
Книга Google о SRE, статьи экспертов, документация и обучающие курсы дают исчерпывающие знания о том, как в идеале должен работать SRE в компаниях. Правда, ключевое здесь – «в идеале». Работа с метриками и управление инцидентами в командах может сильно различаться по ряду причин: количество людей в команде, скорость выкатки нового функционала, число микросервисов, распределение компетенций и тд.
Когда переходишь от теории к реалиям жизни непременно возникают тупики и вопросы: как внедрить бюджет ошибок, кто за него будет ответственен, как договориться с разработкой, должны ли SRE-инженеры лезть в код при инцидентах и многое другое. В этой статье мы поговорим о выстраивании рабочего процесса на старте, когда вам нужно выставить первый SLO, рассчитать бюджет ошибок и мирно обо всем договориться с командой разработки и бизнесом.
Как работает бюджет ошибок
Error budget (бюджет ошибок) – четкая и объективная метрика, которая рассчитывается на основе SLO (Service-Level Objective, внутренний показатель качества работы сервиса). Она определяет, насколько ненадежным может быть ваш сервис в течение одного квартала и помогает разработчикам договариваться с SRE при принятии решения о допустимом уровне риска.
Другими словами, бюджет ошибок (как его иногда называют, «право на ошибку») – это количество ошибок, которые ваш сервис может накопить за определенный период времени, прежде чем ваши пользователи станут недовольны. Вы можете думать об этом как о терпимости к боли для ваших пользователей, но применительно к определенному параметру вашего сервиса: доступности, задержке и так далее.
У компании может быть очень много сервисов и у каждого из них свой собственный error budget, который определяется по степени критичности сервиса. То есть, чем критичнее сервис, тем жестче бюджет ошибок.
Измерение надежности сервисов
Как мы уже сказали, для каждой команды и каждого сервиса можно завести свой собственный бюджет ошибок. Но тут встает другой вопрос – а как рассчитывать бюджеты ошибок?
-
По времени: один из популярных вариантов подсчета, когда оценивается сколько времени доступен или недоступен сервис. Например, если бюджет на ошибки содержит 43 минуты даунтайма в месяц, и 40 минут из них сервис уже был недоступен, то очевидно: чтобы оставаться в рамках SLO, надо сократить риски. Как вариант, остановить выпуск фич и сосредоточиться на баг-фиксах.
-
Per request (по запросу): подходит для контроля надежности именно внутри сервисов. Каждый запрос отмечается, как успешный или неуспешный. Соблюдено SLO или нет, уложился ли сервис в те критерии, которые в него вложили? Если сервис не отвечает, значит он не соблюдает свои SLO, следовательно, запрос считается ошибочным. В этом случае одинаково выглядит, отвечает сервис слишком долго либо отвечает ошибкой. После рассчитывается соотношение «хороших» и «плохих» запросов.
Если говорить про попытку оценки работы приложения, именно applications, SLO лучше оценивать временными парадигмами. Если за какой-то период много ошибок, тогда весь период признается плохим и потом смотрится по времени. Например, за месяц был час интервалов времени, где сервис признан неработоспособным.
Что ставить в SLO на первых порах
Если в вашей компании исторически был определенный мониторинг, начните с наблюдения за ним. Посчитайте, сколько времени ваша система работала, а сколько не работала. На этих данных вы сможете выставить первоначальный SLO.
Еще один стартовый подход измерения доступности – разбор предыдущего опыта с инцидентами. Например, создание разметки большого инцидента по времени, когда что-то критичное перестало работать на 100%. Степень критичности можно определить падением выделенных метрик в два раза. Если любая из этих бизнес-метрик падает в два или три раза относительно бейзлайна – инцидент можно считать тяжелым. Подход не лишен своих недостатков, мелкие инциденты могут проходить под радарами, но так вы получите верхнеуровневую оценку и увидете трендовое снижение вниз на ранних этапах.
В ситуации, когда нет ничего, поможет ретро. Соберите информацию о состоянии сервиса за последний месяц и обсудите с командой, когда и насколько падала система. Оцените все вводные и выставите первый мониторинг на основе этих данных.
Когда нужно пересматривать SLO
Пересмотр SLO – регулярный процесс. На старте SLO можно пересматривать раз в две недели, потом раз в месяц. Что-то менять придется до тех пор, пока SLO не стабилизируется и не будет согласован с командами разработки и стейкхолдерами, которым этот сервис принципиален.
Также важно понимать, как вы хотите конкретизировать SLO и в каком месте его пересматривать. Если мы говорим про весь продукт или какой-то его аспект, то SLO можно менять регулярно. Если же речь о микросервисах, то тут команды могут сами пересматривать SLO из необходимости, организовав свой процесс пересмотра.
Пересматривать метрики придется в любом случае. Во время разбора инцидента проверяется, как стригерились метрики бюджета ошибок, как вели себя метрики SLO, соблюдались они или нет, показали ли они проблему или не показали, пробило ли это бюджет. Если бюджеты исчерпались, значит где-то что-то не так считалось. Каждый раз вам нужно обосновывать, ожидаем ли был инцидент или нужно пересматривать метрики.
Если error budget исчерпывается каждую неделю
Вот вы дошли до настройки метрик и заложили бюджет ошибок на 1-2 недели. А потом бюджет начал не соблюдаться каждую неделю. Что делать? Застопить всю разработку и выкатку релизов? Получается не очень реалистичная картинка.
Когда вы только начали внедрять error budget, расходовать месячный бюджет за пять дней – это нормально. Эти границы ставятся не для того, чтобы шокировать команду разработки, а чтобы менеджмент понимал, что что-то идет не так. На первых порах бюджет ошибок нужно регулярно пересматривать: 98% за неделю было слишком жестко, поставьте 97% или 96%. Двигайте границы до тех пор, пока они не соприкоснуться с реальным отражением вашей системы. Только тогда начинайте улучшать.
В первую очередь вам нужно обкатать процесс: как все это будет читаться и измеряться. Бюджет ошибок говорит лишь о том, что либо мы сейчас занимаемся стабилизацией системы, либо ее развитием. Не добавляйте к нему никакую автоматику и остановки релизов на этапе внедрения. Максимум, что в этот момент стоит делать – просто начать разговаривать с командами. Например, обсудить, нормально ли для нашей системы, что вы израсходовали оговоренное значение бюджет ошибок или нет. Если вы не ожидали этого, то неплохо бы взять в следующий спринт задачи по стабилизации системы.
Как еще измерить стабильность системы
Помимо стандартного подсчета девяток или какой-то другой метрики можно совместно с бюджетом ошибок просчитывать ABDEX по всем сервисам, критичным и конечным точкам.
ABDEX (Application Performance Index) – это числовая мера удовлетворенности пользователей производительностью приложений. Для расчета Apdex используются статистические данные с программных счетчиков, содержащие: наименование операций, время начала каждой операции, и длительность исполнения каждой операции приложением.
Далее эти данные за период (например, сутки) компонуются по наименованию/операции, затем для каждой операции: производится агрегация всех значений длительности выполнения этой операции, относительно целевого времени, на три зоны «отзывчивости» по отношению к пользователю: довольны, удовлетворены, разочарованы.
Application Performance Index дает более полную картину и показывает явную деградацию сервиса, если она присутствует. Какой толк от четырех девяток, если эндпоинт сервиса отвечает по 500+мс. Классический подсчет по бюджету ошибок этого не учитывает, а нам все-таки нужно не только отдать 200, но и достаточно быстро это делать.
Должен ли SRE коммитить в код
Роль SRE начинает потихоньку отделяться и вопрос работы с кодом встает острее. Предполагается, что SRE-инженер при инциденте может прочитать код на уровне изменений в последних релизах сервисов. Вдруг там все очевидно. Выкатить сервис он тоже вполне может. При всем этом во многих компаниях роли SRE-инженера и разработчика остаются смежными.
Как еще может быть:
-
В команде нет отдельной роли SRE, поэтому его обязанности лежат на разработчике. Есть разработчики, которые больше занимаются кодом, а есть внутри команд люди, которые чуть больше занимаются инфраструктурой для этих сервисов. Есть команды разработки, которые состоят только из SRE-инженеров, отвечающих и за код, и за эксплуатацию самой системы.
-
SRE-инженеры работают только с инфраструктурным кодом. Если у проекта инфраструктурная специфика, команды SRE могут отвечать за часть имеющихся сервисов вместо команды разработки. В этом случае они будут отвечать за изменения на уровне скриптов, кода и тд.
-
SRE может вносить правки в код сервиса игнорируя правила и пуша напрямую в мастер, если произошел глобальный инцидент или того требуют обстоятельства. Также он может вывести из-под нагрузки элемент инфраструктуры или перебалансировать трафик. Зачастую команда SRE не видит этот код ежедневно, поэтому ей понадобится больше времени в нем разобраться во время инцидента. Поэтому компании гораздо дешевле и быстрее позвать разработчика.
Резюмируем: SRE-инженерам не всегда нужно лезть в код, но они могут это сделать, если того требуют обстоятельства или их должность в компании совмещена с разработкой. Кроме того, SRE-инженеры могут сами писать тулинги, обвязки и все то, что позволит добавлять более глубокие автоматизации.
Немного про дежурства и мониторинг
Правила разнятся от компании к компании. Но, в командах SRE всегда есть дежурный или дежурные, которые ротируются в зависимости от частоты инцидентов и загруженности.
Как может выглядеть дежурство:
Дежурный разбирает инциденты, в том числе и в коде. В других случаях он отвечает на входящие запросы от других команд и параллельно занимается своей работой. Задачи дежурства остаются в приоритете.
