Возможные ошибки спецификации модели:
1. Неправильный выбор вида уравнения
регрессии
2. В уравнение регрессии включена лишняя
(незначимая) переменная
3. В уравнении регрессии пропущена
значимая переменная
-
Неправильный выбор вида функции в
уравнении
Пусть на первом этапе была сделана
спецификация модели в виде:
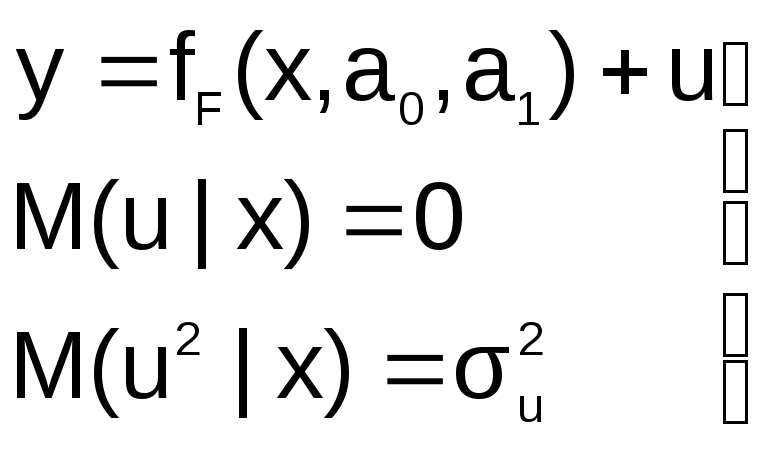
в![]()
которой функция fF(x,a0,a1)
выбрана не верно. Предположим, что
yT=fT(x,a0,a1)+v
– правильный вид функции регрессии.
Тогда справедливо выражение:
И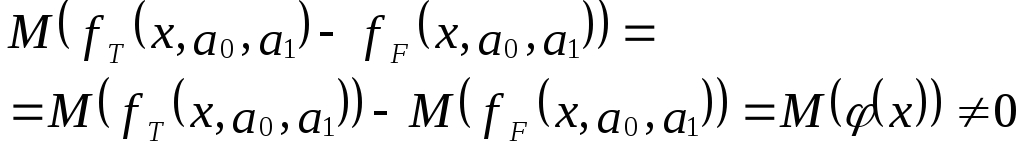 з
з
выражения следует:
Иными словами, математические ожидания
эндогенной переменной, полученные с
помощью функций fT
и fF
не совпадают, т.е. первая предпосылка
теоремы Гаусса-Маркова M(ulx)=0
не выполняется
Следовательно, в результате оценивания
такой модели параметры а0 и а1
будут смещенными
Симптомы наличия ошибки спецификации
первого типа:
1. Несоответствие диаграммы рассеяния,
построенной по имеющейся выборке виду
функции, принятой в спецификации
2. В динамических моделях длительно
сохраняется знак значений оценок
случайных возмущений у смежных (по
номеру t ) уравнений
наблюдений
Именно этот симптом и улавливается
статистикой DW Дарбина–Уотсона!
В силу данного обстоятельства тесту
Дарбина–Уотсона в эконометрике придается
большое значение.
Способ устранения: выбор другой формы
спецификации модели. Например, нелинейная
вместо линейной и т.д.
