Состояние перевода: На этой странице представлен перевод статьи systemd/Journal. Дата последней синхронизации: 10 декабря 2021. Вы можете помочь синхронизировать перевод, если в английской версии произошли изменения.
systemd использует журнал (journal), собственную систему ведения логов, в связи с чем больше не требуется запускать отдельный демон логирования. Для чтения логов используйте команду journalctl(1).
В Arch Linux каталог /var/log/journal/ — это часть пакета systemd и по умолчанию (когда в конфигурационном файле /etc/systemd/journald.conf параметру Storage= задано значение auto) журнал записывается именно в /var/log/journal/. Если каталог будет удалён, systemd не пересоздаст его автоматически и вместо этого будет вести журнал в /run/systemd/journal без сохранения между перезагрузками. Однако каталог будет пересоздан, если добавить Storage=persistent в journald.conf и перезапустить systemd-journald.service (или перезагрузиться).
Сообщения в журнале классифицируются по уровню приоритета и категории (Facility). Классификация записей соответствует классическому протоколу Syslog (RFC 5424).
Уровни приоритета
Коды важности syslog (в systemd называются приоритетами) используются для пометки важности сообщений RFC 5424.
| Значение | Важность | Ключевое слово | Описание | Примеры |
|---|---|---|---|---|
| 0 | Emergency | emerg | Cистема не работоспособна | Серьёзный баг в ядре, дамп памяти systemd. Данный уровень не должен использоваться приложениями. |
| 1 | Alert | alert | Cистема требует немедленного вмешательства | Отказ важной подсистемы. Потеря данных. kernel: BUG: unable to handle kernel paging request at ffffc90403238ffc.
|
| 2 | Critical | crit | Cостояние системы критическое | Аварийные отказы, дампы памяти. Например, знакомое сообщение:systemd-coredump[25319]: Process 25310 (plugin-containe) of user 1000 dumped coreОтказ основных приложений системы, например, X11. |
| 3 | Error | err | Cообщения об ошибках | Сообщение о некритической ошибке:kernel: usb 1-3: 3:1: cannot get freq at ep 0x84,systemd[1]: Failed unmounting /var.,libvirtd[1720]: internal error: Failed to initialize a valid firewall backend
|
| 4 | Warning | warning | Предупреждения о возможных проблемах | В некорневой файловой системе остался всего 1 ГБ свободного места.org.freedesktop. Notifications[1860]: (process:5999): Gtk-WARNING **: Locale not supported by C library. Using the fallback 'C' locale.
|
| 5 | Notice | notice | Cообщения о нормальных, но важных событиях | systemd[1]: var.mount: Directory /var to mount over is not empty, mounting anyway,gcr-prompter[4997]: Gtk: GtkDialog mapped without a transient parent. This is discouraged
|
| 6 | Informational | info | Информационные сообщения | lvm[585]: 7 logical volume(s) in volume group "archvg" now active
|
| 7 | Debug | debug | Отладочные сообщения | kdeinit5[1900]: powerdevil: Scheduling inhibition from ":1.14" "firefox" with cookie 13 and reason "screen"
|
Вышеуказанные правила являются рекомендацией и окончательное решение остаётся за разработчиком приложения. Всегда возможно, что сообщение будет выше или ниже ожидаемого уровня.
Категории
Коды категорий (facility) syslog используются для указания типа программы, добавляющего сообщение в лог RFC 5424.
| Код категории | Ключевое слово | Описание | Информация |
|---|---|---|---|
| 0 | kern | Сообщения ядра | |
| 1 | user | Сообщения программного обеспечения пользователя | |
| 2 | Почтовая система | Архаический POSIX всё ещё поддерживается и иногда используется (см. mail(1) для получения более подробной информации) | |
| 3 | daemon | Системные службы | Все демоны, включая systemd и его подсистемы |
| 4 | auth | Сообщения безопасности (авторизации) | См. также код 10 |
| 5 | syslog | Собственные сообщения syslogd | Для реализаций syslogd (не используется в systemd, см. код 3) |
| 6 | lpr | Подсистема печати (архаическая подсистема) | |
| 7 | news | Подсистема новостных групп (архаическая подсистема) | |
| 8 | uucp | Подсистема UUCP (архаическая подсистема) | |
| 9 | clock daemon | systemd-timesyncd | |
| 10 | authpriv | Сообщения безопасности (авторизации) | См. также код 4 |
| 11 | ftp | Служба FTP | |
| 12 | — | Подсистема NTP | |
| 13 | — | Журнал аудита | |
| 14 | — | Аварийный журнал | |
| 15 | cron | Служба планирования | |
| 16 | local0 | Локальное использование 0 (local0) | |
| 17 | local1 | Локальное использование 1 (local1) | |
| 18 | local2 | Локальное использование 2 (local2) | |
| 19 | local3 | Локальное использование 3 (local3) | |
| 20 | local4 | Локальное использование 4 (local4) | |
| 21 | local5 | Локальное использование 5 (local5) | |
| 22 | local6 | Локальное использование 6 (local6) | |
| 23 | local7 | Локальное использование 7 (local7) |
Полезные категории для наблюдения: 0, 1, 3, 4, 9, 10, 15.
Фильтрация вывода
journalctl позволяет фильтровать вывод по определённым полям. Если должно быть отображено большое количество сообщений или необходима фильтрация большого промежутка времени, то вывод команды может занять значительное время.
Примеры:
- Показать сообщения с момента текущей загрузки системы:
# journalctl -b
Также пользователи часто интересуются сообщениями предыдущей загрузки (например, если произошёл невосстановимый сбой системы). Это возможно, если задать параметр флагу
-b:journalctl -b -0покажет сообщения с момента текущей загрузки,journalctl -b -1— предыдущей загрузки,journalctl -b -2— следующей за предыдущей и т.д. Для просмотра полного описания смотрите страницу справочного руководства journalctl(1), поддерживается и более мощная семантика. - Добавить пояснения к сообщениям логов из каталога сообщений, где это возможно:
# journalctl -x
Обратите внимание, что эту возможность лучше не использовать, когда излишние комментарии нежелательны — например, при добавлении копии логов в сообщение о баге или письмо в поддержку. Вывести существующие пункты каталога можно командой
journalctl --list-catalog. - Показать сообщения, начиная с определённой даты (и, опционально, времени):
# journalctl --since="2012-10-30 18:17:16"
- Показать сообщения за последние 20 минут:
# journalctl --since "20 min ago"
- Следить за появлением новых сообщений:
# journalctl -f
- Показать сообщения конкретного исполняемого файла:
# journalctl /usr/lib/systemd/systemd
- Показать сообщения конкретного процесса:
# journalctl _PID=1
- Показать сообщения конкретного юнита:
# journalctl -u man-db.service
- Показать сообщения от пользовательской службы конкретного юнита:
$ journalctl --user -u dbus
- Показать кольцевой буфер ядра:
# journalctl -k
- Показать сообщения только с приоритетами error, critical и alert:
# journalctl -p err..alert
Также можно использовать числа, например,
journalctl -p 3..1. Если указать одно число/уровень приоритета, например,journalctl -p 3, то также будут показаны сообщения и с более высоким приоритетом (от 0 до 3, в данном случае). - Показать эквивалент auth.log используя фильтрацию категорий syslog:
# journalctl SYSLOG_FACILITY=10
- Если в каталоге с журналами (по умолчанию
/var/log/journal) очень много данных, то фильтрация выводаjournalctlможет занять несколько минут. Процесс можно значительно ускорить с помощью опции--file, указавjournalctlтолько самый свежий журнал:# journalctl --file /var/log/journal/*/system.journal -f
Для получения дополнительной информации смотрите страницы справочного руководства journalctl(1), systemd.journal-fields(7) или пост в блоге Леннарта Пёттеринга.
Совет: По умолчанию journalctl отсекает части строк, которые не вписываются в экран по ширине, хотя иногда перенос строк может оказаться более предпочтительным. Управление этой возможностью производится посредством переменной окружения SYSTEMD_LESS, в которой содержатся опции, передаваемые в less (программу постраничного просмотра, используемую по умолчанию). По умолчанию переменная имеет значение FRSXMK (для получения дополнительной информации смотрите less(1) и journalctl(1)).
Если убрать опцию S, будет достигнут требуемый результат. Например, запустите journalctl, как показано здесь:
$ SYSTEMD_LESS=FRXMK journalctl
Для использования такого поведения по умолчанию, экспортируйте переменную из файла ~/.bashrc или ~/.zshrc.
Совет: Несмотря на то, что журнал хранится в двоичном формате, содержимое сообщений не изменяется. Это означает, что их можно просматривать при помощи strings, например, для восстановления системы в окружении без systemd. Пример команды:
$ strings /mnt/arch/var/log/journal/af4967d77fba44c6b093d0e9862f6ddd/system.journal | grep -i message
Ограничение размера журнала
Если журнал сохраняется при перезагрузке, его размер по умолчанию ограничен значением в 10% от объема соответствующей файловой системы (и максимально может достигать 4 ГиБ). Например, для каталога /var/log/journal, расположенном на корневом разделе в 20 ГиБ, максимальный размер журналируемых данных составит 2 ГиБ. На разделе же 50 ГиБ журнал сможет занять до 4 ГиБ. Текущие пределы для вашей системы можно узнать из логов systemd-journald:
# journalctl -b -u systemd-journald
Максимальный объем постоянного журнала можно задать вручную, раскомментировав и отредактировав следующий параметр:
/etc/systemd/journald.conf
SystemMaxUse=50M
Также возможно использование конфигурационных сниппетов вместо редактирования глобального файла конфигурации. В таком случае поместите переопределения в разделе [Journal]:
/etc/systemd/journald.conf.d/00-journal-size.conf
[Journal] SystemMaxUse=50M
Перезапустите systemd-journald.service для применения изменений.
Для получения дополнительной информации обратитесь к странице справочного руководства journald.conf(5).
Ограничение размера для юнита
Отредактируйте файл юнита службы, которую вы хотите настроить (например, sshd), добавив параметр LogNamespace=ssh в раздел [Service].
