The core file is normally called core and is located in the current working directory of the process. However, there is a long list of reasons why a core file would not be generated, and it may be located somewhere else entirely, under a different name. See the core.5 man page for details:
DESCRIPTION
The default action of certain signals is to cause a process to
terminate and produce a core dump file, a disk file containing an
image of the process’s memory at the time of termination. This image
can be used in a debugger (e.g., gdb(1)) to inspect the state of the
program at the time that it terminated. A list of the signals which
cause a process to dump core can be found in signal(7).…
There are various circumstances in which a core dump file is not produced:
* The process does not have permission to write the core file. (By default, the core file is called core or core.pid, where pid is the ID of the process that dumped core, and is created in the current working directory. See below for details on naming.) Writing the core file will fail if the directory in which it is to be created is nonwritable, or if a file with the same name exists and is not writable or is not a regular file (e.g., it is a directory or a symbolic link). * A (writable, regular) file with the same name as would be used for the core dump already exists, but there is more than one hard link to that file. * The filesystem where the core dump file would be created is full; or has run out of inodes; or is mounted read-only; or the user has reached their quota for the filesystem. * The directory in which the core dump file is to be created does not exist. * The RLIMIT_CORE (core file size) or RLIMIT_FSIZE (file size) resource limits for the process are set to zero; see getrlimit(2) and the documentation of the shell's ulimit command (limit in csh(1)). * The binary being executed by the process does not have read permission enabled. * The process is executing a set-user-ID (set-group-ID) program that is owned by a user (group) other than the real user (group) ID of the process, or the process is executing a program that has file capabilities (see capabilities(7)). (However, see the description of the prctl(2) PR_SET_DUMPABLE operation, and the description of the /proc/sys/fs/suid_dumpable file in proc(5).) * (Since Linux 3.7) The kernel was configured without the CONFIG_COREDUMP option.In addition, a core dump may exclude part of the address space of the
process if the madvise(2) MADV_DONTDUMP flag was employed.Naming of core dump files
By default, a core dump file is named core, but the
/proc/sys/kernel/core_pattern file (since Linux 2.6 and 2.4.21) can
be set to define a template that is used to name core dump files.
The template can contain % specifiers which are substituted by the
following values when a core file is created:%% a single % character %c core file size soft resource limit of crashing process (since Linux 2.6.24) %d dump mode—same as value returned by prctl(2) PR_GET_DUMPABLE (since Linux 3.7) %e executable filename (without path prefix) %E pathname of executable, with slashes ('/') replaced by exclamation marks ('!') (since Linux 3.0). %g (numeric) real GID of dumped process %h hostname (same as nodename returned by uname(2)) %i TID of thread that triggered core dump, as seen in the PID namespace in which the thread resides (since Linux 3.18) %I TID of thread that triggered core dump, as seen in the initial PID namespace (since Linux 3.18) %p PID of dumped process, as seen in the PID namespace in which the process resides %P PID of dumped process, as seen in the initial PID namespace (since Linux 3.12) %s number of signal causing dump %t time of dump, expressed as seconds since the Epoch, 1970-01-01 00:00:00 +0000 (UTC) %u (numeric) real UID of dumped process
What does it mean?
See AU: What is a segmentation fault? post and also this post which have some examples how reproduce it, SO: What is segmentation fault?.
The simplest description I can come with (may be not the perfect):
The program tried to access a memory area out side its own section. Operating system blocks it.
Some cases: Reading value with uninitialized pointer, Going out of range in an array, Function call (when backward compatibility not maintained), …
However, it is not always easy find the cause with large programs or those which relay on other project lib’s. And most of the cases end up with a bug report, either for target program or one of its dependencies (either upstream project or downstream distribution package).
How can I resolve this issue?
-
Fire a bug report
If you didn’t make any custom configuration/setup and you all updates installed. fire a bug report, see How do I report a bug?
If open source supported by Ubuntu use
ubuntu-bug(apport-bug). For 3rd party closed source, check their help pages how to report bugs and collect related data. -
Take initiative to debug
If you you have even a little programming background, it is recommended that you try your best to resolve it yourself. There many bug reports out there inactive for years. At least, you may be able to collect enough debug data that help resolve the issue when reporting it.
That’s means that you are breaking the user abstraction level and opening the black box! (FLOSS actually has transparent box).
Some Useful Tools for Debugging
Some … I mean there are many other useful tools out there that you gonna find when you dig in more.
-
apport-buglogs / core dump / backtraceIf you don’t have an error message before segmentation fault. Run it with
--saveoption and look for back-trace log:apport-bug program-cmd --save bug-report_output.txt -
gdbbacktrace / debuging source codeIf it didn’t work, use
gdb:$ gdb program-cmd (gdb) run (gdb) backtraceIf you get any error message, check the web, launchpad and in upstream project bug tracker if there any similar cases.
