1. Syntax
create-trigger-stmt:
CREATE
TEMP
TEMPORARY
TRIGGER
IF
NOT
EXISTS
schema-name
.
trigger-name
BEFORE
AFTER
INSTEAD
OF
DELETE
INSERT
UPDATE
OF
column-name
,
ON
table-name
FOR
EACH
ROW
WHEN
expr
BEGIN
update-stmt
;
END
insert-stmt
delete-stmt
select-stmt
delete-stmt:
expr:
insert-stmt:
select-stmt:
update-stmt:
2. Description
The CREATE TRIGGER statement is used to add triggers to the
database schema. Triggers are database operations
that are automatically performed when a specified database event
occurs.
Each trigger must specify that it will fire for one of
the following operations: DELETE, INSERT, UPDATE.
The trigger fires once for each row that is deleted, inserted,
or updated. If the «UPDATE OF column-name»
syntax is used, then the trigger will only fire if
column-name appears on the left-hand side of
one of the terms in the SET clause of the UPDATE statement.
Due to an historical oversight, columns named in the «UPDATE OF»
clause do not actually have to exist in the table being updated.
Unrecognized column names are silently ignored.
It would be more helpful if SQLite would fail the CREATE TRIGGER
statement if any of the names in the «UPDATE OF» clause are not
columns in the table. However, as this problem was discovered
many years after SQLite was widely deployed, we have resisted
fixing the problem for fear of breaking legacy applications.
At this time SQLite supports only FOR EACH ROW triggers, not FOR EACH
STATEMENT triggers. Hence explicitly specifying FOR EACH ROW is optional.
FOR EACH ROW implies that the SQL statements specified in the trigger
may be executed (depending on the WHEN clause) for each database row being
inserted, updated or deleted by the statement causing the trigger to fire.
Both the WHEN clause and the trigger actions may access elements of
the row being inserted, deleted or updated using references of the form
«NEW.column-name» and «OLD.column-name«, where
column-name is the name of a column from the table that the trigger
is associated with. OLD and NEW references may only be used in triggers on
events for which they are relevant, as follows:
| INSERT | NEW references are valid |
| UPDATE | NEW and OLD references are valid |
| DELETE | OLD references are valid |
If a WHEN clause is supplied, the SQL statements specified
are only executed if the WHEN clause is true.
If no WHEN clause is supplied, the SQL statements
are executed every time the trigger fires.
The BEFORE or AFTER keyword determines when the trigger actions
will be executed relative to the insertion, modification or removal of the
associated row. BEFORE is the default when neither keyword is present.
An ON CONFLICT clause may be specified as part of an UPDATE or INSERT
action within the body of the trigger.
However if an ON CONFLICT clause is specified as part of
the statement causing the trigger to fire, then conflict handling
policy of the outer statement is used instead.
Triggers are automatically dropped
when the table that they are
associated with (the table-name table) is
dropped. However if the trigger actions reference
other tables, the trigger is not dropped or modified if those other
tables are dropped or modified.
Triggers are removed using the DROP TRIGGER statement.
2.1. Syntax Restrictions On UPDATE, DELETE, and INSERT Statements Within
Triggers
The UPDATE, DELETE, and INSERT
statements within triggers do not support
the full syntax for UPDATE, DELETE, and INSERT statements. The following
restrictions apply:
-
The name of the table to be modified in an UPDATE, DELETE, or INSERT
statement must be an unqualified table name. In other words, one must
use just «tablename» not «database.tablename»
when specifying the table. -
For non-TEMP triggers,
the table to be modified or queried must exist in the
same database as the table or view to which the trigger is attached.
TEMP triggers are not subject to the same-database rule. A TEMP
trigger is allowed to query or modify any table in any ATTACH-ed database. -
The «INSERT INTO table DEFAULT VALUES» form of the INSERT statement
is not supported. -
The INDEXED BY and NOT INDEXED clauses are not supported for UPDATE and
DELETE statements. -
The ORDER BY and LIMIT clauses on UPDATE and DELETE statements are not
supported. ORDER BY and LIMIT are not normally supported for UPDATE or
DELETE in any context but can be enabled for top-level statements
using the SQLITE_ENABLE_UPDATE_DELETE_LIMIT compile-time option. However,
that compile-time option only applies to top-level UPDATE and DELETE
statements, not UPDATE and DELETE statements within triggers. -
Common table expression are not supported for
statements inside of triggers.
3. INSTEAD OF triggers
BEFORE and AFTER triggers work only on ordinary tables.
INSTEAD OF triggers work only on views.
If an INSTEAD OF INSERT trigger exists on a view, then it is
possible to execute an INSERT statement against that view. No actual
insert occurs. Instead, the statements contained within the trigger
are run. INSTEAD OF DELETE and
INSTEAD OF UPDATE triggers work the same way for DELETE and UPDATE statements
against views.
Note that the sqlite3_changes() and sqlite3_total_changes() interfaces
do not count INSTEAD OF trigger firings, but the
count_changes pragma does count INSTEAD OF trigger firing.
4. Some Example Triggers
Assuming that customer records are stored in the «customers» table, and
that order records are stored in the «orders» table, the following
UPDATE trigger
ensures that all associated orders are redirected when a customer changes
his or her address:
CREATE TRIGGER update_customer_address UPDATE OF address ON customers
BEGIN
UPDATE orders SET address = new.address WHERE customer_name = old.name;
END;
With this trigger installed, executing the statement:
UPDATE customers SET address = '1 Main St.' WHERE name = 'Jack Jones';
causes the following to be automatically executed:
UPDATE orders SET address = '1 Main St.' WHERE customer_name = 'Jack Jones';
For an example of an INSTEAD OF trigger, consider the following schema:
CREATE TABLE customer( cust_id INTEGER PRIMARY KEY, cust_name TEXT, cust_addr TEXT ); CREATE VIEW customer_address AS SELECT cust_id, cust_addr FROM customer; CREATE TRIGGER cust_addr_chng INSTEAD OF UPDATE OF cust_addr ON customer_address BEGIN UPDATE customer SET cust_addr=NEW.cust_addr WHERE cust_id=NEW.cust_id; END;
With the schema above, a statement of the form:
UPDATE customer_address SET cust_addr=$new_address WHERE cust_id=$cust_id;
Causes the customer.cust_addr field to be updated for a specific
customer entry that has customer.cust_id equal to the $cust_id parameter.
Note how the values assigned to the view are made available as field
in the special «NEW» table within the trigger body.
5. Cautions On The Use Of BEFORE triggers
If a BEFORE UPDATE or BEFORE DELETE trigger modifies or deletes a row
that was to have been updated or deleted, then the result of the subsequent
update or delete operation is undefined. Furthermore, if a BEFORE trigger
modifies or deletes a row, then it is undefined whether or not AFTER triggers
that would have otherwise run on those rows will in fact run.
The value of NEW.rowid is undefined in a BEFORE INSERT trigger in which
the rowid is not explicitly set to an integer.
Because of the behaviors described above, programmers are encouraged to
prefer AFTER triggers over BEFORE triggers.
6. The RAISE() function
A special SQL function RAISE() may be used within a trigger-program,
with the following syntax
raise-function:
RAISE
(
ROLLBACK
,
error-message
)
IGNORE
ABORT
FAIL
When one of RAISE(ROLLBACK,…), RAISE(ABORT,…) or RAISE(FAIL,…)
is called during trigger-program
execution, the specified ON CONFLICT processing is performed and
the current query terminates.
An error code of SQLITE_CONSTRAINT is returned to the application,
along with the specified error message.
When RAISE(IGNORE) is called, the remainder of the current trigger program,
the statement that caused the trigger program to execute and any subsequent
trigger programs that would have been executed are abandoned. No database
changes are rolled back. If the statement that caused the trigger program
to execute is itself part of a trigger program, then that trigger program
resumes execution at the beginning of the next step.
7. TEMP Triggers on Non-TEMP Tables
A trigger normally exists in the same database as the table named
after the «ON» keyword in the CREATE TRIGGER statement. Except, it is
possible to create a TEMP TRIGGER on a table in another database.
Such a trigger will only fire when changes
are made to the target table by the application that defined the trigger.
Other applications that modify the database will not be able to see the
TEMP trigger and hence cannot run the trigger.
When defining a TEMP trigger on a non-TEMP table, it is important to
specify the database holding the non-TEMP table. For example,
in the following statement, it is important to say «main.tab1» instead
of just «tab1»:
CREATE TEMP TRIGGER ex1 AFTER INSERT ON main.tab1 BEGIN ...
Failure to specify the schema name on the target table could result
in the TEMP trigger being reattached to a table with the same name in
another database whenever any schema change occurs.
This page last modified on 2022-09-27 13:16:55 UTC
(This page was last modified on 2003/07/20 01:16:48 UTC)
The SQLite library understands most of the standard SQL
language. But it does omit some features
while at the same time
adding a few features of its own. This document attempts to
describe percisely what parts of the SQL language SQLite does
and does not support. A list of keywords is
given at the end.
In all of the syntax diagrams that follow, literal text is shown in
bold blue. Non-terminal symbols are shown in italic red. Operators
that are part of the syntactic markup itself are shown in black roman.
This document is just an overview of the SQL syntax implemented
by SQLite. Many low-level productions are omitted. For detailed information
on the language that SQLite understands, refer to the source code and
the grammar file «parse.y».
SQLite implements the follow syntax:
- ATTACH DATABASE
- BEGIN TRANSACTION
- comment
- COMMIT TRANSACTION
- COPY
- CREATE INDEX
- CREATE TABLE
- CREATE TRIGGER
- CREATE VIEW
- DELETE
- DETACH DATABASE
- DROP INDEX
- DROP TABLE
- DROP TRIGGER
- DROP VIEW
- END TRANSACTION
- EXPLAIN
- expression
- INSERT
- ON CONFLICT clause
- PRAGMA
- REPLACE
- ROLLBACK TRANSACTION
- SELECT
- UPDATE
- VACUUM
Details on the implementation of each command are provided in
the sequel.
ATTACH DATABASE
| sql-statement ::= | ATTACH [DATABASE] database-filename AS database-name |
The ATTACH DATABASE statement adds a preexisting database
file to the current database connection. If the filename contains
punctuation characters it must be quoted. The names ‘main’ and
‘temp’ refer to the main database and the database used for
temporary tables. These cannot be detached. Attached databases
are removed using the DETACH DATABASE
statement.
You can read from and write to an attached database, but you cannot
alter the schema of an attached database. You can only CREATE and
DROP in the original database.
You cannot create a new table with the same name as a table in
an attached database, but you can attach a database which contains
tables whose names are duplicates of tables in the main database. It is
also permissible to attach the same database file multiple times.
Tables in an attached database can be referred to using the syntax
database-name.table-name. If an attached table doesn’t have
a duplicate table name in the main database, it doesn’t require a
database name prefix. When a database is attached, all of its
tables which don’t have duplicate names become the ‘default’ table
of that name. Any tables of that name attached afterwards require the table
prefix. If the ‘default’ table of a given name is detached, then
the last table of that name attached becomes the new default.
When there are attached databases, transactions are not atomic.
Transactions continue to be atomic within each individual
database file. But if your machine crashes in the middle
of a COMMIT where you have updated two or more database
files, some of those files might get the changes where others
might not.
There is a compile-time limit of 10 attached database files.
Executing a BEGIN TRANSACTION statement locks all database
files, so this feature cannot (currently) be used to increase
concurrancy.
BEGIN TRANSACTION
| sql-statement ::= | BEGIN [TRANSACTION [name]] [ON CONFLICT conflict-algorithm] |
| sql-statement ::= | END [TRANSACTION [name]] |
| sql-statement ::= | COMMIT [TRANSACTION [name]] |
| sql-statement ::= | ROLLBACK [TRANSACTION [name]] |
Beginning in version 2.0, SQLite supports transactions with
rollback and atomic commit. See ATTACH for
an exception when there are attached databases.
The optional transaction name is ignored. SQLite currently
doesn’t allow nested transactions. Attempting to start a new
transaction inside another is an error.
No changes can be made to the database except within a transaction.
Any command that changes the database (basically, any SQL command
other than SELECT) will automatically start a transaction if
one is not already in effect. Automatically started transactions
are committed at the conclusion of the command.
Transactions can be started manually using the BEGIN
command. Such transactions usually persist until the next
COMMIT or ROLLBACK command. But a transaction will also
ROLLBACK if the database is closed or if an error occurs
and the ROLLBACK conflict resolution algorithm is specified.
See the documention on the ON CONFLICT
clause for additional information about the ROLLBACK
conflict resolution algorithm.
The optional ON CONFLICT clause at the end of a BEGIN statement
can be used to changed the default conflict resolution algorithm.
The normal default is ABORT. If an alternative is specified by
the ON CONFLICT clause of a BEGIN, then that alternative is used
as the default for all commands within the transaction. The default
algorithm is overridden by ON CONFLICT clauses on individual
constraints within the CREATE TABLE or CREATE INDEX statements
and by the OR clauses on COPY, INSERT, and UPDATE commands.
comment
| comment ::= | SQL-comment | C-comment |
| SQL-comment ::= | — single-line |
| C-comment ::= | /* multiple-lines [*/] |
Comments aren’t SQL commands, but can occur in SQL queries. They are
treated as whitespace by the parser. They can begin anywhere whitespace
can be found, including inside expressions that span multiple lines.
SQL comments only extend to the end of the current line.
C comments can span any number of lines. If there is no terminating
delimiter, they extend to the end of the input. This is not treated as
an error. A new SQL statement can begin on a line after a multiline
comment ends. C comments can be embedded anywhere whitespace can occur,
including inside expressions, and in the middle of other SQL statements.
C comments do not nest. SQL comments inside a C comment will be ignored.
COPY
| sql-statement ::= | COPY [ OR conflict-algorithm ] [database-name .] table-name FROM filename [ USING DELIMITERS delim ] |
The COPY command is an extension used to load large amounts of
data into a table. It is modeled after a similar command found
in PostgreSQL. In fact, the SQLite COPY command is specifically
designed to be able to read the output of the PostgreSQL dump
utility pg_dump so that data can be easily transferred from
PostgreSQL into SQLite.
