Стандартное отклонение (SD), измеряет количество изменчивости или дисперсии, из отдельных значений данных, к среднему значению, в то время как стандартная ошибка среднего (SEM) мер, как далеко образец среднее (среднее) данных, вероятно, будет от истинного среднего значения населения. SEM всегда меньше SD.
Ключевые выводы
- Стандартное отклонение (SD) измеряет разброс набора данных относительно его среднего значения.
- Стандартная ошибка среднего (SEM) измеряет, насколько вероятно расхождение между средним значением выборки по сравнению со средним значением генеральной совокупности.
- SEM берет SD и делит его на квадратный корень из размера выборки.
SEM против SD
Стандартное отклонение и стандартная ошибка используются во всех типах статистических исследований, включая исследования в области финансов, медицины, биологии, инженерии, психологии и т. Д. В этих исследованиях стандартное отклонение (SD) и расчетная стандартная ошибка среднего (SEM) ) используются для представления характеристик данных выборки и объяснения результатов статистического анализа. Однако некоторые исследователи иногда путают SD и SEM. Таким исследователям следует помнить, что расчеты SD и SEM включают разные статистические выводы, каждый из которых имеет свое значение. SD – это разброс отдельных значений данных.
Другими словами, SD указывает, насколько точно среднее значение представляет данные выборки. Однако значение SEM включает статистический вывод, основанный на распределении выборки. SEM – это стандартное отклонение теоретического распределения выборочных средних (выборочное распределение).
Расчет стандартного отклонения

Формула SD требует нескольких шагов:
- Во-первых, возьмите квадрат разницы между каждой точкой данных и средним значением выборки, найдя сумму этих значений.
- Затем разделите эту сумму на размер выборки минус один, который представляет собой дисперсию.
- Наконец, извлеките квадратный корень из дисперсии, чтобы получить стандартное отклонение.
Стандартная ошибка среднего
SEM рассчитывается путем деления стандартного отклонения на квадратный корень из размера выборки.
Стандартная ошибка дает точность выборочного среднего путем измерения изменчивости выборочного среднего от образца к образцу. SEM описывает, насколько точное среднее значение выборки является оценкой истинного среднего значения совокупности. По мере увеличения размера выборки данных SEM уменьшается по сравнению с SD; следовательно, по мере увеличения размера выборки среднее значение выборки оценивает истинное среднее значение генеральной совокупности с большей точностью. Напротив, увеличение размера выборки не обязательно делает SD больше или меньше, это просто становится более точной оценкой SD населения.
Стандартная ошибка и стандартное отклонение в финансах
В финансах стандартная ошибка средней дневной доходности актива измеряет точность выборочного среднего как оценки долгосрочной (постоянной) средней дневной доходности актива.
С другой стороны, стандартное отклонение доходности измеряет отклонения индивидуальных доходов от среднего значения. Таким образом, SD является мерой волатильности и может использоваться в качестве меры риска для инвестиций. Активы с более высокими ежедневными движениями цен имеют более высокое SD, чем активы с меньшими ежедневными движениями. Предполагая нормальное распределение, около 68% дневных изменений цен находятся в пределах одного стандартного отклонения от среднего, при этом около 95% дневных изменений цен находятся в пределах двух стандартных значений среднего.
Standard Error of the Mean vs. Standard Deviation: An Overview
Standard deviation (SD) measures the amount of variability, or dispersion, from the individual data values to the mean. SD is a frequently-cited statistic in many applications from math and statistics to finance and investing.
Standard error of the mean (SEM) measures how far the sample mean (average) of the data is likely to be from the true population mean. The SEM is always smaller than the SD.
Standard deviation and standard error are both used in statistical studies, including those in finance, medicine, biology, engineering, and psychology. In these studies, the SD and the estimated SEM are used to present the characteristics of sample data and explain statistical analysis results.
However, even some researchers occasionally confuse the SD and the SEM. Such researchers should remember that the calculations for SD and SEM include different statistical inferences, each of them with its own meaning. SD is the dispersion of individual data values. In other words, SD indicates how accurately the mean represents sample data.
However, the meaning of SEM includes statistical inference based on the sampling distribution. SEM is the SD of the theoretical distribution of the sample means (the sampling distribution).
Key Takeaways
- Standard deviation (SD) measures the dispersion of a dataset relative to its mean.
- SD is used frequently in statistics, and in finance is often used as a proxy for the volatility or riskiness of an investment.
- The standard error of the mean (SEM) measures how much discrepancy is likely in a sample’s mean compared with the population mean.
- The SEM takes the SD and divides it by the square root of the sample size.
- The SEM will always be smaller than the SD.
Click Play to Learn the Difference Between Standard Error and Standard Deviation
Standard error estimates the likely accuracy of a number based on the sample size.
Standard error of the mean, or SEM, indicates the size of the likely discrepancy compared to that of the larger population.
