Сглаживание ошибок измерения (фильтрация)
Технико-экономическая эффективность системы управления энергоснабжением | АСДУ электроэнергетических систем зарубежных стран | АСДУ во Франции | АСДУ в Англии и Уэльсе | АСДУ в США. Эволюция развития оперативных информационно-управляющих комплексов | Обновленная сеть сбора информации | Метод на основе Леммы об обратной матрице | Формирование модели текущего режима при оценке состояния СЭ | Статические методы оценивания состояния | Динамические методы оценивания состояния |
Читайте также:
|
Часто именно эту задачу называют оцениванием состояний, но представляется, что оценивание состояния включают в себя более широкий класс задач, в том числе и обнаружение грубых ошибок.
Суть задачи состоит в следующем: полученные результаты измерений, даже после устранения грубых ошибок, содержит «нормальные» ошибки, соответствующие классу точности телеизмерительного комплекса. Из-за этого точно не соблюдается законы Кирхгофа. Необходимо определить такие оценки параметров режима  , которые удовлетворяют уравнениям электрической цепи и в то же время наиболее близки к измеряемым значениям.
, которые удовлетворяют уравнениям электрической цепи и в то же время наиболее близки к измеряемым значениям.
Несовпадение уравнений цепи возможно при наличии избыточных измерений. Поэтому задача сглаживания сводится к тому, чтобы определить такие оценки , которые наиболее близки к измеренным значениям и удовлетворяют системам контрольных уравнений.
Наиболее часто применяемые методы:
· Метод взвешенных наименьших квадратов
 ,
,
где  — весовая матрица, обратная матрица ковариаций.
— весовая матрица, обратная матрица ковариаций.
Итак, нужно найти min φ при ограничении  .
.
В состав слагаемых критерия  следует вводить данные только тех измерений
следует вводить данные только тех измерений  . Точные данные (нулевые сенъекции мощности в транзитных углах и т.п.) достаточно ввести в качестве констант в ограничения и менять их в процессе решения.
. Точные данные (нулевые сенъекции мощности в транзитных углах и т.п.) достаточно ввести в качестве констант в ограничения и менять их в процессе решения.
В такой подстановке можно учесть и ограничения:
 ,
,
где реально пределы измерения параметров режима помогут дополнительно отфильтровать ошибки. Это типичная задача нелинейного программирования.
Могут быть найдены относительно простые соотношения для получения оценок  , уже сбалансированных с точки зрения наблюдения контрольных уравнений;
, уже сбалансированных с точки зрения наблюдения контрольных уравнений;

Видно, что невязки контрольных уравнений «размываются» по всем измерениям пропорционально их априорной точности и коэффициентам (т.е производной  ), к которым они входят в контрольное уравнение.
), к которым они входят в контрольное уравнение.
Полученные оценки используются для расчетов всех остальных параметров режима. Для этого из выделяется базисный состав данных измерений  и решается система нелинейных уравнений,
и решается система нелинейных уравнений,
 , (**)
, (**)
где х – модули и фазы напряжений узлов.
Задача (**) не сложнее обычной задачи потокораспределения, но матрица  может иметь значительно меньшую заполненность, если в состав
может иметь значительно меньшую заполненность, если в состав  будут включены не инъекции узлов, потоки мощностей и модули напряжения узлов. Кроме того, решение уравнения (**) нужно только тогда, когда требуется получить данные о неизмеренных параметрах режима.
будут включены не инъекции узлов, потоки мощностей и модули напряжения узлов. Кроме того, решение уравнения (**) нужно только тогда, когда требуется получить данные о неизмеренных параметрах режима.
Дата добавления: 2015-11-04; просмотров: 104 | Нарушение авторских прав
mybiblioteka.su — 2015-2023 год. (0.015 сек.)
Задача планирования логистики —
разработать проекты, устанавливающие
на перспективу определенные параметры
логистической деятельности, в результате
чего достигается цель логистической
системы предприятия.
Принятие решения — это выбор оптимальной
альтернативы при заданной цели с учетом
побочных условий.
Прогнозирование в логистике (прогноз)
— вероятностное представление о появлении
событий (последствий и данных) в будущем,
основываемое на наблюдениях и теоретических
положениях. Прогноз — прогностическая
информация.
Планирование в логистике — систематическое
принятие планово-управленческих решений
в отношении физического перемещения и
передачи собственности на продукцию
от производителя к потребителю, включая
транспортировку, хранение и совершение
сделок.
План — это результат планирования.
Стратегическое планирование предприятия
— деятельность по выработке плана с
дальним прицелом, касающегося форм и
способов поддержания существующего
уровня бизнеса, его поддержания и
развития в постоянно изменяющейся
среде.
Этапы планирования:
• формулирование целей;
• постановка логистических проблем;
• поиск альтернатив;
• прогнозирование;
• оценка и принятие решений.
Система планирования — упорядоченная
структура отдельных частей планирования.
По срокам различаются следующие виды
планирования:
• стратегическое рамочное планирование;
• долгосрочное планирование;
• среднесрочное планирование;
• бюджетное планирование;
• скользящее краткосрочное планирование.
Планирование продаж определяет
потребности в сырье, продукции и услугах,
которые будут приобретены специалистами
отдела закупок предприятия.
Планирование потребности в материалах
— это система планирования, определяющая
количество и график выпуска требуемой
продукции, определяющая время и объем
потребности в материалах в пределах
периода планирования.
План потребности в материалах — разделенный
на временные фазы график для планируемого
выполнения заказов на закупку компонентов
и материалов после принятия в расчет
их наличного количества и ожидаемого
цикла заказов, чтобы определить правильную
дату размещения заказа на закупку.
Планирование производства:
• планирование количества изделий,
необходимых для производства;
• планирование промежутка времени, в
течение которого будет произведена
продукция;
• планирование обеспечения сырья и
оборудования для производства необходимого
количества продукции в рамках
запланированного периода времени.
11.3 Сглаживание данных
Анализ временных рядов — Две основные
цели.
Имеются две основные цели анализа
временных рядов:
а) определение природы ряда;
б) прогнозирование (предсказание будущих
значений временного ряда по настоящим
и прошлым значениям).
Обе эти цели требуют, чтобы модель ряда
была идентифицирована и, более или
менее, формально описана. Как только
модель определена, Вы можете с ее помощью
интерпретировать рассматриваемые
данные (например, использовать в Вашей
теории для понимания сезонного изменения
цен на товары, если занимаетесь
экономикой). Не обращая внимания на
глубину понимания и справедливость
теории, Вы можете экстраполировать
затем ряд на основе найденной модели,
т.е. предсказать его будущие значения.
Основные идеи и понятия
В дальнейшем нам понадобятся очень
важные понятия, использующиеся в анализе
временных рядов, такие как: тренд ряда,
циклическая составляющая ряда,
трендциклическая компонента ряда,
сезонная составляющая ряда и шумовая
компонента или просто шум. Дадим краткое
пояснение данным элементам:
1. Формально Временной ряд— это
ряд наблюдений анализируемой случайной
величины![]() ,
,
произведенных в последовательные
моменты времени![]() .
.
В чем же состоят принципиальные отличия
ряда от простой последовательности
наблюдений, образующих случайную
выборку? Этих отличий два:

Рисунок 1. График временного ряда.
Во-первых, в отличие от элементов
случайной выборки члены временного
ряда не являются статистически
независимыми.
Во-вторых, члены временного ряда
не являются одинаково распределенными,
т.е. верно следующее соотношение между
вероятностями.
![]()
2. Трендомназывают неслучайную
функцию, формируемую под действием
общих или долговременных тенденций,
влияющих на наш ряд. Например, в качестве
формирующей тенденции, может выступать
фактор роста исследуемого рынка.
Не существует автоматического способа
обнаружения тренда в временном ряде.
Однако если тренд является монотонным
(устойчиво возрастает или устойчиво
убывает), то анализировать такой ряд
обычно нетрудно. Если временные ряды
содержат значительную ошибку, то первым
шагом выделения тренда является
сглаживание.
Сглаживание.Сглаживание всегда
включает некоторый способ локального
усреднения данных, при котором
несистематические компоненты взаимно
погашают друг друга. Самый общий метод
сглаживания — скользящее среднее, в
котором каждый член ряда заменяется
простым или взвешенным средним n соседних
членов, где n — ширина окна. Вместо среднего
можно использовать медиану значений,
попавших в окно. Основное преимущество
медианного сглаживания, в сравнении со
сглаживанием скользящим средним, в том,
что результаты становятся более
устойчивыми к выбросам (имеющимся внутри
окна). Таким образом, если в данных
имеются выбросы (связанные, например,
с ошибками измерений), то сглаживание
медианой обычно приводит к более гладким
или, по крайней мере, более надежным
кривым, по сравнению со скользящим
средним с тем же самым окном. Основной
недостаток медианного сглаживания в
том, что при отсутствии явных выбросов,
он приводит к более зубчатым кривым
(чем сглаживание скользящим средним) и
не позволяет использовать веса.
Все эти быстрые преобразования
присутствуют в модуле Временные ряды.
Относительно реже, когда ошибка измерения
очень большая, используется сглаживание
методом наименьших квадратов, взвешенных
относительно расстояния или метод
отрицательного экспоненциально
взвешенного сглаживания. Все эти методы
отфильтровывают шум и преобразуют
данные в относительно гладкую кривую.
Ряды с относительно небольшим количеством
наблюдений и систематическим расположением
точек могут быть сглажены с помощь
бикубических сплайнов.
Подгонка функции. Многие
монотонные временные ряды можно адекватно
приблизить линейной функцией. Если же
имеется явная монотонная нелинейная
компонента, то данные вначале следует
преобразовать, чтобы устранить
нелинейность. Обычно для этого используют
логарифмическое, экспоненциальное или
(менее часто) полиномиальное преобразование
данных. Имеется несколько способов
выполнить эти преобразования в STATISTICA.
Можно экспериментировать с преобразованиями
практически неограниченной сложности,
используя формулы таблиц исходных
данных и далее анализировать преобразованные
ряды с помощью линейной регрессии (в
модуле Множественная регрессия или в
модуле Временные ряды) и строить прогноз
(Множественная регрессия). Нелинейные
функции практически неограниченной
сложности, включая кусочно-линейные с
точками разрыва (различные функции
могут быть одновременно подогнаны на
различных участках ряда) могут быть
получены в модуле Нелинейное оценивание.
Наконец, STATISTICA предлагает подгонку
различных кривых: полиномов (с определенным
пользователем порядком), логарифмических
функций (с определенным пользователем
основанием), экспоненциальных и других.
3. Циклической компонентойтакже
является неслучайная функция, обусловленная
действием долговременных циклов
различной природы.
4. Для удобства, вместо предыдущих двух
понятий используют совместное понятие
трендциклической компоненты (см.
Классическая сезонная декомпозиция
(Метод Census I)). Характер поведения отображен
на рисунке.

Рисунок 2. График трендцицклической
компоненты временного ряда.
5. Понятие сезон временного рядаилисезонная компонентаиспользуется для обозначения неслучайной
функции. Данная функция формируется на
основе периодически повторяющихся в
определенное время года колебаний
исследуемого ряда. Часто данную функцию
измеряют в процентах, которые характеризуют
сезонные отклонения от трендциклической
компоненты. Пример данной функции
приведен на рисунке.

Рисунок 3. График сезонной компоненты
временного ряда.
Периодическая и сезонная зависимость
(сезонность) представляет собой другой
общий тип компонент временного ряда.
Это понятие было проиллюстрировано
ранее на примере авиаперевозок пассажиров.
Можно легко видеть, что каждое наблюдение
очень похоже на соседнее; дополнительно,
имеется повторяющаяся сезонная
составляющая, это означает, что каждое
наблюдение также похоже на наблюдение,
имевшееся в том же самом месяце год
назад. В общем, периодическая зависимость
может быть формально определена как
корреляционная зависимость порядка k
между каждым i-м элементом ряда и (ik)-м
элементом. Ее можно измерить с помощью
автокорреляции (т.е. корреляции между
самими членами ряда); k обычно называют
лагом (иногда используют эквивалентные
термины: сдвиг, запаздывание). Если
ошибка измерения не слишком большая,
то сезонность можно определить визуально,
рассматривая поведение членов ряда
через каждые k временных единиц.
Автокорреляционная коррелограмма.
Сезонные составляющие временного ряда
могут быть найдены с помощью коррелограммы.
Коррелограмма (автокоррелограмма)
показывает численно и графически
автокорреляционную функцию (AКФ), иными
словами коэффициенты автокорреляции
(и их стандартные ошибки) для
последовательности лагов из определенного
диапазона (например, от 1 до 30). На
коррелограмме обычно отмечается диапазон
в размере двух стандартных ошибок на
каждом лаге, однако обычно величина
автокорреляции более интересна, чем ее
надежность, потому, что интерес в основном
представляют очень сильные (а,
следовательно, высоко значимые)
автокорреляции.
Исследование коррелограмм. При
изучении коррелограмм следует помнить,
что автокорреляции последовательных
лагов формально зависимы между собой.
Рассмотрим следующий пример. Если первый
член ряда тесно связан со вторым, а
второй с третьим, то первый элемент
должен также каким-то образом зависеть
от третьего и т.д. Это приводит к тому,
что периодическая зависимость может
существенно измениться после удаления
автокорреляций первого порядка, т.е.
после взятия разности с лагом 1. Взятие
разности также удаляет тренд, который
обычно подавляет другие автокорреляции.
Например, если имеется устойчивый
линейный тренд, как в ряде авиаперевозок,
то каждое наблюдение в большой степени
является линейной функцией предыдущего
наблюдения.
Частные автокорреляции. Другой
полезный метод исследования периодичности
состоит в исследовании частной
автокорреляционной функции (ЧАКФ),
представляющей собой углубление понятия
обычной автокорреляционной функции. В
ЧАКФ устраняется зависимость между
промежуточными наблюдениями (наблюдениями
внутри лага). Другими словами, частная
автокорреляция на данном лаге аналогична
обычной автокорреляции, за исключением
того, что при вычислении из нее удаляется
влияние автокорреляций с меньшими
лагами. На лаге 1 (когда нет промежуточных
элементов внутри лага), частная
автокорреляция равна, очевидно, обычной
автокорреляции. На самом деле, частная
автокорреляция дает более чистую картину
периодических зависимостей.
Удаление периодической зависимости.
Как отмечалось выше, периодическая
составляющая для данного лага k может
быть удалена взятием разности
соответствующего порядка. Это означает,
что из каждого i-го элемента ряда
вычитается (i-k)-й элемент. Имеются два
довода в пользу таких преобразований.
Во-первых, таким образом можно
определить скрытые периодические
составляющие ряда. Напомним, что
автокорреляции на последовательных
лагах зависимы. Поэтому удаление
некоторых автокорреляций изменит другие
автокорреляции, которые, возможно,
подавляли их, и сделает некоторые другие
сезонные составляющие более заметными.
Во-вторых, удаление сезонных
составляющих делает ряд стационарным,
что необходимо для применения АРПСС и
других методов, например, спектрального
анализа.
6. Шумом во временном ряде,
называют случайные не поддающиеся
регистрации величины. Как и большинство
других видов анализа, анализ временных
рядов предполагает, что данные содержат
систематическую составляющую (обычно
включающую несколько компонент) и
случайный шум (ошибку), который затрудняет
обнаружение регулярных компонент.
Большинство методов исследования
временных рядов включает различные
способы фильтрации шума, позволяющие
увидеть регулярную составляющую более
отчетливо.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
ш
УДК 519.254 Ермаков Анатолий Анатольевич,
к. т. н., доцент, Иркутский государственный университет путей сообщения, тел. 89149126048
Михайлов Дмитрий Игоревич, аспирант, Иркутский государственный университет путей сообщения, тел. 89501408363
ОСНОВЫ ПОШАГОВОГО СГЛАЖИВАНИЯ ПРИ ОБРАБОТКЕ СТАТИСТИЧЕСКИХ ДАННЫХ
A. A. Ermakov, D. I. Mikhailov
STEP-BY-STEP SMOOTHING BASICS IN THE PROCESSING OF STATISTICAL DATA
Аннотация. Для контроля сложных технических систем в момент эксплуатации необходимо обрабатывать обширные объемы статистических данных. Часто при обработке полученных данных (определении закона распределения, нахождении функциональных зависимостей тренда экспериментальных данных) в результат вносится ошибка измерения. Наличие такой ошибки может привести не только к неточному определению коэффициентов функции, но и к неправильному выбору самой функции. Для исключения случайных факторов (ошибок измерения) предлагается метод предварительной обработки данных. Предлагаемый метод — метод пошагового сглаживания, основан на вычислении на каждом измерении некоторой фактической величины полусуммы значения этого измерения и знании прогноза, рассчитанного во время предыдущего измерения. Метод пошагового сглаживания можно рекомендовать как метод предварительного сглаживания статистических данных. Обладая точностью, сопоставимой с точностью метода скользящего среднего, метод пошагового сглаживания обеспе-чиивает обработку с самого первого измерения, используя всю предысторию исходного ряда, а также имеет достаточно простое выражение сглаживания для любой i-й наблюдаемой точки, что удобно при расчетах. Стоит отметить, что предлагаемый метод сохраняет вероятностные характеристики исходного ряда наблюдений при существенном уменьшении его дисперсии. На основе результатов эксперимента в статье приведено сравнение этого метода с известными методами скользящего среднего. В результате сравнения двух методов выявлено, что метод пошагового сглаживания имеет право на существование в области монотонных трендов. После предварительного сглаживания можно приступать к распознаванию состояний системы в задачах диагноза или прогноза.
Ключевые слова: обработка данных, метод пошагового сглаживания, случайные величины.
Abstract. For complex technical systems control at the time of operation it is necessary to process a vast amounts of statistical data. Frequently, in the processing of the data (the definition of the distribution law, finding functional dependencies trend of experimental data), the result of measurement error is introduced. The presence of such errors can not only lead to an inaccurate determination of the coefficients of the functions, but not to the correct selection of the function itself. To avoid accidental factors (measurement error), a data preprocessing method is proposed. The proposed method of step-by-step smoothing, based on the calculation for each dimension of the actual value of a half-sum of the values of the measurements and the knowledge of the forecast calculated during the previous measurement. Step-by-step smoothing method can be recommended as a method of pre-smoothing statistics. With an accuracy comparable to the accuracy of the method of moving average, the smoothing method will provide the processing step from the first measurement using the whole backstory of the original series, as well as has a rather simple expression smoothing for any i observation point, which is convenient for calculations. It should be noted that the proposed method preserves the probabilistic characteristics of the original set of observations with a significant reduction of its dispersion. Based on the results of the experiment, the article shows a comparison of this method to the known method of moving average. As a result, comparison of the two methods revealed that the step-by-step smoothing method has a right to exist in monotone trend. After the pre-smoothing we can begin to recognize the system states in problems of diagnosis or prognosis.
Keywords: processing, step-by-step smoothing method, random values.
Введение
При определении состояний сложных технических систем (СТС) по результатам фиксации значений их параметров при исследовании поведения этих систем необходимо обрабатывать большие массивы экспериментальных данных, которые представляют собой наблюдаемые значения выходных параметров СТС.
Традиционная обработка таких данных в зависимости от поставленной задачи сводится либо к определению теоретического закона рас-
пределения, наилучшим образом описывающего статистическое распределение, либо к нахождению функциональной зависимости тренда экспериментальных данных. При этом все операции обработки ведутся, как правило, с исходной статистикой, имеющей сколь угодно большое рассеивание. Предварительная же обработка исходных данных сможет снизить влияние случайных факторов. Действительно, при определении функциональной зависимости тренда результат измерения выходных параметров системы содержит ошибку
измерения. Наличие такой ошибки создаёт неблагоприятные условия при оценке тренда. Эти условия могут привести не только к неточному определению коэффициентов функции, описывающей тренд, но и к неправильному выбору самой функции.
Описание метода
Пусть модель выходного параметра исследуемой системы представлена в виде [3, 8, 9]
у *($) = у(0+Ау(0, (1)
где у(1) — неслучайная составляющая, или тренд параметра; Ау(1) — аддитивный шум, состоящий из шумов, воздействующих на систему и измеритель, дрейфа системы и ошибок измерения. Предположим, что составляющие шума — это независимые случайные величины с конечными дисперсиями. В настоящей статье предлагается один из возможных методов предварительного сглаживания экспериментальных данных.
Таким образом, у * (^) представляет собой случайный процесс с трендом уи случайной составляющей Ау(1), а его значения измерение в 7 -й момент времени ti (/’ = 0, 1, …, п) является случайной величиной
у, * = у + Ау. (2)
Аддитивный шум Ау(^), исходя из ранее высказанных предположений, считать распределенным нормально с нулевым математическим ожиданием [3].
Для распознавания состояний системы в любой момент времени необходимо оценить значение тренда, в общем случае неизвестного, модели (1) по измерениям (2). Одним из этапов оценивания является фильтрация или сглаживание. Фильтрацию результатов измерений можно условно разделить на два этапа:
— предварительная обработка данных;
— выбор сглаживающей функции и оценка ее коэффициентов.
