-
#1
Code:
node 1 main:
/etc/pve/nodes/AAEX-HINET/qemu-server# ls
123.conf 124.conf 125.conf 126.conf
node 2 join cluster:
/etc/pve/nodes/aaex-hk/qemu-server# ls
100.conf 101.conf 102.conf 103.conf 104.conf 105.conf 107.conf 108.conf 109.conf 110.conf 111.conf 112.conf
()
detected the following error(s):
* this host already contains virtual guests
TASK ERROR: Check if node may join a cluster failed!
![]()
-
#2
this host already contains virtual guests
you can only join a host without vm on it
-
#3
you can only join a host without vm on it
yes,just host
i dont know what happend
![]()
oguz
Proxmox Retired Staff
-
#4
yes,just host
i dont know what happend
there are VMs on both hosts.
clean one of them and then you can join it.
-
#5
vmid does not conflict, why should you clean it up? Any good ideas?
there are VMs on both hosts.
clean one of them and then you can join it.
![]()
oguz
Proxmox Retired Staff
-
#6
as a precaution it’s not allowed to join a cluster when you already have VMs on a node (pve-cluster related issues).
just make a backup of the VMs on one node. transfer the backups somewhere, then clean the node and you’ll be able to join.
edit: «clean the node» meaning remove the VMs
-
#7
as a precaution it’s not allowed to join a cluster when you already have VMs on a node (pve-cluster related issues).
just make a backup of the VMs on one node. transfer the backups somewhere, then clean the node and you’ll be able to join.
edit: «clean the node» meaning remove the VMs
ok..i need remove vm,then join
-
#8
you can only join a host without vm on it
so how to transfer all VM to new cluster 7.0 ?
i just install 7.0 on new hardware, then want to transfer VM from old (6.4) no new 7.0 : what is the best way ?
thank you
Last edited: Sep 10, 2021
![]()
-
#9
so how to transfer all VM to new cluster 7.0 ?
i just install 7.0 on new hardware, then want to transfer VM from old (6.4) no new 7.0 : what is the best way ?
thank you
Hi, the easiest way is, Backup and then Restore to the new Cluster.
-
#10
Hi, the easiest way is, Backup and then Restore to the new Cluster.
ok thank you, i will do that.
-
#11
VM (debian 10 based) are very very slow under proxmox 7.0 … why ?
perhaps ZFS raidz 8TB is initiate ?
Last edited: Sep 11, 2021
-
#12
VM (debian 10 based) are very very slow under proxmox 7.0 … why ?
perhaps ZFS raidz 8TB is initiate ?
probably restore 
-
#1
I’m trying to join a new PVE node to an existing cluster. All the machines are on PVE 7.1-8.
When I attempted to join the existing cluster from the GUI’s «Assisted join», I get the following error.
Code:
()
detected the following error(s):
* this host already contains virtual guests
TASK ERROR: Check if node may join a cluster failed!There is 1 VM on the new node and obviously the cluster has many VMs/CTs running.
Thanks in advance for the guidance!
-
#2
The new host can not have a VM or LXC setup, even shutdown, when it joins a cluster.
if you want to proceed will have to delete that single VM on the unjoined node first. You can backup the VM and save to USB or network disk then restore from backup later or move it to one of the other already joined cluster nodes before deleting, same process backup, move it via network or USB and then restore from backup on the new Proxmox node. Verify it works and proceed.
https://pve.proxmox.com/pve-docs/pve-admin-guide.html#pvecm_join_node_to_cluster
Last edited: Jan 9, 2022
-
#3
Thanks, I backed up to a temp NFS share and restored from that, worked great.
Hey everyone, another Failover Cluster issue i came across lately. And i wanted to share this one as i could not find any good resources online for this issue. So here we go.
A client contacted me a few weeks back about a node that would not come online again in the cluster after a reboot. It would not join back to the cluster at all. When looking at the cluster it just did not want to join back to the cluster. The only good error msg’s under failover clustering i could find where these.
