How To Audit rel=”next” and rel=”prev” Using The SEO Spider
The rel=”next” and rel=”prev” pagination attributes are used to indicate the relationship between component URLs in a paginated series to search engines. They help consolidate indexing properties in the sequence, and direct users to the most relevant URL within the series.
They are commonly used on ecommerce category pages which display many products split across multiple URLs, articles that have been broken into shorter pieces, or forum threads as examples.
While they are a relatively simple concept, it’s extremely common for websites to implement pagination attributes incorrectly. Google announced on the 21st of March 2019 that they have not used rel=”next” and rel=”prev” in indexing for a long time, other search engines such as Bing (which also powers Yahoo), still use it as a hint for discovery and understanding site structure.
This tutorial walks you through how you can use the Screaming Frog SEO Spider to check rel=”next” and rel=”prev” pagination implementation quickly and efficiently. The SEO Spider will crawl pagination attributes, report upon their set-up and common errors.
To get started, you’ll need to download the SEO Spider, own a paid licence, and then follow these steps.
1) Select ‘Crawl’ & ‘Store’ Pagination under ‘Configuration > Spider’
The SEO Spider ‘Configuration’ is available in the top level menu.
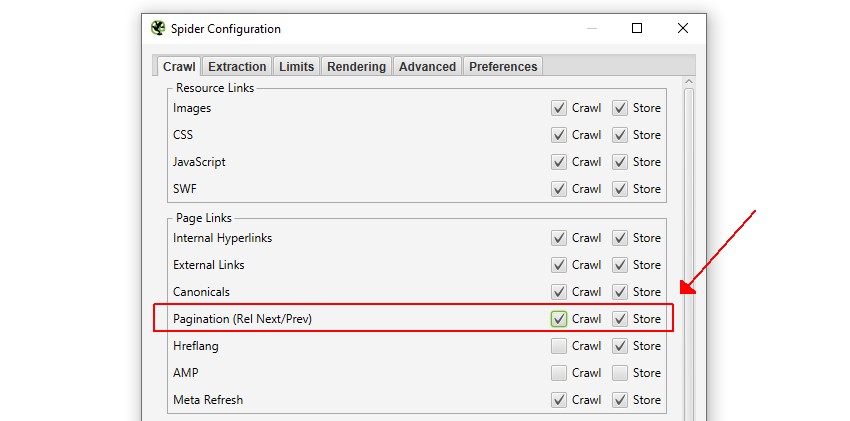
By default ‘crawl’ is disabled, so enabling it will mean URLs referenced in rel=”next” and rel=”prev” attributes will be crawled, as well as extracted and reported. Next, click ‘OK’. This option will only make a difference to the crawl, if these pages are not already linked to with regular anchor tags.
2) Crawl The Website
Open up the SEO Spider, type or copy in the website you wish to crawl in the ‘Enter URL to spider’ box and hit ‘Start’.

The website will be crawled and rel=”next” and rel=”prev” attributes will be crawled.
Now grab a coffee and wait until the progress bar reaches 100%, and the crawl is completed.
3) View The Pagination Tab
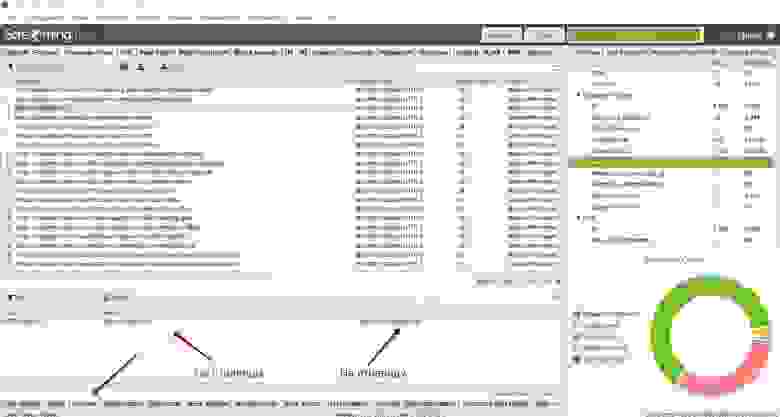
The Pagination tab shows all URLs found in a crawl and will show any URLs referenced in rel=”next” and rel=”prev” attributes in individual columns in the main window pane.
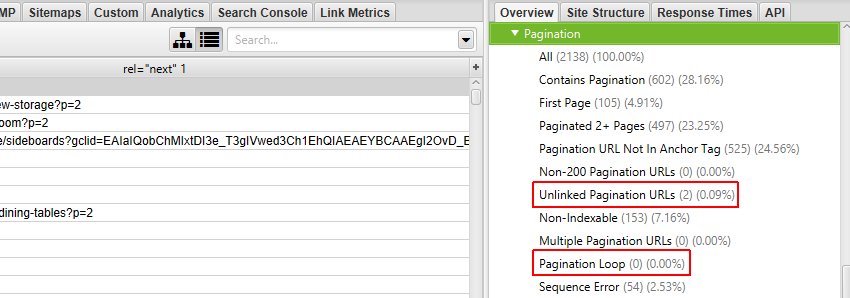
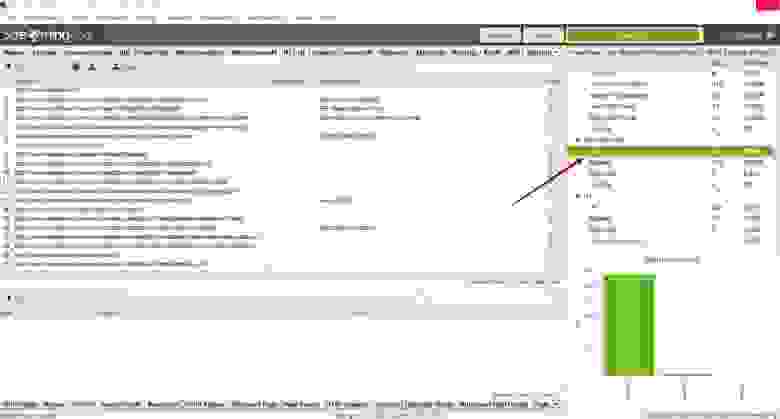
The Pagination tab has 10 filters (as shown in the image below) that help you understand your pagination attribute implementation, and identify common pagination problems.
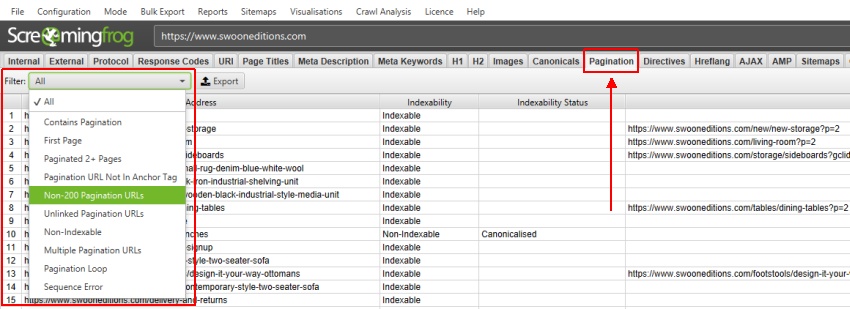
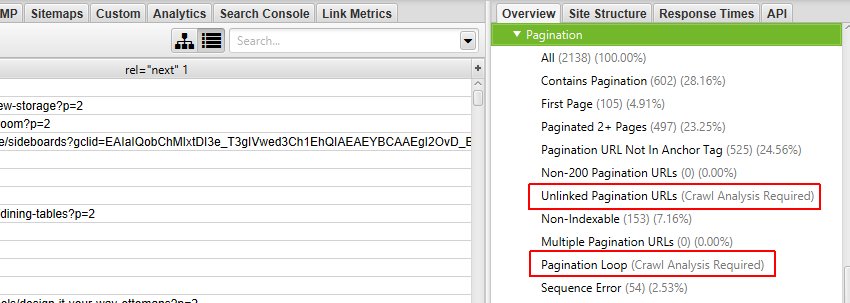
8 of the 10 filters are available to view immediately during, or at the end of a crawl. The ‘Unlinked Pagination URLs’ and ‘Pagination Loop’ filters require calculation at the end of the crawl via post ‘Crawl Analysis‘ for them to be populated with data (more on this in just a moment).
The right hand ‘overview’ pane, displays a ‘(Crawl Analysis Required)’ message against this filter that requires post crawl analysis to be populated with data.
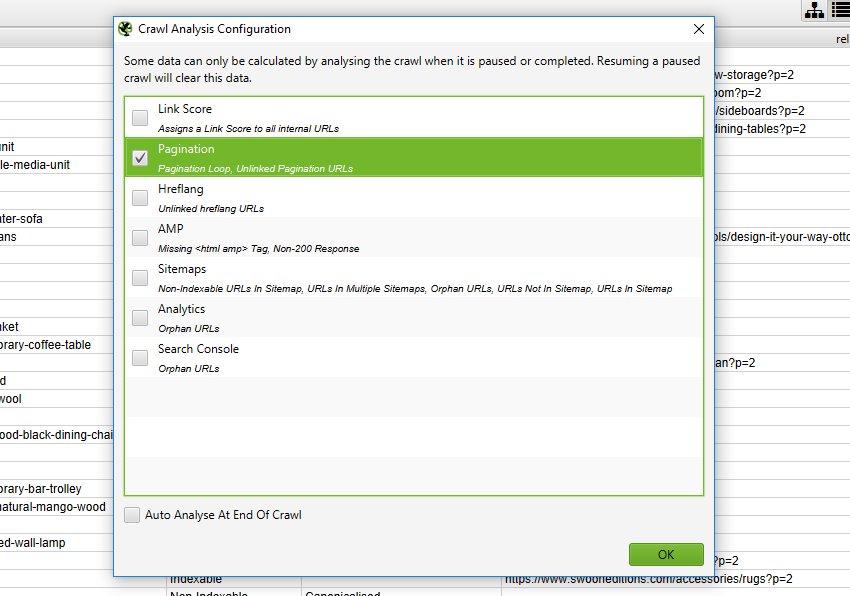
4) Click ‘Crawl Analysis > Start’ To Populate Pagination Filters
To populate the ‘Unlinked Pagination URLs’ and ‘Pagination Loop’ filters, you simply need to click a button to start crawl analysis.

However, if you have configured ‘Crawl Analysis’ previously, you may wish to double check, under ‘Crawl Analysis > Configure’ that ‘Pagination’ is ticked.
You can also untick other items that also require post crawl analysis to make this step quicker.
When crawl analysis has completed the ‘analysis’ progress bar will be at 100% and the filters will no longer have the ‘(Crawl Analysis Required)’ message.
5) Click ‘Pagination’ & View Populated Filters
After performing post crawl analysis, all pagination filters will now be populated with data where applicable.
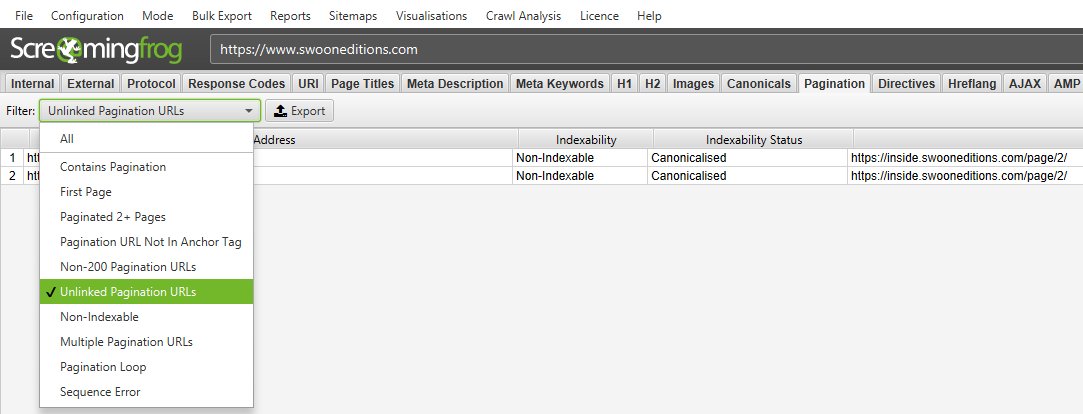
The pagination data collected can then be reviewed in columns, to ensure the implementation is as required. You’re able to filter by the following –
- Contains Pagination – The URL has a rel=”next” and/or rel=”prev” attribute, indicating it’s part of a paginated series.
- First Page – The URL only has a rel=“next” attribute, indicating it’s the first page in a paginated series. It’s easy and useful to scroll through these URLs and ensure they are accurately implemented on the parent page in the series.
- Paginated 2+ Pages – The URL has a rel=“prev” on it, indicating it’s not the first page, but a paginated page in a series. Again, it’s useful to scroll through these URLs and ensure only paginated pages appear under this filter.
- Pagination URL Not In Anchor Tag – A URL contained in either, or both, the rel=”next” and rel=”prev” attributes of the page, are not found as a hyperlink in an HTML anchor element on the page itself. Paginated pages should be linked to with regular links to allow users to click and navigate to the next page in the series. They also allow Google to crawl from page to page, and PageRank to flow between pages in the series. Google’s own Webmaster Trends analyst John Mueller recommended proper HTML links for pagination as well in a Google Webmaster Central Hangout.
- Non-200 Pagination URL – The URLs contained in the rel=”next” and rel=”prev” attributes do not respond with a 200 ‘OK’ status code. This can include URLs blocked by robots.txt, no responses, 3XX (redirects), 4XX (client errors) or 5XX (server errors). Pagination URLs must be crawlable and indexable and therefore non-200 URLs are treated as errors, and ignored by the search engines. The non-200 pagination URLs can be exported in bulk via the ‘Reports > Pagination > Non-200 Pagination URLs’ export.
- Unlinked Pagination URL – The URL contained in the rel=”next” and rel=”prev” attributes are not linked to across the website. Pagination attributes may not pass PageRank like a traditional anchor element, so this might be a sign of a problem with internal linking, or the URLs contained in the pagination attribute. The unlinked pagination URLs can be exported in bulk via the ‘Reports > Pagination > Unlinked Pagination URLs’ export.
- Non-Indexable – The paginated URL is non-indexable. Generally they should all be indexable, unless there is a ‘view-all’ page set, or there are extra parameters on pagination URLs, and they require canonicalising to a single URL. One of the most common mistakes is canonicalising page 2+ paginated pages to the first page in a series. Google recommend against this implementation because the component pages don’t actually contain duplicate content. Another common mistake is using ‘noindex’, which can mean Google drops paginated URLs from the index completely and stops following outlinks from those pages, which can be a problem for the products on those pages. This filter will help identify these common set-up issues.
- Multiple Pagination URLs – There are multiple rel=”next” and rel=”prev” attributes on the page (when there shouldn’t be more than a single rel=”next” or rel=”prev” attribute). This may mean that they are ignored by the search engines.
- Pagination Loop – This will show URLs that have rel=”next” and rel=”prev” attributes that loop back to a previously encountered URL. Again, this might mean that the expressed pagination series are simply ignored by the search engines.
- Sequence Error – This shows URLs that have an error in the rel=”next” and rel=”prev” HTML link elements sequence. This check ensures that URLs contained within rel=”next” and rel=”prev” HTML link elements reciprocate and confirm their relationship in the series.
6) Use The ‘Reports > Pagination > X’ Exports To Bulk Export Source URLs & Errors
To bulk export details of source pages, that contain errors or issues for pagination, use the ‘Reports > Pagination’ options.
For example, the ‘Reports > Pagination > Unlinked Pagination URLs’ export, will include details of the source pages that contain the rel=”next” and rel=”prev” attributes that are not linked to across the site.
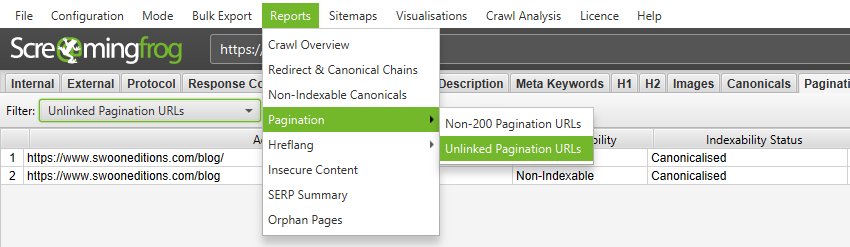
This can sometimes be easier to digest, than in the user interface, as source URLs and pagination links are included in individual rows.
Further Support
The guide above should help illustrate the simple steps required to test pagination implementation and issues across a website using the SEO Spider.
Please also read our Screaming Frog SEO Spider FAQs and full user guide for more information on the tool.
If you have any further queries, then just get in touch via support.
Наличие технических ошибок на сайте может негативно сказаться на его ранжировании, что в свою очередь приведет к снижению поискового трафика и позиций в поисковых системах. Чтобы выявить технические ошибки, необходимо провести комплексный технический SEO-аудит сайта. Одним из основных помощников в этой сложной и трудозатратной задаче для нас выступает десктопная программа Screaming Frog.
О Screaming Frog
Screaming Frog – это софт для сканирования сайта, ключевыми функциями которого являются:
-
поиск битых ссылок;
-
поиск ссылок с редиректом;
-
поиск дублей страниц;
-
анализ изображений;
-
поиск страниц, где отсутствуют мета-теги или основной заголовок h1;
-
извлечение элементов со страниц сайта;
-
поиск пустых страниц или неинформативных страниц, где крайне мало контента.
С помощью данной программы можно проанализировать страницы, которые закрыты в файле robots.txt, проверить наличие и корректность заполнения тегов alt у изображений, а также наличие атрибута Canonical и многое другое.
Screaming Frog может просканировать весь сайт полностью, либо же определенный каталог, либо заданный вручную список страниц. Чтобы не создавать сильную нагрузку на сервер, можно в любой момент остановить сканирование.
Важным плюсом является то, что результат сканирования можно выгрузить в формате csv или xlsx. Но есть и некоторые минусы:
-
сложный и интуитивно непонятный интерфейс для новых пользователей;
-
данные хранятся в оперативной памяти вашего ПК, в связи чем довольно проблематично полностью сканировать объемный сайт. А также при работе с софтом работа ПК может замедлиться;
-
программа платная (но есть бесплатная версия с ограничениями).
А теперь подробнее.
Поиск битых ссылок
Мы намеренно перескочили через тему «Настройка Screaming Frog», так как в сети присутствует большое количество мануалов по настройке программы, описаний интерфейса и вводной информации о том, как работать с программой и сканировать сайт. Переходим сразу к техническому анализу сайта.
Итак, мы просканировали сайт. Для поиска битых ссылок необходимо справа найти вкладку «Response Code» — «Client Error (4xx)». Теперь мы видим список битых ссылок при их наличии на сайте.

Как определить на каких страницах находятся битые ссылки?
Необходимо выбрать ссылку или выделить несколько ссылок и внизу слева выбрать вкладку «Inlinks». В нижней части появится список страниц, где размещена выбранная ссылка или список ссылок.
Такие ссылки рекомендуется убирать, так как большое количество битых ссылок может негативно сказаться на ранжировании сайта.
Как найти битые ссылки на странице сайта?
Если при осмотре страницы битая ссылка не бросается в глаза, необходимо открыть код сайта «ctrl + shift + i», далее открыть форму поиска в коде «ctrl + а» и вбить адрес битой ссылки.

