Ни одна модель машинного обучения не выдаст осмысленных результатов, если вы предоставите ей сырые данные. После формирования выборки данных их необходимо очистить.
Очистка данных – это процесс обнаружения и исправления (или удаления) поврежденных или неточных записей из набора записей, таблицы или базы данных. Процесс включает в себя выявление неполных, неправильных, неточных или несущественных данных, а затем замену, изменение или удаление «загрязненных» данных.
Определение очень длинное и не очень понятное 
Чтобы детально во всем разобраться, мы разбили это определение на составные части и создали пошаговый гайд по очистке данных на Python. Здесь мы разберем методы поиска и исправления:
- отсутствующих данных;
- нетипичных данных – выбросов;
- неинформативных данных – дубликатов;
- несогласованных данных – одних и тех же данных, представленных в разных регистрах или форматах.
Для работы с данными мы использовали Jupyter Notebook и библиотеку Pandas.
***
Базой для наших экспериментов послужит набор данных по ценам на жилье в России, найденный на Kaggle. Мы не станем очищать всю базу целиком, но разберем на ее основе главные методы и операции.
Прежде чем переходить к процессу очистки, всегда нужно представлять исходный датасет. Давайте быстро взглянем на сами данные:
# импорт пакетов
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib.mlab as mlab
import matplotlib
plt.style.use('ggplot')
from matplotlib.pyplot import figure
%matplotlib inline
matplotlib.rcParams['figure.figsize'] = (12,8)
pd.options.mode.chained_assignment = None
# чтение данных
df = pd.read_csv('sberbank.csv')
# shape and data types of the data
print(df.shape)
print(df.dtypes)
# отбор числовых колонок
df_numeric = df.select_dtypes(include=[np.number])
numeric_cols = df_numeric.columns.values
print(numeric_cols)
# отбор нечисловых колонок
df_non_numeric = df.select_dtypes(exclude=[np.number])
non_numeric_cols = df_non_numeric.columns.values
print(non_numeric_cols)
Этот код покажет нам, что набор данных состоит из 30471 строки и 292 столбцов. Мы увидим, являются ли эти столбцы числовыми или категориальными признаками.
Теперь мы можем пробежаться по чек-листу «грязных» типов данных и очистить их один за другим.
***
1. Отсутствующие данные
Работа с отсутствующими значениями – одна из самых сложных, но и самых распространенных проблем очистки. Большинство моделей не предполагают пропусков.
1.1. Как обнаружить?
Рассмотрим три метода обнаружения отсутствующих данных в наборе.
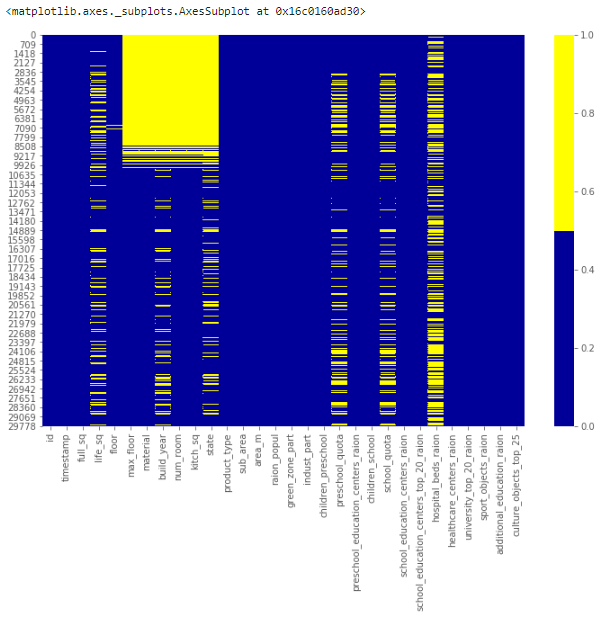
1.1.1. Тепловая карта пропущенных значений
Когда признаков в наборе не очень много, визуализируйте пропущенные значения с помощью тепловой карты.
cols = df.columns[:30] # первые 30 колонок
# определяем цвета
# желтый - пропущенные данные, синий - не пропущенные
colours = ['#000099', '#ffff00']
sns.heatmap(df[cols].isnull(), cmap=sns.color_palette(colours))
Приведенная ниже карта демонстрирует паттерн пропущенных значений для первых 30 признаков набора. По горизонтальной оси расположены признаки, по вертикальной – количество записей/строк. Желтый цвет соответствует пропускам данных.
Заметно, например, что признак life_sq имеет довольно много пустых строк, а признак floor – напротив, всего парочку – около 7000 строки.
1.1.2. Процентный список пропущенных данных
Если в наборе много признаков и визуализация занимает много времени, можно составить список долей отсутствующих записей для каждого признака.
for col in df.columns:
pct_missing = np.mean(df[col].isnull())
print('{} - {}%'.format(col, round(pct_missing*100)))
Такой список для тех же 30 первых признаков выглядит следующим образом:
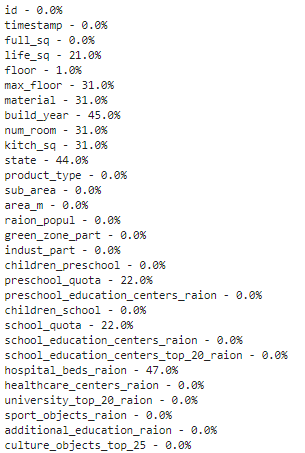
У признака life_sq отсутствует 21% значений, а у floor – только 1%.
Этот список является полезным резюме, которое может отлично дополнить визуализацию тепловой карты.
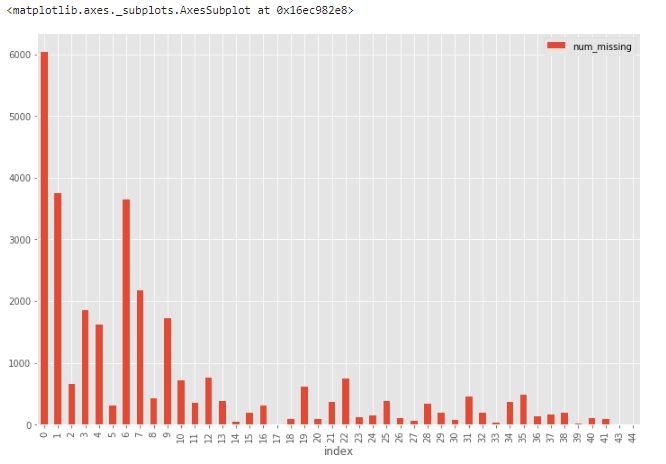
1.1.3. Гистограмма пропущенных данных
Еще одна хорошая техника визуализации для наборов с большим количеством признаков – построение гистограммы для числа отсутствующих значений в записи.
# сначала создаем индикатор для признаков с пропущенными данными
for col in df.columns:
missing = df[col].isnull()
num_missing = np.sum(missing)
if num_missing > 0:
print('created missing indicator for: {}'.format(col))
df['{}_ismissing'.format(col)] = missing
# затем на основе индикатора строим гистограмму
ismissing_cols = [col for col in df.columns if 'ismissing' in col]
df['num_missing'] = df[ismissing_cols].sum(axis=1)
df['num_missing'].value_counts().reset_index().sort_values(by='index').plot.bar(x='index', y='num_missing')
Отсюда понятно, что из 30 тыс. записей более 6 тыс. строк не имеют ни одного пропущенного значения, а еще около 4 тыс.– всего одно. Такие строки можно использовать в качестве «эталонных» для проверки различных гипотез по дополнению данных.
1.2. Что делать с пропущенными значениями?
Не существует общих решений для проблемы отсутствующих данных. Для каждого конкретного набора приходится искать наиболее подходящие методы или их комбинации.
Разберем четыре самых распространенных техники. Они помогут в простых ситуациях, но, скорее всего, придется проявить творческий подход и поискать нетривиальные решения, например, промоделировать пропуски.
1.2.1. Отбрасывание записей
Первая техника в статистике называется методом удаления по списку и заключается в простом отбрасывании записи, содержащей пропущенные значения. Это решение подходит только в том случае, если недостающие данные не являются информативными.
Для отбрасывания можно использовать и другие критерии. Например, из гистограммы, построенной в предыдущем разделе, мы узнали, что лишь небольшое количество строк содержат более 35 пропусков. Мы можем создать новый набор данных df_less_missing_rows, в котором отбросим эти строки.
# отбрасываем строки с большим количеством пропусков
ind_missing = df[df['num_missing'] > 35].index
df_less_missing_rows = df.drop(ind_missing, axis=0)
1.2.2. Отбрасывание признаков
Как и предыдущая техника, отбрасывание признаков может применяться только для неинформативных признаков.
В процентном списке, построенном ранее, мы увидели, что признак hospital_beds_raion имеет высокий процент недостающих значений – 47%. Мы можем полностью отказаться от этого признака:
cols_to_drop = ['hospital_beds_raion']
df_less_hos_beds_raion = df.drop(cols_to_drop, axis=1)
1.2.3. Внесение недостающих значений
Для численных признаков можно воспользоваться методом принудительного заполнения пропусков. Например, на место пропуска можно записать среднее или медианное значение, полученное из остальных записей.
Для категориальных признаков можно использовать в качестве заполнителя наиболее часто встречающееся значение.
Возьмем для примера признак life_sq и заменим все недостающие значения медианой этого признака:
med = df['life_sq'].median()
print(med)
df['life_sq'] = df['life_sq'].fillna(med)
Одну и ту же стратегию принудительного заполнения можно применить сразу для всех числовых признаков:
# impute the missing values and create the missing value indicator variables for each numeric column.
df_numeric = df.select_dtypes(include=[np.number])
numeric_cols = df_numeric.columns.values
for col in numeric_cols:
missing = df[col].isnull()
num_missing = np.sum(missing)
if num_missing > 0: # only do the imputation for the columns that have missing values.
print('imputing missing values for: {}'.format(col))
df['{}_ismissing'.format(col)] = missing
med = df[col].median()
df[col] = df[col].fillna(med)
К счастью, в нашем наборе не нашлось пропусков в категориальных признаках. Но это не мешает нам продемонстрировать использование той же стратегии:
df_non_numeric = df.select_dtypes(exclude=[np.number])
non_numeric_cols = df_non_numeric.columns.values
for col in non_numeric_cols:
missing = df[col].isnull()
num_missing = np.sum(missing)
if num_missing > 0: # only do the imputation for the columns that have missing values.
print('imputing missing values for: {}'.format(col))
df['{}_ismissing'.format(col)] = missing
top = df[col].describe()['top'] # impute with the most frequent value.
df[col] = df[col].fillna(top)
1.2.4. Замена недостающих значений
Можно использовать некоторый дефолтный плейсхолдер для пропусков, например, новую категорию _MISSING_ для категориальных признаков или число -999 для числовых.
Таким образом, мы сохраняем данные о пропущенных значениях, что тоже может быть ценной информацией.
# категориальные признаки
df['sub_area'] = df['sub_area'].fillna('_MISSING_')
# численные признаки
df['life_sq'] = df['life_sq'].fillna(-999)
***
2. Нетипичные данные (выбросы)
Выбросы – это данные, которые существенно отличаются от других наблюдений. Они могут соответствовать реальным отклонениям, но могут быть и просто ошибками.
2.1. Как обнаружить выбросы?
Для численных и категориальных признаков используются разные методы изучения распределения, позволяющие обнаружить выбросы.
2.1.1. Гистограмма/коробчатая диаграмма
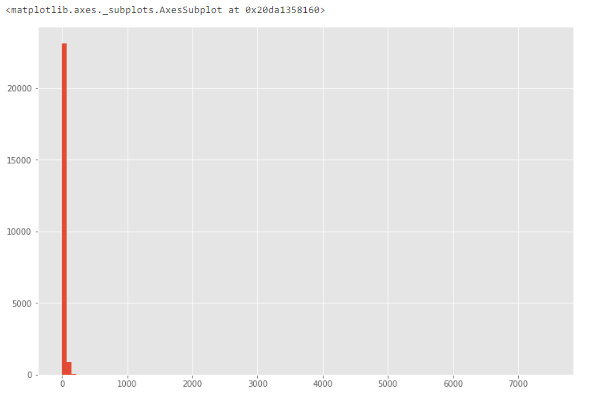
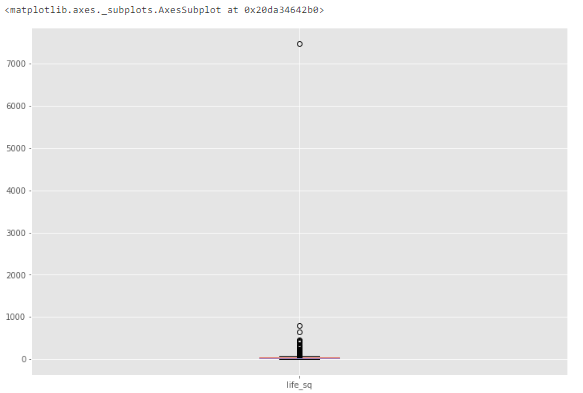
Если признак численный, можно построить гистограмму или коробчатую диаграмму (ящик с усами). Посмотрим на примере уже знакомого нам признака life_sq.
df['life_sq'].hist(bins=100)
Из-за возможных выбросов данные выглядят сильно искаженными.
Чтобы изучить особенность поближе, построим коробчатую диаграмму.
df.boxplot(column=['life_sq'])
Видим, что есть выброс со значением более 7000.
2.1.2. Описательная статистика
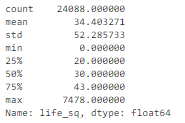
Отклонения численных признаков могут быть слишком четкими, чтобы не визуализироваться коробчатой диаграммой. Вместо этого можно проанализировать их описательную статистику.
Например, для признака life_sq видно, что максимальное значение равно 7478, в то время как 75% квартиль равен только 43. Значение 7478 – выброс.
df['life_sq'].describe()
2.1.3. Столбчатая диаграмма
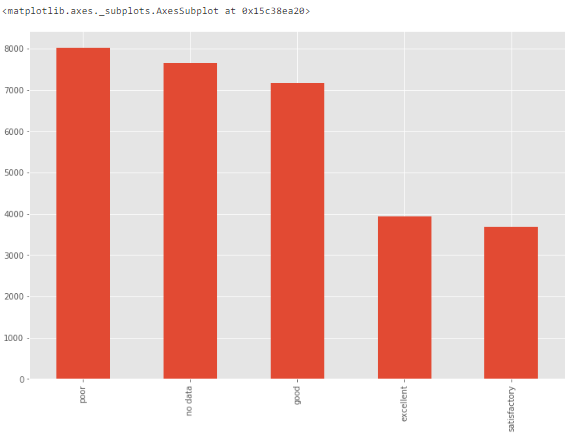
Для категориальных признаков можно построить столбчатую диаграмму – для визуализации данных о категориях и их распределении.
Например, распределение признака ecology вполне равномерно и допустимо. Но если существует категория только с одним значением "другое", то это будет выброс.
df['ecology'].value_counts().plot.bar()
2.1.4. Другие методы
Для обнаружения выбросов можно использовать другие методы, например, построение точечной диаграммы, z-оценку или кластеризацию. В этом руководстве они не рассматриваются.
2.2. Что делать?
Выбросы довольно просто обнаружить, но выбор способа их устранения слишком существенно зависит от специфики набора данных и целей проекта. Их обработка во многом похожа на обработку пропущенных данных, которую мы разбирали в предыдущем разделе. Можно удалить записи или признаки с выбросами, либо скорректировать их, либо оставить без изменений.
***

