From Wikipedia, the free encyclopedia
In statistics, a forecast error is the difference between the actual or real and the predicted or forecast value of a time series or any other phenomenon of interest. Since the forecast error is derived from the same scale of data, comparisons between the forecast errors of different series can only be made when the series are on the same scale.[1]
In simple cases, a forecast is compared with an outcome at a single time-point and a summary of forecast errors is constructed over a collection of such time-points. Here the forecast may be assessed using the difference or using a proportional error. By convention, the error is defined using the value of the outcome minus the value of the forecast.
In other cases, a forecast may consist of predicted values over a number of lead-times; in this case an assessment of forecast error may need to consider more general ways of assessing the match between the time-profiles of the forecast and the outcome. If a main application of the forecast is to predict when certain thresholds will be crossed, one possible way of assessing the forecast is to use the timing-error—the difference in time between when the outcome crosses the threshold and when the forecast does so. When there is interest in the maximum value being reached, assessment of forecasts can be done using any of:
- the difference of times of the peaks;
- the difference in the peak values in the forecast and outcome;
- the difference between the peak value of the outcome and the value forecast for that time point.
Forecast error can be a calendar forecast error or a cross-sectional forecast error, when we want to summarize the forecast error over a group of units. If we observe the average forecast error for a time-series of forecasts for the same product or phenomenon, then we call this a calendar forecast error or time-series forecast error. If we observe this for multiple products for the same period, then this is a cross-sectional performance error. Reference class forecasting has been developed to reduce forecast error. Combining forecasts has also been shown to reduce forecast error.[2][3]
Calculating forecast error[edit]
The forecast error is the difference between the observed value and its forecast based on all previous observations. If the error is denoted as  then the forecast error can be written as:
then the forecast error can be written as:

