One of the most popular InnoDB’s errors is InnoDB lock wait timeout exceeded, for example:
SQLSTATE[HY000]: General error: 1205 Lock wait timeout exceeded; try restarting transactionThe above simply means the transaction has reached the innodb_lock_wait_timeout while waiting to obtain an exclusive lock which defaults to 50 seconds. The common causes are:
- The offensive transaction is not fast enough to commit or rollback the transaction within innodb_lock_wait_timeout duration.
- The offensive transaction is waiting for row lock to be released by another transaction.
The Effects of a InnoDB Lock Wait Timeout
InnoDB lock wait timeout can cause two major implications:
- The failed statement is not being rolled back by default.
- Even if innodb_rollback_on_timeout is enabled, when a statement fails in a transaction, ROLLBACK is still a more expensive operation than COMMIT.
Let’s play around with a simple example to better understand the effect. Consider the following two tables in database mydb:
mysql> CREATE SCHEMA mydb;
mysql> USE mydb;The first table (table1):
mysql> CREATE TABLE table1 ( id INT PRIMARY KEY AUTO_INCREMENT, data VARCHAR(50));
mysql> INSERT INTO table1 SET data = 'data #1';The second table (table2):
mysql> CREATE TABLE table2 LIKE table1;
mysql> INSERT INTO table2 SET data = 'data #2';We executed our transactions in two different sessions in the following order:
|
Ordering |
Transaction #1 (T1) |
Transaction #2 (T2) |
|
1 |
SELECT * FROM table1; (OK) |
SELECT * FROM table1; (OK) |
|
2 |
UPDATE table1 SET data = ‘T1 is updating the row’ WHERE id = 1; (OK) |
|
|
3 |
UPDATE table2 SET data = ‘T2 is updating the row’ WHERE id = 1; (OK) |
|
|
4 |
UPDATE table1 SET data = ‘T2 is updating the row’ WHERE id = 1; (Hangs for a while and eventually returns an error “Lock wait timeout exceeded; try restarting transaction”) |
|
|
5 |
COMMIT; (OK) |
|
|
6 |
COMMIT; (OK) |
However, the end result after step #6 might be surprising if we did not retry the timed out statement at step #4:
mysql> SELECT * FROM table1 WHERE id = 1;
+----+-----------------------------------+
| id | data |
+----+-----------------------------------+
| 1 | T1 is updating the row |
+----+-----------------------------------+
mysql> SELECT * FROM table2 WHERE id = 1;
+----+-----------------------------------+
| id | data |
+----+-----------------------------------+
| 1 | T2 is updating the row |
+----+-----------------------------------+After T2 was successfully committed, one would expect to get the same output “T2 is updating the row” for both table1 and table2 but the results show that only table2 was updated. One might think that if any error encounters within a transaction, all statements in the transaction would automatically get rolled back, or if a transaction is successfully committed, the whole statements were executed atomically. This is true for deadlock, but not for InnoDB lock wait timeout.
Unless you set innodb_rollback_on_timeout=1 (default is 0 – disabled), automatic rollback is not going to happen for InnoDB lock wait timeout error. This means, by following the default setting, MySQL is not going to fail and rollback the whole transaction, nor retrying again the timed out statement and just process the next statements until it reaches COMMIT or ROLLBACK. This explains why transaction T2 was partially committed!
The InnoDB documentation clearly says “InnoDB rolls back only the last statement on a transaction timeout by default”. In this case, we do not get the transaction atomicity offered by InnoDB. The atomicity in ACID compliant is either we get all or nothing of the transaction, which means partial transaction is merely unacceptable.
Dealing With a InnoDB Lock Wait Timeout
So, if you are expecting a transaction to auto-rollback when encounters an InnoDB lock wait error, similarly as what would happen in deadlock, set the following option in MySQL configuration file:
innodb_rollback_on_timeout=1A MySQL restart is required. When deploying a MySQL-based cluster, ClusterControl will always set innodb_rollback_on_timeout=1 on every node. Without this option, your application has to retry the failed statement, or perform ROLLBACK explicitly to maintain the transaction atomicity.
To verify if the configuration is loaded correctly:
mysql> SHOW GLOBAL VARIABLES LIKE 'innodb_rollback_on_timeout';
+----------------------------+-------+
| Variable_name | Value |
+----------------------------+-------+
| innodb_rollback_on_timeout | ON |
+----------------------------+-------+To check whether the new configuration works, we can track the com_rollback counter when this error happens:
mysql> SHOW GLOBAL STATUS LIKE 'com_rollback';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| Com_rollback | 1 |
+---------------+-------+Tracking the Blocking Transaction
There are several places that we can look to track the blocking transaction or statements. Let’s start by looking into InnoDB engine status under TRANSACTIONS section:
mysql> SHOW ENGINE INNODB STATUSG
------------
TRANSACTIONS
------------
...
---TRANSACTION 3100, ACTIVE 2 sec starting index read
mysql tables in use 1, locked 1
LOCK WAIT 2 lock struct(s), heap size 1136, 1 row lock(s)
MySQL thread id 50, OS thread handle 139887555282688, query id 360 localhost ::1 root updating
update table1 set data = 'T2 is updating the row' where id = 1
------- TRX HAS BEEN WAITING 2 SEC FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 6 page no 4 n bits 72 index PRIMARY of table `mydb`.`table1` trx id 3100 lock_mode X locks rec but not gap waiting
Record lock, heap no 2 PHYSICAL RECORD: n_fields 4; compact format; info bits 0
0: len 4; hex 80000001; asc ;;
1: len 6; hex 000000000c19; asc ;;
2: len 7; hex 020000011b0151; asc Q;;
3: len 22; hex 5431206973207570646174696e672074686520726f77; asc T1 is updating the row;;
------------------
---TRANSACTION 3097, ACTIVE 46 sec
2 lock struct(s), heap size 1136, 1 row lock(s), undo log entries 1
MySQL thread id 48, OS thread handle 139887556167424, query id 358 localhost ::1 root
Trx read view will not see trx with id >= 3097, sees < 3097From the above information, we can get an overview of the transactions that are currently active in the server. Transaction 3097 is currently locking a row that needs to be accessed by transaction 3100. However, the above output does not tell us the actual query text that could help us figuring out which part of the query/statement/transaction that we need to investigate further. By using the blocker MySQL thread ID 48, let’s see what we can gather from MySQL processlist:
mysql> SHOW FULL PROCESSLIST;
+----+-----------------+-----------------+--------------------+---------+------+------------------------+-----------------------+
| Id | User | Host | db | Command | Time | State | Info |
+----+-----------------+-----------------+--------------------+---------+------+------------------------+-----------------------+
| 4 | event_scheduler | localhost | | Daemon | 5146 | Waiting on empty queue | |
| 10 | root | localhost:56042 | performance_schema | Query | 0 | starting | show full processlist |
| 48 | root | localhost:56118 | mydb | Sleep | 145 | | |
| 50 | root | localhost:56122 | mydb | Sleep | 113 | | |
+----+-----------------+-----------------+--------------------+---------+------+------------------------+-----------------------+Thread ID 48 shows the command as ‘Sleep’. Still, this does not help us much to know which statements that block the other transaction. This is because the statement in this transaction has been executed and this open transaction is basically doing nothing at the moment. We need to dive further down to see what is going on with this thread.