Если говорить про мониторинг и реакцию не него, то, обычно, есть первая линия поддержки. Она реагирует, если пришло оповещение о проблеме. SRE – это вторая или третья линия поддержки, которая, как правило, не занимается круглосуточным наблюдением за мониторингом.
Еще одна распространенная практика распределения обязанностей при инцидентах – создание алерт схемы, которая описывает произвольное количество триггеров, пороги и что делать, если триггер сработал. Например, сработал триггер неуспешных оплат через банк. В одном месте указаны контакты, кому звонить, лежат рекомендации по расследованиям инцидентов и другие инструкции.

Старт практического курса SRE: data-driven подход к управлению надёжностью систем 28 февраля.
Итог
Варианты использования бюджета ошибок могут различаться, как и обязанности SRE-инженеров в зависимости от компании, ее нужд и специфики системы.
-
В начале пути сделайте бюджет ошибок показателем того, чем вам нужно заниматься. Отвечать за стабильность он будет позже, когда начнет точно отражать состояние системы на текущий момент. Не спешите добавлять к нему автоматизацию и останавливать разработку.
-
Процесс внедрения бюджета ошибок может занять от трех месяцев. И даже тогда для начала используйте голову. Смотрите на уже использованный бюджет и на то, как это отразилось на состоянии продакшена. Может это случилось по причинам, на которые вы сейчас не можете повлиять, или закралась ошибка в расчетах.
-
Пересматривать метрики придется в любом случае. Во время разбора инцидента проверяйте, как повел себя бюджет ошибок, как вели себя метрики SLO, соблюдались они или нет, показали ли они проблему или не показали, пробило ли это бюджет. Каждый раз вам нужно все обосновать.
-
Использовать оставшийся бюджет ошибок не только можно, но и нужно. Вы можете потратить его на различного рода оптимизации, например, расселить базы, которые обычно считаются критичным элементом.
-
И хотя в книге Google SRE-инженеры – в первую очередь разработчики, в реальности существует гораздо больше вариаций. Однако SRE-инженера, который как-то взаимодействует с кодом, вы встретите чаще, чем SRE-инженера, который с ним вообще не работает.
Как грамотно внедрять практики SRE
28 февраля стартует новый поток обновленного курса «Site Reliability Engineering: data-driven подход к управлению надежности систем». Будем учиться три недели, за которые вы разберете современные практики SRE и инструменты для повышения доступности и надежности ваших IT-систем, включая мониторинг, автоматизацию, оптимизацию процессов и управление инцидентами.
Чтобы после курса вы смогли применить знания на реальных проектах, мы выстроили обучение вокруг специально разработанного приложения по продаже билетов для кинотеатров. На нем вы будете решать реальные задачи связанные с надежностью. В общей сложности вы проведете в роли SRE-инженера более 24 часов.
На курсе вы
-
узнаете, как снизить ущерб от отказов в будущем;
-
внедрите правки прямо в прод;
-
узнаете, как решать конкретные проблемы, связанные с надежностью сервиса;
-
поймете, какие метрики собирать и как это делать правильно;
-
научитесь быстро поднимать продакшн силами команды.
Помимо того, что учиться будет интересно, благодаря новым знаниям и практике вы сможете настроить:
-
мониторинг SRE-метрик (SLO, SLI, error budget) для своего сервиса. Поймете как эти метрики выбрать;
-
мониторинг SRE-инфраструктурных сервисов. Сможете опознавать и решать проблемы с инфраструктурой;
-
alerting и healthcheck;
-
разные методы деплоймента и будете знать, какие инструменты для этого существуют.
-
пожарную команду в случае инцидента, раздать роли коллегам и выступить лидером.
-
надежные коммуникации между сервисами retry, timeout, circuit breaker.
Вас ждут теория и AMA-cессии в течении недели, а также субботние 4-часовые практики, чтобы спокойно погрузиться в профессию и потрогать инструменты.
Для команд от 5 человек у нас хорошие скидки, а для тех, кто оплачивает не от компании — рассрочка, и возможность вернуть 13%
Количество мест ограниченно. Подать заявку и узнать подробности.
Что вообще за SRE, что это значит?
SRE (Site Reliability Engineering) — это сфера обеспечения бесперебойной работы высоконагруженных сервисов. Соответственно, SRE-инженер — это специалист по надёжности.
Термин SRE придумали в Google, в этой компании появились первые разработчики, которые затачивают свою работу на безотказность и быстрое исправление ошибок. Это направление стало очень популярно, сегодня SRE-инженеры есть в любом мощном сервисе — и в Яндексе в том числе.

А что, до SRE безотказности сервисов не было?
Была — но её обеспечивали иначе. Представим большой и популярный онлайн-кинотеатр. Это сложный сервис, который должен показывать сериалы и фильмы 24/7 с минимальной задержкой.
Предположим, что в пятницу у сервиса два важных события: вечером выходит финальный эпизод сериала «Игры у стола» и тем же вечером разработчики апдейтят бэк. Тесты проходят, всё работает, «Игры» летят — разработчики уходят в бар отмечать долгожданный релиз. А в субботу утром десятки тысяч людей не могут нормально посмотреть сериал: вместо 20 мс сайт работает с задержкой 100500 мс.
При традиционном подходе к надёжности первыми о ситуации узнают сотрудники поддержки, ведь расстроенные зрители заполнят все чаты. Специалист поддержки не может восстановить работу сервиса — он эскалирует проблему, передав её в технический хелп. Там увидят, что случилась большая беда, и начнут вызванивать разработчиков. Не факт, что все они на связи в субботу, ведь у всех нас есть свои дела по выходным. В итоге через несколько часов соберётся консилиум программистов и будет решать, что делать: откатывать апдейт или попытаться пофиксить текущий билд. На восстановление нормальной работоспособности уйдут часы или даже дни — а такой простой очень дорого обходится бизнесу.
А что в такой ситуации сделает SRE-инженер?
Возьмёт и починит сам. SRE-инженер — это «дежурный программист», который не только первым узнаёт о проблеме, но и сразу же приступает к её решению. В итоге он экономит несколько часов для своей компании и пользователей. А программисты могут спокойно отдыхать, даже если у сервиса проблемы.
В компаниях с командой из 10–15 человек можно обойтись без SRE: обычно разработчики дежурят по очереди. А вот большому высоконагруженному сервису, например банку, без такого специалиста не обойтись: в случае проблем счёт идёт на минуты.
У нас в Readymag небольшая команда разработчиков и отдельного SRE нет. Но есть дежурства, по неделе на каждого специалиста. Во время дежурства разработчик должен быть доступен всегда — даже в бар ходит с ноутбуком. Ну и конечно, на время дежурства приходится ограничивать активности, пойти на балет или уехать за город не всегда получается.
Анна Шишлякова, фулстек в Readymag
А как SRE узнает, что что-то случилось?
У команды по доступности работает мощный мониторинг, отслеживаются десятки показателей жизнедеятельности сервиса. Если метрики начинают сыпаться, срабатывают алерты.
Но обычного письма или пуша для SRE-инженера мало. Алерт в его случае работает многоступенчато. Например, сперва разработчик получает уведомление через телеграм-бота. После этого он должен быстро отметить в мониторинговой админке, что увидел проблему. Если этого не сделать, мониторинг начнёт звонить SRE-специалисту по телефону, вызывая на бой с багами. Многоступенчатость важна, ведь сервис может упасть и ночью, а во сне можно случайно пропустить вызов или машинально отменить его, как будильник.
В небольших и средних компаниях обычно дежурит один SRE-инженер. Если он пропустит алерт, то решение ситуации придётся откладывать. В больших компаниях инженеров сразу несколько — они могут подстраховать друг друга.
Получается, SRE-специалист — это такой сисадмин-девопс-программист?
Вроде того, он настоящий Бэтмен. Чтобы задержать преступника быстрее полиции, важно действовать не хуже настоящего полицейского. SRE должен разбираться в инфраструктуре, конфигурации серверов, быстро читать логи. Он умеет писать код не хуже программистов — ведь часто для исправления бага нужно быстро переписать что-то руками.
Чтобы работать очень быстро, в SRE используют парадигму «инфраструктура как код». Инженеры могут управлять инфраструктурой и настраивать её через процедуры в коде — так они работают со всеми компонентами в одной среде и не отвлекаются на ручное «накликивание» настроек серверов.
Чтобы SRE-инженер хорошо знал свой продукт, он часто участвует в его разработке. Как правило, это очень опытный, сильный программист, вожак стаи с самыми мощными лапищами. Иначе команда просто не будет ему доверять.
Внутренняя облачная инфраструктура Яндекса представляет из себя пачку сильно и слабо связанных между собой сервисов которые, в совокупности, для внутренних заказчиков выглядят как один большой сервис. К инфраструктурным сервисам выдвигаются особые требования к надежности их работы, поэтому подходы к проектированию и эксплуатации таких сервисов могут сильно отличаться от канонических о которых написано в книгах про SRE-подходы.
В инфраструктуре мы стараемся придерживаться как общепринятых подходов к проектированию и эксплуатации сервисов, так и делать упор на важные для нас аспекты обеспечения надежности. У нас есть мониторинг, алертинг, дежурства, репликация, шардирование сервисов, плавные выкладки в production, тестовые и приемочные стенды. Где-то больше, где-то меньше, но в целом — достаточно для обеспечения бесперебойности работы инфраструктуры. Тут хочется обратить внимание на одну из проблем обеспечения надежности инфраструктуры — человеческий фактор. Пару лет назад коллега обнаружил замечательный пост в блоге. Наверняка каждый кто занимается эксплуатацией различных сервисов сталкивался со всеми описанными там проблемами в том или ином виде.