2. В уравнение регрессии включена
лишняя переменная
П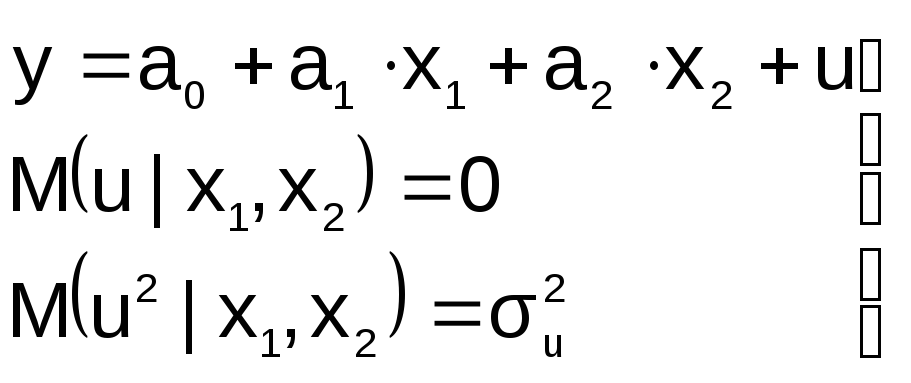 усть
усть
на этапе спецификации в модель включена
«лишняя» переменная, например, X2
«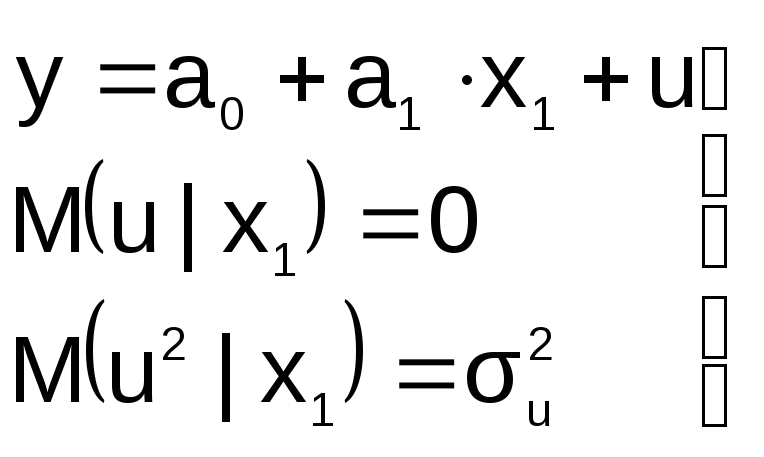 Правильная»
Правильная»
спецификация должна иметь вид:
Последствия:
![]() 1.
1.
Оценки параметров а0, а1, а2
останутся несмещенными, но потеряют
свою эффективность (точность)
2. Увеличивается ошибка прогноза по
модели
как за счет ошибок оценок коэффициентов
и σu,
так и за счет последнего слагаемого.
Это особенно опасно при больших абсолютных
значениях регрессора
Диагностика:
В моделях множественной регрессии
необходимо для каждого коэффициента
уравнения проверять статистическую
гипотезу H0: ai=0.
Вспомним, что для этого достаточно
оценить дробь Стьюдента и сравнить ее
значение с критическим значением
распределения Стьюдента, которое
вычисляется по значению доверительной
вероятности и значению степени свободы
n2 = n – (k+1)
3![]() .
.
В модели не достает важной переменной
Последствия такие же, как и в первом
случае: получаем смещенные оценки
параметров модели
Для устранения необходимо вернуться к
изучению особенностей поведения
экономического объекта, выявить опущенные
переменные и дополнить ими модель
29. Фиктивные переменные и особенности их использования в моделях.
На практике приходится учитывать в
моделях факторы, носящие качественный
характер, значения которых в наблюдениях
не возможно измерить с помощью числовой
шкалы.
Примеры.
Моделирование влияния пола специалистов
на уровень зарплаты.
