Different Scenarios to Handle SQL Server Error 983
SQL Server primary purpose is to archive, manipulate and retrieve data as per requested by other several software applications. These applications may run either on identical computers or on different systems connected via the Internet (or a network). To handle such large amount of data, which can also be lost or damaged due to some issue, there is a very common feature in SQL server i.e. AlwaysOn Availability groups. This feature aims to provide high-availability and disaster recovery solution, generally, providing an alternative to business-level users to backup their database.
In addition, there may occur multiple errors in SQL server like SQL Server error 983, SQL Server error 976, SQL Server 156, etc. Therefore, in this article. we are going to discuss SQL Server Error 983 and different scenarios, which will help you to get rid of this error.
Error: 983, Severity: 14, State: 1.
Unable to access database ‘HADB’ because its replica role is RESOLVING which does not allow connections. Try the operation again later.
Scenario 1: Examine Value of FailureConditionLevel
For setting the conditions related to AlwaysOn feature, we require an additional property named as FailureConditionLevel. This property performs controlling when failover occurs either from failover cluster or from AlwaysOn availability group. In SQL Server, by default, the value of FailureConditionLevel is 3 and one can also modify this value using T-SQL script.
To resolve the Microsoft SQL Server error 983, first examine whether the condition of SQL server service is down or not. If it is down, then increase up the service; else check the conditions described in below snapshot.

NOTE: Perform the Cluster action only if any sub-system encounters any kind of error, do not perform any action when a warning occurs.
Scenario 2: Cluster Diagnostic
The Cluster Diagnostic logs (or Cluster log) are situated in the log directory of MS SQL server and are different from log files. These files are of the format:
ServerName_InstanceName_SQLDIAG_*.xel
When you double-click on the cluster log file, you will find several events present in it. Multiple attributes of the events will display in front of you.
These attributes define the health status of SQL server i.e. whether sp_server_diagnostics displays an error or not. The error occurs when the resource is performing its functioning and suddenly an interruption named Failure, occurs. Such failure occurs due to FailureConditionLevel set up & display that the resources are unhealthy i.e. NOTHEALTH
Scenario 3: AlwaysOn Extended Event Log
SQL Server comprises of multiple extended events log files, which are related to AlwaysOn feature. To view such files, make use of the following query:
SELECT * FROM sys.dm_xe_objects WHERE name LIKE ‘%hadr%’
One such extended event log file is AlwaysOn Health Extended Event log, which deals with the AlwaysOn availability group related to diagnostics like State changes for Group, errors report, expiration days, etc. These files are of the format:
AlwaysOn_health*.xel
One can double-click on the health file and view the events related to such file. Sometimes, we find that availability groups are to be expired, and warned to go for failover that will migrate the states from PRIMARY_NORMAL to RESOLVING_NORMAL.
Scenario 4: Dealing with Cluster Log Files
In this scenario, we are going to deal with restart operation of nodes. Within cluster log files, one can see the ‘restart action’ command, which indicates that a restart is tried on a present node before performing failover to the previous node. Therefore, if restart action is successful it denotes that failing over was unsuccessful to previous node.
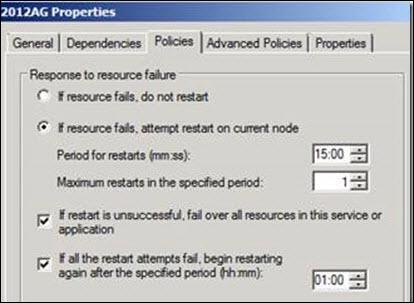
In addition, we have a property box that confirms the Restart action of node.
Scenario 5: ErrorLog of SQL Server
Microsoft SQL Server Error 983 occurs due to multiple reasons. Commonly, it is the outcome of SAP performing re-connection during its working process. In addition, we have several events (in sequence) initially documented in stack of SQL Server ErrorLog.

Conclusion
There are multiple reasons behind occurrence of Microsoft SQL Server error 983, but when it comes to resolving it different scenario helps us to troubleshoot this error. A User should learn about these scenarios and then perform activities accordingly.
I was faced an situation in AlwaysOn on one of the Production server which was showing the error message as
Error: 983, Severity: 14, State: 1.
Unable to access database ‘DBNAME’ because its replica role is RESOLVING which does not allow connections. Try the operation again later.
When googling about the issue i found an useful blog in MSDN which iam sharing below :
Thanks to Denzil Ribeiro for posting this article.
I was dealing with an issue where we had an AlwaysOn availability group with 2 replicas configured for Automatic failover. There was a 30 second glitch where folks could not connect to the Database on the primary and automatic failover did not kick in. Well, that was our initial impression at least. The purpose of this post is to expose you to the different logs available in troubleshooting AlwaysOn Availability group issues, not so much on this particular problem itself.
Symptoms on Primary: Connections failed for a brief moment with the error below and then was all good.
Error: 983, Severity: 14, State: 1.
Unable to access database ‘HADB’ because its replica role is RESOLVING which does not allow connections. Try the operation again later.
So there were 3 questions to answer:
a. What was the reason for the error?
b. Why didn’t automatic failover kick in? Or did it?
c. Was it supposed to fail over to the other node?