The table-name is the name of an existing table which is to
be filled with data. The filename is a string or identifier that
names a file from which data will be read. The filename can be
the STDIN to read data from standard input.
Each line of the input file is converted into a single record
in the table. Columns are separated by tabs. If a tab occurs as
data within a column, then that tab is preceded by a baskslash «»
character. A baskslash in the data appears as two backslashes in
a row. The optional USING DELIMITERS clause can specify a delimiter
other than tab.
If a column consists of the character «N», that column is filled
with the value NULL.
The optional conflict-clause allows the specification of an alternative
constraint conflict resolution algorithm to use for this one command.
See the section titled
ON CONFLICT for additional information.
When the input data source is STDIN, the input can be terminated
by a line that contains only a baskslash and a dot:
«.«.
CREATE INDEX
| sql-statement ::= | CREATE [TEMP | TEMPORARY] [UNIQUE] INDEX index-name ON [database-name .] table-name ( column-name [, column-name]* ) [ ON CONFLICT conflict-algorithm ] |
| column-name ::= | name [ ASC | DESC ] |
The CREATE INDEX command consists of the keywords «CREATE INDEX» followed
by the name of the new index, the keyword «ON», the name of a previously
created table that is to be indexed, and a parenthesized list of names of
columns in the table that are used for the index key.
Each column name can be followed by one of the «ASC» or «DESC» keywords
to indicate sort order, but the sort order is ignored in the current
implementation. Sorting is always done in ascending order.
There are no arbitrary limits on the number of indices that can be
attached to a single table, nor on the number of columns in an index.
If the UNIQUE keyword appears between CREATE and INDEX then duplicate
index entries are not allowed. Any attempt to insert a duplicate entry
will result in an error.
The optional conflict-clause allows the specification of an alternative
default constraint conflict resolution algorithm for this index.
This only makes sense if the UNIQUE keyword is used since otherwise
there are not constraints on the index. The default algorithm is
ABORT. If a COPY, INSERT, or UPDATE statement specifies a particular
conflict resolution algorithm, that algorithm is used in place of
the default algorithm specified here.
See the section titled
ON CONFLICT for additional information.
The exact text
of each CREATE INDEX statement is stored in the sqlite_master
or sqlite_temp_master table, depending on whether the table
being indexed is temporary. Everytime the database is opened,
all CREATE INDEX statements
are read from the sqlite_master table and used to regenerate
SQLite’s internal representation of the index layout.
Non-temporary indexes cannot be added on tables in attached
databases. They are removed with the DROP INDEX
command.
CREATE TABLE
| sql-command ::= | CREATE [TEMP | TEMPORARY] TABLE table-name ( column-def [, column-def]* [, constraint]* ) |
| sql-command ::= | CREATE [TEMP | TEMPORARY] TABLE table-name AS select-statement |
| column-def ::= | name [type] [[CONSTRAINT name] column-constraint]* |
| type ::= | typename | typename ( number ) | typename ( number , number ) |
| column-constraint ::= | NOT NULL [ conflict-clause ] | PRIMARY KEY [sort-order] [ conflict-clause ] | UNIQUE [ conflict-clause ] | CHECK ( expr ) [ conflict-clause ] | DEFAULT value |
| constraint ::= | PRIMARY KEY ( name [, name]* ) [ conflict-clause ]| UNIQUE ( name [, name]* ) [ conflict-clause ] | CHECK ( expr ) [ conflict-clause ] |
| conflict-clause ::= | ON CONFLICT conflict-algorithm |
A CREATE TABLE statement is basically the keywords «CREATE TABLE»
followed by the name of a new table and a parenthesized list of column
definitions and constraints. The table name can be either an identifier
or a string. Tables names that begin with «sqlite_» are reserved
for use by the engine.
Each column definition is the name of the column followed by the
datatype for that column, then one or more optional column constraints.
SQLite is typeless.
The datatype for the column does not restrict what data may be put
in that column.
All information is stored as null-terminated strings.
The UNIQUE constraint causes an index to be created on the specified
columns. This index must contain unique keys.
The DEFAULT constraint
specifies a default value to use when doing an INSERT.
Specifying a PRIMARY KEY normally just creates a UNIQUE index
on the primary key. However, if primary key is on a single column
that has datatype INTEGER, then that column is used internally
as the actual key of the B-Tree for the table. This means that the column
may only hold unique integer values. (Except for this one case,
SQLite ignores the datatype specification of columns and allows
any kind of data to be put in a column regardless of its declared
datatype.) If a table does not have an INTEGER PRIMARY KEY column,
then the B-Tree key will be a automatically generated integer. The
B-Tree key for a row can always be accessed using one of the
special names «ROWID«, «OID«, or «_ROWID_«.
This is true regardless of whether or not there is an INTEGER
PRIMARY KEY.
If the «TEMP» or «TEMPORARY» keyword occurs in between «CREATE»
and «TABLE» then the table that is created is only visible to the
process that opened the database and is automatically deleted when
the database is closed. Any indices created on a temporary table
are also temporary. Temporary tables and indices are stored in a
separate file distinct from the main database file.
The optional conflict-clause following each constraint
allows the specification of an alternative default
constraint conflict resolution algorithm for that constraint.
The default is abort ABORT. Different constraints within the same
table may have different default conflict resolution algorithms.
If an COPY, INSERT, or UPDATE command specifies a different conflict
resolution algorithm, then that algorithm is used in place of the
default algorithm specified in the CREATE TABLE statement.
See the section titled
ON CONFLICT for additional information.
CHECK constraints are ignored in the current implementation.
Support for CHECK constraints may be added in the future. As of
version 2.3.0, NOT NULL, PRIMARY KEY, and UNIQUE constraints all
work.
There are no arbitrary limits on the number
of columns or on the number of constraints in a table.
The total amount of data in a single row is limited to about
1 megabytes. (This limit can be increased to 16MB by changing
a single #define in the source code and recompiling.)
The CREATE TABLE AS form defines the table to be
the result set of a query. The names of the table columns are
the names of the columns in the result.
The exact text
of each CREATE TABLE statement is stored in the sqlite_master
table. Everytime the database is opened, all CREATE TABLE statements
are read from the sqlite_master table and used to regenerate
SQLite’s internal representation of the table layout.
If the original command was a CREATE TABLE AS then then an equivalent
CREATE TABLE statement is synthesized and store in sqlite_master
in place of the original command.
The text of CREATE TEMPORARY TABLE statements are stored in the
sqlite_temp_master table.
Tables are removed using the DROP TABLE
statement. Non-temporary tables in an attached database cannot be
dropped.
CREATE TRIGGER
| sql-statement ::= | CREATE [TEMP | TEMPORARY] TRIGGER trigger-name [ BEFORE | AFTER ] database-event ON [database-name .] table-name trigger-action |
| sql-statement ::= | CREATE [TEMP | TEMPORARY] TRIGGER trigger-name INSTEAD OF database-event ON [database-name .] view-name trigger-action |
| database-event ::= | DELETE | INSERT | UPDATE | UPDATE OF column-list |
| trigger-action ::= | [ FOR EACH ROW | FOR EACH STATEMENT ] [ WHEN expression ] BEGIN trigger-step ; [ trigger-step ; ]* END |
| trigger-step ::= | update-statement | insert-statement | delete-statement | select-statement |
The CREATE TRIGGER statement is used to add triggers to the
database schema. Triggers are database operations (the trigger-action)
that are automatically performed when a specified database event (the
database-event) occurs.
A trigger may be specified to fire whenever a DELETE, INSERT or UPDATE of a
particular database table occurs, or whenever an UPDATE of one or more
specified columns of a table are updated.
At this time SQLite supports only FOR EACH ROW triggers, not FOR EACH
STATEMENT triggers. Hence explicitly specifying FOR EACH ROW is optional. FOR
EACH ROW implies that the SQL statements specified as trigger-steps
may be executed (depending on the WHEN clause) for each database row being
inserted, updated or deleted by the statement causing the trigger to fire.
Both the WHEN clause and the trigger-steps may access elements of
the row being inserted, deleted or updated using references of the form
«NEW.column-name» and «OLD.column-name«, where
column-name is the name of a column from the table that the trigger
is associated with. OLD and NEW references may only be used in triggers on
trigger-events for which they are relevant, as follows:
| INSERT | NEW references are valid |
| UPDATE | NEW and OLD references are valid |
| DELETE | OLD references are valid |
If a WHEN clause is supplied, the SQL statements specified as trigger-steps are only executed for rows for which the WHEN clause is true. If no WHEN clause is supplied, the SQL statements are executed for all rows.
The specified trigger-time determines when the trigger-steps
will be executed relative to the insertion, modification or removal of the
associated row.
An ON CONFLICT clause may be specified as part of an UPDATE or INSERT
trigger-step. However if an ON CONFLICT clause is specified as part of
the statement causing the trigger to fire, then this conflict handling
policy is used instead.
Triggers are automatically dropped when the table that they are
associated with is dropped.
Triggers may be created on views, as well as ordinary tables, by specifying
INSTEAD OF in the CREATE TRIGGER statement. If one or more ON INSERT, ON DELETE
or ON UPDATE triggers are defined on a view, then it is not an error to execute
an INSERT, DELETE or UPDATE statement on the view, respectively. Thereafter,
executing an INSERT, DELETE or UPDATE on the view causes the associated
triggers to fire. The real tables underlying the view are not modified
(except possibly explicitly, by a trigger program).
Example:
Assuming that customer records are stored in the «customers» table, and
that order records are stored in the «orders» table, the following trigger
ensures that all associated orders are redirected when a customer changes
his or her address:
CREATE TRIGGER update_customer_address UPDATE OF address ON customers
BEGIN
UPDATE orders SET address = new.address WHERE customer_name = old.name;
END;
With this trigger installed, executing the statement:
UPDATE customers SET address = '1 Main St.' WHERE name = 'Jack Jones';
causes the following to be automatically executed:
UPDATE orders SET address = '1 Main St.' WHERE customer_name = 'Jack Jones';
Note that currently, triggers may behave oddly when created on tables
with INTEGER PRIMARY KEY fields. If a BEFORE trigger program modifies the
INTEGER PRIMARY KEY field of a row that will be subsequently updated by the
statement that causes the trigger to fire, then the update may not occur.
The workaround is to declare the table with a PRIMARY KEY column instead
of an INTEGER PRIMARY KEY column.
A special SQL function RAISE() may be used within a trigger-program, with the following syntax
| raise-function ::= | RAISE ( ABORT, error-message ) | RAISE ( FAIL, error-message ) | RAISE ( ROLLBACK, error-message ) | RAISE ( IGNORE ) |
When one of the first three forms is called during trigger-program execution, the specified ON CONFLICT processing is performed (either ABORT, FAIL or
ROLLBACK) and the current query terminates. An error code of SQLITE_CONSTRAINT is returned to the user, along with the specified error message.
When RAISE(IGNORE) is called, the remainder of the current trigger program,
the statement that caused the trigger program to execute and any subsequent
trigger programs that would of been executed are abandoned. No database
changes are rolled back. If the statement that caused the trigger program
to execute is itself part of a trigger program, then that trigger program
resumes execution at the beginning of the next step.
Triggers are removed using the DROP TRIGGER
statement. Non-temporary triggers cannot be added on a table in an
attached database.
CREATE VIEW
| sql-command ::= | CREATE [TEMP | TEMPORARY] VIEW view-name AS select-statement |
The CREATE VIEW command assigns a name to a pre-packaged
SELECT
statement. Once the view is created, it can be used in the FROM clause
of another SELECT in place of a table name.
You cannot COPY, DELETE, INSERT or UPDATE a view. Views are read-only
in SQLite. However, in many cases you can use a
TRIGGER on the view to accomplish the same thing. Views are removed
with the DROP VIEW
command. Non-temporary views cannot be created on tables in an attached
database.
DELETE
| sql-statement ::= | DELETE FROM [database-name .] table-name [WHERE expr] |
The DELETE command is used to remove records from a table.
The command consists of the «DELETE FROM» keywords followed by
the name of the table from which records are to be removed.
Without a WHERE clause, all rows of the table are removed.
If a WHERE clause is supplied, then only those rows that match
the expression are removed.
DETACH DATABASE
| sql-command ::= | DETACH [DATABASE] database-name |
This statement detaches an additional database connection previously
attached using the ATTACH DATABASE statement. It
is possible to have the same database file attached multiple times using
different names, and detaching one connection to a file will leave the
others intact.
This statement will fail if SQLite is in the middle of a transaction.
DROP INDEX
| sql-command ::= | DROP INDEX [database-name .] index-name |
The DROP INDEX statement removes an index added with the
CREATE INDEX statement. The index named is completely removed from
the disk. The only way to recover the index is to reenter the
appropriate CREATE INDEX command. Non-temporary indexes on tables in
an attached database cannot be dropped.
DROP TABLE
| sql-command ::= | DROP TABLE table-name |
The DROP TABLE statement removes a table added with the CREATE TABLE statement. The name specified is the
table name. It is completely removed from the database schema and the
disk file. The table can not be recovered. All indices associated
with the table are also deleted. Non-temporary tables in an attached
database cannot be dropped.
DROP TRIGGER
| sql-statement ::= | DROP TRIGGER [database-name .] trigger-name |
The DROP TRIGGER statement removes a trigger created by the
CREATE TRIGGER statement. The trigger is
deleted from the database schema. Note that triggers are automatically
dropped when the associated table is dropped. Non-temporary triggers
cannot be dropped on attached tables.
DROP VIEW
| sql-command ::= | DROP VIEW view-name |
The DROP VIEW statement removes a view created by the CREATE VIEW statement. The name specified is the
view name. It is removed from the database schema, but no actual data
in the underlying base tables is modified. Non-temporary views in
attached databases cannot be dropped.
EXPLAIN
| sql-statement ::= | EXPLAIN sql-statement |
The EXPLAIN command modifier is a non-standard extension. The
idea comes from a similar command found in PostgreSQL, but the operation
is completely different.
