i want to tail log file with grep and sent it via mail
like:
tail -f /var/log/foo.log | grep error | mail -s subject name@example.com
how can i do this?
![]()
eumiro
203k34 gold badges297 silver badges260 bronze badges
asked Jan 11, 2011 at 11:03
![]()
3
You want to send an email when emailing errors occur? That might fail 
You can however try something like this:
tail -f $log |
grep --line-buffered error |
while read line
do
echo "$line" | mail -s subject "$email"
done
Which for every line in the grep output sends an email.
Run above shell script with
nohup ./monitor.sh &
so it will keep running in the background.
![]()
kavehmb
9,7721 gold badge19 silver badges22 bronze badges
answered Jan 11, 2011 at 12:49
![]()
7
I’ll have a go at this. Perhaps I’ll learn something if my icky bash code gets scrutinised. There is a chance there are already a gazillion solutions to do this, but I am not going to find out, as I am sure you have trawled the depths and widths of the cyberocean. It sounds like what you want can be separated into two bits: 1) at regular intervals obtain the ‘latest tail’ of the file, 2) if the latest tail actually exists, send it by e-mail. For the regular intervals in 1), use cron. For obtaining the latest tail in 2), you’ll have to keep track of the file size. The bash script below does that — it’s a solution to 2) that can be invoked by cron. It uses the cached file size to compute the chunk of the file it needs to mail. Note that for a file myfile another file .offset.myfile is created. Also, the script does not allow path components in the file name. Rewrite, or fix it in the invocation [e.g. (cd /foo/bar && segtail.sh zut), assuming it is called segtail.sh ].
#!/usr/local/bin/bash
file=$1
size=0
offset=0
if [[ $file =~ / ]]; then
echo "$0 does not accept path components in the file name" 2>&1
exit 1
fi
if [[ -e .offset.$file ]]; then
offset=$(<".offset.$file")
fi
if [[ -e $file ]]; then
size=$(stat -c "%s" "$file") # this assumes GNU stat, possibly present as gstat. CHECK!
# (gstat can also be Ganglias Status tool - careful).
fi
if (( $size < $offset )); then # file might have been reduced in size
echo "reset offset to zero" 2>&1
offset=0
fi
echo $size > ".offset.$file"
if [[ -e $file && $size -gt $offset ]]; then
tail -c +$(($offset+1)) "$file" | head -c $(($size - $offset)) | mail -s "tail $file" foo@bar
fi
answered Jan 11, 2011 at 12:49
![]()
micansmicans
1,0687 silver badges16 bronze badges
4
How about:
mail -s «catalina.out errors» blah@myaddress.com < grep ERROR catalina.out
answered Jan 25, 2019 at 19:56
![]()
i want to tail log file with grep and sent it via mail
like:
tail -f /var/log/foo.log | grep error | mail -s subject name@example.com
how can i do this?
![]()
eumiro
203k34 gold badges297 silver badges260 bronze badges
asked Jan 11, 2011 at 11:03
![]()
3
You want to send an email when emailing errors occur? That might fail
You can however try something like this:
tail -f $log |
grep --line-buffered error |
while read line
do
echo "$line" | mail -s subject "$email"
done
Which for every line in the grep output sends an email.
Run above shell script with
nohup ./monitor.sh &
so it will keep running in the background.
![]()
kavehmb
9,7721 gold badge19 silver badges22 bronze badges
answered Jan 11, 2011 at 12:49
![]()
7
I’ll have a go at this. Perhaps I’ll learn something if my icky bash code gets scrutinised. There is a chance there are already a gazillion solutions to do this, but I am not going to find out, as I am sure you have trawled the depths and widths of the cyberocean. It sounds like what you want can be separated into two bits: 1) at regular intervals obtain the ‘latest tail’ of the file, 2) if the latest tail actually exists, send it by e-mail. For the regular intervals in 1), use cron. For obtaining the latest tail in 2), you’ll have to keep track of the file size. The bash script below does that — it’s a solution to 2) that can be invoked by cron. It uses the cached file size to compute the chunk of the file it needs to mail. Note that for a file myfile another file .offset.myfile is created. Also, the script does not allow path components in the file name. Rewrite, or fix it in the invocation [e.g. (cd /foo/bar && segtail.sh zut), assuming it is called segtail.sh ].
#!/usr/local/bin/bash
file=$1
size=0
offset=0
if [[ $file =~ / ]]; then
echo "$0 does not accept path components in the file name" 2>&1
exit 1
fi
if [[ -e .offset.$file ]]; then
offset=$(<".offset.$file")
fi
if [[ -e $file ]]; then
size=$(stat -c "%s" "$file") # this assumes GNU stat, possibly present as gstat. CHECK!
# (gstat can also be Ganglias Status tool - careful).
fi
if (( $size < $offset )); then # file might have been reduced in size
echo "reset offset to zero" 2>&1
offset=0
fi
echo $size > ".offset.$file"
if [[ -e $file && $size -gt $offset ]]; then
tail -c +$(($offset+1)) "$file" | head -c $(($size - $offset)) | mail -s "tail $file" foo@bar
fi
answered Jan 11, 2011 at 12:49
![]()
micansmicans
1,0687 silver badges16 bronze badges
4
How about:
mail -s «catalina.out errors» blah@myaddress.com < grep ERROR catalina.out
answered Jan 25, 2019 at 19:56
![]()
Содержание
- Как посмотреть логи в Linux
- Расположение логов по умолчанию
- Просмотр логов в Linux
- Команда tail Linux
- Команда tail в Linux
- Использование tail
- Выводы
- Похожие записи
- Оцените статью
- Об авторе
- 7 комментариев к “Команда tail Linux”
- 📝 «Помедленнее, я записываю»: туториал по системным логам Linux
- 👨🏫️ Что такое логи?
- 🔍 Если коротко: где искать логи?
- 📰 Как анализировать журналы
- 🎯 Централизация логов в Linux
- Централизация журналов с помощью Journald
- Централизация журналов с помощью syslog
- ❗Важные файлы журналов для мониторинга
- Журнал /var/log/syslog или /var/log/messages
- Журналы /var/log/kern.log или /var/log/dmesg
- Журналы /var/log/auth.log или /var/log/secure
- Журнал /var/log/cron.log
- Журнал /var/log/mail.log или /var/log/maillog
- 📄 Подведём итоги
Как посмотреть логи в Linux
Системные администраторы, да и обычные пользователи Linux, часто должны смотреть лог файлы для устранения неполадок. На самом деле, это первое, что должен сделать любой сисадмин при возникновении любой ошибки в системе.
Сама операционная система Linux и работающие приложения генерируют различные типы сообщений, которые регистрируются в различных файлах журналов. В Linux используются специальное программное обеспечение, файлы и директории для хранения лог файлов. Знание в каких файлах находятся логи каких программ поможет вам сэкономить время и быстрее решить проблему. В этой статье мы рассмотрим основные части системы логирования в Linux, файлы логов, а также утилиты, с помощью которых можно посмотреть логи Linux.