For some advanced users or who are following a c/c++ learning path, they could download the corresponding
-dbgsymbols packages. Then you can usegdbto trace program flow through the source and get the exact function/instruction that raise the runtime error.For Ubuntu(Debian) based distributions, source code of a package can be downloaded using:
apt-get source <package-name> -
stracesystem call tracingAnother tool that may help is
strace, I like it. It’s really a powerful tool.It presents itself:
In the simplest case
straceruns the specified command until it exits. It intercepts and records the system calls which are called by a
process and the signals which are received by a process. The name of each system call, its arguments and its return value are printed on
standard error or to the file specified with the -o option.straceis a useful diagnostic, instructional, and debugging tool. System administrators, diagnosticians and trouble-shooters will find it
invaluable for solving problems with programs for which the source is not readily available since they do not need to be recompiled in
order to trace them. Students, hackers and the overly-curious will find that a great deal can be learned about a system and its system
calls by tracing even ordinary programs. And programmers will find that since system calls and signals are events that happen at the
user/kernel interface, a close examination of this boundary is very useful for bug isolation, sanity checking and attempting to capture
race conditions.Source:
man strace -
ltracedynamic library call tracingltraceis a program that simply runs the specified command until
it
exits. It intercepts and records the dynamic library calls which are
called by the executed process and the signals which are received by
that process. It can also intercept and print the system calls exe‐
cuted by the program.Its use is very similar to
strace(1).Source:
man ltrace
Programming languages like C and C++ manage the memory in a more direct way than other programming languages like Java, C#, Python, etc. When an application tries to access the memory area that it does not belong to it Segmentation Fault occurs. Generally, the segmentation fault resulted in the core being dumped which is saving the error memory area into a file for later investigation. There are different reasons for the “Segmentation Fault”/”Core Dumped” error like below.
- Modifying String Literal
- Accessing Freed Address
- Accessing Out Of Array Index Bounds
- Improper useof scanf() Function
- Stackoverflow
- Dereferencing Uninitialized Pointer
Modifying String Literal
String literals are stored in a read-only part of the application. String literals can not be edited as they are located in the read-only part of memory. When the string literal is tried to be changed the segmentation fault occurs and the core is dumped with the Abnormal termination of program .
int main()
{
char *s;
/* Stored in read only part of application memory */
s = "wt";
/* Problem: trying to modify read only memory */
*(s+1) = 'x';
return 0;
}
Accessing Freed Address
Pointers are used to allocated memory parts with memory addresses. After usage, the memory areas or addresses are freed and the freed address range can not be used. If the application tries to access the free address locations the “core dump” error occurs.
int main()
{
char* s= (int*) malloc(8*sizeof(int));
*s = 10;
//s memory area is freed
free(s);
//Try to access free memory are
*s = 20;
return 0;
}Accessing Out Of Array Index Bounds
C and C++ programming languages provide arrays in order to store multiple characters and values inside a single variable. The size of the arrays should be set during initialization and the memory area is allocated according to its size. If the application tries to access of range memory area of the array the “core dump” error occurs.
int main()
{
char s[3]="abc";
s[5]="d";
return 0;
}Improper useof scanf() Function
The scanf() function is used to read user input from the standard input interactively. The scanf() function requires the memory address of a variable in order to store read value If the address is not provided properly or read-only.
int main()
{
char s[3];
scanf("%s",&s+1)
return 0;
}StackOverflow
Every application has a limited memory area called the stack. The stack area is used to store data temporarily during the execution of the application when functions are called. When the stack area is filled and there is no free area the StackOverflow occurs. The stack overflow generally occurs in error-prone algorithms like using recursive functions infinitely.
int main()
{
rec();
}
int rec()
{
int a = 5;
rec();
}Dereferencing Uninitialized Pointer
Pointers are used to point to specific memory addresses. In order to use a pointer, it should be initialized before accessing or dereferencing it. Without initialization, the pointer does not point to any memory area or data which can not be used.
int main()
{
int* a;
printf("%d",*a);
return 0;
}Вводная
C является «небезопасным» («unmanaged») языком, поэтому программы могут «вылетать» — аварийно завершать работу без сохранения данных пользователя, сообщения об ошибке и т.п. — стоит только, например, залезть в не инициализированную память. Например:
void fall()
{
char * s = "short_text";
sprintf(s,"This is very long text");
}
или
void fall()
{
int * pointer = NULL;
*pointer = 13;
}
Всем было бы лучше, если бы мы могли «отловить» падение программы — точно так же, как в java ловим исключения — и выполнить хоть что-то перед тем, как программа упадет (сохранить документ пользователя, вывести диалог с сообщением об ошибке и т.п.)