For MySQL 8.0, the InnoDB lock wait instrumentation is available under data_lock_waits table inside performance_schema database (or innodb_lock_waits table inside sys database). If a lock wait event is happening, we should see something like this:
mysql> SELECT * FROM performance_schema.data_lock_waitsG
***************************[ 1. row ]***************************
ENGINE | INNODB
REQUESTING_ENGINE_LOCK_ID | 139887595270456:6:4:2:139887487554680
REQUESTING_ENGINE_TRANSACTION_ID | 3100
REQUESTING_THREAD_ID | 89
REQUESTING_EVENT_ID | 8
REQUESTING_OBJECT_INSTANCE_BEGIN | 139887487554680
BLOCKING_ENGINE_LOCK_ID | 139887595269584:6:4:2:139887487548648
BLOCKING_ENGINE_TRANSACTION_ID | 3097
BLOCKING_THREAD_ID | 87
BLOCKING_EVENT_ID | 9
BLOCKING_OBJECT_INSTANCE_BEGIN | 139887487548648Note that in MySQL 5.6 and 5.7, the similar information is stored inside innodb_lock_waits table under information_schema database. Pay attention to the BLOCKING_THREAD_ID value. We can use the this information to look for all statements being executed by this thread in events_statements_history table:
mysql> SELECT * FROM performance_schema.events_statements_history WHERE `THREAD_ID` = 87;
0 rows in setIt looks like the thread information is no longer there. We can verify by checking the minimum and maximum value of the thread_id column in events_statements_history table with the following query:
mysql> SELECT min(`THREAD_ID`), max(`THREAD_ID`) FROM performance_schema.events_statements_history;
+------------------+------------------+
| min(`THREAD_ID`) | max(`THREAD_ID`) |
+------------------+------------------+
| 98 | 129 |
+------------------+------------------+The thread that we were looking for (87) has been truncated from the table. We can confirm this by looking at the size of event_statements_history table:
mysql> SELECT @@performance_schema_events_statements_history_size;
+-----------------------------------------------------+
| @@performance_schema_events_statements_history_size |
+-----------------------------------------------------+
| 10 |
+-----------------------------------------------------+The above means the events_statements_history can only store the last 10 threads. Fortunately, performance_schema has another table to store more rows called events_statements_history_long, which stores similar information but for all threads and it can contain way more rows:
mysql> SELECT @@performance_schema_events_statements_history_long_size;
+----------------------------------------------------------+
| @@performance_schema_events_statements_history_long_size |
+----------------------------------------------------------+
| 10000 |
+----------------------------------------------------------+However, you will get an empty result if you try to query the events_statements_history_long table for the first time. This is expected because by default, this instrumentation is disabled in MySQL as we can see in the following setup_consumers table:
mysql> SELECT * FROM performance_schema.setup_consumers;
+----------------------------------+---------+
| NAME | ENABLED |
+----------------------------------+---------+
| events_stages_current | NO |
| events_stages_history | NO |
| events_stages_history_long | NO |
| events_statements_current | YES |
| events_statements_history | YES |
| events_statements_history_long | NO |
| events_transactions_current | YES |
| events_transactions_history | YES |
| events_transactions_history_long | NO |
| events_waits_current | NO |
| events_waits_history | NO |
| events_waits_history_long | NO |
| global_instrumentation | YES |
| thread_instrumentation | YES |
| statements_digest | YES |
+----------------------------------+---------+To activate table events_statements_history_long, we need to update the setup_consumers table as below:
mysql> UPDATE performance_schema.setup_consumers SET enabled = 'YES' WHERE name = 'events_statements_history_long';Verify if there are rows in the events_statements_history_long table now:
mysql> SELECT count(`THREAD_ID`) FROM performance_schema.events_statements_history_long;
+--------------------+
| count(`THREAD_ID`) |
+--------------------+
| 4 |
+--------------------+Cool. Now we can wait until the InnoDB lock wait event raises again and when it is happening, you should see the following row in the data_lock_waits table:
mysql> SELECT * FROM performance_schema.data_lock_waitsG
***************************[ 1. row ]***************************
ENGINE | INNODB
REQUESTING_ENGINE_LOCK_ID | 139887595270456:6:4:2:139887487555024
REQUESTING_ENGINE_TRANSACTION_ID | 3083
REQUESTING_THREAD_ID | 60
REQUESTING_EVENT_ID | 9
REQUESTING_OBJECT_INSTANCE_BEGIN | 139887487555024
BLOCKING_ENGINE_LOCK_ID | 139887595269584:6:4:2:139887487548648
BLOCKING_ENGINE_TRANSACTION_ID | 3081
BLOCKING_THREAD_ID | 57
BLOCKING_EVENT_ID | 8
BLOCKING_OBJECT_INSTANCE_BEGIN | 139887487548648Again, we use the BLOCKING_THREAD_ID value to filter all statements that have been executed by this thread against events_statements_history_long table:
mysql> SELECT `THREAD_ID`,`EVENT_ID`,`EVENT_NAME`, `CURRENT_SCHEMA`,`SQL_TEXT` FROM events_statements_history_long
WHERE `THREAD_ID` = 57
ORDER BY `EVENT_ID`;
+-----------+----------+-----------------------+----------------+----------------------------------------------------------------+
| THREAD_ID | EVENT_ID | EVENT_NAME | CURRENT_SCHEMA | SQL_TEXT |
+-----------+----------+-----------------------+----------------+----------------------------------------------------------------+
| 57 | 1 | statement/sql/select | | select connection_id() |
| 57 | 2 | statement/sql/select | | SELECT @@VERSION |
| 57 | 3 | statement/sql/select | | SELECT @@VERSION_COMMENT |
| 57 | 4 | statement/com/Init DB | | |
| 57 | 5 | statement/sql/begin | mydb | begin |
| 57 | 7 | statement/sql/select | mydb | select 'T1 is in the house' |
| 57 | 8 | statement/sql/select | mydb | select * from table1 |
| 57 | 9 | statement/sql/select | mydb | select 'some more select' |
| 57 | 10 | statement/sql/update | mydb | update table1 set data = 'T1 is updating the row' where id = 1 |
+-----------+----------+-----------------------+----------------+----------------------------------------------------------------+Finally, we found the culprit. We can tell by looking at the sequence of events of thread 57 where the above transaction (T1) still has not finished yet (no COMMIT or ROLLBACK), and we can see the very last statement has obtained an exclusive lock to the row for update operation which needed by the other transaction (T2) and just hanging there. That explains why we see ‘Sleep’ in the MySQL processlist output.