Calculating SD and SEM
standard deviation
σ
=
∑
i
=
1
n
(
x
i
−
x
ˉ
)
2
n
−
1
variance
=
σ
2
standard error
(
σ
x
ˉ
)
=
σ
n
where:
x
ˉ
=
the sample’s mean
n
=
the sample size
begin{aligned} &text{standard deviation } sigma = sqrt{ frac{ sum_{i=1}^n{left(x_i — bar{x}right)^2} }{n-1} } \ &text{variance} = {sigma ^2 } \ &text{standard error }left( sigma_{bar x} right) = frac{{sigma }}{sqrt{n}} \ &textbf{where:}\ &bar{x}=text{the sample’s mean}\ &n=text{the sample size}\ end{aligned}
standard deviation σ=n−1∑i=1n(xi−xˉ)2variance=σ2standard error (σxˉ)=nσwhere:xˉ=the sample’s meann=the sample size
Standard Deviation
The formula for the SD requires a few steps:
- First, take the square of the difference between each data point and the sample mean, finding the sum of those values.
- Next, divide that sum by the sample size minus one, which is the variance.
- Finally, take the square root of the variance to get the SD.
Standard Error of the Mean
SEM is calculated simply by taking the standard deviation and dividing it by the square root of the sample size.
Standard error gives the accuracy of a sample mean by measuring the sample-to-sample variability of the sample means. The SEM describes how precise the mean of the sample is as an estimate of the true mean of the population.
As the size of the sample data grows larger, the SEM decreases vs. the SD. As the sample size increases, the sample mean estimates the true mean of the population with greater precision.
Increasing the sample size does not make the SD necessarily larger or smaller; it just becomes a more accurate estimate of the population SD.
A sampling distribution is a probability distribution of a sample statistic taken from a greater population. Researchers typically use sample data to estimate the population data, and the sampling distribution explains how the sample mean will vary from sample to sample. The standard error of the mean is the standard deviation of the sampling distribution of the mean.
Standard Error and Standard Deviation in Finance
In finance, the SEM daily return of an asset measures the accuracy of the sample mean as an estimate of the long-run (persistent) mean daily return of the asset.
On the other hand, the SD of the return measures deviations of individual returns from the mean. Thus, SD is a measure of volatility and can be used as a risk measure for an investment.
Assets with greater day-to-day price movements have a higher SD than assets with lesser day-to-day movements. Assuming a normal distribution, around 68% of daily price changes are within one SD of the mean, with around 95% of daily price changes within two SDs of the mean.
How Are Standard Deviation and Standard Error of the Mean Different?
Standard deviation measures the variability from specific data points to the mean. Standard error of the mean measures the precision of the sample mean to the population mean that it is meant to estimate.
Is the Standard Error Equal to the Standard Deviation?
No, the standard deviation (SD) will always be larger than the standard error (SE). This is because the standard error divides the standard deviation by the square root of the sample size.
If the sample size is one, they will be the same, but a sample size of one is rarely useful.
How Can You Compute the SE From the SD?
If you have the standard error (SE) and want to compute the standard deviation (SD) from it, simply multiply it by the square root of the sample size.
Why Do We Use Standard Error Instead of Standard Deviation?
What Is the Empirical Rule, and How Does It Relate to Standard Deviation?
A normal distribution is also known as a standard bell curve, since it looks like a bell in graph form. According to the empirical rule, or the 68-95-99.7 rule, 68% of all data observed under a normal distribution will fall within one standard deviation of the mean. Similarly, 95% falls within two standard deviations and 99.7% within three.
The Bottom Line
Investors and analysts measure standard deviation as a way to estimate the potential volatility of a stock or other investment. It helps determine the level of risk to the investor that is involved. When reading an analyst’s report, the level of riskiness of an investment may be labeled «standard deviation.»
Standard error of the mean is an indication of the likely accuracy of a number. The larger the sample size, the more accurate the number should be.
Standard Error of the Mean vs. Standard Deviation: An Overview
Standard deviation (SD) measures the amount of variability, or dispersion, from the individual data values to the mean. SD is a frequently-cited statistic in many applications from math and statistics to finance and investing.
Standard error of the mean (SEM) measures how far the sample mean (average) of the data is likely to be from the true population mean. The SEM is always smaller than the SD.
Standard deviation and standard error are both used in statistical studies, including those in finance, medicine, biology, engineering, and psychology. In these studies, the SD and the estimated SEM are used to present the characteristics of sample data and explain statistical analysis results.
However, even some researchers occasionally confuse the SD and the SEM. Such researchers should remember that the calculations for SD and SEM include different statistical inferences, each of them with its own meaning. SD is the dispersion of individual data values. In other words, SD indicates how accurately the mean represents sample data.
However, the meaning of SEM includes statistical inference based on the sampling distribution. SEM is the SD of the theoretical distribution of the sample means (the sampling distribution).