If you determine «human error» as the root cause, then you’re doing it wrong. И, действительно, это так. Надежные системы должны проектироваться и эксплуатироваться с оглядкой на то, что люди ошибаются и нельзя предугадать когда будет совершена ошибка которая приведет к даунтайму, поэтому лучше считать что люди ошибаются всегда. Считая так, при проектировании систем мы встраиваем на всех уровнях различные механизмы автоматической защиты от человеческих ошибок и валидации как входных данных так и результатов выполнения каких-либо изменений. В разработке инфраструктурных сервисов предпочитаем использовать языки со статической типизацией и для дополнительной защиты утилизировать возможности системы типов этих языков так, чтобы невозможно было выполнять противоречивые действия над сущностями в коде. Как результат такого подхода к проектированию и эксплуатации сервисов мы автоматически получаем высокий уровень автоматизации эксплуатации инфраструктурных сервисов и наши дежурные спокойно спят по ночам. Инциденты происходят, но у «автора» инцидента всегда есть инструмент для диагностики проблем и отката ломающих изменений без необходимости вмешательства дежурного от инфраструктурного сервиса.
Антон Суворов, руководитель группы эксплуатации внутреннего облака
Хорошо. А чему разработчики и команды могут научиться у парадигмы SRE, даже если таких специалистов в штате нет?
Есть две хорошие практики, которые может взять на вооружение любая команда.
Бюджет ошибки. SRE-команды считают так называемый бюджет ошибки — допустимый период, в течение которого сервис может работать ниже целевых уровней. С помощью бюджета можно измерять серьёзность инцидентов. Если, например, инцидент истратил 30% бюджета, его можно считать серьёзным. Это помогает SRE-инженерам не отвлекаться на минорные проблемы, которые регулярно возникают даже в самых оттестированных проектах.
Постмортемы. Это грустное слово означает отчёт или небольшую статью, которую пишут по результатам решения проблемы. С помощью постмортемов SRE-инженер делится важным знанием с командами разработки, помогая избежать ошибок в будущих проектах.
Что такое бюджет ошибок и почему он важен?
Каждая команда разработки, операционный отдел и ИТ-команда знает, что инциденты иногда случаются.
Даже крупнейшие компании с самыми талантливыми сотрудниками, известные своей почти 100-процентной бесперебойной работой, иногда сталкиваются с выходом систем из строя. Просто посмотрите на Apple, Delta или Facebook: им всем приходилось терпеть убытки в десятки миллионов долларов в результате инцидентов за последние пять лет.
На самом деле соглашение об уровне обслуживания (SLA) никогда не должно обещать 100-процентной безотказной работы. Потому что ни одна компания не может сдержать такое обещание.
Если ваша компания очень хорошо избегает инцидентов или разрешает их, возможно, вам удается стабильно превосходить свой целевой показатель времени безотказной работы. Например, вы обещаете 99-процентную бесперебойность вашей работы, а в действительности близки к 99,5 %. Либо вы обещаете 99,5 % времени безотказной работы, а на самом деле обычно достигаете 99,99 % в течение месяца.
Однако когда так происходит, отраслевые эксперты не рекомендуют формировать у пользователей слишком высокие ожидания и постоянно увеличивать свои обещания. Вместо этого необходимо считать дополнительные 0,99 % бюджетом ошибок, т. е. временем, которое компенсирует возможные риски вашей команды.
Что такое бюджет ошибок?
Бюджет ошибок — это максимальное время, в течение которого техническая система может выходить из строя без оговоренных в соглашении последствий.
Например, если соглашение об уровне обслуживания (SLA) указывает, что системы будут работать 99,99 % времени, а при нарушении этого обязательства компания должна будет компенсировать клиентам убытки из-за сбоя работы, то это означает, что ваш бюджет ошибок (или время, на которое ваши системы могут выходить из эксплуатации без последствий) составляет 52 минуты и 35 секунд в год.
Если в соглашении SLA обещается 99,95 % времени безотказной работы, бюджет ошибок составляет 4 часа, 22 минуты и 48 секунд. Если в соглашении SLA обещается 99,9 % времени безотказной работы, бюджет ошибок составляет 8 часов, 46 минут и 12 секунд.
Зачем техническим командам нужны бюджеты ошибок?
На первый взгляд, бюджеты ошибок не так уж важны. Разве это не просто еще одна метрика для ИТ-специалистов и DevOps, которую нужно отслеживать, чтобы убедиться, что все работает правильно?
Ответ, к счастью, «нет». Бюджеты ошибок — это не просто хороший способ убедиться, что вы выполняете договорные обязательства. Они также дают возможность командам разработчиков внедрять инновации и рисковать.
В нашей статье по SRE мы объясняем:
«Команда разработчиков может потратить этот бюджет ошибок, как ей захочется. Если продукт в настоящее время работает безупречно, с небольшим количеством ошибок или вовсе без них, разработчики могут запускать в любой момент все, что захотят. И наоборот, если они потратили или превысили бюджет ошибок и работают на уровне, определенном в SLA (или ниже его), то запуск любых новых возможностей замораживается до тех пор, пока команда не уменьшит количество ошибок до уровня, позволяющего продолжить запуск».
Преимущество этого подхода заключается в том, что он побуждает команды минимизировать реальные инциденты и максимизировать инновации, принимая на себя риски в разумных пределах. Он также устраняет разрыв между командами разработчиков, целями которых являются инновации и гибкость, и операционным отделом, который занимается стабильностью и безопасностью. До тех пор, пока время сбоев работы остается маленьким, разработчики могут сохранять свою гибкость и продвигать изменения, не затрудняя работу операционного отдела.
Как использовать бюджет ошибок
Во-первых, вам нужно свериться с соглашением об уровне обслуживания (SLA) и целевыми показателями уровня обслуживания (SLO). Какие цели вы уже поставили перед собой в отношении безотказной работы или успешного выполнения системных запросов? Какие обещания ваша компания дала клиентам? Все это будет определять ваш бюджет ошибок.
Бюджеты ошибок на основе времени безотказной работы
Большинство команд отслеживают время безотказной работы на ежемесячной основе. Если время доступности больше времени, обещанного в SLA или SLO, команда может выпустить новые возможности и принять на себя связанный с этим риск. Если оно меньше целевого показателя, обновления функциональности останавливаются до тех пор, пока целевые показатели не вернутся в нужное русло.
Чтобы эффективно использовать этот метод, вам нужно будет перевести цель SLO (обычно процент) в реальное время, в течение которого смогут работать ваши разработчики, т. е. вычислить количество часов и минут, на которое фактически приходится 1 %, 0,5 % или 0,1 % допустимого времени простоя. Ниже приведены распространенные целевые показатели.
цель SLA |
Ежегодно допустимый простой |
Ежемесячно допустимый простой |
|---|---|---|
|
99.99% uptime |
Ежегодно допустимый простой 52 минуты, 35 секунд |
Ежемесячно допустимый простой 4 минуты, 23 секунды |
|
99,95% безотказной работы |
Ежегодно допустимый простой 4 часа, 22 минуты, 48 секунд |
Ежемесячно допустимый простой 21 минута, 54 секунды |
|
99,9% безотказной работы |
Ежегодно допустимый простой 8 часов, 45 минут, 57 секунд |
Ежемесячно допустимый простой 43 минуты, 50 секунд |
|
99,5% безотказной работы |
Ежегодно допустимый простой 43 часа, 49 минут, 45 секунд |
Ежемесячно допустимый простой 3 часа, 39 минут |
|
99% безотказной работы |
Ежегодно допустимый простой 87 часов, 39 минут |
Ежемесячно допустимый простой 7 часов, 18 минут |
Бюджеты ошибок на основе успешных запросов
Соглашения SLO вызывают меньше неодобрения, чем SLA, но могут создать не меньше проблем, если будут расплывчатыми, излишне усложненными или не поддающимися измерению. По мнению инженеров, главная черта хороших соглашений SLO — простота и ясность. Претендовать на статус SLO могут только самые важные показатели. Цели должны быть изложены простым языком и, как и в случае SLA, должны всегда учитывать такие проблемы, как задержки на стороне клиента.
Соблюдайте SLA с помощью Jira Service Management: решайте запросы на основе приоритетов, используйте правила автоматической эскалации, чтобы отправлять уведомления нужным участникам команды и предотвращать нарушения SLA.
Популярность SRE растёт, но знаний о нём всё ещё недостаточно. Я не буду повторять формальные определения, а вместо этого расскажу несколько историй из жизни системного инженера Лёхи. Путь выдуманного Лёхи во многом похож на путь, который прошли реальные крупные компании, где впервые и возникли SRE-инженеры (даже если назывались иначе).
Через историю Лёхи вы узнаете о задачах, которые решает SRE, и причинах, по которым для решения этих задач пришлось выделять отдельный класс инженеров.
Глава 1. Hope is not a strategy
Утро понедельника, инженеру эксплуатации Лёхе звонит разработчик Толя:
— У нас проблема! Ошибки в сервисе «Плутон».
— Подробности будут?
— Там какие-то проблемы при работе с внешними ресурсами. Надо срочно починить! У нас всё лежит в проде.
— Хорошо, сейчас посмотрим.