В статье в качестве метода предварительной обработки данных предлагается пошаговое сглаживание. Предлагаемый метод не является радикальной альтернативой методу скользящего среднего. Однако можно указать ряд недостатков последнего:
— не существует точных рекомендаций выбора количества точек для сглаживания;
— формальное выражение сглаживания при любом количестве точек существует только для «средней» точки;
— вид сглаживающей формулы для «крайних» точек зависит от выбранного количества точек.
Другим распространенным методом является фильтрация на основе фильтра Калмана [5]. Этот метод требует достаточно сложного математического описания задачи. Кроме того, такие фильтры не всегда удобны для реализации.
Суть метода пошагового сглаживания (МПС) состоит в получении после очередного измерения у *(г = 0,1,…,п) оценки у , истинного
значения параметра у .
В основе сглаживания лежит вычисление полусуммы значения измерения, полученного в г -й момент времени и значения частного прогноза уг_1)г на г -й момент времени, полученного в предыдущий (г — 1) момент:
уг =
у * +Уд—1), 2
(3)
Величина частного прогноза у(,г—1)г определяется через оценки ~у и ~у , полученные на предыдущих измерениях. Получение (3) можно проиллюстрировать с помощью рис. 1. Для этого необходимо рассмотреть три следующих друг за другом момента времени: ?-_2, ^, ^ . Пусть для
моментов времени , получены соответствующие оценки у , Уу . Элемент сглаживающей функции, лежащий между точками
-1, У г—1), представляет собой линейный отрезок, наклоненный к оси абсцисс под углом а ._2 = аг х. Естественно предположить, что тенденция угловых характеристик этого отрезка, лежащего на временном интервале (/г_2, х), сохранится и на соседнем интервале , ). Тогда, при продолжении отрезка линейной функции до сечения ^ получится точка В, ордината которой и
будет частным прогнозом У(г—1)г возможного значения у .
Использование полусуммы (3) может быть оправдано по следующим причинам:
— в момент времени ^ получены значения измерения у * и частного прогноза у^г—1)г. Следовательно, для данного момента это уже детерминированные величины, относительно которых оценка тренда У является неизвестной случайной величиной, лежащей в интервале от у * до у(г—^ ;
— значение случайной величины у при попадании в интервал (у, *,У(,г—1у) с равной вероятностью
Информатика, вычислительная техника и управление. Моделирование. Приборостроение. Метрология. Информационно-измерительные приборы и системы
9(1-1)1 Б
——1 Щ-1 с * У; V
У1-1
У1-2
к-2 к-1 к 1
Рис. 1. Получение полусуммы (3)
может появиться в любой точке этого интервала. Тогда закон распределения этой случайной величины при условии, что ух ,ух е(ух *,у^_Г)1) является равномерным с математическим ожиданием
* жг~ -I у- * + ~(‘_!)’
М [у ] =—, что соответствует выражению (3);
— нет никаких объективных данных для того, чтобы включать слагаемые числителя (3) с разными по весу и отличающимися от единицы коэффициентами.
Таким образом, с помощью преобразования (3) из исходного ряда у0*,у1 *,…,уп * получается
новый ряд: ,..уп. Общий член нового ряда
может быть записан в виде рекуррентного соотношения
Уо + 1 2°_1) у1 * +Е 2(М)(у_г_ ~_2)
ук = ■
1=1
1=2
2
. (4)
Здесь имеет место допущение: в момент получено измерение у0 *, для которого полагаем, что у0 = уо *, так как до момента измерений не было.
Выражение (4) линейно преобразует измерения у * в оценку у. Действительно, (4) можно представить в виде
к к _1
У к = 1 агуг * + 1 Ъх У г , (5)
г=1 1=0
2(«-1) 2г
где ^ =^ =при 1 = 0, 1, …, к-2 21
и Ъi =— при 1 = к _ 1.
Из (5) следует, что для любого 1 < к < п оценка Уу является линейным преобразованием
измерения ух * . Тогда закон распределения ряда оценок идентичен закону ряда измерений.
Для оценки разброса сглаженной статистики измерений предлагается использовать частное от деления дисперсии оценок на дисперсию измерений:
I (У- _ у )2
о =
г =0
(6)
I (уг * _уг )2
Модельный эксперимент
Исходя из вышеприведенного можем предположить, что оценка (6) должна быть правильной положительной дробью, так как целью МПС является уменьшение дисперсии измерения для целей более точного прогноза. Для подтверждения этого предположения проведен модельный эксперимент с использованием ПЭВМ. Суть эксперимента заключается в следующем: задается некая известная функция в качестве тренда, на неё накладывается нормальный случайный процесс с постоянной дисперсией, заранее установленным шагом, моделирующим некий временной интервал Дt, и функцией математического ожидания в виде заданного тренда. Наложенный случайный процесс моделирует измерения выходного параметра гипотетической СТС. Затем случайный процесс сглаживается с помощью МПС. В результате сглаживания получается новый случайный процесс, оценивающий тренд. После этого рассчитывается оценка (6) на базе исходного и сглаженного случайных процессов. В качестве тренда были использованы следующие монотонные функции:
1=0
у$) = аг; У 2 (г) = аг + Ъ; Уз(г) = е~а; У4(г) = 1- е~а а
У 5 =
Уб =
Ъ+е а
-г
-Г ‘
1 + Ъе~
Предлагаемые функции характерны для описания незашумленных выходных параметров различных технических систем [1, 2, 4, 6, 7, и др.]. Значения коэффициентов а и Ъ были выбраны произвольно (примем их равными а = Ъ = 0,5), так как, предположительно, они не должны влиять на результаты.
Продолжительность наблюдений в ходе эксперимента составила 600 единиц условного времени. Было проведено по 50 измерений каждого случайного процесса с различными вариантами дисперсий (от 0,2 до 0,9) и с равными интервалами между измерениями через каждые Аг = 12 единиц условного времени. Результаты измерений сведены в табл. 1.
Как видно из таблицы, значения качества полностью соответствуют выводам пункта 3.2 и лежат в диапазоне от минимального значения
0,3128672 для тренда х(г) = е~°’5г с ст = 0,4 до максимального значения 0,8966029 для того же тренда со средним квадратическим отклонением (с. к. о.), равным 0,6. Использование других значений коэффициентов и других величин дисперсий также приводит к результатам, не противоречащим выводам теоремы.
Результаты эксперимента показывают, что А = — > 0, что соответствует начальным
предположениям.
Следующим этапом эксперимента была оценка коэффициентов этих же шести функций по данным:
— несглаженного зашумленного временного ряда;
— сглаженного зашумленного ряда методом пошагового сглаживания;
— сглаженного зашумленного ряда трехточечным методом скользящей средней (МСС);
— сглаженного зашумленного ряда пятиточечным МСС.
iНе можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
Сглаживание трёх- и пятиточечным МСС и дальнейшая оценка коэффициентов проводилась с помощью метода наименьших квадратов. Ниже приводятся таблицы с результатами оценивания. Оценки для:
1. Линейной функции х(г) = аг (приведены в табл. 2).
2. Линейной функции х(г) = аг + Ъ (приведены в табл. 3).
3. Нелинейной
—аг,
х(г) = е а’ (приведены в табл. 4).
4. Нелинейной функции (приведены в табл. 5).
функции х(г) = 1 — е~аг
5. Нелинейной функции х(г) = (приведены в табл. 6).
6. Нелинейной функции х(г) =
а
Ъ + е~
а
1 + Ъе~
(приведены в табл. 7).
Т а б л и ц а 1
Результаты модельного эксперимента
Функция Коэф-ты СКО
0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9
а Ь Оценка О
х(г) = аг 0,5 — 0,6003575 0,3694950 0,8374345 0,6397602 0,6473997 0,4916939 0,4234376 0,5386353
х(г) = аг+Ъ 0,5 0,5 0,6003569 0,3694590 0,8374338 0,6397604 0,6473999 0,4916941 0,4234376 0,5386352
х(г) = е~а 0,5 — 0,5064889 0,3128670 0,8966026 0,6509480 0,6587199 0,5085787 0,4217945 0,5453926
х(г) = 1 — е-аг 0,5 — 0,6220262 0,3435210 0,8342351 0,6576769 0,6420969 0,4954006 0,4297238 0,5335760
, , а х(г) = и —г Ъ + е 0,5 0,5 0,5922028 0,3390020 0,8368902 0,6544768 0,6421866 0,4959345 0,4274258 0,5350060
. ч а х(г) = 1 т —г 1 + Ъе ‘ 0,5 0,5 0,5330376 0,3214990 0,8530750 0,6534748 0,6467974 0,4897750 0,4262425 0,5374114
ш
Т а б л и ц а 2
Функция вида х(г) = аг
СКО шума Коэффиц. тренда Оценка к-тов МНК по шуму Оценка к-тов МНК по МПС Оценка к-тов МНК по МСС3 Оценка к-тов МНК по МСС5
О а а а а а
0,2 0,5 0,4988545 0,4988247 0,4988497 0,5096186
0,4 0,5 0,4996659 0,5000678 0,4995122 0,5103278
0,6 0,5 0,4962999 0,4962517 0,4962234 0,5070680
0,8 0,5 0,5011413 0,5012652 0,5010183 0,5112152
1,0 0,5 0,5031147 0,5026605 0,5033873 0,5141924
1,2 0,5 0,4954727 0,4965186 0,4951000 0,5052923
1, 4 0,5 0,5079270 0,5077390 0,5075793 0,5183021
1,6 0,5 0,5027862 0,5003039 0,5036218 0,5137751
Примечание. В таблицах 2-7 применяются следующие аббревиатуры: МНК — метод наименьших квадратов; МПС — метод пошагового сглаживания; МСС3 — трехточечный метод скользящей средней; МСС5 -пятиточечный метод скользящей средней.
Т а б л и ц а 3
Функция вида х(г) = аг + Ъ
СКО К-тов Оценки к-тов МНК Оценки к-тов МНК Оценки к-тов МНК Оценки к-тов МНК
шума тренда по шуму по МПС по МСС3 по МСС5
О а Ъ а Ъ а Ъ а Ъ а Ъ
0,2 0,5 0,5 0,4995489 0,4863515 0,5007167 0,4452097 0,4996172 0,4838380 0,5208461 0,1325024
0,4 0,5 0,5 0,4990620 0,5309495 0,5030666 0,4371847 0,4981436 0,5572208 0,5198604 0,1907270
0,6 0,5 0,5 0,4973845 0,4729438 0,4988276 0,4217120 0,4969989 0,4835628 0,5183241 0,1315252
0,8 0,5 0,5 0,4948993 0,7246381 0,4931525 0,7889065 0,4951907 0,7104045 0,5171244 0,3461230
1,0 0,5 0,5 0,5061079 0,4073763 0,4920201 0,4319234 0,4883848 0,7408934 0,5276122 0,3571897
1,2 0,5 0,5 0,4886254 0,7454371 0,4920201 0,6644370 0,4883848 0,7408934 0,5073311 0,4416660
1,4 0,5 0,5 0,5033539 0,6673081 0,5063585 0,5576286 0,5025288 0,6837263 0,5242499 0,3138798
1,6 0,5 0,5 0,5040834 0,4656422 0,5086894 0,5223117 0,5039057 0,5004501 0,5234078 0,1872861
Т а б л и ц а 4
Функция вида х(г) = е а
СКО шума Коэффиц. тренда Оценка к-тов МНК по шуму Оценка к-тов МНК по МПС Оценка к-тов МНК по МСС3 Оценка к-тов МНК по МСС5
О а а а а а
0,2 0,5 0,407 0,403 0,390 0,369
0,4 0,5 0,916 0,693 0,527 0,384
0,6 0,5 0,535 0,489 0,530 0,486
0,8 0,5 0,113 0,116 0,114 0,116
1,0 0,5 0,811 0,711 0,870 1,080
1,2 0,5 0,332 0,338 0,334 0,317
1, 4 0,5 0,175 0,180 0,166 0,148
1,6 0,5 1,000 0,833 0,732 0,418
Т а б л и ц а 5
Функция вида х(г) = 1 — е а
СКО шума Коэффиц. тренда Оценка к-тов МНК по шуму Оценка к-тов МНК по МПС Оценка к-тов МНК по МСС3 Оценка к-тов МНК по МСС5
О а а а а а
0,2 0,5 0,654 0,580 0,604 0,509
0,4 0,5 0,380 0,380 0,427 0,470
0,6 0,5 0,400 0,447 0,350 0,334
0,8 0,5 2,150 1,160 0,920 0,610
1,0 0,5 0,293 0,296 0,283 0,263
1,2 0,5 2,300 1,610 2,130 0,800
1, 4 0,5 1,100 0,870 1,800 2,300
1,6 0,5 0,190 0,200 0,220 1,200
Функция вида х(‘) =
Ь + е~’
Т а б л и ц а 6
а
СКО шума К-ты тренда Оценки к-тов МНК по шуму Оценки к-тов МНК по МПС Оценки к-тов МНК по МСС3 Оценки к-тов МНК по МСС5
О а Ь а Ь а Ь а Ь а Ь
0,2 0,5 0,5 0,720 0,750 0,470 0,490 0,667 0,696 0,711 0,737
0,4 0,5 0,5 1,100 1,200 0,150 0,150 1,900 1,830 1,920 1,370
0,6 0,5 0,5 0,820 0,910 0,396 0,511 0,873 1,000 1,110 1,120
0,8 0,5 0,5 0,796 0,859 0,681 0,650 0,213 0,223 0,900 0,886
1,0 0,5 0,5 0,200 0,320 0,340 0,300 0,200 0,204 0,200 0,200
1,2 0,5 0,5 1,000 1,100 1,000 1,100 1,100 1,100 1,000 1,100
1,4 0,5 0,5 1,100 0,920 0,526 0,411 0,591 0,476 0,611 0,512
1,6 0,5 0,5 1,100 0,914 0,313 0,308 0,811 0,795 1,100 0,938
Т а б л и ц а 7
Функция вида х(Г) =
1 + Ье-‘
СКО шума К-ты тренда Оценки к-тов МНК по шуму Оценки к-тов МНК по МПС Оценки к-тов МНК по СС3 Оценки к-тов МНК по СС5
О а Ь а Ь а Ь а Ь а Ь
0,2 0,5 0,5 0,510 0,320 0,508 0,512 0,514 0,420 0,500 0,218
0,4 0,5 0,5 0,497 0,201 0,512 0,693 0,503 0,221 0,500 0,198
0,6 0,5 0,5 0,410 0,320 0,420 0,223 0,300 0,217 0,410 0,330
0,8 0,5 0,5 0,630 1,100 0,612 0,326 0,601 1,120 0,587 0,980
iНе можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
1,0 0,5 0,5 0,621 1,160 0,620 1,080 0,610 1,110 0,600 1,100
1,2 0,5 0,5 0,423 0,210 0,500 0,220 0,450 0,260 0,468 1,090
1,4 0,5 0,5 0,690 0,341 0,690 0,437 0,695 0,430 0,699 0,312
1,6 0,5 0,5 0,500 0,610 0,430 0,510 0,502 0,636 0,625 0,219
а
Выводы
Из табл. 2-7 видно, что оценки коэффициентов а и Ь , вычисленные на основе трёх- и пятиточечного МСС, имеют в среднем тот же порядок ошибки по сравнению с истинными значениями этих коэффициентов, что и полученные по предлагаемому методу пошагового сглаживания. Из этого можно сделать вывод, что оценки коэффициентов тренда для любого / -го момента времени, полученные на основе статистического материала, сглаженного с помощью МПС, не хуже тех, которые получены с помощью МСС. Однако последний метод имеют ряд недостатков:
1. Не существует точных рекомендаций выбора количества точек для сглаживания. Известно, что большее число точек обеспечивает большую точность, но более медленную реакцию на изменение тренда. Меньшее число точек даёт меньшую точность, но более быструю реакцию. В [7] говорится, что количество точек для сглаживания целесообразно выбирать от 6 до 20. Диапазон достаточно велик, и поэтому выбор количества точек не определён.
2. Общее формальное выражение сглаживания при любом количестве точек существует толь-
ко для «средней» точки. Вид сглаживающих формул для «крайних» точек зависит от способа сглаживания, например в трехточечном методе существуют выражения для «первой» и «третьей» точек группы, а в пятиточечном — для «первой», «второй», «четвёртой» и «пятой» точек.
3. Удобный расчёт по «средней» точке оставляет неосредненными важные для прогнозирования «крайние» точки.
Метод пошагового сглаживания можно рекомендовать как метод предварительного сглаживания статистических данных. Обладая точностью, сопоставимой с точностью МСС, он:
— обеспечивает обработку с самого первого измерения, используя всю предысторию исходного ряда;
— имеет достаточно простое выражение сглаживания для любой / -й наблюдаемой точки, что удобно при расчётах;
— сохраняет вероятностные характеристики исходного ряда наблюдений при существенном уменьшении его дисперсии.
Сравнение МПС с МСС говорит о том, что метод пошагового сглаживания имеет право на существование в области монотонных трендов.
m
После предварительного сглаживания можно приступать к распознаванию состояний системы в задачах диагноза или прогноза.
БИБЛИОГРАФИЧЕСКИЙ СПИСОК
1. Дедков В.К., Северцев Н.А. Основные вопросы эксплуатации сложных систем. М. : Высшая школа, 1976. 405 с.
2. Инженерно-авиационная служба и эксплуатация авиационного оборудования / под ред. Е.А. Румянцева. М. : ВВИА им. проф. Н. Е. Жуковского, 1970. 514 с.
3. Новицкий П.В., Зоограф И.А. Оценка погрешностей результатов измерений. Л. : Энергоатомоиздат, 1985. 246 с.
4. Рабочая книга по прогнозированию / под ред. И В. Бестужева-Лады. М. : Мысль, 1982. 430 с.
5. Современные методы идентификации систем / под ред. Эйкхоффа П. М. : Мир, 1985. 686 с.
6. Теория прогнозирования и принятия решений / под ред. Саркисяна С.А. М. : Высшая школа, 1977. 351 с.
7. Чуев Ю.В., Михайлов Ю.Б., Кузьмин В.И. Прогнозирование количественных характеристик процессов. М. : Соврадио, 1975. 400 с.
8. Ермаков А.А. К вопросу о распознавании состояний технического объекта методом последовательных процедур // Науч.-метод.. материалы по вопр. эксплуатации авиационного оборудования. ВВИА им. проф. Н.Е. Жуковского. М., 1981. С. 9-14.
9. Ермаков А.А. Многоальтернативная последовательная процедура в задачах распознавания технических состояний // Идентификация, измерение характеристик и имитация случайных сигналов : тез. докл. научн.-тех. конф. Новосибирск, 1994. С.165-166.
УДК 681.518:378 Воропаева Виктория Яковлевна,
к. т. н., профессор кафедры автоматики и телекоммуникаций, Донецкий национальный технический университет, е-mail: voropayeva@meta.ua
Шапо Владлен Феликсович,
к. т. н., доцент кафедры теории автоматического управления и вычислительной техники,
Одесская национальная морская академия, е-mail: stani@te.net.ua
МЕТОД РАСЧЕТА ЗАГРУЗКИ ПРОМЫШЛЕННЫХ КОМПЬЮТЕРНЫХ СЕТЕЙ И ВЫБОРА КОНФИГУРАЦИИ УПРАВЛЯЮЩИХ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ
V. Y. Voropayeva, V. F. Shapo
METHOD OF INDUSTRIAL COMPUTER SYSTEMS UTILIZATION CALCULATING AND CONFIGURATION OF CONTROL COMPUTER SYSTEMS CHOOSING
Аннотация. Статья посвящена актуальным проблемам построения открытых систем автоматизации с обеспечением согласованного взаимодействия разнообразных конечных устройств автоматики и протоколов промышленных сетей от различных производителей.
Предложен метод расчета объема данных, передающихся по промышленной компьютерной сети, в зависимости от решаемых задач и количества промышленного оборудования. Проанализированы характеристики микроконтроллеров, являющихся основой для управляющих вычислительных систем на производстве.
Получены математические зависимости, позволяющие рассчитать объем данных, передаваемых по промышленной компьютерной сети, и ее требуемую пропускную способность. Даны рекомендации по выбору пропускной способности сегментов промышленной компьютерной сети, производительности процессоров и объема памяти микроконтроллеров при выборе конфигурации управляющих вычислительных систем в промышленных компьютерных сетях.
Предложен метод расчета объема данных, передающихся по промышленной компьютерной сети в зависимости от решаемых задач и количества промышленного оборудования, формализующий процедуру выбора сетевой технологии, пропускных способностей сегментов промышленной компьютерной сети.
Ключевые слова: промышленная сеть, fieldbus, датчик, исполнительный механизм, микроконтроллер, пропускная способность, сетевой трафик.
Abstract. The article is devoted to an actual problems of open systems automation software coordinated interaction of various endpoints automation and industrial networking protocols from various manufacturers.