Расположение логов по умолчанию
Большинство файлов логов Linux находятся в папке /var/log/ вы можете список файлов логов для вашей системы с помощью команды ls:
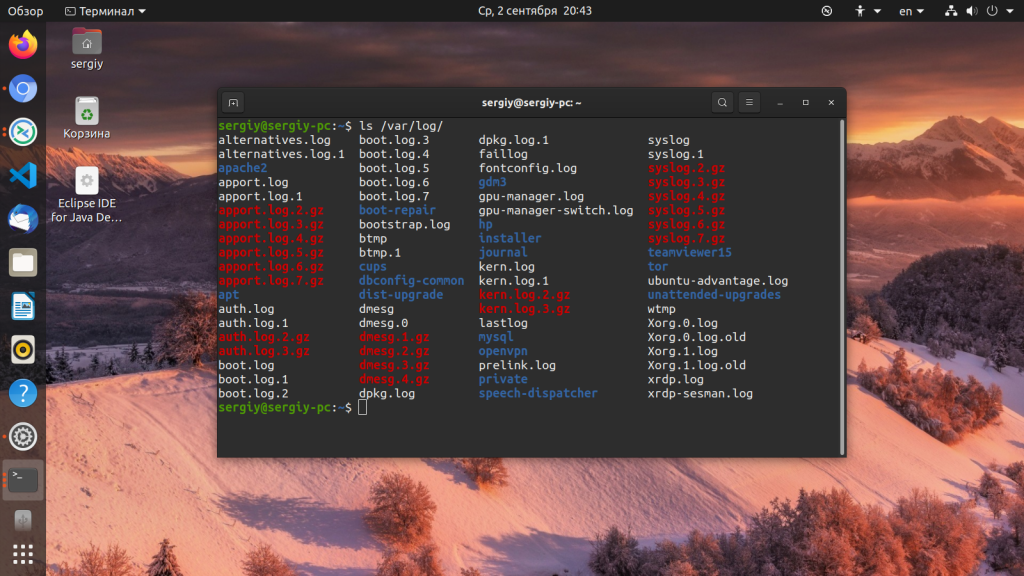
Ниже мы рассмотрим 20 различных файлов логов Linux, размещенных в каталоге /var/log/. Некоторые из этих логов встречаются только в определенных дистрибутивах, например, dpkg.log встречается только в системах, основанных на Debian.
- /var/log/messages — содержит глобальные системные логи Linux, в том числе те, которые регистрируются при запуске системы. В этот лог записываются несколько типов сообщений: это почта, cron, различные сервисы, ядро, аутентификация и другие.
- /var/log/dmesg — содержит сообщения, полученные от ядра. Регистрирует много сообщений еще на этапе загрузки, в них отображается информация об аппаратных устройствах, которые инициализируются в процессе загрузки. Можно сказать это еще один лог системы Linux. Количество сообщений в логе ограничено, и когда файл будет переполнен, с каждым новым сообщением старые будут перезаписаны. Вы также можете посмотреть сообщения из этого лога с помощью команды dmseg.
- /var/log/auth.log — содержит информацию об авторизации пользователей в системе, включая пользовательские логины и механизмы аутентификации, которые были использованы.
- /var/log/boot.log — Содержит информацию, которая регистрируется при загрузке системы.
- /var/log/daemon.log — Включает сообщения от различных фоновых демонов
- /var/log/kern.log — Тоже содержит сообщения от ядра, полезны при устранении ошибок пользовательских модулей, встроенных в ядро.
- /var/log/lastlog — Отображает информацию о последней сессии всех пользователей. Это нетекстовый файл, для его просмотра необходимо использовать команду lastlog.
- /var/log/maillog /var/log/mail.log — журналы сервера электронной почты, запущенного в системе.
- /var/log/user.log — Информация из всех журналов на уровне пользователей.
- /var/log/Xorg.x.log — Лог сообщений Х сервера.
- /var/log/alternatives.log — Информация о работе программы update-alternatives. Это символические ссылки на команды или библиотеки по умолчанию.
- /var/log/btmp — лог файл Linux содержит информацию о неудачных попытках входа. Для просмотра файла удобно использовать команду last -f /var/log/btmp
- /var/log/cups — Все сообщения, связанные с печатью и принтерами.
- /var/log/anaconda.log — все сообщения, зарегистрированные при установке сохраняются в этом файле
- /var/log/yum.log — регистрирует всю информацию об установке пакетов с помощью Yum.
- /var/log/cron — Всякий раз когда демон Cron запускает выполнения программы, он записывает отчет и сообщения самой программы в этом файле.
- /var/log/secure — содержит информацию, относящуюся к аутентификации и авторизации. Например, SSHd регистрирует здесь все, в том числе неудачные попытки входа в систему.
- /var/log/wtmp или /var/log/utmp — системные логи Linux, содержат журнал входов пользователей в систему. С помощью команды wtmp вы можете узнать кто и когда вошел в систему.
- /var/log/faillog — лог системы linux, содержит неудачные попытки входа в систему. Используйте команду faillog, чтобы отобразить содержимое этого файла.
- /var/log/mysqld.log — файлы логов Linux от сервера баз данных MySQL.
- /var/log/httpd/ или /var/log/apache2 — лог файлы linux11 веб-сервера Apache. Логи доступа находятся в файле access_log, а ошибок в error_log
- /var/log/lighttpd/ — логи linux веб-сервера lighttpd
- /var/log/conman/ — файлы логов клиента ConMan,
- /var/log/mail/ — в этом каталоге содержатся дополнительные логи почтового сервера
- /var/log/prelink/ — Программа Prelink связывает библиотеки и исполняемые файлы, чтобы ускорить процесс их загрузки. /var/log/prelink/prelink.log содержит информацию о .so файлах, которые были изменены программой.
- /var/log/audit/— Содержит информацию, созданную демоном аудита auditd.
- /var/log/setroubleshoot/ — SE Linux использует демон setroubleshootd (SE Trouble Shoot Daemon) для уведомления о проблемах с безопасностью. В этом журнале находятся сообщения этой программы.
- /var/log/samba/ — содержит информацию и журналы файлового сервера Samba, который используется для подключения к общим папкам Windows.
- /var/log/sa/ — Содержит .cap файлы, собранные пакетом Sysstat.
- /var/log/sssd/ — Используется системным демоном безопасности, который управляет удаленным доступом к каталогам и механизмами аутентификации.
Просмотр логов в Linux
Чтобы посмотреть логи на Linux удобно использовать несколько утилит командной строки Linux. Это может быть любой текстовый редактор, или специальная утилита. Скорее всего, вам понадобятся права суперпользователя для того чтобы посмотреть логи в Linux. Вот команды, которые чаще всего используются для этих целей:
Я не буду останавливаться подробно на каждой из этих команд, поскольку большинство из них уже подробно рассмотрены на нашем сайте. Но приведу несколько примеров. Просмотр логов Linux выполняется очень просто:
Смотрим лог /var/log/dmesg, с возможностью прокрутки:
Источник
Команда tail Linux
Все знают о команде cat, которая используется для просмотра содержимого файлов. Но в некоторых случаях вам не нужно смотреть весь файл, иногда достаточно посмотреть только то, что находится в конце файла. Например, когда вы хотите посмотреть содержимое лог файла, то вам не нужно то, с чего он начинается, вам будет достаточно последних сообщений об ошибках.
Для этого можно использовать команду tail, она позволяет выводить заданное количество строк с конца файла, а также выводить новые строки в интерактивном режиме. В этой статье будет рассмотрена команда tail Linux.
Команда tail в Linux
Перед тем как мы будем рассматривать примеры tail linux, давайте разберем ее синтаксис и опции. А синтаксис очень прост:
$ tail опции файл
По умолчанию утилита выводит десять последних строк из файла, но ее поведение можно настроить с помощью опций:
- -c — выводить указанное количество байт с конца файла;
- -f — обновлять информацию по мере появления новых строк в файле;
- -n — выводить указанное количество строк из конца файла;
- —pid — используется с опцией -f, позволяет завершить работу утилиты, когда завершится указанный процесс;
- -q — не выводить имена файлов;
- —retry — повторять попытки открыть файл, если он недоступен;
- -v — выводить подробную информацию о файле;
В качестве значения параметра -c можно использовать число с приставкой b, kB, K, MB, M, GB, G T, P, E, Z, Y. Еще есть одно замечание по поводу имен файлов. По умолчанию утилита не отслеживает изменение имен, но вы можете указать что нужно отслеживать файл по дескриптору, подробнее в примерах.