За пару минут Лёха выясняет, что «Плутон» — это третьестепенный сервис, который обращается во внешние ресурсы и получает от них не очень важные данные. Обработка ошибок в нём не предусмотрена, поэтому если «Плутон» недоступен, то всё ломается. Плюс выяснилось, что до одного из внешних сервисов есть потери пакетов у магистрального провайдера.
— Там потери у магистрального провайдера, часть запросов теряются.
— Ну и? Когда починишь?
— Эм, что? Это не у нас проблема, это у магистрального провайдера!
— Ну значит, звони магистральному провайдеру, пусть срочно чинят!
— Серьезно? Да им пофиг на нас. Могу позвонить в администрацию президента, толку и то больше будет…
— Ну тогда звони нашему провайдеру, пусть с магистральным разберётся, мы платим за сетевое соединение, всё должно быть доступно на 100%!
До перехода в эксплуатацию Лёха 3,5 года работал программистом. Он решил вспомнить прошлое и написал маленький патч для «Плутона» с возможностью автоматически выполнять retry в течение заданного времени.
А диалога про 100% доступность могло бы не состояться, если бы Толик понимал: рассчитывать, что хоть один сервис в мире (да что там в мире, в галактике!) имеет 100% доступность, глупо. Сколько бы ты ни платил денег, это недостижимо. В погоне за 100% доступностью можно растратить весь бюджет, но так и не достигнуть её. Куда лучше быть готовым к нестабильности и уметь с ней работать.
Леха понимает, что 100% доступность чего угодно невозможна, но он не разработчик, хоть у него и есть опыт работы разработчиком, это не его зона ответственности. Толик разрабатывает приложения и мог бы научить приложение работать стабильно в нестабильных условиях. Если приложение попадет в зону ответственности Лехи, то мы получим первого SRE.
Сложность систем и взаимодействия между ними, а также требование стабильной работы в нестабильных условиях привели к тому, что знаний одного только разработчика или инженера эксплуатации стало недостаточно. Требовались люди, которые сочетают в себе умения двух специальностей.
«Почему никто не стремится к 100% доступности?» — спросил Толя
100% доступность невозможна и бессмысленна. Надо исходить из предположения, что ошибки и сбои неизбежны, и также учитывать стабильность работы внешних компонентов, таких как браузер, мобильная ОС, сеть клиента, так как их надежность зачастую ниже даже 99%, и наши усилия будут незаметны для пользователя . Более того, предстоящие сбои надо учитывать при разработке и эксплуатации.
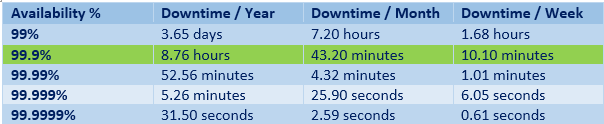
Оценивая доступность, говорят о «девятках»:
- две девятки — 99%,
- три девятки — 99,9%,
- четыре девятки — 99,99%,
- пять девяток — 99,999%.
Пять девяток — это чуть больше 5 минут даунтайма в год, две девятки — это 3,5 дня даунтайма.
Стремиться к повышению доступности нормально, однако чем ближе она к 100%, тем выше стоимость и техническая сложность сервиса. В какой-то момент происходит уменьшение ROI — отдача инвестиций снижается.
Например, переход от двух девяток к трём уменьшает даунтайм на три с лишним дня в год. Заметный прогресс! А вот переход с четырёх девяток до пяти уменьшает даунтайм всего на 47 минут. Для бизнеса это может быть не критично. При этом затраты на повышение доступности могут превышать рост выручки.
При постановке целей учитывают также надёжность окружающих компонентов. Пользователь не заметит переход стабильности приложения от 99,99% к 99,999%, если стабильность его смартфона 99%. Грубо говоря, из 10 сбоев 8 будет приходится на сбои, связанные с работой смартфона, а не самого сервиса. Пользователь к этому привык, поэтому на один лишний раз в год не обратит внимания.
Глава 2. Нестабильность сохраняется
Прошло несколько недель. Лёха расслабился и спокойно занимался привычной работой.
Но однажды вечером пятницы, за 20 минут до конца рабочего дня, в кабинет ворвался технический директор Иван Эрнестович.
— Сударь, а вы осведомлены, что у вас приложение работает из рук вон плохо? Я бы даже сказал, отвратительно.
Произносит он это без мата и криков, спокойным тихим голосом, отчего становится еще страшнее. Мониторинг не сообщал ни о каких инцидентах, поэтому придётся выяснять подробности.
— Добрый вечер, Иван Эрнестович. А не могли бы вы рассказать, почему сделали такой вывод? Давайте начнём по порядку: о каком приложении речь?
— Я сожалею, что вы не осведомлены о проблемах, но коль уж так, извольте слушать. Во время обеда с партнёром решил я рассказать ему про наш новый продукт «Русь». А он в ответ: «Да слышал я, и даже заходил поглядеть, но так и не дождался загрузки главной страницы». Я ринулся проверять и тут же сам убедился в его словах (лицо Ивана Эрнестовича изобразило отчаяние).
— Мониторинг молчит, но я сейчас все проверю. Изволите ожидать, или отправить результаты расследования почтой?
— Я подожду.
Быстрый обзор системы мониторинга показал, что все показатели в рамках нормы. В частности, за последние 3 часа было всего ~ 1000 неуспешных запросов (неуспешными по мнению Лехи считаются только те запросы, на которые был получен 50x код ответа).
— Проверил данные системы мониторинга, за последние часы было всего 1000 неуспешных запросов, новый сервис работает.
— Сколько? И вы смеете называть это «работает»? Это недопустимый показатель!
— Вы, как всегда, правы, Иван Эрнестович. 1000 неуспешных запросов — звучит грустно. Но это всего 1.5% от общего количества запросов. А это, согласитесь, не так уж и плохо.
— Действительно, 1.5% не так страшно, но все ж почему мы не смогли открыть приложение?
— А вы, говорите, обедали? В таком случае, проблема может быть не с нашим приложением, а с мобильным интернетом или Wi-Fi в ресторане.
— Не исключено. Но 1000 запросов — это много, будьте любезны с этим разобраться.
— Конечно, я уже завёл задачу, мы проведём диагностику и пришлём отчёт.
— И прекратите пугать людей большими цифрами! Жду предложение по изменению системы мониторинга. Твоя идея с соотношением мне понравилась, надобно ее проработать.
С этими словами Иван Эрнестович удалился, а наш герой Лёха выдохнул, дооформил задачу по инциденту, передал данные ночному дежурному и тоже удалился.
К причинам инцидента и отчету мы вернёмся чуть позже, а вот историю про метрики вынесем как вывод к этой главе. После этого диалога Лёха придумал систему оценки качества работы продукта и за выходные её прописал.
Фактически Лёха создал то, что сейчас обязательно используется в рамках SRE подхода:
Целевые показатели: SLA, SLI, SLO
Чтобы в следующий раз Иван Эрнестович не был удивлён, узнав о 1,5% проваленных запросов, Лёха выбрал ключевые метрики, по которым можно отслеживать, насколько стабильно работает наш сервис. Также предложил сразу установить для данных метрик границы, при пересечении которых команда, отвечающая за сервис, понимает, что все стало плохо и пора сфокусироваться над стабильностью. И даже придумал название для таких метрик: соглашение о целевом уровне обслуживания — Service-Level Objective (SLO).
Это соглашение позволяет всем в компании прийти к общему пониманию, что такое надежность (стабильность, доступность) системы. Потому что без него надёжность заботит только отдел эксплуатации. Разработчики ей пренебрегают, а для бизнеса это вообще абстракция, и цифры только путают.
В SLO закрепляют целевые показатели доступности, которые вырабатывают вместе с продакт-оунером. То есть Лёха может их предложить, но утвердить не может. Здесь нужно согласие всех лиц, принимающих решение.
Чтобы понимание было ясным, соглашение должно содержать конкретные числовые показатели — Service Level Indicator (SLI). Это может быть время ответа, количество ошибок в процентном соотношении, пропускная способность, корректность ответа — что угодно в зависимости от продукта.
SLO и SLI — это внутренние соглашения, нужные для взаимодействия команды. Обязанности компании перед клиентами закрепляются в Service Level Agreement (SLA). Это соглашение описывает работоспособность всего сервиса и штрафы за превышение времени простоя или другие нарушения.
Примеры SLA: сервис доступен 99,95% времени в течение года; 99 критических тикетов техподдержки будет закрыто в течение трёх часов за квартал; 85% запросов получат ответы в течение 1,5 секунд каждый месяц.
Среднее время между сбоями и среднее время восстановления — MTBF и MTTR
Чтобы избежать претензий, Лёха пошёл дальше — сформулировал ещё два показателя: MTBF и MTTR.
MTBF (Mean Time Between Failures) — среднее время между сбоями.
Показатель MTBF зависит от качества кода. То есть чем меньше будет косячить разработчик Толя, тем лучше будет показатель MTBF. Но поскольку каждый косяк Толи влияет на Лёху, у Лёхи должна быть возможность делать ревью кода и, в случае совсем уж очевидных проблем, говорить «Нет!».
По крайней мере, это предполагает подход SRE. Он же предполагает понимание со стороны команды: когда SRE блокирует какой-то коммит, он делает это не из вредности, а потому, что иначе страдать будут все.
MTTR (Mean Time To Recovery) — среднее время восстановления (сколько прошло от появления ошибки до отката к нормальной работе).