Затем создайте файл journald@ssh.conf, скопировав содержимое файла /etc/systemd/journald.conf. Отредактируйте его, задав необходимое значение SystemMaxUse.
Перезапустите юнит, чтобы включилась новая служба журнала systemd-journald@ssh.service. Логи службы из определённого «пространства имён» можно увидеть командой journalctl --namespace ssh.
Подробнее о пространствах имён журнала см. systemd-journald.service(8) § JOURNAL NAMESPACES.
Очистка файлов журнала вручную
Файлы журнала можно удалить из директории /var/log/journal/, к примеру, с помощью rm или journalctl для удаления части журналов по определённым критериям. Например:
- Удалять заархивированные файлы журнала, пока занимаемое ими место не составит менее 100 МиБ:
# journalctl --vacuum-size=100M
- Ограничить все файлы журнала хранением данных только за последние две недели:
# journalctl --vacuum-time=2weeks
Для получения дополнительной информации, обратитесь к journalctl(1).
Journald вместе с syslog
Совместимость с классической реализацией syslog можно обеспечить, перенаправляя все сообщения systemd через сокет /run/systemd/journal/syslog. Для работы демона syslog с журналом, следует привязать его к данному сокету вместо /dev/log (официальное сообщение).
Для перенаправления данных в сокет, в journald.conf по умолчанию задан параметр ForwardToSyslog=no, чтобы избежать перегрузки на систему, так как rsyslog или syslog-ng самостоятельно получают сообщения из журнала.
Смотрите Syslog-ng#Overview и Syslog-ng#syslog-ng and systemd journal или rsyslog для получения подробной информации о конфигурировании.
Перенаправление журнала в /dev/tty12
Создайте drop-in каталог /etc/systemd/journald.conf.d и файл fw-tty12.conf в нём со следующим содержимым:
/etc/systemd/journald.conf.d/fw-tty12.conf
[Journal] ForwardToConsole=yes TTYPath=/dev/tty12 MaxLevelConsole=info
Затем перезапустите службу systemd-journald.
Выбор журнала для просмотра
Иногда необходимо проверить логи другой системы, например, загружаясь с работоспособной системы для восстановления неисправной. В таком случае примонтируйте диск, к примеру, в /mnt и укажите путь журнала с помощью флага -D/--directory следующим образом:
# journalctl -D /mnt/var/log/journal -e
Доступ к журналу как пользователь
По умолчанию обычные пользователи могут читать только свой собственный пользовательский журнал. Чтобы дать доступ на чтение системного журнала обычному пользователю, добавьте его в группу systemd-journal. Для групп adm и wheel также предоставляется доступ на чтение.
Подробнее смотрите journalctl(1) § DESCRIPTION и Пользователи и группы#Пользовательские группы.
Note that this document describes the binary on-disk format of journals only.
For interfacing with web technologies there’s the Journal JSON Format.
For transfer of journal data across the network there’s the Journal Export Format.
The systemd journal stores log data in a binary format with several features:
- Fully indexed by all fields
- Can store binary data, up to 2^64-1 in size
- Seekable
- Primarily append-based, hence robust to corruption
- Support for in-line compression
- Support for in-line Forward Secure Sealing
This document explains the basic structure of the file format on disk. We are
making this available primarily to allow review and provide documentation. Note
that the actual implementation in the systemd
codebase is the
only ultimately authoritative description of the format, so if this document
and the code disagree, the code is right. That said we’ll of course try hard to
keep this document up-to-date and accurate.
Instead of implementing your own reader or writer for journal files we ask you
to use the Journal’s native C
API to access
these files. It provides you with full access to the files, and will not
withhold any data. If you find a limitation, please ping us and we might add
some additional interfaces for you.
If you need access to the raw journal data in serialized stream form without C
API our recommendation is to make use of the Journal Export
Format, which you can
get via journalctl -o export or via systemd-journal-gatewayd. The export
format is much simpler to parse, but complete and accurate. Due to its
stream-based nature it is not indexed.
Or, to put this in other words: this low-level document is probably not what
you want to use as base of your project. You want our C
API instead!
And if you really don’t want the C API, then you want the
Journal Export Format or Journal JSON Format
instead! This document is primarily for your entertainment and education.
Thank you!
This document assumes you have a basic understanding of the journal concepts,
the properties of a journal entry and so on. If not, please go and read up,
then come back! This is a good opportunity to read about the basic properties
of journal
entries,
in particular realize that they may include binary non-text data (though
usually don’t), and the same field might have multiple values assigned within
the same entry.
This document describes the current format of systemd 246. The documented
format is compatible with the format used in the first versions of the journal,
but received various compatible and incompatible additions since.
If you are wondering why the journal file format has been created in the first
place instead of adopting an existing database implementation, please have a
look at this
thread.
Basics
- All offsets, sizes, time values, hashes (and most other numeric values) are 32bit/64bit unsigned integers in LE format.
- Offsets are always relative to the beginning of the file.
- The 64bit hash function siphash24 is used for newer journal files. For older files Jenkins lookup3 is used, more specifically
jenkins_hashlittle2()with the first 32bit integer it returns as higher 32bit part of the 64bit value, and the second one uses as lower 32bit part. - All structures are aligned to 64bit boundaries and padded to multiples of 64bit
- The format is designed to be read and written via memory mapping using multiple mapped windows.
- All time values are stored in usec since the respective epoch.
- Wall clock time values are relative to the Unix time epoch, i.e. January 1st, 1970. (
CLOCK_REALTIME) - Monotonic time values are always stored jointly with the kernel boot ID value (i.e.
/proc/sys/kernel/random/boot_id) they belong to. They tend to be relative to the start of the boot, but aren’t for containers. (CLOCK_MONOTONIC) - Randomized, unique 128bit IDs are used in various locations. These are generally UUID v4 compatible, but this is not a requirement.
General Rules
If any kind of corruption is noticed by a writer it should immediately rotate
the file and start a new one. No further writes should be attempted to the
original file, but it should be left around so that as little data as possible
is lost.
If any kind of corruption is noticed by a reader it should try hard to handle
this gracefully, such as skipping over the corrupted data, but allowing access
to as much data around it as possible.
A reader should verify all offsets and other data as it reads it. This includes
checking for alignment and range of offsets in the file, especially before
trying to read it via a memory map.
A reader must interleave rotated and corrupted files as good as possible and
present them as single stream to the user.
All fields marked as “reserved” must be initialized with 0 when writing and be
ignored on reading. They are currently not used but might be used later on.
Structure
The file format’s data structures are declared in
journal-def.h.
The file format begins with a header structure. After the header structure
object structures follow. Objects are appended to the end as time
progresses. Most data stored in these objects is not altered anymore after
having been written once, with the exception of records necessary for
indexing. When new data is appended to a file the writer first writes all new
objects to the end of the file, and then links them up at front after that’s
done. Currently, seven different object types are known:
enum {
OBJECT_UNUSED,
OBJECT_DATA,
OBJECT_FIELD,
OBJECT_ENTRY,
OBJECT_DATA_HASH_TABLE,
OBJECT_FIELD_HASH_TABLE,
OBJECT_ENTRY_ARRAY,
OBJECT_TAG,
_OBJECT_TYPE_MAX
};
- A DATA object, which encapsulates the contents of one field of an entry, i.e. a string such as
_SYSTEMD_UNIT=avahi-daemon.service, orMESSAGE=Foobar made a booboo.but possibly including large or binary data, and always prefixed by the field name and “=”. - A FIELD object, which encapsulates a field name, i.e. a string such as
_SYSTEMD_UNITorMESSAGE, without any=or even value. - An ENTRY object, which binds several DATA objects together into a log entry.
- A DATA_HASH_TABLE object, which encapsulates a hash table for finding existing DATA objects.
- A FIELD_HASH_TABLE object, which encapsulates a hash table for finding existing FIELD objects.
- An ENTRY_ARRAY object, which encapsulates a sorted array of offsets to entries, used for seeking by binary search.
- A TAG object, consisting of an FSS sealing tag for all data from the beginning of the file or the last tag written (whichever is later).
The Header struct defines, well, you guessed it, the file header:
_packed_ struct Header {
uint8_t signature[8]; /* "LPKSHHRH" */
le32_t compatible_flags;
le32_t incompatible_flags;
uint8_t state;
uint8_t reserved[7];
sd_id128_t file_id;
sd_id128_t machine_id;
sd_id128_t boot_id; /* last writer */
sd_id128_t seqnum_id;
le64_t header_size;
le64_t arena_size;
le64_t data_hash_table_offset;
le64_t data_hash_table_size;
le64_t field_hash_table_offset;
le64_t field_hash_table_size;
le64_t tail_object_offset;
le64_t n_objects;
le64_t n_entries;
le64_t tail_entry_seqnum;
le64_t head_entry_seqnum;
le64_t entry_array_offset;
le64_t head_entry_realtime;
le64_t tail_entry_realtime;
le64_t tail_entry_monotonic;
/* Added in 187 */
le64_t n_data;
le64_t n_fields;
/* Added in 189 */
le64_t n_tags;
le64_t n_entry_arrays;
/* Added in 246 */
le64_t data_hash_chain_depth;
le64_t field_hash_chain_depth;
/* Added in 252 */
le32_t tail_entry_array_offset;
le32_t tail_entry_array_n_entries;
};
The first 8 bytes of Journal files must contain the ASCII characters LPKSHHRH.
If a writer finds that the machine_id of a file to write to does not match
the machine it is running on it should immediately rotate the file and start a
new one.
When journal file is first created the file_id is randomly and uniquely
initialized.
When a writer opens a file it shall initialize the boot_id to the current
boot id of the system.
The currently used part of the file is the header_size plus the
arena_size field of the header. If a writer needs to write to a file where
the actual file size on disk is smaller than the reported value it shall
immediately rotate the file and start a new one. If a writer is asked to write
to a file with a header that is shorter than its own definition of the struct
Header, it shall immediately rotate the file and start a new one.
