Wondering how to fix PostgreSQL Error code 23505? We can help you.
One of the most common error codes with the PostgreSQL database is 23505. It can be seen along with the error message “duplicate key violates unique constraint”
Here at Bobcares, we often handle requests from our customers to fix similar PostgreSQL errors as a part of our Server Management Services. Today we will see how our support engineers fix this for our customers.
How PostgreSQL Error code 23505
At times we may get the following message when trying to insert data into a PostgreSQL database:
ERROR: duplicate key violates unique constraint
This happens when the primary key sequence in the table we’re working on becomes out of sync. And this might likely be because of a mass import process.
Here we have to manually reset the primary key index after restoring it from a dump file.
To check whether the values are out of sync, we can run the following commands:
SELECT MAX(the_primary_key) FROM the_table;
SELECT nextval('the_primary_key_sequence');
If the first value is higher than the second value, our sequence is out of sync.
We can back up our PG database and then run the following command:
SELECT setval('the_primary_key_sequence', (SELECT MAX(the_primary_key) FROM the_table)+1);
This will set the sequence to the next available value that’s higher than any existing primary key in the sequence.
To Resolve this error in VMware
When vpxd process crashes randomly after upgrading to vCenter Server 6.5 with the following error:
ODBC error: (23505) - ERROR: duplicate key value violates unique constraint "pk_vpx_guest_disk"; Panic: Unrecoverable database error. Shutting down VC
In the vpxd.log file, we can see entries similar to the one given below:
error vpxd[7F8DD228C700] [Originator@6876 sub=InvtVmDb opID=HB-host-476@72123-38e1cc31] >[VpxdInvtVm::SaveGuestNetworkAndDiskToDb] Failed to insert guest disk info for VM id = 976because of database error: "ODBC error: >(23505) - ERROR: duplicate key value violates unique constraint "pk_vpx_guest_disk";
–> Error while executing the query” is returned when executing SQL statement “INSERT INTO VPX_GUEST_DISK (VM_ID, PATH, CAPACITY, >FREE_SPACE) VALUES (?, ?, ?, ?)”
And in the postgresql.log file, you see entries similar to the one given below:
VCDB vc ERROR: duplicate key value violates unique constraint "pk_vpx_guest_disk" VCDB vc DETAIL: Key (vm_id, path)=(976, /tmp) already exists.
Steps to fix the error are given below:
vCenter Services can be given a service restart. If the starting fails to initialize the service and shows the same crash reason, we can fix this by removing the impacted guest disk entry from vCenter Server Database. This information is safe to remove as it will be re-populated from the host.
For vCenter Server with vPostgres database:
1. First, take a snapshot of the vCenter Server machine before proceeding.
2. Then connect the vCenter Database.
3. And identify the guest disk entry using the following query:
select FROM vc.vpx_guest_disk where vm_id= and path='/tmp';For example: select FROM vc.vpx_guest_disk where vm_id='976' and path='/tmp';
4. For deleting the duplicate value we can use the following command:
delete FROM vc.vpx_guest_disk where vm_id= and path='/tmp';For example:
select FROM vc.vpx_guest_disk where vm_id='976' and path='/tmp';We can get the VM id from the vpxd.log error entry
5. Finally start the Service.
We can delete the snapshot after observing the stability of the vCenter Server.
[Need assistance? We can help you]
Conclusion
In short, we saw how our Support Techs fix PostgreSQL Error code 23505 for our customers.
PREVENT YOUR SERVER FROM CRASHING!
Never again lose customers to poor server speed! Let us help you.
Our server experts will monitor & maintain your server 24/7 so that it remains lightning fast and secure.
GET STARTED
var google_conversion_label = «owonCMyG5nEQ0aD71QM»;
На Хабре уже было несколько статей упоминающих deferred constraints.
- Postgres: bloat, pg_repack и deferred constraints
- Ограничения (сonstraints) PostgreSQL: exclude, частичный unique, отложенные ограничения и др
Но хочется рассказать о них подробнее.

От переводчика: терминология
- Constraint — ограничение
- SQL statement — SQL-запрос
Одна из сильных сторон реляционных СУБД это постоянная бдительность за согласованностью данных (ACID, C — Согласованность). Разработчик может задать ограничения данным, а СУБД будет следить за их исполнением. Это позволяется избежать многих потенциальных ошибок.
Автоматическая проверка ограничений это мощный функционал, который при возможности должен быть использован. Однако, бывают случаи, когда удобно и даже необходимо временно отложить их исполнение.
Гранулярность проверки ограничений
В PostgreSQL есть 3 уровня проверки ограничений
- По строке. SQL-запрос, который обновляем множество строк, остановится на первой строке, не удовлетворяющей ограничению.
- По запросу. В этом случае запрос произведет все изменения, прежде чем проверить ограничения.
- По транзакции. Любой запрос внутри транзакции может нарушить ограничение. Но в момент фиксации, ограничения будут проверены и транзакция откатится, если хотя бы одно из них не будет выполнено.
В PostgreSQL уровень всех ограничений по умолчанию — NOT DEFERRABLE.