Общего решения задача не имеет, так как C не имеет собственной модели обработки исключений, связанных с работой с памятью. Тем не менее, мы рассмотрим два способа, использующих особенности операционной системы, вызвавшей исключение.
Есть 2 класса:
1) UI
//UI.h
#ifndef UI_H
#define UI_H
#include <map>
#include <string>
#include <FL/Fl_Button.H>
#include <FL/Fl_Window.H>
#include <FL/Fl_Box.H>
#include <FL/Fl_Output.H>
#include <FL/Fl_Widget.H>
using namespace std;
class App;
class Calculator;
class UI {
public:
Fl_Window *flWindow;
map< string, Fl_Box* > flBox;
map< string, Fl_Button*> flButtons;
Fl_Output *output;
App *app;
Calculator *calc;
UI(App* app);
void startWindow();
void endWindow();
void createUI();
static void resetOutputCb(Fl_Widget *w, void *data);
void changeOutputValue();
void prepareOutput(string& insertedValue, bool isNewAction);
};
#endif /* UI_H */2) Calculator:
//Calculator.h
#ifndef CALCULATOR_H
#define CALCULATOR_H
#include <string>
#include <FL/Fl_Widget.H>
using namespace std;
class UI;
class Calculator {
public:
Calculator(UI *ui);
UI *ui;
string leftOperand;
string action;
string rightOperand;
static void clickButtonCb(Fl_Widget *w, void *data);
bool isNewAction(string action);
private:
void makeCalc(bool isNewValue);
double plus(double x, double y);
};
#endif /* CALCULATOR_H */Класс UI инициализирует класс Calсulator и передает ему указатель на самого себя:
UI::UI(App *app) {
this->app = app;
this->calc = new Calculator(this);
}Класс Calculator в свою очередь записывает указатель на UI в одно из своих свойств:
Calculator::Calculator(UI *ui) :
leftOperand("0"),
rightOperand(""),
action("") {
this->ui = ui;
}
}Однако теперь при попытке вызвать из Calculator метод класса UI:
void UI::prepareOutput(string& insertedValue, bool isNewAction) {
if (calc->action != "" && !isNewAction) { // странно, что при calc->action != "" ошибки нет
if (calc->rightOperand == "0") {
calc->rightOperand = "";
}
calc->rightOperand = insertedValue; // НО ВОТ ТУТ Возникает ошибка при работе с calc->rightOperand
} else if (!isNewAction) {
if (calc->leftOperand == "0") {
calc->leftOperand = "";
}
calc->leftOperand = insertedValue;
}
if (isNewAction && calc->rightOperand == "" && calc->action != "" && insertedValue != "=") {
calc->action = insertedValue;
}
}возникает ошибка:
Segmentation fault; core dumped;
Такая же возникает ошибка, если в классе Calculator сделать что-то вроде :
string str = this->ui->calc->leftOperand; // Segmentation fault; core dumpedПри дебаге в переменных видны “странные” для меня значения, ведь ожидаются простые строки: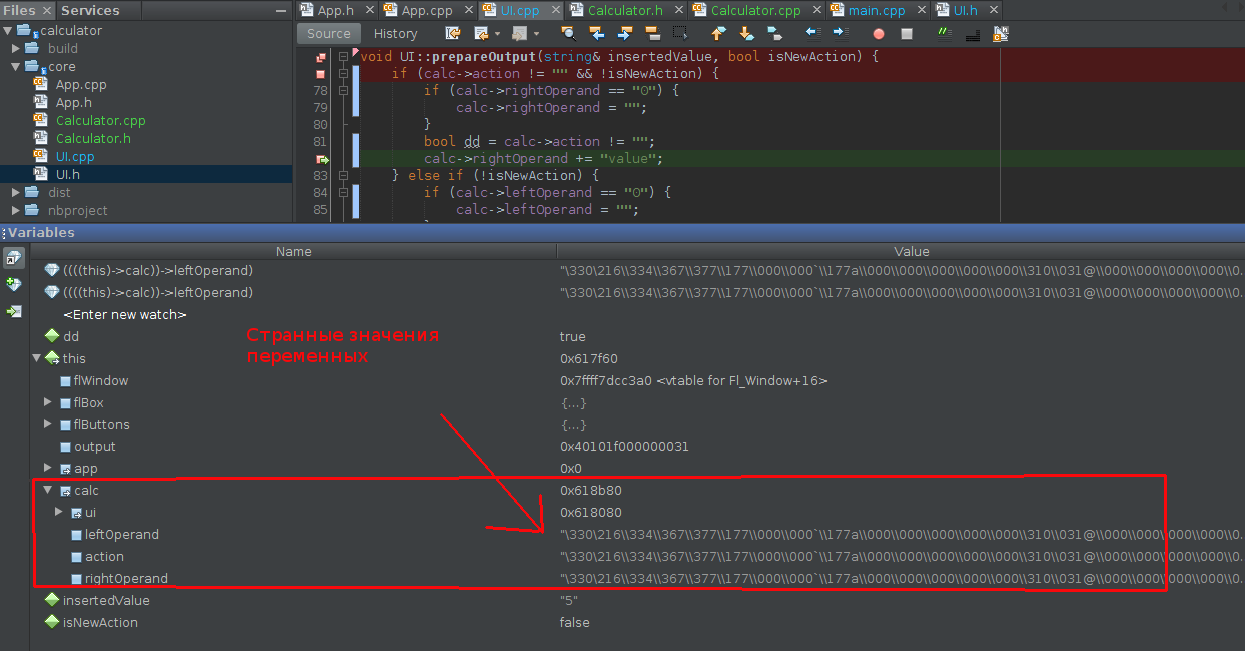
Почему возникает эта ошибка и как ее исправить?
