Содержание
- Расчет ошибки средней арифметической
- Способ 1: расчет с помощью комбинации функций
- Способ 2: применение инструмента «Описательная статистика»
- Вопросы и ответы

Стандартная ошибка или, как часто называют, ошибка средней арифметической, является одним из важных статистических показателей. С помощью данного показателя можно определить неоднородность выборки. Он также довольно важен при прогнозировании. Давайте узнаем, какими способами можно рассчитать величину стандартной ошибки с помощью инструментов Microsoft Excel.
Расчет ошибки средней арифметической
Одним из показателей, которые характеризуют цельность и однородность выборки, является стандартная ошибка. Эта величина представляет собой корень квадратный из дисперсии. Сама дисперсия является средним квадратном от средней арифметической. Средняя арифметическая вычисляется делением суммарной величины объектов выборки на их общее количество.
В Экселе существуют два способа вычисления стандартной ошибки: используя набор функций и при помощи инструментов Пакета анализа. Давайте подробно рассмотрим каждый из этих вариантов.
Способ 1: расчет с помощью комбинации функций
Прежде всего, давайте составим алгоритм действий на конкретном примере по расчету ошибки средней арифметической, используя для этих целей комбинацию функций. Для выполнения задачи нам понадобятся операторы СТАНДОТКЛОН.В, КОРЕНЬ и СЧЁТ.
Для примера нами будет использована выборка из двенадцати чисел, представленных в таблице.

- Выделяем ячейку, в которой будет выводиться итоговое значение стандартной ошибки, и клацаем по иконке «Вставить функцию».
- Открывается Мастер функций. Производим перемещение в блок «Статистические». В представленном перечне наименований выбираем название «СТАНДОТКЛОН.В».
- Запускается окно аргументов вышеуказанного оператора. СТАНДОТКЛОН.В предназначен для оценивания стандартного отклонения при выборке. Данный оператор имеет следующий синтаксис:
=СТАНДОТКЛОН.В(число1;число2;…)«Число1» и последующие аргументы являются числовыми значениями или ссылками на ячейки и диапазоны листа, в которых они расположены. Всего может насчитываться до 255 аргументов этого типа. Обязательным является только первый аргумент.
Итак, устанавливаем курсор в поле «Число1». Далее, обязательно произведя зажим левой кнопки мыши, выделяем курсором весь диапазон выборки на листе. Координаты данного массива тут же отображаются в поле окна. После этого клацаем по кнопке «OK».
- В ячейку на листе выводится результат расчета оператора СТАНДОТКЛОН.В. Но это ещё не ошибка средней арифметической. Для того, чтобы получить искомое значение, нужно стандартное отклонение разделить на квадратный корень от количества элементов выборки. Для того, чтобы продолжить вычисления, выделяем ячейку, содержащую функцию СТАНДОТКЛОН.В. После этого устанавливаем курсор в строку формул и дописываем после уже существующего выражения знак деления (/). Вслед за этим клацаем по пиктограмме перевернутого вниз углом треугольника, которая располагается слева от строки формул. Открывается список недавно использованных функций. Если вы в нем найдете наименование оператора «КОРЕНЬ», то переходите по данному наименованию. В обратном случае жмите по пункту «Другие функции…».
- Снова происходит запуск Мастера функций. На этот раз нам следует посетить категорию «Математические». В представленном перечне выделяем название «КОРЕНЬ» и жмем на кнопку «OK».
- Открывается окно аргументов функции КОРЕНЬ. Единственной задачей данного оператора является вычисление квадратного корня из заданного числа. Его синтаксис предельно простой:
=КОРЕНЬ(число)
Как видим, функция имеет всего один аргумент «Число». Он может быть представлен числовым значением, ссылкой на ячейку, в которой оно содержится или другой функцией, вычисляющей это число. Последний вариант как раз и будет представлен в нашем примере.
Устанавливаем курсор в поле «Число» и кликаем по знакомому нам треугольнику, который вызывает список последних использованных функций. Ищем в нем наименование «СЧЁТ». Если находим, то кликаем по нему. В обратном случае, опять же, переходим по наименованию «Другие функции…».
- В раскрывшемся окне Мастера функций производим перемещение в группу «Статистические». Там выделяем наименование «СЧЁТ» и выполняем клик по кнопке «OK».
- Запускается окно аргументов функции СЧЁТ. Указанный оператор предназначен для вычисления количества ячеек, которые заполнены числовыми значениями. В нашем случае он будет подсчитывать количество элементов выборки и сообщать результат «материнскому» оператору КОРЕНЬ. Синтаксис функции следующий:
=СЧЁТ(значение1;значение2;…)В качестве аргументов «Значение», которых может насчитываться до 255 штук, выступают ссылки на диапазоны ячеек. Ставим курсор в поле «Значение1», зажимаем левую кнопку мыши и выделяем весь диапазон выборки. После того, как его координаты отобразились в поле, жмем на кнопку «OK».
- После выполнения последнего действия будет не только рассчитано количество ячеек заполненных числами, но и вычислена ошибка средней арифметической, так как это был последний штрих в работе над данной формулой. Величина стандартной ошибки выведена в ту ячейку, где размещена сложная формула, общий вид которой в нашем случае следующий:
=СТАНДОТКЛОН.В(B2:B13)/КОРЕНЬ(СЧЁТ(B2:B13))Результат вычисления ошибки средней арифметической составил 0,505793. Запомним это число и сравним с тем, которое получим при решении поставленной задачи следующим способом.










Но дело в том, что для малых выборок (до 30 единиц) для большей точности лучше применять немного измененную формулу. В ней величина стандартного отклонения делится не на квадратный корень от количества элементов выборки, а на квадратный корень от количества элементов выборки минус один. Таким образом, с учетом нюансов малой выборки наша формула приобретет следующий вид:
=СТАНДОТКЛОН.В(B2:B13)/КОРЕНЬ(СЧЁТ(B2:B13)-1)

Урок: Статистические функции в Экселе
Способ 2: применение инструмента «Описательная статистика»
Вторым вариантом, с помощью которого можно вычислить стандартную ошибку в Экселе, является применение инструмента «Описательная статистика», входящего в набор инструментов «Анализ данных» («Пакет анализа»). «Описательная статистика» проводит комплексный анализ выборки по различным критериям. Одним из них как раз и является нахождение ошибки средней арифметической.
Но чтобы воспользоваться данной возможностью, нужно сразу активировать «Пакет анализа», так как по умолчанию в Экселе он отключен.
- После того, как открыт документ с выборкой, переходим во вкладку «Файл».
- Далее, воспользовавшись левым вертикальным меню, перемещаемся через его пункт в раздел «Параметры».
- Запускается окно параметров Эксель. В левой части данного окна размещено меню, через которое перемещаемся в подраздел «Надстройки».
- В самой нижней части появившегося окна расположено поле «Управление». Выставляем в нем параметр «Надстройки Excel» и жмем на кнопку «Перейти…» справа от него.
- Запускается окно надстроек с перечнем доступных скриптов. Отмечаем галочкой наименование «Пакет анализа» и щелкаем по кнопке «OK» в правой части окошка.
- После выполнения последнего действия на ленте появится новая группа инструментов, которая имеет наименование «Анализ». Чтобы перейти к ней, щелкаем по названию вкладки «Данные».
- После перехода жмем на кнопку «Анализ данных» в блоке инструментов «Анализ», который расположен в самом конце ленты.
- Запускается окошко выбора инструмента анализа. Выделяем наименование «Описательная статистика» и жмем на кнопку «OK» справа.
- Запускается окно настроек инструмента комплексного статистического анализа «Описательная статистика».
В поле «Входной интервал» необходимо указать диапазон ячеек таблицы, в которых находится анализируемая выборка. Вручную это делать неудобно, хотя и можно, поэтому ставим курсор в указанное поле и при зажатой левой кнопке мыши выделяем соответствующий массив данных на листе. Его координаты тут же отобразятся в поле окна.
В блоке «Группирование» оставляем настройки по умолчанию. То есть, переключатель должен стоять около пункта «По столбцам». Если это не так, то его следует переставить.
Галочку «Метки в первой строке» можно не устанавливать. Для решения нашего вопроса это не важно.