Использование tail
Теперь, когда вы знаете основные опции, рассмотрим приемы работы с утилитой. Самый простой пример — выводим последние десять строк файла:
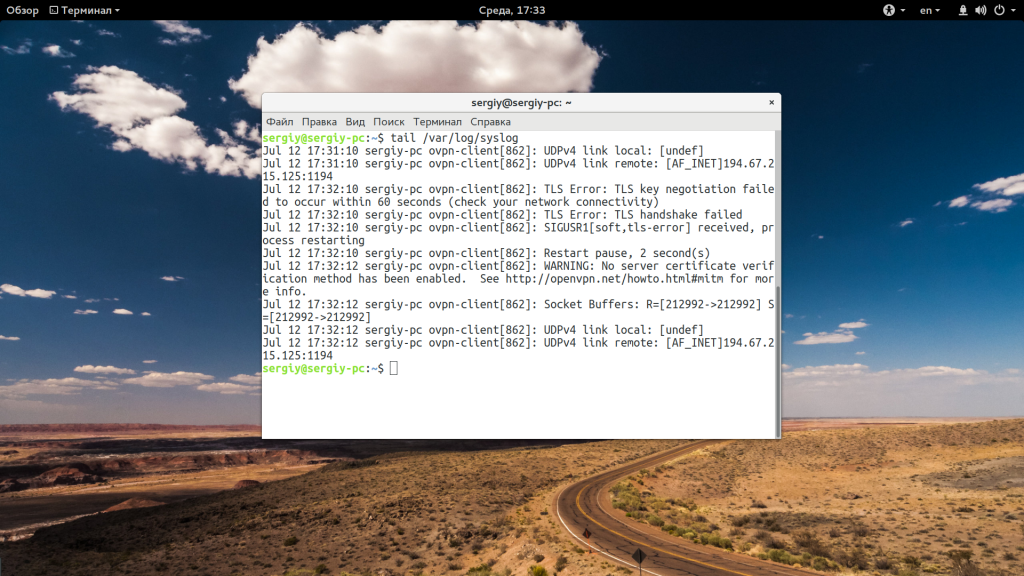
Если вам недостаточно 10 строк и нужно намного больше, то вы можете увеличить этот параметр с помощью опции -n:
tail -n 100 /var/log/syslog
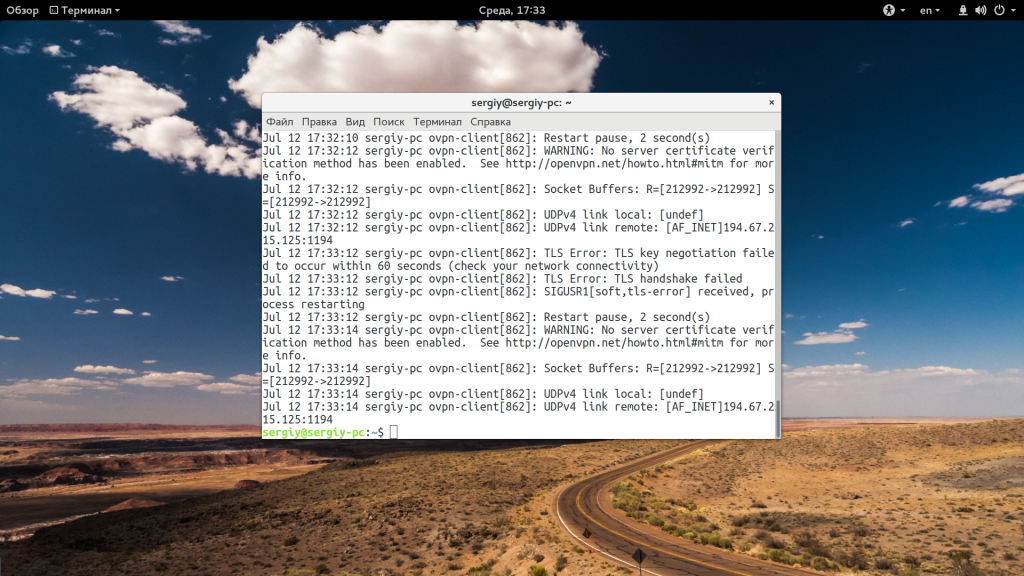
Когда вы хотите отслеживать появление новых строк в файле, добавьте опцию -f:
tail -f /var/log/syslog
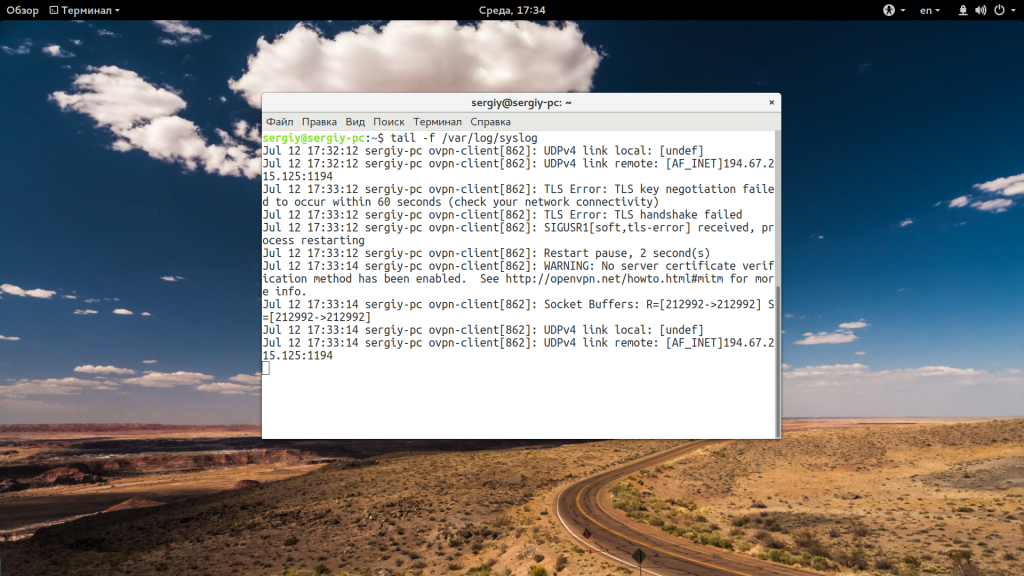
Вы можете открыть несколько файлов одновременно, просто перечислив их в параметрах:
tail /var/log/syslog /var/log/Xorg.0.log
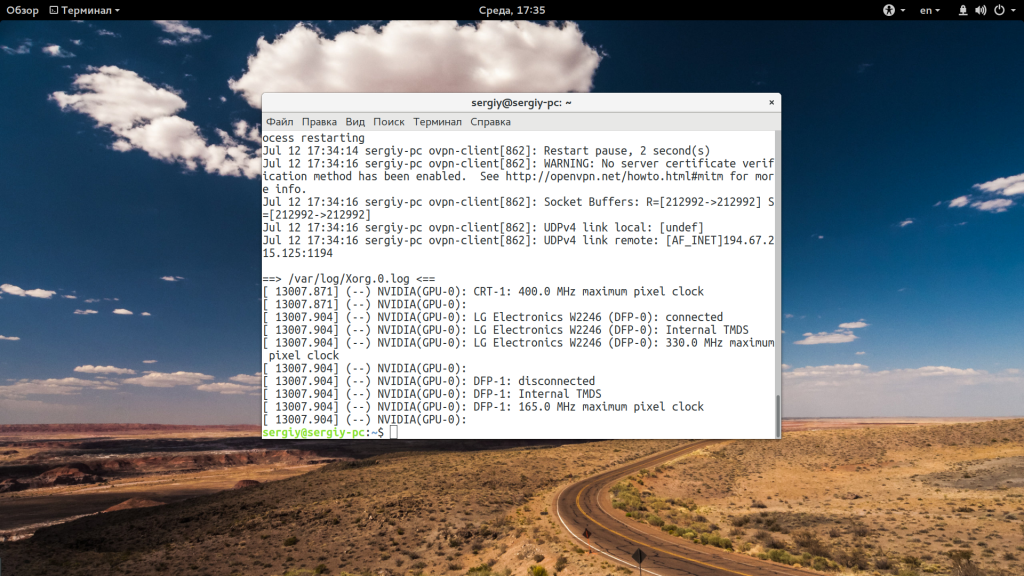
С помощью опции -s вы можете задать частоту обновления файла. По умолчанию данные обновляются раз в секунду, но вы можете настроить, например, обновление раз в пять секунд:
tail -f -s 5 /var/log/syslog
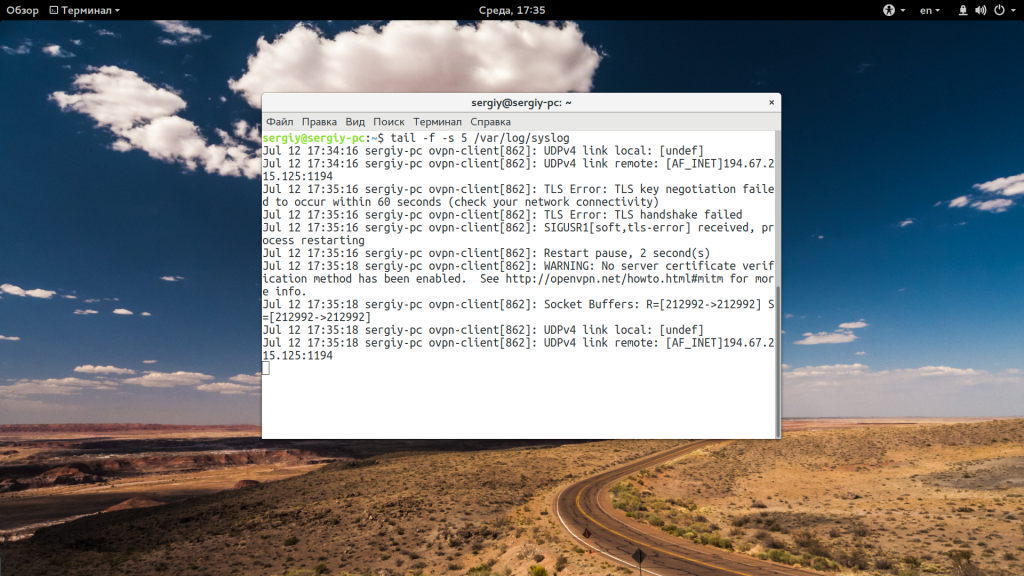
При открытии нескольких файлов будет выводиться имя файла перед участком кода. Если вы хотите убрать этот заголовок, добавьте опцию -q:
tail -q var/log/syslog /var/log/Xorg.0.log
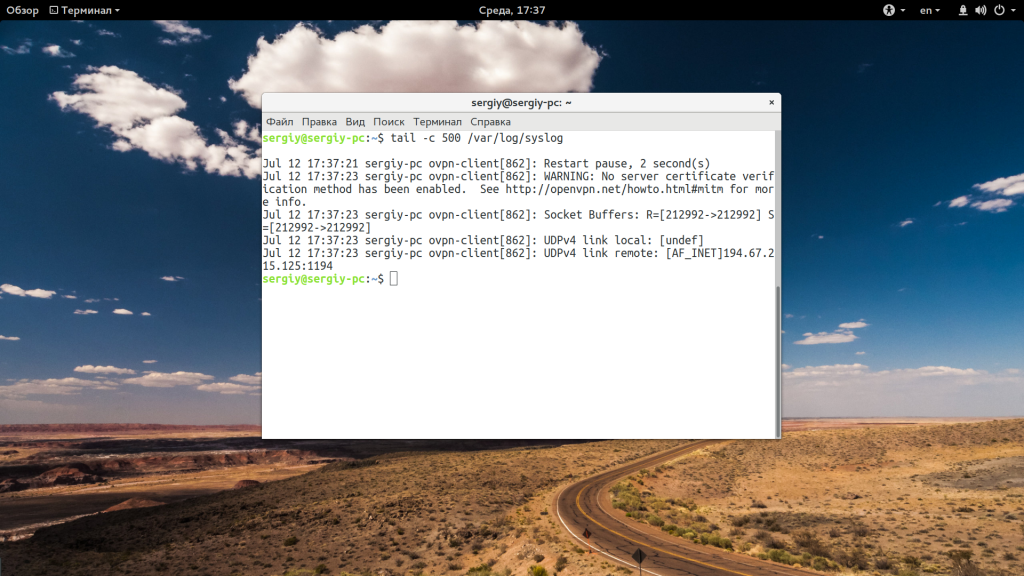
Если вас интересует не число строк, а именно число байт, то вы можете их указать с помощью опции -c:
tail -c 500 /var/log/syslog
Для удобства, вы можете выбирать не все строки, а отфильтровать интересующие вас:
tail -f /var/log/syslog | grep err
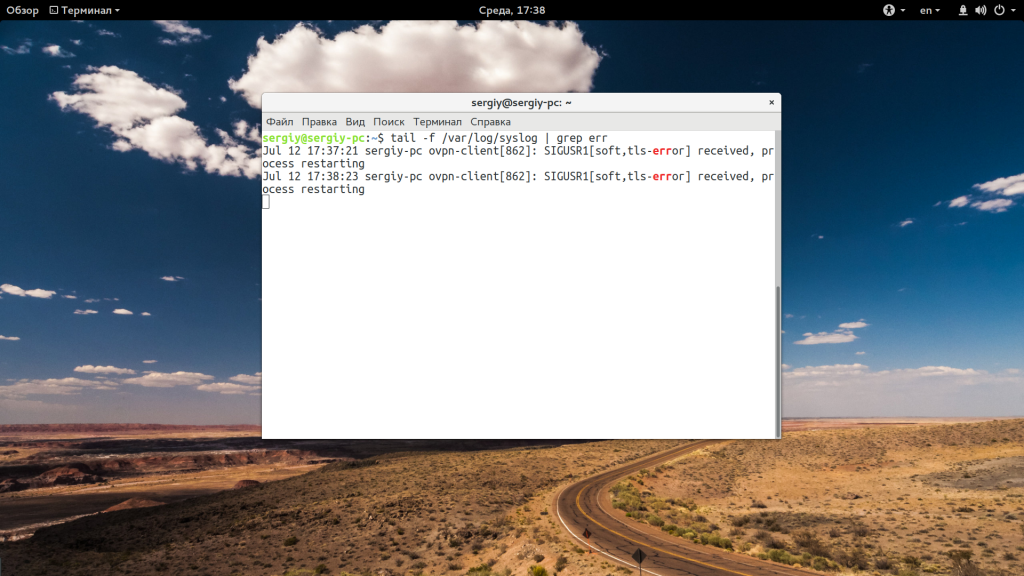
Особенно, это полезно при анализе логов веб сервера или поиске ошибок в реальном времени. Если файл не открывается, вы можете использовать опцию retry чтобы повторять попытки:
tail -f —retry /var/log/syslog | grep err
Как я говорил в начале статьи, по умолчанию опция -f или —follow отслеживает файл по его имени, но вы можете включить режим отслеживания по дескриптору файла, тогда даже если имя измениться, вы будете получать всю информацию:
tail —follow=descriptor /var/log/syslog | grep err
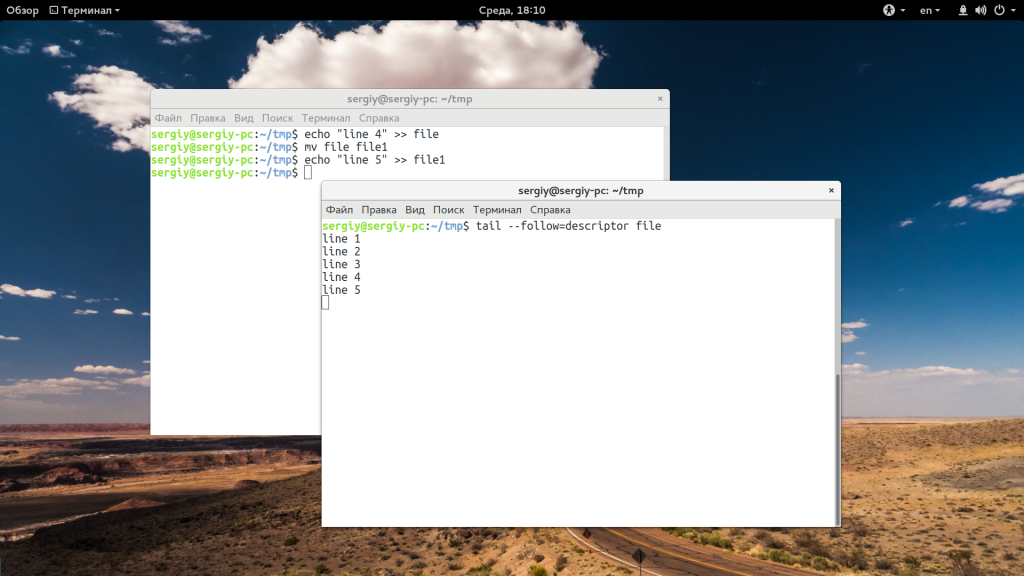
Выводы
В этой статье была рассмотрена команда tail linux. С помощью нее очень удобно анализировать логи различных служб, а также искать в них ошибки. Надеюсь, эта информация была полезной для вас.