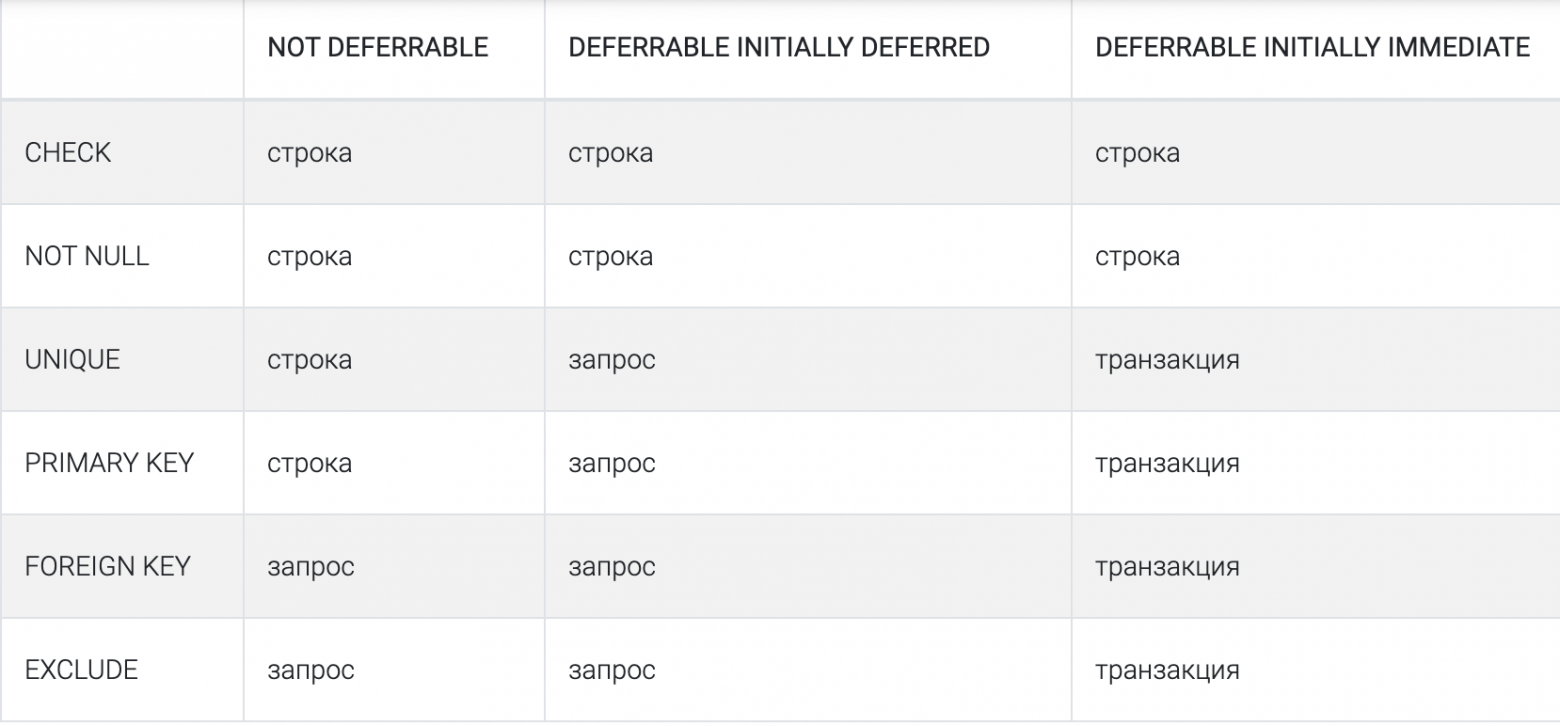
Чтобы изменить гранулярность проверки ограничения мы должны явно объявить ограничение как отложенное. При этом некоторые ограничения нельзя отложить. CHECK и NOT NULL всегда будут проверяться для каждой строки. Это поведение PostgreSQL нарушает SQL-стандарт.
От переводчика
Вероятно, имеется ввиду стандарт SQL92. Раздел 4.10 Integrity constraints
Every constraint descriptor includes:
- the name of the constraint;
- an indication of whether or not the constraint is deferrable;
- an indication of whether the initial constraint mode is deferred or immediate;
Прежде чем рассмотреть когда/зачем использовать отложенные ограничения, давайте рассмотрим как они работают. Вначале создадим отложенное ограничение.
ALTER TABLE foo
ADD CONSTRAINT foo_bar_fk
FOREIGN KEY (bar_id) REFERENCES bar (id)
DEFERRABLE INITIALLY IMMEDIATE; -- магия, объявляющая ограничение с возможностью быть отложенным, но по умолчанию оно будет проверяться сразу.
Отложенные ограничения дают транзакциям гибкость. Любая транзакция может выбрать отложить или нет проверку foo_bar_fk:
BEGIN;
-- Отложить проверку ограничения
SET CONSTRAINTS foo_bar_fk DEFERRED;
-- ...
-- Производим операции над bar_id
-- ...
COMMIT; -- В данном месте произойдёт проверка ограничения
Кроме того, мы можем использовать другой подход и объявить ограничение при создании как DEFERRABLE INITIALLY DEFERRED. Если транзакция не хочет откладывать проверку такого ограничения, то она может выполнить SET CONSTRAINTS constraint_name IMMEDIATE.
Без явного начала транзакции через BEGIN каждый запрос выполняется в своей неявной транзакции из одного запроса, поэтому нет разницы между IMMEDIATE и DEFERRED для одного запроса.
Попытка отложить ограничения вне транзакции не работает и приведёт к предупреждению WARNING: 25P01: SET CONSTRAINTS can only be used in transaction blocks.
Ещё одно важно замечание. Ограничения UNIQUE и PRIMARY KEY, объявленные как DEFERRABLE INITIALLY IMMEDIATE будут проверяться не на уровне строки, а на уровне запроса. Даже если транзакция не откладывает проверку ограничения, гранулярность всё равно изменится.
Давайте рассмотрим отличие гранулярности проверки на уровне строки и запроса на следующем примере.
CREATE TABLE snowflakes ( i int UNIQUE NOT DEFERRABLE);
INSERT INTO snowflakes VALUES (1), (2), (3);
UPDATE snowflakes SET i = i + 1;
UNIQUE ограничение здесь не отложенное, поэтому UPDATE будет в режиме «по строке» и не выполнится со следующей ошибкой.
ERROR: 23505: duplicate key value violates unique constraint "snowflakes_i_key"
DETAIL: Key (i)=(2) already exists.
Если бы PostgreSQL дождался обновления всех строк (как в проверке на уровне «по запросу»), то проблем бы не было. Значение i в строках будет последовательно увеличиваться и в итоге они все станут уникальными. Так как PostgreSQL проверяет ограничения сразу, то после обновления первой строки с i=1 на i=2 состояние таблицы будет 2, 2, 3.
Построчная проверка ограничений хрупка и зависит от физического расположения строк. Например, если бы мы заполнили таблицу в обратном порядке INSERT INTO snowflakes VALUES (3), (2), (1)), то UPDATE сработал бы.
Подводя итог, объявление ограничения отложенным позволяет транзакциям отложить проверку до фиксации. А также влияет на поведение некоторых ограничений вне транзакций. Например, следующий SQL отработает безошибочно.
CREATE TABLE snowflakes ( i int UNIQUE DEFERRABLE INITIALLY IMMEDIATE);
INSERT INTO snowflakes VALUES (1), (2), (3);
UPDATE snowflakes SET i = i + 1;
Зачем нужны отложенные ограничения?
Циклические внешние ключи
Классический пример — создание двух таблиц, связанных циклическими проверками согласованности.