If the EXPLAIN keyword appears before any other SQLite SQL command
then instead of actually executing the command, the SQLite library will
report back the sequence of virtual machine instructions it would have
used to execute the command had the EXPLAIN keyword not been present.
For additional information about virtual machine instructions see
the architecture description or the documentation
on available opcodes for the virtual machine.
expression
| expr ::= | expr binary-op expr | expr like-op expr | unary-op expr | ( expr ) | column-name | table-name . column-name | database-name . table-name . column-name | literal-value | function-name ( expr-list | * ) | expr (+) | expr ISNULL | expr NOTNULL | expr [NOT] BETWEEN expr AND expr | expr [NOT] IN ( value-list ) | expr [NOT] IN ( select-statement ) | ( select-statement ) | CASE [expr] ( WHEN expr THEN expr )+ [ELSE expr] END |
| like-op ::= | LIKE | GLOB | NOT LIKE | NOT GLOB |
This section is different from the others. Most other sections of
this document talks about a particular SQL command. This section does
not talk about a standalone command but about «expressions» which are
subcomponents of most other commands.
SQLite understands the following binary operators, in order from
highest to lowest precedence:
||
* / %
+ -
<< >> & |
< <= > >=
= == != <> IN
AND
OR
Supported unary operaters are these:
- + ! ~
Any SQLite value can be used as part of an expression.
For arithmetic operations, integers are treated as integers.
Strings are first converted to real numbers using atof().
For comparison operators, numbers compare as numbers and strings
compare using the strcmp() function.
Note that there are two variations of the equals and not equals
operators. Equals can be either
= or ==.
The non-equals operator can be either
!= or <>.
The || operator is «concatenate» — it joins together
the two strings of its operands.
The operator % outputs the remainder of its left
operand modulo its right operand.
The LIKE operator does a wildcard comparision. The operand
to the right contains the wildcards.
A percent symbol % in the right operand
matches any sequence of zero or more characters on the left.
An underscore _ on the right
matches any single character on the left.
The LIKE operator is
not case sensitive and will match upper case characters on one
side against lower case characters on the other.
(A bug: SQLite only understands upper/lower case for 7-bit Latin
characters. Hence the LIKE operator is case sensitive for
8-bit iso8859 characters or UTF-8 characters. For example,
the expression ‘a’ LIKE ‘A’ is TRUE but
‘æ’ LIKE ‘Æ’ is FALSE.). The infix
LIKE operator is identical the user function
like(X,Y).
The GLOB operator is similar to LIKE but uses the Unix
file globbing syntax for its wildcards. Also, GLOB is case
sensitive, unlike LIKE. Both GLOB and LIKE may be preceded by
the NOT keyword to invert the sense of the test. The infix GLOB
operator is identical the user function
glob(X,Y).
A column name can be any of the names defined in the CREATE TABLE
statement or one of the following special identifiers: «ROWID«,
«OID«, or «_ROWID_«.
These special identifiers all describe the
unique random integer key (the «row key») associated with every
row of every table.
The special identifiers only refer to the row key if the CREATE TABLE
statement does not define a real column with the same name. Row keys
act like read-only columns. A row key can be used anywhere a regular
column can be used, except that you cannot change the value
of a row key in an UPDATE or INSERT statement.
«SELECT * …» does not return the row key.
SQLite supports a minimal Oracle8 outer join behavior. A column
expression of the form «column» or «table.column» can be followed by
the special «(+)» operator. If the table of the column expression
is the second or subsequent table in a join, then that table becomes
the left table in a LEFT OUTER JOIN. The expression that uses that
table becomes part of the ON clause for the join.
The exact Oracle8 behavior is not implemented, but it is possible to
construct queries that will work correctly for both SQLite and Oracle8.
SELECT statements can appear in expressions as either the
right-hand operand of the IN operator or as a scalar quantity.
In both cases, the SELECT should have only a single column in its
result. Compound SELECTs (connected with keywords like UNION or
EXCEPT) are allowed.
A SELECT in an expression is evaluated once before any other processing
is performed, so none of the expressions within the select itself can
refer to quantities in the containing expression.
When a SELECT is the right operand of the IN operator, the IN
operator returns TRUE if the result of the left operand is any of
the values generated by the select. The IN operator may be preceded
by the NOT keyword to invert the sense of the test.
When a SELECT appears within an expression but is not the right
operand of an IN operator, then the first row of the result of the
SELECT becomes the value used in the expression. If the SELECT yields
more than one result row, all rows after the first are ignored. If
the SELECT yeilds no rows, then the value of the SELECT is NULL.
Both simple and aggregate functions are supported. A simple
function can be used in any expression. Simple functions return
a result immediately based on their inputs. Aggregate functions
may only be used in a SELECT statement. Aggregate functions compute
their result across all rows of the result set.
The functions shown below are available by default. Additional
functions may be written in C and added to the database engine using
the sqlite_create_function()
API.
| abs(X) | Return the absolute value of argument X. |
| coalesce(X,Y,…) | Return a copy of the first non-NULL argument. If all arguments are NULL then NULL is returned. There must be at least 2 arguments. |
| glob(X,Y) | This function is used to implement the «Y GLOB X» syntax of SQLite. The sqlite_create_function() interface can be used to override this function and thereby change the operation of the GLOB operator. |
| ifnull(X,Y) | Return a copy of the first non-NULL argument. If both arguments are NULL then NULL is returned. This behaves the same as coalesce() above. |
| last_insert_rowid() | Return the ROWID of the last row insert from this connection to the database. This is the same value that would be returned from the sqlite_last_insert_rowid() API function. |
| length(X) | Return the string length of X in characters. If SQLite is configured to support UTF-8, then the number of UTF-8 characters is returned, not the number of bytes. |
| like(X,Y) | This function is used to implement the «Y LIKE X» syntax of SQL. The sqlite_create_function() interface can be used to override this function and thereby change the operation of the LIKE operator. |
| lower(X) | Return a copy of string X will all characters converted to lower case. The C library tolower() routine is used for the conversion, which means that this function might not work correctly on UTF-8 characters. |
| max(X,Y,…) | Return the argument with the maximum value. Arguments may be strings in addition to numbers. The maximum value is determined by the usual sort order. Note that max() is a simple function when it has 2 or more arguments but converts to an aggregate function if given only a single argument. |
| min(X,Y,…) | Return the argument with the minimum value. Arguments may be strings in addition to numbers. The mminimum value is determined by the usual sort order. Note that min() is a simple function when it has 2 or more arguments but converts to an aggregate function if given only a single argument. |
| nullif(X,Y) | Return the first argument if the arguments are different, otherwise return NULL. |
| random(*) | Return a random integer between -2147483648 and +2147483647. |
| round(X) round(X,Y) |
Round off the number X to Y digits to the right of the decimal point. If the Y argument is omitted, 0 is assumed. |
| soundex(X) | Compute the soundex encoding of the string X. The string «?000» is returned if the argument is NULL. This function is omitted from SQLite by default. It is only available the -DSQLITE_SOUNDEX=1 compiler option is used when SQLite is built. |
| sqlite_version(*) | Return the version string for the SQLite library that is running. Example: «2.8.0» |
| substr(X,Y,Z) | Return a substring of input string X that begins with the Y-th character and which is Z characters long. The left-most character of X is number 1. If Y is negative the the first character of the substring is found by counting from the right rather than the left. If SQLite is configured to support UTF-8, then characters indices refer to actual UTF-8 characters, not bytes. |
| typeof(X) | Return the type of the expression X. The only return values are «numeric» and «text». SQLite’s type handling is explained in Datatypes in SQLite. |
| upper(X) | Return a copy of input string X converted to all upper-case letters. The implementation of this function uses the C library routine toupper() which means it may not work correctly on UTF-8 strings. |
The following aggregate functions are available by default. Additional
aggregate functions written in C may be added using the
sqlite_create_aggregate() API.
| avg(X) | Return the average value of all X within a group. |
| count(X) count(*) |
The first form return a count of the number of times that X is not NULL in a group. The second form (with no argument) returns the total number of rows in the group. |
| max(X) | Return the maximum value of all values in the group. The usual sort order is used to determine the maximum. |
| min(X) | Return the minimum value of all values in the group. The usual sort order is used to determine the minimum. |
| sum(X) | Return the numeric sum of all values in the group. |
INSERT
| sql-statement ::= | INSERT [OR conflict-algorithm] INTO [database-name .] table-name [(column-list)] VALUES(value-list) | INSERT [OR conflict-algorithm] INTO [database-name .] table-name [(column-list)] select-statement |
The INSERT statement comes in two basic forms. The first form
(with the «VALUES» keyword) creates a single new row in an existing table.
If no column-list is specified then the number of values must
be the same as the number of columns in the table. If a column-list
is specified, then the number of values must match the number of
specified columns. Columns of the table that do not appear in the
column list are filled with the default value, or with NULL if not
default value is specified.
The second form of the INSERT statement takes it data from a
SELECT statement. The number of columns in the result of the
SELECT must exactly match the number of columns in the table if
no column list is specified, or it must match the number of columns
name in the column list. A new entry is made in the table
for every row of the SELECT result. The SELECT may be simple
or compound. If the SELECT statement has an ORDER BY clause,
the ORDER BY is ignored.
The optional conflict-clause allows the specification of an alternative
constraint conflict resolution algorithm to use during this one command.
See the section titled
ON CONFLICT for additional information.
For compatibility with MySQL, the parser allows the use of the
single keyword REPLACE as an alias for «INSERT OR REPLACE».
ON CONFLICT clause
| conflict-clause ::= | ON CONFLICT conflict-algorithm |
| conflict-algorithm ::= | ROLLBACK | ABORT | FAIL | IGNORE | REPLACE |
The ON CONFLICT clause is not a separate SQL command. It is a
non-standard clause that can appear in many other SQL commands.
It is given its own section in this document because it is not
part of standard SQL and therefore might not be familiar.
The syntax for the ON CONFLICT clause is as shown above for
the CREATE TABLE, CREATE INDEX, and BEGIN TRANSACTION commands.
For the COPY, INSERT, and UPDATE commands, the keywords
«ON CONFLICT» are replaced by «OR», to make the syntax seem more
natural. But the meaning of the clause is the same either way.
The ON CONFLICT clause specifies an algorithm used to resolve
constraint conflicts. There are five choices: ROLLBACK, ABORT,
FAIL, IGNORE, and REPLACE. The default algorithm is ABORT. This
is what they mean:
- ROLLBACK
-
When a constraint violation occurs, an immediate ROLLBACK
occurs, thus ending the current transaction, and the command aborts
with a return code of SQLITE_CONSTRAINT. If no transaction is
active (other than the implied transaction that is created on every
command) then this algorithm works the same as ABORT. - ABORT
-
When a constraint violation occurs, the command backs out
any prior changes it might have made and aborts with a return code
of SQLITE_CONSTRAINT. But no ROLLBACK is executed so changes
from prior commands within the same transaction
are preserved. This is the default behavior. - FAIL
-
When a constraint violation occurs, the command aborts with a
return code SQLITE_CONSTRAINT. But any changes to the database that
the command made prior to encountering the constraint violation
are preserved and are not backed out. For example, if an UPDATE
statement encountered a constraint violation on the 100th row that
it attempts to update, then the first 99 row changes are preserved
but changes to rows 100 and beyond never occur. - IGNORE
-
When a constraint violation occurs, the one row that contains
the constraint violation is not inserted or changed. But the command
continues executing normally. Other rows before and after the row that
contained the constraint violation continue to be inserted or updated
normally. No error is returned. - REPLACE
-
When a UNIQUE constraint violation occurs, the pre-existing rows
that are causing the constraint violation are removed prior to inserting
or updating the current row. Thus the insert or update always occurs.
The command continues executing normally. No error is returned.
If a NOT NULL constraint violation occurs, the NULL value is replaced
by the default value for that column. If the column has no default
value, then the ABORT algorithm is used.When this conflict resolution strategy deletes rows in order to
statisfy a constraint, it does not invoke delete triggers on those
rows. But that may change in a future release.
The conflict resolution algorithm can be specified in three places,
in order from lowest to highest precedence:
-
On individual constraints within a CREATE TABLE or CREATE INDEX
statement. -
On a BEGIN TRANSACTION command.
-
In the OR clause of a COPY, INSERT, or UPDATE command.
The algorithm specified in the OR clause of a COPY, INSERT, or UPDATE
overrides any algorithm specified on the BEGIN TRANSACTION command and
the algorithm specified on the BEGIN TRANSACTION command overrides the
algorithm specified in the a CREATE TABLE or CREATE INDEX.
If no algorithm is specified anywhere, the ABORT algorithm is used.
PRAGMA
| sql-statement ::= | PRAGMA name [= value] | PRAGMA function(arg) |
The PRAGMA command is used to modify the operation of the SQLite library.
The pragma command is experimental and specific pragma statements may be
removed or added in future releases of SQLite. Use this command
with caution.
The pragmas that take an integer value also accept
symbolic names. The strings «on«, «true«, and «yes»
are equivalent to 1. The strings «off«, «false«,
and «no» are equivalent to 0. These strings are case-
insensitive, and do not require quotes. An unrecognized string will be
treated as 1, and will not generate an error. When the value
is returned it is as an integer.
The current implementation supports the following pragmas:
-
PRAGMA cache_size;
PRAGMA cache_size = Number-of-pages;Query or change the maximum number of database disk pages that SQLite
will hold in memory at once. Each page uses about 1.5K of memory.
The default cache size is 2000. If you are doing UPDATEs or DELETEs
that change many rows of a database and you do not mind if SQLite
uses more memory, you can increase the cache size for a possible speed
improvement.When you change the cache size using the cache_size pragma, the
change only endures for the current session. The cache size reverts
to the default value when the database is closed and reopened. Use
the default_cache_size
pragma to check the cache size permanently. -
PRAGMA count_changes = ON; (1)
PRAGMA count_changes = OFF; (0)When on, the COUNT_CHANGES pragma causes the callback function to
be invoked once for each DELETE, INSERT, or UPDATE operation. The
argument is the number of rows that were changed.This pragma may be removed from future versions of SQLite.
