Оглавление
1. Что такое Stable Diffusion?
2. Что нужно для запуска Stable Diffusion на своём ПК?
3. Как установить и запустить Stable Diffusion в Windows
3.1 Установка Git
3.2 Установка Miniconda3
3.3 Загрузите репозиторий Stable Diffusion GitHub и последнюю контрольную точку
4. Как использовать Stable Diffusion
4.1 Как сделать изображение со Stable Diffusion
4.2 Что означают аргументы в команде?
5. Онлайн демо версия Stable Diffusion

Смотрите также:
- Как запустить Stable Diffusion локально с графическим интерфейсом в Windows
- Diffusion Bee — это самый простой способ запустить Stable Diffusion на Mac
Художественные произведения искусственного интеллекта (ИИ) в настоящее время в моде, но большинство генераторов изображений ИИ работают в облаке. Stable Diffusion отличается — вы можете запустить его на своём собственном ПК и создать столько изображений, сколько захотите. Эта инструкция расскажет как вы можете установить и использовать Stable Diffusion в Windows.
Stable Diffusion — это модель машинного обучения с открытым исходным кодом, которая может генерировать изображения из текста, изменять изображения на основе текста или заполнять детали изображений с низким разрешением или низкой детализацией. Он был обучен на миллиардах изображений и может давать результаты, сравнимые с теми, которые вы получите от DALL-E 2 и MidJourney. Он разработан Stability AI и впервые публично выпущен 22 августа 2022 года.
Смотрите также:
- Stable Diffusion позволяет создавать изображения с помощью искусственного интеллекта на ПК
- Как создать синтетические картинки с помощью искусственного интеллекта Midjourney
- Что такое LaMDA AI от Google и почему инженер Google подумал что в LaMDA AI зародился разум?
- DALL-E 2 AI от OpenAI — плохая новость для некоторых художников
- Насколько мы близки к загрузке разума в компьютер?
- В чем разница между сильным ИИ и слабым ИИ?
У Stable Diffusion нет аккуратного пользовательского интерфейса (пока), как у некоторых генераторов изображений AI, но у него очень либеральная лицензия, и, что лучше всего, его можно совершенно бесплатно использовать на вашем собственном ПК (или Mac).
Не пугайтесь того факта, что Stable Diffusion в настоящее время работает в интерфейсе командной строки (CLI). Установить его и запустить довольно просто. Если вы можете дважды щёлкнуть исполняемый файл и ввести текст в поле, вы можете запустить Stable Diffusion на своём компьютере за несколько минут.
2. Что нужно для запуска Stable Diffusion на своём ПК?
Stable Diffusion не будет работать на вашем телефоне или большинстве ноутбуков, но в 2022 году он будет работать на среднем игровом ПК. Вот требования:
-
Графический процессор с не менее 6 гигабайтами (ГБ) видеопамяти. К таким относятся большинство современных графических процессоров NVIDIA. Смотрите также:
— Как узнать сколько видеопамяти (VRAM) в Windows 11
— Что такое видеопамять (VRAM)?
— Имеет ли значение память видеокарты? Сколько видеопамяти нужно? - 10 ГБ свободного места на жёстком или твердотельном диске
- Установщик Miniconda3
- Файлы Stable Diffusion с GitHub
- Последние контрольные точки (версия 1.4 на момент написания, но скоро должна быть выпущена версия 1.5)
- Установщик Git
- Windows 8, 10 или 11. Stable Diffusion также можно запустить на Linux и macOS.
3. Как установить и запустить Stable Diffusion в Windows
Вам понадобятся две программы: Git и Miniconda3.
Примечание. Git и Miniconda3 — безопасные программы, созданные авторитетными организациями. Вам не нужно беспокоиться о вредоносных программах при условии, что вы загружаете их из официальных источников, указанных в этой статье.
3.1 Установка Git
Git — это инструмент, который позволяет разработчикам управлять различными версиями разрабатываемого ими программного обеспечения. Они могут одновременно поддерживать несколько версий программного обеспечения, над которым они работают, в центральном репозитории и позволять другим разработчикам вносить свой вклад в проект.
Если вы не разработчик, Git предоставляет удобный способ доступа к этим проектам и их загрузки, и именно так мы будем использовать его в данном случае. Загрузите установщик Windows x64 с веб-сайта Git и запустите его.
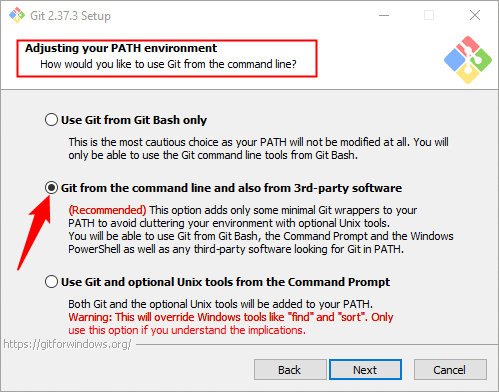
Во время работы установщика вам будет предложено выбрать несколько параметров — оставьте для них значения по умолчанию. Одна страница параметров Adjusting Your PATH Environment, («Настройка вашей среды PATH») особенно важна. Он должен быть установлен на Git From The Command Line And Also From 3rd-Party Software («Git из командной строки, а также из стороннего программного обеспечения»).
3.2 Установка Miniconda3
Stable Diffusion использует несколько разных библиотек Python. Если вы мало знаете о Python, не беспокойтесь об этом — достаточно сказать, что библиотеки — это просто программные пакеты, которые ваш компьютер может использовать для выполнения определённых функций, таких как преобразование изображения или выполнение сложных математических операций.
Miniconda3 — это, говоря по-простому, инструмент для удобства. Он позволяет загружать, устанавливать и управлять всеми библиотеками, необходимыми для работы Stable Diffusion, без особого ручного вмешательства. На самом деле мы будем использовать Stable Diffusion через этот инструмент.
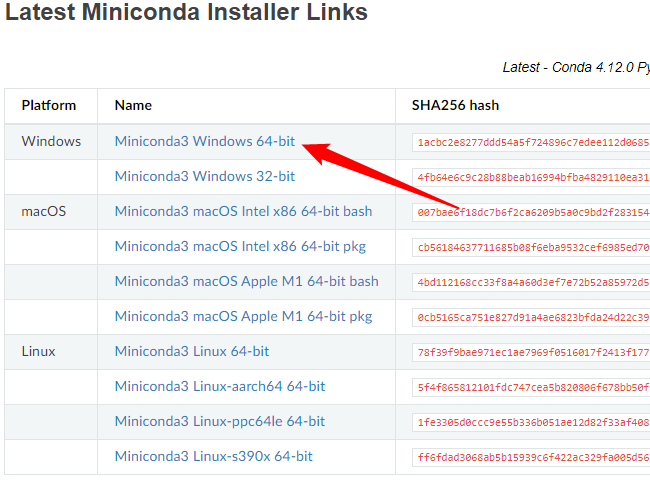
Перейдите на страницу загрузки Miniconda3 и нажмите «Miniconda3 Windows 64-bit», чтобы получить последнюю версию установщика.
Дважды щёлкните исполняемый файл после его загрузки, чтобы начать установку. Установка Miniconda3 требует меньше кликов по вкладкам, чем Git, но вам нужно следить за этой опцией:
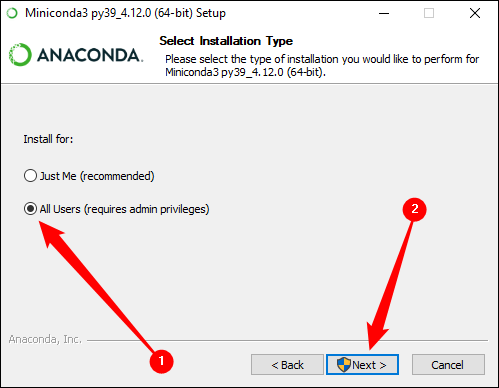
Убедитесь, что вы выбрали All Users («Все пользователи»), прежде чем нажать «Далее» и завершить установку.
Вам будет предложено перезагрузить компьютер после установки Git и Miniconda3. Мы не сочли это необходимым, но это не повредит, если вы это сделаете.
3.3 Загрузите репозиторий Stable Diffusion GitHub и последнюю контрольную точку
Теперь, когда мы установили необходимое программное обеспечение, мы готовы загрузить и установить Stable Diffusion.
Сначала загрузите последнюю контрольную точку — версия 1.4 весит почти 5 ГБ, так что это может занять некоторое время. Вам необходимо создать учётную запись, чтобы загрузить контрольную точку, но для этого требуется только имя и адрес электронной почты. Всё остальное необязательно.
Примечание. На момент написания (4 сентября 2022 г.) последней контрольной точкой была версия 1.4. Если есть более новая версия, загрузите её.

