ИНФОРМАЦИОННЫЕ ТЕХНОЛОГИИ АВТОМАТИЧЕСКОГО АНАЛИЗА РЕЧИ
УДК 004.522
А. А. Карпов, И. С. Кипяткова
МЕТОДОЛОГИЯ ОЦЕНИВАНИЯ РАБОТЫ СИСТЕМ АВТОМАТИЧЕСКОГО РАСПОЗНАВАНИЯ РЕЧИ
Представлена современная методология количественного оценивания результатов работы автоматических систем распознавания и диаризации речи. Приведены различные показатели и методы оценивания по критериям точности распознавания речи и скорости обработки речевого сигнала.
Ключевые слова: автоматическое распознавание речи, точность распознавания речи, скорость обработки сигнала, критерии и показатели оценивания.
Введение. Одной из основных проблем в работе систем автоматического распознавания речи является объективное количественное оценивание результатов распознавания, что имеет важное значение как для разработчиков, так и для конечных пользователей систем. Методология количественного оценивания производительности предназначена для сравнения и сопоставления различных систем распознавания, в ней выделяют критерий, показатель и метод:
— критерий — это область оценивания, т.е. то, что необходимо оценить: например, точность распознавания речи, скорость ее обработки, робастность и т.п.;
— показатель (мера или метрика) определяет конкретное свойство, которое оценивается для выбранного критерия: например, процент правильно распознанных слов, время обработки сигнала, уровень максимально допустимого шума при сохранении работоспособности и т.п.
— метод — это способ определения соответствующего значения для данного показателя: например, сравнение распознанных слов с последовательностью сказанных слов, оценка времени обработки в секундах и т.п.
При разработке систем автоматического распознавания речи, как правило, используются три набора данных: обучающий («train»), отладочный («dev»), оценочный или тестовый («eval»). Обучающий набор данных (обычно это наибольшая часть речевых данных) применяется только для создания и обучения/тренировки системы; отладочный набор используется для настройки и адаптации параметров автоматической системы перед финальной стадией оценивания, этот набор данных должен иметь тот же формат, что и тестовые данные; оценочный набор содержит речевые данные, которые не использовались для обучения и настройки системы и доступны только при ее окончательной оценке.
Предметом рассмотрения в данной статье являются показатели точности и скорости распознавания речи.
Показатели точности распознавания речи. В системах автоматического распознавания речи основным показателем качества является точность распознавания, которая определяется как процент правильно распознанных слов (WRR — Word Recognition Rate) или, на-
оборот, неправильно распознанных слов (WER — Word Error Rate). Иногда также используется показатель ошибок распознавания фраз/предложений (SER — Sentence Error Rate), который является важным в диалоговых системах, где корректировка гипотезы распознавания невозможна в отличие от задачи диктовки текста. В последнее время в качестве основного показателя точности работы систем распознавания речи используется показатель WER, а именно, его абсолютное значение или относительное, если сравниваются различные модели/системы. Поскольку с развитием речевых технологий показатель WER все более приближается к нулю, то улучшение его значения более наглядно, чем повышение точности распознавания слов. Метод определения показателя WER состоит в выравнивании двух текстовых строк (первая — это результат распознавания, а вторая — запись того, что было сказано в действительности) с помощью алгоритма динамического программирования с вычислением расстояния Левенштейна [1]. Расстояние Левенштейна представляет собой „стоимость» редактирования данных (минимальное количество или взвешенная сумма операций редактирования [2]) для преобразования первой строки во вторую с наименьшим числом операций ручной замены (S), удаления (D) и вставки (I) слов:
WER = S + D +1, WRR = 1 — WER,
где Т — количество слов в распознаваемой фразе.
Для оценивания результатов автоматического распознавания речи используется и такой показатель, как процент корректно распознанных слов (WCR — Word Correctly Recognized), который не учитывает ошибочные вставки слов, сделанные системой:
WCR = H • 100%, H = N — D — S,
где H — количество правильно распознанных слов.
WER — интуитивно понятный показатель качества распознавания для аналитических языков с достаточно простой морфологией, в которых грамматические значения однозначно выражаются самим словом (например, английский или французский). Однако синтетические языки (например, агглютинативные финский, турецкий или флективные русский, украинский) имеют богатую морфологию словообразования; в некоторых азиатских языках (китайском, корейском и т.п.) используются слоги взамен слов; в тайском языке отсутствуют явные разделители границ слов. Поэтому эти языки могут синтезировать достаточно длинные осмысленные словоформы из нескольких частей (морфем), определяющих грамматические признаки. Обычно конец словоформы произносится в беглой речи не так четко, как начальная часть слова, что приводит к акустической неопределенности и в среднем к более высоким по сравнению с аналитическими языками значениям показателя WER.
В синтетических языках для оценивания точности автоматического распознавания речи могут применяться другие показатели: ошибки распознавания букв/символов [3], фонем (звуков речи) [4], слогов [5] или морфем [6]. Кроме того, для некоторых синтетических языков (например, русского) адекватным их структуре показателем является флективная ошибка распознавания слов (IWER — Inflectional Word Error Rate) [7], которая определяется следующим образом:
TWPR = Shard • Chard + Ssoft ‘ Csoft + D + 1 C < C C >ln <
IWER =-T-‘ Csoft < Chard , Chard ^ 1 0 S Csoft < 1 .
Показатель IWER приписывает вес Chard всем неверным заменам слов, которые приводят к замене лексемы слова, т.е. к грубым ошибам распознавания (Shard — количество ошибок), и меньший вес Csoft — всем негрубым ошибкам в словах, где было неверно распознано окончание словоформы, но основа слова распознана правильно (Ssoft — количество негрубых ошибок).
При оценивании точности автоматического распознавания речи по показателю WER предполагается, что все слова во входной (поступающей на вход системы) фразе одинаково информативны и важны. Однако очевидно, что в системах, отличных от диктовки текста, например в диалоговых или в системах понимания (смысла) речи, некоторые значащие (ключевые) слова более важны, чем остальные (функциональные слова, предлоги, слова-заполнители и т.п.). В работе [8] предложено оценивать точность распознавания, используя взвешенный показатель неправильно распознанных слов (WWER — Weighted Word Error Rate), который определяется как
Vs + VD + VI
WWER =
V
t
vt = Z vw,, vi = Z vw. , vd = Z vw, , vs = Z vs} , vs} = max
wiet wwiei ‘ wied s;eS
где vw — вес слова Wi, которое является i-м во входной фразе, и vw — вес слова Wt, кото-
i wi
рое является i-м в гипотезе распознавания; Sj — j-й замененный фрагмент фразы (или одно слово) и vs — вес данного фрагмента Sj.
Таким образом, согласно показателю WWER каждое слово может иметь различный вес (установленный экспертом или полуавтоматически) в соответствии с его влиянием на последующее понимание смысла сказанной фразы.
Национальным институтом стандартов и технологий (NIST, США) недавно был предложен такой показатель, как количество неправильно распознанных слов в речи каждого из дикторов (SAWER — Speaker Attributed Word Error Rate) — для задачи стенографирования совещаний [9], в которых предполагается участие нескольких дикторов. Данная задача объединяет технологии автоматического распознавания речи и диаризации голоса диктора (разметки звукового сигнала на фрагменты „кто и когда говорил» — «Who Spoke When») [10]. Результатом этой объединенной системы является текстовая транскрипция входного однока-нального звукового сигнала для каждого распознанного слова с явным указанием на говорящего. Показатель SAWER определяется следующим выражением:
SAWER = S1D1HL,
T
где V — количество слов (или других языковых единиц), правильно распознанных системой автоматического распознавания речи, но с неправильной идентификацией диктора по результатам диаризации.
Однако следует понимать, что процент неправильного распознавания — это в действительности только количественный показатель точности распознавания (количество ошибок распознавания на фразу или слово), но не вероятность распознавания слова во фразе, так как показатель WER не ограничивается интервалом вероятности [0; 1] и не имеет верхнего предела. Например, представим, что кто-то произнес фразу, состоящую из 10 слов, но система ее полностью распознала неправильно и предложила гипотезу из 15 других слов. В этом случае WER=150 % (S=10, I=5, H=D=0), и, следовательно, показатель точности WRR отрицательный (т.е. -50 %), что не имеет смысла. Для того чтобы решить эту проблему, недавно были предложены другие показатели, в частности: ошибка распознавания соответствий (MER — Match Error Rate) и показатель потери информации, содержащейся в словах (WIL — Word Information Lost) [11], основанные на величине относительной потери информации и определяемые следующим образом:
MER =-S + D +1-= 1 — —; WIL = 1 —H—, если H >> S +D +1,
TP = H + S + D +1 T/ T • TO
где T0 — количество слов в гипотезе распознавания; однако оба этих показателя редко применяются, так как обеспечивают обычно несколько меньшую точность распознавания по сравнению со стандартными показателями.
Все названные выше показатели учитывают только одну наилучшую гипотезу распознавания каждой произнесенной фразы, и совсем не обязательно, что этот единственный результат распознавания окажется действительно правильным. Однако некоторые системы автоматического распознавания речи (например, фонетический декодер) способны выдавать сразу несколько гипотез распознавания с наибольшими вероятностями — так называемый список N лучших гипотез (N-best List). Дополнительным показателем для оценки таких результатов является показатель ошибок распознавания слов в списке лучших гипотез [12], который оценивается путем выбора из N гипотез, ранжированных по уменьшению оценки правдоподобия, единственной гипотезы, имеющей наименьший уровень ошибок. Показатель WER гипотезы с минимальным уровнем ошибок по каждой входной фразе выбирается как основной результат распознавания, характеризующий процент ошибок распознавания в списке N лучших гипотез.
При моделировании и распознавании речи на основе теории вероятностей также используются доверительные интервалы для того, чтобы показать значимость результатов. При оценивании результатов автоматического распознавания речи доверительный интервал (confidence interval) иногда указывается вместе со средним значением показателя WER (например, WER=18,5 ± 2,3 %). В общем случае доверительные интервалы показывают, во-первых, какое значение показателя WER можно ожидать при изменении набора тестовых данных, во-вторых, насколько значимым является предложенное улучшение модели распознавания. Однако на практике доверительные интервалы показателя WER оказываются весьма широкими, что объясняется высокой вариативностью речи и голоса дикторов, а также речевыми сбоями (некоторые фразы распознаются с нулевым показателем WER, но другие приводят к очень высокому уровню ошибок). Большинство производимых улучшений в моделях автоматического распознавания речи не вызывают изменения значений, выходящих за пределы доверительного интервала, из-за ограниченности наборов тестовых данных, что несколько снижает значимость результатов. Однако как новые, так и базовые методы распознавания речи обычно оцениваются разработчиками исходя из одинаковых тестовых данных (эти речевые данные не являются в разных сравниваемых моделях распознавания независимыми); в этом случае при количественной оценке точности распознавания доверительные интервалы могут не рассматриваться. Но в случае когда модели распознавания тестируются с использованием различных и независимых тестовых наборов, требуется вычисление доверительного интервала дополнительно к среднему значению показателя WER [13].
Показатели скорости распознавания речи. Второй важный критерий работы системы автоматического распознавания речи — скорость обработки речи. Скорость обработки вычисляется, как правило, с использованием меры, называемой показателем скорости (SF — Speed Factor) и также известной как показатель реального времени (RT — Real Time) [9], который определяется отношением общего времени обработки, требуемого для анализа всей записанной речи на одном ядре процессора, к длительности исходного анализируемого аудиосигнала. Например, если 10-минутный аудиофайл обрабатывается системой распознавания речи в течение 5 минут, то SF=0,5 RT, если файл обрабатывается в течение 20 минут, то SF=2,0 RT, что значительно хуже. Скорость обработки может быть также указана в абсолютных значениях времени (например, количество минут/секунд для обработки входного сигнала), однако это не является наглядным. Другим показателем скорости автоматического распознавания речи может быть период ожидания обработки отсчета (SPL — Sample Processing Latency) [9]. Этот показатель означает максимальное количество аудиоданных, которое алгоритм распознавания должен обработать до выдачи результата о первом отсчете сигнала.
