From Wikipedia, the free encyclopedia

For a value that is sampled with an unbiased normally distributed error, the above depicts the proportion of samples that would fall between 0, 1, 2, and 3 standard deviations above and below the actual value.
The standard error (SE)[1] of a statistic (usually an estimate of a parameter) is the standard deviation of its sampling distribution[2] or an estimate of that standard deviation. If the statistic is the sample mean, it is called the standard error of the mean (SEM).[1]
The sampling distribution of a mean is generated by repeated sampling from the same population and recording of the sample means obtained. This forms a distribution of different means, and this distribution has its own mean and variance. Mathematically, the variance of the sampling mean distribution obtained is equal to the variance of the population divided by the sample size. This is because as the sample size increases, sample means cluster more closely around the population mean.
Therefore, the relationship between the standard error of the mean and the standard deviation is such that, for a given sample size, the standard error of the mean equals the standard deviation divided by the square root of the sample size.[1] In other words, the standard error of the mean is a measure of the dispersion of sample means around the population mean.
In regression analysis, the term «standard error» refers either to the square root of the reduced chi-squared statistic or the standard error for a particular regression coefficient (as used in, say, confidence intervals).
Standard error of the sample mean[edit]
Exact value[edit]
Suppose a statistically independent sample of  observations
observations  is taken from a statistical population with a standard deviation of
is taken from a statistical population with a standard deviation of  . The mean value calculated from the sample,
. The mean value calculated from the sample,  , will have an associated standard error on the mean,
, will have an associated standard error on the mean,  , given by:[1]
, given by:[1]
 .
.

Practically this tells us that when trying to estimate the value of a population mean, due to the factor  , reducing the error on the estimate by a factor of two requires acquiring four times as many observations in the sample; reducing it by a factor of ten requires a hundred times as many observations.
, reducing the error on the estimate by a factor of two requires acquiring four times as many observations in the sample; reducing it by a factor of ten requires a hundred times as many observations.
Estimate[edit]
The standard deviation of the population being sampled is seldom known. Therefore, the standard error of the mean is usually estimated by replacing with the sample standard deviation  instead:
instead:
- .

As this is only an estimator for the true «standard error», it is common to see other notations here such as:
- or alternately .


A common source of confusion occurs when failing to distinguish clearly between:
Accuracy of the estimator[edit]
When the sample size is small, using the standard deviation of the sample instead of the true standard deviation of the population will tend to systematically underestimate the population standard deviation, and therefore also the standard error. With n = 2, the underestimate is about 25%, but for n = 6, the underestimate is only 5%. Gurland and Tripathi (1971) provide a correction and equation for this effect.[3] Sokal and Rohlf (1981) give an equation of the correction factor for small samples of n < 20.[4] See unbiased estimation of standard deviation for further discussion.
Derivation[edit]
The standard error on the mean may be derived from the variance of a sum of independent random variables,[5] given the definition of variance and some simple properties thereof. If are independent samples from a population with mean and standard deviation , then we can define the total

which due to the Bienaymé formula, will have variance

where we’ve approximated the standard deviations, i.e., the uncertainties, of the measurements themselves with the best value for the standard deviation of the population. The mean of these measurements is simply given by
- .

The variance of the mean is then

The standard error is, by definition, the standard deviation of which is simply the square root of the variance:
- .

For correlated random variables the sample variance needs to be computed according to the Markov chain central limit theorem.
Independent and identically distributed random variables with random sample size[edit]
There are cases when a sample is taken without knowing, in advance, how many observations will be acceptable according to some criterion. In such cases, the sample size  is a random variable whose variation adds to the variation of
is a random variable whose variation adds to the variation of  such that,
such that,
- [6]

If has a Poisson distribution, then  with estimator
with estimator  . Hence the estimator of
. Hence the estimator of  becomes
becomes  , leading the following formula for standard error:
, leading the following formula for standard error:

(since the standard deviation is the square root of the variance)
Student approximation when σ value is unknown[edit]
In many practical applications, the true value of σ is unknown. As a result, we need to use a distribution that takes into account that spread of possible σ’s.
When the true underlying distribution is known to be Gaussian, although with unknown σ, then the resulting estimated distribution follows the Student t-distribution. The standard error is the standard deviation of the Student t-distribution. T-distributions are slightly different from Gaussian, and vary depending on the size of the sample. Small samples are somewhat more likely to underestimate the population standard deviation and have a mean that differs from the true population mean, and the Student t-distribution accounts for the probability of these events with somewhat heavier tails compared to a Gaussian. To estimate the standard error of a Student t-distribution it is sufficient to use the sample standard deviation «s» instead of σ, and we could use this value to calculate confidence intervals.
Note: The Student’s probability distribution is approximated well by the Gaussian distribution when the sample size is over 100. For such samples one can use the latter distribution, which is much simpler.
Assumptions and usage[edit]
An example of how  is used is to make confidence intervals of the unknown population mean. If the sampling distribution is normally distributed, the sample mean, the standard error, and the quantiles of the normal distribution can be used to calculate confidence intervals for the true population mean. The following expressions can be used to calculate the upper and lower 95% confidence limits, where is equal to the sample mean, is equal to the standard error for the sample mean, and 1.96 is the approximate value of the 97.5 percentile point of the normal distribution:
is used is to make confidence intervals of the unknown population mean. If the sampling distribution is normally distributed, the sample mean, the standard error, and the quantiles of the normal distribution can be used to calculate confidence intervals for the true population mean. The following expressions can be used to calculate the upper and lower 95% confidence limits, where is equal to the sample mean, is equal to the standard error for the sample mean, and 1.96 is the approximate value of the 97.5 percentile point of the normal distribution:
- Upper 95% limit and
- Lower 95% limit


In particular, the standard error of a sample statistic (such as sample mean) is the actual or estimated standard deviation of the sample mean in the process by which it was generated. In other words, it is the actual or estimated standard deviation of the sampling distribution of the sample statistic. The notation for standard error can be any one of SE, SEM (for standard error of measurement or mean), or SE.
Standard errors provide simple measures of uncertainty in a value and are often used because:
- in many cases, if the standard error of several individual quantities is known then the standard error of some function of the quantities can be easily calculated;
- when the probability distribution of the value is known, it can be used to calculate an exact confidence interval;
- when the probability distribution is unknown, Chebyshev’s or the Vysochanskiï–Petunin inequalities can be used to calculate a conservative confidence interval; and
- as the sample size tends to infinity the central limit theorem guarantees that the sampling distribution of the mean is asymptotically normal.
Standard error of mean versus standard deviation[edit]
In scientific and technical literature, experimental data are often summarized either using the mean and standard deviation of the sample data or the mean with the standard error. This often leads to confusion about their interchangeability. However, the mean and standard deviation are descriptive statistics, whereas the standard error of the mean is descriptive of the random sampling process. The standard deviation of the sample data is a description of the variation in measurements, while the standard error of the mean is a probabilistic statement about how the sample size will provide a better bound on estimates of the population mean, in light of the central limit theorem.[7]
Put simply, the standard error of the sample mean is an estimate of how far the sample mean is likely to be from the population mean, whereas the standard deviation of the sample is the degree to which individuals within the sample differ from the sample mean.[8] If the population standard deviation is finite, the standard error of the mean of the sample will tend to zero with increasing sample size, because the estimate of the population mean will improve, while the standard deviation of the sample will tend to approximate the population standard deviation as the sample size increases.
Extensions[edit]
Finite population correction (FPC)[edit]
The formula given above for the standard error assumes that the population is infinite. Nonetheless, it is often used for finite populations when people are interested in measuring the process that created the existing finite population (this is called an analytic study). Though the above formula is not exactly correct when the population is finite, the difference between the finite- and infinite-population versions will be small when sampling fraction is small (e.g. a small proportion of a finite population is studied). In this case people often do not correct for the finite population, essentially treating it as an «approximately infinite» population.
If one is interested in measuring an existing finite population that will not change over time, then it is necessary to adjust for the population size (called an enumerative study). When the sampling fraction (often termed f) is large (approximately at 5% or more) in an enumerative study, the estimate of the standard error must be corrected by multiplying by a »finite population correction» (a.k.a.: FPC):[9]
[10]

which, for large N:

to account for the added precision gained by sampling close to a larger percentage of the population. The effect of the FPC is that the error becomes zero when the sample size n is equal to the population size N.
This happens in survey methodology when sampling without replacement. If sampling with replacement, then FPC does not come into play.
Correction for correlation in the sample[edit]

Expected error in the mean of A for a sample of n data points with sample bias coefficient ρ. The unbiased standard error plots as the ρ = 0 diagonal line with log-log slope −½.
If values of the measured quantity A are not statistically independent but have been obtained from known locations in parameter space x, an unbiased estimate of the true standard error of the mean (actually a correction on the standard deviation part) may be obtained by multiplying the calculated standard error of the sample by the factor f:

where the sample bias coefficient ρ is the widely used Prais–Winsten estimate of the autocorrelation-coefficient (a quantity between −1 and +1) for all sample point pairs. This approximate formula is for moderate to large sample sizes; the reference gives the exact formulas for any sample size, and can be applied to heavily autocorrelated time series like Wall Street stock quotes. Moreover, this formula works for positive and negative ρ alike.[11] See also unbiased estimation of standard deviation for more discussion.
See also[edit]
- Illustration of the central limit theorem
- Margin of error
- Probable error
- Standard error of the weighted mean
- Sample mean and sample covariance
- Standard error of the median
- Variance
References[edit]
- ^ a b c d Altman, Douglas G; Bland, J Martin (2005-10-15). «Standard deviations and standard errors». BMJ: British Medical Journal. 331 (7521): 903. doi:10.1136/bmj.331.7521.903. ISSN 0959-8138. PMC 1255808. PMID 16223828.
- ^ Everitt, B. S. (2003). The Cambridge Dictionary of Statistics. CUP. ISBN 978-0-521-81099-9.
- ^ Gurland, J; Tripathi RC (1971). «A simple approximation for unbiased estimation of the standard deviation». American Statistician. 25 (4): 30–32. doi:10.2307/2682923. JSTOR 2682923.
- ^ Sokal; Rohlf (1981). Biometry: Principles and Practice of Statistics in Biological Research (2nd ed.). p. 53. ISBN 978-0-7167-1254-1.
- ^ Hutchinson, T. P. (1993). Essentials of Statistical Methods, in 41 pages. Adelaide: Rumsby. ISBN 978-0-646-12621-0.
- ^ Cornell, J R, and Benjamin, C A, Probability, Statistics, and Decisions for Civil Engineers, McGraw-Hill, NY, 1970, ISBN 0486796094, pp. 178–9.
- ^ Barde, M. (2012). «What to use to express the variability of data: Standard deviation or standard error of mean?». Perspect. Clin. Res. 3 (3): 113–116. doi:10.4103/2229-3485.100662. PMC 3487226. PMID 23125963.
- ^ Wassertheil-Smoller, Sylvia (1995). Biostatistics and Epidemiology : A Primer for Health Professionals (Second ed.). New York: Springer. pp. 40–43. ISBN 0-387-94388-9.
- ^ Isserlis, L. (1918). «On the value of a mean as calculated from a sample». Journal of the Royal Statistical Society. 81 (1): 75–81. doi:10.2307/2340569. JSTOR 2340569. (Equation 1)
- ^ Bondy, Warren; Zlot, William (1976). «The Standard Error of the Mean and the Difference Between Means for Finite Populations». The American Statistician. 30 (2): 96–97. doi:10.1080/00031305.1976.10479149. JSTOR 2683803. (Equation 2)
- ^ Bence, James R. (1995). «Analysis of Short Time Series: Correcting for Autocorrelation». Ecology. 76 (2): 628–639. doi:10.2307/1941218. JSTOR 1941218.
A standard error of measurement, often denoted SEm, estimates the variation around a “true” score for an individual when repeated measures are taken.
It is calculated as:
SEm = s√1-R
where:
- s: The standard deviation of measurements
- R: The reliability coefficient of a test
Note that a reliability coefficient ranges from 0 to 1 and is calculated by administering a test to many individuals twice and calculating the correlation between their test scores.
The higher the reliability coefficient, the more often a test produces consistent scores.
Example: Calculating a Standard Error of Measurement
Suppose an individual takes a certain test 10 times over the course of a week that aims to measure overall intelligence on a scale of 0 to 100. They receive the following scores:
Scores: 88, 90, 91, 94, 86, 88, 84, 90, 90, 94
The sample mean is 89.5 and the sample standard deviation is 3.17.
If the test is known to have a reliability coefficient of 0.88, then we would calculate the standard error of measurement as:
SEm = s√1-R = 3.17√1-.88 = 1.098
How to Use SEm to Create Confidence Intervals
Using the standard error of measurement, we can create a confidence interval that is likely to contain the “true” score of an individual on a certain test with a certain degree of confidence.
If an individual receives a score of x on a test, we can use the following formulas to calculate various confidence intervals for this score:
- 68% Confidence Interval = [x – SEm, x + SEm]
- 95% Confidence Interval = [x – 2*SEm, x + 2*SEm]
- 99% Confidence Interval = [x – 3*SEm, x + 3*SEm]
For example, suppose an individual scores a 92 on a certain test that is known to have a SEm of 2.5. We could calculate a 95% confidence interval as:
- 95% Confidence Interval = [92 – 2*2.5, 92 + 2*2.5] = [87, 97]
This means we are 95% confident that an individual’s “true” score on this test is between 87 and 97.
Reliability & Standard Error of Measurement
There exists a simple relationship between the reliability coefficient of a test and the standard error of measurement:
- The higher the reliability coefficient, the lower the standard error of measurement.
- The lower the reliability coefficient, the higher the standard error of measurement.
To illustrate this, consider an individual who takes a test 10 times and has a standard deviation of scores of 2.
If the test has a reliability coefficient of 0.9, then the standard error of measurement would be calculated as:
- SEm = s√1-R = 2√1-.9 = 0.632
However, if the test has a reliability coefficient of 0.5, then the standard error of measurement would be calculated as:
- SEm = s√1-R = 2√1-.5 = 1.414
This should make sense intuitively: If the scores of a test are less reliable, then the error in the measurement of the “true” score will be higher.
Errors are of various types and impact the research process in different ways. Here’s a deep exploration of the standard error, the types, implications, formula, and how to interpret the values
What is a Standard Error?
The standard error is a statistical measure that accounts for the extent to which a sample distribution represents the population of interest using standard deviation. You can also think of it as the standard deviation of your sample in relation to your target population.
The standard error allows you to compare two similar measures in your sample data and population. For example, the standard error of the mean measures how far the sample mean (average) of the data is likely to be from the true population mean—the same applies to other types of standard errors.
Explore: Survey Errors To Avoid: Types, Sources, Examples, Mitigation
Why is Standard Error Important?
First, the standard error of a sample accounts for statistical fluctuation.
Researchers depend on this statistical measure to know how much sampling fluctuation exists in their sample data. In other words, it shows the extent to which a statistical measure varies from sample to population.
In addition, standard error serves as a measure of accuracy. Using standard error, a researcher can estimate the efficiency and consistency of a sample to know precisely how a sampling distribution represents a population.
How Many Types of Standard Error Exist?
There are five types of standard error which are:
- Standard error of the mean
- Standard error of measurement
- Standard error of the proportion
- Standard error of estimate
- Residual Standard Error
1. Standard Error of the Mean (SEM)
The standard error of the mean accounts for the difference between the sample mean and the population mean. In other words, it quantifies how much variation is expected to be present in the sample mean that would be computed from every possible sample, of a given size, taken from the population.
How to Find SEM (With Formula)
SEM = Standard Deviation ÷ √n
Where;
n = sample size
Suppose that the standard deviation of observation is 15 with a sample size of 100. Using this formula, we can deduce the standard error of the mean as follows:
SEM = 15 ÷ √100
Standard Error of Mean in 1.5
2. Standard Error of Measurement
The standard error of measurement accounts for the consistency of scores within individual subjects in a test or examination.
This means it measures the extent to which estimated test or examination scores are spread around a true score.
A more formal way to look at it is through the 1985 lens of Aera, APA, and NCME. Here, they define a standard error as “the standard deviation of errors of measurement that is associated with the test scores for a specified group of test-takers….”
Read: 7 Types of Data Measurement Scales in Research
How to Find Standard Error of Measurement
Where;
rxx is the reliability of the test and is calculated as:
Rxx = S2T / S2X
Where;
S2T = variance of the true scores.
S2X = variance of the observed scores.
Suppose an organization has a reliability score of 0.4 and a standard deviation of 2.56. This means
SEm = 2.56 × √1–0.4 = 1.98
3. Standard Error of the Estimate
The standard error of the estimate measures the accuracy of predictions in sampling, research, and data collection. Specifically, it measures the distance that the observed values fall from the regression line which is the single line with the smallest overall distance from the line to the points.
How to Find Standard Error of the Estimate
The formula for standard error of the estimate is as follows:
Where;
σest is the standard error of the estimate;
Y is an actual score;
Y’ is a predicted score, and;
N is the number of pairs of scores.
The numerator is the sum of squared differences between the actual scores and the predicted scores.
4. Standard Error of Proportion
The standard of error of proportion in an observation is the difference between the sample proportion and the population proportion of your target audience. In more technical terms, this variable is the spread of the sample proportion about the population proportion.
How to Find Standard Error of the Proportion
The formula for calculating the standard error of the proportion is as follows:
Where;
P (hat) is equal to x ÷ n (with number of success x and the total number of observations of n)
5. Residual Standard Error
Residual standard error accounts for how well a linear regression model fits the observation in a systematic investigation. A linear regression model is simply a linear equation representing the relationship between two variables, and it helps you to predict similar variables.
How to Calculate Residual Standard Error
The formula for residual standard error is as follows:
Residual standard error = √Σ(y – ŷ)2/df
where:
y: The observed value
ŷ: The predicted value
df: The degrees of freedom, calculated as the total number of observations – total number of model parameters.
As you interpret your data, you should note that the smaller the residual standard error, the better a regression model fits a dataset, and vice versa.
How Do You Calculate Standard Error?
The formula for calculating standard error is as follows:
Where
σ – Standard deviation
n – Sample size, i.e., the number of observations in the sample
Here’s how this works in real-time.
Suppose the standard deviation of a sample is 1.5 with 4 as the sample size. This means:
Standard Error = 1.5 ÷ √4
That is; 1.5 ÷2 = 0.75
Alternatively, you can use a standard error calculator to speed up the process for larger data sets.
How to Interpret Standard Error Values
As stated earlier, researchers use the standard error to measure the reliability of observation. This means it allows you to compare how far a particular variable in the sample data is from the population of interest.
Calculating standard error is just one piece of the puzzle; you need to know how to interpret your data correctly and draw useful insights for your research. Generally, a small standard error is an indication that the sample mean is a more accurate reflection of the actual population mean, while a large standard error means the opposite.
Standard Error Example
Suppose you need to find the standard error of the mean of a data set using the following information:
Standard Deviation: 1.5
n = 13
Standard Error of the Mean = Standard Deviation ÷ √n
1.5 ÷ √13 = 0.42
How Should You Report the Standard Error?
After calculating the standard error of your observation, the next thing you should do is present this data as part of the numerous variables affecting your observation. Typically, researchers report the standard error alongside the mean or in a confidence interval to communicate the uncertainty around the mean.
Applications of Standard Error
The most common application of standard error are in statistics and economics. In statistics, standard error allows researchers to determine the confidence interval of their data sets, and in some cases, the margin of error. Researchers also use standard error in hypothesis testing and regression analysis.
FAQs About Standard Error
- What Is the Difference Between Standard Deviation and Standard Error of the Mean?
The major difference between standard deviation and standard error of the mean is how they account for the differences between the sample data and the population of interest.
Researchers use standard deviation to measure the variability or dispersion of a data set to its mean. On the other hand, the standard error of the mean accounts for the difference between the mean of the data sample and that of the target population.
Something else to note here is that the standard error of a sample is always smaller than the corresponding standard deviation.
- What Is The Symbol for Standard Error?
During calculation, the standard error is represented as σx̅.
- Is Standard Error the Same as Margin of Error?
No. Margin of Error and standard error are not the same. Researchers use the standard error to measure the preciseness of an estimate of a population, meanwhile margin of error accounts for the degree of error in results received from random sampling surveys.
The standard error is calculated as s / √n where;
s: Sample standard deviation
n: Sample size
On the other hand, margin of error = z*(s/√n) where:
z: Z value that corresponds to a given confidence level
s: Sample standard deviation
n: Sample size
What Is the Standard Error?
The standard error (SE) of a statistic is the approximate standard deviation of a statistical sample population.
The standard error is a statistical term that measures the accuracy with which a sample distribution represents a population by using standard deviation. In statistics, a sample mean deviates from the actual mean of a population; this deviation is the standard error of the mean.
Key Takeaways
- The standard error (SE) is the approximate standard deviation of a statistical sample population.
- The standard error describes the variation between the calculated mean of the population and one which is considered known, or accepted as accurate.
- The more data points involved in the calculations of the mean, the smaller the standard error tends to be.
Standard Error
Understanding Standard Error
The term «standard error» is used to refer to the standard deviation of various sample statistics, such as the mean or median. For example, the «standard error of the mean» refers to the standard deviation of the distribution of sample means taken from a population. The smaller the standard error, the more representative the sample will be of the overall population.
The relationship between the standard error and the standard deviation is such that, for a given sample size, the standard error equals the standard deviation divided by the square root of the sample size. The standard error is also inversely proportional to the sample size; the larger the sample size, the smaller the standard error because the statistic will approach the actual value.
The standard error is considered part of inferential statistics. It represents the standard deviation of the mean within a dataset. This serves as a measure of variation for random variables, providing a measurement for the spread. The smaller the spread, the more accurate the dataset.
Standard error and standard deviation are measures of variability, while central tendency measures include mean, median, etc.
Formula and Calculation of Standard Error
The standard error of an estimate can be calculated as the standard deviation divided by the square root of the sample size:
SE = σ / √n
where
- σ = the population standard deviation
- √n = the square root of the sample size
If the population standard deviation is not known, you can substitute the sample standard deviation, s, in the numerator to approximate the standard error.
Requirements for Standard Error
When a population is sampled, the mean, or average, is generally calculated. The standard error can include the variation between the calculated mean of the population and one which is considered known, or accepted as accurate. This helps compensate for any incidental inaccuracies related to the gathering of the sample.
In cases where multiple samples are collected, the mean of each sample may vary slightly from the others, creating a spread among the variables. This spread is most often measured as the standard error, accounting for the differences between the means across the datasets.
The more data points involved in the calculations of the mean, the smaller the standard error tends to be. When the standard error is small, the data is said to be more representative of the true mean. In cases where the standard error is large, the data may have some notable irregularities.
The standard deviation is a representation of the spread of each of the data points. The standard deviation is used to help determine the validity of the data based on the number of data points displayed at each level of standard deviation. Standard errors function more as a way to determine the accuracy of the sample or the accuracy of multiple samples by analyzing deviation within the means.
Standard Error vs. Standard Deviation
The standard error normalizes the standard deviation relative to the sample size used in an analysis. Standard deviation measures the amount of variance or dispersion of the data spread around the mean. The standard error can be thought of as the dispersion of the sample mean estimations around the true population mean. As the sample size becomes larger, the standard error will become smaller, indicating that the estimated sample mean value better approximates the population mean.
Example of Standard Error
Say that an analyst has looked at a random sample of 50 companies in the S&P 500 to understand the association between a stock’s P/E ratio and subsequent 12-month performance in the market. Assume that the resulting estimate is -0.20, indicating that for every 1.0 point in the P/E ratio, stocks return 0.2% poorer relative performance. In the sample of 50, the standard deviation was found to be 1.0.
The standard error is thus:
SE = 1.0/√50 = 1/7.07 = 0.141
Therefore, we would report the estimate as -0.20% ± 0.14, giving us a confidence interval of (-0.34 — -0.06). The true mean value of the association of the P/E on returns of the S&P 500 would therefore fall within that range with a high degree of probability.
Say now that we increase the sample of stocks to 100 and find that the estimate changes slightly from -0.20 to -0.25, and the standard deviation falls to 0.90. The new standard error would thus be:
SE = 0.90/√100 = 0.90/10 = 0.09.
The resulting confidence interval becomes -0.25 ± 0.09 = (-0.34 — -0.16), which is a tighter range of values.
What Is Meant by Standard Error?
Standard error is intuitively the standard deviation of the sampling distribution. In other words, it depicts how much disparity there is likely to be in a point estimate obtained from a sample relative to the true population mean.
What Is a Good Standard Error?
Standard error measures the amount of discrepancy that can be expected in a sample estimate compared to the true value in the population. Therefore, the smaller the standard error the better. In fact, a standard error of zero (or close to it) would indicate that the estimated value is exactly the true value.
How Do You Find the Standard Error?
The standard error takes the standard deviation and divides it by the square root of the sample size. Many statistical software packages automatically compute standard errors.
The Bottom Line
The standard error (SE) measures the dispersion of estimated values obtained from a sample around the true value to be found in the population. Statistical analysis and inference often involves drawing samples and running statistical tests to determine associations and correlations between variables. The standard error thus tells us with what degree of confidence we can expect the estimated value to approximate the population value.
Standard error of the mean measures how spread out the means of the sample can be from the actual population mean. Standard error allows you to build a relationship between a sample statistic (computed from a smaller sample of the population) and the population’s actual parameter.
 Standard Error – A practical guide with examples. Photo by Sergio.
Standard Error – A practical guide with examples. Photo by Sergio.
What is Standard Error?
The sample error serves as a means to understand the actual population parameter (like population mean) without actually estimating it.
Consider the following scenario:
A researcher ‘X’ is collecting data from a large population of voters. For practical reasons he can’t reach out to each and every voter. So, only a small randomized sample (of voters) is selected for data collection.
Once the data for the sample is collected, you calculate the mean (or any statistic) of that sample. But then, this mean you just computed is only the sample mean. It cannot be considered the entire population’s mean. You can however expect it to be somewhere close to population’s mean.
So how can you know the actual population mean?
While its not possible to compute the exactly value, you can use standard error to estimate how far the sample mean may spread from the actual population mean.
To be more precise,
The Standard Error of the Mean describes how far a sample mean may vary from the population mean.
In this post, you will understand clearly:
- What Standard Error Tells Us?
- What is the Sample Error Formula?
- How to calculate Standard Error?
- How to use standard error to compute confidence interval?
- Example Problem and solution
How to understand Standard Error?
Let’s first clearly understand the intuition behind and the need for standard error.
Now, let’s suppose you are working in agriculture domain and you want to know the annual yield of a particular variety of coconut trees. While the entire population of coconut trees has a certain mean (and standard deviation) of annual yield, it is not practical to take measurements of each and every tree out there.
So, what do you do?
To estimate this you collect samples of coconut yield (number of nuts per tree per year) from different trees. And to keep your findings unbiased, you collect samples across different places.
MLPlus Industry Data Scientist Program
Do you want to learn Data Science from experienced Data Scientists?
Build your data science career with a globally recognised, industry-approved qualification. Solve projects with real company data and become a certified Data Scientist in less than 12 months.
.
![]()
Get Free Complete Python Course
Build your data science career with a globally recognised, industry-approved qualification. Get the mindset, the confidence and the skills that make Data Scientist so valuable.
Let’s say, you collected data from approx ~5 trees per sample from different places and the numbers are shown below.
# Annual yield of coconut
sample1 = [400, 420, 470, 510, 590]
sample2 = [430, 500, 570, 620, 710, 800, 900]
sample3 = [360, 410, 490, 550, 640]
In above data, the variables sample1, sample2 and sample3 contain the samples of annual yield values collected, where each number represents the yield of one individual tree.
Observe that the yield varies not just across the trees, but also across the different samples.
Although we compute means of the samples, we are actually not interested in the means of the sample, but the overall mean annual yield of coconut of this variety.
Now, you may ask: ‘Why can’t we just put the values from all these samples in one bucket and simply compute the mean and standard deviation and consider that as the population’s parameter?‘
Well, the problem is, if you do that practically what happens is, as you receive few more samples, the real population’s parameter begins to come out which is likely to be (slightly) different from the parameter you computed earlier.
Below is a code demo.
from statistics import mean, stdev
# Overall mean from the first two samples
sample1 = [400, 420, 470, 510, 590]
sample2 = [430, 500, 570, 620, 710, 800, 900]
print("Mean of first two samples: ", mean(sample1 + sample2))
# Overall mean after introducing 3rd sample
sample3 = [360, 410, 490, 550, 640]
print("Mean after including 3rd sample: ", mean(sample1 + sample2 + sample3))
Output:
Mean of first two samples: 576.6666666666666
Mean after including 3rd sample: 551.1764705882352
As you add more and more samples, the computed parameters keep changing.
So how to tackle this?
If you notice, each sample has its own mean that varies between a particular range. This mean (of the sample) has its own standard deviation. This measure of standard deviation of the mean is called the standard error of the mean.
Its important to note, it is different from the standard deviation of the data. The difference is, while standard deviation tells you how the overall data is distributed around the mean, the standard error tells you how the mean itself is distributed.
This way, it can be used to generalize the sample mean so it can be used as an estimate of the whole population.
In fact, standard error can be generalized to any statistic like standard deviation, median etc. For example, if you compute the standard deviation of the standard deviations (of the samples), it is called, standard error of the standard deviation. Feels like a tongue twister. But most commonly, when someone mention ‘Standard error’ it typically refers to the ‘Standard error of of the mean’.
What is the Formula?
To calculate standard error, you simply divide the standard deviation of a given sample by the square root of the total number of items in the sample.
$$SE_{bar{x}} = frac{sigma}{sqrt{n}}$$
where, $SE_{bar{x}}$ is the standard error of the mean, $sigma$ is the standard deviation of the sample and n is the number of items in sample.
Do not confuse this with standard deviation. Because standard error of the sample statistic (like mean) is typically much smaller than the population standard deviation.
Notice few things here:
- The Standard error depends on the number of items in the sample. As you increase the number of items in the sample, lower will be the standard error and more certain you will be about the estimates.
- It uses statistics (standard deviation and number of items) computed from the sample itself, and not of the population. That is, you don’t need to know the population parameters beforehand to compute standard error. This makes it pretty convenient.
- Standard error can also be used as an estimate of how representative a given sample is of a population. The smaller the value, more representative is the sample of the whole population.
Below is a computation for the standard error of the mean:
# Compute Standard Error
sample1 = [400, 420, 470, 510, 590]
se = stdev(sample1)/len(sample1)
print('Standard Error: ', round(se, 2))
Standard Error: 15.19
How to calculate standard error?
Problem Statement
A school aptitude test for 15 year old students studying in a particular territory’s curriculum, is designed to have a mean score of 80 units and a standard deviation of 10 units. A sample of 15 answer papers has a mean score of 85. Can we assume that these 15 scores come from the designated population?
Solution
Our task is to determine if this sample comes from the above mentioned population.
How to solve this?
We approach this problem by computing the standard error of the sample means and use it to compute the confidence interval between which the sample means are expected to fall.
If the given sample mean falls inside this interval, then its safe to assume that the sample comes from the given population.
Time to get into the math.
Using standard error to compute confidence interval
Standard error is often used to compute confidence intervals
We know, n = 15, x_bar = 85, σ = 10
$$SE_bar{x} = frac{sigma}{sqrt{n}} = frac{10}{sqrt{15}} = 2.581$$
From a property of normal distribution, we can say with 95% confidence level that the sample means are expected to lie within a confidence interval of plus or minus two standard errors of the sample statistic from the population parameter.
But where did ‘normal distribution’ come from? You may wonder how we can directly assume a normal distribution is followed in this case. Or rather shouldn’t we test if the sample follows a normal distribution first before computing the confidence intervals.
Well, that’s NOT required. Because, the Central Limit Theorem tells us that even if a population is not normally distributed, a collection of sample means from that population will infact follow a normal distribution. So, its a valid assumption.
Back to the problem, let’s compute the confidence intervals for 95% Confidence Level.
- Lower Limit :
80 - (2*2.581)= 74.838 - Upper Limit :
80 + (2*2.581)= 85.162
So, 95% of our 15 item sample means are expected to fall between 74.838 and 85.162.
Since the sample mean of 85.0 lies within the computed range, there is no reason to believe that the sample does not belong to the population.
Conclusion
Standard error is a commonly used term that we sometimes ignore to fully understand its significance. I hope the concept is clear and you can now relate how you can use standard error in appropriate situations.
Next topic: Confidence Interval
What is a Standard Error Formula?
The standard error is the error that arises in the sampling distribution while performing statistical analysis. It is a standard deviation variant as both concepts correspond to the spread measures. A high standard error corresponds to the higher spreading of data for the undertaken sample. Calculating the standard error formula is done for a sample. At the same time, the standard deviation determines the population.
Table of contents
- What is a Standard Error Formula?
- Explanation
- Example of Standard error formula
- Standard Error Calculator
- Relevance and Use
- Standard Error Formula in Excel
- Recommended Articles
Therefore, a standard error on mean one would express and determine as per the relationship described as follows: –
σ͞x = σ/√n

You are free to use this image on your website, templates, etc., Please provide us with an attribution linkArticle Link to be Hyperlinked
For eg:
Source: Standard Error Formula (wallstreetmojo.com)
Here,
- The standard error expressed as σ͞x.
- The standard deviation of the population is expressed as σ.
- The number of variables in the sample expressed as n.
In statistical analysis, mean, median, and mode are central tendencyCentral Tendency is a statistical measure that displays the centre point of the entire Data Distribution & you can find it using 3 different measures, i.e., Mean, Median, & Mode.read more measures. The standard deviation, variance, and standard error on mean classifies as the variability measures. The standard error on mean for sample data is directly related to the standard deviation of the larger population and inversely proportional or related to the square rootThe Square Root function is an arithmetic function built into Excel that is used to determine the square root of a given number. To use this function, type the term =SQRT and hit the tab key, which will bring up the SQRT function. Moreover, this function accepts a single argument.read more of several variables taken up for making a sample. Hence, if the sample sizeThe sample size formula depicts the relevant population range on which an experiment or survey is conducted. It is measured using the population size, the critical value of normal distribution at the required confidence level, sample proportion and margin of error.read more is small, then there could be an equal probability that the standard error would also be large.
Explanation
One can explain the formula for standard error on mean by using the following steps:
- Identify and organize the sample and determine the number of variables.
- Next, the average means of the sample corresponds to the number of variables present in the sample.
- Next, determine the standard deviation of the sample.
- Next, determine the square root of the number of variables taken up in the sample.
- Now, divide the standard deviation computed in step 3 by the resulting value in step 4 to arrive at the standard error.
Example of Standard error formula
Below are the formula examples for calculating standard error.
You can download this Standard Error Formula Excel Template here – Standard Error Formula Excel Template
Example #1
Let us take the example of stock ABC. For 30 years, the stock delivered a mean dollar return of $45. In addition, one observed that the stock delivered returns with a standard deviation of $2. Help the investor to calculate the overall standard error on the mean returns offered by the stock ABC.
Solution:
- Standard Deviation (σ) = $2
- Number of Years (n) = 30
- Mean Dollar Return = $45
The calculation of standard error is as follows:
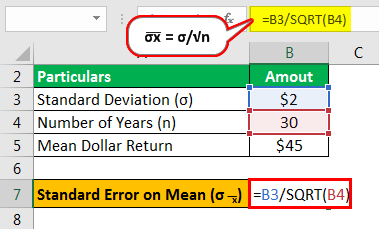
- σ͞x = σ/√n
- = $2/√30
- = $2/ 5.4773
The standard error is,

- σ͞x =$0.3651
Therefore, the investment offers a dollar standard error on the mean of $0.36515 to the investor when holding the stock ABC position for 30 years. However, if the stock held for a higher investment horizon, then the standard error on the dollar means would reduce significantly.
Example #2
Let us take the example of an investor who has received the following returns on stock XYZ: –
| Investment Year | Return Offered |
|---|---|
| 1 | 20% |
| 2 | 25% |
| 3 | 5% |
| 4 | 10% |
Help the investor calculate the overall standard error on the mean returns offered by the stock XYZ.
Solution:
First, determine the average mean of the returns as displayed below: –

- ͞X = (x1+x2+x3+x4)/number of years
- = (20+25+5+10)/4
- =15%
Now, determine the standard deviation of the returns as displayed below: –
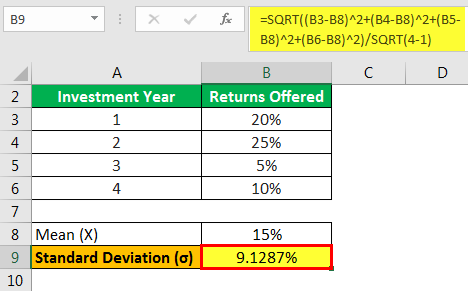
- σ = √ ((x1-͞X)2 + (x2-͞X)2 + (x3-͞X)2 + (x4-͞X)2) / √ (number of years -1)
- = √ ((20-15) 2 + (25-15) 2 + (5-15) 2 + (10-15) 2) / √ (4-1)
- = (√ (5) 2 + (10) 2 + (-10) 2 + (-5) 2 ) / √ (3)
- = (√25+100+100+25)/ √ (3)
- =√250 /√ 3
- =√83.3333
- = 9.1287%
Now, the calculation of standard error is as follows,

- σ͞x = σ/√n
- = 9.128709/√4
- = 9.128709/ 2
The standard Error is,

- σ͞x = 4.56%
Therefore, the investment offers a dollar standard error on the mean of 4.56% to the investor when holding the stock XYZ position for 4 years.
Standard Error Calculator
You can use the following calculator.
| σ | |
| n | |
| Standard Error Formula | |
Relevance and Use
The standard error tends to be high if the sample size for the analysis is small. Therefore, a sample is always taken from a larger population, which comprises a larger size of variables. It always helps the statistician determine the sample mean’s credibility concerning the population mean.
A large standard error tells the statistician that the sample is not uniform concerning the population mean. There is a large variation in the sample concerning the population. Similarly, a small standard error tells the statistician that the sample is uniform concerning the population mean. There is no or small variation in the sample concerning the population.
One should not mix it with the standard deviation. Instead, one should calculate the standard deviation for the entire population. The standard errorStandard Error (SE) is a metric that measures the accuracy of a sample distribution that signifies a population by using standard deviation. In other words, it is a measure to the dispersion of a sample mean concerned with the population mean and is not standard deviation.read more, on the other hand, is determined for the sample mean.
Standard Error Formula in Excel
Now, let us take the excel example to illustrate the concept of the standard error formula in the Excel template below. Suppose the school administration wants to determine the standard error on mean on the height of the football players.
The sample comprises of following values: –

Help the administration assess standard error on mean.
Step 1: Determine the mean as displayed below: –

Step 2: Determine the standard deviation as displayed below: –

Step 3: Determine the standard error on mean as displayed below: –

Therefore, the standard error on the mean for football players is 1.846 inches. The management should observe that it is significantly large. Therefore, the sample data taken up for the analysis is not uniform and displays a large variance.
The management should either omit smaller players or add significantly taller players to balance the football team’s average height by replacing them with individuals with smaller heights compared to their peers.
Recommended Articles
This article has been a guide to Standard Error Formula. Here, we discuss the formula for calculating the mean, standard error, examples, and downloadable Excel sheet. You can learn more from the following articles: –
- EBITDA Margin Formula
- Gross Margin Formula
- Formula of Relative Standard Deviation
- Formula of Margin of Error
A mathematical tool used in statistics to measure variability
What is Standard Error?
Standard error is a mathematical tool used in statistics to measure variability. It enables one to arrive at an estimation of what the standard deviation of a given sample is. It is commonly known by its abbreviated form – SE.

Standard error is used to estimate the efficiency, accuracy, and consistency of a sample. In other words, it measures how precisely a sampling distribution represents a population.
It can be applied in statistics and economics. It is especially useful in the field of econometrics, where researchers use it in performing regression analyses and hypothesis testing. It is also used in inferential statistics, where it forms the basis for the construction of the confidence intervals.
Some commonly used measures in the field of statistics include:
- Standard error of the mean (SEM)
- Standard error of the variance
- Standard error of the median
- Standard error of a regression coefficient
Calculating Standard Error of the Mean (SEM)
The SEM is calculated using the following formula:
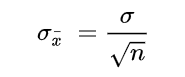
Where:
- σ – Population standard deviation
- n – Sample size, i.e., the number of observations in the sample
In a situation where statisticians are ignorant of the population standard deviation, they use the sample standard deviation as the closest replacement. SEM can then be calculated using the following formula. One of the primary assumptions here is that observations in the sample are statistically independent.
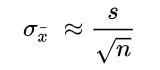
Where:
- s – Sample standard deviation
- n – Sample size, i.e., the number of observations in the sample
Importance of Standard Error
When a sample of observations is extracted from a population and the sample mean is calculated, it serves as an estimate of the population mean. Almost certainly, the sample mean will vary from the actual population mean. It will aid the statistician’s research to identify the extent of the variation. It is where the standard error of the mean comes into play.
When several random samples are extracted from a population, the standard error of the mean is essentially the standard deviation of different sample means from the population mean.
However, multiple samples may not always be available to the statistician. Fortunately, the standard error of the mean can be calculated from a single sample itself. It is calculated by dividing the standard deviation of the observations in the sample by the square root of the sample size.
Relationship between SEM and the Sample Size
Intuitively, as the sample size increases, the sample becomes more representative of the population.
For example, consider the marks of 50 students in a class in a mathematics test. Two samples A and B of 10 and 40 observations, respectively, are extracted from the population. It is logical to assert that the average marks in sample B will be closer to the average marks of the whole class than the average marks in sample A.
Thus, the standard error of the mean in sample B will be smaller than that in sample A. The standard error of the mean will approach zero with the increasing number of observations in the sample, as the sample becomes more and more representative of the population, and the sample mean approaches the actual population mean.
It is evident from the mathematical formula of the standard error of the mean that it is inversely proportional to the sample size. It can be verified using the SEM formula that if the sample size increases from 10 to 40 (becomes four times), the standard error will be half as big (reduces by a factor of 2).
Standard Deviation vs. Standard Error of the Mean
Standard deviation and standard error of the mean are both statistical measures of variability. While the standard deviation of a sample depicts the spread of observations within the given sample regardless of the population mean, the standard error of the mean measures the degree of dispersion of sample means around the population mean.
Related Readings
CFI is the official provider of the Business Intelligence & Data Analyst (BIDA)® certification program, designed to transform anyone into a world-class financial analyst.
To keep learning and developing your knowledge of financial analysis, we highly recommend the additional resources below:
- Coefficient of Variation
- Basic Statistics Concepts for Finance
- Regression Analysis
- Arithmetic Mean
- See all data science resources
Стандартная ошибка измерения: определение и пример
17 авг. 2022 г.
читать 2 мин
Стандартная ошибка измерения , часто обозначаемая как SE m , оценивает отклонение от «истинного» показателя для индивидуума при повторных измерениях.
Он рассчитывается как:
SE m = s√ 1-R
куда:
- s: стандартное отклонение измерений
- R: коэффициент надежности теста.
Обратите внимание, что коэффициент надежности находится в диапазоне от 0 до 1 и рассчитывается путем двукратного проведения теста для многих людей и расчета корреляции между их результатами теста.
Чем выше коэффициент надежности, тем чаще тест дает стабильные результаты.
Пример: расчет стандартной ошибки измерения
Предположим, человек проходит определенный тест 10 раз в течение недели, целью которого является измерение общего интеллекта по шкале от 0 до 100. Он получает следующие баллы:
Очки: 88, 90, 91, 94, 86, 88, 84, 90, 90, 94.
Среднее значение выборки равно 89,5, а стандартное отклонение выборки равно 3,17.
Если известно, что тест имеет коэффициент надежности 0,88, то мы рассчитываем стандартную ошибку измерения как:
SE м = с√1 -R = 3,17√1-0,88 = 1,098
Как использовать SE m для создания доверительных интервалов
Используя стандартную ошибку измерения, мы можем создать доверительный интервал, который, вероятно, будет содержать «истинную» оценку человека по определенному тесту с определенной степенью достоверности.
Если человек получает по тесту оценку x , мы можем использовать следующие формулы для расчета различных доверительных интервалов для этой оценки:
- 68% доверительный интервал = [ x – SE m , x + SE m ]
- 95% доверительный интервал = [ x – 2*SE m , x + 2*SE m ]
- 99% доверительный интервал = [ x – 3*SE m , x + 3*SE m ]
Например, предположим, что человек набрал 92 балла по определенному тесту, который, как известно, имеет SE m 2,5. Мы могли бы рассчитать 95% доверительный интервал как:
- 95% доверительный интервал = [92 – 2*2,5, 92 + 2*2,5] = [87, 97]
Это означает, что мы на 95% уверены в том, что «истинный» результат этого теста человека находится между 87 и 97.
Надежность и стандартная ошибка измерения
Существует простая зависимость между коэффициентом надежности теста и стандартной ошибкой измерения:
- Чем выше коэффициент надежности, тем меньше стандартная ошибка измерения.
- Чем ниже коэффициент надежности, тем выше стандартная ошибка измерения.
Чтобы проиллюстрировать это, рассмотрим человека, который проходит тест 10 раз и имеет стандартное отклонение баллов, равное 2 .
Если тест имеет коэффициент надежности 0,9 , то стандартная ошибка измерения будет рассчитываться как:
- SE m = s√1 -R = 2√1-0,9 = 0,632
Однако, если тест имеет коэффициент надежности 0,5 , то стандартная ошибка измерения будет рассчитываться как:
- SE м = с√ 1-R = 2√ 1-,5 = 1,414
Это должно иметь смысл интуитивно: если результаты теста менее надежны, то ошибка измерения «истинного» результата будет выше.
An online standard error calculator helps you to calculate the sample mean dispersion from the given raw data set or from the sample mean for statistical data analysis. Give a complete read to this useful & important content to know about the basic terms, formulas and calculations related to the standard error.
Read on!
What is the Standard Error Formula?
The standard error equation is as follows:
$$ S.E = frac{s}{sqrt{n}} $$
S.E = s/√n
Where,
s is the standard deviation of the numbers.
n is the number of samples.
You can use a coefficient of variation calculator to calculate CV that is the ratio of the standard deviation to the mean (average).
When You Have Raw Data:
When you have raw data points, first you need to find the standard deviation and sample mean of the data. The formulas for standard deviation & population mean are:
S.D = √⅀(Xi -µ)2/N-1
Where,
Xi is each value in the data set.
µ is the mean of all values in the data set.
N is the total number of values in the data set.
Now, the formula for sample mean is:
µ =X1 + X2 + X3 + X4 +…….+ XN / N
These are the formulas which are also used by this online standard error calculator for the estimated results of your problem. Just read on, we have the complete step by step manual example for both the calculations.
Difference Between SEM & SD:
The SD and SEM both are used in statistical studies, in Finance, biology, engineering, psychology, medicine etc. The standard deviation (SD) & standard error of the mean (SEM) are used to represent the characteristics of the sample data and explain statistical analysis results. Remember that, SD & SEM both are different, each have its own meaning. Standard deviation (SD) is the measure of dispersion of the individual data values. In simple words, SD determines how the sample data represents the mean accurately. While, the SEM includes the statistical results of a particular value or sampling distribution. The SEM is the SD of theoretical distribution of sample means. Here you get a central tendency calculator that helps you to calculate mean, median. mode and range of the given date set.
You can try the online standard error of the mean calculator that allows you to find out the standard error from the sample mean & standard deviation.
Applications of Standard Error:
It is the most important and widely used measure in Statistics to determine the reliability of the sample data or mean. The major applications of standard error include, test of significance or hypothesis testing for large & small sample size (Z & t statistic) to measure the reliability of sample, to determine the confidence interval for sample. It’s a statistical measure calculated from the sampling distribution where the large size samples minimize the SE of the statistic & vice versa. For the accurate & quick results, people may use this standard error calculator to determine the results with complete step-by-step calculations.
How to Calculate Standard Error Manually (Step-by-Step):
The formula for standard error is discussed earlier. Now, we have an example with complete step-by-step calculations.
Example:
Let’s have raw data 12, 23, 45, 33, 65, 54. Find the standard error of the given data?
Solution:
The formula to calculate SE is:
S.E = s/√n
Step1:
First of all, we have to calculate the mean of the data. The formula is:
µ =X1 + X2 + X3 + X4 +…….+ XN / N
So,
µ =12 + 23 + 45 + 33 + 65 + 54/ 6
µ =232/ 6
µ =38.66
Step 2:
Then, determine the standard deviation of the data.
S.D = √⅀(Xi -µ)2/N-1
Here,
µ = 38.66
So,
S.D = √⅀(Xi -µ)2/N-1
S.D = √ {(12-38.66)2 + (23-38.66)2 + (45-38.66)2 + (33-38.66)2 + (65-38.66)2 + (54-38.66)2}/6-1
S.D = √ {(-26.66)2 + (-15.66)2 + (6.34)2 + (-5.66)2 + (26.34)2 + (15.34)2}/5
S.D = √ {710.75 + 245.23 + 40.19 + 32.03 + 693.79 + 235.31}/5
S.D = √1957.3/5
S.D = √391.46
S.D = 19.7
Step 3:
Now,
S.E = s/√n
S.E = 19.7/√6
S.E = 19.7/2.44
S.E = 8.07
You can use the online standard error calculator to verify your answers with complete step-by-step calculations.
How to Find Standard Error With Standard Error Calculator:
Calculating standard error becomes very easy with this online sem calculator. Give a detailed calculation of the standard error.
Swipe on!
Calculations from the Raw Data:
To calculate the standard error from the raw data, just stick to these following points:
Inputs:
- First of all, enter the data points in the designated field separated with commas.
- Then, hit the calculate button.
Outputs:
The calculator will show:
- Standard Error of the numbers.
- Total numbers.
- Sum of the numbers.
- Mean of the numbers.
- Standard deviation between the numbers.
- Complete Step-by-Step calculation.
Calculations from the Summary Data:
Inputs:
- Firstly, enter the standard deviation between the numbers.
- Very next, plug-in the total number of samples (n) in the designated field.
- Lastly, click on the calculate button.
Outputs:
The tool shows:
- Standard Error of the numbers.
- Complete Step-by-Step calculation.
Simply, use the online standard error calculator for the complete step-by-step calculations from both raw data & from summary of the data.
Frequently Ask Questions (FAQ’s):
What is Standard Error?
It is a statistical term that measures the accuracy of the sample by using the standard deviation. The SE of a statistic is the standard deviation of the statistical sample population. In Statistics, the sample mean diverges from the actual mean and this deviation is the standard error of the mean.
What is a good value for standard error?
As the SE is an indication of the accuracy of sample mean as compared with the population mean. The smaller it is, the less spreading of data and more likely it is. So, the smaller value of standard error is a good thing.
How do I calculate standard error in Excel?
For the calculations in the excel, you can simply use the following function.
=STDEV (Sampling Range) / SQRT(COUNT(sampling range))
How do you read standard error (SE) bars?
SE bars can tell how the data is spread around the mean value. Smaller the SD bar lowers the suspension, larger SD bar larger suspension of data around the mean.
What does a SE of 2 mean?
As we know from the empirical rule, the 95% values fall in the range of 2 standard errors and approximately 99.7% of means will be in the range of 3 standard errors of the mean.
Why is the standard error important?
It is very important because it tells the fluctuation of the sample in statistics. The standard error helps in the construction of confidence intervals & significance testing, so it is really helpful.
End-Note:
Thankfully, you come to know about the standard error, its applications including; hypothesis testing, confidence interval of the sample and many others in the Statistics. Simply, use this online standard error calculator that helps you to determine the reliability of the sample data. Typically, students & education experts use this online tool to solve their education related problems.
References:
From the source Wikipedia: Standard error of the mean, Student approximation when σ value is unknown and all other statistical approaches.
From the source of investopedia: SE of the Mean vs. Standard Deviation: The Difference
From the source of corporatefinanceinstitute: Complete Overview of SE and it’s important