First of all we need to understand the FailureConditionLevel which controls when failover occurs both from an SQL FCI (failover cluster) or AlwaysOn Availability group Automatic failover perspective. For detailed information regarding Failover Policies for Failover Cluster Instances, refer to this article: http://msdn.microsoft.com/en-us/library/ff878664.aspx

In my case the FailoverConditionLevel is set to 5 (Default is 3). This setting can be altered with the following TSQL script:

If I look at the article referenced above, I notice that the FailoverConditionLevel has the following attributes:
|
5 |
Indicates that a server restart or failover will be triggered if any of the following conditions are raised:
|
One thing to note here is that the Cluster action is only if any of the subsystems report an “error”, no action is taken on a warning.
So effectively what happens is the following:
-
Cluster service runs LooksAlive check
-
Sp_server_diagnostics results sent to Resource Monitor DLL
-
Resource Monitor DLL detects any error state and notifies the cluster service
-
Cluster Service takes the resource offline
-
Notifies SQL Server to issue an internal command to take the availability group offline.
-
There is also the whole concept of a lease that is explained here:
In order to understand this better I attempted and was able to reproduce the scenario.
I then looked at the Cluster Diagnostic extended event Log, the AlwaysOn extended event log, the cluster log, and the SQL Server error log to try to piece together what exactly happened.
Cluster Diagnostic Extended Event Log:
We see from this log that the System component did throw an error. Which equates to there were N number of dumps created and or a spinlock orhpaned after an Access violation or a detected Memory scribbler condition
The Cluster Diagnostics Logs are located in the Log directory as shown below and are different log files than the cluster log itself.
They are of the format : ServerName_InstanceName_SQLDIAG_*.xel

As we can see below, you see the component_health_result indicate that the system component of sp_server_diagnostics returned an error, when the resource monitor than interpretted as a Failure due to the FailureConditionLevel set, and propagated the resource “NOTHEALTH” to the cluster service which triggered the LooksAlive check to return “not alive” or false status.

AlwaysOn Extended Event log
The AlwaysOn Health Extended Event logs cover the Availability Group related diagnostics such as State changes for the Group or Replica or Databases, errors reported, lease expiration and any Availability Group Related DDL that is executed. The format of the logs is:AlwaysOn_health*.xel

If we look at the log snippet below, we see that the AG lease expired, and that triggered us to attempt a failover which in turn changes the state from PRIMARY_NORMAL to RESOLVING_NORMAL.

Cluster Log
Note: The times are in UTC so you have to convert them to match up with the other log files.
00006918.00015978::2013/04/03-18:54:37.251 INFO [RES] SQL Server Availability Group: [hadrag] SQL Server component ‘system’ health state has been changed from ‘warning’ to ‘error’ at 2013-04-03 11:54:37.247
00006918.00014ef4::2013/04/03-18:54:37.970 ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, the state of system component is error
00006918.00014ef4::2013/04/03-18:54:37.970 ERR [RES] SQL Server Availability Group< 2012AG>: [hadrag] Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel
00006918.00014ef4::2013/04/03-18:54:37.970 ERR [RES] SQL Server Availability Group< 2012AG>: [hadrag] Resource Alive result 0.
00006918.00014ef4::2013/04/03-18:54:37.970 ERR [RES] SQL Server Availability Group< 2012AG>: [hadrag] Resource Alive result 0.
00006918.00014ef4::2013/04/03-18:54:37.970 WARN [RHS] Resource 2012AG IsAlive has indicated failure.
00019d20.00000e5c::2013/04/03-18:54:37.970 INFO [RCM] HandleMonitorReply: FAILURENOTIFICATION for ‘2012AG’, gen(0) result 1.
00019d20.00000e5c::2013/04/03-18:54:37.970 INFO [RCM] TransitionToState(2012AG) Online–>ProcessingFailure.
00019d20.00000e5c::2013/04/03-18:54:37.970 INFO [RCM] rcm::RcmGroup::UpdateStateIfChanged: (2012AG, Online –> Failed)
00019d20.00000e5c::2013/04/03-18:54:37.970 INFO [RCM] resource 2012AG: failure count: 1, restartAction: 2.
00019d20.00000e5c::2013/04/03-18:54:37.970 INFO [RCM] Will restart resource in 500 milliseconds.
— If you see the “restart action” highlighted above, a restart is attempted on the current node first before failing over to the other node and in this case the restart is successful so it doesn’t really fail over to the other node. If we take a look at the cluster Availability group Resource Properties, you can confirm that the Restart action does indicate that a restart will be attempted on the current node first
— 
00019d20.00019418::2013/04/03-18:55:06.079 INFO [RCM] TransitionToState(2012AG) DelayRestartingResource–>OnlineCallIssued.
00019d20.00019418::2013/04/03-18:55:06.079 INFO [RCM] HandleMonitorReply: ONLINERESOURCE for ‘2012AG’, gen(1) result 997.
00019d20.00019418::2013/04/03-18:55:06.079 INFO [RCM] TransitionToState(2012AG) OnlineCallIssued–>OnlinePending.
…
00006918.0001f1c0::2013/04/03-18:55:07.298 INFO [RHS] Resource 2012AG has come online. RHS is about to report status change to RCM
SQL Server Errorlog
2013-04-03 11:54:43.59 Server Error: 19407, Severity: 16, State: 1.
2013-04-03 11:54:43.59 Server The lease between availability group ‘2012AG’ and the Windows Server Failover Cluster has expired. A connectivity issue occurred between the instance of SQL Server and the Windows Server Failover Cluster. To determine whether the availability group is failing over correctly, check the corresponding availability group resource in the Windows Server Failover Cluster.