Битые ссылки могут быть размещены в текстах страниц. В таком случае необходимо убирать ссылки вручную. В некоторых случаях ссылка может быть размещена сразу на нескольких страницах. Это говорит о том, что ссылка размещена в меню, в футере или в каком-либо другом сквозном блоке. В таком случае не нужно заходить на каждую страницу отдельно, а можно просто удалить или заменить ссылку.
Почему битые ссылки – это плохо?
Битые ссылки не оказывают прямого влияния на ранжирование сайта, и каких-либо санкций за битые ссылки со стороны поисковых систем нет. Однако они могут потратить часть краулингового бюджета поисковых роботов, понизить показатель качества сайта, увеличить количество отказов. Кроме того, битые ссылки не передают вес другим страницам, а если на неё стоят ссылки с внешних ресурсов, вес такой ссылки не учитывается. Поэтому битые ссылки необходимо удалять с сайта либо заменять их на действующие.
Поиск ссылок с 301 редиректом
301 редирект – перенаправление со старого адреса на новый, если изменился адрес страницы, а контент не менялся. Это делается как раз для того, чтобы не появлялись битые ссылки. Но лучше сразу ставить ссылку с 200 кодом ответа на существующую страницу. Если нет возможности менять ссылки, тогда настраивают 301 редирект. Обычно мы от таких ссылок избавляемся.
Поиск ссылок с 301 редиректом производится аналогичным поиску битых ссылок образом. Необходимо справа найти вкладку «Response Code» — «Redirection (3xx)». Теперь мы видим список ссылок с 301 редиректом и другими редиректами с 3xx кодом при их наличии на сайте.

Как определить на каких страницах находятся ссылки с 301 редиректом?
Поиск таких ссылок осуществляется так же, как и поиск битых ссылок. Необходимо выбрать ссылку или выделить несколько ссылок и внизу слева выбрать вкладку «Inlinks». В нижней части появится список страниц, где размещена выбранная ссылки или список ссылок, как и в случае с битыми ссылками.
Рядом присутствует вкладка Outlinks, где указаны страницы, куда приходит редирект.
Почему желательно избавляться от таких ссылок?
Небольшое количество таких ссылок никак не отразится на ранжировании сайта. Однако, если ссылок с редиректами много или такие ссылки размещены на всех страницах в меню, футере или других сквозных блоках, рекомендуется заменить данные ссылки на существующие страницы, на которые настроен редирект. Такие ссылки не несут в себе информацию о том, почему происходит перенаправление на другой адрес, что усложняет поисковым системам обработку данного редиректа.
Поиск дублей страниц
Наличие дублей страниц негативно сказывается на ранжировании сайта, так как из двух страниц поисковые системы вероятнее всего будут индексировать только одну наиболее релевантную, на их взгляд, страницу. Дублями страниц могут восприниматься страницы с разным контентом, но одинаковыми тегами title. Бывает, что у страниц услуг и статей идентичные теги title, и такие страницы признаются дублями. При этом интент запросов совсем разный: у первой – информационный, у второй – коммерческий. Для избежания возникновения дублей следует в первую очередь проверять сайт на наличие дубликатов title и при наличии дублей корректировать мета-теги.
Как искать дубликаты title?
Выбираем справа вкладку «Page Titles» — «Duplicate» и получаем список страниц на которых дублируются мета-теги.

В случае, когда на страницах разный контент и одинаковые теги title, необходимо скорректировать мета-теги.
Если страницы идентичны и по тегами, и по контенту, следует удалить одну страницу и настроить 301 редирект с адреса удаленной страницы на существующую страницу. Это поможет, если ссылки на удаленные страницы размещены на других сайтах или находится в индексе. 301 редирект здесь нужен, чтобы пользователи попадали не на удаленную, а на нужную страницу.
Но на самом сайте такие ссылки нужно удалить. Поэтому рекомендуем сразу проверить, есть ли на сайте ссылки на удаленную страницу (см. инструкции выше) и заменить их на существующую страницу.
Анализ заголовков h1
На каждой странице должен присутствовать основной заголовок в тегах <h1>, который максимально подробно и при этом кратко отражает содержание страницы. Это позволяет поисковым система более точно определить, что за информация размещена на странице. При проведении SEO-аудита необходимо проверить наличие основного заголовка на всех страницах сайта. Кроме того, тегами <h1> должен быть размечен только один основной заголовок.
Как найти страницы, где отсутствует основной заголовок h1?
Необходимо справа выбрать вкладку «H1» — «Missing>. Вы увидите список страниц, где отсутствует заголовок h1. Следует добавить данный заголовок на все страницы сайта.
В том же блоке справа во вкладке «Multiple» будут страницы, где присутствует несколько заголовков h1. В таком случае необходимо удалить второй заголовок, если он дублирует первый либо в нём нет необходимости, или разметить заголовок тегами <h2> — <h6> в соответствии с его иерархией.

Рекомендуем также проверить вкладку «Duplicate» на наличие дублей заголовков h1. В целом, дубли h1 не являются проблемой. Однако при наличии большого количества дублей рекомендуем корректировать заголовки, в особенности на страницах товаров / услуг / статей и в случаях, когда на сайте настроена автоматическая генерация мета-тегов.
Проверка наличия и корректности Canonical
Для избежания возникновения дублей страниц рекомендуется на всех страницах размещать атрибут Canonical с указанием канонической (основной) страницы. Атрибут rel=canonical тега <link> указывает поисковым системам, что некоторые страницы могут быть одинаковыми, несмотря на разные URL-адреса (например, страницы пагинации).
Наличие данного атрибута не является фактором ранжирования, но в некоторых случаях может положительно сказаться на индексации сайта и избежать возникновения дублей страниц, например когда в URL добавляются GET-параметры (рекламные метки, сортировка и т.п.).
Для того, чтобы проверить на каких страницах размещен данный атрибут и корректно ли указаны ссылки, необходимо справа выбрать вкладку «Canonicals» — «All». Во вкладке «Missing» можно посмотреть список страниц, где данный атрибут отсутствует.

Поиск пустых или малоинформативных страниц
Наличие пустых или малоинформативных страниц может негативно сказаться на ранжировании сайта. Чаще всего такие страницы исключаются из индекса поисковых систем. Такие страницы рекомендуется удалять или дорабатывать таким образом, чтобы страница полностью отвечала на вопросы пользователя.
Для поиска пустых или малоинформативных страниц необходимо справа выбрать вкладку «Crawl Dara» — «Internal» — «All».
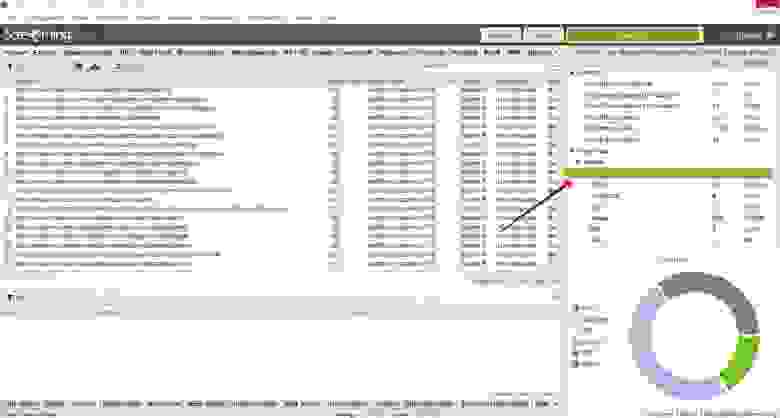
Через форму поиска следует отфильтровать страницы с контентом.
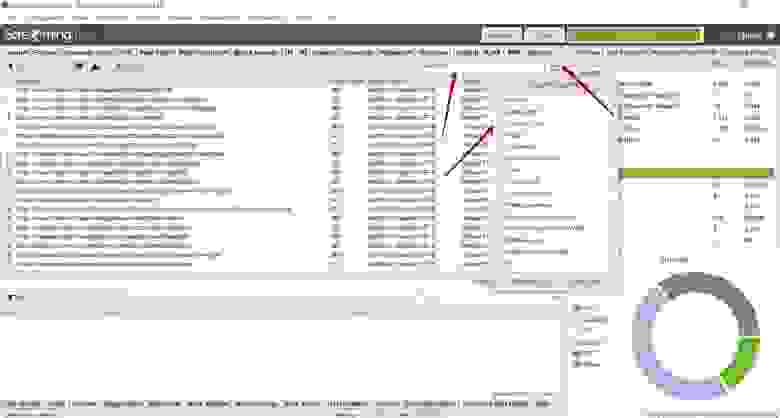
Далее необходимо в поле со списком страниц найти столбец «Word Count», отсортировать список страниц по убыванию количества слов и уже вручную проверить страницы с низким количеством слов в тексте страниц.
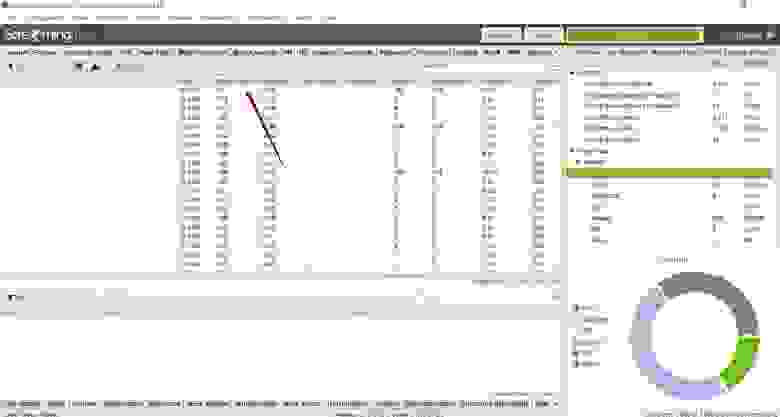
Спамный тег Keywords
Тег Keywords давно не учитывается поисковыми системами как фактор ранжирования и не оказывает положительного влияния. Однако при наличии на сайте спамных текстов и мета-тегов данный тег может стать одним из сигналов, что страница продвигается неестественными способами.
Для избежания таких ситуаций, мы рекомендуем удалять теги Keywords со всех страниц сайта.
Чтобы найти страницы, где размещен данный тег, необходимо справа выбрать вкладку «Meta Keywords» — «Missing», и вы увидите список страниц, где присутствует данный тег.
Анализ изображений
Изображения на сайте очень важны для продвижения и правильная оптимизация изображений может положительно сказаться на ранжировании сайтов и принести дополнительный трафик, например с поиска по картинкам.
Чтобы приступить к анализу изображений, следует перейти справа во вкладку «Crawl Data» — «Internal» — «Images». Вы увидите список ссылок на изображения. Необходимо проверить код ответа сервера в столбце «Status Code» — все ссылки должны отдавать 200 код ответа. Битые изображения следует удалить либо заменить на существующие. Если закрыты служебные папки, изображения рекомендуем открывать в файле robots.txt , чтобы они индексировались поисковыми системами.

Следует также проверить вес изображений в столбце «Size». Изображения с весом более 3 мб рекомендуем сжимать, чтобы они не замедляли скорость загрузки страниц.
Анализ тегов Noindex и Nofollow
На некоторых страницах могут быть размещены теги «noindex», «nofollow». Чаще всего с помощью таких тегов намеренно закрывают страницы, которые не должны индексироваться. Однако некоторые теги могут быть размещены на страницах сайта ошибочно, в результате чего нужные страницы не попадут в индекс и не будут приносить трафик.
Поэтому рекомендуем проверять наличие данных тегов на страницах сайта. Для этого необходимо справа выбрать вкладку «Directives» — «noindex» и «nofollow» и проверить, не размещены ли данные теги на нужных для продвижения страницах. При наличии таких тегов на важных страницах рекомендуем убрать их из кода, чтобы страницы индексировались поисковыми системами.
Извлечение элементов со страниц сайта
Иногда возникает потребность извлечь какой либо элемент со страниц сайта. Например, подзаголовки, цены, названия каких-то определенных блоков и т.д.
В случае с нашим клиентом мы обнаружили, что на некоторых страницах отсутствуют цены. Наличие цены на коммерческих страницах является одним из факторов ранжирования, в связи с чем мы подготовили рекомендацию о необходимости разместить цену на всех страницах сайта. Чтобы подготовить список страниц, где отсутствует цена, мы воспользовались функцией Custom Extraction.
Как это сделать?
Для начала необходимо определить, где находится нужный элемент на странице сайта, и скопировать стиль данного элемента.

В интерфейсе Screaming Frog необходимо выбрать вкладку Configuration — Custom — Extraction.
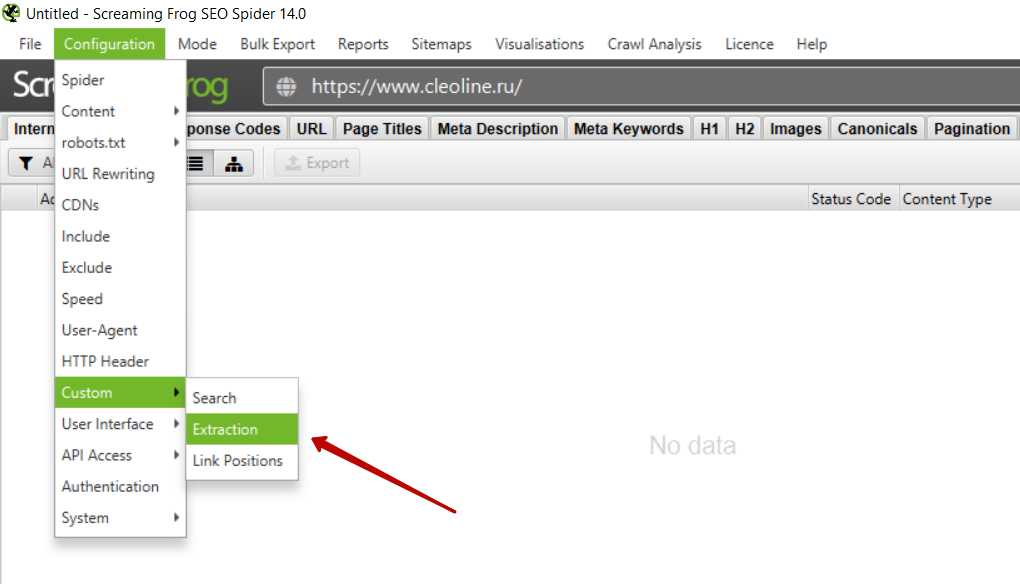
Далее необходимо добавить новый элемент, нажав на кнопку add, и выбрать способ извлечения — CSSPath и что извлекаем — Extract Inner HTML. Далее указываем CSS стиль элемента, который ранее мы скопировали из кода сайта и ставим перед названием стиля точку.

После этого запускаем парсинг.
Нас интересуют только страницы услуг, поэтому необходимо отфильтровать только страницы раздела /services/, где размещены ссылки на страницы услуг. И мы получаем список извлеченных страниц и элементов и можем найти страницы, где отсутствует цена.

Функционал Custom Extraction довольно сложен, мы привели лишь небольшой пример, как с его помощью можно извлечь элементы страницы. Если вам будет интересно, мы можем рассказать о возможностях этой функции более подробно в следующей статье.
Выводы
Мы рассмотрели основные моменты, которые необходимо всегда проверять при проведении технического SEO-аудита в программе Screaming Frog. Многие технические проблемы / недочеты могут не оказывать прямого влияния на ранжирование сайта, однако в совокупности большое количество технических ошибок может значительно затруднить поисковое продвижение.
Обращаем внимание, что технический анализ должен проводиться не только через Screaming Frog, но и с помощью других инструментов, например Яндекс.Вебмастер и Google Search Console.
Мы рекомендуем не останавливаться на одной технической проверке и проводить такой анализ раз в 1-3 месяца, в зависимости от обновления страниц сайта.
Стоит учитывать, что устранение технических недочетов не гарантирует улучшение позиций и рост поискового трафика. Для увеличения видимости сайта в поисковых системах необходима комплексная доработка технической составляющей сайта, коммерческих факторов, работа с текстами и мета-тегами, структурой сайта, ссылочным окружением и другими факторами.
Если у вас остались какие-либо вопросы, — готовы ответить на них в комментариях.
А если вопросов будет много, подробнее раскроем их уже в следующих статьях.
Если вам нужно просто собрать с сайта мета-данные, можно воспользоваться бесплатным парсером SiteAnalyzer. Но бывает, что надо копать гораздо глубже и добывать больше данных, и тут уже без сложных (и небесплатных) инструментов не обойтись.

Евгений Костин рассказал о том, как спарсить любой сайт, даже если вы совсем не дружите с программированием. Разбор сделан на примере Screaming Frog Seo Spider.
- Что такое парсинг и зачем он нужен
- ПО для парсинга
- Пример 1. Как спарсить цену
- Пример 2. Как спарсить фотографии
- Пример 3. Как спарсить характеристики товаров
- Пример 4. Как парсить отзывы (с рендерингом)
- Пример 5. Как спарсить скрытые телефоны на сайте ЦИАН
- Пример 6. Как парсить структуру сайта на примере DNS-Shop
- Возможности парсинга на основе XPath
- Ограничения при парсинге
Что такое парсинг и зачем он нужен
Парсинг нужен, чтобы получить с сайтов некую информацию. Например, собрать данные о ценах с сайтов конкурентов.
Одно из применений парсинга — наполнение каталога новыми товарами на основе уже существующих сайтов в интернете.
Упрощенно, парсинг — это сбор информации. Есть более сложные определения, но так как мы говорим о парсинге «для чайников», то нет никакого смысла усложнять терминологию. Парсинг — это сбор, как правило, структурированной информации. Чаще всего — в виде таблицы с конкретным набором данных. Например, данных по характеристикам товаров.
Парсер — программа, которая осуществляет этот сбор. Она ходит по ссылкам на страницы, которые вы указали, и собирает нужную информацию в Excel-файл либо куда-то еще.
Парсинг работает на основе XPath-запросов. XPath — язык запросов, который обращается к определенному участку кода страницы и собирает из него заданную информацию.

ПО для парсинга
Здесь есть важный момент. Если вы введете в поисковике слово «парсинг» или «заказать парсинг», то, как правило, вам будут предлагаться услуги от компаний, которые создадут парсер под ваши задачи. Стоят такие услуги относительно дорого. В результате программисты под заказ напишут некую программу либо на Python, либо на каком-то еще языке, которая будет собирать информацию с нужного вам сайта. Эта программа нацелена только на сбор конкретных данных, она не гибкая и без знаний программирования вы не сможете ее самостоятельно перенастроить для других задач.
При этом есть готовые решения, которые можно под себя настраивать как угодно и собирать что угодно. Более того, если вы — SEO-специалист, возможно, одной из этих программ вы уже пользуетесь, но просто не знаете, что в ней есть такой функционал. Либо знаете, но никогда не применяли, либо применяли не в полной мере.
Вот две программы, которые являются аналогами.
- Screaming Frog SEO Spider (есть только годовая лицензия).
- Netpeak Spider (есть триал на 14 дней, лицензии на месяц и более).
Эти программы занимаются сбором информации с сайта. То есть они анализируют, например, его заголовки, коды, теги и все остальное. Помимо прочего, они позволяют собрать те данные, которые вы им зададите.
Давайте смотреть на реальных примерах.
Пример 1. Как спарсить цену
Предположим, вы хотите с некого сайта собрать все цены товаров. Это ваш конкурент, и вы хотите узнать, сколько у него стоят товары.
Возьмем для примера сайт mosdommebel.ru.
У нас есть страница карточки товара, есть название и есть цена этого товара. Как нам собрать эту цену и цены всех остальных товаров?

Мы видим, что цена отображается вверху справа, напротив заголовка h1. Теперь нам нужно посмотреть, как эта цена отображается в html-коде.
Нажимаем правой кнопкой мыши прямо на цену (не просто на какой-то фон или пустой участок). Затем выбираем пункт Inspect Element для того, чтобы в коде сразу его определить (Исследовать элемент или Просмотреть код элемента, в зависимости от браузера — прим. ред.).

Мы видим, что цена у нас помещается в тег с классом totalPrice2. Так разработчик обозначил в коде стоимость данного товара, которая отображается в карточке.
Фиксируем: есть некий элемент span с классом totalPrice2. Пока это держим в голове.
Есть два варианта работы с парсерами.
Первый способ. Вы можете прямо в коде (любой браузер) нажать правой кнопкой мыши на тег <span> и выбрать Скопировать > XPath. У вас таким образом скопируется строка, которая обращается к данному участку кода.