The n_objects field contains a counter for objects currently available in
this file. As objects are appended to the end of the file this counter is
increased.
The first object in the file starts immediately after the header. The last
object in the file is at the offset tail_object_offset, which may be 0 if
no object is in the file yet.
The n_entries, n_data, n_fields, n_tags, n_entry_arrays are
counters of the objects of the specific types.
tail_entry_seqnum and head_entry_seqnum contain the sequential number
(see below) of the last or first entry in the file, respectively, or 0 if no
entry has been written yet.
tail_entry_realtime and head_entry_realtime contain the wallclock
timestamp of the last or first entry in the file, respectively, or 0 if no
entry has been written yet.
tail_entry_monotonic is the monotonic timestamp of the last entry in the
file, referring to monotonic time of the boot identified by boot_id.
data_hash_chain_depth is a counter of the deepest chain in the data hash
table, minus one. This is updated whenever a chain is found that is longer than
the previous deepest chain found. Note that the counter is updated during hash
table lookups, as the chains are traversed. This counter is used to determine
when it is a good time to rotate the journal file, because hash collisions
became too frequent.
Similar, field_hash_chain_depth is a counter of the deepest chain in the
field hash table, minus one.
tail_entry_array_offset and tail_entry_array_n_entries allow immediate
access to the last entry array in the global entry array chain.
Extensibility
The format is supposed to be extensible in order to enable future additions of
features. Readers should simply skip objects of unknown types as they read
them. If a compatible feature extension is made a new bit is registered in the
header’s compatible_flags field. If a feature extension is used that makes
the format incompatible a new bit is registered in the header’s
incompatible_flags field. Readers should check these two bit fields, if
they find a flag they don’t understand in compatible_flags they should continue
to read the file, but if they find one in incompatible_flags they should
fail, asking for an update of the software. Writers should refuse writing if
there’s an unknown bit flag in either of these fields.
The file header may be extended as new features are added. The size of the file
header is stored in the header. All header fields up to n_data are known to
unconditionally exist in all revisions of the file format, all fields starting
with n_data needs to be explicitly checked for via a size check, since they
were additions after the initial release.
Currently only five extensions flagged in the flags fields are known:
enum {
HEADER_INCOMPATIBLE_COMPRESSED_XZ = 1 << 0,
HEADER_INCOMPATIBLE_COMPRESSED_LZ4 = 1 << 1,
HEADER_INCOMPATIBLE_KEYED_HASH = 1 << 2,
HEADER_INCOMPATIBLE_COMPRESSED_ZSTD = 1 << 3,
HEADER_INCOMPATIBLE_COMPACT = 1 << 4,
};
enum {
HEADER_COMPATIBLE_SEALED = 1 << 0,
};
HEADER_INCOMPATIBLE_COMPRESSED_XZ indicates that the file includes DATA objects
that are compressed using XZ. Similarly, HEADER_INCOMPATIBLE_COMPRESSED_LZ4
indicates that the file includes DATA objects that are compressed with the LZ4
algorithm. And HEADER_INCOMPATIBLE_COMPRESSED_ZSTD indicates that there are
objects compressed with ZSTD.
HEADER_INCOMPATIBLE_KEYED_HASH indicates that instead of the unkeyed Jenkins
hash function the keyed siphash24 hash function is used for the two hash
tables, see below.
HEADER_INCOMPATIBLE_COMPACT indicates that the journal file uses the new binary
format that uses less space on disk compared to the original format.
HEADER_COMPATIBLE_SEALED indicates that the file includes TAG objects required
for Forward Secure Sealing.
Dirty Detection
enum {
STATE_OFFLINE = 0,
STATE_ONLINE = 1,
STATE_ARCHIVED = 2,
_STATE_MAX
};
If a file is opened for writing the state field should be set to
STATE_ONLINE. If a file is closed after writing the state field should be
set to STATE_OFFLINE. After a file has been rotated it should be set to
STATE_ARCHIVED. If a writer is asked to write to a file that is not in
STATE_OFFLINE it should immediately rotate the file and start a new one,
without changing the file.
After and before the state field is changed, fdatasync() should be executed on
the file to ensure the dirty state hits disk.
Sequence Numbers
All entries carry sequence numbers that are monotonically counted up for each
entry (starting at 1) and are unique among all files which carry the same
seqnum_id field. This field is randomly generated when the journal daemon
creates its first file. All files generated by the same journal daemon instance
should hence carry the same seqnum_id. This should guarantee a monotonic stream
of sequential numbers for easy interleaving even if entries are distributed
among several files, such as the system journal and many per-user journals.
Concurrency
The file format is designed to be usable in a simultaneous
single-writer/multiple-reader scenario. The synchronization model is very weak
in order to facilitate storage on the most basic of file systems (well, the
most basic ones that provide us with mmap() that is), and allow good
performance. No file locking is used. The only time where disk synchronization
via fdatasync() should be enforced is after and before changing the state
field in the file header (see below). It is recommended to execute a memory
barrier after appending and initializing new objects at the end of the file,
and before linking them up in the earlier objects.
This weak synchronization model means that it is crucial that readers verify
the structural integrity of the file as they read it and handle invalid
structure gracefully. (Checking what you read is a pretty good idea out of
security considerations anyway.) This specifically includes checking offset
values, and that they point to valid objects, with valid sizes and of the type
and hash value expected. All code must be written with the fact in mind that a
file with inconsistent structure might just be inconsistent temporarily, and
might become consistent later on. Payload OTOH requires less scrutiny, as it
should only be linked up (and hence visible to readers) after it was
successfully written to memory (though not necessarily to disk). On non-local
file systems it is a good idea to verify the payload hashes when reading, in
order to avoid annoyances with mmap() inconsistencies.
Clients intending to show a live view of the journal should use inotify() for
this to watch for files changes. Since file writes done via mmap() do not
result in inotify() writers shall truncate the file to its current size after
writing one or more entries, which results in inotify events being
generated. Note that this is not used as a transaction scheme (it doesn’t
protect anything), but merely for triggering wakeups.
Note that inotify will not work on network file systems if reader and writer
reside on different hosts. Readers which detect they are run on journal files
on a non-local file system should hence not rely on inotify for live views but
fall back to simple time based polling of the files (maybe recheck every 2s).
Objects
All objects carry a common header:
enum {
OBJECT_COMPRESSED_XZ = 1 << 0,
OBJECT_COMPRESSED_LZ4 = 1 << 1,
OBJECT_COMPRESSED_ZSTD = 1 << 2,
};
_packed_ struct ObjectHeader {
uint8_t type;
uint8_t flags;
uint8_t reserved[6];
le64_t size;
uint8_t payload[];
};
The type field is one of the object types listed above. The flags field
currently knows three flags: OBJECT_COMPRESSED_XZ, OBJECT_COMPRESSED_LZ4 and
OBJECT_COMPRESSED_ZSTD. It is only valid for DATA objects and indicates that
the data payload is compressed with XZ/LZ4/ZSTD. If one of the
OBJECT_COMPRESSED_* flags is set for an object then the matching
HEADER_INCOMPATIBLE_COMPRESSED_XZ/HEADER_INCOMPATIBLE_COMPRESSED_LZ4/HEADER_INCOMPATIBLE_COMPRESSED_ZSTD
flag must be set for the file as well. At most one of these three bits may be
set. The size field encodes the size of the object including all its
headers and payload.
Data Objects
_packed_ struct DataObject {
ObjectHeader object;
le64_t hash;
le64_t next_hash_offset;
le64_t next_field_offset;
le64_t entry_offset; /* the first array entry we store inline */
le64_t entry_array_offset;
le64_t n_entries;
union {
struct {
uint8_t payload[] ;
} regular;
struct {
le32_t tail_entry_array_offset;
le32_t tail_entry_array_n_entries;
uint8_t payload[];
} compact;
};
};
Data objects carry actual field data in the payload[] array, including a
field name, a = and the field data. Example:
_SYSTEMD_UNIT=foobar.service. The hash field is a hash value of the
payload. If the HEADER_INCOMPATIBLE_KEYED_HASH flag is set in the file header
this is the siphash24 hash value of the payload, keyed by the file ID as stored
in the file_id field of the file header. If the flag is not set it is the
non-keyed Jenkins hash of the payload instead. The keyed hash is preferred as
it makes the format more robust against attackers that want to trigger hash
collisions in the hash table.
next_hash_offset is used to link up DATA objects in the DATA_HASH_TABLE if
a hash collision happens (in a singly linked list, with an offset of 0
indicating the end). next_field_offset is used to link up data objects with
the same field name from the FIELD object of the field used.
entry_offset is an offset to the first ENTRY object referring to this DATA
object. entry_array_offset is an offset to an ENTRY_ARRAY object with
offsets to other entries referencing this DATA object. Storing the offset to
the first ENTRY object in-line is an optimization given that many DATA objects
will be referenced from a single entry only (for example, MESSAGE= frequently
includes a practically unique string). n_entries is a counter of the total
number of ENTRY objects that reference this object, i.e. the sum of all
ENTRY_ARRAYS chained up from this object, plus 1.
The payload[] field contains the field name and date unencoded, unless
OBJECT_COMPRESSED_XZ/OBJECT_COMPRESSED_LZ4/OBJECT_COMPRESSED_ZSTD is set in the
ObjectHeader, in which case the payload is compressed with the indicated
compression algorithm.
If the HEADER_INCOMPATIBLE_COMPACT flag is set, Two extra fields are stored to
allow immediate access to the tail entry array in the DATA object’s entry array
chain.
Field Objects
_packed_ struct FieldObject {
ObjectHeader object;
le64_t hash;
le64_t next_hash_offset;
le64_t head_data_offset;
uint8_t payload[];
};
Field objects are used to enumerate all possible values a certain field name
can take in the entire journal file.