Переходим к более простой части очистки данных – удалению мусора.
Вся информация, поступающая в модель, должна служить целям проекта. Если она не добавляет никакой ценности, от нее следует избавиться.
Три основных типа «ненужных» данных:
- неинформативные признаки с большим количеством одинаковых значений,
- нерелевантные признаки,
- дубликаты записей.
Рассмотрим работу с каждым типом отдельно.
3. Неинформативные признаки
Если признак имеет слишком много строк с одинаковыми значениями, он не несет полезной информации для проекта.
3.1. Как обнаружить?
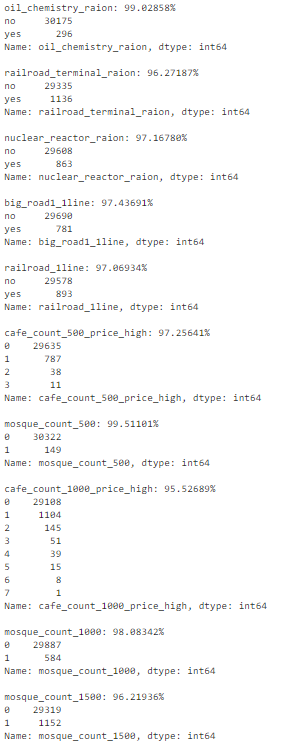
Составим список признаков, у которых более 95% строк содержат одно и то же значение.
num_rows = len(df.index)
low_information_cols = [] #
for col in df.columns:
cnts = df[col].value_counts(dropna=False)
top_pct = (cnts/num_rows).iloc[0]
if top_pct > 0.95:
low_information_cols.append(col)
print('{0}: {1:.5f}%'.format(col, top_pct*100))
print(cnts)
print()
Теперь можно последовательно перебрать их и определить, несут ли они полезную информацию.
3.2. Что делать?
Если после анализа причин получения повторяющихся значений вы пришли к выводу, что признак не несет полезной информации, используйте drop().
4. Нерелевантные признаки
Нерелевантные признаки обнаруживаются ручным отбором и оценкой значимости. Например, признак, регистрирующий температуру воздуха в Торонто точно не имеет никакого отношения к прогнозированию цен на российское жилье. Если признак не имеет значения для проекта, его нужно исключить.
5. Дубликаты записей
Если значения признаков (всех или большинства) в двух разных записях совпадают, эти записи называются дубликатами.
5.1. Как обнаружить повторяющиеся записи?
Способ обнаружения дубликатов зависит от того, что именно мы считаем дубликатами. Например, в наборе данных есть уникальный идентификатор id. Если две записи имеют одинаковый id, мы считаем, что это одна и та же запись. Удалим все неуникальные записи:
# отбрасываем неуникальные строки
df_dedupped = df.drop('id', axis=1).drop_duplicates()
# сравниваем формы старого и нового наборов
print(df.shape)
print(df_dedupped.shape)
Получаем в результате 10 отброшенных дубликатов:

Другой распространенный способ вычисления дубликатов: по набору ключевых признаков. Например, неуникальными можно считать записи с одной и той же площадью жилья, ценой и годом постройки.
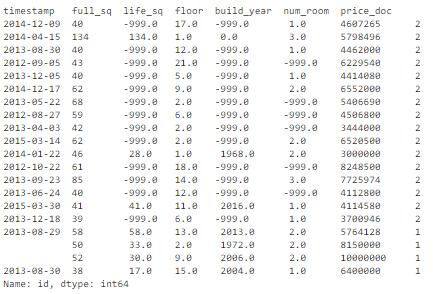
Найдем в нашем наборе дубликаты по группе критических признаков – full_sq, life_sq, floor, build_year, num_room, price_doc:
key = ['timestamp', 'full_sq', 'life_sq', 'floor', 'build_year', 'num_room', 'price_doc']
df.fillna(-999).groupby(key)['id'].count().sort_values(ascending=False).head(20)
Получаем в результате 16 дублирующихся записей:
5.2. Что делать с дубликатами?
Очевидно, что повторяющиеся записи нам не нужны, значит, их нужно исключить из набора.
Вот так выглядит удаление дубликатов, основанное на наборе ключевых признаков:
key = ['timestamp', 'full_sq', 'life_sq', 'floor', 'build_year', 'num_room', 'price_doc']
df_dedupped2 = df.drop_duplicates(subset=key)
print(df.shape)
print(df_dedupped2.shape)
В результате новый набор df_dedupped2 стал короче на 16 записей.