Выглядит она так:
/html/body/div[1]/div[2]/div[4]/table/tbody/tr/td/div[1]/div/table[2]/tbody/tr/td[2]/form/table/tbody/tr[1]/td/table/tbody/tr[1]/td/div[1]/span[1]
Но этот вариант не очень надежен: если у вас в другой карточке товара верстка выглядит немного иначе (например, нет каких-то блоков или блоки расположены по-другому), то такой метод обращения может ни к чему не привести. И нужная информация не соберется.
Поэтому мы будем использовать второй способ. Есть специальные справки по языку XPath. Их очень много, можно просто загуглить «XPath примеры».
Например, такая справка:

Здесь указано как что-то получить. Например, если мы хотим получить содержимое заголовка h1, нам нужно написать вот так:
//h1/text()
Если мы хотим получить текст заголовка с классом productName, мы должны написать вот так:
//h1[@class="productName"]/text()
То есть поставить «//» как обращение к некому элементу на странице, написать тег h1 и указать в квадратных скобках через символ @ «класс равен такому-то».
То есть не копировать что-то, не собирать информацию откуда-то из кода. А написать строку запроса, который обращается к нужному элементу. Куда ее написать — сейчас мы разберемся.
Куда вписывать XPath-запрос
Мы идем в один из парсеров. В данном случае — Screaming Frog Seo Spider.
Эта программа бесплатна для анализа небольшого сайта — до 500 страниц. Интерфейс Screaming Frog Seo Spider.

Например, мы можем — бесплатно — посмотреть заголовки страниц, проверить нет ли у нас каких-нибудь пустых тайтлов или дубликатов тега h1, незаполненных метатегов или каких-нибудь битых ссылок.
Но за функционал для парсинга в любом случае придется платить, он доступен только в платной версии.
Предположим, вы оплатили годовую лицензию и получили доступ к полному набору функций сервиса. Если вы серьезно занимаетесь анализом данных и регулярно нуждаетесь в функционале сервиса — это разумная трата денег.
Во вкладке меню Configuration у нас есть подпункт Custom, и в нем есть еще один подпункт Extraction. Здесь мы можем дополнительно что-то поискать на тех страницах, которые мы укажем.

Заходим в Extraction. Нам нужно с сайта Московского дома мебели собрать цены товаров.
Мы выяснили в коде, что у нас все цены на карточках товара обозначаются тегом <span> с классом totalPrice2. Формируем вот такой XPath запрос:
//span[@class="totalPrice2"]/span
И указываем его в разделе Configuration > Custom > Extractions. Для удобства можем назвать как-нибудь колонку, которая у нас будет выгружаться. Например, «стоимость»:

Таким образом мы будем обращаться к коду страниц и из этого кода вытаскивать содержимое стоимости.
Также в настройках мы можем указать, что парсер будет собирать: весь html-код или только текст. Нам нужен только текст, без разметки, стилей и других элементов.

Нажимаем ОК. Мы задали кастомные параметры парсинга.
Как подобрать страницы для парсинга
Дальше есть еще один важный этап. Это, собственно, подбор страниц, по которым будет осуществляться парсинг.
Если мы просто укажем адрес сайта в Screaming Frog, парсер пойдет по всем страницам сайта. На инфостраницах и страницах категорий у нас нет цен, а нам нужны именно цены, которые указаны на карточках товара. Чтобы не тратить время, лучше загрузить в парсер конкретный список страниц, по которым мы будем ходить, — карточки товаров.
Откуда их взять? Как правило, на любом сайте есть карта сайта XML, и находится она чаще всего по адресу: «адрес сайта/sitemap.xml». В случае с сайтом из нашего примера — это адрес:
https://www.mosdommebel.ru/sitemap.xml.
Либо вы можете зайти в robots.txt (site.ru/robots.txt) и посмотреть. Чаще всего в этом файле внизу содержится ссылка на карту сайта. Ссылка на карту сайта в файле robots.txt.

Даже если карта называется как-то странно, необычно, нестандартно, вы все равно увидите здесь ссылку.
Но если не увидите — если карты сайта нет — то нет никакого решения для отбора карточек товара. Тогда придется запускать стандартный режим в парсере — он будет ходить по всем разделам сайта. Но нужную вам информацию соберет только на карточках товара. Минус здесь в том, что вы потратите больше времени и дольше придется ждать нужных данных.
У нас карта сайта есть, поэтому мы переходим по ссылке https://www.mosdommebel.ru/sitemap.xml и видим, что сама карта разделяется на несколько карт. Отдельная карта по статичным страницам, по категориям, по продуктам (карточкам товаров), по статьям и новостям.

Нас интересует карта продуктов, то есть карточек товаров.

Возвращаемся в Screaming Frog Seo Spider. Сейчас он запущен в стандартном режиме, в режиме Spider (паук), который ходит по всему сайту и анализирует все страницы. Нам нужно его запустить в режиме List.
Мы загрузим ему конкретный список страниц, по которому он будет ходить. Нажимаем на вкладку Mode и выбираем List.

Жмем кнопку Upload и кликаем по Download Sitemap.

Указываем ссылку на Sitemap карточек товара, нажимаем ОК.

Программа скачает все ссылки, указанные в карте сайта. В нашем случае Screaming Frog обнаружил более 40 тысяч ссылок на карточки товаров:

Нажимаем ОК, и у нас начинается парсинг сайта.

После завершения парсинга на первой вкладке Internal мы можем посмотреть информацию по всем характеристикам: код ответа, индексируется/не индексируется, title страницы, description и все остальное.


Это все полезная информация, но мы шли за другим.
Вернемся к исходной задаче — посмотреть стоимость товаров. Для этого в интерфейсе Screaming Frog нам нужно перейти на вкладку Custom. Чтобы попасть на нее, нужно нажать на стрелочку, которая находится справа от всех вкладок. Из выпадающего списка выбрать пункт Custom.

И на этой вкладке из выпадающего списка фильтров (Filter) выберите Extraction.

Вы как раз и получите ту самую информацию, которую хотели собрать: список страниц и колонка «Стоимость 1» с ценами в рублях.

Задача выполнена, теперь все это можно выгрузить в xlsx или csv-файл.

После выгрузки стандартной заменой вы можете убрать букву «р», которая обозначает рубли. Просто, чтобы у вас были цены в чистом виде, без пробелов, буквы «р» и прочего.
Таким образом, вы получили информацию по стоимости товаров у сайта-конкурента.
Если бы мы хотели получить что-нибудь еще, например, дополнительно еще собрать названия этих товаров, то нам нужно было бы зайти снова в Configuration > Custom > Extraction. И выбрать после этого еще один XPath-запрос и указать, например, что мы хотим собрать тег <h1>.

Просто запустив еще раз парсинг, мы собираем уже не только стоимость, но и названия товаров.

В результате получаем такую связку: url товара, его стоимость и название этого товара.
Если мы хотим получить описание или что-то еще — продолжаем в том же духе.
Например, мы хотим собрать описание. Нужно снова идти в Inspect Element.

Оказывается, все описание товара лежит в теге <table> с классом product_description. Если мы его соберем, то у нас в таблицу выгрузится полное описание.

Здесь есть нюанс. Текст описания на странице сайта сделан с разметкой. Например, здесь есть переносы на новую строчку, что-то выделяется жирным.

Если вам нужно спарсить текст описания с уже готовой разметкой, то в настройках Extraction в парсере мы можем выбрать парсинг с html-кодом.

Если вы не хотите собирать весь html-код (потому что он может содержать какие-то классы, которые к вашему сайту никакого отношения не имеют), а нужен текст в чистом виде, выбираем только текст. Но помните, что тогда переносы строк и все остальное придется заполнять вручную.
Собрав все необходимые элементы и прогнав по ним парсинг, вы получите таблицу с исчерпывающей информацией по товарам у конкурента.
Такой парсинг можно запускать регулярно (например, раз в неделю) для отслеживания цен конкурентов. И сравнивать, у кого что стоит дороже/дешевле.
Пример 2. Как спарсить фотографии
Рассмотрим вариант решения другой прикладной задачи — парсинга фотографий.
На сайте Эльдорадо у каждого товара есть довольно-таки немало фотографий. Предположим, вы их хотите взять — это универсальные фото от производителя, которые можно использовать для демонстрации на своем сайте.

Задача: собрать в Excel адреса всех картинок, которые есть у разных карточек товара. Не в виде файлов, а в виде ссылок. Потом по ссылкам вы сможете их скачать либо напрямую загрузить на свой сайт. Большинство движков интернет-магазинов, таких как Битрикс и Shop-Script, поддерживают загрузку фотографий по ссылке. Если вы в CSV-файле, который используете для импорта-экспорта, укажете ссылки на фотографии, то по ним движок сможет загрузить эти фотографии.
Ищем свойства картинок
Для начала нам нужно понять, где в коде указаны свойства, адрес фотографии на каждой карточке товара.
Нажимаем правой клавишей на фотографию, выбираем Inspect Element, начинаем исследовать.

Смотрим, в каком элементе и с каким классом у нас находится данное изображение, что оно из себя представляет, какая у него ссылка и т.д.

Изображения лежат в элементе <span>, у которого id — firstFotoForma. Чтобы спарсить нужные нам картинки, понадобится вот такой XPath-запрос:
//*[@id="firstFotoForma"]/*/img/@src
У нас здесь обращение к элементам с идентификатором firstFotoForma, дальше есть какие-то вложенные элементы (поэтому прописана звездочка), дальше тег img, из которого нужно получить содержимое атрибута src. То есть строку, в которой и прописан URL-адрес фотографии. Попробуем это сделать.
Берем XPath-запрос, в Screaming Frog переходим в Configuration > Custom > Extraction, вставляем и жмем ОК.

Для начала попробуем спарсить одну карточку. Нужно скопировать ее адрес и добавить в Screaming Frog таким образом: Upload > Paste


Нажимаем ОК. У нас начинается парсинг.
Screaming Frog спарсил одну карточку товара и у нас получилась такая табличка. Рассмотрим ее подробнее.

Мы загрузили один URL на входе, и у нас автоматически появилось сразу много столбцов «фото товара». Мы видим, что по этому товару собралось 9 фотографий.

Для проверки попробуем открыть одну из фотографий. Копируем адрес фотографии и вставляем в адресной строке браузера.

Фотография открылась, значит парсер сработал корректно и вытянул нужную нам информацию.
Теперь пройдемся по всему сайту в режиме Spider (для переключения в этот режим нужно нажать Mode > Spider). Укажем адрес https://www.eldorado.ru, нажимаем старт и запускаем парсинг.

Так как программа парсит весь сайт, то по страницам, которые не являются карточками товара, ничего не находится.
А с карточек товаров собираются ссылки на все фотографии.

Таким образом мы сможем собрать их и положить в Excel-таблицу, где будут указаны ссылки на все фотографии для каждого товара.
Если бы мы собирали артикулы, то еще раз зашли бы в Configuration > Custom > Extraction и добавили бы еще два XPath-запроса: для парсинга артикулов, а также тегов h1, чтобы собрать еще названия. Так мы бы убили сразу двух зайцев и собрали бы связку: название товара + артикул + фото.
Пример 3. Как спарсить характеристики товаров
Следующий пример — ситуация, когда нам нужно насытить карточки товаров характеристиками. Представьте, что вы продаете книжки. Для каждой книги у вас указано мало характеристик — всего лишь год выпуска и автор. А у Озона (сильный конкурент, сильный сайт) — характеристик много.

Вы хотите собрать в Excel все эти данные с Озона и использовать их для своего сайта. Это техническая информация, вопросов с авторским правом нет.
Изучаем характеристики
Нажимаете правой кнопкой по характеристике, выбираете Inspect Element и смотрите, как называется элемент, который содержит каждую характеристику.

У нас это элемент <div>, у которого в качестве класса указана строка eItemProperties_Line.

И дальше внутри каждого такого элемента <div> содержится название характеристики и ее значение.

Значит нам нужно собирать элементы <div> с классом eItemProperties_Line.
Для парсинга нам понадобится вот такой XPath-запрос:
//*[@class="eItemProperties_line"]
Идем в Screaming Frog, Configuration > Custom > Extraction. Вставляем XPath-запрос, выбираем Extract Text (так как нам нужен только текст в чистом виде, без разметки), нажимаем ОК.

Переключаемся в режим Mode > List. Нажимаем Upload, указываем адрес страницы, с которой будем собирать характеристики, нажимаем ОК.
После завершения парсинга переключаемся на вкладку Custom, в списке фильтров выбираем Extraction.
И видим — парсер собрал нам все характеристики. В каждой ячейке находится название характеристики (например, «Автор») и ее значение («Игорь Ашманов»).

Пример 4. Как парсить отзывы (с рендерингом)
Следующий пример немного нестандартен — на грани «серого» SEO. Это парсинг отзывов с того же Озона. Допустим, мы хотим собрать и перенести на свой сайт тексты отзывов ко всем книгам.

Покажем процесс на примере одного URL. Начнем с того, что посмотрим, где отзывы лежат в коде.

Они находятся в элементе <div> с классом jsCommentContent:

Следовательно, нам нужен такой XPath-запрос:
//*[@class="jsCommentContents"]
Добавляем его в Screaming Frog. Теперь копируем адрес страницы, которую будем анализировать, и загружаем в парсер.

Жмем ОК и видим, что никакие отзывы у нас не загрузились:

Почему так? Разработчики Озона сделали так, что текст отзывов грузится в момент, когда вы докручиваете до места, где отзывы появляются (чтобы не перегружать страницу). То есть они изначально в коде нигде не видны.
Чтобы с этим справиться, нам нужно зайти в Configuration > Spider, переключиться на вкладку Rendering и выбрать JavaScript. Так при обходе страниц парсером будет срабатывать JavaScript и страница будет отрисовываться полностью — так, как пользователь увидел бы ее в браузере. Screaming Frog также будет делать скриншот отрисованной страницы.

Мы выбираем устройство, с которого мы якобы заходим на сайт (десктоп). Настраиваем время задержки перед тем, как будет делаться скриншот, — одну секунду.

Нажимаем ОК. Введем вручную адрес страницы, включая #comments (якорная ссылка на раздел страницы, где отображаются отзывы).

Для этого жмем Upload > Enter Manually и вводим адрес:

Обратите внимание! При рендеринге (особенно, если страниц много) парсер может работать очень долго.
Итак, парсер собрал 20 отзывов. Внизу они показываются в качестве отрисованной страницы. А вверху в табличном варианте мы видим текст этих отзывов.

Пример 5. Как спарсить скрытые телефоны на сайте ЦИАН
Следующий пример — сбор телефонов с сайта cian.ru. Здесь есть предложения о продаже квартир. Допустим, стоит задача собрать телефоны с каких-то предложений или вообще со всех.
У этой задачи есть особенности. На странице объявления телефон скрыт кнопкой «Показать телефон».

После клика он виден. А до этого в коде видна только сама кнопка.

Но на сайте есть недоработка, которой мы воспользуемся. После нажатия на кнопку «Показать телефон» мы видим, что она начинается «+7 967…». Теперь обновим страницу, как будто мы не нажимали кнопку, посмотрим исходный код страницы и поищем в нем «967».

И вот, мы видим, что этот телефон уже есть в коде. Он находится у ссылки, с классом a10a3f92e9—phone—3XYRR. Чтобы собрать все телефоны, нам нужно спарсить содержимое всех элементов с таким классом.
Используем этот класс в XPath-запросе:
//*[@class="a10a3f92e9--phone--3XYRR"]
Идем в Screaming Frog, Custom > Extraction. Указываем XPath-запрос и даем название колонке, в которую будут собираться телефоны:

Берем список ссылок (для примера я отобрал несколько ссылок на страницы объявлений) и добавляем их в парсер.

В итоге мы видим связку: адрес страницы — номер телефона.

Также мы можем собрать в дополнение к телефонам еще что-то. Например, этаж.
Алгоритм такой же:
- Кликаем по этажу, Inspect Element.
- Смотрим, где в коде расположена информация об этажах и как обозначается.
- Используем класс или идентификатор этого элемента в XPath-запросе.
- Добавляем запрос и список страниц, запускаем парсер и собираем информацию.
Пример 6. Как парсить структуру сайта на примере DNS-Shop
И последний пример — сбор структуры сайта. С помощью парсинга можно собрать структуру какого-то большого каталога или интернет-магазина.
Рассмотрим, как собрать структуру dns-shop.ru. Для этого нам нужно понять, как строятся хлебные крошки.
Нажимаем на любую ссылку в хлебных крошках, выбираем Inspect Element.

Эта ссылка в коде находится в элементе <span>, у которого атрибут itemprop (атрибут микроразметки) использует значение «name».

Используем элемент span со значением микроразметки в XPath-запросе:
//span[@itemprop="name"]
Указываем XPath-запрос в парсере:

Пробуем спарсить одну страницу и получаем результат:

Таким образом мы можем пройтись по всем страницам сайта и собрать полную структуру.
Возможности парсинга на основе XPath
Что можно спарсить:
1. Любую информацию с почти любого сайта.
Нужно понимать, что есть сайты с защитой от парсинга. Например, если вы захотите спарсить любой проект Яндекса — у вас ничего не получится. Авито — тоже довольно-таки сложно. Но большинство сайтов можно спарсить.
2. Цены, наличие товаров, любые характеристики, фото, 3D-фото.
3. Описание, отзывы, структуру сайта.
4. Контакты, неочевидные свойства и т.д.
Любой элемент на странице, который есть в коде, вы можете вытянуть в Excel.
Ограничения при парсинге
- Бан по user-agent. При обращении к сайту парсер отсылает запрос user-agent, в котором сообщает сайту информацию о себе. Некоторые сайты сразу блокируют доступ парсеров, которые в user-agent представляются как приложения. Это ограничение можно легко обойти. В Screaming Frog нужно зайти в Configuration > User-Agent и выбрать YandexBot или Googlebot.