Моделирование доходов граждан от типа
учебного заведения, в котором он получил
образование (государственное, частное,
специализированное,…)
Модель инфляции с учетом различных
видов регулирования со стороны государства
Возможны два подхода к решению задачи:
— построить несколько моделей отдельно
для каждого значения (градации)
качественной переменной
— учесть влияние качественного фактора
в одной модели
Второй способ представляется более
прогрессивным, т.к в этом случае появляется
возможность оценить статистическую
значимость влияния данного фактора на
поведение эндогенной переменной на
фоне других факторов, внесенных в
спецификацию модели
Пример. Изучается зависимость
расходов на образование «С» в «обычных»
и «специализированных» школах в
зависимости от числа учащихся N
Предположим:
-
Зависимость затрат на обучение от
количества учащихся N в
обоих типах школ одинакова
2. Разница в затратах объясняется
необходимостью приобретения
специализированного оборудования для
обучения специальным дисциплинам
Тогда если строить различные модели
для каждого типа школ, то спецификацию
моделей можно записать в виде:
Yo
= a0 +
a1N +u
Ys
= b0 +
a1N +
v
О бе
бе
модели можно объединить, если ввести
переменную d, область
определения которой два целых числа :
0 и 1. При этом:
Спецификация такой модели имеет вид:
Y = a0
+ a1N
+ δd + u
Тогда при d=0 получим Yo
= a0 + a1N
+ u
при d=1 получим Ys
= (a0+δ)
+a1N +
v
d – фиктивная переменная
сдвига
Фиктивные переменные часто применяются
при построении динамических моделей,
когда с определенного момента времени
начинает действовать какой-либо
качественный фактор
Пусть некоторый качественный фактор
имеет несколько градаций (более 2-х)
Введение в модель фиктивных переменных
с несколькими градациями рассмотрим
на примере шанхайских школ, где имеются
4 категории школ: общеобразовательные,
технические, ПТУ и специализированные
Казалось достаточно ввести фиктивную
переменную сдвига d, придав
ей четыре различных значения и проблема
будет решена
Такой подход мало эффективен, т.к не
удается оценить статистическую значимость
влияния каждой градации на значения
эндогенной переменной
В этом случае имеет смысл ввести отдельную
переменную для каждой градации фактора
Н апример:
апример:
Однако, если взять спецификацию модели
в виде:
Y=a0
+ a1d1+a2d2+a3d3+a4d4+a5N+u
при этом всегда верно тождество
d1+d2+d3+d4=1
Это означает, что матрица Х коэффициентов
системы уравнений наблюдений будет
коллинеарной т.к в ней присутствует
столбец из 1, и как следствие отсутствует
возможность применения МНК для оценки
параметров модели.
Предлагается в спецификацию ввести
(к-1) фиктивную переменную (к- кол-во
градаций), сделав одну из градаций
базовой, относительно которой изучать
влияние остальных градаций. Проблемы
мультиколинеарности в этом случае не
возникает
Для учета возможного изменения наклона
графика модели при изменении градации
качественного фактора предлагается
ввести в спецификацию модели еще одно
слагаемое вида «d умноженное
на x»
Вернемся к примеру изучения зависимости
расходов на образование в различных
школах. Для простоты ограничимся лишь
двумя градациями фактора «тип школы»:
d=0 – обычная школа;
d=1 – профессиональная
школа
Спецификацию модели следует записать
в виде:
Y = a0
+ a1N
+ a2*d
+ a3dN
+U
50
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Assume that on the basis of the criteria just listed we arrive at a model that we accept as a good model. To be concrete, let this model be
Yi = ft ft Xi ft X ft X3 Uli (13.2.1)
where Y = total cost of production andX = output. Equation (13.2.1) is the familiar textbook example of the cubic total cost function.
But suppose for some reason (say, laziness in plotting the scattergram) a researcher decides to use the following model:
Yi = ai a2 Xi a3 X2 Ui (13.2.2)
Note that we have changed the notation to distinguish this model from the true model.
Since (13.2.1) is assumed true, adopting (13.2.2) would constitute a specification error, the error consisting in omitting a relevant variable (X3). Therefore, the error term u2i in (13.2.2) is in fact
U2i = U1i ft X3 (13.2.3)
We shall see shortly the importance of this relationship.
Now suppose that another researcher uses the following model:
Yi = ft ft Xi A 3 X} ft X3 ft X4 U3i (13.2.4)
If (13.2.1) is the «truth,» (13.2.4) also constitutes a specification error, the error here consisting in including an unnecessary or irrelevant variable
in the sense that the true model assumes ft to be zero. The new error term is in fact
u3i = u1i — ftX4 = u1i since ft = 0 in the true model (Why?)
Now assume that yet another researcher postulates the following model:
ln Yi = Y1 Y2 Xi Y3 Xf Y4 X3 m (13.2.6)
In relation to the true model, (13.2.6) would also constitute a specification bias, the bias here being the use of the wrong functional form: In (13.2.1) Y appears linearly, whereas in (13.2.6) it appears log-linearly.
