The interesting error codes from Linux program segfault kernel messages
February 10, 2018
When I wrote up what the Linux kernel’s messages about segfaulting
programs mean, I described what went
into the ‘error N‘ codes and how to work out what any particular
one meant, but I didn’t inventory them all. Rather than put myself
through reverse engineering what any particular error code means,
I’m going to list them all here, in ascending order.
The basic kernel message looks like this:
testp[9282]: segfault at 0 ip 0000000000401271 sp 00007ffd33b088d0 error 4 in testp[400000+98000]
We’re interested in the ‘error N‘ portion, and a little bit
in the ‘at N‘ portion (which is the faulting address).
For all of these, the fault happens in user mode so I’m not going
to mention it specifically for each one. Also, the list of potential
reasons for these segfaults is not exhaustive or fully detailed.
error 4: (Data) read from an unmapped area.This is your classic wild pointer read. On 64-bit x86, most of the
address space is unmapped so even a program that uses a relatively
large amount of memory is hopefully going to have most bad pointers
go to memory that has no mappings at all.A faulting address of 0 is a NULL pointer and falls into page
zero, the lowest page in memory. The kernel prevents people
from mapping page zero, and in general
low memory is never mapped, so reads from small faulting addresses
should always be error 4s.error 5: read from a memory area that’s mapped but not readable.This is probably a pointer read of a pointer that is so wild that
it’s pointing somewhere in the kernel’s area of the address space.
It might be a guard page,
but at least some of the timemmap()‘ing things withPROT_NONE
appears to make Linux treat them as unmapped areas so you get
error code 4 instead. You might think this could be an area
mmap()‘d with other permissions but withoutPROT_READ, but
it appears that in practice other permissions imply the
ability to read the memory as well.(I assume that the Linux kernel is optimizing
PROT_NONEmappings
by not even creating page table entries for the memory area, rather
than carefully assembling PTEs that deny all permissions. The error
bits come straight from the CPU, so if there are no PTEs the CPU says
‘fault for an unmapped area’ regardless of what Linux thinks and will
report in, eg,/proc/PID/maps.)error 6: (data) write to an unmapped area.This is your classic write to a wild or corrupted pointer, including
to (or through) a null pointer. As with reads, writes to guard pages
mmap()‘d withPROT_NONEwill generally show up as this, not as
‘write to a mapped area that denies permissions’.(As with reads, all writes with small faulting addresses should be
error 6s because no one sane allows low memory to be mapped.)error 7: write to a mapped area that isn’t writable.This is either a wild pointer that was unlucky enough to wind up
pointing to a bit of memory that was mapped, or an attempt to
change read-only data, for example the classical C mistake of
trying to modify a string constant (as seen in the first entry). You might also be trying to
write to a file that wasmmap()‘d read only, or in general
a memory mapping that lacksPROT_WRITE.(All attempts to write to the kernel’s area of address space
also get this error, instead of error 6.)error 14: attempt to execute code from an unmapped area.This is the sign of trying to call through a mangled function
pointer (or a NULL one), or perhaps returning from a call when
the stack is in an unexpected or corrupted state so that the
return address isn’t valid. One source of mangled function pointers
is use-after-free issues where the (freed) object contains embedded
function pointers.(Error 14 with a faulting address of 0 often means a function
call through a NULL pointer, which in turn often means ‘making
an indirect call to a function without checking that it’s defined’.
There are various larger scale causes of this in code.)error 15: attempt to execute code from a mapped memory area that
isn’t executable.This is probably still a mangled function pointer or return
address, it’s just that you’re unlucky (or lucky) and there’s
mapped memory there instead of nothing.(Your code could have confused a function pointer with a data
pointer somehow, but this is a lot rarer a mistake than confusing
writable data with read-only data.)
If you’re reporting a segfault bug in someone else’s program, the
error code can provide useful clues as to what’s wrong. Combined
with the faulting address and the instruction pointer at the time,
it might be enough for the developers to spot the problem even
without a core dump. If you’re debugging your own programs, well,
hopefully you have core dumps; they’ll give you a lot of additional
information (starting with a stack trace).
(Now that I know how to decode them, I find these kernel messages
to be interesting to read just for the little glimpses they give
me into what went wrong in a program I’m using.)
On 64-bit x86 Linux, generally any faulting address over 0x7fffffffffff
will be reported as having a mapping and so you’ll get error codes
5, 7, or 15 respective for read, write, and attempt to execute.
These are always wild or corrupted pointers (or addresses more
generally), since you never have valid user space addresses up
there.
A faulting address of 0 (sometimes printed as ‘(null)‘, as covered
in the first entry) is a NULL pointer itself. A faulting address
that is small, for example 0x18 or 0x200, is generally an offset
from a NULL pointer. You get these offsets if you have a NULL pointer
to a structure and you try to look at one of the fields (in C,
‘sptr = NULL; a = sptr->fld;‘), or you have a NULL pointer to an
array or a string and you’re looking at an array element or a
character some distance into it. Under some circumstances a very
large address, one near 0xffffffffffffffff (the very top of memory
space), can be a sign of a NULL pointer that your code then subtracted
from.
(If you see a fault address of 0xffffffffffffffff itself, it’s
likely that your code is treating -1 as a pointer or is failing to
check the return value of something that returns a pointer or ‘(type
*)-1’ on error. Sadly there are C APIs that are that perverse.)
В предыдущей статье описывающей что означают сообщения ядра Linux о segfault программах, было описано, что входит в коды ‘error N’ и как выяснить, что означает тот или иной код. Вместо того, чтобы разбираться, что означает тот или иной код ошибки, в данном статье перечислены здесь, в порядке возрастания.
Основное сообщение ядра выглядит следующим образом:
testp[1234]: segfault at 0 ip 0000000000401271 sp 00007ffd33b088d0 error 4 in testp[400000+98000].Нас интересует часть ‘error N’, и немного часть ‘at N’ (которая является адресом неисправности).
Во всех этих случаях сбой происходит в пользовательском режиме, поэтому я не буду упоминать его конкретно для каждого из них. Кроме того, список возможных причин этих ошибок не является исчерпывающим или полностью подробным.
Содержание
- error 4: (Данные) прочитаны из не отображенной области.
- error 5: чтение из области памяти, которая отображена, но не доступна для чтения.
- error 6: (данные) запись в неотмеченную область.
- error 7: запись в сопоставленную область, которая недоступна для записи.
- error 14: попытка выполнить код из не отображенной области.
- error 15: попытка выполнить код из неисполняемой области памяти.
- Выводы
error 4: (Данные) прочитаны из не отображенной области.
Это классическое чтение по произвольному указателю. На 64-битном x86 большая часть адресного пространства не отображена, поэтому даже в программе, использующей относительно большой объем памяти, большинство плохих указателей будут попадать в память, которая вообще не имеет отображений.
Ошибочный адрес 0 является NULL-указателем и попадает в нулевую страницу, самую нижнюю страницу в памяти. Ядро не позволяет людям отображать нулевую страницу, и в целом низкая память никогда не отображается, поэтому чтение с маленьких ошибочных адресов всегда должно быть ошибкой 4s.
error 5: чтение из области памяти, которая отображена, но не доступна для чтения.
Вероятно, это чтение указателя, который настолько произвольный, что указывает куда-то в область адресного пространства ядра. Это может быть защитная страница, но, по крайней мере, в некоторых случаях mmap()’ing вещи с PROT_NONE, кажется, заставляет Linux рассматривать их как неотмеченные области, так что вы получаете код ошибки 4 вместо этого.
Вы можете подумать, что это может быть область mmap()’d с другими разрешениями, но без PROT_READ, но, похоже, что на практике другие разрешения подразумевают возможность чтения памяти.
(Я предполагаю, что ядро Linux оптимизирует отображения PROT_NONE, даже не создавая записей в таблице страниц для этой области памяти, а не тщательно собирая PTE, которые запрещают все разрешения. Биты ошибки приходят прямо от CPU, так что если нет PTE, CPU говорит «ошибка из-за неразмеченной области», независимо от того, что Linux думает и сообщает, например, в /proc/PID/maps).
error 6: (данные) запись в неотмеченную область.
Это классическая запись в случайны или поврежденный указатель, в том числе в нулевой указатель (или через него). Как и при чтении, запись на защитные страницы mmap()’d с PROT_NONE будет обычно проявляться именно так, а не как «запись в отображенную область, на которую запрещены разрешения».
(Как и в случае с чтением, все записи с маленькими ошибочными адресами должны быть ошибкой 6, потому что никто в здравом уме не разрешает маппить низкую память).
error 7: запись в сопоставленную область, которая недоступна для записи.
Это либо «случайный» указатель, которому не повезло попасть на часть памяти, которая была отображена, либо попытка изменить данные, доступные только для чтения, например, классическая ошибка языка Си — попытка изменить строковую константу (как показано в первой записи). Вы также можете пытаться записать в файл, который был создан mmap() только для чтения, или вообще в память, в которой отсутствует PROT_WRITE.
(Все попытки записи в область адресного пространства ядра также приводят к этой ошибке, вместо ошибки 6).
error 14: попытка выполнить код из не отображенной области.
Это признак попытки вызова через искаженный указатель функции (или NULL-указатель), или, возможно, возврата из вызова, когда стек находится в неожиданном или поврежденном состоянии, так что адрес возврата недостоверен. Одним из источников искаженных указателей функций являются проблемы с использованием после освобождения, когда (освобожденный) объект содержит встроенные указатели функций.
(Ошибка 14 с ошибочным адресом 0 часто означает вызов функции через указатель NULL, что, в свою очередь, часто означает «косвенный вызов функции без проверки ее определения». В коде есть различные более масштабные причины этого).
error 15: попытка выполнить код из неисполняемой области памяти.
Вероятно, это все еще искаженный указатель функции или адрес возврата, просто вам не повезло (или повезло), и там есть отображенная память, а не пустота.
(Ваш код мог каким-то образом перепутать указатель функции с указателем данных, но это гораздо более редкая ошибка, чем перепутать данные, доступные для записи, с данными, доступными только для чтения).
Если вы сообщаете об ошибке segfault в чужой программе, код ошибки может дать полезные подсказки о том, что не так. В сочетании с адресом неисправности и указателем инструкции в тот момент времени, этого может быть достаточно, чтобы разработчики смогли обнаружить проблему даже без дампа ядра. Если вы отлаживаете свои собственные программы, то, надеюсь, у вас есть дампы ядра; они дадут вам много дополнительной информации (начиная с трассировки стека).
Выводы
В 64-битном x86 Linux, как правило, любой неисправный адрес больше 0x7fffffffffff сообщается как имеющий отображение, и поэтому вы получите коды ошибок 5, 7 или 15, соответствующие для чтения, записи и попытки выполнения. Это всегда случайные или поврежденные указатели (или адреса в более общем случае), поскольку у вас никогда не будет действительных адресов пространства пользователя.
Ошибочный адрес 0 (иногда печатается как ‘(null)’, как описано в первой записи) сам по себе является указателем NULL. Маленький ошибочный адрес, например 0x18 или 0x200, обычно является смещением от указателя NULL. Вы получаете эти смещения, если у вас есть NULL-указатель p
This article/section is a stub — probably a pile of half-sorted notes, is not well-checked so may have incorrect bits. (Feel free to ignore, or tell me)
Contents
- 1 Segfault, Bus Error, Abort, and such
- 1.1 Segfault
- 1.2 Bus error
- 1.3 Aborted (core dumped)
- 1.4 On core dumps
- 2 Illegal instruction (core dumped)
Segfault, Bus Error, Abort, and such
tl;dr:
- segfault means the kernel says: there is something at that address, but your process may not access it
- bus error means the kernel says: that address doesn’t even exist — anymore, or at all
- pointer bugs can lead to either segfault or bus error
- …note that specific bugs are biased to cause one or the other, due to the likeliness of hitting existing versus non-existing addresses
- (and various things can influence that likeliness, e.g. 32-bit address spaced usually being mostly or fully mapped, 64-bit not)
- abort() means code itself says «okay, continuing running is a Bad Idea, let’s stop now»
- usually based on a test that should never fail.
- if you look from a distance it’s much like an exit(). The largest practical differences:
- abort implies dumping core, so that you can debug this
- abort avoids calling exit handlers
- …and the earlier this happens, the more meaningful debugging of the dumped core is. Hence the explicit test and abort.
- a fairly common case is memory allocation (as signalled by something that actually checks; not doing so is often a segfault very soon after, particularly if dereferencing null)
Segfault
Segmentation refers to the fact that processes are segmented from each other.
A segmentation fault (segfault) signals that the requested memory location exists, but the process is not allowed to do what it is trying.
Which is often one of:
- the address isn’t of the requesting processess’s currently mapped space, e.g.
- a the null pointer dereference, because most OSes don’t map the very start of memory to any process (mostly for this special case)
- buffer overflow when it gets to memory outside the mapped space
- a stack overflow can cause it (though other errors may be more likely, because depending on setup it may trample all of the heap before it does)
- attempt to write to read-only memory
A segfault is raised by hardware that supports memory protection (the MPU in most modern computers), which is caught by the kernel.
The kernel then decides what to do, which in linux amounts to sending a signal (SIGSEGV) to the originating process, where the default signal handler quits that program.
Bus error
Means the processor / memory subsystem cannot even attempt to access the memory it was asked to access.
Also sent by hardware, received by the kernel, and on linux handled by sending it SIGBUS, triggering the default signal handler.
Possible causes include:
- address does not make sense, in that it cannot possibly be there (outside of mappable addresses)
-
- e.g. a using random number as a pointer pointer has a decent chance of being this or a segfault
- IO
- device became unavailable (verify)
- device has to reports something is unavailable, e.g. a RAID controller refusing access to a broken drive (e.g. search for combination with «rejecting I/O to offline device»)
- memory mapped IO where the backing device is not currently available
- …or ran out of space, e.g. when mmapping on a ram disk (verify)
- address fails the platform’s alignment requirements
- larger-than-byte units often have to be aligned to their size, e.g. 16-bit to the nearest 16-bit address
- Less likely on x86 style platforms than others (x86 is more lenient around misalignments than others)
- Theoretically rare anyway, as compilers tend to pad data that is not ideally aligned.
- cannot page in the backing memory (verify)
- e.g.
- a broken swap device? (verify)
- accessing a memory-mapped file that was removed
- executing a binary image that was removed (similar note as above)
In comparison to a segfault:
- similar in that it is about the address
- and having a mangled or random-valued pointer value could lead to either
- similar in that both are raised by the underlying hardware, that the OS sends the originating process a signal, and that the default (kernel-supplied) signal handler kills that originating process.
- differs in that a segfault means the request is valid in a mechanical way, but the requesting process may not do this operation
Aborted (core dumped)
This message comes from the default signal handler(verify) for an incoming SIGABRT.
The reason for the handler is often to abort() and stop the process as soon as possible (without calling exit handlers(verify)), typically the process itself intentionally stopping/crashing as soon as possible, which is done for two good reasons:
- the sooner you do, the more meaningful the core dump is to figuring out what went wrong
- the sooner you do, the less likely you go on to nonsense things to data (and potentially write corrupted data to persistent storage)
Ideally, this is only seen during debugging, but the latter reason is why you’ld leave this in.
The likeliest sources are the process itself asking for this via a failed
assert()
, from your own code or runtime checking from libraries, e.g. glibc noticing double free()s, malloc() noticing overflow corruption, etc.
On core dumps
A process core dump contains (most/all?(verify)) writeable segments specific to the process,
which basically means the data segment and stack segment.
A core dump uses ELF format,
though is seems to be a bit of a de facto thing wider than the ELF standard.
By default it does not contain the text segment, which contains the code,
which is when debugging you also have to tell it what executable was being used.
It wouldn’t be executable even them, since it’s missing some details (entry point, CPU state).
Illegal instruction (core dumped)
Illegal instruction means the CPU got an instruction it did not support.
It can happen when executable code becoming corrupted.
More commonly, though it comes from programs being compiled with very specific optimizations within the wider platform it is part of.
Most programs are compiled to avoid this ever happening, by being conservative about what it’s being run on, which is what compilers and code defaults to.
But when you e.g. compile for instructions that were recently introduced, and omit fallbacks (e.g. via intrinsics), and run it on an older CPU, you’ll get this.
For example, some recent tensorflow builds just assume your CPU has AVX instructions, which didn’t exist in any CPUs from before 2011[2] and still don’t in some lower-end x86 CPUs (Pentium, Celeron, Atom).
From Wikipedia, the free encyclopedia
In computing, a segmentation fault (often shortened to segfault) or access violation is a fault, or failure condition, raised by hardware with memory protection, notifying an operating system (OS) the software has attempted to access a restricted area of memory (a memory access violation). On standard x86 computers, this is a form of general protection fault. The operating system kernel will, in response, usually perform some corrective action, generally passing the fault on to the offending process by sending the process a signal. Processes can in some cases install a custom signal handler, allowing them to recover on their own,[1] but otherwise the OS default signal handler is used, generally causing abnormal termination of the process (a program crash), and sometimes a core dump.
Segmentation faults are a common class of error in programs written in languages like C that provide low-level memory access and few to no safety checks. They arise primarily due to errors in use of pointers for virtual memory addressing, particularly illegal access. Another type of memory access error is a bus error, which also has various causes, but is today much rarer; these occur primarily due to incorrect physical memory addressing, or due to misaligned memory access – these are memory references that the hardware cannot address, rather than references that a process is not allowed to address.
Many programming languages may employ mechanisms designed to avoid segmentation faults and improve memory safety. For example, Rust employs an ownership-based[2] model to ensure memory safety.[3] Other languages, such as Lisp and Java, employ garbage collection,[4] which avoids certain classes of memory errors that could lead to segmentation faults.[5]
Overview[edit]
Example of human generated signal

Segmentation fault affecting Krita in KDE desktop environment
A segmentation fault occurs when a program attempts to access a memory location that it is not allowed to access, or attempts to access a memory location in a way that is not allowed (for example, attempting to write to a read-only location, or to overwrite part of the operating system).
The term «segmentation» has various uses in computing; in the context of «segmentation fault», a term used since the 1950s,[citation needed] it refers to the address space of a program.[6] With memory protection, only the program’s own address space is readable, and of this, only the stack and the read/write portion of the data segment of a program are writable, while read-only data and the code segment are not writable. Thus attempting to read outside of the program’s address space, or writing to a read-only segment of the address space, results in a segmentation fault, hence the name.
On systems using hardware memory segmentation to provide virtual memory, a segmentation fault occurs when the hardware detects an attempt to refer to a non-existent segment, or to refer to a location outside the bounds of a segment, or to refer to a location in a fashion not allowed by the permissions granted for that segment. On systems using only paging, an invalid page fault generally leads to a segmentation fault, and segmentation faults and page faults are both faults raised by the virtual memory management system. Segmentation faults can also occur independently of page faults: illegal access to a valid page is a segmentation fault, but not an invalid page fault, and segmentation faults can occur in the middle of a page (hence no page fault), for example in a buffer overflow that stays within a page but illegally overwrites memory.
At the hardware level, the fault is initially raised by the memory management unit (MMU) on illegal access (if the referenced memory exists), as part of its memory protection feature, or an invalid page fault (if the referenced memory does not exist). If the problem is not an invalid logical address but instead an invalid physical address, a bus error is raised instead, though these are not always distinguished.
At the operating system level, this fault is caught and a signal is passed on to the offending process, activating the process’s handler for that signal. Different operating systems have different signal names to indicate that a segmentation fault has occurred. On Unix-like operating systems, a signal called SIGSEGV (abbreviated from segmentation violation) is sent to the offending process. On Microsoft Windows, the offending process receives a STATUS_ACCESS_VIOLATION exception.
Causes[edit]
The conditions under which segmentation violations occur and how they manifest themselves are specific to hardware and the operating system: different hardware raises different faults for given conditions, and different operating systems convert these to different signals that are passed on to processes. The proximate cause is a memory access violation, while the underlying cause is generally a software bug of some sort. Determining the root cause – debugging the bug – can be simple in some cases, where the program will consistently cause a segmentation fault (e.g., dereferencing a null pointer), while in other cases the bug can be difficult to reproduce and depend on memory allocation on each run (e.g., dereferencing a dangling pointer).
The following are some typical causes of a segmentation fault:
- Attempting to access a nonexistent memory address (outside process’s address space)
- Attempting to access memory the program does not have rights to (such as kernel structures in process context)
- Attempting to write read-only memory (such as code segment)
These in turn are often caused by programming errors that result in invalid memory access:
- Dereferencing a null pointer, which usually points to an address that’s not part of the process’s address space
- Dereferencing or assigning to an uninitialized pointer (wild pointer, which points to a random memory address)
- Dereferencing or assigning to a freed pointer (dangling pointer, which points to memory that has been freed/deallocated/deleted)
- A buffer overflow
- A stack overflow
- Attempting to execute a program that does not compile correctly. (Some compilers[which?] will output an executable file despite the presence of compile-time errors.)
In C code, segmentation faults most often occur because of errors in pointer use, particularly in C dynamic memory allocation. Dereferencing a null pointer, which results in undefined behavior, will usually cause a segmentation fault. This is because a null pointer cannot be a valid memory address. On the other hand, wild pointers and dangling pointers point to memory that may or may not exist, and may or may not be readable or writable, and thus can result in transient bugs. For example:
char *p1 = NULL; // Null pointer char *p2; // Wild pointer: not initialized at all. char *p3 = malloc(10 * sizeof(char)); // Initialized pointer to allocated memory // (assuming malloc did not fail) free(p3); // p3 is now a dangling pointer, as memory has been freed
Dereferencing any of these variables could cause a segmentation fault: dereferencing the null pointer generally will cause a segfault, while reading from the wild pointer may instead result in random data but no segfault, and reading from the dangling pointer may result in valid data for a while, and then random data as it is overwritten.
Handling[edit]
The default action for a segmentation fault or bus error is abnormal termination of the process that triggered it. A core file may be generated to aid debugging, and other platform-dependent actions may also be performed. For example, Linux systems using the grsecurity patch may log SIGSEGV signals in order to monitor for possible intrusion attempts using buffer overflows.
On some systems, like Linux and Windows, it is possible for the program itself to handle a segmentation fault.[7] Depending on the architecture and operating system, the running program can not only handle the event but may extract some information about its state like getting a stack trace, processor register values, the line of the source code when it was triggered, memory address that was invalidly accessed[8] and whether the action was a read or a write.[9]
Although a segmentation fault generally means that the program has a bug that needs fixing, it is also possible to intentionally cause such failure for the purposes of testing, debugging and also to emulate platforms where direct access to memory is needed. On the latter case, the system must be able to allow the program to run even after the fault occurs. In this case, when the system allows, it is possible to handle the event and increment the processor program counter to «jump» over the failing instruction to continue the execution.[10]
Examples[edit]

Segmentation fault on an EMV keypad
Writing to read-only memory[edit]
Writing to read-only memory raises a segmentation fault. At the level of code errors, this occurs when the program writes to part of its own code segment or the read-only portion of the data segment, as these are loaded by the OS into read-only memory.
Here is an example of ANSI C code that will generally cause a segmentation fault on platforms with memory protection. It attempts to modify a string literal, which is undefined behavior according to the ANSI C standard. Most compilers will not catch this at compile time, and instead compile this to executable code that will crash:
int main(void) { char *s = "hello world"; *s = 'H'; }
When the program containing this code is compiled, the string «hello world» is placed in the rodata section of the program executable file: the read-only section of the data segment. When loaded, the operating system places it with other strings and constant data in a read-only segment of memory. When executed, a variable, s, is set to point to the string’s location, and an attempt is made to write an H character through the variable into the memory, causing a segmentation fault. Compiling such a program with a compiler that does not check for the assignment of read-only locations at compile time, and running it on a Unix-like operating system produces the following runtime error:
$ gcc segfault.c -g -o segfault $ ./segfault Segmentation fault
Backtrace of the core file from GDB:
Program received signal SIGSEGV, Segmentation fault. 0x1c0005c2 in main () at segfault.c:6 6 *s = 'H';
This code can be corrected by using an array instead of a character pointer, as this allocates memory on stack and initializes it to the value of the string literal:
char s[] = "hello world"; s[0] = 'H'; // equivalently, *s = 'H';
Even though string literals should not be modified (this has undefined behavior in the C standard), in C they are of static char [] type,[11][12][13] so there is no implicit conversion in the original code (which points a char * at that array), while in C++ they are of static const char [] type, and thus there is an implicit conversion, so compilers will generally catch this particular error.
Null pointer dereference[edit]
In C and C-like languages, null pointers are used to mean «pointer to no object» and as an error indicator, and dereferencing a null pointer (a read or write through a null pointer) is a very common program error. The C standard does not say that the null pointer is the same as the pointer to memory address 0, though that may be the case in practice. Most operating systems map the null pointer’s address such that accessing it causes a segmentation fault. This behavior is not guaranteed by the C standard. Dereferencing a null pointer is undefined behavior in C, and a conforming implementation is allowed to assume that any pointer that is dereferenced is not null.
int *ptr = NULL; printf("%d", *ptr);
This sample code creates a null pointer, and then tries to access its value (read the value). Doing so causes a segmentation fault at runtime on many operating systems.
Dereferencing a null pointer and then assigning to it (writing a value to a non-existent target) also usually causes a segmentation fault:
int *ptr = NULL; *ptr = 1;
The following code includes a null pointer dereference, but when compiled will often not result in a segmentation fault, as the value is unused and thus the dereference will often be optimized away by dead code elimination:
Buffer overflow[edit]
The following code accesses the character array s beyond its upper boundary. Depending on the compiler and the processor, this may result in a segmentation fault.
char s[] = "hello world"; char c = s[20];
Stack overflow[edit]
Another example is recursion without a base case:
int main(void) { return main(); }
which causes the stack to overflow which results in a segmentation fault.[14] Infinite recursion may not necessarily result in a stack overflow depending on the language, optimizations performed by the compiler and the exact structure of a code. In this case, the behavior of unreachable code (the return statement) is undefined, so the compiler can eliminate it and use a tail call optimization that might result in no stack usage. Other optimizations could include translating the recursion into iteration, which given the structure of the example function would result in the program running forever, while probably not overflowing its stack.
See also[edit]
- General protection fault
- Storage violation
- Guru Meditation
References[edit]
- ^ Expert C programming: deep C secrets By Peter Van der Linden, page 188
- ^ «The Rust Programming Language — Ownership».
- ^ «Fearless Concurrency with Rust — The Rust Programming Language Blog».
- ^ McCarthy, John (April 1960). «Recursive functions of symbolic expressions and their computation by machine, Part I». Communications of the ACM. 4 (3): 184–195. doi:10.1145/367177.367199. S2CID 1489409. Retrieved 2018-09-22.
- ^ Dhurjati, Dinakar; Kowshik, Sumant; Adve, Vikram; Lattner, Chris (1 January 2003). «Memory Safety Without Runtime Checks or Garbage Collection» (PDF). Proceedings of the 2003 ACM SIGPLAN Conference on Language, Compiler, and Tool for Embedded Systems. ACM. 38 (7): 69–80. doi:10.1145/780732.780743. ISBN 1581136471. S2CID 1459540. Retrieved 2018-09-22.
- ^ «Debugging Segmentation Faults and Pointer Problems — Cprogramming.com». www.cprogramming.com. Retrieved 2021-02-03.
- ^ «Cleanly recovering from Segfaults under Windows and Linux (32-bit, x86)». Retrieved 2020-08-23.
- ^ «Implementation of the SIGSEGV/SIGABRT handler which prints the debug stack trace». GitHub. Retrieved 2020-08-23.
- ^ «How to identify read or write operations of page fault when using sigaction handler on SIGSEGV?(LINUX)». Retrieved 2020-08-23.
- ^ «LINUX – WRITING FAULT HANDLERS». Retrieved 2020-08-23.
- ^ «6.1.4 String literals». ISO/IEC 9899:1990 — Programming languages — C.
- ^ «6.4.5 String literals». ISO/IEC 9899:1999 — Programming languages — C.
- ^ «6.4.5 String literals». ISO/IEC 9899:2011 — Programming languages — C.
- ^ What is the difference between a segmentation fault and a stack overflow? at Stack Overflow
External links[edit]
- Process: focus boundary and segmentation fault[dead link]
- A FAQ: User contributed answers regarding the definition of a segmentation fault
- A «null pointer» explained
- Answer to: NULL is guaranteed to be 0, but the null pointer is not?
- The Open Group Base Specifications Issue 6 signal.h
Материал из Национальной библиотеки им. Н. Э. Баумана
Последнее изменение этой страницы: 16:36, 24 августа 2017.
Ошибка сегментации (англ. Segmentation fault, сокр. segfault, жарг. сегфолт) — ошибка программного обеспечения, возникающая при попытке обращения к недоступным для записи участкам памяти либо при попытке изменения памяти запрещённым способом.
Сегментная адресация памяти является одним из подходов к управлению и защите памяти в операционной системе. Для большинства целей она была вытеснена страничной памятью, однако в документациях по традиции используют термин «Ошибка сегментации». Некоторые операционные системы до сих пор используют сегментацию на некоторых логических уровнях, а страничная память используется в качестве основной политики управления памятью.
Сегментная адресация памяти является одним из подходов к управлению и защите памяти в операционной системе. Для большинства целей она была вытеснена страничной памятью, однако в документациях по традиции используют термин «Ошибка сегментации». Некоторые операционные системы до сих пор используют сегментацию на некоторых логических уровнях, а страничная память используется в качестве основной политики управления памятью.
Общие понятия
Сегментная адресация памяти — схема логической адресации памяти компьютера в архитектуре x86. Линейный адрес конкретной ячейки памяти, который в некоторых режимах работы процессора будет совпадать с физическим адресом, делится на две части: сегмент и смещение. Сегментом называется условно выделенная область адресного пространства определённого размера, а смещением — адрес ячейки памяти относительно начала сегмента. Базой сегмента называется линейный адрес (адрес относительно всего объёма памяти), который указывает на начало сегмента в адресном пространстве. В результате получается сегментный (логический) адрес, который соответствует линейному адресу база сегмента+смещение и который выставляется процессором на шину адреса.
Ошибка сегментации происходит , когда программа пытается получить доступ к месту памяти, на которое она не имеет права доступа, или пытается получить доступ к ячейке памяти таким образом, каким не допускается условиями системы.
Термин «сегментация» применяется в разных сферах вычислительной техники. В контексте обсуждаемой темы, термин используется с 1950 года , и относится к адресное пространству программы. Таким образом, при попытке чтения за пределами адресного пространства программы или запись на фрагмент, предназначенного только для чтения сегмента адресного пространства, приводит к ошибке сегментации, отсюда и название.