A method for calculating the amount of data transmitted over a computer network in the industry depending on the task and the number of industrial equipment is proposed. Characteristics of microcontrollers which are the base of industrial computer systems are analyzed.
Mathematical dependences, which allow calculating data transferring through industrial computer network and its necessary bandwidth are obtained. Recommendations on bandwidths choosing of industrial computer network segments,
![]()
Анализ временных рядов
- Общее введение
- Две основные цели
- Идентификация модели
временных рядов- Систематическая
составляющая и случайный шум - Два общих типа компонент
временных рядов - Анализ тренда
- Анализ сезонности
- Систематическая
- АРПСС (Бокс и Дженкинс) и
автокорреляции- Общее введение
- Два основных процесса
- Модель АРПСС
- Идентификация
- Оценивание параметров
- Оценивание модели
- Прерванные временные ряды
- Экспоненциальное
сглаживание- Общее введение
- Простое экспоненциальное
сглаживание - Выбор лучшего значения
параметра a (альфа) - Индексы качества подгонки
- Сезонная и несезонная модели
с трендом или без тренда
- Сезонная декомпозиция (метод
Census I)- Общее введение
- Вычисления
- Сезонная корректировка X-11
(метод Census II)- Сезонная корректировка:
основные идеи и термины - Метод Census II
- Таблицы результатов
корректировки X-11 - Подробное описание всех
таблиц результатов, вычисляемых в методе X-11
- Сезонная корректировка:
- Анализ распределенных лагов
- Общая цель
- Общая модель
- Распределенный лаг Алмона
- Одномерный анализ Фурье
- Кросс-спектральный анализ
- Общее введение
- Основные понятия и принципы
- Результаты для каждой
переменной - Кросс-периодограмма,
кросс-плотность, квадратурная плотность и
кросс-амплитуда - Квадрат когерентности,
усиление и фазовый сдвиг - Как создавались данные для
примера
- Спектральный анализ —
Основные понятия и принципы- Частота и период
- Общая структура модели
- Простой пример
- Периодограмма
- Проблема рассеяния
- Добавление констант во
временной ряд (пэддинг) - Косинус-сглаживание
- Окна данных и оценки
спектральной плотности - Подготовка данных к анализу
- Результаты для случая, когда в
ряде отсутствует периодичность
- Быстрое преобразование Фурье
- Общее введение
- Вычисление БПФ во временных
рядах
В следующих разделах мы вначале представим
обзор методов, используемых для идентификации
моделей временных рядов (таких как сглаживание,
подгонка и автокорреляции). Затем опишем общий
класс моделей, которые могут быть использованы
для описания рядов и построения прогнозов
(модели авторегрессии и скользящего среднего).
Наконец, расскажем о некоторых простых, но часто
используемых методах, основанных на линейной
регрессии. За дальнейшей информацией обратитесь
к соответствующим разделам.
Общее введение
Вначале дадим краткий обзор методов анализа
данных, представленных в виде временных рядов,
т.е. в виде последовательностей измерений,
упорядоченных в неслучайные моменты времени. В
отличие от анализа случайных выборок, анализ
временных рядов основывается на предположении,
что последовательные значения в файле данных
наблюдаются через равные промежутки времени
(тогда как в других методах нам не важна и часто
не интересна привязка наблюдений ко времени).
Подробное обсуждение этих методов можно найти
в следующих работах: Anderson (1976), Бокс и Дженкинс
(1976), Kendall (1984), Kendall and Ord (1990), Montgomery, Johnson, and Gardiner (1990),
Pankratz (1983), Shumway (1988), Vandaele (1983), Walker (1991), Wei (1989).
Две основные цели
Существуют две основные цели анализа временных
рядов: (1) определение природы ряда и (2)
прогнозирование (предсказание будущих значений
временного ряда по настоящим и прошлым
значениям). Обе эти цели требуют, чтобы модель
ряда была идентифицирована и, более или менее,
формально описана. Как только модель определена,
вы можете с ее помощью интерпретировать
рассматриваемые данные (например, использовать в
вашей теории для понимания сезонного изменения
цен на товары, если занимаетесь экономикой). Не
обращая внимания на глубину понимания и
справедливость теории, вы можете
экстраполировать затем ряд на основе найденной
модели, т.е. предсказать его будущие значения.
Идентификация модели временных
рядов
- Систематическая
составляющая и случайный шум - Два общих типа компонент
временных рядов - Анализ тренда
- Анализ сезонности
За более полной информацией о простых
автокорреляциях (обсуждаемых в этом разделе) и
других автокорреляциях, см. Anderson (1976), Box and Jenkins
(1976), Kendall (1984), Pankratz (1983), and Vandaele (1983). См. также:
- АРПСС (Бокс и Дженкинс) и
автокорреляции - Прерванные временные ряды
- Экспоненциальное
сглаживание - Сезонная декомпозиция (метод
Census I) - Сезонная корректировка X-11
(метод Census II) - Таблицы результатов
корректировки X-11 - Анализ распределенных лагов
- Одномерный анализ Фурье
- Кросс-спектральный анализ
- Основные понятия и принципы
- Быстрое преобразование Фурье
Систематическая составляющая и
случайный шум
Как и большинство других видов анализа, анализ
временных рядов предполагает, что данные
содержат систематическую составляющую (обычно
включающую несколько компонент) и случайный шум
(ошибку), который затрудняет обнаружение
регулярных компонент. Большинство методов
исследования временных рядов включает различные
способы фильтрации шума, позволяющие увидеть
регулярную составляющую более отчетливо.
Два общих типа компонент
временных рядов
Большинство регулярных составляющих временных
рядов принадлежит к двум классам: они являются
либо трендом, либо сезонной составляющей. Тренд
представляет собой общую систематическую
линейную или нелинейную компоненту, которая
может изменяться во времени. Сезонная
составляющая — это периодически повторяющаяся
компонента. Оба эти вида регулярных компонент
часто присутствуют в ряде одновременно.
Например, продажи компании могут возрастать из
года в год, но они также содержат сезонную
составляющую (как правило, 25% годовых продаж
приходится на декабрь и только 4% на август).

Эту общую модель можно понять на
«классическом» ряде — Ряд G (Бокс и
Дженкинс, 1976, стр. 531), представляющем месячные
международные авиаперевозки (в тысячах) в
течение 12 лет с 1949 по 1960 (см. файл Series_g.sta).
График месячных перевозок ясно показывает почти
линейный тренд, т.е. имеется устойчивый рост
перевозок из года в год (примерно в 4 раза больше
пассажиров перевезено в 1960 году, чем в 1949). В то же
время характер месячных перевозок повторяется,
они имеют почти один и тот же характер в каждом
годовом периоде (например, перевозок больше в
отпускные периоды, чем в другие месяцы). Этот
пример показывает довольно определенный тип
модели временного ряда, в которой амплитуда
сезонных изменений увеличивается вместе с
трендом. Такого рода модели называются моделями
с мультипликативной сезонностью.
Анализ тренда
Не существует «автоматического» способа
обнаружения тренда в временном ряде. Однако если
тренд является монотонным (устойчиво возрастает
или устойчиво убывает), то анализировать такой
ряд обычно нетрудно. Если временные ряды
содержат значительную ошибку, то первым шагом
выделения тренда является сглаживание.
Сглаживание. Сглаживание всегда включает
некоторый способ локального усреднения данных,
при котором несистематические компоненты
взаимно погашают друг друга. Самый общий метод
сглаживания — скользящее среднее, в котором
каждый член ряда заменяется простым или
взвешенным средним n соседних членов, где n
— ширина «окна» (см. Бокс и Дженкинс, 1976; Velleman
and Hoaglin, 1981). Вместо среднего можно использовать
медиану значений, попавших в окно. Основное
преимущество медианного сглаживания, в
сравнении со сглаживанием скользящим средним,
состоит в том, что результаты становятся более
устойчивыми к выбросам (имеющимся внутри окна).
Таким образом, если в данных имеются выбросы
(связанные, например, с ошибками измерений), то
сглаживание медианой обычно приводит к более
гладким или, по крайней мере, более
«надежным» кривым, по сравнению со
скользящим средним с тем же самым окном. Основной
недостаток медианного сглаживания в том, что при
отсутствии явных выбросов, он приводит к более
«зубчатым» кривым (чем сглаживание
скользящим средним) и не позволяет использовать
веса.
Относительно реже, когда ошибка измерения
очень большая, используется метод сглаживания
методом наименьших квадратов, взвешенных
относительно расстояния или метод отрицательного
экспоненциально взвешенного сглаживания. Все
эти методы отфильтровывают шум и преобразуют
данные в относительно гладкую кривую (см.
соответствующие разделы, где каждый из этих
методов описан более подробно). Ряды с
относительно небольшим количеством наблюдений и
систематическим расположением точек могут быть
сглажены с помощью бикубических сплайнов.
Подгонка функции. Многие монотонные
временные ряды можно хорошо приблизить линейной
функцией. Если же имеется явная монотонная
нелинейная компонента, то данные вначале следует
преобразовать, чтобы устранить нелинейность.
Обычно для этого используют логарифмическое,
экспоненциальное или (менее часто)
полиномиальное преобразование данных.
Анализ сезонности
Периодическая и сезонная зависимость
(сезонность) представляет собой другой общий тип
компонент временного ряда. Это понятие было
проиллюстрировано ранее на примере
авиаперевозок пассажиров. Можно легко видеть,
что каждое наблюдение очень похоже на соседнее;
дополнительно, имеется повторяющаяся сезонная
составляющая, это означает, что каждое
наблюдение также похоже на наблюдение, имевшееся
в том же самом месяце год назад. В общем,
периодическая зависимость может быть формально
определена как корреляционная зависимость
порядка k между каждым i-м элементом ряда и
(i-k)-м элементом (Kendall, 1976). Ее можно измерить с
помощью автокорреляции (т.е. корреляции между
самими членами ряда); k обычно называют лагом
(иногда используют эквивалентные термины:
сдвиг, запаздывание). Если ошибка измерения не
слишком большая, то сезонность можно определить
визуально, рассматривая поведение членов ряда
через каждые k временных единиц.
Автокорреляционная коррелограмма. Сезонные
составляющие временного ряда могут быть найдены
с помощью коррелограммы. Коррелограмма
(автокоррелограмма) показывает численно и
графически автокорреляционную функцию (AКФ),
иными словами коэффициенты автокорреляции (и их
стандартные ошибки) для последовательности
лагов из определенного диапазона (например, от 1
до 30). На коррелограмме обычно отмечается
диапазон в размере двух стандартных ошибок на
каждом лаге, однако обычно величина
автокорреляции более интересна, чем ее
надежность, потому что интерес в основном
представляют очень сильные (а, следовательно,
высоко значимые) автокорреляции (см. Элементарные
понятия статистики).
Исследование коррелограмм. При изучении
коррелограмм следует помнить, что
автокорреляции последовательных лагов
формально зависимы между собой. Рассмотрим
следующий пример. Если первый член ряда тесно
связан со вторым, а второй с третьим, то первый
элемент должен также каким-то образом зависеть
от третьего и т.д. Это приводит к тому, что
периодическая зависимость может существенно
измениться после удаления автокорреляций
первого порядка, т.е. после взятия разности с
лагом 1).

Частные автокорреляции. Другой полезный
метод исследования периодичности состоит в
исследовании частной автокорреляционной
функции (ЧАКФ), представляющей собой
углубление понятия обычной автокорреляционной
функции. В ЧАКФ устраняется зависимость между
промежуточными наблюдениями (наблюдениями внутри
лага). Другими словами, частная автокорреляция на
данном лаге аналогична обычной автокорреляции,
за исключением того, что при вычислении из нее
удаляется влияние автокорреляций с меньшими
лагами (см. Бокс и Дженкинс, 1976; см. также McDowall,
McCleary, Meidinger, and Hay, 1980). На лаге 1 (когда нет
промежуточных элементов внутри лага), частная
автокорреляция равна, очевидно, обычной
автокорреляции. На самом деле, частная
автокорреляция дает более «чистую» картину
периодических зависимостей.
Удаление периодической зависимости. Как
отмечалось выше, периодическая составляющая для
данного лага k может быть удалена взятием
разности соответствующего порядка. Это означает,
что из каждого i-го элемента ряда вычитается (i-k)-й
элемент. Имеются два довода в пользу таких
преобразований.
Во-первых, таким образом можно определить
скрытые периодические составляющие ряда.
Напомним, что автокорреляции на
последовательных лагах зависимы. Поэтому
удаление некоторых автокорреляций изменит
другие автокорреляции, которые, возможно,
подавляли их, и сделает некоторые другие
сезонные составляющие более заметными.
Во-вторых, удаление сезонных составляющих
делает ряд стационарным,
что необходимо для применения АРПСС
и других методов, например, спектрального
анализа.
АРПСС
- Общее введение
- Два основных процесса
- Модель АРПСС
- Идентификация
- Оценивание параметров
- Оценивание модели
Дополнительная информация о методах Анализа
временных рядов дана также в следующих
разделах:
- Идентификация модели
временных рядов - Прерванные временные ряды
- Экспоненциальное
сглаживание - Сезонная декомпозиция (метод
Census I) - Сезонная корректировка X-11
(метод Census II) - Таблицы результатов
корректировки X-11 - Анализ распределенных лагов
- Одномерный анализ Фурье
- Кросс-спектральный анализ
- Основные понятия и принципы
- Быстрое преобразование Фурье
Общее введение
Процедуры оценки параметров и прогнозирования,
описанные в разделе Идентификация
модели временных рядов, предполагают, что
математическая модель процесса известна. В
реальных данных часто нет отчетливо выраженных
регулярных составляющих. Отдельные наблюдения
содержат значительную ошибку, тогда как вы
хотите не только выделить регулярные компоненты,
но также построить прогноз. Методология АРПСС,
разработанная Боксом и Дженкинсом (1976), позволяет
это сделать. Данный метод чрезвычайно популярен
во многих приложениях, и практика подтвердила
его мощность и гибкость (Hoff, 1983; Pankratz, 1983; Vandaele, 1983).
Однако из-за мощности и гибкости, АРПСС — сложный
метод. Его не так просто использовать, и
требуется большая практика, чтобы овладеть им.
Хотя часто он дает удовлетворительные
результаты, они зависят от квалификации
пользователя (Bails and Peppers, 1982). Следующие разделы
познакомят вас с его основными идеями. Для
интересующихся кратким, рассчитанным на
применение, (нематематическим) введением в АРПСС,
рекомендуем книгу McCleary, Meidinger, and Hay (1980).
Два основных процесса
Процесс авторегрессии. Большинство
временных рядов содержат элементы, которые
последовательно зависят друг от друга. Такую
зависимость можно выразить следующим
уравнением:
xt = ![]()
+ ![]() 1*x(t-1) +
1*x(t-1) + ![]() 2*x(t-2) +
2*x(t-2) + ![]() 3*x(t-3) + … +
3*x(t-3) + … + ![]()
Здесь:
![]() —
—
константа (свободный член),
![]() 1,
1,
![]() 2,
2,
![]() 3
3
— параметры авторегрессии.
Вы видите, что каждое наблюдение есть сумма
случайной компоненты (случайное воздействие, ![]() ) и линейной
) и линейной
комбинации предыдущих наблюдений.
Требование стационарности. Заметим, что
процесс авторегрессии будет стационарным
только, если его параметры лежат в определенном
диапазоне. Например, если имеется только один
параметр, то он должен находиться в интервале -1<![]() <+1. В противном случае,
<+1. В противном случае,
предыдущие значения будут накапливаться и
значения последующих xt могут быть
неограниченными, следовательно, ряд не будет стационарным.
Если имеется несколько параметров
авторегрессии, то можно определить аналогичные
условия, обеспечивающие стационарность (см.
например, Бокс и Дженкинс, 1976; Montgomery, 1990).
Процесс скользящего среднего. В отличие от
процесса авторегрессии, в процессе скользящего
среднего каждый элемент ряда подвержен
суммарному воздействию предыдущих ошибок. В
общем виде это можно записать следующим образом:
xt = µ + ![]() t —
t — ![]() 1*
1*![]() (t-1) —
(t-1) — ![]() 2*
2*![]() (t-2) —
(t-2) — ![]() 3*
3*![]() (t-3) — …
(t-3) — …
Здесь:
µ —
константа,
![]() 1,
1,
![]() 2,
2,
![]() 3 —
3 —
параметры скользящего среднего.
Другими словами, текущее наблюдение ряда
представляет собой сумму случайной компоненты
(случайное воздействие, ![]() ) в данный момент и линейной
) в данный момент и линейной
комбинации случайных воздействий в предыдущие
моменты времени.
Обратимость. Не вдаваясь в детали, отметим,
что существует «двойственность» между
процессами скользящего среднего и авторегрессии
(см. например, Бокс и Дженкинс, 1976; Montgomery, Johnson, and
Gardiner, 1990). Это означает, что приведенное выше
уравнение скользящего среднего можно переписать
(обратить) в виде уравнения авторегрессии
(неограниченного порядка), и наоборот. Это так
называемое свойство обратимости. Имеются
условия, аналогичные приведенным выше условиям стационарности,
обеспечивающие обратимость модели.
Модель АРПСС
Модель авторегрессии и скользящего среднего. Общая
модель, предложенная Боксом и Дженкинсом (1976)
включает как параметры авторегрессии, так и
параметры скользящего среднего. Именно, имеется
три типа параметров модели: параметры
авторегрессии (p), порядок разности (d), параметры
скользящего среднего (q). В обозначениях Бокса
и Дженкинса модель записывается как АРПСС (p, d, q).
Например, модель (0, 1, 2) содержит 0
(нуль) параметров авторегрессии (p) и 2
параметра скользящего среднего (q), которые
вычисляются для ряда после взятия разности с
лагом 1.
Идентификация. Как отмечено ранее, для
модели АРПСС необходимо, чтобы ряд был стационарным,
это означает, что его среднее постоянно, а
выборочные дисперсия и автокорреляция не
меняются во времени. Поэтому обычно необходимо
брать разности ряда до тех пор, пока он не станет
стационарным
(часто также применяют логарифмическое
преобразование для стабилизации дисперсии).
Число разностей, которые были взяты, чтобы
достичь стационарности, определяются параметром
d (см. предыдущий раздел). Для того чтобы
определить необходимый порядок разности, нужно
исследовать график ряда и автокоррелограмму.
Сильные изменения уровня (сильные скачки вверх
или вниз) обычно требуют взятия несезонной
разности первого порядка (лаг=1). Сильные
изменения наклона требуют взятия разности
второго порядка. Сезонная составляющая требует
взятия соответствующей сезонной разности (см.
ниже). Если имеется медленное убывание
выборочных коэффициентов автокорреляции в
зависимости от лага, обычно берут разность
первого порядка. Однако следует помнить, что для
некоторых временных рядов нужно брать разности
небольшого порядка или вовсе не брать их.
Заметим, что чрезмерное количество взятых
разностей приводит к менее стабильным оценкам
коэффициентов.
На этом этапе (который обычно называют идентификацией
порядка модели, см. ниже) вы также должны
решить, как много параметров авторегрессии (p)
и скользящего среднего (q) должно
присутствовать в эффективной и экономной модели
процесса. (Экономность модели означает, что в
ней имеется наименьшее число параметров и
наибольшее число степеней свободы среди всех
моделей, которые подгоняются к данным). На
практике очень редко бывает, что число
параметров p или q больше 2 (см. ниже более
полное обсуждение).
Оценивание и прогноз. Следующий, после
идентификации, шаг (Оценивание) состоит в
оценивании параметров модели (для чего
используются процедуры минимизации функции
потерь, см. ниже; более подробная информация о
процедурах минимизации дана в разделе Нелинейное оценивание).
Полученные оценки параметров используются на
последнем этапе (Прогноз) для того, чтобы
вычислить новые значения ряда и построить
доверительный интервал для прогноза. Процесс
оценивания проводится по преобразованным данным
(подвергнутым применению разностного оператора).
До построения прогноза нужно выполнить обратную
операцию (интегрировать данные). Таким
образом, прогноз методологии будет сравниваться
с соответствующими исходными данными. На
интегрирование данных указывает буква П в
общем названии модели (АРПСС = Авторегрессионное
Проинтегрированное Скользящее Среднее).
Константа в моделях АРПСС. Дополнительно
модели АРПСС могут содержать константу,
интерпретация которой зависит от подгоняемой
модели. Именно, если (1) в модели нет параметров
авторегрессии, то константа ![]() есть среднее значение ряда, если (2)
есть среднее значение ряда, если (2)
параметры авторегрессии имеются, то константа
представляет собой свободный член. Если бралась
разность ряда, то константа представляет собой
среднее или свободный член преобразованного
ряда. Например, если бралась первая разность
(разность первого порядка), а параметров
авторегрессии в модели нет, то константа
представляет собой среднее значение
преобразованного ряда и, следовательно, коэффициент
наклона линейного тренда исходного.