Показатель MTTR рассчитывается на основе SLO. Инженер по SRE влияет на него за счёт автоматизации. Например, в SLO прописан аптайм 99,99% на квартал, значит, у команды есть 13 минут даунтайма на 3 месяца. В таком случае время восстановления никак не может быть больше 13 минут, иначе за один инцидент весь «бюджет» на квартал будет исчерпан, SLO нарушено.
13 минут на реакцию — это очень мало для человека, поэтому здесь нужна автоматизация. Что человек сделает за 7-8 минут, с тем скрипт справится за несколько секунд. При автоматизации процессов MTTR очень часто достигает секунд, иногда миллисекунд.
Бюджет на ошибки
Как мы выяснили, пытаться достичь 100% стабильности не самая лучшая идея, потому что это дорого, технически сложно, а часто и бесполезно — скорее всего, пользователь не оценит старания из-за проблем в «соседних» системах.
Поэтому Лёха предложил ввести еще одно понятие — бюджет ошибок. Это степень риска, которая допустима для данного сервиса, и ее можно прописать в SLO.
Бюджет на ошибки помогает разработчикам оценить, на чем нужно сфокусироваться в данный момент: на стабильности или новом функционале.
Если бюджет на ошибки содержит 43 минуты даунтайма в месяц, и 40 минут из них сервис уже лежал, то очевидно: чтобы оставаться в рамках SLO, надо сократить риски. Как вариант, остановить выпуск фич и сосредоточиться на баг-фиксах.
Если бюджет на ошибки не исчерпан, то у команды остаётся пространство для экспериментов.
Чтобы не выйти за рамки, Error budget делят на несколько частей в зависимости от задач. Каждая команда должна оставаться в пределах своего бюджета на ошибки.
Если это все будет внедрено, можно будет получить объективную картину, насколько стабильно работает наш сервис. Но остается одна серая зона: что делать, если бюджет на ошибки был исчерпан. Лёха посчитал, что очень важно договориться об этом заранее и оформить в виде документа —;Error budget policy.
Для примера он решил зафиксировать, что при исчерпании бюджета на ошибки останавливается вся разработка бизнес-функционала и вся команда работает над повышением стабильности. Лёха уверен: этот документ позволит избежать конфликтных ситуаций в и без того напряженной ситуации.
Леха закончил подготовку предложений и обнаружил, что уже вечер воскресенья, и уже совсем скоро опять на работу.
Глава 3. Post mortem
Придя в понедельник в офис, первым делом Лёха открыл результаты расследования инцидента. Увиденное не радовало.
Небольшая цитата:
«В период с 14-00 до 18-00 наблюдались проблемы с сервисом “Русь”. Они были связаны с тем, что сервис “Плутон”, от которого зависит наш сервис, переезжал в другой ДЦ и были потери пакетов. Написали служебку на запрет проведения работ в рабочее время для команды разработки и эксплуатации сервиса “Плутон!”»
Лёха грустно вздохнул: от такого расследования проку мало, и принялся писать свой отчет для Ивана Эрнестовича.
«Иван Эрнестович, наши отчеты об инцидентах, как и система мониторинга, деструктивны. Я подготовил собственный отчет, предлагаю данный вид документа сделать стандартным и назвать его, допустим, post-mortem. Цель этого документа не найти виноватых, а понять, в каких процессах есть проблемы и как можно их улучшить!»
Что и когда произошло
16.10. 2015 19.45 поступила жалоба от Генерального директора о недоступности сервиса Русь, примерно в 16 часов.
16.10. 2015 19.55 Инженер по эксплуатации Анатолий по данным системы мониторинга зафиксировал 1000 неудачных запросов в период с 14 до 17 часов. В момент поступления жалобы инцидент уже был разрешен.
Причины и факторы
Нетехническая причина:
Переезд одного из микросервисов, от которого зависит сервис «Русь» во время повышенной нагрузки, без предупреждения команды сервиса «Русь».Техническая причина:
Отсутствие механизма повтора запросов у сервиса «Русь».
Обнаружение
Жалоба генерального директора.
Решение
Инцидент был обнаружен уже после завершения, вмешательства со стороны службы эксплуатации не потребовалось.
Что прошло хорошо
В системе мониторинга присутствовали все необходимые графики.
В системе логирования был достаточный объем логов, чтобы установить причину появления неуспешных запросов.
Что можно улучшить
Разработать единую библиотеку, которая реализует функционал повтора запросов в случае кратковременной недоступности внешних сервисов. Данное решение было опробовано в рамках сервиса «Русь» и показало хорошие результаты.
Доработать систему алертов, чтобы получать уведомления о проблемах не от пользователей.
Внедрить метрики на основе соотношения успешных и неуспешных запросов.
Где нам повезло
Количество неуспешных запросов было 1.5%, и большинство пользователей не заметили проблему.
Задачи
RUS-347 — доработка системы мониторинга. Добавление метрик соотношения неуспешных запросов к общему числу запросов.
RUS-354 — разработка библиотеки для реализации механизма повтора неуспешных запросов.
Лёха сложил два документа в одно письмо и отправил их курьером Ивану Эрнестовичу, так как тот больше любил бумажные письма.
Прошло несколько недель, наш инженер Леха уже отчаялся получить хоть какую-то обратную связь, и уже даже почти перестал расстраиваться из-за зря потраченного времени. И тут раздается звонок от Ивана Эрнестовича:
«Алексей, я рассмотрел твои предложения и сделал вывод, что на текущем месте работы ты работаешь неэффективно. Ты мог бы принести больше пользы моей компании, поэтому я перевожу тебя на новую работу. Ты будешь инженером по стабильности — SRE. Даю тебе полгода, чтобы реализовать твои подходы и показать их эффективность».
P. S. история может показаться утрированной, таковой она и является. Примерно такой путь прошли компании, которые придумали SRE.
Так чем же будет заниматься инженер по SRE Лёха
- Формировать целевые показатели надёжности системы и поддерживать их.
- Проверять и оптимизировать код, опираясь на знания о надёжности системы.
- Анализировать возникающие ошибки. Делать выводы, писать скрипты автоматизации для разрешения проблем.
И это только малая часть обязанностей SRE-инженера. Если вам интересны подробности, то прочтите обзорную статью по SRE от Слёрма (выдержки из неё вошли в этот текст). В конце обзорной статьи вы найдёте ещё массу полезных ссылок.
А если есть желание попробовать свои силы на практике, то приходите на интенсив. Там будет много практических кейсов и практикующие SRE-инженеры из крупнейших ИТ-компаний мира.
Содержание
- SRE-инженер: что это за профессия
- Когда в компании возникает потребность в SRE
- Чем занимается SRE-инженер
- Кто может стать таким специалистом
- Какими навыками он обладает
- Как стать SRE-инженером и какие у него перспективы
SRE-инженер: что это за профессия
Site Reliability Engineering — это инженерная специальность, цель которой обеспечивать надежность и безотказность разрабатываемых сервисов.
В таком виде профессии SRE не больше пяти лет, но сами практики и подходы стали появляться в компаниях раньше, — когда возник запрос на сервисы с уровнем надежности, которого сложно достичь.
Это, например, соцсети, почта, поисковые системы, телефония, а постепенно подключились банки и такси. Люди привыкли, что такие сервисы доступны 24/7, это незаметно стало частью нашей жизни.
Если пять лет назад межбанковские переводы могли идти 2—3 дня, и никто не ожидал от них более высокой скорости, то сейчас деньги зачисляются мгновенно через приложение. Чтобы обеспечивать и поддерживать такой уровень бесперебойной работы, и нужны SRE-инженеры.
Когда в компании возникает потребность в SRE
Есть мнение, что отдельные SRE-специалисты и тем более целые команды востребованы только в крупных компаниях.
С одной стороны, это действительно так: небольшому проекту не требуется такой же уровень надежности, как, например, банку.
Минимальный уровень надежности легко получить, почти ничего не делая. В простом интернет-магазине не нужен SRE-инженер: задач для него нет, со всем справятся программисты, которые разрабатывают сайт.
Отталкиваться нужно от потребностей и возможностей бизнеса, поскольку SRE — это дорогостоящая история.
В какой-то момент бизнес начинает больше дорожить своей репутацией: например, у интернет-магазина появляется очень много покупателей, он растет и становится популярным.
Другие же проекты изначально нельзя создавать без специалистов по надежности: скажем, атомную станцию или банковское приложение.
Но я встречал и кейс стартапа, где успешно применяют SRE. Они не формировали команду инженеров, но силами разработчиков внедрили очень много практик: стали считать бюджет ошибок, договорились о них, начали дежурить, думать, как и что в сервисе можно улучшить, и встраивать эти инструменты. Получилось очень похоже на SRE, но без отдельных людей.
Любой разработчик может заниматься SRE, если работает в ИТ достаточно долго, чтобы разбираться в архитектуре приложения. Идеально, если он это приложение и проектировал. А отдельная специализация нужна в больших командах от 20—30 человек.
Читайте также: Надежно, как у Google: почему SRE-подход поможет вашим сайтам работать без перебоев
Чем занимается SRE-инженер
SRE-специалист обеспечивает нормальное использование сервиса и его бесперебойную работу. Все его обязанности исходят из этой главной цели — обеспечения устойчивости.
- Определение и контроль SLA, SLO, SLI (соглашение об уровне услуг) и бюджета на ошибки.
Это начало работы SRE: ответ на вопрос, что для конкретной компании означает «нормальная работа». Сбои все равно будут, но нужно понять, что такое «не слишком много сбоев».
Например, если пользователь в соцсетях не может редактировать свои настройки или просматривать сторис — соцсеть все еще работает или уже нет?