Далее переходим к блоку настроек «Параметры вывода». Здесь следует указать, куда именно будет выводиться результат расчета инструмента «Описательная статистика»:
- На новый лист;
- В новую книгу (другой файл);
- В указанный диапазон текущего листа.
Давайте выберем последний из этих вариантов. Для этого переставляем переключатель в позицию «Выходной интервал» и устанавливаем курсор в поле напротив данного параметра. После этого клацаем на листе по ячейке, которая станет верхним левым элементом массива вывода данных. Её координаты должны отобразиться в поле, в котором мы до этого устанавливали курсор.
Далее следует блок настроек определяющий, какие именно данные нужно вводить:
- Итоговая статистика;
- К-ый наибольший;
- К-ый наименьший;
- Уровень надежности.
Для определения стандартной ошибки обязательно нужно установить галочку около параметра «Итоговая статистика». Напротив остальных пунктов выставляем галочки на свое усмотрение. На решение нашей основной задачи это никак не повлияет.
После того, как все настройки в окне «Описательная статистика» установлены, щелкаем по кнопке «OK» в его правой части.
- После этого инструмент «Описательная статистика» выводит результаты обработки выборки на текущий лист. Как видим, это довольно много разноплановых статистических показателей, но среди них есть и нужный нам – «Стандартная ошибка». Он равен числу 0,505793. Это в точности тот же результат, который мы достигли путем применения сложной формулы при описании предыдущего способа.










Урок: Описательная статистика в Экселе
Как видим, в Экселе можно произвести расчет стандартной ошибки двумя способами: применив набор функций и воспользовавшись инструментом пакета анализа «Описательная статистика». Итоговый результат будет абсолютно одинаковый. Поэтому выбор метода зависит от удобства пользователя и поставленной конкретной задачи. Например, если ошибка средней арифметической является только одним из многих статистических показателей выборки, которые нужно рассчитать, то удобнее воспользоваться инструментом «Описательная статистика». Но если вам нужно вычислить исключительно этот показатель, то во избежание нагромождения лишних данных лучше прибегнуть к сложной формуле. В этом случае результат расчета уместится в одной ячейке листа.
Excel для Microsoft 365 Excel для Microsoft 365 для Mac Excel для Интернета Excel 2021 Excel 2021 for Mac Excel 2019 Excel 2019 для Mac Excel 2016 Excel 2016 для Mac Excel 2013 Excel 2010 Excel 2007 Excel для Mac 2011 Excel Starter 2010 Еще…Меньше
В этой статье описаны синтаксис формулы и использование функции СТОШYX в Microsoft Excel.
Описание
Возвращает стандартную ошибку предсказанных значений y для каждого значения x в регрессии. Стандартная ошибка — это мера ошибки предсказанного значения y для отдельного значения x.
Синтаксис
СТОШYX(известные_значения_y;известные_значения_x)
Аргументы функции СТОШYX описаны ниже.
-
Известные_значения_y Обязательный. Массив или диапазон зависимых точек данных.
-
Известные_значения_x Обязательный. Массив или диапазон независимых точек данных.
Замечания
-
Аргументы могут быть либо числами, либо содержащими числа именами, массивами или ссылками.
-
Учитываются логические значения и текстовые представления чисел, которые непосредственно введены в список аргументов.
-
Если аргумент, который является массивом или ссылкой, содержит текст, логические значения или пустые ячейки, то такие значения пропускаются; однако ячейки, которые содержат нулевые значения, учитываются.
-
Аргументы, которые представляют собой значения ошибок или текст, не преобразуемый в числа, вызывают ошибку.
-
Если аргументы «известные_значения_y» и «известные_значения_x» содержат различное количество точек данных, то функция СТОШYX возвращает значение ошибки #Н/Д.
-
Если known_y и known_x пустые или имеют менее трех точек данных, steYX возвращает #DIV/0! значение ошибки #ЗНАЧ!.
-
Уравнение для стандартной ошибки предсказанного y имеет следующий вид:
где x и y — выборочные средние значения СРЗНАЧ(известные_значения_x) и СРЗНАЧ(известные_значения_y), а n — размер выборки.
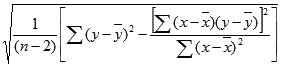
Пример
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
|
Данные |
||
|
Известные значения y |
Известные значения x |
|
|
2 |
6 |
|
|
3 |
5 |
|
|
9 |
11 |
|
|
1 |
7 |
|
|
8 |
5 |
|
|
7 |
4 |
|
|
5 |
4 |
|
|
Формула |
Описание (результат) |
Результат |
|
=СТОШYX(A3:A9;B3:B9) |
Стандартная ошибка предсказанных значений y для каждого значения x в регрессии (3,305719) |
3,305719 |
Нужна дополнительная помощь?
Стандартная ошибка появляется при прогнозировании каких-либо данных или арифметических вычислениях, поэтому важно научиться находить этот параметр. В этой публикации разбираем, как найти и исправить стандартную ошибку путем использования инструментов Excel.
Расчет средней арифметической ошибки
В Microsoft Excel цельность и однородность выборки определяется при помощи стандартной ошибки. Стандартная ошибка — это квадратный корень из дисперсии. В приложении предусмотрено два варианта поиска стандартной ошибки: при помощи пакетного анализа и расширенных функций программы.
Чтобы найти значение средней арифметической, необходимо выполнить деление суммарной величины выборки на ее количество в электронной книге.
Расчет стандартной ошибки при помощи встроенных функций
Для того, чтобы правильно вычислять, необходимо изучить пошаговую инструкцию. В этом способе подбор результатов будет осуществляться с помощью комбинированных манипуляций.
- Для расчетов будем использовать таблицу с выборкой чисел. Кликаем на любой пустой ячейке на листе, где будет отображаться результат. Затем нажимаем кнопку «Вставить функцию.
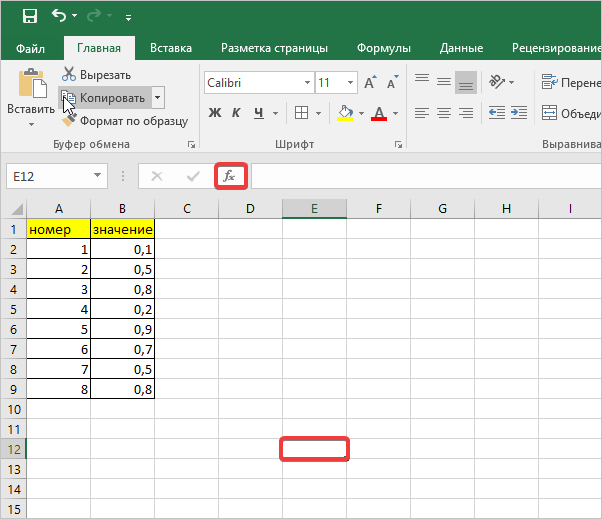
- Далее перед вами открывается диалоговое окно, в котором необходимо использовать «СТАНДОТКЛ.В», для этого в поле «Категория» необходимо выбрать «Полный алфавитный перечень». Затем нажмите кнопку «ОК».
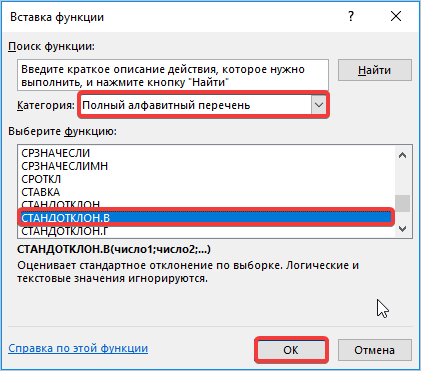
- В окне «Аргументы функции» кликаем в первом поле «Число 1», затем выполняем выделение мышью диапазона ячеек со значениями таблицы и нажимаем кнопку «ОК».
- Далее активируем ячейку с нашими значениями, переходим в строку формулы и ставим после значений наклонную линию. Переходим в поле наименования, кликаем на указывающий вниз флажок, где из списка выбираем «Другие функции».