Идентификация
Число оцениваемых параметров. Конечно, до
того, как начать оценивание, вам необходимо
решить, какой тип модели будет подбираться к
данным, и какое количество параметров
присутствует в модели, иными словами, нужно
идентифицировать модель АРПСС. Основными
инструментами идентификации порядка модели
являются графики, автокорреляционная функция
(АКФ), частная автокорреляционная функция (ЧАКФ).
Это решение не является простым и требуется
основательно поэкспериментировать с
альтернативными моделями. Тем не менее,
большинство встречающихся на практике временных
рядов можно с достаточной степенью точности
аппроксимировать одной из 5 основных моделей (см.
ниже), которые можно идентифицировать по виду
автокорреляционной (АКФ) и частной
автокорреляционной функции (ЧАКФ). Ниже дается
список этих моделей, основанный на рекомендациях
Pankratz (1983); дополнительные практические советы
даны в Hoff (1983), McCleary and Hay (1980), McDowall, McCleary, Meidinger, and Hay
(1980), and Vandaele (1983). Отметим, что число параметров
каждого вида невелико (меньше 2), поэтому нетрудно
проверить альтернативные модели.
- Один параметр (p): АКФ — экспоненциально
убывает; ЧАКФ — имеет резко выделяющееся значение
для лага 1, нет корреляций на других лагах. - Два параметра авторегрессии (p): АКФ имеет
форму синусоиды или экспоненциально убывает;
ЧАКФ имеет резко выделяющиеся значения на лагах 1,
2, нет корреляций на других лагах. - Один параметр скользящего среднего (q): АКФ
имеет резко выделяющееся значение на лаге 1,
нет корреляций на других лагах. ЧАКФ
экспоненциально убывает. - Два параметра скользящего среднего (q): АКФ
имеет резко выделяющиеся значения на лагах 1, 2,
нет корреляций на других лагах. ЧАКФ имеет форму
синусоиды или экспоненциально убывает. - Один параметр авторегрессии (p) и один параметр
скользящего среднего (q): АКФ экспоненциально
убывает с лага 1; ЧАКФ — экспоненциально
убывает с лага 1.
Сезонные модели. Мультипликативная сезонная
АРПСС представляет естественное развитие и
обобщение обычной модели АРПСС на ряды, в которых
имеется периодическая сезонная компонента. В
дополнении к несезонным параметрам, в модель
вводятся сезонные параметры для определенного
лага (устанавливаемого на этапе идентификации
порядка модели). Аналогично параметрам простой
модели АРПСС, эти параметры называются: сезонная
авторегрессия (ps), сезонная разность (ds) и
сезонное скользящее среднее (qs). Таким
образом, полная сезонная АРПСС может быть
записана как АРПСС (p,d,q)(ps,ds,qs).
Например, модель (0,1,2)(0,1,1) включает 0
регулярных параметров авторегрессии, 2
регулярных параметра скользящего среднего и 1
параметр сезонного скользящего среднего. Эти
параметры вычисляются для рядов, получаемых
после взятия одной разности с лагом 1 и далее
сезонной разности. Сезонный лаг, используемый
для сезонных параметров, определяется на этапе
идентификации порядка модели.
Общие рекомендации относительно выбора
обычных параметров (с помощью АКФ и ЧАКФ)
полностью применимы к сезонным моделям. Основное
отличие состоит в том, что в сезонных рядах АКФ и
ЧАКФ имеют существенные значения на лагах,
кратных сезонному лагу (в дополнении к
характерному поведению этих функций,
описывающих регулярную (несезонную) компоненту
АРПСС).
Оценивание параметров
Существуют различные методы оценивания
параметров, которые дают очень похожие оценки, но
для данной модели одни оценки могут быть более
эффективны, а другие менее эффективны. В общем, во
время оценивания порядка модели используется
так называемый квазиньютоновский алгоритм
максимизации правдоподобия (вероятности)
наблюдения значений ряда по значениям
параметров (см. Нелинейное
оценивание). Практически это требует
вычисления (условных) сумм квадратов (SS)
остатков модели. Имеются различные способы
вычисления суммы квадратов остатков SS; вы
можете выбрать: (1) приближенный метод
максимального правдоподобия МакЛеода и Сейлза
(1983), (2) приближенный метод максимального
правдоподобия с итерациями назад, (3)точный метод
максимального правдоподобия по Meларду (1984).
Сравнение методов. В общем, все методы дают
очень похожие результаты. Также все методы
показали примерно одинаковую эффективность на
реальных данных. Однако метод 1 (см. выше) —
самый быстрый, и им можно пользоваться для
исследования очень длинных рядов (например,
содержащих более 30,000 наблюдений). Метод Меларда
(номер 3) может оказаться неэффективным, если
оцениваются параметры сезонной модели с большим
сезонным лагом (например, 365 дней). С другой
стороны, вы можете использовать вначале
приближенный метод максимального правдоподобия
(для того, чтобы найти прикидочные оценки
параметров), а затем точный метод; обычно
требуется только несколько итераций точного
метода (номер 3, выше), чтобы получить
окончательные оценки.
Стандартные ошибки оценок. Для всех оценок
параметров вычисляются так называемые асимптотические
стандартные ошибки, для вычисления которых
используется матрица частных производных
второго порядка, аппроксимируемая конечными
разностями (см. также раздел Нелинейное
оценивание).
Штраф. Процедура оценивания минимизирует
(условную) сумму квадратов остатков модели. Если
модель не является адекватной, может случиться
так, что оценки параметров на каком-то шаге
станут неприемлемыми — очень большими (например,
не удовлетворяют условию стационарности). В
таком случае, SS будет приписано очень большое
значение (штрафное значение). Обычно это
«заставляет» итерационный процесс удалить
параметры из недопустимой области. Однако в
некоторых случаях и эта стратегия может
оказаться неудачной, и вы все равно увидите на
экране (во время процедуры оценивания) очень
большие значения SS на серии итераций. В таких
случаях следует с осторожностью оценивать
пригодность модели. Если модель содержит много
параметров и, возможно, имеется интервенция (см.
ниже), то следует несколько раз испытать процесс
оценивания с различными начальными. Если модель
содержит много параметров и, возможно,
интервенцию (см. ниже), вам следует повторить
процедуру с различными начальными значениями
параметров.
Оценивание модели
Оценки параметров. Если значения
вычисляемой t статистики не значимы,
соответствующие параметры в большинстве случаев
удаляются из модели без ущерба подгонки.
Другой критерий качества. Другой обычной
мерой надежности модели является сравнение
прогноза, построенного по урезанному ряду с
«известными (исходными) данными».

Однако качественная модель должна не только
давать достаточно точный прогноз, но быть
экономной и иметь независимые остатки,
содержащие только шум без систематических
компонент (в частности, АКФ остатков не должна
иметь какой-либо периодичности). Поэтому
необходим всесторонний анализ остатков. Хорошей
проверкой модели являются: (a) график остатков и
изучение их трендов, (b) проверка АКФ остатков (на
графике АКФ обычно отчетливо видна
периодичность).
Анализ остатков. Если остатки
систематически распределены (например,
отрицательны в первой части ряда и примерно
равны нуля во второй) или включают некоторую
периодическую компоненту, то это
свидетельствует о неадекватности модели. Анализ
остатков чрезвычайно важен и необходим при
анализе временных рядов. Процедура оценивания
предполагает, что остатки не коррелированы и
нормально распределены.
Ограничения. Следует напомнить, что модель
АРПСС является подходящей только для рядов,
которые являются стационарными
(среднее, дисперсия и автокорреляция примерно
постоянны во времени); для нестационарных рядов
следует брать разности. Рекомендуется иметь, как
минимум, 50 наблюдений в файле исходных данных.
Также предполагается, что параметры модели
постоянны, т.е. не меняются во времени.
Прерванные временные ряды
Обычный вопрос, возникающий при анализе
временных рядов, состоит в следующем,
воздействует или нет внешнее событие на
последовательность наблюдений. Например,
привела ли новая экономическая политика к росту
экономики, как обещалось; изменил ли новый закон
интенсивность преступлений и т.д. В общем, нужно
оценивать воздействия одного или нескольких
дискретных событий на значения ряда. Этот вид
анализа прерванных временных рядов подробно
описан в книге McDowall, McCleary, Meidinger, and Hay (1980).
Различают следующие три типа воздействий: (1)
устойчивое скачкообразное, (2) устойчивое
постепенное, (3) скачкообразное временное. См.
также следующие разделы:
- Идентификация модели
временных рядов - АРПСС
- Экспоненциальное
сглаживание - Сезонная декомпозиция (метод
Census I) - Сезонная корректировка X-11
(метод Census II) - Таблицы результатов
корректировки X-11 - Анализ распределенных лагов
- Одномерный анализ Фурье
- Кросс-спектральный анализ
- Основные понятия и принципы
- Быстрое преобразование Фурье
Экспоненциальное сглаживание
- Общее введение
- Простое экспоненциальное
сглаживание - Выбор лучшего значения
параметра a (альфа) - Индексы качества подгонки
- Сезонная и несезонная модели
с трендом или без тренда
См. также:
- Идентификация модели
временных рядов - АРПСС (Бокс и Дженкинс) и
автокорреляции - Прерванные временные ряды
- Сезонная декомпозиция (метод
Census I) - Сезонная корректировка X-11
(метод Census II) - Таблицы результатов
корректировки X-11 - Анализ распределенных лагов
- Одномерный анализ Фурье
- Кросс-спектральный анализ
- Основные понятия и принципы
- Быстрое преобразование Фурье
Общее введение
Экспоненциальное сглаживание — это очень
популярный метод прогнозирования многих
временных рядов. Исторически метод был
независимо открыт Броуном и Холтом. Броун служил
на флоте США во время второй мировой войны, где
занимался обнаружением подводных лодок и
системами наведения. Позже он применил открытый
им метод для прогнозирования спроса на запасные
части. Свои идеи он описал в книге, вышедшей в
свет в 1959 году. Исследования Холта были
поддержаны Департаментом военно-морского флота
США. Независимо друг от друга, Броун и Холт
открыли экспоненциальное сглаживание для
процессов с постоянным трендом, с линейным
трендом и для рядов с сезонной составляющей.
Gardner (1985), предложил «единую» классификацию
методов экспоненциального сглаживания.
Превосходное введение в эти методы можно найти в
книгах Makridakis, Wheelwright, and McGee (1983), Makridakis and Wheelwright (1989),
Montgomery, Johnson, and Gardiner (1990).
Простое экспоненциальное
сглаживание
Простая и прагматически ясная модель
временного ряда имеет следующий вид: Xt = b + ![]() t, где b —
t, где b —
константа и ![]()
(эпсилон) — случайная ошибка. Константа b относительно
стабильна на каждом временном интервале, но
может также медленно изменяться со временем.
Один из интуитивно ясных способов выделения b
состоит в том, чтобы использовать сглаживание
скользящим средним, в котором последним
наблюдениям приписываются большие веса, чем
предпоследним, предпоследним большие веса, чем
пред-предпоследним и т.д. Простое
экспоненциальное именно так и устроено. Здесь
более старым наблюдениям приписываются
экспоненциально убывающие веса, при этом, в
отличие от скользящего среднего, учитываются все
предшествующие наблюдения ряда, а не те, что
попали в определенное окно. Точная формула
простого экспоненциального сглаживания имеет
следующий вид:
St = ![]() *Xt + (1-
*Xt + (1-![]() )*St-1
)*St-1
Когда эта формула применяется рекурсивно, то
каждое новое сглаженное значение (которое
является также прогнозом) вычисляется как
взвешенное среднее текущего наблюдения и
сглаженного ряда. Очевидно, результат
сглаживания зависит от параметра ![]() (альфа). Если
(альфа). Если ![]() равно 1, то
равно 1, то
предыдущие наблюдения полностью игнорируются.
Если ![]() равно 0, то
равно 0, то
игнорируются текущие наблюдения. Значения ![]() между 0, 1 дают
между 0, 1 дают
промежуточные результаты.
Эмпирические исследования Makridakis и др. (1982;
Makridakis, 1983) показали, что весьма часто простое
экспоненциальное сглаживание дает достаточно
точный прогноз.
Выбор лучшего значения
параметра ![]() (альфа)
(альфа)
Gardner (1985) обсуждает различные теоретические и
эмпирические аргументы в пользу выбора
определенного параметра сглаживания. Очевидно,
из формулы, приведенной выше, следует, что ![]() должно попадать в интервал между 0
должно попадать в интервал между 0
(нулем) и 1 (хотя Brenner et al., 1968, для дальнейшего
применения анализа АРПСС считают, что 0<![]() <2). Gardner (1985)
<2). Gardner (1985)
сообщает, что на практике обычно рекомендуется
брать ![]() меньше .30.
меньше .30.
Однако в исследовании Makridakis et al., (1982), ![]() большее .30, часто
большее .30, часто
дает лучший прогноз. После обзора литературы,
Gardner (1985) приходит к выводу, что лучше оценивать
оптимально ![]() по данным
по данным
(см. ниже), чем просто «гадать» или
использовать искусственные рекомендации.
Оценивание лучшего значения ![]() с помощью данных. На
с помощью данных. На
практике параметр сглаживания часто ищется с поиском
на сетке. Возможные значения параметра
разбиваются сеткой с определенным шагом.
Например, рассматривается сетка значений от ![]() = 0.1 до
= 0.1 до ![]() = 0.9, с шагом 0.1.
= 0.9, с шагом 0.1.
Затем выбирается ![]() ,
,
для которого сумма квадратов (или средних
квадратов) остатков (наблюдаемые значения минус
прогнозы на шаг вперед) является минимальной.
Индексы качества подгонки
Самый прямой способ оценки прогноза,
полученного на основе определенного значения ![]() — построить график
— построить график
наблюдаемых значений и прогнозов на один шаг
вперед. Этот график включает в себя также остатки
(отложенные на правой оси Y). Из графика ясно
видно, на каких участках прогноз лучше или хуже.

Такая визуальная проверка точности прогноза
часто дает наилучшие результаты. Имеются также
другие меры ошибки, которые можно использовать
для определения оптимального параметра ![]() (см. Makridakis, Wheelwright, and McGee,
(см. Makridakis, Wheelwright, and McGee,
1983):
Средняя ошибка. Средняя ошибка (СО)
вычисляется простым усреднением ошибок на
каждом шаге. Очевидным недостатком этой меры
является то, что положительные и отрицательные
ошибки аннулируют друг друга, поэтому она не
является хорошим индикатором качества прогноза.
Средняя абсолютная ошибка. Средняя
абсолютная ошибка (САО) вычисляется как среднее абсолютных
ошибок. Если она равна 0 (нулю), то имеем
совершенную подгонку (прогноз). В сравнении со
средней квадратической ошибкой, эта мера
«не придает слишком большого значения»
выбросам.
Сумма квадратов ошибок (SSE),
среднеквадратическая ошибка. Эти величины
вычисляются как сумма (или среднее) квадратов
ошибок. Это наиболее часто используемые индексы
качества подгонки.
Относительная ошибка (ОО). Во всех
предыдущих мерах использовались действительные
значения ошибок. Представляется естественным
выразить индексы качества подгонки в терминах относительных
ошибок. Например, при прогнозе месячных продаж,
которые могут сильно флуктуировать (например, по
сезонам) из месяца в месяц, вы можете быть вполне
удовлетворены прогнозом, если он имеет точность
?10%. Иными словами, при прогнозировании
абсолютная ошибка может быть не так интересна
как относительная. Чтобы учесть относительную
ошибку, было предложено несколько различных
индексов (см. Makridakis, Wheelwright, and McGee, 1983). В первом
относительная ошибка вычисляется как:
ООt = 100*(Xt — Ft )/Xt
где Xt — наблюдаемое
значение в момент времени t, и Ft — прогноз (сглаженное
значение).
Средняя относительная ошибка (СОО).
Это значение вычисляется как среднее
относительных ошибок.
Средняя абсолютная относительная ошибка
(САОО). Как и в случае с обычной средней
ошибкой отрицательные и положительные
относительные ошибки будут подавлять друг друга.
Поэтому для оценки качества подгонки в целом (для
всего ряда) лучше использовать среднюю абсолютную
относительную ошибку. Часто эта мера более
выразительная, чем среднеквадратическая ошибка.
Например, знание того, что точность прогноза ±5%,
полезно само по себе, в то время как значение 30.8
для средней квадратической ошибки не может быть
так просто проинтерпретировано.
Автоматический поиск лучшего параметра.
Для минимизации средней квадратической ошибки,
средней абсолютной ошибки или средней
абсолютной относительной ошибки используется
квази-ньютоновская процедура (та же, что и в АРПСС). В большинстве случаев
эта процедура более эффективна, чем обычный
перебор на сетке (особенно, если параметров
сглаживания несколько), и оптимальное значение ![]() можно быстро
можно быстро
найти.
Первое сглаженное значение S0.
Если вы взгляните снова на формулу простого
экспоненциального сглаживания, то увидите, что
следует иметь значение S0 для
вычисления первого сглаженного значения
(прогноза). В зависимости от выбора параметра ![]() (в частности, если
(в частности, если ![]() близко к 0), начальное
близко к 0), начальное
значение сглаженного процесса может оказать
существенное воздействие на прогноз для многих
последующих наблюдений. Как и в других
рекомендациях по применению экспоненциального
сглаживания, рекомендуется брать начальное
значение, дающее наилучший прогноз. С другой
стороны, влияние выбора уменьшается с длиной
ряда и становится некритичным при большом числе
наблюдений.
Сезонная и несезонная модели с
трендом или без тренда
В дополнение к простому экспоненциальному
сглаживанию, были предложены более сложные
модели, включающие сезонную компоненту и
трендом. Общая идея таких моделей состоит в том,
что прогнозы вычисляются не только по предыдущим
наблюдениям (как в простом экспоненциальном
сглаживании), но и с некоторыми задержками, что
позволяет независимо оценить тренд и сезонную
составляющую. Gardner (1985) обсудил различные модели в
терминах сезонности (отсутствует, аддитивная
сезонность, мультипликативная) и тренда
(отсутствует, линейный тренд, экспоненциальный,
демпфированный).
Аддитивная и мультипликативная
сезонность. Многие временные ряды имеют
сезонные компоненты. Например, продажи игрушек
имеют пики в ноябре, декабре и, возможно, летом,
когда дети находятся на отдыхе. Эта
периодичность имеет место каждый год. Однако
относительный размер продаж может слегка
изменяться из года в год. Таким образом, имеет
смысл независимо экспоненциально сгладить
сезонную компоненту с дополнительным
параметром, обычно обозначаемым как ![]() (дельта). Сезонные
(дельта). Сезонные
компоненты, по природе своей, могут быть
аддитивными или мультипликативными. Например, в
течение декабря продажи определенного вида
игрушек увеличиваются на 1 миллион долларов
каждый год. Для того чтобы учесть сезонное
колебание, вы можете добавить в прогноз на каждый
декабрь 1 миллион долларов (сверх
соответствующего годового среднего). В этом
случае сезонность — аддитивная. Альтернативно,
пусть в декабре продажи увеличились на 40%, т.е. в 1.4
раза. Тогда, если общие продажи малы, то
абсолютное (в долларах) увеличение продаж в
декабре тоже относительно мало (процент роста
константа). Если в целом продажи большие, то
абсолютное (в долларах) увеличение продаж будет
пропорционально больше. Снова, в этом случае
продажи увеличатся в определенное число раз, и
сезонность будет мультипликативной (в данном
случае мультипликативная сезонная составляющая
была бы равна 1.4). На графике различие между двумя
видами сезонности состоит в том, что в аддитивной
модели сезонные флуктуации не зависят от
значений ряда, тогда как в мультипликативной
модели величина сезонных флуктуаций зависит от
значений временного ряда.
Параметр сезонного сглаживания ![]() . В общем, прогноз
. В общем, прогноз
на один шаг вперед вычисляется следующим образом
(для моделей без тренда; для моделей с линейным и
экспоненциальным трендом, тренд добавляется; см.
ниже):
Аддитивная модель:
Прогнозt = St + It-p
Мультипликативная модель:
Прогнозt = St*It-p
В этой формуле St
обозначает (простое) экспоненциально сглаженное
значение ряда в момент t, и It-p обозначает сглаженный
сезонный фактор в момент t
минус p (p —
длина сезона). Таким образом, в сравнении с
простым экспоненциальным сглаживанием, прогноз
«улучшается» добавлением или умножением
сезонной компоненты. Эта компонента оценивается
независимо с помощью простого экспоненциального
сглаживания следующим образом:
Аддитивная модель:
It = It-p + ![]() *(1-
*(1-![]() )*et
)*et
Мультипликативная модель:
It = It-p + ![]() *(1-
*(1-![]() )*et/St
)*et/St
Обратите внимание, что предсказанная сезонная
компонента в момент t
вычисляется, как соответствующая компонента на
последнем сезонном цикле плюс ошибка (et,
наблюдаемое минус прогнозируемое значение в
момент t). Ясно, что параметр ![]() принимает значения
принимает значения
между 0 и 1. Если он равен нулю, то сезонная
составляющая на следующем цикле та же, что и на
предыдущем. Если ![]()
равен 1, то сезонная составляющая
«максимально» меняется на каждом шаге из-за
соответствующей ошибки (множитель (1-![]() ) не
) не
рассматривается из-за краткости введения). В
большинстве случаев, когда сезонность
присутствует, оптимальное значение ![]() лежит между 0 и 1.
