-
#1
I’ve got a VM that is suspended to disk.
When I try to resume, it errors with «TASK ERROR: NUMA needs to be enabled for memory hotplug»
I cannot enable NUMA, since the VM is locked.
So I wonder how to resolve that problem.
BTW: While suspended no backups were made.
Here is the config of the VM:
Code:
# qm config 114
agent: 1
balloon: 0
boot: order=scsi0;ide2;net0
cores: 6
cpu: kvm64,flags=+ibpb;+virt-ssbd;+amd-ssbd;+aes
hotplug: disk,network,usb,memory,cpu
ide2: zdata-pve:iso/debian-live-10.8.0-amd64-xfce.iso,media=cdrom
lock: suspended
memory: 8000
name: debian-xfce
net0: virtio=8A:58:3E:B7:F7:0F,bridge=vmbr1,firewall=1
numa: 0
ostype: l26
rng0: source=/dev/urandom
runningcpu: kvm64,+aes,+amd-ssbd,enforce,+ibpb,+kvm_pv_eoi,+kvm_pv_unhalt,+lahf_lm,+sep,+virt-ssbd
runningmachine: pc-i440fx-5.1+pve0
scsi0: local-zfs:vm-114-disk-0,discard=on,size=64G,ssd=1
scsihw: virtio-scsi-pci
serial0: socket
smbios1: uuid=d2c002a3-7f12-4896-bcc3-4462b22afd8d
sockets: 1
vmgenid: 58320bb1-22d7-4dd1-b1ac-e7860195a65d
vmstate: local-zfs:vm-114-state-suspend-2021-03-26And the pveversion:
Code:
# pveversion -v
proxmox-ve: 6.3-1 (running kernel: 5.4.106-1-pve)
pve-manager: 6.3-6 (running version: 6.3-6/2184247e)
pve-kernel-5.4: 6.3-8
pve-kernel-helper: 6.3-8
pve-kernel-5.4.106-1-pve: 5.4.106-1
pve-kernel-5.4.103-1-pve: 5.4.103-1
pve-kernel-5.4.73-1-pve: 5.4.73-1
ceph-fuse: 12.2.11+dfsg1-2.1+b1
corosync: 3.1.0-pve1
criu: 3.11-3
glusterfs-client: 5.5-3
ifupdown: residual config
ifupdown2: 3.0.0-1+pve3
ksm-control-daemon: 1.3-1
libjs-extjs: 6.0.1-10
libknet1: 1.20-pve1
libproxmox-acme-perl: 1.0.8
libproxmox-backup-qemu0: 1.0.2-1
libpve-access-control: 6.1-3
libpve-apiclient-perl: 3.1-3
libpve-common-perl: 6.3-5
libpve-guest-common-perl: 3.1-5
libpve-http-server-perl: 3.1-1
libpve-storage-perl: 6.3-7
libqb0: 1.0.5-1
libspice-server1: 0.14.2-4~pve6+1
lvm2: 2.03.02-pve4
lxc-pve: 4.0.6-2
lxcfs: 4.0.6-pve1
novnc-pve: 1.1.0-1
proxmox-backup-client: 1.0.13-1
proxmox-mini-journalreader: 1.1-1
proxmox-widget-toolkit: 2.4-9
pve-cluster: 6.2-1
pve-container: 3.3-4
pve-docs: 6.3-1
pve-edk2-firmware: 2.20200531-1
pve-firewall: 4.1-3
pve-firmware: 3.2-2
pve-ha-manager: 3.1-1
pve-i18n: 2.2-2
pve-qemu-kvm: 5.1.0-8
pve-xtermjs: 4.7.0-3
pve-zsync: 2.0-4
qemu-server: 6.3-8
smartmontools: 7.2-pve2
spiceterm: 3.1-1
vncterm: 1.6-2
zfsutils-linux: 2.0.4-pve1
![]()
oguz
Proxmox Retired Staff
-
#2
hi,
you can try running qm unlock VMID, and then you should be able to enable numa (also try taking a snapshot or backup)
-
#3
After qm unlock, the symbol for suspended to disk disappeared.
I enabled NUMA. The Resume button changed to start.
New error message: TASK ERROR: memory size (8000) must be aligned to 512 for hotplugging
![]()
oguz
Proxmox Retired Staff
-
#4
: TASK ERROR: memory size (8000) must be aligned to 512 for hotplugging
it needs to be a multiple of 512, e.g. 8192
-
#5
I changed the memory to 8192, no error, but it did not start either. Then the resume button reappeared, and it started.
Hooray! But now I cannot unlock the encrypted disk.
OK my suspend to disk experiment has failed.
To sum it up:
It needs NUMA enabled and RAM to be a power of 2.
Anything else?
Last edited: Apr 12, 2021
-
#6
I did a restore from Backup, and it is wokring again.
Thanks @oguz
![]()
oguz
Proxmox Retired Staff
-
#7
OK my suspend to disk experiment has failed.
To sum it up:
It needs NUMA enabled and RAM to be a power of 2.
Anything else?
to clarify, suspend to disk should work. numa was needed for memory hotplugging (which you had in your configuration)
you’re welcome!
-
#8
Ah OK. I think I just enabled the memory hotplugging, because I thought it’s a cool feature.
I wasn’t aware that NUMA needs to be enabled to use it.
Thanks again.
-
#1
Hi,
We have tried to start a VM from Proxmox but getting an error below,
=======
TASK ERROR: command ‘ha-manager set vm:100 —state started’ failed: exit code 255
=======
First got an error » TASK ERROR: NUMA needs to be enabled for memory hotplug » and I have enabled it from Hardware>> Processor. After that, I am getting this above error. Also, the VM status is stopped and the HA state is error. Please help in this case.
Thank you.
-
#2
Hi,
Please help us with this.
-
#3
Hi,
Somebody here to help in this case?
-
#4
try to disable HA on the vm first, then start it again, maybe you’ll have more information.
if you have enable NUMA + memory hotplug, the memory size should be a multiple of 1024 too.
-
#5
Hi,
I am noob in the Proxmox. Can you please let me know how to disable HA from the VM? Also, may I know if there will be any issue to disable it?
Also, I could see that the memory is 32768 now.
-
#6
Hi,
I am noob in the Proxmox. Can you please let me know how to disable HA from the VM? Also, may I know if there will be any issue to disable it?
Also, I could see that the memory is 32768 now.
>>I am noob in the Proxmox. Can you please let me know how to disable HA from the VM?
The same way where you have enable it ->datacenter->HA , on the ressources list, remove the vm from HA.
>>Also, may I know if there will be any issue to disable it?
No, just HA will not be enable.
(BTW, if you are new to Proxmox, my recommandation is to play with it a little bit,before enable HA. (and for HA, read carefully the documentation).
-
#7
Hi,
Thank you for the detailed explanation.
I have found the option from Datacenter. May I confirm again if the VM will not have any issues after removing it?
So sorry for the trouble again.
-
#8
Hi,
Thank you so much for your kind help. The VM started now.
How to Unlock a Proxmox VM

From time to time, you’ll come across the need to kill a lock on your Proxmox server. Fear not, in today’s guide we’ll discuss the various lock errors you may face and how to unlock a Proxmox VM.
Proxmox Locked VM Errors
Error: VM is locked
The «VM is locked» error is the most common circumstance in which you may want to kill a VM lock. This error has a lot of variants including:
- Error: VM is locked (backup)
- Error: VM is locked (snapshot)
- Error: VM is locked (clone)
 Error: VM is locked in Proxmox
Error: VM is locked in Proxmox
As you can see, they all share the same «Error: VM is locked» root, but with a suffix that indicates the task that initiated the lock, whether that task be a backup, a snapshot, or clone. This can be useful for determining IF you should clear the lock. (i.e. if the backup job is still running, you probably shouldn’t clear the lock and just let the backup process complete).
can’t lock file ‘/var/lock/qemu-server/lock- .conf’ – got timeout
This is another common error, often seen when you’re trying to shutdown/stop a virtual machine or when qm unlock fails (see below).
Proxmox Unlock VM Methods
There are two main ways of clearing a lock on a Proxmox VM: 1) using the qm unlock command and 2) manually deleting the lock.
qm unlock
qm unlock should be your first choice for unlocking a Proxmox VM.
First, find your VM ID (it’s the number next to your VM in the Proxmox GUI). If you’re not using the WebGUI, you can obtain a list of your VM IDs with:
Unlock the VM/kill the lock with:
Now, this may not always work, and the command may fail with:
In that case, let’s move on to plan B: manually deleting the lock.
Manually Deleting the Lock
If you received the error message, «can’t lock file ‘/var/lock/qemu-server/lock- .conf’ — got timeout», you can fix this by manually deleting the lock at that location. Simply put, you can just run the following command:
Obviously, this should be a last resort. It’s generally not a great practice to go around killing locks, but sometimes you have no choice.
I hope this guide helped you out. Let me know if you have any questions or feel I left something out in the comments/forums below!
Источник
TASK ERROR: VM is locked (snapshot)
dison4linux
Active Member
Unable to take new snapshots/backups because there seems to be a snapshot in progress.
I’ve rebooted to the hypervisor, no change.
The snapshots tab shows a ‘vzdump’ snapshot with a status of ‘prepare’

t.lamprecht
Proxmox Staff Member
Best regards,
Thomas
Do you already have a Commercial Support Subscription? — If not, Buy now and read the documentation
dison4linux
Active Member
I think that got me a little further, but no joy on a new snapshot yet.
t.lamprecht
Proxmox Staff Member
Using our pct snapshot command works?
Best regards,
Thomas
Do you already have a Commercial Support Subscription? — If not, Buy now and read the documentation
dison4linux
Active Member
It works to create a new one, but not to remove the troublesome one.
dison4linux
Active Member
For what it’s worth the backup process seems unable to delete the snapshot as well:

dietmar
Proxmox Staff Member
Best regards,
Dietmar
Do you already have a Commercial Support Subscription? — If not, Buy now and read the documentation
About
The Proxmox community has been around for many years and offers help and support for Proxmox VE, Proxmox Backup Server, and Proxmox Mail Gateway.
We think our community is one of the best thanks to people like you!
Quick Navigation
Get your subscription!
The Proxmox team works very hard to make sure you are running the best software and getting stable updates and security enhancements, as well as quick enterprise support. Tens of thousands of happy customers have a Proxmox subscription. Get your own in 60 seconds.
Источник
TASK ERROR: VM is locked (backup)
jmjosebest
Active Member
Hi, after a full host restart I get this error starting a virtual machine KVM.
TASK ERROR: VM is locked (backup)
/var/lib/vz/lock is empty.
How can I unlock?
Thanks
jmjosebest
Active Member
PC Rescue
New Member
RollMops
Active Member

fabian
Proxmox Staff Member
Best regards,
Fabian
Do you already have a Commercial Support Subscription? — If not, Buy now and read the documentation
RollMops
Active Member
fabian
Proxmox Staff Member
check the system logs around the time of the failed backup, try manually backing up the VM a couple of times and check for failure.
it might have been a one time fluke.
Best regards,
Fabian
Do you already have a Commercial Support Subscription? — If not, Buy now and read the documentation
RollMops
Active Member
I can provoke a system crash by manually starting a backup of the VE that I use to find in a locked state.
After 1 or 2 mins., process z_wr_iss takes 97% CPU and subsequently the server fails. It then automatically reboots, but the VE is still locked from the pending/failed backup process and does not automatically recover.
I attach a screenshot of the last state seen in «top».
Could this be prevented by adding some RAM to the box?
Источник
TASK ERROR: start failed
Mellgood
New Member
Hi, after a failed clone and proxmox + host restart I got this error:
TASK ERROR: VM is locked (clone)
I tried:
qm unlock 106
but now i got another error:
kvm: -drive file=/var/lib/vz/images/106/vm-106-disk-1.qcow2,if=none,id=drive-scsi0,format=qcow2,cache=none,aio=native,detect-zeroes=on: qcow2: Image is corrupt; cannot be opened read/write
TASK ERROR: start failed: command ‘/usr/bin/kvm -id 106 -chardev ‘socket,id=qmp,path=/var/run/qemu-server/106.qmp,server,nowait’ -mon ‘chardev=qmp,mode=control’ -pidfile /var/run/qemu-server/106.pid -daemonize -smbios ‘type=1,uuid=24d6521e-95c7-463e-97fe-e79e16051387’ -name TMP -smp ‘4,sockets=2,cores=2,maxcpus=4’ -nodefaults -boot ‘menu=on,strict=on,reboot-timeout=1000,splash=/usr/share/qemu-server/bootsplash.jpg’ -vga std -vnc unix:/var/run/qemu-server/106.vnc,x509,password -cpu kvm64,+lahf_lm,+sep,+kvm_pv_unhalt,+kvm_pv_eoi,enforce -m 10000 -k it -device ‘pci-bridge,id=pci.1,chassis_nr=1,bus=pci.0,addr=0x1e’ -device ‘pci-bridge,id=pci.2,chassis_nr=2,bus=pci.0,addr=0x1f’ -device ‘piix3-usb-uhci,id=uhci,bus=pci.0,addr=0x1.0x2’ -device ‘usb-tablet,id=tablet,bus=uhci.0,port=1’ -chardev ‘socket,path=/var/run/qemu-server/106.qga,server,nowait,id=qga0’ -device ‘virtio-serial,id=qga0,bus=pci.0,addr=0x8’ -device ‘virtserialport,chardev=qga0,name=org.qemu.guest_agent.0’ -device ‘virtio-balloon-pci,id=balloon0,bus=pci.0,addr=0x3’ -iscsi ‘initiator-name=iqn.1993-08.org.debian:01:3681fcbb6821’ -drive ‘file=/var/lib/vz/template/iso/debian-9.4.0-amd64-netinst.iso,if=none,id=drive-ide2,media=cdrom,aio=threads’ -device ‘ide-cd,bus=ide.1,unit=0,drive=drive-ide2,id=ide2,bootindex=200’ -device ‘virtio-scsi-pci,id=scsihw0,bus=pci.0,addr=0x5’ -drive ‘file=/var/lib/vz/images/106/vm-106-disk-1.qcow2,if=none,id=drive-scsi0,format=qcow2,cache=none,aio=native,detect-zeroes=on’ -device ‘scsi-hd,bus=scsihw0.0,channel=0,scsi-id=0,lun=0,drive=drive-scsi0,id=scsi0,bootindex=100’ -netdev ‘type=tap,id=net0,ifname=tap106i0,script=/var/lib/qemu-server/pve-bridge,downscript=/var/lib/qemu-server/pve-bridgedown’ -device ‘e1000,mac=86:CA:F0:6E:FB:EB,netdev=net0,bus=pci.0,addr=0x12,id=net0,bootindex=300» failed: exit code 1
Is it possible to recover the corrupted img?
ty in advice
Источник
[SOLVED] Resuming suspended VM -> TASK ERROR: NUMA needs to be enabled for memory hotplug
0xd149e38e
Member
I’ve got a VM that is suspended to disk.
When I try to resume, it errors with «TASK ERROR: NUMA needs to be enabled for memory hotplug»
I cannot enable NUMA, since the VM is locked.
So I wonder how to resolve that problem.
BTW: While suspended no backups were made.
Here is the config of the VM:
And the pveversion:

Proxmox Retired Staff
you can try running qm unlock VMID , and then you should be able to enable numa (also try taking a snapshot or backup)
Best regards,
Oguz
Do you already have a Commercial Support Subscription? — If not, Buy now and read the documentation
0xd149e38e
Member
After qm unlock, the symbol for suspended to disk disappeared.
I enabled NUMA. The Resume button changed to start.
New error message: TASK ERROR: memory size (8000) must be aligned to 512 for hotplugging
Proxmox Retired Staff
Best regards,
Oguz
Do you already have a Commercial Support Subscription? — If not, Buy now and read the documentation
0xd149e38e
Member
I changed the memory to 8192, no error, but it did not start either. Then the resume button reappeared, and it started.
Hooray! But now I cannot unlock the encrypted disk.
OK my suspend to disk experiment has failed.
To sum it up:
It needs NUMA enabled and RAM to be a power of 2.
Anything else?
0xd149e38e
Member
Proxmox Retired Staff
OK my suspend to disk experiment has failed.
To sum it up:
It needs NUMA enabled and RAM to be a power of 2.
Anything else?
to clarify, suspend to disk should work. numa was needed for memory hotplugging (which you had in your configuration)
Best regards,
Oguz
Do you already have a Commercial Support Subscription? — If not, Buy now and read the documentation
Источник
Современные серверные решения на базе архитектуры x86, которые сейчас используются почти во всех программно-аппаратных комплексах, имеют некоторые нюансы. Многопроцессорные сервера, имеющие на материнской плате 2, 4 или даже 8 процессорных сокетов, являются по сути NUMA-архитектурой. NUMA (Non-Uniform Memory Architecture) означает, что каждый процессорный сокет имеет свой пул локальных модулей оперативной памяти и такая связка называется узлом NUMA (рис. 1).
 |
| Рис. 1. UMA и NUMA архитектуры. |
Все процессорные ядра и вся оперативная память объединены в одну систему, но обращение процессора к своим (локальным) модулям памяти происходит с большей скоростью (или меньшими задержками), чем к памяти соседнего процессора.
Все современные операционные системы и программные решения более высокого уровня (например, виртуальный гипервизор или СУБД) понимают особенности этой архитектуры. В идеале, это понимание позволяет большинство операций выполнять с памятью локального процессора, не ходя в «дальние края» за памятью соседа.
vSphere от VMware тоже прекрасно разбирается в NUMA. При конфигурировании виртуальной машины (если вы не активируете опцию «Enable CPU Hot Add») и при её работе гипервизор будет размещать виртуальные процессорные ядра (vCPU) и память виртуальной машины в один узел NUMA. Причём, эта функция работает по умолчанию, ничего отдельно настраивать не надо.
Это всё прекрасно работает для небольших виртуальных машин, которые занимают гораздо меньше памяти, чем имеется в одном узле NUMA. Для работы большого количества таких относительно небольших виртуальных машин на одном сервере решения виртуализации и были прежде всего разработаны. Но у нас немного другой профиль — SAP системы, которые обычно требуют много ресурсов процессора и памяти.
Хочу на своём примере показать недостаточно корректную настройку размера виртуальных машин, с учётом NUMA архитектуры. На проекте, про который хочу рассказать, были сервера двух типов:
- 4-х сокетный сервер (8 ядер/16 потоков в каждом процессоре) и 384 Гб оперативной памяти,
- 2-х сокетный сервер (8 ядер/16 потоков в каждом процессоре) и 256 Гб оперативной памяти.
Таким образом, в сервере первого типа узел NUMA = 16 ядер (с учётом HT) + 96 Гб.
А в серверах второго типа узел NUMA = 16 ядер (с учётом HT) + 128 Гб памяти.
Понимая, всю ситуацию с NUMA архитектурой я разместил на серверах первого типа виртуальные машины с характеристиками:
- 16 vCPU + 192 Гб памяти,
- 8 vCPU + 96 Гб памяти.
А на серверах второго типа работают виртуальные машины с максимальным размером:
- 8 vCPU + 96 Гб памяти.
При конфигурировании такой системы я был очень доволен — ведь я точно попал в узлы NUMA. Большая машина идеально вписывается в 2 узла NUMA. А те, что поменьше идеально вписаны в один узел NUMA, как на первых серверах, так и на вторых.
Но после прокачки своих знаний по VMware, мне открылось, что я совершил ошибку при конфигурации объёмов памяти.
Для мониторинга работы виртуальных машин на узлах ESXi есть команда esxtop (аналог команды top в Linux) (рис. 2). Так вот, для мониторинга работы с памятью и NUMA диагностики, необходимо запустить команду esxtop, нажать «m», перейдя в мониторинг памяти. После этого нажать «f» и добавить к формату вывод статистику по NUMA (рис. 3).
 |
| Рис. 2. Основной экран утилиты esxtop. |
 |
| Рис. 3. Активация просмотра статистики по NUMA узлам. |
После этого на экране появится несколько важных полей:
- NHN — текущий домашний узел для виртуальной машины,
- NMIG — количество NUMA миграций с узла на узел,
- NRMEM (MB) — текущее количество «дальней памяти» (из соседней NUMA), используемой виртуальной машиной,
- NLMEM (MB) — текущее количество локальной памяти, используемой виртуальной машиной,
- N%L — текущий процент запрошенной виртуальной машиной памяти, являющейся локальной.
Последний параметр помогает проанализировать итог работы виртуальной машины на NUMA узлах. Если он равен 100%, значит производительность оптимальна. Если же ниже 100%, значит не всегда в процессе работы на реальных процессорных ядрах для текущей виртуальной машины идёт попадание в память локального узла NUMA.
По моей ситуации. Первые две большие виртуальные машины не всегда попадают в память локального NUMA узла (рис. 4 и 5). Напомню, что обе машины работают на серверах с размером узла NUMA = 16 ядер (с учётом HT) + 96 Гб.
 |
| Рис. 4. Статистика по NUMA виртуальной машины 8 vCPU + 96 Гб. |
 |
| Рис. 5. Статистика по NUMA виртуальной машины 16 vCPU + 192 Гб. |
Процент попадания в локальный NUMA узел 93% и 92% соответственно. Причём, если посмотреть по другим параметрам статистики: виртуальной машине при работе не хватает всего 6-7 Гб памяти на локальном узле.
«Небольшие» виртуальные машины, работающие на серверах второго типа (с размером узла NUMA = 16 ядер (с учётом HT) + 128 Гб памяти), отлично умещаются в локальных NUMA узлах (рис. 6). Забора «чужой» памяти нет, всё работает оптимально.
 |
| Рис. 6. Статистика по NUMA виртуальной машины, работающей на сервере второго типа. |
Моя ошибка при конфигурировании размера оперативной памяти больших виртуальных машин в данном случае была в том, что я не учёл накладные расходы гипервизора. Точнее я решил, что накладные расходы общие на весь сервер. А оказалось, что надо учитывать их на каждый узел NUMA. И более оптимально было бы взять не всю память NUMA узла для виртуальной машины, а максимум 90%. Оставив 10% на накладные расходы гипервизора и инфраструктуры VMware.
Максим Мошков рекомендует пользоваться правилом при конфигурировании любых ресурсов в среде VMware — 80% ресурсов можно использовать, а 20% всегда оставлять на запас, накладные расходы и тому подобное.
Если у меня будет возможность, то я переконфигурирую данные виртуальные машины, которые не оптимально попадают в узлы NUMA. И потом поделюсь с вами результатами статистики.
Update: результаты оптимизации можно найти в этом посте.
Автор: Шиболов Вячеслав Анатольевич
Моя первая виртуальная машина: как не накосячить
Время прочтения
5 мин
Просмотры 17K
Итак, вот перед вами свеженькая организация в vCloud Director, и вам только предстоит создать свою первую виртуальную машину. Сегодня расскажу, какие настройки выбирать при создании виртуальной машины, чтобы она работала и не просила есть. Поехали!

Источник: drive2.ru
Операционная система. Выбирайте современные дистрибутивы. Если берете Windows 2008 R2 и более старую или Linux до ядра 4.19.x, ждите проблем. Каких? Ну, например, вендор уже перестал поддерживать актуальное состояние Windows 2008 R2 аж в 2013 году (EOL). Это означает, что он больше не разрабатывает драйвера под вышедшее с тех пор железо, не модифицирует ОС под новое что угодно. С древними операционками вы точно не сможете использовать все возможности, которые предоставляет современный гипервизор. А уже в эти новогодние праздники остро встанет проблема с безопасностью, так как 14 января 2020 года заканчивается расширенная поддержка Windows Server 2008 R2 и перестанут выходить Security Update.
Cores per socket. Оставляйте 1 ядро на сокет, ставьте столько сокетов, сколько вам нужно виртуальных процессоров. Да, логично наоборот, но правильно так. Если у вас нет специализированных лицензионных требований. Например, вы платите за сокет, а больше сокетов означает больше лицензий. Не ставьте 2/2, чтобы получить 4. Сделайте 4/1. Такую машину гипервизор будет обслуживать оптимальным образом. Scheduler гипервизора будет меньше пенализировать такие ВМ.
Объясню на пальцах. Представьте, что проводник рассаживает пассажиров по вагону, вагон – как в Сапсане. В роли проводника scheduler, пассажиры – это ВМ. Пассажиров, которые едут в одиночку (однопроцессорные ВМ), ему распределить проще всего: их можно посадить на любое место. Семью из 4 человек (4-процессорные ВМ) уже сложнее. Им нужно найти 4 места в одном вагоне. А теперь представим, что все в семье хотят ехать только лицом друг другу, а таких групп мест – 4 вокруг стола – в вагоне только 2. С большой вероятностью такой семье придется пройти в следующий вагон (на следующий тик планирования). Это как раз та ситуация, как если бы вы выбрали 2 сокета по 2 ядра, чтобы получить 4. Скорее всего, придется подождать, чтобы нашлись подходящие места. Так же и с ВМ: ей придется ждать дольше, чем менее “прихотливым” ВМ с 1 сокетом и кучкой процессоров.
Хотя эта история актуальнее для старых версий ESXi. Начиная с 6.5 (но не ранее!) механизм vNUMA отвязан от количества виртуальных сокетов, и старая рекомендация “не плодить сокеты” не так категорична. Но все еще зависит от приложения внутри гостевой ОС.

Hot Add для CPU и Memory. Это опция добавления памяти CPU для работающей виртуальной машины. Казалось бы, прекрасная функция: не нужно гасить машину, чтобы докинуть ей ресурсов. Так вот, не все так просто, и не зря они по дефолту отключены. Лучше и не включать, если вы не знаете, что такое NUMA-топология. Допустим, под капотом облака у нас двухсокетный сервер. На каждом сокете 4 ядра. Работает это именно как 4+4, а не 8 ядер. Такая же тема с памятью: если на каждом сокете 128 ГБ, это не дает в сумме 256 ГБ. Каждый процессорный сокет имеет прямой доступ только к определенным слотам памяти. Каждый сокет вместе с причитающейся ему процессором и памятью – это физическая NUMA-нода.
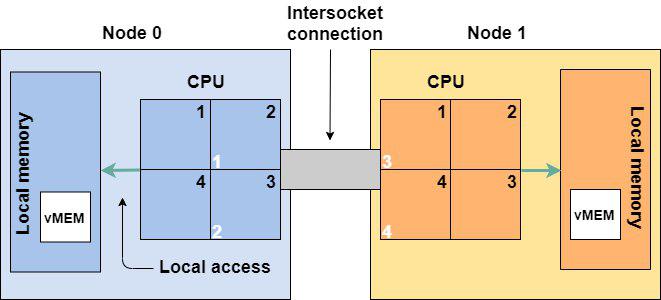
Если виртуальная машина влезает в размер физической NUMA-ноды, то она исполняется внутри этой ноды. Если виртуалка не умещается в NUMA-ноду, например по памяти, то она будет использовать память из соседней NUMA-ноды. Путь к удаленной памяти будет извилист – через межпроцессорную шину. Работать это будет не так быстро, как если бы виртуалка использовала ресурсы одной ноды.

Когда вы включаете добавления виртуальных процессоров и памяти на горячую, все это идет только в нулевую NUMA-ноду. Например, добавилось еще 4 процессора, и на NUMA-ноде 0 стало 6, а на NUMA-ноде 1 – 2 процессора. Машину немного перекосило, и работает она также косо. Это связано с тем, что при включении vCPU Hot-Plug перестает работать vNUMA, через которую vSphere старается оптимизировать топологию NUMA для ВМ. Поэтому, принимая решение о включении CPU Hot-Add, учитывайте физическую топологию NUMA для обеспечения производительности ВМ. Это очень критично, если по каким-либо причинам в ВМ имеется несколько виртуальных сокетов. В этом случае несоответствие физической топологии вызовет сильное падение производительности: CPU Scheduler сойдет с ума, пытаясь предоставить процессорное время такой ВМ, что вызовет рост CPU Ready и Co-Stop.
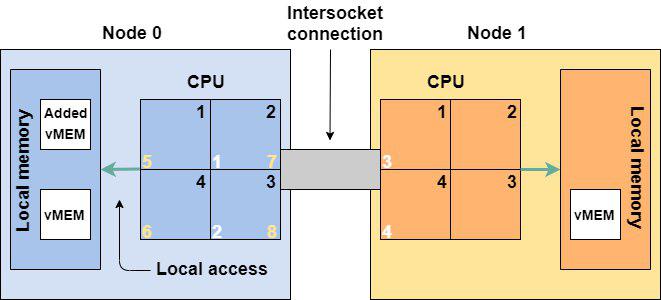
Все добавленные виртуальные процессоры (5-8) и память попали на NUMA-ноду 0.
Отдельная история в том, что будет происходить внутри ОС и приложения после таких “добавок”. Поэтому если уж решили пользоваться этой опцией, то проверьте, поддерживает ли ваша ОС такое. Non-NUMA-Aware приложения могут сильно просесть по производительности при расположении на нескольких NUMA-нодах.
Если вы все-таки добавили процессоры или память на горячую, сразу планируйте перезагрузку ВМ (не только ОС) на ближайший запланированный даунтайм.

Галочки не ставим.
Дисковый контроллер (Bus type). Для дисков выбирайте дисковый контроллер Paravirtual. Этот тип контроллера требует установки драйверов в ОС VMware Tools. Paravirtual – это специальное виртуальное устройство, которое создавалось для работы в виртуализации и не эмулирует работу какого-то другого аппаратного устройства. Любая эмуляция аппаратного устройства всегда работает медленнее.
Если вы не хотите использовать Paravirtual (но почему?), выбирайте LSI Logic SAS. Если ОС не поддерживает и его — LSI Logic Parallel. Никогда не используйте SATA и IDE. ВМ будет медленно работать, в итоге вы не получите производительности, за которой идут в облако.
При инсталляции ОС даже свежая версия Windows может не найти драйвер для Paravirtual адаптера. В этом случае примонтируйте к ВМ два ISO файла — ваш загрузочный образ Windows и диск с VMware tools. На последнем есть необходимый драйвер.

Сетевой адаптер. Правильный выбор – VMXNet3. VMXNet3, как и дисковый адаптер Paravirtual, это паравиртуальное устройство. Оно также требует драйверов, которые входят в VMware Tools.
Если вдруг VMXNet3 не подходит (проявляется какая-то несовместимость), то на крайний случай используйте E1000E. Но не ожидайте от адаптера E1000E производительности больше, чем 1 Гбит.
В общем, E1000E без прямых указаний вендоров не используйте. Казалось бы, оно новее, но сделано для обеспечения еще большей совместимости c legacy.

Вот не надо E1000E.