При создании обладающей (сверх)большим словарем системы автоматического распознавания речи, которая работает в реальном масштабе времени с использованием микрофона (онлайн режим), часто требуется найти компромисс между точностью распознавания и скоростью обработки. Настройка некоторых параметров системы может улучшить точность распознавания, но уменьшить скорость обработки. В этом случае может быть полезным график зависимости показателя WER от скорости распознавания в некоторых контрольных точках [14]; результаты анализа этого графика позволяют выбрать оптимальные параметры системы.
Заключение. Представлен аналитический обзор различных критериев, количественных показателей и методов, применяемых для оценки результатов работы систем автоматического распознавания и диаризации речи. Рассмотрены основные и альтернативные показатели качества, такие как точность и корректность распознавания речи, ошибка распознавания фраз, слов и символов, скорость обработки речевого сигнала и ряд других.
Статья подготовлена по результатам исследований, проводимых при поддержке Ми-нобрнауки РФ (федеральная целевая программа „Исследования и разработки», госконтракт № 07.514.11.4139); совета по грантам Президента РФ (проект № MK-1880.2012.8) и Российского фонда фундаментальных исследований (проект № 12-08-01265-а).
СПИСОК ЛИТЕРАТУРЫ
1. Levenshtein V. I. Binary codes capable of correcting deletions, insertions and reversals // Sov. Phys. Dokl. 1966. Vol. 6. P. 707—710.
2. Khokhlov Y., Tomashenko N. Speech recognition performance evaluation for LVCSR system // Proc. of the 14th Intern. Conf. «Speech and Computer» SPEC0M—2011, Kazan, Russia. 2011. P. 129—135.
3. Kurimo M., Creutz M., Varjokallio M., Arsoy E., Saraclar M. Unsupervised segmentation of words into morphemes — Morpho challenge 2005 Application to automatic speech recognition // Proc. Interspeech-2006, Pittsburgh, РА. 2006. P. 1021—1024.
4. Schlippe T., Ochs S., Schultz T. Grapheme-to-phoneme model generation for indo-european languages // Proc. ICASSP-2012, Kyoto, Japan. 2012.
5. Huang C., Chang E., Zhou J., Lee K. Accent modeling based on pronunciation dictionary adaptation for large vocabulary Mandarin speech recognition // Proc. Interspeech-2000, Beijing, China. 2000. P. 818—821.
6. Ablimit M., Neubig G., Mimura M., Mori S., Kawahara T., Hamdulla A. Uyghur morpheme-based language models and ASR // Proc. of the 10th IEEE Intern. Conf. on Signal Processing ICSP-2010, Beijing, China. 2010. P. 581—584.
7. Karpov A., Kipyatkova I., Ronzhin A. Very large vocabulary ASR for spoken russian with syntactic and morphemic analysis // Proc. Interspeech-2011, Florence, Italy. 2011. P. 3161—3164.
8. Nanjo H., Kawahara T. A new ASR evaluation measure and minimum bayes-risk decoding for open-domain speech understanding // Proc. ICASSP-2005, Philadelphia, РА. 2005. P. 1053—1056.
9. The US NIST 2009 (RT-09) Rich Transcription Meeting Recognition Evaluation Plan [Электронный ресурс]: <http://www.itl.nist.gov/iad/mig/tests/rt/2009/>.
10. Ронжин А. Л., Будков В. Ю. Система протоколирования дикторов на базе алгоритма определения речевой активности в многоканальном аудиопотоке // Речевые технологии. 2010. № 3. С. 98—102.
11. Morris A. C., Maier V., Green P. From WER and RIL to MER and WIL: improved evaluation measures for connected speech recognition // Proc. Interspeech- 2004, Jeju Island, Korea. 2004. P. 2765—2768.
12. Tran B.-H., Seide F., Steinbiss T. A word graph based N-best search in continuous speech recognition // Proc. ICSLP-96, Philadelphia, РА. 1996. P. 2127—2130.
13. Vilar J. M. Efficient computation of confidence intervals for word error rates // Proc. ICASSP-2008, Las Vegas, NV. 2008. P. 5101—5104.
14. Hruz M., Campr P., Dikici E., Kindirouglu A., Krnoul Z., Ronzhin Al., Sak H., Schorno D., Akarun L., Aran O., Karpov A., Saraclar M., Zelezny M. Automatic fingersign to speech translation system // J. on Multimodal User Interfaces. 2011. Vol. 4, N 2. P. 61—79.
Анализ современных методов и систем диаризации дикторов
43
Сведения об авторах
— канд. техн. наук; СПИИРАН, лаборатория речевых и многомодальных интерфейсов; E-mail: karpov@iias.spb.su
— канд. техн. наук; СПИИРАН, лаборатория речевых и многомодальных интерфейсов; E-mail: kipyatkova@iias.spb.su
Поступила в редакцию 10.06.12 г.
УДК 004.896
А. Л. Ронжин, В. Ю. Будков АНАЛИЗ СОВРЕМЕННЫХ МЕТОДОВ И СИСТЕМ ДИАРИЗАЦИИ ДИКТОРОВ
Рассматривается проблема диаризации (протоколирования) речи нескольких дикторов, записанной одно- или многоканальными аудиосистемами. Проанализированы современные подходы к решению проблемы и приведены методики оценивания эффективности работы систем диаризации.
Ключевые слова: цифровая обработка аудиосигнала, протоколирование речи дикторов, уровень ошибок диаризации.
Введение. Задача протоколирования речи дикторов (Speaker Diarization — SD), также известная в зарубежной литературе под названием «Who Spoke When» (кто и когда говорил), заключается в сегментации входного звукового сигнала по типу аудиоинформации и его источнику [1—3]. Аудиосигнал может содержать речь диктора, одновременную речь нескольких дикторов, музыку, фоновые шумы. Наиболее перспективными областями применения систем диаризации дикторов являются:
— системы аннотирования, добавляющие к речевым аудиофайлам различные метаданные, такие как временная разметка границ фраз, информация о говорящем: это позволяет ускорить „ручной» поиск данных и упростить их автоматизированную обработку;
— системы автоматического распознавания речи, использующие диаризацию дикторов для адаптации моделей фонем к речи пользователя, что повышает точность распознавания речи.
Структура типовой системы диаризации. Процесс протоколирования речи дикторов состоит из двух основных этапов: сегментации реплик каждого диктора в аудиосигнале и последующей группировки всех сегментов по принадлежности к каждому из дикторов [2]. Структура типовой системы диаризации дикторов приведена на рисунке.
Вначале определяются фрагменты, содержащие паузы или шумы, и выделяются границы речевого сегмента. Полученный речевой сегмент используется для определения (проверки) его
Алексей Анатольевич Карпов Ирина Сергеевна Кипяткова
Рекомендована СПИИРАН
If you’ve spent any time at all using an automatic speech recognition service, you may have seen the phrase “word error rate,” or WER, for short. But even if you’re brand new to transcriptions, WER is the most common metric you’ll see when comparing ASR services. Luckily, you don’t have to be a math whiz to figure it out – you just need to know this formula:
Word Error Rate = (Substitutions + Insertions + Deletions) / Number of Words Spoken
And that’s it! To go a bit more in depth, here’s how to effectively determine each of these factors:
- Substitutions are anytime a word gets replaced (for example, “twinkle” is transcribed as “crinkle”)
- Insertions are anytime a word gets added that wasn’t said (for example, “trailblazers” becomes “tray all blazers”)
- Deletions are anytime a word is omitted from the transcript (for example, “get it done” becomes “get done”)
Word Error Rate in Practice
Let’s take a look at an example audio.
The correct text is below:
We wanted people to know that we’ve got something brand new and essentially this product is, uh, what we call disruptive, changes the way that people interact with technology.
Now, here’s how that sentence was translated using Google’s speech to text API:
We wanted people to know that how to me where i know and essentially this product is what we call scripted changes the way people are rapid technology.
To correctly calculate WER, we take a look at the substitutions, insertions, and deletions between the two.

Add up the substitutions, insertions, and deletions, and you get a total of 11. Divide that by 29 (the total number of words spoken in the original file) to get a word error rate of about 38 percent. In some cases, the entire meaning of the sentence was changed.

Recently, we ran a test. We took 30 popular podcasts of varying topics and number of speakers, and transcribed them with Rev AI, Google, and Speechmatics. The overall WER for each service is below:
- Rev AI: 17.1%
- Google (video model): 18.3%
- Speechmatics: 21.3%
As these results suggest, you’ll get a different word error rate from whichever service you choose. And though WER is an important and standard metric, it’s not the only thing you should focus on.
The Power of Speaker Diarization
Are all of your transcriptions just one person narrating into a recorder? Great! You’ve somehow found the sweet spot of perfect audio.
What’s more likely, however, is that your files contain multiple speakers. Those speakers may sometimes cut each other off or talk over each other. They may even sound fairly similar.
One of the cool features of Rev AI is speaker diarization. This recognizes the different speakers in the room and attributes text to each. Whether it’s two people having an interview or a panel of four speakers, you can see who said what and when they said it. This is particularly useful if you’re planning to quote the speakers later. Imagine attributing a statement to the incorrect person – and even worse, getting the crux of their message wrong because of a high WER rate. You just may have two people upset with you: the actual speaker and the person you incorrectly cited.

Not all ASR services offer diarization, so keep that in mind if you’re often recording multiple people talking at once. You’ll want to be able to quickly discern between them.
Other Factors to Consider
WER can be an incredibly useful tool; however, it’s just one consideration when you’re choosing an ASR service.
A key thing to remember is that your WER will be inaccurate if you don’t normalize things like capitalization, punctuation, or numbers across your transcripts. Rev AI automatically transcribes spoken words into sentences and paragraphs. This is especially important if you are transcribing your audio files to increase accessibility. Transcripts formatted with these features will be significantly easier for your audience to read.
Word error rate can also be influenced by a number of additional factors, such as background noise, speaker volume, and regional dialects. Think about the times you’ve recorded someone or heard an interview during an event. Were you able to find a quiet, secure room away from all the hubbub? Did the speaker have a clear, booming voice? Chances are, there were some extenuating circumstances that didn’t allow for the perfect environment – and that’s just a part of life.
Certain ASR services are unable to distinguish sounds in these situations. Others, like Rev AI, can accurately transcribe the speakers no matter their volume or how far away they are from the recorder. Not everyone is going to have the lung capacity of Mick Jagger, and that’s fine. While we don’t require a minimum volume, other ASR services may. If you tend to interview quieter talkers or are in environments where you can’t make a lot of noise, be mindful of any requirements before making your selection.
Final Thoughts
Now that you’re comfortable calculating word error rate, you can feel more confident in your search for an ASR service. See how the power of a low WER can help your business reach new heights. Try Rev AI for free and get five hours of credit simply for signing up.
Try it free
Transfer from the connection:https://www.cnblogs.com/findyou/p/10646312.html
After the speech transfer text (ASR) is completed, the current result is pure manual calculation, labeling the typical words and clicking words, I feel very expensive, a small amount, a lot of effort.
So, in order to liberate your own labor, let the code help do more things, so investigate how to compare the identification results of the ASR.