2013-04-03 11:54:43.64 Server AlwaysOn: The local replica of availability group ‘2012AG’ is going offline because either the lease expired or lease renewal failed. This is an informational message only. No user action is required.
2013-04-03 11:54:43.64 Server The state of the local availability replica in availability group ‘2012AG’ has changed from ‘PRIMARY_NORMAL’ to ‘RESOLVING_NORMAL’. The replica state changed because of either a startup, a failover, a communication issue, or a cluster error. For more information, see the availability group dashboard, SQL Server error log, Windows Server Failover Cluster management console or Windows Server Failover Cluster log.
2013-04-03 11:54:43.84 spid31s The availability group database «HADB» is changing roles from «PRIMARY» to «RESOLVING» because the mirroring session or availability group failed over due to role synchronization. This is an informational message only. No user action is required.
2013-04-03 11:54:43.84 spid27s AlwaysOn Availability Groups connection with secondary database terminated for primary database ‘HADB’ on the availability replica with Replica ID: {89c5680c-371b-45b9-ae19-2042d8eec27b}. This is an informational message only. No user action is required.
n The error below can occur if the Local Log records are hardened but quorum is lost with the cluster so the remote harden cannot be completed.
2013-04-03 11:54:45.16 spid58 Remote harden of transaction ‘user_transaction’ (ID 0x00000000001ee9e2 0000:000006eb) started at Apr 3 2013 11:54AM in database ‘HADB’ at LSN (37:28:204) failed.
2013-04-03 11:54:46.42 spid31s Nonqualified transactions are being rolled back in database HADB for an AlwaysOn Availability Groups state change. Estimated rollback completion: 100%. This is an informational message only. No user action is required.
n This phase is after the “restart action” as seen in the cluster log where we are attempting a restart on the same node before failing over to the other node.
2013-04-03 11:55:06.25 spid58 AlwaysOn: The local replica of availability group ‘2012AG’ is preparing to transition to the primary role in response to a request from the Windows Server Failover Clustering (WSFC) cluster. This is an informational message only. No user action is required.
2013-04-03 11:55:07.27 spid58 The state of the local availability replica in availability group ‘2012AG’ has changed from ‘RESOLVING_NORMAL’ to ‘PRIMARY_PENDING’. The replica state changed because of either a startup, a failover, a communication issue, or a cluster error. For more information, see the availability group dashboard, SQL Server error log, Windows Server Failover Cluster management console or Windows Server Failover Cluster log.
2013-04-03 11:55:07.55 Server The state of the local availability replica in availability group ‘2012AG’ has changed from ‘PRIMARY_PENDING’ to ‘PRIMARY_NORMAL’. The replica state changed because of either a startup, a failover, a communication issue, or a cluster error. For more information, see the availability group dashboard, SQL Server error log, Windows Server Failover Cluster management console or Windows Server Failover Cluster log.
So in answering the 3 prior questions I had with the logs
a. The reason we got into this state was the system component reported an error ( was a bunch of exceptions), we won’t go into those here
b. Failover was attempted, but initial attempt is to restart on the same node and it did end up coming online on that node.
c. No, it should not have failed over to the other node
Hope the exposure to these logs is helpful in troubleshooting AlwaysON Availability group issues
Ref : https://blogs.msdn.microsoft.com/sql_pfe_blog/2013/04/08/sql-2012-alwayson-availability-groups-automatic-failover-doesnt-occur-or-does-it-a-look-at-the-logs/
SQL Server Failover Clustered Instances (FCI) and Availability Groups (AG) depend a lot on Windows Server Failover Clustering (WSFC). Understanding how the underlying WSFC platform works can help us maintain availability of our databases
This blog post is the second in a series that talks about the process that I follow when troubleshooting availability of SQL Server failover clustered instances and Availability Groups. Note that the focus of this series is primarily on availability – identifying and dealing with downtime.
As I was driving out of my driveway, I noticed something that is considered to be every car owner’s worst nightmare: the check engine light. And what’s frustrating about it is that it comes without a warning and no explanation whatsoever.
I’ve seen this light go off in the past. So, I did what I did before to get it to turn off. I opened the gas tank, cleaned the gas cap and the surrounding area and closed it real tight. That didn’t work. I was hoping to save a few hundred bucks and a trip to the car mechanic. I was unlucky. I had to take it to the mechanic.
Modern vehicles are equipped with sensors and mini-computers that track what’s wrong with your car. Your car dealer or mechanic will have devices that can read these sensors and mini-computers to identify the code that is triggered the check engine light. If you really want to know what caused that check engine light to turn on, you have to read the error codes with a scanner tool. See, even cars have error codes.
The SQL Server error log contains information about the operational aspects of your databases. Depending on how you log operational events, it can contain everything from failed logins, corrupted data pages, failed (and annoyingly successful) backups, out-of-memory issues, etc. Reading the SQL Server error log can be overwhelming, especially if you don’t know what you’re looking for.
Troubleshooting availability issues with a SQL Server failover clustered instance (FCI) or Availability Groups (AGs) can feel like reading the codes that triggered your car’s check engine light. But, hey, you don’t need any special code reader to do it. You can use any text editor/reader to open the SQL Server error log even when the SQL Server instance is offline. In fact, this is one common misconception about reading the SQL Server error log: you can read it even when the SQL Server instance is offline. You just need to know where to find it.