The payload[] array contains the actual field name, without ‘=’ or any
field value. Example: _SYSTEMD_UNIT. The hash field is a hash value of
the payload. As for the DATA objects, this too is either the .file_id keyed
siphash24 hash of the payload, or the non-keyed Jenkins hash.
next_hash_offset is used to link up FIELD objects in the FIELD_HASH_TABLE
if a hash collision happens (in singly linked list, offset 0 indicating the
end). head_data_offset points to the first DATA object that shares this
field name. It is the head of a singly linked list using DATA’s
next_field_offset offset.
Entry Objects
_packed_ struct EntryObject {
ObjectHeader object;
le64_t seqnum;
le64_t realtime;
le64_t monotonic;
sd_id128_t boot_id;
le64_t xor_hash;
union {
struct {
le64_t object_offset;
le64_t hash;
} regular[];
struct {
le32_t object_offset;
} compact[];
} items;
};
An ENTRY object binds several DATA objects together into one log entry, and
includes other metadata such as various timestamps.
The seqnum field contains the sequence number of the entry, realtime
the realtime timestamp, and monotonic the monotonic timestamp for the boot
identified by boot_id.
The xor_hash field contains a binary XOR of the hashes of the payload of
all DATA objects referenced by this ENTRY. This value is usable to check the
contents of the entry, being independent of the order of the DATA objects in
the array. Note that even for files that have the
HEADER_INCOMPATIBLE_KEYED_HASH flag set (and thus siphash24 the otherwise
used hash function) the hash function used for this field, as singular
exception, is the Jenkins lookup3 hash function. The XOR hash value is used to
quickly compare the contents of two entries, and to define a well-defined order
between two entries that otherwise have the same sequence numbers and
timestamps.
The items[] array contains references to all DATA objects of this entry,
plus their respective hashes (which are calculated the same way as in the DATA
objects, i.e. keyed by the file ID).
If the HEADER_INCOMPATIBLE_COMPACT flag is set, DATA object offsets are stored
as 32-bit integers instead of 64bit and the unused hash field per data object is
not stored anymore.
In the file ENTRY objects are written ordered monotonically by sequence
number. For continuous parts of the file written during the same boot
(i.e. with the same boot_id) the monotonic timestamp is monotonic too. Modulo
wallclock time jumps (due to incorrect clocks being corrected) the realtime
timestamps are monotonic too.
Hash Table Objects
_packed_ struct HashItem {
le64_t head_hash_offset;
le64_t tail_hash_offset;
};
_packed_ struct HashTableObject {
ObjectHeader object;
HashItem items[];
};
The structure of both DATA_HASH_TABLE and FIELD_HASH_TABLE objects are
identical. They implement a simple hash table, with each cell containing
offsets to the head and tail of the singly linked list of the DATA and FIELD
objects, respectively. DATA’s and FIELD’s next_hash_offset field are used to
chain up the objects. Empty cells have both offsets set to 0.
Each file contains exactly one DATA_HASH_TABLE and one FIELD_HASH_TABLE
objects. Their payload is directly referred to by the file header in the
data_hash_table_offset, data_hash_table_size,
field_hash_table_offset, field_hash_table_size fields. These offsets do
not point to the object headers but directly to the payloads. When a new
journal file is created the two hash table objects need to be created right
away as first two objects in the stream.
If the hash table fill level is increasing over a certain fill level (Learning
from Java’s Hashtable for example: > 75%), the writer should rotate the file
and create a new one.
The DATA_HASH_TABLE should be sized taking into account to the maximum size the
file is expected to grow, as configured by the administrator or disk space
considerations. The FIELD_HASH_TABLE should be sized to a fixed size; the
number of fields should be pretty static as it depends only on developers’
creativity rather than runtime parameters.
Entry Array Objects
_packed_ struct EntryArrayObject {
ObjectHeader object;
le64_t next_entry_array_offset;
union {
le64_t regular[];
le32_t compact[];
} items;
};
Entry Arrays are used to store a sorted array of offsets to entries. Entry
arrays are strictly sorted by offsets on disk, and hence by their timestamps
and sequence numbers (with some restrictions, see above).
If the HEADER_INCOMPATIBLE_COMPACT flag is set, offsets are stored as 32-bit
integers instead of 64bit.
Entry Arrays are chained up. If one entry array is full another one is
allocated and the next_entry_array_offset field of the old one pointed to
it. An Entry Array with next_entry_array_offset set to 0 is the last in the
list. To optimize allocation and seeking, as entry arrays are appended to a
chain of entry arrays they should increase in size (double).
Due to being monotonically ordered entry arrays may be searched with a binary
search (bisection).
One chain of entry arrays links up all entries written to the journal. The
first entry array is referenced in the entry_array_offset field of the
header.
Each DATA object also references an entry array chain listing all entries
referencing a specific DATA object. Since many DATA objects are only referenced
by a single ENTRY the first offset of the list is stored inside the DATA object
itself, an ENTRY_ARRAY object is only needed if it is referenced by more than
one ENTRY.
Tag Object
#define TAG_LENGTH (256/8)
_packed_ struct TagObject {
ObjectHeader object;
le64_t seqnum;
le64_t epoch;
uint8_t tag[TAG_LENGTH]; /* SHA-256 HMAC */
};
Tag objects are used to seal off the journal for alteration. In regular
intervals a tag object is appended to the file. The tag object consists of a
SHA-256 HMAC tag that is calculated from the objects stored in the file since
the last tag was written, or from the beginning if no tag was written yet. The
key for the HMAC is calculated via the externally maintained FSPRG logic for
the epoch that is written into epoch. The sequence number seqnum is
increased with each tag. When calculating the HMAC of objects header fields
that are volatile are excluded (skipped). More specifically all fields that
might validly be altered to maintain a consistent file structure (such as
offsets to objects added later for the purpose of linked lists and suchlike)
after an object has been written are not protected by the tag. This means a
verifier has to independently check these fields for consistency of
structure. For the fields excluded from the HMAC please consult the source code
directly. A verifier should read the file from the beginning to the end, always
calculating the HMAC for the objects it reads. Each time a tag object is
encountered the HMAC should be verified and restarted. The tag object sequence
numbers need to increase strictly monotonically. Tag objects themselves are
partially protected by the HMAC (i.e. seqnum and epoch is included, the tag
itself not).
Algorithms
Reading
Given an offset to an entry all data fields are easily found by following the
offsets in the data item array of the entry.
Listing entries without filter is done by traversing the list of entry arrays
starting with the headers’ entry_array_offset field.
Seeking to an entry by timestamp or sequence number (without any matches) is
done via binary search in the entry arrays starting with the header’s
entry_array_offset field. Since these arrays double in size as more are
added the time cost of seeking is O(log(n)*log(n)) if n is the number of
entries in the file.
When seeking or listing with one field match applied the DATA object of the
match is first identified, and then its data entry array chain traversed. The
time cost is the same as for seeks/listings with no match.
If multiple matches are applied, multiple chains of entry arrays should be
traversed in parallel. Since they all are strictly monotonically ordered by
offset of the entries, advancing in one can be directly applied to the others,
until an entry matching all matches is found. In the worst case seeking like
this is O(n) where n is the number of matching entries of the “loosest” match,
but in the common case should be much more efficient at least for the
well-known fields, where the set of possible field values tend to be closely
related. Checking whether an entry matches a number of matches is efficient
since the item array of the entry contains hashes of all data fields
referenced, and the number of data fields of an entry is generally small (<
30).
When interleaving multiple journal files seeking tends to be a frequently used
operation, but in this case can be effectively suppressed by caching results
from previous entries.
When listing all possible values a certain field can take it is sufficient to
look up the FIELD object and follow the chain of links to all DATA it includes.
Writing
When an entry is appended to the journal, for each of its data fields the data
hash table should be checked. If the data field does not yet exist in the file,
it should be appended and added to the data hash table. When a data field’s data
object is added, the field hash table should be checked for the field name of
the data field, and a field object be added if necessary. After all data fields
(and recursively all field names) of the new entry are appended and linked up
in the hashtables, the entry object should be appended and linked up too.
At regular intervals a tag object should be written if sealing is enabled (see
above). Before the file is closed a tag should be written too, to seal it off.
Before writing an object, time and disk space limits should be checked and
rotation triggered if necessary.
Optimizing Disk IO
A few general ideas to keep in mind:
The hash tables for looking up fields and data should be quickly in the memory
cache and not hurt performance. All entries and entry arrays are ordered
strictly by time on disk, and hence should expose an OK access pattern on
rotating media, when read sequentially (which should be the most common case,
given the nature of log data).
The disk access patterns of the binary search for entries needed for seeking
are problematic on rotating disks. This should not be a major issue though,
since seeking should not be a frequent operation.
When reading, collecting data fields for presenting entries to the user is
problematic on rotating disks. In order to optimize these patterns the item
array of entry objects should be sorted by disk offset before
writing. Effectively, frequently used data objects should be in the memory
cache quickly. Non-frequently used data objects are likely to be located
between the previous and current entry when reading and hence should expose an
OK access pattern. Problematic are data objects that are neither frequently nor
infrequently referenced, which will cost seek time.
And that’s all there is to it.
Thanks for your interest!
Журналы — это один из самых важных источников информации при возникновении любых ошибок в операционной системе Linux. Я это уже много раз говорил ранее и вот сказал ещё раз. Раньше в Linux для сохранения журналов сервисов использовался отдельный демон под названием syslogd. Но с приходом системы инициализации systemd большинство функций касающихся управления сервисами перешли под её управление. В том числе и управление логами.
Теперь для просмотра логов определенного сервиса или загрузки системы необходимо использовать утилиту journalctl. В этой статье мы разберем примеры использования journalctl, а также основные возможности этой команды и её опции. По сравнению с обычными файлами журналов, у journalctl есть несколько преимуществ. Все логи находятся в одном месте, они индексируются и структурируются, поэтому к ним можно получить доступ в нескольких удобных форматах.