As we can see, the above SELECT statement requires you to get the thread_id value beforehand. To simplify this query, we can use IN clause and a subquery to join both tables. The following query produces an identical result like the above:
mysql> SELECT `THREAD_ID`,`EVENT_ID`,`EVENT_NAME`, `CURRENT_SCHEMA`,`SQL_TEXT` from events_statements_history_long WHERE `THREAD_ID` IN (SELECT `BLOCKING_THREAD_ID` FROM data_lock_waits) ORDER BY `EVENT_ID`;
+-----------+----------+-----------------------+----------------+----------------------------------------------------------------+
| THREAD_ID | EVENT_ID | EVENT_NAME | CURRENT_SCHEMA | SQL_TEXT |
+-----------+----------+-----------------------+----------------+----------------------------------------------------------------+
| 57 | 1 | statement/sql/select | | select connection_id() |
| 57 | 2 | statement/sql/select | | SELECT @@VERSION |
| 57 | 3 | statement/sql/select | | SELECT @@VERSION_COMMENT |
| 57 | 4 | statement/com/Init DB | | |
| 57 | 5 | statement/sql/begin | mydb | begin |
| 57 | 7 | statement/sql/select | mydb | select 'T1 is in the house' |
| 57 | 8 | statement/sql/select | mydb | select * from table1 |
| 57 | 9 | statement/sql/select | mydb | select 'some more select' |
| 57 | 10 | statement/sql/update | mydb | update table1 set data = 'T1 is updating the row' where id = 1 |
+-----------+----------+-----------------------+----------------+----------------------------------------------------------------+However, it is not practical for us to execute the above query whenever InnoDB lock wait event occurs. Apart from the error from the application, how would you know that the lock wait event is happening? We can automate this query execution with the following simple Bash script, called track_lockwait.sh:
$ cat track_lockwait.sh
#!/bin/bash
## track_lockwait.sh
## Print out the blocking statements that causing InnoDB lock wait
INTERVAL=5
DIR=/root/lockwait/
[ -d $dir ] || mkdir -p $dir
while true; do
check_query=$(mysql -A -Bse 'SELECT THREAD_ID,EVENT_ID,EVENT_NAME,CURRENT_SCHEMA,SQL_TEXT FROM events_statements_history_long WHERE THREAD_ID IN (SELECT BLOCKING_THREAD_ID FROM data_lock_waits) ORDER BY EVENT_ID')
# if $check_query is not empty
if [[ ! -z $check_query ]]; then
timestamp=$(date +%s)
echo $check_query > $DIR/innodb_lockwait_report_${timestamp}
fi
sleep $INTERVAL
doneApply executable permission and daemonize the script in the background:
$ chmod 755 track_lockwait.sh
$ nohup ./track_lockwait.sh &Now, we just need to wait for the reports to be generated under the /root/lockwait directory. Depending on the database workload and row access patterns, you might probably see a lot of files under this directory. Monitor the directory closely otherwise it would be flooded with too many report files.
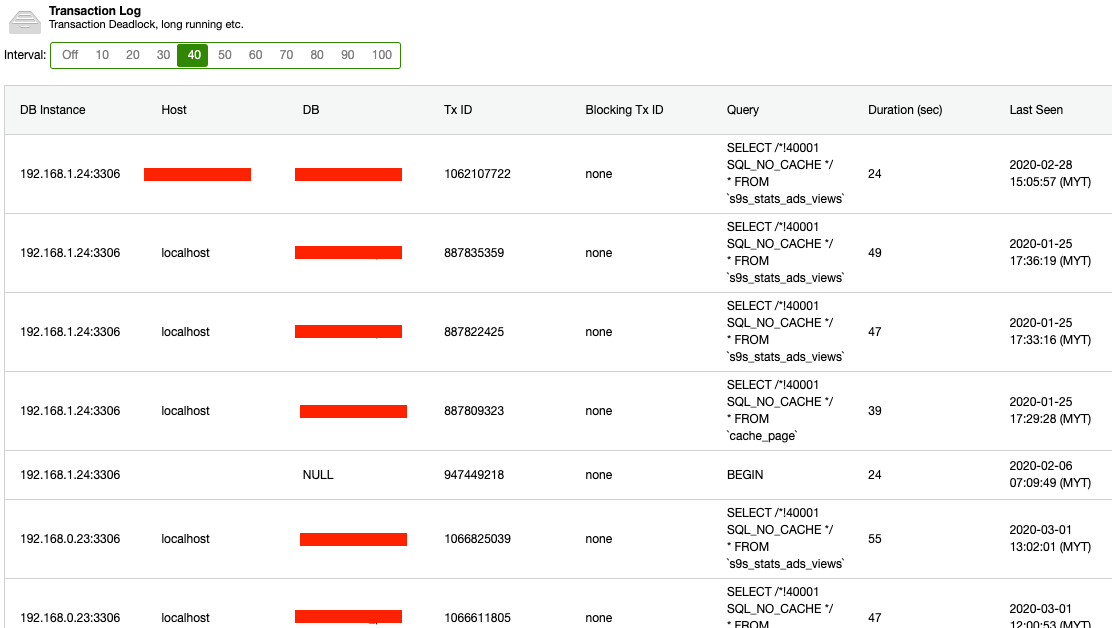
If you are using ClusterControl, you can enable the Transaction Log feature under Performance -> Transaction Log where ClusterControl will provide a report on deadlocks and long-running transactions which will ease up your life in finding the culprit.
Conclusion
In summary, if we face a “Lock Wait Timeout Exceeded” error in MySQL, we need to first understand the effects that such an error can have to our infrastructure, then track the offensive transaction and act on it either with shell scripts like track_lockwait.sh, or database management software like ClusterControl.