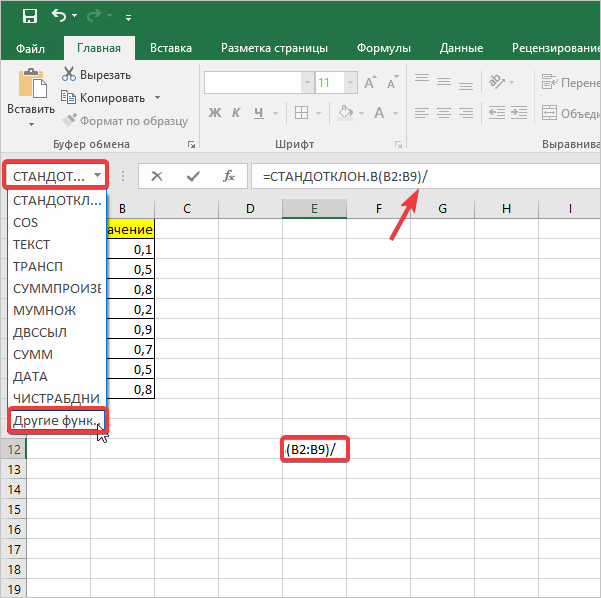
- Снова активируется окно с перечнем функций, в котором необходимо выбрать категорию «Математические», затем функцию «Корень». Далее нажмите кнопку «ОК».
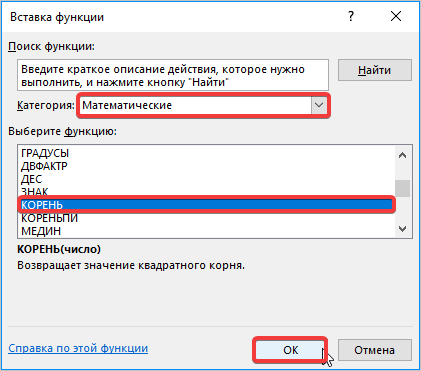
- Далее открывается окно, в котором необходимо заполнить поле с числом. Для этого переходим в поле «Имя», где спускаемся к пункту «Счет». Если его нет, ищите в дополнительных функциях.
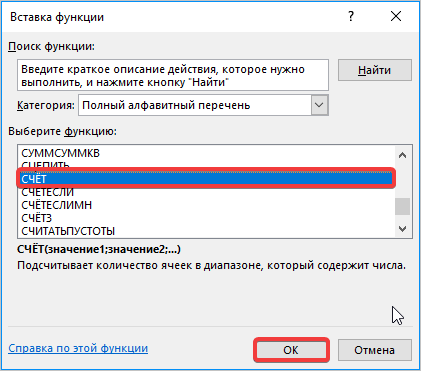
После выполнения этих шагов, стандартная ошибка высчитывается автоматически, пользователю остается только сверить их и проверить значение на некорректное отображение.
Для малых и стандартных выборок необходимо использовать разные формулы. В первом случае (если находится до 30 значений), ее необходимо видоизменить.
Решение задачи с помощью опции «Описательная статистика»
Благодаря опции «Описательная статистика» удается выполнить вычисление по различным критериям. По этим правилам удается найти среднюю арифметическую ошибку. Для использования данного метода предварительно нужно запустить «Пакет анализа».
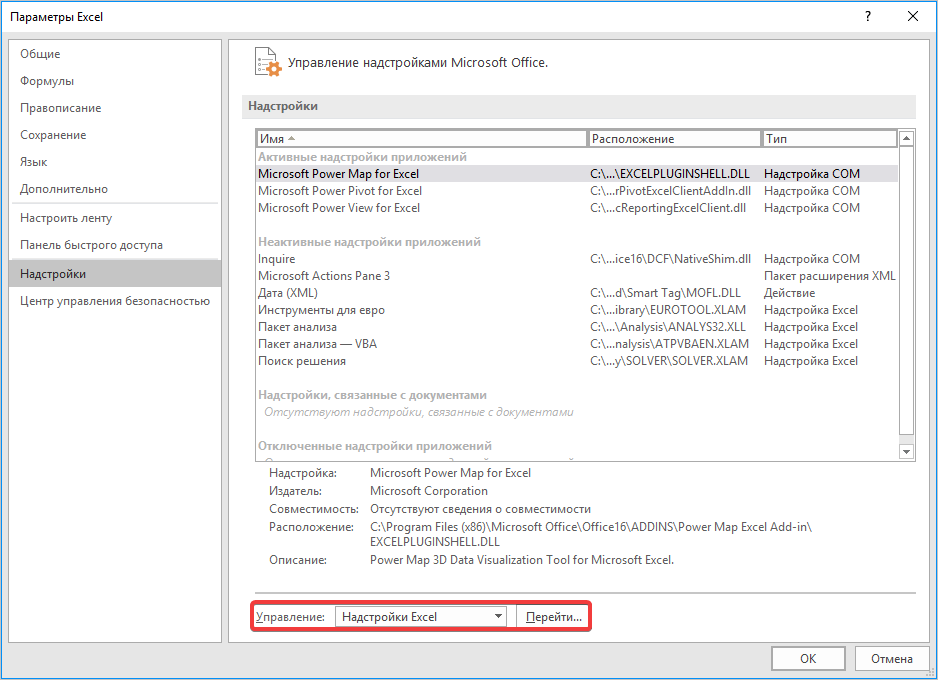
- Переходим во вкладку «Файл», где перемещаемся в пункт «Параметры». Далее нажимаем на запись «Надстройки».
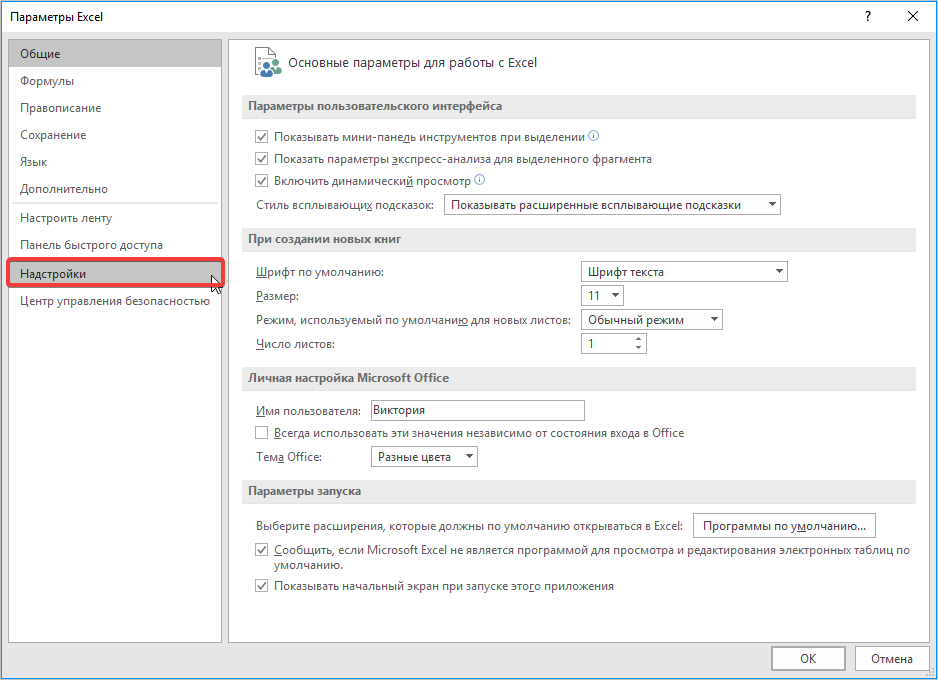
- Открывается окошко, в нем в графе «Управление» должно быть прописано «Надстройки Excel», затем рядом нажимаем кнопку «Параметры».
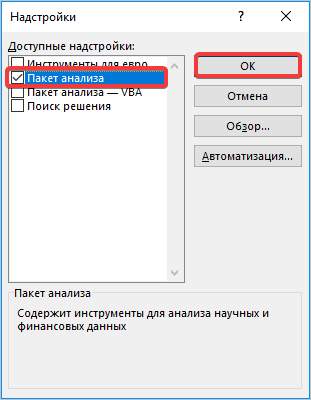
- В появившемся окне находим «Пакет анализа» и нажимаем кнопку «ОК».
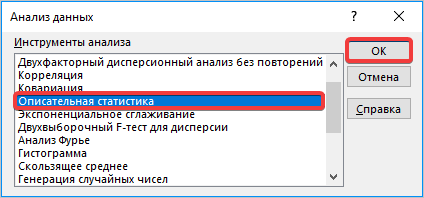
- Далее выбираем любую свободную ячейку, переходим во вкладку «Данные» и нажимаем «Анализ данных» в блоке «Анализ».