***
Большая проблема очистки данных – разные форматы записей. Для корректной работы модели важно, чтобы набор данных соответствовал определенным стандартам – необходимо тщательное исследование с учетом специфики самих данных. Мы рассмотрим четыре самых распространенных несогласованности:
- Разные регистры символов.
- Разные форматы данных (например, даты).
- Опечатки в значениях категориальных признаков.
- Адреса.
6. Разные регистры символов
Непоследовательное использование разных регистров в категориальных значениях является очень распространенной ошибкой, которая может существенно повлиять на анализ данных.
6.1. Как обнаружить?
Давайте посмотрим на признак sub_area:
df['sub_area'].value_counts(dropna=False)
В нем содержатся названия населенных пунктов. Все выглядит вполне стандартизированным:

Но если в какой-то записи вместо Poselenie Sosenskoe окажется poselenie sosenskoe, они будут расценены как два разных значения.
6.2. Что делать?
Эта проблема легко решается принудительным изменением регистра:
# пусть все будет в нижнем регистре
df['sub_area_lower'] = df['sub_area'].str.lower()
df['sub_area_lower'].value_counts(dropna=False)

7. Разные форматы данных
Ряд данных в наборе находится не в том формате, с которым нам было бы удобно работать. Например, даты, записанные в виде строки, следует преобразовать в формат DateTime.
7.1. Как обнаружить?
Признак timestamp представляет собой строку, хотя является датой:
df

7.2. Что же делать?
Чтобы было проще анализировать транзакции по годам и месяцам, значения признака timestamp следует преобразовать в удобный формат:
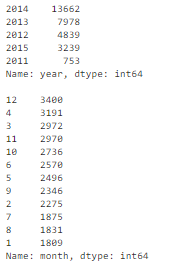
df['timestamp_dt'] = pd.to_datetime(df['timestamp'], format='%Y-%m-%d')
df['year'] = df['timestamp_dt'].dt.year
df['month'] = df['timestamp_dt'].dt.month
df['weekday'] = df['timestamp_dt'].dt.weekday
print(df['year'].value_counts(dropna=False))
print()
print(df['month'].value_counts(dropna=False))
Взгляните также на публикацию How To Manipulate Date And Time In Python Like A Boss.
8. Опечатки
Опечатки в значениях категориальных признаков приводят к таким же проблемам, как и разные регистры символов.
8.1. Как обнаружить?
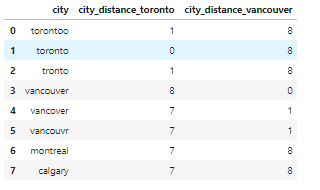
Для обнаружения опечаток требуется особый подход. В нашем наборе данных о недвижимости опечаток нет, поэтому для примера создадим новый набор. В нем будет признак city, а его значениями будут torontoo и tronto. В обоих случаях это опечатки, а правильное значение – toronto.
Простой способ идентификации подобных элементов – нечеткая логика или редактирование расстояния. Суть этого метода заключается в измерении количества букв (расстояния), которые нам нужно изменить, чтобы из одного слова получить другое.
Предположим, нам известно, что в признаке city должно находиться одно из четырех значений: toronto, vancouver, montreal или calgary. Мы вычисляем расстояние между всеми значениями и словом toronto (и vancouver).
Те слова, в которых содержатся опечатки, имеют меньшее расстояние с правильным словом, так как отличаются всего на пару букв.
from nltk.metrics import edit_distance
df_city_ex = pd.DataFrame(data={'city': ['torontoo', 'toronto', 'tronto', 'vancouver', 'vancover', 'vancouvr', 'montreal', 'calgary']})
df_city_ex['city_distance_toronto'] = df_city_ex['city'].map(lambda x: edit_distance(x, 'toronto'))
df_city_ex['city_distance_vancouver'] = df_city_ex['city'].map(lambda x: edit_distance(x, 'vancouver'))
df_city_ex
8.2. Что делать?
Мы можем установить критерии для преобразования этих опечаток в правильные значения.
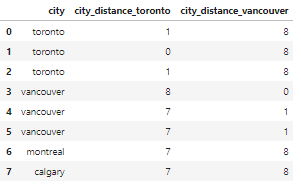
Например, если расстояние некоторого значения от слова toronto не превышает 2 буквы, мы преобразуем это значение в правильное – toronto.
msk = df_city_ex['city_distance_toronto'] <= 2
df_city_ex.loc[msk, 'city'] = 'toronto'
msk = df_city_ex['city_distance_vancouver'] <= 2
df_city_ex.loc[msk, 'city'] = 'vancouver'
df_city_ex
9. Адреса
Адреса – ужасная головная боль для всех аналитиков данных. Ведь мало кто следует стандартному формату, вводя свой адрес в базу данных.
9.1. Как обнаружить?
Проще предположить, что проблема разных форматов адреса точно существует. Даже если визуально вы не обнаружили беспорядка в этом признаке, все равно стоит стандартизировать их для надежности.
В нашем наборе данных по соображениям конфиденциальности отсутствует признак адреса, поэтому создадим новый набор df_add_ex:
df_add_ex = pd.DataFrame(['123 MAIN St Apartment 15', '123 Main Street Apt 12 ', '543 FirSt Av', ' 876 FIRst Ave.'], columns=['address'])
df_add_ex
Признак адреса здесь загрязнен:
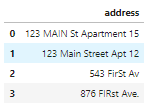
9.2. Что делать?
Минимальное форматирование включает следующие операции:
- приведение всех символов к нижнему регистру;
- удаление пробелов в начале и конце строки;
- удаление точек;
- стандартизация формулировок: замена
streetнаst,apartmentнаaptи т. д.
df_add_ex['address_std'] = df_add_ex['address'].str.lower()
df_add_ex['address_std'] = df_add_ex['address_std'].str.strip()
df_add_ex['address_std'] = df_add_ex['address_std'].str.replace('\.', '')
df_add_ex['address_std'] = df_add_ex['address_std'].str.replace('\bstreet\b', 'st')
df_add_ex['address_std'] = df_add_ex['address_std'].str.replace('\bapartment\b', 'apt')
df_add_ex['address_std'] = df_add_ex['address_std'].str.replace('\bav\b', 'ave')
df_add_ex
Теперь признак стал намного чище:
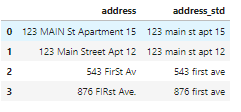
***
Мы сделали это! Это был долгий и трудный путь, но теперь все «грязные» данные очищены и готовы к анализу, а вы стали спецом по чистке данных 
У нас есть еще куча полезных статей по Data Science, например, среди недавних:
- 10 Data Science книг к прочтению в 2020 году
- 10 инструментов искусственного интеллекта Google, доступных каждому
- 100+ лекций экспертов Постнауки об анализе данных, ИИ, роботах, математике и сетях
Или просто посмотрите тег Data Science.

Алгоритмы машинного обучения могут собирать, хранить и анализировать данные и выдавать ценный результат. Эти инструменты позволяют оценить состояние, используя сложные и кластеризованные данные. Можно также сказать, что машинное обучение предлагает различные инструменты для понимания сложных данных путем сегментации и упрощения. Кроме того, оно позволяет автоматизировать бизнес-задачи и принимать лучшие решения на основе упорядоченных данных.
Конечно, в машинном обучении данные работают как топливо. Вы вводите новые данные в модель машинного обучения, и она генерирует желаемый результат, анализируя все необходимые данные. Для получения результатов алгоритм будет использовать соответствующие данные. Поэтому важно последовательно уточнять данные. Уточнение поможет удалить из наборов данных неактуальные и устаревшие данные. Вам больше не нужно, чтобы эти данные влияли на результат.
Нерелевантные данные в алгоритме будут влиять на результат и воздействовать на точность и успешность модели. Поэтому удаление нерелевантных данных необходимо для повышения эффективности результата. Следовательно, это объясняет важность очистки данных в машинном обучении. Поскольку ученые, изучающие данные, не часто говорят на эту тему, новички не знают, зачем и как удалять ненужные данные. В результате начинающие специалисты не могут добиться эффективности и точности своих результатов. Поэтому мы подготовили для вас это исчерпывающее руководство.
Очистка данных
Очистка данных означает избавление от неактуальных данных во всей модели. Этот процесс устраняет неточность результатов путем удаления ненужных данных. Он также гарантирует, что данные являются последовательными, корректными и пригодными для использования. Процесс очистки данных можно начать с выявления ошибок и решения проблем путем удаления данных. Очистка ненужных данных осуществляется с помощью таких инструментов, как Python. Этот инструмент поможет вам написать код и удалить данные. Помимо использования языка программирования для интерпретации кода очистки данных, вам также придется удалять данные вручную. Помните, что основная цель очистки данных – удаление ошибки, которая влияет на результат. Поэтому, когда вы приступите к очистке данных, процесс может показаться вам сложным, но результат будет замечательным.
Шаги для очистки данных
Первым шагом к очистке данных будет определение ваших целей. Вы не сможете выполнить свои задачи, если не имеете представления о своих ожиданиях. Как только вы узнаете свои цели, вы сможете разработать план их достижения. В данном случае ваша главная цель – добиться точности и устранить ошибки. В процессе планирования вы выберете стратегию, которой будете следовать. Лучшим решением будет начать с фокусировки на главных метриках. Однако для того, чтобы найти подходящие метрики, необходимо задать несколько вопросов.
- Какая метрика будет самой высокой для достижения желаемого результата?
- Каковы ваши ожидания от очистки данных?
Как только вы поймете причину необходимости очистки данных, вы сможете выполнить следующие шаги:
Выявление ошибок
Прежде чем исправить ошибку и внести точность в вывод модели, необходимо сначала ее выявить. Выявление ошибок поможет вам найти оптимальное решение за минимальное время. Однако оценка всех данных может быть пугающей и может повлиять на функции моделей. Поэтому ведите учет всех наборов данных, в которых вы встречаете больше ошибок. Ведение записей позволит вам упростить процесс выявления и устранения поврежденных или неправильных данных.
Стандартизируйте процесс
В процессе очистки данных вы также должны определить, является ли ошибка следствием неправильного значения. Каждое значение данных должно быть в стандартизированном формате. Например, вы должны проверить нижний и верхний регистры строк или измерить единицы измерения числовых значений. Иногда модель считает данные неточными из-за таких опечаток и искажений.
Убедитесь в точности данных
После анализа базы данных для очистки данных подтвердите точность данных с помощью различных инструментов. Для оптимизации и ускорения процесса очистки данных необходимо инвестировать в инструменты обработки данных. Большинство таких инструментов используют алгоритм машинного обучения для определения подходящих данных и их очистки в режиме реального времени. Впоследствии это положительно сказывается на точности модели и позволяет получить наилучшие результаты.
Проверьте наличие дубликатов данных
Дублирующиеся данные могут не вызывать ошибок, но отнимать много времени для получения результата. Однако вы можете решить эту проблему, выявляя дубликаты в процессе анализа данных. Поищите инструменты анализа данных для очистки данных от дубликатов. Выберите автоматизированный инструмент для анализа и удаления дубликатов данных.
Оценка данных
После того как вы определите, стандартизируете и удалите ненужные и дублирующиеся данные, добавьте их в базу данных с помощью сторонних инструментов. Эти инструменты будут накапливать данные из сторонней модели, очищать их и предоставлять полную информацию о точности данных. Как только вы очистите данные с помощью этих сторонних источников, используйте их для точной бизнес-аналитики.
Обсудите со своей командой
Если вы поделитесь этими методами со своей командой, это позволит добиться последовательности и точности за меньшее время. Когда вы объедините свою команду для продвижения этих новых протоколов, вы укрепите ее. Задействуйте свою команду, разработав план очистки данных, и поделитесь им с ними. Следовательно, это принесет точность моделям и ускорит процесс очистки данных.
Важность очистки данных
Как и во многих других компаниях, данные могут иметь центральное значение и в вашем бизнесе. Имея точные данные, вы можете улучшить свои бизнес-операции и принимать лучшие решения. Например, вы занимаетесь доставкой, и ваш бизнес зависит от адреса ваших клиентов. Чтобы данные были точными, вы должны постоянно обновлять базу данных. Поскольку многие клиенты в городе могут переехать в другой район, вам следует регулярно обновлять данные. Если ваши данные будут неточными и устаревшими, ваши сотрудники будут допускать ошибки при выполнении бизнес-задач. Поэтому сосредоточьтесь на обновлении новых данных и очистке старых. Вот некоторые преимущества очистки данных для вашего бизнеса:
- Экономически эффективный метод
- Снижает риск ошибок
- Улучшает привлечение клиентов
- Повышение бесперебойности данных
- Позволяет принимать лучшие решения
- Повышение производительности труда сотрудников
Заключение
Очистка данных – это эффективная техника для повышения точности модели машинного обучения. Многие компании не справляются с очисткой ненужных данных из базы данных своей модели. В этом руководстве мы рассмотрели, как можно очистить и повысить эффективность набора данных машинного обучения и уменьшить количество ошибок.
Все курсы > Анализ и обработка данных > Занятие 5
На прошлом занятии, посвященном практике EDA, мы работали с «чистыми данными», то есть такими данными, в которых нет ни ошибок, ни пропущенных значений. К сожалению, так бывает далеко не всегда.
Сегодня мы научимся очищать данные от дубликатов, неверных и плохо отформатированных значений, а также исправлять ошибки в дате и времени. На следующем занятии мы поговорим про работу с пропусками.
Откроем ноутбук к этому занятию⧉
Ошибки в данных могут встречаться по многим причинам. Они могут быть связаны с человеческим фактором, например, простой невнимательностью, или вызваны сбоями в работе записывающего какие-либо показатели оборудования.
В качестве примера мы будем использовать несложный датасет, в котором содержатся данные за 2019 год об отдельных финансовых показателях сети магазинов одежды, представленной в нескольких городах мира. В частности, нам доступна следующая информация:
- month — за какой месяц сделана запись
- profit — прибыль (profit) по сети
- MoM — изменение выручки (revenue) сети по отношению к предыдущему месяцу
- high — магазин с наибольшей маржинальностью (margin) продаж
Создадим датафрейм из словаря.
|
financials = pd.DataFrame({‘month’ : [’01/01/2019′, ’01/02/2019′, ’01/03/2019′, ’01/03/2019′, ’01/04/2019′, ’01/05/2019′, ’01/06/2019′, ’01/07/2019′, ’01/08/2019′, ’01/09/2019′, ’01/10/2019′, ’01/11/2019′, ’01/12/2019′, ’01/12/2019′], ‘profit’ : [‘1.20$’, ‘1.30$’, ‘1.25$’, ‘1.25$’, ‘1.27$’, ‘1.11$’, ‘1.23$’, ‘1.20$’, ‘1.31$’, ‘1.24$’, ‘1.18$’, ‘1.17$’, ‘1.23$’, ‘1.23$’], ‘MoM’ : [0.03, —0.02, 0.01, 0.02, —0.01, —0.015, 0.017, 0.04, 0.02, 0.01, 0.00, —0.01, 2.00, 2.00], ‘high’ : [‘Dubai’, ‘Paris’, ‘singapour’, ‘singapour’, ‘moscow’, ‘Paris’, ‘Madrid’, ‘moscow’, ‘london’, ‘london’, ‘Moscow’, ‘Rome’, ‘madrid’, ‘madrid’] }) financials |
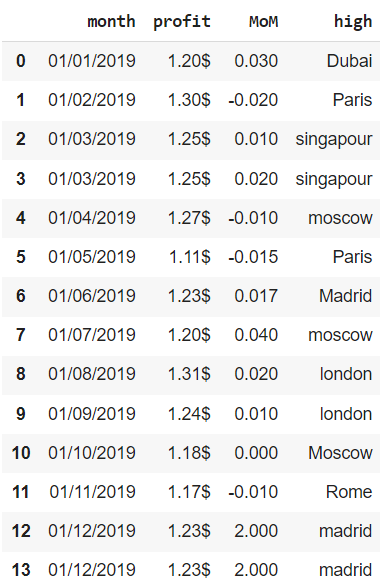
Воспользуемся методом .info() для получения общей информации о датасете.
|
<class ‘pandas.core.frame.DataFrame’> RangeIndex: 14 entries, 0 to 13 Data columns (total 4 columns): # Column Non-Null Count Dtype — —— ————— —— 0 month 14 non-null object 1 profit 14 non-null object 2 MoM 14 non-null float64 3 high 14 non-null object dtypes: float64(1), object(3) memory usage: 576.0+ bytes |
Перейдем к поиску ошибок в данных.
Дубликаты
Поиск дубликатов
Заметим, что хотя данные представлены за 12 месяцев, в датафрейме тем не менее содержится 14 значений. Это заставляет задуматься о дубликатах (duplicates) или повторяющихся значениях. Воспользуемся методом .duplicated(). На выходе мы получим логический массив, в котором повторяющееся значение обозначено как True.
|
# keep = ‘first’ (параметр по умолчанию) # помечает как дубликат (True) ВТОРОЕ повторяющееся значение financials.duplicated(keep = ‘first’) |
|
0 False 1 False 2 False 3 False 4 False 5 False 6 False 7 False 8 False 9 False 10 False 11 False 12 False 13 True dtype: bool |
|
# keep = ‘last’ соответственно считает дубликатом ПЕРВОЕ повторяющееся значение financials.duplicated(keep = ‘last’) |
|
0 False 1 False 2 False 3 False 4 False 5 False 6 False 7 False 8 False 9 False 10 False 11 False 12 True 13 False dtype: bool |
Результат метода .duplicated() можно использовать как фильтр.
|
# с параметром keep = ‘last’ будет выведено наблюдение с индексом 12 financials[financials.duplicated(keep = ‘last’)] |

Также заметим, что если смотреть по месяцам, у нас две дублирующихся записи, а не одна. В частности, повторяется запись не только за декабрь, но и за март. Проверим это с помощью параметра subset.
|
# с помощью параметра subset мы ищем дубликаты по конкретным столбцам financials.duplicated(subset = [‘month’]) |
|
0 False 1 False 2 False 3 True 4 False 5 False 6 False 7 False 8 False 9 False 10 False 11 False 12 False 13 True dtype: bool |
|
# посчитаем количество дубликатов по столбцу month financials.duplicated(subset = [‘month’]).sum() |
Создадим новый фильтр и выведем дубликаты по месяцам.
|
# укажем параметр keep = ‘last’, больше доверяя, таким образом, # последнему записанному за конкретный месяц значению financials[financials.duplicated(subset = [‘month’], keep = ‘last’)] |

Аналогичным образом мы можем посмотреть на неповторяющиеся значения.
|
( ~ financials.duplicated(subset = [‘month’])).sum() |
Этот логический массив можно также использовать как фильтр.
|
financials[ ~ financials.duplicated(subset = [‘month’], keep = ‘last’)] |
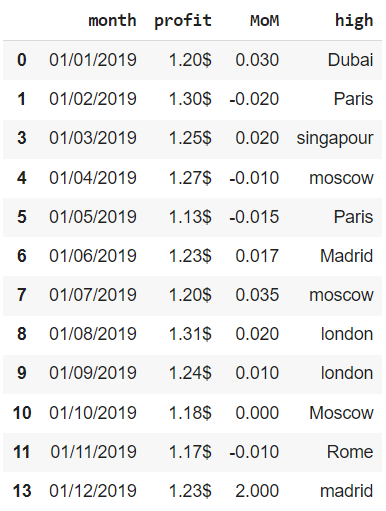
Обратите внимание, индекс остался прежним (из него просто выпали наблюдения 2 и 12). Мы исправим эту неточность при удалении дубликатов.
Удаление дубликатов
Метод .drop_duplicates() удаляет дубликаты из датафрейма и, по сути, принимает те же параметры, что и метод .duplicated().
|
# параметр ignore_index создает новый индекс financials.drop_duplicates(keep = ‘last’, subset = [‘month’], ignore_index = True, inplace = True) financials |
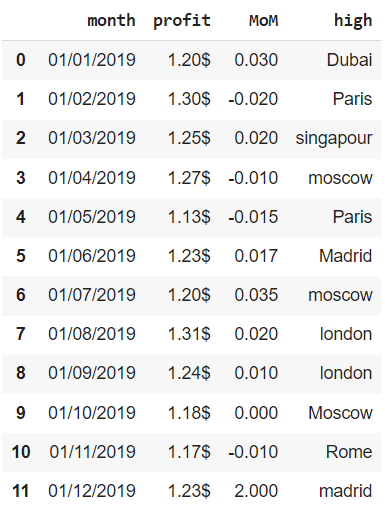
Неверные значения
Распространенным типом ошибок в данных являются неверные значения.
Базовый подход к поиску неверных значений — проверить, что данные не противоречат своей природе. Например, цена товара не может быть отрицательной.
В нашем случае мы видим, что в столбце MoM все строки отражают доли процента, а последняя строка — проценты. Из-за этого сильно искажается, например, средний показатель изменения выручки за год.
|
# рассчитаем среднемесячный рост financials.MoM.mean() |
С учетом имеющихся данных вряд ли среднее изменение выручки (в месячном, а не годовом выражении) составило 17,3%. Заменим проценты на доли процента.
|
# заменим 2% на 0.02 financials.iloc[11, 2] = 0.02 |
Вновь рассчитаем средний показатель.
Новое среднее значение 0,8% выглядит гораздо реалистичнее.
Форматирование значений
Тип str вместо float
Попробуем сложить данные о прибыли.
|
‘1.20$1.30$1.25$1.27$1.13$1.23$1.20$1.31$1.24$1.18$1.17$1.23$’ |
Так как столбец profit содержит тип str, произошло объединение (concatenation) строк. Преобразуем данные о прибыли в тип float.
|
# вначале удалим знак доллара с помощью метода .strip() financials[‘profit’] = financials[‘profit’].str.strip(‘$’) # затем воспользуемся знакомым нам методом .astype() financials[‘profit’] = financials[‘profit’].astype(‘float’) |
Проверим полученный результат с помощью нового для нас ключевого слова assert (по-англ. «утверждать»).
Если условие идущее после assert возвращает True, программа продолжает исполняться. В противном случае Питон выдает AssertionError.
Приведем пример.
|
# напишем простейшую функцию деления одного числа на другое def division(a, b): # если делитель равен нулю, Питон выдаст ошибку (текст ошибки указывать не обязательно) assert b != 0 , ‘На ноль делить нельзя’ return round(a / b, 2) |
|
# попробуем разделить 5 на 0 division(5, 0) |

Выражение
b != 0 превратилось в False и Питон выдал ошибку. Теперь вернемся к нашему коду.
|
# проверим превратился ли тип данных во float assert financials.profit.dtype == float |
Сообщения об ошибке не появилось, значит выражение верное (True). Теперь снова рассчитаем прибыль за год.
Названия городов с заглавной буквы
Остается сделать так, чтобы названия всех городов в столбце high начинались с заглавной буквы. Для этого подойдет метод .title().
|
financials[‘high’] = financials[‘high’].str.title() financials |
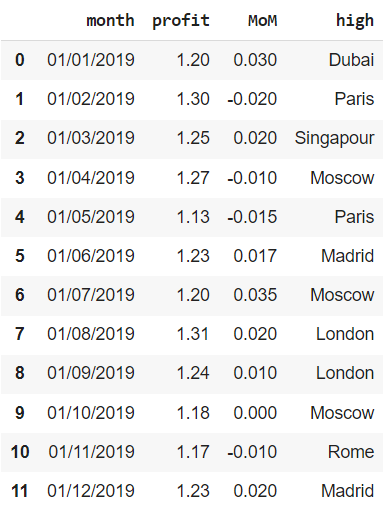
Дата и время
Как мы уже знаем, с датой и временем гораздо удобнее работать, когда они представляют собой объект datetime. В этом случае мы можем использовать все возможности Питона по анализу и прогнозированию временных рядов.
Начнем с того, что воспользуемся функцией pd.to_datetime(), которой передадим столбец month и формат, которого следует придерживаться при создании объекта datetime.
|
# запишем дату в формате datetime в столбец date1 financials[‘date1’] = pd.to_datetime(financials[‘month’], format = ‘%d/%m/%Y’) financials |

Мы получили верный результат. Как и должно быть в Pandas на первом месте в столбце date1 стоит год, затем месяц и наконец день. Теперь давайте попросим Питон самостоятельно определить формат даты.
|
# для этого подойдет параметр infer_datetime_format = True financials[‘date2’] = pd.to_datetime(financials[‘month’], infer_datetime_format = True) financials |

У нас снова получилось создать объект datetime, однако возникла одна сложность. Функция pd.to_datetime() предположила, что в столбце month данные содержатся в американском формате (месяц/день/год), тогда как у нас они записаны в европейском (день/месяц/год). Из-за этого в столбце date2 мы получили первые 12 дней января, а не 12 месяцев 2019 года.
|
# исправить неточность с месяцем можно с помощью параметра dayfirst = True financials[‘date3’] = pd.to_datetime(financials[‘month’], infer_datetime_format = True, dayfirst = True) financials |

Теперь мы снова получили верный формат.
|
# убедимся, что столбцы с датами имеют тип данных datetime financials.dtypes |
|
month object profit float64 MoM float64 high object date1 datetime64[ns] date2 datetime64[ns] date3 datetime64[ns] dtype: object |
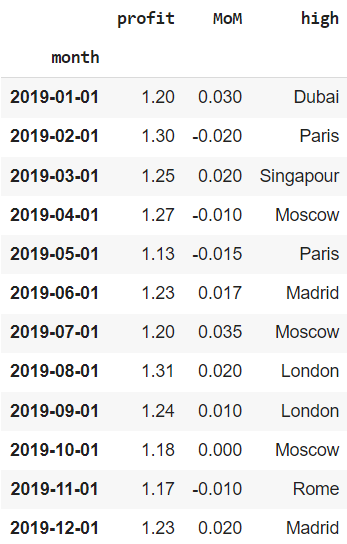
Удалим избыточные столбцы и сделаем дату индексом.
|
financials.set_index(‘date3’, drop = True, inplace = True) # drop = True удаляет столбец date3 financials.drop(labels = [‘month’, ‘date1’, ‘date2’], axis = 1, inplace = True) financials.index.rename(‘month’, inplace = True) financials |
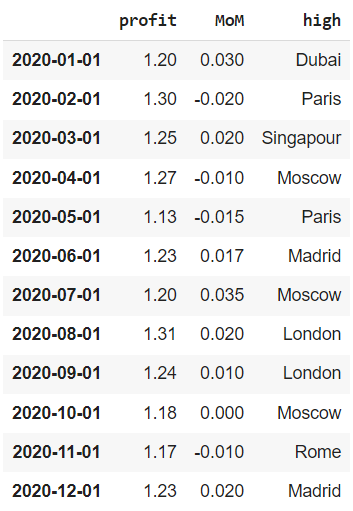
Посмотрим на еще один интересный инструмент. Предположим, что мы ошиблись с годом (вместо 2019 у нас на самом деле данные за 2020 год) или просто хотим создать индекс с датой с нуля. Для таких случаев подойдет функция pd.data_range().
|
# создадим последовательность из 12 месяцев, # передав начальный период (start), общее количество периодов (periods) # и день начала каждого периода (MS, т.е. month start) range = pd.date_range(start = ‘1/1/2020’, periods = 12, freq = ‘MS’) # сделаем эту последовательность индексом датафрейма financials.index = range financials |
Как мы уже знаем, когда индекс имеет тип данных datetime, мы можем делать срезы по датам.
|
# напоминаю, что для datetime конечная дата входит в срез financials[‘2020-01’: ‘2020-06’] |

Завершим раздел про дату и время построением двух подграфиков. Для этого вначале преобразуем индекс из объекта datetime обратно в строковый формат с помощью метода .strftime().
|
# будем выводить только месяцы (%B), так как все показатели у нас за 2020 год financials.index = financials.index.strftime(‘%B’) financials |

Теперь используем метод .plot() библиотеки Pandas с параметром subplots = True.
|
# построим графики для размера прибыли и изменения выручки за месяц financials[[‘profit’, ‘MoM’]].plot(subplots = True, # обозначим, что хотим несколько подграфиков layout = (1,2), # зададим сетку kind = ‘bar’, # укажем тип диаграммы rot = 65, # повернем деления шкалы оси x grid = True, # добавим сетку figsize = (16, 6), # укажем размер figure legend = False, # уберем легенду title = [‘Profit 2020’, ‘MoM Revenue Change 2020’]); # добавим заголовки |
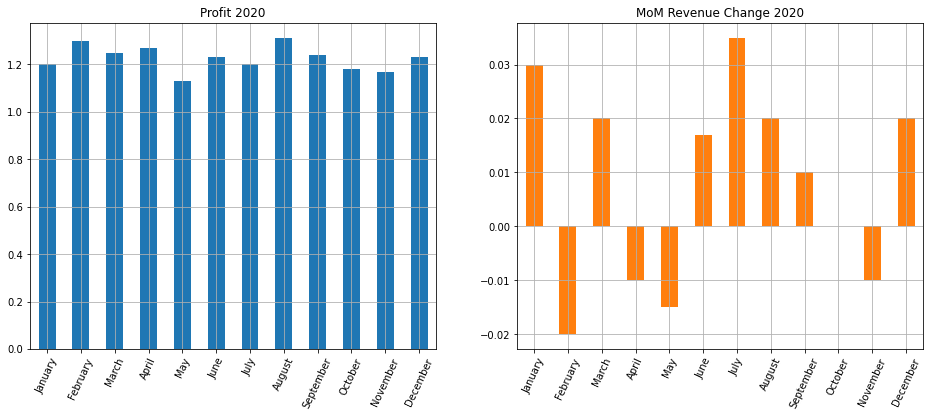
Подведем итог
Сегодня мы рассмотрели типичные ошибки в данных и способы их исправления. В частности, мы изучили как выявить и удалить дубликаты, обнаружить неверные значения и скорректировать неподходящий формат. Кроме того, мы еще раз обратились к объекту datetime и посмотрели на возможности изменения даты и времени.
Перейдем к работе с пропущенными значениями.
I’m trying to analyze some data I have but there is a lot of inconsistencies in my data.
I have a SQL table that I’m trying to analyze.
The table is a table of universities with the following structure: name:string, city:string, state:string, country:string
Name is always present however city, state, country can be missing.
My main issue is that there are a ton of typos and different declination of a university name.
For example here are the declination of Standford Unversity I find when I do SELECT "universities".* FROM "perm_universities" WHERE (name like '%stanford%'):
stanford university - stanford - ca - united states of america
the leland stanford junior university - stanford - ca - united states of america
leland stanford jr. university - stanford - ca - united states of america
stanford university graduate school of business - stanford - ca - united states of america
the leland stanford junior university (stanford university) - stanford - ca - united states of america
leland stanford junior university - stanford - ca - united states of america
stanford university - stanford - -
leland stanford jr. university, graduate school of business - stanford - ca - united states of america
stanford law school - stanford - ca - united states of america
stanford - stanford - ca - united states of america
stanford university, graduate school of business - stanford - ca - united states of america
stanford graduate school of business - stanford - ca - united states of america
stanford univerity - stanford - ca - united states of america
stanford university (the leland stanford junior university) - stanford - ca - united states of america
the leland stanford jr. university - palo alto - ca - united states of america
leland stanford junior university, school of law - stanford - ca / n/a - united states of america
stanford universit - stanford - ca - united states of america
the leland stanford university - stanford - ca - united states of america
leland standford stanford junior university - stanford - ca - united states of america
stanford university - cambridge - ma - united states of america
the leland stanford junior university 'stanford university' - stanford - ca - united states of america
stanford university school of law - stanford - ca - united states of america
stanford univresity - stanford - ca - united states of america
the leland stanford jr. university (stanford university) - stanford - ca - united states of america
leeland stanford junior university - stanford - ca - united states of america
leland stanford junion university - - ca - united states of america
leland stanford junior university (stanford university) - stanford - ca - united states of america
the leland stanford junior university - stanford - -
stanford university - graduate school of business - stanford - ca - united states of america
graduate school of business, stanford university - stanford - ca - united states of america
stanford universoty - stanford - ca - united states of america
leland stanford junior university - stanford - -
stanford univeristy - palo alto - ca - united states of america
leland stanford university - palo alto - ca - united states of america
stanford university - stanford - ca / n/a - united states of america
the leland stanford junior university, stanford university - stanford - ca - united states of america
the leland stanford junior university graduate school of business - stanford - ca - united states of america
stanford universtiy - stanford - ca - united states of america
stanford univerisity - stanford - ca - united states of america
stanford university - stanford - ct - united states of america
stanford law scool - stanford - ca - united states of america
mba: stanford university - stanford - ca - united states of america
They are all the same university, but some have typos, some have different names, some have no cities, some have the wrong cities, … The data isn’t great.
So I’m trying to fix it. How can I consolidate this data?
I’m trying to analyze some data I have but there is a lot of inconsistencies in my data.
I have a SQL table that I’m trying to analyze.
The table is a table of universities with the following structure: name:string, city:string, state:string, country:string
Name is always present however city, state, country can be missing.
My main issue is that there are a ton of typos and different declination of a university name.
For example here are the declination of Standford Unversity I find when I do SELECT "universities".* FROM "perm_universities" WHERE (name like '%stanford%'):
stanford university - stanford - ca - united states of america
the leland stanford junior university - stanford - ca - united states of america
leland stanford jr. university - stanford - ca - united states of america
stanford university graduate school of business - stanford - ca - united states of america
the leland stanford junior university (stanford university) - stanford - ca - united states of america
leland stanford junior university - stanford - ca - united states of america
stanford university - stanford - -
leland stanford jr. university, graduate school of business - stanford - ca - united states of america
stanford law school - stanford - ca - united states of america
stanford - stanford - ca - united states of america
stanford university, graduate school of business - stanford - ca - united states of america
stanford graduate school of business - stanford - ca - united states of america
stanford univerity - stanford - ca - united states of america
stanford university (the leland stanford junior university) - stanford - ca - united states of america
the leland stanford jr. university - palo alto - ca - united states of america
leland stanford junior university, school of law - stanford - ca / n/a - united states of america
stanford universit - stanford - ca - united states of america
the leland stanford university - stanford - ca - united states of america
leland standford stanford junior university - stanford - ca - united states of america
stanford university - cambridge - ma - united states of america
the leland stanford junior university 'stanford university' - stanford - ca - united states of america
stanford university school of law - stanford - ca - united states of america
stanford univresity - stanford - ca - united states of america
the leland stanford jr. university (stanford university) - stanford - ca - united states of america
leeland stanford junior university - stanford - ca - united states of america
leland stanford junion university - - ca - united states of america
leland stanford junior university (stanford university) - stanford - ca - united states of america
the leland stanford junior university - stanford - -
stanford university - graduate school of business - stanford - ca - united states of america
graduate school of business, stanford university - stanford - ca - united states of america
stanford universoty - stanford - ca - united states of america
leland stanford junior university - stanford - -
stanford univeristy - palo alto - ca - united states of america
leland stanford university - palo alto - ca - united states of america
stanford university - stanford - ca / n/a - united states of america
the leland stanford junior university, stanford university - stanford - ca - united states of america
the leland stanford junior university graduate school of business - stanford - ca - united states of america
stanford universtiy - stanford - ca - united states of america
stanford univerisity - stanford - ca - united states of america
stanford university - stanford - ct - united states of america
stanford law scool - stanford - ca - united states of america
mba: stanford university - stanford - ca - united states of america
They are all the same university, but some have typos, some have different names, some have no cities, some have the wrong cities, … The data isn’t great.
So I’m trying to fix it. How can I consolidate this data?