Two Common Keywords That Identify Potential Availability Issues
I could list a ton of reasons why a SQL Server FCI or AG is offline. Which is why my first step in troubleshooting availability issues on a SQL Server FCI or AG is to look at the Cluster Dependency Report. More often than not, you can quickly identify availability issues for a SQL Server FCI using the Cluster Dependency Report. The most common availability issues for a SQL Server FCI are caused by the underlying Windows Server Failover Cluster (WSFC). Just take a look at this Failover Cluster Troubleshooting guide to see what I mean.
But what about SQL Server AGs?
Because SQL Server AGs work on the database-level, anything related to availability issues at the database-level can cause issues at the AG-level. Below are two of the common keywords that identify SQL Server AG availability issues. You can use them to filter the results in the SQL Server error log. These are simply meant to give you a sense of how you can use the SQL Server error log to start identifying availability issues.
RESOLVING
This could be caused by a number of different reasons. Here’s one example.
Error 983, Severity 14: Unable to access database ‘%.*ls’ because its replica role is RESOLVING which does not allow connections.
This could be caused by a network communication issue between the primary and the secondary.
Here’s a tip that helps me simplify this idea: Think of this as a typical client-server communication issue with the primary replica acting as the client (sending log records) to the secondary replica and vice versa.
- firewall – Windows Firewall or otherwise
- endpoint permissions – the SQL Server service account does not have access to the endpoint
- bad cable – you need to keep rats off your data center
- corrupted storage on the secondary – this renders your database offline regardless
- offline secondary WSFC node – this renders your database server offline regardless
- large number of VLFs on database that is taking time to analyze during a restart of the secondary – this is just like any other databases undergoing crash recovery
- Transparent Data Encryption enabled on the primary but not on the secondary
I could go on and on and list other reasons. But the point is to find this keyword in the SQL Server error log and think of reasons why your primary replica could not connect to the secondary and vice versa.
Now, this does not mean that your SQL Server AG is offline. If the WSFC is properly configured and you have proper quorum, your SQL Server AG will still be online with the primary replica just happily doing its thing. It’s like being able to drive your car even with the check engine light on.
FAILOVER
This could be related to the previous item RESOLVING. Now, you can be as paranoid as I am to get alerted when a SQL Server AG (or FCI) failover occurred so that you can quickly identify what caused it. But you can also be confident that your system just works as expected.
The failover process is initiated by the WSFC. But in order for the WSFC to automatically failover the SQL Server AG from the primary to the secondary replica, the following conditions should be met.
- The WSFC has quorum and can decide to automatically failover
- Maximum failure threshold has not been exceeded
- Cluster service on the secondary replica is running and healthy
- The secondary replica configured for automatic failover is fully synchronized
Noticed that the first three items in the list all pertain the WSFC. The last item applies specifically to the database. Which is why you need to quickly identify and resolve any error messages that contain the keyword RESOLVING to guarantee automatic failover.
Here’s an example error message.
Error 19406, Severity 10: The state of the local availability replica in availability group ‘%.*ls’ has changed from ‘%ls’ to ‘%ls’.
Of course, you won’t see anything like this when a SQL Server FCI fails over because that is no different from starting a SQL Server instance. The SQL Server error log would be recycled as a side effect of the failover.
NOTE: Automatic failover is not available on SQL Server AGs when one of the replicas is running a SQL Server FCI because the SQL Server FCI automatic failover takes precedence over the SQL Server AG automatic failover.
Reading the SQL Server Errror Log
I’ve been using the undocumented sp_readerrorlog (was xp_readerrorlog) system stored procedure ever since I can remember to search for keywords inside the SQL Server error log. I’m still not good with SQL Server Management Studio, even SQL Server Enterprise Manager from the good old days of SQL Server 2000 and earlier. To use the sp_readerrorlog stored procedure to search the current SQL Server error log for the RESOLVING keyword,
--to search for the RESOLVING keyword --in the current SQL Server error log sp_readerrorlog 0,1, 'RESOLVING'
My friend and SQL Server senior escalation engineer Balmukund Lakhani (blog | Twitter) wrote about the different parameters that you can use when calling this system stored procedure. This makes it easy for me to search the SQL Server error log to look for these keywords.
UPDATE: I’ve included Rob Sewell’s (blog | Twitter) one-line PowerShell script example below. This just demonstrates how powerful PowerShell is when performing tasks like this.
(Get-SQLErrorLog -Server SERVER/INSTANCE).Where{$_.Message -like '*Resolving*' -or $_.Message -like '*Failover*'}
Additional Resources
- Troubleshooting automatic failover problems in SQL Server 2012 AlwaysOn environments
- Troubleshoot SQL Server AlwaysOn
- Troubleshoot Always On Availability Groups Configuration (SQL Server)
- Failover Cluster Troubleshooting guide
- Troubleshooting AlwaysOn Issues
-
All, I have this error in a logfile «Unable to access availability database because the database replica is not in the PRIMARY or SECONDARY role. Connections to an availability database is permitted only when the database replica is in the PRIMARY or SECONDARY role. Try the operation again later.
2016-06-26 19:43:31.60 Logon Error: 983, Severity: 14, State: 1.
Not freaking out but would like to know on how to solve.
-
TheSQLGuru
SSC Guru
Points: 134017
What is the status of the other database? Is it suspect, offline or something like that?
Best,
Kevin G. Boles
SQL Server Consultant
SQL MVP 2007-2012
TheSQLGuru on googles mail service -
johnwalker10
SSCrazy Eights
Points: 9124
-
Chitown
Hall of Fame
Points: 3237
TheSQLGuru (6/27/2016)
What is the status of the other database? Is it suspect, offline or something like that?