ECONOMETRIC MODELING
Finally, consider the researcher who uses the following model:
Y* = fa* fa2* X* fa X*2 fa X*3 u* (13.2.7)
where Y* = Y* e* and X* = X* w*, e* and w* being the errors of measurement. What (13.2.7) states is that instead of using the true Y and X* we use their proxies, Y* and X*, which may contain errors of measurement. Therefore, in (13.2.7) we commit the errors of measurement bias. In applied work data are plagued by errors of approximations or errors of incomplete coverage or simply errors of omitting some observations. In the social sciences we often depend on secondary data and usually have no way of knowing the types of errors, if any, made by the primary data-collecting agency.
Another type of specification error relates to the way the stochastic error u* (or ut) enters the regression model. Consider for instance, the following bivariate regression model without the intercept term:
Y = fa XiUi (13.2.8)
where the stochastic error term enters multiplicatively with the property that ln u* satisfies the assumptions of the CLRM, against the following model
Y = a X* U (13.2.9)
where the error term enters additively. Although the variables are the same in the two models, we have denoted the slope coefficient in (13.2.8) by fa and the slope coefficient in (13.2.9) by a. Now if (13.2.8) is the «correct» or «true» model, would the estimated a provide an unbiased estimate of the true fa? That is, will E(a) = fa ? If that is not the case, improper stochastic specification of the error term will constitute another source of specification error.
To sum up, in developing an empirical model, one is likely to commit one or more of the following specification errors:
- Omission of a relevant variable(s)
- Inclusion of an unnecessary variable(s)
- Adopting the wrong functional form
- Errors of measurement
- Incorrect specification of the stochastic error term
Before turning to an examination of these specification errors in some detail, it may be fruitful to distinguish between model specification errors and model mis-specification errors. The first four types of error discussed above are essentially in the nature of model specification errors in that we have in mind a «true» model but somehow we do not estimate the correct model. In model mis-specification errors, we do not know what the true model is to begin with. In this context one may recall the controversy
RELAXING THE ASSUMPTIONS OF THE CLASSICAL MODEL
The monetarists give primacy to money in explaining changes in GDP, whereas the Keynesians emphasize the role of government expenditure to explain changes in GDP. So to speak, there are two competing models.
Continue reading here: Vif
Was this article helpful?
В этой главе мы сконцентрируемся на том, как при помощи эконометрики получать корректные ответы на вопросы о причинно-следственных связях. Чтобы это сделать, нужно верно специфицировать вашу модель. Под верной спецификацией будем понимать такую, которая позволяет получить состоятельные оценки коэффициентов при интересующих вас переменных. А также получить состоятельные стандартные ошибки для тестирования гипотез.
Глава будет устроена так: мы будем перечислять типичные ловушки, которые приводят к неверной спецификации. Далее для каждой такой ловушки мы будем указывать возможные способы избежать её и устранить проблему.
В каких-то случаях мы будем опираться на уже знакомые вам концепции и понятия. В некоторых же ситуациях мы будем, наоборот, ссылаться на более продвинутые методы и модели, с которыми нам ещё предстоит разобраться в следующих главах учебника (надеемся, это станет для вас дополнительной мотивацией все-таки дочитать его до конца).
Напомним, что в предыдущей главе мы сформулировали два важных определения:
- Эндогенный регрессор — регрессор, который коррелирован со случайными ошибками модели.
- Экзогенный регрессор — регрессор, который не коррелирован со случайными ошибками модели.
Кроме того, в той же главе мы выяснили, что для состоятельности оценки коэффициента при переменной необходимо, чтобы эта переменная была экзогенной (точнее, необходимо выполнение предпосылки №4 линейной регрессионной модели со стохастическими регрессорами из главы 6). Если же регрессор эндогенный, результаты вашего моделирования нельзя интерпретировать в терминах причинно-следственных связей. Нарушение предпосылки №4 об экзогенности регрессора — это самая частая проблема при проведении прикладных исследований на пространственных и панельных данных. Поэтому важно понимать, в каких случаях вам следует опасаться её возникновения. Есть следующие типичные ситуации:
- Эндогенность регрессора из-за пропуска существенной переменной. В качестве важного частного случая тут также следует указать проблему эндогенности из-за самоотбора.
- Эндогенность регрессора из-за выбора неверной функциональной формы связи.
- Эндогенность регрессора из-за двусторонней причинно-следственной связи.
- Эндогенность регрессора из-за ошибок измерения.
В последующих четырех параграфах главы мы подробно обсудим каждый из этих пунктов. В пятом параграфе мы поговорим о других (помимо эндогенности) проблемах, которые могут делать выводы эконометрических исследований необоснованными. В каждом случае мы также укажем основные возможные пути преодоления перечисленных трудностей.
-
7.1. Эндогенность из-за пропуска существенной переменной
-
7.2. Эндогенность из-за выбора неверной функциональной формы связи
-
7.3. Эндогенность из-за двусторонней причинно-следственной связи
-
7.4. Эндогенность из-за ошибок измерения
-
7.5. Другие (помимо эндогенности) потенциальные угрозы обоснованности выводов эконометрического исследования
-
7.6. Чек-лист эконометриста
-
Задания для самостоятельного решения
When we think about model assumptions, we tend to focus on assumptions like independence, normality, and constant variance. The other big assumption, which is harder to see or test, is that there is no specification error. The assumption of linearity is part of this, but it’s actually a bigger assumption.
What is this assumption of no specification error?
The basic idea is that when you choose a final model, you want to choose one that accurately represents the real relationships among variables.
There are a few common ways of specifying a linear model inaccurately.
Specifying a linear relationship between X & Y when the relationship isn’t linear
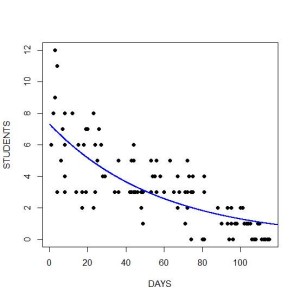 It’s often the case that the relationship between a predictor X and Y isn’t a straight line. Let’s use a common one as an example: a curvilinear relationship.
It’s often the case that the relationship between a predictor X and Y isn’t a straight line. Let’s use a common one as an example: a curvilinear relationship.
Specifying a line when the relationship is really a curve will result in less-than-optimal model fit, non-independent residuals, and inaccurate predicted values.
One way to check for a curvilinear relationship is with bivariate graphing before you get started modeling. Many times (though not always) the fix is simple: a log transformation of X or an addition of a quadratic (X squared) term.
Other ways to find it include residual graphs and, if they make theoretical sense, adding transformations of X to the model and assessing model fit.
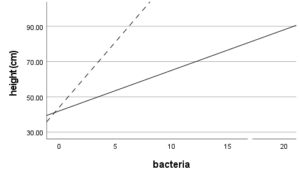 Another example is an interaction term.
Another example is an interaction term.
If the effect of a variable X is moderated by another predictor, it means X doesn’t have a simple linear relationship with Y. X’s relationship with Y depends on the value of a third variable–the moderator.
Including that interaction in the model will accurately represent the real relationship between X and Y. Failing to include it means mis-specification of X’s real effect.
Leaving out important predictors
The basic idea here is that if you’ve left out some important predictor or covariate, your model isn’t an accurate representation.
On the other hand, it’s impossible to realistically include every predictor that predicts or explains the outcome, as much as you may want to.
(And there are certainly models whose job is not to represent all predictors of an outcome. Rather it’s to test the relationship with specific predictors).
So you have to be comfortable with some level of specification error here and focus on minimizing it.
One of the most problematic mistakes here is to leave out an important confounding variable. Of course, you’re limited to the variables in your data set. So this is something to think about long before you’ve collected data.
Including unimportant predictors in the model
Just to make sure this doesn’t get too easy, another cause of model mis-specification is including predictors that are unrelated to the outcome variable.
So we can’t avoid missing an important predictor by throwing every possible predictor we have into the model.
There are many ways to build a model. The goal of all of them is to find the best model. The best model is one that includes all the important predictors in the right form, but not any unimportant ones.

Consequences of specification error
Specification error often, but not always, causes other assumptions to fail.
For example, sometimes you can solve non-normality of the residuals by adding a missed covariate or interaction term.
So the first step in solving problems with other assumptions is usually not to jump to transformations or some other complicated modeling, but to reassess the predictors you’ve put into the model.