18
Ч
а с т ь I
ОБРАБОТКА РЕЗУЛЬТАТОВ
ИЗМЕРЕНИЙ
1.
КРАТКИЕ СВЕДЕНИЯ ИЗ ТЕОРИИ ОШИБОК
Абсолютная
и относительная ошибки
Никакую
физическую величину невозможно измерить
абсолютно точно: как бы тщательно ни
был поставлен опыт, измеренное значение
величины х
будет
отличаться от ее истинного значения Х.
Разница между этими значениями
представляет собой абсолютную
ошибку (или
абсолютную
погрешность*)
измерения х :
х
= х – Х.
(1)
Абсолютная погрешность
является размерной величиной: она
выражается в тех же единицах, что и сама
измеряемая величина (например, абсолютная
погрешность измерения длины выражается
в метрах, силы тока – в амперах и т.д.).
Как следует из выражения (1), х
может быть как положительной, так и
отрицательной величиной.
Хотя
величина х
показывает, насколько измеренное
значение отличается от истинного, одной
лишь абсолютной ошибкой нельзя полностью
характеризовать точность проделанного
измерения. Пусть, например, известно,
что абсолютная погрешность измерения
расстояния равна 1 м.
Если измерялось расстояние между
географическими пунктами (порядка
нескольких километров), то точность
такого измерения следует признать
весьма высокой; если же измерялись
размеры помещения (не превышающие
десятка метров), то измерение является
грубым. Для характеристики точности
существует понятие относительной
ошибки
(или относительной
погрешности)
Е,
представляющей собой отношение модуля
абсолютной ошибки к измеряемой величине:
![]() .
.
(2)
Очевидно, что
относительная погрешность – величина
безразмерная, чаще всего ее выражают в
процентах.
При
определении ошибок измерений важно
иметь в виду следующее. Выражения (1) и
(2) содержат истинное значение измеряемой
величины Х,
которое точно знать невозможно: поэтому
значения х
и Е
в принципе не могут быть рассчитаны
точно. Можно лишь оценить
эти значения, т.е. найти их приближенно
с той или иной степенью достоверности.
Поэтому все расчеты, связанные с
определением погрешностей, должны
носить приближенный (оценочный) характер.
Случайная
и приборная погрешности
Разнообразные ошибки,
возникающие при измерениях, можно
классифицировать как по их происхождению,
так и по характеру их проявления.
По происхождению
ошибки делятся на инструментальные и
методические.
Инструментальные
погрешности обусловлены несовершенством
применяемых измерительных приборов и
приспособлений. Эти погрешности могут
быть уменьшены за счет применения более
точных приборов. Так, размер детали
можно измерить линейкой или штанген-циркулем.
Очевидно, что во втором случае ошибка
измерения меньше, чем в первом.
Методические
погрешности возникают из-за того, что
реальные физические процессы всегда в
той или иной степени отличаются от их
теоретических моделей. Например, формула
для периода колебаний математического
маятника в точности верна лишь при
бесконечно малой амплитуде колебаний;
формула Стокса, определяющая силу трения
при движении шарика в вязкой жидкости,
справедлива только в случае идеально
сферической формы и т.д. Обнаружить и
учесть методическую погрешность можно
путем измерения той же величины совершенно
иным независимым методом.
По характеру проявления
ошибки бывают систематические и
случайные.
Систематическая
погрешность может быть обусловлена как
приборами, так и методикой измерения.
Она имеет две характерные особенности.
Во-первых, систематическая погрешность
всегда либо положительна, либо отрицательна
и не меняет своего знака от опыта к
опыту. Во-вторых, систематическую
погрешность нельзя уменьшить за счет
увеличения числа измерений. Например,
если при отсутствии внешних воздействий
стрелка измерительного прибора показывает
величину х0 , отличную от
нуля, то во всех дальнейших измерениях
будет присутствовать систематическая
ошибка, равная х0 .
Случайная
ошибка также может быть как инструментальной,
так и методической. Причину ее появления
установить трудно, а чаще всего –
невозможно (это могут быть различные
помехи, случайные толчки, вибрации,
неверно взятый отсчет по прибору и
т.д.). Случайная погрешность бывает и
положительной и отрицательной, причем
непредсказуемо изменяет свой знак от
опыта к опыту. Значение ее можно уменьшить
путем увеличения числа измерений.
Детальный
анализ погрешностей измерения представляет
собой сложную задачу, для решения которой
не существует единого рецепта. Поэтому
в каждом конкретном случае этот анализ
проводят по-разному. Однако, в первом
приближении, если исключена систематическая
ошибка, то остальные можно условно
свести к следующим двум видам: приборная
и случайная.
Приборной
погрешностью в дальнейшем будем
называть случайную ошибку, обусловленную
измерительными приборами и приспособлениями,
а случайной – ошибку, причина
появления которой неизвестна. Приборную
погрешность измерения величины х
будем обозначать как х,
случайную – как s x.
Оценка
случайной погрешности. Доверительный
интервал
Методика оценки
случайной погрешности основана на
положениях теории вероятностей и
математической статистики. Оценить
случайную ошибку можно только в том
случае, когда проведено неоднократное
измерение одной и той же величины.
Пусть
в результате проделанных измерений
получено п
значений величины х:
х1 ,
х2 ,
…, хп .
Обозначим через
![]()
среднеарифметическое значение
![]() .
.
(3)
В
теории вероятностей доказано, что при
увеличении числа измерений п
среднеарифметическое значение измеряемой
величины приближается к истинному:
![]()
При
небольшом числе измерений (п 10)
среднее значение может существенно
отличаться от истинного. Для того, чтобы
знать, насколько точно значение
![]()
характеризует измеряемую величину,
необходимо определить так называемый
доверительный интервал полученного
результата.
Поскольку
абсолютно точное измерение невозможно,
то вероятность правильности утверждения
«величина х
имеет значение, в точности равное
![]() »
»
равна нулю. Вероятность же утверждения
«величина х
имеет какое-либо значение»
равна единице (100%). Таким образом,
вероятность правильности любого
промежуточного утверждения лежит в
пределах от 0 до 1. Цель измерения – найти
такой интервал, в котором с наперед
заданной вероятностью
(0 < < 1)
находится истинное значение измеряемой
величины. Этот интервал называется
доверительным
интервалом,
а неразрывно связанная с ним величина
–
доверительной вероятностью
(или коэффициентом
надежности).
За середину интервала принимается
среднее значение, рассчитанное по
формуле (3). Половина ширины доверительного
интервала представляет собой случайную
погрешность s x
(рис. 1).

Рис.1
Очевидно,
что
ширина доверительного интервала (а
следовательно, и ошибка s x)
зависит от того, насколько сильно
отличаются отдельные измерения величины
хi
от среднего
значения
![]() .
.
«Разброс» результатов измерений
относительно среднего характеризуется
среднеквадратичной
ошибкой ,
которую находят по формуле
![]() ,
,
(4)
где
![]() .
.
Ширина
искомого доверительного интервала
прямо пропорциональна среднеквадратичной
ошибке:
![]() .
.
(5)
Коэффициент
пропорциональности tn,
называется
коэффициентом
Стьюдента;
он зависит от числа опытов п
и доверительной вероятности .
На
рис. 1, а, б
наглядно
показано, что при прочих равных условиях
для увеличения вероятности попадания
истинного значения в доверительный
интервал необходимо увеличить ширину
последнего (вероятность «накрывания»
значения Х
более широким интервалом выше).
Следовательно, величина tn,
должна быть тем больше, чем выше
доверительная вероятность
.
С
увеличением количества опытов среднее
значение приближается к истинному;
поэтому при той же вероятности
доверительный интервал можно взять
более узким (см. рис. 1, а,в).
Таким образом, с ростом п
коэффициент Сьюдента должен
уменьшаться. Таблица значений коэффи-циента
Стьюдента в зависимости от п
и
дана в приложениях к настоящему пособию.
Следует
отметить, что доверительная вероятность
никак не связана с точностью результата
измерений. Величиной
задаются
заранее, исходя из требований к их
надежности. В большинстве технических
экспериментов и в лабораторном практикуме
значение
принимается
равным 0,95.
Расчет
случайной погрешности измерения величины
х проводится
в следующем порядке:
1) вычисляется
сумма измеренных значений, а затем –
среднее значение величины
![]()
по формуле (3);
2) для
каждого i-го
опыта рассчитываются разность между
измеренным и средним значениями
![]() ,
,
а также квадрат этой разности (отклонения)
( хi)2 ;
3) находится
сумма квадратов отклонений, а затем –
средне-квадратичная ошибка
по формуле (4);
4) по
заданной доверительной вероятности
и числу
проведенных опытов п
из таблицы на с. 149 приложений выбирается
соответствующее значение коэффициента
Стьюдента tn,
и определяется случайная погрешность
s x
по формуле (5).
Для
удобства расчетов и проверки промежуточных
результатов данные заносятся в таблицу,
три последних столбца которой заполняются
по образцу табл.1.
Таблица
1
|
Номер опыта |
… |
х |
х |
( х)2 |
|
1 |
… |
|||
|
2 |
… |
|||
|
… |
… |
|||
|
п |
… |
|||
|
= |
= |
В
каждом конкретном случае величина х
имеет определенный физический смысл и
соответствующие единицы измерения. Это
может быть, например, ускорение свободного
падения g
(м/с2),
коэффициент вязкости жидкости
(Пас)
и т.д. Пропущенные столбцы табл. 1
могут содержать промежуточные измеряемые
величины, необходимые для расчета
соответствующих значений х.
Пример
1. Для
определения ускорения а
движения тела измерялось время t
прохождения им пути S
без начальной
скорости. Используя известное соотношение
![]() ,
,
получим расчетную формулу
![]() .
.
(6)
Результаты
измерений пути S
и времени t
приведены во втором и третьем столбцах
табл. 2. Проведя вычисления по формуле
(6), заполним
четвертый
столбец значениями ускорения ai
и найдем их сумму, которую запишем под
этим столбцом в ячейку «
= ». Затем рассчитаем среднее значение
![]()
по формуле (3)
![]() .
.
Таблица
2
|
Номер |
S, м |
t, c |
а, м/с2 |
а, м/с2 |
(а)2, (м/с2)2 |
|
1 |
5 |
2,20 |
2,07 |
0,04 |
0,0016 |
|
2 |
7 |
2,68 |
1,95 |
-0,08 |
0,0064 |
|
3 |
9 |
2,91 |
2,13 |
0,10 |
0,0100 |
|
4 |
11 |
3,35 |
1,96 |
-0,07 |
0,0049 |
|
= |
8,11 |
= |
0,0229 |
Вычитая
из каждого значения ai
среднее, найдем разности ai
и занесем их в пятый столбец таблицы.
Возводя эти разности в квадрат, заполним
последний столбец. Затем рассчитаем
сумму квадратов отклонений и запишем
ее во вторую ячейку «
= ». По формуле (4) определим
среднеквадратичную погрешность:
![]() .
.
Задавшись
величиной доверительной вероятности
= 0,95,
для числа опытов п = 4
из таблицы в приложениях (с. 149) выбираем
значение коэффициента Стьюдента tn,
= 3,18; с помощью формулы (5) оценим
случайную погрешность измерения
ускорения
s а
= 3,180,0437 0,139 (м/с2) .
Способы
определения приборных ошибок
Основными характеристиками
измерительных приборов являются предел
измерения и цена деления, а также –
главным образом для электро-измерительных
приборов – класс точности.
Предел
измерения П
– это максимальное значение величины,
которое может быть измерено с помощью
данной шкалы прибора. Если
предел измерения не указан отдельно,
то его определяют по оцифровке шкалы.
Так, если рис. 2
изображает шкалу миллиамперметра, то
его предел измерения равен 100 мА.
Р
ис.2
Цена
деления Ц –
значение измеряемой величины,
соответствующее самому малому делению
шкалы. Если шкала начинается с нуля, то
![]() ,
,
где
N
– общее количество делений (например,
на рис. 2
N = 50).
Если эта шкала принадлежит амперметру
с пределом измерения 5 А,
то цена деления равна 5/50 = 0,1 (А).