Похожие записи
Оцените статью
Об авторе
Основатель и администратор сайта losst.ru, увлекаюсь открытым программным обеспечением и операционной системой Linux. В качестве основной ОС сейчас использую Ubuntu. Кроме Linux, интересуюсь всем, что связано с информационными технологиями и современной наукой.
7 комментариев к “Команда tail Linux”
Захотел проверить на текстовом файле. Создал файл 1.txt, написал в терминале tail -f 1.txt, стал менять файл через текстовый редактор и изменения почему-то не отслеживались. Зато заработало с флагом -F, почему так? Неужели изменение файла через текстовый редактор — это его удаление и создание с тем же именем нового?
Как выйти или закрыть это?
sudo tail -n5 -f /var/.
Ctrl+Z только [2]+ Stopped делает
Ctrl+Z сворачивает в фоновый режим. Для выхода используйте Ctrl+C.
подскажите ,пожалуйста, как с помощью tail просматривать лог последне-созданного файла ?
классная статья! наконец то что то годное. Уже 5 лет как захожу сюда, хороший справочник кстати )
Спасибо за статью!
Не подскажете, как исключить из вывода строки содержащие определенную последовательность символов?
tail -f /var/log/syslog | grep err
Выводит те строки в которых есть err. А что, если мне нужно наоборот. Чтобы выводилось все кроме err?
Благодарю!
Источник
📝 «Помедленнее, я записываю»: туториал по системным логам Linux

👨🏫️ Что такое логи?
Логи (журнал сервера, англ. server log) – это записываемые фрагменты данных, описывающие то, что в конкретный момент времени делает сервер, ядро, службы и приложения. Вот пример лога SSH из /var/log/auth.log :
Обратите внимание, что непосредственно перед сообщением лог содержит несколько полей: метка времени, имя хоста, инициатор события и идентификатор процесса.
Логи в Linux поступают из разных источников. Ниже перечислены основные.
Подсистема systemd . Большинство дистрибутивов Linux для управления службами имеют в своём составе systemd. Подсистема инициализации и управления ловит выходные данные служб и записывает их в журнал. Для работы с логами systemd используется система журналирования journalctl (шпаргалка по работе с journalctl):
Сообщения процессов по стандарту syslog. При отсутствии systemd такие процессы, как SSH, могут записывать данные в UNIX-сокет в формате syslog. Демон syslog, например, rsyslog, выбирает сообщение, анализирует и по умолчанию записывает его в /var/log .
Ядро Linux пишет собственные логи в особый буфер. Подсистемы systemd или syslog могут считывать журналы из этого буфера, а затем записывать их в свои журналы или файлы – обычно /var/log/kern.log . Чтобы посмотреть логи ядра, воспользуйтесь dmesg:
Audit logs. Особый случай сообщений ядра, предназначенных для аудита событий, таких как доступ к файлам. Обычно для прослушивания таких журналов безопасности, существует специальная служба, например, auditd, записывающая свои сообщения в /var/log/audit/audit.log .
Журнал приложений. Несистемные приложения имеют тенденцию записывать данные в /var/log :
- Apache (httpd) обычно пишет в /var/log/httpd или /var/log/apache2 . Журналы HTTP-доступа находятся в файле /var/log/httpd/access.log .
- Логи MySQL обычно находятся в /var/log/mysql.log или /var/log/mysqld.log .
- Старые версии Linux могут записывать свои логи загрузки с помощью bootlogd в /var/log/boot или /var/log/boot.log . В современных ОС об этом заботится systemd: вы можете просматривать связанные с загрузкой журналы с помощью journalctl -b . Дистрибутивы без systemd снабжены syslog-демоном, считывающим данные из буфера ядра. Таким образом, вы можете найти свои boot/reboot-журналы в /var/log/messages или /var/log/syslog .
🔍 Если коротко: где искать логи?
Как правило, вы найдете журналы пингвиньего сервера в каталоге /var/log и подкаталогах. Это место, где syslog -демонам даны полные права на запись. Также это то место, которое у большинства приложений (например, Apache) указано по умолчанию, как место хранения логов.
Для systemd расположение по умолчанию – /var/log/journal , но просматривать файлы логов напрямую не получится – они хранятся в двоичном формате. Как же быть?
📰 Как анализировать журналы
Если ваш дистрибутив Linux использует Systemd (как и большинство современных дистрибутивов), то все ваши системные журналы находятся в специальной области journal. Просмотреть их можно с помощью journalctl (наиболее важные команды journalctl).
Если ваш дистрибутив использует syslog, для их просмотра используются стандартные инструменты: cat , less или grep :
Если для управления журналами вы используете auditd , всё найдётся в файле /var/log/audit.log . В поиске и анализе поможет ausearch.
Заметим, что хорошим тоном является хранение всех логов централизованно, в одном месте. Особенно если у вас несколько серверов. Обсудим эту задачу подробнее.
🎯 Централизация логов в Linux

Системные журналы могут находиться в двух местах: в systemd или в обычных текстовых файлах, записанных демоном syslog . В некоторых дистрибутивах, например, Ubuntu, есть и то, и другое: journald настроен на пересылку в syslog . Это осуществляется путем установки ForwardToSyslog=Yes в конфиге journald.conf .
Централизация журналов с помощью Journald
Если в ваш дистрибутив включён systemd, для централизации журналов м ы рекомендуем использовать journal-upload .
Централизация журналов с помощью syslog
Существует несколько случаев, в которых подойдет централизация с применением syslog :
- Если в ваш дистрибутив не включён journald. Это означает, что системные журналы направляются непосредственно в syslog-демон.
- Когда необходимо собирать и анализировать журналы приложений. Например, в случае с журналами для Apache через rsyslog и Elasticsearch.