CREATE TABLE husbands (
id int PRIMARY KEY,
wife_id int NOT NULL
);
CREATE TABLE wives (
id int PRIMARY KEY,
husband_id int NOT NULL
);
ALTER TABLE husbands ADD CONSTRAINT h_w_fk
FOREIGN KEY (wife_id) REFERENCES Wives;
ALTER TABLE wives ADD CONSTRAINT w_h_fk
FOREIGN KEY (husband_id) REFERENCES husbands;
Для создание строки в таблице husbands, необходимо в то же время создать строку в таблице wives. В данном случае у нас ничего не получится, так как внешние ключи проверяются на уровне строк, и для вставки в две таблицы нужно два запроса INSERT. Чтобы разрешить данную задачу мы можем отложить проверку ограничений.
ALTER TABLE husbands ALTER CONSTRAINT h_w_fk
DEFERRABLE INITIALLY DEFERRED;
ALTER TABLE wives ALTER CONSTRAINT w_h_fk
DEFERRABLE INITIALLY DEFERRED;
Так как циклические ограничения с большой вероятностью нужно всегда откладывать, то мы объявили их отложенными по умолчанию. Теперь мы можем заполнить таблицы данными.
BEGIN;
INSERT INTO husbands (id, wife_id) values (1, 1);
INSERT INTO wives (id, husband_id) values (1, 1);
COMMIT;
-- и жили они долго и счастливо :)
У нас получился аккуратный пример, как по учебнику. Но есть один маленький грязный хак.
PostgreSQL имеет альтернативный вариант решения без использовния отложенных ограничений.
-- Сделаем ограничения вновь проверяемыми сразу
ALTER TABLE husbands ALTER CONSTRAINT h_w_fk
NOT DEFERRABLE;
ALTER TABLE wives ALTER CONSTRAINT w_h_fk
NOT DEFERRABLE;
-- Вместо двух INSERT выполним один SQL-запрос
WITH wife AS (
INSERT INTO wives (id, husband_id)
VALUES (2, 2)
)
INSERT INTO husbands (id, wife_id)
VALUES (2, 2);
Общие табличные выражения (CTEs) позволяют выполнить несколько SQL-запросов, которые будут считаться одним при проверке ограничений, так как внешние ключи проверяются на уровне запроса.
Хотя мы и нашли способ не использовать отложенные ограничения для циклических внешних ключей, это всё равно хорошее начало чтобы познакомиться с отложенными ограничениями.
Перестановка элементов, по одному на группу
В данном примере, мы рассмотрим набор классов школы с ровно одним прикрепленным учителем. Пусть мы хотим переставить учителей двух классов. Ограничения усложняют нам жизнь.
CREATE TABLE classes (
id int PRIMARY KEY,
teacher_id int UNIQUE NOT NULL
);
INSERT INTO classes VALUES (1, 1), (2, 2);
Трюк с CTE не получится так как не отложенное ограничение UNIQUE проверяется на уровне строки, а не запроса.
WITH swap AS (
UPDATE classes
SET teacher_id = 2
WHERE id = 1
)
UPDATE classes
SET teacher_id = 1
WHERE id = 2;
ERROR: 23505: duplicate key value violates unique constraint "classes_teacher_id_key"
DETAIL: Key (teacher_id)=(1) already exists.
Чтобы переставить учителей без отложенного ограничения на teacher_id, мы можем
использовать временного учителя.
-- Временный учитель 999, позволит произвести перестановку
UPDATE classes SET teacher_id = 999 WHERE id = 1;
UPDATE classes SET teacher_id = 1 WHERE id = 2;
UPDATE classes SET teacher_id = 2 WHERE id = 1;
Использование временного учителя это грязный хак. Более естественно создать таблицу с отложенным ограничением.
CREATE TABLE classes (
id int PRIMARY KEY,
teacher_id int NOT NULL UNIQUE
DEFERRABLE INITIALLY IMMEDIATE
);
Это позволит произвести обмен намного проще:
BEGIN;
SET CONSTRAINTS classes_teacher_id_key DEFERRED;
UPDATE classes SET teacher_id = 1 WHERE id = 2;
UPDATE classes SET teacher_id = 2 WHERE id = 1;
COMMIT;
Теперь будет работать подход CTE с неявной транзакцией, так как ограничение проверяется на уровне запроса, а не строки.
Перенумерация списка
Можно смоделировать список дел в упорядоченном порядке, использую целочисленный столбец position:
CREATE TABLE todos (
list_id int,
position int,
task text,
PRIMARY KEY (list_id, position)
);
INSERT INTO todos VALUES
(1, 1, 'write grocery list'),
(1, 2, 'go to store'),
(1, 3, 'buy items');
Каждая позиция уникальна в рамках списка из-за составного ограничения первичного ключа.
Допустим мы вспомнили, что забыли добавить элемент в начало списка «составить меню». Если мы хотим установить данному элементу позицию 1, то нужно сместить все остальные элементы на +1. Это такая же задача как и в прошлом примере про снежинки.
Объявив первичный ключ как отложенный, мы исправим данную проблему:
CREATE TABLE todos (
list_id int,
position int,
task text,
PRIMARY KEY (list_id, position)
DEFERRABLE INITIALLY IMMEDIATE
);
В данном случае PostgreSQL будет проверять ограничение на уровне запроса, и нам не нужно дополнительного запроса в транзакции, чтобы отложить проверку ограничения SET… DEFERRED.
UPDATE todos
SET position = position + 1
WHERE list_id = 1;
INSERT INTO todos VALUES
(1, 1, 'plan menus');
Но отложенные ограничения не лучшее решение в данном случае. Изменяемую позицию лучше хранить как дробь (рациональное число), вместо целого. Данный подход всегда позволит найти позицию между двумя существующими элементами. Посмотрите мою статью User-defined Order in SQL. Такой подход позволит не использовать отложенные ограничения.
Загрузка данных в таблицы
Отложенные ограничения могут сделать процесс наполнения таблиц более удобным.
Например, отложенные внешние ключи позволяют загружать данные в таблицы в любом порядке. Например вначале потомков, а затем родителей.