What we found
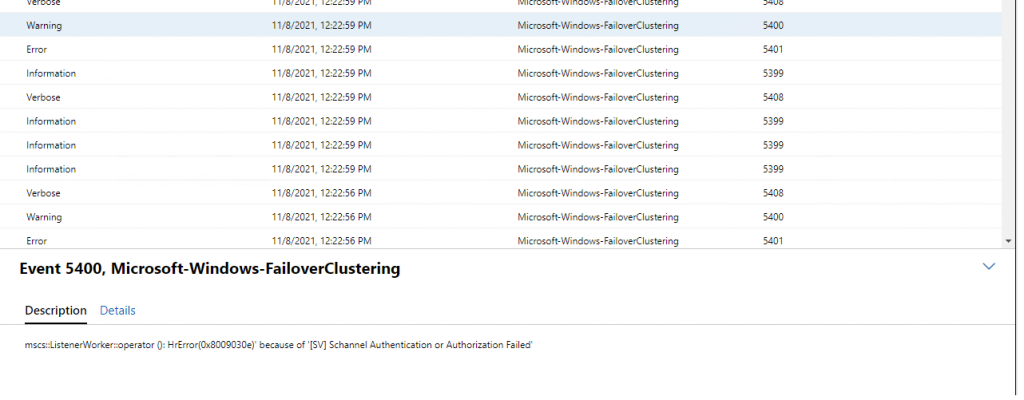
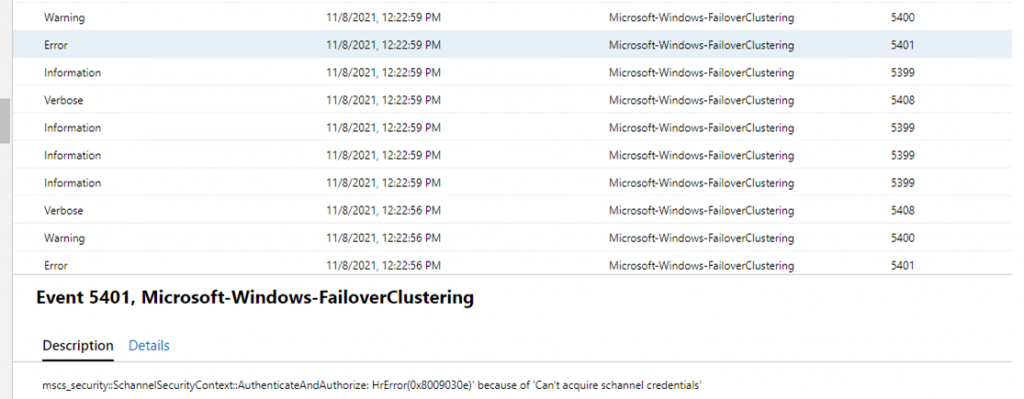
The error msg’s are saying there is an authentication failure between the node and the cluster. And it’s referencing schannel in the 5401 event id. Looking at schannel event id 36869 it was showing that the certificate was missing the private key information.

So my first thought was ok, let’s find the cert and delete it and reboot the node, as Failover Cluster will get the cert back from the other nodes when trying to join the cluster. Well that did not work. After some more troubleshooting and googling and not finding an answer a premier support ticket was created. Unfortunately MS support has been overwhelmed with support cases and been backlogged for a while so the ticket has taken some time to resolve.
Troubleshooting
MS wanted us to run the tss_tool found at https://github.com/walter-1/TSS . Download the zip file and extract it to a folder and run the command
tss sdp:Cluster
It will create a folder named MS_Data under c:
Inside one of the logs the we found this little error event
11/17/2021 1:58:25 AM Error node1.contoso.local 1653 Microsoft-Windows-FailoverClustering Node-to-Node Communications NT AUTHORITYSYSTEM Cluster node ‘node1’ failed to join the cluster because it could not communicate over the network with any other node in the cluster. Verify network connectivity and configuration of any network firewalls.
11/17/2021 1:58:25 AM Error node1.contoso.local 5398 Microsoft-Windows-FailoverClustering Startup/Shutdown NT AUTHORITYSYSTEM Cluster failed to start. The latest copy of cluster configuration data was not available within the set of nodes attempting to start the cluster. Changes to the cluster occurred while the set of nodes were not in membership and as a result were not able to receive configuration data updates. . Votes required to start cluster: 3 Votes available: 1 Nodes with votes: Quorum Disk node2 node3 node4 Guidance: Attempt to start the cluster service on all nodes in the cluster so that nodes with the latest copy of the cluster configuration data can first form the cluster. The cluster will be able to start and the nodes will automatically obtain the updated cluster configuration data. If there are no nodes available with the latest copy of the cluster configuration data, run the ‘Start-ClusterNode -FQ’ Windows PowerShell cmdlet. Using the ForceQuorum (FQ) parameter will start the cluster service and mark this node’s copy of the cluster configuration data to be authoritative. Forcing quorum on a node with an outdated copy of the cluster database may result in cluster configuration changes that occurred while the node was not participating in the cluster to be lost.
And then this error msg
11/17/2021 1:58:38 AM Error node1.contoso.local 36869 Schannel N/A NT AUTHORITYSYSTEM The TLS client credential’s certificate does not have a private key information property attached to it. This most often occurs when a certificate is backed up incorrectly and then later restored. This message can also indicate a certificate enrollment failure
We tried the Clear-ClusterNode -Name node1 -Force on the faulty node and on one of the nodes in the cluster to try and clear the node information but it did not work.