- Если вы хотите перенаправить записи – ForwardToSyslog=Yes . Для этого в качестве транспорта следует использовать syslog-протокол. Однако подход приведет к потере некоторых структурированных данных journald т. к. он пересылает только поля syslog-specific .
- Когда вы настроили syslog-демон для чтения из журналов (как это делает journalctl). Такой подход не приводит к потере структурированных данных, но более чувствителен к ошибкам (например, в случае повреждения журнала) и увеличивает накладные расходы.
Во всех перечисленных ситуациях информация будут проходить через демон syslog , а оттуда их можно отправить в любое место и использовать на своё усмотрение.
Большинство дистрибутивов Linux поставляются с rsyslog . Чтобы пересылать данные на другой сервер через TCP, добавьте следующую строку в /etc/rsyslog.conf :
Эта строка будет заворачивать данные на сервер example . com. В ы можете заменить logsene-syslog-receiver.[…..] именем своего syslog-хоста.
Некоторые демоны могут выводить данные в Elasticsearch через HTTP/HTTPS. Одним из них является наш rsyslog. Например, если вы юзаете rsyslog на Ubuntu, сначала установите модуль Elasticsearch:
Затем в конфигурационном файле вам потребуется поправить два элемента: ш аблон JSON для Elasticsearch:
и action , который пересылает данные в Elasticsearch , используя указанный выше шаблон:
В приведенном примере показано, как отправлять сообщения в API Elasticsearch на example . com. Н астройте action на ваш локальный Elasticsearch:
- searchIndex – будет вашим алиасом;
- server – имя хоста (ноды) Elasticsearch;
- serverport может быть 9200 или кастомным, главное, чтобы на нем слушал Elasticsearch;
- usehttps= «off» – отправление данных по http.
Независимо от того, используете ли вы syslog-протокол или что-то еще, лучше перенаправлять данные непосредственно из демона, чем искать проблемы в отдельных файлах из /var/log .
Это не значит, что файлы в /var/log бесполезны. Они пригодятся в следующих случаях:
- приложения пишут туда свои логи, например, HTTP, FTP, MySQL и т. д.,
- требуется обработать системные журналы, например, с помощью grep.
❗Важные файлы журналов для мониторинга
Здесь мы рассмотрим ключевые файлы логов, какую информацию они хранят, как настраивается rsyslog для записи и как посмотреть информацию с помощью journalctl .
Журнал /var/log/syslog или /var/log/messages
Это «всеохватывающий» системный лог:
Вы найдёте здесь все сообщения: ошибки, информационные сообщения и все другие серьёзности . Исключением является stop action .
Если в /var/log/syslog или /var/log/messages пусто, скорее всего, journald не перенаправляет данные в syslog. Все те же данные можно просмотреть, вызвав journalctl без параметров.
Журналы /var/log/kern.log или /var/log/dmesg
Сюда по умолчанию отправляются сообщения ядра:
И снова, если у вас нет syslog (или файл пустой/отсутствует) – используйте journalctl:
Журналы /var/log/auth.log или /var/log/secure
Здесь вы найдете сообщения об аутентификации, генерируемые такими службами, как sshd :
Вот ещё один фильтр по значениям auth и authpriv :
Вы можете использовать такие фильтры в journalctl, используя числовые уровни объектов :
Журнал /var/log/cron.log
Сюда отправляются ваши cron-сообщения (jobs-ы, выполняемые регулярно):
С journalctl можно сделать так:
Журнал /var/log/mail.log или /var/log/maillog
Практически все демоны (такие как Postfix, cron и т. д.) обычно пишут свои логи в syslog. Затем rsyslog раскладывает эти логи по файлам:
С помощью journald просматривать журналы можно так:
📄 Подведём итоги
- Расположение и формат системных журналов Linux зависят от того, как настроен дистрибутив.
- Большинство дистрибутивов имеют systemd, и все логи «живут» там. Чтобы что-то просмотреть и найти, используйте journalctl.
- Некоторые дистрибутивы передают системные журналы в syslog, либо напрямую, либо через journal. В этом случае у вас, скорее всего, есть логи, записанные в отдельные файлы в /var/log .
- Если вы управляете несколькими серверами, вам потребуется централизовать журналирование с помощью специального ПО или использовать собственный ELK-стек.
Логгирование событий невероятно важная и серьёзная штука в любой сфере администрирования и ОС. Рекомендуем отнестись ответственно к данной теме – она будет полезна при дебагинге, разработке и просто в управлении инфраструктурой.
Источник

Эта статья также есть на английском.
Однажды вечером, перечитывая Джеффри Фридла, я осознал, что даже несмотря на всем доступную документацию, существует множество приемов заточенных под себя. Все люди слишком разные. И приемы, которые очевидны для одних, могут быть неочевидны для других и выглядеть какой-то магией для третьих. Кстати, несколько подобных моментов я уже описывал здесь.
Командная строка для администратора или пользователя — это не только инструмент, которым можно сделать все, но и инструмент, который кастомизируется под себя любимого бесконечно долго. Недавно пробегал перевод на тему удобных приемов в CLI. Но у меня сложилось впечатление, что сам переводчик мало пользовался советами, из-за чего важные нюансы могли быть упущены.
Под катом — дюжина приемов в командной строке — из личного опыта.
Маленькое отступление — в реале я использую множество приемов, в которых могут случайно встретиться имена реальных серверов или юзеров, что может попасть под NDA, поэтому я не мог копи-пастить и специально переписал и максимально упростил все примеры в статье — и если вам покажется, что какой-то прием в данном контексте совершенно бесполезен — возможно это как раз по этой причине. Но в любом случае делитесь вашими идеями в комментариях!
1. Разбиение строки при помощи variable expansions
Часто используют cut или даже awk, чтобы просто получить значение какого-то одного столбца.
Если нужно взять первые символов в строке, используют ${VARIABLE:0:5}.
Но есть очень мощный инструмент, который позволяет манипулировать строками при помощи #, ##, % и %% (bash variable expansions) — с их помощью можно отрезать ненужное по паттерну с любой стороны.
Пример ниже показывает, как из строки «username:homedir:shell» можно получить только третий столбец (shell) при помощи cut или при помощи variable expansions (мы используем маску
*:
и команду ##, что означает отрезать слева все символы до последнего найденного двоеточия):
$ STRING="username:homedir:shell"
$ echo "$STRING"|cut -d ":" -f 3
shell
$ echo "${STRING##*:}"
shellВторой вариант не запускает еще один процесс (cut), и вообще не использует пайпы, что должно работать гораздо быстрее. А если подобный скрипт выполнить в bash-подсистеме на windows, где пайпы еле шевелятся, разница в скорости будет
огромна
.
Давайте посмотрим пример на Ubuntu — крутим нашу команду в цикле 1000 раз
$ cat test.sh
#!/usr/bin/env bash
STRING="Name:Date:Shell"
echo "using cut"
time for A in {1..1000}
do
cut -d ":" -f 3 > /dev/null <<<"$STRING"
done
echo "using ##"
time for A in {1..1000}
do
echo "${STRING##*:}" > /dev/null
done
Результат выполнения
$ ./test.sh
using cut
real 0m0.950s
user 0m0.012s
sys 0m0.232s
using ##
real 0m0.011s
user 0m0.008s
sys 0m0.004s
Разница — в несколько десятков раз!
Конечно, пример выше — слишком искусственный. В реальной жизни мы будем обрабатывать реальный файл. А в этом случае из него нужно читать. И для cut мы просто перенаправим файлик /etc/passwd. А в случае использования ##, нам придется создать цикл с использованием read. Итак, кто победит в этом варианте?
