догадаться, что основные задачи электроники — это управление механикой диска, а также преобразование магнитных сигналов в цифровые и наоборот. |
Температура имеет огромное влияние на срок службы диска. По непонятным причинам этот атрибут отсутствует у Western Digital.
* Device (Drive) Power Cycle Count — число полных циклов включения-выключения винчестера.
По этому атрибуту можно оценить, как часто использовался диск.
* Power-On Hours — количество наработанных часов.
Поле «value» этого параметра показывает общее время работы диска. В качестве порогового значения выбирается паспортное время наработки на отказ (MTBF — Mean Time Between Failures). Принимая во внимание заоблачно высокие паспортные значения MTBF, маловероятно, что атрибут может достигнуть критического порога.
* Start/Stop Count — число циклов запуск-остановка шпинделя.
Моторчик жесткого диска может пережить определенное — гарантированное производителем — число старт-стопов. Это значение и выбирается в качестве критического порога. Важно сказать, что первые модели дисков со скоростью вращения 7200 оборотов в минуту имели не самый надежный двигатель и, как следствие, частенько выходили из строя.
* G-Sense Error Rate — частота появления ошибок в результате ударных нагрузок.
Хранит показания ударочувствительного сенсора. Точнее, выводит общее количество ошибок, возникших в результате удара, падения или неаккуратной установки диска в корпус компьютера.
* Load-in Friction (HoursTime) — общее время работы головки под влиянием нагрузок.
Предположительно, данный атрибут показывает общее время работы блока головок под воздействием центробежных сил. Не углубляясь в туманные просторы физики, попробую объяснить сей факт на пальцах. На высокой скорости вращения дисков (5000-10000 оборотов в минуту) в накопителе неизбежно возникают центробежные силы. Очевидно, что головка при перемещении по диску также испытывает воздействие этих сил.
* GMR Head Amplitude — амплитуда дрожания головок в рабочем состоянии.
Воздействие центробежной силы приводит к дрожанию головок над поверхностью диска. Высокая амплитуда дрожания может вызвать соприкосновение блока головок с поверхностью. Как следствие — появление поврежденных секторов. Чем меньше амплитуда, тем лучше. Тем не менее, касательно значения, данного атрибутом, все в точности наоборот. Больше — лучше!
* Recalibration Retries — количество повторов рекалибровки.
Характеризует количество попыток установки головок на нулевую дорожку, при условии что первая попытка была неудачной. Значение этого атрибута, меньшее порогового threshold, говорит о неполадках в механике жесткого диска.
* Soft Read Error Rate — частота появления «программных» ошибок при чтении данных с диска.
В переводе на общедоступный язык — параметр информирует нас о программных ошибках чтения данных. К таковым можно отнести ошибки программного обеспечения, драйверов, файловой системы и неверную разметку диска. Словом, почти все, что не относится к аппаратной части винчестера.
* Throughput Performance — средняя производительность диска.
Предположительно, параметр показывает среднюю пропускную способность жесткого диска. Уменьшение значения с некоторой вероятностью указывает на проблемы в накопителе.
* UltraDMA CRC Error Count — общее количество ошибок CRC в режиме UltraDMA.
Выражаясь простым русским языком, атрибут отображает число ошибок контрольной суммы CRC. На практике подобные ошибки появляются при разгоне системы, сильно перекрученном шлейфе, а также по вине драйверов нерадивого Windows.
* Uncorrectable Sector Count — число нескорректированных ошибок.
Этот атрибут информирует нас об ошибках чтения/записи, которые не удалось исправить. Возможной причиной возникновения ошибок подобного рода может быть повреждение поверхности диска.
* Write Error Rate (Multi Zone Error Rate) — частота появления ошибок при записи данных.
Показывает общее число ошибок записи на диск. Чем больше значение, тем хуже состояние поверхности или механики винчестера.
Все происходящие ошибки и изменения параметров заносятся в журналы S.M.A.R.T. При значении атрибута ниже величины порога threshold жесткий диск сиюминутно рапортует о неполадке напрямую в BIOS системы. Затем информация по цепочке передается драйверам Windows, которые и сообщают пользователю о возникшей проблеме.
Защити данные с умом!
Жаль, но встроенными — зачастую скромными — функциями BIOS и операционной системы не отделаешься. Системный драйвер на пару с БИОСом не покажут вам текущую температуру жесткого диска, не сообщат об очередной ошибке чтения и не поведают о количестве переназначенных секторов. Поэтому имеет смысл установить специальные утилиты для чтения показаний атрибутов и содержимого журналов S.M.A.R.T.
Одна из самых простых и несложных программок — DTemp (ищите на нашем диске). Весит она не больше 100 кб, но пользы способна принести на целый гигабайт!
Как и любая другая программа подобного рода, DTemp выводит таблицу со значениями каждого атрибута, величинами критического порога, а также, кроме всего прочего, показывает приблизительную дату того самого «дня X«.