Не запускается сервер
Ошибка segmentation fault (core dumped)
Есть данный код на СИ, суть в том, чтобы в двумерном массиве с помощью потоков (Linux) найти самую большую последовательность чисел по возрастанию. При компиляции всё хорошо, а как запускаю программу появляется ошибка Segmentation fault (core dumped)
#include <unistd.h>
#include <stdio.h>
#include <pthread.h>
#include <stdlib.h>
#include <sys/types.h>
#include <time.h>
void random1(int arr[5][100]) {
int i,j;
for(i=0; i<5;i )
{
for(j=0; j<100;j )
{
arr[i][j]=rand()0;
printf("%dt", arr[i][j]);
}
printf("n");
}
printf("n");
}
void* thread_func1(int arr[5][100]){
int buffer = 1, maxbuffer=0, max=0, minElement=0, maxElement;
int i,j;
for(i=0;i<5;i )
{
for(j=0;j<100;j )
{
if(arr[i][j 1]>arr[i][j])
{
buffer ;
max=buffer;
if(maxbuffer<max)
{
maxbuffer = max;
maxElement = arr[i][j 1];
}
}
if(arr[i][j 1]<=arr[i][j])
{
max=buffer;
if(maxbuffer<max)
{ maxbuffer = max;
maxElement = arr[i][j 1];
}
buffer = 1;
}
}
minElement = (maxElement 1)-maxbuffer;
for( i = minElement; i<=maxElement; i )
{
printf("%dt", arr[i][j]);
}
}
}
int main() {
int A[5][100];
int stime;
stime=time(NULL);
srand(stime);
random1(A);
pthread_t k1,k2;
pthread_create(&k1, NULL, (void*)thread_func1,(int*)A);
pthread_join(k1,NULL);
printf("%ld",k1);
exit (0);
}
Еще один пример реализации функции thread_func1, но там тоже выходит эта ошибка
void* thread_func1(int arr[5][100]){
int start=0, lenght=1, max_start=0, max_lenght=0;
int i,j;
for(i=0;i<5;i ){
for(j=0;j<100;j ){
for(int k=j 1;k<100;k )
{
if(arr[i][j]<arr[i][k])
lenght ;
else{
if(lenght>max_lenght)
max_lenght= lenght, max_start=start;
start = k, lenght = 1;
}
}
}
}
for(i = max_start; i<max_start max_lenght; i ){
for (j=max_start; i<max_start max_lenght; i ){
printf("%p", arr[i][j]);}}}
Ошибка:segmentation fault (core dumped): как можно исправить (shared memory) c
Ошибка слишком проста – Вы пытаетесь обращаться к объекту, который не создали
std::queue<std::string>* str = (std::queue<std::string>*)shmat(ShmID, 0, 0);
то есть, str указывает на память, но что там… а кто его знает. Если обычную структуру так можно размещать, то с классы нужно только через конструктор.
// получим указатель на память
void *p = shmat(ShmID, 0, 0);
// используем placement new для создания объекта по месту
std::queue<std::string> * str = new(p)std::queue<std::string>();
после такого изменения уже не падает. Но нужно не забыть вызвать деструктор (delete str;). И видимо его нужно вызвать только в одном из процессов. И самое главное – не вызвать его тогда, когда ещё другой процесс использует его.
Также нужно аккуратно посинхронизировать обращения к памяти, а то может быть очень весело – std::queue не ожидает, что он работает с разных процессов.
Способ 1: seh
Если Вы используете OS Windows в качестве целевой ОС и Visual C в качестве компилятора, то Вы можете использовать
— расширение языка С от Microsoft, позволяющее отлавливать любые исключения, происходящие в программе.
Общий синтаксис обработки исключений выглядит следующим образом:
__try
{
segfault1();
}
__except( condition1 )
{
// обработка исключения, если condition1 == EXCEPTION_EXECUTE_HANDLER.