where,
 = observation
= observation
 = denote the forecast of based on all previous observations
= denote the forecast of based on all previous observations
Forecast errors can be evaluated using a variety of methods namely mean percentage error, root mean squared error, mean absolute percentage error, mean squared error. Other methods include tracking signal and forecast bias.
For forecast errors on training data
denotes the observation and is the forecast
For forecast errors on test data
 denotes the actual value of the h-step observation and the forecast is denoted as
denotes the actual value of the h-step observation and the forecast is denoted as 
Academic literature[edit]
Dreman and Berry in 1995 «Financial Analysts Journal», argued that securities analysts’ forecasts are too optimistic, and that the investment community relies too heavily on their forecasts. However, this was countered by Lawrence D. Brown in 1996 and then again in 1997 who argued that the analysts are generally more accurate than those of «naive or sophisticated time-series models» nor have the errors been increasing over time.[4][5]
Hiromichi Tamura in 2002 argued that herd-to-consensus analysts not only submit their earnings estimates that end up being close to the consensus but that their personalities strongly affect these estimates.[6]
Examples of forecasting errors[edit]
Michael Fish — A few hours before the Great Storm of 1987 broke, on 15 October 1987, he said during a forecast: «Earlier on today, apparently, a woman rang the BBC and said she heard there was a hurricane on the way. Well, if you’re watching, don’t worry, there isn’t!». The storm was the worst to hit South East England for three centuries, causing record damage and killing 19 people.[7]
Great Recession — The financial and economic crisis that erupted in 2007—arguably the worst since the Great Depression of the 1930s—was not foreseen by most of the forecasters, even if a few lone analysts had been predicting it for some time (for example, Stephen Roach, Meredith Whitney, Gary Shilling, Marc Faber, Nouriel Roubini and Robert Shiller). The failure to forecast the «Great Recession» has caused a lot of soul searching in the profession. The UK’s Queen Elizabeth herself asked why had nobody noticed that the credit crunch was on its way, and a group of economists—experts from business, the City, its regulators, academia, and government—tried to explain in a letter.[8]
It was not just forecasting the Great Recession, but also its impact where it was clear that economists struggled. For example, in Singapore, Citi argued the country would experience «the most severe recession in Singapore’s history». The economy grew in 2009 by 3.1% and in 2010, the nation saw a 15.2% growth rate.[9][10]
At the end of 2019 the International Monetary Fund estimated global growth in 2020 to reach 3.4%, but as a result of the coronavirus pandemic, the IMF have revised its estimate in November 2020 to expect the global economy to shrink by 4.4%.[11][12]
See also[edit]
- Calculating demand forecast accuracy
- Errors and residuals in statistics
- Forecasting
- Forecasting accuracy
- Mean squared prediction error
- Optimism bias
- Reference class forecasting
References[edit]
- ^ 2.5 Evaluating forecast accuracy | OTexts. www.otexts.org. Retrieved 2016-05-12.
- ^ J. Scott Armstrong (2001). «Combining Forecasts». Principles of Forecasting: A Handbook for Researchers and Practitioners (PDF). Kluwer Academic Publishers.
- ^ J. Andreas Graefe; Scott Armstrong; Randall J. Jones, Jr.; Alfred G. Cuzán (2010). «Combining forecasts for predicting U.S. Presidential Election outcomes» (PDF).
- ^ Brown, Lawrence D. (1996). «Analyst Forecasting Errors and Their Implications for Security Analysis: An Alternative Perspective». Financial Analysts Journal. 52 (1): 40–47. doi:10.2469/faj.v52.n1.1965. ISSN 0015-198X. JSTOR 4479895. S2CID 153329250.
- ^ Brown, Lawrence D. (1997). «Analyst Forecasting Errors: Additional Evidence». Financial Analysts Journal. 53 (6): 81–88. doi:10.2469/faj.v53.n6.2133. ISSN 0015-198X. JSTOR 4480043. S2CID 153810721.
- ^ Tamura, Hiromichi (2002). «Individual-Analyst Characteristics and Forecast Error». Financial Analysts Journal. 58 (4): 28–35. doi:10.2469/faj.v58.n4.2452. ISSN 0015-198X. JSTOR 4480404. S2CID 154943363.
- ^ «Michael Fish revisits 1987’s Great Storm». BBC. 16 October 2017. Retrieved 16 October 2017.
- ^ British Academy-The Global Financial Crisis Why Didn’t Anybody Notice?-Retrieved July 27, 2015 Archived July 7, 2015, at the Wayback Machine
- ^ Chen, Xiaoping; Shao, Yuchen (2017-09-11). «Trade policies for a small open economy: The case of Singapore». The World Economy. doi:10.1111/twec.12555. ISSN 0378-5920. S2CID 158182047.
- ^ Subler, Jason (2009-01-02). «Factories slash output, jobs around world». Reuters. Retrieved 2020-09-20.
- ^ «IMF warns world growth slowest since financial crisis». BBC News. 2019-10-15. Retrieved 2020-11-22.
- ^ «IMF: Economy ‘losing momentum’ amid virus second wave». BBC News. 2020-11-19. Retrieved 2020-11-22.
Measurement is the first step that leads to control and eventually improvement.
H. James Harrington
In many business applications, the ability to plan ahead is paramount and in a majority of such scenario we use forecasts to help us plan ahead. For eg., If I run a retail store, how many boxes of that shampoo should I order today? Look at the Forecast. Will I achieve my financial targets by the end of the year? Let’s forecast and make adjustments if necessary. If I run a bike rental firm, how many bikes do I need to keep at a metro station tomorrow at 4pm?
If for all of these scenarios, we are taking actions based on the forecast, we should also have an idea about how good those forecasts are. In classical statistics or machine learning, we have a few general loss functions, like the squared error or the absolute error. But because of the way Time Series Forecasting has evolved, there are a lot more ways to assess your performance.
In this blog post, let’s explore the different Forecast Error measures through experiments and understand the drawbacks and advantages of each of them.
Metrics in Time Series Forecasting
There are a few key points which makes the metrics in Time Series Forecasting stand out from the regular metrics in Machine Learning.
1. Temporal Relevance
As the name suggests, Time Series Forecasting have the temporal aspect built into it and there are metrics like Cumulative Forecast Error or Forecast Bias which takes this temporal aspect as well.
2. Aggregate Metrics
In most business use-cases, we would not be forecasting a single time series, rather a set of time series, related or unrelated. And the higher management would not want to look at each of these time series individually, but rather an aggregate measure which tells them directionally how well we are doing the forecasting job. Even for practitioners, this aggregate measure helps them to get an overall sense of the progress they make in modelling.
3. Over or Under Forecasting
Another key aspect in forecasting is the concept of over and under forecasting. We would not want the forecasting model to have structural biases which always over or under forecasts. And to combat these, we would want metrics which doesn’t favor either over-forecasting or under-forecasting.
4. Interpretability
The final aspect is interpretability. Because these metrics are also used by non-analytics business functions, it needs to be interpretable.
Because of these different use cases, there are a lot of metrics that is used in this space and here we try to unify it under some structure and also critically examine them.
Taxonomy of Forecast Metrics