The solution
The last suggestion we had was to try and remove the node from the cluster. So we ran the following
# On Node1 run Remove-ClusterNode -Name node1 -Force #Once the node is out run this command on node1 Clear-ClusterNode -Name node1 -Force #Then run the same command on any of the other nodes in the cluster Clear-ClusterNode -Name node12 -Force
Once this was done, the node was outside the cluster. And we could try and add it back to the cluster. Which worked flawless
So to sum this up, something happened with the schannel certificate on the node that was rebooted. And it could not authenticate back safely. The only way to get it back in was to remove the node and re add it to the cluster. Hopefully this will help someone in the future.
![]()
Environment
- RabbitMQ 3.6.1
- Erlang 18.2.1
rabbitmqctljoin_cluster fails with below error if a Node is re-joining cluster after it got reset.
Example, Node A, B and C are cluster members. Server running Node C is crashed and unable to recover, so create a brand new Server but with same HostName as C, install Rabbit and try to join Cluster running with Node A and B, it throws following error.
Error
{"init terminating in do_boot",{function_clause,[{rabbit_control_misc,print_cmd_result,[join_cluster,already_member],[{file,"src/rabbit_control_misc.erl"},{line,96}]},{rabbit_cli,main,3,[{file,"src/rabbit_cli.erl"},{line,83}]},{init,start_it,1,[]},{init,start_em,1,[]}]}}
I understand that running RabbitMQ nodes(A and B) cannot know if node C is down temporarily or permanently, but Nodes (A and B) should ignore that fact that C is already a member of cluster but not running now and join C, when join_cluster request comes from Node C.
other-wise Node C will never be able to join A and B until forget_cluster_node NodeC is manually executed.
So, i am wondering why can’t running Nodes(A and B) automatically forget_cluster_node NodeC when join_custer NodeA or join_custer NodeB is executed on NodeC.
Steps to reproduce on EC2.
- Launch three ec2-instances with host names NodeA, NodeB and NodeC
- Install rabbitmq on all three hosts and configure cluster with members NodeA, NodeB and NodeC.
- Terminate NodeC.
- Launch a new ec2-instance with Host name NodeC , install rabbitmq.
- run `$ rabbitmqctl join_cluster rabbit@NodeA on NodeC server.
Steps to reproduce on laptop.
- Start three rabbimq nodes.
$ RABBITMQ_NODE_PORT=8001 RABBITMQ_SERVER_START_ARGS="-rabbitmq_management listener [{port,15671}] -rabbit ssl_listeners [8101]" RABBITMQ_NODENAME=rabbit1 ./rabbitmq-server -detached
$ RABBITMQ_NODE_PORT=8002 RABBITMQ_SERVER_START_ARGS="-rabbitmq_management listener [{port,15672}] -rabbit ssl_listeners [8102]" RABBITMQ_NODENAME=rabbit2 ./rabbitmq-server -detached
$ RABBITMQ_NODE_PORT=8003 RABBITMQ_SERVER_START_ARGS="-rabbitmq_management listener [{port,15673}] -rabbit ssl_listeners [8103]" RABBITMQ_NODENAME=rabbit3 ./rabbitmq-server -detached - Join rabbit2 with rabbit1
$ rabbitmqctl -n rabbit2 stop_app
$ rabbitmqctl -n rabbit2 join_cluster rabbit1@'hostname -s' - Join rabbit3 with rabbit1
$ rabbitmqctl -n rabbit3 stop_app
$ rabbitmqctl -n rabbit3 join_cluster rabbit1@'hostname -s' - Force reset rabbit3
$ rabbitmqctl -n rabbit3 stop_app
$ rabbitmqctl -n rabbit3 force_reset - Start rabbit3, causes running rabbit3 alone with joining cluster with rabbit1 and 2.
- So, Try again join_cluster with with rabbit1 or rabbit2
$ rabbitmqctl -n rabbit2 stop_app
$ rabbitmqctl -n rabbit2 join_cluster rabbit1@'hostname -s'
![]()
The cluster thinks it is already s member.
On 28 mar 2016, at 4:32, Giri notifications@github.com wrote:
Environment
RabbitMQ 3.6.1
Erlang 18.2.1
rabbitmqctljoin_cluster fails with below error if a Node is re-joining cluster after it got reset.
Example, Node A, B and C are cluster members. Server running Node C is crashed and unable to recover, so create a brand new Server but with same HostName as C, install Rabbit and try to join Cluster running with Node A and B, it throws following error.Error
{«init terminating in do_boot»,{function_clause,[{rabbit_control_misc,print_cmd_result,[join_cluster,already_member],[{file,»src/rabbit_control_misc.erl»},{line,96}]},{rabbit_cli,main,3,[{file,»src/rabbit_cli.erl»},{line,83}]},{init,start_it,1,[]},{init,start_em,1,[]}]}}I understand that running RabbitMQ nodes(A and B) cannot know if node C is down temporarily or permanently, but Nodes (A and B) should ignore that fact that C is already a member of cluster but not running now and join C, when join_cluster request comes from Node C.
other-wise Node C will never be able to join A and B until forget_cluster_node NodeC is manually executed.So, i am wondering why can’t running Nodes(A and B) automatically forget_cluster_node NodeC when join_custer NodeA or join_custer NodeB is executed on NodeC.