В системах, использующих аппаратные средства сегментации памяти для обеспечения виртуальной памяти, сбой сегментации возникает, когда оборудование системы обнаруживает попытку программы обратиться к несуществующему сегменту, и пытается сослаться на место вне границ сегмента, или сослаться на место на которое у нее нет разрешений.
В системах , использующих только пейджинг недопустимая страница, как правило, ведет к сегментации, ошибки сегментации или ошибки страницы, в виду устройства алгоритмов системы виртуальной памяти.
Страницы — это области физической памяти фиксированного размера, мельчайшая и неделимая единица памяти, которой может оперировать ОС.
На аппаратном уровне, неисправность возникает по причине реагирования блока управления памяти (MMU) на неправомерный доступ к памяти.
На уровне операционной системы эта ошибка ловится и сигнал передается в блок «offending process», где эта ошибка обрабатывается:
- В UNIX-подобных операционных системах процесс, обращающийся к недействительным участкам памяти, получает сигнал «SIGSEGV».
- В Microsoft Windows, процесс, получающий доступ к недействительным участкам памяти, создаёт исключение «STATUS_ACCESS_VIOLATION», и, как правило, предлагает запустить отладчик приложения Dr. Watson, которая показывает пользователю окно с предложением отправить отчет об ошибке Microsoft.
Суммирую можно сказать, когда пользовательский процесс хочет обратиться к памяти, то он просит MMU переадресовать его. Но если полученный адрес ошибочен, — находится вне пределов физического сегмента, или если сегмент не имеет нужных прав (попытка записи в read only-сегмент), — то ОС по умолчанию отправляет сигнал SIGSEGV, что приводит к прерыванию выполнения процесса и выдаче сообщения “segmentation fault”.
Причины сегментации
Наиболее распространенные причины ошибки сегментации:
- Разыменование нулевых указателей
- Попытка доступа к несуществующему адресу памяти (за пределами адресного пространства процесса)
- Попытка доступа к памяти программой, которая не имеет права на эту часть памяти
- Попытка записи в память, предназначенной только для чтения
Причины зачастую вызваны ошибками программирования, которые приводят к ошибкам связанными с памятью:
- Создание операций с разыменованым указателем или создание неинициализированного указателя (указатель, который указывает на случайный адрес памяти)
- Разыменование или возложение на освобожденной указатель (использование оборванного указателя, который указывает на память, которая была освобождена или перераспределена).
- Переполнение буфера
- Переполнение стека
- Попытка выполнить программу, которая не компилируется правильно. (Некоторые компиляторы будут выводить исполняемый файл , несмотря на наличие ошибок во время компиляции.)
Пример Segmentation Fault
Рассмотрим пример кода на ANSI C, который приводит к ошибке сегментации вследствие присутствия квалификатора Сonst — type:
const char *s = "hello world"; *(char *)s = 'H';
Когда программа, содержащая этот код, скомпилирована, строка «hello world» размещена в секции программы с бинарной пометкой «только для чтения». При запуске операционная система помещает её с другими строками и константами в сегмент памяти, предназначенный только для чтения. После запуска переменная s указывает на адрес строки, а попытка присвоить значение символьной константы H через переменную в памяти приводит к ошибке сегментации.
Компиляция и запуск таких программ на OpenBSD 4.0 вызывает следующую ошибку выполнения:
$ gcc segfault.c -g -o segfault $ ./segfault Segmentation fault
Вывод отладчика gdb:
Program received signal SIGSEGV, Segmentation fault. 0x1c0005c2 in main () at segfault.c:6 6 *s = 'H';
В отличие от этого, gcc 4.1.1 на GNU/Linux возвращает ошибку ещё во время компиляции:
$ gcc segfault.c -g -o segfault segfault.c: In function ‘main’: segfault.c:4: error: assignment of read-only location
Условия, при которых происходят нарушения сегментации, и способы их проявления зависят от операционной системы.
Этот пример кода создаёт нулевой указатель и пытается присвоить значение по несуществующему адресу. Это вызывает ошибки сегментации во время выполнения программы на многих системах.
int* ptr = (int*)0; *ptr = 1;
Ещё один способ вызвать ошибку сегментации заключается в том, чтобы вызвать функцию main рекурсивно, что приведёт к переполнению стека:
Обычно, ошибка сегментации происходит потому что: указатель или нулевой, или указывает на произвольный участок памяти (возможно, потому что не был инициализирован), или указывает на удаленный участок памяти. Например:
char* p1 = NULL; /* инициализирован как нулевой, в чем нет ничего плохого, но на многих системах он не может быть разыменован */ char* p2; /* вообще не инициализирован */ char* p3 = (char *)malloc(20); /* хорошо, участок памяти выделен */ free(p3); /* но теперь его больше нет */
Теперь разыменование любого из этих указателей может вызвать ошибку сегментации.
Также, при использовании массивов, если случайно указать в качестве размера массива неинициализированную переменную. Вот пример:
int main()
{
int const nmax=10;
int i,n,a[n];
}
Такая ошибка не прослеживается G++ при компоновке, но при запуске приложения вызовет ошибку сегментации.
Видеопример Segmentation Fault на примере C:
Источники
- wiki info about Segmentation Fault
- wiki Segmentation_fault
- Почему возникает ошибка сегментации
- Segmentation Fault
Операционные системы |
|||||
|---|---|---|---|---|---|
| Общая информация |
|
||||
| Ядро |
|
||||
| Управление процессами |
|
||||
| Управление памятью |
|
||||
| Память для хранения Файловые системы |
|
||||
| Список |
|
||||
| Прочее |
|
В этом руководстве объясняется, как анализировать сообщение segfault в файле messages и выявлять проблему на стороне приложения или операционной системы.
Что такое «segfault»?
Ошибка сегментации (в оригинале segmentation fault часто сокращаемая до segfault) или нарушение доступа – это ошибка, возникшая у оборудования с защитой памяти, чтобы уведомить операционную систему (ОС) о нарушении доступа к памяти.
Ядро Linux отвечает на него, выполняя некоторые корректирующие действия, обычно передавая ошибку в процесс-нарушитель, посылая процессу сигнал типа # 11.