If you decide to go with shell scripts, just bear in mind that they may save you money but will cost you time, as you’d need to know a thing or two about how they work, apply permissions, and possibly make them run in the background, and if you do get lost in the shell jungle, we can help.
Whatever you decide to implement, make sure to follow us on Twitter or subscribe to our RSS feed to get more tips on improving the performance of both your software and the databases backing it, such as this post covering 6 common failure scenarios in MySQL.
Updating websites can often show MySQL error 1205 lock wait timeout when it fails to insert data in MySQL tables.
Fortunately, when MySQL server detects a problem, it will be logged into the error log file.
Also, this error occurs when lock_wait_timeout expires or when an existing process prevents a new process being executed on the same table.
That’s why, at Bobcares, we often get requests from our customers to fix MySQL errors as part of our Server Management Services.
Today, we’ll see how our Support Engineers fix MySQL error 1205 lock wait timeout.
Why MySQL error 1205 lock wait timeout?
MySQL is a database management system that is used by all CMS to store and collect website data. Also, it allow multiple users to manage and create databases.
Moreover, to retrieve data from the database, popular content management systems like WordPress, Joomla, Magento, etc performs SQL queries to generate content dynamically.
However, while managing the website database, customers may get an error SQLSTATE[HY000]: General error: 1205 Lock wait timeout due to an incomplete MySQL query.
This lock_wait_timeout variable specifies the timeout in seconds for attempts to acquire metadata locks of the database.
Sometimes, this error could occur if you run a bunch of custom scripts and kill the scripts before the database closes the connection.
How we fixed MySQL error 1205 lock wait timeout
From our experience in managing MySQL servers, we’ve seen many customers facing this error. Here, Let’s see top reasons for 1205 error and how our Support Engineers solved the problem.
1. Inactive process
An inactive process can cause problems while writing to MySQL tables.
Recently, one of our customers came up with an error ERROR 1205 (HY000): Lock wait timeout exceeded;try restarting transaction. He was getting this error while trying to update a row on a specific table of a database.
Then we took the following steps to solve the issue.
1. Initially, we logged into the server as a root user.
2. We login to MySQL prompt from CLI and ran the command
SHOW PROCESSLIST;It showed the MySQL processes running on the server as
+———+—————–+——————-+—————–+———+——+——-+——————+———–+—————+———–+
| Id | User | Host | db | Command | Time | State | Info | Rows_sent | Rows_examined | Rows_read |
+———+—————–+——————-+—————–+———+——+——-+——————+———–+—————+———–+
| 545566 | db_user| 91.xx.yy.65:21532 | db_name| Sleep | 3800 | | NULL | 0 | 0 | 0 |
| 547967 | db_user| 91.xx.yy.65:27488 | db_name| Sleep | 3757 | | NULL | 0 | 0 | 0 |
| 549360 | db_user| 91.xx.yy.65:32670 | db_name| Sleep | 3731 | | NULL | 0 | 0 | 0 |
| 549450 | db_user| 91.xx.yy.65:47424 | db_name | Sleep |2639 | | NULL | 0 | 0 | 0 |
| 549463 | db_user| 91.xx.yy.65:56029 | db_name| Sleep | 2591 | | NULL | 0 | 0 | 0 |From the output, we found that the process with id 545566 was in sleep status for a time of 3800 seconds. This exceeded the lock timeout settings and caused the problem.
In addition to this, when an existing process is running, it can prevent a new process from executing on the same tables.
Therefore, we analyzed the process status and found that it was perfectly fine to end the process. So, we solved this error by killing the processes in sleep status using the command.
kill -9 To avoid unwanted website behavior, it is always recommended to have a detailed check of the process by a Database expert.
2. Insufficient innodb_lock_wait_timeout
Similarly, many customers have heavy traffic websites may need to run different processes simultaneously. They might experience this MySQL error 1205 lock wait timeout due to insufficient innodb_lock_wait_timeout. That means the query is taking too long to perform.
For instance, one of the customers had a website with 8000 visitors a day. Also, they added 6000 articles to the website without optimizing server resources. As a result, when they tried to save articles, the website showed a blank page. The error was intermittent as some time later, it showed the original website.
On checking, we found that the problem was related to the SQL query on the MySQL server. When too many people edited the same article at the same time, it created a lot of calls to one MySQL database table. Then query that waited too long was rolled back. Hence, the customer got a blank page on the original website.
So, our Support Engineers fixed this error by increasing the value of the innodb_lock_wait_timeout in the MySQL configuration file at /etc/my.cnf.
Then, it allowed the SQL query to wait longer for other transactions to complete.
Nonetheless, tweaking MySQL configuration parameters always have a key role in the smooth working of any website.
[Getting MySQL error 1205 lock wait timeout? We’ll fix it for you.]
Conclusion
In short, MySQL error 1205 lock wait timeout occurs when lock_wait_timeout expires or when an existing process prevents a new process being executed on the same table. Today, we saw the reasons how our Support Engineers fixed related errors.
PREVENT YOUR SERVER FROM CRASHING!
Never again lose customers to poor server speed! Let us help you.
Our server experts will monitor & maintain your server 24/7 so that it remains lightning fast and secure.
GET STARTED
var google_conversion_label = «owonCMyG5nEQ0aD71QM»;
Содержание
- Laravel — Lock wait timeout exceeded
- 7 Answers 7
- SQLSTATE[HY000]: General error: 1205 Lock wait timeout exceeded on INSERT query
- 2 Answers 2
- ERROR 1205 (HY000): Lock wait timeout exceeded on update mysql
- 3 Answers 3
- mysql error 1205 lock wait timeout – Quick ways to fix it
- Why MySQL error 1205 lock wait timeout?
- How we fixed MySQL error 1205 lock wait timeout
- 1. Inactive process
- 2. Insufficient innodb_lock_wait_timeout
- Conclusion
- PREVENT YOUR SERVER FROM CRASHING!
- How to Fix a Lock Wait Timeout Exceeded Error in MySQL
- The Effects of a InnoDB Lock Wait Timeout
- Dealing With a InnoDB Lock Wait Timeout
- Tracking the Blocking Transaction
- Conclusion
Laravel — Lock wait timeout exceeded
I have a lot of transactions in my code, and if an error occurs in executing in one of these transactions that doesn’t trigger commit or rollback, then the database is locked and any subsequent attempts to access the database results in this:
production.ERROR: PDOException: SQLSTATE[HY000]: General error: 1205 Lock wait timeout exceeded; try restarting transaction in /home/forge/default/vendor/laravel/framework/src/Illuminate/Database/Connection.php:390
In the Controller:
So even php artisan migrate:refresh or php artisan migrate:reset stops working as well. How should I go about fixing this?