В некоторых интернет статьях утверждают, что отложенные ограничения позволяют быстрее выполнять массовые вставки (bulk INSERTs). По моим оценкам, это миф. Во время фиксации транзакции такое же кол-во проверок будет выполнено для отложенных и не отложенных ограничений. Для проверки:
CREATE TABLE parent (
id int PRIMARY KEY,
name text NOT NULL
);
CREATE TABLE child (
id int PRIMARY KEY,
parent_id int REFERENCES parent
DEFERRABLE INITIALLY IMMEDIATE,
name text
);
INSERT INTO parent
SELECT
generate_series(1,1000000) AS id,
md5(random()::text) as name;
Теперь вставим 5 миллион строк в таблицу child и замерим время вставки и проверки внешнего ключа. Запуск был на моём ноутбуке с PostgreSQL 9.6.3:
INSERT INTO child
SELECT
generate_series(1,5000000) AS id,
generate_series(1,1000000) AS parent_id,
md5(random()::text) as name;
--
-- Time: 89064.987 ms
Попробуем ещё раз, но теперь отложим проверку ограничения:
BEGIN;
SET CONSTRAINTS child_parent_id_fkey DEFERRED;
INSERT INTO child
SELECT
generate_series(1,5000000) AS id,
generate_series(1,1000000) AS parent_id,
md5(random()::text) as name;
--
-- Time: 40828.810 ms
COMMIT;
--
-- Time: 47211.533 ms
-- Total: 88040.343 ms
Время, которое мы экономим при вставке, мы теряем в момент фиксации транзакции.
Единственный способ ускорить загрузку — это временно отключить проверку внешнего ключа (при условии, что мы заранее знаем, что данные для загрузки верны). Как правило, это плохая идея, потому что мы можем потратить больше времени на последующую отладку неконсистентности данных, чем на проверку согласованности во время вставки.
Причины не использовать отложенные ограничения
Кажется что отложенные ограничения это круто! Объявление ограничений отложенными даёт нам большую гибкость, но почему не стоит откладывать все ограничения?
Планировщик запросов и штраф производительности
Планировщик запросов СУБД использует факты о данных для выбора правильных и эффективных стратегий выполнения. Его первая обязанность — возвращать правильные результаты, и он будет использовать оптимизацию только тогда, когда ограничения базы данных гарантируют корректность. По определению нет гарантий, что откладываемые ограничения будут выполняться всё время, поэтому они мешают планировщику.
Чтобы узнать больше, я спросил Andrew Gierth, RhodiumToad, в IRC, и получил следующий ответ: «Планировщик может определить, что набор условий в таблице гарантирует уникальность результата. Если существует уникальный, неотложный индекс, он может исключить этап сортировки/уникальности или хеширования. Но при отложенных ограничениях могут присутствовать повторяющиеся значения».
Он обрисовал в общих чертах две оптимизации: одну в PostgreSQL 9 и одну в 10ой версии. Старый функционал — это удаление JOIN’a из запроса:
CREATE TABLE foo (
a integer UNIQUE,
b integer UNIQUE DEFERRABLE
);
EXPLAIN
SELECT t1.*
FROM foo t1
LEFT JOIN foo t2
ON (t1.a = t2.a);
Заметьте JOIN исчез, и используется обычный Seq Scan:
QUERY PLAN
----------------------------------------------------------
Seq Scan on foo t1 (cost=0.00..32.60 rows=2260 width=8)
Но если использовать JOIN по b, с отложенным ограничением, то JOIN останется:
EXPLAIN
SELECT t1.*
FROM foo t1
LEFT JOIN foo t2
ON (t1.b = t2.b);
QUERY PLAN
----------------------------------------------------------------------
Hash Left Join (cost=60.85..124.53 rows=2260 width=8)
Hash Cond: (t1.b = t2.b)
-> Seq Scan on foo t1 (cost=0.00..32.60 rows=2260 width=8)
-> Hash (cost=32.60..32.60 rows=2260 width=4)
-> Seq Scan on foo t2 (cost=0.00..32.60 rows=2260 width=4)
В PostgreSQL 10 есть другая оптимизация, которая превращает semi-JOIN из подзапроса IN в обычный JOIN, когда столбец подзапроса гарантировано уникален.
EXPLAIN
SELECT *
FROM foo
WHERE a IN (
SELECT a FROM foo
);
-- Планировщик понял, что столбец а уникальный
QUERY PLAN
-------------------------------------------------------------------------
Hash Join (cost=60.85..121.97 rows=2260 width=8)
Hash Cond: (foo.a = foo_1.a)
-> Seq Scan on foo (cost=0.00..32.60 rows=2260 width=8)
-> Hash (cost=32.60..32.60 rows=2260 width=4)
-> Seq Scan on foo foo_1 (cost=0.00..32.60 rows=2260 width=4)
В случае с b, отложенное ограничение помешает оптимизации
EXPLAIN
SELECT *
FROM foo
WHERE b IN (
SELECT b FROM foo
);
QUERY PLAN
-------------------------------------------------------------------------
Hash Semi Join (cost=60.85..124.53 rows=2260 width=8)
Hash Cond: (foo.b = foo_1.b)
-> Seq Scan on foo (cost=0.00..32.60 rows=2260 width=8)
-> Hash (cost=32.60..32.60 rows=2260 width=4)
-> Seq Scan on foo foo_1 (cost=0.00..32.60 rows=2260 width=4)
Усложнение отладки
Получение ошибок только после завершения набора запросов усложняет отладку. Ошибка не позволяет точно определить, какой запрос вызвал проблему. Вы можете и не найти нужный запрос по сообщению об ошибке.
CREATE TABLE u (
i int UNIQUE DEFERRABLE INITIALLY IMMEDIATE
);
BEGIN;
SET CONSTRAINTS u_i_key DEFERRED;
INSERT INTO u (i) VALUES (1), (2);
-- ... другие SQL-запросы
INSERT intu u (i) VALUES (2), (3);
-- ... другие SQL-запросы
INSERT intu u (i) VALUES (3), (4);
COMMIT;
ERROR: 23505: duplicate key value violates unique constraint "u_i_key"
DETAIL: Key (i)=(2) already exists.
В данном случае сообщение даёт достаточно информации, чтобы найти проблемный запрос, но может быть и более сложный случай без конкретных значений.
Ошибки во время фиксации транзакции могут не только сбить с толку, но и внести погрешность в ORM. DataMapper предназначены для упрощенного доступа к СУБД и не все могут правильно обработать ошибки ограничений на уровне транзакций.
Так же любая работа выполненная после отложенного ограничения может быть в итоге потеряна, после отката транзакции. Отложенные ограничения могут тратить CPU впустую.
Откладывание ограничения по столбцу
Последний трюк для развлечения.
Команда SET CONSTRAINTS принимает имя ограничения. Но может быть удобнее отложить ограничения по столбцам. PostgreSQL information_schema позволяет искать ограничения по столбцам.