// в condition1 может (должен) быть вызов метода, проверяющего
// тип исключения, и возвращающего EXCEPTION_EXECUTE_HANDLER
// если тип исключения соответствует тому, что мы хотим обработать
}
__except( condition2 )
{
// еще один обработчик
}
__finally
{
// то, что выполнится если ни один из обработчиков не почешется
}
Вот «работающий пример» — «скопируй и вставь в Visual Studio»
#include <stdio.h>
#include <windows.h>
#include <excpt.h>
int memento() // обработка Segfault
{
MessageBoxA(NULL,"Memento Mori","Exception catched!",NULL);
return 0;
}
void fall() // генерация segfault
{
int* p = 0x00000000;
*p = 13;
}
int main(int argc, char *argv[])
{
__try
{
fall();
}
__except (EXCEPTION_EXECUTE_HANDLER)
{
memento();
}
}
Мне лично не удалось заставить заработать __finally (поэтому я и написал __except с кодом проверки, который всегда работает), но это, возможно, кривизна моих рук.
Данная методика, при всей ее привлекательности, имеет ряд минусов:
- Один компилятор. Одна ОС. Не «чистый С ». Если Вы хотите работать без средств MS — Вы не сможете использовать эту методику
- Один поток — одна таблица. Если Вы напишете конструкцию из __try… __except, внутри __try запустите другой поток и, не выходя из __try второй поток вызовет segfault, то… ничего не произойдет, программа упадет «как обычно». Потому, что на каждый поток нужно писать отдельный обработчик SEH.
Минусов оказалось настолько много, что приходится искать второе решение.
Способ 2: posix — сигналы
Способ рассчитан на то, что в момент падения программа получает POSIX-сообщение SIGSEGV. Это безусловно так во всех UNIX-системах, но это фактически так (хотя никто не гарантировал, windows — не posix-совместима) и в windows тоже.
Методика простая — мы должны написать обработчик сообщения SIGSEGV, в котором программа совершит «прощальные действия» и, наконец, упадет:
void posix_death_signal(int signum)
{
memento(); // прощальные действия
signal(signum, SIG_DFL); // перепосылка сигнала
exit(3); //выход из программы. Если не сделать этого, то обработчик будет вызываться бесконечно.
}
после чего мы должны зарегистрировать этот обработчик:
signal(SIGSEGV, posix_death_signal);
Вот готовый пример:
#include <stdio.h>
#include <stdio.h>
#include <windows.h>
#include <stdlib.h>
#include <signal.h>
int memento()
{
int a=0;
MessageBoxA(NULL,"Memento mori","POSIX Signal",NULL);
return 0;
}
void fall()
{
int* p = 0x00000000;
*p = 13;
}
void posix_death_signal(int signum)
{
memento();
signal(signum, SIG_DFL);
exit(3);
}
int main(int argc, char *argv[])
{
signal(SIGSEGV, posix_death_signal);
fall();
}
В отличие от SEH, это работает всегда: решение «многопоточное» (вы можете уронить программу в любом потоке, обработчик запустится в любом случае) и «кроссплатформенное» — работает под любым компилятором, и под любой POSIX-совместимой ОС.
Understanding and solving errors are essential skills for any Linux administrator. The most common errors you will get are: “no such file or directory found” or “unable to access or permission denied”. If you are a Linux administrator, it is mandatory to know how to detect and solve segmentation faults. In this article, we will explain what segmentation fault is, what causes them, and how to detect or troubleshoot them. So let’s get started.
What Is a Segmentation Fault?
A segmentation fault is nothing but the error that occurs due to failed attempts to access Linux OS’s memory regions. These types of faults are detected by the kernel. Once detected, the process is immediately terminated, and a “segmentation violation signal” or “segmentation fault” is issued.
We can find most segmentation faults in lower-level languages like C (the most commonly used/ fundamental language in both LINUX and UNIX). It allows a great deal on memory allocation and usage. Hence, developers can have full control over the memory allocation.
What Causes a Segmentation Fault?
In the Linux or kernel operating system, the following are the conditions that cause a segmentation fault:
- Segmentation Violation Mapping Error (SEGV_MAPERR): This is the error that occurs when you want to access memory outside the application that requires an address space.
- Segmentation Violation Access Error (SEGV_ACCERR): This is the error that occurs when you want to access memory where the application does not have permission or write source codes on read-only memory space.
Sometimes we assume that these two conditions cause major problems, but that’s not always true. There might be chances of getting errors through referencing NULL values, freed pointers available for the reference memory areas, non-initialized parameters, and StackOverflow.