Синтаксис команды очень простой. Достаточно выполнить команду без опций или передав ей нужные опции. Если утилита не выводит ничего, выполните её от имени суперпользователя:
journalctl опции
А теперь давайте разберем основные опции journalctl:
- —full, -l — отображать все доступные поля;
- —all, -a — отображать все поля в выводе full, даже если они содержат непечатаемые символы или слишком длинные;
- —pager-end, -e — отобразить только последние сообщения из журнала;
- —lines, -n — количество строк, которые нужно отображать на одном экране, по умолчанию 10;
- —no-tail — отображать все строки доступные строки;
- —reverse, -r — отображать новые события в начале списка;
- —output, -o — настраивает формат вывода лога;
- —output-fields — поля, которые нужно выводить;
- —catalog, -x — добавить к информации об ошибках пояснения, ссылки на документацию или форумы там, где это возможно;
- —quiet, -q — не показывать все информационные сообщения;
- —merge, -m — показывать сообщения из всех доступных журналов;
- —boot, -b — показать сообщения с момента определенной загрузки системы. По умолчанию используется последняя загрузка;
- —list-boots — показать список сохраненных загрузок системы;
- —dmesg, -k — показывает сообщения только от ядра. Аналог вызова команды dmesg;
- —identifier, -t — показать сообщения с выбранным идентификатором;
- —unit, -u — показать сообщения от выбранного сервиса;
- —user-unit — фильтровать сообщения от выбранной сессии;
- —priority, -p — фильтровать сообщения по их приоритету. Есть восемь уровней приоритета, от 0 до 7;
- —grep, -g — фильтрация по тексту сообщения;
- —cursor, -c — начать просмотр сообщений с указанного места;
- —since, -S, —until, -U — фильтрация по дате и времени;
- —field, -F — вывести все данные из выбранного поля;
- —fields, -N — вывести все доступные поля;
- —system — выводить только системные сообщения;
- —user — выводить только сообщения пользователя;
- —machine, -M — выводить сообщения от определенного контейнера;
- —header — выводить заголовки полей при выводе журнала;
- —disk-usage — вывести общий размер лог файлов на диске;
- —list-catalog — вывести все доступные подсказки для ошибок;
- —sync — синхронизировать все не сохраненные журналы с файловой системой;
- —flush — перенести все данные из каталога /run/log/journal в /var/log/journal;
- —rotate — запустить ротацию логов;
- —no-pager — выводить информацию из журнала без возможности листать страницы;
- -f — выводить новые сообщения в реальном времени, как в команде tail;
- —vacuum-time — очистить логи, давностью больше указанного периода;
- —vacuum-size — очистить логи, чтобы размер хранилища соответствовал указанному.
Горячие клавиши journalctl
По умолчанию информация лога выводится в формате, в котором её можно листать. Давайте разберем горячие клавиши, которые вы можете для этого использовать:
- Стрелка вниз, Enter, e или j — переместиться вниз на одну строку;
- Стрелка вверх, y или k — переместиться на одну строку вверх;
- Пробел — переместиться на одну страницу вниз;
- b — переместиться на одну страницу вверх;
- Стрелка вправо, стрелка влево — горизонтальна прокрутка;
- g — перейти на первую строку;
- G — перейти на последнюю строку;
- p — перейти на позицию нужного процента сообщений. Например, 50p перенесет курсор на середину вывода;
- / — поиск по журналу;
- n — найти следующее вхождение;
- N — предыдущее вхождение;
- q — выйти.
Теперь вы знаете основные опции команды и клавиши, с помощью которых можно ею управлять. Дальше небольшая шпаргалка journalctl.
Шпаргалка по journalctl
Вывод journalctl представляет из себя цельный список всех сохраненных сообщений. Если вы запустите команду journalctl без параметров, то получите самые первые сообщения, которые были сохранены. В моем случае это данные за 13 января:
sudo journalctl
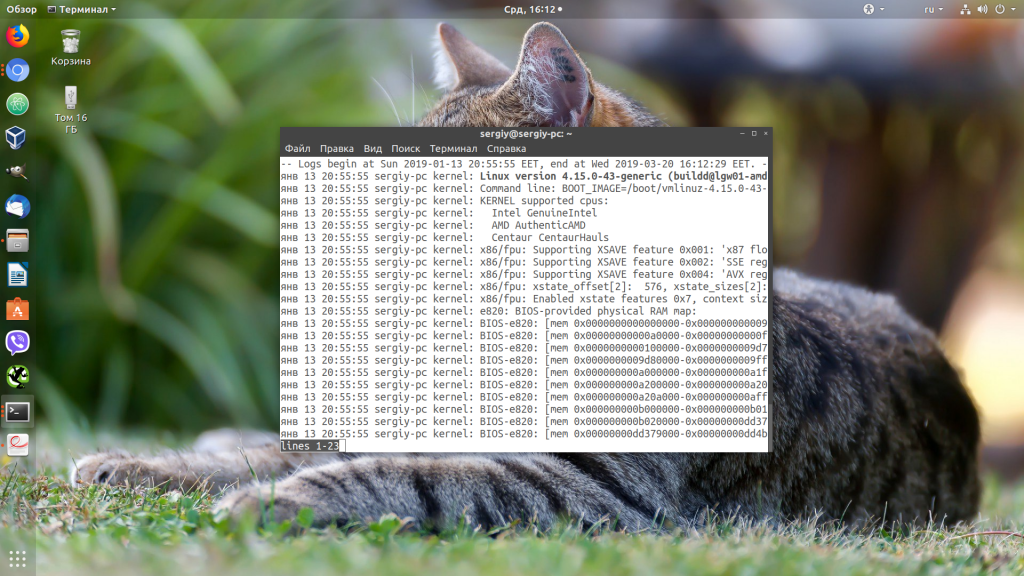
Чтобы найти именно то, что вам нужно, необходимо научится перемещаться по этому списку. Формат вывода лога довольно простой:
янв 13 20:55:55 sergiy-pc kernel: Linux version 4.15.0-43-generic
- янв 13 20:55:55 — дата и время события;
- sergiy-pc — хост, на котором произошло событие;
- kernel — источник события, обычно это программа или сервис. В данном случае ядро;
- Linux version 4.15.0-43-generic — само сообщение.
Давайте перейдем к примерам фильтрации и перемещения.
1. Просмотр логов сервисов
Самый частый случай использования journalctl — это когда вы пытаетесь запустить какой-либо сервис с помощью systemd, он не запускается и systemd выдает вам такое сообщение подобного содержания: Failed to start service use journalctl -xe for details. Система сама предлагает вам какую команду надо выполнить:
sudo journalctl -xe
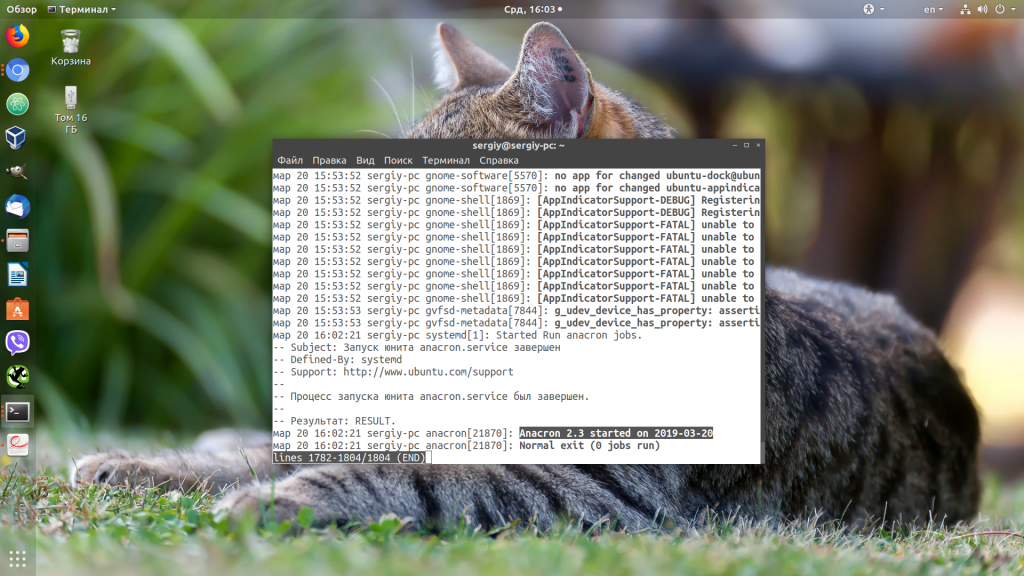
Как вы помните из опций, эта команда отображает последние сообщения в журнале и добавляет к ним дополнительную информацию, если она есть. Учитывая, что последнее, что мы делали — был наш сервис, то здесь будут сообщения от него и вы быстро сможете понять почему он не запускается.
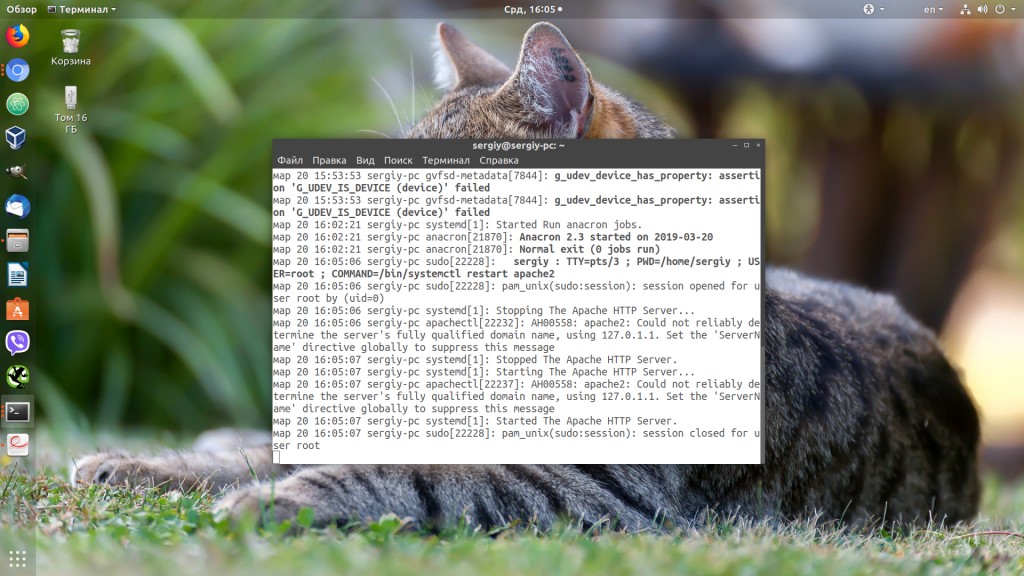
Чтобы отфильтровать сообщения только от определенного сервиса можно использовать опцию -u. Например:
sudo journalctl -eu apache2.service
2. Просмотр логов в режиме tail
С помощью опции -f можно указать утилите, что необходимо выводить новые сообщения в реальном времени:
sudo journalctl -f
В этом режиме less не поддерживается, поэтому для выхода нажмите сочетание клавиш Ctrl+C.