Steps to reproduce on EC2.
Launch three ec2-instances with host names NodeA, NodeB and NodeC
Install rabbitmq on all three hosts and configure cluster with members NodeA, NodeB and NodeC.
Terminate NodeC.
Launch a new ec2-instance with Host name NodeC , install rabbitmq.
run `$ rabbitmqctl join_cluster rabbit@NodeA on NodeC server.
Steps to reproduce on laptop.
- Start three rabbimq nodes.
$ RABBITMQ_NODE_PORT=8001 RABBITMQ_SERVER_START_ARGS=»-rabbitmq_management listener [{port,15671}] -rabbit ssl_listeners [8101]» RABBITMQ_NODENAME=rabbit1 ./rabbitmq-server -detached
$ RABBITMQ_NODE_PORT=8002 RABBITMQ_SERVER_START_ARGS=»-rabbitmq_management listener [{port,15672}] -rabbit ssl_listeners [8102]» RABBITMQ_NODENAME=rabbit2 ./rabbitmq-server -detached
$ RABBITMQ_NODE_PORT=8003 RABBITMQ_SERVER_START_ARGS=»-rabbitmq_management listener [{port,15673}] -rabbit ssl_listeners [8103]» RABBITMQ_NODENAME=rabbit3 ./rabbitmq-server -detached- Join rabbit2 with rabbit1
$ rabbitmqctl -n rabbit2 stop_app
$ rabbitmqctl -n rabbit2 join_cluster rabbit1@’hostname -s’- Join rabbit3 with rabbit1
$ rabbitmqctl -n rabbit3 stop_app
$ rabbitmqctl -n rabbit3 join_cluster rabbit1@’hostname -s’- Force reset rabbit3
$ rabbitmqctl -n rabbit3 stop_app
$ rabbitmqctl -n rabbit3 force_reset- Start rabbit3, causes running rabbit3 alone with joining cluster with rabbit1 and 2.
- So, Try again join_cluster with with rabbit1 or rabbit2
$ rabbitmqctl -n rabbit2 stop_app
$ rabbitmqctl -n rabbit2 join_cluster rabbit1@’hostname -s’—
You are receiving this because you are subscribed to this thread.
Reply to this email directly or view it on GitHub
![]()
Resetting a node wipes out all of its data. As far as the rest of the cluster is concerned, that node is still a member. You need to use ‘rabbitmqctl forget_cluster_node’ first.
![]()
I know rabbitmqctl forget_clister_node solves the probelm. My question was why not automatically run this command on running nodes when a node tries to join cluster before making cluster.
It will help us automate the thinings on AWS deployment.
![]()
We cannot assume that every time a node leaves a cluster it also has to be reset. We will consider it.
On 28 mar 2016, at 14:50, Giri notifications@github.com wrote:
I know rabbitmqctl forget_clister_node solves the probelm. My question was why not automatically run this command on running nodes when a node tries to join cluster before making cluster.
It will help us automate the thinings on AWS deployment.
—
You are receiving this because you modified the open/close state.
Reply to this email directly or view it on GitHub
![]()
Agreed. But if joining node tells it got reset , there is no harm in ignoring the fact that it was a cluster mememebr.
![]()
MK, do you want me re-open this issue as you are willing to consider it for future enhancements ?
binarin
added a commit
to binarin/rabbitmq-common
that referenced
this issue
Jun 30, 2016
![]()
This was referenced
Jun 30, 2016
binarin
added a commit
to binarin/rabbitmq-common
that referenced
this issue
Jun 30, 2016
![]()
![]()
Somewhat related: #868 makes rabbitmqctl join_cluster idempotent, which makes sense. Thank you, @binarin.
![]()
@michaelklishin and @binarin Thanks for making rabbitmqctl join_cluster idempotent!!
it reduces lot of complexity in my anisble scripts.
@michaelklishin
I think main issue is not solved yet. A node is still not able to re-join Cluster after it got reset, Cluster thinks this node is already member but off-line.
{«init terminating in do_boot»,{function_clause,[{rabbit_control_misc,print_cmd_result,[join_cluster,already_member],[{file,»src/rabbit_control_misc.erl»},{line,92}]},{rabbit_cli,main,3,[{file,»src/rabbit_cli.erl»},{line,89}]},{init,start_it,1,[]},{init,start_em,1,[]}]}}
init terminating in do_boot ()
![]()
![]()
II received the same problems.