Об этом нужно договориться с бизнесом, а затем — с командой бэкенда и всех внутренних сервисов.
После того как поняли, что значит «работает», нужно определить, сколько мы хотим, чтобы сервис работал. Определить индикаторы работоспособности и показатели, которых хотим достичь.
Если соцсеть не показывает сторис только 0,1% пользователей — она работает или нет? Здесь нужно договориться о каких-то разумных цифрах, потому что поддерживать систему всегда работающей на 100% трудозатратно и неоправданно дорого.
- Бюджет ошибок — это SLA наоборот.
SRE-инженеры договариваются о том, сколько процентов времени нужно обязательно предоставлять доступ. Все оставшееся время — это наш бюджет ошибок. Его принято расходовать, поэтому и называют бюджетом.
Он расходуется сам, когда случается непредвиденный сбой. Его можно расходовать на сложный деплой, когда мы хотим пользователю показать даунтайм и израсходовать выделенный бюджет ошибок.
- Настройка мониторинга и алертов, постмортемы.
SRE-инженеры настраивают мониторинг и алерты, чтобы проверить, укладываются ли они в оговоренные показатели или нет.
Если говорить о реактивном реагировании на инциденты, то это могут быть диагностические инструменты, встроенные в сами приложения, метрики и логи, тулы, которые сокращают время диагностики.
SRE стремится автоматизировать максимум работы, потому что ручные действия медленны: нужно заранее писать админки и утилиты, чтобы ускорить диагностику во время инцидентов.
- Проактивное реагирование — это то, чем занимается SRE-инженер все оставшееся время.
Он думает над тем, что не так может быть с сервисом, почему он может перестать нормально работать. Либо пытается предугадать, где сервис может сломаться, и создать инструменты на этот случай, либо расследовать прошлые инциденты и написать постмортемы.
- Дежурство, реагирование на инциденты.
В команде SRE выделяют дежурного, который отвечает за продакшен и должен быть всегда доступен.
У него есть договоренности на дежурство. Они выглядят так: «От момента начала инцидента до начала работы SRE должно пройти пять минут».
Это довольно жесткий тайминг: например, если инцидент произошел в нерабочее время и ты был вне дома, то за пять минут приступить нереально. Поэтому мы устанавливаем понятные правила дежурств, определяем, кто как реагирует, а наши дежурные могут друг друга подменять.
Какими навыками обладает SRE-инженер
Hard skills
Я опишу портрет условного сеньора. Любой SRE-инженер — это очень широкий T-shaped-специалист (то есть эксперт в одной сфере, который разбирается на среднем или минимальном уровне во многих других сферах).
Навыков у SRE-инженера очень много:
- умение автоматизировать, в сложных случаях используя языки программирования;
- знание сетей и операционных систем;
- знание оркестраторов и виртуализации;
- навыки работы с базами данных разных типов;
- знание энтерпрайзных хранилищ, дисков, клаудов;
- знание архитектуры распределенных сервисов;
- умение разбираться в оборудовании, железе;
- понимание фронтенда и мобильной разработки;
- знание пользовательских интерфейсов и многое другое.
Список может показаться устрашающим, но, как я и сказал, быть гуру в каждой сфере не надо. Нужно понимать, как это устроено, поскольку SRE-инженер обеспечивает работу масштабного сервиса, в котором все это есть. При этом ломаться может что угодно — и по-разному воздействовать на связанные системы.
Soft skills
- Первое и главное — это стрессоустойчивость.
Работа в SRE очень стрессовая. Много стресса вызывает дежурство, особенно в начале, если ты сам не разрабатывал эту систему.
Постоянно думаешь: вот-вот что-то сломается и нужно будет быстро чинить, а компания в это время теряет деньги из-за падения системы. Это прямой источник стресса, поэтому SRE-инженеру очень важно быть к нему устойчивым и действовать в критических ситуациях хладнокровно.
- Второе — это навыки коммуникации.
Конечно, они нужны всем, но для SRE крайне важны. Как правило, за разные части системы, которые SRE делают надежными, отвечают разные команды — и со всеми надо выстроить отношения.
Нужно коммуницировать в том числе и во время сбоев: позвать коллег из зависимых сервисов, а бизнес-владельцам объяснить происходящее на понятном им языке.
Кто может стать SRE-инженером
Есть программисты, которым все в ИТ любопытно и интересно, они постоянно что-то пробуют вне работы, делают проекты для себя. Если занимаются фронтендом, то пробуют бэкенд, и наоборот. Именно такие специалисты в будущем становятся SRE, если их привлекает надежность и безопасность в программировании.
SRE-инженер — это специалист с широким кругозором, который уже многое в ИТ попробовал: писал код и автоматизировал, знает операционные системы и сети, разбирается в железе и базах данных.
По моему опыту, чаще в SRE приходят бэкенд-разработчики, которые занимались обслуживанием. Либо системные администраторы, у которых хобби — программирование.
Но в целом специализация здесь неважна: SRE становятся и фронтендеры, и мобильные разработчики. Хорошие SRE-инженеры — это специалисты в любой сфере, которые по крупицам собирали знания о надежности и обладают широким опытом в ИТ.
Читайте также: Необходимые навыки для работы в сфере eCommerce — каким специалистам из IT она подойдет?
Чем SRE-инженер отличается от DevOps
SRE и DevOps отличаются системой ценностей, поэтому в одних и тех же ситуациях они принимают разные решения.
Основные ценности в DevOps — это автоматизация и быстрый time to market, то есть скорость поставки. Их задача — как можно больше релизить и больше автоматизировать, сокращая рутинные действия.
Грубо говоря, их KPI — это то, как быстро мы можем релизиться. А KPI SRE — это то, как хорошо мы укладываемся в оговоренные условия обслуживания.
Если у нас много человеческого фактора и нужна высокая степень надежности, то автоматизация помогает этого достичь. В этом случае мы похожи на DevOps.
Но иногда автоматизация мешает. Бывают сложные нетривиальные решения, где автоматика ошибается и вредит главной цели.
Например, частая практика — автоскеллинг. Многие его делают, потому что он экономит ресурсы. Но SRE он не нужен почти никогда. Любая автоматизация по скалированию вверх и вниз уменьшает надежность вашей системы, потому что она вероятнее будет ломаться.
SRE неважно, как именно специалисты разрабатывают приложение, как у них настроен пайплайн для тестирования — это побочные вопросы.
SRE интересует, тестируют ли они код вообще. А насколько хорошо это настроено — как раз зона ответственности DevOps. SRE затрагивает все, что касается продакшена, — это приоритет.
Как стать SRE-инженером и какие у него перспективы
- Где искать работу
Тому, кто хочет стать SRE, нужно недолго поработать в бэкенде — получить уровень мидла. Затем перейти в DevOps и тоже стать мидл-специалистом. После этого он уже готовый SRE-инженер. Если сразу не берут в SRE, то можно прийти в компанию на позицию мидл-бэкенд-разработчика или DevOps, поработать какое-то время и перейти в SRE. Главное — помнить, что надо широко развиваться. Делать это можно либо в своей компании, либо искать варианты на открытом рынке. Вакансий именно SRE-инженера не слишком много, поэтому начать можно с бэкенда или DevOps.
- Зарплаты и перспективы
Перспективы у профессии большие. Несмотря на то что уровень вознаграждения программистов сейчас высок везде, у SRE он может быть и больше в некоторых компаниях и сферах.
Владимир Скляренко, руководитель ИТ-подбора в «Тинькофф»
Кандидаты на позицию SRE-инженера выдвигают такие зарплатные ожидания (cуммы после вычета налогов):
мидл — 180—300 тыс. рублей;
сеньор — 250—400 тыс. рублей.
.jpg)
- Плюсы и минусы профессии
Плюсы:
- высокие зарплаты и большие перспективы;
- приобретение уникальных навыков, которые всегда востребованы на рынке;
- отсутствие бюрократии и долгих согласований: придумываешь и приоритезируешь задачи сам.
Минусы:
- стрессовая работа;
- большая ответственность за весь проект.
Читайте также: Российские разработчики назвали наиболее значимые для бизнеса IT-специальности
- Где учиться
Лучший способ научиться — это личный опыт, приобретаемый в разных сферах разработки и в разных компаниях. Если же хочется первоначально получить теоретическую базу о методиках SRE, то сегодня рынок предлагает варианты обучения:
- Site Reliability Engineering: Measuring and Managing Reliability от Coursera;
- «SRE практики и инструменты» от Otus;
- Интенсив «SRE: внедряем DevOps от Google» от Слёрм.
Важное качество, без которого не стать хорошим SRE, — умение решать проблемы. В какой-то степени это даже предпринимательский скилл.
SRE-инженер обнаруживает проблему, придумывает ее решение, сам ее решает вместе с командой — и сервис становится лучше.
Как правило, надежностью аналитики и бизнес озадачиваются, только когда все совсем плохо. Задача SRE — сделать так, чтобы ни аналитики, ни продакты, ни бизнес-владельцы не вспоминали про надежность. Для этого нужно много чего делать, но что конкретно, вам не скажет никто.
А если когда-нибудь SRE надоест, можно уйти в любое направление: в бэкенд, фронтенд, руководство. У SRE-инженера есть навыки во всем, а развиться чуть больше под конкретную область легко. Главное — это опыт решения проблем, который всегда пригодится и высоко ценится бизнесом.
Фото на обложке: khwanchai / Adobe Stock
Подписывайтесь на наш Telegram-канал, чтобы быть в курсе последних новостей и событий!