7 Answers 7
Here’s some tips from my experience .
If you are doing test driven development, isolate which combination of tests produce the error. Utilize whatever mechanism your ecosystem provides to selectively run tests (Example: @group only on test methods and phpunit —group only )
Next, reduce the lock wait timeout ( SET GLOBAL innodb_lock_wait_timeout = 10 ). This way you get quick feedback and don’t spend your whole day waiting for tests to run. Mileage may vary. Adjust to your specific conditions.
Thirdly, look for unclosed transactions, ie begin without rollback or commit. This turned out to be exactly what my problem was. My try/catch was not wrapping enough of the logic and it was erroring between begin transaction and try-catch-rollback.
Fourth, consider placing all parts of transaction in the same try-catch, which has some benefits in making sure all parts are there and easily visible. Example:
That’s my two cents. Hopefully useful to someone on the internet.
Источник
SQLSTATE[HY000]: General error: 1205 Lock wait timeout exceeded on INSERT query
I am getting Lock wait timeout exceeded error at my laravel jobs at frequent intervals
I am unable to trace, how could an INSERT statement not get a LOCK
As per my understanding an INSERT will be made at a new row, so no issues of waiting for lock
MySQL is used as database
Kindly suggest how to deal, or what could be the root cause ?

2 Answers 2
You are using a transaction; autocommit does not disable transactions, it just makes them automatically commit at the end of the statement.
What is happening is, some thread is holding a record lock on some record for too long, and your thread is being timed out.
If you use MySQL you can check the status in
You should FORCE UNLOCK for locked tables in MySQL, but this is dangerous, i only recommend it if you need to fix it fast
Enter MySQL mysql -u your_user -p
See the list of locked tables mysql> show open tables where in_use>0;
See the list of the current processes, one of them is locking your table(s) mysql> show processlist;
Kill one of these processes mysql> kill
I also faced the same issue. I was running PHP code that make SELECT and INSERT requests to DB. The error was thrown only upon INSERT query.
Issue was happening because I also had a MySQL Workbench open connection on the same machine. Although, I did not run any kind of query that could cause this error, Workbench connection was somehow locking the tables and causing this error in INSERT query in PHP connection.
Closing Workbench DB connection solved issue.
But, even if you not using Workbench, run SHOW processlist; command which will list MySQL processes running. The ones with Command=Sleep are sleeping open connections. Try to close those connections by running KILL
Basically, sessions hold the table locks, so you need to find and kill the session that holds lock to the table you are using.
Источник
ERROR 1205 (HY000): Lock wait timeout exceeded on update mysql
I am running following update —
update table_x set name= ‘xyz’ where >
and getting — ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
I googled it number of times and adding extra time to innodb_lock_wait_timeout not helping me out.
Please let me know the root cause of this issue and how I can solve it. I am using mysql 5.6(master-master replication) on dedicated server. Also table_x(Innodb table) heavily used in database. Autocommit is on.
3 Answers 3
Find out what other statement is running at the same time as this UPDATE . It sounds as if it is running a long time and hanging onto the rows that this UPDATE needs. Meanwhile this statement is waiting.
One way to see it is to do SHOW FULL PROCESSLIST; while the UPDATE is hung.
(In my opinion, the default of 50 seconds for innodb_lock_wait_timeout is much to high. Raising the value only aggravates the situation.)
If you give up on fixing the ‘root cause’ of the conflict, then you might tackle the issue a different way.
- Lower innodb_lock_wait_timeout to, say, 5.
- Programmatically catch the error when it times out and restart the UPDATE .
- Do likewise for all other transactions. Other queries may also be piling up; restarting some may «uncork» the problem.
SHOW VARIABLES LIKE ‘tx_isolation’; — There may be a better setting for it, especially if a long-running SELECT is the villain.
Источник
mysql error 1205 lock wait timeout – Quick ways to fix it
by Jilu Joseph | Jun 8, 2019
Updating websites can often show MySQL error 1205 lock wait timeout when it fails to insert data in MySQL tables.
Fortunately, when MySQL server detects a problem, it will be logged into the error log file.
Also, this error occurs when lock_wait_timeout expires or when an existing process prevents a new process being executed on the same table.
That’s why, at Bobcares, we often get requests from our customers to fix MySQL errors as part of our Server Management Services.
Today, we’ll see how our Support Engineers fix MySQL error 1205 lock wait timeout.
Why MySQL error 1205 lock wait timeout?
MySQL is a database management system that is used by all CMS to store and collect website data. Also, it allow multiple users to manage and create databases.
Moreover, to retrieve data from the database, popular content management systems like WordPress, Joomla, Magento, etc performs SQL queries to generate content dynamically.
However, while managing the website database, customers may get an error SQLSTATE[HY000]: General error: 1205 Lock wait timeout due to an incomplete MySQL query.
This lock_wait_timeout variable specifies the timeout in seconds for attempts to acquire metadata locks of the database.
Sometimes, this error could occur if you run a bunch of custom scripts and kill the scripts before the database closes the connection.
How we fixed MySQL error 1205 lock wait timeout
From our experience in managing MySQL servers, we’ve seen many customers facing this error. Here, Let’s see top reasons for 1205 error and how our Support Engineers solved the problem.
1. Inactive process
An inactive process can cause problems while writing to MySQL tables.
Recently, one of our customers came up with an error ERROR 1205 (HY000): Lock wait timeout exceeded;try restarting transaction. He was getting this error while trying to update a row on a specific table of a database.
Then we took the following steps to solve the issue.
1. Initially, we logged into the server as a root user.
2. We login to MySQL prompt from CLI and ran the command
It showed the MySQL processes running on the server as
From the output, we found that the process with id 545566 was in sleep status for a time of 3800 seconds. This exceeded the lock timeout settings and caused the problem.
In addition to this, when an existing process is running, it can prevent a new process from executing on the same tables.
Therefore, we analyzed the process status and found that it was perfectly fine to end the process. So, we solved this error by killing the processes in sleep status using the command.
To avoid unwanted website behavior, it is always recommended to have a detailed check of the process by a Database expert.
2. Insufficient innodb_lock_wait_timeout
Similarly, many customers have heavy traffic websites may need to run different processes simultaneously. They might experience this MySQL error 1205 lock wait timeout due to insufficient innodb_lock_wait_timeout. That means the query is taking too long to perform.