Consider using the sqlite_changes() API function instead. -
PRAGMA database_list;
For each open database, invoke the callback function once with
information about that database. Arguments include the index and
the name the datbase was attached with. The first row will be for
the main database. The second row will be for the database used to
store temporary tables. -
PRAGMA default_cache_size;
PRAGMA default_cache_size = Number-of-pages;Query or change the maximum number of database disk pages that SQLite
will hold in memory at once. Each page uses 1K on disk and about 1.5K in memory.
This pragma works like the cache_size
pragma with the additional
feature that it changes the cache size persistently. With this pragma,
you can set the cache size once and that setting is retained and reused
everytime you reopen the database. -
PRAGMA default_synchronous;
PRAGMA default_synchronous = FULL; (2)
PRAGMA default_synchronous = NORMAL; (1)
PRAGMA default_synchronous = OFF; (0)Query or change the setting of the «synchronous» flag in
the database. The first (query) form will return the setting as an
integer. When synchronous is FULL (2), the SQLite database engine will
pause at critical moments to make sure that data has actually been
written to the disk surface before continuing. This ensures that if
the operating system crashes or if there is a power failure, the database
will be uncorrupted after rebooting. FULL synchronous is very
safe, but it is also slow.
When synchronous is NORMAL (1, the default), the SQLite database
engine will still pause at the most critical moments, but less often
than in FULL mode. There is a very small (though non-zero) chance that
a power failure at just the wrong time could corrupt the database in
NORMAL mode. But in practice, you are more likely to suffer
a catastrophic disk failure or some other unrecoverable hardware
fault. So NORMAL is the default mode.
With synchronous OFF (0), SQLite continues without pausing
as soon as it has handed data off to the operating system.
If the application running SQLite crashes, the data will be safe, but
the database might become corrupted if the operating system
crashes or the computer loses power before that data has been written
to the disk surface. On the other hand, some
operations are as much as 50 or more times faster with synchronous OFF.This pragma changes the synchronous mode persistently. Once changed,
the mode stays as set even if the database is closed and reopened. The
synchronous pragma does the same
thing but only applies the setting to the current session. -
PRAGMA default_temp_store;
PRAGMA default_temp_store = DEFAULT; (0)
PRAGMA default_temp_store = MEMORY; (2)
PRAGMA default_temp_store = FILE; (1)Query or change the setting of the «temp_store» flag stored in
the database. When temp_store is DEFAULT (0), the compile-time default
is used for the temporary database. When temp_store is MEMORY (2), an
in-memory database is used. When temp_store is FILE (1), a temporary
database file on disk will be used. Note that it is possible for
the library compile-time options to override this setting. Once
the temporary database is in use, its location cannot be changed.This pragma changes the temp_store mode persistently. Once changed,
the mode stays as set even if the database is closed and reopened. The
temp_store pragma does the same
thing but only applies the setting to the current session. -
PRAGMA empty_result_callbacks = ON; (1)
PRAGMA empty_result_callbacks = OFF; (0)When on, the EMPTY_RESULT_CALLBACKS pragma causes the callback
function to be invoked once for each query that has an empty result
set. The third «argv» parameter to the callback is set to NULL
because there is no data to report. But the second «argc» and
fourth «columnNames» parameters are valid and can be used to
determine the number and names of the columns that would have been in
the result set had the set not been empty. -
PRAGMA full_column_names = ON; (1)
PRAGMA full_column_names = OFF; (0)The column names reported in an SQLite callback are normally just
the name of the column itself, except for joins when «TABLE.COLUMN»
is used. But when full_column_names is turned on, column names are
always reported as «TABLE.COLUMN» even for simple queries. -
PRAGMA index_info(index-name);
For each column that the named index references, invoke the
callback function
once with information about that column, including the column name,
and the column number. -
PRAGMA index_list(table-name);
For each index on the named table, invoke the callback function
once with information about that index. Arguments include the
index name and a flag to indicate whether or not the index must be
unique. -
PRAGMA integrity_check;
The command does an integrity check of the entire database. It
looks for out-of-order records, missing pages, malformed records, and
corrupt indices.
If any problems are found, then a single string is returned which is
a description of all problems. If everything is in order, «ok» is
returned. -
PRAGMA parser_trace = ON; (1)
PRAGMA parser_trace = OFF; (0)Turn tracing of the SQL parser inside of the
SQLite library on and off. This is used for debugging.
This only works if the library is compiled without the NDEBUG macro. -
PRAGMA show_datatypes = ON; (1)
PRAGMA show_datatypes = OFF; (0)When turned on, the SHOW_DATATYPES pragma causes extra entries containing
the names of datatypes of columns to be
appended to the 4th («columnNames») argument to sqlite_exec()
callbacks. When
turned off, the 4th argument to callbacks contains only the column names.
The datatype for table columns is taken from the CREATE TABLE statement
that defines the table. Columns with an unspecified datatype have a
datatype of «NUMERIC» and the results of expression have a datatype of
either «TEXT» or «NUMERIC» depending on the expression.
The following chart illustrates the difference for the query
«SELECT ‘xyzzy’, 5, NULL AS empty «:show_datatypes=OFF show_datatypes=ON azCol[0] = «xyzzy»;
azCol[1] = «5»;
azCol[2] = «empty»;
azCol[3] = 0;azCol[0] = «xyzzy»;
azCol[1] = «5»;
azCol[2] = «empty»;
azCol[3] = «TEXT»;
azCol[4] = «NUMERIC»;
azCol[5] = «TEXT»;
azCol[6] = 0; -
PRAGMA synchronous;
PRAGMA synchronous = FULL; (2)
PRAGMA synchronous = NORMAL; (1)
PRAGMA synchronous = OFF; (0)Query or change the setting of the «synchronous» flag affecting
the database for the duration of the current database connection.
The synchronous flag reverts to its default value when the database
is closed and reopened. For additional information on the synchronous
flag, see the description of the
default_synchronous pragma. -
PRAGMA table_info(table-name);
For each column in the named table, invoke the callback function
once with information about that column, including the column name,
data type, whether or not the column can be NULL, and the default
value for the column. -
PRAGMA temp_store;
PRAGMA temp_store = DEFAULT; (0)
PRAGMA temp_store = MEMORY; (2)
PRAGMA temp_store = FILE; (1)Query or change the setting of the «temp_store» flag affecting
the database for the duration of the current database connection.
The temp_store flag reverts to its default value when the database
is closed and reopened. For additional information on the temp_store
flag, see the description of the
default_temp_store pragma. Note that it is possible for
the library compile-time options to override this setting. -
PRAGMA vdbe_trace = ON; (1)
PRAGMA vdbe_trace = OFF; (0)Turn tracing of the virtual database engine inside of the
SQLite library on and off. This is used for debugging. See the
VDBE documentation for more
information.
No error message is generated if an unknown pragma is issued.
Unknown pragmas are ignored.
REPLACE
| sql-statement ::= | REPLACE INTO [database-name .] table-name [( column-list )] VALUES ( value-list ) | REPLACE INTO [database-name .] table-name [( column-list )] select-statement |
The REPLACE command is an alias for the «INSERT OR REPLACE» variant
of the INSERT command. This alias is provided for
compatibility with MySQL. See the
INSERT command documentation for additional
information.
SELECT
| sql-statement ::= | SELECT [ALL | DISTINCT] result [FROM table-list] [WHERE expr] [GROUP BY expr-list] [HAVING expr] [compound-op select]* [ORDER BY sort-expr-list] [LIMIT integer [( OFFSET | , ) integer]] |
| result ::= | result-column [, result-column]* |
| result-column ::= | * | table-name . * | expr [ [AS] string ] |
| table-list ::= | table [join-op table join-args]* |
| table ::= | table-name [AS alias] | ( select ) [AS alias] |
| join-op ::= | , | [NATURAL] [LEFT | RIGHT | FULL] [OUTER | INNER | CROSS] JOIN |
| join-args ::= | [ON expr] [USING ( id-list )] |
| sort-expr-list ::= | expr [sort-order] [, expr [sort-order]]* |
| sort-order ::= | ASC | DESC |
| compound_op ::= | UNION | UNION ALL | INTERSECT | EXCEPT |
The SELECT statement is used to query the database. The
result of a SELECT is zero or more rows of data where each row
has a fixed number of columns. The number of columns in the
result is specified by the expression list in between the
SELECT and FROM keywords. Any arbitrary expression can be used
as a result. If a result expression is
* then all columns of all tables are substituted
for that one expression. If the expression is the name of
a table followed by .* then the result is all columns
in that one table.
The DISTINCT keyword causes a subset of result rows to be returned,
in which each result row is different. NULL values are not treated as
distinct from eachother. The default behavior is that all result rows
be returned, which can be made explicit with the keyword ALL.
The query is executed against one or more tables specified after
the FROM keyword. If multiple tables names are separated by commas,
then the query is against the cross join of the various tables.
The full SQL-92 join syntax can also be used to specify joins.
A sub-query
in parentheses may be substituted for any table name in the FROM clause.
The entire FROM clause may be omitted, in which case the result is a
single row consisting of the values of the expression list.
The WHERE clause can be used to limit the number of rows over
which the query operates.
The GROUP BY clauses causes one or more rows of the result to
be combined into a single row of output. This is especially useful
when the result contains aggregate functions. The expressions in
the GROUP BY clause do not have to be expressions that
appear in the result. The HAVING clause is similar to WHERE except
that HAVING applies after grouping has occurred. The HAVING expression
may refer to values, even aggregate functions, that are not in the result.
The ORDER BY clause causes the output rows to be sorted.
The argument to ORDER BY is a list of expressions that are used as the
key for the sort. The expressions do not have to be part of the
result for a simple SELECT, but in a compound SELECT each sort
expression must exactly match one of the result columns. Each
sort expression may be optionally followed by ASC or DESC to specify
the sort order.
The LIMIT clause places an upper bound on the number of rows
returned in the result. A negative LIMIT indicates no upper bound.
The optional OFFSET following LIMIT specifies how many
rows to skip at the beginning of the result set.
In a compound query, the LIMIT clause may only appear on the
final SELECT statement.
The limit is applied to the entire query not
to the individual SELECT statement to which it is attached.
A compound SELECT is formed from two or more simple SELECTs connected
by one of the operators UNION, UNION ALL, INTERSECT, or EXCEPT. In
a compound SELECT, all the constituent SELECTs must specify the
same number of result columns. There may be only a single ORDER BY
clause at the end of the compound SELECT. The UNION and UNION ALL
operators combine the results of the SELECTs to the right and left into
a single big table. The difference is that in UNION all result rows
are distinct where in UNION ALL there may be duplicates.
The INTERSECT operator takes the intersection of the results of the
left and right SELECTs. EXCEPT takes the result of left SELECT after
removing the results of the right SELECT. When three are more SELECTs
are connected into a compound, they group from left to right.
UPDATE
| sql-statement ::= | UPDATE [ OR conflict-algorithm ] [database-name .] table-name SET assignment [, assignment]* [WHERE expr] |
| assignment ::= | column-name = expr |
The UPDATE statement is used to change the value of columns in
selected rows of a table. Each assignment in an UPDATE specifies
a column name to the left of the equals sign and an arbitrary expression
to the right. The expressions may use the values of other columns.
All expressions are evaluated before any assignments are made.
A WHERE clause can be used to restrict which rows are updated.
The optional conflict-clause allows the specification of an alternative
constraint conflict resolution algorithm to use during this one command.
See the section titled
ON CONFLICT for additional information.
VACUUM
| sql-statement ::= | VACUUM [index-or-table-name] |
The VACUUM command is an SQLite extension modelled after a similar
command found in PostgreSQL. If VACUUM is invoked with the name of a
table or index then it is suppose to clean up the named table or index.
In version 1.0 of SQLite, the VACUUM command would invoke
gdbm_reorganize() to clean up the backend database file.
VACUUM became a no-op when the GDBM backend was removed from
SQLITE in version 2.0.0.
VACUUM was reimplimented in version 2.8.1. It now cleans
the database by copying its contents to a temporary database file and
reloading the original database file from the copy. This will eliminate
free pages, align table data to be contiguous, and otherwise clean up
the database file structure. The index or table name argument is now
ignored.
This command will fail if there is an active transaction. This
command has no effect on an in-memory database.
SQLite keywords
The following keywords are used by SQLite. Most are either reserved
words in SQL-92 or were listed as potential reserved words. Those which
aren’t are shown in italics. Not all of these words are actually used
by SQLite. Keywords are not reserved in SQLite. Any keyword can be used
as an identifier for SQLite objects (columns, databases, indexes, tables,
triggers, views, …) but must generally be enclosed by brackets or
quotes to avoid confusing the parser. Keyword matching in SQLite is
case-insensitive.
Keywords can be used as identifiers in three ways:
| ‘keyword’ | Interpreted as a literal string if it occurs in a legal string context, otherwise as an identifier. |
| «keyword» | Interpreted as an identifier if it matches a known identifier and occurs in a legal identifier context, otherwise as a string. |
| [keyword] | Always interpreted as an identifer. (This notation is used by MS Access and SQL Server.) |
Fallback Keywords
These keywords can be used as identifiers for SQLite objects without
delimiters.
ABORT
AFTER
ASC
ATTACH
BEFORE
BEGIN
DEFERRED
CASCADE
CLUSTER
CONFLICT
COPY
CROSS
DATABASE
DELIMITERS
DESC
DETACH
EACH
END
EXPLAIN
FAIL
FOR
FULL
IGNORE
IMMEDIATE
INITIALLY
INNER
INSTEAD
KEY
LEFT
MATCH
NATURAL
OF
OFFSET
OUTER
PRAGMA
RAISE
REPLACE
RESTRICT
RIGHT
ROW
STATEMENT
TEMP
TEMPORARY
TRIGGER
VACUUM
VIEW
Normal keywords
These keywords can be used as identifiers for SQLite objects, but
must be enclosed in brackets or quotes for SQLite to recognize them as
an identifier.
ALL
AND
AS
BETWEEN
BY
CASE
CHECK
COLLATE
COMMIT
CONSTRAINT
CREATE
DEFAULT
DEFERRABLE
DELETE
DISTINCT
DROP
ELSE
EXCEPT
FOREIGN
FROM
GLOB
GROUP
HAVING
IN
INDEX
INSERT
INTERSECT
INTO
IS
ISNULL
JOIN
LIKE
LIMIT
NOT
NOTNULL
NULL
ON
OR
ORDER
PRIMARY
REFERENCES
ROLLBACK
SELECT
SET
TABLE
THEN
TRANSACTION
UNION
UNIQUE
UPDATE
USING
VALUES
WHEN
WHERE
Special words
The following are not keywords in SQLite, but are used as names of
system objects. They can be used as an identifier for a different
type of object.
_ROWID_
MAIN
OID
ROWID
SQLITE_MASTER
SQLITE_TEMP_MASTER

Back to the SQLite Home Page
Привет, посетитель сайта ZametkiNaPolyah.ru! Продолжаем изучать базы данных и наше знакомство с библиотекой SQLite3. Тем в рубрике SQLite осталось не так уж и много. Вернее про SQLite можно писать очень много, долго и упорно, и всё равно часть вопросов останется не освещенной и освещенной не в полной мере. Под словосочетанием «тем осталось немного» я понимаю следующее: мы практически закончили изучать реализацию SQL в библиотеки SQLite. Задачу, которую я сам перед собой поставил, можно озвучить следующим образом: дать начинающему разработчику максимально понятное и подробное представление о языке SQL, а в качестве примера используется библиотека SQLite. В данной теме мы поговорим о том, что собой представляют триггеры в SQL на примере базы данных под управлением SQLite. Тему триггеров я не стал делить на части, поэтому запись получилось довольно объемной(более 4300 слов, поэтому пользуйтесь постраничной навигацией).

Триггеры в SQL на примере базы данных SQLite
Отсутствие деления темы SQL триггеров на части не вызвано желанием написать огромный текст, просто все разделы данной записи очень тесно связаны между собой и я не захотел разбивать эту связь, делая деление на части. Итак, поехали! По традиции небольшая аннотация к записи:
- Сначала мы поговорим о назначении триггеров в SQL и реляционных базах данных, попутно рассмотрев синтаксис триггеров в SQLite.
- Затем мы поговорим о том, как срабатывают триггеры в базах данных: до возникновения события (триггер BEFORE) и после возникновения события (триггер AFTER) и параллельно разберемся в чем между ними разница.
- Далее мы опишем триггеры по событиям, на которые они срабатывают. Событий у нас всего три, так как триггеры в SQLite срабатывают только на операции, которые тем или иным образом изменяют данные в таблицы: UPDATE, INSERT, DELETE.
- Далее мы рассмотрим, как составить уточняющее выражение WHEN для триггера.
- Рассмотрим особенности INSTEAD OF триггера, который позволяет реализовать команды манипуляции данными для представлений, отметим, что в SQLite представления нельзя редактировать, об этом мы поговорим в следующей теме.
- Также мы поговорим про устранение конфликтов и обеспечение целостности данных при помощи триггеров и специальной функции RAISE.
- И в завершении публикации вы узнаете о том, как получить информацию о триггерах/списков триггеров в базах данных SQLite3.Рассмотрим явное и неявное удаление триггеров из базы данных SQLite. И разберемся с некоторыми особенностями работы временных триггеров в SQLite.
Что такое триггер в контексте SQL? Использование триггеров в базах данных SQLite
Содержание статьи:
- Что такое триггер в контексте SQL? Использование триггеров в базах данных SQLite
- SQL синтаксис триггеров в базах данных SQLite
- SQL событие BEFORE: выполнение триггера перед запросом
- SQL событие AFTER: выполнение триггера после запроса
- INSERT триггеры и DELETE триггеры. Триггеры добавления и удаления данных
- UPDATE триггеры: AFTER UPDATE и BEFORE UPDATE триггер. Триггеры модификации.
- Условия срабатывания триггера WHEN. Уточняющие выражения
- Некоторые особенности триггеров в базах данных SQLite
- Изменение данных VIEW в SQLite. Редактирование VIEW при помощи INSTEAD OF триггера в SQLite
- Функция RAISE () и SQL триггеры в библиотеки SQLite3. Устранение конфликтов в базе данных при помощи триггеров
- Временные триггеры в базах данных SQLite3
- Получит информацию о триггерах в базе данных SQLite
- Удаление триггеров из базы данных SQLite
Триггер – это особая разновидность хранимых процедур в базе данных. Особенность триггеров заключается в том, что SQL код, написанные в теле триггера, будет исполнен после того, как в базе данных произойдет какое-либо событие. События в базах данных происходят в результате выполнения DML команд или команд манипуляции данными. Если вы помните, то к командам манипуляции данными относятся: UPDATE, INSERT, DELETE и SELECT.
Команду SELECT мы не берем в расчет из-за того, что она никак не изменяет данные в базе данных, а лишь делает выборку данных. Основное назначение триггеров заключается в обеспечение целостности данных в базе данных, еще при помощи триггеров в SQL можно реализовать довольно-таки сложную бизнес-логику.
SQL код, написанный в теле триггера, будет выполнен автоматически, как только в базе данных произойдет одно из трех, указанных выше событий. Также мы можем задать самостоятельно события, по которым триггер будет срабатывать, а также SQL таблицу, для которой триггер будет срабатывать.
Для любой СУБД триггер – это в первую очередь объект базы данных, поэтому имя триггера должно быть уникальным во всей базе данных, SQLite в этом плане не исключение. У триггеров в SQL есть момент запуска. Момент запуска триггера можно разделить на два вида: BEFORE и AFTER. Момент запуска триггера AFTER говорит о том, что триггер будет запущен после выполнения какого-либо события в базе данных. Соответственно, момент запуска триггера BEFORE говорит о том, что триггер будет запущен до выполнения события в базе данных.
Мы еще поговорим про представления или VIEW в SQL, и вы узнаете, что SQLite позволяет только читать данные из VIEW, в отличии, скажем, от MySQL или Oracle. Триггеры могут быть назначены для представлений с целью расширить набор операций манипуляции данными того или иного представления. Такой вид триггеров получил название INSTEAD OF триггер.
Итак, триггеры можно разделить на три вида по их применению:
- триггер BEFORE, который срабатывает до выполнения какого-либо события в базе данных;
- триггер AFTER, который срабатывает после выполнения события в базе данных;
- INSTEAD OF триггер, который используется для манипуляции данными представлений.
Так же мы можем разделить триггеры по типам SQL команд:
- DELETE триггер. Триггер DELETE запускается при попытке удаления данных/строк из таблицы базы данных;
- UPDATE триггер. Триггер UPDATE будет запущен при попытке обновления/модификации данных в таблице базы данных;
- INSERT триггер. Триггер INSERT будет запущен в том случае, если вы попытаетесь вставить/добавить строку в таблицу базы данных.
В некоторых СУБД триггер – это довольно мощное и полезное явление. Будьте аккуратны, используя триггеры, не используйте триггеры в рабочих базах данных. Перед тем, как реализовать триггер, создайте тестовую базу данных и посмотрите, что в итоге получится. Неправильный составленный триггер может навредить вашему проекту, повредив часть данных или удалив данные из базы данных.
Давайте перечислим самые распространенные функции триггеров:
- Функция журнализации. Часто при помощи триггеров разработчики создают таблицы-журналы, в которых фиксируются различные изменения в базе данных. Обычно журналы создаются для фиксации изменений, которые вносят различные пользователи базы данных, таким образом можно отследить какой пользователь внес то или иное изменение в ту или иную таблицу базы данных.
- Функция согласования данных. Мы уже упоминали, что триггеры используются для обеспечения целостности данных в базе данных. Мы можем связать триггер с той или иной SQL командой, таким образом, чтобы триггер проверял связанные таблицы на согласованность данных, тем самым мы обезопасим данные.
- Функция очистки данных. Данная функция является подмножество функции из второго пункта. Например, вы выполняете каскадное удаление данных, в этом случае данные удаляются из таблиц, связанных ограничением внешнего ключа, но что если данные об одном объекте хранятся в несвязанных таблицах? В этом случае нас спасают триггеры. То же самое можно сказать и про операции каскадной модификации данных.
- Другие функции триггеров. К сожалению, в SQLite3 нет хранимых процедур за исключением триггеров. В тех СУБД, у которых реализованы хранимые процедуры, мы можем создавать собственные процедуры в теле триггера, которые могут выполнять операции, не связанные с изменением данных.
Давайте приступим к рассмотрению триггеров на примере библиотеки SQLite.
SQL синтаксис триггеров в базах данных SQLite
Здесь мы коротко рассмотрим SQL синтаксис триггеров, реализованный в реляционных базах данных под управлением библиотеки SQLite3. Ранее мы уже говорили о том, как создать триггер, когда разбирались с командой CREATE в SQLite (у нас был раздел CREATE TRIGGER) и мы рассматривали, как удалить триггер, когда разбирались с особенностями команды DROP в SQLite3 (раздел DROP TRIGGER). Давайте повторим и дополним уже имеющуюся информацию о триггерах. Общий SQL синтаксис создания триггеров в SQLite вы можете увидеть на рисунке ниже.
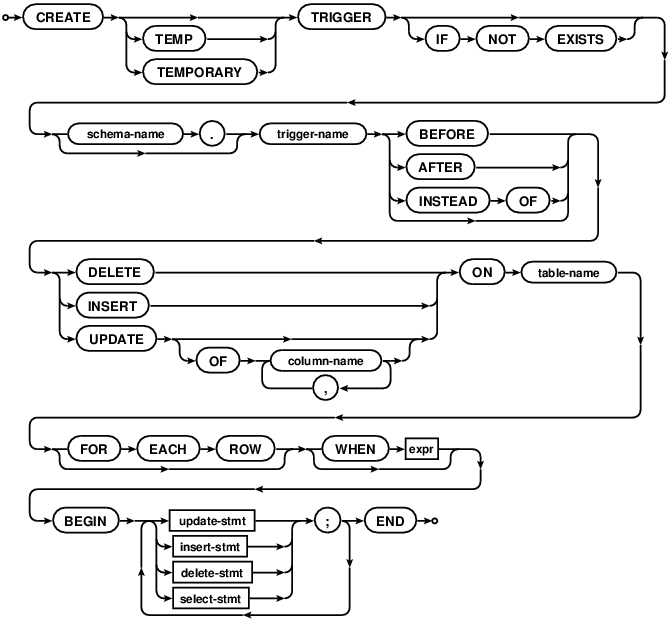
Общий синтаксис создания триггера в базе данных под управлением SQLite3
Мы видим, что операция по созданию триггера начинается с команды CREATE, как и операция создания таблицы в базе данных, это обусловлено тем, что триггер, как и таблица, является объектом базы данных.
Далее идет модификатор TEMP или TEMPORARY, этот модификатор необязательный и его можно опускать. Временный триггер будет доступен только для того пользователя, который его создали, а существовать временный триггер будет до тех пор, пока пользователь не разорвет соединение или же пока не удалит его.
Далее мы указываем, что хотим создать триггер при помощи ключевого слова TRIGGER. Мы можем воспользоваться оператором EXISTS, чтобы проверить существует ли триггер в базе данных, перед тем как его создать. Данная проверка не является обязательно, но если вы попытаетесь создать триггер, который уже существует в базе данных, то произойдет ошибка, а программный код, отправлявший такой запрос, может быть остановлен.
После ключевого слова TRIGGER мы указываем его имя, имя триггера должно быть уникальным во всей базе данных. Так же мы можем использовать квалификатор, чтобы указать полное имя триггера, состоящее из имени базы данных, в которой будет создан триггер и непосредственно имени триггера.
Далее мы указываем как мы хотим, чтобы триггер работал: для VIEW – INSTEAD OF, перед выполнением SQL команды – BEFORE, после выполнения SQL операции – AFTER. После чего мы связываем триггер с той или иной командой. Обратите внимание: для всех трех команд манипуляции данными обязательным является указание таблицы или представления, для которых триггер создается, а вот для команды UPDATE можно указать еще и столбец, который будет отслеживать триггер.
Обратите внимание: мы можем создавать строковые триггеры при помощи конструкции FOR EACH ROW. Обычно триггеры создаются для какой-нибудь команды и, соответственно, выполняются по событию DELETE, UPDATE или INSERT, но мы можем сделать так, чтобы код триггера вызывался после изменения каждой строки таблицы при помощи конструкции FOR EACH ROW.
Так же стоит отметить, что выше мы говорили не совсем правду в контексте SQLite3. Многие СУБД поддерживают две разновидности триггеров: табличные и строчные. Строчные триггеры создаются при помощи конструкции FOR EACH ROW, но в SQLite нет табличных триггеров, поэтому даже если вы не укажите FOR EACH ROW явно, SQLite будет считать триггер строчным.
Также вы можете использовать уточняющую фразу WHEN, с которой мы разберемся на примере ниже. После того, как вы описали триггер, вы можете задать SQL команды, которые будут выполняться по тому или иному событию, другими словами – создать тело триггера. В теле триггера, создаваемого в базе данных SQLite, можно использовать четыре команды манипуляции данными: INSERT, UPDATE, SELECT, DELETE. Команды определения данных, команды определения доступа к данным и команды управления транзакциями в теле триггера SQLite не предусмотрены. Но нам стоит заметить,что триггеры, выполняя команды и отлавливая события сами работают так, как будто это транзакция.
Обратим внимание на то, что перечисленные команды в теле триггера поддерживают свой практически полный синтаксис. Например, вы можете составить сколь угодно сложный SQL запрос SELECT, в котором будете объединять таблицы или объединять результаты запросов. Чтобы сообщить SQLite, что тело триггера закончилось, используйте ключевое слово END.
Итак, мы разобрались с SQL синтаксисом создания триггеров, давайте посмотрим на SQL синтаксис удаления триггеров. SQL синтаксис удаления триггеров, реализованный в SQLite3, представлен на рисунке ниже.
![]()
Синтаксис удаления триггеров из базы данных SQLite
Для удаления триггера, как и для удаления таблицы из базы данных, используйте команду DROP. Далее идет ключевая фраза TRIGGER, которая сообщает SQLite о том, что вы хотите удалить триггер из базы данных, после чего вы можете сделать проверку IF EXISTS, о которой мы не раз уже говорили. И в конце указываете имя триггера или квалификатор. Как видите, удалить триггер намного проще, чем его создать.
Давайте перейдем к примерам использования триггеров в базах данных под управлением SQLite.
SQL событие BEFORE: выполнение триггера перед запросом
Итак, не забываем, что триггер создается для какой-либо конкретной таблицы и отслеживает события, происходящие с таблицей, для которой он создан. В SQLite нет табличных триггеров, а есть только триггеры строчные, то есть FOR EACH ROW триггеры, которые срабатывают при изменении каждой строки в таблице.
Давайте напишем триггер, который будет срабатывать при вставке данных в базу данных, до того, как будет выполнена операция вставки. Но сначала создадим две таблицы, в первой мы будем хранить информацию о покупателе, во второй дату его посещения:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
CREATE TABLE users( id INTEGER PRIMARY KEY, name TEXT NOT NULL, age INTEGER NOT NULL, address TEXT NOT NULL, mydate TEXT NOT NULL ); CREATE TABLE user_log ( Id_u INTEGER NOT NULL, u_date TEXT NOT NULL ); |
Таблицы довольно простые, заметьте, вторую таблицу мы не связывали с первой при помощи ограничения внешнего ключа FOREIGN KEY, так как для наполнения второй таблицы мы будем использовать триггер. Так же для таблиц мы задали ограничения уровня столбца и ограничения уровня таблицы. Первичный ключ или PRIMARY KEY – это не только ограничение, но еще и индекс таблицы в базе данных.
Давайте напишем триггер, который будет срабатывать перед тем, как SQLite выполнит запрос:
|
CREATE TRIGGER my_u_log BEFORE INSERT ON users BEGIN INSERT INTO user_log(id_u, u_date) VALUES (NEW.id, datetime(‘now’)); END; |
Этот триггер срабатает перед тем, как новая строка будет добавлена в таблицу users. Давайте в этом убедимся:
|
INSERT INTO users(name, age, address, mydate) VALUES (‘Пупкин’, 27, ‘Адрес’, datetime(‘now’)); SELECT * FROM users; id name age address mydate 1 Пупкин 27 Адрес 2016—07—15 06:58:36 SELECT * FROM user_log; Id_u u_date —1 2016—07—15 06:58:36 |
Мы видим, что данные в таблицу user_log были добавлены автоматически. К сожалению, поле date в данном случае не показывает, что вставка данных в таблицу user_log произошла до того, как были вставлены данные в таблицу users. Но этот факт мы можем заметить по значению столбца id_u, которое равно -1, так как SQLite3 просто не знает: какое значение будет в столбце id таблицы users.
SQL событие AFTER: выполнение триггера после запроса
Давайте теперь изменим наш пример, таблица останется той же, но мы изменим код триггера, только одну его часть: поменяем BEFORE на AFTER, чтобы посмотреть, как сработает триггер после выполнения запроса:
|
CREATE TRIGGER my_u_log AFTER INSERT ON users BEGIN INSERT INTO user_log(id_u, u_date) VALUES (NEW.id, datetime(‘now’)); END; |
Мы создали триггер (не забудьте удалить все объекты, чтобы пример работал корректно), который будет добавлять строки в таблицу user_log после того, как выполнится запрос INSERT, об этом нам говорит ключевое слово AFTER, давайте в этом убедимся:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
INSERT INTO users(name, age, address, mydate) VALUES (‘Пупкин’, 27, ‘Адрес’, datetime(‘now’)); INSERT INTO users(name, age, address, mydate) VALUES (‘Сумкин’, 17, ‘Адрес2’, datetime(‘now’)); SELECT * FROM users; id name age address mydate 1 Пупкин 27 Адрес 2016—07—15 07:08:46 2 Сумкин 17 Адрес2 2016—07—15 07:08:46 SELECT * FROM user_log; Id_u u_date 1 2016—07—15 07:08:46 2 2016—07—15 07:08:46 |
Теперь идентификаторы записываются корректно во вторую таблицу. Обратите внимание на модификатор NEW. Модификатор NEW – это ключевое слово, которое используется в теле триггера для того, чтобы сказать СУБД о том, что нужно брать новые значения (значение, которое мы добавляем в таблицу или модифицированный вариант значения). Надеюсь, что вы разобрались в разнице между BEFORE и AFTER.
INSERT триггеры и DELETE триггеры. Триггеры добавления и удаления данных
Ранее мы уже рассмотрели триггеры AFTER INSERT и BEFORE INSERT, поэтому мы не будем уделять здесь им особого внимания и сразу поговорим про триггеры BEFORE DELETE и AFTER DELETE. Таблица users у нас останется прежней, а вот структуру таблицы user_log мы немного изменим:
|
CREATE TABLE user_log ( Id_u INTEGER NOT NULL, u_date TEXT NOT NULL, operation TEXT NOT NULL ); |
Мы добавили столбец operation, в котором будем хранить информацию о том, что мы сделали с пользователем: удалили или добавили. Давайте напишем триггер AFTER DELETE, который у нас будет срабатывать по событию удаления строки из таблицы users:
|
CREATE TRIGGER after_delete AFTER DELETE ON users BEGIN INSERT INTO user_log(id_u, u_date, operation) VALUES (OLD.id, datetime(‘now’), ‘del’); END; |
А теперь давайте посмотрим на то, как будет работать триггер AFTER DELETE:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 |
INSERT INTO users(name, age, address, mydate) VALUES (‘Пупкин’, 27, ‘Адрес’, datetime(‘now’)); INSERT INTO users(name, age, address, mydate) VALUES (‘Сумкин’, 17, ‘Адрес2’, datetime(‘now’)); INSERT INTO users(name, age, address, mydate) VALUES (‘Иванов’, 37, ‘Адрес3’, datetime(‘now’)); INSERT INTO users(name, age, address, mydate) VALUES (‘Петров’, 47, ‘Адрес4’, datetime(‘now’)); INSERT INTO users(name, age, address, mydate) VALUES (‘Сидоров’, 57, ‘Адрес5’, datetime(‘now’)); INSERT INTO users(name, age, address, mydate) VALUES (‘Парамонов’, 7, ‘Адрес6’, datetime(‘now’)); DELETE FROM users WHERE id = 4; SELECT * FROM user_log; 1|2016—07—15 07:29:28|ins 2|2016—07—15 07:29:28|ins 3|2016—07—15 07:29:28|ins 4|2016—07—15 07:29:28|ins 5|2016—07—15 07:29:28|ins 6|2016—07—15 07:29:28|ins 4|2016—07—15 07:29:28|del SELECT * FROM users; id name age address mydate 1 Пупкин 27 Адрес 2016—07—15 07:29:28 2 Сумкин 17 Адрес2 2016—07—15 07:29:28 3 Иванов 37 Адрес3 2016—07—15 07:29:28 5 Сидоров 57 Адрес5 2016—07—15 07:29:28 6 Парамонов 7 Адрес6 2016—07—15 07:29:28 |
Чтобы получилась такие результаты, я немного изменил код первого триггера, добавив столбец operation. Но давайте обратим внимание на код триггера AFTER DELETE, в котором мы использовали модификатор OLD, модификатор OLD в SQL и SQLite используется в коде триггера для того, чтобы обратиться к старому значению или к значению, которое хранится в таблице (значение, которое будет изменено или модифицировано).
Теперь мы разобрались с модификаторами OLD и NEW:
- NEW позволяет обратиться к значению, которое указано в SQL запросе или же можно сказать, что это значение, которое мы хотим добавить или на которое хотим изменить.
- OLD позволяет обратиться к значению, которое хранится в таблице или же можно сказать, что это значение, которое мы хотим удалить или которое хотим изменить.
Также мы разобрались с тем, как работает триггер AFTER DELETE, думаю, вы без труда разберетесь с тем, как работает триггер BEFORE DELETE, просто заменив в примере триггера DELETE AFTER на BEFORE, поэтому демонстрировать триггер BEFORE DELETE мы здесь не будем и перейдем к другим примерам.
UPDATE триггеры: AFTER UPDATE и BEFORE UPDATE триггер. Триггеры модификации.
Теперь рассмотрим триггеры, срабатывающие при событии обновления данных: AFTER UPDATE триггер и BEFORE UPDATE триггер. Давайте напишем AFTER UPDATE триггер, который будет записывать в таблицу логов строки, хранящие информацию о модификации данных в таблице users, сделать это проще простого:
|
CREATE TRIGGER after_update AFTER UPDATE ON users BEGIN INSERT INTO user_log(id_u, u_date, operation) VALUES (OLD.id, datetime(‘now’), ‘upd’); END; |
Таким образом мы создали триггер, который сработает после выполнения команды UPDATE или AFTER UPDATE триггер, давайте в этом убедимся:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
UPDATE users SET name = ‘Марков’ WHERE id = 6; SELECT * FROM user_log; Id_u u_date operation 1 2016—07—15 07:29:28 ins ………………………………………………….. 6 2016—07—15 07:29:28 ins 4 2016—07—15 07:29:28 del 6 2016—07—15 08:12:44 upd SELECT * FROM users; id name age address mydate 1 Пупкин 27 Адрес 2016—07—15 07:29:28 …………………………………………………………………………….. 6 Марков 7 Адрес6 2016—07—15 07:29:28 |
Видим, что триггер сработал и в лог записалась информация о том, что для пользователя с id=6 вносились изменения. Думаю, вы легко разберетесь с тем, как сделать триггер BEFORE UPDATE по примеру AFTER UPDATE, чтобы вносимые изменения фиксировались до того, как они произойдут. Ничего сложно в триггере BEFORE UPDATE нет.
Обратите внимание: триггер модификации или UPDATE триггер может отслеживать изменения не только для всей таблицы, но и для какого-то конкретного столбца, чтобы указать столбец, который будет отслеживать триггер модификации, используйте следующий синтаксис:
|
CREATE TRIGGER trigg_name AFTER UPDATE OF (column1, column2) BEGIN — тело триггера END; |
Для такого триггера модификации вы можете использовать любое количество столбцов, имена которых указываются в круглых скобках, после ключевого слова OF идет тело триггеры модификации.
Условия срабатывания триггера WHEN. Уточняющие выражения
Библиотека SQLite, как и многие другие реляционные СУБД, позволяет использовать условие WHEN, которое позволяет задать область применения триггера при помощи SQL выражений. Синтаксис выражения в SQLite показан на рисунке ниже.
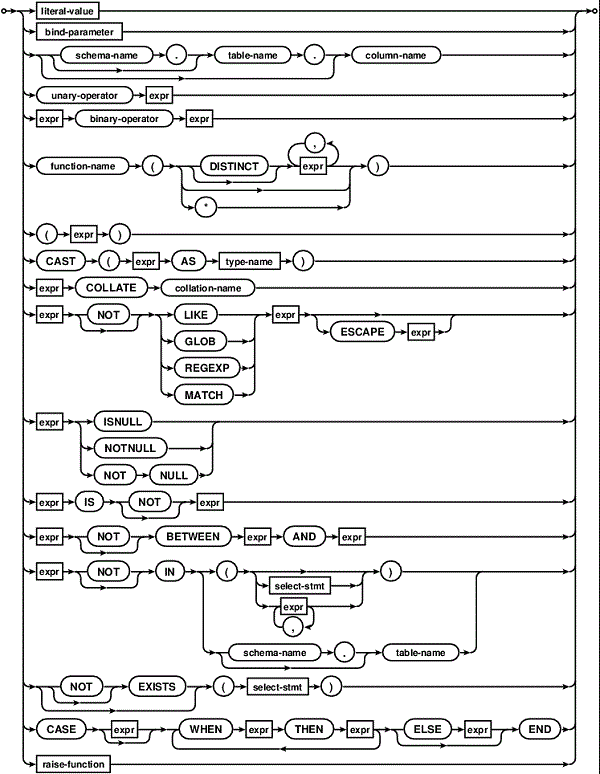
Синтаксис использования выражений в базах данных SQLite
Как видим, мы можем задавать очень сложные выражения для условия WHEN, когда мы создаем триггер. Любая СУБД вычисляет это выражение для строки таблицы, к которой привязан триггер? и в том случае, если WHEN вернет значение TRUE, триггер будет выполнен. SQLite не будет вычислять выражение WHEN, если не будет происходить событие, инициирующее выполнение триггера.
Давайте напишем триггер с условием WHEN, который будет срабатывать, как AFTER INSERT:
|
CREATE TRIGGER after_insert AFTER INSERT ON users WHEN (SELECT count(*) FROM user_log) > 21 BEGIN DELETE FROM user_log WHERE u_date = (SELECT min(u_date) FROM user_log); INSERT INTO user_log(id_u, u_date, operation) VALUES (NEW.id, datetime(‘now’), ‘ins’); END; |
Этот триггер делает очень простую вещь: он ограничивает количество записей в логе до двадцати одной. То есть в таблице user_log будет храниться информация не обо всех модификациях, а только о последних, понятно, что количество записей в таблице можно регулировать.
Попробуйте реализовать данный триггер, чтобы посмотреть, как работает условие WHEN. Демонстрировать его работу здесь мы не будем. Также обратите внимание на то, что теперь в теле триггера выполняется две операции: первая удаляет лишнюю строку из лог-таблицы, вторая добавляет новую строку в таблицу лога.
Некоторые особенности триггеров в базах данных SQLite
Ранее мы говорили, что в теле триггера можно использовать любую команду манипуляции данных с довольно полным синтаксисом. Но ключевая часть выражения здесь: довольно полный синтаксис. Всё дело в том, что синтаксис команд манипуляции данными в теле триггера SQLite поддерживается не полностью. Итак, ваш триггер не будет создан/не будет работать если:
- В теле триггера вы не можете использовать квалификаторы для обращения к таблицам базы данных. Можно использовать только имена таблиц.