лежит между 0 и 1.
Линейный, экспоненциальный,
демпфированный тренд. Возвращаясь к примеру
с игрушками, мы можем увидеть наличие линейного
тренда (например, каждый год продажи
увеличивались на 1 миллион), экспоненциального
(например, каждый год продажи возрастают в 1.3
раза) или демпфированного тренда (в первом году
продажи возросли на 1 миллион долларов; во втором
увеличение составило только 80% по сравнению с
предыдущим, т.е. на $800,000; в следующем году вновь
увеличение было только на 80%, т.е. на $800,000 * .8 = $640,000
и т.д.). Каждый тип тренда по-своему проявляется в
данных. В целом изменение тренда — медленное в
течение времени, и опять (как и сезонную
компоненту) имеет смысл экспоненциально
сгладить его с отдельным параметром
[обозначаемым ![]() (гамма)
(гамма)
— для линейного и экспоненциального тренда, ![]() (фи) — для
(фи) — для
демпфированного тренда].
Параметры сглаживания ![]() (линейный и экспоненциальный тренд) и
(линейный и экспоненциальный тренд) и ![]() (демпфированный тренд). Аналогично
(демпфированный тренд). Аналогично
сезонной компоненте компонента тренда
включается в процесс экспоненциального
сглаживания. Сглаживание ее производится в
каждый момент времени независимо от других
компонент с соответствующими параметрами. Если ![]() равно 0, то тренд
равно 0, то тренд
постоянен для всех значений временного ряда (и
для всех прогнозов). Если ![]() равно 1, то тренд «максимально»
равно 1, то тренд «максимально»
определяется ошибками наблюдений. Параметр ![]() учитывает, как сильно
учитывает, как сильно
изменяется тренд, т.е. как быстро он
«демпфируется» или, наоборот, возрастает.
Сезонная декомпозиция (метод Census I)
- Общее введение
- Вычисления
См. также:
- Идентификация модели
временных рядов - АРПСС (Бокс и Дженкинс) и
автокорреляции - Прерванные временные ряды
- Экспоненциальное
сглаживание - Сезонная корректировка X-11
(метод Census II) - Таблицы результатов
корректировки X-11 - Анализ распределенных лагов
- Одномерный анализ Фурье
- Кросс-спектральный анализ
- Основные понятия и принципы
- Быстрое преобразование Фурье
Общее введение
Предположим, что у вас имеются ежемесячные
данные о пассажиропотоке на международных
авиалиниях за 12 лет (см. Бокс и Дженкинс, 1976). Если
изобразить эти данные на графике, то будет хорошо
видно, что (1) объем пассажиропотока имеет во
времени возрастающий линейный тренд, и (2) в ряде
имеется ежегодно повторяющаяся закономерность — сезонность
(большинство перевозок приходится на летние
месяцы, кроме того, имеется пик меньшей высоты в
районе декабрьских каникул). Цель сезонной
декомпозиции и корректировки как раз и состоит в
том, чтобы отделить эти компоненты, то есть
разложить ряд на составляющую тренда, сезонную
компоненту и оставшуюся нерегулярную
составляющую. «Классический» прием,
позволяющий выполнить такую декомпозицию,
известен как метод Census I. Этот метод
описывается и обсуждается в работах Makridakis,
Wheelwright, and McGee (1983) и Makridakis and Wheelwright (1989).
Общая модель. Основная идея сезонной
декомпозиции проста. В общем случае временной
ряд типа того, который описан выше, можно
представить себе состоящим из четырех различных
компонент: (1) сезонной компоненты (обозначается St,
где t обозначает момент времени), (2) тренда (Tt),
(3) циклической компоненты (Ct) и (4)
случайной, нерегулярной компоненты или
флуктуации (It). Разница между
циклической и сезонной компонентой состоит в
том, что последняя имеет регулярную (сезонную)
периодичность, тогда как циклические факторы
обычно имеют более длительный эффект, который к
тому же меняется от цикла к циклу. В методе Census I
тренд и циклическую компоненту обычно
объединяют в одну тренд-циклическую компоненту
(TCt). Конкретные функциональные
взаимосвязи между этими компонентами могут
иметь самый разный вид. Однако, можно выделить
два основных способа, с помощью которых они могут
взаимодействовать: аддитивно и мультипликативно:
Аддитивная модель:
Xt = TCt + St + It
Мультипликативная модель:
Xt = Tt*Ct*St*It
Здесь Xt обозначает
значение временного ряда в момент времени t. Если имеются какие-то априорные сведения
о циклических факторах, влияющих на ряд
(например, циклы деловой конъюнктуры), то можно
использовать оценки для различных компонент для
составления прогноза будущих значений ряда.
(Однако для прогнозирования предпочтительнее экспоненциальное
сглаживание, позволяющее учитывать сезонную
составляющую и тренд.)
Аддитивная и мультипликативная
сезонность. Рассмотрим на примере различие
между аддитивной и мультипликативной сезонными
компонентами. График объема продаж детских
игрушек, вероятно, будет иметь ежегодный пик в
ноябре-декабре, и другой — существенно меньший по
высоте — в летние месяцы, приходящийся на
каникулы. Такая сезонная закономерность будет
повторяться каждый год. По своей природе
сезонная компонента может быть аддитивной или
мультипликативной. Так, например, каждый год
объем продаж некоторой конкретной игрушки может
увеличиваться в декабре на 3 миллиона долларов.
Поэтому вы можете учесть эти сезонные изменения, прибавляя
к своему прогнозу на декабрь 3 миллиона. Здесь
мы имеем аддитивную сезонность. Может
получиться иначе. В декабре объем продаж
некоторой игрушки может увеличиваться на 40%, то
есть умножаться на множитель 1.4. Это значит,
например, что если средний объем продаж этой
игрушки невелик, то абсолютное (в денежном
выражении) увеличение этого объема в декабре
также будет относительно небольшим (но в
процентном исчислении оно будет постоянным);
если же игрушка продается хорошо, то и абсолютный
(в долларах) рост объема продаж будет
значительным. Здесь опять, объем продаж
возрастает в число раз, равное определенному множителю,
а сезонная компонента, по своей природе,
мультипликативная компонента (в данном случае
равная 1.4). Если перейти к графикам временных
рядов, то различие между этими двумя видами
сезонности будет проявляться так: в аддитивном
случае ряд будет иметь постоянные сезонные
колебания, величина которых не зависит от общего
уровня значений ряда; в мультипликативном случае
величина сезонных колебаний будет меняться в
зависимости от общего уровня значений ряда.
Аддитивный и мультипликативный тренд-цикл. Рассмотренный
пример можно расширить, чтобы проиллюстрировать
понятия аддитивной и мультипликативной
тренд-циклических компонент. В случае с
игрушками, тренд «моды» может привести к
устойчивому росту продаж (например, это может
быть общий тренд в сторону игрушек
образовательной направленности). Как и сезонная
компонента, этот тренд может быть по своей
природе аддитивным (продажи ежегодно
увеличиваются на 3 миллиона долларов) или
мультипликативным (продажи ежегодно
увеличиваются на 30%, или возрастают в 1.3 раза).
Кроме того, объем продаж может содержать
циклические компоненты. Повторим еще раз, что
циклическая компонента отличается от сезонной
тем, что она обычно имеет большую временную
протяженность и проявляется через неравные
промежутки времени. Так, например, некоторая
игрушка может быть особенно «горячей» в
течение летнего сезона (например, кукла,
изображающая персонаж популярного мультфильма,
которая к тому же агрессивно рекламируется). Как
и в предыдущих случаях, такая циклическая
компонента может изменять объем продаж
аддитивно, либо мультипликативно.
Вычисления
В вычислительном отношении процедура метода Сезонной
декомпозиции (Census I) следует стандартным
формулам, см. Makridakis, Wheelwright, and McGee (1983) или Makridakis and
Wheelwright (1989).

Скользящее среднее. Сначала
вычисляется скользящее среднее для временного
ряда, при этом ширина окна берется равной периоду
сезонности. Если период сезонности — четное
число, пользователь может выбрать одну из двух
возможностей: брать скользящее среднее с
одинаковыми весами или же с неравными весами так,
что первое и последнее наблюдения в окне имеют
усредненные веса.
Отношения или разности. После взятия
скользящих средних вся сезонная (т.е. внутри
сезона) изменчивость будет исключена, и поэтому
разность (в случае аддитивной модели) или
отношение (для мультипликативной модели) между
наблюдаемым и сглаженным рядом будет выделять
сезонную составляющую (плюс нерегулярную
компоненту). Более точно, ряд скользящих средних
вычитается из наблюдаемого ряда (в аддитивной
модели) или же значения наблюдаемого ряда
делятся на значения скользящих средних (в
мультипликативной модели).
Сезонная составляющая. На следующем
шаге вычисляется сезонная составляющая, как
среднее (для аддитивных моделей) или урезанное
среднее (для мультипликативных моделей) всех
значений ряда, соответствующих данной точке
сезонного интервала.

Сезонная корректировка ряда. Исходный
ряд можно скорректировать, вычитая из него
(аддитивная модель) или деля его значения на
(мультипликативная модель) значения сезонной
составляющей.

Получающийся в результате ряд называется
сезонной корректировкой ряда (из ряда убрана
сезонная составляющая)..
Тренд-циклическая компонента.
Напомним, что циклическая компонента отличается
от сезонной компоненты тем, что
продолжительность цикла, как правило, больше, чем
один сезонный период, и разные циклы могут иметь
разную продолжительность. Приближение для
объединенной тренд-циклической компоненты можно
получить, применяя к ряду с сезонной поправкой
процедуру 5-точечного (центрированного)
взвешенного скользящего среднего с весами 1, 2, 3, 2,
1.
Случайная или нерегулярная компонента.
На последнем шаге выделяется случайная или
нерегулярная компонента (погрешность) путем
вычитания из ряда с сезонной поправкой
(аддитивная модель) или делением этого ряда
(мультипликативная модель) на тренд-циклическую
компоненту.
Сезонная корректировка X-11 (метод Census II)
Общие идеи, лежащие в основе сезонной
декомпозиции и корректировки, изложены в
разделе, посвященном методу сезонной
корректировки Census I (см. Сезонная
декомпозиция (метод Census I)). Метод Census II (2)
является развитием и уточнением обычного метода
корректировки. На протяжении многих лет
различные варианты метода Census II развивались в
Бюро Переписи США (US Census Bureau); один из вариантов
этого метода, получивший широкую известность и
наиболее часто применяемый в государственных
органах и сфере бизнеса, называется «вариант X-11
метода Census II» (см. Shiskin, Young, and Musgrave, 1967).
Впоследствии этот усовершенствованный вариант
метода Census II стал называться просто X-11.
Помимо документации, которую можно получить из
Census Bureau, подробное описание метода дано в работах
Makridakis, Wheelwright and McGee (1983), Makridakis and Wheelwright (1989).
За дополнительной информацией обратитесь к
следующим разделам:
- Сезонная корректировка:
основные идеи и термины - Метод Census II
- Таблицы результатов
корректировки X-11 - Подробное описание всех
таблиц результатов, вычисляемых в методе X-11
За дальнейшей информацией обратитесь к Анализу временных рядов и
следующим разделам:
- Идентификация модели
временных рядов - АРПСС (Бокс и Дженкинс) и
автокорреляции - Прерванные временные ряды
- Экспоненциальное
сглаживание - Сезонная декомпозиция (метод
Census I) - Анализ распределенных лагов
- Одномерный анализ Фурье
- Кросс-спектральный анализ
- Основные понятия и принципы
- Быстрое преобразование Фурье
Сезонная корректировка: основные идеи и
термины
Предположим, что у вас имеются ежемесячные
данные о пассажиропотоке на международных
авиалиниях за 12 лет (см. Бокс и Дженкинс, 1976). Если
изобразить эти данные на графике, то будет хорошо
видно, что (1) объем пассажиропотока имеет во
времени возрастающий линейный тренд, и что (2) в
ряде имеется ежегодно повторяющаяся
закономерность — сезонность (большинство
перевозок приходится на летние месяцы, кроме
того, имеется пик меньшей высоты в районе
декабрьских каникул). Цель сезонной декомпозиции
и корректировки как раз и состоит в том, чтобы
отделить эти компоненты, то есть разложить ряд на
составляющую тренда, сезонную компоненту и
оставшуюся нерегулярную составляющую.
«Классический» прием, позволяющий выполнить
такую декомпозицию, известен как метод Census I
(см. раздел Census I). Этот метод
описывается и обсуждается в работах Makridakis,
Wheelwright, and McGee (1983) и Makridakis and Wheelwright (1989).
Общая модель. Основная идея сезонной
декомпозиции проста. В общем случае временной
ряд типа того, который описан выше, можно
представить себе состоящим из четырех различных
компонент: (1) сезонной компоненты (обозначается St,
где t обозначает момент времени), (2) тренда (Tt),
(3) циклической компоненты (Ct) и (4)
случайной, нерегулярной компоненты или
флуктуации (It). Разница между
циклической и сезонной компонентой состоит в
том, что последняя имеет регулярную (сезонную)
периодичность, тогда как циклические факторы
обычно имеют более длительный эффект, который к
тому же меняется от цикла к циклу. В методе Census I
тренд и циклическую компоненту обычно
объединяют в одну тренд-циклическую компоненту
(TCt). Конкретные функциональные
взаимосвязи между этими компонентами могут
иметь самый разный вид. Однако, можно выделить
два основных способа, с помощью которых они могут
взаимодействовать: аддитивно и мультипликативно:
Аддитивная модель:
Xt = TCt + St + It
Мультипликативная модель:
Xt = Tt*Ct*St*It
Здесь Xt обозначает
значение временного ряда в момент времени t.
Если имеются какие-то априорные сведения о
циклических факторах, влияющих на ряд (например,
циклы деловой конъюнктуры), то можно
использовать оценки для различных компонент для
составления прогноза будущих значений ряда.
(Однако для прогнозирования предпочтительнее экспоненциальное
сглаживание, позволяющее учитывать сезонную
составляющую и тренд.)
Аддитивная и мультипликативная
сезонность. Рассмотрим на примере различие
между аддитивной и мультипликативной сезонными
компонентами. График объема продаж детских
игрушек, вероятно, будет иметь ежегодный пик в
ноябре-декабре, и другой — существенно меньший по
высоте — в летние месяцы, приходящийся на
каникулы. Такая сезонная закономерность будет
повторяться каждый год. По своей природе
сезонная компонента может быть аддитивной или
мультипликативной. Так, например, каждый год
объем продаж некоторой конкретной игрушки может
увеличиваться в декабре на 3 миллиона долларов.
Поэтому вы можете учесть эти сезонные изменения, прибавляя
к своему прогнозу на декабрь 3 миллиона. Здесь
мы имеем аддитивную сезонность. Может
получиться иначе. В декабре объем продаж
некоторой игрушки может увеличиваться на 40%, то
есть умножаться на множитель 1.4. Это значит,
например, что если средний объем продаж этой
игрушки невелик, то абсолютное (в денежном
выражении) увеличение этого объема в декабре
также будет относительно небольшим (но в
процентном исчислении оно будет постоянным);
если же игрушка продается хорошо, то и абсолютный
(в долларах) рост объема продаж будет
значительным. Здесь опять, объем продаж
возрастает в число раз, равное определенному множителю,
а сезонная компонента, по своей природе,
мультипликативная компонента (в данном случае
равная 1.4). Если перейти к графикам временных
рядов, то различие между этими двумя видами
сезонности будет проявляться так: в аддитивном
случае ряд будет иметь постоянные сезонные
колебания, величина которых не зависит от общего
уровня значений ряда; в мультипликативном случае
величина сезонных колебаний будет меняться в
зависимости от общего уровня значений ряда.
Аддитивный и мультипликативный тренд-цикл.
Рассмотренный пример можно расширить, чтобы
проиллюстрировать понятия аддитивной и
мультипликативной тренд-циклических компонент.
В случае с игрушками, тренд «моды» может
привести к устойчивому росту продаж (например,
это может быть общий тренд в сторону игрушек
образовательной направленности). Как и сезонная
компонента, этот тренд может быть по своей
природе аддитивным (продажи ежегодно
увеличиваются на 3 миллиона долларов) или
мультипликативным (продажи ежегодно
увеличиваются на 30%, или возрастают в 1.3 раза).
Кроме того, объем продаж может содержать
циклические компоненты. Повторим еще раз, что
циклическая компонента отличается от сезонной
тем, что она обычно имеет большую временную
протяженность и проявляется через неравные
промежутки времени. Так, например, некоторая
игрушка может быть особенно «горячей» в
течение летнего сезона (например, кукла,
изображающая персонаж популярного мультфильма,
которая к тому же агрессивно рекламируется). Как
и в предыдущих случаях, такая циклическая
компонента может изменять объем продаж
аддитивно, либо мультипликативно.
Метод Census II
Основной метод сезонной декомпозиции и
корректировки, рассмотренный в разделе Сезонная корректировка:
основные идеи и термины, может быть
усовершенствован различными способами. На самом
деле, в отличие от многих методов моделирования
временных рядов (в частности, АРПСС),
которые основаны на определенной теоретической
модели, вариант X-11 метода Census II представляет
собой просто результат многочисленных специально
разработанных приемов и усовершенствований,
которые доказали свою работоспособность в
многолетней практике решения реальных задач (см.
Burman, 1979, Kendall and Ord, 1990, Makridakis and Wheelwright, 1989; Wallis, 1974).
Некоторые из наиболее важных усовершенствований
перечислены ниже.
Поправка на число рабочих дней. В
месяцах разное число дней и разное число рабочих
дней. Если мы анализируем, например, цифры
ежемесячной выручки парка аттракционов, то
разница в числе суббот и воскресений (пиковые
дни) в разных месяцах существенным образом
скажется на различиях в ежемесячных показателях
дохода. Вариант X-11 метода Census II дает
пользователю возможность проверить,
присутствует ли во временном ряду этот эффект
числа рабочих дней, и если да, то внести
соответствующие поправки.
Выбросы. Большинство реальных
временных рядов содержит выбросы, то есть резко
выделяющиеся наблюдения, вызванные какими-то
исключительными событиями. Например, забастовка
персонала может сильно повлиять на месячные или
годовые показатели выпуска продукции фирмы.
Такие выбросы могут исказить оценки сезонной
компоненты и тренда. В процедуре X-11
предусмотрены корректировки на случай появления
выбросов, основанные на использовании
«принципов статистического контроля»:
значения, выходящие за определенный диапазон
(который определяется в терминах, кратных сигма,
т.е. стандартных отклонений), могут быть
преобразованы или вовсе пропущены, и только
после этого будут вычисляться окончательные
оценки параметров сезонности.
Последовательные уточнения.
Корректировки, связанные с наличием выбросов и
различным числом рабочих дней можно производить
многократно, чтобы последовательно получать для
компонент оценки все лучшего качества. В методе X-11
делается несколько последовательных уточнений
оценок для получения окончательных компонент
тренд-цикличности и сезонности, нерегулярной
составляющей, и самого временного ряда с
сезонными поправками.
Критерии и итоговые статистики. Помимо
оценки основных компонент ряда, можно вычислить
различные сводные статистики. Например, можно
сформировать таблицы дисперсионного анализа для
проверки значимости фактора сезонной
изменчивости и ряда и фактора рабочих дней (см.
выше), процедура метода X-11 вычисляет также
ежемесячные относительные изменения в случайной
и тренд-циклической компонентах. С увеличением
продолжительности временного промежутка,
измеряемого в месяцах или, в случае квартального
варианта метода X-11 — в кварталах года,
изменения в тренд-циклической компоненте, вообще
говоря, будут нарастать, в то время как изменения
случайной составляющей должны оставаться
примерно на одном уровне. Средняя длина
временного интервала, на котором изменения
тренд-циклической компоненты становятся
примерно равными изменениям случайной
компоненты, называется месяцем (кварталом)
циклического доминирования, или сокращенно
МЦД (соответственно КЦД). Например, если МЦД равно
двум, то на сроках более двух месяцев
тренд-циклическая компонента станет
доминировать над флуктуациями нерегулярной
(случайной) компоненты. Эти и другие результаты
более подробно будут обсуждаться далее.
Таблицы результатов
корректировки X-11
Вычисления, которые производятся в процедуре
X-11, лучше всего обсуждать в контексте
таблиц результатов, которые при этом выдаются.
Процедура корректировки разбивается на семь
этапов, которые обычно обозначаются буквами A
— G.