Examples That Generate Segmentation Faults in Linux
Here, we are going to explain a few code snippets that generate the segmentation default in Linux:
void main (void) {
char *buffer; /* Non initialized buffer */
buffer[0] = 0; /* Trying to assign 0 to its first position will cause a segmentation fault */
}We can now run and compile them on Linux kernel as follows:
$ gcc -o seg_fault -ggdb seg_fault.cOutput:
Segmentation fault (core dumped)In the above example, ulimit dumps the process memory on errors, and the compiling done with the help of GCC or -ggtb options, adds debug information on the resulting binary.
In addition, we can also enable get debug information and core dumping where the error occurred as shown in the below example:
$ gdb ./seg_fault /var/crash/core.seg_faultOutput:
... <snip> ...
Reading symbols from ./seg_fault...
[New LWP 6291]
Core was generated by `./seg_fault'.
Program terminated with signal SIGSEGV, Segmentation fault.
#0 0x000055ea4064c135 in main () at seg_fault.c:4
4 buffer[0] = 0;Note: However, if you don’t have to debug information, you can still identify the errors with the help of the name of the function, and values where we are getting errors.
How to Detect a Segmentation Fault
Till now, we have seen a few examples where we get errors. In this section, we will explain how to diagnose/detect the segmentation fault.
Using a debugger, you might detect segmentation faults. There are various kinds of debuggers available, but the most often used debuggers are GDB or -ggtb. GDB is a well-known GNU debugger that helps us view the backtrace of the core file, which is dumped by the program.
Whenever a segmentation fault occurs in the program, it usually dumps the memory content at the time of the core file crash process. Start your debugger, GDB, with the “gdb core” command. Then, use the “backtrace” command to check for the program crash.
If you are unable to detect the segmentation fault using the above solution, try to run your program under “debugger” control. Then, go through the source code, one code line or one code function at a time. To perform this task, all you need to do is compile your program codes without optimization, and use the “-g” flag to find out the errors.
Let us explain the simple steps required to identify segFault inside GDB:
-
Make sure you have enabled the debugger mode (-g flag should also be a part of the GCC line). It looks like this:
gcc -g -o segfault segfault.c-
Then load the file into the gdb format:
-
For the sample code, use this navigation to identify the codes that cause SegFault:
-
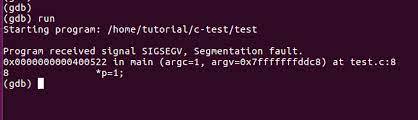
Then, run your program: Starting program: /home/pi/segfault
program received signal SIGSEGV, Segmentation fault.The following image illustrates the above steps:
How to Prevent Segmentation Faults in Linux?
When you write a program using pointers, memory allocators, or references, make sure that all the memory accessories are within the boundary and compile with proper access restrictions.
The below are the important things which you should take care of them to avoid segmentation faults:
- Using gdb debugger to track the source of the problem while using dynamic memory location.
- Make sure that you have installed or configured the correct hardware or software components.
- Maintaining type consistency throughout the program code and the function parameters that call convention values will reduce the Segfault.
- Always make sure that all operating system dependencies are installed inside the jail.
- Stop using conditional statements in recursive functions.
- Turn on the core dumping support services (especially Apache) to prevent the segmentation fault in the Linux program.
These tips are very important as they improve code robustness and security services.
Final Take
If you are a Linux developer, you might have gone through the segmentation fault scenarios many times. In this post, we have tried to brief you about SegFault, given real-time examples, explained the causes for the SegFault, and discussed how to detect and prevent segmentation faults.
We hope this blog may help a few Linux communities, Linux administrators, and Linux experts worldwide who want to master the core concepts of the Linux kernel system.
Fault (technology)
Linux kernel
Segmentation fault
Memory (storage engine)
shell
operating system
Opinions expressed by DZone contributors are their own.

This error may strike your Ubuntu at any point at the moment. A few days ago when I was doing my routine work in my Ubuntu laptop, suddenly I encountered with an error “Segmentation fault ( core dumped)” then I got to know that, this error can strike you Ubuntu or any other operating system at any point of the moment as binaries crashing doesn’t depend on us.
Segmentation fault is when your system tries to access a page of memory that doesn’t exist. Core dumped means when a part of code tries to perform read and write operation on a read-only or free location. Segfaults are generally associated with the file named core and It generally happens during up-gradation.

While running some commands during the core-dump situation you may encounter with “Unable to open lock file” this is because the system is trying to capture a bit block which is not existing, This is due to the crashing of binaries of some specific programs.
You may do backtracking or debugging to resolve it but the solution is to repair the broken packages and we can do it by performing the below-mentioned steps:
Command-line:
Step 1: Remove the lock files present at different locations.
sudo rm -rf /var/lib/apt/lists/lock /var/cache/apt/archives/lock /var/lib/dpkg/lock and restart your system h.cdccdc
Step 2: Remove repository cache.