В общем и целом табличный вывод программы расшифровывается следующим образом.
| Attribute |
Value |
Threshold |
RAW |
Attribute Flags |
| Spin Up Time |
102 |
21 |
000000001612h |
PR SP CR OC |
* Attribute — имя атрибута;
* ID — номер атрибута;
* Value — значение атрибута (чем оно больше — тем супер);
* Threshold — пороговое значение атрибута (если value меньше, чем threshold, готовьтесь к неприятностям);
* Raw — текущее значение атрибута в шестнадцатеричной системе исчисления;
* Type (Flags) — тип атрибута.
Стоит ли говорить, что DTemp следит за температурой вашего диска и в случае перегрева незамедлительно бьет тревогу. Плюс ко всему, эта чудо-программка бесплатна! То бишь, не мудрствуя лукаво, достаем компакт-диск «Игромании», лезем в раздел «По журналу», устанавливаем и наслаждаемся.
По сути дела, возможностей DTemp должно хватить за глаза. Тем не менее, существуют и другие утилиты, достойные нашего пристального внимания. Как вариант, на страже здоровья вашего диска встанет DriveHealth, который по своим возможностям даже несколько превосходит расхваленный выше DTemp. В частности, DriveHealth выводит краткую аннотацию к каждому атрибуту, фиксирует любое изменение состояния диска, следит за температурой винчестера. Словом, целая корзина вкусностей и полезностей. Свежую версию программы можно скачать с сайта разработчика — www.drivehealth.com — или взять с нашего компакта.
Закончить сегодняшнюю статью хочется словами одного небезызвестного телеведущего: «В наши дни надежность ценится все больше. Покупая автомобиль, мы непременно хотим приобрести надежный. Приятно иметь надежных друзей, а директор счастлив, если его работники отличаются надежностью«… Чего уж говорить про жесткие диски?
|
Терминология |
||
Блок головок — или, попросту, головка жесткого диска. Данные с поверхности диска считываются непосредственно магнитной головкой. Принцип действия головок жесткого диска мало чем отличается от принципа действия головки обычного магнитофона. Действительно, при записи головка создает магнитное поле, за счет чего участок диска намагничивается. При считывании же — наоборот, поле диска возбуждает сигнал в головке. |

|
Показать сообщения за Поле сортировки |
|---|
|
Программы Hard Drive Ispector и HDDlife показывают, что состояние винта 21% из-за ошибок позиционирования (текущее значение 45). Хотя винт отработал всего ~72 часа. Стоит-ли нести в сервис? |
|
MBear |
если ето написано про ошибки позицирования то они у меня врядли поднимутся до такого, потому что уже выражены 12-значным числом |
|
Используй фирминую утилиту от Seagate или HDTune, а HDDlife давно потеряла доверие своей глюченностью. Кстате у меня тоже рыба только на 250 Гиг, и как помню HDDlife показывала здоровье новенького HDD около 45, и в тоже время на четырех/пятилетнем Maxtor было 100 |

|
Garry89
смотреть нужно на VAL — текущее значение как я уже говорил со временем «Seek error rate» начнет подниматься (параметр VAL начнет расти) |
|
Garry89 |
")
|
У меня нечто похожее. только винту намного больше. ошибок позиционирования в избытке. 13-ти значное число.
ST3320620AS 9QF3QE8A
кажет виктория. Ошибки и фиг с ними. Но! У меня винт начал щелкать периодически во время работы. Даже в режиме рабочего стола бывают щелчки. уже пару месяцев такая картина. Прошерстил викой, среднее время доступа 14.4-15.5 и больше. По моим впечатлениям винт стал работать медленнее. винт на резиновых ножках на поролоне. сверху радиатор алюминиевый, сбоку вентиль обдувает его. вообщем буду рад вашим мнениям. |
|
Evilshik, а фиг его знает.. Например, рекалибровка постоянная. Почему — понятия не имею. От произвольно плавающей температуры внутри до соответствующего сбоя электроники. Но вот что знаю точно — если винт начал «щелкать», «трещать», «свистеть» — в общем, издавать звуки коих ранее не издавал — то его надо менять. Чтобы не было мучительно больно и обидно. Сколько он проживет — прогнозов дать не могу. Может день, а может — год. Дело в другом: абсолютное большинство померших винтов перед «смертью» начинают звуки издавать. Я не для количества текста мысль повторил… |
|
Ясно. А то, что сейчас он стал медленее работать говорит о ближущемся конце? |
|
Evilshik SMART нормальный.
электронику не перегревайте, она что закрыта?
проверить на вирусы, снести форточку… |
|
MBear CACHE: 16384k; L/A=ON; Wr=OFF; ! строка про кэш мне не нравится. воскл знак красным. что-то с кэшем не так? |
|
Evilshik
я говорю, что ее затыкать поролоном не нужно.
а KIS разве не вирус?
ОСь на каком? к каким контролерам подключены харды?
хз что за вике вкладка… |