- Когда в деле триггера вы выполняете операцию INSERT, то вы не можете добавлять значения DEFAULT. Добавляемые значения должны быть явно указаны.
- Нельзя использовать ключевые слова INDEX BY и NOT INDEXED в командах UPDATE и DELETE.
- Клаузулы LIMIT и ORDER BY нельзя использовать с командами UPDATE и DELETE в теле триггера.
Вот такие ограничения накладывает SQLite на команды SQL, которые мы можем использовать в теле триггера.
Изменение данных VIEW в SQLite. Редактирование VIEW при помощи INSTEAD OF триггера в SQLite
В SQLite нет возможности редактировать VIEW. Напомним, что VIEW в SQL – это хранимый запрос, который СУБД выполняет, когда мы обращаемся к представлениям. Но мы можем манипулировать данными VIEW, которые хранятся в представлениях (данное выражение не совсем корректно, так как данные в представлениях не хранятся, это всего лишь результирующая таблица запроса SELECT) при помощи INSTEAD OF триггера.
Стоит заметить, что функция манипулирования данными представлений – это основная функция триггера INSTEAD OF, но не единственная. Триггер INSTEAD OF работает очень интересно, он позволяет выполнять команды INSERT, DELETE и UPDATE над представлениями, но результаты изменений, внесенных триггером INSTEAD OF, никак не отражаются на таблице/таблицах, на основе которых создано VIEW.
Общий синтаксис триггера INSTEAD OF UPDATE для обновления данных представления можно записать как:
|
CREATE TRIGGER trigg_name INSTEAD OF UPDATE OF column_name ON view_name BEGIN — делаем команду UPDATE для таблицы, на основе которой создана VIEW END; |
Синтаксис триггера INSTEAD OF INSERT для добавления строк в представление выглядит так:
|
CREATE TRIGGER trigg_name INSTEAD OF INSERT ON view_name BEGIN — делаем команду INSERT для таблицы, на основе которой создана VIEW END; |
Синтаксис триггера INSTEAD OF DELETE для удаления строк из представления выглядит так:
|
CREATE TRIGGER trigg_name INSTEAD OF DELETE ON view_name BEGIN — делаем команду DELETE для таблицы, на основе которой создана VIEW END; |
Мы познакомились с основным способом применения триггера INSTEAD OF в SQL и базах данных SQLite. Более подробные примеры по редактированию VIEW при помощи INSTEAD OF триггера в SQLite3, вы найдете в следующей теме, в которой речь пойдет о представлениях.
Функция RAISE () и SQL триггеры в библиотеки SQLite3. Устранение конфликтов в базе данных при помощи триггеров
Мы очень много говорили про обеспечение целостности данных и когда рассматривали различные ограничения СУБД SQLite, и когда говорили про нормальные формы в базе данных. Напомню, что первая нормальная форма – самое незащищенное отношение в базе данных. К тому же, первая нормальная форма – это всегда избыточность данных, плюс ко всему – это всевозможные проблемы, которые называются аномалиями. Вторая нормальная форма помогает нам избавиться от избыточности данных.
А третья нормальная форма устраняет всевозможные аномалии и различные зависимости, это всё важно знать и понимать при проектировании базы данных, но, к сожалению, ни одна в мире СУБД не знает, например, что Хемингуэй написал «Старик и море», а Исаак Ньютон – это физик, поэтому когда мы наполняем наши таблицы данными, могут возникать не очевидные ошибки с точки зрения логики реляционных баз данных, от которых не сможет защитить ни одна нормальная форма.
Например, когда мы говорили про внешние ключи, мы реализовывали связь один ко многим между таблицами, для этого мы создавали результирующую таблицу и я демонстрировал пример неудачно добавления данных, при котором получалось, что Джек Лондон написал «Войну и мир». Такие ошибки могут происходить довольно часто и их можно назвать конфликтами в базе данных.
Конфликт в базе данных не стоит путать с аномалией, потому что с точки зрения логики СУБД ничего криминального не происходит, а вот с точки зрения человека, знающего предметную область происходит существенная ошибка, которая может ввести человека в ступор.
Избавиться от подобных конфликтов мы можем при помощи триггеров и функции RAISE (). В SQLite есть специальные ключевые слова ON CONFLICT, которые используются для исключения конфликтов, происходящих во время операций манипуляции данными. О устранении конфликтов мы поговорим более подробно отдельно. Сейчас сконцентрируемся на триггерах и функции RAISE (). Отметим, что RAISE () – это специальная функция, которая используется только вместе с триггерами, ее синтаксис вы найдете на рисунке ниже.
Функция RAISE может принимать два аргумента. Первый аргумент описывает действие при возникновении конфликта:
- Значение IGNORE. Говорит SQLite3 о том, чтобы она игнорировала строку породившую конфликт и продолжала выполнение последующих операций.
- Значение ROLLBACK. ROLLBACK говорит о том, что SQLite должна откатить все операции к исходному состоянию при возникновении конфликта. При этом пользователь может изменить и повторить запрос. Не путайте с командой ROLLBACK, которая откатывая транзакцию
- Значение ABORT. Данное значение похоже на ROLLBACK, но разница в том, что оно отменяет не все выполненные ранее SQL запросы, а только тот запрос, при котором возникла конфликтная ситуация.
- Значение FAIL. Данное значение говорит СУБД о том, что нужно прервать выполнение текущей операции и сохранить результаты успешных операций, при этом операции, следующие за конфликтной, выполнены не будут.
Вообще тело триггера выполняется как транзакция, мы даже используем похожие команды, например тело триггера начинается после ключевого слова BEGIN, а вот начало транзакции обозначается ключевой фразой BEGIN TRANSACTION. Подтверждение транзакции- COMMIT или END, а завершение тела триггера обозначается при помощи ключевого слова END. А функция RAISE дает возможность триггеру работать, как команда SAVEPOINT.
Второй аргумент, который принимает функция триггера RAISE – это пояснение к ошибке. Пояснение – это обычная строка, которую вы вводите с клавиатуры. По сути данное пояснение является сообщением об ошибке, которая произошла в результате операции манипуляции данными.
Давайте повторим пример связи многие ко многим:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 |
PRAGMA foreign_keys=on; CREATE TABLE books( Id INTEGER PRIMARY KEY, title TEXT NOT NULL, count_page INTEGER NOT NULL CHECK (count_page >0), price REAL CHECK (price >0) ); CREATE TABLE auth( id INTEGER PRIMARY KEY, name TEXT NOT NULL, age INTEGER CHECK (age >16) ); CREATE TABLE auth_book ( auth_id INTEGER NOT NULL, books_id INTEGER NOT NULL, FOREIGN KEY (auth_id) REFERENCES auth(id) FOREIGN KEY (books_id) REFERENCES books(id) ); — Сперва добавим несколько строк в таблицу книг INSERT INTO books (id, title, count_page, price) VALUES (1, ‘Белый клык’, 287, 300.00); INSERT INTO books (id, title, count_page, price) VALUES (2, ‘Война и мир’, 806, 780.00); INSERT INTO books (id, title, count_page, price) VALUES (3, ’12 стульев’, 516, 480.00); — Затем добавим несколько авторов INSERT INTO auth (id, name, age) VALUES (1, ‘Джек Лондон’, 40); INSERT INTO auth (id, name, age) VALUES (2, ‘Лев Толстой’, 82); INSERT INTO auth (id, name, age) VALUES (3, ‘Илья Ильф’, 39); INSERT INTO auth (id, name, age) VALUES (4, ‘Евгений Петров’, 38); |
Мы наполнили две таблицы, но не наполнили таблицу-справочник, которая реализует связь многие ко многим. Давайте напишем триггер, который будет проверять смысл значений перед их добавлением в таблицу-справочник.
Давайте сперва реализуем триггер с использованием функции RAISE (), который будет проверять данные перед их вставкой:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
CREATE TRIGGER books_result BEFORE INSERT ON auth_book BEGIN SELECT RAISE(FAIL, ‘Произошла ошибка, вы неправильно связали автора и книгу’) FROM auth_book WHERE (NEW.auth_id = 1 AND books_id = 2) OR (NEW.auth_id = 1 AND NEW.books_id = 3) OR (NEW.auth_id = 2 AND NEW.books_id = 3) OR (NEW.auth_id = 2 AND NEW.books_id = 3) OR (NEW.auth_id = 3 AND NEW.books_id = 2) OR (NEW.auth_id = 3 AND NEW.books_id = 1) OR (NEW.auth_id = 4 AND NEW.books_id = 2) OR (NEW.auth_id = 4 AND NEW.books_id = 1); END; |
Конечно, пример не самый эффективный и не самый жизненный, функция RAISE в триггере проверяет и сравнивает значения столбцов, при этом строк у нас не очень много в таблицах. В его защиту скажу, что он хорошо демонстрирует возможности функции RAISE по обеспечению целостности данных. Ссылку NEW мы использовали, потому что нам необходимо проверять данные, которые мы хотим добавить в таблицу.
А вся это красота будет работать благодаря тому, что команды внутри триггера выполняются так, как будто это транзакция. Давайте теперь попытаемся наполнить результирующую таблицу данными.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
INSERT INTO auth_book (auth_id, books_id) VALUES (1, 1); INSERT INTO auth_book (auth_id, books_id) VALUES (2, 2); INSERT INTO auth_book (auth_id, books_id) VALUES (3, 3); INSERT INTO auth_book (auth_id, books_id) VALUES (4, 3); INSERT INTO auth_book (auth_id, books_id) VALUES (1, 2); Error: Произошла ошибка, вы неправильно связали автора и книгу SELECT * FROM auth_book; auth_id books_id 1 1 2 2 3 3 4 3 |
Этот триггер срабатывает при каждой операции добавления строки в таблицу, а функция RAISE сравнивает добавляемое значение с исходным, которое мы задавали при помощи SQL операторов AND и OR в условии WHERE. Обратите внимание: и скобки, знак равно – это тоже SQL операторы.
Временные триггеры в базах данных SQLite3
Демонстрировать примеры создания временных триггеров в базах данных SQLite3 мы не будем. Скажем лишь о том, что временный триггер доступен только для создавшего его пользователя и существует временный триггер всё то время, пока пользователь не разорвет сессию, либо не удалит триггер.
Отметим, что временные триггеры могут быть созданы не только для временных таблиц, но и для обычных таблиц.
Получит информацию о триггерах в базе данных SQLite
Вы можете получить информацию о триггерах или посмотреть созданные триггеры в базе данных SQLite при помощи команды SELECT, следующее предложение покажет вам все триггеры в базе данных:
|
SELECT name FROM sqlite_master WHERE type = ‘trigger’; |
Если вы хотите получить список триггеров для таблицы в базе данных SQLite, то воспользуйтесь следующей командой:
|
SELECT name FROM sqlite_master WHERE type = ‘trigger’ AND tbl_name = ‘укажите_имя_таблицы’; |
Таким образом вы можете получить список триггеров во всей базе данных или для конкретной таблицы в базе данных SQLite. Обратит внимание: в других СУБД эти команды работать не будут.
Удаление триггеров из базы данных SQLite
Поговорим теперь про удаление триггеров из базы данных. Вспомним общий синтаксис удаления триггера из базы данных:
|
DROP TRIGGER IF EXISTS db_name.trigger_name; |
Таким образом мы можем явно удалить триггер из базы данных SQLite. Неявное удаление триггеров происходит при удалении из базы данных таблицы, к которой он привязан. Если вы привязали обычный триггер к временной таблице, то можете смело его считать временным, так как он будет существовать до первого разрыва соединения с базой данных, после чего триггер будет удален, так как таблица перестанет существовать.

Small. Fast. Reliable.
Choose any three.
SQL As Understood By SQLite
[Top]
create-trigger-stmt:
delete-stmt:
expr:
insert-stmt:
select-stmt:
update-stmt:
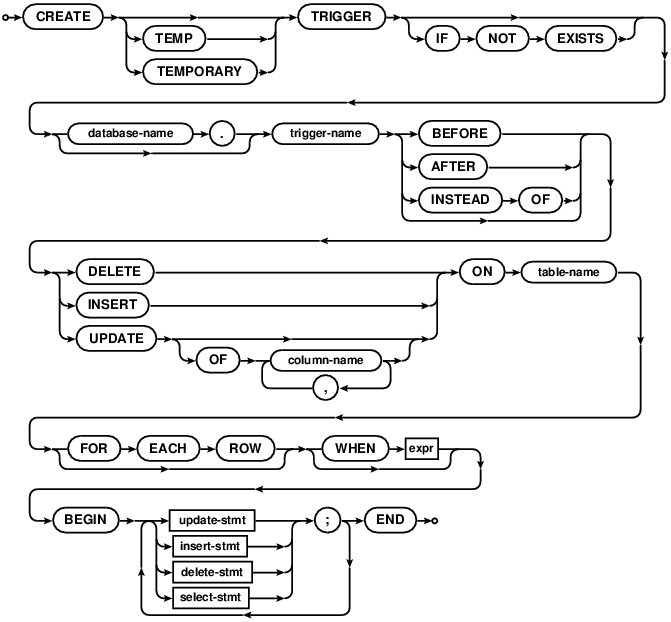
The CREATE TRIGGER statement is used to add triggers to the
database schema. Triggers are database operations
that are automatically performed when a specified database event
occurs.
A trigger may be specified to fire whenever a DELETE, INSERT,
or UPDATE of a
particular database table occurs, or whenever an UPDATE occurs on
on one or more specified columns of a table.
At this time SQLite supports only FOR EACH ROW triggers, not FOR EACH
STATEMENT triggers. Hence explicitly specifying FOR EACH ROW is optional.
FOR EACH ROW implies that the SQL statements specified in the trigger
may be executed (depending on the WHEN clause) for each database row being
inserted, updated or deleted by the statement causing the trigger to fire.
