
To clean up transmission errors introduced by Earth’s atmosphere (left), Goddard scientists applied Reed–Solomon error correction (right), which is commonly used in CDs and DVDs. Typical errors include missing pixels (white) and false signals (black). The white stripe indicates a brief period when transmission was interrupted.
In information theory and coding theory with applications in computer science and telecommunication, error detection and correction (EDAC) or error control are techniques that enable reliable delivery of digital data over unreliable communication channels. Many communication channels are subject to channel noise, and thus errors may be introduced during transmission from the source to a receiver. Error detection techniques allow detecting such errors, while error correction enables reconstruction of the original data in many cases.
Definitions[edit]
Error detection is the detection of errors caused by noise or other impairments during transmission from the transmitter to the receiver.
Error correction is the detection of errors and reconstruction of the original, error-free data.
History[edit]
In classical antiquity, copyists of the Hebrew Bible were paid for their work according to the number of stichs (lines of verse). As the prose books of the Bible were hardly ever written in stichs, the copyists, in order to estimate the amount of work, had to count the letters.[1] This also helped ensure accuracy in the transmission of the text with the production of subsequent copies.[2][3] Between the 7th and 10th centuries CE a group of Jewish scribes formalized and expanded this to create the Numerical Masorah to ensure accurate reproduction of the sacred text. It included counts of the number of words in a line, section, book and groups of books, noting the middle stich of a book, word use statistics, and commentary.[1] Standards became such that a deviation in even a single letter in a Torah scroll was considered unacceptable.[4] The effectiveness of their error correction method was verified by the accuracy of copying through the centuries demonstrated by discovery of the Dead Sea Scrolls in 1947–1956, dating from c.150 BCE-75 CE.[5]
The modern development of error correction codes is credited to Richard Hamming in 1947.[6] A description of Hamming’s code appeared in Claude Shannon’s A Mathematical Theory of Communication[7] and was quickly generalized by Marcel J. E. Golay.[8]
Introduction[edit]
All error-detection and correction schemes add some redundancy (i.e., some extra data) to a message, which receivers can use to check consistency of the delivered message, and to recover data that has been determined to be corrupted. Error-detection and correction schemes can be either systematic or non-systematic. In a systematic scheme, the transmitter sends the original data, and attaches a fixed number of check bits (or parity data), which are derived from the data bits by some deterministic algorithm. If only error detection is required, a receiver can simply apply the same algorithm to the received data bits and compare its output with the received check bits; if the values do not match, an error has occurred at some point during the transmission. In a system that uses a non-systematic code, the original message is transformed into an encoded message carrying the same information and that has at least as many bits as the original message.
Good error control performance requires the scheme to be selected based on the characteristics of the communication channel. Common channel models include memoryless models where errors occur randomly and with a certain probability, and dynamic models where errors occur primarily in bursts. Consequently, error-detecting and correcting codes can be generally distinguished between random-error-detecting/correcting and burst-error-detecting/correcting. Some codes can also be suitable for a mixture of random errors and burst errors.
If the channel characteristics cannot be determined, or are highly variable, an error-detection scheme may be combined with a system for retransmissions of erroneous data. This is known as automatic repeat request (ARQ), and is most notably used in the Internet. An alternate approach for error control is hybrid automatic repeat request (HARQ), which is a combination of ARQ and error-correction coding.
Types of error correction[edit]
There are three major types of error correction.[9]
Automatic repeat request[edit]
Automatic repeat request (ARQ) is an error control method for data transmission that makes use of error-detection codes, acknowledgment and/or negative acknowledgment messages, and timeouts to achieve reliable data transmission. An acknowledgment is a message sent by the receiver to indicate that it has correctly received a data frame.
Usually, when the transmitter does not receive the acknowledgment before the timeout occurs (i.e., within a reasonable amount of time after sending the data frame), it retransmits the frame until it is either correctly received or the error persists beyond a predetermined number of retransmissions.
Three types of ARQ protocols are Stop-and-wait ARQ, Go-Back-N ARQ, and Selective Repeat ARQ.
ARQ is appropriate if the communication channel has varying or unknown capacity, such as is the case on the Internet. However, ARQ requires the availability of a back channel, results in possibly increased latency due to retransmissions, and requires the maintenance of buffers and timers for retransmissions, which in the case of network congestion can put a strain on the server and overall network capacity.[10]
For example, ARQ is used on shortwave radio data links in the form of ARQ-E, or combined with multiplexing as ARQ-M.
Forward error correction[edit]
Forward error correction (FEC) is a process of adding redundant data such as an error-correcting code (ECC) to a message so that it can be recovered by a receiver even when a number of errors (up to the capability of the code being used) are introduced, either during the process of transmission or on storage. Since the receiver does not have to ask the sender for retransmission of the data, a backchannel is not required in forward error correction. Error-correcting codes are used in lower-layer communication such as cellular network, high-speed fiber-optic communication and Wi-Fi,[11][12] as well as for reliable storage in media such as flash memory, hard disk and RAM.[13]
Error-correcting codes are usually distinguished between convolutional codes and block codes:
- Convolutional codes are processed on a bit-by-bit basis. They are particularly suitable for implementation in hardware, and the Viterbi decoder allows optimal decoding.
- Block codes are processed on a block-by-block basis. Early examples of block codes are repetition codes, Hamming codes and multidimensional parity-check codes. They were followed by a number of efficient codes, Reed–Solomon codes being the most notable due to their current widespread use. Turbo codes and low-density parity-check codes (LDPC) are relatively new constructions that can provide almost optimal efficiency.
Shannon’s theorem is an important theorem in forward error correction, and describes the maximum information rate at which reliable communication is possible over a channel that has a certain error probability or signal-to-noise ratio (SNR). This strict upper limit is expressed in terms of the channel capacity. More specifically, the theorem says that there exist codes such that with increasing encoding length the probability of error on a discrete memoryless channel can be made arbitrarily small, provided that the code rate is smaller than the channel capacity. The code rate is defined as the fraction k/n of k source symbols and n encoded symbols.
The actual maximum code rate allowed depends on the error-correcting code used, and may be lower. This is because Shannon’s proof was only of existential nature, and did not show how to construct codes which are both optimal and have efficient encoding and decoding algorithms.
Hybrid schemes[edit]
Hybrid ARQ is a combination of ARQ and forward error correction. There are two basic approaches:[10]
- Messages are always transmitted with FEC parity data (and error-detection redundancy). A receiver decodes a message using the parity information, and requests retransmission using ARQ only if the parity data was not sufficient for successful decoding (identified through a failed integrity check).
- Messages are transmitted without parity data (only with error-detection information). If a receiver detects an error, it requests FEC information from the transmitter using ARQ, and uses it to reconstruct the original message.
The latter approach is particularly attractive on an erasure channel when using a rateless erasure code.
Error detection schemes[edit]
Error detection is most commonly realized using a suitable hash function (or specifically, a checksum, cyclic redundancy check or other algorithm). A hash function adds a fixed-length tag to a message, which enables receivers to verify the delivered message by recomputing the tag and comparing it with the one provided.
There exists a vast variety of different hash function designs. However, some are of particularly widespread use because of either their simplicity or their suitability for detecting certain kinds of errors (e.g., the cyclic redundancy check’s performance in detecting burst errors).
Minimum distance coding[edit]
A random-error-correcting code based on minimum distance coding can provide a strict guarantee on the number of detectable errors, but it may not protect against a preimage attack.
Repetition codes[edit]
A repetition code is a coding scheme that repeats the bits across a channel to achieve error-free communication. Given a stream of data to be transmitted, the data are divided into blocks of bits. Each block is transmitted some predetermined number of times. For example, to send the bit pattern «1011», the four-bit block can be repeated three times, thus producing «1011 1011 1011». If this twelve-bit pattern was received as «1010 1011 1011» – where the first block is unlike the other two – an error has occurred.
A repetition code is very inefficient, and can be susceptible to problems if the error occurs in exactly the same place for each group (e.g., «1010 1010 1010» in the previous example would be detected as correct). The advantage of repetition codes is that they are extremely simple, and are in fact used in some transmissions of numbers stations.[14][15]
Parity bit[edit]
A parity bit is a bit that is added to a group of source bits to ensure that the number of set bits (i.e., bits with value 1) in the outcome is even or odd. It is a very simple scheme that can be used to detect single or any other odd number (i.e., three, five, etc.) of errors in the output. An even number of flipped bits will make the parity bit appear correct even though the data is erroneous.
Parity bits added to each «word» sent are called transverse redundancy checks, while those added at the end of a stream of «words» are called longitudinal redundancy checks. For example, if each of a series of m-bit «words» has a parity bit added, showing whether there were an odd or even number of ones in that word, any word with a single error in it will be detected. It will not be known where in the word the error is, however. If, in addition, after each stream of n words a parity sum is sent, each bit of which shows whether there were an odd or even number of ones at that bit-position sent in the most recent group, the exact position of the error can be determined and the error corrected. This method is only guaranteed to be effective, however, if there are no more than 1 error in every group of n words. With more error correction bits, more errors can be detected and in some cases corrected.
There are also other bit-grouping techniques.
Checksum[edit]
A checksum of a message is a modular arithmetic sum of message code words of a fixed word length (e.g., byte values). The sum may be negated by means of a ones’-complement operation prior to transmission to detect unintentional all-zero messages.
Checksum schemes include parity bits, check digits, and longitudinal redundancy checks. Some checksum schemes, such as the Damm algorithm, the Luhn algorithm, and the Verhoeff algorithm, are specifically designed to detect errors commonly introduced by humans in writing down or remembering identification numbers.
Cyclic redundancy check[edit]
A cyclic redundancy check (CRC) is a non-secure hash function designed to detect accidental changes to digital data in computer networks. It is not suitable for detecting maliciously introduced errors. It is characterized by specification of a generator polynomial, which is used as the divisor in a polynomial long division over a finite field, taking the input data as the dividend. The remainder becomes the result.
A CRC has properties that make it well suited for detecting burst errors. CRCs are particularly easy to implement in hardware and are therefore commonly used in computer networks and storage devices such as hard disk drives.
The parity bit can be seen as a special-case 1-bit CRC.
Cryptographic hash function[edit]
The output of a cryptographic hash function, also known as a message digest, can provide strong assurances about data integrity, whether changes of the data are accidental (e.g., due to transmission errors) or maliciously introduced. Any modification to the data will likely be detected through a mismatching hash value. Furthermore, given some hash value, it is typically infeasible to find some input data (other than the one given) that will yield the same hash value. If an attacker can change not only the message but also the hash value, then a keyed hash or message authentication code (MAC) can be used for additional security. Without knowing the key, it is not possible for the attacker to easily or conveniently calculate the correct keyed hash value for a modified message.
Error correction code[edit]
Any error-correcting code can be used for error detection. A code with minimum Hamming distance, d, can detect up to d − 1 errors in a code word. Using minimum-distance-based error-correcting codes for error detection can be suitable if a strict limit on the minimum number of errors to be detected is desired.
Codes with minimum Hamming distance d = 2 are degenerate cases of error-correcting codes, and can be used to detect single errors. The parity bit is an example of a single-error-detecting code.
Applications[edit]
Applications that require low latency (such as telephone conversations) cannot use automatic repeat request (ARQ); they must use forward error correction (FEC). By the time an ARQ system discovers an error and re-transmits it, the re-sent data will arrive too late to be usable.
Applications where the transmitter immediately forgets the information as soon as it is sent (such as most television cameras) cannot use ARQ; they must use FEC because when an error occurs, the original data is no longer available.
Applications that use ARQ must have a return channel; applications having no return channel cannot use ARQ.
Applications that require extremely low error rates (such as digital money transfers) must use ARQ due to the possibility of uncorrectable errors with FEC.
Reliability and inspection engineering also make use of the theory of error-correcting codes.[16]
Internet[edit]
In a typical TCP/IP stack, error control is performed at multiple levels:
- Each Ethernet frame uses CRC-32 error detection. Frames with detected errors are discarded by the receiver hardware.
- The IPv4 header contains a checksum protecting the contents of the header. Packets with incorrect checksums are dropped within the network or at the receiver.
- The checksum was omitted from the IPv6 header in order to minimize processing costs in network routing and because current link layer technology is assumed to provide sufficient error detection (see also RFC 3819).
- UDP has an optional checksum covering the payload and addressing information in the UDP and IP headers. Packets with incorrect checksums are discarded by the network stack. The checksum is optional under IPv4, and required under IPv6. When omitted, it is assumed the data-link layer provides the desired level of error protection.
- TCP provides a checksum for protecting the payload and addressing information in the TCP and IP headers. Packets with incorrect checksums are discarded by the network stack, and eventually get retransmitted using ARQ, either explicitly (such as through three-way handshake) or implicitly due to a timeout.
Deep-space telecommunications[edit]
The development of error-correction codes was tightly coupled with the history of deep-space missions due to the extreme dilution of signal power over interplanetary distances, and the limited power availability aboard space probes. Whereas early missions sent their data uncoded, starting in 1968, digital error correction was implemented in the form of (sub-optimally decoded) convolutional codes and Reed–Muller codes.[17] The Reed–Muller code was well suited to the noise the spacecraft was subject to (approximately matching a bell curve), and was implemented for the Mariner spacecraft and used on missions between 1969 and 1977.
The Voyager 1 and Voyager 2 missions, which started in 1977, were designed to deliver color imaging and scientific information from Jupiter and Saturn.[18] This resulted in increased coding requirements, and thus, the spacecraft were supported by (optimally Viterbi-decoded) convolutional codes that could be concatenated with an outer Golay (24,12,8) code. The Voyager 2 craft additionally supported an implementation of a Reed–Solomon code. The concatenated Reed–Solomon–Viterbi (RSV) code allowed for very powerful error correction, and enabled the spacecraft’s extended journey to Uranus and Neptune. After ECC system upgrades in 1989, both crafts used V2 RSV coding.
The Consultative Committee for Space Data Systems currently recommends usage of error correction codes with performance similar to the Voyager 2 RSV code as a minimum. Concatenated codes are increasingly falling out of favor with space missions, and are replaced by more powerful codes such as Turbo codes or LDPC codes.
The different kinds of deep space and orbital missions that are conducted suggest that trying to find a one-size-fits-all error correction system will be an ongoing problem. For missions close to Earth, the nature of the noise in the communication channel is different from that which a spacecraft on an interplanetary mission experiences. Additionally, as a spacecraft increases its distance from Earth, the problem of correcting for noise becomes more difficult.
Satellite broadcasting[edit]
The demand for satellite transponder bandwidth continues to grow, fueled by the desire to deliver television (including new channels and high-definition television) and IP data. Transponder availability and bandwidth constraints have limited this growth. Transponder capacity is determined by the selected modulation scheme and the proportion of capacity consumed by FEC.
Data storage[edit]
Error detection and correction codes are often used to improve the reliability of data storage media.[19] A parity track capable of detecting single-bit errors was present on the first magnetic tape data storage in 1951. The optimal rectangular code used in group coded recording tapes not only detects but also corrects single-bit errors. Some file formats, particularly archive formats, include a checksum (most often CRC32) to detect corruption and truncation and can employ redundancy or parity files to recover portions of corrupted data. Reed-Solomon codes are used in compact discs to correct errors caused by scratches.
Modern hard drives use Reed–Solomon codes to detect and correct minor errors in sector reads, and to recover corrupted data from failing sectors and store that data in the spare sectors.[20] RAID systems use a variety of error correction techniques to recover data when a hard drive completely fails. Filesystems such as ZFS or Btrfs, as well as some RAID implementations, support data scrubbing and resilvering, which allows bad blocks to be detected and (hopefully) recovered before they are used.[21] The recovered data may be re-written to exactly the same physical location, to spare blocks elsewhere on the same piece of hardware, or the data may be rewritten onto replacement hardware.
Error-correcting memory[edit]
Dynamic random-access memory (DRAM) may provide stronger protection against soft errors by relying on error-correcting codes. Such error-correcting memory, known as ECC or EDAC-protected memory, is particularly desirable for mission-critical applications, such as scientific computing, financial, medical, etc. as well as extraterrestrial applications due to the increased radiation in space.
Error-correcting memory controllers traditionally use Hamming codes, although some use triple modular redundancy. Interleaving allows distributing the effect of a single cosmic ray potentially upsetting multiple physically neighboring bits across multiple words by associating neighboring bits to different words. As long as a single-event upset (SEU) does not exceed the error threshold (e.g., a single error) in any particular word between accesses, it can be corrected (e.g., by a single-bit error-correcting code), and the illusion of an error-free memory system may be maintained.[22]
In addition to hardware providing features required for ECC memory to operate, operating systems usually contain related reporting facilities that are used to provide notifications when soft errors are transparently recovered. One example is the Linux kernel’s EDAC subsystem (previously known as Bluesmoke), which collects the data from error-checking-enabled components inside a computer system; besides collecting and reporting back the events related to ECC memory, it also supports other checksumming errors, including those detected on the PCI bus.[23][24][25] A few systems[specify] also support memory scrubbing to catch and correct errors early before they become unrecoverable.
See also[edit]
- Berger code
- Burst error-correcting code
- ECC memory, a type of computer data storage
- Link adaptation
- List of algorithms § Error detection and correction
- List of hash functions
References[edit]
- ^ a b «Masorah». Jewish Encyclopedia.
- ^ Pratico, Gary D.; Pelt, Miles V. Van (2009). Basics of Biblical Hebrew Grammar: Second Edition. Zondervan. ISBN 978-0-310-55882-8.
- ^ Mounce, William D. (2007). Greek for the Rest of Us: Using Greek Tools Without Mastering Biblical Languages. Zondervan. p. 289. ISBN 978-0-310-28289-1.
- ^ Mishneh Torah, Tefillin, Mezuzah, and Sefer Torah, 1:2. Example English translation: Eliyahu Touger. The Rambam’s Mishneh Torah. Moznaim Publishing Corporation.
- ^ Brian M. Fagan (5 December 1996). «Dead Sea Scrolls». The Oxford Companion to Archaeology. Oxford University Press. ISBN 0195076184.
- ^ Thompson, Thomas M. (1983), From Error-Correcting Codes through Sphere Packings to Simple Groups, The Carus Mathematical Monographs (#21), The Mathematical Association of America, p. vii, ISBN 0-88385-023-0
- ^ Shannon, C.E. (1948), «A Mathematical Theory of Communication», Bell System Technical Journal, 27 (3): 379–423, doi:10.1002/j.1538-7305.1948.tb01338.x, hdl:10338.dmlcz/101429, PMID 9230594
- ^ Golay, Marcel J. E. (1949), «Notes on Digital Coding», Proc.I.R.E. (I.E.E.E.), 37: 657
- ^ Gupta, Vikas; Verma, Chanderkant (November 2012). «Error Detection and Correction: An Introduction». International Journal of Advanced Research in Computer Science and Software Engineering. 2 (11). S2CID 17499858.
- ^ a b A. J. McAuley, Reliable Broadband Communication Using a Burst Erasure Correcting Code, ACM SIGCOMM, 1990.
- ^ Shah, Pradeep M.; Vyavahare, Prakash D.; Jain, Anjana (September 2015). «Modern error correcting codes for 4G and beyond: Turbo codes and LDPC codes». 2015 Radio and Antenna Days of the Indian Ocean (RADIO): 1–2. doi:10.1109/RADIO.2015.7323369. ISBN 978-9-9903-7339-4. S2CID 28885076. Retrieved 22 May 2022.
- ^ «IEEE SA — IEEE 802.11ac-2013». IEEE Standards Association.
- ^ «Transition to Advanced Format 4K Sector Hard Drives | Seagate US». Seagate.com. Retrieved 22 May 2022.
- ^ Frank van Gerwen. «Numbers (and other mysterious) stations». Archived from the original on 12 July 2017. Retrieved 12 March 2012.
- ^ Gary Cutlack (25 August 2010). «Mysterious Russian ‘Numbers Station’ Changes Broadcast After 20 Years». Gizmodo. Retrieved 12 March 2012.
- ^ Ben-Gal I.; Herer Y.; Raz T. (2003). «Self-correcting inspection procedure under inspection errors» (PDF). IIE Transactions. IIE Transactions on Quality and Reliability, 34(6), pp. 529-540. Archived from the original (PDF) on 2013-10-13. Retrieved 2014-01-10.
- ^ K. Andrews et al., The Development of Turbo and LDPC Codes for Deep-Space Applications, Proceedings of the IEEE, Vol. 95, No. 11, Nov. 2007.
- ^ Huffman, William Cary; Pless, Vera S. (2003). Fundamentals of Error-Correcting Codes. Cambridge University Press. ISBN 978-0-521-78280-7.
- ^ Kurtas, Erozan M.; Vasic, Bane (2018-10-03). Advanced Error Control Techniques for Data Storage Systems. CRC Press. ISBN 978-1-4200-3649-7.[permanent dead link]
- ^ Scott A. Moulton. «My Hard Drive Died». Archived from the original on 2008-02-02.
- ^ Qiao, Zhi; Fu, Song; Chen, Hsing-Bung; Settlemyer, Bradley (2019). «Building Reliable High-Performance Storage Systems: An Empirical and Analytical Study». 2019 IEEE International Conference on Cluster Computing (CLUSTER): 1–10. doi:10.1109/CLUSTER.2019.8891006. ISBN 978-1-7281-4734-5. S2CID 207951690.
- ^ «Using StrongArm SA-1110 in the On-Board Computer of Nanosatellite». Tsinghua Space Center, Tsinghua University, Beijing. Archived from the original on 2011-10-02. Retrieved 2009-02-16.
- ^ Jeff Layton. «Error Detection and Correction». Linux Magazine. Retrieved 2014-08-12.
- ^ «EDAC Project». bluesmoke.sourceforge.net. Retrieved 2014-08-12.
- ^ «Documentation/edac.txt». Linux kernel documentation. kernel.org. 2014-06-16. Archived from the original on 2009-09-05. Retrieved 2014-08-12.
Further reading[edit]
- Shu Lin; Daniel J. Costello, Jr. (1983). Error Control Coding: Fundamentals and Applications. Prentice Hall. ISBN 0-13-283796-X.
- SoftECC: A System for Software Memory Integrity Checking
- A Tunable, Software-based DRAM Error Detection and Correction Library for HPC
- Detection and Correction of Silent Data Corruption for Large-Scale High-Performance Computing
External links[edit]
- The on-line textbook: Information Theory, Inference, and Learning Algorithms, by David J.C. MacKay, contains chapters on elementary error-correcting codes; on the theoretical limits of error-correction; and on the latest state-of-the-art error-correcting codes, including low-density parity-check codes, turbo codes, and fountain codes.
- ECC Page — implementations of popular ECC encoding and decoding routines
To clean up transmission errors introduced by Earth’s atmosphere (left), Goddard scientists applied Reed–Solomon error correction (right), which is commonly used in CDs and DVDs. Typical errors include missing pixels (white) and false signals (black). The white stripe indicates a brief period when transmission was interrupted.
In information theory and coding theory with applications in computer science and telecommunication, error detection and correction (EDAC) or error control are techniques that enable reliable delivery of digital data over unreliable communication channels. Many communication channels are subject to channel noise, and thus errors may be introduced during transmission from the source to a receiver. Error detection techniques allow detecting such errors, while error correction enables reconstruction of the original data in many cases.
Definitions[edit]
Error detection is the detection of errors caused by noise or other impairments during transmission from the transmitter to the receiver.
Error correction is the detection of errors and reconstruction of the original, error-free data.
History[edit]