Подмена юзер-агента вполне себе решает данное ограничение. К большинству сайтов мы получим доступ таким образом.
- Запрет в robots.txt. Например, в robots.txt может быть прописан запрет индексирования каких-то разделов для Google-бота. Если мы user-agent настроили как Googlebot, то спарсить информацию с этого раздела не сможем.
Чтобы обойти ограничение, заходим в Screaming Frog в Configuration > Robots.txt > Settings

И выбираем игнорировать robots.txt

- Бан по IP. Если вы долгое время парсите какой-то сайт, то вас могут заблокировать на определенное или неопределенное время. Здесь два варианта решения: использовать VPN или в настройках парсера снизить скорость, чтобы не делать лишнюю нагрузку на сайт и уменьшить вероятность бана.
- Анализатор активности / капча. Некоторые сайты защищаются от парсинга с помощью умного анализатора активности. Если ваши действия похожи на роботизированные (когда обращаетесь к странице, у вас нет курсора, который двигается, или браузер не похож на стандартный), то анализатор показывает капчу, которую парсер не может обойти. Такое ограничение можно обойти, но это долго и дорого.
Теперь вы знаете, как собрать любую нужную информацию с сайтов конкурентов. Пользуйтесь приведенными примерами и помните — почти все можно спарсить. А если нельзя — то, возможно, вы просто не знаете как.
Оригинал статьи взят с сайта PromoPult
Screaming Frog
Как проверить скорость загрузки всех страниц на сайте
Время чтения — 10 мин
Время чтения с применением — 25 мин
Дата публикации —
25 декабря 2021

Частный SEO-специалист и автор статьи
Сегодня мы с вами проверим скорость все страниц на сайте с помощью программы Screaming Frog
Настройка скорости парсинга в Screaming Frog
Перед тем, как проверять скорость вам нужно сделать так, чтобы Google не понял, что вы используете бота, для этого необходимо уменьшить потоки сканирования:
В верхнем меню нажимаем Configuration → Spider
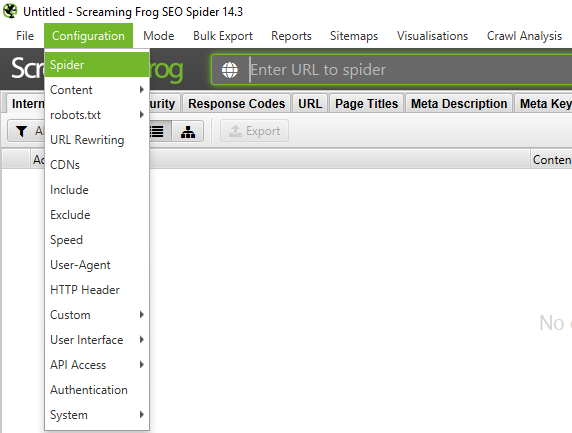
Переходим в раздел Rendering → Выбираем JavaScript (там в начале будет стоять Text Only).
С помощью данной функции вы просите краулер, чтобы при обходе сайта он учитывал Javascript. Подробнее можно изучить тут
Увеличиваем тайм-аут AJAX с 5 до 10-20
AJAX Timeout — Это время в секундах, в течение которого Screaming Frog должен разрешать выполнение JavaScript, прежде чем считать страницу загруженной. Этот таймер запускается после того, как браузер загрузит веб-страницу и любые связанные ресурсы, такие как JS, CSS и изображения.
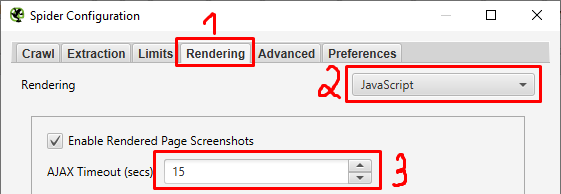
Выбираем устройство, для которого будем проверять скорость загрузки
Остаемся в старом разделе Rendering (надеюсь вы не вышли) и выбираем устройство, для которого необходимо проверить скорость загрузки сайта.
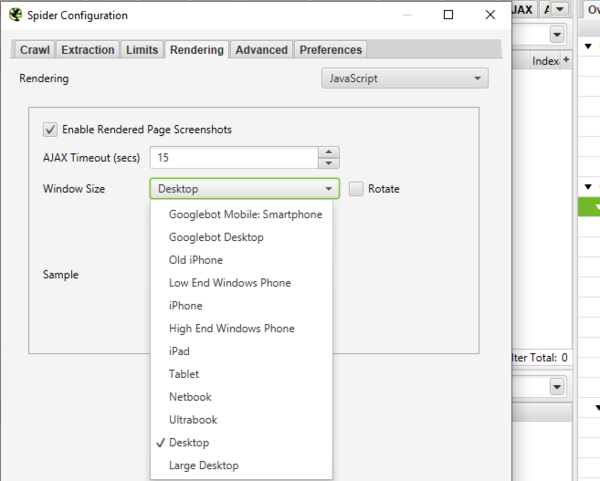
Decktop — Если вам нужно проверить скорость загрузки на ПК
Googlebot Mobile: Smartphone — Если вам нужно проверить скорость загрузки на мобильных устройствах
Ipad — Это проверка скорости загрузки для Ipad
Tablet — Проверка скорости загрузки для всех остальных планшетов
Чтобы не ошибиться в разделе Sample при выборе устройства вам покажет для какого разрешения будет происходить парсинг вашего устройства
После уменьшаем количество потоков: Configuration → Speed
Делается это для того, чтобы вы получили точные показатели по скорости. При парсинге Screaming Frog сильно нагружает ваш сайт и из-за этого вы получаете не правильные данные по скорости. Чтобы этого не произошло мы специально уменьшаем нагрузку на сайт при обходе.
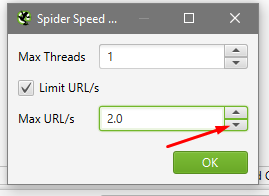
Max Threads — устанавливаем 1
Max URL/s — выставляем в диапазоне от 0.5 до 1
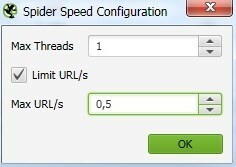
Когда будите менять значение в вкладке Max URL/s нажимайте на стрелочки, так как просто стереть значение и написать не получится, система всё равно оставит 2.0
Переходим к проверке скорости
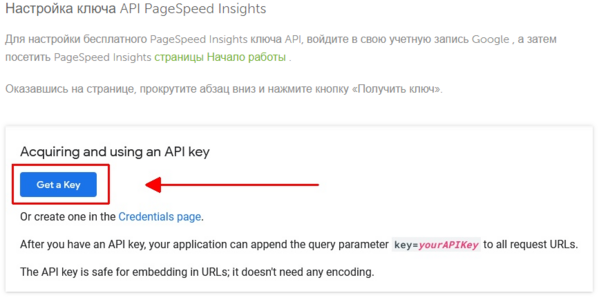
В начале нам нужно получить ключ Page Speed → Для этого переходим сюда
И выполняем все описанные действия для получения ключа
Полученный ключ вставляем в Screaming Frog
Configuration → API Access → PageSpeed Insights
Вставляем ключ и нажимаем «Connect». Если у вас выдаёт ошибку, то выйдите из программы, прогоните проект через программу ещё раз и после этого вставьте ключ ещё раз. У меня сработало.
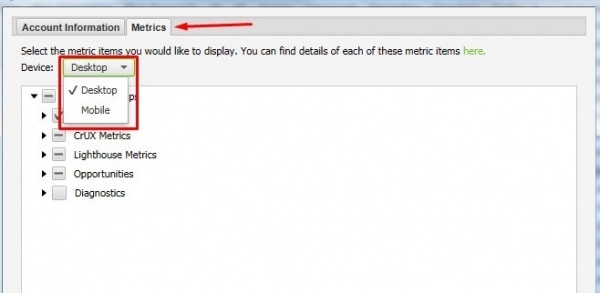
Чтобы закрепить для каких устройств (мобильных или десктопных) мы будем анализировать скорость необходимо перейти во вкладку Metrics и выбрать подходящий для вас вариант.
«После того, как мы подключились к Google PageSpeed нам необходимо ещё раз запустить краулер по сайту, чтобы на этот раз он собрал дополнительно к остальному и скорость загрузки страниц.»
Совет
Не забывайте уменьшать число потоков при обходе сайта, чтобы получать реальную скорость. Иначе вы увеличите нагрузку на сервер и получите неточные данные (чтобы сделать это, сделайте точно так, как написано в гайде и делать постоянно, так как Screaming Frog при новом открытии программы откатывает данные)
После того, как сканирование было успешно пройдено находим раздел «PageSpeed» в правом меню экрана
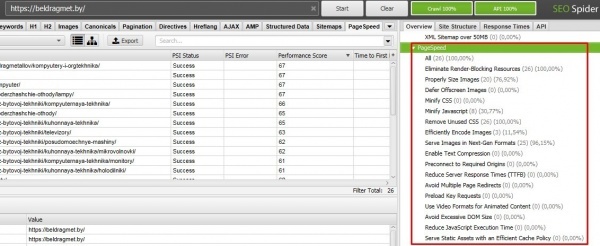
Перевод названий основных показателей, на которые следует обратить внимание
Performance Score – Общая оценка производительности, которую показывает Google PageSpeed. Ранее вы привыкли её видеть в таком виде
First Contentful Paint Time – Необходимое время для появления первого контента (Важный показатель)
Speed Index Time – Скорость загрузки страницы по времени (Важный поазатель)
Time to Interactive – Необходимое время, чтобы пользователь мог взаимодействовать с страницей сайта (Важный показатель)
Total Size Savings – Потенциальный размер страницы, который можно уменьшить
Total Time Savings – Количество времени на которое можно ускорить загрузку страницы
HTML Count – Количество кода html
Image Count – Общее количество изображений
CSS Count – Общее количество кода CSS
JavaScript Count – Общее количество JS скриптов
Total Image Optimization Savings – Общая экономия на оптимизации изображений
Ответы на часто задаваемый вопрос
1. Как сканировать сайт с cookie?
Выбираем пункт в меню Configuration → Spider → Раздел Advanced → Ставим галочку напротив «Allow Cookies»


Есть предложения по поводу статьи?
Напишите ниже, если вы хотите дополнить статью интересными фактами и размышлениями, я с радостью их изучу
Еще статьи по данной теме:

Никогда не уделял особого внимания не хватке оперативной памяти при сканировании сайтов для их анализа, т. к. на основном рабочем компе 32Гб оперативки стоит, а на ноутбуке сейчас у меня всего 8. Если страниц на сайте много и данные для отчета начинают занимать около 2Гб — программа выдает ошибку о нехватке оперативной памяти для дальнейшей работы. Но у меня английский только с «переводчиком» и особо ранее никогда не читал что же там написано в сообщении…
Оказывается прогой можно проходить и сайты не только со 100к страницами на сайте, но и более 1 млн. Для этого нужно только переключить режим хранения базы данных. Перевод:
Обзор
Screaming Frog SEO Spider использует настраиваемый гибридный механизм хранения, который может позволить ему сканировать миллионы URL-адресов. Однако для этого требуется конфигурация памяти и хранилища, а также рекомендуемое оборудование.
По умолчанию SEO Spider будет сканировать с использованием оперативной памяти, а не сохранять на диск. У этого есть преимущества, но он не может ползать в масштабе, без выделения большого количества оперативной памяти.
SEO Spider может быть настроен для хранения на диск с использованием режима хранения базы данных, что позволяет ему сканировать в масштабе, открывать сохраненные обходы намного быстрее и постоянно сохранять данные обхода, чтобы избежать «потерянных обходов», таких как случайный перезапуск машины или ‘очистка’ обхода.
Режим хранения памяти
В стандартном режиме хранения памяти нет установленного количества страниц, которые он может сканировать, это зависит от сложности сайта и спецификаций пользователей. SEO Spider устанавливает максимальную память 1 ГБ для 32-битных и 2 ГБ для 64-битных машин, что позволяет ему сканировать обычно между 10k-100k URL-адресами сайта.
Вы можете увеличить выделение памяти SEO Spider и проникнуть в сотни тысяч URL-адресов исключительно с использованием оперативной памяти. 64-битная машина с 8 ГБ оперативной памяти, как правило, позволит вам сканировать пару сотен тысяч URL-адресов, если выделение памяти будет увеличено.
Режим хранения базы данных
SEO Spider может быть настроен для сохранения данных обхода на диск, что позволяет ему сканировать миллионы URL-адресов. Обходы также автоматически сохраняются в режиме хранения базы данных, и они открываются значительно быстрее через меню ‘Файл> Обходы’.
Мы рекомендуем режим хранения базы данных в качестве конфигурации хранения по умолчанию для всех пользователей с твердотельными накопителями (SSD), так как жесткие диски значительно медленнее при записи и чтении данных. Это можно настроить, выбрав режим хранения базы данных (в разделе ‘Конфигурация> Система> Хранилище’).
В качестве приблизительного руководства SSD и 4 ГБ оперативной памяти, выделенные в режиме хранения базы данных, должны позволить SEO Spider сканировать ок. 2 миллиона URL-адресов. Мы рекомендуем эту конфигурацию в качестве настройки по умолчанию для большинства пользователей изо дня в день.
Для активации этой настройки нужно открыть «Configuration > System > Storage» и сменить Mode с Memory на Database.
В результате почти 0.5 млн. страниц сайта просканировано. По времени конечно это довольно долго занимает, но порой оно стоит того.
Screaming Frog SEO spider — незаменимый помощник SEO-оптимизатора при внутреннем техническом анализе веб-сайтов.
В программе есть множество функций, о которых мы расскажем в этой статье. Также в конце приведем конкретные
примеры, как можно применять разные опции в работе.
Прочитав инструкцию, вы научитесь использовать нужные инструменты, предоставляемые сервисом, для технического
аудита сайтов. В будущем это может пригодиться при выявлении технических ошибок и составлений ТЗ на доработку
сайта.
Для начала рассмотрим по порядку все вкладки интерфейса программы.
Содержание:
- File
- Mode
- Configuration
- Spider
- Crawl
- Extraction
- Limits
- Rendering
- Advanced
- Preferences
- Content
- Robots.txt
- URL Rewriting
- CDNs
- Include/Exclude
- Speed
- User-Agent
- HTTP Header
- Custom
- User Interface
- API Access
- Authentication
- System
- Spider
- Bulk export
- Reports
- Sitemaps
- Visualizations
- Crawl Analysis
- License
- Help
- FAQ
File
Раздел, предназначенный для работы с файлами — загрузкой проектов и конфигураций, планирования будущих проверок
и т.д.
Доступные опции:
- Open — используется для загрузки и открытия файла с ранее проводившимся парсингом.
- Open Recent — похожая функция, но открывает последний проведенный парсинг. То есть, Open можно использовать
для открытия любых файлов, а Open Recent — для последнего файла. - Save — сохранение парсинга.
- Configuration — важный параметр, позволяющий загружать и/или сохранять конфигурации — специальные
предварительно заданные настройки с параметрами парсинга. Подробнее расскажем в разделе про Configuration. - Crawl Recent — используется для повторного парсинга последнего сайта, который ранее проверялся. Удобно, если
нужно быстро провести второй технический аудит. - Scheduling — применяется для планирования будущих парсингов и других задач программы.
- Exit — очевидный выход.
Mode
Устанавливает режим, в котором будет проводиться парсинг. Можно выбрать 1 из 3 опций:
- Spider — режим по-умолчанию. Парсинг будет проводиться по внутренним линкам. Для старта достаточно
ввести в адресную строку приложения нужный домен. - List — парсинг предварительно собранных URL. Сами веб-адреса можно загрузить из файла (опция From a
file), указать вручную (Enter Manually) или воспользоваться картой сайта (Download Sitemap). - SERP Mode — позволяет загрузить мета-данные с сайта и редактировать их, посмотреть, как они будут
отображаться в браузере. Сканирование при этом не проводится.
Configuration
Одна из самых обширных вкладок — в ней расположены основные настройки «паука» и опции по парсингу сайтов. Всего
в ней доступно 13 пунктов подменю. Рассмотрим каждый подробнее.
Spider
В этом подпункте расположены основные настройки парсингов сайта. Включает в себя 5 вкладок: Crawl, Limits,
Rendering, Advanced и Preferences.
Crawl
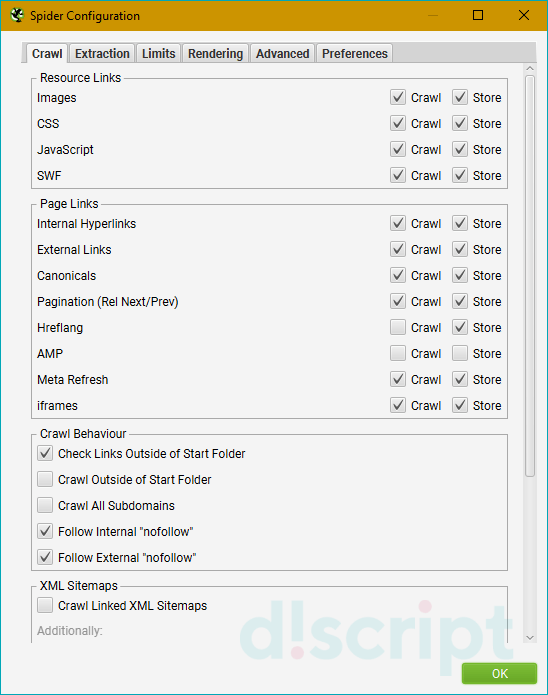
Позволяет выбрать, что именно и как вы хотите парсить. Основные опции вкладки разделены на 4 блока:
Resource Links — определяют, какие файлы и элементы будут парситься. Включают в себя 4 опции:
- Check Images — парсит картинки.
- Check CSS — парсит подключенные к сайту файлы CSS.
- Check JavaScript — парсит JS-скрипты.
- Check SWF — применяется, когда нужно включить в отчет анализ Flash-анимаций.
Page Links — определяют, какие ссылки будут парситься. В этом разделе доступны следующие опции:
- Internal Hyperlinks — добавляет в отчет внутренние ссылки.
- External Links — добавляет в отчет внешние ссылки.
- Canonicals — при сканировании веб-страниц будут анализироваться канонические (canonical) параметры.
- Pagination (Rel Next/Prev) — используется для анализа страниц с атрибутами rel = next и rel = prev.
- Hreflang — извлекает атрибут hreflang.
- AMP — извлекает с сайта и добавляет в отчет AMP-ссылки.
- Meta Refresh — сканирует и сохраняет URL-адреса, содержащиеся в мета-обновлениях
(например, такие: <meta http-equiv=»refresh» content=»5; url=https://example.com/&quot; />.). - iframes — сканирует и сохраняет адреса, содержащиеся в теге <iframe> (например, такие: <iframe
src=»htttps://example.com»>.
Crawl Behaviour — определяет поведение краулера. Доступные опции:
- Check Links Outside of Start Folder — активируйте эту опцию, если хотите получить анализ всех линков,
а не только тех, что расположены в стартовой папке. - Crawl Outside of Start Folder — стандартно программа будет сканировать только указанную пользователем
подпапку. Включение этой опции позволяет сканировать весь сайт. При этом парсинг все равно начнется с
поддомена. - Crawl All Subdomains — активируйте эту опцию, если хотите сканировать все поддомены веб-сайта.
- Follow internal «nofollow» — позволяет сканировать ссылки с тегом nofollow.
- Follow external «nofollow» — по принципу действия почти та же опция, что и предыдущая, но вместо внутренних
ссылок анализирует внешние.
XML Sitemaps — отвечает за сканирование карты сайта. Здесь доступна всего 1 опция и 2 подпункта для неё:
- Crawl Linked XML Sitemap — сканирует карту сайта. Поисковый робот может либо взять ее из файла robots.txt
(опция Auto Discover SML Sitemaps via robots.txt), либо по ручному пути, указанному пользователем — тогда
вам нужно будет выбрать опцию «Crawl These Sitemaps» и указать нужные.
Также все опции имеют 2 опции — «Crawl» и «Store». Первая отвечает за сканирование. Если отключить ее в
каком-либо элементе, он не будет анализироваться пауком. Например, сняв флажок со сканирования ссылок, вы
позволите поисковому роботу обнаруживать их и хранить, но не переходить по ним и не получать коды ответов
сервера.
Поначалу может показаться, что опций слишком много, но главное в освоении этой программы — практика и
умеренность. Выбирайте те, которые могут пригодиться вам в работе, а с остальными познакомитесь по ходу
использования приложения.
Extraction
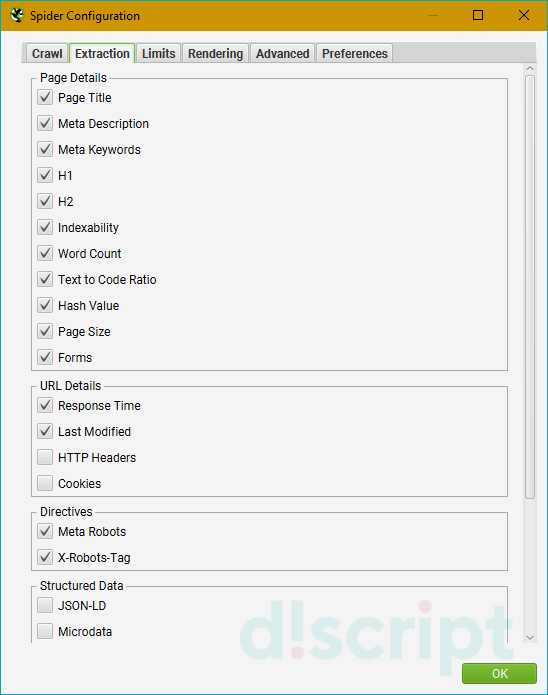
Вкладка отвечает за то, какие элементы будут извлекаться парсером и добавляться в отчет. Разделена на 5 секций:
Page Details
Отвечает за извлечение следующих элементов:
- Page Title — метатег title.
- Meta Description — метатег description.
- Meta Keywords — метатег keywords.
- H1 — заголовок 1 уровня.
- H2 — заголовок 2 уровня.
- Indexability — статус индексируемости.
- Word Count — количество слов.
- Text to Code Ratio — соотношение текста к коду.
- Hash Value — хэш-значение.
- Page Size — размер страницы.
- Forms — формы.
URL details
- Response Time — время в секундах для загрузки URL-адреса.
- Last Modified — чтение из заголовка Last-Modified в HTTP-ответе сервера. Если сервер не предоставит ответ,
поле останется пустым. - HTTP Headers — полные заголовки запросов и ответов HTTP.
- Cookies — файлы cookie, найденные во время сканирования. Будут храниться на нижней вкладке отчета «Cookies
files».
Directives
- Meta Robots — сохраняет директиву мета-роботов.
- X-Robots Tag — добавляет в отчет директиву X-Robots-Tag.
Structred Data
- JSON-LD — используется для извлечения микроразметки JSON-LD.
- Microdata — извлекает микроразметку сайта Microdata.
- RDFa — извлекает RDF микроразметку.
- Schema.org Validation —настраивает проверку микроразметки по механизму Schema Validation.
- Google Rich Result Feature Validation — включает проверку по Google Validation.
- Case-Sensitive — активирует проверку по Case-Sensitive методу.
HTML
- Store HTML — позволяет хранить статический HTML каждого URL, просканированного парсером. Полезно, если нужно
изучить его до того, как будет подключен JavaScript. - Store Rendered HTML — похожая опция, но хранится уже отображенный HTML после обработки JS.
Limits
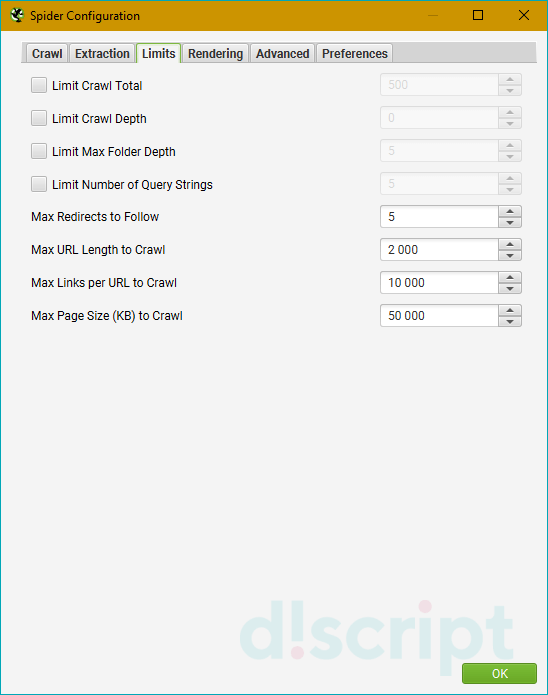
Применяется для установки лимитов парсинга. Содержит пункты:
- Limit Crawl Total — задает общий лимит веб-страниц для сканирования. С помощью этой опции можно установить
точное количество страниц, которые будут выгружены в отчет. - Limit Crawl Depth — определяет, насколько глубоко может зайти поисковый робот во время сканирования.
Например, если указать число «0», краулер просканирует только указанный документ и остановится. Если указать
«1», паук проанализирует документ, перейдет по ссылкам из него и остановится на следующей странице. Указав
«2», робот продвинется на 3 страницы (первичный документ > переход на следующую страницу по ссылкам >
переход на последующую веб-страницу по ссылкам из предыдущей). - Limit Max Folder Depth — более специфический параметр, в котором можно установить глубину до конкретной
папки. Работает по принципу, схожему с предыдущим пунктом, только указывать нужно конкретные папки. Пример:
URL site.com/folder-1/folder-2/folder-3. Где цифры — глубина проверки. - Limit Number of Query Strings — задает глубину парсинга для страниц с параметрами. Может быть полезно, если
у вас на статической странице есть пара фильтров, которые могут создать большое количество динамических
веб-страниц. Если не задать этот лимит, парсер будет сканировать все страницы, что увеличит время проверки,
при этом полезной информации вы получите по-минимуму. - Max Redirects to Follow — используется, чтобы задать максимальное количество редиректов с 1 веб-адреса.
- Max URL Length to Crawl — устанавливает максимальную длину URL в символах.
- Max Links per URL to Crawl — определяет максимальное количество ссылок в сканируемых страницах. Например,
если на странице 5 ссылок, но параметр установлен на «4», то робот проанализирует 4 ссылки и добавит их в
отчет. - Max Page Size (KB) to Crawl — максимальный размер страницы для сканирования, указывается в килобайтах.
Rendering
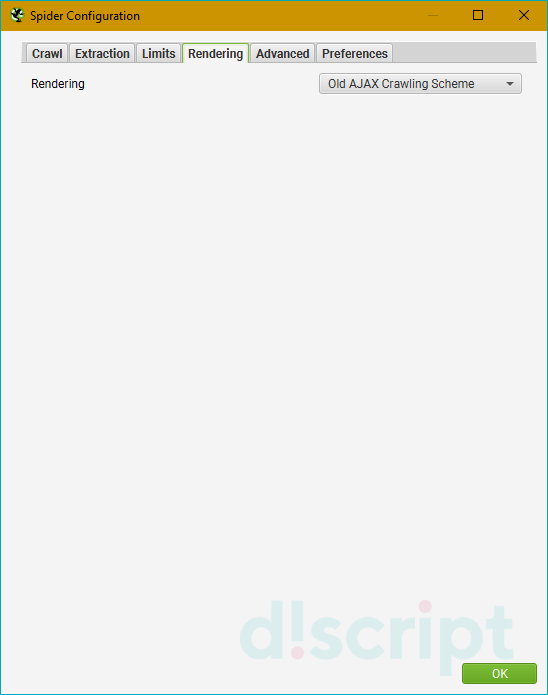
Эта вкладка понадобится вам, если вы включили сканирование JavaScript в отчет и хотите настроить параметры
рендеринга. На выбор доступно 3 режима:
- Text Only — анализ только текста страницы, без учета JS/AJAX.
- Old AJAX Crawling Scheme — использование устаревшей схемы сканирования AJAX.
- JavaScript — учитывает JS-скрипты при рендеринге.
Последний режим также имеет несколько дополнительных опций:
- Enable Rendered Page Screen Shots — позволяет включить сохранение скриншотов анализируемых страниц в папку
на вашем компьютере. - AJAX Timeout (secs) — устанавливает лимиты таймаута.
- Window Size — выбирает размер окна. На выбор их представлено много, от больших экранов (Large Desktop) до
iPhone старых и новых версий. - Sample — показывает пример окна, выбранный в пункте Window Size.
- Rotate — позволяет повернуть демонстрацию окна из Sample.
Advanced
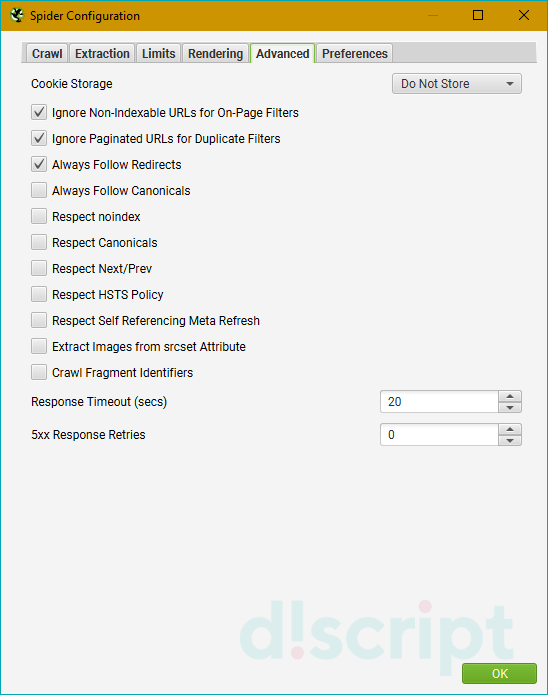
Позволяет настроить продвинутые опции парсинга. Доступные опции:
- Cookie Storage — выбирает, где будут храниться куки-файлы во время сканирования.
- Ignore Paignated URL for Duplicate Filters
- Always Follow Redirects — разрешает поисковому роботу всегда следовать по редиректам вплоть до финальной
страницы с учетом всех ответов сервера. - Always Follow Canonicals — позволяет краулеру учитывать все атрибуты canonical. Может пригодиться, если вы
несколько раз переезжали и еще не навели порядок с этим атрибутом. - Respect noindex — запрещает сканировать страницы, обернутые в тег noindex.
- Respect Canonical — исключает канонические страницы из отчета. Полезная опция, если нужно убрать дубли по
метаданным. - Respect Next/Prev — исключает страницы с rel=”next/prev” из отчета. Так же, как и предыдущий пункт,
позволяет убрать дубли по метаданным. - Respect HSTS Policy — указывает поисковому боту, что все запросы должны выполняться через протокол HTTPS.
- Respect Self Referencing Meta Refresh — позволяет учитывать принудительную переадресацию на ту же страницу
по метатегу Refresh. - Extract Images from img srcset Attribute — извлекает и добавляет в отчет изображения из атрибута srscet,
который прописывается в теге .
. - Crawl Fragment Identifiers — позволяет сканировать URL-адреса с хэш-фрагментами и считать их за уникальные
URL. - Response Timeout — устанавливает время ожидания ответа страницы перед тем, как краулер перейдет к анализу
следующего URL. Для медленных сайтов рекомендуем устанавливать большее число. - 5xx Response Retries — определяет, сколько раз парсер будет пытаться проанализировать страницы с ответом
сервера 5хх. Например, если установлен параметр «5», то поисковый робот будет посылать запросы веб-странице
5 раз, после чего остановится.
Preferences
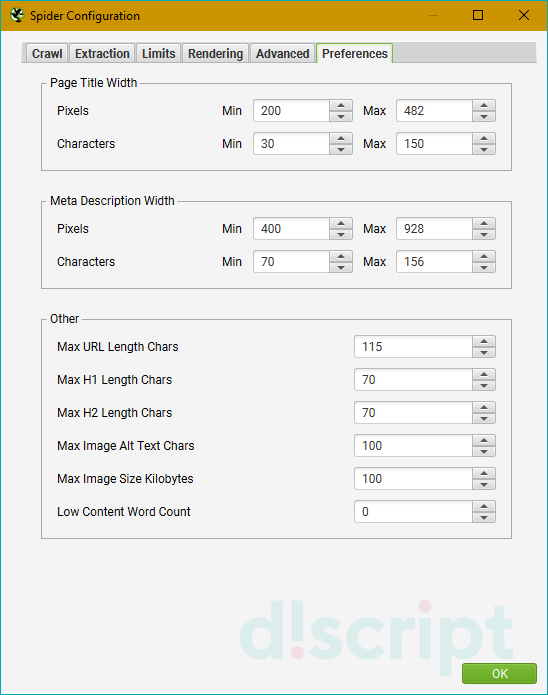
Позволяет задать предпочтения для сканируемых мета-тегов и тегов (title, description, URL, H1-H2, alt и размеры
картинок). Если размеры будут не соответствовать заданным в этой вкладке, Screaming Frog об этом сообщит.
Доступные опции:
- Page Title Width — ширина заголовка страницы. Можно указать в пикселях или символах.
- Meta Description Width — аналогично предыдущему пункту, только вместо заголовка указывается метатег title.
- Other — все остальные пункты, включая URL, заголовки 1 и 2 уровней, изображения и атрибуты alt к ним.
Не обязательная вкладка, в ней можно оставить параметры по умолчанию.
Content
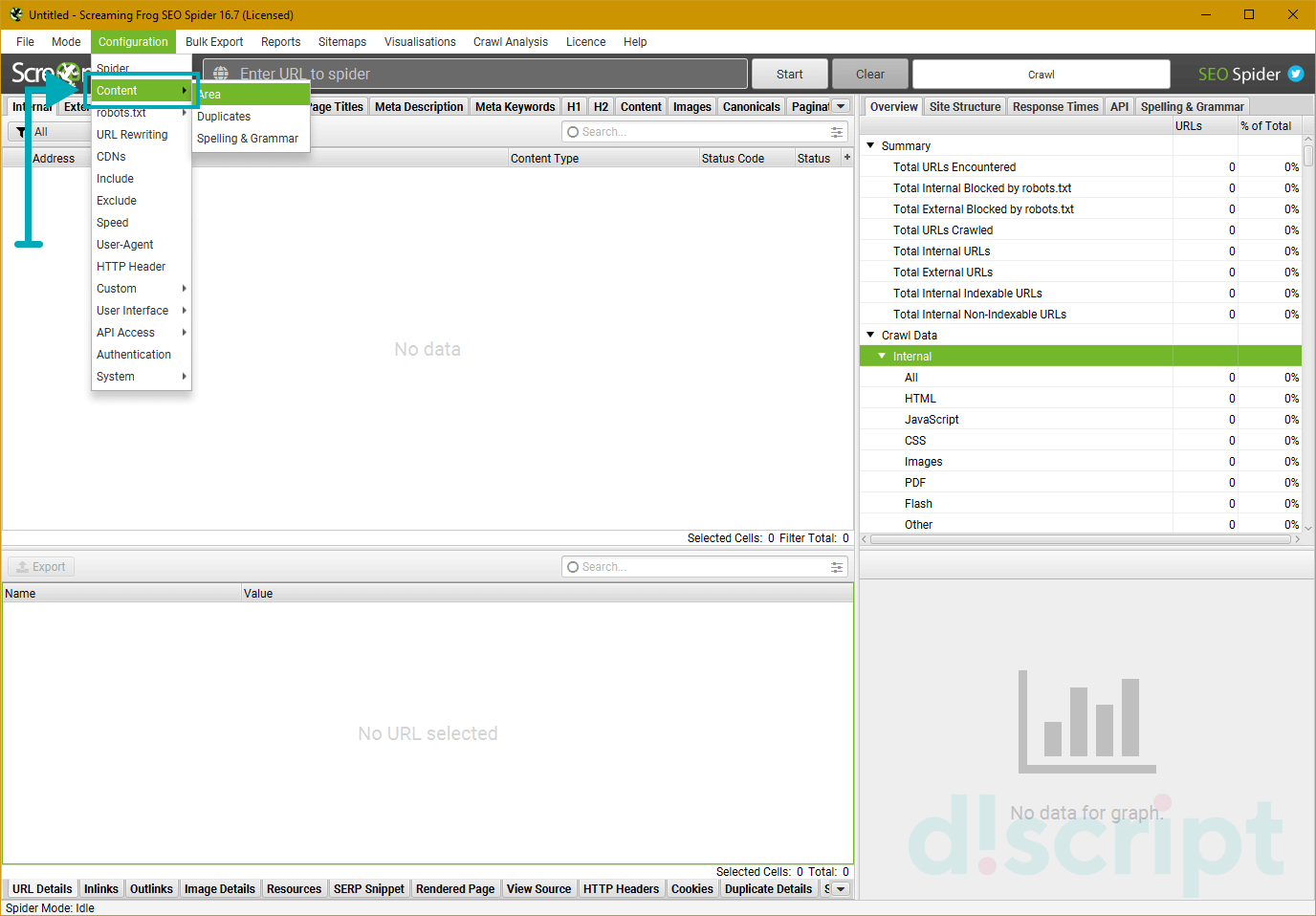
Подпункт меню, отвечающий за поведение краулера при сканировании контента. Имеет 3 вкладки:
- Area — отвечает за область контента, которая будет учитываться при сканировании. Используйте эту
функцию, если хотите сфокусировать анализ на какой-либо конкретной области страницы.
- Duplications — позволяет найти точные дубликаты страниц или веб-страницы, контент на которых
совпадает в некоторых местах. Помогает в поиске дублей.
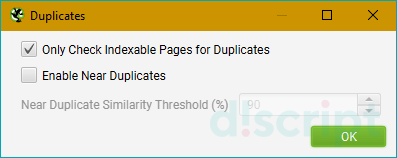
- Spelling & Grammar — проверяет правописание и грамматику. Поддерживает 39 языков, включая
русский. По-умолчанию эта функция отключена.
Robots.txt
Позволяет определить, каким правилам должен следовать краулер при парсинге. Имеет 2 вкладки: Settings и Custom.
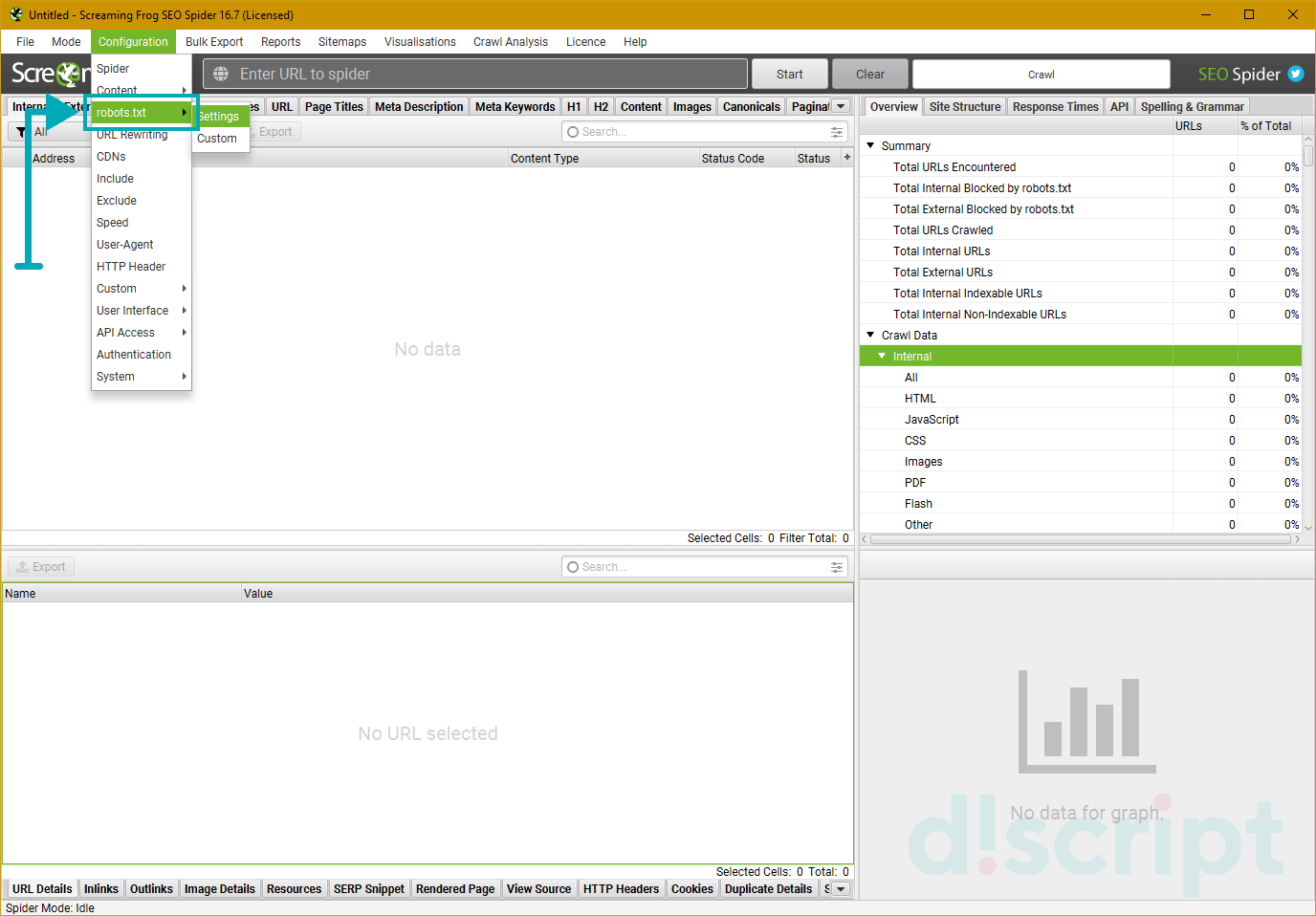
Settings — используется для настройки парсинга с учетом (или игнорированием) правил Robots.txt. На выбор
предоставляется 3 режима:
- Respect robots.txt — парсер будет полностью следовать правилам, прописанным в файле для роботов, и
учитывать только те папки и файлы, которые были открыты. - Ignore robots.txt — позволяет игнорировать правила, прописанные в robots. В таком случае, в отчет
попадут все папки и файлы сайта. - Ignore robots.txt but report status — игнорирует правила, но выводит статус страницы (индексируемая
или закрытая от индексации).
Также можно указать, хотите ли вы видеть в итоговом отчете внутренние и внешние ссылки, закрытые от индексации.
Эти опции будут работать, только если вы выбрали 1-й режим парсинга (respect robots.txt).
Custom — позволяет вручную отредактировать robots.txt для текущего парсинга. Удобно, если нужно добавить
или исключить только конкретные папки, или добавить дополнительные правила для поддоменов сайта. Также с помощью
этого режима можно сформировать собственный файл robots.txt, проверить его и потом при необходимости загрузить
на веб-сайт.
Чтобы добавить собственный файл, нажмите кнопку «Add» в нижнем меню. Для проверки используйте кнопку «Test»,
расположенную справа внизу.
URL Rewriting
Используется для перезаписи сканируемых URL во время парсинга. Если вам надо изменить какие-либо URL во время
работы, этот раздел может пригодиться.
Имеет 4 вкладки:
- Remove Parameters — позволяет указать параметры, которые будут удаляться из URL при анализе сайта.
Также можно исключить сразу все, если поставить галочку в чекбоксе «Remove all».
- Regex Replace — позволяет изменить сканируемые URL с использованием регулярных выражений.
Применяется, например, для изменения ссылок с HTTP на HTTPS.
- Options — здесь можно активировать перезапись прописных URL в строчные.
- Test — позволяет сразу увидеть, как будет выглядеть URL при использовании опции Regex Replace.
CDNs
В этой вкладке можно включать дополнительные домены и папки в процесс парсинга. Они будут считаться за
внутренние ссылки. Также можно указать только конкретные папки для сканирования. Указывать нужные папки и файлы
необходимо во вкладке «Config»:
Последняя вкладка «Test» позволяет увидеть, как будут изменяться URL. Итог будет выводиться в виде параметра
Internal или External. Если, например, в результате показывает External, то ссылка будет считаться внешней:
Include/Exclude
Используется для включения или исключения конкретных папок, ссылок, файлов или страниц при парсинге.
Например, во вкладке Exclude будут указаны исключения парсинга для всех папок, кроме указанных.
К примеру, вы можете запретить парсинг конкретного домена. Проверить результат можно во вкладке Test — вместо
указанного URL там будет указано, что этот веб-адрес был исключен из парсинга. Также эта опция поддерживает
регулярные выражения.
Speed
Используется для установки лимитов на количество потоков и одновременно сканируемых адресов. Меняйте параметры
аккуратно — если установить слишком низкие лимиты, поискового бота могут забанить, даже если скорость парсинга
существенно повысится.
User-Agent
В этой вкладке можно задать тип поискового бота, который будет использоваться для сканирования. Может
пригодиться, если, например, в настройках сайта запрещена индексация Yandex-ботам.
Также можно указать версии ботов для смартфонов, чтобы найти технические ошибки в мобильных версиях.
HTTP Header
Позволяет указать реакции краулера на HTTP-заголовки, если таковые будут найдены на сайте. Можно указать, будет
ли учитываться контент и cookie-файлы, как именно они будут обрабатываться и т.д.
Custom
Включает в себя 2 вкладки: Search и Extraction. В них можно указать с помощью собственного кода дополнительные
правила для парсинга. Например, если у вас на какой-то странице используется тег <i> вместо
тега <em>, вы можете указать это в Custom Search.
Во вкладке Extraction можно указывать пользовательские настройки для извлечения любой информации из HTML-кода.
User Interface
Довольно простой раздел, с помощью которого можно сбросить сортировку столбцов и вкладок программы. Также в нем
можно изменить тему со светлой на темную. На этом функции заканчиваются.
API Access
Позволяет подключить сторонние сервисы типа Google Analytics или Majestic. Вам потребуется войти в свою учетную
запись в приложении. Для каждого варианта будут свои отдельные настройки по выгрузки данных, которые будут
различаться от приложения к приложению.
Authentication
Если сайт будет запрашивать аутентификацию, вы можете указать настройки для них тут. Во вкладке есть 2 подпункта
— Standards Based и Forms Based. Стандартно используется первый вариант — если придет запрос, он отобразится в
соответствующем окне в программном обеспечении.
Если вам нужен встроенный браузер для указания данных, используйте опцию Forms Based. С ее помощью можно,
например, пройти капчу, указав логин и пароль.
System
Позволяет задать настройки самой программе. Насчитывает 5 пунктов:
- Memory — указание лимитов оперативной памяти для парсинга. Стандартно стоит 2ГБ.
- Storage — выбирает режим сохранения информации. Ее можно хранить либо в оперативной памяти, либо в
указанной пользователем папки. - Proxy — при использовании позволяет указать данные подключенного прокси-сервера для парсинга.
- Embedded Browser — включает или выключает встроенный браузер приложения.
- Language — выбор языка. Русский не поддерживается.
Bulk Export
Здесь можно настроить массовый экспорт данных из отчетов. В целом, этот раздел можно использовать, чтобы
вытягивать нужную информацию и затем составить ТЗ для доработок сайта.
Доступные подпункты меню экспорта:
- Queued URLs — все ссылки, которые были обнаружены и находятся в очереди на сканирование.
- Пункт Links
- All Inlinks — все входящие ссылки на URL-адреса, зафиксированные поисковым роботом во время
парсинга. - All Outlinks — все исходящие ссылки.
- All Anchor Text — экспорт анкоров со всех ссылок
- External Links — все внешние ссылки
- All Inlinks — все входящие ссылки на URL-адреса, зафиксированные поисковым роботом во время
- Пункт Web
- Screenshots — все сделанные скриншоты.
- All Page Source — статистический или визуализированный (rendered) HTML код просканированных страниц.
- All HTTP Headers
- All Cookies
- Path Type — позволяет экспортировать ссылки определенного типа со страницами, к которым они привязаны. Можно
указать абсолютные, относительные, корневые и путевые (path-relative) ссылки. - Security — страницы сайта с потенциально опасным контентом. Например, таким образом можно организовать
экспорт ссылок, ведущие на страницы сайта с небезопасными линками. - Response Codes — все страницы в зависимости от нужного кода ответа. Например, так можно выгрузить URL,
ведущие на страницы с ошибкой 404. - Content — весь контент. Может пригодиться, если нужно организовать экспорт дубликатов и составления
последующего ТЗ на их удаление. - All Images — выгрузка картинок без атрибута alt, слишком тяжелых изображений.
- Canonicals — все страницы-первоисточники.
- Directives — все директивы.
- AMP — все линки на AMP-контент.
- Structured Data — все ссылки из фильтра структурированных данных.
- Sitemaps — все страницы в карте сайта, неиндексируемые страницы в карте сайта и т.п.
- Custom Search — выгрузка всех элементов из пользовательского поиска.
- Custom Extraction — все элементы, заранее настроенные по фильтру пользовательского извлечения.
Reports
Вкладка, отвечающая за отчеты. Доступные подпункты меню:
- Crawl Overview — содержит всю сводку сканирования, включая обнаруженные URL-адреса, заблокированные файлом
robots.txt, количество просканированных ссылок, типы контента, коды ответов и т.д. - Redirects — описывает найденные перенаправления и URL-адреса, через которые удалось найти редиректы. Также
здесь отображаются канонические цепочки перенаправлений и канонические символы, указывается количество
переходов и цикличность (если она присутствует). - Canonicals — в этом разделе показываются ошибки и проблемы, найденные с каноническими цепочками или
элементами. В ответе канонических цепочек отображаются все URL, имеющие больше 2 канонических линков. - Pagination — отображает ошибки и проблемы, связанные с атрибутами rel=next/prev, которые применяются для
обозначения содержимого, разбитого на страницы. - Hreflang — сообщает о возможных проблемах с атрибутами hreflang, например: некорректных ответах серверов,
страниц без гиперссылок, разных кодах языка на 1 веб-странице и т.п. - Insecure Content — содержит HTTPS URL-адреса, на которых были обнаружены небезопасные элементы. Например,
внутренние ссылки без SSL-сертификата. - SERP summary — позволяет быстро выгрузить URL-адреса, title и description страниц. Их длина будет
указываться в символах, а ширина в пикселях. - Orphan Pages — отображает список потерянных страниц, собранных при помощи Google Analytics API и Search
Console, а также XML Sitemap, которые не были сопоставлены с URL, обнаруженными во время сканирования. - Structured Data — показывает отчет об обнаруженных ошибках валидации микроразметки веб-страниц.
- PageSpeed — содержит отчет о скорости загрузки каждой страницы. Работает, только если была подключена
интеграция PageSpeed Insights. - HTTP Headers — содержит отчет по заголовкам HTTP, обнаруженных во время сканирования. Показывает каждый
уникальный заголовок и количество URL, ответивших этим заголовком. - Cookies — содержит отчет о файлах cookie, обнаруженных во время сканирования, с указанием имени, домена,
срока действия, безопасности и значения HttpOnly.
Sitemaps
Через этот пункт меню можно создавать свои карты сайта в формате XML. На выбор предлагается 2 пункта:
- XML Sitemap — генерация XML-карты сайта
- Images Sitemap — генерация XML-карты сайта для определенного изображения.
После выбора нужного варианта откроется всплывающее окно, в котором можно будет задать нужные параметры —
например, создание карты для закрытых от индексации страниц, URL, разбитых на пагинацию и т.п.
Страница имеет 6 вкладок.
Pages — отвечает за тип страниц, которые будут включены в карту сайта.
- Noindex Pages — закрытые от индексации страницы.
- Canonicalised — каноникализированные страницы, говоря простым языком с атрибутом rel=canonical.
- Paginated URLs — страницы пагинации.
- PDFs — PDF-файлы.
- No response — не отвечающие страницы.
- Blocked by robots.txt — страницы, закрытые от индексации файлом robots.txt.
- 2xx — страницы с кодом ответа сервера 2хх (работающие страницы).
- 3xx — страницы с редиректами.
- 4xx — битые ссылки.
- 5xx — страницы с проблемами сервера при загрузке.
Last Modified — необязательная опция, позволяет выставить дату последнего обновления карты. Можно
установить использование тега lastmod, либо применять ответ сервера при создании карты. Также возможно ручное
указание даты.
Priority — используется для выставления приоритета ссылки в зависимости от глубины страницы.
Change Frequency — используется для выставления вероятной частоты обновления веб-страниц с помощью тега
changefreq. Рассчитать тег можно либо по последнему измененному заголовку, либо по глубине страницы.
Images — позволяет добавить картинки в карту сайта, включая закрытые от индексации картинки или
изображения с конкретным числом входящих ссылок.
Hreflang — отвечает за использование или не использование атрибута hreflang в карте сайта.
Visualisations
С помощью этого пункта меню можно получить визуализированную структуру сайта, которая будет отображаться в
программе.
Пользователю на выбор предоставляется несколько вариантов визуализации, которые отображаются во встроенном
браузере — это повышает эффективность работы с ними. Например, их можно масштабировать прямо в Screaming Frog.
Доступные режимы:
- Crawl Tree Graph — визуализирует структуру сайта на основании сканирования в виде дерева каталогов.
- Directory Tree Graph — показывает все каталоги, найденные после сканирования. В отличие от
первого режима, показывает даже папки, закрытые от индексации - Force Directed Crawl-Diagram — похожий вариант на 2 других, только оформленный в виде кружков.
- Force Directed Tree-Diagram — похожий, но более масштабный способ визуализации.
- Inlink Anchor Text Word Cloud — визуализирует анкоры внутренних ссылок. Каждая страница отображается
по отдельности. Помогает в анализе анкоров. - Body Text Word Cloud — визуализирует плотность слов на веб-странице. Помогает понять, какие слова
встречаются чаще других и нет ли переспама ими на странице.
Crawl Analysis
Помогает проанализировать и включить в отчет данные, которые не попадают в основную статистику в ходе
сканирования. Это могут быть параметры Link Score, Orphan URLs (потерянные URL) и , и т.п.
Дополнительное сканирование запускается после основного парсинга. Во вкладке Configure можно настроить,
какие данные будут добавляться в отчет.
Возможные опции:
- Link Score — присваивает оценки всем внутренним линкам веб-сайта.
- Pagination — показывает неправильно настроенные пагинации и страницы, которые были найдены только благодаря
атрибуту rel next/prev. - Hreflang — отображает URL с атрибутом hreflang без гиперссылок.
- AMP — показывает страницы без тегов HTML amp.
- Sitemaps — вносит в отчет неидексируемые страницы, найденные в карте сайта, дубли URL в нескольких sitemap,
потерянные страницы. - Analytics — потерянные страницы, найденные в аналитике.
- Search Console — потерянные страницы, найденные в консоли веб-мастера.
Licence
Раздел, в котором можно купить лицензию и ввести лицензионный ключ.
Help
Пункт меню, в котором собрана информация, полезная пользователю.
Доступные подпункты:
- User Guide — супер-подробное руководство по работе с программой.
- FAQ — часто задаваемые вопросы.
- Support — техническая поддержка.
- Feedback — предложения по работе или новым функциям.
- Check for Updates — ручная проверка на наличие обновлений.
- Auto Check for Updates — автоматическая проверка на наличие обновлений.
- Debug — сообщить о каком-либо баге разработчику.
- About — краткая информация о программе.
FAQ
Как включить русский язык?
К сожалению, официально это сделать никак нельзя — программа не поддерживает русскоязычную локализацию.
Но вы можете поискать русификаторы в интернете. Мы не рекомендуем их использовать. Помните, что вы устанавливаете на свой страх и риск.
Как посмотреть структуру сайта?
Воспользуйтесь вкладкой «Visualisations» — в ней наглядно можно будет посмотреть примерную
структуру сайта, основываясь на отчете. Программа предлагает несколько видов графиков, например,
древовидный и в виде «кружков».
Как включить rendering?
Воспользуйтесь следующим путем: configuration > spider > rendering > выбрать нужный пункт
(например, Rendered Page Screenshots).
Как игнорировать Robots.txt?
Во вкладке configuration перейдите в подпункт меню robots.txt и выберите режим «Ignore robots.txt».
Как ограничить скорость сканирования?
Если вы хотите ограничить скорость сканирования, рекомендуем воспользоваться пунктом Limits во вкладке
Configuration > Spider. Также можно выделить меньше RAM для программы — тогда сканирование будет идти
медленнее.
Хорошо, когда у бизнеса есть свой сайт. А ещё лучше – когда он стабильно работает и попадает на высокие позиции в поисковой выдаче. Как и любой технически сложной вещи сайту требуются регулярные проверки и диагностики. Самый простой способ это сделать — поручить поддержку и обслуживание сайта профессионалам. Но некоторые базовые вещи можно проверить самостоятельно с помощью всего одной программы. Называется она Screaming Frog SEO Spider. Утилита позволит найти конкретные проблемы сайта, требующие решения и исправления. А дальше починить ресурс самостоятельно или составить подробное ТЗ для стороннего исполнителя.
Предупреждаем — если вы опытный SEO-специалист, то скорее всего ничего нового для себя здесь не найдёте. Материал предназначен для людей, которые не разбираются в технических тонкостях работы сайтов и хотят получит хотя бы примерное представление о состоянии их ресурса.
Официальный сайт разработчиков — https://www.screamingfrog.co.uk/
Для владельцев маленьких сайтов достаточно бесплатной версии, в которой стоит ограничение проверки на 500 страниц и недоступны настройки работы сервиса.
Первые шаги
Прежде чем приступить к подробным инструкциям нужно понять, а что собственно Screaming Frog SEO Spider делает? Больше всего это похоже на работу поисковых роботов, сервис обходит доступные страницы сайта и собирает о них информацию.
Сбор информации
Первый шаг очень простой: «Нажми на кнопку, получишь результат»