- Априорная корректировка (помесячная сезонная
корректировка). Перед тем, как к временному
ряду, содержащему ежемесячные значения, будет
применяться какая-либо сезонная корректировка,
могут быть произведены различные корректировки,
заданные пользователем. Можно ввести еще один
временной ряд, содержащий априорные
корректирующие факторы; значения этого ряда
будут вычитаться из исходного ряда (аддитивная
модель), или же значения исходного ряда будут
поделены на значения корректирующего ряда
(мультипликативная модель). В случае
мультипликативной модели пользователь может
также определить свои собственные поправочные
коэффициенты (веса) на число рабочих дней. Эти
веса будут использоваться для корректировки
ежемесячных наблюдений, так чтобы учитывалось
число рабочих дней в этом месяце. - Предварительное оценивание вариации числа
рабочих дней (месячный вариант X-11) и весов. На
следующем шаге вычисляются предварительные
поправочные коэффициенты на число рабочих дней
(только в месячном варианте X-11) и веса,
позволяющие уменьшить эффект выбросов. - Окончательное оценивание вариации числа
рабочих дней и нерегулярных весов (месячный
вариант X-11). Поправки и веса, вычисленные в
пункте B, используются для построения
улучшенных оценок тренд-циклической и сезонной
компонент. Эти улучшенные оценки используются
для окончательного вычисления факторов числа
рабочих дней (в месячном варианте X-11) и весов. - Окончательное оценивание сезонных факторов,
тренд-циклической, нерегулярной и сезонно
скорректированной компонент ряда. Окончательные
значения факторов рабочих дней и весов,
вычисленные в пункте C, используются для
вычисления окончательных оценок для компонент
ряда. - Модифицированные ряды: исходный, сезонно
скорректированный и нерегулярный. Исходный и
окончательный сезонно скорректированный ряды, а
также нерегулярная компонента модифицируются
путем сглаживания выбросов. Полученные в
результате этого, модифицированные ряды
позволяют пользователю проверить устойчивость
сезонной корректировки. - Месяц (квартал) циклического доминирования
(МЦД, КЦД), скользящее среднее и сводные
показатели. IНа этом этапе вычислений
рассчитываются различные сводные
характеристики (см. далее), позволяющие
пользователю исследовать относительную
важность разных компонент, среднюю флуктуацию от
месяца к месяцу (от квартала к кварталу), среднее
число идущих подряд изменений в одну сторону и
др. - Графики. Наконец, вы можете построить
различные графики итоговых результатов.
Например, можно построить окончательно
скорректированный ряд в хронологическом порядке
или по месяцам (см. ниже).
Подробное описание всех таблиц
результатов, вычисляемых в методе X-11
На каждом из этапов A — G (см. раздел Таблицы результатов
корректировки X-11) вычислялись различные
таблицы результатов. Обычно все они нумеруются, а
также им приписывается буква, соответствующая
этапу анализа. Например, таблица B 11 содержит
предварительно сезонно скорректированный ряд; C
11 — это более точно сезонно скорректированный
ряд, а D 11 — окончательный сезонно
скорректированный ряд. Далее приводится
перечень всех таблиц. Таблицы, помеченные
звездочкой (*), недоступны (или неприменимы) при
анализе квартальных показателей. Кроме того, в
случае квартальной корректировки некоторые из
описанных ниже вычислений несколько
видоизменяются. Так, например, для вычисления
сезонных факторов вместо 12-периодного (т.е.
12-месячного) скользящего среднего используется
4-периодное (4-квартальное) скользящее среднее;
предварительная тренд-циклическая компонента
вычисляется по центрированному 4-периодному
скользящему среднему, а окончательная оценка
тренд-циклической компоненты вычисляется по
5-точечному среднему Хендерсона.
В соответствии со стандартом метода X-11,
принятым Бюро переписи США, предусмотрены три
степени подробности вывода: Стандартный (17 — 27
таблиц), Длинный (27 — 39 таблиц) и Полный (44 —
59 таблиц). Имеется также возможность выводить
только таблицы результатов, выбранные
пользователем. В следующих далее описаниях
таблиц, буквы С, Д и П рядом с
названием таблицы указывают, какие таблицы
выводятся и/или распечатываются в
соответствующем варианте вывода. (Для графиков
предусмотрены два уровня подробности вывода: Стандартный
и Все.)
Щелкните на имени таблицы для
получения информации о ней.
| * A 1. Исходный ряд (С) |
| * A 2. Априорные месячные поправки (С) |
| * A 3. Исходный ряд, скорректированный с помощью априорных месячных поправок (С) |
| * A 4. Априорные поправки на рабочие дни (С) |
| B 1. Ряд после априорной корректировки либо исходный ряд (С) |
| B 2. Тренд-цикл (Д) |
| B 3. Немодифицированные S-I разности или отношения (П) |
| B 4. Значения для замены выбросов S-I разностей (отношений) (П) |
| B 5. Сезонная составляющая (П) |
| B 6. Сезонная корректировка ряда (П) |
| B 7. Тренд-цикл (Д) |
| B 8. Немодифицированные S-I разности (отношения) (П) |
| B 9. Значения для замены выбросов S-I разностей (отношений) (П) |
| B 10. Сезонная составляющая (Д) |
| B 11. Сезонная корректировка ряда (П) |
| B 12. (не используется) |
| B 13. Нерегулярная составляющая ряда (Д) |
| Таблицы B 14 — B 16, B 18 и B 19: Поправка на число рабочих дней. Эти таблицы доступны только при анализе ежемесячных данных. Число разных дней недели (понедельников, вторников и т.д.) колеблется от месяца к месяцу. Бывают ряды, в которых различия в числе рабочих дней в месяце могут давать заметный разброс ежемесячных показателей (например, месячный доход парка аттракционов сильно зависит от того, сколько в этом месяце было выходных дней). Пользователь имеет возможность определить начальные веса для каждого дня недели (см. A 4), и/или эти веса могут быть оценены по данным (пользователь также может сделать использование этих весов условным, т.е. только в тех случаях, когда они объясняют значительную часть дисперсии). |
| * B 14. Выбросы нерегулярной составляющей, исключенные из регрессии рабочих дней (Д) |
| * B 15. Предварительная регрессия рабочих дней (Д) |
| * B 16. Поправки на число рабочих дней, полученные из коэффициентов регрессии (П) |
| B 17. Предварительные веса нерегулярной компоненты (Д) |
| * B 18. Поправки на число рабочих дней, полученные из комбинированных весов дней недели (П) |
| * B 19. Исходный ряд с поправками на рабочие дни и априорную вариацию (П) |
| C 1. Исходный ряд, модифицированный с помощью предварительных весов, с поправкой на рабочие дни и априорную вариацию (Д) |
| C 2. Тренд-цикл (П) |
| C 3. (не используется) |
| C 4. Модифицированные S-I разности (отношения) (П) |
| C 5. Сезонная составляющая (П) |
| C 6. Сезонная корректировка ряда (П) |
| C 7. Тренд-цикл (Д) |
| C 8. (не используется) |
| C 9. Модифицированные S-I разности (отношения) (П) |
| C 10. Сезонная составляющая (Д) |
| C 11. Сезонная корректировка ряда (П) |
| C 12. (не используется) |
| C 13. Нерегулярная составляющая (С) |
| Таблицы C 14 — C 16, C 18 и C 19: Поправка на число рабочих дней. Эти таблицы доступны только при анализе ежемесячных данных и если при этом требуется поправка на различное число рабочих дней. В этом случае поправки на число рабочих дней вычисляются по уточненным значениям сезонно скорректированных рядов аналогично тому, как это делалось в пункте B (B 14 — B 16, B 18, B 19). |
| * C 14. Выбросы нерегулярной составляющей, исключенные из регрессии рабочих дней (С) |
| * C 15. Регрессия рабочих дней — окончательный вариант (С) |
| * C 16. Поправки на число рабочих дней, полученные из коэффициентов регрессии, — окончательный вариант (С) |
| C 17. Окончательные веса нерегулярной компоненты (С) |
| * C 18. Поправки на число рабочих дней, полученные из комбинированных весов дней недели — окончательный вариант (С) |
| * C 19. Исходный ряд с поправками на рабочие дни и априорную вариацию (С) |
| D 1. Исходный ряд, модифицированный с помощью окончательных весов, с поправкой на рабочие дни и априорную вариацию (Д) |
| D 2. Тренд-цикл (П) |
| D 3. (не используется) |
| D 4. Модифицированные S-I разности (отношения) (П) |
| D 5. Сезонная составляющая (П) |
| D 6. Сезонная корректировка ряда (П) |
| D 7. Тренд-цикл (Д) |
| D 8. Немодифицированные S-I разности (отношения) — окончательный вариант (С) |
| D 9. Окончательные значения для замены выбросов S-I разностей (отношений) (С) |
| D 10. Сезонная составляющая — окончательный вариант (С) |
| D 11. Сезонная корректировка ряда — окончательный вариант (С) |
| D 12. Тренд-циклическая компонента — окончательный вариант (С) |
| D 13. Нерегулярная составляющая — окончательный вариант (С) |
| E 1. Модифицированный исходный ряд (С) |
| E 2. Модифицированный ряд с сезонной поправкой (С) |
| E 3. Модифицированная нерегулярная составляющая (С) |
| E 4. Разности (отношения) годовых сумм (С) |
| E 5. Разности (относительные изменения) исходного ряда (С) |
| E 6. Разности (относительные изменения) окончательного варианта ряда с сезонной поправкой (С) |
| F 1. МЦД (КЦД) скользящее среднее (С) |
| F 2. Сводные показатели (С) |
| G 1. График (С) |
| G 2. График (С) |
| G 3. График (В) |
| G 4. График (В) |
Анализ распределенных лагов
- Общая цель
- Общая модель
- Распределенный лаг Алмона
За дальнейшей информацией обратитесь к Анализу временных рядов и
следующим разделам:
- Идентификация модели
временных рядов - АРПСС (Бокс и Дженкинс) и
автокорреляции Вводный обзор АРПСС - Прерванные временные ряды
- Экспоненциальное
сглаживание - Сезонная декомпозиция (метод
Census I) - Сезонная корректировка X-11
(метод Census II) - Таблицы результатов
корректировки X-11 - Одномерный анализ Фурье
- Кросс-спектральный анализ
- Основные понятия и принципы
- Быстрое преобразование Фурье
Общая цель
Анализ распределенных лагов — это специальный
метод оценки запаздывающей зависимости между
рядами. Например, предположим, вы производите
компьютерные программы и хотите установить
зависимость между числом запросов, поступивших
от покупателей, и числом реальных заказов. Вы
могли бы записывать эти данные ежемесячно в
течение года и затем рассмотреть зависимость
между двумя переменными: число запросов и число
заказов зависит от запросов, но зависит с
запаздыванием. Однако очевидно, что запросы
предшествуют заказам, поэтому можно ожидать, что
число заказов. Иными словами, в зависимости между
числом запросов и числом продаж имеется
временной сдвиг (лаг) (см. также автокорреляции и
кросскорреляции).
Такого рода зависимости с запаздыванием
особенно часто возникают в эконометрике.
Например, доход от инвестиций в новое
оборудование отчетливо проявится не сразу, а
только через определенное время. Более высокий
доход изменяет выбор жилья людьми; однако эта
зависимость, очевидно, тоже проявляется с
запаздыванием. [Подобные задачи возникают в
страховании, где временной ряд клиентов и ряд
денежных поступлений сдвинуты друг относительно
друга].
Во всех этих случаях, имеется независимая или объясняющая
переменная, которая воздействует на зависимые
переменные с некоторым запаздыванием (лагом).
Метод распределенных лагов позволяет
исследовать такого рода зависимость.
Подробные обсуждения зависимостей с
распределенными лагами имеются в
эконометрических учебниках, например, в Judge, Griffith,
Hill, Luetkepohl, and Lee (1985), Maddala (1977), and Fomby, Hill, and Johnson (1984).
Ниже дается краткое описание этих методов.
Предполагается, что вы знакомы с понятием
корреляции (см. Основные
статистики и таблицы), кросскорреляции и
основными идеями множественной регрессии (см. Множественная регрессия).
Общая модель
Пусть y — зависимая переменная, a независимая
или объясняющая x. Эти переменные измеряются
несколько раз в течение определенного отрезка
времени. В некоторых учебниках по эконометрике
зависимая переменная называется также эндогенной
переменной, a зависимая или объясняемая
переменная экзогенной переменной.
Простейший способ описать зависимость между
этими двумя переменными дает следующее линейное
уравнение:
Yt = ![]()
![]() i*xt-i
i*xt-i
В этом уравнении значение зависимой переменной
в момент времени t является
линейной функцией переменной x,
измеренной в моменты t, t-1,
t-2 и т.д. Таким образом, зависимая
переменная представляет собой линейные функции x и x, сдвинутых на
1, 2, и т.д. временные периоды. Бета коэффициенты
(![]() i) могут
i) могут
рассматриваться как параметры наклона в этом
уравнении. Будем рассматривать это уравнение как
специальный случай уравнения линейной регрессии
(см. раздел Множественная
регрессия). Если коэффициент переменной с
определенным запаздыванием (лагом) значим, то
можно заключить, что переменная y
предсказывается (или объясняется) с
запаздыванием.
Распределенный лаг Алмона
Обычная проблема, возникающая в множественной
регрессии, состоит в том, что соседние значения x
сильно коррелируют. В самом крайнем случае, это
приводит к тому, что корреляционная матрица не
будет обратимой и коэффициенты бета не могут
быть вычислены. В менее экстремальных ситуациях
вычисления этих коэффициентов и их стандартные
ошибки становятся ненадежными из-за
вычислительных ошибок (ошибок округления). В
контексте множественной регрессии эта проблема
хорошо известна как проблема мультиколлинеарности
(см. раздел Множественная
регрессия).
Алмон (1965) предложил специальную процедуру,
которая в данном случае уменьшает
мультиколлинеарность. Именно, пусть каждый
неизвестный коэффициент записан в виде:
![]() i =
i =
![]() 0 +
0 + ![]() 1*i + … +
1*i + … + ![]() q*iq
q*iq
Алмон показал, что во многих случаях (в
частности, чтобы избежать мультиколлинеарности)
легче оценить коэффициенты альфа, чем
непосредственно коэффициенты бета. Такой
метод оценивания коэффициентов бета
называется полиномиальной аппроксимацией.
Неправильная спецификация. Общая
проблема полиномиальной аппроксимации, состоит
в том, что длина лага и степень полинома
неизвестны заранее. Последствия
неправильного определения (спецификации) этих
параметров потенциально серьезны (в силу
смещения, возникающего в оценках при
неправильном задании параметров). Этот вопрос
подробно обсуждается в книгах Frost (1975), Schmidt and Waud
(1973), Schmidt and Sickles (1975) и Trivedi and Pagan (1979).
Одномерный анализ Фурье
В спектральном анализе исследуются
периодические модели данных. Цель анализа —
разложить комплексные временные ряды с
циклическими компонентами на несколько основных
синусоидальных функций с определенной длиной
волн. Термин «спектральный» — своеобразная
метафора для описания природы этого анализа.
Предположим, вы изучаете луч белого солнечного
света, который, на первый взгляд, кажется
хаотически составленным из света с различными
длинами волн. Однако, пропуская его через призму,
вы можете отделить волны разной длины или
периодов, которые составляют белый свет.
Фактически, применяя этот метод, вы можете теперь
распознавать и различать разные источники света.
Таким образом, распознавая существенные
основные периодические компоненты, вы узнали
что-то об интересующем вас явлении. В сущности,
применение спектрального анализа к временным
рядам подобно пропусканию света через призму. В
результате успешного анализа можно обнаружить
всего несколько повторяющихся циклов различной
длины в интересующих вас временных рядах,
которые, на первый взгляд, выглядят как случайный
шум.
Наиболее известный пример применения
спектрального анализа — циклическая природа
солнечных пятен (например, см. Блумфилд, 1976 или
Шамвэй, 1988). Оказывается, что активность
солнечных пятен имеет 11-ти летний цикл. Другие
примеры небесных явлений, изменения погоды,
колебания в товарных ценах, экономическая
активность и т.д. также часто используются в
литературе для демонстрации этого метода. В
отличие от АРПСС или метода экспоненциального
сглаживания (см. разделы АРПСС
и Экспоненциальное
сглаживание), цель спектрального анализа —
распознать сезонные колебания различной длины, в
то время как в предшествующих типах анализа,
длина сезонных компонент обычно известна (или
предполагается) заранее и затем включается в
некоторые теоретические модели скользящего
среднего или автокорреляции.
Классический текст по спектральному анализу —
Bloomfield (1976); однако другие подробные обсуждения
могут быть найдены в Jenkins and Watts (1968), Brillinger (1975), Brigham
(1974), Elliott and Rao (1982), Priestley (1981), Shumway (1988) или Wei (1989).
За дальнейшей информацией обратитесь к Анализу временных рядов и
следующим разделам:
- Основные понятия и принципы
- Быстрое преобразование Фурье
- Идентификация модели
временных рядов - АРПСС (Бокс и Дженкинс) и
автокорреляции Вводный обзор АРПСС - Прерванные временные ряды
- Анализ распределенных лагов
- Сезонная декомпозиция (метод
Census I) - Экспоненциальное
сглаживание - Кросс-спектральный анализ
Кросс-спектральный анализ
- Общее введение
- Основные понятия и принципы
- Результаты для каждой
переменной - Кросс-периодограмма,
кросс-плотность, квадратурная плотность и
кросс-амплитуда - Квадрат когерентности,
усиление и фазовый сдвиг - Как создавались данные для
примера
За дальнейшей информацией обратитесь к Анализу временных рядов и
следующим разделам:
- Идентификация модели
временных рядов - АРПСС (Бокс и Дженкинс) и
автокорреляции Вводный обзор АРПСС - Прерванные временные ряды
- Экспоненциальное
сглаживание - Сезонная декомпозиция (метод
Census I) - Сезонная корректировка X-11
(метод Census II) - Таблицы результатов
корректировки X-11 - Анализ распределенных лагов
- Одномерный анализ Фурье
- Основные понятия и принципы
- Быстрое преобразование Фурье
Общее введение
Кросс-спектральный анализ развивает Одномерный анализ Фурье и
позволяет анализировать одновременно два ряда.
Мы предполагаем, что вы уже прочитали введение к
разделу одномерного спектрального анализа.
Подробное обсуждение кросс-спектрального
анализа можно найти в книгах Bloomfield (1976), Jenkins and Watts
(1968), Brillinger (1975), Brigham (1974), Elliott and Rao (1982), Priestley (1981),
Shumway (1988), or Wei (1989).
Периодичность ряда на определенных
частотах. Наиболее известный пример
применения спектрального анализа — циклическая
природа солнечных пятен (например, см. Блумфилд,
1976 или Шамвэй, 1988). Оказывается, что активность
солнечных пятен имеет 11-ти летний цикл. Другие
примеры небесных явлений, изменения погоды,
колебания в товарных ценах, экономическая
активность и т.д. также часто используются в
литературе для демонстрации этого метода.
Основные понятия и принципы
Простой пример. Рассмотрим следующие два
ряда с 16 наблюдениями:
| ПЕРЕМ1 | ПЕРЕМ2 | |
|---|---|---|
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
1.000 1.637 1.148 -.058 -.713 -.383 .006 -.483 -1.441 -1.637 -.707 .331 .441 -.058 -.006 .924 |
-.058 -.713 -.383 .006 -.483 -1.441 -1.637 -.707 .331 .441 -.058 -.006 .924 1.713 1.365 .266 |
С первого взгляда нелегко рассмотреть
взаимосвязь между двумя рядами. Тем не менее, как
показано ниже, ряды создавались так, что содержат
две сильно коррелируемые периодичности. Далее
показаны части таблицы результатов из
кросс-спектрального анализа (спектральные
оценки были сглажены окном Парзена ширины 3).
| Незавмсимая (X): ПЕРЕМ1 Зависимая (Y): ПЕРЕМ2 |
||||||
|---|---|---|---|---|---|---|
| Частота |
Период |
X плотность |
Y плотность |
Кросс плотность |
Кросс квадр. |
Кросс амплит. |
| 0.000000 .062500 .125000 .187500 .250000 .312500 .375000 .437500 .500000 |
16.00000 8.00000 5.33333 4.00000 3.20000 2.66667 2.28571 2.00000 |
.000000 8.094709 .058771 3.617294 .333005 .091897 .052575 .040248 .037115 |
.024292 7.798284 .100936 3.845154 .278685 .067630 .036056 .026633 0.000000 |
-.00000 2.35583 -.04755 -2.92645 -.26941 -.07435 -.04253 -.03256 0.00000 |
0.00000 -7.58781 .06059 2.31191 .14221 .02622 .00930 .00342 0.00000 |
.000000 7.945114 .077020 3.729484 .304637 .078835 .043539 .032740 0.000000 |
Результаты для каждой
переменной
Полная таблица результатов содержит все
спектральные статистики, вычисленные для
каждого ряда, как описано в разделе Одномерный анализ Фурье.
Взглянув на приведенные выше результаты,
очевидно, что оба ряда имеют основные
периодичности на частотах .0625 и .1875.
Кросс-периодограмма,
кросс-плотность, квадратурная плотность и
кросс-амплитуда
Аналогично результатам для одной переменной,
полная итоговая таблица результатов также
покажет значения периодограммы для
кросс-периодограммы. Однако кросс-спектр состоит
из комплексных чисел,
которые могут быть разделены на действительную и
мнимую части. Они могут быть сглажены для
вычисления оценок кросс-плотности и
квадратурной плотности (квадр-плотность для
краткости), соответственно. (Причины сглаживания
и различные функции весов для сглаживания
обсуждаются в разделе Одномерный
анализ Фурье.) Квадратный корень из суммы
квадратов значений кросс-плотности и
квадр-плотности называется кросс-амплитудой.
Кросс-амплитуда может интерпретироваться как
мера ковариации между соответствующими
частотными компонентами двух рядов. Таким
образом из результатов, показанных в таблице
результатов выше, можно заключить, что частотные
компоненты .0625 и .1875 двух рядов взаимосвязаны.
Квадрат когерентности, усиление
и фазовый сдвиг
Существуют дополнительные статистики, которые
будут показаны в полной итоговой таблице
результатов.
Квадрат когерентности. Можно
нормировать значения кросс-амплитуды, возведя их
в квадрат и разделив на произведение оценок
спектральной плотности каждого ряда. Результат
называется квадратом когерентности, который
может быть проинтерпретирован как квадрат
коэффициента корреляции (см. раздел Корреляции); т.е.
значение когерентности — это квадрат корреляции
между циклическими компонентами двух рядов
соответствующей частоты. Однако значения
когерентности не следует объяснять таким
образом; например, когда оценки спектральной
плотности обоих рядов очень малы, могут
получиться большие значения когерентности
(делитель в выражении когерентности может быть
очень маленьким), даже если нет существенных
циклических компонент в каждом ряду
соответствующей частоты.
Усиление. Значение усиления в анализе
вычисляется делением значения кросс-амплитуды
на оценки спектральной плотности одного или двух
рядов. Следовательно, может быть вычислено два
значения усиления, которые могут
интерпретироваться как стандартные
коэффициенты регрессии, соответствующей
частоты, полученные методом наименьших
квадратов.
Фазовый сдвиг. В заключение, оценки
фазового сдвига вычисляются как арктангенс (tan**-1)
коэффициента пропорциональности оценки
квадр-плотности и оценки кросс-плотности. Оценки
фазового сдвига (обычно обозначаемые греческой
буквой y) измеряют, насколько каждая частотная
компонента одного ряда опережает частотные
компоненты другого.
Как создавались данные для
примера
Теперь вернемся к примеру данных, приведенному
выше. Большие оценки спектральной плотности для
обоих рядов и значения кросс-амплитуды для
частот ![]() = 0.0625 и
= 0.0625 и ![]() = .1875 предполагают две
= .1875 предполагают две
существенных синхронных периодичности с этими
частотами в обоих рядах. Фактически, два ряда
создавались как:
v1 = cos(2*![]() *.0625*(v0-1))
*.0625*(v0-1))
+ .75*sin(2*![]() *.2*(v0-1))
*.2*(v0-1))
v2 = cos(2*![]() *.0625*(v0+2)) +
*.0625*(v0+2)) +
.75*sin(2*![]() *.2*(v0+2))
*.2*(v0+2))
(где v0 — номер наблюдения).
Действительно, анализ, представленный в этом
обзоре, очень хорошо воспроизводит
периодичность, заложенную в данные.
Спектральный анализ — Основные понятия и
принципы
- Частота и период
- Общая структура модели
- Простой пример
- Периодограмма
- Проблема рассеяния
- Добавление констант во
временной ряд (пэддинг) - Косинус-сглаживание
- Окна данных и оценки
спектральной плотности - Подготовка данных к анализу
- Результаты для случая, когда в
ряде отсутствует периодичность
За дальнейшей информацией обратитесь к Анализу временных рядов и
следующим разделам:
- Идентификация модели
временных рядов - АРПСС (Бокс и Дженкинс) и
автокорреляции Вводный обзор АРПСС - Прерванные временные ряды
- Экспоненциальное
сглаживание - Сезонная декомпозиция (метод
Census I) - Сезонная корректировка X-11
(метод Census II) - Таблицы результатов
корректировки X-11 - Анализ распределенных лагов
- Одномерный анализ Фурье
- Кросс-спектральный анализ
- Быстрое преобразование Фурье
Частота и период
Длина волны функций синуса или косинуса, как
правило, выражается числом циклов (периодов) в
единицу времени (Частота), часто обозначается
греческой буквой ню (![]() ; в некоторых учебниках также
; в некоторых учебниках также
используют f). Например, временной ряд,
состоящий из количества писем, обрабатываемых
почтой, может иметь 12 циклов в году. Первого числа
каждого месяца отправляется большое количество
корреспонденции (много счетов приходит именно
первого числа каждого месяца); затем, к середине
месяца, количество корреспонденции уменьшается;
и затем вновь возрастает к концу месяца. Поэтому
каждый месяц колебания в количестве
корреспонденции, обрабатываемой почтовым
отделением, будут проходить полный цикл. Таким
образом, если единица анализа — один год, то ![]() будет равно 12 (поскольку
будет равно 12 (поскольку
имеется 12 циклов в году). Конечно, могут быть и
другие циклы с различными частотами. Например,
годичные циклы (![]() =1)
=1)
и, возможно, недельные циклы (![]() =52 недели в год).
=52 недели в год).
Период Т функций синуса или косинуса
определяется как продолжительность по времени
полного цикла. Таким образом, это обратная
величина к частоте: T = 1/![]() . Возвратимся к примеру с почтой из
. Возвратимся к примеру с почтой из
предыдущего абзаца, здесь месячный цикл будет
равен 1/12 = 0.0833 года. Другими словами, это период
составляет 0.0833 года.
Общая структура модели
Как было отмечено ранее, цель спектрального
анализа — разложить ряд на функции синусов и
косинусов различных частот, для определения тех,
появление которых особенно существенно и
значимо. Один из возможных способов сделать это —
решить задачу линейной множественной
регрессии (см. раздел Множественная
регрессия), где зависимая переменная
-наблюдаемый временной ряд, а независимые
переменные или регрессоры: функции синусов всех
возможных (дискретных) частот. Такая модель
линейной множественной регрессии может быть
записана как:
xt = a0 + ![]() [ak*cos(
[ak*cos(![]() k*t) + bk*sin(
k*t) + bk*sin(![]() k*t)] (для k = 1 до q)
k*t)] (для k = 1 до q)
Следующее общее понятие классического
гармонического анализа в этом уравнении — ![]() (лямбда) -это
(лямбда) -это
круговая частота, выраженная в радианах в
единицу времени, т.е. ![]() = 2*
= 2*![]() *
*![]() k, где
k, где ![]() — константа пи =
— константа пи =
3.1416 и ![]() k = k/q. Здесь
k = k/q. Здесь
важно осознать, что вычислительная задача
подгонки функций синусов и косинусов разных длин
к данным может быть решена с помощью
множественной линейной регрессии. Заметим, что
коэффициенты ak при
косинусах и коэффициенты bk
при синусах — это коэффициенты регрессии,
показывающие степень, с которой соответствующие
функции коррелируют с данными [заметим, что сами
синусы и косинусы на различных частотах не
коррелированы или, другим языком, ортогональны.
Таким образом, мы имеем дело с частным случаем
разложения по ортогональным полиномам.] Всего
существует q различных синусов
и косинусов (см. также Множественная регрессия);
интуитивно ясно, что число функций синусов и
косинусов не может быть больше числа данных в
ряде. Не вдаваясь в подробности, отметим, если n —
количество данных, то будет n/2+1 функций
косинусов и n/2-1 функций синусов. Другими
словами, различных синусоидальных волн будет
столько же, сколько данных, и вы сможете
полностью воспроизвести ряд по основным
функциям. (Заметим, если количество данных в ряде
нечетно, то последнее наблюдение обычно
опускается. Для определения синусоидальной
функции нужно иметь, по крайней мере, две точки:
высокого и низкого пика.)
В итоге, спектральный анализ определяет
корреляцию функций синусов и косинусов
различной частоты с наблюдаемыми данными. Если
найденная корреляция (коэффициент при
определенном синусе или косинусе) велика, то
можно заключить, что существует строгая
периодичность на соответствующей частоте в
данных.
Комплексные числа (действительные и мнимые
числа). Во многих учебниках по спектральному
анализу структурная модель, показанная выше,
представлена в комплексных числах; т.е. параметры
оцениваемого процесса описаны с помощью
действительной и мнимой части преобразования
Фурье. Комплексное число состоит из
действительного и мнимого числа. Мнимые числа, по
определению, — это числа, умноженные на константу i,
где i определяется как квадратный корень из -1.
Очевидно, корень квадратный из -1 не существует в
обычном сознании (отсюда термин мнимое число);
однако арифметические операции над мнимыми
числами могут производиться естественным
образом [например, (i*2)**2= -4]. Полезно представление
действительных и мнимых чисел, образующих
двумерную координатную плоскость, где
горизонтальная или X-ось представляет все
действительные числа, а вертикальная или Y-ось
представляет все мнимые числа. Комплексные числа
могут быть представлены точками на двумерной
плоскости. Например, комплексное число 3+i*2 может
быть представлено точкой с координатами {3,2} на
этой плоскости. Можно также представить
комплексные числа как углы; например, можно
соединить точку, соответствующую комплексному
числу на плоскости с началом координат
(комплексное число 0+i*0), и измерить угол наклона
этого вектора к горизонтальной оси. Таким
образом интуитивно ясно, каким образом формула
спектрального разложения, показанная выше, может
быть переписана в комплексной области. В таком
виде математические вычисления часто более
изящны и проще в выполнении, поэтому многие
учебники предпочитают представление
спектрального анализа в комплексных числах.
Простой пример
Шамвэй (1988) предлагает следующий простой пример
для объяснения спектрального анализа. Создадим
ряд из 16 наблюдений, полученных из уравнения,
показанного ниже, а затем посмотрим, каким
образом можно извлечь из него информацию.
Сначала создадим переменную и определим ее как:
x = 1*cos(2*![]() *.0625*(v0-1))
*.0625*(v0-1))
+ .75*sin(2*![]() *.2*(v0-1))
*.2*(v0-1))
Эта переменная состоит из двух основных
периодичностей — первая с частотой ![]() =.0625 (или периодом 1/
=.0625 (или периодом 1/![]() =16; одно наблюдение
=16; одно наблюдение
составляет 1/16-ю длины полного цикла, или весь
цикл содержит каждые 16 наблюдений) и вторая с
частотой ![]() =.2 (или
=.2 (или
периодом 5). Коэффициент при косинусе (1.0) больше
чем коэффициент при синусе (.75). Итоговая таблица
результатов спектрального анализа показана
ниже.
| Спектральный анализ: ПЕРЕМ1 (shumex.sta) Число наблюдений: 16 |
|||||
|---|---|---|---|---|---|
| t |
Час- тота |
Период |
Косинус корэфф. |
Синус корэфф. |
Периодо- грамма |
| 0 1 2 3 4 5 6 7 8 |
.0000 .0625 .1250 .1875 .2500 .3125 .3750 .4375 .5000 |
16.00 8.00 5.33 4.00 3.20 2.67 2.29 2.00 |
.000 1.006 .033 .374 -.144 -.089 -.075 -.070 -.068 |
0.000 .028 .079 .559 -.144 -.060 -.031 -.014 0.000 |
.000 8.095 .059 3.617 .333 .092 .053 .040 .037 |
Теперь рассмотрим столбцы таблицы результатов.
Ясно, что наибольший коэффициент при косинусах
расположен напротив частоты .0625. Наибольший
коэффициент при синусах соответствует частоте
.1875. Таким образом, эти две частоты, которые были
«внесены» в данные, отчетливо проявились.
Периодограмма
Функции синусов и косинусов независимы (или
ортогональны); поэтому можно просуммировать
квадраты коэффициентов для каждой частоты, чтобы
вычислить периодограмму. Более часто,
значения периодограммы вычисляются как:
Pk = синус-коэффициентk2
+ косинус-коэффициентk2 * N/2
где Pk — значения
периодограммы на частоте ![]() k , и N — общая
k , и N — общая
длина ряда. Значения периодограммы можно
интерпретировать как дисперсию (вариацию) данных
на соответствующей частоте. Обычно значения
периодограммы изображаются в зависимости от
частот или периодов.

Проблема рассеяния
В примере, приведенном выше, функция синуса с
частотой 0.2 была «вставлена» в ряд. Однако
из-за того, что длина ряда равна 16, ни одна из
частот, полученных в таблице результатов, не
совпадает в точности с этой частотой. На практике
в этих случаях часто оказывается, что
соответствующая частота «рассеивается» на
близкие частоты. Например, могут быть найдены
большие значения периодограммы для двух близких
частот, когда в действительности существует
только одна основная функция синуса или косинуса
с частотой, которая попадает на одну из этих
частот или лежит между найденными частотами.
Существует три подхода к решению проблемы
рассеяния:
- При помощи добавление констант во временной
ряда ряда можно увеличить частоты, - Применяя сглаживание ряда перед анализом,
можно уменьшить рассеяние или - Применяя сглаживание периодограммы, можно
идентифицировать основные частотные области или
(спектральные плотности), которые
существенно влияют на циклическое поведение
ряда.
Ниже смотрите описание каждого из этих
подходов.
Добавление констант во
временной ряд (пэддинг)
Так как частотные величины вычисляются как N/t,
можно просто добавить в ряд константы (например,
нули), и таким образом получить увеличение
частот. Фактически, если вы добавите в файл
данных, описанный в примере выше, десять нулей,
результаты не изменятся; т.е. наибольшие пики
периодограммы будут находиться по-прежнему на
частотах близких к .0625 и .2. (Добавление констант
во временной ряд также часто желательно для
увеличения вычислительной эффективности; см.
ниже.)
Косинус-сглаживание
Так называемый процесс косинус-сглаживания —
рекомендуемое преобразование ряда,
предшествующее спектральному анализу. Оно
обычно приводит к уменьшению рассеяния в
периодограмме. Логическое обоснование этого
преобразования подробно объясняется в книге
Bloomfield (1976, стр. 80-94). По существу, количественное
отношение (p) данных в начале и в конце ряда
преобразуется при помощи умножения на веса:
wt = 0.5*{1-cos[![]() *(t — 0.5)/m]} (для t=0 до m-1)
*(t — 0.5)/m]} (для t=0 до m-1)
wt = 0.5*{1-cos[![]() *(N — t +
*(N — t +
0.5)/m]} (для t=N-m до N-1)
где m выбирается так, чтобы 2*m/N было равно коэффициенту
пропорциональности сглаживаемых данных (p).
Окна данных и оценки
спектральной плотности
На практике, при анализе данных обычно не очень
важно точно определить частоты основных функций
синусов или косинусов. Скорее, т.к. значения
периодограммы — объект существенного случайного
колебания, можно столкнуться с проблемой многих
хаотических пиков периодограммы. В этом случае
хотелось бы найти частоты с большими спектральными
плотностями, т.е. частотные области, состоящие
из многих близких частот, которые вносят
наибольший вклад в периодическое поведение
всего ряда. Это может быть достигнуто путем
сглаживания значений периодограммы с помощью
преобразования взвешенного скользящего
среднего. Предположим, ширина окна скользящего
среднего равна m (должно быть нечетным
числом); следующие наиболее часто используемые
преобразования (заметим: p = (m-1)/2).
Окно Даниэля (равные веса). Окно
Даниэля (Daniell, 1946) означает простое (с равными
весами) сглаживание скользящим средним значений
периодограммы; т.е. каждая оценка спектральной
плотности вычисляется как среднее m/2
предыдущих и последующих значений
периодограммы.
Окно Тьюки. В окне Тьюки (Blackman and Tukey, 1958)
или Тьюки-Ханна (Hanning) (названное в честь Julius Von Hann),
для каждой частоты веса для взвешенного
скользящего среднего значений периодограммы
вычисляются как:
wj = 0.5 + 0.5*cos(![]() *j/p) (для j=0 до p)
*j/p) (для j=0 до p)
w-j = wj (для j ![]() 0)
0)
Окно Хемминга. В окне Хемминга
(названного в честь R. W. Hamming) или Тьюки-Хемминга
(Blackman and Tukey, 1958), для каждой частоты, веса для
взвешенного скользящего среднего значений
периодограммы вычисляются как:
wj = 0.54 + 0.46*cos(![]() *j/p) (для j=0 до p)
*j/p) (для j=0 до p)
w-j = wj (для j ![]() 0)
0)
Окно Парзена. В окне Парзена (Parzen, 1961),
для каждой частоты, веса для взвешенного
скользящего среднего значений периодограммы
вычисляются как:
wj = 1-6*(j/p)2 + 6*(j/p)3 (для
j = 0 до p/2)
wj = 2*(1-j/p)3 (для j = p/2 + 1 до p)
w-j = wj (для j ![]() 0)
0)
Окно Бартлетта. В окне Бартлетта (Bartlett,
1950) веса вычисляются как:
wj = 1-(j/p) (для j = 0 до p)
w-j = wj (для j ![]() 0)
0)
За исключением окна Даниэля, все весовые
функции приписывают больший вес сглаживаемому
наблюдению, находящемуся в центре окна и меньшие
веса значениям по мере удаления от центра. Во
многих случаях, все эти окна данных получают
очень похожие результаты.
Подготовка данных к анализу
Теперь рассмотрим несколько других
практических моментов спектрального анализа.
Обычно, полезно вычесть среднее из значений ряда
и удалить тренд (чтобы добиться стационарности)
перед анализом. Иначе периодограмма и
спектральная плотность «забьются» очень
большим значением первого коэффициента при
косинусе (с частотой 0.0). По существу, среднее — это
цикл частоты 0 (нуль) в единицу времени; т.е.
константа. Аналогично, тренд также не
представляет интереса, когда нужно выделить
периодичность в ряде. Фактически оба этих
эффекта могут заслонить более интересные
периодичности в данных, поэтому и среднее, и
(линейный) тренд следует удалить из ряда перед
анализом. Иногда также полезно сгладить данные
перед анализом, чтобы убрать случайный шум,
который может засорять существенные
периодические циклы в периодограмме.
Результаты для случая, когда в
ряде отсутствует периодичность
В заключение, зададим вопрос: что, если
повторяющихся циклов в данных нет, т.е. если
каждое наблюдение совершенно независимо от всех
других наблюдений? Если распределение
наблюдений соответствует нормальному, такой
временной ряд может быть белым шумом (подобный
белый шум можно услышать, настраивая радио). Если
исходный ряд — белый шум, то значения
периодограммы будут иметь экспоненциальное
распределение. Таким образом, проверкой на
экспоненциальность значений периодограммы
можно узнать, отличается ли исходный ряд от
белого шума. Пользователь может также построить
одновыборочную статистику d статистику
Колмогорова-Смирнова (cм. также раздел Непараметрическая статистика и
распределения).
Проверка, что шум — белый в ограниченной
полосе частот. Заметим, что также можно
получить значения периодограммы для
ограниченной частотной области. Снова, если
введенный ряд — белый шум с соответствующими
частотами (т.е. если нет существенных
периодических циклов этих частот), то
распределение значений периодограммы должно
быть снова экспоненциальным.
Быстрое преобразование Фурье (БПФ)
- Общее введение
- Вычисление БПФ во временных
рядах
За дальнейшей информацией обратитесь к Анализу временных рядов и
следующим разделам:
- Идентификация модели
временных рядов - АРПСС (Бокс и Дженкинс) и
автокорреляции Вводный обзор АРПСС - Прерванные временные ряды
- Экспоненциальное
сглаживание - Сезонная декомпозиция (метод
Census I) - Сезонная корректировка X-11
(метод Census II) - Таблицы результатов
корректировки X-11 - Анализ распределенных лагов
- Одномерный анализ Фурье
- Кросс-спектральный анализ
- Основные понятия и принципы
Общее введение
Интерпретация результатов спектрального
анализа обсуждается в разделе Основные
понятия и принципы, однако там мы не
обсуждали вычислительные проблемы, которые в
действительности очень важны. До середины 1960-х
для представления спектрального разложения
использовались точные формулы для нахождения
параметров синусов и косинусов. Соответствующие
вычисления требовали как минимум N**2 (комплексных)
умножений. Таким образом, даже сегодня
высокоскоростному компьютеру потребовалось бы
очень много времени для анализа даже небольшого
временного ряда (для 8,000 наблюдений
потребовалось бы по меньшей мере 64 миллиона
умножений).
Ситуация кардинально изменилась с открытием
так называемого алгоритма
быстрого преобразования Фурье, или БПФ для
краткости. Достаточно сказать, что при
применении алгоритма БПФ время выполнения
спектрального анализа ряда длины N стало
пропорционально N*log2(N) что конечно
является огромным прогрессом.