Step 3: Update and upgrade your repository cache.
sudo apt-get update && sudo apt-get upgrade
Step 4: Now upgrade your distribution, it will update your packages.
sudo apt-get dist-upgrade
Step 5: Find the broken packages and delete them forcefully.
sudo dpkg -l | grep ^..r | apt-get purge
Apart from the command line, the best way which will always work is:
Step 1: Run Ubuntu in startup mode by pressing the Esc key after the restart.
Step 2: Select Advanced options for Ubuntu

Step 3: Run Ubuntu in the recovery mode and you will be listed with many options.

Step 4: First select “Repair broken packages”

Step 5: Then select “Resume normal boot”
So, we have two methods of resolving segmentation fault: CLI and the GUI. Sometimes, it may also happen that the “apt” command is not working because of segfault, so our CLI method will not work, in that case also don’t worry as the GUI method gonna work for us always.
Segmentation faults commonly occur when programs attempt to access memory regions that they are not allowed to access. This article provides an overview of segmentation faults with practical examples. We will discuss how segmentation faults can occur in x86 assembly as well as C along with some debugging techniques.
See the previous article in the series, How to use the ObjDump tool with x86.
What are segmentation faults in x86 assembly?
A segmentation fault occurs when a program attempts to access a memory location that it is not allowed to access, or attempts to access a memory location in a way that is not allowed (for example, attempting to write to a read-only location).
Let us consider the following x86 assembly example.
message db “Welcome to Segmentation Faults! ”
section .text
global _start
_printMessage:
mov eax, 4
mov ebx, 1
mov ecx, message
mov edx, 32
int 0x80
ret
_start:
call _printMessage
As we can notice, the preceding program calls the subroutine _printMessage when it is executed. When we read this program without executing, it looks innocent without any evident problems. Let us assemble and link it using the following commands.
ld print.o -o print -m elf_i386
Now, let us run the program and observe the output.
Welcome to Segmentation Faults! Segmentation fault (core dumped)
As we can notice in the preceding excerpt, there is a segmentation fault when the program is executed.
How to detect segmentation faults in x86 assembly
Segmentation faults always occur during runtime but they can be detected at the code level. The previous sample program that was causing the segmentation faults, is due to lack of an exit routine within the program. So when the program completes executing the code responsible for printing the string, it doesn’t know how to exit and thus lands on some invalid memory address.
Another way to detect segmentation faults is to look for core dumps. Core dumps are usually generated when there is a segmentation fault. Core dumps provide the situation of the program at the time of the crash and thus we will be able to analyze the crash. Core dumps must be enabled on most systems as shown below.
When a segmentation fault occurs, a new core file will be generated as shown below.
Welcome to Segmentation Faults! Segmentation fault (core dumped)
$ ls
core seg seg.nasm seg.o
$
As shown in the proceeding excerpt, there is a new file named core in the current directory.
How to fix segmentation faults x86 assembly
Segmentation faults can occur due to a variety of problems. Fixing a segmentation fault always depends on the root cause of the segmentation fault. Let us go through the same example we used earlier and attempt to fix the segmentation fault. Following is the original x86 assembly program causing a segmentation fault.
message db “Welcome to Segmentation Faults! ”
section .text
global _start
_printMessage:
mov eax, 4
mov ebx, 1
mov ecx, message
mov edx, 32
int 0x80
ret
_start:
call _printMessage
As mentioned earlier, there isn’t an exit routine to gracefully exit this program. So, let us add a call to the exit routine immediately after the control is returned from _printMessage. This looks as follows
message db “Welcome to Segmentation Faults! ”
section .text
global _start
_printMessage:
mov eax, 4
mov ebx, 1
mov ecx, message
mov edx, 32
int 0x80
ret
_exit:
mov eax, 1
mov ebx, 0
int 0x80
_start:
call _printMessage
call _exit
Notice the additional piece of code added in the preceding excerpt. When _printMessage completes execution, the control will be transferred to the caller and call _exit instruction will be executed, which is responsible for gracefully exiting the program without any segmentation faults. To verify, let us assemble and link the program using the following commands.
ld print-exit.o -o print-exit -m elf_i386
Run the binary and we should see the following message without any segmentation fault.
Welcome to Segmentation Faults!
$
As mentioned earlier, the solution to fix a segmentation fault always depends on the root cause.
How to fix segmentation fault in c
Segmentation faults in C programs are often seen due to the fact that C programming offers access to low-level memory. Let us consider the following example written in C language.
{
char *str;
str = “test string”;
*(str+1) = ‘x’;
return 0;
}
The preceding program causes a segmentation fault when it is run. The string variable str in this example stores in read-only part of the data segment and we are attempting to modify read-only memory using the line *(str+1) = ‘x’;
Similarly, segmentation faults can occur when an array out of bound is accessed as shown in the following example.