Environment
RabbitMQ 3.7.21
Erlang 21.1.1
peer_discovery_backend =rabbitmq_peer_discovery_etcd
but when he joins, he reports the following problems. Why can’t he automatically do rabbitmqctl rest and then join?
**********************************************************
*** Publishers will be blocked until this alarm clears ***
**********************************************************
2019-11-22 09:46:25.053 [info] <0.446.0> Node rabbit@node1 is down, deleting its listeners
2019-11-22 09:46:25.062 [info] <0.446.0> node rabbit@node3 down: connection_closed
2019-11-22 09:46:25.062 [info] <0.446.0> node rabbit@node3 up
2019-11-22 09:46:25.063 [warning] <0.21658.0> Received a 'DOWN' message from rabbit@iZwz9b0u6ogs6zb7ifriazZ but still can communicate with it
2019-11-22 09:46:25.142 [info] <0.446.0> Autoheal request sent to rabbit@iZwz9b0u6ogs6zb7ifriazZ
2019-11-22 09:46:25.667 [warning] <0.21662.0> Received a 'DOWN' message from rabbit@iZwz9b0u6ogs6zb7ifriazZ but still can communicate with it
2019-11-22 09:46:25.853 [error] <0.446.0> Partial partition disconnect from rabbit@master1
2019-11-22 09:46:26.853 [info] <0.446.0> rabbit on node rabbit@master1 down
2019-11-22 09:46:26.859 [info] <0.446.0> Node rabbit@master1 is down, deleting its listeners
2019-11-22 09:46:26.861 [info] <0.446.0> node rabbit@master1 down: disconnect
2019-11-22 09:46:26.861 [info] <0.446.0> node rabbit@master1 up
2019-11-22 09:46:26.861 [error] <0.446.0> Partial partition disconnect from rabbit@master1
2019-11-22 09:46:27.860 [error] <0.186.0> Mnesia(rabbit@master2): ** ERROR ** mnesia_event got {inconsistent_database, running_partitioned_network, rabbit@master1}
2019-11-22 09:46:27.862 [info] <0.446.0> node rabbit@master1 down: connection_closed
2019-11-22 09:46:27.862 [info] <0.446.0> node rabbit@master1 up
2019-11-22 09:46:27.862 [error] <0.446.0> Partial partition disconnect from rabbit@master1
2019-11-22 09:46:28.867 [error] <0.186.0> Mnesia(rabbit@master2): ** ERROR ** mnesia_event got {inconsistent_database, running_partitioned_network, rabbit@master1}
2019-11-22 09:46:28.869 [info] <0.446.0> Autoheal request sent to rabbit@iZwz9b0u6ogs6zb7ifriazZ
2019-11-22 09:46:28.869 [info] <0.446.0> node rabbit@master1 down: disconnect
2019-11-22 09:46:28.869 [info] <0.446.0> node rabbit@master1 up
2019-11-22 09:46:28.872 [info] <0.446.0> Autoheal request sent to rabbit@iZwz9b0u6ogs6zb7ifriazZ
2019-11-22 09:46:28.989 [error] <0.446.0> Partial partition detected:
* We saw DOWN from rabbit@master1
* We can still see rabbit@iZwz9dn6ueqa6otmtpfhajZ which can see rabbit@master1
We will therefore intentionally disconnect from rabbit@iZwz9dn6ueqa6otmtpfhajZ
2019-11-22 09:46:29.990 [info] <0.446.0> rabbit on node rabbit@iZwz9dn6ueqa6otmtpfhajZ down
2019-11-22 09:46:30.004 [info] <0.446.0> Node rabbit@iZwz9dn6ueqa6otmtpfhajZ is down, deleting its listeners
2019-11-22 09:46:30.038 [error] <0.186.0> Mnesia(rabbit@master2): ** ERROR ** mnesia_event got {inconsistent_database, running_partitioned_network, rabbit@iZwz9dn6ueqa6otmtpfhajZ}
2019-11-22 09:46:30.551 [info] <0.446.0> node rabbit@iZwz9dn6ueqa6otmtpfhajZ down: disconnect
2019-11-22 09:46:30.552 [error] <0.446.0> Partial partition detected:
* We saw DOWN from rabbit@master1
* We can still see rabbit@iZwz9dn6ueqa6otmtpfhaiZ which can see rabbit@master1
We will therefore intentionally disconnect from rabbit@iZwz9dn6ueqa6otmtpfhaiZ
2019-11-22 09:46:30.653 [warning] <0.21726.0> global: rabbit@master2 failed to connect to rabbit@iZwz9dn6ueqa6otmtpfhajZ
2019-11-22 09:46:30.654 [warning] <0.21727.0> global: rabbit@master2 failed to connect to rabbit@iZwz9dn6ueqa6otmtpfhaiZ