For instance, one of the customers had a website with 8000 visitors a day. Also, they added 6000 articles to the website without optimizing server resources. As a result, when they tried to save articles, the website showed a blank page. The error was intermittent as some time later, it showed the original website.
On checking, we found that the problem was related to the SQL query on the MySQL server. When too many people edited the same article at the same time, it created a lot of calls to one MySQL database table. Then query that waited too long was rolled back. Hence, the customer got a blank page on the original website.
So, our Support Engineers fixed this error by increasing the value of the innodb_lock_wait_timeout in the MySQL configuration file at /etc/my.cnf.
Then, it allowed the SQL query to wait longer for other transactions to complete.
Nonetheless, tweaking MySQL configuration parameters always have a key role in the smooth working of any website.
[Getting MySQL error 1205 lock wait timeout? We’ll fix it for you.]
Conclusion
In short, MySQL error 1205 lock wait timeout occurs when lock_wait_timeout expires or when an existing process prevents a new process being executed on the same table. Today, we saw the reasons how our Support Engineers fixed related errors.
PREVENT YOUR SERVER FROM CRASHING!
Never again lose customers to poor server speed! Let us help you.
Our server experts will monitor & maintain your server 24/7 so that it remains lightning fast and secure.
Источник
How to Fix a Lock Wait Timeout Exceeded Error in MySQL
Published March 11, 2020

One of the most popular InnoDB’s errors is InnoDB lock wait timeout exceeded, for example:
The above simply means the transaction has reached the innodb_lock_wait_timeout while waiting to obtain an exclusive lock which defaults to 50 seconds. The common causes are:
- The offensive transaction is not fast enough to commit or rollback the transaction within innodb_lock_wait_timeout duration.
- The offensive transaction is waiting for row lock to be released by another transaction.
The Effects of a InnoDB Lock Wait Timeout
InnoDB lock wait timeout can cause two major implications:
- The failed statement is not being rolled back by default.
- Even if innodb_rollback_on_timeout is enabled, when a statement fails in a transaction, ROLLBACK is still a more expensive operation than COMMIT.
Let’s play around with a simple example to better understand the effect. Consider the following two tables in database mydb:
The first table (table1):
The second table (table2):
We executed our transactions in two different sessions in the following order:
Ordering
Transaction #1 (T1)
Transaction #2 (T2)
SELECT * FROM table1;
SELECT * FROM table1;
UPDATE table1 SET data = ‘T1 is updating the row’ WHERE >
UPDATE table2 SET data = ‘T2 is updating the row’ WHERE >
UPDATE table1 SET data = ‘T2 is updating the row’ WHERE >
(Hangs for a while and eventually returns an error “Lock wait timeout exceeded; try restarting transaction”)
After T2 was successfully committed, one would expect to get the same output “ T2 is updating the row ” for both table1 and table2 but the results show that only table2 was updated. One might think that if any error encounters within a transaction, all statements in the transaction would automatically get rolled back, or if a transaction is successfully committed, the whole statements were executed atomically. This is true for deadlock, but not for InnoDB lock wait timeout.
Unless you set innodb_rollback_on_timeout=1 (default is 0 – disabled), automatic rollback is not going to happen for InnoDB lock wait timeout error. This means, by following the default setting, MySQL is not going to fail and rollback the whole transaction, nor retrying again the timed out statement and just process the next statements until it reaches COMMIT or ROLLBACK. This explains why transaction T2 was partially committed!
The InnoDB documentation clearly says “InnoDB rolls back only the last statement on a transaction timeout by default”. In this case, we do not get the transaction atomicity offered by InnoDB. The atomicity in ACID compliant is either we get all or nothing of the transaction, which means partial transaction is merely unacceptable.
Dealing With a InnoDB Lock Wait Timeout
So, if you are expecting a transaction to auto-rollback when encounters an InnoDB lock wait error, similarly as what would happen in deadlock, set the following option in MySQL configuration file:
A MySQL restart is required. When deploying a MySQL-based cluster, ClusterControl will always set innodb_rollback_on_timeout=1 on every node. Without this option, your application has to retry the failed statement, or perform ROLLBACK explicitly to maintain the transaction atomicity.
To verify if the configuration is loaded correctly:
To check whether the new configuration works, we can track the com_rollback counter when this error happens:
Tracking the Blocking Transaction
There are several places that we can look to track the blocking transaction or statements. Let’s start by looking into InnoDB engine status under TRANSACTIONS section:
From the above information, we can get an overview of the transactions that are currently active in the server. Transaction 3097 is currently locking a row that needs to be accessed by transaction 3100. However, the above output does not tell us the actual query text that could help us figuring out which part of the query/statement/transaction that we need to investigate further. By using the blocker MySQL thread ID 48, let’s see what we can gather from MySQL processlist:
Thread ID 48 shows the command as ‘Sleep’. Still, this does not help us much to know which statements that block the other transaction. This is because the statement in this transaction has been executed and this open transaction is basically doing nothing at the moment. We need to dive further down to see what is going on with this thread.
For MySQL 8.0, the InnoDB lock wait instrumentation is available under data_lock_waits table inside performance_schema database (or innodb_lock_waits table inside sys database). If a lock wait event is happening, we should see something like this:
Note that in MySQL 5.6 and 5.7, the similar information is stored inside innodb_lock_waits table under information_schema database. Pay attention to the BLOCKING_THREAD_ID value. We can use the this information to look for all statements being executed by this thread in events_statements_history table:
It looks like the thread information is no longer there. We can verify by checking the minimum and maximum value of the thread_id column in events_statements_history table with the following query:
The thread that we were looking for (87) has been truncated from the table. We can confirm this by looking at the size of event_statements_history table:
The above means the events_statements_history can only store the last 10 threads. Fortunately, performance_schema has another table to store more rows called events_statements_history_long, which stores similar information but for all threads and it can contain way more rows:
However, you will get an empty result if you try to query the events_statements_history_long table for the first time. This is expected because by default, this instrumentation is disabled in MySQL as we can see in the following setup_consumers table:
To activate table events_statements_history_long, we need to update the setup_consumers table as below:
Verify if there are rows in the events_statements_history_long table now:
Cool. Now we can wait until the InnoDB lock wait event raises again and when it is happening, you should see the following row in the data_lock_waits table:
Again, we use the BLOCKING_THREAD_ID value to filter all statements that have been executed by this thread against events_statements_history_long table:
Finally, we found the culprit. We can tell by looking at the sequence of events of thread 57 where the above transaction (T1) still has not finished yet (no COMMIT or ROLLBACK), and we can see the very last statement has obtained an exclusive lock to the row for update operation which needed by the other transaction (T2) and just hanging there. That explains why we see ‘Sleep’ in the MySQL processlist output.