VMware Tools. Следите, чтобы они были установлены в ОС, запущены и актуальны. В VMware Tools входят драйвера устройств и разные другие компоненты, которые позволяют общаться ОС виртуальной машины с гипервизором, и наоборот. Через них происходит синхронизация времени ОС с хостом виртуализации (отключаемо), ходят heartbeat’ы, которые показывают гипервизору, что виртуалка жива, и прочее. Для работы ОС на виртуальной машине нужны как минимум драйверы сетевой карточки, дискового адаптера. Свежие версии всего вот этого входят в VMware Tools.
По умолчанию актуальные версии Windows и Linux имеют драйвера для работы с виртуальными устройствами VMware, но если у вас будут VMware Tools, то эти драйвера будут всегда свежими. Для Linux рекомендуется использовать open-vm-tools. Это не просто лучшая интеграция с ОС, но и обновление драйверов вместе с системой.

Отдельные диски для данных. Используйте разные виртуальные диски под данные и операционную систему. Да и на физических серверах стоит так делать. Вы сможете отдельно бекапить эти диски (с разным расписанием, например), сможете переключить диск с данными или его клон на другую ВМ и прочее.
Кроме того, новый виртуальный диск также получит дополнительную квоту на дисковую производительность.

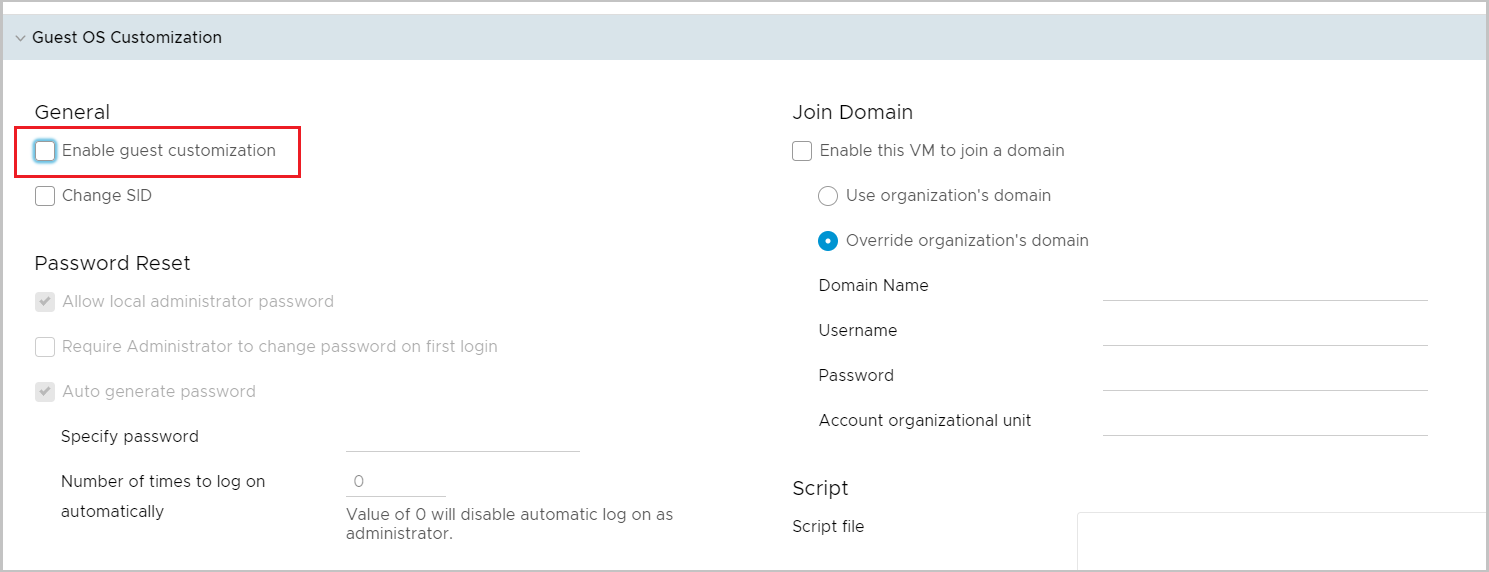
Кастомизация. При первом включении ВМ нужно кастомизировать, чтобы все настройки из облака (например выданный облаком IP-адрес) применились к ОС. После уберите эту галку от греха подальше, чтобы нечаянно не сбросить настройки ОС: SID, пароль администратора и т. п.
Конечно, все вышесказанное – упрощенная картина, слова “капитана О” и, вообще, “все же это знают”. Но, как показывает практика, более 70% ВМ в облаке содержат одну или сразу несколько описанных ошибок.