2019-11-22 09:46:31.553 [error] <0.446.0> Partial partition detected:
* We saw DOWN from rabbit@master1
* We can still see rabbit@iZwz9dn6ueqa6otmtpfhaiZ which can see rabbit@master1
We will therefore intentionally disconnect from rabbit@iZwz9dn6ueqa6otmtpfhaiZ
2019-11-22 09:46:31.556 [error] <0.186.0> Mnesia(rabbit@master2): ** ERROR ** mnesia_event got {inconsistent_database, running_partitioned_network, rabbit@iZwz9dn6ueqa6otmtpfhaiZ}
2019-11-22 09:46:32.256 [error] <0.186.0> Mnesia(rabbit@master2): ** ERROR ** mnesia_event got {inconsistent_database, running_partitioned_network, rabbit@node2}
2019-11-22 09:46:32.477 [error] <0.186.0> Mnesia(rabbit@master2): ** ERROR ** mnesia_event got {inconsistent_database, running_partitioned_network, rabbit@iZwz9dn6ueqa6otmtpfhajZ}
2019-11-22 09:46:32.554 [error] <0.446.0> Partial partition detected:
* We saw DOWN from rabbit@master1
* We can still see rabbit@iZwz9dn6ueqa6otmtpfhaiZ which can see rabbit@master1
We will therefore intentionally disconnect from rabbit@iZwz9dn6ueqa6otmtpfhaiZ
2019-11-22 09:46:33.555 [info] <0.446.0> node rabbit@iZwz9dn6ueqa6otmtpfhajZ up
2019-11-22 09:46:33.556 [info] <0.446.0> node rabbit@iZwz9dn6ueqa6otmtpfhajZ down: connection_closed
2019-11-22 09:46:33.556 [info] <0.446.0> rabbit on node rabbit@iZwz9dn6ueqa6otmtpfhaiZ down
2019-11-22 09:46:33.562 [info] <0.446.0> Node rabbit@iZwz9dn6ueqa6otmtpfhaiZ is down, deleting its listeners
2019-11-22 09:46:33.824 [info] <0.446.0> node rabbit@iZwz9dn6ueqa6otmtpfhaiZ down: disconnect
2019-11-22 09:46:33.824 [info] <0.446.0> rabbit on node rabbit@node2 down
2019-11-22 09:46:33.831 [info] <0.446.0> Keeping rabbit@node2 listeners: the node is already back
2019-11-22 09:46:33.831 [warning] <0.241.0> memory resource limit alarm cleared for dead node rabbit@node2
2019-11-22 09:46:33.833 [info] <0.446.0> node rabbit@node2 down: connection_closed
2019-11-22 09:46:33.833 [info] <0.446.0> node rabbit@iZwz9dn6ueqa6otmtpfhaiZ up
2019-11-22 09:46:33.834 [info] <0.446.0> node rabbit@node2 up
2019-11-22 09:46:33.834 [info] <0.446.0> node rabbit@iZwz9dn6ueqa6otmtpfhajZ up
2019-11-22 09:46:33.835 [warning] <0.241.0> memory resource limit alarm set on node rabbit@node2.
**********************************************************
*** Publishers will be blocked until this alarm clears ***
**********************************************************
2019-11-22 09:46:33.835 [info] <0.446.0> node rabbit@iZwz9dn6ueqa6otmtpfhaiZ down: disconnect
2019-11-22 09:46:33.836 [info] <0.446.0> node rabbit@iZwz9dn6ueqa6otmtpfhaiZ up
2019-11-22 09:46:33.837 [error] <0.186.0> Mnesia(rabbit@master2): ** ERROR ** mnesia_event got {inconsistent_database, running_partitioned_network, rabbit@iZwz9dn6ueqa6otmtpfhaiZ}
2019-11-22 09:46:33.837 [info] <0.446.0> Autoheal request sent to rabbit@iZwz9b0u6ogs6zb7ifriazZ
2019-11-22 09:46:34.658 [info] <0.446.0> rabbit on node rabbit@iZwz9dn6ueqa6otmtpfhaiZ down
2019-11-22 09:46:34.664 [info] <0.446.0> Node rabbit@iZwz9dn6ueqa6otmtpfhaiZ is down, deleting its listeners
2019-11-22 09:46:34.666 [info] <0.446.0> node rabbit@iZwz9dn6ueqa6otmtpfhaiZ down: connection_closed
2019-11-22 09:46:35.669 [info] <0.446.0> node rabbit@iZwz9dn6ueqa6otmtpfhaiZ up
2019-11-22 09:46:35.669 [error] <0.186.0> Mnesia(rabbit@master2): ** ERROR ** mnesia_event got {inconsistent_database, running_partitioned_network, rabbit@iZwz9dn6ueqa6otmtpfhaiZ}
2019-11-22 09:46:35.670 [info] <0.446.0> Autoheal request sent to rabbit@iZwz9b0u6ogs6zb7ifriazZ
2019-11-22 09:46:45.742 [warning] <0.446.0> Autoheal: we were selected to restart; winner is rabbit@node3
2019-11-22 09:46:45.742 [info] <0.21818.0> RabbitMQ is asked to stop...