$ cat test.sh
#!/usr/bin/env bash
echo "using cut"
time for count in {1..1000}
do
cut -d ":" -f 7 </etc/passwd > /dev/null
done
echo "using ##"
time for count in {1..1000}
do
while read
do
echo "${REPLY##*:}" > /dev/null
done </etc/passwd
done
Результат выполнения
$ ./test.sh
$ ./test.sh
using cut
real 0m0.827s
user 0m0.004s
sys 0m0.208s
using ##
real 0m0.613s
user 0m0.436s
sys 0m0.172s
Без комментариев =)
Еще парочка примеров:
$ VAR="myClassName = helloClass"
$ echo ${VAR##*= }
helloClass
$ VAR="Hello my friend (enemy)"
$ TEMP="${VAR##*(}"
$ echo "${TEMP%)}"
enemy
2. Автокомплит в bash с использованием TAB
Пакет bash-completion сейчас идет в поставке практически всех дистрибутивов, включить его можно или в /etc/bash.bashrc или /etc/profile.d/bash_completion.sh, но чаще всего он уже включен из коробки. В общем автокомплит по TAB — это один из тех удобных моментов, с которыми новичок знакомится в первую очередь.
А вот то, что не все активно используют, и на мой взгляд совершенно зря, так это то что автокомплит работает не только с именами файлов, а также с алиасами, именами переменных, а если копнуть в скрипты автокомплита, которые собственно являются тоже шелл скриптами, можно даже дописать автокомплит для вашего скрипта или приложения. Но вернемся к алиасам.
Алиасам не нужно прописывать PATH, не нужно создавать отдельные исполняемый файл — они комфортно могут лежать в .profile или .bashrc.
В *nix обычно используется lowercase для файлов и каталогов, поэтому мне показалось удобным использовать алиасы с использованием uppercase — тогда автокомплит
угадывает вашу мелодию с первой ноты
работает буквально с первых букв:
$ alias TAsteriskLog="tail -f /var/log/asteriks.log"
$ alias TMailLog="tail -f /var/log/mail.log"
$ TA[tab]steriksLog
$ TM[tab]ailLog3. Автокомплит в bash с использованием TAB — 2
Для более сложных случаев, часто пишутся скрипты и кладутся например в $HOME/bin.
Но есть же функции.
Им опять же не нужен PATH, и для них тоже работает автокомплит.
Поместим функцию LastLogin в .profile (не забудьте перегрузить .profile):
function LastLogin {
STRING=$(last | head -n 1 | tr -s " " " ")
USER=$(echo "$STRING"|cut -d " " -f 1)
IP=$(echo "$STRING"|cut -d " " -f 3)
SHELL=$( grep "$USER" /etc/passwd | cut -d ":" -f 7)
echo "User: $USER, IP: $IP, SHELL=$SHELL"
}(На самом деле тут не так важно, что я написал внутри функции, это исключительно наглядный многострочный пример, который было бы не так удобно запихивать в alias)
Затем в консоли:
$ L[tab]astLogin
User: saboteur, IP: 10.0.2.2, SHELL=/bin/bash4. Sensitive data
Если перед командой поставить пробел, она не попадет в bash history, следовательно если в командной строке нужно ввести пароль открытым текстом, лучше такую команду исключить из истории — на примере ниже, echo «hello 2» в истории не появляется:
$ echo "hello"
hello
$ history 2
2011 echo "hello"
2012 history 2
$ echo "my password secretmegakey"
my password secretmegakey
$ history 2
2011 echo "hello"
2012 history 2Заголовок спойлера
Поведение с пробелом контролируется следующей опцией:
export HISTCONTROL=ignoreboth
В скриптах, которые например нужно выложить в git или раскладывать их через ansible, можно сделать external bash file который будет лежать только на целевой машине, с правами 600, добавленный в .gitignore и содержать нужные пароли только для конкретного окружения, а в основной скрипт вызываться через source:
secret.sh
PASSWORD=LOVESEXGOD
myapp.sh
. ~/secret.sh
sqlplus -l user/"$PASSWORD"@database:port/sid @mysqfile.sqlНо это также небезопасно — как заметил Tanriol, такой пароль можно будет увидеть в списке процессов, где отображается вся командная строка со всеми аргументами, поэтому лучше, чтобы приложение умело читать пароль из нужного файла самостоятельно.
Например, безопасный ssh не имеет опции, которая позволяет передать ему пароль в командной строке. А небезопасный wget — поддерживает опцию —password, и если на данной машине работают другие пользователи, они могут увидеть в списке процессов все параметры вашего wget, пока он запущен.
И наконец самый правильный вариант — шифровать данные (пароли сертификатов, пароли для доступа к удаленным системам, пароли от SQL) используя openssl и мастер ключ.
openssl поддерживает все необходимые опции, чтобы использовать его для шифрования паролей прямо в скриптах. Пример шифрования и дешифрования:
Файл secret.key хранит только одну строку:
$ echo "secretpassword" > secret.key; chmod 600 secret.keyШифруем нашу строку алгоритмом aes-256-cbc, c использованием случайной соли:
$ echo "string_to_encrypt" | openssl enc -pass file:secret.key -e -aes-256-cbc -a
U2FsdGVkX194R0GmFKCL/krYCugS655yLhf8aQyKNcUnBs30AE5lHN5MXPjjSFML
Такую строку можно смело вставлять в скрипт или в конфигурационный файл какого-либо, который безопасно положить в .git — без secret.key его расшифровать будет сложно.
Перед использованием дешифровать в первоначальный вид можно той же командой, заменив только опцию -e на -d:
$ echo 'U2FsdGVkX194R0GmFKCL/krYCugS655yLhf8aQyKNcUnBs30AE5lHN5MXPjjSFML' | openssl enc -pass file:secret.key -d -aes-256-cbc -a
string_to_encryptТакже можно, чтобы приложение самостоятельно умело расшифровывать данные из конфигов, останется только согласовать, чтобы и ваш скрипт и приложение пользовались тем же secret.key и тем же алгоритмом.
5. Просмотр логов и grep
Часто можно использовать что-то вроде
tail -f application.log | grep -i errorИли даже так
tail -f application.log | grep -i -P "(error|warning|failure)"Но не забывайте про опцию -v, которая выводит наоборот — строки, которые НЕ соответствуют шаблону — это позволяет вывести не только строку с проблемой, но и в случае exception все остальные строки, которые к нему относятся вот таким образом (исключаем все строки, в которых есть info, выводим все остальные):
tail -f application.log | grep -v -i "info"Дополнительные нюансы:
Не забывайте использовать -P, так как по умолчанию grep использует basic regular expression, а не PCRE, и вы можете столкнуться с тем, что просто так группы не работают.
Не забывайте и про другие популярные опции «—line-buffered», «-i».
Если вы знаете регулярные выражения, то при помощи —only-matching, можно значительно улучшить вывод. Но в принципе это редко используется в случае разового использования. Зато очень рекомендую почитать мануал по grep, если вы пишете алиас/функцию/скрипт для многоразового использования.
6. Уменьшение размера лог файлов
В обычном состоянии, если приложение запущено и пишет в лог файл, его не рекомендуется удалять, поскольку в *nix, открытый файловый дескриптор связан не с именем файла, а с iNode.
И если мы удалим лог файл, приложение может не начать писать в новый файл с нуля, я продолжать писать в старый, который для нас уже будет недоступен по имени (мы же его удалили). Затем, когда приложение остановится и закроет дескриптор, данные удалятся с файловой системы.
(Большинство программ при записи в лог, каждый раз открывают и закрывают файл, и тогда этой проблеме они не подвержены)
Поэтому очистку файла следует делать либо так (очистим файл, не удаляя его):
> application.logЛибо так (файл будет урезан до указанного размера):
truncate --size=1M application.logНо команда выше именно урежет, что означает, что в файле останутся старые данные, а свежие как раз и будут урезаны.