Also seen related formulas, stealing a lazy, Baidu, haha
This article helps very much, there is already mature in the market.
Foreword
I haven’t sent a text for a long time, I see that there are so many small friends who are concerned, I feel that I don’t want to send it. I really didn’t have an output of the experience summary related documentation, took a time, sorted out the note, and issued an agreement on the ASR common test indicator. For example, wordless rate, sentence error rate indicators, and use of computing tools HRESULTS, follow-up slowly search for some artificial intelligence, Xiaobai can understand the basics available, or organize some other notes.
Reprint
This article is original article, if you need to reprint, please indicate the authorFindyouSource
First, the foundation concept
1.1, Speech Recognition (ASR)
Speech Recognition Technology, also known as automatic voice recognition (English:Automatic Speech Recognition, ASR),
Narrow a little whitening said:Convert voice into text.

- Wikipedia:Https://en.wikipedia.org/wiki/ Voice recognition
Findyou: General use of ASR abbreviations.
1.2, error rate (SER)
- Sentence error rate: Sentence Error Rate
- Explanation: The sentence identifies the number of errors, divided by the total number of sentences
-
Calculation formula: (all formula province* 100%)
Ser = error sentence / total sentence
1.3, the correct rate (s.corr)
- Positive rate: SENTENCE CORRECT
-
Calculation formula:
S.CORR = 1 — Ser = correct sentence / total sentence
1.4, Word Rate (WER / CER)
WER, WORD ERROR RATE, word error rate, but generally referred to as a word fault rate, is a key assessment indicator in the field of speech recognition, the lower the WER, the better the effect!
CER, Character Error Rate, Character Error Rate, Chinese General Use CER to indicate the word error rate, please see 1.4.3.
- Wikipedia:https://en.wikipedia.org/wiki/Word_error_rate
»1.4.1, calculation principle
String Edit Distance (Levenshtein Distance) Algorithm
- Edit distance:https://en.wikipedia.org/wiki/Levenshtein_distance
»1.4.2, calculation formula (important)
WER = (S + D + I ) / N = (S + D + I ) / (S + D + H )

(Formula pictures, like text, only convenient to copy)
- S is the number of words replacedCommon abbreviations WS
- D is the number of words deletedCommon abbreviation WD
- I is insertedGenerally used abbreviations Wi
- H is the correct word number, Wikipedia is C, but I am unifiedH
- N is (S replacement + D deletion + h correct)
Findyou:
1. Correct words: Wikipedia is used by C. H = N — (S + D) = C, I directly changed directly to H, reducing excessive concepts and variables.
2. Most articles have not given n’s calculation mode, which is easy to consider the total number of words in the original sentence or the total number of identification results.
3. Don’t understand it, the following instance will help understand.
»1.4.3, problem
- Question 1: Why WER will be greater than 100%
Because there is insert word (more than one word), WER may be more than 100%, in the following instance, I will exemplify (see 2.3.5), but the actual scene, especially the amount of the big sample, basically too It is impossible to appear.
- Question 2: Speaking Chinese should use CER, ie «Character Error Rate)
Findyou lifted a chestnut:
|
1 2 |
|
, :
English, because the minimum unit is Word, speech recognition should use «word error rate» (WER),
Chinese, because the minimum unit is character, speech recognition should use «Character Error Rate» (CER).
But (that isbutthe meaning of...),He is the same as me in front of me, saying nonsense!
Who is calculated when we calculate?: Chinese characters = one word in English,What is the problem with this use of WER’s formula?
Whoever bites with you, let him, make it strong!
After finishing, I’m going back to rigorously, it is recommended to use CER to express, hahahahaha …
1.5, word correctivity (w.corr)
Word correction rate, Word Correct, general domestic publicity,Identification (identify the correct rate)How much is reached (see 1.7).
-
Calculate formula
W.Corr = ( N — D — S ) / N = H / N
-
Question: Only the correct words are calculated, there is no more words (i insertion), of course, there is no problem in general.
1.6, word accuracy (w.acc)
Word Accuracy, Word Accuracy
-
Calculate formula
W.Acc = 1 — WER = ( N — D — S — I ) / N = (H — I) / N

(The picture is the same as the text, it is convenient to copy, W.Acc is the shorthand of FindYou yourself)
- Special circumstances: When i = 0, w.acc = w.corr
-
Question: Why is W.ACC a negative number?
With WER, because there is inserted word. Replacement, because word accuracy = 1 — WER, WER may be greater than 1, so W.Acc will have a negative number, but the actual situation does not exist.
1.7, chatting
-
ASR influence
- Crowd: Male, female, old man, child …
- volume)
- Distance (distance from the pickup)
- Angle (angle with the pickup device)
- Equipment (hardware of pickup equipment)
- Environment: Quiet, noisy (self-noise, external noise), family, shopping mall …
- Long
- Accent, dialect
- Speed speed
- Language: Chinese, English
- and many more
Probably several influencing factors (too lazy to make the brain map, the text is also convenient for everyone to copy),
Because ASR’s identification is too much, many times will be tested from various latitude, such as: male, wrong, wrong, or children’s word fault rate, mean word fault ratio, etc.
If there is no test data and method, it is not credible, and there are several operations, the biggest problem is:
Extra-fit:Training data, test data, verification data is the same, and the earlier said: The scroll for the exam is that the practice volume issued by the teacher issued before the day also has an answer.
First pull this, then find time and then organize an ASR test system to tell,
As a test we depends on ASR and develop a variety of test criteria.
-
Industry level
-
- English -Wer;
- IBM: Industry Standard Switchboard voice recognition task, 6.9% in 2016, 5.5% 2017
- Microsoft: Industry standard Switchboard voice recognition task, 6.3% in 2016 -> 5.9%, 5.1% in 2017, this is the lowest.
- English -Wer;
Note: ICASSP2017 IBM said that human berry WER is 5.1%, which is generally considered to be 5.9% of the wrong rate is the level of human berice.
-
- Chinese -Wer / Cer:
- Xiaomi: 2018 Xiaomi TV 2.81%
- Baidu: 2016 phrase 3.7%
- Chinese -W.Corr:
- Baidu: 2016 recognition accuracy is 97%
- Sogou: 2016 recognition accuracy is 97%
- Xunfei: Identification accuracy is 97% in 2016
- Chinese -Wer / Cer:
Findyou section data Source:
Microsoft WER 5.9%:https://arxiv.org/abs/1610.05256
Microsoft WER 5.1%:https://www.microsoft.com/en-us/research/wp-content/uploads/2017/08/ms_swbd17-2.pdf
Xiaomi TV CER 2.81%:https://arxiv.org/pdf/1707.07167.pdf
Domestic Baidu and other announcement of recognition accuracy of 97%:https://www.zhihu.com/question/53001402
Second, HTK Tools
Understand the ASR-related indicators, need tools to make the results statistical calculations,
This time mainly introduces HTK tools, Python also has Levenshtein’s libraries, but there is no simplicity of HRESULTS.
2.1, HTK Tool Introduction
HTK tool, HMM Toolkit, a voice processing tool based on HMM model (hidden Markov model),HTK is mainly used for speech recognition researchAlthough it has been used in many other applications, includingSpeech synthesis, character recognition and DNA sequencing. HTK was originally developed in the Cambridge University Engineering (CUED) Machine Intelligence Lab (previously known as voice vision and robotic group). The post-right version is transferred to Microsoft, which retains the copyright of the original HTK code. For details, please move the HTK official website.
- HTK Official Homepage:http://htk.eng.cam.ac.uk/
- Latest stability:HTK 3.4.1
- new:HTK 3.5
Findyou: Download you need to register the user first, remember your password, when FTP is downloaded.
2.2, HRESULTS introduction and use
HTK has a series of tools, but I mainly want to write HRESULTS.
HTK3.4.1 after CentOS system, HRESULTS download address
Baidu network disk:https://pan.baidu.com/s/1gfm9jjqjZzJXU0lyGrLrCA Extraction code: WBFP
»2.2.1, use help

$ HResultsUSAGE: HResults [options] labelList recFiles... Option Default -a s Redefine string level label SENT -b s Redefine unitlevel label WORD -c Ignore case differences off -d N Find best of N levels 1 -e s t Label t is equivalent to s -f Enable full results off -g fmt Set test label format to fmt HTK -h Enable NIST style formatting off -k s Results per spkr using mask s off -m N Process only the first N rec files all -n Use NIST alignment procedure off -p Output phoneme statistics off -s Strip triphone contexts off -t Output time aligned transcriptions off -u f False alarm time units (hours) 1.0 -w Enable word spotting analysis off -z s Redefine null class name to s ??? -A Print command line arguments off -C cf Set config file to cf default -D Display configuration variables off -G fmt Set source label format to fmt as config -I mlf Load master label file mlf -L dir Set input label (or net) dir current -S f Set script file to f none -T N Set trace flags to N 0 -V Print version information off -X ext Set input label (or net) file ext lab
HTKBook: https://labrosa.ee.columbia.edu/doc/HTKBook21/node233.html
»2.2.2, text conversion to mlf file
- Test case: src.txt (temporarily do not deport professional terminology)
1 How is the weather today? 2 How to get tomorrow
Findyou:
1. The first column is a number, mainly in order to correspond to the ASR result.
2. We generally remove the punctuation calculation WER, so pay attention to the punctuation
- Src.txt -> src.mlf file
#!MLF!# "*No1.lab" Now sky sky gas How NS Sample . "*No2.lab" bright sky sky gas How NS Sample .
Findyou:
1. Pay attention to the first line plus: #! Mlf! #
2. Note «* xxx.lab»
3. Note the point of each sentence
- ASR recognition result: TestResult.txt file
1 shocking weather 2 How to get tomorrow
Findyou:
1. Many times are automated execution, or manually performing recognition results
2. Test results, the first column should align with src.txt, identify the corpus required to be compared by the first column.
Example: HRESULTS will find the corresponding text calculation WER according to «* no1.REC» according to «* no1.Lab».
- TestResult.txt -> TestResult.mlf file
#!MLF!# "*No1.rec" shock sky sky gas . "*No2.rec" bright sky sky gas How NS Sample .
Findyou:
1.TXT is converted to MLF to convert, pay attention to the different two MLF files, LAB and REC keywords.
»2.2.3, TXT Convert to MLF scripts
- src2mlf.py
1 #-*- coding:utf-8 -*-
2 import os,sys
3
4 def to_mlf(xi):
5 dx={
6 "0": "zero",
7 "1": "One",
8 "2": "two",
9 "3": "three",
10 "4": "four",
11 "5": "Five",
12 "6": "Six",
13 "7": "Seven",
14 "8": "eight",
15 "9": "Nine"
16 };
17 d=[]
18 eng=[]
19 tx=[",",".","!","(",")",",","。","!",';','、',':','?','“','”'];
20 for x in xi:
21 u=x.encode("utf-8")
22 if u in tx:
23 continue;
24 if len(u)==1:
25 if u in dx:
26 u=dx[u]
27 eng.append(str(u, encoding='utf-8'))
28 else:
29 if len(eng)>0:
30 d.append("".join(eng).upper())
31 eng=[]
32 d.append(str(u, encoding='utf-8'))
33 if len(eng)>0:
34 d.append("".join(eng).upper())
35 return d
36
37 def fn_to_lab(s):
38 x=s.split()
39 for i in x:
40 d=to_mlf(i.strip())
41 if len(d)>0:
42 print("n".join(d))
43 print('.')