CREATE VIEW deferrables AS
SELECT table_schema, table_name, column_name,
conname, contype
FROM
pg_constraint,
information_schema.constraint_column_usage
WHERE constraint_name = conname
AND condeferrable = TRUE;
-- Отложить все ограничения для столбца
CREATE FUNCTION defer_col_constraints(
t_name information_schema.sql_identifier,
c_name name
) RETURNS void AS $$
DECLARE
names text;
BEGIN
names := (
SELECT array_to_string(array_agg(conname), ', ')
FROM deferrables
WHERE table_name = $1
AND column_name = $2
);
EXECUTE format(
'SET CONSTRAINTS %s DEFERRED',
names
);
END;
$$ LANGUAGE plpgsql;
В примере выше мы могли бы использовать данную функцию для того чтобы отложить ограничения по столбца child и parent_id.
BEGIN;
SELECT defer_col_constraints('child', 'parent_id');
-- ...
COMMIT;
When I use this query everything is fine:
UPDATE users
SET f_name='Mike',
l_name='MyLastName',
username='blabla',
"password"='asdfsdaf',
"class"=12,
lang='en'
WHERE id=50;
I created a view which combines two tables:
CREATE OR REPLACE VIEW students_data AS
SELECT students.id,
users.f_name,
users.l_name,
users.username,
users."password",
users."class",
users.permission,
users.sessionid,
users.lastlogin,
users.lang
FROM students
LEFT JOIN users ON students.id = users.id;
And I also created this rule:
CREATE OR REPLACE RULE students_data_update AS
ON UPDATE TO students_data DO INSTEAD
UPDATE users
SET f_name = new.f_name,
l_name = new.l_name,
username = new.username,
"password" = new."password",
"class" = new."class",
permission = new.permission,
sessionid = new.sessionid,
lastlogin = new.lastlogin,
lang = new.lang;
When I execute this query I get an error:
UPDATE students_data
SET f_name='Mikaa',
l_name='MikeL',
username='blabla',
"password"='asdfsdaf',
"class"=12,
lang='en'
WHERE id=50;
ERROR: duplicate key violates unique constraint «username» SQL
status:23505
I have no idea why I get this error, username is a unique column but I shouldn’t give any problems when I update this column.
-- Table: users
-- DROP TABLE users;
CREATE TABLE users
(
id serial NOT NULL,
f_name character varying,
l_name character varying,
username character varying NOT NULL,
"password" character varying NOT NULL,
"class" integer NOT NULL,
permission integer NOT NULL,
sessionid character varying,
lastlogin integer,
lang character varying(5),
CONSTRAINT users_pkey PRIMARY KEY (id),
CONSTRAINT "class" FOREIGN KEY ("class")
REFERENCES "class" (id) MATCH SIMPLE
ON UPDATE NO ACTION ON DELETE NO ACTION,
CONSTRAINT username UNIQUE (username)
)
WITHOUT OIDS;
![]()
The Problem
When we insert a new row in a table with a sequential primary key, we get a «23505: duplicate key value violates unique constraint» error.
This implies that a record already exists for the next number being returned for the sequence.
The reason this happens is that the primary key sequence is out of sync with the table rows.
Assumptions
- The table name is «table»
- The column with the issue is «id.»
Validate that the sequence is out-of-sync
Before we reset the sequence, let us make sure that it is out of sync.
SELECT nextval(PG_GET_SERIAL_SEQUENCE('"table"', 'id'));
SELECT
CURRVAL(PG_GET_SERIAL_SEQUENCE('"table"', 'id')) AS "Current Value",
MAX("id") AS "Max Value"
FROM "table";
Enter fullscreen mode
Exit fullscreen mode
Line #1: We make a call to nextval because if we call currval before calling nextval in the current session, it will give us an error similar to «ERROR: currval of sequence «table_id_seq» is not yet defined in this session«.
Line #3-6: Gets the value most recently obtained by nextval for this sequence in the current session along with the maximum value for id in table.
Our sequence is out-of-sync when the Current Value is less than Max Value.
What does PG_GET_SERIAL_SEQUENCE do?
PG_GET_SERIAL_SEQUENCE('"table"', 'id') can be used to get the sequence name.
Using this, we can avoid hard-coding the actual sequence name, which helps avoid any incorrect assumptions about the sequence name.
Note that the table name is in double-quotes, surrounded by single quotes.
The Fix
SELECT SETVAL(
(SELECT PG_GET_SERIAL_SEQUENCE('"table"', 'id')),
(SELECT (MAX("id") + 1) FROM "table"),
FALSE);
Enter fullscreen mode
Exit fullscreen mode
This will set the sequence to the next available value higher than any existing value for «id» in table. Further inserts will not result in a «duplicate key value violates unique constraint» error.
References
- Sequence Manipulation Functions
A common coding strategy is to have multiple application servers attempt to insert the same data into the same table at the same time and rely on the database unique constraint to prevent duplication. The “duplicate key violates unique constraint” error notifies the caller that a retry is needed. This seems like an intuitive approach, but relying on this optimistic insert can quickly have a negative performance impact on your database. In this post, we examine the performance impact, storage impact, and autovacuum considerations for both the normal INSERT and INSERT..ON CONFLICT clauses. This information applies to PostgreSQL whether self-managed or hosted in Amazon Relational Database Service (Amazon RDS) for PostgreSQL or Amazon Aurora PostgreSQL-Compatible Edition.
Understanding the differences between INSERT and INSERT..ON CONFLICT
In PostgreSQL, an insert statement can contain several clauses, such as simple insert with the values to be put into a table, an insert with the ON CONFLICT DO NOTHING clause, or an insert with the ON CONFLICT DO UPDATE SET clause. The usage and requirements for all these types differ, and they all have a different impact on the performance of the database.
Let’s compare the case of attempting to insert a duplicate value with and without the ON CONFLICT DO NOTHING clause. The following table outlines the advantages of the ON CONFLICT DO NOTHING clause.
| .. | Regular INSERT | INSERT..ON CONFLICT DO NOTHING |
| Dead tuples generated | Yes | No |
| Transaction ID used up | Yes | No |
| Autovacuum has more cleanup | Yes | No |
| FreeStorageSpace used up | Yes | No |
Let’s look at simple examples of each type of insert, starting with a regular INSERT:
postgres=> CREATE TABLE blog (
id int PRIMARY KEY,
name varchar(20)
);
CREATE TABLE
postgres=> INSERT INTO blog
VALUES (1,'AWS Blog1');
INSERT 0 1The INSERT 0 1 depicts that one row was inserted successfully.