Both the WHEN clause and the trigger actions may access elements of
the row being inserted, deleted or updated using references of the form
«NEW.column-name» and «OLD.column-name«, where
column-name is the name of a column from the table that the trigger
is associated with. OLD and NEW references may only be used in triggers on
events for which they are relevant, as follows:
| INSERT | NEW references are valid |
| UPDATE | NEW and OLD references are valid |
| DELETE | OLD references are valid |
If a WHEN clause is supplied, the SQL statements specified
are only executed for rows for which the WHEN
clause is true. If no WHEN clause is supplied, the SQL statements
are executed for all rows.
The BEFORE or AFTER keyword determines when the trigger actions
will be executed relative to the insertion, modification or removal of the
associated row.
An ON CONFLICT clause may be specified as part of an UPDATE or INSERT
action within the body of the trigger.
However if an ON CONFLICT clause is specified as part of
the statement causing the trigger to fire, then conflict handling
policy of the outer statement is used instead.
Triggers are automatically dropped
when the table that they are
associated with (the table-name table) is
dropped. However if the trigger actions reference
other tables, the trigger is not dropped or modified if those other
tables are dropped or modified.
Triggers are removed using the DROP TRIGGER statement.
Syntax Restrictions On UPDATE, DELETE, and INSERT Statements Within
Triggers
The UPDATE, DELETE, and INSERT
statements within triggers do not support
the full syntax for UPDATE, DELETE, and INSERT statements. The following
restrictions apply:
-
The name of the table to be modified in an UPDATE, DELETE, or INSERT
statement must be an unqualified table name. In other words, one must
use just «tablename» not «database.tablename»
when specifying the table. The table to be modified must exist in the
same database as the table or view to which the trigger is attached. -
The «INSERT INTO table DEFAULT VALUES» form of the INSERT statement
is not supported. -
The INDEXED BY and NOT INDEXED clauses are not supported for UPDATE and
DELETE statements. -
The ORDER BY and LIMIT clauses on UPDATE and DELETE statements are not
supported. ORDER BY and LIMIT are not normally supported for UPDATE or
DELETE in any context but can be enabled for top-level statements
using the SQLITE_ENABLE_UPDATE_DELETE_LIMIT compile-time option. However,
that compile-time option only applies to top-level UPDATE and DELETE
statements, not UPDATE and DELETE statements within triggers.
INSTEAD OF triggers
Triggers may be created on views, as well as ordinary tables, by
specifying INSTEAD OF in the CREATE TRIGGER statement.
If one or more ON INSERT, ON DELETE
or ON UPDATE triggers are defined on a view, then it is not an
error to execute an INSERT, DELETE or UPDATE statement on the view,
respectively. Instead,
executing an INSERT, DELETE or UPDATE on the view causes the associated
triggers to fire. The real tables underlying the view are not modified
(except possibly explicitly, by a trigger program).
Note that the sqlite3_changes() and sqlite3_total_changes() interfaces
do not count INSTEAD OF trigger firings, but the
count_changes pragma does count INSTEAD OF trigger firing.
Some Example Triggers
Assuming that customer records are stored in the «customers» table, and
that order records are stored in the «orders» table, the following
UPDATE trigger
ensures that all associated orders are redirected when a customer changes
his or her address:
CREATE TRIGGER update_customer_address UPDATE OF address ON customers
BEGIN
UPDATE orders SET address = new.address WHERE customer_name = old.name;
END;
With this trigger installed, executing the statement:
UPDATE customers SET address = '1 Main St.' WHERE name = 'Jack Jones';
causes the following to be automatically executed:
UPDATE orders SET address = '1 Main St.' WHERE customer_name = 'Jack Jones';
For an example of an INSTEAD OF trigger, consider the following schema:
CREATE TABLE customer( cust_id INTEGER PRIMARY KEY, cust_name TEXT, cust_addr TEXT ); CREATE VIEW customer_address AS SELECT cust_id, cust_addr FROM customer; CREATE TRIGGER cust_addr_chng INSTEAD OF UPDATE OF cust_addr ON customer_address BEGIN UPDATE customer SET cust_addr=NEW.cust_addr WHERE cust_id=NEW.cust_id; END;
With the schema above, a statement of the form:
UPDATE customer_address SET cust_addr=$new_address WHERE cust_id=$cust_id;
Causes the customer.cust_addr field to be updated for a specific
customer entry that has customer.cust_id equal to the $cust_id parameter.
Note how the values assigned to the view are made available as field
in the special «NEW» table within the trigger body.
Cautions On The Use Of BEFORE triggers
If a BEFORE UPDATE or BEFORE DELETE trigger modifies or deletes a row
that was to have been updated or deleted, then the result of the subsequent
update or delete operation is undefined. Furthermore, if a BEFORE trigger
modifies or deletes a row, then it is undefined whether or not AFTER triggers
that would have otherwise run on those rows will in fact run.
The value of NEW.rowid is undefined in a BEFORE INSERT trigger in which
the rowid is not explicitly set to an integer.
Because of the behaviors described above, programmers are encouraged to
prefer AFTER triggers over BEFORE triggers.
The RAISE() function
A special SQL function RAISE() may be used within a trigger-program,
with the following syntax
raise-function:
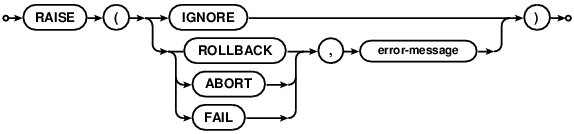
When one of RAISE(ROLLBACK,…), RAISE(ABORT,…) or RAISE(FAIL,…)
is called during trigger-program
execution, the specified ON CONFLICT processing is performed
the current query terminates.
An error code of SQLITE_CONSTRAINT is returned to the application,
along with the specified error message.
When RAISE(IGNORE) is called, the remainder of the current trigger program,
the statement that caused the trigger program to execute and any subsequent
trigger programs that would have been executed are abandoned. No database
changes are rolled back. If the statement that caused the trigger program
to execute is itself part of a trigger program, then that trigger program
resumes execution at the beginning of the next step.
TEMP Triggers on Non-TEMP Tables
A trigger normally exists in the same database as the table named
after the «ON» keyword in the CREATE TRIGGER statement. Except, it is
possible to create a TEMP TRIGGER on a table in another database.
Such a trigger will only fire when changes
are made to the target table by the application that defined the trigger.
Other applications that modify the database will not be able to see the
TEMP trigger and hence cannot run the trigger.
When defining a TEMP trigger on a non-TEMP table, it is important to
specify the database holding the non-TEMP table. For example,
in the following statement, it is important to say «main.tab1» instead
of just «tab1»:
CREATE TEMP TRIGGER ex1 AFTER INSERT ON main.tab1 BEGIN ...
Failure to specify the database name on the target table could result
in the TEMP trigger being reattached to a table with the same name in
another database whenever any schema change occurs.
Summary: this tutorial discusses SQLite trigger, which is a database object fired automatically when the data in a table is changed.
What is an SQLite trigger
An SQLite trigger is a named database object that is executed automatically when an INSERT, UPDATE or DELETE statement is issued against the associated table.
When do we need SQLite triggers
You often use triggers to enable sophisticated auditing. For example, you want to log the changes in the sensitive data such as salary and address whenever it changes.
In addition, you use triggers to enforce complex business rules centrally at the database level and prevent invalid transactions.
SQLite CREATE TRIGGER statement
To create a new trigger in SQLite, you use the CREATE TRIGGER statement as follows:
Code language: SQL (Structured Query Language) (sql)
CREATE TRIGGER [IF NOT EXISTS] trigger_name [BEFORE|AFTER|INSTEAD OF] [INSERT|UPDATE|DELETE] ON table_name [WHEN condition] BEGIN statements; END;
In this syntax:
- First, specify the name of the trigger after the
CREATE TRIGGERkeywords. - Next, determine when the trigger is fired such as
BEFORE,AFTER, orINSTEAD OF. You can createBEFOREandAFTERtriggers on a table. However, you can only create anINSTEAD OFtrigger on a view. - Then, specify the event that causes the trigger to be invoked such as
INSERT,UPDATE, orDELETE. - After that, indicate the table to which the trigger belongs.
- Finally, place the trigger logic in the
BEGIN ENDblock, which can be any valid SQL statements.
If you combine the time when the trigger is fired and the event that causes the trigger to be fired, you have a total of 9 possibilities:
BEFORE INSERTAFTER INSERTBEFORE UPDATEAFTER UPDATEBEFORE DELETEAFTER DELETEINSTEAD OF INSERTINSTEAD OF DELETEINSTEAD OF UPDATE
Suppose you use a UPDATE statement to update 10 rows in a table, the trigger that associated with the table is fired 10 times. This trigger is called FOR EACH ROW trigger. If the trigger associated with the table is fired one time, we call this trigger a FOR EACH STATEMENT trigger.
As of version 3.9.2, SQLite only supports FOR EACH ROW triggers. It has not yet supported the FOR EACH STATEMENT triggers.
If you use a condition in the WHEN clause, the trigger is only invoked when the condition is true. In case you omit the WHEN clause, the trigger is executed for all rows.
Notice that if you drop a table, all associated triggers are also deleted. However, if the trigger references other tables, the trigger is not removed or changed if other tables are removed or updated.
For example, a trigger references to a table named people, you drop the people table or rename it, you need to manually change the definition of the trigger.
You can access the data of the row being inserted, deleted, or updated using the OLD and NEW references in the form: OLD.column_name and NEW.column_name.
the OLD and NEW references are available depending on the event that causes the trigger to be fired.
The following table illustrates the rules.:
| Action | Reference |
|---|---|
| INSERT | NEW is available |
| UPDATE | Both NEW and OLD are available |
| DELETE | OLD is available |
SQLite triggers examples
Let’s create a new table called leads to store all business leads of the company.
Code language: SQL (Structured Query Language) (sql)
CREATE TABLE leads ( id integer PRIMARY KEY, first_name text NOT NULL, last_name text NOT NULL, phone text NOT NULL, email text NOT NULL, source text NOT NULL );
1) SQLite BEFORE INSERT trigger example
Suppose you want to validate the email address before inserting a new lead into the leads table. In this case, you can use a BEFORE INSERT trigger.
First, create a BEFORE INSERT trigger as follows:
Code language: SQL (Structured Query Language) (sql)
CREATE TRIGGER validate_email_before_insert_leads BEFORE INSERT ON leads BEGIN SELECT CASE WHEN NEW.email NOT LIKE '%_@__%.__%' THEN RAISE (ABORT,'Invalid email address') END; END;
We used the NEW reference to access the email column of the row that is being inserted.
To validate the email, we used the LIKE operator to determine whether the email is valid or not based on the email pattern. If the email is not valid, the RAISE function aborts the insert and issues an error message.
Second, insert a row with an invalid email into the leads table.
Code language: SQL (Structured Query Language) (sql)
INSERT INTO leads (first_name,last_name,email,phone) VALUES('John','Doe','jjj','4089009334');
SQLite issued an error: “Invalid email address” and aborted the execution of the insert.
Third, insert a row with a valid email.
Code language: SQL (Structured Query Language) (sql)
INSERT INTO leads (first_name, last_name, email, phone) VALUES ('John', 'Doe', 'john.doe@sqlitetutorial.net', '4089009334');
Because the email is valid, the insert statement executed successfully.
Code language: SQL (Structured Query Language) (sql)
SELECT first_name, last_name, email, phone FROM leads;
![]()
2) SQLite AFTER UPDATE trigger example
The phones and emails of the leads are so important that you can’t afford to lose this information. For example, someone accidentally updates the email or phone to the wrong ones or even delete it.
To protect this valuable data, you use a trigger to log all changes which are made to the phone and email.
First, create a new table called lead_logs to store the historical data.
Code language: SQL (Structured Query Language) (sql)
CREATE TABLE lead_logs ( id INTEGER PRIMARY KEY, old_id int, new_id int, old_phone text, new_phone text, old_email text, new_email text, user_action text, created_at text );
Second, create an AFTER UPDATE trigger to log data to the lead_logs table whenever there is an update in the email or phone column.
Code language: SQL (Structured Query Language) (sql)
CREATE TRIGGER log_contact_after_update AFTER UPDATE ON leads WHEN old.phone <> new.phone OR old.email <> new.email BEGIN INSERT INTO lead_logs ( old_id, new_id, old_phone, new_phone, old_email, new_email, user_action, created_at ) VALUES ( old.id, new.id, old.phone, new.phone, old.email, new.email, 'UPDATE', DATETIME('NOW') ) ; END;
You notice that in the condition in the WHEN clause specifies that the trigger is invoked only when there is a change in either email or phone column.
Third, update the last name of John from Doe to Smith.
Code language: SQL (Structured Query Language) (sql)
UPDATE leads SET last_name = 'Smith' WHERE id = 1;
The trigger log_contact_after_update was not invoked because there was no change in email or phone.
Fourth, update both email and phone of John to the new ones.
Code language: SQL (Structured Query Language) (sql)
UPDATE leads SET phone = '4089998888', email = 'john.smith@sqlitetutorial.net' WHERE id = 1;
If you check the log table, you will see there is a new entry there.
Code language: SQL (Structured Query Language) (sql)
SELECT old_phone, new_phone, old_email, new_email, user_action FROM lead_logs;
![]()
You can develop the AFTER INSERT and AFTER DELETE triggers to log the data in the lead_logs table as an excercise.
SQLite DROP TRIGGER statement
To drop an existing trigger, you use the DROP TRIGGER statement as follows:
Code language: SQL (Structured Query Language) (sql)
DROP TRIGGER [IF EXISTS] trigger_name;
In this syntax:
- First, specify the name of the trigger that you want to drop after the
DROP TRIGGERkeywords. - Second, use the
IF EXISTSoption to delete the trigger only if it exists.
Note that if you drop a table, SQLite will automatically drop all triggers associated with the table.
For example, to remove the validate_email_before_insert_leads trigger, you use the following statement:
Code language: SQL (Structured Query Language) (sql)
DROP TRIGGER validate_email_before_insert_leads;
In this tutorial, we have introduced you to SQLite triggers and show you how to create and drop triggers from the database.
Was this tutorial helpful ?