В специальном поле нужно указать адрес сайта и запустить процесс.
Программа немедленно начнёт обходить ресурс. Внизу появятся ссылки на страницы сайта, картинки и другие составляющие, а справа сверху можно наблюдать прогресс действия.

Проверка состояния страниц
Итак, сбор закончен, куда смотреть? Первым делом обратите внимание на коды ответа страниц сайта. Для удобства рекомендуем их отсортировать.
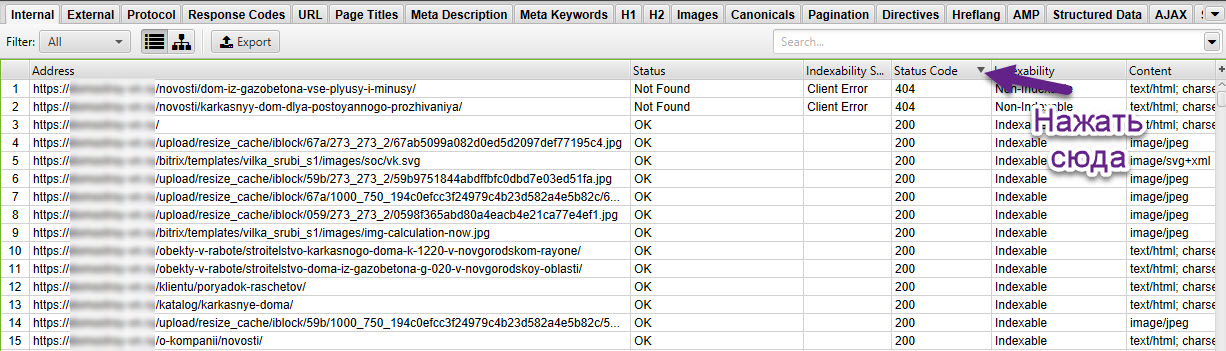
О чём говорят эти цифры? Разберем самые частые варианты:
200 – OK, успешный запрос. Это значит, что со страницей всё хорошо, она работает так, как надо;
404 – Not found (Не найдено). Сервис не смог найти по ссылке страницу. От таких «битых» ссылок необходимо избавляться, поисковые системы относятся к ним негативно. Тут же в программе можно найти, где 404 ссылка находится.

Чтобы избавиться от проблемы, нужно на странице с «битой» ссылкой её найти и прописать правильно или удалить.
301 — Moved Permanently (Перемещено навсегда). Этот код говорит нам, что страница по этому адресу перемещена и адрес необходимо обновить. Найти нужные страницы с 301 ссылкой можно так же, как и с 404.
502 — Bad Gateway. Появление такого кода означает, что с сервером, на котором находится сайт, возникли какие-то проблемы. В таком случае сайт может быть недоступен для посетителей. Иногда такой код может появляться, если на сайте стоит защита от роботов. Чтобы обойти ограничение нужно сменить поискового агента программы:
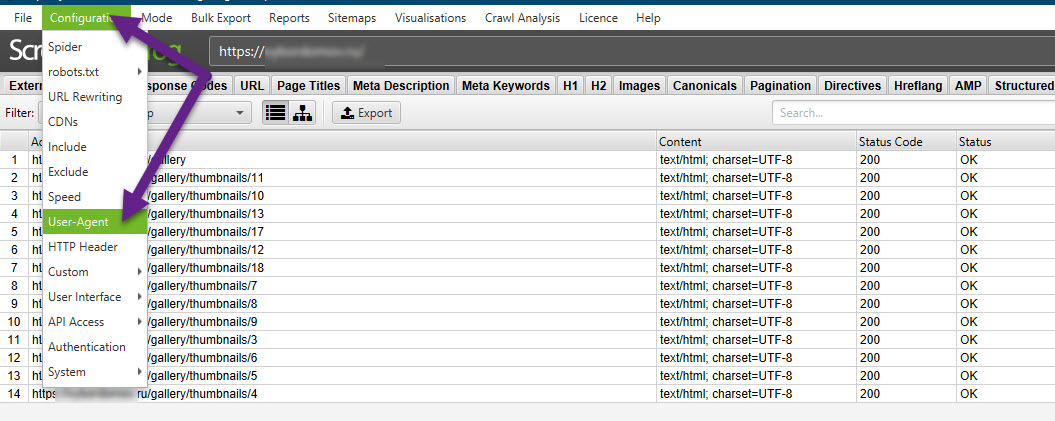
Например на бота Яндекс
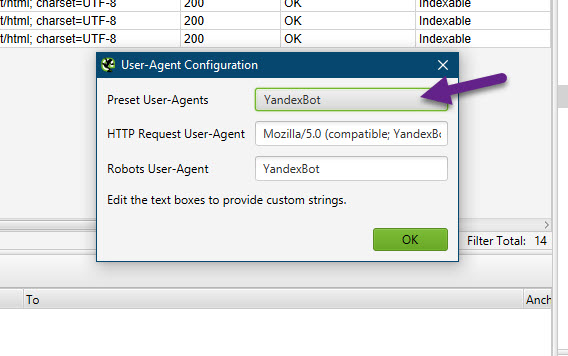
Существует большое количество других кодов ответа, но в подавляющем большинстве случаев вы увидите именно эти 4 варианта.
Проверка заполнения метатегов
Простым языком метатеги – данные о странице, которые учитываются поисковиками и которые будут показаны пользователю в выдаче. Два главных тега: title и description.