Key Takeaways
- Standard deviation (SD) measures the dispersion of a dataset relative to its mean.
- SD is used frequently in statistics, and in finance is often used as a proxy for the volatility or riskiness of an investment.
- The standard error of the mean (SEM) measures how much discrepancy is likely in a sample’s mean compared with the population mean.
- The SEM takes the SD and divides it by the square root of the sample size.
- The SEM will always be smaller than the SD.
Click Play to Learn the Difference Between Standard Error and Standard Deviation
Standard error estimates the likely accuracy of a number based on the sample size.
Standard error of the mean, or SEM, indicates the size of the likely discrepancy compared to that of the larger population.
Calculating SD and SEM
standard deviation
σ
=
∑
i
=
1
n
(
x
i
−
x
ˉ
)
2
n
−
1
variance
=
σ
2
standard error
(
σ
x
ˉ
)
=
σ
n
where:
x
ˉ
=
the sample’s mean
n
=
the sample size
begin{aligned} &text{standard deviation } sigma = sqrt{ frac{ sum_{i=1}^n{left(x_i — bar{x}right)^2} }{n-1} } \ &text{variance} = {sigma ^2 } \ &text{standard error }left( sigma_{bar x} right) = frac{{sigma }}{sqrt{n}} \ &textbf{where:}\ &bar{x}=text{the sample’s mean}\ &n=text{the sample size}\ end{aligned}
standard deviation σ=n−1∑i=1n(xi−xˉ)2variance=σ2standard error (σxˉ)=nσwhere:xˉ=the sample’s meann=the sample size
Standard Deviation
The formula for the SD requires a few steps:
- First, take the square of the difference between each data point and the sample mean, finding the sum of those values.
- Next, divide that sum by the sample size minus one, which is the variance.
- Finally, take the square root of the variance to get the SD.
Standard Error of the Mean
SEM is calculated simply by taking the standard deviation and dividing it by the square root of the sample size.
Standard error gives the accuracy of a sample mean by measuring the sample-to-sample variability of the sample means. The SEM describes how precise the mean of the sample is as an estimate of the true mean of the population.
As the size of the sample data grows larger, the SEM decreases vs. the SD. As the sample size increases, the sample mean estimates the true mean of the population with greater precision.
Increasing the sample size does not make the SD necessarily larger or smaller; it just becomes a more accurate estimate of the population SD.
A sampling distribution is a probability distribution of a sample statistic taken from a greater population. Researchers typically use sample data to estimate the population data, and the sampling distribution explains how the sample mean will vary from sample to sample. The standard error of the mean is the standard deviation of the sampling distribution of the mean.
Standard Error and Standard Deviation in Finance
In finance, the SEM daily return of an asset measures the accuracy of the sample mean as an estimate of the long-run (persistent) mean daily return of the asset.
On the other hand, the SD of the return measures deviations of individual returns from the mean. Thus, SD is a measure of volatility and can be used as a risk measure for an investment.
Assets with greater day-to-day price movements have a higher SD than assets with lesser day-to-day movements. Assuming a normal distribution, around 68% of daily price changes are within one SD of the mean, with around 95% of daily price changes within two SDs of the mean.
How Are Standard Deviation and Standard Error of the Mean Different?
Standard deviation measures the variability from specific data points to the mean. Standard error of the mean measures the precision of the sample mean to the population mean that it is meant to estimate.
Is the Standard Error Equal to the Standard Deviation?
No, the standard deviation (SD) will always be larger than the standard error (SE). This is because the standard error divides the standard deviation by the square root of the sample size.
If the sample size is one, they will be the same, but a sample size of one is rarely useful.
How Can You Compute the SE From the SD?
If you have the standard error (SE) and want to compute the standard deviation (SD) from it, simply multiply it by the square root of the sample size.
Why Do We Use Standard Error Instead of Standard Deviation?
What Is the Empirical Rule, and How Does It Relate to Standard Deviation?
A normal distribution is also known as a standard bell curve, since it looks like a bell in graph form. According to the empirical rule, or the 68-95-99.7 rule, 68% of all data observed under a normal distribution will fall within one standard deviation of the mean. Similarly, 95% falls within two standard deviations and 99.7% within three.
The Bottom Line
Investors and analysts measure standard deviation as a way to estimate the potential volatility of a stock or other investment. It helps determine the level of risk to the investor that is involved. When reading an analyst’s report, the level of riskiness of an investment may be labeled «standard deviation.»
Standard error of the mean is an indication of the likely accuracy of a number. The larger the sample size, the more accurate the number should be.
Содержание
- Расчет ошибки средней арифметической
- Способ 1: расчет с помощью комбинации функций
- Способ 2: применение инструмента «Описательная статистика»
- Вопросы и ответы

Стандартная ошибка или, как часто называют, ошибка средней арифметической, является одним из важных статистических показателей. С помощью данного показателя можно определить неоднородность выборки. Он также довольно важен при прогнозировании. Давайте узнаем, какими способами можно рассчитать величину стандартной ошибки с помощью инструментов Microsoft Excel.