Команды по проектированию надежности сайта (SRE) измеряют качество предоставления услуг и надежность, используя указанные ниже показатели.
Целевые уровни обслуживания
Целевые уровни обслуживания (SLO) – это конкретные и поддающиеся количественной оценке цели, которые, как вы уверены, может достичь программное обеспечение по разумной цене по сравнению с другими показателями, такими как следующие:
- Время безотказной работы или время работы системы
- Пропускная способность системы или
- выход
- Скорость загрузки или скорость загрузки приложения
SLO обещает заказчику доставку через программное обеспечение. Например, вы устанавливаете время безотказной работы 99,95% для приложения вашей компании по доставке еды.
Индикаторы уровня обслуживания
Индикаторы уровня обслуживания (SLI) – это фактические измерения метрики, определяемой SLO. В реальных ситуациях вы можете получить значения, которые соответствуют или отличаются от SLO. Например, ваше приложение запускается и работает 99,92% времени, что ниже обещанного уровня обслуживания.
Соглашения об уровне обслуживания
Соглашения об уровне обслуживания (SLA) – это юридические документы, в которых указано, что произойдет, если один или несколько SLO не будут выполнены. Например, в согласии об уровне обслуживания указано, что техническая группа решит проблему вашего клиента в течение 24 часов после получения отчета. Если ваша команда не смогла решить проблему в течение указанного срока, возможно, вы будете обязаны выполнить возмещение.
Бюджеты ошибок
Бюджеты ошибок – это допустимый уровень несоответствия для SLO. Например, время безотказной работы в SLO 99,95 % означает, что допустимое время простоя составляет 0,05 %. Если время простоя программного обеспечения превышает бюджет ошибок, команда разработчиков программного обеспечения выделяет все ресурсы и внимание для стабилизации приложения.
Блог компании Southbridge, DevOps, Системное администрирование, Управление разработкой, IT-инфраструктура
Рекомендация: подборка платных и бесплатных курсов дизайна интерьера — https://katalog-kursov.ru/
Site Reliability Engineering (SRE) — это одна из форм реализации DevOps. SRE-подход возник в Google и стал популярен в среде продуктовых IT-компаний после выхода одноимённой книги в 2016 году.
В статье опишем, как SRE-подход соотносится с DevOps, какие задачи решает инженер по SRE и о каких показателях заботится.

От DevOps к SRE
Во многих IT-компаниях разработкой и эксплуатацией занимаются разные команды с разными целями. Цель команды разработки — выкатывать новые фичи. Цель команды эксплуатации — обеспечить работу старых и новых фич в продакшене. Разработчики стремятся поставить как можно больше кода, системные администраторы — сохранить надёжность системы.
Цели команд противоречат друг другу. Чтобы разрешить эти противоречия, была создана методология DevOps. Она предполагает уменьшение разрозненности, принятие ошибок, опору на автоматизацию и другие принципы.
Проблема в том, что долгое время не было чёткого понимания, как воплощать принципы DevOps на практике. Редкая конференция по этой методологии обходилась без доклада «Что такое DevOps?». Все соглашались с заложенными идеями, но мало кто понимал, как их реализовать.
Ситуация изменилась в 2016 году, когда Google выпустила книгу «Site Reliability Engineering». В этой книге описывалась конкретная реализация DevOps. С неё и началось распространение SRE-подхода, который сейчас применяется во многих международных IT-компаниях.
DevOps — это философия. SRE — реализация этой философии. Если DevOps — это интерфейс в языке программирования, то SRE — конкретный класс, который реализует DevOps.
Цели и задачи SRE-инженера
Инженеры по SRE нужны, когда в компании пытаются внедрить DevOps и разработчики не справляются с возросшей нагрузкой.
В отличие от классического подхода, согласно которому эксплуатацией занимается обособленный отдел, инженер по SRE входит в команду разработки. Иногда его нанимают отдельно, иногда им становится кто-то из разработчиков. Есть подход, где роль SRE переходит от одного разработчика к другому.
Цель инженера по SRE — обеспечить надёжную работу системы. Он занимается тем же, что раньше входило в задачи системного администратора, — решает инфраструктурные проблемы.
Как правило, инженерами SRE становятся опытные разработчики или, реже, администраторы с сильным бэкграундом в разработке. Кто-то скажет: «программист в роли инженера — не лучшее решение». Возможно и так, если речь идёт о новичке. Но в случае SRE мы говорим об опытном разработчике. Это человек, который хорошо знает, что и когда может сломаться. У него есть опыт и внутри компании, и снаружи.
Предпочтение не просто так отдаётся разработчикам. Имея сильный бэкграунд в программировании и зная систему с точки зрения кода, они более склонны к автоматизации, чем к рутинной администраторской работе. Кроме того, они имеют больший багаж знаний и навыков для внедрения автоматизации.
В задачи инженера по SRE входит ревью кода. Нужно, чтобы на каждый деплой SRE сказал: «OK, это не повлияет на надёжность, а если повлияет, то в допустимых пределах». Он следит, чтобы сложность, которая влияет на надёжность работы системы, была необходимой.
- Необходимая — сложность системы повышается в том объёме, которого требуют новые продуктовые фичи.
- Случайная — сложность системы повышается, но продуктовая фича и требования бизнеса напрямую на это не влияют. Тут либо разработчик ошибся, либо алгоритм не оптимален.
Хороший SRE блокирует любой коммит, деплой или пул-реквест, который повышает сложность системы без необходимости. В крайнем случае SRE может наложить вето на изменение кода (и тут неизбежны конфликты, если действовать неправильно).
Во время ревью SRE взаимодействует с оунерами изменений, от продакт-менеджеров до специалистов по безопасности.
Кроме того, инженер по SRE участвует в выборе архитектурных решений. Оценивает, как они повлияют на стабильность всей системы и как соотносятся с бизнес-потребностями. Отсюда уже делает вывод — допустимы нововведения или нет.
Целевые показатели: SLA, SLI, SLO
Одно из главных противоречий между отделом эксплуатации и разработки происходит из разного отношения к надёжности системы. Если для отдела эксплуатации надёжность — это всё, то для разработчиков её ценность не так очевидна.
SRE подход предполагает, что все в компании приходят к общему пониманию. Для этого определяют, что такое надёжность (стабильность, доступность и т. д.) системы, договариваются о показателях и вырабатывают стандарты действий в случае проблем.
Показатели доступности вырабатываются вместе с продакт-оунером и закрепляются в соглашении о целевом уровне обслуживания — Service-Level Objective (SLO). Оно становится гарантом, что в будущем разногласий не возникнет.
Специалисты по SRE рекомендуют указывать настолько низкий показатель доступности, насколько это возможно. «Чем надёжнее система, тем дороже она стоит. Поэтому определите самый низкий уровень надёжности, который может сойти вам с рук, и укажите его в качестве SLO», сказано в рекомендациях Google. Сойти с рук — значит, что пользователи не заметят разницы или заметят, но это не повлияет на их удовлетворенность сервисом.
Чтобы понимание было ясным, соглашение должно содержать конкретные числовые показатели — Service Level Indicator (SLI). Это может быть время ответа, количество ошибок в процентном соотношении, пропускная способность, корректность ответа — что угодно в зависимости от продукта.
SLO и SLI — это внутренние документы, нужные для взаимодействия команды. Обязанности компании перед клиентами закрепляются в в Service Level Agreement (SLA). Это соглашение описывает работоспособность всего сервиса и штрафы за превышение времени простоя или другие нарушения.
Примеры SLA: сервис доступен 99,95% времени в течение года; 99 критических тикетов техподдержки будет закрыто в течение трёх часов за квартал; 85% запросов получат ответы в течение 1,5 секунд каждый месяц.
Почему никто не стремится к 100% доступности
SRE исходит из предположения, что ошибки и сбои неизбежны. Более того, на них рассчитывают.
Оценивая доступность, говорят о «девятках»:
- две девятки — 99%,
- три девятки — 99,9%,
- четыре девятки — 99,99%,
- пять девяток — 99,999%.
Пять девяток — это чуть больше 5 минут даунтайма в год, две девятки — это 3,5 дня даунтайма.
Стремиться к повышению доступности нормально, однако чем ближе она к 100%, тем выше стоимость и техническая сложность сервиса. В какой-то момент происходит уменьшение ROI — отдача инвестиций снижается.
Например, переход от двух девяток к трём уменьшает даунтайм на три с лишним дня в год. Заметный прогресс! А вот переход с четырёх девяток до пяти уменьшает даунтайм всего на 47 минут. Для бизнеса это может быть не критично. При этом затраты на повышение доступности могут превышать рост выручки.
При постановке целей учитывают также надёжность окружающих компонентов. Пользователь не заметит переход стабильности приложения от 99,99% к 99,999%, если стабильность его смартфона 99%. Грубо говоря, из 10 сбоев приложения 8 приходится на ОС. Пользователь к этому привык, поэтому на один лишний раз в год не обратит внимания.
Среднее время между сбоями и среднее время восстановления — MTBF и MTTR
Для работы с надёжностью, ошибками и ожиданиями в SRE применяют ещё два показателя: MTBF и MTTR.
MTBF (Mean Time Between Failures) — среднее время между сбоями.
Показатель MTBF зависит от качества кода. Инженер по SRE влияет на него через ревью и возможность сказать «Нет!». Здесь важно понимание команды, что когда SRE блокирует какой-то коммит, он делает это не из вредности, а потому что иначе страдать будут все.
MTTR (Mean Time To Recovery)— среднее время восстановления (сколько прошло от появления ошибки до отката к нормальной работе).
Показатель MTTR рассчитывается на основе SLO. Инженер по SRE влияет на него за счёт автоматизации. Например, в SLO прописан аптайм 99,99% на квартал, значит, у команды есть 13 минут даунтайма на 3 месяца. В таком случае время восстановления никак не может быть больше 13 минут, иначе за один инцидент весь «бюджет» на квартал будет исчерпан, SLO нарушено.
13 минут на реакцию — это очень мало для человека, поэтому здесь нужна автоматизация. Что человек сделает за 7-8 минут, скрипт — за несколько секунд. При автоматизации процессов MTTR очень часто достигает секунд, иногда миллисекунд.
В идеале инженер по SRE должен полностью автоматизировать свою работу, потому что это напрямую влияет на MTTR, на SLO всего сервиса и, как следствие, на прибыль бизнеса.
Обычно при внедрении автоматизации стараются оценивать время на подготовку скрипта и время, которое этот скрипт экономит. По интернету ходит табличка, которая показывает, как долго можно автоматизировать задачу:
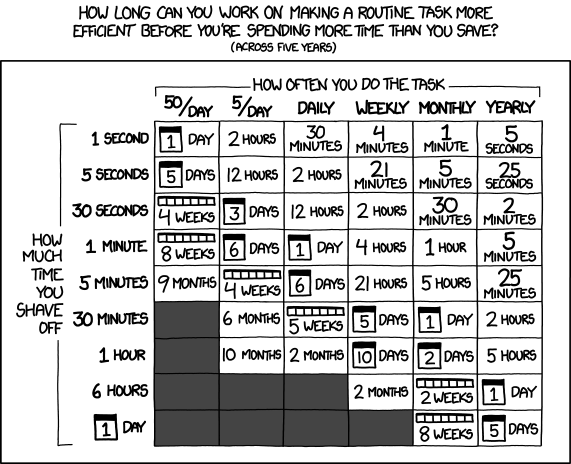
Всё это справедливо, но не относится к работе SRE. По факту, практически любая автоматизация от SRE имеет смысл, потому что экономит не только время, но и деньги, и моральные силы сотрудников, уменьшает рутину. Всё это вместе положительно сказывается на работе и на бизнесе, даже если кажется, что с точки зрения временных затрат автоматизация не имеет смысла.
Бюджет на ошибки
Как мы выяснили, пытаться достичь 100% стабильности не самая лучшая идея, потому что это дорого, технически сложно, а часто и бесполезно — скорее всего, пользователь не оценит старания из-за проблем в «соседних» системах.
Поэтому команды всегда принимают некоторую степень риска и прописывают её в SLO. На основе SLO рассчитывается бюджет на ошибки (Error budget).

Бюджет на ошибки помогает разработчикам договариваться с SRE.
Если бюджет на ошибки содержит 43 минуты даунтайма в месяц, и 40 минут из них сервис уже лежал, то очевидно: чтобы оставаться в рамках SLO, надо сократить риски. Как вариант, остановить выпуск фич и сосредоточиться на баг-фиксах.
Если бюджет на ошибки не исчерпан, то у команды остаётся пространство для экспериментов. В рамках SRE подхода Error budget можно тратить буквально на всё:
- релиз фич, которые могут повлиять на производительность,
- обслуживание,
- плановые даунтаймы,
- тестирование в условиях продакшена.
Чтобы не выйти за рамки, Error budget делят на несколько частей в зависимости от задач. Каждая команда должна оставаться в пределах своего бюджета на ошибки.

В ситуации «профицитного» бюджета на ошибки заинтересованы все: и SRE, и разработчики. Для разработчиков такой бюджет сулит возможность заниматься релизами, тестами, экспериментами. Для SRE является показателем хорошей работы.
Эксперименты в продакшене — это важная часть SRE в больших командах. С подачи команды Netflix её называют Chaos Engineering.
В Netflix выпустили несколько утилит для Chaos Engineering: Chaos Monkey подключается к CI/CD пайплайну и роняет случайный сервер в продакшене; Chaos Gorilla полностью выключает одну из зон доступности в AWS. Звучит дико, но в рамках SRE считается, что упавший сервер — это само по себе не плохо, это ожидаемо. И если это входит в бюджет на ошибки, то не вредит бизнесу.
Chaos Engineering помогает:
- Выявить скрытые зависимости, когда не совсем понятно, что на что влияет и от чего зависит (актуально при работе с микросервисами).
- Выловить ошибки в коде, которые нельзя поймать на стейджинге. Любой стейджинг — это не точная симуляция: другой масштаб и паттерн нагрузок, другое оборудование.
- Отловить ошибки в инфраструктуре, которые стейджинг, автотесты, CI/CD-пайплайн никогда не выловят.
Post mortem вместо поиска виноватых
В SRE придерживаются культуры blameless postmortem, когда при возникновении ошибок не ищут виноватых, а разбирают причины и улучшают процессы.
Предположим, даунтайм в квартал был не 13 минут, а 15. Кто может быть виноват? SRE, потому что допустил плохой коммит или деплой; администратор дата-центра, потому что провел внеплановое обслуживание; технический директор, который подписал договор с ДЦ и не обратил внимания, что его SLA не поддерживает нужный даунтайм. Все понемногу виноваты, значит, нет смысла возлагать вину на кого-то одного. В таком случае организуют постмортемы и правят процессы.
Мониторинг и прозрачность
Без мониторинга нельзя понять, вписывается ли команда в бюджет и соблюдает ли критерии, описанные в SLO. Поэтому задача инженера по SRE — настроить мониторинг. Причём настроить его так, чтобы уведомления приходили только тогда, когда требуются действия.
В стандартном случае есть три уровня событий:
- алерты — требуют немедленного действия («чини прямо сейчас!»);
- тикеты — требуют отложенного действия («нужно что-то делать, делать вручную, но не обязательно в течение следующих нескольких минут»);
- логи — не требуют действия, и при хорошем развитии событий никто их не читает («о, на прошлой неделе у нас микросервис отвалился, пойди посмотри в логах, что случилось»).
SRE определяет, какие события требуют действий, а затем описывает, какими эти действия должны быть, и в идеале приходит к автоматизации. Любая автоматизация начинается с реакции на событие.
С мониторингом связан критерий прозрачности (Observability). Это метрика, которая оценивает, как быстро вы можете определить, что именно пошло не так и каким было состояние системы в этот момент.
С точки зрения кода: в какой функции или сервисе произошла ошибка, каким было состояние внутренних переменных, конфигурации. С точки зрения инфраструктуры: в какой зоне доступности произошел сбой, а если у вас стоит какой-нибудь Kubernetes, то в каком поде, каким было его состояние при этом.
Observability напрямую связана с MTTR. Чем выше Observability сервиса, тем проще определить ошибку, исправить и автоматизировать, и тем ниже MTTR.
SRE для небольших компаний и компаний без разработки
SRE работает везде, где нужно выкатывать апдейты, менять инфраструктуру, расти и масштабироваться. Инженеры по SRE помогают предсказать и определить возможные проблемы, сопутствующие росту. Поэтому они нужны даже в тех компаниях, где основная деятельность не разработка ПО. Например, в энтерпрайзе.
При этом необязательно нанимать на роль SRE отдельного человека, можно сделать роль переходной, а можно вырастить человека внутри команды. Последний вариант подходит для стартапов. Исключение — жёсткие требования по росту (например, со стороны инвесторов). Когда компания планирует расти в десятки раз, тогда нужен человек, ответственный за то, что при заданном росте ничего не сломается.
Внедрять принципы SRE можно с малого: определить SLO, SLI, SLA и настроить мониторинг. Если компания не занимается ПО, то это будут внутренние SLA и внутренние SLO. Обсуждение этих соглашений приводит к интересным открытиям. Нередко выясняется, что компания тратит на инфраструктуру или организацию идеальных процессов гораздо больше времени и сил, чем надо.
Кроме того, для любой компании полезно принять, что ошибки — это нормально, и начать работать с ними. Определить Error budget, стараться тратить его на развитие, а возникающие проблемы разбирать и по результатам разбора внедрять автоматизацию.
Что почитать
В одной статье невозможно рассказать всё об SRE. Вот подборка материалов для тех, кому нужны детали.
Книги об SRE от Google:
Site Reliability Engineering
The Site Reliability Workbook
Building Secure & Reliable Systems
Статьи и списки статей:
SRE как жизненный выбор
SLA, SLI, SLO
Принципы Chaos Engineering от Chaos Community и от Netflix
Список из более чем 200 статей по SRE
Доклады по SRE в разных компаниях (видео):
Keys to SRE
SRE в Дропбоксе
SRE в Гугл
SRE в Нетфликсе
Где поучиться
Одно дело читать о новых практиках, а другое дело — внедрять их. Если вы хотите глубоко погрузиться в тему, приходите на онлайн-интенсив по SRE от Слёрма. Он пройдет 11–13 декабря 2020.
Научим формулировать показатели SLO, SLI, SLA, разрабатывать архитектуру и инфраструктуру, которая их обеспечит, настраивать мониторинг и алёртинг.
На практическом примере рассмотрим внутренние и внешние факторы ухудшения SLO: ошибки разработчиков, отказы инфраструктуры, наплыв посетителей, DoS-атаки. Разберёмся в устойчивости, Error budget, практике тестирования, управлении прерываниями и операционной нагрузкой.
Узнать больше и зарегистрироваться