- Происходит запуск вспомогательного окошка, в котором необходимо выбрать из всех инструментов «Описательную статистику» и нажать кнопку «ОК».
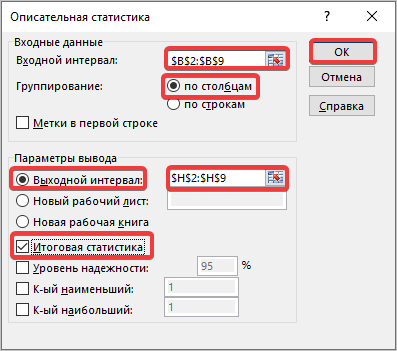
- Открывается новый мастер значений. Здесь нужно вводить данные предельно внимательно. В поле «Входной интервал» вносим адрес диапазона ячеек с выборкой. Затем указываем параметр «Группирование» «По столбцам». Затем выбираем место для «выходного интервала», его должно быть столько же, сколько и «входного». Ставим галочку напротив «Итоговая статистика» и нажимаем кнопку «ОК».
В результате вычислений вы получаете небольшую таблицу, в которой указаны все данные с определенной стандартной ошибкой.
17 авг. 2022 г.
читать 2 мин
Стандартная ошибка среднего — это способ измерить, насколько разбросаны значения в наборе данных. Он рассчитывается как:
Стандартная ошибка = с / √n
куда:
- s : стандартное отклонение выборки
- n : размер выборки
Вы можете рассчитать стандартную ошибку среднего для любого набора данных в Excel, используя следующую формулу:
= СТАНДОТКЛОН (диапазон значений) / КОРЕНЬ ( СЧЁТ (диапазон значений))
В следующем примере показано, как использовать эту формулу.
Пример: Стандартная ошибка в Excel
Предположим, у нас есть следующий набор данных:
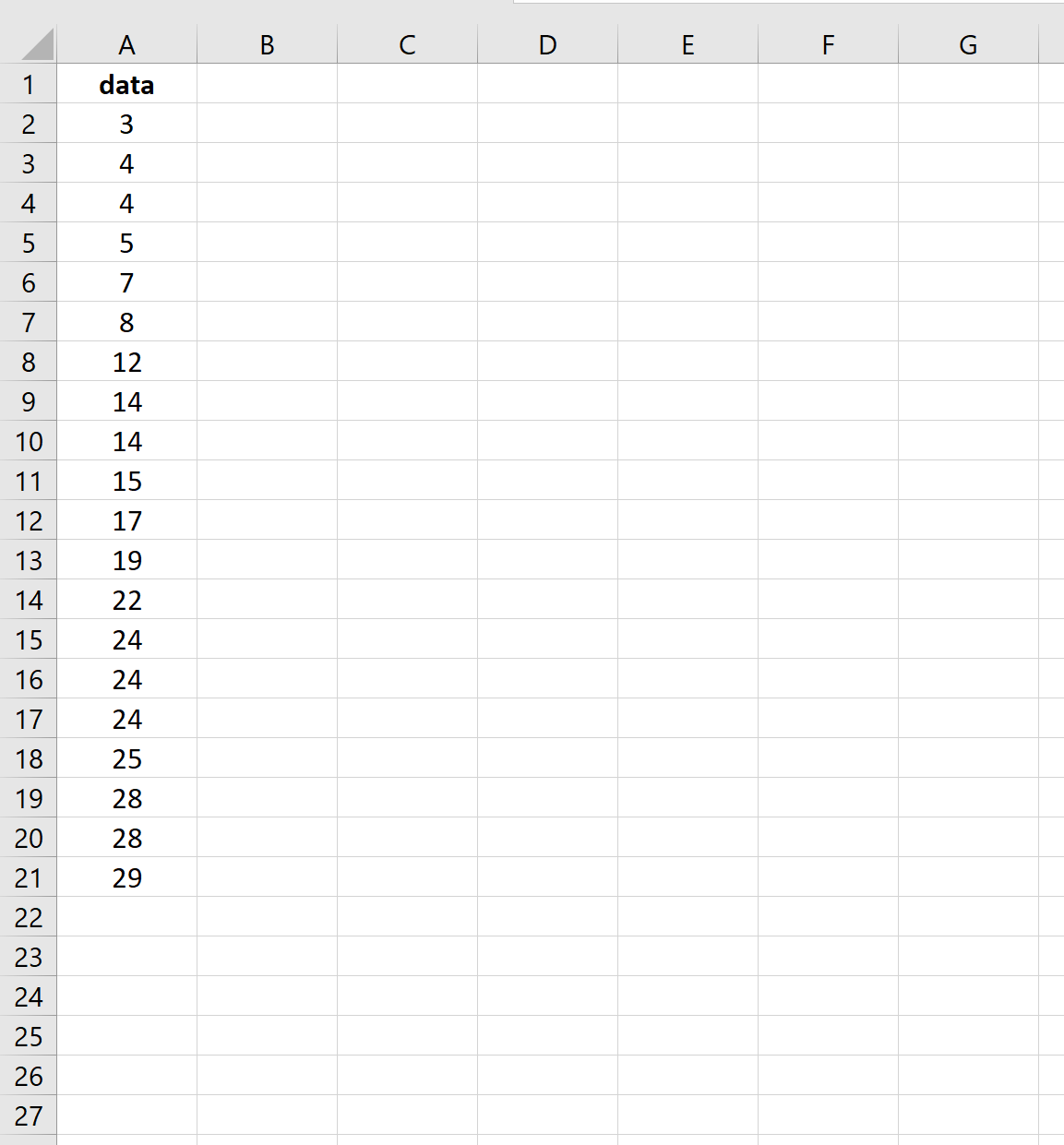
На следующем снимке экрана показано, как рассчитать стандартную ошибку среднего значения для этого набора данных:
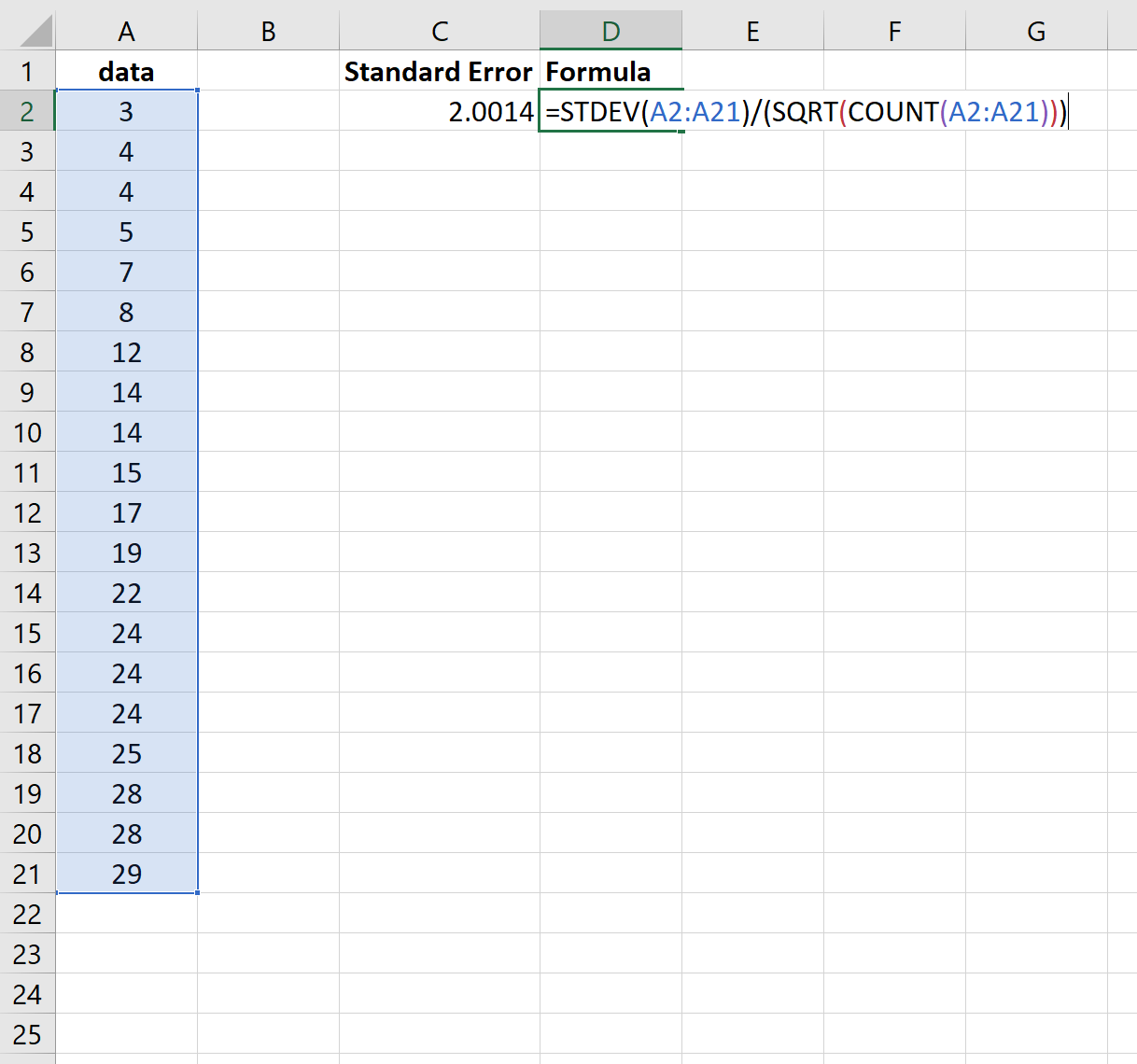
Стандартная ошибка оказывается равной 2,0014 .
Обратите внимание, что функция =СТАНДОТКЛОН() вычисляет выборочное среднее, что эквивалентно функции =СТАНДОТКЛОН.С() в Excel.
Таким образом, мы могли бы использовать следующую формулу для получения тех же результатов:
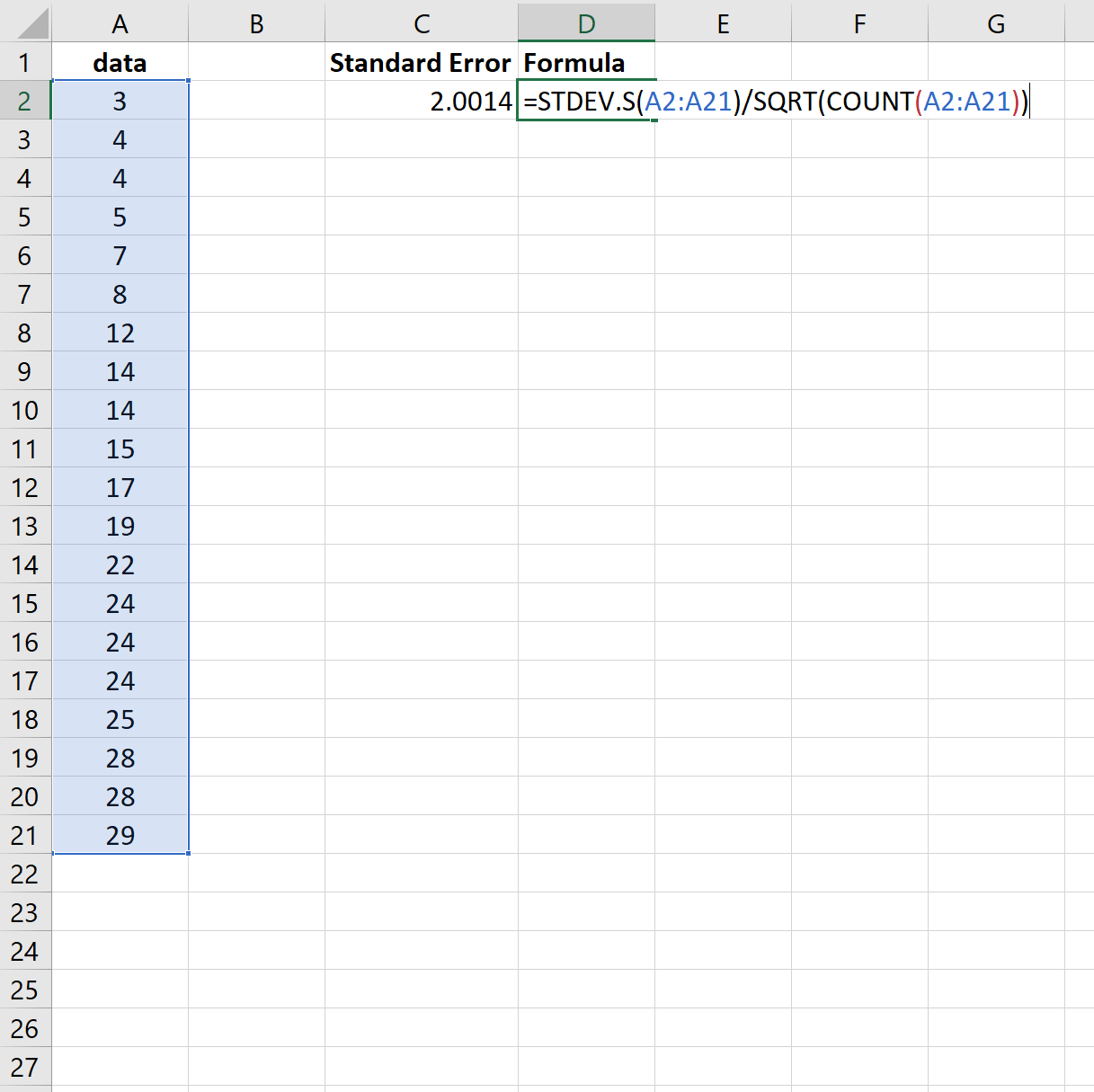
И снова стандартная ошибка оказывается равной 2,0014 .
Как интерпретировать стандартную ошибку среднего
Стандартная ошибка среднего — это просто мера того, насколько разбросаны значения вокруг среднего. При интерпретации стандартной ошибки среднего следует помнить о двух вещах:
1. Чем больше стандартная ошибка среднего, тем более разбросаны значения вокруг среднего в наборе данных.
Чтобы проиллюстрировать это, рассмотрим, изменим ли мы последнее значение в предыдущем наборе данных на гораздо большее число:
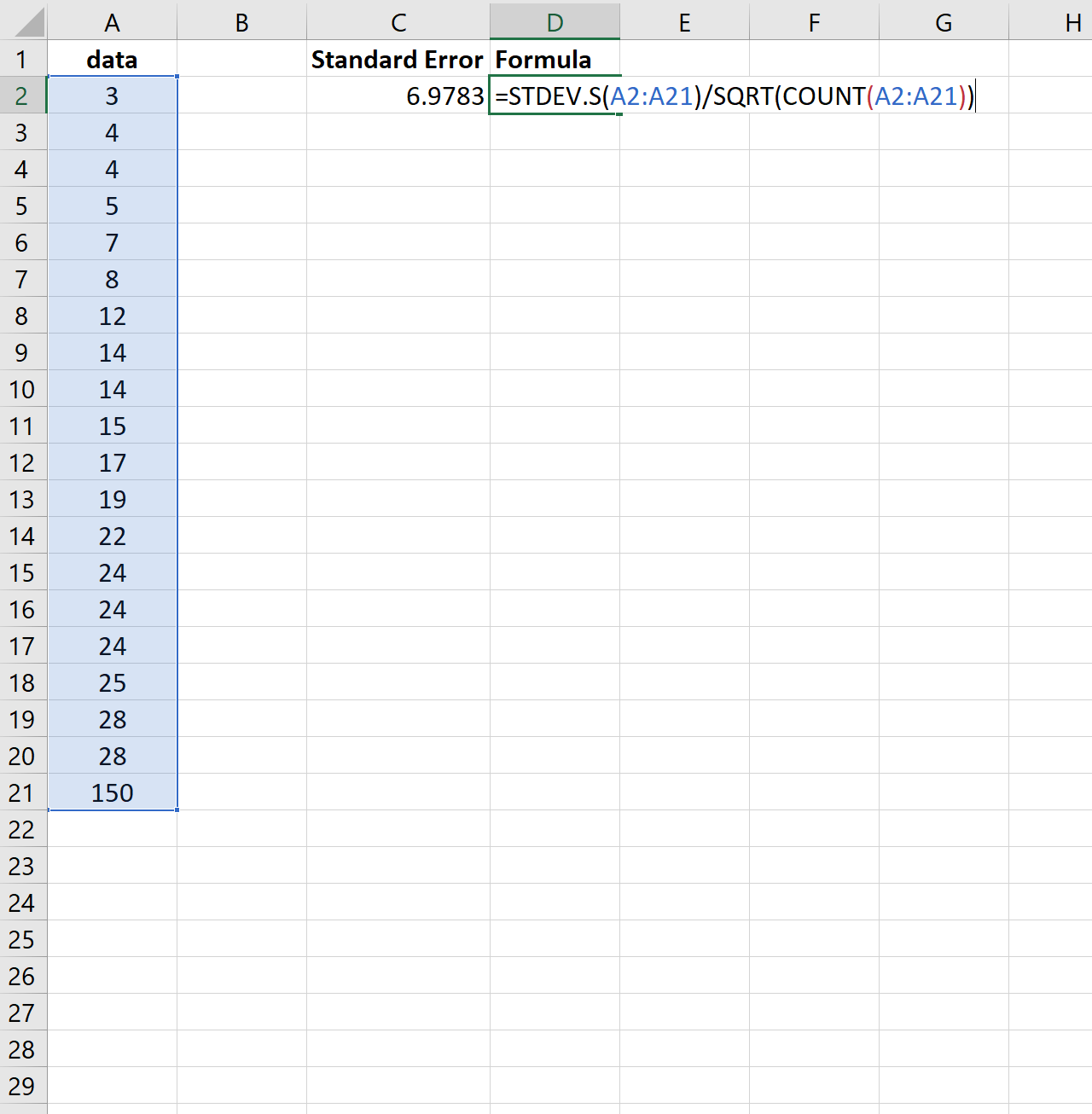
Обратите внимание на скачок стандартной ошибки с 2,0014 до 6,9783.Это указывает на то, что значения в этом наборе данных более разбросаны вокруг среднего значения по сравнению с предыдущим набором данных.
2. По мере увеличения размера выборки стандартная ошибка среднего имеет тенденцию к уменьшению.
Чтобы проиллюстрировать это, рассмотрим стандартную ошибку среднего для следующих двух наборов данных:
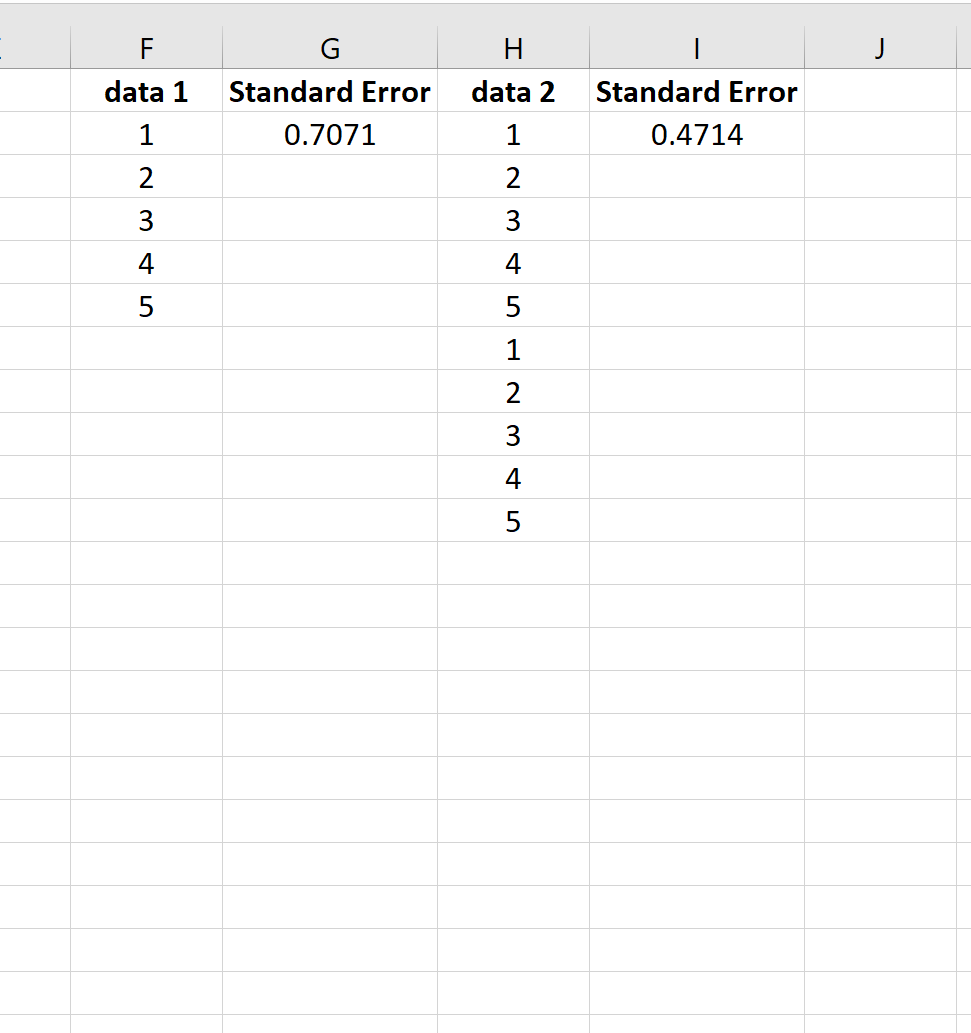
Второй набор данных — это просто первый набор данных, повторенный дважды. Таким образом, два набора данных имеют одинаковое среднее значение, но второй набор данных имеет больший размер выборки, поэтому стандартная ошибка меньше.
Whenever we fit a linear regression model, the model takes on the following form:
Y = β0 + β1X + … + βiX +ϵ
where ϵ is an error term that is independent of X.
No matter how well X can be used to predict the values of Y, there will always be some random error in the model.
One way to measure the dispersion of this random error is by using the standard error of the regression model, which is a way to measure the standard deviation of the residuals ϵ.
This tutorial provides a step-by-step example of how to calculate the standard error of a regression model in Excel.
Step 1: Create the Data
For this example, we’ll create a dataset that contains the following variables for 12 different students:
- Exam Score
- Hours Spent Studying
- Current Grade

Step 2: Fit the Regression Model
Next, we’ll fit a multiple linear regression model using Exam Score as the response variable and Study Hours and Current Grade as the predictor variables.
To do so, click the Data tab along the top ribbon and then click Data Analysis:

If you don’t see this option available, you need to first load the Data Analysis ToolPak.
In the window that pops up, select Regression. In the new window that appears, fill in the following information:

Once you click OK, the output of the regression model will appear:

Step 3: Interpret the Standard Error of Regression
The standard error of the regression model is the number next to Standard Error:

The standard error of this particular regression model turns out to be 2.790029.
This number represents the average distance between the actual exam scores and the exam scores predicted by the model.
Note that some of the exam scores will be further than 2.79 units away from the predicted score while some will be closer. But, on average, the distance between the actual exam scores and the predicted scores is 2.790029.
Also note that a smaller standard error of regression indicates that a regression model fits a dataset more closely.
Thus, if we fit a new regression model to the dataset and ended up with a standard error of, say, 4.53, this new model would be worse at predicting exam scores than the previous model.
Additional Resources
Another common way to measure the precision of a regression model is to use R-squared. Check out this article for a nice explanation of the benefits of using the standard error of the regression to measure precision compared to R-squared.
Whenever we fit a linear regression model, the model takes on the following form:
Y = β0 + β1X + … + βiX +ϵ
where ϵ is an error term that is independent of X.
No matter how well X can be used to predict the values of Y, there will always be some random error in the model.
One way to measure the dispersion of this random error is by using the standard error of the regression model, which is a way to measure the standard deviation of the residuals ϵ.
This tutorial provides a step-by-step example of how to calculate the standard error of a regression model in Excel.
Step 1: Create the Data
For this example, we’ll create a dataset that contains the following variables for 12 different students:
- Exam Score
- Hours Spent Studying
- Current Grade
Step 2: Fit the Regression Model
Next, we’ll fit a multiple linear regression model using Exam Score as the response variable and Study Hours and Current Grade as the predictor variables.
To do so, click the Data tab along the top ribbon and then click Data Analysis:
If you don’t see this option available, you need to first load the Data Analysis ToolPak.
In the window that pops up, select Regression. In the new window that appears, fill in the following information:
Once you click OK, the output of the regression model will appear:
Step 3: Interpret the Standard Error of Regression
The standard error of the regression model is the number next to Standard Error:
The standard error of this particular regression model turns out to be 2.790029.
This number represents the average distance between the actual exam scores and the exam scores predicted by the model.
Note that some of the exam scores will be further than 2.79 units away from the predicted score while some will be closer. But, on average, the distance between the actual exam scores and the predicted scores is 2.790029.
Also note that a smaller standard error of regression indicates that a regression model fits a dataset more closely.
Thus, if we fit a new regression model to the dataset and ended up with a standard error of, say, 4.53, this new model would be worse at predicting exam scores than the previous model.
Additional Resources
Another common way to measure the precision of a regression model is to use R-squared. Check out this article for a nice explanation of the benefits of using the standard error of the regression to measure precision compared to R-squared.
Стандартная ошибка — важный статистический параметр. Но знаете ли вы, как это выяснить при раздаче выборки? Эта статья покажет вам формулу для расчета стандартной ошибки среднего в Excel.
Вычислить стандартную ошибку среднего в Excel
Вычислить стандартную ошибку среднего в Excel
Как вы знаете, стандартная ошибка = стандартное отклонение / квадратный корень из общего количества образцов, поэтому мы можем перевести его в формулу Excel как Стандартная ошибка = STDEV (диапазон выборки) / SQRT (COUNT (диапазон выборки)).
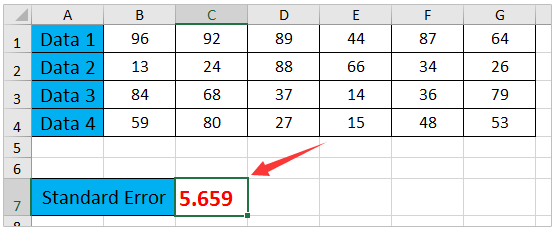
Например, ваш диапазон выборки находится в диапазоне B1: G4, как показано на скриншоте ниже. Вы можете выбрать ячейку, в которую вы поместите рассчитанный результат, введите формулу =STDEV(B1:G4)/SQRT(COUNT(B1:G4)), и нажмите Enter ключ. Смотрите скриншот:

Теперь вы можете получить стандартную ошибку среднего значения, как показано на скриншоте ниже:
Статьи по теме:
Первоклассный инструмент поможет вам в 2 шага создать диаграмму колоколообразной кривой в Excel
Замечательная надстройка Excel, Kutools for Excel, предоставляет более 300 функций, которые помогут вам значительно повысить эффективность работы. И это Нормальное распределение / кривая колокола (диаграмма) функция позволяет создать идеальную диаграмму колоколообразной кривой всего за 2 шага!
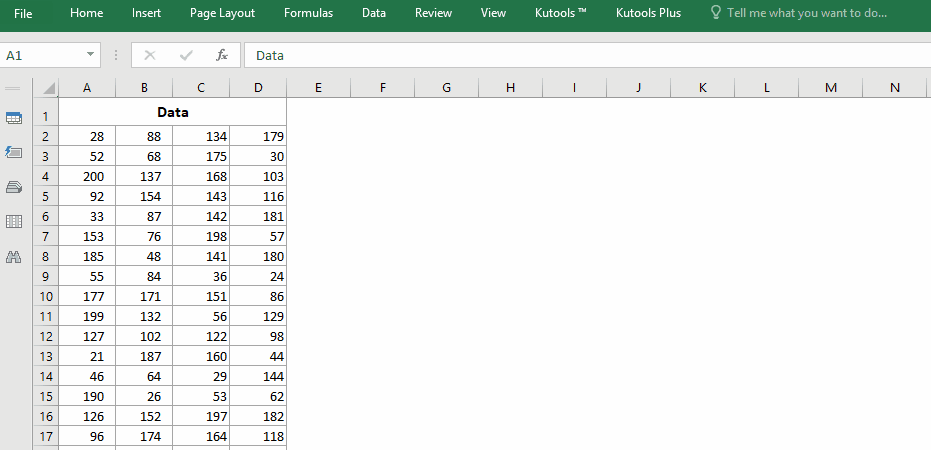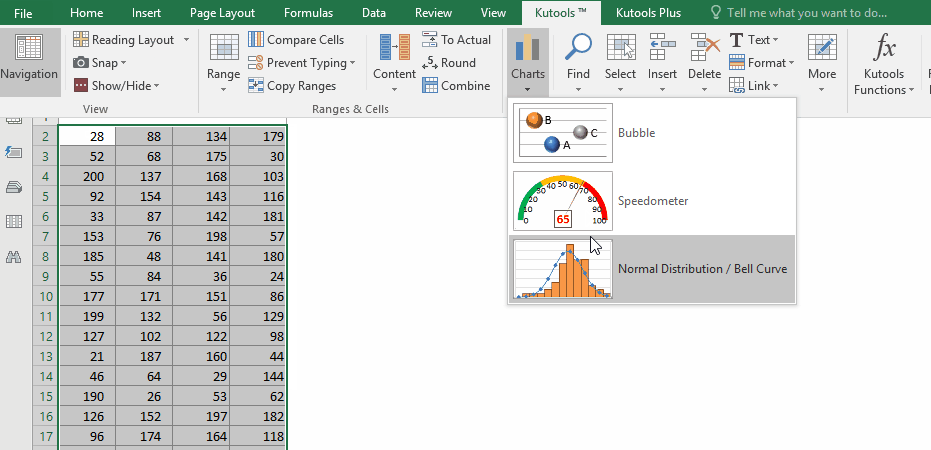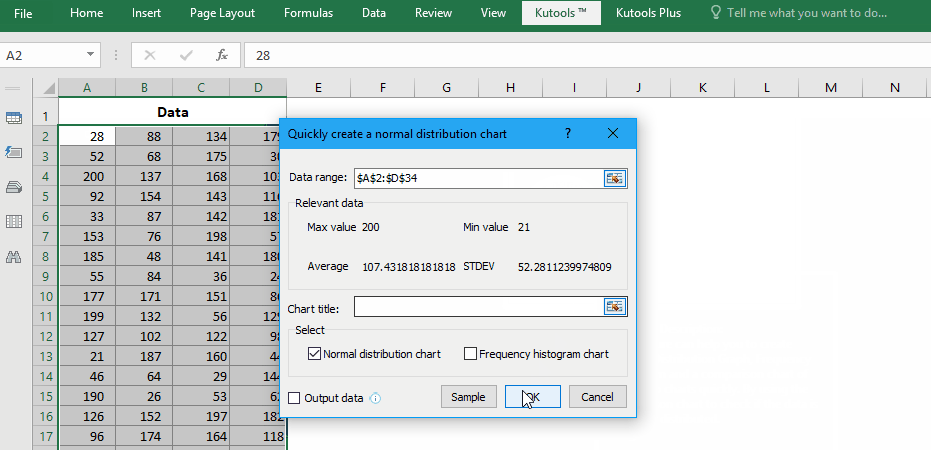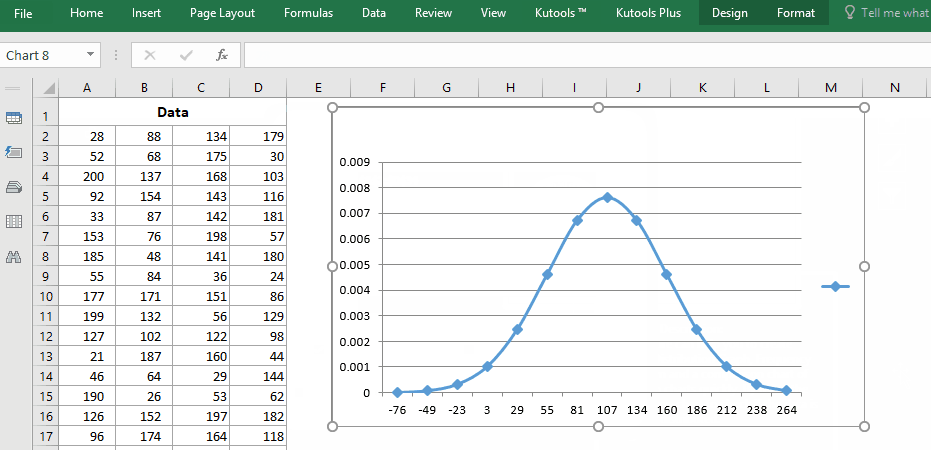
Kutools for Excel — Включает более 300 удобных инструментов для Excel. Полнофункциональная бесплатная пробная версия 30-день, кредитная карта не требуется! Get It Now
Лучшие инструменты для работы в офисе
Kutools for Excel решает большинство ваших проблем и увеличивает вашу производительность на 80%
- Снова использовать: Быстро вставить сложные формулы, диаграммы и все, что вы использовали раньше; Зашифровать ячейки с паролем; Создать список рассылки и отправлять электронные письма …
- Бар Супер Формулы (легко редактировать несколько строк текста и формул); Макет для чтения (легко читать и редактировать большое количество ячеек); Вставить в отфильтрованный диапазон…
- Объединить ячейки / строки / столбцы без потери данных; Разделить содержимое ячеек; Объединить повторяющиеся строки / столбцы… Предотвращение дублирования ячеек; Сравнить диапазоны…
- Выберите Дубликат или Уникальный Ряды; Выбрать пустые строки (все ячейки пустые); Супер находка и нечеткая находка во многих рабочих тетрадях; Случайный выбор …
- Точная копия Несколько ячеек без изменения ссылки на формулу; Автоматическое создание ссылок на несколько листов; Вставить пули, Флажки и многое другое …
- Извлечь текст, Добавить текст, Удалить по позиции, Удалить пробел; Создание и печать промежуточных итогов по страницам; Преобразование содержимого ячеек в комментарии…
- Суперфильтр (сохранять и применять схемы фильтров к другим листам); Расширенная сортировка по месяцам / неделям / дням, периодичности и др .; Специальный фильтр жирным, курсивом …
- Комбинируйте книги и рабочие листы; Объединить таблицы на основе ключевых столбцов; Разделить данные на несколько листов; Пакетное преобразование xls, xlsx и PDF…
- Более 300 мощных функций. Поддерживает Office/Excel 2007-2021 и 365. Поддерживает все языки. Простое развертывание на вашем предприятии или в организации. Полнофункциональная 30-дневная бесплатная пробная версия. 60-дневная гарантия возврата денег.