Поэтому можно делать вот так, сохраняя последние 1000 строк:
echo "$(tail -n 1000 application.log)" > application.log
Спасибо Himura за оптимизацию.
P.S. В данном примере мы не рассматриваем самый правильный способ — когда приложение само следит за своим лог-файлом пользуясь, например, log4j, или своим велосипедом или rotatelogs.
7. watch следит за тобой!
Бывает ситуация, когда ждешь какого-то события. Например, пока подключится пользователь (жмешь who несколько десятков раз), или кто-то скопирует по ftp файл (жмешь ls десятки раз).
Можно использовать
watch <команда>
По умолчанию, команда будет выполняться каждые 2 секунды с очисткой экрана, пока не нажать Ctrl+C. Частоту выполнения можно изменить опцией при запуске.
Очень полезно, когда работаешь на одном сервере
8. Последовательности в bash
Есть удобная возможность создавать диапазоны значений, например вместо такого:
for srv in 1 2 3; do echo "server${srv}";done
server1
server2
server3использовать вот такое:
for srv in server{1..3}; do echo "$srv";done
server1
server2
server3А еще можно использовать команду seq, чтобы форматировать вывод. Например выравниваем ширину автоматически:
for srv in $(seq -w 1 10); do echo "server${srv}";done
server01
server02
server03
server04
server05
server06
server07
server08
server09
server10А вот еще один пример конструкции с фигурными скобками, которая позволит массово переименовать файлы. Для получения имени файла без расширения используем basename:
for file in *.txt; do name=$(basename "$file" .txt);mv $name{.txt,.lst}; doneА можно еще короче, с использованием %:
for file in *.txt; do mv ${file%.txt}{.txt,.lst}; doneДля переименования файлов лучше использовать утилиту «rename»
Или вот пример для создания структуры каталогов под новый java проект:
mkdir -p project/src/{main,test}/{java,resources}Получим
project/
!--- src/
|--- main/
| |-- java/
| !-- resources/
!--- test/
|-- java/
!-- resources/9. tail, несколько файлов и несколько юзеров
Ранее упоминался multitail, который может следить за несколькими файлами сразу. Но он не поставляется из-под коробки, а права для установки есть не всегда.
Но с этим вполне может справиться и обычный tail:
tail -f /var/logs/*.log
Кстати, вернемся на минуту к алиасам с «tail -f».
Бывает, что на сервере, где крутится некое приложение, лазят разные тестировщики, разработчики и все смотрят лог приложения через tail -f. Даже на продакшене несколько саппортеров
-индусов
могут смотреть один и тот же лог каждый из своей сессии.
При перезапуске приложения, остаются висящие «tail -f», которые могут висеть несколько дней или даже месяцев. Это не то, чтобы проблема, но не аккуратненько.
Полезно будет сделать алиас, который получает PID вашего приложения из PID файла, и автоматически завершит tail при завершении процесса:
alias TFapplog='tail -f --pid=$(cat /opt/app/tmp/app.pid) /opt/app/logs/app.log'И добавить этот алиас во все профайлы. Даже если все ушли домой, забыв остановить свой tail, он автоматически завершится при рестарте приложения.
10. создание файла нужного размера
Часто пользуются dd
dd if=/dev/zero of=out.txt bs=1M count=10Но я рекомендую использовать fallocate:
fallocate -l 10M file.txtНа файловых системах, которые поддерживают аллокацию места (xfs, ext4, Btrfs…), данная команда будет выполнена мгновенно, в отличие от dd.
11. xargs
Всего два момента, которые полезны, если мы обрабатываем очень большой список.
Первое — список может просто не влезть в командную строку.
Но мы можем ограничить обработку аргументов через опцию -n:
$ # создаем файл из 5 строк
for string in string{1..5}; do echo $string >> file.lst; done
$ cat file.lst
string1
string2
string3
string4
string5
saboteur@ubuntu:~$ cat file.lst | xargs -n 2
string1 string2
string3 string4
string5Второе — команда может выполняться слишком долго, ибо мы запустили ее выполняться в один поток. А если у нас несколько ядер, то полезно запускать xargs в три потока, каждый будет обрабатывать по 2 аргумента:
cat file | xargs -n 2 -P 3Если мы хотим запустить на все доступные ядра, то можно даже использовать nproc, скрипт автоматически определит количество доступных ядер на текущей машине:
cat file | xargs -n 2 -P $(nproc)12. sleep? while? read!
Вместо sleep или бесконечного цикла while, я пишу read, что позволяет одной командой сделать паузу, которую можно в любой момент прервать:
read -p "Press any key to continue " -n 1Или добавить таймаут, который также можно в любой момент прервать и продолжить выполнение:
read -p "Press any key to continue (autocontinue in 30 seconds) " -t 30 -n 1Можно усложнить конструкцию до полноценной обработки:
REPLY=""
until [ "$REPLY" = "y" ]; do
# executing some command
read "Press 'y' to continue or 'n' to break, any other key to repeat this step" -n 1
if [ "$REPLY" = 'n' ]; then exit 1; fi
done
На этом я прощаюсь, и буду благодарен за участие в опросе.
И конечно — жду разумной критики и новых приемов от вас!
P.S. Update:
1. все переменные заключены в кавычки — так надо!
2. « заменен на $() — так правильно!
3. исправлено несколько опечаток, и даже парочка ошибок.
Всем, кто со мной спорит — несмотря на мою воинственность, я действительно стараюсь услышать и разобраться =), поэтому огромное спасибо+ следующим комментаторам: khim, Tanriol, Himura, bolk, firegurafiku, а также dangerous3, RPG, ALexhha, IRyston, McAaron
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Попалось ли вам что-то новое?
36.23%
Удивил прием с ## и %%
304
25.98%
Забавная штука с read вместо sleep
218
10.85%
Не знал про openssl
91
54.11%
Больше половины полезно!
454
18.12%
Ничто не ново под луной :/
152
Проголосовали 839 пользователей.
Воздержались 253 пользователя.
I’m trying to read a log file which is being written to by a simple daemon. I would like to filter my «live» output to certain — multiple — «types».
My types are: DEBUG|INFO|WARN|ERROR|FATAL
This is what I have so far, and it works for one case, but I cannot get it working for multiple cases though.
tail -f log.txt | grep INFO
I’ve tried a couple of things to try and say I want «WARN‘s & ERROR‘s», but nothing is really working for me. How would I correct this?
![]()
asked Oct 23, 2009 at 15:05
![]()
Try:
tail -f log.txt | egrep 'WARN|ERROR'
![]()
answered Oct 23, 2009 at 15:11
![]()
Doug HarrisDoug Harris
26.9k17 gold badges77 silver badges105 bronze badges
1
In addition to switching to egrep/grep -E to get the alternation operator of extended regular expressions, you can you can also use multiple -e arguments to regular grep or even fgrep/grep -F
In fact, if your searches are all static strings (like the original question), you can even ‘downgrade’ all the way to fgrep/grep -F which might give a speed boost (since it always does direct string comparisons without regexps).
fgrep -e DEBUG -e INFO -e WARN -e ERROR -e FATAL
Also POSIX allows patterns to be separated by newlines.
# bash-ish to put a newlines into the string
fgrep $'DEBUGnINFOnWARNnERRORnFATAL'
# Standard syntax, but easier to break while editing(?):
fgrep "$(for f in DEBUG INFO WARN ERROR FATAL; do echo "$f"; done)"
answered Oct 23, 2009 at 20:19
![]()
Chris JohnsenChris Johnsen
38.4k6 gold badges107 silver badges108 bronze badges
This also works (regular grep and escape the pipe character):
tail -f log.txt | grep 'WARN|ERROR'
answered Oct 23, 2009 at 18:37
![]()
Dennis WilliamsonDennis Williamson
104k19 gold badges164 silver badges187 bronze badges
1