Расчет ошибки средней арифметической
Одним из показателей, которые характеризуют цельность и однородность выборки, является стандартная ошибка. Эта величина представляет собой корень квадратный из дисперсии. Сама дисперсия является средним квадратном от средней арифметической. Средняя арифметическая вычисляется делением суммарной величины объектов выборки на их общее количество.
В Экселе существуют два способа вычисления стандартной ошибки: используя набор функций и при помощи инструментов Пакета анализа. Давайте подробно рассмотрим каждый из этих вариантов.
Способ 1: расчет с помощью комбинации функций
Прежде всего, давайте составим алгоритм действий на конкретном примере по расчету ошибки средней арифметической, используя для этих целей комбинацию функций. Для выполнения задачи нам понадобятся операторы СТАНДОТКЛОН.В, КОРЕНЬ и СЧЁТ.
Для примера нами будет использована выборка из двенадцати чисел, представленных в таблице.

- Выделяем ячейку, в которой будет выводиться итоговое значение стандартной ошибки, и клацаем по иконке «Вставить функцию».
- Открывается Мастер функций. Производим перемещение в блок «Статистические». В представленном перечне наименований выбираем название «СТАНДОТКЛОН.В».
- Запускается окно аргументов вышеуказанного оператора. СТАНДОТКЛОН.В предназначен для оценивания стандартного отклонения при выборке. Данный оператор имеет следующий синтаксис:
=СТАНДОТКЛОН.В(число1;число2;…)«Число1» и последующие аргументы являются числовыми значениями или ссылками на ячейки и диапазоны листа, в которых они расположены. Всего может насчитываться до 255 аргументов этого типа. Обязательным является только первый аргумент.
Итак, устанавливаем курсор в поле «Число1». Далее, обязательно произведя зажим левой кнопки мыши, выделяем курсором весь диапазон выборки на листе. Координаты данного массива тут же отображаются в поле окна. После этого клацаем по кнопке «OK».
- В ячейку на листе выводится результат расчета оператора СТАНДОТКЛОН.В. Но это ещё не ошибка средней арифметической. Для того, чтобы получить искомое значение, нужно стандартное отклонение разделить на квадратный корень от количества элементов выборки. Для того, чтобы продолжить вычисления, выделяем ячейку, содержащую функцию СТАНДОТКЛОН.В. После этого устанавливаем курсор в строку формул и дописываем после уже существующего выражения знак деления (/). Вслед за этим клацаем по пиктограмме перевернутого вниз углом треугольника, которая располагается слева от строки формул. Открывается список недавно использованных функций. Если вы в нем найдете наименование оператора «КОРЕНЬ», то переходите по данному наименованию. В обратном случае жмите по пункту «Другие функции…».
- Снова происходит запуск Мастера функций. На этот раз нам следует посетить категорию «Математические». В представленном перечне выделяем название «КОРЕНЬ» и жмем на кнопку «OK».
- Открывается окно аргументов функции КОРЕНЬ. Единственной задачей данного оператора является вычисление квадратного корня из заданного числа. Его синтаксис предельно простой:
=КОРЕНЬ(число)
Как видим, функция имеет всего один аргумент «Число». Он может быть представлен числовым значением, ссылкой на ячейку, в которой оно содержится или другой функцией, вычисляющей это число. Последний вариант как раз и будет представлен в нашем примере.
Устанавливаем курсор в поле «Число» и кликаем по знакомому нам треугольнику, который вызывает список последних использованных функций. Ищем в нем наименование «СЧЁТ». Если находим, то кликаем по нему. В обратном случае, опять же, переходим по наименованию «Другие функции…».
- В раскрывшемся окне Мастера функций производим перемещение в группу «Статистические». Там выделяем наименование «СЧЁТ» и выполняем клик по кнопке «OK».
- Запускается окно аргументов функции СЧЁТ. Указанный оператор предназначен для вычисления количества ячеек, которые заполнены числовыми значениями. В нашем случае он будет подсчитывать количество элементов выборки и сообщать результат «материнскому» оператору КОРЕНЬ. Синтаксис функции следующий:
=СЧЁТ(значение1;значение2;…)В качестве аргументов «Значение», которых может насчитываться до 255 штук, выступают ссылки на диапазоны ячеек. Ставим курсор в поле «Значение1», зажимаем левую кнопку мыши и выделяем весь диапазон выборки. После того, как его координаты отобразились в поле, жмем на кнопку «OK».
- После выполнения последнего действия будет не только рассчитано количество ячеек заполненных числами, но и вычислена ошибка средней арифметической, так как это был последний штрих в работе над данной формулой. Величина стандартной ошибки выведена в ту ячейку, где размещена сложная формула, общий вид которой в нашем случае следующий:
=СТАНДОТКЛОН.В(B2:B13)/КОРЕНЬ(СЧЁТ(B2:B13))Результат вычисления ошибки средней арифметической составил 0,505793. Запомним это число и сравним с тем, которое получим при решении поставленной задачи следующим способом.