")
Вкладка Office: интерфейс с вкладками в Office и упрощение работы
- Включение редактирования и чтения с вкладками в Word, Excel, PowerPoint, Издатель, доступ, Visio и проект.
- Открывайте и создавайте несколько документов на новых вкладках одного окна, а не в новых окнах.
- Повышает вашу продуктивность на 50% и сокращает количество щелчков мышью на сотни каждый день!
")
Комментарии (2)
Оценок пока нет. Оцените первым!
Download PC Repair Tool to quickly find & fix Windows errors automatically
While Excel is useful for many applications, it is an indispensable tool for those managing statistics. Two common terms used in statistics are Standard Deviation and Standard Error of the Mean. It is difficult to calculate these values manually and while calculators make it easier, Excel is the preferred tool for finding these values over a range of cells.
The Standard Deviation is a term used in statistics. The term describes how much the numbers if a set of data vary from the mean. The syntax to calculate the Standard Deviation is as follows:
=STDEV(sampling range)
Where the sampling range represented by:
(<first cell in the range>:<last cell in the range>)
- <first cell in the range> is the top-left cell in the range of cells
- <last cell in the range> is the bottom-right cell in the range of cells
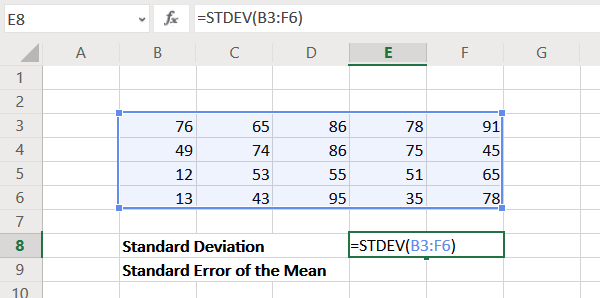
Eg. If you need to find the Standard Error of the Mean across a range of cells in Excel from B3 to F6, the formula would become as follows:
=STDEV(B3:F6)
The Standard Error of the Mean is an important statistical measurement. It is used in applications associated with medicine, engineering, psychology, finance, biology, etc. If you wish to learn how to calculate Standard Error of the Mean in Excel, please read through this article.
The Standard Error of the Mean measures how far the sample mean is from the main population mean. While the formula for calculating it is a little complex, Excel makes it simple.
Read: How to insert Formulas and Functions in Microsoft Excel.
How to calculate Standard Error of the Mean in Excel
The syntax for the formula to calculate the Standard Error of the Mean in Excel is as follows:
Standard Error:
=STDEV(sampling range)/SQRT(COUNT(sampling range))
Where the sampling range represented by:
(<first cell in the range>:<last cell in the range>)
- <first cell in the range> is the top-left cell in the range of cells
- <last cell in the range> is the bottom-right cell in the range of cells
Eg. If you need to find the Standard Error of the Mean across a range of cells in Excel from B3 to F6, the formula would become as follows:
=STDEV(B3:F6)/SQRT(COUNT(B3:F6))
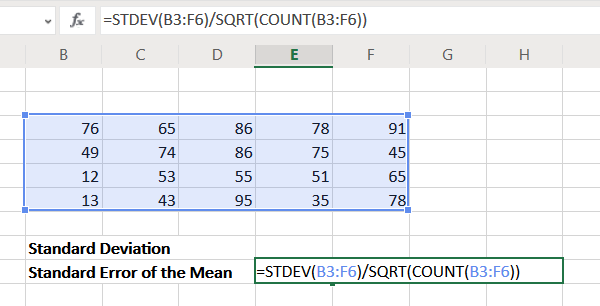
Enter this formula in the cell in which you need the value of Standard Error of the Mean.
Basically, Standard Error of the Mean = Standard Deviation/square root of number of samples
Hope it helps!

Karan Khanna is a passionate Windows user who loves troubleshooting Windows 11/10 problems in specific and writing about Microsoft technologies in general.
Download PC Repair Tool to quickly find & fix Windows errors automatically
While Excel is useful for many applications, it is an indispensable tool for those managing statistics. Two common terms used in statistics are Standard Deviation and Standard Error of the Mean. It is difficult to calculate these values manually and while calculators make it easier, Excel is the preferred tool for finding these values over a range of cells.
The Standard Deviation is a term used in statistics. The term describes how much the numbers if a set of data vary from the mean. The syntax to calculate the Standard Deviation is as follows:
=STDEV(sampling range)
Where the sampling range represented by:
(<first cell in the range>:<last cell in the range>)
- <first cell in the range> is the top-left cell in the range of cells
- <last cell in the range> is the bottom-right cell in the range of cells
Eg. If you need to find the Standard Error of the Mean across a range of cells in Excel from B3 to F6, the formula would become as follows:
=STDEV(B3:F6)
The Standard Error of the Mean is an important statistical measurement. It is used in applications associated with medicine, engineering, psychology, finance, biology, etc. If you wish to learn how to calculate Standard Error of the Mean in Excel, please read through this article.
The Standard Error of the Mean measures how far the sample mean is from the main population mean. While the formula for calculating it is a little complex, Excel makes it simple.
Read: How to insert Formulas and Functions in Microsoft Excel.
How to calculate Standard Error of the Mean in Excel
The syntax for the formula to calculate the Standard Error of the Mean in Excel is as follows:
Standard Error:
=STDEV(sampling range)/SQRT(COUNT(sampling range))
Where the sampling range represented by:
(<first cell in the range>:<last cell in the range>)
- <first cell in the range> is the top-left cell in the range of cells
- <last cell in the range> is the bottom-right cell in the range of cells
Eg. If you need to find the Standard Error of the Mean across a range of cells in Excel from B3 to F6, the formula would become as follows:
=STDEV(B3:F6)/SQRT(COUNT(B3:F6))
Enter this formula in the cell in which you need the value of Standard Error of the Mean.
Basically, Standard Error of the Mean = Standard Deviation/square root of number of samples
Hope it helps!
Karan Khanna is a passionate Windows user who loves troubleshooting Windows 11/10 problems in specific and writing about Microsoft technologies in general.