2019-11-22 09:46:45.801 [info] <0.21818.0> Stopping RabbitMQ applications and their dependencies in the following order:
rabbitmq_management
rabbitmq_web_stomp
rabbitmq_stomp
amqp_client
rabbitmq_web_dispatch
cowboy
cowlib
rabbitmq_peer_discovery_etcd
rabbitmq_peer_discovery_common
rabbitmq_management_agent
rabbitmq_event_exchange
rabbit
mnesia
rabbit_common
sysmon_handler
os_mon
2019-11-22 09:46:45.801 [info] <0.21818.0> Stopping application 'rabbitmq_management'
2019-11-22 09:46:45.802 [warning] <0.642.0> RabbitMQ HTTP listener registry could not find context rabbitmq_management_tls
2019-11-22 09:46:45.805 [info] <0.42.0> Application rabbitmq_management exited with reason: stopped
2019-11-22 09:46:45.805 [info] <0.21818.0> Stopping application 'rabbitmq_web_stomp'
2019-11-22 09:46:45.807 [info] <0.42.0> Application rabbitmq_web_stomp exited with reason: stopped
2019-11-22 09:46:45.807 [info] <0.21818.0> Stopping application 'rabbitmq_stomp'
2019-11-22 09:46:45.807 [info] <0.606.0> stopped STOMP TCP listener on [::]:61613
2019-11-22 09:46:45.809 [info] <0.42.0> Application rabbitmq_stomp exited with reason: stopped
2019-11-22 09:46:45.809 [info] <0.21818.0> Stopping application 'amqp_client'
2019-11-22 09:46:45.811 [info] <0.21818.0> Stopping application 'rabbitmq_web_dispatch'
2019-11-22 09:46:45.811 [info] <0.42.0> Application amqp_client exited with reason: stopped
2019-11-22 09:46:45.813 [info] <0.42.0> Application rabbitmq_web_dispatch exited with reason: stopped
2019-11-22 09:46:45.813 [info] <0.21818.0> Stopping application 'cowboy'
2019-11-22 09:46:45.814 [info] <0.42.0> Application cowboy exited with reason: stopped
2019-11-22 09:46:45.814 [info] <0.21818.0> Stopping application 'cowlib'
2019-11-22 09:46:45.814 [info] <0.21818.0> Stopping application 'rabbitmq_peer_discovery_etcd'
2019-11-22 09:46:45.814 [info] <0.42.0> Application cowlib exited with reason: stopped
2019-11-22 09:46:45.816 [info] <0.21818.0> Stopping application 'rabbitmq_peer_discovery_common'
2019-11-22 09:46:45.816 [info] <0.42.0> Application rabbitmq_peer_discovery_etcd exited with reason: stopped
2019-11-22 09:46:45.818 [info] <0.42.0> Application rabbitmq_peer_discovery_common exited with reason: stopped
2019-11-22 09:46:45.818 [info] <0.21818.0> Stopping application 'rabbitmq_management_agent'
2019-11-22 09:46:45.820 [info] <0.42.0> Application rabbitmq_management_agent exited with reason: stopped
2019-11-22 09:46:45.820 [info] <0.21818.0> Stopping application 'rabbitmq_event_exchange'
2019-11-22 09:46:45.820 [info] <0.42.0> Application rabbitmq_event_exchange exited with reason: stopped
2019-11-22 09:46:45.820 [info] <0.21818.0> Stopping application 'rabbit'
2019-11-22 09:46:45.820 [info] <0.237.0> Will unregister with peer discovery backend rabbit_peer_discovery_etcd
2019-11-22 09:46:45.820 [info] <0.237.0> Unregistering node with etcd
2019-11-22 09:46:45.821 [info] <0.541.0> stopped TLS (SSL) listener on [::]:5671
2019-11-22 09:46:45.822 [info] <0.525.0> stopped TCP listener on [::]:5672
2019-11-22 09:46:45.823 [info] <0.467.0> Closing all connections in vhost '/' on node 'rabbit@master2' because the vhost is stopping
2019-11-22 09:46:45.823 [info] <0.486.0> Stopping message store for directory '/var/lib/rabbitmq/mnesia/rabbit@master2/msg_stores/vhosts/628WB79CIFDYO9LJI6DKMI09L/msg_store_persistent'
2019-11-22 09:46:45.827 [info] <0.486.0> Message store for directory '/var/lib/rabbitmq/mnesia/rabbit@master2/msg_stores/vhosts/628WB79CIFDYO9LJI6DKMI09L/msg_store_persistent' is stopped
2019-11-22 09:46:45.827 [info] <0.483.0> Stopping message store for directory '/var/lib/rabbitmq/mnesia/rabbit@master2/msg_stores/vhosts/628WB79CIFDYO9LJI6DKMI09L/msg_store_transient'