44
45 fn=sys.argv[1]
46 print('#!MLF!#')
47 for l in open(fn):
48 l=l.strip()
49 x=l.split()
50 k=x[0].strip()
51 v=" ".join(x[1:])
52 t=".".join(k)
53 print('"*No%s.lab" ' % t)
54 fn_to_lab(v)
Findyou:
1. This script is to turn the test case to src.mlf
2. If you need to turn the test results TestResult.txt.mlf, copy a keyword LAB such as REC2MLF.PY to change the 53rd line to REC.
- Script use
1 python src2mlf.py src.txt >src.mlf 2 python rec2mlf.py testResult.txt >testResult.mlf
»2.2.4, common command
Take the above 2.2.2 Example text as an example
-
HResults -t -I src.mlf /dev/null testResult.mlf
Aligned transcription: *No.1.lab vs *No.1.rec
Lab: Is it good today?
REC: shocking days
,-------------------------------------------------------------.
| HTK Results Analysis at Wed Apr 3 16:26:59 2019 |
| Ref: src.mlf |
| Rec: testResult.mlf |
|=============================================================|
| # Snt | Corr Sub Del Ins Err S. Err |
|-------------------------------------------------------------|
| Sum/Avg | 2 | 76.92 7.69 15.38 0.00 23.08 50.00 |
`-------------------------------------------------------------'
-
HResults -t -I src.mlf /dev/null testResult.mlf
Aligned transcription: *No.1.lab vs *No.1.rec Lab: Is it good today? REC: shocking days ====================== HTK Results Analysis ======================= Date: Wed Apr 3 16:26:59 2019 Ref : src.mlf Rec : testResult.mlf ------------------------ Overall Results -------------------------- SENT: %Correct=50.00 [H=1, S=1, N=2] WORD: %Corr=76.92, Acc=76.92 [H=10, D=2, S=1, I=0, N=13] ===================================================================
2.3, HRESULTS sample analysis
Taking a test case and test results as an example, a real example allows you to quickly understand the WER of HRESULTS.
»2.3.1 Only delete (d)
# instruction Lab: test case Rec: identification result # result Aligned transcription: *No.1.lab vs *No.1.rec Lab: How is the weather today? Rec: Today's day ,-------------------------------------------------------------. | HTK Results Analysis at Tue Apr 2 22:37:09 2019 | | Ref: src.mlf | | Rec: testResult.mlf | |=============================================================| | # Snt | Corr Sub Del Ins Err S. Err | |-------------------------------------------------------------| | Sum/Avg | 1 | 57.14 0.00 42.86 0.00 42.86 100.00 | `-------------------------------------------------------------' ... ------------------------ Overall Results -------------------------- SENT: %Correct=0.00 [H=0, S=1, N=1] WORD: %Corr=57.14, Acc=57.14 [H=4, D=3, S=0, I=0, N=7] ===================================================================
- SER (error rate) = 1/1 = 100%
- S. Correct (correct rate of sentence) = 0 S.H / 1 S.N = 0.00%
- N = 0 replacement + 3 delete + 4 correct = 7
- WER (Word Rate) = (S 0 + D 3 + I 0) / 7 = 42.86%
- W.corRect (word correct rate) = h / n = 4/7 = 57.14%
- W.accuracY = (H — i) / n = 1 — w.err = 57.14%
»2.3.2 Replacement (S) + Delete (D)
Lab: How is the weather today? REC: shocking days # result ... |=============================================================| | # Snt | Corr Sub Del Ins Err S. Err | |-------------------------------------------------------------| | Sum/Avg | 1 | 42.86 14.29 42.86 0.00 57.14 100.00 | `-------------------------------------------------------------' ... SENT: %Correct=0.00 [H=0, S=1, N=1] WORD: %Corr=42.86, Acc=42.86 [H=3, D=3, S=1, I=0, N=7]
- SER = 1 — S.Corr = 100 %
- S.Correct = S.H / S.N = 0.00 %
- N = 1 replace + 3 delete + 3h = 7
- WER = (S + D + I ) / N = 57.14 %
- W.Correct = H / N = 42.86 %
- W.Accuracy = (H — I) / N = 1 — W.Err = 42.86 %
»2.3.3 Replacement (S) + Delete (D) + Insert (i)
Lab: How is the weather today? REC: Sapphire # result ... |=============================================================| | # Snt | Corr Sub Del Ins Err S. Err | |-------------------------------------------------------------| | Sum/Avg | 1 | 42.86 14.29 42.86 14.29 71.43 100.00 | `-------------------------------------------------------------' ... SENT: %Correct=0.00 [H=0, S=1, N=1] WORD: %Corr=42.86, Acc=28.57 [H=3, D=3, S=1, I=1, N=7]
- SER = 1 — S.Corr = 100 %
- S.Correct = S.H / S.N = 0.00 %
- N = 1S + 3D + 3H = 7
- WER = (S + D + I) / N = 5/7 = 71.43 %
- W.Correct = H / N = 42.86 %
- W.Accuracy = (H — I) / N = 1 — W.Err = 28.57 %
»2.3.4 Full fault (the number of results <Circular number)
Lab: Is it good today? Rec: I don't know
... |=============================================================| | # Snt | Corr Sub Del Ins Err S. Err | |-------------------------------------------------------------| | Sum/Avg | 1 | 0.00 50.00 50.00 0.00 100.00 100.00 | `-------------------------------------------------------------' ... SENT: %Correct=0.00 [H=0, S=1, N=1] WORD: %Corr=0.00, Acc=0.00 [H=0, D=3, S=3, I=0, N=6]
- SER = 1 — S.Corr = 100 %
- S.Correct = S.H / S.N = 0.00 %
- N = 3S + 3D + 0H = 6
- WER = (S + D + I) / N = 6/6 = 100.00 %
- W.Correct = H / N = 0.00 %
- W.Accuracy = (H — I) / N = 1 — W.Err = 0.00 %
»2.3.5 Full fault (Result Word Number> Cylinder number)
Lab: Is it good today? REC: Amazing Tianzuo ... |=============================================================| | # Snt | Corr Sub Del Ins Err S. Err | |-------------------------------------------------------------| | Sum/Avg | 1 | 0.00 100.00 0.00 16.67 116.67 100.00 | `-------------------------------------------------------------' ... SENT: %Correct=0.00 [H=0, S=1, N=1] WORD: %Corr=0.00, Acc=-16.67 [H=0, D=0, S=6, I=1, N=6]
- SER = 1 — S.Corr = 100 %
- S.Correct = S.H / S.N = 0.00 %
- N = 6S + 0D + 0H = 6
- WER = (S + D + I) / N = 7/6 = 116.67 %
- W.Correct = H / N = 0.00 %
- W.Accuracy = (H — I) / N = 1 — W.Err = -16.67 %
From Wikipedia, the free encyclopedia
Word error rate (WER) is a common metric of the performance of a speech recognition or machine translation system.
The general difficulty of measuring performance lies in the fact that the recognized word sequence can have a different length from the reference word sequence (supposedly the correct one). The WER is derived from the Levenshtein distance, working at the word level instead of the phoneme level. The WER is a valuable tool for comparing different systems as well as for evaluating improvements within one system. This kind of measurement, however, provides no details on the nature of translation errors and further work is therefore required to identify the main source(s) of error and to focus any research effort.
This problem is solved by first aligning the recognized word sequence with the reference (spoken) word sequence using dynamic string alignment. Examination of this issue is seen through a theory called the power law that states the correlation between perplexity and word error rate.[1]
Word error rate can then be computed as:

where
- S is the number of substitutions,
- D is the number of deletions,
- I is the number of insertions,
- C is the number of correct words,
- N is the number of words in the reference (N=S+D+C)
The intuition behind ‘deletion’ and ‘insertion’ is how to get from the reference to the hypothesis. So if we have the reference «This is wikipedia» and hypothesis «This _ wikipedia», we call it a deletion.
When reporting the performance of a speech recognition system, sometimes word accuracy (WAcc) is used instead:

Note that since N is the number of words in the reference, the word error rate can be larger than 1.0, and thus, the word accuracy can be smaller than 0.0.
Experiments[edit]
It is commonly believed that a lower word error rate shows superior accuracy in recognition of speech, compared with a higher word error rate. However, at least one study has shown that this may not be true. In a Microsoft Research experiment, it was shown that, if people were trained under «that matches the optimization objective for understanding», (Wang, Acero and Chelba, 2003) they would show a higher accuracy in understanding of language than other people who demonstrated a lower word error rate, showing that true understanding of spoken language relies on more than just high word recognition accuracy.[2]
Other metrics[edit]
One problem with using a generic formula such as the one above, however, is that no account is taken of the effect that different types of error may have on the likelihood of successful outcome, e.g. some errors may be more disruptive than others and some may be corrected more easily than others. These factors are likely to be specific to the syntax being tested. A further problem is that, even with the best alignment, the formula cannot distinguish a substitution error from a combined deletion plus insertion error.
Hunt (1990) has proposed the use of a weighted measure of performance accuracy where errors of substitution are weighted at unity but errors of deletion and insertion are both weighted only at 0.5, thus:

There is some debate, however, as to whether Hunt’s formula may properly be used to assess the performance of a single system, as it was developed as a means of comparing more fairly competing candidate systems. A further complication is added by whether a given syntax allows for error correction and, if it does, how easy that process is for the user. There is thus some merit to the argument that performance metrics should be developed to suit the particular system being measured.
Whichever metric is used, however, one major theoretical problem in assessing the performance of a system is deciding whether a word has been “mis-pronounced,” i.e. does the fault lie with the user or with the recogniser. This may be particularly relevant in a system which is designed to cope with non-native speakers of a given language or with strong regional accents.
The pace at which words should be spoken during the measurement process is also a source of variability between subjects, as is the need for subjects to rest or take a breath. All such factors may need to be controlled in some way.
For text dictation it is generally agreed that performance accuracy at a rate below 95% is not acceptable, but this again may be syntax and/or domain specific, e.g. whether there is time pressure on users to complete the task, whether there are alternative methods of completion, and so on.
The term «Single Word Error Rate» is sometimes referred to as the percentage of incorrect recognitions for each different word in the system vocabulary.
Edit distance[edit]
The word error rate may also be referred to as the length normalized edit distance.[3] The normalized edit distance between X and Y, d( X, Y ) is defined as the minimum of W( P ) / L ( P ), where P is an editing path between X and Y, W ( P ) is the sum of the weights of the elementary edit operations of P, and L(P) is the number of these operations (length of P).[4]
See also[edit]
- BLEU
- F-Measure
- METEOR
- NIST (metric)
- ROUGE (metric)
References[edit]
Notes[edit]
- ^ Klakow, Dietrich; Jochen Peters (September 2002). «Testing the correlation of word error rate and perplexity». Speech Communication. 38 (1–2): 19–28. doi:10.1016/S0167-6393(01)00041-3. ISSN 0167-6393.
- ^ Wang, Y.; Acero, A.; Chelba, C. (2003). Is Word Error Rate a Good Indicator for Spoken Language Understanding Accuracy. IEEE Workshop on Automatic Speech Recognition and Understanding. St. Thomas, US Virgin Islands. CiteSeerX 10.1.1.89.424.
- ^ Nießen et al.(2000)
- ^ Computation of Normalized Edit Distance and Application:AndrCs Marzal and Enrique Vidal
Other sources[edit]
- McCowan et al. 2005: On the Use of Information Retrieval Measures for Speech Recognition Evaluation
- Hunt, M.J., 1990: Figures of Merit for Assessing Connected Word Recognisers (Speech Communication, 9, 1990, pp 239-336)
- Zechner, K., Waibel, A.Minimizing Word Error Rate in Textual Summaries of Spoken Language
Word Error Rate (WER) is a common metric for measuring speech-to-text accuracy of automatic speech recognition (ASR) systems. Microsoft claims to have a word error rate of 5.1%. Google boasts a WER of 4.9%. For comparison, human transcriptionists average a word error rate of 4%.