Now if we insert the same value of id again, it errors out with a duplicate key violation because of the unique primary key:
postgres=> INSERT INTO blog
VALUES (1, 'AWS Blog1');
ERROR: duplicate key value violates unique constraint "blog_pkey"
DETAIL: Key (n)=(1) already exists.The following code shows how the INSERT… ON CONFLICT clause handles this violation error when inserting data:
postgres=> INSERT INTO blog
VALUES (1,'AWS Blog1')
ON CONFLICT DO NOTHING;
INSERT 0 0The INSERT 0 0 indicates that while nothing was inserted in the table, the query didn’t error out. Although the end results appear identical (no rows inserted), there are important differences when you use the ON CONFLICT DO NOTHING clause.
In the following sections, we examine the performance impact, bloat considerations, transaction ID acceleration and autovacuum impact, and finally storage impact of a regular INSERT vs. INSERT..ON CONFLICT.
Performance impact
The following excerpt of the commit message adding the INSERT..ON CONFLICT clause describes the improvement:
“This is implemented using a new infrastructure called ‘speculative insertion’. It is an optimistic variant of regular insertion that first does a pre-check for existing tuples and then attempts an insert. If a violating tuple was inserted concurrently, the speculatively inserted tuple is deleted and a new attempt is made. If the pre-check finds a matching tuple the alternative DO NOTHING or DO UPDATE action is taken. If the insertion succeeds without detecting a conflict, the tuple is deemed inserted.”
This pre-check avoids the overhead of inserting a tuple into the heap to later delete it in case it turns out to be a duplicate. The heap_insert () function is used to insert a tuple into a heap. Back in version 9.5, this code was modified (along with a lot of other code) to incorporate speculative inserts. HEAP_INSERT_IS_SPECULATIVE is used on so-called speculative insertions, which can be backed out afterwards without canceling the whole transaction. Other sessions can wait for the speculative insertion to be confirmed, turning it into a regular tuple, or canceled, as if it never existed and therefore never made visible. This change eliminates the overhead of performing the insert, finding out that it is a duplicate, and marking it as a dead tuple.
For example, the following is a simple select query on a table that attempted 1 million regular inserts that were duplicates:
postgres=> SELECT count(*) FROM blog;
-[ RECORD 1 ]
count | 1
Time: 54.135 msFor comparison, the following is a simple select query on a table that used the INSERT..ON CONFLICT statement:
postgres=> SELECT count(*) FROM blog;
-[ RECORD 1 ]
count | 1
Time: 0.761 msThe difference in time is because of the 1 million dead tuples generated in the first case by the regular duplicate inserts. To count the actual visible rows, the entire table has to be scanned, and when it’s full of dead tuples, it takes considerably longer. On the other hand, in the case of INSERT..ON CONFLICT DO NOTHING, because of the pre-check, no dead tuples are generated, and the count(*) completes much faster, as expected for just one row in the table.
Bloat considerations
In PostgreSQL, when a row is updated, the actual process is to mark the original row deleted (old value) and then insert a new row (new value). This causes dead tuple generation, and if not cleared up by vacuum can cause bloat. This bloat can lead to unnecessary space utilization and performance loss as queries scan these dead rows.
As discussed earlier, in a regular insert, there is no duplicate key pre-check before attempting to insert the tuple into the heap. Therefore, if it’s a duplicate value, it’s similar to first inserting a row and then deleting it. The result is a dead tuple, which must then be handled by vacuum.
In this example, with the pg_stat_user_tables view, we can see these dead tuples are generated when an insert fails due to a duplicate key violation:
postgres=> SELECT relname, n_dead_tup, n_live_tup
FROM pg_stat_user_tables
WHERE relname = 'blog';
-[ RECORD 1 ]-------+-------
relname | blog
n_live_tup | 7
n_dead_tup | 4As we can see, n_dead_tup currently is 4. We attempt inserting five duplicate values:
postgres=> DO $$
BEGIN
FOR r IN 1..5 LOOP
BEGIN
INSERT INTO blog VALUES (1, 'AWS Blog1');
EXCEPTION
WHEN UNIQUE_VIOLATION THEN
RAISE NOTICE 'duplicate row';
END;
END LOOP;
END;
$$;
NOTICE: duplicate row
NOTICE: duplicate row
NOTICE: duplicate row
NOTICE: duplicate row
NOTICE: duplicate row
DOWe now observe five additional dead tuples generated:
postgres=> SELECT relname, n_dead_tup, n_live_tup
FROM pg_stat_user_tables
WHERE relname = 'blog';
-[ RECORD 1 ]-------+-------
relname | blog
n_live_tup | 7
n_dead_tup | 9This highlights that even though no rows were successfully inserted, there is an increase in dead tuples (n_dead_tup).
Now, we run the following insert with the ON CONFLICT DO NOTHING clause five times:
DO $$
BEGIN
FOR r IN 1..5 LOOP
BEGIN
INSERT INTO blog VALUES (1, 'AWS Blog1') ON CONFLICT DO NOTHING;
END;
END LOOP;
END;
$$;Again, checking pg_stat_user_tables, we observe that there is no increase in n_dead_tup and therefore no dead tuples generated:
postgres=> SELECT relname, n_dead_tup, n_live_tup
FROM pg_stat_user_tables
WHERE relname = 'blog';
-[ RECORD 1 ]-------+-------
relname | blog
n_live_tup | 7
n_dead_tup | 9In the normal insert, we see dead tuples increasing, whereas no dead tuples are generated when we use the ON CONFLICT DO NOTHING clause. These dead tuples result in unnecessary table bloat as well as consumption of FreeStorageSpace.
Transaction ID usage acceleration and autovacuum impact
A PostgreSQL database can have two billion “in-flight” unvacuumed transactions before PostgreSQL takes dramatic action to avoid data loss. If the number of unvacuumed transactions reaches (2^31 – 10,000,000), the log starts warning that vacuuming is needed. If the number of unvacuumed transactions reaches (2^31 – 1,000,000), PostgreSQL sets the database to read-only mode and requires an offline, single-user, standalone vacuum. This is when the database reaches a “Transaction ID wraparound”, which is described in more detail in the PostgreSQL documentation. This vacuum requires multiple hours or days of downtime (depending on database size). More details on how to avoid this situation are described in Implement an Early Warning System for Transaction ID Wraparound in Amazon RDS for PostgreSQL.