3. Просмотр логов загрузки
В логе journalctl содержатся все логи, в том числе и логи загрузки. Для того чтобы открыть лог последней загрузки используйте опцию -b:
sudo journalctl -b
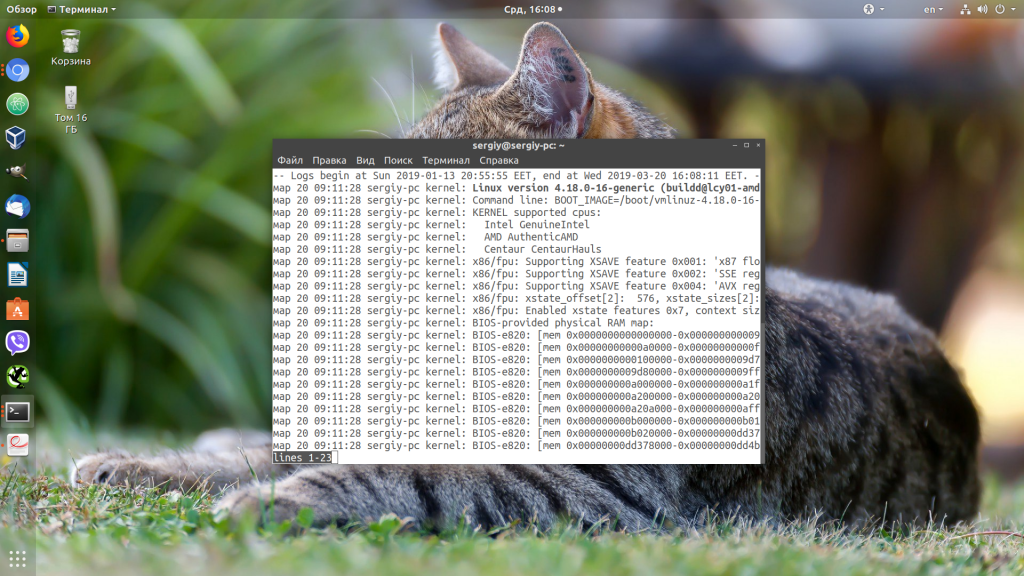
Посмотреть список всех сохраненных загрузок можно командой:
sudo journalctl -list-boots
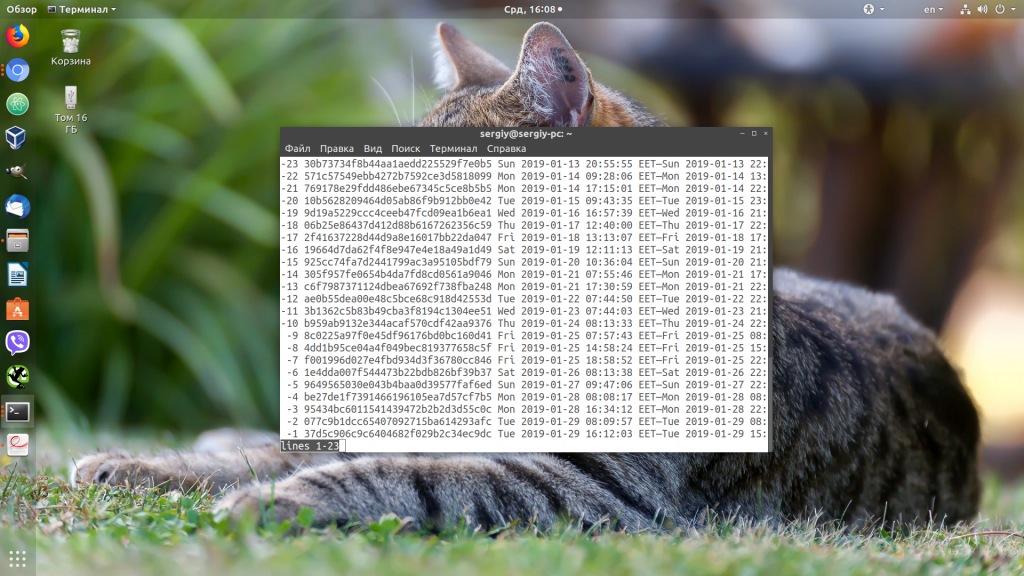
Теперь, чтобы посмотреть сообщения для нужной загрузки используйте её идентификатор:
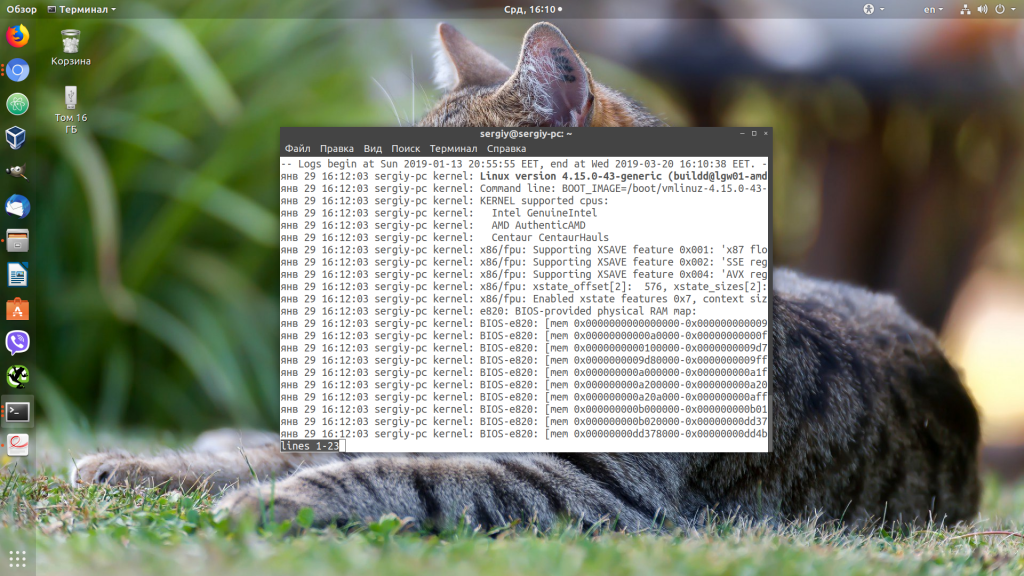
sudo journalctl -b 37d5c906c9c6404682f029b2c34ec9dc
4. Фильтрация по дате
С помощью опции —since вы можете указать дату и время, начиная с которой нужно отображать логи:
sudo journalctl --since "2019-01-20 15:10:10"
Опция —until помогает указать по какую дату вы хотите получить информацию:
sudo journalctl -e --until "2019-01-20 15:05:50"
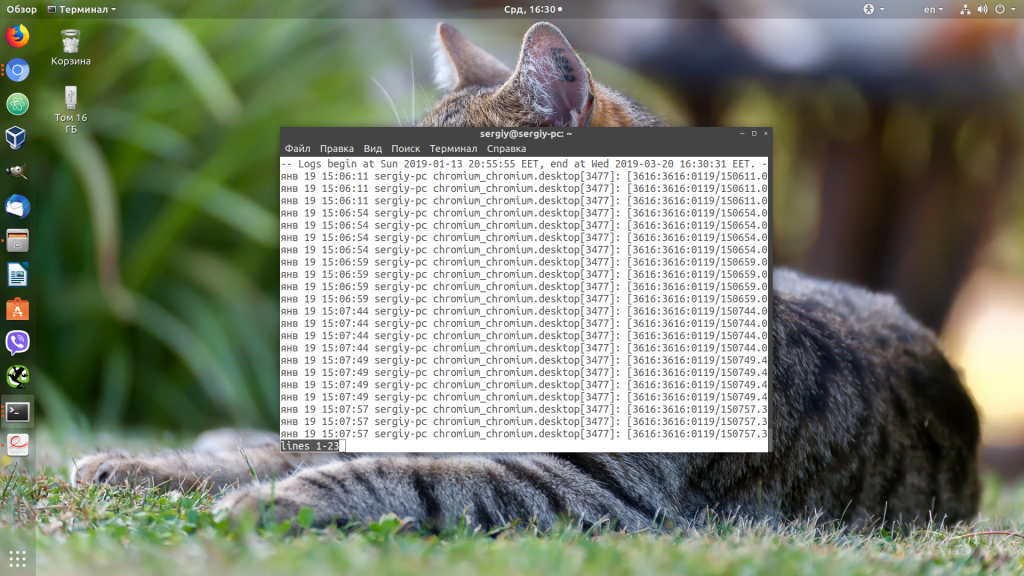
Или сразу скомбинируем две эти опции чтобы получить логи за нужный период:
sudo journalctl --since "2019-01-20 15:10:10" --until "2019-01-20 15:05:50"
Кроме даты в формате YYYY-MM-DD в этих опциях можно использовать такие слова, как yesterday, today, и tomorrow. Также допустимы конструкции 1 day ago (один день назад) или 3 hours ago (три часа назад). Ещё можно использовать знаки + и -. Например -1h30min будет означать полтора часа назад.
5. Журнал ядра
Если вы хотите посмотреть только сообщения ядра используйте опцию -k:
sudo journalctl -ek

6. Настройка формата вывода
По умолчанию journalctl выводит информацию с помощью утилиты less, в которой вы можете её удобно листать и просматривать. Но формат вывода можно изменить:
- short — используется по умолчанию;
- verbose — также, как и short, только выводится намного больше информации;
- json — вывод в формате json, одна строка лога в одной строке вывода;
- json-pretty — форматированный вывод json для более удобного восприятия;
- cat — отображать только сообщения, без метаданных.