Но дело в том, что для малых выборок (до 30 единиц) для большей точности лучше применять немного измененную формулу. В ней величина стандартного отклонения делится не на квадратный корень от количества элементов выборки, а на квадратный корень от количества элементов выборки минус один. Таким образом, с учетом нюансов малой выборки наша формула приобретет следующий вид:
=СТАНДОТКЛОН.В(B2:B13)/КОРЕНЬ(СЧЁТ(B2:B13)-1)

Урок: Статистические функции в Экселе
Способ 2: применение инструмента «Описательная статистика»
Вторым вариантом, с помощью которого можно вычислить стандартную ошибку в Экселе, является применение инструмента «Описательная статистика», входящего в набор инструментов «Анализ данных» («Пакет анализа»). «Описательная статистика» проводит комплексный анализ выборки по различным критериям. Одним из них как раз и является нахождение ошибки средней арифметической.
Но чтобы воспользоваться данной возможностью, нужно сразу активировать «Пакет анализа», так как по умолчанию в Экселе он отключен.
- После того, как открыт документ с выборкой, переходим во вкладку «Файл».
- Далее, воспользовавшись левым вертикальным меню, перемещаемся через его пункт в раздел «Параметры».
- Запускается окно параметров Эксель. В левой части данного окна размещено меню, через которое перемещаемся в подраздел «Надстройки».
- В самой нижней части появившегося окна расположено поле «Управление». Выставляем в нем параметр «Надстройки Excel» и жмем на кнопку «Перейти…» справа от него.
- Запускается окно надстроек с перечнем доступных скриптов. Отмечаем галочкой наименование «Пакет анализа» и щелкаем по кнопке «OK» в правой части окошка.
- После выполнения последнего действия на ленте появится новая группа инструментов, которая имеет наименование «Анализ». Чтобы перейти к ней, щелкаем по названию вкладки «Данные».
- После перехода жмем на кнопку «Анализ данных» в блоке инструментов «Анализ», который расположен в самом конце ленты.
- Запускается окошко выбора инструмента анализа. Выделяем наименование «Описательная статистика» и жмем на кнопку «OK» справа.
- Запускается окно настроек инструмента комплексного статистического анализа «Описательная статистика».
В поле «Входной интервал» необходимо указать диапазон ячеек таблицы, в которых находится анализируемая выборка. Вручную это делать неудобно, хотя и можно, поэтому ставим курсор в указанное поле и при зажатой левой кнопке мыши выделяем соответствующий массив данных на листе. Его координаты тут же отобразятся в поле окна.
В блоке «Группирование» оставляем настройки по умолчанию. То есть, переключатель должен стоять около пункта «По столбцам». Если это не так, то его следует переставить.
Галочку «Метки в первой строке» можно не устанавливать. Для решения нашего вопроса это не важно.
Далее переходим к блоку настроек «Параметры вывода». Здесь следует указать, куда именно будет выводиться результат расчета инструмента «Описательная статистика»:
- На новый лист;
- В новую книгу (другой файл);
- В указанный диапазон текущего листа.
Давайте выберем последний из этих вариантов. Для этого переставляем переключатель в позицию «Выходной интервал» и устанавливаем курсор в поле напротив данного параметра. После этого клацаем на листе по ячейке, которая станет верхним левым элементом массива вывода данных. Её координаты должны отобразиться в поле, в котором мы до этого устанавливали курсор.
Далее следует блок настроек определяющий, какие именно данные нужно вводить:
- Итоговая статистика;
- К-ый наибольший;
- К-ый наименьший;
- Уровень надежности.
Для определения стандартной ошибки обязательно нужно установить галочку около параметра «Итоговая статистика». Напротив остальных пунктов выставляем галочки на свое усмотрение. На решение нашей основной задачи это никак не повлияет.
После того, как все настройки в окне «Описательная статистика» установлены, щелкаем по кнопке «OK» в его правой части.
- После этого инструмент «Описательная статистика» выводит результаты обработки выборки на текущий лист. Как видим, это довольно много разноплановых статистических показателей, но среди них есть и нужный нам – «Стандартная ошибка». Он равен числу 0,505793. Это в точности тот же результат, который мы достигли путем применения сложной формулы при описании предыдущего способа.










Урок: Описательная статистика в Экселе
Как видим, в Экселе можно произвести расчет стандартной ошибки двумя способами: применив набор функций и воспользовавшись инструментом пакета анализа «Описательная статистика». Итоговый результат будет абсолютно одинаковый. Поэтому выбор метода зависит от удобства пользователя и поставленной конкретной задачи. Например, если ошибка средней арифметической является только одним из многих статистических показателей выборки, которые нужно рассчитать, то удобнее воспользоваться инструментом «Описательная статистика». Но если вам нужно вычислить исключительно этот показатель, то во избежание нагромождения лишних данных лучше прибегнуть к сложной формуле. В этом случае результат расчета уместится в одной ячейке листа.