Now let’s look at how these two different inserts impact the transaction ID usage by running some tests. All tests after this point are run on two different identical instances: one for regular INSERT testing and another one for the INSERT..ON CONFLICT clause.
Duplicate key with regular inserts
In the case of regular inserts, when the inserts error out, the transaction is canceled. This means if the application inserts 100 duplicate key values, 100 transaction IDs are consumed. This could lead to autovacuum runs to prevent wraparound in peak hours, which consumes resources that could otherwise be used for user workload.
For testing the impact of this, we ran a script using pgbench to repeatedly insert multiple key values into the blog table:
DO $$
BEGIN
FOR r in 1..1000000 LOOP
BEGIN
INSERT INTO blog VALUES (1, 'AWS Blog1');
EXCEPTION
WHEN UNIQUE_VIOLATION THEN
RAISE NOTICE 'duplicate row';
END;
END LOOP;
END;
$$;The script runs the INSERT statement 1 million times, and if it throws an error, prints out duplicate row.
We used the following pgbench command to run it through multiple connections:
pgbench --host=iocblog.abcedfgxymxvb.eu-west-1.rds.amazonaws.com --port=5432 --username=postgres -c 1000 -f script postgresWe observed multiple notice messages, because all were duplicate values:
NOTICE: duplicate row
NOTICE: duplicate row
NOTICE: duplicate row
NOTICE: duplicate row
NOTICE: duplicate row
NOTICE: duplicate row
NOTICE: duplicate rowFor this test, we modified some autovacuum parameters. First, we set log_autovacuum_min_duration to 0, to log all autovacuum actions. Secondly, we set rds.force_autovacuum_logging_level to debug5 in order to log detailed information about each run.
As the script did more and more loops, the transaction ID usage increased, as shown in the following visualization.

On this test instance, only our contrived workload was being run. We used Amazon CloudWatch to observe that as soon as MaximumUsedTransactionIds hit autovacuum_freeze_max_age (default 200 million), autovacuum worker was launched to prevent wraparound. The following is a snapshot of pg_stat_activity for that time:
postgres=> select * from pg_stat_activity where query like '%autovacuum%';
-[ RECORD 1 ]----+--------------------------------------------------------------------
datid | 14007
datname | postgres
pid | 3049
usesysid |
usename |
application_name |
client_addr |
client_hostname |
client_port |
backend_start | 2020-11-26 12:22:37.364145+00
xact_start | 2020-11-26 12:22:37.403818+00
query_start | 2020-11-26 12:22:37.403818+00
state_change | 2020-11-26 12:22:37.403818+00
wait_event_type | LWLock
wait_event | ProcArrayLock
state | active
backend_xid |
backend_xmin | 205602359
query | autovacuum: VACUUM public.blog (to prevent wraparound)
backend_type | autovacuum workerWhen we observe the query output and the graph, we can see that the autovacuum started at the time MaximumUsedTransactionIds reached 200 million (around 12:22 UTC; this was expected so as to prevent transaction ID wraparound). During the same time, we observed the following in postgresql.log:
2020-11-26 12:22:37 UTC::@:[3049]:DEBUG: blog: vac: 5971078 (threshold 50), anl: 0 (threshold 50)
.
.
2020-11-26 12:22:45 UTC::@:[3202]:WARNING: oldest xmin is far in the past
2020-11-26 12:22:45 UTC::@:[3202]:HINT: Close open transactions soon to avoid wraparound problems.
You might also need to commit or roll back old prepared transactions, or drop stale replication slots.The preceding code shows autovacuum running and having to act on 5.9 million dead tuples in the table. The warning about wraparound problems is because of the script generating the dead tuples, and advancing the transaction IDs. As time passed, autovacuum finally completed cleaning up the dead tuples:
2020-11-26 13:05:28 UTC::@:[62084]:LOG: automatic aggressive vacuum of table "postgres.public.blog": index scans: 2
pages: 0 removed, 1409317 remain, 48218 skipped due to pins, 0 skipped frozen
tuples: 115870210 removed, 96438 remain, 0 are dead but not yet removable, oldest xmin: 460304384
buffer usage: 4132095 hits, 21 misses, 1732480 dirtied
avg read rate: 0.000 MB/s, avg write rate: 37.730 MB/s
system usage: CPU: user: 22.71 s, system: 1.23 s, elapsed: 358.73 sAutovacuum had to act on approximately 115 million tuples. This is what we observed on an idle system with only a script running to insert duplicate values. The table here was pretty simple, with only two columns and two live rows. For bigger production tables, which realistically have more columns and more data, it could be much worse. Let’s now see how to avoid this by using INSERT..ON CONFLICT.
Duplicate key with INSERT..ON CONFLICT
We modified the same script as in the previous section to include the ON CONFLICT DO NOTHING clause:
DO $$
BEGIN
FOR r IN 1..1000000 LOOP
BEGIN
INSERT INTO blog VALUES (1, 'AWS Blog1') ON CONFLICT DO NOTHING;
EXCEPTION
WHEN UNIQUE_VIOLATION THEN
RAISE NOTICE 'duplicate row';
END;
END LOOP;
END;
$$;We ran the script on the instance in the following steps:
// Check the live rows in the table
postgres=> SELECT * FROM blog;
n | name
---+-----------
1 | AWS Blog1
2 | AWS Blog2
(2 rows)
postgres=> timing
Timing is on.
postgres=> SELECT now();
now
-------------------------------
2020-11-29 22:25:26.426271+00
(1 row)
Time: 2.689 ms
// Check the current transaction ID of the database (before running the script) :
postgres=> SELECT txid_current();
txid_current
--------------
16373267
(1 row)
//Run the script in another session as follows :
pgbench --host=iocblog2.abcdefghivb.eu-west-1.rds.amazonaws.com --port=5432 --username=postgres -c 1000 -f script2 postgres
Password:
starting vacuum...end.