В некоторых случаях процессы могут устанавливать пользовательский обработчик сигналов, что позволяет им восстанавливаться самостоятельно, но в противном случае используется обработчик сигналов по умолчанию в Linux.
Обычно segfault приводит к завершению процесса и генерирует дамп ядра с правильной настройкой ulimit.
Как проверить?
1. Определить segfault
Segfault обычно просто означает ошибку в одном конкретном процессе или программе.
Это не означает ошибку ядра Linux.
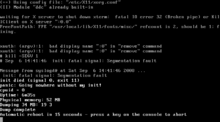
Ядро просто обнаруживает ошибку процесса или программы и (на некоторых архитектурах) выводит информацию в журнал, как показано ниже:
kernel: login[118125]: segfault at 0 ip 00007f4e4d5334a8 sp 00007fffe9177d60 error 15 in pam_unity_uac.so[7f4e4d530000+b000] kernel: crond[16398]: segfault at 14 ip 00007fd612c128f2 sp 00007fff6a689010 error 4 in pam_seos.so[7fd612baf000+f5000] kernel: crond[17719]: segfault at 14 ip 00007fd612c128f2 sp 00007fff6a689010 error 4 in pam_seos.so[7fd612baf000+f5000
2. Что означает подробности этого сообщения?
Значение RIP – это значение регистра указателя команды, а RSP – значение регистра указателя стека.
Значением ошибки является битовая маска битов кода ошибки страницы (из arch/x86/mm/fault.c):
* bit 0 == 0: no page found 1: protection fault * bit 1 == 0: read access 1: write access * bit 2 == 0: kernel-mode access 1: user-mode access * bit 3 == 1: use of reserved bit detected * bit 4 == 1: fault was an instruction fetch
Вот определение бита ошибки:
enum x86_pf_error_code {
PF_PROT = 1 << 0,
PF_WRITE = 1 << 1,
PF_USER = 1 << 2,
PF_RSVD = 1 << 3,
PF_INSTR = 1 << 4,
};
Код ошибки 15 – 1111 бит.
Наконец, мы можем узнать значение 1111 следующим образом:
01111 ^^^^^ ||||+---> bit 0 |||+----> bit 1 ||+-----> bit 2 |+------> bit 3 +-------> bit 4
Это сообщение указывает, что приложение вызывает ошибку защиты, потому что этот процесс пытался записать доступ к зарезервированному разделу памяти в режиме пользователя.
This post explains how to analyse the segfault message in message file and to identify the problem in application or operating system side.
A segmentation fault (often shortened to segfault) or access violation is a fault raised by hardware with memory protection, to notify operating system (OS) about a memory access violation. The Linux kernel will response it by performing some corrective action, generally passing the fault to the offending process by sending the process a signal like #11. Processes can in some cases install a custom signal handler, allowing them to recover on their own, but otherwise the Linux default signal handler is used. The segfault generally will cause process to be terminated, and generates a core dump with proper ulimit setup.
How to check?
1. Signify segfault
A segfault typically just signifies an error in one particular process or program. It does not signify an error of the Linux Kernel. The kernel just detects the error of the process or program and (on some architectures) prints the information to the log like below:
kernel: login[118125]: segfault at 0 ip 00007f4e4d5334a8 sp 00007fffe9177d60 error 15 in pam_unity_uac.so[7f4e4d530000+b000] kernel: crond[16398]: segfault at 14 ip 00007fd612c128f2 sp 00007fff6a689010 error 4 in pam_seos.so[7fd612baf000+f5000] kernel: crond[17719]: segfault at 14 ip 00007fd612c128f2 sp 00007fff6a689010 error 4 in pam_seos.so[7fd612baf000+f5000
2. What does mean details this message?
The RIP value is the instruction pointer register value, the RSP is the stack pointer register value. The error value is a bit mask of page fault error code bits (from arch/x86/mm/fault.c):
* bit 0 == 0: no page found 1: protection fault * bit 1 == 0: read access 1: write access * bit 2 == 0: kernel-mode access 1: user-mode access * bit 3 == 1: use of reserved bit detected * bit 4 == 1: fault was an instruction fetch
Here’s error bit definition:
enum x86_pf_error_code {
PF_PROT = 1 << 0,
PF_WRITE = 1 << 1,
PF_USER = 1 << 2,
PF_RSVD = 1 << 3,
PF_INSTR = 1 << 4,
};
The error code 15 is 1111 bit. Finally, we can know the meaning of 1111 as follows:
01111 ^^^^^ ||||+---> bit 0 |||+----> bit 1 ||+-----> bit 2 |+------> bit 3 +-------> bit 4
This message indicates that the application triggers protection fault because that process tried to write access to a reserved section of memory in user-mode.
Understanding and solving errors are essential skills for any Linux administrator. The most common errors you will get are: “no such file or directory found” or “unable to access or permission denied”. If you are a Linux administrator, it is mandatory to know how to detect and solve segmentation faults. In this article, we will explain what segmentation fault is, what causes them, and how to detect or troubleshoot them. So let’s get started.
What Is a Segmentation Fault?
A segmentation fault is nothing but the error that occurs due to failed attempts to access Linux OS’s memory regions. These types of faults are detected by the kernel. Once detected, the process is immediately terminated, and a “segmentation violation signal” or “segmentation fault” is issued.
We can find most segmentation faults in lower-level languages like C (the most commonly used/ fundamental language in both LINUX and UNIX). It allows a great deal on memory allocation and usage. Hence, developers can have full control over the memory allocation.
What Causes a Segmentation Fault?
In the Linux or kernel operating system, the following are the conditions that cause a segmentation fault:
- Segmentation Violation Mapping Error (SEGV_MAPERR): This is the error that occurs when you want to access memory outside the application that requires an address space.
- Segmentation Violation Access Error (SEGV_ACCERR): This is the error that occurs when you want to access memory where the application does not have permission or write source codes on read-only memory space.
Sometimes we assume that these two conditions cause major problems, but that’s not always true. There might be chances of getting errors through referencing NULL values, freed pointers available for the reference memory areas, non-initialized parameters, and StackOverflow.