We can classify the different forecast metrics. broadly,. into two buckets – Intrinsic and Extrinsic. Intrinsic measures are the measures which just take the generated forecast and ground truth to compute the metric. Extrinsic measures are measures which use an external reference forecast also in addition to the generated forecast and ground truth to compute the metric.
Let’s stick with the intrinsic measures for now(Extrinsic ones require a whole different take on these metrics). There are four major ways in which we calculate errors – Absolute Error, Squared Error, Percent Error and Symmetric Error. All the metrics that come under these are just different aggregations of these fundamental errors. So, without loss of generality, we can discuss about these broad sections and they would apply to all the metrics under these heads as well.
Absolute Error
This group of error measurement uses the absolute value of the error as the foundation.
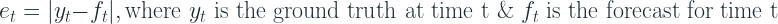
Squared Error
Instead of taking the absolute, we square the errors to make it positive, and this is the foundation for these metrics.
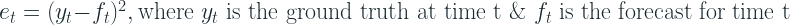
Percent Error
In this group of error measurement, we scale the absolute error by the ground truth to convert it into a percentage term.

Symmetric Error
Symmetric Error was proposed as an alternative to Percent Error, where we take the average of forecast and ground truth as the base on which to scale the absolute error.

Experiments
Instead of just saying that these are the drawbacks and advantages of such and such metrics, let’s design a few experiments and see for ourselves what those advantages and disadvantages are.
Scale Dependency
In this experiment, we try and figure out the impact of the scale of timeseries in aggregated measures. For this experiment, we
- Generate 10000 synthetic time series at different scales, but with same error.
- Split these series into 10 histogram bins
- Sample Size = 5000; Iterate over each bin
- Sample 50% from current bin and res, equally distributed, from other bins.
- Calculate the aggregate measures on this set of time series
- Record against the bin lower edge
- Plot the aggregate measures against the bin edges.
Symmetricity
The error measure should be symmetric to the inputs, i.e. Forecast and Ground Truth. If we interchange the forecast and actuals, ideally the error metric should return the same value.
To test this, let’s make a grid of 0 to 10 for both actuals and forecast and calculate the error metrics on that grid.
Complementary Pairs
In this experiment, we take complementary pairs of ground truths and forecasts which add up to a constant quantity and measure the performance at each point. Specifically, we use the same setup as we did the Symmetricity experiment, and calculate the points along the cross diagonal where ground truth + forecast always adds up to 10.
Loss Curves
Our metrics depend on two entities – forecast and ground truth. We can fix one and vary the other one using a symmetric range of errors((for eg. -10 to 10), then we expect the metric to behave the same way on both sides of that range. In our experiment, we chose to fix the Ground Truth because in reality, that is the fixed quantity, and we are measure the forecast against ground truth.
Over & Under Forecasting Experiment
In this experiment we generate 4 random time series – ground truth, baseline forecast, low forecast and high forecast. These are just random numbers generated within a range. Ground Truth and Baseline Forecast are random numbers generated between 2 and 4. Low forecast is a random number generated between 0 and 3 and High Forecast is a random number generated between 3 and 6. In this setup, the Baseline Forecast should act as a baseline for us, Low Forecast is a forecast where we continuously under-forecast, and High Forecast is a forecast where we continuously over-forecast. And now let’s calculate the MAPE for these three forecasts and repeat the experiment for 1000 times.

Outlier Impact
To check the impact on outliers, we setup the below experiment.
We want to check the relative impact of outliers on two axes – number of outliers, scale of outliers. So we define a grid – number of outliers [0%-40%] and scale of outliers [0 to 2]. Then we picked a synthetic time series at random, and iteratively introduced outliers according to the parameters of the grid we defined earlier and recorded the error measures.
Results and Discussion
Absolute Error
Symmetricity

That’s a nice symmetric heatmap. We see zero errors along the diagonal, and higher errors spanning away from it in a nice symmetric pattern.
Loss Curves

Again symmetric. MAE varies equally if we go on both sides of the curve.
Complementary Pairs

Again good news. If we vary forecast, keeping actuals constant, and vice versa the variation in the metric is also symmetric.
Over and Under Forecasting

As expected, over or under forecasting doesn’t make much of a difference in MAE. Both are equally penalized.
Scale Dependency

This is the Achilles heel of MAE. here, as we increase the base level of the time-series, we can see that the MAE increases linearly. This means that when we are comparing performances across timeseries, this is not the measure you want to use. For eg., when comparing two timeseries, one with a level of 5 and another with a level of 100, using MAE would always assign a higher error to the timeseries with level 100. Another example is when you want to compare different sub-sections of your set of timeseries to see where the error is higher(for eg. different product categories, etc.), then using MAE would always tell you that the sub-section which has a higher average sales would also have a higher MAE, but that doesn’t mean that sub-section is not doing well.
Squared Error
Symmetricity