//After some time later, go to previous session and check transaction ID along with pg_stat_activity. It increased by 4 transactions (which were the ones including our testing).
postgres=> SELECT now();
-[ RECORD 1 ]----------------------
now | 2020-11-29 22:56:59.241092+00
Time: 8.692 ms
postgres=> SELECT txid_current();
-[ RECORD 1 ]+---------
txid_current | 16373271
Time: 234.526 ms
//The following query shows the 1001 active transactions which are active because of the script, but aren't causing a spike in transaction IDs.
postgres=> SELECT now();
-[ RECORD 1 ]----------------------
now | 2020-11-29 22:59:44.373064+00
Time: 7.297 ms
postgres=> SELECT COUNT(*)
FROM pg_stat_activity
WHERE query like '%blog%'
AND backend_type='client backend';
-[ RECORD 1 ]
count | 1001
Time: 181.370 ms
postgres=> SELECT now();
-[ RECORD 1 ]----------------------
now | 2020-11-29 22:59:52.661102+00
Time: 6.212 ms
postgres=> SELECT txid_current();
-[ RECORD 1 ]+---------
txid_current | 16373273
Time: 741.437 msThe preceding testing shows that if we use INSERT..ON CONFLICT, the transaction IDs aren’t consumed. The following visualization shows the MaximumUsedTransactionIds metric.

There is still one more benefit to examine by using this clause: storage space.
Storage space considerations
In the case of the normal insert, the dead tuples that are generated result in unnecessary space consumption. Even in our small test workload, we were able to quickly end up in a storage full situation. If this happens in a production system, a scale storage is required.
Duplicate key with regular inserts
As discussed earlier, the tuples are inserted into the heap and checked if they are valid as per the constraint. If it fails, it’s marked as deleted. We can observe the impact on the FreeStorageSpace metric.
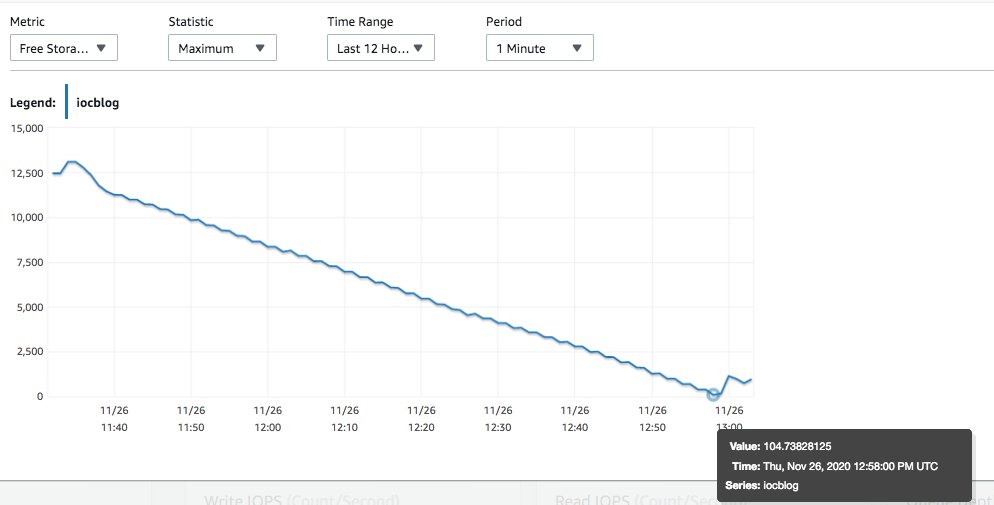
FreeStorageSpace went down all the way to a few MBs because these dead rows consume disk space. We used the following queries to monitor the script, they show that while there are only two visible tuples, space is consumed by the dead rows.
postgres=> select count(*) from blog;
-[ RECORD 1 ]
count | 2
postgres=> select pg_size_pretty (pg_table_size('blog'));
-[ RECORD 1 ]--+------
pg_size_pretty | 5718 MB
(1 row)In our small instance, we went into Storage-full state during our script execution.

Duplicate key with INSERT..ON CONFLICT
For comparison, when we ran the script using INSERT..ON CONFLICT, there was absolutely no drop in storage. This is because the transaction is prechecked and the tuple isn’t inserted in the table. With no dead tuples generated, no space is taken up by them, and the instance doesn’t run out of storage space due to duplicate inserts.

Summary
Let’s recap each of the considerations we discussed in the previous sections.
| .. | Regular INSERT | INSERT..ON CONFLICT DO NOTHING |
| Bloat considerations | Dead tuples generated for each conflicting tuples inserted in the relation. | Pre-check before inserting into the heap ensures no duplicates are inserted. Therefore, no dead tuples are generated. |
| Transaction ID considerations | Each failed insert causes the transaction to cancel, which causes consumption of 1 transaction ID. If too many duplicate values are inserted, this can spike up quickly. | The transaction can be backed out and not canceled in the case of a duplicate, and therefore, a transaction ID is not consumed. |
| Autovacuum Impact | As transaction IDs increase, autovacuum to prevent wraparound is triggered, consuming resources to clean up the dead rows. | No dead tuples, no transaction ID consumption, no autovacuum to prevent wraparound is triggered. |
| FreeStorageSpace considerations | The dead tuples also cause storage consumption. | No dead tuples generated, so no extra space is consumed. |
In this post, we showed you some of the issues that duplicate key violations can cause in a PostgreSQL database. They can cause wasted disk storage, high transaction ID usage and unnecessary Autovacuum work.
We offered an alternative approach using the “INSERT..ON CONFLICT“ clause which avoid these problems. It is recommended to use this alternative if you are constantly observing high volumes of the “duplicate key violates unique constraint” error in your logs. You might need to make some application code changes while using this option to see whether the INSERT succeeded or failed. This can not be determined by the error anymore (as there will be none generated) but by checking the number of rows affected with the insert query.
If you have any questions, let us know in the comments section.
About the Authors
 Divya Sharma is a Database Specialist Solutions architect at AWS, focusing on RDS/Aurora PostgreSQL. She has helped multiple enterprise customers move their databases to AWS, providing assistance on PostgreSQL performance and best practices.
Divya Sharma is a Database Specialist Solutions architect at AWS, focusing on RDS/Aurora PostgreSQL. She has helped multiple enterprise customers move their databases to AWS, providing assistance on PostgreSQL performance and best practices.
 Shawn McCoy is a Senior Database Engineer for RDS & Aurora PostgreSQL. After being an Oracle DBA for many years he became one of the founding engineers for the launch of RDS PostgreSQL in 2013. Since then he has been improving the service to help customers succeed and scale their applications.
Shawn McCoy is a Senior Database Engineer for RDS & Aurora PostgreSQL. After being an Oracle DBA for many years he became one of the founding engineers for the launch of RDS PostgreSQL in 2013. Since then he has been improving the service to help customers succeed and scale their applications.