All DBs are online and in sync
This was the error in the log file
AlwaysOn: The availability replica manager is going offline because the local Windows Server Failover Clustering (WSFC) node has lost quorum.
-
TheSQLGuru
SSC Guru
Points: 134017
Chitown (6/28/2016)
TheSQLGuru (6/27/2016)
What is the status of the other database? Is it suspect, offline or something like that?
All DBs are online and in sync
This was the error in the log file
AlwaysOn: The availability replica manager is going offline because the local Windows Server Failover Clustering (WSFC) node has lost quorum.
The error tells you quite directly what the issue is. There are a number of possible scenarios and recoveries here. Can’t advise you without details of your environment. But WSFC quorum stuff is easily searchable …
Best,
Kevin G. Boles
SQL Server Consultant
SQL MVP 2007-2012
TheSQLGuru on googles mail service -
Perry Whittle
SSC Guru
Points: 233806
Chitown (6/28/2016)
TheSQLGuru (6/27/2016)
What is the status of the other database? Is it suspect, offline or something like that?
All DBs are online and in sync
This was the error in the log file
AlwaysOn: The availability replica manager is going offline because the local Windows Server Failover Clustering (WSFC) node has lost quorum.
Check the event logs and the cluster events, my guess is a network comm issue.
Can you provide more detail on the networks used for the WSFC, also does a cluster validation report come back clean
————————————————————————————————————
«Ya can’t make an omelette without breaking just a few eggs» 😉
-
Chitown
Hall of Fame
Points: 3237
The validation report didn’t come clean. There are some network related issues we are experiencing. For time being, I have deleted Always ON. (T logs backup are in place every 15 minutes). Question. Do I shutdown failover cluster as well and leave it as it is? Because I am still seeing connectivity issues.
Viewing 7 posts — 1 through 6 (of 6 total)
Hello Experts,
Good day! We encountered a problem with our production system which are running on two-node WSFC/SQL AlwaysOn environment, and SQL AG was stuck in ‘RESOLVING’ state on 2016/04/13 from 21:17:19 to 21:18:15.(About 1 min).
This two-node are running Windows Server 2012 Standard, and DBMS are running SQL Server 2012 Service Pack 3.
Microsoft SQL Server 2012 (SP3) (KB3072779) — 11.0.6020.0 (X64)
Oct 20 2015 15:36:27 Copyright (c) Microsoft Corporation Enterprise Edition: Core-based Licensing (64-bit) on Windows NT 6.2 <X64> (Build 9200: ))
In some research, we’ve conducted to read some MS-KB article which mentioned similar situation issues/problem are listed below.
KB2699013-FIX_SQL Server 2012, SQL Server 2008 R2 or SQL Server 2008 stops responding and a ‘Non-yielding Scheduler’ error is logged
KB3081074-FIX_A stalled dispatcher system dump forces a failover and service outage in SQL Server 2014 or SQL Server 2012
KB3112363-Improvements for SQL Server AlwaysOn Lease Timeout supportability in SQL Server 2012
I thought/bold assumption this version of service pack/cumulative update was supposed to fix related problem, or not?
Anyway, finally the issue has initiative found us, I just want to clarify and know, Is it still a unresolved potential bug?
Any recommendation or advice is highly appreciated, thanks a lot!
Kevin
=====================================================================
SQL Error Log
=====================================================================
04/13/2016 21:18:15,spid30s,Unknown,AlwaysOn Availability Groups connection with secondary database established for primary database ‘QAP’ on the availability replica with Replica ID: {ad0236ba-a1cf-449d-b1c1-ce7d3c86e9cc}. This is an
informational message only. No user action is required.
04/13/2016 21:18:01,spid164,Unknown,The log shipping secondary database DL980-4.QAP has restore threshold of 45 minutes and is out of sync. No restore was performed for 520600 minutes. Restored latency is 10 minutes. Check agent log and
logshipping monitor information.
04/13/2016 21:18:01,spid164,Unknown,Error: 14421<c/> Severity: 16<c/> State: 1.
04/13/2016 21:17:40,Logon,Unknown,Unable to access database ‘QAP’ because its replica role is RESOLVING which does not allow connections. Try the operation again later.
04/13/2016 21:17:40,Logon,Unknown,Error: 983<c/> Severity: 14<c/> State: 1.
04/13/2016 21:17:40,spid49s,Unknown,Nonqualified transactions are being rolled back in database QAP for an AlwaysOn Availability Groups state change. Estimated rollback completion: 100%. This is an informational message only. No user action
is required.
04/13/2016 21:17:40,Logon,Unknown,Unable to access database ‘QAP’ because its replica role is RESOLVING which does not allow connections. Try the operation again later.
04/13/2016 21:17:40,Logon,Unknown,Error: 983<c/> Severity: 14<c/> State: 1.
………………………………………
04/13/2016 21:17:23,Logon,Unknown,Unable to access database ‘QAP’ because its replica role is RESOLVING which does not allow connections. Try the operation again later.
04/13/2016 21:17:23,Logon,Unknown,Error: 983<c/> Severity: 14<c/> State: 1.
04/13/2016 21:17:23,Logon,Unknown,Unable to access database ‘QAP’ because its replica role is RESOLVING which does not allow connections. Try the operation again later.
04/13/2016 21:17:23,Logon,Unknown,Error: 983<c/> Severity: 14<c/> State: 1.
04/13/2016 21:17:23,Logon,Unknown,Unable to access database ‘QAP’ because its replica role is RESOLVING which does not allow connections. Try the operation again later.
04/13/2016 21:17:23,Logon,Unknown,Error: 983<c/> Severity: 14<c/> State: 1.
04/13/2016 21:17:23,Logon,Unknown,Unable to access database ‘QAP’ because its replica role is RESOLVING which does not allow connections. Try the operation again later.
04/13/2016 21:17:23,Logon,Unknown,Error: 983<c/> Severity: 14<c/> State: 1.
………………………………………
04/13/2016 21:17:09,spid49s,Unknown,The availability group database «QAP» is changing roles from «PRIMARY» to «RESOLVING» because the mirroring session or availability group failed over due to role
synchronization. This is an informational message only. No user action is required.
04/13/2016 21:17:09,Server,Unknown,Stopped listening on virtual network name ‘dbgrpqap’. No user action is required.
………………………………………
04/13/2016 21:17:09,spid49s,Unknown,AlwaysOn Availability Groups connection with secondary database terminated for primary database ‘QAP’ on the availability replica with Replica ID: {ad0236ba-a1cf-449d-b1c1-ce7d3c86e9cc}. This is an informational
message only. No user action is required.
04/13/2016 21:17:09,Server,Unknown,The state of the local availability replica in availability group ‘AGQAP’ has changed from ‘PRIMARY_NORMAL’ to ‘RESOLVING_NORMAL’. The replica state changed because of either a startup<c/> a failover<c/>
a communication issue<c/> or a cluster error. For more information<c/> see the availability group dashboard<c/> SQL Server error log<c/> Windows Server Failover Cluster management console or Windows Server Failover Cluster log.
04/13/2016 21:17:09,Server,Unknown,AlwaysOn: The local replica of availability group ‘AGQAP’ is going offline because either the lease expired or lease renewal failed. This is an informational message only. No user action is required.
04/13/2016 21:17:08,Server,Unknown,Process 0:0:0 (0xfe4) Worker 0x0000000006B16160 appears to be non-yielding on Scheduler 28. Thread creation time: 13102488101502. Approx Thread CPU Used: kernel 1591 ms<c/> user 0 ms. Process
Utilization 7%. System Idle 94%. Interval: 74565 ms.
04/13/2016 21:17:08,Server,Unknown,The lease between availability group ‘AGQAP’ and the Windows Server Failover Cluster has expired. A connectivity issue occurred between the instance of SQL Server and the Windows Server Failover
Cluster. To determine whether the availability group is failing over correctly<c/> check the corresponding availability group resource in the Windows Server Failover Cluster.
04/13/2016 21:17:08,Server,Unknown,Error: 19407<c/> Severity: 16<c/> State: 1.
………………………………………
04/13/2016 21:17:08,Server,Unknown,DoMiniDump () encountered error (0x80004005) — Unspecified error
04/13/2016 21:17:07,Server,Unknown,Timeout waiting for external dump process 8480.
04/13/2016 21:17:07,Server,Unknown,Windows Server Failover Cluster did not receive a process event signal from SQL Server hosting availability group ‘AGQAP’ within the lease timeout period.
04/13/2016 21:17:07,Server,Unknown,Error: 19419<c/> Severity: 16<c/> State: 1.
04/13/2016 21:16:18,Server,Unknown,Stack Signature for the dump is 0x000000000000036A
04/13/2016 21:16:18,Server,Unknown,* *******************************************************************************
04/13/2016 21:16:18,Server,Unknown,*
04/13/2016 21:16:18,Server,Unknown,* Non-yielding Scheduler
04/13/2016 21:16:18,Server,Unknown,*
04/13/2016 21:16:18,Server,Unknown,* 04/13/16 21:16:18 spid 3976
04/13/2016 21:16:18,Server,Unknown,* BEGIN STACK DUMP:
04/13/2016 21:16:18,Server,Unknown,*
04/13/2016 21:16:18,Server,Unknown,* *******************************************************************************
04/13/2016 21:16:18,Server,Unknown,***Unable to get thread context for spid 0
=====================================================================
BugCheck Dump
=====================================================================
Current time is 21:16:17 04/13/16.
This file is generated by Microsoft SQL Server
version 11.0.6020.0
upon detection of fatal unexpected error. Please return this file,
the query or program that produced the bugcheck, the database and
the error log, and any other pertinent information with a Service Request.
Computer type is Intel(R) Xeon(R) CPU X7560 @ 2.27GHz.
Bios Version is HP — 2
128 X64 level 8664, 2 Mhz processor (s).
Windows NT 6.2 Build 9200 CSD .
Memory
MemoryLoad = 99%
Total Physical = 1048565 MB
Available Physical = 3472 MB
Total Page File = 1348565 MB
Available Page File = 364906 MB
Total Virtual = 8388607 MB
Available Virtual = 7188925 MB
***Unable to get thread context for spid 0
* *******************************************************************************
*
* BEGIN STACK DUMP:
* 04/13/16 21:16:18 spid 3976
*
* Non-yielding Scheduler
*
* *******************************************************************************
=====================================================================
SQL Server Memory Configuration & Availability Group Properties
=====================================================================
Memory_usedby_Sqlserver_MB Locked_pages_used_Sqlserver_MB Total_VAS_in_MB process_physical_memory_low process_virtual_memory_low
————————— —————————— ——————— ————————— —————————
960375 950171 8388607 0
0
=====================================================================
Object Name Value
Type
—— —- ——
—-
AGQAP VerboseLogging 0
UInt32
AGQAP LeaseTimeout 100000 UInt32
AGQAP FailureConditionLevel 1 UInt32
AGQAP HealthCheckTimeout 150000 UInt32
Environment

-> I was working on an application connectivity issue. It was advised that the application had trouble connecting to database server.
-> When we checked the database server, database that the application connects to is part of Always On availability group. This database was online and synchronized. We did not see any issue at a higher level.
-> In the meantime, application team advised back in sometime while we were checking that Application services were restarted and now Application is working fine.
-> I started checking the SQL Server error log and could see below messages,
2020-12-08 02:11:25.51 Server Error: 19421, Severity: 16, State: 1.
2020-12-08 02:11:25.51 Server SQL Server hosting availability group ‘JBAG’ did not receive a process event signal from the Windows Server Failover Cluster within the lease timeout period.
2020-12-08 02:11:25.60 spid466 Remote harden of transaction ‘implicit_transaction’ (ID 0x00000001d7cac619 0005:b58e22ae) started at Dec 8 2020 02:11AM in database ‘JBDB1’ at LSN (1430698:161982:3) failed.
2020-12-08 02:11:25.88 Server Error: 19407, Severity: 16, State: 1.
2020-12-08 02:11:25.88 Server The lease between availability group ‘JBAG’ and the Windows Server Failover Cluster has expired. A connectivity issue occurred between the instance of SQL Server and the Windows Server Failover Cluster. To determine whether the availability group is failing over correctly, check the corresponding availability group resource in the Windows Server Failover Cluster.
2020-12-08 02:11:25.98 Server Always On: The local replica of availability group ‘JBAG’ is going offline because either the lease expired or lease renewal failed. This is an informational message only. No user action is required.
2020-12-08 02:11:26.47 Server The state of the local availability replica in availability group ‘JBAG’ has changed from ‘PRIMARY_NORMAL’ to ‘RESOLVING_NORMAL’. The state changed because the lease between the local availability replica and Windows Server Failover Clustering (WSFC) has expired. For more information, see the SQL Server error log, Windows Server Failover Clustering (WSFC) management console, or WSFC log.
2020-12-08 02:11:26.47 spid214s Always On Availability Groups connection with secondary database terminated for primary database ‘JBDB1’ on the availability replica ‘JBSAG2’ with Replica ID: {9c105a39-d2cc-4b31-a913-b21b02b3ddf4}. This is an informational message only. No user action is required.
2020-12-08 02:11:26.47 spid531 Remote harden of transaction ‘implicit_transaction’ (ID 0x00000001d7cac805 0005:b58e22b8) started at Dec 8 2020 02:11AM in database ‘JBDB1’ at LSN (1430698:162003:15) failed.
2020-12-08 02:11:26.48 spid285s The availability group database “JBDB2” is changing roles from “PRIMARY” to “RESOLVING” because the mirroring session or availability group failed over due to role synchronization. This is an informational message only. No user action is required.
2020-12-08 02:11:26.48 spid428s The availability group database “JBDB” is changing roles from “PRIMARY” to “RESOLVING” because the mirroring session or availability group failed over due to role synchronization. This is an informational message only. No user action is required.
2020-12-08 02:11:26.48 spid300s The availability group database “JBDB1” is changing roles from “PRIMARY” to “RESOLVING” because the mirroring session or availability group failed over due to role synchronization. This is an informational message only. No user action is required.
2020-12-08 02:11:26.48 spid75 Remote harden of transaction ‘INSERT’ (ID 0x00000001d7caca99 0000:01445700) started at Dec 8 2020 02:11AM in database ‘JBDB’ at LSN (1099:57413:3) failed.
2020-12-08 02:11:26.48 spid248 Remote harden of transaction ‘implicit_transaction’ (ID 0x00000001d7cac8e7 0005:b58e22ba) started at Dec 8 2020 02:11AM in database ‘JBDB1’ at LSN (1430698:162008:9) failed.
2020-12-08 02:11:26.54 Logon Error: 983, Severity: 14, State: 1.
2020-12-08 02:11:26.54 Logon Unable to access availability database ‘JBDB1’ because the database replica is not in the PRIMARY or SECONDARY role. Connections to an availability database is permitted only when the database replica is in the PRIMARY or SECONDARY role. Try the operation again later.
2020-12-08 02:11:26.54 Backup Error: 18210, Severity: 16, State: 1.
2020-12-08 02:11:30.79 spid52 Always On: The local replica of availability group ‘JBAG’ is preparing to transition to the resolving role in response to a request from the Windows Server Failover Clustering (WSFC) cluster. This is an informational message only. No user action is required.
2020-12-08 02:11:39.53 Server Started listening on virtual network name ‘JBDBAG’. No user action is required.
2020-12-08 02:11:39.54 Server The lease worker of availability group ‘JBAG’ is now sleeping the excess lease time (156313 ms) supplied during online. This is an informational message only. No user action is required.
-> From the messages, I could see that there was a lease time out. LeaseTimeout which happens only on the primary replica controls the lease mechanism and when the lease expires there is a very high probability of a system wide event taking place.
-> The SQL Server resource DLL is responsible for the lease heartbeat activity. Every 1/4 of the LeaseTimeout setting the dedicated, lease thread wakes up and attempts to renew the lease. The lease is a simple handshake between the resource DLL and the SQL Server instance supporting the AG on the same node. For a lease to expire the server lease worker is not able to wait on and respond to the event handshake when it is dedicated to the task and running at a priority above most threads on the system.
-> Details from SQL Server error log,
Initial failure
2020-12-08 02:11:25.51 Server SQL Server hosting availability group ‘JBAG’ did not receive a process event signal from the Windows Server Failover Cluster within the lease timeout period.
2020-12-08 02:11:25.88 Server Error: 19407, Severity: 16, State: 1.
2020-12-08 02:11:25.88 Server The lease between availability group ‘JBAG’ and the Windows Server Failover Cluster has expired. A connectivity issue occurred between the instance of SQL Server and the Windows Server Failover Cluster. To determine whether the availability group is failing over correctly, check the corresponding availability group resource in the Windows Server Failover Cluster.
2020-12-08 02:11:25.98 Server Always On: The local replica of availability group ‘JBAG’ is going offline because either the lease expired or lease renewal failed. This is an informational message only. No user action is required.
2020-12-08 02:11:26.47 Server The state of the local availability replica in availability group ‘JBAG’ has changed from ‘PRIMARY_NORMAL’ to ‘RESOLVING_NORMAL’. The state changed because the lease between the local availability replica and Windows Server Failover Clustering (WSFC) has expired. For more information, see the SQL Server error log, Windows Server Failover Clustering (WSFC) management console, or WSFC log.
Availability group getting online automatically
2020-12-08 02:11:39.53 spid54 The state of the local availability replica in availability group ‘JBAG’ has changed from ‘RESOLVING_NORMAL’ to ‘PRIMARY_PENDING’. The state changed because the availability group is coming online. For more information, see the SQL Server error log, Windows Server Failover Clustering (WSFC) management console, or WSFC log.
2020-12-08 02:11:39.53 Server Started listening on virtual network name ‘JBDBAG’. No user action is required.
2020-12-08 02:11:40.68 Server The state of the local availability replica in availability group ‘JBAG’ has changed from ‘PRIMARY_PENDING’ to ‘PRIMARY_NORMAL’. The state changed because the local replica has completed processing Online command from Windows Server Failover Clustering (WSFC). For more information, see the SQL Server error log, Windows Server Failover Clustering (WSFC) management console, or WSFC log.
2020-12-01 18:06:34.90 spid48s The availability group database “JBDB” is changing roles from “RESOLVING” to “PRIMARY” because the mirroring session or availability group failed over due to role synchronization. This is an informational message only. No user action is required.
-> Details from Cluster.log
You can generate cluster.log using this article.
539453 00003926.00009z60::2020/12/07-20:41:26.485 ERR [RES] SQL Server Availability Group : [hadrag] Availability Group lease is no longer valid
539454 00003926.00009z60::2020/12/07-20:41:26.485 ERR [RES] SQL Server Availability Group : [hadrag] Resource Alive result 0.
539455 00003926.00009z60::2020/12/07-20:41:26.485 ERR [RES] SQL Server Availability Group : [hadrag] Availability Group lease is no longer valid
539456 00003926.00009z60::2020/12/07-20:41:26.485 ERR [RES] SQL Server Availability Group : [hadrag] Resource Alive result 0.
539458 00002546.00008ge4::2020/12/07-20:41:26.485 INFO [RCM] HandleMonitorReply: FAILURENOTIFICATION for ‘JBAG’, gen(0) result 1/0.
539472 00003926.00005h38::2020/12/07-20:41:26.544 ERR [RES] SQL Server Availability Group : [hadrag] Lease renewal failed because the existing lease is no longer valid.
539473 00003926.00005h38::2020/12/07-20:41:26.544 ERR [RES] SQL Server Availability Group : [hadrag] The lease is expired. The lease should have been renewed by 2020/12/07-20:41:15.482
-> It is clear from the entries in cluster.log that SQL Server did not complete the handshake with resource DLL and this caused the lease time out. This resulted in Availability group going into resolving state and the database was not accessible.
-> In this case Availability group JBAG went to resolving state and then recovered automatically in sometime. There are many reason why lease time out fails, but most of the time it is due to a resource issue on the Primary replica.
-> Fortunately in my case we capture performance monitor logs on all database server. I checked the logs and was able to see that CPU utilization at that time was 100% when the lease timeout happened.

-> High resource utilization on the database server would have resulted SQL server not to respond for sometime and this SQL Server freeze like situation would have resulted in lease timeout.
-> I checked the process counter in Perfmon BLG file and was able to see SQL Server utilizing most of the CPU and some system processes “Privileged time” was also high. We get to know that application load at that time was very high and that could be a contributing factor. But we couldn’t get more details as what queries within SQL server could have increased SQL Server CPU utilization as we did not have any trace at that time.
-> In case this issue occurrence is frequent, we can try increasing the LeaseTimeout value.

-> But increasing LeaseTimeout value will just be a workaround for time being, but the actual resolution will be to understand the reason behind high CPU utilization. A typical performance troubleshooting on the database server will be required/enough to understand the reason and fix it.
More Reads
How It Works: SQL Server AlwaysOn Lease Timeout | Microsoft Docs
Diagnose Unexpected Failover or Availability Group in RESOLVING State | Microsoft Docs
Thank You,
Vivek Janakiraman
Disclaimer:
The views expressed on this blog are mine alone and do not reflect the views of my company or anyone else. All postings on this blog are provided “AS IS” with no warranties, and confers no rights.
List of error messages between 1 and 999 in SQL Server 2017.
These error messages are all available by querying the sys.messages catalog view on the master database.