When comparing conversational AI solutions that automate interactions over telephony, is WER a good metric to gauge how well the virtual agent will understand you?
How to Calculate WER
Word Error Rate is a straightforward concept and simple to calculate – it’s basically the number of errors divided by the total number of words.
Word Error Rate = (Substitutions + Insertions + Deletions) / Number of Words Spoken
Where errors are:
- Substitution: when a word is replaced (for example, “shipping” is transcribed as “sipping”)
- Insertion: when a word is added that wasn’t said (for example, “hostess” is transcribed as “host is”)
- Deletion: when a word is omitted from the transcript (for example, “get it done” is transcribed as “get done”)
Variables that Affect WER
The issue with WER is that it does not account for the variables that impact speech recognition. For humans, the ability to distinguish between speech and background noise is fairly easy — if someone calls me from a concert, I can differentiate the speaker’s voice from the music that’s playing. But for machines, separating speech from background noise – even if it is music – is difficult to do.
In the absence of background noise, other factors significantly impact a machine’s ability to transcribe speech:
Accents and Homophones
Whether you realize it or not, you have an accent. In fact, everyone has an accent. The way we speak varies tremendously, even if we are native speakers of the same language. For example, I pronounce “aunt” like “ant” the insect. The American Heritage Dictionary also recognizes “aunt” — like “daunt” — as a correct pronunciation.
Understanding different accents and disambiguating homophones go beyond the capabilities of most, if not all ASR systems. Without contextual training or an NLU engine to correct the error, the sentence “I have ants in the kitchen” can be transcribed as “I have aunts in the kitchen.”
Crosstalk
When two people speak over each other, it’s not too difficult to follow the conversation if you’re in the same room as they are. But hearing a recording and transcribing a conversation of two people speaking at the same time is difficult for humans, let alone for machines to get right.
How does the ASR know which voice to prioritize?
The answer – it doesn’t. Depending on the ASR system, different methods can be applied to handle crosstalk (one method is to omit a speaker’s words entirely) – all of which inevitably lowers the WER.
Audio Quality
If a person is using a speakerphone, their distance from the microphone will impact audio quality and introduce ambient noise. If a person is calling through a landline or cell phone, the audio traverses through a telephony network that compresses the information to low fidelity, reducing the audio to a mere 8k resolution. Since most people aren’t speaking in a vacuum, the audio quality from these real-world scenarios make it less than ideal to transcribe.
Industry-Specific Language
Accurately capturing technical or industry-specific terminology takes skill and effort. For this reason, human transcriptionists often specialize in transcribing for a particular field (e.g. legal or medical) and charge more for their services because of their subject matter knowledge. Similarly, speech recognition systems trained on general data will struggle with complex or industry-specific language because it lacks that frame of reference.
WER is Flawed
When it comes to evaluating conversational AI solutions, keep in mind that the ASR is only one component of the technology stack, and WER is only one metric to evaluate ASRs — an imperfect one at that.
WER offers a myopic view of speech recognition because it only counts the errors and does not factor the variables causing the errors. Moreover, it doesn’t consider that some words are more important than others. Every word (whether it’s an article, noun, or verb) is weighted equally, even if it’s just one word that alters the meaning of the sentence.
WER as a Marketing Tool
Some of the very companies that boast low error rates also recognize that WER is not a good metric and that it “counts errors at the surface level.” What’s more critical to note is that many of these companies use the same corpus to train their models and test for accuracy. In other words, they’re achieving human-level accuracy because they are testing their ASR systems on the very same dataset used to train those systems.
So, take WER with a grain of salt — it’s more of marketing gimmick than a true measure of accuracy.
Calls in the Wild
At SmartAction, we see 20% of inbound calls are significantly impacted by noise — to the point where even a human would have trouble understanding. These “calls in the wild” are the true test for any ASR system.
To illustrate my point, check out this real-world conversation featuring a stranded driver calling AAA roadside assistance. Can you clearly hear and understand what the caller is trying to say?
On its own, even the best speech recognition engine will not transcribe the above conversation correctly. In fact, it didn’t. The ASR in the above example transcribed very literally what it heard because the “F” in “Ford F250” was barely audible. As a result, it only heard “Ord” then transcribe “Aboard” as the closest word match. Herein lies the problem with even the best speech rec engines – they are very 100% right. In fact, they are wrong quite often.
But as you heard, the AI correctly read back “Ford F250.” How did it do that? Because the ASR was backed by a Natural Language Understanding engine that knew what it was listening for. And it knew it was listening for vehicle makes and models. When the ASR transcription didn’t match an expected output, the NLU engine kicked in to compare the language acoustic models against what it expected to hear. The closes match was correct – “Ford F250.”
If your ASR isn’t backed by a NLU engine that has been tailored by developers to the specifics of your interactions across every question and answers, you ASR will not meet the expectations of your customers despite whatever the WER claim might be.
When it comes Word Error Rate and Automatic Speech Recognition, here are a few things to remember:
- WER is one metric to use – and by no means the only metric you should use.
- ASR systems have come a long way but are still far from perfect.
- The secret to great speech technology is not the ASR itself, but rather the associated NLU engine that augments accuracy.
Содержание
- Char Error Rate¶
- Module Interface¶
- Functional Interface¶
- jiwer 2.5.1
- Навигация
- Ссылки проекта
- Статистика
- Метаданные
- Классификаторы
- Описание проекта
- JiWER: Similarity measures for automatic speech recognition evaluation
- Installation
- Usage
- pre-processing
- transforms
- Compose
- ReduceToListOfListOfWords
- ReduceToSingleSentence
- RemoveSpecificWords
- RemoveWhiteSpace
- RemovePunctuation
- RemoveMultipleSpaces
- Strip
- RemoveEmptyStrings
- ExpandCommonEnglishContractions
- Evaluate OCR Output Quality with Character Error Rate (CER) and Word Error Rate (WER)
- Key concepts, examples, and Python implementation of measuring Optical Character Recognition output quality
- Contents
- Importance of Evaluation Metrics
- Error Rates and Levenshtein Distance
- Character Error Rate (CER)
- (i) Equation
- (ii) Illustration with Example
- (iii) CER Normalization
- (iv) What is a good CER value?
- Word Error Rate (WER)
- Python Example (with TesseractOCR and fastwer)
- Summing it up
Char Error Rate¶
Module Interface¶
Character Error Rate (CER) is a metric of the performance of an automatic speech recognition (ASR) system.
This value indicates the percentage of characters that were incorrectly predicted. The lower the value, the better the performance of the ASR system with a CharErrorRate of 0 being a perfect score. Character error rate can then be computed as:

 is the number of substitutions,
is the number of substitutions,
 is the number of deletions,
is the number of deletions,
 is the number of insertions,
is the number of insertions,
 is the number of correct characters,
is the number of correct characters,
 is the number of characters in the reference (N=S+D+C).
is the number of characters in the reference (N=S+D+C).
Compute CharErrorRate score of transcribed segments against references.
kwargs¶ ( Any ) – Additional keyword arguments, see Advanced metric settings for more info.
Character error rate score
Initializes internal Module state, shared by both nn.Module and ScriptModule.
Calculate the character error rate.
Character error rate score
Store references/predictions for computing Character Error Rate scores.
preds¶ ( Union [ str , List [ str ]]) – Transcription(s) to score as a string or list of strings
target¶ ( Union [ str , List [ str ]]) – Reference(s) for each speech input as a string or list of strings
Functional Interface¶
character error rate is a common metric of the performance of an automatic speech recognition system. This value indicates the percentage of characters that were incorrectly predicted. The lower the value, the better the performance of the ASR system with a CER of 0 being a perfect score.
preds¶ ( Union [ str , List [ str ]]) – Transcription(s) to score as a string or list of strings
target¶ ( Union [ str , List [ str ]]) – Reference(s) for each speech input as a string or list of strings
Источник
jiwer 2.5.1
pip install jiwer Скопировать инструкции PIP
Выпущен: 6 сент. 2022 г.
Evaluate your speech-to-text system with similarity measures such as word error rate (WER)
Навигация
Ссылки проекта
Статистика
Метаданные
Лицензия: Apache Software License (Apache-2.0)
Требует: Python >=3.7, nikvaessen
Классификаторы
- License
- OSI Approved :: Apache Software License
- Programming Language
- Python :: 3
- Python :: 3.7
- Python :: 3.8
- Python :: 3.9
- Python :: 3.10
Описание проекта
JiWER: Similarity measures for automatic speech recognition evaluation
This repository contains a simple python package to approximate the Word Error Rate (WER), Match Error Rate (MER), Word Information Lost (WIL) and Word Information Preserved (WIP) of a transcript. It computes the minimum-edit distance between the ground-truth sentence and the hypothesis sentence of a speech-to-text API. The minimum-edit distance is calculated using the Python C module Levenshtein.
Installation
You should be able to install this package using poetry:
Or, if you prefer old-fashioned pip and you’re using Python >= 3.7 :
Usage
The most simple use-case is computing the edit distance between two strings:
Similarly, to get other measures:
You can also compute the WER over multiple sentences:
We also provide the character error rate:
pre-processing
It might be necessary to apply some pre-processing steps on either the hypothesis or ground truth text. This is possible with the transformation API:
By default, the following transformation is applied to both the ground truth and the hypothesis. Note that is simply to get it into the right format to calculate the WER.
transforms
We provide some predefined transforms. See jiwer.transformations .
Compose
jiwer.Compose(transformations: List[Transform]) can be used to combine multiple transformations.
Note that each transformation needs to end with jiwer.ReduceToListOfListOfWords() , as the library internally computes the word error rate based on a double list of words. `
ReduceToListOfListOfWords
jiwer.ReduceToListOfListOfWords(word_delimiter=» «) can be used to transform one or more sentences into a list of lists of words. The sentences can be given as a string (one sentence) or a list of strings (one or more sentences). This operation should be the final step of any transformation pipeline as the library internally computes the word error rate based on a double list of words.
ReduceToSingleSentence
jiwer.ReduceToSingleSentence(word_delimiter=» «) can be used to transform multiple sentences into a single sentence. The sentences can be given as a string (one sentence) or a list of strings (one or more sentences). This operation can be useful when the number of ground truth sentences and hypothesis sentences differ, and you want to do a minimal alignment over these lists. Note that this creates an invariance: wer([a, b], [a, b]) might not be equal to wer([b, a], [b, a]) .
RemoveSpecificWords
jiwer.RemoveSpecificWords(words_to_remove: List[str]) can be used to filter out certain words. As words are replaced with a character, make sure to that jiwer.RemoveMultipleSpaces , jiwer.Strip() and jiwer.RemoveEmptyStrings are present in the composition after jiwer.RemoveSpecificWords .
RemoveWhiteSpace
jiwer.RemoveWhiteSpace(replace_by_space=False) can be used to filter out white space. The whitespace characters are , t , n , r , x0b and x0c . Note that by default space ( ) is also removed, which will make it impossible to split a sentence into a list of words by using ReduceToListOfListOfWords or ReduceToSingleSentence . This can be prevented by replacing all whitespace with the space character. If so, make sure that jiwer.RemoveMultipleSpaces , jiwer.Strip() and jiwer.RemoveEmptyStrings are present in the composition after jiwer.RemoveWhiteSpace .
RemovePunctuation
jiwer.RemovePunctuation() can be used to filter out punctuation. The punctuation characters are defined as all unicode characters whose catogary name starts with P . See https://www.unicode.org/reports/tr44/#General_Category_Values.