В рамках данной статьи мы не будем останавливаться на том, как правильно их заполнять. Самое главное то, что они должны быть на каждой странице сайта, которая попадёт в поисковые системы.
Как проверить наличие метатегов с помощью Screaming Frog SEO Spider?
Достаточно просто переключиться на одноимённые вкладки:

В списке будут указаны страницы и их метатеги. Если поля Meta Description 1 и Title 1 пустые — значит тегов нет и их нужно заполнить. А во вкладке Length показана длина тега в символах и пикселях, что позволяет выявить слишком длинные или слишком короткие и в дальнейшем оптимизировать.
Sitemap – это XML файл, содержащий для поисковых роботов информацию на сайте. Обычно его можно найти по адресу САЙТ.ru/sitemap.xml.
Актуальность информации, содержащейся в sitemap очень важна. Именно по ней ориентируются и индексируют страницы поисковые роботы. Поэтому содержание sitemap должно соответствовать реальному положению вещей на сайте. Screaming Frog SEO Spider поможет быстро и наглядно проверить sitemap и найти ошибки и «битые» ссылки.
Для этого в настройках нужно указать ссылку на sitemap. Сделать это можно в настройках сбора:

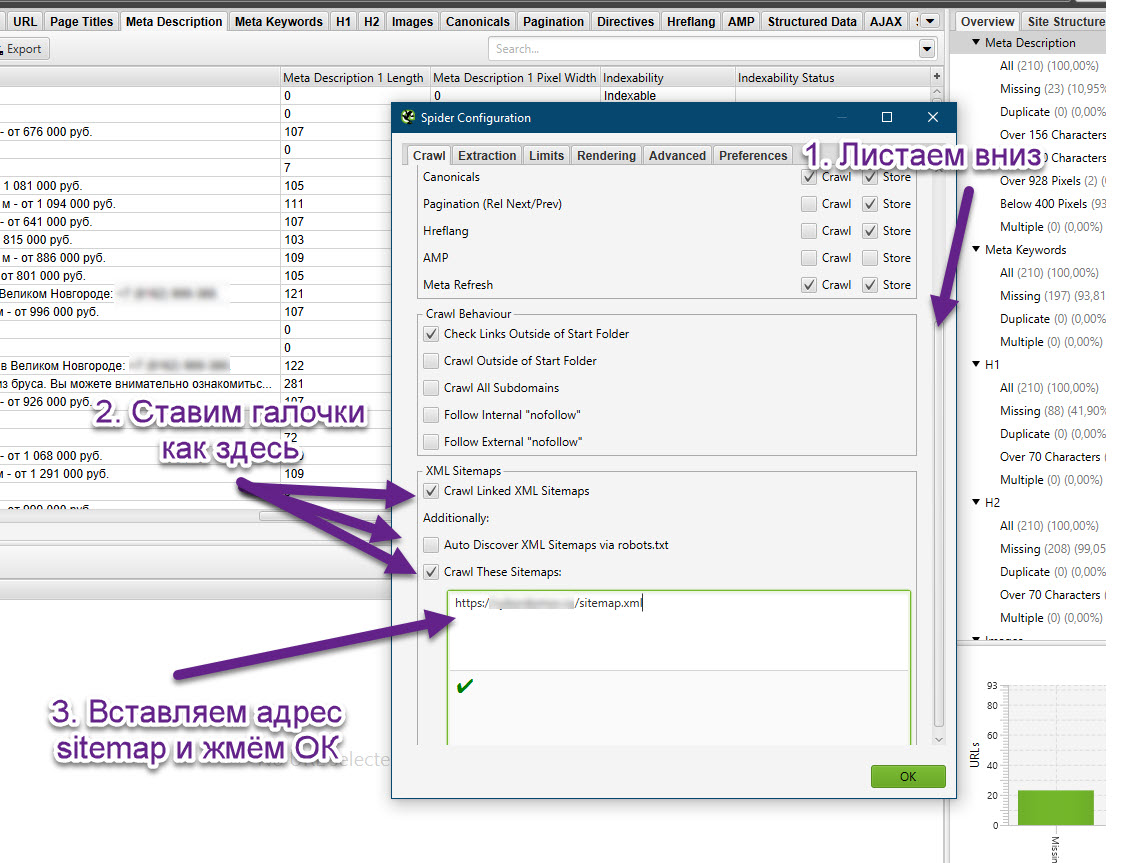
А дальше запускаем сбор по алгоритму из начала статьи. По его окончанию необходимо включить Crawl Analysis, который проверит sitemap.

Сбор информации закончен, осталось лишь в ней разобраться. Для этого правое поле программы необходимо промотать вниз до вкладки sitemap.

Нажав на вкладку All можно увидеть состояние ссылок в sitemap (в том числе битые) по тому же принципу, который описывался во второй части статьи. Ещё один важный момент – вкладка URLs not in Sitemap. Здесь находятся ссылки, которых нет в sitemap. Очевидно, что если в списке оказались важные ссылки, которые должны видеть поисковики, то их нужно как можно скорее добавить в карту сайта.
В рамках данного материала мы описали лишь малую часть функционала Screaming Frog SEO Spider. Но этого достаточно, чтобы иметь хотя бы базовое представление о состоянии сайта. И что самое удобное — это не займёт много времени, сторонних сервисов и не требует специальных знаний.
Attention! Много букв! Много скринов! Много смысла!
Доброго времени суток, друзья. Сегодня я хочу рассказать вам о настройке Screaming Frog (он же SF, он же краулер, он же паук, он же парсер — сразу определимся со всеми синонимами, ок?).
SF — очень полезная программа для анализа внутрянки сайтов. С помощью этой утилиты можно быстро выцепить технические косяки сайта, чтобы составить грамотное ТЗ на доработку. Но чтобы увидеть проблему, надо правильно настроить краулера, верно? Об этом мы сегодня с вами и поговорим.
- Примечание автора: сразу скажу — программа имеет много вкладок и настроек, которые по сути не нужны рядовому пользователю, потому я подробно опишу только наиболее важные моменты, а второстепенные пройдем вскользь… хотя кого я обманываю, когда это у меня были статьи меньше 30 к символов? *Зануда mode on*
- Примечание автора 2: при написании статьи я пользовался дополнительными материалами в виде официального мануала от разработчиков. Если что, почитать его можно тут https://www.screamingfrog.co.uk/seo-spider/user-guide/. Не пугайтесь английского, Google-переводчик в помощь — вполне себе сносная адаптация получается.
- Примечание автора 3: я люблю оставлять примечания…
- File
- Configuration
- Spider — настройки парсинга сайта
- Robots.txt — определяем каким правилам следовать при парсинге
- URL Rewriting — функция перезаписи URL
- CDNs — парсим поддомены
- Include/Exclude — сканирование/удаление определенных папок
- Speed — регулируем скорость парсинга сайта
- User-Agent — выбираем под кого маскируемся
- HTTP Header — настройка реагирования на разные http-заголовки
- Custom — дополнительные настройки поиска
- User Interface — обнуление настроек для колонок таблицы
- API Access — интеграция с разными сервисами
- Authentification — настройки аутентификации
- System — внутренние настройки самой программы
- Mode
- Bulk export
- Reports
- Sitemaps
- Visualisations
- Crawl Analysis
- License
- Help
Настройка Screaming Frog по шагам
Рассмотрим основное меню программы, для того чтобы понимать что где лежит и что за что отвечает (тавтология… Вова может в копирайт!).

Верхнее меню — управление парсингом, выгрузкой и многое другое
File
Из названия понятно, что это работа с файлами программы (загрузка проектов, конфиги, планирование задач — что-то вроде того).

- Open — открыть файл с уже проведенным парсингом.
- Open Recent — открыть последний парсинг (если вы его сохраняли отдельным файлом).
- Save — собственно, сохранить парсинг.
- Configuration — загрузка/сохранение специальных настроек парсинга вроде выведения дополнительных параметров проверки и т.д. (про то, как задавать эти настройки, я далее расскажу подробнее).
- Crawl Recent — повторно парсить один из последних сайтов, который уже проверялся в этой программе.
- Scheduling — отложенное планирование задач для программы… ни разу не пользовался этой опцией…стыдно.
- Exit — призвать к ответу Друзя… нет, ну серьезно,тут все очевидно.

Configuration
Один из самых интересных и важных пунктов меню, тут мы задаем настройки парсинга.

Ох, сейчас будет сложно — у многих пунктов есть подпункты, у этих подпунктов всплывающие окна с вкладками и кучей настроек…в общем крепитесь, ребята, будет много инфы.
Spider — собственно, настройки парсинга сайта

Вкладка Basic — выбираем что парсить
- Check Images — в отчет включаем анализ картинок.
- Check CSS — в отчет включаем анализ css-файлов (скрипты).
- Check JavaScript — в отчет включаем анализ JS-файлов (скрипты).
- Check SWF — в отчет включаем анализ Flash-анимации.
- Check External Link — в отчет включаем анализ ссылок с сайта на другие ресурсы.
- Check Links Outside of Start Folder — проверка ссылок вне стартовой папки. Т.е. отчет будет только по стартовой папке, но с учетом ссылок всего сайта.
- Follow internal “nofollow” — сканировать внутренние ссылки, закрытые в тег “nofollow”.
- Follow external “nofollow” — сканировать ссылки на другие сайты, закрытые в тег “nofollow”.
- Crawl All Subdomains — парсить все поддомены сайта, если ссылки на них встречаются на сканируемом домене.
- Crawl Outside of Start Folder — позволяет сканировать весь сайт, однако проверка начинается с указанной папки.
- Crawl Canonicals — выведение в отчете атрибута rel=”canonical” при сканировании страниц.
- Crawl Next/Prev — выведение в отчете атрибутов rel=”next”/”prev” при сканировании страниц пагинации.
- Extract hreflang/Crawl hreflang — при сканировании учитываются языковой атрибут hreflang и отображаются коды языка и региона страницы + формирование отчета по таким страницам.
- Extract AMP Links/Crawl AMP Links — извлечение в отчет ссылок с атрибутом AMP (определение версии контента на странице).
- Crawl Linked XML Sitemap — сканирование карты сайта. Тут краулер либо берет sitemap из robots.txt (Auto Discover XML Sitemap via robots.txt), либо берет карту по указанному пользователем пути (Crawl These Sitemaps).
Ну что, сложно? На самом деле просто нужна привычка и немного практики, чтобы освоить основные настройки SF и понять что нужно использовать в конкретных случаях, а от чего можно отказаться. Все, передохнули, теперь дальше… будет проще (нет).
Вкладка Limits — определяем лимиты парсинга

- Limit Crawl Total — задаем лимиты страниц для сканирования. Сколько всего страниц выгружаем для одного проекта.
- Limit Crawl Depth — задаем глубину парсинга. До какого уровня может дойти краулер при сканировании проекта.
- Limit Max Folder Depth — можно контролировать глубину парсинга вплоть до уровня вложенности папки.
- Limit Number of Query Strings — тут, если честно, сам не до конца разобрался, потому объясню так, как понял — мы ограничиваем лимит страниц с параметрами. Другими словами, если на одной статической странице есть несколько фильтров, то их комбинация может породить огромное количество динамических страниц. Вот чтобы такие “полезные” страницы не парсились (увеличивает время анализа в разы, а толковой информации по сути ноль), мы и выводим лимиты по Query Strings. Пример динамики — site.ru/?query1&query2&query3&queryN+1.
- Max Redirects to Follow — задаем максимальное количество редиректов, по которым паук может переходить с одного адреса.
- Max URL Length to Crawl — максимальная длина URL для обхода (указываем в символах, я так понимаю).
- Max Links per URL to Crawl — максимальное количество ссылок на URL для обхода (указываем в штуках).
- Max Page Size (KB) to Crawl — максимальный размер страницы для обхода (указываем в килобайтах).
Вкладка Rendering — настраиваем параметры рендеринга (только для JS)

На выбор три опции — “Text Only” (паук анализирует только текст страницы, без учета Аякса и JS), “Old AJAX Crawling Scheme” (проверяет по устаревшей схеме сканирования Аякса) и “JavaScript” (учитывает скрипты при рендеринге). Детальные настройки есть только у последнего, их и рассмотрим.

- Enable Rendered Page Screen Shots — SF делает скриншоты анализируемых страниц и сохраняет их в папке на ПК.
- AJAX Timeout (secs) — лимиты таймаута. Как долго SEO Spider должен разрешать выполнение JavaScript, прежде чем проверять загруженную страницу.
- Window Size — выбор размера окна (много их — смотрим скриншот).
- Sample — пример окна (зависит от выбранного Window Size).
- Чекбокс Rotate — повернуть окно в Sample.
Вкладка Advanced — дополнительные опции парсинга

- Allow Cookies — учитывать Cookies, как это делает поисковый бот.
- Pause on High Memory Used — тормозит сканирование сайта, если процесс забирает слишком много оперативной памяти.
- Always Follows Redirect — разрешаем краулеру идти по редиректам вплоть до финальной страницы с кодом 200, 4хх, 5хх (по факту все ответы сервера, кроме 3хх).
- Always Follows Canonicals — разрешаем краулеру учитывать все атрибуты “canonical” вплоть до финальной страницы. Полезно, если на страницах сайта бардак с настройкой этого атрибута (например, после нескольких переездов).
- Respect Noindex — страницы с “noindex” не отображаются в отчете SF.
- Respect Canonical — учет атрибута “canonical” при формировании итогового отчета. Полезно, если у сайта много динамических страниц с настроенным rel=”canonical” — позволяет убрать из отчета дубли по метаданным (т.к. на страницах настроен нужный атрибут).
- Respect Next/Prev — учет атрибутов rel=”next”/”prev” при формировании итогового отчета. Полезно, если у сайта есть страницы пагинации с настроенными “next”/”prev”- позволяет убрать из отчета дубли по метаданным (т.к. на страницах настроен нужный атрибут).
- Extract Images from img srscet Attribute — изображения извлекаются из атрибута srscet тега <img>. SRSCET — атрибут, который позволяет вам указывать разные типы изображений для разных размеров экрана/ориентации/типов отображения.
- Respect HSTS Policy — если чекбокс активен, SF будет выполнять все будущие запросы через HTTPS, даже если перейдет по ссылке на URL-адрес HTTP (в этом случае код ответа будет 307). Если же чекбокс неактивен, краулер покажет «истинный» код состояния за перенаправлением (например, постоянный редирект 301).
- Respect Self Referencing Meta Refresh — учитывать принудительную переадресацию на себя же (!) по метатегу Refresh.
- Response Timeout — время ожидания ответа страницы, перед тем как парсер перейдет к анализу следующего урла. Можно сделать больше (для медленных сайтов), можно меньше.
- 5хх Response Retries — количество попыток “достучаться” до страниц с 5хх ответом сервера.
- Store HTML — можно сохранить статический HTML-код каждого URL-адреса, просканированного SEO Spider, на диск и просмотреть его до того, как JavaScript “вступит в игру”.
- Store Rendered HTML — позволяет сохранить отображенный HTML-код каждого URL-адреса, просканированного SEO Spider, на диск и просмотреть DOM после обработки JavaScript.
- Extract JSON-LD — извлекаем микроразметку сайта JSON-LD. При выборе — дополнительные чекбоксы с типами валидации микроразметки (Schema.org, Google Validation, Case-Sensitive).
- Extract Microdata — извлекаем микроразметку сайта Microdata. При выборе — дополнительные чекбоксы с типами валидации микроразметки (Schema.org, Google Validation, Case-Sensitive).
- Extract RDFa — извлекаем микроразметку сайта RDFa. При выборе — дополнительные чекбоксы с типами валидации микроразметки (Schema.org, Google Validation, Case-Sensitive).
Вкладка Preferences — так называемые “предпочтения”
Здесь задаем желаемые параметры для некоторых сканируемых элементов (title, description, url, H1, H2, alt картинок, размер картинок). Соответственно, если сканируемые элементы сайта не будут соответствовать нашим предпочтениям, программа нам об этом сообщит в научно-популярной форме. Совершенно необязательные настройки — каждый прописывает для себя свой идеал… или вообще их не трогает, от греха подальше (как делаю я).

- Page Title Width — оптимальная ширина заголовка страницы. Указываем желаемые размеры от и до в пикселях и в символах.
- Meta Description Width — оптимальная ширина описания страницы. Аналогично, как и с тайтлом, указываем желаемые размеры.
- Other — сюда входит максимальная желаемая длина урл-адреса в символах (Max URL Length Chars), максимальная длина H1 в символах (Max H1 Length Chars), максимальная длина H2 в символах (Max H2 Length Chars), максимальная длина ALT картинок в символах (Max Image Length Chars) и максимальный вес картинок в КБ (Max Image Size Kilobytes).
Robots.txt — определяем каким правилам следовать при парсинге

Вкладка Settings — настраиваем парсинг относительно правил robots.txt

- Respect robots.txt — следуем всем правилам, прописанным в robots.txt. Т.е. учитываем в анализе те папки и файлы, которые открыты для робота.
- Ignore robots.txt — не учитываем robots.txt сайта при парсинге. В отчет попадают все папки и файлы, относящиеся к домену.
- Ignore robots.txt but report status — не учитываем robots.txt сайта при парсинге, однако в дополнительном меню выводится статус страницы (индексируемая или не индексируемая).
- Show internal/external URLs blocked by robots.txt — отмечаем в чекбоксах хотим ли мы видеть в итоговом отчете внутренние и внешние ссылки, закрытые от индексации в robots.txt. Данная опция работает только при условии выбора “Respect robots.txt”.

Вкладка Custom — ручное редактирование robots.txt в пределах текущего парсинга
Удобно, если вам нужно при парсинге сайта учитывать (или исключить) только определенные папки, либо же добавить правила для поддоменов. Кроме того, можно быстро сформировать и проверить свой рабочий robots, чтобы потом залить его на сайт.

Шаг 1. Прописать анализируемый домен в основной строке

Шаг 2. Кликнуть на Add, чтобы добавить robots.txt домена
Тут на самом деле все очень просто, поэтому я по верхам пробегусь по основным опциям (а в конце будет видео, где я бездумно прокликиваю все кнопки).

- Блок Subdomains — сюда, собственно, можно добавлять домены/поддомены, robots.txt которых мы хотим учитывать при парсинге сайта.
- Окно справа — для редактирования выгруженного robots.txt. Итоговый вариант будет считаться каноничным для парсера.
- Окошко снизу — проверка индексации url в зависимости от настроенного robots.txt. Справа выводится статус страницы (Allowed или Disallowed).
URL Rewriting — функция перезаписи URL «на лету»

Тут мы можем настроить перезапись урл-адресов домена прямо в ходе парсинга. Полезно, когда нужно заменить определенные регулярные выражения, которые засоряют итоговый отчет по парсингу.
Вкладка Remove Parameters
Вручную вводим параметры, которые нужно удалять из url при анализе сайта, либо исключить вообще все возможные параметры (чекбокс “Remove all”). Полезно, если у страниц сайта есть идентификаторы сеансов, отслеживание контекста (utm_source, utm_medium, utm_campaign) или другие фишки.