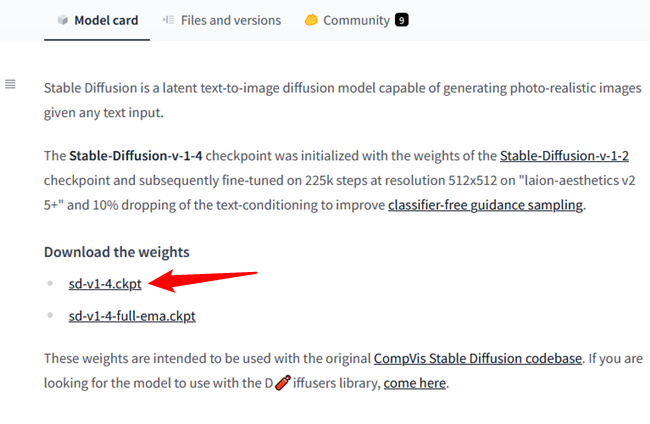
Нажмите «sd-v1-4.ckpt», чтобы начать загрузку.
Примечание. Другой файл, «sd-v1-4-full-ema.ckpt», может дать лучшие результаты, но его размер примерно в два раза больше. Вы можете использовать любой из них.
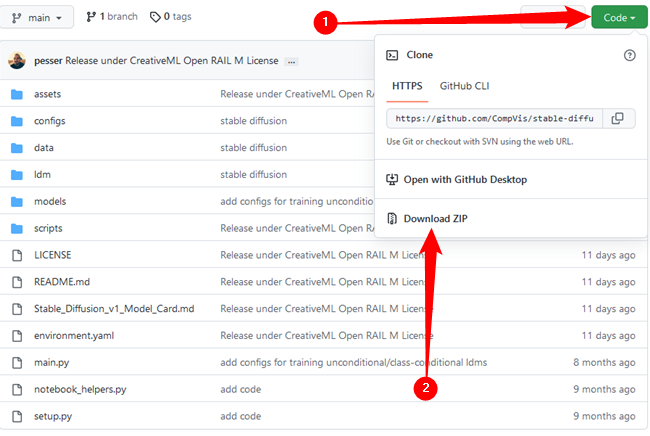
Затем вам нужно скачать Stable Diffusion с GitHub. Нажмите зелёную кнопку «Код», затем нажмите «Загрузить ZIP». Кроме того, вы можете использовать эту прямую ссылку для скачивания.
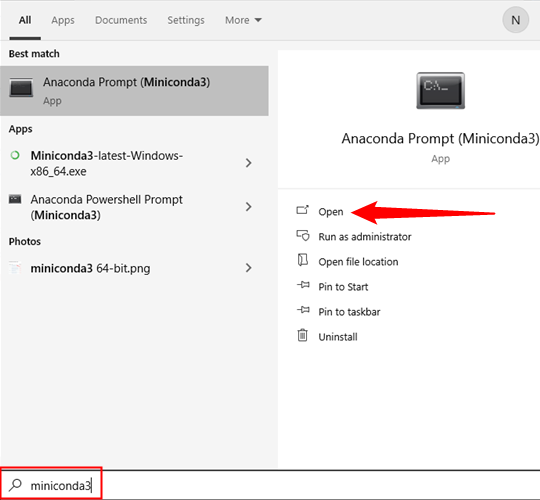
Теперь нам нужно подготовить несколько папок, куда мы распаковываем все файлы Stable Diffusion. Нажмите кнопку «Пуск» и введите «miniconda3» в строку поиска меню «Пуск», затем нажмите «Открыть» или нажмите Enter.
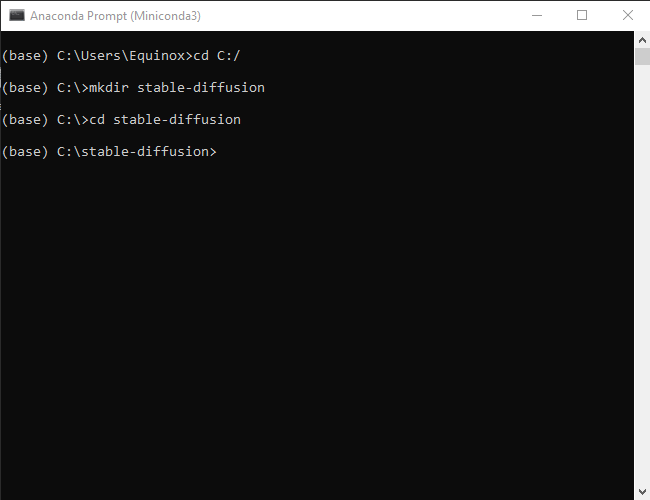
Мы собираемся создать папку с именем «stable-diffusion» с помощью командной строки. Скопируйте и вставьте приведённый ниже блок кода в окно Miniconda3, затем нажмите Enter.
cd C:/ mkdir stable-diffusion cd stable-diffusion
Примечание. Почти каждый раз, когда вы вставляете блок кода в терминал, например Miniconda3, вам нужно нажать Enter в конце, чтобы выполнить последнюю команду.
Если всё прошло хорошо, вы увидите что-то вроде этого:
Держите окно Miniconda3 открытым, оно нам снова понадобится через минуту.
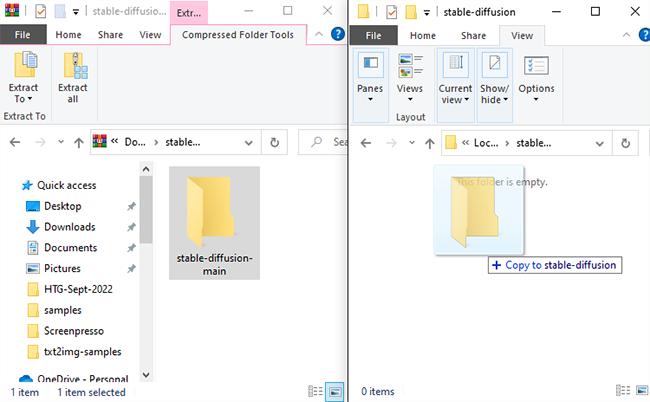
Откройте ZIP-файл «stable-diffusion-main.zip», который вы скачали с GitHub, в вашей любимой программе архивации файлов. Кроме того, Windows также может сама открывать ZIP-файлы, если у вас нет архиватора. Держите ZIP-файл открытым в одном окне, затем откройте другое окно Проводника и перейдите в папку «C:stable-diffusion», которую мы только что создали.
Перетащите папку в ZIP-файле «stable-diffusion-main» в папку «stable-diffusion».
Вернитесь в Miniconda3, затем скопируйте и вставьте в окно следующие команды:
cd C:stable-diffusionstable-diffusion-main conda env create -f environment.yaml conda activate ldm mkdir modelsldmstable-diffusion-v1

Не прерывайте этот процесс. Размер некоторых файлов превышает гигабайт, поэтому загрузка может занять некоторое время. Если вы случайно прервёте процесс, вам нужно будет удалить папку среды и снова запустить
conda env create -f environment.yaml
Если это произойдёт, попробуйте следующую команду:
conda env update -f environment.yaml
Либо перейдите в «C:Users(Ваша учётная запись пользователя).condaenvs» и удалите папку «ldm», а затем выполните предыдущую команду conda env create -f environment.yaml.
Примечание: Итак, что мы только что сделали? Python позволяет сортировать проекты кодирования по «средам». Каждая среда отделена от других сред, поэтому вы можете загружать разные библиотеки Python в разные среды, не беспокоясь о конфликтующих версиях. Это бесценно, если вы работаете над несколькими проектами на одном ПК.
Строки, которые мы запустили, создали новую среду с именем «ldm», загрузили и установили все необходимые библиотеки Python для работы Stable Diffusion, активировали среду ldm, а затем изменили каталог на новую папку (перешли в неё).
Мы находимся на последнем этапе установки. Перейдите к «C:stable-diffusionstable-diffusion-mainmodelsldmstable-diffusion-v1» в проводнике, затем скопируйте и вставьте файл контрольной точки (sd-v1-4.ckpt) в папку.
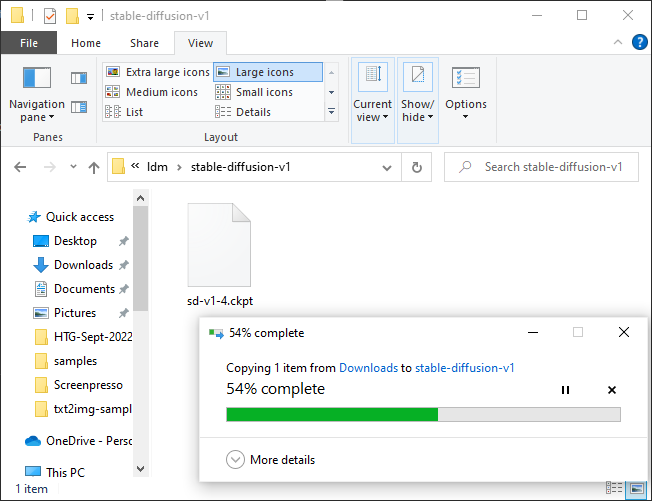
Дождитесь завершения передачи файла, щёлкните правой кнопкой мыши «sd-v1-4.ckpt» и выберите «Переименовать». Введите «model.ckpt» в выделенное поле, затем нажмите Enter, чтобы изменить имя файла.
Смотрите также: Как сделать так, чтобы Windows показывала расширения файлов
Примечание. Если вы используете Windows 11, вы не увидите «переименовать» в контекстном меню, вызываемом правой кнопкой мыши. Вместо этого есть значок, который выглядит как миниатюрное текстовое поле.
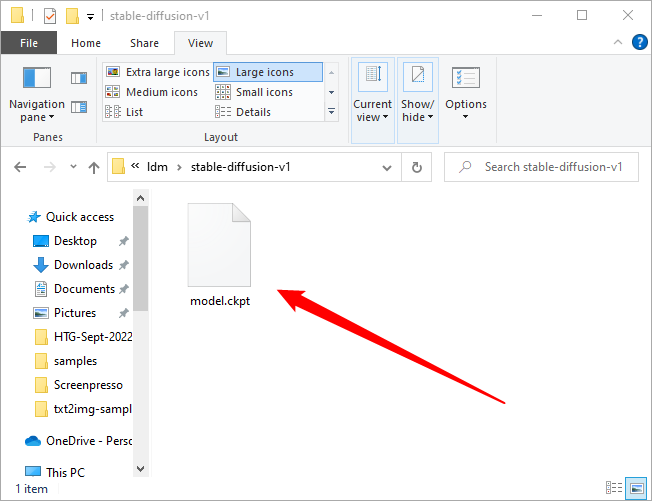
Вот и всё — мы закончили. Теперь мы готовы использовать Stable Diffusion.
4. Как использовать Stable Diffusion
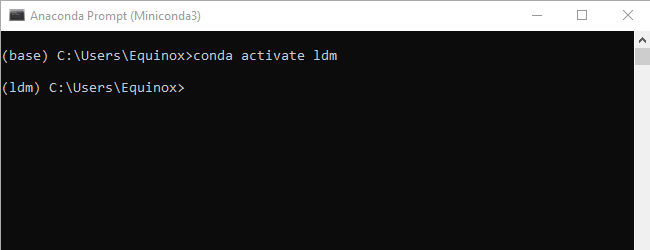
Созданная нами среда ldm необходима, и вам нужно активировать её каждый раз, когда вы хотите использовать Stable Diffusion. Введите
conda activate ldm
в окне Miniconda3 и нажмите «Enter». (ldm) слева указывает на то, что среда ldm активна.
Примечание. Эту команду нужно вводить только при открытии Miniconda3. Среда ldm будет оставаться активной до тех пор, пока вы не закроете окно.
Затем нам нужно изменить каталог (то есть использовать команду cd) на «C:stable-diffusionstable-diffusion-main», прежде чем мы сможем создавать какие-либо образы. Вставьте cd C:stable-diffusionstable-diffusion-main в командную строку.
4.1 Как сделать изображение со Stable Diffusion
Мы собираемся вызвать скрипт txt2img.py, который позволяет нам преобразовывать текстовые запросы в изображения размером 512×512. Вот пример. Попробуйте это, чтобы убедиться, что всё работает правильно:
python scripts/txt2img.py --prompt "a close-up portrait of a cat by pablo picasso, vivid, abstract art, colorful, vibrant" --plms --n_iter 5 --n_samples 1
Ваша консоль будет отображать индикатор выполнения по мере создания изображений.
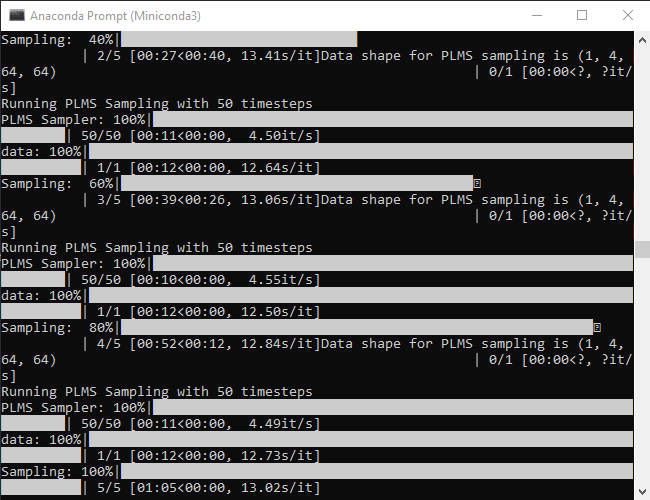
Эта команда создаст пять изображений кошек, все они расположены в папке «C:stable-diffusionstable-diffusion-mainoutputstxt2img-samplessamples».

Он не идеален, но отчётливо напоминает стиль Пабло Пикассо, как мы и указали в запросе. Ваши изображения должны выглядеть похожими, но не обязательно идентичными.
Каждый раз, когда вы хотите изменить сгенерированное изображение, вам просто нужно изменить текст, содержащийся в двойных кавычках после —prompt.
Совет: не переписывайте всю строку каждый раз. Используйте клавиши со стрелками для перемещения текстового курсора и просто замените запрос, удалив старые слова и вписав новые.
python scripts/txt2img.py --prompt "ЗДЕСЬ ВАШЕ ОПИСАНИЕ КАРТИНКИ" --plms --n_iter 5 --n_samples 1
Скажем, мы хотели создать реалистично выглядящего суслика в волшебном лесу в шляпе волшебника. Мы могли бы попробовать команду:
python scripts/txt2img.py --prompt "a photograph of a gopher wearing a wizard hat in a forest, vivid, photorealistic, magical, fantasy, 8K UHD, photography" --plms --n_iter 5 --n_samples 1

Это действительно так просто — просто опишите, что вы хотите, как можно конкретнее. Если вы хотите что-то фотореалистичное, не забудьте включить термины, относящиеся к реалистичному изображению. Если вы хотите что-то, вдохновлённое стилем конкретного художника, укажите исполнителя.
Stable Diffusion не ограничивается портретами и животными, она также может создавать поразительные пейзажи.

4.2 Что означают аргументы в команде?
Stable Diffusion имеет огромное количество настроек и аргументов, которые вы можете предоставить для настройки результатов. Несколько включённых здесь в основном необходимы для обеспечения работы Stable Diffusion на обычном игровом компьютере.
- —plms — указывает, как будут сэмплироваться изображения. Об этом есть статья, если вы хотите проверить математику.
- —n_iter — указывает количество итераций, которые вы хотите сгенерировать для каждого запроса. 5 — приличное число, чтобы увидеть, какие результаты вы получаете.
- —n_samples — указывает количество сэмплов, которые будут сгенерированы. По умолчанию установлено значение 3, но у большинства компьютеров недостаточно видеопамяти для этого. Придерживайтесь 1, если у вас нет особой причины изменить его.
Конечно, Stable Diffusion имеет массу различных аргументов, которые вы можете использовать для настройки результатов. Запустите
python scripts/txt2img.py --help
чтобы получить исчерпывающий список аргументов, которые вы можете использовать.
Для получения отличных результатов необходимо пройти массу проб и ошибок, но это, по крайней мере, половина удовольствия. Убедитесь, что вы записываете или сохраняете аргументы и описания, которые возвращают результаты, которые вам нравятся. Если вы не хотите проводить все эксперименты самостоятельно, на Reddit (и в других местах) появляются растущие сообщества, посвящённые обмену изображениями и подсказками, которые их сгенерировали.
Смотрите также: Как писать хорошие запросы для Stable Diffusion
5. Онлайн демо версия Stable Diffusion
Также вы можете воспользоваться онлайн демо версией: https://huggingface.co/spaces/stabilityai/stable-diffusion
Смотрите также:
- Что такое машинное обучение?
- Проблема искусственного интеллекта: машина может учиться, но не может понимать
- Как пересекаются искусственный интеллект, машинное обучение и безопасность конечных точек
Связанные статьи:
- Stable Diffusion позволяет создавать изображения с помощью искусственного интеллекта на ПК (100%)
- Diffusion Bee — это самый простой способ запустить Stable Diffusion на Mac (100%)
- Форк Stable Diffusion может генерировать мозаичные изображения (100%)
- Хотите Stable Diffusion в HD? Попробуйте этот AI генератор картинок (100%)
- Лучшие генераторы изображений AI, которые вы можете использовать прямо сейчас (100%)
- Как быстро переключаться между виртуальными рабочими столами в Windows 10 (RANDOM — 3%)
- Home
- Tech
27 Sep 2022 1:13 PM +00:00 UTC
Try these tips and the Stable Diffusion runtime error will be a thing of the past.

Credit: Stability.ai
If the Stable Diffusion runtime error is preventing you from making art, here is what you need to do.
Stable Diffusion is one of the best AI image generators out there. Unlike DALL-E and MidJourney AI, Stable Diffusion is available for the public and anyone with a powerful machine can generate images from texts.
However, Stable Diffusion might sometimes run into memory issues and stop working. If you are experiencing the Stable Diffusion runtime error, try the following tips.

How To Fix Runtime Error: CUDA Out Of Memory In Stable Diffusion
So you are running Stable Diffusion locally on your PC, maybe trying to make some NSFW images and bam! You are hit by the infamous RuntimeError: CUDA out of memory.
The error is accompanied by a long message that basically looks like this. The amount of memory may change but the content is the same.
RuntimeError: CUDA out of memory. Tried to allocate 30.00 MiB (GPU 0; 6.00 GiB total capacity; 5.16 GiB already allocated; 0 bytes free; 5.30 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
It appears you have run out of GPU memory. It is worth mentioning that you need at least 4 GB VRAM in order to run Stable Diffusion. If you have 4 GB or more of VRAM, below are some fixes that you can try.
- Restarting the PC worked for some people.
- Reduce the resolution. Start with 256 x 256 resolution. Just change the -W 256 -H 256 part in the command.
- Try this fork as it requires a lot less VRAM according to many Reddit users.
If the issue persists, don’t worry. We have some additional troubleshooting tips for you to try. Keep reading!
Other Troubleshooting Tips
So you have tried all the simple and quick fixes but the runtime error seems to have no intention to leave you, huh? No worries! Let’s dive into relatively more complex steps. Here you go.
- As mentioned in the error message, run the following command first: PYTORCH_CUDA_ALLOC_CONF=garbage_collection_threshold:0.6, max_split_size_mb:128. Then run the image generation command with: —n_samples 1.
- Call the optimized python script. Use the following command: python optimizedSD/optimized_txt2img.py —prompt «a drawing of a cat on a log» —n_iter 5 —n_samples 1 —H 512 —W 512 —precision full
- You can also try removing the safety checks aka NSFW filters, which take up 2GB of VRAM. Just replace scripts/txt2img.py with this:
https://github.com/JustinGuese/stable-diffusor-docker-text2image/blob/master/txt2img.py
Hopefully, one of the suggestions will work for you and you will be able to generate images again. Now that the Stable Diffusion runtime error is fixed, have a look at how to access Stable Diffusion using Google Colab.
- The program is tested to work on Python 3.10.6. Don’t use other versions unless you are looking for trouble.
- The program needs 16gb of regular RAM to run smoothly. If you have 8gb RAM, consider making an 8gb page file/swap file, or use the —lowram option (if you have more gpu vram than ram).
- The installer creates a python virtual environment, so none of the installed modules will affect existing system installations of python.
- To use the system’s python rather than creating a virtual environment, use custom parameter replacing
set VENV_DIR=-. - To reinstall from scratch, delete directories:
venv,repositories. - When starting the program for the first time, the path to python interpreter is displayed. If this is not the python you installed, you can specify full path in the
webui-userscript; see Running with custom parameters. - If the desired version of Python is not in PATH, modify the line
set PYTHON=pythoninwebui-user.batwith the full path to the python executable.- Example:
set PYTHON=B:softPython310python.exe
- Example:
- Installer requirements from
requirements_versions.txt, which lists versions for modules specifically compatible with Python 3.10.6. If this doesn’t work with other versions of Python, setting the custom parameterset REQS_FILE=requirements.txtmay help.
Low VRAM Video-cards
When running on video cards with a low amount of VRAM (<=4GB), out of memory errors may arise.
Various optimizations may be enabled through command line arguments, sacrificing some/a lot of speed in favor of using less VRAM:
- If you have 4GB VRAM and want to make 512×512 (or maybe up to 640×640) images, use
--medvram. - If you have 4GB VRAM and want to make 512×512 images, but you get an out of memory error with
--medvram, use--lowvram --always-batch-cond-uncondinstead. - If you have 4GB VRAM and want to make images larger than you can with
--medvram, use--lowvram.
Green or Black screen
Video cards
When running on video cards which don’t support half precision floating point numbers (a known issue with 16xx cards), a green or black screen may appear instead of the generated pictures.
This may be fixed by using the command line arguments --precision full --no-half at a significant increase in VRAM usage, which may require --medvram.
«CUDA error: no kernel image is available for execution on the device» after enabling xformers
Your installed xformers is incompatible with your GPU. If you use Python 3.10, have a Pascal or higher card and run on Windows, add --reinstall-xformers --xformers to your COMMANDLINE_ARGS to upgrade to a working version. Remove --reinstall-xformers after upgrading.
NameError: name ‘xformers’ is not defined
If you use Windows, this means your Python is too old. Use 3.10
If Linux, you’ll have to build xformers yourself or just avoid using xformers.
ИИ также не сможет копировать стили известных художников.
- Stable Diffusion 2.0 выпустили 24 ноября 2022 года — создатели нейросети рассказали о ряде улучшений, включая внедрение отдельной модели для распознавания глубины в изображениях.
- С выходом новой версии пользователи Stable Diffusion заметили, что нейросеть теперь намного хуже повторяет стили известных художников вроде Винсента ван Гога или студий Pixar и Ghibli.
- Если Stable Diffusion 1.5 в большинстве случаев точно понимала текстовый запрос, то уже в Stable Diffusion 2.0 нейросеть выдаёт картинки, которые лишь отдалённо похожи на работы знаменитых авторов.
- Вместе с этим в Stable Diffusion 2.0 сильно ограничили генерацию NSFW-изображений. Создатели нейросети приняли такое решение из-за распространения порно-картинок, в том числе с несовершеннолетними.
- Некоторые пользователи раскритиковали такое решение, назвав это «актом цензуры». По их мнению, в программе с открытым исходным кодом принимать решение о создании NSFW-контента должен сам автор.
- Другие художники подчеркнули, что подобные модели обучения можно легко внедрить в Stable Diffusion 2.0 с помощью сторонних утилит, так что это ограничение со стороны разработчиков не должно сильно сказаться на работах NSFW-авторов.
Нейросеть обучили рисовать «пышногрудых дам», вайфу и «гигачадов»
Статьи редакции
Даже лица получаются удачно.

Skip to content
- ТВикинариум
- Форум
- Поддержка
- PRO
- Войти
Stable Diffusion

Цитата: Сергей от 09.01.2023, 22:16Artem, превью настраивается тут.
Цитата: Artem от 09.01.2023, 22:08И ещё, как сделать что бы имя не отображалось при генерации картинки? Ели строку оставляю пустой, то картинка не генерится
Не пропускай видео, Хачатур про все мелочи рассказывает. YouTube.
Artem, превью настраивается тут.
Цитата: Artem от 09.01.2023, 22:08И ещё, как сделать что бы имя не отображалось при генерации картинки? Ели строку оставляю пустой, то картинка не генерится
Не пропускай видео, Хачатур про все мелочи рассказывает. YouTube.

Цитата: Artem от 09.01.2023, 22:20Цитата: Сергей от 09.01.2023, 22:16Artem, превью настраивается тут.
Цитата: Artem от 09.01.2023, 22:08И ещё, как сделать что бы имя не отображалось при генерации картинки? Ели строку оставляю пустой, то картинка не генерится
Не пропускай видео, Хачатур про все мелочи рассказывает. YouTube.
Спасибо. Да, я уже все видео досмотрел и помню, что где-то встречал. Но реально большой объём материала и где я это видел — оказалось проблемой вспомнить.
Цитата: Сергей от 09.01.2023, 22:16Artem, превью настраивается тут.
Цитата: Artem от 09.01.2023, 22:08И ещё, как сделать что бы имя не отображалось при генерации картинки? Ели строку оставляю пустой, то картинка не генерится
Не пропускай видео, Хачатур про все мелочи рассказывает. YouTube.
Спасибо. Да, я уже все видео досмотрел и помню, что где-то встречал. Но реально большой объём материала и где я это видел — оказалось проблемой вспомнить.

Цитата: Alaim от 10.01.2023, 01:44Доброй ночи всем. Возникла ошибка при запуске portable SD:
StableDiffusion UI запускается без проблем. Как можно исправить ошибку, подскажите, пожалуйста? Всем четких промтовОшибка в cmdloading stable diffusion model: AttributeError
Traceback (most recent call last):
File "D:PortableStableDiffusionwebui.py", line 74, in initialize
modules.sd_models.load_model()
File "D:PortableStableDiffusionmodulessd_models.py", line 321, in load_model
load_model_weights(sd_model, checkpoint_info)
File "D:PortableStableDiffusionmodulessd_models.py", line 202, in load_model_weights
sd = read_state_dict(checkpoint_file)
File "D:PortableStableDiffusionmodulessd_models.py", line 184, in read_state_dict
sd = get_state_dict_from_checkpoint(pl_sd)
File "D:PortableStableDiffusionmodulessd_models.py", line 155, in get_state_dict_from_checkpoint
pl_sd = pl_sd.pop("state_dict", pl_sd)
AttributeError: 'NoneType' object has no attribute 'pop'
Stable diffusion model failed to load, exiting
Доброй ночи всем. Возникла ошибка при запуске portable SD:
Скопированоloading stable diffusion model: AttributeErrorСкопированоTraceback (most recent call last):СкопированоFile "D:PortableStableDiffusionwebui.py", line 74, in initializeСкопированоmodules.sd_models.load_model()СкопированоFile "D:PortableStableDiffusionmodulessd_models.py", line 321, in load_modelСкопированоload_model_weights(sd_model, checkpoint_info)СкопированоFile "D:PortableStableDiffusionmodulessd_models.py", line 202, in load_model_weightsСкопированоsd = read_state_dict(checkpoint_file)СкопированоFile "D:PortableStableDiffusionmodulessd_models.py", line 184, in read_state_dictСкопированоsd = get_state_dict_from_checkpoint(pl_sd)СкопированоFile "D:PortableStableDiffusionmodulessd_models.py", line 155, in get_state_dict_from_checkpointСкопированоpl_sd = pl_sd.pop("state_dict", pl_sd)СкопированоAttributeError: 'NoneType' object has no attribute 'pop'
СкопированоStable diffusion model failed to load, exiting
StableDiffusion UI запускается без проблем. Как можно исправить ошибку, подскажите, пожалуйста? Всем четких промтов

Цитата: Pavel от 10.01.2023, 03:36Привет, спасибо за видео про Embedding!
Хочу уточнить пару вещей:
1. При создании файла мы насчитали 23 «Number of vectors per token», но, похоже, нейросеть интерпретирует некоторые слова иначе, например rutkowski считает за 2, в итоге выходит 25. Стоит доверять своим подсчетам и писать 23 или все же 25? А если сразу выкрутить в максимальные 75?
2. В разделе Train мы ставим галочку для использования промпта из txt2img. Правильно ли я понимаю, что это именно для генерации превью и там можно сразу писать [name], sdarts в нашем случае, для наглядности? В видео там стоит тот же промпт из тренировке и превью не похожи на итоговый стиль.
Привет, спасибо за видео про Embedding!
Хочу уточнить пару вещей:
1. При создании файла мы насчитали 23 «Number of vectors per token», но, похоже, нейросеть интерпретирует некоторые слова иначе, например rutkowski считает за 2, в итоге выходит 25. Стоит доверять своим подсчетам и писать 23 или все же 25? А если сразу выкрутить в максимальные 75?
2. В разделе Train мы ставим галочку для использования промпта из txt2img. Правильно ли я понимаю, что это именно для генерации превью и там можно сразу писать [name], sdarts в нашем случае, для наглядности? В видео там стоит тот же промпт из тренировке и превью не похожи на итоговый стиль.

Цитата: XpucT от 10.01.2023, 04:10Pavel, привет 🖐
- Почему Ты решил, что именно Greg Rutkowski считается за 1 =))
Нет, это не так. Не забывай про совпадение a girl, отними их и получишь 23.- Эта галочка служит исключительно для того, чтобы показывать Тебе то, что получается у нейросети, используя то, что прописано на вкладке txt2img
Это ни больше, ни меньше. Это именно это ☝ Можно писать, как понимаешь, что угодно, на результат обучения это не повлияет.Ещё бонусом напишу то, что не вошло в видео, ибо не особо важно. Но может кому-то пригодится.
Изображения, которые показывал с серыми «круглыми пикселями» также можно использовать отдельно, без pt, а можно вместе с ним.
Но важно помнить, что именно pt как назовёшь, так и придётся использовать. Таких тонкостей много на самом деле, но всё быстро меняется. Прям очень быстро. То, что в видео останется, ибо база есть база.
Pavel, привет 🖐
- Почему Ты решил, что именно Greg Rutkowski считается за 1 =))
Нет, это не так. Не забывай про совпадение a girl, отними их и получишь 23. - Эта галочка служит исключительно для того, чтобы показывать Тебе то, что получается у нейросети, используя то, что прописано на вкладке txt2img
Это ни больше, ни меньше. Это именно это ☝ Можно писать, как понимаешь, что угодно, на результат обучения это не повлияет.
Ещё бонусом напишу то, что не вошло в видео, ибо не особо важно. Но может кому-то пригодится.
Изображения, которые показывал с серыми «круглыми пикселями» также можно использовать отдельно, без pt, а можно вместе с ним.
Но важно помнить, что именно pt как назовёшь, так и придётся использовать. Таких тонкостей много на самом деле, но всё быстро меняется. Прям очень быстро. То, что в видео останется, ибо база есть база.
Цитата: Pavel от 10.01.2023, 04:32Цитата: XpucT от 10.01.2023, 04:10Pavel, привет
- Почему Ты решил, что именно Greg Rutkowski считается за 1 =))
Нет, это не так. Не забывай про совпадение a girl, отними их и получишь 23.- Эта галочка служит исключительно для того, чтобы показывать Тебе то, что получается у нейросети, используя то, что прописано на вкладке txt2img
Это ни больше, ни меньше. Это именно этоМожно писать, как понимаешь, что угодно, на результат обучения это не повлияет.
Ещё бонусом напишу то, что не вошло в видео, ибо не особо важно. Но может кому-то пригодится.
Изображения, которые показывал с серыми «круглыми пикселями» также можно использовать отдельно, без pt, а можно вместе с ним.
Но важно помнить, что именно pt как назовёшь, так и придётся использовать. Таких тонкостей много на самом деле, но всё быстро меняется. Прям очень быстро. То, что в видео останется, ибо база есть база.Если в промпте оставить только «Greg Rutkowski», то будет писать 3, а «Rutkowski» определяет как 2. Вот это и смутило + расширение Tokenizer разделяет на два.
Цитата: XpucT от 10.01.2023, 04:10Pavel, привет
- Почему Ты решил, что именно Greg Rutkowski считается за 1 =))
Нет, это не так. Не забывай про совпадение a girl, отними их и получишь 23.- Эта галочка служит исключительно для того, чтобы показывать Тебе то, что получается у нейросети, используя то, что прописано на вкладке txt2img
Это ни больше, ни меньше. Это именно этоМожно писать, как понимаешь, что угодно, на результат обучения это не повлияет.
Ещё бонусом напишу то, что не вошло в видео, ибо не особо важно. Но может кому-то пригодится.
Изображения, которые показывал с серыми «круглыми пикселями» также можно использовать отдельно, без pt, а можно вместе с ним.
Но важно помнить, что именно pt как назовёшь, так и придётся использовать. Таких тонкостей много на самом деле, но всё быстро меняется. Прям очень быстро. То, что в видео останется, ибо база есть база.
Если в промпте оставить только «Greg Rutkowski», то будет писать 3, а «Rutkowski» определяет как 2. Вот это и смутило + расширение Tokenizer разделяет на два.
Цитата: Artem от 10.01.2023, 10:41Здравствуйте. Не получается определить описание картинки. Что это за ошибка?
Здравствуйте. Не получается определить описание картинки. Что это за ошибка?

Цитата: Artem от 10.01.2023, 10:44Цитата: Artist от 10.01.2023, 10:42Всем привет.
А есть ли системные требования SD Portable? Запустить и генерировать на ноуте с видеокартой 2 гб, оперативной память 4 гб — потянет?Привет. Да нет конечно, это будет мучение. Хотя бы 4гб видео надо. Вся нагрузка на неё
Цитата: Artist от 10.01.2023, 10:42Всем привет.
А есть ли системные требования SD Portable? Запустить и генерировать на ноуте с видеокартой 2 гб, оперативной память 4 гб — потянет?
Привет. Да нет конечно, это будет мучение. Хотя бы 4гб видео надо. Вся нагрузка на неё

Цитата: Mikhail от 10.01.2023, 10:45Цитата: Artist от 10.01.2023, 10:42Всем привет.
А есть ли системные требования SD Portable? Запустить и генерировать на ноуте с видеокартой 2 гб, оперативной памятью 4 гб — потянет?Добрый🖐.
Не потянет, всего мало.
Цитата: Artist от 10.01.2023, 10:42Всем привет.
А есть ли системные требования SD Portable? Запустить и генерировать на ноуте с видеокартой 2 гб, оперативной памятью 4 гб — потянет?
Добрый🖐.
Не потянет, всего мало.

Цитата: Artist от 10.01.2023, 10:47Цитата: Artem от 10.01.2023, 10:44Цитата: Artist от 10.01.2023, 10:42Всем привет.
А есть ли системные требования SD Portable? Запустить и генерировать на ноуте с видеокартой 2 гб, оперативной память 4 гб — потянет?Привет. Да нет конечно, это будет мучение. Хотя бы 4гб видео надо. Вся нагрузка на неё
Цитата: Mikhail от 10.01.2023, 10:45Цитата: Artist от 10.01.2023, 10:42Всем привет.
А есть ли системные требования SD Portable? Запустить и генерировать на ноуте с видеокартой 2 гб, оперативной памятью 4 гб — потянет?Добрый
.
Не потянет, всего мало.Спасибо.
Цитата: Artem от 10.01.2023, 10:44Цитата: Artist от 10.01.2023, 10:42Всем привет.
А есть ли системные требования SD Portable? Запустить и генерировать на ноуте с видеокартой 2 гб, оперативной память 4 гб — потянет?Привет. Да нет конечно, это будет мучение. Хотя бы 4гб видео надо. Вся нагрузка на неё
Цитата: Mikhail от 10.01.2023, 10:45Цитата: Artist от 10.01.2023, 10:42Всем привет.
А есть ли системные требования SD Portable? Запустить и генерировать на ноуте с видеокартой 2 гб, оперативной памятью 4 гб — потянет?Добрый
.
Не потянет, всего мало.
Спасибо.
Цитата: Artist от 10.01.2023, 12:06А вообще, у кого-нибудь получалось извлечь такой (мультяшный, плоский, с обводкой) стиль?
А вообще, у кого-нибудь получалось извлечь такой (мультяшный, плоский, с обводкой) стиль?

Цитата: Maks от 10.01.2023, 12:23Цитата: Artem от 10.01.2023, 10:44Цитата: Artist от 10.01.2023, 10:42Всем привет.
А есть ли системные требования SD Portable? Запустить и генерировать на ноуте с видеокартой 2 гб, оперативной память 4 гб — потянет?Привет. Да нет конечно, это будет мучение. Хотя бы 4гб видео надо. Вся нагрузка на неё
И то, если отключить турбо режим в UI версии SD. Ибо у меня например карта NVIDIA GeForce GTX 1050 4 гб и с турбо режимом рендеринг изображений падал с ошибками. А для портативной SD на моей карте почему-то не хочет работать связка CUDA + CUDNN. И эту проблему пока до сих пор не решил.
Цитата: Artem от 10.01.2023, 10:44Цитата: Artist от 10.01.2023, 10:42Всем привет.
А есть ли системные требования SD Portable? Запустить и генерировать на ноуте с видеокартой 2 гб, оперативной память 4 гб — потянет?Привет. Да нет конечно, это будет мучение. Хотя бы 4гб видео надо. Вся нагрузка на неё
И то, если отключить турбо режим в UI версии SD. Ибо у меня например карта NVIDIA GeForce GTX 1050 4 гб и с турбо режимом рендеринг изображений падал с ошибками. А для портативной SD на моей карте почему-то не хочет работать связка CUDA + CUDNN. И эту проблему пока до сих пор не решил.
Update — vedroboev resolved this issue with two pieces of advice:
-
With my NVidia GTX 1660 Ti (with Max Q if that matters) card, I had to use the https://github.com/basujindal/stable-diffusion repo.
-
Remember to call the optimized python script python optimizedSD/optimized_txt2img.py instead of standard scripts/txt2img.
-
-
If you’re getting green squares, add —precision full to the command line.
This command rendered 5 good images on my machine with the NVidia GeForce 1660Ti card using the basujindal repo:
python optimizedSD/optimized_txt2img.py —prompt «a drawing of a cat on a log» —n_iter 5 —n_samples 1 —precision full
======
Original:
Getting the CUDA out of memory error.
(RuntimeError: CUDA out of memory. Tried to allocate 30.00 MiB (GPU 0; 6.00 GiB total capacity; 5.16 GiB already allocated; 0 bytes free; 5.30 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF)
Things I’ve tried:
-
Used repo recommended in https://github.com/CompVis/stable-diffusion/issues/39 to use https://github.com/basujindal/stable-diffusion — same result.
-
Dialed the image —H and —W down to 128 and even 64 — same error.
Questions:
-
I have two GPUs — a intel UHD and a GeForceTI 1660 with 6GB VRAM. The error here implies PyTorch has already reserved 5.3GB and is requesting 30 MB more, which there should be sufficient capacity for (6.0 — 5.3 = .7GB, 700 MB).
-
Searched documentation for «See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF» but that seems to be for custom python scripts and I don’t see how to add that to txt2img command. I don’t see where to specify max_split_size_mb or PYTOURH_CUDA_ALLOC_CONF.
-
I think this is using the GeForce but don’t see how to specify this in the txt2img command. Can/should I specify a GPU? Do I need to/How do I kill any programs that might be reserving GPU memory, though it implies that PyTorch is reserving most of it?
0 / 0 / 0
Регистрация: 06.12.2022
Сообщений: 3
1
Проблема с видеопамятью при использовании ИИ
06.12.2022, 18:27. Показов 1150. Ответов 8