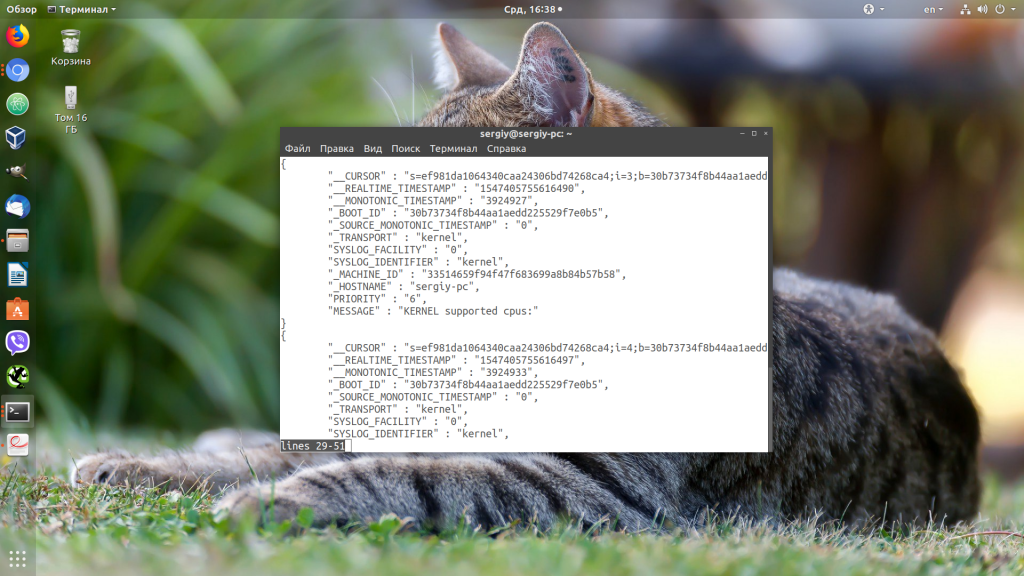
Чтобы указать нужный формат используйте опцию -o. Например:
sudo journalctl -o json-pretty
Или:
sudo journalctl -eo json-pretty
7. Очистка логов
Сначала нужно посмотреть сколько ваши логи занимают на диске. Для этого используйте такую команду:
sudo journalctl --disk-usage
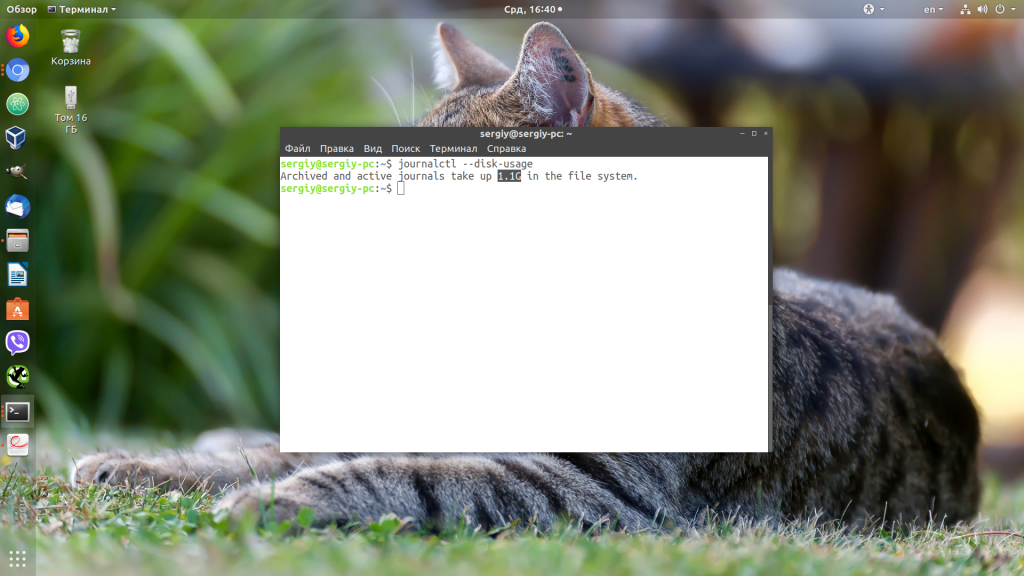
Чтобы уменьшить размер лога можно использовать опцию —vacuum-size. Например, если вы хотите, чтобы ваши файлы журналов занимали на диске не более 2 Гб, выполните команду:
sudo journalctl --vacuum-size=2G
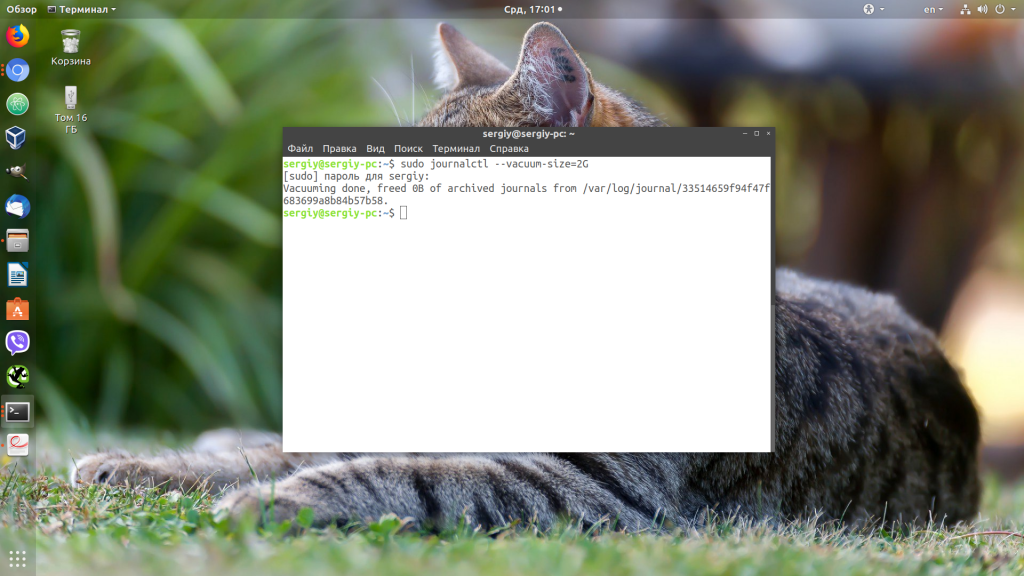
Теперь старые логи будут удалены, пока общий объем хранилища не будет составлять 2 гигабайта. Также можно удалять логи по времени. Для этого используется опция —vacuum-time. Например, оставим только логи за последний год:
journalctl --vacuum-time=1years
Выводы
В этой статье мы разобрали как пользоваться journalctl в Linux. Наличие этой утилиты в системе не означает, что теперь вы не можете пользоваться обычными файлами логов. Большинство сервисов как и раньше пишут свои основные логи в файлы, а в лог journalctl пишутся сообщения при старте сервисов, а также различные системные сообщения.

Статья распространяется под лицензией Creative Commons ShareAlike 4.0 при копировании материала ссылка на источник обязательна .
В systemd используется принципиально иной подход к записи логов, по сравнению с традиционным инструментом syslog. Специализированный компонент journal cобирает все системные сообщения — от ядра, различных служб и приложений. Специально настраивать отправку логов не нужно — приложения могут просто писать в stdout и stderr. Все сообщения сохраняются в бинарном виде, что существенно упрощает систематизацию и поиск.
Хранение логов в бинарных файлах позволяет избежать сложностей с использованием парсеров для разных видов логов. Но при необходимости логи можно конвертировать в другие форматы. Journal может работать как совместно с syslog, так и полностью заменить его. Для просмотра логов используется утилита journalctl.
Установка времени
Одним из существенных недостатков syslog является сохранение записей без учёта часового пояса. В journal этот недостаток устранён: для логируемых событий можно указывать как местное время, так и универсальное координированное время (UTC). Просмотреть список часовых поясов можно при помощи команды:
$ timedatectl list-timezones Africa/Abidjan Africa/Accra Africa/Addis_Ababa .......... Pacific/Wake Pacific/Wallis UTC
Установить нужный часовой пояс можно так:
$ timedatectl set-timezone Europe/Moscow
Проверить, какой часовой пояс установлен:
$ timedatectl status Local time: Сб 2020-03-14 09:08:10 MSK Universal time: Сб 2020-03-14 06:08:10 UTC RTC time: Сб 2020-03-14 06:08:09 Time zone: Europe/Moscow (MSK, +0300) System clock synchronized: no systemd-timesyncd.service active: yes RTC in local TZ: no
Просмотр логов
Если ввести команду journalсtl без каких-либо аргументов, на консоль будет выведен огромный список:
$ journalctl -- Logs begin at Wed 2019-11-13 15:01:02 MSK, end at Sat 2020-03-14 09:11:42 MSK ноя 13 15:01:02 web-server kernel: Linux version 5.0.0-23-generic (buildd@lgw01 ноя 13 15:01:02 web-server kernel: Command line: BOOT_IMAGE=/boot/vmlinuz-5.0.0 ноя 13 15:01:02 web-server kernel: KERNEL supported cpus: ноя 13 15:01:02 web-server kernel: Intel GenuineIntel ноя 13 15:01:02 web-server kernel: AMD AuthenticAMD ноя 13 15:01:02 web-server kernel: Hygon HygonGenuine ноя 13 15:01:02 web-server kernel: Centaur CentaurHauls ..........
Фильтрация логов
Логи с момента последней загрузки
С помощью опции -b можно просмотреть все логи, собранные с момента последней загрузки системы:
$ journalctl -b -- Logs begin at Wed 2019-11-13 15:01:02 MSK, end at Sat 2020-03-14 09:12:15 MSK мар 14 09:03:09 web-server kernel: Linux version 5.3.0-40-generic (buildd@lcy01- мар 14 09:03:09 web-server kernel: Command line: BOOT_IMAGE=/boot/vmlinuz-5.3.0- мар 14 09:03:09 web-server kernel: KERNEL supported cpus: мар 14 09:03:09 web-server kernel: Intel GenuineIntel мар 14 09:03:09 web-server kernel: AMD AuthenticAMD мар 14 09:03:09 web-server kernel: Hygon HygonGenuine мар 14 09:03:09 web-server kernel: Centaur CentaurHauls
Просмотр логов предыдущих сессий
Можно просматривать информацию о предыдущих сессиях работы в системе. Получаем список предыдущих загрузок:
$ journalctl --list-boots -46 6ab45fd4f20b4c688367749c5a319c36 Wed 2019-11-13 15:01:02 MSK—Wed 2019-11-13 15:02:54 MSK -45 483b31301b0f49e781cf8441aaf209af Wed 2019-11-13 15:04:38 MSK—Wed 2019-11-13 15:06:14 MSK -44 ea2435c1f0aa4b6eb6ad5f0efd7bb779 Wed 2019-11-13 15:06:26 MSK—Wed 2019-11-13 15:24:00 MSK .......... -2 304d7cadb64a46e185fad345f732ec0b Mon 2020-03-02 10:55:49 MSK—Mon 2020-03-02 16:48:21 MSK -1 c0ed77121b1c4e53a01e78c3666a4389 Fri 2020-03-06 14:52:51 MSK—Fri 2020-03-06 18:18:19 MSK 0 49f60c5b2dbe48a1955e892db356ec66 Sat 2020-03-14 09:03:09 MSK—Sat 2020-03-14 09:17:37 MSK
В первой колонке указывается порядковый номер загрузки, во второй — её идентификатор, в третьей — дата и время. Чтобы просмотреть лог для конкретной загрузки, можно использовать идентификаторы как из первой, так и из второй колонки:
$ journalctl -b -1
$ journalctl -b c0ed77121b1c4e53a01e78c3666a4389
Сохранение информации о предыдущих сессиях поддерживается по умолчанию не во всех дистрибутивах, иногда его требуется активировать.
$ sudo nano /etc/systemd/journald.conf
[Journal] Storage=persistent
Фильтрация по дате и времени
Для этого используются опции since и until. Например, нам нужно просмотреть логи, начиная с 14 часов 55 минут 6 марта 2020 года:
$ journalctl --since "2020-03-06 14:55:00"
Можно воспользоваться и вот такими человекопонятными конструкциями:
$ journalctl ---since yesterday $ journalctl --since 09:00 --until now $ journalctl --since 10:00 --until "1 hour ago"
Фильтрация по приложениям и службам
Для просмотра логов конкретного приложения или службы:
$ journalctl -u mysql.service
$ journalctl -u mysql.service --since yesterday
Фильтрация по процессам, пользователям и группам
Просмотреть логи для какого-либо процесса можно, указав его идентификатор:
$ journalctl _PID=655
$ pstree -p systemd(1)─┬─ModemManager(542)─┬─{ModemManager}(572) │ └─{ModemManager}(576) ├─NetworkManager(527)─┬─dhclient(715) │ ├─{NetworkManager}(587) │ └─{NetworkManager}(591) ├─accounts-daemon(533)─┬─{accounts-daemon}(539) │ └─{accounts-daemon}(545) ├─acpid(494) ├─apache2(655)─┬─apache2(4385)─┬─{apache2}(4415) │ │ ├─{apache2}(4416) │ │ ├─{apache2}(4417) │ │ ├─{apache2}(4418) │ │ └─{apache2}(4440) │ └─apache2(4386)─┬─{apache2}(4389) │ ├─{apache2}(4390) │ ├─{apache2}(4391) │ ├─{apache2}(4392) │ └─{apache2}(4414)
Для просмотра логов процессов, запущенных от имени определённого пользователя или группы, используются фильтры _UID и _GID соответственно. Предположим, у нас есть веб-сервер, запущенный от имени пользователя www-data. Определим сначала идентификатор этого пользователя:
$ id -u www-data 33
Теперь можно просмотреть логи всех процессов, запущенных от имени этого пользователя:
$ journalctl _UID=33
Просмотр сообщений ядра
Для просмотра сообщений ядра используется опция -k или --dmesg:
$ journalctl -k
Приведённая команда покажет все сообщения ядра для текущей загрузки. Чтобы просмотреть сообщения ядра для предыдущих сессий, нужно воспользоваться опцией -b:
$ journalctl -k -b -2
Фильтрация по уровню ошибки
Во время диагностики и исправления неполадок в системе нередко требуется просмотреть логи и выяснить, есть ли в них сообщения о критических ошибках.
$ journalctl -p err -b 0
Приведённая команда покажет все сообщения об ошибках, имевших место в системе, с момента последней загрузки. В journal используется такая же классификация уровней ошибок, как и в syslog:
emerg— система неработоспособнаalert— требуется немедленное вмешательствоcrit— критическое состояниеerr— ошибкаwarning— предупреждениеnotice— следует обратить вниманиеinfo— информационное сообщениеdebug— отладочные сообщения
Запись логов в стандартный вывод
По умолчанию journalctl использует для вывода сообщений логов внешнюю утилиту less. В этом случае к ним невозможно применять стандартные утилиты для обработки текстовых данных. Эта проблема решается легко:
$ journalctl --no-pager
Выбор формата вывода
C помощью опции -o можно преобразовывать данные логов в различные форматы, что облегчает их парсинг и дальнейшую обработку, например:
$ journalctl -u apache2.service -o json
Объект json можно представить в более структурированном и человекочитаемом виде, указав формат json-pretty:
$ journalctl -u apache2.service -o json-pretty
{ "__CURSOR" : "s=39af8c988a2447198f83abd4ba184866;i=48cc;b=2ebfbe0d4ea74da7969703dd4409beeb...", "__REALTIME_TIMESTAMP" : "1577868308021968", "__MONOTONIC_TIMESTAMP" : "509869391", "_BOOT_ID" : "2ebfbe0d4ea74da7969703dd4409beeb", "PRIORITY" : "6", "SYSLOG_FACILITY" : "3", "SYSLOG_IDENTIFIER" : "systemd", "_TRANSPORT" : "journal", "_PID" : "1", "_UID" : "0", "_GID" : "0", "_COMM" : "systemd", "_EXE" : "/lib/systemd/systemd", "_CMDLINE" : "/sbin/init splash", "_CAP_EFFECTIVE" : "3fffffffff", "_SELINUX_CONTEXT" : "unconfinedn", "_SYSTEMD_CGROUP" : "/init.scope", "_SYSTEMD_UNIT" : "init.scope", "_SYSTEMD_SLICE" : "-.slice", "_MACHINE_ID" : "82c67903ca0f4f43b9b0083895c9505e", "CODE_FILE" : "../src/core/unit.c", "CODE_LINE" : "1718", "CODE_FUNC" : "unit_status_log_starting_stopping_reloading", "MESSAGE_ID" : "7d4958e842da4a758f6c1cdc7b36dcc5", "_HOSTNAME" : "web-server", "MESSAGE" : "Starting The Apache HTTP Server...", "UNIT" : "apache2.service", "INVOCATION_ID" : "0c74ebdfcbf04d57a23fd40df88859cc", "_SOURCE_REALTIME_TIMESTAMP" : "1577868308021921" }
Помимоjson данные логов могут быть преобразованы в следующие форматы:
cat— только сообщения из логов без служебных полейexport— бинарный формат, подходит для резервного копирования логовshort— формат выводаsyslogshort-iso— формат выводаsyslogс метками времени в формате ISO 8601short-monotonic— формат выводаsyslogc метками монотонного времениshort-precise— формат выводаsyslogс метками точного времениverbose— максимально подробный формат представления данных
Прочие возможности
Опция -n используется для просмотра информации о недавних событиях в системе:
$ journalctl -n
По умолчанию на консоль выводится информация о последних 10 событиях. Но можно указать необходимое число событий:
$ journalctl -n 20
Для просмотра логов в режиме реального времени используется опция -f:
$ journalctl -f
Управление логированием
Со временем объём логов растёт, и они занимают всё больше места на жёстком диске. Узнать объём имеющихся на текущий момент логов можно с помощью команды:
$ journalctl --disk-usage Journals take up 18.0M on disk.
Настройка ротации логов осуществляется с помощью опций --vacuum-size и --vacuum-time.
Первая из них устанавливает максимальный размер логов, а вторая — предельный срок хранения.
$ sudo journalctl --vacuum-size=1G
$ sudo journalctl --vacuum-time=1years
Настройки ротации логов можно также прописать в конфигурационном файле /etc/systemd/journald.conf:
$ sudo nano /etc/systemd/journald.conf
[Journal] # максимальный объём, который логи могут занимать на диске SystemMaxUse=1G
Вместо редактирования глобального файла конфигурации можно переопределить заданные в нем значения:
$ sudo nano /etc/systemd/journald.conf.d/00-journal-size.conf
[Journal] # максимальный объём, который логи могут занимать на диске SystemMaxUse=1G
Для применения изменений нужно перезапустить службу journald:
$ sudo systemctl restart systemd-journald.service
Journald вместе с syslog (rsyslog)
События журнала могут быть переданы демону syslog двумя способами:
- Перенаправлять все сообщения
systemdв сокет/run/systemd/journal/syslog, где их может читать демонsyslog. Это контролируется опциейForwardToSyslogфайла конфигурацииjournald.conf. - Демон
syslogведет себя как обычный клиент журнала и считывает сообщения из файлов журнала аналогичноjournalctl. Этот метод доступен только в том случае, если опцияStorageне равнаnone.
Демон syslog по умолчанию использует второй способ, поэтому важна опция Storage, а не ForwardToSyslog.
Поиск:
CLI • Linux • Systemd • Команда • Настройка • Сервер • Файл • journalctl • syslog • Лог • Служба • Service
Каталог оборудования
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.
Производители
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.
Функциональные группы
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.