Examples That Generate Segmentation Faults in Linux
Here, we are going to explain a few code snippets that generate the segmentation default in Linux:
void main (void) {
char *buffer; /* Non initialized buffer */
buffer[0] = 0; /* Trying to assign 0 to its first position will cause a segmentation fault */
}We can now run and compile them on Linux kernel as follows:
$ gcc -o seg_fault -ggdb seg_fault.cOutput:
Segmentation fault (core dumped)In the above example, ulimit dumps the process memory on errors, and the compiling done with the help of GCC or -ggtb options, adds debug information on the resulting binary.
In addition, we can also enable get debug information and core dumping where the error occurred as shown in the below example:
$ gdb ./seg_fault /var/crash/core.seg_faultOutput:
... <snip> ...
Reading symbols from ./seg_fault...
[New LWP 6291]
Core was generated by `./seg_fault'.
Program terminated with signal SIGSEGV, Segmentation fault.
#0 0x000055ea4064c135 in main () at seg_fault.c:4
4 buffer[0] = 0;Note: However, if you don’t have to debug information, you can still identify the errors with the help of the name of the function, and values where we are getting errors.
How to Detect a Segmentation Fault
Till now, we have seen a few examples where we get errors. In this section, we will explain how to diagnose/detect the segmentation fault.
Using a debugger, you might detect segmentation faults. There are various kinds of debuggers available, but the most often used debuggers are GDB or -ggtb. GDB is a well-known GNU debugger that helps us view the backtrace of the core file, which is dumped by the program.
Whenever a segmentation fault occurs in the program, it usually dumps the memory content at the time of the core file crash process. Start your debugger, GDB, with the “gdb core” command. Then, use the “backtrace” command to check for the program crash.
If you are unable to detect the segmentation fault using the above solution, try to run your program under “debugger” control. Then, go through the source code, one code line or one code function at a time. To perform this task, all you need to do is compile your program codes without optimization, and use the “-g” flag to find out the errors.
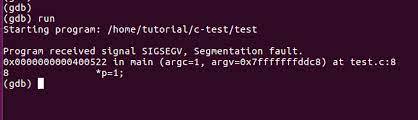
Let us explain the simple steps required to identify segFault inside GDB:
-
Make sure you have enabled the debugger mode (-g flag should also be a part of the GCC line). It looks like this:
gcc -g -o segfault segfault.c-
Then load the file into the gdb format:
-
For the sample code, use this navigation to identify the codes that cause SegFault:
-
Then, run your program: Starting program: /home/pi/segfault
program received signal SIGSEGV, Segmentation fault.The following image illustrates the above steps:
How to Prevent Segmentation Faults in Linux?
When you write a program using pointers, memory allocators, or references, make sure that all the memory accessories are within the boundary and compile with proper access restrictions.
The below are the important things which you should take care of them to avoid segmentation faults:
- Using gdb debugger to track the source of the problem while using dynamic memory location.
- Make sure that you have installed or configured the correct hardware or software components.
- Maintaining type consistency throughout the program code and the function parameters that call convention values will reduce the Segfault.
- Always make sure that all operating system dependencies are installed inside the jail.
- Stop using conditional statements in recursive functions.
- Turn on the core dumping support services (especially Apache) to prevent the segmentation fault in the Linux program.
These tips are very important as they improve code robustness and security services.
Final Take
If you are a Linux developer, you might have gone through the segmentation fault scenarios many times. In this post, we have tried to brief you about SegFault, given real-time examples, explained the causes for the SegFault, and discussed how to detect and prevent segmentation faults.
We hope this blog may help a few Linux communities, Linux administrators, and Linux experts worldwide who want to master the core concepts of the Linux kernel system.
Fault (technology)
Linux kernel
Segmentation fault
Memory (storage engine)
shell
operating system
Opinions expressed by DZone contributors are their own.
Ошибка сегментации (в оригинале segmentation fault часто сокращаемая до segfault) или нарушение доступа — это ошибка, возникшая у оборудования с защитой памяти, чтобы уведомить операционную систему (ОС) о нарушении доступа к памяти.
Ядро Linux отвечает на него, выполняя некоторые корректирующие действия, обычно передавая ошибку в процесс-нарушитель, посылая процессу сигнал типа # 11.
В некоторых случаях процессы могут устанавливать пользовательский обработчик сигналов, что позволяет им восстанавливаться самостоятельно, но в противном случае используется обработчик сигналов по умолчанию в Linux.
Обычно segfault приводит к завершению процесса и генерирует дамп ядра с правильной настройкой ulimit.
Как проверить?
1. Определить segfault
Segfault обычно просто означает ошибку в одном конкретном процессе или программе.
Это не означает ошибку ядра Linux.
Ядро просто обнаруживает ошибку процесса или программы и (на некоторых архитектурах) выводит информацию в журнал, как показано ниже:
|
kernel: login[118125]: segfault at 0 ip 00007f4e4d5334a8 sp 00007fffe9177d60 error 15 in pam_unity_uac.so[7f4e4d530000+b000] kernel: crond[16398]: segfault at 14 ip 00007fd612c128f2 sp 00007fff6a689010 error 4 in pam_seos.so[7fd612baf000+f5000] kernel: crond[17719]: segfault at 14 ip 00007fd612c128f2 sp 00007fff6a689010 error 4 in pam_seos.so[7fd612baf000+f5000 |
2. Что означает подробности этого сообщения?
Значение RIP — это значение регистра указателя команды, а RSP — значение регистра указателя стека.
Значением ошибки является битовая маска битов кода ошибки страницы (из arch/x86/mm/fault.c):
|
* bit 0 == 0: no page found 1: protection fault * bit 1 == 0: read access 1: write access * bit 2 == 0: kernel-mode access 1: user-mode access * bit 3 == 1: use of reserved bit detected * bit 4 == 1: fault was an instruction fetch |
Вот определение бита ошибки:
|
enum x86_pf_error_code { PF_PROT = 1 << 0, PF_WRITE = 1 << 1, PF_USER = 1 << 2, PF_RSVD = 1 << 3, PF_INSTR = 1 << 4, }; |
Код ошибки 15 — 1111 бит.
Наконец, мы можем узнать значение 1111 следующим образом:
|
01111 ^^^^^ ||||+—> bit 0 |||+——> bit 1 ||+——> bit 2 |+——> bit 3 +———> bit 4 |
Это сообщение указывает, что приложение вызывает ошибку защиты, потому что этот процесс пытался записать доступ к зарезервированному разделу памяти в режиме пользователя.