Здравствуйте!
Я ничего не понимаю в программировании, но, похоже, пора научиться.
У меня появилась проблема: при использовании stable diffusion (работает на Python) используется не вся доступная видеопамять. Это я так понял. Оригинал ошибки приложу снизу.
Помогите, пожалуйста, разобраться, как это исправить и можно ли.
P.s. для комфортной работы в программе достаточно 4 гб видеопамяти. У меня ноутбучная 3060 с 6 гб.
Оригинал ошибки:
Preparing dataset…
100%|█████████████████████████████████████████████ ███████████████████████████████████| 162/162 [00:16<00:00, 9.92it/s]
0%| | 0/50000 [00:00<?, ?it/s]Traceback (most recent call last):
File «C:UsersNikolaistable-diffusion-webuimoduleshypernetworkshypernetwork.py», line 511, in train_hypernetwork
scaler.scale(loss).backward()
File «C:UsersNikolaistable-diffusion-webuivenvlibsite-packagestorch_tensor.py», line 396, in backward
torch.autograd.backward(self, gradient, retain_graph, create_graph, inputs=inputs)
File «C:UsersNikolaistable-diffusion-webuivenvlibsite-packagestorchautograd__init__.py», line 173, in backward
Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
File «C:UsersNikolaistable-diffusion-webuivenvlibsite-packagestorchautogradfunction.py», line 253, in apply
return user_fn(self, *args)
File «C:UsersNikolaistable-diffusion-webuivenvlibsite-packagestorchutilscheckpoint.py», line 130, in backward
outputs = ctx.run_function(*detached_inputs)
File «C:UsersNikolaistable-diffusion-webuirepositoriesstable-diffusion-stability-aildmmodulesattention.py», line 262, in _forward
x = self.attn1(self.norm1(x), context=context if self.disable_self_attn else None) + x
File «C:UsersNikolaistable-diffusion-webuivenvlibsite-packagestorchnnmodulesmodule.py», line 1130, in _call_impl
return forward_call(*input, **kwargs)
File «C:UsersNikolaistable-diffusion-webuimoduleshypernetworkshypernetwork.py», line 332, in attention_CrossAttention_forward
attn = sim.softmax(dim=-1)
RuntimeError: CUDA out of memory. Tried to allocate 512.00 MiB (GPU 0; 6.00 GiB total capacity; 4.13 GiB already allocated; 0 bytes free; 4.88 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
Applying cross attention optimization (Doggettx).
__________________
Помощь в написании контрольных, курсовых и дипломных работ, диссертаций здесь
0
I’ve already done this, so there is no button to do so again. And yet I’m still getting the error. I seem to have no way to proceed now.
Edit: Seems fixed when I tried again today. Everything else was the same. Strange.
Yeah it happened to me too kinda weird and I’ve accepted the license and all but it didn’t work for some reason even refreshed a ton of times still the same problem.
I have the same issue. Anyone else running into this or have a solution?
I am also having this issue.
Is there a way to allow me to accept it again?
i am also having this error
same issue even after accepting the license — EDIT waited a few minutes (like, 5 or so) now it’s all good
I’ve accepted the terms on both links from all 3 different major browsers and still getting the same issue
EDIT: It works now. I was adding the auth token in between single quotes. I removed the quotes and it’s working now
There was a specific connection error when trying to load CompVis/stable-diffusion-v1-4:
<class ‘requests.exceptions.HTTPError’> (Request ID: bnhNFO6r4jqqKNaYYE2F7)
HTTPError: 403 Client Error: Forbidden for url: https://huggingface.co/CompVis/stable-diffusion-v1-4/resolve/fp16/model_index.json
andOSError: There was a specific connection error when trying to load CompVis/stable-diffusion-v1-4: <class 'requests.exceptions.HTTPError'> (Request ID: xOpbQN_WipKp1D2fSP5U-)
https://huggingface.co/CompVis/stable-diffusion-v1-4
accept this will resolve
Solved. however new issue is as follows:
RuntimeError Traceback (most recent call last)
<ipython-input-5-af4f9f89fc6e> in <module>
36
37 prompt = "a cat sitting on a bench"
---> 38 images = pipe.inpaint(prompt=prompt, init_image=init_image, mask_image=mask_image, strength=0.75).images
15 frames
/usr/local/lib/python3.7/dist-packages/torch/nn/modules/conv.py in _conv_forward(self, input, weight, bias)
452 _pair(0), self.dilation, self.groups)
453 return F.conv2d(input, weight, bias, self.stride,
--> 454 self.padding, self.dilation, self.groups)
455
456 def forward(self, input: Tensor) -> Tensor:
RuntimeError: Input type (torch.cuda.FloatTensor) and weight type (torch.cuda.HalfTensor) should be the same
i cant see any license acceptance button , am I missing anything?
move to the ‘Files and versions’ tab, and then the buttom comes.
Had to use write token instead read token to make http 403 error go away
Can some one help with this error pls (RuntimeError: «log» «_vml_cpu» not implemented for ‘Half’)
Can somebody help me with this error please.
venv «C:AivenvScriptsPython.exe»
Python 3.10.6 (tags/v3.10.6:9c7b4bd, Aug 1 2022, 21:53:49) [MSC v.1932 64 bit (AMD64)]
Commit hash:
Installing torch and torchvision
Traceback (most recent call last):
File «C:Ailaunch.py», line 255, in
prepare_enviroment()
File «C:Ailaunch.py», line 173, in prepare_enviroment
run(f'»{python}» -m {torch_command}’, «Installing torch and torchvision», «Couldn’t install torch»)
File «C:Ailaunch.py», line 34, in run
raise RuntimeError(message)
RuntimeError: Couldn’t install torch.
Command: «C:AivenvScriptspython.exe» -m pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 —extra-index-url https://download.pytorch.org/whl/cu113
Error code: 2
stdout: Looking in indexes: https://pypi.org/simple, https://download.pytorch.org/whl/cu113
Collecting torch==1.12.1+cu113
Downloading https://download.pytorch.org/whl/cu113/torch-1.12.1%2Bcu113-cp310-cp310-win_amd64.whl (2143.8 MB)
—— 0.4/2.1 GB 7.4 MB/s eta 0:04:03
stderr: ERROR: Exception:
Traceback (most recent call last):
File «C:Aivenvlibsite-packagespip_vendorurllib3response.py», line 435, in _error_catcher
yield
File «C:Aivenvlibsite-packagespip_vendorurllib3response.py», line 516, in read
data = self._fp.read(amt) if not fp_closed else b»»
File «C:Aivenvlibsite-packagespip_vendorcachecontrolfilewrapper.py», line 90, in read
data = self.__fp.read(amt)
File «C:UsersreeceAppDataLocalProgramsPythonPython310libhttpclient.py», line 465, in read
s = self.fp.read(amt)
File «C:UsersreeceAppDataLocalProgramsPythonPython310libsocket.py», line 705, in readinto
return self._sock.recv_into(b)
File «C:UsersreeceAppDataLocalProgramsPythonPython310libssl.py», line 1274, in recv_into
return self.read(nbytes, buffer)
File «C:UsersreeceAppDataLocalProgramsPythonPython310libssl.py», line 1130, in read
return self._sslobj.read(len, buffer)
TimeoutError: The read operation timed out
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File «C:Aivenvlibsite-packagespip_internalclibase_command.py», line 167, in exc_logging_wrapper
status = run_func(*args)
File «C:Aivenvlibsite-packagespip_internalclireq_command.py», line 247, in wrapper
return func(self, options, args)
File «C:Aivenvlibsite-packagespip_internalcommandsinstall.py», line 369, in run
requirement_set = resolver.resolve(
File «C:Aivenvlibsite-packagespip_internalresolutionresolvelibresolver.py», line 92, in resolve
result = self._result = resolver.resolve(
File «C:Aivenvlibsite-packagespip_vendorresolvelibresolvers.py», line 481, in resolve
state = resolution.resolve(requirements, max_rounds=max_rounds)
File «C:Aivenvlibsite-packagespip_vendorresolvelibresolvers.py», line 348, in resolve
self._add_to_criteria(self.state.criteria, r, parent=None)
File «C:Aivenvlibsite-packagespip_vendorresolvelibresolvers.py», line 172, in _add_to_criteria
if not criterion.candidates:
File «C:Aivenvlibsite-packagespip_vendorresolvelibstructs.py», line 151, in bool
return bool(self._sequence)
File «C:Aivenvlibsite-packagespip_internalresolutionresolvelibfound_candidates.py», line 155, in bool
return any(self)
File «C:Aivenvlibsite-packagespip_internalresolutionresolvelibfound_candidates.py», line 143, in
return (c for c in iterator if id(c) not in self._incompatible_ids)
File «C:Aivenvlibsite-packagespip_internalresolutionresolvelibfound_candidates.py», line 47, in _iter_built
candidate = func()
File «C:Aivenvlibsite-packagespip_internalresolutionresolvelibfactory.py», line 206, in _make_candidate_from_link
self._link_candidate_cache[link] = LinkCandidate(
File «C:Aivenvlibsite-packagespip_internalresolutionresolvelibcandidates.py», line 297, in init
super().init(
File «C:Aivenvlibsite-packagespip_internalresolutionresolvelibcandidates.py», line 162, in init
self.dist = self._prepare()
File «C:Aivenvlibsite-packagespip_internalresolutionresolvelibcandidates.py», line 231, in _prepare
dist = self._prepare_distribution()
File «C:Aivenvlibsite-packagespip_internalresolutionresolvelibcandidates.py», line 308, in _prepare_distribution
return preparer.prepare_linked_requirement(self._ireq, parallel_builds=True)
File «C:Aivenvlibsite-packagespip_internaloperationsprepare.py», line 438, in prepare_linked_requirement
return self._prepare_linked_requirement(req, parallel_builds)
File «C:Aivenvlibsite-packagespip_internaloperationsprepare.py», line 483, in _prepare_linked_requirement
local_file = unpack_url(
File «C:Aivenvlibsite-packagespip_internaloperationsprepare.py», line 165, in unpack_url
file = get_http_url(
File «C:Aivenvlibsite-packagespip_internaloperationsprepare.py», line 106, in get_http_url
from_path, content_type = download(link, temp_dir.path)
File «C:Aivenvlibsite-packagespip_internalnetworkdownload.py», line 147, in call
for chunk in chunks:
File «C:Aivenvlibsite-packagespip_internalcliprogress_bars.py», line 53, in _rich_progress_bar
for chunk in iterable:
File «C:Aivenvlibsite-packagespip_internalnetworkutils.py», line 63, in response_chunks
for chunk in response.raw.stream(
File «C:Aivenvlibsite-packagespip_vendorurllib3response.py», line 573, in stream
data = self.read(amt=amt, decode_content=decode_content)
File «C:Aivenvlibsite-packagespip_vendorurllib3response.py», line 509, in read
with self._error_catcher():
File «C:UsersreeceAppDataLocalProgramsPythonPython310libcontextlib.py», line 153, in exit
self.gen.throw(typ, value, traceback)
File «C:Aivenvlibsite-packagespip_vendorurllib3response.py», line 440, in _error_catcher
raise ReadTimeoutError(self._pool, None, «Read timed out.»)
pip._vendor.urllib3.exceptions.ReadTimeoutError: HTTPSConnectionPool(host=’download.pytorch.org’, port=443): Read timed out.
[notice] A new release of pip available: 22.2.1 -> 22.3.1
[notice] To update, run: C:AivenvScriptspython.exe -m pip install —upgrade pip
Can some one help with this error pls (RuntimeError: «log» «_vml_cpu» not implemented for ‘Half’)
same problem update now «get pull»
The yaml file for using SD 2.1 does not save as yaml file. It saves as a text file.
HTTPError Traceback (most recent call last)
/usr/local/lib/python3.8/dist-packages/huggingface_hub/utils/_errors.py in hf_raise_for_status(response, endpoint_name)
238 try:
—> 239 response.raise_for_status()
240 except HTTPError as e:
9 frames
HTTPError: 404 Client Error: Not Found for url: https://huggingface.co/CompVis/stable-diffusion-v1-4/resolve/main/vae/diffusion_pytorch_model.bin
The above exception was the direct cause of the following exception:
EntryNotFoundError Traceback (most recent call last)
EntryNotFoundError: 404 Client Error. (Request ID: Root=1-63c8ae65-55b53e701509fafd146cdd19)
Entry Not Found for url: https://huggingface.co/CompVis/stable-diffusion-v1-4/resolve/main/vae/diffusion_pytorch_model.bin.
During handling of the above exception, another exception occurred:
OSError Traceback (most recent call last)
/usr/local/lib/python3.8/dist-packages/diffusers/modeling_utils.py in _get_model_file(cls, pretrained_model_name_or_path, weights_name, subfolder, cache_dir, force_download, proxies, resume_download, local_files_only, use_auth_token, user_agent, revision)
627 )
628 except EntryNotFoundError:
—> 629 raise EnvironmentError(
630 f»{pretrained_model_name_or_path} does not appear to have a file named {weights_name}.»
631 )
OSError: CompVis/stable-diffusion-v1-4 does not appear to have a file named diffusion_pytorch_model.bin.
«any idea what must be causing this «
Hi everybody, also dealing with RuntimeError: «log» «_vml_cpu» not implemented for ‘Half’
I logged in and issued the token then went to «Files and versions» on https://huggingface.co/runwayml/stable-diffusion-v1-5 but there is nothing looking a button for accepting the license, tried a few browsers, what I am doing wrong?
Thanks!