Стандартная ошибка среднего — это способ измерить, насколько разбросаны значения в наборе данных. Он рассчитывается как:
Стандартная ошибка среднего = s / √n
куда:
- s : стандартное отклонение выборки
- n : размер выборки
В этом руководстве объясняются два метода, которые вы можете использовать для вычисления стандартной ошибки среднего значения для набора данных в Python. Обратите внимание, что оба метода дают одинаковые результаты.
Способ 1: используйте SciPy
Первый способ вычислить стандартную ошибку среднего — использовать функцию sem() из библиотеки SciPy Stats.
Следующий код показывает, как использовать эту функцию:
from scipy. stats import sem
#define dataset
data = [3, 4, 4, 5, 7, 8, 12, 14, 14, 15, 17, 19, 22, 24, 24, 24, 25, 28, 28, 29]
#calculate standard error of the mean
sem(data)
2.001447
Стандартная ошибка среднего оказывается равной 2,001447 .
Способ 2: использовать NumPy
Другой способ вычислить стандартную ошибку среднего для набора данных — использовать функцию std() из NumPy.
Обратите внимание, что мы должны указать ddof=1 в аргументе этой функции, чтобы вычислить стандартное отклонение выборки, а не стандартное отклонение генеральной совокупности.
Следующий код показывает, как это сделать:
import numpy as np
#define dataset
data = np.array([3, 4, 4, 5, 7, 8, 12, 14, 14, 15, 17, 19, 22, 24, 24, 24, 25, 28, 28, 29])
#calculate standard error of the mean
np.std(data, ddof= 1 ) / np.sqrt (np.size (data))
2.001447
И снова стандартная ошибка среднего оказывается равной 2,001447 .
Как интерпретировать стандартную ошибку среднего
Стандартная ошибка среднего — это просто мера того, насколько разбросаны значения вокруг среднего. При интерпретации стандартной ошибки среднего следует помнить о двух вещах:
1. Чем больше стандартная ошибка среднего, тем более разбросаны значения вокруг среднего в наборе данных.
Чтобы проиллюстрировать это, рассмотрим, изменим ли мы последнее значение в предыдущем наборе данных на гораздо большее число:
from scipy. stats import sem
#define dataset
data = [3, 4, 4, 5, 7, 8, 12, 14, 14, 15, 17, 19, 22, 24, 24, 24, 25, 28, 28, 150 ]
#calculate standard error of the mean
sem(data)
6.978265
Обратите внимание на скачок стандартной ошибки с 2,001447 до 6,978265.Это указывает на то, что значения в этом наборе данных более разбросаны вокруг среднего значения по сравнению с предыдущим набором данных.
2. По мере увеличения размера выборки стандартная ошибка среднего имеет тенденцию к уменьшению.
Чтобы проиллюстрировать это, рассмотрим стандартную ошибку среднего для следующих двух наборов данных:
from scipy.stats import sem
#define first dataset and find SEM
data1 = [1, 2, 3, 4, 5]
sem(data1)
0.7071068
#define second dataset and find SEM
data2 = [1, 2, 3, 4, 5, 1, 2, 3, 4, 5]
sem(data2)
0.4714045
Второй набор данных — это просто первый набор данных, повторенный дважды. Таким образом, два набора данных имеют одинаковое среднее значение, но второй набор данных имеет больший размер выборки, поэтому стандартная ошибка меньше.
Дополнительные ресурсы
Как рассчитать стандартную ошибку среднего в R
Как рассчитать стандартную ошибку среднего в Excel
Как рассчитать стандартную ошибку среднего в Google Sheets
Чтобы
судить о том, насколько точно проведенные
измерения отражают состав генеральной
совокупности, необходимо вычислить
стандартную ошибку средней арифметической
выборочной совокупности.
Стандартная
ошибка средней арифметической
характеризует степень отклонения
выборочной средней арифметической от
средней арифметической генеральной
совокупности.
Стандартная
ошибка средней арифметической вычисляется
по формуле:
![]() ,
,
где
– стандартное отклонение результатов
измерений, n
– объем выборки.
Зачастую
мы имеем дело с одной случайной выборкой
и с одной полученной при ее обработке
выборочной средней. Задача заключается
в суждении о величине неизвестной
генеральной средней по полученной
неточной величине случайной выборочной
средней.
Вычислим
среднюю ошибку найденного выборочного
среднего значения роста:
![]() 195
195
см; σ = 8,8 см;
![]() см.
см.
2,8 см
составляют не максимальную, а среднюю
возможную ошибку среднего. Отдельные
выборочные средние могут отклоняться
от генеральной как больше, так и меньше,
чем на 2,8 см.