{
char test[3];
test[4] = ‘A’;
}
This example also leads to a segmentation fault. In addition to it, if the data being passed to the test variable is user-controlled, it can lead to stack-based buffer overflow attacks. Running this program shows the following error due to a security feature called stack cookies.
*** stack smashing detected ***: terminated
Aborted (core dumped)
$
The preceding excerpt shows that the out-of-bound access on an array can also lead to segfaults. Fixing these issues in C programs again falls back to the reason for the Segfault. We should avoid accessing protected memory regions to minimize segfaults.
How to debug segmentation fault
Let us go through our first x86 example that was causing a segfault to get an overview of debugging segmentation faults using gdb. Let us begin by running the program, so we can get the core dump when the segmentation fault occurs.
Welcome to Segmentation Faults! Segmentation fault (core dumped)
$
Now, a core dump should have been generated. Let us load the core dump along with the target executable as shown in the following command. Loading the executable along with the core dump makes the debugging process much easier.
GEF for linux ready, type `gef’ to start, `gef config’ to configure
78 commands loaded for GDB 9.1 using Python engine 3.8
[*] 2 commands could not be loaded, run `gef missing` to know why.
[New LWP 6172]
Core was generated by `./print’.
Program terminated with signal SIGSEGV, Segmentation fault.
#0 0x0804901c in ?? ()
gef➤
As we can notice in the preceding output, the core dump is loaded using GDB and the segmentation fault occurred at the address 0x0804901c. To confirm this, we can check the output of info registers.
eax 0x20 0x20
ecx 0x804a000 0x804a000
edx 0x20 0x20
ebx 0x1 0x1
esp 0xffbe8aa0 0xffbe8aa0
ebp 0x0 0x0
esi 0x0 0x0
edi 0x0 0x0
eip 0x804901c 0x804901c
eflags 0x10202 [ IF RF ]
cs 0x23 0x23
ss 0x2b 0x2b
ds 0x2b 0x2b
es 0x2b 0x2b
fs 0x0 0x0
gs 0x0 0x0
gef➤
As highlighted, the eip register contains the same address. This means, the program attempted to execute the instruction at this address and it has resulted in a segmentation fault. Let us go through the disassembly and understand where this instruction is.
First, let us get the list of functions available and identify which function possibly caused the segfault.
All defined functions:
Non-debugging symbols:
0x08049000 _printMessage
0x08049017 _start
0xf7fae560 __kernel_vsyscall
0xf7fae580 __kernel_sigreturn
0xf7fae590 __kernel_rt_sigreturn
0xf7fae9a0 __vdso_gettimeofday
0xf7faecd0 __vdso_time
0xf7faed10 __vdso_clock_gettime
0xf7faf0c0 __vdso_clock_gettime64
0xf7faf470 __vdso_clock_getres
gef➤
As highlighted in the preceding excerpt, the _printMessage and _start functions’ address ranges are close to the address that caused the segmentation fault. So, let us begin with the disassembly of the function _printMessage.
Dump of assembler code for function _printMessage:
0x08049000 <+0>: mov eax,0x4
0x08049005 <+5>: mov ebx,0x1
0x0804900a <+10>: mov ecx,0x804a000
0x0804900f <+15>: mov edx,0x20
0x08049014 <+20>: int 0x80
0x08049016 <+22>: ret
End of assembler dump.
gef➤
Let us set a breakpoint at ret instruction and run the program. The following command shows how to setup the breakpoint.
Breakpoint 1 at 0x8049016
gef➤
Type run to start the program execution.
0x804900f <_printMessage+15> mov edx, 0x20
0x8049014 <_printMessage+20> int 0x80
→ 0x8049016 <_printMessage+22> ret
↳ 0x804901c add BYTE PTR [eax], al
0x804901e add BYTE PTR [eax], al
0x8049020 add BYTE PTR [eax], al
0x8049022 add BYTE PTR [eax], al
0x8049024 add BYTE PTR [eax], al
0x8049026 add BYTE PTR [eax], al
As we can notice in the preceding excerpt, when the ret instruction gets executed, the control gets passed to the region not controlled by the program code leading to unauthorized memory access and thus a segmentation fault.
Conclusion
This article has outlined some basic concepts around segmentation faults in x86 assembly and how one can use them for debugging programs. We have seen various simple examples to better understand the concepts. We briefly discussed core dumps, which can help us to detect and analyze program crashes.
See the next article in this series, How to control the flow of a program in x86 assembly.
Sources
- https://www.geeksforgeeks.org/core-dump-segmentation-fault-c-cpp/
- http://www.brendangregg.com/blog/2016-08-09/gdb-example-ncurses.html
- https://embeddedbits.org/linux-core-dump-analysis/