RemoveMultipleSpaces
jiwer.RemoveMultipleSpaces() can be used to filter out multiple spaces between words.
Strip
jiwer.Strip() can be used to remove all leading and trailing spaces.
RemoveEmptyStrings
jiwer.RemoveEmptyStrings() can be used to remove empty strings.
ExpandCommonEnglishContractions
jiwer.ExpandCommonEnglishContractions() can be used to replace common contractions such as let’s to let us .
Currently, this method will perform the following replacements. Note that ␣ is used to indicate a space ( ) to get around markdown rendering constrains.
Источник
Evaluate OCR Output Quality with Character Error Rate (CER) and Word Error Rate (WER)
Key concepts, examples, and Python implementation of measuring Optical Character Recognition output quality
Contents
Importance of Evaluation Metrics
Great job in successfully generating output from your OCR model! You have done the hard work of labeling and pre-processing the images, setting up and running your neural network, and applying post-processing on the output.
The final step now is to assess how well your model has performed. Even if it gave high confidence scores, we need to measure performance with objective metrics. Since you cannot improve what you do not measure, these metrics serve as a vital benchmark for the iterative improvement of your OCR model.
In this article, we will look at two metrics used to evaluate OCR output, namely Character Error Rate (CER) and Word Error Rate (WER).
Error Rates and Levenshtein Distance
The usual way of evaluating prediction output is with the accuracy metric, where we indicate a match ( 1) or a no match ( 0). However, this does not provide enough granularity to assess OCR performance effectively.
We should instead use error rates to determine the extent to which the OCR transcribed text and ground truth text (i.e., reference text labeled manually) differ from each other.
A common intuition is to see how many characters were misspelled. While this is correct, the actual error rate calculation is more complex than that. This is because the OCR output can have a different length from the ground truth text.
Furthermore, there are three different types of error to consider:
- Substitution error: Misspelled characters/words
- Deletion error: Lost or missing characters/words
- Insertion error: Incorrect inclusion of character/words
The question now is, how do you measure the extent of errors between two text sequences? This is where Levenshtein distance enters the picture.
Levenshtein distance is a distance metric measuring the difference between two string sequences. It is the minimum number of single-character (or word) edits (i.e., insertions, deletions, or substitutions) required to change one word (or sentence) into another.
For example, the Levenshtein distance between “ mitten” and “ fitting” is 3 since a minimum of 3 edits is needed to transform one into the other.
The more different the two text sequences are, the higher the number of edits needed, and thus the larger the Levenshtein distance.
Character Error Rate (CER)
(i) Equation
CER calculation is based on the concept of Levenshtein distance, where we count the minimum number of character-level operations required to transform the ground truth text (aka reference text) into the OCR output.
It is represented with this formula:
- S = Number of Substitutions
- D = Number of Deletions
- I = Number of Insertions
- N = Number of characters in reference text (aka ground truth)
Bonus Tip: The denominator N can alternatively be computed with:
N = S + D + C (where C = number of correct characters)
The output of this equation represents the percentage of characters in the reference text that was incorrectly predicted in the OCR output. The lower the CER value (with 0 being a perfect score), the better the performance of the OCR model.
(ii) Illustration with Example
Let’s look at an example:
Several errors require edits to transform OCR output into the ground truth:
- g instead of 9 (at reference text character 3)
- Missing 1 (at reference text character 7)
- Z instead of 2 (at reference text character


With that, here are the values to input into the equation:
- Number of Substitutions (S) = 2
- Number of Deletions ( D) = 1
- Number of Insertions ( I) = 0
- Number of characters in reference text ( N) = 9
Based on the above, we get (2 + 1 + 0) / 9 = 0.3333. When converted to a percentage value, the CER becomes 33.33%. This implies that every 3rd character in the sequence was incorrectly transcribed.
We repeat this calculation for all the pairs of transcribed output and corresponding ground truth, and take the mean of these values to obtain an overall CER percentage.
(iii) CER Normalization
One thing to note is that CER values can exceed 100%, especially with many insertions. For example, the CER for ground truth ‘ ABC’ and a longer OCR output ‘ ABC12345’ is 166.67%.
It felt a little strange to me that an error value can go beyond 100%, so I looked around and managed to come across an article by Rafael C. Carrasco that discussed how normalization could be applied:
Sometimes the number of mistakes is divided by the sum of the number of edit operations ( i + s + d ) and the number c of correct symbols, which is always larger than the numerator.
The normalization technique described above makes CER values fall within the range of 0–100% all the time. It can be represented with this formula:
where C = Number of correct characters
(iv) What is a good CER value?
There is no single benchmark for defining a good CER value, as it is highly dependent on the use case. Different scenarios and complexity (e.g., printed vs. handwritten text, type of content, etc.) can result in varying OCR performances. Nonetheless, there are several sources that we can take reference from.
An article published in 2009 on the review of OCR accuracy in large-scale Australian newspaper digitization programs came up with these benchmarks (for printed text):
- Good OCR accuracy: CER 1‐2% (i.e. 98–99% accurate)
- Average OCR accuracy: CER 2-10%
- Poor OCR accuracy: CER >10% (i.e. below 90% accurate)
For complex cases involving handwritten text with highly heterogeneous and out-of-vocabulary content (e.g., application forms), a CER value as high as around 20% can be considered satisfactory.
Word Error Rate (WER)
If your project involves transcription of particular sequences (e.g., social security number, phone number, etc.), then the use of CER will be relevant.
On the other hand, Word Error Rate might be more applicable if it involves the transcription of paragraphs and sentences of words with meaning (e.g., pages of books, newspapers).
The formula for WER is the same as that of CER, but WER operates at the word level instead. It represents the number of word substitutions, deletions, or insertions needed to transform one sentence into another.
WER is generally well-correlated with CER (provided error rates are not excessively high), although the absolute WER value is expected to be higher than the CER value.
- Ground Truth: ‘my name is kenneth’
- OCR Output: ‘myy nime iz kenneth’
From the above, the CER is 16.67%, whereas the WER is 75%. The WER value of 75% is clearly understood since 3 out of 4 words in the sentence were wrongly transcribed.
Python Example (with TesseractOCR and fastwer)
We have covered enough theory, so let’s look at an actual Python code implementation.
In the demo notebook, I ran the open-source TesseractOCR model to extract output from several sample images of handwritten text. I then utilized the fastwer package to calculate CER and WER from the transcribed output and ground truth text (which I labeled manually).
Summing it up
In this article, we covered the concepts and examples of CER and WER and details on how to apply them in practice.
While CER and WER are handy, they are not bulletproof performance indicators of OCR models. This is because the quality and condition of the original documents (e.g., handwriting legibility, image DPI, etc.) play an equally (if not more) important role than the OCR model itself.
I welcome you to join me on a data science learning journey! Give this Medium page a follow to stay in the loop of more data science content, or reach out to me on LinkedIn. Have fun evaluating your OCR model!
Источник
Шёпот и эмоции в Алисе: история развития голосового синтеза Яндекса
Время прочтения
15 мин
Просмотры 28K

Четыре года назад мы запустили Алису. С самого начала она обладала собственным, узнаваемым голосом. Хотя проблемы тоже были: интонации хромали, эмоции скакали от слова к слову, а омонимы и вовсе ставили синтез в тупик. Алиса звучала пусть и не как робот, но ещё и не как человек.
Исследования показывают, что желание общаться с голосовым помощником напрямую зависит от того, насколько точно он имитирует речь людей. Поэтому мы постоянно работаем над «очеловечениванием» голоса Алисы. С тех пор сменилось несколько поколений нашего голосового синтеза. Мы научились расставлять интонации, отличать «замОк» от «зАмка» и многое другое.
Сейчас мы переходим на следующий уровень: учим Алису управлять эмоциями и стилем своей речи, распознавать шёпот и отвечать на него шёпотом. Казалось бы, что в этом сложного и почему всё это было невозможно ещё несколько лет назад? Вот об этом я и расскажу сегодня сообществу Хабра.
Ранний параметрический синтез: эпоха до Алисы
Мы начали заниматься голосовыми технологиями в 2012 году. Через год родился SpeechKit. Ещё через год мы научились синтезировать голос — возможно, вы помните YaC 2014 и экспериментальный проект Яндекс.Диктовка. С тех пор прогресс не останавливается.
Исторически речевой синтез бывает двух видов: конкатенативный и параметрический. В случае с первым, есть база кусочков звука, размеченных элементами речи — словами или фонемами. Мы собираем предложение из кусочков, конкатенируя (то есть склеивая) звуковые сегменты. Такой метод требует большой базы звука, он очень дорогой и негибкий, зато до пришествия нейросетей давал самое высокое качество.
При параметрическом синтезе базы звука нет — мы рисуем его с нуля. Из-за большого прыжка в размерности end2end работает плохо даже сейчас. Лучше разделить это преобразование на два шага: сначала нарисовать звук в особом параметрическом (отсюда название метода) пространстве, а затем преобразовать параметрическое представление звука в wav-файл.
В 2014 году нейросетевые методы речевого синтеза только зарождались. Тогда качеством правил конкатенативный синтез, но нам в эру SpeechKit было необходимо легковесное решение (для Навигатора), поэтому остановились на простом и дешёвом параметрическом синтезе. Он состоял из двух блоков:
- Первый — акустическая модель. Она получает лингвистические данные (разбитые на фонемы слова и дополнительную разметку) и переводит их в промежуточное состояние, которое описывает основные свойства речи — скорость и темп произнесения слов, интонационные признаки и артикуляцию — и спектральные характеристики звука. К примеру, в начале, до появления Алисы, в качестве модели мы обучали рекуррентную нейросеть (RNN) с предсказанием длительности. Она достаточно хорошо подходит для задач, где нужно просто последовательно проговаривать фонемы и не надо рисовать глобальную интонацию.
- Затем данные передаются на второй блок — вокодер — который и генерирует звук (то есть создаёт условный wav) по его параметрическому представлению. Вокодер определяет низкоуровневые свойства звука: sampling rate, громкость, фазу в сигнале. Наш вокодер в первой системе был детерминированным DSP-алгоритмом (не обучался на данных) — подобно декодеру mp3, он «разжимал» параметрическое представление звука до полноценного wav. Естественно, такое восстановление сопровождалось потерями — искусственный голос не всегда был похож на оригинал, могли появляться неприятные артефакты вроде хрипов для очень высоких или низких голосов.
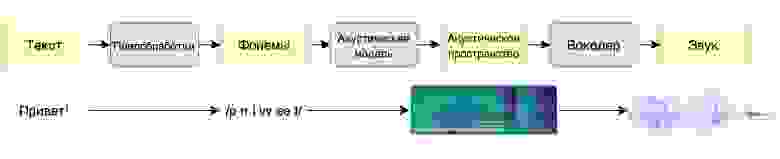
Схема параметрического синтеза
Это стандартная архитектура для любой ранней параметрики со своими достоинствами и недостатками. Главный плюс — для обучения модели нужно мало данных (нам хватило 5-10 часов записей человеческой речи). Можно синтезировать любой произвольный текст, который даже будет плавно звучать. К сожалению, слишком плавно: недостатком раннего параметрического синтеза было то, что полученный голос звучал неестественно. Он был слишком гладким, лишённым интонаций и эмоций, звенел металлом. Люди так не говорят.
Вот как звучал голос при раннем параметрическом синтезе:

Причина неестественности синтезированного голоса кроется в самой архитектуре. У акустической модели мало информации о тексте в целом. Даже рекуррентная нейросеть, которая, казалось бы, умеет запоминать предыдущие состояния, очень быстро забывает их и фактически не учитывает полный текст. При этом человек обычно произносит речь, понимая, что только что прозвучало и что будет дальше по тексту.
Кроме того, человеческая речь мультимодальна — есть несколько способов произнести текст, каждый из которых описывается сигналом и звучит более-менее нормально. Но среднее между этими способами звучит неестественно. Проблема стандартных регрессионных методов глубокого обучения в том, что они ищут одну моду — «хорошее среднее» — и попадают в такие «провалы неестественности». В результате оказывается, что лучше случайно выбрать один из двух способов, чем попасть в среднее между ними.
Впрочем, даже если акустическая модель и смогла бы разобраться в контексте и выдать обогащённое информацией промежуточное состояние, то с ним уже не мог справиться примитивный вокодер. Поэтому мы не остановились и стали искать более совершенные решения.
Конкатенативный синтез: рождение Алисы
В 2016 году мы решили создать Алису — сразу было понятно, что это более амбициозная задача, чем всё, чем занимались раньше. Дело в том, что в отличие от простых TTS-инструментов, голосовой помощник должен звучать человечно, иначе люди просто не станут с ним (или с ней) общаться. Предыдущая архитектура совершенно не подходила. К счастью, был и другой подход. Точнее, даже два.
Тогда как раз набирал обороты нейропараметрический подход, в котором задачу вокодера выполняла сложная нейросетевая модель. Например, появился проект WaveNet на базе свёрточной нейросети, которая могла обходиться и без отдельной акустической модели. На вход можно было загрузить простые лингвистические данные, а на выходе получить приличную речь.
Первым импульсом было пойти именно таким путём, но нейросети были совсем сырые и медленные, поэтому мы не стали их рассматривать как основное решение, а исследовали эту задачу в фоновом режиме. На генерацию секунды речи уходило до пяти минут реального времени. Это очень долго: чтобы использовать синтез в реальном времени, нужно генерировать секунду звука быстрее, чем за секунду.
Что же делать? Если нельзя синтезировать живую речь с нуля, нужно взять крошечные фрагменты речи человека и собрать из них любую произвольную фразу. Напомню, что в этом суть конкатенативного синтеза, который обычно ассоциируется с методом unit selection. Пять лет назад он уже давал наилучшее качество (при достаточном количестве данных) в задачах, где была нужна качественная речь в реальном времени. И здесь мы смогли переиспользовать нейросети нашей старой параметрики. Работало это следующим образом:
- На первом шаге мы использовали нейросетевую параметрику, чтобы синтезировать речь с нуля — подобному тому, как делали раньше. Напомню, что по качеству звучания результат нас не устраивал, но мог использоваться как референс по содержанию.
- На втором шаге другая нейросеть подбирала из базы фрагментов записанной речи такие, из которых можно было собрать фразу, достаточно близкую к сгенерированной параметрикой. Вариантов комбинаций фрагментов много, поэтому модель смотрела на два ключевых показателя. Первый — target-cost, точность соответствия найденного фрагмента гипотезе, то есть сгенерированному фрагменту. Второй показатель — join-cost, насколько два найденных соседних фрагмента соответствуют друг другу. По сути, нужно было выбрать вариант, для которого сумма target-cost и join-cost минимальна. Эти параметры можно считать разными способами — для join-cost мы использовали нейросети на базе Deep Similarity Network, а для target-cost считали расстояние до сгенерированной параметрикой гипотезы. Сумму этих параметров, как и принято в unit selection, оптимизировали динамическим программированием.
Кстати, подобный подход использовался и при создании Siri 2.0, согласно опубликованной в 2017 году статье разработчиков Apple, которую мы нашли после того, как запустили прототип Алисы.
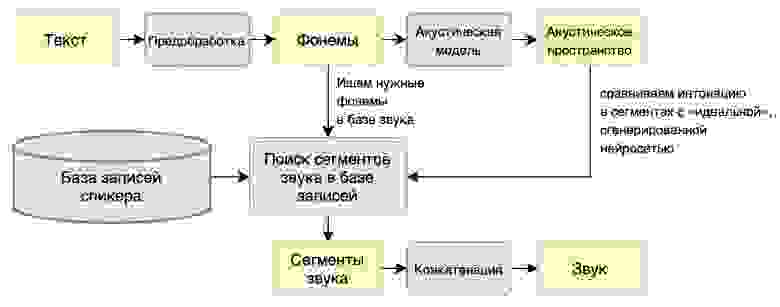
Схема конкатенативного синтеза
У такого подхода тоже есть плюсы и минусы. Среди достоинств — более естественное звучание голоса, ведь исходный материал не синтезирован, а записан вживую. Правда, есть и обратная сторона: чем меньше данных, тем более грубо будут звучать места склейки фрагментов. Для шаблонных фраз всё более-менее хорошо, но шаг влево или вправо — и вы замечаете склейку. Поэтому нужно очень много исходного материала, а это требует многих часов записи голоса диктора. К примеру, в первые несколько лет работы над Алисой нам пришлось записать несколько десятков часов. Это несколько месяцев непрерывной работы с актрисой Татьяной Шитовой в студии.
При этом нужно не просто «прочитать текст по листочку». Чем более нейтрально будет звучать голос, тем лучше. Обычно от актёров ждут эмоциональности, проявления темперамента в своей речи. У нас ровно обратная задача, потому что нужны универсальные «кубики» для создания произвольных фраз.
Вот характерный пример работы синтеза:
В этом главный недостаток метода unit selection: несмотря на все усилия, фрагменты речи не будут идеально соответствовать друг другу по эмоциям и стилю. Из-за этого сгенерированная речь Алисы постоянно «переключалась» между ними. На коротких фразах это не всегда заметно, но если хотите услышать произвольный ответ длиной хотя бы в пару предложений (например, быстрый ответ из поиска), то недостатки подхода становятся очевидны.
В общем, unit selection перестал нас устраивать и нужно было развиваться дальше.
Иногда они возвращаются: опять параметрический синтез
В результате мы вернулись к архитектуре из двух последовательных блоков: акустическая модель и вокодер. Правда, на более низком уровне обновилось примерно всё.
1. Акустическая модель
В отличие от старой параметрики, новую модель мы построили на основе seq2seq-подхода с механизмом внимания.
Помните проблему с потерей контекста в нашей ранней параметрике? Если нет нормального контекста, то нет и нормальной интонации в речи. Решение пришло из машинного перевода.
Дело в том, что в машинном переводе как раз возникает проблема глобального контекста — смысл слов в разных языках может задаваться разным порядком или вообще разными структурами, поэтому порой для корректного перевода предложения нужно увидеть его целиком. Для решения этой задачи исследователи предложили механизм внимания — идея в том, чтобы рассмотреть всё предложение разом, но сфокусироваться (через softmax-слой) на небольшом числе «важных» токенов.
При генерации каждого нового выходного токена нейросеть смотрит на обработанные токены (фонемы для речевого синтеза или символы языка для перевода) входа и «решает», насколько каждый из них важен на этом шаге. Оценив важность, сеть учитывает её при агрегировании результатов и получает информацию для генерации очередного токена выхода.
Таким образом нейросеть может заглянуть в любой элемент входа на любом шаге и при этом не перегружается информацией, поскольку фокусируется на небольшом количестве входных токенов. Для синтеза важна подобная глобальность, так как интонация сама по себе глобальна и нужно «видеть» всё предложение, чтобы правильно его проинтонировать.
На тот момент для синтеза была хорошая seq2seq-архитектура Tacotron 2 — она и легла в основу нашей акустической модели.
2. Мел-спектрограмма
Параметрическое пространство можно сжать разными способами. Более сжатые представления лучше работают с примитивными акустическими моделями и вокодерами — там меньше возможностей для ошибок. Более полные представления позволяют лучше восстановить wav, но их генерация — сложная задача для акустической модели. Кроме того, восстановление из таких представлений у детерминированных вокодеров не очень качественное из-за их нестабильности. С появлением нейросетевых вокодеров сложность промежуточного пространства стала расти и сейчас в индустрии одним из стандартов стала мел-спектрограмма.
Она отличается от обычного распределения частоты звука по времени тем, что частоты переводятся в особую мел-частоту звука. Другими словами, мел-спектрограмма — это спектрограмма, в которой частота звука выражена в мелах, а не герцах. Мелы пришли из музыкальной акустики, а их название — это просто сокращение слова «мелодия».
Строение улитки уха (из Википедии)
Эта шкала не линейная и основана на том, что человеческое ухо по-разному воспринимает звук различной частоты. Вспомните строение улитки в ухе: это просто канал, закрученный по спирали. Высокочастотный звук не может «повернуть» по спирали, поэтому воспринимается достаточно короткой частью слуховых рецепторов. Низкочастотный же звук проходит вглубь. Поэтому люди хорошо различают низкочастотные звуки, но высокочастотные сливаются.
Мел-спектрограмма как раз позволяет представить звук, акцентируясь на той части спектра, которая значимо различается слухом. Это полезно, потому что мы генерируем звук именно для человека, а не для машины.
Вот как выглядит мел-спектрограмма синтеза текста «Я — Алиса»:
У мел-спектрограммы по одному измерению [X на рисунке выше] — время, по другому [Y] — частота, а значение [яркость на рисунке] — мощность сигнала на заданной частоте в определенный момент времени. Проще говоря, эта штуковина показывает, какое распределение по мощностям было у различных частот звука в конкретный момент. Мел-спектрограмма непрерывна, то есть с ней можно работать как с изображением.
А так звучит результат синтеза:
3. Новый вокодер
Вероятно, вы уже догадались, что мы перешли к использованию нового нейросетевого вокодера. Именно он в реальном времени превращает мел-спектрограмму в голос. Наиболее близкий аналог нашего первого решения на основе нейросетей, которое вышло в 2018 году — модель WaveGlow.
Архитектура WaveGlow основана на генеративных потоках — довольно изящном методе создания генеративных сетей, впервые предложенном в статье про генерацию лиц. Сеть обучается конвертировать случайный шум и мел-спектрограмму на входе в осмысленный wav-сэмпл. За счёт случайного шума на входе обеспечивается выбор случайной wav-ки — одной из множества соответствующих мел-спектрограмме. Как я объяснил выше, в домене речи такой случайный выбор будет лучше детерминированного среднего по всем возможным wav-кам.
В отличие от WaveNet, WaveGlow не авторегрессионен, то есть не требует для генерации нового wav-сэмпла знания предыдущих. Его параллельная свёрточная архитектура хорошо ложится на вычислительную модель видеокарты, позволяя за одну секунду работы генерировать несколько сотен секунд звука.
Затем вышла модель HiFi-GAN, которая сильно выигрывала по качеству у других решений. HiFi-GAN — доработка генеративно-состязательной сети MelGAN, создающей wav-сэмплы на основе мел-спектрограммы.
Главное отличие, за счёт которого HiFi-GAN обеспечивает гораздо лучшее качество, заключается в наборе подсетей-дискриминаторов. Они валидируют натуральность звука, смотря на сэмплы с различными периодами и на различном масштабе. Как и WaveGlow, HiFi-GAN не имеет авторегрессионной зависимости и хорошо параллелится, при этом новая сеть намного легковеснее, что позволило при реализации ещё больше повысить скорость синтеза. Кроме того, оказалось, что HiFi-GAN лучше работает на экспрессивной речи, что в дальнейшем позволило запустить эмоциональный синтез — об этом подробно расскажу чуть позже. Летом 2021 года мы полностью перешли на HiFi-GAN.
Схема HiFi-GAN из статьи авторов модели
Комбинация этих трёх компонентов позволила вернуться к параметрическому синтезу голоса, который звучал плавно и качественно, требовал меньше данных и давал больше возможностей в кастомизации и изменении стиля голоса.
Параллельно мы работали над улучшением отдельных элементов синтеза:
- Летом 2019 года выкатили разрешатор омографов (homograph resolver) — он научил Алису правильно ставить ударения в парах «зАмок» и «замОк», «белкИ» и «бЕлки» и так далее. Здесь мы нашли остроумное решение. В русском языке эти слова пишутся одинаково, но в английском написание отличается, например, castle и lock, proteins и squirrels. Поэтому мы воспользовались моделью машинного перевода: взяли энкодер переводческой нейросети ru->en и извлекли эмбеддинг русского текста. Из этого представления легко выделить информацию о том, как произносить омограф, ведь перевод должен различать формы для корректного подбора английского варианта. Буквально на 20 примерах можно выучить классификатор для нового омографа, чтобы по эмбеддингу перевода понимать, какую форму нужно произнести.
- Летом 2020 года допилили паузер для расстановки пауз внутри предложения. Язык — хитрая штука. Не все знаки препинания в речи выражаются паузами Например, после вводного слова «конечно» на письме мы ставим запятую, но в речи обычно не делаем паузу. А там, где знаков препинания нет, мы часто делаем паузы. Если эту информацию не передавать в акустическую модель, то она пытается её выводить и не всегда успешно. Первая модель Алисы из-за этого могла начать вздыхать в случайных местах длинного предложения. Задача паузера — предсказать класс паузы (отсутствует/короткая/средняя/длинная) после каждого слова. Для этого мы взяли датасет, разметили его детектором активности голоса, сгруппировали паузы по длительности, ввели класс длины паузы, на каждое слово навесили тэг и на этом корпусе обучили ещё одну голову внимания из тех же нейросетевых эмбеддингов, что использовались для детекции омографов.
- Осенью 2020 года мы перевели на трансформеры нормализацию — в синтезе она нужна, чтобы решать сложные случаи, когда символы читаются не «буквально», а по неким правилам. Например, «101» нужно читать не как «один-ноль-один», а как «сто один», а в адресе yandex.ru нужно произносить точку — «яндекс точка ру». Обычно нормализацию делают через комбинацию взвешенных трансдьюсеров (FST) — правила напоминают последовательность замен по регулярным выражениям, где выбирается замена, имеющая наибольший вес. Мы долго писали правила вручную, но это отнимало много сил, было очень сложно и не масштабируемо. Тогда решили перейти на трансформерную сеть, «задистиллировав» знания наших FST в нейронку. Теперь новые «правила раскрытия» можно добавлять через доливание синтетики и данных, размеченных пользователями Толоки, а сеть показывает лучшее качество, чем FST, потому что учитывает глобальный контекст.
Итак, мы научили Алису говорить с правильными интонациями, но это не сделало ее человеком — ведь в нашей речи есть еще стиль и эмоции. Работа продолжалась.
С чувством, толком, расстановкой: стили голоса Алисы
Один и тот же текст можно произнести десятком разных способов, при этом сам исходный текст, как правило, никаких подсказок не содержит. Если отправить такой текст в акустическую модель без дополнительных меток и обучить её на достаточно богатом различными стилями и интонациями корпусе, то модель сойдёт с ума — либо переусреднит всё к металлическому «голосу робота», либо начнёт генерировать случайный стиль на каждое предложение. Это и произошло с Алисой: в начале она воспроизводила рандомные стили в разговоре. Казалось, что у неё менялось настроение в каждом предложении.
Вот пример записи с явными перебоями в стилях:
Чтобы решить проблему, мы добавили в акустическую модель стили: в процессе обучения нейросети специально ввели «утечку». Суть в том, что через очень lossy-пространство (всего 16 чисел на всё предложение) разрешаем сетке посмотреть на ответ — истинную мел-спектрограмму, которую ей и нужно предсказать на обучении. За счёт такой «шпаргалки» сеть не пытается выдумывать непредсказуемую по тексту компоненту, а для другой информации не хватит размерности шпаргалки.
На инференсе мы генерируем стилевую подсказку, похожую на те, что были в обучающем сете. Это можно делать, взяв готовый стиль из обучающего примера или обучив специальную подсеть генерировать стили по тексту.
Если эту подсеть обучить на особом подмножестве примеров, можно получить специальные стили для, скажем, мягкого или дружелюбного голоса. Или резкого и холодного. Или относительно нейтрального. Чтобы определиться со стилем по умолчанию, мы устроили турнир, где судьями выступали пользователи Толоки. Там не было разметки, мы просто нашли кластеры стилей и провели между ними соревнование. Победил кластер с очень мягкой и приятной интонацией.
Дальше началось самое интересное. Мы взяли образцы синтезированной «мягкой» речи Алисы и фрагменты речи актрисы Татьяны Шитовой, которые относились к более резкому стилю. Затем эти образцы с одним и тем же текстом протестировали вслепую на толокерах. Оказалось, что люди выбирают синтезированный вариант Алисы, несмотря на более плохое качество по сравнению с реальной речью человека. В принципе, этого можно было ожидать: уверен, многие предпочтут более ласковый разговор по телефону (то есть с потерей в качестве) живому, но холодному общению.
К примеру, так звучал резкий голос:
А так — мягкий:
Результаты турниров позволили нам выделить во всем обучающем датасете данные, которые относятся к стилю-победителю, и использовать для обучения только их. Благодаря этому Алиса по умолчанию стала говорить более мягким и дружелюбным голосом.
Этот пример показывает, что с точки зрения восприятия важно работать не только над качеством синтеза, но и над стилем речи. После этого оставалось только обогатить Алису новыми эмоциями.
Бодрая или спокойная: управляем эмоциями Алисы
Когда вы включаете утреннее шоу Алисы или запускаете автоматический перевод лекции на YouTube, то слышите разные голоса — бодрый в первом случае и более флегматичный в другом. Эту разницу сложно описать словами, но она интуитивно понятна — люди хорошо умеют распознавать эмоции и произносить один и тот же текст с разной эмоциональной окраской. Мы обучили этому навыку Алису с помощью той же разметки подсказок, которую применили для стилей.
У языка есть интересное свойство — просодия, или набор элементов, которые не выражаются словами. Это особенности произношения, интенсивность, придыхание и так далее. Один текст можно произнести со множеством смыслов. Как и в случае со стилями речи, можно, например, выделить кластеры «веселая Алиса», «злая Алиса» и так далее.
Поскольку стилевой механизм отделяет просодию («как говорим») от артикуляции («что говорим»), то новую эмоцию можно получить буквально из пары часов данных. По сути, нейросети нужно только выучить стиль, а информацию о том, как читать сочетания фонем, она возьмёт из остального корпуса.
Прямо сейчас доступны три эмоции. Например, часть пользователей утреннего шоу Алисы слышат бодрую эмоцию. Кроме того, её можно услышать, спросив Алису «Кем ты работаешь?» или «Какую музыку ты любишь?». Флегматичная эмоция пригодилась для перевода видео — оказалось, что голос по умолчанию слишком игривый для этой задачи. Наконец, радостная эмоция нужна для ответов Алисы на специфические запросы вроде «Давай дружить» и «Орёл или решка?». Ещё есть негативная эмоция, которую пока не знаем, как использовать — сложно представить ситуацию, когда людям понравится, что на них ругается робот.
Первый корпус эмоций мы записали ещё при WaveGlow, но результат нас не устроил и выкатывать его не стали. С переходом на HiFi-GAN стало понятно, что он хорошо работает с эмоциями, это позволило запустить полноценный эмоциональный синтез.
Наконец, мы решили внедрить шёпот. Когда люди обращаются к Алисе шёпотом, она должна и отвечать шёпотом — это делает её человечнее. При этом шёпот — не просто тихая речь, там слова произносятся без использования голосовых связок. Спектр звука получается совсем другим.
С одной стороны, это упрощает детекцию шёпота: по «картинке» мел-спектрограммы можно понять, где заканчивается обычная речь и начинается шепот. С другой стороны, это усложняет синтез шёпота: привычные механизмы обработки и подготовки речи перестают работать. Поэтому шёпотный синтез нельзя получить детерминированным преобразованием сигнала из речи.
Так выглядят мел-спектрограммы обычной речи и шёпота при произнесении одной и той же фразы:
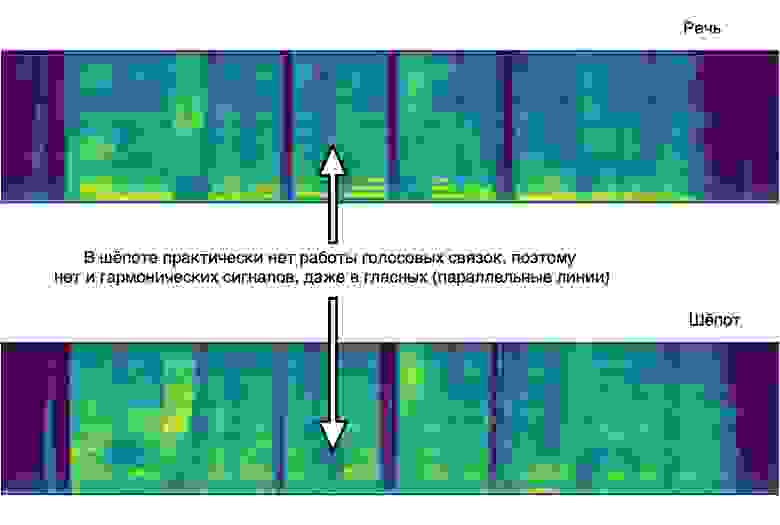
Так звучит обычная речь:
А так — шёпот:
Сначала мы научили Алису понимать шёпот. Для этого обучили нейросеть различать спектры звука для обычного голоса и шёпота. Система смотрит на спектр звука и решает, когда говорят шёпотом, а когда — голосом.
В процессе обучения оказалось, что спектры шёпота и речи курильщиков похожи, так что пришлось научить нейросеть их различать. Для этого собрали больше пограничных данных с речью курильщиков и простуженных людей и донастроили нейросеть на них.
Чтобы научить Алису говорить шёпотом, мы записали несколько часов шёпота речи в исполнении Татьяны Шитовой. Сложности начались уже на предобработке данных: наш VAD (детектор тишины в речи) сломался на шёпотных гласных — трудно отличить сказанное шёпотом «а!» от обычного громкого вздоха. Починить его удалось, только совместив признаки энергии сигнала и данные от распознавания речи, при этом под шёпот конструкцию пришлось калибровать отдельно.
Затем записанные данные добавили в обучающий корпус акустической модели. Мы решили рассматривать шёпот как еще один «стиль» речи или, в терминах нашего синтеза, «эмоцию». Добавив данные в трейнсет, мы дали акустической модели на вход дополнительную информацию — шёпот или эмоцию она сейчас проигрывает. По этому входу модель научилась по команде пользователя переключаться между генерацией речи и шёпота.
Сгенерированный шёпот по качеству не отличался от обычной речи. По нашей метрике PSER (Pronunciation Sentence Error Rate — средняя доля ошибок произношения в предложении) он оказался даже лучше. Оказалось, что ряд ошибок интонации в шёпотной речи были значительно менее ярко выражены.
Этот голос будет полезен при общении с Алисой ночью, чтобы не мешать близким. Можно задавать вопросы тихим голосом и Алиса будет отвечать шёпотом. Кроме того, такой стиль ещё и звучит очень приятно — поклонники ASMR оценят.
Послушайте, как шепчет Алиса:
На этом мы не останавливаемся — в планах дальнейшее развитие голосового синтеза, добавление новых стилей и эмоций. Обязательно продолжим рассказывать о том, как Алиса учится говорить по-человечески.