Каковы
же пределы возможных ошибок случайной
выборки, какова ее максимальная ошибка?
Величина максимальной ошибки зависит
от величины средней ошибки и вычисляется
по формуле
![]() .
.
При
объеме выборки n
= 10:
![]() .
.
Все
случайные выборочные средние, которые
могут быть получены в подобных опытах
(в том числе и фактически полученная
выборочная средняя
![]() = 195 см), при своем варьировании около
= 195 см), при своем варьировании около
неизвестного генерального среднего в
подавляющем количестве группируются
около него так, что лишь ничтожный
процент их отклоняется от генеральной
средней более, чем на величину максимальной
ошибки.
Другими
словами, генеральная средняя определяется
как
![]() .
.
Эти пределы
колебаний значительно сужаются, если
средняя ошибка уменьшается благодаря
увеличению численности выборки.
Искомая
генеральная средняя лежит между
![]() и
и![]() .
.
Таким образом, при высокой точности
выполнения эксперимента и достаточно
большом числе измерений можно определить
среднюю арифметическую бесконечно
большого числа экспериментов.
До сих
пор мы определяли максимальную ошибку
выборочной средней, исходя из того, что
все остальные показатели известны. Если
же мы хотим достичь определенной
точности, определенного приближения к
генеральной средней, в этом случае
встает вопрос о численности выборки (о
том, сколько измерений, опытов необходимо
провести).
Допустим, что
максимальная ошибка должна быть равна
5 см. Сколько человек надо обследовать
(измерить) в нашем случае?
![]() .
.
Следовательно,
мы должны провести измерения роста у
36 баскетболистов высокого класса.
10. Достоверность различий
Следующим
важным вопросом практически для каждого
экспериментатора является умение
доказать достоверность различий между
двумя рядами признаков.
Проверку
достоверности различия двух рядов
измерений производят путем вычисления
критерия достоверности различия – t:
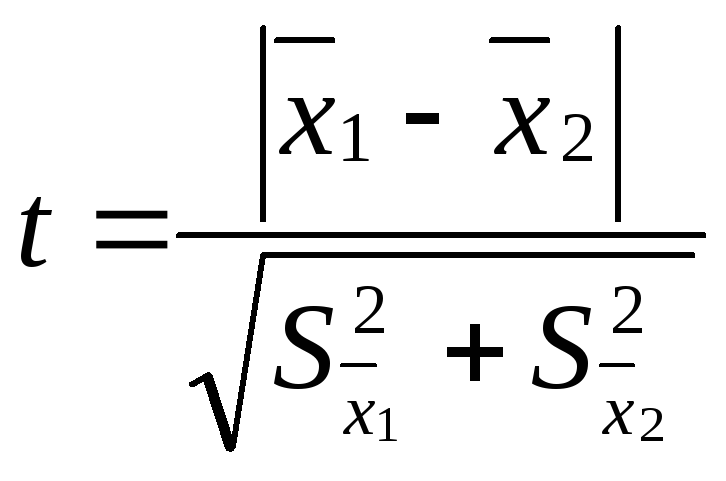 ,
,
где
![]() – средняя одной выборки;
– средняя одной выборки;![]() – средняя другой выборки;
– средняя другой выборки;![]() – средняя ошибка первой выборки;
– средняя ошибка первой выборки;![]() – второй выборки. Если t < 2, то различие
– второй выборки. Если t < 2, то различие
между двумя выборками считается
недостоверным, если t
2, то различие между двумя выборками
достоверно на 95%.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Среднее арифметическое, как известно, используется для получения обобщающей характеристики некоторого набора данных. Если данные более-менее однородны и в них нет аномальных наблюдений (выбросов), то среднее хорошо обобщает данные, сведя к минимуму влияние случайных факторов (они взаимопогашаются при сложении).
Когда анализируемые данные представляют собой выборку (которая состоит из случайных значений), то среднее арифметическое часто (но не всегда) выступает в роли приближенной оценки математического ожидания. Почему приближенной? Потому что среднее арифметическое – это величина, которая зависит от набора случайных чисел, и, следовательно, сама является случайной величиной. При повторных экспериментах (даже в одних и тех же условиях) средние будут отличаться друг от друга.
Для того, чтобы на основе статистического анализа данных делать корректные выводы, необходимо оценить возможный разброс полученного результата. Для этого рассчитываются различные показатели вариации. Но то исходные данные. И как мы только что установили, среднее арифметическое также обладает разбросом, который необходимо оценить и учитывать в дальнейшем (в выводах, в выборе метода анализа и т.д.).
Интуитивно понятно, что разброс средней должен быть как-то связан с разбросом исходных данных. Основной характеристикой разброса средней выступает та же дисперсия.