In classical antiquity, copyists of the Hebrew Bible were paid for their work according to the number of stichs (lines of verse). As the prose books of the Bible were hardly ever written in stichs, the copyists, in order to estimate the amount of work, had to count the letters.[1] This also helped ensure accuracy in the transmission of the text with the production of subsequent copies.[2][3] Between the 7th and 10th centuries CE a group of Jewish scribes formalized and expanded this to create the Numerical Masorah to ensure accurate reproduction of the sacred text. It included counts of the number of words in a line, section, book and groups of books, noting the middle stich of a book, word use statistics, and commentary.[1] Standards became such that a deviation in even a single letter in a Torah scroll was considered unacceptable.[4] The effectiveness of their error correction method was verified by the accuracy of copying through the centuries demonstrated by discovery of the Dead Sea Scrolls in 1947–1956, dating from c.150 BCE-75 CE.[5]
The modern development of error correction codes is credited to Richard Hamming in 1947.[6] A description of Hamming’s code appeared in Claude Shannon’s A Mathematical Theory of Communication[7] and was quickly generalized by Marcel J. E. Golay.[8]
Introduction[edit]
All error-detection and correction schemes add some redundancy (i.e., some extra data) to a message, which receivers can use to check consistency of the delivered message, and to recover data that has been determined to be corrupted. Error-detection and correction schemes can be either systematic or non-systematic. In a systematic scheme, the transmitter sends the original data, and attaches a fixed number of check bits (or parity data), which are derived from the data bits by some deterministic algorithm. If only error detection is required, a receiver can simply apply the same algorithm to the received data bits and compare its output with the received check bits; if the values do not match, an error has occurred at some point during the transmission. In a system that uses a non-systematic code, the original message is transformed into an encoded message carrying the same information and that has at least as many bits as the original message.
Good error control performance requires the scheme to be selected based on the characteristics of the communication channel. Common channel models include memoryless models where errors occur randomly and with a certain probability, and dynamic models where errors occur primarily in bursts. Consequently, error-detecting and correcting codes can be generally distinguished between random-error-detecting/correcting and burst-error-detecting/correcting. Some codes can also be suitable for a mixture of random errors and burst errors.
If the channel characteristics cannot be determined, or are highly variable, an error-detection scheme may be combined with a system for retransmissions of erroneous data. This is known as automatic repeat request (ARQ), and is most notably used in the Internet. An alternate approach for error control is hybrid automatic repeat request (HARQ), which is a combination of ARQ and error-correction coding.
Types of error correction[edit]
There are three major types of error correction.[9]
Automatic repeat request[edit]
Automatic repeat request (ARQ) is an error control method for data transmission that makes use of error-detection codes, acknowledgment and/or negative acknowledgment messages, and timeouts to achieve reliable data transmission. An acknowledgment is a message sent by the receiver to indicate that it has correctly received a data frame.
Usually, when the transmitter does not receive the acknowledgment before the timeout occurs (i.e., within a reasonable amount of time after sending the data frame), it retransmits the frame until it is either correctly received or the error persists beyond a predetermined number of retransmissions.
Three types of ARQ protocols are Stop-and-wait ARQ, Go-Back-N ARQ, and Selective Repeat ARQ.
ARQ is appropriate if the communication channel has varying or unknown capacity, such as is the case on the Internet. However, ARQ requires the availability of a back channel, results in possibly increased latency due to retransmissions, and requires the maintenance of buffers and timers for retransmissions, which in the case of network congestion can put a strain on the server and overall network capacity.[10]
For example, ARQ is used on shortwave radio data links in the form of ARQ-E, or combined with multiplexing as ARQ-M.
Forward error correction[edit]
Forward error correction (FEC) is a process of adding redundant data such as an error-correcting code (ECC) to a message so that it can be recovered by a receiver even when a number of errors (up to the capability of the code being used) are introduced, either during the process of transmission or on storage. Since the receiver does not have to ask the sender for retransmission of the data, a backchannel is not required in forward error correction. Error-correcting codes are used in lower-layer communication such as cellular network, high-speed fiber-optic communication and Wi-Fi,[11][12] as well as for reliable storage in media such as flash memory, hard disk and RAM.[13]
Error-correcting codes are usually distinguished between convolutional codes and block codes:
- Convolutional codes are processed on a bit-by-bit basis. They are particularly suitable for implementation in hardware, and the Viterbi decoder allows optimal decoding.
- Block codes are processed on a block-by-block basis. Early examples of block codes are repetition codes, Hamming codes and multidimensional parity-check codes. They were followed by a number of efficient codes, Reed–Solomon codes being the most notable due to their current widespread use. Turbo codes and low-density parity-check codes (LDPC) are relatively new constructions that can provide almost optimal efficiency.
Shannon’s theorem is an important theorem in forward error correction, and describes the maximum information rate at which reliable communication is possible over a channel that has a certain error probability or signal-to-noise ratio (SNR). This strict upper limit is expressed in terms of the channel capacity. More specifically, the theorem says that there exist codes such that with increasing encoding length the probability of error on a discrete memoryless channel can be made arbitrarily small, provided that the code rate is smaller than the channel capacity. The code rate is defined as the fraction k/n of k source symbols and n encoded symbols.
The actual maximum code rate allowed depends on the error-correcting code used, and may be lower. This is because Shannon’s proof was only of existential nature, and did not show how to construct codes which are both optimal and have efficient encoding and decoding algorithms.
Hybrid schemes[edit]
Hybrid ARQ is a combination of ARQ and forward error correction. There are two basic approaches:[10]
- Messages are always transmitted with FEC parity data (and error-detection redundancy). A receiver decodes a message using the parity information, and requests retransmission using ARQ only if the parity data was not sufficient for successful decoding (identified through a failed integrity check).
- Messages are transmitted without parity data (only with error-detection information). If a receiver detects an error, it requests FEC information from the transmitter using ARQ, and uses it to reconstruct the original message.
The latter approach is particularly attractive on an erasure channel when using a rateless erasure code.
Error detection schemes[edit]
Error detection is most commonly realized using a suitable hash function (or specifically, a checksum, cyclic redundancy check or other algorithm). A hash function adds a fixed-length tag to a message, which enables receivers to verify the delivered message by recomputing the tag and comparing it with the one provided.
There exists a vast variety of different hash function designs. However, some are of particularly widespread use because of either their simplicity or their suitability for detecting certain kinds of errors (e.g., the cyclic redundancy check’s performance in detecting burst errors).
Minimum distance coding[edit]
A random-error-correcting code based on minimum distance coding can provide a strict guarantee on the number of detectable errors, but it may not protect against a preimage attack.
Repetition codes[edit]
A repetition code is a coding scheme that repeats the bits across a channel to achieve error-free communication. Given a stream of data to be transmitted, the data are divided into blocks of bits. Each block is transmitted some predetermined number of times. For example, to send the bit pattern «1011», the four-bit block can be repeated three times, thus producing «1011 1011 1011». If this twelve-bit pattern was received as «1010 1011 1011» – where the first block is unlike the other two – an error has occurred.
A repetition code is very inefficient, and can be susceptible to problems if the error occurs in exactly the same place for each group (e.g., «1010 1010 1010» in the previous example would be detected as correct). The advantage of repetition codes is that they are extremely simple, and are in fact used in some transmissions of numbers stations.[14][15]
Parity bit[edit]
A parity bit is a bit that is added to a group of source bits to ensure that the number of set bits (i.e., bits with value 1) in the outcome is even or odd. It is a very simple scheme that can be used to detect single or any other odd number (i.e., three, five, etc.) of errors in the output. An even number of flipped bits will make the parity bit appear correct even though the data is erroneous.
Parity bits added to each «word» sent are called transverse redundancy checks, while those added at the end of a stream of «words» are called longitudinal redundancy checks. For example, if each of a series of m-bit «words» has a parity bit added, showing whether there were an odd or even number of ones in that word, any word with a single error in it will be detected. It will not be known where in the word the error is, however. If, in addition, after each stream of n words a parity sum is sent, each bit of which shows whether there were an odd or even number of ones at that bit-position sent in the most recent group, the exact position of the error can be determined and the error corrected. This method is only guaranteed to be effective, however, if there are no more than 1 error in every group of n words. With more error correction bits, more errors can be detected and in some cases corrected.
There are also other bit-grouping techniques.
Checksum[edit]
A checksum of a message is a modular arithmetic sum of message code words of a fixed word length (e.g., byte values). The sum may be negated by means of a ones’-complement operation prior to transmission to detect unintentional all-zero messages.
Checksum schemes include parity bits, check digits, and longitudinal redundancy checks. Some checksum schemes, such as the Damm algorithm, the Luhn algorithm, and the Verhoeff algorithm, are specifically designed to detect errors commonly introduced by humans in writing down or remembering identification numbers.
Cyclic redundancy check[edit]
A cyclic redundancy check (CRC) is a non-secure hash function designed to detect accidental changes to digital data in computer networks. It is not suitable for detecting maliciously introduced errors. It is characterized by specification of a generator polynomial, which is used as the divisor in a polynomial long division over a finite field, taking the input data as the dividend. The remainder becomes the result.
A CRC has properties that make it well suited for detecting burst errors. CRCs are particularly easy to implement in hardware and are therefore commonly used in computer networks and storage devices such as hard disk drives.
The parity bit can be seen as a special-case 1-bit CRC.
Cryptographic hash function[edit]
The output of a cryptographic hash function, also known as a message digest, can provide strong assurances about data integrity, whether changes of the data are accidental (e.g., due to transmission errors) or maliciously introduced. Any modification to the data will likely be detected through a mismatching hash value. Furthermore, given some hash value, it is typically infeasible to find some input data (other than the one given) that will yield the same hash value. If an attacker can change not only the message but also the hash value, then a keyed hash or message authentication code (MAC) can be used for additional security. Without knowing the key, it is not possible for the attacker to easily or conveniently calculate the correct keyed hash value for a modified message.
Error correction code[edit]
Any error-correcting code can be used for error detection. A code with minimum Hamming distance, d, can detect up to d − 1 errors in a code word. Using minimum-distance-based error-correcting codes for error detection can be suitable if a strict limit on the minimum number of errors to be detected is desired.
Codes with minimum Hamming distance d = 2 are degenerate cases of error-correcting codes, and can be used to detect single errors. The parity bit is an example of a single-error-detecting code.
Applications[edit]
Applications that require low latency (such as telephone conversations) cannot use automatic repeat request (ARQ); they must use forward error correction (FEC). By the time an ARQ system discovers an error and re-transmits it, the re-sent data will arrive too late to be usable.
Applications where the transmitter immediately forgets the information as soon as it is sent (such as most television cameras) cannot use ARQ; they must use FEC because when an error occurs, the original data is no longer available.
Applications that use ARQ must have a return channel; applications having no return channel cannot use ARQ.
Applications that require extremely low error rates (such as digital money transfers) must use ARQ due to the possibility of uncorrectable errors with FEC.
Reliability and inspection engineering also make use of the theory of error-correcting codes.[16]
Internet[edit]
In a typical TCP/IP stack, error control is performed at multiple levels:
- Each Ethernet frame uses CRC-32 error detection. Frames with detected errors are discarded by the receiver hardware.
- The IPv4 header contains a checksum protecting the contents of the header. Packets with incorrect checksums are dropped within the network or at the receiver.
- The checksum was omitted from the IPv6 header in order to minimize processing costs in network routing and because current link layer technology is assumed to provide sufficient error detection (see also RFC 3819).
- UDP has an optional checksum covering the payload and addressing information in the UDP and IP headers. Packets with incorrect checksums are discarded by the network stack. The checksum is optional under IPv4, and required under IPv6. When omitted, it is assumed the data-link layer provides the desired level of error protection.
- TCP provides a checksum for protecting the payload and addressing information in the TCP and IP headers. Packets with incorrect checksums are discarded by the network stack, and eventually get retransmitted using ARQ, either explicitly (such as through three-way handshake) or implicitly due to a timeout.
Deep-space telecommunications[edit]
The development of error-correction codes was tightly coupled with the history of deep-space missions due to the extreme dilution of signal power over interplanetary distances, and the limited power availability aboard space probes. Whereas early missions sent their data uncoded, starting in 1968, digital error correction was implemented in the form of (sub-optimally decoded) convolutional codes and Reed–Muller codes.[17] The Reed–Muller code was well suited to the noise the spacecraft was subject to (approximately matching a bell curve), and was implemented for the Mariner spacecraft and used on missions between 1969 and 1977.
The Voyager 1 and Voyager 2 missions, which started in 1977, were designed to deliver color imaging and scientific information from Jupiter and Saturn.[18] This resulted in increased coding requirements, and thus, the spacecraft were supported by (optimally Viterbi-decoded) convolutional codes that could be concatenated with an outer Golay (24,12,8) code. The Voyager 2 craft additionally supported an implementation of a Reed–Solomon code. The concatenated Reed–Solomon–Viterbi (RSV) code allowed for very powerful error correction, and enabled the spacecraft’s extended journey to Uranus and Neptune. After ECC system upgrades in 1989, both crafts used V2 RSV coding.
The Consultative Committee for Space Data Systems currently recommends usage of error correction codes with performance similar to the Voyager 2 RSV code as a minimum. Concatenated codes are increasingly falling out of favor with space missions, and are replaced by more powerful codes such as Turbo codes or LDPC codes.
The different kinds of deep space and orbital missions that are conducted suggest that trying to find a one-size-fits-all error correction system will be an ongoing problem. For missions close to Earth, the nature of the noise in the communication channel is different from that which a spacecraft on an interplanetary mission experiences. Additionally, as a spacecraft increases its distance from Earth, the problem of correcting for noise becomes more difficult.
Satellite broadcasting[edit]
The demand for satellite transponder bandwidth continues to grow, fueled by the desire to deliver television (including new channels and high-definition television) and IP data. Transponder availability and bandwidth constraints have limited this growth. Transponder capacity is determined by the selected modulation scheme and the proportion of capacity consumed by FEC.
Data storage[edit]
Error detection and correction codes are often used to improve the reliability of data storage media.[19] A parity track capable of detecting single-bit errors was present on the first magnetic tape data storage in 1951. The optimal rectangular code used in group coded recording tapes not only detects but also corrects single-bit errors. Some file formats, particularly archive formats, include a checksum (most often CRC32) to detect corruption and truncation and can employ redundancy or parity files to recover portions of corrupted data. Reed-Solomon codes are used in compact discs to correct errors caused by scratches.
Modern hard drives use Reed–Solomon codes to detect and correct minor errors in sector reads, and to recover corrupted data from failing sectors and store that data in the spare sectors.[20] RAID systems use a variety of error correction techniques to recover data when a hard drive completely fails. Filesystems such as ZFS or Btrfs, as well as some RAID implementations, support data scrubbing and resilvering, which allows bad blocks to be detected and (hopefully) recovered before they are used.[21] The recovered data may be re-written to exactly the same physical location, to spare blocks elsewhere on the same piece of hardware, or the data may be rewritten onto replacement hardware.
Error-correcting memory[edit]
Dynamic random-access memory (DRAM) may provide stronger protection against soft errors by relying on error-correcting codes. Such error-correcting memory, known as ECC or EDAC-protected memory, is particularly desirable for mission-critical applications, such as scientific computing, financial, medical, etc. as well as extraterrestrial applications due to the increased radiation in space.
Error-correcting memory controllers traditionally use Hamming codes, although some use triple modular redundancy. Interleaving allows distributing the effect of a single cosmic ray potentially upsetting multiple physically neighboring bits across multiple words by associating neighboring bits to different words. As long as a single-event upset (SEU) does not exceed the error threshold (e.g., a single error) in any particular word between accesses, it can be corrected (e.g., by a single-bit error-correcting code), and the illusion of an error-free memory system may be maintained.[22]
In addition to hardware providing features required for ECC memory to operate, operating systems usually contain related reporting facilities that are used to provide notifications when soft errors are transparently recovered. One example is the Linux kernel’s EDAC subsystem (previously known as Bluesmoke), which collects the data from error-checking-enabled components inside a computer system; besides collecting and reporting back the events related to ECC memory, it also supports other checksumming errors, including those detected on the PCI bus.[23][24][25] A few systems[specify] also support memory scrubbing to catch and correct errors early before they become unrecoverable.
See also[edit]
- Berger code
- Burst error-correcting code
- ECC memory, a type of computer data storage
- Link adaptation
- List of algorithms § Error detection and correction
- List of hash functions
References[edit]
- ^ a b «Masorah». Jewish Encyclopedia.
- ^ Pratico, Gary D.; Pelt, Miles V. Van (2009). Basics of Biblical Hebrew Grammar: Second Edition. Zondervan. ISBN 978-0-310-55882-8.
- ^ Mounce, William D. (2007). Greek for the Rest of Us: Using Greek Tools Without Mastering Biblical Languages. Zondervan. p. 289. ISBN 978-0-310-28289-1.
- ^ Mishneh Torah, Tefillin, Mezuzah, and Sefer Torah, 1:2. Example English translation: Eliyahu Touger. The Rambam’s Mishneh Torah. Moznaim Publishing Corporation.
- ^ Brian M. Fagan (5 December 1996). «Dead Sea Scrolls». The Oxford Companion to Archaeology. Oxford University Press. ISBN 0195076184.
- ^ Thompson, Thomas M. (1983), From Error-Correcting Codes through Sphere Packings to Simple Groups, The Carus Mathematical Monographs (#21), The Mathematical Association of America, p. vii, ISBN 0-88385-023-0
- ^ Shannon, C.E. (1948), «A Mathematical Theory of Communication», Bell System Technical Journal, 27 (3): 379–423, doi:10.1002/j.1538-7305.1948.tb01338.x, hdl:10338.dmlcz/101429, PMID 9230594
- ^ Golay, Marcel J. E. (1949), «Notes on Digital Coding», Proc.I.R.E. (I.E.E.E.), 37: 657
- ^ Gupta, Vikas; Verma, Chanderkant (November 2012). «Error Detection and Correction: An Introduction». International Journal of Advanced Research in Computer Science and Software Engineering. 2 (11). S2CID 17499858.
- ^ a b A. J. McAuley, Reliable Broadband Communication Using a Burst Erasure Correcting Code, ACM SIGCOMM, 1990.
- ^ Shah, Pradeep M.; Vyavahare, Prakash D.; Jain, Anjana (September 2015). «Modern error correcting codes for 4G and beyond: Turbo codes and LDPC codes». 2015 Radio and Antenna Days of the Indian Ocean (RADIO): 1–2. doi:10.1109/RADIO.2015.7323369. ISBN 978-9-9903-7339-4. S2CID 28885076. Retrieved 22 May 2022.
- ^ «IEEE SA — IEEE 802.11ac-2013». IEEE Standards Association.
- ^ «Transition to Advanced Format 4K Sector Hard Drives | Seagate US». Seagate.com. Retrieved 22 May 2022.
- ^ Frank van Gerwen. «Numbers (and other mysterious) stations». Archived from the original on 12 July 2017. Retrieved 12 March 2012.
- ^ Gary Cutlack (25 August 2010). «Mysterious Russian ‘Numbers Station’ Changes Broadcast After 20 Years». Gizmodo. Retrieved 12 March 2012.
- ^ Ben-Gal I.; Herer Y.; Raz T. (2003). «Self-correcting inspection procedure under inspection errors» (PDF). IIE Transactions. IIE Transactions on Quality and Reliability, 34(6), pp. 529-540. Archived from the original (PDF) on 2013-10-13. Retrieved 2014-01-10.
- ^ K. Andrews et al., The Development of Turbo and LDPC Codes for Deep-Space Applications, Proceedings of the IEEE, Vol. 95, No. 11, Nov. 2007.
- ^ Huffman, William Cary; Pless, Vera S. (2003). Fundamentals of Error-Correcting Codes. Cambridge University Press. ISBN 978-0-521-78280-7.
- ^ Kurtas, Erozan M.; Vasic, Bane (2018-10-03). Advanced Error Control Techniques for Data Storage Systems. CRC Press. ISBN 978-1-4200-3649-7.[permanent dead link]
- ^ Scott A. Moulton. «My Hard Drive Died». Archived from the original on 2008-02-02.
- ^ Qiao, Zhi; Fu, Song; Chen, Hsing-Bung; Settlemyer, Bradley (2019). «Building Reliable High-Performance Storage Systems: An Empirical and Analytical Study». 2019 IEEE International Conference on Cluster Computing (CLUSTER): 1–10. doi:10.1109/CLUSTER.2019.8891006. ISBN 978-1-7281-4734-5. S2CID 207951690.
- ^ «Using StrongArm SA-1110 in the On-Board Computer of Nanosatellite». Tsinghua Space Center, Tsinghua University, Beijing. Archived from the original on 2011-10-02. Retrieved 2009-02-16.
- ^ Jeff Layton. «Error Detection and Correction». Linux Magazine. Retrieved 2014-08-12.
- ^ «EDAC Project». bluesmoke.sourceforge.net. Retrieved 2014-08-12.
- ^ «Documentation/edac.txt». Linux kernel documentation. kernel.org. 2014-06-16. Archived from the original on 2009-09-05. Retrieved 2014-08-12.
Further reading[edit]
- Shu Lin; Daniel J. Costello, Jr. (1983). Error Control Coding: Fundamentals and Applications. Prentice Hall. ISBN 0-13-283796-X.
- SoftECC: A System for Software Memory Integrity Checking
- A Tunable, Software-based DRAM Error Detection and Correction Library for HPC
- Detection and Correction of Silent Data Corruption for Large-Scale High-Performance Computing
External links[edit]
- The on-line textbook: Information Theory, Inference, and Learning Algorithms, by David J.C. MacKay, contains chapters on elementary error-correcting codes; on the theoretical limits of error-correction; and on the latest state-of-the-art error-correcting codes, including low-density parity-check codes, turbo codes, and fountain codes.
- ECC Page — implementations of popular ECC encoding and decoding routines
-
Методы контроля данных. Форматный и логический контроль информации.
Цель работы:
освоить основные методы обнаружения
ошибок; получить навыки определения
форматных и логических ошибок в
информационных сообщениях, отработать
эти навыки на примере сообщения 02.
-
Структурный и логический контроль входных сообщений.
-
Пример выявления ошибок в служебной и информационной фразах сообщения 02.
Контрольные
вопросы.
Основой
функционирования автоматизированных
систем управления является информационный
поток. Во время подготовки, передачи и
обработки информация может искажаться,
что приводит к снижению достоверности
получаемых результатов и снижает
эффективность функционирования АСУ.
Основными
причинами снижения достоверности
получаемых результатов (выходной
информации) в АСУ являются:
—
искажение информации из-за сбоев и
отказов аппаратуры подготовки данных
(АПД) при ее передаче, обработке и
отображении;
—
воздействие электромагнитных и других
помех в каналах связи при передаче,
хранении и обработке информации;
—
алгоритмические и программные ошибки;
—
человеческий фактор, то есть ошибки
оператора как звена автоматизированной
управляющей системы в процессе заполнения
первичных документов.
3.1. Основные методы обнаружения ошибок.
Методы обнаружения
ошибок базируются на анализе информации
по синтаксическому (контролируются
элементарные составляющие информации
– знаки) и семантическому (контролируется
смысловое содержание информации, ее
логичность, согласованность данных)
содержанию.
Основными методами
контроля и обнаружения ошибок в
информации, которые базируются на
информационной и программной избыточности,
являются:
— метод контрольных
сумм;
— защита кодов и
реквизитов контрольным числом;
— контроль формата
сообщения;
— программно-логические
методы.
Метод контрольных
сумм широко используется на этапах
подготовки первичной информации, ввода
массива данных в ЭВМ, считывании
информации с накопителей и записи на
них.
При обработке
первичных документов и записи информации
на машинные носители все или часть
реквизитов строки (столбца) охватывают
контрольной суммой, которая пореквизитно
суммирует все показатели строки
(столбца). Итог (контрольную сумму)
заносят в соответствующую графу
документа. При дальнейшем занесении
информации на машинный носитель
контрольную сумму вводят в счетчик
устройства. Регистрируемые данные
пореквизитно вычитают из контрольной
суммы. Регистрация считается правильной,
если после занесения на машинный носитель
последнего реквизита имеет место нулевое
значение счетчика.
Для контроля
правильности ввода информации в ЭВМ
определяют контрольные суммы по массивам
вводимой информации. Программным путем
предусматривают суммирование разрядов
вводимых информационных массивов и
сравнение полученного результата с
контрольной суммой, указанной в конце
массива. При совпадении контрольных
сумм информация считается введенной
правильно.
Метод защиты
реквизитов контрольным числом
подразумевает дополнение кода объекта
контрольным числом, определенным по
определенному алгоритму (модулю). При
автоматическом контроле записи кода
по тому же алгоритму вычисляется значение
контрольного числа и сравнивается с
имеющимся в коде.
Метод контроля
формата сообщения основан на
использовании внутренней избыточности
информации и проверки
Различают
форматный
и логический
контроль.
При
форматном контроле:
-
определяется
число знаков в каждом введенном
показателе и сравнивается с необходимым
их количеством, -
проверяется
наличие допустимого количества
показателей во введенном сообщении, -
проверяется
наличие алфавитного символа там, где
должен стоять цифровой символ и наоборот.
При
логическом контроле:
-
проверяется
значение каждого показателя сообщения
области допустимых значений, которая
содержится в НСИ, -
делается
проверка на взаимное логическое
соответствие отдельных показателей
друг другу внутри каждой фразы введенного
сообщения (внутрифразовый) и между
различными фразами (межфразовый
контроль), -
выявляется
наличие ошибок в наиболее важных
показателях сообщения (коды станций,
номера вагонов и т.д.) с помощью расчета
контрольных знаков.
Форматный
и логический контроли выполняются для
служебной и информационных фраз
сообщения.
При
обнаружении ошибок абоненту, пославшему
сообщение, выдается диагностическое
сообщение 497, содержащее наименование
показателей, где обнаружены ошибки и
коды ошибок. В табл.1 приведены примеры
ошибок, выявляемых в процессе форматного
и логического контроля.
Таблица
1.
|
Приложение |
||||
|
Перечень |
||||
|
Номер |
Номер |
Текст |
Характер |
Краткая |
|
.01 |
02, |
Ю2 |
Несуществующий |
Исправить |
|
.02 |
02, |
.02 |
Количество |
Для |
|
Для |
||||
|
.02 |
02, |
.02 |
Количество |
Для |
|
Для |
||||
|
Для |
||||
|
Для |
||||
|
.02 |
02, |
.02 |
Количество |
Для |
|
.03 |
02, |
.03 |
Отсутствуют |
|
|
.04 |
02, |
.04 |
Неверно |
Маршрут, |
|
.05 |
02, |
.05 |
Не |
Для |
|
.05 |
02, |
.05 |
Не |
Для |
|
.07 |
02, |
.07 |
Отсутствует |
необходимо |
|
.08 |
02, |
.08 |
Значение |
К |
|
.09 |
.02 |
.09 |
Неверно |
Если |
|
.09 |
200-205, |
.09 |
Значение |
Показатель |
|
10 |
02, |
.10 |
Одинаковые |
|
|
11 |
02, |
.11 |
Код |
|
|
12 |
02, |
.12 |
Сбой |
|
|
13 |
02, |
.13 |
Нет |
|
|
14 |
.02 |
.14 |
В |
Если |
|
14 |
09, |
.14 |
Информация |
|
|
15 |
02, |
.15 |
Недопустимое |
NC |
|
16 |
02, |
.16 |
Недопустимое |
NC |
|
17 |
02, |
.17 |
Количество |
|
|
19 |
09, |
.19 |
Корректируемых |
Для |
|
20 |
241, |
.20 |
Нарушена |
|
|
21 |
200, |
.21 |
Локомотив |
|
|
22 |
02, |
.22 |
Недопустимый |
|
|
23 |
200-205 |
.23 |
Нарушена |
Текущая |
|
25 |
02, |
.25 |
Время |
Для |
|
26 |
09, |
.26 |
Дата |
Дата |
|
33 |
02, |
.33 |
Неверно |
|
|
34 |
.02 |
.34 |
Количество |
|
|
90 |
02, |
.90 |
Нарушение |
|
|
92 |
02, |
.92 |
Поезд |
Ошибка |
|
93 |
02, |
.93 |
Поезд |
Ошибка |
|
Р1 |
200-205 |
.Р1 |
Повторный |
В |
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Лекция: Методы обнаружения ошибок
Методы обнаружения ошибок основаны на передаче в составе блока данных избыточной служебной информации, по которой можно судить с некоторой степенью вероятности о достоверности принятых данных. В сетях с коммутацией пакетов такой единицей информации может быть PDU любого уровня, для определенности будем считать, что мы контролируем кадры.
Избыточную служебную информацию принято называть контрольной суммой, или контрольной последовательностью кадра (Frame Check Sequence, FCS). Контрольная сумма вычисляется как функция от основной информации, причем не обязательно путем суммирования. Принимающая сторона повторно вычисляет контрольную сумму кадра по известному алгоритму и в случае ее совпадения с контрольной суммой, вычисленной передающей стороной, делает вывод о том, что данные были переданы через сеть корректно. Рассмотрим несколько распространенных алгоритмов вычисления контрольной суммы, отличающихся вычислительной сложностью и способностью обнаруживать ошибки в данных. Контроль по паритету представляет собой наиболее простой метод контроля данных. В то же время это наименее мощный алгоритм контроля, так как с его помощью можно обнаруживать только одиночные ошибки в проверяемых данных. Метод заключается в суммировании по модулю 2 всех битов контролируемой информации. Нетрудно заметить, что для информации, состоящей из нечетного числа единиц, контрольная сумма всегда равна 1, а при четном числе единиц — 0. Например, для данных 100101011 результатом контрольного суммирования будет значение 1. Результат суммирования также представляет собой один дополнительный бит данных, который пересылается вместе с контролируемой информацией. При искажении в процессе пересылки любого одного бита исходных данных (или контрольного разряда) результат суммирования будет отличаться от принятого контрольного разряда, что говорит об ошибке. Однако двойная ошибка, например 110101010, будет неверно принята за корректные данные. Поэтому контроль по паритету применяется к небольшим порциям данных, как правило, к каждому байту, что дает коэффициент избыточности для этого метода 1/8. Метод редко используется в компьютерных сетях из-за значительной избыточности и невысоких диагностических возможностей.
Вертикальный и горизонтальный контроль по паритету представляет собой модификацию описанного метода. Его отличие состоит в том, что исходные данные рассматриваются в виде матрицы, строки которой составляют байты данных. Контрольный разряд под- считывается отдельно для каждой строки и для каждого столбца матрицы. Этот метод позволяет обнаруживать большую часть двойных ошибок, однако он обладает еще большей избыточностью. На практике этот метод сейчас также почти не применяется при передаче информации по сети.
Циклический избыточный контроль (Cyclic Redundancy Check, CRC) является в настоящее время наиболее популярным методом контроля в вычислительных сетях (и не только в сетях, например, этот метод широко применяется при записи данных на гибкие и жесткие диски). Метод основан на представлении исходных данных в виде одного многоразрядного двоичного числа. Например, кадр стандарта Ethernet, состоящий из 1024 байт, рассматривается как одно число, состоящее из 8192 бит. Контрольной информацией считается остаток от деления этого числа на известный делитель R. Обычно в качестве делителя выбирается семнадцати- или тридцатитрехразрядное число, чтобы остаток от деления имел длину 16 разрядов (2 байт) или 32 разряда (4 байт). При получении кадра данных снова вычисляется остаток от деления на тот же делитель R, но при этом к данным кадра добавляется и содержащаяся в нем контрольная сумма. Если остаток от деления на R равен нулю, то делается вывод об отсутствии ошибок в полученном кадре, в противном случае кадр считается искаженным.
Этот метод обладает более высокой вычислительной сложностью, но его диагностические возможности гораздо выше, чем у методов контроля по паритету. Метод CRC позволяет обнаруживать все одиночные ошибки, двойные ошибки и ошибки в нечетном числе битов. Метод обладает также невысокой степенью избыточности. Например, для кадра Ethernet размером 1024 байт контрольная информация длиной 4 байт составляет только 0,4 %.
Реферат по информатике
Методы обмена данными в локальных сетях
22 Января 2016
Реферат по информатике
Методы обеспечения живучести сети
22 Января 2016
Реферат по информатике
Параметры подпрограмм
22 Января 2016
Реферат по информатике
Параллельная коммутация
22 Января 2016
Аннотация: Контроль по четности, CRC, алгоритм Хэмминга. Введение в коды Рида-Соломона: принципы, архитектура и реализация. Метод коррекции ошибок FEC (Forward Error Correction).
Каналы передачи данных ненадежны (шумы, наводки и т.д.), да и само оборудование обработки информации работает со сбоями. По этой причине важную роль приобретают механизмы детектирования ошибок. Ведь если ошибка обнаружена, можно осуществить повторную передачу данных и решить проблему. Если исходный код по своей длине равен полученному коду, обнаружить ошибку передачи не предоставляется возможным. Можно, конечно, передать код дважды и сравнить, но это уже двойная избыточность.
Простейшим способом обнаружения ошибок является контроль по четности. Обычно контролируется передача блока данных ( М бит). Этому блоку ставится в соответствие кодовое слово длиной N бит, причем N>M. Избыточность кода характеризуется величиной 1-M/N. Вероятность обнаружения ошибки определяется отношением M/N (чем меньше это отношение, тем выше вероятность обнаружения ошибки, но и выше избыточность).
При передаче информации она кодируется таким образом, чтобы с одной стороны характеризовать ее минимальным числом символов, а с другой – минимизировать вероятность ошибки при декодировании получателем. Для выбора типа кодирования важную роль играет так называемое расстояние Хэмминга.
Пусть А и Б — две двоичные кодовые последовательности равной длины. Расстояние Хэмминга между двумя этими кодовыми последовательностями равно числу символов, которыми они отличаются. Например, расстояние Хэмминга между кодами 00111 и 10101 равно 2.
Можно показать, что для детектирования ошибок в n битах схема кодирования требует применения кодовых слов с расстоянием Хэмминга не менее N + 1. Можно также показать, что для исправления ошибок в N битах необходима схема кодирования с расстоянием Хэмминга между кодами не менее 2N + 1. Таким образом, конструируя код, мы пытаемся обеспечить расстояние Хэмминга между возможными кодовыми последовательностями большее, чем оно может возникнуть из-за ошибок.
Широко распространены коды с одиночным битом четности. В этих кодах к каждым М бит добавляется 1 бит, значение которого определяется четностью (или нечетностью) суммы этих М бит. Так, например, для двухбитовых кодов 00, 01, 10, 11 кодами с контролем четности будут 000, 011, 101 и 110. Если в процессе передачи один бит будет передан неверно, четность кода из М+1 бита изменится.
Предположим, что частота ошибок ( BER – Bit Error Rate) равна р = 10-4. В этом случае вероятность передачи 8 бит с ошибкой составит 1 – (1 – p)8 = 7,9 х 10-4. Добавление бита четности позволяет детектировать любую ошибку в одном из переданных битах. Здесь вероятность ошибки в одном из 9 битов равна 9p(1 – p)8. Вероятность же реализации необнаруженной ошибки составит 1 – (1 – p)9 – 9p(1 – p)8 = 3,6 x 10-7. Таким образом, добавление бита четности уменьшает вероятность необнаруженной ошибки почти в 1000 раз. Использование одного бита четности типично для асинхронного метода передачи. В синхронных каналах чаще используется вычисление и передача битов четности как
для строк, так и для столбцов передаваемого массива данных. Такая схема позволяет не только регистрировать, но и исправлять ошибки в одном из битов переданного блока.
Контроль по четности достаточно эффективен для выявления одиночных и множественных ошибок в условиях, когда они являются независимыми. При возникновении ошибок в кластерах бит метод контроля четности неэффективен, и тогда предпочтительнее метод вычисления циклических сумм ( CRC — Cyclic Redundancy Check). В этом методе передаваемый кадр делится на специально подобранный образующий полином. Дополнение остатка от деления и является контрольной суммой.
В Ethernet вычисление CRC производится аппаратно. На
рис.
4.1 показан пример реализации аппаратного расчета CRC для образующего полинома R(x) = 1 + x2 + x3 + x5 + x7. В этой схеме входной код приходит слева.
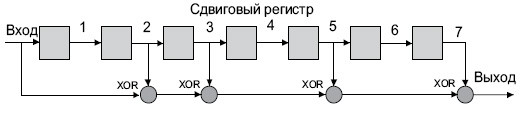
Рис.
4.1.
Схема реализации расчета CRC
Эффективность CRC для обнаружения ошибок на многие порядки выше простого контроля четности. В настоящее время стандартизовано несколько типов образующих полиномов. Для оценочных целей можно считать, что вероятность невыявления ошибки в случае использования CRC, если ошибка на самом деле имеет место, равна (1/2)r, где r — степень образующего полинома.
| CRC -12 | x12 + x11 + x3 + x2 + x1 + 1 |
| CRC -16 | x16 + x15 + x2 + 1 |
| CRC -CCITT | x16 + x12 + x5 + 1 |
4.1. Алгоритмы коррекции ошибок
Исправлять ошибки труднее, чем их детектировать или предотвращать. Процедура коррекции ошибок предполагает два совмещеных процесса: обнаружение ошибки и определение места (идентификации сообщения и позиции в сообщении). После решения этих двух задач исправление тривиально — надо инвертировать значение ошибочного бита. В наземных каналах связи, где вероятность ошибки невелика, обычно используется метод детектирования ошибок и повторной пересылки фрагмента, содержащего дефект. Для спутниковых каналов с типичными для них большими задержками системы коррекции ошибок становятся привлекательными. Здесь используют коды Хэмминга или коды свертки.
Код Хэмминга представляет собой блочный код, который позволяет выявить и исправить ошибочно переданный бит в пределах переданного блока. Обычно код Хэмминга характеризуется двумя целыми числами, например, (11,7), используемыми при передаче 7-битных ASCII-кодов. Такая запись говорит, что при передаче 7-битного кода используется 4 контрольных бита (7 + 4 = 11). При этом предполагается, что имела место ошибка в одном бите и что ошибка в двух или более битах существенно менее вероятна. С учетом этого исправление ошибки осуществляется с определенной вероятностью. Например, пусть возможны следующие правильные коды (все они, кроме первого и последнего, отстоят друг от друга на расстояние Хэмминга 4):
00000000
11110000
00001111
11111111
При получении кода 00000111 нетрудно предположить, что правильное значение полученного кода равно 00001111. Другие коды отстоят от полученного на большее расстояние Хэмминга.
Рассмотрим пример передачи кода буквы s = 0x073 = 1110011 с использованием кода Хэмминга (11,7). Таблица 4.2.
| Позиция бита | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Значение бита | 1 | 1 | 1 | * | 0 | 0 | 1 | * | 1 | * | * |
Символами * помечены четыре позиции, где должны размещаться контрольные биты. Эти позиции определяются целой степенью 2 (1, 2, 4, 8 и т.д.). Контрольная сумма формируется путем выполнения операции XoR (исключающее ИЛИ) над кодами позиций ненулевых битов. В данном случае это 11, 10, 9, 5 и 3. Вычислим контрольную сумму:
| 11= | 1011 |
| 10= | 1010 |
| 09= | 1001 |
| 05= | 0101 |
| 03= | 0011 |
 |
1110 |
Таким образом, приемник получит код
| Позиция бита | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Значение бита | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 1 | 1 | 0 |
Просуммируем снова коды позиций ненулевых битов и получим нуль;
| 11= | 1011 |
| 10= | 1010 |
| 09= | 1001 |
| 08= | 1000 |
| 05= | 0101 |
| 04= | 0100 |
| 03= | 0011 |
| 02= | 0010 |
|
0000 |
Ну а теперь рассмотрим два случая ошибок в одном из битов посылки, например в бите 7 (1 вместо 0) и в бите 5 (0 вместо 1). Просуммируем коды позиций ненулевых битов еще раз:
|
|
В обоих случаях контрольная сумма равна позиции бита, переданного с ошибкой. Теперь для исправления ошибки достаточно инвертировать бит, номер которого указан в контрольной сумме. Понятно, что если ошибка произойдет при передаче более чем одного бита, код Хэмминга при данной избыточности окажется бесполезен.
В общем случае код имеет N = M + C бит и предполагается, что не более чем один бит в коде может иметь ошибку. Тогда возможно N+1 состояние кода (правильное состояние и n ошибочных). Пусть М = 4, а N = 7, тогда слово-сообщение будет иметь вид: M4, M3, M2, C3, M1, C2, C1. Теперь попытаемся вычислить значения С1, С2, С3. Для этого используются уравнения, где все операции представляют собой сложение по модулю 2:
С1 = М1 + М2 + М4 С2 = М1 + М3 + М4 С3 = М2 + М3 + М4
Для определения того, доставлено ли сообщение без ошибок, вычисляем следующие выражения (сложение по модулю 2):
С11 = С1 + М4 + М2 + М1 С12 = С2 + М4 + М3 + М1 С13 = С3 + М4 + М3 + М2
Результат вычисления интерпретируется следующим образом:
| C11 | C12 | C13 | Значение |
|---|---|---|---|
| 1 | 2 | 4 | Позиция бит |
| 0 | 0 | 0 | Ошибок нет |
| 0 | 0 | 1 | Бит С3 неверен |
| 0 | 1 | 0 | Бит С2 неверен |
| 0 | 1 | 1 | Бит M3 неверен |
| 1 | 0 | 0 | Бит С1 неверен |
| 1 | 0 | 1 | Бит M2 неверен |
| 1 | 1 | 0 | Бит M1 неверен |
| 1 | 1 | 1 | Бит M4 неверен |
Описанная схема легко переносится на любое число n и М.
Число возможных кодовых комбинаций М помехоустойчивого кода делится на n классов, где N — число разрешенных кодов. Разделение на классы осуществляется так, чтобы в каждый класс вошел один разрешенный код и ближайшие к нему (по расстоянию Хэмминга ) запрещенные коды. В процессе приема данных определяется, к какому классу принадлежит пришедший код. Если код принят с ошибкой, он заменяется ближайшим разрешенным кодом. При этом предполагается, что кратность ошибки не более qm.
В теории кодирования существуют следующие оценки максимального числа N n -разрядных кодов с расстоянием D.
| d=1 | n=2n |
| d=2 | n=2n-1 |
| d=3 | N 2n/(1 + n) |
| d = 2q + 1 | (для кода Хэмминга это неравенство превращается в равенство) |
В случае кода Хэмминга первые k разрядов используются в качестве информационных, причем
K = n – log(n + 1), откуда следует (логарифм по основанию 2), что k может принимать значения 0, 1, 4, 11, 26, 57 и т.д., это и определяет соответствующие коды Хэмминга (3,1); (7,4); (15,11); (31,26); (63,57) и т.д.
Обобщением кодов Хэмминга являются циклические коды BCH (Bose-Chadhuri-hocquenghem). Эти коды имеют широкий выбор длин и возможностей исправления ошибок.
Одной из старейших схем коррекции ошибок является двух-и трехмерная позиционная схема (
рис.
4.2). Для каждого байта вычисляется бит четности (бит <Ч>, направление Х). Для каждого столбца также вычисляется бит четности (направление Y. Производится вычисление битов четности для комбинаций битов с координатами (X,Y) (направление Z, слои с 1 до N ). Если при транспортировке будет искажен один бит, он может быть найден и исправлен по неверным битам четности X и Y. Если же произошло две ошибки в одной из плоскостей, битов четности данной плоскости недостаточно. Здесь поможет плоскость битов четности N+1.
Таким образом, на 512 передаваемых байтов данных пересылается около 200 бит четности.
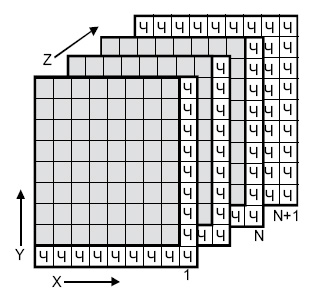
Рис.
4.2.
Позиционная схема коррекции ошибок
Так как каждая из 2k разрешенных комбинаций в результате действия помех может трансформироваться в любую другую, то всегда имеется 2k*2n возможных случаев передачи. В это число входят:
-
2k случаев безошибочной передачи;
-
2k(2k –1) случаев перехода в другие разрешенные комбинации, что соответствует необнаруженным ошибкам;
-
2k(2n – 2k) случаев перехода в неразрешенные комбинации, которые могут быть обнаружены.
Следовательно, часть обнаруживаемых ошибочных кодовых комбинаций от общего числа возможных случаев передачи составляет
.
Пример22: Определить обнаруживающую способность кода, каждая комбинация которого содержит всего один избыточный символ (n=k+1).
Решение : 1. Общее число выходных последовательностей составляет 2k+1, т.е. вдвое больше общего числа кодируемых входных последовательностей.
2. За подмножество разрешенных кодовых комбинаций можно принять, например, подмножество 2k комбинаций, содержащих четное число единиц (или нулей).
3. При кодировании к каждой последовательности из k информационных символов добавляют один символ (0 или 1), такой, чтобы число единиц в кодовой комбинации было четным. Исполнение любого нечетного числа символов переводит разрешенную кодовую комбинацию в подмножество запрещенных комбинаций, что обнаруживается на приемной стороне по нечетности числа единиц. Часть опознанных ошибок составляет
.
Любой метод декодирования можно рассматривать как правило разбиения всего множества запрещенных кодовых комбинаций на 2k пересекающихся подмножеств Mi, каждая из которых ставится в соответствие одной из разрешенных комбинаций. При получении запрещенной комбинации, принадлежащей подмножеству Mi, принимают решение, что передавалась запрещенная комбинация Ai. Ошибка будет исправлена в тех случаях, когда полученная комбинация действительно образовалась из Ai, т.е. 2n-2k cлучаях.
Всего случаев перехода в неразрешенные комбинации 2k(2n – 2k). Таким образом, при наличии избыточности любой код способен исправлять ошибки.
Отношение числа исправляемых кодом ошибочных кодовых комбинаций к числу обнаруживаемых ошибочных комбинаций равно
.
Способ разбиения на подмножества зависит от того, какие ошибки должны направляться конкретным кодом.
Большинство разработанных кодов предназначено для корректирования взаимно независимых ошибок определенной кратности и пачек (пакетов) ошибок.
Взаимно независимыми ошибками называют такие искажения в передаваемой последовательности символов, при которых вероятность появления любой комбинации искаженных символов зависит только от числа искаженных символов r и вероятности искажения обычного символа p.
При взаимно независимых ошибках вероятность искажения любых r символов в n-разрядной кодовой комбинации:
,
где p – вероятность искажения одного символа;
r – число искаженных символов;
n – число двоичных символов на входе кодирующего устройства;
– число ошибок порядка r.
Если учесть, что p<<1, то в этом случае наиболее вероятны ошибки низшей кратности. Их следует обнаруживать и исправлять в первую очередь.
4.3 Связь корректирующей способности кода с кодовым расстоянием
При взаимно независимых ошибках наиболее вероятен переход в кодовую комбинацию, отличающуюся от данной в наименьшем числе символов.
Степень отличия любых двух кодовых комбинаций характеризуется расстоянием между ними в смысле Хэмминга или просто кодовым расстоянием.
Кодовое расстояние выражается числом символов, в которых комбинации отличаются одна от другой, и обозначается через d.
Ч
тобы получить кодовое расстояние между двумя комбинациями двоичного кода, достаточно подсчитать число единиц в сумме этих комбинаций по модулю 2. Например
(Сложение ”по модулю 2”: y= х1 х2, сумма равна 1 тогда и только тогда, когда х1 и x2 не совпадают ).
Минимальное расстояние, взятое по всем парам кодовых разрешенных комбинаций кода, называют минимальным кодовым расстоянием.
Более полное представление о свойствах кода дает матрица расстояний D, элементы которой dij (i,j = 1,2,…,m) равны расстояниям между каждой парой из всех m разрешенных комбинаций.
Пример23: Представить симметричной матрицей расстояний код х1 = 000; х2 = 001; х3 = 010; х4 = 111.
Решение. 1. Минимальное кодовое расстояние для кода d=1.
-
Симметричная матрица четвертого порядка для кода
Таблица 4.1.
|
x1 |
x2 |
x3 |
x4 |
||
|
000 |
001 |
010 |
111 |
||
|
x1 |
000 |
1 |
1 |
3 |
|
|
x2 |
001 |
1 |
2 |
2 |
|
|
x3 |
010 |
1 |
2 |
2 |
|
|
x4 |
111 |
3 |
2 |
2 |
Декодирование после приема производится таким образом, что принятая кодовая комбинация отождествляется с той разрешенной, которая находится от нее на наименьшем кодовом расстоянии.
Такое декодирование называется декодированием по методу максимального правдоподобия.
Очевидно, что при кодовом расстоянии d=1 все кодовые комбинации являются разрешенными.
Например, при n=3 разрешенные комбинации образуют следующее множество: 000, 001, 010, 011, 100, 101, 110, 111.
Любая одиночная ошибка трансформирует данную комбинацию в другую разрешенную комбинацию. Это случай безызбыточного кода, не обладающего корректирующей способностью.
Если d = 2, то ни одна из разрешенных кодовых комбинаций при одиночной ошибке не переходит в другую разрешенную комбинацию. Например, подмножество разрешенных кодовых комбинаций может быть образовано по принципу четности в нем числа единиц. Например, для n=3:
000, 011, 101, 110 – разрешенные комбинации;
001, 010, 100, 111 – запрещенные комбинации.
Код обнаруживает одиночные ошибки, а также другие ошибки нечетной кратности (при n=3 тройные).
В общем случае при необходимости обнаруживать ошибки кратности до r включительно минимальное хэммингово расстояние между разрешенными кодовыми комбинациями должно быть по крайней мере на единицу больше r, т.е d0 minr+1.
Действительно, в этом случае ошибка, кратность которой не превышает r, не в состоянии перевести одну разрешенную кодовую комбинацию в другую.
Для исправления одиночной ошибки кодовой комбинации необходимо сопоставить подмножество запрещенных кодовых комбинаций.
Чтобы эти подмножества не пересекались, хэммингово расстояние между разрешенными кодовыми комбинациями должно быть не менее трех. При n=3 за разрешенные кодовые комбинации можно, например, принять 000 и 111. Тогда разрешенной комбинации 000 необходимо приписать подмножество запрещенных кодовых комбинаций 001, 010, 100, образующихся в результате двоичной ошибки в комбинации 000.
Подобным же образом разрешенной комбинации 111 необходимо приписать подмножество запрещенных кодовых комбинаций: 110, 011, 101, образующихся в результате возникновения единичной ошибки в комбинации 111:
Рис. 4.1.
В общем случае для обеспечения возможности исправления всех ошибок кратности до s включительно при декодировании по методу максимального правдоподобия, каждая из ошибок должна приводить к запрещенной комбинации, относящейся к подмножеству исходной разрешенной кодовой комбинации.
Любая n-разрядная двоичная кодовая комбинация может быть интерпретирована как вершина m-мерного единичного куба, т.е. куба с длиной ребра, равной 1.
При n=2 кодовые комбинации располагаются в вершинах квадрата:
Рис. 4.2.
При n=3 кодовые комбинации располагаются в вершинах единичного куба:
Рис. 4.3.
В общем случае n-мерный единичный куб имеет 2n вершин, что равно наибольшему возможному числу кодовых комбинаций.
Такая модель дает простую геометрическую интерпретацию и кодовому расстоянию между отдельными кодовыми комбинациями. Оно соответствует наименьшему числу ребер единичного куба, которые необходимо пройти, чтобы попасть от одной комбинации к другой.
Ошибка будет не только обнаружена, но и исправлена, если искаженная комбинация остается ближе к первоначальной, чем к любой другой разрешенной комбинации, то есть должно быть: или
В общем случае для того, чтобы код позволял обнаруживать все ошибки кратности r и исправлять все ошибки кратности s (r>s), его кодовое расстояние должно удовлетворять неравенству d r+s+1 (rs).
Метод декодирования при исправлении одиночных независимых ошибок можно пояснить следующим образом. В подмножество каждой разрешенной комбинации относят все вершины, лежащие в сфере с радиусом (d-1)/2 и центром в вершине, соответствующей данной разрешенной кодовой комбинации. Если в результате действия помехи комбинация переходит в точку, находящуюся внутри сферы (d-1)/2, то такая ошибка может быть исправлена.
Если помеха смещает точку разрешенной комбинации на границу двух сфер (расстояние d/2) или больше (но не в точку, соответствующую другой разрешенной комбинации), то такое искажение может быть обнаружено.
Для кодов с независимым искажением символов лучшие корректирующие коды – это такие, у которых точки, соответствующие разрешенным кодовым комбинациям, расположены в пространстве равномерно.
Проиллюстрируем построение корректирующего кода на следующем примере. Пусть исходный алфавит, состоящий из четырех букв, закодирован двоичным кодом: х1 = 00; х2 = 01; х3 = 10; х4 = 11. Этот код использует все возможные комбинации длины 2, и поэтому не может обнаруживать ошибки (так как d=1).
Припишем к каждой кодовой комбинации один элемент 0 или 1 так, чтобы число единиц в нем было четное, то есть х1 = 000; х2 = 011; х3 = 101; х4 = 110.
Для этого кода d=2, и, следовательно, он способен обнаруживать все однократные ошибки. Так как любая запрещенная комбинация содержит нечетное число единиц, то для обнаружения ошибки достаточно проверить комбинацию на четность (например, суммированием по модулю 2 цифр кодовой комбинации). Если число единиц в слове четное, то сумма по модулю 2 его разрядов будет 0, если нечетное – то 1. Признаком четности называют инверсию этой суммы.
Рассмотрим общую схему организации контроля по четности (контроль по нечетности, parity check – контроль по паритету).

Рис. 4.4.
На n-входовом элементе формируется признак четности Р числа, который в качестве дополнительного, (n+1)-го контрольного разряда (parity bit) отправляется вместе с передаваемым словом в линию связи или запоминающее устройство. Передаваемое (n+1)-разрядное слово имеет всегда нечетное число единиц. Если в исходном слове оно было нечетным, то инверсия функции М2 от такого слова равна 0, и нулевое значение контрольного разряда не меняет число единиц при передаче слова. Если же число единиц в исходном слове было четным, то контрольный разряд Р для такого числа будет равен 1, и результирующее число единиц в передаваемом (n+1)-разрядном слове станет нечетным. Вид контроля, когда по линии передается нечетное число единиц, по строгой терминологии называют контролем по нечетности.
На приемном конце линии или из памяти от полученного (n+1)-разрядного слова снова берется свертка по четности, Если значение этой свертки равно 1, то или в передаваемом слове, или в контрольном разряде при передаче или хранении произошла ошибка. Столь простой контроль не позволяет исправить ошибку, но он, по крайней мере, дает возможность при обнаружении ошибки исключить неверные данные, затребовать повторную передачу и т.д.
Систему контроля можно построить на основе не только инверсии функции М2, но и прямой функции М2 (строго контроль по четности). Однако, в этом случае исходный код “все нули” будет иметь контрольный разряд, равный 0. В линию отправится посылка из сплошных нулей, и на приемном конце она будет неотличима от весьма опасной неисправности – полного пропадания связи. Поэтому контроль по четности в своем чистом виде почти никогда не применяют, контрольный разряд формируют как четности, и в нестрогой терминологии “контролем по четности” называют то, что, строго говоря, на самом деле является контролем по нечетности.
Контроль по четности основан на том, что одиночная ошибка (безразлично – пропадание единицы или появление линией) инвертирует признак четности. Однако две ошибки проинвертируют его дважды, то есть оставят без изменения, поэтому двойную ошибку контроль по четности не обнаруживает. Рассуждая аналогично, легко прийти к выводу, что контроль по четности обнаруживает все нечетные ошибки и не реагирует на любые четные. Пропуск четных ошибок – это не какой-либо дефект системы контроля. Это следствие предельно малой избыточности, равной всего одному разряду. Для более глубокого контроля требуется соответственно и большая избыточность. Если ошибки друг от друга не зависят, то из не обнаруживаемых чаще всего будет встречаться двойная ошибка, а при вероятности одиночной ошибки, равной Р, вероятность двойной будет Р2. Поскольку в нормальных цифровых устройствах P<<1, необнаруженные двойные ошибки встречаются значительно реже, чем обнаруженные одиночные. Поэтому далее при таком простом контроле качество работы устройства существенно возрастает. Это верно лишь для взаимно независимых ошибок.
Признаки четности можно использовать для контроля только неизменяемых данных. При выполнении над данными каких-либо логических операций признаки четности слов в общем изменяются, и попытки компенсировать эти изменения оказываются неэффективными. Счастливое исключение – операция арифметического сложения: сумма по модулю 2 признаков четности двоичных слагаемых и всех, возникших в процессе сложения переносов, равна признаку четности кода арифметической суммы этих слагаемых.
Контроль по четности – самый дешевый по аппаратурным затратам вид контроля, и применяется он очень широко. Практически любой канал передачи цифровых данных или запоминающее устройство, если они не имеют какого-либо более сильного метода контроля, защищены контролем по четности.
Продолжим рассмотрение примера построения корректирующего метода. Чтобы код был способен и исправлять однократные ошибки, необходимо добавить еще не менее двух разрядов. Это можно сделать различными способами, например, повторить первые две цифры:
х1 = 00000; х2 = 01101; х3 = 10110; х4 = 11011;
Матрица расстояний этого кода:
Таблица 4.2.
|
x1 |
x2 |
x3 |
x4 |
||
|
D= |
3 |
3 |
4 |
x1 |
|
|
3 |
4 |
3 |
x2 |
||
|
3 |
4 |
3 |
x3 |
||
|
4 |
3 |
3 |
x4 |
Видно, что d 3, что отвечает неравенству (d 2+3+1).
Пример23: Постройте корректирующий код для передачи двух сообщений:
-
обнаруживающий одну ошибку;
-
обнаруживающий и исправляющий одну ошибку;
-
обнаруживающий две и исправляющий одну ошибку.
КОНТРОЛЬ ПРАВИЛЬНОСТИ РАБОТЫ ЦИФРОВЫХ УСТРОЙСТВ
Общие сведения
В процессе работы цифрового устройства возникают ошибки, искажающие информацию. Причинами таких ошибок могут быть:
◙ выход из строя какого-либо элемента, из-за чего устройство теряет работоспособность;
◙ воздействие различного рода помех, возникающих из-за проникновения сигналов из одних цепей в другие через различные паразитные связи.
Выход из строя элемента устройства рассматривается как неисправность. При этом в устройстве наблюдается постоянное искажение информации.
Иной характер искажений информации имеет место под воздействием помех. Вызвав ошибку, помехи могут затем в течение длительного времени не проявлять себя. Такие ошибки называют случайными сбоями.
В связи с возникновением ошибок необходимо снабжать цифровые устройства системой контроля правильности циркулирующей в ней информации. Такие системы контроля могут предназначаться для решения задач двух типов:
◙ задачи обнаружения ошибок;
◙ задачи исправления ошибок.
Система обнаружения ошибок, производя контроль информации, способна лишь выносить решения: нет ошибок и есть ошибка, причем в последнем случае она не указывает, какие разряды слов искажены.
Система исправления ошибок сигнализирует о наличии ошибок и указывает, какие из разрядов искажены. При этом непосредственное исправление цифр искаженных разрядов представляет собой уже несложную операцию. Если известно, что некоторый разряд двоичного слова ошибочен, то появление в нем ошибочного лог.0 означает, что правильное значение — лог. 1 и наоборот.
Трудно локализовать ошибку, т.е. указать, в каких разрядах слова она возникла. После решения этой задачи само исправление сводится лишь к инверсии цифр искаженных разрядов, поэтому обычно под исправлением ошибок понимают решение задачи локализации ошибок.
При постоянном нарушении правильности информации, обнаружив ошибку, можно принять меры для поиска неисправного элемента и заменить его исправным. Причины же случайных сбоев обычно выявляются чрезвычайно трудно, и такие изредка возникающие ошибки желательно было бы устранять автоматически, восстанавливая правильное значение слов с помощью системы исправления ошибок. Однако следует иметь в виду, что система исправления ошибок требует значительно большего количества оборудования, чем система обнаружения ошибок.
Ниже раздельно рассматриваются методы контроля:
◙ цифровых устройств хранения и передачи информации;
◙ цифровых устройств обработки информации.
К устройствам первого типа могут быть отнесены запоминающие устройства, регистры, цепи передачи и другие устройства, в которых информация не должна изменяться. На выходе этих устройств информация та же, что и на входе. К устройствам второго типа относятся устройства, у которых входная информация не совпадает с выходной и в тех случаях, когда ошибки не возникают. Примером могут служить арифметические и логические устройства.
Обнаружение одиночных ошибок в устройствах хранения и передачи информации
Для дальнейшего изложения потребуется понятие кодовое расстояние по Хеммингу. Для двух двоичных слов кодовое расстояние по Хеммингу есть число разрядов, в которых разнятся эти слова. Так, для слов 11011 и 10110 кодовое расстояние d = 3, так как эти слова различаются в трех разрядах (первом, третьем и четвертом).
Пусть используемые слова имеют m разрядов. Для представления информации можно использовать все 2 возможных комбинаций от 00 … 0 до 11 … 1. Тогда для каждого слова найдутся другие такие слова, которые отличаются от данного не более чем в одном разряде. Например, для некоторого слова 1101 можно найти следующие слова: 0101, отличающиеся только в четвертом разряде; 1001, отличающееся только в третьем разряде, и т.д. Таким образом, минимальное кодовое расстояние d
= 1. Обнаружить ошибки в таких словах невозможно. Например, если передавалось слово N
= 1101, а принято N
= 0101, то в принятом слове невозможно обнаружить никаких признаков наличия ошибки (ведь могло бы быть передано и слово N
= 0101). Для того чтобы можно было обнаружить одиночные ошибки (ошибки, возникающие не более чем в одном из разрядов слова), минимальное кодовое расстояние должно удовлетворять условию d
≥ 2. Это условие требует, чтобы любая пара используемых слов отличалась друг от друга не менее чем в двух разрядах. При этом, если возникает ошибка, она образует такую комбинацию цифр, которая не используется для представления слов, т.е. образует так называемую запрещенную комбинацию.
Для получения d = 2 достаточно к словам, использующим любые комбинации из m информационных двоичных разрядов, добавить один дополнительный разряд, называемый контрольным. При этом значение цифры контрольного разряда выбирают таким, чтобы общее число единиц в слове было четным. Например:
![]()
В первом из приведенных примеров число единиц информационной части четно (8), поэтому контрольный разряд должен содержать 0. Во втором примере число единиц в информационной части слова нечетно (7), и для того, чтобы общее число единиц в слове было четным, контрольный разряд должен содержать единицу. Таким способом во все слова вводится определенный признак — четность числа единиц. Принятые слова проверяются на наличие в них этого признака, и, если он оказывается нарушенным (т.е. обнаруживается, что число содержащихся в разрядах слова единиц нечетно), принимается решение, что слово содержит ошибку.
Этот метод позволяет обнаруживать ошибку. Но с его помощью нельзя определить, в каком разряде слова содержится ошибка, т.е. нельзя исправить ее. Кроме того, при этом методе не могут обнаруживаться ошибки четной кратности, т.е. ошибки одновременно в двух, четырех и т.д. разрядах, так как при таком четном числе ошибок не нарушается четность числа единиц в разрядах слова. Однако наряду с одиночными ошибками могут обнаруживаться ошибки, возникающие одновременно в любом нечетном числе разрядов.
На практике часто вместо признака четности используется признак нечетности, т.е. цифра контрольного разряда выбирается такой, чтобы общее число единиц в разрядах слова было нечетным. При этом, если имеет место, например, обрыв линии связи, это обнаруживается, так как принимаемые слова будут иметь 0 во всех разрядах и нарушится принцип нечетности числа единиц.
Рассмотрим схемы, выполняющие операцию проверки на четность (нечетность). Проверка на четность требует суммирования по модулю 2 цифр разрядов слова. Если а , а
,…, а
— цифры разрядов, результат проверки на четность определится выражением р = а
а
а
,…, а
. Если р = 0, то число единиц в разрядах слова четно, в противном случае оно нечетно.
Наиболее просто эта операция реализуется, когда контролируемое слово передается в последовательной форме. Суммирование в этом случае может быть выполнено в последовательности р = …((a а
) а
) … а
. К результату суммирования р
первых разрядов прибавляется цифра очередного поступающего разряда (i + 1), находится результат суммирования (i + 1) разрядов p
= p
а
, и так до тех пор, пока не будут просуммированы цифры всех разрядов.
Из таблицы истинности
Таблица 1

для операции p = p
а
(табл. 1) видно, что лог.0 не должен менять состояния устройства суммирования (p
= p
), лог.1 переводит устройство в новое состояние (p
=
). Эта логика соответствует работе триггера со счетным входом (рис.1).

Рис.1. Триггер со счетным входом.
Действительно, пусть триггер был предварительно установлен в состояние 0, после чего на его синхронизирующий вход стали поступать логические уровни, соответствующие цифрам контролируемого слова. При этом первая лог.1 переведет триггер в состояние 1, вторая лог. 1 вернет триггер в состояние 0 и т.д. Следовательно, после подачи четного числа единиц триггер окажется в состоянии р = 0; при поступлении нечетного числа единиц — в состоянии р = 1.
Если разряды контролируемого слова передаются в параллельной форме, то последовательность действий при проверке на четность может быть следующая:
![]()
Согласно этому выражению для нахождения р вначале попарно суммируются по модулю 2 цифры разрядов контролируемого слова, далее полученные результаты также суммируются попарно и т.д.
Этот принцип вычисления р использован в схеме проверки на четность на рис.2.

Рис.2. Схема проверки на четность.
Цифры разрядов (и их инверсии) поступают на входы элементов (на рис.2 обозначены =1) первого яруса схемы, в которых они попарно суммируются по модулю 2. Полученные результаты попарно суммируются в элементах второго яруса и т.д.
Результат проверки на четность образуется на выходе элемента старшего яруса. Каждый из элементов схемы реализует следующую логическую функцию:
![]()
Построенная по данному выражению схема элемента, выполняющего операцию суммирования по модулю 2, приведена на рис.3.

Рис.3.Схема элемента, выполняющего операцию суммирования по модулю 2.
Определим число ярусов и число элементов в этой схеме проверки на четность. Пусть число разрядов n контролируемого слова составляет целую степень двух. Число элементов в отдельных ярусах а составляет геометрическую прогрессию 1,2,4,8,…, n/2, знаменатель которой q = 2. Для последнего k-то яруса а
= 1, для первого яруса а
=a
q
откуда 2
= n/2 или 2
= n.
Из этого соотношения можно найти число ярусов k. Число суммирующих элементов в схеме равно сумме членов приведенной выше геометрической прогрессии:
![]()
Контроль арифметических операций
В устройствах хранения и передачи информации одиночная ошибка вызывала искажение цифры лишь одного разряда слова. При выполнении арифметических операций одиночная ошибка в получаемом результате может вызвать искажение одновременно группы разрядов. Пусть в суммирующем счетчике хранится число N = 10111 и на вход поступает очередная единица. Произойдет сложение: N
= N
+1. При этом

Пусть в процессе суммирования из-за ошибочной работы устройства не будет передан перенос из 2-го разряда в 3-й. Такая одиночная ошибка приведет к следующему результату:

Сравнивая ошибочный результат N с правильным N
, видим, что они различаются в двух разрядах. Тем не менее считаем, что в N
содержится одиночная ошибка. Во всех случаях, когда ошибочный результат связан с арифметическим прибавлением (или вычитанием) ошибочной единицы к одному из разрядов, имеет место одиночная ошибка. И если ошибочный результат может быть получен из правильного результата путем арифметического суммирования (или вычитания) единицы не менее чем в k разрядах, кратность ошибки равна k.
Для контроля арифметических операций чаще всего используется контроль по модулю q. Этот метод более универсален и годится также для контроля устройств хранения и передачи информации. Сущность метода состоит в следующем.
Контролируемое число N арифметически делится на q, и выделяется остаток r . Остаток вписывается в контрольные разряды числа N вслед за его информационными разрядами. Принятое число N* делится на q и выделяется остаток r
*. Эту операцию выполняет устройство свертки по модулю q (рис.4).

Рис.4. Устройство свертки по модулю q.
Устройство сравнения сравнивает r и r
*, в случае их несовпадения выносит решение о наличии ошибки в принятом слове. Схема на рис. 5 иллюстрирует принцип контроля суммирующего устройства.

Рис.5. Схема, иллюстрирующая принцип контроля суммирующего устройства.
Пусть в результате суммирования чисел N и N
получено N*. Остатки r
и r
также суммируются с выделением остатка r
. Если остаток r
*, полученный от деления числа N* на модуль q, не совпадает с r
, то элемент сравнения сигнализирует о наличии ошибок в работе устройства.
Чаще всего используется q = 3, иногда выбирается q = 7. При увеличении значения q возрастает способность метода к обнаружению ошибок, но одновременно увеличивается объем контролирующего оборудования.
Рассмотрим пример применительно к схеме на рис. 5. Пусть q = 3, N = 32
= 100000
, N
= 29
= 011101
. Соответствующие этим числам остатки равны r
= 2
= 10
, r
= 2
= 10
(при q = 3 остатки могут принимать значения 0, 1, 2 и для их представления в двоичной форме достаточно двух контрольных разрядов). При отсутствии ошибок в работе устройства результат суммирования чисел N* = N
+ N
= 61
= = 111101
, значение свертки по модулю 3 равно r
* = 01
. Суммируя r
и r
и выделяя остаток по модулю 3, получаем r
= 01
. Совпадение r
* = r
указывает на отсутствие ошибок. При наличии ошибок не имело бы места совпадение остатков r
* и r
.
Эффективность контроля по модулю характеризуется данными, приведенными в табл. 2.
Таблица 2

В таблице указано, какую часть всех возможных комбинаций ошибок составляют ошибки, которые не обнаруживаются при контроле по модулю. Как видно из приведенных данных, обнаруживаются все однократные ошибки; доля ошибок высокой кратности, оказывающихся необнаруженными, при модуле 7 меньше, чем при модуле 3. Тем самым эффективность контроля по модулю 7 выше, чем при модуле 3. Однако при контроле по модулю 7 контрольная часть слов содержит три двоичных разряда (вместо двух разрядов при модуле 3) и, кроме того, сложнее схемы формирования остатков (схемы свертки).
В заключение рассмотрим построение схем свертки по модулю 3. Общим для этих схем является следующий метод получения остатка. Каждый разряд числа вносит определенный вклад в формируемый остаток. В табл. 3 приведены остатки от деления на 3 значений, выражаемых единицами отдельных разрядов (т.е. весовых коэффициентов разрядов). Эти остатки для единиц нечетных разрядов равны 1, для четных разрядов они равны 2. Следовательно, для получения остатка от деления на 3 всего числа достаточно просуммировать остатки для единиц отдельных его разрядов и затем для получения суммы найти остаток от деления на 3.
Таблица 3

Например, пусть N = 11001011 ; сумма остатков, создаваемых отдельными разрядами, S=1·2+1·1 + 0·2 + 0·1 + 1·2+0·1+1·2+1·1 = 8; далее, деля 8 на 3, получаем остаток r
= 2.
Схема свертки по модулю 3 для последовательной формы передачи чисел
Схема может быть выполнена в виде двухразрядного счетчика с циклом 3, построенного таким образом, что единицы нечетных разрядов поступающего на вход числа вызывают увеличение содержимого счетчика на единицу, а единицы четных разрядов вызывают увеличение числа в счетчике на два. Функционирование такого счетчика описывается табл. 4.
Здесь b— код, определяющий четность номера очередного разряда числа, поступающего на вход счетчика; примем для четных разрядов b = 0, для нечетных разрядов b = 1.
Таблица 4

Таблица 5

По этой таблице и таблице переходов JK-триггера (табл. 5) построены приведенные на рис. 6 карты, по которым находят логические выражения для входов триггеров ТТ1 и ТТ2 счетчика:


Рис.6. Карты, по которым находят логические выражения для входов триггеров ТТ1 и ТТ2 счетчика.
Представив выражения для J и J
в базисе И-НЕ:
![]()
![]()
получим схему межтриггерных связей на рис.7. Логическая переменная b формируется триггером 3.
Этот триггер переключается тактовыми импульсами (ТИ), следующими с частотой поступления разрядов числа на вход счетчика. Таким образом, в моменты поступления нечетных разрядов триггер 3 устанавливается в состояние 1 и b = 1, в моменты поступления четных разрядов b= 0.

Рис.7. Схема межтриггерных связей.
Схема свертки для параллельной формы представления числа
При параллельной форме представления числа обычно используется пирамидальный способ построения схемы свертки, показанный на рис. 8.

Элементы А первого яруса формируют остатки для пар разрядов числа, выдавая уровень лог. 1 на один из выходов А ,А
,А
в зависимости от значения остатка (0,1,2). В последующих ярусах используются однотипные элементы В, которые формируют остатки по результатам, выдаваемым парой элементов предыдущего яруса. На выходе элемента последнего яруса образуется остаток для всего числа.
Выходы элементов определяются следующими логическими выражениями: для первого яруса

для остальных ярусов

Если число разрядов n = 2 , то число ярусов в схеме свертки равно k, а число элементов составляет (n – 1).
4.4 Понятие качества корректирующего кода
Одной из основных характеристик корректирующего кода является избыточность кода, указывающая степень удлинения кодовой комбинации для достижения определенной корректирующей способности.
Если на каждые m символов выходной последовательности кодера канала приходится k информационных и (m-k) проверочных, то относительная избыточность кода может быть выражена одним из соотношений: Rm = (m-k)/m или Rk = (m-k)/k.
Величина Rk, изменяющаяся от 0 до , предпочтительнее, так как лучше отвечает смыслу понятия избыточности. Коды, обеспечивающие заданную корректирующую способность при минимально возможной избыточности, называют оптимальными.
В связи с нахождением оптимальных кодов оценим, например, возможное наибольшее число Q разрешенных комбинаций m-значного двоичного кода, обладающего способностью исправлять взаимно независимые ошибки кратности до s включительно. Это равносильно отысканию числа комбинаций, кодовое расстояние между которыми не менее d=2s+1.
Общее число различных исправляемых ошибок для каждой разрешающей комбинации составляет
,
где Cmi – число ошибок кратности i.
Каждая из таких ошибок должна приводить к запрещенной комбинации, относящейся к подмножеству данной разрешенной комбинации. Совместно с этой комбинацией подмножество включает комбинаций.
1+
Однозначное декодирование возможно только в том случае, когда названные подмножества не пересекаются. Так как общее число различных комбинаций m-значного двоичного кода составляет 2m, число разрешенных комбинаций не может превышать
Или .
Эта верхняя оценка найдена Хэммингом. Для некоторых конкретных значений кодового расстояния d, соответствующие Q укажем в таблице:
Таблица 4.3.
|
d |
Q |
d |
Q |
|
1 |
|
5 |
|
|
2 |
|
… |
… |
|
3 |
|
… |
… |
|
4 |
|
… |
|
Коды, для которых в приведенном соотношении достигается равенство, называют также плотноупакованными.
Однако не всегда целесообразно стремиться к использованию кодов, близких к оптимальным. Необходимо учитывать другой, не менее важный показатель качества корректирующего кода – сложность технической реализации процессов кодирования и декодирования.
Если информация должна передаваться по медленно действующей и дорогостоящей линии связи, а кодирующее и декодирующее устройства предполагается выполнить на высоконадежных и быстродействующих элементах, то сложность этих устройств не играет существенной роли. Решающим фактором в этом случае является повышение эффективности пользования линией связи, поэтому желательно применение корректирующих кодов с минимальной избыточностью.
Если же корректирующий код должен быть применен в системе, выполненной на элементах, надежность и быстродействие которых равны или близки надежности и быстродействию элементов кодирующей и декодирующей аппаратуры. Это возможно, например, для повышения достоверности воспроизведения информации с запоминающего устройства ЭВМ. Тогда критерием качества корректирующего кода является надежность системы в целом, то есть с учетом возможных искажений и отказов в устройствах кодирования и декодирования. В этом случае часто более целесообразны коды с большей избыточностью, но простые в технической реализации.
4.5 Линейные коды
Самый большой класс разделимых кодов составляют линейные коды, у которых значения проверочных символов определяются в результате проведения линейных операций над определенными информационными символами. Для случая двоичных кодов каждый проверочный символ выбирают таким образом, чтобы его сумма с определенными информационными символами была равна 0. Символ проверочной позиции имеет значение 1, если число единиц информационных разрядов, входящих в данное проверочное равенство, нечетно, и 0, если оно четно. Число проверочных равенств (а следовательно, и число проверочных символов) и номера конкретных информационных разрядов, входящих в каждое из равенств, определяется тем, какие и сколько ошибок должен исправлять или обнаруживать данный код. Проверочные символы могут располагаться на любом месте кодовой комбинации. При декодировании определяется справедливость проверочных равенств. В случае двоичных кодов такое определение сводится к проверкам на четность числа единиц среди символов, входящих в каждое из равенств (включая проверочные). Совокупность проверок дает информацию о том, имеется ли ошибка, а в случае необходимости и о том, на каких позициях символы искажены.
Любой двоичный линейный код является групповым, так как совокупность входящих в него кодовых комбинаций образует группу. Уточнение понятий линейного и группового кода требует ознакомления с основами линейной алгебры.
4.6 Математическое введение к линейным кодам
Основой математического описания линейных кодов является линейная алгебра (теория векторных пространств, теория матриц, теория групп). Кодовые комбинации рассматривают как элементы множества, например, кодовые комбинации двоичного кода принадлежат множеству положительных двоичных чисел.
Множества, для которых определены некоторые алгебраические операции, называют алгебраическими системами. Под алгебраической операцией понимают однозначные сопоставление двум элементам некоторого третьего элемента по определенным правилам. Обычно основную операцию называют сложением (обозначают a+b=c) или умножением (обозначают a*b=c), а обратную ей – вычитанием или делением, даже, если эти операции проводятся не над числами и не идентичны соответствующим арифметическим операциям.
Рассмотрим кратко основные алгебраические системы, которые широко используют в теории корректирующих кодов.
Группой множество элементов, в котором определена одна основная операция и выполняются следующие аксиомы:
-
В результате применения операции к любым двум элементам группы образуется элемент этой же группы (требование замкнутости).
-
Для любых трех элементов группы a,b,c удовлетворяется равенство (a+b)+c=a+(b+c), если основная операция – сложение, и равенство a(bc)=(ab)c, если основная операция – умножение.
-
В любой группе Gn существует однозначно определенный элемент, удовлетворяющий при всех значениях a из Gn условию а+0=0+а, если основная операция – сложение, или условию а*1=1*а=а, если основная операция – умножение. В первом случае этот элемент называют нулем и обозначают символом 0, а во втором – единицей и обозначают символом 1.
-
Всякий элемент а группы обладает элементом, однозначно определенным уравнением а+(-а)=-а+а=0, если основная операция – сложение, или уравнением а*а-1= а-1*а=1, если основная операция – умножение.
В первом случае этот элемент называют противоположным и обозначают (-а), а во втором – обратным и обозначают а-1.
Если операция, определенная в группе, коммутативна, то есть справедливо равенство a+b=b+a (для группы по сложению) или равенство a*b=b*a (для группы по умножению), то группу называют коммутативной или абелевой.
Группу, состоящую из конечного числа элементов, называют порядком группы.
Чтобы рассматриваемое нами множество n-разрядных кодовых комбинаций было конечной группой, при выполнении основной операции число разрядов в результирующей кодовой комбинации не должно увеличиваться. Этому условию удовлетворяет операция символического поразрядного сложения по заданному модулю q (q – простое число), при которой цифры одинаковых разрядов элементов группы складываются обычным порядком, а результатом сложения считается остаток от деления полученного числа по модулю q.
При рассмотрении двоичных кодов используется операция сложения по модулю 2. Результатом сложения цифр данного разряда является0, если сумма единиц в нем четная, и 1, если сумма единиц в нем нечетная, например,
Выбранная нами операция коммутативна, поэтому рассматриваемые группы будут абелевыми.
Нулевым элементом является комбинация, состоящая из одних нулей. Противоположным элементом при сложении по модулю 2 будет сам заданный элемент. Следовательно, операция вычитания по модулю 2 тождественна операции сложения.
Пример24. Определить, являются ли группами следующие множества кодовых комбинаций:
-
0001, 0110, 0111, 0011;
-
0000, 1101, 1110, 0111;
-
000, 001, 010, 011, 100, 101, 110, 111.
Решение: Первое множество не является группой, так как не содержит нулевого элемента.
Второе множество не является группой, так как не выполняется условие замкнутости, например, сумма по модулю 2 комбинаций 1101 и 1110 дает комбинацию 0011, не принадлежащую исходному множеству.
Третье множество удовлетворяет всем перечисленным условиям и является группой.
Подмножества группы, являющиеся сами по себе группами относительно операции, определенной в группе, называют подгруппами. Например, подмножество трехразрядных кодовых комбинаций: 000, 001, 010, 011 образуют подгруппу указанной в примере группы трехразрядных кодовых комбинаций.
Пусть в абелевой группе Gn задана определенная подгруппа А. Если В – любой, не входящий в А элемент из Gn, то суммы (по модулю 2) элементов В с каждым из элементов подгруппы А образуют определенный класс группы Gn по подгруппе А, порождаемый элементом В.
Элемент В, естественно, содержится в этом смежном классе, так как любая подгруппа содержит нулевой элемент. Взяв последовательно некоторые элементы Bj группы, не вошедшие в уже образованные смежные классы, можно разложить всю группу на смежные классы по подгруппе А.
Элементы Bj называют образующими элементами смежных классов по подгруппам.
В таблице разложения, иногда называемой групповой таблицей, образующие элементы обычно располагают в крайнем левом столбце, причем крайним левым элементом подгруппы является нулевой элемент.
Пример25: Разложить группу трехразрядных двоичных кодовых комбинаций по подгруппе двухразрядных кодовых комбинаций.
Решение: Разложение выполняют в соответствии с таблицей:
Таблица 4.4.
|
A1=0 |
A2 |
A3 |
A4 |
|
000 |
001 |
010 |
011 |
|
B1 |
A2B1 |
A3B1 |
A4B1 |
|
100 |
101 |
110 |
111 |
Пример26: Разложить группу четырехразрядных двоичных кодовых комбинаций по подгруппе двухразрядных кодовых комбинаций.
Решение: Существует много вариантов разложения в зависимости от того, какие элементы выбраны в качестве образующих смежных классов.
Один из вариантов:
Таблица 4.5.
|
A1=0 |
A2 |
A3 |
A4 |
|
0000 |
0001 |
0110 |
0111 |
|
B1 0100 |
A2B1 0101 |
A3B1 0110 |
A4B1 0111 |
|
B2 1010 |
A2B2 1011 |
A3B2 1000 |
A4B2 1001 |
|
B3 1100 |
A2B3 1101 |
A3B3 1110 |
A4B3 1111 |
Кольцом называют множество элементов R, на котором определены две операции (сложение и умножение), такие, что
-
множество R является коммутативной группой по отношению;
-
произведение элементов аR и bR есть элемент R (замкнутость по отношению и умножению);
-
для любых трех элементов a,b,c из R справедливо равенство a(bc)=(ab)c (ассоциативный закон для умножения);
-
для любых трех элементов a,b,c из R выполняются соотношения a(b+c)=ab+ac и (b+c)a=ba+ca (дистрибутивные законы);
Если для любых двух элементов кольца справедливо соотношение ab=ba, то кольцо называют коммутативным.
Кольцо может не иметь единичного элемента по умножению и обратных элементов.
Примером кольца может служить множество действительных четных целых чисел относительно обычных операций сложения и умножения.
Полем F называют множество, по крайней мере, двух элементов, в котором определены две операции – сложение и умножение, и выполняются следующие аксиомы:
-
множество элементов образуют коммутативную группу по сложению;
-
множество ненулевых элементов образуют коммутативную группу по умножению;
-
для любых трех элементов множества a,b,c выполняется соотношение (дистрибутивный закон) a(b+c)=ab+ac.
Поле F является, следовательно, коммутативным кольцом с единичным элементом по умножению, в котором каждый ненулевой элемент обладает обратным элементом. Примером поля может служить множество всех действительных чисел.
Поле GF(P), состоящее из конечного числа элементов Р, называют конечным полем или полем Галуа. Для любого числа Р, являющегося степенью простого числа q, существует поле, насчитывающее р элементов. Например, совокупность чисел по модулю q, если q — простое число, является полем.
Поле не может содержать менее двух элементов, поскольку в нем должны быть по крайней мере единичный элемент относительно операции сложения (0) и единичный элемент относительно операции умножения (1). Поле, включающее только 0 и 1, обозначим GF(2). Правила сложения и умножения в поле с двумя элементами следующие:
|
+ |
0 |
1 |
× |
0 |
1 |
|
|
0 |
0 |
1 |
0 |
0 |
0 |
|
|
1 |
1 |
0 |
1 |
0 |
1 |
Рис. 4.5 Правила сложения и умножения в поле с двумя элементами
Двоичные кодовые комбинации, являющиеся упорядоченными последовательностями из n Элементов поля GF(2), рассматриваются в теории кодирования как частный случай последовательностей из n элементов поля GF(P). Такой подход позволяет строить и анализировать коды с основанием, равным степени простого числа. В общем случае суммой кодовых комбинаций Aj и Ai называют комбинацию Af = Ai + Aj, в которой любой символ Ak (k=1,2,…,n) представляет собой сумму k-х символов комбинаций, причем суммирование производится по правилам поля GF(P). При этом вся совокупность n-разрядных кодовых комбинаций оказывается абелевой группой.
В частном случае, когда основанием кода является простое число q, правило сложения в поле GF(q) совпадает с правилом сложения по заданному модулю q.
4.7 Линейный код как пространство линейного векторного пространства
В рассмотренных алгебраических системах (группа, кольцо, поле) операции относились к единому классу математических объектов (элементов). Такие операции называют внутренними законами композиции элементов.
В теории кодирования широко используются модели, охватывающие два класса математических объектов (например, L и ). Помимо внутренних законов композиции в них задаются внешние законы композиции элементов, по которым любым двум элементам и аL ставится в соответствие элемент сL.
Линейным векторным пространством над полем элементов F (скаляров) называют множество элементов V (векторов), если для него выполняются следующие аксиомы:
-
множество V является коммутативной группой относительно операции сложения;
-
для любого вектора v изV и любого скаляра с из F определено произведение cv, которое содержится в V (замкнутость по отношению умножения на скаляр);
-
если u и v из V векторы, а с и d из F скаляры, то справедливо с(с+v)=cu+cv; (c+d)v=cv+dv (дистрибутивные законы);
-
если v-вектор, а с и d-скаляры, то (cd)v=c(dv) и 1*v=v
(ассоциативный закон для умножения на скаляр).
Выше было определено правило поразрядного сложения кодовых комбинаций, при котором вся их совокупность образует абелеву группу. Определим теперь операцию умножения последовательности из n элементов поля GF(P) (кодовой комбинации) на элемент поля ai GF(P)аналогично правилу умножения вектора на скаляр: ai(a1, a2, … , an)= (ai a1, ai a2, … , ai an)
(умножение элементов производится по правилам поля GF(P)).
Поскольку при выбранных операциях дистрибутивные законы и ассоциативный закон (п.п.3.4) выполняются, все множество n-разрядных кодовых комбинаций можно рассматривать как векторное линейное пространство над полем GF(2) (т.е. 0 и 1). Сложение производят поразрядно по модулю 2. При умножении вектора на один элемент поля (1) он не изменяется, а умножение на другой (0) превращает его в единичный элемент векторного пространства, обозначаемый символом 0=(0 0…0).
Если в линейном пространстве последовательностей из n элементов поля GF(P) дополнительно задать операцию умножения векторов, удовлетворяющую определенным условиям (ассоциативности, замкнутости, билинейности по отношению к умножению на скаляр), то вся совокупность n-разрядных кодовых комбинаций превращается в линейную коммутативную алгебру над полем коэффициентов GF(P).
Подмножество элементов векторного пространства, которое удовлетворяет аксиомам векторного пространства, называют подпространством.
Линейным кодом называют множество векторов, образующих подпространства векторного пространства всех n-разрядных кодовых комбинаций над полем GF(P).
В случае двоичного кодирования такого подпространства комбинаций над полем GF(2) образует любая совокупность двоичных кодовых комбинаций, являющаяся подгруппой группы всех n-разрядных двоичных кодовых комбинаций. Поэтому любой двоичный линейный код является групповым.
4.8 Построение двоичного группового кода
Построение конкретного корректирующего кода производят, исходя из требуемого объема кода Q, т. е. необходимого числа передаваемых команд или дискретных значений измеряемой величины и статистических данных о наиболее вероятных векторах ошибок в используемом канале связи.
Вектором ошибки называют n-разрядную двоичную последовательность, имеющую единицы в разрядах, подвергшихся искажению, и нули во всех остальных разрядах. Любую искаженную кодовую комбинацию можно рассматривать теперь как сумму (или разность) но модулю 2 исходной разрешенной кодовой комбинации и вектора ошибки.
Исходя из неравенства 2k – l Q (нулевая комбинация часто не используется, так как не меняет состояния канала связи), определяем число информационных разрядов k, необходимое для передачи заданного числа команд обычным двоичным кодом.
Каждой из 2k — 1 ненулевых комбинаций k -разрядного безызбыточного кода нам необходимо поставить в соответствие комбинацию из п символов. Значения символов в п – k проверочных разрядах такой комбинации устанавливаются в результате суммирования по модулю 2 значений символов в определенных информационных разрядах.
Поскольку множество 2k комбинаций информационных символов (включая нулевую) образует подгруппу группы всех n-разрядных комбинаций, то и множество 2k n-разрядных комбинаций, полученных по указанному правилу, тоже является подгруппой группы n-разрядных кодовых комбинаций. Это множество разрешенных кодовых комбинаций и будет групповым кодом.
Нам надлежит определить число проверочных разрядов и номера информационных разрядов, входящих в каждое из равенств для определения символов в проверочных разрядах.
Разложим группу 2n всех n-разрядных комбинаций на смежные классы по подгруппе 2k разрешенных n-разрядных кодовых комбинаций, проверочные разряды в которых еще не заполнены. Помимо самой подгруппы кода в разложении насчитывается 2n—k – 1 смежных классов. Элементы каждого класса представляют собой суммы по модулю 2 комбинаций кода и образующих элементов данного класса. Если за образующие элементы каждого класса принять те наиболее вероятные для заданного канала связи вектора ошибок, которые должны быть исправлены, то в каждом смежном классе сгруппируются кодовые комбинации, получающиеся в результате воздействия на все разрешенные комбинации определенного вектора ошибки. Для исправления любой полученной на выходе канала связи кодовой комбинации теперь достаточно определить, к какому классу смежности она относится. Складывая ее затем (по модулю 2) с образующим элементом этого смежного класса, получаем истинную комбинацию кода.
Ясно, что из общего числа 2n – 1 возможных ошибок групповой код может исправить всего 2n—k – 1 разновидностей ошибок по числу смежных классов.
Чтобы иметь возможность получить информацию о том, к какому смежному классу относится полученная комбинация, каждому смежному классу должна быть поставлена в соответствие некоторая контрольная последовательность символов, называемая опознавателем (синдромом).
Каждый символ опознавателя определяют в результате проверки на приемной стороне справедливости одного из равенств, которые мы составим для определения значений проверочных символов при кодировании.
Ранее указывалось, что в двоичном линейном коде значения проверочных символов подбирают так, чтобы сумма по модулю 2 всех символов (включая проверочный), входящих в каждое из равенств, равнялась нулю. В таком случае число единиц среди этих символов четное. Поэтому операции определения символов опознавателя называют проверками на четность. При отсутствии ошибок в результате всех проверок на четность образуется опознаватель, состоящий из одних нулей. Если проверочное равенство не удовлетворяется, то в соответствующем разряде опознавателя появляется единица. Исправление ошибок возможно лишь при наличии взаимно однозначного соответствия между множеством опознавателей и множеством смежных классов, а следовательно, и множеством подлежащих исправлению векторов ошибок.
Таким образом, количество подлежащих исправлению ошибок является определяющим для выбора числа избыточных символов п – k . Их должно быть достаточно для того, чтобы обеспечить необходимое число опознавателей. Если, например, необходимо исправить все одиночные независимые ошибки, то исправлению подлежат п ошибок:
000…01
000…10
……….
010…00
100…00
Различных ненулевых опознавателей должно быть не менее п. Необходимое число проверочных разрядов, следовательно, должно определяться из соотношения
2n—k -1 n или 2n—k -1
Если необходимо исправить не только все единичные, но и все двойные независимые ошибки, соответствующее неравенство принимает вид
2n—k-l
+
В общем случае для исправления всех независимых ошибок кратности до s включительно получаем
2n—k-l
+
+…+
Стоит подчеркнуть, что в приведенных соотношениях указывается теоретический предел минимально возможного числа проверочных символов, который далеко не во всех случаях можно реализовать практически. Часто проверочных символов требуется больше, чем следует из соответствующего равенства.
Одна из причин этого выяснится при рассмотрении процесса сопоставления каждой подлежащей исправлению ошибки с ее опознавателем.
4.8.1 Составление таблицы опознавателей
Начнем для простоты с установления опознавателей для случая исправления одиночных ошибок. Допустим, что необходимо закодировать 15 команд. Тогда требуемое число информационных разрядов равно четырем. Пользуясь соотношением 2n—k — 1= п, определяем общее число разрядов кода, а следовательно, и число ошибок, подлежащих исправлению (n = 7). Три избыточных разряда позволяют использовать в качестве опознавателей трехразрядные двоичные последовательности.
В данном случае ненулевые последовательности в принципе могут быть сопоставлены с подлежащими исправлению ошибками в любом порядке. Однако более целесообразно сопоставлять их с ошибками в разрядах, начиная с младшего, в порядке возрастания двоичных чисел (табл. 4.6).
Таблица 4.6.
|
Векторы ошибок |
Опознаватели |
Векторы ошибок |
Опознаватели |
|
0000001 |
001 |
0010000 |
101 |
|
0000010 |
010 |
0100000 |
110 |
|
0000100 |
011 |
1000000 |
111 |
|
0001000 |
100 |
При таком сопоставлении каждый опознаватель представляет собой двоичное число, указывающее номер разряда, в котором произошла ошибка.
Коды, в которых опознаватели устанавливаются по указанному принципу, известны как коды Хэмминга.
Возьмем теперь более сложный случай исправления одиночных и двойных независимых ошибок. В качестве опознавателей одиночных ошибок в первом и втором разрядах можно принять, как и ранее, комбинации 0…001 и 0…010.
Однако в качестве опознавателя одиночной ошибки в третьем разряде комбинацию 0…011 взять нельзя. Такая комбинация соответствует ошибке одновременно в первом и во втором разрядах, а она также подлежит исправлению и, следовательно, ей должен соответствовать свой опознаватель 0…011.
В качестве опознавателя одиночной ошибки в третьем разряде можно взять только трехразрядную комбинацию 0…0100, так как множество двухразрядных комбинаций уже исчерпано. Подлежащий исправлению вектор ошибки 0…0101 также можно рассматривать как результат суммарного воздействия двух векторов ошибок 0…0100 и 0…001 и, следовательно, ему должен быть поставлен в соответствие опознаватель, представляющий собой сумму по модулю 2 опознавателей этих ошибок, т.е. 0…0101.
Аналогично находим, что опознавателем вектора ошибки 0…0110 является комбинация 0…0110.
Определяя опознаватель для одиночной ошибки в четвертом разряде, замечаем, что еще не использована одна из трехразрядных комбинаций, а именно 0…0111. Однако, выбирая в качестве опознавателя единичной ошибки в i-м разряде комбинацию с числом разрядов, меньшим i, необходимо убедиться в том, что для всех остальных подлежащих исправлению векторов ошибок, имеющих единицы в i-м и более младших разрядах, получатся опознаватели, отличные от уже использованных. В нашем случае подлежащими исправлению векторами ошибок с единицами в четвертом и более младших разрядах являются: 0…01001, 0…01010, 0…01100.
Если одиночной ошибке в четвертом разряде поставить в соответствие опознаватель 0…0111, то для указанных векторов опознавателями должны были бы быть соответственно
0…0111
0…0111
0…0111
0…0001 0…0010 0…0100
_______ ________ _______
0…0110 0…0101 0…0011
Однако эти комбинации уже использованы в качестве опознавателей других векторов ошибок, а именно: 0…0110, 0…0101, 0…0011.
Следовательно, во избежание неоднозначности при декодировании в качестве опознавателя одиночной ошибки в четвертом разряде следует взять четырехразрядную комбинацию 1000. Тогда для векторов ошибок
0…01001, 0…01010, 0…01100
опознавателями соответственно будут:
0…01001, 0…01010, 0…01100.
Аналогично можно установить, что в качестве опознавателя одиночной ошибки в пятом разряде может быть выбрана не использованная ранее четырехразрядная комбинация 01111.
Действительно, для всех остальных подлежащих исправлению векторов ошибок с единицей в пятом и более младших разрядах получаем опознаватели, отличающиеся от ранее установленных:
Векторы ошибок Опознаватели
0…010001 0…01110
0…010010 0…01101
0…010100 0…01011
0…011000 0…00111
Продолжая сопоставление, можно получить таблицу опознавателей для векторов ошибок данного типа с любым числом разрядов. Так как опознаватели векторов ошибок с единицами в нескольких разрядах устанавливаются как суммы по модулю 2 опознавателей одиночных ошибок в этих разрядах, то для определения правил построения кода и составления проверочных равенств достаточно знать только опознаватели одиночных ошибок в каждом из разрядов. Для построения кодов, исправляющих двойные независимые ошибки, таблица таких опознавателей определена с помощью вычислительной машины вплоть до 29-го разряда [Теория кодирования. Сборник. – М.:Мир, 1964]. Опознаватели одиночных ошибок в первых пятнадцати разрядах приведены в табл. 4.7.
По тому же принципу аналогичные таблицы определены и для ошибок других типов, например для тройных независимых ошибок, пачек ошибок в два и три символа.
4.8.2 Определение проверочных равенств
Итак, для любого кода, имеющего целью исправлять наиболее вероятные векторы ошибок заданного канала связи (взаимно независимые ошибки или пачки ошибок), можно составить таблицу опознавателей одиночных ошибок в каждом из разрядов. Пользуясь этой таблицей, нетрудно определить, символы каких разрядов должны входить в каждую из проверок на четность.
Таблица 4.7.
|
Номер разряда |
Опознаватель |
Номер разряда |
Опознаватель |
Номер разряда |
Опознаватель |
|
1 |
00000001 |
6 |
00010000 |
11 |
01101010 |
|
2 |
00000010 |
7 |
00100000 |
12 |
10000000 |
|
3 |
00000100 |
8 |
00110011 |
13 |
10010110 |
|
4 |
00001000 |
9 |
01000000 |
14 |
10110101 |
|
5 |
00001111 |
10 |
01010101 |
15 |
11011011 |
Рассмотрим в качестве примера опознаватели для кодов, предназначенных исправлять единичные ошибки (табл. 4.8).
Таблица 4.8.
|
Номер разрядов |
Опознаватель |
Номер разрядов |
Опознаватель |
Номер разрядов |
Опознаватель |
|
1 |
0001 |
7 |
0111 |
12 |
1100 |
|
2 |
0010 |
8 |
1000 |
13 |
1101 |
|
3 |
0011 |
9 |
1001 |
14 |
1110 |
|
4 |
0100 |
10 |
1010 |
15 |
1111 |
|
5 |
0101 |
11 |
1011 |
16 |
10000 |
|
6 |
0110 |
В принципе можно построить код, усекая эту таблицу на любом уровне. Однако из таблицы видно, что оптимальными будут коды (7, 4), (15, 11), где первое число равно n, а второе k, и другие, которые среди кодов, имеющих одно и то же число проверочных символов, допускают наибольшее число информационных символов.
Усечем эту таблицу на седьмом разряде и найдем номера разрядов, символы которых должны войти в каждое из проверочных равенств.
Предположим, что в результате первой проверки на четность для младшего разряда опознавателя будет получена единица. Очевидно, это может быть следствием ошибки в одном из разрядов, опознаватели которых в младшем разряде имеют единицу. Следовательно, первое проверочное равенство должно включать символы 1, 3, 5 и 7-го разрядов: a1 a3
a5
a7=0.
Единица во втором разряде опознавателя может быть следствием ошибки в разрядах, опознаватели которых имеют единицу во втором разряде. Отсюда второе проверочное равенство должно иметь вид a2 a3
a6
a7= 0 .
Аналогично находим и третье равенство: a4 a5
a6
a7= 0 .
Чтобы эти равенства при отсутствии ошибок удовлетворялись для любых значений информационных символов в кодовой комбинации, в нашем распоряжении имеется три проверочных разряда. Мы должны так выбрать номера этих разрядов, чтобы каждый из них входил только в одно из равенств. Это обеспечит однозначное определение значений символов в проверочных разрядах при кодировании. Указанному условию удовлетворяют разряды, опознаватели которых имеют по одной единице. В нашем случае это будут первый, второй и четвертый разряды.
Таким образом, для кода (7, 4), исправляющего одиночные ошибки, искомые правила построения кода, т. е. соотношения, реализуемые в процессе кодирования, принимают вид:
a1=a3 a5
a7,
a2=a3 a6
a7, (4.1)
a4=a5 a6
a7 .
Поскольку построенный код имеет минимальное хэммингово расстояние dmin = 3, он может использоваться с целью обнаружения единичных и двойных ошибок. Обращаясь к табл. 4.8, легко убедиться, что сумма любых двух опознавателей единичных ошибок дает ненулевой опознаватель, что и является признаком наличия ошибки.
Пример 27. Построим групповой код объемом 15 слов, способный исправлять единичные и обнаруживать двойные ошибки.
В соответствии с dи 0 min r+s+1код должен обладать минимальным хэмминговым расстоянием, равным 4. Такой код можно построить в два этапа. Сначала строим код заданного объема, способный исправлять единичные ошибки. Это код Хэмминга (7, 4). Затем добавляем еще один проверочный разряд, который обеспечивает четность числа единиц в разрешенных комбинациях.
Таким образом, получаем код (8, 4). В процессе кодирования реализуются соотношения:
a1=a3 a5
a7,
a2=a3 a6
a7,
a4=a5 a6
a7 .
a8=a1 a2
a3
a4
a5
a6
a7,
Обозначив синдром кода (7, 4) через S1, результат общей проверки на четность — через S2(S2 = ) и пренебрегая возможностью возникновения ошибок кратности 3 и выше, запишем алгоритм декодирования:
при S1= 0 и S2= 0 ошибок нет;
при S1= 0 и S2= 1 ошибка в восьмом разряде;
при S1 0 и S2= 0 двойная ошибка (коррекция блокируется, посылается запрос повторной передачи);
при S1 0 и S2= 1 одиночная ошибка (осуществляется ее исправление).
Пример 28. Используя табл. 4.8, составим правила построения кода (8,2), исправляющего все одиночные и двойные ошибки.
Усекая табл. 4.7 на восьмом разряде, найдем следующие проверочные равенства:
a1 a5
a8=0,
a2 a5
a8=0,
a3 a5=0,
a4 a5=0,
a6 a8=0,
a7 a8=0.
Соответственно правила построения кода выразим соотношениями
a1=a5 a8 (4.2 а)
a2=a5 a8 (4.2 б)
a3=a5 (4.2 в)
a4=a5 (4.2 г)
a6=a8 (4.2 д)
a7=a8 (4.2 е)
Отметим, что для построенного кода dmin = 5, и, следовательно, он может использоваться для обнаружения ошибок кратности от 1 до 4.
Соотношения, отражающие процессы кодирования и декодирования двоичных линейных кодов, могут быть реализованы непосредственно с использованием сумматоров по модулю два. Однако декодирующие устройства, построенные таким путем для кодов, предназначенных исправлять многократные ошибки, чрезвычайно громоздки. В этом случае более эффективны другие принципы декодирования.
4.8.3 Мажоритарное декодирование групповых кодов
Для линейных кодов, рассчитанных на исправление многократных ошибок, часто более простыми оказываются декодирующие устройства, построенные по мажоритарному принципу. Это метод декодирования называют также принципом голосования или способом декодирования по большинству проверок. В настоящее время известно значительное число кодов, допускающих мажоритарную схему декодирования, а также сформулированы некоторые подходы при конструировании таких кодов.
Мажоритарное декодирование тоже базируется на системе проверочных равенств. Система последовательно может быть разрешена относительно каждой из независимых переменных, причем в силу избыточности это можно сделать не единственным способом.
Любой символ аi выражается d (минимальное кодовое расстояние) различными независимыми способами в виде линейных комбинаций других символов. При этом может использоваться тривиальная проверка аi = аi. Результаты вычислений подаются на соответствующий этому символу мажоритарный элемент. Последний представляет собой схему, имеющую d входов и один выход, на котором появляется единица, когда возбуждается больше половины его входов, и нуль, когда возбуждается число таких входов меньше половины. Если ошибки отсутствуют, то проверочные равенства не нарушаются и на выходе мажоритарного элемента получаем истинное значение символа. Если число проверок d 2s+ 1 и появление ошибки кратности s и менее не приводит к нарушению более s проверок, то правильное решение может быть принято по большинству неискаженных проверок. Чтобы указанное условие выполнялось, любой другой символ aj(j
i) не должен входить более чем в одно проверочное равенство. В этом случае мы имеем дело с системой разделенных проверок.
Пример 29. Построим систему разделенных проверок для декодирования информационных символов рассмотренного ранее группового кода (8,2).
Поскольку код рассчитан на исправление любых единичных и двойных ошибок, число проверочных равенств для определения каждого символа должно быть не менее 5. Подставив в равенства (4.2 а) и (4.2 б) значения а8, полученные из равенств (4.2 д) и (4.2 е) и записав их относительно a5 совместно с равенствами (4.2 в) и (4.2 г) и тривиальным равенством a5 = a5, получим следующую систему разделенных проверок для символа a5:
a5 = a6 a1,
a5 = a7 a2,
а5 = а3,
а5 = a4,
а5 = а5.
Для символа a8 систему разделенных проверок строим аналогично:
a8 = a3 a1,
a8 = a4 a2,
a8 = а6,
a8 = a7,
a8 = а8.
4.8.4 Матричное представление линейных кодов
Матрицей размерности l n называют упорядоченное множество l
n элементов, расположенных в виде прямоугольной таблицы с l строками и n столбцами:
Транспонированной матрицей к матрице А называют матрицу, строками которой являются столбцы, а столбцами строки матрицы А:
Матрицу размерности n n называют квадратной матрицей порядка n. Квадратную матрицу, у которой по одной из диагоналей расположены только единицы, а все остальные элементы равны нулю, называют единичной матрицей I. Суммой двух матриц А
|аij| и В
|bij| размерности l
n называют матрицу размерности l
n:
А + В |аij| + |bij|
|аij + bij|.
Умножение матрицы А |аij| размерности l
n на скаляр с дает матрицу размерности l
n: сА
c |аij|
|c аij|.
Матрицы А |аij| размерности l
n и В
|bjk| размерности n
m могут быть перемножены, причем элементами cik матрицы — произведения размерности l
m являются суммы произведений элементов l-й строки матрицы А на соответствующие элементы k-го столбца матрицы В:
cik =
В теории кодирования элементами матрицы являются элементы некоторого поля GF(P), а строки и столбцы матрицы рассматриваются как векторы. Сложение и умножение элементов матриц осуществляется по правилам поля GF(P).
Пример 30. Вычислим произведение матриц с элементами из поля GF (2):
Элементы cik матрицы произведения М = M1M2 будут равны:
c11 = (011) (101) = 0 + 0 + 1 = 1
c12 = (011) (110) = 0 + 1 + 0 = 1
c13 = (011) (100) = 0 + 0 + 0 = 0
c21 = (100) (101) = 1 + 0 + 0 = 1
c22 = (100) (110) = 1 + 0 + 0 = 1
c23 = (100) (100) = 1 + 0 + 0 = 1
c31 = (001) (101) = 0 + 0 + 1 = 1
c32 = (001) (110) = 0 + 0 + 0 = 0
c33 = (001) (100) = 0 + 0 + 0 = 0
Следовательно,
Зная закон построения кода, определим все множество разрешенных кодовых комбинаций. Расположив их друг под другом, получим матрицу, совокупность строк которой является подпространством векторного пространства n-разрядных кодовых комбинаций (векторов) из элементов поля GF(P). В случае двоичного (n, k)-кода матрица насчитывает n столбцов и 2k—1 строк (исключая нулевую). Например, для рассмотренного ранее кода (8,2), исправляющего все одиночные и двойные ошибки, матрица имеет вид
При больших n и k матрица, включающая все векторы кода, слишком громоздка. Однако совокупность векторов, составляющих линейное пространство разрешенных кодовых комбинаций, является линейно зависимей, так как часть векторов может быть представлена в виде линейной комбинации некоторой ограниченной совокупности векторов, называемой базисом пространства.
Совокупность векторов V1, V2, V3, …, Vn называют линейно зависимой, когда существуют скаляры с1,..сn (не все равные нулю), при которых
c1V1 + c2V2+…+ cnVn= 0
В приведенной матрице, например, третья строка представляет собой суммы по модулю два первых двух строк. Для полного определения пространства разрешенных кодовых комбинаций линейного кода достаточно записать в виде матрицы только совокупность линейно независимых векторов. Их число называют размерностью векторного пространства.
Среди 2k – 1 ненулевых двоичных кодовых комбинаций — векторов их только k. Например, для кода (8,2)
Матрицу, составленную из любой совокупности векторов линейного кода, образующей базис пространства, называют порождающей (образующей) матрицей кода.
Если порождающая матрица содержит k строк по n элементов поля GF(q), то код называют (n, k)-кодом. В каждой комбинации (n, k)-кода k информационных символов и n – k проверочных. Общее число разрешенных кодовых комбинаций (исключая нулевую) Q = qk-1.
Зная порождающую матрицу кода, легко найти разрешенную кодовую комбинацию, соответствующую любой последовательности Аki из k информационных символов.
Она получается в результате умножения вектора Аki на порождающую матрицу Мn,k:
Аni = Аki • Мn,k .
Найдем, например, разрешенную комбинацию кода (8,2), соответствующую информационным символам a5=l, a8 = 1:
.
Пространство строк матрицы остается неизменным при выполнении следующих элементарных операций над строками: 1) перестановка любых двух строк; 2) умножение любой строки на ненулевой элемент поля; 3) сложение какой-либо строки с произведением другой строки на ненулевой элемент поля, а также при перестановке столбцов.
Если образующая матрица кода M2 получена из образующей матрицы кода M1 с помощью элементарных операций над строками, то обе матрицы порождают один и тот же код. Перестановка столбцов образующей матрицы кода приводит к образующей матрице эквивалентного кода. Эквивалентные коды весьма близки по своим свойствам. Корректирующая способность таких кодов одинакова.
Для анализа возможностей линейного (n, k)-кода, а также для упрощения процесса кодирования удобно, чтобы порождающая матрица (Мn,k) состояла из двух матриц: единичной матрицы размерности k k и дописываемой справа матрицы-дополнения (контрольной подматрицы) размерности k • (n – k), которая соответствует n – k проверочным разрядам:
(4.3)
Разрешенные кодовые комбинации кода с такой порождающей матрицей отличаются тем, что первые k символов в них совпадают с исходными информационными, а проверочными оказываются (n — k) последних символов. Действительно, если умножим вектор-строку Ak,i = = (a1 a2…ai…ak) на матрицу Мn,k= [IkPk,n—k], получим вектор
An,i = (a1a2…ai…ak…ak+1…aj…an),
где проверочные символы аj(k +1 j
n) являются линейными комбинациями информационных:
(4.4)
Коды, удовлетворяющие этому условию, называют систематическими. Для каждого линейного кода существует эквивалентный систематический код. Как следует из (4.3), (4.4), информацию о способе построения такого кода содержит матрица-дополнение. Если правила построения кода (уравнения кодирования) известны, то значения символов любой строки матрицы-дополнения получим, применяя эти правила к символам соответствующей строки единичной матрицы.
Пример 31. Запишем матрицы Ik, Рk,n—k_и Mn,k для двоичного кода (7,4).
Единичная матрица на четыре разряда имеет вид
Один из вариантов матрицы дополнения можно записать, используя соотношения (4.1)
Тогда для двоичного кода Хэммннга имеем:
Запишем также матрицу для систематического кода (7,4):
В свою очередь, по заданной матрице-дополнению Pk,n-k можно определить равенства, задающие правила построения кода. Единица в первой строке каждого столбца указывает на то, что в образовании соответствующего столбцу проверочного разряда участвовал первый информационный разряд. Единица в следующей строке любого столбца говорит об участии в образовании проверочного разряда второго информационного разряда и т, д.
Так как матрица-дополнение содержит всю информацию о правилах построения кода, то систематический код с заданными свойствами можно синтезировать путем построения соответствующей матрицы-дополнения.
Так как минимальное кодовое расстояние d для линейного кода равно минимальному весу его ненулевых векторов, то в матрицу-дополнение должны быть включены такие k строк, которые удовлетворяли бы следующему общему условию: вектор-строка образующей матрицы, получающаяся при суммировании любых l (1 l
k) строк, должна содержать не менее d – l отличных от нуля символов.
Действительно, при выполнении указанного условия любая разрешенная кодовая комбинация, полученная суммированием l строк образующей матрицы, имеет не менее d ненулевых символов, так как l ненулевых символов она всегда содержит в результате суммирования строк единичной матрицы. Синтезируем таким путем образующую матрицу двоичного систематического кода (7,4) с минимальным кодовым расстоянием d = 3. В каждой вектор-строке матрицы-дополнения согласно сформулированному условию (при l=1) должно быть не менее двух единиц. Среди трехразрядных векторов таких имеется четыре: 011, 110, 101, 111.
Эти векторы могут быть сопоставлены со строками единичной матрицы в любом порядке. В результате получим матрицы систематических кодов, эквивалентных коду Хэмминга, например:
Нетрудно убедиться, что при суммировании нескольких строк такой матрицы (l>1) получим вектор-строку, содержащую не менее d=3 ненулевых символов.
Имея образующую матрицу систематического кода Мn,k= [IkPk,n—k], можно построить так называемую проверочную (контрольную) матрицу Н размерности (n – k) n:
При умножении неискаженного кодового вектора Аni на матрицу, транспонированную к матрице Н, получим вектор, все компоненты которого равны нулю:
Каждая компонента Sj является результатом проверки справедливости соответствующего уравнения декодирования:
В общем случае, когда кодовый вектор Аni =(a1, a2,…, ai,…,ak,ak+1,…,aj,…,an) искажен вектором ошибки ξni =(ξ1, ξ2,…, ξi,…,ξk,aξk+1,…,ξj,…,ξn), умножение вектора (Аni + ξni) на матрицу Нт дает ненулевые компоненты:
Отсюда видно, что Sj(k +1 j
n) представляют собой символы, зависящие только от вектора ошибки, а вектор S = (Sk + 1, Sk + 2, …,, Sj, …, Sn) является не чем иным, как опознавателем ошибки (синдромом).
Для двоичных кодов (операция сложения тождественна операции вычитания) проверочная матрица имеет вид
Пример 32. Найдем проверочную матрицу Н для кода (7,4) с образующей матрицей М:
Определим синдромы в случаях отсутствия и наличия ошибки в кодовом векторе 1100011.
Выполним транспонирование матрицы P4,3
Запишем проверочную матрицу:
Умножение на Нт неискаженного кодового вектора 1100011 дает нулевой синдром:
При наличии в кодовом векторе ошибки, например, в 4-м разряде (1101011) получим:
Следовательно, вектор-строка 111 в данном коде является опознавателем (синдромом) ошибки в четвертом разряде. Аналогично можно найти и синдромы других ошибок. Множество всех опознавателей идентично множеству опознавателей кода Хэмминга (7,4), но сопоставлены они конкретным векторам ошибок по-иному, в соответствии с образующей матрицей данного (эквивалентного) кода.
4.8.5 Технические средства кодирования и декодирования для групповых кодов
Кодирующее устройство строится на основании совокупности равенств, отражающих правила построения кода. Определение значений символов в каждом из n – k проверочных разрядов в кодирующем устройстве осуществляется посредством сумматоров по модулю два.
На каждый разряд сумматора (кроме первого) используется четыре элемента И (вентиля) и два элемента ИЛИ.
Сумматор по модулю два выпускают в виде отдельного логического элемента, который на схеме изображается прямоугольником с надписью внутри — М2. Приведем несколько примеров реализации кодирующих и декодирующих устройств групповых кодов.
Пример 33. Рассмотрим техническую реализацию кода (7,4), имеющего целью исправление одиночных ошибок.
Правила построения кода определяются равенствами
a1=a3 a5
a7,
a2=a3 a6
a7,
a4=a5 a6
a7.
Схема кодирующего устройства приведена на рис. 4.6.
Рис. 4.6.
При поступлении импульса синхронизации со схемы управления подлежащая кодированию k-разрядная комбинация неизбыточного кода переписывается, например, с аналого-кодового преобразователя в информационные разряды n-разрядного регистра. Предположим, что в результате этой операции триггеры регистра установились в состояния, указанные в табл. 4.9.
С некоторой задержкой формируются выходные импульсы сумматоров С1, С2 С3, которые устанавливают триггеры проверочных разрядов в положение 0 или 1 в соответствии с приведенными выше равенствами. Например, в нашем случае ко входам сумматора C1 подводится информация, записанная в 3, 5 и 7-разрядах и, следовательно, триггер Тг1 первого проверочного разряда устанавливается в положение 1, аналогично триггер Тг2 устанавливается в положение 0, а триггер Тг4 — в положение 1.
Сформированная в регистре разрешенная комбинация (табл. 4.10) импульсом, поступающим с блока управления, последовательно или параллельно считывается в линию связи. Далее начинается кодирование следующей комбинации.
Рассмотрим теперь схему декодирования и коррекции ошибок (рис. 4.7), строящуюся на основе совокупности проверочных равенств. Для кода (7, 4) они имеют вид:
a1 a3
a5
a7= 0 ,
a2 a3
a6
a7= 0,
a4 a5
a6
a7= 0 .
Таблица 4.9.
|
Тr1 |
Тr2 |
Tr3 |
Тr4 |
Тr5 |
Tr6 |
Тr7 |
|
— |
— |
1 |
— |
0 |
1 |
0 |
Кодовая комбинация, возможно содержащая ошибку, поступает на n-разрядный приемный регистр (на рис. 4.7 триггеры Тг1 –Тг7). По окончании переходного процесса в триггерах с блока управления на каждый из сумматоров (C1 – С3) поступает импульс опроса.
Таблица 4.10.
|
Тг1 |
Тг2 |
Тг3 |
Тг4 |
Тг5 |
Tг6 |
Тг7 |
|
1 |
0 |
1 |
1 |
0 |
1 |
0 |
Рис. 4.7.
Выходные импульсы сумматоров устанавливают в положение 0 или 1 триггеры регистра опознавателей. Если проверочные равенства выполняются, все триггеры регистра опознавателей устанавливаются в положение 0, что соответствует отсутствию ошибок. При наличии ошибки в регистр опознавателей запишется опознаватель этого вектора ошибки. Дешифратор ошибки DC ставит в соответствие множеству опознавателей множество векторов ошибок. При опросе выходных вентилей дешифратора сигналы коррекции поступают только на те разряды, в которых вектор ошибки, соответствующий записанному на входе опознавателю, имеет единицы. Сигналы коррекции воздействуют на счетные входы триггеров. Последние изменяют свое состояние, и, таким образом, ошибка исправлена. На триггеры проверочных разрядов импульсы коррекции можно не посылать, если после коррекции информация списывается только с информационных разрядов. Для кода Хэмминга (7,4) любой опознаватель представляет собой двоичное трехразрядное число, равное номеру разряда приемного регистра, в котором записан ошибочный символ.
Предположим, что сформированная ранее в кодирующем устройстве комбинация при передаче исказилась и на приемном регистре была зафиксирована в виде, записанном в табл. 4.11.
Таблица 4.11.
|
Тг1 |
Тг2 |
Тг3 |
Тг4 |
Тг5 |
Тг6 |
Tг7 |
|
1 |
0 |
1 |
1 |
1 |
1 |
0 |
По результатам опроса сумматоров получаем:
на выходе С1 a1 a3
a5
a7= 1+1+1+0=1,
на выходе С2 a2 a3
a6
a7= 0+1+1+0=0,
на выходе С3 a4 a5
a6
a7= 1+1+1+0=1 .
Рис. 4.8.
Следовательно, номер разряда, в котором произошло искажение, 101 или 5. Импульс коррекции поступит на счетный вход триггера Тг5, и ошибка будет исправлена.
Пример 34. Реализуем мажоритарное декодирование для группового кода (8,2), рассчитанного на исправление двойных ошибок.
В случае мажоритарного декодирования сигналы с триггеров приемного регистра поступают непосредственно или после сложения по модулю два в соответствии с уравнениями системы разделённых проверок на мажоритарные элементы М, формирующие скорректированные информационные символы.
Схема декодирования представлена на рис. 4.8. На входах мажоритарных элементов указаны сигналы, соответствующие случаю поступления из канала связи кодовой информации, искаженной в обоих информационных разрядах (5-м и 8-м). Реализуя принцип решения «по большинству», мажоритарные элементы восстанавливают на выходе правильные значения информационных символов.
4.9 Построение циклических кодов
4.9.1 Общие понятия и определения
Любой групповой код (n, k) может быть записан в виде матрицы, включающей k линейно независимых строк по n символов и, наоборот, любая совокупность k линейно независимых n-разрядных кодовых комбинаций может рассматриваться как образующая матрица некоторого группового кода. Среди всего многообразия таких кодов можно выделить коды, у которых строки образующих матриц связаны дополнительным условием цикличности.
Все строки образующей матрицы такого кода могут быть получены циклическим сдвигом одной комбинации, называемой образующей для данного кода. Коды, удовлетворяющие этому условию, получили название циклических кодов.
Сдвиг осуществляется справа налево, причем крайний левый символ каждый раз переносится в конец комбинации. Запишем, например, совокупность кодовых комбинаций, получающихся циклическим сдвигом комбинации 001011:

Число возможных циклических (n, k)-кодов значительно меньше числа различных групповых (n, k)-кодов.
При описании циклических кодов n-разрядные кодовые комбинации представляются в виде многочленов фиктивной переменной х. Показатели степени у x соответствуют номерам разрядов (начиная с нулевого), а коэффициентами при х в общем случае являются элементы поля GF(q). При этом наименьшему разряду числа соответствует фиктивная переменная х0 = 1. Многочлен с коэффициентами из поля GF(q) называют многочленом над полем GF(q). Так как мы ограничиваемся рассмотрением только двоичных кодов, то коэффициентами при х будут только цифры 0 и 1. Иначе говоря, будем оперировать с многочленами над полем GF(2). Запишем, например, в виде многочлена образующую кодовую комбинацию 01011:
G(x) = 0·x4 + 1·x3 + 0·x2 + 1·x + 1
Поскольку члены с нулевыми коэффициентами при записи многочлена опускаются, образующий многочлен:
G(x) = x3 + x + 1
Наибольшую степень х в слагаемом с ненулевым коэффициентом называют степенью многочлена. Теперь действия над кодовыми комбинациями сводятся к действиям над многочленами. Суммирование многочленов осуществляется с приведением коэффициентов по модулю два.
Указанный циклический сдвиг некоторого образующего многочлена степени n — k без переноса единицы в конец кодовой комбинации соответствует простому умножению на х. Умножив, например, первую строку матрицы (001011), соответствующую многочлену g0(х) = x3 + x + 1, на х, получим вторую строку матрицы (010110), соответствующую многочлену х • g0(x).
Нетрудно убедиться, что кодовая комбинация, получающаяся при сложении этих двух комбинаций, также будет соответствовать результату умножения многочлена x3 + x + 1 на многочлен x+1. Действительно,

Циклический сдвиг строки матрицы с единицей в старшем (n-м) разряде (слева) равносилен умножению соответствующего строке многочлена на х с одновременным вычитанием из результата многочлена хn + 1= хn – 1, т. е. с приведением по модулю хn + 1.
Отсюда ясно, что любая разрешенная кодовая комбинация циклического кода может быть получена в результате умножения образующего многочлена на некоторый другой многочлен с приведением результата по модулю xn + l. Иными словами, при соответствующем выборе образующего многочлена любой многочлен циклического кода будет делиться на него без остатка.
Ни один многочлен, соответствующий запрещенной кодовой комбинации, на образующий многочлен без остатка не делится. Это свойство позволяет обнаружить ошибку. По виду остатка можно определить и вектор ошибки.
Умножение и деление многочленов весьма просто осуществляется на регистрах сдвига с обратными связями, что и явилось причиной широкого применения циклических кодов.
4.9.2 Математическое введение к циклическим кодам
Так как каждая разрешенная комбинация n-разрядного циклического кода есть произведение двух многочленов, один из которых является образующим, то эти комбинации можно рассматривать как подмножества всех произведений многочленов степени не выше n—1. Это наталкивает на мысль использовать для построения этих кодов еще одну ветвь теории алгебраических систем, а именно теорию колец.
Как следует из приведенного ранее определения, для образования кольца на множестве n-разрядных кодовых комбинаций необходимо задать две операции: сложение и умножение.
Операция сложения многочленов уже выбрана нами с приведением коэффициентов по модулю два.
Определим теперь операцию умножения. Нетрудно видеть, что операция умножения многочленов по обычным правилам с приведением подобных членов по модулю два может привести к нарушению условия замкнутости. Действительно, в результате умножения могут быть получены многочлены более высокой степени, чем n—1, вплоть до 2(n-1), а соответствующие им кодовые комбинации будут иметь число разрядов, превышающее n и, следовательно, не относятся к рассматриваемому множеству. Поэтому операция символического умножения задается так:
1) многочлены перемножаются по обычным правилам, но с приведением подобных членов по модулю два;
2) если старшая степень произведения не превышает n-1, то оно и является результатом символического умножения;
3) если старшая степень произведения больше или равна n, то многочлен произведения делится на заранее определенный многочлен степени n и результатом символического умножения считается остаток от деления.
Степень остатка не превышает n—1, и, следовательно, этот многочлен принадлежит к рассматриваемому множеству k-разрядных кодовых комбинаций.
При анализе циклического сдвига с перенесением единицы в конец кодовой комбинации установлено, что таким многочленом n-й степени является многочлен хn + 1.
Действительно, в результате умножения многочлена степени n-1 на х получим
G(x) = (xn-1 + xn-2 + … + x + 1)x = xn + xn-1 + … + x
Следовательно, чтобы результат умножения и теперь соответствовал кодовой комбинации, образующейся путем циклического сдвига исходной кодовой комбинации, в нем необходимо заменить хn на 1. Такая замена эквивалентна делению полученного при умножении многочлена на xn + 1 с записью в качестве результата остатка от деления, что обычно называют взятием остатка или приведением по модулю xn + 1 (сам остаток при этом называют вычетом).
Выделим теперь в нашем кольце подмножество всех многочленов, кратных некоторому многочлену g(x). Такое подмножество называют идеалом, а многочлен g(x)-порождающим многочленом идеала.
Количество различных элементов в идеале определяется видом его порождающего многочлена. Если на порождающий многочлен взять 0, то весь идеал будет составлять только этот многочлен, так как умножение его на любой другой многочлен дает 0.
Если за порождающий многочлен принять 1[g(x) = 1], то в идеал войдут все многочлены кольца. В общем случае число элементов идеала, порожденного простым многочленом степени n-k, составляет 2k.
Теперь становится понятным, что циклический двоичный код в построенном нами кольце n-разрядных двоичных кодовых комбинаций является идеалом. Остается выяснить, как выбрать многочлен g(x), способный породить циклический код с заданными свойствами.
4.9.3 Требования, предъявляемые к образующему многочлену
Согласно определению циклического кода все многочлены, соответствующие его кодовым комбинациям, должны делиться на g(x) без остатка. Для этого достаточно, чтобы на g(x) делились без остатка многочлены, составляющие образующую матрицу кода. Последние получаются циклическим сдвигом, что соответствует последовательному умножению g(x) на х с приведением по модулю xn + 1.
Следовательно, в общем случае многочлен gi(x) является остатком от деления произведения g(x)·хi на многочлен xn + 1 и может быть записан так:
gi(x)=g(x)xi + c(xn + 1)
где с =1, если степень g(x) хi превышает п-1; с = 0, если степень g(x) хi не превышает п-1.
Отсюда следует, что все многочлены матрицы, а поэтому и все многочлены кода будут делиться на g(x) без остатка только в том случае, если на g(x) будет делиться без остатка многочлен xn + 1.
Таким образом, чтобы g(x) мог породить идеал, а, следовательно, и циклический код, он должен быть делителем многочлена xn + 1.
Поскольку для кольца справедливы все свойства группы, а для идеала — все свойства подгруппы, кольцо можно разложить на смежные классы, называемые в этом случае классами вычетов по идеалу.
Первую строку разложения образует идеал, причем нулевой элемент располагается крайним слева. В качестве образующего первого класса вычетов можно выбрать любой многочлен, не принадлежащий идеалу. Остальные элементы данного класса вычетов образуются путем суммирования образующего многочлена с каждым многочленом идеала.
Если многочлен g(x) степени m = n-k является делителем xn + 1, то любой элемент кольца либо делится на g(x) без остатка (тогда он является элементом идеала), либо в результате деления появляется остаток r(х), представляющий собой многочлен степени не выше m-1.
Элементы кольца, дающие в остатке один и тот же многочлен ri(x), относятся к одному классу вычетов. Приняв многочлены r(х) за образующие элементы классов вычетов, разложение кольца по идеалу с образующим многочленом g(x) степени m можно представить табл. 4.12, где f(x)-произвольный многочлен степени не выше n-m-1.
Таблица 4.12.
|
0 |
g(x) |
x·g(x) |
(x+1)·g(x) |
… |
f(x)·g(x) |
|
r1(x) r2(x) … … rn(x) |
g(x) + r1(x) g(x) + r2(x) … … g(x) + rn(x) |
x·g(x) + r1(x) x·g(x) + r2(x) … … x·g(x) + rn(x) |
(x+1)·g(x) + r1(x) (x+1)·g(x) + r2(x) … … (x+1)·g(x) + rn(x) |
… … … … … |
f(x)·g(x) + r1(x) f(x)·g(x) + r2(x) … … f(x)·g(x) + rn(x) |
Как отмечалось, групповой код способен исправить столько разновидностей ошибок, сколько различных классов насчитывается в приведенном разложении. Следовательно, корректирующая способность циклического кода будет тем выше, чем больше остатков может быть образовано при делении многочлена, соответствующего искаженной кодовой комбинации, на образующий многочлен кода.
Наибольшее число остатков, равное 2m — 1 (исключая нулевой), может обеспечить только неприводимый (простой) многочлен, который делится сам на себя и не делится ни на какой другой многочлен (кроме 1).
4.10 Выбор образующего многочлена по заданному объему кода и заданной корректирующей способности
По заданному объему кода однозначно определяется число информационных разрядов k. Далее необходимо найти наименьшее n, обеспечивающее обнаружение или исправление ошибок заданной кратности. В случае циклического кода эта проблема сводится к нахождению нужного многочлена g(x).
Начнем рассмотрение с простейшего циклического кода, обнаруживающего все одиночные ошибки.
4.10.1 Обнаружение одиночных ошибок
Любая принятая по каналу связи кодовая комбинация h(x), возможно содержащая ошибку, может быть представлена в виде суммы по модулю два неискаженной комбинации кода f(x) и вектора ошибки ξ(x):
h(x) = f(x) ξ(x)
При делении h(x) на образующий многочлен g(x) остаток, указывающий на наличие ошибки, обнаруживается только в том случае, если многочлен, соответствующий вектору ошибки, не делится на g(x): f(x)-неискаженная комбинация кода и, следовательно, на g(x) делится без остатка.
Вектор одиночной ошибки имеет единицу в искаженном разряде и нули во всех остальных разрядах. Ему соответствует многочлен ξ(x) = xi. Последний не должен делиться на g(x). Среди неприводимых многочленов, входящих в разложении хn+1, многочленом наименьшей степени, удовлетворяющим указанному условию, является x + 1. Остаток от деления любого многочлена на x + 1 представляет собой многочлен нулевой степени и может принимать только два значения: 0 или 1. Все кольцо в данном случае состоит из идеала, содержащего многочлены с четным числом членов, и одного класса вычетов, соответствующего единственному остатку, равному 1. Таким образом, при любом числе информационных разрядов необходим только один проверочный разряд. Значение символа этого разряда как раз и обеспечивает четность числа единиц в любой разрешенной кодовой комбинации, а, следовательно, и делимость ее на xn + 1.
Полученный циклический код с проверкой на четность способен обнаруживать не только одиночные ошибки в отдельных разрядах, но и ошибки в любом нечетном числе разрядов.
4.10.2 Исправление одиночных или обнаружение двойных ошибок
Прежде чем исправить одиночную ошибку в принятой комбинации из п разрядов, необходимо определить, какой из разрядов был искажен. Это можно сделать только в том случае, если каждой одиночной ошибке в определенном разряде соответствуют свой класс вычетов и свой опознаватель. Так как в циклическом коде опознавателями ошибок являются остатки от деления многочленов ошибок на образующий многочлен кода g(x), то g(x) должно обеспечить требуемое число различных остатков при делении векторов ошибок с единицей в искаженном разряде. Как отмечалось, наибольшее число остатков дает неприводимый многочлен. При степени многочлена m = n-k он может дать 2n—k — 1 ненулевых остатков (нулевой остаток является опознавателем безошибочной передачи).
Следовательно, необходимым условием исправления любой одиночной ошибки является выполнение неравенства
2n—k — 1 = n,
где — общее число разновидностей одиночных ошибок в кодовой комбинации из п символов; отсюда находим степень образующего многочлена кода
m = n – k log2(n+1)
и общее число символов в кодовой комбинации. Наибольшие значения k и п для различных m можно найти пользуясь табл. 4.13.
Таблица 4.13.
|
M |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
|
N |
1 |
3 |
7 |
15 |
31 |
63 |
127 |
255 |
511 |
1023 |
|
K |
0 |
1 |
4 |
11 |
26 |
57 |
120 |
247 |
502 |
1013 |
Как указывалось, образующий многочлен g(x) должен быть делителем двучлена хn+1. Доказано, что любой двучлен типа х2m-1+ 1 = хn+1 может быть представлен произведением всех неприводимых многочленов, степени которых являются делителями числа т (от 1 до т включительно). Следовательно, для любого т существует по крайней мере один неприводимый многочлен степени т, входящий сомножителем в разложение двучлена хn+1.
Пользуясь этим свойством, а также имеющимися в ряде книг таблицами многочленов, неприводимых при двоичных коэффициентах, выбрать образующий многочлен при известных n и m несложно. Определив образующий многочлен, необходимо убедиться в том, что он обеспечивает заданное число остатков.
Пример 35. Выберем образующий многочлен для случая n = 15 и m = 4.
Двучлен x15 + 1 можно записать в виде произведения всех неприводимых многочленов, степени которых являются делителями числа 4. Последнее делится на 1, 2, 4.
В таблице неприводимых многочленов находим один многочлен первой степени, а именно x+1, один многочлен второй степени x2 + x + 1 и три многочлена четвертой степени: х4 + x + 1, х4 + х3 + 1, х4 + х3 + х2 + х + 1. Перемножив все многочлены, убедимся в справедливости соотношения (х + 1)(х2 + х + 1)(х4 + х + 1)(х4 + х3+ 1)(х4 + х3 + х2 + х + 1) = x15 + 1
Один из сомножителей четвертой степени может быть принят за образующий многочлен кода. Возьмем, например, многочлен х4 + х3 + 1, или в виде двоичной последовательности 11001.
Чтобы убедиться, что каждому вектору ошибки соответствует отличный от других остаток, необходимо поделить каждый из этих векторов на 11001.Векторы ошибок m младших разрядов имеют вид: 00…000, 00…0010, 00…0100, 00…1000.
Степени соответствующих им многочленов меньше степени образующего многочлена g(x). Поэтому они сами являются остатками при нулевой целой части. Остаток, соответствующий вектору ошибки в следующем старшем разряде, получаем при делении 00…10000 на 11001, т.е.

Аналогично могут быть найдены и остальные остатки. Однако их можно получить проще, деля на g(x) комбинацию в виде единицы с рядом нулей и выписывая все промежуточные остатки:

При последующем делении остатки повторяются.
Таким образом, мы убедились в том, что число различных остатков при выбранном g(x) равно п = 15, и, следовательно, код, образованный таким g(x), способен исправить любую одиночную ошибку. С тем же успехом за образующий многочлен кода мог быть принят и многочлен х4 + х + 1. При этом был бы получен код, эквивалентный выбранному.
Однако использовать для тех же целей многочлен х4 + х3 + x2 + х + 1 нельзя. При проверке числа различных остатков обнаруживается, что их у него не 15, а только 5. Действительно,

Это объясняется тем, что многочлен x4 + х3 + х2 + х + 1 входит в разложение не только двучлена x15+ 1, но и двучлена x5 + 1.
Из приведенного примера следует, что в качестве образующего следует выбирать такой неприводимый многочлен g(x) (или произведение таких многочленов), который, являясь делителем двучлена хп + 1, не входит в разложение ни одного двучлена типа хλ+ 1, степень которого λ меньше п. В этом случае говорят, что многочлен g(x) принадлежит показателю степени п.
В табл. 4.14 приведены основные характеристики некоторых кодов, способных исправлять одиночные ошибки или обнаруживать все одиночные и двойные ошибки.
Таблица 4.14.
|
Показатель неприводимого многочлена |
Образующий многочлен |
Число остатков |
Длина кода |
|
2 3 3 4 4 5 5 |
x2 + x + 1 x3 + x + 1 x3 + x2 + 1 x4 + x3 + 1 x4 + x + 1 x5 + x2 + 1 x5 + x3 + 1 |
3 7 7 15 15 31 31 |
3 7 7 15 15 31 31 |
Это циклические коды Хэмминга для исправления одной ошибки, в которых в отличие от групповых кодов Хэмминга все проверочные разряды размещаются в конце кодовой комбинации.
Эти коды могут быть использованы для обнаружения любых двойных ошибок. Многочлен, соответствующий вектору двойной ошибки, имеет вид ξ(х) = хi – хj, или ξ(x) = хi(хj – i + 1) при j>i. Так как j – ig(x) не кратен х и принадлежит показателю степени п, то ξ(x) не делится на g(x), что и позволяет обнаружить двойные ошибки.
4.10.3 Обнаружение ошибок кратности три и ниже
Образующие многочлены кодов, способных обнаруживать одиночные, двойные и тройные ошибки, можно определить, базируясь на следующем указании Хэмминга. Если известен образующий многочлен р(хт) кода длины п, позволяющего обнаруживать ошибки некоторой кратности z, то образующий многочлен g(x) кода, способного обнаруживать ошибки следующей кратности (z + 1), может быть получен умножением многочлена р(хт) на многочлен х + 1, что соответствует введению дополнительной проверки на четность. При этом число символов в комбинациях кода за счет добавления еще одного проверочного символа увеличивается до n + l.
В табл. 4.15 приведены основные характеристики некоторых кодов, способных обнаруживать ошибки кратности три и менее.
Таблица 4.15.
|
Показатель неприводимого многочлена |
Образующий многочлен |
Число информационных символов |
Длина кода |
|
3 4 5 |
(x+1)(x3 + x + 1) (x+1)(x4+ x + 1) (x+1)(x5+ x + 1) |
4 11 26 |
8 16 32 |
4.10.4 Обнаружение и исправление независимых ошибок произвольной кратности
Важнейшим классом кодов, используемых в каналах, где ошибки в последовательностях символов возникают независимо, являются коды Боуза-Чоудхури-Хоквингема. Доказано, что для любых целых положительных чисел m и sп = 2т—1 с числом проверочных символов не более ms, который способен обнаруживать ошибки кратности 2s или исправлять ошибки кратности s. Для понимания теоретических аспектов этих кодов необходимо ознакомиться с рядом новых понятий высшей алгебры.
4.10.5 Обнаружение и исправление пачек ошибок
Для произвольного линейного блокового (п, k)-кода, рассчитанного на исправление пакетов ошибок длины b или менее, основным соотношением, устанавливающим связь корректирующей способности с числом избыточных символов, является граница Рейджера: n – k 2b
При исправлении линейным кодом пакетов длины b или менее с одновременным обнаружением пакетов длины l b или менее требуется по крайней мере b + l проверочных символов.
Из циклических кодов, предназначенных для исправления пакетов ошибок, широко известны коды Бартона, Файра и Рида-Соломона.
Первые две разновидности кодов служат для исправления одного пакета ошибок в блоке. Коды Рида-Соломона способны исправлять несколько пачек ошибок.
Особенности декодирования циклических кодов, исправляющих пакеты ошибок, рассмотрены далее на примере кодов Файра.
4.10.6 Методы образования циклического кода
Существует несколько различных способов кодирования. Принципиально наиболее просто комбинации циклического кода можно получить, умножая многочлены а(х), соответствующие комбинациям безызбыточного кода (информационным символам), на образующий многочлен кода g(x). Такой способ легко реализуется. Однако он имеет тот существенный недостаток, что получающиеся в результате умножения комбинации кода не содержат информационные символы в явном виде. После исправления ошибок такие комбинации для выделения информационных символов приходится делить на образующий многочлен кода.
Применительно к циклическим кодам принято (хотя это и не обязательно) отводить под информационные k символов, соответствующих старшим степеням многочлена кода, а под проверочные n—k символов низших разрядов. Чтобы получить такой систематический код, применяется следующая процедура кодирования.
Многочлен а(х), соответствующий k-разрядной комбинации безызбыточного кода, умножаем на хт, где m = n—k. Степень каждого одночлена, входящего в а(х), увеличивается, что по отношению к комбинации кода означает необходимость приписать со стороны младших разрядов m нулей. Произведение а(х)хт делим на образующий многочлен g(x). В общем случае при этом получаем некоторое частное q(x) той же степени, что и а(х) и остаток r(х). Последний прибавляем к а(х)хт. В результате получаем многочлен
f(x) = a(x)xm + r(x)
Поскольку степень g(x) выбираем равной т, степень остатка r(х) не превышает m – 1. В комбинации, соответствующей многочлену а(х)хт, т младших разрядов нулевые, и, следовательно, указанная операция сложения равносильна приписыванию r(х) к а(х) со стороны младших разрядов.
Покажем, что f(x) делится на g(x) без остатка, т. е. является многочленом, соответствующим комбинации кода. Действительно, запишем многочлен а(х)хт в виде
a(x)xm = q(x)g(x) + r(x)
Так как операции сложения и вычитания по модулю два идентичны, r(х) можно перенести влево, тогда что и требовалось доказать.
a(x)xm+ r(x) = f(x) = q(x)g(x)
Таким образом, циклический код можно строить, приписывая к каждой комбинации безызбыточного кода остаток от деления соответствующего этой комбинации многочлена на образующий многочлен кода. Для кодов, число информационных символов в которых больше числа проверочных, рассмотренный способ реализуется наиболее просто.
Следует указать еще на один способ кодирования. Так как циклический код является разновидностью группового кода, то его проверочные символы должны выражаться через суммы по модулю два определенных информационных символов.
Равенства для определения проверочных символов могут быть получены путем решения рекуррентных соотношений:
(4.5)
где h—двоичные коэффициенты так называемого генераторного многочлена h(x), определяемого так
h(x) = (xn + 1)/g(x) = h0 + h1x + … + hkxk
Соотношение (4.5) позволяет по заданной последовательности информационных сигналов a0, a1, …, ak-1 вычислить n—k проверочных символов ak, ak+1, … …, an-1. Проверочные символы, как и ранее, размещаются на местах младших разрядов. При одних и тех же информационных символах комбинации кода, получающиеся таким путем, полностью совпадают с комбинациями, получающимися при использовании предыдущего способа кодирования. Применение данного способа целесообразно для кодов с числом проверочных символов, превышающим число информационных, например для кодов Боуза-Чоудхури-Хоквингема.
4.10.7 Матричная запись циклического кода
Полная образующая матрица циклического кода Mn,k составляется из двух матриц: единичной Ik (соответствующей k информационным разрядам) и дополнительной Сk,n—k (соответствующей проверочным разрядам):
Mn,k = || IkCk,n—k ||
Построение матрицы Ik трудностей не представляет. Если образование циклического кода производится на основе решения рекуррентных соотношений, то его дополнительную матрицу можно определить, воспользовавшись правилами, указанными ранее. Однако обычно строки дополнительной матрицы циклического кода Сk,n—k определяются путем вычисления многочленов r(х). Для каждой строки матрицы Ik соответствующий r(х) находят делением информационного многочлена а(х)хт этой строки на образующий многочлен кода g(x).
Дополнительную матрицу можно определить и не строя Ik. Для этого достаточно делить на g(x) комбинацию в виде единицы с рядом нулей и получающиеся остатки записывать в качестве строк дополнительной матрицы. При этом если степень какого-либо r(х) оказывается меньше n – k – 1, то следующие за этим остатком строки матрицы получают путем циклического сдвига предыдущей строки влево до тех пор, пока степень r(х) не станет равной п-k— 1. Деление производится до получения k строк дополнительной матрицы.
Пример 36. Запишем образующую матрицу для циклического кода (15,11) с порождающим многочленом g(x) = х4 + х3 + 1.
Воспользовавшись результатами ранее проведенного деления, получим

Существует другой способ построения образующей матрицы, базирующийся на основной особенности циклического (n, k)-кода. Он проще описанного, но получающаяся матрица менее удобна.
Матричная запись кодов достаточно широко распространена.
4.10.8 Укороченные циклические коды
Корректирующие возможности циклических кодов определяются степенью т образующего многочлена. В то время как необходимое число информационных символов может быть любым целым числом, возможности в выборе разрядности кода весьма ограничены.
Если, например, необходимо исправить единичные ошибки при k = 5, то нельзя взять образующий многочлен третьей степени, поскольку он даст только семь остатков, а общее число разрядов получится равным 8.
Следовательно, необходимо брать многочлен четвертой степени и тогда n= 15. Такой код рассчитан на 11 информационных разрядов.
Однако можно построить код минимальной разрядности, заменив в (n, k) -коде j первых информационных символов нулями и исключив их из кодовых комбинаций. Код уже не будет циклическим, поскольку циклический сдвиг одной разрешенной кодовой комбинации не всегда приводит к другой разрешенной комбинации того же кода. Получаемый таким путем линейный (n—j, k—j)-код называют укороченным циклическим кодом. Минимальное расстояние этого кода не менее, чем минимальное кодовое расстояние (n, k)-кода, из которого он получен. Матрица укороченного кода получается из образующей матрицы (n, k)-кода исключением j строк и столбцов, соответствующих старшим разрядам. Например, образующая матрица кода (9,5), полученная из матрицы кода (15,11), имеет вид

4.11 Технические средства кодирования и декодирования для циклических кодов
4.11.1 Линейные переключательные схемы
Основу кодирующих и декодирующих устройств циклических кодов составляют регистры сдвига с обратными связями, позволяющие осуществлять как умножение, так и деление многочленов с приведением коэффициентов по модулю два. Такие регистры также называют многотактными линейными переключательными схемами и линейными кодовыми фильтрами Хаффмена. Они состоят из ячеек памяти, сумматоров по модулю два и устройств умножения на коэффициенты многочленов множителя или делителя. В случае двоичных кодов для умножения на коэффициент, равный 1, требуется только наличие связи в схеме. Если коэффициент равен 0, то связь отсутствует. Сдвиг информации в регистре осуществляется импульсами, поступающими с генератора продвигающих импульсов, который на схеме, как правило, не указывается. На вход устройств поступают только коэффициенты многочленов, причем начиная с коэффициента при переменной в старшей степени.
Рис. 4.9.
На рис. 4.9 представлена схема, выполняющая умножение произвольного (например, информационного) многочлена
a(x) = a0 + a1x + … + ak-1xk-1
на некоторый фиксированный (например, образующий) многочлен
g(x) = g0 + g1x + … + gn-kxn-k.
Произведение этих многочленов равно
a(x)g(x)=a0g0 + (a0g1 + a1g0)x + … +(ak-2gn-k + ak-1gn-k-1)xn-2 +ak-1gn-kxn-1
Предполагаем, что первоначально ячейки памяти находятся в нулевом состоянии и что за коэффициентами множимого следует n—k нулей.
На первом такте на вход схемы поступает первый коэффициент аk-1 многочлена а(х) и на выходе появляется первый коэффициент произведения, равный
ak-1gn—k
На следующем такте на выход поступит сумма
ak-2gn-k + ak-1gn-k-1 ,
т.е. второй коэффициент произведения, и т. д. На n-м такте все ячейки, кроме последней, будут в нулевом состоянии и на выходе получим последний коэффициент а0g0
Используется также схема умножения многочленов при поступлении множимого младшим разрядом вперед (рис. 4.10).
На рис. 4.11 представлена схема, выполняющая деление произвольного многочлена, например
a(x)xm = a0 + a1x + … + an-1xn-1
на некоторый фиксированный (например, образующий) многочлен
g(x) = g0 + g1x + … + gn-kxn-k
Обратные связи регистра соответствуют виду многочлена g(x). Количество включаемых в него сумматоров равно числу отличных от нуля коэффициентов g(x), уменьшенному на единицу. Это объясняется тем, что сумматор сложения коэффициентов старших разрядов многочленов делимого и делителя в регистр не включается, так как результат сложения заранее известен (он равен 0).
Рис. 4.10.
Рис. 4.11.
За первые n—k тактов коэффициенты многочлена-делимого заполняют регистр, причем коэффициент при х в старшей степени достигает крайней правой ячейки. На следующем такте «единица» делимого, выходящая из крайней ячейки регистра, по цепи обратной связи подается к сумматорам по модулю два, что равносильно вычитанию многочлена-делителя из многочлена-делимого. Если в результате предыдущей операции коэффициент при старшей степени х у остатка оказался равным нулю, то на следующем такте делитель не вычитается. Коэффициенты делимого только сдвигаются вперед по регистру на один разряд, что находится в полном соответствии с тем, как это делается при делении многочленов столбиком.
Деление заканчивается с приходом последнего символа многочлена-делимого. При этом разность будет иметь более низкую степень, чем делитель. Эта разность и есть остаток.
Отметим, что если в качестве многочлена-делителя выбран простой многочлен степени m = n—k, то, продолжая делить образовавшийся остаток при отключенном входе, будем получать в регистре по одному разу каждое из ненулевых m-разрядных двоичных чисел. Затем эта последовательность чисел повторяется.
Пример 37. Рассмотрим процесс деления многочлена а(х)хт =(x3+1)x3 на образующий многочлен g(x) = х3+ х2+1. Схема для этого случая представлена на рис. 4.12, где 1, 2, 3-ячейки регистра. Работа схемы поясняется табл. 4.16.
Рис. 4.12.
Вычисление остатка начинается с четвертого такта и заканчивается после седьмого такта. Последующие сдвиги приводят к образованию в регистре последовательности из семи различных ненулевых трехразрядных чисел. В дальнейшем эта последовательность чисел повторяется.
Рассмотренные выше схемы умножения и деления многочленов непосредственно в том виде, в каком они представлены на рис. 4.10, 4.11, в качестве кодирующих устройств циклических кодов на практике не применяются: первая — из-за того, что образующаяся кодовая комбинация в явном виде не содержит информационных символов, а вторая — из-за того, что между информационными и проверочными символами образуется разрыв в n — k разрядов.
4.11.2 Кодирующие устройства
Все известные кодирующие устройства для любых типов циклических кодов, выполненные на регистрах сдвига, можно свести к двум типам схем согласно рассмотренным ранее методам кодирования.
Таблица 4.16.
|
Номер такта |
Вход |
Состояние ячеек регистра |
Номер такта |
Вход |
Состояние ячеек регистра |
||||
|
1 |
2 |
3 |
1 |
2 |
3 |
||||
|
1 2 3 4 5 6 7 |
1 0 0 1 0 0 0 |
1 0 0 0 1 1 1 |
0 1 0 0 0 1 1 |
0 0 1 1 1 1 0 |
8 9 10 11 12 13 14 |
— — — — — — — |
0 1 0 0 1 1 1 |
1 0 1 0 0 1 1 |
1 0 0 1 1 1 0 |
Схемы первого типа вычисляют значения проверочных символов путем непосредственного деления многочлена а(х)хт на образующий многочлен g(x). Это делается с помощью регистра сдвига, содержащего n—k разрядов (рис. 4.13).
Рис. 4.13.
Схема отличается от ранее рассмотренной тем, что коэффициенты кодируемого многочлена участвуют в обратной связи не через n—k сдвигов, а сразу с первого такта. Это позволяет устранить разрыв между информационными и проверочными символами.
В исходном состоянии ключ К1 находится в положении 1. Информационные символы одновременно поступают как в линию связи, так и в регистр сдвига, где за k тактов образуется остаток. Затем ключ K1 переходит в положение 2 и остаток поступает в линию связи.
Пример 38. Рассмотрим процесс деления многочлена а(х)хт = (х3 + 1)x3 на многочлен g(x) = x3 + х2+ 1 за k тактов.
Схема кодирующего устройства для заданного g(x) приведена на рис. 4.14. Процесс формирования кодовой комбинации шаг за шагом представлен в табл. 4.17, где черточками отмечены освобождающиеся ячейки, занимаемые новыми информационными символами.
С помощью схем второго типа вычисляют значения проверочных символов как линейную комбинацию информационных символов, т. е. они построены на использовании основного свойства систематических кодов. Кодирующее устройство строится на основе k-разрядного регистра сдвига (рис. 4.15).
Рис. 4.14.
Таблица 4.17.
|
Номер такта |
Вход |
Состояние ячеек регистра |
Выход |
||
|
1 |
2 |
3 |
|||
|
1 2 3 4 5 6 7 |
1 0 0 1 0 0 0 |
1 1 1 1 — — — |
0 1 1 1 1 — — |
1 1 0 0 1 1 — |
1 01 001 1001 01001 101001 1101001 |
Выходы ячеек памяти подключаются к сумматору в цепи обратной связи в соответствии с видом генераторного многочлена
h(x) = (xn + 1)/g(x) = h0 + h1x + … + hkxk
В исходном положении ключ К1 находится в положении 1. За первые k тактов поступающие на вход информационные символы заполняют все ячейки регистра. После этого ключ переводят в положение 2. На каждом из последующих тактов один из информационных символов выдается в канал связи и одновременно формируется проверочный символ, который записывается в последнюю ячейку регистра. Через n—k тактов процесс формирования проверочных символов заканчивается и ключ K1 снова переводится в положение 1.
В течение последующих k тактов содержимое регистра выдается в канал связи с одновременным заполнением ячеек новой последовательности информационных символов.
Пример 39. Рассмотрим процесс формирования кодовой комбинации с использованием генераторного многочлена для случая g(x) = x3 + x2 + 1 и а(x) = x3 + 1.
Определяем генераторный многочлен:
Рис. 4.15.
Рис. 4.16.
Соответствующая h(x) схема кодирующего устройства приведена на рис. 4.16. Формирование кодовой комбинации поясняется табл. 4.18. Оно начинается после заполнения регистра информационными символами.
4.11.3 Декодирующие устройства
Декодирование комбинаций циклического кода можно проводить различными методами. Существуют методы, основанные на использовании рекуррентных соотношений, на мажоритарном принципе, на вычислении остатка от деления принятой комбинации на образующий многочлен кода и др. Целесообразность применения каждого из них зависит от конкретных характеристик используемого кода.
Рассмотрим сначала устройства декодирования, в которых для обнаружения и исправления ошибок производится деление произвольного многочлена f(x), соответствующего принятой комбинации, на образующий многочлен кода g0(x). В этом случае при декодировании могут использоваться те же регистры сдвига, что и при кодировании.
Таблица 4.18.
|
Номер такта |
Состояние ячеек регистра |
Выход |
|||
|
1 |
2 |
3 |
4 |
||
|
1 2 3 4 5 6 7 |
1 0 1 1 — — — |
0 1 0 1 1 — — — |
0 0 1 0 1 1 — — |
1 0 0 1 0 1 1 — |
1 01 001 1001 01001 101001 1101001 |
Рис. 4.17.
Декодирующие устройства для кодов, обнаруживающих ошибки, по существу ничем не отличаются от схем кодирующих устройств. В них добавляется лишь буферный регистр для хранения принятого сообщения на время проведения операции деления. Если остатка не обнаружено (случай отсутствия ошибки), то информация с буферного регистра считывается в дешифратор сообщения. Если остаток обнаружен (случай наличия ошибки), то информация в буферном регистре уничтожается и на передающую сторону посылается импульс запроса повторной передачи.
В случае исправления ошибок схема несколько усложняется. Информацию о разрядах, в которых произошла ошибка, несет, как и ранее, остаток. Схема декодирующего устройства представлена на рис. 4.17.
Символы подлежащей декодированию кодовой комбинации, возможно, содержащей ошибку, последовательно, начиная со старшего разряда, вводятся в n-разрядный буферный регистр сдвига и одновременно в схему деления, где за n тактов определяется остаток, который в случае непрерывной передачи сразу же переписывается в регистр второй аналогичной схемы деления.
Начиная с (n + 1)-го такта в буферный регистр и первую схему деления начинают поступать символы следующей кодовой комбинации. Одновременно на каждом такте буферный регистр покидает один символ, а в регистре второй схемы деления появляется новый остаток (синдром). Детектор ошибок, контролирующий состояния ячеек этого регистра, представляет собой комбинаторно-логическую схему, построенную с таким расчетом, чтобы она отмечала все те синдромы («выделенные синдромы»), которые появляются в схеме деления, когда каждый из ошибочных символов занимает крайнюю правую ячейку в буферном регистре. При последующем сдвиге детектор формирует сигнал «1», который, воздействуя на сумматор коррекции, исправляет искаженный символ.
Одновременно по цепи обратной связи с выхода детектора подается сигнал «1» на входной сумматор регистра второй схемы деления. Этот сигнал изменяет выделенный синдром так, чтобы он снова соответствовал более простому типу ошибки, которую еще подлежит исправить. Продолжая сдвиги, обнаружим и другие выделенные синдромы. После исправления последней ошибки все ячейки декодирующего регистра должны оказаться в нулевом состоянии. Если в результате автономных сдвигов состояние регистра не окажется нулевым, это означает, что произошла неисправимая ошибка.
Для декодирования кодовых комбинаций, разнесенных во времени, достаточно одной схемы деления, осуществляющей декодирование за 2n тактов.
Сложность детектора ошибок зависит от числа выделенных синдромом. Простейшие детекторы получаются при реализации кодов, рассчитанных на исправление единичных ошибок.
Выделенный синдром появляется в схеме деления раньше всего в случае, когда ошибка имеет место в старшем разряде кодовой комбинации, так как он первым достигает крайней правой ячейки буферного регистра. Поскольку неискаженная кодовая комбинация делится на g0(x) без остатка, то для определения выделенного синдрома достаточно разделить на g0(x) вектор ошибки с единицей в старшем разряде. Остаток, получающийся на n-м такте, и является искомым выделенным синдромом.
В зависимости от номера искаженного разряда после первых тактов будем получать различные остатки (опознаватели соответствующих векторов ошибок). Вследствие этого выделенный синдром будет появляться в регистре схемы деления через различное число последующих тактов, обеспечивая исправление искаженного символа.
В качестве схем деления в декодирующем устройстве могут быть использованы как схемы, определяющие остаток за n тактов (см. рис. 4.11), так и схемы, определяющие остаток за k тактов (рис. 4.13). При использовании схемы деления за k тактов векторам одиночных ошибок ξ(х) будут соответствовать другие остатки на n-м такте, являющиеся результатом деления на образующий многочлен кода векторов ξ(х)хт, а на ξ(x). Поэтому выделенные синдромы, а следовательно, и детекторы ошибок для указанных схем будут различны.
Пример 40. Рассмотрим процесс исправления единичной ошибки при использовании кода (7,4) с образующим многочленом g(x) = х3 + х2 + 1 и применении в декодирующем устройстве схем деления за n и k тактов.
Определим опознаватели ошибок и выделенный синдром для случая использования схемы деления за n тактов:

Детектор ошибки, обеспечивающий формирование на выходе сигнала только в случае появления в схеме деления остатка 110, можно реализовать посредством двух логических элементов НЕ и одного логического элемента ИЛИ-НЕ.
На рис. 4.18 приведена схема соответствующего декодирующего устройства. В табл. 4.19 представлен процесс исправления ошибки для случая, когда кодовая комбинация 1001011 (см. табл. 4.18) поступила на вход декодирующего устройства с искаженным символом в 4-м разряде (1000011).
После n (в данном случае 7) тактов в схему деления II переписывается опознаватель ошибки 101.
Рис. 4.18.
Таблица 4.19.
|
Номер такта |
Вход |
Состояние ячеек схем деления |
Выход после коррекции |
||
|
1 |
2 |
3 |
|||
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
1 0 0 0 0 1 1 0 0 0 0 0 0 0 |
1 0 0 1 1 0 1 1 1 0 0 0 0 0 |
0 1 0 0 1 1 0 1 1 1 0 0 0 0 |
0 0 1 1 1 0 1 1 0 1 0 0 0 0 |
Переписывается в схему деления II 1 01 001 1001 01001 101001 1101001 |
На каждом последующем такте на выходе буферного регистра появляется неискаженный символ корректируемой кодовой комбинации, а в схеме деления II новый остаток. Выделенный синдром появится в схеме деления на 10-м такте, когда искаженный символ займет крайнюю правую ячейку регистра. На следующем такте он попадет в корректирующий сумматор и будет там исправлен импульсом, поступающим с выхода детектора ошибки. Этот же импульс по цепи обратной связи приводит ячейки схемы деления II в нулевое состояние (корректирует выделенный синдром). При использовании схемы деления за k тактов соответствие между векторами ошибок и остатками на n-м такте иное.

Рис. 4.19.
Таблица 4.20.
|
Номер такта |
Вход |
Состояние ячеек схем деления |
Выход после коррекции |
||
|
1 |
2 |
3 |
|||
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
1 0 0 0 0 1 1 0 0 0 0 0 0 0 |
1 1 1 0 1 1 0 1 0 0 0 0 0 0 |
0 1 1 1 0 1 1 0 1 0 0 0 0 0 |
1 1 0 1 0 1 1 0 0 1 0 0 0 |
Переписывается в схему деления II 1 01 001 1001 01001 101001 1101001 |
Детектор для выделенного синдрома 100 можно построить из одного логического элемента НЕ и одного элемента ИЛИ-НЕ.
На рис. 4.19 представлена схема декодирующего устройства для этого случая. Табл. 4.20 позволяет проследить по тактам процесс исправления ошибки в кодовой комбинации 1000011 (искажен символ в 4-м разряде).
Сравнение показывает, что использование в декодирующем устройстве схемы деления за k тактов предпочтительнее, так как выделенный синдром в этом случае при любом объеме кода содержит единицу в старшем и нули во всех остальных разрядах, что приводит к более простому детектору ошибки.
Пример 41. Рассмотрим более сложный случай исправления одиночных и двойных смежных ошибок. Для этой цели может использоваться циклический код (7,3) с образующим многочленом g(x) = (х + 1)(x3 + x2+1).
Ориентируясь на схему деления за k тактов, найдем выделенный синдром для двойных смежных ошибок:

Для одиночных ошибок соответственно получим

Детектор ошибок в этом случае должен формировать сигнал коррекции при появлении каждого выделенного синдрома. Схема декодирующего устройства представлена на рис. 4.20.
Процесс исправления кодовой комбинации 1000010 с искаженными символами в 4-м и 5-м разрядах поясняется табл. 4.21.
На 9-м такте в схеме деления II появляется первый выделенный синдром 1100. На следующем такте на выходе аналогично обозначенного элемента ИЛИ-НЕ детектора ошибок формируется импульс коррекции, который исправляет 5-й разряд кодовой комбинации и одновременно по цепи обратной связи изменяет остаток в схеме деления II, приводя его в соответствие выделенному синдрому еще не исправленной одиночной ошибки в 4-м разряде (1000). На 11-м такте импульс коррекции формирует элемент ИЛИ-НЕ детектора ошибок, соответствующий указанному выделенному синдрому. Этим импульсом обеспечивается исправление 4-го разряда кодовой комбинации и получение нулевого остатка в схеме деления II.
Рис. 4.20.
Таблица 4.21.
|
Номер такта |
Вход |
Состояние ячеек схем деления |
Выход после коррекции |
|||
|
1 |
2 |
3 |
4 |
|||
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
1 0 0 0 1 0 0 0 0 0 0 0 0 0 |
1 0 1 1 1 0 1 0 0 0 0 0 0 0 |
1 1 1 0 0 1 1 1 0 0 0 0 0 0 |
1 1 0 0 1 0 0 1 1 0 0 0 0 0 |
0 1 1 0 0 1 0 0 1 1 0 0 0 0 |
Переписывается в схему деления II 1 01 101 1101 11101 011101 0011101 |
Список литературы
-
Дмитриев В.И. Прикладная теория информации. Учебник для студентов ВУЗов по специальности «Автоматизированные системы обработки информации и управления». – М.: Высшая школа, 1989 – 320 с.