Squared Error also shows the symmetry we are looking for. But one additional point we can see here is that the errors are skewed towards higher errors. The distribution of color from the diagonal is not as uniform as we saw in Absolute Error. This is because the squared error(because of the square term), assigns higher impact to higher errors that lower errors. This is also why Squared Errors are, typically, more prone to distortion due to outliers.
Side Note: Since squared error and absolute error are also used as loss functions in many machine learning algorithms, this also has the implications on the training of such algorithms. If we choose squared error loss, we are less sensitive to smaller errors and more to higher ones. And if we choose absolute error, we penalize higher and lower errors equally and therefore a single outlier will not influence the total loss that much.
Loss Curves

We can see the same pattern here as well. It is symmetric around the origin, but because of the quadratic form, higher errors are having disproportionately more error as compared to lower ones.
Complementary Pairs

Over and Under Forecasting

Similar to MAE, because of the symmetry, Over and Under Forecasting has pretty much the same impact.
Scale Dependency

Similar to MAE, RMSE also has the scale dependency problem, which means that all the disadvantages we discussed for MAE, applied here as well, but worse. We can see that RMSE scales quadratically when we increase the scale.
Percent Error
Percent Error is the most popular error measure used in the industry. A couple of reasons why it is hugely popular are:
- Scale Independent – As we saw in the scale dependency plots earlier, the MAPE line is flat as we increase the scale of the timeseries.
- Interpretability – Since the error is represented as a percentage term, which is quite popular and interpretable, the error measure also instantly becomes interpretable. If we say the RMSE is 32, it doesn’t mean anything in isolation. But on the other hand, if we say the MAPE is 20%, we instantly know ho good or bad the forecast is.
Symmetricity

Now that doesn’t look right, does it? Percent Error, the most popular of them all, doesn’t look symmetric at all. In fact, we can see that the errors peak when actuals is close to zero and tending to infinity when actuals is zero(the colorless band at the bottom is where the error is infinity because of division by zero).
We can see two shortcomings of the percent error here:
- It is undefined when ground truth is zero(because of division by zero)
- It assigns higher error when ground truth value is lower(top right corner)
Let’s look at the Loss Curves and Complementary Pairs plots to understand more.
Loss Curves

Suddenly, the asymmetry we are seeing is no more. If we keep the ground truth fixed, Percent Error is symmetric around the origin.
Complementary Pairs

But when we look at complementary pairs, we see the asymmetry we were seeing earlier in the heatmap. When the actuals are low, the same error is having a much higher Percent Error than the same error when the forecast was low.
All of this is because of the base which we take for scaling it. Even if we have the same magnitude of error, if the ground truth is low, the percent error will be high and vice versa. For example, let’s review two cases:
- F = 8, A=2 –> Absolute Percent Error =

- F=2, A=8 –> Absolute Percent Error =


There are countless papers and blogs which claim the asymmetry of percent error to be a deal breaker. The popular claim is that absolute percent error penalizes over-forecasting more than under-forecasting, or in other words, it incentivizes under-forecasting.
One argument against this point is that this asymmetry is only there because we change the ground truth. An error of 6 for a time series which has an expected value of 2 is much more serious than an error of 2 for a time series which has an expected value of 6. So according to that intuition, the percent error is doing what it is supposed to do, isn’t it?
Over and Under Forecasting

Not exactly. On some levels the criticism of percent error is rightly justified. Here we see that the forecast where we were under-forecasting has a consistently lower MAPE than the ones where we were over-forecasting. The spread of the low MAPE is also considerably lower than the others. But does that mean that the forecast which always predicts on the lower side is the better forecast as far as the business is concerned? Absolutely not. In a Supply Chain, that leads to stock outs, which is not where you want to be if you want to stay competitive in the market.
Symmetric Error
Symmetric Error was proposed as an better alternative to Percent error. There were two key disadvantages for Percent Error – Undefined when Ground Truth is zero and Asymmetry. And Symmetric Error proposed to solve both by using the average of ground truth and forecast as the base over which we calculate the percent error.
Symmetricity

Right off the bat, we can see that this is symmetric around the diagonal, almost similar to Absolute Error in case of symmetry. And the bottom bar which was empty, now has colors(which means they are not undefined). But a closer look reveals something more. It is not symmetric around the second diagonal. We see the errors are higher when both actuals and forecast are low.
Loss Curves

This is further evident in the Loss Curves. We can see the asymmetry as we increase errors on both sides of the origin. And contrary to the name, Symmetric error penalizes under forecasting more than over forecasting.
Complementary Pairs

But when we look at complementary pairs, we can see it is perfectly symmetrical. This is probably because of the base, which we are keeping constant.
Over and Under Forecasting

We can see the same here as well. The over forecasting series has a consistently lower error as compared to the under forecasting series. So in the effort to normalize the bias towards under forecasting of Percent Error, Symmetric Error shot the other way and is biased towards over forecasting.
Outlier Impact
In addition to the above experiments, we had also ran an experiment to check the impact of outliers(single predictions which are wildly off) on the aggregate metrics.