Если шкала принадлежит термометру и
проградуирована в С,
то цена деления Ц = 100/50 = 2 (С).
Многие электроизмерительные приборы
имеют несколько пределов измерения.
При переключении их с одного предела
на другой изменяется и цена деления
шкалы.
Класс
точности К
представляет собой отношение абсолютной
приборной погрешности к пределу измерения
шкалы, выраженное в процентах:
![]() .
.
(7)
Значение класса
точности (без символа «%») указывается,
как правило, на электроизмерительных
приборах.
В зависимости от вида
измерительного устройства абсолютная
приборная погрешность определяется
одним из нижеперечисленных способов.
1. Погрешность
указана непосредственно на приборе.
Так, на микрометре есть надпись «0,01 мм».
Если с помощью этого прибора измеряется,
например, диаметр шарика D
(лабораторная работа 1.2), то погрешность
его измерения D = 0,01 мм.
Абсолютная ошибка указывается обычно
на жидкостных (ртутных, спиртовых)
термометрах, штангенциркулях и др.
2. На приборе указан
класс точности. Согласно определению
этой величины, из формулы (7) имеем
![]() .
.
(8)
Например, для вольтметра
с классом точности 2,5 и пределом измерения
600 В абсолютная приборная ошибка
измерения напряжения
![]() .
.
3. Если на приборе
не указаны ни абсолютная погрешность,
ни класс точности, то в зависимости от
характера работы прибора возможны два
способа определения величины х:
а) указатель
значения измеряемой величины может
занимать только определенные (дискретные)
положения, соответствующие делениям
шкалы (например, электронные часы,
секундомеры, счетчики импульсов и т.п.).
Такие приборы являются приборами
дискретного действия, и их абсолютная
погрешность равна цене деления шкалы:
х = Ц.
Так, при измерении промежутка времени
t секундомером с ценой
деления 0,2 с погрешность t = 0,2 с;

б) указатель
значения измеряемой величины может
занимать любое положение на шкале
(линейки, рулетки, стрелочные весы,
термометры и т.п.). В этом случае абсолютная
приборная погрешность равна половине
цены деления: х = Ц/2.
Точность снимаемых показаний прибора
не должна превышать его возможностей.
Например, при показанном на рис. 3
положении стрелки прибора следует
записать либо 62,5 либо 63,0 – в обоих
случаях ошибка не превысит половины
цены деления. Записи же типа 62,7 или 62,8
не имеют смысла.
Рис.3
4. Если какая-либо
величина не измеряется в данном оыте,
а была измерена независимо и известно
лишь ее значение, то она является заданным
параметром. Так, в работе 2.1 по
определению коэффициента вязкости
воздуха такими параметрами являются
размеры капилляра, в опыте Юнга по
интерференции света (работа 5.1) –
расстояние между щелями и т.д. Погрешность
заданного параметра принимается равной
половине единицы последнего разряда
числа, которым задано значение этого
параметра. Например, если радиус капилляра
r задан с точностью
до сотых долей миллиметра, то его
погрешность r = 0,005 мм.
Погрешности
косвенных измерений
В большинстве физических
экспериментов искомая величина и
не измеряется непосредственно каким-либо
одним прибором, а рассчитывается на
основе измерения ряда промежуточных
величин x, y, z,…
Расчет проводится по определенной
формуле, которую в общем виде можно
записать как
и = и ( x, y, z,…).
(9)
В этом случае говорят,
что величина и представляет собой
результат косвенного измерения в
отличие от x, y, z,…,
являющихся результатами прямых
измерений. Например, в
работе 1.2 коэффициент вязкости жидкости
рассчитывается по формуле
![]() ,
,
(10)
где ш
– плотность материала шарика; ж
– плотность жидкости; g
– ускорение свободного падения; D
– диаметр шарика; t –
время его падения в жидкости; l
– расстояние между метками на сосуде.
В данном случае результатами прямых
измерений являются величины l,
D и t,
а коэффициент вязкости
– результат косвенного
измерения. Величины ш,
ж
и g представляют
собой заданные параметры.
Абсолютная
погрешность косвенного измерения и
зависит от погрешностей прямых измерений
x,
y,
z…и
от вида функции (9). Как правило, величину
и
можно оценить по формуле
вида
![]() ,
,
(11)
где
коэффициенты kx ,
ky ,
kz ,…
определяются видом зависимостей величины
и от x,
y, z,…
Приведенная ниже табл. 3 позволяет
найти эти коэффициенты для наиболее
распространенных элементарных функций
(a, b, c, n
– заданные константы).
Таблица
3
|
и(х) |
kx |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
На
практике зависимость (9) чаще всего имеет
вид степенной функции
![]() ,
,
показатели степеней
которой k,
m, n,…
– вещественные (положительные или
отрицательные, целые или дробные) числа;
С – постоянный коэффициент. В этом
случае абсолютная приборная погрешность
и
оценивается по формуле
![]() ,
,
(12)
где
![]()
– среднее значение величины и;
![]()
– относительные приборные погрешности
прямых измерений величин x,
y, z,…
Для подстановки в формулу (12) выбираются
наиболее представительные, т.е.
близкие к средним значения x,
y, z,…
При расчетах по
формулам типа (12) необходимо помнить
следующее.
1. Измеряемые
величины и их абсолютные погрешности
(например, х и х)
должны быть выражены в одних и тех же
единицах.
2. Расчеты не требуют
высокой точности вычислений и должны
иметь оценочный характер. Так, входящие
в подкоренное выражение и возводимые
в квадрат величины ( kEx ,
mEy ,
nEz ,…)
обычно округляются с точностью до
двух значащих цифр (напомним, что ноль
является значащей цифрой только тогда,
когда перед ним слева есть хотя бы одна
цифра, отличная от нуля). Далее, если
одна из этих величин (например, | kEx | ) по
модулю превышает наибольшую из остальных
( | mEy | ,
| nEz | ,…)
более чем в три раза, то можно, не прибегая
к вычислениям по формуле (12), принять
абсолютную ошибку равной
![]() .
.
Если же одна из них более чем в три раза
меньше наименьшей из остальных, то при
расчете по формуле (12) ею можно пренебречь.
Пример 2.
Пусть при определении ускорения тела
(см. пример 1) путь S
измерялся рулеткой с ценой деления
1 мм, а время t
– электронным секундомером. Тогда, в
соответствии с изложенными в п.3, а, б
(с. 13) правилами, погрешности прямых
измерений будут равны
S = 0,5 мм = 0,0005 м;
t = 0,01 с.
Расчетную формулу
(6) можно записать в виде степенной
функции
a( S, t ) = 2S 1t – 2 ;
тогда на основании
(12) погрешность косвенного измерения
ускорения а
определится выражением
![]() .
.
В
качестве наиболее представительных
значений измеренных величин возьмем
(см. табл. 2) S 8 м;
t 3 с
и оценим по модулю относительные
приборные ошибки прямых измерений с
учетом их весовых коэффициентов:
![]() ;
;
![]() .
.
Очевидно,
что в данном случае величиной ES
можно пренебречь и принять погрешность
а
равной
![]()
Пример 3.
Вернемся к определению коэффициента
вязкости жидкости (работа 1.2). Расчетную
формулу (10) можно представить в виде
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Результат любого измерения не определён однозначно и имеет случайную составляющую.
Поэтому адекватным языком для описания погрешностей является язык вероятностей.
Тот факт, что значение некоторой величины «случайно», не означает, что
она может принимать совершенно произвольные значения. Ясно, что частоты, с которыми
возникает те или иные значения, различны. Вероятностные законы, которым
подчиняются случайные величины, называют распределениями.
2.1 Случайная величина
Случайной будем называть величину, значение которой не может быть достоверно определено экспериментатором. Чаще всего подразумевается, что случайная величина будет изменяться при многократном повторении одного и того же эксперимента. При интерпретации результатов измерений в физических экспериментах, обычно случайными также считаются величины, значение которых является фиксированным, но не известно экспериментатору. Например смещение нуля шкалы прибора. Для формализации работы со случайными величинами используют понятие вероятности. Численное значение вероятности того, что какая-то величина примет то или иное значение определяется либо как относительная частота наблюдения того или иного значения при повторении опыта большое количество раз, либо как оценка на основе данных других экспериментов.
Замечание.
Хотя понятия вероятности и случайной величины являются основополагающими, в литературе нет единства в их определении. Обсуждение формальных тонкостей или построение строгой теории лежит за пределами данного пособия. Поэтому на начальном этапе лучше использовать «интуитивное» понимание этих сущностей. Заинтересованным читателям рекомендуем обратиться к специальной литературе: [5].
Рассмотрим случайную физическую величину x, которая при измерениях может
принимать непрерывный набор значений. Пусть
P[x0,x0+δx] — вероятность того, что результат окажется вблизи
некоторой точки x0 в пределах интервала δx: x∈[x0,x0+δx].
Устремим интервал
δx к нулю. Нетрудно понять, что вероятность попасть в этот интервал
также будет стремиться к нулю. Однако отношение
w(x0)=P[x0,x0+δx]δx будет оставаться конечным.
Функцию w(x) называют плотностью распределения вероятности или кратко
распределением непрерывной случайной величины x.
Замечание. В математической литературе распределением часто называют не функцию
w(x), а её интеграл W(x)=∫w(x)𝑑x. Такую функцию в физике принято
называть интегральным или кумулятивным распределением. В англоязычной литературе
для этих функций принято использовать сокращения:
pdf (probability distribution function) и
cdf (cumulative distribution function)
соответственно.
Гистограммы.
Проиллюстрируем наглядно понятие плотности распределения. Результат
большого числа измерений случайной величины удобно представить с помощью
специального типа графика — гистограммы.
Для этого область значений x, размещённую на оси абсцисс, разобьём на
равные малые интервалы — «корзины» или «бины» (англ. bins)
некоторого размера h. По оси ординат будем откладывать долю измерений w,
результаты которых попадают в соответствующую корзину. А именно,
пусть k — номер корзины; nk — число измерений, попавших
в диапазон x∈[kh,(k+1)h]. Тогда на графике изобразим «столбик»
шириной h и высотой wk=nk/n.
В результате получим картину, подобную изображённой на рис. 2.1.
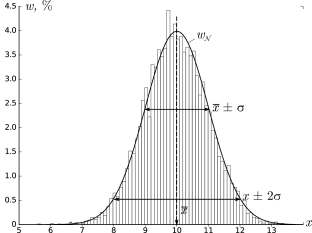
σ=1,0, h=0,1, n=104)
Высоты построенных столбиков будут приближённо соответствовать значению
плотности распределения w(x) вблизи соответствующей точки x.
Если устремить число измерений к бесконечности (n→∞), а ширину корзин
к нулю (h→0), то огибающая гистограммы будет стремиться к некоторой
непрерывной функции w(x).
Самые высокие столбики гистограммы будут группироваться вблизи максимума
функции w(x) — это наиболее вероятное значение случайной величины.
Если отклонения в положительную и отрицательную стороны равновероятны,
то гистограмма будет симметрична — в таком случае среднее значение ⟨x⟩
также будет лежать вблизи этого максимума. Ширина гистограммы будет характеризовать разброс
значений случайной величины — по порядку величины
она, как правило, близка к среднеквадратичному отклонению sx.
Свойства распределений.
Из определения функции w(x) следует, что вероятность получить в результате
эксперимента величину x в диапазоне от a до b
можно найти, вычислив интеграл:
| Px∈[a,b]=∫abw(x)𝑑x. | (2.1) |
Согласно определению вероятности, сумма вероятностей для всех возможных случаев
всегда равна единице. Поэтому интеграл распределения w(x) по всей области
значений x (то есть суммарная площадь под графиком w(x)) равен единице:
Это соотношение называют условием нормировки.
Среднее и дисперсия.
Вычислим среднее по построенной гистограмме. Если размер корзин
h достаточно мал, все измерения в пределах одной корзины можно считать примерно
одинаковыми. Тогда среднее арифметическое всех результатов можно вычислить как
Переходя к пределу, получим следующее определение среднего значения
случайной величины:
где интегрирование ведётся по всей области значений x.
В теории вероятностей x¯ также называют математическим ожиданием
распределения.
Величину
| σ2=(x-x¯)2¯=∫(x-x¯)2w𝑑x | (2.3) |
называют дисперсией распределения. Значение σ есть
срекднеквадратичное отклонение в пределе n→∞. Оно имеет ту
же размерность, что и сама величина x и характеризует разброс распределения.
Именно эту величину, как правило, приводят как характеристику погрешности
измерения x.
Доверительный интервал.
Обозначим как P|Δx|<δ вероятность
того, что отклонение от среднего Δx=x-x¯ составит величину,
не превосходящую по модулю значение δ:
| P|Δx|<δ=∫x¯-δx¯+δw(x)𝑑x. | (2.4) |
Эту величину называют доверительной вероятностью для
доверительного интервала |x-x¯|≤δ.
2.2 Нормальное распределение
Одним из наиболее примечательных результатов теории вероятностей является
так называемая центральная предельная теорема. Она утверждает,
что сумма большого количества независимых случайных слагаемых, каждое
из которых вносит в эту сумму относительно малый вклад, подчиняется
универсальному закону, не зависимо от того, каким вероятностным законам
подчиняются её составляющие, — так называемому нормальному
распределению (или распределению Гаусса).
Доказательство теоремы довольно громоздко и мы его не приводим (его можно найти
в любом учебнике по теории вероятностей). Остановимся
кратко на том, что такое нормальное распределение и его основных свойствах.
Плотность нормального распределения выражается следующей формулой:
| w𝒩(x)=12πσe-(x-x¯)22σ2. | (2.5) |
Здесь x¯ и σ
— параметры нормального распределения: x¯ равно
среднему значению x, a σ —
среднеквадратичному отклонению, вычисленным в пределе n→∞.
Как видно из рис. 2.1, распределение представляет собой
симметричный
«колокол», положение вершины которого
соответствует x¯ (ввиду симметрии оно же
совпадает с наиболее вероятным значением — максимумом
функции w𝒩(x)).
При значительном отклонении x от среднего величина
w𝒩(x)
очень быстро убывает. Это означает, что вероятность встретить отклонения,
существенно большие, чем σ, оказывается пренебрежимо
мала. Ширина «колокола» по порядку величины
равна σ — она характеризует «разброс»
экспериментальных данных относительно среднего значения.
Замечание. Точки x=x¯±σ являются точками
перегиба графика w(x) (в них вторая производная по x
обращается в нуль, w′′=0), а их положение по высоте составляет
w(x¯±σ)/w(x¯)=e-1/2≈0,61
от высоты вершины.
Универсальный характер центральной предельной теоремы позволяет широко
применять на практике нормальное (гауссово) распределение для обработки
результатов измерений, поскольку часто случайные погрешности складываются из
множества случайных независимых факторов. Заметим, что на практике
для приближённой оценки параметров нормального распределения
случайной величины используются выборочные значения среднего
и дисперсии: x¯≈⟨x⟩, sx≈σx.
Вычислим некоторые доверительные вероятности (2.4) для нормально Замечание. Значение интеграла вида ∫e-x2/2𝑑x Вероятность того, что результат отдельного измерения x окажется Вероятность отклонения в пределах x¯±2σ: а в пределах x¯±3σ: Иными словами, при большом числе измерений нормально распределённой Пример. В сообщениях об открытии бозона Хиггса на Большом адронном коллайдере Полученные значения доверительных вероятностей используются при означает, что измеренное значение лежит в диапазоне (доверительном Замечание. Хотя нормальный закон распределения встречается на практике довольно Теперь мы можем дать количественный критерий для сравнения двух измеренных Пусть x1 и x2 (x1≠x2) измерены с Допустим, одна из величин известна с существенно большей точностью: Пусть погрешности измерений сравнимы по порядку величины: Замечание. Изложенные здесь соображения применимы, только если x¯ и x-x0σ2=2w(x)σ1=1
x-x0σ2=2w(x)σ1=1Доверительные вероятности.
распределённых случайных величин.
(его называют интегралом ошибок) в элементарных функциях не выражается,
но легко находится численно.
в пределах x¯±σ оказывается равна
P|Δx|<σ=∫x¯-σx¯+σw𝒩𝑑x≈0,68.
величины можно ожидать, что лишь треть измерений выпадут за пределы интервала
[x¯-σ,x¯+σ]. При этом около 5%
измерений выпадут за пределы [x¯-2σ;x¯+2σ],
и лишь 0,27% окажутся за пределами
[x¯-3σ;x¯+3σ].
говорилось о том, что исследователи ждали подтверждение результатов
с точностью «5 сигма». Используя нормальное распределение (2.5)
нетрудно посчитать, что они использовали доверительную вероятность
P≈1-5,7⋅10-7=0,99999943. Такую точность можно назвать фантастической.
стандартной записи результатов измерений. В физических измерениях
(в частности, в учебной лаборатории), как правило, используется P=0,68,
то есть, запись
интервале) x∈[x¯-δx;x¯+δx] с
вероятностью 68%. Таким образом погрешность ±δx считается
равной одному среднеквадратичному отклонению: δx=σ.
В технических измерениях чаще используется P=0,95, то есть под
абсолютной погрешностью имеется в виду удвоенное среднеквадратичное
отклонение, δx=2σ. Во избежание разночтений доверительную
вероятность следует указывать отдельно.
часто, стоит помнить, что он реализуется далеко не всегда.
Полученные выше соотношения для вероятностей попадания значений в
доверительные интервалы можно использовать в качестве простейшего
признака нормальности распределения: в частности, если количество попадающих
в интервал ±σ результатов существенно отличается от 2/3 — это повод
для более детального исследования закона распределения ошибок.Сравнение результатов измерений.
величин или двух результатов измерения одной и той же величины.
погрешностями σ1 и σ2 соответственно.
Ясно, что если различие результатов |x2-x1| невелико,
его можно объяснить просто случайными отклонениями.
Если же теория предсказывает, что вероятность обнаружить такое отклонение
слишком мала, различие результатов следует признать значимым.
Предварительно необходимо договориться о соответствующем граничном значении
вероятности. Универсального значения здесь быть не может,
поэтому приходится полагаться на субъективный выбор исследователя. Часто
в качестве «разумной» границы выбирают вероятность 5%,
что, как видно из изложенного выше, для нормального распределения
соответствует отклонению более, чем на 2σ.
σ2≪σ1 (например, x1 — результат, полученный
студентом в лаборатории, x2 — справочное значение).
Поскольку σ2 мало, x2 можно принять за «истинное»:
x2≈x¯. Предполагая, что погрешность измерения
x1 подчиняется нормальному закону с и дисперсией σ12,
можно утверждать, что
различие считают будет значимы, если
σ1∼σ2. В теории вероятностей показывается, что
линейная комбинация нормально распределённых величин также имеет нормальное
распределение с дисперсией σ2=σ12+σ22
(см. также правила сложения погрешностей (2.7)). Тогда
для проверки гипотезы о том, что x1 и x2 являются измерениями
одной и той же величины, нужно вычислить, является ли значимым отклонение
|x1-x2| от нуля при σ=σ12+σ22.
Пример. Два студента получили следующие значения для теплоты испарения
некоторой жидкости: x1=40,3±0,2 кДж/моль и
x2=41,0±0,3 кДж/моль, где погрешность соответствует
одному стандартному отклонению. Можно ли утверждать, что они исследовали
одну и ту же жидкость?
Имеем наблюдаемую разность |x1-x2|=0,7 кДж/моль,
среднеквадратичное отклонение для разности
σ=0,22+0,32=0,36 кДж/моль.
Их отношение |x2-x1|σ≈2. Из
свойств нормального распределения находим вероятность того, что измерялась
одна и та же величина, а различия в ответах возникли из-за случайных
ошибок: P≈5%. Ответ на вопрос, «достаточно»
ли мала или велика эта вероятность, остаётся на усмотрение исследователя.
его стандартное отклонение σ получены на основании достаточно
большой выборки n≫1 (или заданы точно). При небольшом числе измерений
(n≲10) выборочные средние ⟨x⟩ и среднеквадратичное отклонение
sx сами имеют довольно большую ошибку, а
их распределение будет описываться не нормальным законом, а так
называемым t-распределением Стъюдента. В частности, в зависимости от
значения n интервал ⟨x⟩±sx будет соответствовать несколько
меньшей доверительной вероятности, чем P=0,68. Особенно резко различия
проявляются при высоких уровнях доверительных вероятностей P→1.
2.3 Независимые величины
Величины x и y называют независимыми если результат измерения одной
из них никак не влияет на результат измерения другой. Для таких величин вероятность того, что x окажется в некоторой области X, и одновременно y — в области Y,
равна произведению соответствующих вероятностей:
Обозначим отклонения величин от их средних как Δx=x-x¯ и
Δy=y-y¯.
Средние значения этих отклонений равны, очевидно, нулю: Δx¯=x¯-x¯=0,
Δy¯=0. Из независимости величин x и y следует,
что среднее значение от произведения Δx⋅Δy¯
равно произведению средних Δx¯⋅Δy¯
и, следовательно, равно нулю:
| Δx⋅Δy¯=Δx¯⋅Δy¯=0. | (2.6) |
Пусть измеряемая величина z=x+y складывается из двух независимых
случайных слагаемых x и y, для которых известны средние
x¯ и y¯, и их среднеквадратичные погрешности
σx и σy. Непосредственно из определения (1.1)
следует, что среднее суммы равно сумме средних:
Найдём дисперсию σz2. В силу независимости имеем
| Δz2¯=Δx2¯+Δy2¯+2Δx⋅Δy¯≈Δx2¯+Δy2¯, |
то есть:
Таким образом, при сложении независимых величин их погрешности
складываются среднеквадратичным образом.
Подчеркнём, что для справедливости соотношения (2.7)
величины x и y не обязаны быть нормально распределёнными —
достаточно существования конечных значений их дисперсий. Однако можно
показать, что если x и y распределены нормально, нормальным
будет и распределение их суммы.
Замечание. Требование независимости
слагаемых является принципиальным. Например, положим y=x. Тогда
z=2x. Здесь y и x, очевидно, зависят друг от друга. Используя
(2.7), находим σ2x=2σx,
что, конечно, неверно — непосредственно из определения
следует, что σ2x=2σx.
Отдельно стоит обсудить математическую структуру формулы (2.7).
Если одна из погрешностей много больше другой, например,
σx≫σy,
то меньшей погрешностью можно пренебречь, σx+y≈σx.
С другой стороны, если два источника погрешностей имеют один порядок
σx∼σy, то и σx+y∼σx∼σy.
Эти обстоятельства важны при планирования эксперимента: как правило,
величина, измеренная наименее точно, вносит наибольший вклад в погрешность
конечного результата. При этом, пока не устранены наиболее существенные
ошибки, бессмысленно гнаться за повышением точности измерения остальных
величин.
Пример. Пусть σy=σx/3,
тогда σz=σx1+19≈1,05σx,
то есть при различии двух погрешностей более, чем в 3 раза, поправка
к погрешности составляет менее 5%, и уже нет особого смысла в учёте
меньшей погрешности: σz≈σx. Это утверждение
касается сложения любых независимых источников погрешностей в эксперименте.
2.4 Погрешность среднего
Выборочное среднее арифметическое значение ⟨x⟩, найденное
по результатам n измерений, само является случайной величиной.
Действительно, если поставить серию одинаковых опытов по n измерений,
то в каждом опыте получится своё среднее значение, отличающееся от
предельного среднего x¯.
Вычислим среднеквадратичную погрешность среднего арифметического
σ⟨x⟩.
Рассмотрим вспомогательную сумму n слагаемых
Если {xi} есть набор независимых измерений
одной и той же физической величины, то мы можем, применяя результат
(2.7) предыдущего параграфа, записать
| σZ=σx12+σx22+…+σxn2=nσx, |
поскольку под корнем находится n одинаковых слагаемых. Отсюда с
учётом ⟨x⟩=Z/n получаем
Таким образом, погрешность среднего значения x по результатам
n независимых измерений оказывается в n раз меньше погрешности
отдельного измерения. Это один из важнейших результатов, позволяющий
уменьшать случайные погрешности эксперимента за счёт многократного
повторения измерений.
Подчеркнём отличия между σx и σ⟨x⟩:
величина σx — погрешность отдельного
измерения — является характеристикой разброса значений
в совокупности измерений {xi}, i=1..n. При
нормальном законе распределения примерно 68% измерений попадают в
интервал ⟨x⟩±σx;
величина σ⟨x⟩ — погрешность
среднего — характеризует точность, с которой определено
среднее значение измеряемой физической величины ⟨x⟩ относительно
предельного («истинного») среднего x¯;
при этом с доверительной вероятностью P=68% искомая величина x¯
лежит в интервале
⟨x⟩-σ⟨x⟩<x¯<⟨x⟩+σ⟨x⟩.
2.5 Результирующая погрешность опыта
Пусть для некоторого результата измерения известна оценка его максимальной
систематической погрешности Δсист и случайная
среднеквадратичная
погрешность σслуч. Какова «полная»
погрешность измерения?
Предположим для простоты, что измеряемая величина в принципе
может быть определена сколь угодно точно, так что можно говорить о
некотором её «истинном» значении xист
(иными словами, погрешность результата связана в основном именно с
процессом измерения). Назовём полной погрешностью измерения
среднеквадратичное значения отклонения от результата измерения от
«истинного»:
Отклонение x-xист можно представить как сумму случайного
отклонения от среднего δxслуч=x-x¯
и постоянной (но, вообще говоря, неизвестной) систематической составляющей
δxсист=x¯-xист=const:
Причём случайную составляющую можно считать независимой от систематической.
В таком случае из (2.7) находим:
| σполн2=⟨δxсист2⟩+⟨δxслуч2⟩≤Δсист2+σслуч2. | (2.9) |
Таким образом, для получения максимального значения полной
погрешности некоторого измерения нужно квадратично сложить максимальную
систематическую и случайную погрешности.
Если измерения проводятся многократно, то согласно (2.8)
случайная составляющая погрешности может быть уменьшена, а систематическая
составляющая при этом остаётся неизменной:
Отсюда следует важное практическое правило
(см. также обсуждение в п. 2.3): если случайная погрешность измерений
в 2–3 раза меньше предполагаемой систематической, то
нет смысла проводить многократные измерения в попытке уменьшить погрешность
всего эксперимента. В такой ситуации измерения достаточно повторить
2–3 раза — чтобы убедиться в повторяемости результата, исключить промахи
и проверить, что случайная ошибка действительно мала.
В противном случае повторение измерений может иметь смысл до
тех пор, пока погрешность среднего
σ⟨x⟩=σxn
не станет меньше систематической.
Замечание. Поскольку конкретная
величина систематической погрешности, как правило, не известна, её
можно в некотором смысле рассматривать наравне со случайной —
предположить, что её величина была определена по некоторому случайному
закону перед началом измерений (например, при изготовлении линейки
на заводе произошло некоторое случайное искажение шкалы). При такой
трактовке формулу (2.9) можно рассматривать просто
как частный случай формулы сложения погрешностей независимых величин
(2.7).
Подчеркнем, что вероятностный закон, которому подчиняется
систематическая ошибка, зачастую неизвестен. Поэтому неизвестно и
распределение итогового результата. Из этого, в частности, следует,
что мы не можем приписать интервалу x±Δсист какую-либо
определённую доверительную вероятность — она равна 0,68
только если систематическая ошибка имеет нормальное распределение.
Можно, конечно, предположить,
— и так часто делают — что, к примеру, ошибки
при изготовлении линеек на заводе имеют гауссов характер. Также часто
предполагают, что систематическая ошибка имеет равномерное
распределение (то есть «истинное» значение может с равной вероятностью
принять любое значение в пределах интервала ±Δсист).
Строго говоря, для этих предположений нет достаточных оснований.
Пример. В результате измерения диаметра проволоки микрометрическим винтом,
имеющим цену деления h=0,01 мм, получен следующий набор из n=8 значений:
Вычисляем среднее значение: ⟨d⟩≈386,3 мкм.
Среднеквадратичное отклонение:
σd≈9,2 мкм. Случайная погрешность среднего согласно
(2.8):
σ⟨d⟩=σd8≈3,2
мкм. Все результаты лежат в пределах ±2σd, поэтому нет
причин сомневаться в нормальности распределения. Максимальную погрешность
микрометра оценим как половину цены деления, Δ=h2=5 мкм.
Результирующая полная погрешность
σ≤Δ2+σd28≈6,0 мкм.
Видно, что σслуч≈Δсист и проводить дополнительные измерения
особого смысла нет. Окончательно результат измерений может быть представлен
в виде (см. также правила округления
результатов измерений в п. 4.3.2)
d=386±6мкм,εd=1,5%.
Заметим, что поскольку случайная погрешность и погрешность
прибора здесь имеют один порядок величины, наблюдаемый случайный разброс
данных может быть связан как с неоднородностью сечения проволоки,
так и с дефектами микрометра (например, с неровностями зажимов, люфтом
винта, сухим трением, деформацией проволоки под действием микрометра
и т. п.). Для ответа на вопрос, что именно вызвало разброс, требуются
дополнительные исследования, желательно с использованием более точных
приборов.
Пример. Измерение скорости
полёта пули было осуществлено с погрешностью δv=±1 м/c.
Результаты измерений для n=6 выстрелов представлены в таблице:
Усреднённый результат ⟨v⟩=162,0м/с,
среднеквадратичное отклонение σv=13,8м/c, случайная
ошибка для средней скорости
σv¯=σv/6=5,6м/с.
Поскольку разброс экспериментальных данных существенно превышает погрешность
каждого измерения, σv≫δv, он почти наверняка связан
с реальным различием скоростей пули в разных выстрелах, а не с ошибками
измерений. В качестве результата эксперимента представляют интерес
как среднее значение скоростей ⟨v⟩=162±6м/с
(ε≈4%), так и значение σv≈14м/с,
характеризующее разброс значений скоростей от выстрела к выстрелу.
Малая инструментальная погрешность в принципе позволяет более точно
измерить среднее и дисперсию, и исследовать закон распределения выстрелов
по скоростям более детально — для этого требуется набрать
бо́льшую статистику по выстрелам.
Пример. Измерение скорости
полёта пули было осуществлено с погрешностью δv=10 м/c. Результаты
измерений для n=6 выстрелов представлены в таблице:
Усреднённый результат ⟨v⟩=163,3м/с,
σv=12,1м/c, σ⟨v⟩=5м/с,
σполн≈11,2м/с. Инструментальная
погрешность каждого измерения превышает разброс данных, поэтому в
этом опыте затруднительно сделать вывод о различии скоростей от выстрела
к выстрелу. Результат измерений скорости пули:
⟨v⟩=163±11м/с,
ε≈7%. Проводить дополнительные выстрелы при такой
большой инструментальной погрешности особого смысла нет —
лучше поработать над точностью приборов и методикой измерений.
2.6 Обработка косвенных измерений
Косвенными называют измерения, полученные в результате расчётов,
использующих результаты прямых (то есть «непосредственных»)
измерений физических величин. Сформулируем основные правила пересчёта
погрешностей при косвенных измерениях.
2.6.1 Случай одной переменной
Пусть в эксперименте измеряется величина x, а её «наилучшее»
(в некотором смысле) значение равно x⋆ и оно известно с
погрешностью σx. После чего с помощью известной функции
вычисляется величина y=f(x).
В качестве «наилучшего» приближения для y используем значение функции
при «наилучшем» x:
Найдём величину погрешности σy. Обозначая отклонение измеряемой
величины как Δx=x-x⋆, и пользуясь определением производной,
при условии, что функция y(x) — гладкая
вблизи x≈x⋆, запишем
где f′≡dydx — производная фукнции f(x), взятая в точке
x⋆. Возведём полученное в квадрат, проведём усреднение
(σy2=⟨Δy2⟩,
σx2=⟨Δx2⟩), и затем снова извлечём
корень. В результате получим
Пример. Для степенной функции
y=Axn имеем σy=nAxn-1σx, откуда
σyy=nσxx,или εy=nεx,
то есть относительная погрешность степенной функции возрастает пропорционально
показателю степени n.
Пример. Для y=1/x имеем ε1/x=εx
— при обращении величины сохраняется её относительная
погрешность.
Упражнение. Найдите погрешность логарифма y=lnx, если известны x
и σx.
Упражнение. Найдите погрешность показательной функции y=ax,
если известны x и σx. Коэффициент a задан точно.
2.6.2 Случай многих переменных
Пусть величина u вычисляется по измеренным значениям нескольких
различных независимых физических величин x, y, …
на основе известного закона u=f(x,y,…). В качестве
наилучшего значения можно по-прежнему взять значение функции f
при наилучших значениях измеряемых параметров:
Для нахождения погрешности σu воспользуемся свойством,
известным из математического анализа, — малые приращения гладких
функции многих переменных складываются линейно, то есть справедлив
принцип суперпозиции малых приращений:
где символом fx′≡∂f∂x обозначена
частная производная функции f по переменной x —
то есть обычная производная f по x, взятая при условии, что
все остальные аргументы (кроме x) считаются постоянными параметрами.
Тогда пользуясь формулой для нахождения дисперсии суммы независимых
величин (2.7), получим соотношение, позволяющее вычислять
погрешности косвенных измерений для произвольной функции
u=f(x,y,…):
| σu2=fx′2σx2+fy′2σy2+… | (2.11) |
Это и есть искомая общая формула пересчёта погрешностей при косвенных
измерениях.
Отметим, что формулы (2.10) и (2.11) применимы
только если относительные отклонения всех величин малы
(εx,εy,…≪1),
а измерения проводятся вдали от особых точек функции f (производные
fx′, fy′ … не должны обращаться в бесконечность).
Также подчеркнём, что все полученные здесь формулы справедливы только
для независимых переменных x, y, …
Остановимся на некоторых важных частных случаях формулы
(2.11).
Пример. Для суммы (или разности) u=∑i=1naixi имеем
σu2=∑i=1nai2σxi2.
(2.12)
Пример. Найдём погрешность степенной функции:
u=xα⋅yβ⋅…. Тогда нетрудно получить,
что
σu2u2=α2σx2x2+β2σy2y2+…
или через относительные погрешности
εu2=α2εx2+β2εy2+…
(2.13)
Пример. Вычислим погрешность произведения и частного: u=xy или u=x/y.
Тогда в обоих случаях имеем
εu2=εx2+εy2,
(2.14)
то есть при умножении или делении относительные погрешности складываются
квадратично.
Пример. Рассмотрим несколько более сложный случай: нахождение угла по его тангенсу
u=arctgyx.
В таком случае, пользуясь тем, что (arctgz)′=11+z2,
где z=y/x, и используя производную сложной функции, находим
ux′=uz′zx′=-yx2+y2,
uy′=uz′zy′=xx2+y2, и наконец
σu2=y2σx2+x2σy2(x2+y2)2.
Упражнение. Найти погрешность вычисления гипотенузы z=x2+y2
прямоугольного треугольника по измеренным катетам x и y.
По итогам данного раздела можно дать следующие практические рекомендации.
-
•
Как правило, нет смысла увеличивать точность измерения какой-то одной
величины, если другие величины, используемые в расчётах, остаются
измеренными относительно грубо — всё равно итоговая погрешность
скорее всего будет определяться самым неточным измерением. Поэтому
все измерения имеет смысл проводить примерно с одной и той же
относительной погрешностью. -
•
При этом, как следует из (2.13), особое внимание
следует уделять измерению величин, возводимых при расчётах в степени
с большими показателями. А при сложных функциональных зависимостях
имеет смысл детально проанализировать структуру формулы
(2.11):
если вклад от некоторой величины в общую погрешность мал, нет смысла
гнаться за высокой точностью её измерения, и наоборот, точность некоторых
измерений может оказаться критически важной. -
•
Следует избегать измерения малых величин как разности двух близких
значений (например, толщины стенки цилиндра как разности внутреннего
и внешнего радиусов): если u=x-y, то абсолютная погрешность
σu=σx2+σy2
меняется мало, однако относительная погрешность
εu=σux-y
может оказаться неприемлемо большой, если x≈y.
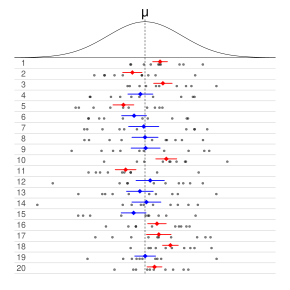
Each row of points is a sample from the same normal distribution. The colored lines are 50% confidence intervals for the mean, μ. At the center of each interval is the sample mean, marked with a diamond. The blue intervals contain the population mean, and the red ones do not.
In frequentist statistics, a confidence interval (CI) is a range of estimates for an unknown parameter. A confidence interval is computed at a designated confidence level; the 95% confidence level is most common, but other levels, such as 90% or 99%, are sometimes used.[1][2] The confidence level represents the long-run proportion of CIs (at the given confidence level) that theoretically contain the true value of the parameter. For example, out of all intervals computed at the 95% level, 95% of them should contain the parameter’s true value.[3]
Factors affecting the width of the CI include the sample size, the variability in the sample, and the confidence level.[4] All else being the same, a larger sample produces a narrower confidence interval, greater variability in the sample produces a wider confidence interval, and a higher confidence level produces a wider confidence interval.[5]
Definition[edit]
Let X be a random sample from a probability distribution with statistical parameter θ, which is a quantity to be estimated, and φ, representing quantities that are not of immediate interest. A confidence interval for the parameter θ, with confidence level or coefficient γ, is an interval  determined by random variables
determined by random variables  and
and  with the property:
with the property:

The number γ, whose typical value is close to but not greater than 1, is sometimes given in the form  (or as a percentage
(or as a percentage  ), where
), where  is a small positive number, often 0.05 .
is a small positive number, often 0.05 .
It is important for the bounds and to be specified in such a way that as long as X is collected randomly, every time we compute a confidence interval, there is probability γ that it would contain θ, the true value of the parameter being estimated. This should hold true for any actual θ and φ.[2]
Approximate confidence intervals[edit]
In many applications, confidence intervals that have exactly the required confidence level are hard to construct, but approximate intervals can be computed. The rule for constructing the interval may be accepted as providing a confidence interval at level  if
if

to an acceptable level of approximation. Alternatively, some authors[6] simply require that

which is useful if the probabilities are only partially identified or imprecise, and also when dealing with discrete distributions. Confidence limits of form
- and


are called conservative;[7](p 210) accordingly, one speaks of conservative confidence intervals and, in general, regions.
Desired properties[edit]
When applying standard statistical procedures, there will often be standard ways of constructing confidence intervals. These will have been devised so as to meet certain desirable properties, which will hold given that the assumptions on which the procedure relies are true. These desirable properties may be described as: validity, optimality, and invariance.
Of the three, «validity» is most important, followed closely by «optimality». «Invariance» may be considered as a property of the method of derivation of a confidence interval, rather than of the rule for constructing the interval. In non-standard applications, these same desirable properties would be sought:
Validity[edit]
This means that the nominal coverage probability (confidence level) of the confidence interval should hold, either exactly or to a good approximation.
Optimality[edit]
This means that the rule for constructing the confidence interval should make as much use of the information in the data-set as possible.
Recall that one could throw away half of a dataset and still be able to derive a valid confidence interval. One way of assessing optimality is by the length of the interval so that a rule for constructing a confidence interval is judged better than another if it leads to intervals whose lengths are typically shorter.
Invariance[edit]
In many applications, the quantity being estimated might not be tightly defined as such.
For example, a survey might result in an estimate of the median income in a population, but it might equally be considered as providing an estimate of the logarithm of the median income, given that this is a common scale for presenting graphical results. It would be desirable that the method used for constructing a confidence interval for the median income would give equivalent results when applied to constructing a confidence interval for the logarithm of the median income: Specifically the values at the ends of the latter interval would be the logarithms of the values at the ends of former interval.
Methods of derivation[edit]
For non-standard applications, there are several routes that might be taken to derive a rule for the construction of confidence intervals. Established rules for standard procedures might be justified or explained via several of these routes. Typically a rule for constructing confidence intervals is closely tied to a particular way of finding a point estimate of the quantity being considered.
Summary statistics[edit]
This is closely related to the method of moments for estimation. A simple example arises where the quantity to be estimated is the population mean, in which case a natural estimate is the sample mean. Similarly, the sample variance can be used to estimate the population variance. A confidence interval for the true mean can be constructed centered on the sample mean with a width which is a multiple of the square root of the sample variance.
Likelihood theory[edit]
Estimates can be constructed using the maximum likelihood principle, the likelihood theory for this provides two ways of constructing confidence intervals or confidence regions for the estimates.
Estimating equations[edit]
The estimation approach here can be considered as both a generalization of the method of moments and a generalization of the maximum likelihood approach. There are corresponding generalizations of the results of maximum likelihood theory that allow confidence intervals to be constructed based on estimates derived from estimating equations.[citation needed]
Hypothesis testing[edit]
If hypothesis tests are available for general values of a parameter, then confidence intervals/regions can be constructed by including in the 100 p % confidence region all those points for which the hypothesis test of the null hypothesis that the true value is the given value is not rejected at a significance level of (1 − p) .[7](§ 7.2 (iii))
Bootstrapping[edit]
In situations where the distributional assumptions for the above methods are uncertain or violated, resampling methods allow construction of confidence intervals or prediction intervals. The observed data distribution and the internal correlations are used as the surrogate for the correlations in the wider population.
Central limit theorem[edit]
The central limit theorem is a refinement of the law of large numbers. For a large number of independent identically distributed random variables  with finite variance, the average
with finite variance, the average  approximately has a normal distribution, no matter what the distribution of the
approximately has a normal distribution, no matter what the distribution of the  is, with the approximation roughly improving in proportion to
is, with the approximation roughly improving in proportion to  [2]
[2]
Example[edit]
Suppose {X1, …, Xn} is an independent sample from a normally distributed population with unknown parameters mean μ and variance σ2. Let


Where X is the sample mean, and S2 is the sample variance. Then

has a Student’s t distribution with n − 1 degrees of freedom.[8] Note that the distribution of T does not depend on the values of the unobservable parameters μ and σ2; i.e., it is a pivotal quantity. Suppose we wanted to calculate a 95% confidence interval for μ. Then, denoting c as the 97.5th percentile of this distribution,

Note that «97.5th» and «0.95» are correct in the preceding expressions. There is a 2.5% chance that  will be less than
will be less than  and a 2.5% chance that it will be larger than
and a 2.5% chance that it will be larger than  . Thus, the probability that will be between and is 95%.
. Thus, the probability that will be between and is 95%.
Consequently,

and we have a theoretical (stochastic) 95% confidence interval for μ.
After observing the sample we find values x for X and s for S, from which we compute the confidence interval
![{displaystyle left[{bar {x}}-{frac {cs}{sqrt {n}}},{bar {x}}+{frac {cs}{sqrt {n}}}right].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/02a90d533cc8ae393c6949495405824f49865b80)

In this bar chart, the top ends of the brown bars indicate observed means and the red line segments («error bars») represent the confidence intervals around them. Although the error bars are shown as symmetric around the means, that is not always the case. In most graphs, the error bars do not represent confidence intervals (e.g., they often represent standard errors or standard deviations)
Interpretation[edit]
Various interpretations of a confidence interval can be given (taking the 95% confidence interval as an example in the following).
- The confidence interval can be expressed in terms of a long-run frequency in repeated samples (or in resampling): «Were this procedure to be repeated on numerous samples, the proportion of calculated 95% confidence intervals that encompassed the true value of the population parameter would tend toward 95%.»[9]
- The confidence interval can be expressed in terms of probability with respect to a single theoretical (yet to be realized) sample: «There is a 95% probability that the 95% confidence interval calculated from a given future sample will cover the true value of the population parameter.» [10] This essentially reframes the «repeated samples» interpretation as a probability rather than a frequency. See Neyman construction.
- The confidence interval can be expressed in terms of statistical significance, e.g.: «The 95% confidence interval represents values that are not statistically significantly different from the point estimate at the .05 level«.[11]

Interpretation of the 95% confidence interval in terms of statistical significance.
Common misunderstandings[edit]
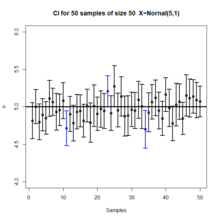
Plot of 50 confidence intervals from 50 samples generated from a normal distribution.
See also: § Counterexamples
Confidence intervals and levels are frequently misunderstood, and published studies have shown that even professional scientists often misinterpret them.[12][13][14][15][16][17]
- A 95% confidence level does not mean that for a given realized interval there is a 95% probability that the population parameter lies within the interval (i.e., a 95% probability that the interval covers the population parameter).[18] According to the strict frequentist interpretation, once an interval is calculated, this interval either covers the parameter value or it does not; it is no longer a matter of probability. The 95% probability relates to the reliability of the estimation procedure, not to a specific calculated interval.[19] Neyman himself (the original proponent of confidence intervals) made this point in his original paper:[10]
It will be noticed that in the above description, the probability statements refer to the problems of estimation with which the statistician will be concerned in the future. In fact, I have repeatedly stated that the frequency of correct results will tend to α. Consider now the case when a sample is already drawn, and the calculations have given [particular limits]. Can we say that in this particular case the probability of the true value [falling between these limits] is equal to α? The answer is obviously in the negative. The parameter is an unknown constant, and no probability statement concerning its value may be made…
- Deborah Mayo expands on this further as follows:[20]
It must be stressed, however, that having seen the value [of the data], Neyman–Pearson theory never permits one to conclude that the specific confidence interval formed covers the true value of 0 with either (1 − α)100% probability or (1 − α)100% degree of confidence. Seidenfeld’s remark seems rooted in a (not uncommon) desire for Neyman–Pearson confidence intervals to provide something which they cannot legitimately provide; namely, a measure of the degree of probability, belief, or support that an unknown parameter value lies in a specific interval. Following Savage (1962), the probability that a parameter lies in a specific interval may be referred to as a measure of final precision. While a measure of final precision may seem desirable, and while confidence levels are often (wrongly) interpreted as providing such a measure, no such interpretation is warranted. Admittedly, such a misinterpretation is encouraged by the word ‘confidence’.
- A 95% confidence level does not mean that 95% of the sample data lie within the confidence interval.
- A confidence interval is not a definitive range of plausible values for the sample parameter, though it is often heuristically taken as a range of plausible values.
- A particular confidence level of 95% calculated from an experiment does not mean that there is a 95% probability of a sample parameter from a repeat of the experiment falling within this interval.[16]
Counterexamples[edit]
Since confidence interval theory was proposed, a number of counter-examples to the theory have been developed to show how the interpretation of confidence intervals can be problematic, at least if one interprets them naïvely.
Confidence procedure for uniform location[edit]
Welch[21] presented an example which clearly shows the difference between the theory of confidence intervals and other theories of interval estimation (including Fisher’s fiducial intervals and objective Bayesian intervals). Robinson[22] called this example «[p]ossibly the best known counterexample for Neyman’s version of confidence interval theory.» To Welch, it showed the superiority of confidence interval theory; to critics of the theory, it shows a deficiency. Here we present a simplified version.
Suppose that  are independent observations from a Uniform(θ − 1/2, θ + 1/2) distribution. Then the optimal 50% confidence procedure for
are independent observations from a Uniform(θ − 1/2, θ + 1/2) distribution. Then the optimal 50% confidence procedure for  is[23]
is[23]
![{displaystyle {bar {X}}pm {begin{cases}{dfrac {|X_{1}-X_{2}|}{2}}&{text{if }}|X_{1}-X_{2}|<1/2\[8pt]{dfrac {1-|X_{1}-X_{2}|}{2}}&{text{if }}|X_{1}-X_{2}|geq 1/2.end{cases}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/80260117bd9ee1f05d0928e0b5697663a297ecbc)
A fiducial or objective Bayesian argument can be used to derive the interval estimate

which is also a 50% confidence procedure. Welch showed that the first confidence procedure dominates the second, according to desiderata from confidence interval theory; for every  , the probability that the first procedure contains
, the probability that the first procedure contains  is less than or equal to the probability that the second procedure contains . The average width of the intervals from the first procedure is less than that of the second. Hence, the first procedure is preferred under classical confidence interval theory.
is less than or equal to the probability that the second procedure contains . The average width of the intervals from the first procedure is less than that of the second. Hence, the first procedure is preferred under classical confidence interval theory.
However, when  , intervals from the first procedure are guaranteed to contain the true value : Therefore, the nominal 50% confidence coefficient is unrelated to the uncertainty we should have that a specific interval contains the true value. The second procedure does not have this property.
, intervals from the first procedure are guaranteed to contain the true value : Therefore, the nominal 50% confidence coefficient is unrelated to the uncertainty we should have that a specific interval contains the true value. The second procedure does not have this property.
Moreover, when the first procedure generates a very short interval, this indicates that are very close together and hence only offer the information in a single data point. Yet the first interval will exclude almost all reasonable values of the parameter due to its short width. The second procedure does not have this property.
The two counter-intuitive properties of the first procedure—100% coverage when are far apart and almost 0% coverage when are close together—balance out to yield 50% coverage on average. However, despite the first procedure being optimal, its intervals offer neither an assessment of the precision of the estimate nor an assessment of the uncertainty one should have that the interval contains the true value.
This counter-example is used to argue against naïve interpretations of confidence intervals. If a confidence procedure is asserted to have properties beyond that of the nominal coverage (such as relation to precision, or a relationship with Bayesian inference), those properties must be proved; they do not follow from the fact that a procedure is a confidence procedure.
Confidence procedure for ω2[edit]
Steiger[24] suggested a number of confidence procedures for common effect size measures in ANOVA. Morey et al.[18] point out that several of these confidence procedures, including the one for ω2, have the property that as the F statistic becomes increasingly small—indicating misfit with all possible values of ω2—the confidence interval shrinks and can even contain only the single value ω2 = 0; that is, the CI is infinitesimally narrow (this occurs when  for a
for a  CI).
CI).
This behavior is consistent with the relationship between the confidence procedure and significance testing: as F becomes so small that the group means are much closer together than we would expect by chance, a significance test might indicate rejection for most or all values of ω2. Hence the interval will be very narrow or even empty (or, by a convention suggested by Steiger, containing only 0). However, this does not indicate that the estimate of ω2 is very precise. In a sense, it indicates the opposite: that the trustworthiness of the results themselves may be in doubt. This is contrary to the common interpretation of confidence intervals that they reveal the precision of the estimate.
History[edit]
Confidence intervals were introduced by Jerzy Neyman in 1937.[25] Statisticians quickly took to the idea, but adoption by scientists was more gradual. Some authors in medical journals promoted confidence intervals as early as the 1970s. Despite this, confidence intervals were rarely used until the following decade, when they quickly became standard.[26] By the late 1980s, medical journals began to require the reporting of confidence intervals.[27]
See also[edit]
- CLs upper limits (particle physics)
- 68–95–99.7 rule
- Confidence band, an interval estimate for a curve
- Confidence distribution
- Confidence region, a higher dimensional generalization
- Credence (statistics) – measure of belief strength used in statistics
- Credible interval, a Bayesian alternative for interval estimation
- Cumulative distribution function-based nonparametric confidence interval
- Error bar – Graphical representations of the variability of data
- Estimation statistics – Data analysis approach in frequentist statistics
- Margin of error, the CI halfwidth
- p-value – Function of the observed sample results
- Prediction interval, an interval estimate for a random variable
- Probable error
- Robust confidence intervals
Confidence interval for specific distributions[edit]
- Confidence interval for binomial distribution
- Confidence interval for exponent of the power law distribution
- Confidence interval for mean of the exponential distribution
- Confidence interval for mean of the Poisson distribution
- Confidence intervals for mean and variance of the normal distribution
References[edit]
- ^ Zar, Jerrold H. (199). Biostatistical Analysis (4th ed.). Upper Saddle River, N.J.: Prentice Hall. pp. 43–45. ISBN 978-0130815422. OCLC 39498633.
- ^ a b c Dekking, Frederik Michel; Kraaikamp, Cornelis; Lopuhaä, Hendrik Paul; Meester, Ludolf Erwin (2005). «A Modern Introduction to Probability and Statistics». Springer Texts in Statistics. doi:10.1007/1-84628-168-7. ISBN 978-1-85233-896-1. ISSN 1431-875X.
- ^ Illowsky, Barbara. Introductory statistics. Dean, Susan L., 1945-, Illowsky, Barbara., OpenStax College. Houston, Texas. ISBN 978-1-947172-05-0. OCLC 899241574.
- ^ Hazra, Avijit (October 2017). «Using the confidence interval confidently». Journal of Thoracic Disease. 9 (10): 4125–4130. doi:10.21037/jtd.2017.09.14. ISSN 2072-1439. PMC 5723800. PMID 29268424.
- ^ Khare, Vikas; Nema, Savita; Baredar, Prashant (2020). Ocean Energy Modeling and Simulation with Big Data Computational Intelligence for System Optimization and Grid Integration. ISBN 978-0-12-818905-4. OCLC 1153294021.
- ^ Roussas, George G. (1997). A Course in Mathematical Statistics (2nd ed.). Academic Press. p. 397.
- ^ a b Cox, D.R.; Hinkley, D.V. (1974). Theoretical Statistics. Chapman & Hall.
- ^ Rees. D.G. (2001) Essential Statistics, 4th Edition, Chapman and Hall/CRC. ISBN 1-58488-007-4 (Section 9.5)
- ^ Cox D.R., Hinkley D.V. (1974) Theoretical Statistics, Chapman & Hall, p49, p209
- ^ a b Neyman, J. (1937). «Outline of a Theory of Statistical Estimation Based on the Classical Theory of Probability». Philosophical Transactions of the Royal Society A. 236 (767): 333–380. Bibcode:1937RSPTA.236..333N. doi:10.1098/rsta.1937.0005. JSTOR 91337.
- ^ Cox D.R., Hinkley D.V. (1974) Theoretical Statistics, Chapman & Hall, pp 214, 225, 233
- ^ Kalinowski, Pawel (2010). «Identifying Misconceptions about Confidence Intervals» (PDF). Retrieved 2021-12-22.
- ^ «Archived copy» (PDF). Archived from the original (PDF) on 2016-03-04. Retrieved 2014-09-16.
{{cite web}}: CS1 maint: archived copy as title (link) - ^ Hoekstra, R., R. D. Morey, J. N. Rouder, and E-J. Wagenmakers, 2014. Robust misinterpretation of confidence intervals. Psychonomic Bulletin Review, in press. [1]
- ^ Scientists’ grasp of confidence intervals doesn’t inspire confidence, Science News, July 3, 2014
- ^ a b Greenland, Sander; Senn, Stephen J.; Rothman, Kenneth J.; Carlin, John B.; Poole, Charles; Goodman, Steven N.; Altman, Douglas G. (April 2016). «Statistical tests, P values, confidence intervals, and power: a guide to misinterpretations». European Journal of Epidemiology. 31 (4): 337–350. doi:10.1007/s10654-016-0149-3. ISSN 0393-2990. PMC 4877414. PMID 27209009.
- ^ Helske, Jouni; Helske, Satu; Cooper, Matthew; Ynnerman, Anders; Besancon, Lonni (2021-08-01). «Can Visualization Alleviate Dichotomous Thinking? Effects of Visual Representations on the Cliff Effect». IEEE Transactions on Visualization and Computer Graphics. Institute of Electrical and Electronics Engineers (IEEE). 27 (8): 3397–3409. arXiv:2002.07671. doi:10.1109/tvcg.2021.3073466. ISSN 1077-2626. PMID 33856998. S2CID 233230810.
- ^ a b Morey, R. D.; Hoekstra, R.; Rouder, J. N.; Lee, M. D.; Wagenmakers, E.-J. (2016). «The Fallacy of Placing Confidence in Confidence Intervals». Psychonomic Bulletin & Review. 23 (1): 103–123. doi:10.3758/s13423-015-0947-8. PMC 4742505. PMID 26450628.
- ^ «1.3.5.2. Confidence Limits for the Mean». nist.gov. Archived from the original on 2008-02-05. Retrieved 2014-09-16.
- ^ Mayo, D. G. (1981) «In defence of the Neyman–Pearson theory of confidence intervals», Philosophy of Science, 48 (2), 269–280. JSTOR 187185
- ^ Welch, B. L. (1939). «On Confidence Limits and Sufficiency, with Particular Reference to Parameters of Location». The Annals of Mathematical Statistics. 10 (1): 58–69. doi:10.1214/aoms/1177732246. JSTOR 2235987.
- ^ Robinson, G. K. (1975). «Some Counterexamples to the Theory of Confidence Intervals». Biometrika. 62 (1): 155–161. doi:10.2307/2334498. JSTOR 2334498.
- ^ Pratt, J. W. (1961). «Book Review: Testing Statistical Hypotheses. by E. L. Lehmann». Journal of the American Statistical Association. 56 (293): 163–167. doi:10.1080/01621459.1961.10482103. JSTOR 2282344.
- ^ Steiger, J. H. (2004). «Beyond the F test: Effect size confidence intervals and tests of close fit in the analysis of variance and contrast analysis». Psychological Methods. 9 (2): 164–182. doi:10.1037/1082-989x.9.2.164. PMID 15137887.
- ^ [Neyman, J., 1937. Outline of a theory of statistical estimation based on the classical theory of probability. Philosophical Transactions of the Royal Society of London. Series A, Mathematical and Physical Sciences, 236(767), pp.333-380]
- ^ Altman, Douglas G. (1991). «Statistics in medical journals: Developments in the 1980s». Statistics in Medicine. 10 (12): 1897–1913. doi:10.1002/sim.4780101206. ISSN 1097-0258. PMID 1805317.
- ^ Sandercock, Peter A.G. (2015). «Short History of Confidence Intervals». Stroke. Ovid Technologies (Wolters Kluwer Health). 46 (8): e184-7. doi:10.1161/strokeaha.115.007750. ISSN 0039-2499. PMID 26106115.
Bibliography[edit]
- Fisher, R.A. (1956) Statistical Methods and Scientific Inference. Oliver and Boyd, Edinburgh. (See p. 32.)
- Freund, J.E. (1962) Mathematical Statistics Prentice Hall, Englewood Cliffs, NJ. (See pp. 227–228.)
- Hacking, I. (1965) Logic of Statistical Inference. Cambridge University Press, Cambridge. ISBN 0-521-05165-7
- Keeping, E.S. (1962) Introduction to Statistical Inference. D. Van Nostrand, Princeton, NJ.
- Kiefer, J. (1977). «Conditional Confidence Statements and Confidence Estimators (with discussion)». Journal of the American Statistical Association. 72 (360a): 789–827. doi:10.1080/01621459.1977.10479956. JSTOR 2286460.
- Mayo, D. G. (1981) «In defence of the Neyman–Pearson theory of confidence intervals», Philosophy of Science, 48 (2), 269–280. JSTOR 187185
- Neyman, J. (1937) «Outline of a Theory of Statistical Estimation Based on the Classical Theory of Probability» Philosophical Transactions of the Royal Society of London A, 236, 333–380. (Seminal work.)
- Robinson, G.K. (1975). «Some Counterexamples to the Theory of Confidence Intervals». Biometrika. 62 (1): 155–161. doi:10.1093/biomet/62.1.155. JSTOR 2334498.
- Savage, L. J. (1962), The Foundations of Statistical Inference. Methuen, London.
- Smithson, M. (2003) Confidence intervals. Quantitative Applications in the Social Sciences Series, No. 140. Belmont, CA: SAGE Publications. ISBN 978-0-7619-2499-9.
- Mehta, S. (2014) Statistics Topics ISBN 978-1-4992-7353-3
- «Confidence estimation», Encyclopedia of Mathematics, EMS Press, 2001 [1994]
- Morey, R. D.; Hoekstra, R.; Rouder, J. N.; Lee, M. D.; Wagenmakers, E.-J. (2016). «The fallacy of placing confidence in confidence intervals». Psychonomic Bulletin & Review. 23 (1): 103–123. doi:10.3758/s13423-015-0947-8. PMC 4742505. PMID 26450628.
External links[edit]
- The Exploratory Software for Confidence Intervals tutorial programs that run under Excel
- Confidence interval calculators for R-Squares, Regression Coefficients, and Regression Intercepts
- Weisstein, Eric W. «Confidence Interval». MathWorld.
- CAUSEweb.org Many resources for teaching statistics including Confidence Intervals.
- An interactive introduction to Confidence Intervals
- Confidence Intervals: Confidence Level, Sample Size, and Margin of Error by Eric Schulz, the Wolfram Demonstrations Project.
- Confidence Intervals in Public Health. Straightforward description with examples and what to do about small sample sizes or rates near 0.
Each row of points is a sample from the same normal distribution. The colored lines are 50% confidence intervals for the mean, μ. At the center of each interval is the sample mean, marked with a diamond. The blue intervals contain the population mean, and the red ones do not.
In frequentist statistics, a confidence interval (CI) is a range of estimates for an unknown parameter. A confidence interval is computed at a designated confidence level; the 95% confidence level is most common, but other levels, such as 90% or 99%, are sometimes used.[1][2] The confidence level represents the long-run proportion of CIs (at the given confidence level) that theoretically contain the true value of the parameter. For example, out of all intervals computed at the 95% level, 95% of them should contain the parameter’s true value.[3]
Factors affecting the width of the CI include the sample size, the variability in the sample, and the confidence level.[4] All else being the same, a larger sample produces a narrower confidence interval, greater variability in the sample produces a wider confidence interval, and a higher confidence level produces a wider confidence interval.[5]
Definition[edit]
Let X be a random sample from a probability distribution with statistical parameter θ, which is a quantity to be estimated, and φ, representing quantities that are not of immediate interest. A confidence interval for the parameter θ, with confidence level or coefficient γ, is an interval determined by random variables and with the property:
The number γ, whose typical value is close to but not greater than 1, is sometimes given in the form (or as a percentage ), where is a small positive number, often 0.05 .
It is important for the bounds and to be specified in such a way that as long as X is collected randomly, every time we compute a confidence interval, there is probability γ that it would contain θ, the true value of the parameter being estimated. This should hold true for any actual θ and φ.[2]
Approximate confidence intervals[edit]
In many applications, confidence intervals that have exactly the required confidence level are hard to construct, but approximate intervals can be computed. The rule for constructing the interval may be accepted as providing a confidence interval at level if
to an acceptable level of approximation. Alternatively, some authors[6] simply require that
which is useful if the probabilities are only partially identified or imprecise, and also when dealing with discrete distributions. Confidence limits of form
- and
are called conservative;[7](p 210) accordingly, one speaks of conservative confidence intervals and, in general, regions.
Desired properties[edit]
When applying standard statistical procedures, there will often be standard ways of constructing confidence intervals. These will have been devised so as to meet certain desirable properties, which will hold given that the assumptions on which the procedure relies are true. These desirable properties may be described as: validity, optimality, and invariance.
Of the three, «validity» is most important, followed closely by «optimality». «Invariance» may be considered as a property of the method of derivation of a confidence interval, rather than of the rule for constructing the interval. In non-standard applications, these same desirable properties would be sought:
Validity[edit]
This means that the nominal coverage probability (confidence level) of the confidence interval should hold, either exactly or to a good approximation.
Optimality[edit]
This means that the rule for constructing the confidence interval should make as much use of the information in the data-set as possible.
Recall that one could throw away half of a dataset and still be able to derive a valid confidence interval. One way of assessing optimality is by the length of the interval so that a rule for constructing a confidence interval is judged better than another if it leads to intervals whose lengths are typically shorter.
Invariance[edit]
In many applications, the quantity being estimated might not be tightly defined as such.
For example, a survey might result in an estimate of the median income in a population, but it might equally be considered as providing an estimate of the logarithm of the median income, given that this is a common scale for presenting graphical results. It would be desirable that the method used for constructing a confidence interval for the median income would give equivalent results when applied to constructing a confidence interval for the logarithm of the median income: Specifically the values at the ends of the latter interval would be the logarithms of the values at the ends of former interval.
Methods of derivation[edit]
For non-standard applications, there are several routes that might be taken to derive a rule for the construction of confidence intervals. Established rules for standard procedures might be justified or explained via several of these routes. Typically a rule for constructing confidence intervals is closely tied to a particular way of finding a point estimate of the quantity being considered.
Summary statistics[edit]
This is closely related to the method of moments for estimation. A simple example arises where the quantity to be estimated is the population mean, in which case a natural estimate is the sample mean. Similarly, the sample variance can be used to estimate the population variance. A confidence interval for the true mean can be constructed centered on the sample mean with a width which is a multiple of the square root of the sample variance.
Likelihood theory[edit]
Estimates can be constructed using the maximum likelihood principle, the likelihood theory for this provides two ways of constructing confidence intervals or confidence regions for the estimates.
Estimating equations[edit]
The estimation approach here can be considered as both a generalization of the method of moments and a generalization of the maximum likelihood approach. There are corresponding generalizations of the results of maximum likelihood theory that allow confidence intervals to be constructed based on estimates derived from estimating equations.[citation needed]
Hypothesis testing[edit]
If hypothesis tests are available for general values of a parameter, then confidence intervals/regions can be constructed by including in the 100 p % confidence region all those points for which the hypothesis test of the null hypothesis that the true value is the given value is not rejected at a significance level of (1 − p) .[7](§ 7.2 (iii))
Bootstrapping[edit]
In situations where the distributional assumptions for the above methods are uncertain or violated, resampling methods allow construction of confidence intervals or prediction intervals. The observed data distribution and the internal correlations are used as the surrogate for the correlations in the wider population.
Central limit theorem[edit]
The central limit theorem is a refinement of the law of large numbers. For a large number of independent identically distributed random variables with finite variance, the average approximately has a normal distribution, no matter what the distribution of the is, with the approximation roughly improving in proportion to [2]
Example[edit]
Suppose {X1, …, Xn} is an independent sample from a normally distributed population with unknown parameters mean μ and variance σ2. Let
Where X is the sample mean, and S2 is the sample variance. Then
has a Student’s t distribution with n − 1 degrees of freedom.[8] Note that the distribution of T does not depend on the values of the unobservable parameters μ and σ2; i.e., it is a pivotal quantity. Suppose we wanted to calculate a 95% confidence interval for μ. Then, denoting c as the 97.5th percentile of this distribution,
Note that «97.5th» and «0.95» are correct in the preceding expressions. There is a 2.5% chance that will be less than and a 2.5% chance that it will be larger than . Thus, the probability that will be between and is 95%.
Consequently,
and we have a theoretical (stochastic) 95% confidence interval for μ.
After observing the sample we find values x for X and s for S, from which we compute the confidence interval
In this bar chart, the top ends of the brown bars indicate observed means and the red line segments («error bars») represent the confidence intervals around them. Although the error bars are shown as symmetric around the means, that is not always the case. In most graphs, the error bars do not represent confidence intervals (e.g., they often represent standard errors or standard deviations)
Interpretation[edit]
Various interpretations of a confidence interval can be given (taking the 95% confidence interval as an example in the following).
- The confidence interval can be expressed in terms of a long-run frequency in repeated samples (or in resampling): «Were this procedure to be repeated on numerous samples, the proportion of calculated 95% confidence intervals that encompassed the true value of the population parameter would tend toward 95%.»[9]
- The confidence interval can be expressed in terms of probability with respect to a single theoretical (yet to be realized) sample: «There is a 95% probability that the 95% confidence interval calculated from a given future sample will cover the true value of the population parameter.» [10] This essentially reframes the «repeated samples» interpretation as a probability rather than a frequency. See Neyman construction.
- The confidence interval can be expressed in terms of statistical significance, e.g.: «The 95% confidence interval represents values that are not statistically significantly different from the point estimate at the .05 level«.[11]
Interpretation of the 95% confidence interval in terms of statistical significance.
Common misunderstandings[edit]
Plot of 50 confidence intervals from 50 samples generated from a normal distribution.
See also: § Counterexamples
Confidence intervals and levels are frequently misunderstood, and published studies have shown that even professional scientists often misinterpret them.[12][13][14][15][16][17]
- A 95% confidence level does not mean that for a given realized interval there is a 95% probability that the population parameter lies within the interval (i.e., a 95% probability that the interval covers the population parameter).[18] According to the strict frequentist interpretation, once an interval is calculated, this interval either covers the parameter value or it does not; it is no longer a matter of probability. The 95% probability relates to the reliability of the estimation procedure, not to a specific calculated interval.[19] Neyman himself (the original proponent of confidence intervals) made this point in his original paper:[10]
It will be noticed that in the above description, the probability statements refer to the problems of estimation with which the statistician will be concerned in the future. In fact, I have repeatedly stated that the frequency of correct results will tend to α. Consider now the case when a sample is already drawn, and the calculations have given [particular limits]. Can we say that in this particular case the probability of the true value [falling between these limits] is equal to α? The answer is obviously in the negative. The parameter is an unknown constant, and no probability statement concerning its value may be made…
- Deborah Mayo expands on this further as follows:[20]
It must be stressed, however, that having seen the value [of the data], Neyman–Pearson theory never permits one to conclude that the specific confidence interval formed covers the true value of 0 with either (1 − α)100% probability or (1 − α)100% degree of confidence. Seidenfeld’s remark seems rooted in a (not uncommon) desire for Neyman–Pearson confidence intervals to provide something which they cannot legitimately provide; namely, a measure of the degree of probability, belief, or support that an unknown parameter value lies in a specific interval. Following Savage (1962), the probability that a parameter lies in a specific interval may be referred to as a measure of final precision. While a measure of final precision may seem desirable, and while confidence levels are often (wrongly) interpreted as providing such a measure, no such interpretation is warranted. Admittedly, such a misinterpretation is encouraged by the word ‘confidence’.
- A 95% confidence level does not mean that 95% of the sample data lie within the confidence interval.
- A confidence interval is not a definitive range of plausible values for the sample parameter, though it is often heuristically taken as a range of plausible values.
- A particular confidence level of 95% calculated from an experiment does not mean that there is a 95% probability of a sample parameter from a repeat of the experiment falling within this interval.[16]
Counterexamples[edit]
Since confidence interval theory was proposed, a number of counter-examples to the theory have been developed to show how the interpretation of confidence intervals can be problematic, at least if one interprets them naïvely.
Confidence procedure for uniform location[edit]
Welch[21] presented an example which clearly shows the difference between the theory of confidence intervals and other theories of interval estimation (including Fisher’s fiducial intervals and objective Bayesian intervals). Robinson[22] called this example «[p]ossibly the best known counterexample for Neyman’s version of confidence interval theory.» To Welch, it showed the superiority of confidence interval theory; to critics of the theory, it shows a deficiency. Here we present a simplified version.
Suppose that are independent observations from a Uniform(θ − 1/2, θ + 1/2) distribution. Then the optimal 50% confidence procedure for is[23]
A fiducial or objective Bayesian argument can be used to derive the interval estimate
which is also a 50% confidence procedure. Welch showed that the first confidence procedure dominates the second, according to desiderata from confidence interval theory; for every , the probability that the first procedure contains is less than or equal to the probability that the second procedure contains . The average width of the intervals from the first procedure is less than that of the second. Hence, the first procedure is preferred under classical confidence interval theory.
However, when , intervals from the first procedure are guaranteed to contain the true value : Therefore, the nominal 50% confidence coefficient is unrelated to the uncertainty we should have that a specific interval contains the true value. The second procedure does not have this property.
Moreover, when the first procedure generates a very short interval, this indicates that are very close together and hence only offer the information in a single data point. Yet the first interval will exclude almost all reasonable values of the parameter due to its short width. The second procedure does not have this property.
The two counter-intuitive properties of the first procedure—100% coverage when are far apart and almost 0% coverage when are close together—balance out to yield 50% coverage on average. However, despite the first procedure being optimal, its intervals offer neither an assessment of the precision of the estimate nor an assessment of the uncertainty one should have that the interval contains the true value.
This counter-example is used to argue against naïve interpretations of confidence intervals. If a confidence procedure is asserted to have properties beyond that of the nominal coverage (such as relation to precision, or a relationship with Bayesian inference), those properties must be proved; they do not follow from the fact that a procedure is a confidence procedure.
Confidence procedure for ω2[edit]
Steiger[24] suggested a number of confidence procedures for common effect size measures in ANOVA. Morey et al.[18] point out that several of these confidence procedures, including the one for ω2, have the property that as the F statistic becomes increasingly small—indicating misfit with all possible values of ω2—the confidence interval shrinks and can even contain only the single value ω2 = 0; that is, the CI is infinitesimally narrow (this occurs when for a CI).
This behavior is consistent with the relationship between the confidence procedure and significance testing: as F becomes so small that the group means are much closer together than we would expect by chance, a significance test might indicate rejection for most or all values of ω2. Hence the interval will be very narrow or even empty (or, by a convention suggested by Steiger, containing only 0). However, this does not indicate that the estimate of ω2 is very precise. In a sense, it indicates the opposite: that the trustworthiness of the results themselves may be in doubt. This is contrary to the common interpretation of confidence intervals that they reveal the precision of the estimate.
History[edit]
Confidence intervals were introduced by Jerzy Neyman in 1937.[25] Statisticians quickly took to the idea, but adoption by scientists was more gradual. Some authors in medical journals promoted confidence intervals as early as the 1970s. Despite this, confidence intervals were rarely used until the following decade, when they quickly became standard.[26] By the late 1980s, medical journals began to require the reporting of confidence intervals.[27]
See also[edit]
- CLs upper limits (particle physics)
- 68–95–99.7 rule
- Confidence band, an interval estimate for a curve
- Confidence distribution
- Confidence region, a higher dimensional generalization
- Credence (statistics) – measure of belief strength used in statistics
- Credible interval, a Bayesian alternative for interval estimation
- Cumulative distribution function-based nonparametric confidence interval
- Error bar – Graphical representations of the variability of data
- Estimation statistics – Data analysis approach in frequentist statistics
- Margin of error, the CI halfwidth
- p-value – Function of the observed sample results
- Prediction interval, an interval estimate for a random variable
- Probable error
- Robust confidence intervals
Confidence interval for specific distributions[edit]
- Confidence interval for binomial distribution
- Confidence interval for exponent of the power law distribution
- Confidence interval for mean of the exponential distribution
- Confidence interval for mean of the Poisson distribution
- Confidence intervals for mean and variance of the normal distribution
References[edit]
- ^ Zar, Jerrold H. (199). Biostatistical Analysis (4th ed.). Upper Saddle River, N.J.: Prentice Hall. pp. 43–45. ISBN 978-0130815422. OCLC 39498633.
- ^ a b c Dekking, Frederik Michel; Kraaikamp, Cornelis; Lopuhaä, Hendrik Paul; Meester, Ludolf Erwin (2005). «A Modern Introduction to Probability and Statistics». Springer Texts in Statistics. doi:10.1007/1-84628-168-7. ISBN 978-1-85233-896-1. ISSN 1431-875X.
- ^ Illowsky, Barbara. Introductory statistics. Dean, Susan L., 1945-, Illowsky, Barbara., OpenStax College. Houston, Texas. ISBN 978-1-947172-05-0. OCLC 899241574.
- ^ Hazra, Avijit (October 2017). «Using the confidence interval confidently». Journal of Thoracic Disease. 9 (10): 4125–4130. doi:10.21037/jtd.2017.09.14. ISSN 2072-1439. PMC 5723800. PMID 29268424.
- ^ Khare, Vikas; Nema, Savita; Baredar, Prashant (2020). Ocean Energy Modeling and Simulation with Big Data Computational Intelligence for System Optimization and Grid Integration. ISBN 978-0-12-818905-4. OCLC 1153294021.
- ^ Roussas, George G. (1997). A Course in Mathematical Statistics (2nd ed.). Academic Press. p. 397.
- ^ a b Cox, D.R.; Hinkley, D.V. (1974). Theoretical Statistics. Chapman & Hall.
- ^ Rees. D.G. (2001) Essential Statistics, 4th Edition, Chapman and Hall/CRC. ISBN 1-58488-007-4 (Section 9.5)
- ^ Cox D.R., Hinkley D.V. (1974) Theoretical Statistics, Chapman & Hall, p49, p209
- ^ a b Neyman, J. (1937). «Outline of a Theory of Statistical Estimation Based on the Classical Theory of Probability». Philosophical Transactions of the Royal Society A. 236 (767): 333–380. Bibcode:1937RSPTA.236..333N. doi:10.1098/rsta.1937.0005. JSTOR 91337.
- ^ Cox D.R., Hinkley D.V. (1974) Theoretical Statistics, Chapman & Hall, pp 214, 225, 233
- ^ Kalinowski, Pawel (2010). «Identifying Misconceptions about Confidence Intervals» (PDF). Retrieved 2021-12-22.
- ^ «Archived copy» (PDF). Archived from the original (PDF) on 2016-03-04. Retrieved 2014-09-16.
{{cite web}}: CS1 maint: archived copy as title (link) - ^ Hoekstra, R., R. D. Morey, J. N. Rouder, and E-J. Wagenmakers, 2014. Robust misinterpretation of confidence intervals. Psychonomic Bulletin Review, in press. [1]
- ^ Scientists’ grasp of confidence intervals doesn’t inspire confidence, Science News, July 3, 2014
- ^ a b Greenland, Sander; Senn, Stephen J.; Rothman, Kenneth J.; Carlin, John B.; Poole, Charles; Goodman, Steven N.; Altman, Douglas G. (April 2016). «Statistical tests, P values, confidence intervals, and power: a guide to misinterpretations». European Journal of Epidemiology. 31 (4): 337–350. doi:10.1007/s10654-016-0149-3. ISSN 0393-2990. PMC 4877414. PMID 27209009.
- ^ Helske, Jouni; Helske, Satu; Cooper, Matthew; Ynnerman, Anders; Besancon, Lonni (2021-08-01). «Can Visualization Alleviate Dichotomous Thinking? Effects of Visual Representations on the Cliff Effect». IEEE Transactions on Visualization and Computer Graphics. Institute of Electrical and Electronics Engineers (IEEE). 27 (8): 3397–3409. arXiv:2002.07671. doi:10.1109/tvcg.2021.3073466. ISSN 1077-2626. PMID 33856998. S2CID 233230810.
- ^ a b Morey, R. D.; Hoekstra, R.; Rouder, J. N.; Lee, M. D.; Wagenmakers, E.-J. (2016). «The Fallacy of Placing Confidence in Confidence Intervals». Psychonomic Bulletin & Review. 23 (1): 103–123. doi:10.3758/s13423-015-0947-8. PMC 4742505. PMID 26450628.
- ^ «1.3.5.2. Confidence Limits for the Mean». nist.gov. Archived from the original on 2008-02-05. Retrieved 2014-09-16.
- ^ Mayo, D. G. (1981) «In defence of the Neyman–Pearson theory of confidence intervals», Philosophy of Science, 48 (2), 269–280. JSTOR 187185
- ^ Welch, B. L. (1939). «On Confidence Limits and Sufficiency, with Particular Reference to Parameters of Location». The Annals of Mathematical Statistics. 10 (1): 58–69. doi:10.1214/aoms/1177732246. JSTOR 2235987.
- ^ Robinson, G. K. (1975). «Some Counterexamples to the Theory of Confidence Intervals». Biometrika. 62 (1): 155–161. doi:10.2307/2334498. JSTOR 2334498.
- ^ Pratt, J. W. (1961). «Book Review: Testing Statistical Hypotheses. by E. L. Lehmann». Journal of the American Statistical Association. 56 (293): 163–167. doi:10.1080/01621459.1961.10482103. JSTOR 2282344.
- ^ Steiger, J. H. (2004). «Beyond the F test: Effect size confidence intervals and tests of close fit in the analysis of variance and contrast analysis». Psychological Methods. 9 (2): 164–182. doi:10.1037/1082-989x.9.2.164. PMID 15137887.
- ^ [Neyman, J., 1937. Outline of a theory of statistical estimation based on the classical theory of probability. Philosophical Transactions of the Royal Society of London. Series A, Mathematical and Physical Sciences, 236(767), pp.333-380]
- ^ Altman, Douglas G. (1991). «Statistics in medical journals: Developments in the 1980s». Statistics in Medicine. 10 (12): 1897–1913. doi:10.1002/sim.4780101206. ISSN 1097-0258. PMID 1805317.
- ^ Sandercock, Peter A.G. (2015). «Short History of Confidence Intervals». Stroke. Ovid Technologies (Wolters Kluwer Health). 46 (8): e184-7. doi:10.1161/strokeaha.115.007750. ISSN 0039-2499. PMID 26106115.
Bibliography[edit]
- Fisher, R.A. (1956) Statistical Methods and Scientific Inference. Oliver and Boyd, Edinburgh. (See p. 32.)
- Freund, J.E. (1962) Mathematical Statistics Prentice Hall, Englewood Cliffs, NJ. (See pp. 227–228.)
- Hacking, I. (1965) Logic of Statistical Inference. Cambridge University Press, Cambridge. ISBN 0-521-05165-7
- Keeping, E.S. (1962) Introduction to Statistical Inference. D. Van Nostrand, Princeton, NJ.
- Kiefer, J. (1977). «Conditional Confidence Statements and Confidence Estimators (with discussion)». Journal of the American Statistical Association. 72 (360a): 789–827. doi:10.1080/01621459.1977.10479956. JSTOR 2286460.
- Mayo, D. G. (1981) «In defence of the Neyman–Pearson theory of confidence intervals», Philosophy of Science, 48 (2), 269–280. JSTOR 187185
- Neyman, J. (1937) «Outline of a Theory of Statistical Estimation Based on the Classical Theory of Probability» Philosophical Transactions of the Royal Society of London A, 236, 333–380. (Seminal work.)
- Robinson, G.K. (1975). «Some Counterexamples to the Theory of Confidence Intervals». Biometrika. 62 (1): 155–161. doi:10.1093/biomet/62.1.155. JSTOR 2334498.
- Savage, L. J. (1962), The Foundations of Statistical Inference. Methuen, London.
- Smithson, M. (2003) Confidence intervals. Quantitative Applications in the Social Sciences Series, No. 140. Belmont, CA: SAGE Publications. ISBN 978-0-7619-2499-9.
- Mehta, S. (2014) Statistics Topics ISBN 978-1-4992-7353-3
- «Confidence estimation», Encyclopedia of Mathematics, EMS Press, 2001 [1994]
- Morey, R. D.; Hoekstra, R.; Rouder, J. N.; Lee, M. D.; Wagenmakers, E.-J. (2016). «The fallacy of placing confidence in confidence intervals». Psychonomic Bulletin & Review. 23 (1): 103–123. doi:10.3758/s13423-015-0947-8. PMC 4742505. PMID 26450628.
External links[edit]
- The Exploratory Software for Confidence Intervals tutorial programs that run under Excel
- Confidence interval calculators for R-Squares, Regression Coefficients, and Regression Intercepts
- Weisstein, Eric W. «Confidence Interval». MathWorld.
- CAUSEweb.org Many resources for teaching statistics including Confidence Intervals.
- An interactive introduction to Confidence Intervals
- Confidence Intervals: Confidence Level, Sample Size, and Margin of Error by Eric Schulz, the Wolfram Demonstrations Project.
- Confidence Intervals in Public Health. Straightforward description with examples and what to do about small sample sizes or rates near 0.