As we can see, the above SELECT statement requires you to get the thread_id value beforehand. To simplify this query, we can use IN clause and a subquery to join both tables. The following query produces an identical result like the above:
However, it is not practical for us to execute the above query whenever InnoDB lock wait event occurs. Apart from the error from the application, how would you know that the lock wait event is happening? We can automate this query execution with the following simple Bash script, called track_lockwait.sh :
Apply executable permission and daemonize the script in the background:
Now, we just need to wait for the reports to be generated under the /root/lockwait directory. Depending on the database workload and row access patterns, you might probably see a lot of files under this directory. Monitor the directory closely otherwise it would be flooded with too many report files.
If you are using ClusterControl, you can enable the Transaction Log feature under Performance -> Transaction Log where ClusterControl will provide a report on deadlocks and long-running transactions which will ease up your life in finding the culprit.
Conclusion
In summary, if we face a “Lock Wait Timeout Exceeded” error in MySQL, we need to first understand the effects that such an error can have to our infrastructure, then track the offensive transaction and act on it either with shell scripts like track_lockwait.sh , or database management software like ClusterControl.
If you decide to go with shell scripts, just bear in mind that they may save you money but will cost you time, as you’d need to know a thing or two about how they work, apply permissions, and possibly make them run in the background, and if you do get lost in the shell jungle, we can help.
Whatever you decide to implement, make sure to follow us on Twitter or subscribe to our RSS feed to get more tips on improving the performance of both your software and the databases backing it, such as this post covering 6 common failure scenarios in MySQL.
Источник
Rowlock timeout errors can occur in an application because of contention with transactions or uncommitted transactions. Refer to the following sections to resolve lock wait timeout errors.
Contention with Transactions
Updates and deletes in SingleStore are row locking operations. If a row is currently locked by query q1 running in transaction t1, a second query q2 in transaction t2 that operates on the same row will be blocked until q1 completes.
Updates and deletes on a columnstore table lock the entire table if the count of rows being updated is greater than columnstore_disk_insert_threshold. See Locking in Columnstores for more information.
The “Lock wait timeout exceeded; try restarting transaction” error will occur when a query cannot proceed because it is blocked by a rowlock.
Deadlock between Transactions
Typically, a deadlock happens when two or more transactions are writing to the same rows, but in a different order. For example, consider two concurrently running queries q1 and q2 in different transactions, where both q1 and q2 want to write to rows r1 and r2. If the query q1 wants to write to rows r1 and then r2, but the query q2 wants to write to row r2 first and then r1, they will deadlock.
A single transaction that runs multiple statements should not deadlock itself, because queries are executed in the order they are defined.
Solutions
-
To resolve contention when two or more transactions are writing to the same row (in the same order), add indexes on the columns being updated. Adding indexes to the columns ensures that the row locks are taken in the same order that the write statements are specified in each transaction. Note: This solution will not resolve a deadlock (defined previously).
For example, if the following query generates a lock wait timeout exceeded error:
DELETE FROM bucket WHERE meta_uid_id = ?
Add an index on meta_uid_id.
Consider the following
INSERT ... ON DUPLICATE KEY UPDATEstatement:INSERT INTO allotments (DevID, DevName, Orders) SELECT * FROM deprAllot ON DUPLICATE KEY UPDATE DevID = VALUES(DevID), Orders = VALUES (Orders);
To reduce the chance of a lock wait timeout exceeded error, add individual indexes to the
DevIDandOrderscolumns. -
You can decrease the
lock_wait_timeoutvalue to more quickly fail a query that is blocked by a lock. -
To resolve a deadlock (defined above) you should change the flow of your application logic execute queries that write to the same rows in the same order.
-
You can also disable
multistatement_transactions.Note: Disabling
multistatement_transactionsto prevent deadlocks is not recommended because it can lead to data loss or other serious issues.show variables like '%multistatement_transactions%';
Shows whether multistatement transactions are on, and
SET GLOBAL multistatement_transactions = off;
turns it off.
Disabling
multistatement_transactionsturns off cross-node transactions for write queries. Hence, write queries that span across multiple nodes, commit locally when the processing finishes on the node.To persist disabling multi-statement transactions through node restart, use the update-config command to update the
memsql.cnffile as shown below:SingleStore Tools
sdb-admin update-config --key multistatement_transactions --value off --set-global --all
By turning off multi-statement transactions, write queries that touch multiple nodes will commit locally when the processing finishes on the node. For example, if node 1 hits a duplicate key error, node 2 will still commit its transaction.
Uncommitted Transactions
Open transactions hold the locks on rows affected by the transaction until they are committed or rolled back, and any other write query modifying the same rows has to wait for the open transaction to release the locks. If the query has to wait for more than the lock_wait_timeout (default 60 seconds), it fails. This happens most often when the open transaction is idle and unnecessarily holding the locks.
Solutions
-
To resolve the issue, identify the idle transaction and kill its connection.
-
To prevent the issue from recurring, ensure that all the transactions are committed or rolled back.
Resolving the current locking issue
If a query has failed because it waited long enough to exceed the lock_wait_timeout, identify the transaction that is causing the timeout, and kill its connection. Killing the connection rolls back the uncommitted writes of the open transaction. For example, a write operation is performed in the following transaction, but it is not committed.
START TRANSACTION; UPDATE cust SET ORDERS = (ORDERS + 1) WHERE ID > 7680;
In another connection start a transaction, and run a query that tries to update the same set of rows as the transaction above.
START TRANSACTION; UPDATE cust SET ORDER_DATE = DATE_ADD(ORDER_DATE, INTERVAL 1 DAY) WHERE ID > 7680; **** ERROR 1205 (HY000): Leaf Error (192.168.3.152:3307): Lock wait timeout exceeded; try restarting transaction. Lock owned by connection id 76, query `open idle transaction`
To get the list of all the running transactions, query the INFORMATION_SCHEMA.PROCESSLIST table. This management view table contains the processlist information for all nodes in the workspace, and you can join this table with the INFORMATION_SCHEMA.MV_NODES table to identify the nodes on which each process is running.