All four error measures have similar behavior, when coming to outliers. The number of outliers have a much higher impact than the scale of outliers.
Among the four, RMSE is having the biggest impact from outliers. We can see the contour lines are spaced far apart, showing the rate of change is high when we introduce outliers. On the other end of the spectrum, we have sMAPE which has the least impact from outliers. It is evident from the flat and closely spaced contour lines. MAE and MAPE are behaving almost similarly, probably MAPE a tad bit better.
Summary

To close off, there is no one metric which satisfies all the desiderata of an error measure. And depending on the use case, we need to pick and choose. Out of the four intrinsic measures( and all its aggregations like MAPE, MAE, etc.), if we are not concerned by Interpretability and Scale Dependency, we should choose Absolute Error Measures(that is also a general statement. there are concerns with Reliability for Absolute and Squared Error Measures). And when we are looking for scale independent measures, Percent Error is the best we have(even with all of it’s short comings). Extrinsic Error measures like Scaled Error offer a much better alternative in such cases(May be in another blog post I’ll cover those as well.)
All the code to recreate the experiments are at my github repository:
https://github.com/manujosephv/forecast_metrics/tree/master
Checkout the rest of the articles in the series
- Forecast Error Measures: Understanding them through experiments
- Forecast Error Measures: Scaled, Relative, and other Errors
- Forecast Error Measures: Intermittent Demand
Featured Image Source
Further Reading
- Shcherbakov et al. 2013, A Survey of Forecast Error Measures
- Goodwin & Lawton, 1999, On the asymmetry of symmetric MAPE
Edited
- Fixed a mislabeling in the Contour Maps
Перевод
Ссылка на автора
Показатели эффективности прогнозирования по временным рядам дают сводку об умениях и возможностях модели прогноза, которая сделала прогнозы.
Есть много разных показателей производительности на выбор. Может быть непонятно, какую меру использовать и как интерпретировать результаты.
В этом руководстве вы узнаете показатели производительности для оценки прогнозов временных рядов с помощью Python.
Временные ряды, как правило, фокусируются на прогнозировании реальных значений, называемых проблемами регрессии. Поэтому показатели эффективности в этом руководстве будут сосредоточены на методах оценки реальных прогнозов.
После завершения этого урока вы узнаете:
- Основные показатели выполнения прогноза, включая остаточную ошибку прогноза и смещение прогноза.
- Вычисления ошибок прогноза временного ряда, которые имеют те же единицы, что и ожидаемые результаты, такие как средняя абсолютная ошибка.
- Широко используются вычисления ошибок, которые наказывают большие ошибки, такие как среднеквадратическая ошибка и среднеквадратичная ошибка.
Давайте начнем.