2019-11-22 09:46:45.831 [info] <0.483.0> Message store for directory '/var/lib/rabbitmq/mnesia/rabbit@master2/msg_stores/vhosts/628WB79CIFDYO9LJI6DKMI09L/msg_store_transient' is stopped
2019-11-22 09:46:45.834 [info] <0.42.0> Application rabbit exited with reason: stopped
2019-11-22 09:46:45.835 [info] <0.21818.0> Stopping application 'mnesia'
2019-11-22 09:46:45.846 [info] <0.42.0> Application mnesia exited with reason: stopped
2019-11-22 09:46:45.846 [info] <0.21818.0> Stopping application 'rabbit_common'
2019-11-22 09:46:45.846 [info] <0.21818.0> Stopping application 'sysmon_handler'
2019-11-22 09:46:45.846 [info] <0.42.0> Application rabbit_common exited with reason: stopped
2019-11-22 09:46:45.848 [info] <0.21818.0> Stopping application 'os_mon'
2019-11-22 09:46:45.848 [info] <0.42.0> Application sysmon_handler exited with reason: stopped
2019-11-22 09:46:45.850 [info] <0.21818.0> Successfully stopped RabbitMQ and its dependencies
2019-11-22 09:46:45.850 [info] <0.42.0> Application os_mon exited with reason: stopped
2019-11-22 09:47:26.936 [info] <0.21818.0> Stopping application 'syslog'
2019-11-22 09:47:26.936 [info] <0.21818.0> Stopping application 'lager'
2019-11-22 09:47:26.955 [info] <0.21818.0> Log file opened with Lager
2019-11-22 09:47:27.149 [info] <0.42.0> Application mnesia exited with reason: stopped
2019-11-22 09:47:27.169 [info] <0.42.0> Application mnesia exited with reason: stopped
2019-11-22 09:47:27.184 [error] <0.21818.0>
Error description:
rabbit_node_monitor:do_run_outside_app_fun/1 line 742
rabbit:start_it/1 line 491
rabbit:'-start/0-fun-0-'/0 line 326
rabbit_mnesia:check_cluster_consistency/0 line 671
throw:{error,{inconsistent_cluster,"Node rabbit@master2 thinks it's clustered with node rabbit@node3, but rabbit@node3 disagrees"}}
Log file(s) (may contain more information):
/var/log/rabbitmq/rabbit@master2.log
/var/log/rabbitmq/rabbit@master2_upgrade.log
2019-11-22 09:47:28.286 [error] <0.21818.0> rabbit_outside_app_process:
{error,{inconsistent_cluster,"Node rabbit@master2 thinks it's clustered with node rabbit@node3, but rabbit@node3 disagrees"}}
[{rabbit,log_boot_error_and_exit,3,[{file,"src/rabbit.erl"},{line,1019}]},{rabbit,start_it,1,[{file,"src/rabbit.erl"},{line,494}]},{rabbit_node_monitor,do_run_outside_app_fun,1,[{file,"src/rabbit_node_monitor.erl"},{line,742}]}]
When the process is killed by the oom, it cannot be added automatically
I think this should be a very important basic feature of a cluster. If a node is not shut down normally, it cannot be added automatically when it recovers, which is very serious.
![]()
@JayenLee please don’t add a comment to a GitHub issue that has been closed for over three years. There is a good chance nobody will notice it.
Instead, ask your question in one of these places and reference #709
- The
rabbitmq-usersmailing list. - The
discussionsGitHub repository.
When you ask your question do NOT paste log file contents into the body of the message. Attach them to the message instead. Always attach the complete contents of your RabbitMQ configuration files as well.
![]()
The node reports alarms in effect. Relevant doc guides:
- Reasoning About Memory Use
- Alarms
Then there is
Node rabbit@master2 thinks it's clustered with node rabbit@node3, but rabbit@node3 disagrees
which is covered in this doc section.
RabbitMQ nodes do not automatically reset (the autoheal partition handling strategy is an exception, and it’s not the default behavior) for fairly obvious reasons: it’s no generally safe and should be an operator opt-in.
![]()
rabbitmq
locked and limited conversation to collaborators
Nov 22, 2019