SELECT TYPE, IP_ADDR, PORT, mvp.ID, USER, HOST, COMMAND, TIME, TRANSACTION_STATE, ROW_LOCKS_HELD FROM INFORMATION_SCHEMA.MV_PROCESSLIST mvp JOIN INFORMATION_SCHEMA.MV_NODES mvn ON mvp.NODE_ID = mvn.ID WHERE TRANSACTION_STATE = "open" AND COMMAND = "Sleep" AND TIME > 60 ORDER BY TYPE; **** +------+---------------+------+-----+-------------+---------------------+---------+------+-------------------+----------------+ | TYPE | IP_ADDR | PORT | ID | USER | HOST | COMMAND | TIME | TRANSACTION_STATE | ROW_LOCKS_HELD | +------+---------------+------+-----+-------------+---------------------+---------+------+-------------------+----------------+ | CA | 192.168.1.146 | 3306 | 143 | root | localhost:58322 | Sleep | 385 | open | 0 | | LEAF | 192.168.3.152 | 3307 | 76 | distributed | 192.168.1.146:9555 | Sleep | 385 | open | 5168 | | LEAF | 192.168.0.24 | 3307 | 125 | distributed | 192.168.1.146:7371 | Sleep | 385 | open | 5047 | | LEAF | 192.168.0.24 | 3307 | 104 | distributed | 192.168.1.146:60874 | Sleep | 385 | open | 5001 | | LEAF | 192.168.0.24 | 3307 | 115 | distributed | 192.168.1.146:63178 | Sleep | 385 | open | 5044 | | LEAF | 192.168.3.242 | 3307 | 55 | distributed | 192.168.1.146:10118 | Sleep | 385 | open | 5129 | | LEAF | 192.168.3.242 | 3307 | 77 | distributed | 192.168.1.146:21382 | Sleep | 385 | open | 5168 | | LEAF | 192.168.3.242 | 3307 | 81 | distributed | 192.168.1.146:26758 | Sleep | 385 | open | 4998 | | LEAF | 192.168.3.242 | 3307 | 122 | distributed | 192.168.1.146:55942 | Sleep | 385 | open | 5021 | | LEAF | 192.168.0.24 | 3307 | 75 | distributed | 192.168.1.146:40650 | Sleep | 385 | open | 5015 | | LEAF | 192.168.1.100 | 3307 | 131 | distributed | 192.168.1.146:23998 | Sleep | 385 | open | 5013 | | LEAF | 192.168.3.152 | 3307 | 78 | distributed | 192.168.1.146:11603 | Sleep | 385 | open | 5124 | | LEAF | 192.168.3.152 | 3307 | 83 | distributed | 192.168.1.146:21331 | Sleep | 385 | open | 5018 | | LEAF | 192.168.3.152 | 3307 | 120 | distributed | 192.168.1.146:39763 | Sleep | 385 | open | 5092 | | LEAF | 192.168.1.100 | 3307 | 79 | distributed | 192.168.1.146:1726 | Sleep | 385 | open | 5090 | | LEAF | 192.168.1.100 | 3307 | 82 | distributed | 192.168.1.146:6078 | Sleep | 385 | open | 5065 | | LEAF | 192.168.1.100 | 3307 | 114 | distributed | 192.168.1.146:21438 | Sleep | 385 | open | 5160 | | MA | 192.168.0.231 | 3306 | 490 | root | localhost:32737 | Sleep | 73 | open | 0 | +------+---------------+------+-----+-------------+---------------------+---------+------+-------------------+----------------+
In the result, each aggregator and each partition on each leaf has one idle open transaction which is holding row locks. The locks are only held on the leaves, because that is where the data is stored. Look for an aggregator process with the same run time as the leaf processes that are holding locks. In the result above, it is the process with connection ID 143, which is running on the child aggregator on host 192.168.1.146:3306. To resolve the current issue, connect to this aggregator and kill the connection with ID 143.
KILL CONNECTION 143;
Alternatively, you can kill the open connections that have been idle for more than lock_wait_timeout.
Note: Although the error message indicates that the lock is owned by the connection with ID 76, it is not the connection that needs to be killed. It is the connection for one of the distributed leaf processes, which holds the lock that our query was waiting on. Instead, we need to kill the connection for the aggregator process, which will roll back the entire transaction.
The original connection on the child aggregator that was updating ORDERS is now closed, and the transaction is rolled back. If you try to use that session again, it automatically re-establishes a new connection with a new ID.
SELECT COUNT(*) FROM cust; **** ERROR 2013 (HY000): Lost connection to MySQL server during query
SELECT COUNT(*) FROM cust; **** ERROR 2006 (HY000): MySQL server has gone away No connection. Trying to reconnect... Connection id: 160 Current database: db1 +----------+ | COUNT(*) | +----------+ | 390955 | +----------+
Preventing the Issue from Recurring
To prevent the issue from recurring, inspect the application code and ensure that all the transactions are either committed or rolled back, including the transactions in exception handling. Additionally, all manually run transactions must be committed or rolled back as well.
A common cause of this error is if the transaction is executed as part of a stored procedure, but exception handling causes the final commit to get skipped. To prevent this issue, add rollbacks for the transaction in the exception handling section of the stored procedure. For more information, see Transactions in Stored Procedures.
The impact of this error can be mitigated by setting a session timeout for the client, in order to automatically kill the idle transactions. When a client ends a session, the database rolls back the uncommitted transactions and closes the connection on its end. If the session timeout value is set lower than the lock wait timeout (default 60 seconds), then idle connections will not cause lock wait timeouts to be breached.
Note: Setting a query timeout in Resource Governance will not affect idle transactions. The query timeout limit only applies to executing queries.

У меня есть простой запрос в базу
UPDATE users SET username=’test’ WHERE id=’3′
После этого запрос зависает на 120 секунд и появлееться ошибка «Lock wait timeout exceeded; try restarting transaction». Это касается только одного пользователя, во всех других случаях все хорошо.
Командой
show full processlist;
убил все апдейты которые зависли к этому юзеру и вновь запустил этот апдейт и все равно то же.
Как мне разлочить его?
-
Вопрос заданболее трёх лет назад
-
16042 просмотра
Пригласить эксперта
Взято отсюда:
1) Войдите в MySQLmysql -u your_user -p
2) Посмотрите список залоченых таблиц:show open tables where in_use>0;
3) Посмотрите список процессов (один из них лочит вашу таблицу):show processlist;
4) Убейте этот процесс (процессы)kill <put_process_id_here>;
Для debian
1) systemctl restart mysql
-
Показать ещё
Загружается…
10 февр. 2023, в 04:49
50000 руб./за проект
10 февр. 2023, в 02:20
3000 руб./за проект
10 февр. 2023, в 01:33
1500 руб./за проект