Однако недостаток стандартного алгоритма БПФ
состоит в том, что число данных ряда должно быть
равным степени 2 (т.е. 16, 64, 128, 256, …). Обычно это
приводит к необходимости добавлять нули во
временной ряд, который, как описано выше, в
большинстве случаев не меняет характерные пики
периодограммы или оценки спектральной
плотности. Тем не менее, в некоторых случаях,
когда единица времени значительна, добавление
констант во временной ряд может сделать
результаты более громоздкими.
Вычисление БПФ во временных
рядах
Выполнение быстрого преобразования Фурье
чрезвычайно эффективно. На большинстве
стандартных компьютеров, ряд с более чем 100,000
наблюдений легко анализируется. Однако
существует несколько моментов, которые надо
помнить при анализе рядов большого размера.
Как упоминалось ранее, для применения
стандартного (и наиболее эффективного) алгоритма
БПФ требуется, чтобы длина исходного ряда была
равна степени 2. Если это не так, должны быть
проведены дополнительные вычисления. Будут
использоваться простые точные вычислительные
формулы, пока исходный ряд относительно мал, и
вычисления можно выполнить за относительно
короткое время. Для длинных временных рядов,
чтобы применить алгоритм БПФ, используется
основной подход, описанный Monro и Branch (1976). Этот
метод требует значительно больше памяти; однако
ряд рассматриваемой длины может анализироваться
все еще очень быстро, даже если число наблюдений
не является степенью 2.
Для временных рядов, длина которых не равна
степени 2, мы можем дать следующие рекомендации:
если размер исходного ряда не превосходит
средний размер (т.е. имеется только несколько
тысяч наблюдений), не стоит беспокоиться. Анализ
займет несколько секунд. Для анализа средних и
больших рядов (например, содержащих свыше 100,000
наблюдений), добавьте в ряд константы (например
нули) до тех пор, пока длина ряда не станет
степенью 2 и затем примените косинус-сглаживание
ряда в разведочной части анализа ваших данных.
Дополнительная информация по методам анализа данных, добычи данных,
визуализации и прогнозированию содержится на
Портале StatSoft (http://www.statsoft.ru/home/portal/default.asp)
и в Углубленном Учебнике StatSoft (Учебник с формулами).
Все права на материалы электронного учебника принадлежат компании StatSoft
- Авторы
- Резюме
- Файлы
- Ключевые слова
- Литература
Печников А.А.
1
1 ФГБУН «Институт прикладных математических исследований Карельского научного центра Российской академии наук»
На примере вебометрического индикатора «размер сайта», измеряемого для множества веб-сайтов Российской академии наук, рассмотрен вопрос об ошибочных измерениях, полученных в результате использования поисковых систем. Предложим подход к «сглаживанию» ошибок поисковых систем, основанный на использовании результатов сканирования сайтов с помощью авторской программы BeeCrawler.
вебометрика
веб-сайт
вебометрическое ранжирование
индикаторы
1. Bar-Ilan J. Expectations versus reality – Search engine features needed for Web research at mid / J. Bar-Ilan // International Journal of Scientometrics, Informetrics and Bibliometrics. 2005. Vol. 9. URL:http://www.cybermetrics.info/articles/v9i1p2.pdf.
2. Bar-Ilan J. How much information do search engines disclose on the links to a web page? A longitudinal case study of the ‘cybermetrics’ home page / J. Bar-Ilan // Journal of Information Science. 2002. Vol. 28, No. 6. P. 455-466.
3. Snyder H. Can search engines be used as tools for web-link analysis? A critical view / H. Snyder, H. Rosenbaum // Journal of documentation. 1999. Vol. 55(4). P. 375-384.
4. Thelwall M. Web impact factors and search engine coverage / M. Thelwall // Journal of Documentation. 2000. Vol. 56(2). P. 185-189.
5. Вебометрический рейтинг научных учреждений России [Электронный ресурс]. Режим доступа: http://webometrics-net.ru (дата обращения 15.07.2013).
6. Рейтинг сайтов научных учреждений СО РАН [Электронный ресурс]. Режим доступа: http://www.ict.nsc.ru/ranking (дата обращения 16.07.2013).
7. Вебометрический индекс российских вузов и НИИ [Электронный ресурс]. Режим доступа: http://ru-webometrics.info (дата обращения 17.07.2013).
8. Ranking Web of World universities [Электронный ресурс]. Режим доступа: http:// www.webometrics.info (дата обращения 17.07.2013).
9. Чернобровкин Д.И., Печников А.А. Свидетельство о гос. регистрации программы для ЭВМ «Программа для поиска и сбора внешних гиперссылок BeeCrawler» Федеральной службы по интеллектуальной собственности, патентам и товарным знакам РФ № 2012619665 от 26 октября 2012 г.
10. Pant G., Srinivasan P., Menczer F. Crawling the Web // In Web Dynamics / Springer. – 2004. Levene M. and Poulovassilis A., eds. P. 153-178.
Еще в 2005 году в работе [1] было отмечено, что исследования Веба зачастую основываются на данных, полученных, если можно так выразиться, с помощью самого Веба, и, в частности, с использованием возможностей наиболее распространенных поисковых систем. Однако, поисковые системы, являясь коммерческими проектами, ориентированы на некоего условного «среднего» пользователя (с возможностью адаптации к его запросам), а не на исследователя.
Критические публикации на тему использования поисковых машин в качестве средств измерений появились достаточно давно [2-4]. Например, в работе [2] показано, что для подобранных конкретных примеров Google (по неизвестным причинам) «скрывает» от 48 до 70% проиндексированных им же страниц, содержащих ссылки на заданный сайт. Даже в случае очевидной ошибки в результатах вывода по запросу к поисковой системе мы не получим ответа на вопрос о том, почему эта ошибка произошла. Это, однако, не останавливает исследователей, имеющих в качестве «измерительных устройств» только поисковые системы [6, 7].
В процессе работы по проекту «Вебометрический рейтинг научных учреждений России» [5] в процессе измерений значений вебометрических индикаторов авторам пришлось столкнуться с возникновением ситуаций, которые нельзя назвать иначе как ошибками поисковых систем. Наиболее явно такие ситуации проявились при измерениях с помощью Google индикатора, характеризующего размер сайтов, когда получаемое количество страниц выражалось сотнями тысяч для сайтов весьма скромных размеров (об этом достоверно можно судить из других источников).
Поисковые системы как «измерительные устройства» обладают низкой надежностью, измерения, проведенные в одинаковых условиях, не всегда дают согласующиеся результаты [1]. Это объяснимо, если измерения проводятся через большие интервалы времени (сказывается динамика Веба), но неприемлемо в тех случаях, когда причин для больших расхождений не видно. Измерения индикаторов в рамках проекта [5] проводятся в течение компактного временного интервала (в течение двух недель) и дальнейшая обработка полученных значений не подразумевает новых замеров при обнаружении предполагаемых ошибок, поскольку в этом случае нужно заново измерять все индикаторы.
Однако ни в первом проекте по ранжированию веб-сайтов [8], ни в других проектах [6, 7], вопросу об ошибочных измерениях вебометрических индикаторов должного внимания не уделяется. В данной статье мы предложим подход к «сглаживанию» ошибок поисковых систем при измерениях размеров сайтов.
Вебометрические индикаторы. Общеизвестны основные вебометрические индикаторы, используемые при решении задач ранжирования веб-ресурсов. Можно считать, что 4 индикатора, введенные ещё в 2004 году в проекте [8], не вызывают принципиальных возражений и в настоящее время:
- размер сайта (S, size) – общее количество страниц,
- видимость сайта (V, visibility) – количество гипертекстовых ссылок с других веб-ресурсов,
- количество полнотекстовых файлов (R, «rich files», т.е. файлов с расширениями doc, pdf, ppt и т.д.),
- научность сайта (Sc, «scholar») – количество ссылок на сайт, обнаруживаемых Google Scholar.
Для первых трёх индикаторов следует добавить фразу «обнаруживаемых с помощью Google/Яндекс/ …». Отметим также, что разработчики проекта [8] недавно анонсировали использование в качестве индикаторов данных, предоставляемых коммерческими системами Ahrefs Pte Ltd (https://ahrefs.com) и Majestic SEO (http://www.majesticseo.com), чем еще больше усугубили ситуацию в плане прозрачности и отсутствия коммерческих влияний [1].
В проекте «Вебометрический рейтинг научных учреждений России» для сбора значений вебометрических индикаторов используются поисковые системы Яндекс и Google и специализированная программа сбора внешних гиперссылок BeeCrawler [9].
Измерения вебометрических индикаторов. В проекте [5] на сегодняшний день проведены измерения индикаторов примерно для 400 сайтов РАН (далее количество сайтов будем обозначать N).
Пусть 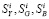 – размеры i-го сайта по Яндексу, Google и BeeCrawler, а
– размеры i-го сайта по Яндексу, Google и BeeCrawler, а 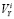 – видимость i-го сайта по Яндексу (она нам понадобится в разделе «Сглаживание ошибок»).
– видимость i-го сайта по Яндексу (она нам понадобится в разделе «Сглаживание ошибок»).
Приемы измерений поясним на примере сайта Российской академии наук (www.ras.ru). в Google на запрос вида «site:www.ras.ru» (текст набирается в поисковой строке, кавычки не нужны) будет выдан ответ «Результатов: примерно 513000». Это значение далее и будет принято в качестве 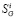 для сайта www.ras.ru (более точно – это значение
для сайта www.ras.ru (более точно – это значение 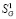 , поскольку сайт РАН имеет порядковый номер 1).
, поскольку сайт РАН имеет порядковый номер 1).
В Яндексе для получения количества страниц также можно использовать запрос вида «site:www.ras.ru». Ответ «Нашлось 85 тыс. ответов» округлен, хотя и его можно использовать в качестве приближенного значения 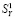 . Более удобным представляется использование специального сервиса Яндекс.XML, для чего необходимо зарегистрироваться в системе. Здесь запрос о количестве страниц на www.ras.ru выглядит следующим образом:
. Более удобным представляется использование специального сервиса Яндекс.XML, для чего необходимо зарегистрироваться в системе. Здесь запрос о количестве страниц на www.ras.ru выглядит следующим образом:
http://xmlsearch.yandex.ru/xmlsearch?text=site:www.ras.ru&user=USER&key=KEY,
где USER и KEY – логин и ключ пользователя. В одной из строк развернутого ответа на запрос будет строка <found−docs−human>нашёл 85145 ответов</ found−docs−human>, и 85145 будет являться значением индикатора 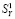 .
.
Удивляться существенному расхождению в результатах разных поисковых систем не следует: нам неизвестны правила отбора страниц на сайте, принятые в поисковых системах, и, по-видимому, в Google и Яндексе они различные. При последовательном просмотре результатов вывода Google вскоре выдаст информацию «Мы скрыли некоторые результаты, которые очень похожи на уже представленные выше (683)», то есть проверяемыми являются только 683 результата из 513000 заявленных, а что собой представляют остальные результаты проверить не удастся. Яндекс также выдает не все, а только 1000 ответов по запросу «site:www.ras.ru».
В BeeCrawler реализован порядок обхода страниц «вначале вширь»: сканируется начальная страница нулевого уровня, находятся страницы первого уровня, сканируются страницы первого уровня и находятся страницы второго уровня и т.д. В процессе сканирования создается вспомогательная таблица количества страниц на каждом уровне, т.е. мы имеем
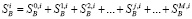 ,
,
где 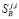 – количество страниц на j-м уровне i-го сайта, а М – номер наибольшего сканируемого уровня, устанавливаемого при запуске программы (в последней версии сканирования M=7).
– количество страниц на j-м уровне i-го сайта, а М – номер наибольшего сканируемого уровня, устанавливаемого при запуске программы (в последней версии сканирования M=7).
В табл. 1 приводятся значения индикаторов для нескольких веб-сайтов РАН.
Последние измерения, используемые в статье, проводились в июне-июле 2013 года. Полужирным шрифтом выделены значения 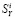 и
и 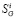 , которые представляются ошибочными. В частности, сайт Красноярского научного центра можно оценить визуально в любом браузере.
, которые представляются ошибочными. В частности, сайт Красноярского научного центра можно оценить визуально в любом браузере.
На рис. 1 приводятся значения размеров сайтов 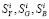 . Для удобства восприятия в едином масштабе значения
. Для удобства восприятия в едином масштабе значения 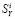 умножены на коэффициент 6 и упорядочены по убыванию, поэтому соответствующий график выглядит как непрерывная убывающая кривая, хотя и скрытая за пиками на заднем плане.
умножены на коэффициент 6 и упорядочены по убыванию, поэтому соответствующий график выглядит как непрерывная убывающая кривая, хотя и скрытая за пиками на заднем плане.
Таблица 1
Фрагмент таблицы значений вебометрических индикаторов
|
i |
Научное учреждение |
Имя сайта |
|
|
|
|
|
1 |
Российская академия наук |
www.ras.ru |
83013 |
606000 |
599904 |
20772 |
|
3 |
Отделение физических наук РАН |
www.gpad.ac.ru |
517 |
523 |
460 |
770 |
|
29 |
Пущинский научный центр РАН |
www.psn.ru |
5829 |
153 |
153 |
857 |
|
34 |
Красноярский научный центр СО РАН |
www.krasn.ru |
7291 |
93 |
1 |
500 |
|
44 |
Камчатский научный центр ДВО РАН |
www.kscnet.ru |
5757 |
177000 |
1525 |
6784 |
|
52 |
Библиотека по естественным наукам РАН |
www.benran.ru |
6471 |
177000 |
864 |
4154 |
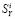
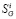
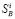
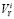
Значения 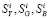 .
.
Графики по 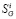 и
и 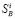 в черно-белом изображении не слишком выразительны и в основном характеризуют пики значений, подозрительных на ошибки. При этом регистрируемые ошибки по
в черно-белом изображении не слишком выразительны и в основном характеризуют пики значений, подозрительных на ошибки. При этом регистрируемые ошибки по 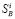 практически во всех случаях имеют содержательное объяснение: как правило, это так называемые «паучьи ловушки», когда разработчики сайтов (умышленно или неумышленно) создают условия для зацикливания поискового робота [10]. К ним относится организация меню сайта в виде дерева, динамические календари и т.д.
практически во всех случаях имеют содержательное объяснение: как правило, это так называемые «паучьи ловушки», когда разработчики сайтов (умышленно или неумышленно) создают условия для зацикливания поискового робота [10]. К ним относится организация меню сайта в виде дерева, динамические календари и т.д.
Обозначим 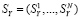 ,
, 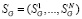 и
и 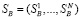 . Коэффициенты корреляции по Пирсону имеют следующие значения:
. Коэффициенты корреляции по Пирсону имеют следующие значения: 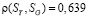 ,
, 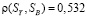 и
и 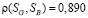 . Таким образом, можно говорить о высокой степени взаимосвязи между
. Таким образом, можно говорить о высокой степени взаимосвязи между 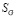 и
и 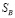 , и низкой между остальными парами индикаторов.
, и низкой между остальными парами индикаторов.
Функция ранжирования. Функция ранжирования в проекте «Вебометрический рейтинг научных учреждений России» [5] находится в процессе исследования и разработки, но для лучшего понимания процедуры сглаживания ошибок здесь стоит коротко остановиться на основных подходах к ее построению.
Обозначим 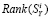 ранг i-го сайта по индикатору S, измеренному поисковой системой Яндекс. Здесь ранг – это порядковый номер сайта в упорядоченном по убыванию векторе
ранг i-го сайта по индикатору S, измеренному поисковой системой Яндекс. Здесь ранг – это порядковый номер сайта в упорядоченном по убыванию векторе 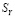 , то есть сайт с максимальным значением
, то есть сайт с максимальным значением 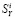 имеет ранг, равный 1. Для остальных индикаторов ранги определяются аналогично.
имеет ранг, равный 1. Для остальных индикаторов ранги определяются аналогично.
Для i-го сайта вычисляется интегральный показатель R(i) как функция от рангов сайта по каждому индикатору. Далее сайты упорядочиваются по возрастанию значений R(i), сайт с минимальным значением R(i) получает вебометрический ранг WR(i), равный 1, и т.д. В настоящее время R(i) определяется как сумма рангов i-го сайта.
При таком построении функции ранжирования WR в случае ошибочных значений вебометрических индикаторов нас интересуют, собственно говоря, не их реальные значения, а ранги по соответствующим индикаторам. Это замечание мы будем иметь в виду в следующем разделе.
Сглаживание ошибок. Сглаживанием ошибок поисковых систем будем называть процедуру вычисления правдоподобных значений индикаторов «размер сайта» вместо измеренных и представляющихся ошибочными значений с использованием данных о количестве страниц сайта, обнаруживаемых BeeCrawler.
Первым шагом такой процедуры является визуальное выявление подозрительных на ошибку значений 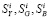 (с использованием графиков, аналогичных приведенному на рис. 1) и очистка таблицы значений вебометрических индикаторов от строк, соответствующих сайтам, у которых обнаружены такие значения.
(с использованием графиков, аналогичных приведенному на рис. 1) и очистка таблицы значений вебометрических индикаторов от строк, соответствующих сайтам, у которых обнаружены такие значения.
Обработка таблицы вебометрических индикаторов, измеренных в июне-июле 2013 года, выявила около 40 таких сайтов. После очистки значения коэффициентов корреляции изменились, теперь 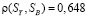 и
и 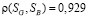 .
.
Предположим, что Яндекс формирует значения  исходя из следующих правил:
исходя из следующих правил:
- на каждом уровне сайта индексируется часть страниц, и чем ниже уровень, тем меньше эта часть;
- чем больше внешних ссылок сделано на сайт, тем большее количество его страниц индексируется.
Эксперименты, проведенные с результатами работы BeeCrawler с учётом сделанных предположений, приводят нас к построению формулы следующего вида:
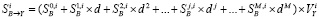 , (1)
, (1)
где 0<d<1 – коэффициент затухания, чем ниже уровень сайта, тем меньше страниц индексируется. Вычисления  для очищенной таблицы индикаторов показывают, что максимальное значение коэффициента корреляции, равное 0,826, достигается при d=0,075 и M=7 (здесь, как и ранее
для очищенной таблицы индикаторов показывают, что максимальное значение коэффициента корреляции, равное 0,826, достигается при d=0,075 и M=7 (здесь, как и ранее  ).
).
Учитывая достаточно сильную статистическую зависимость между  и
и 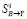 , для сглаживания ошибок Яндекса предлагается использовать соответствующие значения
, для сглаживания ошибок Яндекса предлагается использовать соответствующие значения 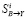 . Точнее, как было сказано ранее, нас интересуют не сами значения ошибочных
. Точнее, как было сказано ранее, нас интересуют не сами значения ошибочных 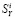 , а их
, а их 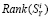 . Поэтому для ошибочного значения с индексом i по формуле (1) вычисляется
. Поэтому для ошибочного значения с индексом i по формуле (1) вычисляется 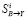 , далее определяется его ранг
, далее определяется его ранг 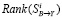 для вектора
для вектора 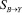 и полученное значение присваивается
и полученное значение присваивается 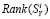 как правильное.
как правильное.
Эксперименты показали, что для Google также можно построить формулу следующего вида:
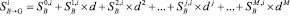 . (2)
. (2)
Обратим внимание на то, что индикатор ссылочной популярности сайта V в (2) не используется. Вычисления 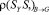 для очищенной таблицы индикаторов показывают, что максимальное значение коэффициента корреляции, равное 0,941, достигается при d=0,5 и M=7. Отсюда следует, что формулу (2) можно использовать для сглаживания ошибочных
для очищенной таблицы индикаторов показывают, что максимальное значение коэффициента корреляции, равное 0,941, достигается при d=0,5 и M=7. Отсюда следует, что формулу (2) можно использовать для сглаживания ошибочных  по аналогии с формулой (1) для Яндекса (хотя и корреляция между
по аналогии с формулой (1) для Яндекса (хотя и корреляция между  и
и  была уже достаточно большой).
была уже достаточно большой).
Заключение
В статье предложен подход к сглаживанию ошибок поисковых систем, возникающих при измерениях вебометрического индикатора «размер сайта». Данный подход применяется в проекте «Вебометрический рейтинг научных учреждений России» и в большинстве случаев позволяет использовать точные процедуры исправления очевидных ошибок вместо слабо формализуемых мнений экспертов, в качестве которых пока выступают сами разработчики проекта.
Работа выполняется при поддержке гранта РГНФ № 12-03-12001.
Библиографическая ссылка
Печников А.А. ОБ ИЗМЕРЕНИЯХ ВЕБОМЕТРИЧЕСКИХ ИНДИКАТОРОВ // Международный журнал экспериментального образования. – 2013. – № 10-2.
– С. 400-404;
URL: https://expeducation.ru/ru/article/view?id=4258 (дата обращения: 13.02.2023).
Предлагаем вашему вниманию журналы, издающиеся в издательстве «Академия Естествознания»
(Высокий импакт-фактор РИНЦ, тематика журналов охватывает все научные направления)