Ошибка прогноза (или остаточная ошибка прогноза)
ошибка прогноза рассчитывается как ожидаемое значение минус прогнозируемое значение.
Это называется остаточной ошибкой прогноза.
forecast_error = expected_value - predicted_valueОшибка прогноза может быть рассчитана для каждого прогноза, предоставляя временной ряд ошибок прогноза.
В приведенном ниже примере показано, как можно рассчитать ошибку прогноза для серии из 5 прогнозов по сравнению с 5 ожидаемыми значениями. Пример был придуман для демонстрационных целей.
expected = [0.0, 0.5, 0.0, 0.5, 0.0]
predictions = [0.2, 0.4, 0.1, 0.6, 0.2]
forecast_errors = [expected[i]-predictions[i] for i in range(len(expected))]
print('Forecast Errors: %s' % forecast_errors)При выполнении примера вычисляется ошибка прогноза для каждого из 5 прогнозов. Список ошибок прогноза затем печатается.
Forecast Errors: [-0.2, 0.09999999999999998, -0.1, -0.09999999999999998, -0.2]Единицы ошибки прогноза совпадают с единицами прогноза. Ошибка прогноза, равная нулю, означает отсутствие ошибки или совершенный навык для этого прогноза.
Средняя ошибка прогноза (или ошибка прогноза)
Средняя ошибка прогноза рассчитывается как среднее значение ошибки прогноза.
mean_forecast_error = mean(forecast_error)Ошибки прогноза могут быть положительными и отрицательными. Это означает, что при вычислении среднего из этих значений идеальная средняя ошибка прогноза будет равна нулю.
Среднее значение ошибки прогноза, отличное от нуля, указывает на склонность модели к превышению прогноза (положительная ошибка) или занижению прогноза (отрицательная ошибка). Таким образом, средняя ошибка прогноза также называется прогноз смещения,
Ошибка прогноза может быть рассчитана непосредственно как среднее значение прогноза. В приведенном ниже примере показано, как среднее значение ошибок прогноза может быть рассчитано вручную.
expected = [0.0, 0.5, 0.0, 0.5, 0.0]
predictions = [0.2, 0.4, 0.1, 0.6, 0.2]
forecast_errors = [expected[i]-predictions[i] for i in range(len(expected))]
bias = sum(forecast_errors) * 1.0/len(expected)
print('Bias: %f' % bias)При выполнении примера выводится средняя ошибка прогноза, также известная как смещение прогноза.
Bias: -0.100000Единицы смещения прогноза совпадают с единицами прогнозов. Прогнозируемое смещение нуля или очень маленькое число около нуля показывает несмещенную модель.
Средняя абсолютная ошибка
средняя абсолютная ошибка или MAE, рассчитывается как среднее значение ошибок прогноза, где все значения прогноза вынуждены быть положительными.
Заставить ценности быть положительными называется сделать их абсолютными. Это обозначено абсолютной функциейабс ()или математически показано как два символа канала вокруг значения:| Значение |,
mean_absolute_error = mean( abs(forecast_error) )кудаабс ()делает ценности позитивными,forecast_errorодна или последовательность ошибок прогноза, иимею в виду()рассчитывает среднее значение.
Мы можем использовать mean_absolute_error () функция из библиотеки scikit-learn для вычисления средней абсолютной ошибки для списка прогнозов. Пример ниже демонстрирует эту функцию.
from sklearn.metrics import mean_absolute_error
expected = [0.0, 0.5, 0.0, 0.5, 0.0]
predictions = [0.2, 0.4, 0.1, 0.6, 0.2]
mae = mean_absolute_error(expected, predictions)
print('MAE: %f' % mae)При выполнении примера вычисляется и выводится средняя абсолютная ошибка для списка из 5 ожидаемых и прогнозируемых значений.
MAE: 0.140000Эти значения ошибок приведены в исходных единицах прогнозируемых значений. Средняя абсолютная ошибка, равная нулю, означает отсутствие ошибки.
Средняя квадратическая ошибка
средняя квадратическая ошибка или MSE, рассчитывается как среднее значение квадратов ошибок прогноза. Возведение в квадрат значений ошибки прогноза заставляет их быть положительными; это также приводит к большему количеству ошибок.
Квадратные ошибки прогноза с очень большими или выбросами возводятся в квадрат, что, в свою очередь, приводит к вытягиванию среднего значения квадратов ошибок прогноза, что приводит к увеличению среднего квадрата ошибки. По сути, оценка дает худшую производительность тем моделям, которые делают большие неверные прогнозы.
mean_squared_error = mean(forecast_error^2)Мы можем использовать mean_squared_error () функция из scikit-learn для вычисления среднеквадратичной ошибки для списка прогнозов. Пример ниже демонстрирует эту функцию.
from sklearn.metrics import mean_squared_error
expected = [0.0, 0.5, 0.0, 0.5, 0.0]
predictions = [0.2, 0.4, 0.1, 0.6, 0.2]
mse = mean_squared_error(expected, predictions)
print('MSE: %f' % mse)При выполнении примера вычисляется и выводится среднеквадратическая ошибка для списка ожидаемых и прогнозируемых значений.
MSE: 0.022000Значения ошибок приведены в квадратах от предсказанных значений. Среднеквадратичная ошибка, равная нулю, указывает на совершенное умение или на отсутствие ошибки.
Среднеквадратическая ошибка
Средняя квадратичная ошибка, описанная выше, выражается в квадратах единиц прогнозов.
Его можно преобразовать обратно в исходные единицы прогнозов, взяв квадратный корень из среднего квадрата ошибки Это называется среднеквадратичная ошибка или RMSE.
rmse = sqrt(mean_squared_error)Это можно рассчитать с помощьюSQRT ()математическая функция среднего квадрата ошибки, рассчитанная с использованиемmean_squared_error ()функция scikit-learn.
from sklearn.metrics import mean_squared_error
from math import sqrt
expected = [0.0, 0.5, 0.0, 0.5, 0.0]
predictions = [0.2, 0.4, 0.1, 0.6, 0.2]
mse = mean_squared_error(expected, predictions)
rmse = sqrt(mse)
print('RMSE: %f' % rmse)При выполнении примера вычисляется среднеквадратичная ошибка.
RMSE: 0.148324Значения ошибок RMES приведены в тех же единицах, что и прогнозы. Как и в случае среднеквадратичной ошибки, среднеквадратическое отклонение, равное нулю, означает отсутствие ошибки.
Дальнейшее чтение
Ниже приведены некоторые ссылки для дальнейшего изучения показателей ошибки прогноза временных рядов.
- Раздел 3.3 Измерение прогнозирующей точности, Практическое прогнозирование временных рядов с помощью R: практическое руководство,
- Раздел 2.5 Оценка точности прогноза, Прогнозирование: принципы и практика
- scikit-Learn Metrics API
- Раздел 3.3.4. Метрики регрессии, scikit-learn API Guide
Резюме
В этом руководстве вы обнаружили набор из 5 стандартных показателей производительности временных рядов в Python.
В частности, вы узнали:
- Как рассчитать остаточную ошибку прогноза и как оценить смещение в списке прогнозов.
- Как рассчитать среднюю абсолютную ошибку прогноза, чтобы описать ошибку в тех же единицах, что и прогнозы.
- Как рассчитать широко используемые среднеквадратические ошибки и среднеквадратичные ошибки для прогнозов.
Есть ли у вас какие-либо вопросы о показателях эффективности прогнозирования временных рядов или об этом руководстве?
Задайте свои вопросы в комментариях ниже, и я сделаю все возможное, чтобы ответить.
Measuring the performance of any machine learning model is very important, not only from the technical point of view but also from the business perspective. Especially when the business decisions are dependent on the insights generated from the forecasting models, knowing its accuracy becomes vital. There are different types of evaluation metrics used in machine learning depending on the model used and the results generated. In the same context, there are different evaluation metrics used to measure the performance of a time-series forecasting model. In this post, we will discuss different evaluation metrics used for measuring the performance of a time series model with their importance and applicability. The major points to be covered in this article are listed below.
Table of Contents
- Measuring Time Series Forecasting Performance
- Evaluation Metrics to Measure Performance
- R-Squared
- Mean Absolute Error
- Mean Absolute Percentage Error
- Mean Squared Error
- Root Mean Squared Error
- Normalized Root Mean Squared Error
- Weighted Absolute Percentage Error
- Weighted Mean Absolute Percentage Error
- Summary
Let’s start the discussion by understanding why measuring the performance of a time series forecasting model is necessary.
Measuring Time Series Forecasting Performance
The fact that the future is wholly unknown and can only be predicted from what has already occurred is a significant distinction in forecasting. The ability of a time series forecasting model to predict the future is defined by its performance. This is frequently at the expense of being able to explain why a particular prediction was made, confidence intervals, and even a greater grasp of the problem’s underlying causes.
THE BELAMY
Sign up for your weekly dose of what’s up in emerging technology.
Time series prediction performance measurements provide a summary of the forecast model’s skill and capability in making the forecasts. There are numerous performance metrics from which to pick. Knowing which metric to use and how to interpret the data might be difficult.
Moving further, we will see different performance measures that can be applied to evaluate the forecasting model under different circumstances.
Download our Mobile App
![]()
![]()
Evaluation Metrics to Measure Performance
Now, let us have a look at the popular evaluation metrics used to measure the performance of a time-series forecasting model.
R-Squared
The stationary R-squared is used in time series forecasting as a measure that compares the stationary part of the model to a simple mean model. It is defined as,

Where SSres denotes the sum of squared residuals from expected values and SStot denotes the sum of squared deviations from the dependent variable’s sample mean. It denotes the proportion of the dependent variable’s variance that may be explained by the independent variable’s variance. A high R2 value shows that the model’s variance is similar to that of the true values, whereas a low R2 value suggests that the two values are not strongly related.
The most important thing to remember about R-squared is that it does not indicate whether or not the model is capable of making accurate future predictions. It shows whether or not the model is a good fit for the observed values, as well as how good of a fit it is. A high R2 indicates that the observed and anticipated values have a strong association.
Mean Absolute Error (MAE)
The MAE is defined as the average of the absolute difference between forecasted and true values. Where yi is the expected value and xi is the actual value (shown below formula). The letter n represents the total number of values in the test set.

The MAE shows us how much inaccuracy we should expect from the forecast on average. MAE = 0 means that the anticipated values are correct, and the error statistics are in the original units of the forecasted values.
The lower the MAE value, the better the model; a value of zero indicates that the forecast is error-free. In other words, the model with the lowest MAE is deemed superior when comparing many models.
However, because MAE does not reveal the proportional scale of the error, it can be difficult to distinguish between large and little errors. It can be combined with other measures to see if the errors are higher (see Root Mean Square Error below). Furthermore, MAE might obscure issues related to low data volume; for more information, check the last two metrics in this article.
Mean Absolute Percentage Error (MAPE)
MAPE is the proportion of the average absolute difference between projected and true values divided by the true value. The anticipated value is Ft, and the true value is At. The number n refers to the total number of values in the test set.

It works better with data that is free of zeros and extreme values because of the in-denominator. The MAPE value also takes an extreme value if this value is exceedingly tiny or huge.
The model is better if the MAPE is low. Remember that MAPE works best with data that is devoid of zeros and extreme values. MAPE, like MAE, understates the impact of big but rare errors caused by extreme values.
Mean Square Error can be utilized to address this issue. This statistic may obscure issues related to low data volume; for more information, check the last two metrics in this article.
Mean Squared Error (MSE)
MSE is defined as the average of the error squares. It is also known as the metric that evaluates the quality of a forecasting model or predictor. MSE also takes into account variance (the difference between anticipated values) and bias (the distance of predicted value from its true value).

Where y’ denotes the predicted value and y denotes the actual value. The number n refers to the total number of values in the test set. MSE is almost always positive, and lower values are preferable. This measure penalizes large errors or outliers more than minor errors due to the square term (as seen in the formula above).
The closer MSE is to zero, the better. While it overcomes MAE and MAPE extreme value and zero problems, it may be harmful in some instances. When dealing with low data volume, this statistic may ignore issues; to address this, see Weighted Absolute Percentage Error and Weighted Mean Absolute Percentage Error.
Root Mean Squared Error(RMSE)
This measure is defined as the square root of mean square error and is an extension of MSE. Where y’ denotes the predicted value and y denotes the actual value. The number n refers to the total number of values in the test set. This statistic, like MSE, penalizes greater errors more.

This statistic is likewise always positive, with lower values indicating higher performance. The RMSE number is in the same unit as the projected value, which is an advantage of this technique. In comparison to MSE, this makes it easier to comprehend.
The RMSE can also be compared to the MAE to see whether there are any substantial but uncommon inaccuracies in the forecast. The wider the gap between RMSE and MAE, the more erratic the error size. This statistic can mask issues with low data volume.
Normalized Root Mean Squared Error (NRMSE)
The normalized RMSE is used to calculate NRMSE, which is an extension of RMSE. The mean or the range of actual values are the two most used methods for standardizing RMSE (difference of minimum and maximum values). The maximum true value is ymax, while the smallest true value is ymin.

NRMSE is frequently used to compare datasets or forecasting models with varying sizes (units and gross revenue, for example). The smaller the value, the better the model’s performance. When working with little amounts of data, this metric can be misleading. However, Weighted Absolute Percentage Error and Weighted Mean Absolute Percentage Error can help.
Weighted Mean Absolute Percentage Error (WMAPE)
WMAPE (sometimes called wMAPE) is an abbreviation for Weighted Mean Absolute Percentage Error. It is a measure of a forecasting method’s prediction accuracy. It is a MAPE version in which errors are weighted by real values (e.g. in the case of sales forecasting, errors are weighted by sales volume).

where A is the current data vector and F is the forecast This metric has an advantage over MAPE in that it avoids the ‘infinite error’ problem.
The higher the model’s performance, the lower the WMAPE number. When evaluating forecasting models, this metric is useful for low volume data where each observation has a varied priority. The weight value of observations with a higher priority is higher. The WMAPE number increases as the error in high-priority forecast values grows.
Summary
Let’s have a quick summary of all the above-mentioned measures.
- When the relation between the forecasted and actual value is to be known then R2 is used.
- When absolute error must be measured, MAE is useful. It is simple to understand, but in the case of data with extreme values, it is inefficient. MAPE is also simple to understand and is used to compare different forecast models or datasets because it is a percentage value. MAPE has the same problem as MAE in that it is inefficient when data contains extreme values.
- MSE is beneficial when the spread of prediction values is significant and larger values must be punished. However, because it is a squared value, this metric is frequently difficult to comprehend.
- When the spread is important and bigger values need to be penalized, RMSE (NRMSE) is also useful. When compared to MSE, RMSE is easier to interpret because the RMSE number is on the same scale as the projected values.
- When dealing with low-volume data, WMAPE is also useful. WMAPE uses the weight (priority value) of each observation to help incorporate the priority.
Conclusion
Through this post, we have seen different performance evaluation metrics used in time series forecasting in different scenarios. Most of all above-mentioned measures can directly be utilized from sklearn.metrics class or can be directly implemented from scratch with NumPy and math modules.
References
- A Comparative Study of Performance Estimation Methods for Time Series Forecasting
- How to Evaluate Your Forecast