Вкладка Regex Replace
Изменяет все сканируемые урлы с использованием регулярных выражений. Применений данной настройки масса, я приведу только несколько самых распространенных примеров:

- Изменение всех ссылок с http на https (Регулярное выражение: http Заменить: https).
- Изменение всех ссылок на site.by на site.ru (Регулярное выражение: .by Заменить: .ru).
- Удаление всех параметров (Регулярное выражение: ?. * Заменить: ).
- Добавление параметров в URL (Регулярное выражение: $ Заменить: ?ПАРАМЕТР).
Вкладка Options
Вы рассчитывали увидеть здесь еще 100500 дополнительных опций для суперточной настройки URL Rewriting, я прав? Как бы странно это ни звучало, но здесь мы всего лишь определяем перезаписывать все прописные url-адреса в строчные или нет… вот как-то так, не спрашивайте, я сам не знаю почему для этой опции сделали целую отдельную вкладку.

Вкладка Test
Тут мы можем предварительно протестировать видоизменение url перед началом парсинга и, соответственно, подправить регулярные выражения, чтобы на выходе не получилось какой-нибудь ерунды.

CDNs — парсим поддомены, не отходя от кассы
Использование настройки CDNs позволяет включать в парсинг дополнительные домены/поддомены/папки, которые будут обходиться пауком и при этом считаться внутренними ссылками. Полезно, если нужно проанализировать массив сайтов, принадлежащих одному владельцу (например, крупный интернет-магазин с сетью сайтов под регионы). Также можно прописывать регулярные выражения на конкретные пути сканирования — т.е. парсить только определенные папки.

Во вкладке Test можно посмотреть как будут определяться урлы в зависимости от используемых параметров (Internal или External).
Include/Exclude — сканирование/удаление определенных папок

Можно регулярными выражениями задать пути, которые будут сканироваться внутри домена. Также можно запретить парсинг определенных папок. Единственный нюанс в настройках — при использовании Include будут парситься только УКАЗАННЫЕ папки, если же мы добавляем урлы в Exclude, сканироваться будут все папки, КРОМЕ УКАЗАННЫХ.

Выбираем папки для парсинга

Удаляем папки из парсинга
Примеры регулярных выражений для Exclude:
- http://site.by/obidnye-shutki-pro-seo.html (исключение конкретной страницы).
- http://site.by/obidnye-shutki-pro-seo/.* (исключение целой папки).
- http://site.by/.*/obidnye-shutki-pro-seo/.* (исключение всех страниц, после указанной).
- .*?price.* (исключение страниц с определенным параметром).
- .*jpg$ (исключение файлов с определенным расширением).
- .*seo.* (исключение страниц с вхождением в url указанного слова).
- .*https.* (исключение страниц с https).
- http://site.by/.* (исключение всех страниц домена/поддомена).
Speed — регулируем скорость парсинга сайта

Можно выставить как количество потоков (по умолчанию 5), так и число одновременно сканируемых адресов. Влияет на скорость парсинга и вероятность бана бота, так что тут лучше не усердствовать.

User-Agent — выбираем под кого маскируемся

В списке user-agent можно выбрать от лица какого бота будет происходить парсинг сайта. Удобно, если в настройках сайта есть директивы, блокирующие того или иного бота (например, запрещен google-bot). Также полезно иногда прокраулить сайт гугл-ботом для смартфона, чтобы проверить косяки адаптива или мобильной версии.


Скажу сразу — это опция очень индивидуальна, лично я ее не пользую, потому что чаще всего незачем. В любом случае, настройка реагирования на http-заголовки позволяет определить, как паук будет их обрабатывать (если указаны нюансы в настройках). По крайней мере я так это понял.

Т.е. можно индивидуально настроить, например, какого формата контент обрабатывать, учитывать ли cookie и т.д. Нюансов там довольно много.

Custom — дополнительные настройки поиска по исходному коду

Custom Search
По сути обычный фильтр, с помощью которого можно вытягивать дополнительные данные, например, страницы, в которых вместо тега <strong> используется <bold> или еще лучше — страницы, которые НЕ содержат определенного контента (например, без кода счетчика метрики). Фактически в настройках можно задать все что угодно.

Custom Extraction
Это пользовательское извлечение любых данных из html (например, текстовое содержимое).

User Interface — обнуление настроек для колонок таблицы
Просто сбрасывает сортировку столбцов, ничего особенного, проходим дальше, граждане, не толпимся.

API Access — интеграция с разными сервисами
Для того чтобы получать больше данных по сайту, можно настроить интеграцию с разными сервисами статистики типа Google Analytics или Majestic, при условии того, что у вас есть аккаунт в этом сервисе.

При этом для каждого сервиса отдельные настройки выгрузки по типам данных.

На примере GA
Authentification — настройки аутентификации (если есть запрос от сайта)

Есть два вида аутентификации — Standart Based и Form Based. По умолчанию используется Standart Base — если при парсинге от сайта приходит запрос на аутентификацию, в программе появляется соответствующее окно.

Form Based — использование для аутентификации встроенного в SF браузера (полезно, когда для подтверждения аутентификации нужно, например, пройти капчу). В данном случае необходимо вручную вводить урл сайта и в открывшемся окне браузера вводить логин/пароль, кликать recaptcha и т.д.

System — внутренние настройки самой программы
Настройки работы самой программы — сколько оперативной памяти выделять на процесс, куда сохранять экспорт и т.д.

Давайте как обычно — подробнее о каждом пункте.
- Memory — выделяем лимиты оперативной памяти для парсинга. По дефолту стоит 2GB, но можно выделить больше (если ПК позволяет).

- Storage — выбор базы для хранения данных. Либо сохранение в ОЗУ (для этого у SF есть свой движок), либо в указанной папке на ПК пользователя.

- Proxy — подключение прокси-сервера для парсинга.

- Embedded Browser — использование встроенного в программу браузера (вкл/выкл).

Mode
- Spider (Режим паука) — классический парсинг сайта по внутренним ссылкам. Просто вводим нужный домен в адресную строку программы и запускаем работу.
- List — парсим только предварительно собранный список урл-адресов! Адреса можно выгрузить из файла (From a file), вбить вручную (Enter Manually), подтянуть их из карты сайта (Download Sitemap) и т.д. Если честно, этих трех способов получения списка урлов должно быть более чем достаточно.
- SERP Mode — в этом режиме нет сканирования, зато здесь можно загружать мета-данные сайта, редактировать их и предварительно понимать как они будут отображаться в браузере. Делать все это можно пакетно, что вполне себе удобно.
Bulk export
В этом пункте меню висят все опции SF, отвечающие за массовый экспорт данных из основного и дополнительного меню отчета…сейчас покажу на скриншоте.

В общем и целом с помощью bulk export можно вытянуть много разной полезной информации для последующей постановки ТЗ на доработки. Например, выгрузить в excel страницы, на которых найдены ссылки с 3хх ответом сервера + сами 3хх-ссылки, что позволяет сформировать задание для программиста или контент-менеджера (зависит от того, где зашиты 3хх-ссылки) на замену этих 3хх-ссылок на прямые с кодом 200. Теперь подробнее про то, что можно экспортировать при помощи Bulk Export.

- All Inlinks — получаем все входящие ссылки на каждый URI, с которым столкнулся краулер при сканировании сайта.
- All Outlinks — получаем все исходящие ссылки с каждого URI, с которым столкнулся краулер при сканировании сайта.
- All Anchor Text — выгрузка анкоров всех ссылок.
- All Images — выгрузка всех картинок (урл-адресами, естественно).
- Screenshots — экспорт снимков экрана.
- All Page Source — получаем статический HTML-код или обработанный HTML-код просканированных страниц (рендеринг HTML доступен только в режиме рендеринга JavaScript) .
- External Links — все внешние ссылки со всех просканированных страниц.
- Response Codes — все страницы в зависимости от выбранного кода ответа сервера (закрытые от индекса, с кодом 200, с кодом 3хх и т.д.).
- Directives — все страницы с директивами в зависимости от выбранной (Index Inlinks, Noindex Inlinks, Nofollow Inlinks и т.д.).
- Canonicals — страницы, содержащие канонические атрибуты, страницы без указания этих атрибутов, каноникализированные (*перекрестился*) страницы и т.д.
- AMP — страницы с AMP, ссылки с AMP (но код ответа не 200) и т.д.
- Structured Data — выгрузка страниц с микроразметкой.
- Images — выгрузка картинок без альт-текста, тяжелых картинок (в соответствии с указанным в настройках размером).
- Sitemaps — выгрузка всех страниц в карте сайта, неиндексируемых страниц в карте сайта и проч.
- Custom — выгрузка пользовательских фильтров.
Reports
Здесь содержится множество различных отчетов, которые также можно выгрузить.

- Crawl Overview — в этом отчете содержится сводная информация о сканировании, включая такие данные, как количество найденных URL-адресов, заблокированных robots.txt, число сканированных, тип контента, коды ответов и т. д.
- Redirect & Canonical Chains — отчет о перенаправлении и канонических цепочках. Здесь отображаются цепочки перенаправлений и канонических символов, показывается количество переходов по пути и идентифицируется источник, а также цикличность (если есть).
- Non-Indexable Canonicals — здесь можно получить выгрузку, в которой освещаются ошибки и проблемы с canonical. В частности, этот отчет покажет любые канонические файлы, которые не отдают корректного ответа сервера — заблокированы файлом robots.txt, с перенаправлением 3хх, ошибкой 4хх или 5хх (вообще все что угодно, кроме ответа «ОК» 200).
- Pagination — ошибки и проблемы с атрибутами rel=”next” и rel=”prev”, которые используются для обозначения содержимого, разбитого на пагинацию.
- Hreflang — проблемы с атрибутами hreflang (некорректный ответ сервера, страницы, на которые нет гиперссылок, разные коды языка на одной странице и т.д.).
- Insecure Content — показаны любые защищенные (HTTPS) URL-адреса, на которых есть небезопасные элементы, такие как внутренние ссылки HTTP, изображения, JS, CSS, SWF или внешние изображения в CDN, профили социальных сетей и т. д.
- SERP Summary — этот отчет позволяет быстро экспортировать URL-адреса, заголовки страниц и мета-описания с соответствующими длинами символов и шириной в пикселях.
- Orphan Pages — список потерянных страниц, собранных из Google Analytics API, Google Search Console (Search Analytics API) и XML Sitemap, которые не были сопоставлены с URL-адресами, обнаруженными во время парсинга.
- Structured Data — отчет содержит данные об ошибках валидации микроразметки страниц.
Sitemaps
С помощью этого пункта можно сгенерировать XML-карту сайта (страницы и картинки).

Все просто — выбираем что будем генерировать. В появившемся окне при необходимости выбираем нужные параметры и создаем карту сайта, которую потом заливаем в корневой каталог сайта.
Рассмотрим подробнее параметры, которые нам предлагают выбрать при генерации карты сайта.

Вкладка Pages — выбираем какие типы страниц включить в карту сайта.
- Noindex Pages — страницы, закрытые от индексации.
- Canonicalised — каноникализированные (опять это страшное слово!) страницы . Другими словами, динамика, у которой есть rel=”canonical”.
- Paginated URLs — страница пагинации.
- PDFs — PDF-документы.
- No response — страницы с кодом ответа сервера 0 (не отвечает).
- Blocked by robots.txt — страницы закрытые от индекса в robots.txt.
- 2xx — страницы с кодом 2хх (они будут в карте в любом случае).
- 3хх — страницы с кодом ответа 3хх (редиректы).
- 4хх — страницы с кодом ответа 4хх (битые ссылки на несуществующие страницы).
- 5хх — страницы с кодом ответа 5хх (проблема сервера при загрузке).
Вкладка Last Modified — выставляем дату последнего обновления карты.

- nclude <lastmod> tag — использовать в sitemap тег <lastmod> (дата последнего обновления карты).
- Use server report — использовать ответ сервера при создании карты, либо проставить дату вручную.
Вкладка Priority — выставляем приоритет ссылки в зависимости от глубины залегания страницы.

- Include <priority> tag — добавляет в карту сайта тег <priority>, показывающий приоритет страницы.
- Crawl Depth 0-5+ — в зависимости от глубины залегания страницы, можно проставить ее приоритет сканирования для поискового робота.
Вкладка Change Frequency — выставляем вероятную частоту обновления страниц.

- Include <changefreq> tag — использовать тег <changefreq> в карте сайта. Показывает частоту обновления страницы.
- Calculate from Last Modified header — рассчитать тег по последнему измененному заголовку.
- Use crawl depth settings — проставить тег в зависимости от глубины страницы.
Вкладка Images — добавляем картинки в карту сайта.

- Include Images — выводить в общей карте сайта картинки.
- Include Noindex Images — добавить картинки, закрытые от индекса.
- Include only relevant Images with up to … inlinks — добавить только картинки с заданным числом входящих ссылок.
- Regex list of CDNs hosting images to be included — честно, так и не понял что это такое… возможно настройка выгрузки в карту сайта картинок из хостинга (т.е. можно вбить списком несколько хостов и оттуда подтянуть картинки), но это всего лишь мои предположения.
Вкладка Hreflang — использовать в sitemap атрибут <hreflang> (или не использовать).

Visualisations
Это выбор интерактивной визуализации структуры сайта в программе. Можно получить отображение дерева сканирования и дерева каталогов. Основная фишка в том, что открываются эти карты и диаграммы во встроенном браузере программы, что позволяет эффективнее с ними работать (настраивать выведение, масштабировать, перескакивать к нужным урлам через поиск и т.д.).

Crawl Tree Graph — визуализация сканирования. По факту после завершения краулинга показывает текущую структуру сайта на основании анализа.

Directory Tree Graph — показывает ВСЕ каталоги после сканирования. Т.е. отличие от Crawl Tree Graph в том, что в этом отчете показываются, например, папки, закрытые от индекса.

Назначение Crawl Tree Graph и Directory Tree Graph в основном заключается в упрощении анализа структуры текущего сайта, можно глазами пробежаться по всем папкам, зацепиться за косяки (т.к. они выделены цветом). При наведении на папку, показывается ее данные (url, title, h1, h2 и т.д.).

Force Directed Crawl-Diagram — по сути то же самое, что и Crawl Tree Graph, только оформленное по-другому + показывает сканирование сайта относительно главной страницы (ну или стартовой). Кому-то покажется нагляднее, хотя по мне, выглядит гораздо сложнее для восприятия.

Force Directed Tree-Diagram — аналогично, другой тип визуализации дерева каталогов сайта.

Inlink Anchor Text Word Cloud — визуализация анкоров (ссылочного текста) внутренней ссылки. Анализирует каждую страницу по-отдельности. Помогает понять какими анкорами обозначена страница, как их много, насколько разнообразны и т.д.

Р- Разнообразие
Body Text Word Cloud — визуализация плотности отдельных слов на странице. По сути выглядит так же, как и Inlink Anchor Text Word Cloud, так что отдельный скрин делать смысла особого нет — обычное облако слов, по размеру можно определить какое слово встречается чаще, по общему числу посмотреть разнообразие слов на странице и т.д.
Каждая визуализация имеет массу настроек вывода данных, маркировки — про них я писать не буду, если станет интересно, сами поиграетесь, ок? Там ничего сложного.

Crawl Analysis

Большинство параметров сайта вычисляется пауком в ходе сбора статистики, однако некоторые данные (Link Score, некоторые фильтры и прочее) нуждаются в дополнительном анализе, чтобы попасть в финальный отчет. Данные, которые нуждаются в Crawl Analysis, помечены соответствующим образом в правом меню навигации.

Crawl Analysis запускается после основного парсинга. Перед запуском дополнительного анализа, можно настроить его (какие данные выводить в отчет).

- Link Score — присвоение оценок всем внутренним ссылкам сайта.
- Pagination — показывает петлевые пагинации, а также страницы, которые обнаружены только через атрибуты rel=”next”/”prev”.
- Hreflang — урлы hreflang без гиперссылки, битые ссылки.
- AMP — страницы без тегов “html amp”, теги не с 200 кодом ответа.
- Sitemaps — неиндексируемые страницы в карте сайта, урлы в нескольких картах сайта, потерянные страницы (например, есть в Google Analytics, есть в sitemap, не обнаружено при парсинге), страницы, которых нет в карте сайта, страницы в карте сайта.
- Analytics — потерянные страницы (есть в аналитике, нет в парсинге).
- Search Console — потерянные страницы (есть в вебмастере, нет в парсинге).
License
Исходя из названия, логично предположить, что этот пункт меню отвечает за разного рода манипуляции с активацией продукта…иии так оно и есть!

Buy a License — купить лицензию. При клике переход на соответствующую страницу официалов https://www.screamingfrog.co.uk/seo-spider/licence/. Стоимость ключа для одного ПК — 149 фунтов стерлинга. Есть пакеты для нескольких ПК, там, как обычно, идут скидки за опт.

Enter License — ввести логин и ключ лицензии, чтобы активировать полный функционал парсера.

Заметили, да? Лицензия покупается на год, не бессрочная
Help
Помощь юзеру — гайды, FAQ, связь с техподдержкой, в общем все, что связано с работой программы, ее багами и их решением.

- User Guide — мануал по работе с программой. Собственно, его я использовал, как один из источников, для написания этой статьи. При желании, можете ознакомиться, если я что-то непонятно рассказал или не донес. Еще раз оставлю ссылку https://www.screamingfrog.co.uk/seo-spider/user-guide/.
- FAQ — часто задаваемые вопросы по работе с SF и ответы на них https://www.screamingfrog.co.uk/seo-spider/faq/.
- Support — обратная связь с техподдержкой https://www.screamingfrog.co.uk/seo-spider/support/. Если программа ведет себя некрасиво (например, не принимает ключ лицензии), можно пожаловаться куда надо и все починят.
- Feedback — обратная связь. Та же самая страница, что и в Support. Т.е. можно не только жаловаться, но и вносить предложения по работе программы, предлагать партнерку, сказать банальное “спасибо” за такой крутой сервис (думаю ребятам будет приятно).
- Check for Updates и Auto Check for Updates — проверка на наличие обновлений программы. Screaming Frog нерегулярно, но довольно часто дорабатывается, поэтому есть смысл периодически проверять апдейты. Но лучше поставить галочку на Auto Check for Updates и программа сама будет автоматически предлагать обновиться при выходе нового апа.
- Debug — отчет о текущем состоянии программы. Нужно, если вы словили какой-то баг и хотите о нем сообщить разработчику. Там еще дополнительно есть настройки дебага, но я думаю, нет смысла заострять на этом внимание.
- About — собственно, краткая информация о самой программе (копирайт, сервисы, которые использовались при разработке).
Итог
Screaming Frog — очень гибкая в плане настройке утилита, с помощью которой можно вытянуть массу данных для анализа, нужно только (только… ха-ха) правильно настроить парсинг. Я надеюсь, мой мануал поможет вам в этом, хотя и не все я рассмотрел как надо, есть пробелы, но основные функции должны быть понятны.
Теперь от себя — текста много, скринов много, потому, если вы начинающий SEO-специалист, рекомендую осваивать SF поэтапно, не хватайтесь за все сразу, ибо есть шанс упустить важные нюансы.
Ну вот и все, ребята, я отчаливаю за новым материалом для нашего крутого блога. Подписывайтесь, чтобы не пропустить интересные публикации от меня и моих коллег. Всем удачи, всем пока!

Владимир Еленский
Практикующий SEO-специалист MAXI.BY media. Опыт работы более 5-ти лет. Хороший человек и просто красавчик.