Дисперсия выборочных данных – это средний квадрат отклонения от средней, и рассчитать ее по исходным данным не составляет труда, например, в Excel предусмотрены специальные функции. Однако, как же рассчитать дисперсию средней, если в распоряжении есть только одна выборка и одно среднее арифметическое?
Расчет дисперсии и стандартной ошибки средней арифметической
Чтобы получить дисперсию средней арифметической нет необходимости проводить множество экспериментов, достаточно иметь только одну выборку. Это легко доказать. Для начала вспомним, что средняя арифметическая (простая) рассчитывается по формуле:
![]()
где xi – значения переменной,
n – количество значений.
Теперь учтем два свойства дисперсии, согласно которым, 1) — постоянный множитель можно вынести за знак дисперсии, возведя его в квадрат и 2) — дисперсия суммы независимых случайных величин равняется сумме соответствующих дисперсий. Предполагается, что каждое случайное значение xi обладает одинаковым разбросом, поэтому несложно вывести формулу дисперсии средней арифметической:
![]()
Используя более привычные обозначения, формулу записывают как:
![]()
где σ2 – это дисперсия, случайной величины, причем генеральная.
На практике же, генеральная дисперсия известна далеко не всегда, точнее совсем редко, поэтому в качестве оной используют выборочную дисперсию:
![]()
Стандартное отклонение средней арифметической называется стандартной ошибкой средней и рассчитывается, как квадратный корень из дисперсии.
Формула стандартной ошибки средней при использовании генеральной дисперсии
![]()
Формула стандартной ошибки средней при использовании выборочной дисперсии
![]()
Последняя формула на практике используется чаще всего, т.к. генеральная дисперсия обычно не известна. Чтобы не вводить новые обозначения, стандартную ошибку средней обычно записывают в виде соотношения стандартного отклонения выборки и корня объема выборки.
Назначение и свойство стандартной ошибки средней арифметической
Стандартная ошибка средней много, где используется. И очень полезно понимать ее свойства. Посмотрим еще раз на формулу стандартной ошибки средней:
![]()
Числитель – это стандартное отклонение выборки и здесь все понятно. Чем больше разброс данных, тем больше стандартная ошибка средней – прямо пропорциональная зависимость.
Посмотрим на знаменатель. Здесь находится квадратный корень из объема выборки. Соответственно, чем больше объем выборки, тем меньше стандартная ошибка средней. Для наглядности изобразим на одной диаграмме график нормально распределенной переменной со средней равной 10, сигмой – 3, и второй график – распределение средней арифметической этой же переменной, полученной по 16-ти наблюдениям (которое также будет нормальным).

Судя по формуле, разброс стандартной ошибки средней должен быть в 4 раза (корень из 16) меньше, чем разброс исходных данных, что и видно на рисунке выше. Чем больше наблюдений, тем меньше разброс средней.
Казалось бы, что для получения наиболее точной средней достаточно использовать максимально большую выборку и тогда стандартная ошибка средней будет стремиться к нулю, а сама средняя, соответственно, к математическому ожиданию. Однако квадратный корень объема выборки в знаменателе говорит о том, что связь между точностью выборочной средней и размером выборки не является линейной. Например, увеличение выборки с 20-ти до 50-ти наблюдений, то есть на 30 значений или в 2,5 раза, уменьшает стандартную ошибку средней только на 36%, а со 100-а до 130-ти наблюдений (на те же 30 значений), снижает разброс данных лишь на 12%.
Лучше всего изобразить эту мысль в виде графика зависимости стандартной ошибки средней от размера выборки. Пусть стандартное отклонение равно 10 (на форму графика это не влияет).

Видно, что примерно после 50-ти значений, уменьшение стандартной ошибки средней резко замедляется, после 100-а – наклон постепенно становится почти нулевым.
Таким образом, при достижении некоторого размера выборки ее дальнейшее увеличение уже почти не сказывается на точности средней. Этот факт имеет далеко идущие последствия. Например, при проведении выборочного обследования населения (опроса) чрезмерное увеличение выборки ведет к неоправданным затратам, т.к. точность почти не меняется. Именно поэтому количество опрошенных редко превышает 1,5 тысячи человек. Точность при таком размере выборки часто является достаточной, а дальнейшее увеличение выборки – нецелесообразным.
Подведем итог. Расчет дисперсии и стандартной ошибки средней имеет довольно простую формулу и обладает полезным свойством, связанным с тем, что относительно хорошая точность средней достигается уже при 100 наблюдениях (в этом случае стандартная ошибка средней становится в 10 раз меньше, чем стандартное отклонение выборки). Больше, конечно, лучше, но бесконечно увеличивать объем выборки не имеет практического смысла. Хотя, все зависит от поставленных задач и цены ошибки. В некоторых опросах участие принимают десятки тысяч людей.
Дисперсия и стандартная ошибка средней имеют большое практическое значение. Они используются в проверке гипотез и расчете доверительных интервалов.
Поделиться в социальных сетях: